Правильный robots txt для WordPress сайта – инструкция на 2019-2020 год без плагинов
Содержание
- Для чего нужен robots.txt
- Где лежит файл robots в WordPress
- Как создать правильный robots txt
- Настройка команд
- Рабочий пример инструкций для WordPress
- Как проверить работу robots.txt
- Плагин–генератор Virtual Robots.txt
- Добавить с помощью Yoast SEO
- Изменить модулем в All in One SEO
- Правильная настройка для плагина WooCommerce
- Итог
Для чего нужен robots.txt
Robots.txt создан для регулирования поведения поисковых роботов на сайтах, а именно куда им заходить можно и брать в поиск, а куда нельзя. Лет 10 назад сила данного файла была велика, по его правилам работали все поисковые системы, но сейчас он скорее как рекомендация, чем правило.
Но пока не отменили, вебмастера должны делать его и настраивать правильно исходя из структуры и иерархии сайтов. Отдельная тема это WordPress, потому что CMS содержит множество элементов, которые не нужно сканировать и отдавать в индекс. Разберемся как правильно составить robots.txt
Разберемся как правильно составить robots.txt
Где лежит файл robots в WordPress
На любом из ресурсов robots.txt должен лежать в корневой папке. В случае с вордпресс, там где находится папка wp-admin и ей подобные.
Расположение на сервереЕсли не создавался и не загружался администратором сайта, то по умолчанию на сервере не найти. Стандартная сборка WordPress не предусматривает наличие такого объекта.
Как создать правильный robots txt
Создать правильный robots txt задача не трудная, сложнее прописать в нем правильные директивы. Сначала создадим документ, открываем программу блокнот и нажимаем сохранить как.
Сохраняем документВ следующем окне задаем название robots, оставляем расширение txt, кодировку ANSI и нажимаем сохранить. Объект появится в папке куда произошло сохранение. Пока документ пустой и ничего не содержит в себе, давайте разберемся какие именно директивы он может поддерживать.
Сохранение роботсаПри желании можете сразу скачать его на сервер в корень через программу FileZilla.

Настройка команд
Выделю четыре основные команды:
- User-agent: показывает правила для разных поисковых роботов, либо для всех, либо для отдельных
- Disalow: запрещает доступ
- Allow: разрешаем доступ
- Sitemap: адрес до XML карты
Устаревшие и ненужные конфигурации:
- Host: указывает главное зеркало, стало не нужным, потому что поиск сам определит правильный вариант
- Crawl-delay: ограничивает время на пребывание робота на странице, сейчас сервера мощные и беспокоится о производительности не нужно
- Clean-param: ограничивает загрузку дублирующегося контента, прописать можно, но толку не будет, поисковик проиндексирует все, что есть на сайте и возьмет по–максимому страниц
Рабочий пример инструкций для WordPress
Дело в том что поисковой робот не любит запрещающие директивы, и все равно возьмет в оборот, что ему нужно. Запрет на индексацию должен быть объектов, которые 100% не должны быть в поиске и в базе Яндекса и Гугла. Данный рабочий пример кода помещаем в robots txt.
Данный рабочий пример кода помещаем в robots txt.
User-agent: * Disallow: /wp- Disallow: /tag/ Disallow: */trackback Disallow: */page Disallow: /author/* Disallow: /template.html Disallow: /readme.html Disallow: *?replytocom Allow: */uploads Allow: *.js Allow: *.css Allow: *.png Allow: *.gif Allow: *.jpg Sitemap: https://ваш домен/sitemap.xml
Разберемся с текстом и посмотрим что именно мы разрешили, а что запретили:
- User-agent, поставили знак *, тем самым сообщив что все поисковые машины должны подчиняться правилам
- Блок с Disallow запрещает к индексу все технические страницы и дубли. обратите внимание что я заблокировал папки начинающиеся на wp-
- Блок Allow разрешает сканировать скрипты, картинки и css файлы, это необходимо для правильного представления проекта в поиске иначе вы получите портянку без оформления
- Sitemap: показывает путь до XML карты сайта, обязательно нужно ее сделать, а так же заменить надпись»ваш домен»
Остальные директивы рекомендую не вносить, после сохранения и внесения правок, загружаем стандартный robots txt в корень WordPress. Для проверки наличия открываем такой адрес https://your-domain/robots.txt, заменяем домен на свой, должно отобразится так.
Для проверки наличия открываем такой адрес https://your-domain/robots.txt, заменяем домен на свой, должно отобразится так.
Как проверить работу robots.txt
Стандартный способ проверить через сервис yandex webmaster. Для лучшего анализа нужно зарегистрировать и установить на сайт сервис. Вверху видим загрузившийся robots, нажимаем проверить.
Проверка документа в yandexНиже появится блок с ошибками, если их нет то переходим к следующему шагу, если неверно отображается команда, то исправляем и снова проверяем.
Отсутствие ошибок в валидатореПроверим правильно ли Яндекс обрабатывает команды, спускаемся чуть ниже, введем два запрещенных и разрешенных адреса, не забываем нажать проверить. На снимке видим что инструкция сработала, красным помечено что вход запрещен, а зеленой галочкой, что индексирование записей разрешена.
Проверка папок и страниц в яндексеПроверили, все срабатывает, перейдем к следующему способу это настройка robots с помощью плагинов. Если процесс не понятен, то смотрите наше видео.
Если процесс не понятен, то смотрите наше видео.
Плагин–генератор Virtual Robots.txt
Если не хочется связываться с FTP подключением, то приходит на помощь один отличный WordPress плагин–генератор называется Virtual Robots.txt. Устанавливаем стандартно из админки вордпресс поиском или загрузкой архива, выглядит так.
Как выглядит Virtual Robots.txtПереходим в админку Настройки > Virtual Robots.txt, видим знакомую конфигурацию, но нам нужно ее заменить, на нашу из статьи. Копируем и вставляем, не забываем сохранять.
Настройка Virtual Robots.txtРоботс автоматически создастся и станет доступен по тому же адресу. При желании проверить есть он в файлах WordPress – ничего не увидим, потому что документ виртуальный и редактировать можно только из плагина, но Yandex и Google он будет виден.
Добавить с помощью Yoast SEO
Знаменитый плагин Yoast SEO предоставляет возможность добавить и изменить robots.txt из панели WordPress. Причем созданный файл появляется на сервере (а не виртуально) и находится в корне сайта, то есть после удаления или деактивации роботс остается. Переходим в Инструменты > Редактор.
Yoast SEO редактор файловЕсли robots есть, то отобразится на странице, если нет есть кнопка «создать», нажимаем на нее.
Кнопка создания robotsВыйдет текстовая область, записываем, имеющийся текст из универсальной конфигурации и сохраняем. Можно проверить по FTP соединению документ появится.
Изменить модулем в All in One SEO
Старый плагин All in One SEO умеет изменять robots txt, чтобы активировать возможность переходим в раздел модули и находим одноименный пункт, нажимаем Activate.
Модули в All In one SeoВ меню All in One SEO появится новый раздел, заходим, видим функционал конструктора.
Работа в модуле AIOS- Записываем имя агента, в нашем случае * или оставляем пустым
- Разрешаем или запрещаем индексацию
- Директория или страница куда не нужно идти
- Результат
Модуль не удобный, создать по такому принципу валидный и корректный robots.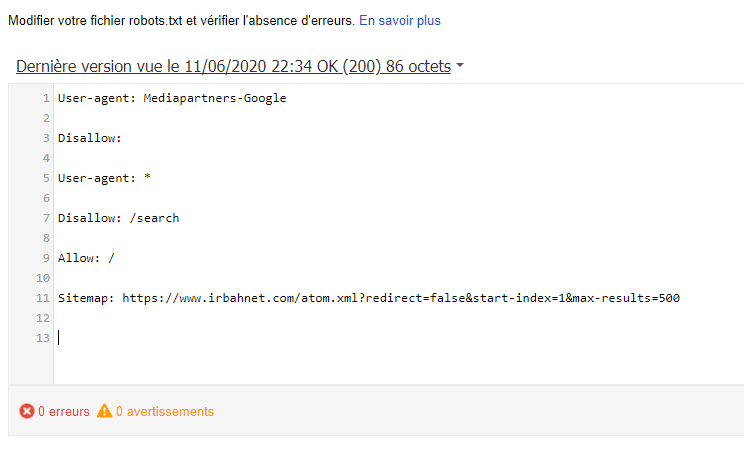 txt трудно. Лучше используйте другие инструменты.
txt трудно. Лучше используйте другие инструменты.
Правильная настройка для плагина WooCommerce
Чтобы сделать правильную настройку для плагина интернет магазина на WordPress WooCommerce, добавьте эти строки к остальным:
Disallow: /cart/ Disallow: /checkout/ Disallow: /*add-to-cart=* Disallow: /my-account/
Делаем аналогичные действия и загружаем на сервер через FTP или плагином.
Итог
Подведем итог что нужно сделать чтобы на сайте WordPress был корректный файл для поисковиков:
- Создаем вручную или с помощью плагина файл
- Записываем в него инструкции из статьи
- Загружаем на сервер
- Проверяем в валидаторе Yandex
- Не пользуйтесь генераторами robots txt в интернете, пошевелите немного руками
Совершенствуйте свои блоги на WordPress, продвигайтесь и правильно настраивайте все параметры, а мы в этом поможем, успехов!
Пожалуйста, оцените материал:
Правильный Robots.
 txt для WordPress (2019) — как сделать?
txt для WordPress (2019) — как сделать?В интернете можно найти много публикаций на тему, как составить лучший (или даже самый лучший) файл robots.txt для WordPress. При этом в ряде таких популярных статей многие правила не объясняются и, как мне кажется, вряд ли понимаются самими авторами. Единственный обзор, который я нашел и который действительно заслуживает внимания, — это статья в блоге wp-kama. Однако и там я нашел не совсем корректные рекомендации. Понятно, что на каждом сайте будут свои нюансы при составлении файла robots.txt. Но существует ряд общих моментов для совершенно разных сайтов, которые можно взять за основу. Robots.txt, опубликованный в этой статье, можно будет просто копировать и вставлять на новый сайт и далее дорабатывать в соответствии со своими нюансами.
Более подробно о составлении robots.txt и значении всех его директив я писал здесь. Ниже я не буду подробно останавливаться на значении каждого правила. Ограничусь тем, что кратко прокомментирую что для чего необходимо.
Правильный Robots.txt для WordPress
Действительно самый лучший robots.txt, который я видел на данный момент, это роботс, предложенный в блоге wp-kama. Ряд директив и комментариев я возьму из его образца + внесу свои корректировки. Корректировки коснутся нескольких правил, почему так напишу ниже. Кроме того, напишем индивидуальные правила для всех роботов, для Яндекса и для Google.
Ниже привожу короткий и расширенный вариант. Короткий не включает отдельные блоки для Google и Яндекса. Расширенный уже менее актуален, т.к. теперь нет принципиальных особенностей между двумя крупными поисковиками: обеим системам нужно индексировать файлы скриптов и изображений, обе не поддерживают директиву Host. Тем не менее, если в этом мире снова что-то изменится, либо вам потребуется все-таки как-то по-отдельному управлять индексацией файлов на сайте Яндексом и Гугл, сохраню в этой статье и второй вариант.
Еще раз обращаю внимание, что это базовый файл robots.txt. В каждом конкретном случае нужно смотреть реальный сайт и по-необходимости вносить корректировки. Поручайте это дело опытным специалистам!
Поручайте это дело опытным специалистам!
Короткий вариант (оптимальный)
User-agent: * # общие правила для роботов, кроме Яндекса и Google, # т.к. для них правила ниже Disallow: /cgi-bin # папка на хостинге Disallow: /? # все параметры запроса на главной Disallow: /wp- # все файлы WP: /wp-json/, /wp-includes, /wp-content/plugins Disallow: /wp/ # если есть подкаталог /wp/, где установлена CMS (если нет, # правило можно удалить) Disallow: *?s= # поиск Disallow: *&s= # поиск Disallow: /search/ # поиск Disallow: /author/ # архив автора Disallow: /users/ # архив авторов Disallow: */trackback # трекбеки, уведомления в комментариях о появлении открытой # ссылки на статью Disallow: */feed # все фиды Disallow: */rss # rss фид Disallow: */embed # все встраивания Disallow: */wlwmanifest.xml # xml-файл манифеста Windows Live Writer (если не используете, # правило можно удалить) Disallow: /xmlrpc.php # файл WordPress API Disallow: *utm*= # ссылки с utm-метками Disallow: *openstat= # ссылки с метками openstat Allow: */uploads # открываем папку с файлами uploads # Укажите один или несколько файлов Sitemap (дублировать для каждого User-agent # не нужно). Google XML Sitemap создает 2 карты сайта, как в примере ниже. Sitemap: http://site.ru/sitemap.xml Sitemap: http://site.ru/sitemap.xml.gz # Укажите главное зеркало сайта, как в примере ниже (с WWW / без WWW, если HTTPS # то пишем протокол, если нужно указать порт, указываем). Команда стала необязательной. Ранее Host понимал # Яндекс и Mail.RU. Теперь все основные поисковые системы команду Host не учитывают. Host: www.site.ru

Расширенный вариант (отдельные правила для Google и Яндекса)
User-agent: * # общие правила для роботов, кроме Яндекса и Google, # т.к. для них правила ниже Disallow: /cgi-bin # папка на хостинге Disallow: /? # все параметры запроса на главной Disallow: /wp- # все файлы WP: /wp-json/, /wp-includes, /wp-content/plugins Disallow: /wp/ # если есть подкаталог /wp/, где установлена CMS (если нет, # правило можно удалить) Disallow: *?s= # поиск Disallow: *&s= # поиск Disallow: /search/ # поиск Disallow: /author/ # архив автора Disallow: /users/ # архив авторов Disallow: */trackback # трекбеки, уведомления в комментариях о появлении открытой # ссылки на статью Disallow: */feed # все фиды Disallow: */rss # rss фид Disallow: */embed # все встраивания Disallow: */wlwmanifest.xml # xml-файл манифеста Windows Live Writer (если не используете, # правило можно удалить) Disallow: /xmlrpc.php # файл WordPress API Disallow: *utm*= # ссылки с utm-метками Disallow: *openstat= # ссылки с метками openstat Allow: */uploads # открываем папку с файлами uploads User-agent: GoogleBot # правила для Google (комментарии не дублирую) Disallow: /cgi-bin Disallow: /? Disallow: /wp- Disallow: /wp/ Disallow: *?s= Disallow: *&s= Disallow: /search/ Disallow: /author/ Disallow: /users/ Disallow: */trackback Disallow: */feed Disallow: */rss Disallow: */embed Disallow: */wlwmanifest.xml Disallow: /xmlrpc.php Disallow: *utm*= Disallow: *openstat= Allow: */uploads Allow: /*/*.js # открываем js-скрипты внутри /wp- (/*/ - для приоритета) Allow: /*/*.css # открываем css-файлы внутри /wp- (/*/ - для приоритета) Allow: /wp-*.png # картинки в плагинах, cache папке и т.д. Allow: /wp-*.jpg # картинки в плагинах, cache папке и т. д. Allow: /wp-*.jpeg # картинки в плагинах, cache папке и т.д. Allow: /wp-*.gif # картинки в плагинах, cache папке и т.д. Allow: /wp-admin/admin-ajax.php # используется плагинами, чтобы не блокировать JS и CSS User-agent: Yandex # правила для Яндекса (комментарии не дублирую) Disallow: /cgi-bin Disallow: /? Disallow: /wp- Disallow: /wp/ Disallow: *?s= Disallow: *&s= Disallow: /search/ Disallow: /author/ Disallow: /users/ Disallow: */trackback Disallow: */feed Disallow: */rss Disallow: */embed Disallow: */wlwmanifest.xml Disallow: /xmlrpc.php Allow: */uploads Allow: /*/*.js Allow: /*/*.css Allow: /wp-*.png Allow: /wp-*.jpg Allow: /wp-*.jpeg Allow: /wp-*.gif Allow: /wp-admin/admin-ajax.php Clean-Param: utm_source&utm_medium&utm_campaign # Яндекс рекомендует не закрывать # от индексирования, а удалять параметры меток, # Google такие правила не поддерживает Clean-Param: openstat # аналогично # Укажите один или несколько файлов Sitemap (дублировать для каждого User-agent # не нужно). Google XML Sitemap создает 2 карты сайта, как в примере ниже. Sitemap: http://site.ru/sitemap.xml Sitemap: http://site.ru/sitemap.xml.gz # Укажите главное зеркало сайта, как в примере ниже (с WWW / без WWW, если HTTPS # то пишем протокол, если нужно указать порт, указываем). Команда стала необязательной. Ранее Host понимал # Яндекс и Mail.RU. Теперь все основные поисковые системы команду Host не учитывают. Host: www.site.ru


В примере я не добавляю правило Crawl-Delay, т.к. в большинстве случаев эта директива не нужна. Однако если у вас крупный нагруженный ресурс, то использование этой директивы поможет снизить нагрузку на сайт со стороны роботов Яндекса, Mail.Ru, Bing, Yahoo и других (Google не учитывает). Подробнее про это читайте в статье Robots.txt.
Ошибочные рекомендации других блогеров для Robots.txt на WordPress
- Использовать правила только для User-agent: *
Для многих поисковых систем не требуется индексация JS и CSS для улучшения ранжирования, кроме того, для менее значимых роботов вы можете настроить большее значение Crawl-Delay и снизить за их счет нагрузку на ваш сайт.

- Прописывание Sitemap после каждого User-agent
Это делать не нужно. Один sitemap должен быть указан один раз в любом месте файла robots.txt
- Закрыть папки wp-content, wp-includes, cache, plugins, themes
Это устаревшие требования. Однако подобные советы я находил даже в статье с пафосным названием «Самые правильный robots для WordPress 2018»! Для Яндекса и Google лучше будет их вообще не закрывать. Или закрывать «по умному», как это описано выше.
- Закрывать страницы тегов и категорий
Если ваш сайт действительно имеет такую структуру, что на этих страницах контент дублируется и в них нет особой ценности, то лучше закрыть. Однако нередко продвижение ресурса осуществляется в том числе за счет страниц категорий и тегирования. В этом случае можно потерять часть трафика
- Закрывать от индексации страницы пагинации /page/
Это делать не нужно. Для таких страниц настраивается тег rel=»canonical», таким образом, такие страницы тоже посещаются роботом и на них учитываются расположенные товары/статьи, а также учитывается внутренняя ссылочная масса.

- Прописать Crawl-Delay
Модное правило. Однако его нужно указывать только тогда, когда действительно есть необходимость ограничить посещение роботами вашего сайта. Если сайт небольшой и посещения не создают значительной нагрузки на сервер, то ограничивать время «чтобы было» будет не самой разумной затеей.
- Ляпы
Некоторые правила я могу отнести только к категории «блогер не подумал». Например:
Disallow: /20— по такому правилу не только закроете все архивы, но и заодно все статьи о 20 способах или 200 советах, как сделать мир лучше 🙂
Спорные рекомендации других блогеров для Robots.txt на WordPress
- Комментарии
Некоторые ребята советуют закрывать от индексирования комментарии
Disallow: /commentsиDisallow: */comment-*. - Открыть папку uploads только для Googlebot-Image и YandexImages
User-agent: Googlebot-ImageAllow: /wp-content/uploads/
User-agent: YandexImages
Allow: /wp-content/uploads/ Совет достаточно сомнительный, т.
 к. для ранжирования страницы необходима информация о том, какие изображения и файлы размещены на ней.
к. для ранжирования страницы необходима информация о том, какие изображения и файлы размещены на ней.
Спасибо за ваше внимание! Если у вас возникнут вопросы или предложения, пишите в комментариях!
Правильный robots.txt для WordPress
АвторЕвгений Лукин
Оригинал статьи в блоге Дениса Биштейнова https://seogio.ru/robots-txt-dlya-wordpress/
Ниже привожу короткий и расширенный вариант. Короткий не включает отдельные блоки для Google и Яндекса. Расширенный уже менее актуален, т.к. теперь нет принципиальных особенностей между двумя крупными поисковиками: обеим системам нужно индексировать файлы скриптов и изображений, обе не поддерживают директиву Host. Тем не менее, если в этом мире снова что-то изменится, либо вам потребуется все-таки как-то по-отдельному управлять индексацией файлов на сайте Яндексом и Гугл, сохраню в этой статье и второй вариант.
Еще раз обращаю внимание, что это базовый файл robots.txt. В каждом конкретном случае нужно смотреть реальный сайт и по-необходимости вносить корректировки. Поручайте это дело опытным специалистам!
Короткий вариант (оптимальный)
User-agent: * # общие правила для роботов, кроме Яндекса и Google,
# т.к. для них правила ниже
Disallow: /cgi-bin # папка на хостинге
Disallow: /? # все параметры запроса на главной
Disallow: /wp- # все файлы WP: /wp-json/, /wp-includes, /wp-content/plugins
Disallow: /wp/ # если есть подкаталог /wp/, где установлена CMS (если нет,
# правило можно удалить)
Disallow: *?s= # поиск
Disallow: *&s= # поиск
Disallow: /search/ # поиск
Disallow: /author/ # архив автора
Disallow: /users/ # архив авторов
Disallow: */trackback # трекбеки, уведомления в комментариях о появлении открытой
# ссылки на статью
Disallow: */feed # все фиды
Disallow: */rss # rss фид
Disallow: */embed # все встраивания
Disallow: */wlwmanifest. xml # xml-файл манифеста Windows Live Writer (если не используете,
# правило можно удалить)
Disallow: /xmlrpc.php # файл WordPress API
Disallow: *utm*= # ссылки с utm-метками
Disallow: *openstat= # ссылки с метками openstat
Allow: */uploads # открываем папку с файлами uploads
# Укажите один или несколько файлов Sitemap (дублировать для каждого User-agent
# не нужно). Google XML Sitemap создает 2 карты сайта, как в примере ниже.
Sitemap: http://site.ru/sitemap.xml
Sitemap: http://site.ru/sitemap.xml.gz
# Укажите главное зеркало сайта, как в примере ниже (с WWW / без WWW, если HTTPS
# то пишем протокол, если нужно указать порт, указываем). Команда стала необязательной. Ранее Host понимал
# Яндекс и Mail.RU. Теперь все основные поисковые системы команду Host не учитывают.
Host: www.site.ru
xml # xml-файл манифеста Windows Live Writer (если не используете,
# правило можно удалить)
Disallow: /xmlrpc.php # файл WordPress API
Disallow: *utm*= # ссылки с utm-метками
Disallow: *openstat= # ссылки с метками openstat
Allow: */uploads # открываем папку с файлами uploads
# Укажите один или несколько файлов Sitemap (дублировать для каждого User-agent
# не нужно). Google XML Sitemap создает 2 карты сайта, как в примере ниже.
Sitemap: http://site.ru/sitemap.xml
Sitemap: http://site.ru/sitemap.xml.gz
# Укажите главное зеркало сайта, как в примере ниже (с WWW / без WWW, если HTTPS
# то пишем протокол, если нужно указать порт, указываем). Команда стала необязательной. Ранее Host понимал
# Яндекс и Mail.RU. Теперь все основные поисковые системы команду Host не учитывают.
Host: www.site.ruРасширенный вариант (отдельные правила для Google и Яндекса)
User-agent: * # общие правила для роботов, кроме Яндекса и Google,
# т. к. для них правила ниже
Disallow: /cgi-bin # папка на хостинге
Disallow: /? # все параметры запроса на главной
Disallow: /wp- # все файлы WP: /wp-json/, /wp-includes, /wp-content/plugins
Disallow: /wp/ # если есть подкаталог /wp/, где установлена CMS (если нет,
# правило можно удалить)
Disallow: *?s= # поиск
Disallow: *&s= # поиск
Disallow: /search/ # поиск
Disallow: /author/ # архив автора
Disallow: /users/ # архив авторов
Disallow: */trackback # трекбеки, уведомления в комментариях о появлении открытой
# ссылки на статью
Disallow: */feed # все фиды
Disallow: */rss # rss фид
Disallow: */embed # все встраивания
Disallow: */wlwmanifest.xml # xml-файл манифеста Windows Live Writer (если не используете,
# правило можно удалить)
Disallow: /xmlrpc.php # файл WordPress API
Disallow: *utm*= # ссылки с utm-метками
Disallow: *openstat= # ссылки с метками openstat
Allow: */uploads # открываем папку с файлами uploads
Disallow: /*attachment*
Disallow: /cart # для WooCommerce
Disallow: /checkout # для WooCommerce
Disallow: *?filter* # для WooCommerce
Disallow: *?add-to-cart* # для WooCommerce
Clean-param: add-to-cart # для WooCommerce
User-agent: GoogleBot # правила для Google (комментарии не дублирую)
Disallow: /cgi-bin
Disallow: /?
Disallow: /wp-
Disallow: /wp/
Disallow: *?s=
Disallow: *&s=
Disallow: /search/
Disallow: /author/
Disallow: /users/
Disallow: */trackback
Disallow: */feed
Disallow: */rss
Disallow: */embed
Disallow: */wlwmanifest.
к. для них правила ниже
Disallow: /cgi-bin # папка на хостинге
Disallow: /? # все параметры запроса на главной
Disallow: /wp- # все файлы WP: /wp-json/, /wp-includes, /wp-content/plugins
Disallow: /wp/ # если есть подкаталог /wp/, где установлена CMS (если нет,
# правило можно удалить)
Disallow: *?s= # поиск
Disallow: *&s= # поиск
Disallow: /search/ # поиск
Disallow: /author/ # архив автора
Disallow: /users/ # архив авторов
Disallow: */trackback # трекбеки, уведомления в комментариях о появлении открытой
# ссылки на статью
Disallow: */feed # все фиды
Disallow: */rss # rss фид
Disallow: */embed # все встраивания
Disallow: */wlwmanifest.xml # xml-файл манифеста Windows Live Writer (если не используете,
# правило можно удалить)
Disallow: /xmlrpc.php # файл WordPress API
Disallow: *utm*= # ссылки с utm-метками
Disallow: *openstat= # ссылки с метками openstat
Allow: */uploads # открываем папку с файлами uploads
Disallow: /*attachment*
Disallow: /cart # для WooCommerce
Disallow: /checkout # для WooCommerce
Disallow: *?filter* # для WooCommerce
Disallow: *?add-to-cart* # для WooCommerce
Clean-param: add-to-cart # для WooCommerce
User-agent: GoogleBot # правила для Google (комментарии не дублирую)
Disallow: /cgi-bin
Disallow: /?
Disallow: /wp-
Disallow: /wp/
Disallow: *?s=
Disallow: *&s=
Disallow: /search/
Disallow: /author/
Disallow: /users/
Disallow: */trackback
Disallow: */feed
Disallow: */rss
Disallow: */embed
Disallow: */wlwmanifest. xml
Disallow: /xmlrpc.php
Disallow: *utm*=
Disallow: *openstat=
Allow: */uploads
Allow: /*/*.js # открываем js-скрипты внутри /wp- (/*/ - для приоритета)
Allow: /*/*.css # открываем css-файлы внутри /wp- (/*/ - для приоритета)
Allow: /wp-*.png # картинки в плагинах, cache папке и т.д.
Allow: /wp-*.jpg # картинки в плагинах, cache папке и т.д.
Allow: /wp-*.jpeg # картинки в плагинах, cache папке и т.д.
Allow: /wp-*.gif # картинки в плагинах, cache папке и т.д.
Allow: /wp-admin/admin-ajax.php # используется плагинами, чтобы не блокировать JS и CSS
User-agent: Yandex # правила для Яндекса (комментарии не дублирую)
Disallow: /cgi-bin
Disallow: /?
Disallow: /wp-
Disallow: /wp/
Disallow: *?s=
Disallow: *&s=
Disallow: /search/
Disallow: /author/
Disallow: /users/
Disallow: */trackback
Disallow: */feed
Disallow: */rss
Disallow: */embed
Disallow: */wlwmanifest.xml
Disallow: /xmlrpc.php
Allow: */uploads
Allow: /*/*.js
Allow: /*/*.
xml
Disallow: /xmlrpc.php
Disallow: *utm*=
Disallow: *openstat=
Allow: */uploads
Allow: /*/*.js # открываем js-скрипты внутри /wp- (/*/ - для приоритета)
Allow: /*/*.css # открываем css-файлы внутри /wp- (/*/ - для приоритета)
Allow: /wp-*.png # картинки в плагинах, cache папке и т.д.
Allow: /wp-*.jpg # картинки в плагинах, cache папке и т.д.
Allow: /wp-*.jpeg # картинки в плагинах, cache папке и т.д.
Allow: /wp-*.gif # картинки в плагинах, cache папке и т.д.
Allow: /wp-admin/admin-ajax.php # используется плагинами, чтобы не блокировать JS и CSS
User-agent: Yandex # правила для Яндекса (комментарии не дублирую)
Disallow: /cgi-bin
Disallow: /?
Disallow: /wp-
Disallow: /wp/
Disallow: *?s=
Disallow: *&s=
Disallow: /search/
Disallow: /author/
Disallow: /users/
Disallow: */trackback
Disallow: */feed
Disallow: */rss
Disallow: */embed
Disallow: */wlwmanifest.xml
Disallow: /xmlrpc.php
Allow: */uploads
Allow: /*/*.js
Allow: /*/*. css
Allow: /wp-*.png
Allow: /wp-*.jpg
Allow: /wp-*.jpeg
Allow: /wp-*.gif
Allow: /wp-admin/admin-ajax.php
Clean-Param: utm_source&utm_medium&utm_campaign # Яндекс рекомендует не закрывать
# от индексирования, а удалять параметры меток,
# Google такие правила не поддерживает
Clean-Param: openstat # аналогично
# Укажите один или несколько файлов Sitemap (дублировать для каждого User-agent
# не нужно). Google XML Sitemap создает 2 карты сайта, как в примере ниже.
Sitemap: http://site.ru/sitemap.xml
Sitemap: http://site.ru/sitemap.xml.gz
# Укажите главное зеркало сайта, как в примере ниже (с WWW / без WWW, если HTTPS
# то пишем протокол, если нужно указать порт, указываем). Команда стала необязательной. Ранее Host понимал
# Яндекс и Mail.RU. Теперь все основные поисковые системы команду Host не учитывают.
Host: www.site.ru
css
Allow: /wp-*.png
Allow: /wp-*.jpg
Allow: /wp-*.jpeg
Allow: /wp-*.gif
Allow: /wp-admin/admin-ajax.php
Clean-Param: utm_source&utm_medium&utm_campaign # Яндекс рекомендует не закрывать
# от индексирования, а удалять параметры меток,
# Google такие правила не поддерживает
Clean-Param: openstat # аналогично
# Укажите один или несколько файлов Sitemap (дублировать для каждого User-agent
# не нужно). Google XML Sitemap создает 2 карты сайта, как в примере ниже.
Sitemap: http://site.ru/sitemap.xml
Sitemap: http://site.ru/sitemap.xml.gz
# Укажите главное зеркало сайта, как в примере ниже (с WWW / без WWW, если HTTPS
# то пишем протокол, если нужно указать порт, указываем). Команда стала необязательной. Ранее Host понимал
# Яндекс и Mail.RU. Теперь все основные поисковые системы команду Host не учитывают.
Host: www.site.ru В примере я не добавляю правило Crawl-Delay, т.к. в большинстве случаев эта директива не нужна. Однако если у вас крупный нагруженный ресурс, то использование этой директивы поможет снизить нагрузку на сайт со стороны роботов Яндекса, Mail.Ru, Bing, Yahoo и других (Google не учитывает).
Однако если у вас крупный нагруженный ресурс, то использование этой директивы поможет снизить нагрузку на сайт со стороны роботов Яндекса, Mail.Ru, Bing, Yahoo и других (Google не учитывает).
Ошибочные рекомендации
- Использовать правила только для User-agent: *
Для многих поисковых систем не требуется индексация JS и CSS для улучшения ранжирования, кроме того, для менее значимых роботов вы можете настроить большее значение Crawl-Delay и снизить за их счет нагрузку на ваш сайт. - Прописывание Sitemap после каждого User-agent
Это делать не нужно. Один sitemap должен быть указан один раз в любом месте файла robots.txt - Закрыть папки wp-content, wp-includes, cache, plugins, themes
Это устаревшие требования. Для Яндекса и Google лучше будет их вообще не закрывать. Или закрывать «по умному», как это описано выше. - Закрывать страницы тегов и категорий
Если ваш сайт действительно имеет такую структуру, что на этих страницах контент дублируется и в них нет особой ценности, то лучше закрыть. Однако нередко продвижение ресурса осуществляется в том числе за счет страниц категорий и тегирования. В этом случае можно потерять часть трафика
Однако нередко продвижение ресурса осуществляется в том числе за счет страниц категорий и тегирования. В этом случае можно потерять часть трафика - Закрывать от индексации страницы пагинации /page/
Это делать не нужно. Для таких страниц настраивается тегrel="canonical", таким образом, такие страницы тоже посещаются роботом и на них учитываются расположенные товары/статьи, а также учитывается внутренняя ссылочная масса. - Прописать Crawl-Delay
Модное правило. Однако его нужно указывать только тогда, когда действительно есть необходимость ограничить посещение роботами вашего сайта. Если сайт небольшой и посещения не создают значительной нагрузки на сервер, то ограничивать время «чтобы было» будет не самой разумной затеей. - Ляпы
Некоторые правила я могу отнести только к категории «блогер не подумал». Например:Disallow: /20— по такому правилу не только закроете все архивы, но и заодно все статьи о 20 способах или 200 советах, как сделать мир лучше.
Спорные рекомендации
- Комментарии
Некоторые ребята советуют закрывать от индексирования комментарииDisallow: /commentsиDisallow: */comment-*. - Открыть папку uploads только для Googlebot-Image и YandexImages
User-agent: Googlebot-Image
Allow: /wp-content/uploads/
User-agent: YandexImages
Allow: /wp-content/uploads/
Совет достаточно сомнительный, т.к. для ранжирования страницы необходима информация о том, какие изображения и файлы размещены на ней.
UPD: Нашёл статью Prevent robots crawling “add-to-cart” links on WooCommerce (Не давайте роботам обходить ссылки WooCommerce “добавить в корзину”) в которой наглядно показывается результат закрытия ссылок с параметром ?add-to-cart=.
Но Яндекс всё равно продолжает индексировать эти ссылки. Нашёл в справке Яндекса, как можно их закрывать – через директиву Clean-param (https://yandex.ru/support/webmaster/robot-workings/clean-param.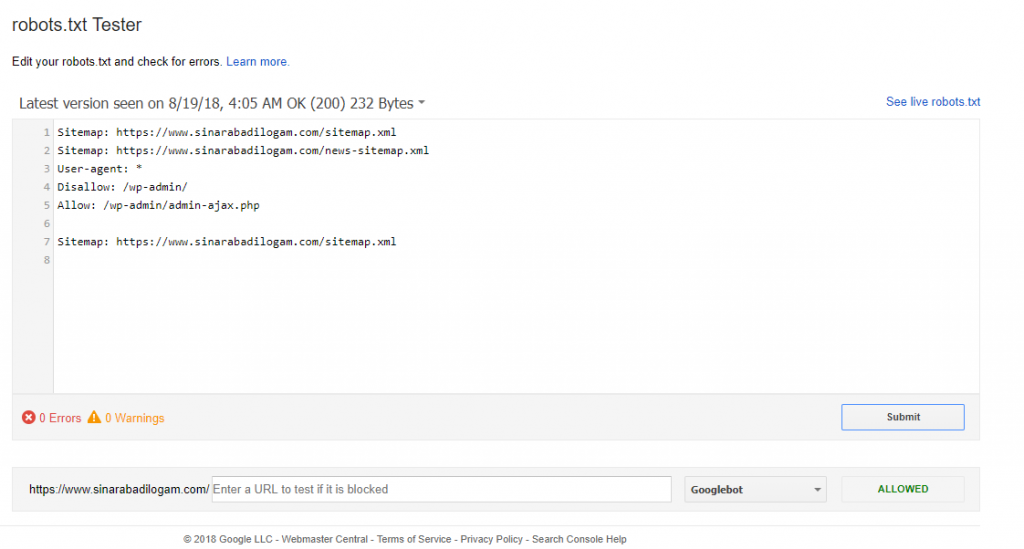 html).
html).
Поэтому добавил в robots.txt эту директиву.
Метки записи: #robots.txt
Евгений Лукин
Делаю интернет-магазины с 2010 года. Пишу об автоматизации рутины.
Похожие записи
База знаний
Python — парсим Excel прайс от поставщика
ЧасыЗадача — ежедневно обновлять цены и наличие товаров с прайса поставщика в excel. Решение — написать скрипт на Python, который будет скачивать прайс автоматически.
База знаний
Как добавить телефон в шапку Storefront
ЧасыРазработчик темы Storefront рекомендует изменять шапку через специальную функцию, которая выводит содержимое в storefront_header.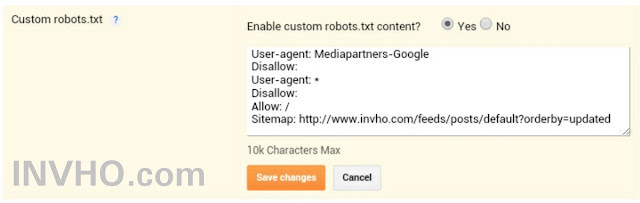
Правильный Robots.txt для WordPress
Всем привет! Сегодня статья о том, каким должен быть правильный файл robots.txt для WordPress. С функциями и предназначением robots.txt мы разбирались несколько дней назад, а сейчас разберём конкретный пример для ВордПресс.
С помощью этого файла у нас есть возможность задать основные правила индексации для различных поисковых систем, а также назначить права доступа для отдельных поисковых ботов. На примере я разберу как составить правильный robots.txt для WordPress. За основу возьму две основные поисковые системы — Яндекс и Google.
В узких кругах вебмастеров можно столкнуться с мнением, что для Яндекса необходимо составлять отдельную секцию, обращаясь к нему по User-agent: Yandex. Давайте вместе разберёмся, на чём основаны эти убеждения.
Яндекс поддерживает директивы Clean-param и Host, о которых Google ничего не знает и не использует при обходе.
Разумно использовать их только для Yandex, но есть нюанс — это межсекционные директивы, которые допустимо размещать в любом месте файла, а Гугл просто не станет их учитывать. В таком случае, если правила индексации совпадают для обеих поисковых систем, то вполне достаточно использовать
В таком случае, если правила индексации совпадают для обеих поисковых систем, то вполне достаточно использовать User-agent: * для всех поисковых роботов.
При обращении к роботам по User-agent важно помнить, что чтение и обработка файла происходит сверху вниз, поэтому используя User-agent: Yandex или User-agent: Googlebot необходимо размещать эти секции в начале файла.
Сразу хочу предупредить: не существует идеального файла, который подойдет абсолютно всем сайтам, работающим на ВордПресс! Не идите на поводу, слепо копируя содержимое файла без проведения анализа под ваш конкретный случай! Многое зависит от выбранных настроек постоянных ссылок, структуры сайта и даже установленных плагинов. Я рассматриваю пример, когда используется ЧПУ и постоянные ссылки вида /%postname%/.
WordPress, как и любая система управления контентом, имеет свои административные ресурсы, каталоги администрирования и прочее, что не должно попасть в индекс поисковых систем. Для защиты таких страниц от доступа необходимо запретить их индексацию в данном файле следующими строками:
Disallow: /cgi-bin Disallow: /wp-
Директива во второй строке закроет доступ по всем каталогам, начинающимся на /wp-, в их число входят:
- wp-admin
- wp-content
- wp-includes
Но мы знаем, что изображения по умолчанию загружаются в папку uploads, которая находится внутри каталога wp-content. Разрешим их индексацию строкой:
Allow: */uploads
Служебные файлы закрыли, переходим к исключению дублей с основным содержимым, которые снижают уникальность контента в пределах одного домена и увеличивают вероятность наложения на сайт фильтра со стороны ПС. К дублям относятся страницы категорий, авторов, тегов, RSS-фидов, а также постраничная навигация, трекбеки и отдельные страницы с комментариями. Обязательно запрещаем их индексацию:
Disallow: /category/ Disallow: /author/ Disallow: /page/ Disallow: /tag/ Disallow: */feed/ Disallow: */trackback Disallow: */comments
Далее хотелось бы уделить особое внимание такому аспекту как постоянные ссылки. Если вы используете ЧПУ, то страницы содержащие в URL знаки вопроса зачастую являются «лишними» и опять же дублируют основной контент. Такие страницы с параметрами следует запрещать аналогичным образом:
Если вы используете ЧПУ, то страницы содержащие в URL знаки вопроса зачастую являются «лишними» и опять же дублируют основной контент. Такие страницы с параметрами следует запрещать аналогичным образом:
Disallow: */?
Это правило распространяется на простые постоянные ссылки ?p=1, страницы с поисковыми запросами ?s= и другими параметрами. Ещё одной проблемой могут стать страницы архивов, содержащие в URL год, месяц. На самом деле их очень просто закрыть, используя маску 20*, тем самым запрещая индексирование архивов по годам:
Disallow: /20*
Для ускорения и полноты индексации добавим путь к расположению карты сайта. Робот обработает файл и при следующем посещении сайта будет его использовать для приоритетного обхода страниц.
Sitemap: https://webliberty.ru/sitemap.xml
В файле robots.txt можно разместить дополнительную информацию для роботов, повышающую качество индексации. Среди них директива Host — указывает на главное зеркало для Яндекса:
Host: webliberty.ru
При работе сайта по HTTPS необходимо указать протокол:
Host: https://webliberty.ru
С 20 марта 2018 года Яндекс официально прекратил поддержку директивы Host. Её можно удалить из robots.txt, а если оставить, то робот её просто игнорирует.
Подводя итог, я объединил всё выше сказанное воедино и получил содержимое файла robots.txt для WordPress, который использую уже несколько лет и при этом в индексе нет дублей:
User-agent: * Disallow: /cgi-bin Disallow: /wp- Disallow: /category/ Disallow: /author/ Disallow: /page/ Disallow: /tag/ Disallow: */feed/ Disallow: /20* Disallow: */trackback Disallow: */comments Disallow: */? Allow: */uploads Sitemap: https://webliberty.ru/sitemap.xml
Постоянно следите за ходом индексации и вовремя корректируйте файл в случае появления дублей.
От того правильно или нет составлен файл зависит очень многое, поэтому обратите особо пристальное внимание к его составлению, чтобы поисковики быстро и качественно индексировали сайт. Если у вас возникли вопросы — задавайте, с удовольствием отвечу!
Если у вас возникли вопросы — задавайте, с удовольствием отвечу!
Правильный robots.txt для сайта wordpress, как закрыть ссылки от индексации
Индексация сайта представляет собой процесс, благодаря которому страницы вашего сайта попадают в поисковые системы.
Для того чтобы сайт индексировался хорошо, вам нужно создать правильный файл robots txt и вписать туда необходимые директивы.
Файл можно создать в стандартной программе «Блокнот», которая доступна абсолютно каждому пользователю ПК.
Добавляется файл robots txt в корневую папку сайта. Для того чтобы осуществить это действие, вам потребуется программа FileZilla или же обычный Total Commander при условии наличия FTP соединения. На некоторых хостингах есть возможность непосредственного добавления каких-либо файлов.
Содержание
- Что будет, если файл robots txt неправильно настроен
- Настройка robots txt
- Несколько советов и примечаний
Что будет, если файл robots txt неправильно настроен
Чтобы ответить на данный вопрос, давайте представим, что сайт wordpress это офис, в который приходят клиенты. В вашем офисе есть как гостевые комнаты, так и служебные, вход в которые доступен только сотрудникам. На дверях служебных помещений обычно вешается табличка с надписью «вход воспрещен» или «вход только для сотрудников». Таким образом, ваши клиенты будут понимать, что туда им лучше не соваться.
В вашем офисе есть как гостевые комнаты, так и служебные, вход в которые доступен только сотрудникам. На дверях служебных помещений обычно вешается табличка с надписью «вход воспрещен» или «вход только для сотрудников». Таким образом, ваши клиенты будут понимать, что туда им лучше не соваться.
Теперь поговорим о сайте wordpress. Если придерживаться аналогии, то его гостевыми комнатами будут открытые к индексации страницы, а служебными — закрытые к индексации страницы. Клиенты же являются поисковыми роботами, которые посещают сайт и вносят в поисковый индекс определенные страницы.
После небольшого экскурса перейдем непосредственно к последствиям, которые могут возникнуть при неправильной настройке файла роботс. Если вы не впишите запрещающие директивы, то поисковый робот будет индексировать абсолютно все подряд, включая данные панели администратора сайта, тем, скриптов и так далее. Также в выдаче могут появиться страницы-дубли. Поисковый робот может запутаться и случайно проиндексировать одну и ту же страницу несколько раз. Бывают случаи, когда роботы вовсе не индексируют сайт из-за того, что директивы файла индексации неправильно настроены, но чаще всего такое последствие является санкцией, которая возлагается на сайт при продаже ссылок. Чтобы выяснить причину, вам нужно зайти в панель управления, которую предоставляют поисковые системы, которая отказывается индексировать сайт и обратить внимание на какие-либо оповещения.
Бывают случаи, когда роботы вовсе не индексируют сайт из-за того, что директивы файла индексации неправильно настроены, но чаще всего такое последствие является санкцией, которая возлагается на сайт при продаже ссылок. Чтобы выяснить причину, вам нужно зайти в панель управления, которую предоставляют поисковые системы, которая отказывается индексировать сайт и обратить внимание на какие-либо оповещения.
Настройка robots txt
Запомните, что правильный файл robots txt состоит из 3 компонентов: выбор робота, которому вы задаете директивы; запрет на индексацию; разрешение индексации.
Для того чтобы указать конкретного робота, которому будут адресоваться правила, можно использовать директиву User-agent. Ниже представлены возможные примеры.
- User-agent: * (правила будут распространятся на всех поисковых роботов).
- User-agent: название поискового робота (правила будут распространятся только на тех роботов, которых вы впишете).
 В большинстве случаев сюда вписывают yandex и googlebot.
В большинстве случаев сюда вписывают yandex и googlebot.
Чтобы запретить индексацию определенных разделов на wordpress, вам стоит использовать правильный комплекс директив Disallow. Помимо разделов вы можете также запретить индексировать какую-либо папку или файл. Итак, перейдем к примерам.
- Disallow: (на индексацию нет никаких запретов).
- Disallow: /file.pdf (закрыть файл file.pdf). Таким же образом можете попросить закрыть конкретные папки.
- Disallow: /nazvanie-razdela (закрыть страницы, которые находятся в разделе «nazvanie-razdela»).
- Disallow: */*slovo (закрыть страницы, ссылки на которые включают в себя «slovo»). Звездочки означают любой текст ссылки, который стоит перед или после указанного вами слова. При использовании такой комбинации символов поисковый робот будет считать, что звездочка находится и в конце. Поэтому, если хотите закрыть страницы, ссылки на которые заканчиваются определенным текстом, то вам стоит добавить еще «$» после директивы.

- Disallow: / (закрыть весь сайт).
Если же хотите разрешить индексирование конкретных файлов сайта, которые находятся в запрещенных для индексации разделах, то вам поможет директива Allow. Наглядный пример смотрите ниже.
адресуется поисковым роботам Google
User-agent: googlebot
закрыть страницы, которые находятся в разделе «nazvanie-razdela»
Disallow: /nazvanie-razdela
разрешено добавлять в индекс абсолютно все файлы с расширением txt, независимо от раздела сайта
Allow: *.txt$
В случае наличия XML карты сайта вы можете указать текст ее ссылки в директиву Sitemap. Она является неофициальной и поддерживается не всеми поисковыми роботами. Основными же (Yandex, Google, Bing и Yahoo) эта директива поддерживается. Если у сайта есть несколько XML карт, то вы можете указать все, используя ссылки на них. Никаких проблем не должно возникнуть. Основная ваша задача это правильно указать адрес ссылки каждой из них.
Sitemap: сайт.ru/название-карты-сайта.xml
Sitemap: сайт.ru/название-карты-сайта1.xml
У многих сайтов вордпресс есть зеркала. Чтобы указать основное, вам потребуется вписать адрес его ссылки в директиву Host. Ее понимают только поисковые роботы системы Yandex. Данную директиву можно вписать как под User-agent, так и в любое другое место роботс тхт. Обратите внимание, что адрес ссылки основного зеркала может содержать www. Если вы забудете его туда вписать, то тогда могут возникнуть проблемы.
Host: основное-зеркало.ru
Теперь, зная директивы, вы можете самостоятельно создать правильный файл роботс под любые поисковые системы. Для этого вам нужно в первую очередь проанализировать структуру сайта вордпресс и решить, что же закрыть от поисковиков, а что открыть. Если же вам лень этим заниматься, то можете использовать пример, который представлен ниже.
Для удобства вам рекомендуется использовать плагин wordpress All in One Seo Pack. Он содержит опцию, благодаря которой можно закрыть индексацию архивов, тегов и страниц поиска. Если у вас нет такого плагина, то вам стоит дописать в robots txt представленные ниже атрибуты после директивы Disallow.
Если у вас нет такого плагина, то вам стоит дописать в robots txt представленные ниже атрибуты после директивы Disallow.
- */20 — отвечает за архивы
- */tag — отвечает за теги
- *?s= — отвечает за страницы поиска
Если вам лень прописывать полное название служебных разделов, то можете прописать директиву Disallow: /wp- при условии, что на вашем сайте wordpress нет страниц с таким названием, которые вы бы хотели добавить в индекс. Поэтому будьте внимательны при выборе названия для неслужебных разделов.
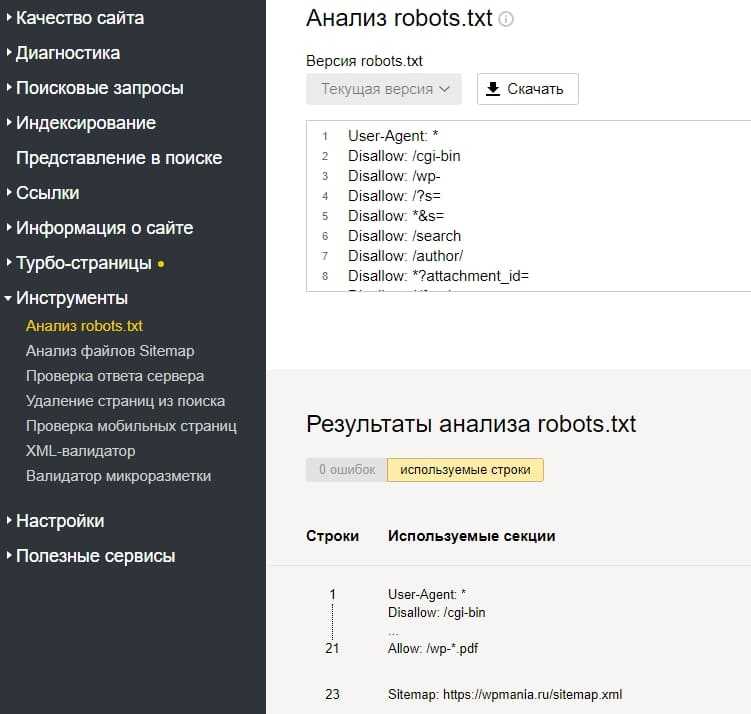
При изменении директив файла robots txt вам стоит помнить, что его индексация это не быстрый процесс. Иногда на это требуется не одна неделя. Чтобы проверить статус индексирования этого файла Яндексом, вам нужно перейти в панель вебмастера сервиса Яндекс, выбрать сайт и перейти в раздел «Настройка индексирования». Потом вам нужно будет выбрать «Анализ robots txt».
Потом вам нужно будет выбрать «Анализ robots txt».
Чтобы проверить статус индексирования файла в Google, вам нужно перейти в раздел «Сканирование» и выбрать «Инструмент проверки robots txt».
После того как настроите директивы, поисковики должны начать добавлять ваш сайт wordpress в индекс. Стоит отметить, что этот процесс может пойти не так гладко, как вы думаете. Многие вебмастера жалуются на Google из-за того, что он вопреки каким-либо запретам производит индексацию сайта так, как пожелает. Работники Google говорят, что файл роботс является не более, чем рекомендацией.
Даже если прописать запрещающие директивы отдельно для Google, то желаемый результат вы не факт, что получите. К тому же, из-за произвольной индексации роботов Google могут появиться страницы-дубли. Их количество со временем может увеличиться и сайт может попасть под фильтр. Чаще всего это Panda.
Чтобы справиться с этой проблемой, вы можете поставить пароль в панели управления wordpress на конкретный файл или же добавить атрибут noindex в метатеги страниц, на которые желаете наложить запрет индексации. Выглядеть это будет так.
Выглядеть это будет так.
<meta name="robots" content="noindex">
Альтернативой для атрибута noindex является атрибут nofollow. Разница между ними лишь в том, что они по-разному оцениваются поисковыми системами. В случае же с Google вам лучше использовать noindex. Если прислушаться к рекомендации, то вы добьетесь желаемого результата.
В справке сервиса Google можно более детально изучить особенности использования атрибута noindex.
Если вы не хотите вручную создавать роботс для своего wordpress, то можете воспользоваться плагином DL Robots.txt. Его можно установить прямо в панели администратора. Для этого вам нужно будет кликнуть по разделу «Плагины» и выбрать «Добавить новый». Теперь вам останется лишь вписать название и кликнуть «Установить», а затем «Активировать». После этого в панели администратора должна появиться вкладка с названием плагина. Кликнув на нее, вы перейдете в настройки и сможете посмотреть обучающее видео. После проведения настройки вы получите адрес ссылки вашего роботс.
Альтернативами данного плагина wordpress являются PC Robots.txt и iRobots.txt. Они имеют свои особенности, но в целом похожи и являются легкими в настройке. Так что, если первый по каким-либо причинам не будет работать, вы всегда можете воспользоваться последними.
Несколько советов и примечаний
- Помните, что правильный файл роботс wordpress не должен занимать более 32 Кбайта дискового пространства. В противном случае могут возникнуть проблемы и индексацией. Чем меньше вес, тем быстрее обработка.
- Не желательно указывать несколько директив в одной строке.
- Не нужно добавлять в кавычки каждый атрибут директивы, который находится в роботс.
- При отсутствии файла роботс поисковики будут считать, что запрет на индексацию не установлен. Произвольная индексация может привести к фильтрации.
- Стоит отметить, что правильный роботс не должен содержать пробелы в начале каждой строки директивы.
Делаем правильный файл Robots.
 txt для WordPress
txt для WordPressПриветствую вас, друзья. Сегодня я покажу как сделать правильный файл Robots.txt для WordPress блога. Файл Robots является ключевым элементом внутренней оптимизации сайта, так как выступает в роли гида-проводника для поисковых систем, посещающих ваш ресурс — показывает, что нужно включать в поисковый индекс, а что нет.
Содержание:
- Зачем нужен файл robots.txt
- Принцип работы файла robots
- Как создать и проверить robots.txt
- Robots.txt для WordPress
- Дополнения и заблуждения
Само название файла robots.txt подсказываем нам, что он предназначен для роботов, а не для людей. В статье о том, как работают поисковые системы, я описывал алгоритм их работы, если не читали, рекомендую ознакомиться.
Зачем нужен файл robots.txt
Представьте себе, что ваш сайт – это дом. В каждом доме есть разные служебные помещения, типа котельной, кладовки, погреба, в некоторых комнатах есть потаенные уголки (сейф).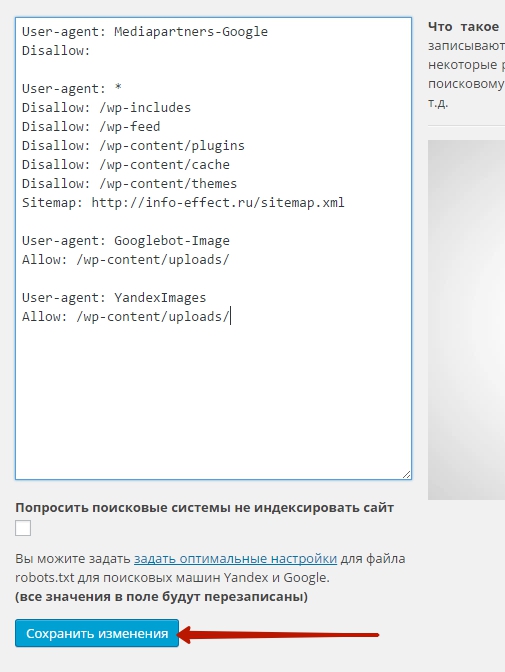 Все эти тайные пространства гостям видеть не нужно, они предназначены только для хозяев.
Все эти тайные пространства гостям видеть не нужно, они предназначены только для хозяев.
Аналогичным образом, каждый сайт имеет свои служебные помещения (разделы), а поисковые роботы – это гости. Так вот, задача правильного robots.txt – закрыть на ключик все служебные разделы сайта и пригласить поисковые системы только в те блоки, которые созданы для внешнего мира.
Примерами таких служебных зон являются – админка сайта, папки с темами оформления, скриптами и т.д.
Вторая функция этого файла – это избавление поисковой выдачи от дублированного контента. Если говорить о WordPress, то, часто, мы можем по разным URL находить одни и те же статьи или их части. Допустим, анонсы статей в разделах с архивами и рубриках идентичны друг другу (только комбинации разные), а страница автора обычного блога на 100% копирует весь контент.
Поисковики интернета могут просто запутаться во всем многообразии таких страниц и неверно понять – что нужно показывать в поисковой выдаче. Закрыв одни разделы, и открыв другие, мы дадим однозначную рекомендацию роботам по правильной индексации сайта, и в поиске окажутся те страницы, которые мы задумывали для пользователей.
Если у вас нет правильно настроенного файла Robots.txt, то возможны 2 варианта:
1. В выдачу попадет каша из всевозможных страниц с сомнительной релевантностью и низкой уникальностью.
2. Поисковик посчитает кашей весь ваш сайт и наложит на него санкции, удалив из выдачи весь сайт или отдельные его части.
Есть у него еще пара функций, о них я расскажу по ходу.
Принцип работы файла robots
Работа файла строится всего на 3-х элементах:
- Выбор поискового робота
- Запрет на индексацию разделов
- Разрешение индексации разделов
1. Как указать поискового робота
С помощью директивы User-agent прописывается имя робота, для которого будут действовать следующие за ней правила. Она используется вот в таком формате:
User-agent: * # для всех роботов
User-agent: имя робота # для конкретного робота
После символа «#» пишутся комментарии, в обработке они не участвуют.
Таким образом, для разных поисковых систем и роботов могут быть заданы разные правила.
Основные роботы, на которые стоит ориентироваться – это yandex и googlebot, они представляют соответствующие поисковики.
2. Как запретить индексацию в Robots.txt
Запрет индексации осуществляется в помощью директивы Disallow. После нее прописывается раздел или элемент сайта, который не должен попадать в поиск. Указывать можно как конкретные папки и документы, так и разделы с определенными признаками.
Если после этой директивы не указать ничего, то робот посчитает, что запретов нет.
Disallow: #запретов нет
Для запрета файлов указываем путь относительного домена.
Disallow: /zapretniy.php #запрет к индексации файла zapretniy.php
Запрет разделов осуществляется аналогичным образом.
Disallow: /razdel-sajta #запрет к индексации всех страниц, начинающихся с /razdel-sajta
Если нам нужно запретить разные разделы и страницы, содержащие одинаковые признаки, то используем символ «*». Звездочка означает, что на ее месте могут быть любые символы (любые разделы, любой степени вложенности).
Disallow: */*test #будут закрыты все страницы, в адресе которых содержится test
Обратите внимание, что на конце правила звездочка не ставится, считается, что она там есть всегда. Отменить ее можно с помощью знака «$»
Disallow: */*test$ #запрет к индексации всех страниц, оканчивающихся на test
Выражения можно комбинировать, например:
Disallow: /test/*.pdf$ #закрывает все pdf файлы в разделе /test/ и его подразделах.
3. Как разрешить индексацию в Robots.txt
По-умолчанию, все разделы сайта открыты для поисковых роботов. Директива, разрешающая индексацию нужна в тех случаях, когда вам необходимо открыть какой-либо кусочек из блока закрытого директивой disallow.
Для открытия служит директива Allow. К ней применяются те же самые атрибуты. Пример работы может выглядеть вот так:
User-agent: * # для всех роботов Disallow: /razdel-sajta #запрет к индексации всех страниц, начинающихся с /razdel-sajta Allow: *.pdf$ #разрешает индексировать pdf файлы, даже в разделе /razdel-sajta
Теорию мы изучили, переходим к практике.
Как создать и проверить Robots.txt
Проверить, что содержит ваш файл на данный момент можно в сервисе Яндекса — Проверка Robots.txt. Введете там адрес своего сайта, и он покажет всю информацию.
Если у вас такого файла нет, то необходимо срочного его создать. Открываете текстовый редактор (блокнот, notepad++, akelpad и т.д.), создаете файл с названием robots, заполняете его нужными директивами и сохраняете с txt расширением (ниже я расскажу, как выглядит правильный robots.txt для WordPress).
Дальше, помещаем файл в корневую папку вашего сайта (рядом с index.php) с помощью файлового менеджера вашего хостинга или ftp клиента, например, filezilla (как пользоваться).
Если у вас WordPress и установлен All in One SEO Pack, то в нем все делается прямо из админки, в этой статье я рассказывал как.
Robots.txt для WordPress
Под особенности каждой CMS должен создаваться свой правильный файл, так как конфигурация системы отличается и везде свои служебные папки и документы.
Мой файл robots.txt имеет следующий вид:
User-agent: * Disallow: /wp-admin Disallow: /wp-content Disallow: /wp-includes Disallow: /wp-comments Disallow: /wp-login.php Disallow: /wp-register.php Disallow: */trackback Disallow: /xmlrpc.php Disallow: */feed Disallow: */author Allow: /wp-content/themes/папка_вашей_темы/ Allow: /wp-content/plugins/ Allow: /wp-includes/js/ User-agent: Googlebot-Image Allow: /wp-content/uploads/ User-agent: YandexImages Allow: /wp-content/uploads/ host: biznessystem.ru Sitemap: https://biznessystem.ru/sitemap.xml
Первый блок действует для всех роботов, так как в строке User-agent стоит «*». Со 2 по 9 строки закрывают служебные разделы самого вордпресс. 10 – удаляет из индекса страницы RSS ленты. 11 – закрывает от индексации авторские страницы.
По последним требованиям поисковиков, необходимо открыть доступ к стилям и скриптам. Для этих целей в 12, 13 и 14 строках прописываем разрешение на индексирование папки с шаблоном сайта, плагинами и Java скриптами.
Дальше у меня идет 2 блока, открывающих доступ к папке с картинками роботам YandexImages и Googlebot-Image. Можно их не выделять отдельно, а разрешающую директиву для папки с картинками перенести выше на 15 строку, чтобы все роботы имели доступ к изображениям сайта.
Если бы я не использовал All-in-One-Seo-Pack, то добавил бы правило, закрывающее архивы (Disallow: */20) и метки (Disallow: */tag).
При использовании стандартного поиска по сайту от WordPress, стоит поставить директиву, закрывающую страницы поиска (Disallow: *?s=). А лучше, настройте Яндекс поиск по сайту, как это сделано на моем блоге.
Обратите внимание на 2 правила:
1. Все директивы для одного робота идут подряд без пропуска строк.
2. Блоки для разных роботов обязательно разделяются пустой строкой.
В самом конце есть директивы, которые мы ранее не рассматривали – это host и sitemap. Обе эти директивы называют межсекционными (можно ставить вне блоков).
Host – указывает главное зеркало ресурса (с 2018 года отменена и больше не используется). Обязательно стоит указать какой домен является главным для вашего сайта – с www или без www. Если у сайта есть еще зеркала, то в их файлах тоже нужно прописать главное. Данную директиву понимает только Яндекс.
Обязательно стоит указать какой домен является главным для вашего сайта – с www или без www. Если у сайта есть еще зеркала, то в их файлах тоже нужно прописать главное. Данную директиву понимает только Яндекс.
Sitemap – это директива, в которой прописывается путь к XML карте вашего сайта. Ее понимают и Гугл и Яндекс.
Дополнения и заблуждения
1. Некоторые вебмастера делают отдельный блок для Яндекса, полностью дублируя общий и добавляя директиву host. Якобы, иначе yandex может не понять. Это лишнее. Мой файл robots.txt известен поисковику давно, и он в нем прекрасно ориентируется, полностью отрабатывая все указания.
2. Можно заменить несколько строк, начинающихся с wp- одной директивой Disallow: /wp-, я не стал такого делать, так как боюсь – вдруг у меня есть статьи, начинающиеся с wp-, если вы уверены, что ваш блог такого не содержит, смело сокращайте код.
3. Переиндексация файла robots.txt проходит не мгновенно, поэтому, ваши изменения поисковики могут заметить лишь спустя пару месяцев.
4. Гугл рекомендует открывать доступ своим ботам к файлам темы оформления и скриптам сайта, пугая вебмастеров возможными санкциями за несоблюдение этого правила. Я провел эксперимент, где оценивал, насколько сильно влияет это требование на позиции сайта в поиске — подробности и результаты эксперимента тут.
Резюме
Правильный файл Robots.txt для WordPress является почти шаблонным документом и его вид одинаков для 99% проектов, созданных на этом движке. Максимум, что требуется для вебмастера — это внести индивидуальные правила для используемого шаблона.
Идеальный пример WordPress Robots.txt [2019]
Файл Robots.txt находится в корневом каталоге вашего сайта. Например, на веб-сайте www.example.com адрес файла robots.txt будет выглядеть как https://www.shoutmecrunch.com/ robots.txt и должен быть доступен по этому адресу. Он представляет собой типичный текстовый файл, соответствующий стандарту исключений для роботов, и включает одно или несколько правил, каждое из которых запрещает или разрешает тому или иному веб-роботу доступ к заданному пути на сайте.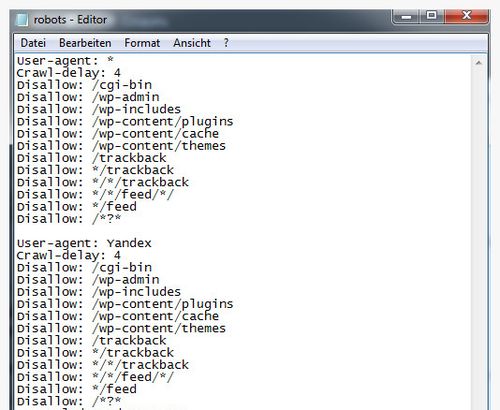
Идеальный формат кодирования
Файл предлагает веб-роботам рекомендации относительно того, какие страницы/файлы следует сканировать. Он работает в кодировке UTF-8 с кодировкой , и если он должен содержать символы какой-либо другой кодировки, веб-роботы могут обработать их неправильно. Правила, перечисленные в файле robots.txt, действительны в отношении хоста, протокола и номера порта, на которых находятся данные.
С индексом или без индекса
Эта опция позволяет установить ограничение на количество запросов, которые получает ваш веб-сервер, и снизить нагрузку. Он не предназначен для запрета показов страниц в результатах Google. Если вы не хотите, чтобы некоторые из ваших материалов с вашего сайта были в Google, используйте теги или директивы без индекса. Также вы можете создавать разделы сайта, зашифрованные паролем.
В Интернете можно найти множество публикаций на тему того, как создать более качественный (или даже самый лучший) файл robots. txt для WordPress. В то же время в некоторых таких популярных статьях многие правила не объясняются и, как мне кажется, плохо понимаются самими авторами. Единственный обзор, который я нашел, который заслуживает внимания, — это статья в блоге wp-kama.
txt для WordPress. В то же время в некоторых таких популярных статьях многие правила не объясняются и, как мне кажется, плохо понимаются самими авторами. Единственный обзор, который я нашел, который заслуживает внимания, — это статья в блоге wp-kama.
Читать: Штраф Google – Как проверить?
Однако там я нашел не совсем правильные рекомендации. Понятно, что у каждого сайта будут свои нюансы при составлении файл robots.txt . Однако есть много характерных моментов для совершенно разных сайтов, которые могут быть положены в основу. Robots.txt, опубликованный в этой статье, можно напрямую скопировать и вставить на новый сайт, а затем доработать в соответствии с его нюансами.
Подробнее о составлении robots.txt и значении всех его директив я писал здесь. Ниже я не буду подробно останавливаться на назначении каждого правила. Ограничусь кратким комментарием, что для чего нужно.
Причина существования robots.txt
Например, иногда robots. txt не должен посещать
txt не должен посещать
- Страницы с личной информацией пользователя;
- страниц с разными формами выгрузки материалов;
- Скребковые площадки;
- страниц с результатами поиска.
Правильный файл robots.txt для WordPress
лучших файлов robots.txt , которые я видел сейчас, — это robots, предложенные в блоге wp-kama. Возьму некоторые директивы и замечания из его образца + внесу свои коррективы. Корректировки коснутся нескольких правил, о чем пишу ниже. Кроме того, мы напишем индивидуальные правила для всех роботов, для Google.
Есть короткая и расширенная версии. Короткая версия не включает отдельные блоки для Google. Расширенный уже менее актуален, потому что сейчас между двумя основными поисковиками нет принципиальных особенностей: обе системы должны индексировать файлы скриптов и изображений, обе не поддерживают директиву Host. Впрочем, если в этом мире снова что-то изменится, или вам все-таки нужно будет отдельно управлять индексацией данных на сайте Google, я тоже сохраню в этой статье второй вариант.
Еще раз отмечу, что это базовый файл robots.txt. В каждом случае нужно смотреть на реальный сайт и при необходимости вносить коррективы. Доверьте это дело опытным специалистам!
Ошибки, допущенные другими блоггерами для Robots.txt на WordPress
- Использовать правила только для User-agent: *
Для многих поисковых систем индексация JS и CSS не требуется для повышения ранжирования, также для менее значимых роботов можно настроить более высокое значение Crawl-Delay и снизить нагрузку на сайт за их счет.
- Назначение карты сайта после каждого User-agent
Не нужно. Одна карта сайта должна быть указана один раз в любом месте файла robots.txt.
- Закрыть папки wp-content, wp-includes, cache, plugins, themes
Это устаревшие требования. Впрочем, такой совет я нашел даже в статье с грандиозной риторикой «Правильные роботы для WordPress 2018»! Для Google было бы лучше их вообще не закрывать. Как вариант, закрыть «умно», как описано выше.
Как вариант, закрыть «умно», как описано выше.
Читать: Ускорьте WordPress с помощью 11 проверенных советов по оптимизации [2019]
- Закройте теги и страницы категорий
Если ваш сайт имеет такую структуру, что контент на этих страницах дублируется и особой ценности в них нет, лучше его закрыть. Однако зачастую продвижение ресурса осуществляется в том числе и через страницы категорий и тэгов. В этом случае вы можете потерять часть трафика.
- Закрытие страниц/страниц/от индексации
Не нужно. Для таких страниц настраивается тег rel=»canonical»; таким образом, на такие страницы заходили роботы, и они учитывают позиционируемые товары/статьи, а также внутреннюю ссылочную массу.
- Задержка обхода регистра
Модное правило. Однако это должно быть только тогда, когда есть необходимость ограничить посещение роботами вашего сайта. Если сайт небольшой, то ограничение времени «быть» будет не самой разумной затеей.
Если сайт небольшой, то ограничение времени «быть» будет не самой разумной затеей.
- Отказ
Некоторые правила я могу отнести только к разряду «блогер не подумал». Например Disallow/20 — по этому правилу закрывать не только все архивы, но и все статьи про 20 способов или 200 советов, как сделать мир лучше.
С помощью robots.txt можно задавать инструкции веб-роботам, продвигать себя, свой бренд, искать специалистов. Есть много места для экспериментов. Просто имейте в виду, чтобы заполнить файл правильно и о распространенных ошибках.
Используйте индексированный файл с умом, и ваш сайт всегда будет в результатах поиска.
Об авторе
Своим письмом Мелиса Марзетт заявляет, что она знает, что интересно увлеченному читателю. Сама являюсь такой и в настоящее время работает на www.findwritingservice.com/. Она пишет прекрасные статьи, читать которые одно удовольствие.
Куда поставить и как оптимизировать
Глубокое понимание WordPress robots.txt поможет вам улучшить SEO вашего сайта. В этом руководстве вы узнаете, что такое robot.txt, и, самое главное, узнаете, как его использовать.
По сути, robot.txt создан для роботов, которые, например, представляют собой программное обеспечение, просматривающее веб-страницы и индексирующее их для результатов поиска .
Позволяет владельцам веб-сайтов запрещать поисковым роботам сканировать определенные страницы или контент на своем веб-сайте. Неправильное использование robot.txt может испортить SEO вашего сайта.
Таким образом, его следует использовать с осторожностью. Но не волнуйтесь, все, что вам нужно узнать по этому вопросу, описано в этом руководстве.
Содержание:
- Что такое файл WordPress robots.txt?
- Преимущества файла robots.txt
- Где находится файл robots.
 txt?
txt? - Как создать файл robots.txt
- Заключение
Что такое файл WordPress Robots.txt?
Содержимое файла robots.txt обычно выглядит следующим образом:
Агент пользователя: *
Запретить: /wp-admin/
Разрешить: /wp-admin/admin-ajax.php
Disallow , в этом случае сообщает поисковым ботам: «Эй, вам не разрешено сканировать папку wp-admin». А Разрешите, ну вы угадали.
Каждый день в Интернете публикуются тысячи новых веб-сайтов. Чтобы поисковикам было легко находить эти веб-сайты, Google и другие поисковые системы индексируют каждый веб-сайт.
Принимая во внимание огромный объем работы, Google полагается на своих поисковых роботов, чтобы быстро выполнить работу.
Когда поисковый робот попадает на ваш веб-сайт, он сначала изучит XML-карту вашего веб-сайта, чтобы узнать все содержащиеся в ней страницы.
Далее бот сканирует и индексирует не только страницы сайта, но и его содержимое, включая папку JS и CSS.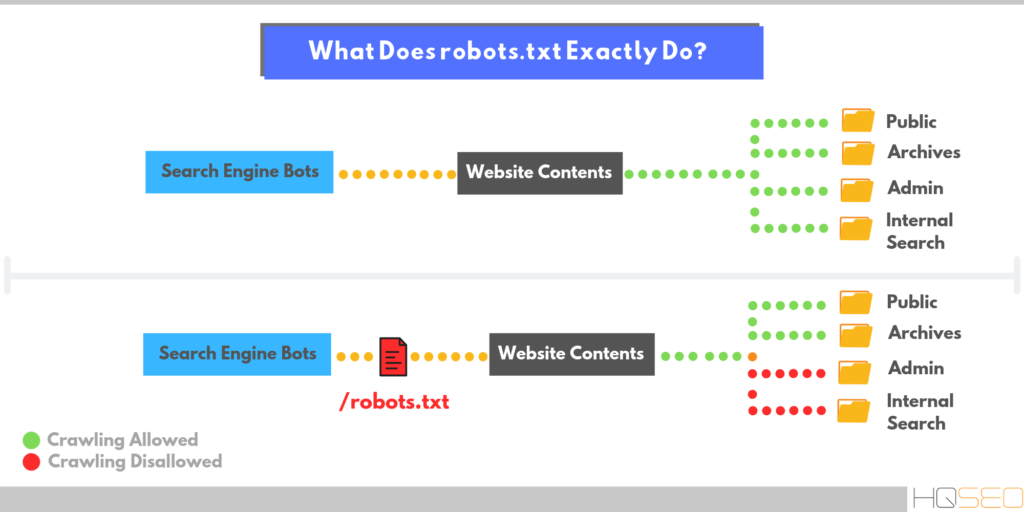 Если это веб-сайт WordPress, бот также просканирует wp-admin 9.0220 папка.
Если это веб-сайт WordPress, бот также просканирует wp-admin 9.0220 папка.
Вы точно не хотите, чтобы это произошло, и единственный способ остановить их — дать им указание не делать этого в файле robots.txt .
Хотя создание файла robots.txt не является обязательным, так как поисковые роботы все равно будут сканировать ваш веб-сайт независимо от того, есть он у вас или нет, его наличие дает множество преимуществ.
Преимущества создания оптимизированного файла robots txt
Основной причиной создания файла robots.txt является предотвращение сканирования роботами поисковых систем определенного содержимого вашего веб-сайта.
Например, вы не хотите, чтобы пользователи имели доступ к папке темы и администратора, файлам плагинов и странице категорий вашего веб-сайта.
Кроме того, оптимизированный файл robots.txt помогает сохранить так называемую квоту сканирования. Квота сканирования — это максимально допустимое количество страниц веб-сайта, которые поисковые роботы могут сканировать за один раз.
Вы хотите убедиться, что сканируются только полезные страницы, иначе ваша квота на сканирование будет исчерпана. Это значительно улучшит SEO вашего сайта.
В-третьих, хорошо написанный файл robots.txt может помочь вам свести к минимуму действия поисковых ботов, в том числе вредоносных ботов на вашем веб-сайте. Таким образом, скорость загрузки вашего сайта значительно улучшится.
Где находится файл robots.txt?
По умолчанию файл robots.txt создается и сохраняется в корневом каталоге вашего веб-сайта всякий раз, когда вы устанавливаете веб-сайт WordPress. Чтобы просмотреть его, откройте свой веб-сайт в браузере и добавьте «/robots.txt» в конце. Например:
https://mywebsite.com/robots.txt
Вот как выглядит наш файл в Fixrunner:
Файл robots.txt WordPress по умолчанию является виртуальным, поэтому к нему нельзя получить доступ или отредактировать. Чтобы получить к нему доступ или отредактировать его, вам придется его создать, и есть много способов сделать это. Давайте посмотрим на некоторые из них!
Давайте посмотрим на некоторые из них!
Как создать файл robots.txt в WordPress
Создание файла robots.txt в WordPress — простой процесс. Вы можете сделать это вручную или использовать плагины WordPress. Здесь мы увидим оба процесса, и плагин, который мы будем использовать, называется Yoast SEO.
Использование плагина Yoast SEO
Плагин Yoast SEO может создать файл robot.txt для WordPress на лету. Конечно, он делает гораздо больше, когда речь идет о SEO для WordPress.
Для начала установите и активируйте плагин, если вы этого еще не сделали.
После того, как Yoast будет запущен и запущен на вашем веб-сайте, перейдите к SEO >> Инструменты
Затем щелкните ссылку Редактор файлов на панели управления Yoast.
Это приведет вас на страницу, где вы можете создать файл robots.txt. Нажмите Создать кнопку .
Это приведет вас к редактору, где вы сможете добавлять и редактировать правила в файле robots. txt вашего WordPress.
txt вашего WordPress.
Добавьте новые правила в редактор файлов и сохраните изменения. Не волнуйтесь, мы покажем вам правила, которые нужно добавить в ближайшее время.
Добавление Robots.txt вручную с помощью FTP в WordPressЭтот метод довольно прост, и его может сделать практически любой. Для начала запустите Блокнот — или любой ваш любимый редактор, если это не текстовый процессор, такой как Microsoft Word — на вашем компьютере.
Для начала добавьте в только что созданный файл следующие правила.
Агент пользователя: *
Запретить: /wp-admin/
Разрешить: /wp-admin/admin-ajax.php
Сохраните файл как robots.txt. Далее вам нужно загрузить его на свой веб-сайт с помощью FTP-программы, такой как FileZilla.
Прежде всего, установите соединение с вашим сайтом в FileZilla. Затем перейдите в папку public_html . В эту папку загрузите только что созданный файл robots. txt.
txt.
Как только загрузка будет завершена, все готово.
Добавление правилПо сути, есть только две инструкции, которые вы можете дать поисковым ботам: Разрешить и Запретить. Разрешить предоставляет им доступ к папке, а Запретить делает наоборот.
Чтобы разрешить доступ к папке, добавьте:
Агент пользователя: *
Разрешить: /wp-content/uploads/
звездочка (*)0010 говорит поисковым ботам: «Эй, это правило применимо ко всем вам».
Чтобы заблокировать доступ к папке, используйте следующее правило
Запретить: /wp-content/plugins/
В данном случае мы запрещаем поисковым ботам доступ к папке плагинов.
Вам решать, какое правило наиболее применимо к вашему веб-сайту. Например, если вы управляете форумом, вы можете заблокировать поисковых роботов на странице форума с помощью следующего правила:
Disallow: /forum/
Как правило, чем меньше правил, тем лучше. Следующего правила достаточно, чтобы выполнить задание:
Следующего правила достаточно, чтобы выполнить задание:
User-Agent: *
Разрешить: /wp-content/uploads/
Запретить: /wp-content/plugins/
2 9 : /wp-admin/Как проверить созданный вами файл robots.txt в Google Search Console
Теперь, когда вы создали файл robots.txt в WordPress, вам нужно убедиться, что он работает должным образом. И нет лучшего способа сделать это, кроме как с помощью инструмента для тестирования robots.txt.
В Google Search Console есть подходящий инструмент для этой цели. Итак, прежде всего, войдите в свою учетную запись Google Console. Вы всегда можете создать учетную запись, если у вас ее нет.
В Google Search Console прокрутите вниз и нажмите Перейти к старой версии.
Перейдя в старую версию, перейдите к Crawl >> robots.txt tester.
В текстовом редакторе вставьте правила, которые вы добавили в файл robots.txt, наконец, нажмите Тест.
Если все получилось, то все готово!
Заключение
Иногда поисковые боты могут вести себя неуправляемо, и единственный способ остановить их действия на вашем веб-сайте — использовать файл robots.txt . Даже при этом некоторые боты по-прежнему будут полностью игнорировать любые установленные вами правила — вам просто нужно смириться с этим.
Несмотря на то, что WordPress автоматически создает файл robots.txt при установке, создать его для себя — хорошая идея. Хорошо оптимизированный файл robots.txt предотвратит причинение вреда вашему сайту поисковыми ботами.
Если эта статья оказалась вам полезной, поделитесь ею. Для получения дополнительных руководств по WordPress следите за нашим блогом WordPress.
Дополнительные ресурсы:
- Двухфакторная аутентификация WordPress
- Ошибка заголовка Vary Accept-encoding: как исправить в WordPress
- Как найти, создать и использовать файл htaccess в WordPress
- Как установить и настроить All-in-One SEO Pack Plugin
Подробнее Полезные статьи:
WordPress и файл Robots.
txt: примеры и рекомендации [издание 2020 г.]Вопрос : Я использую WordPress, и мне интересно, следует ли мне создать файл robots.txt. Я читал в разных местах, что должен, и в других местах, что WordPress создает свой собственный файл robots.txt. Какова реальная история? – Тим, Мэдисон, Висконсин
WordPress и файл Robots.txt: что лучше для вас
Тим, еще один отличный вопрос. Что делать с файлом robots.txt при использовании WordPress?
На этот вопрос есть два ответа. Первый — это короткий и быстрый ответ, а второй — длинный и сложный… вы услышите, как эксперты обсуждают файл WordPress robots.txt до тошноты .
Итак, давайте сначала перейдем к быстрому ответу, а затем посмотрим на «длинный ответ» и завалим вас ссылками, где эксперты обсуждают этот вопрос до посинения.
WordPress и файл Robots.TXT: виртуальный файл robots.txt по умолчанию
Тим, быстрый ответ: ты.
Чтобы просмотреть этот файл, вы можете посетить http://yoursite. com/robots.txt .
Файл должен выглядеть примерно так:
User-agent: * Запретить: /wp-admin/ Запретить: /wp-includes/ Карта сайта: http://yoursite.com/sitemap.xml.gz
Первая строка этого файла, строка «user-agent», представляет собой объявление бота . * указывает на всех поисковых ботов (таких как Google, Yahoo и т. д.). И по умолчанию будет проиндексировано все, кроме строк, о которых мы упомянем ниже.
Вторая и третья строки этого файла сообщают пользовательским агентам ( в данном случае все они ) не выполнять поиск в этих конкретных каталогах WordPress, поскольку они не содержат дополнительного контента.
Наконец, строка карты «Карта сайта» информирует ботов о расположении вашего файла карты сайта. Эта строка предположительно полезный и должен быть включен в ваш файл robots.txt. Если вы используете плагин карт сайта Google XML (что вам и следует делать), эта строка будет включена… и разрыв строки после последней строки disallow также должен быть там.
Что делать, если вы не видите файл robots.txt?
Тим, у некоторых людей есть эта проблема, поэтому я решил дать ответ и на нее.
Если вы не видите виртуальный файл robots.txt, который должен был создать WordPress, возможно, вы используете устаревшую версию WordPress ИЛИ виртуальный файл robots.txt был вытеснен плагином.
В этом случае вы можете легко создать свой собственный файл robots.txt. Используя приведенный выше пример WordPress, просто скопируйте и вставьте информацию в текстовый файл, назовите его robots.txt, а затем загрузите в корневой каталог. Очевидно, вы хотите изменить yoursite на фактический URL вашего веб-сайта.
Создайте свой собственный Robots.Txt: примеры
Могут быть случаи, когда вы хотите, чтобы другие каталоги (каталоги, которые, возможно, существуют за пределами вашей среды WordPress) также были запрещены, потому что вы не хотите, чтобы они отображались в результатах поиска.
Это также легко сделать, создав собственный файл robots. txt . Если у вас есть подкаталог вашего веб-сайта, который вы не хотите включать в боты, просто добавьте такую строку:
. Запретить: /эта директория/
Не забудьте добавить в конце «/» ! Если вы этого не сделаете, он не будет индексировать ничего, начинающееся со слов «thisdirectory».
Будет ли ваш robots.txt перезаписывать виртуальный Robots.txt WordPress?
Да. Если вы загрузите свой собственный файл robots.txt, вы увидите, что он теперь 9-й.0192 активный файл , посетив http://yoursite.com/robots.txt .
Пример Robots.Txt для загрузки
Тим, если вам не нужно запрещать какие-либо другие файлы, подойдет виртуальный файл robots.txt WordPress.
Однако, если вы не видите виртуальный файл robots.txt или вам нужно создать его вручную, чтобы исключить другие подкаталоги на вашем веб-сайте, используйте следующие строки в качестве шаблона:
Пользовательский агент: * Запретить: /wp-admin/ Запретить: /wp-includes/ Запретить: /subdirdontindex1/ Запретить: /subdirdontindex2/ Карта сайта: http://yoursite.com/sitemap.xml
Приложение: файл WordPress Robots.Txt — исчерпывающее обсуждение
Я считаю, что большинству из вас достаточно упомянутых выше стратегий. Это связано с тем, что «окончательный ответ» не был объявлен со 100% уверенностью, и, за исключением серьезной ошибки, такой как непреднамеренный запрет всего вашего сайта ( это было сделано! ), ваш файл robots.txt должен быть в порядке.
Тем не менее, исчерпывающее обсуждение WordPress и Robots.txt продолжается.
Вот несколько ссылок, в которых обсуждается этот вопрос с кратким описанием каждой ссылки:
Поисковая оптимизация для WordPress: это обсуждение сайта WordPress.org SEO для WordPress, и здесь они представляют рекомендуемый файл robots.txt. Вы, конечно, можете использовать их рекомендованный файл robots.txt, но он был опровергнут в нескольких статьях из-за запрета слишком многого.
Руководство по WordPress Robots.txt — что это такое и как его использовать. Подробно изучите файл robots.txt с помощью этого подробного сообщения от Kinsta.com.
Как оптимизировать ваш WordPress Robots.txt для SEOЭтот сайт полностью посвящен WordPress, и в этой статье они уделяют внимание файлу robots.txt со множеством убедительных примеров того, что вы должны и не должны делать.
WordPress robots.txt Пример: Один автор, которого я очень уважаю, поскольку он является создателем лучшего SEO-плагина для WordPress, говорит, что рекомендации WordPress слишком строгие. Он говорит, что единственная строка, которая должна быть в вашем robots.txt, это: «User-agent: *».
WordPress требуется файл robots.txt по умолчанию и многое другое…: Знаете ли вы, что на WordPress.org есть раздел идей ? Что ж, они это делают, и одна из идей — предоставить файл robots.txt по умолчанию. Мне нравится эта идея (хотя она действительно существует с виртуальным robots.txt), и она позволила бы нам всем довольствоваться одним ответом.
Инструменты для создания robots. txt: если вам неудобно создавать собственный файл robots.txt, эта ссылка содержит инструменты, которые вам помогут.
- О
- Последние сообщения
Ричард Каммингс
Директор по SEO, социальным сетям и разработке веб-контента в SEO System
Ричард Каммингс много лет занимается онлайн-маркетингом, настроил и оптимизировал сотни WordPress сайты. Он основал The SEO System, чтобы предоставлять компаниям услуги SEO, социальные сети, онлайн-маркетинг и программное обеспечение.
Последние сообщения Ричарда Каммингса (посмотреть все)
Файл WordPress robots.txt — Как создать robots.txt
Использование файла robots.txt на вашем сайте, построенном на WordPress? Если нет, вы должны.
Как его создать? Просто откройте Блокнот Microsoft и создайте текстовый файл и назовите его robots.txt
Затем загрузите его в свою установку WordPress.
Войдите в cPanel > Диспетчер файлов > public_html (путь может отличаться для настройки вашего веб-сайта) > загрузите здесь robots. txt.
Когда вам нужно предоставить директивы, чтобы вы могли лучше контролировать (или даже блокировать) сканирование поисковых систем, таких как Google, вот все, что вам нужно знать об использовании файла robots.txt для системы управления контентом WordPress.
Крайне важно, чтобы вы действительно понимали, что делают эти директивы, иначе вы можете увидеть много ошибок Google Search Console (например, URL-адреса заблокированы robots.txt).
Поисковая система Google перед тем, как проиндексировать ваш веб-сайт, СКАНИРУЕТ ЕГО с помощью пользовательского агента под названием Googlebot.
Другие пользовательские агенты = поисковые роботы, поисковые роботы означают одно и то же. В основном они запрашивают URL-адрес, чтобы увидеть, что находится на этом URL-адресе. Это называется Протокол исключения роботов . Ниже приведены 2 дополнительных материала, которые помогут расширить ваши знания о Google и оптимизации веб-сайтов.
- Введение в robots. txt
- Создайте файл robots.txt
Как создать и использовать robots.txt в WordPress (видео от RankYa)
Расположение файла robots.txt в WordPress
По умолчанию при установке WordPress НЕТ файла robots.txt. Хотя это так, WordPress автоматически создаст виртуальный файл robots.txt. Отсюда путаница, когда вы пытаетесь найти такой файл на своем веб-сервере. Обычно вы смотрите здесь:
Диспетчер файлов > public_html > файл robots.txt
И тогда вы ничего не видите, потому что НЕТ физического файла robots.txt. Это означает, что вам нужно создать его следующим образом:
Пример файла WordPress robots.txt 1
User-agent: *
Запретить: Просто создайте текстовый файл и назовите его robots.txt, а затем вставьте приведенный выше код и загрузите его на свой веб-сервер, где установлен ваш WordPress. Вышеприведенный пример кода говорит:
Эй, Googlebot, вы МОЖЕТЕ получить доступ ко всему моему веб-сайту, я запрещаю вам НЕ
Пример файла WordPress robots.
txt 2: User-agent: Googlebot
Запретить&двоеточие; /cgi-бен/
Запретить&двоеточие; /wp-админ/$
Запретить&двоеточие; */трекбэк/$
Запретить&двоеточие; /комментарии/лента*
Запретить&двоеточие; /wp-логин.php?*
Разрешить&двоеточие; /*.js*
Разрешить&двоеточие; /*.css*
Разрешить&двоеточие; /wp-admin/admin-ajax.php
Разрешить&двоеточие; /wp-admin/admin-ajax.php?action=*
Разрешить&двоеточие; /wp-контент/загрузки/*
Агент пользователя&двоеточие; *
Запретить&двоеточие; /cgi-бен/
Запретить&двоеточие; /wp-админ/$
Запретить&двоеточие; */трекбэк/$
Запретить&двоеточие; /комментарии/лента*
Запретить&двоеточие; /wp-логин.php?*
Разрешить&двоеточие; /*.js*
Разрешить&двоеточие; /*.css*
Разрешить&двоеточие; /wp-admin/admin-ajax.php
Разрешить&двоеточие; /wp-admin/admin-ajax.php?action=*
Разрешить&двоеточие; /wp-контент/загрузки/*
#Карта сайта: https://ИЗМЕНИТЬ/page-sitemap.xml
#Карта сайта: https://ИЗМЕНИТЬ/post-sitemap.xml
#Карта сайта: https://ИЗМЕНИТЬ/product-sitemap. xml
В приведенном выше примере файла robots.txt все, что вам нужно изменить, — это расположение ваших карт сайта, а затем удалить тег #, поскольку он используется в качестве комментария. Просто создайте текстовый файл и назовите его robots.txt, а затем поместите приведенный выше код и загрузите его на свой веб-сервер, где установлен ваш WordPress (после того, как вы измените расположение карты сайта). Вы можете безопасно использовать приведенный выше код, так как он поможет вашему сайту WordPress избежать многих ошибок Google Search Console, таких как ошибки сервера 5xx.
Скачать файл robots.txt Пример
robots.txt (формат .zip, просто распакуйте его)
WordPress robots.txt не обновляется?
Обычно это связано с тем, что вы видите кешированную версию своего веб-сайта. Вам необходимо очистить кэш вашего интернет-браузера.
WordPress robots.txt Плагин Yoast SEO?
Плагин Yoast SEO для WordPress создает для вас файл robots. txt и позволяет вам изменять его с панели управления WordPress. Просто используйте примеры кода выше и сохраните изменения в файле robots.txt.
Плагин robots.txt для WordPress?
НЕ используйте плагины для работы с файлом robots.txt, потому что создать его просто, как описано выше.
URL-адрес заблокирован robots.txt WordPress
Это означает, что когда Google пытается просканировать ваш веб-сайт / веб-страницы, он видит в файле robots.txt что-то, что говорит: «Эй, Google, тебе НЕ разрешено (следовательно, DISallow) сканировать этот URL», что приводит к блокировке URL из-за ошибок файла robots.txt в консоли поиска Google.
Как разблокировать URL-адрес, заблокированный robots.txt в WordPress
Просто используйте инструкции, показанные в Пример файла WordPress robots.txt 1 выше, так как это разблокирует любые директивы в вашем файле robots.txt
Как разблокировать URL-адрес, заблокированный robots.txt в WordPress
Чтобы избежать большинства проблем с Google Search Console robots. txt, блокирующим определенные URL-адреса с вашего собственного веб-сайта, созданного на WordPress, поймите тот факт, что процессы CRAWLING и INDEXING Google — это два совершенно разных процесса.
Это означает, что то, что вы используете файл robots.txt, НЕ означает, что вы говорите Google НЕ индексировать определенные части вашего веб-сайта. Чтобы иметь возможность контролировать индексирование определенных частей Google, вам необходимо использовать метатеги с параметром noindex. Пример только для WordPress CMS Путь к этому файлу: . Войдите в веб-хостинг > Диспетчер файлов > public_html > wp-content > themes > YourThemeName > header.php
По сути, найдите файл header.php, найдите часть
и измените приведенный выше код PHP, а затем скопировать вставить сохранить, чтобы контролировать индексацию Google для определенных частей вашего сайта WordPress.RankYa WordPress SEO Совет
- НЕ индексируйте теги, поэтому используйте is_tag()
- НЕ индексируйте is_attachment URL-адреса вложения (если только ваш веб-сайт не посвящен фотографии или сайту обмена фотографиями)
- НЕ индексировать разбивку на страницы is_single() && is_paged()
Руководство по оптимизации файла WordPress Robots.Txt | by Visualmodo
Вы слышали о файле Robots.txt? Если вы знакомы с WordPress, возможно, вы знаете файл robots. Это имеет очень важное влияние на эффективность SEO вашего сайта. Хорошо оптимизированный файл Robots может улучшить рейтинг вашего сайта в поисковых системах. С другой стороны, неправильно настроенный файл Robots.txt может сильно повлиять на SEO вашего сайта.
WordPress автоматически создает файл Robots.txt для вашего веб-сайта. Но все же, вам нужно предпринять некоторые действия, чтобы правильно его оптимизировать. Есть так много других факторов для SEO, но этот файл неизбежен. Поскольку его редактирование предполагает использование некоторой строки кода, большинство владельцев веб-сайтов не решаются вносить в него изменения. Вам не о чем беспокоиться. Сегодняшняя статья посвящена его важности и тому, как оптимизировать файл роботов WordPress для улучшения SEO. Прежде чем двигаться дальше, давайте узнаем некоторые фундаментальные вещи.
Robots.txt — это текстовый файл, который веб-мастера создают для того, чтобы инструктировать веб-роботов (обычно роботов поисковых систем) о том, как сканировать страницы на их веб-сайте. Кроме того, файл robots.txt является частью протокола исключения роботов (REP), группы веб-стандартов, которые регулируют, как роботы сканируют Интернет, получают доступ и индексируют контент, а также предоставляют этот контент пользователям. REP также включает в себя такие директивы, как метароботы, а также инструкции для страницы, подкаталога или сайта о том, как поисковые системы должны обрабатывать ссылки (например, «follow» или «nofollow»).
Я уже говорил, что на каждом сайте WordPress есть файл robots.txt по умолчанию в корневом каталоге. Вы можете проверить файл robots.txt, перейдя по адресу http://yourdomain.com/robots.txt. Например, вы можете проверить наш файл robots.txt здесь: https://visualmodo.com/robots.txt
Если у вас нет файла robots, вам придется его создать. Это очень легко сделать. Просто создайте текстовый файл на своем компьютере и сохраните его как .txt. Наконец, загрузите его в корневой каталог. Вы можете загрузить его через FTP-менеджер или файловый менеджер cPanel.
Теперь давайте посмотрим, как отредактировать файл .txt. Вы можете редактировать файл robots с помощью FTP-менеджера или файлового менеджера cPanel. Однако это долго и немного сложно.
Лучший способ редактировать файл Robots — использовать подключаемый модуль. Существует несколько плагинов WordPress .txt. Я предпочитаю Yoast SEO. Это лучший SEO-плагин для WordPress. Я уже рассказывал, как настроить Yoast SEO. В результате этот плагин позволяет вам изменять файл robots из вашей административной области WordPress. Однако, если вы не хотите использовать плагин Yoast, вы можете использовать другие плагины, такие как WP Robots Txt. После того, как вы установили и активировали плагин Yoast SEO, перейдите в Панель администратора WordPress > SEO > Инструменты.
Затем нажмите «Редактор файлов». после этого нужно нажать на «Создать файл robots.txt». Затем вы получите редактор файла Robots.txt. Здесь вы можете настроить файл robots. Прежде чем редактировать файл, вам нужно понять команды файла. В основном это три команды.
User-agent — определяет имя ботов поисковых систем, таких как Googlebot или Bingbot. Вы можете использовать звездочку (*) для обозначения всех ботов поисковых систем. Запретить — запрещает поисковым системам сканировать и индексировать некоторые части вашего сайта. Разрешить — указывает поисковым системам сканировать и индексировать, какие части вы хотите индексировать.
Вот пример файла Robots.txt.
User-agent: *
Disallow: /wp-admin/
Alow: /
Этот файл robots указывает всем роботам поисковых систем сканировать сайт. Во второй строке он сообщает поисковым роботам не сканировать часть /wp-admin/. В 3-й строке он указывает ботам поисковых систем сканировать и индексировать весь веб-сайт.
Простая неправильная настройка в файле Robots может полностью деиндексировать ваш сайт в поисковых системах. Например, если вы используете команду «Запретить: /» в файле Robots, ваш сайт будет деиндексирован поисковыми системами. Так что нужно быть осторожным при настройке.
Еще одним важным моментом является оптимизация файла Robots.txt для SEO. Прежде чем перейти к лучшим практикам роботов SEO, я хотел бы предупредить вас о некоторых плохих практиках.
- Файл WordPress Robots для скрытия некачественного содержимого. Лучше всего использовать метатеги noindex и nofollow. Вы можете сделать это с помощью плагина Yoast SEO.
- Файл Robots.txt, чтобы запретить поисковым системам индексировать ваши категории, теги, архивы, страницы авторов и т. д. Вы можете добавить на эти страницы метатеги nofollow и noindex с помощью плагина Yoast SEO.
- Используйте файл Robots.txt для обработки повторяющегося содержимого. Есть и другие способы.
Во-первых, вам нужно определить, какие части вашего сайта не должны сканироваться роботами поисковых систем. Я предпочитаю запрещать /wp-admin/, /wp-content/plugins/, /readme.html, /trackback/. Во-вторых, производные «Разрешить: /» в файле Robots не так важны, так как боты все равно будут сканировать ваш сайт. Но вы можете использовать его для конкретного бота. Добавление карты сайта в файл Robots также является хорошей практикой. Кроме того, прочитайте эту статью о картах сайта WordPress.
Вот пример идеального файла .txt для WordPress.
Агент пользователя: *
Запретить: /wp-admin/
Запретить: /readme.html
Разрешить: /wp-admin/admin-ajax.phpЗапретить: /wp-content/plugins/
Разрешить: /wp-content/uploads/Запретить: /trackback/
Карта сайта: https://visualmodo.com/post-sitemap.xml
Запретить: /go/
Карта сайта: https://visualmodo.com/page -sitemap.xml
После обновления файла Robots.txt необходимо протестировать файл Robots.txt, чтобы проверить, не затрагивает ли обновление какое-либо содержимое.
Вы можете использовать Google Search Console, чтобы проверить, есть ли какие-либо «Ошибки» или «Предупреждения» для вашего файла Robots. Просто войдите в Google Search Console и выберите сайт. Затем перейдите в Crawl > robots Test the er и нажмите кнопку «Отправить». Появится окно. Просто нажмите на кнопку «Отправить».
Наконец, перезагрузите страницу и проверьте, обновлен ли файл. Обновление файла robots может занять некоторое время. Если он еще не обновлен, вы можете ввести код файла Robots в поле, чтобы проверить наличие ошибок или предупреждений. Он покажет ошибки и предупреждения там. Сохранить
Если вы заметили какие-либо ошибки или предупреждения в файле, вы должны исправить их, отредактировав файл robots.
Как создавать и оптимизировать для SEO
Всякий раз, когда мы говорим о SEO блогов Wp, файл WordPress robots.txt играет важную роль в рейтинге поисковых систем.
Блокирует роботов поисковых систем и помогает индексировать и сканировать важные разделы нашего блога. Хотя иногда неправильно настроенный файл Robots.txt может полностью скрыть ваше присутствие от поисковых систем.
Поэтому важно, чтобы при внесении изменений в файл robots.txt он был хорошо оптимизирован и не блокировал доступ к важным частям вашего блога.
Существует множество недоразумений относительно индексации и неиндексации контента в Robots.txt, и мы рассмотрим и этот аспект.
SEO состоит из сотен элементов, и одной из основных частей SEO является Robots.txt. Этот небольшой текстовый файл, находящийся в корне вашего сайта, может помочь в серьезной оптимизации вашего сайта.
Большинство веб-мастеров избегают редактирования файла Robots.txt, но это не так сложно, как убить змею. Любой человек с базовыми знаниями может создать и отредактировать файл Robots, и если вы новичок в этом, этот пост идеально подходит для ваших нужд.
Если на вашем сайте нет файла Robots.txt, вы можете узнать, как это сделать здесь. Если в вашем блоге/веб-сайте есть файл Robots.txt, но он не оптимизирован, вы можете прочитать этот пост и оптимизировать файл Robots.txt.
Содержание страницы
Что такое WordPress Robots.txt и почему мы должны его использовать Позвольте мне начать с основ. Во всех поисковых системах есть боты для сканирования сайта. Сканирование и индексирование — это два разных термина, и если вы хотите углубиться в них, вы можете прочитать: Сканирование и индексирование Google.
Когда бот поисковой системы (бот Google, бот Bing, сканеры сторонних поисковых систем) заходит на ваш сайт по ссылке или по ссылке на карту сайта, представленной на панели управления веб-мастером, он переходит по всем ссылкам в вашем блоге, чтобы сканировать и индексировать ваш сайт.
Теперь эти два файла — Sitemap.xml и Robots.txt — находятся в корневом каталоге вашего домена. Как я уже упоминал, боты следуют правилам Robots.txt, чтобы определить сканирование вашего сайта. Вот как используется файл robots.txt:
Когда поисковые роботы заходят на ваш блог, у них ограниченные ресурсы для сканирования вашего сайта. Если они не смогут просканировать все страницы вашего сайта с выделенными ресурсами, они перестанут сканировать, что затруднит вашу индексацию.
Теперь, в то же время, есть много частей вашего сайта, которые вы не хотите, чтобы роботы поисковых систем сканировали. Например, ваша папка WP-admin, ваша панель администратора или другие страницы, которые бесполезны для поисковых систем. Используя Robots.txt, вы указываете поисковым роботам (ботам) не сканировать такие области вашего веб-сайта. Это не только ускорит сканирование вашего блога, но также поможет в глубоком сканировании ваших внутренних страниц.
Самое большое заблуждение относительно файла Robots.txt состоит в том, что люди используют его для неиндексирования .
Помните, что файл Robots.txt не предназначен для Do Index или Noindex. Это прямой поисковых ботов, чтобы остановить сканирование определенных частей вашего блога . Например, если вы посмотрите на файл ShoutMeLoud Robots.txt (платформа WordPress), вы четко поймете, какую часть моего блога я не хочу сканировать ботами поисковых систем.
Файл Robots.txt помогает роботам поисковых систем и указывает, какую часть следует сканировать, а какую избегать. Когда поисковый бот или паук поисковой системы заходит на ваш сайт и хочет проиндексировать ваш сайт, они сначала следуют файлу Robots.txt. Поисковый бот или паук следует указаниям файла для индексации или не индексации страниц вашего сайта.
Если вы используете WordPress, вы найдете файл Robots.txt в корне вашей установки WordPress.
Для статических веб-сайтов, если вы или ваши разработчики создали их, вы найдете их в корневой папке. Если вы не можете, просто создайте новый файл блокнота и назовите его Robots.txt и загрузите его в корневой каталог вашего домена с помощью FTP.
Вот пример файла Robots.txt, и вы можете увидеть содержимое и его расположение в корне домена.
https://www.shoutmeloud.com/robots.txt
Как создать файл robots.txt?
Как я упоминал ранее, Robots.txt — это обычный текстовый файл. Итак, если у вас нет этого файла на вашем сайте, откройте любой текстовый редактор, какой вам нравится (Блокнот, например) и создайте файл Robots.txt, состоящий из одной или нескольких записей. Каждая запись содержит важную информацию для поисковой системы. Пример:
User-agent: googlebot
Disallow: /cgi-bin
Если эти строки прописаны в файле Robots.txt, это означает, что он позволяет боту Google индексировать каждую страницу вашего сайта. Но cgi-bin папка корневого каталога не позволяет индексировать. Это означает, что бот Google не будет индексировать папку cgi-bin .
С помощью параметра «Запретить» вы можете запретить любому поисковому роботу или поисковому роботу индексировать страницу или папку. Есть много сайтов, которые не используют индекс в архивной папке или странице, чтобы не создавать дублированного контента .
Где взять имена поисковых ботов? Вы можете получить его в журнале вашего сайта, но если вы хотите много посетителей из поисковой системы, вы должны разрешить каждому поисковому роботу. Это означает, что каждый поисковый бот будет индексировать ваш сайт. Вы можете написать User-agent: * для разрешения каждому поисковому роботу. Например:
User-agent: *
Disallow: /cgi-bin
Поэтому каждый поисковый бот будет индексировать ваш сайт.
Не следует использовать файл Robots.txt
1. Не используйте комментарии в файле Robots.txt.
2. Не оставляйте пробел в начале любой строки и не делайте в файле обычный пробел. Пример:
Плохая практика:
User-agent: *
Запретить: /support
Рекомендуемая практика:
Агент пользователя: *
Запретить: /support
3. Не меняйте правила управления.
Плохая практика:
Запретить: /support
User-agent: *
Передовая практика:
User-agent: *
Если вы не хотите делать: /support 90.204 90. индексировать более одного каталога или страницы, не пишите вместе с этими именами:
Плохая практика:
Агент пользователя: *
Disallow: /support /cgi-bin /images/
Хорошая практика:
User-agent: *
Disallow0: /support /cgi-bin
Запретить: /images
5. Правильно используйте заглавные и строчные буквы. Например, если вы хотите проиндексировать каталог «Скачать», но пишете «скачать» в файле Robots.txt, он примет его за поискового бота.
6. Если вы хотите проиндексировать все страницы и каталог вашего сайта, напишите:
User-agent: *
Disallow:
7. Но если вы не хотите индексировать все страницы и каталоги вашего сайта, напишите:
User-agent: *
After Disallow: /
25 отредактировав файл Robots.txt, загрузите его через любое программное обеспечение FTP в корневую или домашнюю директорию вашего сайта.
Руководство по WordPress Robots.txt:
Вы можете либо отредактировать файл WordPress Robots.txt, войдя в свою учетную запись FTP на сервере, либо использовать плагины, такие как метаданные Robots, для редактирования файла Rrobots.txt с панели управления WordPress. Есть несколько вещей, которые вы должны добавить в файл Robots.txt вместе с URL-адресом вашей карты сайта. Добавление URL-адреса карты сайта помогает ботам поисковых систем найти файл карты сайта и приводит к более быстрому индексированию страниц.
Вот пример файла Robots.txt для любого домена. В карте сайта замените URL-адрес карты сайта на URL вашего блога:
Карта сайта: https://www.shoutmeloud.com/sitemap.xml Пользовательский агент: * # запретить все файлы в этих каталогах Запретить: /cgi-bin/ Запретить: /wp-admin/ Запретить: /архив/ запретить: /*?* Запретить: *?replytocom Запретить: /comments/feed/ Агент пользователя: Mediapartners-Google* Разрешать: / Агент пользователя: Googlebot-Image Разрешить: /wp-content/uploads/ Агент пользователя: Adsbot-Google Разрешать: / Агент пользователя: Googlebot-Mobile Разрешать: /
Блокировка плохих SEO-ботов (полный список)
Существует множество инструментов SEO, таких как Ahrefs, SEMRush, Majestic и многие другие, которые продолжают сканировать ваш сайт в поисках секретов SEO. Эти стратегии используются вашими конкурентами в своих целях и не приносят вам никакой пользы. Более того, эти поисковые роботы также увеличивают нагрузку на ваш сервер и увеличивают его стоимость.
Если вы не используете один из этих инструментов SEO, вам лучше заблокировать их от сканирования вашего сайта. Вот что я использую в своем файле robots.txt, чтобы заблокировать некоторые из самых популярных SEO-агентов:
User-agent: MJ12bot
Disallow: /
User-agent: SemrushBot
Disallow: /
User-agent: SemrushBot-SA
Disallow: /
User-agent: dotbot
Disallow:/
User-agent: Ahrefs9Bot 9069Bot
Disallow: /
User-agent: Alexibot
Disallow: /
User-agent: SurveyBot
Disallow: /
User-agent: Xenu’s
Disallow: /
User-agent: Xenu’s Link Sleuth 1.1c
Disallow: /
User- агент: rogerbot
Disallow: /
# Block NextGenSearchBot
User-agent: NextGenSearchBot
Disallow: /
# Блокировать ia-archiver от сканирования сайта
User-agent: ia_archiver
Disallow: /
# Блокировать archive. org_bot от сканирования сайта
User-agent: archive.org_bot
Disallow: /
# Заблокировать бота Archive.org от сканирования сайта
Агент пользователя: Archive.org Bot
Запретить: /
# Заблокировать LinkWalker от сканирования сайта
Пользовательский агент: LinkWalker
Запретить: /
# Заблокировать GigaBlast Spider от сканирования сайта
User-agent: GigaBlast Spider
Disallow: /
# Блокировать ia_archiver-web.archive.org_bot от сканирования сайта
User-agent: ia_archiver-web.archive.org
Disallow: /
# Блокировать PicScout Crawler от сканирования сайта
Агент пользователя: PicScout
Запретить: /
# Блокировать BLEXBot Crawler от сканирования сайта
Пользовательский агент: BLEXBot Crawler
Запретить: /
# Заблокировать TinEye от сканирования сайта # Заблокировать SEO-кики
User-agent: SEOkicks-Robot
Disallow: /
# Block BlexBot
User-agent: BLEXBot
Disallow: /
# Block SISTRIX
User-agent: SISTRIX Crawler
Disallow: /
5 900 robot Агент пользователя: UptimeRobot/2. 0
Запретить: /
# Заблокировать робота Ezooms
Агент пользователя: Робот Ezooms
Запретить: /
# Заблокировать Crawler netEstate NE (+http://www.website-datenbank.de/)
Агент пользователя: netEstate NE Crawler (+http://www.website-datenbank.de/)
Запретить: /
# Заблокировать робота WiseGuys
Агент пользователя: Робот WiseGuys
Запретить: /
# Заблокировать робота Turnitin
Агент пользователя: Робот Turnitin
Запретить: /
# Заблокировать Heritrix
Агент пользователя 90: Disallow: /
# Block pricepi
User-agent: pimonster
Disallow: /
User-agent: Pimonster
Disallow: /
User-agent: Pi-Monster
Disallow: /
# Block Eniro
User-agent: ECCP/1.0 ([электронная почта защищена])
DISLAING: /
# Блок PSBOT
Пользовательский агент: PSBOT
DISLAING: /
# Block YouDao
Пользовательский агент: Youdaobot
DISLAING: /
# BlexBOT
Пользователь-Агент: BlexBOT
9999999999999999
# BlexBOT
: BlexBOT
99999999999999999 годы
99999999999
. # Заблокировать NaverBot
Пользовательский агент: NaverBot
Пользовательский агент: Yeti
Запретить: /
# Заблокировать ZBot
Пользовательский агент: ZBot
Запретить: /
# Заблокировать Vagabondo
Пользовательский агент: Vagabondo /
Disallow0:5
# Заблокировать LinkWalker
User-agent: LinkWalker
Disallow: /
# Block SimplePie
User-agent: SimplePie
Disallow: /
# Block Wget
User-agent: Wget
Disallow: /
# Block Pixray-Seeker 9 агент: Pixray-Seeker
Disallow: /
# Block BoardReader
User-agent: BoardReader
Disallow: /
# Block Quantify
User-agent: Quantify
Disallow: /
# Block Plukkie-agent 906:
Запретить: /
# Заблокировать Cuam
User-agent: Cuam
Disallow: /
# https://megaindex.com/crawler
User-agent: MegaIndex.ru
Disallow: /
User-agent: megaindex.com
Disallow : /
User-agent: +http://megaindex. com/crawler
Disallow: /
User-agent: MegaIndex.ru/2.0
Disallow: /
User-agent: megaIndex.ru
Disallow: /
Убедитесь, что новый файл Robots.txt не влияет на содержимое
Итак, вы внесли некоторые изменения в файл Robots.txt, и пришло время проверить, не повлияло ли на какое-либо ваше содержимое обновление в файле Robots.txt. файл robots.txt.
Вы можете использовать консоль поиска Google «Просмотреть как инструмент Google», чтобы узнать, может ли файл Robots.txt получить доступ к вашему контенту.
Эти шаги просты.
Войдите в консоль поиска Google, выберите свой сайт, перейдите к диагностике и выберите «Получить как Google».
Добавьте сообщения своего сайта и проверьте, нет ли проблем с доступом к вашему сообщению.
Вы также можете проверить наличие ошибок сканирования, вызванных файлом Robots.txt, в разделе ошибок сканирования в консоли поиска.
В разделе «Сканирование» > «Ошибка сканирования» выберите «Ограничено Robots.