Файл robots.txt для WordPress в 2023 году: где находится, как настроить
Главная » WordPress
robots.txt — файл с инструкциями для роботов поисковых систем и других сервисов по обходу содержимого вашего сайта. В данной статье речь пойдёт об его применении для WordPress, но описанные принципы применимы для любого движка.
Содержание
- Где находится robots.txt для WordPress
- Как редактировать robots.txt
- Пример robots.txt
- Настройка robots.txt
Где находится robots.txt для WordPress
Сам файл лежит в корне сайта. В зависимости от используемого хостинга эта папка может иметь разное название, но чаще всего она называется public_html.
Пример местоположения файла на скрине.
Если указанного файла на вашем сайте нет, создайте его в любом текстовом редакторе (или скачайте по ссылке в этой статье) и поместите на сервере в корне вашего сайта. Поисковый робот при заходе на ваш сайт в первую очередь ищет именно этот файл, поскольку в нем находятся инструкции для его дальнейшей работы.
В общем сайт может существовать и без него, но, например, яндекс вебмастер расценивает его отсутствие как ошибку.
Некоторые seo-плагины создают виртуальный файл. В этом случае он будет открываться по адресу ваш_сайт/robots.txt, но вы не сможете найти его на хостинге. В этом случае надо искать, какой именно плагин мог его создать. Виртуальный файл — это отличный вариант. Как правило плагины предлагают уже готовый и оптимальный вариант настроек.
Как редактировать robots.txt
Это обычный текстовый файл и редактировать его можно в самом простом редакторе: блокноте и т.п. Обычно виртуальные хостинги предлагают файл-менеджеры. В этом случае вы можете открыть его прямо там и внести необходимые корректировки. На скрине показано, как можно открыть файл для редактирования на хостинге Бегет.
Пример robots.txt
На примере ниже показан простой стандартный вариант. В нем указан запрет индексации служебных папок и результатов поиска.
User-agent: * Disallow: /wp-admin Disallow: /wp-includes Disallow: /wp-content/plugins Disallow: /wp-content/cache Disallow: /wp-json/ Disallow: /xmlrpc.php Disallow: /readme.html Disallow: /*? Disallow: /?s= Allow: /*.css Allow: /*.js Sitemap: https://delaemsait.info/sitemap.xml
1 2 3 4 5 6 7 8 9 10 11 12 13 | User-agent: * Disallow: /wp-admin Disallow: /wp-includes Disallow: /wp-content/plugins Disallow: /wp-content/cache Disallow: /wp-json/ Disallow: /xmlrpc.php Disallow: /readme.html Disallow: /*? Disallow: /?s= Allow: /*.css Allow: /*.js Sitemap: https://delaemsait.info/sitemap.xml |
Вы можете скачать этот файл по ссылке и взять его за шаблон.
Обратите внимание, что нужно заменить delaemsait.
info на адрес вашего ресурса в последней строке.

Настройка robots.txt
Нельзя говорить о каком-то стандартном или самом правильном robots.txt. Для каждого сайта в нем могут быть свои директивы в зависимости от установленных плагинов и т.д.
Рассмотрим основные применяемые инструкции.
User-Agent означает, что следующие после него инструкции предназначены именно для этого юзерагента. В данном случае под юзерагентом подразумевается название поискового робота. Можно создать разные разделы разных поисковых систем, то есть для Яндекс, Гугл. Универсальные инструкции находятся в блоке со «*».
Директива disallow означает, что адреса страниц, соответствующие указанной после нее маске, не подлежат обходу и индексации. Например, маска /wp-admin закрывает все файлы из служебного каталога wp-admin.
Сайт WP содержит большое количество служебных папок, индексировать которые поисковикам не нужно. Поэтому рекомендуется сделать так, чтобы поисковик не тратил на них ресурсы, а индексировал лишь необходимое.
Команда allow обладает, соответственно, противоположным смыслом и указывает, что эти адреса можно обходить. Рекомендуется открыть файлы js и css, чтобы поисковые системы могли формировать полные страницы (в вышеприведенном примере это есть).
Sitemap указывает на адрес карты сайта, обычно — sitemap.xml. В том случае, если карты сайта у вас нет, ее желательно создать. (Статья о создании карты сайта.)
Существуют сервисы и плагины — генераторы robots.txt по заданным параметрам. Их легко найти в поисковых системах.
Автор Ложников АндрейВремя чтения 3 мин.Просмотры 148Опубликовано Обновлено
Как создать правильный файл robots.txt для WordPress
Последнее обновление — 19 февраля 2023 в 10:19
Сегодня небольшая заметка о том, как создать файл robots.txt для сайта, работающего на CMS WordPress. Как при помощи входящих в его состав директив управлять поведением поисковых роботов.
Важность наличия роботс на сайте, на мой взгляд, неоспорима. Ведь недаром, WP-разработчики предусмотрели его присутствие в системе по умолчанию, как говорится, “из коробки”.
Содержание:- Что такое robots.txt и где его найти
- Как создать и как корректировать robots.txt
- Основные директивы robots.txt
- Пример правильного robots.txt
- Как проверить robots.txt
- Видео
Что такое robots.txt и где его найти
Robots.txt представляет собой текстовый файл, расположенный в корневой директории сайта, там же, где находится .htaccess и sitemap. xml. Данный файл влияет на индексирование веб-страниц поисковыми системами. При помощи специальных директив он запрещает или разрешает индексировать те или иные записи, это очень удобно.
xml. Данный файл влияет на индексирование веб-страниц поисковыми системами. При помощи специальных директив он запрещает или разрешает индексировать те или иные записи, это очень удобно.
Как создать и как корректировать robots.txt
Надо отметить, что robots.txt сразу начинает работать по умолчанию, одновременно с установкой WordPress. И, по сути, изначально с ним ничего делать не надо. Если перейти по адресу https://nazvanie-saita.ru/robots.txt, то мы увидим вот такое содержание файлика, рекомендованное разработчиками CMS.
Очевидно, что рекомендовано скрыть от поисковиков раздел админки. Однако, обработчик запросов admin-ajax.php из этой же директории должен быть открыт для индексирования.
Как правило, этого бывает достаточно. Вмешиваться в работу robots.txt следует в том случае, если, к примеру, вебмастер фиксирует наличие дублированного контента. Тогда идут в ход запрещающие директивы Disallow.
Чтобы провести корректировку файла, можно пойти двумя путями. Изменения вносятся либо при помощи создания физического файла, размещаемого в корне сайта, либо включением соответствующей функции плагина.
Изменения вносятся либо при помощи создания физического файла, размещаемого в корне сайта, либо включением соответствующей функции плагина.
Я, к примеру, использую СЕО-плагин All in One SEO, в котором реализована возможность внесения изменений в файл robots.txt, включения его в работу. Ранее, у меня был установлен физический файл в корневой директории сайта. Его лучше сразу удалить, если включаем динамический виртуальный robots.txt плагином.
Основные директивы robots.txt
Какие же основные директивы или указания применяются для поисковых систем? Их немного, очень просто запомнить:
Здесь надо отметить, что все вышеперечисленные директивы подходят для всех поисковиков, кроме Clean-param, которую понимает только Яндекс.
Если иным образом не закрыты от индексации системные директории и файлы, а также параметры URL, то их рекомендуется запретить для обхода поисковыми роботами. Это могут быть:
- /wp-admin – админпанель.
- /wp-json – JSON REST API.

- /xmlrpc.php – протокол XML-RPC.
Или, например, такие параметры:
- s – стандартная функция поиска.
- author – личная страница пользователя.
Недавно, в панели Яндекс.Вебмастер я заметил присутствие дублированного контента. Были проиндексированы некоторые URL с параметрами. Для того, чтобы от них избавиться, я включил запрещающую директиву: Disallow: /*?/.
Пример правильного robots.txt
Иногда применяют вариант раздельного содержимого файла robots.txt для более гибкой настройки индексации. То есть, вписывают директивы отдельно для Яндекса и отдельно для остальных поисковиков. Делается это для того, чтобы исключить лишние “телодвижения” поисковых роботов. К примеру, зачем Яндексу сканировать AMP-страницы, которые он не поддерживает?
В этом случае правильный robots.txt может выглядеть следующим образом:
User-agent: *
Allow: /wp-admin/admin-ajax.php
Disallow: /xmlrpc.php
Disallow: /wp-admin
Disallow: /wp-json
Disallow: /*?
User-agent: Yandex
Allow: /wp-admin/admin-ajax. php
php
Disallow: /xmlrpc.php
Disallow: /wp-admin
Disallow: /wp-json
Disallow: /*?
Disallow: /amp
Sitemap: https://vash-supersite/wp-sitemap.xml
Существует возможность ещё более тонкой настройки индексации страниц сайта с параметрами посредством файла robots.txt. Делается это при помощи директивы Clean-param. С ней работает поисковик Яндекс.
Как проверить robots.txt
Правильность работы robots.txt можно проверить в настройках Яндекс.Вебмастер, в разделе “Инструменты”. Здесь можно проверить любую страницу, открыта или закрыта она от индексации.
Кроме того, подобную проверку можно выполнить и в Google, в старой версии Search Console, по ссылке: https://www.google.com/webmasters/tools/robots-testing-tool. В новой версии Search Console, к сожалению, этот функционал пока не реализован.
Видео
Видео, конечно, не по теме. Но лучше, если оно тут будет.
Всем удачи!
Как создать и оптимизировать для SEO
Всякий раз, когда мы говорим о SEO блогов Wp, файл WordPress robots.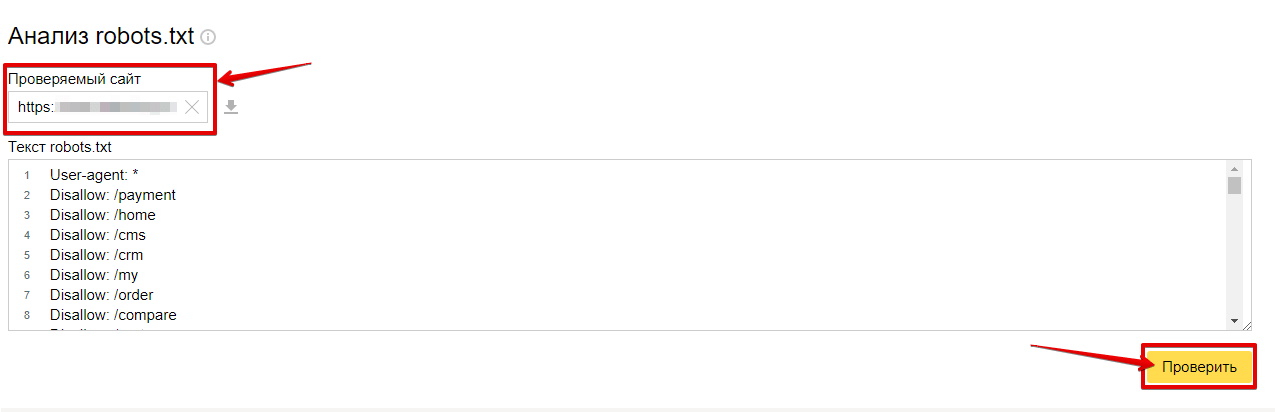 txt играет важную роль в рейтинге поисковых систем.
txt играет важную роль в рейтинге поисковых систем.
Блокирует роботов поисковых систем и помогает индексировать и сканировать важные разделы нашего блога. Хотя иногда неправильно настроенный файл Robots.txt может полностью скрыть ваше присутствие от поисковых систем.
Итак, важно, чтобы при внесении изменений в файл robots.txt он был хорошо оптимизирован и не блокировал доступ к важным частям вашего блога.
Существует множество недоразумений относительно индексации и неиндексации контента в Robots.txt, и мы рассмотрим и этот аспект.
SEO состоит из сотен элементов, и одной из основных частей SEO является Robots.txt. Этот небольшой текстовый файл, находящийся в корне вашего сайта, может помочь в серьезной оптимизации вашего сайта.
Большинство веб-мастеров избегают редактирования файла Robots.txt, но это не так сложно, как убить змею. Любой человек с базовыми знаниями может создать и отредактировать файл Robots, и если вы новичок в этом, этот пост идеально подходит для ваших нужд.
Если на вашем веб-сайте нет файла Robots.txt, вы можете узнать, как это сделать, здесь. Если в вашем блоге/веб-сайте есть файл Robots.txt, но он не оптимизирован, вы можете прочитать этот пост и оптимизировать файл Robots.txt.
Содержание страницы
Что такое WordPress Robots.txt и почему мы должны его использоватьПозвольте мне начать с основ. Во всех поисковых системах есть боты для сканирования сайта. Сканирование и индексирование — это два разных термина, и если вы хотите углубиться в них, вы можете прочитать: Сканирование и индексирование Google.
Когда бот поисковой системы (бот Google, бот Bing, сканеры сторонних поисковых систем) заходит на ваш сайт по ссылке или по ссылке на карту сайта, представленной на панели управления веб-мастером, он переходит по всем ссылкам в вашем блоге, чтобы сканировать и индексировать ваш сайт.
Теперь эти два файла — Sitemap.xml и Robots.txt — находятся в корневом каталоге вашего домена.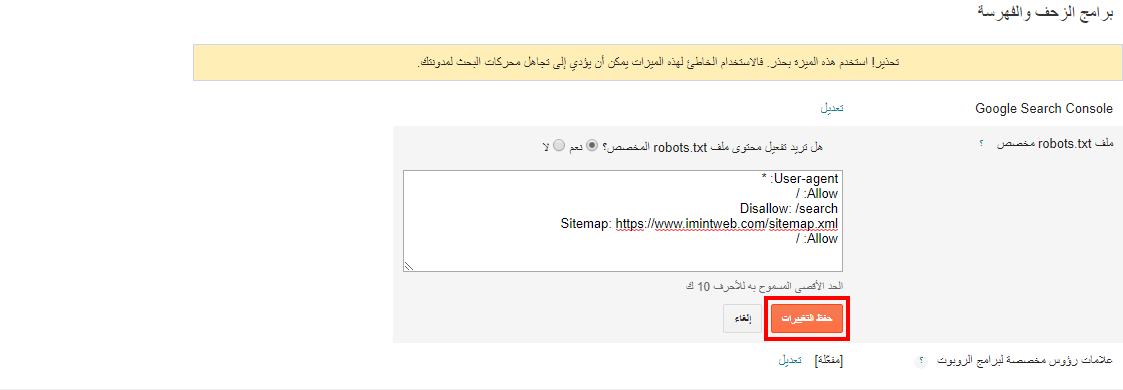 Как я уже упоминал, боты следуют правилам Robots.txt, чтобы определить сканирование вашего сайта. Вот как используется файл robots.txt:
Как я уже упоминал, боты следуют правилам Robots.txt, чтобы определить сканирование вашего сайта. Вот как используется файл robots.txt:
Когда поисковые роботы заходят на ваш блог, у них ограниченные ресурсы для сканирования вашего сайта. Если они не смогут просканировать все страницы вашего сайта с выделенными ресурсами, они перестанут сканировать, что затруднит вашу индексацию.
Теперь, в то же время, есть много частей вашего веб-сайта, которые вы не хотите, чтобы роботы поисковых систем сканировали. Например, ваша папка WP-admin, ваша панель администратора или другие страницы, которые бесполезны для поисковых систем. Используя Robots.txt, вы указываете поисковым роботам (ботам) не сканировать такие области вашего веб-сайта. Это не только ускорит сканирование вашего блога, но также поможет в глубоком сканировании ваших внутренних страниц.
Самое большое заблуждение о файле Robots.txt заключается в том, что люди используют его для запрета индексации .
Помните, что файл Robots.txt не предназначен для Do Index или Noindex. Это прямой поисковых ботов, чтобы остановить сканирование определенных частей вашего блога . Например, если вы посмотрите на файл ShoutMeLoud Robots.txt (платформа WordPress), вы четко поймете, какую часть моего блога я не хочу сканировать ботами поисковых систем.
Файл Robots.txt помогает роботам поисковых систем и указывает, какую часть следует сканировать, а какую избегать. Когда поисковый бот или паук поисковой системы заходит на ваш сайт и хочет проиндексировать ваш сайт, они сначала следуют файлу Robots.txt. Поисковый бот или паук следует указаниям файла для индексации или не индексации страниц вашего сайта.
Если вы используете WordPress, вы найдете файл Robots.txt в корне вашей установки WordPress.
Для статических веб-сайтов, если вы или ваши разработчики создали их, вы найдете их в корневой папке. Если вы не можете, просто создайте новый файл блокнота и назовите его Robots. txt и загрузите его в корневой каталог вашего домена с помощью FTP.
txt и загрузите его в корневой каталог вашего домена с помощью FTP.
Вот пример файла Robots.txt, и вы можете увидеть содержимое и его расположение в корне домена.
https://www.shoutmeloud.com/robots.txt
Как создать файл robots.txt?
Как я упоминал ранее, Robots.txt — это обычный текстовый файл. Итак, если у вас на сайте нет этого файла, откройте любой текстовый редактор, какой вам нравится (Блокнот, например) и создайте файл Robots.txt, состоящий из одной или нескольких записей. Каждая запись содержит важную информацию для поисковой системы. Пример:
User-agent: googlebot
Disallow: /cgi-bin
Если эти строки прописаны в файле Robots.txt, это означает, что он позволяет боту Google индексировать каждую страницу вашего сайта. Но cgi-bin папка корневого каталога не позволяет индексировать. Это означает, что бот Google не будет индексировать папку
Это означает, что бот Google не будет индексировать папку cgi-bin .
С помощью параметра «Запретить» вы можете запретить любому поисковому роботу или поисковому роботу индексировать страницу или папку. Есть много сайтов, которые не используют индекс в архивной папке или странице, чтобы не создавать дублирующегося контента .
Где взять имена поисковых ботов? Вы можете получить его в журнале вашего сайта, но если вы хотите много посетителей из поисковой системы, вы должны разрешить каждого поискового бота. Это означает, что каждый поисковый бот будет индексировать ваш сайт. Вы можете написать User-agent: * для разрешения каждому поисковому роботу. Например:
User-agent: *
Disallow: /cgi-bin
Поэтому каждый поисковый бот будет индексировать ваш сайт.
Не следует использовать файл Robots.txt
1. Не используйте комментарии в файле Robots. txt.
txt.
2. Не оставляйте пробел в начале любой строки и не делайте в файле обычный пробел. Пример:
Плохая практика:
User-agent: *
Запретить: /support
Рекомендуемая практика:
Агент пользователя: *
Запретить: /support
3. Не меняйте правила управления.
Плохая практика:
Запретить: /support
User-agent: *
Надлежащая практика:
User-agent: *
Если вы не хотите делать: /support 90.204 90. индексировать более одного каталога или страницы, не пишите вместе с этими именами:
Плохая практика:
Агент пользователя: *
Запрет: /support /cgi-bin /images/
Хорошая практика:
Агент пользователя: *
Запрет0: /support /cgi-bin
Запретить: /images
5. Правильно используйте заглавные и строчные буквы. Например, если вы хотите проиндексировать каталог «Скачать», но пишете «скачать» в файле Robots. txt, он примет его за поискового бота.
txt, он примет его за поискового бота.
6. Если вы хотите проиндексировать все страницы и каталог вашего сайта, напишите:
User-agent: *
Disallow:
7. Но если вы не хотите индексировать все страницы и каталоги вашего сайта, напишите:
User-agent: *
After Disallow: /
25 отредактировав файл Robots.txt, загрузите его через любое программное обеспечение FTP в корневую или домашнюю директорию вашего сайта.
Руководство по WordPress Robots.txt:
Вы можете либо отредактировать файл WordPress Robots.txt, войдя в свою учетную запись FTP на сервере, либо использовать плагины, такие как метаданные Robots, для редактирования файла Rrobots.txt с панели управления WordPress. Есть несколько вещей, которые вы должны добавить в файл Robots.txt вместе с URL-адресом вашей карты сайта. Добавление URL-адреса карты сайта помогает ботам поисковых систем найти файл карты сайта и приводит к более быстрому индексированию страниц.
Вот пример файла Robots.txt для любого домена. В карте сайта замените URL-адрес карты сайта на URL вашего блога:
Карта сайта: https://www.shoutmeloud.com/sitemap.xml Пользовательский агент: * # запретить все файлы в этих каталогах Запретить: /cgi-bin/ Запретить: /wp-admin/ Запретить: /архив/ запретить: /*?* Запретить: *?replytocom Запретить: /comments/feed/ Агент пользователя: Mediapartners-Google* Позволять: / Агент пользователя: Googlebot-Image Разрешить: /wp-content/uploads/ Агент пользователя: Adsbot-Google Позволять: / Агент пользователя: Googlebot-Mobile Позволять: /
Блокировка плохих SEO-ботов (полный список)
Существует множество инструментов SEO, таких как Ahrefs, SEMRush, Majestic и многие другие, которые продолжают сканировать ваш сайт в поисках секретов SEO. Эти стратегии используются вашими конкурентами в своих целях и не приносят вам никакой пользы. Более того, эти поисковые роботы также увеличивают нагрузку на ваш сервер и увеличивают его стоимость.
Если вы не используете один из этих инструментов SEO, вам лучше заблокировать их от сканирования вашего сайта. Вот что я использую в своем файле robots.txt, чтобы заблокировать некоторые из самых популярных SEO-агентов:
Агент пользователя: MJ12bot
Запретить: /
Агент пользователя: SemrushBot
Запретить: /
Агент пользователя: SemrushBot-SA
Запретить: /
Агент пользователя: dotbot
Запретить:/
Агент пользователя: Ahrefs192t
Disallow: /
User-agent: Alexibot
Disallow: /
User-agent: SurveyBot
Disallow: /
User-agent: Xenu’s
Disallow: /
User-agent: Xenu’s Link Sleuth 1.1c
Disallow: /
User- агент: rogerbot
Disallow: /
# Block NextGenSearchBot
User-agent: NextGenSearchBot
Disallow: /
# Блокировать ia-archiver от сканирования сайта
User-agent: ia_archiver
Disallow: /
# Блокировать archive.org_bot от сканирования сайта
User-agent: archive. org_bot
org_bot
Disallow: /
# Заблокировать бот Archive.org от сканирования сайта
Агент пользователя: Бот Archive.org
Запретить: /
# Заблокировать LinkWalker от сканирования сайта
Пользовательский агент: LinkWalker
Запретить: /
# Заблокировать GigaBlast Spider от сканирования сайта
User-agent: GigaBlast Spider
Disallow: /
# Блокировать ia_archiver-web.archive.org_bot от сканирования сайта
User-agent: ia_archiver-web.archive.org
Disallow: /
# Блокировать PicScout Crawler от сканирования сайта
Агент пользователя: PicScout
Запретить: /
# Блокировать BLEXBot Crawler от сканирования сайта
Пользовательский агент: BLEXBot Crawler
Запретить: /
# Заблокировать TinEye от сканирования сайта # Заблокировать SEO-кики
User-agent: SEOkicks-Robot
Disallow: /
# Block BlexBot
User-agent: BLEXBot
Disallow: /
# Block SISTRIX
User-agent: SISTRIX Crawler
Disallow: /
5 900 robot Агент пользователя: UptimeRobot/2. 0
0
Запретить: /
# Заблокировать робота Ezooms
Агент пользователя: Робот Ezooms
Запретить: /
# Заблокировать Crawler netEstate NE (+http://www.website-datenbank.de/)
Агент пользователя: netEstate NE Crawler (+http://www.website-datenbank.de/)
Запретить: /
# Заблокировать робота WiseGuys
Агент пользователя: Робот WiseGuys
Запретить: /
# Заблокировать робота Turnitin
Агент пользователя: Робот Turnitin
Запретить: /
# Заблокировать Heritrix
Агент пользователя
Disallow: /
# Block pricepi
User-agent: pimonster
Disallow: /
User-agent: Pimonster
Disallow: /
User-agent: Pi-Monster
Disallow: /
# Block Eniro
User-agent: ECCP/1.0 ([электронная почта защищена])
DISLAING: /
# Блок PSBOT
Пользовательский агент: PSBOT
DISLAING: /
# Block YouDao
Пользовательский агент: YouDaobot
DISLAING: /
# BlexBOT
Пользователь-Агент: BLEXBOT
Дис. # Заблокировать NaverBot
# Заблокировать NaverBot
Пользовательский агент: NaverBot
Пользовательский агент: Yeti
Запретить: /
# Заблокировать ZBot
Пользовательский агент: ZBot
Запретить: /
# Заблокировать Vagabondo
Пользовательский агент: Vagabondo
# Заблокировать LinkWalker
User-agent: LinkWalker
Disallow: /
# Block SimplePie
User-agent: SimplePie
Disallow: /
# Block Wget
User-agent: Wget
Disallow: /
# Block Pixray-192 User-9 агент: Pixray-Seeker
Disallow: /
# Block BoardReader
User-agent: BoardReader
Disallow: /
# Block Quantify
User-agent: Quantify
Disallow: /
# Block Plukkie-agent 9019:
Запретить: /
# Заблокировать Cuam
User-agent: Cuam
Disallow: /
# https://megaindex.com/crawler
User-agent: MegaIndex.ru
Disallow: /
User-agent: megaindex.com
Disallow : /
User-agent: +http://megaindex. com/crawler
com/crawler
Disallow: /
User-agent: MegaIndex.ru/2.0
Disallow: /
User-agent: megaIndex.ru
Disallow: /
Убедитесь, что новый файл Robots.txt не влияет на содержимое
Итак, вы внесли некоторые изменения в файл Robots.txt, и пришло время проверить, не повлияло ли на какое-либо содержимое ваше файл robots.txt.
Вы можете использовать консоль поиска Google «Просмотреть как инструмент Google», чтобы узнать, может ли ваш контент быть доступен для файла Robots.txt.
Эти шаги просты.
Войдите в консоль поиска Google, выберите свой сайт, перейдите к диагностике и выберите «Получить как Google».
Добавьте сообщения своего сайта и проверьте, нет ли проблем с доступом к вашему сообщению.
Вы также можете проверить наличие ошибок сканирования, вызванных файлом Robots.txt, в разделе ошибок сканирования в консоли поиска.
В разделе «Сканирование» > «Ошибка сканирования» выберите «Ограничено Robots. txt», и вы увидите, что все ссылки были отклонены файлом Robots.txt.
txt», и вы увидите, что все ссылки были отклонены файлом Robots.txt.
Вот пример ошибки сканирования Robots.txt для ShoutMeLoud:
Вы можете ясно видеть, что ссылки Replytocom были отклонены Robots.txt, а также другие ссылки, которые не должны быть частью Google. К вашему сведению, файл Robots.txt является важным элементом SEO, и вы можете избежать многих проблем с дублированием постов, обновив файл Robots.txt.
Используете ли вы WordPress Robots.txt для оптимизации своего сайта? Хотите добавить больше информации в файл Robots.txt? Дайте нам знать, используя раздел комментариев ниже. Не забудьте подписаться на нашу рассылку по электронной почте, чтобы получать больше советов по SEO.
Вот еще несколько тщательно отобранных руководств, которые вы можете прочитать далее:
- Как сгенерировать файл отклонения с помощью Ahrefs SEO Suite
- Как исправить внутреннюю ошибку сервера 500 в WordPress Расширенное руководство)
Подписаться на YouTube
Основное руководство по WordPress Robots txt
Если вы являетесь владельцем бизнеса и используете веб-сайт WordPress для общения со своими клиентами, для вас жизненно важно продвигать его в поисковых системах. Поисковая оптимизация включает в себя множество важных шагов. Одним из них является создание хорошего файла robots.txt.
Поисковая оптимизация включает в себя множество важных шагов. Одним из них является создание хорошего файла robots.txt.
Для чего вам нужен этот файл? Какова его роль? Где он находится на вашем сайте WordPress? Какие есть способы его создания?
Где находится файл robots.txt для WordPress?
Некоторые основные требования к текстовому файлу роботов WordPress
Виды инструкций robots.txt для поисковых роботов:
Когда следует использовать robots.txt?
Структура файла robots.txt
Типичные ошибки в файле robots.txt
Как создать файл robots.txt для вашего сайта WordPress
Использование плагина Yoast SEO
Использование плагина All in One SEO Pack
Создание и загрузка файла robots.txt для WordPress через FTP
Как протестировать файл robots.txt для вашего сайта WordPress
Заключение
Давайте рассмотрим подробнее.
Что такое текстовый файл robots?
Когда вы создаете новый веб-сайт, поисковые системы, такие как Google, Bing и т. д., используют специальных ботов для его сканирования. После этого он создает подробную карту всех своих страниц. Это помогает им определить, какие страницы показывать, когда кто-то вводит поисковый запрос, используя соответствующие ключевые слова.
д., используют специальных ботов для его сканирования. После этого он создает подробную карту всех своих страниц. Это помогает им определить, какие страницы показывать, когда кто-то вводит поисковый запрос, используя соответствующие ключевые слова.
Проблема в том, что современные веб-сайты помимо страниц содержат множество других элементов. Например, WordPress позволяет устанавливать плагины, которые часто имеют собственные каталоги. Не рекомендуется показывать их на странице результатов поиска, потому что эти папки содержат конфиденциальный контент, который может представлять большую угрозу безопасности для сайта.
Чтобы указать, какие папки сканировать, большинство владельцев веб-сайтов используют файл WordPress robots.txt, который содержит набор рекомендаций для ботов поисковых систем. Вы можете настроить, какие папки можно сканировать, а какие должны оставаться скрытыми от поисковых ботов. Этот файл может быть настолько подробным, насколько вы хотите, и его очень легко создать.
На практике поисковые системы все равно будут сканировать ваш сайт, даже если вы не создадите файл robots.txt. Однако не создавать его — очень нерациональный шаг. Без этого файла вы разрешаете поисковым роботам индексировать все содержимое вашего сайта и они решают, что вы можете показывать все части вашего сайта, даже те, которые вы хотели бы скрыть от общего доступа.
Более важный момент: без txt-файла для роботов WordPress поисковые роботы будут слишком часто заходить на ваш сайт. Это негативно скажется на его работе. Даже если посещаемость вашего сайта пока невелика, скорость загрузки страниц — это то, что всегда должно быть в приоритете и на самом высоком уровне. В конце концов, есть всего несколько вещей, которые людям не нравятся больше, чем медленная загрузка сайта.
Где находится файл robots.txt для WordPress?
Когда вы создаете веб-сайт WordPress, сервер автоматически создает файл robots.txt и размещает его в вашем корневом каталоге на сервере. Например, если адрес вашего веб-сайта — example.com, вы можете найти его по адресу example.com/robots.txt. Вы можете открыть и отредактировать его в любом текстовом редакторе. Он будет содержать следующие строки:
Например, если адрес вашего веб-сайта — example.com, вы можете найти его по адресу example.com/robots.txt. Вы можете открыть и отредактировать его в любом текстовом редакторе. Он будет содержать следующие строки:
- Агент пользователя: *
- Запретить: /wp-admin/
- Запретить: /wp-includes/ 904:00
Это пример самого простого базового файла robots.txt. Переводя на человеческий язык, правая часть после User-agent: объявляет, для каких роботов предназначены правила. Звездочка означает, что правило универсально и распространяется на всех ботов. В этом случае файл сообщает ботам, что они не могут сканировать каталоги wp-admin и wp-includes. Смысл этих правил в том, что в этих каталогах содержится множество файлов, требующих защиты от публичного доступа.
Конечно, вы можете добавить в свой файл дополнительные правила. Прежде чем это сделать, нужно понимать, что это виртуальный файл. Обычно файл WordPress robots.txt находится в корневом каталоге, который часто называется public_html, www или по названию вашего сайта:
Вы можете использовать любой FTP-менеджер, например FileZilla, для доступа к этому файлу и загрузки новой версии на сервер.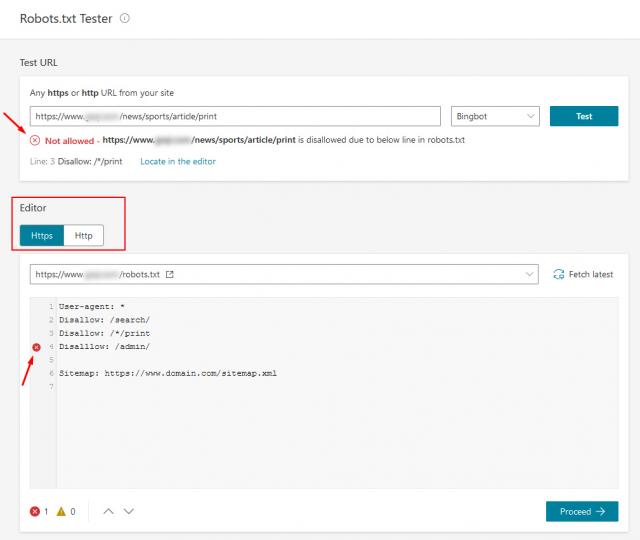 Все, что вам нужно, это знать логин и пароль для FTP-подключения. Вы можете связаться со службой технической поддержки, чтобы узнать больше.
Все, что вам нужно, это знать логин и пароль для FTP-подключения. Вы можете связаться со службой технической поддержки, чтобы узнать больше.
Некоторые основные требования к текстовому файлу роботов WordPress
- Должен быть доступен в корне сайта. Его адрес будет иметь вид example.com/robots.txt.
- Размер файла не должен превышать 32 килобайта. 904:00
- Текст должен содержать только латинские символы. Если в вашем доменном имени используются другие символы, воспользуйтесь специальным программным обеспечением, чтобы правильно преобразовать его в латинские символы.
Не забывайте, что:
Инструкции- txt носят рекомендательный характер. Настройки
- txt не влияют на другие сайты (в robots.txt можно закрыть только страницы или файлы на текущем сайте). Команды
- txt чувствительны к регистру.
Типы robots.txt инструкция к поисковым роботам:
- Частичный доступ к определенным частям сайта.

- Запрет полной проверки.
Когда следует использовать robots.txt?
С помощью txt файла WordPress robots мы можем закрыть страницы от поисковых роботов, которые вы не хотите индексировать, например:
- страниц с личной информацией пользователя;
- страниц с документацией и служебной информацией, не влияющей на отображение интерфейса на экране;
- определенные типы файлов, например, PDF-файлы;
- Панель инструментов WordPress и т. д.
Структура файла robots.txt
Веб-мастер может создать текстовый файл роботов WordPress с помощью любого текстового редактора. Его синтаксис включает три основных элемента:
.1 User-agent: [имя поискового робота]
2 Запретить: [путь, к которому вы хотите закрыть доступ]
3 Разрешить: [путь, к которому вы хотите открыть доступ]
Кроме того, файл может содержать еще два дополнительных элемента:
1 Карта сайта: [адрес карты сайта]
Затем поместите созданный файл robots. txt в корневой каталог сайта. Если ваш сайт использует основной домен, файл будет находиться в папке /public_html/ или /www/. Это зависит от хостинг-провайдера. В некоторых случаях это может быть немного иначе, но большинство компаний используют указанную структуру. Если домен дополнительный, имя папки будет включать имя веб-сайта и выглядеть как /example.com/.
txt в корневой каталог сайта. Если ваш сайт использует основной домен, файл будет находиться в папке /public_html/ или /www/. Это зависит от хостинг-провайдера. В некоторых случаях это может быть немного иначе, но большинство компаний используют указанную структуру. Если домен дополнительный, имя папки будет включать имя веб-сайта и выглядеть как /example.com/.
Для размещения файла в соответствующей папке вам потребуется FTP-клиент (например, FileZilla) и доступ к FTP, который вам дает провайдер при покупке хостинг-плана.
Агент пользователя
Все инструкции воспринимаются роботами как единое целое и относятся только к тем поисковым роботам, которые были указаны в первой строке. Всего насчитывается около 300 различных поисковых роботов. Если вы хотите применить ко всем поисковым роботам одинаковые правила, то в поле «User-agent» достаточно поставить звездочку (*). Этот символ означает любую последовательность символов. В итоге это будет выглядеть так:
1 Агент пользователя: *
Запретить
Эта команда дает рекомендации поисковым роботам, какие части сайта не следует сканировать. Если в robots.txt поставить Disallow:/, то он закроет весь контент сайта от сканирования. Если вам нужно закрыть определенную папку от сканирования, используйте Disallow: /folder.
Если в robots.txt поставить Disallow:/, то он закроет весь контент сайта от сканирования. Если вам нужно закрыть определенную папку от сканирования, используйте Disallow: /folder.
Точно так же вы можете скрыть определенный URL-адрес, файл или определенный формат файла. Например, если вам нужно закрыть все PDF-файлы на сайте от индексации, вам нужно написать в WordPress robots txt следующую инструкцию:
1 Запретить: /*.pdf$
Звездочка перед расширением файла означает любую последовательность символов (любое имя), а знак доллара в конце означает, что вы закрываете от индексации только файлы с расширением .pdf.
В следующих справочных материалах от Google вы найдете список команд для блокировки URL-адресов в файле robots.txt.
Разрешить
Эта команда позволяет сканировать любой файл, папку или страницу. Допустим, нужно открыть для сканирования роботами только те страницы, которые содержат слово /other, и закрыть весь остальной контент.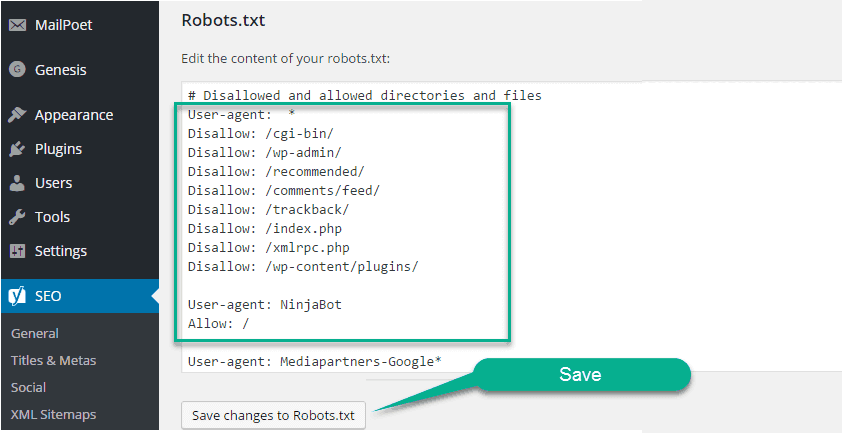 В этом случае используйте следующую комбинацию:
В этом случае используйте следующую комбинацию:
1 Агент пользователя: *
2 Разрешить: /другое
3 Запретить: /
Правила «Разрешить» и «Запретить» сортируются по префиксу URL-адреса (от самого короткого до самого длинного) и применяются последовательно. В примере будет следующий порядок инструкций: сначала робот просканирует Disallow:/, а затем Allow:/other, то есть будет проиндексирована папка /other.
Типичные ошибки в файле robots.txt
Неправильный порядок команд. Должна быть четкая логическая последовательность инструкций. Сначала агент пользователя, затем разрешить и запретить. Если вы разрешаете весь сайт, но запрещаете какие-то отдельные разделы или файлы, то сначала ставьте Разрешить, а после него Запретить. Если вы запрещаете весь раздел, но хотите открыть некоторые его части, то Disallow будет располагаться выше, чем Allow.
Несколько папок или каталогов в одной инструкции Разрешить или Запретить. Если вы хотите прописать в файле robots.txt несколько разных инструкций Allow и Disallow, то вводите каждую из них с новой строки:
Если вы хотите прописать в файле robots.txt несколько разных инструкций Allow и Disallow, то вводите каждую из них с новой строки:
Запретить: /папка
Запретить: /admin
Неверное имя файла. Имя должно быть исключительно «robots.txt», состоящим только из строчных латинских букв.
Пустое правило агента пользователя. Если вы хотите установить общие инструкции для всех роботов, то поставьте звездочку.
Синтаксические ошибки. Если вы ошибочно указали один из дополнительных элементов синтаксиса в одной из инструкций, робот может их неправильно интерпретировать.
Как создать файл robots.txt для вашего веб-сайта WordPress
Как только вы решите создать файл robots.txt, все, что вам нужно, это найти способ его создать. Вы можете отредактировать robots.txt в WordPress с помощью плагина или сделать это вручную. В этом разделе мы научим вас использовать два самых популярных плагина для этой задачи и обсудим, как создать и скачать файл вручную. Пойдем!
Пойдем!
Использование плагина Yoast SEO
ПлагинYoast SEO очень популярен для внедрения. Это самый известный SEO-плагин для WordPress, он позволяет улучшать посты и страницы, чтобы лучше использовать ключевые слова. Кроме того, он также оценит читабельность вашего контента, а это увеличит потенциальную аудиторию. Многие разработчики восхищаются плагином Yoast SEO из-за его простоты и удобства.
Одной из его основных функций является создание файла robots.txt для вашего веб-сайта. После установки и активации плагина перейдите на вкладку SEO — Tools в консоли плагина и найдите параметр File Editor:
Нажав на эту ссылку, вы сможете редактировать файл .htaccess, не выходя из консоли администратора. Также есть кнопка Создать файл robots.txt:
После нажатия кнопки на вкладке плагин отобразит новый редактор, где вы сможете напрямую редактировать файл robots.txt. Обратите внимание, что Yoast SEO устанавливает свои правила по умолчанию, которые переопределяют правила существующего виртуального файла robots.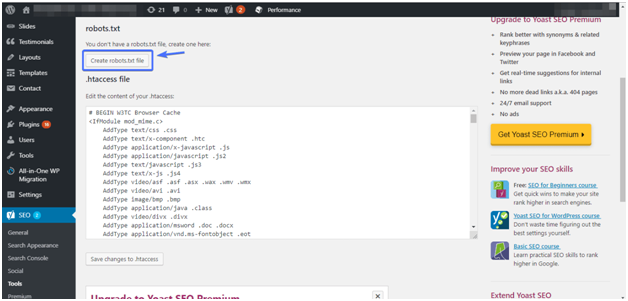 txt.
txt.
После удаления или добавления правил нажмите кнопку «Сохранить изменения» в файле robots.txt, чтобы применить их:
Вот и все! Давайте теперь посмотрим на другой популярный плагин, который позволит выполнить ту же задачу.
Использование плагина All in One SEO Pack
Плагин All in One SEO Pack — еще один отличный плагин WordPress для поисковой оптимизации. Он включает в себя большинство функций плагина Yoast SEO, но некоторые владельцы веб-сайтов предпочитают его, потому что он более легкий. Что касается создания файла robots.txt, то создать его в этом плагине тоже несложно.
После установки плагина перейдите в All in One SEO — Manage Modules в консоли. Внутри вы найдете опцию Robots.txt с большой синей кнопкой «Активировать» в правом нижнем углу. Нажмите на него:
Теперь вы сможете найти новую вкладку Robots.txt в меню All in One SEO. Нажмите на нее, чтобы увидеть настройки добавления новых правил в ваш файл. Далее сохраняем изменения или удаляем все:
Далее сохраняем изменения или удаляем все:
Обратите внимание, что в отличие от Yoast SEO, который позволяет вам вводить все, что вы хотите, вы не можете напрямую изменять файл robots.txt с помощью этого плагина. Содержимое файла будет неактивным. Вы просто увидите серый фон.
Но так как добавлять новые правила очень просто, этот факт не должен вас расстраивать. Что еще более важно, All in One SEO Pack также включает в себя функцию, которая поможет вам блокировать «плохих» ботов. Вы можете найти его во вкладке All in One SEO:
Это все, что вам нужно сделать, если вы выберете этот метод. Теперь поговорим о том, как создать txt файл WordPress robots вручную, если вы не хотите устанавливать дополнительный плагин только для этой задачи.
Создание и загрузка файла robots.txt для WordPress через FTP
Чтобы создать файл robots.txt вручную, откройте свой любимый редактор (например, Блокнот или TextEdit), добавьте все необходимые команды и сохраните файл с расширением txt на локальный диск. Это буквально займет несколько секунд, поэтому вы можете создать robots.txt для WordPress без использования плагина.
Это буквально займет несколько секунд, поэтому вы можете создать robots.txt для WordPress без использования плагина.
Вот краткий пример такого файла:
После того, как вы создали свой собственный файл, вам необходимо подключиться к вашему сайту через FTP и поместить файл в корневую папку. В большинстве случаев это каталог public_html или www. Вы можете загрузить файл, щелкнув правой кнопкой мыши файл в локальном FTP-менеджере или просто перетащив файл:
Это также занимает несколько секунд. Как видите, этот способ не сложнее, чем использование плагина.
Как протестировать файл robots.txt для вашего веб-сайта WordPress
Теперь пришло время проверить файл robots.txt на наличие ошибок в Google Search Console. Search Console — это один из инструментов Google, предназначенный для отслеживания того, как ваш контент отображается на странице результатов поиска. Один из этих инструментов проверяет robots.txt, вы можете использовать его, перейдя к файлу Robots.