Robots.txt — как настроить и загрузить на сайт
Михаил Шумовский
07 октября, 2022
Кому нужен robots.txt Как настроить robots.txt Как создать robots.txt Требования к файлу robots.txt Как проверить правильность Robots.txt
Мы в Telegram
В канале «Маркетинговые щи» только самое полезное: подборки, инструкции, кейсы.
Не всегда на серьёзных щах — шуточки тоже шутим =)
Подписаться
Станьте email-рокером 🤘
Пройдите бесплатный курс и запустите свою первую рассылку
Подробнее
Robots.txt — документ, который нужен для индексирования и продвижения сайта.
Если у сайта нет robots.txt, поисковые роботы считают все страницы ресурса открытыми для индексирования. Если файл есть, владелец сайта может запретить роботам индексировать определённые страницы.
Например, контентным ресурсам или медиа можно работать без robots.txt — тут все страницы участвуют в индексации.
На других ресурсах могут быть страницы, которые не нужно показывать поисковым роботам:
- Админ-панели сайта: пути, которые начинаются с /user, /admin, /administrator и т.д.
- Пустые страницы ресурса: если на них нет контента, в индексации они не помогут.
- Формы регистрации.
- Личные страницы в интернет-магазинах: кабинеты пользователей, корзины и т.
 д.
д.
Начну с основных параметров.
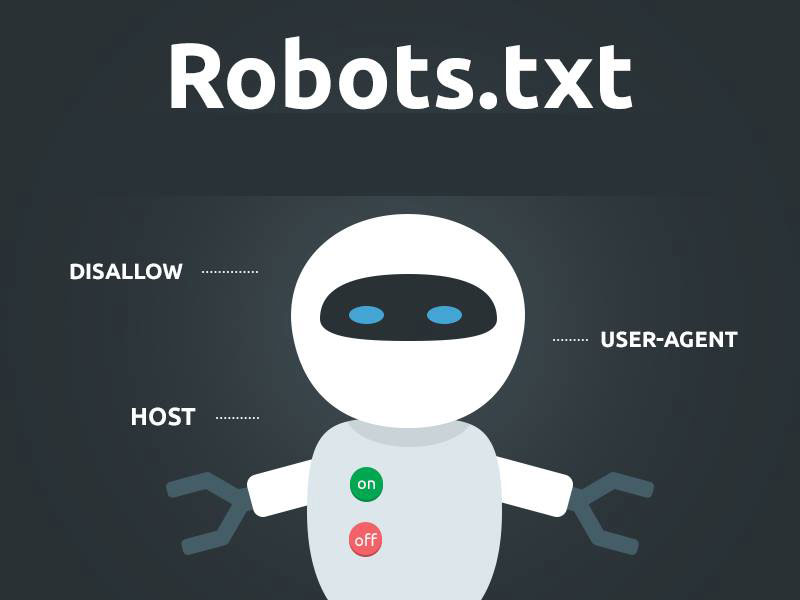
User-agent: Yandex
Disallow: catalog/
Allow: /catalog/cucumbers/
Sitemap: http://www.example.com/sitemap.xml
User-agent — указывает название робота, к которому применяется правило. Например, User-agent: Yandex означает, что правило применяется к роботу Яндекса.
А user-agent: * означает, что правило применяется ко всем роботам. Но о звёздочках поговорим ниже.
Основные типы роботов, которые можно указать в User-agent:
- Yandex. Все роботы Яндекса.
- YandexBot. Основной робот Яндекса
- YandexImages. Индексирует изображения.
- YandexMedia. Индексирует видео и другие мультимедийные данные.
- Google. Все роботы Google.
- Googlebot. Основной робот Google.
- Googlebot-Image.

Disallow. Указывает на каталог или страницу ресурса, которые роботы индексировать не будут. Если нельзя индексировать конкретную страницу, например, определённый раздел в каталоге, нужно указывать полный путь к ней — как в поисковой строке браузера.
В начале строки должен быть символ /. Если правило касается каталога, строка должна заканчиваться символом /.
Например, disallow: /catalog/gloves. Так мы запретим индексацию раздела с перчаткам.
Если оставить disallow пустым, роботы будут индексировать все страницы сайта.
Allow. Указывает на каталог или страницу, которые можно сканировать роботу. Его используют, чтобы внести исключения в пункт disallow и разрешить сканирование подкаталога или страницы в каталоге, который закрыт для обработки.
Если требуется индексировать конкретную страницу, нужно указывать к ней полный путь. Как и в disallow. Например, allow: /story/marketing. Так мы разрешили индексировать статью о маркетинге.
Так мы разрешили индексировать статью о маркетинге.
Если правило касается каталога, строка должна заканчиваться символом /.
Если allow пустой, робот не будет индексировать никакие страницы.
Sitemap.
Лендингам и небольшим сайтам sitemap не нужен. А вот таким ресурсам без sitemap не обойтись:
- Cайтам без хлебных крошек (навигационных цепочек).
- Большим ресурсам. Например, если сайт содержит большой объём мультимедиа или новостного контента.
- Сайтам с глубокой вложенностью. Например, «Главная/Каталог/Перчатки/Резиновые».
- Молодым ресурсам, на которые мало внешних ссылок, — их роботам сложно найти.
- Сайтам с большим архивом страниц, которые изолированы или не связаны друг с другом.

Файл нужно прописывать в XML-формате. Создание sitemap — тема для отдельной статьи. Подробную инструкцию читайте на Google Developers или в Яндекс.Справке.
Основные моменты robots.txt разобрали. Теперь расскажу про дополнительные параметры, которые используют в коде.
Для начала посмотрим на robots.txt Unisender. Для этого в поисковой строке браузера пишем Unisender.com/robots.txt.
По такой же формуле можно проверять файлы на всех сайтах: URL сайта + домен/robots.txt.
Robots.txt Unisender отличается от файла, который я приводил в пример. Дело в том, что здесь использованы дополнительные параметры:
Директива # (решётка) — комментарий. Решётки прописывают для себя, а поисковые роботы комментариев не видят.
User-agent: Yandex
Allow: /example/* # разрешает ‘/example/blog’
# разрешает ‘/example/blog/test’
Звёздочку роботы видят, а решётку — нет
Директива * (звёздочка) — любая последовательность символов после неё.
Например, если поставить звёздочку в поле
User-agent: Yandex
Disallow: /example/* # запрещает ‘/example/blog’
# запрещает ‘/example/blog/test’
Disallow: */shop # запрещает не только ‘/shop’,
# но и ‘/example/shop’
Также и с полем allow: всё, что стоит на месте звёздочки, — разрешено для индексации.
User-agent: Yandex
Allow: /example/* # разрешает ‘/example/blog’
# разрешает ‘/example/blog/test’
Allow: */shop # разрешает не только ‘/shop’,
# но и ‘/example/shop’
Например, у Google есть особенность: компания рекомендует не закрывать от поисковых роботов файлы с css-стилями и js-скриптами. Вот как это нужно прописывать:
User-agent: Googlebot
Disallow: /site
Allow: *.css
Allow: *. js
js
Директива $ (знак доллара) — точное соответствие указанному параметру.
Например, использование доллара в disallow запретит доступ к определённому пути.
User-agent: Yandex
Disallow: /example # запрещает ‘/example’,
# запрещает ‘/example.html’
Disallow: /example$ # запрещает ‘/example’,
# не запрещает ‘/example1’
# не запрещает ‘/example-new’
Таким способом можно исключить из сканирования все файлы определённого типа, например, GIF или JPG. Для этого нужно совместить * и $. Звёздочку ставим до расширения, а $ — после.
User-agent: Yandex
Disallow: / *.gif$ # вместо * могут быть любые символы,
# $ запретит индексировать файлы gif
Директива Clean-param — новый параметр Яндекс-роботов, который не будет сканировать дублированную информацию и поможет быстрее анализировать ресурс.
Дело в том, что из-за повторяющейся информации роботы медленнее проверяют сайт, а изменения на ресурсе дольше попадают в результаты поиска. Когда роботы Яндекса увидят эту директиву, не будут несколько раз перезагружать дубли информации и быстрее проверят сайт, а нагрузка на сервер снизится.
www.example.com/dir/get_card.pl?ref=site_1&card_id=10
www.example.com/dir/get_card.pl?ref=site_2&card_id=10
Параметр ref нужен, чтобы отследить, с какого ресурса сделан запрос. Он не меняет содержимое страницы, значит два адреса покажут одну и ту же страницу с книгой card_id=10. Поэтому директиву можно указать так:
User-agent: Yandex
Disallow:
Clean-param: ref /dir/get_card.pl
Робот Яндекса сведёт страницы к одной: www.example.com/dir/get_card.pl?card_id=10
Чтобы директива применялась к параметрам на страницах по любому адресу, не указывайте адрес:
User-agent: Yandex
Disallow:
Clean-param: utm
Директива Crawl-delay — устанавливает минимальный интервал в секундах между обращениями робота к сайту. Это помогает снизить нагрузку на сервер ресурса. Чем выше указанное значение, тем меньше страниц робот загрузит за сессию.
Это помогает снизить нагрузку на сервер ресурса. Чем выше указанное значение, тем меньше страниц робот загрузит за сессию.
Значения можно указывать целыми или дробными числами через точку.
User-agent: Yandex
Disallow:
Crawl-delay: 0.5
Для Яндекса максимальное значение в crawl-delay — 2. Более высокое значение можно установить инструментами Яндекс.Вебмастер.
Для Google-бота можно установить частоту обращений в панели вебмастера Search Console.
Директива Host — инструкция для робота Яндекса, которая указывает главное зеркало сайта. Нужна, если у сайта есть несколько доменов, по которым он доступен. Вот как её указывают:
User-agent: Yandex
Disallow: /example/
Host: example.ru
Если главное зеркало сайта — домен с протоколом HTTPS, его указывают так:
Host: https://site.ru
Как создать robots.txtСпособ 1. Понадобится текстовый редактор: блокнот, TextEdit, Vi, Emacs или любой другой. Не используйте приложения Microsoft Office, потому что они сохраняют файлы в неподходящем формате или добавляют в них лишние символы, которые не распознаются поисковыми роботами.
Не используйте приложения Microsoft Office, потому что они сохраняют файлы в неподходящем формате или добавляют в них лишние символы, которые не распознаются поисковыми роботами.
Способ 2. Создать на CMS с помощью плагинов — в этом случае robots.txt установится сам.
Если вы используете CMS хостинга, редактировать файл robots.txt не потребуется. Скорее всего, у вас даже не будет такой возможности. Вместо этого провайдер будет указывать поисковым системам, нужно ли сканировать контент, с помощью страницы настроек поиска или другого инструмента.
Способ 3. Воспользоваться генератором robots.txt — век технологий всё-таки.
Сгенерировать файл можно на PR-CY, IKSWEB, Smallseotools.
Требования к файлу robots.txtКогда создадите текстовый файл, сохраните его в кодировке utf-8. Иначе поисковые роботы не смогут прочитать документ. После создания загрузите файл в корневую директорию на сайте хостинг-провайдера. Корневая директория — это папка public. html.
html.
Папка, в которой нужно искать robots.txt. Источник
Если файла нет, его придётся создавать самостоятельно.
Требования, которым должен соответствовать robots.txt:
- Каждая директива начинается с новой строки.
- Одна директива в строке, сам параметр также написан в одну строку.
- В начале строки нет пробелов.
- Нет кавычек в директивах.
- Директивы не нужно закрывать точкой или точкой с запятой.
- Файл должен называться robots.txt. Нельзя называть его Robots.txt или ROBOTS.TXT.
- Размер файла не должен превышать 500 КБ.
- robots.txt должен быть написан на английском языке. Буквы других алфавитов не разрешаются.
Если файл не соответствует одному из требований, весь сайт считается открытым для индексирования.
Как проверить правильность Robots.txtПроверить robots. txt помогают сервисы от Яндекс и Google. В Яндексе можно проверять файл даже без сайта — например, если вы написали robots.txt, но пока не загрузили его на сайт.
txt помогают сервисы от Яндекс и Google. В Яндексе можно проверять файл даже без сайта — например, если вы написали robots.txt, но пока не загрузили его на сайт.
Вот как это сделать:
- Перейдите на Яндекс.Вебмастер.
- В открывшееся окно вставьте текст robots.txt и нажмите проверить.
Если файл написан правильно, Яндекс.Вебмастер не увидит ошибок.
А если увидит ошибку — подсветит её и опишет возможную проблему.
На Яндекс.Вебмастер можно проверить robots.txt и по URL сайта. Для этого нужно указать запрос: URL сайта/robots.txt. Например, unisender.com/robots.txt.
Ещё один вариант — проверить файл robots.txt через Google Search Console. Но сначала нужно подтвердить владение сайтом. Пошаговый алгоритм проверки robots.txt описан в видеоинструкции:
Поделиться
СВЕЖИЕ СТАТЬИ
Другие материалы из этой рубрики
Не пропускайте новые статьи
Подписывайтесь на соцсети
Делимся новостями и свежими статьями, рассказываем о новинках сервиса
«Честно» — авторская рассылка от редакции Unisender
Искренние письма о работе и жизни. Свежие статьи из блога. Эксклюзивные кейсы
и интервью с экспертами диджитала.
Свежие статьи из блога. Эксклюзивные кейсы
и интервью с экспертами диджитала.
Наш юрист будет ругаться, если вы не примете 🙁
Как запустить email-маркетинг с нуля?
В бесплатном курсе «Rock-email» мы за 15 писем расскажем, как настроить email-маркетинг в компании. В конце каждого письма даем отбитые татуировки об email ⚡️
*Вместе с курсом вы будете получать рассылку блога Unisender
Оставляя свой email, я принимаю Политику конфиденциальностиНаш юрист будет ругаться, если вы не примете 🙁
Robots.
 txt Generator — Создание файла robots.txt мгновенно
txt Generator — Создание файла robots.txt мгновенноRobots.txt Проведи для Краулеров – Использование Google Роботы Txt Генератор
Robots.txt это файл, который содержит инструкции о том, как сканировать веб-сайт. Он также известен как протокол исключений для роботов, и этот стандарт используется сайтами сказать боты, какая часть их веб-сайта нуждается индексацией. Кроме того, вы можете указать, какие области вы не хотите, чтобы обрабатываемого этих гусеничные; такие области содержат дублированный контент или находятся в стадии разработки. Поисковые системы, такие как вредоносные детекторы, почтовые комбайны не следует этому стандарту и будут проверять слабые места в ваших ценных бумагах, и существует значительная вероятность того, что они начнут рассмотрение вашего сайта из областей, которые не хотят быть проиндексированы.
Полный Robots.txt файл содержит «User-Agent», а под ним, вы можете написать другие директивы, такие как «Разрешить», «Disallow», «Crawl-Delay» и т.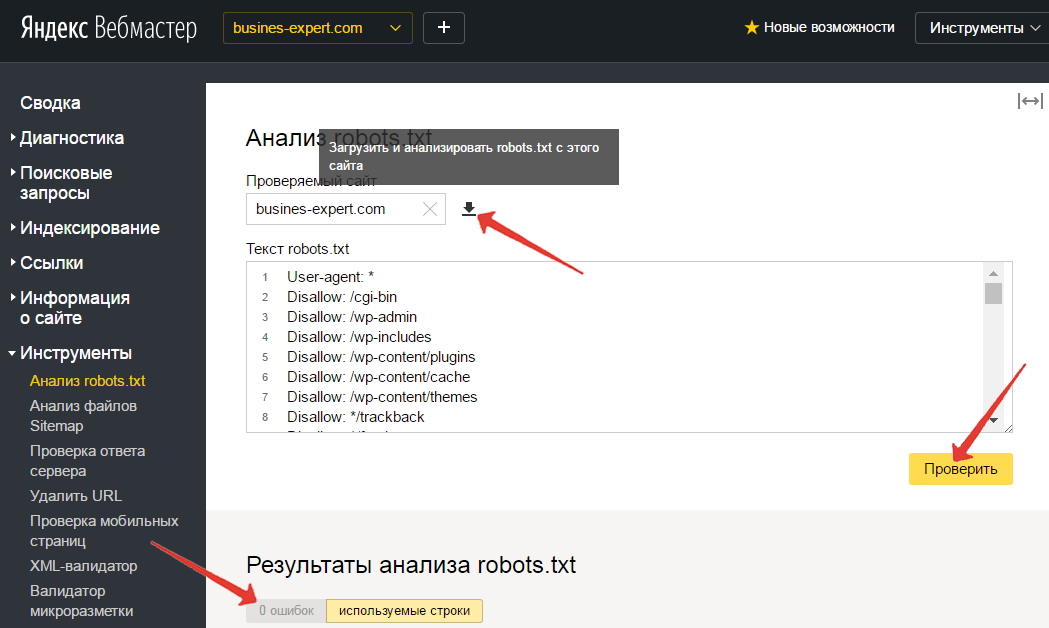 д., если написано вручную это может занять много времени, и вы можете ввести несколько строк команд в одном файле. Если вы хотите исключить страницы, вам нужно будет написать «Disallow: ссылка не хотите ботов посетить» То же самое касается разрешительной атрибута. Если вы думаете, что это все есть в файле robots.txt, то это не так просто, одна неправильная линия может исключить страницу из очереди индексации. Таким образом, это лучше оставить задачу профи, пусть наш Robots.txt генератор Заботьтесь файла для вас.
д., если написано вручную это может занять много времени, и вы можете ввести несколько строк команд в одном файле. Если вы хотите исключить страницы, вам нужно будет написать «Disallow: ссылка не хотите ботов посетить» То же самое касается разрешительной атрибута. Если вы думаете, что это все есть в файле robots.txt, то это не так просто, одна неправильная линия может исключить страницу из очереди индексации. Таким образом, это лучше оставить задачу профи, пусть наш Robots.txt генератор Заботьтесь файла для вас.
Что такое робот Txt в SEO?
Вы знаете, это небольшой файл, это способ, чтобы разблокировать более ранг для вашего сайта?
Первые поиска файлов двигатели боты посмотреть на это текстовый файл робота, если он не найден, то есть вероятность того, что массовый сканерам не будет индексировать все страницы вашего сайта. Этот крошечный файл может быть изменен позже, когда вы добавляете больше страниц с помощью маленьких инструкций, но убедитесь, что вы не добавляете главную страницу в Disallow directive. Google работает на бюджете ползания; этот бюджет основан на пределе ползать. Предел ползать является количество времени гусеничном будет тратить на веб-сайте, но если Google узнает, что ползает ваш сайт встряхивая опыт пользователя, то он будет сканировать сайт медленнее. Это означает, что медленнее, каждый раз, когда Google посылает паук, он будет проверять только несколько страниц вашего сайта и самого последнего поста потребуется время, чтобы получить индексироваться. Для снятия этого ограничения, ваш сайт должен иметь карту сайта и файл robots.txt.
Google работает на бюджете ползания; этот бюджет основан на пределе ползать. Предел ползать является количество времени гусеничном будет тратить на веб-сайте, но если Google узнает, что ползает ваш сайт встряхивая опыт пользователя, то он будет сканировать сайт медленнее. Это означает, что медленнее, каждый раз, когда Google посылает паук, он будет проверять только несколько страниц вашего сайта и самого последнего поста потребуется время, чтобы получить индексироваться. Для снятия этого ограничения, ваш сайт должен иметь карту сайта и файл robots.txt.
Так как каждый бот имеет ползать котировку на веб-сайт, это делает необходимым иметь лучший файл робот для сайта WordPress, а также. Причина заключается в том, что содержит много страниц, которые не нуждаются в индексации вы можете даже генерировать WP роботов текстовый файл с нашими инструментами. Кроме того, если у вас нет робототехники текстового файла, сканеры все равно будет проиндексировать ваш сайт, если это блог и сайт не имеет много страниц, то это не обязательно иметь один.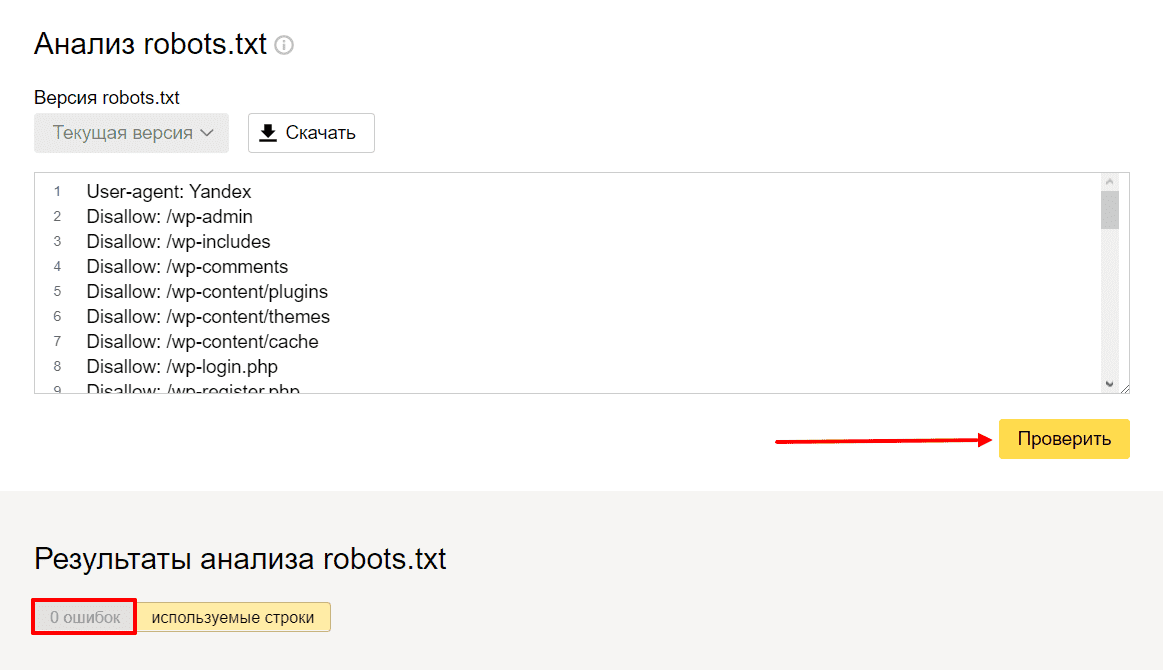
Цель директив в файле robots.txt
Если вы создаете файл вручную, то вы должны быть осведомлены о руководящих принципах, используемых в файле. Вы даже можете изменить файл позже, после обучения, как они работают.
- Crawl-оттянуть
Эту директива используются для предотвращения сканеров от перегрузки хозяина, слишком много запросов могут перегрузить сервер , который приведет к плохому опыту пользователя. Crawl задержка трактуется по- разному различными ботами из поисковых систем, Bing, Google, Яндекс лечить эту директиву по – разному. Для Яндекса это между последовательными визитами, для Bing, это как временное окно , в котором боты будут посещать сайт только один раз, и для Google, вы можете использовать поисковую консоль для управления визитами бот. - Разрешение
Позволяющей директивы используются для включения индексации по следующему адресу. Вы можете добавить столько же URL , как вы хотите , особенно если это торговый сайт , то ваш список может быть большим. Тем не менее, использовать только файл роботов , если ваш сайт имеет страницы , которые вы не хотите , чтобы получить индексироваться.
Тем не менее, использовать только файл роботов , если ваш сайт имеет страницы , которые вы не хотите , чтобы получить индексироваться. - Запрет
Основное назначение файла роботов является мусоровозов гусеничном от посещения указанных ссылок, каталоги и т.д. Эти каталоги, однако, доступ к другим роботам , которые необходимо проверить на наличие вредоносных программ , потому что они не сотрудничают со стандартом.
Разница между файлом Sitemap и robots.txt,
Карта сайт имеет жизненно важное значение для всех сайтов, так как он содержит полезную информацию для поисковых систем. Карта сайт говорит ботам, как часто вы обновляете свой сайт, какой контент вашего сайта предоставляет. Его основным мотивом является извещением в поисковых системах всех страниц вашего сайта имеет, что нужно просматривать в то время как робототехника TXT файл для поисковых роботов. Он сообщает сканерам, какие страницы ползать и которые не в. Карта сайта необходима для того, чтобы ваш сайт индексируется, тогда как TXT робота нет (если у вас нет страниц, которые не должны быть проиндексированы).
Как сделать робота, используя Google роботов генератор файлов?
Роботы текстового файла легко сделать, но люди, которые не знают о том, как они должны следовать следующим инструкциям, чтобы сэкономить время.
- Когда вы приземлились на странице новых роботов тхт генератора , вы увидите несколько вариантов, не все параметры являются обязательными, но вам нужно тщательно выбирать. Первая строка содержит значение по умолчанию для всех роботов , и если вы хотите сохранить ползания задержки. Оставьте их , как они, если вы не хотите , чтобы изменить их , как показано на рисунке ниже:
- Вторая строка о карте сайта, убедитесь, что у вас есть один и не забудьте упомянуть об этом в текстовом файле робота.
- После этого, вы можете выбрать один из нескольких вариантов для поисковых систем, если вы хотите, чтобы поисковые системы роботов сканировать или нет, второй блок для изображений, если вы собираетесь разрешить их индексации третьего столбца для мобильной версии Веб-сайт.
- Последний вариант для запрещая, где вы будете ограничивать искатель индексировать области страницы. Убедитесь в том, чтобы добавить слэш перед заполнением поля с адресом каталога или страницы.
Другие языки: English, русский, 日本語, italiano, français, Português, Español, Deutsche, 中文
Как добавить файл robots.txt
Текстовый файл robots или файл robots.txt (часто ошибочно называемый файлом robot.txt) является обязательным для каждого веб-сайта. Добавление файла robots.txt в корневую папку вашего сайта — очень простой процесс, и наличие этого файла на самом деле является «знаком качества» для поисковых систем. Давайте посмотрим на параметры robots.txt, доступные для вашего сайта.
Что такое текстовый файл robots?
Файл robots.txt – это простой текстовый файл в формате ASCII, который сообщает поисковым системам, на какие сайты им нельзя заходить, что также известно как стандарт исключения роботов. Любые файлы или папки, перечисленные в этом документе, не будут просканированы и проиндексированы поисковыми роботами. Наличие robots.txt, даже пустого, показывает, что вы признаете, что поисковые системы разрешены на вашем сайте и что они могут иметь к нему свободный доступ. Мы рекомендуем добавить текстовый файл robots в ваш основной домен и все поддомены на вашем сайте.
Наличие robots.txt, даже пустого, показывает, что вы признаете, что поисковые системы разрешены на вашем сайте и что они могут иметь к нему свободный доступ. Мы рекомендуем добавить текстовый файл robots в ваш основной домен и все поддомены на вашем сайте.
Параметры форматирования robots.txt
Создание файла robots.txt — простой процесс. Выполните следующие простые шаги:
- Откройте Блокнот, Microsoft Word или любой текстовый редактор и сохраните файл как «роботы», все в нижнем регистре, обязательно выбрав .txt в качестве расширения типа файла (в Word выберите «Обычный текст»). .
- Затем добавьте в файл следующие две строки текста:
User-agent: *
Disallow:
«User-agent» — это другое слово для роботов или пауков поисковых систем. Звездочка (*) означает, что эта строка относится ко всем паукам. Здесь нет файлов или папок, перечисленных в строке «Запретить», что означает, что каждый каталог на вашем сайте может быть доступен. Это основной текстовый файл robots.
Это основной текстовый файл robots.
- Блокировка поисковых роботов на всем вашем сайте также является одной из опций robots.txt. Для этого добавьте в файл эти две строки:
User-agent: *
Disallow: /
- Если вы хотите заблокировать пауков из определенных областей вашего сайта, ваш robots.txt может выглядеть примерно так:
User-agent: *
Disallow: /database/
Disallow: /scripts/
Эти три строки сообщают всем роботам, что им не разрешен доступ к чему-либо в каталогах или подкаталогах базы данных и скриптов. Имейте в виду, что в строке Disallow можно использовать только один файл или папку. Вы можете добавить столько строк Disallow, сколько вам нужно.
- Не забудьте добавить XML-файл карты сайта, удобный для поисковых систем, в текстовый файл robots. Это гарантирует, что пауки смогут найти вашу карту сайта и легко проиндексировать все страницы вашего сайта. Используйте этот синтаксис:
Карта сайта: http://www. mydomain.com/sitemap.xml
mydomain.com/sitemap.xml
- После завершения сохраните и загрузите файл robots.txt в корневой каталог вашего сайта. Например, если ваш домен www.mydomain.com, вы разместите файл по адресу www.mydomain.com/robots.txt.
- Когда файл будет на месте, проверьте файл robots.txt на наличие ошибок.
Search Guru может помочь реализовать этот и другие технические элементы SEO. Свяжитесь с нами сегодня чтобы начать!
Что такое Robots.txt и как его использовать
Поддержка > Продвижение вашего сайта > Поисковая оптимизация
Как использовать Robots.txt
Перейти к разделу
- Что такое robots.txt?
- Как работает файл robots.txt?
- Как настроить файл robots.txt на моем веб-сайте?
- Где находится файл robots.txt?
- Как настроить файл robots.txt (примеры)
- Как загрузить собственный файл robots.
 txt
txt
Что такое robots.txt?
Файл Robots.txt — это текстовый файл, связанный с вашим веб-сайтом, который используется поисковыми системами для определения того, какие страницы вашего веб-сайта вы хотите, чтобы они посещали, а какие нет.
Как работает файл robots.txt?
Структура файла robots.txt очень проста. По сути, это заметка, которая сообщает поисковым системам, как вы хотите, чтобы они индексировали ваши страницы. Самый простой файл robots.txt выглядит так, как показано ниже, что позволяет любой поисковой системе индексировать все, что она может найти:
User-agent: *
Disallow:
Это направление нарушено вниз в две части, первая — User-agent. Это (по большей части) поисковые системы, которые сканируют ваш сайт. Вы можете структурировать файл robots.txt, чтобы применять правила к определенным поисковым системам. Например, вы можете использовать следующее правило для ссылки на роботов Bing:
Например, вы можете использовать следующее правило для ссылки на роботов Bing:
User-agent: bingbot
Disallow:
В большинстве случаев за User-agent следует символ *, означающий, что правила применяются ко всем роботам.
Вторая часть — это функция Disallow:, которая указывает страницу или каталог, которые поисковые системы не должны индексировать. Таким образом, приведенный выше пример сообщает Bing, что они могут получить доступ ко всему, поскольку команда не указана.
Как настроить файл robots.txt на моем веб-сайте?
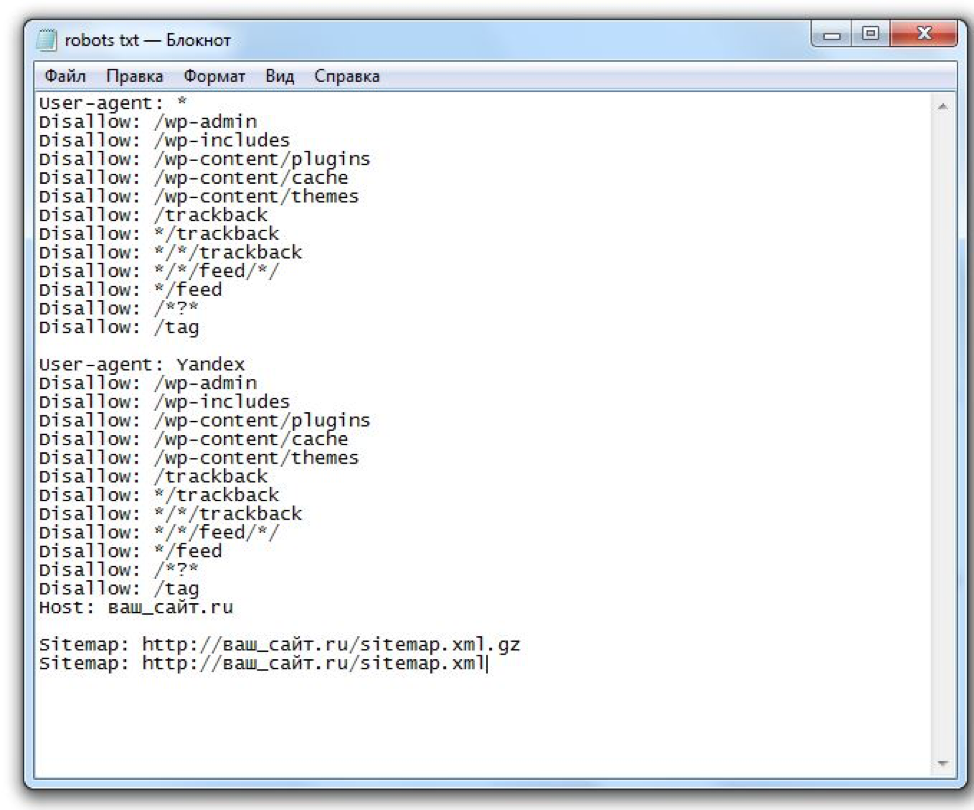
Мы автоматически настроили ваш файл robots.txt следующим образом:
user-agent: *
Карта сайта: http://yourdomain.co.uk/sitemap.xml
disallow: / include/
disallow: /shop/basket_new.php
disallow: /shop/checkout_process. php
php
disallow: /account/
90 088 Запретить: /cdn-cgi/запретить: /websiteusers.html
Где находится файл robots.txt?
Чтобы получить доступ к файлу robots.txt, как это сделают поисковые системы, введите свое полное доменное имя в адресную строку браузера и добавьте «/robots.txt» в конце адреса вашего веб-сайта.
Например: https://www.yourdomain.co.uk/robots.txt
Как настроить файл robots.txt
Вы можете полностью настроить файл robots.txt, следуя приведенным ниже инструкциям:
На компьютере откройте Блокнот (или TextEdit на Mac)
Используйте эту программу для записи нового файла robots в виде обычного текста без стилей и форматирования
Сохраните файл под именем: robots.
 txt
txt
Примеры
Ниже приведены несколько сценариев, которые могут потребоваться для вашего веб-сайта, и способы настройки файла robots.txt для разрешения этого:
1. Разрешить всем поисковым системам доступ к изображениям
Чтобы указать все поисковые системы вам нужно будет добавить символ * в качестве вашего пользовательского агента, так как он представляет все поисковые системы:
Агент пользователя: *
Разрешить: /siteimages/
2. Запретить всем поисковым системам доступ к изображениям
Агент пользователя: * 90 023
Запретить: /siteimages/
3. Разрешить только некоторые поисковые системы
Если вы хотите разрешить только определенные поисковые системы, вам необходимо указать их, как показано ниже:
Агент пользователя: *
Запретить: /sitefiles/
Запретить: /siteimages/
Агент пользователя: googlebot
Запретить:
Агент пользователя: bingbot
Disallow:
В приведенном выше примере все поисковые системы заблокированы для сканирования ваших файлов и изображений, кроме Bing (bingbot) и Google (googlebot).
4. Разрешить доступ к изображениям только некоторым поисковым системам
Если вы хотите, чтобы только определенные поисковые системы сканировали ваши изображения, вам необходимо указать их, как показано ниже:
User-agent: *
Disallow: /siteimages/
User-agent: googlebot-image
Disallow: 9002 3
5. Разрешите Google сканировать ваши изображения, но не отображаться в Google Картинках
Если вы хотите, чтобы Google сканировал ваши изображения, но чтобы они не отображались в Google Картинках, вам нужно указать это, указав робота изображений Google в файле robots.txt, как показано ниже:
User-agent: *
Disallow: /sitefiles/
User-agent: googlebot-image
Disallow: /siteimages/
Указав конкретно этого робота Google Image, вы останавливаете свой изображения не появляются в поиске изображений Google, однако, если Google продолжит их сканирование, это означает, что они все еще могут появляться в веб-поиске Google.
6. Запретите некоторые поисковые системы, чтобы они ничего не сканировали
Если вы хотите, чтобы конкретная поисковая система вообще не сканировала ваш веб-сайт, вам необходимо добавить символ /, так как он представляет весь ваш контент:
Агент пользователя: *
Запретить: /sitefiles/
Disallow: /siteimages/
User-agent: bingbot
Disallow: /
В приведенном выше примере ваш робот s не разрешает Bing доступ к вашему веб-сайту, но ко всем другим сайтам такие, как Google может!
7. Разрешить всем поисковым системам доступ ко всем страницам сайта
Если вы хотите разрешить всем поисковым системам доступ ко всему, вам необходимо добавить в файл robots.txt следующее:
User-agent: *
Disallow:
8. Запретить поисковым системам доступ к некоторым страницам сайта
Запретить поисковым системам доступ к некоторым страницам сайта
имя файла страницы в ваш файл, как показано ниже:
Агент пользователя: *
Запретить: /guestbook/
Запретить: /onlineshop/
Если страницы защищены паролем, эти страницы могут быть просканированы вашими роботами, но это сайт не может получить доступ посетитель без логина и пароля. Из-за этого, а также из-за того, что страница, вероятно, будет иметь очень мало преимуществ для SEO, если вы вообще не хотите, чтобы эта страница индексировалась, вы можете добавить это в свой файл robots.txt, но это не обязательно, так как к ней не может получить доступ все посетители.
9. Запретить поисковым системам доступ к личным документам любые страницы или личные документы, проиндексированные на вашем веб-сайте с помощью robots.txt, чтобы люди могли найти их через ваш файл robots. txt, если они искали его. Если вы хотите ограничить доступ к этим ресурсам на своем веб-сайте, мы рекомендуем защитить вашу страницу паролем.
txt, если они искали его. Если вы хотите ограничить доступ к этим ресурсам на своем веб-сайте, мы рекомендуем защитить вашу страницу паролем.
Как загрузить собственный файл robots.txt
Чтобы загрузить свой файл robots.txt и заменить созданный, выполните следующие действия:
Войдите в свою учетную запись Создать учетную запись
Нажмите «Содержимое» в верхнем меню
Нажмите «Файлы» в меню слева
Нажмите зеленую кнопку «Добавить файл» в правом верхнем углу
Нажмите кнопку «Загрузить» и выберите файл.
Нажмите зеленую кнопку Загрузить файл
Опубликуйте свой веб-сайт, чтобы изменения вступили в силу
Теперь файл robots.