Robots.txt для WordPress — правильный роботс.тхт UP: 2020
<pre>User-agent: grub-client
Disallow: /
User-agent: grub
Disallow: /
User-agent: looksmart
Disallow: /
User-agent: WebZip
Disallow: /
User-agent: larbin
Disallow: /
User-agent: b2w/0.1
Disallow: /
User-agent: psbot
Disallow: /
User-agent: Python-urllib
Disallow: /
User-agent: NetMechanic
Disallow: /
User-agent: URL_Spider_Pro
Disallow: /
User-agent: CherryPicker
Disallow: /
User-agent: EmailCollector
Disallow: /
User-agent: EmailSiphon
Disallow: /
User-agent: WebBandit
Disallow: /
User-agent: EmailWolf
Disallow: /
User-agent: ExtractorPro
Disallow: /
User-agent: CopyRightCheck
Disallow: /
User-agent: Crescent
Disallow: /
User-agent: SiteSnagger
Disallow: /
User-agent: ProWebWalker
Disallow: /
User-agent: CheeseBot
Disallow: /
User-agent: LNSpiderguy
User-agent: ia_archiver
Disallow: /
User-agent: ia_archiver/1.6
Disallow: /
User-agent: Teleport
Disallow: /
User-agent: TeleportPro
Disallow: /
User-agent: MIIxpc
Disallow: /
User-agent: Telesoft
Disallow: /
User-agent: Website Quester
Disallow: /
User-agent: moget/2.1
Disallow: /
User-agent: WebZip/4.0
Disallow: /
User-agent: WebStripper
Disallow: /
User-agent: WebSauger
Disallow: /
User-agent: WebCopier
Disallow: /
User-agent: NetAnts
Disallow: /
User-agent: Mister PiX
Disallow: /
User-agent: WebAuto
Disallow: /
User-agent: TheNomad
User-agent: WWW-Collector-E
Disallow: /
User-agent: RMA
Disallow: /
User-agent: libWeb/clsHTTP
Disallow: /
User-agent: asterias
Disallow: /
User-agent: httplib
Disallow: /
User-agent: turingos
Disallow: /
User-agent: spanner
Disallow: /
User-agent: InfoNaviRobot
Disallow: /
User-agent: Harvest/1. 5
5
Disallow: /
User-agent: Bullseye/1.0
Disallow: /
User-agent: Mozilla/4.0 (compatible; BullsEye; Windows 95)
Disallow: /
User-agent: Crescent Internet ToolPak HTTP OLE Control v.1.0
User-agent: CherryPickerSE/1.0
Disallow: /
User-agent: CherryPickerElite/1.0
Disallow: /
User-agent: WebBandit/3.50
Disallow: /
User-agent: NICErsPRO
Disallow: /
User-agent: Microsoft URL Control — 5.01.4511
Disallow: /
User-agent: DittoSpyder
Disallow: /
User-agent: Foobot
Disallow: /
User-agent: WebmasterWorldForumBot
Disallow: /
User-agent: SpankBot
Disallow: /
User-agent: BotALot
Disallow: /
User-agent: lwp-trivial/1.34
Disallow: /
User-agent: lwp-trivial
Disallow: /
User-agent: BunnySlippers
Disallow: /
User-agent: Microsoft URL Control — 6.00.8169
User-agent: URLy Warning
Disallow: /
User-agent: Wget/1.6
Disallow: /
User-agent: Wget/1.5.3
Disallow: /
User-agent: Wget
Disallow: /
User-agent: LinkWalker
Disallow: /
User-agent: cosmos
Disallow: /
User-agent: moget
Disallow: /
User-agent: hloader
Disallow: /
User-agent: humanlinks
Disallow: /
User-agent: LinkextractorPro
Disallow: /
User-agent: Offline Explorer
Disallow: /
User-agent: Mata Hari
Disallow: /
User-agent: LexiBot
Disallow: /
User-agent: Web Image Collector
Disallow: /
User-agent: The Intraformant
User-agent: True_Robot/1.0
Disallow: /
User-agent: True_Robot
Disallow: /
User-agent: BlowFish/1.0
Disallow: /
User-agent: JennyBot
Disallow: /
User-agent: MIIxpc/4.2
Disallow: /
User-agent: BuiltBotTough
Disallow: /
User-agent: ProPowerBot/2.14
Disallow: /
User-agent: BackDoorBot/1. 0
0
Disallow: /
User-agent: toCrawl/UrlDispatcher
Disallow: /
User-agent: WebEnhancer
Disallow: /
User-agent: suzuran
Disallow: /
User-agent: VCI WebViewer VCI WebViewer Win32
Disallow: /
User-agent: VCI
Disallow: /
User-agent: Szukacz/1.4
Disallow: /
User-agent: QueryN Metasearch
Disallow: /
User-agent: Openfind data gathere
Disallow: /
User-agent: Openfind
Disallow: /
User-agent: Xenu’s Link Sleuth 1.1c
Disallow: /
User-agent: Xenu’s
Disallow: /
User-agent: Zeus
Disallow: /
User-agent: RepoMonkey Bait & Tackle/v1.01
Disallow: /
User-agent: RepoMonkey
Disallow: /
User-agent: Microsoft URL Control
Disallow: /
User-agent: Openbot
Disallow: /
User-agent: URL Control
Disallow: /
User-agent: Zeus Link Scout
Disallow: /
User-agent: Zeus 32297 Webster Pro V2.9 Win32
User-agent: Webster Pro
Disallow: /
User-agent: EroCrawler
Disallow: /
User-agent: LinkScan/8.1a Unix
Disallow: /
User-agent: Keyword Density/0.9
Disallow: /
User-agent: Kenjin Spider
Disallow: /
User-agent: Iron33/1.0.2
Disallow: /
User-agent: Bookmark search tool
Disallow: /
User-agent: GetRight/4.2
Disallow: /
User-agent: FairAd Client
Disallow: /
User-agent: Gaisbot
Disallow: /
User-agent: Aqua_Products
Disallow: /
User-agent: Radiation Retriever 1.1
Disallow: /
User-agent: Flaming AttackBot
Disallow: /
User-agent: Oracle Ultra Search
User-agent: MSIECrawler
Disallow: /
User-agent: PerMan
Disallow: /
User-agent: searchpreview
Disallow: /
</pre>
Правильный robots.txt для Вордпресс
Наверное, только ленивый не писал про то, как должен выглядеть правильный Robots. txt для Вордпресс. Я попробую объяснить, почему многие старые способы больше не работают.
txt для Вордпресс. Я попробую объяснить, почему многие старые способы больше не работают.
Прежде напомню, на дворе 2017-й год — прогресс не стоит на месте, технологии развиваются. Кто давно в теме — знают, что поисковые системы за последнее десятилетие сильно эволюционировали. Поисковые алгоритмы стали более сложными. Сложными стали и факторы ранжирования, их количество существенно увеличилось. Естественно, всё это не могло не отразиться на методах поисковой оптимизации сайтов и отрасли в целом.
Robots.txt — это текстовый файл, находящийся в корневой директории сайта, в котором записываются специальные инструкции для поисковых роботов, разработан Мартином Костером и принят в качестве стандарта 30 июня 1994 года.
Robots.txt — мощное оружие SEO-оптимизации, грамотная настройка которого может существенно помочь в индексации.
В то же время, кривая настройка robots.txt может нанести проекту огромный вред. Рассуждать о правильности того или иного примера robots.txt можно бесконечно долго. Предлагаю остановиться на фактах.
Еще недавно Google был настолько примитивен, что видел сайты лишь в виде HTML-кода. В прошлом году, с приходом алгоритма Panda 4, Google стал видеть сайты такими же, какими их видят пользователи. Вместе с CSS и исполненным JavaScript.
Это изменение коснулось и Вордпресс.
На многих сайтах используются старые приёмы, которые блокируют индексацию системной директории /wp-includes/, в которой часто хранятся JS-библиотеки и стили, необходимые для работы сайта. А это значит, Google увидит сайт уже не таким, каким его видят посетители.
Получается, что старая практика больше не работает.
На многих Вордпресс-сайтах закрывалась от индексации и другая системная директория /wp-admin/. Что правильно, по-сути. Но если на сайте используется асинхронная загрузка страниц (AJAX), это может блокировать загрузку внутренних страниц. Потому что admin-ajax.php, который за всё это отвечает, расположен в /wp-admin/.
Потому что admin-ajax.php, который за всё это отвечает, расположен в /wp-admin/.
Директорию /wp-admin/ можно оставить закрытой от индексации, но тогда необходимо отдельно разрешить индексацию admin-ajax.php.
Allow: /wp-admin/admin-ajax.php
Если в вашем Вордпресс используется один из старых способов оформления robots.txt, нужно обязательно проверить какие конкретно директории скрываются от индексации и удалить все запреты, блокирующие загрузку страниц.
Для проверки рекомендую использовать Google Search Console, в котором необходимо предварительно зарегистрироваться, добавить проверяемый сайт и подтвердить права на него. Это делается очень просто.
Как проверить Robots.txt
Проверить robots.txt на ошибки можно с помощью инструмента проверки файла robots.txt — именно так и называется этот инструмент в разделе «Сканирование» Google для веб-мастеров.
Кстати, проверить robots.txt на ошибки можно и в Яндекс Вебмастере. Но в Google Search Console все равно нужно зарегистрироваться, потому что только там можно проверить видимость сайта поисковыми пауками Гугла. Конкретно это делается в разделе «Сканирование» с помощью инструмента «Просмотреть как Googlebot».
Если сайт выглядит таким же как и в браузере, значит все в порядке, robots.txt ничего не блокирует. Если же имеются какие-то отличия, что-то не отображается или сайт не виден вообще, значит придется выяснить, где происходит блокировка и ликвидировать её.
Как же должен выглядеть правильный Robots.txt для Вордпресс
Я все больше убеждаюсь, что лучше делать сразу минимальный robots.txt и закрывать только /wp-admin/. Естественно, открыв admin-ajax.php, если есть AJAX-запросы. И обязательно указываем Host и Sitemap.
Мой robots.txt чаще всего выглядит так:
User-agent: * Disallow: /wp-admin/ Allow: /wp-admin/admin-ajax.php Host: https://danilin.biz Sitemap: https://danilin.biz/sitemap.xml
В заключение
Создать универсальный правильный robots.txt для всех сайтов на Вордпресс невозможно.
На каждом сайте работает конкретная тема, набор плагинов и типов данных (CPT), которые генерируют свой уникальный пул URL.
Robots.txt часто корректируется уже в процессе эксплуатации сайта. Для этого осуществляется постоянный мониторинг индекса сайта. И если в него попадают какие-то ненужные страницы, они исключаются. Например, в индекс иногда попадают страницы с параметрами ?p и ?s.
Их можно исключить.
Disallow: /?p= Disallow: /?s=
Иногда даже попадают фиды, которые тоже можно закрыть.
Disallow: */feed
Вообще, задачи по исключению страниц из индекса правильнее решать на уровне кода, закрывая страницы от сканирования с помощью метатега «noindex».
Для Яндекса инструкции в robots.txt и метатег «noindex» работают одинаково — страница удаляется из индекса. А вот для Гугла robots.txt — это запрет на индексирование, а метатег «noindex» — запрет на сканирование. И если, допустим, страница заблокирована в robots.txt, поисковый робот может просто не обнаружить метатег «noindex» на этой странице, и она останется в индексе. Об этом прямо написано в Справке Search Console.
Как видим, Robots.txt может быть очень опасен для сайта.
Бездумные действия с этим файлом могут привести к печальным последствиям. Не спешите с помощью него закрывать все подряд директории. Пользуйтесь плагином Yoast SEO — он позволяет настроить правильные запреты с помощью метатегов.
Подпишитесь на мой телеграм и первыми получайте новые материалы, в том числе которых нет на сайте.
Правильный robots.txt для WordPress | PRIME
Пример верно написанного robots. txt, в случае если вы используете ЧПУ:
txt, в случае если вы используете ЧПУ:
User-agent: * -
Disallow: /wp-includes
Disallow: /wp-content/plugins
Disallow: /wp-content/cache
Disallow: /wp-content/themes
Disallow: /trackback
Disallow: */trackback
Disallow: */*/trackback
Disallow: */*/feed/*/
Disallow: */feed
Disallow: /*?*
Disallow: /tag
User-agent: Yandex
Disallow: /wp-admin
Disallow: /wp-includes
Disallow: /wp-content/plugins
Disallow: /wp-content/cache
Disallow: /wp-content/themes
Disallow: /trackback
Disallow: */trackback
Disallow: */*/trackback
Disallow: */*/feed/*/
Disallow: */feed
Disallow: /*?*
Disallow: /tag
Host: mysite.com
Sitemap: http://mysite.com/sitemap. xml.gz
xml.gz
Sitemap: http://mysite.com/sitemap.xml
составляем правильный роботс для WordPress и других систем
Содержание статьи
Вы знаете, насколько важна индексация — это основа основ в продвижении сайтов. Потому что если ваш сайт не индексируется, то хрен вы какой трафик из поиска получите. Если он индексируется некорректно — то у вас даже при прочих идеальных условиях будет обрубаться часть трафика. Тут все просто — если вы, например, запретили к индексации папку с изображениями, то у вас почти не будет по ним трафа (хотя многие сознательно идут на такой шаг).
Индексация сайта — это процесс, в ходе которого страницы вашего сайта попадают в Яндекс, Гугл или другой поисковик. И после этого пользователь может найти страницу вашего сайта по какому-нибудь запросу.
Управляете вы такой важной штукой, как индексация, именно посредством файла robots.txt. Начну с азов.
Что такое robots.txt
Robots.txt — файл, который говорит поисковой системе, какие разделы и страницы вашего сайта нужно включать в поиск, а какие — нельзя. Ну то есть он говорит не поисковой системе напрямую, а её роботу, который обходит все сайты интернета. Вот что такое роботс. Этот файл всегда создается в универсальном формате .txt, который сможет открыть даже компьютер вашего деда.
Вот видос от Яндекса:
Основное назначение – контроль за доступом к публикуемой информации. При необходимости определенную информацию можно закрыть для роботов. Стандарт robots был принят в начале 1994 года, но спустя десятилетие продолжает жить.
При необходимости определенную информацию можно закрыть для роботов. Стандарт robots был принят в начале 1994 года, но спустя десятилетие продолжает жить.
Использование стандарта осуществляется на добровольной основе владельцами сайтов. Файл должен включать в себя специальные инструкции, на основе которых проводится проверка сайта поисковыми роботами.
Самый простой пример robots:
User-agent: * Allow: /
Данный код открывает весь сайт, структура которого должна быть безупречной.
Зачем закрывают какие-то страницы? Не проще ли открыть всё?
Смотрите — у каждого сайта есть свой лимит, который называется краулинговый бюджет. Это максимальное количество страниц одного конкретного сайта, которое может попасть в индекс. То есть, допустим, у какого-нибудь М-Видео краулинговый бюджет может составлять десять миллионов страниц, а у сайта дяди Вани, который вчера решил продавать огурцы через интернет — всего сотню страниц. Если вы откроете для индексации всё, то в индекс, скорее всего, попадет куча мусора, и с большой вероятностью этот мусор займет в индексе место некоторых нужных страниц. Вот чтобы такой хрени не случилось, и нужен запрет индексации.
Где находится Robots
Robots традиционно загружают в корневой каталог сайта.
Это корневой каталог, и в нем лежит роботс.
Для загрузки текстового файла обычно используется FTP доступ. Некоторые CMS, например WordPress или Joomla, позволяют создавать robots из админпанели.
Для чего нужен этот файл
А вот для чего:
- запрета на индексацию мусора — страниц и разделов, которые не содержат в себе полезный контент;
- разрешение индексации нужных страниц и разделов;
- чтобы давать разные задачи роботам разных поисковиков — то есть, например, Яндексу разрешить индексировать всё, а Рамблеру — ничего;
- можно также задавать роботам разные категории. Заморочиться например вплоть до того, что Гуглу разрешить индексировать только картинки, а Яху — только карту сайта;
- чтобы показать через директиву Host Яндексу, какое у сайта главное зеркало;
- еще некоторые вебмастера запрещают всяким нехорошим парсерам сканировать сайт с помощью этого файла;
То есть большую часть проблем по индексации он решает. Есть конечно помимо роботса еще и такие инструменты, как метатег роботс (не путайте!), заголовок Last-Modified и другие, но это уже для профессионалов и нужны они лишь в особых случаях. Для решения большинства базовых проблем с индексацией хватает манипуляций с роботсом.
Есть конечно помимо роботса еще и такие инструменты, как метатег роботс (не путайте!), заголовок Last-Modified и другие, но это уже для профессионалов и нужны они лишь в особых случаях. Для решения большинства базовых проблем с индексацией хватает манипуляций с роботсом.
Как работают поисковые роботы и как они обрабатывают данный файл
В большинстве случаев, очень упрощенно, они работают так:
- Обходят Интернет;
- Проверяют, какие документы разрешено индексировать, а какие запрещено;
- Включает разрешенные документы в базу;
- Затем уже другие механизмы решают, какие страницы достаточно полезны для включения в индекс.
Вот ссылка на справку Яндекса о работе поисковых роботов, но там все довольно отдаленно описано.
Справка Google свидетельствует: robots – рекомендация. Файл создается для того, чтобы страница не добавлялась в индекс поисковой системы, а не чтобы она не сканировалась поисковыми системами. Гугл позволяет запрещенной странице попасть в индекс, если на нее направляется ссылка внутри ресурса или с внешнего сайта.
По-разному ли Яндекс и Google воспринимают этот файл
Многие прописывают для роботов разных поисковиков разные директивы. Даже если список этих директив ничем не отличается.
Наверное, это для того, чтобы выразить уважение к Господину Поисковику. Как там раньше делали — «великий князь челом бьет… и просит выдать ярлык на княжение». Других соображений по поводу того, зачем разным юзер-агентам прописывают одни и те же директивы, у меня нет, да и вебмастера, так делающие, дать нормальных объяснений своим действиям не могут.
А те, кто может ответить, аргументируют это так: мол, Google не воспринимает директиву Host и поэтому её нужно указывать только для Яндекса, и вот почему, мол, для яндексовского юзер-агента нужны отдельные директивы. Но я скажу так: если какой-то робот не воспринимает какую-то директиву, то он её просто проигнорирует. Так что лично я не вижу смысла указывать одни и те же директивы для разных роботов отдельно. Хотя, отчасти понимаю перестраховщиков.
Так что лично я не вижу смысла указывать одни и те же директивы для разных роботов отдельно. Хотя, отчасти понимаю перестраховщиков.
Чем может грозить неправильно составленный роботс
Некоторые при создании сайта на WordPress ставят галочку, чтобы система закрывала сайт от индексации (и забывают потом убрать её). Тогда Вордпресс автоматом ставит вам такой роботс, чтобы поисковики не включали ваш сайт в индекс, и это — самая страшная ошибка. Те страницы, на которые вы намерены получать трафик, обязательно должны быть открыты для индексации.
Потом, если вы не закрыли ненужные страницы от индексации, в индекс может попасть, как я уже говорил выше, очень много мусора (ненужных страниц), и они могут занять в индексе место нужных страниц.
Вообще, если вкратце, неправильный роботс грозит вам тем, что часть страниц не попадет в поиск и вы лишитесь части посетителей.
Как создать файл robots.txt
В Блокноте или другом редакторе создаем файл с расширением .txt, чтобы он в итоге назывался robots.txt. Заполняем его правильно (дальше расскажу, как) и загружаем в корень сайта. Готово!
Вот тут разработчик сайта Loftblog создает файл с нуля в режиме реального времени и делает настройку роботс:
Пример правильного robots.txt для WordPress
Составить правильный robots.txt для сайта WordPress проще всего. Я сам видел очень много таких роботсов (обязательно замените znet.ru на название вашего сайта, если хотите копировать):
User-agent: Yandex Disallow: /wp-admin Disallow: /wp-includes Disallow: /wp-login.php Disallow: /wp-register.php Disallow: /xmlrpc.php Disallow: /search Disallow: */trackback/ Disallow: */feed Disallow: */comments/ Disallow: *?* Disallow: */comment Disallow: */attachment/* Disallow: */print/ Disallow: *?print=* Allow: /wp-content/uploads/ Host: znet.ru User-agent: Googlebot Disallow: /wp-admin Disallow: /wp-login.php Disallow: /wp-register.php Disallow: /xmlrpc.php Disallow: /search Disallow: */trackback/ Disallow: */feed Disallow: */comments/ Disallow: *?* Disallow: */comment Disallow: */attachment/* Disallow: */print/ Disallow: *?print=* Allow: /wp-content/uploads/ User-agent: Mail.Ru Disallow: /wp-admin Disallow: /wp-includes Disallow: /wp-login.php Disallow: /wp-register.php Disallow: /xmlrpc.php Disallow: /search Disallow: */trackback/ Disallow: */feed Disallow: */comments/ Disallow: *?* Disallow: */comment Disallow: */attachment/* Disallow: */print/ Disallow: *?print=* Allow: /wp-content/uploads/ User-agent: * Disallow: /wp-admin Disallow: /wp-includes Disallow: /wp-login.php Disallow: /wp-register.php Disallow: /xmlrpc.php Disallow: /search Disallow: */trackback/ Disallow: */feed Disallow: */comments/ Disallow: *?* Disallow: */comment Disallow: */attachment/* Disallow: */print/ Disallow: *?print=* Allow: /wp-content/uploads/ Sitemap: https://znet.ru/sitemap.xml
Этот роботс для WordPress довольно проверенный. Большую часть задач он выполняет — закрывает версию для печати, файлы админки, результаты поиска и так далее.
«Универсальный» роботс
Если вы ищете какое-то решение, которое подойдет для всех сайтов на всех CMS (или для лендинга), «волшебную таблетку» — такой нет. Для всех CMS одинаково хорошо подойдет лишь решение, при котором вы говорите разрешить все для индексации:
Для всех CMS одинаково хорошо подойдет лишь решение, при котором вы говорите разрешить все для индексации:
User-agent: * Allow: /
В остальном — нужно отталкиваться от системы, на которой написан ваш сайт. Потому что у каждой из них уникальная структура и разные разделы/служебные страницы.
Роботс для Joomla
Joomla — ужасный движок, вы ужасный человек, если до сих пор им пользуетесь. Дублей страниц там просто дофига. В основном нормально работает такой код (обязательно замените znet.ru на название вашего сайта, если хотите копировать):
User-agent: * Disallow: /administrator/ Disallow: /cache/ Disallow: /includes/ Disallow: /installation/ Disallow: /language/ Disallow: /libraries/ Disallow: /media/ Disallow: /modules/ Disallow: /plugins/ Disallow: /templates/ Disallow: /tmp/ Disallow: /xmlrpc/ Sitemap: https://znet.ru/sitemap.xml User-agent: Yandex Disallow: /administrator/ Disallow: /cache/ Disallow: /includes/ Disallow: /installation/ Disallow: /language/ Disallow: /libraries/ Disallow: /media/ Disallow: /modules/ Disallow: /plugins/ Disallow: /templates/ Disallow: /tmp/ Disallow: /xmlrpc/ Host: znet.ru Sitemap: https://znet.ru/sitemap.xml
Но я вам настоятельно советую отказаться от этого жестокого движка и перейти на WordPress (а если у вас интернет-магазин — на Opencart или Bitrix). Потому что Joomla — это жесть.
Robots для Битрикса
Как составить robots.txt для Битрикс (обязательно замените znet.ru на название вашего сайта, если хотите копировать):
User-agent: * Disallow: /bitrix/ Disallow: /upload/ Disallow: /search/ Allow: /search/map.php Disallow: /club/search/ Disallow: /club/group/search/ Disallow: /club/forum/search/ Disallow: /communication/forum/search/ Disallow: /communication/blog/search.php Disallow: /club/gallery/tags/ Disallow: /examples/my-components/ Disallow: /examples/download/download_private/ Disallow: /auth/ Disallow: /auth.php Disallow: /personal/ Disallow: /communication/forum/user/ Disallow: /e-store/paid/detail.php Disallow: /e-store/affiliates/ Disallow: /club/$ Disallow: /club/messages/ Disallow: /club/log/ Disallow: /content/board/my/ Disallow: /content/links/my/ Disallow: /*/search/ Disallow: /*PAGE_NAME=search Disallow: /*PAGE_NAME=user_post Disallow: /*PAGE_NAME=detail_slide_show Disallow: /*/slide_show/ Disallow: /*/gallery/*order=* Disallow: /*?print= Disallow: /*&print= Disallow: /*register=yes Disallow: /*forgot_password=yes Disallow: /*change_password=yes Disallow: /*login=yes Disallow: /*logout=yes Disallow: /*auth=yes Disallow: /*action=ADD_TO_COMPARE_LIST Disallow: /*action=DELETE_FROM_COMPARE_LIST Disallow: /*action=ADD2BASKET Disallow: /*action=BUY Disallow: /*print_course=Y Disallow: /*bitrix_*= Disallow: /*backurl=* Disallow: /*BACKURL=* Disallow: /*back_url=* Disallow: /*BACK_URL=* Disallow: /*back_url_admin=* Disallow: /*index.php$ Host: znet.ru Sitemap: https://znet.ru/sitemap.xml
Как правильно составить роботс
У каждой поисковой системы есть свой User-Agent. Когда вы прописываете юзер-эйджент, то вы обращаетесь к какой-то определенной поисковой системе. Вот названия ботов поисковых систем:
Google: Googlebot
Яндекс: Yandex
Мэйл.ру: Mail.Ru
Yahoo!: Slurp
MSN: MSNBot
Рамблер: StackRambler
Это основные, которые включают ваш сайт в текстовые индексы поисковиков. А вот их вспомогательные роботы:
Googlebot-Mobile — это юзер-агент для мобильных
Googlebot-Image — это для картинок
Mediapartners-Google — этот робот сканирует содержание обьявлений AdSense
Adsbot-Google — это для качества целевых страниц AdWords
MSNBot-NewsBlogs – это для новостей MSN
Сначала в любом нормальном роботсе идет указание юзер-агента, а потом директивы ему. Юзер-агента мы указываем в первой строке, вот так:
Юзер-агента мы указываем в первой строке, вот так:
User-agent: Yandex
Это будет обращение к роботу Яндекса. А вот обращение ко всем роботам всех систем сразу:
User-agent: *
После юзер-агента идут указания, относящиеся именно к нему. Пример:
User-agent: Yandex Disallow: /wp-admin Disallow: /wp-includes Disallow: /wp-login.php Disallow: /wp-register.php Disallow: /xmlrpc.php Disallow: /search Disallow: */trackback/ Disallow: */feed Disallow: */comments/ Disallow: *?* Disallow: */comment Disallow: */attachment/* Disallow: */print/ Disallow: *?print=* Allow: /wp-content/uploads/
Сначала мы прописываем директивы для всех интересующих нас юзер-агентов. Затем дополняем их тем, что нас интересует, и заканчиваем обычно ссылкой на XML-карту сайта:
Sitemap: https://znet.ru/sitemap.xml
А вот что прописывать в директивах — это для каждой CMS, как я уже писал выше, по-разному. Но в принципе можно выделить основные типы страниц, которые нужно закрывать во всех роботсах.
Что нужно закрывать в нем
Всю эту хрень нужно закрыть от индексации:
- Страницы поиска. Обычно поиск генерирует очень много страниц, которые нам не будут нести трафика;
- Корзина и страница оформления заказа. Обычно они не должны попадать в индекс;
- Страницы пагинации. Некоторые мастера знают, как получать с них трафик, но если вы не профессионал, лучше закройте их;
- Фильтры и сравнение товаров могут генерировать мусорные страницы;
- Страницы регистрации и авторизации. На этих страницах вводится только конфиденциальная информация;
- Системные каталоги и файлы. Каждый ресурс включает в себя административную часть, таблицы CSS, скрипты. В индексе нам это все не нужно;
- Языковые версии, если вы не продвигаетесь в других странах и они нужны вам чисто для информации;
- Версии для печати.

Как закрыть страницы от индексации и использовать Disallow
Вот чтобы закрыть от индексации какой-то тип страниц, нам потребуется она. Disallow – директива для запрета индексации. Чтобы закрыть, допустим, страницу znet.ru/page.html на своем блоге, я должен добавить в роботс:
Disallow: /page.html
А если мне нужно закрыть все страницы, которые начинаются с https://znet.ru/instrumenty/? То есть страницы https://znet.ru/instrumenty/1.html, https://znet.ru/instrumenty/2.html и другие? Тогда я добавляю такую строку в роботс:
Disallow: /instrumenty/
Короче, это самая нужная директива.
Нужно ли использовать директиву Allow?
Крайне редко ей пользуюсь. Вообще, она нужна для того, чтобы разрешать роботу индексировать определенные страницы. Но он индексирует все, что не запрещено. Так что Allow я почти не использую. За исключением редких случаев, например, таких:
Допустим, у меня в роботсе закрыта категория /instrumenty/. Но страницу https://znet.ru/instrumenty/44.html я должен открыть для индексации. Тогда у меня в роботс тхт будет написано так:
Disallow: /instrumenty/ Allow: /instrumenty/44.html
В таком случае проблема будет решена. Как пишет Яндекс, «При конфликте между двумя директивами с префиксами одинаковой длины приоритет отдается директиве Allow». Короче, Allow я использую тогда, когда нужно перебить требования какой-то из директив Disallow.
Регулярные выражения
Когда прописываем директивы, мы можем использовать спецсимволы * и $ для создания регулярных выражений. Для чего они нужны? Давайте на практике рассмотрим:
User-agent: Yandex Disallow: /cgi-bin/*.aspx
Такая директива запретит Яндексу индексировать страницы, которые начинаются на /cgi-bin/ и заканчиваются на .aspx, то есть вот эти страницы:
/cgi-bin/loh.
aspx
/cgi-bin/pidr.aspx
И подобные им будут закрыты.
А вот спецсимвол $ «фиксирует» запрет какой-то конкретной страницы. То есть такой код:
User-agent: Yandex Disallow: /example$
Запретит индексировать страницу /example, но не запрещает индексировать страницы /example-user, /example.html и другие. Только конкретную страницу /example.
Для чего нужна директива Host
Если сайт доступен сразу по нескольким адресам, директива Host указывает главное зеркало одного ресурса. Эту директиву распознают только роботы Яндекса, остальные поисковики забивают на нее болт. Пример:
User-agent: Yandex Disallow: /page Host: znet.ru
Host используется в robots только один раз. Если же их будет указано несколько, учитываться будет только первая директива.
Что такое Crawl-delay
Директива Crawl-delay устанавливает минимальное время между завершением загрузки роботом страницы 1 и началом загрузки страницы 2. То есть если у вас в роботсе добавлено такое:
User-agent: Yandex Crawl-delay: 2
То таймаут между загрузками двух страниц составит две секунды.
Это нужно, если ваш сервер плохо выдерживает запросы на загрузку страниц. Но я скажу так: если это так и есть, то ваш сервер — говно, и тут не Crawl-delay нужно устанавливать, а менять сервер.
Нужно ли указывать Sitemap в роботсе
В конце роботса нужно указывать ссылку на сайтмап, да. Я вам скажу, что это очень круто помогает индексации.
Был у меня один сайт, который хреново индексировался месяца полтора, когда я еще только начинал в SEO. Я не мог никак понять, в чем причина. Оказалось, я просто не указал путь к сайтмапу. Когда я это сделал — все нужные страницы через 1 апдейт уже попали в индекс.
Указывается путь к сайтмапу так:
Sitemap: https://znet.ru/sitemap.xml
Это если ваша карта сайта открывается по этому адресу. Если она открывается по другому адресу — прописывайте другой.
Прочие рекомендации к составлению
Рекомендую соблюдать:
- В одной строке — одна директива;
- Без пробелов в начале строк;
- Директива будет работать, только если написана целиком и без лишних знаков;
- Как пишет сам Яндекс, «Если для данной страницы сайта подходит несколько директив, то робот выбирает последнюю в порядке появления в сортированном списке»;
- Правильный код роботс должен содержать как минимум одну директиву Dissallow.
А вот еще видео для продвинутых с вебмастерской Яндекса:
Как запретить индексацию всего сайта
Вот этот код поможет закрыть сайт от индексации:
User-agent: * Disallow: /
Пригодиться это может, если вы делаете новый сайт, но он еще не готов, и поэтому его лучше закрыть, чтобы он во время доработки не попал под какой-нибудь фильтр АГС.
Как проверить, правильно ли составлен файл
В Яндекс Вебмастере и Гугл Вебмастере есть инструмент, который поможет вам понять, правильно ли составлен роботс. Рекомендую обязательно проверять файл в этих сервисах перед размещением. В Яндекс Вебмастере вы также сможете добавить список страниц, чтобы проверить, разрешены ли они к индексации роботом.
Правильный robots.txt для wordpress, зачем нужен robots.txt, тэг more
23 Ноябрь 2011 6381 202Здравствуйте, дорогие читатели моего блога!
Сегодня я Вам расскажу о том, как составить правильный robots.txt для WordPress.
Многие новички в блоггинге совершают одну очень важную ошибку: они забывают составлять, или составляют неправильно очень важный файл, который называется robots.txt.
Зачем нужен robots.txt?
Платформа WordPress является очень удобной платформой, однако у нее имеется ряд недостатков. Самым главным из которых является дублирование контента.
Вот смотрите, если вы опубликовали статью, то она появляется сразу на нескольких страницах и может иметь разные адреса (урлы).
Статья появляется на главной странице, в архиве, в рубрике, в ленте RSS, в поиске и т.д.
Так вот, если на блоге появляется несколько статей с одинаковым содержанием и различными адресами, то это называется дублирование контента.
Это все равно, что скопировать контент с чужого блога и вставить на свой. Эти статьи будут неуникальными.
За такие действия поисковые системы однозначно наложат на блог санкции в виде всеми любимого фильтра АГС.
Чтобы избежать дублирования контента на платформе wordpress, необходимо использовать некоторые обязательные мероприятия. Одним из которых является запрет индексации поисковыми системами тех разделов блога, на которых дубли создаются ввиду особенностей самой платформы.
Как раз robots.txt позволяет нам исключить из индекса поисковиков подобные страницы.
Кроме этого в корне блога содержатся различные служебные каталоги (например, для хранения файлов), которые тоже желательно исключать из индекса.
Как составить правильный robots.txt для WordPress?
Перед тем как приступить к составлению этого файла, нам необходимо знать основные правила его написания – директивы.
1. Директива User-agent
Эта директива определяет, какому именно поисковому роботу следует выполнять команды, которые будут указаны далее.
Например, если Вы хотите запретить индексацию чего-либо поисковому роботу Яндекса, то следует для этой директивы задать следующий параметр:
User-agent: Yandex
Если Вы хотите дать указание всем без исключения поисковым системам, то директива будет выглядеть следующим образом:
User-agent: *
В случае с рунетом, особые указания необходимо задать для Яндекса, а для роботов остальных поисковых систем подойдут общие, которые мы зададим так:
User-agent: *
2. Следующими директивами являются «Allow» и «Disallow».
Allow – разрешает индексацию указанных в ней элементов.
Disallow – соответственно запрещает индексацию.
Правильный robots.txt должен обязательно содержать директиву «Disallow».
Если написать так:
User-agent: Yandex
Disallow:
То мы разрешим индексацию поисковому роботу Яндекса всего блога полностью.
Если написать так:
User-agent: Yandex
Disallow: /
То запретим Яндексу индексировать весь ресурс.
Таким образом, мы можем разрешать или запрещать индексацию своего блога отдельным или всем роботам.
Например:
User-agent: *
Disallow:
User-agent: Yandex
Disallow: /
Здесь мы разрешили индексирование всем поисковикам, а Яндексу запретили. Надеюсь, это понятно.
Теперь нам необходимо знать, что именно следует запретить для индексации в WordPress, то есть какие разделы могут содержать дубли страниц и другой мусор.
1. все системные и служебные файлы:
— wp-login.php
— wp-register.php
— wp-content/
— wp-admin/
— wp-includes/
Отдельно хочу сказать про каталог wp-content.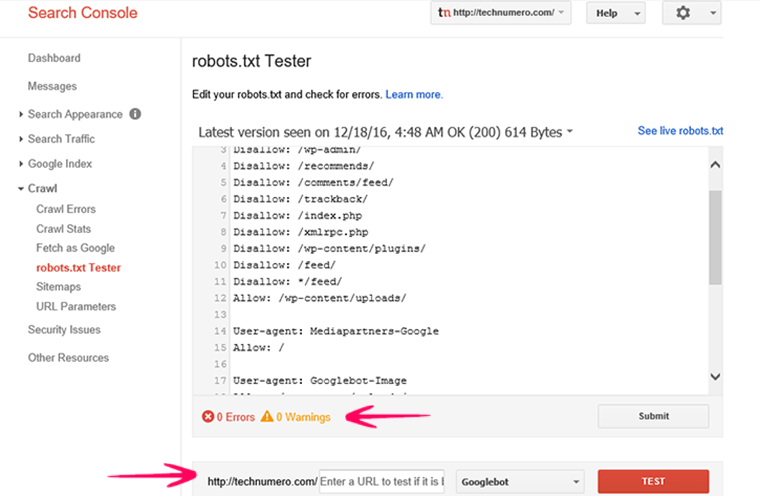 В принципе, все содержимое в нем необходимо закрыть, за исключением папки «uploads» в которой располагаются изображения. Потому что, в случае запрета индексирования «uploads», ваши картинки на блоге индексироваться не будут.
В принципе, все содержимое в нем необходимо закрыть, за исключением папки «uploads» в которой располагаются изображения. Потому что, в случае запрета индексирования «uploads», ваши картинки на блоге индексироваться не будут.
Поэтому будем закрывать каталоги, размещенные внутри папки «wp-content» отдельно:
Disallow: /wp-content/themes
Disallow: /wp-content/plugins
Disallow: /wp-content/languages
Disallow: /wp-content/cache
Если в каталоге «wp-content» Вашего блога есть еще какие-либо папки, то можно (и даже нужно) их закрыть (за исключением «uploads»).
2. Дубли страниц в категориях:
— category/*/*
3. RSS ленту:
— feed
4. Дубли страниц в результатах поиска:
— *?*
— *?
5. Комментарии:
— comments
6. Трэкбэки:
— trackback
Я не буду описывать структуру WordPress, а выкладываю Вам свой файл robots.txt, который установлен на моем блоге. Я считаю, что он наиболее правильный. Если Вы найдете в нем какие-либо недочеты, то просьба написать об этом в комментариях.
User-agent: *
Disallow: /wp-login.php
Disallow: /wp-register.php
Disallow: /xmlrpc.php
Disallow: /webstat/
Disallow: /feed/
Disallow: /trackback
Disallow: */trackback
Disallow: */feed
Disallow: */comments
Disallow: /*?*
Disallow: /*?
Disallow: /category/*/*
Disallow: /wp-content/themes
Disallow: /wp-content/plugins
Disallow: /wp-content/languages
Disallow: /wp-content/cache
Disallow: /wp-admin/
Disallow: /wp-includes/
Disallow: /comments
Здесь же нужно задать отдельные указания Яндексу:
User-agent: Yandex
Disallow: /wp-login.php
Disallow: /wp-register.php
Disallow: /xmlrpc.php
Disallow: /webstat/
Disallow: /feed/
Disallow: /trackback
Disallow: */trackback
Disallow: */feed
Disallow: */comments
Disallow: /*?*
Disallow: /*?
Disallow: /category/*/*
Disallow: /wp-content/themes
Disallow: /wp-content/plugins
Disallow: /wp-content/languages
Disallow: /wp-content/cache
Disallow: /wp-admin/
Disallow: /wp-includes/
Disallow: /comments
Host: mysite. ru
ru
Sitemap: http://mysite.ru/sitemap.xml
Sitemap: http:// mysite.ru/sitemap.xml.gz
Если Вы не составляли файл robots.txt или сомневаетесь в правильности его составления, советую Вам использовать этот.
Для этого необходимо создать обычный текстовый документ, скопировать весь текст, представленный выше, вставить его в свой файл. Затем сохранить его под именем: robots.txt (первая буква не должна быть заглавной).
Не забудьте поменять mysite.ru на свой.
После создания файл robots.txt необходимо разместить в корне блога, затем добавить его в панель вебмастера Яндекса.
Рекомендую Вам посмотреть видео, посвященное дублированию контента:
Еще пару слов о дублировании контента. Тэг «More»
Дело в том, что у нас на главной странице блога (mysite.ru) тоже выводятся статьи.
При нажатии на заголовок поста, мы переходим на его страницу (mysite.ru/…./….html). Таким образом, часть поста (та, что на главной) является дублем такой же части текста основной статьи.
Закрыть от индексации здесь ничего нельзя. Поэтому рекомендую Вам выводить на главную страницу как можно меньше текста основной статьи.
А именно приветствие и небольшой анонс.
Пример Вы можете посмотреть у меня на главной странице (анонс к этой статье).
Для этого используется тэг more.
Проще говоря: набрали небольшой фрагмент (приветствие и анонс), который будет выведен на главную, перешли в редактор HTML и вставили следующий код:
<!- -more- ->
И продолжаете дальше писать статью.
Вся часть текста, расположенная перед тэгом more, будет выведена на главную страницу.
Рекомендую посмотреть видео: «Что такое Robots.txt?»:
На этом у меня все. Обязательно создайте правильный robots.txt для WordPress!
Обязательно создайте правильный robots.txt для WordPress!
С уважением, Александр Бобрин
Поделись с друзьями:
Обратите внимание:
Похожие статьи
Правильный Robots.txt для WordPress (2021) | BoostSEO ru
В интернете можно найти много публикаций на тему, как составить лучший (или даже самый лучший) файл robots.txt для WordPress. При этом в ряде таких популярных статей многие правила не объясняются и, как мне кажется, вряд ли понимаются самими авторами. Единственный обзор, который я нашел и который действительно заслуживает внимания, — это статья в блоге wp-kama. Однако и там я нашел не совсем корректные рекомендации. Понятно, что на каждом сайте будут свои нюансы при составлении файла robots.txt. Но существует ряд общих моментов для совершенно разных сайтов, которые можно взять за основу. Robots.txt, опубликованный в этой статье, можно будет просто копировать и вставлять на новый сайт и далее дорабатывать в соответствии со своими нюансами.
Правильный Robots.txt для WordPress
Действительно самый лучший robots.txt, который я видел на данный момент, это роботс, предложенный в блоге wp-kama. Ряд директив и комментариев я возьму из его образца + внесу свои корректировки. Корректировки коснутся нескольких правил, почему так напишу ниже. Кроме того, напишем индивидуальные правила для всех роботов, для Яндекса и для Google.
Ниже привожу короткий и расширенный вариант. Короткий не включает отдельные блоки для Google и Яндекса. Расширенный уже менее актуален, т.к. теперь нет принципиальных особенностей между двумя крупными поисковиками: обеим системам нужно индексировать файлы скриптов и изображений, обе не поддерживают директиву Host. Тем не менее, если в этом мире снова что-то изменится, либо вам потребуется все-таки как-то по-отдельному управлять индексацией файлов на сайте Яндексом и Гугл, сохраню в этой статье и второй вариант.
Еще раз обращаю внимание, что это базовый файл robots.txt. В каждом конкретном случае нужно смотреть реальный сайт и по-необходимости вносить корректировки. Поручайте это дело опытным специалистам!
Короткий вариант (оптимальный)User-agent: * # общие правила для роботов, кроме Яндекса и Google,
# т.к. для них правила ниже
Disallow: /cgi-bin # папка на хостинге
Disallow: /? # все параметры запроса на главной
Disallow: /wp- # все файлы WP: /wp-json/, /wp-includes, /wp-content/plugins
Disallow: /wp/ # если есть подкаталог /wp/, где установлена CMS (если нет,
# правило можно удалить)
Disallow: *?s= # поиск
Disallow: *&s= # поиск
Disallow: /search/ # поиск
Disallow: /author/ # архив автора
Disallow: /users/ # архив авторов
Disallow: */trackback # трекбеки, уведомления в комментариях о появлении открытой
# ссылки на статью
Disallow: */feed # все фиды
Disallow: */rss # rss фид
Disallow: */embed # все встраивания
Disallow: */wlwmanifest.xml # xml-файл манифеста Windows Live Writer (если не используете,
# правило можно удалить)
Disallow: /xmlrpc.php # файл WordPress API
Disallow: *utm*= # ссылки с utm-метками
Disallow: *openstat= # ссылки с метками openstat
Allow: */uploads # открываем папку с файлами uploads# Укажите один или несколько файлов Sitemap (дублировать для каждого User-agent
# не нужно). Google XML Sitemap создает 2 карты сайта, как в примере ниже.
Sitemap: http://site.ru/sitemap.xmlРасширенный вариант (отдельные правила для Google и Яндекса)
Sitemap: http://site.ru/sitemap.xml.gz# Укажите главное зеркало сайта, как в примере ниже (с WWW / без WWW, если HTTPS
www.site.ru
# то пишем протокол, если нужно указать порт, указываем). Команда стала необязательной. Ранее Host понимал
# Яндекс и Mail.RU. Теперь все основные поисковые системы команду Host не учитывают.
Host:
User-agent: * # общие правила для роботов, кроме Яндекса и Google,
# т.к. для них правила ниже
Disallow: /cgi-bin # папка на хостинге
Disallow: /? # все параметры запроса на главной
Disallow: /wp- # все файлы WP: /wp-json/, /wp-includes, /wp-content/plugins
Disallow: /wp/ # если есть подкаталог /wp/, где установлена CMS (если нет,
# правило можно удалить)
Disallow: *?s= # поиск
Disallow: *&s= # поиск
Disallow: /search/ # поиск
Disallow: /author/ # архив автора
Disallow: /users/ # архив авторов
Disallow: */trackback # трекбеки, уведомления в комментариях о появлении открытой
# ссылки на статью
Disallow: */feed # все фиды
Disallow: */rss # rss фид
Disallow: */embed # все встраивания
Disallow: */wlwmanifest.xml # xml-файл манифеста Windows Live Writer (если не используете,
# правило можно удалить)
Disallow: /xmlrpc.php # файл WordPress API
Disallow: *utm*= # ссылки с utm-метками
Disallow: *openstat= # ссылки с метками openstat
Allow: */uploads # открываем папку с файлами uploadsUser-agent: GoogleBot # правила для Google (комментарии не дублирую)
Disallow: /cgi-bin
Disallow: /?
Disallow: /wp-
Disallow: /wp/
Disallow: *?s=
Disallow: *&s=
Disallow: /search/
Disallow: /author/
Disallow: /users/
Disallow: */trackback
Disallow: */feed
Disallow: */rss
Disallow: */embed
Disallow: */wlwmanifest.xml
Disallow: /xmlrpc.php
Disallow: *utm*=
Disallow: *openstat=
Allow: */uploads
Allow: /*/*.js # открываем js-скрипты внутри /wp- (/*/ — для приоритета)
Allow: /*/*.css # открываем css-файлы внутри /wp- (/*/ — для приоритета)
Allow: /wp-*.png # картинки в плагинах, cache папке и т.д.
Allow: /wp-*.jpg # картинки в плагинах, cache папке и т.д.
Allow: /wp-*.jpeg # картинки в плагинах, cache папке и т.д.
Allow: /wp-*.gif # картинки в плагинах, cache папке и т.д.
Allow: /wp-admin/admin-ajax.php # используется плагинами, чтобы не блокировать JS и CSSUser-agent: Yandex # правила для Яндекса (комментарии не дублирую)
Disallow: /cgi-bin
Disallow: /?
Disallow: /wp-
Disallow: /wp/
Disallow: *?s=
Disallow: *&s=
Disallow: /search/
Disallow: /author/
Disallow: /users/
Disallow: */trackback
Disallow: */feed
Disallow: */rss
Disallow: */embed
Disallow: */wlwmanifest.xml
Disallow: /xmlrpc.php
Allow: */uploads
Allow: /*/*.js
Allow: /*/*.css
Allow: /wp-*.png
Allow: /wp-*.jpg
Allow: /wp-*.jpeg
Allow: /wp-*.gif
Allow: /wp-admin/admin-ajax.php
Clean-Param: utm_source&utm_medium&utm_campaign # Яндекс рекомендует не закрывать
# от индексирования, а удалять параметры меток,
# Google такие правила не поддерживает
Clean-Param: openstat # аналогично# Укажите один или несколько файлов Sitemap (дублировать для каждого User-agent
http://site.ru/sitemap.xml
# не нужно). Google XML Sitemap создает 2 карты сайта, как в примере ниже.
Sitemap:
Sitemap: http://site.ru/sitemap.xml.gz# Укажите главное зеркало сайта, как в примере ниже (с WWW / без WWW, если HTTPS
www.site.ru
# то пишем протокол, если нужно указать порт, указываем). Команда стала необязательной. Ранее Host понимал
# Яндекс и Mail.RU. Теперь все основные поисковые системы команду Host не учитывают.
Host:
В примере я не добавляю правило Crawl-Delay, т.к. в большинстве случаев эта директива не нужна. Однако если у вас крупный нагруженный ресурс, то использование этой директивы поможет снизить нагрузку на сайт со стороны роботов Яндекса, Mail. Ru, Bing, Yahoo и других (Google не учитывает). Подробнее про это читайте в статье Robots.txt.
Ru, Bing, Yahoo и других (Google не учитывает). Подробнее про это читайте в статье Robots.txt.
Индивидуальная настройка Robots.txt
Если вы хотите заказать индивидуальную настройку технического файла Robots.txt как для CMS WordPress, так и для других платформ, то обращайтесь к Александру Дружному. Разовая оптимизация сайта от BoostSEO или сразу на WhatsApp по телефону +7 (992) 345-41-55.
Ошибочные рекомендации других блогеров для Robots.txt на WordPress- Использовать правила только для User-agent: *
Для многих поисковых систем не требуется индексация JS и CSS для улучшения ранжирования, кроме того, для менее значимых роботов вы можете настроить большее значение Crawl-Delay и снизить за их счет нагрузку на ваш сайт. - Прописывание Sitemap после каждого User-agent
Это делать не нужно. Один sitemap должен быть указан один раз в любом месте файла robots.txt - Закрыть папки wp-content, wp-includes, cache, plugins, themes
Это устаревшие требования. Однако подобные советы я находил даже в статье с пафосным названием «Самые правильный robots для WordPress 2018»! Для Яндекса и Google лучше будет их вообще не закрывать. Или закрывать «по умному», как это описано выше. - Закрывать страницы тегов и категорий
Если ваш сайт действительно имеет такую структуру, что на этих страницах контент дублируется и в них нет особой ценности, то лучше закрыть. Однако нередко продвижение ресурса осуществляется в том числе за счет страниц категорий и тегирования. В этом случае можно потерять часть трафика - Закрывать от индексации страницы пагинации /page/
Это делать не нужно. Для таких страниц настраивается тег rel=»canonical», таким образом, такие страницы тоже посещаются роботом и на них учитываются расположенные товары/статьи, а также учитывается внутренняя ссылочная масса. - Прописать Crawl-Delay
Модное правило. Однако его нужно указывать только тогда, когда действительно есть необходимость ограничить посещение роботами вашего сайта. Если сайт небольшой и посещения не создают значительной нагрузки на сервер, то ограничивать время «чтобы было» будет не самой разумной затеей.
Если сайт небольшой и посещения не создают значительной нагрузки на сервер, то ограничивать время «чтобы было» будет не самой разумной затеей. - Ляпы
Некоторые правила я могу отнести только к категории «блогер не подумал». Например: Disallow: /20 — по такому правилу не только закроете все архивы, но и заодно все статьи о 20 способах или 200 советах, как сделать мир лучше 🙂
Источник: seogio.ru/robots-txt-dlya-wordpress/
Правильный robots.txt для сайта wordpress, как закрыть ссылки от индексации
Индексация сайта представляет собой процесс, благодаря которому страницы вашего сайта попадают в поисковые системы.
Для того чтобы сайт индексировался хорошо, вам нужно создать правильный файл robots txt и вписать туда необходимые директивы.
Файл можно создать в стандартной программе “Блокнот”, которая доступна абсолютно каждому пользователю ПК.
Добавляется файл robots txt в корневую папку сайта. Для того чтобы осуществить это действие, вам потребуется программа FileZilla или же обычный Total Commander при условии наличия FTP соединения. На некоторых хостингах есть возможность непосредственного добавления каких-либо файлов.
Что будет, если файл robots txt неправильно настроен
Чтобы ответить на данный вопрос, давайте представим, что сайт wordpress это офис, в который приходят клиенты. В вашем офисе есть как гостевые комнаты, так и служебные, вход в которые доступен только сотрудникам. На дверях служебных помещений обычно вешается табличка с надписью “вход воспрещен” или “вход только для сотрудников”. Таким образом, ваши клиенты будут понимать, что туда им лучше не соваться.
Теперь поговорим о сайте wordpress. Если придерживаться аналогии, то его гостевыми комнатами будут открытые к индексации страницы, а служебными — закрытые к индексации страницы. Клиенты же являются поисковыми роботами, которые посещают сайт и вносят в поисковый индекс определенные страницы.
После небольшого экскурса перейдем непосредственно к последствиям, которые могут возникнуть при неправильной настройке файла роботс. Если вы не впишите запрещающие директивы, то поисковый робот будет индексировать абсолютно все подряд, включая данные панели администратора сайта, тем, скриптов и так далее. Также в выдаче могут появиться страницы-дубли. Поисковый робот может запутаться и случайно проиндексировать одну и ту же страницу несколько раз. Бывают случаи, когда роботы вовсе не индексируют сайт из-за того, что директивы файла индексации неправильно настроены, но чаще всего такое последствие является санкцией, которая возлагается на сайт при продаже ссылок. Чтобы выяснить причину, вам нужно зайти в панель управления, которую предоставляют поисковые системы, которая отказывается индексировать сайт и обратить внимание на какие-либо оповещения.
Настройка robots txt
Запомните, что правильный файл robots txt состоит из 3 компонентов: выбор робота, которому вы задаете директивы; запрет на индексацию; разрешение индексации.
Для того чтобы указать конкретного робота, которому будут адресоваться правила, можно использовать директиву User-agent. Ниже представлены возможные примеры.
- User-agent: * (правила будут распространятся на всех поисковых роботов).
- User-agent: название поискового робота (правила будут распространятся только на тех роботов, которых вы впишете). В большинстве случаев сюда вписывают yandex и googlebot.
Чтобы запретить индексацию определенных разделов на wordpress, вам стоит использовать правильный комплекс директив Disallow. Помимо разделов вы можете также запретить индексировать какую-либо папку или файл. Итак, перейдем к примерам.
- Disallow: (на индексацию нет никаких запретов).
- Disallow: /file.pdf (закрыть файл file.pdf). Таким же образом можете попросить закрыть конкретные папки.
- Disallow: /nazvanie-razdela (закрыть страницы, которые находятся в разделе “nazvanie-razdela”).
- Disallow: */*slovo (закрыть страницы, ссылки на которые включают в себя “slovo”). Звездочки означают любой текст ссылки, который стоит перед или после указанного вами слова. При использовании такой комбинации символов поисковый робот будет считать, что звездочка находится и в конце. Поэтому, если хотите закрыть страницы, ссылки на которые заканчиваются определенным текстом, то вам стоит добавить еще “$” после директивы.
- Disallow: / (закрыть весь сайт).
Если же хотите разрешить индексирование конкретных файлов сайта, которые находятся в запрещенных для индексации разделах, то вам поможет директива Allow. Наглядный пример смотрите ниже.
адресуется поисковым роботам Google
User-agent: googlebot
закрыть страницы, которые находятся в разделе “nazvanie-razdela”
Disallow: /nazvanie-razdela
разрешено добавлять в индекс абсолютно все файлы с расширением txt, независимо от раздела сайта
Allow: *.txt$
В случае наличия XML карты сайта вы можете указать текст ее ссылки в директиву Sitemap. Она является неофициальной и поддерживается не всеми поисковыми роботами. Основными же (Yandex, Google, Bing и Yahoo) эта директива поддерживается. Если у сайта есть несколько XML карт, то вы можете указать все, используя ссылки на них. Никаких проблем не должно возникнуть. Основная ваша задача это правильно указать адрес ссылки каждой из них.
Sitemap: сайт.ru/название-карты-сайта.xml
Sitemap: сайт.ru/название-карты-сайта1.xml
У многих сайтов вордпресс есть зеркала. Чтобы указать основное, вам потребуется вписать адрес его ссылки в директиву Host. Ее понимают только поисковые роботы системы Yandex. Данную директиву можно вписать как под User-agent, так и в любое другое место роботс тхт. Обратите внимание, что адрес ссылки основного зеркала может содержать www. Если вы забудете его туда вписать, то тогда могут возникнуть проблемы.
Host: основное-зеркало. ru
ru
Теперь, зная директивы, вы можете самостоятельно создать правильный файл роботс под любые поисковые системы. Для этого вам нужно в первую очередь проанализировать структуру сайта вордпресс и решить, что же закрыть от поисковиков, а что открыть. Если же вам лень этим заниматься, то можете использовать пример, который представлен ниже.
Для удобства вам рекомендуется использовать плагин wordpress All in One Seo Pack. Он содержит опцию, благодаря которой можно закрыть индексацию архивов, тегов и страниц поиска. Если у вас нет такого плагина, то вам стоит дописать в robots txt представленные ниже атрибуты после директивы Disallow.
- */20 – отвечает за архивы
- */tag – отвечает за теги
- *?s= – отвечает за страницы поиска
При прописывании директив обратите внимание на то, что все директивы, которые адресуются одному поисковому роботу, нужно прописывать без пробела между строками. В ином же случае вам этот пробел будет необходим.
Стоит отметить, что если вы прописали директивы для всех поисковых систем, не нужно их по 10 раз переписывать для каждой отдельно. Это будет лишней тратой времени. Директива User-agent универсальна, поэтому просто вписываете туда звездочку и никаких проблем не должно возникнуть.
Если вам лень прописывать полное название служебных разделов, то можете прописать директиву Disallow: /wp- при условии, что на вашем сайте wordpress нет страниц с таким названием, которые вы бы хотели добавить в индекс. Поэтому будьте внимательны при выборе названия для неслужебных разделов.
При изменении директив файла robots txt вам стоит помнить, что его индексация это не быстрый процесс. Иногда на это требуется не одна неделя. Чтобы проверить статус индексирования этого файла Яндексом, вам нужно перейти в панель вебмастера сервиса Яндекс, выбрать сайт и перейти в раздел “Настройка индексирования”. Потом вам нужно будет выбрать “Анализ robots txt”.
Потом вам нужно будет выбрать “Анализ robots txt”.
Чтобы проверить статус индексирования файла в Google, вам нужно перейти в раздел “Сканирование” и выбрать “Инструмент проверки robots txt”.
После того как настроите директивы, поисковики должны начать добавлять ваш сайт wordpress в индекс. Стоит отметить, что этот процесс может пойти не так гладко, как вы думаете. Многие вебмастера жалуются на Google из-за того, что он вопреки каким-либо запретам производит индексацию сайта так, как пожелает. Работники Google говорят, что файл роботс является не более, чем рекомендацией.
Даже если прописать запрещающие директивы отдельно для Google, то желаемый результат вы не факт, что получите. К тому же, из-за произвольной индексации роботов Google могут появиться страницы-дубли. Их количество со временем может увеличиться и сайт может попасть под фильтр. Чаще всего это Panda.
Чтобы справиться с этой проблемой, вы можете поставить пароль в панели управления wordpress на конкретный файл или же добавить атрибут noindex в метатеги страниц, на которые желаете наложить запрет индексации. Выглядеть это будет так.
<meta name="robots" content="noindex">
Альтернативой для атрибута noindex является атрибут nofollow. Разница между ними лишь в том, что они по-разному оцениваются поисковыми системами. В случае же с Google вам лучше использовать noindex. Если прислушаться к рекомендации, то вы добьетесь желаемого результата.
В справке сервиса Google можно более детально изучить особенности использования атрибута noindex.
Если вы не хотите вручную создавать роботс для своего wordpress, то можете воспользоваться плагином DL Robots.txt. Его можно установить прямо в панели администратора. Для этого вам нужно будет кликнуть по разделу “Плагины” и выбрать “Добавить новый”. Теперь вам останется лишь вписать название и кликнуть “Установить”, а затем “Активировать”. После этого в панели администратора должна появиться вкладка с названием плагина. Кликнув на нее, вы перейдете в настройки и сможете посмотреть обучающее видео. После проведения настройки вы получите адрес ссылки вашего роботс.
Кликнув на нее, вы перейдете в настройки и сможете посмотреть обучающее видео. После проведения настройки вы получите адрес ссылки вашего роботс.
Альтернативами данного плагина wordpress являются PC Robots.txt и iRobots.txt. Они имеют свои особенности, но в целом похожи и являются легкими в настройке. Так что, если первый по каким-либо причинам не будет работать, вы всегда можете воспользоваться последними.
Несколько советов и примечаний
- Помните, что правильный файл роботс wordpress не должен занимать более 32 Кбайта дискового пространства. В противном случае могут возникнуть проблемы и индексацией. Чем меньше вес, тем быстрее обработка.
- Не желательно указывать несколько директив в одной строке.
- Не нужно добавлять в кавычки каждый атрибут директивы, который находится в роботс.
- При отсутствии файла роботс поисковики будут считать, что запрет на индексацию не установлен. Произвольная индексация может привести к фильтрации.
- Стоит отметить, что правильный роботс не должен содержать пробелы в начале каждой строки директивы.
Robots.txt Editor — плагин для WordPress
Плагин позволяет создавать и редактировать файл robots.txt на вашем сайте.
Характеристики
- Работает с многосайтовой сетью на поддоменах;
- Пример правильного файла для WordPress;
- Работает «из коробки»;
- Совершенно бесплатно.
- Настройки Robots.txt
- Распакуйте загруженный zip-файл.
- Загрузите папку плагина в каталог
wp-content / plugins /вашего сайта WordPress. - Активируйте
Robots.txt Editorсо страницы плагинов
Я никогда не видел поддержки мультисайта с этим плагином. Удалено. Совершенно бесполезная вещь.
Отличный плагин как говорится из коробки. Без спама и апселлов, вообще ничего. Просто хорошо!
Такой полезный плагин для просмотра и редактирования содержимого Robots.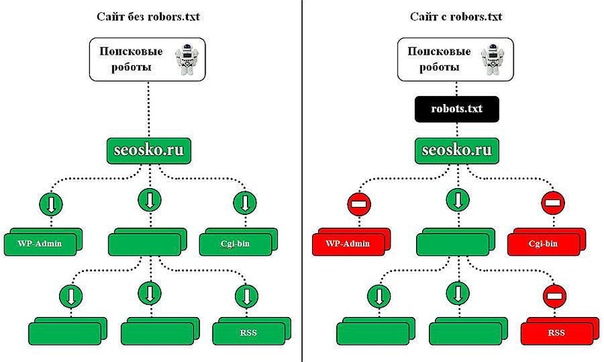 txt легко. Я не использую два плагина SEO, которые позволяют редактировать Robots.txt, и я считаю использование FTP и Блокнота слишком громоздким / трудоемким. Вместо этого использование этого плагина сэкономит мне драгоценное время. Так что спасибо за создание этого плагина!
txt легко. Я не использую два плагина SEO, которые позволяют редактировать Robots.txt, и я считаю использование FTP и Блокнота слишком громоздким / трудоемким. Вместо этого использование этого плагина сэкономит мне драгоценное время. Так что спасибо за создание этого плагина!
Работает безупречно, сразу после установки, просто, так как не требует настройки. Просто «поставил и забыл».
Легкий и идеальный для установки на нескольких площадках. Но в документации нужно указать, где установлен параметр / редактор (Настройки> Параметры чтения).
Спасибо за плагин. Так приятно найти тот, который так легко использовать для работы с несколькими сайтами. Надеюсь, вы будете обновлять плагин.
Посмотреть все 7 отзывов«Редактор Robots.txt» — это программа с открытым исходным кодом. Следующие люди внесли свой вклад в этот плагин.
авторов1.1.4
Дата выпуска: 16 января 2021 г.
- Совместимость с WordPress 5.6
1.1,3
Дата выпуска: 19 апр.2020 г.
- Совместимость с WordPress 5.4
1.1.2
Дата выпуска: 27 июля 2019 г.
- Добавить — совместимость с WordPress 5.2.2
1.1.1
Дата выпуска: 6 мая 2019 г.
- Улучшено — обнаружение карты сайта
1,1
Дата выпуска: 6 мая 2019 г.
- Добавить — просмотр ссылки в robots.txt
1,0
Дата выпуска: 2 мая 2019 г.
Как использовать роботов.txt | Поддержка Bluehost
Для чего нужен файл роботов?
Когда поисковая система просматривает (посещает) ваш веб-сайт, первое, что она ищет, — это ваш файл robots.txt. Этот файл сообщает поисковым системам, что они должны и не должны индексировать (сохранять и делать общедоступными в качестве результатов поиска). Он также может указывать на расположение вашей XML-карты сайта. Затем поисковая система отправляет своего «бота», «робота» или «паука» для сканирования вашего сайта, как указано в файле robots. txt (или не отправлять его, если вы сказали, что они не могут).
txt (или не отправлять его, если вы сказали, что они не могут).
Бот Google называется Googlebot, а бот Microsoft Bing — Bingbot. Многие другие поисковые системы, такие как Excite, Lycos, Alexa и Ask Jeeves, также имеют своих собственных ботов. Большинство ботов поступают из поисковых систем, хотя иногда другие сайты рассылают ботов по разным причинам. Например, некоторые сайты могут попросить вас разместить код на своем веб-сайте, чтобы подтвердить, что вы являетесь его владельцем, а затем они отправят бота, чтобы узнать, разместили ли вы код на своем сайте.
Имейте в виду, что robots.txt работает как знак «Вход воспрещен».Он сообщает роботам, хотите ли вы, чтобы они сканировали ваш сайт или нет. Фактически он не блокирует доступ. Достопочтенные и законные боты будут соблюдать вашу директиву относительно того, могут они посещать или нет. Боты-мошенники могут просто игнорировать robots.txt.Прочтите официальную позицию Google по файлу robots.txt.
Куда идет robots.txt?
Файл robots.txt находится в корневой папке вашего документа.
Вы можете просто создать пустой файл и назвать его robots.txt .Это уменьшит количество ошибок сайта и позволит всем поисковым системам ранжировать все, что они хотят.
Блокировка сканирования роботов и поисковых систем
Если вы хотите, чтобы запретил ботам посещать ваш сайт и запретил поисковым системам ранжировать вас, используйте этот код:
# Код, запрещающий работу поисковых систем!
Агент пользователя: *
Disallow: / Вы также можете запретить роботам сканировать части вашего сайта, разрешив им сканировать другие разделы.В следующем примере поисковым системам и роботам предлагается не сканировать папку cgi-bin, папку tmp, папку нежелательной почты и все, что находится в этих папках на вашем веб-сайте.
# Блокирует роботов из определенных папок / каталогов
User-agent: *
Disallow: / cgi-bin /
Disallow: / tmp /
Disallow: / junk / В приведенном выше примере http://www. yoursitesdomain.com/junk/index.html будет одним из заблокированных URL-адресов, но http://www.yoursitesdomain.com/index.html и http: // www.yoursitesdomain.com/someotherfolder/ можно будет сканировать.
yoursitesdomain.com/junk/index.html будет одним из заблокированных URL-адресов, но http://www.yoursitesdomain.com/index.html и http: // www.yoursitesdomain.com/someotherfolder/ можно будет сканировать.
Создайте файл robots.txt для максимальной эффективности SEO
Есть разные способы создать файл robots.txt. Вы можете создать его со своего:
- Система управления контентом
- Компьютер, после которого вы загружаете его через свой веб-сервер
Создание robots.txt из вашей системы управления контентом
Часто современные системы управления контентом (CMS) имеют функции для создания и обслуживания ваших роботов.txt из CMS. Если он не входит в состав CMS по умолчанию, вы часто можете найти плагины, которые помогут с этим.
WordPress + Yoast SEO
Например, плагин Yoast SEO в WordPress поддерживает создание и обслуживание файла robots.txt:
- Войдите в свой
wp-adminраздел. - На боковой панели перейдите к
Yoast SEO plugin>Tools. - Перейти в
Редактор файлов.
WordPress + Rank Math
Для создания и обслуживания роботов.txt в плагине Rank Math SEO:
- Войдите в свой
wp-adminраздел. - На боковой панели выберите
Rank Math>Общие настройки. - Перейдите на страницу
Отредактируйте robots.txt.
WordPress + все в одном SEO
В плагине All in One SEO Pack можно создать файл robots.txt следующим образом:
- Войдите в свой
wp-adminраздел. - На боковой панели перейдите к
All in One SEO>Robots.txt.
Magento 2
В Magento 2 ваш файл robots.txt находится здесь:
-
Содержимое>Конфигурация(доДизайн).
- Здесь отредактируйте настройки для
Main WebsiteвместоDefault Store View, потому что последний не позволяет вам изменять файл robots.txt.
На следующем экране прокрутите вниз до Search Engine Robots .Здесь вы можете определить свой контент robots.txt:
Торговое оборудование 5
Поскольку Shopware 5 не поставляется с редактором robot.txt из коробки, вам необходимо установить плагин (открывается в новой вкладке) или внести изменения в код (открывается в новой вкладке), который генерирует robots.txt.
Создание robots.txt на вашем компьютере
Если вы не используете CMS или CMS не поддерживает создание файла robots.txt, вы всегда можете создать файл robots.txt самостоятельно и вручную загрузите его на свой веб-сервер.
- Откройте редактор, например Блокнот в Windows или textEdit в Mac OS X.
- Создайте новый файл.
- Скопируйте и вставьте один из примеров файлов robots.txt.
- При необходимости отрегулируйте содержимое.
- Сохраните его с именем файла
robots.txt. - Загрузите его на свой веб-сервер.
ContentKing Academy
Прочтите всю статью об Академии, чтобы узнать все о роботах.txt
Как получить доступ и изменить файл robots.txt в WordPress [Руководство]
Последнее обновление 15 марта 2021 г.
В этом кратком руководстве я покажу вам, как создать, получить доступ и изменить файл robots.txt в WordPress 4 простыми способами.
Robots.txt — это файл, который информирует роботов поисковых систем о страницах или файлах, которые следует или не следует сканировать.
- Файл robots.txt предназначен для защиты веб-сайта от перегрузки его запросами от сканеров.

- Файл robots.txt не позволяет заблокировать индексирование и отображение веб-страниц или файлов в результатах поиска.
- Сканеры поисковых систем всегда начинают сканирование вашего веб-сайта с проверки директив в файле robots.txt .
Если вы серьезно относитесь к своему веб-сайту, вы обязательно должны иметь доступ к его файлу robots.txt и управлять им. К счастью, с веб-сайтами WordPress это сделать довольно просто.
Вот 4 простых способа получить доступ к robots.txt в WordPress.
⚡ Если вы читаете это руководство, вы должны быть заинтересованы в техническом SEO. Обязательно проверьте мой технический SEO-аудит и мой контрольный список SEO на странице.
Где находится файл robots.txt в WordPress?
Давайте сначала проясним ситуацию.
- Единственное правильное расположение robots.txt — это корень (основной каталог) веб-сайта. Это применимо к любому веб-сайту, независимо от того, является ли он веб-сайтом WordPress.
- На одном веб-сайте может быть только один файл robots.txt .
- Единственное допустимое имя для файла — robots.txt .
- Robots.txt должен быть текстовым файлом в кодировке UTF-8.
Имея это в виду, расположение файла robots.txt в WordPress такое же, как и для любого другого веб-сайта. Это корень веб-сайта. В случае моего веб-сайта это https://seosly.com/robots.txt.
Хорошая вещь в WordPress заключается в том, что он позволяет вам получить доступ к своим файлам robots.txt несколькими способами, даже если у вас нет доступа к FTP.
Если вы хотите узнать больше о файле robots.txt, о том, как он работает, что это такое, обязательно ознакомьтесь с введением в robots.txt в Центре поиска Google.
4 способа получить доступ к robots.txt в WordPress
Если вы используете WordPress, вам может быть интересно мое руководство о том, как проверить консоль поиска Google в WordPress.
# 1: используйте плагин SEO
Существует много плагинов для SEO для WordPress, но реально учитываются только два:
Также есть All in One SEO, но этот имеет гораздо меньшее значение.Все эти плагины SEO позволяют легко открывать и изменять robots.txt.
Доступ к robots.txt с помощью Rank Math
Если вы используете Rank Math, вам нужно сделать следующее:
- Войдите в свою панель управления WordPress как администратор. Обратите внимание, что только администраторы могут изменять плагины.
- Перейти к Rank Math.
- На левой боковой панели под Rank Math вы увидите различные настройки Rank Math. Щелкните Общие настройки с.
- Теперь вы увидите список общих настроек SEO.Нажмите Изменить robots.txt .
- Если вы ничего не сделаете, Rank Math автоматически обработает файл robots.txt, как вы можете видеть на скриншоте ниже.
- Если вы хотите изменить robots.txt, просто начните вводить текст в текстовое поле и нажмите Сохранить изменения .
- Если вы не уверены, что поместить в robots.txt, или делаете что-то не так, просто нажмите Параметры сброса .
Вот и все по математике рангов и роботам.текст.
Доступ к robots.txt с помощью Yoast SEO
Вот что делать, если вы используете Yoast SEO:
- Войдите в свою панель управления WordPress как администратор. Помните, что только администраторы могут изменять настройки плагина.
- Перейдите к SEO .
- На левой боковой панели вы увидите несколько настроек в разделе SEO . Нажмите Инструменты .
- Теперь вы можете изменить файл robots.txt.
- Когда вы закончите, просто нажмите Сохранить изменения в robots.txt.
На большинстве веб-сайтов WordPress подходят эти два метода с использованием этих двух плагинов SEO. Но есть и другие способы.
Но есть и другие способы.
# 2: используйте специальный плагин robots.txt
Существует также множество различных плагинов WordPress, специально разработанных для редактирования robots.txt.
Вот самые популярные плагины robots.txt для WordPress, которые вы, возможно, захотите проверить:
Каждый из них позволяет легко получать доступ к роботам и изменять их.текст. Ниже приведены быстрые шаги, которые нужно предпринять для доступа к файлу robots.txt с помощью этих 3 плагинов WordPress.
❗ Обратите внимание, что некоторые плагины создают файл robots.txt, который помещается в корень вашего веб-сайта, в то время как другие создают его динамически. Если файл robots.txt создается динамически, вы не найдете его в корневом каталоге своего веб-сайта (например, через FTP).
❗ Не используйте одновременно несколько плагинов robots.txt!
Virtual Robots.txt
- На панели инструментов WordPress перейдите к Настройки , а затем Виртуальные роботы.txt .
- Теперь вы можете просмотреть свой файл robots.txt и изменить его. Когда вы закончите, нажмите Сохранить изменения .
Вот оно!
Better Robots.txt
Этот плагин robots.txt немного отличается от плагинов, которые я показал вам выше. С Better Robots.txt вы не изменяете текстовый файл, а просто настраиваете параметры на удобной панели внутри WordPress.
Вот что нужно:
- Установите и активируйте Better Robots.текст. Плагин также называется оптимизацией WordPress Robots.txt.
- Предоставьте подключаемому модулю необходимые разрешения.
- Перейдите в Better Robots.txt. Плагин будет доступен на левой боковой панели.
- Теперь вы увидите множество полезных и удобных настроек.
- Плагин также позволяет вручную разрешать или запрещать использование определенных поисковых роботов.

- Вы также можете настроить некоторые параметры для защиты данных или оптимизации производительности загрузки.
- Плагин предлагает и другие интересные настройки. Я рекомендую проверить их.
Better Robots.txt по сути позволяет создавать полностью настраиваемый файл robots.txt без необходимости касаться строчки кода.
Редактор Robots.txt
- Перейдите к Плагины > Установленные плагины на панели инструментов WordPress. Вы также можете получить доступ к robots.txt, выбрав Настройки> Чтение .
- Щелкните Settings в разделе Robots.txt Editor.
- Теперь вы можете получить доступ к файлу robots.txt и отредактировать его. Когда вы закончите, нажмите Сохранить изменения .
❗ Будьте осторожны и избегайте одновременного использования нескольких редакторов robots.txt. Это действительно может все испортить. Если вы используете плагин SEO, вам следует придерживаться только его редактора robots.txt.
# 3: Доступ к robots.txt через cPanel на вашем хостинге
Здесь я покажу вам, как загружать robots.txt в WordPress без доступа по FTP.
Вы также можете использовать cPanel на своем хостинге для создания или изменения robots.txt.
Обратите внимание, что некоторые из показанных выше подключаемых модулей динамически создают файл robots.txt. Это означает, что вы не сможете найти файл в корневом каталоге своего сайта.
❗ Если вы используете плагин для создания файла robots.txt и управления им, вам не следует пытаться вручную добавить новый файл robots.txt с помощью cPanel или FTP (см. Ниже).
Однако, если вы не полагаетесь на эти плагины, вы можете вручную создать и обновить файл robots.txt на свой сайт WordPress.
Вот как это сделать с помощью Bluehost:
- Войдите в cPanel на вашем хостинге.

- Развернуть раздел Продвинутый .
- Перейдите в корневой каталог вашего веб-сайта.
- Если вы не используете плагин, который динамически генерирует robots.txt, вы должны увидеть файл robots.txt в корне.
- Щелкните файл robots.txt и выберите Изменить .
- Теперь вы можете редактировать содержимое robots.txt. Когда закончите, нажмите Сохранить изменение s.
Если на вашем веб-сайте нет файла robots.txt, вам необходимо создать и загрузить его.
Вот что нужно делать:
- Откройте редактор текстовых файлов, например «Блокнот» или «Блокнот ++».
- Создайте файл robots.txt.
- Загрузите файл в основную директорию вашего сайта. В случае с Bluehost вы просто нажимаете Загрузить в диспетчере файлов.Просто убедитесь, что вы находитесь в корне.
Этот метод будет работать как для сайтов WordPress, так и не на WordPress.
# 4: Используйте FTP для доступа к robots.txt
Здесь я покажу вам, как получить доступ к robots.txt через FTP.
Самый быстрый и «профессиональный» способ получить доступ к robots.txt — использовать FTP. Этот метод также работает для любого типа веб-сайтов, включая сайты WordPress.
❗ Я не рекомендую этот метод, если вы используете плагин для автоматической генерации роботов.txt для вас.
Этот метод аналогичен тому, что вы делаете с помощью cPanel на своем хостинге, за исключением того, что на этот раз вы используете FTP-клиент для доступа к своему веб-сайту.
Для использования этого метода вам потребуются имя пользователя и пароль FTP, а также клиент FTP, например Filezilla.
Вот что вам нужно сделать:
- Подключитесь к своему сайту через FTP-клиент.
- Перейдите в корневой каталог вашего веб-сайта, если вы еще не там.

- Загрузите файл robots.txt, если он там есть.
- Откройте файл robots.txt в текстовом редакторе, например Notepad ++.
- При необходимости измените файл. Сохранить изменения.
- Загрузите файл в корневой каталог. Это перезапишет существующий файл robots.txt.
Если на вашем веб-сайте нет файла robots.txt, вы также можете создать и загрузить его.
Как проверить файл robots.txt на своем веб-сайте
Если вы внесли некоторые изменения в robots.txt, я настоятельно рекомендую вам протестировать свои robots.txt, чтобы убедиться, что файл правильный и действительно выполняет то, что должен делать.
Вот что нужно делать:
⚡ Ознакомьтесь с моим руководством по отчету о статистике сканирования Google Search Console.
Удалось ли вам получить доступ к файлу robots.txt на вашем веб-сайте? Какой метод вы использовали? Было ли это руководство полезным?
Сообщите мне, что вы думаете. Если вам нравится это руководство, поделитесь им с другими. Спасибо!
Ольга Зарзечна — старший SEO-специалист с опытом работы более 8 лет.Она занималась поисковой оптимизацией как для крупнейших мировых брендов, так и для малых предприятий. На данный момент она провела более 100 SEO-аудитов. Ольга закончила курсы SEO и получила ученую степень в университетах, таких как Калифорнийский университет в Дэвисе, Мичиганский университет и Университет Джона Хопкинса. Она также закончила Академию Moz! И, конечно же, имеет сертификаты Google. Она продолжает изучать SEO, и ей это нравится. Ольга также является экспертом по продуктам Google, специализируясь в таких областях, как поиск Google и веб-мастера Google.
Как создавать и оптимизировать для SEO
Всякий раз, когда мы говорим о SEO блогов Wp, WordPress robots.txt играет важную роль в рейтинге поисковых систем.
Блокирует ботов поисковых систем и помогает индексировать и сканировать важные части нашего блога. Хотя иногда неправильно настроенный файл Robots.txt может полностью скрыть ваше присутствие от поисковых систем.
Хотя иногда неправильно настроенный файл Robots.txt может полностью скрыть ваше присутствие от поисковых систем.
Итак, важно, чтобы при внесении изменений в файл robots.txt он был хорошо оптимизирован и не блокировал доступ к важным частям вашего блога.
Есть много недоразумений относительно индексации и отсутствия индексации контента в Robots.txt, и мы рассмотрим этот аспект.
SEO состоит из сотен элементов, и одной из важнейших частей SEO является Robots.txt. Этот небольшой текстовый файл, расположенный в корне вашего сайта, может помочь в серьезной оптимизации вашего сайта.
Большинство веб-мастеров стараются не редактировать файл Robots.txt, но это не так сложно, как убить змею. Любой, у кого есть базовые знания, может создавать и редактировать файл Robots, и если вы новичок в этом, этот пост идеально подходит для ваших нужд.
Если на вашем сайте нет файла Robots.txt, вы можете узнать, как это сделать, здесь. Если в вашем блоге / веб-сайте есть файл Robots.txt, но он не оптимизирован, вы можете следить за этим сообщением и оптимизировать файл Robots.txt.
Что такое WordPress Robots.txt и почему мы должны его использоватьПозвольте мне начать с основ. Во всех поисковых системах есть боты для сканирования сайта. Сканирование и индексирование — это два разных термина, и если вы хотите углубиться в них, вы можете прочитать: Сканирование и индексирование Google.
Когда бот поисковой системы (бот Google, бот Bing, сторонние сканеры поисковых систем) заходит на ваш сайт по ссылке или по ссылке карты сайта, представленной в панели управления веб-мастером, они переходят по всем ссылкам в вашем блоге, чтобы сканировать и индексировать ваш сайт. .
Теперь эти два файла — Sitemap.xml и Robots.txt — находятся в корне вашего домена. Как я уже упоминал, боты следуют правилам Robots.txt, чтобы определить сканирование вашего сайта. Вот пример использования файла robots.txt:
Когда в ваш блог появляются боты поисковых систем, у них есть ограниченные ресурсы для сканирования вашего сайта. Если им не удастся просканировать все страницы вашего сайта с выделенными ресурсами, они перестанут сканировать, что затруднит индексацию.
Если им не удастся просканировать все страницы вашего сайта с выделенными ресурсами, они перестанут сканировать, что затруднит индексацию.
В то же время есть много частей вашего веб-сайта, которые вы не хотите, чтобы поисковые роботы сканировали.Например, ваша папка WP-admin, ваша панель администратора или другие страницы, которые бесполезны для поисковых систем. Используя Robots.txt, вы указываете роботам поисковых систем, чтобы они не сканировали такие области вашего веб-сайта. Это не только ускорит сканирование вашего блога, но также поможет в глубоком сканировании ваших внутренних страниц.
Самое большое заблуждение относительно файла Robots.txt состоит в том, что люди используют его для Noindexing .
Помните, что файл Robots.txt не предназначен для Do Index или Noindex.Это к прямым роботам поисковых систем, чтобы прекратить сканирование определенных частей вашего блога . Например, если вы посмотрите файл ShoutMeLoud Robots.txt (платформа WordPress), вы четко поймете, какую часть моего блога я не хочу, чтобы роботы поисковых систем сканировали.
Файл Robots.txt помогает роботам поисковых систем и указывает, какую часть сканировать, а какую избегать. Когда поисковый бот или паук поисковой системы приходит на ваш сайт и хочет проиндексировать ваш сайт, они следуют за роботами.txt сначала. Поисковый бот или паук следует указаниям файла для индексации или отсутствия индексации страниц вашего веб-сайта.
Если вы используете WordPress, вы найдете файл Robots.txt в корне вашей установки WordPress.
Для статических веб-сайтов, если вы или ваши разработчики создали его, вы найдете его в своей корневой папке. Если у вас не получается, просто создайте новый файл блокнота, назовите его Robots.txt и загрузите его в корневой каталог своего домена с помощью FTP.
Вот пример роботов.txt, и вы сможете увидеть его содержимое и его расположение в корне домена.
https://www.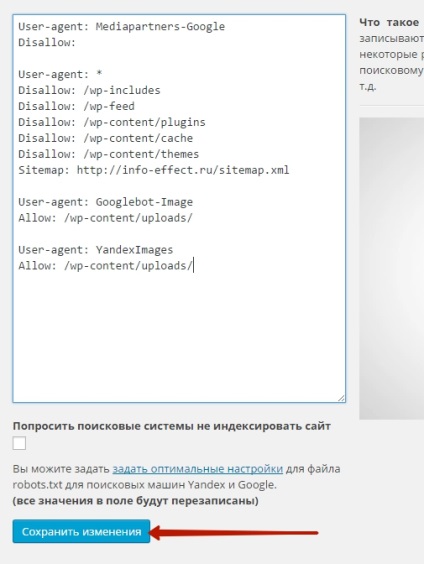 shoutmeloud.com/robots.txt
shoutmeloud.com/robots.txt
Как создать файл robots.txt?
Как я упоминал ранее, Robots.txt — это обычный текстовый файл. Итак, если у вас нет этого файла на вашем веб-сайте, откройте любой текстовый редактор по своему усмотрению (например, Блокнот) и создайте файл Robots.txt, состоящий из одной или нескольких записей. Каждая запись содержит важную информацию для поисковой системы.Пример:
Пользовательский агент: googlebot
Disallow: / cgi-bin
Если эти строки записаны в файле Robots.txt, это означает, что это позволяет роботу Google индексировать каждую страницу вашего сайта. Но папка cgi-bin корневого каталога не позволяет индексировать. Это означает, что бот Google не будет индексировать папку cgi-bin .
Используя параметр Disallow, вы можете запретить любому поисковому роботу или пауку индексировать страницу или папку. Есть много сайтов, которые не используют индекс в архивной папке или на странице, чтобы не создавать дублированного контента .
Где взять имена поисковых роботов? Вы можете записать его в журнал своего веб-сайта, но если вы хотите, чтобы поисковая система привлекала много посетителей, вы должны разрешить каждому поисковому боту. Это означает, что каждый поисковый бот проиндексирует ваш сайт. Вы можете написать User-agent: * для разрешения каждого поискового бота. Например:
Пользовательский агент: *
Disallow: / cgi-bin
Вот почему каждый поисковый бот проиндексирует ваш сайт.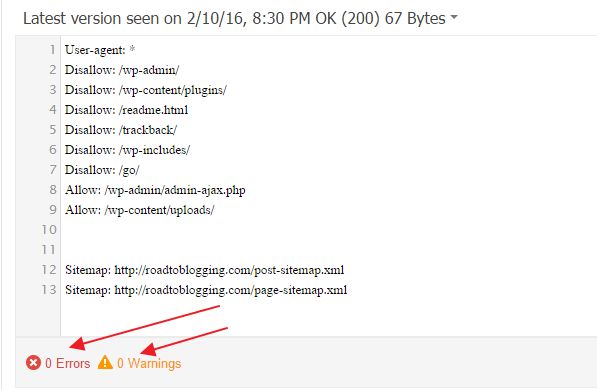
Роботов нет.txt файл
1. Не используйте комментарии в файле Robots.txt.
2. Не оставляйте пробел в начале строки и не оставляйте обычное пространство в файле. Пример:
Плохая практика:
Пользовательский агент: *
Dis allow: / support
Передовая практика:
Пользовательский агент: *
Disallow: / support
3. Не меняйте правила командования.
Плохая практика:
Disallow: / support
Пользовательский агент: *
Передовая практика:
Пользовательский агент: *
Disallow: / support
4.Если вы не хотите индексировать более одного каталога или страницы, не пишите вместе с этими именами:
Плохая практика:
Пользовательский агент: *
Запрещено: / support / cgi-bin / images /
Передовая практика:
Пользовательский агент: *
Disallow: / support
Disallow: / cgi-bin
Disallow: / изображений
5. Правильно используйте заглавные и строчные буквы. Например, если вы хотите проиндексировать каталог «Download», но напишите «загрузка» в Robots.txt, он ошибочно принимает его за поискового бота.
6. Если вы хотите проиндексировать все страницы и каталог вашего сайта, напишите:
Пользовательский агент: *
Disallow:
7. Но если вы не хотите индексировать всю страницу и каталог вашего сайта, напишите:
Пользовательский агент: *
Disallow: /
После редактирования файла Robots.txt загрузите его с помощью любого программного обеспечения FTP в корневой или домашний каталог вашего сайта.
Руководство по WordPress Robots.txt:
Вы можете редактировать файл WordPress Robots.txt, войдя в свою учетную запись FTP на сервере, или вы можете использовать плагины, такие как Robots meta, для редактирования файла Rrobots.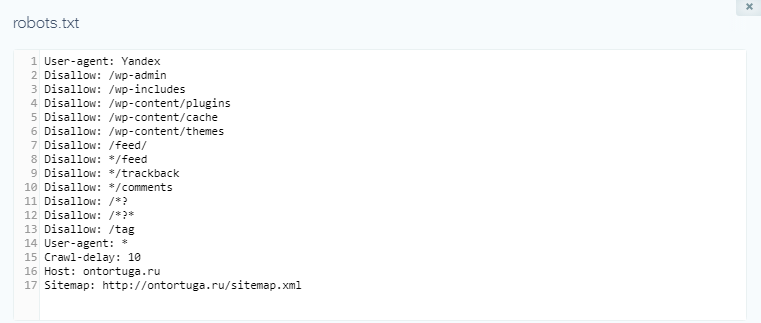 txt с панели управления WordPress. Есть несколько вещей, которые вы должны добавить в файл Robots.txt вместе с URL-адресом карты сайта. Добавление URL-адреса карты сайта помогает роботам поисковых систем находить файл карты сайта и приводит к более быстрой индексации страниц.
txt с панели управления WordPress. Есть несколько вещей, которые вы должны добавить в файл Robots.txt вместе с URL-адресом карты сайта. Добавление URL-адреса карты сайта помогает роботам поисковых систем находить файл карты сайта и приводит к более быстрой индексации страниц.
Вот пример файла Robots.txt для любого домена. В карте сайта замените URL-адрес файла Sitemap на URL-адрес своего блога:
карта сайта: https: // www.shoutmeloud.com/sitemap.xml Пользовательский агент: * # запретить все файлы в этих каталогах Disallow: / cgi-bin / Запретить: / wp-admin / Запретить: / архивы / disallow: / *? * Запретить: *? Replytocom Запретить: / комментарии / фид / Пользовательский агент: Mediapartners-Google * Позволять: / Пользовательский агент: Googlebot-Image Разрешить: / wp-content / uploads / Пользовательский агент: Adsbot-Google Позволять: / Пользовательский агент: Googlebot-Mobile Позволять: /
Блокировать плохих SEO-ботов (Полный список)
Существует множество инструментов SEO, таких как Ahrefs, SEMRush, Majestic и многие другие, которые продолжают сканировать ваш сайт в поисках секретов SEO.Эти стратегии используются вашими конкурентами в своих интересах и не приносят вам пользы. Более того, эти поисковые роботы также увеличивают нагрузку на ваш сервер и увеличивают стоимость вашего сервера.
Если вы не используете один из этих инструментов SEO, вам лучше заблокировать их от взлома вашего сайта. Вот что я использую в своем файле robots.txt для блокировки некоторых из самых популярных SEO-агентов:
Агент пользователя: MJ12bot
Disallow: /
Агент пользователя: SemrushBot
Disallow: /
Агент пользователя: SemrushBot-SA
Disallow: /
Агент пользователя: dotbot
Disallow: /
Агент пользователя: Ahrefsallow 90 : /
User-agent: Alexibot
Disallow: /
User-agent: SurveyBot
Disallow: /
User-agent: Xenu’s
Disallow: /
User-agent: Xenu’s Link Sleuth 1. 1c
1c
Disallow: /
User-agent: rogerbot
Disallow: /
# Блокировать NextGenSearchBot
User-agent: NextGenSearchBot
Disallow: /
# Блокировать ia-архиватор от сканирования сайта
User-agent: ia_archiver
Disallow: /
# Блокировать archive.org_bot от сканирования сайта
User-agent: archive.org_bot
Disallow: /
# Block Archive.org Bot from crawling site
User-agent: Archive.org Bot
Disallow: /
# Заблокировать LinkWalker от сканирования сайта
User-agent: LinkWalker
Disallow: /
# Блокировать GigaBlast Spider от сканирования сайта
Пользовательский агент: GigaBlast Spider
Disallow: /
# Блокировать ia_archiver-web.archive.org_bot со сканирующего сайта
User-agent: ia_archiver-web.archive.org
Disallow: /
# Заблокировать сканеру PicScout от сканирования сайта
Пользовательский агент: PicScout
Запретить: /
# Заблокировать BLEXBot Crawler от сканирования сайта
User-agent: BLEXBot Crawler
Disallow: /
# Заблокировать TinEye от сканирования сайта
User-agent: TinEye
Disallow: /
# Блокировать SEOkicks
Пользовательский агент: SEOkicks-Robot
Disallow: /
# Блокировать BlexBot
User-agent: BLEXBot
Disallow: /
# Блокировать SISTRIX
Пользовательский агент: SISTRIX Crawler
Disallow: /
# Block Uptime robot
User-agent: UptimeRobot / 2.0
Disallow: /
# Блокировать Ezooms Robot
Пользовательский агент: Ezooms Robot
Disallow: /
# Блокировать сканер netEstate NE (+ http: //www.website-datenbank.de/)
Агент пользователя: сканер netEstate NE (+ http: //www.website-datenbank.de/)
Disallow: /
# Block WiseGuys Robot
Пользовательский агент: WiseGuys Robot
Disallow: /
# Block Turnitin Robot
Пользовательский агент: Turnitin Robot
Disallow: /
# Блокировать Heritrix
Пользовательский агент: Heritrix
Disallow: /
# Блокировать прицепи
User-agent: pimonster
Disallow: /
User-agent: Pimonster
Disallow: /
User-agent: Pi-Monster
Disallow: /
# Блок Eniro
Агент пользователя: ECCP / 1. 0 ([адрес электронной почты])
0 ([адрес электронной почты])
Запрещено: /
# Заблокировать Psbot
User-agent: Psbot
Disallow: /
# Блокировать Youdao
User-agent: YoudaoBot
Disallow: /
# BLEXBot
Пользовательский агент: BLEXBot
Disallow: /
# Блокировать NaverBot
User-agent: NaverBot
User-agent: Yeti
Disallow: /
# Block ZBot
User-agent: ZBot
Disallow: /
# Block Vagabondo
Пользовательский агент: Vagabondo
Disallow: /
# Блокировать LinkWalker
Пользовательский агент: LinkWalker
Запрещать: /
# Block SimplePie
User-agent: SimplePie
Disallow: /
# Block Wget
User-agent: Wget
Disallow: /
# Block Pixray-Seeker
Пользовательский агент: Pixray-Seeker
Disallow: /
# Блок BoardReader
Агент пользователя: BoardReader
Disallow: /
# Block Quantify
User-agent: Quantify
Disallow: /
# Block Plukkie
Агент пользователя: Plukkie
Disallow: /
# Block Cuam
Пользовательский агент: Cuam
Disallow: /
# https: // мегаиндекс.com / crawler
User-agent: MegaIndex.ru
Disallow: /
Агент пользователя: megaindex.com
Disallow: /
User-agent: + http: //megaindex.com/crawler
Disallow: /
User-agent: MegaIndex.ru/2.0
Disallow: /
User-agent: megaIndex.ru
Disallow: /
Убедиться, что новый файл Robots.txt не влияет на контент
Итак, теперь вы внесли некоторые изменения в свой файл Robots.txt, и пора проверить, не повлияло ли какое-либо ваше содержание из-за обновления в файле robots.txt файл.
Вы можете использовать поисковую консоль Google «Просмотреть как инструмент Google», чтобы узнать, доступен ли ваш контент для файла Robots.txt.
Эти шаги просты.
Войдите в консоль поиска Google, выберите свой сайт, перейдите в диагностику и выберите «Просмотреть как Google».
Добавьте сообщения на свой сайт и проверьте, нет ли проблем с доступом к вашему сообщению.
Вы также можете проверить ошибки сканирования, вызванные файлом Robots.txt, в разделе ошибок сканирования консоли поиска.
В разделе «Сканирование»> «Ошибка сканирования» выберите «Ограничено файлом Robots.txt», и вы увидите, все ссылки были отклонены файлом Robots.txt.
Вот пример ошибки сканирования Robots.txt для ShoutMeLoud:
Вы можете ясно видеть, что ссылки Replytocom были отклонены Robots.txt и, следовательно, содержат другие ссылки, которые не должны быть частью Google. К вашему сведению, файл Robots.txt является важным элементом SEO, и вы можете избежать многих проблем с дублированием сообщений, обновив свои файлы Robots.txt файл.
Вы используете WordPress Robots.txt для оптимизации своего сайта? Вы хотите добавить больше информации в свой файл Robots.txt? Дайте нам знать, используя раздел комментариев ниже. Не забудьте подписаться на нашу рассылку новостей по электронной почте, чтобы получать больше советов по поисковой оптимизации.
Вот еще несколько подобранных руководств, которые вы можете прочитать дальше:
WordPress Robots.txt — Как добавить за несколько шагов
Недостаточно просто создать сайт.Попадание в списки поисковых систем — основная цель всех владельцев веб-сайтов, чтобы веб-сайт стал видимым в поисковой выдаче по определенным ключевым словам. Этот список веб-сайтов и видимость самого свежего контента в основном обусловлены роботами поисковых систем, которые сканируют и индексируют веб-сайты. Веб-мастера могут контролировать способ, которым эти роботы анализируют веб-сайты, вставляя инструкции в специальный файл с именем robots.txt.
В этой статье я расскажу, как настроить файл robots.txt WordPress для лучшего SEO-оптимизации сайта. Обратите внимание, что некоторые страницы веб-сайта WordPress могут не индексироваться поисковыми системами.
Обратите внимание, что некоторые страницы веб-сайта WordPress могут не индексироваться поисковыми системами.
Что такое файл Robots.txt?
Файл robots.txt — это текстовый файл, расположенный в корне вашего веб-сайта, который сообщает сканерам поисковых систем не сканировать части вашего веб-сайта. Он также известен как протокол исключения роботов, который не позволяет поисковым системам индексировать определенное бесполезное и / или определенное содержимое (например, вашу страницу входа и конфиденциальные файлы).
Короче говоря, robots.txt сообщает ботам поисковых систем, что им не следует сканировать на вашем веб-сайте.
Вот как это работает! Когда бот поисковой системы собирается сканировать URL-адрес вашего веб-сайта (то есть сканировать и извлекать информацию, чтобы ее можно было проиндексировать), он сначала ищет ваш файл robots.txt.
Зачем создавать Robots.txt для WordPress?
Обычно вам не нужно добавлять файл robots.txt для веб-сайтов WordPress. По умолчанию поисковые системы индексируют все сайты WordPress. Однако для лучшего SEO вы можете добавить файл robots.txt в свой корневой каталог, чтобы специально запретить поисковым системам доступ к определенным областям вашего веб-сайта WordPress.
IdeaBox — Пример использования
Прочтите, как Cloudways помогли агентству WordPress создавать лучшие продукты.
Спасибо
Ваша электронная книга в папке «Входящие».
Как создать Robots.txt для WordPress?
Войдите в систему на панели управления управляемым веб-хостингом WordPress. В моем примере я использую Cloudways — платформу управляемого облачного хостинга.
Перейдите на вкладку Servers в верхней строке меню и получите доступ по SSH / SFTP из Server Management → Master Credentials .
Используйте любое приложение FTP-сервера для доступа к файлам базы данных WordPress. Для этого урока я использую FileZilla . Запустите его и подключитесь к серверу, используя Master Credentials .
Для этого урока я использую FileZilla . Запустите его и подключитесь к серверу, используя Master Credentials .
После подключения перейдите в папку / applications файлов базы данных WordPress. Вы увидите там разные папки.
Теперь вернитесь на платформу Cloudways и в верхней левой панели перейдите к Applications .Выберите приложение, для которого вы хотите добавить файл robots.txt:
На левой панели перейдите в Управление приложениями → Настройки приложения → Общие . Вы найдете имя папки вашего приложения.
Вернитесь в FileZilla и перейдите в папку / applications / [ИМЯ ПАПКИ] / public_html . Создайте здесь новый текстовый файл и назовите его robots.txt .
Щелкните правой кнопкой мыши файл robots.txt и нажмите Просмотр / редактирование , чтобы открыть его в текстовом редакторе (Блокнот — удобный вариант).
Advanced Robots.txt для WordPress
Поисковые системы, такие как Google и Bing, поддерживают использование подстановочных знаков в файле robots.txt. Эти подстановочные знаки могут использоваться для разрешения / запрета определенных типов файлов на веб-сайте WordPress.
Звездочка (*) может использоваться для обработки широкого диапазона опций / вариантов выбора.
Агент пользователя: * Запретить: / images / image *.jpg
Здесь «*» означает, что все изображения, начинающиеся с «image» и с расширением «jpg», не будут индексироваться поисковыми системами. Вот несколько примеров файла robots.txt для WordPress.
Пример: image1.jpg, image2.jpg, imagexyz.jpg не будут индексироваться поисковыми системами.
Возможности * не ограничиваются только изображениями. Вы даже можете запретить использование всех файлов с определенным расширением.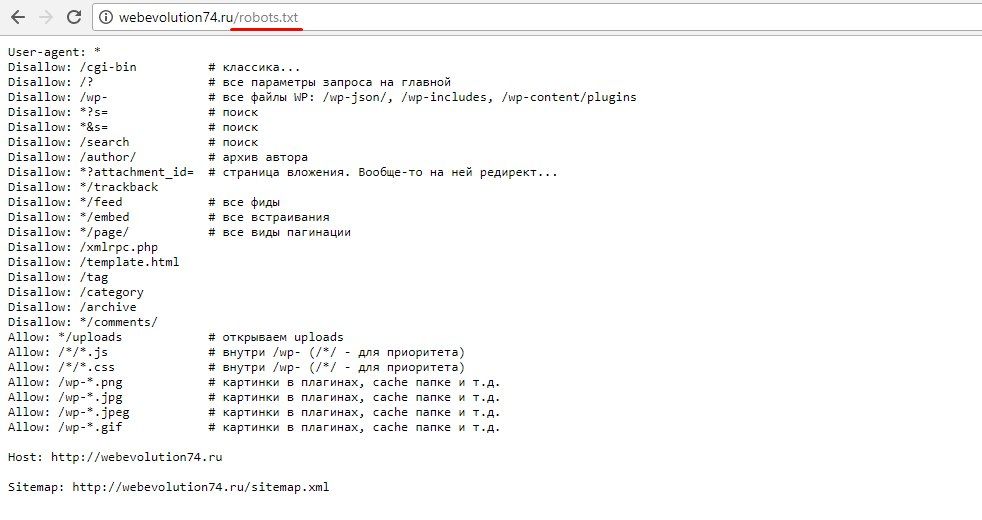
Агент пользователя: * Запретить: /downloads/*.pdf Запретить: / downloads / *.png
Приведенные выше утверждения потребуют от всех поисковых систем запретить использование всех файлов с расширениями «pdf» и «png» в папке загрузок.
Вы даже можете запретить использование основных каталогов WordPress, используя *.
Агент пользователя: * Disallow: / wp - * /
Вышеупомянутая строка просит поисковые системы не сканировать каталоги, начинающиеся с «wp-».
Пример: wp-includes, wp-content и т. Д. Не будут индексироваться поисковыми системами.
Еще один подстановочный знак, используемый в роботах WordPress.txt — это символ доллара ($).
Агент пользователя: * Запрещено: referral.php
Приведенное выше утверждение попросит поисковые системы не индексировать referral.php, а также referral.php? Id = 123 и так далее.
Но что, если вы хотите заблокировать только файл referral.php? Вам нужно только включить символ $ сразу после файла referral.php.
Символ $ гарантирует, что блокируется только файл referral.php, но не referral.php? Id = 123.
Агент пользователя: * Запрещено: referral.php $
Вы также можете использовать $ для каталогов.
Агент пользователя: * Запретить: / wp-content /
Это даст указание поисковым системам запретить папку wp-content, а также все каталоги, расположенные внутри wp-content. Если вы хотите запретить только wp-content, а не все подпапки, вы должны использовать символ $. Например:
Агент пользователя: * Disallow: / wp-content /долларов США.
Символ $ означает, что запрещен только wp-content. Все каталоги в этой папке по-прежнему доступны.
Ниже представлены роботы.txt для блога Cloudways.
Агент пользователя: * Запретить: / admin / Запретить: / admin / *? * Запретить: / admin / *? Запретить: / blog / *? * Запретить: / blog / *?
В первой строке указан User-agent. Это относится к поисковой системе, которой разрешен доступ к веб-сайту и его индексирование. Полный список всех ботов поисковых систем доступен здесь .
Агент пользователя: *
Где * означает все поисковые системы. Вы можете указать каждую поисковую систему отдельно.
Запретить: / admin / Запретить: / admin / *? * Запретить: / admin / *?
Это не позволит поисковым системам сканировать каталог «admin». Поисковым системам часто не нужно индексировать эти каталоги.
Disallow: / blog / *? * Запретить: / blog / *?
Если ваш сайт WordPress является сайтом для ведения блогов, рекомендуется ограничить роботов поисковых систем, чтобы они не сканировали ваши поисковые запросы.
Если на вашем сайте есть карта сайта. Добавление его URL-адреса помогает роботам поисковых систем находить файл карты сайта.Это приводит к более быстрой индексации страниц.
карта сайта: http://www.yoursite.com/sitemap.xml
Что включить в Robots.txt для WordPress?
Вы сами решаете, какие части сайта WordPress вы хотите включить в поисковую выдачу. У каждого свои взгляды на настройку файла robots.txt WordPress. Некоторые рекомендуют не добавлять файл robots.txt в WordPress. Хотя, на мой взгляд, следует добавлять и запрещать папку / wp-admin /. Файл robots.txt является общедоступным. Вы можете найти файл robots.txt любого веб-сайта, посетив www.example.com/robots.txt.
Мы закончили работу с файлом robots.txt в WordPress. Если у вас есть какие-либо вопросы о настройке файла robots.txt, не стесняйтесь спрашивать в разделе комментариев ниже.
Подведение итогов!
Как видите, файл robots.txt — интересный инструмент для вашего SEO. Это позволяет указать роботам поисковых систем, что индексировать, а что нет. Но обращаться с этим нужно осторожно. Неправильная конфигурация может привести к полной деиндексации вашего веб-сайта (пример: если вы используете Disallow: /).Так что будь осторожен!
Теперь ваша очередь. Подскажите, используете ли вы этот тип файла и как вы его настраиваете. Делитесь своими комментариями и отзывами в комментариях.
Часто задаваемые вопросы1 кв. Что такое robots.txt?
robots.txt — это текстовый файл, размещаемый в корне вашего веб-сайта. Этот файл предназначен для запрета роботам поисковых систем индексировать определенные области вашего веб-сайта. Файл robots.txt — один из первых файлов, проверенных пауками (роботами).
2 кв. Почему используется файл robots.txt?
Файл robots.txt содержит инструкции для роботов поисковых систем, которые анализируют ваш веб-сайт, это протокол исключения для роботов. Благодаря этому файлу вы можете запретить исследование и индексацию вашего сайта некоторым роботам (также называемым «сканерами» или «пауками»).
Начни расти с Cloudways уже сегодня!
Мы никогда не идем на компромисс в отношении производительности, безопасности и поддержки.
Мустасам Салим
Мустаасам — менеджер сообщества WordPress в Cloudways — управляемой платформе хостинга WordPress, где он активно работает и любит делиться своими знаниями с сообществом WordPress.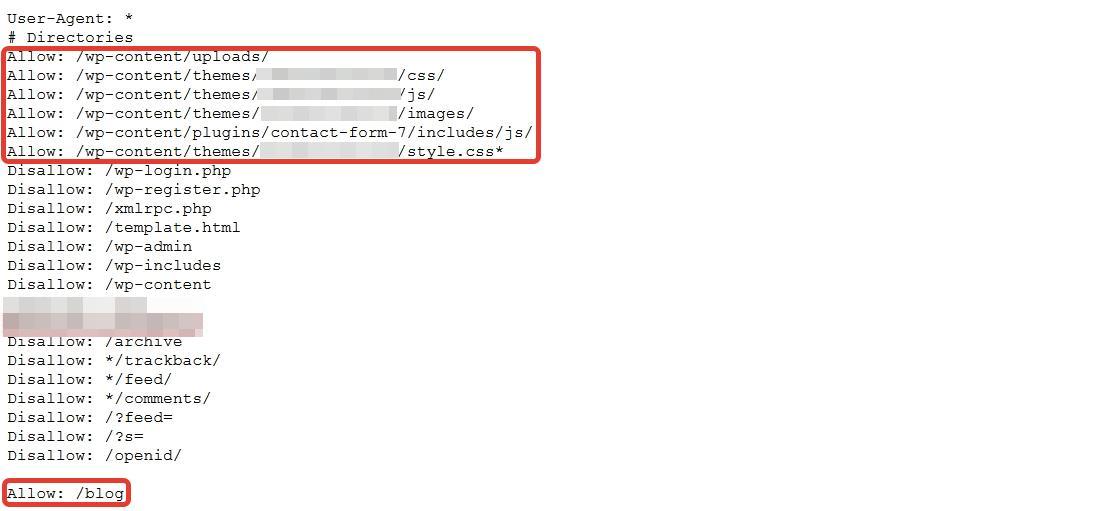 Когда он не работает, вы можете увидеть, как он играет в сквош со своими друзьями или защищается в футболе и слушает музыку. Вы можете написать ему по адресу [email protected]
Когда он не работает, вы можете увидеть, как он играет в сквош со своими друзьями или защищается в футболе и слушает музыку. Вы можете написать ему по адресу [email protected]
Получите наш информационный бюллетень
Будьте первым, кто получит последние обновления и руководства.
Спасибо за подписку на нас!
Как редактировать файл Robots.txt в WordPress
9 сентября. 2019
На этой неделе мы рассмотрим еще один вопрос, который возникает у начинающих пользователей WP — как редактировать файл robots.txt в WordPress. Причина этого достаточно проста — приносит пользу вашим усилиям по поисковой оптимизации . Файл robots.txt — невероятно мощный инструмент в SEO, потому что он работает как руководство по веб-сайту для роботов , сканирующих поисковые системы.Вот почему эксперты WordPress признают его важность и то, как лучше всего реализовать это при оптимизации своего сайта. Здесь мы, , пошагово рассмотрим всю тему .
Чтобы отредактировать файл robots.txt в WordPress, вам понадобится только простое руководство.Начнем с более подробного определения файла robots.txt
Роботам поисковых систем требуется инструкций о том, как сканировать и индексировать внутренние страницы вашего сайта . Именно здесь в игру вступают файлы robots.txt.В этом файле представлена структура ваших страниц, что упрощает их чтение и оценку роботами поисковых систем.
Обычно вы можете найти файл robots.txt, хранящийся в корневом каталоге. Этот каталог также известен как основная папка всего вашего веб-сайта . Прежде чем мы перейдем к редактированию файла robots.txt в WordPress, нам сначала нужно научиться его распознавать. Итак, вот пример того, как выглядит типичный файл robots.txt:
Прежде чем мы перейдем к редактированию файла robots.txt в WordPress, нам сначала нужно научиться его распознавать. Итак, вот пример того, как выглядит типичный файл robots.txt:
| 1 2 3 4 5 6 7 8 | User-agent: [имя user-agent] Disallow: [URL-строка не должна сканироваться] User-agent: [user-agent name] Allow: [URL string to сканироваться] Sitemap: [URL вашего XML Sitemap] |
Сам файл предлагает достаточно места для настройки, например, разрешает / запрещает определенные URL-адреса или добавляет несколько файлов карты сайта .Итак, если у вас есть URL-адрес, который вы не хотите, чтобы роботы поисковых систем сканировали и ранжировали, вам необходимо запретить его через robots.txt. Вот пример разрешения / запрета роботам поисковых систем сканировать определенные URL-адреса:
| 1 2 3 4 5 6 | User-Agent: * Разрешить: / wp-content / uploads / Запретить: / wp-content / plugins / Запретить: / wp-admin / Карта сайта: https ://пример.ru / sitemap_index.xml |
Наконец, мы добавляем нашу карту сайта в смесь, делая URL-адрес видимым для роботов поисковых систем.
Важность наличия файла robots.txt в WordPress
Важно понимать, что даже если у вас нет файла robots.txt, боты поисковых систем все равно будут сканировать ваши страницы . Однако они будут сканировать их все. Вы не сможете указать, какие страницы они должны сканировать, а какие — нет.
Для свежих веб-сайтов WP это может не представлять слишком большой проблемы или проблемы. Однако для сайтов с бесконечным содержанием вам понадобится , чтобы лучше контролировать его сканирование и индексирование . Файл robots.txt обеспечивает надлежащий способ обслуживания вашего веб-сайта WordPress и того, как его видят роботы поисковых систем.
Однако для сайтов с бесконечным содержанием вам понадобится , чтобы лучше контролировать его сканирование и индексирование . Файл robots.txt обеспечивает надлежащий способ обслуживания вашего веб-сайта WordPress и того, как его видят роботы поисковых систем.
Почему это так важно для начала?
Каждый веб-сайт имеет квоту сканирования — именно так работают поисковые роботы. Это означает, что боты будут сканировать ваш сайт по одной странице за раз. Если им не удалось завершить сканирование всех ваших страниц в течение одного сеанса, они возобновят сканирование в следующий раз.А это то, что может значительно замедлить индексацию вашего сайта ( коэффициент индексации ) .
Однако, , когда вы редактируете файл robots.txt в WordPress, чтобы запретить сканирование определенных страниц , вы сохраняете свою квоту на сканирование . Наиболее распространенные и ненужные страницы, которые пользователи WP обычно запрещают, включают страницы администратора WordPress, плагины и темы. Удалив эти страницы, вы даете сканерам больше места для индексации других релевантных страниц на вашем сайте.
Как должен выглядеть идеальный файл robots.txt в WordPress?
Популярные сайты блогов выбирают упрощенный пример файла robots.txt — форма, которая меняется в зависимости от потребностей этого сайта:
| 1 2 3 4 5 | User-agent: * Disallow: Sitemap: https: // www.example.com/post-sitemap.xml Карта сайта: https://www.example.com/page-sitemap.xml |
В этом примере показано, как разрешить ботам индексировать весь контент, давая ему ссылку на XML-карту сайта веб-сайта в процессе.
Однако это рекомендуемая форма для пользователей веб-сайтов WordPress, как редактировать файл robots. txt в WordPress :
txt в WordPress :
| 1 2 3 4 5 6 7 8 9343 9 User-Agent: * | Разрешить: / wp-content / uploads / Запретить: / wp-content / plugins / Запретить: / wp-admin / Запретить: / readme.html Disallow: / refer / Карта сайта: https://www.example.com/post-sitemap.xml Карта сайта: https://www.example.com/page-sitemap .xml |
Здесь вы можете ясно видеть, что боты получили указание проиндексировать все изображения и файлы WP . Однако он также запрещает роботам поисковых систем индексировать следующее:
- Файлы подключаемых модулей WP
- Область администрирования WP
- Файл readme WP
- Партнерские ссылки
Причина, по которой вы должны добавить ссылку в свою карту сайта XML, состоит в том, чтобы облегчить ботам поиск всех страниц на вашем сайте.
Как создать и отредактировать файл robots.txt в WordPress
Как и все WordPress, есть универсальные решения для каждой задачи. Итак, на самом деле есть два способа создать robots.txt в WordPress:
Решение №1: Использование Yoast SEO для редактирования файла robots.txt в WordPress
Если вы используете плагин Yoast SEO, вам повезло! Плагин поставляется с генератором файлов robots.txt . И вы можете использовать этот генератор для создания и редактирования файла robots.txt прямо из панели инструментов вашей роли администратора.
Все, что вам нужно сделать, это перейти на страницу SEO >> Инструменты в качестве администратора . Оказавшись там, нажмите ссылку «Редактор файлов». Страница, на которую он ведет, должна содержать существующий файл robots.txt. А если этого не произойдет, Yoast SEO сгенерирует для вас файл. Некоторые версии Yoast SEO создают файл по умолчанию в следующем виде:
Страница, на которую он ведет, должна содержать существующий файл robots.txt. А если этого не произойдет, Yoast SEO сгенерирует для вас файл. Некоторые версии Yoast SEO создают файл по умолчанию в следующем виде:
| 1 2 | User-agent: * Disallow: / |
Как только это произойдет, убедитесь, что удалили этот текст , потому что в противном случае он заблокирует сканирование вашего сайта всеми ботами.После удаления текста по умолчанию обязательно введите свою версию скрипта robots.txt. Вы можете использовать шаблон, которым мы поделились ранее.
После завершения редактирования файла вам просто нужно нажать « Сохранить файл robots.txt » и сохранить изменения.
Решение № 2: Использование FTP для ручного редактирования файла robots.txt в WordPress
Этот конкретный подход требует использования FTP-клиента для редактирования файла. Итак, первое, что вам нужно сделать, это использовать FTP-клиент для подключения к вашей учетной записи хостинга WordPress .Оказавшись там, вы найдете файл robots.txt в корневой папке вашего веб-сайта.
Если вы не можете найти файл robots.txt, скорее всего, на вашем сайте WP его нет. Если это так, вы можете создать его. Учитывая тот факт, что файл robots.txt представляет собой простой текстовый файл , вы можете просто загрузить его, а затем отредактировать в любом простом редакторе, таком как Блокнот или TextEdit . После редактирования файла вы можете просто загрузить его обратно в корневую папку своего веб-сайта.
После редактирования файла robots.txt в WordPress обязательно проверьте его
Тестирование всегда является следующим логическим шагом после редактирования. И это особенно важно в случаях, когда используется robots.txt, по причинам, о которых мы упоминали ранее. Не волнуйтесь — есть инструменты, которые вы можете использовать, чтобы это проверить.