[По полочкам] Кэширование / Хабр
Всем привет! Меня зовут Илья Денисов, я занимаюсь backend разработкой уже более пяти лет и сейчас пишу на языке go. Сегодня я предлагаю вам поговорить о кэшировании. Постараюсь рассказать о базовых концепциях, а также затронуть ряд особенностей, неочевидных на первый взгляд.
Что такое кэширование?
Кэширование – это способ хранения данных как можно ближе к месту их использования. Как правило, для этого используется быстродействующая память (RAM).
Для чего нужно кэширование?
Кэширование появилось давно и использовалось для ускорения работы процессора с оперативной памятью. Наверняка каждый из вас слышал об иерархии кэша L1, L2 и L3, применяемого в процессорах. Добавление кэша значительно ускорило работу с памятью, но и принесло дополнительные проблемы. Самая известная и сложная из них – это инвалидация данных. Мы уделим ей особое внимание чуть позже.
С этой проблемой (и рядом других, о которых мы тоже поговорим) связан главный принцип работы с кэшем. Он очень прост: если вы можете обойтись без кэширования, то именно так и сделайте.
Он очень прост: если вы можете обойтись без кэширования, то именно так и сделайте.
Например, если у вас простое приложение или небольшая нагрузка, то кэширование вам не нужно. Важно понимать, что кэширование само по себе “не бесплатное”, оно привносит в систему дополнительную сложность: появляются дополнительные компоненты, которые надо сопровождать, усложняется структура кода.
Но если у вас большая частота запросов (Requests per Second, RPS), если запросы эти “тяжелые ”, если вам слишком дорого масштабировать основное хранилище – любой из этих причин и, тем более, их сочетания достаточно, чтобы задуматься о кэшировании всерьез. При грамотном подходе оно поможет уменьшить в разы время ответа при обращении к данным.
Поэтому более продвинутый вариант принципа работы с кэшем можно сформулировать, перефразируя знаменитую цитату немецкого богослова XVIII века Карла Фридриха Этингера: “Дай мне удачу, чтобы без кэша можно было обойтись, дай мне сил, если обойтись без него нельзя – и дай мне мудрости отличить одну ситуацию от другой”.
Как работает кэширование?
Логически кэш представляет из себя базу типа ключ-значение. Каждая запись в кэше имеет “время жизни”, по истечении которого она удаляется. Это время называют термином Time To Live или TTL. Размер кэша гораздо меньше, чем у основного хранилища, но этот недостаток компенсируется высокой скоростью доступа к данным. Это достигается за счет размещения кэша в быстродействующей памяти ОЗУ (RAM). Поэтому обычно кэш содержит самые “горячие” данные.
Вот самый базовый пример работы кэша:
Пример работы кэша
На первой схеме изображено первое обращение за данными:
Пользователь запрашивает некие данные
Кэш приложения ПУСТ, поэтому приложение обращается к базе данных (БД)
БД возвращает запрошенные данные приложению
Приложение сохраняет полученные данные в кэше
Пользователь получает данные
Вторая схема иллюстрирует последующие обращения за данными:
Пользователь запрашивает данные
Приложение уже имеет эти данные в кэше (ведь они были записаны туда при первом обращении) и поэтому НЕ ОБРАЩАЕТСЯ за ними к БД
Пользователь получает данные
Из этого простого примера видно, что только первый запрос данных приводит к обращению к БД. Все последующие запросы попадают в кэш до тех пор, пока не истечет TTL. Как только это произойдет, новый запрос снова обращается к БД и заново кэширует данные. Так будет продолжаться все время, пока приложение работает.
Все последующие запросы попадают в кэш до тех пор, пока не истечет TTL. Как только это произойдет, новый запрос снова обращается к БД и заново кэширует данные. Так будет продолжаться все время, пока приложение работает.
В результате мы экономим время не только на обработке запросов в БД, но и на сетевом обмене с БД. Все это значительно ускоряет время получения ответа пользователем.
Метрики кэша
Работу кэша можно оценивать при помощи множества метрик разной степени полезности. Я опишу те, которые считаю базовыми и наиболее полезными.
Объем памяти, выделенной под кэш. Это базовый показатель, по которому можно судить, сколько используется ресурсов
RPS чтения/записи – количество операций чтения/записи за единицу времени. В обычной ситуации количество операций чтения должно быть в разы больше количества операций записи. Обратное соотношение свидетельствует о проблемах в работе кэша
Количество элементов в кэше.
 Его полезно знать в дополнение к объему памяти, чтобы обнаруживать большие записи
Его полезно знать в дополнение к объему памяти, чтобы обнаруживать большие записиHit rate – процент извлечения данных из кэша. Чем он ближе к 100%, тем лучше. Этот параметр буквально определяет то, насколько наш кэш полезен и эффективен
Expired rate – процент удаления записей по истечении TTL. Этот показатель помогает обнаружить проблемы с производительностью, вызванные большим количеством записей с одновременно истекшим TTL
Eviction rate – процент вытеснения записей из кэша при достижении лимита используемой памяти. Важный показатель при выборе стратегий вытеснения, о которых мы поговорим чуть позже
Что можно кэшировать?
Строго говоря, кэшировать можно что угодно, но не всегда это целесообразно. Все сильно зависит от данных и паттерна их использования.
Все данные можно условно разделить на 3 группы по частоте изменений:
Меняются часто. Такие данные изменяются в течение секунд или нескольких минут.
 Их кэширование чаще всего бессмысленно, хотя иногда может и пригодится.
Их кэширование чаще всего бессмысленно, хотя иногда может и пригодится.
Пример: ошибки (кэширование ошибок может быть настолько важным, что мы посвятили ему целую главу ближе к концу статьи)
Меняются нечасто. Такие данные изменяются в течение минут, часов, дней. Именно в этом случае вы чаще всего задаетесь вопросом “Стоит ли мне кэшировать это?”
Примеры: списки товаров на сайте, описания товаров
Меняются крайне редко или не меняются никогда. Такие данные меняются в течение недель, месяцев и лет. В этом случае данные можно спокойно кэшировать. НО! Ни в коем случае нельзя усыплять бдительность верой в то, что какие-либо данные никогда не изменятся. Рано или поздно они изменятся, поэтому всегда выставляйте всем данным разумный TTL. ВСЕГДА!
Пример: картинки, DNS
Типы кэшей
С точки зрения архитектуры, можно выделить два типа кэшей: встроенный кэш (inline) и отдельный кэш (sidecar).
Встроенный кэш – это кэш, который “живет” в том же процессе, что и основное приложение. Они делят один сегмент памяти, поэтому за данными можно обращаться напрямую. В качестве такого кэша может выступать map – обычный инструмент из арсенала go – или другие структуры данных (подробнее об этом можно почитать здесь: https://github.com/hashicorp/golang-lru). Вот принципиальная схема работы inline cache:
Встроенный кэш (inline)
Отдельные кэши (sidecar) – это обособленный процесс со своей выделенной памятью. Как правило, это хранилище типа ключ-значение, которое используется как кэш для основного. Примеры такого типа кэша – Redis, Memcached и другие хранилища типа ключ-значение. Вот принципиальная схема их работы:
Отдельные кэши (sidecar)
Сравнение двух типов кэшей:
Характеристика | Встроенный кэш (inline) | Отдельные кэши (sidecar) |
Скорость ответа | Выше: обращаемся напрямую к памяти | Ниже: есть сетевые вызовы, а также оверхед на работу самого хранилища |
Память | Кэш и приложение делят одну область памяти, поэтому ее тратится меньше | Под кэш выделена отдельная память, поэтому ее тратится больше |
Согласованность данных | Плохая: каждая копия приложения содержит только свои данные | Хорошая: все копии приложения обращаются к единому хранилищу |
Масштабирование | Кэш нельзя масштабировать отдельно от приложения | Кэш и приложение можно масштабировать независимо друг от друга |
Ресурсы (память, ЦПУ и т. | Общие, поскольку “живут” в одном процессе | Выделенные, поскольку “живут” в разных процессах |
Простота сопровождения | Проще: кэш – просто структура данных, предоставляемая библиотекой | Сложнее: кэш – отдельно разворачиваемый компонент, требующий отдельного мониторинга и экспертизы |
Изолированность | Низкая: проводить отдельно работы над кэшем крайне сложно | Высокая: мы можем проводить любые работы над кэшем независимо от приложения |
Горячий старт | Сложнее: приложение обычно не общается с диском напрямую | Проще: например, redis может периодически сбрасывать данные на диск и восстанавливать состояние после рестарта |
 д.)
д.)Не стоит думать, что один тип кэша хуже другого. У каждого из них свои достоинства и недостатки и каждый из них нужно применять с умом. Более того, их можно комбинировать. Например, вы можете использовать встроенный кэш как L1, а отдельный кэш как L2 перед основным хранилищем. В результате, такая схема может в разы сократить время ответа и снизить нагрузку на основное хранилище.
У каждого из них свои достоинства и недостатки и каждый из них нужно применять с умом. Более того, их можно комбинировать. Например, вы можете использовать встроенный кэш как L1, а отдельный кэш как L2 перед основным хранилищем. В результате, такая схема может в разы сократить время ответа и снизить нагрузку на основное хранилище.
Стратегии работы с кэшем
Рассмотрим стратегии чтения и записи при работе с кэшем. В приведенных далее примерах кэш может быть как встроенным, так отдельным. Под “приложением” подразумевается некая бизнес-логика. Упор делается на описание взаимодействия компонентов друг с другом.
Cache through (Сквозное кэширование)
В рамках этой этой стратегии все запросы от приложения проходят через кэш. В коде это может выглядеть как связующее звено или “декоратор” над основным хранилищем. Таким образом, для приложения кэш и основная БД выглядят как один компонент хранилища.
Read through (Сквозное чтение)
Read through (Сквозное чтение)
Приходит запрос на получение данных
Пытаемся прочитать данные из кэша
В кэше нужных данных нет, происходит промах (miss)
Кэш перенаправляет запрос в БД.
 Это важный нюанс стратегии: к БД обращается именно кэш, а не приложение
Это важный нюанс стратегии: к БД обращается именно кэш, а не приложениеХранилище отдает данные
Сохраняем данные в кэш
Отдаем запрошенные данные приложению. Для приложения это выглядит так, как если бы хранилище просто вернуло ему данные, то есть шаги 3-6 скрыты от основной бизнес-логики
Возвращаем результат запроса
Write through (Сквозная запись)
Write through (Сквозная запись)
Приходит запрос на вставку каких-либо данных
Отправляем запрос на запись через кэш. В этот момент кэш выступает только как прокси и сам по себе ничего не делает
Сохраняем данные в БД
БД возвращает результат запроса
Сохраняем данные в кэш. Делаем мы это специально после вставки, чтобы кэш и БД были консистентны. Если бы мы писали данные в кэш на шаге 2, а при этом на шаге 3 произошла бы ошибка, то кэш содержал бы данные, которых нет в БД, что может привести к печальным последствиям
Отдаем запрошенные данные приложению
Возвращаем результат запроса
Преимущества:
Недостатки:
Cache aside (Кэширование на стороне)
В этой стратегии, приложение координирует запросы в кэш и БД и само решает, куда и в какой момент нужно обращаться. В коде это выглядит как два хранилища: одно постоянное, второе – временное.
В коде это выглядит как два хранилища: одно постоянное, второе – временное.
Read aside (Чтение на стороне)
Read aside (Чтение на стороне)
Приходит запрос на получение данных
Пытаемся читать из кэша
В кэше нужных данных нет, происходит промах (miss)
Приложение само обращается к хранилищу. В этом главное отличие от сквозного подхода: бизнес-логика в любой момент времени сама решает, куда обращаться – к кэшу или к БД
БД отдает данные
Сохраняем данные в кэш
Возвращаем результат запроса
Write aside (Запись на стороне)
Write aside (Запись на стороне)
Приходит запрос на вставку каких-либо данных
Сохраняем данные в БД
БД возвращает результат запроса
Сохраняем данные в кэш. Опять-таки, мы намеренно делаем это после вставки, чтобы кэш и БД были консистентны. Сохранение данных в кэше перед шагом 2 и ошибка на шаге 2 привели бы к появлению в кэше данных, которых нет в БД.
 Результат был бы все тот же – печальные последствия
Результат был бы все тот же – печальные последствияВозвращаем результат запроса
Преимущества:
Недостатки:
Схема работы немного сложнее с точки зрения организации кода
В коде сложнее добавить/убрать кэш, поскольку это отдельный компонент, с которым взаимодействует бизнес-логика. Изменить этого взаимодействие может быть сложно
Cache ahead (Опережающие кэширование)
Эта стратегия предназначена только для запросов на чтение. Они всегда идут только в кэш, никогда не попадая в БД напрямую. По факту мы работаем со снимком состояния БД и обновляем его с некоторой периодичностью. Для приложения это выглядит просто как хранилище, как и в случае со сквозным кэшированием.
Cache ahead (Опережающие кэширование)
Входящие запросы на чтение:
Приходит запрос на получение данных
Читаем из кэша. Если в кэше нет нужных данных, то возвращаем ошибку. К БД в случае промаха не обращаемся
Если данные есть, то отдаем их приложению
Возвращаем результат запроса
Обновление кэша:
Периодически запускается фоновый процесс, который читает данные из БД.

Читаем актуальные данные из БД
БД отдает данные
Сохраняем данные в кэш
Преимущества:
Минимальная и полностью контролируемая нагрузка на БД. Клиентские запросы не могут повлиять на БД
В коде легко добавить/убрать кэш, поскольку можно просто заменить кэш на основное хранилище и обращаться уже к нему
Простота, так как не приходится иметь дело с двумя хранилищами
Недостатки:
Кэш отстает от основного хранилища на период между запусками обновления кэша. Нужно помнить, что на момент обращения свежие данные могут еще “не доехать” до кэша. Эта проблема может быть решена использованием сквозной записи или записи на стороне. Тогда, при обновлении данных в БД, данные будут обновляться и в кэше
Вы можете использовать описанные стратегии в любых комбинациях. Например, вы можете взять опережающие кэширование, добавить туда сквозную запись и чтение на стороне, чтобы добиться максимальный актуальности данных и избежать промахов по максимуму!
Стратегии инвалидации
Инвалидация – это процесс удаления данных из кэша или пометка их как недействительных. Делается это для того, чтобы гарантировать актуальность данных, с которыми работает приложение.
Делается это для того, чтобы гарантировать актуальность данных, с которыми работает приложение.
Инвалидация по TTL
TTL (Time To Live) – время жизни данных в кэше. При сохранении данных в кэш для них устанавливается TTL и данные будут обновляться с периодичностью не менее TTL.
Это самый простой способ инвалидации данных. Тем не менее, у этой стратегии есть свои подводные камни.
Самый главный из них – вопрос длительности TTL. Если TTL слишком короткий, то запись может “протухнуть” и стать недействительной раньше, чем обновление было бы необходимо, что приведет к отправке повторного запроса в источник данных. Если TTL слишком длинный, то запись может содержать устаревшие данные, что может привести к ошибкам или неправильной работе приложения. Обычно ответ на этот вопрос подбирается эмпирическим путем.
Есть, впрочем, и другой вариант. Источник данных может присылать TTL сам, тогда клиенту не придется выбирать TTL, а просто брать предлагаемый. Такой подход, например, можно использовать в HTTP.
Такой подход, например, можно использовать в HTTP.
Сложность иного рода возникает, если записи становятся недействительными одновременно в большом количестве. В таком случае возникает множество запросов в источник данных, что может привести к проблемам с производительностью, а то и вовсе “положить” его. Для избежания подобной ситуации, можно использовать jitter.
Jitter – это случайное значение, добавляемое к TTL. Если в обычном случае все записи имеют, например, TTL = 60 сек., то при использовании jitter с диапазоном от 0 до 10 сек. TTL будет принимать значение от 60 до 70 сек. Это позволит сгладить количество записей, переходящих в состояние недействительных одновременно.
Jitter позволил нам сгладить нагрузку на источник данных, когда “протухает” много записей сразу. Но что делать, если есть одна запись, которую интенсивно используют? Ее инвалидация приведет к тому, что все запросы, которые не нашли данных в кэше, одновременно обратятся к источнику. Тогда нам нужно схлопнуть все эти запросы в один. В go есть для этого отличная библиотека singleflight. Она определяет одинаковые запросы, возникающие одномоментно, выполняет лишь один запрос в источник, а затем отдает результат всем изначальным запросам. Таким образом, если у нас возникли десять запросов, библиотека выполнит только один из них, а результат вернет всем десяти. Стоит отметить, что эта библиотека работает только в рамках одного экземпляра приложения. Если у вас их несколько, то даже с использованием этой библиотеки в источник может уйти больше одного запроса.
В go есть для этого отличная библиотека singleflight. Она определяет одинаковые запросы, возникающие одномоментно, выполняет лишь один запрос в источник, а затем отдает результат всем изначальным запросам. Таким образом, если у нас возникли десять запросов, библиотека выполнит только один из них, а результат вернет всем десяти. Стоит отметить, что эта библиотека работает только в рамках одного экземпляра приложения. Если у вас их несколько, то даже с использованием этой библиотеки в источник может уйти больше одного запроса.
Инвалидация по событию
При таком подходе данные инвалидируют при наступлении некоего события – обычно это обновление данных в источнике. На самом деле, мы уже рассмотрели этот способ, когда говорили про стратегии использования кэширования, а именно write through и write aside.
Также в качестве события для инвалидации данных может выступать время последней модификации данных. Такой способ используется в HTTP.
Стратегии вытеснения
Размер кэша ограничен, он гораздо меньше основного хранилища, а значит, мы не может разместить в нем все данные. Что делать, когда память, выделенная под кэш, полностью заполнена, а новые записи продолжают поступать?
Что делать, когда память, выделенная под кэш, полностью заполнена, а новые записи продолжают поступать?
Ничего не делать
Конечно, можно игнорировать все новые записи и ждать, пока существующие истекут по TTL. Однако в общем случае это крайне неэффективно, поскольку все запросы идут в источник данных и все преимущества кэша нивелируются. Поэтому обычно используются более эффективные стратегии вытеснения.
Random
Random – стратегия вытеснения, при которой удаляются случайные записи. Это самая простая стратегия: просто удаляем то, что первым попалось под руку. Но этот способ недалеко ушел от стратегии “ничего не делать”.
TTL
TTL – стратегия вытеснения, предусматривающая удаление той записи, которой осталось меньше всего “жить”, то есть у которой TTL истечет раньше всех. Как и random, эта стратегия немного лучше, чем “ничего не делать”, но все еще недостаточно эффективна.
LRU
LRU (Least Recently Used) – стратегия вытеснения, которая опирается на время последнего использования записи. Она удаляет записи, у которых время последнего использования старше остальных. Таким образом, в кэше остаются записи, которые использовались недавно. Эта стратегия опирается уже не на случай, а на паттерн использования данных, поэтому она гораздо эффективнее предыдущих.
Она удаляет записи, у которых время последнего использования старше остальных. Таким образом, в кэше остаются записи, которые использовались недавно. Эта стратегия опирается уже не на случай, а на паттерн использования данных, поэтому она гораздо эффективнее предыдущих.
Эта стратегия хорошо подходит, когда:
недавно использованные данные, скорее всего, будут использованы снова в ближайшем будущем
нет данных, которые используются чаще остальных
вы не знаете, что именно вам нужно
LFU
LFU (Least Frequently Used) – стратегия вытеснения, опирающаяся на частоту использования записи. Она удаляет записи, которые использовались реже всего. Так в кэше остаются данные, которые использовались чаще других. Эта стратегия тоже опирается не на случай, а на паттерн использования данных, поэтому она тоже эффективнее остальных и является альтернативой LRU.
Эта стратегия хорошо подходит, когда есть данные, которые используются значительно чаще остальных. Такие данные разумно не вытеснять из кэша, чтобы избежать лишних “походов” в источник.
Такие данные разумно не вытеснять из кэша, чтобы избежать лишних “походов” в источник.
Кэширование ошибок
Ранее я упомянул, что мы можем кэшировать ошибки. На первый взгляд это может показаться странным: зачем нам вообще кэшировать ошибки? На самом деле, это крайне полезная штука.
Представим себе, что клиент запрашивает данные, которых нет в источнике. Пусть это будем информация о товаре по id. Казалось бы, нет данных и ладно: просто сходим в источник, ничего не получим и сообщим клиенту. Но что, если таких запросов много? А что, если кто-то делает это специально?
Это типичная схема так называемой атаки через промахи кэша (cache miss attack). Ее суть в запрашивании данных, которых заведомо не может быть в кэше, поскольку их нет в источнике. Вал таких запросов может привести к проблемам с производительностью источника и даже к его “падению”. Этого можно избежать, если кэшировать ошибку, тогда последующие запросы того же рода будут попадать в кэш и источник не пострадает.
Но тут тоже нужно быть осторожным. Если хранить в одном кэше и полезные данные, и ошибки, то в случае атаки полезные данные могут вытеснены из кэша. Поэтому я бы рекомендовал иметь выделенный кэш под ошибки. Он может быть меньшего объема, чем основной кэш.
Также кэширование ошибок полезно, если сервис, к которому вы обращаетесь, “почувствовал себя плохо”. Чтобы не забивать его запросами, которые, скорее всего, не будут выполнены, а лишь усугубят проблему, лучше кэшировать ошибки на несколько секунд. Таким образом, мы перестанем оказывать негативное воздействие на сервис и дадим ему возможность нормализоваться. Но с этой задачей лучше справляется паттерн Circuit Breaker, который мы не будем рассматривать в рамках этой статьи.
Заключение
На этом пока все. Я не ставил перед собой целью раскрыть тему кэширования исчерпывающе: наверняка многие вещи остались не рассмотренными в рамках этой статьи. Я хотел лишь предоставить структурированную основу и хочу верить, что у меня это получилось.
Надеюсь, данный материал оказался вам полезен, вы открыли для себя что-то новое или структурировали уже известное.
Полезные ссылки
О стратегиях вытеснения на примере инструментов redis
Трудности и стратегии кэширования на сайте Amazon
Основы кэширования от Amazon
Базовый “ликбез” и ссылки на первоисточники от Wikipedia
Кэш (cache) — что это: процесс кеширования данных в памяти
Кэш — это один из уровней памяти устройства или программы. Это высокоскоростное буферное хранилище, в котором располагаются нужные данные. Обычно кэш небольшого размера, и в нем хранится временная информация или та, к которой обращаются чаще всего.
Процесс помещения информации в кэш называется кэшированием.
Кэш есть в компьютерах и мобильных телефонах, отдельные кэши есть у программ, например у браузеров и веб-приложений. Он важен, потому что позволяет быстрее получать доступ к часто используемым данным, оптимизирует и ускоряет работу.
Аппаратный кэш устройства — сервера, компьютера или телефона — это специальный участок памяти с особой архитектурой. Кэш приложений и сервисов — чаще всего программный: он хранится в обычной памяти, в папках на устройстве или на отдельных серверах. Скорость доступа оптимизируется с помощью кода.
Кто пользуется кэшемВ широком смысле кэш используют все, у кого есть компьютер или мобильное устройство. Во всех этих девайсах есть аппаратный кэш, которым пользуется система, и программные кэши приложений. Например, кэш браузера, позволяющий быстрее открывать страницы.
В узком смысле кэшем занимаются разработчики, создающие то или иное приложение или программу. Они могут непосредственно писать логику кэширования и определять порядок хранения файлов. С кэшем на разных уровнях также могут работать системные или сетевые инженеры, архитекторы, проектировщики и другие специалисты.
Для чего нужен кэшВ кэше сохраняются данные, к которым программа или устройство обращаются часто. Если бы кэша не было, эти данные пришлось бы читать из обычной памяти или, в случае веба, скачивать из сети. Как результат — более долгая загрузка, большая нагрузка на память или на сеть. Тем более, таких данных может быть много: без кэша скорость работы компьютеров и их приложений была бы намного меньше.
Если бы кэша не было, эти данные пришлось бы читать из обычной памяти или, в случае веба, скачивать из сети. Как результат — более долгая загрузка, большая нагрузка на память или на сеть. Тем более, таких данных может быть много: без кэша скорость работы компьютеров и их приложений была бы намного меньше.
Поэтому кэшем пользуется большинство приложений, которые оперируют большим набором данных. Это браузеры, разнообразные мессенджеры, программы, работающие с сетью или информацией, СУБД и другие.
Аппаратный кэш есть практически во всех компьютерных устройствах: без него операционная система не сможет работать как надо.
Как устроен кэшВнутреннее устройство кэша похоже на базу данных с более простой структурой и своими особенностями. Это перечень записей с информацией. Данные в них — копии данных, которые есть в «обычной» памяти или на серверах. У каждой записи есть свой идентификатор, или тег, — он показывает, в каком участке «обычной» памяти расположена эта же информация.
Когда системе или программе нужны данные, она находит их по идентификатору. Сначала она проверяет кэш: если в памяти обнаружилась запись, имеющая соответствующий тег, информация берется оттуда. Это быстрее. Если в кэше таких данных нет, значит, нужно обратиться по этому же идентификатору в «обычную» память или на сервер, а затем поместить в кэш полученные оттуда данные. Так в следующий раз обращение к ним будет быстрее.
Алгоритмы кэширования и вытеснения различаются в зависимости от реализации, и их мы обсудим позже.
Виды кэшаАппаратная реализация используется процессором, системой, различными низкоуровневыми, то есть близкими к «железу» процессами. Кэш-память отличается от обычного хранилища данных на физическом уровне, она принципиально другая.
Программная реализация используется программами и сервисами. У каждого приложения она своя. Это по сути код, который описывает, как размещать, кэшировать и хранить данные. При этом сама информация находится в обычных участках памяти: на жестком диске, SSD, сервере. На аппаратном, «железном» уровне такой кэш практически не отличается от простого хранилища данных.
При этом сама информация находится в обычных участках памяти: на жестком диске, SSD, сервере. На аппаратном, «железном» уровне такой кэш практически не отличается от простого хранилища данных.
Если о кэше заходит речь в контексте веба, баз данных и других подобных систем, то обычно имеется в виду программный. С аппаратными кэшами работают инженеры и низкоуровневые программисты.
Устройство аппаратного кэшаКэш процессора. У процессора есть понятие тактовой частоты — это то, с какой скоростью операции выполняются на физическом уровне. В современной технике тактовая частота очень высокая, но постоянные обращения к «обычной» памяти сводили бы эту скорость на нет. Чтобы работа была эффективнее, в процессорах предусматривают кэш. На этом уровне он еще называется сверхоперативной памятью и иначе устроен с точки зрения физики. Мы не будем углубляться в сложные технические детали, просто скажем, что доступ к любой ячейке данных в такой памяти обычно занимает одно и то же время.
Особенность сверхоперативной памяти — она энергозависима. Это значит, что такой кэш поддерживается, только пока устройство включено. Если выключить компьютер, содержимое этой памяти очистится, как и в случае с оперативной. После повторного включения содержимое кэша окажется непредсказуемым.
Процессорный кэш обычно разделен на уровни от первого, самого быстрого, до четвертого. Меньше уровней в конкретном процессоре может быть, больше — нет. У большинства устройств только три уровня.
Кэш внешних устройств. Аппаратный кэш также может быть у внешних хранилищ, например жестких дисков. Он опять же обеспечивает более быстрый доступ к памяти. Кроме того, сама система при работе с внешним накопителем может пользоваться частью оперативной памяти компьютера как «дисковым кэшем».
Устройство программного кэшаПрограммный кэш какого-либо приложения описывается кодом. Кэшированные данные иначе записываются, хранятся в особых структурах данных, и доступ к ним происходит по определенным оптимизированным алгоритмам.
Особенности записи данных. Информацию в программный кэш записывают одним из двух способов:
- сквозной — сначала полученные сведения оказываются в основной памяти, а потом оттуда дублируются в кэш;
- отложенный — сначала данные кэшируются, а потом, по истечении определенного срока или при вытеснении, переносятся в основную память.
Структуры для хранения кэша. Для хранения закэшированных данных обычно используются программные структуры с более быстрым доступом, чем к стандартным файлам или переменным. Чаще всего это ассоциативные массивы или хэш-таблицы — о них вы подробнее можете прочитать в соответствующих статьях. В небольших программах они могут быть заданы как переменные, но чаще представляют собой нечто вроде простой базы данных в памяти устройства. Также это могут быть отдельные файлы и папки, где хранится информация.
Ассоциативные структуры данных используются потому, что позволяют хранить пары «ключ-значение», где ключ может быть числом, текстом, хэшем или чем-то еще. Доступ к ним производится по особым алгоритмам и благодаря этому оказывается быстрее.
Доступ к ним производится по особым алгоритмам и благодаря этому оказывается быстрее.
Алгоритмы кэширования. Одна из особенностей кэша — это относительно небольшой участок памяти. Если он становится слишком объемным, то начинает занимать слишком много места, может ухудшиться и быстродействие. Так что размер программного кэша ограничивают. А если он оказывается заполнен, срабатывают алгоритмы вытеснения — какая-то информация «выбрасывается» из него, а новая записывается.
Алгоритмов, которые описывают добавление и вытеснение, несколько. Наиболее известных — четыре:
- MRU — убираются данные, которые испольовались последними;
- LFU — вытесняются данные, которые используются реже всего;
- LRU — вытесняются данные, к которым не обращались дольше всего;
- ARC — комбинация двух предыдущих типов.
Существует теоретический алгоритм, который невозможно реализовать в общем виде: отбрасываться должна наименее полезная информация.
Это только несколько примеров. Сфера использования кэш-памяти как концепта намного шире, мы только привели несколько наглядных вариантов.
Кэш браузера. Браузер открывает сайты. Если упростить: чтобы отобразить страницу как надо, он скачивает информацию с ее сервера и показывает вам. Этот процесс занимает время и отнимает ресурсы: нужно обратиться к сети, получить ответ, подгрузить и отобразить контент. Поэтому, чтобы ускорить загрузку, часть данных кэшируется.
Кэш браузера — это обычно папка в каталоге, где находятся его файлы. В кэше хранятся локальные копии некоторых данных с сайтов, на которых вы находились. Какие именно это данные, зависит от браузеров, но чаще всего сохраняются сведения, которые много весят и редко изменяются. Это картинки, участки видеороликов, графические элементы интерфейса. Если человек зайдет на сайт, данные которого закэшировались, то сможет получить к ним доступ быстрее и это не потребует активного скачивания «тяжелой» информации из сети.
Это картинки, участки видеороликов, графические элементы интерфейса. Если человек зайдет на сайт, данные которого закэшировались, то сможет получить к ним доступ быстрее и это не потребует активного скачивания «тяжелой» информации из сети.
Иногда браузерный кэш нужно очищать — например, если он закэшировал страницу, на которой была ошибка, и теперь все время показывает ее как ошибочную. Это можно сделать через настройки самого браузера.
Сетевой кэш. Им обычно пользуются крупные ресурсы, на которые заходят из разных точек мира. На самом низком уровне все происходящее в вычислительной технике – электрические импульсы, а у них есть конечная скорость. Поэтому, если компьютер в какой-то части мира захочет обратиться к компьютеру в противоположном полушарии, данные будут идти дольше.
Для разрешения этой проблемы используют CDN, сети доставки контента. Это распределенная система из большого количества устройств, которые находятся в разных точках мира. По сути, это кэш с хранением данных в разных местах.
Такое использование кэша позволяет сайтам быстро загружаться из любой точки мира: устройства находятся в разных странах и на разных материках. С CDN работают соответствующие специалисты, повлиять на их использование простой пользователь не может.
Кэш серверной части сайта. В веб-разработке кэш может быть не только браузерным. У самих владельцев ресурса есть еще один способ ускорить доступ к страницам. Это использование специального кэш-сервера: он кэширует контент, соответствующий самым популярным запросам. В результате те страницы, которые пользователи посещают часто, будут загружаться у них быстрее, а это полезно сразу по многим причинам. Это делает сайт более удобным, помогает его ранжированию, улучшает пользовательский опыт.
К серверному кэшу нет доступа у обычного пользователя. С ним могут соприкасаться бэкендеры и другие специалисты, работающие непосредственно с «внутренней» частью сайта.
Кэш программ, работающих с памятью. Приложения могут использовать кэш как способ хранить свои внутренние данные, к которым нужен быстрый доступ. Это, например, промежуточные результаты каких-то вычислений или действий — они понадобятся в дальнейшем. Или параметры, которые нужно передавать разным модулям.
Это, например, промежуточные результаты каких-то вычислений или действий — они понадобятся в дальнейшем. Или параметры, которые нужно передавать разным модулям.
Кэш приложения может представлять собой папку с файлами на устройстве, а может существовать в рамках кода — тогда это какая-либо переменная или структура данных.
Преимущества кэшаКэш — нечто обязательное для современных компьютеров, серверов, веб-приложений и других сущностей. Без него интернет и в целом IT не функционировали бы как надо. Вот какие преимущества дает его использование.
Повышение производительности. С кэшем приложения работают быстрее и эффективнее: им не приходится постоянно тратить время на подгрузку каких-то данных, ведь они могут просто взять их из кэша. Иначе все постоянно зависало бы, приходилось бы долго ждать.
Снижение нагрузки. Так как к основному хранилищу благодаря кэшу обращаются реже, на него снижается нагрузка. Это особенно важно в случае с серверами, так как помогает избежать отказов и резкого снижения производительности из-за нагрузки в пиковых ситуациях.
Это особенно важно в случае с серверами, так как помогает избежать отказов и резкого снижения производительности из-за нагрузки в пиковых ситуациях.
Повышение пропускной способности. Как следствие всего перечисленного, повышается пропускная способность операций. Дело в том, что чтение и запись данных — операции, которые занимают время и могут выполняться только в определенном количестве за момент времени. У кэша пропускная способность намного выше, чем у обычной памяти, поэтому операций за один момент может быть множество — намного больше, чем при работе с сервером, базой данным или другим хранилищем.
Оптимизация. Представьте себе, что к каким-то данным обращаются чаще, чем к другим. Это может быть определенная популярная страница сайта или какая-то информация из приложения, что-то еще. Если эти данные будут храниться в обычной памяти, это создаст лишнюю нагрузку и снизит скорость доступа. А их кэширование позволяет оптимизировать доступ и сделать нагрузку более равномерной.
Меньшие затраты. Это опять же преимущество, важное для веба. Использование серверного или сетевого кэша приводит к тому, что сервису нужно платить за меньшее количество ресурсов для базы данных или серверов. Несмотря на то что сам кэш тоже не бесплатный, выходит тем не менее дешевле, чем без него.
Недостатки кэша- Аппаратный кэш — очень дорогая в производстве структура. К тому же он обычно энергозависим: стоит выключить устройство — все данные потеряются.
- Программный кэш не решит всех вопросов, связанных с памятью. Он ограничен по размеру, а специфические алгоритмы не позволяют хранить в нем что-то неограниченное количество времени. Для долговременного хранения важной информации он не подходит.
- Алгоритма кэширования, оптимального в любых ситуациях, не существует. Поэтому алгоритм выбирают разработчики в зависимости от целей конкретной программы: он обычно довольно узкоспециализированный и не подходит для широкого спектра задач.

- Закэшировать «весь интернет» или всю память не получится — размер кэша довольно маленький.
Это не минусы в классическом понимании: кэшем все равно пользуются все. Просто надо понимать, что это специализированный инструмент со своей сферой использования.
Аппаратный кэш реализуется на уровне полупроводников и электрических схем. Программный куда разнообразнее.
Кэширование в приложении может быть устроено как хранение данных в специальных структурах, существующих в коде, или как сохранение информации в отдельные файлы и папки. Соответственно, код описывает то, как данные добавляются и удаляются из кэша.
В случае с сетевой инфраструктурой обычно используются специальные сервисы. Они предоставляют сайту мощности кэш-памяти или кэш-сервер за определенную абонентскую плату.
В разработке также применяют API и фреймворки, в которых есть реализации программного кэша разных типов. Такие инструменты позволяют не писать реализацию с нуля, а чтобы начать работать с ними, понадобится изучить соответствующую технологию.
Чтобы написать собственную реализацию программного кэша в самом простом виде, понадобится изучить алгоритмы его наполнения и особенности хранения данных. Тогда вы сможете создать код, который реализует максимально простой кэш.
Для более сложных решений понадобится пользоваться фреймворками и соответствующими технологиями. А при создании веб-архитектуры, возможно, придется арендовать кэш-сервер для сайта или базы данных — но это уже более продвинутый уровень, таким занимаются владельцы ресурсов и старшие специалисты.
Лучшие практики кэширования | Amazon Web Services
Как применять кэширование
Кэширование применимо к широкому спектру вариантов использования, но полное использование кэширования требует определенного планирования. При принятии решения о кэшировании фрагмента данных рассмотрите следующие вопросы:
- Безопасно ли использовать кэшированное значение? Один и тот же фрагмент данных может иметь разные требования к согласованности в разных контекстах.
 Например, во время онлайн-заказа вам нужна официальная цена товара, поэтому кэширование может быть неуместным. Однако на других страницах цена может быть устаревшей на несколько минут без негативного влияния на пользователей.
Например, во время онлайн-заказа вам нужна официальная цена товара, поэтому кэширование может быть неуместным. Однако на других страницах цена может быть устаревшей на несколько минут без негативного влияния на пользователей. - Эффективно ли кэширование для этих данных? Некоторые приложения генерируют шаблоны доступа, которые не подходят для кэширования, например, просматривая ключевое пространство большого набора данных, который часто меняется. В этом случае поддержание кэша в актуальном состоянии может свести на нет все преимущества, которые может предложить кэширование.
- Хорошо ли структурированы данные для кэширования? Простого кэширования записи базы данных часто бывает достаточно, чтобы обеспечить значительные преимущества в производительности. Однако в других случаях данные лучше кэшировать в формате, объединяющем несколько записей. Поскольку кэши — это простые хранилища пар «ключ-значение», вам также может понадобиться кэшировать запись данных в нескольких различных форматах, чтобы вы могли получить к ней доступ по различным атрибутам в записи.

Вам не нужно принимать все эти решения заранее. По мере того как вы расширяете использование кэширования, помните об этих рекомендациях, когда решаете, следует ли кэшировать данный фрагмент данных.
Ленивое кэширование
Ленивое кэширование, также называемое ленивым заполнением или кэшированием, является наиболее распространенной формой кэширования. Лень должна служить основой любой хорошей стратегии кэширования. Основная идея состоит в том, чтобы заполнять кеш только тогда, когда приложение действительно запрашивает объект. Общий поток приложений выглядит следующим образом:
- Ваше приложение получает запрос данных, например, 10 самых последних новостей.
- Ваше приложение проверяет кэш, чтобы узнать, находится ли объект в кеше.
- Если это так (попадание в кэш), кэшированный объект возвращается, и поток вызовов завершается.
- Если нет (промах кеша), то объект запрашивается в базе данных.

Этот подход имеет ряд преимуществ по сравнению с другими методами:
- Кэш содержит только те объекты, которые фактически запрашиваются приложением, что помогает поддерживать управляемость размера кеша. Новые объекты добавляются в кэш только по мере необходимости. Затем вы можете пассивно управлять своей кеш-памятью, просто позволяя движку, который вы используете, вытеснять наименее используемые ключи по мере заполнения вашего кеша, что он и делает по умолчанию.
- По мере того, как новые узлы кэша подключаются к сети, например, по мере масштабирования вашего приложения, метод ленивого заполнения будет автоматически добавлять объекты в новые узлы кэша, когда приложение впервые запрашивает их.
- Истечение срока действия кэша легко устраняется простым удалением кэшированного объекта. Новый объект будет извлечен из базы данных при следующем запросе.
- Ленивое кэширование широко известно, и многие веб-фреймворки и платформы приложений поддерживают его по умолчанию.

Вот пример ленивого кэширования в псевдокоде Python:
# Python
защита get_user (user_id):
# Проверяем кеш
запись = cache.get(user_id)
если запись отсутствует:
# Запустить запрос к БД
запись = db.query ("выбрать * из пользователей, где id =?", user_id)
# Заполняем кеш
cache.set(user_id, запись)
обратная запись
# Код приложения
пользователь = get_user(17) Вы можете найти библиотеки во многих популярных средах программирования, которые инкапсулируют этот шаблон. Но независимо от языка программирования общий подход одинаков.
Вы должны применять стратегию ленивого кэширования в любом месте вашего приложения, где у вас есть данные, которые будут часто считываться, но нечасто записываются. Например, в типичном веб-приложении или мобильном приложении профиль пользователя редко меняется, но доступ к нему осуществляется через приложение. Человек может обновлять свой профиль всего несколько раз в год, но к профилю могут обращаться десятки или сотни раз в день, в зависимости от пользователя.
Сквозная запись
В кэше со сквозной записью кэш обновляется в реальном времени при обновлении базы данных. Таким образом, если пользователь обновляет свой профиль, обновленный профиль также помещается в кеш. Вы можете думать об этом как об упреждающем, чтобы избежать ненужных промахов кеша, в случае, если у вас есть данные, к которым, как вы точно знаете, будет доступ. Хорошим примером является любой тип агрегации, такой как топ-100 лидеров игр, топ-10 самых популярных новостей или даже рекомендации. Поскольку эти данные обычно обновляются определенным фрагментом кода приложения или фонового задания, можно легко обновить и кэш.
Шаблон сквозной записи также легко продемонстрировать в псевдокоде:
# Python
def save_user (user_id, значения):
# Сохранить в БД
запись = db. query ("обновить пользователей... где id =?", user_id, значения)
# Поместить в кеш
cache.set(user_id, запись)
обратная запись
# Код приложения
user = save_user(17, {"name": "Nate Dogg"})
query ("обновить пользователей... где id =?", user_id, значения)
# Поместить в кеш
cache.set(user_id, запись)
обратная запись
# Код приложения
user = save_user(17, {"name": "Nate Dogg"}) Этот подход имеет определенные преимущества по сравнению с ленивым заполнением:
- Он позволяет избежать промахов кеша, что может помочь приложению работать лучше и работать быстрее.
- Переносит любую задержку приложения на обновление данных пользователем, что лучше соответствует ожиданиям пользователя. Напротив, серия промахов кеша может создать у пользователя впечатление, что ваше приложение просто медленное.
- Упрощает истечение срока действия кэша. Кэш всегда актуален.
Однако кэширование со сквозной записью также имеет некоторые недостатки:
- Кэш может быть заполнен ненужными объектами, к которым фактически нет доступа. Это может не только потреблять дополнительную память, но и неиспользуемые элементы могут вытеснять более полезные элементы из кеша.

- Многократное обновление некоторых записей может привести к большому оттоку кэша.
- Когда (не если) узлы кэша выходят из строя, эти объекты больше не будут находиться в кэше. Вам нужен какой-то способ повторно заполнить кеш отсутствующих объектов, например, с помощью ленивого заполнения.
Очевидно, что для решения этих проблем можно комбинировать отложенное кэширование с кэшированием со сквозной записью, поскольку они связаны с противоположными сторонами потока данных. Ленивое кэширование выявляет промахи в кеше при чтении, а кэширование со сквозной записью заполняет данные при записи, поэтому эти два подхода дополняют друг друга. По этой причине часто лучше рассматривать отложенное кэширование как основу, которую вы можете использовать во всем приложении, а кэширование со сквозной записью — как целевую оптимизацию, которую вы применяете в определенных ситуациях.
Time-to-live
Срок действия кэша может очень быстро стать очень сложным. В наших предыдущих примерах мы работали только с одной пользовательской записью. В реальном приложении данная страница или экран часто одновременно кэшируют целую кучу разных вещей — данные профиля, главные новости, рекомендации, комментарии и т. д., которые обновляются разными способами.
В наших предыдущих примерах мы работали только с одной пользовательской записью. В реальном приложении данная страница или экран часто одновременно кэшируют целую кучу разных вещей — данные профиля, главные новости, рекомендации, комментарии и т. д., которые обновляются разными способами.
К сожалению, не существует панацеи от этой проблемы, а истечение срока действия кэша — это целая область информатики. Но есть несколько простых стратегий, которые вы можете использовать:
- Всегда применяйте время жизни (TTL) ко всем ключам кэша, кроме тех, которые вы обновляете путем кэширования со сквозной записью. Вы можете использовать долгое время, скажем, часы или даже дни. Этот подход выявляет ошибки приложения, когда вы забываете обновить или удалить заданный ключ кэша при обновлении базовой записи. В конце концов срок действия ключа кэша истечет автоматически, и он будет обновлен.
- Для быстро меняющихся данных, таких как комментарии, списки лидеров или потоки действий, вместо добавления кэширования со сквозной записью или сложной логики истечения срока действия просто установите короткий TTL в несколько секунд.
 Если у вас есть запрос к базе данных, который забивается в рабочей среде, достаточно всего нескольких строк кода, чтобы добавить к запросу ключ кэша с 5-секундным TTL. Этот код может быть прекрасным пластырем, чтобы поддерживать ваше приложение в рабочем состоянии, пока вы оцениваете более элегантные решения.
Если у вас есть запрос к базе данных, который забивается в рабочей среде, достаточно всего нескольких строк кода, чтобы добавить к запросу ключ кэша с 5-секундным TTL. Этот код может быть прекрасным пластырем, чтобы поддерживать ваше приложение в рабочем состоянии, пока вы оцениваете более элегантные решения. - В результате работы, проделанной командой Ruby on Rails, появился новый шаблон, кеширование матрешек. В этом шаблоне вложенные записи управляются с помощью собственных ключей кэша, а ресурс верхнего уровня представляет собой набор этих ключей кэша. Допустим, у вас есть новостная веб-страница, содержащая пользователей, истории и комментарии. При таком подходе каждый из них является собственным ключом кэша, и страница соответственно запрашивает каждый из этих ключей.
- Если вы сомневаетесь, просто удалите ключ кэша, если вы не уверены, затронут ли он данным обновлением базы данных или нет. Ваш ленивый фонд кэширования обновит ключ, когда это необходимо.
 При этом ваша база данных будет не хуже, чем без кэширования.
При этом ваша база данных будет не хуже, чем без кэширования.
Хороший обзор сроков действия кэша и кэширования матрешки см. в статье Влияние кэширования «русской матрешки» на производительность в блоге Basecamp Signal vs Noise.
Вытеснение
Выселение происходит, когда память переполняется или превышает параметр maxmemory в кэше, в результате чего механизм выбирает ключи для вытеснения, чтобы управлять своей памятью. Выбранные ключи основаны на выбранной политике вытеснения.
По умолчанию Amazon ElastiCache для Redis устанавливает политику исключения volatile-lru для вашего кластера Redis. Эта политика выбирает наименее использовавшиеся ключи, для которых установлено значение срока действия (TTL). Другие доступные политики вытеснения могут быть применены как настраиваемый параметр maxmemory-policy. Политику выселения можно резюмировать следующим образом:
allkeys-lfu: из кэша удаляются наименее часто используемые (LFU) ключи независимо от установленного TTL
allkeys-lru: из кэша удаляются наименее часто используемые (LRU) независимо от установленного TTL часто используемые (LFU) ключи из тех, для которых установлено значение TTL
. volatile-lru: Кэш вытесняет наименее использовавшиеся (LRU) из тех, для которых установлено значение TTL
volatile-lru: Кэш вытесняет наименее использовавшиеся (LRU) из тех, для которых установлено значение TTL
. volatile-ttl: Кэш удаляет ключи с самым коротким значением TTL, установленным
. volatile-random: Кэш случайным образом удаляет ключи с TTL, равным 9.0012 allkeys-random: Кэш случайным образом удаляет ключи независимо от установленного значения TTL.
no-eviction: Кэш вообще не удаляет ключи. Это блокирует будущие записи, пока память не освободится.
Хорошей стратегией при выборе соответствующей политики вытеснения является рассмотрение данных, хранящихся в вашем кластере, и результатов вытеснения ключей.
Как правило, политики на основе LRU более распространены для базовых вариантов использования кэширования, но в зависимости от ваших целей вы можете использовать политику вытеснения на основе TTL или Random, если это лучше соответствует вашим требованиям.
Кроме того, если вы столкнулись с вытеснением кластера, это обычно является признаком того, что вам необходимо увеличить масштаб (использовать узел с большим объемом памяти) или масштабировать (добавить дополнительные узлы в кластер) для размещения дополнительные данные. Исключением из этого правила является случай, когда вы намеренно полагаетесь на механизм кэширования для управления своими ключами посредством вытеснения, также называемого кэшем LRU.
Исключением из этого правила является случай, когда вы намеренно полагаетесь на механизм кэширования для управления своими ключами посредством вытеснения, также называемого кэшем LRU.
Громовое стадо
Эффект грозового стада, также известный как нагромождение собак, возникает, когда множество различных прикладных процессов одновременно запрашивают ключ кэша, получают промах кэша, а затем каждый из них параллельно выполняет один и тот же запрос к базе данных. Чем дороже этот запрос, тем большее влияние он оказывает на базу данных. Если задействованный запрос входит в первую десятку запросов, требующих ранжирования большого набора данных, влияние может быть значительным.
Одна из проблем с добавлением значений TTL ко всем ключам кэша заключается в том, что это может усугубить эту проблему. Например, предположим, что миллионы людей подписаны на популярного пользователя на вашем сайте. Этот пользователь не обновлял свой профиль и не публиковал никаких новых сообщений, но срок действия кеша его профиля все еще истекает из-за TTL. Ваша база данных может внезапно оказаться заваленной серией идентичных запросов.
Ваша база данных может внезапно оказаться заваленной серией идентичных запросов.
TTL в стороне, этот эффект также распространен при добавлении нового узла кэша, поскольку память нового узла кэша пуста. В обоих случаях решение состоит в том, чтобы предварительно прогреть кеш, выполнив следующие действия:
- Напишите сценарий, выполняющий те же запросы, что и ваше приложение. Если это веб-приложение, этот сценарий может быть сценарием оболочки, который обращается к набору URL-адресов.
- Если ваше приложение настроено на ленивое кэширование, промахи кеша приведут к заполнению ключей кеша, и новый узел кеша будет заполнен.
- Когда вы добавляете новые узлы кэша, запустите сценарий, прежде чем присоединять новый узел к приложению. Поскольку ваше приложение необходимо перенастроить, чтобы добавить новый узел в согласованное кольцо хеширования, вставьте этот сценарий в качестве шага перед запуском перенастройки приложения.
- Если вы планируете добавлять и удалять узлы кэша на регулярной основе, предварительное прогревание можно автоматизировать, запуская сценарий всякий раз, когда ваше приложение получает событие реконфигурации кластера через Amazon Simple Notification Service (Amazon SNS).

Наконец, есть еще один тонкий побочный эффект повсеместного использования TTL. Если вы постоянно используете одну и ту же длину TTL (скажем, 60 минут), срок действия многих ваших ключей кеша может истечь в течение одного и того же временного окна, даже после предварительного прогрева кеша. Одна из стратегий, которую легко реализовать, состоит в том, чтобы добавить некоторую случайность к вашему TTL:
ttl = 3600 + (rand() * 120) /* +/- 2 минуты */
Хорошей новостью является то, что только крупные сайты обычно должны беспокоиться о проблеме масштабирования такого уровня. Это хорошо знать, но это также хорошая проблема, чтобы иметь.
Кэшировать (почти) все
Наконец, может показаться, что вы должны кэшировать только сильно загруженные запросы к базе данных и дорогостоящие вычисления, но другие части вашего приложения могут не выиграть от кэширования. На практике кэширование в памяти широко используется, потому что гораздо быстрее извлечь ключ плоского кэша из памяти, чем выполнить даже самый оптимизированный запрос к базе данных или удаленный вызов API. Просто имейте в виду, что кэшированные данные являются устаревшими по определению, а это означает, что могут быть случаи, когда они неуместны, например, доступ к цене товара во время онлайн-оформления заказа. Вы можете отслеживать статистику, такую как промахи кеша, чтобы увидеть, эффективен ли ваш кеш.
Просто имейте в виду, что кэшированные данные являются устаревшими по определению, а это означает, что могут быть случаи, когда они неуместны, например, доступ к цене товара во время онлайн-оформления заказа. Вы можете отслеживать статистику, такую как промахи кеша, чтобы увидеть, эффективен ли ваш кеш.
Технологии кэширования
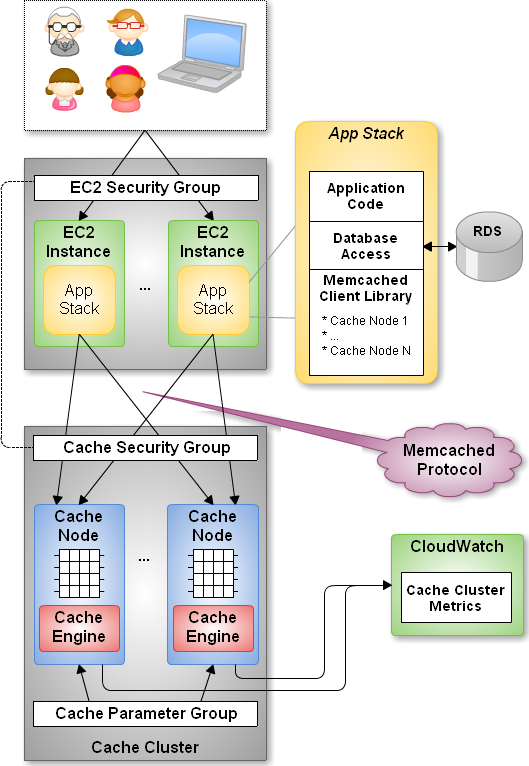
Наиболее популярные технологии кэширования относятся к категории «ключ-значение» в памяти баз данных NoSQL. Хранилище «ключ-значение» в памяти — это база данных NoSQL, оптимизированная для рабочих нагрузок приложений с интенсивным чтением (таких как социальные сети, игры, обмен мультимедиа и порталы вопросов и ответов) или рабочих нагрузок с интенсивными вычислениями (например, механизм рекомендаций). Два ключевых преимущества делают хранилища ключей и значений в памяти популярными в качестве решений для кэширования: скорость и простота. Хранилища ключевых значений не имеют сложной логики запросов или агрегации, что делает запросы быстрыми. Хранилища ключей и значений в памяти работают особенно быстро, поскольку они используют память, а не более медленный диск. Кроме того, их простота делает их легкими в освоении и использовании. На рынке доступно множество технологий ключ-значение, многие из них можно использовать в качестве решений для кэширования. Два очень популярных хранилища ключей и значений в памяти — это Memcached и Redis. AWS позволяет полностью управлять обоими этими механизмами через Amazon ElastiCache.
Хранилища ключей и значений в памяти работают особенно быстро, поскольку они используют память, а не более медленный диск. Кроме того, их простота делает их легкими в освоении и использовании. На рынке доступно множество технологий ключ-значение, многие из них можно использовать в качестве решений для кэширования. Два очень популярных хранилища ключей и значений в памяти — это Memcached и Redis. AWS позволяет полностью управлять обоими этими механизмами через Amazon ElastiCache.
Начало работы с Amazon ElastiCache
Начать работу с кэшированием в облаке с помощью полностью управляемого сервиса, такого как Amazon ElastiCache, очень просто. Это устраняет сложность настройки, управления и администрирования вашего кэша и позволяет вам сосредоточиться на том, что приносит пользу вашей организации. Зарегистрируйтесь сегодня для Amazon ElastiCache.
Кэширование в GitLab CI/CD | Гитлаб
- Чем кеш отличается от артефактов
- Кэш
- Артефакты
- Надлежащая практика кэширования
- Использование нескольких кэшей
- Использовать резервный ключ кэша
- Резервные ключи для каждого кэша
- Глобальный резервный ключ
- Отключить кэш для определенных заданий
- Наследовать глобальную конфигурацию, но переопределить определенные настройки для каждого задания
- Общие варианты использования кешей
- Совместное использование кешей между заданиями в одной ветви
- Совместное использование кешей между заданиями в разных ветвях
- Использование переменной для управления политикой кэширования задания
- Кэшировать зависимости Node.
 js
js- Вычислить ключ кэша из файла блокировки
- Кэшировать зависимости PHP
- Кэшировать зависимости Python
- Кэшировать зависимости Ruby
- Кэшировать зависимости Go 9001 4
- Наличие кэша
- Где хранятся кэши
- Имена ключей кэша
- Использовать один и тот же кэш для всех ветвей
- Имена ключей кэша
- Где хранятся кэши
- Очистка кэша
- Очистить кэш, изменив
cache:key - Очистить кэш вручную
- Очистить кэш, изменив
- Устранение неполадок
- Несоответствие кэша
- Пример несоответствия кэша 1
- Пример несоответствия кэша 2
- Несоответствие кэша
Кэш — это один или несколько файлов, загружаемых и сохраняемых заданием. Последующие задания, использующие тому же кешу не нужно снова загружать файлы, поэтому они выполняются быстрее.
Чтобы узнать, как определить кэш в файле .gitlab-ci.yml ,
см. ссылку кэша .
Чем кеш отличается от артефактов
Используйте кэш для зависимостей, таких как пакеты, которые вы загружаете из Интернета. Кэш хранится там, где установлен GitLab Runner, и загружается на S3, если распределенный кеш включен.
Используйте артефакты для передачи промежуточных результатов сборки между этапами. Артефакты генерируются заданием, сохраняются в GitLab и могут быть загружены.
И артефакты, и кэши определяют свои пути относительно каталога проекта и не может ссылаться на файлы вне его.
Кэш
- Определите кэш для каждого задания с помощью ключевого слова
cache. В противном случае он отключен. - Последующие конвейеры могут использовать кэш.
- Последующие задания в том же конвейере могут использовать кэш, если зависимости идентичны.
- Разные проекты не могут совместно использовать кеш.
- По умолчанию защищенные и незащищенные ветки не используют общий кеш. Однако вы можете изменить это поведение.

Артефакты
- Определение артефактов для каждого задания.
- Последующие задания на более поздних этапах того же конвейера могут использовать артефакты.
- Различные проекты не могут совместно использовать артефакты.
- Срок действия артефактов по умолчанию истекает через 30 дней. Вы можете определить пользовательское время истечения срока действия.
- Срок действия последних артефактов не истекает, если включен параметр сохранения последних артефактов.
- Используйте зависимости для управления тем, какие задания извлекают артефакты.
Надлежащая практика кэширования
Чтобы обеспечить максимальную доступность кэша, выполните одно или несколько из следующих действий:
- Отметьте своих бегунов и используйте тег на вакансиях которые разделяют кеш.
- Используйте бегунов, которые доступны только для конкретного проекта.
- Используйте ключ
 Например,
вы можете настроить отдельный кеш для каждой ветки.
Например,
вы можете настроить отдельный кеш для каждой ветки.
Чтобы бегуны могли эффективно работать с кэшем, необходимо выполнить одно из следующих действий:
- Использовать один бегун для всех ваших заданий.
- Использовать несколько направляющих, у которых есть распределенное кэширование, где кеш хранится в корзинах S3. Общие раннеры на GitLab.com ведут себя именно так. Эти бегуны могут быть в режиме автомасштабирования, но они не должны быть.
- Использовать несколько бегунов с одинаковой архитектурой и иметь эти бегуны совместно использовать общий сетевой каталог для хранения кеша. Этот каталог должен использовать NFS или что-то подобное. Эти бегуны должны быть в режиме автомасштабирования.
Использовать несколько кэшей
История версий- Представлено в GitLab 13.10.
- Флаг функции удален, в GitLab 13.12.
У вас может быть максимум четыре кэша:
тестовое задание:
этап: сборка
кеш:
- ключ:
файлы:
- Gemfile. lock
пути:
- продавец/рубин
- ключ:
файлы:
- пряжа.замок
пути:
- .пряжа-кэш/
сценарий:
- комплект конфигурации пакета --local path 'vendor/ruby'
- пакетная установка
- установка пряжи --cache-folder .yarn-cache
- эхо Запустить тесты...
lock
пути:
- продавец/рубин
- ключ:
файлы:
- пряжа.замок
пути:
- .пряжа-кэш/
сценарий:
- комплект конфигурации пакета --local path 'vendor/ruby'
- пакетная установка
- установка пряжи --cache-folder .yarn-cache
- эхо Запустить тесты...
Если несколько кэшей объединены с резервным ключом кэша, глобальный резервный кеш извлекается каждый раз, когда кеш не найден.
Использовать резервный ключ кэша
Резервные ключи для каждого кэша
Представлено в GitLab 16.0
Каждая запись кэша поддерживает до пяти резервных ключей с ключевым словом fallback_keys .
Если задание не находит ключ кэша, вместо этого оно пытается получить резервный кэш.
Резервные ключи ищутся по порядку, пока не будет найден кеш. Если кэш не найден,
задание выполняется без использования кеша. Например:
тестовое задание:
этап: сборка
кеш:
- ключ: кеш-$CI_COMMIT_REF_SLUG
запасные_ключи:
- кеш-$CI_DEFAULT_BRANCH
- кэш по умолчанию
пути:
- продавец/рубин
сценарий:
- комплект конфигурации пакета --local path 'vendor/ruby'
- пакетная установка
- эхо Запустить тесты. ..
..
В этом примере:
- Задание ищет кэш
-$CI_COMMIT_REF_SLUG. - Если
cache-$CI_COMMIT_REF_SLUGне найден, задание ищеткэш-$CI_DEFAULT_BRANCHкак запасной вариант. - Если
cache-$CI_DEFAULT_BRANCHтакже не найден, задание ищетcache-defaultкак второй запасной вариант. - Если ничего не найдено, задание загружает все зависимости Ruby без использования кэша,
но создает новый кеш для
cache-$CI_COMMIT_REF_SLUG, когда задание завершается.
Резервные ключи следуют той же логике обработки, что и cache:key :
- Если вы очищаете кэши вручную, добавляются резервные ключи для каждого кэша. с индексом, как и другие ключи кэша.
- Если включен параметр Использовать отдельные кэши для защищенных ветвей ,
резервные ключи для каждого кэша добавляются с
-protectedили-non_protected.
Глобальный резервный ключ
Представлено в GitLab Runner 13.4.
Вы можете использовать предопределенную переменную $CI_COMMIT_REF_SLUG указать свой кэш:ключ . Например, если ваш $CI_COMMIT_REF_SLUG — это test , вы можете настроить задание на загрузку кеша с тегом test .
Если кэш с этим тегом не найден, вы можете использовать CACHE_FALLBACK_KEY для
укажите кеш для использования, когда его не существует.
В следующем примере, если $CI_COMMIT_REF_SLUG не найден, задание использует определенный ключ
по переменной CACHE_FALLBACK_KEY :
переменные:
CACHE_FALLBACK_KEY: запасной ключ
задание1:
сценарий:
- эхо
кеш:
ключ: "$CI_COMMIT_REF_SLUG"
пути:
- двоичные файлы/
Порядок извлечения кэшей:
- Попытка извлечения кэша
:ключ - Попытки извлечения для каждой записи по порядку в
fallback_keys - Попытка получения глобального резервного ключа в
CACHE_FALLBACK_KEY
Процесс извлечения кэша останавливается после извлечения первого успешного кэша.
Отключить кэш для определенных заданий
Если вы определяете кэш глобально, каждое задание использует такое же определение. Вы можете переопределить это поведение для каждого задания.
Чтобы полностью отключить его для задания, используйте пустой список:
задание: кеш: []
Наследовать глобальную конфигурацию, но переопределять определенные настройки для каждого задания
Вы можете переопределить параметры кэша без перезаписи глобального кэша с помощью
якоря. Например, если вы хотите переопределить политика для одного задания:
по умолчанию:
кеш: &global_cache
ключ: $CI_COMMIT_REF_SLUG
пути:
- node_modules/
- общественный/
- продавец/
политика: тяни-толкай
работа:
кеш:
# наследовать все настройки глобального кеша
<<: *глобальный_кэш
# переопределить политику
политика: тянуть
Дополнительные сведения см. в разделе Кэш : политика .
Общие варианты использования кэшей
Обычно вы используете кеши, чтобы избежать загрузки контента, например зависимостей или библиотеки каждый раз, когда вы запускаете задание. пакеты Node.js, Пакеты PHP, драгоценные камни Ruby, библиотеки Python и другие могут кэшироваться.
Примеры см. в шаблонах GitLab CI/CD.
Совместное использование кэшей между заданиями в одной ветке
Чтобы задания в каждой ветви использовали один и тот же кеш, определите кеш с ключом : $CI_COMMIT_REF_SLUG :
кеш: ключ: $CI_COMMIT_REF_SLUG
Эта конфигурация предотвращает случайную перезапись кэша. Однако Первый конвейер для запроса на слияние работает медленно. В следующий раз, когда коммит будет отправлен в ветку, кеш повторно используется, и задания выполняются быстрее.
Чтобы включить кэширование для отдельных заданий и ветвей:
кэш: ключ: "$CI_JOB_NAME-$CI_COMMIT_REF_SLUG"
Чтобы включить кэширование для отдельных стадий и ветвей:
кэш: ключ: "$CI_JOB_STAGE-$CI_COMMIT_REF_SLUG"
Совместное использование кешей для заданий в разных ветвях
Чтобы совместно использовать кеш для всех филиалов и всех заданий, используйте один и тот же ключ для всего:
кеш: ключ: один ключ, чтобы управлять ими всеми
Чтобы разделить кеш между филиалами, но иметь уникальный кеш для каждого задания:
кэш: ключ: $CI_JOB_NAME
Использование переменной для управления политикой кэширования задания
Представлено в GitLab 16. 1.
1.
Чтобы уменьшить дублирование заданий, когда единственная разница заключается в политике извлечения, можно использовать переменную CI/CD.
Например:
условная политика:
правила:
- если: $CI_COMMIT_BRANCH == $CI_DEFAULT_BRANCH
переменные:
ПОЛИТИКА: тяни-толкай
- если: $CI_COMMIT_BRANCH != $CI_DEFAULT_BRANCH
переменные:
ПОЛИТИКА: тянуть
этап: сборка
кеш:
ключ: драгоценные камни
политика: $POLICY
пути:
- продавец/комплект
сценарий:
- echo "Это задание извлекает и выталкивает кеш в зависимости от ветки"
- echo "Загрузка зависимостей..."
В этом примере политика кэширования задания:
-
pull-pushдля изменения ветки по умолчанию. -
потянитедля внесения изменений в другие ветки.
Кэш зависимостей Node.js
Если ваш проект использует npm для установки Node.js
зависимостей, в следующем примере определяется кэш по умолчанию , чтобы все задания наследовали его. По умолчанию npm хранит данные кеша в домашней папке (
По умолчанию npm хранит данные кеша в домашней папке ( ~/.npm ). Однако вы
не может кэшировать вещи за пределами каталога проекта.
Вместо этого скажите npm использовать ./.npm и кешировать его для каждой ветки:
по умолчанию:
изображение: узел: последний
cache: # Кэшировать модули между заданиями
ключ: $CI_COMMIT_REF_SLUG
пути:
- .нпм/
до_скрипта:
- npm ci --cache .npm --prefer-offline
тест_асинхронный:
сценарий:
- узел ./specs/start.js ./specs/async.spec.js
Вычислить ключ кэша из файла блокировки
Вы можете использовать cache:key:files для вычисления кеша
ключ из файла блокировки, например package-lock.json или yarn.lock и повторно использовать его во многих заданиях.
по умолчанию:
cache: # Кэшировать модули с помощью файла блокировки
ключ:
файлы:
- пакет-lock.json
пути:
- .нпм/
Если вы используете Yarn, вы можете использовать yarn-offline-mirror для кэширования заархивированных архивов node_modules . Кэш генерируется быстрее, т.к.
нужно сжать меньше файлов:
Кэш генерируется быстрее, т.к.
нужно сжать меньше файлов:
задание:
сценарий:
- echo 'yarn-offline-mirror ".yarn-cache/"' >> .yarnrc
- echo 'yarn-offline-mirror-pruning true' >> .yarnrc
- установка пряжи --frozen-lockfile --no-progress
кеш:
ключ:
файлы:
- пряжа.замок
пути:
- .пряжа-кэш/
Кэш зависимостей PHP
Если ваш проект использует Composer для установки
зависимостей PHP, в следующем примере определяется кэш по умолчанию , чтобы
все задания наследуют его. Модули библиотек PHP установлены в поставщика/ и
кэшируются для каждой ветки:
по умолчанию:
изображение: php:7.2
cache: # Кешировать библиотеки между заданиями
ключ: $CI_COMMIT_REF_SLUG
пути:
- продавец/
до_скрипта:
# Устанавливаем и запускаем Composer
- curl --show-error --silent "https://getcomposer.org/installer" | php
- установить php composer.phar
тест:
сценарий:
-vendor/bin/phpunit --configuration phpunit. xml --coverage-text --colors=never
xml --coverage-text --colors=never
Кэшировать зависимости Python
Если ваш проект использует pip для установки
Python, в следующем примере определяется кэш по умолчанию , чтобы
все задания наследуют его. Кэш pip определяется в .cache/pip/ и кэшируется для каждой ветки:
по умолчанию:
изображение: питон: последний
cache: # Кэш Pip не хранит пакеты python
пути: # https://pip.pypa.io/en/stable/topics/caching/
- .кэш/пип
до_скрипта:
- python -V # Распечатать версию Python для отладки
- пип установить виртуалэнв
- виртуальный венв
- источник venv/bin/активировать
переменные: # Изменить каталог кеша pip так, чтобы он находился внутри каталога проекта, поскольку мы можем кэшировать только локальные элементы.
PIP_CACHE_DIR: "$CI_PROJECT_DIR/.cache/pip"
тест:
сценарий:
- тест python setup.py
- пип установить ерш
- ерш --format=gitlab .
Кэш зависимостей Ruby
Если ваш проект использует Bundler для установки
gem, в следующем примере определяется кэш по умолчанию , чтобы все
рабочие места наследуют его. Gems устанавливаются в
Gems устанавливаются в vendor/ruby/ и кэшируются для каждой ветки:
по умолчанию:
изображение: рубин: 2,6
cache: # Кэшировать гем между сборками
ключ: $CI_COMMIT_REF_SLUG
пути:
- продавец/рубин
до_скрипта:
- ruby -v # Распечатать версию ruby для отладки
- набор конфигурации пакета --local path 'vendor/ruby' # Место для установки указанных драгоценных камней
- bundle install -j $(nproc) # Установить зависимости в ./vendor/ruby
rspec:
сценарий:
- спецификация rspec
Если у вас есть задания, требующие разных драгоценных камней, используйте префикс .
ключевое слово в определении глобального кэша . Эта конфигурация создает другой
кеш для каждой работы.
Например, для задания тестирования могут не требоваться те же драгоценные камни, что и для задания, развертываемого на производство:
по умолчанию:
кеш:
ключ:
файлы:
- Gemfile.lock
префикс: $CI_JOB_NAME
пути:
- продавец/рубин
test_job:
этап: тест
до_скрипта:
- комплект конфигурации пакета --local path 'vendor/ruby'
- пакетная установка -- без производства
сценарий:
- пакет exec rspec
развертывание_работа:
этап: производство
до_скрипта:
- набор конфигурации пакета --local path 'vendor/ruby' # Место для установки указанных драгоценных камней
- пакетная установка -- без теста
сценарий:
- развертывание исполняемого пакета
Кэш Go зависимостей
Если в вашем проекте для установки используются модули Go
Go, в следующем примере определяется кэш в шаблоне go-cache , который
любая работа может расширяться. Модули Go устанавливаются в
Модули Go устанавливаются в ${GOPATH}/pkg/mod/ и
кэшируются для всех проектов go :
.go-cache:
переменные:
GOPATH: $CI_PROJECT_DIR/.go
до_скрипта:
- mkdir -p .go
кеш:
пути:
- .go/упаковка/мод/
тест:
изображение: голанг: 1.13
расширяет: .go-кэш
сценарий:
- пройти тест ./... -v -short
Наличие кэша
Кэширование — это оптимизация, но не всегда гарантируется, что она будет работать. Вам может понадобиться для регенерации кэшированных файлов в каждом задании, которое в них нуждается.
После определения кэша в .gitlab-ci.yml ,
доступность кеша зависит от:
- Тип исполнителя бегуна.
- Используются ли разные бегуны для передачи кэша между заданиями.
Где хранятся тайники
Все кэши, определенные для задания, архивируются в одном cache.zip файл.
Конфигурация бегуна определяет, где хранится файл. По умолчанию кеш
хранится на машине, где установлен GitLab Runner. Расположение также зависит от типа исполнителя.
Расположение также зависит от типа исполнителя.
| Runner executor | Путь кэша по умолчанию |
|---|---|
| Shell | Локально, под gitlab-runner 902 Домашний каталог пользователя 43: |
| Docker | Локально, в томах Docker: /var/lib/docker/volumes/ . |
| Docker Machine (автомасштабируемые бегуны) | То же, что и Docker executor. |
Если вы используете кеш и артефакты для хранения одного и того же пути в своих заданиях, кеш может перезаписываться, потому что кэши восстанавливаются раньше артефактов.
Имена ключей кэша
Представлено в GitLab 15.0.
К ключу кэша добавляется суффикс, за исключением ключа глобального резервного кэша.
В качестве примера предположим, что cache. имеет значение  key
key $CI_COMMIT_REF_SLUG и что у нас есть две ветви main и функция , то в следующей таблице представлены результирующие ключи кэша:
| Имя ветки | Ключ кэша |
|---|---|
основной | основной защищенный |
функциональный | функциональный незащищенный 90 243 |
Использовать один и тот же кеш для всех ветвей
Представлено в GitLab 15.0.
Если вы не хотите использовать имена ключей кэша, все ветки (защищенные и незащищенные) могут использовать один и тот же кеш.
Разделение кеша с именами ключей кеша является функцией безопасности и его следует отключать только в среде, где все пользователи с ролью разработчика пользуются большим доверием.
Чтобы использовать один и тот же кеш для всех веток:
- На левой боковой панели вверху выберите Search GitLab (), чтобы найти свой проект.

- Выберите Настройки > CI/CD .
- Развернуть Трубопроводы общего назначения .
- Снимите флажок Использовать отдельные кэши для защищенных веток .
- Выберите Сохранить изменения .
В этом примере показаны два задания на двух последовательных этапах:
этапов:
- строить
- тест
по умолчанию:
кеш:
ключ: build-cache
пути:
- продавец/
до_скрипта:
- эхо "Привет"
задание А:
этап: сборка
сценарий:
- продавец mkdir/
- эхо "сборка" > поставщик/hello.txt
после_скрипта:
- эхо "Мир"
задание Б:
этап: тест
сценарий:
- продавец кота/hello.txt
Если на одной машине установлен один бегун, то все задания для вашего проекта запустить на том же хосте:
- Конвейер запускается.
- Задание
Aвыполняется. - Кэш извлечен (если найден).
-
выполняется before_script.
-
скриптвыполняется. -
выполняется after_script. -
cacheзапускается, а каталогvendor/заархивируется вcache.zip. Затем этот файл сохраняется в каталоге на основе настройка бегуна и 9Кэш 0242: ключ . -
задание Bвыполняется. - Кэш извлечен (если найден).
-
выполняется before_script. -
скриптвыполняется. - Отделка трубопроводов.
Используя один бегун на одной машине, вы не столкнетесь с проблемой
Задание B может выполняться на бегуне, отличном от задания A . Эта установка гарантирует
кеш можно повторно использовать между этапами. Это работает, только если выполнение идет от сборка стадия
к этапу теста в том же бегуне/машине. В противном случае кэш может быть недоступен.
В процессе кэширования также необходимо учитывать несколько моментов:
- Если какое-то другое задание с другой конфигурацией кэша сохранило свои
cache в том же zip-файле, он перезаписывается.
 Если общий кеш на основе S3
используется, файл дополнительно загружается на S3 в объект на основе кеша
ключ. Таким образом, два задания с разными путями, но одним и тем же ключом кеша перезаписывают
их кеш.
Если общий кеш на основе S3
используется, файл дополнительно загружается на S3 в объект на основе кеша
ключ. Таким образом, два задания с разными путями, но одним и тем же ключом кеша перезаписывают
их кеш. - При извлечении кеша из
cache.zipвсе в zip файле извлекается в рабочий каталог задания (обычно это репозиторий, вытащил), и бегун не возражает, если архив заданияAперезапишется вещи в архивезадание Б.
Так работает потому что кеш создается для одного раннера часто недействителен при использовании другим. Другой бегун может бежать на другую архитектуру (например, когда кеш включает бинарные файлы). Также, потому что разные шаги могут выполняться бегунами, бегущими по разным машины, это безопасное значение по умолчанию.
Очистка кеша
Бегуны используют кеш для ускорения выполнения
ваших заданий за счет повторного использования существующих данных. Иногда это может привести к
непоследовательное поведение.
Есть два способа начать работу со свежей копией кэша.
Очистите кеш, изменив
cache:key Измените значение кэша : ключ в файле .gitlab-ci.yml .
При следующем запуске конвейера кэш сохраняется в другом месте.
Очистить кеш вручную
Вы можете очистить кеш в пользовательском интерфейсе GitLab:
- На левой боковой панели вверху выберите Search GitLab (), чтобы найти свой проект.
- На левой боковой панели выберите Build > Pipelines .
- В правом верхнем углу выберите Очистить кэш бегунов .
При следующей фиксации ваши задания CI/CD используют новый кеш.
примечание При каждой очистке кэша вручную имя внутреннего кэша обновляется. Имя использует формат cache- , а индекс увеличивается на единицу. Старый кеш не удаляется. Вы можете вручную удалить эти файлы из хранилища бегуна.Поиск и устранение неисправностей
Несоответствие кэша
Если у вас есть несоответствие кэша, выполните следующие действия для устранения неполадок.
| Причина несоответствия кеша | Как это исправить |
|---|---|
| Вы используете несколько автономных исполнителей (не в режиме автомасштабирования), прикрепленных к одному проекту без общего кеша. | Используйте только один бегун для своего проекта или используйте несколько бегунов с включенным распределенным кэшем. |
| Вы используете бегунов в режиме автомасштабирования без включенного распределенного кэша. | Настройте средство выполнения автомасштабирования для использования распределенного кэша. |
| На машине, на которой установлен бегун, мало места на диске или, если вы настроили распределенный кеш, в корзине S3, где хранится кеш, недостаточно места. | Убедитесь, что вы освободили место для хранения новых кэшей. Нет автоматического способа сделать это. |
Вы используете один и тот же ключ для заданий, где кэшируются разные пути. | Используйте разные ключи кеша, чтобы архив кеша хранился в другом месте и не перезаписывал неправильные кеши. |
| Вы не включили кэширование распределенного бегуна на своих бегунах. | Установите Shared = false и перенастройте своих бегунов. |
Несоответствие кэша пример 1
Если вашему проекту назначен только один бегун, кэш хранится на машине бегуна по умолчанию.
Если два задания имеют один и тот же ключ кэша, но разные пути, кэши могут быть перезаписаны. Например:
этапов:
- строить
- тест
задание А:
этап: сборка
скрипт: сделать сборку
кеш:
ключ: тот же ключ
пути:
- общественный/
задание Б:
этап: тест
скрипт: сделать тест
кеш:
ключ: тот же ключ
пути:
- продавец/
- Задание
Aвыполняется. -
public/кэшируется какcache.zip. -
задание Bвыполняется.
- Предыдущий кэш, если он был, разархивирован.
-
поставщик/кэшируется какcache.zipи перезаписывает предыдущий. - При следующем запуске задания
Aиспользуется кеш заданияB, которое отличается и поэтому не эффективен.
Чтобы устранить эту проблему, используйте разные ключи для каждого задания.
Несоответствие кэша, пример 2
В этом примере у вас есть несколько бегунов, назначенных вашему проект, а распределенный кеш не включен.
Во второй раз, когда конвейер запускается, вы хотите, чтобы задание A и задание B повторно использовали свой кэш (который в данном случае
отличается):
этапов:
- строить
- тест
задание А:
этап: сборка
сценарий: построить
кеш:
ключ: ключА
пути:
- продавец/
задание Б:
этап: тест
сценарий: тест
кеш:
ключ: ключ Б
пути:
- продавец/
Даже если ключ отличается, кэшированные файлы могут «очищаться» перед каждым
stage, если задания выполняются на разных исполнителях в последующих конвейерах.