Компания Яндекс — Технологии — Индексирование интернета
Поисковая машина Яндекса отвечает на вопросы пользователей, находя нужные документы в интернете. А размеры современного интернета исчисляются в эксабайтах, то есть в миллиардах миллиардов байтов. Конечно же, Яндекс не обходит весь интернет каждый раз, когда ему задают вопрос. Поисковая система, так сказать, делает домашнее задание.
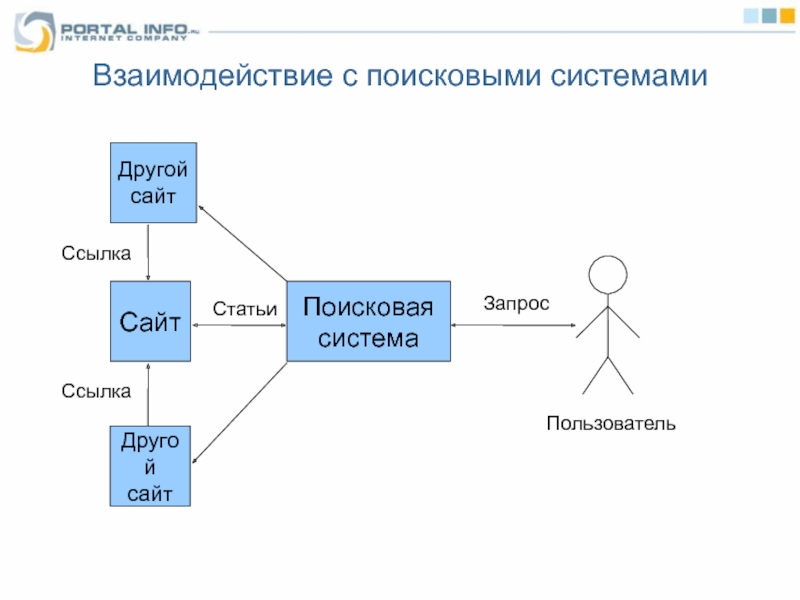
Поиск в интернете состоит из двух частей. Первая — поисковик обходит интернет, создавая его слепок на своих серверах. Вторая — пользователь задаёт запрос и получает ответ с серверов поисковика.
Яндекс ищет по поисковому индексу — базе данных, где для всех слов, которые есть на известных поиску сайтах, указано их местонахождение — адрес страницы и место на ней. Индекс можно сравнить с предметным указателем в книге или адресным справочником. В отличие от обычного предметного указателя, индекс содержит не только термины, а вообще все слова. А в отличие от адресного справочника, у каждого слова-адресата есть не одно, а очень много «мест прописки».
Подготовка данных, по которым ищет поисковая машина, называется индексированием. Специальная компьютерная система — поисковый робот — регулярно обходит интернет, выкачивает документы и обрабатывает их. Создается своего рода слепок интернета, который хранится на серверах поисковика и обновляется при каждом новом обходе.
У Яндекса два поисковых робота — основной и быстрый (он называется Orange). Основной робот индексирует интернет в целом, а Orange отвечает за то, чтобы в поиске можно было найти самые свежие документы, которые появились минуты или даже секунды назад. У каждого робота есть список адресов документов, которые нужно проиндексировать.
Когда при обходе робот видит на уже известных сайтах новые ссылки, он добавляет их в свой список, увеличивая количество индексируемых страниц. Впрочем, владелец сайта сам может помочь основному роботу Яндекса найти свой ресурс и подсказать, например, как часто обновляются его страницы — через сервис Яндекс.Вебмастер.
Сначала программа-планировщик выстраивает маршрут — очередность обхода документов. При этом планировщик учитывает важные для поисковой системы характеристики сайтов, такие как, например, цитируемость или частота обновления документов. После создания маршрута планировщик отдаёт его другой части поискового робота — «пауку». Паук регулярно обходит документы по заданному маршруту. Если сайт на месте, то есть работает и доступен, паук выкачивает запланированные в маршруте документы. Он определяет тип скачанного документа (html, pdf, swf и т.п.), кодировку и язык, а затем отправляет данные в хранилище.
При этом планировщик учитывает важные для поисковой системы характеристики сайтов, такие как, например, цитируемость или частота обновления документов. После создания маршрута планировщик отдаёт его другой части поискового робота — «пауку». Паук регулярно обходит документы по заданному маршруту. Если сайт на месте, то есть работает и доступен, паук выкачивает запланированные в маршруте документы. Он определяет тип скачанного документа (html, pdf, swf и т.п.), кодировку и язык, а затем отправляет данные в хранилище.
Там программа разбирает документ по кирпичику: очищает от html-разметки, оставляя чистый текст, выделяет данные о местоположении каждого слова и добавляет их в индекс. Сам документ в исходном виде также остается в хранилище до следующего обхода. Благодаря этому пользователи могут найти в Яндексе и посмотреть документы, даже если сайт временно недоступен. Если сайт закрылся или документ был удалён или обновлён, Яндекс удалит копию со своих серверов или заменит её на новую.
Поисковый индекс, данные о типе документов, кодировке, языке и сохраненные копии документов вместе составляют поисковую базу. Она обновляется постоянно, но, чтобы это обновление стало доступно пользователям, её нужно перенести на «базовый поиск». Базовый поиск — сервера, которые отвечают пользователям на запросы. Туда переносится не вся поисковая база, а только её полезная часть — без спама, дубликатов сайтов (зеркал) и других ненужных документов.
Обновление поисковой базы из хранилища основного робота попадает в поиск «пакетами» — раз в несколько дней. Этот процесс создаёт дополнительную нагрузку на сервера, поэтому производится ночью, когда к Яндексу обращаются на порядок меньше пользователей. Сначала новые части базы помещаются рядом с такими же частями из прошлого обхода. Затем они проверяются по целому ряду факторов, чтобы обновление не ухудшило качество поиска. Если проверка прошла успешно, новая часть базы заменяет собой старую.
Робот Orange предназначен для поиска в реальном времени. Его планировщик и паук настроены так, чтобы находить новые документы и выбирать из огромного их количества все, хоть сколько-нибудь интересные. Каждый такой документ Orange сразу обрабатывает и выкладывает на базовый поиск. Срочных документов не очень много по сравнению с общим объемом интернета, поэтому обновление базы в реальном времени можно делать и при дневных нагрузках на сервера.
Его планировщик и паук настроены так, чтобы находить новые документы и выбирать из огромного их количества все, хоть сколько-нибудь интересные. Каждый такой документ Orange сразу обрабатывает и выкладывает на базовый поиск. Срочных документов не очень много по сравнению с общим объемом интернета, поэтому обновление базы в реальном времени можно делать и при дневных нагрузках на сервера.
Как работает поиск Яндекса — Статьи
Поиск находит информацию практически моментально, но что в это время происходит внутри него? Как он понимает, какой ответ подойдет пользователю лучше всего? Руководитель Поиска Яндекса Максим Загребин рассказывает, как алгоритмы обрабатывают запросы и почему ссылка на сайт — не всегда лучший ответ.
Как устроен поиск?Поиск в интернете состоит из двух частей:
- Поисковик обходит интернет, создавая его образ на своих серверах
- Выбрать из этих образов самую полезную информацию по запросу
Ежедневно Яндекс обрабатывает запросов больше, чем живет людей в России.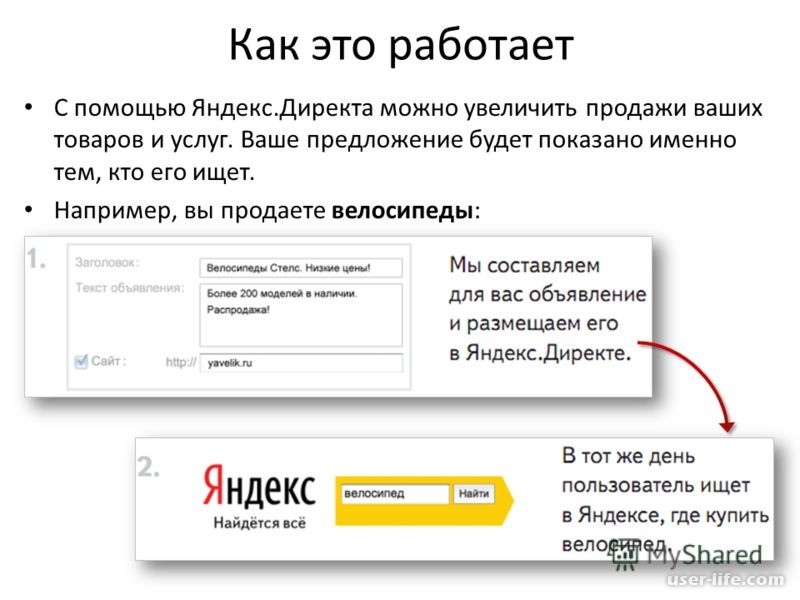 Примерно половина из них никогда раньше не задавалась. Понятно, что отслеживать все эти показатели руками – невозможно. Невозможно написать для поисковой системы такую программу, в которой предусмотрен каждый запрос и для каждого запроса известен лучший ответ.
Примерно половина из них никогда раньше не задавалась. Понятно, что отслеживать все эти показатели руками – невозможно. Невозможно написать для поисковой системы такую программу, в которой предусмотрен каждый запрос и для каждого запроса известен лучший ответ.
Сначала поиск выбирает из миллиардов ответов, потом из миллионов, и через какое-то количество этапов остаются те 10 сайтов на первой странице, которые лучше всего решают задачу пользователя. А для человека это все происходит моментально.
Люди не приходят в поиск, чтобы убить время, человек спрашивает что-то в Яндексе, когда у него есть какая-то конкретная задача. Например, найти какой-то фильм, который он помнит по описанию, но не помнит, как называется. Поэтому задача поиска – не просто найти и показать какую-то информацию, а помочь решить задачу пользователя. И страницу выдачи Яндекс формирует так, чтобы она лучше всего делала именно это – решала ту задачу, которую пользователь сформулировал в строке запроса.
При этом важно, чтобы поиск делал это быстро и удобно. Чтобы человеку не нужно было собирать всю информацию по крупицам с разных сайтов и не приходилось перепроверять ее, если сайт какой-то подозрительный. Например, если пользователь ищет ресторан или кафе, чтобы была сразу понятная шкала с проверенными отзывами: вот в этом ресторане чаще хвалят кухню, а здесь лучше интерьер и атмосфера.
Чтобы человеку не нужно было собирать всю информацию по крупицам с разных сайтов и не приходилось перепроверять ее, если сайт какой-то подозрительный. Например, если пользователь ищет ресторан или кафе, чтобы была сразу понятная шкала с проверенными отзывами: вот в этом ресторане чаще хвалят кухню, а здесь лучше интерьер и атмосфера.
Обычно пользователю нужно обойти несколько отзовиков или сайтов, чтобы собрать эту информацию самому. Почему бы не показать это сразу на странице выдачи?
Как понять, что поиск справился?В Яндексе работают инженеры, поэтому во всем они ориентируются на цифры и показатели. В данном случае показатели бывают двух типов.
Например, на запрос и на ответ на него может посмотреть человек, или сразу много разных людей – они называются асессорами – и оценить, насколько этот результат полезен и помогает решить задачу. Понятно, чт не всегда человек может оценить это, это довольно субъективно. Поэтом важно также смотреть на то, как пользователи ведут себя на странице результатов.
Если человек на запрос [как научить собаку ходить на поводке] чаще выбирает сайт с курсами дрессировки, который находится ниже, чем страница с общей инструкцией, то поисковая машина поднимает сайт с курсами выше в выдаче, потому что понимает, что он лучше решает задачу по этому запросу. Это называется принципом или показателем профицита*.
Профицит – это метрика, которая определяет полезность объекта в поиске по кликам пользователя.
Раньше просто оценивались переходы, Яндекс считал, что если человек перешел на какой-то сайт и провел там продолжительное время, это значит, что он для него уже оказался полезным. Но понятно, что это не всегда так. Поэтому Яндекс начал смотреть на то, решил ли человек свою конечную задачу на этом сайте.
Например, если он искал кофеварку, положил ли он ее в корзину, после перехода на сайт, оплатил ли заказ. Чтобы поиск мог это понять, сайты сами передают эту информацию через Яндекс.Метрику. Теперь Яндекс может показывать выше в выдаче те результаты, которые лучше решают задачу уже на самом сайте.
Поиск Яндекса использует машинное обучение. Именно потому, что невозможно каждый раз оценивать профицит того или иного сайта. Точно также, как инженеры поиска смотрят на все эти показатели – на оценки асессоров и на поведение пользователя на странице – алгоритм учится их оценивать и находить такие результаты, которые эти показатели улучшают.
Поисковая система должна уметь принимать решения самостоятельно и очень быстро, то есть выбирать из сотен миллиардов документов тот, который лучше всего отвечает пользователю. Алгоритмам машинного обучения демонстрируются примеры, огромное количество примеров, что вот тут человек решил свою задачу, а вот тут – нет. И дальше машинно-обученный алгоритм создает для себя такое правило и подбирает результаты.
Откуда берутся короткие ответы?Иногда поиск понимает, что человеку нужно получить ответ на свой вопрос быстро, но емко. Например, если пользователь задает запрос [почему море соленое], он не хочет читать подробную статью о морской воде, а хочет получить ответ сразу. Тогда пользователь показывает ему быстрый ответ на вопрос. А если человек хочет найти обувную мастерскую, то гораздо лучше решит его задачу карта, на которой будут все обувные мастерские его района, а не просто куча ссылок для них.
Тогда пользователь показывает ему быстрый ответ на вопрос. А если человек хочет найти обувную мастерскую, то гораздо лучше решит его задачу карта, на которой будут все обувные мастерские его района, а не просто куча ссылок для них.
Такие ответы появляются по тем запросам, где поиск точно видит, что они полезнее, чем набор ссылок – то есть их профицит намного выше.
А если человек хочет почитать подробнее про состав морской воды, или про конкретную обувную мастерскую, он переходит на сайт. На самом деле поиск уже уходит от того, чтобы искать просто сайты: технологии идут к тому, чтобы поиск стал универсальным и искал сразу по контенту.
Например, пользователь ищет фильм «Семнадцать мгновений весны», поиск должен понять смысл того, что тот ищет, и найти этот фильм на 5 онлайн-кинотеатрах. А дальше пользователь уже сам выберет, где именно этот фильм посмотреть.
оптимизаторов недооценивают утечку Яндекса
Памятка роста
Многие SEO-специалисты игнорируют утечку исходного кода Яндекса, но упускают шанс узнать что-то новое.
Кевин Индиг
• 6 мин чтения
В конце января хакеры получили около 45 ГБ исходного кода Яндекса, включая списки факторов ранжирования и их коэффициенты (веса). С тех пор некоторые участники SEO-сцены усердно работали над расшифровкой материала.
Однако многие SEO-специалисты также публично отвергли ценность утечки Яндекса. Наиболее распространенные аргументы:
- Яндекс не Google
- Мы не знаем, реальна ли утечка Яндекса
- Не зацикливайтесь на факторах ранжирования
- Яндекс очистил Google, это просто копия
- просто крошечное окно в том, как Яндекс ранжирует веб-сайты
- «Что бы вы изменили в том, как вы оптимизируете?»
- Репозиторий кода устарел
Я был очень удивлен тем, как много SEO-специалистов игнорировали ценность документов. Я зарабатываю на жизнь SEO уже 13 лет, и я никогда не сталкивался с лучшим пониманием того, как работают современные поисковые системы. Какая лучшая модель у нас есть?
Я зарабатываю на жизнь SEO уже 13 лет, и я никогда не сталкивался с лучшим пониманием того, как работают современные поисковые системы. Какая лучшая модель у нас есть?
Мое мнение: эта реакция в основном основана на страхе ошибиться, потерять работу и иметь меньше возможностей для интерпретации. Есть много преимуществ SEO как черного ящика, но также и затраты. Выбор времени также интересен: доходы Google за четвертый квартал были слабыми, а Chat GPT разрушает поисковую экосистему. Многие опасаются, что SEO может исчезнуть или эволюционировать из своей нынешней формы и оставить меньше места для конкуренции.
Наиболее распространенные возражения против утечки Яндекса
Я хочу почтительно возразить некоторые из наиболее распространенных аргументов, которые я слышу, потому что думаю, что они сдерживают нас:
«Яндекс — это не Google. » Если сравнить несколько результаты поиска, вы понимаете, что перекрытие мало. Яндекс имеет некоторое совпадение с аналогичными результатами в топ-10 (пример в таблице ниже), но не для точных позиций.
Можно спорить о том, какие результаты «лучше» и что вообще означает «лучше» в контексте поиска. Является ли Google доминирующей поисковой системой, потому что она обеспечивает наилучшие результаты? Были бы мы счастливы с Яндексом, если бы Google и Bing не существовали?
И все же Яндекс — это не хобби-проект, а публичная компания, которая заработала почти 5 миллиардов долларов в 2021 году. Это также поисковая система, которая подвергается цензуре со стороны российского режима и ранжирует конспирологический контент. Но в целом это не так далеко от Google, как многим кажется.
Сравните результаты поиска между Google и Bing. Большинство людей, вероятно, поставят Bing ближе к Google, чем к Яндексу. И все же перекрытие столь же мало (см. таблицу ниже).
Перекрытие рангов между Google и Bing«Мы не знаем, реальна ли утечка Яндекса.» Яндекс официально подтвердил утечку (источник).
«Репозиторий кода устарел». Утечка файлов датируется февралем 2022 года, поэтому репозиторий кода не сильно устарел. Не случайно бывшие сотрудники слили код в то время, ведь именно тогда Россия начала войну против Украины. На самом деле бывшие сотрудники Яндекса слили код, чтобы пролить свет на широко распространенную цензуру и дезинформацию Яндекса.
Утечка файлов датируется февралем 2022 года, поэтому репозиторий кода не сильно устарел. Не случайно бывшие сотрудники слили код в то время, ведь именно тогда Россия начала войну против Украины. На самом деле бывшие сотрудники Яндекса слили код, чтобы пролить свет на широко распространенную цензуру и дезинформацию Яндекса.
Конечно, Яндекс заинтересован в том, чтобы то, что просочилось в открытый доступ, выглядело так, как будто оно больше не используется, чтобы свести к минимуму риски безопасности. Но разработчик Арсений Шестаков » подтвердил, что по крайней мере некоторые из архивов наверняка содержат современный исходный код для сервисов компании, а также документацию, указывающую на реальные URL интрасети. » (источник)
Яндекс ранжирует сайты». Некоторые утверждают, что утечка произошла только из одного репозитория кода Яндекса, поскольку не весь исходный код хранится в одном репозитории. Однако даже у Google большая часть кода находится в одном репозитории:
Как и код, лежащий в основе Windows, 2 миллиарда строк, управляющих работой Google, представляют собой одно целое .Они управляют поиском Google, картами Google, документами Google, Google+, календарем Google, Gmail, YouTube и любой другой интернет-службой Google, и все же все 2 миллиарда строк находятся в едином репозитории кода, доступном для всех 25 000 инженеров Google. (источник)
«Яндекс скопировал Google, это просто копия.» Часть исходного кода показывает, что Яндекс просканировал Google, но нет доказательств (пока) того, что Яндекс использовал данные для ранжирования результатов поиска. Вероятно, Яндекс просканировал Google для сравнения результатов.
«Не зацикливайтесь на факторах ранжирования.» Есть большая разница между одержимостью и любопытством. То, что вы пытаетесь понять, что работает в SEO, не означает, что вы зациклены на факторах ранжирования. « Просто создавайте хороший контент », « сосредоточьтесь на пользовательском опыте » или « Google разберется с этим » — это почти наивные упрощения. С таким же успехом можно сказать: «, просто сосредоточься на том, чтобы не столкнуться с другими машинами », когда учишься водить машину.
Самые успешные оптимизаторы всегда проявляли почти патологическое любопытство к тому, как все устроено. « Не гонитесь за алгоритмом » — еще одна поговорка, которая используется для развеивания мифа о том, что мы можем реконструировать сигналы, которые Google вознаграждает или наказывает обновлением алгоритма. Но не пытаться узнать больше из обновлений — такое же невежество.
«Что бы вы изменили в способе оптимизации?» Ах, одна из лучших реакций! » Мы давно это знаем » — это то, что многие SEO-специалисты утверждают, когда читают об исходном коде Яндекса. Но это неправда. Зная и , предполагая, что — это две пары обуви. Наши знания SEO основаны на опыте, анекдотах, экспериментах, рейтинге. Факторные исследования и несколько сигналов, официально подтвержденных Google. Мы никогда раньше не видели эти сигналы в исходном коде современной поисковой системы, такой как Яндекс. Тот факт, что Яндекс использует множество факторов ранжирования, которые мы долгое время считали верными, показывает, что они вполне реально работают. 0003
0003
Основные моменты SEO исходного кода Яндекса
Спасибо Мартину Макдональду, Майку Кингу, Алексу Бураксу и Дэну Тейлору за проделанную работу и обмен полезными сведениями об утечке кода Яндекса.
Мальте Ландвер обнаружил, что 19 % факторов ранжирования Яндекса сосредоточены на сигналах пользователей, 6 % — на ссылках и 6 % — на релевантности контента. Помните, когда Semrush опубликовал исследование фактора ранжирования, которое показало, что трафик на сайт имеет самый высокий коэффициент ранжирования и подвергся резкой критике со стороны SEO-сообщества? Надеюсь, в следующий раз мы будем более любопытными.
Когда я работал в Searchmetrics, мы обнаружили, что факторы ранжирования все больше зависят от категории, а сегодня я бы сказал, что они зависят от запроса. Исходный код Яндекса включает бинарные, статические и зависящие от запроса факторы ранжирования. Статические факторы применяются к веб-сайту, динамические факторы — к запросу, а пользовательские факторы — к местоположению пользователя, языку, истории поиска и т. д. кажется только 1,900 не устарели. Точно так же, как люди плохо понимают влияние сложных процентов, результат алгоритмов со многими факторами невероятно сложно оценить. Добавьте бинарные и градиентные факторы ранжирования, как объяснялось ранее, и обратный инжиниринг станет невозможным. Тот факт, что так много частей веб-сайта и веб-экосистемы влияют на ранжирование в органическом поиске, удивителен, но также обнадеживает SEO-специалистов, потому что это означает, что есть возможность конкурировать.
д. кажется только 1,900 не устарели. Точно так же, как люди плохо понимают влияние сложных процентов, результат алгоритмов со многими факторами невероятно сложно оценить. Добавьте бинарные и градиентные факторы ранжирования, как объяснялось ранее, и обратный инжиниринг станет невозможным. Тот факт, что так много частей веб-сайта и веб-экосистемы влияют на ранжирование в органическом поиске, удивителен, но также обнадеживает SEO-специалистов, потому что это означает, что есть возможность конкурировать.
Яндекс, кажется, следует тем же передовым методам поиска информации, что и Google, таким как инвертирующий индекс или встраивание. Яндекс также использует различные модели, такие как его нейронная сеть MatrixNet, которая использовалась для определения коэффициентов ранжирования до того, как ее заменил CatBoost в 2017 году. Знание того, где и как использовалась MatrixNet, дает представление о том, как современные поисковые системы корректируют и настраивают ранжирование. факторы.
Предложение по поводу утечки из Яндекса
Если бы у исследователей была полная последовательность ДНК рака у мышей, отклонили бы они ее, потому что мыши отличаются от людей? Нет! Итак, почему мы так быстро отметаем утечку Яндекса?
На мой взгляд, лучший способ сделать это — использовать факторы ранжирования Яндекса в качестве основы для SEO-тестов.
Представьте, что мы получили факторы ранжирования Google, а затем поиск изменился на модель, подобную Chat GPT. Разве мы все еще не хотели бы понять, какова была формула победы все эти годы?
Что такое Яндекс и зачем мне это? | SEO Форум
Ваш браузер не поддерживает JavaScript. В результате ваши впечатления от просмотра будут уменьшены, и вы будете переведены в режим
Загрузите браузер, поддерживающий JavaScript, или включите его, если он отключен (например, NoScript).
- Дом
- Средний и продвинутый SEO
- Что такое Яндекс и зачем мне это?
 org/BreadcrumbList»>
org/BreadcrumbList»>Эта тема была удалена. Его могут видеть только пользователи с правами управления вопросами.
Я заметил в недавнем ответе на вопросы и ответы, что наряду с инструментами веб-мастера Bing и Google была ссылка на Яндекс.

-
Яндекс занимает более 60% рынка поисковых систем в России, а несколько лет назад (2013 г.) был лишь одной из четырех стран, где Google не занимал первое место по доле рынка. (http://returnonnow.com/internet-marketing-resources/2013-search-engine-market-share-by-country/)
Как было сказано выше, они также предоставляют некоторые инструменты, похожие на Google, такие как электронная почта, документы, и т. д., а также предоставить раздел инструментов для веб-мастеров для владельцев сайтов, аналогичный Google. (Я не думаю, что инструменты для веб-мастеров связаны с затратами.
 ) Он также оказался довольно успешным на разблокированных телефонах Android по сравнению с другими SE в других регионах мира.
) Он также оказался довольно успешным на разблокированных телефонах Android по сравнению с другими SE в других регионах мира.Одним из предостережений, которые действительно помогают Яндексу выйти на первое место по использованию SE в России, является способность анализировать русский язык по-другому, и некоторые утверждают, что лучше, чем Google. Он также утверждает, что не использует ссылки в своем алгоритме из-за большого количества ссылочного спама в России. Подробнее о тонких различиях было опубликовано в Интернете, но статью высокого уровня можно найти здесь: http://www.semrush.com/blog/publications/5-advantages-yandex-google-russia/
Если вы не пытаетесь чтобы работать в России, иметь дело с русскими, то Яндекс не должен вызывать особых опасений. Тонкие различия никогда не помешают изучить, и эти специфичные для региона SE, такие как NAVER и Baidu, станут более важными в будущем, или, по крайней мере, это мое предположение, по мере увеличения населения.

http://en.wikipedia.org/wiki/Yandex Инструменты для веб-мастеров, размещенные на нем, бесплатны: https://webmaster.yandex.com/ Еще один сервис на основе поисковой системы, помогающий сканировать, связывать и использовать другие инструменты. Если ваш сайт не является международным, это, вероятно, не вызывает особого беспокойства, поскольку они в основном являются поисковой системой из России.
-
Яндекс — ответ России на Google. Может предоставить вам данные, и вы можете ранжироваться, и это точно так же, как и любая другая поисковая система, но она специфична для России.

Если вы часто пользуетесь международным поиском, вам будет не все равно. У него также есть несколько уникальных локальных инструментов, которые не так хороши, как MozLocal, но совсем не плохи. По сравнению с большинством местных наборов инструментов. Если вы находитесь в Европе или России и вам нужно настроить таргетинг на эту область, вы захотите подружиться с Яндексом.
Я использую его, у него есть несколько довольно крутых инструментов.
Надеюсь, это поможет,
Том
У вас есть животрепещущий вопрос по SEO?
Подпишитесь на Moz Pro, чтобы получить полный доступ к вопросам и ответам, отвечать на вопросы и задавать свои.
Начать бесплатную пробную версию
Есть вопрос?
Просмотр вопросов
Посмотреть Все вопросыНовые (нет ответов)ОбсуждениеОтветыПоддержка продуктаБез ответа
От Все времяПоследние 30 днейПоследние 7 днейПоследние 24 часа
Сортировка по Последние вопросыНедавняя активностьБольше всего лайковБольшинство ответовМеньше всего ответовСамые старые вопросы
С категорией Все категорииПартнерский маркетингОбновления алгоритмовAPIBandingСообществоКонкурентные исследованияРазработка контентаОптимизация коэффициента конверсииЦифровой маркетингЗапросы функцийНачало работыОптимизация изображений и видеоОтраслевые событияНовости отраслиПромежуточное и продвинутое SEOМеждународное SEOВакансии и возможностиИсследование ключевых словИсследование ключевых словСоздание ссылокЛокальные спискиЛокальное SEOЛокальная оптимизация веб-сайтовMoz BarMoz LocalMoz NewsMoz ProMoz ToolsOn- Оптимизация страницДругие инструменты SEOПлатный поисковый маркетингПоддержка продуктовОтчетность и аналитикаИсследования и тенденцииОтзывы и рейтингиПоведение при поискеSEO ТактикаТренды поисковой выдачиСоциальные сетиТехническое SEOВеб-дизайнБелое/черное SEO
Связанные вопросы
- Кто-нибудь хочет поделиться некоторыми хитростями SEO для конкурентоспособных отраслей?
[Вставьте слово «хак», если хотите, но оно настолько часто используется, что вместо него я использую «трюк»] Я занимаюсь поисковой оптимизацией уже десять лет, и я неплохо разбираюсь в своих основах. Для клиента, с которым я ищу помощи, вот что мы делаем: сильный и регулярный контент, оптимизированный по ключевым словам на месте (как с длинным хвостом, так и с ключевыми фразами конкурентов), хорошее локальное SEO, высококачественные гостевые публикации на соответствующих местных новостных сайтах и в блогах, интенсивное участие и поддержка сообщества, стипендии и спонсорство, множество видео, все социальные сети, тонны конкурентных исследований и создания ссылок, постоянный анализ и настройка архитектуры веб-сайта, систематизированный процесс получения отзывов, чат на месте, Google Search Ads и т.
 д.
Этот клиент уже много лет работает в очень конкурентной отрасли в американском городе среднего размера. У нас все в порядке в локальном пакете для определенных поисковых запросов, но в целом его рейтинг не очень хорош.
Для тех, кто работает в сверхконкурентной отрасли, есть ли у вас какие-нибудь хитрости, которыми вы хотели бы поделиться? Я не хочу красть твои секреты, но мне не помешал бы совет. Спасибо!
д.
Этот клиент уже много лет работает в очень конкурентной отрасли в американском городе среднего размера. У нас все в порядке в локальном пакете для определенных поисковых запросов, но в целом его рейтинг не очень хорош.
Для тех, кто работает в сверхконкурентной отрасли, есть ли у вас какие-нибудь хитрости, которыми вы хотели бы поделиться? Я не хочу красть твои секреты, но мне не помешал бы совет. Спасибо!Средний и продвинутый SEO | | новый почему
1
- Насколько необходимо дезавуировать ссылки в 2017 году? Разве алгоритм Google не заботится о том, чтобы определить, что он будет учитывать, а что нет?
Привет всем! Так что это очевидный вопрос сейчас.
 Мы можем видеть внезапное падение или повышение рейтинга; сильные колебания. Новые обратные ссылки вносят достаточный вклад. Google утверждает, что позаботится о любых обратных ссылках низкого качества, не передавая PageRank веб-сайту. С другой стороны, мы можем увидеть множество сценариев, в которых веб-сайты улучшали рейтинг и избегали наказания с помощью инструмента дезавуирования.
Заявление Google и инструмент Disavow — два противоположных понятия. Итак, когда некоторые неизвестные обратные ссылки низкого качества указывают и увеличиваются на веб-сайте? Какова идеальная мера?
Мы можем видеть внезапное падение или повышение рейтинга; сильные колебания. Новые обратные ссылки вносят достаточный вклад. Google утверждает, что позаботится о любых обратных ссылках низкого качества, не передавая PageRank веб-сайту. С другой стороны, мы можем увидеть множество сценариев, в которых веб-сайты улучшали рейтинг и избегали наказания с помощью инструмента дезавуирования.
Заявление Google и инструмент Disavow — два противоположных понятия. Итак, когда некоторые неизвестные обратные ссылки низкого качества указывают и увеличиваются на веб-сайте? Какова идеальная мера?Средний и продвинутый SEO | | втмоз
0
- Наш домен неплохо ранжируется на google.
 ru, но совсем не на Яндексе. Что здесь может быть главным отличием?
ru, но совсем не на Яндексе. Что здесь может быть главным отличием? Привет, Интернет подвел меня в этом вопросе. В чем проблема? Мы неплохо ранжируемся по наиболее важным ключевым словам для нашего бизнеса с нашим доменом верхнего уровня .ru в Google.ru. Однако в Яндексе мы вообще не ранжируемся. Что здесь может быть главным отличительным фактором? Мог ли сыграть роль тот факт, что наши сервера находятся в США? Спасибо за ваше время. Джейкоб
Средний и продвинутый SEO | | Юнилин
0
- Есть ли автоматизированный способ проверить ранжирование HREFLANG в Google и Яндексе?
Всем привет! Мы внедрили код HREFLANG для наших международных сайтов.
 Нам интересно, есть ли автоматизированный способ проверить, работает ли HREFLANG, по сравнению с ручным просмотром в каждой международной поисковой системе?
Кроме того, мы внедрили это несколько дней назад, и инструменты Google для веб-мастеров еще не обнаружили, что мы это внедрили. Я слышал, что это занимает от 2 до 8 дней. В какой момент мы увидим результаты. наш сайт http://www.datacard.com
Существует ли порядок, которому должны следовать списки сайтов, например, должен ли x-default быть последним в списке?
Спасибо,
Лаура
Нам интересно, есть ли автоматизированный способ проверить, работает ли HREFLANG, по сравнению с ручным просмотром в каждой международной поисковой системе?
Кроме того, мы внедрили это несколько дней назад, и инструменты Google для веб-мастеров еще не обнаружили, что мы это внедрили. Я слышал, что это занимает от 2 до 8 дней. В какой момент мы увидим результаты. наш сайт http://www.datacard.com
Существует ли порядок, которому должны следовать списки сайтов, например, должен ли x-default быть последним в списке?
Спасибо,
ЛаураСредний и продвинутый SEO | | Лорамробинсон32
0
- Насколько осторожно нужно относиться к изменениям удобочитаемых URL-адресов?
Мы переходим на Sitecore, где стандартный стандарт заключается в том, что если вы меняете заголовок страницы, он также изменяет URL-адрес.
 Я беспокоюсь, что это приведет к проблемам с SEO, и думаю, нужно ли нам заблокировать его, чтобы, если заголовок страницы будет изменен (только незначительным образом), он также не изменил URL-адрес.
Я никогда раньше не работал с удобочитаемыми URL-адресами. Каковы последствия того, что URL-адрес не совсем соответствует формулировке заголовка страницы?
Я беспокоюсь, что это приведет к проблемам с SEO, и думаю, нужно ли нам заблокировать его, чтобы, если заголовок страницы будет изменен (только незначительным образом), он также не изменил URL-адрес.
Я никогда раньше не работал с удобочитаемыми URL-адресами. Каковы последствия того, что URL-адрес не совсем соответствует формулировке заголовка страницы?Средний и продвинутый SEO | | болезнь альцгеймера
0
- Инструменты для веб-мастеров: какие используете вы? Яндекс да или нет?
Обычно я проверяю веб-сайты в Google и Bing Webmaster. Насколько важно пройти верификацию на Яндекс Вебмастер, если Россия не входит в число целевых местоположений?
Средний и продвинутый SEO | | избирательно
0
 org/ListItem»> Должен ли я заботиться об этом сообщении Инструментов для веб-мастеров
org/ListItem»> Должен ли я заботиться об этом сообщении Инструментов для веб-мастеров Вот сообщение: «Робот Googlebot обнаружил очень большое количество URL-адресов на вашем сайте: http://www.uncommongoods.com/» Должен ли я попытаться сделать что-нибудь об этом? У нас нет проблем с индексацией, поэтому мы считаем, что Google все еще сканирует весь наш сайт. Какие могут быть возможные последствия игнорирования этого? Спасибо, Моззерс! -Зак
Средний и продвинутый SEO | | заметки
0
- Веб-мастера Яндекса не дают мне добавить свой сайт
Я покупаю домен xxx.

 schema.org/ItemList» data-nextstart=»» data-set=»»>
schema.org/ItemList» data-nextstart=»» data-set=»»>