Поисковые алгоритмы Яндекса с 2007 по 2022 год
Алгоритмы — это набор формул и факторов, по которым поисковая система определяет релевантность страниц в соответствии с введенным запросом пользователя. Говоря простым языком, это совокупность определенных параметров, которые учитывает поисковик при распределении мест в выдаче на заданный запрос пользователя.
Когда я еще не была знакома с SEO, мне было интересно, как поисковик составляет рейтинг веб-страниц, как решает, какой сайт попадет в ТОП, какому место на 10-ой, 25-ой или 100-ой странице поисковой выдачи. Так вот, за это отвечают поисковые алгоритмы. У Яндекса начиналось все с того, что поисковик учитывал количество ключевых запросов и их расположение на странице. Достаточно было высчитать число ключей в текстах конкурентов и добавить больше у себя, и вы были бы на вершине выдачи. Но такая стратегия не устроила разработчиков поисковика, ведь результаты должны быть более объективными. С этого и началась активная работа над поисковыми алгоритмами.
Стоит отметить, что у каждого поисковика свои алгоритмы, и они отличаются друг от друга. Регулярно Яндекс, Google или другая система обновляет алгоритмы, совершенствует их, выпускает новые. Предлагаю воспроизвести хронологию поисковых алгоритмов Яндекса с самого первого. В нашем блоге вы уже могли познакомиться с Королевым, Палехом, Минусинском, Баден-Баденом и многими другими. В этой же статье я постараюсь кратко рассказать про все алгоритмы российской поисковой системы Яндекс по порядку с указанием названия, даты анонса и описанием смысла. Но для начала сводная таблица:
| Дата выпуска | Название алгоритма |
|---|---|
| 2 июля 2007 года | Версия 7 |
| декабрь 2007- январь 2008 гг | «Версия 8» и «Восьмерка SP1» |
| 16 мая 2008 год, 2 июля 2008 года | Магадан и Магадан 2.0 |
| 11 сентября 2008 года | Находка 7 |
| Анонс был выпущен 10 апреля 2009 года, далее в течение года было проведено 5 обновлений алгоритма | Арзамас/Анадырь 7 |
| 17 ноября 2009 года | Снежинск 7 |
| 22 декабря 2009 года | Конаково 7 |
| 10 марта 2010 года | Конаково 1. |
| сентябрь 2010 года | Обнинск |
| 15 декабря 2010 года | Краснодар |
| 17 августа 2011 года | Рейкьявик |
| 12 декабря 2012 года | Калининград |
| 30 мая 2013 года | Дублин |
| 12 марта 2014 года | Без ссылок |
| 5 июня 2014 года | Острова |
| 1 апреля 2015 года | Объектный ответ |
| 15 мая 2015 года | Минусинск |
| 14 сентября 2015 года | |
| 2 февраля 2016 года | Владивосток |
| 2 ноября 2016 года | Палех |
| 23 марта 2017 года | Баден-Баден |
| 22 августа 2017 года | Королев |
| 19 ноября 2018 года | Андромеда |
| 17 декабря 2019 года | Вега |
| сентябрь 2020 | YATI |
| 10 июня 2021 | Y1 |
| 5 августа 2022 | Мимикрия |
Таблица 1.
Версия 7 (2 июля 2007 года)
До этой даты про внутреннюю работу системы Яндекс было мало что известно. Нововведения появлялись постоянно: стали учитываться ссылки, поисковик научился индексировать изображения, мета-теги, PDF и RTF документы и другие форматы, появился ТИЦ, стал учитываться региональный поиск и еще много всего.
Но началом истории алгоритмов считается Версия 7, когда 2.07.2007 г. господин Садовский на специальном форуме для Вебмастеров сделал анонс, что Яндекс представил новую формулу ранжирования. Предполагалось, что по ряду запросов релевантность станет лучше.
«Версия 8» и «Восьмерка SP1» (декабрь 2007— январь 2008 гг)
Одни из самых первых алгоритмов Яндекса, после появления которых авторитетные и трастовые ресурсы получили огромное преимущество в ранжировании. Также был внедрен фильтр «Прогонов», который боролся с накруткой ссылочных факторов.
Далее Яндекс стал внедрять новые алгоритмы с периодичностью 1-2 раза в год, что интересно, названия алгоритмам присваивались по принципу игры в города. Каждому новому алгоритму разработчики давали имя города первая буква, которого была последней в названии предшествующего. Самым первым стал Магадан.
Каждому новому алгоритму разработчики давали имя города первая буква, которого была последней в названии предшествующего. Самым первым стал Магадан.
Магадан и Магадан 2.0 (16 мая 2008 год, 2 июля 2008 года)
Этот алгоритм имел особую значимость, его можно считать своего рода революцией поисковой выдачи. Выделю основные изменения:
- Факторы ранжирования были увеличены в 2 раза.
- Была расширена база аббревиатур, синонимов, транслитераций. Яндекс стал переводить слова, индексировать сайты на других языках и представлять в выдаче ресурсы на английском, немецком и других языках. Стали учитываться переведенные или транслитерованные адреса страниц.
- Расширены классификаторы документов. Яндекс стал лучше различать одни типы страниц и ссылок от других.
- Добавлены факторы, которые отслеживали контент на уникальность.
- Добавлены факторы, классифицирующие коммерческие и геозависимые запросы. С появлением алгоритма, к примеру, пользователям из Новосибирска реже стали попадаться ресурсы из Уфы и других городов.

- Анализ текстов и семантического ядра стал более тщательным.
С приходом Магадана выдача стала значительно чище, а вот продвигать сайты и выводить их в ТОП стало гораздо труднее.
Находка (11 сентября 2008 года)
С анонсом можно ознакомиться здесь. Основные особенности алгоритма:
- Учет стоп-слов (знаков препинаний, местоимений, междометий и т.д.) в ключевых запросах, качество выдачи по таким поисковым запросам значительно выросло.
- Внедрен абсолютно новый подход к машинному обучению.
- Заметно был расширен тезаурус (словари Яндекса), к примеру, поисковик научился понимать слова, обозначающее одно и то же при слитном и раздельном написании. К примеру, «сельхоз техника» и «сельхозтехника» стало считаться равносильным запросом.
Арзамас/Анадырь (анонс был выпущен 10 апреля 2009 года, далее в течение года было проведено 5 обновлений алгоритма)
Основные изменения:
- Снятие омонимии.
 Было улучшено ранжирование по запросам, имеющим несколько значений. К примеру, пользователь вводил запрос «фото львов», при этом не понятно, что именно ему требовалось фотографии животных или изображения города Львов. Яндекс усовершенствовал выдачу многозначных слов, учитывая историю других пользователей и частотность слов.
Было улучшено ранжирование по запросам, имеющим несколько значений. К примеру, пользователь вводил запрос «фото львов», при этом не понятно, что именно ему требовалось фотографии животных или изображения города Львов. Яндекс усовершенствовал выдачу многозначных слов, учитывая историю других пользователей и частотность слов. - Стал учитываться регион пользователя, результаты выдачи у пользователей из разных городов отличались. Было определено 19 регионов, в которые не входили Москва, Санкт-Петербург и Екатеринбург.
- Запросы стали разделяться на геозависимые и независимые от географии пользователя. Определяя зависимость запроса от его нахождения, применялась новая формула ранжирования. К примеру, если пользователь вводил «недорогое кафе», в выдаче показывались ресурсы с учетом города, если же запрос общий геонезависимый, то принципы ранжирования не менялись.
Так ресурсам был присвоен регион, который определялся исходя из IP хостинга, контактов на сайте или данных из Яндекс. Каталога.
Каталога.
Рис.1. Региональная формула ранжирования
Кроме того, нововведения коснулись popunder, clickunder рекламы, к которым после прихода Арзамаса поисковик стал относиться очень негативно, наличие такой рекламы отрицательно влияло на ранжирование. Также была усовершенствована формула ранжирования сайтов по запросам, которые включают много слов.
Снежинск (17 ноября 2009 года)
Алгоритм, в рамках которого впервые был запущен новый метод машинного обучения Matrixnet. Он во много раз увеличил количество факторов ранжирования, тем самым улучшив качество поиска.
Рис.2. Матрикснет
С запуском Снежинска поисковая выдача была сильно изменена. Внедрили дополнительные региональные факторы ранжирования, стали работать фильтры АГС. Кроме того, были понижены в выдаче страницы, содержащие объемные тексты с высокой плотностью ключевых запросов.
Конаково, 22 декабря 2009 года
Расширен учет геофактора — теперь региональное ранжирование стало не только для 19 крупнейших регионов, которые изначально были определены при алгоритме Арзамас, но еще и для 1250 российских городов.
Конаково 1.1 (он же Снежинск 1.1), 10 марта 2010 года
Была улучшена формула ранжирования для геонезависимых запросов. Значительный рост после запуска алгоритма Снежинск 1.1 был у информационных некоммерческих ресурсов. Выросли позиции у энциклопедий, интернет-журналов, сайтов с обзорами и прочих инфоресурсов.
Обнинск, сентябрь 2010 года
Основная цель Обнинска — улучшение ранжирования по геонезависимым запросам, которых, по данным Яндекса, до 70 % от общего количества.
Рис.3. Анонс алгоритма «Обнинск»
Основные изменения:
- Перенастройка формулы, повышение производительности и совершенствование факторов ранжирования для геонезависимых запросов.
- Сложность формулы ранжирования достигла 280 МБ (в сравнении с 2006 годом она составляла 0,02 килобайта, в июле 2010 года — 120 Мбайт).
- Снижено влияние на ранжирование искусственных SEO-ссылок.
- ыл расширен словарь транслитерации, улучшилось качество выдачи на запросы, введенные на английском языке.
- Появилась возможность определять авторство текстов.
Краснодар (15 декабря 2010 года)
Главным внедрением алгоритма стала технология «Спектр», которая могла классифицировать запросы под разные потребности и разделять на разные категории. Всего было выделено 60 категорий.
Рис.4 Технология «Спектр»
Так, например, по запросу пользователя «Наполеон» нельзя было понять, что он хочет найти рецепт торта или узнать информацию о великом французском полководце. Исходя из истории других пользователей, поисковик определял, что 70 процентов искали биографию и все, что касается Наполеона Бонапарта; 30 процентов — рецепты торта. Поэтому в результатах выдачи выдавалось 7 страниц о полководце Наполеоне и 3 о приготовлении тортов.
Среди основных нововведений:
- Распределение запросов по категориям (товары, фильмы, поэты, города и пр.).
- Улучшение ранжирования по поисковым запросам, зависимым от региона.
- Впервые Яндекс проиндексировал соцсеть Вконтакте.

- Внедрение расширенных сниппетов для определенных видов организаций.
Рейкьявик, 17 августа 2011 г
Первый шаг к персонализированной выдаче. Основным новшеством стал учет языковых предпочтений пользователей. Так, поисковая система стала изучать, что чаще выбирает пользователь при вводе запроса на латинском, страницы на английском или же отечественные сайты. Если ранее он предпочитал в основном англоязычные ресурсы в сравнение с русским контентом, то в будущем система стала выдавать ему такие сайты чаще.
Дополнительные нововведения в Рейкьявике:
- Появилась новая формула для поисковых запросов с опечатками, появилась выдача по запросам с исправлением и в неизменном варианте с опечаткой.
- В Яндекс.Вебмастере был запущен инструмент, позволяющий закрепить права на авторство текстов. В нем можно было сразу добавить свой текст и указать, что именно ваш ресурс является первоисточником.
- Появилась возможность добавления информации об организации в Яндекс.
 Справочник
Справочник - Появились колдунщики (математический, онлайн-игр).
Калининград, 12 декабря 2012 года
Глобальные перемены в поиске, значительная персонализация выдачи для поисковых подсказок и запросов.
Поисковая система стала учитывать историю и интересы пользователя и выдавать предпочтительные для пользователя варианты как в подсказках, так и в результатах поиска. Так, например, при вводе запроса «Гарри Поттер», любителям кино — предлагались фильмы о Гарри Поттере, а вот тем, кто любит читать — книги Джоан Роулинг.
Рис.5. Персонализация выдачи по запросу «Сталкер»
Такой подход значительно усложнил работу оптимизаторов, ведь выдача стала уникальной для каждого пользователя. Теперь в продвижении начали учитываться многие факторы: ссылочный профиль, контент, оптимизация под ключевые запросы, дизайн и юзабилити ресурса, работа с социальными платформами.
Дублин, 30 мая 2013 года
Разработчики Яндекса не остановили работу над совершенствованием персонализации выдачи, и если при Калининграде учитывались долгосрочные интересы пользователей, то после внедрения Дублина система стала учитывать его предпочтения в режиме реального времени. Т.е. выдача формировалась на основе текущей сессии, исходя из сиюминутных поисковых запросов.
Т.е. выдача формировалась на основе текущей сессии, исходя из сиюминутных поисковых запросов.
Рис.6. Учет сиюминутных запросов пользователей
Далее игра в «Города» Яндексом прекращается, и алгоритмам присваиваются названия без определенной последовательности, хотя наименования населенных пунктов еще встречаются.
Без ссылок, 12 марта 2014 года
Заложен фундамент по отмене ссылочного продвижения. Ряд ссылочных факторов перестал учитываться для определенных запросов в Москве. Пока алгоритм задел только ресурсы, работающие в области недвижимости, туризма, электроники и бытовой техники.
Острова, 5 июня 2014 года
Был обновлен дизайн поисковой выдачи, появились так называемые «острова». Они представляли собой интерактивные ответы, появляющиеся прямо на странице результатов выдачи — пользователь мог воспользоваться ими без перехода на сам сайт. С помощью островных сервисов можно было узнать прогноз погоды, найти авиабилеты, узнать курс валют и не только.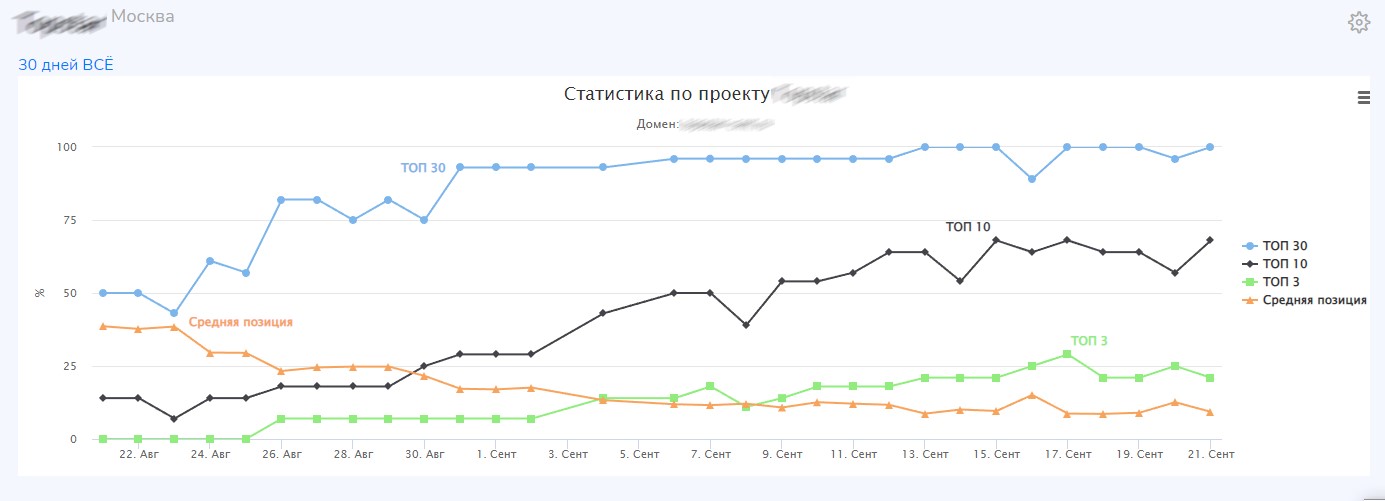
Позже инструмент был признан неуспешным и закрыт. Сейчас же «острова» действуют для сервисов самого Яндекса.
Рис.7. Пример «острова» в поисковой выдаче Яндекса
Объектный ответ, 1 апреля 2015 года
Снова изменения пришлись на дизайн страницы выдачи. Справа от основных результатов по запросу стала показываться карточка (блок) с информацией о запрашиваемом объекте. Яндекс сформировал собственную базу, в которой хранится свыше нескольких десятков миллионов объектных карточек.
Рис.8. Объектный ответ в поисковой выдаче Яндекса
Минусинск, 15 мая 2015 года
Пессимизация сайтов с большим количеством SEO-ссылок с некачественной ссылочной массой. После запуска данного алгоритма многие сайты, занимающие высокие позиции в поиске, значительно «просели», был наложен фильтр, который владельцы сайтов могли снять путем удаления ссылок, но после снятия фильтра редко у кого получалось восстановить прежние позиции.
Рис.9. Падение трафика после наложения фильтры Минусинск
После запуска Минусинска SEO-отрасль подверглась большим изменениям. Биржи SEO-ссылок практически остались без работы. Теперь в продвижении нужно было делать упор на внутреннюю оптимизацию (тех.параметры, качество контента, дизайн, юзабилити и пр.). Что касается ссылок, то они по-прежнему учитываются в продвижении, но речь идет исключительно о естественных ссылках.
Биржи SEO-ссылок практически остались без работы. Теперь в продвижении нужно было делать упор на внутреннюю оптимизацию (тех.параметры, качество контента, дизайн, юзабилити и пр.). Что касается ссылок, то они по-прежнему учитываются в продвижении, но речь идет исключительно о естественных ссылках.
Покупные — табу, которое приведет к очень негативным последствиям со стороны Яндекса. К естественным ссылкам стоит относить ссылки с ресурсов, схожих по тематике, путем размещения статей, ссылки с каталогов сайтов, с отзовиков, блогов, форумов и т.д.
О том, какие ссылки являются естественными и безопасными для Минусинска, мы уже рассказывали в одной из наших статей.
Многорукие бандиты Яндекса, 14 сентября 2015 года
Экспериментальный алгоритм, в рамках которого была проведена рандомизация поисковой выдачи. Так в ТОП попадали сайты, которые ранее были на низких позициях, к трастовым ресурсам, занимавшим первые позиции, подмешивались сайты-новички. Стратегия была введена с целью анализа поведенческих особенностей.
Владивосток, 2 февраля 2016 года
Доля мобильного трафика стала значительно расти, пользователей, которые искали информацию через планшеты, смартфоны или другие девайсы, становилось с каждым днем все больше. Яндекс запустил алгоритм, выявляющий сайты на мобилопригодность. В анонсе говорилось, что теперь адаптация ресурса под мобильную выдачу стала еще одним важным фактором в ранжировании. Кстати, об алгоритме Владивосток мы тоже упоминали в своем блоге.
Рис.10. Проверка сайта на адаптацию под мобильные устройства в Яндексе
Палех, 2 ноября 2016 года
После внедрения алгоритма Яндекс научился понимать сложные запросы пользователей. При этом поиск стал проводиться не формально по словам, входящих в состав запроса, а по смыслу запроса и заголовка (Title) страницы. Т.е. теперь Яндекс мог находить нужные ответы на запрос пользователя, даже если на странице совсем не содержалось соответствующих ключевых слов. Теоретически понять немного трудно, попробую привести пример.
Допустим, вы введете запрос «фильм про Джека Воробья», поисковая система по смыслу найдет соответствующие результаты:
Рис.11. Пример результата выдачи при Палехе
Более развернуто мы уже рассказывали о Палехе.
Именно после запуска Палеха многие оптимизаторы поняли, что акцент нужно в первую очередь делать не на вхождении ключевых запросов, а на смысловую и техническую уникальность текста. Чтобы не роботы видели оптимизированные тексты, а пользователи с интересом изучали контент.
Баден-Баден, 23 марта 2017 года
Алгоритм Яндекса, запущенный в целях борьбы с переоптимизированным контентом. Поисковик стал понижать страницы или полностью сайты, в которых обнаруживал тексты с избытком ключевых слов, со скрытым контентом, мелким шрифтом. Такой контент поисковая система не считала полезным для пользователей, а написанным только для влияния на ранжирование. О том, как не попасть под Баден-Баден, как правильно писать тексты на сайт. мы писали много раз. Чтобы понять основную суть алгоритма, рекомендую к прочтению одну из таких статей.
Чтобы понять основную суть алгоритма, рекомендую к прочтению одну из таких статей.
Рис.12. Пример переоптимизированного текста, представленный Яндексом
Королев, 22 августа 2017 года
Усовершенствованный алгоритм Палеха, который научился давать ответы на сложные и многозначные запросы. Ориентируясь на смысловую составляющую запроса, поисковик стал сопоставлять не только заголовки, как это было при его предшественнике Палехе, но и в целом содержимое всей страницы. Система искусственного интеллекта стала учитывать поисковую статистику, мнение ассесоров и толокеров, а также оценки самих пользователей.
Допустим, вы введете запрос «фильм, в котором все кладут телефоны на стол». Вуаля — Яндекс сразу же выдает название фильма, при этом на страницах с описанием нет ключевых фраз «фильм, в котором все кладут телефоны на стол». Всё просто, искусственный интеллект. Так можно задавать сложные запросы, уточнять то, что-то в формате разговорной речи.
Рис. 13. Применение Королева при вводе сложного запроса
13. Применение Королева при вводе сложного запроса
Подробная статья о Королеве в нашем блоге, в ней мы рассказывали, как стал работать алгоритм, пояснили разницу между Королевым и Палехом, привели примеры.
Андромеда, 19 ноября 2018 года
Глобальный алгоритм от Яндекса, который внедрил множество интересных и весьма нужных нововведений. Был запущен новый алгоритм ранжирования Яндекс Proxima. Большая часть изменений коснулась колдунщиков и Яндекс-сервисов.
Итак, изучим основные модернизации:
-
Появились специальные значки качества, которые стали влиять на место в поисковой выдаче.
Рис.14. Примеры знаков качества в Яндексе
-
Улучшился сервис быстрых ответов Яндекса, который позволяет оперативно решать нужные задачи пользователей.
Рис. 15. Пример быстрых ответов
-
Появление Яндекс.Коллекций — инструмента, позволяющего сохранять в одном место все необходимое пользователю.

Это лишь краткий обзор алгоритма Андромеда, с более подробным можно ознакомиться в нашей статье.
Вега, 17 декабря 2019 года
Яндекс Вега – важное нововведение, касающееся пользовательских запросов, в рамках которого произошли следующие изменения:
- Если ранее по алгоритму Палех поисковик мог определять запросы по словам и по смыслу, то теперь при Веге будут выявляться близкие по смыслу страницы. Поисковая выдача формируется на смысловых кластерах.
- Внедрена технология пререндеринга SERP по запросу, что ускорит выдачу результатов поиска.
- Добавлена экспертность в ассесорские оценки с целью улучшения выдачи по тематикам.
- Улучшена гиперлокальность. Теперь результаты поиска будут формироваться не только на уровне города, но и микрорайона.
Yati, сентябрь 2020 года
Новая технология оценки текстов от Яндекс – YATI (Yet Another Transformer with Improvements), в основу которой легли алгоритмы «Палех» и «Королев». Более подробно о взаимосвязи с предшественниками можно ознакомиться в статье.
Более подробно о взаимосвязи с предшественниками можно ознакомиться в статье.
YATI – «архитектура нейросетей-трансформеров». Главная задача алгоритма – повысить точность выдачи. Теперь поисковые роботы учитывают до 10 предложений целиком, а именно:
- Смысл заголовков
- Фрагменты текста
- Структуру текста
- Контекст
Это все сопоставляется со смыслом запроса пользователя и отдается предпочтение наиболее релевантному сайту.
Сейчас необходимо уделить внимание семантическому ядру и качеству текста на сайте, поскольку неинтересные для поиска страницы будут снижать релевантность действительно важных страниц сайта.
В результате нововведений алгоритмы стали лучше сопоставлять смысловую связь между запросами пользователей и текстовыми документами. По словам специалистов Яндекс, технология показала рекордный уровень в качестве поиска.
Y1, 10 июня 2021 года
Завершает хронологию поисковых алгоритмов – Y1. Это большое обновление поиска (+2000 улучшений) с использованием технологий YaTI и YaLM на основе нейросетей-трансформеров. Главная задача обновления – сэкономить время пользователя.
Это большое обновление поиска (+2000 улучшений) с использованием технологий YaTI и YaLM на основе нейросетей-трансформеров. Главная задача обновления – сэкономить время пользователя.
Основные изменения:
Яндекс порадовал пользователей существенным апгрейдом, выкатив обновленные функции.
- Быстрые ответы – теперь имеют более широкую направленность, да и самих ответов в поисковой выдаче стало больше.
- Поиск фрагментов видео – основная суть в том, что поисковая система анализирует видео и включает видео ролик с момента, где начинается ответ на запрос пользователя.
- Оценка по отзывам – алгоритмы самостоятельно анализируют отзывы, а пользователю сразу показывают визуальную шкалу оценок.
- Поиск с помощью камеры – умная камера Яндекс, которая распознает различные объекты
Мы уже развернуто писали об изменениях в выдаче после внедрения Y1. Самый важный вывод – стандартных работ по SEO уже недостаточно, для продвижения необходимо тщательно прорабатывать контент на сайте, а также применять комплексный подход (омниканальность).
Самый важный вывод – стандартных работ по SEO уже недостаточно, для продвижения необходимо тщательно прорабатывать контент на сайте, а также применять комплексный подход (омниканальность).
Мимикрия, 5 августа 2022 года
Пока еще мало известно о новом алгоритме «Мимикрия», но суть ее проста: Яндекс понижает позиции тех сайтов, кто копирует текстовый или графический контент с известных ресурсов.
Оценка происходит по нескольким критериям:
- текстовый контент,
- оптимизация страниц под навигационные запросы
- и, естественно, визуальная составляющая
Если ваш сайт использует логотип, фавикон, сниппет и фирменный стиль одного из популярных сайтов, он в зоне риска. Подробнее о новом алгоритме читайте в этой статье.
Вывод
В этой статье собрана вся хронология алгоритмов поисковой системы. Зачем я это сделала? Чтобы вы понимали, как ведется работа поисковика. А самое главное, чтобы вы знали, как правильно продвигать свои сайты, на что смотрит поисковик, что появилось нового, а что уже в далеком прошлом. Теперь вы знаете, что написать оптимизированные тексты и «навешать» внешних ссылок совсем недостаточно, а скорее и вовсе во вред. Если же вникать в процесс продвижения вам совсем некогда, а попасть в ТОП выдачи все же хочется, обращайтесь к нашим специалистам.
Теперь вы знаете, что написать оптимизированные тексты и «навешать» внешних ссылок совсем недостаточно, а скорее и вовсе во вред. Если же вникать в процесс продвижения вам совсем некогда, а попасть в ТОП выдачи все же хочется, обращайтесь к нашим специалистам.
# алгоритмы яндекса # минусинск # оптимизация сайта # продвижение сайта # продвижение ссылками # региональное продвижение # яндекс
| Яндекс | |
| Алгоритмы, анализирующие качество контента | |
Флорида (Florida) Запуск: ноябрь, 2003 г. Особенности:
| Магадан Запуск: май, июль, 2008 г. Особенности:
|
Остин (Austin) Запуск: январь, 2004 г. Особенности:
| АГС-17, АГС-30, АГС-40 Запуск: сентябрь, декабрь, 2009 г., ноябрь, 2012 г. Особенности:
|
Панда (Panda) Запуск: февраль, 2011 г. Особенности:
| Снежинск Запуск: ноябрь, 2009 г. Особенности:
|
Колибри (Hummingbird) Запуск: сентябрь, 2013 г. Особенности:
| Краснодар Запуск: декабрь, 2010 г. Особенности:
|
Пират (Pirate) Запуск: октябрь, 2014 г. Особенности:
| Баден-Баден Запуск: март, 2017 г. Особенности:
|
Фред (Fred) Запуск: март, 2017 г. Особенности:
| |
| Алгоритмы, анализирующие качество ссылок | |
PageRank Запуск: впервые в 1998 г. С тех пор было несколько обновлений. Особенности:
| 8 SP1 Запуск: январь, 2008 г. Особенности:
|
Кассандра (Cassandra) Запуск: апрель, 2003 г. Особенности:
| Обнинск Запуск: сентябрь, 2010 г. Особенности:
|
Хилтоп (Hilltop) Запуск: декабрь, 2010 г. Особенности:
| Минусинск Запуск: май, 2015 г. Особенности:
|
Пингвин (Penguin) Запуск: апрель, 2012 г. Особенности:
| |
| Алгоритмы, анализирующие пригодность сайта для мобильных устройств | |
Mobile friendly Запуск: апрель, 2015 г. Особенности:
| Владивосток Запуск: февраль, 2016 г. Особенности:
|
| Алгоритмы, работающие со сложными и редкими запросами | |
Орион (Orion) Запуск: 2006 г. Особенности:
| Палех Запуск: ноябрь, 2016 г. Особенности:
|
RankBrain Запуск: октябрь, 2015 г. Особенности:
| Королев Запуск: август, 2017 г. Особенности:
|
| Алгоритмы, учитывающие интересы пользователя (персонализация) | |
Персональный поиск Запуск: июнь, 2005 г. Особенности:
| Рейкьявик Запуск: август, 2011 г. Особенности:
|
Search Plus Your World Запуск: январь, 2012 г. Особенности:
| Калининград Запуск: декабрь, 2012 г. Особенности:
|
Дублин Запуск: май, 2013 г. Особенности:
| |
| Алгоритмы, направленные на улучшение качества ранжирования в целом | |
Кофеин (Caffeine) Запуск: июнь, 2010 г. Особенности:
| Находка Запуск: сентябрь, 2008 г. Особенности:
|
| Алгоритмы, отвечающие за региональное ранжирование | |
Опоссум (Possum) Запуск: сентябрь, 2016 г. Особенности:
| Арзамас / Анадырь Запуск: первая версия — апрель, 2009 г.; затем еще несколько версий в июне, августе и сентябре 2009 г. Особенности:
|
Конаково Запуск: декабрь, 2009 г., март 2010 г. Особенности:
| |







 В действительности их у поисковых систем гораздо больше, и все они оказывают то или иное влияние на результаты поиска. Главное, что необходимо помнить — действие алгоритмов направлено на то, чтобы предотвратить появление в выдаче сайтов с бесполезным контентом, обилием рекламы и использующим «черные» методы продвижения. Соблюдение требований поисковиков и знание основных принципов ранжирования поможет вашим сайтам оставаться «на плаву» и улучшать позиции в выдаче.
В действительности их у поисковых систем гораздо больше, и все они оказывают то или иное влияние на результаты поиска. Главное, что необходимо помнить — действие алгоритмов направлено на то, чтобы предотвратить появление в выдаче сайтов с бесполезным контентом, обилием рекламы и использующим «черные» методы продвижения. Соблюдение требований поисковиков и знание основных принципов ранжирования поможет вашим сайтам оставаться «на плаву» и улучшать позиции в выдаче.История развития алгоритмов ранжирования Яндекс
Долгое время специалисты компании Яндекс предпочитали не информировать пользователей о сменах алгоритмов ранжирования. Лишь в 2007 году сотрудники стали анонсировать введение новшеств в поисковую машину, слегка облегчив продвижение сайтов вебмастерам. В начале 2008 года Яндекс анонсировал выход нового алгоритма 8PS1, пообещав в дальнейшем придумывать своим новшествам более благозвучные названия. Начиная с мая 2008 года, Яндекс в названиях своих алгоритмов начинает играть в «Города» (каждый новый алгоритм начинается с последней буквы предыдущего).
Нововведения Яндекса
16 мая 2008 года – алгоритм «Магадан»
- Яндекс начал индексировать зарубежные веб-ресурсы
- Распознаются аббревиатуры, транслитерации, перевод запроса
- Увеличена скорость обработки информации по запросам, содержащихся в большом количестве документов
- Добавляются классификаторы ссылок
- Добавляются классификаторы контента
- Количество факторов, влияющих на ранжирование, увеличилось в 2 раза
- Увеличено расстояние между ключевыми словами, содержащимися в запросе. В документе они могут находиться на расстоянии в несколько слов друг от друга
- Оптимизирован «колдунщик» — улучшилось качество выдачи информации по запросу пользователя между поисковой строкой и ТОП-1.
В июльский апдейт алгоритма были добавлены очередные факторы ранжирования страниц, относящие контент к определенным категориям и тематикам, учитывающие процент уникальности контента и исправлены ошибки первой версии алгоритма Магадан.
11 сентября 2008 года – алгоритм «Находка»
- Машинное обучение вышло на новый уровень
- Подмешивание информационных сайтов в коммерческую выдачу
- Улучшение ранжирования по запросам со стоп-словами
- Расширение словарей Яндекса
- Санкции к сайтам с редиректом
- Оптимизаторы заметили, что новые сайты на старых доменах стало проще продвигать в ТОП-10Б
В апдейт алгоритма в поисковую строку добавились подсказки.
10 апреля 2009 года – алгоритм «Арзамас»
- Появление в выдаче сервиса «Яндекс-картинки»
- Происходит разделение на геозависимые и геонезависимые запросы
- Яндекс стал различать омонимы (ключ – к замку, родник)
Алгоритм совершенствовался 4 раза: с мая 2009 по сентябрь 2010. С этого периода Яндекс стал предупреждать пользователей о вредоносных сайтах, строже стал относиться к сайтам запрещенных тематик (порно), ужесточил меры к сайтам с рекламой, открывающейся при заходе на сайт (поп-апы и пр).
Так же алгоритм существенно понизил влияние SEO-ссылок как основного фактора ранжирования. Обнаруженное несовершенство алгоритма (можно было продвигать страницу, повлияв на выдачу огромным текстом в 15 000-30 000 знаков, перенасытив кючевыми фразами) напомнило вебмастерам и оптимизаторам, что тексты на сайты пишутся для людей и переспамленные ключевыми словами огромные тексты сильно понизились в результатах поисковой выдачи.
17 ноября 2009 года – алгоритм «Снежинск»
- Появление поведенческих факторов – полезность страницы определяется пользователем, а не поисковой машиной
- Проседание коммерческих сайтов по геонезависимым запросам и взлет в ТОП информационных
- Для каждого запроса определяется собственная формула ранжирования (для разных запросов доминирующими становятся разные факторы)
В апдейт алгоритма для новостных сайтов появляется свой «новостной» поисковый робот и фильтр АГС. Сайты, попавшие под АГС, практически полностью исчезают из поисковой выдачи.
Алгоритм «Снежинск» явился последним новым алгоритмом. Все последующие алгоритмы являются, по сути, дополнениями к «Снежинску». Обусловлено это введением Матрикснет – самообучающимся алгоритмом.
6 августа 2010 года – алгоритм «Обнинск»
- Искусственно проставленные (покупные) ссылки ограничили влияние на ранжирование
- Для пользователей России было улучшено ранжирование по геонезависимым запросам, составляющих 70% от количества всех запросов россиян
В этом же году Яндекс проиндексировал социальную сеть «Вконтакте» и заключил договор с Facebook.
15 декабря 2010 года – алгоритм «Краснодар»
- Появление в выдаче спектра похожих на запрос пользователя поисковых запросов
- Оптимизировано ранжирование по геозависимым запросам
- Увеличилось влияние поведенческих факторов
- Происходит классификация и разделение запросов на категории (товары, книги, писатели и тп) и объекты (имена, марки, бренды и тп)
Выход «Краснодара» обусловлен появлением технологии «Спектр» — нового подхода к результатам поисковой выдачи.
С 24 декабря 2010 года по 15 августа 2011 года происходили следующие изменения:
- Яндекс приобрел WebVisor – технологию, с помощью которой стало возможно анализировать действия пользователя на сайте. технология доступна пользователям Яндекс-Метрики.
- Поисковые подсказки стали региональными.
- Яндекс учитывает атрибут rel=»canonical».
- Появляется сервис – защита авторского контента – ввод оригинального текста перед публикацией.
- Санкции за накрутку поведенческих факторов. Сайты, замеченные в злоупотреблении, были значительно понижены в поисковой выдаче.
- Санкции за «неудобные для пользователя тексты». Сайты, на которых располагались неформатированные (не разбитый на абзацы, без подзаголовков) «простынный» тексты, были пессимизированы.
17 августа 2011 года – алгоритм «Рейкьявик»
Яндекс стал учитывать запросы пользователя, заданные на английском языке и начал показывать в результатах выдаче англоязычные ресурсы, отфильтровывая запросы латиницей, запросы, заданные в другой раскладке клавиатуры, транслит и тд.
23 ноября 2011 года – безымянная надстройка
Асессоры (люди, оценивающие соответствие поисковой выдачи поисковому запросу) вооружаются дополнительными параметрами оценки сайта: дизайн сайта, качество предоставляемой на сайте услуги, ассортимент, удобство выбора и степень доверия пользователя. Иными словами, отныне самостоятельно можно определить вероятность повышения или понижения сайта в поисковой выдаче на основе вышеперечисленных параметров.
Что хорошо для российского коммерческого сайта
- Наличие на видном месте (в шапке сайта) городских телефонных номеров и бесплатных номеров, начинающихся с 8-800.
- Наличие нескольких офисов по стране или в пределах региона (области, города).
- Узнаваемость бренда в интернет-пространстве: поисковые запросы по названию фирмы, упоминание в документах.
- Большой ассортимент товаров\услуг
- Гибкая ценовая политика
- Несколько способов оплаты
- Акции, специальные предложения, скидки, распродажи.

- При совершении транзакции (процесса покупки-оплаты) редирект на протокол https.
- Положительные отзывы клиентов, портфолио, рейтинги, сервисы, обзоры.
- Доступность товра\услуги в 1-2 клика с любой страницы сайта.
- Удобный поиск: по категории товара, по наименованию, по бренду.
- Наличие e-mail, соответствующего доменному имени (например, [email protected])
- Стилистически, орфографически, пунктуационно грамотный текст.
- Качественные уникальные фото.
Что плохо для российского коммерческого сайта
- Отсутствие контактных данных либо указание только мобильного телефона.
- Отсутствие адреса офиса.
- Негативные отзывы о бренде (фирме, продукте и пр).
- Отсутствие цены товара\услуги.
- Реклама сторонних ресурсов (ссылки, баннеры, контекстная реклама).
- Запутанная сложная форма заказа.
- Невалидный код, ошибки кода, таблицы стилей (CSS) находятся не в отдельном файле.

- Незаполненные страницы с товаром, ошибочная классификация товара.
Все эти параметры не являются руководством к действию и носят рекомендательный характер.
Как будет работать поиск в 2021? YATI – новый алгоритм ранжирования Яндекс — SEO на vc.ru
В конце минувшего года Яндекс запустил новый алгоритм поискового ранжирования YATI, действие которого основано на нейросетях-трансформерах. Эта нейросетевая архитектура опирается на смысловую составляющую, обеспечивая совершенно новый подход, который устанавливает наилучшее семантическое единение между намерением пользователя, запросом и документом.
18 485 просмотров
YATI (Yet Another Transformer with Improvements) в переводе означает «Ещё один трансформер с улучшениями»
По заверениям специалистов по машинному обучению в Яндекс – внедрение YATI рекордным образом улучшило ранжирование и стало наиболее значимым событием для отечественного поисковика за последние 10 лет, со времен внедрения Матрикснета.

Совместный эффект Палеха и Королёва оказали меньшее влияние на поиск, чем новая модель на трансформерах. Вместе с тем, следует понимать, что нейросети не отменяют тысячи ранее заложенных правил в общую поисковою формулу. Однако значимость YATI ярко прослеживается в факте, свидетельствующем о том, что если убрать из общей формулы все прочие факторы и оставить только новую модель, то качество ранжирования, как заявил руководитель группы нейросетевых технологий в поиске Яндекс Александр Готманов, по основной офлайн-метрике упадёт лишь на 4-5%.
Как было раньше?
Система поиска всегда определяла релевантность выдачи путем сопоставления множества разнообразных факторов, намекающих на семантическую связь между поисковым запросом и материалом, изложенном на отдельной веб-странице. То есть, в упрощенном представлении, если статья и запрос имели множество одинаковых слов, то роботом данная страница воспринималась наиболее приоритетной. Разумеется, учитывался и расчет количества фраз, объем материала, поведенческие факторы, поисковая история пользователей и многое другое, но робот при этом никогда не понимал сути документа.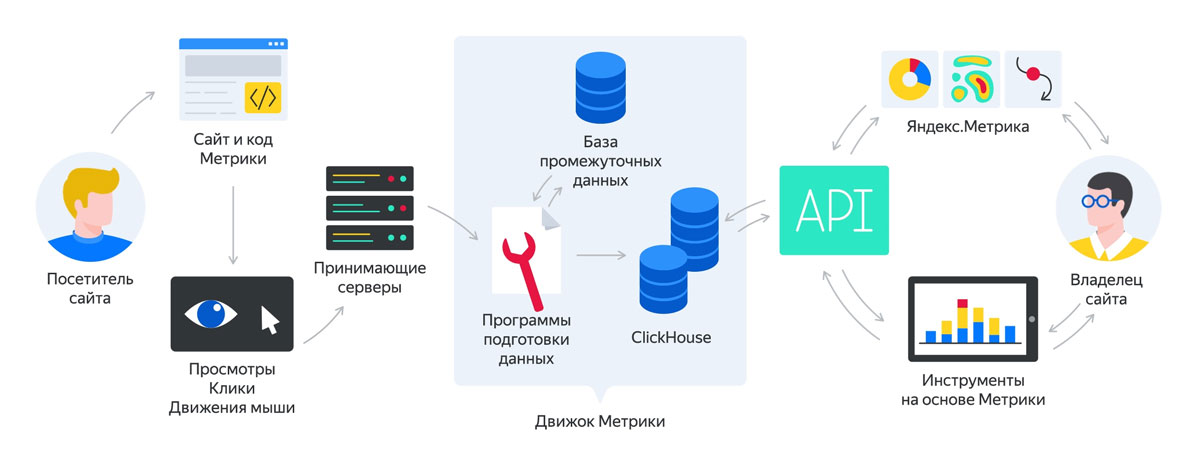
Алгоритмы Яндекс на 2015 год
Так происходило вплоть до 2016 года, пока не появились такие алгоритмы как Палех и Королев. Тогда Яндекс впервые публично заявил о применении нейросетей, обозначив, меж тем, что дальнейшее развитие поиска им видится в том, чтобы в финале получить модель, которая сможет всякий раз понимать любые запросы на уровне, сопоставимом с человеческим. Технология YATI являет собой еще один значительный шаг к этому, а Палех и Королев являлись важнейшими вехами развития поиска на пути к YATI.
Палех
Палех обеспечил возможность понимания сложных запросов пользователей. То есть поиск стал проводиться не строго по словам, которые написал пользователь, но также по смыслу запроса и заголовка страницы. Так, Яндекс научился находить требуемые ответы даже при отсутствии ключевых слов.
Выдача при Палехе стала формироваться по смыслу, а не по точным вхождениям
С этого момента точное вхождение ключевых запросов стало менее значимым фактором при ранжировании и акцент при SEO-продвижении стал смещаться в сторону смысловой и технической уникальности текста, мотивируя к созданию более полезного и содержательного контента.
Королев
Более совершенной вариацией Палеха стал Королев. Он еще лучше научился обрабатывать сложные и многозначные запросы, ориентируясь при этом не только на сопоставление заголовков, но и на содержимое страницы в целом. Алгоритм также стал учитывать поисковую статистику, мнение ассесоров и толокеров, а также оценки самих пользователей.
Например, пользователь вводит запрос «фильм, в котором нельзя шуметь». В этом случае Яндекс сразу выведет название фильма, при этом ключевых фраз в Title и Description не будет.
Работа Королева при сложном запросе
Таким образом, стало возможным задавать поисковой системе сложные вопросы в формате разговорной речи и получать на это корректные ответы.
Существенным преимуществом Королева также стала возможность его применения к существенно большему количеству страниц без ущерба ко времени выдачи результатов по запросу. Палех был относительно тяжелым алгоритмом и использовался исключительно на поздних стадиях ранжирования, приблизительно к 150 лучшим страницам из отфильтрованного по старым правилам списка.
О трансформерах
Палех и Королев позволили Яндексу не просто находить совпадения, а понимать суть вопроса, значительно улучшили процесс ранжирования, но всё же справлялись с этим неидеально. Лишь с момента ввода YATI факторы смысла стали превосходить факторы вхождений по мНЧ-фразам.
Путь Яндекса к YATI
Прежде, чем мы начнем подробнее говорить о YATI, следует отдельно пояснить что такое трансформеры.
Говоря простыми словами, трансформерами в данном случае называют сверхбольшие и сверхсложные нейросети, способные легко справляться с разнообразными задачами в сфере обработки естественного языка, будь то перевод или создание текста.
Скрываются за этим огромные вычислительные мощности. Причем стремительно нарастающие. Так, до применения трансформеров, используемая в Яндексе нейросеть, обучалась только на одном графическом ускорителе Tesla v100. Уходило на такое обучение не более одного часа. А вот обучение нейросети-трансформера на таком ускорителе заняло бы около 10 лет. Потому внедрение новых технологий потребовало использования около сотни похожих ускорителей с быстрой передачей данных между друг другом. Для этого Яндекс построил специальный кластер, предназначенный для вычислений, с распределенным обучением внутри него.
Потому внедрение новых технологий потребовало использования около сотни похожих ускорителей с быстрой передачей данных между друг другом. Для этого Яндекс построил специальный кластер, предназначенный для вычислений, с распределенным обучением внутри него.
То есть переход на новый алгоритм YATI был довольно сложной задачей с инженерной точки зрения. Множество ускорителей объединили в кластеры, связали в сеть и разработали для получившихся серверов мощную систему охлаждения. Но даже с такими мощностями на обучение модели сейчас уходит около месяца.
Классическая техника обучения трансформеров предполагает демонстрацию им неструктурированных текстов. То есть берется текст, в нем маскируется определенный процент слов, а перед трансформером ставится задача угадывать данные слова. Для YATI задача была усложнена: ему показывался не просто текст отдельного документа, а действительные запросы и тексты документов, которые видели пользователи. YATI угадывал, какой из документов понравился пользователям, а какой нет. Для этого использовалась экспертная разметка асессоров, которые оценивали релевантность каждого документа запросу по сложной шкале.
Для этого использовалась экспертная разметка асессоров, которые оценивали релевантность каждого документа запросу по сложной шкале.
После этого Яндекс брал массив полученных данных и дообучал трансформер угадывать экспертную оценку, обучаясь, таким образом, ранжировать. В результате поисковой алгоритм был существенно улучшен и Яндекс вышел на рекордный уровень в качестве поиска.
Преимущества YATI и трансформеров
В отличие от предшествующих нейросетевых алгоритмов Яндекса Палех и Королёв, YATI умеет предсказывать не клик пользователя, а экспертную оценку, что являет собой фундаментальную разницу.
Кроме этого, преимущества трансформеров заключаются в следующем:
- поиск работает не только с запросами и заголовками, но и способен оценивать длинные тексты;
- присутствует «механизм внимания», выделяющий в тексте наиболее значимые фрагменты;
- учитывается порядок слов и контекст, то есть влияние слов друг на друга.

Теперь, к примеру, когда вы будете искать билеты на самолет из Екатеринбурга в Москву, поисковик поймет, что вам нужно именно из Екатеринбурга в Москву, а не наоборот. Помимо того, Яндекс стал лучше распознавать опечатки.
YATI намного лучше предшественников работает со смыслом запроса, алгоритм направлен на более глубокий анализ текста, понимание его сути. Это значит, что поисковик будет точнее понимать, какая информация является наиболее релевантной запросу пользователя.
Говоря о ранжировании, можно спрогнозировать, что смысловая нагрузка контента возымеет более значимую роль. То есть экспертные тексты, полностью раскрывающие ответ на запрос пользователя, будут всё больше и чаще попадать в ТОП.
Особенности YATI:
1. Переформулирование запросов и «пред-обучение на клик». Яндекс имеет базу из 1 млрд. переформулированных запросов: [1 формулировка] → без клика → [2 формулировка]. Так, модель учится предсказывать вероятность клика.
2. Оценки на Яндекс.Толоке. Использование оценок толокеров.
3. Оценки асессоров. Использование экспертных оценок релевантности.
4. Данные, которые подаются на вход:
- текст запроса;
- расширение запроса;
- «хорошие» фрагменты документа;
- стримы для документа: анкор-лист, запросный индекс для документа.
YATI и Google Bert
Одним из последних обновлений главного конкурента в области поиска Яндекса Google стало внедрение алгоритма BERT. Эта нейронная сеть также, как и YATI, решает задачу анализа поисковых запросов и их контекста, а не отдельный анализ ключевых запросов. То есть BERT анализирует предложение целиком.
И YATI, и BERT ориентированы на лучшее понимание смысла поискового запроса. Однако, как утверждают специалисты Яндекс, алгоритм YATI лучше справляется со своими задачами, поскольку кроме текста запроса анализирует еще и тексты документов, а также учится предсказывать клики.

Ниже в таблице представлено сравнение качества алгоритмов, основанных на нейронных сетях, в задаче ранжирования, где “% NDCG” – нормированное значение метрики качества DCG по отношению к идеальному ранжированию на датасете Яндекс. 100% здесь означает, что модель располагает документы в порядке убывания их настоящих офлайн-оценок.
Вместе с тем, требуется отметить, что BERT решает существенно большее количество задач, среди которых распознавание «смысла» текста лишь одна из множества других. На BERT базируется большое семейство языковых моделей:
С точки же зрения компьютерной лингвистики, BERT и YATI – довольно похожие алгоритмы.
Как изменится ранжирование в условиях действия Яндекс YATI
Владельцев ресурсов, а также всех, кто занимается продвижением сайта, очевидно, должен интересовать вопрос, как YATI повлияет на способы оптимизации. Если исходить из утверждения, что новый алгоритм обеспечивает более 50% вклада в ранжирование, то можно предположить, что «смысл» окончательно победил возможности SEO-специалистов в проработке текстов, а значит оптимизировать ничего не нужно. А также можно решить, что такие факторы, как «точное вхождение», «Title» и «добавить ключей» больше не имеют влияния.
А также можно решить, что такие факторы, как «точное вхождение», «Title» и «добавить ключей» больше не имеют влияния.
Данные суждения будут поспешны и ошибочны. Новый алгоритм не отменяет старые факторы ранжирования, а лишь дополняет их более качественным анализом текстов. Дело в том, что изначально для улучшения распределения, поиск Яндекс обучался на редких запросах, где документов и без того недостаточно. И когда речь идет о 50%-ом вкладе в ранжирование, то имеются ввиду именно редкие запросы. Борьба между «смыслом» и «вхождением», где «смысл» начал побеждать, видна именно на них.
А вот ситуация по ВЧ-запросам, по средне- и низкочастотным не претерпела значительных изменений. Это означает, что техническую оптимизацию, привлечение естественных ссылок и улучшение поведенческих факторов как на поиске, так и на сайте – забрасывать не нужно.
Исследования независимых специалистов показывают, что значимость фактора «точное вхождение в тексте» по НЧ-запросам после запуска YATI ничуть не ослабла, а, напротив, увеличила свою значимость. А вот тут ситуация с точным вхождением поменялась – явного влияния в ТОП-10 теперь нет, хотя вне его оно сохраняется.
А вот тут ситуация с точным вхождением поменялась – явного влияния в ТОП-10 теперь нет, хотя вне его оно сохраняется.
Среднее значение ключевого фактора ТОП-10 и вне его:
Среднее значение фактора здесь находится в районе единицы. То есть, если имеется одно вхождение, значит этого вполне достаточно.
Фактор «наличие всех слов из запроса в тексте» также не потерял своего значения. Выборка коммерческих запросов в Яндексе демонстрирует, что существенной разницы между НЧ и СЧ+ВЧ запросами нет. Тем не менее, наблюдается взаимосвязь между попаданием в ТОП и наличием всех слов запроса в документе. Значение этого фактора составляет 0.8, то есть, работает это для 80% сайтов.
Проверка фактора «слова в Title» после YATI показывает рост среднего значения этого фактора. То есть в выдаче стали чаще встречаться документы, Title которых содержит все слова в запросе, но вместе с тем, здесь наблюдается заметное понижение взаимосвязи с позицией.
Практические советы
Итак, перейдем к конкретным рекомендациям по оптимизации сайта в условиях работы алгоритма YATI:
- Адаптируйтесь под YATI.
 Увеличивайте количество слов, встречаемых в контексте со словами из запроса. К таковым могут относиться слова из подсветки выдачи, а также слова, задающие тематику и встречаемые у конкурентов, но отсутствующие на продвигаемой странице.
Увеличивайте количество слов, встречаемых в контексте со словами из запроса. К таковым могут относиться слова из подсветки выдачи, а также слова, задающие тематику и встречаемые у конкурентов, но отсутствующие на продвигаемой странице. - Расставляйте акценты в тексте и форматируйте его. В текстах свыше 12-14 предложений обязательно требуется использовать заголовки, выносить в них и в выделенные фрагменты тематические и ключевые слова.
- Выполняйте анализ и оптимизацию запросного индекса и для документов, и для сайта в целом в Яндекс.Вебмастере. Проверяйте релевантность запросов, по которым были как переходы на заданный URL, так и только показы без переходов. Данные всего сайта, как и прежде, также сказываются на факторах для заданной страницы. Поэтому проверки имеют смысл в разрезе всего сайта, а не только URL.
- Расширяйте семантическое ядро для продвижения в сторону НЧ-запросов. Синонимичные и, так называемые, вложенные запросы помогают в продвижении по более общим и близким по смыслу.

- Выполняйте конкурентный анализ. Анализируйте показы страниц конкурентов по запросам. Изучайте чужие тексты: какие тематические слова и фразы в них используются, какова структура и т.п.
- Проводите классическую оптимизацию: текст, точные вхождения, слова в Title.
Заключение
Трансформеры значительно улучшили качество поиска в Яндексе и вывели его на новый рекордный уровень. Применение тяжелых моделей, основанных на работе нейронных сетей, способных приближать структуру естественного языка и лучше учитывать семантические связи между словами в тексте, помогает пользователям все чаще встречаться с эффектом «поиска по смыслу», а не по словам.
Тем не менее несмотря на то, что YATI преподносится и по праву считается прорывной технологией, принципы работы поиска в Яндексе всегда формируются эволюционным, а не революционным образом. То есть, его обновление выполняется путем последовательного добавления новых факторов ранжирования к старым, а не радикальной сменой всех основ. Это означает, что поисковая оптимизация с приходом YATI не потеряла своей актуальности, а лишь требует некоторых корректировок ряда своих методов.
Это означает, что поисковая оптимизация с приходом YATI не потеряла своей актуальности, а лишь требует некоторых корректировок ряда своих методов.
Управляющий директор группы компаний Яндекс Тигран Худавердян о внедрение алгоритма YATI в интервью на конференции YaС 2020
YATI безусловно изменит поисковую выдачу Яндекса, но поскольку система требует обучения, то для этого потребуется время. Поэтому сейчас у вас есть хорошая возможность внести необходимые изменения на сайте и доработать SEO-тексты устаревшего формата, сохранив тем самым свои позиции и улучшив их к тому моменту, когда поиск окончательно перестроится на новый формат. С оптимизацией вам могут помочь советы, изложенные в этой статье, а также наша компания ADVIANA.
Заметим, что мы никогда не гнались за некачественными и серыми методами оптимизации и всегда много внимания уделяли описаниям на сайте, а также всем видам текста. Для наших проектов переход на новый алгоритм не был болезненным, так как все они уже соответствовали новым требованиям.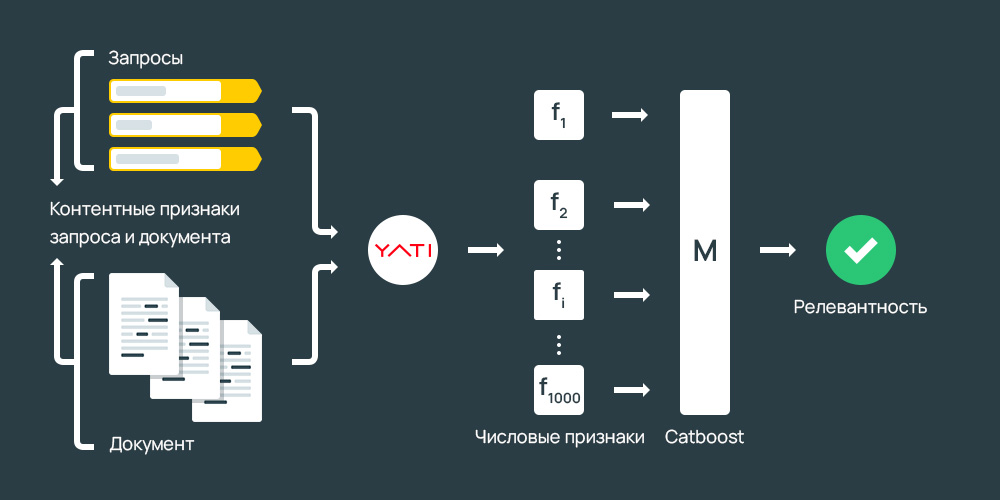 Кроме того, мы постоянно следим за изменениями в мире digital-маркетинга в целом и SEO-оптимизации в частности, что позволяет нам использовать в своей работе только актуальные методы продвижения по понятной цене и с прогнозируемым результатом.
Кроме того, мы постоянно следим за изменениями в мире digital-маркетинга в целом и SEO-оптимизации в частности, что позволяет нам использовать в своей работе только актуальные методы продвижения по понятной цене и с прогнозируемым результатом.
Желаем всем высоких позиций в поиске!
В статье используются графические иллюстрации из вебинара Дмитрия Севальнева («Пиксель Тулс»).
Поисковые алгоритмы Google и Yandex 🚀 хронология
Содержание
- 1 Яндекс: виды алгоритмов с зачатия до сегодня
- 1.1 Магадан
- 1.1.1 Особенности
- 1.1.2 Результаты
- 1.2 Находка
- 1.2.1 Особенности
- 1.2.2 Результаты
- 1.3 Арзамас
- 1.3.1 Особенности
- 1.3.2 Результаты
- 1.4 Снежинск
- 1.4.1 Особенности
- 1.4.2 Результаты
- 1.5 Обнинск
- 1.5.1 Особенности
- 1.5.2 Результаты
- 1.6 Краснодар
- 1.6.1 Особенности
- 1.6.2 Результаты
- 1.
 7 Рейкьявик
7 Рейкьявик- 1.7.1 Особенности
- 1.7.2 Результаты
- 1.8 Калининград
- 1.8.1 Особенности
- 1.8.2 Результаты
- 1.9 Дублин
- 1.9.1 Особенности
- 1.9.2 Результаты
- 1.10 Острова
- 1.10.1 Особенности
- 1.10.2 Результаты
- 1.11 Минусинск
- 1.11.1 Особенности
- 1.11.2 Результаты
- 1.12 Владивосток
- 1.12.1 Особенности
- 1.12.2 Результаты
- 1.1 Магадан
- 2 Google: история создания и развития алгоритмов
- 2.1 Кофеин
- 2.1.1 Особенности
- 2.1.2 Результаты
- 2.2 Panda (Панда)
- 2.2.1 Особенности
- 2.2.2 Результаты
- 2.3 Page Layout (Пейдж Лайот)
- 2.3.1 Особенности
- 2.3.2 Результаты
- 2.4 (Венеция)
- 2.4.1 Особенности
- 2.4.2 Результаты
- 2.5 (Пингвин)
- 2.5.1 Особенности
- 2.5.2 Результаты
- 2.6 Pirate (Пират)
- 2.
 6.1 Особенности
6.1 Особенности - 2.6.2 Результаты
- 2.
- 2.7 HummingBird (Колибри)
- 2.7.1 Особенности
- 2.7.2 Результаты
- 2.8 (Голубь)
- 2.8.1 Особенности
- 2.8.2 Результаты
- 2.9 (Дружелюбный к мобильным устройствам)
- 2.9.1 Особенности
- 2.9.2 Результаты
- 2.1 Кофеин
- 3 Резюме
Все мы не понаслышке знаем о существующих алгоритмах поисковых систем Яндекс и Google. Именно для соблюдения их «постоянно обновляемых» правил все оптимизаторы ломают свой мозг все новыми и новыми способами попасть в ТОП выдачи поиска. Из последних новшеств, которые ощутили на себе владельцы сайтов со стороны ПС — это требования к мобильности интернет-ресурсов и понижение в поиске тех площадок, которые не умеют покупать ссылки. Какие алгоритмы до этого времени, внедренные в поиск, существенно повлияли на ранжирование сайтов? На самом деле, не все оптимизаторы знают, какие технологии, когда и зачем были созданы, чтобы максимально справедливо дать позицию каждому сайту в поиске и очистить выдачу от «хлама». Историю создания и развития поисковых алгоритмов мы и рассмотрим в этой статье.
Историю создания и развития поисковых алгоритмов мы и рассмотрим в этой статье.
Яндекс: виды алгоритмов с зачатия до сегодня
Алгоритмы не создавались все в один день, и каждый из них проходил много этапов доработки и преобразования. Основная масса названий алгоритмов Яндекса состоит из названий городов. Каждый из них имеет свои принципы работы, точки взаимодействия и уникальные функциональные особенности, гармонично дополняющие друг друга. Какие алгоритмы есть у Яндекса и как они влияют на сайты, рассмотрим далее.
Помимо информации о поисковых алгоритмах полезной будет и статья про новые фишки в Яндекс Директ. Советы по созданию качественного SEO-контента подходящего для поисковиков Гугл и Яндекс я предлагаю вам прочесть по этой ссылке.
Магадан
Алгоритм «Магадан» распознает аббревиатуры и отожествляет существительные с глаголами. Был впервые запущен в тестовом режиме в апреле 2008, а вторая постоянная версия вышла в свет в мае того же года.
Особенности
«Магадан» выдает пользователю, который написал аббревиатуру, сайты и с расшифровками. Например, если в поисковой строке вбили запрос МВД, то кроме площадок с таким ключевым словом в списке будут присутствовать и те, у кого аббревиатуры нет, но есть расшифровка «Министерство внутренних дел». Распознавание транслитерации дало пользователям возможность не думать на каком языке правильно писать названия, к примеру, Mercedes или Мерседес. Ко всему этому Яндекс включил в список индексирования почти миллиард зарубежных сайтов. Распознавание частей речи и признание их равноценными поисковыми запросами выпустили в один поиск сайты с разными ключевыми фразами. То есть теперь по ключевику «оптимизация сайтов» в выдаче выводятся и площадки с вхождением словосочетания «оптимизировать сайт».
Результаты
После запуска алгоритма «Магадан» стало труднее, в основном, малоавторитетным сайтам. В ранжировании понизились позиции по релевантным запросам малопосещаемые и молодые ресурсы, а на первые места выдвинулись авторитетные, даже с некачественным контентом, учитывая при этом морфологию и разбавленность ключевиков. Из-за учета транслитерации в ТОП Рунета вышли и зарубежные ресурсы. То есть оптимизированный текст по теме мог оказать на второй странице, только потому, что, якобы, по этой же тематике есть более посещаемый сайт или аналогичный зарубежный. Из-за этого резко возросла конкуренция по низкочастотным ключевикам и иностранным фразам. Подорожала и реклама — ставки возросли, потому что ранее сайты конкурировали только по одному конкретному запросу, а теперь и с «коллегами» с морфологическими фразами, транслитерацией, переходящими в другую часть речи словами.
Из-за учета транслитерации в ТОП Рунета вышли и зарубежные ресурсы. То есть оптимизированный текст по теме мог оказать на второй странице, только потому, что, якобы, по этой же тематике есть более посещаемый сайт или аналогичный зарубежный. Из-за этого резко возросла конкуренция по низкочастотным ключевикам и иностранным фразам. Подорожала и реклама — ставки возросли, потому что ранее сайты конкурировали только по одному конкретному запросу, а теперь и с «коллегами» с морфологическими фразами, транслитерацией, переходящими в другую часть речи словами.
Находка
Алгоритм «Находка » — расширенный тезаурус и внимательное отношение к стоп-словам. Выпущен «на ринг» сразу после «Магадана». Ранжирует основную выдачу с сентября 2008.
Особенности
Это инновационный подход к машинному обучению — ранжирование стало четче и корректней. Расширенный словарь связей и внимательность к стоп-словам в алгоритме «Находка» очень сильно повлияли на поисковую выдачу. К примеру, запрос «СЕО оптимизация» теперь ассоциировался и с ключем «сеооптимизация», а коммерческие сайты разбавлялись информационными порталами, в том числе в списке появились развернутые сниппеты с ответами, по особенному отображалась Википедия.
Результаты
Коммерческие сайты сделали больший акцент на продажные запросы, так как конкуренция увеличилась по информационным не конкретным фразам в несколько раз. В свою очередь, информационные площадки смогли расширить свою монетизацию с помощью страниц рекомендаций, участвуя в партнерских программах. Топовые инфосайты, продвинутые по коммерческим запросам стали продавать ссылки на заказ. Конкуренция ужесточилась.
Арзамас
Алгоритм «Арзамас» — внедрена лексическая статистика поисковых запросов и создана географическая привязка сайта. Первая версия «Арзамаса» (апрель 2009) без геозависимости выпущена сразу в основную выдачу, а «Арзамас 2» с классификатором по привязке сайта к региону анонсирован в августе 2009.
Особенности
Снятие привязки к омонимам облегчила пользователю жизнь, ведь теперь по фразе «американский пирог» выдавались только сайты на тему фильмов, без всяких там рецептов десертов, как могло быть раньше. Привязка к региону совершила прорыв, сместив ключевые фразы с добавкой города на несколько пунктов вниз. Теперь пользователь мог просто ввести слово «рестораны» и увидеть в лидерах только сайты из города его местонахождения. Если помните, раньше нужно было бы ввести более конкретную фразу, например «Рестораны в Санкт-Петербурге», иначе Яндекс мог выдать ответ «уточните запрос — найдено слишком много вариантов». Геонезависимые ключевые слова выдавали только релевантные запросу сайты из любых регионов, без привязки.
Теперь пользователь мог просто ввести слово «рестораны» и увидеть в лидерах только сайты из города его местонахождения. Если помните, раньше нужно было бы ввести более конкретную фразу, например «Рестораны в Санкт-Петербурге», иначе Яндекс мог выдать ответ «уточните запрос — найдено слишком много вариантов». Геонезависимые ключевые слова выдавали только релевантные запросу сайты из любых регионов, без привязки.
Результаты
Ура! Наконец-то сайты из небольших регионов перестали конкурировать с крупными мегаполисами. Выйти в ТОП по своему региону теперь намного проще. Именно в этот период времени была предложена услуга «региональное продвижение». Алгоритм «Армазас» дал возможность мелким компаниям быстрее развиваться в своей местности, но подвох все равно остался. Яндекс не мог определить геолокацию у всех площадок. И как вы сами понимаете — без привязки ресурсы оставались, мягко говоря, в одном не очень приятном месте. Рассмотрение заявки на геозависимость могло длиться несколько месяцев, а молодые сайты без трафика и ссылочной массы (было ограничение по ТИЦ), вообще, не могли подать запрос на присвоение им региональности. Палка о двух концах.
Палка о двух концах.
Снежинск
Алгоритм «Снежинск» — усиление геозависимости и уточнение релевантности запросов к выдаче с помощью технологии машинного обучения «Матрикснет». Анонс состоялся в ноябре 2009, а улучшенная модель под именем «Конаково» заработала в декабре того же года.
Особенности
Поисковая выдача стала более точной к вводимым вопросам. Особую роль теперь играет привязка по геолокации — коммерческие сайты не ассоциировались у алгоритма «Снежинск» с регионами, поэтому выпадали из выдачи. Ключевые слова, не привязанные к местности, отожествляются с информационными ресурсами. Сложная архитектура подсчета релевантности сильно усложнила жизнь оптимизаторов, которые заметили, что при малейшем изменении одного из показателей, позиция сайта в выдаче моментально изменялась.
Результаты
На тот момент было отмечено, что закупка внешних ссылок на молодые сайты влияла на показатели новых ресурсов слишком вяло, если сравнить аналогичную закупку на площадку, давненько находящуюся на интернет-рынке. Новые методы определения релевантности контента к поисковым запросам выбрасывали из выдачи сайты, тексты которых были перенасыщены ключевыми фразами. Началась новая эра качественного текста, где во всем должна была быть мера, без нее площадка могла просто попасть под санкции за спам. Коммерческие ресурсы забили панику, потому что выйти по геонезависимым ключевым словам в ТОП (а они были самые высокочастотные) было практически нереально. В связи с этим на блоге Яндекса была опубликована запись, что в идеале хотелось бы видеть на первых страницах коммерческие организации, которые не пишут красиво, а выполняют свою работу хорошо, но для этого придется научить алгоритмы оценивать качество предлагаемых услуг. Так как на данный момент это оказалось непосильной задачей, репутация коммерческих интернет-ресурсов играла ключевую роль в выдаче, как в онлайне так и в оффлайне.
Новые методы определения релевантности контента к поисковым запросам выбрасывали из выдачи сайты, тексты которых были перенасыщены ключевыми фразами. Началась новая эра качественного текста, где во всем должна была быть мера, без нее площадка могла просто попасть под санкции за спам. Коммерческие ресурсы забили панику, потому что выйти по геонезависимым ключевым словам в ТОП (а они были самые высокочастотные) было практически нереально. В связи с этим на блоге Яндекса была опубликована запись, что в идеале хотелось бы видеть на первых страницах коммерческие организации, которые не пишут красиво, а выполняют свою работу хорошо, но для этого придется научить алгоритмы оценивать качество предлагаемых услуг. Так как на данный момент это оказалось непосильной задачей, репутация коммерческих интернет-ресурсов играла ключевую роль в выдаче, как в онлайне так и в оффлайне.
Обнинск
Алгоритм «Обнинск» — улучшение ранжирования и расширения базы географической принадлежности интернет-площадок и снижение влияния на показатели сайта искусственных СЕО-ссылок. Запущен в сентябре 2010.
Запущен в сентябре 2010.
Особенности
Падает популярность закупки ссылочных масс, появляется понятие «ссылочного взрыва», которого теперь боялись все. Конкуренты могли навредить друг другу возможностью введения алгоритма в заблуждение, закупив на «коллегу» огромное количество ссылок с «плохих источников». После этого конкурент выпадал из поисковой выдачи и долго не мог туда попасть. Геозависимые слова чаще добавляются на разные страницы коммерческих сайтов, чтобы обратить внимание робота на работу с этим регионом.
Результаты
Коммерческие сайты теперь тщательней относятся к своей репутации, что не может не радовать, но многие все равно прибегали к грязным методам (искусственно завышали посещаемость и покупали отзывы). После выпуска алгоритма «Обнинск» более популярной стала закупка вечных ссылок и статей, обычная покупка ссылок уже так не влияла на ранжирование, как раньше, а в случае попадания источника бэклинка под санкции могла потянуть за собой цепную реакцию. Качественные СЕО-тексты — обязательный атрибут любого ресурса. Молодой сайт с уникальным и правильно оптимизированным контентом мог попасть в ТОП.
Качественные СЕО-тексты — обязательный атрибут любого ресурса. Молодой сайт с уникальным и правильно оптимизированным контентом мог попасть в ТОП.
Краснодар
Алгоритм «Краснодар» — внедрение технологии «Спектр» для разбавления поисковой выдачи, расширения сниппетов и индексация социальных сетей. Запуск состоялся в декабре 2010 года.
Особенности
Технология «Спектр» была создана для классификации запросов по категориям и использовалась в случаях ввода не конкретизированных ключевых фраз. «Краснодар» разбавлял поисковую выдачу, предлагая такому пользователю больше разнообразных вариантов. Например, при фразе «фото Москвы» в поиске можно было увидеть не только общие пейзажи, но и фотографии по категориям типа «достопримечательности», «карты», «рестораны». Был сделан акцент на уникальные названия чего-либо (сайтов, моделей, товаров) — конкретика стала выделяться. Расширенные сниппеты дали возможность сразу в поисковой выдаче показывать пользователям контакты и другие данные организаций.
Результаты
Сильно изменилось ранжирование коммерческих сайтов, особое внимание уделяется деталям (карточкам товаров, разделением короткого описания от общего). Социальная сеть в ВК начала индексироваться и профили участников равноценно теперь видны прямо в поисковой выдаче. Сообщения в форумах могли занимать первые позиции, если имели более расширенный ответ на вопрос пользователя, чем другие сайты.
Рейкьявик
Алгоритм «Рейкьявик» — создана персонализация поисковой выдачи и добавлена технологи «Колдунщики» для отображения предварительных итогов запроса. Улучшена формула подсказок при вводе. Алгоритм запущен в августе 2011 года.
Особенности
Девизом персонализированного поискового результата — «Каждому пользователю — своя выдача». Система запоминания интересов ищущих работала через куки, поэтому если запросы пользователя чаще были связаны, например, с зарубежными ресурсами, в следующий раз в лидерах поисковой выдачи отображались именно они. Подсказки в поисковой строке обновляются каждый час, тем самым расширяя возможности конкретизированного поиска. Конкуренция по высокочастотным запросам возрастает с неимоверной силой.
Результаты
Авторитетные новостные сайты чаще попадают в ТОП из-за расширенного семантического ядра (наличие огромного количества разных низкочастотных ключевых запросов). Увеличение количества страниц под конкретные поисковые запросы на информационных сайтах стала играть одну из главных ролей после выпуска алгоритма «Рейкьвик». Каждая площадка пыталась попасть в закладки пользователя, чтобы стать частью системы персонализации, для этого использовались методы подписки на RSS ленту, всплывающие баннеры-подсказки для занесения сайта в закладки. Интернет-ресурсы начали больше уделять внимания индивидуальному подходу, а не давить на массы.
Калининград
Алгоритм «Калининград» — глобальная персонализация поиска и поисковой строки, упор на поведенческие факторы. Запуск «Калининграда» в декабре 2012 существенно повысил стоимость seo услуг.
Особенности
Интересы пользователя перевернули с ног на голову всю поисковую выдачу — владельцы сайтов, ранее не заботившиеся о комфорте пребывания посетителя на сайте, стали терять трафик с молниеносной скоростью. Теперь Яндекс делил интересы на краткосрочные и долговременные, обновляя свои шпионские базы раз в сутки. Это означало, что сегодня и завтра по одному и тому же запросу одному и тому же пользователю могла показываться совершенно иная выдача. Интересы теперь играют особую роль и пользователю, который ранее интересовался поездками, вбивая фразу такси — показываются услуги такси, а тому, кто постоянно смотрит фильмы — получит в результатах поиска все о кинокомедии «Такси». В поисковой строке каждого «страждущего найти информацию» теперь на первых позициях отображаются подсказки по предыдущим интересам.
Результаты
Оптимизаторы стали охватывать все больше способов задержать пользователя: улучшалось юзабилити, дизайн, контент создается более разнообразный и качественный. При выходе могли всплывать окна типа «вы уверены, что хотите покинуть страницу» и в пользователя впивалась грустная рожица какого-то существа. Хорошо продуманная перелинковка страниц и всегда доступное меню улучшали показатели активности пользователей, чем повышали позиции сайтов в поисковой выдаче. Малопонятные широкому кругу интернет-пользователей сайты сначала просто понижались в позициях, а после и вообще болтались в конце списка предложенных результатов.
Дублин
Алгоритм «Дублин» — улучшена персонализация с помощью определения текущих целей. Это модернизированная версия «Калининграда» вышла в мир в мае 2013.
Особенности
В технологию внедрена функция слежения за изменчивыми интересами пользователей. То есть при наличии двух совершенно разных поисковых взглядов за определенный период времени, алгоритм предпочтет последний и включит его в поисковую выдачу.
Результаты
Для сайтов практически ничего не изменилось. Продолжается борьба не просто за трафик, а за улучшение поведенческих показателей. Старые макеты сайтов начинают забрасываться, потому что проще делать новый, чем пытаться исправить что-то на старом. Предложение услуг шаблонов сайтов увеличивается, начинается конкуренция за удобные и красивые макеты вебресурсов.
Острова
Алгоритм «Острова» — внедрена технология показа интерактивных блоков в поисковой выдаче, позволяя взаимодействовать пользователю с сайтом прямо на странице Яндекс поиска. Алгоритм был запущен в июле 2013 года, с предложением к вебмастерам активно поддержать бета-версию и использовать шаблоны создания интерактивных «островов». Сейчас технология тестируется в закрытом режиме.
Особенности
Теперь пользователю при поиске информации, которую можно узнать сразу из поиска предлагались «острова» — формы и другие элементы, с которыми можно работать, не посещая сайт. Например, вы ищете конкретный фильм или ресторан. По фильму в поиске и справа от него отобразятся блоки с обложкой фильма, его названием, составом актеров, часами прохождения сеансов в кинотеатрах в вашем городе и формой покупки билетов. По ресторану будет показано его фото, адрес, телефоны, форма бронирования столика.
Результаты
Ничего существенного в ранжировании сайтов сначала не изменилось. Единственное, что стало заметным — это появление вебресурсов с интерактивными блоками на первом месте и справа от поисковой выдачи. Если бы количество площадок, принимавших участие в бета-тестировании было значительным, они могли бы вытеснить обычные сайты за счет своей привлекательности и броскости для пользователей. Оптимизаторы задумались об улучшении видимости своего контента в поисковых результатах, добавляя больше фото, видео, рейтинги и отзывы. Лучше живется интернет-магазинам — корректно настроенные карточки товара могут быть отличным интерактивным «островком».
Минусинск
Алгоритм «Минусинск» — при определении SEO-ссылок как таковых, которые были куплены для искажения результатов ранжирования поиска, на сайт ложился фильтр, который существенно портил позиции сайта. Анонсирован «Минусинск» в апреле 2015, полностью вступил в свои права в мае этого же года. Именно с этим алгоритмом и связана знаменитая Санта Барбара Яндекс.
Особенности
Перед выходом «Минусинска» Яндекс в 2014 для тестирования отключил влияние SEO-ссылок по множеству коммерческих ключей в Москве и проанализировал результаты. Итог оказался предсказуемым — покупная ссылочная масса все еще используется, а для поисковой системы — это спам. Выпуск «Минусинска» знаменовался днем, когда владельцы сайтов должны были почистить свои ссылочные профили, а бюджет, который тратится на ссылочное продвижение, использовать для улучшения качества своего интернет-ресурса.
Результаты
«Авторитетные» сайты, которые добились ТОПа благодаря массовой закупке ссылок, вылетели из первых страниц, а некоторые получили санкции за нарушения правил. Качественные и молодые площадки, не наглеющие по бэклинкам, внезапно оказались в ТОП 10. «Попавшие под раздачу» вебсайты, нежелающие долго ждать, создавали новые площадки, перенося контент и ставя заглушку на старые, либо хитро шаманили с редиректом. Примерно через 3 месяца нашли дыру в алгоритме, позволяющую почти моментально снимать данный фильтр.
Массово начинает дорабатываться юзабилити и улучшаться контент. Ссылки закупаются с еще большей осторожностью, а контроль за бэклинками становится одной из функциональных обязанностей оптимизатора.
По данным на сегодня — при неумелой закупке ссылок — даже за 100 ссылок можно получить фильтр. Но если ссылочную массу правильно разбавлять, то смело можно покупать тысячи ссылок как и в старые добрые. То-есть, по сути — сильно выросли ссылочные бюджеты на это самое разбавление, в роли которого выступил крауд и упоминания.
Владивосток
Алгоритм «Владивосток» — внедрение в поиск технологии проверки сайта на полную совместимость с мобильными устройствами. Полный старт проекта произошел в феврале 2016 года.
Особенности
Яндекс сделал очередной шаг навстречу к мобильным пользователям. Специально для них был разработан алгоритм «Владивосток». Теперь для лучшего ранжирования в мобильном поиске сайт обязан соответствовать требованиям мобилопригодности. Чтобы опередить своих конкурентов в поисковой выдаче интернет-ресурс должен корректно отображаться на любом web-устройстве, включая планшеты и смартфоны. «Владивосток» проверяет отсутствие java и flash плагинов, адаптивность контента к расширению экрана (вместимость текста по ширине дисплея), удобство чтения текста и возможность комфортно нажимать на ссылки и кнопки.
Результаты
К запуску алгоритма «Владивосток» мобилопригодными оказались всего 18% сайтов — остальным пришлось быстренько избавляться от «тяжести» на страницах, которая не отображается или мешает корректно отображаться контенту на смартфонах и планшетах. Основным фактором, который влияет на понижение вебсайта в мобильной выдаче — это поведение мобильного пользователя. Во всяком случае, пока. Ведь идеально мобилопригодных сайтов не так уж много, поэтому свободные места в поиске занимают те, кто способен предоставить пользователю максимально комфортные условия, пусть даже не полностью. Из мобильного поиска неадаптированные к мобильным устройствам сайты не выбрасываются, а просто ранжируются ниже тех, кто достиг в улучшении качества предоставления услуг для смартпользователей лучших результатов. На данный момент самый популярный вид заказов макетов сайтов — адаптивные, а не мобильные, как можно было подумать. Прошедшие все требования алгоритма сайты получают максимальное количество мобильного трафика в своей нише.
Google: история создания и развития алгоритмов
Алгоритмы и фильтры Гугла и до сей поры не совсем поняты русскоязычным оптимизаторам. Для компании Google всегда важным моментом являлось скрытие подробностей по методам ранжирования, объясняя это тем, что «порядочным» сайтам боятся нечего, а «непорядочным» лучше не знать, что их ожидает. Поэтому про алгоритмы Гугла до сих слагают легенды и множество информации было получено только после того, как задавались вопросы поддержке, когда сайт проседал в поисковой выдаче. Мелких доработок у Google было столько, что и не перечесть, а на вопросы, что именно изменилось, зарубежная ПС просто отмалчивалась. Рассмотрим основные алгоритмы, которые влияли на позиции сайтов существенно.
Кофеин
Алгоритм «Кофеин» — на первой странице поиска может находиться сразу несколько страниц одного и того же сайта по бренду, появляется возможность пред просмотра. Запуск произошел в июне 2010 года.
Особенности
Выделение сайтов компаний, в случае поиска по бренду. Возле строки с выдачей появляется «лупа» для предосмотра. Ключевые слова по бренду дают положительную тенденцию роста на позициях интернет-ресурса в целом. Обновился индекс Page Rank, при этом PR повысился на известных и посещаемых площадках.
Результаты
Оптимизаторы стали больше уделять внимания брендированию вебсайтов, включая цветовые схемы, логотипы, названия. Ключевые слова на бренд по-особенному выделяли страницы сайта в поиске, а при переходе с такой фразы посетителя на главный page, его позиции в выдаче росли (если до этого ресурс был не лидером). СЕО-оптимизаторы стали закупать больше ссылок для повышения «цитированности». молодым и малоузнаваемым брендам практически невозможно было пробиться в ТОП выдачи.
Panda (Панда)
Алгоритм «Панда» — технология проверки сайта на качество и полезность контента, включая множество СЕО факторов. Сайты с «черным» SEO исключаются из поиска. Анонсирована «Panda» в январе 2012 года.
Особенности
«Панда» вышла в поиск и почистила его от мусора. Именно так можно сказать после того, как множество не релевантных ключевым запросам web-сайты исчезли из выдачи Google. Алгоритм обращает внимание на: переспам ключевыми словами и неравномерное их использование, уникальность контента, постоянство публикаций и обновления, активность пользователя и взаимодействие его с сайтом. Пролистывание посетителя страницы до конца со скоростью чтения считалось положительным фактором.
Результаты
После включения «Панды» огромное количество сайтов поддались санкциям с боку поисковой системы Google и поначалу все думали, что это связано с участием в ссылочных пирамидах и закупкой ссылочных масс. В итоге, СЕОоптимизаторы провели процесс тестирования алгоритма и проанализировали влияние. Вывод экспериментов заключался в том, что «Панда» все-таки проверяет качество сайта на ценность для посетителей. Интернет-ресурсы перестали копипастить и активно принялись за копирайтинг. Поведенческие факторы улучшались за счет преобразования структуры сайта в более удобные варианты, а перелинковка внутри статей с помощью особых выделений стала важной частью оптимизации. Популярность SEO как услуги стремительно возросла. Замечено, что сайты, не соответствующие правилам «Панды», исчезали из поиска очень быстро.
Page Layout (Пейдж Лайот)
Алгоритм «Пейдж Лайот» — технология по борьбе с поисковым спамом, подсчитывающая на страницах web-сайтов соотношение полезного контента к спамному. Запущен в январе 2012 и обновлялся до 2014 включительно.
Особенности
«Page Layout» был создан после многочисленных жалоб пользователей на недобросовестных владельцев сайтов, у которых на страницах подходящего контента было совсем мало или искомые данные оказывались труднодоступными, а иногда вообще отсутствовали. Алгоритм рассчитывал в процентном соотношении нахождение на странице по входящему запросу релевантного контента и спама. На несоответствующие требованиям площадки накладывались санкции и сайт выбрасывался из поиска. К несоблюдению правил размещения документов также относилось забитая рекламой шапка сайта, когда для просмотра текста требовалось перейти на второй экран.
Результаты
Слишком заспамленные рекламой сайты слетели со своих позиций, даже при том, что контент на страницах был оптимизирован под ключевые слова в меру. Нерелевантные запросам страницы были понижены в поисковой выдаче. Но площадок нагло не соблюдая правила и не беспокоясь о комфортности посетителей оказалось не так уже и много. За три обновления алгоритма приблизительное количество ресурсов, попавших под фильтр, оказалось не более 3%.
(Венеция)
Алгоритм «Венеция» — геопривязка сайта к определенному региону, учитывая при этом наличие названий городов на страницах сайта. Запущен в феврале 2012 года.
Особенности
«Венеция» требовала от вебмастеров наличие на их сайтах страницы «О нас», с указанием адреса местоположения, не обращая при этом внимания, что фактического расположения у компании могло и не быть. В контексте алгоритм искал названия городов, чтобы вывести отдельную страницу по указанному в нем региону. Начала использоваться разметка schema-creator.org, чтобы пояснить поисковому роботу свою географическую привязанность.
Результаты
Сайты выпали в поисковой выдаче по тем регионам, о которых они не упоминают на своих страницах, не учитывая геонезависимые запросы. Оптимизаторы активно включают геозависимые ключевые слова и пытаются создавать микроразметку. Контент на каждой странице персонализируется под каждый конкретный город или регион в целом. Активно стал использоваться локализированный линкбилдинг, чтобы повышать позиции по выбранному региону.
(Пингвин)
Алгоритм «Пингвин» — умная технология определения веса сайтов и качества обратных ссылок. Система редактирования накрученных показателей авторитетности интернет-ресурсов. Запущена в поиск в апреле 2012.
Особенности
«Пингвин» нацелен на войну с закупкой обратных ссылок, неестественным, то есть искусственным, набором авторитетности сайта. Алгоритм формирует свою базу значимых ресурсов, исходя от качества бэклинков. Побуждением на запуск «Пингвина» являлось появление ссылочных оптимизаторов, когда любая ссылка на вебресурс имела одинаковый вес и подымала такой сайт в поисковой выдаче. Кроме этого, в поиске начали ранжироваться наравне со стандартными интернет-ресурсами обычные профили пользователей социальных сетей, что еще больше популяризовало раскрутку обычных сайтов с помощью социальных сигналов. Одновременно с этими возможностями алгоритма система стала бороться с нерелевантными вставками поисковых запросов в keywords и в названия доменов.
Результаты
Пингвин «попустил» множество сайтов в поисковой выдаче за неестественный рост обратных ссылок и нерелевантность контента к запросам пользователей. Значимость каталогов и площадок по продаже ссылок быстро снижалось к минимуму, а авторитетных ресурсов (новостных сайтов, тематических и околотематических площадок) росло на глазах. Из-за введения алгоритма «Пингвин» у, практически, всех публичных сайтов был пересчитан PR. Популярность массовой закупки бэклинков резко упала. Сайты максимально начали подгонять ключевые фразы к контенту на страницах площадок. Началась «мания релевантности». Установка социальных кнопок на страницах в виде модулей имела массовый характер за счет быстрой индексации аккаунтов социальных сетей в поиске.
Pirate (Пират)
Алгоритм «Пират» — технология реагирования на жалобы пользователей и выявления фактов нарушения авторских прав. Старт системы произошел в августе 2012 года.
Особенности
«Пират» принимал жалобы авторов на нарушение их авторских прав владельцами сайтов. Кроме текстов и картинок, основной удар на себя приняли площадки с видео-контентом, которые размещали пиратские съемки фильмов из кинотеатров. Описания и рецензии к видео тоже подверглись фильттрованию — теперь не разрешалось копипастить под страхом наложения санкций. За большое количество жалоб на сайт за нарушения, такая площадка выкидывалась из поисковой выдачи.
Результаты
По результатам первого месяца работы «Пирата» от Google на практически всех сайтах, включая видехостинги и онлайн-кинотеатры, были заблокированы к просмотру миллионы видео-файлов, нарушающих права правообладателей. Вебсайты, имеющие только пиратский контент, оказались под санкцией и выпали из поиска. Массовая зачистка от «ворованного» контента продолжается до сих пор.
HummingBird (Колибри)
Алгоритм «Колибри» — внедрение технологии понимания пользователя, когда запросы не соответствуют точным вхождениям. Запущена система «определения точных желаний» в сентябре 2013 года.
Особенности
Теперь пользователь не изменял фразу, чтобы конкретней найти нужную информацию. Алгоритм «Колибри» давал возможность не искать по прямым точным вхождениям, а выдавал результаты из базы «расшифровки пожеланий». Например, пользователь вбивал в поисковую строку фразу «места для отдыха», а «Колибри» ранжировала в поиске сайты с данными о санаториях, отелях, СПА-центрах, бассейнах, клубах. То есть в алгоритме были сгруппирована стандартная база с человеческими фразами об их описании. Понимающая система изменила поисковую выдачу существенно.
Результаты
С помощью технологии «Колибри» сеооптимизаторы смогли расширить свое семантическое ядро и получить больше пользователей на сайт за счет морфологических ключей. Ранжирование площадок уточнилось, потому что теперь учитывались не только вхождения прямых ключевых фраз и релевантных тексту запросов, но и околотематические пожелания пользователей. Появилось понятие LSI-копирайтинг — написание текста, учитывающего латентное семантическое индексирование. То есть теперь статьи писались не только со вставкой ключевых слов, но и максимально включая синонимы и околотематические фразы.
(Голубь)
Алгоритм «Голубь» — система локализации пользователей и привязки поисковой выдачи к месту нахождения. Технология запущена в июле 2014 года.
Особенности
Месторасположение пользователя теперь играло ключевую роль для выдачи результатов. Органический поиск превратился в сплошную геолокацию. Привязка сайтов к Гугл-картам сыграла особую роль. Теперь при запросе пользователя, алгоритм сначала искал ближайшие по местоположению сайты или таргетированный контент, далее шел на удаление от посетителя. Органическая выдача видоизменилась существенно.
Результаты
Локальные сайты быстро возвысились в поиске и получили местный трафик. Интернет-площадки без геозависимости упали в позициях. Снова началась борьба за каждый город и количественно возросли ситуации, когда начали плодить одинаковые сайты с отрерайченным контентом и привязкой к разной местности. До получения точной информации о внедрении алгоритма «Голубь» в русскоязычном интернет-поиске, многие вебмастера думали, что попали под санкции «Пингвина».
(Дружелюбный к мобильным устройствам)
Алгоритм Mobile-Friendly — внедрение технологии проверки сайтов на адаптивность к мобильным устройствам. Система запущена в апреле 2015 года и успела «обозваться» в интернете как: «Мобильный Армагеддон» (mobilegeddon), «Мобильный Апокалипсис» (mobilepocalyse, mobocalypse, mopocalypse).
Особенности
Mobile-Friendly запустил новую эру для мобильных пользователей, рекомендуя оптимизаторам в срочном порядке обеспечить комфортное пребывание мобильных посетителей на их сайтах. Адаптивность площадок к мобильным устройствам стала одним из важнейших показателей заботы владельцев сайтов о своих посетителях. Неадаптивным веб-площадкам пришлось в кратчайшие сроки исправлять недоработки: избавляться от плагинов, не поддерживающихся на планшетах и смартфонах, корректировать размер текста под расширение разных экранов, убирать модули, мешающие пребыванию посетителей с маленьким экранчиком перемещаться по сайту. Кто-то просто верстал отдельную мобильную версию своего интернет-ресурса.
Результаты
Заранее готовые к такому повороту ресурсы получили особое выделение среди других интернет-площадок в поисковой выдаче, а трафик из разнообразных не декстопных устройств на такие вебсайты повысился более чем на 25%. Совсем неадаптивные сайты были понижены в мобильном поиске. Направленность на мобильность сыграла свою роль — на ресурсах свели к минимуму наличие тяжелых скриптов, рекламы и страницы, естественно, начали грузиться быстрее, учитывая, что большинство пользователей с планшетами/смартфонами используют мобильный интернет, который в разы медленнее, чем стандартный.
Резюме
Вот и все
Теперь вам известно, как по годам развивался поиск как для обычных пользователей, так и для «попавших по раздачу» сайтов. Каждый из вышеперечисленных алгоритмов поиска периодически модернизируется. Но это не значит, что оптимизаторам и вебмастерам стоит чего-то бояться (если конечно вы не используете черное СЕО), но держать ухо востро все же стоит, чтобы неожиданно не просесть в поиске из-за очередного нового фильтра.
Обновленный алгоритм Яндекса
Поисковой алгоритм – это ряд подобранных и разработанных инструкций для поисковой системы. На их основе ранжируются сайты в выдаче, когда поступает запрос посетителя.
Поисковые алгоритмы непрерывно улучшаются, так как важно сделать выдачу релевантнее с каждым разом.
В то время, когда веб-ресурсов было не так много, чтобы продвинуть сайт было достаточно использовать ключевую фразу несколько раз в текстах и сайт уже был в топе поисковика.
А по мере увеличения количества источников, стала распространяться SEO-оптимизация посредством обмана алгоритма.
Поэтому поиск стали улучшать еще в аспекте борьбы с нечестными методами продвижения, вычисляя их.
Используя искусственный интеллект и нейронные сети, придуман обновленный алгоритм от Яндекса – YATI. Предназначен для анализа релевантных статей, чтобы выдать страницы, которые соответствуют запросу пользователя. То есть, если в статье нет точного вхождения в запрос, нейронная сеть найдет нужную информацию, подобно диалогу двух людей, когда один никак не вспомнит название продукта, но подбирает ассоциации:
Развитие у алгоритмов было стремительное и разнообразное, представим это в таблице:
|
Название |
Дата выхода |
Особенности |
|
«Версия 7» |
2.07.2007 г. |
Учитываются ссылки, индексируются изображения, мета-теги, PDF и RTF; Появляется тематический индекс цитирования, учитывается регион поиска. |
|
«Версия 8», «Восьмерка SP1» |
Декабрь 2007 г. |
Авторитетные ресурсы, которым можно доверять, получили преимущества в ранжировании. Введен фильтр для борьбы с накруткой ссылочных факторов. |
|
«Магадан», «Магадан 2.0» |
16.05 и 2.07 2008 года |
Факторы ранжирования увеличены в 2 раза. Расширилась база аббревиатур, синонимов, транслитераций. Расширились классификаторы документов. Добавились факторы, отслеживающие уникальность, коммерческие запросы и геозависимость. |
|
«Находка» |
11.09.2008 г. |
Добавлены стоп-слова, машинное обучение и расширен тезаурус. |
|
«Арзамас/Анадырь» |
10.04.2009 г. (5 обновлений в течение года) |
Снята омонимия, запросы стали геозависимыми. |
|
«Снежинск» |
17.10.2009 г. |
Запущен метод машинного обучения Matrixnet. Понижены в выдаче страницы с объемными текстами и обилием ключевых слов. |
|
«Конаково», «Конаково 1.1» (Снежинск 1.1) |
22.12.2009 г., 10.03.2010 г. |
Расширен учет геофактора, улучшен поиск по геонезависимым запросам |
|
«Обнинск» |
Сентябрь 2010 года |
Улучшено ранжирование по геонезависимым запросам. Расширен словарь и появилось определение автора текста. |
|
«Краснодар» |
15.12.2010 г. |
Внедрена технология «Спектр», которая адаптирует запросы под потребности и категории. |
|
«Рейкьявик» |
17.08.2011 г. |
Шаги к персонализированной выдаче – учеб языковых особенностей пользователя. |
|
«Калининград» |
12.12.12 г. |
Персонализация выдачи для поисковых подсказок и запросов. |
|
«Дублин» |
30. |
Учитываются предпочтения пользователя в режиме реального времени. |
|
«Без ссылок» |
12.03.14 г. |
Ряд ссылочных факторов перестал учитываться при поиске в Москве. |
|
«Острова» |
5.06.14 г. |
Обновлен дизайн выдачи. Появились интерактивные ответы, которыми пользователь мог воспользоваться, не заходя на сам сайт. |
|
«Объектный ответ» |
1.04.15 г. |
Справа от результатов поиска показывается карточка с информацией об интересующем объекте. |
|
«Минусинск» |
15.05.15 г. |
Добавлен фильтр для пессимизации сайтов с большим количеством SEO-ссылок. |
|
«Многорукие бандиты Яндекса» |
14.09.15 г. |
Эксперимент, когда в поисковой выдаче к трастовым сайтам помешивались сайты-новички с низкими позициями. |
|
«Владивосток» |
2.02.16 г. |
Добавлен алгоритм. Выявляющий наличие у сайта мобильной версии. |
|
«Палех» |
2.10.16 г. |
Поиск стал происходить не только по словам в запросе, но и по Title. |
|
«Баден-Баден» |
23.03.17 г. |
Внедрен алгоритм, понижающий страницы с избытком ключевых слов. |
|
«Королев» |
22.08.17 г. |
Поисковик теперь умеет давать ответы на сложные и многозначные запросы. |
|
«Андромеда» |
19.10.18 г. |
Появился алгоритм ранжирования Proxima: значки качества, улучшился сервис быстрых ответов, появилась «Яндекс.Коллекция». |
|
«Вега» |
17.12.19 г. |
Выявляются близкие по смыслу страницы. Внедрилась технология для переранжирования SERP, которая ускоряет поиск. Добавлена экспертность и улучшена гиперлокальность. |
И последнее обновление поискового алгоритма Яндекс – это YATI (Yet Another transformer with Improvement – «еще один преобразователь с улучшением»).
Выход был анонсирован в ноябре 2020 года.
Сам алгоритм разрабатывался в течение 10 лет. Разработчики обещали, что YATI изменит поиск и искать контент станет еще легче и быстрее.
Главными особенностями обновления стали:
1. Внедрена новая архитектура нейросетей-трансформеров:
-
поиск учитывает не только запросы и заголовки, но и весь текст целиком;
-
в тексте выделяются значимые фрагменты;
-
учитывается влияние слов друг на друга.

2. Модель учится предсказывать вероятность клика.
3. Используются оценки на Яндекс Толоке.
4. Используются экспертные оценки релевантности.
5. При поиске учитывается анкор-лист, запросный индекс для URL по кликам.
6. Тексты до 10 предложений учитываются целиком.
Стоит также упомянуть, что алгоритм YATI выступает конкурентом алгоритма BERT от Google. Сам Яндекс позиционирует их алгоритм, как улучшенный алгоритм Гугл. Но скорее такое утверждение работает только в русскоязычном сегменте.
Основополагающая цель, конечно, улучшение поиска для выдачи ответов на многозначные вопросы.
Теперь сайты продвигаются за счет использования высокочастотных запросов без злоупотребления. Но это недостаточно.
Чтобы держать верхнюю строчку в поисковой выдаче, так же нужно:
-
отвечать на запрос развернуто, текст должен содержать не менее 3000 символов;
-
поисковик учитывает время, проведенное на сайте посетителем.
Поэтому сделайте контент захватывающим и оригинальным – подробный текст, но не «простыня», картинки и деление на абзацы;
-
не забывайте о перелинковке – размещайте ссылки в статьях на ваши другие статьи на сайте.
-
Текст понятный, информация легко воспринимается и не используются сложные термины, т.к. это отрицательно сказывается на поведении посетителей.
-
Выделите заголовки и подзаголовки, добавив в них ключи.
-
Используйте для перечисления нумерованные и маркированные списки.
-
Используйте синонимы, слова и фразы из подсветки выдачи. Проверяйте морфологические вхождения ключей. Между ключами вставляйте дополнительные слова для разбавления.
-
Среднечастотные и низкочастотные запросы добавляйте в органическом виде.
Для описания товаров и услуг
-
Составьте подробное описание продукта.
-
Укажите характеристики.
-
Создайте поле для посетителя проголосовать или оставить отзыв.
-
Добавьте параметры продукта – размер, состав, ткань и так далее.
-
YATI сортирует выдачу на 50%, а факторы ранжирования остались теми же.
Новый алгоритм YATI взял на себя только половину работы, остальные методы продвижения так же работают:
-
Поднятие индекса качества сайта с размещением ссылок на сторонних сайтах.
-
Регулярно заполняйте сайт новыми статьями.
-
Позаботьтесь об удобстве меню и доступе к контенту. До статьи не должно быть более трех щелчков.
-
Смотрите за уникальностью. Плагиат понижает вас в выдаче.
-
Размещайте ссылки на свой сайт на сторонних ресурсах, но не переборщите. Лучше разместить на нескольких авторитетных сайтах, чем на множестве бесполезных.
-
Повышайте трафик и время, проведенное на сайте, посредством интересного и уникального контента.
-
Следите за поведенческими факторами, в зависимости от специфики ресурса. После анализа улучшайте сайт и вносите правки в работу ресурса.
-
Не стоит использовать различные способы накрутки, поисковик понижает в выдаче такие сайты.
Новый алгоритм YATI – это анализ контента посредством нейронных сетей, подобно человеку. Впоследствии, в выдаче показывается точная информация, которая дает максимально подходящий ответ на запрос пользователя.
Машинное обучение в Baidu и Яндексе
Когда дело доходит до машинного обучения и SEO, за последнее десятилетие был достигнут ряд успехов, и Google получил широкую огласку и похвалу за такие проекты, как RankBrain, BERT и SMITH.
При этом они не единственная поисковая система в мире, добившаяся больших успехов в развитии машинного обучения.
За тот же период времени, что и Google, Яндекс включил аналогичные проекты в свои процессы ранжирования, такие как MatrixNet, Палех и его вторая, более усовершенствованная итерация Королев, а совсем недавно — ЯТИ. Baidu также принимала участие в разработке технологий машинного обучения для поиска, причем их наиболее известной моделью машинного обучения является ERNIE.
В этой статье я использую слово «Трансформер» несколько раз, и я думаю, что важно иметь общее представление о том, что такое «Трансформер», и как такие модели, как BERT и SMITH, связаны с YATI. и ЭРНИ.
Что такое трансформаторы?
Проще говоря, преобразователь — это модель глубокого обучения, которая используется в рекуррентных нейронных сетях (RNN) для обработки задач, связанных с последовательными данными и естественным языком.
Они облегчают нечто, известное как распараллеливание, означающее, что входные данные не нужно обрабатывать по порядку, что позволяет обрабатывать и поддерживать гораздо более крупные наборы данных большего масштаба.
Таким образом, мы получили в SEO предварительно обученные системы, такие как BERT, GPT и SMITH.
Что такое ЯТИ (Яндекс)?
С 2017 года от Яндекса было мало новых технологий машинного обучения, но в конце 2020 года Яндекс запустил YATI, новый алгоритм ранжирования, основанный на преобразовании нейронных сетей.
YATI расшифровывается как «Еще один трансформер с улучшениями».
Возможно, это звучит не слишком поэтично, но это было провозглашено самым значительным и влиятельным изменением, которое Яндекс внес в свои алгоритмы ранжирования поиска с момента появления MatrixNet в 2009 году..
Со всеми новыми достижениями поисковых систем машинное обучение не заменяет переменные и параметры, с которыми мы работали раньше, а делает их лучше.
Как и Google, Яндекс полагается на ряд алгоритмов для улучшения результатов поиска для пользователей, но с 2016 года и внедрения нейронных сетей в свой алгоритм Яндекс строит гораздо более сильный алгоритм.
Как YATI повлияет на оптимизацию Яндекса
Основываясь на информации и заявлениях Яндекса, связанных с раскрытием YATI на ЯК2020, на новый компонент алгоритма машинного обучения будет приходиться более 50% окончательного взвешивания.
Это означает, что благодаря лучшему пониманию веб-документов и текстов внесение небольших изменений в страницы, таких как изменение тегов заголовков, добавление большего количества ключевых слов и даже доменов с точным соответствием, больше не будет столь эффективным (в зависимости от конкуренции и ниши). .
Как упоминалось ранее, это не означает, что теперь больше не нужны сильные технические, внутренние и внешние ресурсы. Теперь это только усложняет игру в систему.
Можно ли оптимизировать для YATI?
Так как YATI — это эволюция алгоритмов Яндекса, а не революция, то общие принципы оптимизации Яндекса по большей части остаются, а если что, то только усиливаются.
Заполнение пробелов в темах контента
Помимо ключевых слов и тем, вы должны убедиться, что ваш контент так же богат ими, как и ваши конкуренты.
Хорошим примером этого является ситуация, когда вы пытаетесь привлечь пользователей, желающих купить протеиновые порошки и коктейли-заменители пищи, и вы не говорите об их ингредиентах, разбивке по калориям, солям и сахарам или о том, как они производятся, но ваши конкуренты производят, вы лишний в наборе данных.
Улучшение структуры длинного текста
Разделение фрагментов текста заголовками может помочь пользователям просматривать и находить нужные части текста, которые они хотят прочитать, а также добавить структуру для поисковых систем.
Основываясь на документации по YATI, в российском поисковом сообществе широко распространено мнение, что разделение текста, состоящего из 250–300 слов, заголовком может принести пользу.
Что такое ЭРНИ (Baidu)?
Переходя от достижений Яндекса в области машинного обучения, я собираюсь взглянуть на ERNIE.
Baidu, как и Google и Яндекс, имеет опыт работы с искусственным интеллектом и машинным обучением, а в 2016 году открыла исходный код платформы PaddlePaddle.
PaddlePaddle использовалась внутри Baidu в течение нескольких лет для помощи в разработке алгоритмов и технологий для улучшения их поискового продукта, масштабируемой классификации изображений, машинного перевода текстов и их рекламной платформы.
ERNIE (версия 1.0) был представлен в PaddlePaddle и в более широкой экосфере Baidu) в начале 2019 г., а обновленная версия (2.0) выйдет примерно в июле того же года.
ERNIE превзошел BERT и XLNet на момент своего появления в 16 задачах НЛП и возглавил общедоступную таблицу лидеров GLUE.
XLNet, являющийся совместным предприятием Google и Университета Карнеги-Меллона, в то время XLNet превзошел BERT.
Помимо помощи в развитии технологий и поисковых продуктов, еще одним важным продуктом ERNIE является система DuTongChuan, которая является первой моделью синхронного перевода с учетом контекста.
Воздействие ERNIE
ERNIE является активной частью более широкого поискового алгоритма Baidu и используется как для общих результатов поиска, так и для улучшения диверсификации новостных лент путем удаления повторяющихся статей (несмотря на разные заголовки).
ЭРНИ также играет активную роль в AI-помощнике Baidu, Сяо Ду.
Используя модели реального времени, подобные DuTongChuan, Сяо Ду использует ERNIE, чтобы лучше понимать и более точно отвечать на голосовые запросы.
Много литературы, опубликованной вокруг ERNIE, посвящено тому, как он работает и обрабатывает данные.
Фактическое влияние, которое это оказало на поиск Baidu в целом, неизвестно, однако мы также должны помнить, что результаты поисковой выдачи Baidu заполняются совершенно иначе, чем Google и Яндекс в данный момент времени.
Baidu извлекает ряд расширенных фрагментов из других своих продуктов, таких как Baike, Zhidao и Tieba, а это означает, что обычные запросы могут быть только одним или двумя результатами на первой странице.
Можете ли вы оптимизировать для ЭРНИ?
Как и другие алгоритмы машинного обучения, применяемые в поиске, ERNIE представляет собой эволюцию существующих принципов.
Базовые алгоритмы Baidu (Money Plant, Pomegranate, Ice Bucket) уже несколько лет побуждают веб-мастеров создавать более удобные веб-интерфейсы для пользователей, и теперь ERNIE укрепляет эти принципы и вознаграждает веб-сайты, которые инвестировали в пользовательский опыт поиска. , а не просто пытался в нее поиграть.
История поисковых систем
Введение Поисковые системы играют неотъемлемую роль в жизни многих из нас, иногда сами того не осознавая. Покупка на Amazon обычно начинается с поиска товара. Бронирование нового отпуска часто начинается с поиска отеля. Ответ на любой вопрос находится на расстоянии простого поиска в Интернете. Мы смотрим на историю одного типа поисковой системы — веб-поисковика.
Интернет существовал много лет до появления первой веб-страницы. Первоначально это был военный проект США в DARPA, затем он использовался как способ обмена академическими и научными знаниями. Интернет, каким мы его знаем, работает на TCP/IP, технологии, изобретенной в 1974 году Бобом Каном и Винтом Серфом (ныне работающим в Google). [1]
Тим Бернерс-Ли Всемирную паутину изобрел английский ученый сэр Тим Бернерс-Ли в 1989 во время работы в CERN в Швейцарии. В нем использовалась технология под названием «Протокол передачи гипертекста» (HTTP), которая передавала данные по протоколу TCP/IP, поэтому все URL-адреса и по сей день начинаются с «HTTP». Чтобы упростить взаимодействие с HTTP, Бернерс-Ли создал первый в мире веб-сервер и веб-браузер для навигации по нему в 1990 году. Он также изобрел HTML (на основе разметки SGML CERN) для форматирования текстового контента, распространяя технологию за пределами CERN. в 1991 году. Бернерс-Ли заявил, что технология должна оставаться в свободном доступе, без патентов или лицензионных отчислений, чтобы быть доступной для всех.
Группы новостей Usenet были способом общения пользователей Интернета за десять лет до изобретения Интернета. Даже после широкого внедрения технологии сэра Тима Бернерса-Ли веб-страницами часто делились и ссылались на них в группах новостей по интересам. Некоторые пользователи начали создавать веб-страницы, которые объединяли URL-адреса, общие в группах новостей, в каталоги или каталоги. Вместо того, чтобы загружать каждое сообщение в группе новостей и искать в них информацию или URL-адреса, теперь пользователи могли посещать каталог/портал и перемещаться по категориям, чтобы найти соответствующие веб-страницы.
Проект Open Directory Одним из самых известных каталогов был DMOZ (или проект Open Directory), созданный в 1998 году двумя инженерами Sun Microsystems. Каталог стал для многих стандартным способом поиска информации в Интернете с функцией поиска для более быстрой навигации по каталогам.
DMOZ был приобретен Netscape позже в том же году, проиндексировав (перечислив) около 100 000 URL-адресов. Год спустя в каталоге DMOZ было указано более миллиона URL-адресов, а его пиковое значение достигло более пяти миллионов URL-адресов, прежде чем он закрылся в 2017 году. Цели каталога стали размытыми, когда AOL приобрела Netscape, и стоимость его бесплатного использования стала под вопросом.
Добровольные редакторы каталога почувствовали себя преданными, став бесплатными работниками AOL, а не благородной, свободной и открытой инициативой. Создателям коммерческого контента, таким как CNN, были предоставлены редакционные права на добавление/редактирование/удаление записей, что поставило под вопрос беспристрастность проекта. Было обнаружено, что редакторы продают включение в каталог после того, как ходили слухи, что листинг DMOZ повышает рейтинг веб-сайта в поисковых системах.
AOL несколько раз не удалось реанимировать DMOZ, и в итоге веб-сайт отключился. Каталог, основанный на исходной базе данных DMOZ и поддерживаемый бывшими редакторами DMOZ, до сих пор существует на Curlie.org.
Арчи не был первой поисковой системой в ИнтернетеТест в пабе скажет вам, что Арчи был первой поисковой системой, что технически верно. Но Archie, созданный в 1987 году в Университете Макгилла, был разработан для поиска файлов в Интернете (FTP-серверы), а не контента во всемирной паутине.
W3Catalog (первоначально называвшийся «Jughead») был позже запущен в сентябре 1993 года Оскаром Нирстразом из Женевского университета. Служба в основном брала существующие списки/каталоги веб-страниц и делала их доступными для поиска в стандартизированном формате.
Aliweb (Archie Like Indexing for the Web) считается первой поисковой системой в Интернете. Запущенный в ноябре 1993 года, Aliweb позволял веб-мастерам отправлять свои веб-страницы и вводить соответствующие ключевые слова и описания для этих страниц. Однако поисковая система была в значительной степени забыта, поскольку в то время пользователи Интернета по-прежнему предпочитали перемещаться по веб-сайтам, используя каталоги, списки и каталоги.
WebCrawler была первой широко используемой поисковой системой, а также первой, которая полностью индексировала содержимое веб-страниц, делая возможным поиск по каждому слову и фразе. Он был разработан в Вашингтонском университете и запущен в 1994 году, в том же году, что и Lycos из Университета Карнеги-Меллона. И WebCrawler, и Lycos стали коммерческими предприятиями, причем WebCrawler поддерживали два основных инвестора, одним из которых был соучредитель Microsoft Пол Аллен.
Lycos вложила значительные средства в свой бренд, разместив телевизионную рекламу с изображением своего культового черного лабрадора, а также наняв большую команду добровольцев и платных редакторов для своего веб-каталога.
1995 — Рассвет поисковых систем
Рождение Excite, AltaVista и Yahoo Через два года после Aliweb поисковые системы стали массовым и крупным бизнесом. Excite и AltaVista были запущены в 1995 году вместе с менее известными MetaCrawler, Magellan и Daum. Но самым значительным успехом стала Yahoo, основанная Джерри Янгом и Дэвидом Фило.
«Яху!» в 1994 году два выпускника Стэнфордского университета создали традиционный веб-каталог, а в 19 году запустили поисковую систему.95. К неудовольствию своих менее известных конкурентов, Yahoo не создала никаких значительных новых технологий. Они покупали и заимствовали сторонние технологии, пока в 2002 году не приобрели Inktomi (поисковую систему по найму). Успех Yahoo был полностью связан с упаковкой, с забавным брендом и удобным интерфейсом.
Подключенные к Интернету компьютеры стали широко доступны в школах, библиотеках и домах по всему миру. Новое поколение начало использовать веб-сайты больше, чем книги, и поисковые системы больше, чем веб-каталоги. Доминировали Yahoo, AltaVista и Lycos, при этом значительные инвестиции поддерживали убыточные сайты.
Кто такая Робин Ли?
(Ли Яньхун / 李彦宏) Он держал голову опущенной
«Робин» Ли Яньхун в основном неизвестен в западном мире, но является одним из самых богатых людей в Китае, его состояние оценивается в девятнадцать миллиардов долларов.
Его родители были фабричными рабочими, и у него было еще четверо детей, о которых нужно было заботиться. Они помогли Ли поступить в Пекинский университет, где он изучал управление информацией. Затем Ли продолжил обучение в Университете Буффало в Нью-Йорке, где получил докторскую степень в области компьютерных наук. После окончания университета Ли присоединился к подразделению Dow Jones в Нью-Джерси, где он разработал программное обеспечение для управления онлайн-изданием The Wall Street Journal.
В 1996 году Ли создал и запатентовал систему под названием RankDex для ранжирования важности веб-страниц в результатах поиска. Впервые он использовал «анализ ссылок» для определения важности веб-страниц по количеству других страниц, ссылающихся на них.
RankDex сегодня является основой алгоритма ранжирования каждой крупной поисковой системы. Он появился на два года раньше Google PageRank и упоминается в первом патенте Ларри Пейджа. Без RankDex поисковые системы могут по-прежнему использовать ключевые слова, а не ссылки, в качестве основного фактора ранжирования сегодня.
Вскоре после вступления в новое тысячелетие Робин Ли и Эрик Сюй основали и зарегистрировали крупнейшую поисковую систему Китая Baidu. Точно так же, как PageRank — это душа Google, RankDex — это душа Baidu и отец современных алгоритмов ранжирования в поисковых системах.
Почему бы тебе не спросить Дживса?Так же, как Boo.com «опередил свое время» в электронной коммерции (трехмерные вращающиеся изображения продуктов в 1998 году?!), Ask Jeeves опередил свое время в поиске. Поисковик запущен в 1997, с уникальной способностью отвечать на вопросы.
До сих пор пользователям приходилось тщательно обдумывать, какие «ключевые слова» следует искать в AltaVista, Yahoo и Excite, чтобы получить полезную страницу результатов. Типичная поисковая система будет придавать каждому слову в вопросе одинаковый вес и важность, часто возвращая нерелевантные результаты. Программа Ask Jeeves смогла выделить важные слова и основной смысл вопроса, что дало гораздо более релевантные результаты. Он стал чрезвычайно популярным благодаря растущему числу неспециалистов, занимающихся серфингом в Интернете, которые не привыкли думать, как компьютер.
Компания была приобретена IAC (Match.com) в 2005 году, но ей было трудно конкурировать с более крупными конкурентами, такими как Google. В 2006 году он был переименован в Ask.com, чтобы сэкономить на гонорарах за имущество П. Г. Вудхауза (Дживс был персонажем дворецкого в одной из его книг) и выглядеть более современным [2] . В 2010 году Ask уволил свою поисковую группу и передал ее на аутсорсинг другому поставщику поисковых систем.
Технология поисковой системы Teoma, которую они приобрели, испытывала трудности с ранжированием и индексированием релевантных страниц в постоянно расширяющейся сети. Получение дохода также, казалось, имело приоритет над пользовательским опытом. Рекламные объявления потребляли страницы результатов поиска, когда у Google в то время был чистый, быстрый и относительно свободный от рекламы внешний вид. Любой поисковый запрос, связанный с компьютером, в Ask Jeeves вернет страницу с рекламой Dell, что усложнит поиск обычных результатов.
Спустя год после отказа от поисковых технологий генеральный директор Ask Дуг Лидс сказал, что они по-прежнему предоставляют поиск более чем 100 миллионам человек каждый месяц. Возможно, если бы Ask продолжал развивать свою технологию, они были бы лидерами голосового поиска сегодня, где поиск на основе вопросов является ключевым.
Рождение гиганта-монополиста
Google Первоначально названный «Backrub» из-за алгоритма ранжирования на основе ссылок, Google был основан Ларри Пейджем и Сергеем Брином в Стэнфордском университете. Играя на термине «гугол» (10 в степени 100), у компании с самого начала были большие амбиции. Пейдж и Брин получили начальные инвестиции в размере 100 000 долларов от соучредителя Sun Microsystems Энди Бехтольшайма еще до того, как компания была зарегистрирована. В ходе раунда посевного финансирования было привлечено в общей сложности 1 миллион долларов, большая часть из которых поступила от трех ключевых инвесторов. Одним из таких инвесторов был Джефф Безос, основатель перспективного книжного интернет-магазина Amazon.
Google относительно поздно пришел к поисковой группе, опираясь на несколько существующих идей в 1996 году и запущенный в конце 1997 года. Другие поисковые системы начали страдать от спама и проблем с релевантностью, что должно было стать золотой пулей Google и секретом их успех.
Фото: Стив Джурветсон — первая серверная стойка Google
Поисковая оптимизация сделала Google гигантом Поисковая оптимизация началась как хобби любознательных веб-мастеров, которые интересовались, как поисковые системы оценивают порядок веб-страниц в своих результатах. Старые поисковые системы в значительной степени полагались на доверие к метатегу «ключевое слово» на веб-странице, чтобы сообщить ему, какие поисковые запросы по ключевым словам отображать на странице. Это требовало определенного уровня доверия к веб-мастерам, чтобы они вводили только релевантные ключевые слова. Новые поисковые системы использовали содержимое веб-страницы для определения ее важности, часто подсчитывая количество раз, когда ключевое слово появлялось на странице. Оба они использовались сначала для развлечения, а затем для получения прибыли. Веб-сайты будут перечислять все мыслимые ключевые слова в своих метатегах и контенте, повторяя одни и те же ключевые слова несколько раз. Эти уродливые списки часто были скрыты внизу страницы или шрифтом того же цвета, что и фон, что делало их невидимыми.
Основатель Baidu Робин Ли был одним из первых, кто решил эту проблему с помощью RankDex, который использовал ссылки с других веб-сайтов в качестве оценки важности. Новые поисковые системы перешли на эту модель цитирования на основе ссылок, но считали все ссылки равными. Некоторые веб-мастера воспользовались этим, создав веб-страницы с тысячами ссылок, и все они указывали на другие их веб-сайты.
Ларри Пейдж решил эту проблему с помощью своей формулы PageRank, которая учитывала не только количество обратных ссылок на странице, но и важность этих ссылающихся страниц. Ссылка с BBC была важнее, чем ссылка со страницы спам-хаба, поскольку тысячи других сайтов будут ссылаться на эту страницу BBC, и многие из этих сайтов сами будут иметь тысячи релевантных ссылок. Веб-мастерам было трудно манипулировать этим волновым эффектом, поскольку каждая ссылка требовала множества уровней других ссылок, указывающих на нее, чтобы дать ей право поднять веб-страницу вверх в рейтинге. [3]
Результаты без спама становились все более важными, поскольку Интернет все больше использовался в коммерческих целях. Поиски научных статей с одним или двумя результатами были заменены десятками тысяч поисков в месяц [автострахования], [дизайнерской одежды] и [кредитных карт], каждый из которых содержал сотни тысяч конкурирующих страниц. У Google была волшебная формула для отсеивания спамных страниц с ключевыми словами SEO и ранжирования более надежных веб-сайтов в первую очередь.
Украденная идея на триллион долларов
В поисках прибыли Если формула ранжирования PageRank была золотой пулей Google, то «AdWords» был порохом, который ее выстрелил. Вычислительная мощность, необходимая для сканирования растущей сети и построения сложного графа ссылок Пейджа, стоила недешево, и все инвесторы ожидали хорошей окупаемости своих инвестиций.
Реклама была сложной проблемой в 1999 году. Поисковые системы должны были размещать рекламные баннеры в своих результатах поиска, чтобы платить за свою инфраструктуру, но рекламные баннеры отвлекали пользователей и замедляли их страницы результатов. Ask Jeeves и Yahoo начали экспериментировать с платным включением, когда веб-сайты могли платить за более высокий рейтинг в результатах поиска или гарантию попадания в список.
GoTo.com был второстепенным игроком на рынке, купив одну из старейших компаний, занимающихся поисковыми технологиями, World Wide Web Worm. Их умение заключалось в монетизации поисковых запросов: в 1998 году они создали первую систему аукционов объявлений, в которой компании делали ставки по ключевым словам. Вместо того, чтобы платить за просмотры баннеров, компании будут платить до 1 доллара за клик в списке результатов поиска премиум-класса. В 2001 году компания была переименована в Overture и начала продавать свое рекламное решение в MSN и Yahoo, монетизируя сотни миллионов поисковых запросов в день. Это значительно превысило доход от их собственной поисковой системы GoTo, но также дало им капитал для приобретения конкурирующих поисковых систем, AltaVista и AllTheWeb. Другие поисковые системы покупались за статус и трафик; эти покупки были чисто коммерческими, увеличивая охват рекламной платформы Overture и сохраняя 100% дохода.
Google AdWords был запущен в октябре 2000 г., первоначально на основе CPM (цена за тысячу показов), а в 2002 г. перешел на PPC (оплата за клик). Модель PPC была удивительно похожа на запатентованную рекламу Overture. Платформа. Позже в том же году Overture подала иск, утверждая, что Google украла их запатентованную технологию.
В 2003 году Yahoo купила Overture за 1,63 миллиарда долларов. Это защитило рекламную платформу, которая приносила большую часть дохода Yahoo, а также увеличило их долю на рынке за счет портфеля поисковых систем, ранее приобретенного Overture. Затем, в 2004 году, Google урегулировала судебный процесс с недавно приобретенной Overture, предложив Yahoo 2,7 миллиона акций GOOG в качестве компенсации. При сегодняшней оценке акций и учете дробления акций Google в 2014 году эти акции будут стоить 6,9 доллара.миллиард. [4]
В последующие годы Yahoo испытывала трудности, делая плохие инвестиции, приобретения и бизнес-приоритеты. Веб-сайты для ведения блогов, обмена фотографиями и аукционов были приобретены, а затем оставлены на произвол судьбы, в то время как конкурирующие веб-сайты превратились в предприятия с оборотом в миллиарды долларов. Поисковые пользователи уходили толпами, как и партнерские поисковые системы, которые ранее работали на базе Yahoo. Наконец, в 2017 году компания была приобретена Verizon всего за 4,5 миллиарда долларов.
Как это снова называется?
Борьба Microsoft за доминирование Ничто так не символизирует панику и нерешительность, как падение Microsoft в мир поисковых систем. Поиск MSN был запущен в 1998 году вслед за Google, когда операционную систему Microsoft Windows использовали более 90% американцев. Первоначально MSN использовала результаты поиска Inktomi (поисковая система по найму), которая также работала на Yahoo. Они пытались выделиться, смешивая результаты Looksmart, а затем результаты AltaVista со своим сервисом, но с ограниченным успехом.
В 2004 году Microsoft, наконец, вложила в поиск нужные ей средства, разработав внутреннюю технологию поисковой системы и запустив ее в эксплуатацию в 2005 году. Самый значительный успех MSN в то время был в мире B2B, в котором Microsoft чувствовала себя комфортно. технологии другим поисковым системам, интернет-провайдерам и порталам, увеличивая долю рынка и уменьшая доходы от рекламы.
Как только поиск MSN начал набирать обороты (чему способствовало то, что он стал домашней страницей по умолчанию для миллионов браузеров Internet Explorer), Microsoft совершила харакири, переименовав службу в «Microsoft Live» в 2006 году. кроме укрепления бренда «Windows» компании и придания ему современного вида. Всего год спустя компания снова провела ребрендинг своей поисковой системы, удалив упоминание «Windows» и назвав ее «Live Search».
Бывший руководитель поисковой отрасли Дэнни Салливан:
«Почему бы не вернуться к MSN или Microsoft Search? Почему бы не изменить его — или он изменится?»
Кевин Джонсон из Microsoft ответил:
«У нас есть возможность исправить эти бренды. Мы признаем, что нам нужно это исправить. Если у вас есть предложения, мы их примем».
В 2009 году Microsoft объявила, что Live Search будет в последний раз переименован в Bing. С годами изменения бренда и качество результатов поиска Microsoft стали предметом насмешек, но в последующие годы Bing стал серьезным соперником Google. Он редко занимал более 10% рынка в США, но конкурировал с Google и часто превосходил его в слепых сравнениях результатов и исследованиях удовлетворенности пользователей. В том же году, когда был запущен Bing, Microsoft подписала соглашение со своим ближайшим конкурентом поисковой системы, чтобы улучшить результаты поиска Yahoo. По сей день Yahoo по-прежнему работает на базе Bing™. [5]
Фото: Si1very — Дэнни Салливан и Кевин Джонсон
Яндекс (Яндекс на русском языке)
Поиск в РоссииСообщил Константин Канин
Яндекс стал публичным в 1997 году и стал лидером рынка в России в 2001 году. В то время существовали и другие российские поисковые системы, такие как Aport.ru и Rambler.ru, но позже они превратились в торговую площадку и медиа-портал соответственно.
Доминирование Яндекса над Google в России связано с тем, что он лучше понимает морфологию русского языка, что приводит к более точным результатам поиска для российских веб-сайтов. Затем компания выпустила конкурирующие продукты Maps и Market/Shopping, которые также были лучше адаптированы к потребностям российских пользователей. Поначалу Google не казался очень заинтересованным в российском рынке, что позволило Яндексу стать настолько доминирующим. По мере роста Яндекса поиск стал частью гораздо большей экосистемы продуктов компании.
Однако российские интернет-пользователи уже несколько лет пользуются двумя поисковиками. Благодаря распространению Android и Chrome Google удалось отвоевать большую долю поиска, в частности, среди молодых и более продвинутых пользователей. В какой-то момент Google даже обогнал Яндекс по мобильному поиску, но затем снова потерял лидерство.
Принимая во внимание текущую глобальную тенденцию к ужесточению регулирования общенациональных сегментов Интернета, я бы предсказал, что Яндекс получит еще большую долю рынка по сравнению с Google.
Одни из лучших в мире технологий машинного обучения и распознавания речи разрабатываются в России. У Яндекса есть собственный голосовой помощник, который также считается одним из лучших. Конечно, через 5-10 лет мы будем пользоваться поиском по-другому, и я уверен, что в технологическом плане Яндекс будет одним из ведущих игроков, как в России, так и в мире.
Думаю, секрет успеха Яндекса прост: они делают первоклассный продукт, полностью адаптированный к привычкам и потребностям локального пользователя. Яндекс стал частью русской интернет-культуры — не только поисковик, но и его продукты «Карта», «Маркет/Покупки», «Такси» и «Голосовой поиск».
Фото: Константин Канин
Baidu — Китайский Google
Непреодолимая силаУ Baidu впечатляющая родословная с момента запуска в 2000 году как поисковой системы, ориентированной на Китай. Компания была основана Робином Ли, который вдохновил Ларри Пейджа из Google и его патент PageRank. Идея RankDex Ли о ранжировании страниц на основе их ссылочного профиля была опубликована еще в 1996 году, но теперь Ли играл в догонялки с уже популярным Google.
Рост поисковой системы был обеспечен доходами от рекламы и соблюдением требований китайского правительства. Baidu запустила свою рекламную платформу с оплатой за клик на основе аукциона раньше Google, но не столкнулась с тем же судебным иском о нарушении патентных прав от Overture, что и Google. Он также выполнил требования китайского правительства о цензуре ключевых слов и источников новостей, которые Google либо отклонил, либо сопротивлялся. Выделенный в 2009 году внутренним документом, просочившимся в сеть, у Baidu был длинный список ключевых слов, тем и веб-сайтов, которые не должны давать никаких результатов. В него вошли новостные сайты, которые критиковали правительство, гражданские права, протесты, этнические конфликты, демократию и имена лидеров Китая. [6] Это было необходимым злом, чтобы у поисковой системы был хоть какой-то шанс добиться успеха в «Великом китайском брандмауэре».
Google запустил свою поисковую систему для упрощенного и традиционного китайского языка в том же году, что и Baidu. Китайское правительство периодически блокировало веб-сайт .com, поэтому Google запустил цензурированную версию своей поисковой системы по адресу Google.cn. Однако отношения продолжали оставаться непростыми, и Google прекратил цензуру в 2010 году после атаки хакеров, связанных с китайским правительством. [7] Он изо всех сил пытался сохранить значительную долю рынка, поскольку веб-сайт неоднократно блокировался, а китайские пользователи предпочитали собственные альтернативы, такие как Baidu.
Сообщил Allen Qu (渠成)
Baidu уже долгое время является доминирующим игроком в Китае. Но до того, как Google покинул китайский рынок, у него было почти 50% рынка. Sogou и 360 Search также популярны в Китае, получая большую часть своего трафика за счет создания собственных веб-браузеров.
Теперь Baidu сталкивается с новым вызовом от Toutiao Search, популярность которого растет. До него еще далеко, но он может составить конкуренцию Baidu в ближайшие 3-5 лет.
В Китае совершенно другая интернет-среда как с политической, так и с культурной точек зрения. Таким образом, международным игрокам, таким как Google, очень сложно выжить на рынке. Конкурируя с отечественными игроками, у Baidu действительно было много преимуществ перед американскими конкурентами.
Голосовой поиск становится все более распространенным в Китае, но благодаря Baidu Smart Speaker, а не Amazon Alexa или Google Assistant.
Фото: Аллен Ку (渠成)
Безумный мир DuckDuckGo
DuckDuckGo после конфиденциальностиЗапущенный в начале 2008 года, DuckDuckGo было трудно воспринимать всерьез. Поисковик был основан Габриэлем Вайнбергом, который недавно закончил магистратуру в Массачусетском технологическом институте и потерпел неудачу при запуске новой социальной сети. Сначала не было финансовой поддержки, и результаты поиска в основном были связаны друг с другом из API других поисковых систем. Зачем людям это использовать? УТП было конфиденциальностью — ваши поиски не отслеживались и не записывались, как в большинстве других поисковых систем.
Двумя годами ранее AOL опубликовала в исследовательских целях файл данных с историей поиска за три месяца. Он включал 20 миллионов поисковых запросов от 650 000 пользователей. Хотя данные учетной записи искателя не отображались, им был присвоен случайный идентификатор, который позволял исследователям группировать поиск по отдельным пользователям. Некоторые поиски включали PII (личную информацию), и личность некоторых пользователей была раскрыта. Беспокойство по поводу конфиденциальности поиска перестало быть параноидальной проблемой технарей и стало общепринятым.
В течение следующих нескольких лет DuckDuckGo начал привлекать культ поклонников, озабоченных конфиденциальностью. Google и Facebook начали раскрывать свои карты как сборщики и продавцы персональных данных. В 2011 году Union Square Ventures вложила деньги в DDG: «Не потому, что мы думали, что она превзойдет Google. Мы инвестировали в него, потому что есть потребность в частной поисковой системе. Мы сделали это для интернет-анархистов, людей, которые тусуются на Reddit и Hacker News». К 2012 году поисковая система объявила, что обслуживает 1,5 миллиона поисковых запросов в день и зарабатывает 115 000 долларов на рекламе, не нарушающей конфиденциальность.
Год спустя газеты The Guardian и The Washington Post опубликовали разоблачение операции АНБ под названием PRISM. Слайды Powerpoint, опубликованные Эдвардом Сноуденом, показывают, как крупные технологические компании передавали пользовательские данные и историю поиска американской разведке. В нем говорится, что «98% данных PRISM получены от Yahoo, Google и Microsoft». В том году DuckDuckGo совершало 4 миллиона поисковых запросов в день. [8]
Спрос был достаточен для того, чтобы браузеры Firefox и Safari предоставили DuckDuckGo в качестве опции поисковой системы по умолчанию в 2014 году. Google последовал этому примеру только в 2019 году..
DuckDuckGo теперь отвечает на 1,8 миллиарда поисковых запросов в месяц и имеет долю на рынке США 1,24% (у Yahoo 3,65%). [9]
Мобильный поиск опережает рабочий стол
Мобильный поиск Люди могли выполнять поиск в Интернете на своих мобильных устройствах еще до того, как был изобретен Google, а сам поисковый гигант запустил свой WAP-сайт для мобильных пользователей в 2000 году. WAP-телефоны превратились в «функциональные телефоны». Например, Blackberry с предустановленными приложениями для поиска и неудобной навигацией с помощью физической клавиатуры телефона или «трекбола», если повезет. У каждого производителя устройств и телекоммуникационной компании были свои предложения по предварительной установке поисковой системы на свои телефоны в обмен на долю дохода или контрактную сделку.
Смартфоны стали катализатором поистине неограниченного поиска и работы в Интернете, благодаря чему маленький компьютер теперь есть в каждом кармане. Но также произошел крах разнообразного рынка телефонов и программного обеспечения, на котором конкурировали десятки производителей оборудования и программного обеспечения. Когда-то мощные Nokia и Motorola потеряли свое преимущество и в конечном итоге были приобретены Microsoft и Google соответственно. Microsoft не смогла закрепиться на рынке телефонов, потеряв доходы от оборудования (Nokia), программного обеспечения (Windows Mobile) и поиска (Bing).
Это сделало мощь поисковых систем еще более выгодной для Google. Apple (iPhone) и Google (Android) были королями мобильных устройств. На большинстве Android-смартфонов был предустановлен Google Chrome, а поисковой системой по умолчанию был Google. Что еще хуже для Bing и Yahoo, Google подписала соглашение с Apple, чтобы сделать их поисковую систему по умолчанию также и в браузере Safari на iPhone, по сообщениям, платя за эту привилегию 9 миллиардов долларов в год. [10]
В 2015 году Google объявил, что количество поисковых запросов на мобильных устройствах впервые превысило количество на настольных компьютерах в 10 странах, включая США и Японию. [11] Эта тенденция продолжается и сегодня: мобильные телефоны и планшеты становятся основными поисковыми устройствами в домах людей.
Голосовой поиск Голосовой поиск — это следующий этап поиска, позволяющий пользователям задавать свои вопросы «умному устройству» вместо того, чтобы вводить ключевые слова в веб-браузере. На данный момент в голосовом поиске больше шумихи, чем смысла. Он подходит для запросов, которые имеют только один ответ, например «Какая столица Франции?», но не может конкурировать с браузером, когда пользователь ожидает много результатов или подробной информации. Это новинка — разрешать споры, включать музыку, сохранять взгляды на часы или переключаться на The Weather Channel.
Microsoft должна надеяться, что голосовой поиск останется в моде, а их голосовой помощник Cortana изо всех сил пытается выйти за пределы настольного приложения Windows. Доля Windows на рынке мобильных устройств в большинстве стран составляет менее 1%, а несколько умных колонок-неудачников, использующих Microsoft Cortana, с трудом продаются или переходят на конкурирующую систему.
Amazon стал неожиданным победителем в битве умных колонок с долей мирового рынка 28% в 2019/2020 гг. и 53% в США. Это больше, чем у Google 24,9.% мирового рынка и 30,9% в США. [12] Несмотря на то, что Amazon владеет поисковой системой под названием A9 (управляемой бывшими руководителями WebCrawler и AltaVista), эта технология ориентирована на поиск товаров и предприятий. Вместо этого веб-поиск Amazon Alexa осуществляется с помощью Bing, что впервые дает Microsoft преимущество над Google. Иногда выгодно быть вторым лучшим, особенно когда компания стоимостью в триллион долларов является заклятым соперником ведущей поисковой системы.
Проблема с голосовым поиском заключается в том, что как бы реалистично ни звучали синтетические голоса, никто не хочет слышать, как компьютер читает им веб-страницы из первой десятки результатов поиска. Голосовой поиск останется в основном односторонним разговором, используемым для ответов на простые вопросы, выполнения задач и иногда выполнения основных транзакций. Говорят, что изображение стоит тысячи слов — Alexa и Google потребовалось бы примерно 10 минут, чтобы произнести эти слова, по сравнению с секундами, необходимыми для беглого чтения веб-страницы и определения необходимой информации.
Будущее поиска Чат-боты и автоответчики на основе машинного обучения, вероятно, будут играть более важную роль в жизни каждого человека в будущем. Финансовые учреждения уже используют технологии для замены своего человеческого персонала для выполнения фактических, транзакционных или числовых задач (проверка баланса, открытие счетов, увеличение овердрафта, проверка кредитоспособности и возвратные платежи).
Поисковые системы также начинают погружаться в эти воды, предлагая интеллектуальные службы сравнения рейсов и кредитных карт, которые отображаются непосредственно в результатах поиска. Это только вопрос времени, когда поисковые системы возьмут на себя весь процесс транзакций из SERP (страницы результатов поисковой системы). Пользователь будет избавлен от хлопот, связанных с навигацией и заказом на стороннем веб-сайте. Продукты, изображения, контент, корзина и оформление заказа могут быть представлены в поисковой выдаче. Поисковые системы получат долю от общей транзакции, а не только доллар за клик. Пользователи чувствуют себя в большей безопасности, когда их деньги хранятся и управляются в «Google Кошельке».
Компании будут просто благодарны поисковым системам за то, что они не стерты с лица земли (пока).
Google Glass потерпели огромный провал, в основном благодаря маркетингу и пиару. Они забыли, что создают аксессуар для моды и образа жизни, который каждый наденет на лицо, а не просто умную технику. Модой руководят влиятельные лица, которыми люди стремятся быть. Никто не стремится быть техническим блоггером Робертом Скоблом или тем парнем, который до сих пор живет в подвале своих родителей. Распространяя устройства для предварительного просмотра среди клавиатурных воинов Силиконовой долины, которые обычно рассматривают программные продукты Google; у компании с самого начала были проблемы с имиджем. Полные жуткие имитаторы Робокопа не собираются продавать устройство, как это сделали бы Бейонсе или Дэвид Бекхэм. Не волнуйтесь, хотя; вы будете знать, фотографируют ли они вас, так как им нужно подмигнуть, чтобы сделать снимок. ммм… ОЗУ .
Но мир носимых технологий по-прежнему процветает, а умные очки еще не умерли. Google Glass находит новый рынок в сфере B2B, помогая работникам склада находить продукты и врачам искать данные о пациентах. Появляются новые бренды, такие как North и Lance, которые знают, как привлечь знаменитость Instagram. Amazon строит свои собственные прототипы Glass, а в качестве поддержки им пользуется «черная книга» голливудских знаменитостей Джеффа Безоса.
Умные очки или контактные линзы — это разумный следующий шаг для поиска, поскольку они не требуют помощи рук, но при этом хорошо видят. Возможно больше задач и больше ответов на визуальный поиск. Он может заменить экран вашего рабочего стола, намного лучше, чем новый радио-будильник под названием Alexa.
Обгонит ли кто-нибудь Google?
Отвечая на 40 000 поисковых запросов в секунду [13] , их конкуренты должны подняться по крутому склону.
поисковых запросов Google с начала
Ссылки
[1] История Интернета — Википедия
[2] На этом пока все, Дживс — The Guardian
[3] Что такое Google PageRank? — Поисковая система земли
[4] Google и Yahoo урегулировали спор о патенте на поиск — The New York Times
[5] Основной доклад с Кевином Джонсоном в Microsoft — Круглый стол поисковых систем
[6] Утечка документа Baidu о внутреннем мониторинге и цензуре
[7] Почему Google уходит из Китая — The Atlantic
[8] Трафик DuckDuckGo — DDG
[9] Доля рынка поисковых систем — США — StatCounter
[10] Google платит Apple 9 миллиардов долларов за сохранение поисковой системы по умолчанию в Safari — 9to5 Mac
[11] Готовимся к следующему моменту – Google
[12] Доля поставок смарт-колонок за квартал с 2016 по 2019 год в разбивке по поставщикам — Statista
[13] Сколько данных мы создаем каждый день? — Форбс
Яндекс, российская история успеха и высокотехнологичный тигр Путина (мнение)
Михаил Метцель / ТАСС На прошлой неделе Яндекс, гигантская поисковая система и символ российского технологического мастерства, отпраздновала свое 20-летие.
Ее основатель Аркадий Волож принимал у себя президента России Владимира Путина, который похвалил Яндекс за его стильную стеклянную штаб-квартиру в центре Москвы.
Это было не совсем идеально.
Блогеры с сарказмом отметили, что российский лидер, как известно, не пользуется интернетом, и однажды назвали его детищем ЦРУ. Кремлевцы увидели в этом визите знак того, что российский лидер формирует новый имидж: от человека, который позирует с обнаженной грудью и напряженными мышцами, до человека с айфоном в руке — отражение собственного перехода России от грубой силы к технологическому прогрессу.
Обозреватель Олег Кашин с иронией заметил, что Путину, должно быть, случайно передали список приемов, уже использованных экс-президентом Дмитрием Медведевым в 2009 году. Трудно найти две более контрастные культуры. Как и в других ведущих технологических компаниях, сотрудники Яндекса наслаждаются свободной атмосферой творчества, неформальным дресс-кодом, открытыми офисами и модными кафе, где сотрудники играют в видеоигры.
Словно чтобы подчеркнуть контраст с Кремлем, многие из этих тусовок были закрыты перед визитом президента. Сообщается, что сотрудникам не разрешалось вставать со своих рабочих мест в течение 30 минут до визита Путина по приказу Федеральной службы охраны (ФСО). Один программист Яндекса написал в соцсетях, что в день визита Путина его попросили остаться дома якобы из-за его политических взглядов.
В отличие от унаследованных от Советского Союза нефтяных гигантов, которые существовали за десятилетия до возрождения России, продолжительность жизни Яндекса превышает время пребывания Путина у власти всего на два года.
Компанию основали два математика и близкие друзья: Аркадий Волож и Илья Сегалович. Волож работал генеральным директором компании (он ушел в отставку в 2014 году и стал генеральным директором голландской группы Яндекс), а Сегалович отвечал за программирование и технологии. Волож был бизнес-стратегом, Сегалович был сердцем и двигателем компании.
Компания быстро росла и вскоре превзошла отечественных конкурентов, таких как Рамблер. В какой-то момент Яндекс обогнал Google и в России, став одной из немногих стран, которым это удалось. В 2011 году Яндекс стал публичным и сделал своих основателей мультимиллионерами.
Многие начинающие миллионеры не являются поклонниками путинского режима, а Сегалович, либерал, был увлечен будущим России. Он и некоторые его коллеги по Яндексу активно участвовали в акциях протеста против результатов парламентских выборов в конце 2011 и 2012 годах.
Он умер от рака в 2013 году в возрасте 46 лет. тяготел к консерватизму и изоляционизму.
Государство усилило давление на свободную прессу и интернет-СМИ, и Яндекс не стал исключением.
Чтобы защитить себя от недружественного поглощения, владельцы Яндекса продали золотую акцию Сбербанку, генеральный директор которого, бывший министр экономического развития и знакомый Путина Герман Греф известен как один из самых либеральных в правительственных кругах.
Но это не помогло полностью защитить его от влияния цензуры и общего регулятивного давления на свободу слова. С 2014 года Яндекс был вынужден ограничивать результаты, которые он показывает на своей странице новостей — российском эквиваленте Новостей Google — СМИ, зарегистрированными в государственном органе по надзору за СМИ.
В последние годы компанию покинули такие ключевые сотрудники, как Лев Гершензон, основатель «Яндекс Новостей», и Елена Колмановская, ее первый главный редактор. За ними последовала глава «Яндекс.Новостей» Татьяна Исаева, перешедшая на оппозиционно настроенный телеканал «Дождь», а затем уехавшая в Испанию.
Лидер оппозиции Алексей Навальный недавно пожаловался, что «Яндекс Новости» скрыл из своей ленты сообщения о его недавних всероссийских антикоррупционных протестах. В ответ Яндекс заявил, что его результаты автоматически генерируются алгоритмами, и отрицает возможность каких-либо манипуляций.
Лояльность к государству и сложившиеся отношения с властями также принесли компании определенные преимущества.
Яндекс недавно выиграл антимонопольную войну с Google. В России Google не разрешается предварительно устанавливать свои приложения на телефоны Android, что дает Яндексу возможность разрабатывать свои продукты. Это могло бы помочь Яндексу сохранить свою долю рынка, которая весной 2017 года упала до исторического минимума – 54 %.
Но победа в этом небольшом сражении дома не помогла на глобальном рынке. Яндекс пытался расширить свой бизнес в Турции и Германии, но пока не получил значительных результатов.
Несмотря на беспрецедентный успех Яндекса на родине, его цена за акцию на закрытии в пятницу была примерно идентична цене, когда Яндекс вышел на биржу весной 2011 года. Для сравнения: с тех пор цена акций Google выросла втрое, а стоимость китайского интернет-магазина Alibaba удвоилась.
Без всякой иронии: Яндекс — высокотехнологичное отечественное чудо, которым россияне должны гордиться. Никакое лобби не смогло бы сделать Яндекс ведущей поисковой системой, если бы продукт был плохим или поддельным.
Но в сегодняшних российских реалиях возможности Яндекса на успех очень ограничены. Это очень местный и легко управляемый домашний тигр. Что-то, с чем Путин мог бы поиграть.
Елизавета Осетинская — российский редактор, руководившая газетой «Ведомости», российским изданием Forbes и медиахолдингом РБК. Она также является основателем Bell и в настоящее время является научным сотрудником Калифорнийского университета в Беркли.
Мнения, выраженные в авторских статьях, не обязательно отражают позицию The Moscow Times.
Мнения, выраженные в авторских статьях, не обязательно отражают позицию The Moscow Times.
Подробнее о: Вставить , Яндекс
История поисковых систем
Я одна из старейших душ в нашем молодом и модном офисе цифрового маркетинга. Многие никогда не знали жизни без Интернета и, следовательно, не имели опыта мира поиска, в котором доминировал Google.
В настоящее время Google незаменим, но когда появились поисковые системы, Google был всего лишь опечаткой от слова гугол. (Число, равное 10 в сотой степени, или, точнее, непостижимое число.) Только в 1996, когда Google получил свой первый выход под названием backrub, потому что система проверяла обратные ссылки, чтобы оценить важность сайта для его ранжирования.
Первой признанной поисковой системой была система под названием Archie, но это было не совсем то, что вы бы назвали поисковой системой в современном мире. Арчи просматривал папки и файлы в каталогах FTP. Они сформировали коллекцию, которая была отсортирована и обработана, а затем стала доступной для искателя. Основная проблема с Арчи заключалась в том, что поисковая система не искала текст, а только файлы и папки.
World Wide Web – 1994
В 1994 году была разработана первая общепризнанная поисковая система. WebCrawler был первой поисковой системой, обеспечивающей полнотекстовый поиск. В 1994 году Брайан Пинкертон, студент факультета компьютерных наук Вашингтонского университета, использовал свободное время для создания WebCrawler. С помощью WebCrawler Брайан составил список 25 лучших веб-сайтов 15 марта 1994 года. Всего через месяц он объявил о запуске WebCrawler в прямом эфире в Интернете с базой данных из 4000 сайтов.
11 июня 1994 года Брайан объявил WebCrawler доступным для исследований. 14 ноября 1994 года число посещений WebCrawler превысило миллион. В феврале 1996 года это был второй по посещаемости веб-сайт в Интернете, но он быстро опустился ниже конкурирующих поисковых систем.
В отличие от своих предшественников, он позволял пользователям искать любое слово на любой веб-странице, что с тех пор стало стандартом для всех основных поисковых систем. Он также был первым, получившим широкую известность среди публики.
В июне 1995 года America Online (AOL) приобрела WebCrawler. Но чуть более 2 лет спустя, 19 апреля97 WebCrawler был продан AOL компании Excite. В 2001 году Excite обанкротилась. Несмотря на это, WebCrawler все еще существует, но больше не использует собственную базу данных для отображения результатов. В 2018 году в последний раз двигатель подвергался фейслифтингу и новому логотипу в виде паука.
AltaVista была запущена в 1994 году и за несколько лет зарекомендовала себя как стандарт среди поисковых систем. Он был первым со своим индексом. Alta Vista долгое время продолжала занимать видное место на рынке поисковых систем, поскольку использовала робота под названием Scooter, который был особенно мощным. В наши дни AltaVista.com перенаправляет на Yahoo!
Lycos появился на рынке летом 1994 года . Функция и принцип были новаторскими, потому что Lycos не только мог искать документы, но также имел один алгоритм, который измерял частоту поискового термина на странице, а также смотрел на близость слов друг к другу.
В том же году Yahoo! вывела свою службу каталогов в онлайн. По сути, это началось как просто набор избранных ссылок, потому что Yahoo! не делал ничего, кроме сбора веб-адресов. Таким образом, пользователь мог создавать ссылки в соответствии со своими личными интересами. По мере того как количество ссылок со временем росло, были добавлены категории и подкатегории, чтобы помочь пользователям найти нужные веб-сайты.
Перенесемся на два года вперед, в 1996 год, когда был представлен мой личный фаворит того времени под названием HotBot. HotBot был запущен с использованием маркетинговой стратегии «новые ссылки», заявляя, что еженедельно индексирует всю сеть, чаще, чем конкуренты, такие как AltaVista, чтобы предоставлять своим пользователям гораздо более свежие и актуальные результаты. В то время их заявления заключались в том, что они были «самым полным веб-индексом в Интернете» с более чем 54 миллионами документов в их базе данных.
HotBot использовал данные поиска от Direct Hit Technologies в течение определенного периода – это был инструмент, использующий данные о кликах для манипулирования результатами с целью поиска лучших вариантов для высокого рейтинга. Они также включили пользовательские данные в определение рейтинга, поскольку технологии Direct Hit, как известно, использовали время, которое пользователи тратят на просмотр каждой веб-страницы, чтобы помочь определить рейтинг страницы. Direct Hit были куплены Ask Jeeves в 2000 году, когда HotBot был в упадке.
К сожалению, Hotbot больше не существует как поисковая система, но вы можете увидеть ниже красочный интерфейс 90-х, который помог сделать его таким популярным выбором и навевает у меня хорошие воспоминания. По состоянию на 2020 год домен HotBot контролируется VPN-компанией.
Привет, Google – 1998
Первоначально вступая в ландшафт как аутсайдер из-за Alta Vista, Lycos и Yahoo! уже имея самые большие доли рынка, Google не потребовалось много времени, чтобы набрать скорость. Не только пользовательский интерфейс был особенно хорошо структурирован, но и релевантность результатов поиска была выдающейся. Скорость была чрезвычайно высокой для того времени. В то время как конкурирующие поисковые системы в то время пытались обклеить каждый миллиметр рекламы красочными рекламными баннерами, Google воздержался от этого, что также помогло повысить удовлетворенность пользователей.
В том же году Microsoft выпускает собственную поисковую систему «MSN Search». В то время Microsoft обыграла лидера рынка Netscape в битве за самый используемый браузер и смогла привлечь чрезвычайно большое количество пользователей для своей поисковой системы. Однако MSN Search не произвел впечатления на весь мир.
Доминирование Google во всемирной паутине
Годы идут, Google привлекает все больше и больше пользователей своим «лучшим» продуктом, а воздух для других поисковых систем становится все хуже. В 2006 году MSN Search стал называться Windows Live Search, а три года спустя — Bing.
Компания Google с самого начала смогла убедить нас своими гораздо лучшими результатами поиска и с самого начала выиграла гонку за доминирование в поисковых системах. Это произошло потому, что Google использовал не только информацию, предоставленную веб-сайтом, но и другие функции, такие как популярность веб-сайта. Эта популярность в основном определялась ссылками с других сайтов. Таким образом, Google смог обеспечить отображение не просто любого поста по определенному поисковому запросу, а наиболее релевантного поста с самого «популярного» веб-сайта.
Ссылки по-прежнему играют огромную роль в том, как Google ранжирует веб-страницы, но теперь он использует многие другие атрибуты алгоритма, такие как RankBrain, а в прошлом — PageRank.
Сегодняшняя картина рынка поисковых систем
По данным StatCounter, по состоянию на март 2022 года рыночная доля современных поисковых систем во всем мире и здесь, в Великобритании, представлена ниже:
Bing
Bing был запущен Microsoft в 2009 году как преемник live.com (Live Search), чтобы, наконец, иметь возможность конкурировать с Google, и с 2012 года все чаще включает контент социальных сетей. В октябре 2010 года Bing начал работать с Facebook. Интеграция Bing с поисковой системой Facebook рассматривалась как потенциально важный способ, с помощью которого Microsoft могла бы конкурировать с Google. Наряду с собственными полупрограммируемыми поисковыми запросами Facebook пользователи могли подключать веб-поиски, которые возвращали бы структурированную информацию, такую как местная погода.
Но с 2014 года Facebook больше не использует поисковую систему Bing на своей платформе.
В 2009 году Bing и Yahoo сформировали стратегический альянс, чтобы объединиться против гигантского Google. Досягаемость технологии Microsoft увеличилась за счет всех пользователей Yahoo. Но Google по-прежнему отказывался быть отодвинутым в сторону.
ЯХУ!
ЯХУ! была основана в 1994 году Дэвидом Фило и Джерри Янгом и изначально представляла собой чистый веб-каталог.
Yahoo также занимала видное место в мире онлайн-чатов. До служб обмена мгновенными сообщениями 19Интернет 90-х был полон чатов, причем чат Yahoo был одним из самых популярных вариантов из-за их широкого выбора тематических чатов.
В наши дни Yahoo можно описать как мета-поисковик, который получает результаты от нескольких или одной поисковой системы веб-краулера. Другим примером мета-поисковика, который использует результаты поиска Bing, является еще один крупный игрок в Интернете AOL. У этого бывшего известного интернет-провайдера до сих пор работает поисковая система.
DuckDuckGo
DuckDuckGo был разработан Габриэлем Вайнбергом и запущен в 2008 году. Эта поисковая система с необычным названием представляет собой комбинацию метапоисковой системы и собственного поискового робота. Результаты поиска поступают из более чем 400 внешних источников, таких как Bing, Яндекс, Yahoo Search BOSS или Википедия. Кроме того, есть результаты работы нашего собственного поискового робота под названием DuckDuckBot, который регулярно просматривает саму сеть в поисках информации. Согласно Википедии, 13 ноября 2017 года через DuckDuckGo за один день было выполнено более 20 миллионов поисковых запросов.
Система, которая позиционирует себя как «Поисковая система, которая не следит за вами». DuckDuckGo выдает одинаковые результаты для всех пользователей (при отображении рейтинга не учитываются пользовательские данные или предвзятость по местоположению), не хранит никаких данных и не передает никаких личных данных. Компания ссылается на рекламу в своих результатах поиска как на источник дохода, который относится только к результатам поиска, а не к поисковому поведению пользователя, которое Google использует вместе с поисковым запросом пользователя.
Для дальнейшего повышения анонимности DuckDuckGo также можно использовать в качестве скрытого сервиса Tor. Доступ к этому сервису возможен только через браузер Tor, который дополнительно защищает ваши данные.
Поиск на DuckDuckGo предлагает различные варианты, такие как установка страны в поисковом запросе или фильтрация изображений, видео и новостей. Кроме того, есть режим фильтрации, который может исключать контент для взрослых.
Яндекс
Российская поисковая система Яндекс (Яндекс) была основана в 1997 и, согласно Википедии , является компанией, базирующейся в Амстердаме и имеющей оперативный штаб в Москве. Также есть филиалы в Беларуси, Швейцарии, США, Турции и Германии.
По состоянию на март 2022 года они по-прежнему удерживают долю рынка в России с долей рынка 50,21% по сравнению с 39,09% у Google. Как и Google, у которого есть Chrome, Яндекс предоставляет пользователям собственный браузер (Яндекс.Браузер), онлайн-переводчик (Яндекс.Переводчик), картографический сервис (Яндекс. Карты), адреса электронной почты, облачные сервисы или магазин приложений для Android .
Baidu
Baidu — ведущая поисковая система в Китае. Baidu — самая популярная поисковая система в Китае с ошеломляющей долей рынка 84,26%. Bing владеет 6,65%, а Google видит только 1,33% доли китайского рынка.
Ecosia
Поисковик, сажающий деревья. Благодаря пользователям Ecosia было посажено более 35 миллионов.
Как это работает? Ecosia — это поисковая система, которая использует доходы от поисковой рекламы для посадки деревьев. Экологический поисковик, так сказать.
Ecosia GmbH была основана 7 декабря 2009 года и базируется в Берлине. Согласно Википедии, 80% избыточного дохода жертвуется природоохранным организациям. Результаты поиска Ecosia предоставляются Bing, и никакая личная информация не хранится в Ecosia. Они утверждают, что используют технологию поиска эксперта по поиску Bing и делают ее еще более эффективной с помощью собственных алгоритмов.
Краткая история поисковой оптимизации
Начало поисковой оптимизации (SEO) можно приблизительно отнести к рождению поисковых систем, какими мы их знаем сегодня, в середине 19 века.90-е. В то время поисковая оптимизация представляла собой в основном манипулирование результатами поиска с целью вывести сомнительные страницы в топ результатов поиска или нарушить работу поисковой системы.
Распространенным применением были так называемые черные методы, такие как наполнение ключевыми словами ( Обычно относится к чрезмерному использованию ключевых слов на странице с целью повышения рейтинга страницы по этому ключевому слову. Этот метод работал примерно до начала 2000 года. Для этой тактики также было характерно размещать ключевые слова на странице как «скрытый текст»: ключевые слова были реализованы белым цветом на белом фоне .) или маскировка ( Основная цель маскировки — по-разному оптимизировать страницу для посетителя и поисковых систем ).
Google думал, что они могут предоставить пользователям лучшие результаты, используя свою систему обратных ссылок, чтобы показывать результаты только веб-сайтов, которые другие сочли популярными, ссылаясь на них. Однако это была еще одна область, на которую нацелены черные методы SEO, поскольку в начале это был вопрос количества, поэтому владелец веб-сайта мог покупать ссылки у розничных продавцов, чтобы повысить профиль обратных ссылок на свои сайты, или использовать программные инструменты, которые автоматически сканировать Интернет и оставлять обратные ссылки на сайт с помощью автоматизированного процесса. Эти ссылки часто были очень низкого качества и содержали спам и часто не имели отношения к предполагаемому сайту, на который ссылаются.
Google превратился в организацию, которая теперь может понимать разницу между релевантными ссылками и спам-ссылками. В начале 2010-х годов для владельцев веб-сайтов было обычным делом создавать файл отклонения, чтобы убедиться, что их сайт не подвергается воздействию методов создания спам-ссылок, но в наши дни Google обычно понимает эти ссылки и может игнорировать их, когда дело доходит до ранжирования веб-сайта или веб-страницы. .
Одно из многих обновлений алгоритма Google, называемое пингвином, является причиной, по которой Google больше не наказывает большинство веб-сайтов, если на них есть обратные спам-ссылки. Но даже в июле 2021 года они продолжают улучшать это и запускают целевые обновления для защиты от спама в своем алгоритме.
Сегодняшние SEO-специалисты настолько далеко отошли от черных методов 90-х и 00-х годов, насколько это было возможно. С одной стороны, это связано с регулярными обновлениями и мерами по борьбе со спамом от Google, которые выявляют и наказывают практически каждый метод черной шляпы. С другой стороны, он также основан на опыте того, что методология «белой шляпы» имеет смысл и окупается в долгосрочной перспективе.
Успех современных специалистов по поисковой оптимизации основан на технически чистой структуре и программировании веб-сайта, безупречном взаимодействии с пользователем на веб-сайте, быстром и простом в использовании внешнем интерфейсе и, что наиболее важно, качественном контенте, который ведет к высококачественным обратным ссылкам, соответствующим содержанию. .
Будущее поисковых систем
Google никуда не денется в ближайшее время, и, хотя проблемы с конфиденциальностью и отслеживанием остаются, факт заключается в том, что «Google это» теперь гораздо более распространено, чем «искать это», и благодаря постоянным улучшениям Google. , не только в результатах поиска, но и в их встроенных функциях, это означает, что мы будем использовать Google еще много лет.
Персонализация или поиск с контролем местоположения будут становиться все более и более важными. Ограничивая область поиска конкретного пользователя, можно не только сохранить важные ресурсы, но поиск информации становится более личным и, возможно, актуальным для ищущего человека. Сегодня уже нормально, что, например, предыдущие клики и поисковые запросы влияют на будущие запросы и результаты человека.
Google всегда стремится сделать свою SERP (страницу результатов поисковой системы) более персонализированной и адаптированной к человеку, ищущему, чтобы он начал опережать то, что ищет пользователь, предоставляя последующие поиски, которые они могут захотеть сделать в следующий раз. их первоначальный поиск. Уже есть первые попытки «предсказательной» поисковой системы, но поскольку человеческий язык слишком сложен в контексте, вероятно, в обозримом будущем он останется только «предложениями».
С появлением виртуальных помощников, которые можно активировать голосом, виртуальные помощники, такие как Alexa и Siri, занимают место традиционных поисковых систем. Запросы, связанные с контекстом, уже возможны с помощью голосовых помощников. Например, они показывают нам ближайшую заправочную станцию или банкомат. Или они говорят нам самый быстрый способ добраться из того места, где мы находимся, в другое желаемое место. Благодаря своим возможностям громкой связи поисковые системы, активируемые голосом, получат все большее распространение.
Хотя знание всей этой истории не является обязательным требованием для современных SEO-специалистов, мы в Liberty живем и дышим этим материалом, что делает нас одним из ведущих консультационных агентств по SEO в Великобритании.
Yandex NV
Яндекс.Браузер (2012)
Яндекс выпустил собственный браузер, разработанный для удобной и безопасной навигации в Интернете. Это упрощает пользователю ряд различных задач, от поиска информации до защиты от вирусов. Яндекс.Браузер включает в себя лучшие отраслевые технологии и локализован для России, Украины и Турции.
Международный рынок (2011 г.)
Яндекс запустил yandex.com.tr в Турции в сентябре 2011 года, а его услуги, включая веб-поиск, карты и электронную почту, были специально адаптированы к потребностям пользователей сети в этой стране.
Турция стала первой страной, где Яндекс начал работать за пределами русскоязычного сообщества. Вместо локализации своих сервисов Яндекс разработал совершенно новый продукт для местных пользователей.
YNDX (2011)
Яндекс стал публичным на NASDAQ Global Select Market в мае 2011 года. Акции компании торгуются под тикером YNDX.
MatrixNet (2009)
Инновационный подход Яндекса в очередной раз проявился в 2009 году, когда компания внедрила новый метод машинного обучения — MatrixNet. Эта прорывная технология учитывает тысячи поисковых факторов и их комбинаций. Это позволило Яндексу сделать поиск более точным, а также улучшить качество результатов поиска по нескольким классам поисковых запросов. Благодаря MatrixNet Яндекс значительно улучшил качество поиска.
Школа анализа данных (2007 г.)
В 2008 году Яндекс открыл Школу анализа данных — бесплатную двухлетнюю магистерскую программу по подготовке отечественных специалистов по анализу данных и поиску информации. Таким образом, Яндекс помогает создавать и поддерживать научную среду, благоприятную для разработки новых технологий, привлечения новых талантов и обеспечения того, чтобы Яндекс оставался в авангарде инноваций.
Первый офис разработки за пределами Москвы (2006 г.)
В 2006 году Яндекс начал открывать офисы разработки за пределами Москвы. Первоначально центр разработки был создан в Санкт-Петербурге, а затем второй центр в Симферополе, Украина. В 2009, Лаборатория Яндекса открылась в Силиконовой долине.
Первое представительство за пределами России (2005 г.)
В 2005 году Яндекс расширил свою деятельность за пределами России, открыв представительство в Украине. С самого начала целью нового офиса было развитие сервисов Яндекса для украинского пользователя и продажа рекламы в эта страна. Помимо Украины у Яндекса также есть офисы в Казахстане и Белоруссии.
Точка безубыточности (2002 г.)
Яндекс стал прибыльным в 2002 г. – на шесть месяцев раньше, чем ожидалось. Доходы компании превышают ее расходы в августе того же года. Яндекс закончил 2002 год с прибылью и с тех пор не переставал быть прибыльным.
Яндекс.Директ (2001)
В 2001 году Яндекс запустил Яндекс.Директ, автоматизированную систему размещения текстовой рекламы. С помощью Яндекс.Директа любой пользователь мог напрямую, без посредников, размещать свою рекламу на сайтах Яндекса. За первый год работы системы более 2500 рекламодателей разместили свои объявления на Яндекс.
Яндекс как отдельная компания (2000 г.)
Яндекс был зарегистрирован как отдельная компания в 2000 году. Акционеры предшественника Яндекса последовали за Аркадием Воложем и вложили средства в новую компанию. Также в ходе первого раунда инвестиций фонд Рунета предоставил «Яндексу» более $5 млн за пакет в 35%. Кроме того, акционерами компании стали ведущие разработчики и менеджеры Яндекса, а Аркадий стал генеральным директором Яндекса.
Первый контекстный баннер (1998 г.)
В 1998 году контекстная реклама впервые появилась в Яндексе. Реклама сильно коррелировала с запросами пользователей. Таким образом, реклама может быть показана непосредственно ее целевой аудитории. Затем контекстная реклама стала дополнительным ответом на запросы пользователей, а позже и основной бизнес-моделью Яндекса.
www.yandex.ru (1997)
Официальная дата запуска поисковой системы yandex.ru – 23 сентября 1997 года. В этот день система была публично представлена на выставке Softool в Москве. Поисковик Яндекс 1997 учитывал морфологию русского языка и расстояние между словами, а релевантность документа вычислял по сложному алгоритму. За три года Яндекс стал крупнейшей поисковой системой в России.
Слово «Яндекс» (1993)
Слово «Яндекс» придумали два основных основателя компании Илья Сегалович и Аркадий Волож. В то время Илья экспериментировал с разными производными от слов, которые описывали суть технологии. В результате команда изобрела «Яндекс», где Я означает русское «Я». Полное название изначально расшифровывалось как «Еще один iINDEX». Сегодня слово Яндекс стало синонимом интернет-поиска в русскоязычных странах. Миллионы людей ежедневно используют Яндекс для поиска в Интернете и других ценных сервисов.
Объединение поисковых технологий и компьютерной лингвистики (конец 80-х)
История Яндекса насчитывает более 20 лет — когда наши первые поисковые технологии были разработаны нашими основателями во время работы в компании Аркадия. В то время несколько ключевых программистов разработали несколько поисковых программ. К ним относятся «Международный классификатор патентов» и «Поиск по Библии», в которых учитывалась русскоязычная морфология. Позднее эта технология получила название «Яндекс».
ОБНОВЛЕНИЕ 6-Yandex поднимает цену IPO в интернет-ажиотаже
Алина Селюх, Ольга Попова
6 минут чтения
* Ценовой диапазон повышен до $24-25 с $20-$22 — источник привлечь до $1,3 млрд
* Крупнейшая поисковая система России (добавляет волатильность рынка, комментарии аналитиков по торговле, история)
НЬЮ-ЙОРК/МОСКВА, 23 мая (Рейтер) — Российская интернет-компания Яндекс в понедельник повысила ориентир цен для своего Nasdaq первичное публичное размещение акций в ответ на высокий спрос инвесторов после громкого дебюта LNKD. N LinkedIn Corp на прошлой неделе.
Яндекс, самая популярная поисковая система в России, планирует продавать акции по цене от 24 до 25 долларов за штуку, что превышает ранее установленный диапазон от 20 до 22 долларов, сообщил Reuters источник, близкий к проблеме. Ожидается, что цена IPO будет объявлена позднее в понедельник.
При такой цене IPO Яндекса станет крупнейшим интернет-компанией с тех пор, как Google GOOG.O привлекла $1,7 млрд в 2004 году. рынки США с 354-процентным скачком в его дебюте в 2005 году. 9
Baidu, крупнейшая поисковая система Китая, превратилась в один из ведущих мировых брендов после стремительного роста котировок на бирже Nasdaq в августе 2005 года. растущие интернет-рынки в России и соседних странах. В более высоком ценовом диапазоне его IPO может привлечь до 1,3 миллиарда долларов, чтобы оценить компанию до 8 миллиардов долларов.
«Ходили слухи, что подписка на IPO была в 5-10 раз превышена. И на волне сделок прошлой недели, включая LinkedIn, можно ожидать вполне успешного размещения», — сказал Константин Чернышев, руководитель отдела исследований «Уралсиб» в Москве.
Акции LinkedIn выросли более чем в два раза после IPO компании на прошлой неделе, что напомнило о сомнительных оценках, предшествовавших краху доткомов десять лет назад. [ID:nN1939946]
«Я не знаю, получите ли вы такую огромную популярность (с Яндексом), как с LinkedIn», — сказал Даррен Фабрик, управляющий директор IPO инвестиционной компании IPOX Schuster LLC. Но «в первый день он должен торговаться достаточно хорошо, даже при волатильности рынка».
Акции США закрылись на самом низком уровне за месяц в понедельник, в отличие от устойчивости, наблюдавшейся на рынке во время IPO LinkedIn. [ID:nN23187364]
LinkedIn в настоящее время торгуется в 34 раза больше продаж 2010 года, в то время как акции Google сейчас стоят чуть менее шести раз больше продаж 2010 года. Если цена IPO Яндекса будет равна 24,50 доллара, то есть средней точке верхнего диапазона, ее акции будут стоить почти в 18 раз больше продаж 2010 года.
Эта оценка «довольно высока», сказал Рик Саммер, технологический аналитик Morningstar. Но с производительностью Baidu и аппетитом инвесторов к высококачественным интернет-акциям Яндекс может поддерживать эти оценки в торговле, сказал он.
Яндекс контролирует 65 процентов российского рынка интернет-поиска, почти в три раза больше, чем мировой лидер Google. Поклонники Яндекса также подчеркивают рекордный рост прибыли компании благодаря интернет-рекламе: в 2010 году прибыль выросла на 90% до 135 млн долларов при росте продаж на 43% до 445 млн долларов. [ID:nLDE74I143]
NO QUICK FLIP
Инвесторов может успокоить тот факт, что дуэт, основавший Яндекс в 1997 году — генеральный директор Аркадий Волож и технический директор Илья Сегалович — сохранит большую часть своих активов.
Волож, дипломированный специалист по прикладной математике, начал заниматься поисковыми технологиями в 1989 году. Годом позже он основал собственную фирму по разработке программного обеспечения для поиска, где к нему присоединился геофизик Сегалович. В 1997 году они запустили сайт yandex. ru, которым в марте пользовались 38 миллионов уникальных пользователей.
Алгоритм поиска Яндекса, первоначально разработанный для поиска по ключевым словам в патентах, русской классической литературе и Библии, стал прорывом, поскольку он учитывал сложные падежные окончания русского языка.
Дуэт изобрел название «Яндекс» — где «Я» означает русский эквивалент английского местоимения «я» — когда Сегалович экспериментировал с производными от слов, описывающих суть технологии. Полное название изначально расшифровывалось как «Еще один iINDEX».
Сегодня слово «Яндекс» стало синонимом интернет-поиска в русскоязычных странах, так как люди предлагают «спрашивать у Яндекса» ответы на свои запросы.
Частные инвесторы также сохраняют доли, в том числе Baring Vostok Capital Partners, которая купила Яндекс в 2000 году, когда его доход составлял всего 72 000 долларов, а убыток составил 2 миллиона долларов.
Первоначальные инвестиции фонда оценивали Яндекс в 15 миллионов долларов, а это означает, что Baring Vostok и его партнеры могут получить в 93 раза больше своих первоначальных инвестиций.