что это такое, зачем нужен индексный файл и как его настроить – примеры роботс тхт
Если вы хоть немного интересовались вопросом внутренней оптимизации сайтов, то наверняка встречали термин robots txt. Как раз ему и посвящена наша сегодняшняя тема.
Сейчас вы узнаете, что такое robots txt, как он создается, каким образом веб-мастер задает в нем нужные правила, как обрабатывается файл robots.txt поисковыми роботами и почему отсутствие этого файла в корне веб-ресурса — одна из самых серьезных ошибок внутренней оптимизации сайта. Будет интересно!
Что такое robots.txt
Технически robots txt — это обыкновенный текстовый документ, который лежит в корне веб-сайта и информирует поисковых роботов о том, какие страницы и файлы они должны сканировать и индексировать, а для каких наложен запрет. Но это самое примитивное описание. На самом деле c robots txt все немного сложнее.
Файл robots txt — это как «администратор гостиницы». Вы приходите в нее, администратор выдает вам ключи от номера, а также говорит, где ресторан, SPA, зона отдыха, кабинет управляющего и прочее. А вот в другие номера и помещения для персонала вход вам заказан. Точно так же и с robots txt. Только вместо администратора — файл, вместо клиента — поисковые роботы, а вместо помещений — отдельные веб-страницы и файлы. Сравнение грубое, но зато доступное и понятное.
А вот в другие номера и помещения для персонала вход вам заказан. Точно так же и с robots txt. Только вместо администратора — файл, вместо клиента — поисковые роботы, а вместо помещений — отдельные веб-страницы и файлы. Сравнение грубое, но зато доступное и понятное.
Для чего нужен файл robots.txt
Без этого файла поисковики будут хаотично блуждать по сайту, сканировать и индексировать буквально все подряд: дубли, служебные документы, страницы с текстами «заглушками» (Lorem Ipsum) и тому подобное.
Правильный robots txt не дает такому происходить и буквально ведет роботов по сайту, подсказывая, что разрешено индексировать, а что необходимо упустить.
Существуют специальные директивы robots txt для данных задач:
- Allow — допускает индексацию.
- Disallow — запрещает индексацию.
Кроме того, можно сразу прописать, каким конкретно роботам разрешено или запрещено индексировать заданные страницы. Например, чтобы запретить индексацию директории /private/ поисковым роботам «Гугл», в роботс необходимо прописать User-agent:
Например, чтобы запретить индексацию директории /private/ поисковым роботам «Гугл», в роботс необходимо прописать User-agent:
User-agent: Google
Disallow: /private/
Также вы можете указать основное зеркало веб-сайта, задать путь к Sitemap, обозначить дополнительные правила обхода через директивы и прочее. Возможности robots txt достаточно обширны.
И вот мы разобрались, для чего нужен robots txt. Дальше сложнее — создание файла, его наполнение и размещение на сайте.
Как создать файл robots.txt для сайта?
Итак, как создать файл robots txt?
Создать и изменять файл проще всего в приложении «Блокнот» или другом текстовом редакторе, поддерживающим формат .txt. Специальное ПО для работы с robots txt не понадобится.
Создайте обычный текстовый документ с расширением .txt и поместите его в корень веб-ресурса. Для размещения подойдет любой FTP-клиент. После размещения обязательно стоит проверить robots txt — находится ли файл по нужному адресу. Для этого в поисковой строке браузера нужно прописать адрес:
Для этого в поисковой строке браузера нужно прописать адрес:
имя_сайта/robots.txt
Если все сделано правильно, вы увидите во вкладке данные из robots txt. Но без команд и правил он, естественно, работать не будет. Поэтому переходим к более сложному — наполнению.
Символы в robots.txt
Помимо упомянутых выше функций Allow/Disallow, в robots txt прописываются спецсимволы:
- «/» — указывает, что мы закрываем файл или страницу от обнаружения роботами «Гугл» и т. д.;
- «*» — прописывается после каждого правила и обозначает последовательность символов;
- «$» — ограничивает действие «*»;
- «#» — позволяет закомментировать любой текст, который веб-мастер оставляет себе или другим специалистам (своего рода заметка, напоминание, инструкция). Поисковики не считывают закомментированный текст.
Синтаксис в robots.
 txt
txtОписанные в файле robots.txt правила — это его синтаксис и разного рода директивы. Их достаточно много, мы рассмотрим наиболее значимые — те, которые вы, скорее всего, будете использовать.
User-agent
Это директива, указывающая, для каких search-роботов будут действовать следующие правила. Прописывается следующим образом:
User-agent: * имя поискового робота
Примеры роботов: Googlebot и другие.
Allow
Это разрешающая индексацию директива для robots txt. Допустим, вы прописываете следующие правила:
User-agent: * имя поискового робота
Allow: /site
Disallow: /
Так в robots txt вы запрещаете роботу анализировать и индексировать весь веб-ресурс, но запрет не касается папки site.
Disallow
Это противоположная директива, которая закрывает от индексации только прописанные страницы или файлы. Чтобы запретить индексировать определенную папку, нужно прописать:
Disallow: /folder/
Также можно запретить сканировать и индексировать все файлы выбранного расширения. Например:
Например:
Disallow: /*.css$
Sitemap
Данная директива robots txt направляет поисковых роботов к описанию структуры вашего ресурса. Это важно для SEO. Вот пример:
User-agent: *
Disallow: /site/
Allow: /
Sitemap: http://site.com/sitemap1.xml
Sitemap: http://site.com/sitemap2.xml
Crawl-delay
Директива ограничивает частоту анализа сайта и тем самым снижает нагрузку на сервер. Здесь прописывается время в сек. (третья строчка):
User-agent: *
Disallow: /site
Crawl-delay: 4
Clean-param
Запрещает индексацию страниц, сформированных с динамическими параметрами. Суть в том, что поисковые системы воспринимают их как дубли, а это плохо для SEO. О том, как найти дубли страниц на сайте, мы уже рассказывали. Вам нужно прописывать директиву:
Clean-param: p1[&p2&p3&p4&. .&pn] [Путь к динамическим страницам]
.&pn] [Путь к динамическим страницам]
Примеры Clean-param в robots txt:
Clean-param: kol_from1&price_to2&pcolor /polo.html # только для polo.html
или
Clean-param: kol_from1&price_to2&pcolor / # для всех страниц сайта
Кстати, советуем прочесть нашу статью «Как просто проверить индексацию сайта» — в ней много полезного по этой теме. Плюс есть информативная статья «Сканирование сайта в Screaming Frog». Рекомендуем ознакомиться!
Особенности настройки robots.txt для «Гугла»
На практике синтаксис файла robots.txt для этих систем отличается незначительно. Но есть несколько моментов, которые мы советуем учитывать.
Google не рекомендует скрывать файлы с CSS-стилями и JS-скриптами от сканирования. То есть правило должно выглядеть так:
User-agent: Googlebot
Disallow: /site
Disallow: /admin
Disallow: /users
Disallow: */templates
Allow: *. css
css
Allow: *.js
Host: www.site.com
Примеры настройки файла robots.txt
Каждая CMS имеет свою специфику настройки robots txt для сканирования и индексации. И лучший способ понять разницу — рассмотреть каждый пример robots txt для разных систем. Так и поступим!
Пример robots txt для WordPress
Роботс для WordPress в классическом варианте выглядит так:
User-agent: Googlebot
Disallow: /cgi-bin # служебная папка для хранения серверных скриптов
Disallow: /? # все параметры запроса на главной
Disallow: /wp- # файлы WP: /wp-json/, /wp-includes, /wp-content/plugins
Disallow: *?s= # результаты поиска
Disallow: /search # результаты поиска
Disallow: */page/ # страницы пагинации
Disallow: /*print= # страницы для печати
Allow: *. css # открыть все файлы стилей
css # открыть все файлы стилей
Allow: *.js # открыть все с js-скриптами
User-agent: *
Disallow: /cgi-bin # служебная папка для хранения серверных скриптов
Disallow: /? # все параметры запроса на главной
Disallow: /wp- # файлы WP: /wp-json/, /wp-includes, /wp-content/plugins
Disallow: *?s= # результаты поиска
Disallow: /search # результаты поиска
Disallow: */page/ # страницы пагинации
Disallow: /*print= # страницы для печати
Sitemap: http://site.ua/sitemap.xml
Sitemap: http://site.ua/sitemap1.xml
Пример robots.txt для «Битрикс»
Одна из главных проблем «Битрикс» — по дефолту поисковые системы считывают и проводят индексацию служебных страниц и дублей. Но это можно предотвратить, правильно прописав robots txt:
User-Agent: Googlebot
Disallow: /personal/
Disallow: /search/
Disallow: /auth/
Disallow: /bitrix/
Disallow: /login/
Disallow: /*?action=
Disallow: /?mySort=
Disallow: */filter/
Disallow: */clear/
Allow: /bitrix/js/
Allow: /bitrix/templates/
Allow: /bitrix/tools/conversion/ajax_counter. php
php
Allow: /bitrix/components/main/
Allow: /bitrix/css/
Allow: /bitrix/templates/comfer/img/logo.png
Allow: /personal/cart/
Sitemap: https://site.ua/sitemap.xml
Пример robots.txt для OpenCart
Рассмотрим пример robots txt для платформы электронной коммерции OpenCart:
User-agent: Googlebot
Disallow: /*route=account/
Disallow: /*route=affiliate/
Disallow: /*route=checkout/
Disallow: /*route=product/search
Disallow: /index.php
Disallow: /admin
Disallow: /catalog
Disallow: /download
Disallow: /export
Disallow: /system
Disallow: /*?sort=
Disallow: /*&sort=
Disallow: /*?order=
Disallow: /*&order=
Disallow: /*?limit=
Disallow: /*&limit=
Disallow: /*?filter_name=
Disallow: /*&filter_name=
Disallow: /*?filter_sub_category=
Disallow: /*&filter_sub_category=
Disallow: /*?filter_description=
Disallow: /*&filter_description=
Disallow: /*?tracking=
Disallow: /*&tracking=
Disallow: /*?page=
Disallow: /*&page=
Disallow: /wishlist
Disallow: /login
Allow: *. css
css
Allow: *.js
User-agent: *
Disallow: /*route=account/
Disallow: /*route=affiliate/
Disallow: /*route=checkout/
Disallow: /*route=product/search
Disallow: /index.php
Disallow: /admin
Disallow: /catalog
Disallow: /download
Disallow: /export
Disallow: /system
Disallow: /*?sort=
Disallow: /*&sort=
Disallow: /*?order=
Disallow: /*&order=
Disallow: /*?limit=
Disallow: /*&limit=
Disallow: /*?filter_name=
Disallow: /*&filter_name=
Disallow: /*?filter_sub_category=
Disallow: /*&filter_sub_category=
Disallow: /*?filter_description=
Disallow: /*&filter_description=
Disallow: /*?tracking=
Disallow: /*&tracking=
Disallow: /*?page=
Disallow: /*&page=
Disallow: /wishlist
Disallow: /login
Sitemap: http://site.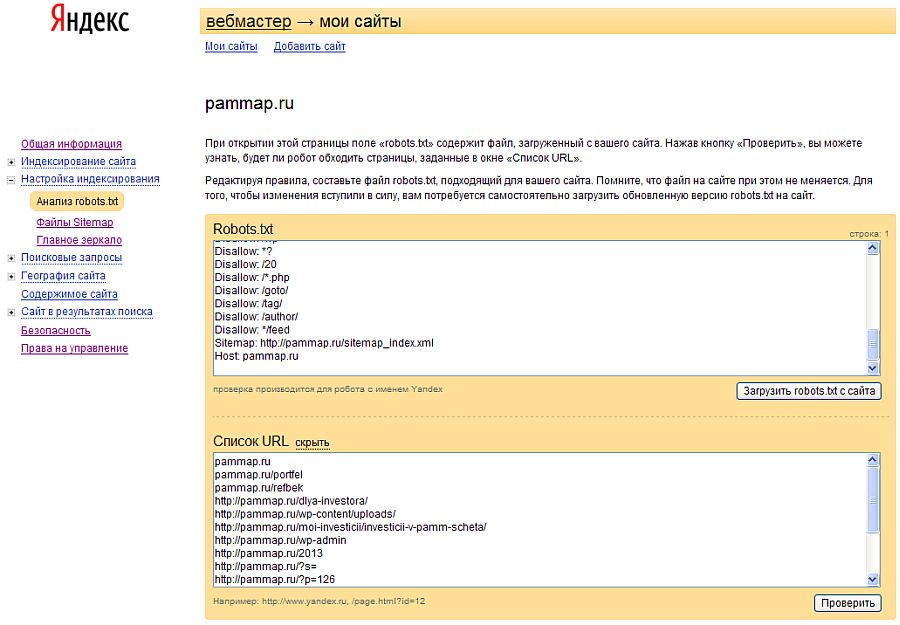 ua/sitemap.xml
ua/sitemap.xml
Пример robots.txt для Joomla
В «Джумле» роботс выглядит так:
User-agent: Googlebot
Disallow: /administrator/
Disallow: /cache/
Disallow: /components/
Disallow: /component/
Disallow: /includes/
Disallow: /installation/
Disallow: /language/
Disallow: /libraries/
Disallow: /media/
Disallow: /modules/
Disallow: /plugins/
Disallow: /templates/
Disallow: /tmp/
Disallow: /*?start=*
Disallow: /xmlrpc/
Allow: *.css
Allow: *.js
User-agent: *
Disallow: /administrator/
Disallow: /cache/
Disallow: /components/
Disallow: /component/
Disallow: /includes/
Disallow: /installation/
Disallow: /language/
Disallow: /libraries/
Disallow: /media/
Disallow: /modules/
Disallow: /plugins/
Disallow: /templates/
Disallow: /tmp/
Disallow: /*?start=*
Disallow: /xmlrpc/
Sitemap: http://www. site.ua/sitemap.xml
site.ua/sitemap.xml
Пример robots.txt для Drupal
Для Drupal:
User-agent: *
Disallow: /database/
Disallow: /includes/
Disallow: /misc/
Disallow: /modules/
Disallow: /sites/
Disallow: /themes/
Disallow: /scripts/
Disallow: /updates/
Disallow: /profiles/
Disallow: /profile
Disallow: /profile/*
Disallow: /xmlrpc.php
Disallow: /cron.php
Disallow: /update.php
Disallow: /install.php
Disallow: /index.php
Disallow: /admin/
Disallow: /comment/reply/
Disallow: /contact/
Disallow: /logout/
Disallow: /search/
Disallow: /user/register/
Disallow: /user/password/
Disallow: *register*
Disallow: *login*
Disallow: /top-rated-
Disallow: /messages/
Disallow: /book/export/
Disallow: /user2userpoints/
Disallow: /myuserpoints/
Disallow: /tagadelic/
Disallow: /referral/
Disallow: /aggregator/
Disallow: /files/pin/
Disallow: /your-votes
Disallow: /comments/recent
Disallow: /*/edit/
Disallow: /*/delete/
Disallow: /*/export/html/
Disallow: /taxonomy/term/*/0$
Disallow: /*/edit$
Disallow: /*/outline$
Disallow: /*/revisions$
Disallow: /*/contact$
Disallow: /*downloadpipe
Disallow: /node$
Disallow: /node/*/track$
Disallow: /*&
Disallow: /*%
Disallow: /*?page=0
Disallow: /*section
Disallow: /*order
Disallow: /*?sort*
Disallow: /*&sort*
Disallow: /*votesupdown
Disallow: /*calendar
Disallow: /*index. php
php
Allow: /*?page=
Disallow: /*?
Sitemap: http://путь к вашей карте XML формата
Выводы
Файл robots txt — функциональный инструмент, благодаря которому веб-разработчик дает инструкции поисковым системам, как взаимодействовать с сайтом. Благодаря ему мы обеспечиваем правильную индексацию, защищаем веб-ресурс от попадания под фильтры поисковых систем, снижаем нагрузку на сервер и улучшаем параметры сайта для SEO.
Чтобы правильно прописать инструкции файла robots.txt, крайне важно отчетливо понимать, что вы делаете и зачем вы это делаете. Соответственно, если не уверены, лучше обратитесь за помощью к специалистам. В нашей компании настройка robots txt входит в услугу внутренней оптимизации сайта для поисковых систем.
Кстати, в нашей практике был случай, когда клиент обратился за услугой раскрутки сайта, в корне которого файл robots txt попросту отсутствовал и индексация происходила некорректно. Почитайте, там много интересных моментов: «SEO-Кейс: Продвижение сайта медицинских справок».
Почитайте, там много интересных моментов: «SEO-Кейс: Продвижение сайта медицинских справок».
FAQ
Что такое файл robots.txt?
Robots txt — это документ, содержащий правила индексации вашего сайта, отдельных его файлов или URL поисковиками. Правила, описанные в файле robots.txt, называются директивами.
Зачем нужен файл robots.txt?
Robots txt помогает закрыть от индексации отдельные файлы, дубли страниц, документы, не несущие никакой пользы для посетителей, а также страницы, содержащие неуникальный контент.
Где находится файл robots.txt?
Он размещается в корневой папке веб-ресурса. Чтобы проверить его наличие, достаточно в URL-адрес вашего веб-ресурса дописать /robots.txt и нажать Enter. Если он на месте, откроется его страница. Так можно просмотреть данный файл на любом сайте, даже на стороннем. Просто добавьте к адресу /robots.txt.
У Вас остались вопросы?
Наши эксперты готовы ответить на них. Оставьте ваши контактные данные. Будем рады обсудить ваш проект!
Оставьте ваши контактные данные. Будем рады обсудить ваш проект!
Получить консультацию
Наш менеджер свяжется с Вами в ближайшее время
Как Google обрабатывает файлы robots.txt — SEO
За последние годы мы несколько раз сталкивались с интересной ситуацией с robots.txt, которая может быть сложной для владельцев сайтов. После выявления проблемы и разговоров с клиентами о том, как её решить, мы обнаружили, что многие люди даже не подозревают, что такое может произойти. А поскольку речь идёт о файлах robots.txt, то это может оказывать большое влияние на SEO
Мы имеем в виду файлы robots.txt, обрабатываемые по поддоменам и протоколам. Другими словами, на сайте может быть одновременно несколько файлов robots.txt, добавленных по поддоменам: www и non-www, или по протоколам: https www и http www.
Поскольку Google обрабатывает каждый из них в отдельности, вы можете передавать совершенно разные инструкции о том, как сайт должен сканироваться.
В статье мы рассмотрим два реальных примера сайтов, которые столкнулись с данной проблемой. Мы также ознакомимся с документацией Google по robots.txt и разберёмся, как обнаружить другие файлы.
Подход Google к обработке файлов robots.txt
Выше мы упоминали, что Google обрабатывает файлы robots.txt по поддомену и протоколу. Например, сайт может иметь один файл robots.txt в версии с www и совершенно другой в версии без www. В своей практике мы несколько раз наблюдали такую ситуацию по сайтам клиентов и недавно снова столкнулись с ней.
Помимо www и non-www, сайт также может иметь файл robots.txt, расположенный в https- и http-версиях поддомена. Таким образом, может быть несколько файлов robots.txt с разными инструкциями для поисковых роботов.
Документация Google чётко объясняет, как обрабатываются файлы robots.txt. Вот несколько примеров того, как будут применяться обнаруженные инструкции:
Такой подход определённо может вызвать проблемы, так как Googlebot может получить разные файлы robots. txt для одного и того же сайта и по-разному сканировать каждую его версию. И тогда возможна ситуация, когда владельцы сайтов полагают, что Googlebot выполняет один набор инструкций в то время, как он также получает ещё один набор во время других обходов сайта.
txt для одного и того же сайта и по-разному сканировать каждую его версию. И тогда возможна ситуация, когда владельцы сайтов полагают, что Googlebot выполняет один набор инструкций в то время, как он также получает ещё один набор во время других обходов сайта.
Ниже мы рассмотрим два случая, где мы столкнулись с такой проблемой.
№ 1. Разные файлы robots.txt с конфликтующими директивами в www и non-www версиях
Недавно, выполняя аудит сканирования на одном из сайтов, мы заметили, что некоторые страницы, заблокированные в robots.txt, по факту сканируются и индексируются. Мы знаем, что Google на 100% соблюдает инструкции в файле robots.txt, поэтому это был явный красный флаг.
Отметим, мы имеем в виду те URL, которые сканируются и индексируются в обычном режиме, несмотря на то что инструкции в robots.txt должны запрещать сканирование. Google также может индексировать URL-адреса, заблокированные файлом robots.txt, не сканируя их, но это другая ситуация, которую мы рассмотрим ниже.
Проверяя файл robots.txt вручную, мы увидели набор инструкций для версии без www, и там было прописано ограничение. Затем мы начали вручную проверять другие версии сайта (по поддомену и протоколу), чтобы посмотреть, есть ли какие-либо проблемы там.
И они были: в поддомене с www был ещё один файл robots.txt. И, как вы можете догадаться, он содержал другие инструкции.
На сайте не было правильной переадресации robots.txt для www-версии на версию без www. Таким образом, Google смог получить доступ к обоим файлам robots.txt и найти два разных набора инструкций для сканирования.
Опять же, как показывает наш опыт, многие владельцы сайтов не знают, что такие ситуации возможны.
Краткое примечание о заблокированных страницах, которые могут быть проиндексированы
Ранее мы упоминали, что страницы, правильно заблокированные в файле robots.txt, могут быть проиндексированы. Они просто не будут сканироваться.
Google объяснял это много раз, и вы можете узнать больше о том, как он может индексировать такие URL-адреса в справочной документациипо robots. txt.
txt.
Мы знаем, что это запутанная тема для многих владельцев сайтов, но Google определенно может индексировать страницы, которые заблокированы. Например, это возможно в том случае, когда Google видит входящие ссылки, указывающие на эти страницы.
Когда это происходит, Google индексирует URL-адреса и указывает в результатах поиска, что информации об этих страницах нет. Они будут отображаться без описания.
Но это не та ситуация, которую мы рассматриваем в данной статье. Вот скриншот из FAQ Google по robots.txt, где говорится про возможную индексацию заблокированных URL:
А как насчёт Search Console и файлов robots.txt?
В Search Console есть отличный инструмент, который можно использовать для отладки файлов robots.txt –
К сожалению, многим владельцам сайтов этот инструмент сложно найти. На него нет ссылок в новом Search Console. Но в него можно попасть из Справочного центра сервиса.
Используя этот инструмент, вы можете просматривать предыдущие файлы robots.txt, которые видел Google. Как вы можете догадаться, мы увидели оба файла robots.txt по анализируемому сайту. Поэтому, да, Google действительно видит второй файл.
Выявив проблему, мы быстро отправили клиенту всю необходимую информацию, скриншоты и т.п. Мы также велели им удалить второй файл robots.txt и настроить переадресацию 301 с www-версии на версию без www. Теперь, когда Google будет заходить на сайт и проверять файл robots.txt, он будет видеть правильный набор инструкций.
При этом на сайте остались те URL, которые были проиндексированы из-за смешанных директив. Поэтому теперь наш клиент открывает эти URL для сканирования, но следит за тем, чтобы файлы были заблокированы от индексации через метатег robots.
Когда общее количество таких URL в GSC снизится, мы снова добавим правильно реализованную директиву disallow, чтобы заблокировать эту область.
№ 2.
Несколько лет назад к нам обратился один вебмастер в связи с падением органического поискового трафика по сайту без видимых причин.
Покопавшись, мы решили проверить разные версии сайта по протоколу (включая файлы robots.txt для каждой версии).
При попытке проверить https-версию файла robots.txt нам сначала пришлось просмотреть предупреждение безопасности в Chrome. И как только мы это сделали, то увидели второй файл robots.txt, который блокировал весь сайт от сканирования.
В https-версии файла robots.txt оно было полностью запрещено с помощью директивы Disallow: /.
Помимо этого, на сайте были и другие проблемы, но наличие нескольких файлов robots.txt, один из которых полностью запрещал сканирование, трудно назвать оптимальным.
Https-версия файла robots.txt (скрытая за предупреждением безопасности в Chrome):
Проблемы по сайту, отображаемые в Search Console для https-ресурса:
Просмотр https-версии сайта как Googlebot показывает, что она заблокирована:
Как и в первом случае, владелец сайта быстро решил проблему (что было нелегко, учитывая их CMS).
Это ещё один хороший пример того, как Google обрабатывает файлы robots.txt, и в чём опасность наличия на сайте нескольких файлов по разным поддоменам или протоколам.
Как найти несколько файлов robots.txt: инструменты
Есть несколько инструментов, которые можно использовать, помимо ручной проверки файлов robots.txt по поддомену или протоколу.
Они также могут помочь увидеть, какие файлы robots.txt ранее отображались по сайту.
Инструмент проверки robots.txt в Search Console
Этот инструмент, который мы уже упоминали выше, позволяет видеть текущий файл robots.txt и предыдущие версии, обработанные Google.
Он также функционирует как «песочница», где можно протестировать новые директивы.
В целом это отличный инструмент, который Google по непонятным причинам поместил в дальний угол.
Wayback Machine
Интернет-архив также может быть полезен в этой ситуации.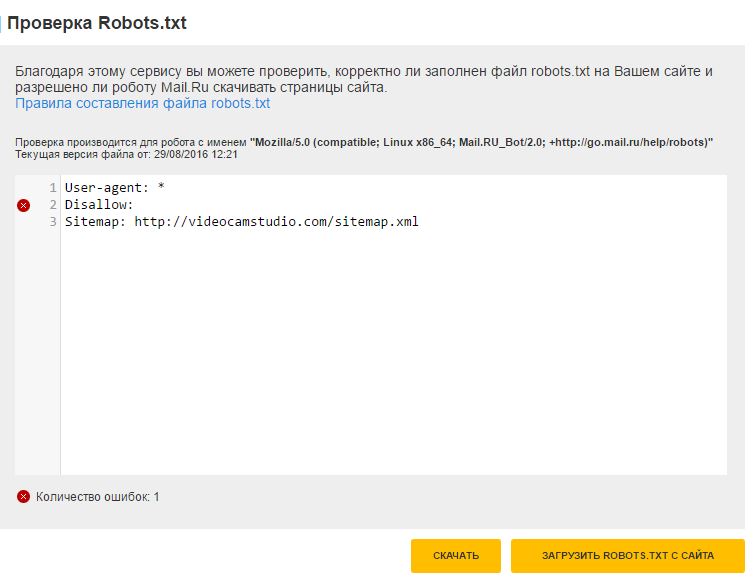 Мы уже рассматривали его использование в своей колонке на Search Engine Land.
Мы уже рассматривали его использование в своей колонке на Search Engine Land.
Однако Wayback Machine можно использовать не только для проверки стандартных веб-страниц. Этот инструмент также позволяет просматривать те файлы robots.txt, которые были на сайте ранее.
Таким образом, это отличный способ отследить предыдущие версии файла robots.txt.
Решение: переадресация 301
Чтобы избежать проблем с robots.txt по поддомену или протоколу, нужно реализовать переадресацию файла robots.txt на нужную версию с помощью 301 редиректа.
Например, если сайт работает на www, нужно перенаправить robots.txt в поддомене без www на версию с www.
Что касается https и http, то у вас уже должна быть настроена эта переадресация. Просто убедитесь, что файл robots.txt переадресован на нужный протокол и версию поддомена. А также – что все URL правильно перенаправлены на нужную версию.
Для других поддоменов вы можете выбрать отдельные файлы robots.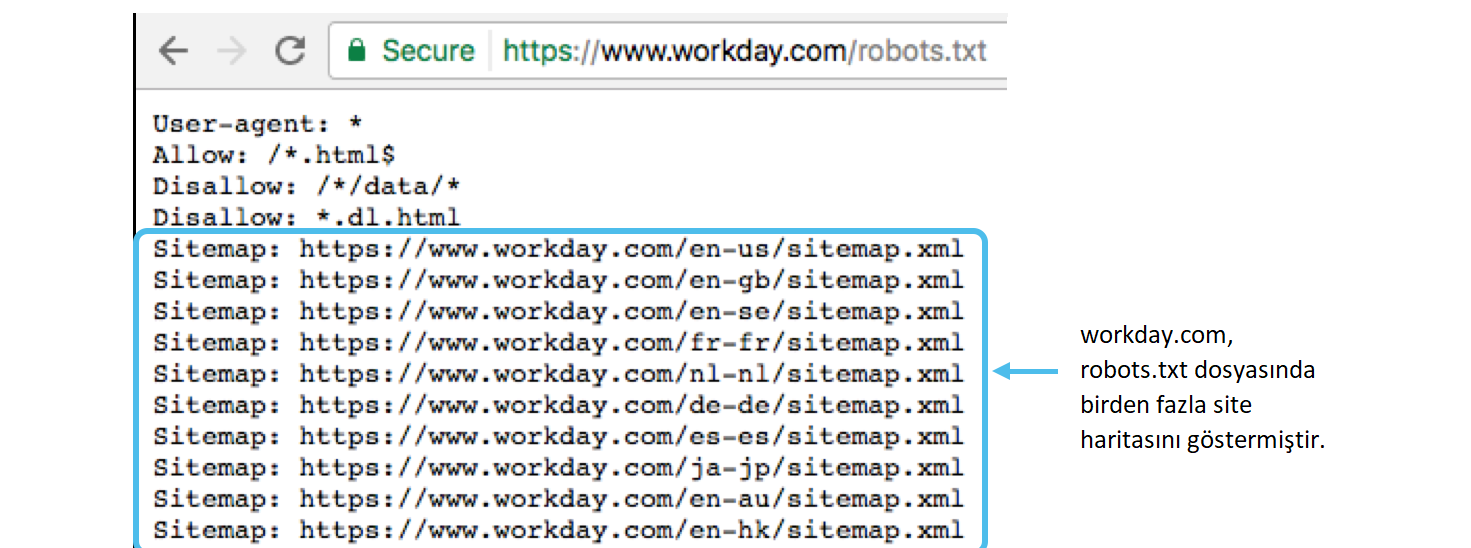 txt, что вполне нормально. Например, у вас может быть форум, расположенный на поддомене forums.domain.com, и инструкции по нему могут отличаться от инструкций для www-версии.
txt, что вполне нормально. Например, у вас может быть форум, расположенный на поддомене forums.domain.com, и инструкции по нему могут отличаться от инструкций для www-версии.
В данной статье мы говорим о www/non-www и http/https для основного сайта.
Вместо заключения: следите, чтобы инструкции в файлах robots.txt совпадали
Поскольку robots.txt контролирует сканирование, чрезвычайно важно понимать, как Google обрабатывает эти файлы.
Некоторые сайты могут содержать несколько файлов robots.txt по отдельным поддоменам и протоколам с разными инструкциями. В зависимости от того, как Google сканирует сайт, он может находить один из этих файлов, что может приводить к проблемам.
Поэтому важно убедиться, что все файлы robots.txt содержат согласованные директивы.
Что следует знать специалистам по контекстной рекламе о файлах Robots.txt
Поисковые системы используют компьютерную программу, известную как бот, для обхода и индексирования Интернета.
 Файл robots.txt — это инструкция, в которой боту сообщается, что можно и что нельзя сканировать на вашем сайте. Неправильно настроенный файл robots.txt может: Понизить ваши показатели качества. Привести к тому, что ваша реклама не будет одобрена. Понизить ваши […]
Файл robots.txt — это инструкция, в которой боту сообщается, что можно и что нельзя сканировать на вашем сайте. Неправильно настроенный файл robots.txt может: Понизить ваши показатели качества. Привести к тому, что ваша реклама не будет одобрена. Понизить ваши […]Брэд Геддес, 15 августа 2011 г., 10:45 | Время чтения: 6 минут
Поисковые системы используют компьютерную программу, известную как бот, для обхода и индексирования Интернета. Файл robots.txt — это инструкция, в которой боту сообщается, что можно и что нельзя сканировать на вашем сайте.
Неправильно настроенный файл robots.txt может:
- Понизить ваши показатели качества
- Причина, по которой ваши объявления не будут одобрены
- Понизьте свой органический рейтинг
- Создать множество других проблем
Файлы robots.txt часто обсуждаются с точки зрения SEO. Поскольку SEO и PPC должны работать вместе, в этой колонке мы рассмотрим, что пользователи PPC должны знать о файлах robots. txt, чтобы они не вызывали проблем ни с их учетными записями платного поиска, ни с их органическим рейтингом.
txt, чтобы они не вызывали проблем ни с их учетными записями платного поиска, ни с их органическим рейтингом.
Робот AdWords
Google использует бота под названием «adsbot-Google» для сканирования целевых URL-адресов с целью оценки качества.
Если бот не может просканировать вашу страницу, вы, как правило, увидите нерелевантные страницы, потому что Google не разрешено индексировать ваши страницы, а это означает, что они не могут проверить страницу, чтобы определить, является ли она релевантной или нет.
Бот Google использует другой набор правил для интерпретации файла robots.txt, чем большинство других ботов.
Большинство ботов увидят глобальный запрет, что означает, что ни один бот не может сканировать страницу или файл, а затем вообще не проверять страницу.
Adsbot-Google игнорирует глобальные запреты. Предполагается, что вы допустили ошибку. Поскольку вы покупаете трафик на страницу и не вызывали конкретно их бота, то они игнорируют запрет и все равно читают страницу.
Однако, если вы вызовете бота конкретно в файле robots.txt, то adsbot-Google будет следовать инструкциям.
Обычно вы не блокируете рекламный бот-гугл целенаправленно.
Однако происходит то, что ИТ или другие отделы проверяют пропускную способность робота и видят, что бот, которого они плохо знают, использует много пропускной способности, когда он сканирует ваш сайт. Поскольку они не знают, что это такое, они блокируют бота. Это приведет к значительному падению показателей качества целевой страницы.
Неспециалистам проще всего увидеть это с помощью инструментов Google для веб-мастеров. Вы можете создать учетную запись инструментов для веб-мастеров, а затем посмотреть, не блокирует ли ваш файл robots.txt робота adsbot-Google сканирование вашего сайта.
Кроме того, инструменты Google для веб-мастеров позволяют просматривать ошибки сканирования на вашем сайте. Проблема, с которой сталкиваются многие более крупные учетные записи PPC, заключается в том, что они в конечном итоге отправляют трафик на неработающие ссылки, поскольку сайт и URL-адреса со временем меняются.
Вы также можете использовать бесплатный поисковый робот для проверки неработающих ссылок в своей учетной записи AdWords.
Робот Microsoft AdCenter
Microsoft также имеет робота, который используется для утверждения рекламы. Этот робот называется «adidxbot» или «MSNPTC/1.0».
Этот файл robots соответствует стандартным соглашениям robots.txt. Если вы используете глобальный запрет, чтобы запретить ботам сканировать части вашего сайта, то этот бот не увидит эти страницы, и у вас возникнут проблемы с одобрением рекламы.
Хотя у Bing также есть Центр веб-мастеров, у него нет способа узнать, блокируете ли вы их рекламного бота.
Тестирование целевых страниц и дублирование содержимого
Часто при тестировании целевых страниц создается несколько версий одной и той же страницы с разными макетами, кнопками, заголовками и преимуществами.
Однако большая часть контента одинакова на всех страницах. Если все эти страницы проиндексированы роботами, участвующими в органическом ранжировании, это может привести к падению вашего органического ранжирования. Поэтому вы хотите убедиться, что ваши тестовые страницы блокируются ботами, которые сканируют в обычных целях, но могут быть проиндексированы для целей PPC.
Поэтому вы хотите убедиться, что ваши тестовые страницы блокируются ботами, которые сканируют в обычных целях, но могут быть проиндексированы для целей PPC.
В AdWords это сделать намного проще, чем в Microsoft AdCenter.
Для тестирования целевых страниц в AdWords можно просто поместить все тестовые страницы в одну папку, а затем использовать глобальный запрет, чтобы заблокировать эту папку. Поскольку adsbot-Google игнорирует глобальные запреты, он будет сканировать страницу; однако органические боты будут подчиняться файлу robots.txt и не будут сканировать ваши страницы.
При использовании AdCenter вам нужно поместить тестовые страницы в папку, а затем заблокировать сканирование этой папки всеми стандартными ботами, кроме «adidxbot».
Сделав дополнительный шаг в процессе тестирования, заблокировав тестовые страницы от сканирования обычными ботами, но оставив их доступными для платных поисковых роботов, вы не повлияете на свой органический рейтинг при тестировании целевых страниц.
Дополнительная информация
Если вы понимаете основную концепцию блокировки соответствующих ботов, но вам нужна дополнительная помощь в понимании того, как работают файлы Robots.txt, см. эту прекрасную статью о том, как понять robots.txt.
За последние несколько лет я видел много случаев, когда SEO-специалисты портили программу платного поиска компании или группу платного поиска, что приводило к снижению органического рейтинга. Эти две программы дополняют друг друга (см. мою последнюю колонку «Стоит ли вам делать ставки на ключевое слово, если вы органически ранжируете этот термин?») и могут помогать друг другу разными способами.
В SMX East я готовлю новую сессию на тему PPC и SEO: разве мы не можем просто поладить?, где Тодд Фризен, Тим Майер и я рассмотрим, как эти две программы могут дополнять друг друга. другое и как заставить их работать на вас, чтобы увеличить общую экспозицию. Если вы хотите узнать больше об AdWords, я проведу расширенный курс AdWords в начале конференции.
SEO и контекстная реклама могут во многом помогать друг другу. Они также могут навредить друг другу, если обе стороны не работают вместе должным образом. Первый шаг, который может сделать ваш отдел PPC, чтобы помочь вашему отделу SEO, — это не повредить их органический рейтинг вашим тестированием. Вам нужно проверить. Тестирование необходимо для улучшения вашей учетной записи.
Тем не менее, если вы потратите несколько дополнительных минут на то, чтобы убедиться, что ваш файл robots.txt настроен правильно, это поможет убедиться, что ваши целевые страницы платного поиска сканируются правильно, и в то же время не вызовет органических штрафов.
Мнения, высказанные в этой статье, принадлежат приглашенному автору и не обязательно принадлежат Search Engine Land. Штатные авторы перечислены здесь.
Добавьте Search Engine Land в свою ленту новостей Google.
Похожие истории
Новое в поисковой системе
Об авторе
Полное руководство по Robots.
 txt для SEO
txt для SEORobots.txt — это файл, который вы можете создать для управления сканированием вашего веб-сайта.
Это практическая реализация протокола исключения роботов, который был создан для того, чтобы не позволял поисковым роботам перегружать веб-сайты слишком большим количеством запросов.
Владельцам служб может быть неудобно, если сканеры посещают все их пространство URI. В этом документе указаны правила, изначально определенные «Протоколом исключения роботов», которым должны подчиняться сканеры при доступе к URI.
источник: Протокол исключения роботов
Несмотря на то, что вашему веб-сайту не обязательно использовать файл robots.txt , наличие файла может положительно повлиять на ваш бизнес, оптимизируя сканирование вашего сайта ботами поисковых систем.
По данным Веб-альманаха 2021 года, около 16,5% веб-сайтов вообще не имеют файла robots.txt. Кроме того, не все реализуют его правильно.
Кроме того, не все реализуют его правильно.
Возможно, веб-сайты неправильно сконфигурировали файлы robots.txt. Например, некоторые популярные веб-сайты (предположительно по ошибке) блокировали поисковые системы. Google может индексировать эти веб-сайты в течение определенного периода времени, но в конечном итоге их видимость в результатах поиска уменьшится.
источник: Веб-альманах
В зависимости от размера вашего веб-сайта неправильное использование robots.txt может быть незначительной ошибкой или очень дорогостоящей ошибкой.
В этой статье показано, как создать файл robots.txt и избежать потенциальных ошибок.
Что такое robots.txt?
Robots.txt — это простой текстовый файл, который вы можете разместить на своем сервере, чтобы контролировать доступ ботов к вашим страницам. Он содержит правила для поисковых роботов, определяющие, какие страницы следует или не следует сканировать.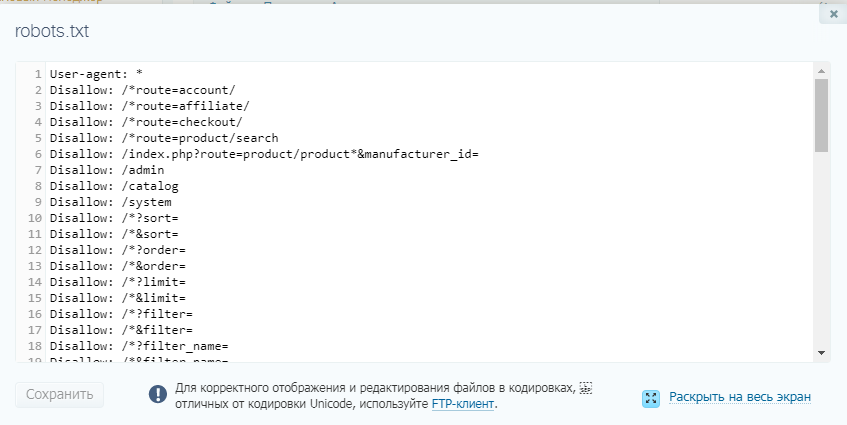
Файл должен находиться в корневом каталоге вашего сайта. Так, например, если ваш веб-сайт называется domain.com, файл robots.txt должен располагаться по адресу domain.com/robots.txt.
Но как работает файл? Как боты узнают об этом?
Краулеры — это программы, которые сканируют Интернет. Они используются по-разному, но поисковые системы используют их для поиска веб-контента для индексации. Этот процесс можно разделить на несколько шагов:
- Поисковые роботы имеют очередь URL-адресов, содержащих как новые, так и ранее известные веб-сайты, которые они хотят просканировать.
- Перед сканированием веб-сайта сканеры сначала ищут файл robots.txt в корневом каталоге веб-сайта.
- Если файл robots.txt не существует, поисковые роботы продолжают свободно сканировать веб-сайт. Однако, если существует действительный файл robots.txt, поисковые роботы ищут в нем директивы и соответствующим образом продолжают сканировать веб-сайт.
Если поисковая система не может просканировать страницу, то эта страница не может быть проиндексирована и, следовательно, не будет отображаться на страницах результатов поиска.
Однако есть два предостережения:
1. Заблокированная для сканирования страница может быть проиндексирована
Запрет сканирования в файле robots.txt не гарантирует, что поисковые системы не будут индексировать страницу. Они все равно могут это сделать, если найдут информацию о контенте в других источниках и решат, что это важно. Например, они могут найти ссылки, ведущие на страницу с других сайтов, использовать анкорный текст и показать его на странице результатов поиска.
Узнайте, как решить эту проблему, прочитав нашу статью о том, как исправить статус «Проиндексировано, но заблокировано robots.txt».
2. Вы не можете заставить роботов подчиняться правилам в robots.txt
Robots.txt является лишь рекомендацией, а не обязательным правилом. Вы не можете заставить ботов ему подчиняться. Большинство сканеров, особенно те, которые используются поисковыми системами, не будут сканировать страницы, заблокированные файлом robots. txt. Однако поисковые системы не единственные, кто использует сканеры. Вредоносные боты могут проигнорировать инструкции и все равно получить доступ к страницам. Вот почему вы не должны использовать robots.txt как способ защиты конфиденциальных данных на вашем веб-сайте от сканирования. Если вам нужно убедиться, что боты не будут сканировать часть вашего контента, лучше защитить его паролем.
txt. Однако поисковые системы не единственные, кто использует сканеры. Вредоносные боты могут проигнорировать инструкции и все равно получить доступ к страницам. Вот почему вы не должны использовать robots.txt как способ защиты конфиденциальных данных на вашем веб-сайте от сканирования. Если вам нужно убедиться, что боты не будут сканировать часть вашего контента, лучше защитить его паролем.
Зачем нужен файл robots.txt?
Robots.txt не является обязательной частью вашего веб-сайта, но хорошо оптимизированный файл может принести вашему сайту множество преимуществ.
Самое главное, это может помочь вам с оптимизацией краулингового бюджета . Боты поисковых систем имеют ограниченные ресурсы, что ограничивает количество URL-адресов, которые они могут сканировать на данном веб-сайте. Поэтому, если вы тратите свой краулинговый бюджет на менее важные страницы, его может не хватить на более ценные. Если у вас небольшой веб-сайт, это может показаться поверхностным вопросом, но любой, кто поддерживает большой веб-сайт, знает, насколько важно эффективно использовать ресурсы поисковых ботов.
С помощью файла robots.txt можно предотвратить сканирование определенных страниц, например некачественных . Это очень важно, потому что если у вас много индексируемых страниц низкого качества, это может повлиять на весь сайт и помешать ботам поисковых систем сканировать даже высококачественные страницы.
Кроме того, файл robots.txt позволяет указать расположение вашей XML-карты сайта. Карта сайта — это текстовый файл со списком URL-адресов, которые поисковые системы должны индексировать. Определение его ссылки в файле robots.txt облегчает его поиск ботам поисковых систем.
Как изменить файл robots.txt
Способ изменения файла robots.txt сильно зависит от используемой системы.
Если вы используете CMS или платформу электронной коммерции, у вас может быть доступ к специальным инструментам или плагинам, которые помогут вам легко получить доступ к файлу и изменить его. Например, Wix и Shopify позволяют напрямую редактировать файл robots. txt. Для WordPress вы можете использовать такие плагины, как Yoast SEO.
txt. Для WordPress вы можете использовать такие плагины, как Yoast SEO.
Если вы не используете CMS или платформу электронной коммерции, вам может потребоваться сначала загрузить файл, отредактировать его, а затем загрузить обратно на свой сайт.
Вы можете загрузить файл различными способами:
- Отобразите файл в браузере, добавив «/robots.txt» в корневой каталог, а затем просто скопируйте содержимое.
- Используйте инструменты, предоставляемые вашим хостингом. Например, это может быть выделенная панель для управления файлами или доступа по протоколу FTP.
- Используйте инструменты консоли, такие как cURL, для загрузки файла, введя эту команду:
завиток https://example.com/robots.txt -o robots.txt
- Используйте тестеры robots.txt от Google или Bing, чтобы загрузить копию файла.
Загрузив robots.txt, вы можете просто отредактировать его в выбранном вами текстовом редакторе, таком как Блокнот (Windows) или TextEdit (Mac).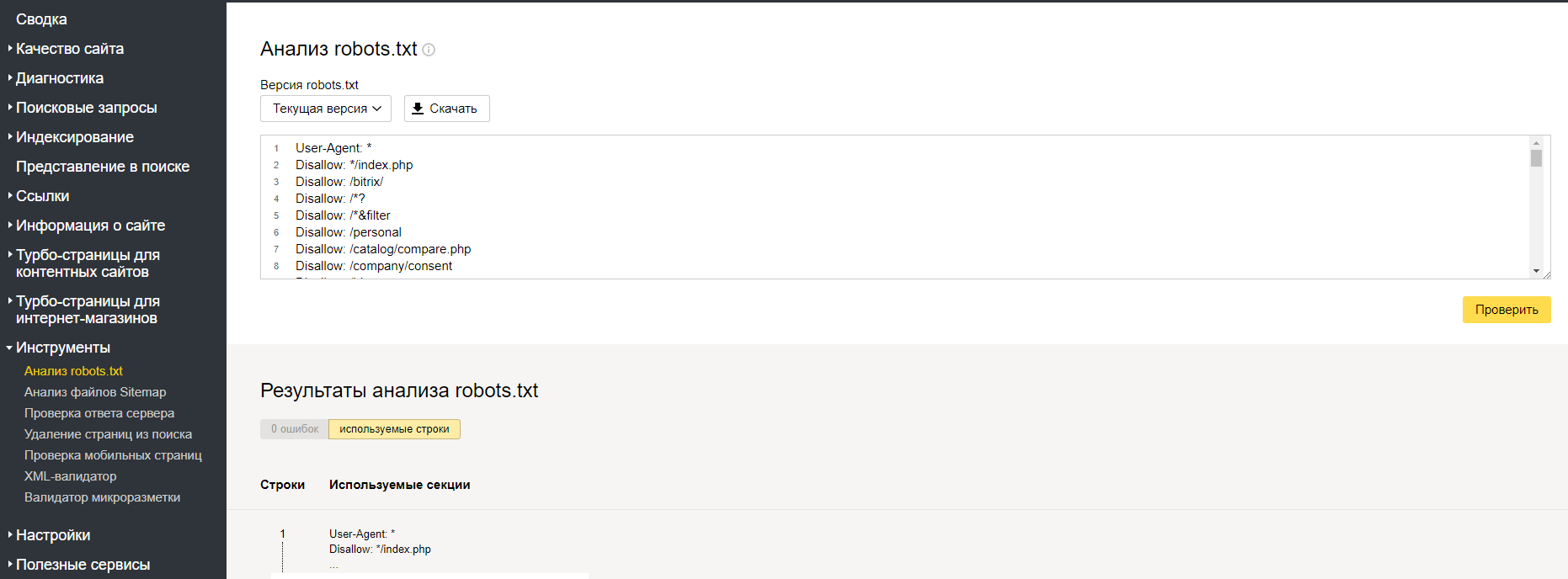 Убедитесь, что файл закодирован в стандарте UTF-8, и помните, что он должен называться «robots.txt».
Убедитесь, что файл закодирован в стандарте UTF-8, и помните, что он должен называться «robots.txt».
После модификации robots.txt вы можете загрузить файл аналогично его скачиванию. Вы можете использовать специальные инструменты, предоставляемые вашим хостингом, использовать встроенные инструменты CMS или отправлять файлы напрямую на сервер по протоколам FTP.
Как только ваш файл станет общедоступным, поисковые системы смогут найти его автоматически. Если по какой-то причине вы хотите, чтобы поисковые системы сразу же увидели изменения, вы можете использовать опцию «Отправить» в тестировщиках robots.txt от Google и Bing.
Во время автоматического сканирования сканеры Google замечают изменения, внесенные вами в файл robots.txt, и обновляют кешированную версию каждые 24 часа. Если вам нужно обновить кеш быстрее, используйте функцию Submit тестера robots.txt .
источник: Google
Синтаксис файла robots.
 txt
txtRobots.txt состоит из блоков текста. Каждый блок начинается со строки User-agent и группирует директивы (правила) для конкретного бота.
Вот пример файла robots.txt:
User-agent: * Запретить: /admin/ Запретить: /пользователи/ #специфические инструкции для робота Googlebot Агент пользователя: Googlebot Разрешить: /wp-admin/ Запретить: /пользователи/ #специфические инструкции для Bingbot Агент пользователя: Bingbot Запретить: /admin/ Запретить: /пользователи/ Запретить:/не для Bingbot/ Задержка сканирования: 10 Карта сайта: https://www.example.com/sitemap.xml
User-agent
Существуют сотни поисковых роботов, которые могут захотеть получить доступ к вашему веб-сайту. Вот почему вы можете захотеть определить для них разные границы в зависимости от их намерений. Вот когда User-agent может пригодиться.
User-agent — это строка текста, идентифицирующая конкретного бота. Так, например, Google использует Googlebot, Bing использует Bingbot, DuckDuckGo использует DuckDuckBot, а Yahoo использует Slurp. Поисковые системы также могут иметь более одного User-agent. Здесь вы можете найти полный список пользовательских агентов, используемых Google и Bing.
Поисковые системы также могут иметь более одного User-agent. Здесь вы можете найти полный список пользовательских агентов, используемых Google и Bing.
User-agent — обязательная строка в каждой группе директив. Вы можете думать об этом как об обращении к ботам по их именам и предоставлении каждому из них конкретной инструкции. Все директивы, которые следуют за User-agent, будут нацелены на определенного бота, пока не будет указан новый User-agent.
Вы также можете использовать подстановочный знак и давать инструкции всем ботам одновременно. Я расскажу о подстановочных знаках позже.
Директивы
Директивы — это правила, которые вы определяете для роботов поисковых систем. Каждый блок текста может иметь одну или несколько директив. Каждая директива должна начинаться с отдельной строки.
Директивы включают:
- Запретить,
- Разрешить,
- Карта сайта,
- Задержка сканирования.
Примечание. Существует также неофициальная директива noindex, которая должна указывать, что страница не должна индексироваться. Однако большинство поисковых систем, включая Google и Bing, его не поддерживают. Если вы не хотите, чтобы некоторые страницы индексировались, используйте заголовок noindex Meta Robots Tag или X-Robots-Tag (я объясню их позже в статье).
Однако большинство поисковых систем, включая Google и Bing, его не поддерживают. Если вы не хотите, чтобы некоторые страницы индексировались, используйте заголовок noindex Meta Robots Tag или X-Robots-Tag (я объясню их позже в статье).
Запретить
Агент пользователя: Googlebot Disallow: /users/
Эта директива указывает, какие страницы не следует сканировать. По умолчанию боты поисковых систем могут сканировать каждую страницу, не заблокированную директивой disallow.
Чтобы заблокировать доступ к определенной странице, необходимо определить ее путь относительно корневого каталога.
Давайте представим, что на вашем сайте есть два сайта:
- Website.com/products/shoes/item1.html
- веб-сайт.com/products/shirts/item2.html
Теперь давайте рассмотрим несколько примеров блокировки этих путей:
| Путь | Заблокировано |
| Запретить: /item1.html | Запрещен только файл /products/shoes/item1. html html |
| Запретить: /products/ | И /products/shoes/item1.html, и /products/shirts/item2.html запрещены |
Вы можете запретить сканирование всего сайта, добавив символ «/» следующим образом:
Агент пользователя: Googlebot Запретить: /
Разрешить
Агент пользователя: Googlebot Запретить: /пользователи/ Разрешить: /users/very-important-user.html
Вы можете использовать директиву allow, чтобы разрешить сканирование страницы в запрещенном каталоге.
В приведенном выше примере запрещены все страницы в каталоге /user/, кроме одной с именем /very-important-user.html.
Карта сайта
Карта сайта: https://website.com/sitemap.xml
Директива карты сайта указывает местоположение вашей карты сайта. Вы можете добавить его в начало или конец вашего файла и определить более одной карты сайта.
В отличие от путей, определенных в других директивах, всегда добавляет полный URL-адрес вашей карты сайта, включая протокол HTTP/HTTPS или версию с www/без www.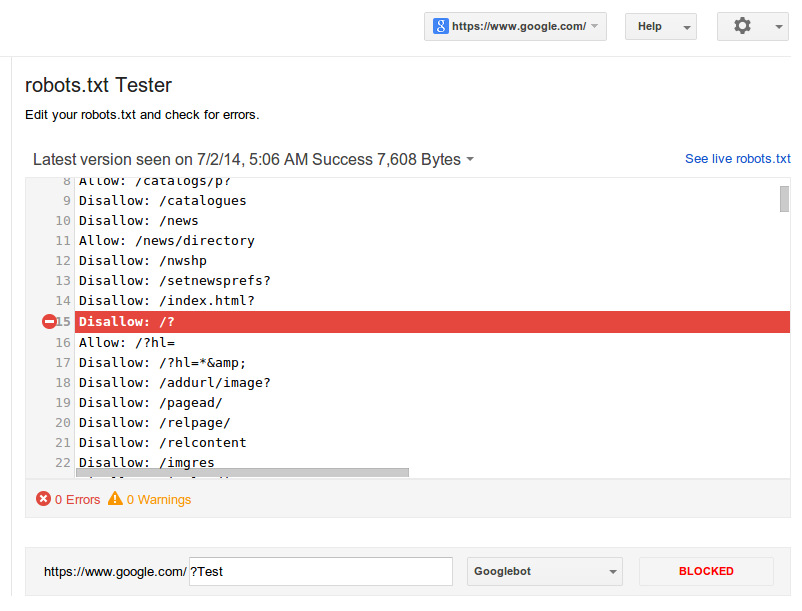
Директива карты сайта не требуется, но настоятельно рекомендуется. Даже если вы отправили карту сайта в Google Search Console или Bing Webmaster Tools, всегда полезно добавить ее в файл robots.txt, чтобы все роботы поисковых систем могли найти ее быстрее.
Crawl-delay
Crawl-delay: 10
Боты поисковых систем могут сканировать многие ваши страницы за короткий промежуток времени. Каждое сканирование использует часть ресурсов вашего сервера.
Если у вас большой веб-сайт с большим количеством страниц или для открытия каждой страницы требуется много ресурсов сервера, ваш сервер может не справиться со всеми запросами. В результате он станет перегруженным, а пользователи и поисковые системы могут временно потерять доступ к вашему сайту. Вот где директива Crawl-delay может пригодиться и замедлить процесс сканирования.
Значение директивы Crawl-delay определяется в секундах. Вы можете установить его в диапазоне от 1 до 30 секунд.
Важно отметить, что не каждая поисковая система следует этой директиве. Например, Google вообще не поддерживает Crawl-delay.
Например, Google вообще не поддерживает Crawl-delay.
Кроме того, его интерпретация может различаться в зависимости от поисковой системы. Например, для Bing и Yahoo Crawl-delay представляет собой продолжительность интервала между окнами, в течение которого бот может получить доступ к странице только один раз.
Для Яндекса Crawl-delay указывает время, в течение которого бот должен ждать, прежде чем запросить другую страницу.
Комментарии в robots.txt
#Блокирует доступ к разделу блога Агент пользователя: Googlebot Запретить: /блог/ Агент пользователя: Bingbot Запретить: /users/ #блокирует доступ к разделу пользователей
Вы можете добавлять комментарии в файл robots.txt, добавляя символ решетки # в начале строки или после директивы. Поисковые системы игнорируют все, что следует за # в той же строке.
Комментарии предназначены для того, чтобы люди могли объяснить, что означает тот или иной раздел. Всегда полезно добавить их, потому что они позволят вам быстрее понять, что происходит, когда вы в следующий раз откроете файл.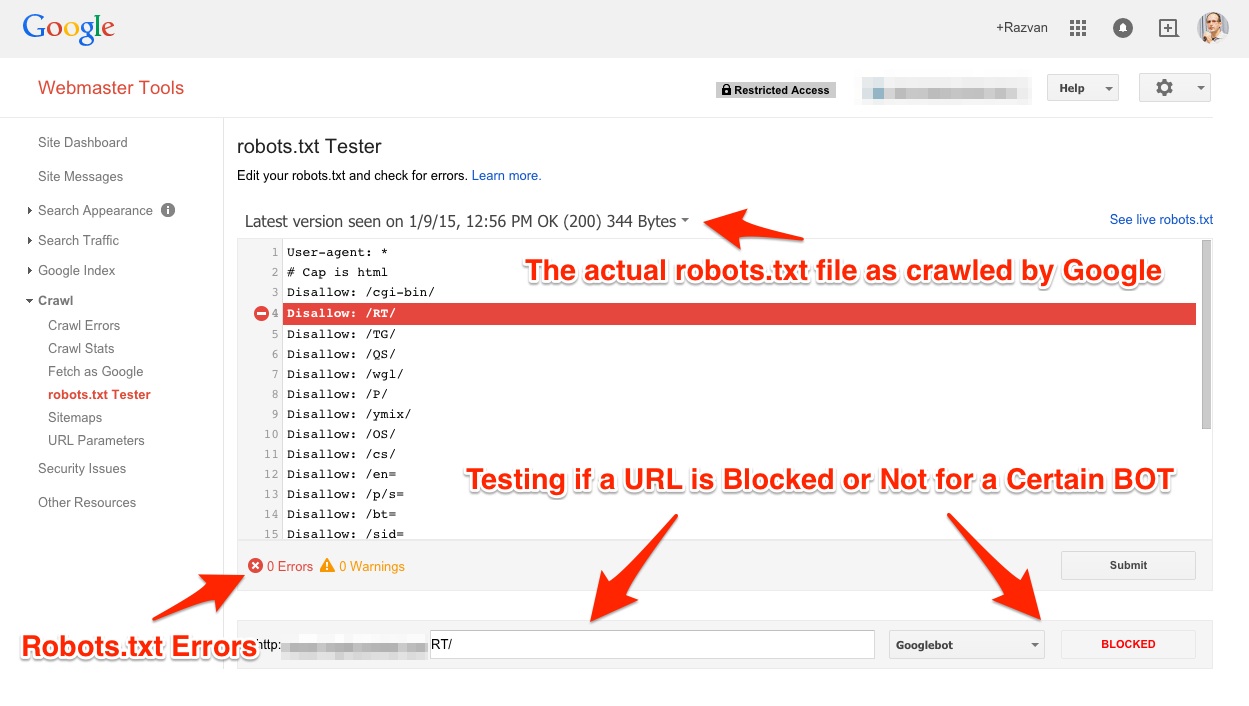
Вы можете использовать комментарии для добавления пасхальных яиц в файл robots.txt. Если вы хотите узнать об этом больше, вы можете прочитать нашу статью о том, как сделать директивы robots интересными для людей, или посмотреть пример в файле robots.txt.
Подстановочные знаки
Подстановочные знаки — это специальные символы, которые могут использоваться в качестве заполнителей для других символов в тексте и, следовательно, упрощают процесс создания файла robots.txt. Среди них:
- Звездочка * и
- Знак доллара $.
Звездочка может заменить любую строку.
User-agent: *
В приведенном выше примере звездочка в строке User-agent указывает на всех ботов поисковых систем. Следовательно, каждая директива, следующая за ней, будет направлена на всех поисковых роботов.
Запретить: /*?
Вы также можете использовать его для определения пути. Приведенные выше примеры означают, что каждый URL-адрес, оканчивающийся на «?» запрещено.
Знак доллара указывает на определенный элемент, который соответствует концу URL-адреса.
Запретить: /*.jpeg$
В приведенном выше примере показано, что все URL-адреса, оканчивающиеся на «.jpeg», должны быть запрещены.
Вы можете использовать подстановочные знаки в каждой директиве, кроме карты сайта.
Тестирование файла robots.txt
Вы можете протестировать его с помощью средства тестирования robots.txt в Google Search Console и Bing Webmaster Tools. Просто введите URL-адрес, который вы хотите проверить, и инструмент покажет вам, разрешен он или запрещен.
Вы также можете отредактировать файл непосредственно в тестировщиках robots.txt и повторно протестировать изменения. Имейте в виду, что изменения не сохраняются на вашем сайте. Вам необходимо самостоятельно скопировать файл и загрузить его на свой сайт.
Если вы более технически подкованы, вы также можете использовать библиотеку robots.txt с открытым исходным кодом Google для локального тестирования файла robots. txt на вашем компьютере.
txt на вашем компьютере.
СЛЕДУЮЩИЕ ШАГИ
Вот что вы можете сделать сейчас:
- Свяжитесь с нами.
- Получите от нас индивидуальный план решения ваших проблем с индексацией.
- Наслаждайтесь своим контентом в индексе Google!
Все еще не уверены, стоит ли писать нам? Узнайте, как услуги технического SEO могут помочь вам улучшить ваш сайт.
Robots.txt, Meta Robots Tag и X-Robots-Tag
Robots.txt — не единственный способ связи со сканерами. Вы также можете использовать теги Meta Robots и X-Robots-Tag.
Наиболее важным отличием является тот факт, что robots.txt контролирует сканирование веб-сайта, , а Meta Robots Tag и X-Robots-Tag позволяют контролировать его индексацию.
Кроме всего прочего, эти методы различаются еще и способами реализации.
| Реализация | |
| Robots.txt | Простой текстовый файл, добавленный в корневой каталог вашего веб-сайта. |
| Метатег роботов | Тег HTML добавлен в раздел кода. |
| X-Robots-Tag | Часть заголовка ответа HTTP добавлена на стороне сервера. |
Когда робот поисковой системы находит страницу, он сначала просматривает файл robots.txt. Если сканирование не запрещено, оно может получить доступ к веб-сайту и только после этого найти потенциальные теги Meta Robots или заголовки X-Robots-Tag. Это важно помнить по двум причинам:
- Комбинирование методов — роботам поисковых систем нужно разрешить сканировать страницу, чтобы увидеть тег Meta Robots и X-Robots-Tag. Если боты не могут получить доступ к странице, они не будут работать корректно.
- Оптимизация краулингового бюджета — из этих трех методов только robots.txt может помочь вам сэкономить краулинговый бюджет.
Рекомендации
Вот несколько рекомендаций и советов по созданию файла robots.txt:
- Не блокируйте файлы JavaScript или CSS с помощью robots.
