что это такое, что будет, если она отсутствует
Мы увеличиваем посещаемость и позиции в выдаче. Вы получаете продажи и платите только за реальный результат, только за целевые переходы из поисковых систем
Заказывайте честное и прозрачное продвижение
Получи нашу книгу «Контент-маркетинг в социальных сетях: Как засесть в голову подписчиков и влюбить их в свой бренд».
Подпишись на рассылку и получи книгу в подарок!
Директива Host – это команда или правило, сообщающее поисковой машине о том, какое зеркало веб-ресурса (с www или без) считать основным. Находится директива Host в файле Robots.txt и предназначена исключительно для Яндекса.
Часто возникает необходимость, чтобы поисковая система не индексировала некоторые страницы сайта или его зеркала. Например, ресурс находится на одном сервере, однако в интернете есть идентичное доменное имя, по которому осуществляется индексация и отображение в результатах поисковой выдачи.
Поисковые роботы Яндекса обходят страницы сайтов и добавляют собранную информацию в базу данных по собственному графику.
Зачем нужен файл Robots.txt
Robots – это обычный текстовый файл. Его можно создать через блокнот, однако работать с ним (открывать и редактировать информацию) рекомендуется в текстовом редакторе Notepad++. Необходимость данного файла при оптимизации веб-ресурсов обуславливается несколькими факторами:
- Если файл Robots.txt отсутствует, сайт будет постоянно перегружен из-за работы поисковых машин.
- Существует риск, что индексироваться будут лишние страницы или сайты зеркала.
Индексация будет проходить гораздо медленнее, а при неправильно установленных настройках он вовсе может исчезнуть из результатов поисковой выдачи Google и Яндекс.
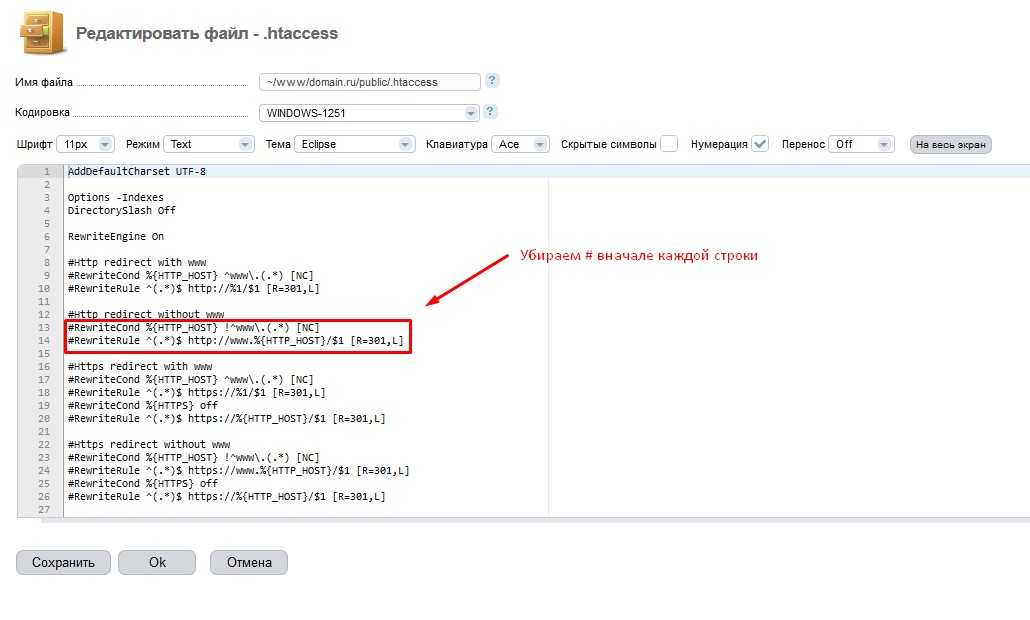
Как оформить директиву Host в файле Robots.txt
Файл Robots включает в себя директиву Host – инструкцию для поисковой машины о том, где главный сайт, а где его зеркала.
Директива имеет следующую форму написания: Host: [необязательный пробел] [значение] [необязательный пробел]. Правила написания директивы требуют соблюдения следующих пунктов:
- Наличие в директиве Host протокола HTTPS для поддержки шифрования. Его необходимо использовать, если доступ к зеркалу осуществляется только по защищенному каналу.
- Доменное имя, не являющееся IP-адресом, а также номер порта веб-ресурса.
Корректно составленная директива позволит веб-мастеру обозначить для поисковых машин, где главное зеркало. Остальные будут считаться второстепенными и, следовательно, индексироваться не будут. Как правило, зеркала можно отличить по наличию или отсутствию аббревиатуры www. Если пользователь не укажет главное зеркало веб-ресурса посредством Host, поисковая система Яндекс пришлет соответствующее уведомление в Вебмастер.
Определить, где главное зеркало сайта можно через поисковик. Необходимо вбить в поисковую строку адрес ресурса и посмотреть на результаты выдачи: сайт, где перед доменом в адресной строке стоит www, является главным доменом.
В случае, если ресурс не отображается на странице выдачи, пользователь может самостоятельно назначить его главным зеркалом, перейдя в соответствующий раздел в Яндекс.Вебмастере. Если веб-мастеру необходимо, чтобы доменное имя сайта не содержало www, следует не указывать его в Хосте.
Многие веб-мастера используют кириллические домены в качестве дополнительных зеркал для своих сайтов. Однако в директиве Host кириллица не поддерживается. Для этого необходимо дублировать слова на латинице, с условием, что их можно будет легко узнать, скопировав адрес сайта из адресной строки.
Хост в файле Роботс
Главное предназначение данной директивы состоит в решении проблем с дублирующими страницами. Использовать Host необходимо в случае, если работа веб-ресурса ориентирована на русскоязычную аудиторию и, соответственно, сортировка сайта должна проходить в системе Яндекса.
Использовать Host необходимо в случае, если работа веб-ресурса ориентирована на русскоязычную аудиторию и, соответственно, сортировка сайта должна проходить в системе Яндекса.
Не все поисковики поддерживают работу директивы Хост. Функция доступна только в Яндексе. При этом даже здесь нет гарантий, что домен будет назначен в качестве главного зеркала, но по заверениям самого Яндекса, приоритет всегда остается за именем, которое указано в хосте.
Чтобы поисковые машины правильно считывали информацию при обработке файла robots.txt, необходимо прописывать директиву Host в соответствующую группу, начинающуюся после слов User-Agent. Однако, роботы смогут использовать Host независимо от того, будет директива прописана по правилам или нет, поскольку она является межсекционной.
Директива Host поисковой системы Яндекс осталась в прошлом — новости СТК Промо
26.07.2021 Шрифт: 18058
Специалисты Яндекс продолжают корректировать и совершенствовать поисковый функционал.
О прекращении дальнейшей поддержки директивы Host специалисты Яндекс сообщили вебмастерам в профильном блоге компании 12 марта. Официальные подтверждения реализации появились уже 20 марта. Дополнительно разработчики поисковой системы опубликовали инструкции по осуществлению переезда с применением редиректа 301.
Основной задачей директивы Host было пояснение для робота-зеркальщика с указанием на главное зеркало. Host появилась еще в первой половине 2000-х годов на базе поисковой системы Рамблер, а спустя некоторое время начала активно применяться и другими поисковиками российских компаний. Сегодня директива остается активной в документации Mail.Ru. Западный интернет-гигант Google никогда не работал с директивой Host.
На протяжении многих лет поисковая система Яндекс применяла Host для внесения рекомендаций с отметкой главного зеркала, что осуществлялось вместе с серверным редиректом. Функция определения направления с предпочтительным доменом для дальнейшего индексирования страниц формата «www» или без него была внедрена еще в 2011 году. Тогда на базе специального сервиса «Яндекс.Вебмастер» поисковик установил инструмент под названием «Главное зеркало». Разработчики указывали, что подобный механизм указания главного зеркала сайта отличается большим потенциалом и возможностями в сравнении с директивой Host, однако уступает редиректу 301 и 302.
Даже при акцентировании внимания вебмастеров на преобладание сервисного редиректа в сравнении с другими методами представители поисковой системы Яндекс ни разу не выступали с рекомендациями о его применении. В рамках применения редиректа классической особенностью был процесс выпадения ресурса из индекса поисковика до тех пор, пока осуществляется индексация сайта, адрес которого указан в редиректе.
Результатом становился слишком долгий переход поискового трафика и оказывающих влияние на характеристики позиций в пользу главного зеркала от второстепенного. В ряде случаев выполнение процесса могло растянуться на несколько месяцев. Директива Host была эффективной и надежной альтернативой для выполнения переклейки главного зеркала. Основная причина заключается в том, что отмеченный в качестве второстепенного зеркала ресурс сохранялся в индексе до проведения переклейки.
Необходимость замены второстепенных и главных зеркал местами подробно рассматривал Платон Щукин. Он отметил, что процедура практически идентична классической склейке, однако применять для переезда редирект не стоит. Щукин указывал на перекрытие доступа к главному зеркалу по причине редиректа, а основной целью редиректа станет второстепенное зеркало, которое не сможет попасть в выдачу. Для решения проблемы желательно применять директиву «Host: https://site.ru» в рамках «Переезда сайта». Тогда изменение адреса в поиске будет осуществлено всего через несколько недель.
Для решения проблемы желательно применять директиву «Host: https://site.ru» в рамках «Переезда сайта». Тогда изменение адреса в поиске будет осуществлено всего через несколько недель.
Теперь описанный совет можно считать устаревшим и недействительным для поисковой системы Яндекс. Разработчики при отмене директивы Host обратили внимание на то, что при выполнении переклейки сайта с использованием постраничной настройки редиректа 301 можно завершить процесс в течение нескольких дней. Подобный результат потенциально доступен только в случае применения инструмента «Переезд сайта» в конфигурации с редиректом 301.
На практике использовать функцию «Переезд сайта» допускается для выполнения склейки зеркал без внесения параметров в редирект. Проблемой такого технического решения станет срок выполнения задачи, который составляет несколько недель. Следует обратить внимание, что второстепенное зеркало сохранится в поисковой выдаче. По этой причине владельцы сайтов готовы обращаться к данному методу и выделять необходимое для осуществления процесса время с целью исключения риска потери трафика.
В ситуациях, при которых вебмастер не может выполнить подтверждение прав каждого из сайтов, подходит вариант только с применением редиректа 301 без использования функции «Переезд сайтов». Проведение склейки ресурсов без инструмента «Переезд сайта» дополнительно подходит для условий, когда ресурс переносится по причине наложения поисковых санкций. По причине того, что функция «Переезд сайта» работает только при выполнении подтверждения прав собственности на каждый из сайтов, санкции Яндекс против первого могут после выполнения процедуры перейти на второй ресурс.
Если поисковая система не располагает достоверными сведениями о возможных связях между владельцами подлежащих склейке ресурсов, Яндексу необходимо полностью исключить вероятность нанесения вреда конкурентам в ситуации подклейки ранее скомпрометированного ресурса, который станет второстепенным зеркалом с дальнейшим переносом санкций. В данном случае поисковая система проводит оценку вероятности присутствия связи между владельцами ресурсов на базе косвенных признаков, к числу которых относятся контент и структура до выполнения переезда.
В данном случае поисковая система проводит оценку вероятности присутствия связи между владельцами ресурсов на базе косвенных признаков, к числу которых относятся контент и структура до выполнения переезда.
В рамках внесенных поисковой системой Яндекс корректировок в процедуру переезда следует акцентировать внимание на потенциальные изменения степени полноты данных при переносе параметров ресурса на домен. Ранее при склейке зеркал сайтов на главное с второстепенного переходили не все основные характеристики. Была исключена возможность изменить возраст сайта, что исключало выполнение искусственного повышения возраста ресурса при помощи применения специальных «дропов».
Ситуация с отказом от поддержки директивы Host с целью активного использования редиректа 301 – новый шаг со стороны руководства Яндекс в пользу приближения имеющихся функциональных параметров к возможностям системы Google. Крупнейший западный поисковик с самого начала применял редирект 301, который является главной процедурой для отметки главного зеркала при склейке.
В течение 2017 года Яндекс постепенно отказывался от некоторых операторов языка запроса, которые не используются в Google. В обозримом будущем можно ожидать отказа Яндекса от обеспечения поддержки ряда других элементов в функциональных параметрах, которые не поддерживаются Google. Одним из основных может стать поддержка тега noindex, а также директивы Crawl-Delay и Clean-param, которые используются в файле robots.txt.
Просмотр примеров страниц, появившихся в поиске или удаленных из поиска. Руководство разработчика
Возвращает URL-адреса страниц, которые появились в результатах поиска или были исключены из поиска (максимум 50 000).
- Формат запроса
- Формат ответа
- Коды ответов
ПОЛУЧИТЬ https://api.webmaster.yandex.net/v4/user/{Type: int64. ID пользователя. Требуется при вызове всех ресурсов API Яндекс.Вебмастера. Чтобы получить его, используйте метод GET /v4/user."}}">}/hosts/{Type: идентификатор хоста (строка). Идентификатор сайта. Чтобы получить его, используйте метод GET /v4/user/{user-id}/hosts."}}">}/search-urls/events/samples
? [Смещение списка. Минимальное значение равно 0."}}">=
Идентификатор сайта. Чтобы получить его, используйте метод GET /v4/user/{user-id}/hosts."}}">}/search-urls/events/samples
? [Смещение списка. Минимальное значение равно 0."}}">=]
& [Размер страницы (1-100). Значение по умолчанию: 50."}}">=] идентификатор пользователя | Тип: int64. ID пользователя. Требуется при вызове всех ресурсов API Яндекс.Вебмастера. Чтобы получить его, используйте метод GET /v4/user. |
идентификатор хоста | Тип: идентификатор хоста (строка). Идентификатор сайта. Чтобы получить его, используйте метод GET /v4/user/{user-id}/hosts. |
смещение | Смещение списка. Минимальное значение равно 0. |
limit | Размер страницы (1-100). Значение по умолчанию: 50. |
{
"количество": 1,
"образцы": [
{
"url": "http://example. com/some/path?a=b",
"title": "какая-то строка",
"event_date": "2016-01-01T00:00:00,000+0300",
"last_access": "2016-01-01T00:00:00,000+0300",
"событие": "APPEARED_IN_SEARCH",
"excluded_url_status": "НИЧЕГО_НАЙДЕНО",
"bad_http_status": 500,
"target_url": "http://example.com/some/path?a=b"
}
]
}
com/some/path?a=b",
"title": "какая-то строка",
"event_date": "2016-01-01T00:00:00,000+0300",
"last_access": "2016-01-01T00:00:00,000+0300",
"событие": "APPEARED_IN_SEARCH",
"excluded_url_status": "НИЧЕГО_НАЙДЕНО",
"bad_http_status": 500,
"target_url": "http://example.com/some/path?a=b"
}
]
} <Данные> < ТребуетсяДа
Тип
int32
Описание
Общее количество доступных примеров.
"}}">>1 < ОбязательноДа
Тип
Описание
Образцы страниц.
"}}">> < ОбязательноДа
Тип
url
Описание
Адрес страницы.
"}}">>http://example.com/some/path?a=b < ОбязательноДа
Тип
строка
Описание
Заголовок страницы.
"}}">>какая-то строка < Обязательно
Да
Тип
datetime
Описание
Дата появления или исключения страницы.
"}}">>2016-01-01T00:00:00,000+0300 < ОбязательноДа
Тип
datetime
Описание
Дата последнего обхода страницы до ее появления или исключения.
"}}">>2016-01-01T00:00:00,000+0300 < ОбязательноДа
Тип
строка (ApiSearchEventEnum)
Описание
Появление или удаление страницы.
"}}">>APPEARED_IN_SEARCH < ОбязательноНет
Тип
строка (ApiExcludedUrlStatus)
Описание
Причина исключения страницы.
"}}">>НИЧЕГО_НАЙДЕНО < ТребуетсяНет
Тип
int32
Описание
Код ответа HTTP страницы для статуса HTTP_ERROR.
"}}">>500 < Обязательно
Нет
Введите
url
Описание
Другой адрес страницы, о которой знает робот. Это может быть цель перенаправления, канонический адрес или дубликат страницы.
"}}">>http://example.com/some/path?a=b
| Name | Required | Type | Description |
|---|---|---|---|
count | Yes | int32 | Total number of available examples. |
образец | образцов | Да | Образцы страниц. | |
URL-адрес | Да | url | Адрес страницы. |
заголовок | Да | строка | Заголовок страницы. |
event_date | Да | datetime | Дата появления или исключения страницы. |
last_access | Да | datetime | Дата последнего сканирования страницы до ее появления или исключения. |
событие | Да | строка (ApiSearchEventEnum) | Появление или удаление страницы. |
exclude_url_status | Нет | строка (ApiExcludedUrlStatus) | Причина исключения страницы. |
bad_http_status | Нет | int32 | Код HTTP-ответа страницы для состояния HTTP_ERROR. |
target_url | Нет | url | Другой адрес страницы, о которой знает робот. Это может быть цель перенаправления, канонический адрес или дубликат страницы. Это может быть цель перенаправления, канонический адрес или дубликат страницы. |
| Индикатор | Описание |
|---|---|
| . | |
| REMOVED_FROM_SEARCH | Страница удалена из результатов поиска. |
| Индикатор | Описание |
|---|---|
| NO NOWER_FOUND | . Отправьте страницу на переиндексацию.|
| HOST_ERROR | При попытке доступа к сайту робот не смог подключиться к серверу. |
| REDIRECT_NOTSEARCHABLE | Страница перенаправляется на другую страницу. Целевая страница индексируется (RedirectTarget). Проверьте индексацию целевой страницы. |
| HTTP_ERROR | Произошла ошибка при доступе к странице «Ошибка HTTP». Проверьте ответ сервера. Если проблема не устранена, обратитесь к администратору вашего сайта или администратору сервера. Если страница уже доступна, отправьте ее на переиндексацию. |
| НЕКАНОНИЧНЫЙ | Страница индексируется по каноническому URL, указанному в атрибуте rel=»canonical» в исходном коде. Исправьте или удалите атрибут, если он указан неправильно. Робот будет отслеживать изменения автоматически. Исправьте или удалите атрибут, если он указан неправильно. Робот будет отслеживать изменения автоматически. |
| NOT_MAIN_MIRROR | Страница принадлежит вторичному зеркалу сайта, поэтому исключена из поиска. |
| PARSER_ERROR | При попытке доступа к странице робот не смог получить ее содержимое. Проверьте ответ сервера или наличие запрещающих элементов HTML. Если проблема не устранена, обратитесь к администратору вашего сайта или администратору сервера. Если страница уже доступна, отправьте ее на переиндексацию. |
| ROBOTS_HOST_ERROR | Индексация сайта запрещена в файле robots. txt. Робот автоматически начнет сканирование страницы, когда сайт станет доступен для индексации. txt. Робот автоматически начнет сканирование страницы, когда сайт станет доступен для индексации. |
| ROBOTS_URL_ERROR | В файле robots.txt запрещено индексирование страниц. Робот автоматически просканирует страницу, когда она станет доступной для индексации. |
| ДУБЛ. | Страница дублирует страницу сайта, которая уже есть в поиске. Для получения дополнительной информации см. раздел справки. |
| LOW_QUALITY | Страница удалена из результатов поиска из-за низкого качества, определенного специальным алгоритмом. Если алгоритм найдет страницу, релевантную поисковым запросам пользователей, она появится в поиске автоматически. |
| CLEAN_PARAMS | Страница была исключена из поиска после обработки роботом директивы Clean-param. Чтобы страница проиндексировалась, отредактируйте файл robots.txt. |
| НЕТ_ИНДЕКС | Страница исключена, так как метатег robots имеет значение noindex. |
| ДРУГОЕ | У робота нет обновленных данных для страницы. Проверить ответ сервера или наличие запрещающих элементов HTML. Если робот не может открыть страницу, обратитесь к администратору вашего сайта или сервера. Если страница уже доступна, отправьте ее на переиндексацию. |
Чтобы подробно просмотреть структуру ответа, щелкните причину.
| Code | Reason | Description |
|---|---|---|
| 200 OK | ||
| 403 | INVALID_USER_ID | The ID of the user who issued the token отличается от указанного в запросе. В приведенных ниже примерах {
"код_ошибки": "INVALID_USER_ID",
"доступный_user_id": 1,
"error_message": "Недопустимый идентификатор пользователя. Следует использовать {user_id}."
} <Данные>
< Описание |
| 404 | HOST_NOT_VERIFIED | Права на управление сайтом не проверены. {
"error_code": "HOST_NOT_VERIFIED",
"host_id": "http:ya.ru:80",
"error_message": "какая-то строка"
} <Данные> < Описание |

 ru:80
< Описание
ru:80
< Описание Была ли статья полезна?
редиректов — Индексный робот Яндекса перенаправляется при запросе этого сайта, поэтому файл robots.txt использоваться не будет. Что исправить?
спросил
Изменено 6 лет, 9 месяцев назад
Просмотрено 204 раза
У нас есть сайт: www.example.com который перенаправляет на https://www.example.com .
Поэтому, когда вы вводите www.example.com/robots.txt , вы перенаправляетесь на https://www.example.com/robots.txt .
Еще одно замечание:
Главное зеркало в Яндексе будет определять краулер, он не позволит нам установить www. или установить 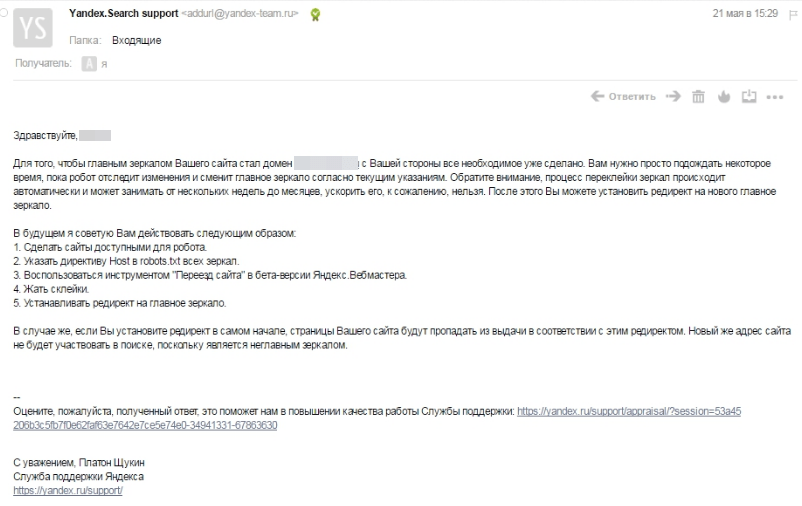 example.com
example.com https://www.example.com в качестве основного зеркала.
Обратите внимание: эта ошибка, которую я получаю
Индексный робот Яндекса перенаправляется при запросе этого сайта, поэтому файл robots.txt не будет использоваться с этой страницы:
https://webmaster.yandex.com/robots.xml
Обновление:
Мы обновили наш Robots.txt до следующего после ответов.
User-agent: Яндекс
Карта сайта: https://www.example.com/sitemap.xml
Запретить: /some_pages/
Хост: https://www.example.com
Пользовательский агент: *
Карта сайта: https://www.example.com/sitemap.xml
Запретить: /some_pages/
- редиректы
- https
- карта сайта
- robots.txt
- yandex
Можно установить главное зеркало в Яндекс. Я думаю, вам нужно что-то вроде этого:
Хост: myhost.ru #uses Пользовательский агент: * Запретить: /cgi-bin User-agent: Яндекс Запретить: /cgi-bin Хост: www.