что это такое и как правильно изменять
SEO оптимизация
9.9k.
Популярный плагин Yoast seo, Wpseo по-старому, не зря считается лучшим, потому что его разработчики не просто программисты и реализуют потребности большинства, но являются крутыми SEO специалистами. Тестировщики с большим стажем, реализуют только то что проверили сами, поэтому разберу проблему yoast seo canonical ссылки.
Содержание
- Canonical url что это
- Как действует canonical в Yoast
- Константа для пагинации
- Правильные canonical в таксономиях
- Каноникал в архивах автора и дат
- Как изменить caninical в записях с помощью Yoast SEO
- Итог
Canonical url что это
Для начала разберемся что такое canonical url, поймем его действие, узнаем везде ли нужен canonical. Так выглядит в исходном коде.
<link rel="canonical" href="https://site.ru/page/2/" />
Атрибут rel canonical помогает вебмастерам и ПС предотвратить проблемы с дублирующимся контентом. Для оптимизации сайта вредно располагать контент с одинаковым содержимым, но разными URL адресами, это называется дублирующийся контент, расценивается как попытка манипуляции. Пример где он располагается в исходном коде ресурса.
Для оптимизации сайта вредно располагать контент с одинаковым содержимым, но разными URL адресами, это называется дублирующийся контент, расценивается как попытка манипуляции. Пример где он располагается в исходном коде ресурса.
Наглядным примером служат интернет магазины, в которых один и тот же товар, с одинаковым описанием, расположен по разным адресам.
Чтобы не происходило индексации, склейки адресов, понижения в выдаче – используется каноникал, он сразу указывает поисковому роботу, что «эта страница полный клон другой, иди туда».
Фактически атрибут rel canonical действует как 301 редирект, только для ПС, при обнаружении такого тега робот Яндекс или Гугл не будет сканировать запись, сразу пойдет на каноническую ссылку, взяв только основную информацию тайтл и дескрипшн. Что получаем:
- Нет дублей с одинаковым контентом
- Сохранение структуры сайта без радикальных редиректов
- Повышение статуса канонического (исходного) документа в поиске, за счет удаления дублей
Как действует canonical в Yoast
Разработчики Yoast тонко настроили процесс формирования тега canonical на пагинации главной и таксономий.
Константа для пагинации
Единственная константа, не подлежащая настройке это пагинация записей на главной, это документы типа https://site.ru/page/2/. В стандартном варианте тег каноникал не указывает на главную страницу https://site.ru/, а остаются неизменными такого вида.
Изменить это параметр нельзя, в настройках плагина не найдете соответствующего раздела. Каждый элемент пагинации главной страницы это самостоятельный документ хоть и динамический.
Зачем сделан такой шаг, создатели YoastSEO считают, что за частую единственным местом откуда поисковой робот сможет добраться до старых статей это пагинация.
Полностью согласен, некоторые админы небрежно относятся к созданию таких фишек, как XML карта сайта, перелинковка, last modified и другие методы оптимизации старых материалов.
Но лучшим решением считаю не проставлять canonical, а закрыть в noindex, follow и использовать Dissalow в robots для /page/. Подробно об этом рассказывал в статье про пагинацию в noindex.
Подробно об этом рассказывал в статье про пагинацию в noindex.
Если просто оставить каноническую ссылку саму на себя, то pagination будут индексироваться и попадать в выдачу, у них будет разный адрес и контент, но title и description одинаковый, что считается ошибкой.
Предупреждение на официальном блоге йоастОтмечу особенность Yoast SEO в отношении canonical, при любом появлении noindex или nofollow он пропадает, это сделано специально разработчиками, чтобы не было ошибок в представлении сайта в поиске, вот официальный текст (перевод автоматический).
Следуя инструкции из статьи сделаете правильную настройку, потому что робот пройдет правильный путь, просканирует все записи и не возьмет в индекс page.
Правильные canonical в таксономиях
Ситуация с настройками canonical в таксономиях намного удобнее. Считаю что рубрики и метки это отличный источник трафика из ПС, но учитываем что у них тоже есть пагинация, с ней что-то нужно делать.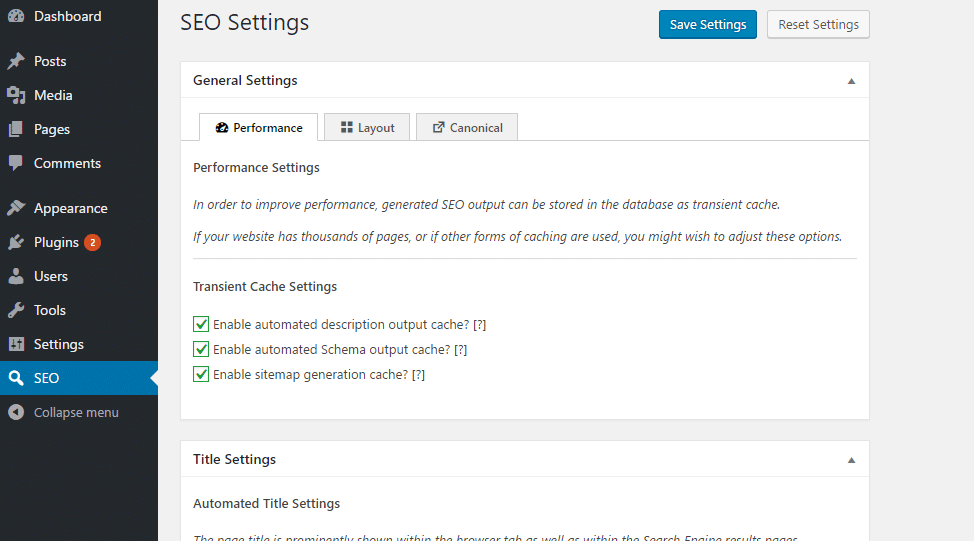 Если включить опцию удаления из поиска рубрик или меток в разделе Таксономии, то ноуиндекс поставиться ко всем элементам включая начальную страницу, сразу же исключая выдачу в поиске.
Если включить опцию удаления из поиска рубрик или меток в разделе Таксономии, то ноуиндекс поставиться ко всем элементам включая начальную страницу, сразу же исключая выдачу в поиске.
Это не правильно, нужно оставить стартовый документ, а остальные закрыть, можно каноникал, но лучше noindex. Помещаем кнопку для меток и рубрик в положение «Нет». Смотрим инструкции дальше.
Отмечу что последующие страницы нам не нужны, робот успешно возьмет весь контент сайта из основной информации стартовой итерации.
Простейший метод – прописать canonical для пагинации рубрик и меток через базовые настройки в специальном блоке yoast. Переходим в редактирование рубрики, возьму для примера «Путешествия» с адресом travel на тестовом сайте test-wp-kurs. Не забудьте почитать про фокусное ключевой слово в плагине yoast.
Правильно настраиваем canonical к категориям- В левой колонке выбираем что нужно изменить
- В списке находим необходимую и изменяем ее (на снимке не показал, думаю знаете как изменить таксономию)
- Спускаемся
- Открываем вкладку «Дополнительно»
- В разделе канонический URL-адрес вписываем начальный урл таксономии
- Обновляем
При проверке увидим на второй итерации в meta теге canonical будет начальный документ.
Справились, начальная страница будет участвовать в поиске, а последующие нет.
Считаю cnonical слишком радикальным методом, но не скажу что не правильный, в своих проектах использую noindex и запрет в robots (давал ссылку в начале статьи). Так мы оставим индексацию, но не дадим взять лишнее в поиск.
Используем наш плагин ClearfyPRO, других достойных вариантов нет. В разделе SEO включаем соответствующий пункт и смотрим что происходит.
ClearfyНа последующих страницах удаляется canonical, добавляется noindex. На https://test-wp-kurs.ru/travel/ его не будет и появится каноникал сам на себя. Советую посмотреть как в клеарфи использовать скрытие внешних ссылок от поисковых систем.
По традиции прикладываю кнопку с промо на ClearfyPRO, нажимайте и скидка вычисляется автоматом.
Clearfy -15%
Каноникал в архивах автора и дат
Если автор на сайте вордпресс один, то советую полностью отключить архивы автора и дат на сайте. Они полностью дублируют пагинацию с главной. Даже если много авторов и сайту много лет, то не рекомендую использовать их в выдаче, конечно если писатель не хочет иметь раздел с его статьями.
Они полностью дублируют пагинацию с главной. Даже если много авторов и сайту много лет, то не рекомендую использовать их в выдаче, конечно если писатель не хочет иметь раздел с его статьями.
Делаем настройку в Yoast SEO, при сохранении все архивы по датам и по авторам начнут отдавать 301 редирект.
Задаем 301 редиректЕсли нужен сам факт наличия раздела писателя, то делаем следующее. Robots txt в данном случае используется только для авторов, в архивах дат не получится – url формируется цифрами по году, чего не стоит делать, возможны ошибки в индексировании.
Также делаем для архивов дат чуть ниже.Вставляем в robots txt такую строчку. Получаем все архивы заключены в noindex включая стартовый url.
Disallow: /author/*Адрес страницы автора
Как изменить caninical в записях с помощью Yoast SEO
По аналогии с рубриками: спускаемся вниз окна редактора, открываем блок дополнительно, находим соответствующий пункт и прописываем каноническую ссылку.
Пункт дополнительно в YoastИтог
Получаем правильный симбиоз линка canonical и поисковых инструкций noindex, nofollow в вордпресс. Чем организуем правильный путь ПС по блогу, применяя жесткие и лояльные команды.
Чем организуем правильный путь ПС по блогу, применяя жесткие и лояльные команды.
Валентин
Давно занимаюсь и разрабатываю сайты на WordPress. Считаю что лучшего решения для ведения бизнеса не найти, поэтому считаю долгом делиться информацией с остальными.
как указывать атрибут правильно и зачем он нужен – PR-CY Блог
Главное об атрибуте rel = «canonical”: что это такое, зачем и где указывать, какие ошибки часто допускают оптимизаторы.
Разбираемся, что нужно знать оптимизатору о работе с каноническими тегами. Материал для начинающих или тех, кто хочет освежить знания в памяти.
В статье:
Что такое rel canonical и для чего он нужен
Когда нужно прописывать канонический тег
Как настроить canonical правильно: 6 способов указать основной URL
Что такое rel canonical и для чего он нужен
Одинаковый контент на разных страницах — плохо, за это следуют санкции. Но есть случаи, когда дубли оправданы. К примеру, одна и та же страница может входить в несколько категорий, один и тот же сайт может быть доступен с www и без, а еще в каталогах товаров есть сортировка и фильтрация.
Но есть случаи, когда дубли оправданы. К примеру, одна и та же страница может входить в несколько категорий, один и тот же сайт может быть доступен с www и без, а еще в каталогах товаров есть сортировка и фильтрация.
Страницы могут быть не полностью одинаковыми. К примеру, на одной включен фильтр товаров по сезона, а на другой — сортировка по цене. Тем не менее, от включенных фильтров уникальными они не станут.
Фильтр в каталоге сайта www.asos.comВ таких случаях нужно указывать, какой вариант страницы роботу считать основным, то есть каноническим, а какие дублями. Для этого придумали канонический тег — rel = «canonical», он решает проблему дублирования контента.
Каноническая страница — это основной URL. Атрибут rel = «canonical» добавляют на страницы-дубли и в нем указывают адрес канонической страницы, чтобы дать боту знать, какую страницу они повторяют.
Зачем указывать основную версию страницы?
Причины указывать canonical:
избежать санкций поисковиков за дублирование контента;
корректно передавать ссылочный вес на нужную версию сайта и страницы;
из контента, доступного по нескольким URL, выбрать страницу, которая будет получать все сигналы и показываться в выдаче;
не тратить краулинговый бюджет на дубли.
Краткая информация о канонических URL из первых уст есть в справке Google и Яндекса.
Например, есть страница, доступная по трем адресам:
site.ru/page?id=123
site.ru/blog/category/tema
site.ru/blog/tema
Допустим, мы хотим, чтобы страница site.ru/blog/category/tema ранжировалась в выдаче, получала весь положенный ей ссылочный вес и другие сигналы — считалась канонической.
Тогда эту страницу мы не трогаем, в коде страниц дублей site.ru/page?id=123 и site.ru/blog/tema указываем ее как каноническую. В коды дублей мы добавляем такую строчку:
<link rel="canonical" href="http://site.ru/blog/category/tema"/>
Неканонические страницы не попадут в индекс?
Страницы, отмеченные как неканонические, все равно могут попасть в выдачу. Яндекс отмечает:
«Они будут показаны в том случае, если они более релевантны запросу и их контент существенно отличался от канонической версии во время сканирования роботом».
В Вебмастере у всех страниц появилась пометка «каноническая», «неканоническая» и «каноническая страница не указана». Вы можно посмотреть неканонические страницы, попавшие в выдачу, для этого откройте «Страницы в поиске» и ищите строчки с пометкой «Неканоническая».
Неканоническая страница в выдачеНо если сеошник указывает этот атрибут, уменьшается риск, что Google сам определит основной не ту версию страницы.
Канонические страницы все равно появляются в поиске чаще и имеют приоритет при показе в выдаче, а ошибки с настройкой canonical могут привести к проблемам в индексировании страниц. Разберем все варианты, когда нужно использовать канонический тег.
Когда нужно прописывать канонический тег
Используйте canonical, когда одинаковый контент доступен по разным URL.
Дублирование страниц
Дублирующиеся страницы с похожим содержанием, которые генерируются CMS. Они бывают на всех сайтах интернет-магазинов, где можно настраивать параметры выбора товара. Ссылки для навигации по каталогу, сортировка товаров, фильтрация, ссылки с UTM-метками для отслеживания, другие страницы с GET-параметрами в URL.
Другой вариант — страница товара подходит сразу под несколько категорий, так что образовываются множественные URL одного предмета. Решение такое же: выбрать популярную в качестве основной и указать ее на остальных дублирующих страницах в rel = «canonical».
Решение такое же: выбрать популярную в качестве основной и указать ее на остальных дублирующих страницах в rel = «canonical».
Страницы пагинации
Вариант 1
Если на странице есть «Показать все», страница со всеми вариантами и будет канонической. На каждой из страниц пагинации укажите ее в атрибуте rel = «canonical».
Например, для страницы https:=»» site.ru=»» <=»» a>category1=»» page-2″=»»>https://site.ru/category1/page-2 нужно прописать канонический URL:
<link rel="canonical" href="http://site.ru/category1/show-all">
Вариант 2
Если «Показать все» нет, для каждой страницы пагинации советуют указывать эти же страницы как канонические.
Например, на странице https://site. ru/category1/page2 нужно указать каноническую ссылку:
ru/category1/page2 нужно указать каноническую ссылку:
<link rel="canonical" href="http://site.ru/category1/page2">
Вариант 3
Есть и другое мнение: если указать canonical страницы саму на себя, все страницы пагинации пойдут в выдачу. Если вы считаете, что плохо, если у разных URL с отличающимся контентом будут одинаковые Title и Description, то не делайте так.
В таком случае не нужно проставлять canonical, а лучше закрыть страницы пагинации в noindex, follow и использовать dissalow в robots для /page. Это значит, что индексировать нельзя, а переходить по ссылкам можно.
<meta name="robots" content="noindex, follow"/>
Напомним, что noindex подходит только для Яндекса.
HTTPS, HTTP, www
Один сайт может быть доступен по трем вариантам: http://site.ru и http://www.site.ru и https://www.site.ru. Но поисковые системы будут рассматривать все три как наборы отдельных страниц, если не указать canonical. Из-за чего могут быть проблемы со сканированием и индексацией сайта.
Из-за чего могут быть проблемы со сканированием и индексацией сайта.
Мобильный URL
Google уже давно переходит на Mobile-First Indexing, то есть при индексировании он ориентируется на мобильную версию сайта.
Представитель Google Джон Мюллер рассказал, что делать с каноническим тегом в этих условиях.
Если у вас есть мобильная версия сайта m.site.ru, обычно у нее указывают rel = «canonical», ведущий на десктопную. А для десктопной используют тег rel=alternate, ведущий на мобильную. Если вы сделали так, ничего менять не надо. Бот распознает мобильную версию как каноническую, даже если в коде канонической указана десктопная. Если и в Sitemap.xml также, то тоже можно не трогать.
URL страны
Бывает, что для конкретной страны у сайта есть несколько версий с разными URL. При этом язык один и контент одинаковый с несущественными отличиями. Тогда нужно выбрать каноническую и сделать отсылки к ней на всех дублях.
Но если речь идет о разных языковых версиях, нужно использовать hreflang, чтобы поисковики выдавали отдельные результаты. Атрибут hreflang нужен для указания дополнительных URL с аналогичным или похожим содержимым на других языках или для отдельных регионов.
Из-за перехода Google на Mobile-First Indexing, нужно правильно настроить hreflang. Десктопные hreflang-теги должны ссылаться на десктопные URL, мобильные — соответственно на мобильные URL. И редиректить пользователей на нужную версию в зависимости от устройства.
Верхний и нижний регистр
Поисковик может посчитать разными два адреса, написанные в разном регистре. При назначении URL система должна применять только нижний регистр, чтобы одни и те же ссылки были действительно одинаковыми.
Материал по теме:
Htaccess для перенаправления верхнего регистра на нижний
Итак, с помощью rel = «canonical» можно указать поисковику, какую страницу считать основной и главной среди дублей, чтобы сканировать ее, индексировать, показывать в выдаче и направлять на нее ссылочный вес. Разберемся, как настраивать тег.
Разберемся, как настраивать тег.
Как настроить canonical правильно: 6 способов указать основной URL
Для использования канонического тега нужно выбрать среди дублей основной URL, вписать его в атрибут:
<link rel="canonical" href="http://site.ru/page/">
и добавить ко всем неосновным страницам.
Для добавления есть несколько способов:
С помощью плагина CMS
Большинство CMS имеют встроенную функцию или плагины, которые позволяют автоматизировать настройку канонического URL.
К примеру:
настроить canonical на WordPress можно с помощью плагина Yoast SEO;
в OpenCart в настройках товара можно задать SEO URL;
в Joomla версии от 3 и выше можно включить функцию SEF. Тогда в код технических страниц вида /index.php?option добавится атрибут rel = «canonical» с указанием основной страницы с ЧПУ.

Для примера подробнее рассмотрим WordPress как самую популярную CMS среди наших подписчиков.
Настройка canonical WordPress
Все просто: установите плагин Yoast SEO, чтобы канонические теги добавлялись автоматически.
Настроить теги для конкретной страницы можно в разделе «Дополнительно» («Advanced»), там нужно указать основной URL:
Настройка канонического тега WordPressYoast SEO делает так, что если на странице появляется noindex или nofollow, тег canonical пропадает, чтобы не было проблем с представлением сайта в выдаче.
Если вы не используете CMS и не можете реализовать канонический тег плагинами, можно сделать все иначе.
Прописать между тегами любой HTML-страницы
Основной способ — прописать rel = «canonical» в секцию < head > любой страницы-копии.
Например, если для страницы https://site.ru/*utm_content= канонической будет https://site. ru/, на страницу https://site.ru/*utm_content= нужно добавить код:
ru/, на страницу https://site.ru/*utm_content= нужно добавить код:
<link rel="canonical" href="http://site.ru/">
В заголовке HTTP
У PDF и других не HTML документов нет секции < head >, так что использовать предыдущий способ не получится. Если у вас есть доступ к настройкам сервера, можно указать канонический тег в заголовке HTTP с использованием .htaccess или PHP.
При запросе дублирующего файла сервер должен отдавать в заголовке ссылку на оригинальный файл:
Link: <http://example.com/file.pdf>; rel="canonical"
К примеру, вы составили руководство, выложили его в блог и отдельно оформили в PDF-файл для скачивания, который разместили в подкаталоге http://site.ru/blog/*. HTTP-заголовок для этого руководства в PDF может выглядеть так:
HTTP/1.1 200 OK Content-Type: application/pdf Link: <http://site.ru/blog/canonical-tags/>; rel="canonical"
С другими страницами так тоже можно.
В файле Sitemap
Поисковики по умолчанию думают обо всех ссылках в XML-файле как о канонических. У Google есть требование включать в Карту сайта только канонические адреса страниц. Но Карта не свод правил для поисковых ботов, а список рекомендаций, который поисковики могут проигнорировать.
Материал по теме:
Как составить Sitemap
Через 301 редирект
Отвести трафик и ссылочный вес от дублей к канонической страницы можно с помощью 301 редиректа. Этот способ можно использовать, если сайт, к примеру, доступен по нескольким адресам:
https://site.ru/
http://site.ru/
http://www.site.ru/
https://www.site.ru/
Можно выбрать в качестве основного https://site.ru/, а со всех остальных настроить перенаправление.
Материал по теме:
Как настроить 301 редирект самостоятельно
Дополнительный сигнал — ссылки
Представитель Google Джон Мюллер в этом видео перечислял все сигналы, которые поисковик использует для определения канонического адреса.
К примеру, между адресами HTTPS и HTTP Google выберет HTTPS, а еще он может предпочесть привлекательный с его точки зрения URL. В числе сигналов каноникализации числятся ссылки с одной страницы на другую. Если вы указали канонической одну страницу, а по совокупности факторов другая кажется поисковику более подходящей, он не будет вас слушать.
Неправильной настройкой можно навредить индексированию страниц. Разберем несколько типичных ошибок оптимизаторов.
Неправильно указан canonical: популярные ошибки настройки
Использование нескольких канонических ссылок для одной страницы
Для одной страницы нужно указать один канонический адрес. Если указано несколько, бот либо проигнорирует страницу вообще, либо примет к сведению первый указанный URL.
Проверяйте, как плагин CMS реализует canonical, иногда из-за неправильной настройки он может указывать несколько адресов.
Настройка разных канонических URL одной странице
Похожий пункт, но речь идет не о нескольких канонических адресах для одной страницы, а в о разных, указанных разными способами.
Если вы используете несколько способов указать канонический тег, например, в HTTP-заголовке и в секции < head >, ссылка на основную страницу должна быть одна и та же.
Настройка цепочки канонических URL
Бот не будет учитывать канонический адрес, если для страницы, которую вы указали основной, настроена какая-то своя основная страница. Например, для адреса site.ru/1 канонической ссылкой указана site.ru/2, а для нее указана site.ru/3.
Размещение rel = «canonical» не в секции head
Тег rel = «canonical» должен находиться только в секции < head >. Если указать его в < body > документа, боты его проигнорируют. Или даже могут проигнорировать всю страницу.
Лучше перепроверить: даже если вы поставили canonical ближе к началу документа, секция < head > может закрыться раньше, например, из-за вставок JavaScript, контейнеров < iframe > или незакрытых парных тегов. Тогда canonical окажется за пределами < head > в секции < body >.
Указание первой страницы пагинации как канонической
Если для всех страниц пагинации канонической указать первую, бот не проиндексирует остальные. Выше мы писали, как лучше сделать, есть три варианта:
сделать канонической страницу «Показать все», если она есть;
для каждой страницы поставить ее же URL в качестве канонической, если нет общей страницы.
Но если вы считаете, что наличие всех страниц пагинации в выдаче плохо повлияет из-за повторяющихся Title и Description, не ставьте канонический тег вообще и закройте их для индексации. Используйте noindex, follow для страниц пагинации и для /page укажите disallow в файле robots. Такая настройка означает, что индексировать нельзя, а переходить по ссылкам можно.
Использование канонических URL вместо 301 редиректа
Тег canonical и 301 редирект кажутся похожими — перенаправляют бота на основную страницу. Но не стоит использовать canonical вместо редиректа. Редирект переводит весь трафик на один URL, а при использовании rel = «canonical» страница откроется, будет активной и сможет получать трафик, но не появится в индексе.
Но не стоит использовать canonical вместо редиректа. Редирект переводит весь трафик на один URL, а при использовании rel = «canonical» страница откроется, будет активной и сможет получать трафик, но не появится в индексе.
Выбор главной как канонической для всех страниц
Ошибкой будет указать главную страницу в качестве канонической для всего сайта. Боты могут проигнорировать все страницы, кроме главной.
Закрытие канонической страницы от индексирования
Если канонический URL закрыт от индексирования или по другой причине недоступен для поискового бота, он не сможет участвовать в формировании выдачи. В этом случае бот возьмет доступный неканонический URL.
Как проверить canonical
Проверить, для каких страниц вы настроили canonical и какие канонические страницы указали, можно с помощью сервиса Screaming Frog SEO Spider.
Результаты проверки страниц краулеромУзнать, какую страницу Google считает основной для конкретного URL, можно через инструмент проверки URL.
Проверить, как поступил Яндекс, можно в Вебмастере: если вы верно указали каноническую страницу, дубли пропадут из поиска. Посмотрите страницу «Индексирование» — «Страницы в поиске». Если страницу исключили из результатов, она будет в блоке «Исключённые страницы».
Проверка наличия дубля в выдачеРассказывайте, о каких необходимых вариантах использования canonical мы забыли, и какие еще ошибки настройки вы встречали в своей практике!
Полное руководство по каноническим URL-адресам
Когда совершенно одинаковый или почти одинаковый контент появляется на двух или более страницах, это называется дублированным контентом. Самая большая проблема с дублированным контентом заключается в том, что поисковые системы не знают, какую версию контента индексировать или показывать в результатах поиска. Также сложно понять, куда направить метрики ссылок, такие как авторитет и доверие. И когда другим сайтам нужно выбирать между дублирующими версиями контента, на которые можно ссылаться, можно выбрать любую из многих ссылок, что снижает ссылочный вес. Вот тут-то и появляются канонические URL-адреса. Они используются для устранения проблем, связанных с дублирующимся контентом, что может улучшить ваш рейтинг в поисковых системах.
Вот тут-то и появляются канонические URL-адреса. Они используются для устранения проблем, связанных с дублирующимся контентом, что может улучшить ваш рейтинг в поисковых системах.
- 1
Что такое канонические URL-адреса?
- 1.1 Почему вы должны использовать канонические URL-адреса
- 1,2 Как правильно использовать канонические теги
- 2 Как канонические URL-адреса влияют на SEO?
- 3
Как установить канонический URL
- 3.1 Установите канонический URL-адрес с помощью WordPress
- 3.2 Установите канонический URL-адрес за пределами WordPress
- 4 Как найти канонический URL
- 5 Как удалить канонический URL
- 6 Заключительные мысли о канонических URL-адресах
Что такое канонические URL-адреса?
Канонический URL-адрес, на который ссылаются из-за тега HTML rel=»canonical» , — это то, что поисковые системы используют для поиска основной версии контента, когда на одном веб-сайте или на разных веб-сайтах существует несколько версий страницы.
Допустим, вы публикуете сообщение в блоге на своем собственном веб-сайте. Затем вы также хотите опубликовать эту запись в блоге в своих учетных записях LinkedIn и Medium. С помощью канонического тега вы можете сообщить поисковым системам, что даже если одна и та же запись в блоге есть на нескольких веб-сайтах, одна на ваш веб-сайт является основной версией, которая должна отображаться в результатах поиска.
И имейте в виду, что технически канонический URL-адрес на самом деле не является URL-адресом — это скорее тег, который прикрепляется к URL-адресу для передачи его значения поисковым системам. Если реальный URL выглядит как http://example.com/blogpost , каноническая версия будет выглядеть так:
Вы не можете перейти по этому каноническому URL-адресу, как по основному URL-адресу. Вместо этого канонизированная версия помещается в HTML-код страницы (или назначается для страницы через плагин).
Почему следует использовать канонические URL-адреса
Канонизация URL-адреса сообщает поисковой системе, какая версия страницы является основной, и это страница, которая должна отображаться в результатах поиска, а не другие дубликаты страницы. Когда люди ищут контент, на который можно сделать обратную ссылку, появится канонизированная страница, и они выберут ту, которая создаст ссылочный вес. Кроме того, метрики для части контента объединяются для одной страницы, что делает ваши отчеты по метрикам более надежными.
Когда люди ищут контент, на который можно сделать обратную ссылку, появится канонизированная страница, и они выберут ту, которая создаст ссылочный вес. Кроме того, метрики для части контента объединяются для одной страницы, что делает ваши отчеты по метрикам более надежными.
Как правильно использовать теги Canonical
Допустим, на вашем веб-сайте (или на двух разных веб-сайтах) есть дублированный контент, но основная версия, на которую вы хотите указать поисковым системам, — http://example.com/blogpost .
Канонический тег, который вы добавляете в исходный код сообщения в блоге (раздел заголовка HTML страницы), будет выглядеть следующим образом:
Если вы используете WordPress, вам не нужно возиться с HTML-кодом, как на некоторых других платформах CMS. Вместо этого вы можете использовать плагин и установить канонический URL-адрес для каждой страницы. Мы вернемся к этому чуть позже.
Канонические URL-адреса и скопированный контент
Скопированное содержимое может быть проблемой. Канонические URL-адреса позволяют любому, кто собирается копировать контент, знать, какой тег использовать в заголовке своей страницы. Копировщик, однако, обязан сообщить поисковым системам, что они скопировали контент, добавив rel=»canonical» в заголовок своего сайта и указав на ваш контент.
Канонические URL-адреса позволяют любому, кто собирается копировать контент, знать, какой тег использовать в заголовке своей страницы. Копировщик, однако, обязан сообщить поисковым системам, что они скопировали контент, добавив rel=»canonical» в заголовок своего сайта и указав на ваш контент.
В других случаях, вы можете быть копировщиком. Например, это обычное дело для пресс-релизов. Вы можете сначала опубликовать пресс-релиз на сайте своей компании, но указать исходный источник контента в сети синдикации. Это сделало бы вас синдикатором, а не первоначальным издателем — по крайней мере, согласно поисковым системам.
Однако следует отметить, что включение канонического URL в копируемый контент не всегда необходимо. Или иногда игнорируется. Поисковые системы отлично справляются с поиском истинного первоисточника контента. Итак, если вы собираетесь использовать канонический URL-адрес для указания на неоригинальный, как в приведенном выше примере с пресс-релизом, просто знайте, что поисковая система может его проигнорировать. Используйте эту тактику по своему усмотрению. Это своего рода неприятная серая зона для SEO, если не полная тактика черной шляпы.
Используйте эту тактику по своему усмотрению. Это своего рода неприятная серая зона для SEO, если не полная тактика черной шляпы.
Выбор структуры URL
Даже если вы не думаете, что у вас есть дублированный контент где-либо в Интернете, структура ваших URL-адресов может случайно создавать дублирующийся контент. Например, даже если следующие URL-адреса отображают один и тот же контент, и вы считаете их одной и той же страницей, поисковые системы рассматривают их как отдельные:
.- http://www.examplesite.com – включает «www»
- http://examplesite.com – здесь нет «www»
- https://examplesite.com — вместо «http» используется «https»
- http://www.examplesite.com/ — с косой чертой в конце
Существуют также вариации в пределах HTTPS и концевой косой черты, а также www. Все они рассматриваются поисковыми системами как отдельные страницы.
Это означает, что вам нужно принять окончательное решение о структуре ваших URL-адресов. Затем используйте эту структуру везде — на своем сайте и везде, где вы ссылаетесь на свой сайт. Если вам нужно обновить свои URL-адреса, используйте структуру, которую вы используете чаще всего, чтобы сделать этот процесс менее утомительным. Однако, если вы получаете конфиденциальную информацию через свой веб-сайт, например информацию о кредитной карте, вам следует использовать HTTPS.
Затем используйте эту структуру везде — на своем сайте и везде, где вы ссылаетесь на свой сайт. Если вам нужно обновить свои URL-адреса, используйте структуру, которую вы используете чаще всего, чтобы сделать этот процесс менее утомительным. Однако, если вы получаете конфиденциальную информацию через свой веб-сайт, например информацию о кредитной карте, вам следует использовать HTTPS.
Дублированный контент также может быть случайно создан вашими категориями и тегами WordPress. Например, эти два URL-адреса могут вести на одну и ту же страницу, но поисковая система увидит их как две отдельные страницы с дублирующимся содержимым:
.- http://examplesite.com/store/candy/chocolate-truffles
- http://examplesite.com/store/foods/chocolate-truffles
Вы можете захотеть, чтобы пользователи находили шоколадные трюфели независимо от того, ищут ли они товары в категории «Конфеты» или «Еда» на вашем веб-сайте. Но поисковым системам все равно нужно знать, какой из них ранжировать в результатах поиска. Вот почему большинство лучших SEO-плагинов WordPress, таких как Yoast и Rank Math, предлагают возможность деиндексировать страницы ваших архивов. Таким образом, эти дубликаты не будут отображаться для робота Googlebot и его аналогов.
Вот почему большинство лучших SEO-плагинов WordPress, таких как Yoast и Rank Math, предлагают возможность деиндексировать страницы ваших архивов. Таким образом, эти дубликаты не будут отображаться для робота Googlebot и его аналогов.
Когда не следует использовать канонические URL-адреса
Когда дело доходит до 301 редиректа, возможно, вы не захотите использовать канонический тег. Подумайте о разнице таким образом: перенаправление означает, что контент появляется только в одном месте, и вы заставляете всех посетителей переходить на эту страницу. С другой стороны, с каноническим URL-адресом могут существовать и просматриваться несколько страниц, содержащих один и тот же контент, с одним исходным источником, предназначенным для поисковых систем.
Кроме того, rel=»canonical» 9Элемент URL 0034 не является решением всех проблем с дублированием контента. SEO — сложная тема, и иногда более подходящим решением является использование файла robots, чтобы не индексировать страницу. Рекомендуется не индексировать страницы, которые не являются желательными точками входа на ваш сайт, а также страницы, которые не очень полезны для большинства посетителей. Например, вам действительно нужно, чтобы ваша страница с условиями и положениями отображалась в результатах поиска? Возможно нет. Но ваши сообщения в блогах, описания продуктов и страницы продаж? Определенно.
Рекомендуется не индексировать страницы, которые не являются желательными точками входа на ваш сайт, а также страницы, которые не очень полезны для большинства посетителей. Например, вам действительно нужно, чтобы ваша страница с условиями и положениями отображалась в результатах поиска? Возможно нет. Но ваши сообщения в блогах, описания продуктов и страницы продаж? Определенно.
Также рекомендуется ознакомиться со статьей Google с пятью распространенными ошибками при использовании тега canonical. Вы не можете быть намного лучше, чем то, что прямо говорит Google.
Как канонические URL-адреса влияют на SEO?
Теперь, хотя мы настоятельно рекомендуем вам устранять проблемы с дублирующимся контентом, используя канонические URL-адреса, важно отметить, что Google технически не наказывает сайты за публикацию дублированного контента. Однако это может повредить вашему рейтингу в поисковых системах, что в любом случае похоже на наказание. Когда поисковым системам трудно определить, какая версия контента является основной, нет версии получает высокий рейтинг.
Также возможно, что поисковая система выберет неправильную версию и свяжется с ненадежным сайтом, а это означает, что он может вообще не щелкнуть и не прочитать, если пользователям не нравится, как выглядит URL-адрес. Кроме того, когда на вашем веб-сайте есть дублированный контент, ваш краулинговый бюджет расходуется. Поисковые системы сканируют и повторно сканируют веб-сайты, чтобы найти новый контент, и если на вашем сайте есть дублированный контент, сканирование всего этого занимает больше времени. Это означает, что поисковой системе потребуется больше времени, чтобы проиндексировать эти новые страницы и ранжировать их в результатах поиска.
Вы можете глубже погрузиться в эту тему, прочитав наше Полное руководство по дублированию контента и SEO. У Google также есть полезная страница о объединении повторяющихся URL-адресов.
Как установить канонический URL-адрес
В этом разделе мы расскажем, как установить канонический URL-адрес на WordPress и на веб-сайте, отличном от WordPress.![]()
Установка канонического URL-адреса с помощью WordPress
Хотя вы можете установить канонические URL-адреса без плагина WordPress, мы считаем, что лучший, самый надежный и гибкий вариант — использовать плагин. В этом пошаговом руководстве мы используем Yoast SEO.
После установки и активации Yoast SEO откройте страницу или запись WordPress. Прокрутите вниз до конца поста, пока не дойдете до поля Yoast SEO. Выбрав вкладку SEO (она будет по умолчанию), прокрутите вниз и нажмите Advanced . В нижней части появившегося меню вы увидите слот с надписью Canonical URL .
Введите в это поле полный URL-адрес, затем сохраните изменения в сообщении или на странице.
All in One SEO и Rank Math SEO — два других плагина, которые вы, возможно, захотите рассмотреть.
Установить канонический URL-адрес за пределами WordPress
Если вы не используете WordPress, вы все равно можете установить канонические URL-адреса. Во-первых, вам нужно получить доступ к HTML-коду веб-страницы. У каждого веб-конструктора будет свой собственный процесс, но его довольно легко найти. Например, вот как добавить код на сайт Wix. Процесс аналогичен для большинства сборщиков, отличных от WP, и платформ CMS; вам просто нужно найти, где они позволяют редактировать страницу/публикацию HTML.
Во-первых, вам нужно получить доступ к HTML-коду веб-страницы. У каждого веб-конструктора будет свой собственный процесс, но его довольно легко найти. Например, вот как добавить код на сайт Wix. Процесс аналогичен для большинства сборщиков, отличных от WP, и платформ CMS; вам просто нужно найти, где они позволяют редактировать страницу/публикацию HTML.
Затем вы добавите URL-адрес с тегом rel=»canonical» , включенным в раздел заголовка. Используя приведенный ниже пример, замените http://example.com/blogpost своим URL-адресом:
.Заголовок HTML — это первая часть кода. Он открывается с и закрывается с. Вот пример:
Чтобы добавить код в раздел head, вы должны поместить его где-то между тегами open и close. Лучше всего добавить ссылку над закрывающим тегом, чтобы все было организовано.
Как найти канонический URL-адрес
Если вы хотите узнать, имеет ли веб-страница назначенный канонический URL-адрес, это очень просто.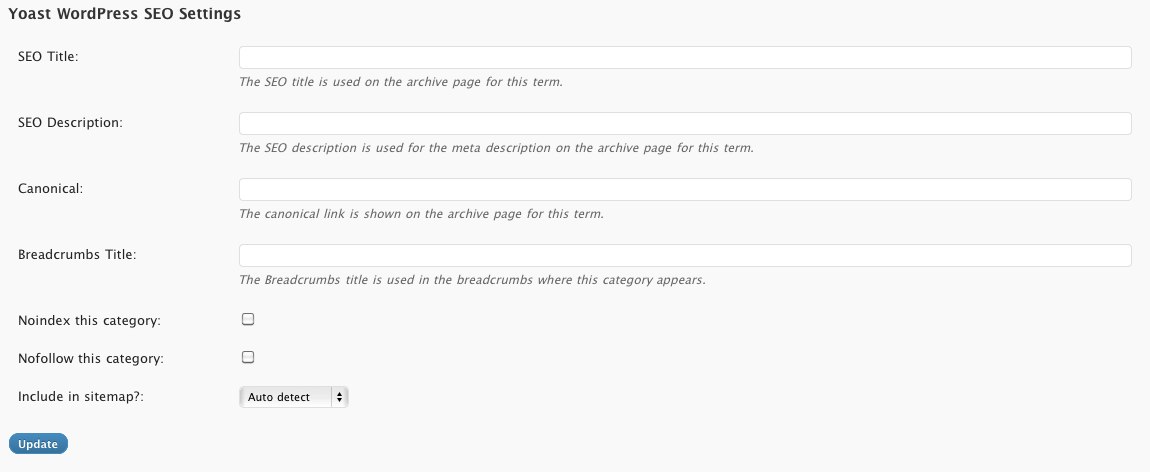 Откройте страницу, затем щелкните правой кнопкой мыши, чтобы открыть меню. Выберите Показать исходный код страницы (или любой другой параметр, близкий к этому, например, Просмотр исходного кода страницы ). Откроется исходная страница с HTML-кодом. Вверху вы должны увидеть головную часть. Проверьте в этом разделе тег rel=»canonical».
Откройте страницу, затем щелкните правой кнопкой мыши, чтобы открыть меню. Выберите Показать исходный код страницы (или любой другой параметр, близкий к этому, например, Просмотр исходного кода страницы ). Откроется исходная страница с HTML-кодом. Вверху вы должны увидеть головную часть. Проверьте в этом разделе тег rel=»canonical».
Как удалить канонический URL-адрес
Удалить канонический URL тоже довольно просто. Вы просто делаете те же шаги, что и для добавления URL-адреса, но на этот раз удаляете его. Если вы использовали такой плагин, как Yoast, вы можете зайти на страницу и удалить канонический URL-адрес из соответствующего поля. Если вы добавили его непосредственно в HTML-код страницы, вы можете просто удалить его, а затем обновить страницу. Вот почему рекомендуется всегда добавлять канонические URL-адреса в одно и то же место, например, прямо над закрывающим тегом head.
Заключительные мысли о канонических URL-адресах
Чем больше страниц на вашем веб-сайте, тем трудоемче будет внедрение стратегии канонических URL. Вот почему лучше решить эту проблему как можно раньше и следить за тем, где ваш контент повторно публикуется в Интернете. Благодаря полезным плагинам WordPress, таким как Yoast SEO, установка канонических URL-адресов проще, чем доступ к HTML-коду каждой страницы и редактирование кода вручную.
Вот почему лучше решить эту проблему как можно раньше и следить за тем, где ваш контент повторно публикуется в Интернете. Благодаря полезным плагинам WordPress, таким как Yoast SEO, установка канонических URL-адресов проще, чем доступ к HTML-коду каждой страницы и редактирование кода вручную.
Каковы ваши рекомендации по использованию канонических URL-адресов? Дайте нам знать об этом в комментариях!
Изображение статьи Thepanyo / Shutterstock.com
Что такое канонический URL-адрес в WordPress?
Канонический URL-адрес — это предпочтительный URL-адрес домашней страницы веб-сайта. Большинство домашних страниц можно найти, введя несколько URL-адресов в адресную строку браузера.
Например, все следующие URL-адреса могут содержать один и тот же контент главной страницы вашего веб-сайта:
http://yoursite.com
https://yoursite.com
http://www.yoursite.com
https://www.yoursite.com
Если вы установили https://yoursite. com/ в качестве предпочтительного URL-адреса, он становится каноническим доменом.
com/ в качестве предпочтительного URL-адреса, он становится каноническим доменом.
Примечание. Не знаете, какую версию URL следует использовать? Вот еще информация о том, следует ли использовать «www» в URL-адресе или нет?
Что такое канонический URL-адрес в WordPress?
Записи и страницы блога WordPress имеют тот же вариант URL-адреса, что и в нашем примере с домашней страницей, и их также можно найти по идентификатору записи.
Например, это iThemes Security Pro Feature Spotlight: Site Scan сообщение в блоге можно найти по обоим из следующих URL-адресов:
https://ithemes.com/ithemes-security-pro-feature-spotlight-site-scan/
или идентификатор сообщения:
ithemes.com/?p=57051
Почему важно устанавливать канонические URL-адреса в WordPress?
Хотя нам легко видеть и рассматривать как https://ithemes.com/ithemes-security-pro-feature-spotlight-site-scan/, так и ithemes.com/?p=57051 как один и тот же контент , бот или веб-краулер будут рассматривать его как два отдельных поста в блоге с двух разных веб-сайтов.
SEO-преимущества определения вашего канонического URL-адреса и домена
Определение канонического URL-адреса для каждого набора URL-адресов позволяет Google и другим поисковым системам узнать, что эти похожие, но разные URL-адреса одинаковы. Это не позволяет роботу Googlebot тратить время на сканирование нескольких страниц в поисках одного фрагмента контента и сокращает время, необходимое Google для поиска и отображения нового и обновленного контента.
Еще одно SEO-преимущество установки канонического URL-адреса заключается в том, что он позволяет вам решать, как поисковая система представляет ваш контент потенциальным посетителям.
Используя наш пример поста в центре внимания из предыдущего примера, https://ithemes.com/ithemes-security-pro-feature-spotlight-site-scan/ имеет заголовок поста в блоге в URL-адресе и является более описательным и приветливым, чем ithemes.com/?p=57051.
Аутентификация сайта Преимущество определения вашего канонического URL-адреса
Многие службы используют канонический домен вашего веб-сайта для аутентификации. Например, наш плагин безопасности WordPress, iThemes Security Pro, использует ваш канонический домен.
Например, наш плагин безопасности WordPress, iThemes Security Pro, использует ваш канонический домен.
Прежде чем использовать сканирование сайта iThemes Security Pro, вы должны сначала активировать лицензию iThemes Security Pro на своем веб-сайте. Допустим, вы не установили канонический домен, а URL-адрес, используемый для лицензирования вашего сайта, был yoursite.com.
Прежде чем сервер iThemes Security Pro Site Scan просканирует ваш веб-сайт на наличие известных уязвимостей, он захватит домен веб-сайта, чтобы убедиться, что он соответствует домену, используемому для активации вашей лицензии iThemes Security Pro. Поскольку канонический домен не определен, сервер Site Scan определяет URL-адрес http://www.yoursite.com.
Как и в случае с Google, если канонический домен не задан, iThemes Security Pro не будет знать, что yoursite.com и yoursite.com следует рассматривать как один домен. Это означает, что Site Scanner не сможет аутентифицировать лицензию вашего сайта и не будет сканировать ваш сайт на наличие известных уязвимостей.
Определение канонического домена для вашего веб-сайта WordPress предотвратит ошибки, когда iThemes Security Pro Site Scanner и другие службы попытаются аутентифицировать ваш домен.
Как проверить, определен ли мой канонический URL-адрес?
Самый быстрый способ проверить, определили ли вы свой канонический домен, — просмотреть исходный код главной страницы вашего веб-сайта. Загрузите свою домашнюю страницу в своем любимом веб-браузере, затем щелкните правой кнопкой мыши и выберите Просмотреть исходный код страницы.
Исходная страница будет отображать все различные источники, из которых извлекается страница, а также различные элементы HTML и CSS, использованные для создания страницы. Исходная страница также покажет, был ли канонический домен установлен с использованием rel="canonical" Тег ссылки или заголовок HTTP.
Глядя на исходную страницу iThemes.com, мы видим, что мы установили канонический домен https://ithemes.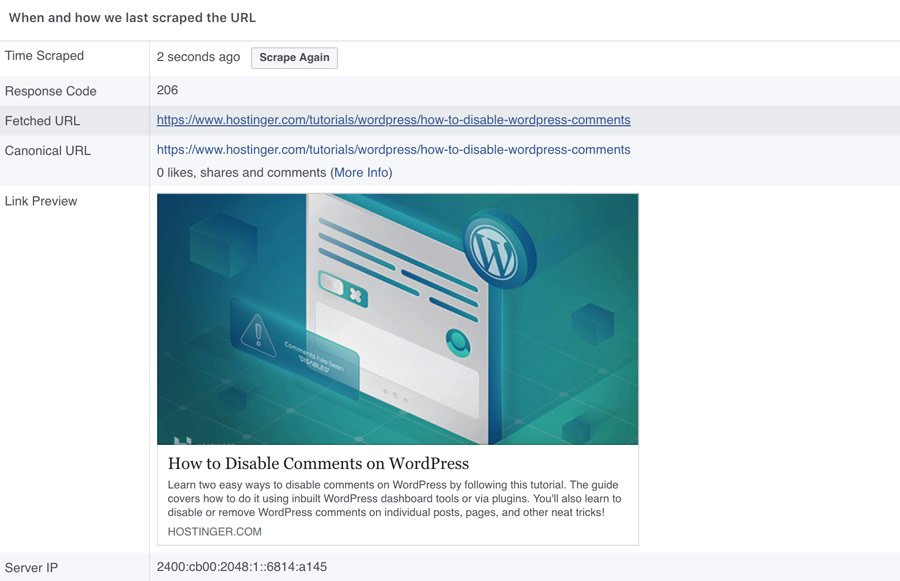 com, используя тег ссылки
com, используя тег ссылки rel="canonical" . Чтобы установить канонический домен с помощью HTTP-заголовка rel="canonical" , мы могли бы добавить ссылку : [https://]( в заголовок страницы.
Еще один способ проверить, определен ли канонический домен, — использовать инструмент проверки URL-адресов Google. Вы можете найти этот инструмент в панели администратора Google Search Console. Добавьте URL-адрес своей домашней страницы в поле поиска и нажмите Enter.
В сводке Сводка покрытия вы увидите значения Канонический, объявленный пользователем, и Канонический, выбранный Google. Объявленный пользователем канонический URL-адрес, который вы установили для своего веб-сайта. Канонический URL, выбранный Google, — это URL-адрес, выбранный Google в качестве официальной версии этой страницы, если вы никогда не определяли канонический URL-адрес для этой страницы.
На приведенном выше снимке экрана показаны результаты Google URL Inspection Tool с сайта, для которого я не определил канонический домен, и это значит, что Google еще не установил канонический домен.
Как установить канонический URL-адрес для моего веб-сайта WordPress?
Самый простой и быстрый способ установить канонический URL-адрес — использовать SEO-плагин WordPress, например Yoast SEO или RankMath.
Если вы используете Yoast SEO, для сообщений, страниц и пользовательских типов сообщений вы можете редактировать канонический URL-адрес на вкладке «Дополнительно» в метабоксе Yoast SEO.
Yoast SEO отлично справляется с автоматическим выбором правильного канонического URL-адреса для большинства сообщений и страниц, но плагин позволяет легко изменить его при необходимости.
Если вы используете SEO-плагин RankMath, вы можете отредактировать канонический URL-адрес на вкладке «Дополнительно» в метабоксе RankMath.
Как и Yoast SEO, RankMath автоматически установит для вас канонические URL-адреса, но также даст вам возможность обновлять их по мере необходимости.