Редактируем Robots.txt в WordPress с помощью плагина All in One SEO
Файл robots.txt — это мощный инструмент SEO, поскольку он работает как руководство по веб-сайту для роботов, выполняющих сканирование страниц сайтов. Указание ботам не сканировать ненужные страницы может увеличить скорость загрузки вашего сайта и улучшить рейтинг в поисковых системах.
Несмотря на то, что однажды я уже создавал пост про этот важный файл для оптимизации работы сайтов, в этом мануале я более подробно расскажу, что такое файл robots.txt и почему он важен. А так же шаг за шагом покажу, как редактировать и как редактировать его в WordPress.
Содержание
- 1 Что такое файл Robots.txt?
- 2 Файл Robots.txt по умолчанию в WordPress
- 3 Почему важен файл Robots.txt?
- 4 Когда использовать мета-тег Noindex вместо robots.txt
- 5 Как редактировать файл Robots.txt в WordPress с помощью AIOSEO
- 6 Включаем пользовательский файл Robots.txt
- 7 Добавление правил с помощью создателя правил
Что такое файл Robots.
 txt?
txt?Файл robots.txt сообщает поисковым системам, как сканировать ваш сайт — где им можно это делать, а где нельзя.
Поисковые системы, такие как Google, используют этих поисковых роботов, иногда называемых веб-роботами, для архивирования и классификации веб-сайтов.
Большинство ботов настроены на поиск файла robots.txt на сервере до того, как он прочитает любой другой файл с вашего сайта. Это делается для того, чтобы увидеть, добавили ли вы особые инструкции по сканированию и индексированию вашего сайта.
Файл robots.txt обычно хранится в корневом каталоге, также известном как основная папка веб-сайта. URL-адрес может выглядеть так: https://www.example.com/robots.txt
Чтобы проверить файл robots.txt на своем веб-сайте, просто замените https://www.example.com/ на свой домен и добавьте robots.txt в конце.
Сейчас же, давайте посмотрим, как выглядит основной формат файла robots.txt:
User-agent: [user-agent name] Disallow: [URL string not to be crawled] User-agent: [user-agent name] Allow: [URL string to be crawled] Sitemap: [URL of your XML Sitemap]
Чтобы это имело смысл, сначала нужно объяснить, что означает User-agent.
По сути, это имя бота или робота поисковой системы, которому вы хотите заблокировать или разрешить сканировать ваш сайт (например, робот Googlebot).
Во-вторых, вы можете включить несколько инструкций, чтобы разрешить или запретить определенные URL-адреса, а также добавить несколько карт сайта. Как вы, наверное, догадались, опция запрета указывает роботам поисковых систем не сканировать эти URL-адреса.
Файл Robots.txt по умолчанию в WordPress
По умолчанию WordPress автоматически создает файл robots.txt для вашего сайта. Так что, даже если вы не пошевелите пальцем, на вашем сайте уже должен быть файл robots.txt WordPress по умолчанию.
Но когда вы позже настроите его своими собственными правилами, содержимое по умолчанию будет заменено.
Стандартные файлы robots.txt выглядит так:
User-agent: * Disallow: /wp-admin/ Allow: /wp-admin/admin-ajax.php
Звездочка после User-agent: * означает, что файл robots.txt предназначен для всех веб-роботов, посещающих ваш сайт. И, как уже упоминалось, Disallow: / wp-admin / указывает роботам не посещать вашу страницу wp-admin.
И, как уже упоминалось, Disallow: / wp-admin / указывает роботам не посещать вашу страницу wp-admin.
Вы можете протестировать свой файл robots.txt, добавив /robots.txt в конце своего доменного имени. Например, если вы введете в адресную строку браузера запись https://aioseo.com/robots.txt , то в нем отобразится файл robots.txt для сайта плагина AIOSEO, который его разработчики настроили вот так:
Теперь, когда вы знаете, что такое файл robots.txt и основы его работы, давайте посмотрим, почему файл robots.txt имеет значение в первую очередь.
Почему важен файл Robots.txt?
Файл robots.txt важен, потому, что с помощью него вы:
1. Оптимизируйте скорость загрузки вашего сайта — указав ботам не тратить время на страницы, которые вы не хотите, чтобы они сканировали и индексировали, вы можете освободить ресурсы и увеличить скорость загрузки вашего сайта.
2. Оптимизируете использования сервера — блокировка ботов, которые тратят ресурсы впустую, очистит ваш сервер и уменьшит количество ошибок 404.
Когда использовать мета-тег Noindex вместо robots.txt
Однако, если ваша основная цель — предотвратить включение определенных страниц в результаты поисковых систем, правильным подходом является использование метатега noindex.
Это связано с тем, что файл robots.txt напрямую не говорит поисковым системам не индексировать контент — он просто говорит им не сканировать его.
Другими словами, вы можете использовать файл robots.txt для добавления определенных правил взаимодействия поисковых систем и других ботов с вашим сайтом, но он не будет явно контролировать, индексируется ли ваш контент или нет.
С учетом сказанного, давайте покажем вам, как легко шаг за шагом редактировать файл robots.txt в WordPress с помощью сео-плагина для WordPress — All in One SEO (AIOSEO)
Как редактировать файл Robots.txt в WordPress с помощью AIOSEO
Самый простой способ отредактировать файл robots.txt — использовать лучший плагин WordPress SEO All in One SEO (AIOSEO).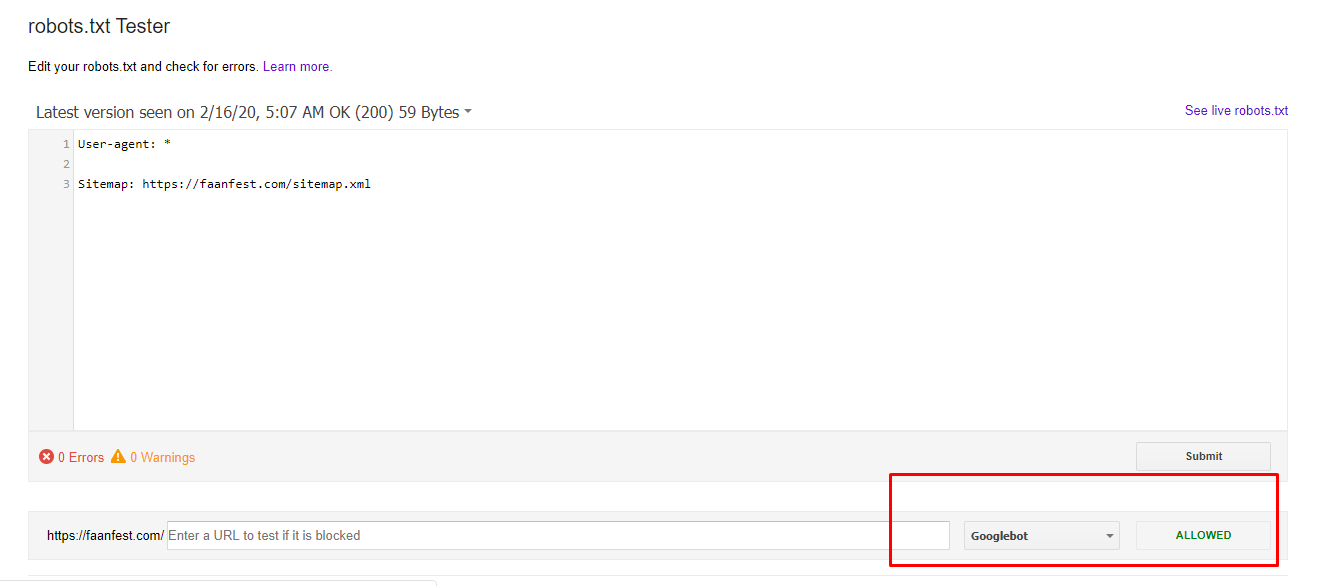 Если вы его установили, то это позволит вам контролировать свой веб-сайт и настраивать файл robots.txt, который заменяет файл WordPress по умолчанию.
Если вы его установили, то это позволит вам контролировать свой веб-сайт и настраивать файл robots.txt, который заменяет файл WordPress по умолчанию.
Если вы этого еще не знали, AIOSEO — это полноценный плагин WordPress для SEO,
который позволяет вам оптимизировать контент для поисковых систем и повысить рейтинг всего за несколько кликов. Ознакомьтесь с его мощными инструментами и функциями SEO здесь.
Включаем пользовательский файл Robots.txt
Чтобы приступить к редактированию файла robots.txt, с помощью уже установленного плагина AIOSEO, выберите в меню плагина строку «Инструменты». Таким образом вы откроете вкладку «Редактор Robots.txt». Далее приступаем к настройкам плагина.
Примечание* Если у вас уже был настроен файл и он вас вполне устраивает, вы можете просто импортировать его в AIOSEO.
Перевод страницы предупреждения и рекомендаций, если у вас уже был установлен файл: «AIOSEO обнаружила физический файл robots.txt в корневой папке вашей установки WordPress. Мы рекомендуем удалить этот файл, так как он может вызвать конфликт с динамически созданным файлом WordPress. AIOSEO может импортировать этот файл и удалить его, или вы можете просто удалить его».
Мы рекомендуем удалить этот файл, так как он может вызвать конфликт с динамически созданным файлом WordPress. AIOSEO может импортировать этот файл и удалить его, или вы можете просто удалить его».
Теперь на странице редактирования можно легко добавлять или удалять необходимые правила. Если вы пожелаете удалить ранее созданный файл-роботс — просто импортируйте и удалите его и пользуйтесь настройками по умолчанию. Но действовать нужно с осторожностью и не спешить удалять старый, несмотря на предупреждения плагина, а лучше используйте редактор.
AIOSEO сгенерирует динамический файл robots.txt. Его содержимое хранится в вашей базе данных WordPress и может быть просмотрено в вашем веб-браузере.
После того, как вы вошли в редактор Robots.txt, вам необходимо включить Custom Robots.txt.
Кнопка включения окна редактирования файла robots.txt
Затем вы увидите раздел предварительного просмотра файла Robots.txt в нижней части экрана, в котором показаны правила WordPress по умолчанию, которые вы можете заменить своими собственными.
Правила по умолчанию предписывают роботам не сканировать ваши основные файлы WordPress (страницы администратора). Также не рекомендуется сканировать плагины и темы. Они не содержат релевантного содержания и не нужны поисковым системам для сканирования.
Теперь давайте перейдем к тому, как вы можете добавить (или редактировать уже созданные) свои собственные правила с помощью создателя правил.
Добавление правил с помощью создателя правил
Конструктор правил используется для добавления ваших собственных правил для того, какие страницы роботы должны сканировать или нет.
Например, если вы хотите добавить правило, которое блокирует всех роботов из временного каталога (имеется в виду временная папка, например, на жестком диске), вы можете использовать для этого создатель правил.
Чтобы добавить собственное правило, просто введите User Agent (например, поисковый робот Googlebot) в поле User Agent. Или вы можете использовать символ *, чтобы ваше правило применялось ко всем пользовательским агентам (роботам).
Затем выберите «Разрешить» или «Запретить», или удалить (справа в таблице значок корзины), чтобы разрешить или заблокировать User Agent.
Или добавить новое правило:
По окончании редактирования и внесения изменений, вернитесь на верх страницы и осуществите просмотр файла в адресной строке браузера «Open Robots.txt»:
Что бы операция установки редактирования файла robots.txt была завершена, не забудьте сохранить изменения, кликнув на соответствующую кнопку в самом верху или внизу страницы редактирования.
Надеюсь, что это руководство показало вам, как легко редактировать файл robots.txt в WordPress. Теперь продолжайте и добавляйте свои собственные правила, и вы в кратчайшие сроки убедитесь, что ваш веб-сайт оптимизирован для достижения оптимальной производительности.
(Visited 1 times, 2 visits today)
Файл robots txt для сайта на WordPress, Joomla, OpenCart, Bitrix
СОДЕРЖАНИЕ
Файл robots.txt для сайта
Где находится robots. txt на сайте?
txt на сайте?
Директивы robots.txt
Правило Disallow
Правило Allow
User-agent
Sitemap
Host
Crawl delay
Clean param
Самые частые вопросы
Как в robots.txt запретить индексацию?
Как в robots.txt указать главное зеркало?
Простейший пример правильного robots.txt
Закрытый от индексации сайт – как выглядит robots.txt?
Как указать главное зеркало для сайта на https robots.txt?
Наиболее частые ошибки в robots.txt
Онлайн-проверка файла robots.txt
Готовые решения для самых популярных CMS
robots.txt для WordPress
robots.txt для Joomla
robots.txt Wix
robots.txt для Opencart
robots.txt для Битрикс (Bitrix)
robots.txt для Modx
Выводы
Файл robots.txt для сайта
Robots.txt для сайта – это индексный текстовый файл в кодировке UTF-8.
Индексным его назвали потому, что в нем прописываются рекомендации для поисковых роботов – какие страницы нужно просканировать, а какие не нужно.
Если кодировка файла отличается от UTF-8, то поисковые роботы могут неправильно воспринимать находящуюся в нем информацию.
Файл действителен для протоколов http, https, ftp, а также имеет «силу» только в пределах хоста/протокола/номера порта, на котором размещен.
Где находится robots.txt на сайте?
У файла robots.txt может быть только одно расположение – корневой каталог на хостинге. Выглядит это примерно вот так: http://vash-site.xyz/robots.txt
Директивы файла robots txt для сайта
Обязательными составляющими файла robots.txt для сайта являются правило Disallow и инструкция User-agent. Есть и второстепенные правила.
Правило Disallow
Disallow – это правило, с помощью которого поисковому роботу сообщается информация о том, какие страницы сканировать нет смысла. И сразу же несколько конкретных примеров применения этого правила:
Пример 1 — разрешено индексировать весь сайт:
Пример 2 — полностью запретить индексацию сайта:
Продвижение сайтов в таком случае будет бесполезно. Применение этого примера актуально в том случае, если сайт «закрыт» на доработку (например, неправильно функционирует). В этом случае сайту в поисковой выдаче не место, поэтому его нужно через файл robots txt закрыть от индексации. Разумеется, после того, как сайт будет доработан, запрет на индексирование надо снять, но об этом забывают.
Применение этого примера актуально в том случае, если сайт «закрыт» на доработку (например, неправильно функционирует). В этом случае сайту в поисковой выдаче не место, поэтому его нужно через файл robots txt закрыть от индексации. Разумеется, после того, как сайт будет доработан, запрет на индексирование надо снять, но об этом забывают.
Пример 3 – запрещено сканирование всех документов, находящихся в папке /papka/:
Пример 4 – запретить индексацию страницы с конкретным URL:
Пример 5 – запрещено индексировать конкретный файл (в данном случае – изображение):
Пример 6 – как в robots txt закрыть от индексации файлы конкретного расширения (в данном случае — .gif):
Звездочка перед .gif$ сообщает, что имя файла может быть любым, а знак $ сообщает о конце строки. Т.е. такая «маска» запрещает сканирование вообще всех GIF-файлов.
Правило Allow в robots txt
Правило Allow все делает с точностью до наоборот – разрешает индексирование файла/папки/страницы.
И сразу же конкретный пример:
Мы с вами уже знаем, что с помощью директивы Disallow: / мы можем закрыть сайт от индексации robots txt. В то же время у нас есть правило Allow: /catalog, которое разрешает сканирование папки /catalog. Поэтому комбинацию этих двух правил поисковые роботы будут воспринимать как «запрещено сканировать сайт, за исключением папки /catalog»
Сортировка правил и директив Allow и Disallow производится по возрастанию длины префикса URL и применяется последовательно. Если для одной и той же страницы подходит несколько правил, то робот выбирает последнее подходящее из списка.
Рассмотрим 2 ситуации с двумя правилами, которые противоречат друг другу — одно правило запрещает индексировать папки /content, а другое – разрешает.
В данном случае будет приоритетнее директива Allow, т.к. оно находится ниже по списку:
А вот здесь приоритетным является директива Disallow по тем же причинам (ниже по списку):
User-agent в robots txt
User-agent — правило, являющееся «обращением» к поисковому роботу, мол, «список рекомендаций специально для вас» (к слову, списков в robots. txt может быть несколько – для разных поисковых роботов от Google и Яндекс).
txt может быть несколько – для разных поисковых роботов от Google и Яндекс).
Например, в данном случае мы говорим «Эй, Googlebot, иди сюда, тут для тебя специально подготовленный список рекомендаций», а он такой «ОК, специально для меня – значит специально для меня» и другие списки сканировать не будет.
Правильный robots txt для Google (Googlebot)
Примерно та же история и с поисковым ботом Яндекса. Забегая вперед, список рекомендаций для Яндекса почти в 100% случаев немного отличается от списка для других поисковых роботов (чем – расскажем чуть позже). Но суть та же: «Эй, Яндекс, для тебя отдельный список» — «ОК, сейчас изучим его».
И последний вариант – рекомендации для всех поисковых роботов (кроме тех, у которых отдельные списки). Через «звездочку» было решено сделать по одной простой причине – чтоб не перечислять «поименно» все 300 с чем-то роботов.
Т.е. если в одном и том же robots.txt есть 3 списка с User-agent: *, User-agent: Googlebot и User-agent: Yandex, это значит, первый является «одним для всех», за исключением Googlebot и Яндекс, т.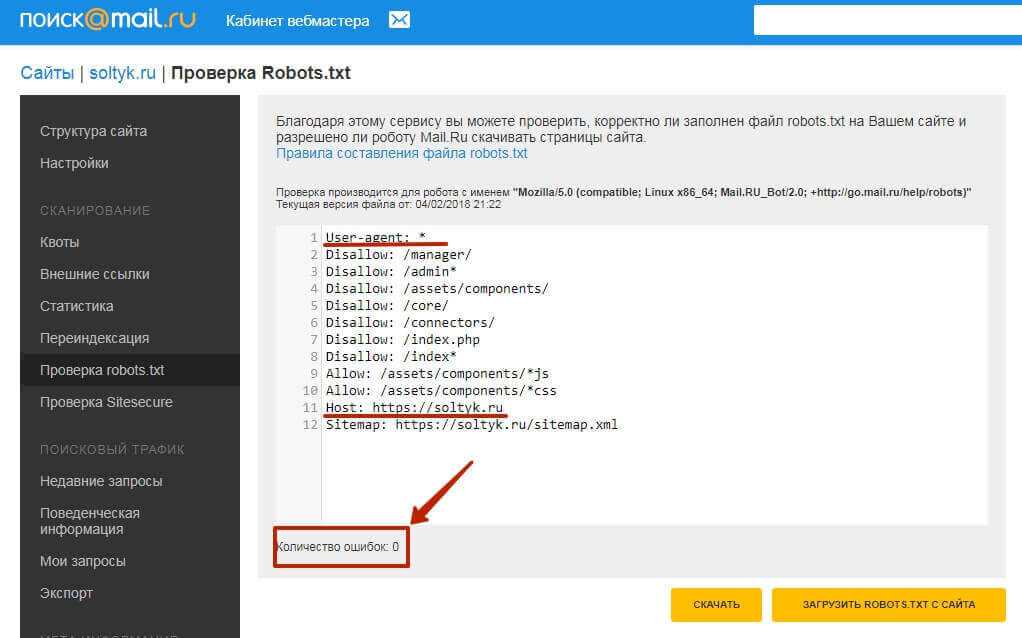 к. для них есть «личные» списки.
к. для них есть «личные» списки.
Sitemap
Правило Sitemap — расположение файла с XML-картой сайта, в которой содержатся адреса всех страниц, являющихся обязательными к сканированию. Как правило, указывается адрес вида http://site.ua/sitemap.xml.
Т.е. каждый раз поисковый робот будет просматривать карту сайта на предмет появления новых адресов, а затем переходить по ним для дальнейшего сканирования, дабы освежить информацию о сайте в базах данных поисковой системы.
Правило Sitemap должно быть вписано в Robots.txt следующим образом:
Директива Host
Межсекционная директива Host в файле robots.txt так же является обязательной. Она необходима для поискового робота Яндекса — сообщает ему, какое из зеркал сайта нужно учитывать при индексировании. Именно поэтому для Яндекса формируется отдельный список правил, т.к. Google и остальные поисковые системы директиву Host не понимают. Поэтому если у вашего сайта есть копии или же сайт может открываться под разными URL адресами, то добавьте директиву host в файл robots txt, чтобы страницы сайта правильно индексировались.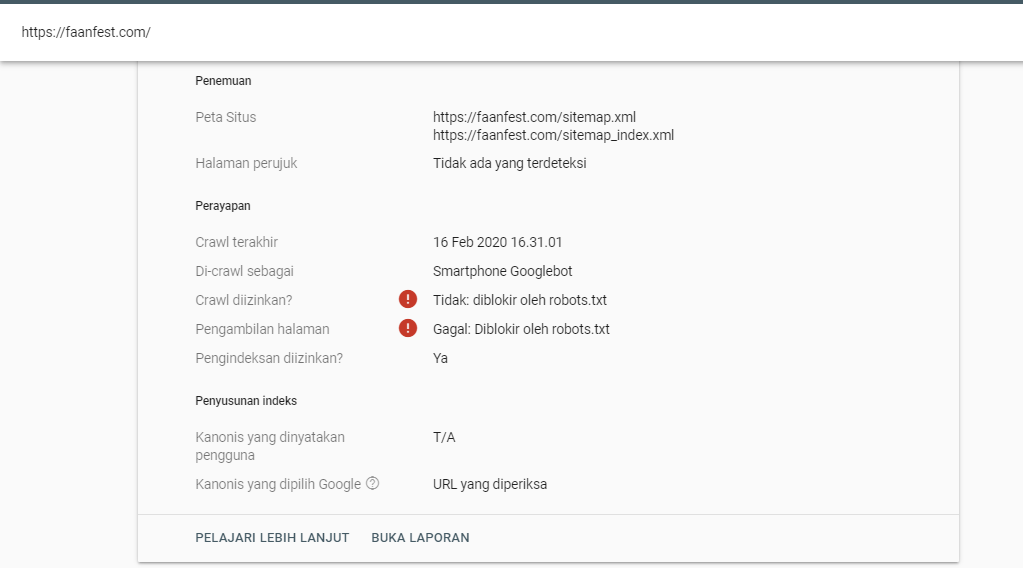
«Зеркалом сайта» принято называть либо точную, либо почти точную «копию» сайта, которая доступна по другому адресу.
Адрес основного зеркала обязательно должно быть указано следующим образом:
— для сайтов, работающих по http — Host: site.ua или Host: http://site.ua (т.е. http:// пишется по желанию)
— для сайтов, работающих по https – Host: https://site.ua (т.е. https:// прописывается в обязательном порядке)
Пример директивы host в robots txt для сайта на протоколе HTTPS:
Crawl delay
В отличие от предыдущих, параметр Crawl-delay уже не является обязательным. Основная его задача – подсказать поисковому роботу, в течение скольких секунд будут грузиться страницы. Обычно применяется в том случае, если Вы используете слабые сервера. Актуален только для Яндекса.
Clean param
С помощью директивы Clean-param можно бороться с get-параметрами, чтобы не происходило дублирование контента, т.к. один и тот же контент бывает доступен по разным динамическим ссылкам (это те, которые со знаками вопроса). Динамические ссылки могут генерироваться сайтом в том случае, когда используются различные сортировки, применяются идентификаторы сессий и т.д.
Динамические ссылки могут генерироваться сайтом в том случае, когда используются различные сортировки, применяются идентификаторы сессий и т.д.
Например, один и тот же контент может быть доступен по трем адресам:
www.site.com/catalog/get_phone.ua?ref=page_1&phone_id=1
www.site.com/catalog/get_phone.ua?ref=page_2&phone_id=1
www.site.com/catalog/get_phone.ua?ref=page_3&phone_id=1
В таком случае директива Clean-param оформляется вот так:
Т.е. после двоеточия прописывается атрибут ref, указывающий на источник ссылки, и только потом указывается ее «хвост» (в данном случае — /catalog/get_phone.ua).
Самые частые вопросы
Как в robots.txt запретить индексацию?
Для этих целей придумано правило Disallow: т.е. копируем ссылку на документ/файл, который нужно закрыть от индексации, вставляем ее после двоеточия:
User-agent: *
Disallow: http://your-site.xyz/privance.html
Disallow: http://your-site. xyz/foord.doc
xyz/foord.doc
Disallow: http://your-site.xyz/barcode.jpg
А затем удаляете адрес домена (в данном случае удалить надо вот эту часть — http://your-site.xyz). После удаления у нас останется ровно то, что и должно остаться:
User-agent: *
Disallow: /privance.html
Disallow: /foord.doc
Disallow: /barcode.jpg
Ну а если требуется закрыть от индексирования все файлы с определенным расширением, то правила будут выглядеть следующим образом:
User-agent: *
Disallow: /*.html
Disallow: /*.doc
Disallow: /*.jpg
Как в robots.txt указать главное зеркало?
Для этих целей придумана директива Host. Т.е. если адреса http://your-site.xyz и http://yoursite.com являются «зеркалами» одного и того же сайта, то одно из них необходимо указать в директиве Host. Пусть основным зеркалом будет http://your-site.xyz. В этом случае правильными вариантами будут следующие:
— если сайт работает по https-протоколу, то нужно делать только так:
User-agent: Yandex
Disallow: /privance.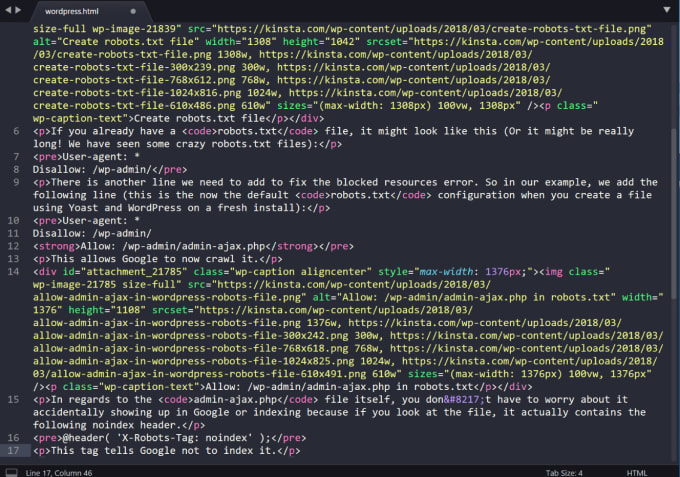 html
html
Disallow: /foord.doc
Disallow: /barcode.jpg
Host: https://your-site.xyz
— если сайт работает по http-протоколу, то оба приведенных ниже варианта будут верными:
User-agent: Yandex
Disallow: /privance.html
Disallow: /foord.doc
Disallow: /barcode.jpg
Host: http://your-site.xyz
User-agent: Yandex
Disallow: /privance.html
Disallow: /foord.doc
Disallow: /barcode.jpg
Host: your-site.xyz
Однако, следует помнить, директива Host является рекомендацией, а не правилом. Т.е. не исключено, что в Host будет указан один домен, а Яндекс посчитает за основное зеркало другой, если у него в панели вебмастера введены соответствующие настройки.
Простейший пример правильного robots.txt
В таком виде файл robots.txt можно разместить практически на любом сайте (с мельчайшими корректировками).
Давайте теперь разберем, что тут есть.
- Здесь 2 списка правил – один «персонально» для Яндекса, другой – для всех остальных поисковых роботов.

- Правило Disallow: пустое, а значит никаких запретов на сканирование нет.
- В списке для Яндекса присутствует директива Host с указанием основного зеркала, а также, ссылка на карту сайта.
НО… Это НЕ значит, что нужно оформлять robots.txt именно так. Правила должны быть прописаны строго индивидуально для каждого сайта. Например, нет смысла индексировать «технические» страницы (страницы ввода логина-пароля, либо тестовые страницы, на которых отрабатывается новый дизайн сайта, и т.д.). Правила, кстати, зависят еще и от используемой CMS.
Закрытый от индексации сайт – как выглядит robots.txt?
Даем сразу же готовый код, который позволит запретить индексацию сайта независимо от CMS:
Как указать главное зеркало для сайта на https robots.txt?
Очень просто:
Host: https://your-site.xyz
ВАЖНО!!! Для https-сайтов протокол должен указываться строго обязательно!
Наиболее частые ошибки в robots.
 txt
txtСпециально для Вас мы приготовили подборку самых распространенных ошибок, допускаемых в robots.txt. Почти все эти ошибки объединяет одно – они допускаются по невнимательности.
1. Перепутанные инструкции:
Правильный вариант:
2. В один Disallow вставляется куча папок:
В такой записи робот может запутаться. Какую папку нельзя индексировать? Первую? Последнюю? Или все? Или как? Или что? Одна папка = одно правило Disallow и никак иначе.
3. Название файла допускается только одно — robots.txt, причем все буквы маленькие. Имена Robots.txt, ROBOTS.TXT и т.п. не допускаются.
4. Правило User-agent запрещено оставлять пустым. Либо указываем имя поискового робота (например, для Яндекса), либо ставим звездочку (для всех остальных).
5. Мусор в файле (лишние слэши, звездочки и т.д.).
6. Добавление в файл полных адресов скрываемых страниц, причем иногда даже без правила Disallow.
Неправильно:
http://mega-site. academy/serrot.html
academy/serrot.html
Тоже неправильно:
Disallow: http://mega-site.academy/serrot.html
Правильно:
Disallow: /serrot.html
Онлайн-проверка файла robots.txt
Существует несколько способов проверки файла robots.txt на соответствие общепринятому в интернете стандарту.
Способ 1. Зарегистрироваться в панелях веб-мастера Яндекс и Google. Единственный минус – придется покопаться, чтоб разобраться с функционалом. Далее вносятся рекомендованные изменения и готовый файл закачивается на хостинг.
Способ 2. Воспользоваться онлайн-сервисами:
— https://services.sl-team.ru/other/robots/
— https://technicalseo.com/seo-tools/robots-txt/
— http://tools.seochat.com/tools/robots-txt-validator/
Итак, robots.txt сформирован. Осталось только проверить его на ошибки. Лучше всего использовать для этого инструменты, предлагаемые самими поисковыми системами.
Google Вебмастерс (Search Console Google): заходим в аккаунт, если в нем сайт не подтвержден – подтверждаем, далее переходим на Сканирование -> Инструмент проверки файла robots. txt.
txt.
Здесь можно:
- моментально обнаружить все ошибки и потенциально возможные проблемы,
- сразу же «на месте» внести поправки и проверить на ошибки еще раз (чтоб не перезагружать файл на сайт по 20 раз)
- проверить правильность запретов и разрешений индексирования страниц.
Яндекс Вебмастер (прямая ссылка — http://webmaster.yandex.ru/robots.xml).
Является аналогом предыдущего, за исключением:
- авторизация не обязательна;
- подтверждение прав на сайт не обязательно;
- доступна массовая проверка страниц на доступность;
- можно убедиться, что все правила правильно восприняты Яндексом.
Готовые решения для самых популярных CMS
Правильный robots.txt для WordPress
User-agent: *
Disallow: /cgi-bin # классика жанра
Disallow: /? # любые параметры запроса на главной
Disallow: /wp- # все файлы WP: /wp-json/, /wp-includes, /wp-content/plugins
Disallow: *?s= # поиск
Disallow: *&s= # поиск
Disallow: /search # поиск
Disallow: /author/ # архив автора
Disallow: *?attachment_id= # страница вложения.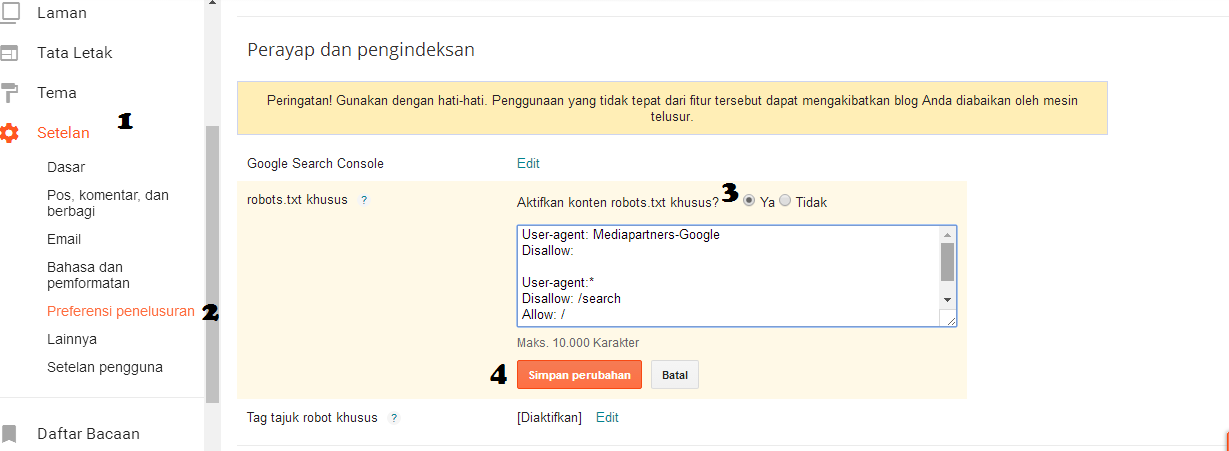 Вообще-то на ней редирект…
Вообще-то на ней редирект…
Disallow: */feed # все фиды
Disallow: */rss # rss фид
Disallow: */embed # все встраивания
Disallow: */page/ # все виды пагинации
Allow: */uploads # открываем uploads
Allow: /*/*.js # внутри /wp- (/*/ — для приоритета)
Allow: /*/*.css # внутри /wp- (/*/ — для приоритета)
Allow: /wp-*.png # картинки в плагинах, cache папке и т.д.
Allow: /wp-*.jpg # картинки в плагинах, cache папке и т.д.
Allow: /wp-*.jpeg # картинки в плагинах, cache папке и т.д.
Allow: /wp-*.gif # картинки в плагинах, cache папке и т.д.
Allow: /wp-*.svg # картинки в плагинах, cache папке и т.д.
Allow: /wp-*.pdf # файлы в плагинах, cache папке и т.д.
#Disallow: /wp/ # когда WP установлен в подкаталог wp
Sitemap: http://site.ru/sitemap.xml
Sitemap: http://site.ru/sitemap2.xml # еще один файл
#Sitemap: http://site.ru/sitemap.xml.gz # сжатая версия (.gz)
Host: www.site.ru # для Яндекса и Mail.![]() RU. (межсекционная)
RU. (межсекционная)
# Версия кода: 1.0
# Не забудьте поменять `site.ru` на ваш сайт.
Давайте разберем код файла robots txt для WordPress CMS:
User-agent: *
Здесь мы указываем, что все правила актуальны для всех поисковых роботов (за исключением тех, для кого составлены «персональные» списки). Если список составляется для какого-то конкретного робота, то * меняется на имя робота:
User-agent: Yandex
User-agent: Googlebot
Allow: */uploads
Здесь мы осознанно даем добро на индексирование ссылок, в которых содержится /uploads. В данном случае это правило является обязательным, т.к. в движке WordPress есть директория /wp-content/uploads (в которой вполне могут содержаться картинки, либо другой «открытый» контент), индексирование которой запрещено правилом Disallow: /wp-. Поэтому с помощью Allow: */uploads мы делаем исключение из правила Disallow: /wp-.
В остальном просто идут запреты на индексирование:
Disallow: /cgi-bin – запрет на индексирование скриптов
Disallow: /feed – запрет на сканирование RSS-фида
Disallow: /trackback – запрет сканирования уведомлений
Disallow: ?s= или Disallow: *?s= — запрет на индексирование страниц внутреннего поиска сайта
Disallow: */page/ — запрет индексирования всех видов пагинации
Правило Sitemap: http://site. ru/sitemap.xml указывает Яндекс-роботу путь к файлу с xml-картой. Путь должен быть прописан полностью. Если таких файлов несколько – прописываем несколько Sitemap-правил (1 файл = 1 правило).
ru/sitemap.xml указывает Яндекс-роботу путь к файлу с xml-картой. Путь должен быть прописан полностью. Если таких файлов несколько – прописываем несколько Sitemap-правил (1 файл = 1 правило).
В строке Host: site.ru мы специально для Яндекса прописали основное зеркало сайта. Оно указывается для того, чтоб остальные зеркала индексировались одинаково. Пустая строка перед Host: является обязательной.
Где находится robots txt WordPress вы все наверное знаете — так как и в другие CMS, данный файл должен находится в корневом каталоге сайта.
Файл robots.txt для Joomla
Joomla — почти самый популярный движок у вебмастеров, т.к. не смотря на широчайшие возможности и множества готовых решений, он поставляется бесплатно. Однако, штатный robots.txt всегда имеет смысл подправить, т.к. для индексирования открыто слишком много «мусора», но картинки закрыты (это плохо).
Вот так выглядит правильный robots.txt для Joomla :
User-agent: *
Disallow: /administrator/
Disallow: /bin/
Disallow: /cache/
Disallow: /cli/
Disallow: /components/
Disallow: /images/
Disallow: /includes/
Disallow: /installation/
Disallow: /language/
Disallow: /layouts/
Disallow: /libraries/
Disallow: /logs/
Disallow: /media/
Disallow: /modules/
Disallow: /plugins/
Disallow: /templates/
Disallow: /tmp/
robots.
 txt Wix
txt WixПлатформа Wix автоматически генерирует файлы robots.txt персонально для каждого сайта Wix. Т.е. к Вашему домену добавляете /robots.txt (например: www.domain.com/robots.txt) и можете спокойно изучить содержимое файла robots.txt, находящегося на Вашем сайте.
Отредактировать robots.txt нельзя. Однако с помощью noindex можно закрыть какие-то конкретные страницы от индексирования.
robots.txt для Opencart
Стандартный файл robots.txt для OpenCart:
User-agent: *
Disallow: /*route=account/
Disallow: /*route=affiliate/
Disallow: /*route=checkout/
Disallow: /*route=product/search
Disallow: /index.php?route=product/product*&manufacturer_id=
Disallow: /admin
Disallow: /catalog
Disallow: /download
Disallow: /export
Disallow: /system
Disallow: /*?sort=
Disallow: /*&sort=
Disallow: /*?order=
Disallow: /*&order=
Disallow: /*?limit=
Disallow: /*&limit=
Disallow: /*?filter_name=
Disallow: /*&filter_name=
Disallow: /*?filter_sub_category=
Disallow: /*&filter_sub_category=
Disallow: /*?filter_description=
Disallow: /*&filter_description=
Disallow: /*?tracking=
Disallow: /*&tracking=
Disallow: /*?page=
Disallow: /*&page=
Disallow: /wishlist
Disallow: /login
Disallow: /index. php?route=product/manufacturer
php?route=product/manufacturer
Disallow: /index.php?route=product/compare
Disallow: /index.php?route=product/category
User-agent: Yandex
Disallow: /*route=account/
Disallow: /*route=affiliate/
Disallow: /*route=checkout/
Disallow: /*route=product/search
Disallow: /index.php?route=product/product*&manufacturer_id=
Disallow: /admin
Disallow: /catalog
Disallow: /download
Disallow: /export
Disallow: /system
Disallow: /*?sort=
Disallow: /*&sort=
Disallow: /*?order=
Disallow: /*&order=
Disallow: /*?limit=
Disallow: /*&limit=
Disallow: /*?tracking=
Disallow: /*&tracking=
Disallow: /*route=product/search
Disallow: /*?page=
Disallow: /*&page=
Clean-param: tracking
Clean-param: filter_name
Clean-param: filter_sub_category
Clean-param: filter_description
Disallow: /wishlist
Disallow: /login
Disallow: /index. php?route=product/manufacturer
php?route=product/manufacturer
Disallow: /index.php?route=product/compare
Disallow: /index.php?route=product/category
Host: Vash_domen
Sitemap: http://Vash_domen/sitemap.xml
robots.txt для Битрикс (Bitrix)
1. Папки /bitrix и /cgi-bin должны быть закрыты, т.к. это чисто технический «хлам», который незачем светить в поисковой выдаче.
Disallow: /bitrix
Disallow: /cgi-bin
2. Папка /search тоже не представляет интереса ни для пользователей, ни для поисковых систем. Да и образование дублей никому не нужно. Поэтому тоже ее закрываем.
Disallow: /search
3. Про формы PHP-аутентификации и авторизации на сайте тоже забывать нельзя – закрываем.
Disallow: /auth/
Disallow: /auth.php
4. Материалы для печати (например, счета на оплату) тоже нет смысла светить в поисковой выдаче. Закрываем.
Disallow: /*?print=
Disallow: /*&print=
5. Один из жирных плюсов «Битрикса» в том, что он фиксирует всю историю сайта – кто когда залогинился, кто когда сменил пароль, и прочую конфиденциальную информацию, утечка которой не допустима. Поэтому закрываем:
Поэтому закрываем:
Disallow: /*register=yes
Disallow: /*forgot_password=yes
Disallow: /*change_password=yes
Disallow: /*login=yes
Disallow: /*logout=yes
Disallow: /*auth=yes
6. Back-адреса тоже нет смысла индексировать. Эти адреса могут образовываться, например, при просмотре фотоальбома, когда Вы сначала листаете его «вперед», а потом – «назад». В эти моменты в адресной строке вполне может появиться что-то типа матерного ругательства: ?back_url_ =%2Fbitrix%2F%2F. Ценность таких адресов равна нулю, поэтому их тоже закрываем от индексирования. Ну а в качестве бонуса – избавляемся от потенциальных «дублей» в поисковой выдаче.
Disallow: /*BACKURL=*
Disallow: /*back_url=*
Disallow: /*BACK_URL=*
Disallow: /*back_url_admin=*
7. Папку /upload необходимо закрывать строго по обстоятельствам. Если там хранятся фотографии и видеоматериалы, размещенные на страницах, то ее скрывать не нужно, чтоб не срезать дополнительный трафик.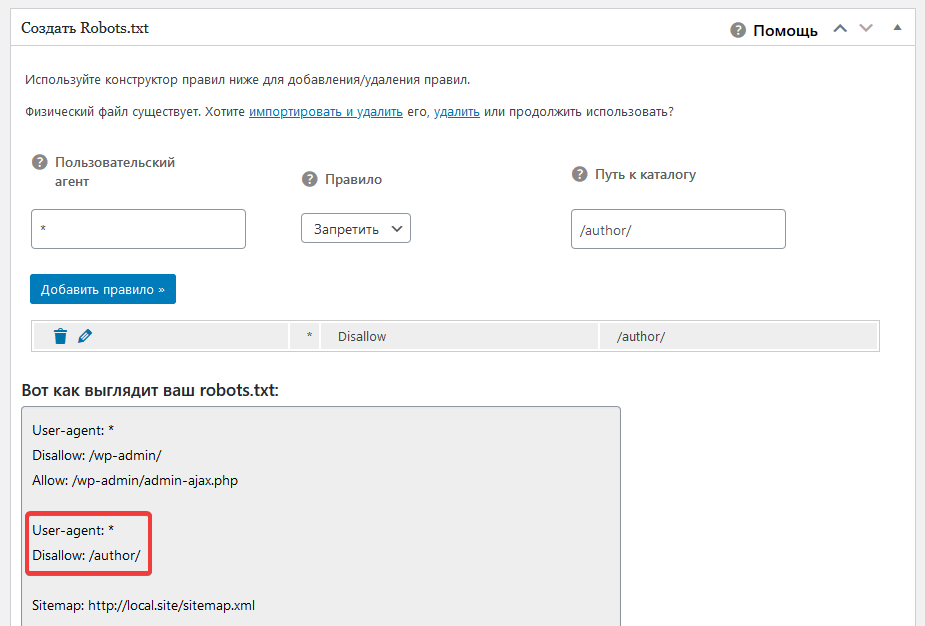 Ну а если что-то конфиденциальное – однозначно закрываем:
Ну а если что-то конфиденциальное – однозначно закрываем:
Disallow: /upload
Готовый файл robots.txt для Битрикс:
User-agent: *
Allow: /map/
Allow: /search/map.php
Allow: /bitrix/templates/
Disallow: */index.php
Disallow: /*action=
Disallow: /*print=
Disallow: /*/gallery/*order=
Disallow: /*/search/
Disallow: /*/slide_show/
Disallow: /*?utm_source=
Disallow: /*ADD_TO_COMPARE_LIST
Disallow: /*arrFilter=
Disallow: /*auth=
Disallow: /*back_url_admin=
Disallow: /*BACK_URL=
Disallow: /*back_url=
Disallow: /*backurl=
Disallow: /*bitrix_*=
Disallow: /*bitrix_include_areas=
Disallow: /*building_directory=
Disallow: /*bxajaxid=
Disallow: /*change_password=
Disallow: /*clear_cache_session=
Disallow: /*clear_cache=
Disallow: /*count=
Disallow: /*COURSE_ID=
Disallow: /*forgot_password=
Disallow: /*ID=
Disallow: /*index. php$
php$
Disallow: /*login=
Disallow: /*logout=
Disallow: /*modern-repair/$
Disallow: /*MUL_MODE=
Disallow: /*ORDER_BY
Disallow: /*PAGE_NAME=
Disallow: /*PAGE_NAME=detail_slide_show
Disallow: /*PAGE_NAME=search
Disallow: /*PAGE_NAME=user_post
Disallow: /*PAGEN_
Disallow: /*print_course=
Disallow: /*print=
Disallow: /*q=
Disallow: /*register=
Disallow: /*register=yes
Disallow: /*set_filter=
Disallow: /*show_all=
Disallow: /*show_include_exec_time=
Disallow: /*show_page_exec_time=
Disallow: /*show_sql_stat=
Disallow: /*SHOWALL_
Disallow: /*sort=
Disallow: /*sphrase_id=
Disallow: /*tags=
Disallow: /access.log
Disallow: /admin
Disallow: /api
Disallow: /auth
Disallow: /auth.php
Disallow: /auto
Disallow: /bitrix
Disallow: /bitrix/
Disallow: /cgi-bin
Disallow: /club/$
Disallow: /club/forum/search/
Disallow: /club/gallery/tags/
Disallow: /club/group/search/
Disallow: /club/log/
Disallow: /club/messages/
Disallow: /club/search/
Disallow: /communication/blog/search.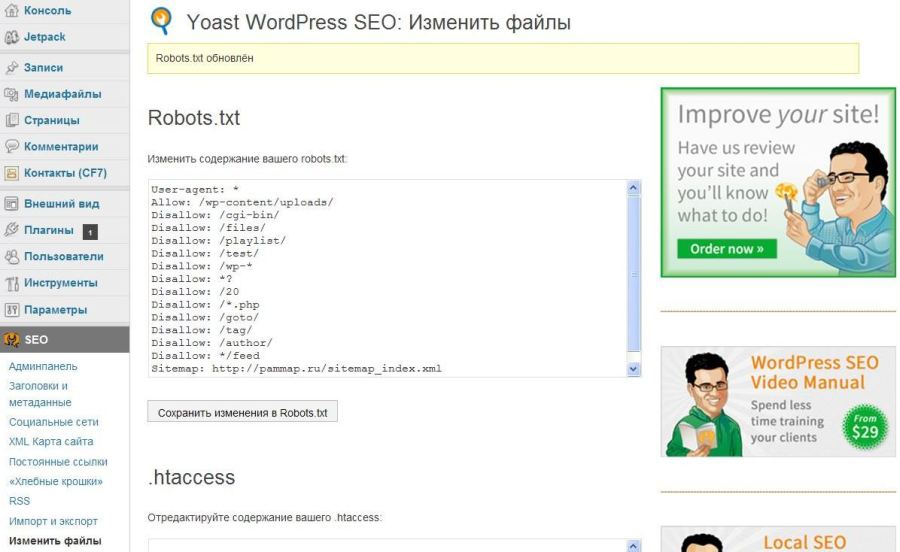 php
php
Disallow: /communication/forum/search/
Disallow: /communication/forum/user/
Disallow: /content/board/my/
Disallow: /content/links/my/
Disallow: /error
Disallow: /e-store/affiliates/
Disallow: /e-store/paid/detail.php
Disallow: /examples/download/download_private/
Disallow: /examples/my-components/
Disallow: /include
Disallow: /personal
Disallow: /search
Disallow: /temp
Disallow: /tmp
Disallow: /upload
Disallow: /*/*ELEMENT_CODE=
Disallow: /*/*SECTION_CODE=
Disallow: /*/*IBLOCK_CODE
Disallow: /*/*ELEMENT_ID=
Disallow: /*/*SECTION_ID=
Disallow: /*/*IBLOCK_ID=
Disallow: /*/*CODE=
Disallow: /*/*ID=
Disallow: /*/*IBLOCK_EXTERNAL_ID=
Disallow: /*/*SECTION_CODE_PATH=
Disallow: /*/*EXTERNAL_ID=
Disallow: /*/*IBLOCK_TYPE_ID=
Disallow: /*/*SITE_DIR=
Disallow: /*/*SERVER_NAME=
Sitemap: http://site.ru/sitemap_index.xml
Sitemap: http://site. ru/sitemap.xml
ru/sitemap.xml
Host: site.ru
robots.txt для Modx и Modx Revo
CMS Modx Revo тоже не лишена проблемы дублей. Однако, она не так сильно обострена, как в Битриксе. Теперь о ее решении.
- Включаем ЧПУ в настройках сайта.
- закрываем от индексации:
Disallow: /index.php # т.к. это дубль главной страницы сайта
Disallow: /*? # разом решаем проблему с дублями для всех страниц
Готовый файл robots.txt для Modx и Modx Revo:
User-agent: *
Disallow: /*?
Disallow: /*?id=
Disallow: /assets
Disallow: /assets/cache
Disallow: /assets/components
Disallow: /assets/docs
Disallow: /assets/export
Disallow: /assets/import
Disallow: /assets/modules
Disallow: /assets/plugins
Disallow: /assets/snippets
Disallow: /connectors
Disallow: /core
Disallow: /index.php
Disallow: /install
Disallow: /manager
Disallow: /profile
Disallow: /search
Sitemap: http://site. ru/sitemap.xml
ru/sitemap.xml
Host: site.ru
Выводы
Без преувеличения файл robots.txt можно назвать «поводырём для поисковых роботов Яндекс и Гугл» (разумеется, если он составлен правильно). Если файл robots txt отсутствует, то его нужно обязательно создать и загрузить на хостинг Вашего сайта. Справка Disallow правил описаны выше в этой статьей и вы можете смело их использоваться в своих целях.
Еще раз резюмируем правила/директивы/инструкции для robots.txt:
- User-agent — указывает, для какого именно поискового робота создан список правил.
- Disallow – «рекомендую вот это не индексировать».
- Sitemap – указывает расположение XML-карты сайта со всеми URL, которые нужно проиндексировать. В большинстве случаев карта расположена по адресу http://[ваш_сайт]/sitemap.xml.
- Crawl-delay — директива, указывающая период (в секундах), через который будет загружена страница сайта.
- Host – показывает Яндексу основное зеркало сайта.
- Allow – «рекомендую вот это проиндексировать, не смотря на то, что это противоречит одному из Disallow-правил».

- Clean-param — помогает в борьбе с get-параметрами, применяется для снижения рисков образования страниц-дублей.
Знаки при составлении robots.txt:
- Знак «$» для «звездочки» является «ограничителем».
- После слэша «/» указывается наименование файла/папки/расширения, которую нужно скрыть (в случае с Disallow) или открыть (в случае с Allow) для индексирования.
- Знаком «*» обозначается «любое количество любых символов».
- Знаком «#» отделяются какие-либо комментарии или примечания, оставленные вэб-мастером для себя, либо для кого-то другого. Поисковые роботы их не читают.
Robots txt для вашего WordPress сайта
4115 2.10.2014 Время на чтение: 5 мин.
Содержание статьи:
1. Для чего сайту нужен файл robots.txt
2. Пример написания файла robots txt для WordPress
3. Когда ждать эффект от файла?
Здравствуйте, дорогие читатели! С вами проект «Анатомия Бизнеса» и вебмастер Александр.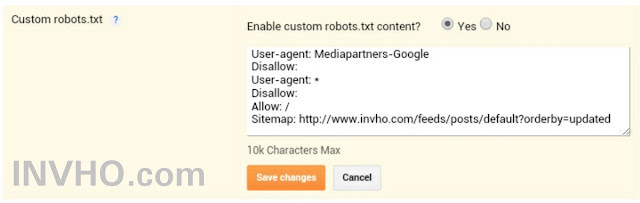 Мы продолжаем цикл статей мануала «Как создать сайт на WordPress и заработать на нем», и сегодня мы поговорим о том, как создать файл robots.txt для WordPress и зачем нужен данный файл.
Мы продолжаем цикл статей мануала «Как создать сайт на WordPress и заработать на нем», и сегодня мы поговорим о том, как создать файл robots.txt для WordPress и зачем нужен данный файл.
В прошлых 16-и уроках мы рассмотрели огромное количество материала. Наш сайт практически готов для того, чтобы начать заполнять его интересным контентом и проводить SEO-оптимизацию.
[warning]Если Вы что-то упустили из прошлого материала, рекомендую повторить хотя бы последние уроки:
Занятие 12. «Делаем ЧПУ на WordPress»
Занятие 13. «Установка виджета ВКонтакте на сайт»
Занятие 14. «Добавляем сайт в Гугл Вебмастер»
Занятие 15. «Устанавливаем социальные кнопки на сайт!»
Занятие 16. «Подключение Google Analytics к сайту»[/warning]
Итак, давайте перейдем к делу!
Для чего сайту нужен файл robots.txt?
Основную ценность на нашем сайте будет представляет именно контент, но помимо него на сайте есть целая куча технических разделов или страниц, которые для поискового робота не является чем-то ценным.
К таким разделам можно отнести:
— админ. панель
— поиск
— возможно, Вы захотите закрыть от индексации комментарии
— или какие-то страницы-дубли, имеющие в своих урлах одни и те же символы
В общем, robots.txt предназначен для того, чтобы запретить поисковому роботу индексацию тех или иных страниц.
В свое время в понимания того, как работает robots txt, мне очень помогла эта картинка:
Авторство на себя не беру, взял на сайте, который написан в левом нижнем углу изображения 😉
Как мы можем видеть, первым делом, когда поисковый робот заходит на сайт, он ищет именно этот Файл! После его анализа он понимает в какие директории ему нужно заходить, а в какие нет.
Многие начинающие веб мастера пренебрегают данным файлом, а зря! Т. к. от того насколько «чистой» будет индексация вашего сайта, зависит его позиции в поисковике.
Пример написания файла robots.txt для WordPress
Давайте теперь разбираться, как писать данный файл.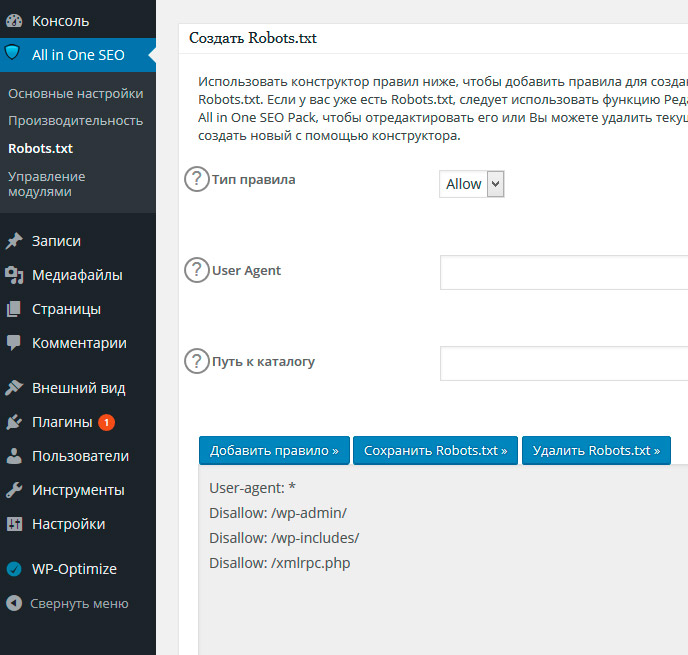 Тут нет ничего сложного, для его написания нам достаточно открыть обычный текстовый редактор «блокнот» или можно воспользоваться профессиональным редактором типа notepad+.
Тут нет ничего сложного, для его написания нам достаточно открыть обычный текстовый редактор «блокнот» или можно воспользоваться профессиональным редактором типа notepad+.
Вводим в редактор следующие данные:
User-agent: Yandex
Disallow: /wp-admin
Disallow: /wp-includes
Disallow: /wp-comments
Disallow: /wp-content/plugins
Disallow: /wp-content/themes
Disallow: /wp-login.php
Disallow: /wp-register.php
Disallow: */trackback
Disallow: */feed
Disallow: /cgi-bin
Disallow: *?s=
Host: site.ruUser-agent: *
Disallow: /wp-admin
Disallow: /wp-includes
Disallow: /wp-comments
Disallow: /wp-content/plugins
Disallow: /wp-content/themes
Disallow: /wp-login.php
Disallow: /wp-register.php
Disallow: */trackback
Disallow: */feed
Disallow: /cgi-bin
Disallow: *?s=Sitemap: http://site.ru/sitemap.xml
А теперь давайте разбираться со всем этим.
Первое, на что нужно обратить внимание, так это на то, что файл разбит на два больших блока.
И в начале каждого блока стоит директория «User-agent», которая указывает для какого робота сделан данный блок.
У нас первый блок сделан для роботов Yandex, о чем свидетельствует данная строка: «User-agent: Yandex»
Второй блок говорит о том, что он для всех остальных роботов. На это указывает звездочка «User-agent: *».
Директория «Disallow» устанавливает, какие именно разделы запрещены к индексации.
Теперь разберем по разделам:
/wp-admin — запрет на индексацию админ. панели
/wp-includes — запрет на индексацию системных папок движка WordPress
/wp-comments — запрет на индексацию комментариев
/wp-content/plugins — запрет на индексацию папки с плагинами для WordPress
/wp-content/themes — запрет на индексацию папки с темами для WordPress
/wp-login.php — запрет на индекс формы входа на сайт
/wp-register.php — закрываем от робота форму регистрации
*/feed — запрет на индекс RSS-фида блога
/cgi-bin — запрет на индекс каталога скриптов на сервере
*?s= — запрет на индексацию всех URL, которые содержат ?s=
Далее указываем основное зеркало сайта строкой:
«Host: site. ru»
ru»
Тут должен быть адрес Вашего сайта.
И в самом конце robots.txt показываем роботу, где находится файл sitemap.xml
Sitemap: http://site.ru/sitemap.xml
После того как файл готов, сохраняем его в корневой директории сайта.
Как закрыть какие-то рубрики от индексации?
Например, Вы не хотите показывать какую-то рубрику на Вашем сайте для поисковых роботов. Причины на это могут быть совершенно разные. Например, Вы хотите, чтобы Ваш личный дневник читали только постоянные посетители сайта.
Допустим, рубрика называется «мой дневник»
Первое, что нам нужно сделать, — это узнать URL данной рубрики. Скорее всего, он будет /moy-dnevnik.
Для того чтобы закрыть данную рубрику, нам достаточно добавить в нее следующую строку: Disallow: /moy-dnevnik
Robots.txt — когда ждать эффект?
Могу сказать из личной практики, что не стоит ожидать, что уже при следующем апдейте все закрытые Вами рубрики уйдут из индекса.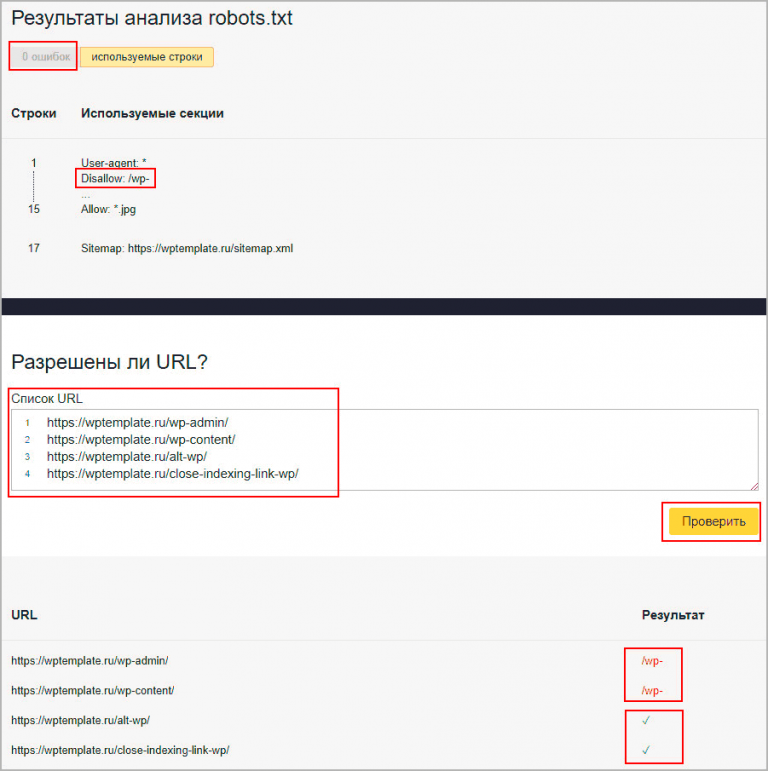 Иногда этот процесс может занимать до двух месяцев. Просто запаситесь терпением.
Иногда этот процесс может занимать до двух месяцев. Просто запаситесь терпением.
Также необходимо учитывать, что роботы Google могут просто игнорировать данный файл, если сочтут, что страница уж очень уникальная и интересная.
О чем нужно помнить ВСЕГДА!
Конечно, техническая составляющая является не маловажной, но в первую очередь нужно делать акцент на полезный и интересный контент, за которым будут возвращаться постоянные читатели Вашего проекта! Именно ставка на качество сделает Ваш ресурс востребованным и популярным 😉
Успехов Вам в интернет-бизнесе 😉
Материал подготовил:
Михаил Каржин
Автор журнала «Анатомия бизнеса».
Поделиться:
Есть вопросы, пожелания, предложения? Пишите нам,
мы обязательно ответим.
Как создать файл robots.txt — WordPress для неспециалистов: бесплатные руководства по WordPress
В этом руководстве объясняется, что такое файл robots.txt и как создать файл robots. txt и загрузить его на сервер.
txt и загрузить его на сервер.
Всегда делайте резервную копию вашего сайта WordPress перед внесением изменений в важные файлы и делайте копии любых файлов, которые вы собираетесь изменить.
Если вы не хотите редактировать файлы WordPress самостоятельно, попросите помочь вам опытного человека.
***
WordPress создает виртуальный файл robots.txt, если на вашем сервере не найден физический файл robots.txt. Из этого руководства вы узнаете, как создать и загрузить физический файл robots.txt на сервер, чтобы заменить виртуальный файл, как отредактировать файл robots.txt и как протестировать файл robots.txt инструкции для поисковых систем.
Файл robots.txt инструктирует поисковых роботов и совместные «боты» о частях вашего веб-сайта, которые вы хотите сохранить в тайне, и к каким областям они могут и не могут получить доступ. Боты или «роботы» — это программы, используемые поисковыми системами, такими как Google и другим программным обеспечением, для сбора информации для своих баз данных.
О robots.txt
Следующая запись взята с robotstxt.org :
Владельцы веб-сайтов используют файл /robots.txt для предоставления веб-роботам инструкций относительно своего сайта; это называется Протокол исключения роботов .
Это работает следующим образом: робот хочет посетить URL-адрес веб-сайта, скажем, http://www.yourdomain.com/welcome.php . Прежде чем это сделать, он сначала проверяет http://www.yourdomain.com/robots.txt и находит:
Часть «User-agent: *» содержит звездочку.
Как указано в Википедии,
В программном обеспечении подстановочный знак — это одиночный символ, например звездочка (*), используемый для представления ряда символов или пустой строки. Он часто используется при поиске файлов, поэтому полное имя вводить не нужно.
(Источник: Википедия)
Это означает, что этот раздел относится ко всем роботам.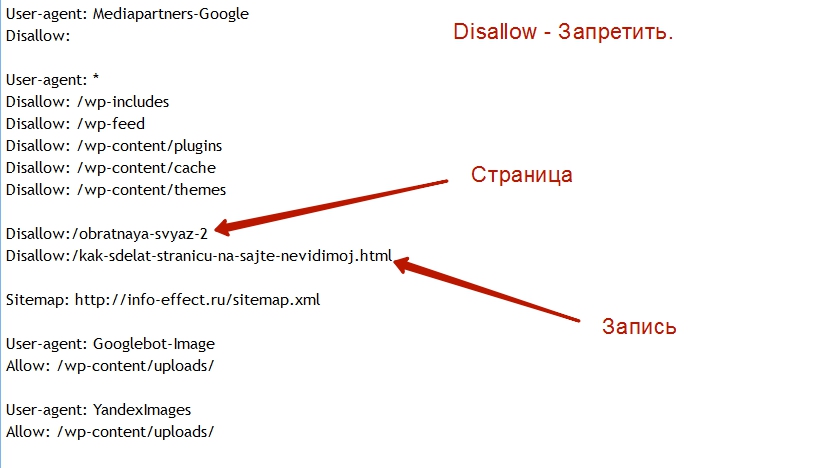
Часть «Запретить: /» сообщает роботу, что он не должен посещать какие-либо страницы на сайте.
При использовании /robots.txt необходимо учитывать два важных момента:
- Роботы могут игнорировать ваши инструкции /robots.txt. Сюда входят вредоносные роботы, которые сканируют Интернет на наличие уязвимостей в системе безопасности, и сборщики адресов электронной почты, используемые спамерами.
- Файл /robots.txt является общедоступным. Любой может увидеть, какие разделы вашего сервера вы не хотите использовать для роботов.
Так что не используйте /robots.txt, чтобы попытаться скрыть информацию.
Если вам нужно защитить контент на вашем сайте WordPress, см. руководство ниже:
- Как защитить контент в WordPress
Доступ к вашему файлу robots.txt
Ваш файл robots.txt должен находиться в том же каталоге, что и установка WordPress … robots.txt после его установки, просто введите URL-адрес вашего сайта в адресную строку браузера и добавьте «robots.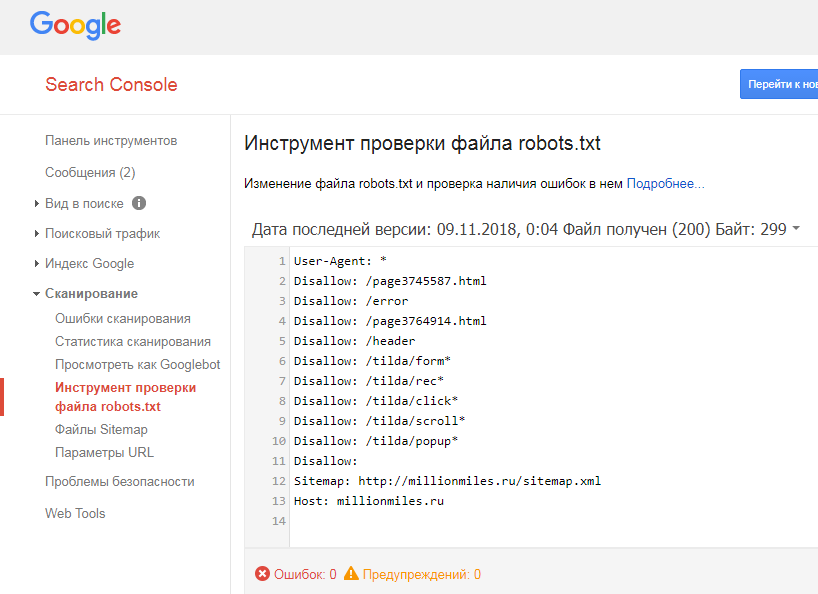 txt» в конец URL-адреса, например:
txt» в конец URL-адреса, например:
http://www.yoursite.com/robots.txt
Это поднимет ваш файл Robots.txt …
(файл Robots.txt)
Настройка ваших Robots. txt
Как правило, при новой установке WordPress, если вы настроите Настройки чтения WordPress , чтобы разрешить поисковым системам индексировать ваш сайт, ваш файл robots.txt будет выглядеть примерно так:
(Настройки чтения WordPress — Разрешена видимость в поисковых системах)
Если вы отключите параметр «Видимость для поисковых систем» в настройках Чтение , инструкции в вашем файле robots.txt будут изменены, чтобы препятствовать поисковым системам сканировать ваш сайт…
(Настройки чтения WordPress – Доступность для поисковых систем запрещена)
Файл robots.txt можно настроить разными способами в зависимости от того, какие инструкции вы хотите дать поисковым роботам и другим посещающим ботам (роботам).
Вот лишь несколько примеров…
(Примеры инструкций к файлу robots.txt. Источник: Википедия )
Как создать файл robots.txt — учебник
s txt, мы рекомендуем создать карту сайта
XML для вашего сайта.- Если вы планируете использовать SEO-плагин WordPress, например Yoast SEO (рекомендуется), плагин автоматически создаст XML-карту сайта для вашего веб-сайта и добавит ее в вашу установку WordPress.
- Если вы не планируете использовать плагин Yoast SEO, вы можете использовать автономный плагин WordPress XML Sitemap, такой как Google XML Sitemaps , для создания XML-карты сайта для вашего сайта.
Покажем, как вручную создать, настроить и загрузить на сервер файл robots.txt , выполняющий ряд важных функций…
(файл robots.txt) файл robots.txt (т.е. первая строка) вы добавите ссылку на ваш сайт XML-карта сайта . Эта карта сайта позволяет поисковым системам быстрее находить и индексировать все страницы вашего сайта.
Эта карта сайта позволяет поисковым системам быстрее находить и индексировать все страницы вашего сайта.
Карта сайта: http://www.yoursite.org/sitemap.xml
Под записью карты сайта рекомендуется ввести агент Google Mediapartners. Разрешая этому агенту доступ, вы предотвращаете появление пробелов или социальной рекламы на своих страницах, если вы добавили Google AdSense на свой сайт. Это происходит, если у Google еще не было возможности проиндексировать страницу вашего сайта с помощью объявлений Google AdSense или определить, о чем эта страница.
Запись выглядит следующим образом:
User-agent: Mediapartners-Google Disallow:
Остальной текст в вашем файле может быть организован по вашему желанию. В примере файла robots.txt , представленном ниже, вы увидите, что текст файла разбит на сегменты или группы для удобства чтения и управления.
В нашем образце файла robots. txt двум группам предшествует « User-agent: * », за которым следует список каталогов или файлов, где каждому элементу списка предшествует « Запретить ». Это представляет каталоги и файлы, к которым поисковые системы не должны иметь доступ.
txt двум группам предшествует « User-agent: * », за которым следует список каталогов или файлов, где каждому элементу списка предшествует « Запретить ». Это представляет каталоги и файлы, к которым поисковые системы не должны иметь доступ.
Например, если на вашем сайте есть папка с названием «private», которую вы не хотите сканировать поисковыми роботами, добавьте в файл robots.txt следующую строку:
Disallow: /private/
Особого внимания заслуживают файлы изображений. Поскольку поиск некоторых изображений (например, образов системы) может привести к некоммерческому доступу к вашему сайту, вы можете запретить поисковым системам доступ к ним.
За этими разделами в нашем примере файла robots.txt следует длинный список пользовательских агентов, которым запрещен доступ к сайту. Они выбраны не обязательно потому, что они «плохие», а потому, что они просто будут использовать пропускную способность вашего сервера и другие ресурсы, если им будет разрешен доступ и просмотр вашего сайта. Записи для этих элементов похожи на приведенный ниже пример:
User-agent: ia_archiver Disallow: /
Наличие «/» в качестве значения «Disallow» предотвращает любой доступ к любому файлу или каталогу на вашем сайте.
Добавление файла robots.txt на ваш сайт
Нажмите кнопку «Поделиться» ниже, чтобы загрузить образцы файлов robots.txt, которые вы можете использовать для своего собственного сайта:
При использовании приведенного выше примера файла robots.txt , не стесняйтесь копировать и использовать файл как есть, но обязательно внесите изменения, указанные в файле, как показано ниже:
Измените части, выделенные красным (т. е. замените yourdomain.com на ваш URL), и удалите инструкции (включая скобки), затем сохраните и повторно загрузите файл на свой сервер (см. следующий раздел для получения подробной информации о добавлении robots.txt на ваш сервер).
Редактирование файла robots.
txtЕсли вы используете предоставленный образец файла robots.txt, либо загрузите указанный выше zip-файл, либо нажмите предоставленную ссылку, чтобы просмотреть файл robots.txt в новом окне браузера.
Выполните одно из следующих действий:
Вариант №1
- Нажмите «Файл» > «Сохранить страницу как…»
- Сохраните страницу на жестком диске. Файл будет сохранен как «robots.txt»
- Откройте файл и измените первую строку файла в соответствии с приведенными выше инструкциями.
- Повторно сохраните и загрузите файл robots.txt через FTP в корневой каталог вашего сайта.
Вариант #2
- Выберите все содержимое в окне браузера и скопируйте его в буфер обмена.
- Создайте новый текстовый файл (например, блокнот).
- Вставьте содержимое буфера обмена в текстовый файл.
- Сохраните файл как «robots.txt»
- Откройте файл и измените первую строку файла в соответствии с приведенными выше инструкциями.

- Пересохраните и загрузите через FTP в корневой каталог вашего сайта.
После загрузки файла robots.txt на сервер убедитесь, что он был загружен правильно (т. е. откройте браузер и перейдите по адресу http://www.yoursite.com/robots.txt ).
Также проверьте следующее:
- Все папки, которые вы хотите запретить, были введены правильно
- «Запретить» определен правильно. Например, «Disallow: /» означает отсутствие доступа вообще, «Disallow:» (без косой черты) означает полный доступ.
- Вы не оставили пробелов или лишних символов. Поисковые системы очень специфичны и могут реагировать не так, как вы ожидаете. Например, слишком много пробелов между группами не рекомендуется (один допустим). Кроме того, специальные символы, такие как «#», имеют особое значение в файле robots.txt, поэтому не забудьте их пропустить.
Тестирование файла robots.txt
Вы можете протестировать файл robots. txt с помощью инструмента проверки, такого как тестер robots.txt, предоставленный Google Search Console (ранее Инструменты Google для веб-мастеров ).
Чтобы использовать инструмент проверки файла robots.txt , вам необходимо настроить Google Search Console аккаунт.
Если вы еще не настроили свои учетные записи для веб-мастеров, см. руководство ниже:
- Как настроить учетные записи веб-мастеров
Для тестирования файла сайта Robots.txt выполните следующее:
В журнал «Консоль поиска »
(Вход в консоль поиска Google)
На поиске Google на главной странице, нажмите на сайт, который хотите проверить…
(главная страница Google Search Console)
В меню Search Console выберите Crawl > Robots.txt Tester …
(Crawl> Robots. txt Tester)
Это подводит вас к Robots.txt Tester …
(Robots.txt Tester …
(Robots.txt Tester. экран)
Если ваш сайт настроен правильно и уже просканирован Google, инструмент заполнит поля на этом экране информацией о вашем сайте.
Вы можете просматривать содержимое вашего robots.txt и проверьте наличие ошибок или предупреждений…
(проверьте содержимое файла robots.txt)
Вы также можете ввести URL-адреса в тестовое поле URL-адреса, выберите пользовательские агенты, которые вы хотите протестировать, из ‘ Список выпадающего меню пользовательских агентов (например, Googlebot, Googlebot для мобильных устройств, Mediapartners-Google и т. д.) …
(Проверьте свои URL-адреса, чтобы увидеть, не заблокированы ли они)
Нажмите кнопку Test , чтобы проанализируйте свой сайт и просмотрите результаты.
Инструмент покажет вам, разрешен ли URL-адрес или каталог (т. е. может ли он быть проиндексирован Google) …
(Разрешено — Google просканирует этот URL-адрес или каталог)
Или, если URL-адрес или каталог не разрешено …
(Заблокировано — Google не будет сканировать этот URL-адрес или каталог)
Любые изменения, внесенные вами в этом инструменте, не будут сохранены. Чтобы сохранить какие-либо изменения, вам нужно скопировать содержимое и вставить его в свой файл robots.txt .
Дополнительные сведения об использовании инструментов и анализе результатов см. в документации Справка по инструментам Google для веб-мастеров .
Robots.txt — Дополнительная информация
Если у вас установлен плагин WordPress SEO , такой как Yoast SEO, и вы не поощряете индексацию вашего сайта поисковыми системами (см. получить сообщение об ошибке, подобное показанному ниже …
(Блокировка доступа к роботам может повлиять на некоторые настройки плагина SEO)
В этом есть смысл… зачем вам оптимизировать свой веб-сайт для поисковых систем, если вы даете WordPress указание блокировать доступ поисковых систем к вашему сайту? ?
Чтобы узнать больше о настройке плагинов SEO для WordPress, см. руководство ниже:
- Плагины SEO для WordPress
Чтобы узнать больше о настройке параметров чтения WordPress, см. руководство ниже:
- Настройки чтения WordPress
Чтобы узнать, как эффективно заблокировать ваш сайт WordPress от доступа поисковых систем, см. руководство ниже:
- Как заблокировать WordPress от поисковых систем
Для получения технической информации о преимуществах и преимуществах использования файла robots.txt посетите этот сайт:
- http://www.robotstxt.org
Поздравляем! Теперь вы знаете, как добавить robots.txt , чтобы запретить поисковым системам и соответствующим ботам индексировать страницы или разделы вашего сайта.
(Источник: Pixabay)
***
***
Что такое файл robots.txt и нужен ли он вам с WordPress?
Большинство владельцев сайтов WordPress слышали о файле robots. txt, но не все знают, что он делает и нужен ли он им. Что это за легкий текстовый файл и почему вас это должно волновать? Нужно ли это современным веб-сайтам? Это руководство для начинающих объясняет все таким образом, что даже неопытный новичок может понять.
Почему он называется файлом robots?
Боты поисковых систем или пауки постоянно сканируют веб-сайты в поисках нового или обновленного контента. Наиболее известен робот Googlebot, но все поисковые системы работают одинаково. Файл RoBOTs.txt соответствует стандарту исключения роботов. Все это означает стандарт, по которому веб-сайты общаются с послушными веб-ботами и поисковыми роботами.
Файл robots.txt не является надежным, поскольку менее послушные боты, такие как программы для очистки электронной почты или вредоносные программы, игнорируют его. Это также публично видно. Несмотря на это, этот текстовый файл является бесценным ресурсом для многих сайтов и блогов.
Файл «Делай, как я прошу»
Задача этого крошечного редактируемого файла — контролировать, как веб-боты взаимодействуют с путями к файлам вашего сайта. То, как они сканируют, полностью зависит от вашего файла robots.txt. Это делает его невероятно мощным, но простым инструментом в вашем наборе инструментов для поисковой оптимизации (SEO).
Суммируя два основных варианта использования файла robots.txt, можно сказать следующее:
- Сообщает послушным ботам, какие страницы, файлы или папки следует сканировать и индексировать
- Сообщает совместимым ботам, какие страницы, файлы или папки НЕ следует сканировать (игнорировать) и индексировать.
Таким образом, robots.txt — это первый файл, который поисковый бот ищет при посещении веб-сайта.
Синтаксис и правила robots.txt
Файл robots.txt не исправлен, то есть вы можете открывать и редактировать его для управления правилами. Используется синтаксис robots.txt. Его легко читать, но он должен быть точным для работы. Большинство веб-мастеров копируют нужный им синтаксис и вставляют его в файл, чтобы сэкономить время и избежать опечаток.
Общие правила разрешения/запрета включают:
- Запретить ботам сканирование каталога и всего его содержимого
- Запретить ботам сканирование одной веб-страницы
- Запретить сканирование файлов определенного типа
- Запретить сканирование всего веб-сайта
- Разрешить доступ только одному названному сканеру
- Разрешить доступ к сайту всем, кроме одного поискового робота
- Блокировать доступ к определенному изображению
- Блокировать все изображения на сайте из результатов поиска изображений
Есть и другие, но вы поняли.
Как читать синтаксис robots.txt
Ваш файл robots.txt содержит как минимум один блок директив (рекомендаций) для инструктирования поисковых роботов. Каждый блок начинается со слов «User-agent», которые относятся к конкретному боту или пауку. Один блок также может адресовать всех ботов поисковых систем, используя подстановочный знак *.
Вот как выглядят часто используемые блоки robots. txt:
Разрешить всем поисковым системам полный доступ:
User-agent: *
Disallow:
Добавление косой черты / после Disallow , блокирует доступ ко всем поисковикам:
User-agent: *
Disallow: /
Блокирует доступ к одному папка (замените / папку / на настоящее имя):
User-agent: *
Disallow: /folder/
Например, на вашем сайте могут быть фотографии, которые вы не хотите, чтобы поисковые системы индексировали . User-agent: * говорит всем ботам не посещать указанную папку.
Заблокировать доступ к одному файлу (замените ‘ файл ‘ на фактическое имя)
User-agent: *
Disallow: /file.html фактическое имя)
User-agent: *
Disallow: /image.png
Крайне важно правильно использовать файл robots.txt и случайно не блокировать или разрешать доступ к материалам. Различные онлайн-валидаторы позволяют проверить файл на наличие ошибок. Рекомендуется, по крайней мере, отправлять любые новые изменения в ваш файл в тестер Google robots.txt.
Common search engine user-agents
Below is a list of the user-agents most used in robots.txt files:
USER-AGENT | SEARCH ENGINE | FIELD |
Googlebot | General | |
Googlebot-Image | Images | |
Googlebot-Mobile | Mobile | |
Googlebot-News | News | |
Googlebot-Video | Video | |
Mediapartners-Google | AdSense | |
AdsBot-Google | AdWords | |
bingbot | Bing | General |
msnbot | Bing | Общие |
msnbot-media | Bing 3 | Video & Images |
adidxbot | Bing | Ads |
slurp | Yahoo! | General |
yandex | Yandex | General |
baiduspider | Baidu | General |
baiduspider-image | Baidu | Images |
baiduspider-mobile | Baidu | Mobile |
baiduspider-news | Baidu | Новости |
0611 |
Причины для запрета ботов поисковых систем
Чем больше сайт, тем больше времени уходит на поиск. Googlebot и другие имеют квоту сканирования. Если файлы на веб-сайте превышают эту квоту, бот движется дальше. Он возобновляет сканирование с того места, где оно было остановлено, когда возвращается для следующего сеанса. Чтобы остановить или решить эту проблему, нужно запретить ботам сканировать ненужные файлы для ускорения индексации.
Проблема в том, что боты сканируют все, если им не указано иное. И есть много файлов сайта в более крупных проектах, которые не нуждаются в сканировании. Типичные исключения файлов должны включать папки тем, файлы плагинов, страницы администрирования и другие. Кроме того, на вашем сайте могут быть частные страницы, которые вы не хотите отображать в веб-поиске. Вы также можете запретить доступ к ним.
Вот как может выглядеть типичный файл robots.txt.
Приведенный выше файл Robots.txt дает посещающим ботам 6 четких инструкций:
- Индексировать ВСЕ файлы контента WordPress
- Индексировать ВСЕ файлы WordPress
- Не индексировать (запретить) файлы плагинов WordPress
- Запретить доступ к админке WP
- Запретить доступ к этому конкретному файлу readme WP
- Запретить доступ к ссылкам, содержащим /refer/
Последние две строки содержат полные URL-адреса карты сайта в формате XML для сообщений и страниц.
Что следует включить в файл robots.txt?
Поисковые системы лучше, чем когда-либо, индексируют сайты. Когда дело доходит до WordPress, Google действительно нужен доступ к папкам, которые блокируют многие веб-мастера. По этой причине я настоятельно рекомендую вам ознакомиться с этой публикацией на сайте Yoast SEO, чтобы ознакомиться с рекомендациями по работе с файлами robots.txt.
Как создать новый файл robots.txt
Вы можете создать новый файл robots.txt в WordPress, если он отсутствует. Есть два способа добиться этого. Один из них — использование популярного плагина Yoast SEO, а другой — ручной подход. Перейдите ко второму способу, если у вас нет и вы не планируете устанавливать плагин YOAST.
#1 Создайте файл robots.txt с помощью плагина Yoast SEO
Войдите в WP Dashboard и перейдите в SEO -> Инструменты из бокового меню.
На экране инструментов щелкните ссылку Редактор файлов .
Нажмите кнопку Создать файл robots.txt .
Генератор файлов Yoast SEO robots.txt добавляет в новый файл некоторые основные правила. Замените их своими, если они не соответствуют тому, что вам нужно. Если вы не уверены, воспользуйтесь правилами, упомянутыми в разделе «Причины запрета поисковых роботов» выше.0003
Когда закончите, нажмите кнопку Сохранить изменения в robots.txt .
#2 Создайте и загрузите файл robots.txt с помощью FTP
Чтобы создать файл robots.txt, откройте Блокнот, введите свои правила и Сохранить как robot.txt. Затем вы загружаете файл в корневой каталог вашего веб-сайта (главную папку) с помощью любого программного обеспечения FTP. Рассмотрите бесплатную программу FileZilla, если у вас ее нет. В моей статье «Использование FTP для установки тем WordPress» есть раздел, если вам нужна помощь в настройке учетной записи FileZilla.
Если вам когда-нибудь понадобится удалить или добавить правила в robots. txt, внесите изменения в локальную копию. Затем вы повторно загружаете измененный файл, чтобы перезаписать файл на сервере.
Какой бы метод вы ни использовали, не забудьте сразу после этого проверить файл с помощью онлайн-тестера. Все они хорошо справляются со своей задачей, но большинство веб-мастеров WordPress предпочитают использовать Google Search Console.
Заключительные комментарии
Теперь вы знаете, что такое файл robots.txt и почему он существует.
Это простой, но мощный инструмент, который дает вам больше возможностей контролировать свои стратегии SEO. Хорошо оптимизированный файл жизненно важен для больших сайтов, поскольку он экономит краулинговый бюджет. Более того, вы можете заблокировать доступ к разделам сайта, которые вы не хотите показывать в результатах поиска.
Хотите изучить WordPress?
WordPress — замечательная платформа для создания веб-сайтов любого типа. Он используется крупными корпорациями и небольшими семейными сайтами.
Как создать дружественный к WordPress файл robots.txt
- 20 декабря 2011 г.
- в: Блог, Ресурсы WordPress
Давайте проясним одну вещь. Robots.txt — это не просто модный файл для веб-мастеров и профессиональных SEO-специалистов. На самом деле, каждый разработчик WordPress должен кое-что знать об этом файле и о том, почему он так важен для SEO каждого блога.
Итак, сначала большой вопрос:
Что такое robots.txt и почему он важен?
Говоря как капитан очевидно: это просто файл. Но есть в этом одна интересная вещь. Он не отображается для реальных посетителей нигде в самом блоге.
Вместо этого он находится в корневом каталоге блога и служит только одной цели. Это файл, который поисковые системы просматривают до того, как они начнут сканировать содержимое блога. И причина для просмотра — найти информацию о том, что они должны и не должны сканировать.
Таким образом, используя этот файл, вы можете информировать поисковые системы о том, что вы хотите, чтобы они индексировали и ранжировали, и о том, что вы НЕ хотите, чтобы они индексировали и ранжировали .
Правда в том, что не каждая страница (или область) блога достойна ранжирования. Как веб-мастер или человек, работающий с WordPress, вы должны уметь определять эти области и использовать robots.txt как место, где вы можете напрямую общаться с поисковыми системами и сообщать им, что происходит.
Создание файла robots.txt для WordPress
Прежде всего, позвольте мне рассмотреть актуальные рекомендации, которые вы можете найти на codex.wordpress.org, в частности на этой странице: Robots.txt Optimization. Есть пример файла. Вот в чем дело… не используйте его как шаблон!
Я не говорю, что это совсем плохо, но для некоторых блогов WP может создать массу проблем. Все зависит от ваших настроек. Такие вещи, как постоянные ссылки, категории и базы тегов. Вот почему вам нужно создать robots.txt для каждого отдельного блога и быть осторожным, когда вы имеете дело с любым шаблоном.
Вещи, которые вы всегда должны блокировать
В каждом блоге WP есть некоторые части, которые всегда должны быть заблокированы: каталог «cgi-bin» и стандартные каталоги WP.
Каталог «cgi-bin» присутствует на каждом веб-сервере, и это место, где можно установить и запустить сценарии CGI. В настоящее время некоторые серверы даже не разрешают доступ к этому каталогу, но вам точно не повредит включить его в директивы Disallow внутри файла robots.txt.
Есть 3 стандартных каталога WP (wp-admin, wp-content, wp-includes). Вы должны заблокировать их, потому что, по сути, там нет ничего, что поисковые системы могли бы счесть интересным.
Но есть одно исключение. Каталог wp-content имеет подкаталог под названием «uploads». Это место, куда помещается все, что вы загружаете с помощью функции загрузки мультимедиа WP. Стандартный подход здесь — оставить его незаблокированным.
Вот инструкции для выполнения вышеуказанного:
Запретить: /cgi-bin/
Запретить: /wp-admin/
Запретить: /wp-includes/
Запретить: /wp-content/plugins/
Запретить: /wp-content/cache/
Запретить: / wp-content/themes/
Разрешить: /wp-content/uploads/
Обратите внимание на небольшую разницу между шаблоном в WP codex. Они говорят вам заблокировать «/wp-admin» (без завершающего символа «/»). Это может быть проблематично, если ваши постоянные ссылки установлены только на «/%postname%/». В этом случае каждый пост, слаг которого начинается с «wp-admin-», не будет проиндексирован.
Я знаю, что есть только небольшая группа блоггеров, которые могли бы создавать такие посты (группа «ведение блога о WordPress»), но как WP-разработчик вы не можете делать никаких предположений о том, что произойдет в вашем блоге. переработаем после того, как он взлетит. Вот почему здесь лучше помнить о завершающем символе «/».
Что блокировать в зависимости от вашей конфигурации WP
Каждый блог имеет набор уникальных настроек, которые необходимо обрабатывать индивидуально при создании файла robots.txt.
Во-первых, используются ли в блоге категории или теги для структурирования контента… или и то, и другое… или нет.
Если вы используете категории для структурирования своего блога, убедитесь, что архивы тегов заблокированы для поисковых систем. Чтобы сделать это, сначала проверьте, что такое «база тегов» для архивов тегов ( Панель администратора > Настройки > Постоянные ссылки ). Если поле пустое, то основой является «тег». Используйте эту базу и поместите ее в директиву Disallow:
Disallow: /tag/
Если вы используете теги для структурирования своего блога, убедитесь, что архивы категорий заблокированы для поисковых систем. Опять же, проверьте базу категорий в том же месте, а затем заблокируйте ее:
Запретить: /category/
Если вы используете и категории, и теги, то ничего здесь не делайте.
Если вы не используете ни категории, ни теги, заблокируйте их обе, используя их базы:
Disallow: /tag/
Disallow: /category/
Зачем тебе беспокоиться? Честный вопрос. Основная причина здесь — проблема с дублированием контента. Например, если вы не используете категории, то ваш архив категорий выглядит точно так же, как и ваша домашняя страница, т. е. есть два совершенно одинаковых сайта, но с разными URL-адресами:
yourdomain.com/
yourdomain.com/ category/uncategorized
Уверен, мне не нужно объяснять, почему это плохо. Вы должны убедиться, что такой ситуации не произойдет.
Далее архив авторов. Если вы имеете дело с блогом одного автора, нет смысла держать архив авторов доступным для поисковых систем. Это создает ту же проблему дублирования контента, что и теговая категория. Вы можете заблокировать авторский архив, используя:
Запретить: /author/
Файлы блокировать отдельно
WordPress использует несколько разных файлов для отображения контента. Большинство из них не должны быть доступны через поисковые системы.
В список чаще всего входят: файлы PHP, файлы JS, файлы INC, файлы CSS. Вы можете заблокировать их, используя:
Disallow: /index.php # отдельная директива для основного файла скрипта WP
Disallow: /*.
Disallow: /*.js$
Disallow: /*.inc$
Disallow: /*.css$
(Символ «$» соответствует концу строки URL.)
Однако будьте осторожны с этим. Не рекомендуется блокировать любые другие файлы (изображения, текстовые файлы и т. д.). Это потому, что даже если такой файл не размещен в каталоге загрузки, вы, вероятно, все равно хотите, чтобы поисковые системы распознали его.
Примечание. Если вы ранее использовали строку «Allow: /wp-content/uploads/», то все файлы PHP, JS, INC и CSS, которые находятся внутри каталога uploads, по-прежнему будут видны поисковым системам — природа директивы Allow .
Вещи, которые нельзя блокировать
Окончательный выбор, конечно, за вами, но я бы не стал блокировать изображения из поиска картинок Google. Это можно сделать отдельной записью:
User-agent: Googlebot-Image
Disallow:
Allow: / # нестандартное использование этой директивы, но Google предпочитает именно так здесь
Другим роботом, с которым можно работать индивидуально, будет робот Google AdSense, конечно, только если вы являетесь частью их программы. В этом случае вам нужно убедиться, что он может видеть все страницы, которые могут видеть ваши пользователи. Проще всего это сделать с помощью очень похожей записи:
User-agent: Mediapartners-Google
Disallow:
Allow: /
Конечно, на этих двух примерах проблема не заканчивается. Вероятно, их намного больше, потому что каждый блог отличается. Не стесняйтесь комментировать и указывать на некоторые дополнительные области блога WP, которые не должны быть заблокированы.
Как обращаться с дублирующимся контентом
Что бы вы ни делали, ваш блог всегда будет содержать дублированный контент. Просто так устроен WP, вы не можете предотвратить это. Но вы все равно можете использовать robots.txt, чтобы запретить поисковым системам доступ к нему.
В каждом блоге есть несколько областей дублированного контента, например:
Результаты поиска
Вот как обычно выглядит URL-адрес страницы результатов поиска для блога WP:
yourdomain.
(Иногда после поисковой фразы указываются дополнительные параметры.)
Это и дублирующий контент, и контент, сгенерированный автоматически, что очень не нравится Google. Вот почему хорошо заблокировать это, используя:
Disallow: /*?
Помимо блокировки результатов поиска, эта директива блокирует доступ ко всем URL-адресам, которые содержат вопросительный знак, но это не должно вызывать проблем, когда речь идет о WordPress.
URL-адреса обратной связи
Некоторые блоги используют URL-адреса обратной связи, которые по существу дублируют содержание исходного сообщения. Вот пример обычного URL-адреса сообщения и его URL-адреса обратной связи:
yourdomain.com/some-post/
yourdomain.com/some-post/trackback/
Чтобы запретить поисковым системам доступ к такому контенту, вы можете использовать:
Запретить: /trackback/
Запретить: */trackback/
Теперь почему повторяются операторы? Дело в том, что реализация Стандарта исключения роботов может различаться для разных роботов. Используя эти две строки, вы можете быть уверены, что они понятны для всех.
RSS-каналы
RSS-каналы — это еще один пример полностью дублированного контента. Вы можете удалить его из поисковых систем, используя:
Disallow: /feed/
Disallow: */feed/
Архивы на основе даты
Очень похоже на RSS-каналы, только архивы на основе даты создают много больше дублированного контента. Позвольте привести пример. Допустим, сегодня 2 января 2012 г., и вы опубликовали пост. Если мы посмотрим только на URL-адреса на основе даты, то этот пост можно будет получить через:
yourdomain.com/2012/
yourdomain.com/2012/01/
yourdomain.com/2012/01/02/
Много дублированного контента. Вы можете удалить его, используя:
# год рождения вашего блога
Disallow: /2009/
Disallow: /2010/
Disallow: /2011/
Disallow: /2012/
# и так далее
Сейчас , что здесь важно. Зачем использовать все отдельные директивы вместо одной «Disallow: /20*/$», которая тоже сработает? Если бы вы использовали такую директиву, вы бы заблокировали каждый пост, слаг которого начинается с «20». И такие посты легко представить, например «20-причин-почему-то», «20-советов-кому-то».
Использование отдельной директивы для каждого уха существования вашего блога — самый безопасный способ заблокировать только архивы на основе даты и ничего больше.
Другой возможный дублированный контент
Есть три вещи, о которых я говорил ранее: категории, теги и авторские архивы. Все это дублированный контент, поэтому обязательно позаботьтесь об этом.
Кроме того, некоторые плагины создают еще больше дублированного контента. Всякий раз, когда вы устанавливаете плагин, обязательно проверьте, не создает ли он какие-либо дополнительные URL-адреса.
Могу привести один пример — плагин WP-Print. Это очень классный плагин, и я настоятельно рекомендую вам его использовать. Он создает удобную для печати версию ваших сообщений и страниц. Единственным недостатком являются дополнительные URL-адреса. Например, вот обычный пост и его версия для печати:
yourdomain.com/some-post/
yourdomain.com/some-post/print/
Классический дублированный контент. Обязательно исключите его, используя:
Disallow: /print/
Запретить: */print/
Как редактировать файл
Есть два основных способа сделать это: вы можете либо использовать плагин, либо обрабатывать файл вручную.
Плагин называется Robots Meta. И это гораздо больше, чем просто создание файла robots.txt. Я действительно советую вам ознакомиться с ним. Правильная настройка может действительно дать вам SEO-преимущество.
Если вы хотите сделать это вручную, просто создайте файл robots.txt в своем блокноте и загрузите его в корневой каталог блога с помощью FTP. Файл должен быть доступен по этому URL-адресу:
yourdomain.
После настройки вы можете протестировать его в Инструментах Google для веб-мастеров (узнайте, что такое Инструменты Google для веб-мастеров и как их использовать здесь.)
Окончательный шаблон, который вы можете использовать
Я знаю, я говорил вам не использовать шаблоны, но мы говорили здесь о многих различных директивах, так что я думаю, было бы неплохо дать вам шаблон, который вы можете использовать в качестве отправной точки при работе над вашим robots.txt.
Опять же, вероятно, это не шаблон, который можно просто скопировать в свой блог без каких-либо настроек.
User-agent: *
Disallow: /cgi-bin/
Disallow: /wp-admin/
Disallow: /wp-includes/
Disallow: /wp-content/plugins/
Disallow: /wp-content/ cache/
Disallow: /wp-content/themes/
Allow: /wp-content/uploads/
# Disallow: /tag/ # раскомментируйте, если вы не используете теги
# Disallow: /category/ # раскомментируйте, если вы’ повторно не использовать категории
# Disallow: /author/ # раскомментировать для однопользовательских блогов
Disallow: /feed/
Disallow: /trackback/
# Disallow: /print/ # блок wp-print
Disallow: /2009/ # год рождения вашего блога
Disallow: /2010/
Disallow: /2011/
Disallow: /2012/ # и так далее
Disallow: /index.