Правильный Robots.txt для WordPress (базовый и расширенный) [2020]
Автор Александр Смирнов На чтение 7 мин. Просмотров 12.9k. Обновлено
Правильный Robots.txt для WordPress в 2020-м году. Несколько версий под разные нужды: простая базовая и расширенная — с проработкой под каждую поисковую систему.
Одной из важнейших вещей при создании и оптимизации сайта для поисковых систем считают Robots.txt. Небольшой файлик, где прописаны правила индексирования для поисковых роботов.
Если файл будет настроен неправильно, то сайт может неправильно индексироваться и терять большие доли трафика. Грамотная настройка наоборот позволяет улучшить SEO, и вывести ресурс в топы.
Сегодня мы поговорим о настройке Robots.txt для WordPress. Я покажу вам правильный вариант, который сам использую для своих проектов.
Что такое Robots.txt
Как я уже и сказал, robots.txt — текстовой файлик, где прописаны правила для поисковых систем.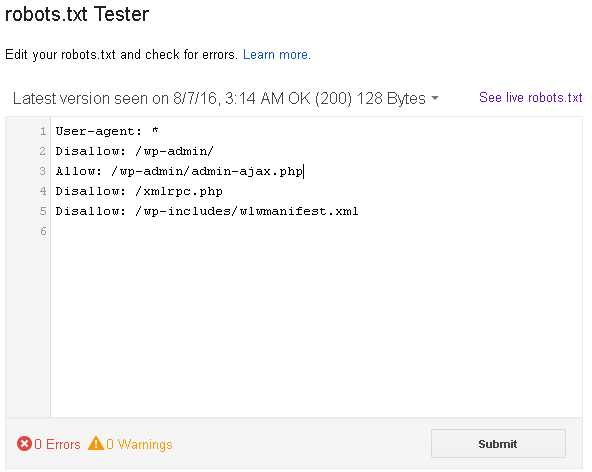 Стандартный robots.txt для WordPress выглядит следующим образом:
Стандартный robots.txt для WordPress выглядит следующим образом:
User-agent: * Disallow: /wp-admin/ Allow: /wp-admin/admin-ajax.php
Именно в таком виде он создается плагином Yoast SEO. Некоторые считают, что этого хватит для правильной индексации. Я же считаю, что нужна более детальная проработка. А если речь идет о нестандартных проектах, то проработка нужна и подавно. Давайте разберемся в основных директивах:
| Директива | Значение | Пояснение |
| User-agent: | Yandex, Googlebot и т.д. | В этой директиве можно указать к какому конкретно роботу мы обращаемся. Обычно используются те значения, которые я указал. |
| Disallow: | Относительная ссылка | Директива запрета. Ссылки, указанные в этой директиве будут игнорироваться поисковыми системами. |
| Allow: | Относительная ссылка | Разрешающая директива. Ссылки, которые указаны с ней будут проиндексированы. |
| Sitemap: | Абсолютная ссылка | Здесь указывается ссылка на XML-карту сайта. Если в файле не указать эту директиву, то придется добавлять карту вручную (через Яндекс.Вебмастер или Search Console). |
| Crawl-delay: | Время в секундах (пример: 2.0 — 2 секунды) | Позволяет указать таймаут между посещениями поисковых роботов. Нужна в случае, если эти самые роботы создают дополнительную нагрузку на хостинг. |
| Clean-param: | Динамический параметр | Если на сайте есть параметры вида site.ru/statia?uid=32, где ?uid=32 — параметр, то с помощью этой директивы их можно скрыть. |
В принципе, ничего сложного. Дам дополнительные пояснения по директивам Clean-param (откройте вкладку).
Подробнее о Clean-param
Параметры, как правило, используются на динамических сайтах. Они могут передавать поисковым системам лишнюю информацию — создавать дубли. Чтобы избежать этого, мы должны указать в Robots.
В нашем примере site.ru/statia?uid=32 — site.ru/statia — ссылка, а все, что после знака вопроса — параметр. Здесь это uid=32. Он динамический, и это значит, что параметр uid может принимать другие значения.
Например, uid=33, uid=34…uid=123434. В теории их может быть сколько угодно, поэтому мы должны закрыть от индексации все параметры uid. Для этого директива должна принять такой вид:
Clean-param: uid /statia # все параметры uid для statia будут закрыты
Более подробно о том, что такое Robots.txt можно узнать из Яндекс.Помощи. Или из этого видеоролика:
Базовый Robots.txt для WordPress
Совсем недавно я приобрел плагин Clearfy Pro для своих проектов. Там очень много разных функций, и одна из них — создание идеального Robots.txt. На самом деле насколько он идеален — я не знаю, вебмастера расходятся во мнениях.
Там очень много разных функций, и одна из них — создание идеального Robots.txt. На самом деле насколько он идеален — я не знаю, вебмастера расходятся во мнениях.
Кто-то предпочитает делать более краткие версии роботса, указывая правила для всех поисковых систем сразу. Другие прописывают отдельные правила для каждого поисковика (в основном для Яндекса и Гугла).
Что из этого правильно — точно сказать не могу. Однако я предлагаю вам ознакомиться с базовой версией Robots.txt для WordPress от Clearfy Pro. Я немного подредактировал ее — указал директиву Sitemap. Удалил директиву Host.
User-agent: * Disallow: /wp-admin Disallow: /wp-includes Disallow: /wp-content/plugins Disallow: /wp-content/cache Disallow: /wp-json/ Disallow: /xmlrpc.php Disallow: /readme.html Disallow: /*? Disallow: /?s= Allow: /*.css Allow: /*.js Sitemap: https://site.ru/sitemap.xml
Не могу сказать, что это лучший вариант для блогов на ВП. Но во всяком случае, он лучше, чем то, что нам предлагает Yoast SEO по умолчанию.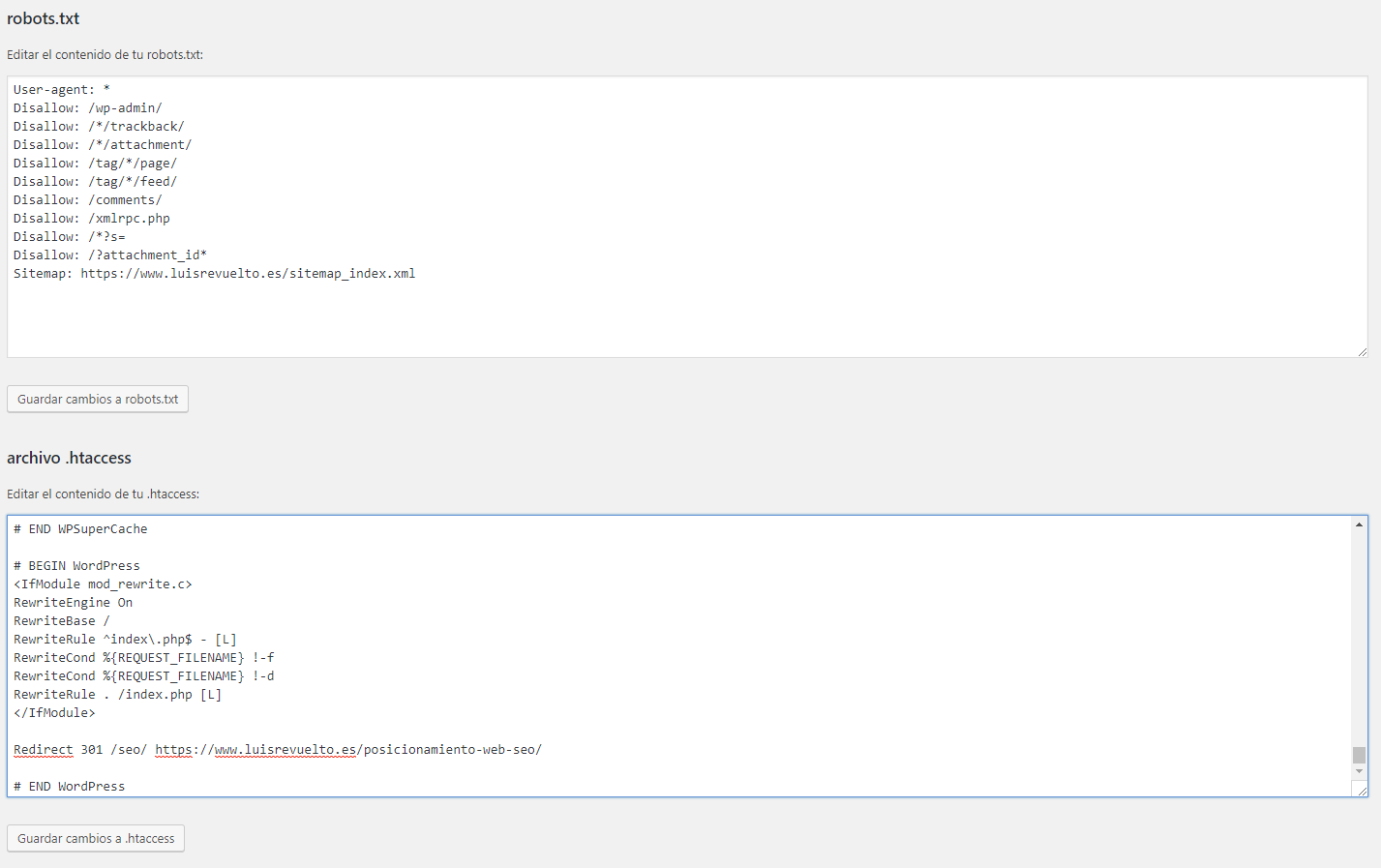
Расширенный Robots.txt для WordPress
Теперь посмотрим на расширенную версию Robots.txt для WordPress. Наверняка вы знаете, что все сайты на WP имеют одинаковую структуру. Одинаковые названия папок, файлов и т.д. позволяют специалистам выявить наиболее приемлемый вариант роботса.
В этой статье я хочу представить вам свой вариант Robots.txt. Его я использую как для своих сайтов, так и для клиентских. Вы могли видеть такой вариант и на других сайтах, т.к. он обладает некоторой популярностью.
Итак, правильный Robots.txt для WordPress выглядит следующим образом:
User-agent: * # Для всех поисковых систем, кроме Яндекса и Гугла Disallow: /cgi-bin Disallow: /? Disallow: /wp- Disallow: *?s= Disallow: *&s= Disallow: /search/ Disallow: /author/ Disallow: /users/ Disallow: */trackback Disallow: */feed Disallow: */rss Disallow: */embed Disallow: /xmlrpc.php Disallow: *utm= Disallow: *openstat= Disallow: /tag/ # Закрываем метки Disallow: /readme.html # Закрываем бесполезный мануал по установке WordPress (лежит в корне) Disallow: *?replytocom Allow: */uploads User-agent: GoogleBot # Для Гугла Disallow: /cgi-bin Disallow: /? Disallow: /wp- Disallow: *?s= Disallow: *&s= Disallow: /search/ Disallow: /author/ Disallow: /users/ Disallow: */trackback Disallow: */feed Disallow: */rss Disallow: */embed Disallow: /xmlrpc.php Disallow: *utm= Disallow: *openstat= Disallow: /tag/ # Закрываем метки Disallow: /readme.html Disallow: *?replytocom Allow: */uploads Allow: /*/*.js Allow: /*/*.css Allow: /wp-*.png Allow: /wp-*.jpg Allow: /wp-*.jpeg Allow: /wp-*.gif Allow: /wp-admin/admin-ajax.php User-agent: Yandex # Для Яндекса Disallow: /cgi-bin Disallow: /? Disallow: /wp- Disallow: *?s= Disallow: *&s= Disallow: /search/ Disallow: /author/ Disallow: /users/ Disallow: */trackback Disallow: */feed Disallow: */rss Disallow: */embed Disallow: /xmlrpc. php Disallow: /tag/ # Закрываем метки Disallow: /readme.html Disallow: *?replytocom Allow: */uploads Allow: /*/*.js Allow: /*/*.css Allow: /wp-*.png Allow: /wp-*.jpg Allow: /wp-*.jpeg Allow: /wp-*.gif Allow: /wp-admin/admin-ajax.php Clean-Param: utm_source&utm_medium&utm_campaign Clean-Param: openstat Sitemap: https://site.com/sitemap_index.xml # Карта сайта, меняем site.com на нужный адрес.


Важно:
Ранее в Robots.txt использовалась директива Host. Она указывала главное зеркало сайта. Теперь это делается при помощи редиректа. Подробнее об этом можно почитать в блоге Яндекса.Обратите внимание на то, что я закрываю метки (теги). Делаю это потому, что они создают большое количество дублей. Это плохо сказывается на SEO, но если вы хотите открыть метки, тогда уберите строчку disallow: /tag/ из файла.
Заключение
В общем-то, вот так выглядит правильный Robots.txt для WordPress. Смело копируйте данные в файл и пользуйтесь. Отмечу, что этот вариант подходит только для стандартных информационных сайтов.
В других ситуациях может потребоваться индивидуальная проработка. На этом все. Спасибо за внимание. Буду благодарен, если вы включите уведомления через колокольчик и подпишитесь на почтовую рассылку. Тут будет круто :).
Видео на десерт: Фермер Хотел Найти Воду, но То Что Случилось Удивило Весь Мир
Если вы нашли ошибку, пожалуйста, выделите фрагмент текста и нажмите Ctrl+Enter.
( 20 оценок, среднее 5 из 5 )
Robots.txt для WordPress — как настроить правильно в 2021 году?
В интернете можно найти много публикаций на тему, как составить лучший (или даже самый лучший) файл robots.
Более подробно о составлении robots.txt и значении всех его директив я писал здесь. Ниже я не буду подробно останавливаться на значении каждого правила. Ограничусь тем, что кратко прокомментирую что для чего необходимо.
Правильный Robots.txt для WordPress
Действительно самый лучший robots.txt, который я видел на данный момент, это роботс, предложенный в блоге wp-kama.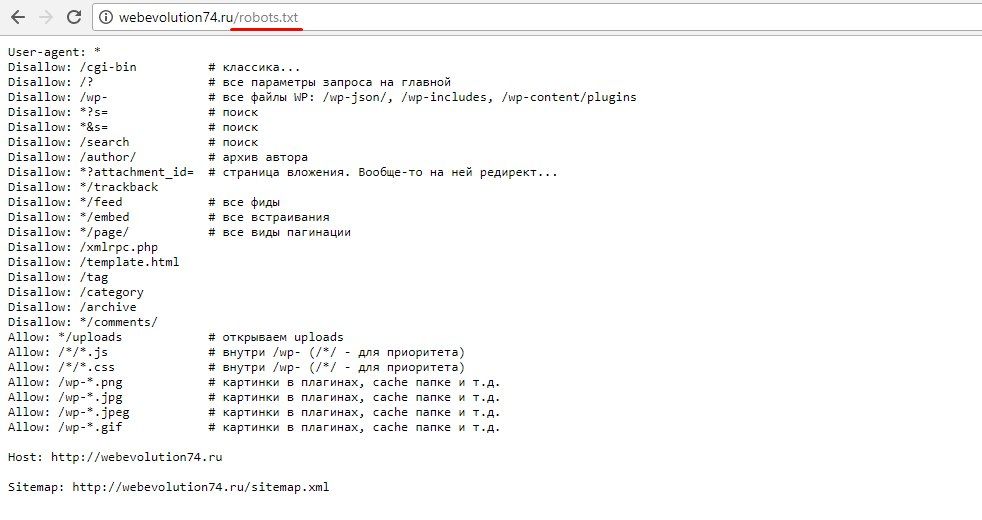 Ряд директив и комментариев я возьму из его образца + внесу свои корректировки. Корректировки коснутся нескольких правил, почему так напишу ниже. Кроме того, напишем индивидуальные правила для всех роботов, для Яндекса и для Google.
Ряд директив и комментариев я возьму из его образца + внесу свои корректировки. Корректировки коснутся нескольких правил, почему так напишу ниже. Кроме того, напишем индивидуальные правила для всех роботов, для Яндекса и для Google.
Ниже привожу короткий и расширенный вариант. Короткий не включает отдельные блоки для Google и Яндекса. Расширенный уже менее актуален, т.к. теперь нет принципиальных особенностей между двумя крупными поисковиками: обеим системам нужно индексировать файлы скриптов и изображений, обе не поддерживают директиву Host. Тем не менее, если в этом мире снова что-то изменится, либо вам потребуется все-таки как-то по-отдельному управлять индексацией файлов на сайте Яндексом и Гугл, сохраню в этой статье и второй вариант.
Еще раз обращаю внимание, что это базовый файл robots.txt. В каждом конкретном случае нужно смотреть реальный сайт и по-необходимости вносить корректировки. Поручайте это дело опытным специалистам!
Короткий вариант (оптимальный)
User-agent: * # общие правила для роботов, кроме Яндекса и Google,
# т. к. для них правила ниже
Disallow: /cgi-bin # папка на хостинге
Disallow: /? # все параметры запроса на главной
Disallow: /wp- # все файлы WP: /wp-json/, /wp-includes, /wp-content/plugins
Disallow: /wp/ # если есть подкаталог /wp/, где установлена CMS (если нет,
# правило можно удалить)
Disallow: *?s= # поиск
Disallow: *&s= # поиск
Disallow: /search/ # поиск
Disallow: /author/ # архив автора
Disallow: /users/ # архив авторов
Disallow: */trackback # трекбеки, уведомления в комментариях о появлении открытой
# ссылки на статью
Disallow: */feed # все фиды
Disallow: */rss # rss фид
Disallow: */embed # все встраивания
Disallow: */wlwmanifest.xml # xml-файл манифеста Windows Live Writer (если не используете,
# правило можно удалить)
Disallow: /xmlrpc.
к. для них правила ниже
Disallow: /cgi-bin # папка на хостинге
Disallow: /? # все параметры запроса на главной
Disallow: /wp- # все файлы WP: /wp-json/, /wp-includes, /wp-content/plugins
Disallow: /wp/ # если есть подкаталог /wp/, где установлена CMS (если нет,
# правило можно удалить)
Disallow: *?s= # поиск
Disallow: *&s= # поиск
Disallow: /search/ # поиск
Disallow: /author/ # архив автора
Disallow: /users/ # архив авторов
Disallow: */trackback # трекбеки, уведомления в комментариях о появлении открытой
# ссылки на статью
Disallow: */feed # все фиды
Disallow: */rss # rss фид
Disallow: */embed # все встраивания
Disallow: */wlwmanifest.xml # xml-файл манифеста Windows Live Writer (если не используете,
# правило можно удалить)
Disallow: /xmlrpc. php # файл WordPress API
Disallow: *utm*= # ссылки с utm-метками
Disallow: *openstat= # ссылки с метками openstat
Allow: */uploads # открываем папку с файлами uploads
# Укажите один или несколько файлов Sitemap (дублировать для каждого User-agent
# не нужно). Google XML Sitemap создает 2 карты сайта, как в примере ниже.
Sitemap: http://site.ru/sitemap.xml
Sitemap: http://site.ru/sitemap.xml.gz
# Укажите главное зеркало сайта, как в примере ниже (с WWW / без WWW, если HTTPS
# то пишем протокол, если нужно указать порт, указываем). Команда стала необязательной. Ранее Host понимал
# Яндекс и Mail.RU. Теперь все основные поисковые системы команду Host не учитывают.
Host: www.site.ru
php # файл WordPress API
Disallow: *utm*= # ссылки с utm-метками
Disallow: *openstat= # ссылки с метками openstat
Allow: */uploads # открываем папку с файлами uploads
# Укажите один или несколько файлов Sitemap (дублировать для каждого User-agent
# не нужно). Google XML Sitemap создает 2 карты сайта, как в примере ниже.
Sitemap: http://site.ru/sitemap.xml
Sitemap: http://site.ru/sitemap.xml.gz
# Укажите главное зеркало сайта, как в примере ниже (с WWW / без WWW, если HTTPS
# то пишем протокол, если нужно указать порт, указываем). Команда стала необязательной. Ранее Host понимал
# Яндекс и Mail.RU. Теперь все основные поисковые системы команду Host не учитывают.
Host: www.site.ruРасширенный вариант (отдельные правила для Google и Яндекса)
User-agent: * # общие правила для роботов, кроме Яндекса и Google,
# т.к. для них правила ниже
Disallow: /cgi-bin # папка на хостинге
Disallow: /? # все параметры запроса на главной
Disallow: /wp- # все файлы WP: /wp-json/, /wp-includes, /wp-content/plugins
Disallow: /wp/ # если есть подкаталог /wp/, где установлена CMS (если нет,
# правило можно удалить)
Disallow: *?s= # поиск
Disallow: *&s= # поиск
Disallow: /search/ # поиск
Disallow: /author/ # архив автора
Disallow: /users/ # архив авторов
Disallow: */trackback # трекбеки, уведомления в комментариях о появлении открытой
# ссылки на статью
Disallow: */feed # все фиды
Disallow: */rss # rss фид
Disallow: */embed # все встраивания
Disallow: */wlwmanifest. xml # xml-файл манифеста Windows Live Writer (если не используете,
# правило можно удалить)
Disallow: /xmlrpc.php # файл WordPress API
Disallow: *utm*= # ссылки с utm-метками
Disallow: *openstat= # ссылки с метками openstat
Allow: */uploads # открываем папку с файлами uploads
User-agent: GoogleBot # правила для Google (комментарии не дублирую)
Disallow: /cgi-bin
Disallow: /?
Disallow: /wp-
Disallow: /wp/
Disallow: *?s=
Disallow: *&s=
Disallow: /search/
Disallow: /author/
Disallow: /users/
Disallow: */trackback
Disallow: */feed
Disallow: */rss
Disallow: */embed
Disallow: */wlwmanifest.xml
Disallow: /xmlrpc.php
Disallow: *utm*=
Disallow: *openstat=
Allow: */uploads
Allow: /*/*.js # открываем js-скрипты внутри /wp- (/*/ - для приоритета)
Allow: /*/*.css # открываем css-файлы внутри /wp- (/*/ - для приоритета)
Allow: /wp-*.
xml # xml-файл манифеста Windows Live Writer (если не используете,
# правило можно удалить)
Disallow: /xmlrpc.php # файл WordPress API
Disallow: *utm*= # ссылки с utm-метками
Disallow: *openstat= # ссылки с метками openstat
Allow: */uploads # открываем папку с файлами uploads
User-agent: GoogleBot # правила для Google (комментарии не дублирую)
Disallow: /cgi-bin
Disallow: /?
Disallow: /wp-
Disallow: /wp/
Disallow: *?s=
Disallow: *&s=
Disallow: /search/
Disallow: /author/
Disallow: /users/
Disallow: */trackback
Disallow: */feed
Disallow: */rss
Disallow: */embed
Disallow: */wlwmanifest.xml
Disallow: /xmlrpc.php
Disallow: *utm*=
Disallow: *openstat=
Allow: */uploads
Allow: /*/*.js # открываем js-скрипты внутри /wp- (/*/ - для приоритета)
Allow: /*/*.css # открываем css-файлы внутри /wp- (/*/ - для приоритета)
Allow: /wp-*. png # картинки в плагинах, cache папке и т.д.
Allow: /wp-*.jpg # картинки в плагинах, cache папке и т.д.
Allow: /wp-*.jpeg # картинки в плагинах, cache папке и т.д.
Allow: /wp-*.gif # картинки в плагинах, cache папке и т.д.
Allow: /wp-admin/admin-ajax.php # используется плагинами, чтобы не блокировать JS и CSS
User-agent: Yandex # правила для Яндекса (комментарии не дублирую)
Disallow: /cgi-bin
Disallow: /?
Disallow: /wp-
Disallow: /wp/
Disallow: *?s=
Disallow: *&s=
Disallow: /search/
Disallow: /author/
Disallow: /users/
Disallow: */trackback
Disallow: */feed
Disallow: */rss
Disallow: */embed
Disallow: */wlwmanifest.xml
Disallow: /xmlrpc.php
Allow: */uploads
Allow: /*/*.js
Allow: /*/*.css
Allow: /wp-*.png
Allow: /wp-*.jpg
Allow: /wp-*.jpeg
Allow: /wp-*.gif
Allow: /wp-admin/admin-ajax.php
Clean-Param: utm_source&utm_medium&utm_campaign # Яндекс рекомендует не закрывать
# от индексирования, а удалять параметры меток,
# Google такие правила не поддерживает
Clean-Param: openstat # аналогично
# Укажите один или несколько файлов Sitemap (дублировать для каждого User-agent
# не нужно).
png # картинки в плагинах, cache папке и т.д.
Allow: /wp-*.jpg # картинки в плагинах, cache папке и т.д.
Allow: /wp-*.jpeg # картинки в плагинах, cache папке и т.д.
Allow: /wp-*.gif # картинки в плагинах, cache папке и т.д.
Allow: /wp-admin/admin-ajax.php # используется плагинами, чтобы не блокировать JS и CSS
User-agent: Yandex # правила для Яндекса (комментарии не дублирую)
Disallow: /cgi-bin
Disallow: /?
Disallow: /wp-
Disallow: /wp/
Disallow: *?s=
Disallow: *&s=
Disallow: /search/
Disallow: /author/
Disallow: /users/
Disallow: */trackback
Disallow: */feed
Disallow: */rss
Disallow: */embed
Disallow: */wlwmanifest.xml
Disallow: /xmlrpc.php
Allow: */uploads
Allow: /*/*.js
Allow: /*/*.css
Allow: /wp-*.png
Allow: /wp-*.jpg
Allow: /wp-*.jpeg
Allow: /wp-*.gif
Allow: /wp-admin/admin-ajax.php
Clean-Param: utm_source&utm_medium&utm_campaign # Яндекс рекомендует не закрывать
# от индексирования, а удалять параметры меток,
# Google такие правила не поддерживает
Clean-Param: openstat # аналогично
# Укажите один или несколько файлов Sitemap (дублировать для каждого User-agent
# не нужно). Google XML Sitemap создает 2 карты сайта, как в примере ниже.
Sitemap: http://site.ru/sitemap.xml
Sitemap: http://site.ru/sitemap.xml.gz
# Укажите главное зеркало сайта, как в примере ниже (с WWW / без WWW, если HTTPS
# то пишем протокол, если нужно указать порт, указываем). Команда стала необязательной. Ранее Host понимал
# Яндекс и Mail.RU. Теперь все основные поисковые системы команду Host не учитывают.
Host: www.site.ru
Google XML Sitemap создает 2 карты сайта, как в примере ниже.
Sitemap: http://site.ru/sitemap.xml
Sitemap: http://site.ru/sitemap.xml.gz
# Укажите главное зеркало сайта, как в примере ниже (с WWW / без WWW, если HTTPS
# то пишем протокол, если нужно указать порт, указываем). Команда стала необязательной. Ранее Host понимал
# Яндекс и Mail.RU. Теперь все основные поисковые системы команду Host не учитывают.
Host: www.site.ruВ примере я не добавляю правило Crawl-Delay, т.к. в большинстве случаев эта директива не нужна. Однако если у вас крупный нагруженный ресурс, то использование этой директивы поможет снизить нагрузку на сайт со стороны роботов Яндекса, Mail.Ru, Bing, Yahoo и других (Google не учитывает). Подробнее про это читайте в статье Robots.txt.
Ошибочные рекомендации других блогеров для Robots.txt на WordPress
- Использовать правила только для User-agent: *
Для многих поисковых систем не требуется индексация JS и CSS для улучшения ранжирования, кроме того, для менее значимых роботов вы можете настроить большее значение Crawl-Delay и снизить за их счет нагрузку на ваш сайт.
- Прописывание Sitemap после каждого User-agent
Это делать не нужно. Один sitemap должен быть указан один раз в любом месте файла robots.txt - Закрыть папки wp-content, wp-includes, cache, plugins, themes
Это устаревшие требования. Однако подобные советы я находил даже в статье с пафосным названием «Самые правильный robots для WordPress 2018»! Для Яндекса и Google лучше будет их вообще не закрывать. Или закрывать «по умному», как это описано выше. - Закрывать страницы тегов и категорий
Если ваш сайт действительно имеет такую структуру, что на этих страницах контент дублируется и в них нет особой ценности, то лучше закрыть. Однако нередко продвижение ресурса осуществляется в том числе за счет страниц категорий и тегирования. В этом случае можно потерять часть трафика - Закрывать от индексации страницы пагинации /page/
Это делать не нужно. Для таких страниц настраивается тег rel=»canonical», таким образом, такие страницы тоже посещаются роботом и на них учитываются расположенные товары/статьи, а также учитывается внутренняя ссылочная масса.
- Прописать Crawl-Delay
Модное правило. Однако его нужно указывать только тогда, когда действительно есть необходимость ограничить посещение роботами вашего сайта. Если сайт небольшой и посещения не создают значительной нагрузки на сервер, то ограничивать время «чтобы было» будет не самой разумной затеей. - Ляпы
Некоторые правила я могу отнести только к категории «блогер не подумал». Например:Disallow: /20— по такому правилу не только закроете все архивы, но и заодно все статьи о 20 способах или 200 советах, как сделать мир лучше 🙂
Спорные рекомендации других блогеров для Robots.txt на WordPress
- Комментарии
Некоторые ребята советуют закрывать от индексирования комментарииDisallow: /commentsиDisallow: */comment-*. - Открыть папку uploads только для Googlebot-Image и YandexImages
User-agent: Googlebot-ImageСовет достаточно сомнительный, т.
Allow: /wp-content/uploads/
User-agent: YandexImages
Allow: /wp-content/uploads/ к. для ранжирования страницы необходима информация о том, какие изображения и файлы размещены на ней.
к. для ранжирования страницы необходима информация о том, какие изображения и файлы размещены на ней.
Спасибо за ваше внимание! Если у вас возникнут вопросы или предложения, пишите в комментариях!
Оцените статью
Загрузка…Друзья, буду благодарен за ваши вопросы, дополнения и рекомендации по теме статьи. Пишите ниже в комментариях.
Буду благодарен, если поставите оценку статье.
Правильный robots.txt для CMS WordPress
Здравствуйте уважаемые посетители блога Web developer. Как известно, в интернете можно найти массу примеров файла robots.txt. Но сегодня хочу представить Вам на мой взгляд самый правильный файл robots.txt для CMS WordPress. Не буду ходить вокруг да около и сразу покажу Вам его, а ниже поясню все директивы по порядку.
User-agent: * Disallow: /cgi-bin Disallow: /? Disallow: /wp- Disallow: /wp/ Disallow: *?s= Disallow: *&s= Disallow: /search/ Disallow: /author/ Disallow: /users/ Disallow: */trackback Disallow: */feed Disallow: */rss Disallow: */embed Disallow: */wlwmanifest.xml Disallow: /xmlrpc.php Disallow: *utm= Disallow: *openstat= Allow: */uploads User-agent: GoogleBot Disallow: /cgi-bin Disallow: /? Disallow: /wp- Disallow: /wp/ Disallow: *?s= Disallow: *&s= Disallow: /search/ Disallow: /author/ Disallow: /users/ Disallow: */trackback Disallow: */feed Disallow: */rss Disallow: */embed Disallow: */wlwmanifest.xml Disallow: /xmlrpc.php Disallow: *utm= Disallow: *openstat= Allow: */uploads Allow: /*/*.js Allow: /*/*.css Allow: /wp-*.png Allow: /wp-*.jpg Allow: /wp-*.jpeg Allow: /wp-*.gif Allow: /wp-admin/admin-ajax.php User-agent: Yandex Disallow: /cgi-bin Disallow: /? Disallow: /wp- Disallow: /wp/ Disallow: *?s= Disallow: *&s= Disallow: /search/ Disallow: /author/ Disallow: /users/ Disallow: */trackback Disallow: */feed Disallow: */rss Disallow: */embed Disallow: */wlwmanifest.
xml Disallow: /xmlrpc.php Allow: */uploads Allow: /*/*.js Allow: /*/*.css Allow: /wp-*.png Allow: /wp-*.jpg Allow: /wp-*.jpeg Allow: /wp-*.gif Allow: /wp-admin/admin-ajax.php Sitemap: http://sitename.ru/sitemap.xml Sitemap: http://sitename.ru/sitemap.xml.gz
Итак, давайте поговорим подробнее о каждой из директив. Ниже описаны директивы с комментариями для каждой из них.
User-agent: * # Это общая директива для всех поисковых роботов, кроме Яндекса и Google. User-agent: Yandex # Директивы указывают на то, что ниже будут прописаны User-agent: GoogleBot # правила для поисковых роботов Яндекс и Google. Disallow: /cgi-bin # Закрываем содержимое папки cgi-bin Disallow: /? # Закрываем все параметры запроса на главной Disallow: /wp- # Закрываем все файлы WP: /wp-json/, /wp-includes, /wp-content/plugins Disallow: /wp/ # если есть подкаталог /wp/, где установлена CMS, то закрываем его, иначе правило можно удалить Disallow: *?s= # Закрываем Disallow: *&s= # результаты Disallow: /search/ # поиска Disallow: /author/ # Закрываем архив автора Disallow: /users/ # Закрываем архив авторов (пользователей) Disallow: */trackback # Закрываем трэкбеки, уведомления в комментариях о появлении открытой ссылки на статью Disallow: */feed # Закрываем все фиды Disallow: */rss # rss Disallow: */embed # и встраивания Disallow: */wlwmanifest.xml # Закрываем xml-файл манифеста Windows Live Writer (если не используете, правило можно удалить) Disallow: /xmlrpc.php # Закрываем файл WordPress API Disallow: *utm= # Закрываем ссылки с utm-метками Disallow: *openstat= # Закрываем ссылки с метками openstat Allow: */uploads # Открываем файлы в папке uploads (изображения и файлы с другими расширениями) Allow: /*/*.js # Открываем js-скрипты внутри /wp- (/*/ - для приоритета) Allow: /*/*.css # Открываем css-файлы внутри /wp- (/*/ - для приоритета) Allow: /wp-*.png # Открываем картинки в плагинах, cache папке и т.д. Allow: /wp-*.jpg # Открываем картинки в плагинах, cache папке и т.д. Allow: /wp-*.jpeg # Открываем картинки в плагинах, cache папке и т.д. Allow: /wp-*.gif # Открываем картинки в плагинах, cache папке и т.д. Allow: /wp-admin/admin-ajax.php # Используется плагинами, чтобы не блокировать JS и CSS Sitemap: http://new-wordpress.
loc/sitemap.xml # Указать путь к файлам Sitemap (карты сайта) Sitemap: http://new-wordpress.loc/sitemap.xml.gz # Google XML Sitemap создает 2 карты сайта как в текущем примере
На этом все. Спасибо! Надеюсь, статья будет Вам полезной.
100% правильный Robots.txt для WordPress
Robots.txt определяет правильную индексацию сайтов, в том числе на WordPress CMS. Это делается один раз и помогает акцентировать внимание поисковых систем только на самых значимых страницах сайта, несущих пользу и осмысленное содержание.
Не секрет, что многие страницы сайтов вне зависимости от желания и намерения его владельца представляют собой технический «мусор». Например, страницы с результатами поиска внутри сайта https://moytop.com/?s=ctr
Поисковики могут неправильно принять эти страницы за важную информацию и начать выдавать их в поиске в ущерб более правильно оптимизированным разделам сайта, отбрасывая их ниже в рейтинге.
Чтобы избежать таких ситуаций, сразу же после создания блога на WordPress рекомендуется составить специальный текстовый файл robots. txt и поместить его в корневую директорию сайта. Каждая поисковая система ориентирована на работу с этим файлом. В нем содержатся конкретные инструкции, с помощью которых можно:
txt и поместить его в корневую директорию сайта. Каждая поисковая система ориентирована на работу с этим файлом. В нем содержатся конкретные инструкции, с помощью которых можно:
- запретить поисковику проиндексировать весь сайт, отдельные папки или файлы.
- указать на дубликат (зекрало) сайта.
- указать карту сайта.
- дать поисковику рекомендации по установке определенных промежутков времени для того, чтобы оптимально проиндексировать сайт и снизить нагрузку на сервер (актуально для больших многостраничных проектов) и так далее.
Как правильно составить robots.txt для WordPress?
Это обычный текстовый файл, поэтому его можно открыть любым текстовым редактором (я вместо стандартного Notepad, который поставляется с каждой Windows, пользуюсь EditPlus). Повторюсь, находится он в корне сайта. А попасть в корень можно по FTP-доступу, который предоставляет любой хостер (читать «Как зайти на сайт через FTP»).
После того, как вы успешно зашли по FTP и открыли файл, смотрим на его содержимое. Для запрета индексации robots.txt должен содержать определенные команды для поисковиков, каждая из которых начинается с новой строки:
Для запрета индексации robots.txt должен содержать определенные команды для поисковиков, каждая из которых начинается с новой строки:
User-Agent
Эта команда задает поисковую систему, для которой предназначены последующие инструкции. Например, если вы укажете User-Agent: Yandex, то все последующие ниже команды будут относиться именно к этой поисковой системе.
Как правило, для блога выгодно, чтобы все страницы одинаково хорошо индексировались как под Яндекс, так и под Google и другие поисковики, поэтому имеет смысл не разделять инструкции для поисковых систем, а использовать общие правила. Для этого достаточно написать эту команду в таком виде: User-Agent: *
Она означает, что все поисковые системы могут проиндексировать сайт.
Disallow
Указывает конкретные страницы и каталоги сайта, которые нужно закрыть от индексации при помощи.
Если все файлы и страницы сайта можно индексировать, то после название оставляете пробел, вот так Disallow: , а если нужно тотально запретить индексацию всех без исключения страниц, то ставите в конце слеш (наклонную черту), вот так: Disallow: /
Но это крайние ситуации. Обычно под «запрет» попадают определенные папки или файлы. Поэтому после слеша указываете полное их наименование.
Обычно под «запрет» попадают определенные папки или файлы. Поэтому после слеша указываете полное их наименование.
Примеры использования команд файла Robots.txt
Ниже вы найдете примеры robots.txt в котором использованы наиболее частые команды User-Agent и Disallow в разных вариациях. Если нужно оставить комментарий в файле, то начните предложение с этого знака #
Примеры использования Disallow
Эта команда запрещает индексирование и чаще всего используется в таких вариантах.
1. Разрешаете проиндексировать всем поисковикам все страницы без исключения:
User-Agent: *
Disallow:
2. Запрещаете проиндексировать только Яндексу все на сайте:
User-Agent: Yandex
Disallow: /
3. Разрешаете проиндексировать все страницы на сайте только поисковой системе Google:
User-Agent: Google
Disallow:
# продолжение: после первой инструкции оставляем пустую строчку, это важно для безошибочного прочтения
User-Agent: *
Disallow: /
4. Разрешаете проиндексировать всем поисковикам каждую папку, кроме /png/:
Разрешаете проиндексировать всем поисковикам каждую папку, кроме /png/:
User-Agent: *
Disallow: /png
5. Разрешаете проиндексировать поисковым системам весь сайт, кроме динамических ссылок (например, поисковых запросов внутри сайта на WordPress)
User-Agent: *
Disallow: /*?s=*
6. Запретить индекацию конкретного файла master.php, который находится в папке includes
User-Agent: *
Disallow: /includes/master.php
7. Запретить индекацию любых каталогов и файлов, которые начинаются с download, например, файл download.gif
User-Agent: *
Disallow: download
Команда Allow
Имеет обратно Disallow значение — разрешает индексацию для указанных файлов и папок.
# Вот так можно разрешить индексацию лишь для файла myfoto.jpg, которая находится в запрещенной для индексации папке Album.
User-Agent: *
Disallow: album
Allow: /album/myfoto.jpg
Host
Эта директива позволяет указать зеркало сайта, то есть как предпочтительнее отображать имя сайта в поиске — с www или без?. Я предпочитаю без www, для этого нужно написать следующую инструкцию:
Host: moytop.com
где вместо moytop.com нужно вписать свое имя сайта.
Sitemap
Позволяет добавить ссылку на карту сайта, если она, конечно, у вас уже создана.
Вот, например, моя карта сайта, которая прописана в robots.txt
Sitemap: https://moytop.com/sitemap.xml
Crawl-delay
Позволяет выставить задержку в секундах перед индексацией отдельных страниц. Если на вашем сайте очень много страниц, которые периодически обновляются, а хостинг — дешевый, то имеет смысл указать значение в 10-15 секунд.
Это позволит снизить нагрузку на хостинг со стороны поисковых систем. Делается это следующей командой:
Crawl-delay: 10
Скачать 100% рабочий файл Robots.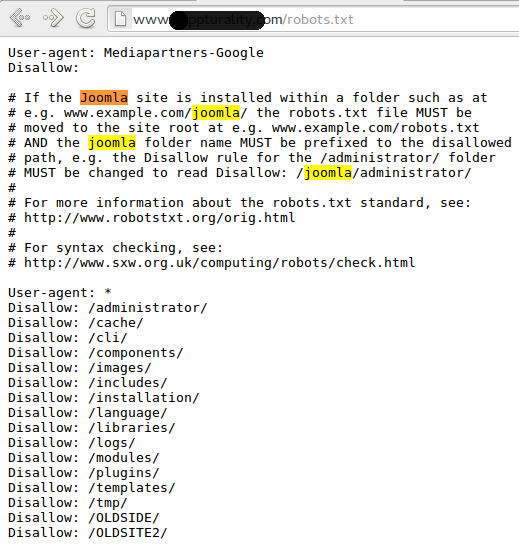 txt для WordPress CMS
txt для WordPress CMS
Эти основные команды вы можете применять для своего сайта на Вордпресс в том или ином виде. У многих сайтов и блогов они будут применяться по-разному, так как могут использоваться разные плагины, разные пути к файлам и разные динамические адреса.
Но я могу порекомендовать вам готовый и проверенный файл Robots.txt, который можно безболезненно использовать на большинстве сайтов под WordPress CMS и который уже отлично себя зарекомендовал. Вы можете посмотреть его в бонусе.
Почему это действительно хороший Robots.txt?
Прежде всего потому, что многие найденные в интернете решения блокируют больше чем нужно, например, запрещают индексацию служебных папок вроде /WP-CONTENT/
Раньше это еще было допустимо, но сейчас поисковики (особенно Google) обязательно должны прочитать все нужные служебные папки, чтобы правильно воспроизвести то, как сайт выглядит в глазах рядовых пользователей. А для этого нужен доступ к служебным папкам, содержащим файлы CSS, JS и другие.
Важно! С помощью версии сайта для мобильных устройств можно получать более высокие места в поиске Google (подробнее о том, как создать мобильную версию для WordPress за 10 минут).
Поэтому нужно не запрещать в файле Robots.txt все подряд, а выкинуть только реальные дубли страниц, остальное же разрешить для сканирования — в этом случае сайт будет показываться правильно и вы не увидите ошибок в Google.Webmasters вроде таких: «Googlebot не может получить доступ к файлам CSS и JS на сайте».
Так что можете смело качать мой файл Robots.txt — он проверен на дубли и отлично работает с Googlebot.
Бонус!
Посмотреть и скачать уже готовый пример robots.txt для WordPress можно прямо сейчас. Контент доступен для подписчиков блога. Достаточно ввести свой правильный емейл, и после подтверждения вам откроется полное содержимое этой страницы.
Бонус
Всё получилось успешно!
Добавьте вот эти строки в ваш файл robots.txt (находится в корне вашего сайта и может быть отредактирован по FTP).
User-Agent: *
Disallow: */wp-json*
Disallow: /xmlrpc.php
Disallow: /readme.html
Disallow: /*?
Disallow: /*?s=*
Disallow: /*?ad=*
Disallow: /cgi-bin
Disallow: */trackback
Disallow: */comments
Disallow: /tag
Disallow: /?attachment
Allow: *.css
Allow: *.js
Allow: *.png
Allow: *.gif
Allow: *.jpg
Allow: *.jpeg
Allow: */feed/*
Sitemap: ссылка на вашу карту
User-agent: YandexBot
Crawl-delay: 10
Disallow: */wp-json*
Disallow: /xmlrpc.php
Disallow: /readme.html
Disallow: /*?
Disallow: /*?s=*
Disallow: /*?ad=*
Disallow: /cgi-bin
Disallow: */trackback
Disallow: */comments
Disallow: /tag
Disallow: /?attachment
Allow: *.css
Allow: *.js
Allow: *.png
Allow: *.gif
Allow: *.jpg
Allow: *.jpeg
Allow: */feed/*
Sitemap: ссылка на вашу карту
Если на ваш емейл после подписки не приходит письмо для подтверждения уведомления (такое бывает иногда в зависимости от типа вашего ящика), то есть такие варианты:
- Подождите минут 5-10.

- Попробуйте другую почтовую сеть, лучше всего работают mail.yandex.ru или gmail.com.
- Проверьте папку СПАМ — может нужное письмо именно там. После чего обязательно отметьте его и кликните — НЕ спам.
- Если ничего не получилось, напишите мне в Контакты и укажите ссылку на страницу, версию браузера и примерный порядок действий.
С помощью этих инструкци или готового примера вы можете составить robots.txt для WordPress CMS правильно, с учетом структуры именно вашего сайта. Но обратите внимание, достаточно будет набрать http://адрес-сайта/robots.txt — и любой желающий увидит перечень ваших служебных и системных папок, которые есть на вашем компьютере.
Получение списка каталогов на сервере — это потенциальная угроза для безопасности сайта. Поэтому рекомендую обязательно сделать невозможным получение доступа к таким каталогам. Это очень просто, а позволяет получить дополнительную защиту от взлома.
Как это сделать? Читайте в статье: «Повышаем безопасность WordPress в 2 клика»
Правильный robots. txt для wordpress — важнейшие моменты — Константин Хмелев
txt для wordpress — важнейшие моменты — Константин Хмелев
Здравствуйте, дорогие друзья!
Сейчас напишу статью о нашумевшем файле, которого так все боятся молодые владельцы сайтов. И не зря, ведь при неправильном его составлении могут возникнуть плохие последствия.
Тема статьи — файл robots.txt. Мы сегодня разберем от основ его составления до примера моего личного файла, который на данный момент хорошо работает. Материал получился довольно сложный и после первого прочтения у вас может не сложиться впечатление целостной картины, но основную мысль вы должны уловить. Будет много советов и инсайдерской информации, которая поможет сделать индексацию сайта более лучшей.
Перед составлением сайта я настоятельно рекомендую ознакомиться с важнейшими моментами работы файла роботс. Вы должны понимать хотя бы базовые принципы работы роботов поисковых систем, чтобы понимать, что и как стоит закрывать от индексации.
СодержаниеПоказать
Важная теория
Сначала определение самого файла.
Файл Robots.txt дает понимание поисковых систем о том, что не нужно индексировать на сайте для предотвращение появления дублированного контента. Можно закрыть от индексации целые разделы, отдельные страницы, папки на хостинге и так далее. Все, что только в голову взбредет.
Именно на этот файл в первую очередь обращают внимание поисковые роботы при заходе на сайт, чтобы понять, куда стоит смотреть, а что необходимо игнорировать и не заносить в поисковую базу.
Также данный файл служит для облегчения работы поисковым роботам, чтобы они не индексировали много мусорных страниц. Это создает нагрузку на наш сайт, так как роботы будут долго лазить в процессе индексирования.
Файл Robots.txt размещается в корневом каталоге любого сайта и имеет расширение обычного текстового документа. То есть мы его можем редактировать у себя на компьютере с помощью обычного текстового редактора — блокнота.
Чтобы просмотреть содержимое этого файла на лбом сайта, стоит к доменному имени дописать название файла через правую наклонную черту вот так: имя домена. ру/robots.txt
ру/robots.txt
Очень важно понимать, что для некоторых сайтов файл может различаться, так как может быть сложная структура. Но основная мысль в том, чтобы закрыть страницы, которые генерируются самим движком и создают дублированный контент. Также задача стоит в том, чтобы предотвратить попадание таких страниц в индекс, а не только их содержимого. Если у вас простой сайт на WordPress, то файл вам подойдет.
Также рекомендую во все вникать и постараться разобраться в тонкостях, так как это те моменты, которые постепенно могут губить ресурс.
Далее стоит понять, как поисковые системы относятся к этому файлу, так как в Яндексе и в Google имеются различия в восприятии запретов, которые прописываются в файле robots.
Различия в работе для Яндекса и Google
Единственное и пожалуй весомое различие проявляется в том, что Яндекс воспринимает запреты в файле, как некое обязательное правило и довольно хорошо следует всем запретам. Мы ему сказали, что эти страницы в индекс брать не нужно, он и не берет их.
В Google же ситуация совершенно иная. Дело в том, что Google действует по принципу «на зло». Что я имею ввиду? Мы ставим запрет на некоторые служебные страницы. Самой частой такой страницей на которую ставят запрет, является страница, создаваемая ссылкой «Ответить» при включенной функции древовидных комментариев.
Страница по такой ссылке имеет приставку «replytocom». Когда мы ставим запрет на такую страницу, google не может получить доступ к ее содержимому и забирает такой адрес в индекс. В итоге, чем больше комментариев на ресурсе, тем больше и мусорных адресов в индексе, что не есть хорошо.
Конечно же, так как мы закрыли такие адреса от индексации, то содержимое страниц не индексируется и не происходит появление дублированного контента в индекс. Об этом свидетельствует надпись «A description for this result is not available because of this site’s robots.txt».
Переводится это так: «Описание веб-страницы не доступно из-за ограничения в robots. txt».
txt».
Как бы ничего страшного. Но страница то попала в индекс, хоть и дублирования не произошло. В общем, это может быть, но можно ведь полностью избавиться от такого мусора.
И тут имеется несколько решений:
- Самый простой вариант — открыть такие адреса для робота google в файле robots, чтобы он смог их просканировать. Тогда он наткнется на мета-тег noindex в исходном коде страницы, который не позволит забрать документ в индекс.
Даем доступ — google сам во всем разбирается. Также на такие страницы добавляется атрибут канонических адресов rel=»canonical», который укажет на главный адрес данной страницы, что скажет поисковой системе:
Данный адрес индексировать не нужно, так как имеется главная версия страницы, которую и стоит взять в базу.
В итоге, имеется 2 настройки, которые не позволят забрать мусор в индекс. Но это при условии, что подобные страницы открыты в файле роботс и гугл полностью имеет к ним доступ;
- Более сложный вариант заключается в полном закрытии таких ссылок от поисковых систем, чтобы их даже обнаружить нельзя было.
 Тут можно использовать различные скрипты и плагины. Хорошая функция имеется в плагине WordPress seo by yoast, которая убирает приставку «replytocom» из ссылок «Ответить».
Тут можно использовать различные скрипты и плагины. Хорошая функция имеется в плагине WordPress seo by yoast, которая убирает приставку «replytocom» из ссылок «Ответить».
Также имеются специальные плагины под настройку комментариев, где имеется функция закрытия таких ссылок. Можно и их использовать. Но зачем изобретать колесо? Ведь можно ничего не делать и все будет хорошо и без нашего участия. Главное здесь — открыть доступ, чтобы google смог разобраться во всей ситуации.
Google обязательно найдет такие страницы по внутренним ссылкам (в нашем случае для примера — ссылка «Ответить»). Об этом нам говорит сама справка гугла:
Хотя Google не сканирует и не индексирует содержание страниц, заблокированных в файле robots.txt, URL, обнаруженные на других страницах в Интернете, по-прежнему могут добавляться в индекс. В результате URL страницы, а также другие общедоступные сведения, например текст ссылок на сайт или заголовок из каталога Open Directory Project (www.
dmoz.org), могут появиться в результатах поиска Google.
Однако даже если вы запретите поисковым роботам сканировать содержание сайта с помощью файла robots.txt, это не исключает, что Google обнаружит его другими способами и добавит в индекс.
А что дальше? Если доступ открыть, то он наткнется на мета-тег Noindex, запрещающий индексирования страницы, и на атрибут rel=»canonical», который укажет на главный адрес страницы. Из последнего роботу гугла будет понятно, что данный документ не является главным и его не стоит брать в индекс. Вот и все дела. Ничего в индекс не попадет и никаких конфликтов с поисковым роботом Google не произойдет. И не придется потом избавляться от мусора в индексе.
Если же доступ будет закрыт, то велика вероятность, а скорее всего 100%, что адреса, найденные по таким ссылкам, googlebot проиндексирует. В этом случае придется от них избавляться, что уже занимает время ни одного дня, недели или даже месяца. Все зависит от количества мусора.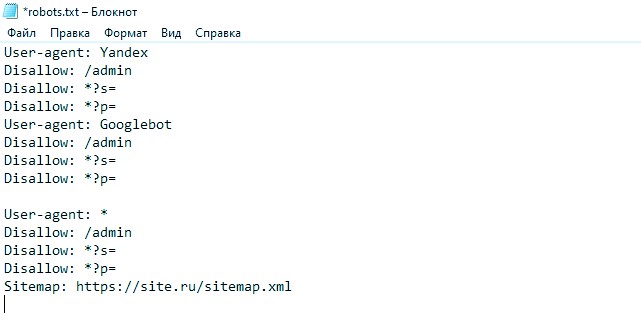
В общем, чтобы не произошло такого, стоит использовать правильный файл без лишних запретов + открытые всех подобных страниц для поисковой системы Google.
Можно конечно же просто закрыть все подобные ссылки скриптами или плагинами и сделать 301 редирект с дублированных страниц на главную, чтобы поискового робота сразу перекидывало на главный адрес, который он и будет индексировать, не обращая внимание на дубли.
Второй вариант является более жестким, так сказать более твердым, так как мы делаем некоторые манипуляции, закрывая весь мусор от поисковиков. Мы нее даем им самим разобраться в сложившейся ситуации. Ни малейшего шанса, что страницы по внутренним ссылкам попадут в индекс.
Лично я так и поступил. У меня все закрыто скриптом и редиректами.
Прежде, чем мы рассмотрим основу правильно файла robots, разберем основные директивы, чтобы на базовом уровне вы понимали, как составляется этот файл и как его можно будет доработать под свои нужды.
Основные директивы
Основными директивами файла robots являются:
- User-agent — директива, которая указывает, к какому роботу поисковых систем принадлежат правила, прописанные для запретов и разрешений. Если правила необходимо присвоить ко всем поисковым системам, то после директивы ставится звездочка *, если же стоит прописать правила к определенному роботу, например к Яндексу, то стоит прописать имя робота. В данном случае директива будет прописана так:
User-agent: Yandex
Название других роботов:
- Google — Googlebot;
- Яндекс — Yandex;
- Рамблер — StackRambler;
- Мэйл.ру — Mail.Ru.
- Disallow — директива призвана для запрета от индексации каталогов, страниц и документов. Чтобы запретить какой-то раздел, что после директивы прописать название каталога через правую наклонную черту. Например необходимо закрыть категорию «inter» на сайте, тогда необходимо будет прописать следующим образом:
Disallow: /inter
В этом случае будет запрещен от индексации каталог «inter», а также все, что находится внутри него;
- Allow — директива для разрешения частей сайта к индексации.
 Если нужно разрешить какую-то часть, то по аналогии с директивой Disallow прописывает название каталога или отдельной страницы. Например, если мне нужно открыть подраздел «pr» внутри каталога «inter», то правило будет прописано следующим образом:
Если нужно разрешить какую-то часть, то по аналогии с директивой Disallow прописывает название каталога или отдельной страницы. Например, если мне нужно открыть подраздел «pr» внутри каталога «inter», то правило будет прописано следующим образом:Allow: /inter/pr
Хоть каталог «inter» мы и закрыли в предыдущем случае, подраздел «pr» будет индексироваться и все, что внутри него также будет доступно для поисковых роботов.
- Host — директива призвана, чтобы указать поисковым роботам основное зеркало сайта (с www или без).
Прописывать стоит только к Яндексу. Также необходимо указать главное зеркало сайта в панели веб-мастера Яндекс.
- Sitemap — директива призвана указать путь к карте сайта в формате XML. Стоит прописывать ко всем поисковым роботам. Достаточно указать только к директиве User-agent: *, которая ко всем роботам и действует.
Важно! После каждой директивы обязательно должен быть отступ в виде одного пробела.
Зная основные моменты в работе robots.txt и базовые принципы его составление, можно приступить к его сборке.
Составляем правильный файл
Вообще, идеальным вариантом было бы полностью открыть свой сайт к индексации и дать возможность поисковым роботам самим разобраться во всей ситуации. Но их алгоритмы не совершенны и они берут в индекс все, что можно только забрать в поисковую базу. А нам это ни к чему, так как будет куча дублированного контента в рамках сайта и куча мусорных страниц.
Чтобы такого не было, нужно составить такой файл, который будет разрешать к индексации только страницы самих статей, то есть контента и по надобности страницы, если они несут полезную информацию посетителю и поисковым системам.
Из пункта 2 сего материала вам стало понятно, что в файле не должно быть лишних запретов для Google, чтобы в индекс не полетели лишние адреса страниц. Это ни к чему. Яндекс же относится к данному файлу нормально и запреты воспринимает хорошо. Что укажем к запрету, то Яндекс и не будет индексировать.
Что укажем к запрету, то Яндекс и не будет индексировать.
На основе этого я сделал файл, который открывает весь сайт для поисковой системи Google (кроме служебных директорий самого движка WordPress) и закрывает все страницы дублей от Яндекса, Mail и других поисковиков.
Мой файл имеет довольно большой вид.
User-agent: Yandex
Disallow: /wp-admin
Disallow: /wp-includes
Disallow: /wp-login.php
Disallow: /wp-register.php
Disallow: /wp-content/plugins
Disallow: /wp-content/cache
Disallow: /xmlrpc.php
Disallow: */author/*
Disallow: */feed/
Disallow: */feed
Disallow: /?feed=
Disallow: */page/*
Disallow: */trackback/
Disallow: /search
Disallow: */tag/*
Disallow: /?wp-subscription-manager*
Allow: /wp-content/uploads/
Host: kostyakhmelev.ru
User-agent: Googlebot
Disallow: /wp-admin
Disallow: /wp-includes
Disallow: /wp-login.php
Disallow: /wp-register. php
Disallow: /wp-content/plugins
Disallow: /wp-content/cache
Allow: /wp-content/uploads/
User-agent: Mail.Ru
Disallow: /wp-admin
Disallow: /wp-includes
Disallow: /wp-login.php
Disallow: /wp-register.php
Disallow: /wp-content/plugins
Disallow: /wp-content/cache
Disallow: /xmlrpc.php
Disallow: */author/*
Disallow: */feed/
Disallow: */feed
Disallow: /?feed=
Disallow: */page/*
Disallow: */trackback/
Disallow: /search
Disallow: */tag/*
Disallow: /?wp-subscription-manager*
Allow: /wp-content/uploads/
User-agent: *
Disallow: /wp-admin
Disallow: /wp-includes
Disallow: /wp-login.php
Disallow: /wp-register.php
Disallow: /wp-content/plugins
Disallow: /wp-content/cache
Disallow: /xmlrpc.php
Disallow: /?wp-subscription-manager*
Allow: /wp-content/uploads/
Sitemap: //kostyakhmelev.ru/sitemap.xml
Sitemap: //kostyakhmelev.ru/sitemap.
php
Disallow: /wp-content/plugins
Disallow: /wp-content/cache
Allow: /wp-content/uploads/
User-agent: Mail.Ru
Disallow: /wp-admin
Disallow: /wp-includes
Disallow: /wp-login.php
Disallow: /wp-register.php
Disallow: /wp-content/plugins
Disallow: /wp-content/cache
Disallow: /xmlrpc.php
Disallow: */author/*
Disallow: */feed/
Disallow: */feed
Disallow: /?feed=
Disallow: */page/*
Disallow: */trackback/
Disallow: /search
Disallow: */tag/*
Disallow: /?wp-subscription-manager*
Allow: /wp-content/uploads/
User-agent: *
Disallow: /wp-admin
Disallow: /wp-includes
Disallow: /wp-login.php
Disallow: /wp-register.php
Disallow: /wp-content/plugins
Disallow: /wp-content/cache
Disallow: /xmlrpc.php
Disallow: /?wp-subscription-manager*
Allow: /wp-content/uploads/
Sitemap: //kostyakhmelev.ru/sitemap.xml
Sitemap: //kostyakhmelev.ru/sitemap. xml.gz
User-agent: Mediapartners-Google
Disallow:
User-agent: YaDirectBot
Disallow:
User-agent: Googlebot-Image
Allow: /wp-content/uploads/
User-agent: YandexImages
Allow: /wp-content/uploads/
xml.gz
User-agent: Mediapartners-Google
Disallow:
User-agent: YaDirectBot
Disallow:
User-agent: Googlebot-Image
Allow: /wp-content/uploads/
User-agent: YandexImages
Allow: /wp-content/uploads/[box]
Не забудьте изменить адрес моего домена на свой в директивах Host и Sitemap.
[/box]
Как видим, файл Robots.txt для wordpress вышел довольно большой. Это связано с тем, что правила я прописал к 3м основным роботам: Яндекс, Google и mail. К первым 2м обязательно нужно сделать. Также и к поисковому роботу mail не помешает, так как в последнее время поисковик довольно неплохо развивается и начинает приводить все больше и больше трафика.
Что касается самого содержимого файла, то для роботов Яндекса, Mail и для дериктивы, работающей со всеми роботами (User-agent: *), правила прописаны одни и те же. Запрет идет для всех основных моментов, связанных с появлением дублей в индексе.
Только к поисковому роботу Google я прописал отдельный вариант, который предполагает открытие всего содержимого сайта, кроме служебных папок самого движка.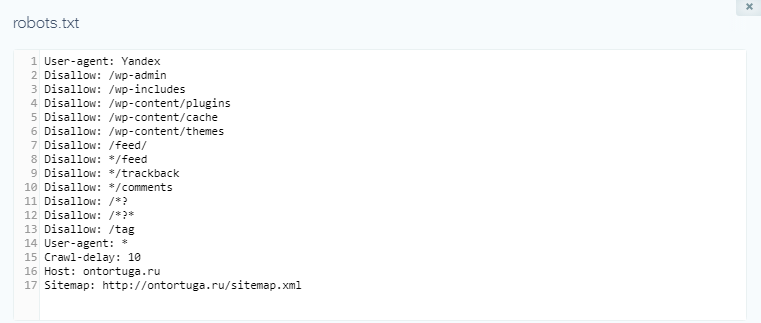 Почему именно так, я рассказывал выше. Нужно, чтобы Googlebot мог просканировать все страницы по внутренним ссылка и увидеть на них запреты в виде мета-тега robots со значением noindex, а также атрибут rel=»canonical», что заставит его оставить дубли в покое.
Почему именно так, я рассказывал выше. Нужно, чтобы Googlebot мог просканировать все страницы по внутренним ссылка и увидеть на них запреты в виде мета-тега robots со значением noindex, а также атрибут rel=»canonical», что заставит его оставить дубли в покое.
Если же мы в файле роботс сделаем запрет, то робот не сможет увидеть этих данных (тегов) и, как я говорил ранее «на зло», возьмет адрес в индекс.
Также к каждому роботу я разрешил индексирование изображений (Allow: /wp-content/uploads/).
В конце файла я отдельно прописал разрешение индексации изображений для картиночных роботов Google и Яндекса. Вместе с этим разрешил весь сайт для роботов контекстной рекламы этих же поисковиков.
Интересным моментом является закрытие ссылки, которая создается плагином Subscribe to comments.
Если вы его используете, то в данном файле используйте запрет на ее индексирование, так как поисковый робот ее также обнаружит.
Для этого используется следующая строка:
Disallow: /?wp-subscription-manager*
Используя данный файл вы не будете бояться, что в индексе будет появляться дублированный контент, который образуется самим движком, а точнее его внутренними ссылками на страницах сайта. Яндекс все запреты сочтет за некую догму, а Google наткнется на запреты, когда зайдет на дубли, создаваемые движком.
Как я уже описывал ранее, то более продвинутыми настройками является скрытие таких ссылок, чтобы поисковые роботы даже не смогли их найти. К тому же это не только в 100% мере обезопасит нас сейчас, но и даст нам некую подстраховку на будущее, так как алгоритмы поисковых систем постоянно меняются и возможно, что запреты, которые работают сейчас, не будут работать через некоторое время.
Но тут также. Разработчики движка всегда идут в ногу со временем и учтут все новые изменения в работе ПС в совершенствовании wordpress. Исходя из этого, бояться в ближайшее время ничего не стоит.
В следующих статьях я буду описать процесс избавления от дублей страниц, которые могут появиться на ресурсе, а также способы скрытия опасных ссылок, создаваемых средствами WordPress, если вы все же решите обезопасить себя на все 100%. Мы ведь не знаем, как поведет себя поисковой робот? Может он начнет игнорировать запреты даже при наличии мета-тега Noindex и атрибута rel=»canonical». В этом случае спасет скрытие опасных ссылок.
Итак, возможно, статья вышла довольно сложная для первого понимания, так как затронут не только вопрос составления самого файла, но и принципов работы поисковых роботов и того, что стоит сделать в идеале, что страшно, а что нет.
Если у вас имеются какие-то вопросы или неясности, то буду благодарен, если напишите об этом в комментариях, чтобы я как-то изменил данный материал для более отзывчивого восприятия другими пользователями.
На этом закончу этот пост. До скорых встреч!
С уважением, Константин Хмелев!
Как составить правильный robots.txt для сайта на wordpress
Начало статьи читайте здесь »
Файл robots.txt — это служебный файл, в котором можно указать роботам ПС (поисковых систем), какие разделы сайта индексировать, а какие нет. Сделать это можно с помощью специальных директив. Директивы можно написать для всех роботов одновременно или отдельно для робота каждой ПС.
Разделы, закрытые от индексации, не попадут в индекс поисковых систем.
Что такое Индекс?
Это база данных поисковой системы, в которой она хранит набор встречающихся на интернет-страницах слов и словосочетаний. Эта информация соотнесена с адресами тех веб-страниц, на которых она встречаются, и постоянно пополняется новой информацией, собираемой роботом-пауком поисковой системы.
Для того, чтобы сайт появлялся в выдаче поисковой системы по определенным запросам, он должен быть занесен в индекс этой поисковой системы.
Вообщем, robots.txt – это очень полезный и нужный любому сайту файл.
Общая для всех сайтов часть файла:
Итак, создаем текстовый документ с названием robots.txt и пишем в него следующее:
User-agent: * Disallow: /cgi-bin/ Disallow: /wp- Disallow: /*trackback Disallow: /feed Disallow: /?s= Disallow: /xmlrpc.php Allow: /wp-content/uploads/ Host: www.yourdomain.ru Sitemap: http://yourdomain.ru/sitemap.xml User-agent: Googlebot-Image Allow: /wp-content/uploads/ User-agent: YandexImages Allow: /wp-content/uploads/ User-agent: ia_archiver Disallow: / |
User-agent: * Disallow: /cgi-bin/ Disallow: /wp- Disallow: /*trackback Disallow: /feed Disallow: /?s= Disallow: /xmlrpc.php Allow: /wp-content/uploads/ Host: www.yourdomain.ru Sitemap: http://yourdomain.ru/sitemap.xml User-agent: Googlebot-Image Allow: /wp-content/uploads/ User-agent: YandexImages Allow: /wp-content/uploads/ User-agent: ia_archiver Disallow: /
Пояснения:
User-agent: * — Директива всем роботам
Если нужно, чтобы эти правила работали только для одного, конкретного робота, то вместо * указываем его имя (User-agent: Yandex, User-agent: Googlebot и т.д.).
Здесь мы запрещаем индексировать папку со скриптами.
- Disallow: /wp- — Запрещает индексацию всех папок и файлов движка, начинающихся с wp- (т.е. папок /wp-admin/, /wp-includes/, /wp-content/ и всех файлов, расположенных в корневой папке).
Disallow: /*trackback Disallow: /*comment- Disallow: /feed
Disallow: /*trackback Disallow: /*comment- Disallow: /feed
Запрещаем индексацию комментариев, трекбеков и фида.
Спецсимвол * означает любую (в том числе пустую) последовательность символов, т.е. все, что находится в адресе до указанной части или после нее.- Disallow: /?s= — Запрещаем индексацию результатов поиска.
Allow: /wp-content/uploads/ — Разрешение индексировать папку uploads (а значит и расположенные в ней картинки).
Правило Яндекса для robots.txt гласит:
«Директивы Allow и Disallow из соответствующего User-agent блока сортируются по длине префикса URL (от меньшего к большему) и применяются последовательно. Если для данной страницы сайта подходит несколько директив, то выбирается последняя в порядке появления в сортированном списке.»
Получается, что директиву Аllow можно указать в любом месте.
Яндекс самостоятельно сортирует список директив и располагает их по длине префикса.
Google понимает Allow и вверху и внизу секции.
Касательно директивы Allow: /wp-content/uploads/ — поскольку, далее мы разрешаем индексировать роботам-индексаторам картинок папку с картинками, я не уверена, что эта директива нужна.
Но, наверное, лишней не будет. Так что, это — на ваше усмотрение.Host: www.glavnoye-zerkalo.ru — Директива Host понимается только Яндексом и не понимается Гуглом.
В ней указывается главное зеркало сайта, в случае, если у вашего сайта есть зеркала. В поиске будет участвовать только главное зеркало.
Директиву Host лучше написать сразу после директив Disallow (для тех роботов, которые не полностью следуют стандарту при обработке robots.txt).
Для Яндекса директива Host являются межсекционной, поэтому будет найдена роботом не зависимо от того, где она указана в файле robots.txt.
Важно: Директива Host в файле robots.txt может быть только одна.
В случае указания нескольких директив, использоваться будет первая.Sitemap: http://mysite.ru/sitemaps.xml — Указываем путь к файлу sitemaps.xml
Для Яндекса и Google Sitemap — это межсекционная директива, но лучше написать ее в конце через пустую строку. Так она будет работать для всех роботов сразу.
User-agent: Googlebot-Image Allow: /wp-content/uploads/ User-agent: YandexImages Allow: /wp-content/uploads/
User-agent: Googlebot-Image Allow: /wp-content/uploads/ User-agent: YandexImages Allow: /wp-content/uploads/
Разрешает роботам Googlebot и YandexImages индексировать наши картинки.
User-agent: ia_archiver Disallow: /
User-agent: ia_archiver Disallow: /
Полностью запрещаем роботу веб архива индексацию нашего сайта.
Это предупредительная мера, которая защитит сайт от массового парсинга контента через веб архив.
Итак, мы рассмотрели стандартную часть файла robots.txt, которая подойдет для любого сайта на wordpress.
Но, нам нужно спрятать от роботов-индексаторов еще некоторые разделы сайта, в частности, те, которые создают дублированный контент — разного рода архивы.
Индивидуальные настройки:
Если на вашем сайте есть система древовидных комментариев, как на моем блоге, тогда нужно запретить индексацию таких адресов:
*?replytocom=
Их создает кнопка (ссылка) «Ответить на комментарий».
- Страницы архивов на разных сайтах имеют различные адреса, в зависимости от того, как формируются URL на сайте, включены ли ЧПУ или нет.
Как определить адреса архивов вашего сайта?Для этого нужно открыть архив любого месяца и посмотреть, как выглядит адрес страницы архива.
Он может выглядеть, например, так: http://sait.ru/archives/date/post-1.
В этом случае, выделяем общую для всех архивов по дате часть адреса:
/archives/date/.
Соответственно, в файле robots.txt указываем:
Disallow: /archives/date/*
Будьте внимательны — у вас архивы могут иметь другие адреса.
Например, архив года может иметь такой адрес: http://sait.ru/2012
Тогда закрывать нужно эту часть — /2012/
Напоминаю, что спецсимвол * означает любую последовательность символов, т.е. все, что находится в адресе далее. - Точно так же определяем адреса архивов тегов и архивов автора.
И закрываем их в robots.txt.Disallow: /archives/tag/ Disallow: /archives/author/
Disallow: /archives/tag/ Disallow: /archives/author/
Рекомендую архивы тегов закрыть примерно на полгода-год, (если у вас молодой сайт) пока он стабильно пропишется в поисковой выдаче.
После этого срока архивы тегов стоит открыть для индексации, так как по наблюдениям, на страницы тегов по поисковым запросам приходит значительно больше посетителей, чем на страницы постов, к которым эти теги созданы.
Но, не добавляйте к постам много тегов, иначе вашему сайту будут грозить санкции за дублированный контент.
Один-два (редко три) тега к одному посту вполне достаточно. - Можно, также, закрыть индексацию всех главных страниц, кроме первой.
Обычно, их адреса выглядят так: http://sait.ru/page/2, http://sait.ru/page/3 и т. д., но лучше проверить.
Перейдите по ссылкам навигации внизу Главной страницы на вторую страницу и посмотрите, как выглядит ее адрес в адресной строке.
Закрываем эти страницы:
Disallow: /page/* Иногда, на сайте требуется закрыть от индексации еще какие то страницы или папки. В этом случае, действуете аналогично — открываете в браузере нужную вам страницу и смотрите ее адрес. А дальше закрываете его в robots.txt.
Учтите, что если вы закрываете, например, папку «book», то автоматически закроются и все файлы, расположенные в этой папке.
Если закрыть страницу, в URL’е которой есть, например, «news» так: */news/,
то закроются и страницы /news/post-1 и /category/news/.
robots.txt полностью ↓
Открыть ↓Справка:
Подробности составления robots.txt можно изучить на странице помощи Яндекса — http://help.yandex.ru/webmaster/?id=996567
Проверить правильность составления файла можно в webmaster.yandex — Настройка индексирования — Анализ robots.txt
В Google robots.txt можно проверить по этой ссылке:
https://www.google.com/webmasters/tools/crawl-access?hl=ru&siteUrl=http://site.ru/
Проверяемый сайт должен быть добавлен в панель веб-мастера.
P.S. Для Яндекса и Google правила составления robots.txt немного различаются.
Толкование правил составления robots.txt можно прочитать здесь — http://robotstxt.org.ru
К сожалению, проверить можно только синтаксис.
Правильно ли вы закрыли от индексации разделы сайта, покажет только время :).
Ну вот и все — файл robots.txt готов, осталось только загрузить его в корневой каталог нашего сайта.
Напоминаю, что корневой каталог это папка в которой находится файл config.php.
И последнее — все, сделанные вами изменения в robots.txt, будут заметны на сайте только спустя несколько месяцев.
В тему:
Однажды видела сайт на wordpress, на котором не было файла robots.txt.
Этот сайт некоторое время простоял пустым — т.е. с одной стандартной записью, которая по умолчанию присутствует в wordpress.
Представьте себе, какой шок испытал владелец сайта, когда обнаружил, что Яндекс проиндексировал 2 страницы с контентом и больше тысячи страниц самого движка 🙂
На этой веселой ноте заканчиваю.
Внутренняя оптимизация сайта:
1. Оптимизация кода шаблона.
2. Оптимизация контента.
3. Перелинковка.
4. Файл robots.txt.
5. Файл sitemap.xml.
6. Пинг.
ОптимизацияWordPress Robots.txt (+ XML Sitemap) — посещаемость веб-сайта, поисковая оптимизация и повышение рейтинга — плагин для WordPress
Better Robots.txt создает виртуальный файл robots.txt WordPress, помогает повысить SEO вашего сайта (возможности индексации, рейтинг Google и т. Д.) И производительность загрузки — Совместимость с Yoast SEO, Google Merchant, WooCommerce и сетевыми сайтами на основе каталогов ( МУЛЬТИСИТ)
С помощью Better Robots.txt вы можете определить, каким поисковым системам разрешено сканировать ваш сайт (или нет), указать четкие инструкции о том, что им разрешено (или нет), и определить задержку сканирования (для защиты вашего хостинг-сервера от агрессивные скребки).Better Robots.txt также дает вам полный контроль над содержимым файла robots.txt в WordPress с помощью окна пользовательских настроек.
Уменьшите экологический след вашего сайта и выбросы парниковых газов (CO2), обусловленные его существованием в Интернете.
Краткий обзор:
ПОДДЕРЖИВАЕТСЯ НА 7 ЯЗЫКАХ
ПлагиныBetter Robots.txt переведены и доступны на следующих языках: китайский — 汉语 / 漢語, английский, французский — Français, русский –Руссɤɢɣ, португальский — Português, испанский — Español, немецкий — Deutsch
Знаете ли вы, что…
- Роботы.txt — это простой текстовый файл, размещаемый на вашем веб-сервере, который сообщает поисковым роботам (например, роботу Google), следует ли им обращаться к файлу.
- Файл robots.txt определяет, как пауки поисковых систем видят ваши веб-страницы и взаимодействуют с ними;
- Этот файл и боты, с которыми они взаимодействуют, являются фундаментальными частями работы поисковых систем;
- Первое, на что смотрит сканер поисковой системы при посещении страницы, — это файл robots.txt;
Роботы.txt — это источник сока SEO, который только и ждет, чтобы его разблокировали. Попробуйте Better Robots.txt!
О версии Pro (дополнительные возможности):
1. Повысьте свой контент в поисковых системах с помощью карты сайта!
Убедитесь, что ваши страницы, статьи и продукты, даже самые последние, принимаются во внимание поисковыми системами!
Плагин Better Robots.txt был создан для работы с плагином Yoast SEO (вероятно, лучшим плагином SEO для веб-сайтов WordPress).Он определит, используете ли вы в настоящее время Yoast SEO и активирована ли функция карты сайта. Если это так, то он автоматически добавит инструкции в файл Robots.txt, предлагая ботам / сканерам прочитать вашу карту сайта и проверить, вносили ли вы недавние изменения на свой сайт (чтобы поисковые системы могли сканировать новый доступный контент).
Если вы хотите добавить свою собственную карту сайта (или если вы используете другой плагин SEO), вам просто нужно скопировать и вставить URL-адрес вашей карты сайта и Better Robots.txt добавит его в ваш WordPress Robots.txt.
2. Защитите свои данные и контент
Не позволяйте плохим ботам сканировать ваш сайт и коммерциализировать ваши данные.
Плагин Better Robots.txt помогает заблокировать сканирование и очистку ваших данных наиболее популярными вредоносными ботами.
Когда дело доходит до сканирования вашего сайта, есть хорошие и плохие боты. Хорошие боты, такие как бот Google, сканируют ваш сайт, чтобы проиндексировать его для поисковых систем. Другие сканируют ваш сайт по более гнусным причинам, таким как удаление вашего контента (текст, цена и т. Д.)) для переиздания, загрузки целых архивов вашего сайта или извлечения ваших изображений. Сообщалось, что некоторые боты даже закрывали целые веб-сайты в результате интенсивного использования широкополосного доступа.
Плагин Better Robots.txt защищает ваш сайт от «пауков» / парсеров, которые Distil Networks определили как плохие боты.
3. Скрыть и защитить обратные ссылки
Не позволяйте конкурентам определять ваши прибыльные обратные ссылки.
Обратные ссылки, также называемые «входящими ссылками» или «входящими ссылками», создаются, когда один веб-сайт ссылается на другой.Ссылка на внешний веб-сайт называется обратной ссылкой. Обратные ссылки особенно ценны для SEO, потому что они представляют собой «вотум доверия» от одного сайта к другому. По сути, обратные ссылки на ваш сайт являются сигналом для поисковых систем о том, что другие ручаются за ваш контент.
Если многие сайты ссылаются на одну и ту же веб-страницу или веб-сайт, поисковые системы могут сделать вывод о том, что контент заслуживает ссылки и, следовательно, также стоит показывать в поисковой выдаче. Таким образом, получение этих обратных ссылок оказывает положительное влияние на позицию сайта в рейтинге или видимость в поисковой сети.В индустрии SEM специалисты очень часто определяют, откуда берутся эти обратные ссылки (от конкурентов), чтобы отсортировать лучшие из них и создать высококачественные обратные ссылки для своих клиентов.
Учитывая, что создание очень прибыльных обратных ссылок для компании занимает много времени (время + энергия + бюджет), позволяя вашим конкурентам так легко идентифицировать и дублировать их, это чистая потеря эффективности.
Better Robots.txt поможет вам заблокировать все поисковые роботы (aHref, Majestic, Semrush), чтобы ваши обратные ссылки не обнаруживались.
4. Избегайте спамовых обратных ссылок
Боты, заполняющие формы комментариев на вашем веб-сайте, говорят вам «отличная статья», «нравится информация», «надеются, что вы скоро сможете подробнее рассказать о теме» или даже предоставляют персональные комментарии, в том числе имя автора. Спам-боты со временем становятся все более и более умными, и, к сожалению, ссылки на спам в комментариях могут действительно повредить вашему профилю обратных ссылок. Улучшенный Robots.txt поможет вам избежать индексации этих комментариев поисковыми системами.
5.SEO инструменты
При улучшении нашего плагина мы добавили ссылки на 2 очень важных инструмента (если вас беспокоит ваш рейтинг в поисковых системах): Google Search Console и Bing Webmaster Tool. Если вы еще не используете их, теперь вы можете управлять индексированием своего сайта, оптимизируя robots.txt! Также был добавлен прямой доступ к инструменту массового пинга, который позволяет пинговать свои ссылки в более чем 70 поисковых системах.
Мы также создали 4 ярлыка, относящиеся к лучшим онлайн-инструментам SEO, непосредственно доступным на Better Robots.txt SEO PRO. Так что теперь, когда вы захотите, вы можете проверить производительность загрузки вашего сайта, проанализировать свой SEO-рейтинг, определить свой текущий рейтинг в поисковой выдаче с помощью ключевых слов и трафика и даже просканировать весь сайт на наличие мертвых ссылок (ошибки 404, 503, …) Прямо из плагина.
6. Будьте уникальны
Мы подумали, что можем добавить нотку оригинальности в Better Robots.txt, добавив функцию, позволяющую «настраивать» ваш файл robots.txt WordPress с помощью собственной уникальной «подписи».«Большинство крупных компаний в мире персонализировали свой robots.txt, добавив пословицы (https://www.yelp.com/robots.txt), слоганы (https://www.youtube.com/robots.txt) или даже рисунки (https://store.nike.com/robots.txt — внизу). И почему не ты тоже? Вот почему мы выделили специальную область на странице настроек, где вы можете писать или рисовать все, что хотите (действительно), не влияя на эффективность работы robots.txt.
7. Запретить роботам сканировать бесполезные ссылки WooCommerce
Мы добавили уникальную функцию, позволяющую блокировать определенные ссылки («добавить в корзину», «заказать», «заполнить», «корзина», «аккаунт», «оформить заказ» и т. Д.) От сканирования поисковыми системами.Для большинства этих ссылок требуется много ресурсов ЦП, памяти и полосы пропускания (на сервере хостинга), поскольку они не кэшируются и / или создают «бесконечные» циклы сканирования (пока они бесполезны). Оптимизация вашего файла robots.txt в WordPress для WooCommerce при наличии интернет-магазина позволяет повысить вычислительную мощность для действительно важных страниц и повысить производительность загрузки.
8. Избегайте ловушек на гусеничном ходу:
«Ловушки поискового робота» — это структурная проблема на веб-сайте, которая заставляет сканеры находить практически бесконечное количество нерелевантных URL-адресов.Теоретически сканеры могут застрять в одной части веб-сайта и никогда не завершить сканирование этих нерелевантных URL-адресов. Улучшенный файл Robots.txt помогает предотвратить ловушки сканера, которые сокращают бюджет сканирования и вызывают дублирование контента.
9. Инструменты взлома роста
Сегодня самые быстрорастущие компании, такие как Amazon, Airbnb и Facebook, добились резкого роста, объединив свои команды вокруг высокоскоростного процесса тестирования / обучения. Речь идет о взломе роста. Взлом роста — это процесс быстрого экспериментирования и реализации маркетинговых и рекламных стратегий, которые направлены исключительно на эффективный и быстрый рост бизнеса.Better Robots.txt предоставляет список из 150+ инструментов, доступных в Интернете, чтобы ускорить ваш рост.
10. Robots.txt Post Meta Box для ручных исключений
Этот мета-блок сообщения позволяет установить «вручную», должна ли страница быть видимой (или нет) в поисковых системах, введя специальное правило «запретить» + «noindex» в файл robots.txt WordPress. Почему это полезно для вашего рейтинга в поисковых системах? Просто потому, что некоторые страницы не предназначены для сканирования / индексации. Страницы с благодарностью, целевые страницы, страницы, содержащие исключительно формы, полезны для посетителей, но не для поисковых роботов, и вам не нужно, чтобы они отображались в поисковых системах.Кроме того, некоторые страницы, содержащие динамические календари (для онлайн-бронирования), НИКОГДА не должны быть доступны для поисковых роботов, поскольку они, как правило, заманивают их в бесконечные циклы сканирования, что напрямую влияет на ваш бюджет сканирования (и ваш рейтинг).
11. Возможность сканирования Ads.txt и App-ads.txt
Чтобы гарантировать, что файлы ads.txt и app-ads.txt могут сканироваться поисковыми системами, плагин Better Robots.txt гарантирует, что они по умолчанию разрешены в файле Robots.txt независимо от вашей конфигурации.Для вашей информации, авторизованные цифровые продавцы для Интернета или ads.txt — это инициатива IAB, направленная на повышение прозрачности программной рекламы. Вы можете создать свои собственные файлы ads.txt, чтобы определить, кто имеет право продавать ваши ресурсы. Эти файлы общедоступны и могут сканироваться биржами, платформами поставщиков (SSP) и другими покупателями и сторонними поставщиками. Авторизованные продавцы для приложений или app-ads.txt — это расширение стандарта авторизованных цифровых продавцов. Он расширяет совместимость для поддержки рекламы, отображаемой в мобильных приложениях.
Как всегда, еще впереди…
Вся информация о WordPress и Datei robots.txt
Это был файл robots.txt?
Такие поисковые роботы или роботы-пауки (все поисковые роботы или родственные пауки), например, веб-сайты, начинающиеся с Einträgen und Unterseiten abzusuchen. Mithilfe der robots.txt-Datei können Sie steuern, welche Unterseiten Ihrer Website nicht von den Crawlern erfasst und somit auch nicht in den Google-Index aufgenommen werden sollen.Die entsprechenden Seiten erscheinen dann также nicht in den Suchergebnissen. Dies können Sie natürlich nicht nur für Google festlegen, sondern auch für andere suchmaschinen wie Bing, Yahoo und Co.
- Файл Datei robots.txt был улучшен, был создан с помощью таких машин через Google von der eigenen Site angezeigt werden soll.
- WordPress erstellt selbst eine virtuelle robots.txt, die automatisch ausgespielt wird.
- Für die meisten Webmaster sind eigene Ergänzungen sinnvoll.
Der Google-Crawler durchsucht Websites regelmäßig nach neuen Beiträgen zum Indexieren
Erstellt WordPress eine robots.txt-Datei automatisch?
WordPress erstellt eine eigene robots.txt-Datei, solange Sie selbst keine отдельный Datei anlegen. Файл robots.txt от WordPress является надежным и понятным.
- Пользовательский агент: *
- Запретить: / wp-admin /
- Запретить: / wp-includes /
WordPress legt fest, welche suchmaschine ihre Crawler (user-agent) bei Ihrer Site vorbeischickt (das Sternchen steht im Beispielfall für all suchmaschinen) und dass diese komplette Website, bis auf die Verzeichnisse / wp -4 admin / wp- und- und-9016 / , indexieren dürfen.Durch den Befehl «запрещает» вирд дем Bot der Zugriff auf die beiden genannten Verzeichnisse versperrt. Die genannten Standard-Einstellungen sind prinzipiell sinnvoll, denn mit ihnen stellen Sie sicher, dass der Crawler alle Seiten aufrufen kann . Dennoch ist es meist ratsam, für WordPress die robots.txt manuell anzupassen. Denn Unterseiten wie das Impressum müssen nicht bei Google gelistet werden. Auch die Plug-ins sollten nicht in den Suchergebnissen auftauchen. Denn Falls ein Plug-in eine Sicherheitslücke aufweist, ist es für Angreifer ein Leichtes, die Websites zu finden, welche die Erweiterung aktiviert haben.Файл robots.txt sollte также является всем, что нужно знать, был nicht für die Öffentlichkeit bestimmt ist und dem Nutzer in der Google-Anzeige keinen Mehrwert bietet.
В файле robots.txt wird festgelegt было nicht gecrawlt werden sollte
Был ли загружен файл WordPress в robots.txt-Datei?
Jeder Webmaster определяет robots.txt-Datei für WordPress anders, je nach der Seitenstruktur und den eigenen Präferenzen.Das folgende Beispiel gibt aber eine gute Orientierung, da es die wichtigsten Fälle abdeckt:
- Пользовательский агент: Googlebot-Image
- Disallow: Allow: / *
- Пользовательский агент: Mediapartners-Google
- Disallow: Allow: / *
- Агент пользователя: duggmirror
- Disallow: /
- Пользовательский агент: *
- Disallow: / cgi-bin /
- Запретить: / wp-admin /
- Disallow: / wp-includes /
- Запретить: / wp-content / plugins /
- Запретить: / wp-content / cache /
- Запретить: / wp-content / themes /
- Disallow: / trackback /
- Disallow: / feed /
- Disallow: / комментарии /
- Disallow: / category /
- Disallow: / tag /
- Disallow: * / trackback /
- Disallow: * / feed / .
- Disallow: * / comments /
- Disallow: / *?
- Разрешить: / wp-content / uploads /
In den ersten Zeilen unter user-agent wird festgelegt, welchen Bots der Zugang erlaubt wird.Demnach sind die Google-Bildersuche sowie Google Ads erlaubt, duggmirror hingegen ist komplett gesperrt. Пользовательский агент Die Zeile : * drückt aus, dass die folgenden Einschränkungen für all suchmaschinen gelten. In den Zeilen darunter wird unter anderem Definiert, dass das Admin-Verzeichnis ( / wp-admin / ) sowie Plug-ins ( / wp-content / plugins / ) и темы ( / wp-content / themes / ) nicht gelistet werden. Auch die Kommentare, Archive und Feeds werden ausgeschlossen, um das Risiko für Duplicate Content zu verringern.Denn sind Beiträge sowohl auf Ihrer Сайт также находится в einem Extra-Archiv gelistet, kann Google Sie für den doppelten Content abstrafen, sodass sich beispielsweise Ihre Rankings verschlechtern. Das Sternchen in den letzten Befehlen sorgt dafür, dass sämtliche Dateien aus den Verzeichnissen «обратный путь», «канал» и «комментарии» nicht gecrawlt werden. In der vorletzten Zeile legt das Sternchen fest, dass all URLs, die ein Fragezeichen enthalten, nicht indexiert werden sollen. Um dem Google Crawler die Webseitenstruktur zu zeigen, kann man außerdem die Sitemap in die robots.txt-Datei eintragen.
Как оптимизировать файл robots.txt в WordPress?
Сделайте из WordPress файл robots.txt, содержащий wp-functions.php -Datei erstellt und ausgegeben. Änderungen lassen sich mit einem Editor wie Notepad ++ vornehmen. Allerdings werden diese Änderungen bei einem WordPress-Update überschrieben, sodass es zu einer Wiederherstellung der Standardeinstellungen kommt. Sinnvoller ist es, в einem Editor eine neue Datei mit dem Namen robots.txt zu erstellen und diese im Stammverzeichnis (auch Root-Verzeichnis genannt) Ihrer Domain abzuspeichern. Домен Лаутет Ихре также http://www.ihre-beispielseite.de , muss der Pfad für die robots.txt wie folgt aussehen: http://www.ihre-beispielseite.de/robots.txt . Истинные даты первого исходного сообщения, более подробные сведения об автоматическом создании robots.txt-Datei от WordPress.
robots.txt-Datei mit WordPress-Plug-ins erstellen
Bei WordPress gibt es für die Erstellung einer robots.txt noch einen einfacheren Weg, der über Plug-ins führt . Разнообразные плагины для SEO доступны только в файле robots.txt, который находится в Backend erstellen или verändern lässt. Zu den bewährtesten Plug-ins zählt Yoast SEO . Haben Sie die Erweiterung erfolgreich installiert und aktiviert, gelangen Sie über die Menüpunkte «SEO => Werkzeuge» und anschließend mit einem Klick auf «Datei-Editor» и Stelle, который является директивой в WordPress для robots.txt-Datei bearenbeiten k. Mit einem Klick auf «Änderungen in der robots.txt übernehmen «werden Ihre Modifikationen gespeichert und sofort aktiv.
Mit einem Klick auf «Datei-Editor» können Sie die robots.txt в WordPress ändern
Vorsicht: Nicht all Bots halten sich and die robots.txt
Die Verhaltensvorschrift, die in der robots.txt-Datei für WordPress festgelegt wurde, dient den suchmaschinen-Crawlern lediglich als Richtlinie, sie ist nicht bindend .Zwar halten sich die Bots von Google und anderen seriösen suchmaschinen stets an deren Angaben, doch andere Crawler tun dies keineswegs immer. Венн Зие также sichergehen möchten, dass bestimmte Teile Ihrer Website nirgendwo indexiert werden, sollten Sie über andere Blockierungsmethoden nachdenken — zum Beispiel über passwortgeschützte Dateien und Ordner auf Ihrem Server.
Fazit: Optimieren Sie die robots.txt для Ihr WordPress ggf. мануэль
Роботы Mit einer.txt-Datei können Sie genau festlegen, welche Bereiche Ihrer Website von den Crawlern der Susmaschinen aufgesucht werden dürfen und welche gesperrt bleiben. Mittels Individualueller Anpassungen können Sie das Verhalten der Sucmaschinen den Gegebenheiten Ihrer Website anpassen.
- Definieren Sie, welche Unterseiten für Google und andere suchmaschinen gelistet werden sollen.
- Die robots.txt-Datei muss stets im Root-Verzeichnis Ihrer Domain gespeichert werden.
- WordPress-SEO-плагины содержат информацию о файле robots.txt.
Hazır Sistemler İçin robots.txt Dosyaları »SEO Hocası
Derlediğim robots.txt dosyaları hazır sistemler içindir ve emin olabilirsiniz ki alanında en iyi robots.txt dosyalarıdır.
WordPress için Robots.txt
Карта сайта: https://www.seohocasi.com/sitemap.xml
Пользовательский агент: Googlebot
Disallow: / wp-content /
Disallow: / trackback /
Disallow: / wp-admin /
Disallow: / feed /
Disallow: / archives /
Disallow: / index.php
Disallow: /*.php$
Disallow: /*.js$
Disallow: /*.css$
Disallow: * / feed /
Disallow: * / trackback /
Disallow: / page /
Disallow: / tag /
Запрещено: / category /
User-agent: Googlebot-Image
Disallow: / wp-includes /
User-agent: ia_archiver
Disallow: /
User-agent: duggmirror
Disallow: /
MyBB için Robots.txt
Карта сайта: httpz: // seohocasi.ru / sitemap adresiniz User-Agent: *
Disallow: /MyBB/captcha.php
Disallow: /MyBB/editpost.php
Disallow: /MyBB/misc.php
Disallow: /MyBB/modcp.php
Disallow mode: / MyBB / php
Disallow: /MyBB/newreply.php
Disallow: /MyBB/newthread.php
Disallow: /MyBB/online.php
Disallow: /MyBB/printthread.php
Disallow: /MyBB/private.php MyBB / ratethread.php
Запретить: /MyBB/report.php
Запретить: / MyBB / репутация.php
Disallow: /MyBB/sendthread.php
Disallow: /MyBB/task.php
Disallow: /MyBB/usercp.php
Disallow: /MyBB/usercp2.php
Disallow: /MyBPB 90/calendar.php MyBB / * action = emailuser *
Disallow: / MyBB / * action = nextnewest *
Disallow: / MyBB / * action = nextoldest *
Disallow: / MyBB / * year = *
Disallow: / MyBB / * action = weekview *
Disallow: / MyBB / * action = nextnewest *
Disallow: / MyBB / * action = nextoldest *
Disallow: / MyBB / * sort = *
Disallow: / MyBB / * order = *
Disallow: / MyBB / * mode = *
Запретить: / MyBB / * datecut = *
Разрешить: /
vBulletin için Robots.txt
User-agent: *
Disallow: /? ref = User-agent: HTTrack
Disallow: /
User-agent: grub-client
Disallow: /
Агент пользователя: grub
Disallow: /
Агент пользователя: lookmart
Disallow: /
Пользовательский агент: WebZip
Disallow: /
Агент пользователя: larbin
Disallow: /
User-agent: b2w / 0.1
Disallow: /
Пользовательский агент: psbot
Disallow: /
User-agent: Python-urllib
Disallow: /
Пользовательский агент: NetMechanic
Disallow: /
User-agent: URL_Spider_Pro
Disallow: /
Пользовательский агент: CherryPicker
Disallow: /
Пользовательский агент: EmailCollector
Disallow: /
Агент пользователя: EmailSiphon
Disallow: /
Пользовательский агент: WebBandit
Disallow: /
User-agent: EmailWolf
Disallow: /
Агент пользователя: ExtractorPro
Disallow: /
Агент пользователя: CopyRightCheck
Disallow: /
User-agent: Crescent
Disallow: /
Пользовательский агент: SiteSnagger
Disallow: /
Агент пользователя: ProWebWalker
Disallow: /
Агент пользователя: CheeseBot
Disallow: /
Агент пользователя: LNSpiderguy
Disallow: /
User-agent: ia_archiver
Disallow: /
Пользовательский агент: ia_archiver / 1.6
Disallow: /
User-agent: Teleport
Disallow: /
Пользовательский агент: TeleportPro
Disallow: /
Агент пользователя: MIIxpc
Disallow: /
Пользовательский агент: Telesoft
Disallow: /
Пользовательский агент: Веб-сайт Quester
Disallow: /
User-agent: moget / 2.1
Disallow: /
User-agent: WebZip / 4.0
Disallow: /
Пользовательский агент: WebStripper
Disallow: /
Агент пользователя: WebSauger
Disallow: /
User-agent: WebCopier
Disallow: /
Пользовательский агент: NetAnts
Disallow: /
Агент пользователя: Mister PiX
Disallow: /
Агент пользователя: WebAuto
Disallow: /
Агент пользователя: TheNomad
Disallow: /
Агент пользователя: WWW-Collector-E
Disallow: /
User-agent: RMA
Disallow: /
Пользовательский агент: libWeb / clsHTTP
Запрещено: /
User-agent: asterias
Disallow: /
Агент пользователя: httplib
Disallow: /
User-agent: turingos
Disallow: /
Агент пользователя: гаечный ключ
Disallow: /
Агент пользователя: InfoNaviRobot
Disallow: /
Пользовательский агент: Harvest / 1.5
Disallow: /
User-agent: Bullseye / 1.0
Disallow: /
User-agent: Mozilla / 4.0 (совместимый; BullsEye; Windows 95)
Disallow: /
Пользовательский агент: Crescent Internet ToolPak HTTP OLE Control v.1.0
Disallow: /
Пользовательский агент: CherryPickerSE / 1.0
Disallow: /
User-agent: CherryPickerElite / 1.0
Disallow: /
User-agent: WebBandit / 3.50
Disallow: /
Агент пользователя: NICErsPRO
Disallow: /
User-agent: Microsoft URL Control — 5.01.4511
Disallow: /
Пользовательский агент: DittoSpyder
Disallow: /
Пользовательский агент: Foobot
Disallow: /
User-agent: WebmasterWorldForumBot
Disallow: /
Пользовательский агент: SpankBot
Disallow: /
Пользовательский агент: BotALot
Disallow: /
User-agent: lwp-trivial / 1.34
Disallow: /
User-agent: lwp-trivial
Disallow: /
Агент пользователя: BunnySlippers
Disallow: /
User-agent: Microsoft URL Control — 6.00.8169
Disallow: /
User-agent: URLy Warning
Disallow: /
Пользовательский агент: Wget / 1.6
Disallow: /
Пользовательский агент: Wget / 1.5.3
Disallow: /
Пользовательский агент: Wget
Disallow: /
Пользовательский агент: LinkWalker
Disallow: /
Агент пользователя: cosmos
Disallow: /
Агент пользователя: moget
Disallow: /
Пользовательский агент: hloader
Disallow: /
User-agent: humanlinks
Disallow: /
Пользовательский агент: LinkextractorPro
Disallow: /
Пользовательский агент: Offline Explorer
Disallow: /
Агент пользователя: Mata Hari
Disallow: /
Пользовательский агент: LexiBot
Disallow: /
User-agent: Web Image Collector
Disallow: /
User-agent: The Intraformant
Disallow: /
Пользовательский агент: True_Robot / 1.0
Disallow: /
Пользовательский агент: True_Robot
Disallow: /
Пользовательский агент: BlowFish / 1.0
Disallow: /
User-agent: JennyBot
Disallow: /
Агент пользователя: MIIxpc / 4.2
Disallow: /
Агент пользователя: BuiltBotTough
Disallow: /
User-agent: ProPowerBot / 2.14
Disallow: /
Пользовательский агент: BackDoorBot / 1.0
Disallow: /
Пользовательский агент: toCrawl / UrlDispatcher
Disallow: /
Пользовательский агент: WebEnhancer
Disallow: /
Агент пользователя: suzuran
Disallow: /
Агент пользователя: VCI WebViewer VCI WebViewer Win32
Disallow: /
Агент пользователя: VCI
Disallow: /
Агент пользователя: Szukacz / 1.4
Disallow: /
User-agent: QueryN Metasearch
Disallow: /
Пользовательский агент: сбор данных Openfind
Disallow: /
Агент пользователя: Openfind
Disallow: /
Пользовательский агент: Xenu’s Link Sleuth 1.1c
Disallow: /
Пользовательский агент: Xenu’s
Disallow: /
Пользовательский агент: Zeus
Disallow: /
Пользовательский агент: RepoMonkey Bait & amp; Tackle / v1.01
Disallow: /
Пользовательский агент: RepoMonkey
Disallow: /
User-agent: Microsoft URL Control
Disallow: /
Пользовательский агент: Openbot
Disallow: /
User-agent: URL Control
Disallow: /
Пользовательский агент: Zeus Link Scout
Disallow: /
Агент пользователя: Zeus 32297 Webster Pro V2.9 Win32
Запрещено: /
Агент пользователя: Webster Pro
Disallow: /
Агент пользователя: EroCrawler
Disallow: /
User-agent: LinkScan / 8.1a Unix
Disallow: /
User-agent: Keyword Density / 0.9
Disallow: /
Агент пользователя: Kenjin Spider
Disallow: /
User-agent: Iron33 / 1.0.2
Disallow: /
User-agent: Инструмент поиска по закладкам
Disallow: /
Пользовательский агент: GetRight / 4.2
Disallow: /
User-agent: FairAd Client
Disallow: /
Пользовательский агент: Gaisbot
Disallow: /
Агент пользователя: Aqua_Products
Disallow: /
Пользовательский агент: Radiation Retriever 1.1
Disallow: /
User-agent: Flaming AttackBot
Disallow: /
Пользовательский агент: Oracle Ultra Search
Disallow: /
User-agent: MSIECrawler
Disallow: /
Агент пользователя: PerMan
Disallow: /
User-agent: searchpreview
Disallow: /
vBulletin için 2. Robots.txt
User-agent: *
Disallow: / admincp /
Disallow: / chat /
Disallow: / tags
Disallow: / архив
Disallow: / ajax.php
Disallow: / forum
Disallow: / clientscript /
Disallow: / cpstyles /
Disallow: / images /
Disallow: / flash /
Disallow: / includes /
Disallow: / install /
Disallow: / modcp /
Disallow : / subscriptions /
Disallow: / customavatars /
Disallow: / customprofilepics /
Disallow: /announcement.php
Disallow: /attachment.php
Disallow: /calendar.php
Disallow: /cron.php
Disallow. php
Disallow: /external.php
Disallow: / faq.php
Disallow: / frm_attach
Disallow: /image.php
Disallow: /inlinemod.php
Disallow: /joinrequests.php
Disallow: /login.php
Disallow: /memberlist.php
Disallow: /misc.php : /moderator.php
Disallow: /newattachment.php
Disallow: /newreply.php
Disallow: /newthread.php
Disallow: /online.php
Disallow: /payment_gateway.php
Disallow: /payments.php /poll.php
Запрещено: /postings.php
Запрещено: / private.php
Disallow: /profile.php
Disallow: /register.php
Disallow: /report.php
Disallow: /reputation.php
Disallow: /search.php
Disallow: /sendmessage.php
Disallow: /showgwg
Disallow: /showpost.php
Disallow: /subscription.php
Disallow: /usercp.php
Disallow: /threadrate.php
Disallow: /usernote.php
Disallow: /showthread.php
Disallow.php Запрещено: /vbSEOcp.php
Запрещено: /vbSEOcpform.php
SMF için Robots.txt
User-agent: *
Disallow: / admin /
Disallow: / adsystem /
için SMF 2. Robots.txt
Агент пользователя: Slurp
Задержка сканирования: 8
Агент пользователя: msnbot
Задержка сканирования: 5
Агент пользователя: nutch
Задержка сканирования: 5
Агент пользователя: yeti
Задержка сканирования: 8
Агент пользователя: Yeti / 1.0
Задержка сканирования: 8
User-agent: naverbot
Crawl-delay: 8
Агент пользователя: Googlebot
Задержка сканирования: 5
User-agent: dotbot
Crawl-delay: 5
Агент пользователя: удвоитель
Задержка сканирования: 8
User-agent: yandex
Crawl-delay: 5
Агент пользователя: Teoma
Задержка сканирования: 5
Агент пользователя: BoardReader
Задержка сканирования: 8
Агент пользователя: Exabot
Задержка сканирования: 10
PhpBB için Robots.txt. / форумы / шаблоны /
Запретить: /forums/common.php
Запретить: /forums/config.php
Запретить: /forums/groupcp.php
Запретить: /forums/memberlist.php
Запретить: /forums/modcp.php
Запрещает: /forums/posting.php
Запрещает: /forums/profile.php
Запрещает: / форумы / privmsg.php
Disallow: /forums/viewonline.php
Disallow: /forums/search.php
Disallow: /forums/faq.php
Управление файлами Robots.txt и Sitemap
- 7 минут на чтение
В этой статье
Руслана Якушева
Набор средств поисковой оптимизации IIS включает в себя функцию исключения роботов , которую можно использовать для управления содержимым роботов.txt для вашего веб-сайта и включает в себя функцию Sitemaps и Sitemap Indexes , которые вы можете использовать для управления картами сайта вашего сайта. В этом пошаговом руководстве объясняется, как и зачем использовать эти функции.
Фон
Поисковые роботыбудут тратить на ваш веб-сайт ограниченное время и ресурсы. Поэтому очень важно сделать следующее:
- Запретить поисковым роботам индексировать контент, который не важен или который не должен отображаться на страницах результатов поиска.
- Направьте поисковые роботы на контент, который вы считаете наиболее важным для индексации.
Существует два протокола, которые обычно используются для решения этих задач: протокол исключения роботов и протокол Sitemap.
Протокол исключения роботов используется для указания сканерам поисковых систем, какие URL-адреса НЕ следует запрашивать при сканировании веб-сайта. Инструкции по исключению помещаются в текстовый файл с именем Robots.txt, который находится в корне веб-сайта.Большинство поисковых роботов обычно ищут этот файл и следуют содержащимся в нем инструкциям.
Протокол Sitemaps используется для информирования сканеров поисковых систем об URL-адресах, доступных для сканирования на вашем веб-сайте. Кроме того, файлы Sitemap используются для предоставления некоторых дополнительных метаданных об URL-адресах сайта, таких как время последнего изменения, частота изменений, относительный приоритет и т. Д. Поисковые системы могут использовать эти метаданные при индексировании вашего веб-сайта.
Предварительные требования
1.Настройка веб-сайта или приложения
Для выполнения этого пошагового руководства вам понадобится размещенный веб-сайт IIS 7 или выше или веб-приложение, которым вы управляете. Если у вас его нет, вы можете установить его из галереи веб-приложений Microsoft. В этом пошаговом руководстве мы будем использовать популярное приложение для ведения блогов DasBlog.
2. Анализ веб-сайта
Если у вас есть веб-сайт или веб-приложение, вы можете проанализировать его, чтобы понять, как обычная поисковая машина будет сканировать его содержимое.Для этого выполните действия, описанные в статьях «Использование анализа сайта для сканирования веб-сайта» и «Использование отчетов анализа сайта». Когда вы проведете свой анализ, вы, вероятно, заметите, что у вас есть определенные URL-адреса, которые доступны для сканирования поисковыми системами, но что нет никакой реальной пользы от их сканирования или индексации. Например, страницы входа или страницы ресурсов даже не должны запрашиваться сканерами поисковых систем. Подобные URL-адреса следует скрыть от поисковых систем, добавив их в файл Robots.txt файл.
Управление файлом Robots.txt
Вы можете использовать функцию исключения роботов IIS SEO Toolkit для создания файла Robots.txt, который сообщает поисковым системам, какие части веб-сайта не должны сканироваться или индексироваться. Следующие шаги описывают, как использовать этот инструмент.
- Откройте консоль управления IIS, набрав INETMGR в меню «Пуск».
- Перейдите на свой веб-сайт, используя древовидное представление с левой стороны (например, веб-сайт по умолчанию).
- Щелкните значок Search Engine Optimization в разделе «Управление»:
- На главной странице SEO щелкните ссылку задачи « Добавить новое правило запрета » в разделе Исключение роботов .
Добавление запрещающих и разрешающих правил
Диалоговое окно «Добавить запрещающие правила» откроется автоматически:
Протокол исключения роботовиспользует директивы «Разрешить» и «Запрещать», чтобы информировать поисковые системы о путях URL, которые можно сканировать, и о тех, которые нельзя сканировать.Эти директивы могут быть указаны для всех поисковых систем или для определенных пользовательских агентов, идентифицированных HTTP-заголовком пользовательского агента. В диалоговом окне «Добавить запрещающие правила» вы можете указать, к какому искателю поисковой системы применяется директива, введя пользовательский агент искателя в поле «Робот (пользовательский агент)».
Дерево пути URL-адреса используется для выбора запрещенных URL-адресов. Вы можете выбрать один из нескольких вариантов при выборе путей URL с помощью раскрывающегося списка «Структура URL»:
- Физическое расположение — вы можете выбрать пути из физического макета файловой системы вашего веб-сайта.
- Из анализа сайта (название анализа) — вы можете выбрать пути из виртуальной структуры URL-адресов, которая была обнаружена при анализе сайта с помощью инструмента анализа сайта IIS.
- <Запустить новый анализ сайта ...> — вы можете запустить новый анализ сайта, чтобы получить виртуальную структуру URL-адресов для вашего веб-сайта, а затем выбрать оттуда пути URL.
После выполнения шагов, описанных в разделе предварительных требований, вам будет доступен анализ сайта. Выберите анализ в раскрывающемся списке, а затем проверьте URL-адреса, которые необходимо скрыть от поисковых систем, установив флажки в дереве «Пути URL-адресов»:
После выбора всех каталогов и файлов, которые необходимо запретить, нажмите OK.Вы увидите новые запрещающие записи в главном окне функций:
Также будет обновлен файл Robots.txt для сайта (или создан, если он не существует). Его содержимое будет выглядеть примерно так:
Агент пользователя: *
Запретить: /EditConfig.aspx
Запретить: /EditService.asmx/
Запретить: / images /
Запретить: /Login.aspx
Запретить: / scripts /
Запретить: /SyndicationService.asmx/
Чтобы увидеть, как работает Robots.txt, вернитесь к функции анализа сайта и повторно запустите анализ для сайта.На странице «Сводка отчетов» в категории Links выберите Links Blocked by Robots.txt . В этом отчете будут отображены все ссылки, которые не были просканированы, поскольку они были запрещены только что созданным файлом Robots.txt.
Управление файлами Sitemap
Вы можете использовать функцию Sitemap и Sitemap Indexes IIS SEO Toolkit для создания карт сайта на своем веб-сайте, чтобы информировать поисковые системы о страницах, которые следует сканировать и проиндексировать.Для этого выполните следующие действия:
- Откройте диспетчер IIS, набрав INETMGR в меню Start .
- Перейдите на свой веб-сайт с помощью древовидной структуры слева.
- Щелкните значок Search Engine Optimization в разделе «Управление»:
- На главной странице SEO щелкните ссылку задачи « Создать новую карту сайта » в разделе «Карты сайта и Индексы ».
- Диалоговое окно Добавить карту сайта откроется автоматически.
- Введите имя файла карты сайта и нажмите ОК . Откроется диалоговое окно Добавить URL-адреса .
Добавление URL-адресов в карту сайта
Диалоговое окно Добавить URL-адреса выглядит следующим образом:
Файл Sitemap — это, по сути, простой XML-файл, в котором перечислены URL-адреса вместе с некоторыми метаданными, такими как частота изменений, дата последнего изменения и относительный приоритет. Используйте диалоговое окно Добавить URL-адреса для добавления новых записей URL-адресов в XML-файл Sitemap.Каждый URL-адрес в карте сайта должен иметь полный формат URI (т.е. он должен включать префикс протокола и имя домена). Итак, первое, что вам нужно указать, — это домен, который будет использоваться для URL-адресов, которые вы собираетесь добавить в карту сайта.
Древовидное представление пути URL-адреса используется для выбора URL-адресов, которые следует добавить в карту сайта для индексации. Вы можете выбрать один из нескольких вариантов, используя раскрывающийся список «Структура URL»:
- Физическое расположение — вы можете выбрать URL-адреса из структуры физической файловой системы вашего веб-сайта.
- Из анализа сайта (название анализа) — вы можете выбрать URL-адреса из виртуальной структуры URL-адресов, которая была обнаружена при анализе сайта с помощью инструмента анализа сайта.
- <Запустить новый анализ сайта ...> — вы можете запустить новый анализ сайта, чтобы получить виртуальную структуру URL-адресов для вашего веб-сайта, а затем выбрать оттуда URL-пути, которые вы хотите добавить для индексации.
После того, как вы выполнили шаги, указанные в разделе предварительных требований, вам будет доступен анализ сайта.Выберите его из раскрывающегося списка, а затем проверьте URL-адреса, которые необходимо добавить в карту сайта.
При необходимости измените параметры Частота изменения , Дата последнего изменения и Приоритет , а затем нажмите ОК , чтобы добавить URL-адреса в карту сайта. Файл sitemap.xml будет обновлен (или создан, если он не существует), и его содержимое будет выглядеть следующим образом:
http: // myblog / 2009/03/11 / Поздравляю, вы установилиDasBlogWithWebDeploy.aspx
2009-06-03T16: 05: 02
еженедельно
0,5
http: //myblog/2009/06/02/ASPNETAndURLRewriting.aspx
2009-06-03T16: 05: 01
еженедельно
0,5
Добавление местоположения карты сайта в файл Robots.txt файл
Теперь, когда вы создали карту сайта, вам нужно сообщить поисковым системам, где она находится, чтобы они могли начать ее использовать. Самый простой способ сделать это — добавить URL-адрес карты сайта в файл Robots.txt.
В функции Sitemaps и Sitemap Indexes выберите только что созданную карту сайта, а затем щелкните Добавить в Robots.txt на панели Действия :
Ваш файл Robots.txt будет выглядеть примерно так:
Агент пользователя: *
Запретить: / EditService.asmx /
Запретить: / images /
Запретить: / scripts /
Запретить: /SyndicationService.asmx/
Запретить: /EditConfig.aspx
Запретить: /Login.aspx
Карта сайта: http: //myblog/sitemap.xml
Регистрация карты сайта в поисковых системах
Помимо добавления местоположения карты сайта в файл Robots.txt, рекомендуется отправить URL-адрес карты сайта в основные поисковые системы. Это позволит вам получать полезный статус и статистику о вашем веб-сайте с помощью инструментов для веб-мастеров поисковой системы.
Резюме
В этом пошаговом руководстве вы узнали, как использовать функции исключения роботов и файлов Sitemap и Sitemap Indexes набора инструментов поисковой оптимизации IIS для управления файлами Robots.txt и Sitemap на вашем веб-сайте. IIS Search Engine Optimization Toolkit предоставляет интегрированный набор инструментов, которые работают вместе, чтобы помочь вам создать и проверить правильность файлов Robots.txt и карты сайта, прежде чем поисковые системы начнут их использовать.
Страницы веб-роботов
О / robots.txt
В двух словах
Владельцы веб-сайтов используют файл /robots.txt для получения инструкций по их сайт для веб-роботов; это называется Исключение роботов Протокол .
Это работает так: робот хочет перейти по URL-адресу веб-сайта, скажем, http://www.example.com/welcome.html. Прежде чем это произойдет, он первым проверяет http://www.example.com/robots.txt и находит:
Агент пользователя: * Запретить: /
«User-agent: *» означает, что этот раздел применим ко всем роботам.»Disallow: /» сообщает роботу, что он не должен посещать никакие страницы на сайте.
При использовании /robots.txt следует учитывать два важных момента:
- роботы могут игнорировать ваш /robots.txt. Особенно вредоносные роботы, сканирующие Интернет на наличие уязвимостей безопасности и сборщики адресов электронной почты, используемые спамерами. не обращаю внимания.
- файл /robots.txt является общедоступным. Все могут видеть, какие разделы вашего сервера вы не хотите, чтобы роботы использовали.
Так что не пытайтесь использовать /robots.txt для сокрытия информации.
Смотрите также:
Детали
/Robots.txt является стандартом де-факто и не принадлежит никому орган по стандартизации. Есть два исторических описания:
Вдобавок есть внешние ресурсы:
Стандарт /robots.txt активно не развивается. См. Как насчет дальнейшего развития /robots.txt? для более подробного обсуждения.
На оставшейся части этой страницы дается обзор того, как использовать / robots.txt на ваш сервер, с несколькими простыми рецептами. Чтобы узнать больше, смотрите также FAQ.
Как создать файл /robots.txt
Куда девать
Краткий ответ: в каталоге верхнего уровня вашего веб-сервера.
Более длинный ответ:
Когда робот ищет URL-адрес в файле «/robots.txt», он удаляет компонент пути из URL-адреса (все, начиная с первой косой черты), и помещает на его место «/robots.txt».
Например, для http: // www.example.com/shop/index.html, он будет удалите «/shop/index.html» и замените его на «/robots.txt», и в итоге будет «http://www.example.com/robots.txt».
Итак, как владельцу веб-сайта вам необходимо поместить его в нужное место на своем веб-сервер для работы полученного URL. Обычно это то же самое место, куда вы помещаете главный «index.html» вашего веб-сайта страница. Где именно это и как поместить файл, зависит от программное обеспечение вашего веб-сервера.
Не забудьте использовать строчные буквы для имени файла: «роботы.txt », а не« Robots.TXT.
Смотрите также:
Что туда класть
Файл «/robots.txt» — это текстовый файл с одной или несколькими записями. Обычно содержит одну запись следующего вида:Пользовательский агент: * Disallow: / cgi-bin / Запрещение: / tmp / Запретить: / ~ joe /
В этом примере исключены три каталога.
Обратите внимание, что для каждого префикса URL-адреса вам нужна отдельная строка «Запретить». хотите исключить — нельзя сказать «Disallow: / cgi-bin / / tmp /» на одна линия.Кроме того, в записи может не быть пустых строк, поскольку они используются для разграничения нескольких записей.
Также обратите внимание, что подстановка и регулярное выражение не поддерживается ни в User-agent, ни в Disallow линий. ‘*’ В поле User-agent — это специальное значение, означающее «любой робот «. В частности, у вас не может быть таких строк, как» User-agent: * bot * «, «Запрещать: / tmp / *» или «Запрещать: * .gif».
Что вы хотите исключить, зависит от вашего сервера. Все, что не запрещено явно, считается справедливым игра для извлечения.Вот несколько примеров:
Чтобы исключить всех роботов со всего сервера
Пользовательский агент: * Запретить: /
Разрешить всем роботам полный доступ
Пользовательский агент: * Запретить:
(или просто создайте пустой файл «/robots.txt», или не используйте его вообще)
Чтобы исключить всех роботов из части сервера
Пользовательский агент: * Disallow: / cgi-bin / Запрещение: / tmp / Disallow: / junk /
Для исключения одного робота
Пользовательский агент: BadBot Запретить: /
Чтобы позволить одному роботу
Пользовательский агент: Google Запретить: Пользовательский агент: * Запретить: /
Для исключения всех файлов, кроме одного
В настоящее время это немного неудобно, поскольку нет поля «Разрешить».В простой способ — поместить все файлы, которые нельзя разрешить, в отдельный директорию, скажите «вещи» и оставьте один файл на уровне выше этот каталог:Пользовательский агент: * Запретить: / ~ joe / stuff /В качестве альтернативы вы можете явно запретить все запрещенные страницы:
Пользовательский агент: * Запретить: /~joe/junk.html Запретить: /~joe/foo.html Запретить: /~joe/bar.html
Как добавить собственный файл Robots.txt в Blogger?
В одном из моих предыдущих постов я обсуждал настройки пользовательских тегов заголовков роботов для blogger.
Если вы читали этот пост, то я надеюсь, что вы, ребята, знаете о его важности в поисковом рейтинге.
Сегодня я вернулся с очень полезным и обязательным для ведения блогов термином Robots.txt.
В blogger он известен как Custom Robots.txt, что означает, что теперь вы можете настроить этот файл по своему усмотрению.
В сегодняшнем руководстве мы подробно обсудим этот термин и узнаем о его использовании и преимуществах. Я также расскажу, как добавить в blogger собственный файл robots.txt.
Итак, приступим к руководству.
Подробнее…
Что такое Robots.txt?
Robots.txt — это текстовый файл, содержащий несколько строк простого кода.
Он сохраняется на веб-сайте или на сервере блога, который инструктирует поисковые роботы о том, как индексировать и сканировать ваш блог в результатах поиска.
Это означает, что вы можете запретить поисковым роботам любую веб-страницу своего блога, чтобы она не могла индексироваться в поисковых системах, таких как страница ярлыков вашего блога, демонстрационная страница или любые другие страницы, которые не так важны для индексации.
Всегда помните, что поисковые роботы сканируют файл robots.txt перед сканированием любой веб-страницы.
Каждый блог, размещенный на blogger, имеет свой файл robots.txt по умолчанию, который выглядит примерно так:
Пользовательский агент: Mediapartners-Google
Disallow:
Пользовательский агент: *
Disallow: / search
Разрешить: /
Sitemap: http://example.blogspot.com/feeds/posts/default?orderby=UPDATED
Пояснение
Этот код разделен на три части.Давайте сначала изучим каждый из них, после чего мы узнаем, как добавить собственный файл robots.txt в блоги blogspot.
Агент пользователя: Mediapartners-Google
Этот код предназначен для роботов Google AdSense, которые помогают им размещать более качественную рекламу в вашем блоге. Либо вы используете Google AdSense в своем блоге, либо просто не оставляете его как есть.
Агент пользователя: *
Это для всех роботов, отмеченных звездочкой (*). В настройках по умолчанию ссылки ярлыков нашего блога могут индексироваться только поисковыми роботами, что означает, что веб-сканеры не будут индексировать ссылки на наши страницы ярлыков из-за кода ниже.
Disallow: / search
Это означает, что ссылки с ключевым словом search сразу после доменного имени будут игнорироваться. См. Ниже пример, который представляет собой ссылку на страницу ярлыка с именем SEO.
http://www.bloggertipstricks.com/search/label/SEO
И если мы удалим Disallow: / search из приведенного выше кода, то сканеры получат доступ ко всему нашему блогу для индексации и сканирования всего его содержания и веб-страниц.
Здесь Разрешить: / относится к домашней странице, что означает, что поисковые роботы могут сканировать и индексировать домашнюю страницу нашего блога.
Запретить определенный пост
Теперь предположим, что если мы хотим исключить конкретное сообщение из индексации, мы можем добавить следующие строки в код.
Disallow: /yyyy/mm/post-url.html
Здесь гггг и мм относятся к году публикации и месяцу публикации соответственно. Например, если мы опубликовали сообщение в 2013 году в марте месяце, мы должны использовать следующий формат.
Disallow: /2013/03/post-url.html
Чтобы упростить эту задачу, вы можете просто скопировать URL-адрес сообщения и удалить имя блога с самого начала.
Запретить определенную страницу
Если нам нужно запретить определенную страницу, мы можем использовать тот же метод, что и выше. Просто скопируйте URL-адрес страницы и удалите из него адрес блога, который будет выглядеть примерно так:
Запрещено: /p/page-url.html
Sitemap: http://example.blogspot.com/feeds/posts/default?orderby=UPDATED
Этот код относится к карте сайта нашего блога. Добавляя сюда ссылку на карту сайта, мы просто оптимизируем скорость сканирования нашего блога.
Означает, что каждый раз поисковые роботы просматривают наших роботов.txt они найдут путь к нашей карте сайта, где присутствуют все ссылки на наши опубликованные сообщения.
Поисковым роботамбудет легко сканировать все наши сообщения.
Следовательно, у веб-сканеров больше шансов просканировать все наши сообщения в блоге, не игнорируя ни одного.
Примечание : Эта карта сайта будет сообщать поисковым роботам только о последних 25 сообщениях. Если вы хотите увеличить количество ссылок в своей карте сайта, замените карту сайта по умолчанию на одну ниже.Он будет работать для первых 500 последних сообщений.
Карта сайта: http://example.blogspot.com/atom.xml?redirect=false&start-index=1&max-results=500
Если в вашем блоге опубликовано более 500 сообщений, вы можете использовать две карты сайта, как показано ниже:
Карта сайта: http://example.blogspot.com/atom.xml?redirect=false&start-index=1&max-results=500Карта сайта: http://example.blogspot.com/atom.xml?redirect=false&start-index=500&max -результаты = 1000
Добавление собственных роботов.Txt в Blogger
Теперь основная часть этого руководства — как добавить собственный файл robots.txt в blogger. Ниже приведены шаги по его добавлению.
- Зайдите в блог блоггера.
- Перейдите в Настройки >> Настройки поиска ›› Сканеры и индексирование ›› Пользовательский файл robots.txt ›› Редактировать ›› Да
- Теперь вставьте код файла robots.txt в это поле.
- Нажмите кнопку «Сохранить изменения».
- Готово!
Как проверить своих роботов.txt файл?
Вы можете проверить этот файл в своем блоге, добавив /robots.txt в конец URL-адреса вашего блога в веб-браузере. Например:
http://www.yourblogurl.blogspot.com/ robots.txt
После перехода по URL-адресу файла robots.txt вы увидите весь код, который вы используете в своем пользовательском файле robots.txt.
См. Изображение ниже.
Заключительное слово!
Это был сегодняшний полный учебник по , как добавлять собственных роботов.txt в blogger .
Я изо всех сил старался сделать это руководство как можно более простым и информативным. Но все же, если у вас есть какие-либо сомнения или вопросы, не стесняйтесь спрашивать меня в разделе комментариев ниже.
Убедитесь, что вы не добавляете код в пользовательские настройки robots.txt, не зная об этом.