Создаем правильный robots.txt для wordpress для Яндекса и Google
Автор Антонио с WPbiz.ru На чтение 3 мин Просмотров 9 Обновлено
Привет, Веб-мастер! Сегодня создадим на 100% правильный robots.txt для вордпресс. Он учитывает все нюансы CMS, так же разграничивает Яндекс и Google — они получают каждый свой фрагмент.
Содержание
- Скачать идеальный robots.txt для WordPress
- Содержание файла robots.txt
- Как проверить правильность robots.txt в Яндексе и Google
Скачать идеальный robots.txt для WordPress
Собственно сам файл
Скачать robots.txt
Не забудьте заменить URL в host на свой домен!
Содержание файла robots.txt
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 | User-agent: * Disallow: /cgi-bin Disallow: /? Disallow: /wp- Disallow: /wp/ Disallow: *?s= Disallow: *&s= Disallow: /search/ Disallow: /author/ Disallow: /users/ Disallow: */trackback Disallow: */feed Disallow: */rss Disallow: */embed Disallow: /xmlrpc. |
 php
Disallow: *utm=
Disallow: *openstat=
Disallow: /tag/
Disallow: /readme.html
Disallow: *?replytocom
Allow: */uploads
Allow: /*/*.js
Allow: /*/*.css
Allow: /wp-*.png
Allow: /wp-*.jpg
Allow: /wp-*.jpeg
Allow: /wp-*.gif
Allow: /wp-*.pdf
Allow: /wp-*.webp
Allow: /wp-*.svg
User-agent: GoogleBot
Disallow: /cgi-bin
Disallow: /?
Disallow: /wp-
Disallow: *?s=
Disallow: *&s=
Disallow: /search/
Disallow: /author/
Disallow: /users/
Disallow: */trackback
Disallow: */feed
Disallow: */rss
Disallow: */embed
Disallow: /xmlrpc.php
Disallow: *utm=
Disallow: *openstat=
Disallow: /tag/
Disallow: /readme.html
Disallow: *?replytocom
Allow: */uploads
Allow: /*/*.js
Allow: /*/*.css
Allow: /wp-*.png
Allow: /wp-*.jpg
Allow: /wp-*.jpeg
Allow: /wp-*.gif
Allow: /wp-*.pdf
Allow: /wp-*.webp
Allow: /wp-*.
php
Disallow: *utm=
Disallow: *openstat=
Disallow: /tag/
Disallow: /readme.html
Disallow: *?replytocom
Allow: */uploads
Allow: /*/*.js
Allow: /*/*.css
Allow: /wp-*.png
Allow: /wp-*.jpg
Allow: /wp-*.jpeg
Allow: /wp-*.gif
Allow: /wp-*.pdf
Allow: /wp-*.webp
Allow: /wp-*.svg
User-agent: GoogleBot
Disallow: /cgi-bin
Disallow: /?
Disallow: /wp-
Disallow: *?s=
Disallow: *&s=
Disallow: /search/
Disallow: /author/
Disallow: /users/
Disallow: */trackback
Disallow: */feed
Disallow: */rss
Disallow: */embed
Disallow: /xmlrpc.php
Disallow: *utm=
Disallow: *openstat=
Disallow: /tag/
Disallow: /readme.html
Disallow: *?replytocom
Allow: */uploads
Allow: /*/*.js
Allow: /*/*.css
Allow: /wp-*.png
Allow: /wp-*.jpg
Allow: /wp-*.jpeg
Allow: /wp-*.gif
Allow: /wp-*.pdf
Allow: /wp-*.webp
Allow: /wp-*.
Директива host убрана, как давно неработающая ни в Яндексе, ни в Гугле.
Как проверить правильность robots.txt в Яндексе и Google
Для проверки рекомендую использовать встроенные инструменты в вебмастере (в разделе «инструменты» — «Анализ robots. txt«) и в google console: https://www.google.com/webmasters/tools/robots-testing-tool.
txt«) и в google console: https://www.google.com/webmasters/tools/robots-testing-tool.
Антонио с WPbiz.ru
Манимейкер в сети с 2008 года
Подпишись
Не уверен, что нужно описывать каждую строчку. Пишите в комментариях — если нужно будет добавлю!
А если у вас остались вопросы — задавайте, с радостью отвечу!
Удачи!
Правильный robots.txt для WordPress
АвторЕвгений Лукин
Оригинал статьи в блоге Дениса Биштейнова https://seogio.ru/robots-txt-dlya-wordpress/
Ниже привожу короткий и расширенный вариант. Короткий не включает отдельные блоки для Google и Яндекса. Расширенный уже менее актуален, т.к. теперь нет принципиальных особенностей между двумя крупными поисковиками: обеим системам нужно индексировать файлы скриптов и изображений, обе не поддерживают директиву Host. Тем не менее, если в этом мире снова что-то изменится, либо вам потребуется все-таки как-то по-отдельному управлять индексацией файлов на сайте Яндексом и Гугл, сохраню в этой статье и второй вариант.
Еще раз обращаю внимание, что это базовый файл robots.txt. В каждом конкретном случае нужно смотреть реальный сайт и по-необходимости вносить корректировки. Поручайте это дело опытным специалистам!
Короткий вариант (оптимальный)
User-agent: * # общие правила для роботов, кроме Яндекса и Google, # т.к. для них правила ниже Disallow: /cgi-bin # папка на хостинге Disallow: /? # все параметры запроса на главной Disallow: /wp- # все файлы WP: /wp-json/, /wp-includes, /wp-content/plugins Disallow: /wp/ # если есть подкаталог /wp/, где установлена CMS (если нет, # правило можно удалить) Disallow: *?s= # поиск Disallow: *&s= # поиск Disallow: /search/ # поиск Disallow: /author/ # архив автора Disallow: /users/ # архив авторов Disallow: */trackback # трекбеки, уведомления в комментариях о появлении открытой # ссылки на статью Disallow: */feed # все фиды Disallow: */rss # rss фид Disallow: */embed # все встраивания Disallow: */wlwmanifest. xml # xml-файл манифеста Windows Live Writer (если не используете, # правило можно удалить) Disallow: /xmlrpc.php # файл WordPress API Disallow: *utm*= # ссылки с utm-метками Disallow: *openstat= # ссылки с метками openstat Allow: */uploads # открываем папку с файлами uploads # Укажите один или несколько файлов Sitemap (дублировать для каждого User-agent # не нужно). Google XML Sitemap создает 2 карты сайта, как в примере ниже. Sitemap: http://site.ru/sitemap.xml Sitemap: http://site.ru/sitemap.xml.gz # Укажите главное зеркало сайта, как в примере ниже (с WWW / без WWW, если HTTPS # то пишем протокол, если нужно указать порт, указываем). Команда стала необязательной. Ранее Host понимал # Яндекс и Mail.RU. Теперь все основные поисковые системы команду Host не учитывают. Host: www.site.ru

Расширенный вариант (отдельные правила для Google и Яндекса)
User-agent: * # общие правила для роботов, кроме Яндекса и Google,
# т.
к. для них правила ниже
Disallow: /cgi-bin # папка на хостинге
Disallow: /? # все параметры запроса на главной
Disallow: /wp- # все файлы WP: /wp-json/, /wp-includes, /wp-content/plugins
Disallow: /wp/ # если есть подкаталог /wp/, где установлена CMS (если нет,
# правило можно удалить)
Disallow: *?s= # поиск
Disallow: *&s= # поиск
Disallow: /search/ # поиск
Disallow: /author/ # архив автора
Disallow: /users/ # архив авторов
Disallow: */trackback # трекбеки, уведомления в комментариях о появлении открытой
# ссылки на статью
Disallow: */feed # все фиды
Disallow: */rss # rss фид
Disallow: */embed # все встраивания
Disallow: */wlwmanifest.xml # xml-файл манифеста Windows Live Writer (если не используете,
# правило можно удалить)
Disallow: /xmlrpc.php # файл WordPress API
Disallow: *utm*= # ссылки с utm-метками
Disallow: *openstat= # ссылки с метками openstat
Allow: */uploads # открываем папку с файлами uploads
Disallow: /*attachment*
Disallow: /cart # для WooCommerce
Disallow: /checkout # для WooCommerce
Disallow: *?filter* # для WooCommerce
Disallow: *?add-to-cart* # для WooCommerce
Clean-param: add-to-cart # для WooCommerce
User-agent: GoogleBot # правила для Google (комментарии не дублирую)
Disallow: /cgi-bin
Disallow: /?
Disallow: /wp-
Disallow: /wp/
Disallow: *?s=
Disallow: *&s=
Disallow: /search/
Disallow: /author/
Disallow: /users/
Disallow: */trackback
Disallow: */feed
Disallow: */rss
Disallow: */embed
Disallow: */wlwmanifest.
xml
Disallow: /xmlrpc.php
Disallow: *utm*=
Disallow: *openstat=
Allow: */uploads
Allow: /*/*.js # открываем js-скрипты внутри /wp- (/*/ - для приоритета)
Allow: /*/*.css # открываем css-файлы внутри /wp- (/*/ - для приоритета)
Allow: /wp-*.png # картинки в плагинах, cache папке и т.д.
Allow: /wp-*.jpg # картинки в плагинах, cache папке и т.д.
Allow: /wp-*.jpeg # картинки в плагинах, cache папке и т.д.
Allow: /wp-*.gif # картинки в плагинах, cache папке и т.д.
Allow: /wp-admin/admin-ajax.php # используется плагинами, чтобы не блокировать JS и CSS
User-agent: Yandex # правила для Яндекса (комментарии не дублирую)
Disallow: /cgi-bin
Disallow: /?
Disallow: /wp-
Disallow: /wp/
Disallow: *?s=
Disallow: *&s=
Disallow: /search/
Disallow: /author/
Disallow: /users/
Disallow: */trackback
Disallow: */feed
Disallow: */rss
Disallow: */embed
Disallow: */wlwmanifest.xml
Disallow: /xmlrpc.php
Allow: */uploads
Allow: /*/*.js
Allow: /*/*.
В примере я не добавляю правило Crawl-Delay, т.к. в большинстве случаев эта директива не нужна. Однако если у вас крупный нагруженный ресурс, то использование этой директивы поможет снизить нагрузку на сайт со стороны роботов Яндекса, Mail.Ru, Bing, Yahoo и других (Google не учитывает).
Однако если у вас крупный нагруженный ресурс, то использование этой директивы поможет снизить нагрузку на сайт со стороны роботов Яндекса, Mail.Ru, Bing, Yahoo и других (Google не учитывает).
Ошибочные рекомендации
- Использовать правила только для User-agent: *
Для многих поисковых систем не требуется индексация JS и CSS для улучшения ранжирования, кроме того, для менее значимых роботов вы можете настроить большее значение Crawl-Delay и снизить за их счет нагрузку на ваш сайт. - Прописывание Sitemap после каждого User-agent
Это делать не нужно. Один sitemap должен быть указан один раз в любом месте файла robots.txt - Закрыть папки wp-content, wp-includes, cache, plugins, themes
Это устаревшие требования. Для Яндекса и Google лучше будет их вообще не закрывать. Или закрывать «по умному», как это описано выше. - Закрывать страницы тегов и категорий
Если ваш сайт действительно имеет такую структуру, что на этих страницах контент дублируется и в них нет особой ценности, то лучше закрыть. Однако нередко продвижение ресурса осуществляется в том числе за счет страниц категорий и тегирования. В этом случае можно потерять часть трафика
Однако нередко продвижение ресурса осуществляется в том числе за счет страниц категорий и тегирования. В этом случае можно потерять часть трафика - Закрывать от индексации страницы пагинации /page/
Это делать не нужно. Для таких страниц настраивается тегrel="canonical", таким образом, такие страницы тоже посещаются роботом и на них учитываются расположенные товары/статьи, а также учитывается внутренняя ссылочная масса. - Прописать Crawl-Delay
Модное правило. Однако его нужно указывать только тогда, когда действительно есть необходимость ограничить посещение роботами вашего сайта. Если сайт небольшой и посещения не создают значительной нагрузки на сервер, то ограничивать время «чтобы было» будет не самой разумной затеей. - Ляпы
Некоторые правила я могу отнести только к категории «блогер не подумал». Например:Disallow: /20— по такому правилу не только закроете все архивы, но и заодно все статьи о 20 способах или 200 советах, как сделать мир лучше.
Спорные рекомендации
- Комментарии
Некоторые ребята советуют закрывать от индексирования комментарииDisallow: /commentsиDisallow: */comment-*. - Открыть папку uploads только для Googlebot-Image и YandexImages
User-agent: Googlebot-Image
Allow: /wp-content/uploads/
User-agent: YandexImages
Allow: /wp-content/uploads/
Совет достаточно сомнительный, т.к. для ранжирования страницы необходима информация о том, какие изображения и файлы размещены на ней.
UPD: Нашёл статью Prevent robots crawling “add-to-cart” links on WooCommerce (Не давайте роботам обходить ссылки WooCommerce “добавить в корзину”) в которой наглядно показывается результат закрытия ссылок с параметром ?add-to-cart=.
Но Яндекс всё равно продолжает индексировать эти ссылки. Нашёл в справке Яндекса, как можно их закрывать – через директиву Clean-param (https://yandex.ru/support/webmaster/robot-workings/clean-param. html).
html).
Поэтому добавил в robots.txt эту директиву.
Метки записи: #robots.txt
Евгений Лукин
Пишу о парсинге, разработке интернет-магазинов и автоматизации рутины. Канал на YouTube.
Donation
Похожие записи
База знаний
Что такое GDPR и зачем им всех нас пугают
Часынесомненно, заметили странную активность огромного числа сервисов, как в B2C-, так и в B2B-сегментах, по обновлению своих правил сервиса и политик конфиденциальности.
База знаний
Как создать сайт, если домен и хостинг в разных местах
ЧасыЭта статья могла бы быть продолжением статьи о том, почему домен и хостинг стоит покупать у разных регистраторов. Но этой статьи скорее всего не будет, потому что я так не считаю. Это мнение той части вебмастеров, которых когда-то не устроила работа хостера и им пришлось переехать на другой хостинг. Но только, если перенести файлы сайта…
Но этой статьи скорее всего не будет, потому что я так не считаю. Это мнение той части вебмастеров, которых когда-то не устроила работа хостера и им пришлось переехать на другой хостинг. Но только, если перенести файлы сайта…
Virtual Robots.txt — Плагин WordPress
- Детали
- отзывов
- Монтаж
- Развитие
Опора
Virtual Robots.txt — это простое (то есть автоматизированное) решение для создания и управления файлом robots.txt для вашего сайта. Вместо того, чтобы возиться с FTP, файлами, разрешениями и т. д., просто загрузите и активируйте плагин, и все готово.
По умолчанию плагин Virtual Robots.txt разрешает доступ к тем частям WordPress, которые нужны хорошим ботам, таким как Google. Другие части заблокированы.
Если плагин обнаружит существующий XML-файл карты сайта, ссылка на него будет автоматически добавлена в ваш файл robots.txt.
- Загрузите папку pc-robotstxt в каталог
/wp-content/plugins/ - Активируйте плагин через меню «Плагины» в WordPress
- После установки и активации плагина вы увидите новую ссылку меню Robots.
 txt в меню «Настройки». Нажмите на эту ссылку меню, чтобы увидеть страницу настроек плагина. Оттуда вы можете редактировать содержимое вашего файла robots.txt.
txt в меню «Настройки». Нажмите на эту ссылку меню, чтобы увидеть страницу настроек плагина. Оттуда вы можете редактировать содержимое вашего файла robots.txt.
Будет ли он конфликтовать с существующим файлом robots.txt?
Если на вашем сайте существует физический файл robots.txt, WordPress не будет обрабатывать запросы на него, поэтому конфликта не будет.
Будет ли это работать для установки WordPress из подпапок?
Из коробки, нет. Поскольку WordPress находится в подпапке, он не «узнает», когда кто-то запрашивает файл robots.txt, который должен находиться в корне сайта.
Изменяет ли этот плагин отдельные сообщения, страницы или категории?
Нет.
Почему подключаемый модуль по умолчанию блокирует определенные файлы и папки?
По умолчанию виртуальный файл robots.txt настроен на блокировку файлов и папок WordPress, доступ к которым поисковым системам не требуется.
 Конечно, если вы не согласны со значениями по умолчанию, вы можете легко их изменить.
Конечно, если вы не согласны со значениями по умолчанию, вы можете легко их изменить.
Просто и легко. Работает отлично.
Отлично работает, прост в использовании и настройке. Он уже установил по умолчанию каталоги, которые не должны сканироваться/индексироваться поисковыми системами… Очень доволен этим!
То, что я увидел, было не тем, что я получил. XML-карта сайта не была включена в файл robots.txt, хотя это было описано как функция, которая должна работать «из коробки». Кроме того, при установке этого плагина он блокировал определенные каталоги без запроса. Наконец, он вставляет строку вверху файла, рекламирующую плагин. Это должна быть необязательная функция, которую пользователи могут отключить. В целом, он предлагает функциональность, но не дотягивает и разочаровывает в других областях.
Это было хорошо
Я думал, что это будет просто. Конечно звучит просто.
Но после того, как я сохранил предлагаемый вами текст в свой новый «виртуальный robots. txt», я щелкнул ссылку, где говорится: «Вы можете просмотреть файл robots.txt здесь (открывается новое окно). Если ваш файл robots.txt не t соответствует тому, что показано ниже, возможно, вместо этого отображается физический файл».
Это новое окно показывает текст, который действительно отличается от текста плагина. Я так понимаю, это означает, что на моем сервере есть физический файл robots.txt.
Так какой из них на самом деле будет использоваться?
Ваш FAQ предлагает это:
В: Будет ли он конфликтовать с каким-либо существующим файлом robots.txt?
О: Если на вашем сайте существует физический файл robots.txt, WordPress не будет обрабатывать запросы на него, поэтому конфликта не будет.
Если физический файл существует, WP не будет обрабатывать НИКАКОЙ запрос на него?
Звучит так, как будто WP будет игнорировать КАК физический файл, так и ваш виртуальный. В таком случае какой смысл? А может и не быть, как мне кажется.
Когда я вручную захожу на mydomain.com/robots.txt, я вижу, что находится в физическом файле, а не то, что сохранил плагин.
txt», я щелкнул ссылку, где говорится: «Вы можете просмотреть файл robots.txt здесь (открывается новое окно). Если ваш файл robots.txt не t соответствует тому, что показано ниже, возможно, вместо этого отображается физический файл».
Это новое окно показывает текст, который действительно отличается от текста плагина. Я так понимаю, это означает, что на моем сервере есть физический файл robots.txt.
Так какой из них на самом деле будет использоваться?
Ваш FAQ предлагает это:
В: Будет ли он конфликтовать с каким-либо существующим файлом robots.txt?
О: Если на вашем сайте существует физический файл robots.txt, WordPress не будет обрабатывать запросы на него, поэтому конфликта не будет.
Если физический файл существует, WP не будет обрабатывать НИКАКОЙ запрос на него?
Звучит так, как будто WP будет игнорировать КАК физический файл, так и ваш виртуальный. В таком случае какой смысл? А может и не быть, как мне кажется.
Когда я вручную захожу на mydomain.com/robots.txt, я вижу, что находится в физическом файле, а не то, что сохранил плагин. Так… работает? Я не знаю!
Должен ли я удалить физический файл и предположить, что виртуальный будет работать? Я не знаю!
Должен ли я удалить этот плагин и отредактировать физический файл вручную? Вероятно.
2 звезды вместо 1, потому что я благодарен за включение предложенных строк в мой файл.
Так… работает? Я не знаю!
Должен ли я удалить физический файл и предположить, что виртуальный будет работать? Я не знаю!
Должен ли я удалить этот плагин и отредактировать физический файл вручную? Вероятно.
2 звезды вместо 1, потому что я благодарен за включение предложенных строк в мой файл.
Мне нравится, что здесь так чисто. Спасибо за его создание!
Прочитать все 9 отзывов
«Virtual Robots.txt» — это программа с открытым исходным кодом. Следующие люди внесли свой вклад в этот плагин.
Авторы
- Мариос Александру
1.10
- Исправление для предотвращения сохранения тегов HTML в поле формы robots.txt. Спасибо TrustWave за выявление этой проблемы.
1.9
- Исправление для PHP 7. Спасибо SharmPRO.
1.8
- Отмена последних исправлений, так как они имели непреднамеренные побочные эффекты.
1.
 7
7- Дальнейшие исправления проблемы с удалением новых строк. Спасибо FAMC за отчет и за исправление кода.
- После обновления зайдите и повторно сохраните свои настройки и убедитесь, что они выглядят правильно.
1.6
- Исправлена ошибка, из-за которой удалялись новые строки. Спасибо FAMC за сообщение.
1.5
- Исправлена ошибка, из-за которой плагин предполагал, что файл robots.txt находится по адресу http, хотя он может находиться по адресу https. Спасибо jeffmcneill за репортаж.
1.4
- Исправлена ошибка для ссылки на robots.txt, которая не настраивалась для установки подпапок WordPress.
- Обновлены директивы robots.txt по умолчанию, чтобы соответствовать последним практикам для WordPress.
- Разработка и поддержка плагинов переданы Мариосу Александру.
1,3
- Теперь использует хук do_robots и проверяет is_robots() в действии плагина.

1.2
- Добавлена поддержка существующего файла sitemap.xml.gz.
1.1
- Добавлена ссылка на страницу настроек, возможность удалить настройки.
1.0
- Начальная версия.
Мета
- Версия: 1.10
- Последнее обновление: 3 дня назад
- Активные установки: 40 000+
- Версия WordPress: 5.0 или выше
- Протестировано до: 6,2
- Языки:
- Теги:
гусеничныйроботроботыrobots.txt
- Расширенный вид
Служба поддержки
Проблемы, решенные за последние два месяца:
0 из 1
Посмотреть форум поддержки
Пожертвовать
Хотите поддержать продвижение этого плагина?
Пожертвовать этому плагину
Как редактировать robots.txt в WordPress
Robots. txt — одна из тех вещей, о которых слышали многие оптимизаторы, но мало кто из нас действительно понимает. Хорошая новость заключается в том, что файл robots.txt не должен быть сложным. Хорошая новость заключается в том, что редактировать robots.txt в WordPress очень просто.
txt — одна из тех вещей, о которых слышали многие оптимизаторы, но мало кто из нас действительно понимает. Хорошая новость заключается в том, что файл robots.txt не должен быть сложным. Хорошая новость заключается в том, что редактировать robots.txt в WordPress очень просто.
Если вы уже знакомы с протоколом исключения роботов, перейдите к видео ниже, где показано пошаговое руководство по обновлению robots.txt с помощью Yoast. В противном случае, вот какой-то фон высокого уровня.
Что такое Robots.txt?Robots.txt — также называемый протоколом исключения роботов — представляет собой механизм, с помощью которого веб-сайты взаимодействуют со сканерами поисковых систем и другими ботами в Интернете.
Сообщает поисковым роботам, к каким URL-адресам на вашем веб-сайте им следует обращаться. Например, если на вашем сайте есть закрытый раздел для зарегистрированных участников, вы можете использовать robots.txt, чтобы исключить доступ к этой части вашего сайта, сканирование и индексирование. В таких случаях вы обычно исключаете поддомен или подпапку. На веб-сайте электронной коммерции вы можете использовать robots.txt, чтобы исключить страницы корзины и оформления заказа.
В таких случаях вы обычно исключаете поддомен или подпапку. На веб-сайте электронной коммерции вы можете использовать robots.txt, чтобы исключить страницы корзины и оформления заказа.
Понимание robots.txt является важной частью экосистемы SEO и, как правило, считается в области «технической SEO» (в отличие от локального SEO или SEO-оптимизации на странице).
Как редактировать robots.txt в WordPressОдин из самых простых способов редактирования robots.txt в WordPress — использовать плагин Yoast SEO. Yoast — это швейцарский армейский нож SEO для сайтов WordPress. Вы можете использовать его для всего: от редактирования карты сайта до блокировки страниц от индексации до изменения отображения ваших страниц в Google SERP (странице результатов поисковой системы).
По умолчанию WordPress создает файл robots.txt, который выглядит следующим образом.
Первая строка означает, что инструкция для всех ботов и краулеров. Звездочка — это регулярное выражение (регулярное выражение), означающее, что включены все. Если по какой-то причине вы хотели иметь разные инструкции для Google (Googlebot), Bing (Bingbot) или Yahoo (Slurp), вы могли это сделать. Вот руководство по 10 самым популярным ботам поисковых систем, включая DuckDuckGo, Baidu и другие.
Если по какой-то причине вы хотели иметь разные инструкции для Google (Googlebot), Bing (Bingbot) или Yahoo (Slurp), вы могли это сделать. Вот руководство по 10 самым популярным ботам поисковых систем, включая DuckDuckGo, Baidu и другие.
В приведенном ниже видеоролике показано, как получить доступ к robots.txt на сайте WordPress и как добавить карту сайта в robots.txt.
Не видео человек? Без проблем. Вы можете проверить 5 шагов, подробно описанных ниже.
Как добавить карту сайта в Robots.txt за 5 шагов с помощью YoastЭто очень быстро. Может быть, даже быстрее, чем 3-минутное видео по ссылке выше.
- После того, как вы вошли на свой сайт WordPress, нажмите «SEO» в левой навигационной панели, чтобы получить доступ к меню Yoast SEO.
- Щелкните Инструменты.
- Нажмите «Редактор файлов».
- Внесите изменения в файл robots.txt. Если вы использовали Yoast для создания карты сайта, вы можете добавить ее сюда, чтобы сделать ее легкодоступной для всех поисковых систем.
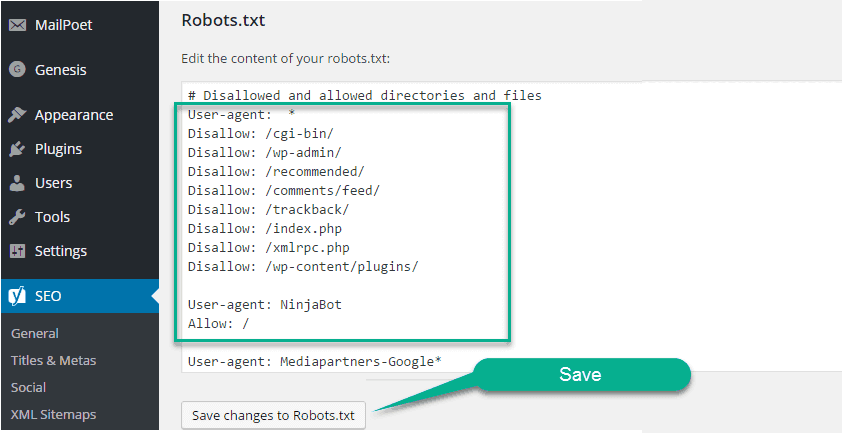 Просто перейдите на новую строку и введите Sitemap: https://www.yoursite.com/sitemap_index.xml
Просто перейдите на новую строку и введите Sitemap: https://www.yoursite.com/sitemap_index.xml - Нажмите кнопку «Сохранить изменения в robots.txt», как показано ниже.
Нет. Это распространенное заблуждение относительно файла robots.txt. Согласно руководству разработчика Google, вы должны заблокировать индексирование с помощью тега noindex или защитить страницу паролем. Это связано с тем, что страница, «заблокированная» файлом robots.txt, все еще может быть проиндексирована Google, если на нее ссылаются другие страницы. Тег noindex решает эту проблему.
Также стоит отметить, что Google рассматривает файл robots.txt как предложение, а не указание веб-сайтов. Кроме того, некоторые другие боты (особенно вредоносные боты) могут полностью игнорировать robots.txt. На самом деле они не следуют правилам.
Сколько времени занимает обновление robots.txt? По словам Google, это займет не более суток.