Правильный robots.txt для WordPress | PRIME
Перейти к содержанию
В этой статье мы разберем каким должен быть правильно написанный служебный файл«robots» для WordPress.
Для начала вспомним, зачем нужен это служебный файл и что это такое. Итак, robots.txt – используется роботами поисковых систем, в нем указывается какие папки, подразделы и файлы можно подвергать индексации, а какие нет. Как скрыть от индексирования те или другие страницы мы подробно разобрали в статье «Запрет индексации в файле robots.txt».
Если у сайта есть поддомены, то для каждого из них robots.txt составляется персонально.
Содержание
- Как написать правильный robots.txt для WordPress
- Как выглядит структурно правильный файл robots.txt
- Проверка правильности составления robots.txt
Как написать правильный robots.txt для WordPress
Сам файл robots.txt должен находиться в корневом каталоге вашего сайта. Что бы его просмотреть, достаточно просто ввести в адресную строку robots.txt, после имени сайта. Например:
Что бы его просмотреть, достаточно просто ввести в адресную строку robots.txt, после имени сайта. Например:
Сразу хочется отметить, что универсального файла, подходящего абсолютно всем сайтам на написанным платформе WordPress, не существует. Достаточно много зависит от настроек сайта, его структуры и даже установленных плагинов.
Рассмотрим пример когда используется человеко-понятный URL (или ЧПУ) и постоянные ссылки вида «postname».
ВордПресс, как и каждая CRM система имеет каталоги, папки, которые не имеют отношения к содержимому сайта и должны быть скрыты. Для этого нужно запретить их индексацию, что делается следующим образом:1 Disallow: /cgi-bin
2 Disallow: /wp-
Директива, прописанная во второй строчке, запретит доступ ко всем файлам , которые начинаются с /wp-, такие как:
- wp-admin
- wp-content
- wp-includes
Обычно все графические файлы загружаются в папку uploads, она входит в состав каталога wp-content. Разрешим их индексацию:
Разрешим их индексацию:
1 Allow: */uploads
Теперь уберем дубли, снижающие уникальность контента. К дублям отностся: страницы категорий, авторов, тегов, RSS-фидов, а также постраничная навигация, трекбеки и отдельные страницы с комментариями. Запретим их индексацию:
Disallow: /category/Disallow: /author/ Disallow: /page/Disallow: /tag/ Disallow: */feed/ Disallow: */trackback Disallow: */comments
Если вы используете ЧПУ, страницы в URL которых содержатся знаки вопроса, часто являются «лишними», дублирующими контент. Их рекомендуется так же скрыть:
Disallow: */?
Проблемой смогут стать страницы в адресной сроке которых указывается год, месяц, например, страницы архивов. Что бы их скрыть применим маску «20*»:
Что бы их скрыть применим маску «20*»:
Disallow: /20*
В правильно написанном robots.txt для WordPress обязательно нужно указать путь к карте сайта:
Sitemap: http://prime-ltd.su/sitemap.xml
Так же нужно прописать доп. информацию для поисковых ботов:
Host: prime-ltd.su – директива Host — указывает на главное зеркало для Яндекса
Host: http://prime-ltd.su– протокол указывается при работе сайта по HTTPS
Вот так выглядит структурно правильный файл robots.txt:
Пример верно написанного robots.txt, в случае если вы используете ЧПУ:
User-agent: * -
Disallow: /wp-admin
Disallow: /wp-includes
Disallow: /wp-content/plugins
Disallow: /wp-content/cache
Disallow: /wp-content/themes
Disallow: /trackback
Disallow: */trackback
Disallow: */*/trackback
Disallow: */*/feed/*/
Disallow: */feed
Disallow: /*?*
Disallow: /tag
User-agent: Yandex
Disallow: /wp-admin
Disallow: /wp-includes
Disallow: /wp-content/plugins
Disallow: /wp-content/cache
Disallow: /wp-content/themes
Disallow: /trackback
Disallow: */trackback
Disallow: */*/trackback
Disallow: */*/feed/*/
Disallow: */feed
Disallow: /*?*
Disallow: /tag
Host: mysite. com
com
Sitemap: http://mysite.com/sitemap.xml.gz
Sitemap: http://mysite.com/sitemap.xml
Пример верно написанного robots.txt, в случае если вы НЕ используете ЧПУ:
User-agent: *
Disallow: /cgi-bin
Disallow: /wp-admin
Disallow: /wp-includes
Disallow: /wp-content/plugins
Disallow: /wp-content/cache
Disallow: /wp-content/themes
Disallow: /trackback
Disallow: */trackback
Disallow: */*/trackback
Disallow: */*/feed/*/
Disallow: */feed
Disallow: /tag
User-agent: Yandex
Disallow: /cgi-bin
Disallow: /wp-admin
Disallow: /wp-includes
Disallow: /wp-content/plugins
Disallow: /wp-content/cache
Disallow: /wp-content/themes
Disallow: /trackback
Disallow: */trackback
Disallow: */*/trackback
Disallow: */*/feed/*/
Disallow: */feed
Disallow: /tag
Host: mysite. com
com
Sitemap: http://mysite.com /sitemap.xml.gz
Sitemap: http://mysite.com /sitemap.xml
Проверка правильности составления robots.txt
Для проверки верности написания файла, можно использовать сервис Яндекс Вебмастер .
Заходим в “Настройки индексирования –> Анализ robots.txt”:
Нажимаем “Загрузить robots.txt с сайта”, а затем “Проверить”:
Если вы увидели следующую картину, то вы все прописали верно.
Go to Top
Правильный robots.txt для WordPress
О том, как сделать правильный robots.txt для WordPress написано уже достаточно. Однако, чтобы угодить своим читателям, я решил опубликовать свой пост на эту тему. Тем более, что моими коллегами эта тема раскрыта не полностью и тут можно многое добавить.
Что такое robots.txt и зачем он нужен?
robots. txt это текстовый документ, составленный в обыкновенном блокноте, расположенный в корневой директории блога и содержащий в себе инструкции по индексации для поисковых роботов. Проще говоря, что индексировать, а что нет. Наличие этого файла является обязательным условием для качественной внутренней поисковой оптимизации блога.
txt это текстовый документ, составленный в обыкновенном блокноте, расположенный в корневой директории блога и содержащий в себе инструкции по индексации для поисковых роботов. Проще говоря, что индексировать, а что нет. Наличие этого файла является обязательным условием для качественной внутренней поисковой оптимизации блога.
Как известно, блоги на платформе WordPress содержат в себе множество дублей (копий основного содержимого блога), а также целый набор служебных файлов. Дубли контента снижают его уникальность на домене и поисковые роботы могут наложить на блог серьезные штрафные санкции.
Чтобы повысить уникальность контента, облегчить поисковым ботам работу и тем самым улучшить качество индексации блога, нам и нужен robots.txt.
Правильный robots.txt для WordPress
Рассмотрим на примере моего robots.txt, как его правильно оформить и что в него должно входить.
Скачайте его себе на жесткий диск по этой ссылке и откройте для редактирования. В качестве редактора текстовых файлов настоятельно рекомендую использовать Notepad++.
В качестве редактора текстовых файлов настоятельно рекомендую использовать Notepad++.
Строки 6,7: Принято считать, что необходимо закрывать поисковым роботам доступ к служебным файлам в папках «wp-content» и «wp-includes». Но, Гугл по этому поводу нам говорит следующее:
Чтобы обеспечить правильное индексирование и отображение страниц, нужно предоставить роботу Googlebot доступ к JavaScript, CSS и графическим файлам на сайте. Робот Googlebot должен видеть ваш сайт как обычный пользователь. Если в файле robots.txt закрыт доступ к этим ресурсам, то Google не удастся правильно проанализировать и проиндексировать содержание. Это может ухудшить позиции вашего сайта в Поиске.
Таким образом, для Googlebot не рекомендуется запрещать доступ к файлам в этих папках.
Строка 40: С весны 2018 года директива «Host«, указывающая главное зеркало сайта Яндексу, больше не действует. Главное зеркало для нашей поисковой системы теперь определяется только через 301 редирект.
Строки 42,43: Если у Вас еще не создана карта сайта, обязательно сделайте ее. В пути к файлам карты вместо моего адреса wordpress-book.ru пропишите свой. Этот ход сделает индексацию блога поисковиками полной и увеличит ее скорость.
Уже сейчас, можно сказать, что ваш правильный robots.txt для WordPress готов. В таком виде он подойдет для абсолютного большинства блогов и сайтов. Останется только закачать его в корень блога (обычно в папку public_html).
Сделать robots.txt для блога можно и с помощью плагина, например, PC Robots.txt. С его помощью вы сможете создать и редактировать свой robots.txt прямо в админке блога. Но я не советую использовать плагины для создания robots.txt, чтобы исключить лишнюю нагрузку на блог.
Содержание robots.txt любого блога или сайта, если он конечно есть, вы всегда можете посмотреть. Для этого достаточно в адресной строке браузера ввести к нему путь – https://wordpress-book.ru/robots.txt.
Ниже приведена информация по содержанию этого документа и некоторые рекомендации по его оформлению и анализу.
Звездочка «*«, прописанная в тексте robots.txt, означает, что на ее месте допускается последовательность любых символов.
Директива «User-agent» определяет, для каких поисковых роботов даны указания по индексации, прописанные под ней. Таким образом, «User-agent: *» (строка 1) указывает, что инструкции, прописанные под ней, предназначены для всех поисковых систем.
Строка 21: Персонально для Яндекса под «User-agent: Yandex» дублируем список этих команд. Дублирование инструкций для Яндекса дает нам гарантию их выполнения поисковой системой.
Директива «Disallow» запрещает индексацию прописанного для нее каталога или страниц. Директива «Allow» разрешает. Командой «Disallow: /wp-content/» (строка 7) я запретил индексацию служебного каталога «wp-content» на сервере и соответственно всех папок в ней с их содержимым, но командой «Allow: /wp-content/uploads» (строка 8) разрешил индексировать все картинки в папке «upload» каталога «wp-content«. Так как «Allow» является приоритетной директивой для поисковых роботов, то в индекс попадут только изображения папки «upload» каталога «wp-content«.
Так как «Allow» является приоритетной директивой для поисковых роботов, то в индекс попадут только изображения папки «upload» каталога «wp-content«.
Для директивы «Disallow» имеет смысл в некоторых случаях дополнительно прописывать следующие запреты:
- — /amp/ — дубли ускоренных мобильных страниц. На всякий случай для Яндекса.
- — /comments — закрыть от индексации комментарии. Зачем закрывать содержащийся в комментариях уникальный контент? Для большей релевантности ключевых слов и неиндексации исходящих ссылок в комментариях. Вряд ли это поможет.
- — /comment-page-* — другое дело древовидные комментарии. Когда комментарии не помещаются на одну страницу (их количество вы проставили в настройках админки), создается дубль страницы типа wordpress-book.ru/…/comment-page-1. Эти дубли конечно же надо закрывать.
- — /xmlrpc.php — служебный файл для удаленных вызовов. У меня его нет и соответственно нет индексации и без запрета.
- — /webstat/ — папка со статистикой сайта.
 Эта папка есть тоже далеко не у всех.
Эта папка есть тоже далеко не у всех.
Нельзя не упомянуть про редко используемую, но очень полезную директиву для Яндекса — «Crawl-delay». Она задает роботу паузу во времени в секундах между скачиванием страниц, прописывается после групп директив «Disallow» и «Allow» и используется в случае повышенной нагрузки на сервер. Прописью «Crawl-delay: 2″ я задал эту паузу в 2 секунды. При нормальной работе сервера качество индексации не пострадает, а при пиковых нагрузках не ухудшится.
Некоторым веб-мастерам может понадобится запретить индексацию файлов определенного типа, например, с расширением pdf. Для этого пропишите — «Disallow: *.pdf$«. Или поместите все файлы, индексацию которых требуется запретить, в предварительно созданную новую папку, например, pdf, и пропишите «Disallow: /pdf/«.
При необходимости запрета индексации всей рубрики, такое бывает ,например, при публикации в нее чужих интересных записей, пропишите — «Disallow: /nazvanie-rubriki/*«, где «nazvanie-rubriki», как вы уже догадались — название рубрики, записи которой поисковикам индексировать не следует.
Тем, кто зарабатывает на своем блоге размещением контекстной рекламы в партнерстве с Google AdSense, будет нелишним прописать следующие две директивы:
User-agent: Mediapartners-Google
Disallow:
Это поможет роботу AdSense избежать ошибок сканирования страниц сайта и подбирать для них более релевантные объявления.
wp-content/uploads/2014/02/YouTube_Downloader_dlya_Ope.jpg»,tid: «OIP.M3a4a31010ee6a500049754479585407do0
Обнаружил у себя только что вот такой вот новый вид дублей в Яндекс Вебмастере. 96 штук уже накопилось и это не предел. А ведь совсем недавно у wordpress-book.ru с дублями был полный порядок. Есть подозрение, что шлак с идентификатором tid:»OIP появляется в индексе поисковика после скачивания картинок роботом Яндекса. Если не лень, посмотрите сколько таких несуществующих страниц разных сайтов уже участвуют в поиске.
Понятно, что с этим чудом надо что-то делать. Достаточно добавить запрещающую директиву — «Disallow: /wp-content/uploads/*.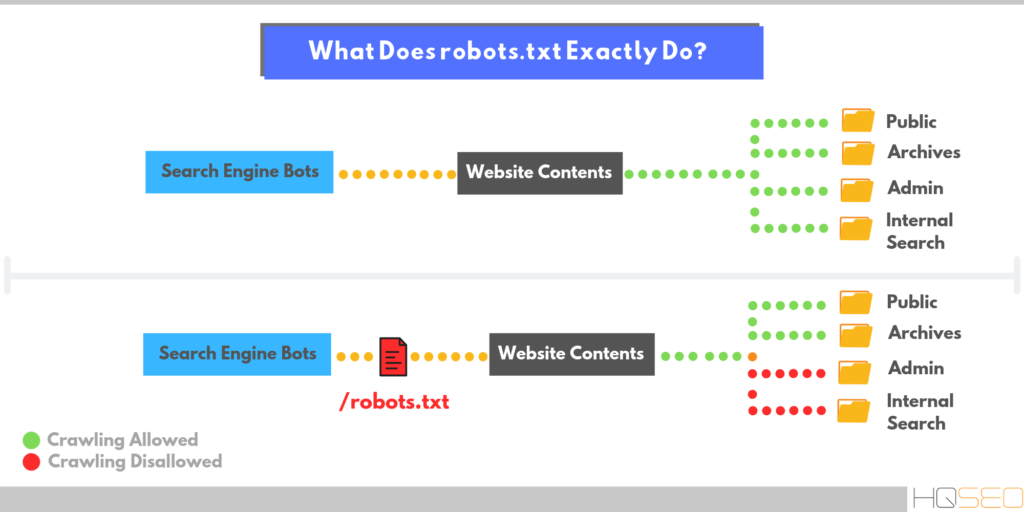 jpg*tid*» в robots.txt. Если на сайте есть картинки png, gif и т.д., добавьте директивы с соответствующими расширениями изображений.
jpg*tid*» в robots.txt. Если на сайте есть картинки png, gif и т.д., добавьте директивы с соответствующими расширениями изображений.
При редактировании robots.txt, учтите, что:
— перед каждой новой директивой «User-agent» должна быть пустая строка, которая обозначает конец инструкций для предыдущего поисковика. И соответственно после «User-agent» и между «Disallow» и «Allow» пустых строк быть не должно;
— запретом индексации страниц в результатах поиска «Disallow: /*?*» вы заодно можете случайно запретить индексацию всего контента, если адреса страниц вашего блога заданы по умолчанию со знаком вопроса в виде — /?p=123. Советую сделать для адресов ЧПУ (человеко понятные урлы :-)). Для этого в настройках постоянных ссылок выберите произвольный шаблон и поставьте плагин Rus-to-Lat.
Анализ robots.txt
Теперь, когда ваш robots.txt отредактирован и залит на сервер, остается только проверить, правильно ли он работает.
Зайдите в свой аккаунт Яндекс Вебмастер и перейдите «Настройки индексирования» → «Анализ robots. txt«. Нажмите на кнопку «Загрузить robots.txt с сайта» и далее на кнопку «Проверить«.
txt«. Нажмите на кнопку «Загрузить robots.txt с сайта» и далее на кнопку «Проверить«.
Если Яндексу понравится ваш файл, под кнопкой «Проверить» появится сообщение, примерно как на картинке выше.
Недавно в инструментах для веб-мастеров Гугла появилось очень полезная функция — «Инструмент проверки файла robots.txt«. Можно проверить свой файл на наличие ошибок и предупреждений.
Просто в своем аккаунте перейдите «Сканирование» → «Инструмент проверки файла robots.txt«.
Через некоторое время, когда бот Яндекса скачает ваш robots.txt, проанализируйте в Яндекс Вебмастере адреса страниц вошедших в индекс и исключенных из него в robots.txt. Вошедшие в индекс дубли срочно запрещайте к индексации.
Теперь ваш robots.txt для WordPress правильный и можно поставить еще одну галочку под пунктом выполнения задач по внутренней поисковой оптимизации блога.
robots.txt запретить индексацию всем
При создании тестового блога или при самом его рождении, если вы хотите полностью запретить индексацию сайта всеми поисковыми системами, в robots. txt должно быть прописано всего лишь следующее:
txt должно быть прописано всего лишь следующее:
User-agent: *
Disallow: /
Хороший человек всегда нажмет на кнопку!
Комментарий > Моя благодарность > Ссылка на секретную страницу блога
▷ Що таке файл Robots.txt — як створити та налаштувати правила в файлі Robots.txt, приклади використання
Що таке Robots.txt?
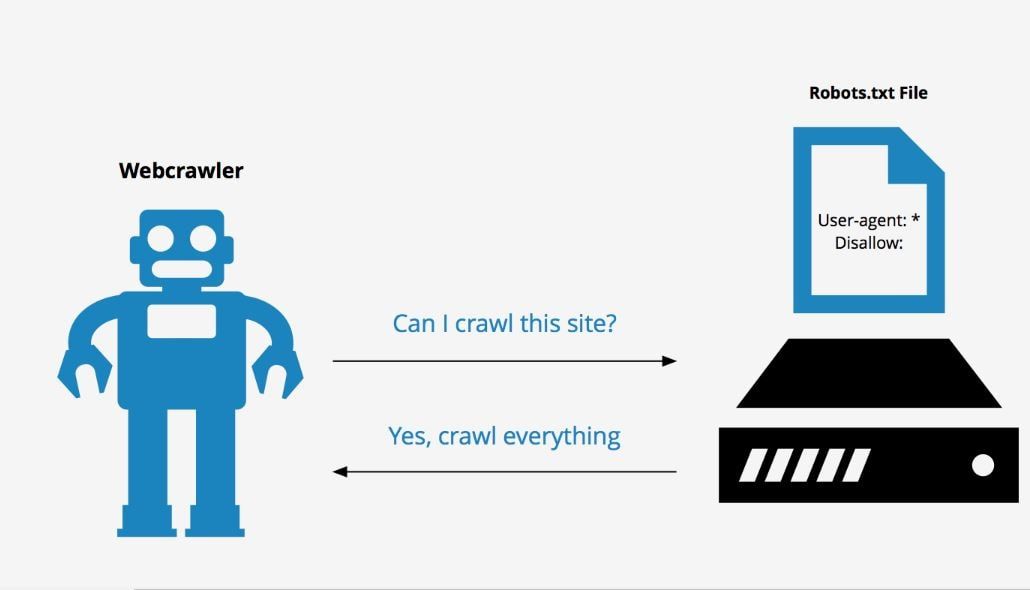
Robots.txt — текстовий файл, в якому вказуються правила сканування сайту для пошукових систем. Файл знаходиться в кореневій папці і є звичайним текстовим документом в форматі .txt.
Пошукові системи спочатку сканують вміст файлу Robots.txt і тільки потім інші сторінки сайту. Якщо файл Robots.txt відсутня – пошуковим системам дозволено сканувати всі сторінки сайту.
Содержание- Що таке Robots.txt?
- Для чого потрібен файл Robots.txt
- Як створити текстовий файл Robots.txt
- Вимоги до файлу Robots.txt
- Обмеження документа Robots.
 txt
txt - Позначення і види директив
- У якому порядку виконуються правила
- Приклади використання файлу Robots.txt
- Найбільш поширені помилки
- Довідкові матеріали
Для чого потрібен файл Robots.txt
- Вказати пошуковим системам правила сканування і індексації сторінок сайту. Для кожного пошукача можна задати як різні правила, так і однакові.
- Вказати пошуковим системам посилання на xml-карту сайту, щоб роботи могли без проблем її знайти і просканувати.
Основним завданням robots.txt є управління доступу до сторінок сайту пошуковим системам і іншим роботам. На сайті може перебувати конфіденційна інформація, наприклад, особисті дані користувачів або внутрішні документи компанії. Завдяки директивам в файлі Robots.txt можна заборонити до них доступ пошуковим системам і їх не знайдуть.
Варто пам’ятати про те, що пошукові системи враховують правила в файлі Robots.txt по-різному. Для Google вміст файлу є рекомендацією по скануванню сайту, а для Яндекса – прямий директивою.
Тобто, якщо сторінка закрита в файлі Robots.txt, вона все одно може потрапити в індекс пошукової системи Google, адже для нього це рекомендації по скануванню, а не індексації.
Щоб не допустити індексації певних сторінок сайту потрібно використовувати метатег robots або X-Robots-Tag.
Яндекс сприймає вміст файлу Robots.txt як директиви і завжди їх виконує.
Тут потрібна картинка, що Яндекс кориться вимогам, а Google ухиляється. Треба намалювати.
Як створити текстовий файл Robots.txt
- Створіть текстовий документ у форматі .txt.
- Поставте йому ім’я robots.txt.
- Вкажіть вміст файлу.
- Додайте його в кореневий каталог сайту, щоб він був доступний за адресою /robots.txt.
- Перевірте коректність файлу через інструмент Яндекса или Google.
Файл Robots.txt повинен обов’язково знаходитися за адресою robots.txt. Якщо він буде розміщений по іншому url-адресою, пошукова система буде його ігнорувати і вважати, що все дозволено для сканування і індексації.
Вірно:
https://inweb.ua/robots.txt
Невірно:
https://inweb.ua/robots.txt
https://inweb.ua/ua/robots.txt
https://inweb.ua/robot.txt
Для популярних CMS є плагіни для редагування файлу Robots.txt:
- WordPress – Clearfy Pro .
- Opencart – редактор Robots.txt .
- Bitrix – є можливість редагувати через адміністративну панель за замовчуванням. Маркетинг & gt; Пошукова оптимізація & gt; Налаштування robots.txt.
За допомогою зазначених модулів можна легко змінювати директиви через адміністративну панель, без використання ftp.
Вимоги до файлу Robots.txt
Щоб пошукові системи виявили і слідували директивам необхідно дотримуватись наступних правил:
- Розмір файлу не перевищує 500кб;
- Це TXT-файл з назвою robots – robots.txt;
- Файл розміщений в кореневому каталозі сайту;
- Файл доступний для роботів – код відповіді сервера – 200. Перевірити можна за допомогою сервісу або інструментів Google Search Console і Яндекс Вебмастера.

- Якщо файл не відповідає вимогам – сайт вважається відкритим для сканування і індексації.
Якщо ж пошукова система, при запиті файлу /robots.txt, отримала код відповіді сервера відмінний від 200 – сканування сайту припиниться. Це може істотно погіршити швидкість сканування сайту.
Обмеження документа Robots.txt
- Не всі пошукові системи обробляють директиви у файлі Robots.txt однаково. У кожної є своя інтерпретація. При складанні правил слід на це звертати увагу.
- Кожна директива повинна починатися з нового рядка.
- У кожної пошукової системи є кілька роботів, які сканують сайти. Деякі з них інтерпретують правила robots.txt інакше.
- У файлі Robots.txt дозволяється використовувати тільки латинські літери. Якщо у вас кириличні url-адреси або домен – необхідно використовувати punycode.
Розглянемо на прикладі, як Robots.txt використовує систему кодування:
Вірно:
User-agent: *
Disallow: /корзина
Sitemap: сайт. рф/sitemap.xml
рф/sitemap.xml
Не вірно:
User-agent: *
Disallow: /%D0%BA%D0%BE%D1%80%D0%B7%D0%B8%D0%BD%D0%B0
Sitemap:http://xn--80aswg.xn--p1ai/sitemap.xml
Позначення і види директив
Нижче розглянемо які є директиви у файлі Robots.txt
- User-agent — вказівка пошукового бота, до якого застосовуються правила. Щоб вибрати всіх роботів – вкажіть “*”. Директива є обов’язковою для використання, без вказівки User-gent не можна використовувати будь-які правила.
Наприклад:
User-agent: * # правила для всіх.
User-agent: Googlebot # правила тільки для Google.
User-agent: Yandex # правила тільки для Яндекса
. - Disallow — директива, яка забороняє сканування певних сторінок або розділів.
Наприклад:
Disallow: / order / # закриває всі сторінки, які починаються з / order /.
Disallow: / * sort-order # закриває всі сторінки, які містять фрагмент “sort-order”.
Disallow: / secretiki / # закриває всі сторінки, які починаються з / secretiki /.
- Sitemap — вказівка посилання на xml-карту сайту. Якщо xml-карт сайту кілька – можна вказати їх все.
Наприклад:
Sitemap: https://inweb.ua/sitemap.xml
Sitemap: https://inweb.ua/sitemap-images.xml - Allow — дозволяє відкрити для робота сторінку або групу сторінок.
Наприклад:
Disallow: /category/
Allo: /category/phones/
Ми закриваємо всі сторінки, які починаються з / category /, але відкриваємо /category/phones/ - Clean-param — повідомляє Яндексу, що в адресі є параметри і мітки, необов’язкові при скануванні. Працює тільки з роботами в Yandex.
- Crawl-delay — з 22 лютого 2018 року не враховується. Раніше враховувалася тільки пошуковою системою Яндекс і впливала на затримку між зверненнями до сайту.
- Host — вказівка головного дзеркала для Яндекса. Не враховується з 12 березня 2018 року. Тепер все пошукові системи ігнорують цю директиву.

- Спецсимволи:* – позначає будь-яку кількість символів.
Наприклад:
Disallow: * # забороняє сканування всього сайту.
Disallow: * limit # Забороняє сканування всіх сторінок, які містять “limit”.
Disallow: / order / * / success / # забороняє сканування всіх сторінок, які починаються з / order /, потім містять будь-яку кількість символів, а потім / success /. - $ – позначає кінець рядка.
Наприклад:
Disallow: /*order$ #забороняє сканування всіх сторінок, які закінчуються на order.
У якому порядку виконуються правила
Yandex і Google обробляє директиви Allow і Disallow не по порядку, в якому вони вказані, а спочатку сортує їх від короткого правила до довгого, а потім обробляє останнім відповідне правило:
User-agent: *
Allow: */uploads
Disallow: /wp-
Буде прочитана як:
User-agent: *
Disallow: /wp-
Allow: */uploads
Таким чином, якщо перевіряється посилання виду: /wp-content/uploads/file. jpg, правило “Disallow: / wp-” посилання заборонить, а наступне правило “Allow: * / uploads” її дозволить і посилання буде доступна для сканування.
jpg, правило “Disallow: / wp-” посилання заборонить, а наступне правило “Allow: * / uploads” її дозволить і посилання буде доступна для сканування.
У разі, якщо директиви рівнозначні або суперечать один одному:
User-agent: *
Disallow: /admin
Allow: /admin
Пріоритет віддається директиві Allow.
Приклади використання файлу Robots.txt
Приклад №1 – повністю закрити сайт від індексації.
User-agent: *
Disallow: /
Приклад №2 – блокуємо доступ до папки для Google, іншим пошуковим системам відкриваємо.
User-agent: *
Disallow:
User-agent: Googlebot
Disallow: /papka/
Приклад №3 – сайт повністю відкритий для індексації.
User-agent: *
Disallow:
Приклад №4 – закриваємо всі сторінки сайту, які містять фрагмент url-адреси “secret”.
User-agent: *
Disallow: *secret
Приклад №5 – закриємо повністю сайт для Яндекса, а для Google відкриємо тільки папку /for-google/
User-agent: Yandex
Disallow: /
User-agent: Googlebot
Disallow: /
Allow: /for-google/
Найбільш поширені помилки
Розглянемо найбільш поширені помилки, які допускають SEO-фахівці при складанні директив.
- Відсутність на самому початку директиви зірочки. Варто пам’ятати, що обов’язково потрібно додавати * перед фрагментом url-адреси, якщо директива містить фрагмент, який знаходиться не на початку url-адреси.
Наприклад, потрібно закрити від сканування url-адреса
https://inweb.ua/catalog/cateogory/?sort=name
Невірно: Disallow: ?sort=
Вірно: Disallow: /*sort= - Директива, крім неякісних url-адрес, забороняє сканування якісних сторінок. При написанні директив варто вказувати їх максимально чітко, щоб навіть теоретично якісні url-адреси не потрапили під заборону.
Невірно: Disallow: *sort
Вірно: Disallow: /*?sort=
У першому випадку, випадково можуть бути сторінки виду:
https://inweb.ua/kak-zakryt-ot-indeksacii-sortirovki/ Адже, теоретично, деякі сторінки можуть містити в url-адресу фрагмент “sort”. - Сторінки одночасно закриті в файлі Robots.txt і через метатег robots.Еслі неякісний документ закритий від сканування в файлі Robots.txt і від індексування через метатег robots – сторінка ніколи не випаде з індексу, оскільки робот пошукової системи Google не побачить noindex, адже не може її просканувати.

- Використання кириличних символів. Варто завжди пам’ятати, що кирилиця не розпізнає пошуковими системами в файлі Robots.txt, обов’язково потрібно замінити на punycode. Посилання на конвертер.
Довідкові матеріали
- Довідка Яндекс по Robots.txt.
- Довідка Google по Robots.txt.
- Види пошукових роботів Google.
- Види пошукових роботів Яндекс.
- Інструмент перевірки файлу Robots.txt.
Тест на знання файлу Robots.txt
Коли-небудь настане день і знамення олдові «Термінатора» стане реальністю – роботи заполонять світ і візьмуть верх над людством. І тільки вправні знавці машин зможуть лавірувати в смертельній сутичці. Як добре ви вмієте спілкуватися з роботами? Чи зможете очолити повстання проти машин? Давайте перевіримо!
Virtual Robots.txt — Плагин WordPress
- Детали
- отзывов
- Монтаж
- Поддерживать
- Развитие
Virtual Robots.txt — это простое (то есть автоматизированное) решение для создания и управления файлом robots. txt для вашего сайта. Вместо того, чтобы возиться с FTP, файлами, разрешениями и т. д., просто загрузите и активируйте плагин, и все готово.
txt для вашего сайта. Вместо того, чтобы возиться с FTP, файлами, разрешениями и т. д., просто загрузите и активируйте плагин, и все готово.
По умолчанию плагин Virtual Robots.txt разрешает доступ к тем частям WordPress, которые нужны хорошим ботам, таким как Google. Другие части заблокированы.
Если плагин обнаружит существующий XML-файл карты сайта, ссылка на него будет автоматически добавлена в ваш файл robots.txt.
- Загрузите папку pc-robotstxt в каталог
- Активируйте плагин через меню «Плагины» в WordPress
- После установки и активации плагина вы увидите новую ссылку меню Robots.txt в меню «Настройки». Нажмите на эту ссылку меню, чтобы увидеть страницу настроек плагина. Оттуда вы можете редактировать содержимое вашего файла robots.txt.
Будет ли он конфликтовать с существующим файлом robots.txt?
Если на вашем сайте существует физический файл robots.
 txt, WordPress не будет обрабатывать запросы на него, поэтому конфликта не будет.
txt, WordPress не будет обрабатывать запросы на него, поэтому конфликта не будет.Будет ли это работать для установки WordPress из подпапок?
Из коробки, нет. Поскольку WordPress находится в подпапке, он не «узнает», когда кто-то запрашивает файл robots.txt, который должен находиться в корне сайта.
Изменяет ли этот плагин отдельные сообщения, страницы или категории?
Нет.
Почему подключаемый модуль по умолчанию блокирует определенные файлы и папки?
По умолчанию виртуальный файл robots.txt настроен на блокировку файлов и папок WordPress, доступ к которым поисковым системам не требуется. Конечно, если вы не согласны со значениями по умолчанию, вы можете легко их изменить.
Просто и легко. Работает отлично.
Отлично работает, прост в использовании и настройке. Он уже установил по умолчанию каталоги, которые не должны сканироваться/индексироваться поисковыми системами.
То, что я увидел, было не тем, что я получил. XML-карта сайта не была включена в файл robots.txt, хотя это было описано как функция, которая должна работать «из коробки». Кроме того, при установке этого плагина он блокировал определенные каталоги без запроса. Наконец, он вставляет строку вверху файла, рекламирующую плагин. Это должна быть необязательная функция, которую пользователи могут отключить. В целом, он предлагает функциональность, но не дотягивает и разочаровывает в других областях.
Это было хорошо
Я думал, что это будет просто. Конечно звучит просто.
Но после того, как я сохранил предложенный вами текст в свой новый «виртуальный robots.txt», я щелкнул ссылку, где говорится: «Вы можете просмотреть файл robots.txt здесь (открывается новое окно). Если ваш файл robots.txt не t соответствует тому, что показано ниже, возможно, вместо этого отображается физический файл».
Это новое окно показывает текст, который действительно отличается от текста плагина.

Мне нравится, что здесь так чисто. Спасибо за его создание!
Прочитать все 9 отзывов
«Virtual Robots.txt» — это программа с открытым исходным кодом. Следующие люди внесли свой вклад в этот плагин.
Авторы
- Мариос Александру
1.10
- Исправление для предотвращения сохранения тегов HTML в поле формы robots.txt. Спасибо TrustWave за выявление этой проблемы.
1.9
- Исправление для PHP 7. Спасибо SharmPRO.
1.8
- Отмена последних исправлений, так как они имели непреднамеренные побочные эффекты.
1.7
- Дальнейшие исправления проблемы с удалением новых строк. Спасибо FAMC за отчет и за исправление кода.
- После обновления зайдите и повторно сохраните свои настройки и убедитесь, что они выглядят правильно.
1.6
- Исправлена ошибка, из-за которой удалялись новые строки.
 Спасибо FAMC за сообщение.
Спасибо FAMC за сообщение.
1.5
- Исправлена ошибка, из-за которой плагин предполагал, что файл robots.txt находится по адресу http, хотя он может находиться по адресу https. Спасибо jeffmcneill за репортаж.
1.4
- Исправлена ошибка для ссылки на robots.txt, которая не настраивалась для установки подпапок WordPress.
- Обновлены директивы robots.txt по умолчанию, чтобы соответствовать последним практикам для WordPress.
- Разработка и поддержка плагинов переданы Мариосу Александру.
1,3
- Теперь использует хук do_robots и проверяет is_robots() в действии плагина.
1.2
- Добавлена поддержка существующего файла sitemap.xml.gz.
1.1
- Добавлена ссылка на страницу настроек, возможность удалить настройки.
1.0
- Начальная версия.
Мета
- Версия: 1.
 10
10 - Последнее обновление: 8 месяцев назад
- Активные установки: 40 000+
- Версия WordPress: 5.0 или выше
- Протестировано до: 5.9.4
- Языки:
- Теги:
гусеничныйроботроботыrobots.txt
- Расширенный вид
Служба поддержки
Проблемы, решенные за последние два месяца:
0 из 1
Посмотреть форум поддержки
Пожертвовать
Хотите поддержать продвижение этого плагина?
Пожертвовать этому плагину
Каковы лучшие правила файла robots.txt для мультисайтов? » Rank Math
Одна из самых важных вещей, которую вы можете сделать для обеспечения успеха своего веб-сайта, — это создать и поддерживать хорошо оптимизированный файл robots.txt.
В файле robots.txt указано, какие страницы вашего веб-сайта поисковые системы, такие как Google, должны сканировать, а какие страницы следует игнорировать. Это важно, потому что вы не хотите, чтобы каждая страница на вашем сайте была проиндексирована, особенно если некоторые из этих страниц имеют низкое качество или дублируют контент.
Это важно, потому что вы не хотите, чтобы каждая страница на вашем сайте была проиндексирована, особенно если некоторые из этих страниц имеют низкое качество или дублируют контент.
Если у вас есть мультисайт WordPress, вам нужно быть особенно осторожным с файлом robots.txt. Это связано с тем, что мультисайт WordPress может иметь сотни или даже тысячи веб-сайтов, каждый со своими индивидуальными настройками.
Хорошей новостью является то, что Rank Math упрощает управление файлом robots.txt на мультисайте WordPress. В этой статье базы знаний мы поможем вам создать лучшие правила файла robots.txt для мультисайтов с помощью Rank Math SEO.
1 Технические данные Robots.txt Синтаксис
Во-первых, давайте посмотрим, что вам нужно включить в файл robots.txt.
- Агент пользователя: Каждая поисковая система идентифицирует себя строкой агента пользователя, которая обычно скрыта от пользователя, но может быть видна в журналах веб-сервера.
 Пользовательские агенты используются для определения того, какой поисковый робот обращается к странице, и могут использоваться для идентификации поисковой системы. Например, роботы Google идентифицируются как Googlebot, роботы Yahoo — как Slurp, а роботы Bing — как BingBot.
Пользовательские агенты используются для определения того, какой поисковый робот обращается к странице, и могут использоваться для идентификации поисковой системы. Например, роботы Google идентифицируются как Googlebot, роботы Yahoo — как Slurp, а роботы Bing — как BingBot. - Disallow: Вы можете запретить поисковым системам открывать или сканировать определенные файлы, страницы или разделы вашего веб-сайта с помощью директивы Disallow. Директива Disallow используется для предотвращения прямого доступа к файлу, папке или ресурсу на веб-сервере.
- Allow: Директива Allow разрешает запрос, если на сервере есть указанный файл, каталог или URL-адрес. Другими словами, он переопределяет директиву Disallow. Он поддерживается как Google, так и Bing. Директивы Allow и Disallow вместе позволяют вам контролировать, какие поисковые роботы, такие как Googlebot, могут видеть и получать доступ к вашему веб-сайту. Вы даже можете установить правила для определенных страниц, чтобы сканер видел только набор страниц в определенной папке и ничего больше.

- Карта сайта: Вы можете использовать эту команду для вызова местоположения любой карты сайта XML, связанной с этим URL-адресом. Это полезно при отправке сайта для целей SEO. Google и Bing — основные поисковые системы, поддерживающие карты сайта.
- Crawl-Delay: Печальная правда веб-хостинга заключается в том, что, хотя большую часть времени ваш сайт работает нормально, вы неизбежно столкнетесь с ситуацией, когда возникает проблема с вашим сервером, и ему может потребоваться некоторое работать над тем, чтобы вернуть все как было. Директива Crawl-delay — это неофициальный метод, позволяющий избежать перегрузки веб-сервера слишком большим количеством запросов.
Теперь, когда вы знаете, что включить в файл robots.txt, давайте посмотрим, как создать наилучшие правила для мультисайта WordPress с помощью Rank Math. Прежде чем мы начнем, вам необходимо убедиться, что на вашем сайте WordPress установлена и активирована последняя версия Rank Math.
Примечание: Если вы хотите узнать, как добавить robots.txt для одного сайта, в этой базе знаний есть статья, в которой объясняется, как настроить robots.txt на одном сайте.
2 Как настроить Robots.txt для мультисайтов?
Когда вы устанавливаете Rank Math на мультисайт или несколько доменов, вы должны установить его в сети и использовать только на отдельных веб-сайтах.
Но учтите, что файл robots.txt можно изменить только на основном сайте сети, а все остальные наследуют настройки от основного сайта.
Это связано с тем, что сайты в сети не имеют фактической файловой структуры, которая могла бы поддерживать эти типы файлов, и это является ограничением функциональности мультисайта.
Обычно файл robots.txt должен находиться в верхнем каталоге вашего веб-сервера. Даже если это установка из подкаталога, файл robots.txt должен быть доступен по основному URL-адресу.
Но Rank Math использует фильтр robots_txt для добавления контента. Если файл robots.txt существует на сервере, Rank Math автоматически отключает возможность редактировать или изменять файл robots.txt. Это делается для того, чтобы пользователь не перезаписал файл.
Если файл robots.txt существует на сервере, Rank Math автоматически отключает возможность редактировать или изменять файл robots.txt. Это делается для того, чтобы пользователь не перезаписал файл.
3 Как обработать файл robots.txt на мультисайте с помощью Rank Math?
Если вы используете мультисайт WordPress, файл robots.txt немного сложнее, и вам нужно быть осторожным при его редактировании. Лучший способ отредактировать файл robots.txt на мультисайте WordPress — использовать сетевые настройки, чтобы определить, какие правила применяются к тем или иным сайтам в вашей сети.
Примечание: Мы предполагаем, что вы уже установили Rank Math на мультисайт WordPress, если нет, мы рекомендуем прочитать эту статью Установка Rank Math в мультисайтовой среде.
Чтобы сделать это, перейдите к Network Admin > Sites .
Затем щелкните вкладку Dashboard для сайта, для которого вы хотите добавить правила robots. txt.
txt.
Когда вы окажетесь на панели инструментов сайта, перейдите Rank Math > General Settings . Здесь вы сможете отредактировать файл robots.txt и добавить необходимые правила.
Убедитесь, что вы сохранили изменения, прежде чем покинуть страницу. Повторите эти шаги для каждого сайта в вашей сети, на который вы хотите добавить правила robots.txt.
4 Примеры правила robots.txt
В файле robots.txt разрешено лишь несколько правил, и их следует использовать немедленно. Если вы совершите небольшую ошибку, вы можете потерять весь с трудом заработанный трафик и потерять позицию в рейтинге. Вот несколько примеров правил robots.txt:
4.1 Разрешить весь домен и заблокировать определенный подкаталог
Это позволит ботам поисковых систем получить доступ ко всем страницам вашего сайта, за исключением страниц, расположенных в папке /subdirectory/ . Если у вас многосайтовая сеть и вы хотите заблокировать доступ к определенному дочернему сайту, вы можете использовать этот код:
Агент пользователя: * Запретить: /подсайт/ Карта сайта: https://www.example.com/sitemap.xml
В приведенном выше примере символ * является подстановочным знаком, который позволяет всем ботам получить доступ к веб-сайту. Disallow говорит ботам не сканировать какие-либо страницы в каталоге дочернего сайта. Карта сайта сообщает ботам, где найти вашу карту сайта, чтобы они могли более эффективно сканировать ваш сайт.
Обязательно замените /subsite/ на нужный каталог.
4.2 Запрет сканирования всего веб-сайта
Это правило запрещает роботам поисковых систем сканировать весь ваш сайт. / в правиле представляет корень каталога веб-сайта и включает все веб-страницы.
Это правило не рекомендуется для действующих веб-сайтов, поскольку оно блокирует сканирование и индексацию вашего веб-сайта ботами поисковых систем.
Вы можете использовать это правило, когда ваш веб-сайт находится в стадии разработки, когда вы не хотите, чтобы поисковые роботы получали доступ и индексировали содержимое, которое еще не показано.
Агент пользователя: * Запретить: /
4.3 Запретить сканирование всего веб-сайта для определенного бота
Если вы хотите защитить доступ к вашему веб-сайту только от определенных поисковых роботов, вы можете заменить подстановочный знак в агенте пользователя на имя поисковых роботов, например как Adsbot Google .
Агент пользователя: AdsBot-Google Disallow: /
Теперь, блокируя вышеупомянутый краулер, если вы хотите, чтобы другие боты поисковых систем сканировали ваш сайт, используйте следующее.
Агент пользователя: AdsBot-Google Запретить: / Пользовательский агент: * Разрешить: /
4.4 Default Robots.txt в Rank Math
По умолчанию вы сможете увидеть следующие правила в поле редактора файла robots.txt Rank Math.
Агент пользователя: * Запретить: /wp-admin/ Разрешить: /wp-admin/admin-ajax.php Карта сайта: yoursite.com/sitemap_index.xml
Вы можете изменить или настроить это правило в соответствии со своими потребностями. Но мы рекомендуем вам сохранить копию этого правила, прежде чем вносить какие-либо изменения.
Но мы рекомендуем вам сохранить копию этого правила, прежде чем вносить какие-либо изменения.
4.5 Запретить доступ к определенному каталогу
Если вы хотите заблокировать доступ к определенным каталогам на своем веб-сайте, вы можете включить относительный путь каталога в правило запрета. Следующее правило показывает вам один пример, когда вы можете заблокировать доступ к страницам каналов на своем веб-сайте.
Агент пользователя: * Запретить: */feed/
4.6 Запретить сканирование файлов определенного типа
Вы также можете рассмотреть возможность использования следующего правила, чтобы запретить сканерам поисковых систем доступ к файлам определенных типов или их сканирование.
Агент пользователя: * Disallow: /*.pdf$
Однако Google не рекомендует блокировать файлы CSS и JS. Потому что это помешает рендерингу страницы для Google, и это потенциально может повлиять на ваш поисковый рейтинг.
5 Заключение
И все! Мы надеемся, что эта статья базы знаний помогла вам понять, как редактировать правила robots. txt для нескольких сайтов или нескольких доменов. Если у вас остались какие-либо вопросы или возникли проблемы при редактировании правила robots.txt для одного или нескольких сайтов, не стесняйтесь обращаться в нашу специальную службу поддержки в любое время, потому что мы доступны 24 часа в сутки, 7 дней в неделю, 365 дней в неделю. год. Мы будем рады помочь вам в любое время.
txt для нескольких сайтов или нескольких доменов. Если у вас остались какие-либо вопросы или возникли проблемы при редактировании правила robots.txt для одного или нескольких сайтов, не стесняйтесь обращаться в нашу специальную службу поддержки в любое время, потому что мы доступны 24 часа в сутки, 7 дней в неделю, 365 дней в неделю. год. Мы будем рады помочь вам в любое время.
Руководство по оптимизации файла WordPress robots.txt для SEO | by Visualmodo
Вы оптимизировали файл WordPress Robots.txt для SEO? Если вы этого не сделали, вы игнорируете важный аспект SEO. Файл robots.txt играет важную роль в SEO вашего сайта. Вам повезло, что WordPress автоматически создает для вас файл Robots.txt. Иметь этот файл — половина дела. Вы должны убедиться, что файл Robots.txt оптимизирован, чтобы получить все преимущества.
Файл Robots.txt сообщает роботам поисковых систем, какие страницы следует сканировать, а какие избегать. В этом посте я покажу вам, как редактировать и оптимизировать файл Robots. txt в WordPress.
txt в WordPress.
Что такое файл robots.txt?
Начнем с основного. Файл robots.txt — это текстовый файл, который указывает ботам поисковых систем, как сканировать и индексировать сайт. Всякий раз, когда какие-либо боты поисковых систем заходят на ваш сайт, они считывают файл robots.txt и следуют инструкциям. Используя этот файл, вы можете указать ботам, какую часть вашего сайта сканировать, а какую избегать. Однако отсутствие robots.txt не помешает роботам поисковых систем сканировать и индексировать ваш сайт.
Редактирование и понимание Robots.txt в WordPress
Я уже говорил, что каждый сайт WordPress имеет файл robots.txt по умолчанию в корневом каталоге. Вы можете проверить файл robots.txt, перейдя по адресу http://yourdomain.com/robots.txt. Например, вы можете проверить наш файл robots.txt здесь: https://roadtoblogging.com/robots.txt
Если у вас нет файла robots.txt, вам придется его создать. Это очень легко сделать. Просто создайте текстовый файл на своем компьютере, сохраните его как robots.txt и загрузите в корневой каталог. Вы можете загрузить его через FTP-менеджер или файловый менеджер cPanel.
Просто создайте текстовый файл на своем компьютере, сохраните его как robots.txt и загрузите в корневой каталог. Вы можете загрузить его через FTP-менеджер или файловый менеджер cPanel.
Теперь давайте посмотрим, как отредактировать файл robots.txt.
Вы можете редактировать файл robots.txt с помощью диспетчера FTP или файлового менеджера cPanel. Но это долго и немного сложно.
Лучший способ редактировать файл Robots.txt — использовать плагин. Существует несколько плагинов WordPress robots.txt. Я предпочитаю Yoast SEO. Это лучший SEO-плагин для WordPress. Я уже рассказывал, как настроить Yoast SEO.
Yoast SEO позволяет вам изменять файл robots.txt из области администрирования WordPress. Однако, если вы не хотите использовать плагин Yoast, вы можете использовать другие плагины, такие как WP Robots Txt.
После того, как вы установили и активировали плагин Yoast SEO, перейдите в Панель администратора WordPress > SEO > Инструменты.
Затем нажмите «Редактор файлов».
Затем нужно нажать «Создать файл robots.txt».
Затем вы получите редактор файла Robots.txt. Здесь вы можете настроить файл robots.txt.
Перед редактированием файла необходимо понять команды файла. В основном это три команды.
- User-agent — определяет имя ботов поисковых систем, таких как Googlebot или Bingbot. Вы можете использовать звездочку (*) для обозначения всех ботов поисковых систем.
- Запретить — Указывает поисковым системам не сканировать и не индексировать некоторые части вашего сайта.
- Разрешить — Указывает поисковым системам сканировать и индексировать, какие части вы хотите индексировать.
Вот пример файла Robots.txt.
Агент пользователя: *
Запретить: /wp-admin/
Разрешить: /
Этот файл robots.txt указывает всем роботам поисковых систем сканировать сайт. Во второй строке он сообщает поисковым роботам не сканировать часть /wp-admin/. В 3-й строке он указывает ботам поисковых систем сканировать и индексировать весь веб-сайт.
В 3-й строке он указывает ботам поисковых систем сканировать и индексировать весь веб-сайт.
Настройка и оптимизация файла Robots.txt для поисковой оптимизации
Простая ошибка в настройке файла Robots.txt может привести к полной деиндексации вашего сайта поисковыми системами. Например, если вы используете команду «Запретить: /» в файле Robots.txt, ваш сайт будет деиндексирован поисковыми системами. Так что нужно быть осторожным при настройке.
Еще одним важным моментом является оптимизация файла Robots.txt для SEO. Прежде чем перейти к лучшим практикам SEO для Robots.txt, я хотел бы предупредить вас о некоторых плохих практиках.
- Не используйте файл Robots.txt для сокрытия некачественного содержимого. Лучше всего использовать метатеги noindex и nofollow. Вы можете сделать это с помощью плагина Yoast SEO.
- Не используйте файл Robots.txt, чтобы запретить поисковым системам индексировать ваши категории, теги, архивы, страницы авторов и т.
 д. Вы можете добавить на эти страницы метатеги nofollow и noindex с помощью плагина Yoast SEO.
д. Вы можете добавить на эти страницы метатеги nofollow и noindex с помощью плагина Yoast SEO. - Не используйте файл Robots.txt для обработки повторяющегося содержимого. Есть и другие способы.
Теперь давайте посмотрим, как сделать файл Robots.txt оптимизированным для SEO.
- Сначала вам нужно определить, какие части вашего сайта не должны сканироваться роботами поисковых систем. Я предпочитаю запрещать /wp-admin/, /wp-content/plugins/, /readme.html, /trackback/.
- Добавление производных «Разрешить: /» в файл Robots.txt не так важно, так как боты все равно будут сканировать ваш сайт. Но вы можете использовать его для конкретного бота.
- Добавление файлов Sitemap в файл Robots.txt также является хорошей практикой. Читайте: Как создать карту сайта
Вот пример идеального файла Robots.txt для WordPress.
Агент пользователя: *
Запретить: /wp-admin/
Запретить: /wp-content/plugins/
Запретить: /readme.html
Запретить: /trackback/
Запретить: /go/
Разрешить: /wp- admin/admin-ajax.php
Разрешить: /wp-content/uploads/
Карта сайта: https://roadtoblogging.com/post-sitemap.xml
Карта сайта: https://roadtoblogging.com/page-sitemap.xml
Вы можете проверить файл RTB Robots.txt здесь: https://roadtoblogging.com/robots.txt
Тестирование файла Robots.txt в Google Webmaster Tools
После обновления файла Robots.txt необходимо протестировать файл Robots.txt, чтобы проверить, не влияет ли обновление на какой-либо контент.
Вы можете использовать Google Search Console, чтобы проверить, есть ли какие-либо «Ошибки» или «Предупреждения» для вашего файла Robots.txt. Просто войдите в Google Search Console и выберите сайт. Затем перейдите в Crawl > robots.txt Tester и нажмите кнопку «Отправить».
Появится окно. Просто нажмите на кнопку «Отправить».
Затем перезагрузите страницу и проверьте, обновлен ли файл.