Как сделать robots.txt для WordPress.Создаем правильный robots.txt для сайта на WordPress
Приветствую, друзья! В этом уроке мы поговорим о создании файла robots.txt, который показывает роботам поисковых систем, какие разделы Вашего сайта нужно посещать, а какие нет.
Фактически, с помощью этого служебного файла можно указать, какие разделы будут индексироваться в поисковых системах, а какие нет.
Создание файла robots.txt
1. Создайте обычный текстовый файл с названием robots в формате .txt.
2. Добавьте в него следующую информацию :
User-agent: Yandex Disallow: /wp-admin Disallow: /wp-includes Disallow: /wp-comments Disallow: /wp-content/plugins Disallow: /wp-content/themes Disallow: /wp-content/cache Disallow: /wp-login.php Disallow: /wp-register.php Disallow: */trackback Disallow: */feed Disallow: /cgi-bin Disallow: /tmp/ Disallow: *?s= User-agent: * Disallow: /wp-admin Disallow: /wp-includes Disallow: /wp-comments Disallow: /wp-content/plugins Disallow: /wp-content/themes Disallow: /wp-content/cache Disallow: /wp-login.php Disallow: /wp-register.php Disallow: */trackback Disallow: */feed Disallow: /cgi-bin Disallow: /tmp/ Disallow: *?s= Host: site.com Sitemap: http://site.com/sitemap.xml
 php
Disallow: /wp-register.php
Disallow: */trackback
Disallow: */feed
Disallow: /cgi-bin
Disallow: /tmp/
Disallow: *?s=
Host: site.com
Sitemap: http://site.com/sitemap.xml
php
Disallow: /wp-register.php
Disallow: */trackback
Disallow: */feed
Disallow: /cgi-bin
Disallow: /tmp/
Disallow: *?s=
Host: site.com
Sitemap: http://site.com/sitemap.xml
3. Замените в в текстовом файле строчку site.com на адрес Вашего сайта.
4. Сохраните изменения и загрузите файл robots.txt (с помощью FTP) в корневую папку Вашего сайта.
5. Готово.
Для просмотра и скачки примера, нажмите кнопку ниже и сохраните файл (Ctrl + S на клавиатуре).
Скачать пример файла robots.txt
Разбираемся в файле robots.txt (директивы)
Давайте теперь более детально разберем, что именно и зачем мы добавили в файл robots.txt.
User-agent — директива, которая используется для указания названия поискового робота. С помощью этой директивы можно запретить или разрешить поисковым роботам посещать Ваш сайт. Примеры:
Запрещаем роботу Яндекса просматривать папку с кэшем:
User-agent: Yandex Disallow: /wp-content/cache
Разрешаем роботу Bing просматривать папку themes (с темами сайта):
User-agent: bingbot Allow: /wp-content/themes
Allow и Disallow — разрешающая и запрещающая директива. Примеры:
Примеры:
Разрешим боту Яндекса просматривать папку wp-admin:
User-agent: Yandex Allow: /wp-admin
Запретим всем ботам просматривать папку wp-content:
User-agent: * Disallow: /wp-content
В нашем robots.txt мы не используем директиву Allow, так как всё, что не запрещено боту с помощью Disallow — по умолчанию будет разрешено.
Host — директива, с помощью которой нужно указать главное зеркало сайта, которое и будет индексироваться роботом.
Sitemap — используя эту директиву, нужно указать путь к карте сайта. Напомню, что карта сайта является очень важным инструментом при продвижении сайта! Обязательно указывайте её в этой директиве!
Если остались какие-то вопросы — задавайте их в комментарий. Если же информации в этом уроке для Вас оказалось недостаточно, рекомендую почитать подробнее о всех директивах и способах их использования перейдя по этой ссылке.
Файл WordPress Robots.txt для SEO: пошаговое руководство (2022)
Файл robots.txt — это одна из самых важных данных на вашем веб-сайте. Настолько важный, что неправильно написанный файл robot.txt может даже отрезать вас от поисковых систем.
Итак, в этом руководстве я покажу вам, как создать собственный файл robots.txt для вашего WordPress Веб-сайт.
SEO состоит из многих факторов, но ничего не получится, если поисковые системы не смогут просканировать ваш сайт. Итак, прежде чем переходить на robots.txt, вы должны понимать, что сканируется.
Содержание
- Что такое поисковый робот
- Что такое Robots.txt
- Основы Robots.txt
- Основные инструкции Robots.txt для блога WordPress:
- Как создать файл robots.txt
Что такое поисковый робот
В поисковых системах есть программы, называемые сканерами, также известными как «боты» или «веб-пауки».
Эти поисковые роботы посещают, сканируют и читают все веб-страницы, находящиеся в их пределах досягаемости, чтобы подготовить поисковый индекс всех известных ссылок, который включает информацию о содержании страниц и другую информацию.
Эти сканеры работают, чтобы пройти через все веб-сети и обнаружить новые сообщения, веб-сайты и другие обновления в Интернете.
Сканеры имеют фиксированный бюджет, ограничение на объем сканирования веб-сайта и время, необходимое для этого. – Это называется ограничением скорости сканирования или бюджетом.
Это также зависит от спроса на сканирование: количество URL-адресов и страниц, которые сканер хочет и должен просканировать на вашем веб-сайте.
Если вы позволите боту сканировать ненужные части вашего веб-сайта и будет достигнут предел скорости сканирования или требование будет выполнено, он покинет ваш сайт и может не сканировать важные страницы, которые вы хотите ранжировать в Google.
Что такое Robots.txt
Сканеры продолжают переходить по ссылкам на каждую вторую страницу веб-сайта, пока все страницы не будут прочитаны, а файл robots.txt используется, чтобы дать сканеру указание остановить или контролировать это.
Robots.txt сообщает сканерам, что нужно исключить из сканирования одну или определенную группу страниц и ссылок. Если они не сканируются ботами, они, скорее всего, не появятся на страницах результатов поисковой системы.
Это зависит от обходчика. Если он подчиняется указаниям robots.txt, вы не можете заставить их.
Robots.txt — это текстовый файл, расположенный в корневой папке вашего сервера. Смотрите пример.
Он также известен как «протокол исключения роботов и стандарт исключения роботов». Они говорят и понимают особый язык, известный как протокол исключения роботов.
Когда сканеры поисковых систем посещают ваш сайт, robots.txt — это первое, что они сканируют. Он либо будет следовать инструкциям, указанным в вашем файле, либо проигнорирует их.
Сканер поисковой системы с меньшей вероятностью проигнорирует вашу инструкцию robots.txt, именно вредоносные программы или «плохие» боты будут их игнорировать каждый раз, и вы ничего не сможете сделать, чтобы их остановить.
Основы Robots.txt
Есть несколько инструкций, которые вам нужно знать, а именно:
- User-Agent: *
- Разрешить: /
- Disallow: /
Вышеупомянутые 3 основные команды образуют файл robots.txt.
Сначала вы вводите пользовательский агент:
User-Agent: *
Звездочка после «пользовательский агент» означает, что инструкция robots.txt будет применяться к каждому боту, посещающему сайт.
Если вы хотите разрешить боту сканировать страницу вашего сайта, вы используете:
Разрешить: /
Если вы не хотите, чтобы ваша страница сканировалась, используйте:
Disallow: /
Обычно вы хотите запретить только определенные страницы, поэтому вы должны указать URL-адрес после косой черты. Если вы просто используете команду disallow, как показано выше, это не позволит сканерам сканировать любую из ваших веб-страниц.
В большинстве случаев вы не допустите, чтобы это произошло, поэтому после команды disallow вы указываете URL-адрес, который сканеры не должны сканировать.
Основные инструкции Robots.txt для блога WordPress:
Ниже я написал базовую команду robots.txt для WordPress, которую вы можете скопировать и вставить, чтобы использовать ее в своем блоге:
Агент пользователя: * Запретить: /wp-admin/ Разрешить: /wp-admin/admin-ajax.php
Необходимо использовать приведенные выше команды в файле robots.txt.
SEO-оптимизированный robots.txt
Агент пользователя: * Disallow: /cgi-bin/ Disallow: /wp-admin/ Disallow: /?* Disallow: /index.php Disallow: /xmlrpc.php
WordPress имеет свою страницу входа через URL «/ Wp-администратора», и эта страница не представляет никакой ценности для поисковые системы. Их лучше заблокировать.
Точно так же страница «/index» — это страница, которую вы не хотите отображать в поисковых системах, поскольку она состоит из ваших файлов, расположенных на вашем сервере. Вы их тоже блокируете.
Затем «/xmlrpc» используется для пингбэков и трекбэков в WordPress, и вы также должны добавить «/?*» в команду disallow. Это заблокирует сканирование ваших внутренних результатов поиска ботами и поможет предотвратить дублирование и слишком много страниц.
Это заблокирует сканирование ваших внутренних результатов поиска ботами и поможет предотвратить дублирование и слишком много страниц.
Это помогает сэкономить много бюджет на обход.
Как создать файл robots.txt
Во-первых, вы должны проверить, есть ли у вас уже файл robots.txt или нет.
Идти к «вашдомен.com/robots.txt» Проверять.
*Замените «yourdomain.com» своим реальным домен.
Если файл robots.txt уже существует, вы можете просто отредактировать его. Если на вашем сервере нет файла robots.txt, значит, вам придется его создать.
Самый простой способ создать файл robots.txt для вашего веб-сайта WordPress — установить Шустрый плагин.
Сквирли — это Плагин SEO который автоматически создаст файл robots.txt для вашего сайта после активации. Вы можете отредактировать его, перейдя в дополнительные настройки:
Однако он не создает физический файл robots.txt, поэтому, если в будущем вы удалите этот плагин и его данные, ваш файл robots.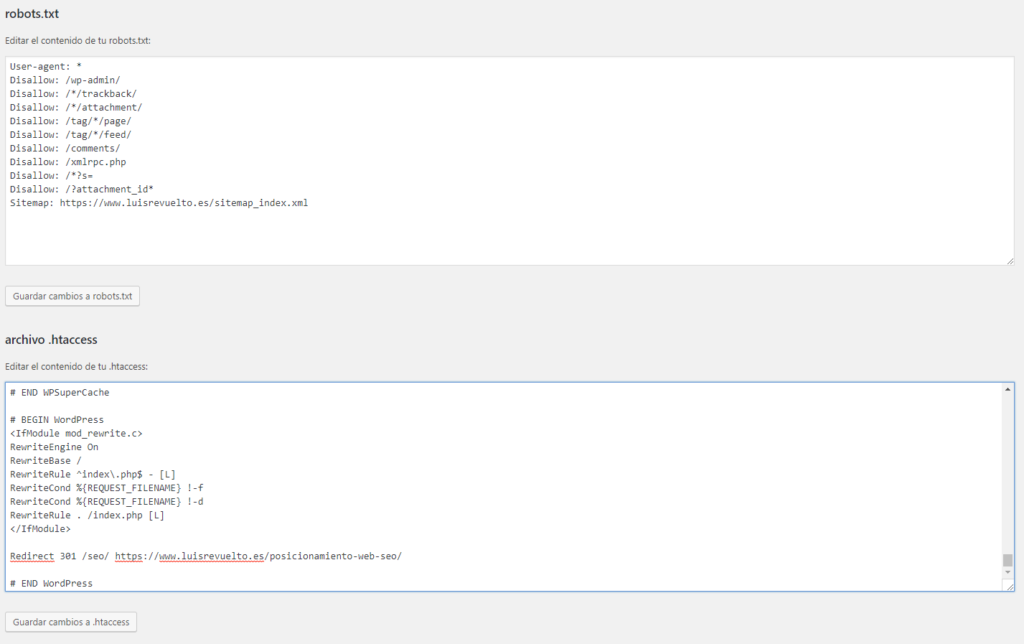 txt также будет потерян. WordPress создает виртуальный файл robots.txt на вашем сервере, если его нет. Чтобы отредактировать его, вы можете использовать Squirrly или Yoast.
txt также будет потерян. WordPress создает виртуальный файл robots.txt на вашем сервере, если его нет. Чтобы отредактировать его, вы можете использовать Squirrly или Yoast.
Веб-хосты, такие как CloudWays изначально запретит вам редактировать файл robots.txt через SEO плагины. Вам необходимо связаться с их службой поддержки или использовать метод FTP ниже.
Я рекомендую вам создать и загрузить файл robots.txt на свой сервер.
1. Получите доступ к вашему серверу на уровне FTP.
Сначала вы должны установить FTP-клиент на свой компьютер, чтобы получить доступ к серверу веб-хостинга. я предпочитаю Filezilla для этого.
Установите Filezilla и подключитесь к своему серверу, используя свое имя пользователя и пароль FTP/SFTP. Если вы не знаете о них, спросите у своего хостинг-провайдера.
2. Найдите файл robots.txt в public.html.
Нажмите на папку public.html в области FTP-сервера. Ниже вы увидите файл robots.txt. Если у вас еще нет файла robots.txt, вы можете его не увидеть. В этом случае вам придется его создать.
В этом случае вам придется его создать.
3. Откройте текстовый редактор
Блокнот будет работать. Откройте Блокнот на своем ПК и скопируйте/вставьте эту инструкцию robots.txt:
Агент пользователя: * Запретить: /wp-admin Запретить: /xmlrpc Запретить: /index.php
Разрешить: /wp-admin/admin-ajax.php
Вы также можете добавить сюда свою карту сайта, но это не обязательно.
Сохраните этот текстовый файл и назовите его robots. Убедитесь, что вы указали расширение «.txt» и не добавляли «.txt» в поле имени.
4. Загрузите его в корень вашего сервера
Вернитесь в Filezilla и щелкните папку public.html.
Перетащите файл robots.txt на пустое место в левой части экрана компьютера.
Вот и все. Ваш файл robots.txt теперь доступен.
Обновление 2019: Недавно Google объявил, что Тег nofollow (rel=»nofollow») будет рассматриваться как подсказка. Это означает, что Google может учитывать или не учитывать тег Nofollow. Google представил два новых тега: «UGC (пользовательский контент)» и «спонсируемый».
Google представил два новых тега: «UGC (пользовательский контент)» и «спонсируемый».
Тег rel=”UGC” можно использовать для пользовательского контента, такого как комментарии в блогах, ссылки на форумы, а тег rel=”спонсорский” можно использовать для партнерских и партнерских ссылок. Вы можете прочитать официальный анонс здесь.
Надеюсь, теперь вы знаете, как подготовить SEO-оптимизированный файл robots.txt для своего веб-сайта WordPress. Теперь сканеры поисковых систем не будут сканировать бесполезные страницы вашего сайта и блога, экономя краулинговый бюджет.
Это позволит им просканировать все страницы, которые вы хотите ранжировать.
Дайте мне знать ваши мысли в разделе комментариев ниже.
шаблон WordPress robots.txt · GitHub
Этот файл содержит двунаправленный текст Unicode, который может быть интерпретирован или скомпилирован не так, как показано ниже. Для просмотра откройте файл в редакторе, который показывает скрытые символы Unicode. Подробнее о двунаправленных символах Unicode
Подробнее о двунаправленных символах Unicode
Показать скрытые символы
| # Роботы рулят! — Иногда… # | |
| Агент пользователя: * | |
| Разрешить: / | |
| # Запретить эти каталоги, типы URL и типы файлов | |
| Запретить: /trackback/ | |
| Запретить: /wp-admin/ | |
| Запретить: /wp-content/ | |
| Запретить: /wp-includes/ | |
Запретить: /xmlrpc. php php | |
| Запретить: /wp- | |
| Запретить: /cgi-bin | |
| Запретить: /readme.html | |
| Запретить: /license.txt | |
| Запретить: /*?* | |
| Запретить: /*.js$ | |
| Запретить: /*.inc$ | |
| Запретить: /*.css$ | |
| Запретить: /*.gz$ | |
| Запретить: /*.wmv$ | |
Запретить: /*.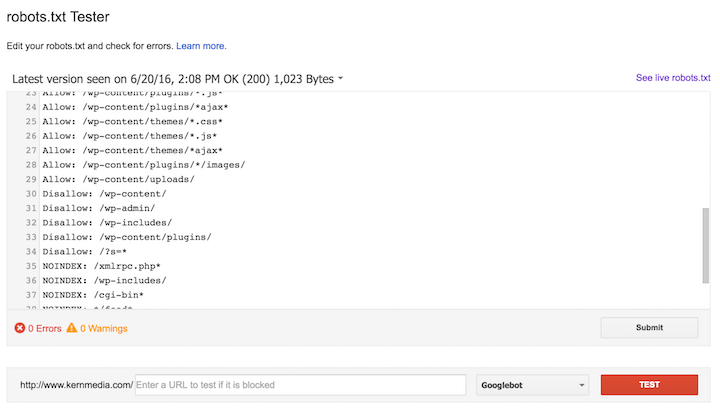 cgi$ cgi$ | |
| Запретить: /*.xhtml$ | |
| Запретить: /*/wp-* | |
| Запретить: /*/канал/* | |
| Запретить: /*/*?s=* | |
| Запретить: /*/*.js$ | |
| Запретить: /*/*.inc$ | |
| Разрешить: /wp-content/uploads/ | |
| Агент пользователя: ia_archiver* | |
| Запретить: / | |
| Агент пользователя: duggmirror | |
| Запретить: / | |
Карта сайта: http://yourdomain. com/sitemap.xml com/sitemap.xml |
Как редактировать robots.txt в WordPress
Robots.txt — это одна из тех вещей, о которых слышали многие SEO-специалисты, но мало кто из нас действительно понимает. Хорошая новость заключается в том, что файл robots.txt не должен быть сложным. Хорошая новость заключается в том, что редактировать robots.txt в WordPress очень просто.
Если вы уже знакомы с протоколом исключения роботов, перейдите к видео ниже, чтобы ознакомиться с пошаговым руководством по обновлению robots.txt с помощью Yoast. В противном случае, вот какой-то фон высокого уровня.
Что такое Robots.txt?Robots.txt — также называемый протоколом исключения роботов — представляет собой механизм, с помощью которого веб-сайты могут взаимодействовать со сканерами поисковых систем и другими ботами в Интернете.
Сообщает поисковым роботам, к каким URL-адресам на вашем веб-сайте им следует обращаться. Например, если на вашем сайте есть закрытый раздел для зарегистрированных участников, вы можете использовать robots. txt, чтобы исключить доступ к этой части вашего сайта, сканирование и индексирование. В таких случаях вы обычно исключаете поддомен или подпапку. На веб-сайте электронной коммерции вы можете использовать robots.txt, чтобы исключить страницы корзины и оформления заказа.
txt, чтобы исключить доступ к этой части вашего сайта, сканирование и индексирование. В таких случаях вы обычно исключаете поддомен или подпапку. На веб-сайте электронной коммерции вы можете использовать robots.txt, чтобы исключить страницы корзины и оформления заказа.
Понимание файла robots.txt является важной частью экосистемы SEO и обычно считается относящимся к области «технической SEO» (в отличие от локального SEO или SEO-оптимизации на странице).
Как редактировать robots.txt в WordPressОдним из самых простых способов редактирования robots.txt в WordPress является использование плагина Yoast SEO. Yoast — это швейцарский армейский нож SEO для сайтов WordPress. Вы можете использовать его для всего: от редактирования карты сайта до блокировки страниц от индексации до изменения отображения ваших страниц в поисковой выдаче Google (страница результатов поисковой системы).
По умолчанию WordPress создает файл robots.txt, который выглядит следующим образом.
Первая строка означает, что инструкция для всех ботов и краулеров. Звездочка — это регулярное выражение (регулярное выражение), означающее, что включены все. Если по какой-то причине вы хотели иметь разные инструкции для Google (Googlebot), Bing (Bingbot) или Yahoo (Slurp), вы могли это сделать. Вот руководство по 10 самым популярным ботам поисковых систем, включая DuckDuckGo, Baidu и другие.
В видеоролике, указанном ниже, показано, как получить доступ к robots.txt на сайте WordPress и как добавить карту сайта в robots.txt.
Не видео человек? Без проблем. Вы можете проверить 5 шагов, подробно описанных ниже.
Как добавить карту сайта в Robots.txt за 5 шагов с помощью Yoast Это очень быстро. Может быть, даже быстрее, чем 3-минутное видео по ссылке выше.
Может быть, даже быстрее, чем 3-минутное видео по ссылке выше.
- После того, как вы вошли на свой сайт WordPress, нажмите «SEO» в левой навигационной панели, чтобы получить доступ к меню Yoast SEO.
- Щелкните Инструменты.
- Нажмите «Редактор файлов».
- Внесите изменения в файл robots.txt. Если вы использовали Yoast для создания карты сайта, вы можете добавить ее сюда, чтобы сделать ее легкодоступной для всех поисковых систем. Просто перейдите на новую строку и введите Sitemap: https://www.yoursite.com/sitemap_index.xml
- Нажмите кнопку «Сохранить изменения в robots.txt», как показано ниже.
Нет. Это распространенное заблуждение относительно файла robots.txt. Согласно руководству разработчика Google, вы должны заблокировать индексирование с помощью тега noindex или защитить страницу паролем. Это связано с тем, что страница, «заблокированная» файлом robots. txt, все еще может быть проиндексирована Google, если на нее ссылаются другие страницы. Тег noindex решает эту проблему.
txt, все еще может быть проиндексирована Google, если на нее ссылаются другие страницы. Тег noindex решает эту проблему.
Также стоит отметить, что Google рассматривает файл robots.txt как предложение, а не указание веб-сайтов. Кроме того, некоторые другие боты (особенно вредоносные боты) могут полностью игнорировать robots.txt. На самом деле они не следуют правилам.
Сколько времени требуется для обновления robots.txt?По словам Google, это займет не более суток. «Сканеры Google замечают изменения, внесенные вами в файл robots.txt, и обновляют кешированную версию каждые 24 часа».
Неплохо!
Если у вас есть свободное время, пока вы ждете, подумайте о том, чтобы проверить дополнительные бесплатные ресурсы, связанные с SEO, Google Analytics, Google Tag Manager и Google Ads, на корневом канале YouTube. Этот об использовании Google Tag Manager и Google Analytics для настройки отслеживания кликов по ссылкам — мой личный фаворит.
Если вам нравится то, что вы видите, и вы решили подписаться, как правило, каждый месяц появляется как минимум несколько новых аналитических и SEO-видео с советами и руководствами.