Файл robot.txt | WordPress.org Русский
Спасибо за ответы, только у меня вопросов прибавилось((( Я НЕ специалист к сожалению((
Мой робот я сделала давно, тогда почему-то сайт долго индексировался и мне с яндекс вебмастера предложили закрыть лишнее, чтобы робот быстрей обходил, ну я и закрыла (в интернете день читала про все — так видимо и не поняла)
Я очень уважаю ваше мнение, но чем больше я смотрю файлов и сайтов, тем больше у меня вопросов ибо в каждом что-то разное — то стоит в конце /, то не стоит и прочие значки вот по ссылке, что прислал SeVlad я вообще ничего не поняла, так как это плюс еще очередной вариант на мою и без того запутанную чайниковую голову
Yui мне лучше совсем убрать то что Вы написали или добавить разрешение allow для моей темы Нирвана (у меня закачано еще три темы — хотела сменить дизайн посмотреть, чтобы не перегружать обходящего робота) Я ОЧЕНЬ боюсь испортить или открыть больше, чем нужно.
Могли бы вы подправить, исправить, проверить мой робот тхт или написать новый , чтобы он был правильным и в тоже время не замедлял обход сайта роботами гугла и яндекса.
User-agent: * Allow: /wp-content/uploads Allow: /wp-content/themes/nirvana/css Disallow: /cgi-bin Disallow: /wp-admin/ Disallow: /wp-content/cache Disallow: /wp-login.php Disallow: */attachment_id=* Disallow: */trackback Disallow: */feed/ Disallow: /?p=* Disallow: *?s= Disallow: /xmlrpc.php User-agent: Yandex Disallow: /cgi-bin Disallow: /wp-admin/ Disallow: /wp-includes/ Disallow: /wp-content/plugins Disallow: /wp-content/themes Disallow: /wp-content/cache Disallow: /wp-login.php Disallow: *?replytocom=* Disallow: */attachment_id=* Disallow: */trackback Disallow: */tag/* Disallow: */feed/ Disallow: /?p=* Disallow: *?s= Disallow: /xmlrpc.php Host: мойсайт.ru Sitemap: http://мойсайт.ru/sitemap.xml Sitemap: http://мойсайт.ru/sitemap.xml
Обязательно здесь ставить вторую строчку с gz в конце,
Грубо говоря — удаляете всё и следите за индексацией (метрика/вебмастер) и если если там появятся нежелательное — закрываете
Как я потом узнаю чем закрыть и что именно (куча значков то вначале, то в конце, то * то все вместе
Тот пример который я приложила изобилует всякими функциями поэтому я и запуталась, а в моем случае многое закрыто, особенно этот css, который гугл так обожает
Заранее Спасибо за вашу помощь.Пустья покажусь бестолковой, но мне очень нужно, а может быть я даже что-то пойму на вашем примере.
ru.wordpress.org
правильный пример на WordPress для Яндекса и Google
Всем привет! Сегодня я бы хотел Вам рассказать про файл robots.txt. Да, про него очень много чего написано в интернете, но, если честно, я сам очень долгое время не мог понять, как же создать правильный robots.txt. В итоге я сделал один и он стоит на всех моих блогах. Проблем с индексацией сайта я не замечаю, robots.txt работает просто великолепно.
Robots.txt для WordPress
А зачем, собственно говоря, нужен robots.txt? Ответ все тот же – продвижение сайта в поисковых системах. То есть составление robots.txt – это одно из частей поисковой оптимизации сайта (кстати, очень скоро будет урок, который будет посвящен всей внутренней оптимизации сайта на WordPress. Поэтому не забудьте подписаться на RSS, чтобы не пропустить интересные материалы.).
Одна из функций данного файла – запрет индексации ненужных страниц сайта. Также в нем задается адрес карты сайта sitemap.xml и прописывается главное
Примечание: для поисковых систем один и тот же сайт с www и без www совсем абсолютно разные сайты. Но, поняв, что содержимое этих сайтов одинаковое, поисковики “склеивают” их. Поэтому важно прописать главное зеркало сайта в robots.txt. Чтобы узнать, какое главное (с www или без www), просто наберите адрес своего сайта в браузере, к примеру, с www, если Вас автоматически перебросит на тот же сайт без www, значит главное зеркало Вашего сайта без www. Надеюсь правильно объяснил.
Было:
Стало (после перехода на сайт, www автоматически удалились, и сайт стал без www):
Так вот, этот заветный, по-моему, правильный robots.txt для WordPress Вы можете увидеть ниже.
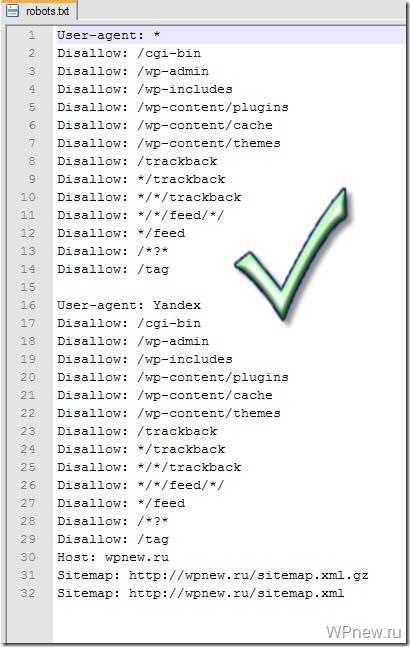
Правильный Robots.txt для WordPress
User-agent: *
Disallow: /cgi-bin
Disallow: /wp-admin
Disallow: /wp-includes
Disallow: /wp-content/plugins
Disallow: /wp-content/cache
Disallow: /wp-content/themes
Disallow: /trackback
Disallow: */trackback
Disallow: */*/trackback
Disallow: */*/feed/*/
Disallow: */feed
Disallow: /*?*
Disallow: /tag
User-agent: Yandex
Disallow: /cgi-bin
Disallow: /wp-admin
Disallow: /wp-includes
Disallow: /wp-content/plugins
Disallow: /wp-content/cache
Disallow: /wp-content/themes
Disallow: /trackback
Disallow: */trackback
Disallow: */*/feed/*/
Disallow: */feed
Disallow: /*?*
Disallow: /tag
Host: wpnew.ru
Sitemap: https://wpnew.ru/sitemap.xml.gz
Sitemap: https://wpnew.ru/sitemap.xml
Все что дано выше, Вам нужно скопировать в текстовой документ с расширением .txt, то есть, чтобы название файла было robots.txt. Данный текстовой документ Вы можете создать, к примеру, с помощью программы Notepad++. Только, не забудьте, пожалуйста, изменить в последних трех строчках адрес wpnew.ru на адрес своего сайта. Файл robots.txt должен располагаться в корне блога, то есть в той же папке, где находятся папки wp-content, wp-admin и др. .
Те, кому же лень создавать данный текстовой файл, можете просто скачать robots.txt и также там подкорректировать 3 строчки.
Хочу отметить, что в техническими частями, о которых речь пойдет ниже, себя сильно загружать не нужно. Привожу их для “знаний”, так сказать общего кругозора, чтобы знали, что и зачем нужно.
Итак, строка:
User-agent
задает правила для какого-то поисковика: к примеру “*” (звездочкой) отмечено, что правила для всех поисковиков, а то, что ниже
User-agent: Yandex
означает, что данные правила только для Яндекса.
Disallow
Здесь же Вы “засовываете” разделы, которые НЕ нужно индексировать поисковикам. К примеру, на странице https://wpnew.ru/tag/seo у меня идет дубль статей (повторение) с обычными статьями, а дублирование страниц отрицательно сказывается на поисковом продвижении, поэтому, крайне желательно, данные секторы нужно закрыть от индексации, что мы и делаем с помощью этого правила:
Disallow: /tag
Так вот, в том robots.txt, который дан выше, от индексации закрыты почти все ненужные разделы сайта на WordPress, то есть просто оставьте все как есть.
Host
Здесь мы задаем главное зеркало сайта, о котором я рассказывал чуть выше.
Sitemap
В последних двух строчках мы задаем адрес до двух карт сайта, созданные с помощью плагина Google XML Sitemaps.
Возможные проблемы
Если у Вас на блоге не стоит ЧПУ (именно так у меня происходит с тем сайтом, которого я занимаюсь продвижением), то с тем robots.txt, который дан выше, могут быть проблемы. Напомню, что без ЧПУ ссылки на сайте на посты выглядят примерно следующим образом:
А вот из-за этой строчки в robots.txt, у меня перестали индексироваться посты сайта:
Disallow: /*?*
Как видите, эта самая строка в robots.txt запрещает индексирование статей, что естественно нам нисколько не нужно. Чтобы исправить это, просто нужно удалить эти 2 строчки (в правилах для всех поисковиков и для Яндекса) и окончательный правильный robots.txt для WordPress сайта без ЧПУ будет выглядеть следующим образом:
User-agent: *
Disallow: /cgi-bin
Disallow: /wp-admin
Disallow: /wp-content/plugins
Disallow: /wp-content/cache
Disallow: /wp-content/themes
Disallow: /trackback
Disallow: */trackback
Disallow: */*/trackback
Disallow: */*/feed/*/
Disallow: */feed
Disallow: /tag
User-agent: Yandex
Disallow: /cgi-bin
Disallow: /wp-admin
Disallow: /wp-includes
Disallow: /wp-content/plugins
Disallow: /wp-content/cache
Disallow: /wp-content/themes
Disallow: /trackback
Disallow: */trackback
Disallow: */*/trackback
Disallow: */*/feed/*/
Disallow: */feed
Disallow: /tag
Host: wpnew.ru
Sitemap: https://wpnew.ru/sitemap.xml.gz
Sitemap: https://wpnew.ru/sitemap.xml
Анализ robots.txt
Заходим в раздел Настройки индексирования –> Анализ robots.txt:
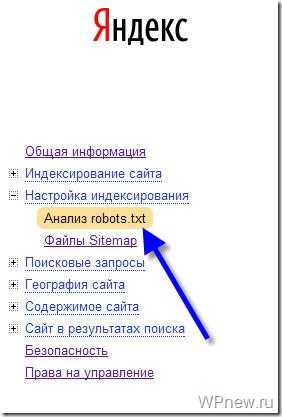
Уже там нажимаете на кнопку “Загрузить robots.txt с сайта”, а затем нажимаете на кнопку “Проверить”:

Если Вы увидите примерно следующее сообщение, значит у Вас правильный robots.txt для Яндекса:
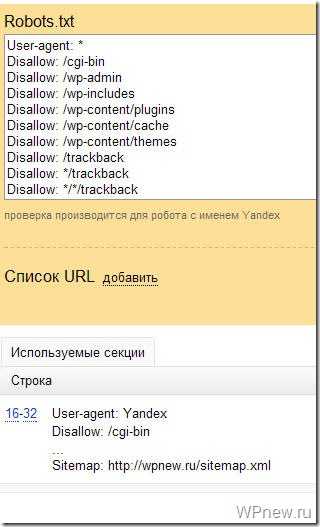
Также Вы можете в “Список URL” добавить адрес любой статьи сайта, чтобы проверить не запрещает ли robots.txt индексирование данной страницы:
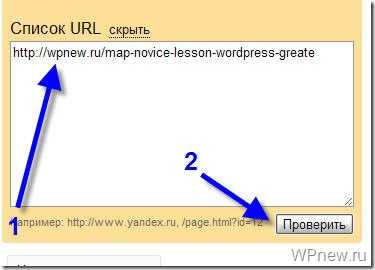
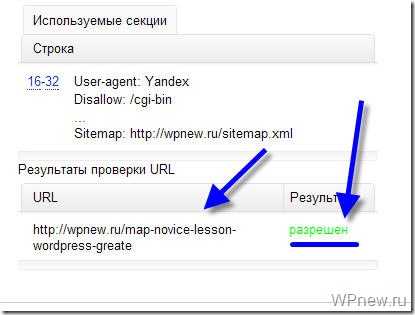
Как видите, никакого запрета на индексирование страницы со стороны robots.txt мы не видим, значит все в порядке :).
Надеюсь больше вопросов, типа: как составить robots.txt или как сделать правильным данный файл у Вас не возникнет. В этом уроке я постарался показать Вам правильный пример robots.txt:
Вы можете посмотреть другие варианты, как еще можно составлять robots.txt.
До скорой встречи!
P.s. Совсем недавно я добавил блог в Яндекс Каталог, что же интересного произошло? 🙂
wpnew.ru
Robots.txt для WordPress, идеальный вариант robots.txt для WP
Файл robots.txt это первоначальный, и один из главнейших инструментов для корректной индексации ваших сайтов и их контента. Отсутствие данного файла приведет к печальным последствиям которые тяжело будет исправить. От того как вы настроите robots.txt зависит что попадет в выдачу по запросам в поисковых системах. Сейчас рассмотрим правильный файл robots.txt для WordPress сайта.
Навигация по странице:
Для чего использовать robots.txt?
Перед тем как приступать к созданию и наполнению давайте разберем саму суть данного файла.
Ваш сайт это набор файлов и папок, некоторые из которых нужно защитить от чтения от сторонних глаз, которыми являются так же и поисковые роботы, пришедшие прочитать и запомнить наш контент, для дальнейшей выдачи в поиске.
Чем занимается поисковой робот на сайте?
Итак, к примеру ваш сайт посетил поисковой робот, что он делает в первую очередь? Во-первых пытается найти уникальную информацию, которую сможет занести в свою базу данных. Если роботс отсутствует, а именно к нему в первую очередь обращается робот, тогда он начинает «читать» файлы находящиеся в корне сайта, что конечно же нам не очень понравиться, ведь он не только не найдет там нужную ему информацию, а и прочитает наши данные настроек, которые созданы для нашей личной цели. Именно для этого и существует robots.txt. Он дает указания роботу куда ходить нужно, а куда заглядывать не стоит.
Создание и размещение файла на сайте WordPress.
Для того что бы создать путеводитель для роботов, вам потребуется обычный блокнот windows, в котором вы будете прописывать нужные команды для поисковых роботов. После этого нужно сохранить файл в формате «txt», под названием «robots». На этом создание завершено, далее в статье мы рассмотрим какие же команды должны находиться в robots.txt для WordPress.
Где размещать?
Robots.txt размещается на вашем хостинге, непосредственно в корневой папке сайта, куда мы перенесли наш сайт. Теперь поисковой робот перед тем как лазить по нашему сайту, сначала спросит разрешение куда ему можно, а куда запрещено заходить.
Важно: при размещении документа в подкаталогах, роботы не смогут найти этот файл.
Зайдя к вам на сайт робот заходит смотрит предназначеную для него «инструкцию» и начинает его изучать. Изучив до конца он пойдет по выбранному вами пути индексации, и будет игнорировать те директории, папки и URL к которым вы запретили обращаться.
Что включает в себя роботс?
Robots.txt несет в себе информативные данные для поисковых роботов и включает в себя такие основные «команды»:
User-agent
Указывает на имя потенциального робота посетителя. Синтаксис «User-agent: *» будет означать что данным командам должны следовать все роботы. Варианты для отдельных роботов рассматривать не будем, их очень много. По этому для примера будет только два варианта (для всех роботов и отдельно для Яндекс).
Disallow
Команда для роботов, рассказывающая о том куда ходить не стоит, запрещает чтение указанных адресов и файлов.
Allow
Команда которая рекомендует «направление» на индексирования данного адреса или файла.
Host
Данная команда указывает роботу, какой из вариантов сайта будет нашим главным зеркалом сайта.
Sitemap
Место нахождения xml карты сайта по которой должен пробежаться посетивший нас робот, в той части за которой он пришел (контент сайта).
Правильный robots.txt для сайта на CMS WordPress.
Для того что бы правильно настроить файл robots.txt специально под «движок» WordPress нужно для начала понимать что ищут роботы и что им будет интересно.
А наши паучки ищут контент нашего ресурса, и им совершенно не нужно знать о всех остальных конфигурационных данных наших сайтов. Во первых они им приходятся не по вкусу, и от переедания таковых они могут покинуть наш сайт так и не найдя то что нам бы хотелось да еще и вынесут наши запрещенные для общего глаза данные на общее обозрение.
Говоря о требуемых размещения директорий в robots.txt для WordPress, нам нужно разобраться с главной (корневой) папкой нашего сайта, в которой мы обнаружим огромное количество стандартных файлов и папок. Роботам незачем их читать, они не найдут там то что ищут, по этому нужно запрещать индексировать по возможности весь «лишний мусор».
Подумайте сами чем может сулить нам например индексация нашего wp-config.php. Робот просто возьмет и «расскажет» всем о наших вводных данных к нашим базам данных, а это крайне плохо для нас.
Сейчас я покажу готовый вариант. Затем разберем каждую строчку в расширенном описании. Итак, правильный robots.txt для WordPress должен выглядеть так:
Disallow: /wp-
Disallow: */trackback
Disallow: /*?*
Disallow: /?s=*
Disallow: */author
Disallow: /2016
Disallow: /xmlrpc.php
Allow: /wp-content/uploads/
Allow: *.js
Allow: *.css
Host: site.ru
Sitemap: http://site.ru/sitemap.xml
Теперь посмотрим как мы смогли добиться такого короткого содержания файла robots.txt для WordPress, рассмотрим расширенную версию файла и постепенно уберем повторы:
Disallow: /wp-admin # Блокируем индексацию папки admin
Disallow: /wp-includes # папки includes
Disallow: /wp-content/languages # папки content/languages
Disallow: /wp-content/plugins # папки content/plugins
Disallow: /wp-content/cache # папки content/cache
Disallow: /wp-content/themes # папки content/themes
Disallow: /trackback # блокируем индекс всех возможных трекбеков
Disallow: */trackback
Disallow: */*/trackback
Disallow: */feed # блокируем индексацию фидов, новостных лент всех вариантов
Disallow: /feed/
Disallow: /?feed=
Disallow: */*/feed
Disallow: */*/feed/*/
Disallow: /*?* # запрет индекса всех ссылок (защита от дублей)
Disallow: /tag # каталоги находящихся в разных директориях ( метки, категории )
Disallow: /tag/*
Disallow: /?s=*
Disallow: /page/* # запрещаем лишние страницы в WP, создающие дубли
Disallow: /author # блокировка индексации автора
Disallow: /2015 # дублирование ссылок с архива # далее блокировка всех административных файлов
Disallow: /xmlrpc.php
Disallow: /wp-activate.php
Disallow: /wp-blog-header.php
Disallow: /wp-comments-post.php
Disallow: /wp-config.php
Disallow: /wp-cron.php
Disallow: /wp-links-opml.php
Disallow: /wp-load.php
Disallow: /wp-login.php
Disallow: /wp-mail.php
Disallow: /wp-register.php
Disallow: /wp-settings.php
Disallow: /wp-signup.php
Disallow: /wp-trackback.php
Disallow: /wp-config-sample.php
Allow: /wp-content/uploads/ # Разрешаем индексировать наши загруженные картинки
Host: site.ru # Указываем основное зеркало
Sitemap: http://site.ru/sitemap.xml # Направляем робота на наши страницы контента
Указанный выше пример заблокирует от индексации все ненужные для поисковой оптимизации файлы и ссылки и укажет на тот материал который должен быть проиндексирован.
Ну уж очень длинный у нас вышел пример, сейчас мы его будем упрощать. Для начала возьмемся за файлы и папки с префиксом «wp-« их все можно объединить воедино.
Disallow: /wp-
Disallow: /trackback
Disallow: */trackback
Disallow: */*/trackback
Disallow: */feed
Disallow: /feed/
Disallow: /?feed=
Disallow: */*/feed
Disallow: */*/feed/*/
Disallow: /*?*
Disallow: /tag
Disallow: /tag/*
Disallow: /?s=*
Disallow: /page/*
Disallow: /author
Disallow: /2015
Disallow: /xmlrpc.php
Allow: /wp-content/uploads/
Allow: *.js
Allow: *.css
Host: site.ru
Sitemap: http://site.ru/sitemap.xml
Значительно уменьшили, но это не предел, пойдем немножко дальше и постараемся еще сократить, да еще и проделать необходимые внутренние настройки.
Все дело в том что при таком варианте файла, Google все равно внесет запрещенные вами страницы в индекс, но выглядеть они будут иначе:
Это не столь опасно как открытые дубли, но все же лучше от этого избавляться. Для того что бы исправить данную ситуацию можно воспользоваться сразу несколькими методами. Я расскажу о самом быстром и простом — запрет индексирования страниц с помощью Google Webmasters Tools «Параметры URL». Кстати в рекомендациях для Яндекса лучше оставить параметр «feed» в указанном варианте.
Избавились от feed с помощью Google, теперь для альтернативы запретим индексирование пагинации с помощью плагина, который скорее всего используется вами, если же это не так, тогда альтернативный так же подойдет. Речь идет о All in One SEO и его настройках тегов «robots» и «canonical».
Для того что бы запретить индексировать поисковикам не нужные нам страницы, такие как страницы пагинации всех видов (главной, рубрик и меток) нужно всего навсего поставить галочки в нужных местах.
Сперва включим канонические ссылки на главные страницы, для избежания их дублирования.
Что мы сделали? В общем все что было нужно, мы указали на страницах которые дублируют наш контент ссылку на основную страницу, что укажет роботу что именно нужно сканировать и считать за основной контент. Теперь добавим еще мета тег robots.
После проведенных настроек, снова обращаемся к нашему варианту файла и смотрим что получилось:
Disallow: /wp-
Disallow: /trackback
Disallow: */trackback
Disallow: */*/trackback
Disallow: /*?*
Disallow: /?s=*
Disallow: /author
Disallow: /2015
Disallow: /xmlrpc.php
Allow: /wp-content/uploads/
Allow: *.js
Allow: *.css
Host: site.ru
Sitemap: http://site.ru/sitemap.xml
По поводу меток и рубрик вопрос спорный, вы можете оптимизировать рубрики, и добиться результата с которым ваши страницы категорий будут не вредны, а наоборот принесут дополнительный трафик. Метки можно подогнать под поисковики аналогично рубрикам.
Если тема, которую вы установили использует картинки, тогда лучше открыть их для индекса:
Allow: /wp-content/themes/название вашей темы/images
Если вы проигнорируете это, у вас могут возникнуть проблемы с поисковиками, они не любят когда от них скрывают важную информацию.
Пример можно расширять, например добавлением запрета для индексации определенных ссылок на страницы, обычно это страницы повторы которые вредят нашей оптимизации.
В документе обычно не указывают конкретно для всех поисковых роботов по отдельности, а делаю два набора команд один для всех второй для Яндекса.
User-agent: *
Disallow: /wp-
…
User-agent: Yandex
Disallow: /wp-
…
Host: site.ru
Sitemap: http://site.ru/sitemap.xml
Host — нужно обязательно указывать, пренебрежение приведет к дублирования индексации ваших страниц между www.site.ru и site.ru, что рассеет ваш трафик и пагубно скажется на вашем сайте.
Как правильно создать карту сайта можно почитать в отдельных уроках по WordPress.
На этом урок по созданию файла robots.txt заканчивается, и помните что от этого по большей степени зависит судьба индексации ваших страниц.
Рекомендую почитать:
yrokiwp.ru
Правильный robots.txt для wordpress, зачем нужен robots.txt, тэг more
23 Ноябрь 2011 4742 202Здравствуйте, дорогие читатели моего блога!
Сегодня я Вам расскажу о том, как составить правильный robots.txt для WordPress.
Многие новички в блоггинге совершают одну очень важную ошибку: они забывают составлять, или составляют неправильно очень важный файл, который называется robots.txt.
Зачем нужен robots.txt?
Платформа WordPress является очень удобной платформой, однако у нее имеется ряд недостатков. Самым главным из которых является дублирование контента.
Вот смотрите, если вы опубликовали статью, то она появляется сразу на нескольких страницах и может иметь разные адреса (урлы).
Статья появляется на главной странице, в архиве, в рубрике, в ленте RSS, в поиске и т.д.
Так вот, если на блоге появляется несколько статей с одинаковым содержанием и различными адресами, то это называется дублирование контента.
Это все равно, что скопировать контент с чужого блога и вставить на свой. Эти статьи будут неуникальными.
За такие действия поисковые системы однозначно наложат на блог санкции в виде всеми любимого фильтра АГС.
Чтобы избежать дублирования контента на платформе wordpress, необходимо использовать некоторые обязательные мероприятия. Одним из которых является запрет индексации поисковыми системами тех разделов блога, на которых дубли создаются ввиду особенностей самой платформы.
Как раз robots.txt позволяет нам исключить из индекса поисковиков подобные страницы.
Кроме этого в корне блога содержатся различные служебные каталоги (например, для хранения файлов), которые тоже желательно исключать из индекса.
Как составить правильный robots.txt для WordPress?
Перед тем как приступить к составлению этого файла, нам необходимо знать основные правила его написания – директивы.
1. Директива User-agent
Эта директива определяет, какому именно поисковому роботу следует выполнять команды, которые будут указаны далее.
Например, если Вы хотите запретить индексацию чего-либо поисковому роботу Яндекса, то следует для этой директивы задать следующий параметр:
User-agent: Yandex
Если Вы хотите дать указание всем без исключения поисковым системам, то директива будет выглядеть следующим образом:
User-agent: *
В случае с рунетом, особые указания необходимо задать для Яндекса, а для роботов остальных поисковых систем подойдут общие, которые мы зададим так:
User-agent: *
2. Следующими директивами являются «Allow» и «Disallow».
Allow – разрешает индексацию указанных в ней элементов.
Disallow – соответственно запрещает индексацию.
Правильный robots.txt должен обязательно содержать директиву «Disallow».
Если написать так:
User-agent: Yandex
Disallow:
То мы разрешим индексацию поисковому роботу Яндекса всего блога полностью.
Если написать так:
User-agent: Yandex
Disallow: /
То запретим Яндексу индексировать весь ресурс.
Таким образом, мы можем разрешать или запрещать индексацию своего блога отдельным или всем роботам.
Например:
User-agent: *
Disallow:
User-agent: Yandex
Disallow: /
Здесь мы разрешили индексирование всем поисковикам, а Яндексу запретили. Надеюсь, это понятно.
Теперь нам необходимо знать, что именно следует запретить для индексации в WordPress, то есть какие разделы могут содержать дубли страниц и другой мусор.
1. все системные и служебные файлы:
— wp-login.php
— wp-register.php
— wp-content/
— wp-admin/
— wp-includes/
Отдельно хочу сказать про каталог wp-content. В принципе, все содержимое в нем необходимо закрыть, за исключением папки «uploads» в которой располагаются изображения. Потому что, в случае запрета индексирования «uploads», ваши картинки на блоге индексироваться не будут.
Поэтому будем закрывать каталоги, размещенные внутри папки «wp-content» отдельно:
Disallow: /wp-content/themes
Disallow: /wp-content/plugins
Disallow: /wp-content/languages
Disallow: /wp-content/cache
Если в каталоге «wp-content» Вашего блога есть еще какие-либо папки, то можно (и даже нужно) их закрыть (за исключением «uploads»).
2. Дубли страниц в категориях:
— category/*/*
3. RSS ленту:
— feed
4. Дубли страниц в результатах поиска:
— *?*
— *?
5. Комментарии:
— comments
6. Трэкбэки:
— trackback
Я не буду описывать структуру WordPress, а выкладываю Вам свой файл robots.txt, который установлен на моем блоге. Я считаю, что он наиболее правильный. Если Вы найдете в нем какие-либо недочеты, то просьба написать об этом в комментариях.
User-agent: *
Disallow: /wp-login.php
Disallow: /wp-register.php
Disallow: /xmlrpc.php
Disallow: /webstat/
Disallow: /feed/
Disallow: /trackback
Disallow: */trackback
Disallow: */feed
Disallow: */comments
Disallow: /*?*
Disallow: /*?
Disallow: /category/*/*
Disallow: /wp-content/themes
Disallow: /wp-content/plugins
Disallow: /wp-content/languages
Disallow: /wp-content/cache
Disallow: /wp-admin/
Disallow: /wp-includes/
Disallow: /comments
Здесь же нужно задать отдельные указания Яндексу:
User-agent: Yandex
Disallow: /wp-login.php
Disallow: /wp-register.php
Disallow: /xmlrpc.php
Disallow: /webstat/
Disallow: /feed/
Disallow: /trackback
Disallow: */trackback
Disallow: */feed
Disallow: */comments
Disallow: /*?*
Disallow: /*?
Disallow: /category/*/*
Disallow: /wp-content/themes
Disallow: /wp-content/plugins
Disallow: /wp-content/languages
Disallow: /wp-content/cache
Disallow: /wp-admin/
Disallow: /wp-includes/
Disallow: /comments
Host: mysite.ru
Sitemap: http://mysite.ru/sitemap.xml
Sitemap: http:// mysite.ru/sitemap.xml.gz
Если Вы не составляли файл robots.txt или сомневаетесь в правильности его составления, советую Вам использовать этот.
Для этого необходимо создать обычный текстовый документ, скопировать весь текст, представленный выше, вставить его в свой файл. Затем сохранить его под именем: robots.txt (первая буква не должна быть заглавной).
Не забудьте поменять mysite.ru на свой.
После создания файл robots.txt необходимо разместить в корне блога, затем добавить его в панель вебмастера Яндекса.
Рекомендую Вам посмотреть видео, посвященное дублированию контента:
Еще пару слов о дублировании контента. Тэг «More»
Дело в том, что у нас на главной странице блога (mysite.ru) тоже выводятся статьи.
При нажатии на заголовок поста, мы переходим на его страницу (mysite.ru/…./….html). Таким образом, часть поста (та, что на главной) является дублем такой же части текста основной статьи.
Закрыть от индексации здесь ничего нельзя. Поэтому рекомендую Вам выводить на главную страницу как можно меньше текста основной статьи.
А именно приветствие и небольшой анонс.
Пример Вы можете посмотреть у меня на главной странице (анонс к этой статье).

Для этого используется тэг more.
Проще говоря: набрали небольшой фрагмент (приветствие и анонс), который будет выведен на главную, перешли в редактор HTML и вставили следующий код:
<!- -more- ->
И продолжаете дальше писать статью.
Вся часть текста, расположенная перед тэгом more, будет выведена на главную страницу.
Рекомендую посмотреть видео: «Что такое Robots.txt?»:
На этом у меня все. Обязательно создайте правильный robots.txt для WordPress!
С уважением, Александр Бобрин
Поделись с друзьями:
Обратите внимание:
Похожие статьи
asbseo.ru
Раздаем правильный файл Robots.txt для WordPress
Главная » Уроки » Раздаем правильный файл Robots.txt для WordPress
Одним из самых важных моментов SEO оптимизации любого сайта, есть правильно созданный файл robots.txt. Этот файл помогает поисковым роботам разобраться в структуре вашего сайта и правильно расставить приоритеты в его сканировании. С ним поисковик будет знать, на что ставить акцент и что выделать при поисковой выдаче, а на что вовсе не нужно обращать внимание и как-то его учитывать.
Очень важно не просто иметь для галочки файл robots.txt у себя, а правильно прописать все настройки конкретно под вашу систему. Ведь если он сделан неправильно, это может не только повысить нагрузку на ваш сайт со стороны поисковых роботов при сканировании, но и полностью исключить его из поисковой выдачи.
Как вы уже поняли, такой файл нам нужно создавать конкретно под движок WordPress. Просто найти какой-то готовый шаблон в интернете и использовать его у себя не разобравшись в назначении — очень глупая затея.
Поэтому, специально для вас мы подготовили Правильный файл robots.txt для движка WordPress, который вы можете скачать, загрузить на свой хостинг, внести параметры своего сайта и сразу использовать у себя.
И так, вот параметры этого файла с комментариями для наглядного просмотра.
User-agent: * # общие правила для всех роботов (для Яндекса и Google отдельно ниже) Disallow: /cgi-bin # папка на хостинге Disallow: /? # все параметры запроса на главной Disallow: /wp- # все файлы WP: /wp-json/, /wp-includes, /wp-content/plugins Disallow: /wp/ # если есть подкаталог /wp/, где установлена CMS Disallow: *?s= # поиск Disallow: *&s= # поиск Disallow: /search/ # поиск Disallow: /author/ # архив автора Disallow: /users/ # архив авторов Disallow: */trackback # трекбеки, уведомления в комментариях о появлении открытой ссылки на статью Disallow: */feed # все фиды Disallow: */rss # rss фид Disallow: */embed # все встраивания Disallow: */page/ # все виды пагинации Disallow: */wlwmanifest.xml # xml-файл манифеста Windows Live Writer Disallow: /xmlrpc.php # файл WordPress API Disallow: *utm*= # ссылки с utm-метками Disallow: *openstat= # ссылки с метками openstat Allow: */uploads # открываем папку с файлами uploads Allow: /*/*.js # внутри /wp- (/*/ — для приоритета) Allow: /*/*.css # внутри /wp- (/*/ — для приоритета) Allow: /wp-*.png # картинки в плагинах, cache папке и т.д. Allow: /wp-*.jpg # картинки в плагинах, cache папке и т.д. Allow: /wp-*.jpeg # картинки в плагинах, cache папке и т.д. Allow: /wp-*.gif # картинки в плагинах, cache папке и т.д. Allow: /wp-*.svg # картинки в плагинах, cache папке и т.д. Allow: /wp-*.pdf # файлы в плагинах, cache папке и т.д. Allow: /wp-admin/admin-ajax.php # используется плагинами, чтобы не блокировать JS и CSS User-agent: GoogleBot # отдельно правила для Google Disallow: /cgi-bin Disallow: /? Disallow: /wp- Disallow: /wp/ Disallow: *?s= Disallow: *&s= Disallow: /search/ Disallow: /author/ Disallow: /users/ Disallow: */trackback Disallow: */feed Disallow: */rss Disallow: */embed Disallow: */page/ Disallow: */wlwmanifest.xml Disallow: /xmlrpc.php Disallow: *utm*= Disallow: *openstat= Allow: */uploads Allow: /*/*.js Allow: /*/*.css Allow: /wp-*.png Allow: /wp-*.jpg Allow: /wp-*.jpeg Allow: /wp-*.gif Allow: /wp-*.svg Allow: /wp-*.pdf Allow: /wp-admin/admin-ajax.php User-agent: Yandex # отдельно правила для Яндекса Disallow: /cgi-bin Disallow: /? Disallow: /wp- Disallow: /wp/ Disallow: *?s= Disallow: *&s= Disallow: /search/ Disallow: /author/ Disallow: /users/ Disallow: */trackback Disallow: */feed Disallow: */rss Disallow: */embed Disallow: */page/ Disallow: */wlwmanifest.xml Disallow: /xmlrpc.php Disallow: *utm*= Disallow: *openstat= Allow: */uploads Allow: /*/*.js Allow: /*/*.css Allow: /wp-*.png Allow: /wp-*.jpg Allow: /wp-*.jpeg Allow: /wp-*.gif Allow: /wp-*.svg Allow: /wp-*.pdf Allow: /wp-admin/admin-ajax.php Clean-Param: utm_source&utm_medium&utm_campaign # Яндекс рекомендует не закрывать от индексирования, а удалять параметры меток, Google такие правила не поддерживает Clean-Param: openstat # аналогично # Укажите один или несколько файлов Sitemap (дублировать для каждого User-agent не нужно). Например, Google XML Sitemap создает 2 карты сайта, как в примере ниже. Sitemap: https://site.ru/sitemap.xml Sitemap: https://site.ru/sitemap.xml.gz # Укажите главное зеркало сайта, как в примере ниже (с WWW / без WWW, если HTTPS то пишем с протоколом, если нужно указать порт указываем). Команду Host понимает Яндекс и Mail.RU, Google не учитывает. Host: https://www.site.ru # Версия кода: 1.0 # Не забудьте поменять `site.ru` на ваш сайт.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 |
User-agent: * # общие правила для всех роботов (для Яндекса и Google отдельно ниже) Disallow: /cgi-bin # папка на хостинге Disallow: /? # все параметры запроса на главной Disallow: /wp- # все файлы WP: /wp-json/, /wp-includes, /wp-content/plugins Disallow: /wp/ # если есть подкаталог /wp/, где установлена CMS Disallow: *?s= # поиск Disallow: *&s= # поиск Disallow: /search/ # поиск Disallow: /author/ # архив автора Disallow: /users/ # архив авторов Disallow: */trackback # трекбеки, уведомления в комментариях о появлении открытой ссылки на статью Disallow: */feed # все фиды Disallow: */rss # rss фид Disallow: */embed # все встраивания Disallow: */page/ # все виды пагинации Disallow: */wlwmanifest.xml # xml-файл манифеста Windows Live Writer Disallow: /xmlrpc.php # файл WordPress API Disallow: *utm*= # ссылки с utm-метками Disallow: *openstat= # ссылки с метками openstat Allow: */uploads # открываем папку с файлами uploads Allow: /*/*.js # внутри /wp- (/*/ — для приоритета) Allow: /*/*.css # внутри /wp- (/*/ — для приоритета) Allow: /wp-*.png # картинки в плагинах, cache папке и т.д. Allow: /wp-*.jpg # картинки в плагинах, cache папке и т.д. Allow: /wp-*.jpeg # картинки в плагинах, cache папке и т.д. Allow: /wp-*.gif # картинки в плагинах, cache папке и т.д. Allow: /wp-*.svg # картинки в плагинах, cache папке и т.д. Allow: /wp-*.pdf # файлы в плагинах, cache папке и т.д. Allow: /wp-admin/admin-ajax.php # используется плагинами, чтобы не блокировать JS и CSS
User-agent: GoogleBot # отдельно правила для Google Disallow: /cgi-bin Disallow: /? Disallow: /wp- Disallow: /wp/ Disallow: *?s= Disallow: *&s= Disallow: /search/ Disallow: /author/ Disallow: /users/ Disallow: */trackback Disallow: */feed Disallow: */rss Disallow: */embed Disallow: */page/ Disallow: */wlwmanifest.xml Disallow: /xmlrpc.php Disallow: *utm*= Disallow: *openstat= Allow: */uploads Allow: /*/*.js Allow: /*/*.css Allow: /wp-*.png Allow: /wp-*.jpg Allow: /wp-*.jpeg Allow: /wp-*.gif Allow: /wp-*.svg Allow: /wp-*.pdf Allow: /wp-admin/admin-ajax.php
User-agent: Yandex # отдельно правила для Яндекса Disallow: /cgi-bin Disallow: /? Disallow: /wp- Disallow: /wp/ Disallow: *?s= Disallow: *&s= Disallow: /search/ Disallow: /author/ Disallow: /users/ Disallow: */trackback Disallow: */feed Disallow: */rss Disallow: */embed Disallow: */page/ Disallow: */wlwmanifest.xml Disallow: /xmlrpc.php Disallow: *utm*= Disallow: *openstat= Allow: */uploads Allow: /*/*.js Allow: /*/*.css Allow: /wp-*.png Allow: /wp-*.jpg Allow: /wp-*.jpeg Allow: /wp-*.gif Allow: /wp-*.svg Allow: /wp-*.pdf Allow: /wp-admin/admin-ajax.php Clean-Param: utm_source&utm_medium&utm_campaign # Яндекс рекомендует не закрывать от индексирования, а удалять параметры меток, Google такие правила не поддерживает Clean-Param: openstat # аналогично
# Укажите один или несколько файлов Sitemap (дублировать для каждого User-agent не нужно). Например, Google XML Sitemap создает 2 карты сайта, как в примере ниже. Sitemap: https://site.ru/sitemap.xml Sitemap: https://site.ru/sitemap.xml.gz
# Укажите главное зеркало сайта, как в примере ниже (с WWW / без WWW, если HTTPS то пишем с протоколом, если нужно указать порт указываем). Команду Host понимает Яндекс и Mail.RU, Google не учитывает. Host: https://www.site.ru
# Версия кода: 1.0 # Не забудьте поменять `site.ru` на ваш сайт. |
А вот сам файл, который вы можете скачать по ссылке robots.txt
После этого файл нужно открыть через любой текстовый редактор и в самом низу вместо site.ru внести данные своего сайта. А конкретно, нужно изменить адреса XML-карт и Host сайта.
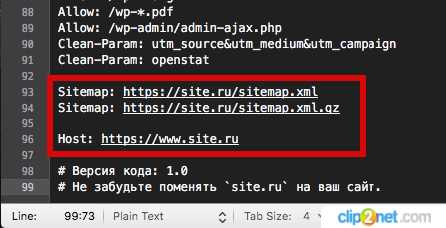
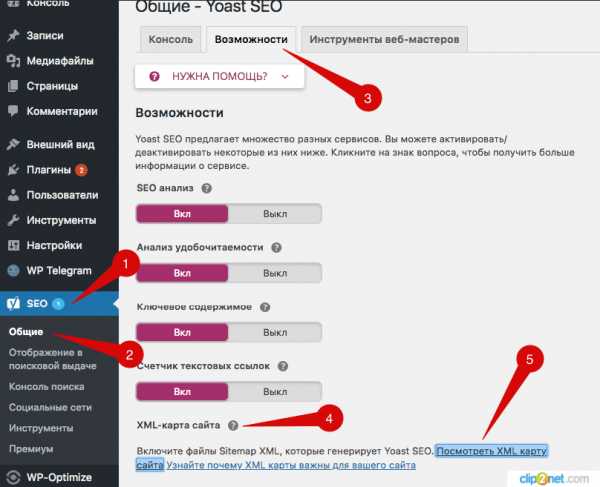
1. Получить адреса XML-карт можно установив плагин Yoast SEO. После его установки и активации заходим в раздел «SEO» —> «Общие» —>«Возможности» —>«XML-карта сайта», нажимаем на иконку знака вопроса и появится ссылка «Посмотреть XML карту сайта». Нажимаем на ее и вы попадете на страницу, где и будут представлены вам адреса XML-Sitemap. Теперь нужно просто перенести их все в файл robots.txt.

2. Host сайта — это его адрес. Если есть https протокол, то с ним и указываем.
Вот, что у нас вышло
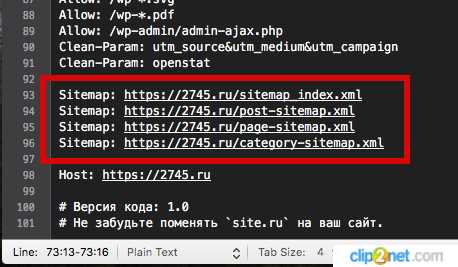
Дальше, после сохранения этих изменений, вам нужно загрузить robots.txt в корневую папку файлов сайта. Что можно сделать либо через панель управления хостингом в разделе Файлы, либо подключиться к нему через ftp-клиент (например, FileZilla).
В нашем случае, мы заходим на своем хостинге в раздел «Файловый менеджер» и загружаем этот файл в корневую папку нужного сайта.

Вот и все, вопрос с настройкой robots.txt у себя вы закрыли. Но важно понимать, что это мы дали уже готовый вариант файла который подойдет многим. Но вы можете внести какие-то изменения под свои нужды, если знаете, что вы делаете и понимаете зачем.
Да, и не забивайте, что SEO оптимизация, это далеко не моментальная вещь, и изменения файла robots.txt на уже рабочем сайте будут заметны не сразу, а только спустя несколько месяцев.
P. S. Так как этот урок создан для тех, кто не хочет во всем этом копаться, а хочет просто получить правильный файл robots.txt и внедрить его у себя. То мы еще сделали полноценный разбор, специально для читателей, которые хотят более подробно пройтись по всей структуре создания такого файла, который вы можете прочитать по ссылке ____.
wp2.ru
Как настроить robots txt для сайта WordPress. Как создать robots txt для WordPress
От автора: одним из файлов, которые используют поисковики при индексации вашего сайта, есть файл robots.txt. Не сложно понять из названия файла, что он используется для роботов. И действительно, этот файл позволяет указать поисковому роботу что можно индексировать на вашем сайте, а что вы не хотите видеть в поисковом индексе. Итак, давайте посмотрим, как настроить robots txt для сайта WordPress.
Статей на эту тему в сети множество. Практически в каждой из этих статей можно найти свой вариант файла robots txt, который можно взять и использовать практически без правок на своем сайте WordPress. Я не буду в очередной раз переписывать в данной статье один из таких вариантов, поскольку особого смысла в этом нет — все эти варианты вы без труда сможете найти в сети. В этой же статье мы просто разберем, как как создать robots txt для WordPress и какой минимум правил там должен быть.
Начнем с того, где должен располагаться файл robots.txt и что в него писать. Данный файл, как и файл sitemap.xml, должен быть расположен в корне вашего сайта, т.е. он должен быть доступен по адресу http://site/robots.txt
Попробуйте обратиться по такому адресу, заменив слово site адресом вашего сайта. Вы можете увидеть при этом примерно такую картину:
Бесплатный курс «Основы создания тем WordPress»
Изучите курс и узнайте, как создавать мультиязычные темы с нестандартной структурой страниц
Скачать курсХотя можете увидеть и вот такую картину:
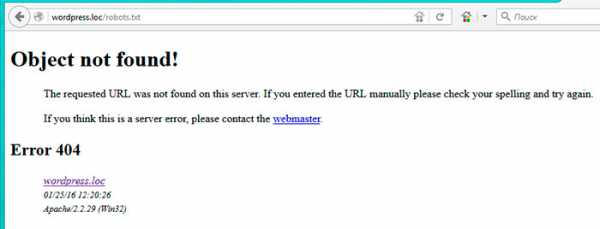
Странная ситуация — скажете вы. Действительно, адрес один и тот же, но в первом случае файл доступен, во втором — нет. При этом если заглянуть в корень сайта, то никакого файла robots.txt вы там не обнаружите. Как так и где же находится robots.txt в WordPress?
Все дело в простой настройке — это настройка ЧПУ. Если на вашем сайте включены ЧПУ, тогда вы увидите динамически сгенерированный движком robots.txt. В противном случае будет возвращена ошибка 404.
Включим ЧПУ в меню Настройки — Постоянные ссылки, отметив настройку Название записи. Сохраним изменения — теперь файл robots.txt будет динамически генерироваться движком.
Как видно на первом рисунке, в этом файле используются некие директивы, задающие определенные правила, а именно — разрешить или запретить индексировать что-либо по заданному адресу. Как несложно догадаться, директива Disallow запрещает индексирование. В данном случае это все содержимое папки wp-admin. Ну а директива Allow разрешает индексирование. В моем случае разрешено индексирование файла admin-ajax.php из запрещенной выше папки wp-admin.
В общем, поисковикам этот файл, конечно, без надобности, даже и не представляю, из каких соображений WordPress прописал это правило. Ну да мне и не жалко, в принципе
К слову, я специально добавлял выше фразу «в моем случае «, поскольку в вашем случае содержимое robots.txt уже может отличаться. Например, может быть запрещена к индексированию папка wp-includes.
Кроме директив Disallow и Allow в robots.txt мы видим директиву User-agent, для которой в качестве значения указана звездочка. Звездочка означает, что идущий далее набор правил относится ко всем поисковикам. Также можно вместо звездочки указывать названия конкретных поисковиков. Файл robots.txt поддерживает и другие директивы. Я на них останавливаться не буду, все их с примерами можно посмотреть в консоли для веб-мастеров Гугла или Яндекса. Также можете прочесть информацию на данном сайте.
Как создать robots txt для WordPress
Итак, файл для поисковых роботов у нас есть, но вполне вероятно, что он вас не устроит в текущем виде. Как же составить свой файл. Здесь есть несколько вариантов. Начнем с первого — ручное создание файла. Создайте обычный текстовый документ в блокноте и сохраните его под именем robots с расширением txt. В этом файле запишите необходимый набор правил и просто сохраните его в корень вашего сайта WordPress, рядом с файлом конфигурации wp-config.php.
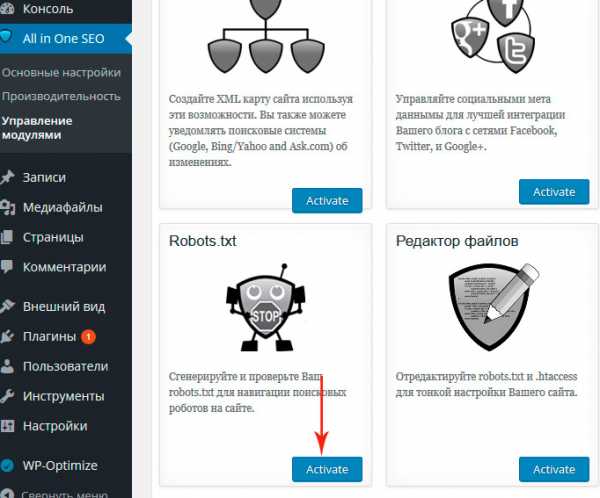
На всякий случай проверьте, что файл загрузился и доступен, обратившись к нему из браузера. Это был первый способ. Второй способ — это все та же динамическая генерация файла, только теперь это сделает плагин. Если вы используете популярный плагин All in One SEO, тогда можно воспользоваться одним из его модулей.
Сначала этот модуль нужно включить. Идем в меню All in One SEO — Управление модулями и активируем модуль Robots.txt.
После этого в меню плагина появится новый пункт — Robots.txt. Перейдем туда и увидим уже предлагаемый набор правил, который можно сохранить.
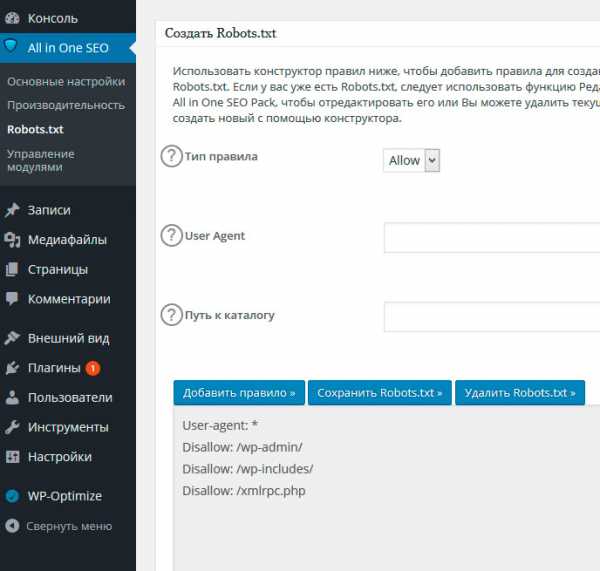
Давайте сохраним и проверим изменения, обратившись на сайте WordPress к robots.txt.
Как видим, все работает. Теперь вы можете написать robots txt для WordPress на свой вкус и так, как вам нужно. Ну а у меня на этом все. Удачи!
Бесплатный курс «Основы создания тем WordPress»
Изучите курс и узнайте, как создавать мультиязычные темы с нестандартной структурой страниц
Скачать курсWordPress-Ученик
12 фишек без которых Вы не создадите полноценный сайт на WordPress!
Смотретьwebformyself.com
Правильный Robots.txt для WordPress
Всем привет! Сегодня статья о том, каким должен быть правильный файл robots.txt для WordPress. С функциями и предназначением robots.txt мы разбирались несколько дней назад, а сейчас разберём конкретный пример для ВордПресс.

С помощью этого файла у нас есть возможность задать основные правила индексации для различных поисковых систем, а также назначить права доступа для отдельных поисковых ботов. На примере я разберу как составить правильный robots.txt для WordPress. За основу возьму две основные поисковые системы — Яндекс и Google.
В узких кругах вебмастеров можно столкнуться с мнением, что для Яндекса необходимо составлять отдельную секцию, обращаясь к нему по User-agent: Yandex. Давайте вместе разберёмся, на чём основаны эти убеждения.
Яндекс поддерживает директивы Clean-param и Host, о которых Google ничего не знает и не использует при обходе.
Разумно использовать их только для Yandex, но есть нюанс — это межсекционные директивы, которые допустимо размещать в любом месте файла, а Гугл просто не станет их учитывать. В таком случае, если правила индексации совпадают для обеих поисковых систем, то вполне достаточно использовать User-agent: * для всех поисковых роботов.
При обращении к роботам по User-agent важно помнить, что чтение и обработка файла происходит сверху вниз, поэтому используя User-agent: Yandex или User-agent: Googlebot необходимо размещать эти секции в начале файла.
Пример Robots.txt для WordPress
Сразу хочу предупредить: не существует идеального файла, который подойдет абсолютно всем сайтам, работающим на ВордПресс! Не идите на поводу, слепо копируя содержимое файла без проведения анализа под ваш конкретный случай! Многое зависит от выбранных настроек постоянных ссылок, структуры сайта и даже установленных плагинов. Я рассматриваю пример, когда используется ЧПУ и постоянные ссылки вида /%postname%/.

WordPress, как и любая система управления контентом, имеет свои административные ресурсы, каталоги администрирования и прочее, что не должно попасть в индекс поисковых систем. Для защиты таких страниц от доступа необходимо запретить их индексацию в данном файле следующими строками:
Disallow: /cgi-bin
Disallow: /wp-Директива во второй строке закроет доступ по всем каталогам, начинающимся на /wp-, в их число входят:
- wp-admin
- wp-content
- wp-includes
Но мы знаем, что изображения по умолчанию загружаются в папку uploads, которая находится внутри каталога wp-content. Разрешим их индексацию строкой:
Allow: */uploadsСлужебные файлы закрыли, переходим к исключению дублей с основным содержимым, которые снижают уникальность контента в пределах одного домена и увеличивают вероятность наложения на сайт фильтра со стороны ПС. К дублям относятся страницы категорий, авторов, тегов, RSS-фидов, а также постраничная навигация, трекбеки и отдельные страницы с комментариями. Обязательно запрещаем их индексацию:
Disallow: /category/
Disallow: /author/
Disallow: /page/
Disallow: /tag/
Disallow: */feed/
Disallow: */trackback
Disallow: */commentsДалее хотелось бы уделить особое внимание такому аспекту как постоянные ссылки. Если вы используете ЧПУ, то страницы содержащие в URL знаки вопроса зачастую являются «лишними» и опять же дублируют основной контент. Такие страницы с параметрами следует запрещать аналогичным образом:
Disallow: */?Это правило распространяется на простые постоянные ссылки ?p=1, страницы с поисковыми запросами ?s= и другими параметрами. Ещё одной проблемой могут стать страницы архивов, содержащие в URL год, месяц. На самом деле их очень просто закрыть, используя маску 20*, тем самым запрещая индексирование архивов по годам:
Disallow: /20*Для ускорения и полноты индексации добавим путь к расположению карты сайта. Робот обработает файл и при следующем посещении сайта будет его использовать для приоритетного обхода страниц.
Sitemap: https:В файле robots.txt можно разместить дополнительную информацию для роботов, повышающую качество индексации. Среди них директива Host — указывает на главное зеркало для Яндекса:
Host: webliberty.ruПри работе сайта по HTTPS необходимо указать протокол:
Host: https:С 20 марта 2018 года Яндекс официально прекратил поддержку директивы Host. Её можно удалить из robots.txt, а если оставить, то робот её просто игнорирует.
Подводя итог, я объединил всё выше сказанное воедино и получил содержимое файла robots.txt для WordPress, который использую уже несколько лет и при этом в индексе нет дублей:
User-agent: *
Disallow: /cgi-bin
Disallow: /wp-
Disallow: /category/
Disallow: /author/
Disallow: /page/
Disallow: /tag/
Disallow: */feed/
Disallow: /20*
Disallow: */trackback
Disallow: */comments
Disallow: */?
Allow: */uploads
Sitemap: https:Постоянно следите за ходом индексации и вовремя корректируйте файл в случае появления дублей.
От того правильно или нет составлен файл зависит очень многое, поэтому обратите особо пристальное внимание к его составлению, чтобы поисковики быстро и качественно индексировали сайт. Если у вас возникли вопросы — задавайте, с удовольствием отвечу!
webliberty.ru