Создаем правильный robots.txt для сайта на WordPress
Здравствуйте, в сегодняшней статье мы продолжим тему базовых настроек. В данной статье мы с вами затронем тему настройки файла robots.txt.
Давайте для начала проанализируем, зачем нам нужен этот файл и нужен ли он нам вообще.
Robots.txt – это текстовый файл предназначенный специально для роботов поисковых систем, с помощью которого можно контролировать все процессы индексации на сайте. Если говорить еще проще с помощью этого файла мы можем закрыть от индексации любой раздел нашего сайта, включая ссылки и системные файлы WordPress.
Зачем что-то закрывать с помощью robots.txt, разве WordPress сам не создает все, что ему нужно при установке? Ответ – нет. Вы, как вебместер или блогер, должны сами контролировать все процессы на сайте. В первую очередь в robots.txt скрываются от индексации системные папки, такие как wp-admin, wp-login и прочие. Также, один и тот же материал сайта построенного на WordPress может размещаться под разными урлами (ссылками), что в свою очередь влечет за собой создание дублей. За наличие большого количества дублей поисковые системы могут наложить санкции на ваш проект, а выйти из под них не так уж и легко. Так что старайтесь исправить эту ситуацию еще в самом начале создания сайта.
Так какой же он правильный robots.txt для WordPress?
Если вы только начинаете свой путь вебмастера, то вам наверняка неизвестны понятия директив: dissalow, allow и других. Сейчас мы с вами пройдемся по основных директивах для того чтобы вы осознанно создавали собственный robots.txt и не писали туда ничего лишнего.
«User—agent:»
Итак, обычно файл robots.txt начинается с того что задается директива – «User-agent:». Эта директива указывает на имя поискового робота. Так, как вам известно, каждая поисковая система имеет своего робота, а в большинстве случаев их несколько.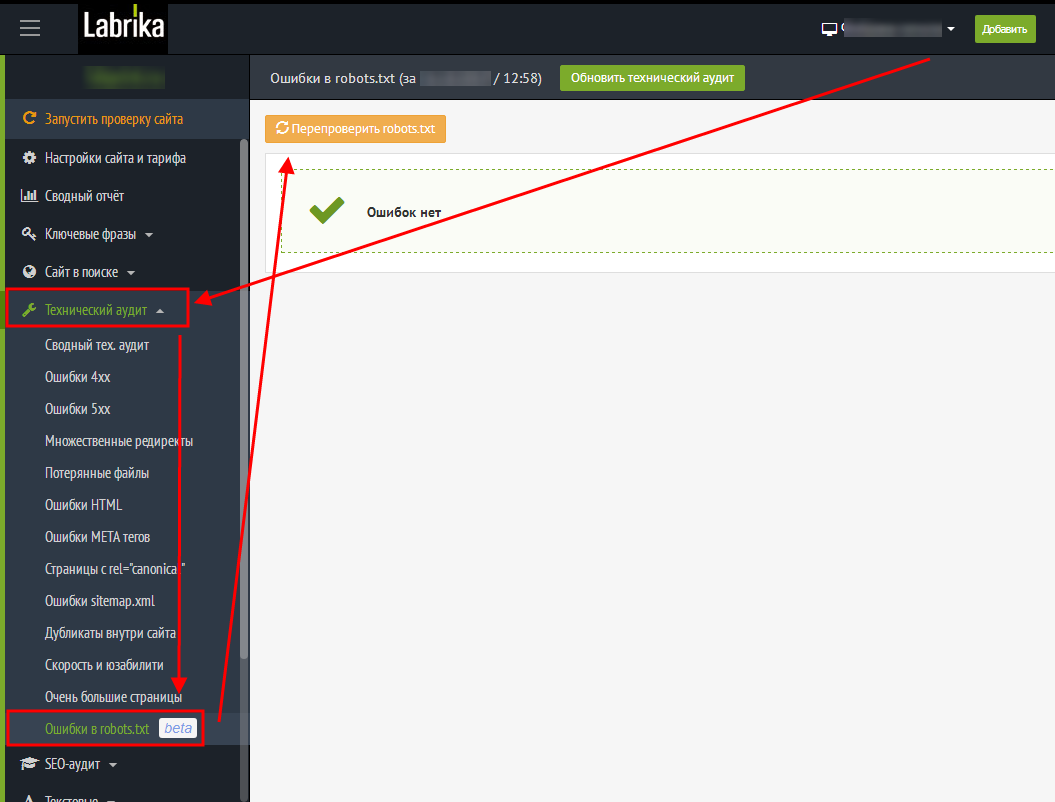
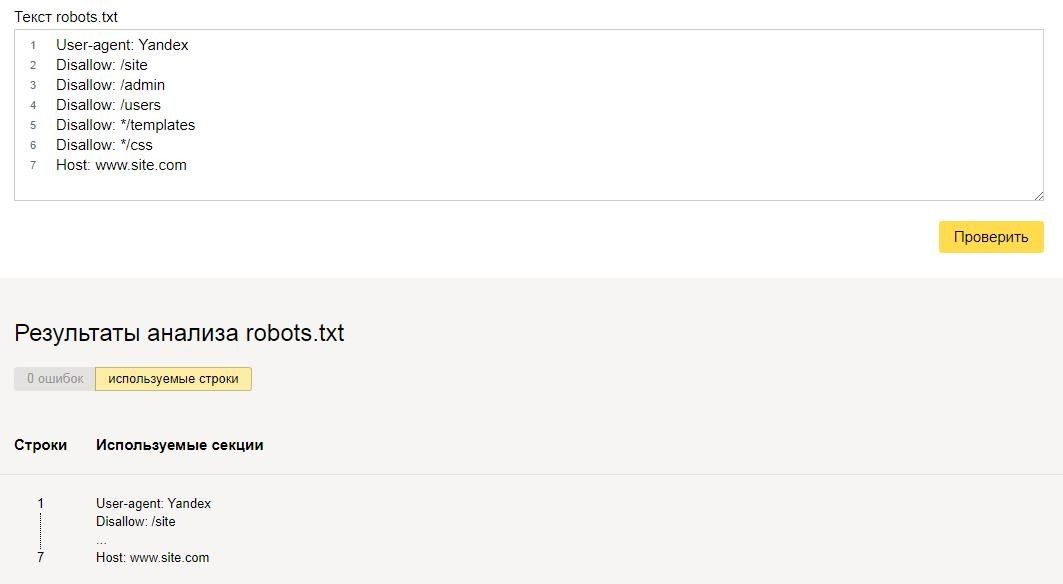
Для того чтобы задать директивы для Яндекса, стоит писать:
User-agent: YandexДля Google она будет иметь следующий вид:
User-agent: GooglebotВ интернете вы можете найти названия роботов и других поисковых систем, если они вдруг вам понадобятся, а так обычно мимо приведенных выше директив, указывается директива:
User-agent: *В которой * — означает любой текст. То есть, таким образом, мы указываем настройки для всех остальных поисковых роботов. Зачастую этого вполне достаточно.
«Disallow:»
Это директива, которая запрещает поисковому роботу индексировать какую либо часть вашего сайта.
Давайте, для того чтобы было бы более понятно рассмотрим несколько примеров ее применения.
Для того чтобы закрыть какую либо папку в дистрибутиве WordPress от индексирования достаточно прописать:
Disallow: /имя вашей папкиДля вложенных папок ситуация таже:
Disallow: /имя вашей папки/имя вложенной папкиИдем дальше, закрывать от индексации можно и по определенным символам, например «?».
Disallow: /*?*Таким способом закрываются все ссылки, где встречается «?». В WordPress такие ссылки формируются по умолчанию.
?post=1Суть, я думаю, понятна. Таким способом можно закрыть комментарии, ленты новостей и прочие разделы сайта.
Будьте внимательны! Если прописать:
Disallow: /То это полностью закроет ваш сайт от индексации.
«Allow:»
Эта директива имеет суть совершенно противоположную приведенной выше. Как вы поняли, с помощью нее, вы можете разрешить к индексированию какой либо раздел сайта, например:
Как вы поняли, с помощью нее, вы можете разрешить к индексированию какой либо раздел сайта, например:
Allow: / имя вашей папки«Host:»
Директива хост задается для указания основного зеркала вашего сайта, то есть с www или без, например.
Host: www.вашсайт.comЗачастую она задается для Яндекса.
И последняя директива, которую мы рассмотрим — «Sitemap:».
Она указывает для поискового робота путь к карте сайта в формате .xml. Пример использования:
Sitemap: http://вашсайт.com/sitemap.xmlИтак, я приведу вам пример файла robots.txt для WordPress, которым пользуюсь я сам. Но под различные проекты я все же его немного изменяю.
User-agent:* Allow: */uploads Disallow: /wp-login.php Disallow: /wp-register.php Disallow: /webstat/ Disallow: /feed/ Disallow: /page/ Disallow: /trackback Disallow: */trackback Disallow: */feed Disallow: */comments Disallow: /*?* Disallow: /*? Disallow: /category/*/* Disallow: /wp-content/ Disallow: /wp-admin/ Disallow: /wp-includes/ Disallow: /comments User-agent: Yandex Allow: */uploads Disallow: /wp-login.php Disallow: /wp-register.php Disallow: /webstat/ Disallow: /feed/ Disallow: /page/ Disallow: /trackback Disallow: */trackback Disallow: */feed Disallow: */comments Disallow: /*?* Disallow: /*? Disallow: /category/*/* Disallow: /wp-content/ Disallow: /wp-admin/ Disallow: /wp-includes/ Disallow: /comments Host: вашсайт.com Sitemap: http://вашсайт.com/sitemap.xml
Для справки. Файл robots.txt лежит в открытом доступе на любом сайте. Заходите и проверяйте его на популярных блогах, делайте свои выводы, но смотрите не переборщите!
До следующих уроков.
Файл robots.txt для WordPress. Создание и правильная индексация
В интернете можно найти много статей какой robots.txt для WordPress лучше использовать, но безусловно администратор сайта должен самостоятельно определить, что необходимо отдавать ботам для индексации, а что запрещать.
Я как и многие другие потратив приличное количество времени на поиск оптимального шаблона robots.txt уяснил только одно, что конкретного варианта нет. Вы можете экспериментировать, никто вам этого не запрещает.
Создаем robots.txt для WordPress
Ниже представлен код одного из моих проектов про технологии и гаджеты, посещаемость ресурса более 7500 уникальных посетителей в сутки.
User-agent: * #Для всех ботов, кроме Яндекса и Google Allow: /wp-content/plugins/*.js #Разрешаем js-скрипты в папке плагинов Allow: /wp-content/plugins/*.css #Разрешаем css файлы в папке плагинов Allow: /wp-content/plugins/*.jpg #Разрешаем картинки в папке плагинов Allow: /wp-content/plugins/*.jpeg #Разрешаем картинки в папке плагинов Allow: /wp-content/plugins/*.png #Разрешаем картинки в папке плагинов Allow: /wp-includes/*.js #Разрешаем js-скриты в главной папке WordPress Allow: /wp-includes/*.css #Разрешаем css в главной папке WordPress Allow: /wp-content/themes/*.js #Разрешаем js-скриты в теме Allow: /wp-content/themes/*.css #Разрешаем css файлы в теме Allow: /wp-content/uploads/*.jpg #Разрешаем индексировать загруженные картинки Allow: /wp-content/uploads/*.jpeg #Разрешаем индексировать загруженные картинки Allow: /wp-content/uploads/*.gif #Разрешаем индексировать загруженные картинки Allow: /wp-content/uploads/*.png #Разрешаем индексировать загруженные картинки Disallow: /xmlrpc.php #Запрещаем файл интеграции WordPress API Disallow: /cgi-bin #Запрещаем папку со скриптами Disallow: /wp-admin #Запрещаем файлы в административной части WordPress Disallow: /wp-includes #Запрещаем файлы в ядре WordPress Disallow: /wp-content/plugins #Запрещаем файлы плагинов Disallow: /wp-content/cache #Запрещаем кеш, отдаем только актуальные файлы Disallow: /wp-content/themes #Запрещаем файлы тем Disallow: /trackback #Запрещаем уведомления о ссылках Disallow: */feed #Запрещаем фиды Disallow: */comment #Запрещаем комментарии Disallow: *comments #Запрещаем комментарии Disallow: */attachment #Запрещаем вложения Disallow: /author/* #Запрещаем страницы авторов и пользователей Disallow: /page/ #Запрещаем индексировать страницы пагинации Disallow: *page #Запрещаем индексировать страницы пагинации Disallow: /*? #Запрещаем индексировать страницы поиска User-agent: GoogleBot #Только для Google Allow: /wp-content/plugins/*.js Allow: /wp-content/plugins/*.css Allow: /wp-content/plugins/*.jpg Allow: /wp-content/plugins/*.jpeg Allow: /wp-content/plugins/*.png Allow: /wp-includes/*.js Allow: /wp-includes/*.css Allow: /wp-content/themes/*.js Allow: /wp-content/themes/*.css Allow: /wp-content/uploads/*.jpg Allow: /wp-content/uploads/*.jpeg Allow: /wp-content/uploads/*.gif Allow: /wp-content/uploads/*.png Disallow: /xmlrpc.php Disallow: /cgi-bin Disallow: /wp-admin Disallow: /wp-includes Disallow: /wp-content/plugins Disallow: /wp-content/cache Disallow: /wp-content/themes Disallow: /trackback Disallow: */feed Disallow: */comment Disallow: *comments Disallow: */attachment Disallow: /author/* Disallow: /page/ Disallow: *page Disallow: /*? User-agent: Yandex #Только для Яндекса Allow: /wp-content/plugins/*.js Allow: /wp-content/plugins/*.css Allow: /wp-content/plugins/*.jpg Allow: /wp-content/plugins/*.jpeg Allow: /wp-content/plugins/*.png Allow: /wp-includes/*.js Allow: /wp-includes/*.css Allow: /wp-content/themes/*.js Allow: /wp-content/themes/*.css Allow: /wp-content/uploads/*.jpg Allow: /wp-content/uploads/*.jpeg Allow: /wp-content/uploads/*.gif Allow: /wp-content/uploads/*.png Allow: /feed/dzen/ #Разрешаю Яндекс Дзен (моя ссылка) Allow: /feed/turbo/ #Разрешаю Янжекс Турбо (моя ссылка) Disallow: /xmlrpc.php Disallow: /cgi-bin Disallow: /wp-admin Disallow: /wp-includes Disallow: /wp-content/plugins Disallow: /wp-content/cache Disallow: /wp-content/themes Disallow: /trackback Disallow: */feed Disallow: */comment Disallow: *comments Disallow: */attachment Disallow: /author/* Disallow: /page/ Disallow: *page Disallow: /*? Host: https://woohelp. ru #Ссылка на сайт Sitemap: https://woohelp.ru/sitemap.xml #Карта сайта Sitemap: https://woohelp.ru/sitemap.xml.gz #Сжатая карта сайта


Правильный Robots.txt для WordPress. Подведём итоги
Сегодня файл robots.txt не влияет на индексацию вашего сайта. Я видел у конкурентных мне сайтов (по категории технологии) совершенно открытый robots.txt ко всем ресурсам и многие из них находятся в топе по ключевым запросам.
Благодаря правильному файлу robots.txt вы можете уменьшить количество мусора в поисковике. Представьте если бы индексировали комментарии на форуме или в статье, то был бы прямо говоря бардак.
Правильный robots.txt для wordpress | Клуб WordPress
Правильный robots.txt для wordpress указывает поисковым роботам на правила индексации вашего блога, т.е. что индексировать, а на что закрывать «глаза».Ведь именно этот файл проверяют в первую очередь поисковые машины, заходя на ваш сайт.О том что такое robots.txt в сети можно найти очень много информации, в т.ч. как этот файл правильно прописать, но все эти статьи либо некорректные либо скопированные друг у друга.
На досуге наткнулся я на пост «Дублированный контент и параметр replytocom», перепроверил файл robots.txt, оказалось, что он требует корректировки.
В свою очередь, спешу поделиться с Вами, дорогие читатели, с правильным robots.txt для wordpress от Студии-ГОСТ.
Где находится файл robots.txt?
Файл размещается в корневой директории сайта. На примере нашего клуба:
http://clubwp.ru/robots.txt
Настройки robots.txt
1. User-Agent
Это имя поискового робота, к которому применяются нижеследующие правила вплоть до конца абзаца(не допускается пустое значение)
2. Allow и Disallow
Разрешает и, соответственно, запрещает индексацию указанных разделов блога. Allow воспринимают только Гугл и Яндекс, остальные поисковики его не видят.
Сначала нужно использовать директиву Allow, а только после нее Disallow. Также между ними не ставятся пустые строки – иначе так робот поймет, что инструкция закончилась. После директивы User-Agent также не допускаются пустые строки.
Также между ними не ставятся пустые строки – иначе так робот поймет, что инструкция закончилась. После директивы User-Agent также не допускаются пустые строки.
3. Host
Указывает какое зеркало сайта считать главным для избежания попадания под фильтр. Сайт доступен по нескольким адресам минимум с www и без www, и для избежания полного дублирования страниц.
4. Sitemap
Указывает роботу наличие и адрес карты сайта в формате XML
Правильный robots.txt для wordpress
User-agent: *
Allow: */uploads
Disallow: /cgi-bin
Disallow: /wp-
Disallow: */feed
Disallow: /search
Disallow: /xmlrpc.php
Disallow: /tag
Disallow: /category
Disallow: /archive
Disallow: */trackback
Disallow: /*?*
Host: clubwp.ru
Sitemap: http://clubwp.ru/sitemap.xmlПроверка robots.txt в инструментах Яндекс и Google
Работоспособность своего файла robots.txt вы всегда можете проверить в вебмастерских разделах поисковиков. При редактировании своего файла я всегда проверяю его на корректность.
I. Вебмастер яндекс
У Яндекса (Для просмотра ссылки Войди илиЗарегистрируйся) раздел находится в «Инструменты->Анализ Robots.txt».
II. Вебмастер google
У Google (Для просмотра ссылки Войди илиЗарегистрируйся) раздел «Сканирование->Инструмент проверки файла robots.txt».
Напоследок хочу напомнить, что изменения в robots.txt на уже рабочем блоге будут заметны только спустя 1-3 месяца.
PS Если кто еще знает как можно улучшить Robots.txt пишите в комментариях.
Зачем вам нужен robots.
 txt
txtПочти в каждом материале по разработке и продвижению мы упоминаем robots.txt. Сегодня не будем упоминать, а всю статью будем рассказывать про него, про правильный robots.txt в 2021 году.
Вот так выглядит robots.txt Google. Примерно так же выглядит и robots.txt вашего сайта. По сути, это текстовый файл со списком исключений для поисковых роботов. Исключения запрещают индексировать одни разделы сайта и разрешают другие. Это необходимо, чтобы защитить конфиденциальную информацию, административные файлы или страницы, которые в силу требований SEO не должны попасть в поиск.
Инструкции
Поисковые роботы законопослушны. Они четко следуют инструкциям robots.txt и сканируют только те ссылки, которые разрешены. Инструкции в файле называются директивами, и в дальнейшем мы будем употреблять именно этот термин.
Директива User-agent для разграничения команд
Все robots.txt начинаются с user-agent. Это своеобразный маршрутизатор, который определяет адресата последующих команд. К ботам Яндекса и Гугла user-agent обращается по-разному — User-agent:Yandex и User-agent:GoogleBot, соответственно. User-agent из файла Google начинается с символа * и это значит, что дальнейшие команды относятся ко всем поисковым ботам.
Сразу отвечаем на закономерно возникающий вопрос: «Зачем указывать отдельные директивы для Яндекса и Гугла, если можно сделать универсальный список?». Поисковых ботов несколько. У одного только Гугла их семь: анализатор рекламы на десктопах и мобильных, индексатор картинок и видео, новостной сканер, бот по оценке рекламы для приложений на Android. Подставляя в user-agent имя нужного бота, можно определить список директив именно для него. Например, запретить индексацию картинок. Плюс у поисковых ботов разный подход к сканированию. Так, команду clean-param воспринимает только Яндекс и бесполезно указывать ее в блоке указаний для Гугла — не поймет.
Для больших сайтов с разными стратегиями продвижения имеет смысл прописывать директивы под конкретных ботов. Маленьким несложным ресурсам мы обычно рекомендует обращаться сразу ко всем индексаторам и использовать User-agent с символом *.
Директива disallow
Disallow — команда запрета. Она запрещает индексировать отдельные файлы, страницы или целые разделы. Обычно, disallow закрывают страницу входа в панель администрирования, документы PDF, DOC, XLS, формы регистрации, корзины, страницы с персональными данными клиентов и пр.
В robots.txt для Bitrix, например, disallow выглядит так:
User-agent: *
Disallow: /wp-admin/
Это в случае, когда мы закрываем доступ к панели управления.
Или так:
User-agent: *
Disallow: /images/
Такая комбинация запретит боту индексировать иллюстрации.
В структуре команды символ / обозначает, что нужно закрыть от индексации, а знак * боты понимают как «любой текст».
Важно! Disallow закрывает доступ поисковым роботам, но не людям, поэтому конфиденциальную информацию на сайте рекомендуем обязательно защищать аутентификацией.
Директивы allow и sitemap
Allow разрешает все, что не запрещает disallow. Это может показаться странным, ведь бот и без того может индексировать все, что не закрыто от сканирования. На самом деле allow нужна для выборочной индексации файлов или документов в закрытом разделе. Допустим, у вас есть закрытый с помощью disallow раздел для дистрибьюторов:
User-agent: *
Disallow: /distributoram/
Он будет выглядеть так, когда вы полностью закрываете индексацию раздела. Но допустим, в закрытом каталоге есть страница или файл, который имеет смысл показать пользователям. Вот тут на сцену выходит allow. Получается так:
Но допустим, в закрытом каталоге есть страница или файл, который имеет смысл показать пользователям. Вот тут на сцену выходит allow. Получается так:
User-agent: *
Disallow: /distributoram/
Allow: /distributoram/usloviya.html
При такой расстановке боты поймут, что из всего раздела distributoram они могут сканировать только контент страницы usloviya.html.
Sitemap одновременно и карта сайта, и директива. Про карту сайта в другой раз, а в роли директивы sitemap используется во всех случаях, когда вы хотите направить роботов на определенные разделы сайта.
Директиву sitemap поисковые боты воспринимают как указатель на приоритетные разделы, но если Яндекс понимает ее как рекомендацию, то GoogleBot как обязательное требование. Само собой, используя в robots.txt команду sitemap, саму карту в корневом каталоге необходимо поддерживать в актуальном состоянии.
Создаем и проверяем robots.txt
Для создания файла подойдет любой текстовый редактор, тот же «Блокнот». На первое место ставим адресную директиву user-agent, потом блоками вносим disallow и allow. Примеры и руководства есть у обоих поисковиков. У Яндекса в разделе «Помощь вебмастеру». У Google в Центре Google Поиска.
Чтобы прописать robots.txt на сайте, файл сохраняем в текстовом формате и загружаем в корень. После загрузки проверьте правильность установки — robots.txt должен открываться по адресу вашсайт/robots.txt. Для проверки работоспособности вставьте ссылку на сайт и код файла в специальные поля сервиса https://webmaster.yandex.ru/tools/robotstxt/ Яндекса и выберите подтвержденный ресурс в https://www.google.com/webmasters/tools/robots-testing-tool в Google.
Зачем проверять robots.txt
В случае с robots ошибки проводят к выпадению из индекса одного раздела и попаданию в выдачу другого, совершенно лишнего и абсолютно ненужного. Кроме того, поисковые системы регулярно меняют правила индексации и добавляют/убирают отдельные директивы. Так, с 22 февраля 2018 года Яндекс перестал учитывать crawl-delay, но у многих сайтов в robots.txt она до сих пор есть и SEO-менеджеры до сих пор уверены, что управляют скоростью обхода.
Кроме того, поисковые системы регулярно меняют правила индексации и добавляют/убирают отдельные директивы. Так, с 22 февраля 2018 года Яндекс перестал учитывать crawl-delay, но у многих сайтов в robots.txt она до сих пор есть и SEO-менеджеры до сих пор уверены, что управляют скоростью обхода.
Держите руку на пульсе и не пренебрегайте базовыми правилами защиты сайта. Тем более, что с маленьким фалом robots.txt это совсем несложно.
Правильный Robots.txt для WordPress
Всем привет! Сегодня статья о том, каким должен быть правильный файл robots.txt для WordPress. С функциями и предназначением robots.txt мы разбирались несколько дней назад, а сейчас разберём конкретный пример для ВордПресс.
С помощью этого файла у нас есть возможность задать основные правила индексации для различных поисковых систем, а также назначить права доступа для отдельных поисковых ботов. На примере я разберу как составить правильный robots.txt для WordPress. За основу возьму две основные поисковые системы — Яндекс и Google.
В узких кругах вебмастеров можно столкнуться с мнением, что для Яндекса необходимо составлять отдельную секцию, обращаясь к нему по User-agent: Yandex. Давайте вместе разберёмся, на чём основаны эти убеждения.
Яндекс поддерживает директивы Clean-param и Host, о которых Google ничего не знает и не использует при обходе.
Разумно использовать их только для Yandex, но есть нюанс — это межсекционные директивы, которые допустимо размещать в любом месте файла, а Гугл просто не станет их учитывать. В таком случае, если правила индексации совпадают для обеих поисковых систем, то вполне достаточно использовать User-agent: * для всех поисковых роботов.
При обращении к роботам по User-agent важно помнить, что чтение и обработка файла происходит сверху вниз, поэтому используя User-agent: Yandex или User-agent: Googlebot необходимо размещать эти секции в начале файла.
Пример Robots.txt для WordPress
Сразу хочу предупредить: не существует идеального файла, который подойдет абсолютно всем сайтам, работающим на ВордПресс! Не идите на поводу, слепо копируя содержимое файла без проведения анализа под ваш конкретный случай! Многое зависит от выбранных настроек постоянных ссылок, структуры сайта и даже установленных плагинов. Я рассматриваю пример, когда используется ЧПУ и постоянные ссылки вида /%postname%/.
WordPress, как и любая система управления контентом, имеет свои административные ресурсы, каталоги администрирования и прочее, что не должно попасть в индекс поисковых систем. Для защиты таких страниц от доступа необходимо запретить их индексацию в данном файле следующими строками:
Disallow: /cgi-bin
Disallow: /wp-Директива во второй строке закроет доступ по всем каталогам, начинающимся на /wp-, в их число входят:
- wp-admin
- wp-content
- wp-includes
Но мы знаем, что изображения по умолчанию загружаются в папку uploads, которая находится внутри каталога wp-content. Разрешим их индексацию строкой:
Allow: */uploadsСлужебные файлы закрыли, переходим к исключению дублей с основным содержимым, которые снижают уникальность контента в пределах одного домена и увеличивают вероятность наложения на сайт фильтра со стороны ПС. К дублям относятся страницы категорий, авторов, тегов, RSS-фидов, а также постраничная навигация, трекбеки и отдельные страницы с комментариями. Обязательно запрещаем их индексацию:
Disallow: /category/
Disallow: /author/
Disallow: /page/
Disallow: /tag/
Disallow: */feed/
Disallow: */trackback
Disallow: */commentsДалее хотелось бы уделить особое внимание такому аспекту как постоянные ссылки. Если вы используете ЧПУ, то страницы содержащие в URL знаки вопроса зачастую являются «лишними» и опять же дублируют основной контент. Такие страницы с параметрами следует запрещать аналогичным образом:
Такие страницы с параметрами следует запрещать аналогичным образом:
Disallow: */?Это правило распространяется на простые постоянные ссылки ?p=1, страницы с поисковыми запросами ?s= и другими параметрами. Ещё одной проблемой могут стать страницы архивов, содержащие в URL год, месяц. На самом деле их очень просто закрыть, используя маску 20*, тем самым запрещая индексирование архивов по годам:
Disallow: /20*Для ускорения и полноты индексации добавим путь к расположению карты сайта. Робот обработает файл и при следующем посещении сайта будет его использовать для приоритетного обхода страниц.
Sitemap: https:В файле robots.txt можно разместить дополнительную информацию для роботов, повышающую качество индексации. Среди них директива Host — указывает на главное зеркало для Яндекса:
Host: webliberty.ruПри работе сайта по HTTPS необходимо указать протокол:
Host: https:С 20 марта 2018 года Яндекс официально прекратил поддержку директивы Host. Её можно удалить из robots.txt, а если оставить, то робот её просто игнорирует.
Подводя итог, я объединил всё выше сказанное воедино и получил содержимое файла robots.txt для WordPress, который использую уже несколько лет и при этом в индексе нет дублей:
User-agent: *
Disallow: /cgi-bin
Disallow: /wp-
Disallow: /category/
Disallow: /author/
Disallow: /page/
Disallow: /tag/
Disallow: */feed/
Disallow: /20*
Disallow: */trackback
Disallow: */comments
Disallow: */?
Allow: */uploads
Sitemap: https:Постоянно следите за ходом индексации и вовремя корректируйте файл в случае появления дублей.
От того правильно или нет составлен файл зависит очень многое, поэтому обратите особо пристальное внимание к его составлению, чтобы поисковики быстро и качественно индексировали сайт. Если у вас возникли вопросы — задавайте, с удовольствием отвечу!
Если у вас возникли вопросы — задавайте, с удовольствием отвечу!
Правильный файл robots.txt под Яндекс и Google для WordPress, Joomla, uCoz
Далеко не все современные вебмастеры умеют работать с HTML-кодом. Многие даже не знают, как должны выглядеть функции, прописанные в ключевых файлах CMS. Внутренности вашего ресурса, такие как файл robots.txt, являются интеллектуальной собственностью, в которой владелец должен быть, как рыба в воде. Тонкая настройка сайта позволяет повысить его поисковые рейтинги, вывести в топ и успешно собирать трафик.
Файл robots.txt — один из основных элементов подгонки ресурса под требования поисковых систем. Он содержит техническую информацию и ограничивает доступ к ряду страниц поисковым роботам. Ведь далеко не каждая написанная страница должна непременно оказаться в выдаче. Раньше для создания файла robots txt был необходим доступ через FTP. Равитие CMS открыло возможность получить к нему доступ прямо через панель управления.
Для чего нужен файл robots.txt
Этот файл содержит ряд рекомендаций, адресованных поисковым ботам. Он ограничивает их доступ к некоторым частям сайта. Из-за размещения этого файла в корневом каталоге, боты никак не смогут его пропустить. В результате, попадая на ваш ресурс, они сначала читают правила его обработки, а уже только после этого начинают проверку.
Таким образом, файл указывает поисковым роботам, какие директории сайта разрешены для индексирования, и какие этому процессу не подлежат.
Учитывая, что на процесс ранжирования наличие файла напрямую не влияет, много сайтов не содержат robots.txt. Но путь полного доступа нельзя считать техически правильным. Рассмотрим преимущества robots.txt, которые он дает ресурсу.
Можно запретить индексирование ресурса целиком или частично, ограничить круг поисковых роботов, которые будут иметь право на проведение индексирования. Приказывая robots.txt запретить все, вы сможете полностью изолировать ресурс на время ремонта или реконструкции.
Кроме того, файл роботс ограничивает доступ на ресурс всевозможных спам-роботов. Их основная цель — сканирование сайта на наличие электронных адресов, которые потом будут использоваться для рассылки спама. Не будем останавливаться на том, к чему это может привести — и так понятно.
От индексирования можно скрыть разделы сайта, предназначенные не для поисковых машин, а для определенного круга пользователей, разделы, содержащие приватную и прочую подобную информацию.
Как создать правильный robots.txt
Правильный robots легко написать вручную, не прибегая к помощи различных конструкторов. Процесс сводится к прописыванию нужных директив в обычном файле блокнота, который, после внесения всех данных, сохраняется под названием «robots». Вам остаётся только закачать его в корневую директорию собственного ресурса. Для одного сайта нужен только один такой файл. В нем можно прописать инструкции для ботов всех нужных поисковых систем. То есть, делать отдельный файл под каждый поисковик не понадобится. Полноценный robots.txt пример может выглядеть так:
Теперь поговорим о том, что должно находиться внутри robots.txt. Обязательно употребление двух директив: User-agent и Disallow. Первая определяет, какому боту адресовано данное послание. Вторая показывает, какую страницу или директорию ресурса запрещено индексировать.
Чтобы задать одинаковые правила для всех ботов, можно в директиве User-agent вместо названия прописать символ: * (звездочку).
Файл robots.txt в таком случае будет выглядеть следующим образом:
Как можно догадаться, /file.html — это название конкретного файла, индексация которого запрещена. /papka/ — название директории, на содержимое которой не будет распространятся индексация.
Если нужно снять ограничения и разрешить индексацию всех страниц, файл следует изменить так:
Особенности настройки robots.txt для Яндекс и Google
Файл robots.txt для Яндекса раньше должен был содержать обязательную директиву host. Это позволяло избежать проблем с индексированием зеркала ресурса или иных дублей его страниц.
Это позволяло избежать проблем с индексированием зеркала ресурса или иных дублей его страниц.
Host — директива, которую понимал только бот Яндекса. Поэтому, при создании файла robots.txt одновременно для Яндекса, Гугла и других поисковых систем, следовало разделить директивы.
Безвременная кончина этой директивы произошла в марте 2018. Так что больше её использовать не нужно.
Создание файла robots.txt Google ничем не отличается от процесса, описанного выше. В директиве User-agent нужно прописать название бота поисковика: Googlebot, Googlebot-Image (для ограничения индексаций изображений),Googlebot-Mobile (для версий сайтов, рассчитанных на мобильные приложения) и т.п.
Желательно указать в файле путь к карте сайта — директива robots.txt sitemap. Благодаря этому робот будет быстрее ориентироваться на страницах ресурса, что значительно ускорит процесс индексации.
Кстати, разработчики Гугл неоднократно напоминали веб-мастерам, что файл robots.txt не должен превышать по размерам 500 Кб. Это непременно приведет к ошибкам при индексации. Если создавать файл вручную, то «достичь» такого размера, конечно, нереально. Но вот некоторые CMS, автоматически формирующие содержание robots.txt, могут значительно его перегрузить.
Простое создание файла для любого поисковика
Если вы боитесь заниматься тонкой настройкой самостоятельно, её можно провести автоматически. Существуют конструкторы, собирающие подобные файлы без вашего участия. Они подходят людям, которые только начинают своё становление в качестве вебмастеров.
Как видно на изображении, настройка конструктора начинается с введения адреса сайта. Далее вы выбираете поисковые системы, с которыми планируете работать. Если вам не важна выдача той или иной поисковой системы, то нет необходимости создавать под неё настройки. Теперь переходите к указанию папок и файлов, доступ к которым планируете ограничить. В данном примере вы сможете указать адрес карты и зеркала вашего ресурса.
Robots.txt generator будет заполнять форму по мере наполнения конструктора. Всё, что в дальнейшем от вас потребуется — это скопировать полученный текст в txt-файл. Не забудьте присвоить ему название robots.
Как проверить эффективность файла robots.txt
Для того, чтобы проанализировать действие файла в Яндексе, следует перейти на соответствующую страницу в разделе Яндекс.Вебмастер. В диалоговом окне укажите имя сайта и нажмите кнопку «загрузить».
Система проанализирует файл robots.txt проверка покажет, будет ли поисковый робот обходить страницы, запрещенные к индексации. Если возникли проблемы, директивы можно отредактировать и проверить прямо в диалоговом окне. Правда после этого вам придётся скопировать отредактированный текст и вставить в свой файл robots.txt в корневом каталоге.
Аналогичную услугу предоставляет сервис «Инструменты для веб-мастеров» от поисковика Google.
Создание robots.txt для WordPress , Joomla и Ucoz
Различные CMS, получившие широкую популярность на просторах Рунета, предлагают пользователям свои версии файлов robots.txt. Некоторые из них не имеют таких файлов вовсе. Зачастую эти файлы либо слишком универсальны и не учитывают особенностей ресурса пользователя, либо имеют ряд существенных недостатков.
Опытный специалист может вручную исправить положение (при недостатке знаний так лучше не делать). Если вы боитесь копаться во внутренностях сайта, воспользуйтесь услугами коллег. Подобные манипуляции, при знании дела, занимают всего пару минут времени. Например, robots.txt WordPress может выглядеть таким образом:
Файл robots.txt для Ucoz предоставляется автоматически. Он имеет оптимальные настройки. Единственный его недостаток — система создаст файл, спустя примерно месяц, после конструирования ресурса. Если неохота ждать, можно написать файл самостоятельно. Выглядеть он будет так:
Joomla позволяет нескольким URL ссылаться на одну и ту же страницу.![]() Поисковые системы примут такие настройки за дублирование контента. Избежать этого поможет установка robots.txt для Joomla следующего содержания:
Поисковые системы примут такие настройки за дублирование контента. Избежать этого поможет установка robots.txt для Joomla следующего содержания:
В последних двух строчках, как несложно догадаться, нужно прописать данные собственного ресурса.
Заключение
Есть ряд навыков, обязательных для освоения любым вебмастером. И самостоятельная настройка и ведение сайта — один из них. Начинающие сайтостроители могут таких дров наломать во время отладки ресурса, что потом не разгребёшь. Если вы не хотите терять потенциальную аудиторию и позиции в выдаче из-за структуры сайта, подходите к процессу её настройка основательно и ответственно.
Примеры robots.txt WordPress для Яндекса и Google. Как правильно составить robots.txt
В сегодняшнем видео уроке по WordPress SEO я расскажу и покажу на примерах особенности создания и использования файла robots.txt для WordPress, этот урок не планировался как исчерпывающее руководство по robots.txt, но он должен дать вам хорошее представление о том что это за файл и что туда добавлять для минимизации попадания ненужных файлов в индекс поисковых систем и как его использовать для управления тем как поисковые роботы Google и Яндекс индексируют ваш сайт. Если у вас возникнут вопросы — пишите в комметариях, ниже привожу текстовый транскрипт видео, на тот случай если у вас возникнут вопросы или будет нужен фрагмент кода в текстовом виде.
Текстовый транскрипт видео:
Здравствуйте,
Меня зовут Дмитрий, и в этом видео вы узнаете о том, как контролировать индексирование вашего сайта поисковыми системами с помощью файла robots.txt. Плюс в качестве примера мы разберем robots.txt для WordPress, который минимизирует индексирование ненужных файлов поисковыми системами. Итак, приступим.
Итак, приступим.
Для чего нужен файл robots.txt
Файл robots.txt – это текстовый файл, находящийся в корневой директории сайта, в котором записываются специальные инструкции, запрещающие посещение и индексирование отдельных разделов сайта. robots.txt предназначен для использования ботами, в качестве примера ботов можно назвать поисковых роботов Яндекса и Google или ботов архиваторов, как например робот Web Archive.
Для создания robots.txt воспользуйтесь любым текстовым редактором, заполните его в соответствии с вашими пожеланиями и примерами в этом видео и сохраните как просто тест без форматирования, расширение файла должно быть .txt. После этого необходимо загрузить файл в корневой каталог вашего сайта.
Используйте файл robots.txt для ограничения поисковых роботов от индексации отдельных разделов вашего сайта. Вы можете указать параметры индексирования своего сайта как для всех роботов сразу, так и для каждой поисковой системы в отдельности, используя директиву User-Agent. Для списка роботов популярных поисковых систем перейдите по ссылке в описании этого видео.
Пример robots.txt для WordPress
В качестве примера robots.txt для WordPress, который минимизирует индексирование ненужных файлов поисковыми системами, вы можете использовать следующий шаблон:
User-Agent: * Disallow: /wp-content/plugins/ Disallow: /wp-content/themes/ Disallow: /wp-admin/ Disallow: /*.swf Disallow: /*.flv Disallow: /*.pdf Disallow: /*.doc Disallow: /*.exe Disallow: /*.htm Disallow: /*.html Disallow: /*.zip Allow: /
Давайте разберем по порядку, что здесь написано. Строчка User-Agent: * говорит, что это относится к любым агентам, к любым поисковым системам, к любым ботам, которые посещают сайт. Строчки, начинающиеся с Disallow: — это директивы, запрещающие индексирование какой-либо части сайта. Например, строчка Disallow: /wp-admin/ запрещает индексирование папки /wp-admin/, любых файлов, которые находятся в папке /wp-admin/. Сейчас у нас запрещены к индексированию папки – плагины, темы и wp-admin (/plugins/ /themes/ /wp-admin/). Директива Disallow: /*. и расширение файла запрещает к индексированию определенный тип файлов. В данный момент запрещены к индексированию .swf, *.flv, *.pdf, *.doc, *.exe, *.js, *.htm, *.html, *.zip. Последняя строчка Allow: / разрешает индексирование любых других частей сайта и любых других файлов.
Например, строчка Disallow: /wp-admin/ запрещает индексирование папки /wp-admin/, любых файлов, которые находятся в папке /wp-admin/. Сейчас у нас запрещены к индексированию папки – плагины, темы и wp-admin (/plugins/ /themes/ /wp-admin/). Директива Disallow: /*. и расширение файла запрещает к индексированию определенный тип файлов. В данный момент запрещены к индексированию .swf, *.flv, *.pdf, *.doc, *.exe, *.js, *.htm, *.html, *.zip. Последняя строчка Allow: / разрешает индексирование любых других частей сайта и любых других файлов.
Если вы используете плагин кеширования, который генерирует статичные версии ваших страниц или структуру постоянных ссылок, оканчивающуюся .htm/.html, уберите строчки
Disallow: /*.htm Disallow: /*.html
В общем, если в адресной строке браузера адреса ваших страниц заканчиваются на .htm или .html, то уберите эти две строчки из robots.txt, иначе вы запретите к индексированию большую часть вашего сайта. Если вы хотите открыть все разделы сайта для индексирования всем роботам, то можете использовать следующий фрагмент:
User-agent: * Disallow:
Так как помимо полезных ботов (например, роботы поисковых систем, которые соблюдают директивы указанные в robots.txt) ваш сайт посещается вредными ботами (спам боты, скрейперы контента, боты которые ищут возможности для инъекции вредоносного кода), которые не только не соблюдают правила, указанные в robots.txt, а, наоборот, посещают запрещенные папки и файлы с целью выявления уязвимостей и кражи пользовательских данных. В таком случае если вы не хотите явно указывать адрес папки или файла, запрещенного к индексированию, вы можете воспользоваться директивой частичного совпадения. Например, у вас есть папка /shop-zakaz/, которую вы хотите запретить к индексированию. Для того, чтобы явно не указывать адрес этой папки для скрейперов и ботов шпионов вы можете указать часть адреса:
Disallow: *op-za*
или
Disallow:*zakaz*
Символ * заменяет произвольное количество символов, тогда любые папки и файлы, содержащие в своем названии эту комбинацию, будут запрещены к индексированию. Старайтесь выбирать часть адреса, который уникален для этой папки, потому что если эта комбинация встретится в других файлах и папках, вы запретите их к индексированию.
Старайтесь выбирать часть адреса, который уникален для этой папки, потому что если эта комбинация встретится в других файлах и папках, вы запретите их к индексированию.
Для того, чтобы случайно не запретить к индексированию нужную часть сайта всегда имеет смысл проверить, как поисковые системы воспринимают правила, указанные в вашем robots.txt. Если вы — подтвержденный владелец сайта в инструментах вебмастера Google или Яндекс — вы можете воспользоваться встроенными инструментами для проверки правил robots.txt.
Для того, чтобы проверить robots.txt в Google Webmaster Tools перейдите в секцию «Crawl>Blocked URLs», здесь вы можете воспользоваться текущей версией robots.txt или же отредактировать ее, чтобы протестировать изменения, затем добавьте список URL, которые вы хотите протестировать и нажмите на кнопку «Проверить». Результаты теста покажут, какие из указанных URL разрешены к индексированию, а какие запрещены.
Проверка robots.txt в Яндекс ВебмастерДля того, чтобы проверить robots.txt в Яндекс Вебмастер перейдите в секцию «Настройка индексирования>Анализ robots.txt», при необходимости внесите изменения в robots.txt, добавьте список URL и нажмите кнопку «Проверить». Результаты теста покажут, какие из указанных URL разрешены к индексированию, а какие запрещены.
Редактируя правила составьте файл robots.txt, подходящий для вашего сайта. Помните, что файл на сайте при этом не меняется. Для того, чтобы изменения вступили в силу, вам потребуется самостоятельно загрузить обновленную версию robots.txt на сайт.
ЗаключениеНу, вот мы и осветили основные моменты работы с robots.txt. Если вам нужны фрагменты и примеры файлов robots.txt, которые я использовал в этом видео, перейдите по ссылке, которая указана в описании этого видео. Спасибо за то, что посмотрели это видео, мне было приятно его для вас делать, буду вам благодарен, если вы поделитесь им в социальных сетях)) Ставьте «палец вверх» и подписывайтесь на новые видео.
Если у вас возникли проблемы с просмотром – вы можете посмотреть видео «Уроки WordPress — правильный файл robots.txt WordPress для Яндекса и Google» на YouTube.
Что такое файл robots.txt и как им пользоваться — Хостинг
Robots.txt — Общая информацияRobots.txt и SEO
Исправления и обходные пути
Robots.txt для WordPress
Robots.txt — Общая информация
Роботы.txt — это текстовый файл, расположенный в корневом каталоге веб-сайта, в котором указывается, какие страницы и файлы веб-сайта вы хотите (или не хотите) посещать сканерам поисковых систем и паукам. Обычно владельцы сайтов хотят, чтобы их заметили поисковые системы; однако бывают случаи, когда в этом нет необходимости. Например, если вы храните конфиденциальные данные или хотите сэкономить трафик за счет отказа от индексации (за исключением страниц с тяжелыми изображениями).
Поисковые системы индексируют веб-сайты, используя ключевых слов и метаданные , чтобы предоставить пользователям Интернета наиболее релевантные результаты, которые ищут что-то в Интернете.Достижение вершины списка результатов поиска особенно важно для владельцев интернет-магазинов. Клиенты редко просматривают дальше первых нескольких страниц из предложенных в поисковой системе страниц.
Для индексирования используются так называемые пауки или краулеры . Это боты, которые компании поисковых систем используют для получения и индексации содержимого всех открытых для них веб-сайтов.
Когда сканер обращается к веб-сайту, он сначала запрашивает файл с именем / robots.txt . Если такой файл найден, сканер затем проверяет его на соответствие инструкциям по индексации веб-сайта . Бот, который не находит никаких директив, имеет собственный алгоритм действий, который в основном все индексирует. Это не только перегружает веб-сайт ненужными запросами, но и само индексирование становится намного менее эффективным.
ПРИМЕЧАНИЕ : может быть только один файл robots.txt для веб-сайта. Файл robots.txt для доменного имени дополнения необходимо поместить в соответствующий корень документа.Например, если ваше доменное имя www.domain.com , его нужно найти по адресу https://www.domain.com/robots.txt .
Также очень важно, чтобы ваш файл robots.txt на самом деле назывался robots.txt. Имя чувствительно к регистру, поэтому убедитесь, что вы написали правильно, иначе оно не сработает.
Официальная позиция Google по файлу robots.txt
Файл robots.txt состоит из строк, содержащих два поля:
- Имя агента пользователя (сканеры поисковых систем).Найдите здесь список имен всех пользовательских агентов.
- . Строка (строки), начинающиеся с директивы Disallow : для блокировки индексации.
Robots.txt должен быть создан в текстовом формате UNIX. Такой файл .txt можно создать прямо в диспетчере файлов cPanel. Более подробные инструкции можно найти здесь .
Основы синтаксиса robots.txt
Обычно файл robots.txt содержит такой код:
User-agent: *
Disallow: / cgi-bin /
Disallow: / tmp /
Disallow: / ~ different /
В этом примере три каталога: / cgi-bin /, / tmp / и / ~ different / исключены из индексации.
ОБРАТИТЕ ВНИМАНИЕ:
- Каждый каталог записывается в отдельной строке . Вы не должны записывать все каталоги в одну строку или разбивать одну директиву на несколько строк. Вместо этого используйте новую строку, чтобы отделить друг от друга директивы.
- Звездочка (*) в поле User-agent означает «любой поисковый робот». Следовательно, такие директивы, как Disallow: * .gif или User-agent: Mozilla * , не поддерживаются. Обратите внимание на эти логические ошибки, поскольку они самые распространенные.
- Другой распространенной ошибкой является случайная опечатка: каталоги с ошибками, пользовательские агенты, пропущенные двоеточия после User-agent и Disallow и т.
 Д. ошибка, чтобы проскользнуть, поэтому есть некоторые инструменты проверки , которые пригодятся.
Д. ошибка, чтобы проскользнуть, поэтому есть некоторые инструменты проверки , которые пригодятся.
Примеры использования
Вот несколько полезных примеров использования robots.txt:
Пример 1
Запретить индексацию всего сайта всеми поисковыми роботами:
User-agent: * Запретить: /
Такая мера, как полная блокировка сканирования, может потребоваться, когда веб-сайт находится под большой нагрузкой запросов или если контент обновляется и не должен появляться в результатах поиска.Иногда настройки SEO-кампании слишком агрессивны, поэтому боты по сути перегружают сайт запросами к его страницам.
Пример 2
Разрешить всем поисковым роботам индексировать весь сайт:
User-agent: * Запретить:
На самом деле нет необходимости сканировать весь сайт. Маловероятно, что посетители будут искать условия использования или страницы входа, например, через Google Поиск. Исключение некоторых страниц или типов контента из индексации было бы полезно для безопасности, скорости и релевантности в рейтинге данного веб-сайта.
Ниже приведены примеры того, как контролировать, какой контент индексируется на вашем веб-сайте.
Пример 1
Запретить индексацию только нескольких каталогов:
User-agent: *Пример 2
Disallow: / cgi-bin /
Запретить индексацию сайта определенным поисковым роботом:
User-agent: *
Disallow: / page_url
Страница обычно идет без полного URL-адреса, только по имени, которое следует за http: // www.yourdomain.com/ . При использовании такого правила любая страница с совпадающим именем блокируется от индексации. Например, будут исключены как / page_url , так и / page_url_new . Чтобы этого избежать, можно использовать следующий код:
User-agent: *
Disallow: / page_url $
Пример 3
Предотвратить индексацию веб-сайта конкретным поисковым роботом .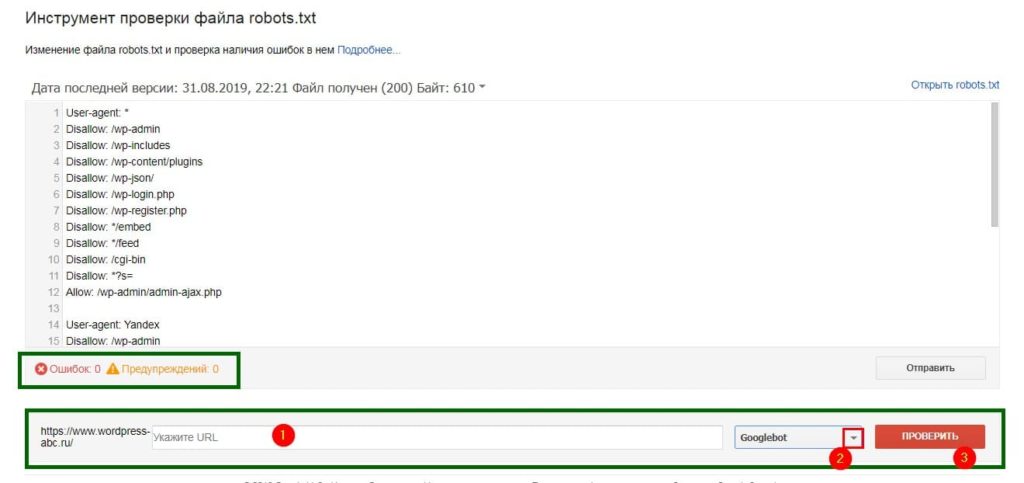 :
:
User-agent: Bot1
Disallow: /
Несмотря на список, некоторые идентификаторы могут со временем измениться.Когда нагрузка на веб-сайт очень высока, и невозможно определить точного бота, чрезмерно использующего ресурсы, лучше временно заблокировать их все.
Пример 4
Разрешить индексацию для определенного поискового робота и запретить индексацию для других:
Агент пользователя: Opera 9
Запретить: Пользовательский агент: * Запретить: /
Пример 5
Запретить индексацию всех файлов, кроме одного.Существует также директива Allow :.Это , но не распознается всеми поисковыми роботами и может быть проигнорирован некоторыми из них. В настоящее время его поддерживают Bing и Google. Следующий пример правила о том, как разрешить только один файл из определенной папки, следует использовать на свой страх и риск:
User-agent: *
Allow: /docs/file.jpeg
Disallow: / docs /
Вместо этого вы можете переместить все файлы в определенный подкаталог и предотвратить его индексацию, за исключением одного файла, который вы разрешаете индексировать:
User-agent: *
Disallow: / docs /
Для этой настройки требуется определенная структура веб-сайта .Также возможно создать отдельную целевую страницу, которая будет перенаправлять на настоящую домашнюю страницу пользователя. Таким образом, вы можете заблокировать фактический каталог с веб-сайтом и разрешить только страницу целевого индекса. Лучше, чтобы такие изменения выполнял разработчик веб-сайта, чтобы избежать проблем.
Вы также можете использовать онлайн-генератор файлов robots.txt здесь . Имейте в виду, что он выполняет настройку по умолчанию, которая не принимает во внимание сложные структуры веб-сайтов с пользовательским кодом.
Файл robots.txt по умолчанию в некоторых версиях CMS настроен так, чтобы исключить папку с изображениями.
 Эта проблема не возникает в последних версиях CMS, но более старые версии необходимо проверять.
Эта проблема не возникает в последних версиях CMS, но более старые версии необходимо проверять. Это исключение означает, что ваши изображения не будут проиндексированы и включены в Поиск картинок Google. Изображения, появляющиеся в результатах поиска, — это то, что вам нужно, так как они повышают ваш рейтинг в SEO. Однако вам нужно обратить внимание на проблему, называемую «хотлинкинг». Когда кто-то репостит изображение, загруженное на ваш сайт в другом месте, ваш сервер загружается с запросами.Чтобы предотвратить хотлинкинг, прочтите соответствующую статью базы знаний . Если вы хотите изменить это, откройте файл robots.txt и удалите строку, которая гласит:
Disallow: / images /
Если на вашем веб-сайте много личного содержания или файлы мультимедиа не хранятся постоянно, а загружаются и удаляются ежедневно, лучше исключить изображения из результатов поиска. В первом случае это вопрос личной жизни. Последнее касается возможной перегрузки активности сканеров, когда они снова и снова проверяют каждое новое изображение.
карта сайта: http: //www.domain.com/sitemap.xmlНе забудьте заменить путь http://www.domain.com/sitemap.xml своей фактической информацией.
Чтобы узнать, как создать sitemap.xml для вашего веб-сайта, вы, , можете найти их здесь .
Разные примечания
- Не блокируйте CSS, Javascript и другие файлы ресурсов по умолчанию. Это мешает роботу Googlebot правильно отображать страницу и понимать, что ваш сайт оптимизирован для мобильных устройств.
- Вы также можете использовать этот файл для предотвращения индексации определенных страниц, таких как страницы входа или страницы 404, но это лучше сделать с помощью метатега robots.
- Добавление операторов запрета в файл robots.txt не приводит к удалению содержимого. Он просто блокирует доступ паукам. Если есть контент, который вы хотите удалить, лучше использовать мета-ноиндекс.

- Как правило, файл robots.txt никогда не должен использоваться для обработки повторяющегося содержания. Есть лучшие способы, такие как тег Rel = canonical, который является частью HTML-заголовка веб-страницы.
- Всегда помните, что файл robots.txt должен быть точным, чтобы ваш веб-сайт мог правильно индексироваться поисковыми системами.
Включение индексации URL-адресов в ‘noindex’
Мета-тег noindex предотвращает индексацию всей страницы поисковой системой. Это может быть нежелательной ситуацией, так как вы хотите, чтобы URL-адреса на этой странице индексировались и отслеживались ботами для лучших результатов. Чтобы это произошло, вы можете отредактировать заголовок своей страницы с помощью следующей строки:
Эта строка предотвратит индексирование самой страницы поисковой системой, но из-за части кода follow размещенные ссылки на этой странице все равно будет извлекаться.Это позволит пауку перемещаться по веб-сайту и связанному с ним контенту. Преимущество этого типа интеграции называется Link Juice — это связь между разными страницами и соответствие их содержания друг другу.
Если добавлено nofollow , поисковый робот остановится, когда достигнет этой страницы, и не перейдет к взаимосвязанному контенту:
С точки зрения SEO это не рекомендуется, но решать вам. Некоторые страницы могут быть удалены с веб-сайта навсегда, поэтому они больше не имеют реальной ценности. Любой устаревший контент должен быть удален из robots.txt, и. htaccess файлов. Последний может содержать перенаправления для страниц, которые больше не актуальны.
Простая блокировка просроченного контента неэффективна. Вместо этого 301 редирект следует применять либо в файле . htaccess, либо через плагины. Если для удаленной страницы нет адекватной замены, она может быть перенаправлена на домашнюю страницу.
htaccess, либо через плагины. Если для удаленной страницы нет адекватной замены, она может быть перенаправлена на домашнюю страницу.
Лучше запретить проиндексированные страницы с конфиденциальными данными на них. Наиболее распространенные примеры:
- Страницы входа
- Область администрирования
- Информация о личных счетах
- Тот факт, что этот URL-адрес отображается в результатах поиска, не отображается. означают, что любой человек без учетных данных может получить к нему доступ. Тем не менее, вы можете захотеть иметь настраиваемую административную панель и URL-адресов для входа в систему , которые известны только вам.
- Рекомендуется не только исключить определенные папки, но и защитить их паролем .
- Если определенный контент на вашем веб-сайте должен быть доступен только зарегистрированным пользователям , обязательно примените эти настройки к страницам. Доступ только по паролю можно настроить , как описано здесь . Примерами являются веб-сайты с премиум-членством, на которых определенные страницы и статьи доступны только после входа в систему.
- Файл robots.txt и его содержимое можно проверить онлайн .Вот почему рекомендуется избегать ввода каких-либо имен или данных, которые могут дать нежелательную информацию о вашей компании.
User-agent: *
Disallow: / profiles /
Не только в качестве меры безопасности, но и для экономии ресурсов вашего хостинга, вы можете исключить нерелевантного контента для посетителей вашего веб-сайта из результатов поиска. Например, это могут быть темы и фоновые изображения, кнопки, сезонные баннеры и т. Д.Использование директивы Disallow для всего каталога / theme не рекомендуется.
Например, это могут быть темы и фоновые изображения, кнопки, сезонные баннеры и т. Д.Использование директивы Disallow для всего каталога / theme не рекомендуется.
Некоторые поисковые системы слишком стремятся проверять содержание при малейшем обновлении.Они делают это слишком часто и создают большой нагрузки на сайте. Никто не хочет, чтобы его страницы загружались медленно из-за голодных поисковых роботов, но полная их блокировка каждый раз может быть слишком экстремальной. Вместо этого их можно замедлить с помощью следующей директивы:
crawl-delay: 10
В этом случае для поисковых роботов существует 10-секундная задержка.
Robots.txt для WordPress
WordPress создает виртуальный файл robots.txt, как только вы публикуете свой первый пост с помощью WordPress.Хотя, если у вас уже есть настоящий файл robots.txt, созданный на вашем сервере, WordPress не добавит виртуальный.
Виртуальный файл robots.txt не существует на сервере, и вы можете получить к нему доступ только по следующей ссылке: http://www.yoursite.com/robots.txt
По умолчанию на нем будет Google Медиабот разрешен, множество спам-ботов запрещены, а некоторые стандартные папки и файлы WordPress запрещены.
Итак, если вы еще не создали настоящий robots.txt, создайте его с помощью любого текстового редактора и загрузите его в корневой каталог своего сервера через FTP.Лучше всего вы также можете использовать один из множества предлагаемых плагинов для SEO. Самые последние и надежные плагины можно найти в официальном руководстве WordPress по SEO .
Блокировка основных каталогов WordPress
В каждой установке WordPress есть 3 стандартных каталога — wp-content, wp-admin, wp-includes , которые не нужно индексировать.
Не выбирайте запретить всю папку wp-content, поскольку она содержит подпапку «uploads» с медиафайлами вашего сайта, которые вы не хотите блокировать.Вот почему вам нужно действовать следующим образом:
Disallow: / wp-admin /
Disallow: / wp-includes /
Disallow: / wp-content / plugins /
Disallow: / wp-content / themes /
Блокировка на основе структуры вашего сайта
Каждый блог может быть структурирован по-разному:
а) По категориям
б) На основе тегов
c) На основе обоих
— ни один из этих
d) На основе архивов по дате
a) Если ваш сайт структурирован по категориям, вам не нужно индексировать архивы тегов.Найдите свою базу тегов на странице Permalinks options в меню Settings . Если поле оставить пустым, база тегов будет просто тегом:
Запретить: / tag /
б) Если ваш сайт имеет теговую структуру, вам необходимо заблокировать архивы категорий. Найдите свою базу категорий и используйте следующую директиву:
Disallow: / category /
c) Если вы используете и категории, и теги, вам не нужно использовать какие-либо директивы.Если вы не используете ни один из них, вам необходимо заблокировать их оба:
Disallow: / tags /
Disallow: / category /
d) Если ваш сайт структурирован на основе архивов на основе даты, вы можете заблокировать их следующими способами:
Запрещено: / 2010/
Запрет: / 2011/
Запрет: / 2012/
Disallow: / 2013 /
ПОЖАЛУЙСТА, ОБРАТИТЕ ВНИМАНИЕ: Вы не можете использовать здесь Disallow: / 20 * /, так как такая директива будет блокировать каждое сообщение в блоге или страницу, начинающуюся с цифры «20».
Проблемы с дублированием контента в WordPress
По умолчанию WordPress имеет дублирующиеся страницы, которые не влияют на ваш рейтинг в SEO. Чтобы исправить это, мы бы посоветовали вам не использовать robots.txt, а вместо этого пойти более тонким способом: тег rel = canonical , который вы используете для размещения единственного правильного канонического URL в разделе вашего сайта. Таким образом, поисковые роботы будут сканировать только каноническую версию страницы.
Более подробное описание от Google того, что такое канонический тег и почему вы должны его использовать , можно найти здесь .
Чтобы исправить это, мы бы посоветовали вам не использовать robots.txt, а вместо этого пойти более тонким способом: тег rel = canonical , который вы используете для размещения единственного правильного канонического URL в разделе вашего сайта. Таким образом, поисковые роботы будут сканировать только каноническую версию страницы.
Более подробное описание от Google того, что такое канонический тег и почему вы должны его использовать , можно найти здесь .
Вот и все!
Нужна помощь? Свяжитесь с нашей службой поддержки
Идеальный файл robots.txt для WordPress? — Ошибка сервера
. Идеальный файл robots.txt для WordPress? — Ошибка сервераСеть обмена стеков
Сеть Stack Exchange состоит из 176 сообществ вопросов и ответов, включая Stack Overflow, крупнейшее и пользующееся наибольшим доверием онлайн-сообщество, где разработчики могут учиться, делиться своими знаниями и строить свою карьеру.
Посетить Stack Exchange- 0
- +0
- Авторизоваться Зарегистрироваться
Server Fault — это сайт вопросов и ответов для системных и сетевых администраторов. Регистрация займет всего минуту.
Регистрация займет всего минуту.
Кто угодно может задать вопрос
Кто угодно может ответить
Лучшие ответы голосуются и поднимаются наверх
Спросил
Просмотрено 827 раз
Я поискал в Интернете идеальных роботов.txt для размещенного блога WordPress. Я нашел несколько вариантов, например здесь и здесь.
Я подумал, что это будет хороший вопрос для ServerFault: для «простого» блога поверх WordPress, какой файл robots.txt будет идеальным?
В настоящее время у меня есть следующий файл robots.txt, который я нашел в другом месте в Интернете:
Агент пользователя: *
Disallow: / cgi-bin
Запретить: / wp-admin
Disallow: / wp-includes
Запретить: / wp-content / plugins
Запретить: / wp-content / cache
Запретить: / wp-content / themes
Запретить: / trackback
Disallow: / feed
Запретить: / комментарии
Запретить: / категория / * / *
Disallow: * / trackback
Disallow: * / feed
Disallow: * / комментарии
Disallow: / *? *
Disallow: / *?
Разрешить: / wp-content / uploads
# Google Image
Пользовательский агент: Googlebot-Image
Запретить:
Позволять: /*
# Google AdSense
Пользовательский агент: Mediapartners-Google *
Запретить:
Позволять: /*
# Интернет-архиватор Wayback Machine
Пользовательский агент: ia_archiver
Запретить: /
# digg зеркало
Пользовательский агент: duggmirror
Запретить: /
Спасибо
Создан 26 авг.
26611 золотых знаков22 серебряных знака1010 бронзовых знаков
1Не бывает «идеальных» роботов.txt, хотя найдется вариант, который вам больше всего подходит. Просто определитесь, что вы хотите, чтобы боты видели, и создайте файл robots.txt, который запрещает все остальное. Нет необходимости в строках «разрешить», поскольку роботы анализируют эти файлы, чтобы определить, на что вы не хотите, чтобы они смотрели, а затем предполагают, что все остальное — честная игра. например Часть моего собственного файла robots.txt, которая применяется к wordpress:
Запретить: /blog/wp-*.php
Запретить: / blog / wp-admin /
Запретить: / blog / wp-includes /
Запретить: / blog / wp-content /
Создан 26 авг.
Джон ГарденерсДжон Гарденерс26.7k1111 золотых знаков5151 серебряный знак108108 бронзовых знаков
1 Я никогда раньше не рассматривал возможность использования файла robots.txt с wordpress — я просто убеждаюсь, что права доступа к файлам, которые не должны запускать случайные пользователи (например, установщик или программа обновления), верны.
Создан 09 сен.
Warrenwarren 16. 5k2222 золотых знака7676 серебряных знаков130130 бронзовых знаков
5k2222 золотых знака7676 серебряных знаков130130 бронзовых знаков
Ваша конфиденциальность
Нажимая «Принять все файлы cookie», вы соглашаетесь с тем, что Stack Exchange может хранить файлы cookie на вашем устройстве и раскрывать информацию в соответствии с нашей Политикой в отношении файлов cookie.
Принимать все файлы cookie Настроить параметры
Лучший robots.txt веб-сайта WordPress
Текстовый файл называется robots.txt, который вы размещаете на своем веб-сайте, чтобы сообщить сканерам, какие страницы вы хотите, чтобы они посещали, а не посещали. Поисковые системы подчиняются тому, чего просят не делать, но robots.txt для них не является обязательным. Robot.txt не является брандмауэром или паролем для поисковых систем. Это также не мешает поисковой системе сканировать ваш сайт. Если у вас действительно есть какие-либо данные, которые вы не хотите отображать в результатах поиска, вам никогда не нужно доверять robots.txt, чтобы он не индексировался и не отображался в результатах поиска.
robots.txt должен находиться в основном каталоге. Поисковые системы могут обнаружить его в основном каталоге, только если он находится в любом другом месте, кроме того, что поисковые системы не ищут его по всему сайту и не могут его найти. Поисковые системы Сначала просматривают его в основном каталоге, и, если он не существует, поисковые системы предполагают, что файл robots.txt не существует на веб-сайте. Таким образом, если файл robots.txt размещен не в нужном месте, поисковая система отображает все, что находит.
Есть много поисковых систем и много разных файлов, которые вы хотите запретить. Синтаксис файла robots.txt следующий: —
Агент пользователя: * Disallow: /Сканеры поисковой системы
записываются в пользовательский агент, а список каталогов и файлов, которые вы не хотите отображать или сканировать, записываются перед Disallow.
Вы также можете добавить строку комментария, используя знак решетки (#) в начале строки.
Например: —
Агент пользователя: * Запрещение: / temp /
В приведенном выше примере показано, что User-agent: * означает, что он включает всех сканеров поисковой системы, а Disallow: / temp / означает, что он запрещает отображение имени файла temp.
Важные вещи для лучшего robots.txt веб-сайта WordPress
Если вы имеете дело с WordPress, вы хотите, чтобы ваши страницы и сообщения отображались поисковыми системами, но вы не хотите, чтобы поисковые системы сканировали ваши основные файлы и каталоги WordPress, а также обратные ссылки и каналы.Содержимое файла robots.txt варьируется от сайта к сайту по-разному. Вам необходимо создать файл robots.txt в корневом каталоге вашего веб-сайта. Для WordPress не существует стандартизированного файла robots.txt, но следующие моменты дадут вам четкое представление о лучшем файле robots.txt для веб-сайта WordPress.
1. Вещи, которые всегда следует блокировать
На сайте WordPress есть некоторые файлы и каталоги, которые следует каждый раз блокировать. Каталоги, которые вы должны запретить в роботе.txt — это каталог cgi-bin и стандартные каталоги WP. Некоторые серверы не позволяют получить доступ к каталогу cgi-bin, но вы должны включить его в свою директиву disallow в файле robot. txt, и он не будет быть вредным, если вы это сделаете.
txt, и он не будет быть вредным, если вы это сделаете.
Стандартные каталоги WordPress, которые вы должны заблокировать: wp-admin, wp-content, wp-includes. В этих каталогах нет данных, которые изначально были бы полезны для поисковых систем, но есть исключение, то есть подкаталог с именем «uploads» существует в каталоге wp-content.Этот подкаталог должен быть разрешен в robot.txt, потому что он включает все, что вы загружаете с помощью функции загрузки мультимедиа WP. Итак, вы должны разблокировать его.
Директивы, использованные выше, приведены ниже: —
Агент пользователя: * Disallow: / cgi-bin / Запретить: / wp-admin / Запретить: / wp-includes / Запретить: /xmlrpc.php Запретить: / wp-content / plugins / Запретить: / wp-content / cache / Запретить: / wp-content / themes / Запретить: / trackback / Запретить: / feed / Запретить: / комментарии / Запретить: / категория / Запретить: / trackback / Запретить: / feed / Запретить: / комментарии / Disallow: / *? Разрешить: / wp-content / uploads /
2.Что нужно заблокировать в зависимости от конфигурации WP
Вы должны знать, что ваш сайт WordPress использует теги или категории для структурирования контента или использует как категории, так и теги или не использует ни один из них. Если вы используете категории, вам необходимо заблокировать архивы тегов от поисковых систем и наоборот. Сначала проверьте базу, просто перейдите в панель администратора > Настройки> Постоянные ссылки.
По умолчанию базой является тег, если поле пустое. Вы должны запретить теги в роботе.txt, как указано ниже:
Disallow: / tag /
Если вы используете категорию, вам необходимо заблокировать категорию в файле robot.txt, как показано ниже:
Disallow: / category /
Если вы используете и категории, и теги, ничего делать в файле robot.txt не нужно.
Если вы не используете ни теги, ни категории, заблокируйте их оба в файле robot. txt, как указано ниже:
txt, как указано ниже:
Disallow: / category / Disallow: / tag /
3. Файлы для отдельной блокировки
В WordPress используются разные файлы для отображения содержимого.Все эти файлы не должны быть доступны для поисковых систем. Так что вы также должны заблокировать их. Различные файлы, в основном используемые для отображения содержимого, — это файлы PHP, файлы JS, файлы INC, файлы CSS.
Вы должны заблокировать их в robot.txt, как указано ниже:
Disallow: /index.php # отдельная директива для основного файла сценария WP Запретить: /*.php$ Запретить: /*.js$ Запретить: /*.inc$ Disallow: /*.css$
Символ «$» соответствует концу строки URL.
Имейте в виду, что не рекомендуется блокировать файлы, которых нет в каталоге загрузок.
4. Что не блокировать
Есть много вещей, которые вы не хотите блокировать, в зависимости от вашего выбора. Здесь я не хочу блокировать изображения из поиска изображений Google, поэтому я должен разрешить это в файле robot.txt, как указано ниже:
Агент пользователя: Googlebot-Image Запретить: Allow: / # Это нестандартное использование этой директивы, но Google предпочитает ее
Вы можете добавить вещи, которые не хотите блокировать, как написано в приведенном выше примере.
Как разблокировать Robots.txt и удалить тег noindex
Устранение неполадок, связанных с индексированием и сканированием: с чего начать
Прежде всего, давайте попробуем сузить проблему. Для этого войдите в Google Search Console. Затем скопируйте и вставьте URL-адрес главной страницы своего веб-сайта в тестер robots.txt и нажмите «Отправить». (На данный момент этот инструмент существует только в старой версии Google Search Console.) Если он «ЗАБЛОКИРОВАН», см. Проблему № 1, если «РАЗРЕШЕН», см. Проблему № 2 ниже.
Проблема №1: домен или URL-адрес заблокированы роботами.txt
Если строка запрета горит красным и вы видите слово «ЗАБЛОКИРОВАНО» в поле в правом нижнем углу, как на скриншоте ниже, виновником является файл robots. txt. Чтобы отменить это, вам потребуется доступ к файлу robots.txt и его редактирование * для своего веб-сайта.
txt. Чтобы отменить это, вам потребуется доступ к файлу robots.txt и его редактирование * для своего веб-сайта.
* Если вы не тот человек, который обычно играет в серверной части вашего веб-сайта, я настоятельно рекомендую вам обратиться к разработчику вашего веб-сайта, ИТ-специалисту или кому-либо еще, кто занимается обслуживанием веб-сайта.
В приведенном выше примере происходят две вещи, одна хорошая и одна плохая, в зависимости от нашего текущего затруднительного положения. Этот URL-адрес, / wp-admin / , намеренно запрещен, поскольку мы не хотим, чтобы серверная часть нашего веб-сайта сканировалась какой-либо из поисковых систем. Это должно остаться.
Однако проблема в строке Disallow: / . Эта строка, или лучше сказать косая черта, блокирует сканирование вашего веб-сайта всеми поисковыми системами… ну, и все это.Итак, чтобы разблокировать robots.txt, эту часть необходимо удалить из файла robots.txt.
Буквально достаточно одного персонажа, чтобы бросить гаечный ключ в вещи. После внесения в файл необходимых изменений верните URL-адрес домашней страницы в тестер robots.txt, чтобы проверить, приветствует ли ваш сайт поисковые системы. Если что-то идет не так, как надо, в поле в правом нижнем углу зеленым цветом будет указано «РАЗРЕШЕНО», и поисковые системы теперь могут начать сканирование сайта.
Это исправление должно успешно разблокировать robots.txt по всему сайту (или, по крайней мере, для любой страницы, которая специально не обозначена как запрещенная, например, с / wp-admin / URL-адресом выше), но не стесняйтесь копировать и вставлять пару дополнительных страниц сайта в инструмент тестера, чтобы убедиться, что проблема были разрешены не только для вашей домашней страницы.
Если вы хотите узнать больше об этой конкретной марке ботов, ознакомьтесь с полным руководством по Robots.txt на Yoast.com.
Проблема № 2: Удаление метатега «noindex» в WordPress.
Если проблема не в том, что беспокоит ваш веб-сайт, поскольку во всем, что происходит «РАЗРЕШЕНО» (как и должно быть), есть еще одна распространенная причина, по которой ваш веб-сайт WordPress не отображаться в поиске — надоедливый тег noindex.
Чтобы проверить, так ли это, вернитесь к новой версии Search Console, вставьте любой URL-адрес в поле поиска «Проверить любой URL-адрес в…» вверху страницы и нажмите Enter.
Если в отчете о проверке URL отображается следующее сообщение: Нет: в метатеге robots обнаружен «noindex» , это единственный флажок в серверной части WordPress, который вызывает всю эту шумиху.
Чтобы разблокировать поисковые системы от индексации вашего веб-сайта, выполните следующие действия:
- Войдите в WordPress
- Перейдите в «Настройки» → «Чтение»
- Прокрутите страницу вниз до места, где написано «Видимость для поисковых систем».
- Снимите флажок рядом с чтобы «Не рекомендовать поисковым системам индексировать этот сайт»
- Нажмите кнопку «Сохранить изменения» ниже
Если вы используете плагин Yoast SEO — WordPress, также проверьте настройки сообщений в блоге, чтобы убедиться, что они установлены аналогичным образом. чтобы разрешить индексацию.
Как только это будет завершено, вернитесь в Search Console и повторно отправьте URL-адрес, который вы пробовали ранее. Если ваши настройки настроены правильно, все должно петь другую мелодию. Теперь, когда вы отправляете URL-адрес, в отчете о проверке URL-адресов не должно быть всех предупреждений и сообщений об ошибках, по крайней мере, тех, которые связаны с индексированием и возможностью сканирования, и вы сможете «Запросить индексирование», что, как я полагаю, было вашей целью с самого начала. .
Я надеюсь, что это поможет, но если описанные выше шаги не помогли решить вашу текущую проблему, я рекомендую прочитать эту статью поддержки веб-мастеров Google о «noindex», чтобы узнать больше.
Очевидная, но важная часть SEO — добиться того, чтобы ваш сайт отображался в результатах поиска. Для этого вам необходимо убедиться, что ваш веб-сайт можно сканировать и проиндексировать, что означает удаление тега «noindex» и разблокировку robots.txt из общедоступных частей вашего сайта. Эти настройки необходимы для успеха, поэтому сделайте себе одолжение и не игнорируйте предупреждения Search Console или нестабильное поведение, устраняйте эти проблемы с помощью советов и ресурсов, приведенных выше.
Почему это важно и как его использовать
Повышение узнаваемости вашего сайта за счет хорошего ранжирования на страницах результатов поисковых систем (SERP) — это цель, к которой стоит стремиться.Однако на вашем сайте, вероятно, есть несколько страниц, на которые вы бы предпочли направлять трафик , а не , например, ваша промежуточная зона или повторяющиеся сообщения.
К счастью, на вашем сайте WordPress есть простой способ сделать это. Использование файла robots.txt уведет поисковые системы (и, следовательно, посетителей) от любого контента, который вы хотите скрыть, и даже может помочь усилить ваши усилия по поисковой оптимизации (SEO).
В этом посте мы поможем вам понять, что такое robots.txt и его отношение к SEO вашего сайта. Затем мы покажем вам, как быстро и легко создать и отредактировать этот файл в WordPress с помощью плагина Yoast SEO. Давайте нырнем!
Введение в файл
robots.txtВкратце, robots.txt — это простой текстовый файл, который хранится в основном каталоге веб-сайта. Его функция состоит в том, чтобы давать инструкции сканерам поисковых систем, прежде чем они изучат и проиндексируют страницы вашего веб-сайта.
Чтобы понять robots.txt , вам нужно немного узнать о сканерах поисковых систем. Это программы (или «боты»), которые посещают веб-сайты, чтобы узнать об их содержании. От того, как сканеры индексируют страницы вашего сайта, зависит, попадут ли они в поисковую выдачу (и насколько высоко они ранжируются).
Когда сканер поисковой системы заходит на веб-сайт, первое, что он делает, это проверяет наличие файла robots.txt в основном каталоге сайта. Если он его найдет, он примет к сведению приведенные в нем инструкции и будет следовать им при изучении сайта.
Если файл robots.txt отсутствует, бот просто просканирует и проиндексирует весь сайт (или всю его часть, которую он сможет найти). Это не всегда проблема, но — это ситуаций, в которых это может оказаться вредным для вашего сайта и его SEO.
Почему
robots.txt Имеет значение для SEOОдно из наиболее распространенных применений файла robots.txt — скрытие содержимого веб-сайта от поисковых систем. Это также называется «запретом» ботам сканировать определенные страницы.Есть несколько причин, по которым вы можете захотеть это сделать.
Первая причина — защитить свой рейтинг в поисковой выдаче. Дублированный контент обычно сбивает с толку сканеров поисковых систем, поскольку они не могут указать все копии в результатах поиска и поэтому должны выбирать, какой версии отдать приоритет. Это может привести к тому, что ваш контент будет конкурировать с самим собой за высокие рейтинги, что контрпродуктивно.
Еще одна причина, по которой вы можете захотеть скрыть контент от поисковых систем, — это запретить им отображать разделы вашего веб-сайта, которые вы хотите сохранить конфиденциальными, например, вашу промежуточную область или частные форумы только для членов.Встреча с этими страницами может сбивать с толку пользователей и отвлекать трафик от остальной части вашего сайта.
Помимо запрета ботам исследовать определенные области вашего сайта, вы также можете указать «задержку сканирования» в файле robots.txt . Это предотвратит перегрузку сервера, вызванную загрузкой ботов и сканированием сразу нескольких страниц вашего сайта. Это также может сократить количество ошибок Connection timed out (), что может очень расстроить ваших пользователей.
Как создавать и редактировать
robots.txt в WordPress (за 3 шага)К счастью, плагин Yoast SEO упрощает создание и редактирование файла robots.txt вашего сайта WordPress. Следующие шаги предполагают, что вы уже установили и активировали Yoast SEO на своем сайте.
Шаг 1. Доступ к редактору файлов Yoast SEO
Один из способов создать или отредактировать файл robots.txt — использовать инструмент Yoast File Editor. Чтобы получить к нему доступ, посетите панель администратора WordPress и перейдите к Yoast SEO> Инструменты на боковой панели:
На появившемся экране выберите File Editor из списка инструментов:
Если у вас уже есть файл robots.txt , откроется текстовый редактор, в котором вы можете внести в него изменения. Если у вас нет файла robots.txt , вместо него вы увидите эту кнопку:
Нажмите на него, чтобы автоматически создать файл robots.txt и сохранить его в основном каталоге вашего веб-сайта. Такая настройка файла robots.txt дает два преимущества.
Во-первых, вы можете быть уверены, что файл сохранен в нужном месте, что необходимо для того, чтобы сканеры поисковых систем могли его найти.Файл также будет назван правильно, в нижнем регистре. Это важно, поскольку сканеры поисковых систем чувствительны к регистру и не распознают файлы с такими именами, как Robots.txt .
Шаг 2. Отформатируйте файл
robots.txtЧтобы эффективно взаимодействовать со сканерами поисковых систем, вам необходимо убедиться, что ваш файл robots.txt имеет правильный формат. Все файлы robots.txt и содержат «пользовательский агент», а затем «директивы», которым должен следовать этот агент.
Пользовательский агент — это специальный сканер поисковой системы, которому вы хотите дать инструкции. К наиболее распространенным из них относятся: bingbot, googlebot, slurp (Yahoo) и яндекс. Директивы — это инструкции, которым должны следовать сканеры поисковых систем. В этом посте мы уже обсуждали два типа директив: запретить и задержка сканирования .
Директивы — это инструкции, которым должны следовать сканеры поисковых систем. В этом посте мы уже обсуждали два типа директив: запретить и задержка сканирования .
Когда вы соединяете эти два элемента, вы получаете полный файл robots.txt . Это может быть всего две строки.Вот наш собственный файл robots.txt в качестве примера:
Чтобы найти больше примеров, просто введите URL-адрес сайта, за которым следует /robots.txt (например, example.com/robots.txt ).
Еще одним важным элементом форматирования является «подстановочный знак». Это символ, используемый для одновременного обозначения нескольких сканеров поисковых систем. В нашем файле robots.txt выше звездочка ( * ) обозначает все пользовательские агенты, поэтому следующие за ней директивы будут применяться к любому боту, который их читает.
Другой часто используемый wild card — символ доллара ( $ ). Он может заменять конец URL-адреса и используется для указания директив, которые должны применяться ко всем страницам с определенным окончанием URL-адреса. Вот пример файла robots.txt в BuzzFeed:
Здесь сайт использует подстановочный знак $ , чтобы блокировать поисковым роботам все файлы .xml . В вашем собственном файле robots.txt вы можете включить столько директив, пользовательских агентов и подстановочных знаков, сколько захотите, в любой комбинации, которая наилучшим образом соответствует вашим потребностям.
Шаг 3. Используйте команды
robots.txt для направления сканерам поисковых системТеперь, когда вы знаете, как создать и отформатировать файл robots.txt , вы можете начать давать инструкции ботам поисковых систем. Есть четыре общие директивы, которые вы можете включить в файл robots.txt :
- Запретить . Указывает сканерам поисковых систем не исследовать и не индексировать указанную страницу или страницы.

- Разрешить . Разрешает сканирование и индексирование подпапок, запрещенных предыдущей директивой. Эта команда работает только с роботом Googlebot.
- Задержка сканирования . Указывает сканерам поисковых систем подождать определенный период времени перед загрузкой рассматриваемой страницы.
- Карта сайта . Предоставляет сканерам поисковых систем расположение карты сайта, которая предоставляет дополнительную информацию, которая поможет ботам более эффективно сканировать ваш сайт.Если вы решите использовать эту директиву, ее следует разместить в самом конце вашего файла.
Ни одна из этих директив не является строго обязательной для вашего файла robots.txt . Фактически, вы можете найти аргументы за или против использования любого из них.
По крайней мере, нет ничего плохого в том, чтобы запретить ботам сканировать страницы, которые вам абсолютно не нужны в поисковой выдаче, и указывать на вашу карту сайта. Даже если вы собираетесь использовать другие инструменты для решения некоторых из этих задач, ваш файл robots.txt может предоставить резервную копию, чтобы убедиться, что директивы выполняются.
Заключение
Есть много причин, по которым вы можете захотеть дать инструкции сканерам поисковых систем. Если вам нужно скрыть определенные области вашего сайта от результатов поиска, настроить задержку сканирования или указать местоположение вашей карты сайта, ваш файл robots.txt может справиться с этой задачей.
Чтобы создать и отредактировать файл robots.txt с помощью Yoast SEO, вам нужно:
- Доступ к редактору файлов Yoast SEO.
- Отформатируйте файл robots.txt .
- Используйте команды robots.txt , чтобы направлять сканеры поисковых систем.
У вас есть вопросы об использовании файла robots.txt для улучшения вашего SEO? Спросите в разделе комментариев ниже!
Изображение предоставлено: Pexels.
WordPress Файл Robots.txt — Руководство для новичков
Я уверен, что вам должно быть интересно, что такое Robots.txt и зачем он мне? Не беспокойся об этом прямо сейчас.К концу этой статьи вы будете знать все о файле Robots.txt, а также сможете добавить его на свой веб-сайт WordPress за считанные секунды. В этой статье я расскажу о каждой мелкой информации о файле Robots.txt, поэтому вам больше не нужно искать эту информацию в Интернете. Если я оставил вам какой-либо вопрос, пожалуйста, оставьте мне сообщение в разделе комментариев ниже, чтобы я мог внести необходимые обновления в эту статью или написать еще одну.
Перед написанием этой статьи я изучил, какие общие вопросы задают люди на форуме Google для веб-мастеров / Quora / Twitter о роботах.txt, индексирование Google, сканирование ботов и т. д. Вот некоторые из них, которые вы можете вспомнить прямо сейчас —
- Что такое Robots.txt?
- Что содержит файл Robots.txt?
- Какой код писать в файле Robots.txt?
- Почему Google деиндексирует уже проиндексированные URL?
- Почему Google индексирует некоторые из моих личных папок?
Не волнуйтесь, если у вас есть другие вопросы, потому что в этой статье я объясню все с нуля.Для быстрой справки — Ниже приведено содержание:
Таблица содержания
- Что такое файл Robot.txt?
- Зачем нужен файл Robot.txt?
- Как получить доступ к файлу Robot.txt с вашей c-панели?
- Расшифровка синтаксиса файла Robots.txt.
- Как оптимизировать файл WordPress Robots.txt?
- Как добавить XML-карту сайта в файл Robots.txt?
- Какой файл Robots.txt лучше всего подходит для веб-сайта?
- Существуют ли инструменты для создания и проверки роботов.txt файл?
- Другие ресурсы Robots.txt.
Что такое файл Robot.txt?
Robots.txt — это текстовый файл, который вы помещаете в корневой каталог своего веб-сайта (например, www. domain.com/robots.txt). Этот текстовый файл всегда называется «robots.txt» и следует строгому синтаксису. Также очень важно, чтобы ваш файл robots.txt действительно назывался «robots.txt» , поскольку это имя чувствительно к регистру. Убедитесь, что вы правильно назвали файл, иначе он будет работать на вас.
domain.com/robots.txt). Этот текстовый файл всегда называется «robots.txt» и следует строгому синтаксису. Также очень важно, чтобы ваш файл robots.txt действительно назывался «robots.txt» , поскольку это имя чувствительно к регистру. Убедитесь, что вы правильно назвали файл, иначе он будет работать на вас.
Функционально этот файл является противоположностью вашей карты сайта.Существует карта сайта, которая сообщает поисковым системам, какие страницы вы хотите, чтобы они проиндексировали, а файл robots делает обратное — сообщает им, какие страницы вы не хотите, чтобы они индексировали.
В этом файле вы указываете, какие части вашего веб-сайта должны сканироваться пауками или поисковыми роботами. Вы можете указать разные правила для разных пауков / ботов в файле Robots.txt. Помните, что это ни в коем случае не является обязательным для поисковых систем, но в целом поисковые системы подчиняются тому, что их просят не делать.
Робот Googlebot — пример паука.Он используется Google для сканирования Интернета и записи информации о веб-сайтах, чтобы знать, насколько высоко ранжируются различные веб-сайты в результатах поиска.
Зачем нужен файл Robot.txt?
Чтобы объяснить вам, зачем вам нужен файл Robots.txt на вашем веб-сайте, я начну с основ. Прежде всего, вы можете спросить — что такое боты? Боты — это роботы поисковых систем или пауки. Они предназначены для сканирования веб-сайта, и у всех поисковых систем есть свои боты для этого. Здесь есть два ключевых термина, которые вам следует понять: i.е. Сканирование и индексирование. Это два разных термина. На высоком уровне сканирование следует по пути (ссылкам). Для веб-сайта сканирование означает переход по веб-ссылкам. Индексирование означает добавление этих веб-ссылок в поисковую систему. Индексирование также зависит от метатега, который вы используете для своих веб-страниц (метатеги — Index или noIndex).
Теперь, когда бот поисковой системы (бот Google, бот Bing или любые сканеры поисковых систем) заходит на ваш сайт по ссылке или по ссылке вашей карты сайта, которую вы отправили в консоль поиска для веб-мастеров, они переходят по всем ссылкам на ваш сайт для сканирования и индексации вашего сайта.
Как работают боты / сканеры —
Когда роботы поисковой системы заходят на ваш сайт, они имеют ограниченные ресурсы для сканирования вашего сайта. Если они не могут просканировать все веб-страницы вашего сайта в определенных ресурсах, они перестают сканировать, и это может затруднить индексацию сайта. Хорошо, если поисковая система завершит индексацию, но есть много частей веб-сайта, которые вы хотите защитить от сканеров или ботов. Например, папка wp-admin, панель администратора или другие страницы, которые не нужны поисковым системам.Используя robots.txt, вы можете указать сканерам поисковых систем (ботам), чтобы они не сканировали такие области вашего сайта. Таким образом, вы не только ускорите сканирование вашего сайта, но и поможете вам в глубоком сканировании ваших внутренних страниц.
Помните, что файл Robots.txt предназначен не для Index или Noindex, а для того, чтобы заставить роботов поисковых систем прекратить сканирование определенной части вашего блога. Например, если вы посмотрите файл DigitalHarpreet robots.txt, вы обязательно поймете, какую часть моего блога я не хочу, чтобы роботы поисковых систем сканировали.
Как получить доступ к файлу Robot.txt?
Файл Robot.txt находится в корневом каталоге вашего веб-сайта. Чтобы отредактировать или просмотреть его, перейдите на c-панель и найдите свой файловый менеджер, а затем перейдите в папку public_html или вы можете подключить свой веб-сайт к FTP-клиенту для доступа к нему.
Это как любой обычный текстовый файл, и вы можете открыть его с помощью обычного текстового редактора, такого как Блокнот. Если у вас нет файла robots.txt в корневом каталоге вашего сайта, вы всегда можете его создать.Все, что вам нужно сделать, это создать новый текстовый файл на вашем компьютере и сохранить его как robots.txt. Затем просто загрузите его в корневую папку вашего сайта.
Синтаксис файла Robots.txt
Вот пример файла Robots.txt.

Агент пользователя: * Disallow: /ebooks/*.pdf Disallow: / staging /Агент пользователя: Googlebot-Image Disallow: / images /
Где,
User-agent: * → Первая строка определяет правила, которым должны следовать все поисковые роботы.В данном контексте звездочка означает всех пауков.
Disallow: /ebooks/*.pdf → В связи с первой строкой эта ссылка означает, что все веб-сканеры не должны сканировать какие-либо файлы pdf в папке электронных книг на этом веб-сайте. Это означает, что поисковые системы не будут включать эти прямые ссылки PDF в результаты поиска.
Disallow: / staging / → В связи с первой строкой эта строка просит всех поисковых роботов ничего не сканировать в промежуточной папке веб-сайта.Это может быть полезно, если вы проводите тестирование и не хотите, чтобы поэтапный контент появлялся в результатах поиска.
User-agent: Googlebot-Image — здесь объясняется, что последующим правилам должен следовать только один конкретный сканер, то есть сканер изображений Google. Каждый паук использует свое имя «пользовательского агента».
Disallow: / images / — В связи со строкой, расположенной непосредственно над этой, это требует от поискового робота Google Images не сканировать изображения в папке изображений.
Как оптимизировать SEO файла WordPress robots.txt?
Файл Robots.txt поможет вам защитить ваши вещи от веб-сканеров / ботов, если он правильно закодирован, но если вы настроите его неправильно, это может полностью повредить вашему веб-присутствию. Поэтому настоятельно рекомендуется соблюдать особую осторожность при внесении изменений в этот файл.
На этом этапе я предполагаю, что вы читаете эту статью сверху и уже знаете, как получить доступ к файлу robots.txt. Если у вас нет robots.txt на своем сайте, то вы можете создать новый с помощью Блокнота (файл . txt). Создавая этот файл, убедитесь, что вы правильно назвали его, то есть robots.txt, а затем отправьте этот файл по FTP в корень вашего веб-сайта. Если вы не используете FTP-клиент, перейдите на свою c-панель и найдите Диспетчер файлов, а затем загрузите файл в корневой каталог (public_html).
После того, как вы нашли файл Robots.txt, самое время что-то записать в него. Теперь, прежде чем вы начнете писать в этот файл, вопрос: Что вы хотите от своих роботов.txt сделать для вас?
Существует три способа кодирования файла Robots.txt —
- Кодируйте его, чтобы разрешить все — все содержимое может сканироваться ботами.
- Закодируйте, чтобы запретить все — боты не могут сканировать контент.
- Закодируйте его как «Условное разрешение». Несколько вещей. Указания, записанные в файле robots.txt, будут определять, какой контент сканировать, а какой нет.
Давайте посмотрим, как закодировать три вышеуказанных параметра в Robots.txt —
Разрешить все — все содержимое может сканироваться ботами —
Большинство людей хотят, чтобы роботы посещали все, что есть на их веб-сайтах.Если это так, и вы хотите, чтобы робот проиндексировал все части вашего сайта, есть три способа добиться этого:
- Не иметь Robots.txt на сайте вообще.
- Создайте пустой файл Robots.txt и добавьте его в корень своего веб-сайта.
- Создайте файл robots.txt и напишите в нем следующий код.
Пользовательский агент: *
Disallow: Если на вашем веб-сайте есть файл robots.txt с этими инструкциями, то вот что происходит.Робот, например. Робот Google приходит в гости. Ищет файл robots.txt. Он находит файл и читает его. Читает первую строку. Затем он читает вторую строку. После этого робот может свободно посещать все ваши веб-страницы и контент, потому что это то, что вы ему сказали.
Запретить все — боты не могут сканировать контент —
Предупреждение.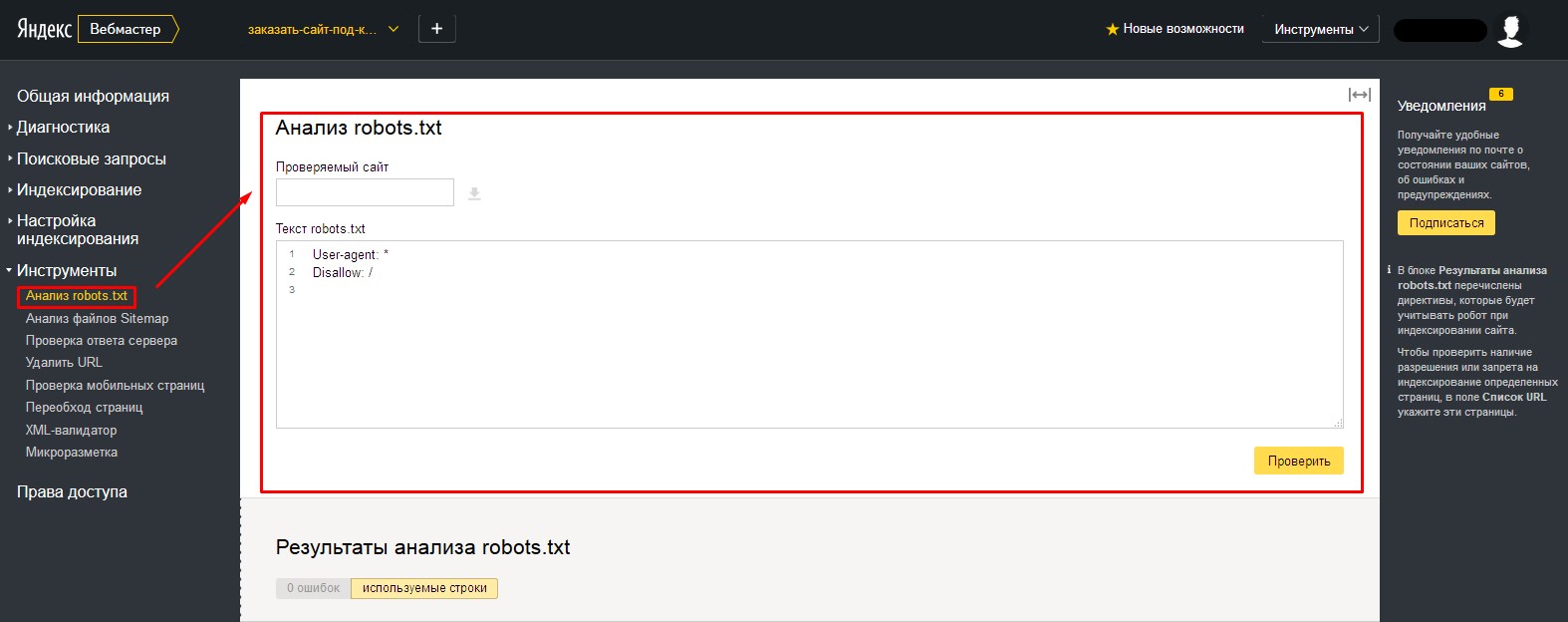 Делая это, вы имеете в виду, что Google и другие поисковые системы не будут индексировать ваши веб-страницы.
Делая это, вы имеете в виду, что Google и другие поисковые системы не будут индексировать ваши веб-страницы.
Чтобы заблокировать доступ всех сканеров поисковых систем к вашему веб-сайту, вам необходимо добавить следующие строки в файл robots.txt файл —
User-agent: * Disallow: /
Conditional Allow — инструкции, записанные в файле robots.txt, будут определять, какой контент сканировать, а какой нет.
Вот пример файла robot.txt для WordPress с условными операторами разрешения / запрета.
Агент пользователя: * Disallow: / cgi-bin / Запретить: / wp-admin / Запретить: / архивы / disallow: / *? * Запретить: *? Replytocom Запретить: / комментарии / фид / Пользовательский агент: Mediapartners-Google * Позволять: / Пользовательский агент: Googlebot-Image Разрешить: / wp-content / uploads / Пользовательский агент: Adsbot-Google Позволять: / Пользовательский агент: Googlebot-Mobile Позволять: / Карта сайта: http: // www.yourdomain.com/sitemap.xml
*** Важные правила кодирования Robots.txt —
- Не используйте комментарии в файле Robots.txt.
- Убедитесь, что вы не добавили пробелов в начале ваших директив. Например,
User-agent: * НЕПРАВИЛЬНЫЙ способ записи в robots.txt User-agent: * - ПРАВИЛЬНЫЙ способ записи в robots.txt
- Не меняйте порядок команд. Например,
Disallow: / support. User-agent: * Это неверные директивы.Вместо того, чтобы писать эти команды, вы должны написать их, как показано ниже: Пользовательский агент: * Disallow: / support
- Если вы хотите запретить использование нескольких каталогов, напишите следующие строки в robots.txt,
User-agent: *
Disallow: / cgi-bin /
Запретить: / wp-admin /
Disallow: / archives / Вместо того, чтобы писать все вместе вот так —
User-agent: *
Disallow: / cgi-bin / wp-admin / archives - Осторожно используйте заглавные и строчные буквы.
 Например, если вы хотите запретить «readme.html», но если вы напишете его как «Readme.html», это запутает бота поисковой системы, и в конечном итоге вы получите желаемый результат.
Например, если вы хотите запретить «readme.html», но если вы напишете его как «Readme.html», это запутает бота поисковой системы, и в конечном итоге вы получите желаемый результат.
- Избегайте логических ошибок. Например —
User-agent: *
Запретить: / temp /
Пользовательский агент: Googlebot
Запретить: / images /
Запретить: / temp /
Disallow: / cgi-bin / Приведенный выше пример взят из файла robots.txt, который позволяет всем агентам получать доступ ко всему на сайте, кроме каталога / temp.До сих пор это нормально, но позже есть еще одна запись, которая определяет более строгие условия для робота Googlebot. Когда робот Googlebot начнет читать файл robots.txt, он увидит, что все пользовательские агенты (включая самого робота Google) имеют доступ ко всем папкам, кроме / temp /. Роботу Googlebot этого достаточно, поэтому он не будет читать файл до конца и проиндексирует все, кроме / temp /, включая / images / и / cgi-bin /, которые, по вашему мнению, вы сказали ему не трогать. Видите ли, структура файла robots.txt проста, но все же можно легко допустить серьезные ошибки.
Как добавить XML-карту сайта в файл Robots.txt?Этого можно добиться, добавив следующие строки в robots.txt. Вы можете заменить приведенные ниже ссылки карты сайта на свой собственный сайт sitemap.xml.
Если вы хотите создать карту сайта в формате XML БЕСПЛАТНО — прочтите это:
Какой файл Robots.txt лучше всего подходит для моего веб-сайта?
Если вам нужен идеальный файл Robots.txt, то он должен быть таким —
Вот еще один пример роботов.txt, который я использую по адресу http://digitalharpreet.com/robots.txt
User-agent: * Disallow: / cgi-bin / Запретить: / wp-admin / Запретить: / wp-content / plugins / Запретить: /readme.html Запретить: /index.php Запретить: /xmlrpc.php Пользовательский агент: NinjaBot Позволять: / Пользовательский агент: Mediapartners-Google * Позволять: / Пользовательский агент: Googlebot-Image Разрешить: / wp-content / uploads / Пользовательский агент: Adsbot-Google Позволять: / Пользовательский агент: Googlebot-Mobile Позволять: / карта сайта: http://digitalharpreet.com/sitemap_index.xml карта сайта: http: // digitalharpreet.ru / post-sitemap.xml карта сайта: http://digitalharpreet.com/page-sitemap.xml карта сайта: http://digitalharpreet.com/category-sitemap.xml
Инструменты для создания и проверки файла Robots.txt
Вы можете напрямую сгенерировать robot.txt в Оптимальном генераторе роботов WordPress. Создайте файл robot.txt и добавьте его в корневой каталог.
Чтобы проверить файл Robots.txt,
- Войдите в панель инструментов Google для веб-мастеров.
- Нажмите «Сканировать», а затем «Просмотреть как Google».
- Добавьте сообщения на свой сайт и проверьте, нет ли проблем с доступом к вашему сообщению.
- Также добавьте запрещенные вами сообщения / страницы в файл robots.txt.
Вот как это будет выглядеть —
Другие ресурсы Robots.txt
Сообщите мне, если вы все еще сомневаетесь или у вас есть какие-либо вопросы? Вы можете разместить свой вопрос ниже или написать мне в Твиттере, используя ссылку ниже, чтобы начать разговор —
Или вы можете отправить мне электронное письмо на [электронная почта защищена] .
И если вы уже используете robots.txt для своего веб-сайта WordPress и хотите добавить больше полезной информации в эту статью, то вы можете оставить свой ценный комментарий, чтобы помочь другим читателям.
Не забудьте подписаться на блог, чтобы получать полезные советы по поисковой оптимизации.
Возможно, вам тоже захочется прочесть это — Проверьте это
Как заблокировать ссылки, такие как Majestic Ahrefs Moz и SEMRush
El mejor robots.txt для WordPress
Вам нужно указать серию cosas sobre el robots.txt , ya que en el SEO se habla mucho de «bloquear ciertas partes de la web a Google» с использованием robots.txt , pero en muy pocos casos se conoce точный пример того, что robots.txt y todos los usos que se le pueden dar, ya que GoogleBot не является единственным ботом, который даёт информацию в Интернете, и новый контент для очистки .
Un bot (también llamado « araña » al traducirlo a español) es un que rastrea sitios web en busca de nuevo contenido, cambios o cualquier cosa para el que haya sido Disñado, existen bots de muchos de tipos, aunchos de tipos los que más oímos hablar es de Google .
El robots.txt lleva utilizándose desde que en 1994 Martijn Koster lo propuso en la empresa en la que trabajaba en ese momento ( Nexor ), con el fin de bloquear todos los bots maliciosan que «и» siteios web .
¿Qué es el robots.txt?Aunque muchos bots actualmente (sobre todo los más «cabrones») pasan del robots.txt , la mayoría de bots y arañas «legales» siguen haciéndole caso a las indicaciones del robots.txt , зайдите на сайт через Google .
La teoría dice que cuando un bot llega a un sitio web, lo primero que revisa es si existe un archivo robots.txt y si este archivo existe, lo analysisa para ver que partes del sitio web tiene bloqueadas y no puede Acceder a ellas o scrapear su contenido.
Podemos usar el archivo robots.txt para que los bots o arañas no puedan Acceder algunas partes de nuestro sitio web, pero no solo eso, sino que también podemos elegir que bots y arañas pueden entrar y cuáles serán en que partes de la web seran bloqueados , además también podemos establecer límites de «velocidad» a la hora de navegar estos bots y arañas por nuestro sitio web con el fin de que «no se pasen». ¿Para que sirve el robots.txt?Como hemos dicho anteriormente, el robots.txt sirve para algo más que para bloquear ciertas partes de nuestro sitio web al robot de Google , es decir, tiene más usos, pero muy pocos webmasters son el capaces de explotar todo que tiene el robots.txt con sus parámetros.
- El robots.txt разрешенных (средний параметр «карта сайта») показателей, указывающих на соответствующие карты сайта на веб-сайте , это означает, что вы можете найти роботов.txt — это архив для начинающих, который пересматривает бот о арабском языке Google и вводит новый веб-сайт (o al menos eso dice la teoría).
- Nos permite bloquear el acceptso de los bots a ciertas partes «tecnicas» u «ocultas» de la aplicación , es decir, zonas donde los crawlers or bots «no pintan nada», como por ejemplo la zona del -ADMIN на WordPress .
- Podemos bloquear el acceptso de las arañas a ciertas zonas del sitio web que no nos interesa que se indexen por alguna razón.
- Podemos bloquear el acceptso a nuestro sitio web a ciertos bots que sabemos a ciencia cierta que no van a hacer nada productivo en nuestro sitio web , aunque también debemos tener en cuenta que los bots más «dañaninos 906» robots.txt , просто перейдите к веб-узлам веб-сайтов и накопите их на объект.
La mayoría de estas aplicaciones que hemos nombrado anteriormente tienen relación o sirven para optimizar el SEO on page de un siteio web , ya que nos permite controlar lo que queremos que indexen los buscadores y lo quee index que se .
Parametros aceptados en el del robots.txtLa sintaxis del robots.txt no es сложная, es decir, no tiene muchos parámetros que se puedan utilizar, pero los pocos que tiene debemos saber usarlos bien para no causar ningún проблема de indexado en nuestro sitiole, ya que sue sue у вас есть проблемы, которые могут быть вызваны персоной, но не экспериментируют с robots.txt siguiendo las indicaciones de algún sitio de internet poco fiable con el objetivo de « bloquear cosas ».
Подробные алгоритмы параметров, которые используются в robots.txt :
- user-agent: Sirve для особых пользовательских агентов, если не разрешено, что правила запрещают и разрешают использование непрерывного действия. Si quieres ver el listado complete de user-agent que podemos encontrarnos, los puedes encontrar en este listado: http://www.robotstxt.org/db.html
- запретить : Podemos especificar una barra / para bloquear el acceptso a todo el sitio o podemos especificar la ruta (incluso usando comodines *) que queremos bloquear.
- разрешить : Es como el disallow pero para enableir, es útil cuando queremos añadir ciertas exclusiones a un disallow, es decir, para hacer excepciones.
- карта сайта : Nos permite especificar donde está el sitemap del sitio web, podemos especificar varios simplemente con añadir varios parámetros sitemap al archivo robots.txt
- crawl-delay : Permite especificar un número de segundos de espera entre cada página revisada por el bot en cuestión, es útil para evitar excesos por parte de los bots y crawlers, aunque muchos bots ni le hacen caso ejemplo el propio GoogleBot.
Para que veas más o menos como se utilizan estos parámetros (aunque ya lo vas a ver después en el archivo robots.txt que hemos preparado para ti) te mostramos algunos ejemplos de cosas que puedes hacer con los parots .txt .
Con este código bloqueas el acceptso a la web a TODOS los bots (Evidentemente solo es recomendable usarlo en webs que no quieras que sean rastreadas por los buscadores):
Пользовательский агент: * Disallow: /
En este otro caso que mostramos a continación, se bloquea el acceptso al bot de Google a TODA la web :
Пользовательский агент: Googlebot Disallow: /
User-agent: Googlebot Disallow: / |
Pero en el siguiente puedes ver como bloqueamos el accessso a GoogleBot (bot de Google) a una ruta definedada y usamos el comodín para hacer lo mismo con todas las subpáginas:
Пользовательский агент: Googlebot Disallow: / aquinoentras / *
User-agent: Googlebot Disallow: / aquinoentras / * |
Y ahora bloqueamos a TODOS los bots ciertas rutas (este código se suele usar para evitar que los buscadores indexen las paginaciones y cuente como contenido duplicado):
Пользовательский агент: * Запрещение: * / page / *
Агент пользователя: * Запрещено: * / page / * |
Y finalmente, есть опция , если есть карта сайта или карта сайта , в том числе, если вы хотите, чтобы она была подключена к сети.es:
Карта сайта: https://raiolanetworks.es/sitemap_index.xml Карта сайта: https://raiolanetworks.es/post-sitemap.xml Карта сайта: https://raiolanetworks.es/page-sitemap.xml Карта сайта: https://raiolanetworks.es/category-sitemap.xml
Карта сайта: https://raiolanetworks.es/sitemap_index.xml Карта сайта: https://raiolanetworks.es/post-sitemap.xml Карта сайта: https: // raiolanetworks.es / page-sitemap.xml Карта сайта: https://raiolanetworks.es/category-sitemap.xml |
Como puedes ver con tus propios ojos, la sintaxis del robots.txt no es сложная , no tiene muchos parámetros y los pocos que tiene son fácilmente configurables si nos interesamos un poco por el tema y sabemos los oraña funcion (también llamado гусеницы ).
Плагины для модификации роботов.txt en WordPressОпция , измененная или создающая архив robots.txt на веб-сайте в США и клиентов FTP для доступа к сервидору или хостингу siempre is disponible (o debería), pero también podemos modificar el От WordPress используйте плагин для этого.
En este artículo vamos a listar unos cuantos plugins que te allowirán modificar el robots.txt de un site web or blog WordPress sin salir del back-end del CMS :
Плагины Algunos важны для Yoast SEO или All in One SEO Pack включает модулей для изменения и управления средой роботов.txt из панель администрирования WordPress , на месте, где есть тендер, в котором есть решение: для того, чтобы установить дополнительный плагин, si ya tenemos uno que nos permite hacer que tenemo .
Архив robots.txt для WordPressEl archivo robots.txt que tienen las instalaciones de WordPress después de su instalación ha ido cambiando con el tiempo según han ido evolucionando las versiones de WordPress, de hecho, hasta hace hace robots.txt — это полная актуальная и актуальная связь с Google, которая включает в себя предопределенную форму в версии 4.4 для WordPress .
из archivo robots.txt из WordPress актуальная версия 4.7 (момент написания статьи) на стадии:
Пользовательский агент: * Запретить: / wp-admin / Разрешить: /wp-admin/admin-ajax.php
Пользовательский агент: * Запретить: / wp-admin / Разрешить: / wp-admin / admin-ajax.php |
Aunque nosotros hemos construido un robots.txt для установки WordPress , un archivo robots.txt полностью и с bloqueos de bots que no sirven para nada, aunque debes revisarlo entero yiotarlo aunque debes revisarlo entero yiotarlo , es decir, cambiar las URL, ya que nosotros hemos utilizado como ejemplo nuestro sitio web.
Para nosotros este robots.txt es útil, es decir, podría ser mucho más agresivo y bloquear muchos más crawlers и muchas más zonas de WordPress , pero debemos tener en cuenta queensi si comado debemos tener en cuenta queensosi 90 , la cosa cambia y debemos anñadir reglas personalizadas al robots.txt для правильной работы и без каких-либо проблем, как для работы с индексными индексами веб-сайтов.
Por esta razón esperamos que el archivo que te pasamos en este artículo (продолжение) te sirva más que nada como referencia, como ejemplo para montar tu propio archivo robots.txt que encaje con la configuración site esiopec .
Этот архив создан для того, чтобы использовать параметры, портировать и использовать, AVISO: этот архив может быть изменен и зависит от новых версий WordPress и веб-сайтов в «Интернете».
#robots de Raiola Networks #es necesario personalizar algunas opciones o puede dar issues # Bloqueo basico para todos los bots y crawlers # puede dar problemas por bloqueo de recursos en GWT Пользовательский агент: * Разрешить: / wp-content / uploads / * Разрешить: /wp-content/*.js Разрешить: /wp-content/*.css Разрешить: /wp-includes/*.js Разрешить: /wp-includes/*.css Disallow: / cgi-bin Запретить: / wp-content / plugins / Запретить: / wp-content / themes / Запретить: / wp-includes / Запретить: / * / вложение / Запретить: / tag / * / page / Запретить: / tag / * / feed / Запретить: / page / Запретить: / комментарии / Запретить: / xmlrpc.php Запретить: /? Attachment_id * # Bloqueo de las URL dinamicas Disallow: / *? #Bloqueo de busquedas Пользовательский агент: * Запретить: /? S = Запретить: / поиск # Bloqueo de trackbacks Пользовательский агент: * Запретить: / trackback Disallow: / * трекбэк Disallow: / * трекбэк * Запретить: / * / trackback # Bloqueo de feeds для сканеров Пользовательский агент: * Разрешить: / feed / $ Запретить: / feed / Запретить: / комментарии / фид / Запрещение: / * / feed / $ Запрещение: / * / feed / rss / $ Запретить: / * / trackback / $ Запретить: / * / * / feed / $ Запретить: / * / * / feed / rss / $ Запретить: / * / * / trackback / $ Запретить: / * / * / * / feed / $ Запретить: / * / * / * / feed / rss / $ Запретить: / * / * / * / trackback / $ # Ralentizamos algunos bots que se suelen volver locos Пользовательский агент: noxtrumbot Задержка сканирования: 20 Пользовательский агент: msnbot Задержка сканирования: 20 Пользовательский агент: Slurp Задержка сканирования: 20 # Bloqueo de bots y crawlers poco utiles Пользовательский агент: MSIECrawler Запретить: / Пользовательский агент: WebCopier Запретить: / Пользовательский агент: HTTrack Запретить: / Пользовательский агент: Microsoft.URL.Control Запретить: / Пользовательский агент: libwww Запретить: / Пользовательский агент: Orthogaffe Запретить: / Пользовательский агент: UbiCrawler Запретить: / Пользовательский агент: DOC Запретить: / Пользовательский агент: Zao Запретить: / Пользовательский агент: sitecheck.internetseer.com Запретить: / Пользовательский агент: Zealbot Запретить: / Пользовательский агент: MSIECrawler Запретить: / Пользовательский агент: SiteSnagger Запретить: / Пользовательский агент: WebStripper Запретить: / Пользовательский агент: WebCopier Запретить: / Пользовательский агент: Fetch Запретить: / Пользовательский агент: Offline Explorer Запретить: / Пользовательский агент: Телепорт Запретить: / Пользователь-агент: TeleportPro Запретить: / Пользовательский агент: WebZIP Запретить: / Пользовательский агент: linko Запретить: / Пользовательский агент: HTTrack Запретить: / Пользовательский агент: Microsoft.URL.Control Запретить: / Пользовательский агент: Xenu Запретить: / Пользовательский агент: ларбин Запретить: / Пользовательский агент: libwww Запретить: / Пользовательский агент: ZyBORG Запретить: / Пользовательский агент: Скачать Ninja Запретить: / Пользовательский агент: wget Запретить: / Пользовательский агент: grub-client Запретить: / Пользовательский агент: k2spider Запретить: / Пользовательский агент: NPBot Запретить: / Пользовательский агент: WebReaper Запретить: / # Previene problemas de recursos bloqueados в Инструментах Google для веб-мастеров Пользовательский агент: Googlebot Позволять: /*.css $ Разрешить: /*.js$ # En condiciones normales este es el sitemap Карта сайта: https://raiolanetworks.es/sitemap.xml # Si utilizas Yoast SEO соответствует принципам карт сайта Карта сайта: https://raiolanetworks.es/sitemap_index.xml Карта сайта: https://raiolanetworks.es/category-sitemap.xml Карта сайта: https://raiolanetworks.es/page-sitemap.xml Карта сайта: https://raiolanetworks.es/post-sitemap.xml
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 9 0019 6465 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 | #robots de Raiola Networks #es necesario personalizar algunas opciones o puede dar problemsas # Bloqueo basico para todos los bots y crawlers # puede dar problemas por bloqueo de recursos 900 User агент: * Разрешить: / wp-content / uploads / * Разрешить: / wp-content / *.js Разрешить: /wp-content/*.css Разрешить: /wp-includes/*.js Разрешить: /wp-includes/*.css Запретить: / cgi-bin Запретить: / wp-content / plugins / Disallow: / wp-content / themes / Disallow: / wp-includes / Disallow: / * / attachment / Disallow: / tag / * / page / Disallow: / tag / * / feed / Disallow: / page / Disallow: / comments / Disallow: /xmlrpc.php Disallow: /? attachment_id * # Bloqueo de las URL dinamicas Disallow : / *? #Bloqueo de busquedas User-agent: * Disallow: /? S = Disallow: / search # Bloqueo de trackbacks User-agent: * Disallow: / trackback Disallow: / * trackback Disallow: / * trackback * Disallow: / * / trackback # Bloqueo de feeds para crawlers User-agent: * Allow: / feed / $ Disallow: / feed / Disallow: / comments / feed / Disallow: / * / feed / $ Disallow: / * / feed / rss / $ Disallow: / * / trackback / $ Запрещено: / * / * / feed / $ Запрещено: / * / * / feed / rss / $ Запрещено: / * / * / trackback / $ Запрещено: / * / * / * / feed / $ Запрещено: / * / * / * / feed / rss / $ Запрещено: / * / * / * / trackback / $ # Ralentizamos alg unos bots que se suelen volver locos User-agent: noxtrumbot Crawl-delay: 20 User-agent: msnbot Crawl-delay: 20 User-agent: Slurp Crawl-delay: 20 # Bloqueo de bots y crawlers poco utiles User-agent: MSIECrawler Disallow: / User-agent: WebCopier Disallow: / User-agent: HTTrack Disallow: / Пользовательский агент: Microsoft.URL.Control Disallow: / User-agent: libwww Disallow: / User-agent: Orthogaffe Disallow: / User-agent: UbiCrawler Disallow: / User-agent: DOC Disallow: / User-agent: Zao Disallow: / User-agent: sitecheck.internetseer.com Disallow: / User-agent: Zealbot Disallow: / Пользователь- агент: MSIECrawler Disallow: / User-agent: SiteSnagger Disallow: / User-agent: WebStripper Disallow: / User-agent: WebCopier Disallow: / User-agent: Fetch Disallow: / User-agent: Offline Explorer Disallow: / User-agent: Teleport Disallow: / Пользовательский агент: TeleportPro Disallow: / User-a гент: WebZIP Disallow: / User-agent: linko Disallow: / User-agent: HTTrack Disallow: / Пользовательский агент: Microsoft.URL.Control Disallow: / User-agent: Xenu Disallow: / User-agent: larbin Disallow: / User-agent: libwww Disallow: / User-agent: ZyBORG Disallow: / User-agent: Download Ninja Disallow: / User-agent: wget Disallow: / User-agent: grub-client Disallow: / User-agent : k2spider Disallow: / User-agent: NPBot Disallow: / User-agent: WebReaper Disallow: / # Предотвратить повторные ошибки в Инструментах Google для веб-мастеров Пользователь -Агент: Googlebot Разрешить: / *.css $ Разрешить: /*.js$ # En condiciones normales este es el sitemap Sitemap: https://raiolanetworks.es/sitemap.xml # Si utilizas Yoast SEO estos son los sitemaps Principales Карта сайта: https://raiolanetworks.es/sitemap_index.xml Карта сайта: https://raiolanetworks.es/category-sitemap.xml Карта сайта: https://raiolanetworks.es/page- sitemap.xml Карта сайта: https: // raiolanetworks.es / post-sitemap.xml |
Google имеет доступ к исходной информации для проверки robots.txt или включительно для проверки правил robots.txt отдельно, является частью формы Google Search Console (все предыдущие версии Google Webmaster Tools Google Webmaster Tools ).
Antes de nada, the dejamos un video que hemos grabado for que veas como utilizar el probador de robots.txt из Google :
Для использования пробного файла robots.txt простых способов ввода нового объекта Google Search Console и управления в разделе «Растрео» Google Search Console и buscamos la opción « Probador de . ”:
Главный интерфейс probador de robots.txt no es Completeja, aunque debemos tener muy en cuenta lo que queremos hacer y mucho más las indicaciones que nos va a dar.Si quieres ver mejor como se utiliza esta herramienta tanto con archivos enteros como con líneas o parametros de robots.txt que queramos probar, puedes ver el video que hemos insertado para ti al Principio de esta sección.
Debemos tener en cuenta que el robots.txt debe estar Definido tal y como marcan los estándares, es decir, que si algo no lo ponemos tal y como especifica el estándar, podemos tener issues.
Debemos tener en cuenta los siguientes puntos antes de ponernos a bloquear cosas con el robots.txt :
- Bloquear el Acceso a una página para los crawlers con el robots.txt no importanta que no tengamos que hacerlo mediante el atributo nofollow o noindex, yo personalmente usaría ambos métodos si quiero que algo no seose, o al que dice la gente de Moz en su blog.
- Solo se puede especificar un disallow o un allow por línea , sino nos aparecerá un error de sintaxis en el probador y no se aplicara ningún efecto.
- Si especificamos dominios externos (es decir, otros dominios) en el archivos robots.txt de nuestro sitio, лос-поисковые роботы по принципам работы с Google или Bing, simplemente pasaran de esos parámetros, es decir, los ignoraran.
- Para Google y para Bing (puede que para otros también, pero no lo sabemos fijo ya que no hay documentación) se aceptan tanto el símbolo del dólar $ como el asterisco * para Crear patrones y comodines , es decir, por ejemplo para especificar todas las subpáginas de una ruta.
- El nombre del archivo robots.txt siempre debe ser así, es decir, siempre en minúsculas y siempre escrito así, por ejemplo RoBoTs.TxT no funcionaria.
- En los parámetros del robots.txt no podemos usar espacios, si quieres usar patrones, lo recomendable es usar asteriscos *.
Desde hace tiempo existe una alternativa al archivo robots.txt , una alternativa que muchos catalogan de mucho más inteligente y efectiva, de hecho, es la manera perfect de hacerlo для всех проблем.
Esta alternativa es usar las metaetiquetas para utilizar el atributo NOINDEX , es la solución perfect ya que es mucho más efectiva que bloquear la página en el robots.txt, la gente de Moz lo explica en su blog, la siguiente dirección URL: https://moz.com/learn/seo/robotstxt
La gente de Moz ha hecho pruebas y han demostrado que en algunas ocasiones cuando añades una URL or ruta al robots.txt aparece igual en los resultados de búsqueda, aunque no salga contenido scrape con el atributo NOINDEX los buscadores tienen en cuenta SI o SI que esa URL no debe aparecer en los resultados de busqueda.
Si queremos ir un poco más lejos, simplemente debemos añadir el atributo NOFOLLOW para que tampoco se transfera linkjuice a través de esa página.
Hace unos meses (ya casi un año) Google empezó a mandar correos electrónicos a la gente y a mostrar un error nuevo en Google Webmaster Tools (ahora Google Search Console ).
Ошибка, которая существует повторных блоков , у многих веб-мастеров возникает тревожная ошибка с проблемой , чтобы получить ядерную бомбу.
Realmente no se trataba de un проблема, simplemente es un indicio de que Google hace lo que le sale de las narices, y en una actualización rutinaria de sus directrices de golpe , sin avisar, dijo que no se podía denegar Чтобы получить доступ к архивам JS и CSS на веб-сайте, используйте файл robots.txt .
¿Cómo podemos solucionar esto? Pues es fácil, simplemente revisamos nuestro robots.txt , lo editamos y al fondo de todo anñadimos esto:
Пользовательский агент: Googlebot Позволять: /*.css $ Разрешить: /*.js$
Пользовательский агент: Googlebot Разрешить: /*.css$ Разрешить: /*.js$ |
Lo que hace este fragment de código es habilitar el access a los archivos JS y CSS al bot de Google .
Realmente Google hizo este cambio para poder «detectar» cosas raras en elisño de los sitios web, ya que si los robots.txt bloqueaban el Acceso a estos recursos necesarios en la carga de la web, Google podía Ver el contenido, pero no podía ver el disño sin saltarse las reglas estándar del archivo robots.