Правильный Robots.txt для WordPress (базовый и расширенный) [2022]
Правильный Robots.txt для WordPress в 2022-м году. Несколько версий под разные нужды: простая базовая и расширенная — с проработкой под каждую поисковую систему.
Одной из важнейших вещей при создании и оптимизации сайта для поисковых систем считают Robots.txt. Небольшой файлик, где прописаны правила индексирования для поисковых роботов.
Если файл будет настроен неправильно, то сайт может неправильно индексироваться и терять большие доли трафика. Грамотная настройка наоборот позволяет улучшить SEO, и вывести ресурс в топы.
Сегодня мы поговорим о настройке Robots.txt для WordPress. Я покажу вам правильный вариант, который сам использую для своих проектов.
✅ Содержание
Что такое Robots.txt
Как я уже и сказал, robots.txt — текстовой файлик, где прописаны правила для поисковых систем. Стандартный robots.txt для WordPress выглядит следующим образом:
User-agent: * Disallow: /wp-admin/ Allow: /wp-admin/admin-ajax.php
 php
phpИменно в таком виде он создается плагином Yoast SEO. Некоторые считают, что этого хватит для правильной индексации. Я же считаю, что нужна более детальная проработка. А если речь идет о нестандартных проектах, то проработка нужна и подавно. Давайте разберемся в основных директивах:
| Директива | Значение | Пояснение |
| User-agent: | Yandex, Googlebot и т.д. | В этой директиве можно указать к какому конкретно роботу мы обращаемся. Обычно используются те значения, которые я указал. |
| Disallow: | Относительная ссылка | Директива запрета. Ссылки, указанные в этой директиве будут игнорироваться поисковыми системами. |
| Allow: | Относительная ссылка | Разрешающая директива. Ссылки, которые указаны с ней будут проиндексированы. |
| Sitemap: | Абсолютная ссылка | Здесь указывается ссылка на XML-карту сайта. Если в файле не указать эту директиву, то придется добавлять карту вручную (через Яндекс. Вебмастер или Search Console). Вебмастер или Search Console). |
| Crawl-delay: | Время в секундах (пример: 2.0 — 2 секунды) | Позволяет указать таймаут между посещениями поисковых роботов. Нужна в случае, если эти самые роботы создают дополнительную нагрузку на хостинг. |
| Clean-param: | Динамический параметр | Если на сайте есть параметры вида site.ru/statia?uid=32, где ?uid=32 — параметр, то с помощью этой директивы их можно скрыть. |
В принципе, ничего сложного. Дам дополнительные пояснения по директивам Clean-param (откройте вкладку).
Подробнее о Clean-param
Параметры, как правило, используются на динамических сайтах. Они могут передавать поисковым системам лишнюю информацию — создавать дубли. Чтобы избежать этого, мы должны указать в Robots.txt директиву Clean-param с указанием параметра и ссылки, к которой это параметр применяется.
В нашем примере site.ru/statia?uid=32 — site.ru/statia — ссылка, а все, что после знака вопроса — параметр.
Например, uid=33, uid=34…uid=123434. В теории их может быть сколько угодно, поэтому мы должны закрыть от индексации все параметры uid. Для этого директива должна принять такой вид:
Clean-param: uid /statia # все параметры uid для statia будут закрыты
Более подробно о том, что такое Robots.txt можно узнать из Яндекс.Помощи. Или из этого видеоролика:
Базовый Robots.txt для WordPress
Совсем недавно я приобрел плагин Clearfy Pro для своих проектов. Там очень много разных функций, и одна из них — создание идеального Robots.txt. На самом деле насколько он идеален — я не знаю, вебмастера расходятся во мнениях.
Кто-то предпочитает делать более краткие версии роботса, указывая правила для всех поисковых систем сразу. Другие прописывают отдельные правила для каждого поисковика (в основном для Яндекса и Гугла).
Что из этого правильно — точно сказать не могу. Однако я предлагаю вам ознакомиться с базовой версией Robots.txt для WordPress от Clearfy Pro. Я немного подредактировал ее — указал директиву Sitemap. Удалил директиву Host.
User-agent: * Disallow: /wp-admin Disallow: /wp-includes Disallow: /wp-content/plugins Disallow: /wp-content/cache Disallow: /wp-json/ Disallow: /xmlrpc.php Disallow: /readme.html Disallow: /*? Disallow: /?s= Allow: /wp-includes/*.css Allow: /wp-includes/*.js Allow: /wp-content/plugins/*.css Allow: /wp-content/plugins/*.js Allow: /*.css Allow: /*.js Sitemap: https://site.ru/sitemap.xml
Не могу сказать, что это лучший вариант для блогов на ВП. Но во всяком случае, он лучше, чем то, что нам предлагает Yoast SEO по умолчанию.
Расширенный Robots.
 txt для WordPress
txt для WordPressТеперь посмотрим на расширенную версию Robots.txt для WordPress. Наверняка вы знаете, что все сайты на WP имеют одинаковую структуру. Одинаковые названия папок, файлов и т.д. позволяют специалистам выявить наиболее приемлемый вариант роботса.
Читайте также: Самые лучшие SEO-оптимизированные шаблоны для WordPress
В этой статье я хочу представить вам свой вариант Robots.txt. Его я использую как для своих сайтов, так и для клиентских. Вы могли видеть такой вариант и на других сайтах, т.к. он обладает некоторой популярностью.
Итак, правильный Robots.txt для WordPress выглядит следующим образом:
User-agent: * # Для всех поисковых систем, кроме Яндекса и Гугла Disallow: /cgi-bin Disallow: /? Disallow: /wp- Disallow: *?s= Disallow: *&s= Disallow: /search/ Disallow: /author/ Disallow: /users/ Disallow: */trackback Disallow: */feed Disallow: */rss Disallow: */embed Disallow: /xmlrpc.php Disallow: *utm= Disallow: *openstat= Disallow: /tag/ # Закрываем метки Disallow: /readme.html # Закрываем бесполезный мануал по установке WordPress (лежит в корне) Disallow: *?replytocom Allow: */uploads User-agent: GoogleBot # Для Гугла Disallow: /cgi-bin Disallow: /? Disallow: /wp- Disallow: *?s= Disallow: *&s= Disallow: /search/ Disallow: /author/ Disallow: /users/ Disallow: */trackback Disallow: */feed Disallow: */rss Disallow: */embed Disallow: /xmlrpc.php Disallow: *utm= Disallow: *openstat= Disallow: /tag/ # Закрываем метки Disallow: /readme.html Disallow: *?replytocom Allow: */uploads Allow: /*/*.js Allow: /*/*.css Allow: /wp-*.png Allow: /wp-*.jpg Allow: /wp-*.jpeg Allow: /wp-*.gif Allow: /wp-admin/admin-ajax.php User-agent: Yandex # Для Яндекса Disallow: /cgi-bin Disallow: /? Disallow: /wp- Disallow: *?s= Disallow: *&s= Disallow: /search/ Disallow: /author/ Disallow: /users/ Disallow: */trackback Disallow: */feed Disallow: */rss Disallow: */embed Disallow: /xmlrpc.
php Disallow: /tag/ # Закрываем метки Disallow: /readme.html Disallow: *?replytocom Allow: */uploads Allow: /*/*.js Allow: /*/*.css Allow: /wp-*.png Allow: /wp-*.jpg Allow: /wp-*.jpeg Allow: /wp-*.gif Allow: /wp-admin/admin-ajax.php Clean-Param: utm_source&utm_medium&utm_campaign Clean-Param: openstat Sitemap: https://site.com/sitemap_index.xml # Карта сайта, меняем site.com на нужный адрес.

Ранее в Robots.txt использовалась директива Host. Она указывала главное зеркало сайта. Теперь это делается при помощи редиректа. Подробнее об этом можно почитать в блоге Яндекса.
Комментарии (текст после #) можно удалить. Указываю Sitemap с https протоколом, т.к. большинство сайтов сейчас используют защищенное соединение. Если у вас нет SSL, то измените протокол на http.
Читайте также: Как правильно настроить WordPress
Обратите внимание на то, что я закрываю метки (теги). Делаю это потому, что они создают большое количество дублей. Это плохо сказывается на SEO, но если вы хотите открыть метки, тогда уберите строчку disallow: /tag/ из файла.
Это плохо сказывается на SEO, но если вы хотите открыть метки, тогда уберите строчку disallow: /tag/ из файла.
Заключение
В общем-то, вот так выглядит правильный Robots.txt для WordPress. Смело копируйте данные в файл и пользуйтесь. Отмечу, что этот вариант подходит только для стандартных информационных сайтов.
В других ситуациях может потребоваться индивидуальная проработка. На этом все. Спасибо за внимание. Буду благодарен, если вы подпишитесь на мой телеграм-канал и мою группу ВК.
Видео на десерт: Фермер Хотел Найти Воду, но То Что Случилось Удивило Весь Мир
( 31 оценка, среднее 5 из 5 )
Правильный robots txt для WordPress сайта – инструкция на 2023 год без плагинов
Содержание
- Для чего нужен robots.
 txt
txt - Где лежит файл robots в WordPress
- Как создать правильный robots txt
- Настройка команд
- Рабочий пример инструкций для WordPress
- Как проверить работу robots.txt
- Плагин–генератор Virtual Robots.txt
- Добавить с помощью Yoast SEO
- Изменить модулем в All in One SEO
- Правильная настройка для плагина WooCommerce
- Итог
Для чего нужен robots.txt
Robots.txt создан для регулирования поведения поисковых роботов на сайтах, а именно куда им заходить можно и брать в поиск, а куда нельзя. Лет 10 назад сила данного файла была велика, по его правилам работали все поисковые системы, но сейчас он скорее как рекомендация, чем правило.
Но пока не отменили, вебмастера должны делать его и настраивать правильно исходя из структуры и иерархии сайтов. Отдельная тема это WordPress, потому что CMS содержит множество элементов, которые не нужно сканировать и отдавать в индекс. Разберемся как правильно составить robots. txt
txt
Где лежит файл robots в WordPress
На любом из ресурсов robots.txt должен лежать в корневой папке. В случае с вордпресс, там где находится папка wp-admin и ей подобные.
Расположение на сервереЕсли не создавался и не загружался администратором сайта, то по умолчанию на сервере не найти. Стандартная сборка WordPress не предусматривает наличие такого объекта.
Как создать правильный robots txt
Создать правильный robots txt задача не трудная, сложнее прописать в нем правильные директивы. Сначала создадим документ, открываем программу блокнот и нажимаем сохранить как.
Сохраняем документВ следующем окне задаем название robots, оставляем расширение txt, кодировку ANSI и нажимаем сохранить. Объект появится в папке куда произошло сохранение. Пока документ пустой и ничего не содержит в себе, давайте разберемся какие именно директивы он может поддерживать.
Сохранение роботсаПри желании можете сразу скачать его на сервер в корень через программу FileZilla.
Настройка команд
Выделю четыре основные команды:
- User-agent: показывает правила для разных поисковых роботов, либо для всех, либо для отдельных
- Disalow: запрещает доступ
- Allow: разрешаем доступ
- Sitemap: адрес до XML карты
Устаревшие и ненужные конфигурации:
- Host: указывает главное зеркало, стало не нужным, потому что поиск сам определит правильный вариант
- Crawl-delay: ограничивает время на пребывание робота на странице, сейчас сервера мощные и беспокоится о производительности не нужно
- Clean-param: ограничивает загрузку дублирующегося контента, прописать можно, но толку не будет, поисковик проиндексирует все, что есть на сайте и возьмет по–максимому страниц
Рабочий пример инструкций для WordPress
Дело в том что поисковой робот не любит запрещающие директивы, и все равно возьмет в оборот, что ему нужно. Запрет на индексацию должен быть объектов, которые 100% не должны быть в поиске и в базе Яндекса и Гугла. Данный рабочий пример кода помещаем в robots txt.
Запрет на индексацию должен быть объектов, которые 100% не должны быть в поиске и в базе Яндекса и Гугла. Данный рабочий пример кода помещаем в robots txt.
User-agent: * Disallow: /wp- Disallow: /tag/ Disallow: */trackback Disallow: */page Disallow: /author/* Disallow: /template.html Disallow: /readme.html Disallow: *?replytocom Allow: */uploads Allow: *.js Allow: *.css Allow: *.png Allow: *.gif Allow: *.jpg Sitemap: https://ваш домен/sitemap.xml
Разберемся с текстом и посмотрим что именно мы разрешили, а что запретили:
- User-agent, поставили знак *, тем самым сообщив что все поисковые машины должны подчиняться правилам
- Блок с Disallow запрещает к индексу все технические страницы и дубли. обратите внимание что я заблокировал папки начинающиеся на wp-
- Блок Allow разрешает сканировать скрипты, картинки и css файлы, это необходимо для правильного представления проекта в поиске иначе вы получите портянку без оформления
- Sitemap: показывает путь до XML карты сайта, обязательно нужно ее сделать, а так же заменить надпись»ваш домен»
Остальные директивы рекомендую не вносить, после сохранения и внесения правок, загружаем стандартный robots txt в корень WordPress.
Как проверить работу robots.txt
Стандартный способ проверить через сервис yandex webmaster. Для лучшего анализа нужно зарегистрировать и установить на сайт сервис. Вверху видим загрузившийся robots, нажимаем проверить.
Проверка документа в yandexНиже появится блок с ошибками, если их нет то переходим к следующему шагу, если неверно отображается команда, то исправляем и снова проверяем.
Отсутствие ошибок в валидатореПроверим правильно ли Яндекс обрабатывает команды, спускаемся чуть ниже, введем два запрещенных и разрешенных адреса, не забываем нажать проверить. На снимке видим что инструкция сработала, красным помечено что вход запрещен, а зеленой галочкой, что индексирование записей разрешена.
Проверка папок и страниц в яндексеПроверили, все срабатывает, перейдем к следующему способу это настройка robots с помощью плагинов. Если процесс не понятен, то смотрите наше видео.
Если процесс не понятен, то смотрите наше видео.
Плагин–генератор Virtual Robots.txt
Если не хочется связываться с FTP подключением, то приходит на помощь один отличный WordPress плагин–генератор называется Virtual Robots.txt. Устанавливаем стандартно из админки вордпресс поиском или загрузкой архива, выглядит так.
Как выглядит Virtual Robots.txtПереходим в админку Настройки > Virtual Robots.txt, видим знакомую конфигурацию, но нам нужно ее заменить, на нашу из статьи. Копируем и вставляем, не забываем сохранять.
Настройка Virtual Robots.txtРоботс автоматически создастся и станет доступен по тому же адресу. При желании проверить есть он в файлах WordPress – ничего не увидим, потому что документ виртуальный и редактировать можно только из плагина, но Yandex и Google он будет виден.
Добавить с помощью Yoast SEO
Знаменитый плагин Yoast SEO предоставляет возможность добавить и изменить robots.txt из панели WordPress. Причем созданный файл появляется на сервере (а не виртуально) и находится в корне сайта, то есть после удаления или деактивации роботс остается. Переходим в Инструменты > Редактор.
Yoast SEO редактор файловЕсли robots есть, то отобразится на странице, если нет есть кнопка «создать», нажимаем на нее.
Кнопка создания robotsВыйдет текстовая область, записываем, имеющийся текст из универсальной конфигурации и сохраняем. Можно проверить по FTP соединению документ появится.
Изменить модулем в All in One SEO
Старый плагин All in One SEO умеет изменять robots txt, чтобы активировать возможность переходим в раздел модули и находим одноименный пункт, нажимаем Activate.
Модули в All In one SeoВ меню All in One SEO появится новый раздел, заходим, видим функционал конструктора.
Работа в модуле AIOS- Записываем имя агента, в нашем случае * или оставляем пустым
- Разрешаем или запрещаем индексацию
- Директория или страница куда не нужно идти
- Результат
Модуль не удобный, создать по такому принципу валидный и корректный robots. txt трудно. Лучше используйте другие инструменты.
txt трудно. Лучше используйте другие инструменты.
Правильная настройка для плагина WooCommerce
Чтобы сделать правильную настройку для плагина интернет магазина на WordPress WooCommerce, добавьте эти строки к остальным:
Disallow: /cart/ Disallow: /checkout/ Disallow: /*add-to-cart=* Disallow: /my-account/
Делаем аналогичные действия и загружаем на сервер через FTP или плагином.
Итог
Подведем итог что нужно сделать чтобы на сайте WordPress был корректный файл для поисковиков:
- Создаем вручную или с помощью плагина файл
- Записываем в него инструкции из статьи
- Загружаем на сервер
- Проверяем в валидаторе Yandex
- Не пользуйтесь генераторами robots txt в интернете, пошевелите немного руками
Совершенствуйте свои блоги на WordPress, продвигайтесь и правильно настраивайте все параметры, а мы в этом поможем, успехов!
Пожалуйста, оцените материал:
WP Robots Txt — плагин WordPress
- Детали
- отзывов
- Монтаж
- Развитие
Опора
WordPress по умолчанию включает простой файл robots. txt, который динамически генерируется в приложении WP. Отлично! но, возможно, вы хотите изменить содержание.
txt, который динамически генерируется в приложении WP. Отлично! но, возможно, вы хотите изменить содержание.
Войдите в WP Robots Txt, плагин, который добавляет дополнительное поле на страницу администратора «Чтение», где вы можете сделать именно это.
Просто посетите https://your-site.com/wp-admin/options-reading.php, и вы сможете управлять содержимым своего https://your-site.com/robots.txt
Журнал изменений
WP Robots Txt изначально был разработан chrisguitarguy. Плагин был принят и обновлен Джорджем Паттихисом, который продолжит разработку.
- Просмотр опции администратора
- Скачать плагин
- Разархивировать
- Загрузить разархивированную папку на
wp-content/pluginsкаталог - Активируйте и наслаждайтесь!
Или вы можете просто установить его через установщик плагинов в админке.
Я полностью испортил свой файл robots.txt. Как я могу восстановить версию по умолчанию?
Удалите все содержимое из поля Robots.
 txt Content и сохраните параметры конфиденциальности.
txt Content и сохраните параметры конфиденциальности.Могу ли я этим случайно заблокировать всех поисковых ботов?
Да. Будь осторожен! Тем не менее,
файлов robots.txtявляются рекомендациями. На самом деле они не столько блокируют ботов, сколько предлагают , что боты не сканируют части сайта. Вот почему параметры на странице настроек конфиденциальности говорят: «Попросить поисковые системы не индексировать этот сайт».Где я могу узнать больше о файлах robots.txt?
Вот общее руководство от Google, а вот SEO-документация WordPress.
Изменить настройки плагина
Мне понадобилось около недели, чтобы заметить это. Посещаемость сайта упала на 600%. Спасибо!
Хороший код, приятный интерфейс.
В нем нет встроенной функции динамической замены (например, {siteurl}/sitemap_index.xml), но его можно добавить с помощью простого фильтра. Спасибо за отличный плагин!
Спасибо за отличный плагин!
Простой плагин, который помог мне исправить ошибку js. проблема в поиске гугл
Я использую этот плагин для решения проблемы с файлом robots.txt. Это очень полезный плагин. http://www.gemstonesprices.in Аметистовый камень
Прочитать 17 отзывов
«WP Robots Txt» — это программное обеспечение с открытым исходным кодом. Следующие люди внесли свой вклад в этот плагин.
Авторы
- Крисгитаргай
- Джордж Паттихис
1.2
- Обновить содержимое robots.txt по умолчанию
- Включить ссылку на карту сайта
- Код устранения предупреждений/ошибок
- Соответствие стандартам кодирования WP
- Обеспечьте совместимость с WP v6
1.1
- Поле настроек перенесено «официально» на страницу чтения
- Очистка общего кода
1.0
- Первоначальная версия
Служба поддержки
Проблемы, решенные за последние два месяца:
1 из 1
Посмотреть форум поддержки
Пожертвовать
Хотите поддержать продвижение этого плагина?
Пожертвовать этому плагину
Ideal WordPress Robots.
 txt Пример [2019]
txt Пример [2019]WordPress
Файл Robots.txt находится в корневом каталоге вашего сайта. Например, на веб-сайте www.example.com адрес файла robots.txt будет выглядеть как https://www.shoutmecrunch.com/ robots.txt и должен быть доступен по этому адресу. Он представляет собой типичный текстовый файл, соответствующий стандарту исключений для роботов, и включает одно или несколько правил, каждое из которых запрещает или разрешает тому или иному веб-роботу доступ к заданному пути на сайте.
Идеальный формат кодирования
Файл предлагает веб-роботам рекомендации относительно того, какие страницы/файлы следует сканировать. Он работает в кодировке UTF-8 , и если он должен содержать символы какой-либо другой кодировки, веб-роботы могут обработать их неправильно. Правила, перечисленные в файле robots.txt, действительны в отношении хоста, протокола и номера порта, на которых находятся данные.
С индексом или без индекса
Эта опция позволяет установить ограничение на количество запросов, которые получает ваш веб-сервер, и снизить нагрузку.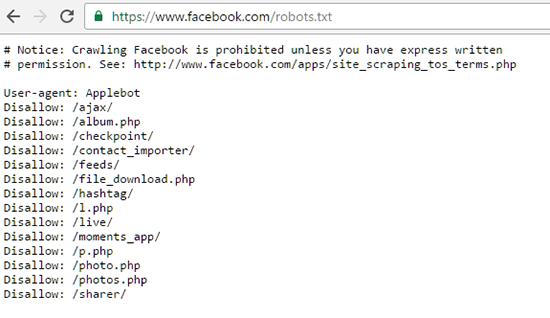 Он не предназначен для запрета показов страниц в результатах Google. Если вы не хотите, чтобы некоторые из ваших материалов с вашего сайта были в Google, используйте теги или директивы без индекса. Также вы можете создавать разделы сайта, зашифрованные паролем.
Он не предназначен для запрета показов страниц в результатах Google. Если вы не хотите, чтобы некоторые из ваших материалов с вашего сайта были в Google, используйте теги или директивы без индекса. Также вы можете создавать разделы сайта, зашифрованные паролем.
В Интернете можно найти множество публикаций на тему того, как создать более качественный (или даже самый лучший) файл robots.txt для WordPress. В то же время в некоторых таких популярных статьях многие правила не объясняются и, как мне кажется, плохо понимаются самими авторами. Единственный обзор, который я нашел, который заслуживает внимания, — это статья в блоге wp-kama.
Читать: Штраф Google – Как проверить?
Однако там я нашел не совсем правильные рекомендации. Понятно, что у каждого сайта будут свои нюансы при составлении файл robots.txt . Однако есть много характерных моментов для совершенно разных сайтов, которые могут быть положены в основу. Robots.txt, опубликованный в этой статье, можно напрямую скопировать и вставить на новый сайт, а затем доработать в соответствии с его нюансами.
Robots.txt, опубликованный в этой статье, можно напрямую скопировать и вставить на новый сайт, а затем доработать в соответствии с его нюансами.
Подробнее о составлении robots.txt и значении всех его директив я писал здесь. Ниже я не буду подробно останавливаться на назначении каждого правила. Ограничусь кратким комментарием, что для чего нужно.
Причина существования robots.txt
Например, иногда robots.txt не должен посещать
- Страницы с личной информацией пользователя;
- Страницы с разными формами выгрузки материалов;
- Скребковые площадки;
- Страницы с результатами поиска.
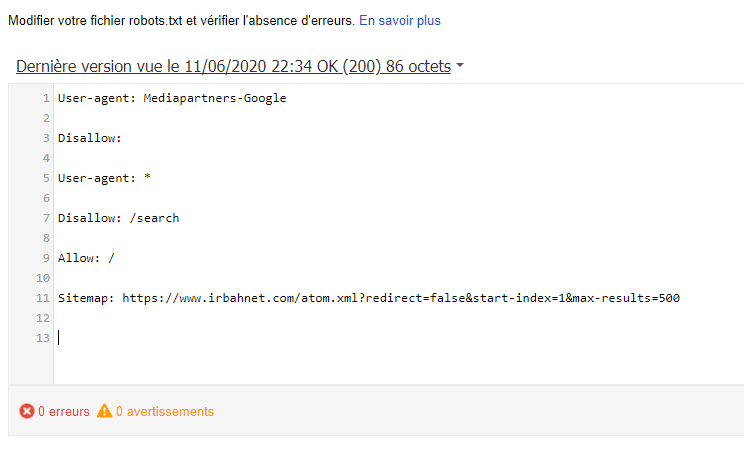
Правильный файл robots.txt для WordPress
лучший файл robots.txt , который я видел, это robots, предложенный в блоге wp-kama. Возьму некоторые директивы и замечания из его образца + внесу свои коррективы. Корректировки коснутся нескольких правил, о чем пишу ниже. Кроме того, мы напишем индивидуальные правила для всех роботов, для Google.
Есть короткие и расширенные версии. Короткая версия не включает отдельные блоки для Google. Расширенный уже менее актуален, потому что сейчас между двумя основными поисковиками нет принципиальных особенностей: обе системы должны индексировать файлы скриптов и изображений, обе не поддерживают директиву Host. Однако, если в этом мире снова что-то изменится, или вам все-таки нужно будет отдельно управлять индексацией данных на сайте Google, я тоже сохраню в этой статье второй вариант.
Еще раз отмечу, что это базовый файл robots.txt. В каждом случае нужно смотреть на реальный сайт и при необходимости вносить коррективы. Доверьте это дело опытным специалистам!
Ошибки, допущенные другими блоггерами для Robots.txt на WordPress
- Использовать правила только для User-agent: , для менее значимых роботов можно настроить более высокое значение Crawl-Delay и снизить нагрузку на сайт за их счет.
- Назначение Sitemap после каждого User-agent
Не обязательно.
 Одна карта сайта должна быть указана один раз в любом месте файла robots.txt.
Одна карта сайта должна быть указана один раз в любом месте файла robots.txt.- Закройте папки wp-content, wp-includes, cache, plugins, themes
Это устаревшие требования. Впрочем, такой совет я нашел даже в статье с грандиозной риторикой «Правильные роботы для WordPress 2018»! Для Google было бы лучше их вообще не закрывать. Как вариант, закрыть «умно», как описано выше.
Читайте: Ускорьте работу WordPress с помощью 11 проверенных советов по оптимизации [2019]
- Закройте теги и страницы категорий
особой ценности в них нет, лучше закрыть. Однако зачастую продвижение ресурса осуществляется в том числе и через страницы категорий и тэгов. В этом случае вы можете потерять часть трафика.
- Закрыть пагинацию страниц/страниц/от индексации
Не нужно. Для таких страниц настраивается тег rel=»canonical»; таким образом, на такие страницы заходили роботы, и они учитывают позиционируемые товары/статьи, а также внутреннюю ссылочную массу.
