Правильный robots.txt для WordPress
О том, как сделать правильный robots.txt для WordPress написано уже достаточно. Однако, чтобы угодить своим читателям, я решил опубликовать свой пост на эту тему. Тем более, что моими коллегами эта тема раскрыта не полностью и тут можно многое добавить.
Что такое robots.txt и зачем он нужен?
robots.txt это текстовый документ, составленный в обыкновенном блокноте, расположенный в корневой директории блога и содержащий в себе инструкции по индексации для поисковых роботов. Проще говоря, что индексировать, а что нет. Наличие этого файла является обязательным условием для качественной внутренней поисковой оптимизации блога.
Как известно, блоги на платформе WordPress содержат в себе множество дублей (копий основного содержимого блога), а также целый набор служебных файлов. Дубли контента снижают его уникальность на домене и поисковые роботы могут наложить на блог серьезные штрафные санкции.
Чтобы повысить уникальность контента, облегчить поисковым ботам работу и тем самым улучшить качество индексации блога, нам и нужен robots. txt.
txt.
Правильный robots.txt для WordPress
Рассмотрим на примере моего robots.txt, как его правильно оформить и что в него должно входить.
Скачайте его себе на жесткий диск по этой ссылке и откройте для редактирования. В качестве редактора текстовых файлов настоятельно рекомендую использовать Notepad++.
Строки 6,7: Принято считать, что необходимо закрывать поисковым роботам доступ к служебным файлам в папках «wp-content» и «wp-includes». Но, Гугл по этому поводу нам говорит следующее:
Чтобы обеспечить правильное индексирование и отображение страниц, нужно предоставить роботу Googlebot доступ к JavaScript, CSS и графическим файлам на сайте. Робот Googlebot должен видеть ваш сайт как обычный пользователь. Если в файле robots.txt закрыт доступ к этим ресурсам, то Google не удастся правильно проанализировать и проиндексировать содержание. Это может ухудшить позиции вашего сайта в Поиске.
Таким образом, для Googlebot не рекомендуется запрещать доступ к файлам в этих папках.
Строка 40: С весны 2018 года директива «Host«, указывающая главное зеркало сайта Яндексу, больше не действует. Главное зеркало для нашей поисковой системы теперь определяется только через 301 редирект.
Строки 42,43: Если у Вас еще не создана карта сайта, обязательно сделайте ее. В пути к файлам карты вместо моего адреса wordpress-book.ru пропишите свой. Этот ход сделает индексацию блога поисковиками полной и увеличит ее скорость.
Уже сейчас, можно сказать, что ваш правильный robots.txt для WordPress готов. В таком виде он подойдет для абсолютного большинства блогов и сайтов. Останется только закачать его в корень блога (обычно в папку public_html).
Сделать robots.txt для блога можно и с помощью плагина, например, PC Robots.txt. С его помощью вы сможете создать и редактировать свой robots.txt прямо в админке блога. Но я не советую использовать плагины для создания robots.txt, чтобы исключить лишнюю нагрузку на блог.
Содержание robots. txt любого блога или сайта, если он конечно есть, вы всегда можете посмотреть. Для этого достаточно в адресной строке браузера ввести к нему путь – https://wordpress-book.ru/robots.txt.
txt любого блога или сайта, если он конечно есть, вы всегда можете посмотреть. Для этого достаточно в адресной строке браузера ввести к нему путь – https://wordpress-book.ru/robots.txt.
Ниже приведена информация по содержанию этого документа и некоторые рекомендации по его оформлению и анализу.
Звездочка «*«, прописанная в тексте robots.txt, означает, что на ее месте допускается последовательность любых символов.
Директива «User-agent» определяет, для каких поисковых роботов даны указания по индексации, прописанные под ней. Таким образом, «User-agent: *» (строка 1) указывает, что инструкции, прописанные под ней, предназначены для всех поисковых систем.
Строка 21: Персонально для Яндекса под «User-agent: Yandex» дублируем список этих команд. Дублирование инструкций для Яндекса дает нам гарантию их выполнения поисковой системой.
Директива «Disallow» запрещает индексацию прописанного для нее каталога или страниц. Директива «Allow» разрешает. Командой «Disallow: /wp-content/» (строка 7) я запретил индексацию служебного каталога «wp-content» на сервере и соответственно всех папок в ней с их содержимым, но командой «Allow: /wp-content/uploads» (строка 8) разрешил индексировать все картинки в папке «upload» каталога «wp-content«.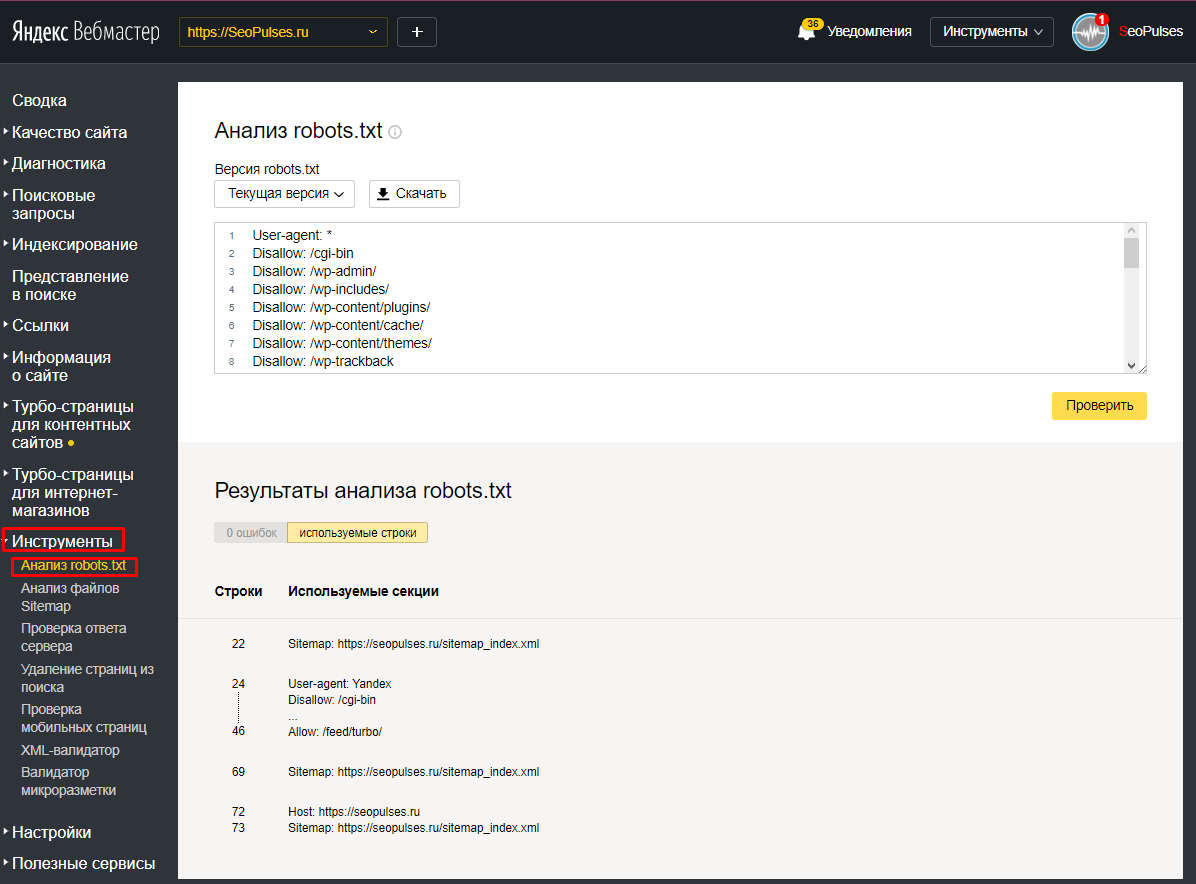 Так как «Allow» является приоритетной директивой для поисковых роботов, то в индекс попадут только изображения папки «upload» каталога «wp-content«.
Так как «Allow» является приоритетной директивой для поисковых роботов, то в индекс попадут только изображения папки «upload» каталога «wp-content«.
Для директивы «Disallow» имеет смысл в некоторых случаях дополнительно прописывать следующие запреты:
- — /amp/ — дубли ускоренных мобильных страниц. На всякий случай для Яндекса.
- — /comments — закрыть от индексации комментарии. Зачем закрывать содержащийся в комментариях уникальный контент? Для большей релевантности ключевых слов и неиндексации исходящих ссылок в комментариях. Вряд ли это поможет.
- — /comment-page-* — другое дело древовидные комментарии. Когда комментарии не помещаются на одну страницу (их количество вы проставили в настройках админки), создается дубль страницы типа wordpress-book.ru/…/comment-page-1. Эти дубли конечно же надо закрывать.
- — /xmlrpc.php — служебный файл для удаленных вызовов. У меня его нет и соответственно нет индексации и без запрета.
- — /webstat/ — папка со статистикой сайта.
 Эта папка есть тоже далеко не у всех.
Эта папка есть тоже далеко не у всех.
Нельзя не упомянуть про редко используемую, но очень полезную директиву для Яндекса — «Crawl-delay». Она задает роботу паузу во времени в секундах между скачиванием страниц, прописывается после групп директив «Disallow» и «Allow» и используется в случае повышенной нагрузки на сервер. Прописью «Crawl-delay: 2″ я задал эту паузу в 2 секунды. При нормальной работе сервера качество индексации не пострадает, а при пиковых нагрузках не ухудшится.
Некоторым веб-мастерам может понадобится запретить индексацию файлов определенного типа, например, с расширением pdf. Для этого пропишите — «Disallow: *.pdf$«. Или поместите все файлы, индексацию которых требуется запретить, в предварительно созданную новую папку, например, pdf, и пропишите «Disallow: /pdf/«.
При необходимости запрета индексации всей рубрики, такое бывает ,например, при публикации в нее чужих интересных записей, пропишите — «Disallow: /nazvanie-rubriki/*«, где «nazvanie-rubriki», как вы уже догадались — название рубрики, записи которой поисковикам индексировать не следует.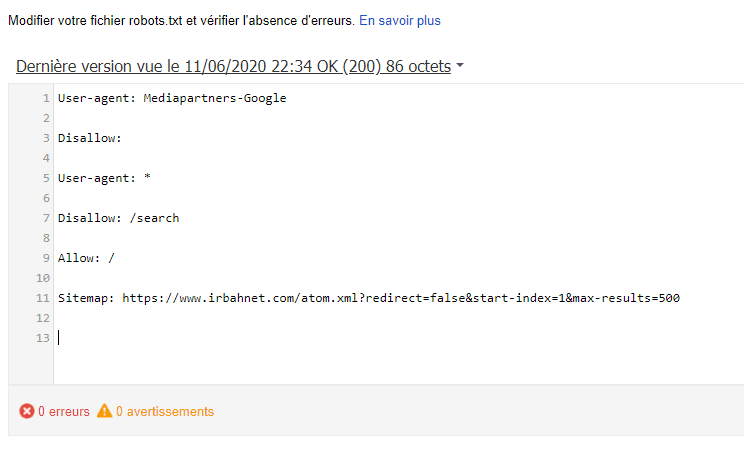
Тем, кто зарабатывает на своем блоге размещением контекстной рекламы в партнерстве с Google AdSense, будет нелишним прописать следующие две директивы:
User-agent: Mediapartners-Google
Disallow:
Это поможет роботу AdSense избежать ошибок сканирования страниц сайта и подбирать для них более релевантные объявления.
wp-content/uploads/2014/02/YouTube_Downloader_dlya_Ope.jpg»,tid: «OIP.M3a4a31010ee6a500049754479585407do0
Обнаружил у себя только что вот такой вот новый вид дублей в Яндекс Вебмастере. 96 штук уже накопилось и это не предел. А ведь совсем недавно у wordpress-book.ru с дублями был полный порядок. Есть подозрение, что шлак с идентификатором tid:»OIP появляется в индексе поисковика после скачивания картинок роботом Яндекса. Если не лень, посмотрите сколько таких несуществующих страниц разных сайтов уже участвуют в поиске.
Понятно, что с этим чудом надо что-то делать. Достаточно добавить запрещающую директиву — «Disallow: /wp-content/uploads/*. jpg*tid*» в robots.txt. Если на сайте есть картинки png, gif и т.д., добавьте директивы с соответствующими расширениями изображений.
jpg*tid*» в robots.txt. Если на сайте есть картинки png, gif и т.д., добавьте директивы с соответствующими расширениями изображений.
При редактировании robots.txt, учтите, что:
— перед каждой новой директивой «User-agent» должна быть пустая строка, которая обозначает конец инструкций для предыдущего поисковика. И соответственно после «User-agent» и между «Disallow» и «Allow» пустых строк быть не должно;
— запретом индексации страниц в результатах поиска «Disallow: /*?*» вы заодно можете случайно запретить индексацию всего контента, если адреса страниц вашего блога заданы по умолчанию со знаком вопроса в виде — /?p=123. Советую сделать для адресов ЧПУ (человеко понятные урлы :-)). Для этого в настройках постоянных ссылок выберите произвольный шаблон и поставьте плагин Rus-to-Lat.
Анализ robots.txt
Теперь, когда ваш robots.txt отредактирован и залит на сервер, остается только проверить, правильно ли он работает.
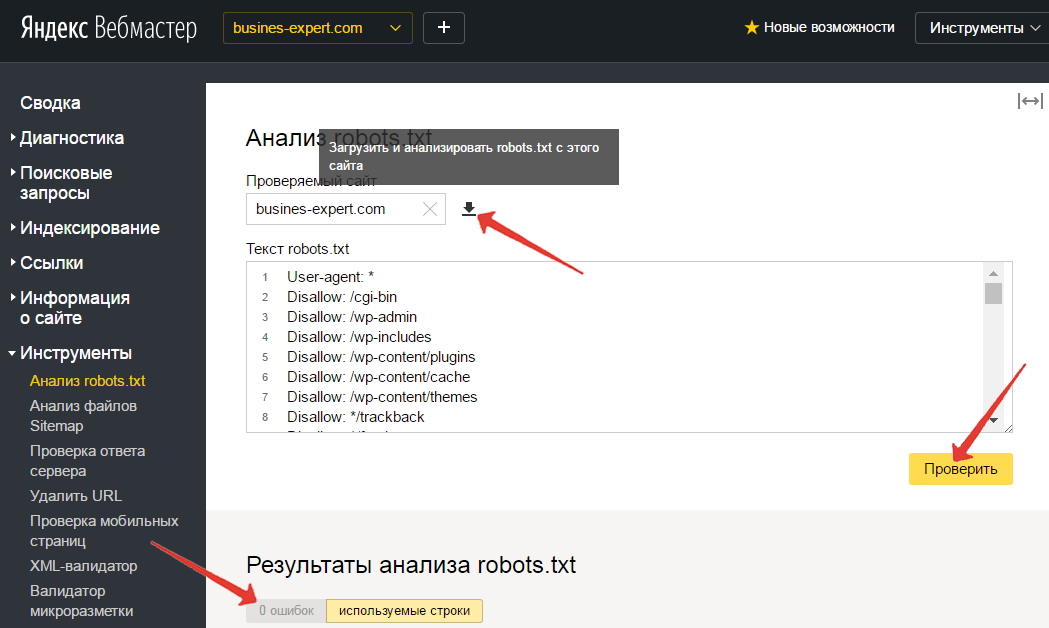
Зайдите в свой аккаунт Яндекс Вебмастер и перейдите «Настройки индексирования» → «Анализ robots. txt«. Нажмите на кнопку «Загрузить robots.txt с сайта» и далее на кнопку «Проверить«.
txt«. Нажмите на кнопку «Загрузить robots.txt с сайта» и далее на кнопку «Проверить«.
Если Яндексу понравится ваш файл, под кнопкой «Проверить» появится сообщение, примерно как на картинке выше.
Недавно в инструментах для веб-мастеров Гугла появилось очень полезная функция — «Инструмент проверки файла robots.txt«. Можно проверить свой файл на наличие ошибок и предупреждений.
Просто в своем аккаунте перейдите «Сканирование» → «Инструмент проверки файла robots.txt«.
Через некоторое время, когда бот Яндекса скачает ваш robots.txt, проанализируйте в Яндекс Вебмастере адреса страниц вошедших в индекс и исключенных из него в robots.txt. Вошедшие в индекс дубли срочно запрещайте к индексации.
Теперь ваш robots.txt для WordPress правильный и можно поставить еще одну галочку под пунктом выполнения задач по внутренней поисковой оптимизации блога.
robots.txt запретить индексацию всем
При создании тестового блога или при самом его рождении, если вы хотите полностью запретить индексацию сайта всеми поисковыми системами, в robots. txt должно быть прописано всего лишь следующее:
txt должно быть прописано всего лишь следующее:
User-agent: *
Disallow: /
Хороший человек всегда нажмет на кнопку!
Комментарий > Моя благодарность > Ссылка на секретную страницу блога
Правильный robots.txt для wordpress: Яндекс и Google
от Виктор
Привет, читатель блога GuideComputer! У меня хорошая новость, я наконец-то разобрался как правильно составить robots.txt. Всех заинтересованных прошу незамедлительно пройти к чтению статьи:
Начну с того, что лет 7 назад я создавал сайты на Ucoz, а затем на Joomla. В поисковой выдаче всегда творился ад — дубли, дубли и служебные страницы… Позже я узнал, можно говорить поисковикам, что нужно индексировать и добавлять в поисковую выдачу, а что нельзя с помощью robots. txt.
txt.
Содержание:
Что такое robots.txt?Роботс (на русский манер) — это текстовый файл, дающий рекомендации поисковым роботам : какие страницы/файлы стоит сканировать.
Где лежит robots.txt в wordpress?Находится файл в корневой папке сайта и располагается по адресу site.ru/robots.txt. Кстати, таким образом вы можете посмотреть роботс не только моего веб-ресураса, но и любого другого.
Сейчас я покажу пример правильного robots.txt для сайта на WordPress:
Строки выше необходимо скопировать, вставить в текстовый документ, сохранить с именем robots.txt и загрузить в корневую папку сайта. К сожалению, из-за популярности кода, мне пришлось его вставить в виде картинки, иначе уникальность статьи падает до 45%.
Не расстраивайтесь, что вам придется переписывать вручную, я приготовил файл, в котором нужно поменять всего две строчки. Написать название своего ресурса и расположение карты sitemap. xml — Загрузить robots.txt.
xml — Загрузить robots.txt.
Для тех, кому вышесказанное показалось сложным существует более простое решение! Если на вашем сайте установлен плагин Yoast Seo, то существует возможность создать robots.txt прямо из админ панели WordPress. Показываю как:
Заходим в настройки плагина, открываем вкладку инструменты:
Открываем редактор файлов.
Вставляем код, который вы загрузили выше, и не забываем сохранить!
Ниже находится файл .htaccess — без знаний что это такое советую туда не лезть. С этим файлом нужно обращаться очень осторожно, потому что изменения могут привести к ошибкам, в следствии которых сайт может перестать загружаться.
Синтаксис
Особо не стоит заморачиваться над синтаксисом файла, поэтому я расскажу лишь об основных частях кода.
User-agent: — данное выражение отвечает для каких поисковых роботов будут применяться правила. Например, * — обозначается для всех, Yandex — для Яндекса, Googlebot — для Гугл робота.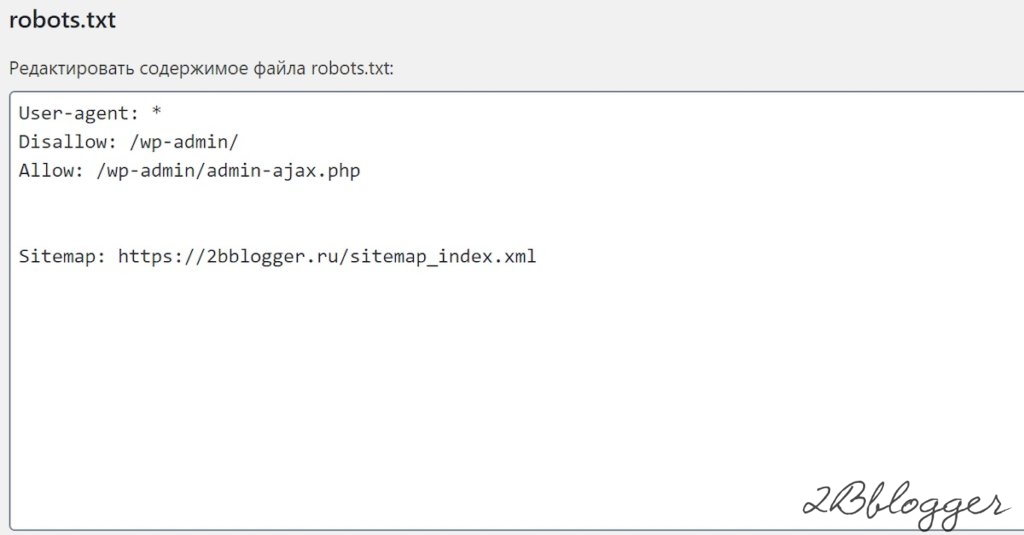
Disallow — выражение, отвечает за запрет индексирования разделов. Если вы не хотите дублей или технических страниц в поиске, то таким образом можете запретить доступ. Например, вот таким образом Disallow: /tag я не разрешаю индексирование тегов.
Host — данное выражение отвечает за главное зеркало сайта. Учтите, что http, https, www и без — это 4 разных варианта. Необходимо выбрать только один и именно его прописать в роботс.
Sitemap — данное выражение задает адрес по которому располагается карта сайта. На моем веб-ресурсе она создана автоматически с помощью плагина Yoast Seo.
Впервые слышишь о карте сайта? — Читай, что такое sitemap и как его создать для wordpress.
Проблемы без ЧПУ
Я уже рассказывал о важности настройки ЧПУ WordPress для сайта. Этот раздел посвящен тем, кто проигнорировал мои рекомендации:
Без ЧПУ ссылки сайта выглядят следующим образом — guidecomputer.ru/?p=123. Строчка Disallow: /*?* запрещает индексирование статей, поэтому её необходимо удалить. Для невнимательных, в коде выше она встречается 2 раза.
Строчка Disallow: /*?* запрещает индексирование статей, поэтому её необходимо удалить. Для невнимательных, в коде выше она встречается 2 раза.
Проверка robots.txt
Чтобы проверить правильность составленного файла — необходимо провести анализ. Для этого существуют два наиболее популярных инструмента:
Проверка robots.txt в Яндекс вебмастере или с помощью инструментов Google. ( Если вы еще не зарегистрировались в сервисах для Вебмастеров — советую это сделать незамедлительно. )
Я покажу как воспользоваться обеими вариантами, выбирайте сами какой больше нравиться. А еще лучше воспользуйтесь каждым, тем более это не займет больше пары минут.
Проверка с помощью Яндекс Вебмастера
Заходим в инструменты в левом меню, и выбираем первый пункт Анализ robots.txt:
Добавляем ссылку на проверяемый сайт, нажимаем кнопку загрузки, а затем проверить.
Немного ждем и смотрим Результаты анализа, в моем случае 0 ошибок.
Проверка с помощью Search Console
Заходим в Сканирование, выбираем раздел инструменты проверки файла:
Вставляем robots.txt и кликаем отправить.
В 3-ем пункте выбираем отправить и смотрим на количество ошибок.
Заключение
Не стоит откладывать с применением вышесказанного: настройка robots.txt — это одно из важнейших первичных действий при создании веб-ресурса. Значительность которого можно сравнить с дверями вашего дома, которые оберегают от непрошеных гостей и обеспечивает безопасность.
После того, как построен каркас дома ставят двери. Так же должно происходить с сайтом — покупка домена и хостинга, установка CMS WordPress, а затем роботс.
Надеюсь, что раскрыл все моменты связанные с правильной настройкой файла robots.txt для wordpress. Но если у вас остались вопросы, с удовольствием отвечу — Добро пожаловать в комментарии!
Понравилась статья? Поделись с друзьями:
Оптимизировать WordPress Robots.
 txt — запретить прямой доступ заголовок страницы. Ваш файл robots.txt блокирует сканирование, но не обязательно индексирование, за исключением файлов веб-сайтов, таких как изображения и документы. Поисковые системы по-прежнему могут индексировать ваши «запрещенные» страницы, если на них есть ссылки из других источников.
txt — запретить прямой доступ заголовок страницы. Ваш файл robots.txt блокирует сканирование, но не обязательно индексирование, за исключением файлов веб-сайтов, таких как изображения и документы. Поисковые системы по-прежнему могут индексировать ваши «запрещенные» страницы, если на них есть ссылки из других источников. So Prevent Direct Access Gold больше не использует правила robots.txt Disallow для блокировки страниц вашего веб-сайта от индексации в поиске. Вместо этого мы используем метатег noindex , который также помогает Google и другим поисковым системам правильно распределять значение входящих ссылок для вашего контента на вашем веб-сайте.
Что включить в файл robots.txt WordPress?
Yoast рекомендует содержать файл robots.txt в чистоте и ничего не блокировать, включая любое из следующего:
Агент пользователя: *
Запретить: /wp-admin/
Разрешить: /wp-admin/admin-ajax.php
Запретить: /wp-content/plugins/
Запретить: /wp-includes/
WordPress также соглашается с тем, что идеальный файл robots. txt вообще ничего не должен запрещать. На самом деле каталоги
txt вообще ничего не должен запрещать. На самом деле каталоги /wp-content/plugins/ и /wp-includes/ содержат изображения, файлы JavaScript или CSS, которые, вероятно, используются вашими темами и плагинами для правильного отображения вашего веб-сайта. Блокировка этих каталогов означает, что все скрипты, стили и изображения поставляются с вашими плагинами, а WordPress блокируется, а Google и другим поисковым роботам становится сложнее анализировать и понимать содержимое вашего веб-сайта. Точно так же вы никогда не должны блокировать свои /wp-content/themes/ либо.
Короче говоря, запрет ваших ресурсов, загрузок и каталога плагинов WordPress, который, как многие утверждают, повышает безопасность вашего сайта от любого, кто использует уязвимые плагины для использования, вероятно, приносит больше вреда, чем пользы, особенно с точки зрения SEO. Вы не должны устанавливать эти плагины в первую очередь.
Вот почему мы по умолчанию удалили эти правила из файла robots. txt. Однако вы все равно можете включить их в наше расширение интеграции WordPress Robots.txt.
txt. Однако вы все равно можете включить их в наше расширение интеграции WordPress Robots.txt.
Карта сайта XML
Хотя Yoast также настоятельно рекомендует вручную отправлять карту сайта в формате XML непосредственно в консоль поиска Google и инструменты Bing для веб-мастеров, вы все же можете включить директиву карты сайта в файл robots.txt в качестве быстрой альтернативы, направляющей другие поисковые системы, где находится ваша карта сайта.
Карта сайта: http://preventdirectaccess.com/post-sitemap.xml Карта сайта: http://preventdirectaccess.com/page-sitemap.xml Карта сайта: http://preventdirectaccess.com/author-sitemap.xml Карта сайта: http://preventdirectaccess.com/offers-sitemap.xml
Заблокировать доступ к файлам Readme.html, licence.txt и wp-config-sample.php
В целях безопасности рекомендуется заблокировать доступ к файлам readme.html, licence.txt и wp-config-sample WordPress. php, чтобы неавторизованные люди не могли проверить и увидеть, какую версию WordPress вы используете.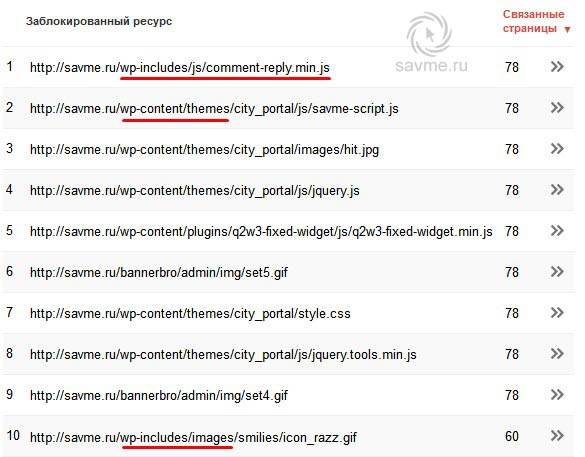
Агент пользователя: * Запретить: /readme.html Запретить: /licence.txt Запретить: /licence.txt
Вы также можете использовать robots.txt, чтобы запретить определенным ботам сканировать содержимое вашего веб-сайта или указать разные правила для разных типов ботов.
# запретить роботу Googlebot сканировать весь веб-сайт
Агент пользователя: Googlebot
Запретить: /
# заблокировать Bingbot от сканирования каталога ссылок
Агент пользователя: Bingbot
Disallow: /refer/ Вот как вы можете запретить ботам сканировать результаты поиска WordPress
User-agent: * Запретить: /?s= Disallow: /search/
Host & Crawl-delay — другие директивы robots.txt, которые вы можете использовать, хотя и менее популярные. Первая директива позволяет указать предпочтительный домен вашего веб-сайта (с www или без www):
Агент пользователя: * #мы предпочитаем домен без www host: preventdirectaccess.com
Последний сообщает жадным до сканирования ботам различных поисковых систем ждать несколько секунд перед каждым сканированием.
Агент пользователя: * #пожалуйста, подождите 8 секунд перед следующим сканированием crawl-delay: 8
Последнее обновление: 9 июня 2018 г.
WordPress Robots.Txt File Optimization Guide | by Visualmodo
5 минут чтения
·
Вы слышали о файле Robots.txt? Если вы знакомы с WordPress, возможно, вы знаете файл robots. Это имеет очень важное влияние на эффективность SEO вашего сайта. Хорошо оптимизированный файл Robots может улучшить рейтинг вашего сайта в поисковых системах. С другой стороны, неправильно настроенный файл Robots.txt может сильно повлиять на SEO вашего сайта.
WordPress автоматически создает файл Robots.txt для вашего веб-сайта. Но все же, вам нужно предпринять некоторые действия, чтобы правильно его оптимизировать. Есть так много других факторов для SEO, но этот файл неизбежен. Поскольку его редактирование предполагает использование некоторой строки кода, большинство владельцев веб-сайтов не решаются вносить в него изменения. Вам не о чем беспокоиться. Сегодняшняя статья посвящена его важности и тому, как оптимизировать файл robots WordPress для улучшения SEO. Прежде чем двигаться дальше, давайте узнаем некоторые фундаментальные вещи.
Есть так много других факторов для SEO, но этот файл неизбежен. Поскольку его редактирование предполагает использование некоторой строки кода, большинство владельцев веб-сайтов не решаются вносить в него изменения. Вам не о чем беспокоиться. Сегодняшняя статья посвящена его важности и тому, как оптимизировать файл robots WordPress для улучшения SEO. Прежде чем двигаться дальше, давайте узнаем некоторые фундаментальные вещи.
Robots.txt — это текстовый файл, который веб-мастера создают для того, чтобы проинструктировать веб-роботов (обычно роботов поисковых систем) о том, как сканировать страницы на их веб-сайте. Кроме того, файл robots.txt является частью протокола исключения роботов (REP), группы веб-стандартов, которые регулируют, как роботы сканируют Интернет, получают доступ и индексируют контент, а также предоставляют этот контент пользователям. REP также включает в себя такие директивы, как метароботы, а также инструкции для страницы, подкаталога или сайта о том, как поисковые системы должны обрабатывать ссылки (например, «follow» или «nofollow»).
Я уже говорил, что на каждом сайте WordPress есть файл robots.txt по умолчанию в корневом каталоге. Вы можете проверить файл robots.txt, перейдя по адресу http://yourdomain.com/robots.txt. Например, вы можете проверить наш файл robots.txt здесь: https://visualmodo.com/robots.txt
Если у вас нет файла robots, вам придется его создать. Это очень легко сделать. Просто создайте текстовый файл на своем компьютере и сохраните его как .txt. Наконец, загрузите его в корневой каталог. Вы можете загрузить его через FTP-менеджер или файловый менеджер cPanel.
Теперь давайте посмотрим, как отредактировать файл .txt. Вы можете редактировать файл robots с помощью FTP-менеджера или файлового менеджера cPanel. Однако это долго и немного сложно.
Лучший способ редактировать файл Robots — использовать подключаемый модуль. Существует несколько плагинов WordPress .txt. Я предпочитаю Yoast SEO. Это лучший SEO-плагин для WordPress. Я уже рассказывал, как настроить Yoast SEO.
Затем нажмите «Редактор файлов». после этого нужно нажать на «Создать файл robots.txt». Затем вы получите редактор файла Robots.txt. Здесь вы можете настроить файл robots. Прежде чем редактировать файл, вам нужно понять команды файла. В основном это три команды.
User-agent — определяет имя ботов поисковых систем, таких как Googlebot или Bingbot. Вы можете использовать звездочку (*) для обозначения всех ботов поисковых систем. Запретить — запрещает поисковым системам сканировать и индексировать некоторые части вашего сайта. Разрешить — указывает поисковым системам сканировать и индексировать, какие части вы хотите индексировать.
Вот пример файла Robots.txt.
User-agent: *
Disallow: /wp-admin/
Alow: /
Этот файл robots предписывает всем роботам поисковых систем сканировать сайт. Во второй строке он сообщает поисковым роботам не сканировать часть /wp-admin/. В 3-й строке он указывает ботам поисковых систем сканировать и индексировать весь веб-сайт.
Простая неправильная настройка в файле Robots может полностью деиндексировать ваш сайт в поисковых системах. Например, если вы используете команду «Запретить: /» в файле Robots, ваш сайт будет деиндексирован поисковыми системами. Так что нужно быть осторожным при настройке.
Еще одним важным моментом является оптимизация файла Robots.txt для SEO. Прежде чем перейти к лучшим практикам роботов SEO, я хотел бы предупредить вас о некоторых плохих практиках.
- Файл WordPress Robots для скрытия некачественного содержимого. Лучше всего использовать метатеги noindex и nofollow. Вы можете сделать это с помощью плагина Yoast SEO.
- Robots.txt, чтобы запретить поисковым системам индексировать ваши категории, теги, архивы, страницы авторов и т. д. Вы можете добавить на эти страницы метатеги nofollow и noindex с помощью плагина Yoast SEO.
- Используйте файл Robots.txt для обработки повторяющегося содержимого. Есть и другие способы.
Во-первых, вам нужно определить, какие части вашего сайта не должны сканироваться роботами поисковых систем. Я предпочитаю запрещать /wp-admin/, /wp-content/plugins/, /readme.html, /trackback/. Во-вторых, производные «Разрешить: /» в файле Robots не так важны, так как боты все равно будут сканировать ваш сайт. Но вы можете использовать его для конкретного бота. Добавление карты сайта в файл Robots также является хорошей практикой. Кроме того, прочитайте эту статью о картах сайта WordPress.
Вот пример идеального файла .txt для WordPress.
Агент пользователя: *
Запретить: /wp-admin/
Запретить: /readme.html
Разрешить: /wp-admin/admin-ajax.php
Запретить: /wp-content/plugins/
Разрешить: /wp-content/uploads/Запретить: /trackback/
Карта сайта: https://visualmodo.com/post-sitemap.xml
Запретить: /go/
Карта сайта: https://visualmodo.com/page -sitemap.xml
После обновления файла Robots.txt необходимо протестировать файл Robots.txt, чтобы проверить, не затронуто ли обновление какое-либо содержимое.
Вы можете использовать Google Search Console, чтобы проверить, есть ли какие-либо «Ошибки» или «Предупреждения» для вашего файла Robots. Просто войдите в Google Search Console и выберите сайт. Затем перейдите в Crawl > robots Test the er и нажмите кнопку «Отправить». Появится окно. Просто нажмите на кнопку «Отправить».
Наконец, перезагрузите страницу и проверьте, обновлен ли файл. Обновление файла robots может занять некоторое время. Если он еще не обновлен, вы можете ввести код файла Robots в поле, чтобы проверить наличие ошибок или предупреждений.