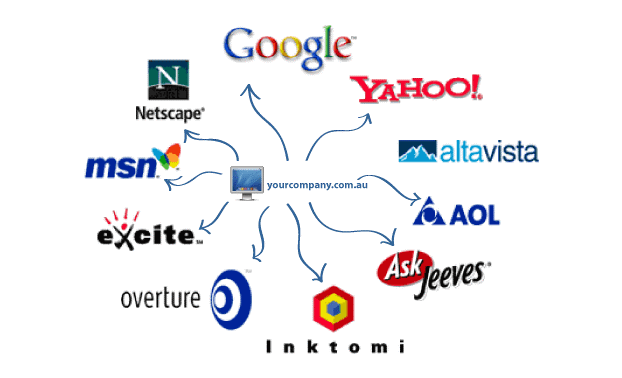
Какие поисковые системы вам известны ?… -reshimne.ru
Новые вопросы
Ответы
Yahoo-Поиск любой информации по WWW-серверам мира.
Alta Vista-Поиск любой информации по WWW-серверам мира.
Rambler-Поиск любой информации по русскоязычным серверам.
Яndex-Поиск любой информации по русскоязычным серверам.
FTP Search-Поиск файлов на ftp-серверах мира.
Похожие вопросы
Сть сетка 5×11. За одну секунду горит сторона квадратика (веревочка горит равномерно, то есть, за полсекунды сгорит половина стороны квадратика). Разрешается поджечь одновременно два узла сетки. Нужно поджечь такие узлы, чтобы время сгорания всей сетки было наименьшим возможным. Чему равно это наименьшее время? В качестве ответа укажите одно натура…
1) сообщение щаписанное буквами из 16 символов алфавита содержит 50 симаолов. Какой объем информаций оно несёт?
Какой объем информаций оно несёт?
2) сколько символов содержит сообщение, записанное с помощью алфавита, если его объем составляет 1/16 часть мегабайта. помогите пожалуйста…
Сколько будет 89÷3 и 18+89…
1. Заменить отрицательный эллемент нулем.
2. Дан массив целых чисел. Найти сумму элементов массива, больших данного числа А ( А вводить с клавиатуры).
3. Определить есть ли 2 пары соседних элементов с одинаковыми знаками. Паскаль….
Математика
Литература
Алгебра
Русский язык
Геометрия
Английский язык
Химия
Физика
Биология
Другие предметы
История
Окружающий мир
География
Українська мова
Українська література
Беларуская мова
Информатика
Экономика
Музыка
Французский язык
Немецкий язык
МХК
ОБЖ
Психология
Ответы Учебник Информатика 7 класс — §1.
 3.Всемирная паутина Босова ► Информатика в школе и дома1.Ознакомьтесь с материалом презентации к параграфу, содержащейся в электронном приложении к учебнику. Что вы можете сказать о формах представления информации в презентации и в учебнике? Какими слайдами вы могли бы дополнить презентацию?2. Выполните дословный перевод словосочетания «World Wide Web».
3.Всемирная паутина Босова ► Информатика в школе и дома1.Ознакомьтесь с материалом презентации к параграфу, содержащейся в электронном приложении к учебнику. Что вы можете сказать о формах представления информации в презентации и в учебнике? Какими слайдами вы могли бы дополнить презентацию?2. Выполните дословный перевод словосочетания «World Wide Web».Свободный доступ к информации, невзирая на границы и расстояния, стал возможен благодаря World Wide Web — всемирному информационному хранилищу, существующему на технической базе сети Интернет.
World Wide Web переводится как:
Всемирная паутина,
мировая паутина,
Всемирная сеть,
Всемирная сеть интернет.
Дословный перевод
World — мир
Wide — широкий
Web — сеть, интернет, веб
Всемирная широкая сеть
3. Опишите в общих чертах организацию WWW.Информация в WWW организована в виде страниц (Web-страниц). В свою очередь, страницы могут объединяться в более крупные составляющие — сайты (англ. «site» — место, участок). Web-сайт — это несколько Web-страниц, связанных между собой по содержанию.
В свою очередь, страницы могут объединяться в более крупные составляющие — сайты (англ. «site» — место, участок). Web-сайт — это несколько Web-страниц, связанных между собой по содержанию.
Каждый сайт и каждая страница имеют свой адрес, по которому к ним можно обратиться. Web-сайты сильно отличаются друг от друга по оформлению, но чаще всего они имеют похожую структуру.
Каждый Web-сайт имеет главную страницу, которая аналогична странице с оглавлением в книге. В текстах, размещённых на страницах сайтов, могут быть выделены ключевые слова — гиперссылки, от которых идут гиперсвязи. Они выделяются цветом или подчёркиванием. Щёлкнув мышью на таком слове, мы переходим к просмотру другого документа, причём этот документ может находиться на другом компьютере, в другой стране, на другом континенте. В качестве гиперссылок может использоваться не только текст, но и любое графическое изображение. Такую организацию информации называют гипертекстом.
Перемещаться пользователю по «паутине» помогают специальные программы (Web-браузеры, англ. «browse», «осматривать», «изучать»).
«browse», «осматривать», «изучать»).
На первый взгляд, Всемирную паутину можно представить как библиотеку, книги в которой расположены без видимого порядка: нет ни единой системы каталогов, ни библиотекарей. При этом посетители «библиотеки» по собственному усмотрению добавляют новые тома или безвозвратно забирают их. Для того чтобы извлечь полезную информацию из Всемирной паутины, нужно знать, где и как вести поиск, нужен опыт поисковой работы.
Таким образом. Организация WWW представляет собой множество информационных ресурсов, организованных в одно целое. Она объединяет многочисленные ресурсы по всему миру, а так же организована так, что информационные ресурсы снабжены гиперссылками.
4. Что обеспечивают гиперссылки в плане навигации по информационным ресурсам всемирной паутины? Какие элементы нелинейной навигации вы встречали в книгах, справочниках, словарях?Гиперссылки обеспечивают быстрый и удобный переход пользователя с одной страницы сайта на другую, а так же на другой сайт. Щёлкнув мышью на таком слове, мы переходим к просмотру другого документа, причём этот документ может находиться на другом компьютере, в другой стране, на другом континенте. В качестве гиперссылок может использоваться не только текст, но и любое графическое изображение.
Щёлкнув мышью на таком слове, мы переходим к просмотру другого документа, причём этот документ может находиться на другом компьютере, в другой стране, на другом континенте. В качестве гиперссылок может использоваться не только текст, но и любое графическое изображение.
Элементы нелинейной навигации в книгах, справочниках, словарях.
Содержание в книгах.
Алфавитный порядок в словарях и справочниках.
Глоссарий, предметный указатель, алфавитный указатель, гиперссылки (в электронных изданиях).
Ключевые слова к тексту параграфа:
WWW,
Всемирная паутина,
web-страница,
web-сайт,
браузер,
поисковая система,
поисковый запрос,
гиперссылки,
гипертекст,
логические связки.

Если знаете, то укажите адрес вашей школы.
http://www.kremlin.ru/ — Официальный сайт Президента Российской Федерации
http://e-parta.ru/ — «E-parta» — информационно-познавательный портал для детей и подростков «Блог школьного Всезнайки»
http://school-collection.edu.ru/ — Федеральное хранилище Единой коллекции цифровых образовательных ресурсов. Единая коллекция цифровых образовательных ресурсов.
7. Каким браузером вы пользуетесь в школе?Браузер — одна из важнейших программ на компьютере с выходом в интернет. Именно через нее мы получаем основной поток информации и проводим в ней большую часть времени.
В нашей школе мы используем браузер…
Google Chrome,
Yandex Browser,
Opera,
Mozilla Firefox,
Microsoft Edge,
Internet Explorer,
Amigo.
Самая быстрая и самая большая поисковая система. Содержит информацию более чем о полутора миллиардах страниц. Имеется возможность выбора языка. Оценивает популярность ресурса по количеству ссылок, ведущих к нему с других страниц.
Содержит информацию более чем о полутора миллиардах страниц. Имеется возможность выбора языка. Оценивает популярность ресурса по количеству ссылок, ведущих к нему с других страниц.
Яндекс
Мощная отечественная поисковая система. Обеспечивает поиск, в основном среди русскоязычных ресурсов, при этом по возможностям не уступает зарубежным системам. Проводит качественный анализ информации с учётом словоформ русского языка.
Rambler
Одна из первых русских поисковых систем. Кроме стандартных возможностей поиска на сайте имеется рейтинг-каталог ресурсов.
Yahoo!
За рубежом эта система обладает колоссальной популярностью. Она давно переведена на русский язык, но большой известности в Рунете так и не получила. Пользователям доступен разный поиск (по картинкам, видеороликам и т.д.).
Известная в Рунете компания, занимается развитием сразу в нескольких направлениях. Помимо собственного поисковика и популярнейшего сервиса почты, они являются владельцами таких проектов как Одноклассники и Вконтакте.
Спутник
Создавался как государственный ресурс в России, но не получил массового распространения. Через него можно проводить разные форматы поиска, а также получать полезную информацию.
Baidu
Разработана для поиска информации в китайском сегменте интернета. Кто знает, возможно и это вам пригодится. Можно получать новости, искать картинки, музыку, получать карты и многое другое.
Bing
Проект всем известной компании Microsoft. По объему трафика, этот сайт занимает второе место в мировом рейтинге поисковиков. Работает он с 1998 года и за это время много раз модернизировался.
AOL
Этим сервисом пользуются только иностранцы. Проект американский и помимо поисковой системы, компания обладает массой других сайтов и сервисов. Стоит отметить, что у них крупнейший каталог ссылок на сайты мировой паутины.
9. Перечислите основные типы поисковых запросовПриступая к поиску, пользователь вводит одно или несколько ключевых слов и выбирает тип поиска. В большинстве поисковых систем есть три основных типа поиска:
В большинстве поисковых систем есть три основных типа поиска:
1) поиск по любому из слов — результатом поиска является огромный список всех страниц, содержащих хотя бы одно из ключевых слов; может быть использован, когда пользователь не уверен в ключевых словах;
2) поиск по всем словам — в этом режиме поиска формируется список всех страниц, содержащий все ключевые слова в любом порядке;
3) поиск точно по фразе — в результате поиска составляется список всех страниц, содержащих фразу, точно совпадающую с ключевой (знаки препинания игнорируются).
10. Найдите во Всемирной паутине информацию о количестве пользователей самых распространённых поисковых систем.Первое место в рунете занимает Яндекс – На его долю приходится 58% переходов. Это подтверждает существующее мнение о том, что именно Яндекс является поисковиком номер один в русскоязычном сегменте интернета.
Второе место у Google – 33%. Являясь поисковиком номер один в мире, он почти в два раза менее популярен у русскоязычной интернет-аудитории. Впрочем, погрешность может вносить то, что оценивая популярность по количеству переходов, нельзя забывать о том факте, что если поисковик сразу дает релевантный ответ на первом месте, то и переходов от одного и того же посетителя на разные сайты с него будет меньше.
Впрочем, погрешность может вносить то, что оценивая популярность по количеству переходов, нельзя забывать о том факте, что если поисковик сразу дает релевантный ответ на первом месте, то и переходов от одного и того же посетителя на разные сайты с него будет меньше.
Другие поисковые системы имеют значительно меньшую долю в общем рейтинге популярности. Поиск от Mail.ru занимает 6.6%, Rambler – 1.7%, поисковик Bing от Microsoft – всего 0.7%.
11. Даны запросы к поисковой системеа) чемпионы | (бег & плавание)
б) чемпионы & плавание
в) чемпионы | бег | плавание
г) чемпионы & Европа & бег & плаваниеПредставьте результаты выполнения этих запросов графически с помощью кругов Эйлера. Укажите обозначения запросов в порядке возрастания количества документов, которые найдёт поисковая система по каждому запросу.Ответ
Из рисунка видно, что по запросу чемпионы & Европа & бег & плаваниеколичество документов, которые найдёт поисковая система будет минимальным. Далее по возрастанию страниц идет запрос — чемпионы & плавание.Следом запрос — а) чемпионы | (бег & плавание).И запрос по которому найдется самое большое количество документов — чемпионы | бег | плавание. Ответ: гбав
Далее по возрастанию страниц идет запрос — чемпионы & плавание.Следом запрос — а) чемпионы | (бег & плавание).И запрос по которому найдется самое большое количество документов — чемпионы | бег | плавание. Ответ: гбав
— Кто такой Норберт Винер и какова его роль в исследовании информационных процессов?
— Кто такой Клод Шеннон и чем он знаменит?
— Кем и когда был введён термин «гипертекст»?
— Кого считают изобретателем WWW и когда это произошло?
— Кто такой Эйлер, в честь которого названа графическая схема, иллюстрирующая отношения между множествами?
Ответ
— Норберт Винер — американский ученый, выдающийся математик и философ, основоположник кибернетики и теории искусственного интеллекта. Его большая роль в том, что именно он впервые смог понять огромное значение того, что информация будет использоваться в процессах управления. — Клод Шеннон — американский инженер и математик, его работы являются синтезом математических идей с конкретным анализом чрезвычайно сложных проблем их технической реализации. Он является основателем.. теории информации, нашедшей применение в современных высокотехнологических системах связи. Шеннон внес огромный вклад в теорию вероятностных схем, теорию автоматов и теорию систем управления -области наук, входящих в понятие «кибернетика». В 1948 году предложил использовать слово «бит» для обозначения наименьшей единицы информации ( в статье «Математическая теория связи»).— Термин гипертекст был введён Тедом Нельсоном в 1965 году для обозначения «текста ветвящегося или выполняющего действия по запросу». Обычно гипертекст представляется набором текстов, содержащих узлы перехода от одного текста к какому-либо другому, позволяющие избирать читаемые сведения или последовательность чтения.— Тим Бернерс-Ли в 1980 году для собственных нужд написал программу «Энквайр» которая заложила концептуальную основу для Всемирной паутины.
— Клод Шеннон — американский инженер и математик, его работы являются синтезом математических идей с конкретным анализом чрезвычайно сложных проблем их технической реализации. Он является основателем.. теории информации, нашедшей применение в современных высокотехнологических системах связи. Шеннон внес огромный вклад в теорию вероятностных схем, теорию автоматов и теорию систем управления -области наук, входящих в понятие «кибернетика». В 1948 году предложил использовать слово «бит» для обозначения наименьшей единицы информации ( в статье «Математическая теория связи»).— Термин гипертекст был введён Тедом Нельсоном в 1965 году для обозначения «текста ветвящегося или выполняющего действия по запросу». Обычно гипертекст представляется набором текстов, содержащих узлы перехода от одного текста к какому-либо другому, позволяющие избирать читаемые сведения или последовательность чтения.— Тим Бернерс-Ли в 1980 году для собственных нужд написал программу «Энквайр» которая заложила концептуальную основу для Всемирной паутины. В 1989 году, работая в CERN над внутренней сетью организации, Тим Бернерс-Ли предложил глобальный гипертекстовый проект, теперь известный как Всемирная паутина. Официально годом рождения Всемирной паутины нужно считать 1989 год. Первый в мире веб-сайт был размещён Бернерсом-Ли 6 августа 1991 года. Теоретические основы веба были-заложены гораздо раньше Бернерса-Ли. Ещё в 1945 году Вэнивар Буш разработал концепцию «Memex» — вспомогательных механических средств «расширения человеческой памяти». Memex — это устройство, в котором человек хранит все свои книги и записи (а в идеале — и все свои знания, поддающиеся формальному описанию) и которое выдаёт нужную информацию с достаточной скоростью и гибкостью. Оно является расширением и дополнением памяти человека. Бушем было также предсказано всеобъемлющее индексирование текстов и мультимедийных ресурсов с возможностью быстрого поиска необходимой информации. Следующим значительным шагом на пути ко Всемирной паутине было создание гипертекста (термин введён Тедом Нельсоном в 1965 году).
В 1989 году, работая в CERN над внутренней сетью организации, Тим Бернерс-Ли предложил глобальный гипертекстовый проект, теперь известный как Всемирная паутина. Официально годом рождения Всемирной паутины нужно считать 1989 год. Первый в мире веб-сайт был размещён Бернерсом-Ли 6 августа 1991 года. Теоретические основы веба были-заложены гораздо раньше Бернерса-Ли. Ещё в 1945 году Вэнивар Буш разработал концепцию «Memex» — вспомогательных механических средств «расширения человеческой памяти». Memex — это устройство, в котором человек хранит все свои книги и записи (а в идеале — и все свои знания, поддающиеся формальному описанию) и которое выдаёт нужную информацию с достаточной скоростью и гибкостью. Оно является расширением и дополнением памяти человека. Бушем было также предсказано всеобъемлющее индексирование текстов и мультимедийных ресурсов с возможностью быстрого поиска необходимой информации. Следующим значительным шагом на пути ко Всемирной паутине было создание гипертекста (термин введён Тедом Нельсоном в 1965 году). — Леонард Эйлер — математик, механик, физик и астроном. По происхождению швейцарец. Идеальный математик 18 века — так часто называют Эйлера. Он был одним из самых великих математиков всех времен. Он разработал основы современной теории чисел и алгебры, топологии, исчисления вероятности и комбинаторики, интегрального исчисления, теории дифференциального исчисления и дифференциальной геометрии, вариационного исчисления, открыл связь между тригонометрическими и экспоненциальными функциями. Леонард Эйлер разработал учения гидродинамики и аэрогидродинамики, создал основы теории гироскопа. Он был гениальным естествоиспытателем, замечательным учителем и наставником. В честь него и назвали «Круги Эйлера».
— Леонард Эйлер — математик, механик, физик и астроном. По происхождению швейцарец. Идеальный математик 18 века — так часто называют Эйлера. Он был одним из самых великих математиков всех времен. Он разработал основы современной теории чисел и алгебры, топологии, исчисления вероятности и комбинаторики, интегрального исчисления, теории дифференциального исчисления и дифференциальной геометрии, вариационного исчисления, открыл связь между тригонометрическими и экспоненциальными функциями. Леонард Эйлер разработал учения гидродинамики и аэрогидродинамики, создал основы теории гироскопа. Он был гениальным естествоиспытателем, замечательным учителем и наставником. В честь него и назвали «Круги Эйлера».
На этой странице размещен вариант решения заданий с страниц учебника по информатике за 7 класс авторов Босова. Здесь вы сможете списать решение домашнего задания или просто посмотреть ответы. ГДЗ
Литература: Учебник по Информатике, 7 класс. Автор: Босова Л. Л., Босова А.Ю. Издательство: Бином. Год: 2016, 2017
Л., Босова А.Ю. Издательство: Бином. Год: 2016, 2017
Информационно-поисковые системы Internet | Открытые системы. СУБД
Пользователям Internet хорошо известны названия таких сервисов и информационных служб, как Lycos, AltaVista, Yahoo, OpenText, InfoSeek и др. — без услуг этих систем сегодня практически нельзя найти что-либо полезное в море информационных ресурсов Сети. Что собой представляют эти сервисы изнутри, как они устроены, почему результат поиска в терабайтных массивах информации осуществляется достаточно быстро и как устроено ранжирование документов при выдаче — все это обычно остается за кадром. Тем не менее без правильного планирования стратегии поиска, знакомства с основными положениями теории ИПС (Информационно-Поисковых Систем), насчитывающей уже двадцатилетнюю историю, трудно эффективно использовать даже такие скорострельные сервисы, как AltaVista или Lycos.
— без услуг этих систем сегодня практически нельзя найти что-либо полезное в море информационных ресурсов Сети. Что собой представляют эти сервисы изнутри, как они устроены, почему результат поиска в терабайтных массивах информации осуществляется достаточно быстро и как устроено ранжирование документов при выдаче — все это обычно остается за кадром. Тем не менее без правильного планирования стратегии поиска, знакомства с основными положениями теории ИПС (Информационно-Поисковых Систем), насчитывающей уже двадцатилетнюю историю, трудно эффективно использовать даже такие скорострельные сервисы, как AltaVista или Lycos.
Информационно-поисковые системы появились на свет достаточно давно. Теории и практике построения таких систем посвящено множество статей, основная масса которых приходится на конец 70-х — начало 80-х годов. Среди отечественных источников следует выделить научно-технический сборник «Научно-техническая информация. Серия 2», который выходит до сих пор. На русском языке издана так же и «библия» по разработке ИПС — «Динамические библиотечно-информационные системы» Ж.
При использовании иерархической модели Gopher приходится довольно долго бродить по дереву каталогов, пока не встретишь нужную информацию. Эти каталоги должны кем-то поддерживаться, и при этом их тематическое разбиение должно совпадать с информационными потребностями пользователя. Учитывая анархичность Internet и огромное количество всевозможных интересов у пользователей Сети, понятно, что кому-то может и не повезти и в сети не будет каталога, отражающего конкретную предметную область.
Аналогичное развитие событий наблюдается и в World Wide Web. Собственно еще в 1988 году в специальном выпуске журнала «Communication of the ACM» [2] среди прочих проблем разработки гипертекстовых систем и их использования Франк Халаз назвал в качестве первоочередной задачи для следующего поколения систем этого типа назвал проблему организации поиска информации в больших гипертекстовых сетях. До сих пор многие идеи, высказанные в той статье, не нашли еще своей реализации. Естественно, что система, предложенная Бернерсом-Ли [3] и получившая такое широкое распространение в Internet, должна была столкнуться с теми же проблемами, что и ее локальные предшественники. Реальное подтверждение этому было продемонстрировано на второй конференции по World Wide Web осенью 1994 года, на которой были представлены доклады о разработке информационно-поисковых систем для Web, а система World Wide Web Worm, разработанная Оливером МакБрайном из Университета Колорадо, получила приз как лучшее навигационное средство.
Разработка новых информационных систем для Web не завершена. Причем как на стадии написания коммерческих систем, так и на стадии исследований. За прошедшие два года снят только верхний слой возможных решений. Однако многие проблемы, которые ставит перед разработчиками ИПС Internet, не решены до сих пор. Именно этим обстоятельством и вызвано появление проектов типа AltaVista компании Digital [4], главной целью которого является разработка программных средств информационного поиска для Web и подбор архитектуры для информационного сервера Web.
Архитектура современных ИПС для WWW
Прежде чем описать проблемы построения информационно-поисковых систем Web и пути их решения рассмотрим типовую схему такой системы. В различных публикациях, посвященных конкретным системам, например [5,6], приводятся схемы, которые отличаются друг от друга только способом применения конкретных программных решений, а не принципом организации различных компонентов системы. Поэтому рассмотрим эту схему на примере, взятом из работы [6] (рис.).
Рис. Типовая схема информационно-поисковой системы.
Client (клиент) на этой схеме — это программа просмотра конкретного информационного ресурса. Наиболее популярны сегодня мультипротокольные программы типа Netscape Navigator. Такая программа обеспечивает просмотр документов WWW, Gopher, Wais, FTP-архивов, почтовых списков рассылки и групп новостей Usenet. В свою очередь все эти информационные ресурсы являются объектом поиска информационно-поисковой системы.
User interface (пользовательский интерфейс) — это не просто программа просмотра, в случае информационно-поисковой системы под этим словосочетанием понимают также способ общения пользователя с поисковым аппаратом: системой формирования запросов и просмотров результатов поиска.
Search engine (поисковая машина) — служит для трансляции запроса на информационно-поисковом языке (ИПЯ), в формальный запрос системы, поиска ссылок на информационные ресурсы Сети и выдачи результатов этого поиска пользователю.
Index database (индекс базы данных) — индекс, который является основным массивом данных ИПС и служит для поиска адреса информационного ресурса. Архитектура индекса устроена таким образом, чтобы поиск происходил максимально быстро и при этом можно было бы оценить ценность каждого из найденных информационных ресурсов сети.
Queries (запросы пользователя) — сохраняются в его (пользователя) личной базе данных. На отладку каждого запроса уходит достаточно много времени, и поэтому чрезвычайно важно запоминать запросы, на которые система дает хорошие ответы.
Index robot (робот-индексировщик) — служит для сканирования Internet и поддержания базы данных индекса в актуальном состоянии. Эта программа является основным источником информации о состоянии информационных ресурсов сети.
WWW sites — это весь Internet или точнее — информационные ресурсы, просмотр которых обеспечивается программами просмотра.
Рассмотрим теперь назначение и принципу построения каждого из этих компонентов более подробно и определим, в чем отличие данной системы от традиционной ИПС локального типа.
Информационные ресурсы и их представление в ИПС
Как видно из рисунка, документальным массивом ИПС Internet является все множество документов шести основных типов: WWW-страницы, Gopher-файлы, документы Wais, записи архивов FTP, новости Usenet и статьи почтовых списков рассылки. Все это довольно разнородная информация, которая представлена в виде различных, никак несогласованных друг с другом форматов данных: тексты, графическая и аудиоинформация и вообще все, что имеется в указанных хранилищах. Естественно возникает вопрос — как информационно-поисковая система должна со всем этим работать?
Естественно возникает вопрос — как информационно-поисковая система должна со всем этим работать?
В традиционных системах используется понятие поискового образа документа — ПОД. Обычно, этим термином обозначают нечто, заменяющее собой документ и использующееся при поиске вместо реального документа. Поисковый образ является результатом применения некоторой модели информационного массива документов к реальному массиву. Наиболее популярной моделью является векторная модель [7], в которой каждому документу приписывается список терминов, наиболее адекватно отражающих его смысл. Если быть более точным, то документу приписывается вектор размерности, равный числу терминов, которыми можно воспользоваться при поиске. При булевой векторной модели элемент вектора равен 1 или 0, в зависимости от наличия или отсутствия термина в ПОД. В более сложных моделях термины взвешиваются — элемент вектора равен не 1 или 0, а некоторому числу (весу), отражающему соответствие данного термина документу. Именно последняя модель стала наиболее популярной в ИПС Internet [4,6,7].
Вообще говоря, существуют и другие модели описания документов: вероятностная модель информационных потоков и поиска и модель поиска в нечетких множествах [7]. Не вдаваясь в подробности, имеет смысл обратить внимание на то, что пока только линейная модель применяется в системах Lycos, WebCrawler, AltaVista, OpenText и AliWeb. Однако ведутся исследования по применению и других моделей, результаты которых отражены в работах [4,6]. Таким образом, первая задача, которую должна решить ИПС, — это приписывание списка ключевых слов документу или информационному ресурсу. Именно эта процедура и называется индексированием. Часто, однако, индексированием называют составление файла инвертированного списка, в котором каждому термину индексирования ставится в соответствие список документов в которых он встречается. Такая процедура является только частным случаем, а точнее, техническим аспектом создания поискового аппарата ИПС. Проблема, связанная с индексированием, заключается в том, что приписывание поискового образа документу или информационному ресурсу опирается на представление о словаре, из которого эти термины выбираются, как о фиксированной совокупности терминов. В традиционных системах существовало разбиение на системы с контролируемым словарем и системы со свободным словарем. Контролируемый словарь предполагал ведение некоторой лексической базы данных, добавление терминов в которую производилось администратором системы, и все новые документы могли быть заиндексированы только теми терминами, которые были в этой базе данных. Свободный словарь пополнялся автоматически по мере появления новых документов. Однако на момент актуализации словарь также фиксировался. Актуализация предполагала полную перезагрузку базы данных. В момент этого обновления перегружались сами документы, и обновлялся словарь, а после его обновления производилась переиндексация документов. Процедура актуализации занимала достаточно много времени и доступ к системе в момент ее актуализации закрывался.
В традиционных системах существовало разбиение на системы с контролируемым словарем и системы со свободным словарем. Контролируемый словарь предполагал ведение некоторой лексической базы данных, добавление терминов в которую производилось администратором системы, и все новые документы могли быть заиндексированы только теми терминами, которые были в этой базе данных. Свободный словарь пополнялся автоматически по мере появления новых документов. Однако на момент актуализации словарь также фиксировался. Актуализация предполагала полную перезагрузку базы данных. В момент этого обновления перегружались сами документы, и обновлялся словарь, а после его обновления производилась переиндексация документов. Процедура актуализации занимала достаточно много времени и доступ к системе в момент ее актуализации закрывался.
Теперь представим себе возможность такой процедуры в анархичном Internet, где ресурсы появляются и исчезают ежедневно. При создании программы Veronica для GopherSpace предполагалось, что все серверы должны быть зарегистрированы, и таким образом велся учет наличия или отсутствия ресурса. Veronica раз в месяц проверяла наличие документов Gopher и обновляла свою базу данных ПОД для документов Gopher. В WWW ничего подобного нет. Для решения этой задачи используются программы сканирования сети или роботы-индексировщики [8]. Разработка роботов — это довольно нетривиальная задача; существует опасность зацикливания робота или его попадания на виртуальные страницы. Робот просматривает сеть, находит новые ресурсы, приписывает им термины и помещает в базу данных индекса. Главный вопрос заключается в том, что за термины приписывать документам, откуда их брать, ведь ряд ресурсов вообще не является текстом. Сегодня роботы обычно используют для индексирования следующие источники для пополнения своих виртуальных словарей: гипертекстовые ссылки, заголовки, заглавия (h2,h3), аннотации, списки ключевых слов, полные тексты документов, а также сообщения администраторов о своих Web-страницах [9]. Для индексирования telnet, gopher, ftp, нетекстовой информации используются главным образом URL, для новостей Usenet и почтовых списков поля Subject и Keywords.
Veronica раз в месяц проверяла наличие документов Gopher и обновляла свою базу данных ПОД для документов Gopher. В WWW ничего подобного нет. Для решения этой задачи используются программы сканирования сети или роботы-индексировщики [8]. Разработка роботов — это довольно нетривиальная задача; существует опасность зацикливания робота или его попадания на виртуальные страницы. Робот просматривает сеть, находит новые ресурсы, приписывает им термины и помещает в базу данных индекса. Главный вопрос заключается в том, что за термины приписывать документам, откуда их брать, ведь ряд ресурсов вообще не является текстом. Сегодня роботы обычно используют для индексирования следующие источники для пополнения своих виртуальных словарей: гипертекстовые ссылки, заголовки, заглавия (h2,h3), аннотации, списки ключевых слов, полные тексты документов, а также сообщения администраторов о своих Web-страницах [9]. Для индексирования telnet, gopher, ftp, нетекстовой информации используются главным образом URL, для новостей Usenet и почтовых списков поля Subject и Keywords. Наибольший простор для построения ПОД дают HTML документы. Однако не следует думать, что все термины из перечисленных элементов документов попадают в их поисковые образы. Очень активно применяются списки запрещенных слов (stop-words), которые не могут быть употреблены для индексирования, общих слов (предлоги, союзы и т.п.). Таким образом даже то, что в OpenText, например, называется полнотекстовым индексированием реально является выбором слов из текста документа и сравнением с набором различных словарей, после которого термин попадает в ПОД, а потом и в индекс системы. Для того чтобы не раздувать словарей и индексов (индекс системы Lycos уже сегодня равен 4 Тбайт), применяется такое понятие, как вес термина [10]. Документ обычно индексируется через 40 — 100 наиболее «тяжелых» терминов.
Наибольший простор для построения ПОД дают HTML документы. Однако не следует думать, что все термины из перечисленных элементов документов попадают в их поисковые образы. Очень активно применяются списки запрещенных слов (stop-words), которые не могут быть употреблены для индексирования, общих слов (предлоги, союзы и т.п.). Таким образом даже то, что в OpenText, например, называется полнотекстовым индексированием реально является выбором слов из текста документа и сравнением с набором различных словарей, после которого термин попадает в ПОД, а потом и в индекс системы. Для того чтобы не раздувать словарей и индексов (индекс системы Lycos уже сегодня равен 4 Тбайт), применяется такое понятие, как вес термина [10]. Документ обычно индексируется через 40 — 100 наиболее «тяжелых» терминов.
Индекс поиска
После того как ресурсы заиндексированы и система составила массив ПОД, начинается построение поискового аппарата. Совершенно очевидно, что лобовой просмотр файла или файлов ПОД займет много времени, что абсолютно не приемлемо для интерактивной системы WWW. Для ускорения поиска строится индекс, которым в большинстве систем является набор связанных между собой файлов, ориентированных на быстрый поиск данных по запросу. Структура и состав индексов различных систем могут отличаться друг от друга и зависят от многих факторов: размер массива поисковых образов, информационно-поисковый язык, размещения различных компонентов системы и т.п. Рассмотрим структуру индекса на примере системы [6], для которой можно реализовывать не только примитивный булевый, но и контекстный и взвешенный поиск, а также ряд других возможностей, отсутствующие во многих поисковых системах Internet, например Yahoo. Индекс рассматриваемой системы состоит из таблицы идентификаторов страниц (page-ID), таблицы ключевых слов (Keyword-ID), таблицы модификации страниц, таблицы заголовков, таблицы гипертекстовых связей, инвертированного (IL) и прямого списка (FL).
Для ускорения поиска строится индекс, которым в большинстве систем является набор связанных между собой файлов, ориентированных на быстрый поиск данных по запросу. Структура и состав индексов различных систем могут отличаться друг от друга и зависят от многих факторов: размер массива поисковых образов, информационно-поисковый язык, размещения различных компонентов системы и т.п. Рассмотрим структуру индекса на примере системы [6], для которой можно реализовывать не только примитивный булевый, но и контекстный и взвешенный поиск, а также ряд других возможностей, отсутствующие во многих поисковых системах Internet, например Yahoo. Индекс рассматриваемой системы состоит из таблицы идентификаторов страниц (page-ID), таблицы ключевых слов (Keyword-ID), таблицы модификации страниц, таблицы заголовков, таблицы гипертекстовых связей, инвертированного (IL) и прямого списка (FL).
Page-ID отображает идентификаторы страниц в их URL, Keyword-ID — каждое ключевое слов в уникальный идентификатор этого слова, таблица заголовков — идентификатор страницы в заголовок страницы, таблица гипертекстовых ссылок — идентификатор страниц в гипертекстовую ссылку на эту страницу. Инвертированный список ставит в соответствие каждому ключевому слову документа список пар — идентификатор страницы, позиция слова в странице. Прямой список — это массив поисковых образов страниц. Все эти файлы так или иначе используются при поиске, но главным среди них является файл инвертированного списка. Результат поиска в данном файле — это объединение и/или пересечение списков идентификаторов страниц. Результирующий список, который преобразовывается в список заголовков, снабженных гипертекстовыми ссылками возвращается пользователю в его программу просмотра Web. Для того чтобы быстро искать записи инвертированного списка, над ним надстраивается еще несколько файлов, например, файл буквенных пар с указанием записей инвертированного списка, начинающихся с этих пар. Кроме этого, применяется механизм прямого доступа к данным — хеширование. Для обновления индекса используется комбинация двух подходов. Первый можно назвать коррекцией индекса «на ходу» с помощью таблицы модификации страниц.
Инвертированный список ставит в соответствие каждому ключевому слову документа список пар — идентификатор страницы, позиция слова в странице. Прямой список — это массив поисковых образов страниц. Все эти файлы так или иначе используются при поиске, но главным среди них является файл инвертированного списка. Результат поиска в данном файле — это объединение и/или пересечение списков идентификаторов страниц. Результирующий список, который преобразовывается в список заголовков, снабженных гипертекстовыми ссылками возвращается пользователю в его программу просмотра Web. Для того чтобы быстро искать записи инвертированного списка, над ним надстраивается еще несколько файлов, например, файл буквенных пар с указанием записей инвертированного списка, начинающихся с этих пар. Кроме этого, применяется механизм прямого доступа к данным — хеширование. Для обновления индекса используется комбинация двух подходов. Первый можно назвать коррекцией индекса «на ходу» с помощью таблицы модификации страниц. Суть такого решения довольно проста: старая запись индекса ссылается на новую, которая и используется при поиске. Когда число таких ссылок становится достаточным для того, чтобы ощутить это при поиске, то происходит полное обновление индекса — его перезагрузка. Эффективность поиска в каждой конкретной ИПС определяется исключительно архитектурой индекса. Как правило, способ организации этих массивов является «секретом фирмы» и ее гордостью. Для того чтобы убедиться в этом, достаточно почитать материалы OpenText [11].
Суть такого решения довольно проста: старая запись индекса ссылается на новую, которая и используется при поиске. Когда число таких ссылок становится достаточным для того, чтобы ощутить это при поиске, то происходит полное обновление индекса — его перезагрузка. Эффективность поиска в каждой конкретной ИПС определяется исключительно архитектурой индекса. Как правило, способ организации этих массивов является «секретом фирмы» и ее гордостью. Для того чтобы убедиться в этом, достаточно почитать материалы OpenText [11].
Информационно-поисковый язык системы
Индекс — это только часть поискового аппарата, скрытая от пользователя. Второй частью этого аппарата является информационно-поисковый язык (ИПЯ), позволяющий сформулировать запрос к системе в простой и наглядной форме. Уже давно осталась позади романтика создания ИПЯ, как естественного языка, — именно этот подход использовался в системе Wais на первых стадиях ее реализации. Если даже пользователю предлагается вводить запросы на естественном языке, то это еще не значит, что система будет осуществлять семантический разбор запроса пользователя. Проза жизни заключается в том, что обычно фраза разбивается на слова, из которых удаляются запрещенные и общие слова, иногда производится нормализация лексики, а затем все слова связываются либо логическим AND, либо OR. Таким образом, запрос типа:
Проза жизни заключается в том, что обычно фраза разбивается на слова, из которых удаляются запрещенные и общие слова, иногда производится нормализация лексики, а затем все слова связываются либо логическим AND, либо OR. Таким образом, запрос типа:
>Software that is used on Unix Platform
будет преобразован в:
>Unix AND Platform AND Software
что будет означать примерно следующее: «Найди все документы, в которых слова Unix, Platform и Software встречаются одновременно«.
Возможны и варианты. Так, в большинстве систем фраза «Unix Platform» будет опознана как ключевая фраза и не будет разделяться на отдельные слова. Другой подход заключается в вычислении степени близости между запросом и документом. Именно этот подход используется в Lycos. В этом случае в соответствии с векторной моделью представления документов и запросов вычисляется их мера близости. Сегодня известно около дюжины различных мер близости. Наиболее часто применяется косинус угла между поисковым образом документа и запросом пользователя. Обычно эти проценты соответствия документа запросу и выдаются в качестве справочной информации при списке найденных документов.
Обычно эти проценты соответствия документа запросу и выдаются в качестве справочной информации при списке найденных документов.
Наиболее развитым языком запросов из современных ИПС Internet обладает Alta Vista. Кроме обычного набора AND, OR, NOT эта система позволяет использовать еще и NEAR, позволяющий организовать контекстный поиск. Все документ в системе разбиты на поля, поэтому в запросе можно указать, в какой части документа пользователь надеется увидеть ключевое слово: ссылка, заглавие, аннотация и т.п. Можно также задавать поле ранжирования выдачи и критерий близости документов запросу.
Интерфейс системы
Важным фактором является вид представления информации в программе-интерфейсе. Различают два типа интерфейсных страниц: страницы запросов и страницы результатов поиска.
При составлении запроса к системе используют либо меню — ориентированный подход, либо командную строку. Первый позволяет ввести список терминов, обычно разделяемых пробелом, и выбрать тип логической связи между ними. Логическая связь распространяется на все термины. На схеме из рисунка указаны сохраненные запросы пользователя — в большинстве систем это просто фраза на ИПЯ, которую можно расширить за счет добавления новых терминов и логических операторов. Но это только один способ использования сохраненных запросов, называемый расширением или уточнением запроса. Для выполнения этой операции традиционная ИПС хранит не запрос как таковой, а результат поиска — список идентификаторов документов, который объединяется/пересекается со списком, полученным при поиске документов по новым терминам. К сожалению, сохранение списка идентификаторов найденных документов в WWW не практикуется, что было вызвано особенностью протоколов взаимодействия программы-клиента и сервера, не поддерживающих сеансовый режим работы.
Логическая связь распространяется на все термины. На схеме из рисунка указаны сохраненные запросы пользователя — в большинстве систем это просто фраза на ИПЯ, которую можно расширить за счет добавления новых терминов и логических операторов. Но это только один способ использования сохраненных запросов, называемый расширением или уточнением запроса. Для выполнения этой операции традиционная ИПС хранит не запрос как таковой, а результат поиска — список идентификаторов документов, который объединяется/пересекается со списком, полученным при поиске документов по новым терминам. К сожалению, сохранение списка идентификаторов найденных документов в WWW не практикуется, что было вызвано особенностью протоколов взаимодействия программы-клиента и сервера, не поддерживающих сеансовый режим работы.
Итак, результат поиска в базе данных ИПС — это список указателей на удовлетворяющие запросу документы. Различные системы представляют этот список по-разному. В некоторых выдается только список ссылок, а в таких, как Lycos, Alta Vista и Yahoo, дается еще и краткое описание, которое заимствуется либо из заголовков, либо из тела самого документа. Кроме этого, система сообщает, на сколько найденный документ соответствует запросу. В Yahoo, например, это количество терминов запроса, содержащихся в ПОД, в соответствии с которым ранжируется результат поиска. Система Lycos выдает меру соответствия документа запросу, по которой производится ранжирование.
Кроме этого, система сообщает, на сколько найденный документ соответствует запросу. В Yahoo, например, это количество терминов запроса, содержащихся в ПОД, в соответствии с которым ранжируется результат поиска. Система Lycos выдает меру соответствия документа запросу, по которой производится ранжирование.
При обзоре интерфейсов и средств поиска нельзя пройти мимо процедуры коррекции запросов по релевантности [7]. Релевантность — это мера соответствия найденного системой документа потребности пользователя. Различают формальную релевантность и реальную. Первую вычисляет система, и на основании чего ранжируется выборка найденных документов. Вторая — это оценка самим пользователем найденных документов. Некоторые системы имеют для этого специальное поле [6], где пользователь может отметить документ как релевантный. При следующей поисковой итерации запрос расширяется терминами этого документа, а результат снова ранжируется. Так происходит до тех пор, пока не наступит стабилизация, означающая, что ничего лучше, чем полученная выборка, от данной системы не добьешься.
Кроме ссылок на документы в списке, полученном пользователем, могут оказаться ссылки на части документов или на их поля. Это происходит при наличии ссылок типа http://host/path#mark или ссылок по схеме WAIS. Возможны ссылки и на скрипты, но обычно такие ссылки роботы пропускают, и система их не индексирует. Если с http-ссылками все более или менее понятно, то ссылки WAIS — это гораздо более сложные объекты. Дело в том, что WAIS реализует архитектуру распределенной информационно-поисковой системы, при которой одна ИПС, например Lycos, строит поисковый аппарат над поисковым аппаратом другой системы — WAIS. При этом серверы WAIS имеют свои собственные локальные базы данных. При загрузке документов в WAIS администратор может описать структуру документов, разбив их на поля, и хранить документы в виде одного файла. Индекс WAIS будет ссылаться на отдельные документы и их поля как на самостоятельные единицы хранения, программа просмотра ресурсов Internet в этом случае должна уметь работать с протоколом WAIS, чтобы получить доступ к этим документам.
Заключение
В обзорной статье были рассмотрены основные элементы информационно-поисковых систем и принципы их построения. Сегодня ИПС являются наиболее мощным механизмом поиска сетевых информационных ресурсов Internet. К сожалению, в российском секторе Internet пока не наблюдается активного изучения этой проблемы за исключением, может быть, проекта LIBWEB, финансируемого РФФИ и системы «Паук», которая работает недостаточно надежно. Наибольшим опытом разработки такого сорта систем безусловно обладает ВИНИТИ, но здесь работа сосредоточена пока на размещении своих собственных ресурсов в Сети, что принципиально отличается от информационно-поисковых систем Internet типа Lycos, OpenText, Alta Vista, Yahoo, InfoSeek и т.п. Казалось бы, что такая работа могла быть сосредоточена в рамках таких проектов, как Россия On-line компании SovamTeleport, но здесь мы пока наблюдаются ссылки на чужие поисковые машины. Развитие ИПС для Internet в США началось два года назад, учитывая отечественные реалии и темпы развития технологий Сети в России, можно надеяться, что у нас еще все впереди.
Литература
1. Дж. Солтон. Динамические библиотечно-информационные системы. Мир, Москва, 1979.
2. Frank G. Halasz. Reflection notecards: seven issues for the next generation of hypermedia systems. Communication of the acm, V31, N7, 1988, p.836-852.
3. Tim Berners-Lee. World Wide Web: Proposal for HyperText Project. 1990.
4. Alta Vista. Digital Equipment Corporation, 1996.
5. Brain Pinkerton. Finding What People Want: Experiences with the WebCrawler.
6. Bodi Yuwono, Savio L.Lam, Jerry H.Ying, Dik L.Lee. A World Wide Web Resource Discovery System.
7. Martin Bartschi. An Overview of Information Retrieval Subjects. IEEE Computer, N5, 1985,p.67-84.
8. Michel L. Mauldin, John R.R. Leavitt. Web Agent Related Research at the Center for Machine Translation.
9. Ian R.Winship. World Wide Web searching tools -an evaluation. VINE (99).
10. G.Salton, C.Buckley. Term-Weighting Approachs in Automatic Text Retrieval. Information Processing & Management, 24(5), pp. 513-523, 1988.
513-523, 1988.
11. Open Text Corporation Releases Industry»s Highest Performance Text Retrieval System.
Павел Храмцов ([email protected]) — независимый эксперт, (Москва).
3 поисковые системы, о которых вы должны знать — помимо Google
Когда дело доходит до разговора о поиске в Интернете, Google является королем. Имея более 90% доли рынка поисковых систем, более 63 000 поисковых запросов в секунду, рыночную стоимость в 739 миллиардов долларов, вполне логично, что когда люди оптимизируют свой веб-сайт для поиска или платят за поисковые объявления, Google является первым местом, куда они обращаются. Тем не менее, Google — не единственная поисковая система, и как маркетолог или владелец бизнеса важно не зацикливаться на этом, сосредоточившись только на этом.
Персонализированный опыт Google достигается за счет обмена личными данными, и некоторые пользователи предпочитают использовать разные браузеры из соображений конфиденциальности, в то время как другие могут использовать другую поисковую систему просто потому, что она установлена по умолчанию в настройках их браузера. Продолжайте читать, чтобы узнать о лучших поисковых системах, помимо Google, о которых вы должны знать.
Продолжайте читать, чтобы узнать о лучших поисковых системах, помимо Google, о которых вы должны знать.
Bing
В прошлом году мы написали в блоге сообщение под названием «Кто использует Bing», потому что это был вопрос, который мы часто получали от наших клиентов. Мы выяснили, что Bing — вторая по величине поисковая система в мире, и почти треть поисковых запросов на ПК выполняется через Bing. Уникальное преимущество Bing заключается в том, что он является поисковой системой по умолчанию для всех продуктов Microsoft. Для тех, кто использует персональные компьютеры дома или даже для тех, кто использует их на работе в корпоративных офисах, где у них есть продукты Microsoft, многие будут использовать Bing в качестве поисковой системы по умолчанию.
Кроме того, типичный пользователь Bing старше (средний возраст пользователя составляет от 45 до 64 лет), является родителем и имеет семейный доход более 100 000 долларов. По этой причине мы рекомендуем многим нашим клиентам в отраслях B2B или с целевым рынком, который относится к их демографическим группам, не игнорировать Bing в своих маркетинговых усилиях. Алгоритмы Bing и Google различаются, и данные показывают, что при ранжировании Bing больше внимания уделяется элементам на странице, чем более сложной аналитике, и больше внимания уделяется размещению и плотности ключевых слов.
Алгоритмы Bing и Google различаются, и данные показывают, что при ранжировании Bing больше внимания уделяется элементам на странице, чем более сложной аналитике, и больше внимания уделяется размещению и плотности ключевых слов.
Yahoo
Yahoo — одна из старейших поисковых систем, старше Google, которая до сих пор существует и используется многими. Хотя средний человек может иметь негативное мнение о Yahoo и думать, что его больше никто не использует, это третья по популярности поисковая система после Google и Bing. Некоторым может показаться, что тот факт, что Yahoo был запущен в 1994 году, означает, что это устаревший продукт, но для других он формирует чувство доверия, и лояльные пользователи сделали его частью своей веб-рутины на протяжении многих лет и продолжают искать там. Главная страница Yahoo.com по-прежнему является очень популярной страницей для просмотра веб-страниц и получения новостей, что побуждает многих людей продолжать использовать их функцию поиска.
В то время как демографические данные Bing старше, Yahoo еще старше — это самая популярная поисковая система для пользователей старше 65 лет. Yahoo также использует тот же алгоритм поиска, что и Bing, поэтому, если вы оптимизируете свой веб-сайт для более старой аудитории, вы можете использовать одни и те же методы для обеих поисковых систем.
Yahoo также использует тот же алгоритм поиска, что и Bing, поэтому, если вы оптимизируете свой веб-сайт для более старой аудитории, вы можете использовать одни и те же методы для обеих поисковых систем.
DuckDuckGo
DuckDuckGo — относительно новая поисковая система, но быстрорастущая. По данным Search Engine Journal, в то время как Google, Bing и Yahoo наблюдают снижение органического поискового трафика, DuckDuckGo продемонстрировал снижение на 49%.% увеличение во 2 квартале 2019 года. Причина? DuckDuckGo фокусируется на конфиденциальности, которая со всеми новостями, касающимися нашей конфиденциальности в Интернете, стала очень важной для пользователей Интернета. Он никогда не отслеживает онлайн-активность, личную информацию или даже IP-адреса пользователей. Он также имеет очень простой и понятный интерфейс и использует бесконечную прокрутку, что делает его более удобным для пользователя.
DuckDuckGo’s использует свой поисковый робот DuckDuckBot и до 400 других источников для компиляции своих результатов, включая сканирование других поисковых систем, таких как Bing и Yahoo. Из-за отсутствия личных данных, доступных для использования маркетологами, может быть сложно ориентироваться на пользователей на этой платформе.
Из-за отсутствия личных данных, доступных для использования маркетологами, может быть сложно ориентироваться на пользователей на этой платформе.
Хотя у нас нет таких подробных данных о типичном пользователе на сайте, как для других платформ, мы можем сделать вывод, что этот пользователь заботится о конфиденциальности и, вероятно, следит за текущими техническими новостями и тенденциями, чтобы быть в курсе в курсе новой, растущей поисковой системы. Хотя вы не можете делать такие вещи, как ретаргетинг или демографический таргетинг, из-за настроек конфиденциальности DuckDuckGo, они по-прежнему разрешают поисковые объявления на основе ключевых слов. Их рекламная сеть далеко не так обширна, как Bing или Google, но это также делает ее менее дорогой и менее конкурентоспособной.
Оптимизируйте свой веб-сайт для поиска с профессиональным цифровым агентством
Процесс оптимизации вашего веб-сайта для поиска или рекламы в поисковых сетях постоянно развивается по мере появления новых продуктов, платформ и технологических тенденций. В Atilus мы можем помочь вашему веб-сайту повысить рейтинг в поиске с помощью технического аудита, контента и локального SEO, а также помочь вам разместить рекламу в Интернете с помощью маркетинга в поисковых системах. Какими бы ни были ваши бизнес-цели или какой целевой рынок вы пытаетесь охватить, мы можем помочь разработать индивидуальный маркетинговый план, который поможет вашему бизнесу расти. Дополнительная информация по телефону 239-362-1271 или свяжитесь с нами онлайн сегодня!
В Atilus мы можем помочь вашему веб-сайту повысить рейтинг в поиске с помощью технического аудита, контента и локального SEO, а также помочь вам разместить рекламу в Интернете с помощью маркетинга в поисковых системах. Какими бы ни были ваши бизнес-цели или какой целевой рынок вы пытаетесь охватить, мы можем помочь разработать индивидуальный маркетинговый план, который поможет вашему бизнесу расти. Дополнительная информация по телефону 239-362-1271 или свяжитесь с нами онлайн сегодня!
Теги : bing, Цифровой маркетинг, duckduckgo, Google, реклама с оплатой за клик, поисковый маркетинг, поисковая оптимизация, технические тенденции, Yahoo
Похожие сообщения
- Copyright © 2022 Atilus LLC.
- Все права защищены.
Все, что вам нужно знать о поисковых системах
Что такое поисковые системы
Поисковые системы — это программы или скрипты, которые широко используются в Интернете, чтобы помочь пользователям найти именно то, что они ищут, просто введя ключевое слово , фразу или вопрос в поле запроса поисковых систем.
Как они работают
Поисковая система использует автоматизированные программные приложения, такие как роботы, пауки или боты, которые сканируют сайты в поисках информации, запрошенной в рамках поискового запроса. Каждая поисковая система использует свою собственную сложную математическую формулу, также известную как алгоритм для отображения определенных результатов. Google, одна из ведущих поисковых систем, предоставляет уникальную формулу, которая становится стандартом для всех других поисковых систем, поэтому большинство владельцев бизнеса стремятся основывать свою SEO-оптимизацию на этих стандартах.
Алгоритм поисковой системы использует ключевые элементы страницы для отображения результатов. Некоторые из ключевых элементов включают заголовок страницы, плотность ключевых слов и содержание, хотя Google больше интересует содержание, чем ключевые слова, они все же применимы.
Поисковые системы, хотя и очень сложные, не способны видеть изображения, аспекты дизайна или другие визуальные факторы на сайте, поэтому текст чрезвычайно важен для успешного ранжирования. Вот почему теги изображений ALT, метатеги, описания и другие области контента на странице всегда обсуждаются, когда SEO является основной темой.
Вот почему теги изображений ALT, метатеги, описания и другие области контента на странице всегда обсуждаются, когда SEO является основной темой.
Поисковая система просматривает миллионы, а иногда и миллиарды веб-сайтов, чтобы вывести наиболее релевантные на верхние страницы результатов своей поисковой системы (SERP). Сканер, или паук, используемый поисковой системой, посещает каждую страницу и индексирует ее в своей огромной базе данных. Процесс включает в себя запись ссылок на странице, содержание и даже проверку плотности ключевых слов, удаление стоп-слов и любой другой информации на странице, такой как изображения и мультимедиа. Собранная информация затем используется не только для быстрого поиска страницы, когда она релевантна поиску, но и для ранжирования страницы, чтобы предположить, где она будет отображаться в поисковой выдаче.
Итак, все эти разговоры о поисковых системах и их работе всегда возвращаются к SEO… Итак, что же такое SEO?
Что такое SEO?
По словам Рэнда Фишкина, SEO, также известное как поисковая оптимизация, представляет собой практику увеличения количества и качества трафика, который вы получаете благодаря органическим результатам в поисковых системах.
Качество трафика является одним из наиболее важных аспектов этого предложения, даже в большей степени, чем количество трафика. Посмотрите на это таким образом, у вас могут быть тысячи посетителей на вашем сайте каждый день, но если их там нет, потому что они ищут то, что вы предлагаете, у вас может и не быть ни одного. Но если у вас есть два посетителя, которые пришли в поисках того, что вы можете предложить, и им понравилось то, что они прочитали, увидели или услышали на вашем сайте, то это гораздо более ценно, чем тысячи, которые не были заинтересованы в том, чтобы быть там с самого начала. , возьми?
Теперь, когда у вас есть нужный трафик, вы хотите увеличить его, это то, где количество приходит на помощь, а не раньше…..
Что такое органический трафик?
Органический трафик лучше, почему? Потому что это бесплатно! Избегая дорогостоящей рекламы, чтобы подняться в поисковой выдаче, вы можете воспользоваться преимуществами увеличения доходов, следуя рекомендациям по SEO, установленным каждой поисковой системой, у Google есть длинный список, которым нужно следовать, но если вы это сделаете, вы можете получить весь качественный трафик, который вы хотите, даже не платя за рекламу. Ознакомьтесь с Руководством для начинающих по поисковой оптимизации Google.
Ознакомьтесь с Руководством для начинающих по поисковой оптимизации Google.
Как работает SEO
SEO работает так же, как и поисковые системы. Это означает, что поисковые системы сканируют вашу страницу, чтобы узнать, о чем вы, и после индексации могут отображать вашу ссылку на релевантные поисковые запросы. Итак, ваша задача — создать свою страницу с учетом этих пользователей, чтобы, когда они появятся в поиске… вас можно было найти.
Существует несколько факторов, которые учитываются при ранжировании вашего веб-сайта поисковой системой.
- Качество ссылок на домен
- Качество ссылок внутри домена
- Качество и длина контента
- Скорость загрузки
- Социальные показатели
- Доменное имя (соответствует ли оно запрашиваемому ключевому слову)
- Использование торговой марки в автономном режиме
- Удобный дизайн
- Актуальность
Это только краткий список, есть еще много факторов, которые следует учитывать при попытке занять первые места в поисковых системах. Теги изображений, мета-теги, теги заголовков и описания — это всего лишь несколько вещей, которые нужно оптимизировать; вся страница должна быть оптимизирована до совершенства, чтобы занимать высокие позиции в поисковой выдаче.
Теги изображений, мета-теги, теги заголовков и описания — это всего лишь несколько вещей, которые нужно оптимизировать; вся страница должна быть оптимизирована до совершенства, чтобы занимать высокие позиции в поисковой выдаче.
Зачем вам SEO
Без SEO маловероятно, что ваша страница когда-либо будет замечена в поисковых системах. Многие владельцы онлайн-бизнеса боролись с концепцией SEO, и многие потерпели неудачу с их реализацией, но это не значит, что вы должны это делать. Сначала создайте свою страницу для пользователя, помня о том, что независимо от того, сколько людей поисковые системы отправят на вашу страницу, если им не понравится то, что они увидят, они уйдут. После того, как вы разместите релевантный, полезный и уникальный контент на своей странице, тогда и только тогда вы должны начать работать над его оптимизацией для поисковых систем. Это не означает, что вы не помните о SEO при разработке своего сайта, потому что, хотите верьте, хотите нет, но дизайн имеет значение!
Вот что Google говорит о SEO и вас.
Когда дело доходит до SEO, чрезмерная оптимизация — это реальная вещь, просто спросите миллионы пользователей Google, которые были оштрафованы после обновления алгоритмов. Помните первое обновление Panda, которое потрясло Интернет, Hummingbird, Penguin и множество обновлений, последовавших за каждым? Эти санкции Google в основном были направлены на веб-сайты, которые использовали теневые методы SEO, также известные как SEO в черной шляпе. Получение штрафа от Google может дорого обойтись, поэтому всегда лучше следовать стандартам, указанным в рекомендациях для поисковых систем. Узнайте, как создать сайт, удобный для Google.
Что такое штраф Google?
Штраф Google отрицательно влияет на рейтинг вашего сайта, а в некоторых случаях может полностью удалить вашу страницу из результатов поиска. Стандарты Google высоки, и они требуют того же от вас, если вы хотите попасть в топ поисковой выдачи, но если вы используете сомнительные стратегии или методы, это может не только повлиять на ваш рейтинг, но и разрушить его.
С 2000 года Google обновляет свои алгоритмы, начиная с расширения панели инструментов. Это был первый раз, когда ранг страницы стал проблемой для многих владельцев онлайн-бизнеса, и все изо всех сил старались получить этот рейтинг номер один. По мере того, как Google настраивал свои алгоритмы и работал над тем, чтобы их посетители получали ТОЛЬКО самые верхние и наиболее релевантные результаты поиска, в игру вступали штрафы.
В 2012 году, когда появилось обновление Penguin, пострадал 1 из 10 результатов поиска, а многие веб-сайты были удалены из массивного индекса Google, что сделало их несуществующими для миллионов людей. Цель состояла в том, чтобы вытеснить некачественные веб-сайты с карты и из поисковых запросов. Дни чрезмерного использования ключевых слов для привлечения внимания прошли, и родилась новая эра качественного контента… СПАСИБО GOOOGLE!
Многие сайты по-прежнему подвергаются штрафным санкциям, и в ближайшем будущем будет выходить все больше и больше обновлений, и эта тенденция будет продолжаться до тех пор, пока все не начнут следовать рекомендациям, установленным гигантом поисковых систем. Прочтите и усвойте Руководство Google для веб-мастеров, чтобы никогда не получить штраф от Google.
Прочтите и усвойте Руководство Google для веб-мастеров, чтобы никогда не получить штраф от Google.
Читайте дальше, чтобы узнать больше о поисковых системах:
- Что такое алгоритм и что он означает для успеха вашего бизнеса?
- Новое SEO, ценный взгляд в будущее
- 11 элементов SEO, которые необходимо реализовать на вашей странице в 2016 году
- Советы по внутренней и внешней поисковой оптимизации
- Почему взаимодействие с пользователем влияет на ваши позиции в поиске
- 6 основных вещей, которые посетители ожидают от вашего сайта?
Уже разбираетесь в поисковых системах? Перейти к одному из следующих разделов…
- Штрафы Google
- Создание веб-сайта с хорошим SEO
- Базовая структура веб-сайта
- Веб-дизайн для SEO
- Письмо 101
- Станьте SEO-экспертом
- Передовые стратегии SEO
- Все, что вы должны знать о ссылках
- Маркетинг PPC
- Почему маркетинг так важен
- Контент-маркетинг
- Интернет-маркетинг
- Маркетинг в социальных сетях для успеха
- Все о блогах
- Безопасность и защита вашего веб-сайта
- Аутсорсинг для успеха
- Будьте в курсе изменений
- Продукты и инструменты на рассмотрении
- Полезные инструменты и советы
- SEO-инструменты
- Предотвращение негативного SEO
- Поиск и устранение неисправностей
- Взгляд назад
Каковы 10 самых популярных поисковых систем?
Вы знаете, кроме самая очевидная поисковая система . И, возможно, второй самый очевидный тоже. Начну опять, какие восемь самых популярных поисковых систем после Google и Bing?
И, возможно, второй самый очевидный тоже. Начну опять, какие восемь самых популярных поисковых систем после Google и Bing?
Первый список ниже содержит самые популярные поисковые системы, доступные в настоящее время, упорядоченные по популярности в США. Рейтинг составлен по версии eBiz в порядке расчетного числа уникальных посетителей в месяц и актуален по состоянию на август 2016 г.
Второй список представляет собой глобальный обзор наиболее популярных поисковых систем согласно Net Market Share, который ранжируется в порядке доли рынка и снова является точным по состоянию на август 2016 года.
В отличие от нашего предыдущего списка альтернатив поисковых систем для Google, этот список будет сосредоточен исключительно на информационном поиске, а не на… Gif или изображениях без авторских прав.
США
1) Google
Оценка уникальных посетителей в месяц: 1,6 миллиарда
Alexa Rank: 1
Почему вы должны его использовать?
Имея 72,48% доли мирового рынка поиска, у вас как у маркетолога нет выбора не использовать его как для платного, так и для органического охвата.
Как обычный пользователь, несмотря на весь наш цинизм и иногда легкомысленные ссылки на The Circle, вы должны признать, что Google совершенно незаменим в вашей повседневной жизни. На каждое вмешательство (постоянное урезание результатов органической выдачи) приходится 10 триумфов… Google Maps, Gmail, ужасающая релевантность Knowledge Graph, убийство рекламы займов до зарплаты, AMP…
Где бы мы все были без… да, я скажу это… поискового гиганта.
2) Bing
Ресурсы
Расчетное количество уникальных посетителей в месяц: 400 миллионов
Alexa Rank: 22
Почему вы должны его использовать?
Как я уже говорил ранее в этом году в вышеупомянутом посте «альтернативы Google», есть несколько веских причин для выбора Bing:
- Поиск видео в Bing значительно лучше, чем в Google.
- Bing часто предлагает в два раза больше вариантов автозаполнения, чем Google.

- В Bing есть отличная функция linkfromdomain:[имя сайта] , которая выделяет исходящие ссылки с этого сайта с лучшим рейтингом, помогая вам выяснить, на какие другие сайты больше всего ссылается выбранный вами сайт.
3) Yahoo.
На данный момент все это находится в подвешенном состоянии, поскольку Verizon только что приобрела Yahoo за 4,8 миллиарда долларов и планирует объединить ее с AoL.
Yahoo будет продолжать работать независимо до одобрения сделки регулирующими органами, которая, как ожидается, будет завершена к началу 2017 года. После этого все новостные, финансовые и спортивные платформы Yahoo будут добавлены к медиаактивам AOL, включая The Huffington Post. и TechCrunch.
4) Спросите
Расчетное количество уникальных посетителей в месяц: 245 миллионов
Alexa Rank: 31
Почему вы должны его использовать?
Несмотря на решимость Google быть основным шрифтом всех знаний в своей собственной поисковой выдаче, Ask по-прежнему хорош для поиска, связанного с конкретными вопросами, с результатами, основанными на совпадениях, связанных с вопросами и ответами.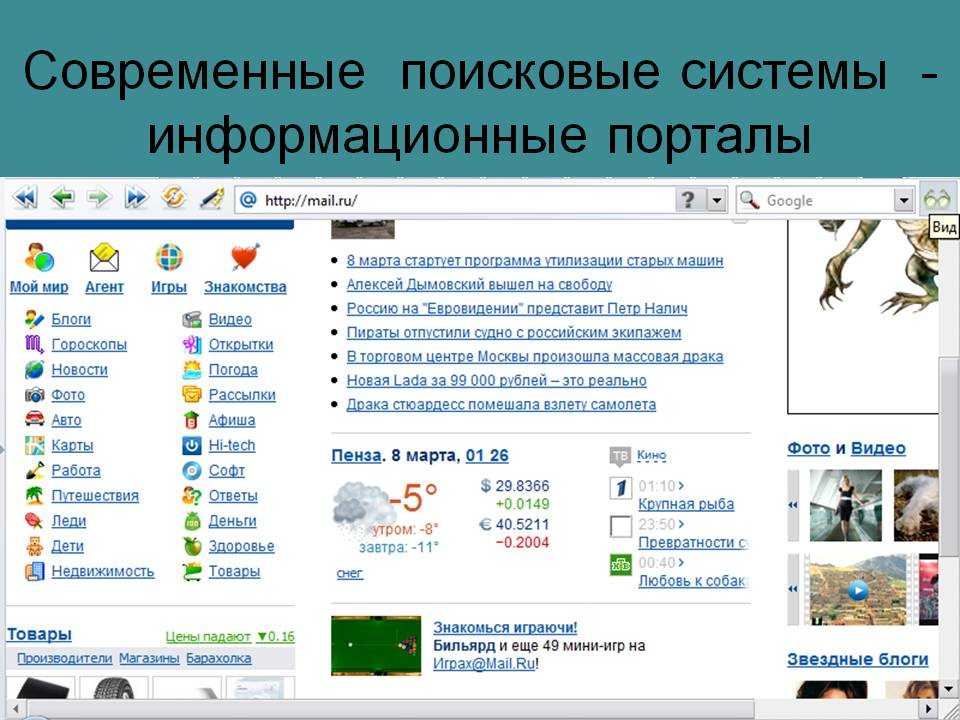
И эй, иногда приятно получить помощь от дворецкого.
5) Aol Search
Расчетное количество уникальных посетителей в месяц: 125 миллионов
Alexa Rank: н/д
Почему вы должны его использовать?
Как упоминалось выше, AOL, которую вы знаете и, возможно, любите, может стать другим зверем после того, как Verizon Communications объединит ее с Yahoo.
Давайте запомним более простые времена…
6) WOW
Оценка уникальных ежемесячных посетителей: 100 млн.
Ранг Alexa: 767
Почему вы используете его?
Потому что он больше похож на новостной сайт, чем на поисковую систему, что удобно, если вам нужно все в одном месте.![]() Существует сильный уклон к новостям и статьям о знаменитостях, а не к чистой информации в стиле Википедии, но удобные ссылки на соответствующие социальные каналы и вики-страницы полезны.
Существует сильный уклон к новостям и статьям о знаменитостях, а не к чистой информации в стиле Википедии, но удобные ссылки на соответствующие социальные каналы и вики-страницы полезны.
7) WebCrawler
Расчетное количество уникальных посетителей в месяц: 65 миллионов
Alexa Rank: 674
Почему вы должны его использовать?
WebCrawler имеет гораздо более четкое разграничение между платной поисковой рекламой и обычными результатами. Кроме того, кажется, что у него гораздо больше естественных «синих ссылок», чем у Google.
8) MyWebSearch
Расчетное количество уникальных посетителей в месяц: 60 миллионов
Alexa Rank: 405
Почему вы должны его использовать?
Э… не надо.
Согласно Malware Wikia, MyWebSearch — это программа-шпион и панель инструментов поиска, которая позволяет пользователю запрашивать различные популярные поисковые системы и поставляется в комплекте с утомительным набором «плюшек», таких как Smiley Central, Webfetti, Cursor Mania, My Mail Stationary, My Mail Signature, My Mail Stamps, FunBuddyIcons… веселье продолжается и продолжается.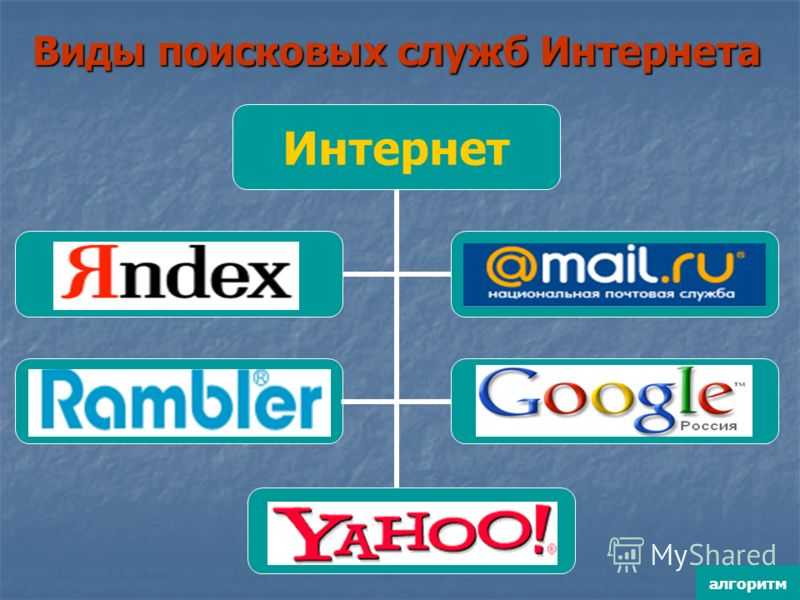
Но самое ужасное, что Malware Wikia сообщает, что, несмотря на отсутствие каких-либо атрибутов вредоносного ПО, независимая ремонтная лаборатория классифицировала панель инструментов как неприятную из-за «замедления работы в обмен на функции, которые уже встроены во многие современные веб-браузеры».
9) Infospace
Расчетное количество уникальных посетителей в месяц: 24 миллиона
Alexa Rank: 2,110
Почему вы должны его использовать?
Возможно, вы уже используете его… InfoSpace является «поставщиком решений для поиска и монетизации с использованием белой этикетки», а также управляет собственными фирменными поисковыми сайтами, включая метапоисковую систему Dogpile, а также Zoo.com и WebCrawler (как упоминалось выше.)
10) Info.com
Расчетное количество уникальных посетителей в месяц: 13,5 миллионов
Alexa Rank: 1 938
Почему вы должны его использовать?
Info.