Как создать и правильно настроить файла robots.txt для индексации сайта
Привет, я руководитель SEO-отдела в компании TRINET.Group. Если на сайте падает трафик, возможно, запрещена индексация для поисковых систем. Причина в файле robots.txt. Если вовремя обнаружить проблему и настроить его работу правильно, индексация веб-страниц восстановится.
В этом видео я рассказываю, как robots.txt влияет на индексацию
В этой статье рассмотрим:
Что такое robots.txt?
Как его правильно настроить?
Какие сервисы использовать для проверок robots.txt?
Почему не стоит запрещать пагинацию?
Что такое robots.txt
Справка: robots.
txt — это файл в корневом каталоге, который отвечает за то, чтобы сайт был открыт для индексации и сканирования страницы или ее элементов поисковыми системами.
 txt — это файл в корневом каталоге, который отвечает за то, чтобы сайт был открыт для индексации и сканирования страницы или ее элементов поисковыми системами.
txt — это файл в корневом каталоге, который отвечает за то, чтобы сайт был открыт для индексации и сканирования страницы или ее элементов поисковыми системами.Пример файла robots.txt
Прежде чем зайти на сайт, поисковая система обращается к файлу robots.txt и индексирует директивы — правила, которые запрещают индексацию страниц. Например, указан «User-agent» — обязательная директива, где указано, для какого робота указаны правила. Если стоит «*» (звездочка), это означает руководство для всех роботов. Можно создать персональные правила для ботов Яндекса (User-agent: Yandex) или Google (User-agent: Googlebot).
Читайте также: Разница SEO-продвижения в «Яндекс» и Google: почему отличаются позиции в поисковиках
Файл передает один из трех вариантов разрешений:
Частичный допуск — сканирование отдельных элементов. Запрещает индексацию данных, которые нельзя допускать в выдачу — формы с личными данными пользователей, дублированные страницы, неуникальные изображения и др.
Полный доступ — разрешено сканировать все.
Полный запрет — нельзя сканировать ничего. Часто такое ограничение применяется при размещении нового сайта, чтобы он был закрыт для посещения, пока ведется его разработка, наполнение и проверка работы.
Часто разработчики при запуске нового сайта забывают обновить этот файл и открыть сайт для индексации. И почему-то делают это по пятницам, не предупреждая никого. Таким образом, страницы нового сайта автоматически будут закрыты на выходные, трафик и продажи упадут. Страницы могут вылетать из индекса — обычно до 2 недель.
Если это быстро заметить, после исправления robots.txt индексация восстановится и позиции могут вернуться обратно. Если до открытия индексации пройдет больше недели, могут быть более негативные последствия.
Читайте также: SEO-специалист: кто это, его задачи, умения и навыки
Файл robots. txt необходим, и его важно корректно настраивать. Например, вам не нужно, чтобы поисковая система просканировала какие-то дублированные изображения или вы хотите скрыть от посетителей раздел, предназначенный только для сотрудников.
txt необходим, и его важно корректно настраивать. Например, вам не нужно, чтобы поисковая система просканировала какие-то дублированные изображения или вы хотите скрыть от посетителей раздел, предназначенный только для сотрудников.
Главное предназначение robots.txt в SEO — закрытие дублей. Например, есть технические дубли страниц сортировки, фильтрации, UTM-метки, которые генерирует система управления сайтом CMS. От таких страниц в индексе необходимо избавиться, закрыть их от индексации.
Как создать robots.txt и настроить его работу
Это обычный текстовый файл, который создается в блокноте. Указываются User-agent с помощью значка «звездочка» и ниже прописываются правила.
Существует несколько способов, как создать robots.txt:
Самый простой метод — посмотреть стандартные правила для CMS сайта. Обычно туда включены рекомендации, что именно нужно закрыть от индексации. Эту информацию можно найти в интернете, например для Bitrix или WordPress. С помощью специальных плагинов и модулей редактирование возможно даже с административной панели CMS.

Инструменты в Яндекс.Вебмастер и в Google Search Console позволят вам осуществить проверку ваших директив, чтобы избежать ошибок.
Если сайт новый, за исходник можно взять стандарт и потом проверить в инструментах через валидатор. Он сканирует robots.txt на содержание ошибок. В него можно добавить страницу сайта и посмотреть, какие элементы открыты, а какие закрыты.
Справка: Файл robots.txt создается через блокнот и сохраняется в формате «.txt». Учитывайте ограничение по размеру до 32 Кб на индексацию поисковой системой Яндекс.
Для формирования файла в CMS есть свои плагины. Классический вариант размещения — публикация через файловый менеджер или FTP-соединение с перезаписыванием файла. Обязательно проверьте результат. Возможно кэширование результатов — в таком случае обновите кэш браузера. Если хочется внедрить изменения и узнать, как будет работать страница, закроется ли она от индексации, не запретили ли лишнего, используйте сервисы проверки от Яндекса.
Читайте также: Актуальный сборник статей по SEO 2021 — статьи о продвижении и оптимизации сайтов
Основные директивы robots.txt
Инструкции для поисковых роботов указываются с помощью символов и текста. Важно разобраться, какие директивы за что отвечают. Есть стандартные формулировки правил. Вот несколько примеров директив:
Disallow — запрет сканирования. Ставится двоеточие и внутри знаков «/» пишется название раздела, который нельзя сканировать. Disallow: /admin/ — будет запрещена индексация содержимого указанного раздела.
Allow — разрешающая директива. По умолчанию все, что не запрещено, то разрешено.
«$» — указывает на конец строки, например Disallow: /poly/$, папку индексировать нельзя, а ее содержимое можно.
Sitemap — указывает путь к карте сайта для ускорения индексации.
C помощью специальных платных программ можно удобно изучать каждую страницу на предмет доступности для индексации.![]()
Пример проверки в Яндекс Вебмастер
Screaming Frog.
Netpeak Spider.
Почему не стоит запрещать пагинацию
Справка: пагинация — это разделение контента на сайте на отдельные страницы. Часто применяется в каталогах интернет-магазинов.
Пример страниц пагинации
Например, в одном из листингов представлены кольца — 1000 видов. Если разместить все в одном разделе, скорость загрузки страницы будет крайне низкой. Чтобы не выводить 1000 позиций в одном листинге, его разбивают на подстраницы для удобства клиентов и поисковых роботов.
Мы не рекомендуем закрывать пагинацию от поисковых роботов, чтобы ссылки на товары появлялись в выдаче и разделы сайта быстро индексировались. Поисковые системы должны просканировать все товары и узнать обо всем ассортименте.
Если правильно настраивать robots.txt и проверять его настройки, проблем с индексацией из-за этого файла не возникнет. Если обнаружены неполадки, рекомендуем обратиться к специалистам либо разобраться в вопросе самостоятельно.
Если обнаружены неполадки, рекомендуем обратиться к специалистам либо разобраться в вопросе самостоятельно.
Workspace.LIVE — мы в Телеграме
Новости в мире диджитал, ответы экспертов на злободневные темы, опросы, статьи и многое другое. Подписывайтесь: https://t.me/workspace
Как создать правильный файл robots.txt, настройка, директивы
Файл robots.txt — текстовый файл в формате .txt, ограничивающий поисковым роботам доступ к содержимому на http-сервере.
Как определение, Robots.txt — это стандарт исключений для роботов, который был принят консорциумом W3C 30 января 1994 года, и который добровольно использует большинство поисковых систем. Файл robots.txt состоит из набора инструкций для поисковых роботов, которые запрещают индексацию определенных файлов, страниц или каталогов на сайте. Рассмотрим описание robots.txt для случая, когда сайт не ограничивает доступ роботам к сайту.![]()
Простой пример:
User-agent: * Allow: /
Здесь роботс полностью разрешает индексацию всего сайта.
Файл robots.txt необходимо загрузить в корневой каталог вашего сайта, чтобы он был доступен по адресу:
ваш_сайт.ru/robots.txt
Для размещения файла в корне сайта обычно необходим доступ через FTP. Однако, некоторые системы управления (CMS) дают возможность создать robots.txt непосредственно из панели управления сайтом или через встроенный FTP-менеджер.
Если файл доступен, то вы увидите содержимое в браузере.
Для чего нужен robots.txt
Сформированный файл для сайта является важным аспектом поисковой оптимизации. Зачем нужен robots.txt? Например, в SEO robots.txt нужен для того, чтобы исключать из индексации страницы, не содержащие полезного контента и многое другое. Как, что, зачем и почему исключается уже было описано в статье про запрет индексации страниц сайта, здесь не будем на этом останавливаться. Нужен ли файл robots.txt всем сайтам? И да и нет. Если использование подразумевает исключение страниц из поиска, то для небольших сайтов с простой структурой и статичными страницами подобные исключения могут быть лишними. Однако, и для небольшого сайта могут быть полезны некоторые директивы, например директива Host или Sitemap, но об этом ниже.
Нужен ли файл robots.txt всем сайтам? И да и нет. Если использование подразумевает исключение страниц из поиска, то для небольших сайтов с простой структурой и статичными страницами подобные исключения могут быть лишними. Однако, и для небольшого сайта могут быть полезны некоторые директивы, например директива Host или Sitemap, но об этом ниже.
Как создать robots.txt
Поскольку это текстовый файл, нужно воспользоваться любым текстовым редактором, например Блокнотом. Как только вы открыли новый текстовый документ, вы уже начали создание robots.txt, осталось только составить его содержимое, в зависимости от ваших требований, и сохранить в виде текстового файла с названием robots в формате txt. Все просто, и создание файла не должно вызвать проблем даже у новичков. О том, как составить и что писать в роботсе на примерах покажу ниже.
Cоздать robots.txt онлайн
Вариант для ленивых: скачать в уже в готовом виде. Создание robots txt онлайн предлагает множество сервисов, выбор за вами. Главное — четко понимать, что будет запрещено и что разрешено, иначе создание файла robots.txt online может обернуться трагедией, которую потом может быть сложно исправить. Особенно, если в поиск попадет то, что должно было быть закрытым. Будьте внимательны — проверьте свой файл роботс, прежде чем выгружать его на сайт. Все же пользовательский файл robots.txt точнее отражает структуру ограничений, чем тот, что был сгенерирован автоматически и скачан с другого сайта. Читайте дальше, чтобы знать, на что обратить особое внимание при редактировании robots.txt.
Главное — четко понимать, что будет запрещено и что разрешено, иначе создание файла robots.txt online может обернуться трагедией, которую потом может быть сложно исправить. Особенно, если в поиск попадет то, что должно было быть закрытым. Будьте внимательны — проверьте свой файл роботс, прежде чем выгружать его на сайт. Все же пользовательский файл robots.txt точнее отражает структуру ограничений, чем тот, что был сгенерирован автоматически и скачан с другого сайта. Читайте дальше, чтобы знать, на что обратить особое внимание при редактировании robots.txt.
Редактирование robots.txt
После того, как вам удалось создать файл robots.txt онлайн или своими руками, вы можете редактировать robots.txt. Изменить его содержимое можно как угодно, главное — соблюдать некоторые правила и синтаксис robots.txt. В процессе работы над сайтом, файл роботс может меняться, и если вы производите редактирование robots.txt, то не забывайте выгружать на сайте обновленную, актуальную версию файла со всем изменениями. Далее рассмотрим правила настройки файла, чтобы знать, как изменить файл robots.txt и «не нарубить дров».
Далее рассмотрим правила настройки файла, чтобы знать, как изменить файл robots.txt и «не нарубить дров».
Правильная настройка robots.txt
Правильная настройка robots.txt позволяет избежать попадания частной информации в результаты поиска крупных поисковых систем. Однако, не стоит забывать, что команды robots.txt не более чем руководство к действию, а не защита. Роботы надежных поисковых систем, вроде Яндекс или Google, следуют инструкциям robots.txt, однако прочие роботы могут легко игнорировать их. Правильное понимание и применение robots.txt — залог получения результата.
Чтобы понять, как сделать правильный robots txt, для начала необходимо разобраться с общими правилами, синтаксисом и директивами файла robots.txt.
Правильный robots.txt начинается с директивы User-agent, которая указывает, к какому роботу обращены конкретные директивы.
Примеры User-agent в robots.txt:
# Указывает директивы для всех роботов одновременно User-agent: * # Указывает директивы для всех роботов Яндекса User-agent: Yandex # Указывает директивы для только основного индексирующего робота Яндекса User-agent: YandexBot # Указывает директивы для всех роботов Google User-agent: Googlebot
Учитывайте, что подобная настройка файла robots. txt указывает роботу использовать только директивы, соответствующие user-agent с его именем.
txt указывает роботу использовать только директивы, соответствующие user-agent с его именем.
Пример robots.txt с несколькими вхождениями User-agent:
# Будет использована всеми роботами Яндекса User-agent: Yandex Disallow: /*utm_ # Будет использована всеми роботами Google User-agent: Googlebot Disallow: /*utm_ # Будет использована всеми роботами кроме роботов Яндекса и Google User-agent: * Allow: /*utm_
Директива User-agent создает лишь указание конкретному роботу, а сразу после директивы User-agent должна идти команда или команды с непосредственным указанием условия для выбранного робота. В примере выше используется запрещающая директива «Disallow», которая имеет значение «/*utm_». Таким образом, закрываем все страницы с UTM-метками. Правильная настройка robots.txt запрещает наличие пустых переводов строки между директивами «User-agent», «Disallow» и директивами следующими за «Disallow» в рамках текущего «User-agent».
Пример неправильного перевода строки в robots. txt:
txt:
User-agent: Yandex Disallow: /*utm_ Allow: /*id= User-agent: * Disallow: /*utm_ Allow: /*id=
Пример правильного перевода строки в robots.txt:
User-agent: Yandex Disallow: /*utm_ Allow: /*id= User-agent: * Disallow: /*utm_ Allow: /*id=
Как видно из примера, указания в robots.txt поступают блоками, каждый из которых содержит указания либо для конкретного робота, либо для всех роботов «*».
Кроме того, важно соблюдать правильный порядок и сортировку команд в robots.txt при совместном использовании директив, например «Disallow» и «Allow». Директива «Allow» — разрешающая директива, является противоположностью команды robots.txt «Disallow» — запрещающей директивы.
Пример совместного использования директив в robots.txt:
User-agent: * Allow: /blog/page Disallow: /blog
Данный пример запрещает всем роботам индексацию всех страниц, начинающихся с «/blog», но разрешает индексации страниц, начинающиеся с «/blog/page».
Прошлый пример robots. txt в правильной сортировке:
txt в правильной сортировке:
User-agent: * Disallow: /blog Allow: /blog/page
Сначала запрещаем весь раздел, потом разрешаем некоторые его части.
Еще один правильный пример robots.txt с совместными директивами:
User-agent: * Allow: / Disallow: /blog Allow: /blog/page
Обратите внимание на правильную последовательность директив в данном robots.txt.
Директивы «Allow» и «Disallow» можно указывать и без параметров, в этом случае значение будет трактоваться обратно параметру «/».
Пример директивы «Disallow/Allow» без параметров:
User-agent: * Disallow: # равнозначно Allow: / Disallow: /blog Allow: /blog/page
Как составить правильный robots.txt и как пользоваться трактовкой директив — ваш выбор. Оба варианта будут правильными. Главное — не запутайтесь.
Для правильного составления robots.txt необходимо точно указывать в параметрах директив приоритеты и то, что будет запрещено для скачивания роботам. Более полно использование директив «Disallow» и «Allow» мы рассмотрим чуть ниже, а сейчас рассмотрим синтаксис robots.txt. Знание синтаксиса robots.txt приблизит вас к тому, чтобы создать идеальный robots txt своими руками.
Более полно использование директив «Disallow» и «Allow» мы рассмотрим чуть ниже, а сейчас рассмотрим синтаксис robots.txt. Знание синтаксиса robots.txt приблизит вас к тому, чтобы создать идеальный robots txt своими руками.
Синтаксис robots.txt
Роботы поисковых систем добровольно следуют командам robots.txt — стандарту исключений для роботов, однако не все поисковые системы трактуют синтаксис robots.txt одинаково. Файл robots.txt имеет строго определённый синтаксис, но в то же время написать robots txt не сложно, так как его структура очень проста и легко понятна.
Вот конкретные список простых правил, следуя которым, вы исключите частые ошибки robots.txt:
- Каждая директива начинается с новой строки;
- Не указывайте больше одной директивы в одной строке;
- Не ставьте пробел в начало строки;
- Параметр директивы должен быть в одну строку;
- Не нужно обрамлять параметры директив в кавычки;
- Параметры директив не требуют закрывающих точки с запятой;
- Команда в robots.
 txt указывается в формате — [Имя_директивы]:[необязательный пробел][значение][необязательный пробел];
txt указывается в формате — [Имя_директивы]:[необязательный пробел][значение][необязательный пробел]; - Допускаются комментарии в robots.txt после знака решетки #;
- Пустой перевод строки может трактоваться как окончание директивы User-agent;
- Директива «Disallow: » (с пустым значением) равнозначна «Allow: /» — разрешить все;
- В директивах «Allow», «Disallow» указывается не более одного параметра;
- Название файла robots.txt не допускает наличие заглавных букв, ошибочное написание названия файла — Robots.txt или ROBOTS.TXT;
- Написание названия директив и параметров заглавными буквами считается плохим тоном и если по стандарту, robots.txt и нечувствителен к регистру, часто к нему чувствительны имена файлов и директорий;
- Если параметр директивы является директорией, то перед название директории всегда ставится слеш «/», например: Disallow: /category
- Слишком большие robots.txt (более 32 Кб) считаются полностью разрешающими, равнозначными «Disallow: »;
- Недоступный по каким-либо причинам robots.
 txt может трактоваться как полностью разрешающий;
txt может трактоваться как полностью разрешающий; - Если robots.txt пустой, то он будет трактоваться как полностью разрешающий;
- В результате перечисления нескольких директив «User-agent» без пустого перевода строки, все последующие директивы «User-agent», кроме первой, могут быть проигнорированы;
- Использование любых символов национальных алфавитов в robots.txt не допускается.
Поскольку разные поисковые системы могут трактовать синтаксис robots.txt по-разному, некоторые пункты можно опустить. Так например, если прописать несколько директив «User-agent» без пустого перевода строки, все директивы «User-agent» будут восприняты корректно Яндексом, так как Яндекс выделяет записи по наличию в строке «User-agent».
В роботсе должно быть указано строго только то, что нужно, и ничего лишнего. Не думайте, как прописать в robots txt все, что только можно и чем его заполнить. Идеальный robots txt — это тот, в котором меньше строк, но больше смысла. «Краткость — сестра таланта». Это выражение здесь как нельзя кстати.
«Краткость — сестра таланта». Это выражение здесь как нельзя кстати.
Как проверить robots.txt
Для того, чтобы проверить robots.txt на корректность синтаксиса и структуры файла, можно воспользоваться одной из онлайн-служб. К примеру, Яндекс и Google предлагают собственные сервисы анализа сайта для вебмастеров, которые включают анализ robots.txt:
Проверка файла robots.txt в Яндекс.Вебмастер: http://webmaster.yandex.ru/robots.xml
Проверка файла robots.txt в Google: https://www.google.com/webmasters/tools/siteoverview?hl=ru
Для того, чтобы проверить robots.txt онлайн необходимо загрузить robots.txt на сайт в корневую директорию. Иначе, сервис может сообщить, что не удалось загрузить robots.txt. Рекомендуется предварительно проверить robots.txt на доступность по адресу где лежит файл, например: ваш_сайт.ru/robots.txt.
Кроме сервисов проверки от Яндекс и Google, существует множество других онлайн валидаторов robots. txt.
txt.
Robots.txt vs Яндекс и Google
Есть субъективное мнение, что указание отдельного блока директив «User-agent: Yandex» в robots.txt Яндекс воспринимает более позитивно, чем общий блок директив с «User-agent: *». Аналогичная ситуация robots.txt и Google. Указание отдельных директив для Яндекс и Google позволяет управлять индексацией сайта через robots.txt. Возможно, им льстит персонально обращение, тем более, что для большинства сайтов содержимое блоков robots.txt Яндекса, Гугла и для других поисковиков будет одинаково. За редким исключением, все блоки «User-agent» будут иметь стандартный для robots.txt набор директив. Так же, используя разные «User-agent» можно установить запрет индексации в robots.txt для Яндекса, но, например не для Google.
Отдельно стоит отметить, что Яндекс учитывает такую важную директиву, как «Host», и правильный robots.txt для яндекса должен включать данную директиву для указания главного зеркала сайта. Подробнее директиву «Host» рассмотрим ниже.
Подробнее директиву «Host» рассмотрим ниже.
Запретить индексацию: robots.txt Disallow
Disallow — запрещающая директива, которая чаще всего используется в файле robots.txt. Disallow запрещает индексацию сайта или его части, в зависимости от пути, указанного в параметре директивы Disallow.
Пример как в robots.txt запретить индексацию сайта:
User-agent: * Disallow: /
Данный пример закрывает от индексации весь сайт для всех роботов.
В параметре директивы Disallow допускается использование специальных символов * и $:
* — любое количество любых символов, например, параметру /page* удовлетворяет /page, /page1, /page-be-cool, /page/kak-skazat и т.д. Однако нет необходимости указывать * в конце каждого параметра, так как например, следующие директивы интерпретируются одинаково:
User-agent: Yandex Disallow: /page
User-agent: Yandex Disallow: /page*
$ — указывает на точное соответствие исключения значению параметра:
User-agent: Googlebot Disallow: /page$
В данном случае, директива Disallow будет запрещать /page, но не будет запрещать индексацию страницы /page1, /page-be-cool или /page/kak-skazat.
Если закрыть индексацию сайта robots.txt, в поисковые системы могут отреагировать на так ход ошибкой «Заблокировано в файле robots.txt» или «url restricted by robots.txt» (url запрещенный файлом robots.txt). Если вам нужно запретить индексацию страницы, можно воспользоваться не только robots txt, но и аналогичными html-тегами:
- <meta name=»robots» content=»noindex»/> — не индексировать содержимое страницы;
- <meta name=»robots» content=»nofollow»/> — не переходить по ссылкам на странице;
- <meta name=»robots» content=»none»/> — запрещено индексировать содержимое и переходить по ссылкам на странице;
- <meta name=»robots» content=»noindex, nofollow»/> — аналогично content=»none».
Разрешить индексацию: robots.txt Allow
Allow — разрешающая директива и противоположность директиве Disallow. Эта директива имеет синтаксис, сходный с Disallow.
Пример, как в robots. txt запретить индексацию сайта кроме некоторых страниц:
txt запретить индексацию сайта кроме некоторых страниц:
User-agent: * Disallow: / Allow: /page
Запрещается индексировать весь сайт, кроме страниц, начинающихся с /page.
Disallow и Allow с пустым значением параметра
Пустая директива Disallow:
User-agent: * Disallow:
Не запрещать ничего или разрешить индексацию всего сайта и равнозначна:
User-agent: * Allow: /
Пустая директива Allow:
User-agent: * Allow:
Разрешить ничего или полный запрет индексации сайта, равнозначно:
User-agent: * Disallow: /
Главное зеркало сайта: robots.txt Host
Директива Host служит для указания роботу Яндекса главного зеркала Вашего сайта. Из всех популярных поисковых систем, директива Host распознаётся только роботами Яндекса. Директива Host полезна в том случае, если ваш сайт доступен по нескольким доменам, например:
mysite.ru mysite.com
Или для определения приоритета между:
mysite.ru www.mysite.ru
Роботу Яндекса можно указать, какое зеркало является главным. Директива Host указывается в блоке директивы «User-agent: Yandex» и в качестве параметра, указывается предпочтительный адрес сайта без «http://».
Пример robots.txt с указанием главного зеркала:
User-agent: Yandex Disallow: /page Host: mysite.ru
В качестве главного зеркала указывается доменное имя mysite.ru без www. Таки образом, в результатах поиска буде указан именно такой вид адреса.
User-agent: Yandex Disallow: /page Host: www.mysite.ru
В качестве основного зеркала указывается доменное имя www.mysite.ru.
Директива Host в файле robots.txt может быть использована только один раз, если же директива Хост будет указана более одного раза, учитываться будет только первая, прочие директивы Host будут игнорироваться.
Если вы хотите указать главное зеркало для робота Google, воспользуйтесь сервисом Google Инструменты для вебмастеров.
Карта сайта: robots.
 txt sitemap
txt sitemapПри помощи директивы Sitemap, в robots.txt можно указать расположение на сайте файла карты сайта sitemap.xml.
Пример robots.txt с указанием адреса карты сайта:
User-agent: * Disallow: /page Sitemap: http://www.mysite.ru/sitemap.xml
Указание адреса карты сайта через директиву Sitemap в robots.txt позволяет поисковому роботу узнать о наличии карты сайта и начать ее индексацию.
Директива Clean-param
Директива Clean-param позволяет исключить из индексации страницы с динамическими параметрами. Подобные страницы могут отдавать одинаковое содержимое, имея различные URL страницы. Проще говоря, будто страница доступна по разным адресам. Наша задача убрать все лишние динамические адреса, которых может быть миллион. Для этого исключаем все динамические параметры, используя в robots.txt директиву Clean-param.
Синтаксис директивы Clean-param:
Clean-param: parm1[&parm2&parm3&parm4&..&parmn] [Путь]
Рассмотрим на примере страницы со следующим URL:
www.mysite.ru/page.html?&parm1=1&parm2=2&parm3=3
Пример robots.txt Clean-param:
Clean-param: parm1&parm2&parm3 /page.html # только для page.html
или
Clean-param: parm1&parm2&parm3 / # для всех
Директива Crawl-delay
Данная инструкция позволяет снизить нагрузку на сервер, если роботы слишком часто заходят на ваш сайт. Данная директива актуальна в основном для сайтов с большим объемом страниц.
Пример robots.txt Crawl-delay:
User-agent: Yandex Disallow: /page Crawl-delay: 3
В данном случае мы «просим» роботов яндекса скачивать страницы нашего сайта не чаще, чем один раз в три секунды. Некоторые поисковые системы поддерживают формат дробных чисел в качестве параметра директивы Crawl-delay robots.txt.
Комментарии в robots.txt
Комментарий в robots.txt начинаются с символа решетки — #, действует до конца текущей строки и игнорируются роботами.
Примеры комментариев в robots.txt:
User-agent: * # Комментарий может идти от начала строки Disallow: /page # А может быть продолжением строки с директивой # Роботы # игнорируют # комментарии Host: www.mysite.ru
В заключении
Файл robots.txt — очень важный и нужный инструмент взаимодействия с поисковыми роботами и один из важнейших инструментов SEO, так как позволяет напрямую влиять на индексацию сайта. Используйте роботс правильно и с умом.
Если у вас есть вопросы — пишите в комментариях.
Рекомендуйте статью друзьям и не забывайте подписываться на блог.
Новые интересные статьи каждый день.
Как настроить и добавить robots.txt на сайт
Поисковые системы ранжируют страницы согласно заданным параметрам. Если не прописать условия ранжирования с помощью специальных инструментов, в топ выдачи попадут ненужные страницы, а нужные — останутся в тени. Чтобы этого избежать, необходимо настроить robots. txt.
txt.
Что такое файл robots.txt, для чего он нужен и за что отвечает
Robots.txt — простой, но важный файл для SEO-продвижения. Он содержит команды и инструкции по индексации сайта.
Правильный robots.txt позволит закрыть от индексации, например, технические страницы. Это нужно для того, чтобы оптимизировать сайт под поисковые системы и повысить его позиции в выдаче.
Как создать и добавить robots.txt на сайт
Если у вашего сайта нет robots.txt, то он считается полностью открытым для индексирования.
Robots.txt сайта yandex.ru
Создаем файл в блокноте или любой текстовой программе — подойдет Word, NotePad и т. д. Главное, чтобы вы сохранили файл в формате “.txt” и назвали его “robots”. В тексте нужно будет прописать страницы, которые можно и нельзя индексировать, указать нужные директивы.
Разрешили сканировать все, что начинается с “/catalog”, запретили доступ к разделам “about”, “info”, “album1”
Исключать из индексации нужно те страницы, которые не содержат полезной и релевантной для целевой аудитории информации:
- страницы авторизации и регистрации;
- результаты поиска;
- служебные разделы;
- страницы фильтров;
- PDF-документы;
- разрабатываемые страницы;
- формы заказа, корзина и т.
 д.
д.
Файл загрузите в корень сайта через панель администратора.
Затем установить галочку в строке «Включить robots.txt» и внести в поле необходимые правила, нажать «Применить». Проверьте, открывается ли файл по адресу ваш_домен/robots.txt.
Как настроить файл robots.txt вручную
Для этого не нужно быть программистом или верстальщиком — достаточно разобраться, за что отвечает каждый параметр, который мы будем вносить в файл.
- User-agent. С этой директивы должен начинаться каждый robots.txt. Она показывает, для бота какой поисковой системы предназначается инструкция.
User-agent: YandexBot — для Яндекса,
User-agent: Googlebot — для Гугла,
User-Agent: * — общий для всех роботов.
https://vk.com/robots.txt предназначается для всех роботов поисковых систем
- Allow. Эта директива показывает, какие страницы может индексировать робот поисковых систем.
Например, в этом файле Яндексу разрешается индексировать весь сайт:
User-Agent: YandexBot
Allow: /
- Disallow.
 Полная противоположность предыдущей директивы — закрывает те страницы, которые запрещается индексировать.
Полная противоположность предыдущей директивы — закрывает те страницы, которые запрещается индексировать.
Директивы в файле robots.txt на сайте apple.com
- Sitemap. Этот параметр показывает, где находится карта сайта в формате XML, если такая у вас есть. Добавляется данная строчка в конец файла. Прописывается так:
Sitemap: http://www.вашсайт.ru/sitemap.xml
- Clean Param. Закрывает от индексации страницы с дублирующимся контентом. Это нужно для того, чтобы снизить нагрузку на сервер, — так робот поисковой системы не будет раз за разом перезагружать дублирующуюся информацию. Например, у вас есть три страницы с одинаковым содержанием, которые отличаются только параметром “get=”. Он нужен, чтобы понять, с какого сайта к вам пришел пользователь. В этом случае URL страниц разные, но все они ведут на одну и ту же страницу. Чтобы робот не индексировал всё как дубли, прописываем:
Clean-param: option /index.php
Готовые шаблоны файлов: где взять и как редактировать
Если нет желания или времени прописывать директивы вручную, можно воспользоваться сервисами для создания готовых файлов robots. txt для сайта. Однако, у этого способа есть свои плюсы и минусы.
txt для сайта. Однако, у этого способа есть свои плюсы и минусы.
Экономия времени — если у вас много сайтов, не придется для каждого вручную прописывать параметры
Директивы будут настроены однотипно, в них не учитываются особенности именно вашего сайта
Рассмотрим самые популярные сервисы:
- CY-PR. Интерфейс довольно простой — все, что требуется сделать, выбрать нужные поля и задать ваши значения. Готовый файл нужно перенести в корень сайта.
Интерфейс CY-PR
- Seo-auditor. Выбираете нужные поля и вводите ваши значения. Можно указать зеркало сайта, запретить скачивание сайта программами и адаптировать robots.txt под движок WordPress.
Интерфейс Seo-auditor
- IKSWEB. Еще один генератор с более разнообразной адаптацией настроек под CMS сайта — доступны WordPress, 1C-Bitrix, Blogger, uCoz и многие другие.
Интерфейс IKSWEB
После создания файла вы можете его редактировать под себя. Для этого достаточно открыть файл в блокноте и внести необходимые изменения в директивы. Не забудьте загрузить обновленный документ в корень сайта.
Не забудьте загрузить обновленный документ в корень сайта.
Как исправить ошибки при проверке robots.txt
В первой части статьи мы писали, как проверить корректную работу файла. Рассмотрим, как исправить ошибки, которые могут возникнуть.
Чек-лист для настройки файла robots.txt
- Файл имеет расширение “.txt” и называется “robots”.
- Файл загружен в корень сайта.
- Файл начинается с директивы User-agent и содержит не более 2 048 правил.
- Каждое правило длиной не более 1 024 символа.
- Файл содержит только одну директиву типа “User-agent: *”.
- После каждой директивы проставлено двоеточие, а затем прописан параметр.
- Файл успешно прошел проверку на сервисе, ошибок не обнаружено.
Перейти ко всем материалам блога
Зачем вам нужен файл robots.txt, и как его создать?
Файл robots. txt, он же стандарт исключений для роботов — это текстовый файл, в котором хранятся определенные указания для роботов поисковых систем.
txt, он же стандарт исключений для роботов — это текстовый файл, в котором хранятся определенные указания для роботов поисковых систем.
Прежде, чем сайт попадает в поисковую выдачу и занимает там определенное место, его исследуют роботы. Именно они передают информацию поисковым системам, и далее ваш ресурс отображается в поисковой строке.
Robots.txt выполняет важную функцию — он может защитить весь сайт или некоторые его разделы от индексации. Особенно это актуально для интернет-магазинов и других ресурсов, через которые совершаются онлайн-оплаты. Вам же не хочется, чтобы кредитные счета ваших клиентов вдруг стали известны всему интернету? Для этого и существует файл robots.txt.
Про директивы
Поисковые роботы по умолчанию сканируют все ссылки подряд, если только не установить им ограничений. Для этого в файле robots.txt составляют определенные команды или инструкции к действию. Такие инструкции называются директивами.
Главная директива-приветствие, с которой начинается индексация файла — это user-agent
Она может выглядеть так:
User-agent: Yandex
Или так:
User-agent: *
Или вот так:
User-agent: GoogleBot
User-agent обращается к конкретному роботу, и дальнейшие руководства к действию будут относиться только к нему.
Так, в первом случае инструкции будут касаться только роботов Яндекс, во втором — роботов всех поисковых систем, в последнем — команды предназначены главному роботу Google.
Резонно спросить: зачем обращаться к роботам по отдельности? Дело в том, что разные поисковые “посланцы” по разному подходят к индексации файла. Так, роботы Google беспрекословно соблюдают директиву sitemap (о ней написано ниже), в то время как роботы Яндекса относятся к ней нейтрально. А вот директива clean-param, которая позволяет исключать дубли страниц, работает исключительно для поисковиков Яндекс.
Однако, если у вас простой сайт с несложными разделами, рекомендуем не делать исключений и обращаться ко всем роботам сразу, используя символ *.
Вторая по значимости директива — disallow
Она запрещает роботам сканировать определенные страницы. Как правило, с помощью disallow закрывают административные файлы, дубликаты страниц и конфиденциальные данные.
На наш взгляд, любая персональная или корпоративная информация должна охраняться более строго, то есть требовать аутентификации. Но, все же, в целях профилактики рекомендуем запретить индексацию таких страниц и в robots.txt.
Директива может выглядеть так:
User-agent: *
Disallow: /wp-admin/
Или так:
User-Agent: Googlebot
Disallow: */index.php
Disallow: */section.php
В первом примере мы закрыли от индексации системную панель сайта, а во втором запретили роботам сканировать страницы index.php и section. php. Знак * переводится для роботов как “любой текст”, / — знак запрета.
php. Знак * переводится для роботов как “любой текст”, / — знак запрета.
Следующая директива — allow
В противовес предыдущей, это команда разрешает индексировать информацию.
Может показаться странным: зачем что-то разрешать, если поисковой робот по умолчанию готов всё сканировать? Оказывается, это нужно для выборочного доступа. К примеру, вы хотите запретить раздел сайта с названием /korobka/.
Тогда команда будет выглядеть так:
User-agent: *
Disallow: /korobka/
Но в то же время в разделе коробки есть сумка и зонт, который вы не прочь показать другим пользователям.
Тогда:
User-agent: *
Disallow: /korobka/
Allow: /korobka/sumka/
Allow: /korobka/zont/
Таким образом, вы закрыли общий раздел korobka, но открыли доступ к страницам с сумкой и зонтом.
Sitemap — еще одна важная директива. По названию можно предположить, что эта инструкция как-то связана с картой сайта. И это верно.
И это верно.
Если вы хотите, чтобы при сканировании вашего сайта поисковые роботы в первую очередь заходили в определенные разделы, нужно в корневом каталоге сайта разместить вашу карту — файл sitemap. В отличие от robots.txt, этот файл хранится в формате xml.
Если представить, что поисковой робот — это турист, который попал в ваш город (он же сайт), логично предположить, что ему понадобится карта. С ней он будет лучше ориентироваться на местности и знать, какие места посетить (то есть проиндексировать) в первую очередь. Директива sitemap послужит роботу указателем — мол, карта вон там. А дальше он уже легко разберется в навигации по вашему сайту.
Как создать и проверить robots.txt
Стандарт исключений для роботов обычно создают в простом текстовом редакторе (например, в Блокноте). Файлу дают название robots и сохраняют формате txt.
Далее его надо поместить в корневой каталог сайта. Если вы все сделаете правильно, то он станет доступен по адресу “название вашего сайта”/robots. txt.
txt.
Самостоятельно прописать директивы и во всем разобраться вам помогут справочные сервисы. Воспользуйтесь любыми на выбор: Яндекс или Google. С их помощью за 1 час даже неопытный пользователь сможет разобраться в основах.
Когда файл будет готов, его обязательно стоит проверить на наличие ошибок. Для этого у главных поисковых систем есть специальные веб-мастерские. Сервис для проверки robots.txt от Яндекс:
https://webmaster.yandex.ru/tools/robotstxt/
Сервис для проверки robots.txt от Google:
https://www.google.com/webmasters/tools/home?hl=ru
Когда забываешь про robots.txt
Как вы уже поняли, файл robots совсем не сложно создать. Однако, многие даже крупные компании почему-то забывают добавлять его в корневую структуру сайта. В результате — попадание нежелательной информации в просторы интернета или в руки мошенников плюс огромный общественный резонанс.
Так, в июле 2018 года СМИ говорили об утечке в Сбербанке: в поисковую выдачу Яндекс попала персональная информация клиентов банка — со скриншотами паспортов, личными счетами и номерами билетов.
Не стоит пренебрегать элементарными правилами безопасности сайта и ставить под сомнение репутацию своей компании. Лучше не рисковать и позаботиться о правильной работе robots.txt. Пусть этот маленький файл станет вашим надежным другом в деле поисковой оптимизации сайтов.
Дальше: 20 способов ускорить загрузку сайта в 2018 году
Файл Robots txt — настройка, как создать и проверить: пример robots txt на сайте, директивы
Текстовый файл, записывающий специальные инструкции для поискового робота, ограничивающие доступ к содержимому на http сервере, находящийся в корневой директории веб-сайта и имеющий путь относительно имени самого сайта (/robots.txt ).
Robots.txt — как создать правильный файл robots.txtФайл robots.txt позволяет управлять индексацией вашего сайта. Закрыть какой-либо раздел можно директивой disallow, открыть — allow. Проверка и анализ robots.txt.
Выгрузить в xls, файл, индексация, сайт, директива, яндекс, настройка, запрет, проверка, пример, генератор, анализ, страница, правильный, закрыть, создать, добавить, проверить, задать, запретить, сделать, robots, txt, host, закрытый, где, disallow
Robots. txt — текстовый файл, содержащий инструкции для поисковых роботов, как нужно индексировать сайт.
txt — текстовый файл, содержащий инструкции для поисковых роботов, как нужно индексировать сайт.
В 2011 году случилось сразу несколько громких скандалов, связанных с нахождением в поиске Яндекса нежелательной информации.
Сначала в выдаче Яндекса оказалось более 8 тысяч SMS-сообщений, отправленных пользователями через сайт компании «МегаФон». В результатах поиска отображались тексты сообщений и телефонные номера, на которые они были отправлены.
Заместитель генерального директора «МегаФона» Валерий Ермаков заявил, что причиной публичного доступа к данным могло стать наличие у клиентов «Яндекс.Бара», который считывал информацию и отправлял поисковому роботу Яндекса.
У Яндекса было другое объяснение:
«Еще раз можем подтвердить, что страницы с SMS с сайта МегаФона были публично доступны всем поисковым системам… Ответственность за размещение информации в открытом доступе лежит на том, кто её разместил или не защитил должным образом.
..
Особо хотим отметить, что никакие сервисы Яндекса не виноваты в утечке данных с сайта МегаФона. Ни Яндекс.Бар, ни Яндекс.Метрика не скачивают содержимое веб-страниц. Если страница закрыта для индексации в файле robots.txt или защищена логином и паролем, то она недоступна и поисковым роботам, то есть информация, размещенная на ней, никогда не окажется в какой-либо поисковой системе».
Вскоре после этого пользователи нашли в Яндексе несколько тысяч страниц со статусами заказов в онлайн-магазинах книг, игр, секс-товаров и т.д. По ссылкам с результатов поиска можно было увидеть ФИО, адрес и контактные данные клиента магазина, IP-адрес, наименование его покупки, дату и время заказа. И снова причиной утечки стал некорректно составленный (или вообще отсутствующий) файл robots.txt.
Чтобы не оказаться в подобных ситуациях, лучше заранее составить правильный robots.txt файл для сайта. Как сделать robots. txt в соответствии с рекомендациями поисковых систем, расскажем ниже.
txt в соответствии с рекомендациями поисковых систем, расскажем ниже.
Настройка robots.txt начинается с создания текстового файла с именем «robots.txt». После заполнения этот файл нужно будет сохранить в корневом каталоге сайта, поэтому лучше заранее проверить, есть ли к нему доступ.
Основные директивы robots.txtВ простейшем файле robots.txt используются следующие директивы:
- User-agent
DisallowAllow
Здесь указываются роботы, которые должны следовать указанным инструкциям. Например, User-agent: Yandex означает, что команды будут распространяться на всех роботов Яндекса. User-agent: YandexBot – только на основного индексирующего робота. Если в данном пункте мы поставим *, правило будет распространяться на всех роботов.
Директива DisallowЭта команда сообщает роботу user-agent, какие URL не нужно сканировать. При составлении файла robots.txt важно помнить, что эта директива будет относиться только к тем роботам, которые были перед этим указаны в директиве user-agent. Если подразумеваются разные запреты для разных роботов, то в файле нужно указать отдельно каждого робота и директиву disallow для него.
При составлении файла robots.txt важно помнить, что эта директива будет относиться только к тем роботам, которые были перед этим указаны в директиве user-agent. Если подразумеваются разные запреты для разных роботов, то в файле нужно указать отдельно каждого робота и директиву disallow для него.
Как закрыть части сайта с помощью директивы Disallow:
- Если нужно закрыть от сканирования весь сайт, необходимо использовать косую черту (
/):Disallow: / -
Если нужно закрыть от сканирования каталог со всем его содержимым, необходимо ввести его название и косую черту в конце:Disallow: /events/ -
Если нужно закрыть страницу, необходимо указать название страницы после косой черты:Disallow: /file.html
Разрешает роботу сканировать сайт или отдельные URL.
В примере ниже robots.txt запрещает роботам Яндекса сканировать весь сайт за исключением страниц, начинающихся с «events»:
User-agent: Yandex
Allow: /events
Disallow: /
Спецсимволы в директивахДля директив Allow и Disallow используются спецсимволы «*» и «$».
Звездочка (*) подразумевает собой любую последовательность символов. Например, если нужно закрыть подкаталоги, начинающиеся с определенных символов:Disallow: /example*/-
По умолчанию символ * ставится в конце каждой строки. Если нужно закончить строку определенным символом, используется спецсимвол $. Например, если нужно закрытьURL, заканчивающиеся наdoc:Disallow: /*.doc$ -
Спецсимвол # используется для написания комментариев и не учитывается роботами.
Директива Host в robots.txt используется, чтобы указать роботу на главное зеркало сайта.
Пример:
https://www.glavnoye-zerkalo.ru является главным зеркалом сайта, и для всех сайтов из группы зеркал необходимо прописать в robots.txt:
User-Agent: *
Disallow: /forum
Disallow: /cgi-bin
Host: https://www.glavnoye-zerkalo.ru
Правила использования директивы Host:
- В файле robots.txt может быть только одна директива
Host. Робот всегда ориентируется на первую директиву, даже если их указано несколько. - Если зеркало доступно по защищенному каналу, нужно добавить протокол HTTPS,
- Должно быть указано одно доменное имя и номер порта в случае необходимости.

Если директива Host прописана неправильно, роботы ее проигнорируют.
Директива Crawl-delayДиректива Crawl-delay задает для робота промежуток времени, с которым он должен загружать страницы. Пригодится в случае сильной нагрузки на сервер.
Например, если нужно задать промежуток в 3 секунды между загрузкой страниц:
User-agent: *
Disallow: /search
Crawl-delay: 3
Директива Clean-paramПригодится для сайтов, страницы которых содержат динамические параметры, которые не влияют на их содержимое (например, идентификаторы сессий). Директива позволяет роботам не перезагружать дублирующуюся информацию, что положительно сказывается на нагрузке на сервер.
Использование кириллицыПри составлении файла robots.txt нельзя использовать кириллические символы. Допускается использование Punycode для доменов.
Как проверить robots.txtДля проверки файла robots. txt можно использовать Яндекс.Вебмастер (Анализ robots.txt) или Google Search Console (Инструмент проверки файла Robots.txt).
txt можно использовать Яндекс.Вебмастер (Анализ robots.txt) или Google Search Console (Инструмент проверки файла Robots.txt).
Как добавить файл robots.txt на сайт
Как только файл robots.txt написан и проверен, его нужно сохранить в виде текстового файла с названием robots.txt и загрузить в каталог верхнего уровня сайта или в корневой каталог.
Robots txt: что это за файл
Файл текстового формата robots.txt содержит информацию, необходимую для индексации сайта поисковиками. Он размещается в корневом каталоге и разбит на директории, содержащие команды, при помощи которых ботам поисковиков открывается доступ к определенным местам на веб-ресурсе и закрывается. Причем роботы разных поисковиков обрабатывают этот файл при помощи собственных алгоритмов, у которых могут быть свои специфические особенности. Работа со ссылками с других площадок проводится независимо от того, как настроен robots.
Основные задачи robots.
 txt
txtУ «роботс» главное назначение – это содержать правила, которые помогают ботам правильно индексировать ресурс. Основные из таких директив – Allow (разрешение индексировать раздел или конкретный файл), Disallow (обратная команда, то есть запрет на такую процедуру) и User-agent (адресация команд Allow и Disallow, то есть определение, какие боты должны им следовать). Следует учитывать, что содержащиеся в «роботс» инструкции имеют характер рекомендаций, а не обязательных предписаний. Поэтому роботы могут в разных ситуациях как использовать, так и игнорировать их.
Создание и размещение «роботс»
Файл должен быть исключительно текстовым, то есть иметь расширение txt, и находиться в корневом каталоге соответствующего сайта. Размещение осуществляется при помощи клиента FTP. Дальше проводится проверка файла на предмет его доступности. С этой целью необходимо перейти на страницу site.com/robots.txt. Причем этот адрес должен отображаться в браузере полностью.
Требования к файлу
Следует учитывать, что при отсутствии «роботс» в корневом каталоге или неправильной его настройке есть риск того, что сайт не будет доступен в поисковике и его посещаемость будет низкой. В файле не может использоваться кириллица, поэтому , если домен кириллический, применяют Punycode. Важно при этом, чтобы поддерживалось соответствие между кодировкой страниц и структурой ресурса.
В файле не может использоваться кириллица, поэтому , если домен кириллический, применяют Punycode. Важно при этом, чтобы поддерживалось соответствие между кодировкой страниц и структурой ресурса.
Дополнительные директивы
Кроме основных команд Allow, Disallow и User-agent, присутствующих в каждом файле «роботс», есть ряд директив специального назначения, которые используются в особых случаях.
Crawl-delay
Если роботы поисковых систем слишком сильно нагружают сервер, поможет эта директива. Она содержит информацию о минимальном интервале между завершением загрузки одной страницы и переходом бота к обработке следующей. Этот промежуток времени указывается в секундах. Причем робот «Яндекса» без проблем считывает не только значения в целых числах, но и дробные, к примеру 0,7 секунды. Но роботы поисковика Google директиву Crawl-delay пока не учитывают.
Clean-param
Эта директива используется поисковыми ботами «Яндекса». Структура названий сайтов может быть сложной, и нередко системы, управляющие контентом, создают в них динамические параметры. Они могут передавать дополнительные сведения о сессиях пребывания на сайте пользователей, реферерах и т. п. Директива Clean-param имеет такой синтаксис:
Они могут передавать дополнительные сведения о сессиях пребывания на сайте пользователей, реферерах и т. п. Директива Clean-param имеет такой синтаксис:
s0[&s1&s2&..&sn] [path].
Здесь два поля, в первом из которых перечисляются параметры, учитывать которые поисковые роботы не должны. Их необходимо разделять при помощи символа &. Во втором поле указываются адреса тех страниц, на которые распространяется данное правило. В качестве примера использования такой директивы можно привести форум, на котором при посещении пользователем страниц формируются ссылки с длинными названиями такого образца: http://forum.com/index.php?id=788987&topic=34. При этом у страниц одинаковое содержание, но у всех пользователей собственные идентификаторы. Чтобы предотвратить индексацию поисковыми роботами всего массива дублирующихся страниц с разными id, директива Clean-param должна выглядеть так: id /forum.com/index.php.
Sitemap
Чтобы сайты индексировались правильно и быстро, создается Sitemap – файл (или несколько) с картой ресурса. Соответствующая директива прописывается в любом месте файла «роботс» и учитывается поисковыми ботами независимо от расположения. Однако, как правило, она находится в конце документа. Обрабатывая директиву, бот запоминает информацию и проводит ее переработку. Именно полученные таким образом данные становятся основой для проведения последующих сессий, в процессе которых для индексации загружаются страницы веб-ресурса.
Соответствующая директива прописывается в любом месте файла «роботс» и учитывается поисковыми ботами независимо от расположения. Однако, как правило, она находится в конце документа. Обрабатывая директиву, бот запоминает информацию и проводит ее переработку. Именно полученные таким образом данные становятся основой для проведения последующих сессий, в процессе которых для индексации загружаются страницы веб-ресурса.
Host
Боты всех поисковиков руководствуются этой директивой, которая позволяет прописать зеркало веб-ресурса, которое при индексации будет восприниматься как главное. Так можно избежать включения в индекс нескольких зеркал, то есть дублирования одного сайта в выдаче поисковой системы. Если значений Host несколько, робот, осуществляющий индексацию, принимает во внимание только первое, а все остальные игнорирует.
Специальные символы
Необходимо учитывать, что в конце каждой директивы по умолчанию прописывается специальный символ *. Его назначение – расширить зону действия правила на весь сайт, то есть на все его страницы или разделы, названия которых начинаются с определенного сочетания символов. Для отмены операции, которая проводится по умолчанию, используется символ $. По стандарту формирования «роботс» рекомендуется после каждого набора указаний User-agent прописывать пустую строку с переводом. Причем для комментирования используется символ #. Информацию, размещенную после него и до пустого перевода, поисковые боты не учитывают.
Для отмены операции, которая проводится по умолчанию, используется символ $. По стандарту формирования «роботс» рекомендуется после каждого набора указаний User-agent прописывать пустую строку с переводом. Причем для комментирования используется символ #. Информацию, размещенную после него и до пустого перевода, поисковые боты не учитывают.
Запрет индексации ресурса или отдельных разделов
Чтобы весь сайт, определенные разделы или страницы не индексировались, можно использовать указание Disallow. Если проставить здесь символ /, будет заблокирован для индексации весь ресурс, а «/ bin» закроет доступ к тем страницам, названия которых начинаются с этого сочетания знаков.
Проверка robots.txt
Когда в файл «роботс» вносятся какие-либо изменения, его необходимо проверить. Это операция, которая проводится в обязательном порядке, так как ошибка в расстановке символов может вызвать немало проблем. Минимальную проверку можно провести при помощи инструментов веб-мастера от Google и «Яндекса». Для их использования следует пройти регистрацию и внести информацию о своем ресурсе.
Для их использования следует пройти регистрацию и внести информацию о своем ресурсе.
|
Рейтинг 5, голосов 6 |
|||||||||
Страницы веб-роботов
В двух словах
Владельцы веб-сайтов используют файл /robots.txt для предоставления инструкций по свой сайт веб-роботам; это называется Исключение роботов Протокол .
Это работает следующим образом: робот хочет просмотреть URL-адрес веб-сайта, скажем,
http://www.example.com/welcome.html. Прежде чем это сделать, он сначала
проверяет наличие http://www. example.com/robots.txt и находит:
example.com/robots.txt и находит:
Агент пользователя: * Запретить: /
«User-agent: *» означает, что этот раздел относится ко всем роботам. «Запретить: /» сообщает роботу, что он не должен посещать страницы на сайте.
При использовании файла /robots.txt необходимо учитывать два важных момента:
- роботы могут игнорировать ваш файл /robots.txt. Особенно вредоносные роботы, которые сканируют web на наличие уязвимостей в системе безопасности и сборщики адресов электронной почты, используемые спамерами не обратит внимания.
- файл /robots.txt является общедоступным. Любой может видеть, какие разделы вашего сервера, который вы не хотите использовать роботами.
Так что не пытайтесь использовать /robots.txt, чтобы скрыть информацию.
Смотрите также:
- Могу ли я заблокировать только плохих роботов?
- Почему этот робот проигнорировал мой /robots.txt?
- Каковы последствия файла /robots.
 txt для безопасности?
txt для безопасности?
Детали
/robots.txt является стандартом де-факто и никому не принадлежит. орган стандартов. Есть два исторических описания:
- оригинал 1994 г. Стандарт для роботов Документ об исключении.
- Спецификация Internet Draft 1997 г. Метод для Интернета Управление роботами
Кроме того, есть внешние ресурсы:
- HTML 4.01 Спецификация, Приложение B.4.1
- Википедия — Стандарт исключения роботов
Стандарт /robots.txt активно не разрабатывается. См. Что насчет дальнейшего развития /robots.txt? для дальнейшего обсуждения.
Остальная часть этой страницы дает обзор того, как использовать /robots.txt на ваш сервер, с некоторыми простыми рецептами. Чтобы узнать больше, см. также FAQ.
Как создать файл /robots.txt
Куда поставить
Краткий ответ: в каталоге верхнего уровня вашего веб-сервера.
Более длинный ответ:
Когда робот ищет файл «/robots. txt» для URL, он удаляет
компонент пути из URL (все, начиная с первой косой черты),
и помещает «/robots.txt» на свое место.
txt» для URL, он удаляет
компонент пути из URL (все, начиная с первой косой черты),
и помещает «/robots.txt» на свое место.
Например, для «http://www.example.com/shop/index.html будет удалите «/shop/index.html» и замените его на «/robots.txt», и в итоге получится «http://www.example.com/robots.txt».
Итак, как владелец веб-сайта, вы должны поместить его в нужное место на своем веб-сайте. веб-сервер, чтобы этот результирующий URL-адрес работал. Обычно это одно и то же место, где вы размещаете приветствие «index.html» вашего веб-сайта страница. Где именно это находится и как туда поместить файл, зависит от программное обеспечение вашего веб-сервера.
Не забудьте использовать все строчные буквы для имени файла: «robots.txt», а не «Robots.TXT.
Смотрите также:
- Какую программу следует использовать для создания файла /robots.txt?
- Как использовать /robots.txt на виртуальном хосте?
- Как использовать /robots.txt на общем хосте?
Что положить
Файл «/robots. txt» — это текстовый файл с одной или несколькими записями.
Обычно содержит одну запись, имеющую вид:
txt» — это текстовый файл с одной или несколькими записями.
Обычно содержит одну запись, имеющую вид:
Пользовательский агент: * Запретить: /cgi-bin/ Запретить: /tmp/ Запретить: /~joe/
В этом примере исключены три каталога.
Обратите внимание, что вам нужна отдельная строка «Запретить» для каждого префикса URL, который вы хотите исключить — вы не можете сказать «Disallow: /cgi-bin/ /tmp/» на одна линия. Кроме того, в записи может не быть пустых строк, так как они используются для разделения нескольких записей.
Также обратите внимание, что подстановка и регулярное выражение не поддерживается либо в User-agent, либо в Disallow линии. ‘*’ в поле User-agent — это специальное значение, означающее «любой робот». В частности, у вас не может быть таких строк, как «User-agent: *bot*», «Запретить: /tmp/*» или «Запретить: *.gif».
То, что вы хотите исключить, зависит от вашего сервера.
Все, что прямо не запрещено, считается справедливым
игра, чтобы получить. Вот несколько примеров:
Вот несколько примеров:
Исключить всех роботов со всего сервера
Пользовательский агент: * Запретить: /
Чтобы разрешить всем роботам полный доступ
Пользовательский агент: * Запретить:
(или просто создайте пустой файл «/robots.txt», или вообще не используйте его)
Исключить всех роботов из части сервера
Пользовательский агент: * Запретить: /cgi-bin/ Запретить: /tmp/ Запретить: /мусор/
Для исключения одного робота
Агент пользователя: BadBot Запретить: /
Для одного робота
Агент пользователя: Google Запретить: Пользовательский агент: * Запретить: /
Чтобы исключить все файлы, кроме одного
В настоящее время это немного неудобно, так как нет поля «Разрешить». простой способ — поместить все файлы, которые нужно запретить, в отдельный директории, произнесите «stuff» и оставьте один файл на уровне выше этот каталог:
Пользовательский агент: * Запретить: /~joe/stuff/
В качестве альтернативы вы можете явно запретить все запрещенные страницы:
Пользовательский агент: * Запретить: /~joe/junk.html Запретить: /~joe/foo.html Запретить: /~joe/bar.html
Robots.txt и SEO: полное руководство
Что такое Robots.txt?
Robots.txt — это файл, указывающий поисковым роботам не сканировать определенные страницы или разделы веб-сайта. Большинство основных поисковых систем (включая Google, Bing и Yahoo) распознают и выполняют запросы Robots.txt.
Почему файл robots.txt важен?
Большинству веб-сайтов не нужен файл robots.txt.
Это потому, что Google обычно может найти и проиндексировать все важные страницы вашего сайта.
И они НЕ будут автоматически индексировать страницы, которые не важны, или дублировать версии других страниц.
Тем не менее, есть 3 основные причины, по которым вы хотели бы использовать файл robots.txt.
Блокировать непубличные страницы. Иногда на вашем сайте есть страницы, которые вы не хотите индексировать. Например, у вас может быть промежуточная версия страницы. Или страница входа. Эти страницы должны существовать. Но вы же не хотите, чтобы на них попадали случайные люди. Это тот случай, когда вы должны использовать robots.txt, чтобы заблокировать эти страницы от сканеров поисковых систем и ботов.
Но вы же не хотите, чтобы на них попадали случайные люди. Это тот случай, когда вы должны использовать robots.txt, чтобы заблокировать эти страницы от сканеров поисковых систем и ботов.
Максимизируйте краулинговый бюджет. Если вам трудно проиндексировать все ваши страницы, у вас может быть проблема с краулинговым бюджетом. Блокируя неважные страницы с помощью файла robots.txt, робот Googlebot может тратить больше вашего краулингового бюджета на страницы, которые действительно важны.
Предотвращение индексации ресурсов: Использование метадиректив может работать так же хорошо, как Robots.txt для предотвращения индексации страниц. Однако метадирективы плохо работают с мультимедийными ресурсами, такими как PDF-файлы и изображения. Вот где в игру вступает robots.txt.
Суть? Robots.txt указывает поисковым роботам не сканировать определенные страницы вашего сайта.
Вы можете проверить, сколько страниц вы проиндексировали в Google Search Console.
Если число совпадает с количеством страниц, которые вы хотите проиндексировать, вам не нужно возиться с файлом Robots. txt.
txt.
Но если это число больше, чем вы ожидали (и вы заметили проиндексированные URL-адреса, которые не должны быть проиндексированы), то пришло время создать файл robots.txt для вашего веб-сайта.
Передовой опыт
Создание файла robots.txt
Первым делом необходимо создать файл robots.txt.
Будучи текстовым файлом, вы можете создать его с помощью блокнота Windows.
И независимо от того, как вы в конечном итоге сделаете свой файл robots.txt, формат будет точно таким же:
User-agent: X
Disallow: Y
User-agent — это конкретный бот, которым вы Разговариваю с.
И все, что идет после «запретить», — это страницы или разделы, которые вы хотите заблокировать.
Вот пример:
User-agent: googlebot
Disallow: /images
Это правило предписывает роботу Googlebot не индексировать папку изображений вашего веб-сайта.
Вы также можете использовать звездочку (*), чтобы обратиться ко всем без исключения ботам, которые заходят на ваш сайт.
Вот пример:
User-agent: *
Disallow: /images
«*» указывает всем и каждому паукам НЕ сканировать вашу папку с изображениями.
Это лишь один из многих способов использования файла robots.txt. В этом полезном руководстве от Google содержится дополнительная информация о различных правилах, которые вы можете использовать, чтобы заблокировать или разрешить ботам сканировать разные страницы вашего сайта.
Сделайте так, чтобы ваш файл robots.txt было легко найти
Когда у вас есть файл robots.txt, пришло время запустить его.
Технически вы можете поместить файл robots.txt в любой основной каталог вашего сайта.
Но чтобы повысить вероятность того, что ваш файл robots.txt будет найден, я рекомендую разместить его по адресу:
https://example.com/robots.txt
(Обратите внимание, что ваш файл robots.txt чувствителен к регистру , Поэтому обязательно используйте строчную букву «r» в имени файла)
Проверка на наличие ошибок и ошибок
ОЧЕНЬ важно, чтобы ваш файл robots. txt был настроен правильно. Одна ошибка, и весь ваш сайт может быть деиндексирован.
txt был настроен правильно. Одна ошибка, и весь ваш сайт может быть деиндексирован.
К счастью, вам не нужно надеяться, что ваш код настроен правильно. У Google есть отличный инструмент для тестирования роботов, который вы можете использовать:
Он показывает вам ваш файл robots.txt… и любые ошибки и предупреждения, которые он находит:
Как видите, мы блокируем пауков от сканирования нашей страницы администратора WP.
Мы также используем robots.txt для блокировки сканирования страниц с автоматически сгенерированными тегами WordPress (для ограничения дублирования контента).
Robots.txt и мета-директивы
Зачем использовать robots.txt, если вы можете блокировать страницы на уровне страницы с помощью метатега «noindex»?
Как я упоминал ранее, тег noindex сложно реализовать на мультимедийных ресурсах, таких как видео и PDF-файлы.
Кроме того, если у вас есть тысячи страниц, которые вы хотите заблокировать, иногда проще заблокировать весь раздел этого сайта с помощью robots. txt, чем вручную добавлять тег noindex к каждой отдельной странице.
txt, чем вручную добавлять тег noindex к каждой отдельной странице.
Существуют также крайние случаи, когда вы не хотите тратить краулинговый бюджет на переход Google на страницы с тегом noindex.
При этом:
Помимо этих трех крайних случаев, я рекомендую использовать метадирективы вместо файла robots.txt. Их легче реализовать. И меньше вероятность катастрофы (например, блокировки всего вашего сайта).
Подробнее
Узнайте о файлах robots.txt: полезное руководство о том, как они используют и интерпретируют robots.txt.
Что такое файл robots.txt? (Обзор SEO + Key Insight): лаконичное видео о различных вариантах использования файла robots.txt.
Редактирование robots.txt.liquid · Справочный центр Shopify
Эта страница была напечатана 27 сентября 2022 г. Актуальную версию можно найти на странице https://help.shopify.com/en/manual/promoting-marketing/seo/editing-robots-txt.
Поисковые системы, такие как Google, постоянно сканируют Интернет в поисках новых данных в качестве источника для своих результатов поиска. Файл
Файл robots.txt сообщает роботам поисковых систем, известным как поисковые роботы, какие страницы запрашивать для просмотра в вашем интернет-магазине. Все магазины Shopify имеют по умолчанию robots.txt , оптимальный для поисковой оптимизации (SEO).
Ваша карта сайта используется поисковыми системами для размещения вашего интернет-магазина в результатах поиска. Узнайте, как найти и отправить карту сайта.
Обзор
Файл robots.txt по умолчанию подходит для большинства магазинов, но вы можете редактировать этот файл с помощью шаблона темы robots.txt.liquid. Вы можете внести следующие изменения:
- разрешить или запретить сканирование определенных URL-адресов
- добавить правила задержки сканирования для определенных сканеров
- добавить дополнительные URL-адреса карты сайта
- заблокировать определенные поисковые роботы
Файл robots.txt находится в корневом каталоге основного доменного имени вашего магазина Shopify. Например:
Например: johns-apparel.com/robots.txt .
Осторожно
Это неподдерживаемая настройка. Служба поддержки Shopify не может помочь с правками файла robots.txt.liquid . Если вам нужно отредактировать robots.txt.liquid , то вы можете нанять эксперта Shopify для редактирования кода для вас. Неправильное использование функции может привести к потере всего трафика.
Редактировать robots.txt.liquid
Если вы хотите отредактировать файл robots.txt.liquid , вам следует обратиться к эксперту Shopify или иметь опыт редактирования кода и SEO.
Вы можете использовать Liquid для добавления или удаления директив из шаблона robots.txt.liquid . Этот метод сохраняет возможность Shopify автоматически обновлять файл в будущем и рекомендуется. Полное руководство по редактированию этого файла см. на странице разработчика Shopify Настроить robots.txt.liquid.
Прежде чем редактировать файл robots. , удалите все предыдущие настройки или обходные пути, например использование стороннего сервиса, такого как Cloudflare. txt.liquid
txt.liquid
Шагов:
В админке Shopify нажмите Настройки > Приложения и каналы продаж .
На странице Приложения и каналы продаж нажмите Интернет-магазин .
Нажмите Открыть канал продаж .
Нажмите Темы .
Щелкните Действия , а затем щелкните Изменить код .
Нажмите Добавить новый шаблон , а затем выберите robots .
Нажмите Создать шаблон .
Внесите необходимые изменения в шаблон по умолчанию. Для получения дополнительной информации о переменных жидкости и распространенных случаях использования, обратитесь к странице разработчика Shopify Настроить robots.
 txt.liquid.
txt.liquid.Сохраните изменения в файле robots.txt.liquid в опубликованной теме.
Изменения происходят мгновенно, но поисковые роботы не всегда реагируют мгновенно. Вы можете протестировать изменения с помощью Google robots.txt Tester.
Вы также можете удалить содержимое шаблона и заменить его обычными текстовыми правилами. Этот способ настоятельно не рекомендуется, так как правила могут устареть. Если вы выберете этот метод, Shopify не сможет гарантировать, что лучшие практики SEO будут применяться к вашему robots.txt с течением времени, или вносить изменения в файл с будущими обновлениями.
Примечание
Изменения ThemeKit или командной строки сохранят файл robots.txt.liquid. При загрузке темы из раздела «Темы» административной панели Shopify не будет импортирован файл robots.txt.liquid.
Удалить настройки robots.txt.liquid
Если вы хотите снова использовать файл robots.txt по умолчанию, сохраните копию настроек шаблона robots., так как вам нужно удалить шаблон, который может не отменить. txt.liquid
txt.liquid
Шагов:
В админке Shopify нажмите Настройки > Приложения и каналы продаж .
На странице Приложения и каналы продаж нажмите Интернет-магазин .
Нажмите Открыть канал продаж .
Нажмите Темы .
Щелкните Действия , а затем щелкните Изменить код .
Нажмите robots.liquid , а затем нажмите Удалить файл .
Если вы все еще хотите удалить robots.txt.liquid, нажмите Удалить файл .
Вы всегда можете отредактировать файл robots.txt.liquid в будущем или, если вы сохранили свои прошлые настройки, вы можете повторить свои изменения, скопировав сохраненные предыдущие настройки.
Пример файла txt Robots: 10 шаблонов для использования
Мы рассмотрим 10 примеров файла robots.txt.
Вы можете либо скопировать их на свой сайт, либо объединить шаблоны, чтобы создать свой собственный.
Помните, что файл robots.txt влияет на SEO, поэтому обязательно проверяйте вносимые вами изменения.
Начнем.
1) Запретить все
Первый шаблон не позволит всем ботам сканировать ваш сайт. Это полезно по многим причинам. Например:
- Сайт еще не готов
- Вы не хотите, чтобы сайт отображался в результатах поиска Google
- Это промежуточный веб-сайт, используемый для тестирования изменений перед добавлением в рабочую среду.
Какой бы ни была причина, именно так вы запретите всем поисковым роботам читать страницы:
Агент пользователя: * Запретить: /
Здесь мы ввели два «правила», а именно:
- User-agent — нацельтесь на определенного бота с помощью этого правила или используйте подстановочный знак *, что означает всех ботов
- Disallow — используется, чтобы сообщить боту, что он не может зайти в эту область сайта.
 Установив это на
Установив это на /бот не будет сканировать ни одну из ваших страниц
Что делать, если мы хотим, чтобы бот просканировал весь сайт?
2) Разрешить все
Если на вашем сайте нет файла robots.txt, то по умолчанию бот будет сканировать весь сайт. Тогда один из вариантов — не создавать и не удалять файл robots.txt.
Но иногда это невозможно и нужно что-то добавить. В этом случае мы бы добавили следующее:
Агент пользователя: * Запретить:
Сначала это кажется странным, так как у нас все еще действует правило Disallow. Тем не менее, он отличается тем, что не содержит /. Когда бот прочитает это правило, он увидит, что ни один URL не имеет правила Disallow.
Другими словами, весь сайт открыт.
3) Заблокировать папку
Иногда бывают случаи, когда нужно заблокировать часть сайта, но разрешить доступ к остальным. Хорошим примером этого является административная область страницы.
Область администратора может позволять администраторам входить в систему и изменять содержимое страниц. Мы не хотим, чтобы боты искали эту папку, поэтому мы можем запретить это следующим образом:
Агент пользователя: * Запретить: /admin/
Теперь бот будет игнорировать эту область сайта.
4) Заблокировать файл
То же самое относится и к файлам. Может быть определенный файл, который вы не хотите показывать в поиске Google. Опять же, это может быть административная область или что-то подобное.
Чтобы заблокировать ботов от этого, вы должны использовать этот файл robots.txt.
Агент пользователя: * Запретить: /admin.html
Это позволит боту сканировать весь веб-сайт, кроме /admin.html 9файл 0255.
5) Запретить расширение файла
Что делать, если вы хотите заблокировать все файлы с определенным расширением. Например, вы можете заблокировать файлы PDF на вашем сайте, чтобы они не попадали в поиск Google. Или у вас есть электронные таблицы, и вы не хотите, чтобы робот Googlebot тратил время на чтение.
Или у вас есть электронные таблицы, и вы не хотите, чтобы робот Googlebot тратил время на чтение.
В этом случае вы можете использовать два специальных символа для блокировки этих файлов:
-
*— это подстановочный знак, который будет соответствовать всему тексту . -
$— Знак доллара остановит сопоставление URL-адресов и представляет собой конец URL-адреса .
При совместном использовании вы можете блокировать PDF-файлы следующим образом:
Агент пользователя: * Запретить: /*.pdf$
или .xls файлы, подобные этому:
Агент пользователя: * Запретить: /*.xls$
Обратите внимание, что правило запрета имеет /*.xls$ . Это означает, что он будет соответствовать всем этим URL-адресам:
-
https://example.com/files/spreadsheet1.xls -
https://example.com/files/folder2/profit.xls -
https://example. com/users.xls
com/users.xls
Тем не менее, он не будет соответствовать этому URL:
-
https://example.com/pink.xlsocks
Поскольку URL-адрес не заканчивается на .xls .
6) Разрешить только Googlebot
Вы также можете добавить правила, применимые к конкретному боту. Вы можете сделать это с помощью правила User-agent , до сих пор мы использовали подстановочный знак, который соответствует всем ботам.
Если бы мы хотели разрешить только роботу Googlebot просматривать страницы на сайте, мы могли бы добавить этот robots.txt:
Агент пользователя: * Запретить: / Агент пользователя: Googlebot Запретить:
7) Запретить определенного бота
Как и в приведенном выше примере, мы можем разрешить всех ботов, но запретить одного бота. Вот как выглядел бы файл robots.txt, если бы мы хотели заблокировать только Googlebot:
Агент пользователя: Googlebot Запретить: / Пользовательский агент: * Запретить:
Существует множество пользовательских агентов ботов, вот список наиболее распространенных, с помощью которых вы можете создавать правила:
- Googlebot — используется для поиска Google
- Bingbot — используется для поиска Bing
- Slurp — поисковый робот Yahoo
- DuckDuckBot — используется поисковой системой DuckDuckGo
- Baiduspider — это китайский поисковик .
- YandexBot - это российская поисковая система
- фейсбот — используется Facebook
- Pinterestbot — используется Pinterest
- TwitterBot — используется Twitter

Когда бот посещает ваш сайт, ему необходимо найти все ссылки на странице. В карте сайта перечислены все URL-адреса вашего сайта. Добавляя карту сайта в файл robots.txt, вы облегчаете боту поиск всех ссылок на вашем сайте.
Для этого нужно использовать правило Sitemap :
Агент пользователя: * Карта сайта: https://pagedart.com/sitemap.xml
Вышеприведенное взято из файла PageDart robots.txt. Вы также можете указать более одной карты сайта, если у вас разные карты сайта для каждого языка.
URL-адрес карты сайта должен быть полным URL-адресом с https:// в начале, чтобы он работал.
9) Уменьшите скорость сканирования
Можно контролировать скорость, с которой бот будет просматривать страницы вашего сайта. Это может быть полезно, если ваш веб-сервер борется с высоким трафиком.
Это может быть полезно, если ваш веб-сервер борется с высоким трафиком.
Bing, Yahoo и Yandex поддерживают правило Crawl-delay . Это позволяет вам установить задержку между каждым просмотром страницы следующим образом:
Агент пользователя: * Задержка обхода: 10
В приведенном выше примере бот будет ждать 10 секунд, прежде чем запросить следующую страницу. Вы можете установить задержку от 1 до 30 секунд.
Google не поддерживает это правило, поскольку оно не является частью исходной спецификации robots.txt.
10) Нарисуй робота
Последний шаблон предназначен для развлечения. Вы можете добавить рисунок ASCII, чтобы добавить робота в файл robots.txt следующим образом:
# _ # [ ] # ( ) # |>| # __/===\__ # //| о=о |\\ # <] | о = о | [> # \=====/ # / / | \\ № <_________>
Если кто-то придет и посмотрит ваш файл robots.txt, это может вызвать у него улыбку.
Некоторые компании уже делают это, у Airbnb есть реклама в файле robots. txt:
txt:
https://www.airbnb.co.uk/robots.txt
У NPM есть робот в robots.txt:
https://www.npmjs.com/robots.txt
У Avvo.com есть рисунок Grumpy Cat в формате ASCII:
https://www.avvo.com/robots.txt
Но мне больше всего нравится Robinhood.com:
https://robinhood.com/robots.txt
Подведение итогов, пример файла txt для роботов
Мы рассмотрели 10 различных шаблонов robots.txt, которые вы можете использовать на своем сайте.
Эти примеры включают:
- Запретить всех ботов со всего сайта
- Разрешить всем ботам везде
- Заблокировать папку от сканирования
- Заблокировать файл от сканирования
- Разрешить одного бота
- Запретить все типы файлов
- Запретить определенного бота
- Ссылка на вашу карту сайта
- Уменьшите скорость, с которой бот сканирует ваш сайт
- Некоторые рисунки в вашем файле robots.txt работают.

Помните, что вы можете комбинировать части этих шаблонов как угодно, пока действуют правила. Чтобы проверить правильность robots.txt, вы можете использовать нашу программу проверки robots.txt.
6 распространенных проблем с файлом robots.txt и способы их устранения
Robots.txt — это полезный и относительно мощный инструмент для указания роботам поисковых систем, как вы хотите, чтобы они сканировали ваш веб-сайт.
Он не всемогущ (по словам самого Google, «это не механизм для защиты веб-страницы от Google»), но он может помочь предотвратить перегрузку вашего сайта или сервера запросами сканера.
Если на вашем сайте установлена эта блокировка сканирования, вы должны быть уверены, что она используется правильно.
Это особенно важно, если вы используете динамические URL-адреса или другие методы, которые теоретически генерируют бесконечное количество страниц.
В этом руководстве мы рассмотрим некоторые из наиболее распространенных проблем с файлом robots.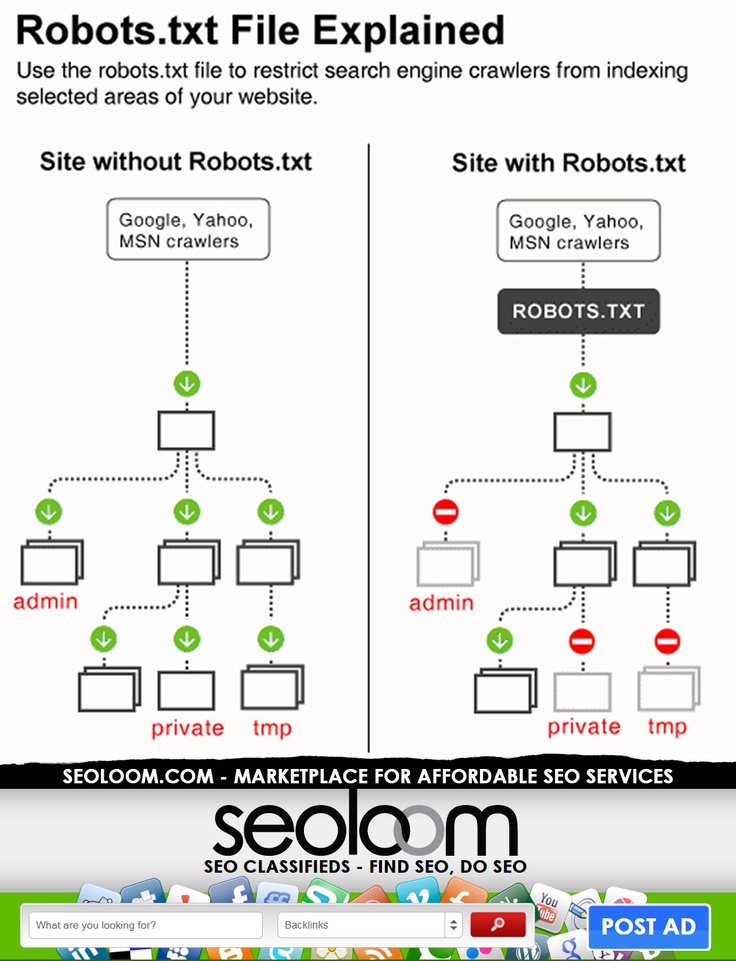 txt, их влияние на ваш веб-сайт и ваше присутствие в поиске, а также способы устранения этих проблем, если вы считаете, что они возникли.
txt, их влияние на ваш веб-сайт и ваше присутствие в поиске, а также способы устранения этих проблем, если вы считаете, что они возникли.
Но сначала давайте кратко рассмотрим файл robots.txt и его альтернативы.
Что такое robots.txt?
Robots.txt использует формат простого текстового файла и размещается в корневом каталоге вашего веб-сайта.
Он должен находиться в самом верхнем каталоге вашего сайта; если вы поместите его в подкаталог, поисковые системы просто проигнорируют его.
Несмотря на свои огромные возможности, robots.txt часто представляет собой относительно простой документ, и простой файл robots.txt можно создать за считанные секунды с помощью редактора, например Блокнота.
Существуют и другие способы достижения тех же целей, для которых обычно используется файл robots.txt.
Отдельные страницы могут включать метатег robots в самом коде страницы.
Вы также можете использовать HTTP-заголовок X-Robots-Tag, чтобы повлиять на то, как (и будет ли) отображаться контент в результатах поиска.
Что может robots.txt?
Robots.txt может достигать различных результатов для различных типов контента:
Веб-страницы могут быть заблокированы от сканирования .
Они могут по-прежнему появляться в результатах поиска, но не будут иметь текстового описания. Содержимое страницы, отличное от HTML, также не будет сканироваться.
Медиафайлы можно заблокировать, чтобы они не отображались в результатах поиска Google.
Сюда входят изображения, видео- и аудиофайлы.
Если файл является общедоступным, он по-прежнему будет «существовать» в сети, и его можно будет просмотреть и связать с ним, но этот частный контент не будет отображаться в результатах поиска Google.
Файлы ресурсов, такие как неважные внешние скрипты, могут быть заблокированы .
Но это означает, что если Google просканирует страницу, для загрузки которой требуется этот ресурс, робот Googlebot «увидит» версию страницы, как если бы этот ресурс не существовал, что может повлиять на индексацию.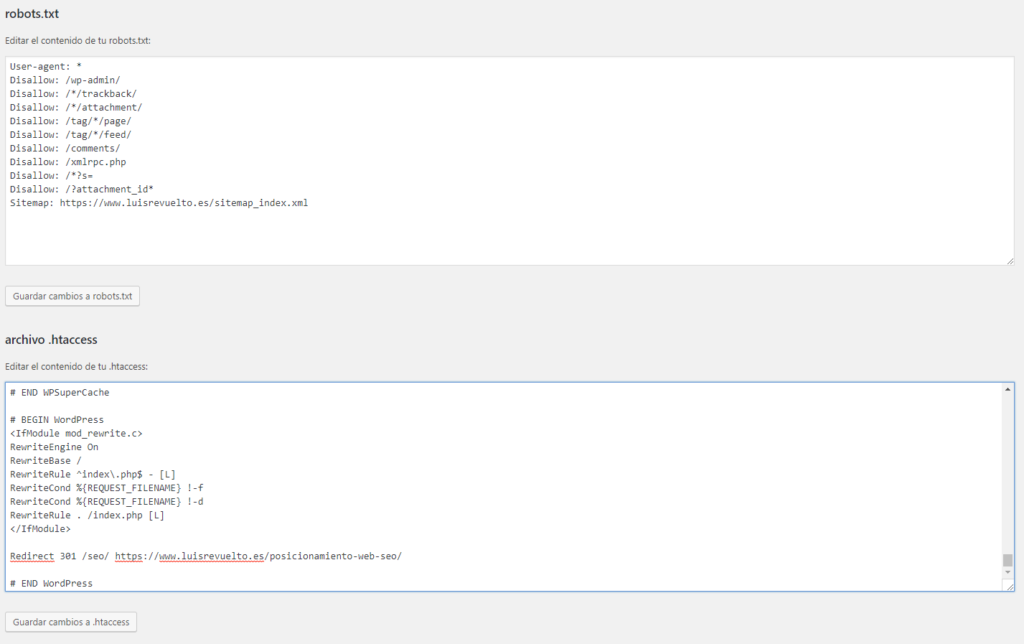
Вы не можете использовать robots.txt, чтобы полностью заблокировать появление веб-страницы в результатах поиска Google.
Для этого необходимо использовать альтернативный метод, например добавить метатег noindex в начало страницы.
Насколько опасны ошибки robots.txt?
Ошибка в robots.txt может иметь непредвиденные последствия, но часто это не конец света.
Хорошая новость заключается в том, что, исправив файл robots.txt, вы сможете быстро и (как правило) полностью восстановиться после любых ошибок.
Руководство Google для веб-разработчиков говорит следующее об ошибках robots.txt:
«Веб-сканеры, как правило, очень гибкие и обычно не реагируют на незначительные ошибки в файле robots.txt. В общем, худшее, что может случиться, это то, что некорректные [или] неподдерживаемые директивы будут проигнорированы.
Помните, однако, что Google не может читать мысли при интерпретации файла robots.txt; мы должны интерпретировать полученный нами файл robots.
txt. Тем не менее, если вы знаете о проблемах в файле robots.txt, их обычно легко исправить».
6 Распространенные ошибки в файле robots.txt
- Robots.txt не находится в корневом каталоге.
- Неправильное использование подстановочных знаков.
- Noindex в файле robots.txt.
- Заблокированные скрипты и таблицы стилей.
- Нет URL-адреса карты сайта.
- Доступ к сайтам разработки.
Если ваш веб-сайт ведет себя странно в результатах поиска, ваш файл robots.txt — это хорошее место для поиска любых ошибок, синтаксических ошибок и превышения правил.
Давайте рассмотрим каждую из вышеперечисленных ошибок более подробно и посмотрим, как убедиться, что у вас есть действительный файл robots.txt.
1. Robots.txt не находится в корневом каталоге
Поисковые роботы могут обнаружить файл только в том случае, если он находится в корневом каталоге.
Вот почему между .com (или эквивалентным доменом) вашего веб-сайта и именем файла robots. txt в URL вашего файла robots.txt должна быть только косая черта.
txt в URL вашего файла robots.txt должна быть только косая черта.
Если там есть подпапка, ваш файл robots.txt, вероятно, не виден поисковым роботам, и ваш сайт, вероятно, ведет себя так, как будто файла robots.txt вообще нет.
Чтобы решить эту проблему, переместите файл robots.txt в корневой каталог.
Стоит отметить, что для этого вам потребуется root-доступ к вашему серверу.
Некоторые системы управления контентом по умолчанию загружают файлы в подкаталог «media» (или что-то подобное), поэтому вам может потребоваться обойти это, чтобы получить файл robots.txt в нужном месте.
2. Неправильное использование подстановочных знаков
Robots.txt поддерживает два подстановочных знака:
- Звездочка * , которая представляет любые экземпляры допустимого символа, например Джокера в колоде карт.
- Знак доллара $ , обозначающий конец URL-адреса, что позволяет применять правила только к последней части URL-адреса, например к расширению типа файла.

Разумно использовать минималистский подход к использованию подстановочных знаков, поскольку они могут налагать ограничения на гораздо более широкую часть вашего веб-сайта.
Также относительно легко заблокировать доступ роботов со всего вашего сайта с помощью неудачно расположенной звездочки.
Чтобы решить проблему с подстановочными знаками, вам нужно найти неправильный подстановочный знак и переместить или удалить его, чтобы файл robots.txt работал должным образом.
3. Noindex In Robots.txt
Этот вариант чаще встречается на веб-сайтах, которым больше нескольких лет.
Компания Google перестала соблюдать правила noindex в файлах robots.txt с 1 сентября 2019 г. результаты поиска.
Решение этой проблемы заключается в реализации альтернативного метода noindex.
Одним из вариантов является метатег robots, который вы можете добавить в заголовок любой веб-страницы, которую вы хотите предотвратить от индексации Google.
4.
 Заблокированные сценарии и таблицы стилей
Заблокированные сценарии и таблицы стилейМожет показаться логичным заблокировать доступ сканера к внешним сценариям JavaScript и каскадным таблицам стилей (CSS).
Однако помните, что роботу Googlebot требуется доступ к файлам CSS и JS, чтобы правильно «видеть» ваши HTML- и PHP-страницы.
Если ваши страницы странно отображаются в результатах Google или кажется, что Google не видит их правильно, проверьте, не блокируете ли вы доступ сканера к необходимым внешним файлам.
Простое решение этой проблемы — удалить из файла robots.txt строку, блокирующую доступ.
Или, если у вас есть файлы, которые нужно заблокировать, вставьте исключение, которое восстанавливает доступ к необходимым CSS и JavaScript.
5. Нет URL карты сайта
Это больше касается SEO, чем что-либо еще.
Вы можете включить URL-адрес вашей карты сайта в файл robots.txt.
Поскольку это первое, на что обращает внимание робот Googlebot при сканировании вашего веб-сайта, это дает краулеру преимущество в знании структуры и основных страниц вашего сайта.
Хотя это не является строго ошибкой, так как отсутствие карты сайта не должно негативно влиять на фактическую основную функциональность и внешний вид вашего веб-сайта в результатах поиска, все же стоит добавить URL-адрес вашей карты сайта в robots.txt, если вы хотите дать свой SEO усилие.
6. Доступ к сайтам разработки
Блокировать поисковые роботы на вашем действующем веб-сайте нельзя, как и разрешать им сканировать и индексировать ваши страницы, которые все еще находятся в стадии разработки.
Рекомендуется добавить инструкцию о запрете в файл robots.txt веб-сайта, находящегося в стадии разработки, чтобы широкая публика не увидела его, пока он не будет завершен.
В равной степени крайне важно удалить команду запрета при запуске готового веб-сайта.
Забыть удалить эту строку из robots.txt — одна из самых распространенных ошибок среди веб-разработчиков, которая может помешать правильному сканированию и индексированию всего вашего веб-сайта.
Если кажется, что ваш сайт разработки получает реальный трафик или ваш недавно запущенный веб-сайт совсем не работает в поиске, найдите универсальное правило запрета пользовательского агента в файле robots.txt:
User-Agent : *
Disallow: /
Если вы видите это, когда не должны (или не видите, когда должны), внесите необходимые изменения в файл robots.txt и убедитесь, что ваш сайт отображается в результатах поиска. обновления соответственно.
Как исправить ошибку robots.txt
Если ошибка в robots.txt оказывает нежелательное влияние на внешний вид вашего веб-сайта в результатах поиска, самым важным первым шагом является исправление файла robots.txt и проверка того, что новые правила имеют желаемое значение. эффект.
Некоторые инструменты SEO-сканирования могут помочь в этом, поэтому вам не нужно ждать, пока поисковые системы снова просканируют ваш сайт.
Если вы уверены, что robots.txt ведет себя должным образом, вы можете попытаться повторно просканировать свой сайт как можно скорее.
Могут помочь такие платформы, как Google Search Console и Bing Webmaster Tools.
Отправьте обновленную карту сайта и запросите повторное сканирование любых страниц, которые были неправомерно удалены из списка.
К сожалению, вы попали в прихоть робота Googlebot — нет никаких гарантий относительно того, сколько времени потребуется, чтобы отсутствующие страницы снова появились в поисковом индексе Google.
Все, что вы можете сделать, это предпринять правильные действия, чтобы максимально сократить это время, и продолжать проверять, пока робот Googlebot не внедрит исправленный файл robots.txt.
Заключительные мысли
Когда речь идет об ошибках robots.txt, их предотвращение определенно лучше, чем их устранение.
На крупном доходном веб-сайте случайный подстановочный знак, который удаляет весь ваш веб-сайт из Google, может немедленно повлиять на доход.
Изменения в robots.txt должны вноситься опытными разработчиками с осторожностью, дважды проверяться и, при необходимости, с учетом второго мнения.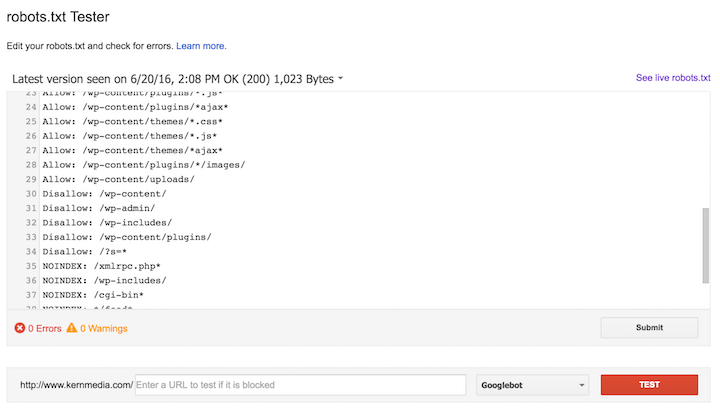
Если возможно, протестируйте в редакторе песочницы перед запуском на реальном сервере, чтобы избежать непреднамеренного возникновения проблем с доступностью.
Помните, когда случается самое худшее, важно не паниковать.
Диагностируйте проблему, внесите необходимые исправления в файл robots.txt и повторно отправьте карту сайта для нового сканирования.
Мы надеемся, что ваше место в поисковом рейтинге будет восстановлено в течение нескольких дней.
Дополнительные ресурсы:
- Возникла ли у Google проблема с файлами Big Robots.txt?
- 7 предупреждений и ошибок SEO-инструмента сканирования, которые вы можете безопасно игнорировать
- Продвинутое техническое SEO: полное руководство
Рекомендуемое изображение: M-SUR/Shutterstock
Категория SEO
руководство по оптимизации для вашего SEO
Перейти к содержимомуСодержание
- Что такое robots.
 txt?
txt? - Как это работает?
- Зачем нужен файл robots.txt?
- Синтаксис файла robots.txt
- Куда поместить robots.txt?
- Как создать robots.txt для сайта?
- Robots.txt и Search Console: проверьте и протестируйте
Протокол исключения роботов, более известный как robots.txt , представляет собой соглашение, предотвращающее доступ поисковых роботов ко всему веб-сайту или его части. Это текстовый файл, используемый для SEO, содержащий команды для индексирующих роботов поисковых систем, которые указывают страницы, которые могут или не могут быть проиндексированы.
Файл robots.txt используется не для деиндексации страниц , а для предотвращения их просмотра.
Если страница никогда ранее не индексировалась, предотвращение ее сканирования позволит никогда не индексировать ее. Но если страница уже проиндексирована или на нее ссылается другой сайт, robots.txt не позволит деиндексировать. Чтобы предотвратить индексацию страницы в Google, необходимо использовать
noindex теги/директивы или защитить его паролем.
Таким образом, основной целью файла robots.txt является управление краулинговым бюджетом робота путем запрета ему просмотра страниц с низкой добавленной стоимостью, но которые должны существовать для пути пользователя (корзина покупок и т. д.). .
PS: файл robots.txt является одним из первых файлов, проанализированных движками.
Пример
Поисковые системы выполняют две основные задачи: просматривают Интернет для обнаружения контента и индексируют этот контент, чтобы его можно было распространять среди пользователей, ищущих информацию.
Объяснение:
Чтобы просканировать сайты, поисковые системы следуют ссылкам, чтобы перейти с одного сайта на другой, они просматривают многие миллиарды ссылок и веб-сайтов. Это называется "паук". Как только робот поисковой системы получает доступ к веб-сайту, он ищет файл robots.txt. Если он найдет его, робот сначала прочитает этот файл, прежде чем продолжить просмотр страницы. Если файл robots.txt не содержит директив, запрещающих деятельность агента пользователя, или если на сайте нет файла robots.txt, он будет сканировать другую информацию на сайте.
Если файл robots.txt не содержит директив, запрещающих деятельность агента пользователя, или если на сайте нет файла robots.txt, он будет сканировать другую информацию на сайте.
Важность файла robots.txt
Файлы robots.txt контролируют доступ роботов к определенным областям вашего сайта. Хотя это может быть очень опасно, если вы случайно запретите роботу Googlebot сканировать весь ваш сайт, в некоторых ситуациях файл robots.txt может быть очень полезен.
Общие варианты использования включают:
- Избегайте сканирования дублированного контента.
- Предотвращение сканирования внутренней поисковой системы.
- Предотвращение индексации поисковыми системами определенных изображений на вашем сайте.
- Укажите расположение карты сайта.
- Указание задержки сканирования, чтобы предотвратить перегрузку серверов, когда сканеры одновременно загружают несколько фрагментов содержимого.
Если на вашем сайте нет областей, доступ к которым вы хотите контролировать, вам может не понадобиться файл robots. txt.
txt.
Язык файла robots.txt
Файл robots.txt состоит из набора блоков инструкций и опциональных директив карты сайта.
Каждый блок состоит из двух частей:
- Один или несколько User-agent директивы : Для каких роботов предназначен этот блок.
- Одна или несколько команд: какие ограничения должны соблюдаться.
Наиболее распространенной командой является Disallow , которая запрещает роботам сканировать часть сайта.
Что такое пользовательский агент?
Когда программа инициирует подключение к веб-серверу (будь то робот или стандартный веб-браузер), она предоставляет основную информацию о своей личности через HTTP-заголовок, называемый «агентом пользователя».
Для Google список пользовательских агентов, используемых поисковыми роботами Google, доступен здесь.
Пример:
# Строки, начинающиеся с #, являются комментариями #
# Начало блока 1
Агент пользователя: Googlebot
Агент пользователя: Googlebot-Новости
Запретить: /directory1/
Запретить: /directory2/
# Начало блока 2
Агент пользователя: *
Запретить: /directory3/
# Дополнительная директива карты сайта
Карта сайта: http://www.
example.com/sitemap.xml
Другие команды блока:
- Разрешить (применимо только к роботу Google) : команда, сообщающая роботу Google, что он может получить доступ к странице или подпапке, даже если родительская страница или подпапка запрещены (эта команда имеет приоритет над командами запретить).
- Crawl-delay : Этот параметр позволяет указать и установить количество секунд, в течение которых робот должен ждать между каждым последующим запросом.
Дополнительные директивы:
- Карта сайта: позволяет легко указывать поисковым системам страницы ваших сайтов для сканирования. Карта сайта — это XML-файл, в котором перечислены URL-адреса сайта, а также дополнительные метаданные для каждого URL-адреса, чтобы обеспечить более интеллектуальное исследование сайта поисковыми системами.
Язык файлов robots.txt: Регулярные выражения
Регулярные выражения — это специальные символы, позволяющие упростить написание robots. txt за счет использования шаблонов.
txt за счет использования шаблонов.
В файле robots.txt большинство поисковых систем (Google, Bing, Yandex...) включают только два из них:
- * : Соответствует любой последовательности символов
- $: соответствует концу URL-адреса.
Примечание: если использование регулярного выражения приводит к совпадению с несколькими блоками для данного робота, будет учитываться только наиболее конкретный блок.
Например, здесь GoogleBot выберет блок 2:
Агент пользователя: * # Начало блока 1
…
Агент пользователя: Googlebot #Начало блока 2
Примеры:
User-agent: *
User-agent может быть любым значением, другими словами блок применим ко всем роботам.Disallow: /*.gif$
Эта команда предотвращает сканирование URL-адресов, содержащих серию символов (*), за которыми следует ".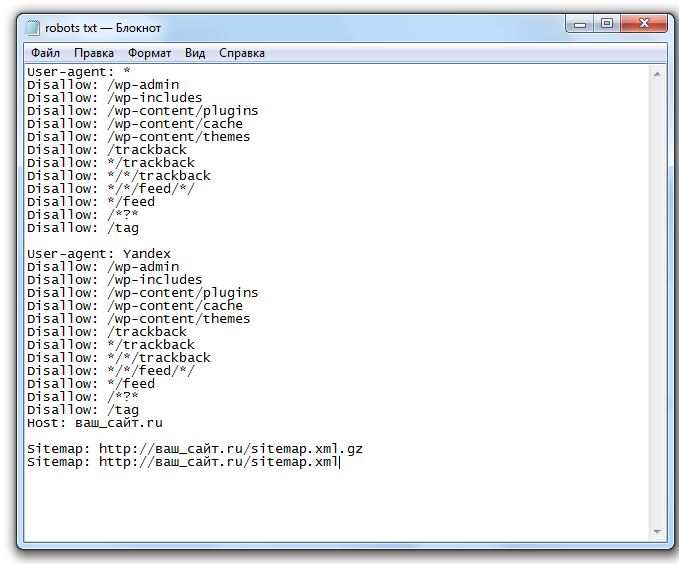 gif" в конце URL-адреса (".gif$"), другими словами изображения в формате gif.
gif" в конце URL-адреса (".gif$"), другими словами изображения в формате gif.
Примечание. В файле robots.txt все URL-адреса начинаются с косой черты, поскольку они исходят из корня сайта, представленного символом «/».Disallow: /private
Предотвращает сканирование всех URL-адресов, начинающихся с /private (включая /privateblabla1.html), идентичных /private*Disallow: /private/
Запрещает сканирование всех URL-адресов, начинающихся с /private/ (включая /private/page1.html), как и /private/*Запретить: /private/$
Предотвратить сканирование именно /private/ (например, /private/page1.html по-прежнему доступен).Allow: /wp-admin/admin-ajax.php = Оператор Allow допускает исключения, здесь он позволяет роботам исследовать admin-ajax.php, который является частью ранее запрещенного каталога /wp-admin/.

Карта сайта: "ссылка на карту сайта" также позволяет указать поисковым системам адрес файла sitemap.xml сайта, если таковой имеется.
Вы не знаете, есть ли у вас файл robots.txt?
- Просто введите свой корневой домен,
- , затем добавьте /robots.txt в конце URL-адреса. Например, файл robots для Panorabanques находится на домене https://www.panorabanques.com.
Если страница .txt не отображается, у вас нет страницы robots.txt (действующей).
Если у вас нет файла robots.txt :
- Он вам нужен? Убедитесь, что у вас нет страниц с низким значением, которые требуют этого. Пример: корзина, поисковые страницы вашей внутренней поисковой системы и т.д.
- Если вам это нужно, создайте файл, следуя указанным выше директивам.
Файл robots.txt состоит из одного или нескольких правил. Следуйте основным правилам для файлов robots. txt, то есть правилам форматирования, синтаксиса и расположения, указанным выше, для создания robots.txt.
txt, то есть правилам форматирования, синтаксиса и расположения, указанным выше, для создания robots.txt.
Что касается формата и местоположения, вы можете использовать практически любой текстовый редактор для создания файла robots.txt. Текстовый редактор должен иметь возможность создавать стандартные текстовые файлы ASCII или UTF-8. Не используйте текстовый процессор, так как эти программы часто сохраняют файлы в собственном формате и могут добавлять неожиданные символы (например, фигурные кавычки), которые могут запутать сканеры.
Форматирование и правила использования
- robots.txt — это текстовый файл, который необходимо поместить в корень сервера/сайта, т.е. https://smartkeyword.io/robots.txt.
- Его нельзя разместить в подкаталоге (например, в http://example.com/pages/robots.txt), но можно применить к поддоменам (например, http://website.example.com/robots. текст).
- Имя файла robots.txt должно быть написано строчными буквами (не использовать Robots.
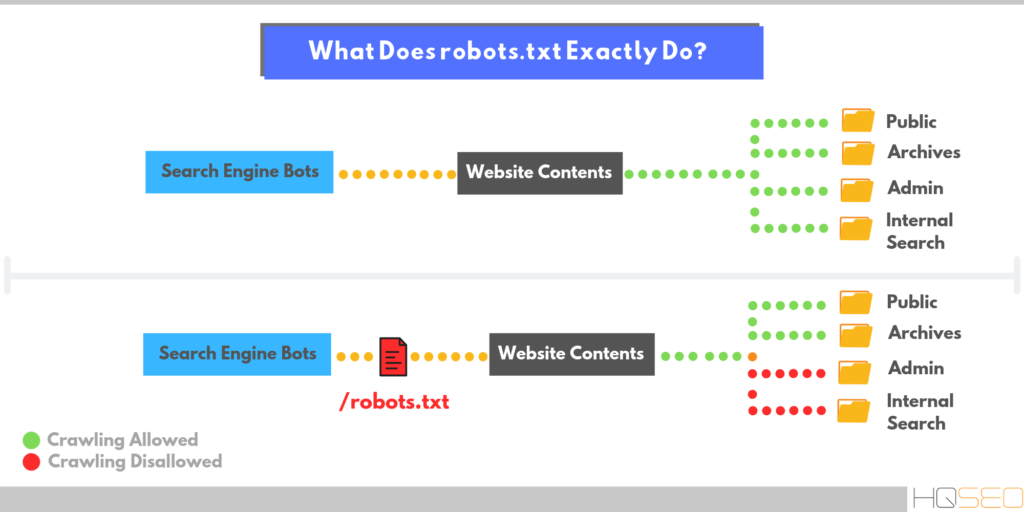 txt или ROBOTS.TXT).
txt или ROBOTS.TXT). - Ваш сайт может содержать только один файл robots.txt.
- При его отсутствии будет отображаться ошибка 404 и роботы будут считать, что нет запрещенного контента.
Передовой опыт
- Убедитесь, что вы не блокируете контент или разделы вашего веб-сайта, которые вы хотите просканировать.
- Ссылки на страницы, заблокированные robots.txt, не будут переходить.
- Не используйте robots.txt, чтобы предотвратить отображение конфиденциальных данных в поисковой выдаче. Поскольку другие страницы могут напрямую ссылаться на страницу, содержащую личную информацию, они все равно могут быть проиндексированы. Если вы хотите заблокировать свою страницу в результатах поиска, используйте другой метод, например защиту паролем или мета-директиву noindex.
- Некоторые поисковые системы имеют несколько пользователей. Например, Google использует Googlebot для обычного поиска и Googlebot-Image для поиска изображений.
 Большинство пользовательских агентов одной и той же поисковой системы следуют одним и тем же правилам. Таким образом, нет необходимости указывать рекомендации для различных ботов поисковых систем, но это позволяет вам уточнить способ анализа контента вашего сайта.
Большинство пользовательских агентов одной и той же поисковой системы следуют одним и тем же правилам. Таким образом, нет необходимости указывать рекомендации для различных ботов поисковых систем, но это позволяет вам уточнить способ анализа контента вашего сайта. - Поисковая система кэширует содержимое robots.txt, но обычно обновляет кэшированное содержимое не реже одного раза в день. Если вы изменили файл и хотите обновить его быстрее, вы можете отправить URL-адрес robots.txt в Google.
Функция "Отправить" инструмента тестирования robots.txt позволяет Google быстрее сканировать и индексировать новый файл robots.txt для вашего сайта. Сообщите Google об изменениях в файле robots.txt, выполнив следующие действия:
- Нажмите «Отправить» в правом нижнем углу редактора файла robots.txt. Откроется диалоговое окно «Отправить».
- Загрузите измененный код robots.txt со страницы средства тестирования Robots.txt, нажав кнопку «Загрузить» в диалоговом окне «Загрузить».
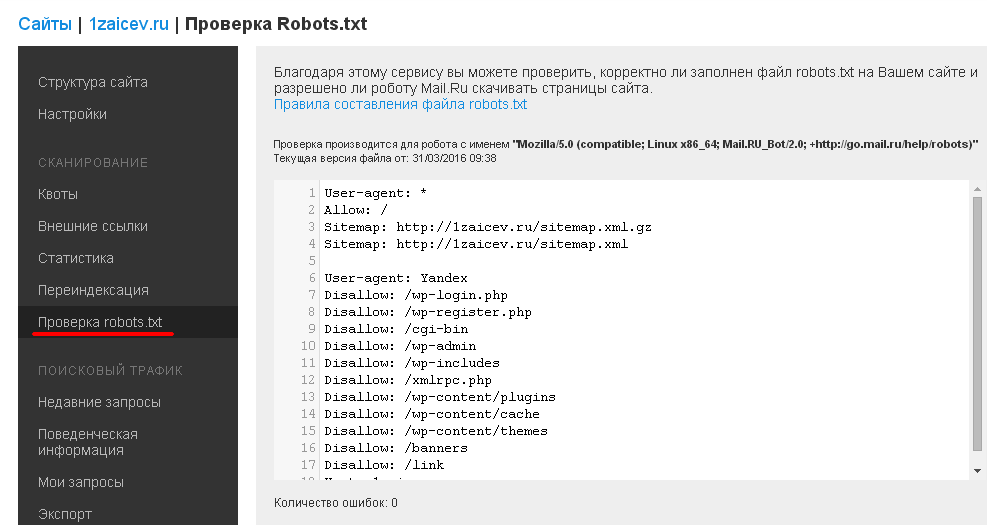
- Добавьте новый файл robots.txt в корень домена в виде текстового файла с именем robots.txt. URL вашего файла robots.txt должен быть /robots.txt.
- Нажмите «Подтвердить онлайн-версию», чтобы убедиться, что онлайн-файл robots.txt — это та версия, которую Google должен сканировать.
- Нажмите «Отправить онлайн-версию», чтобы уведомить Google о том, что ваш файл robots.txt был изменен, и попросить Google просканировать его.
- Убедитесь, что ваша последняя версия успешно просканирована, обновив страницу в браузере, чтобы обновить редактор инструмента и просмотреть код файла robots.txt в Интернете. После обновления страницы вы также можете щелкнуть раскрывающееся меню над текстовым редактором, чтобы отобразить отметку времени, указывающую, когда Google впервые увидел последнюю версию вашего файла robots.txt.
Заключение:
Файл robots.txt позволяет запретить роботам доступ к частям вашего веб-сайта, особенно если область вашей страницы является частной или если содержание не является важным для поисковых систем.