Обзор протокола HTTP — HTTP
HTTP — это протокол, позволяющий получать различные ресурсы, например HTML-документы. Протокол HTTP лежит в основе обмена данными в Интернете. HTTP является протоколом клиент-серверного взаимодействия, что означает инициирование запросов к серверу самим получателем, обычно веб-браузером (web-browser). Полученный итоговый документ будет (может) состоять из различных поддокументов, являющихся частью итогового документа: например, из отдельно полученного текста, описания структуры документа, изображений, видео-файлов, скриптов и многого другого.
Клиенты и серверы взаимодействуют, обмениваясь одиночными сообщениями (а не потоком данных). Сообщения, отправленные клиентом, обычно веб-браузером, называются запросами, а сообщения, отправленные сервером, называются ответами.
Хотя HTTP был разработан ещё в начале 1990-х годов, за счёт своей расширяемости в дальнейшем он все время совершенствовался. HTTP является протоколом прикладного уровня, который чаще всего использует возможности другого протокола — TCP (или TLS — защищённый TCP) — для пересылки своих сообщений, однако любой другой надёжный транспортный протокол теоретически может быть использован для доставки таких сообщений.
HTTP — это клиент-серверный протокол, то есть запросы отправляются какой-то одной стороной — участником обмена (user-agent) (либо прокси вместо него). Чаще всего в качестве участника выступает веб-браузер, но им может быть кто угодно, например, робот, путешествующий по Сети для пополнения и обновления данных индексации веб-страниц для поисковых систем.
Каждый запрос (англ. request) отправляется серверу, который обрабатывает его и возвращает ответ (англ. response). Между этими запросами и ответами как правило существуют многочисленные посредники, называемые прокси, которые выполняют различные операции и работают как шлюзы или кэш, например.
Обычно между браузером и сервером гораздо больше различных устройств-посредников, которые играют какую-либо роль в обработке запроса: маршрутизаторы, модемы и так далее. Благодаря тому, что Сеть построена на основе системы уровней (слоёв) взаимодействия, эти посредники «спрятаны» на сетевом и транспортном уровнях. В этой системе уровней HTTP занимает самый верхний уровень, который называется «прикладным» (или «уровнем приложений»). Знания об уровнях сети, таких как представительский, сеансовый, транспортный, сетевой, канальный и физический, имеют важное значение для понимания работы сети и диагностики возможных проблем, но не требуются для описания и понимания HTTP.
Клиент: участник обмена
Участник обмена (user agent) — это любой инструмент или устройство, действующие от лица пользователя. Эту задачу преимущественно выполняет веб-браузер; в некоторых случаях участниками выступают программы, которые используются инженерами и веб-разработчиками для отладки своих приложений.
Браузер всегда является той сущностью, которая создаёт запрос. Сервер обычно этого не делает, хотя за многие годы существования сети были придуманы способы, которые могут позволить выполнить запросы со стороны сервера.
Чтобы отобразить веб страницу, браузер отправляет начальный запрос для получения HTML-документа этой страницы. После этого браузер изучает этот документ и запрашивает дополнительные файлы, необходимые для отображения содержания веб-страницы (исполняемые скрипты, информацию о макете страницы — CSS таблицы стилей, дополнительные ресурсы в виде изображений и видео-файлов), которые непосредственно являются частью исходного документа, но расположены в других местах сети. Далее браузер соединяет все эти ресурсы для отображения их пользователю в виде единого документа — веб-страницы. Скрипты, выполняемые самим браузером, могут получать по сети дополнительные ресурсы на последующих этапах обработки веб-страницы, и браузер соответствующим образом обновляет отображение этой страницы для пользователя.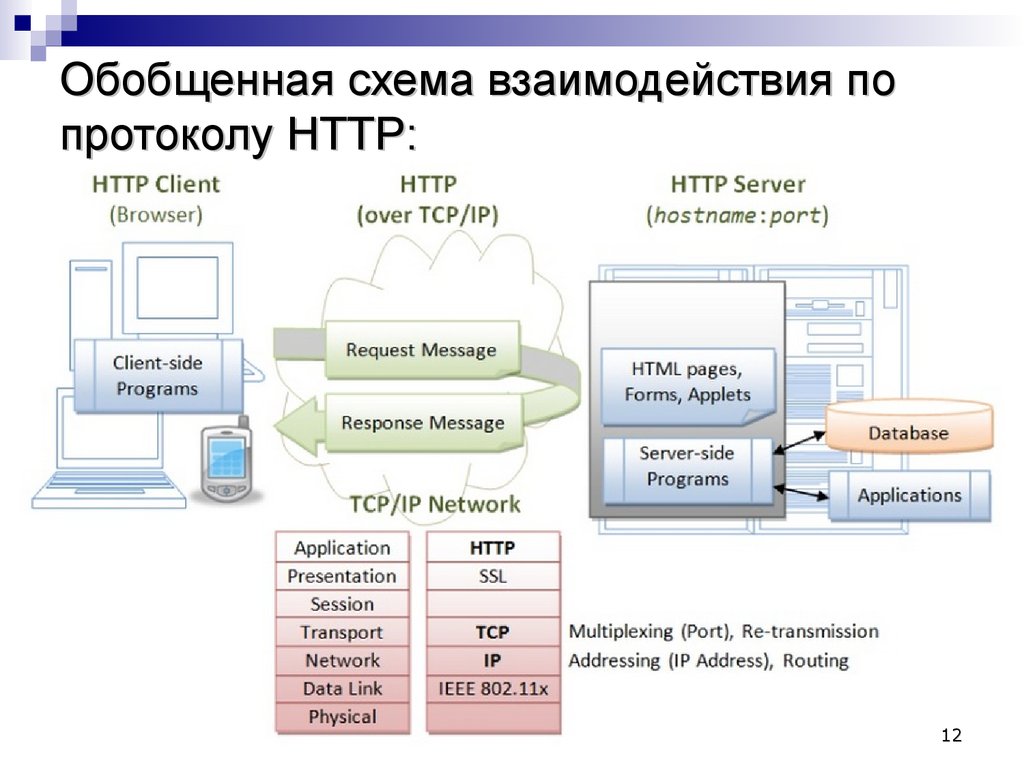
Веб-страница является гипертекстовым документом. Это означает, что некоторые части отображаемого текста являются ссылками, которые могут быть активированы (обычно нажатием кнопки мыши) с целью получения и соответственно отображения новой веб-страницы (переход по ссылке). Это позволяет пользователю «перемещаться» по страницам сети (Internet). Браузер преобразует эти гиперссылки в HTTP-запросы и в дальнейшем полученные HTTP-ответы отображает в понятном для пользователя виде.
Веб-сервер
На другой стороне коммуникационного канала расположен сервер, который обслуживает (англ. serve) пользователя, предоставляя ему документы по запросу. С точки зрения конечного пользователя, сервер всегда является некой одной виртуальной машиной, полностью или частично генерирующей документ, хотя фактически он может быть группой серверов, между которыми балансируется нагрузка, то есть перераспределяются запросы различных пользователей, либо сложным программным обеспечением, опрашивающим другие компьютеры (такие как кеширующие серверы, серверы баз данных, серверы приложений электронной коммерции и другие).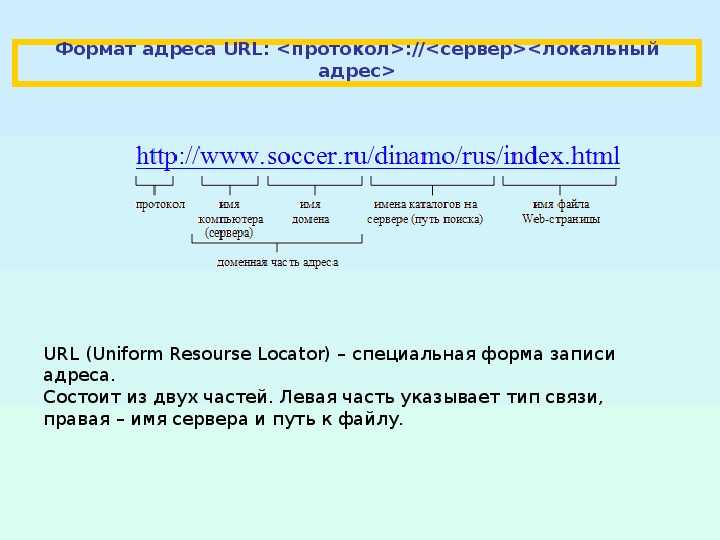
Сервер не обязательно расположен на одной машине, и наоборот — несколько серверов могут быть расположены (хоститься) на одной и той же машине. В соответствии с версией HTTP/1.1 и имея Host заголовок, они даже могут делить тот же самый IP-адрес.
Прокси
Между веб-браузером и сервером находятся большое количество сетевых узлов, передающих HTTP сообщения. Из-за слоистой структуры большинство из них оперируют также на транспортном сетевом или физическом уровнях, становясь прозрачным на HTTP слое и потенциально снижая производительность. Эти операции на уровне приложений называются
- caching (кеш может быть публичным или приватными, как кеш браузера)
- фильтрация (как сканирование антивируса, родительский контроль, …)
- выравнивание нагрузки (позволить нескольким серверам обслуживать разные запросы)
- аутентификация (контролировать доступом к разным ресурсам)
- протоколирование (разрешение на хранение истории операций)
HTTP — прост
Даже с большей сложностью, введённой в HTTP/2 путём инкапсуляции HTTP-сообщений в фреймы, HTTP, как правило, прост и удобен для восприятия человеком. HTTP-сообщения могут читаться и пониматься людьми, обеспечивая более лёгкое тестирование разработчиков и уменьшенную сложность для новых пользователей.
HTTP-сообщения могут читаться и пониматься людьми, обеспечивая более лёгкое тестирование разработчиков и уменьшенную сложность для новых пользователей.
HTTP — расширяемый
Введённые в HTTP/1.0 HTTP-заголовки сделали этот протокол лёгким для расширения и экспериментирования. Новая функциональность может быть даже введена простым соглашением между клиентом и сервером о семантике нового заголовка.
HTTP не имеет состояния, но имеет сессию
HTTP не имеет состояния: не существует связи между двумя запросами, которые последовательно выполняются по одному соединению. Из этого немедленно следует возможность проблем для пользователя, пытающегося взаимодействовать с определённой страницей последовательно, например, при использовании корзины в электронном магазине. Но хотя ядро HTTP не имеет состояния, куки позволяют использовать сессии с сохранением состояния. Используя расширяемость заголовков, куки добавляются к рабочему потоку, позволяя сессии на каждом HTTP-запросе делиться некоторым контекстом или состоянием.
HTTP и соединения
Соединение управляется на транспортном уровне, и потому принципиально выходит за границы HTTP. Хотя HTTP не требует, чтобы базовый транспортный протокол был основан на соединениях, требуя только надёжность, или отсутствие потерянных сообщений (т.е. как минимум представление ошибки). Среди двух наиболее распространённых транспортных протоколов Интернета, TCP надёжен, а UDP — нет. HTTP впоследствии полагается на стандарт TCP, являющийся основанным на соединениях, несмотря на то, что соединение не всегда требуется.
HTTP/1.0 открывал TCP-соединение для каждого обмена запросом/ответом, имея два важных недостатка: открытие соединения требует нескольких обменов сообщениями, и потому медленно, хотя становится более эффективным при отправке нескольких сообщений, или при регулярной отправке сообщений:
Для смягчения этих недостатков, HTTP/1.1 предоставил конвейерную обработку (которую оказалось трудно реализовать) и устойчивые соединения: лежащее в основе TCP соединение можно частично контролировать через заголовок Connection. HTTP/2 сделал следующий шаг, добавив мультиплексирование сообщений через простое соединение, помогающее держать соединение тёплым и более эффективным.
HTTP/2 сделал следующий шаг, добавив мультиплексирование сообщений через простое соединение, помогающее держать соединение тёплым и более эффективным.
Проводятся эксперименты по разработке лучшего транспортного протокола, более подходящего для HTTP. Например, Google экспериментирует с QUIC (которая основана на UDP) для предоставления более надёжного и эффективного транспортного протокола.
Естественная расширяемость HTTP со временем позволила большее управление и функциональность Сети. Кеш и методы аутентификации были ранними функциями в истории HTTP. Способность ослабить первоначальные ограничения, напротив, была добавлена в 2010-е.
Ниже перечислены общие функции, управляемые с HTTP.
- Кеш Сервер может инструктировать прокси и клиенты, указывая что и как долго кешировать. Клиент может инструктировать прокси промежуточных кешей игнорировать хранимые документы.
- Ослабление ограничений источника Для предотвращения шпионских и других нарушающих приватность вторжений, веб-браузер обеспечивает строгое разделение между веб-сайтами.
 Только страницы из того же источника могут получить доступ к информации на веб-странице. Хотя такие ограничение нагружают сервер, заголовки HTTP могут ослабить строгое разделение на стороне сервера, позволяя документу стать частью информации с различных доменов (по причинам безопасности).
Только страницы из того же источника могут получить доступ к информации на веб-странице. Хотя такие ограничение нагружают сервер, заголовки HTTP могут ослабить строгое разделение на стороне сервера, позволяя документу стать частью информации с различных доменов (по причинам безопасности). - Аутентификация Некоторые страницы доступны только специальным пользователям. Базовая аутентификация может предоставляться через HTTP, либо через использование заголовка
WWW-Authenticate(en-US) и подобных ему, либо с помощью настройки спецсессии, используя куки. - Прокси и туннелирование (en-US) Серверы и/или клиенты часто располагаются в интернете и скрывают свои истинные IP-адреса от других. HTTP запросы идут через прокси для пересечения этого сетевого барьера. Не все прокси — HTTP прокси. SOCKS-протокол, например, оперирует на более низком уровне. Другие, как, например, ftp, могут быть обработаны этими прокси.

- Сессии Использование HTTP кук позволяет связать запрос с состоянием на сервере. Это создаёт сессию, хотя ядро HTTP — протокол без состояния. Это полезно не только для корзин в интернет-магазинах, но также для любых сайтов, позволяющих пользователю настроить выход.
Когда клиент хочет взаимодействовать с сервером, являющимся конечным сервером или промежуточным прокси, он выполняет следующие шаги:
- Открытие TCP соединения: TCP-соединение будет использоваться для отправки запроса (или запросов) и получения ответа. Клиент может открыть новое соединение, переиспользовать существующее или открыть несколько TCP-соединений к серверу.
- Отправка HTTP-сообщения: HTTP-сообщения (до HTTP/2) являются человекочитаемыми. Начиная с HTTP/2, простые сообщения инкапсулируются во фреймы, делая невозможным их чтение напрямую, но принципиально остаются такими же.
GET / HTTP/1.1 Host: developer.mozilla.org Accept-Language: fr
- Читает ответ от сервера:
HTTP/1.
 1 200 OK
Date: Sat, 09 Oct 2010 14:28:02 GMT
Server: Apache
Last-Modified: Tue, 01 Dec 2009 20:18:22 GMT
ETag: "51142bc1-7449-479b075b2891b"
Accept-Ranges: bytes
Content-Length: 29769
Content-Type: text/html
<!DOCTYPE html... (here comes the 29769 bytes of the requested web page)
1 200 OK
Date: Sat, 09 Oct 2010 14:28:02 GMT
Server: Apache
Last-Modified: Tue, 01 Dec 2009 20:18:22 GMT
ETag: "51142bc1-7449-479b075b2891b"
Accept-Ranges: bytes
Content-Length: 29769
Content-Type: text/html
<!DOCTYPE html... (here comes the 29769 bytes of the requested web page)
- Закрывает или переиспользует соединение для дальнейших запросов.
Если активирован HTTP-конвейер, несколько запросов могут быть отправлены без ожидания получения первого ответа целиком. HTTP-конвейер тяжело внедряется в существующие сети, где старые куски ПО сосуществуют с современными версиями. HTTP-конвейер был заменён в HTTP/2 на более надёжные мультиплексные запросы во фрейме.
Подробнее в отдельной статье «Сообщения HTTP»
HTTP/1.1 и более ранние HTTP сообщения человекочитаемые. В версии HTTP/2 эти сообщения встроены в новую бинарную структуру, фрейм, позволяющий оптимизации, такие как компрессия заголовков и мультиплексирование. Даже если часть оригинального HTTP сообщения отправлена в этой версии HTTP, семантика каждого сообщения не изменяется и клиент воссоздаёт (виртуально) оригинальный HTTP-запрос.
Существует два типа HTTP сообщений, запросы и ответы, каждый в своём формате.
Запросы
Примеры HTTP запросов:
Запросы содержат следующие элементы:
- HTTP-метод, обычно глагол подобно
GET,POSTили существительное, какOPTIONSилиHEAD, определяющее операцию, которую клиент хочет выполнить. Обычно, клиент хочет получить ресурс (используяGET) или передать значения HTML-формы (используяPOST), хотя другие операции могут быть необходимы в других случаях. - Путь к ресурсу: URL ресурсы лишены элементов, которые очевидны из контекста, например без протокола (
http://), домена (здесьdeveloper.mozilla.org), или TCP порта (здесь80). - Версию HTTP-протокола.
- Заголовки (опционально), предоставляющие дополнительную информацию для сервера.
- Или тело, для некоторых методов, таких как
POST, которое содержит отправленный ресурс.
Ответы
Примеры ответов:
Ответы содержат следующие элементы:
- Версию HTTP-протокола.
- HTTP код состояния, сообщающий об успешности запроса или причине неудачи.
- Сообщение состояния — краткое описание кода состояния.
- HTTP заголовки, подобно заголовкам в запросах.
- Опционально: тело, содержащее пересылаемый ресурс.
HTTP — лёгкий в использовании расширяемый протокол. Структура клиент-сервера, вместе со способностью к простому добавлению заголовков, позволяет HTTP продвигаться вместе с расширяющимися возможностями Сети.
Хотя HTTP/2 добавляет некоторую сложность, встраивая HTTP сообщения во фреймы для улучшения производительности, базовая структура сообщений осталась с HTTP/1.0. Сессионный поток остаётся простым, позволяя исследовать и отлаживать с простым монитором HTTP-сообщений.
Found a content problem with this page?
- Edit the page on GitHub.
- Report the content issue.
- View the source on GitHub.
Want to get more involved?
Learn how to contribute.
This page was last modified on by MDN contributors.
Сообщения HTTP — HTTP | MDN
HTTP сообщения — это обмен данными между сервером и клиентом. Есть два типа сообщений: запросы, отправляемые клиентом, чтобы инициировать реакцию со стороны сервера, и ответы от сервера.
Сообщения HTTP состоят из текстовой информации в кодировке ASCII, записанной в несколько строк. В HTTP/1.1 и более ранних версиях они пересылались в качестве обычного текста. В HTTP/2 текстовое сообщение разделяется на фреймы, что позволяет выполнить оптимизацию и повысить производительность.
Веб разработчики не создают текстовые сообщения HTTP самостоятельно — это делает программа, браузер, прокси или веб-сервер. Они обеспечивают создание HTTP сообщений через конфигурационные файлы (для прокси и серверов), APIs (для браузеров) или другие интерфейсы.
Механизм бинарного фрагментирования в HTTP/2 разработан так, чтобы не потребовалось вносить изменения в имеющиеся APIs и конфигурационные файлы: он вполне прозрачен для пользователя.
HTTP запросы и ответы имеют близкую структуру. Они состоят из:
- Стартовой строки, описывающей запрос, или статус (успех или сбой). Это всегда одна строка.
- Произвольного набора HTTP заголовков, определяющих запрос или описывающих тело сообщения.
- Пустой строки, указывающей, что вся мета информация отправлена.
- Произвольного тела, содержащего пересылаемые с запросом данные (например, содержимое HTML-формы ) или отправляемый в ответ документ. Наличие тела и его размер определяется стартовой строкой и заголовками HTTP.
Стартовую строку вместе с заголовками сообщения HTTP называют головой запроса, а его данные — телом.
Стартовая строка
HTTP запросы — это сообщения, отправляемые клиентом, чтобы инициировать реакцию со стороны сервера. Их стартовая строка состоит из трёх элементов:
- Метод HTTP, глагол (например,
GET,PUTилиPOST) или существительное (например,HEADилиOPTIONS), описывающие требуемое действие. Например,GETуказывает, что нужно доставить некоторый ресурс, аPOSTозначает отправку данных на сервер (для создания или модификации ресурса, или генерации возвращаемого документа). - Цель запроса, обычно URL, или абсолютный путь протокола, порт и домен обычно характеризуются контекстом запроса. Формат цели запроса зависит от используемого HTTP-метода. Это может быть
- Абсолютный путь, за которым следует
'?'и строка запроса. Это самая распространённая форма, называемая исходной формой (origin form) . Используется с методамиGET,POST,HEAD, иOPTIONS.POST / HTTP 1.1 GET /background. png HTTP/1.0 HEAD /test.html?query=alibaba HTTP/1.1 OPTIONS /anypage.html HTTP/1.0 - Полный URL — абсолютная форма (absolute form) , обычно используется с
GETпри подключении к прокси.GET http://developer.mozilla.org/ru/docs/Web/HTTP/Messages HTTP/1.1 - Компонента URL «authority», состоящая из имени домена и (необязательно) порта (предваряемого символом
':'), называется authority form. Используется только с методомCONNECTпри установке туннеля HTTP.CONNECT developer.mozilla.org:80 HTTP/1.1 - Форма звёздочки (asterisk form), просто «звёздочка» (
'*') используетсяс методом OPTIONSи представляет сервер.OPTIONS * HTTP/1.1
- Абсолютный путь, за которым следует
- Версия HTTP, определяющая структуру оставшегося сообщения, указывая, какую версию предполагается использовать для ответа.
Заголовки
Заголовки запроса HTTP имеют стандартную для заголовка HTTP структуру: не зависящая от регистра строка, завершаемая (':') и значение, структура которого определяется заголовком. Весь заголовок, включая значение, представляет собой одну строку, которая может быть довольно длинной.
Существует множество заголовков запроса. Их можно разделить на несколько групп:
- Основные заголовки (General headers), например,
Via(en-US), относящиеся к сообщению в целом - Заголовки запроса (Request headers), например,
User-Agent,Accept-Type, уточняющие запрос (как, например,Accept-Language), придающие контекст (какReferer), или накладывающие ограничения на условия (likeIf-None). - Заголовки сущности, например
Content-Length, относящиеся к телу сообщения. Как легко понять, они отсутствуют, если у запроса нет тела.
Тело
Последней частью запроса является его тело. Оно бывает не у всех запросов: запросы, собирающие (fetching) ресурсы, такие как GET, HEAD, DELETE, или OPTIONS, в нем обычно не нуждаются. Но некоторые запросы отправляют на сервер данные для обновления, как это часто бывает с запросами POST (содержащими данные HTML-форм).
Тела можно грубо разделить на две категории:
- Одноресурсные тела (Single-resource bodies), состоящие из одного отдельного файла, определяемого двумя заголовками:
Content-TypeиContent-Length. - Многоресурсные тела (Multiple-resource bodies), состоящие из множества частей, каждая из которых содержит свой бит информации. Они обычно связаны с HTML-формами.
Строка статуса (Status line)
Стартовая строка ответа HTTP, называемая строкой статуса, содержит следующую информацию:
- Версию протокола,
обычно HTTP/1.. 1 - Код состояния (status code), показывающая, был ли запрос успешным. Примеры:
200,404или302 - Пояснение (status text). Краткое текстовое описание кода состояния, помогающее пользователю понять сообщение HTTP..
Пример строки статуса: HTTP/1.1 404 Not Found.
Заголовки
Заголовки ответов HTTP имеют ту же структуру, что и все остальные заголовки: не зависящая от регистра строка, завершаемая двоеточием (':') и значение, структура которого определяется типом заголовка. Весь заголовок, включая значение, представляет собой одну строку.
Существует множество заголовков ответов. Их можно разделить на несколько групп:
- Основные заголовки (General headers), например,
Via(en-US), относящиеся к сообщению в целом. - Заголовки ответа (Response headers), например,
VaryиAccept-Ranges, сообщающие дополнительную информацию о сервере, которая не уместилась в строку состояния. - Заголовки сущности (Entity headers), например,
Content-Length, относящиеся к телу ответа. Отсутствуют, если у запроса нет тела.
Тело
Последней частью ответа является его тело. Оно есть не у всех ответов: у ответов с кодом состояния, например, 201 или 204, оно обычно отсутствует.
Тела можно разделить на три категории:
- Одноресурсные тела (Single-resource bodies), состоящие из отдельного файла известной длины, определяемые двумя заголовками:
Content-TypeиContent-Length. - Одноресурсные тела (Single-resource bodies), состоящие из отдельного файла неизвестной длины, разбитого на небольшие части (chunks) с заголовком
Transfer-Encoding(en-US), значением которого являетсяchunked. - Многоресурсные тела (Multiple-resource bodies), состоящие из многокомпонентного тела, каждая часть которого содержит свой сегмент информации. Они относительно редки.
Сообщения HTTP/1.x имеют несколько недостатков в отношении производительности:
- Заголовки, в отличие от тел, не сжимаются.
- Заголовки, которые зачастую практически совпадают у идущих подряд сообщений, приходится передавать по отдельности.
- Мультиплексность невозможна. Приходится открывать соединение для каждого сообщения, а тёплые (warm) соединения TCP эффективнее холодных (cold).
HTTP/2 переходит на новый уровень: он делит сообщения HTTP/1.x на фреймы, которые внедряются в поток. Фреймы данных из заголовков отделены друг от друга, что позволяет сжимать заголовки. Несколько потоков можно объединять друг с другом — такой процесс называется мультиплексированием — что позволяет более эффективно использовать TCP-соединения.
Фреймы HTTP сейчас прозрачны для веб-разработчиков. Это дополнительный шаг, который HTTP/2 делает по отношению к сообщениям HTTP/1.1 и лежащему в основе транспортному протоколу. Для реализации фреймов HTTP веб-разработчикам не требуется вносить изменения в имеющиеся APIs; если HTTP/2 доступен и на сервере, и на клиенте, он включается и используется.
Сообщения HTTP играют ключевую роль в использовании HTTP; они имеют простую структуру и хорошо расширяемы. Механизм фреймов в HTTP/2 добавляет ещё один промежуточный уровень между синтаксисом HTTP/1.x и используемым им транспортным протоколом, не проводя фундаментальных изменений: создаётся надстройка над уже зарекомендовавшими себя методами.
Found a content problem with this page?
- Edit the page on GitHub.
- Report the content issue.
- View the source on GitHub.
Want to get more involved?
Learn how to contribute.
This page was last modified on by MDN contributors.
Заголовки HTTP — HTTP | MDN
Заголовки HTTP позволяют клиенту и серверу отправлять дополнительную информацию с HTTP запросом или ответом. В HTTP-заголовке содержится не чувствительное к регистру название, а затем после (:) непосредственно значение. Пробелы перед значением игнорируются.
Пользовательские собственные заголовки исторически использовались с префиксом X, но это соглашение было объявлено устаревшим в июне 2012 года из-за неудобств, вызванных тем, что нестандартные поля стали стандартом в RFC 6648; другие перечислены в реестре IANA, исходное содержимое которого было определено в RFC 4229. IANA также поддерживает реестр предлагаемых новых заголовков HTTP.
HTTP-заголовки сопровождают обмен данными по протоколу HTTP. Они могут содержать описание данных и информацию, необходимую для взаимодействия между клиентом и сервером. Заголовки и их статусы перечислены в реестре IANA, который постоянно обновляется.
Заголовки могут быть сгруппированы по следующим контекстам:
- Основные заголовки применяется как к запросам, так и к ответам, но не имеет отношения к данным, передаваемым в теле.
- Заголовки запроса содержит больше информации о ресурсе, который нужно получить, или о клиенте, запрашивающем ресурс.
- Заголовки ответа (en-US) содержат дополнительную информацию об ответе, например его местонахождение, или о сервере, предоставившем его.
- Заголовки сущности содержат информацию о теле ресурса, например его длину содержимого или тип MIME (en-US).
Заголовки также могут быть сгруппированы согласно тому, как прокси (proxies) обрабатывают их:
ConnectionKeep-Alive(en-US)Proxy-Authenticate(en-US)Proxy-Authorization(en-US)TE(en-US)Trailer(en-US)Transfer-Encoding(en-US)Upgrade(en-US).
Сквозные заголовки Эти заголовки должны быть переданы конечному получателю сообщения: серверу для запроса или клиенту для ответа. Промежуточные прокси-серверы должны повторно передавать эти заголовки без изменений, а кеши должны их хранить.
Хоп-хоп заголовки (Хоп-хоп заголовки) Эти заголовки имеют смысл только для одного соединения транспортного уровня и не должны повторно передаваться прокси или кешироваться. Обратите внимание, что с помощью общего заголовка Connection могут быть установлены только заголовки переходов.
WWW-Authenticate (en-US) Определяет метод аутентификации, который должен использоваться для доступа к ресурсу. Authorization Содержит учётные данные для аутентификации агента пользователя на сервере. Proxy-Authenticate (en-US) Определяет метод аутентификации, который должен использоваться для доступа к ресурсам на прокси-сервере. Proxy-Authorization (en-US) Содержит учётные данные для аутентификации агента пользователя с прокси-сервером.
Ниже перечислены основные HTTP заголовки с кратким описанием:
| Заголовок | Описание | Подробнее | Стандарт |
|---|---|---|---|
Accept | Список MIME типов, которые ожидает клиент. | HTTP Content Negotiation | HTTP/1.1 |
Accept-CHNon-standard | Список конфигурационных данных, которые могут быть учтены сервером при выборе соответствующего ответа клиенту. | HTTP Client Hints | |
Accept-Charset | Список кодировок, которые ожидает клиент. | HTTP Content Negotiation | HTTP/1. 1 |
Accept-Features | HTTP Content Negotiation | RFC 2295, §8.2 | |
Accept-Encoding | Список форматов сжатия данных, которые поддерживает клиент. | HTTP Content Negotiation | HTTP/1.1 |
Accept-Language | Определяет языковые предпочтения клиента. | HTTP Content Negotiation | HTTP/1.1 |
Accept-Ranges | |||
Access-Control-Allow-Credentials | HTTP Access Control and Server Side Access Control | W3C Cross-Origin Resource Sharing | |
Access-Control-Allow-Origin | HTTP Access Control and Server Side Access Control | W3C Cross-Origin Resource Sharing | |
Access-Control-Allow-Methods | HTTP Access Control and Server Side Access Control | W3C Cross-Origin Resource Sharing | |
Access-Control-Allow-Headers | HTTP Access Control and Server Side Access Control | W3C Cross-Origin Resource Sharing | |
Access-Control-Max-Age | HTTP Access Control and Server Side Access Control | W3C Cross-Origin Resource Sharing | |
Access-Control-Expose-Headers | HTTP Access Control and Server Side Access Control | W3C Cross-Origin Resource Sharing | |
Access-Control-Request-Method | HTTP Access Control and Server Side Access Control | W3C Cross-Origin Resource Sharing | |
Access-Control-Request-Headers | HTTP Access Control and Server Side Access Control | W3C Cross-Origin Resource Sharing | |
Age | |||
Allow | |||
Alternates | HTTP Content Negotiation | RFC 2295, §8. 3 | |
Authorization | |||
Cache-Control | HTTP Caching FAQ | ||
Connection | Определяет, остаётся ли сетевое соединение открытым после завершения текущей транзакции (запроса). | ||
Content-Encoding | |||
Content-Language | |||
Content-Length | |||
Content-Location | |||
Content-MD5 | Не реализовано (смотрите баг 232030) | ||
Content-Range | |||
Content-Security-Policy | Реализует механизм защиты от угроз межсайтового выполнения скриптов. | CSP (Content Security Policy) | W3C Content Security Policy |
Content-Type | Позволяет клиенту определить MIME тип документа. | ||
Cookie | RFC 2109 | ||
DNT | With a value of 1, indicates that the user explicitly opts out of any form of online tracking. | Supported by Firefox 4, Firefox 5 for mobile, IE9, and a few major companies. | Tracking Preference Expression (DNT) |
Date | |||
ETag | HTTP Caching FAQ | ||
Expect | |||
Expires | HTTP Caching FAQ | ||
From | |||
Host | |||
If-Match | |||
If-Modified-Since | HTTP Caching FAQ | ||
If-None-Match | HTTP Caching FAQ | ||
If-Range | |||
If-Unmodified-Since | |||
Last-Event-ID | Содержит идентификатор последнего события полученного клиентом от
сервера в предыдущем HTTP запросе. Используется для восстановления
синхронизации потока text/event-stream. | Server-Sent Events | Server-Sent Events spec |
Last-Modified | HTTP Caching FAQ | ||
Link | Содержит ссылки на связанные ресурсы и определяет их отношение к отправленному документу. | For the | Introduced in HTTP 1.1’s RFC 2068, section 19.6.2.4, it was removed in the final HTTP 1.1 spec, then reintroduced, with some extensions, in RFC 5988 |
Location | |||
Max-Forwards | |||
Negotiate | HTTP Content Negotiation | RFC 2295, §8. 4 | |
Origin | HTTP Access Control and Server Side Access Control | More recently defined in the Fetch spec (see Fetch API.) Originally defined in W3C Cross-Origin Resource Sharing | |
Pragma | for the pragma: nocache value see HTTP Caching FAQ | ||
Proxy-Authenticate | |||
Proxy-Authorization | |||
Range | |||
Referer | Содержит URL-адрес ресурса, из которого был запрошен обрабатываемый
запрос. Если запрос поступил из закладки, прямого ввода адреса
пользователем или с помощью других методов, при которых исходного
ресурса нет, то этот заголовок отсутствует или имеет значение
«about:blank». Это ошибочное имя заголовка (referer, вместо referrer) было введено в спецификацию HTTP/0.9, и ошибка должна была быть сохранена в более поздних версиях протокола для совместимости. | ||
Retry-After | |||
Sec-Websocket-Extensions | Websockets | ||
Sec-Websocket-Key | Websockets | ||
Sec-Websocket-Origin | Websockets | ||
Sec-Websocket-Protocol | Websockets | ||
Sec-Websocket-Version | Websockets | ||
Server | |||
Set-Cookie | RFC 2109 | ||
Set-Cookie2 | RFC 2965 | ||
Strict-Transport-Security | HTTP Strict Transport Security | IETF reference | |
TCN | HTTP Content Negotiation | RFC 2295, §8. 5 | |
TE | |||
Trailer | lists the headers that will be transmitted after the message body, in a
trailer block. This allows servers to compute some values, like Content-MD5: while transmitting the data. Note that the Trailer: header must not list the Content-Length:, Trailer: or Transfer-Encoding: headers. | RFC 2616, §14.40 | |
Transfer-Encoding | |||
Upgrade | |||
User-Agent | for Gecko’s user agents see the User Agents Reference | ||
Variant-Vary | HTTP Content Negotiation | RFC 2295, §8. 6 | |
Vary | lists the headers used as criteria for choosing a specific content by the web server. This server is important for efficient and correct caching of the resource sent. | HTTP Content Negotiation & HTTP Caching FAQ | |
Via | |||
Warning | |||
WWW-Authenticate | |||
X-Content-Duration | Configuring servers for Ogg media | ||
X-Content-Security-Policy | Using Content Security Policy | ||
X-DNSPrefetch-Control | Controlling DNS prefetching | ||
X-Frame-Options | The XFrame-Option Response Header | ||
X-Requested-With | Often used with the value «XMLHttpRequest» when it is the case | Not standard |
Примечание: The Keep-Alive request header is not sent by Gecko 5. 0; previous versions did send it but it was not formatted correctly, so the decision was made to remove it for the time being. The Connection or Proxy-Connection header is still sent, however, with the value «keep-alive».
Wikipedia page on List of HTTP headers
Found a content problem with this page?
- Edit the page on GitHub.
- Report the content issue.
- View the source on GitHub.
Want to get more involved?
Learn how to contribute.
This page was last modified on by MDN contributors.
Простым языком об HTTP / Хабр
Вашему вниманию предлагается описание основных аспектов протокола HTTP — сетевого протокола, с начала 90-х и по сей день позволяющего вашему браузеру загружать веб-страницы. Данная статья написана для тех, кто только начинает работать с компьютерными сетями и заниматься разработкой сетевых приложений, и кому пока что сложно самостоятельно читать официальные спецификации.
HTTP — широко распространённый протокол передачи данных, изначально предназначенный для передачи гипертекстовых документов (то есть документов, которые могут содержать ссылки, позволяющие организовать переход к другим документам).
Аббревиатура HTTP расшифровывается как HyperText Transfer Protocol, «протокол передачи гипертекста». В соответствии со спецификацией OSI, HTTP является протоколом прикладного (верхнего, 7-го) уровня. Актуальная на данный момент версия протокола, HTTP 1.1, описана в спецификации RFC 2616.
Протокол HTTP предполагает использование клиент-серверной структуры передачи данных. Клиентское приложение формирует запрос и отправляет его на сервер, после чего серверное программное обеспечение обрабатывает данный запрос, формирует ответ и передаёт его обратно клиенту. После этого клиентское приложение может продолжить отправлять другие запросы, которые будут обработаны аналогичным образом.
Задача, которая традиционно решается с помощью протокола HTTP — обмен данными между пользовательским приложением, осуществляющим доступ к веб-ресурсам (обычно это веб-браузер) и веб-сервером. На данный момент именно благодаря протоколу HTTP обеспечивается работа Всемирной паутины.
Также HTTP часто используется как протокол передачи информации для других протоколов прикладного уровня, таких как SOAP, XML-RPC и WebDAV. В таком случае говорят, что протокол HTTP используется как «транспорт».
API многих программных продуктов также подразумевает использование HTTP для передачи данных — сами данные при этом могут иметь любой формат, например, XML или JSON.
Как правило, передача данных по протоколу HTTP осуществляется через TCP/IP-соединения. Серверное программное обеспечение при этом обычно использует TCP-порт 80 (и, если порт не указан явно, то обычно клиентское программное обеспечение по умолчанию использует именно 80-й порт для открываемых HTTP-соединений), хотя может использовать и любой другой.
Как отправить HTTP-запрос?
Самый простой способ разобраться с протоколом HTTP — это попробовать обратиться к какому-нибудь веб-ресурсу вручную. Представьте, что вы браузер, и у вас есть пользователь, который очень хочет прочитать статьи Анатолия Ализара.
Предположим, что он ввёл в адресной строке следующее:
http://alizar.habrahabr.ru/
Соответственно вам, как веб-браузеру, теперь необходимо подключиться к веб-серверу по адресу alizar.habrahabr.ru.
Для этого вы можете воспользоваться любой подходящей утилитой командной строки. Например, telnet:
telnet alizar.habrahabr.ru 80
Сразу уточню, что если вы вдруг передумаете, то нажмите Ctrl + «]», и затем ввод — это позволит вам закрыть HTTP-соединение. Помимо telnet можете попробовать nc (или ncat) — по вкусу.
После того, как вы подключитесь к серверу, нужно отправить HTTP-запрос. Это, кстати, очень легко — HTTP-запросы могут состоять всего из двух строчек.
Для того, чтобы сформировать HTTP-запрос, необходимо составить стартовую строку, а также задать по крайней мере один заголовок — это заголовок Host, который является обязательным, и должен присутствовать в каждом запросе. Дело в том, что преобразование доменного имени в IP-адрес осуществляется на стороне клиента, и, соответственно, когда вы открываете TCP-соединение, то удалённый сервер не обладает никакой информацией о том, какой именно адрес использовался для соединения: это мог быть, например, адрес alizar.habrahabr.ru, habrahabr.ru или m.habrahabr.ru — и во всех этих случаях ответ может отличаться. Однако фактически сетевое соединение во всех случаях открывается с узлом 212.24.43.44, и даже если первоначально при открытии соединения был задан не этот IP-адрес, а какое-либо доменное имя, то сервер об этом никак не информируется — и именно поэтому этот адрес необходимо передать в заголовке Host.
Стартовая (начальная) строка запроса для HTTP 1.1 составляется по следующей схеме:
Метод URI HTTP/Версия
Например (такая стартовая строка может указывать на то, что запрашивается главная страница сайта):
GET / HTTP/1.1
Метод (в англоязычной тематической литературе используется слово method, а также иногда слово verb — «глагол») представляет собой последовательность из любых символов, кроме управляющих и разделителей, и определяет операцию, которую нужно осуществить с указанным ресурсом. Спецификация HTTP 1.1 не ограничивает количество разных методов, которые могут быть использованы, однако в целях соответствия общим стандартам и сохранения совместимости с максимально широким спектром программного обеспечения как правило используются лишь некоторые, наиболее стандартные методы, смысл которых однозначно раскрыт в спецификации протокола.
URI (Uniform Resource Identifier, унифицированный идентификатор ресурса) — путь до конкретного ресурса (например, документа), над которым необходимо осуществить операцию (например, в случае использования метода GET подразумевается получение ресурса). Некоторые запросы могут не относиться к какому-либо ресурсу, в этом случае вместо URI в стартовую строку может быть добавлена звёздочка (астериск, символ «*»). Например, это может быть запрос, который относится к самому веб-серверу, а не какому-либо конкретному ресурсу. В этом случае стартовая строка может выглядеть так:
OPTIONS * HTTP/1.1
Версия определяет, в соответствии с какой версией стандарта HTTP составлен запрос. Указывается как два числа, разделённых точкой (например 1.1).
Для того, чтобы обратиться к веб-странице по определённому адресу (в данном случае путь к ресурсу — это «/»), нам следует отправить следующий запрос:
GET / HTTP/1.1Host: alizar.habrahabr.ru
При этом учитывайте, что для переноса строки следует использовать символ возврата каретки (Carriage Return), за которым следует символ перевода строки (Line Feed). После объявления последнего заголовка последовательность символов для переноса строки добавляется дважды.
Впрочем, в спецификации HTTP рекомендуется программировать HTTP-сервер таким образом, чтобы при обработке запросов в качестве межстрочного разделителя воспринимался символ LF, а предшествующий символ CR, при наличии такового, игнорировался. Соответственно, на практике бо́льшая часть серверов корректно обработает и такой запрос, где заголовки отделены символом LF, и он же дважды добавлен после объявления последнего заголовка.
Если вы хотите отправить запрос в точном соответствии со спецификацией, можете воспользоваться управляющими последовательностями \r и \n:
echo -en "GET / HTTP/1.1\r\nHost: alizar.habrahabr.ru\r\n\r\n" | ncat alizar.habrahabr.ru 80
Как прочитать ответ?
Стартовая строка ответа имеет следующую структуру:
HTTP/Версия Код состояния Пояснение
Версия протокола здесь задаётся так же, как в запросе.
Код состояния (Status Code) — три цифры (первая из которых указывает на класс состояния), которые определяют результат совершения запроса. Например, в случае, если был использован метод GET, и сервер предоставляет ресурс с указанным идентификатором, то такое состояние задаётся с помощью кода 200. Если сервер сообщает о том, что такого ресурса не существует — 404. Если сервер сообщает о том, что не может предоставить доступ к данному ресурсу по причине отсутствия необходимых привилегий у клиента, то используется код 403. Спецификация HTTP 1.1 определяет 40 различных кодов HTTP, а также допускается расширение протокола и использование дополнительных кодов состояний.
Пояснение к коду состояния (Reason Phrase) — текстовое (но не включающее символы CR и LF) пояснение к коду ответа, предназначено для упрощения чтения ответа человеком. Пояснение может не учитываться клиентским программным обеспечением, а также может отличаться от стандартного в некоторых реализациях серверного ПО.
После стартовой строки следуют заголовки, а также тело ответа. Например:
HTTP/1.1 200 OK Server: nginx/1.2.1 Date: Sat, 08 Mar 2014 22:53:46 GMT Content-Type: application/octet-stream Content-Length: 7 Last-Modified: Sat, 08 Mar 2014 22:53:30 GMT Connection: keep-alive Accept-Ranges: bytes Wisdom
Тело ответа следует через два переноса строки после последнего заголовка. Для определения окончания тела ответа используется значение заголовка Content-Length (в данном случае ответ содержит 7 восьмеричных байтов: слово «Wisdom» и символ переноса строки).
Но вот по тому запросу, который мы составили ранее, веб-сервер вернёт ответ не с кодом 200, а с кодом 302. Таким образом он сообщает клиенту о том, что обращаться к данному ресурсу на данный момент нужно по другому адресу.
Смотрите сами:
HTTP/1.1 302 Moved Temporarily Server: nginx Date: Sat, 08 Mar 2014 22:29:53 GMT Content-Type: text/html Content-Length: 154 Connection: keep-alive Keep-Alive: timeout=25 Location: http://habrahabr.ru/users/alizar/ <html> <head><title>302 Found</title></head> <body bgcolor="white"> <center><h2>302 Found</h2></center> <hr><center>nginx</center> </body> </html>
В заголовке Location передан новый адрес. Теперь URI (идентификатор ресурса) изменился на /users/alizar/, а обращаться нужно на этот раз к серверу по адресу habrahabr.ru (впрочем, в данном случае это тот же самый сервер), и его же указывать в заголовке Host.
То есть:
GET /users/alizar/ HTTP/1.1Host: habrahabr.ru
В ответ на этот запрос веб-сервер Хабрахабра уже выдаст ответ с кодом 200 и достаточно большой документ в формате HTML.
Если вы уже успели вжиться в роль, то можете теперь прочитать полученный от сервера HTML-код, взять карандаш и блокнот, и нарисовать профайл Ализара — в принципе, именно этим бы на вашем месте браузер сейчас и занялся.
А что с безопасностью?
Сам по себе протокол HTTP не предполагает использование шифрования для передачи информации. Тем не менее, для HTTP есть распространённое расширение, которое реализует упаковку передаваемых данных в криптографический протокол SSL или TLS.
Название этого расширения — HTTPS (HyperText Transfer Protocol Secure). Для HTTPS-соединений обычно используется TCP-порт 443. HTTPS широко используется для защиты информации от перехвата, а также, как правило, обеспечивает защиту от атак вида man-in-the-middle — в том случае, если сертификат проверяется на клиенте, и при этом приватный ключ сертификата не был скомпрометирован, пользователь не подтверждал использование неподписанного сертификата, и на компьютере пользователя не были внедрены сертификаты центра сертификации злоумышленника.
На данный момент HTTPS поддерживается всеми популярными веб-браузерами.
А есть дополнительные возможности?
Протокол HTTP предполагает достаточно большое количество возможностей для расширения. В частности, спецификация HTTP 1.1 предполагает возможность использования заголовка Upgrade для переключения на обмен данными по другому протоколу. Запрос с таким заголовком отправляется клиентом. Если серверу требуется произвести переход на обмен данными по другому протоколу, то он может вернуть клиенту ответ со статусом «426 Upgrade Required», и в этом случае клиент может отправить новый запрос, уже с заголовком Upgrade.
Такая возможность используется, в частности, для организации обмена данными по протоколу WebSocket (протокол, описанный в спецификации RFC 6455, позволяющий обеим сторонам передавать данные в нужный момент, без отправки дополнительных HTTP-запросов): стандартное «рукопожатие» (handshake) сводится к отправке HTTP-запроса с заголовком Upgrade, имеющим значение «websocket», на который сервер возвращает ответ с состоянием «101 Switching Protocols», и далее любая сторона может начать передавать данные уже по протоколу WebSocket.
Что-то ещё, кстати, используют?
На данный момент существуют и другие протоколы, предназначенные для передачи веб-содержимого. В частности, протокол SPDY (произносится как английское слово speedy, не является аббревиатурой) является модификацией протокола HTTP, цель которой — уменьшить задержки при загрузке веб-страниц, а также обеспечить дополнительную безопасность.
Увеличение скорости обеспечивается посредством сжатия, приоритизации и мультиплексирования дополнительных ресурсов, необходимых для веб-страницы, чтобы все данные можно было передать в рамках одного соединения.
Опубликованный в ноябре 2012 года черновик спецификации протокола HTTP 2.0 (следующая версия протокола HTTP после версии 1.1, окончательная спецификация для которой была опубликована в 1999) базируется на спецификации протокола SPDY.
Многие архитектурные решения, используемые в протоколе SPDY, а также в других предложенных реализациях, которые рабочая группа httpbis рассматривала в ходе подготовки черновика спецификации HTTP 2. 0, уже ранее были получены в ходе разработки протокола HTTP-NG, однако работы над протоколом HTTP-NG были прекращены в 1998.
На данный момент поддержка протокола SPDY есть в браузерах Firefox, Chromium/Chrome, Opera, Internet Exporer и Amazon Silk.
И что, всё?
В общем-то, да. Можно было бы описать конкретные методы и заголовки, но фактически эти знания нужны скорее в том случае, если вы пишете что-то конкретное (например, веб-сервер или какое-то клиентское программное обеспечение, которое связывается с серверами через HTTP), и для базового понимания принципа работы протокола не требуются. К тому же, всё это вы можете очень легко найти через Google — эта информация есть и в спецификациях, и в Википедии, и много где ещё.
Впрочем, если вы знаете английский и хотите углубиться в изучение не только самого HTTP, но и используемых для передачи пакетов TCP/IP, то рекомендую прочитать вот эту статью.
Ну и, конечно, не забывайте, что любая технология становится намного проще и понятнее тогда, когда вы фактически начинаете ей пользоваться.
Удачи и плодотворного обучения!
Библиотека Requests: HTTP for Humans
Язык Python является универсальным языком программирования. С его помощью можно решать разнообразные задачи в сфере разработки.
Одной из таких сфер, в которой Python занял уверенную позицию, является веб-разработка. Немаловажную роль в этом сыграло обширное комьюнити, различные фреймворки и подключаемые библиотеки, созданные для облегчения жизни программистов. Об одной из таких библиотек сегодня пойдёт речь.
Библиотека Requests: HTTP for Humans
При решении различных задач в сфере веб-разработки, нам часто приходится взаимодействовать с HTTP. Это не самая простая задача для любого языка программирования и Python в этом не исключение. Язык, конечно, содержит встроенные модули, позволяющие отправлять HTTP запросы, но, как это ни парадоксально, их использование едва ли можно отнести к Pythonic-way.
В своё время чтобы обойти монструозность и сложность использования встроенных модулей появилась библиотека Requests. На данный момент она является одной из самых популярных библиотек на github: более 40 000 «звёзд» и используется более, чем в 20 000 open-source проектах. Нередко она используется и в коммерческой разработке.
Для чего и где мы можем применять Requests?
Как было отмечено выше, библиотека позволяет нам легко и с минимальным количеством кода взаимодействовать с веб-приложениями. Это необходимо нам для решения любых задач, связанных с передачей информации от пользователя к серверу и обратно. Но, чтобы что-то хорошо понять, необходимо закрепить теоретические знания практикой, поэтому перейдём от слов к делу.
Примеры использования библиотеки Requests
Для работы с примерами мы будем использовать два способа: работа в командной строке и написание скриптов в . py-файлах для их дальнейшего запуска.
Я показываю использование командной строки, так как это полезный навык, который пригодится в дальнейшем, когда надо будет быстро что-то проверить.
Для начала, поскольку библиотека является внешней, нам необходимо её установить. Делается это очень просто в командной строке:
$ pip install requests
Продолжим использовать консоль. После установки в нашем расположении (у меня это диск D) введем команду:
D:\> python
Python 3.7.4 (tags/v3.7.4:e09359112e, Jul 8 2019, 20:34:20) [MSC v.1916 64 bit (AMD64)] on win32
Type "help", "copyright", "credits" or "license" for more information.
>>>
Теперь можем проверить установку библиотеки произведя импорт:
>>> import requests
Получаем ответ от сайта
Первое, что мы сделаем — проверим статус-код ресурса. Иными словами: узнаем, работает ли сайт. Для этого мы создадим простой запрос GET. Подробнее с кодами состояния HTTP можно ознакомиться на сайте Веб-документация MDN.
>>> r = requests.get('http://learn.python.ru')
Проверим, что возвращает нам данный запрос:
>>> r
<Response [200]>
Как мы можем видеть, в качестве ответа мы получили объект класса Response и код 200. Этот код говорит, что ресурс работает и можно с ним взаимодействовать.
А что будет, если мы отправим неправильный запрос?
>>> r = requests.get('http://learn.python.ru/user')
>>> r
<Response [404]>
Как вы можете заметить, этот запрос вернул нам всё тот же объект класса Response, но с другим кодом — 404. Это означает, что страницы ‘/user’ на сайте http://learn.python. ru нет.
Теперь, когда мы познакомились с тем, как отправлять запрос GET с помощью Requests, мы можем продвинуться дальше и сделать что-то более интересное.
Скачаем изображение с сайта
В этом примере мы будем применять всё тот же запрос GET, но, в отличие от предыдущего, мы будем работать с содержимым ответа.
>>> import requests
>>> image = requests.get('https://learn.python.ru/media/projects/sl1_Cj4bKxp.png')
>>> with open('new_image.png', 'wb') as f:
... f.write(image.content)
После выполнения данного скрипта, мы увидим новое изображение под названием new_image.png в директории, из которой у нас запущен скрипт.
Подробнее с классом Response и методами получения его содержимого можно ознакомиться на официальном сайте библиотеки Requests.
Отправим сообщение в WhatsApp
В этом примере, в отличие от примеров выше, мы познакомимся с другим методом — POST. Стоит отметить, что запросы POST и GET являются самыми часто применяемыми при работе с HTTP.
Для реализации этого примера воспользуемся сервисом, предоставляющим API для отправки сообщений. Я буду использовать сервис Chat-Api. Это платный сервис, но у них есть демо-режим, предоставляющий бесплатный доступ на 3 дня, чего нам для реализации этой задачи будет достаточно. После регистрации на сайте и получении Api URL и токена, мы сможем выполнить отправку сообщений в WhatsApp. Вот что нам для этого потребуется:
>>> import requests
>>> url = '<Ваш API URL>/message?token=<Ваш токен>'
>>> data = {"phone": "<номер телефона, начинающийся с 7>", "body": "<текст сообщения>"}
>>> message = requests.post(url, json=data)
И проверим, отправлено ли сообщение:
>>> print(message.text)
Вы должны будете увидеть что-то вроде этого:
{"sent":true,"message":"<номер телефона адресата>@c. us","id":"true_<номер телефона адресата>@c.us_3EB07324DCD36BD13CC4","queueNumber":1}
Загрузим файл на сервер
Для следующего примера воспользуемся сайтом для тестирования HTTP запросов Webhook.site. В качестве URL мы будем использовать ссылку, которая генерируется на сайте автоматически. У вас она будет отличаться от использованной в примере.
>>> import requests
>>> url = 'https://webhook.site/c253969f-1ad8-4888-812e-e57f4eb4924e'
>>> with open('test.txt', 'w') as f:
... f.write('текст для проверки загрузки файла')
>>> with open('test.txt', 'rb') as f:
... r = requests.post(url, {'files': f})
... print(r)
После выполнения скрипта в терминале мы увидим уже знакомый нам объект класса Response и статус код — 200. Это означает, что запрос выполнился. Вернемся снова на сайт Webhook.site, выберем в правой колонке наш запрос и сможем посмотреть содержание выполненного запроса:
Авторизуемся на сайте
В этом примере будем использовать сайт, который нам также потребуется в следующем примере. Для начала зарегистрируемся на сайте WorldWeatherOnline. После удачной регистрации на сайте в личном кабинете вы увидите API KEY, который потребуется для следующего примера.
Для авторизации на сайте нам необходимо в запросе отправить пользовательские данные на сайт. Помимо логина и пароля, мы должны отправить сайту ключи, которые содержатся в заголовках пакета. Чтобы узнать эти ключи нужно выйти из нашей учётной записи, перейти на страницу входа, затем открыть в браузере Developer tools (F12), перейти на вкладку Network и снова авторизоваться. После того как страница загрузится в Developer tools во вкладке Network пролистайте вверх и найдите строчку login.aspx.
Как мы можем заметить во вкладке Headers, при входе мы осуществили запрос POST для передачи данных серверу. Пролистав вниз до блока Form Data, мы найдём все ключи, которые нам необходимо отправить сайту для авторизации.
>>> import requests
>>> url = 'https://www. worldweatheronline.com/developer/login.aspx'
>>> data = {<заносим сюда все ключи, которые необходимо отправить серверу в формате “key”: “value” и не забываем ставить запятые после каждого “value”>}
>>> s = requests.Session()
>>> s = requests.post(url, data=data)
Для проверки выполнения авторизации выведем содержание ответа сервера:
>>> print(s.text)
После выполнения данной функции в консоли мы увидим содержимое страницы в виде текста, то есть так, как страницу “видит” наш браузер — в формате html. Подтверждением успешной авторизации служат следующие строки:
<li><a href="/developer/my/">My Account</a></li>
<li><a href="/developer/logout.aspx">Logout</a></li>
Неавторизованному пользователю данные кнопки недоступны.
Узнаем погоду в Москве
В этом примере мы будем использовать API KEY с сайта WorldWeatherOnline, на котором мы зарегистрировались в прошлом примере. В разделе документации на сайте WorldWeatherOnline приведено подробное описание параметров.
Теперь уже с использованием вашей любимой IDE напишем скрипт, который будет принимать в качестве аргумента из командной строки город, а возвращать значение температуры.
Создадим файл и назовём его weather.py. Запишем в него:
import sys
import requests
def get_weather():
url = 'http://api.worldweatheronline.com/premium/v1/weather.ashx'
city = sys.argv[1]
params = { 'key': '<копируем сюда ключ, полученный на сайте>',
'q': city,
'format': 'json',
'num_of_days': 1,
'lang': 'ru'}
r = requests.get(url, params=params)
the_weather = r.json()
# данной строкой мы преобразуем полученное содержимое страницы
# в формат json, который очень похож на тип данных dict() в Python
# и с которым очень удобно работать
if 'data' in the_weather:
if 'current_condition' in the_weather['data']:
try:
return the_weather['data']['current_condition'][0]
except(IndexError, TypeError):
return 'Server Error'
return 'Server Error'
if __name__ == '__main__':
weather = get_weather()
print(f'Погода сейчас {weather["temp_C"]}, ощущается как {weather["FeelsLikeC"]}')
Запустим наш скрипт в командной строке:
$ python weather. py Moscow
В качестве ответа мы должны увидеть:
Погода сейчас 20, ощущается как 20
В этом примере мы не просто получили какую-то информацию от сервера, но и обработали содержимое полученного ответа. В следующем примере мы разберем еще один метод обработки полученного содержимого ответа.
Напишем простой парсер новостей
В качестве источника новостей будем использовать хаб о Python сайта Habr.com. В этом примере, помимо Requests нам также понадобится библиотека BeautifulSoup. С данной библиотеке можно подробно познакомиться на официальной странице документации Beautiful Soup. Устанавливается она также просто, как и Requests:
$ pip install beautifulsoup4
Создадим файл с названием news.py и запишем в него следующее:
import requests
from bs4 import BeautifulSoup
class HabrPythonNews:
def __init__(self):
self. url = 'https://habr.com/ru/hub/python/'
self.html = self.get_html()
def get_html(self):
try:
result = requests.get(self.url)
result.raise_for_status()
return result.text
except(requests.RequestException, ValueError):
print('Server error')
return False
Метод get_html() класса HabrPythonNews с помощью библиотеки Requests отправляет наш запрос GET к сайту Habr.com и возвращает содержимое страницы в виде текста. Иными словами, мы получаем html страницы. Если мы посмотрим на содержимое страницы (ctrl + U в Google Chrome), то обнаружим там различные блоки, в которых содержится информация. Нас интересуют только заголовки новостей и ссылки на них. Чтобы извлечь нужную нам информацию из содержимого страницы, мы воспользуемся библиотекой Beautiful Soup. Нужный нам блок называется:
<h3>
Давайте теперь добавим функцию для работы с этим блоком:
def get_python_news(self):
soup = BeautifulSoup(self. html, 'html.parser')
news_list = soup.findAll('h3', class_='post__title')
return news_list
Метод get_python_news() возвращает нам все элементы страницы, с тегом
<h3>
И добавим завершающий блок нашего класса:
if __name__ == "__main__":
news = HabrPythonNews()
print(news.get_python_news())
Итоговый код должен выглядеть у нас так:
import requests
from bs4 import BeautifulSoup
class HabrPythonNews:
def __init__(self):
self.url = 'https://habr.com/ru/hub/python/'
self.html = self.get_html()
def get_html(self):
try:
result = requests.get(self.url)
result.raise_for_status()
return result.text
except(requests.RequestException, ValueError):
print('Server error')
return False
def get_python_news(self):
soup = BeautifulSoup(self. html, 'html.parser')
news_list = soup.findAll('h3', class_='post__title')
return news_list
if __name__ == "__main__":
news = HabrPythonNews()
print(news.get_python_news())
При выполнении данного скрипта мы получим ссылки и заголовки новостей с первой страницы хаба. Изменяя параметры поиска
news_list = soup.findAll('h3', class_='post__title')
мы можем получать различные значения.
В качестве заключения
Использование библиотеки Requests не ограничивается приведенными выше примерами. Данная библиотека является очень удобным инструментом для взаимодействия с HTTP. Продолжить знакомство с библиотекой можно на официальном сайте Requests.
Автор: Виталий Калинин
Выпускник курсов Learn Python
запросы — структура (заголовок и тело), методы, строка статуса и коды состояния, ответы
Большинство используемых нами веб- и мобильных приложений постоянно взаимодействуют с глобальной сетью. Почти все подобные коммуникации совершаются с помощью запросов по протоколу HTTP. Рассказываем о них подробнее.
Базово о протоколе HTTP
HTTP (HyperText Transfer Protocol, дословно — «протокол передачи гипертекста») представляет собой протокол прикладного уровня, используемый для доступа к ресурсам Всемирной Паутины. Под термином гипертекст следует понимать текст, в понятном для человека представлении, при этом содержащий ссылки на другие ресурсы.
Данный протокол описывается спецификацией RFC 2616. На сегодняшний день наиболее распространенной версией протокола является версия HTTP/2, однако нередко все еще можно встретить более раннюю версию HTTP/1.1.
В обмене информацией по HTTP-протоколу принимают участие клиент и сервер. Происходит это по следующей схеме:
- Клиент запрашивает у сервера некоторый ресурс.
- Сервер обрабатывает запрос и возвращает клиенту ресурс, который был запрошен.
По умолчанию для коммуникации по HTTP используется порт 80, хотя вместо него может быть выбран и любой другой порт. Многое зависит от конфигурации конкретного веб-сервера.
Подробнее о протоколе HTTP читайте по ссылке →
HTTP-сообщения: запросы и ответы
Данные между клиентом и сервером в рамках работы протокола передаются с помощью HTTP-сообщений. Они бывают двух видов:
- Запросы (HTTP Requests) — сообщения, которые отправляются клиентом на сервер, чтобы вызвать выполнение некоторых действий. Зачастую для получения доступа к определенному ресурсу. Основой запроса является HTTP-заголовок.
- Ответы (HTTP Responses) — сообщения, которые сервер отправляет в ответ на клиентский запрос.
Само по себе сообщение представляет собой информацию в текстовом виде, записанную в несколько строчек.
В целом, как запросы HTTP, так и ответы имеют следующую структуру:
- Стартовая строка (start line) — используется для описания версии используемого протокола и другой информации — вроде запрашиваемого ресурса или кода ответа. Как можно понять из названия, ее содержимое занимает ровно одну строчку.
- HTTP-заголовки (HTTP Headers) — несколько строчек текста в определенном формате, которые либо уточняют запрос, либо описывают содержимое тела сообщения.
- Пустая строка, которая сообщает, что все метаданные для конкретного запроса или ответа были отправлены.
- Опциональное тело сообщения, которое содержит данные, связанные с запросом, либо документ (например HTML-страницу), передаваемый в ответе.
Рассмотрим атрибуты HTTP-запроса подробнее.
Стартовая строка
Стартовая строка HTTP-запроса состоит из трех элементов:
- Метод HTTP-запроса (method, реже используется термин verb). Обычно это короткое слово на английском, которое указывает, что конкретно нужно сделать с запрашиваемым ресурсом. Например, метод GET сообщает серверу, что пользователь хочет получить некоторые данные, а POST — что некоторые данные должны быть помещены на сервер.
- Цель запроса. Представлена указателем ресурса URL, который состоит из протокола, доменного имени (или IP-адреса), пути к конкретному ресурсу на сервере. Дополнительно может содержать указание порта, несколько параметров HTTP-запроса и еще ряд опциональных элементов.
- Версия используемого протокола (либо HTTP/1.1, либо HTTP/2), которая определяет структуру следующих за стартовой строкой данных.
В примере ниже стартовая строка указывает, что в качестве метода используется GET, обращение будет произведено к ресурсу /index.html, по версии протокола HTTP/1.1:
Основные структурные элементы URL.Разберемся с каждым из названных элементов подробнее.
Методы
Методы позволяют указать конкретное действие, которое мы хотим, чтобы сервер выполнил, получив наш запрос. Так, некоторые методы позволяют браузеру (который в большинстве случаев является источником запросов от клиента) отправлять дополнительную информацию в теле запроса — например, заполненную форму или документ.
Ниже приведены наиболее используемые методы и их описание:
Разберемся с каждым из названных элементов подробнее.
| Метод | Описание |
| GET | Позволяет запросить некоторый конкретный ресурс. Дополнительные данные могут быть переданы через строку запроса (Query String) в составе URL (например ?param=value).О составляющих URL мы поговорим чуть позже. |
| POST | Позволяет отправить данные на сервер. Поддерживает отправку различных типов файлов, среди которых текст, PDF-документы и другие типы данных в двоичном виде. Обычно метод POST используется при отправке информации (например, заполненной формы логина) и загрузке данных на веб-сайт, таких как изображения и документы. |
| HEAD | Здесь придется забежать немного вперед и сказать, что обычно сервер в ответ на запрос возвращает заголовок и тело, в котором содержится запрашиваемый ресурс. Данный метод при использовании его в запросе позволит получить только заголовки, которые сервер бы вернул при получении GET-запроса к тому же ресурсу. Запрос с использованием данного метода обычно производится для того, чтобы узнать размер запрашиваемого ресурса перед его загрузкой. |
| PUT | Используется для создания (размещения) новых ресурсов на сервере. Если на сервере данный метод разрешен без надлежащего контроля, то это может привести к серьезным проблемам безопасности. |
| DELETE | Позволяет удалить существующие ресурсы на сервере. Если использование данного метода настроено некорректно, то это может привести к атаке типа «Отказ в обслуживании» (Denial of Service, DoS) из-за удаления критически важных файлов сервера. |
| OPTIONS | Позволяет запросить информацию о сервере, в том числе информацию о допускаемых к использованию на сервере HTTP-методов. |
| PATCH | Позволяет внести частичные изменения в указанный ресурс по указанному расположению. |
URL
Получение доступа к ресурсам по HTTP-протоколу осуществляется с помощью указателя URL (Uniform Resource Locator). URL представляет собой строку, которая позволяет указать запрашиваемый ресурс и еще ряд параметров.
Использование URL неразрывно связано с другими элементами протокола, поэтому далее мы рассмотрим его основные компоненты и строение:
Поле Scheme используется для указания используемого протокола, всегда сопровождается двоеточием и двумя косыми чертами (://).
Host указывает местоположение ресурса, в нем может быть как доменное имя, так и IP-адрес.
Port, как можно догадаться, позволяет указать номер порта, по которому следует обратиться к серверу. Оно начинается с двоеточия (:), за которым следует номер порта. При отсутствии данного элемента номер порта будет выбран по умолчанию в соответствии с указанным значением Scheme (например, для http:// это будет порт 80).
Далее следует поле Path. Оно указывает на ресурс, к которому производится обращение. Если данное поле не указано, то сервер в большинстве случаев вернет указатель по умолчанию (например index.html).
Поле Query String начинается со знака вопроса (?), за которым следует пара «параметр-значение», между которыми расположен символ равно (=). В поле Query String могут быть переданы несколько параметров с помощью символа амперсанд (&) в качестве разделителя.
Не все компоненты необходимы для доступа к ресурсу. Обязательно следует указать только поля Scheme и Host.
Версии HTTP
Раз уж мы упомянули версию протокола как элемента стартовой строки, то стоит сказать об основных отличиях версий HTTP/1.X от HTTP/2.X.
Последняя стабильная, наиболее стандартизированная версия протокола первого поколения (версия HTTP/1.1) вышла в далеком 1997 году. Годы шли, веб-страницы становились сложнее, некоторые из них даже стали приложениями в том виде, в котором мы понимаем их сейчас. Кроме того, объем медиафайлов и скриптов, которые добавляли интерактивность страницам, рос. Это, в свою очередь, создавало перегрузки в работе протокола версии HTTP/1.1.
Стало очевидно, что у HTTP/1.1 есть ряд значительных недостатков:
- Заголовки, в отличие от тела сообщения, передавались в несжатом виде.
- Часто большая часть заголовков в сообщениях совпадала, но они продолжали передаваться по сети.
- Отсутствовала возможность так называемого мультиплексирования — механизма, позволяющего объединить несколько соединений в один поток данных. Приходилось открывать несколько соединений на сервере для обработки входящих запросов.
С выходом HTTP/2 было предложено следующее решение: HTTP/1.X-сообщения разбивались на так называемые фреймы, которые встраивались в поток данных.
Фреймы данных (тела сообщения) отделялись от фреймов заголовка, что позволило применять сжатие. Вместе с появлением потоков появился и ранее описанный механизм мультиплексирования — теперь можно было обойтись одним соединением для нескольких потоков.
Единственное о чем стоит сказать в завершение темы: HTTP/2 перестал быть текстовым протоколом, а стал работать с «сырой» двоичной формой данных. Это ограничивает чтение и создание HTTP-сообщений «вручную». Однако такова цена за возможность реализации более совершенной оптимизации и повышения производительности.
Заголовки
HTTP-заголовок представляет собой строку формата «Имя-Заголовок:Значение», с двоеточием(:) в качестве разделителя. Название заголовка не учитывает регистр, то есть между Host и host, с точки зрения HTTP, нет никакой разницы. Однако в названиях заголовков принято начинать каждое новое слово с заглавной буквы. Структура значения зависит от конкретного заголовка. Несмотря на то, что заголовок вместе со значениями может быть достаточно длинным, занимает он всего одну строчку.
В запросах может передаваться большое число различных заголовков, но все их можно разделить на три категории:
- Общего назначения, которые применяются ко всему сообщению целиком.
- Заголовки запроса уточняют некоторую информацию о запросе, сообщая дополнительный контекст или ограничивая его некоторыми логическими условиями.
- Заголовки представления, которые описывают формат данных сообщения и используемую кодировку. Добавляются к запросу только в тех случаях, когда с ним передается некоторое тело.
Ниже можно видеть пример заголовков в запросе:
Самые частые заголовки запроса
| Заголовок | Описание |
| Host | Используется для указания того, с какого конкретно хоста запрашивается ресурс. В качестве возможных значений могут использоваться как доменные имена, так и IP-адреса. На одном HTTP-сервере может быть размещено несколько различных веб-сайтов. Для обращения к какому-то конкретному требуется данный заголовок. |
| User-Agent | Заголовок используется для описания клиента, который запрашивает ресурс. Он содержит достаточно много информации о пользовательском окружении. Например, может указать, какой браузер используется в качестве клиента, его версию, а также операционную систему, на которой этот клиент работает. |
| Refer | Используется для указания того, откуда поступил текущий запрос. Например, если вы решите перейти по какой-нибудь ссылке в этой статье, то вероятнее всего к запросу будет добавлен заголовок Refer: https://selectel.ru |
| Accept | Позволяет указать, какой тип медиафайлов принимает клиент. В данном заголовке могут быть указаны несколько типов, перечисленные через запятую (‘ , ‘). А для указания того, что клиент принимает любые типы, используется следующая последовательность — */*. |
| Cookie | Данный заголовок может содержать в себе одну или несколько пар «Куки-Значение» в формате cookie=value. Куки представляют собой небольшие фрагменты данных, которые хранятся как на стороне клиента, так и на сервере, и выступают в качестве идентификатора. Куки передаются вместе с запросом для поддержания доступа клиента к ресурсу. Помимо этого, куки могут использоваться и для других целей, таких как хранение пользовательских предпочтений на сайте и отслеживание клиентской сессии. Несколько кук в одном заголовке могут быть перечислены с помощью символа точка с запятой (‘ ; ‘), который используется как разделитель. |
| Authorization | Используется в качестве еще одного метода идентификации клиента на сервере. После успешной идентификации сервер возвращает токен, уникальный для каждого конкретного клиента. В отличие от куки, данный токен хранится исключительно на стороне клиента и отправляется клиентом только по запросу сервера. Существует несколько типов аутентификации, конкретный метод определяется тем веб-сервером или веб-приложением, к которому клиент обращается за ресурсом. |
Тело запроса
Завершающая часть HTTP-запроса — это его тело. Не у каждого HTTP-метода предполагается наличие тела. Так, например, методам вроде GET, HEAD, DELETE, OPTIONS обычно не требуется тело. Некоторые виды запросов могут отправлять данные на сервер в теле запроса: самый распространенный из таких методов — POST.
Ответы HTTP
HTTP-ответ является сообщением, которое сервер отправляет клиенту в ответ на его запрос. Его структура равна структуре HTTP-запроса: стартовая строка, заголовки и тело.
Строка статуса (Status line)Стартовая строка HTTP-ответа называется строкой статуса (status line). На ней располагаются следующие элементы:
- Уже известная нам по стартовой строке запроса версия протокола (HTTP/2 или HTTP/1.1).
- Код состояния, который указывает, насколько успешно завершилась обработка запроса.
- Пояснение — короткое текстовое описание к коду состояния. Используется исключительно для того, чтобы упростить понимание и восприятие человека при просмотре ответа.
Так выглядит строка состояния ответа.
Коды состояния и текст статуса
Коды состояния HTTP используются для того, чтобы сообщить клиенту статус их запроса. HTTP-сервер может вернуть код, принадлежащий одной из пяти категорий кодов состояния:
| Категория | Описание |
| 1xx | Коды из данной категории носят исключительно информативный характер и никак не влияют на обработку запроса. |
| 2xx | Коды состояния из этой категории возвращаются в случае успешной обработки клиентского запроса. |
| 3xx | Эта категория содержит коды, которые возвращаются, если серверу нужно перенаправить клиента. |
| 4xx | Коды данной категории означают, что на стороне клиента был отправлен некорректный запрос. Например, клиент в запросе указал не поддерживаемый метод или обратился к ресурсу, к которому у него нет доступа. |
| 5xx | Ответ с кодами из этой категории приходит, если на стороне сервера возникла ошибка. |
Полный список кодов состояния доступен в спецификации к протоколу, ниже приведены только самые распространенные коды ответов:
| Категория | Описание |
| 200 OK | Возвращается в случае успешной обработки запроса, при этом тело ответа обычно содержит запрошенный ресурс. |
| 302 Found | Перенаправляет клиента на другой URL. Например, данный код может прийти, если клиент успешно прошел процедуру аутентификации и теперь может перейти на страницу своей учетной записи. |
| 400 Bad Request | Данный код можно увидеть, если запрос был сформирован с ошибками. Например, в нем отсутствовали символы завершения строки. |
| 403 Forbidden | Означает, что клиент не обладает достаточными правами доступа к запрошенному ресурсу. Также данный код можно встретить, если сервер обнаружил вредоносные данные, отправленные клиентом в запросе. |
| 404 Not Found | Каждый из нас, так или иначе, сталкивался с этим кодом ошибки. Данный код можно увидеть, если запросить у сервера ресурс, которого не существует на сервере. |
| 500 Internal Error | Данный код возвращается сервером, когда он не может по определенным причинам обработать запрос. |
Помимо основных кодов состояния, описанных в стандарте, существуют и коды состояния, которые объявляются крупными сетевыми провайдерами и серверными платформами. Так, коды состояния, используемые Selectel, можно посмотреть здесь.
Заголовки ответа
Response Headers, или заголовки ответа, используются для того, чтобы уточнить ответ, и никак не влияют на содержимое тела. Они существуют в том же формате, что и остальные заголовки, а именно «Имя-Значение» с двоеточием (:) в качестве разделителя.
Ниже приведены наиболее часто встречаемые в ответах заголовки:
| Категория | Пример | Описание |
| Server | Server: ngnix | Содержит информацию о сервере, который обработал запрос. |
| Set-Cookie | Set-Cookie:PHPSSID=bf42938f | Содержит куки, требуемые для идентификации клиента. Браузер парсит куки и сохраняет их в своем хранилище для дальнейших запросов. |
| WWW-Authenticate | WWW-Authenticate: BASIC realm=»localhost» | Уведомляет клиента о типе аутентификации, который необходим для доступа к запрашиваемому ресурсу. |
Тело ответа
Последней частью ответа является его тело. Несмотря на то, что у большинства ответов тело присутствует, оно не является обязательным. Например, у кодов «201 Created» или «204 No Content» тело отсутствует, так как достаточную информацию для ответа на запрос они передают в заголовке.
Безопасность HTTP-запросов, или что такое HTTPs
HTTP является расширяемым протоколом, который предоставляет огромное количество возможностей, а также поддерживает передачу всевозможных типов файлов. Однако, вне зависимости от версии, у него есть один существенный недостаток, который можно заметить если перехватить отправленный HTTP-запрос:
Да, все верно: данные передаются в открытом виде. HTTP сам по себе не предоставляет никаких средств шифрования.
Но как же тогда работают различные банковские приложения, интернет-магазины, сервисы оплаты услуг и прочие приложения, в которых циркулирует чувствительная информация пользователей?
Время рассказать про HTTPs!
HTTPs (HyperText Transfer Protocol, secure) является расширением HTTP-протокола, который позволяет шифровать отправляемые данные, перед тем как они попадут на транспортный уровень. Данный протокол по умолчанию использует порт 443.
Теперь если мы перехватим не HTTP , а HTTPs-запрос, то не увидим здесь ничего интересного:
Данные передаются в едином зашифрованном потоке, что делает невозможным получение учетных данных пользователей и прочей критической информации средствами обычного перехвата.
Повысьте безопасность на сетевых портах с Selectel
Три межсетевых экрана для любых потребностей бизнеса.
Выбрать
Если хотите подробнее узнать о деталях работы протокола, читайте статью в нашем блоге →
Как отправить HTTP-запрос и прочитать его ответ
Теория это, конечно, отлично, но ничего так хорошо не закрепляет материал, как практика
Мы рассмотрим несколько способов, как написать HTTP-запрос в браузер, послать HTTP-запрос на сервер и получить ответ:
- Инструменты разработчика в браузере.
- Утилита cURL.
Инструменты разработчика
Основной программой на наших устройствах, которая работает с HTTP-протоколом, в большинстве случаев является браузер. Помимо обычных пользователей, с браузерами часто работают и разработчики веб-приложений. Именно их инструментами мы воспользуемся для работы с запросами и ответами.
По нажатию комбинации клавиш [Ctrl+Shift+I] или просто [F12] в подавляющем большинстве современных браузеров у нас откроется окно инструментов разработчика, которая представляет собой панель с несколькими вкладками. Нужная нам вкладка обычно называется Network. Перейдем в нее, а в адресной строке введем URL того сайта, на который хотим попасть. В качестве примера воспользуемся сайтом блога Selectel — https://selectel.ru/blog/.
После нажатия Enter сайт начнет загружаться, а открытая вкладка Network — заполняться различными элементами, начиная все больше напоминать приборную панель самолета.
Не спешите пугаться. Это всего лишь список ресурсов, которые нужны для правильного отображения и работы сайта.
Нажав на любой из них, мы можем увидеть детали обработки отправленного запроса:
В данном запросе, например:
- URL, к которому было совершено обращение — https://selectel.ru/blog,
- Метод, который был использован в запросе — GET,
- И в качестве кода возврата сервер вернул нам страницу с кодом статуса — 200 OK
Утилита cURL
Следующий инструмент, с помощью которого мы сможем послать запрос на тот или иной сервер, это утилита cURL.
cURL (client URL) является небольшой утилитой командной строки, которая позволяет работать с HTTP и рядом других протоколов.
Для отправки запроса и получения ответа мы можем воспользоваться флагом -v и указанием URL того ресурса, который мы хотим получить. «Схему» HTTP-запроса можно увидеть на скрине ниже:
После запуска утилита выполняет:
- подключение к серверу,
- самостоятельно разрешает все вопросы, необходимые для отправки запроса по HTTPs,
- отправляет запрос, содержимое которого мы можем видеть благодаря флагу -v,
- принимая ответ от сервера, отображает его в командной строке «как-есть».
Помимо этого, у данной утилиты есть огромное количество опций, которые предоставляют возможности по детальной настройке отправляемых запросов. Все эти возможности и делают ее такой популярной у веб-разработчиков и других специалистов, которым приходится работать с протоколом HTTP.
Заключение
HTTP представляет собой расширяемый протокол прикладного уровня, на котором работает весь веб-сегмент интернета. В данной статье мы рассмотрели принцип его работы, структуру, «компоненты» HTTP-запросов. Коснулись вопросов отличия версий протокола, HTTPs — его расширения, добавляющего шифрование. Разобрали устройство запроса, поняли, как можно отправить HTTP-запрос и получить ответ от сервера.
Примеры веб-сайтов
Предоставлено Мэри Савиной, Карлтонский колледж
http://sciencecases.lib.buffalo.edu/cs/ (Этот сайт может быть отключен. )
Домашняя страница Национального центра тематических исследований Преподавание в науке. Я нашел коллекцию тематических исследований и ресурсы в разделе «преподавание тематических исследований» наиболее полезными.
Собрано руководителями семинаров
Введение в тему погоды и климата (дополнительная информация)
Эта страница курса — еще один хороший пример того, как профессор уделяет время тому, чтобы сделать веб-сайт информативным и подробным.
Физическая геология
Онлайн-версия вводного курса с чистым дизайном и четкими пунктами.
Ледники и оледенение
Один из примеров того, как публиковать заметки из класса в удобочитаемой форме для печати.
Заметки и наглядные пособия по физической геологии
Этот сайт класса предоставляет в Интернете большое количество информации о классе.
Создайте свою собственную солнечную систему (подробнее)
Страница астрономии/планетологии. Сложный и увлекательный.
Атлас океанов Явы (подробнее)
Данные вертикального профиля океана и средство просмотра. Пример того, как разместить нужную информацию и инструменты в одном месте.
Энергетический баланс (подробнее)
Интерактивная анимация, демонстрирующая приток и отток воды как метафора потребления энергии. Хороший пример того, как позволить ученику поиграть с возможными ситуациями.
Ураганы: онлайн-справочник по метеорологии (подробнее)
Часть большой системы онлайн-справочников с отличной анимацией и подробными пояснениями.
Структура и поведение воды (LSBU)
Понятная навигация и легкодоступные разделы делают эту энциклопедическую страницу удобной для пользователя.
Глобальные климатические анимации
Эти климатические анимации помогают учащимся понять, что означает глобальная температура и как она себя ведет.
Понимание землетрясений
Предназначен для широкой публики, с некоторым акцентом на исторические отчеты. Включает простую анимацию для демонстрации движения плиты.
Кристаллография 101: Вводный курс
Обширный онлайн-курс с отличной навигацией. Этот сайт предназначен для тех, кто знаком с химией.
Введение в тектонику плит (дополнительная информация)
Краткое изложение основной темы, освещающее основные моменты и описывающее основные достижения, которые привели к существующей в настоящее время теории.
Путешествия с геологией
Виртуальная экскурсия в национальный парк Гранд-Титон. Еще один хороший пример упрощенной, но понятной нотации с отличными фотографиями.
Сайты, используемые на курсах дистанционного обучения геологии в Университете штата Канзас Предоставлено Тиби Марин
http://www.gsfc.nasa.gov
Сайт, посвященный изучению Динамической Земли, от тектоники плит до наук об атмосфере и планетах.
https://hubblesite. org/
Сайт, посвященный космическому телескопу Хаббл и исследованиям, проводимым НАСА. Хороший сайт по астрономии.
http://modis.gsfc.nasa.gov/
Это сайт спутниковой системы наблюдения за Землей Terra/MODIS.
http://terra.nasa.gov/ (Этот сайт может быть отключен. )
«Терра», что на латыни означает «земля», — это название флагманского спутника Системы наблюдения за Землей (EOS) НАСА. Миссия «Терра» стартовала 18 декабря 19 года.99, и начал собирать научные данные 24 февраля 2000 года. Пять датчиков на борту Терры предназначены для того, чтобы ученые могли всесторонне исследовать климатическую систему нашего мира — наблюдать и измерять изменения в ландшафтах Земли, в ее океанах и внутри нижняя атмосфера. Одна из основных целей состоит в том, чтобы определить, как жизнь на Земле влияет на изменения в климатической системе и зависит от них, уделяя особое внимание лучшему пониманию глобального углеродного цикла.
http://landsat.usgs.gov//gallery.php
Сайт изображений со всего мира. Интерактивная карта, на которой вы найдете изображения, сделанные спутниками Landsat. Полезно при поиске изменений с течением времени.
http://eospso.gsfc.nasa.gov/ (дополнительная информация)
Он состоит из серии спутников, научного компонента и системы данных, поддерживающей скоординированную серию полярно-орбитальных спутников с малым наклонением в течение длительного времени. -срочные глобальные наблюдения за земной поверхностью, биосферой, твердой Землей, атмосферой и океанами. EOS позволит лучше понять Землю как интегрированную систему. Научный офис проекта EOS (EOSPSO) стремится предоставлять информацию и ресурсы о программе как ученым, занимающимся программами, так и широкой общественности.
http://www.nasa.gov/multimedia/imagegallery/
Коллекция снимков НАСА
https://svs.gsfc.nasa.gov/2674 (подробнее)
Визуализация данных дистанционного зондирования
http:/ /www.nesdis.noaa.gov/imagery_data.html
Земля из космоса Спутник GOES
https://solarsystem. nasa.gov/ (дополнительная информация)
Исследование Солнечной системы
http://core2.gsfc.nasa. gov/dtam/index.html ( Этот сайт может быть отключен. )
Цифровая карта тектонической активности
http://www.volcanoes.com/
Сайт, посвященный вулканам и вулканам по всему миру. Хороший источник информации о вулканической деятельности и вулканической информации.
http://www.nasa.gov/centers/johnson/gallery/index.html
Космический центр Джонсона, коллекция цифровых изображений, хороший источник информации.
http://www.ucmp.berkeley.edu/geology/tectonics.html (Этот сайт может быть отключен. )
Анимация тектоники плит. Хорошо подходит для обучения динамике плит и прогнозированию движения континентов в будущем.
http://hubble.nasa.gov/
Проект Хаббла
http://hubblesite.org/newscenter/archive/2002/08/
Охотник за галактиками — хороший сайт для детей и взрослых.
http://amazing-space.stsci.edu/ (дополнительная информация)
Amazing Space — замечательный сайт для преподавателей и широкой публики.
http://www-bprc.mps.ohio-state.edu/rsl/radarsat/radarsat.html
Антарктический картографический проект, отличный сайт для исследований в области картирования ледяного покрова Антарктиды.
http://disc.gsfc.nasa.gov/geomorphology/ (подробнее)
Геоморфология из космоса, хороший ресурс для геологов и геоморфологов.
http://eo1.usgs.gov/dataproducts/archtask.asp
Горы Загрос. Study
http://www.noaa.gov/ (дополнительная информация)
Сайт о явлениях, связанных с погодой
http://www.monografias.com/Paleontologia/index.shtml
Сайт на испанском языке для поиска исследований в различных областях, связанных с геологией и другими областями.
http://earthobservatory.nasa.gov/Images/
Место, где Земля и ее процессы видны со спутников.
http://www.doubledeckerpress.com/
Сайт, посвященный материалам, связанным с вулканами (книги и другие вспомогательные материалы) доктора Декера.
http://www.angelfire.com/extreme/volcano/
Лучший сайт для изучения гранулярных потоков, гранулярных процессов, гидродинамики, суперкомпьютерного моделирования и гранулометрического анализа в вулканологии, геофизике и физике.
http://www.pmel.noaa.gov/vents/nemo/
Обсерватория Нового тысячелетия.
http://www.cocori.com/photo/imaren/index.htm
Коста-Рика Вулкан Ареналь
http://www.olywa.net/radu/valerie/StHelens.html
Многоликая гора Сент-Хеленс
http://www.jpl.nasa.gov/radar/ sircxsar/ (Этот сайт может быть отключен.)
Космические радиолокационные изображения Земли
http://earthquake.usgs.gov/data/crust/
Страница опасности землетрясений Геологической службы США
https://science.nasa.gov/science -news/science-at-nasa/2002/22mar_ice
Science@NASA — сайт, посвященный информации об исследованиях НАСА
http://www.rocksandminerals.com/finder/TOCh2.HTM
Горные породы и минералы от А до Я — отличный сайт для обучения минералам и горным породам
http://sohowww.nascom.nasa.gov/
SOHO Exploring the Sun
https://solarscience.msfc.nasa.gov/SunspotCycle.shtml
Солнечные пятна и солнечный цикл сайт, спонсируемый Science@NASA
http://csep10. phys.utk.edu/astr162/lect/
Лекторий по астрономии, звездам и галактикам
http://www.jpl.nasa.gov (подробнее)
Сайт, посвященный исследованию космоса
http://image.gsfc.nasa.gov/poetry/magneto.html
Сайт, посвященный изучению магнитосферы Земли
https://earthdata.nasa.gov/discipline /atmosphere (дополнительная информация)
Ресурсы данных по химии атмосферы
http://www.tsgc.utexas.edu/everything/moon/calculator.html
Калькулятор веса Луны — Сколько вы весите на Луне?
http://www.equisetites.de/palbot/teach/stratiteach.html
Учебные документы по стратиграфии и исторической геологии
http://www.enchantedlearning.com/subjects/dinosaurs/dinofossils/Fossilhow.html
Сайт, посвященный изучению динозавров.
http://encke.jpl.nasa.gov/ (Этот сайт может быть отключен. )
Домашняя страница наблюдений за кометами
http://saturn.jpl.nasa.gov/home/index.cfm
Домашняя страница Cassini
https://space. jpl.nasa.gov/
The Solar System Simulator
http://www.ngdc.noaa.gov/mgg/fliers/97mgg03.html
Глобальная топография морского дна, хороший источник информации для геологи.
http://mineral.galleries.com/ (подробнее)
Сайт, посвященный детальному изучению минералов.
http://www.soest.hawaii.edu/GG/hcv.html
Гавайский центр вулканологии
В чем разница между веб-страницей, веб-сайтом, веб-сервером и поисковой системой? — Изучите веб-разработку
В этой статье мы опишем различные концепции, связанные с Интернетом: веб-страницы, веб-сайты, веб-серверы и поисковые системы. Эти термины часто путают новички в Интернете или используют их неправильно. Давайте узнаем, что они означают!
| Предпосылки: | Ты должен знать как работает интернет. |
|---|---|
| Цель: | Уметь описать различия между веб-страницей, веб-сайтом, веб-сайтом. сервер и поисковая система. |
Как и в любой области знаний, в Интернете много жаргона. Не волнуйся. Мы не будем перегружать вас всем этим (у нас есть глоссарий, если вам интересно). Тем не менее, есть несколько основных терминов, которые вам нужно понять с самого начала, так как вы будете постоянно слышать эти выражения по мере чтения. Эти термины легко смешивать, поскольку они относятся к связанным, но разным функциям. Иногда вы увидите, что эти термины неправильно используются в новостях и других источниках, так что их путаница понятна.
Мы рассмотрим эти термины и технологии более подробно по мере дальнейшего изучения, но эти краткие определения будут для вас отличным началом:
- веб-страница
Документ, который можно отобразить в веб-браузере, таком как Firefox, Google Chrome, Opera, Microsoft Edge или Apple Safari. Их также часто называют просто «страницами».
- сайт
Набор веб-страниц, которые сгруппированы и обычно связаны друг с другом различными способами.
Часто называется «веб-сайтом» или «сайтом».- веб-сервер
Компьютер, на котором размещен веб-сайт в Интернете.
- поисковая система
Веб-служба, помогающая находить другие веб-страницы, такие как Google, Bing, Yahoo или DuckDuckGo. Доступ к поисковым системам обычно осуществляется через веб-браузер (например, вы можете выполнять поиск в поисковых системах непосредственно в адресной строке Firefox, Chrome и т. д.) или через веб-страницу (например, bing.com или duckduckgo.com).
Возьмем простую аналогию — публичная библиотека. Вот что вы обычно делаете при посещении библиотеки:
- Найдите индекс поиска и найдите название книги, которую вы хотите.
- Запишите каталожный номер книги.
- Перейдите в конкретный раздел с книгой, найдите нужный каталожный номер и получите книгу.
Сравним библиотеку с веб-сервером:
- Библиотека похожа на веб-сервер. Он имеет несколько разделов, что похоже на веб-сервер, на котором размещено несколько веб-сайтов.
- Различные разделы (наука, математика, история и т. д.) в библиотеке похожи на веб-сайты. Каждый раздел похож на уникальный сайт (два раздела не содержат одни и те же книги).
- Книги в каждом разделе похожи на веб-страницы. На одном сайте может быть несколько страниц, например, в разделе «Наука» (сайт) будут книги по теплу, звуку, термодинамике, статике и т. д. (страницы). Каждая веб-страница может быть найдена в уникальном месте (URL).
- Поисковый индекс похож на поисковую систему. Каждая книга имеет свое уникальное место в библиотеке (две книги не могут храниться в одном месте), которое определяется каталожным номером.
Активное обучение пока недоступно. Пожалуйста, подумайте над тем, чтобы внести свой вклад.
Итак, давайте углубимся в то, как связаны эти четыре термина и почему их иногда путают друг с другом.
Веб-страница
Веб-страница — это простой документ, отображаемый браузером. Такие документы пишутся на языке HTML (более подробно мы рассмотрим его в других статьях). Веб-страница может включать множество различных типов ресурсов, таких как:
- информация о стиле — управление внешним видом страницы
- скрипты — которые добавляют интерактивности странице
- медиа — изображения, звуки и видео.
Примечание: Браузеры также могут отображать другие документы, такие как PDF-файлы или изображения, но термин веб-страница конкретно относится к HTML-документам. В противном случае мы используем только термин документ .
Все веб-страницы, доступные в Интернете, доступны по уникальному адресу. Чтобы получить доступ к странице, просто введите ее адрес в адресной строке браузера:
Веб-сайт
Веб-сайт представляет собой набор связанных веб-страниц (плюс связанные с ними ресурсы), которые имеют общее уникальное доменное имя. Каждая веб-страница данного веб-сайта содержит явные ссылки — в большинстве случаев в виде фрагментов текста, на которые можно щелкнуть, — которые позволяют пользователю переходить с одной страницы веб-сайта на другую.
Чтобы получить доступ к веб-сайту, введите его доменное имя в адресной строке браузера, и браузер отобразит главную веб-страницу веб-сайта, или домашняя страница (небрежно называемая «домашней»):
Идеи веб-страницы и веб-сайта особенно легко спутать с веб-сайтом , который содержит только одну веб-страницу . Такой веб-сайт иногда называют одностраничным веб-сайтом.
Веб-сервер
Веб-сервер — это компьютер, на котором размещен один или несколько веб-сайтов . «Хостинг» означает, что все веб-страницы и их вспомогательные файлы доступны на этом компьютере. 9Веб-сервер 0272 отправит любую веб-страницу с веб-сайта , который он размещает, в браузер любого пользователя по запросу пользователя.
Не путайте веб-сайты и веб-серверы . Например, если вы слышите, как кто-то говорит: «Мой веб-сайт не отвечает», на самом деле это означает, что веб-сервер не отвечает, и поэтому веб-сайт недоступен. Что еще более важно, поскольку на веб-сервере может размещаться несколько веб-сайтов, термин веб-сервер никогда не используется для обозначения веб-сайта, так как это может вызвать большую путаницу. В нашем предыдущем примере, если мы сказали «Мой веб-сервер не отвечает», это означает, что несколько веб-сайтов на этом веб-сервере недоступны.
Поисковая система
Поисковые системы часто являются источником путаницы в Интернете. Поисковая система — это особый тип веб-сайта, который помогает пользователям находить веб-страницы с других веб-сайтов.
Их много: Google, Bing, Yandex, DuckDuckGo и многие другие. Некоторые из них являются общими, некоторые специализированы по определенным темам. Используйте то, что вы предпочитаете.
Многие новички в Интернете путают поисковые системы и браузеры. Давайте проясним: браузер — это программа, которая извлекает и отображает веб-страницы; поисковая система — это веб-сайт, который помогает людям находить веб-страницы с других веб-сайтов. Путаница возникает из-за того, что при первом запуске браузера браузер отображает домашнюю страницу поисковой системы. Это имеет смысл, потому что, очевидно, первое, что вы хотите сделать с браузером, — это найти веб-страницу для отображения. Не путайте инфраструктуру (например, браузер) со службой (например, поисковой системой). Различие поможет вам немного, но даже некоторые профессионалы говорят расплывчато, так что не беспокойтесь об этом.
Вот пример Firefox, показывающий окно поиска Google в качестве стартовой страницы по умолчанию:
- Копните глубже: что такое веб-сервер
- Посмотрите, как веб-страницы связаны с веб-сайтом: понимание ссылок в Интернете
Обнаружили проблему с содержанием этой страницы?
- Отредактируйте страницу на GitHub.
- Сообщить о проблеме с содержимым.
- Просмотрите исходный код на GitHub.
Хотите принять участие?
Узнайте, как внести свой вклад.
Последний раз эта страница была изменена участниками MDN.
Примеры VirtualHost — HTTP-сервер Apache версии 2.4
HTTP-сервер Apache версии 2.4
Доступные языки: en | фр | я | ко | tr
В этом документе делается попытка ответить на часто задаваемые вопросы о настройка виртуальных хостов. Эти сценарии включают несколько веб-сайты, работающие на одном сервере, через виртуальные хосты на основе имени или IP.
- Запуск нескольких веб-сайтов на основе имен сайты на одном IP-адресе.
- Узлы на основе имени более чем на одном Айпи адрес.
- Подача одного и того же контента на
различные IP-адреса (например, внутренний и внешний
адрес).
- Запуск разных сайтов на разных порты.
- Виртуальный хостинг на базе IP
- Смешанный виртуальный порт и IP-адрес хосты
- Комбинация на основе имен и IP-адресов виртуальные хосты
- Использование
Virtual_hostи mod_proxy вместе - Использование
_по умолчанию_виртуальные хосты - Миграция виртуального хоста на основе имени на vhost на базе IP
- Использование пути к серверу
См. также
- Комментарии
На вашем сервере несколько имен хостов, которые разрешаются в один адрес,
и вы хотите по-другому ответить на www.example.com и www.example.org .
Примечание
Создание виртуального
конфигурации хоста на вашем сервере Apache не волшебным образом
привести к созданию записей DNS для этих имен хостов. Ты должен иметь имена в DNS, разрешающие ваш IP
адрес, иначе никто другой не сможет увидеть ваш веб-сайт. Ты
может поместить записи в ваш файл hosts для локального
тестирование, но это будет работать только с машины с теми содержит записи.
# Убедитесь, что Apache прослушивает порт 80
Слушай 80
<Виртуальный хост *:80>
DocumentRoot "/www/example1"
Имя сервера www.example.com
# Другие директивы здесь
<Виртуальный хост *:80>
DocumentRoot "/www/example2"
Имя сервера www.example.org
# Другие директивы здесь
Звездочки соответствуют всем адресам, поэтому главный сервер не обслуживает
Запросы. В связи с тем, что виртуальный хост с имя_сервера www.example.com первый
в конфигурационном файле он имеет наивысший приоритет и его можно увидеть
как по умолчанию или первичный сервер . Это значит
что в случае получения запроса, не соответствующего одному из указанных ServerName директивы, он будет обслуживаться первым <Виртуальный хост> .
Приведенная выше конфигурация — это то, что вы захотите использовать почти все ситуации виртуального хостинга на основе имени. Единственное, что это конфигурация не будет работать, по сути, это когда вы подаете различный контент на основе разных IP-адресов или портов.
Примечание
Вы можете заменить * на определенный IP-адрес
в системе. Такие виртуальные хосты будут использоваться только для
HTTP-запросы, полученные при подключении к указанному IP-адресу
адрес.
Однако дополнительно полезно использовать * в системах, где IP-адрес непредсказуем — для
например, если у вас есть динамический IP-адрес с вашим интернет-провайдером, и
вы используете какое-то разнообразие динамических DNS-решений. С * соответствует любому IP-адресу, эта конфигурация
будет работать без изменений всякий раз, когда ваш IP-адрес
изменения.
Примечание
Любой из обсуждаемых здесь методов можно распространить на любой количество IP-адресов.
Сервер имеет два IP-адреса. На одном ( 172.20.30.40 ) мы
будет обслуживать «основной» сервер, server.example.com и на
другой ( 172.20.30.50 ), мы будем обслуживать два или более виртуальных хоста.
Прослушать 80
# Это "основной" сервер, работающий по адресу 172.20.30.40.
имя_сервера server.example.com
DocumentRoot "/www/mainserver"
<Виртуальный хост 172.20.30.50>
DocumentRoot "/www/example1"
Имя сервера www.example.com
# Другие директивы здесь...
<Виртуальный хост 172.20.30.50>
DocumentRoot "/www/example2"
Имя сервера www.example.org
# Другие директивы здесь...
Любой запрос на адрес, отличный от 172.20.30.50 будет
обслуживается с основного сервера. Запрос на номер 172.20.30.50 с
неизвестное имя хоста или заголовок Host: будет обслуживаться с www. . example.com
Сервер имеет два IP-адреса ( 192.168.1.1 и 172.20.30.40 ). Машина стоит между
внутренняя (интранет) сеть и внешняя (интернет) сеть. Снаружи
сети, имя server.example.com решает
внешний адрес ( 172.20.30.40 ), но внутри
сети, то же имя разрешается во внутренний адрес
( 192.168.1.1 ).
Сервер может отвечать на внутренние и внешние запросы
с тем же содержимым, только с одним разделом .
<Виртуальный хост 192.168.1.1 172.20.30.40>
DocumentRoot "/www/server1"
имя_сервера server.example.com
ServerAlias сервер
Теперь запросы из обеих сетей будут обслуживаться из одного <Виртуальный хост> .
Примечание:
На внутренней
сети, можно просто использовать имя server вместо
чем полное имя хоста server. . example.com
Также обратите внимание, что в приведенном выше примере вы можете заменить список
IP-адресов с * , что приведет к тому, что сервер
отвечают одинаково на все адреса.
У вас есть несколько доменов, подключенных к одному и тому же IP, и вы хотите обслуживать несколько портов. В приведенном ниже примере показано, что сопоставление имен происходит после наилучшего совпадения IP-адреса и комбинации портов определен.
Прослушать 80
Слушай 8080
<Виртуальный хост 172.20.30.40:80>
Имя сервера www.example.com
DocumentRoot "/www/домен-80"
<Виртуальный хост 172.20.30.40:8080>
Имя сервера www.example.com
DocumentRoot "/www/домен-8080"
<Виртуальный хост 172.20.30.40:80>
Имя сервера www.example.org
DocumentRoot "/www/otherdomain-80"
<Виртуальный хост 172.20.30.40:8080>
Имя сервера www.example.org
DocumentRoot "/www/otherdomain-8080"
Сервер имеет два IP-адреса ( 172. и 20.30.40 172.20.30.50 ), которые разрешаются в имена www.example.com и www.example.org соответственно.
Прослушать 80
<Виртуальный хост 172.20.30.40>
DocumentRoot "/www/example1"
Имя сервера www.example.com
<Виртуальный хост 172.20.30.50>
DocumentRoot "/www/example2"
Имя сервера www.example.org
Запросы на любой адрес, не указанный ни в одном из директивы (например, localhost , например) пойдет на основной сервер, если
есть один.
Сервер имеет два IP-адреса ( 172.20.30.40 и 172.20.30.50 ), которые разрешаются в имена www.example.com и www.example.org соответственно. В каждом случае мы хотим запускать хосты на портах 80 и
8080.
Прослушивание 172.20.30.40:80 Прослушать 172.20.30.40:8080 Слушай 172.
Любой адрес, упомянутый в аргументе виртуального хоста, который никогда не появляется на другом виртуальном хосте, является виртуальным хостом строго на основе IP.
Прослушать 80
<Виртуальный хост 172.20.30.40>
DocumentRoot "/www/example1"
Имя сервера www.example.com
<Виртуальный хост 172.20.30.40>
DocumentRoot "/www/example2"
Имя сервера www.example.org
<Виртуальный хост 172. 20.30.40>
DocumentRoot "/www/example3"
Имя сервера www.example.net
# на базе IP
<Виртуальный хост 172.20.30.50>
DocumentRoot "/www/example4"
Имя сервера www.example.edu
<Виртуальный хост 172.20.30.60>
DocumentRoot "/www/example5"
Имя сервера www.example.gov
В следующем примере интерфейсная машина позволяет проксировать
виртуального хоста на сервер, работающий на другой машине. в
пример, на машине настроен одноименный виртуальный хост
по телефону 192.168.111.2 . ProxyPreserveHost
Директива On используется, чтобы желаемое имя хоста было
пропущено, в случае, если мы проксируем несколько имен хостов на
одиночная машина.
<Виртуальный хост *:*>
ProxyPreserveHost включен
ПроксиПасс "/" "http://192.168.111,2/"
ProxyPassReverse "/" "http://192.168.111.2/"
имя_сервера имя_хоста.example.com
_default_ виртуальные хосты
для всех портов Перехват каждого запроса на любой неуказанный IP-адрес и
порт, т. е. , комбинация адреса/порта, которая не используется для
любой другой виртуальный хост.
<Виртуальный хост _default_:*>
DocumentRoot "/www/по умолчанию"
Использование такого виртуального хоста по умолчанию с подстановочным портом эффективно предотвращает любой запрос, идущий на главный сервер.
Виртуальный хост по умолчанию никогда не обслуживает запрос, отправленный
адрес/порт, который используется для виртуальных хостов на основе имени. Если запрос
содержит неизвестный или отсутствует заголовок Host: , он всегда
обслуживается с основного виртуального хоста на основе имени (виртуального хоста для этого
адрес/порт, указанный первым в файле конфигурации).
Вы можете использовать AliasMatch или RewriteRule для перезаписи любого
запрос на единую информационную страницу (или скрипт).
_по умолчанию_ виртуальные хосты
для разных портов То же, что и настройка 1, но сервер прослушивает несколько портов, и мы хотим
использовать второй виртуальный хост _default_ для порта 80.
DocumentRoot "/www/default80" # ... <Виртуальный хост _default_:*> DocumentRoot "/www/по умолчанию" # ...
Виртуальный хост по умолчанию для порта 80 (который должен появляться перед любым vhost по умолчанию с портом подстановочного знака) перехватывает все отправленные запросы на неопределенный IP-адрес. Главный сервер никогда не используется для обслуживания запрос.
_по умолчанию_ виртуальные хосты
для одного портаМы хотим иметь виртуальный хост по умолчанию для порта 80, но не для другого порта по умолчанию vhosts.
<Виртуальный хост _default_:80>
DocumentRoot "/www/по умолчанию"
...
Запрос на неуказанный адрес через порт 80 обслуживается из виртуальный хост по умолчанию. Любой другой запрос к неуказанному адресу и порту обслуживается с основного сервера.
Любое использование * в объявлении виртуального хоста будет иметь
более высокий приоритет, чем _по умолчанию_ .
Виртуальный хост на основе имени с именем хоста www.example.org (из нашего примера на основе имени, настройка 2) должен получить свой собственный IP-адрес
адрес. Во избежание проблем с DNS-серверами или прокси-серверами, кэшировавшими
старый IP-адрес для виртуального хоста на основе имени, который мы хотим предоставить как
вариантов на этапе миграции.
Решение простое, потому что мы можем просто добавить новый IP-адрес
( 172.20.30.50 ) на виртуальный хост директива.
Прослушать 80
Имя сервера www.example.com
DocumentRoot "/www/example1"
<Виртуальный хост 172.20.30.40 172.20.30.50>
DocumentRoot "/www/example2"
Имя сервера www.example.org
# ...
<Виртуальный хост 172.20.30.40>
DocumentRoot "/www/example3"
Имя сервера www.example.net
Псевдоним сервера *.example.net
# ...
Доступ к виртуальному хосту теперь можно получить через новый адрес (как
vhost на основе IP) и через старый адрес (как на основе имени
вхост).
У нас есть сервер с двумя виртуальными хостами на основе имен. Чтобы соответствовать
правильный виртуальный хост клиент должен отправить правильный хост : заголовок. Старые клиенты HTTP/1.0 не отправляют такой заголовок, а у Apache
понятия не имею, к какому виртуальному хосту пытался подключиться клиент (и обслуживает запрос
с основного виртуального хоста). Чтобы обеспечить как можно большую обратную совместимость,
возможно, мы создадим основной виртуальный хост, который возвращает одну страницу
содержащие ссылки с префиксом URL на виртуальные
хосты. 9(/sub2/.*)» «/www/subdomain$1»
# …
Из-за ServerPath директива запроса к URL http://www.sub1.domain.tld/sub1/ это всегда обслуживается с sub1-vhost.
Запрос к URL http://www.sub1.domain.tld/ только
обслуживается с sub1-vhost, если клиент отправил правильный Хост: заголовок . Если заголовок Host: не отправлен,
клиент получает информационную страницу от основного хоста.
Обратите внимание, что есть одна странность: запрос на http://www.sub2.domain.tld/sub1/ также обслуживается из
sub1-vhost, если клиент не отправил заголовок Host: .
Директивы RewriteRule используются для того, чтобы убедиться, что клиент, отправивший правильный Хост: заголовок может использовать оба варианта URL, т.е. ,
с префиксом URL или без него.
Примечание:
Это не раздел вопросов и ответов. Комментарии, размещенные здесь, должны указывать на предложения по улучшению документации или сервера и могут быть удалены нашими модераторами, если они реализованы или считаются недействительными/не по теме. Вопросы о том, как управлять HTTP-сервером Apache, следует направлять либо на наш IRC-канал #httpd, на Libera.chat, либо в наши списки рассылки.
Что такое веб-страница — Javatpoint
следующий → ← предыдущая Веб-страница — это отдельный гипертекстовый документ, доступный во всемирной паутине (WWW). Он состоит из элементов HTML и отображается в браузере пользователя, таком как Mozilla, Firefox, Chrome и т. д. Он также называется «Страница ». В этой теме мы собираемся обсудить различные детали веб-страницы, включая следующие темы:
Что такое веб-страница? Веб-страница — это документ, написанный в формате HTML, который можно просмотреть в любом веб-браузере. Он содержится на веб-сервере, доступ к которому можно получить, введя URL-адрес этой веб-страницы, и после загрузки он появляется в веб-браузере пользователя. Веб-страница может содержать текст, ссылки на другие страницы, графику, видео и т. д. . Более того, он в основном используется для предоставления информации пользователю в виде текста, изображений и т. д. Веб-страница является частью веб-сайта; это означает, что веб-сайт содержит разные веб-страницы. Например, javaTpoint.com — это веб-сайт, а страница, к которой вы в данный момент обращаетесь, — это веб-страница. Это можно понять как пример книги. Итак, веб-сайт подобен полной книге, а веб-страница — странице этой книги. WWW или Интернет содержат миллионы веб-страниц, и ежедневно их количество увеличивается. Тим Бернерс-Ли разработал первую веб-страницу. Давайте разберемся с некоторыми основными терминами, которые используются с веб-страницей:
Примечание. Для практики вы можете создавать веб-страницы самостоятельно без использования веб-сервера, и ваш браузер будет отображать эти страницы только на вашем компьютере.
Примечание. Веб-браузер также может отображать другие документы, такие как PDF-документ или изображения, но только HTML-документ называется веб-страницей.Характеристики веб-страницыНиже приведены некоторые характеристики веб-страницы:
Разница между веб-страницей и веб-сайтом Поскольку и веб-сайты, и веб-страницы связаны друг с другом, некоторые пользователи могут использовать их взаимозаменяемо, но они сильно отличаются друг от друга.
Примечание. Термины «Веб-страница» и «Веб-страница» одинаковы, и оба они технически правильны. Однако большинство руководств по стилю предлагают использовать веб-страницу вместо веб-страницы.Как работает веб-страница? Простая веб-страница создается с использованием языка разметки HTML. Он создан с использованием HTML, поэтому содержит различные теги разметки, которые определяют, как данные должны быть отформатированы на экране. Веб-страница находится на веб-сервере. Чтобы загрузить эту веб-страницу, клиент отправляет запрос на сервер, и обычно браузер называется клиентом, который может запрашивать страницу в Интернете. Веб-браузер запрашивает страницу в Интернете. Как только сервер отвечает на него, браузер интерпретирует теги разметки и отображает их на экране пользователя в правильном формате. Браузер отправляет запрос страницы или файла через HTTP-запрос. HTTP — это протокол передачи гипертекста , сетевой протокол, который позволяет передавать гипермедиа-документы через Интернет между браузером и сервером. Как только запрос достигает сервера, HTTP-сервер принимает запрос, находит запрошенную страницу и отправляет ее обратно в браузер через HTTP-ответ . Элементы веб-страницыОсновным элементом веб-страницы является текстовый файл, составленный из HTML. Кроме того, веб-страница может иметь следующие элементы:
Хотя каждая веб-страница отличается от другой веб-страницы, некоторые компоненты являются общими почти для всех страниц. Некоторые из этих компонентов приведены ниже; вы также можете связать эти элементы по данному изображению:
Также может быть некоторая дополнительная информация и инструменты, такие как кнопка для печати страницы, которая также может быть полезна для пользователей. Типы веб-страницСуществует два основных типа веб-страниц в зависимости от функциональности:
Статическая веб-страница Статические веб-страницы — это те веб-страницы, которые не могут быть изменены или изменены клиентом. Они также известны как стационарные или плоские веб-страницы. Они отображаются в браузере клиента в том же формате и в том же виде, в каком они сохраняются на веб-сервере. Пользователи могут только загружать страницу и читать информацию, но не могут вносить какие-либо изменения на странице. Статическая веб-страница обычно состоит только из HTML и CSS. Динамическая веб-страницаКак следует из названия, динамические веб-страницы являются динамическими, что означает отображение различной информации в разное время. Динамическая веб-страница показывает разное содержимое при каждом просмотре. Существует два типа динамических веб-страниц:
Примечание. Языки сценариев — это языки программирования, которые позволяют нам писать программы в виде сценариев, которые интерпретируются, а не компилируются.Помимо этих двух веб-страниц, есть несколько примеров общих веб-страниц, которые можно найти на большинстве веб-сайтов, а именно:
Как создать простую веб-страницу?Создать простую веб-страницу очень просто; любой, у кого есть базовые знания компьютеров и HTML, может создать его. Но перед созданием веб-страницы вы должны знать о следующих пунктах:
Чтобы создать веб-страницу, выполните следующие действия:
<голова> первая веб-страницаЭто моя первая веб-страница! В приведенном выше коде используются следующие теги:
Примечание. Важно заканчивать каждый тег в html и помещать все теги либо в верхний, либо в нижний регистр. Однако рекомендуется использовать нижний регистр.
Вы также можете добавить больше тегов для различных элементов, таких как добавление изображений, фоновых изображений, границ, таблиц, таблиц и т. д., используя HTML. Вы можете узнать все это отсюда. Примечание. Эта веб-страница является локальной только для вашего компьютера, и только вы можете видеть ее в своем браузере. Чтобы просмотреть это в Интернете, вам нужно сначала опубликовать его.После создания страницы вы также можете внести изменения в свой файл через редактор. Просто внесите изменения, снова сохраните файл и перезагрузите страницу; эти изменения появятся на экране. Следующая темаСварка ← предыдущая следующий → |
Определение и значение веб-сайта — Merriam-Webster
веб-сайт ˈweb-ˌsīt
: группа страниц всемирной паутины, обычно содержащих гиперссылки друг на друга и доступных в Интернете отдельным лицом, компанией, образовательным учреждением, правительством или организацией.
… позвоните по нашему бесплатному номеру или посетите наш веб-сайт. — реклама в The New York Times Magazine
… официальный веб-сайт НХЛ будет дополнен тем, что, как обещает лига, будет гораздо большей поисковой способностью и большим статистическая база данных.— Sports Illustrated
также : услуга или бизнес, который работает через определенный веб-сайт.
Я подумал, что если бы я мог получить веб-сайт, чтобы рискнуть с кем-то, у кого был только опыт печати, но были связи и он действительно хорошо писал и репортировал, тогда я был бы настроен. — Дара Прант
Инженер-программист из Анкени создал веб-сайт Vaccine Hunter, на котором собраны доступные записи на вакцинацию у сотен поставщиков вакцин по всему штату и которые автоматически публикуются в Интернете. — Микаэла Рамм
Примеры предложений
Недавние примеры в Интернете
Агентство по безопасности сообщает в документах, размещенных на его веб-сайте в четверг, что Tesla исправит проблемы с онлайн-обновлением программного обеспечения в ближайшие недели.
— Том Кришер, ajc , 17 февраля 2023 г.
Компания не разместила письмо на своем веб-сайт или предупредить широкую общественность о проблемах.
— Штатный писатель
Следите, Los Angeles Times , 16 февраля 2023 г.
Tesla не ответила на запрос о комментариях, отправленный на адрес электронной почты для прессы, указанный на ее веб-сайте , но широко известно, что три года назад она распустила свою пресс-команду. — Джон Портер, The Verge , 16 февраля 2023 г.
Агентство сделало результаты этих тестов общедоступными на своем 9-м канале.0272 сайт .
— Крис Мюллер, USA TODAY , 16 февраля 2023 г.
Шахта Dugald River производит цинковый концентрат с побочными продуктами, включая свинец и серебро, сообщает MMG на своем веб-сайте .
— Хилари Уайтман, CNN , 16 февраля 2023 г.
Moft производит некоторые из наших любимых аксессуаров для телефонов, планшетов и настольных компьютеров, а на некоторые товары действует скидка 15% в течение 9 дней.0272 веб-сайт до 6 марта.
— Лорин Страмп, , WIRED , 16 февраля 2023 г.
Агентство по безопасности сообщает в документах, размещенных на его веб-сайте в четверг, что Tesla исправит проблемы с онлайн-обновлением программного обеспечения в ближайшие недели. — Том Кришер, Anchorage Daily News , 16 февраля 2023 г.
С этого момента и до праздничных выходных у бренда есть большие скидки на свои веб-сайт , а также Dick’s Sporting Goods, открыв шлюзы для огромных сбережений, приобретая некоторые из своих самых продаваемых товаров.
— Талин Эпплтон, Men’s Health , 15 февраля 2023 г.
Узнать больше
Эти примеры предложений автоматически выбираются из различных онлайн-источников новостей, чтобы отразить текущее использование слова «веб-сайт». Мнения, выраженные в примерах, не отражают точку зрения Merriam-Webster или ее редакторов. Отправьте нам отзыв.
История слов
Первое известное использование
1993 год, в значении, определенном выше
Путешественник во времени
Первое известное использование сайт был в 1993 году
Другие слова того же года веб-пила
Веб-сайт
веб-спиннер
Посмотреть другие записи поблизости
Процитировать эту запись0006
«Веб-сайт.» Словарь Merriam-Webster.com , Merriam-Webster, https://www.merriam-webster.com/dictionary/website. По состоянию на 4 марта 2023 г.
Копировать ссылку
Детское определение
веб-сайт
сущ.
веб-сайт
ˈweb-ˌsīt
: группа страниц всемирной паутины, обычно содержащих ссылки друг на друга и размещенных в Интернете отдельным лицом, компанией или организацией
Еще от Merriam-Webster на веб-сайте
Перевод веб-сайта для говорящих на испанском языкеBritannica English: Перевод веб-сайта для говорящих на арабском языке
Последнее обновление: — Обновлены примеры предложений
Подпишитесь на крупнейший словарь Америки и получите тысячи дополнительных определений и расширенный поиск без рекламы!
Merriam-Webster без сокращений
ближайший
См. Определения и примеры »
Получайте ежедневно по электронной почте Слово дня!
Старая добрая викторина
- маслобойка виноградная дробилка
- стиральная машина мышеловка
Проверь свои знания и, возможно, узнаешь что-нибудь по пути.
ПРОЙДИТЕ ТЕСТ
Сможете ли вы составить 12 слов из 7 букв?
ИГРАТЬ
Веб-сервер Tornado — документация Tornado 6.2
Tornado — это веб-фреймворк Python,
асинхронная сетевая библиотека, первоначально разработанная в FriendFeed. Используя неблокирующий сетевой ввод-вывод, Tornado
может масштабироваться до десятков тысяч открытых подключений, что делает его идеальным для
долгий опрос,
веб-сокеты и другие
приложения, которые требуют длительного подключения к каждому пользователю.
Быстрые ссылки
Текущая версия: 6.2 (скачать с PyPI, примечания к выпуску)
Источник (GitHub)
Списки рассылки: обсуждения и объявления
Переполнение стека
Вики
Привет, мир
Вот простой пример веб-приложения «Hello, world» для Tornado:
асинхронный импорт
импортировать торнадо.веб
класс MainHandler (tornado.web.RequestHandler):
деф получить(я):
self.write("Привет, мир")
определение make_app():
вернуть tornado.web.Application([
(r"/", MainHandler),
])
асинхронная функция main():
приложение = make_app()
app.listen(8888)
ждать asyncio.Event(). ждать()
если __name__ == "__main__":
asyncio.run(основной())
В этом примере не используются какие-либо асинхронные функции Tornado; для которые видят этот простой чат.
потоков и WSGI
Tornado отличается от большинства веб-фреймворков Python. Это не основано
на WSGI, и это
обычно запускаются только с одним потоком на процесс. См. руководство пользователя
подробнее о подходе Tornado к асинхронному программированию.
Хотя некоторая поддержка WSGI доступна в модуле tornado.wsgi ,
это не цель разработки, и большинство приложений должны быть
написанный для использования собственных интерфейсов Tornado (таких как торнадо.веб )
напрямую вместо использования WSGI.
В общем, код Tornado не является потокобезопасным. Единственный метод в
Торнадо, который безопасно вызывать из других потоков, IOLoop.add_callback . Вы также можете использовать IOLoop.run_in_executor для
асинхронно запустить блокирующую функцию в другом потоке, но обратите внимание
что функция, переданная run_in_executor , должна избегать
ссылки на любые объекты Tornado. run_in_executor — это
рекомендуемый способ взаимодействия с блокирующим кодом.
асинхронный Интеграция Tornado интегрирован со стандартной библиотекой asyncio модулем и
использует один и тот же цикл событий (по умолчанию, начиная с Tornado 5. 0). В общем,
библиотеки, предназначенные для использования с asyncio , можно свободно смешивать с
Торнадо.
Установка
pip установить торнадо
Tornado указан в PyPI и
может быть установлен с pip . Обратите внимание, что исходный дистрибутив
включает демонстрационные приложения, которых нет, когда Tornado
установлен таким образом, поэтому вы можете загрузить копию
исходный tarball или также клонируйте репозиторий git.
Предварительные требования : Tornado 6.2 требует Python 3.7 или новее. Следующее дополнительные пакеты могут быть полезны:
pycurl используется необязательным
торнадо.curl_httpclient. Требуется Libcurl версии 7.22 или выше.pycares является альтернативой неблокирующий преобразователь DNS, который можно использовать, когда потоки не соответствующий.
Платформы : Tornado разработан для Unix-подобных платформ, с лучшими
производительность и масштабируемость в системах, поддерживающих epoll (Линукс), kqueue (BSD/macOS) или /dev/poll (Solaris).
Tornado также будет работать в Windows, хотя эта конфигурация не
официально поддерживается или рекомендуется для использования в производстве. Некоторые особенности
отсутствуют в Windows (включая многопроцессорный режим) и масштабируемость
ограничен (несмотря на то, что Tornado построен на asyncio , что
поддерживает Windows, Tornado не использует API, необходимые для
масштабируемая сеть в Windows).
Документация
Эта документация также доступна в форматах PDF и Epub.
- Руководство пользователя
- Введение
- Асинхронный и неблокирующий ввод-вывод
- Сопрограммы
-
Очередьпример — одновременный веб-паук - Структура веб-приложения Tornado
- Шаблоны и пользовательский интерфейс
- Аутентификация и безопасность
- Запуск и развертывание
- Веб-фреймворк
-
tornado.web—RequestHandlerиApplicationклассы -
tornado.— Генерация гибкого вывода template -
tornado.routing— Базовая реализация маршрутизации -
tornado.escape— Экранирование и манипулирование строками -
tornado.locale— Поддержка интернационализации -
tornado.websocket— Двунаправленная связь с браузером
-
- HTTP-серверы и клиенты
-
tornado.httpserver— Неблокирующий HTTP-сервер -
tornado.httpclient— Асинхронный HTTP-клиент -
tornado.httputil— Управление заголовками HTTP и URL-адресами -
tornado.http1connection— реализация клиент/сервер HTTP/1.x
-
- Асинхронная сеть
-
tornado.ioloop— Основной цикл событий -
торнадо.iostream— Удобные обертки для неблокирующих сокетов -
tornado.netutil— Разные сетевые утилиты -
tornado.— tcpclient IOStreamфабрика соединений -
tornado.tcpserver— базовыйTCP-сервер на базе IOStream
-
- Сопрограммы и параллелизм
-
tornado.gen— Сопрограммы на основе генератора -
tornado.locks— Примитивы синхронизации -
tornado.queues— Очереди для сопрограмм -
tornado.process— Утилиты для нескольких процессов
-
- Интеграция с другими сервисами
-
tornado.auth— Сторонний вход с OpenID и OAuth -
tornado.wsgi— Взаимодействие с другими платформами и серверами Python -
tornado.platform.caresresolver— Асинхронный преобразователь DNS с использованием C-Ares -
tornado.platform.twisted— Мосты между Twisted и Tornado -
tornado.platform.asyncio— Мост междуasyncioи Tornado
-
- Утилиты
-
tornado.— Автоматическое обнаружение изменений кода при разработке autoreload -
tornado.concurrent— Работа сFutureобъектами -
tornado.log— поддержка ведения журнала -
tornado.options— Анализ командной строки -
tornado.testing— Поддержка модульного тестирования для асинхронного кода -
tornado.util— Утилиты общего назначения
-
- Часто задаваемые вопросы
- Примечания к выпуску
- Что нового в Tornado 6.2.0
- Что нового в Tornado 6.1.0
- Что нового в Tornado 6.0.4
- Что нового в Tornado 6.0.3
- Что нового в Tornado 6.0.2
- Что нового в Tornado 6.0.1
- Что нового в Торнадо 6.0
- Что нового в Tornado 5.1.1
- Что нового в Торнадо 5.1
- Что нового в Торнадо 5.0.2
- Что нового в Tornado 5.0.1
- Что нового в Торнадо 5. 0
- Что нового в Торнадо 4.5.3
- Что нового в Tornado 4.5.2
- Что нового в Tornado 4.5.1
- Что нового в Торнадо 4.5
- Что нового в Tornado 4.4.3
- Что нового в Tornado 4.4.2
- Что нового в Tornado 4.4.1
- Что нового в Торнадо 4.4
- Что нового в Торнадо 4.3
- Что нового в Tornado 4.2.1
- Что нового в Торнадо 4.2
- Что нового в Торнадо 4.1
- Что нового в Торнадо 4.0.2
- Что нового в Торнадо 4.0.1
- Что нового в Торнадо 4.0
- Что нового в Tornado 3.2.2
- Что нового в Tornado 3.2.1
- Что нового в Торнадо 3.2
- Что нового в Tornado 3.1.1
- Что нового в Tornado 3.1
- Что нового в Tornado 3.0.2
- Что нового в Торнадо 3.0.1
- Что нового в Торнадо 3.0
- Что нового в Торнадо 2.4.1
- Что нового в Торнадо 2.4
- Что нового в Торнадо 2.3
- Что нового в Tornado 2.