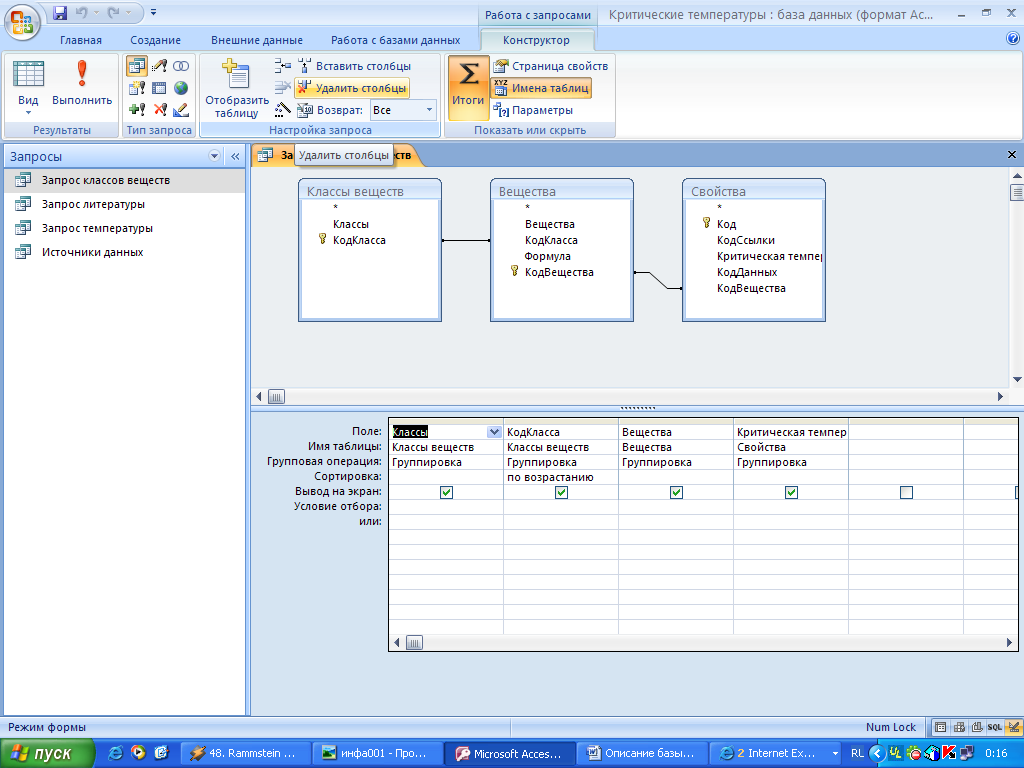
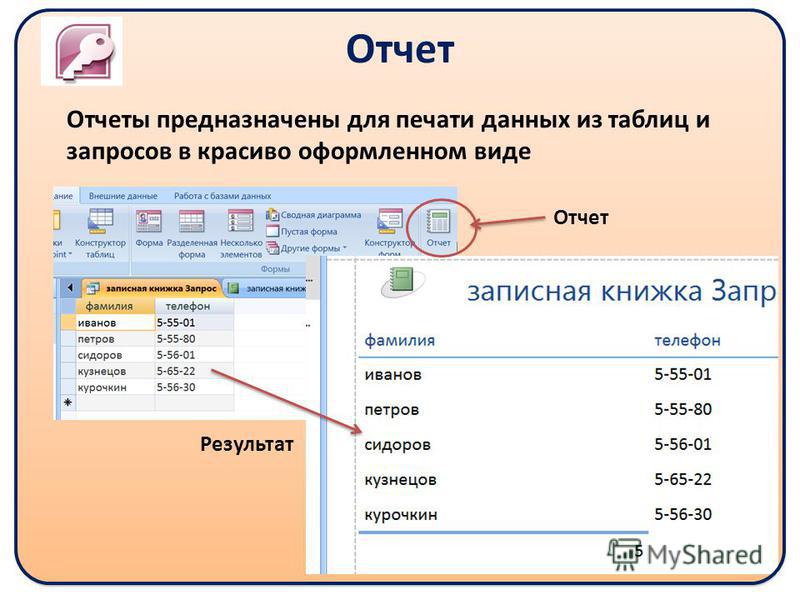
Нечеткие запросы к реляционным базам данных
Введение
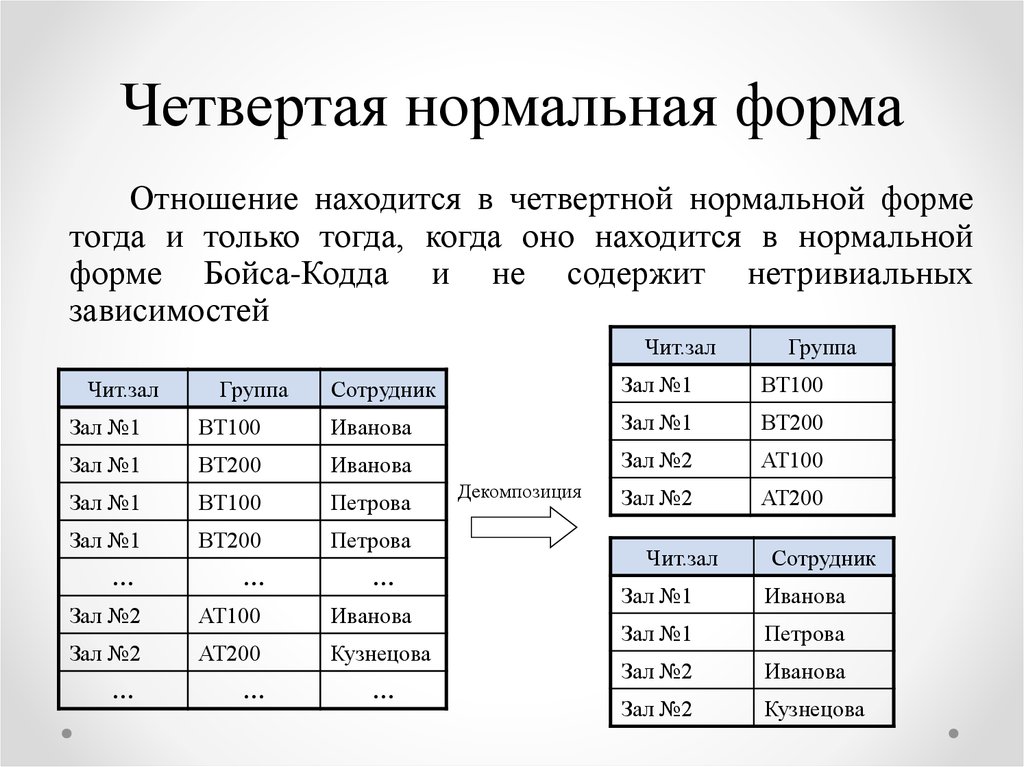
Механизмы нечетких запросов (fuzzy queries, flexible queries) к реляционным базам данных базирующиеся на теории нечетких множеств Заде, были впервые предложены в 1984 году и впоследствии получили развитие в работах Д. Дюбуа и Г. Прада.
Для чего это необходимо
Большая часть данных, обрабатываемых в современных информационных системах, носят четкий, числовой характер. Однако в запросах к базам данных, которые пытается формулировать человек, часто присутствуют неточности и неопределенности. Не удивительно, когда на запрос в поисковой системе Интернета пользователю выдается множество ссылок на документы, упорядоченных по степени релевантности (или соответствия) запросу. Потому что текстовой информации изначально присуща нечеткость и неопределенность, причинами которой является семантическая неоднозначность языка, наличие синонимов и т.д.
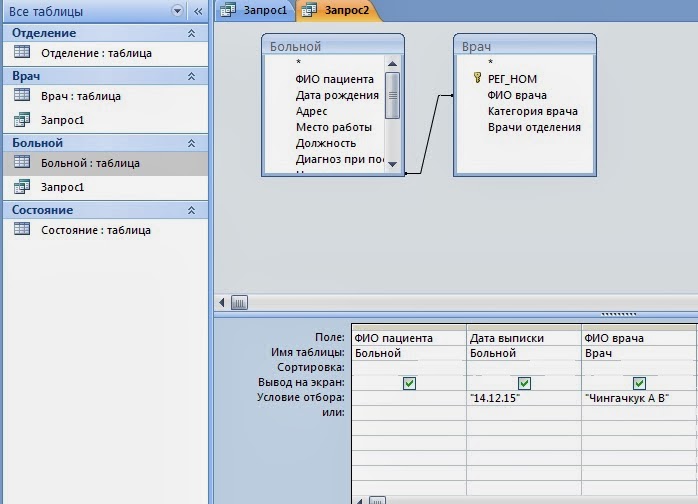
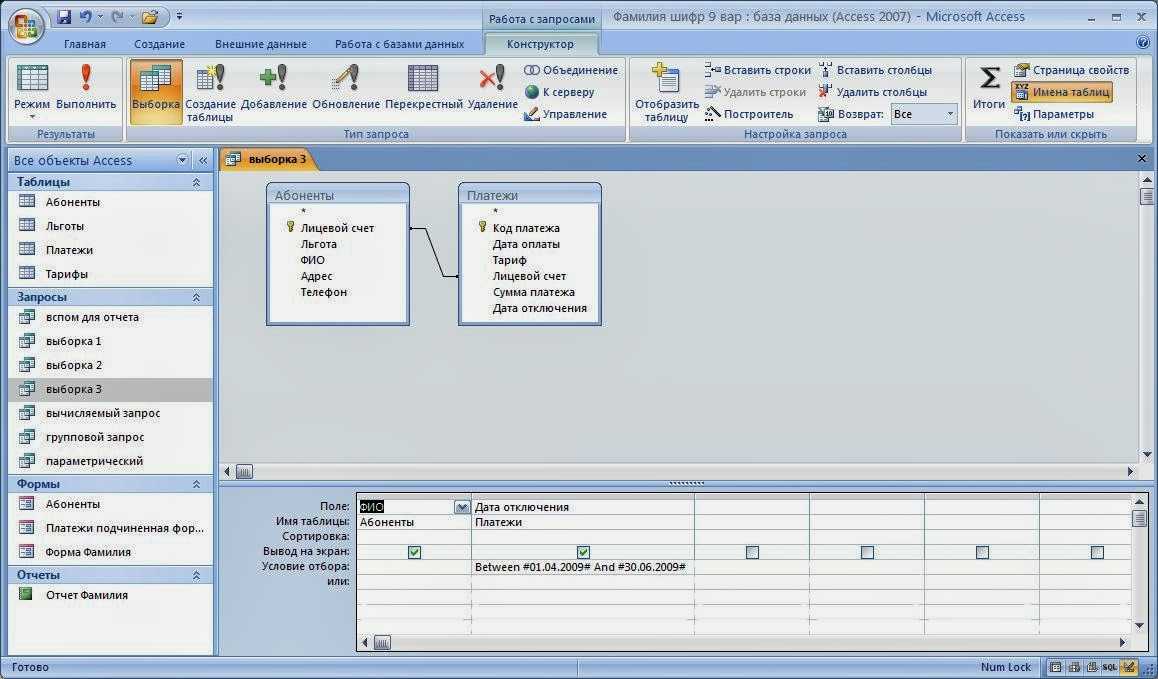
С базами данных информационных систем, или с четкими базами данных (Crisp Databases) ситуация другая. Пусть, например, из базы данных требуется извлечь следующую информацию:
Пусть, например, из базы данных требуется извлечь следующую информацию:
- «Получить список молодых сотрудников с невысокой заработной платой»
- «Найти предложения о сдаче не очень дорогого жилья близко к центру города»
Здесь высказывания «Молодой», «Невысокая», «Не очень дорогой», «Близко» имеют размытый, неточный характер, хотя заработная плата определена до рубля, а удаленность квартиры от центра – с точностью до километра. Причиной всему служит то, что в реальной жизни мы оперируем и рассуждаем неопределенными, неточными категориями. Такие запросы невозможно выполнить средствами языка SQL. И на помощь приходит концепция нечетких запросов.
Продемонстрируем ограниченность четких запросов на следующем примере. Пусть требуется получить сведения о менеджерах по продажам не старше 25 лет, у которых сумма годовых сделок превысила 200 тыс. по такому-то региону. Данный запрос можно записать на языке SQL следующим образом:
where (Managers.
 Age <= 25 AND Managers.Sum > 200000 AND Managers.RegionID = 1)
Age <= 25 AND Managers.Sum > 200000 AND Managers.RegionID = 1)Менеджер по продажам 26 лет с годовой суммой продаж в 400 тыс., или 19 лет с суммой в 198 тыс. не попадут в результат запроса, хотя их характеристики почти удовлетворяют требованиям запроса.
Нечеткие запросы помогают справиться с подобными проблемами «пропадания» информации.
Как это работает
Механизм работы нечетких запросов основан на теории нечетких множеств, основные сведения из которой изложены в предыдущей статье Нечеткая логика – математические основы.
Рассмотрим наиболее распространенные способы генерации новых лингвистических термов на основе базового терм-множества. Это полезно для построения разнообразных семантических конструкций, которые усиливают или ослабляют высказывания, например: «очень высокая цена», «приблизительно среднего возраста» и т.д. Для этого существуют лингвистические модификаторы (linguistic hedges), усиливающие или ослабляющие высказывание. К усиливающим относится модификатор «Очень» (Very), к ослабляющим – «Более-или-менее», или «Приблизительно», «Почти» (more-or-less), нечеткие множества которых описываются функциями принадлежности вида:
$${2,5} MF_{VERY}\,(X) = {(MF\,(X))}^2$$
$$MF_{MORE-OR-LESS}\,(X) = \sqrt{MF\,(X)}$$
Для примера формализуем нечеткое понятие «Возраст сотрудника компании». Это и будет название соответствующей лингвистической переменной. Зададим для нее область определения X = [18; 70] и три лингвистических терма – «Молодой», «Средний», «Выше среднего». Последнее, что осталось сделать – построить фунции принадлежности для каждого лингвистического терма.
Это и будет название соответствующей лингвистической переменной. Зададим для нее область определения X = [18; 70] и три лингвистических терма – «Молодой», «Средний», «Выше среднего». Последнее, что осталось сделать – построить фунции принадлежности для каждого лингвистического терма.
Выберем трапецеидальные функции принадлежности со следующими координатами:
«Молодой» = [18, 18, 28, 34], «Средний» = [28, 35, 45, 50], «Выше среднего» = [42, 53, 60, 60].
Теперь можно вычислить степень принадлежности сотрудника 30 лет к каждому из нечетких множеств:
MF[Молодой](30)=0,67; MF[Средний](30)=0,29; MF[Выше среднего](30)=0.
Основное требование при построении функций принадлежности – значение функций принадлежности должно быть больше нуля хотя бы для одного лингвистического терма.
В заключение определим операцию нечеткого отрицания (NOT): MF[NOT](X)=1-MF(X).
Приведенных выше сведений достаточно для построения и выполнения нечетких запросов.
Вернемся к примеру с менеджерами о продажах. Для простоты предположим, что вся необходимая информация находятся в одной таблице со следующими полями: ID – номер сотрудника, AGE – возраст и SUM (годовая сумма сделок).
Для простоты предположим, что вся необходимая информация находятся в одной таблице со следующими полями: ID – номер сотрудника, AGE – возраст и SUM (годовая сумма сделок).
| ID | AGE | SUM |
|---|---|---|
| 1 | 23 | 120 500 |
| 2 | 25 | 164 000 |
| 3 | 28 | 398 000 |
| 4 | 31 | 489 700 |
| 5 | 33 | 251 900 |
| … | ||
Лингвистическая переменная «Возраст» была задана ранее. Определим еще одну лингвистическую переменную для поля SUM с областью определения X = [0; 600000] и термами «Малая», «Средняя» и «Большая» и аналогично построим для них функции принадлежности:
«Малая» = [0, 0, 0, 200000], «Средняя» = [90000, 180000, 265000, 330000], «Большая» = [300000, 420000, 600000, 600000].
К такой таблице можно делать нечеткие запросы. Например, получить список всех молодых менеджеров по продажам с большой годовой суммой сделок, что на SQL-подобном синтаксисе запишется так:
select * from Managers where (Age = «Молодой» AND Sum = «Большая»)
Рассчитав для каждой записи агрегированное значение функции принадлежности MF (при помощи операции нечетого «И»), получим результат нечеткого запроса:
| ID | AGE | SUM | MF |
|---|---|---|---|
| 3 | 28 | 398 000 | 0,82 |
| 4 | 31 | 489 700 | 0,50 |
Записи 1,2,5 не попали в результат запроса, т. к. для них значение функции принадлежности равно нулю. Записей, точно удовлетворяющих поставленному запросу (MF=1), в таблице не нашлось. Менеджер по продажам 28 лет и годовой суммой 398000 соответствует запросу с функцией принадлежности 0,82. На практике обычно вводят пороговое значение функции принадлежности, при превышении которого записи включаются в результат нечеткого запроса.
к. для них значение функции принадлежности равно нулю. Записей, точно удовлетворяющих поставленному запросу (MF=1), в таблице не нашлось. Менеджер по продажам 28 лет и годовой суммой 398000 соответствует запросу с функцией принадлежности 0,82. На практике обычно вводят пороговое значение функции принадлежности, при превышении которого записи включаются в результат нечеткого запроса.
Аналогичный четкий запрос мог бы быть сформулирован, например, так:
select * from Managers where (Age <= 28 AND Sum >= 420000)
Его результат является пустым. Однако если мы немного расширим рамки возраста в запросе, то рискуем упустить других сотрудников с чуть более большим или меньшим возрастом. Поэтому можно сказать, что нечеткие запросы позволяют расширить область поиска в соответствии с изначально заданными человеком ограничениями.
Используя нечеткие модификаторы, можно формировать и более сложные запросы:
select * from Managers where (Age = «Более-или-менее Средний» AND Sum = «Средняя»)
Результат:
| ID | AGE | SUM | MF |
|---|---|---|---|
| 5 | 33 | 251 900 | 0,85 |
Часто требуется оперировать не лингвистическими переменными, а нечеткими аналогами точных значений. Для этого существует нечеткое отношение «ОКОЛО» (Например, «Цена около 20»). Для реализации подобных нечетких отношений аналогично строится нечеткое множество с соответствующей функцией принадлежности, но уже на некотором относительном интервале (например, [-5; 5]) для избежания зависимости от контекста. При вычислении функции принадлежности нечеткого отношения «Около Q» (Q – некоторое четкое число) производят масштабирование на относительный интервал.
Для этого существует нечеткое отношение «ОКОЛО» (Например, «Цена около 20»). Для реализации подобных нечетких отношений аналогично строится нечеткое множество с соответствующей функцией принадлежности, но уже на некотором относительном интервале (например, [-5; 5]) для избежания зависимости от контекста. При вычислении функции принадлежности нечеткого отношения «Около Q» (Q – некоторое четкое число) производят масштабирование на относительный интервал.
Проиллюстрируем вышесказанное на примере таблицы с данными о ценных бумагах. Пусть она имеет в своем составе следующие поля: PRICE (стоимость ценной бумаги), RATIO (отношение цены к прибыли, price-to-earnings ratio), AYIELD (усредненный доход за последний квартал, average yield, %).
| ID | PRICE | RATIO | AYIELD |
|---|---|---|---|
| 1 | 260 | 15,0 | |
| 2 | 380 | 5 | 7,0 |
| 3 | 810 | 6 | 10,0 |
| 4 | 110 | 9 | 14,0 |
| 5 | 420 | 10 | 16,0 |
Пусть требуется найти ценные бумаги для покупки не дороже $150, с доходностью 15% и отношением цены прибыли 11.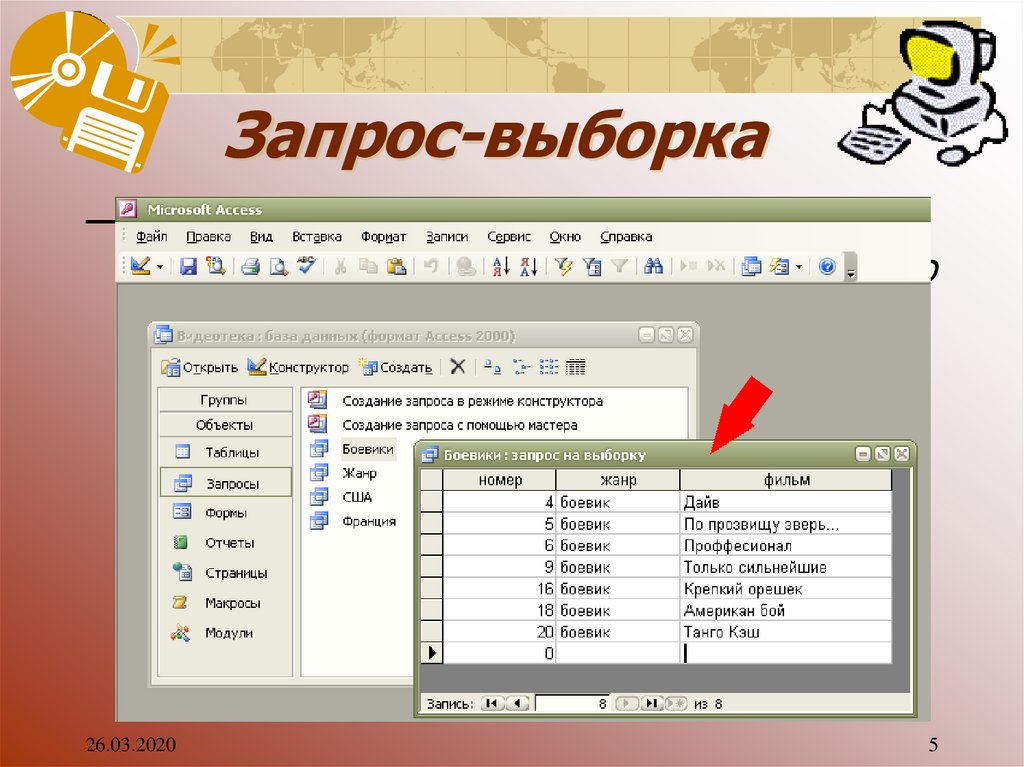 Это эквивалентно следующему SQL-запросу:
Это эквивалентно следующему SQL-запросу:
select * FROM some_table where ((PRICE<=150) AND (RATIO=11) AND (AYIELD=15))
Результат такого запроса будет пустым.
Тогда сформулируем этот же запрос в нечетком виде с использованием отношения «ОКОЛО»:
select * FROM some_table
where ((PRICE = «Около 150») AND (RATIO= «Около 11″) AND (AYIELD=»Около 15»))
Построим нечеткое множество для отношения «ОКОЛО» в относительном интервале [-5; 5]. Это будет трапеция с координатами [-2, -1, 1, 2].
Рассчитаем значение нечеткого запроса «Цена около 250» для цены 380. Предварительно зададим области определения каждой лингвистической переменной: PRICE – [0; 1000], RATIO – [0; 20], AYIELD – [0; 20]. Значение 130 (полученное как разница между 380 и 250) отмасштабируем на интервал [-5; 5], получим величину x=1,3 и MF(1,3)=0,7.
Применив нечеткое отношение ОКОЛО к каждому полю PRICE, RATIO и AYIELD и рассчитав агрегированное значение функции принадлежности с помощью операции нечеткое «И», получим следующий результат запроса.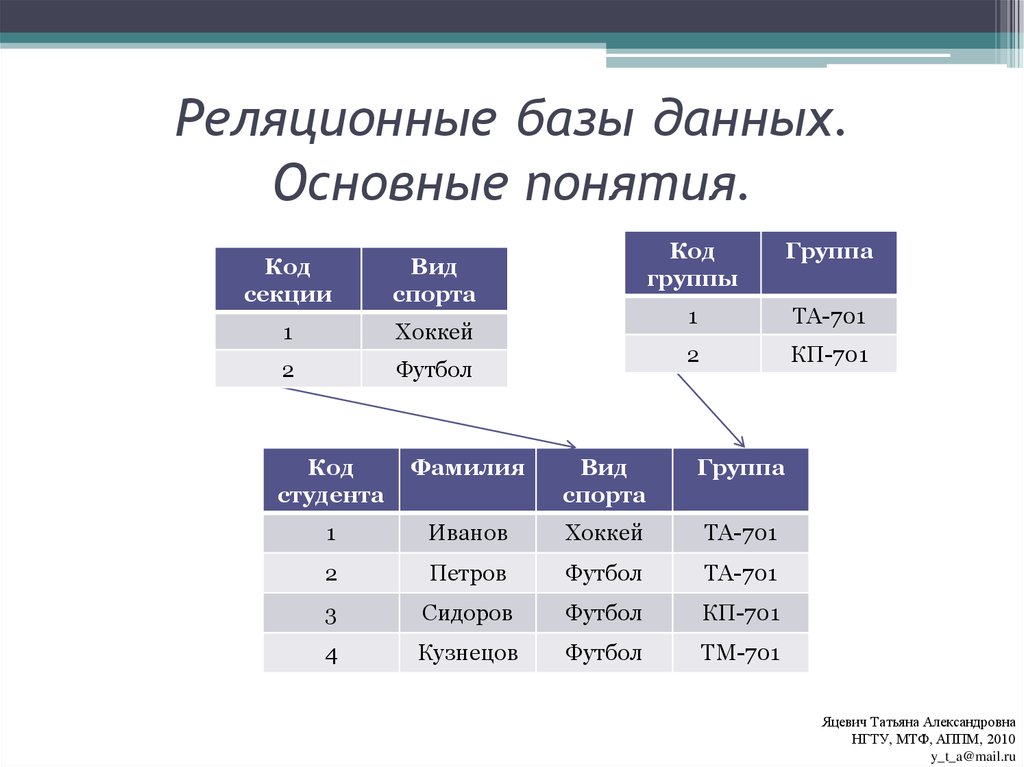
| ID | PRICE | RATIO | AYIELD | MF |
|---|---|---|---|---|
| 1 | 260 | 11 | 15,0 | 1 |
| 4 | 110 | 9 | 14,0 | 0,9 |
Недостатком нечетких запросов является относительная субъективность функций принадлежности.
Области применения нечетких запросов
Нечеткие запросы перспективно использовать в областях, где осуществляется выбор информации из баз данных с использованием качественных критериев и нечетко сформулированных условий, например, Direct Marketing.
В прямом маркетинге очень важен этап выделения целевой аудитории, для которой будут применяться различные инструменты direct marketing. Например, это прямая почтовая реклама (direct mail), используемая при продвижении товаров и услуг организациям и частным лицам. Однако для получения максимального эффекта от direct mail необходим тщательный выбор адресатов. Если отбор адресатов будет либеральным, то возрастут неоправданные расходы на прямой маркетинг, если слишком строгим – будет потерян ряд потенциальных клиентов.
Например, компания проводит рекламную акцию среди своих клиентов о новых услугах с помощью прямой почтовой рассылки. Служба маркетинга установила, что наиболее интересен новый вид услуги будет мужчинам средних лет, отцам семейств с годовым доходом выше среднего. Для получения списка адресатов к базе данных клиентов, скорее всего, будет сделан следующий запрос: выбрать всех лиц мужского пола в возрасте от 40 до 55 лет, имеющих минимум 1 ребенка, годовой доход от 20 до 30 тысяч долл. Такие точные критерии запроса могут отсеять множество потенциальных клиентов: мужчина 39 лет, отец троих детей с доходом в 31 тысячу не попадет в результат запроса, хотя это потенциальный потребитель новой услуги.
Аналогичным образом нечеткие запросы можно использовать при выборе туристических услуг, подборе объектов недвижимости.
Инструмент нечетких запросов позволяет согласовать формальные критерии и неформальные требования к кругу потенциальных клиентов и задавать интервалы выбора потенциальных клиентов как нечеткие множества. В таком случае клиенты, не удовлетворяющие какому-то одному критерию, могут быть выбраны из базы данных, если они имеют хорошие показатели по другим критериям.
В таком случае клиенты, не удовлетворяющие какому-то одному критерию, могут быть выбраны из базы данных, если они имеют хорошие показатели по другим критериям.
Литература
- Дюбуа Д., Прад Г. Теория возможностей. Приложения к представлению знаний в информатике – М.: Радио и связь, 1990.
- Ribeiro R.A., Moreira A.M. Fuzzy Query Interface for a Business Database // International Journal of Human-Computers Studies, Vol. 58 (2003), PP. 363-391.
- Dubois D., Prade H. Using Fuzzy Sets in Database Systems: Why and How? // Proc. of 1996 Workshop on Flexible Query-Answering systems (FQAS’96), Denmark, May 22-24, 1996, PP. 89-103.
- Смолко Д.С.,Черноруцкий И.Г. Система поддержки принятия решения для портфеля ценных бумаг // Сборник докладов I Международной конференции по мягким вычислениям и измерениям (SCM-98), Санкт-Петербург, 1998, том 2, С. 231-234.
Прямые API-запросы к базе данных Tarantool — Документация FindFace Enterprise Server SDK 2.
 5 Прямые API-запросы к базе данных Tarantool — Документация FindFace Enterprise Server SDK 2.5
5 Прямые API-запросы к базе данных Tarantool — Документация FindFace Enterprise Server SDK 2.5В этом разделе:
- Общие сведения
- Добавление лица
- Получение вектора признаков
- Удаление лица
- Поиск лица
- Получение списка лиц
Запрос
POST /:ver/:name/add/:id
Body: необработанный вектор признаков (facen).
Возвращает:
- HTTP 200 и пустое тело в случае успеха.
- HTTP 409, если лицо с таким id уже есть в галерее.
- HTTP с отличным от 200 статусом и описание ошибки в случае неудачи.
Пример
curl -s -D - 'http://localhost:8001/v1/my_gal/add/1234' --data-binary @3827305024709134.facen HTTP/1.1 200 Ok Content-length: 0 Server: Tarantool http (tarantool v1.7.3-673-g23cc4dc) Connection: keep-alive
Запрос
GET /:ver/:name/get/:id
Возвращает:
- Представление лица в формате JSON, содержащее его id и вектор признаков в формате base64 в случае успеха.

- HTTP 404, если лицо с заданным id не найдено в галерее.
- HTTP с отличным от 200 статусом и описание ошибки в случае неудачи.
Совет
Для преобразования вектора признаков из формата base64 в бинарный файл используйте команду:
echo 'facen in base64' |base64 -d> facen
Пример
curl -s -D - 'http://localhost:8001/v1/my_gal/get/1234' HTTP/1.1 200 Ok Content-length: 1754 Server: Tarantool http (tarantool v1.7.3-673-g23cc4dc) Connection: keep-alive {"facen":"BFa9PWNlS7215fI98ETQvJkxML2hUFY9cF\/Tu9ZjnLx\/uVc9EzWSPQTsR7zoysI8+4PSPIsjnr2GV1M8eFMKvfn9mjsPPjA8ZXoNvTEsSr0rJkM9MR0IPINXSj3Em0s9awm5Oos5SD380a693GroPBz6nzxQMDQ9HdOjPd7QhDxUIzC+g90sPUWUDLwjk7U9cpWkPZ83 rTyEDNm8Ti\/0ve4Trr1rnQA+Yc\/KvJzqnbzOPSG998CKPBFpAr77kFO9BonDvK9B0buvjAq9Q7A\/u6awnTw0lvy80QZcvRFQAz0Bdh598hF6vQKRcDy77c08mGRkvQ305DomnBM9XSqwvN54GT0ClFO9a+kWvhp7iT3uqqU9v1+\/vYhzm7uREt091douuyDKRr2PcIG9Uc8xPVJnvzt5T309NicxPD9SAr3f6sO8UmlhvRMI67wlTte880wYvUF8o7xg4\/g8aqNQu\/AAWD2z59C9CQCrPepF7Dy8qUa9iCczPfKv+Dy+bRo9KhyYPZfY0b1xtbY7nKXLuvYFbr0g8rM86o0QPRCKOj1a7rU9bd+3Pbqs7LslJcO9bBh+vVYeUr3S95Y9Wtg5PUZnRr0D0G08lkRkveImPDx4iQ084Qy1vKRBjj3uf4W85qx+vREFX7uccQ++5mMMvetNAL25b409P0GQvDIGLz3mHqg9ca\/Guv2beTy56wg7p\/hTPdxQgr0jxQQ9Ud0CPZcx\/LtRLiU9bECQvUnvszpMVcM8b3OovURPET3JdHs9LyQUPsc9JzvW1ZQ7y2ySPdN4Xb0xi9c8X7UevRqjVL0MLpE9PoQpvFxxjD2NCDO81jH\/PF1KFTzc3pc7qpaFPXxuPb2tjsY9iA5lPR1NoT1+Uuu7G6gpu727wTwo6ii8iaH+PI1WY72D9QG+8lhAPUegx71VsFs8ajQLvOdekrzGqAg+zhPLvbjyNDxaI1E9Wkj\/O1307D1ZMSk9IxqGvYCvFb1bE429hZF4vewikzwDbfG8wwYNPiQn4L2NV6Q9VKrvPTjwTr3dlG05jck+vZ\/KID1+n8Y8qpvnvOJjBj2P4+w8IJGgvROAfz1S4ve8QEouvQ5CkDu0OTI8\/v\/pvFrK5b3bkIO82LVBPcf2Yr0aGaU9RArUvEecJz1r8zk87U4vvC65ljz6kRS956U2PH6JMT5nfAg7KX7qPBz7Ejy60vk9\/iEPPYw8pT3Mfvk8UQYyPUCG+TyD5CO90c6nvSVLvDwRJSW9C3udvDORMz3zqtU8yd+0PXrubj3u9pQ9cGZIPVjlqTz6eIs8Z4wsPIjEIT3gnqI9kjhTPRJ8b73crA492KKIvSvpEz3ROrs9M+ZrO3RDOrwPpgG9+buePbiwi726dSs9k\/iVvZjEhT3W0B69IRojvQGUVj2J6vQ9FiDhPNRUO70bcum9fOOvPKA\/y7yB9wq9ntsBPYL6XL0wgkw7nLu6O\/\/USz1EoUg9JKE9PLDzNL0Pns49fPVyPJfZaj2g6pi8MuZePV0xQLxkR4W9pEe7vYTv7jytv567nakpPcCHZbsfjx89jPENPW0x87vr3Wi84L9mvSGeFL2hsBo9HBI2vXiEJr2uIQW7L0FsPU2w8jz2chi9FB5nvFcj9rknTha9qxCoPb0Qu72sIik9Hn4FvE\/8JL02Vh0879v\/O6weQjxpD7k85Kj2PGb0ej0V6xS8\/4EvPXmv3z0=","id":1234}
Предупреждение
Удаление лица из Tarantool не удалит его из MongoDB.
Запрос
DELETE /:ver/:name/del/:id
Возвращает:
- HTTP 200 и пустое тело в случае успеха.
- HTTP 404, если лицо с заданным id не найдено в галерее.
- HTTP с отличным от 200 статусом и описание ошибки в случае неудачи.
Пример
curl -s -D - -X DELETE 'http://localhost:8001/v1/my_gal/del/1234' HTTP/1.1 200 Ok Content-length: 0 Server: Tarantool http (tarantool v1.7.3-673-g23cc4dc) Connection: keep-alive
Запрос
POST /:ver/:name/search/:limit/:threshold?linear_search
:limit: максимальное количество лиц в ответе.
:threshold: минимальная степень схожести лиц в ответе (от 0 до 1).
linear_search (опционально): установите linear_search=1 (true), чтобы при поиске лиц использовать только пространство linear. Данная настройка имеет приоритет над настройкой only_index (/etc/tarantool/instances.). enabled/FindFace.lua
enabled/FindFace.lua
body: необработанный вектор признаков.
Возвращает:
- Массив JSON с лицами, содержащий поля
confиidв теле в случае успеха. Значение в заголовкеX-search-statпоказывает, был ли использован быстрый индекс для поиска:with_indexилиwithout_index. - HTTP с отличным от 200 статусом и описание ошибки в случае неудачи.
Пример
curl -s -D - 'http://localhost:8001/v1/my_gal/search/1/0.65?linear_search=1' --data-binary @3827305024709134.facen
HTTP/1.1 200 Ok
Content-length: 22
X-search-stat: without_index
Server: Tarantool http (tarantool v1.7.3-673-g23cc4dc)
Connection: keep-alive
[{"conf":1,"id":1234}]
Запрос
GET /:ver/:name/list/:start_id/:count
:start_id: минимальное значение id лица в ответе.
:count: максимальное количество лиц в ответе.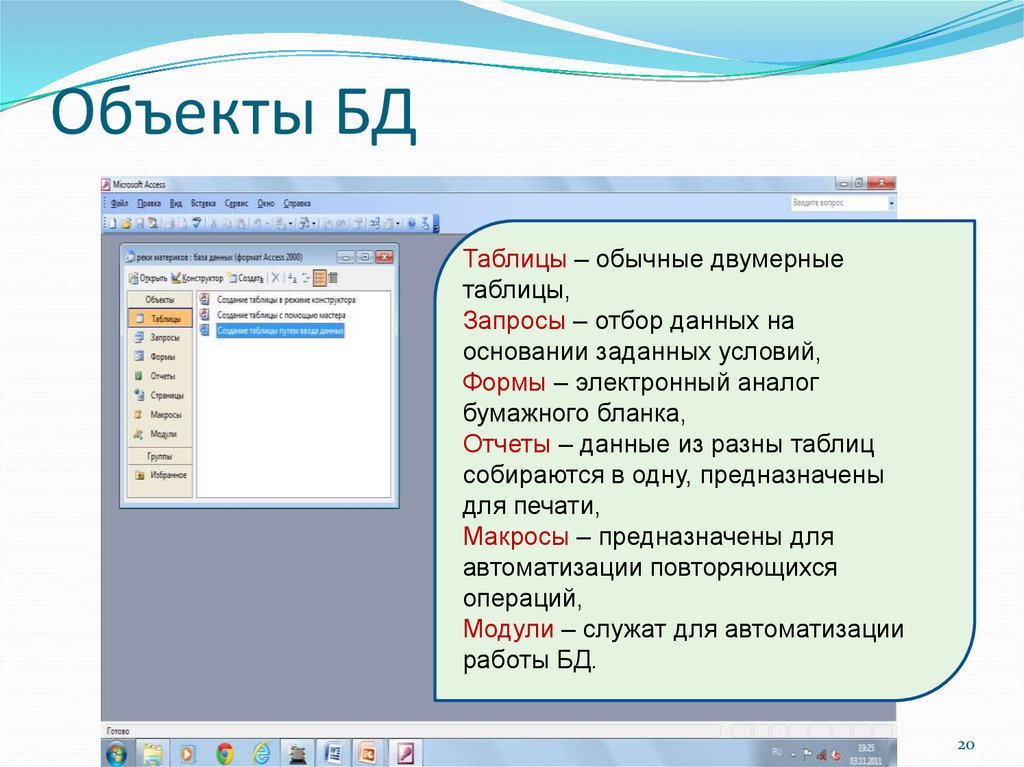
Возвращает:
- Массив JSON с лицами и URL следующей страницы результатов в случае успеха. Для каждого лица указывается его
id, вектор признаков в форматеbase64и имя пространства Tarantool, в котором хранится лицо (linear,preindex, илиindexed). URL следующей страницы должен быть передан в другом запросе как параметр:start_idдля получения следующей страницы результатов. - HTTP с отличным от 200 статусом и описание ошибки в случае неудачи.
Пример
curl -s -D - 'http://localhost:8001/v1/my_gal/list/0/1' HTTP/1.1 200 Ok Content-length: 1795 Server: Tarantool http (tarantool v1.7.3-673-g23cc4dc) Connection: keep-alive {"faces":[{"id":1234,"space":"linear","facen":"BFa9PWNlS7215fI98ETQvJkxML2hUFY9cF\/Tu9ZjnLx\/uVc9EzWSPQTsR7zoysI8+4PSPIsjnr2GV1M8eFMKvfn9mjsPPjA8ZXoNvTEsSr0rJkM9MR0IPINXSj3Em0s9awm5Oos5SD380a693GroPBz6nzxQMDQ9HdO jPd7QhDxUIzC+g90sPUWUDLwjk7U9cpWkPZ83rTyEDNm8Ti\/0ve4Trr1rnQA+Yc\/KvJzqnbzOPSG998CKPBFpAr77kFO9BonDvK9B0buvjAq9Q7A\/u6awnTw0lvy80QZcvRFQAz0Bdh598hF6vQKRcDy77c08mGRkvQ305DomnBM9XSqwvN54GT0ClFO9a+kWvhp7iT3uqqU9v1+\/vYhzm7uREt091douuyDKRr2PcIG9Uc8xPVJnvzt5T309NicxPD9SAr3f6sO8UmlhvRMI67wlTte880wYvUF8o7xg4\/g8aqNQu\/AAWD2z59C9CQCrPepF7Dy8qUa9iCczPfKv+Dy+bRo9KhyYPZfY0b1xtbY7nKXLuvYFbr0g8rM86o0QPRCKOj1a7rU9bd+3Pbqs7LslJcO9bBh+vVYeUr3S95Y9Wtg5PUZnRr0D0G08lkRkveImPDx4iQ084Qy1vKRBjj3uf4W85qx+vREFX7uccQ++5mMMvetNAL25b409P0GQvDIGLz3mHqg9ca\/Guv2beTy56wg7p\/hTPdxQgr0jxQQ9Ud0CPZcx\/LtRLiU9bECQvUnvszpMVcM8b3OovURPET3JdHs9LyQUPsc9JzvW1ZQ7y2ySPdN4Xb0xi9c8X7UevRqjVL0MLpE9PoQpvFxxjD2NCDO81jH\/PF1KFTzc3pc7qpaFPXxuPb2tjsY9iA5lPR1NoT1+Uuu7G6gpu727wTwo6ii8iaH+PI1WY72D9QG+8lhAPUegx71VsFs8ajQLvOdekrzGqAg+zhPLvbjyNDxaI1E9Wkj\/O1307D1ZMSk9IxqGvYCvFb1bE429hZF4vewikzwDbfG8wwYNPiQn4L2NV6Q9VKrvPTjwTr3dlG05jck+vZ\/KID1+n8Y8qpvnvOJjBj2P4+w8IJGgvROAfz1S4ve8QEouvQ5CkDu0OTI8\/v\/pvFrK5b3bkIO82LVBPcf2Yr0aGaU9RArUvEecJz1r8zk87U4vvC65ljz6kRS956U2PH6JMT5nfAg7KX7qPBz7Ejy60vk9\/iEPPYw8pT3Mfvk8UQYyPUCG+TyD5CO90c6nvSVLvDwRJSW9C3udvDORMz3zqtU8yd+0PXrubj3u9pQ9cGZIPVjlqTz6eIs8Z4wsPIjEIT3gnqI9kjhTPRJ8b73crA492KKIvSvpEz3ROrs9M+ZrO3RDOrwPpgG9+buePbiwi726dSs9k\/iVvZjEhT3W0B69IRojvQGUVj2J6vQ9FiDhPNRUO70bcum9fOOvPKA\/y7yB9wq9ntsBPYL6XL0wgkw7nLu6O\/\/USz1EoUg9JKE9PLDzNL0Pns49fPVyPJfZaj2g6pi8MuZePV0xQLxkR4W9pEe7vYTv7jytv567nakpPcCHZbsfjx89jPENPW0x87vr3Wi84L9mvSGeFL2hsBo9HBI2vXiEJr2uIQW7L0FsPU2w8jz2chi9FB5nvFcj9rknTha9qxCoPb0Qu72sIik9Hn4FvE\/8JL02Vh0879v\/O6weQjxpD7k85Kj2PGb0ej0V6xS8\/4EvPXmv3z0="}],"next":5678}
Read the Docs
v: 2. 5
5
- Versions
- latest
- stable
- 2.6
- 2.5
- release-2.5
- Downloads
- On Read the Docs
- Project Home
- Builds
Free document hosting provided by Read the Docs.
Урок по теме «Создание запросов на выборку в базе данных»
Учебник: Л.Л. Босова, А.Я. Босова «Информатика 9».
Тип урока: урок открытия и обретения новых знаний, умений и навыков.
Цель урока: познакомить учащихся с основными понятиями «запрос», «простое логическое выражение», «сложное логическое выражение» и показать практическое применение запросов, научить создавать запросы в базе данных, осуществлять сортировку данных в таблице.
Задачи урока:
- Образовательные: познакомить учащихся с основными понятиями, научить создавать простые и сложные запросы на выборку в базе данных, сортировку данных.
- Развивающие: продолжить развитие внимания и мышления; формирования общеучебных и общекультурных навыков работы с информацией, самоконтроля и интереса к предмету.
- Воспитательные: продолжить воспитывать информационную культуру, навыки учебного труда и ответственного отношения к предмету.
Оборудование, ресурсное обеспечение урока
Используемые на уроке средства ИКТ:
- персональный компьютер учителя, мультимедийный проектор, экран;
- персональные компьютеры учащихся с установленной программой Open Office.org Base.
Электронные образовательные ресурсы
презентация
Дополнительные ресурсы:
- раздаточный материал с практической работой «Города миллионеры РФ» и рефлексией урока
- Приложение 1
- Приложение 2
1. Организационный этап
Организационный этап
Учитель приветствует учащихся, проводит проверку готовности к уроку, способствует формированию положительного эмоционального фона. Учащиеся приветствуют учителя, занимают свои рабочие места.
2. Актуализация опорных знаний
(слайд 2) Учитель задает вопросы по изученному на предыдущих уроках материалу. Проверяет знание основных понятий базы данных, элементов базы данных, функций базы данных, понятий запись и поле в базе данных, типов полей. Учащиеся отвечают на вопросы учителя
(в презентации, по щелчку мыши на поставленный вопрос, появляется верный ответ).
| вопрос | ответ |
Что такое СУБД? | Система управления базами данных (СУБД) — программное обеспечение для создания баз данных, хранения и поиска в них необходимой информации. |
Приведите пример известных Вам СУБД | Open Office Base, Microsoft Access и другие |
С какой системой управления данных вы работаете на уроках? | Open Office Base |
С чего начинается работа с базой данных? (основные этапы работы с БД) |
|
Какие основные объекты СУБД Вам известны? |
|
Какие основные функции они выполняют? |
|
Что такое таблица? | Таблица — главный тип объектов. |
Что такое форма? | Форма — это вспомогательный объект. Объект для удобной работы с данными в таблицах |
Что такое запрос? | Запрос — это команды обращения пользователя к СУБД |
Что такое отчет? | Отчёт — документ, созданный на основе таблиц |
Что такое РБД? | Реляционной база данных (РБД) — это реляционная модель данных, основанная на представлении данных в виде таблиц. |
Что такое запись? | Запись содержит всю информацию об одном объекте, описываемом в базе данных. |
Что такое поле? | Поле — это одна из характеристик объекта. |
Основные характеристики поля? | Поле базы данных имеет имя, тип и длину. |
Перечислите основные типы полей. Приведите пример на каждый вид поля |
|
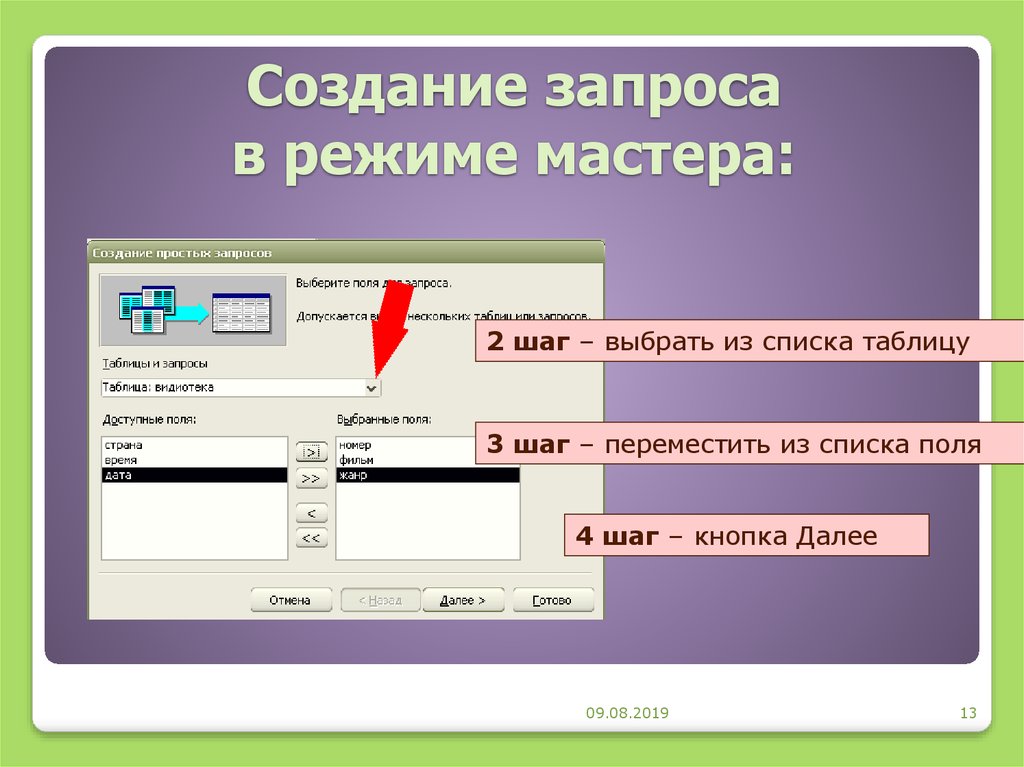 В таблице хранятся данные.
В таблице хранятся данные.
3. Этап получения новых знаний
(слайд 3) Учитель предлагает пример базы данных «10 самых больших стран мира по населению» и предлагает учащимся найти варианты ее использования, тем самым определяется тема и цель урока.
10 самых больших стран мира по населению
(данные на 01.07. 2017)
№ | Страна | Население | % мирового населения |
1 | Китай | 1 384 160 000 | 18,4% |
2 | Индия | 1 318 270 000 | 17,5% |
3 | США | 325 375 000 | 4,33% |
4 | Индонезия | 261 600 000 | 3,48% |
5 | Бразилия | 207 709 000 | 2,76% |
6 | Пакистан | 197 750 000 | 2,63% |
7 | Нигерия | 188 500 000 | 2,51% |
8 | Бангладеш | 162 752 000 | 2,17% |
9 | Россия | 146 400 000 | 1,95% |
10 | Мексика | 129 100 000 | 1,69% |
Как можно использовать данную базу данных?
Возможный вариант ответа: Базу данных можно использовать как справочную систему, сортировать данные в нужном порядке, выбирать нужные данные по одному или нескольким признакам, добавлять, удалять или редактировать данные.
(слайд 4-12) Учитель вводит формулирует и поясняет новые понятия:
- манипулирование данных,
- запрос и справка,
- логическое выражение, простые и сложные логические выражения.
Основные определения:
Манипулирование данных – это действия, выполняемые над информацией, хранящейся в базе данных.
К манипулированию данных относится:
- выборка данных по определенным критериям,
- сортировка данных,
- обновление данных,
- удаление данных,
- добавление данных.
Запрос – это средство извлечения информации из базы данных, отвечающей некоторым условиям.
Справка – это таблица, содержащая интересующие пользователя сведения, извлечённые из базы данных.
Логическое выражение – это высказывание, которые принимает значение Истина или Ложь.
Простые логические выражения – это выражения, которые содержат только операции отношения или поле логического типа.
Сложные логические выражения – это выражения, содержащие логические операции.
Учитель приводит примеры запросов, правила сравнения числовых, текстовых полей и полей типа «дата».
Учащиеся делают записи в тетрадях, приводят свои примеры запросов, решают задачи, представленные на слайдах по сравнению числовых, текстовых полей и полей типа «дата».
Сравнение числовых величин
Производится по математическим правилам
Пример. Какие знаки отношений нужно вставить, чтобы полученные высказывания были истинными?
| 5 | * | 7 |
7 500 000 | * | 7 500 |
132 567 789 | * | 133 567 789 |
Сравнение текстовых величин
Сравнение построено по лексикографическому принципу.
Меньшим считается то слово у которого первая отличающаяся буква от другого слова идет раньше.
Пробел меньше любой буквы.
Пример. Какие знаки отношений нужно вставить, чтобы полученные высказывания были истинными?
| символы | * | данные |
ученик | * | ученица |
11а | * | 5б |
1а | * | 1 а |
Сравнение полей типа «дата»
Сравниваются в соответствии с календарной последовательностью.
Дата, относящаяся к более раннему времени, считается меньше более поздней.
Пример. Какие знаки отношений нужно вставить, чтобы полученные высказывания были истинными?
Какие знаки отношений нужно вставить, чтобы полученные высказывания были истинными?
| 3.07.2001 | * | 3.07.2002 |
12.09.1998 | * | 1.01.1999 |
1.02.2017 | * | 3.02.2017 |
4. Этап первичного закрепления материала
(слайд 13-23) Учитель предлагает учащимся решить задачи по составлению простых и сложных запросов на примере база данных «Подписка», нахождение значений «истина» или «ложь» для данных таблицы. При решении задач определяет правильность и осознанность изученного материала, корректирует выявленные пробелы, при изучении темы, закрепляет действия необходимые для самостоятельной работы по изученному материалу.
Задание: Дана база данных «Подписка».
№ | Фамилия | Имя | Отчество | Адрес | Тип | Название | Дата подписки | Срок | Получение на почте |
1 | Сидорова | Ирина | Сергеевна | пр. Ленина 3-42 | газета | КомПик | 01. | 3 | □ |
2 | Гуляева | Нелли | Ивановна | ул. Строителей 4-5 | журнал | Мир ПК | 01.04.17 | 6 | |
3 | Орлов | Никита | Андреевич | ул. Строителей 8-5 | журнал | Хакер | 01.01.17 | 3 | □ |
4 | Ермолаев | Антон | Вадимович | пр. | газета | КомПик | 01.01.17 | 12 | |
5 | Агафонов | Антон | Иванович | ул. Ленина 3-24 | журнал | Мир ПК | 01.07.17 | 12 | □ |
6 | Фомин | Сергей | Андреевич | ул. Строителей 8-1 | журнал | Железо | 01.04.17 | 6 |
 07.17
07.17 Парковый 4-16
Парковый 4-16Нужно сформулировать запрос к базе данным по заданному высказыванию и указать какое значение (истина/ложь) для номера записи в БД.
Высказывания, сформулированные на естественном языке к БД:
простые запросы:
- срок подписки не превышает полгода
- все, подписавшиеся на журнал
- все подписчики с именем Антон
- все, кто не подписался на Мир ПК
- все, кто получает издания на почте
- все, кто подписался со второго полугодия 2017 года
сложные запросы:
- срок подписки не превышает полгода и издания получают на почте
- все, подписавшиеся на журнал с апреля 2017 года
- все подписчики с именем Антон и датой подписки 01.01.2017
- все, кто подписался на Мир ПК или Железо
5. Динамическая пауза
(слайд 24-26) Проводится динамическая пауза с учащихся, которая состоит из трех групп упражнений гимнастики для глаз, снятия напряжения и утомления по методике Э.С.Аветисова.
6. Этап закрепления изученного материала с последующей самопроверкой
(слайд 27-28) Учитель проводит с учащимся практическую работу по работе с готовой базой данных «Города миллионеры РФ» по составлению запросов и сортировке данных.
Практическая работа
Дана база данных Города миллионеры РФ. Она содержит сведения о городах российской Федерации с населением более 1 млн жителей по данным на 1 января 2017 года. Состоит из следующих полей: № города по порядку, название города, данные на 1 января 2017 и 1 января 2016 года, динамика роста населения в числовой и процентном отношении, название субъекта РФ, в состав которого входит город.
| № | Город | Население на 1.01.17 | Население на 1.01.16 | Динамика | Процент | Субъект РФ, в состав которого входит город |
1 | Москва | 12 380 664 | 12 330 126 | 50 538 | 0,41 | г. |
2 | Санкт-Петербург | 5 281 579 | 5 225 690 | 55 889 | 1,07 | г. Санкт-Петербург |
3 | Новосибирск | 1 602 915 | 1 584 138 | 18 777 | 1,19 | Новосибирская область |
4 | Екатеринбург | 1 455 514 | 1 444 439 | 11 075 | 0,77 | Свердловская область |
5 | Нижний Новгород | 1 261 666 | 1 266 871 | -5 205 | -0,41 | Нижегородская область |
6 | Казань | 1 231 878 | 1 216 965 | 14 913 | 1,23 | Республика Татарстан |
7 | Челябинск | 1 198 858 | 1 191 994 | 6 864 | 0,58 | Челябинская область |
8 | Омск | 1 178 391 | 1 178 079 | 312 | 0,03 | Омская область |
9 | Самара | 1 169 719 | 1 170 910 | -1 191 | -0,10 | Самарская область |
10 | Ростов-на-Дону | 1 125 299 | 1 119 875 | 5 424 | 0,48 | Ростовская область |
11 | Уфа | 1 115 560 | 1 110 976 | 4 584 | 0,41 | Респ. |
12 | Красноярск | 1 082 933 | 1 066 934 | 15 999 | 1,50 | Красноярский край |
13 | Пермь | 1 048 005 | 1 041 876 | 6 129 | 0,59 | Пермский край |
14 | Воронеж | 1 039 801 | 1 032 382 | 7 419 | 0,72 | Воронежская область |
15 | Волгоград | 1 015 586 | 1 016 137 | -551 | -0,05 | Волгоградская область |
 Москва
Москва Башкортостан
БашкортостанНеобходимо, пользуясь инструкцией к заданию, выполнить задания по поиску и сортировке данных в данной таблице. На практическую работу отводится 15 минут. После выполнения работы, проводится проверка результатов работы, и ученики ставят себе оценку за урок.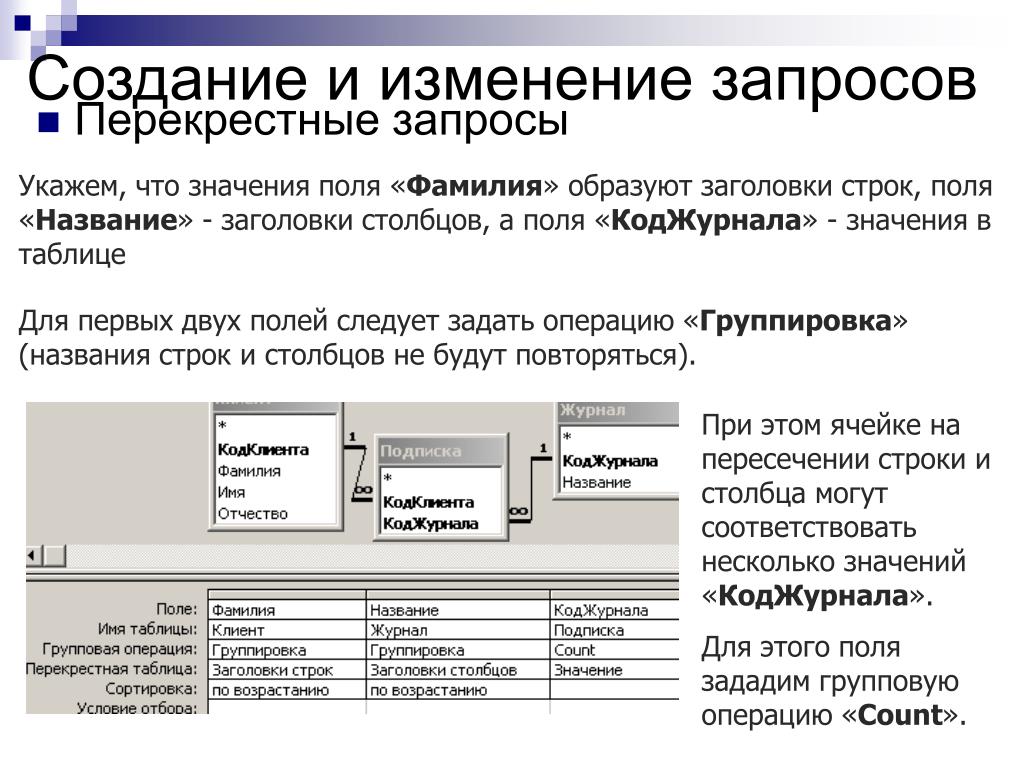
Учитель контролирует ход выполнения работы учащихся, помогает учащимся, у которых не получается самостоятельно выполнить задание.
(слайд 29-31)
Учащиеся под руководством учителя проверяют результаты выполнения практической работы, анализируют полученные ответы, определяются с оценкой результатов работы.
Оценивание практической работы
| Количество верных ответов | Оценка |
10 | 5 |
7-9 | 4 |
3-6 | 3 |
7. Подведение итогов урока, рефлексия урока, постановка домашнего задания
Учитель задает домашнее задание, при необходимости комментирует его.
Домашнее задание
- Выучить лекционный материал
- Учебник Л. Л. Босова, А. Я. Босова «Информатика 9» параграф 1.6.4
- Рабочая тетрадь Л. Л. Босова, А. Я. Босова «Информатика 9» № 61
Учитель с учениками подводит итог урока, выставляет оценки и благодарит за урок, предлагает учащимся заполнить лист рефлексии урока.
Ответьте выборочно на 2-3 из предложенных вопросов:
- сегодня я узнал
- у меня получилось
- у меня возникли трудности
- я выполнял задания
- я научился
- теперь я могу
Используемые ресурсы:
- Л. Л. Босова, А. Я. Босова «Информатика 9».
- И.Г. Семакин, Л.А. Залогова, С.В. Русаков, Л.В. Шестакова «Информатика и ИКТ 9».
- «Информатика и ИКТ», задачник-практикум том 2 под редакцией И. Семакина, Е. Хеннера.
- Сайт о странах, городах, статистике населения и др.
 URL: http://www.statdata.ru/goroda-millionniki-rossii-po-naseleniu.
URL: http://www.statdata.ru/goroda-millionniki-rossii-po-naseleniu.
Задачка и теория по SQL (изучаем базы данных) · GitHub
Этот урок переехал по адресу https://github.com/codedokode/pasta/blob/master/db/databases.md . Копия ниже устарела и не будет больше обновляться.
База данных — это хранилище, в которое можно сохранять данные, а позже делать по ним поиск и загружать их. Ну например, на форуме в базе данных может храниться информация о пользователях сайта и написанных ими сообщениях. При просмотре страницы скрипт на сервере ищет в БД сообщения на определенную тему и выводит их на странице. Почти любой интерактивный сайт использует БД.
Конечно, можно попробовать сделать свое хранилище (к примеру, на файлах), но вряд ли оно будет работать так же быстро и надежно, как профессиональная база данных. Хорошая база данных гарантирует отсутствие потерь сохраненных данных, даже если неожиданно отключится питание, отсутствие проблем при одновременной работе нескольких пользователей, позволяет искать информацию по произвольным критериям.
Есть разные виды баз данных, но этот урок посвящен базам данных, поддерживающим язык SQL. В них любые операции над данными — добавление, удаление, поиск — делаются с помощью отправки SQL-запросов. Сам язык достаточно простой и запросы на нем напоминают обычные предложения на английском языке. Ну к примеру, запрос на удаление из БД пользователя с email [email protected] выглядит так: DELETE FROM users WHERE email = '[email protected]'. Если знать английский («удалить из пользователей где email равен ‘[email protected]'»), то смысл запроса легко понять, даже не зная SQL. Запросы может отправлять как сам разработчик вручную, так и написанная им программа.
SQL это что-то вроде стандарта в мире баз данных. Зная этот язык, можно работать с разными БД от разных производителей.
Есть разные программы, которые позволяют создавать и управлять базой данных. Они называются СУБД (системы управления БД). Из бесплатных самые известные — это MySQL и PostgreSQL. MySQL (в 2016 году) более распространена, а в PostgreSQL больше интересных нестандартных возможностей (а также, считается что она более полно поддерживает стандарт).
MySQL (в 2016 году) более распространена, а в PostgreSQL больше интересных нестандартных возможностей (а также, считается что она более полно поддерживает стандарт).
Есть и коммерческие СУБД — например, MSSQL, Oracle DB.
Наконец, есть еще встраиваемые СУБД, которые используются не отдельно, а встраиваются в другую программу и используются только ей. Ну например, (в 2016 году) встроенную бесплатную СУБД SQLite использовали браузер Chrome, который хранил с ее помощью историю и закладки, Skype для хранения сообщений и множество мобильных приложений под Android и iOS.
Со всеми этими БД можно работать, зная язык SQL.
База данных хранит данные в таблицах. Таблицы создает разработчик, и обычно каждая из них предназначается для своей сущности — например, таблица со списком пользователей, таблица тем на форуме, таблица сообщений на форуме. Таблица состоит из колонок, каждая из которых имеет определенных тип (число, строка).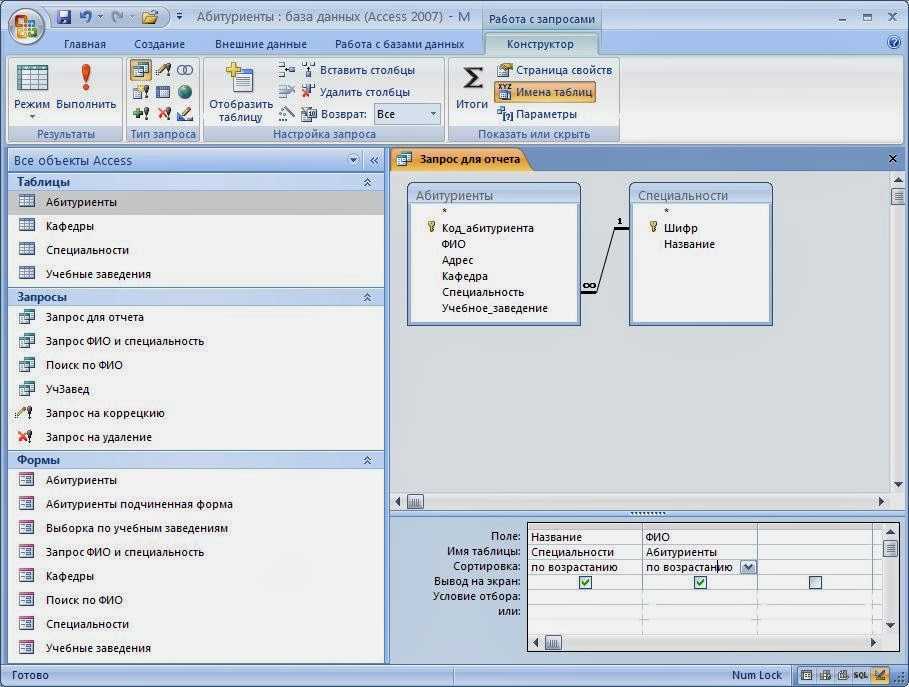 Ну к примеру, таблица для хранения информации о пользователях форума может выглядеть так:
Ну к примеру, таблица для хранения информации о пользователях форума может выглядеть так:
| id | name | password_hash | salt | registered | |
|---|---|---|---|---|---|
| 1 | Администратор | [email protected] | abbs09s7s6s6 | gt9xbxvx4x30 | 2014-08-02 |
| 2 | Иван | [email protected] | hd6bc00c8c7c665ce | gs65s4s4sb0x | 2015-01-01 |
При регистрации скрипт добавляет в нее информацию о новом пользователе, а при логине — проверяет введенные email и пароль. Мы, конечно, в целях безопасности не храним в базе сами пароли в открытом виде, а получаем из них хеш с солью и сохраняем их в колонках password_hash и salt (по которым можно проверить правильность введенного при логине пароля, но нельзя восстановить его). Также, мы присваиваем каждому пользователю уникальный числовой идентификатор (id), который еще называют первичный ключ — это позволяет потом в других таблицах ссылаться на него (например, в таблице сообщений мы можем хранить id автора сообщения, по которому можно достать информацию о нем).
А вот, как может выглядеть таблица сообщений, которые оставили пользователи на форуме. Для простоты представим, что у нас нет отдельных тем, а есть один большой общий поток сообщений:
| id | author_id | posted | text |
|---|---|---|---|
| 1 | 1 | 2014-08-03 | Добро пожаловать на наш форум! Жду ваших сообщений. |
| 2 | 1 | 2014-08-04 | Что-то никого нету… |
| 3 | 1 | 2014-08-05 | Ни души… |
| 4 | 2 | 2015-01-01 | Всем привет. Я новый тут. |
Здесь колонка id хранит идентификатор сообщения, author_id — идентификатор автора сообщения (по которому можно найти его имя, email в первой таблице), posted — дату отправки и text — тело сообщения. Первые 3 сообщения оставил Администратор, а четвертое — Иван.
Все операции с таблицами, включая их создание и заполнение делаются с помощью запросов на языке SQL. Подробнее о том, как это делать, написано ниже по ссылкам.
Подробнее о том, как это делать, написано ниже по ссылкам.
Как правило сам сервер базы данных (программа, которая обеспечивает ее работу) не имеет своего интерфейса и каких-то окошек, кнопочек, чтобы с ним взаимодействовать. Управление базой данных делается с помощью запуска программы-клиента, который подсоединяется к серверу, пересылает ему SQL запросы и выводит полученные ответы. Одновременно к БД может подсоединиться несколько клиентов.
Как правило, у каждой базы данных есть клиент для командной строки. Это программа с минималистичным интерфейсом, в которой можно писать SQL запросы и видеть полученные ответы. Это то, что стоит использовать начинающему.
Те, кто освоил основы, могут использовать и более сложные программы-клиенты с графическим интерфейсом. Они могут отображать информацию из базы данных в виде таблиц, перемещаться по ним, менять значения в них. При этом можно запускать и вручную написанные SQL запросы. Я не буду тут писать названия конкретных программ, но их легко найти по словам вроде «mysql gui», «mysql admin», «postgresql gui» и так далее. Я бы советовал сначала научиться работать исключительно в клиенте командной строки, а только потом переходить к этим программам.
Я бы советовал сначала научиться работать исключительно в клиенте командной строки, а только потом переходить к этим программам.
Наконец, подсоединяться и отправлять запросы к БД можно из программы. Например, скрипт на языке PHP может таким образом выбирать данные из базы и отображать на веб-странице. Для этого нужна библиотека или расширение-клиент для базы данных. В PHP есть даже 2 расширения для этого (PDO и MySQLi), я рекомендую использовать расширение PDO, так как оно поддерживает исключения, за счет чего при какой-то ошибке проще получить информацию о ней.
Теория и туториалы для начинающих:
- основы и туториал по MySQL (немного старый, но еще актуальный): http://phpclub.ru/mysql/doc/tutorial.html
- руководство на русском по PostgreSQL: https://postgrespro.ru/docs/postgresql
- большой учебник по SQL: http://www.pyramidin.narod.ru/rusql/index.htm
Если ты хранишь данные в нескольких таблицах, то необходимо уметь создавать связи между ними. Вот уроки по этой теме:
Вот уроки по этой теме:
- отношения между таблицами в БД: http://jtest.ru/bazyi-dannyix/sql-dlya-nachinayushhix-chast-3.html
- внешние ключи: http://denis.in.ua/foreign-keys-in-mysql.htm
После этого надо научиться правильно проектировать таблицы и связи между ними. Для этого надо изучить нормализацию БД. По этой теме есть разные статьи — некоторые написаны простым языком, а некоторые нет. Это важная тема, если не соблюдать принципы нормализации, то потом с такой базой будет неудобно работать.
Приведу пример. Теория требует избегать дублирования данных. Допустим, разработчик не изучал нормализацию и сделал так, что в форуме в таблице сообщений у каждого сообщения хранится имя написавшего его пользователя. Таким образом, если пользователь оставил много сообщений, то его имя будет сохранено много раз. Если теперь пользователь захочет поменять имя, то нам придется поменять его в таблице пользователей, а также найти все его сообщения и поменять имя там.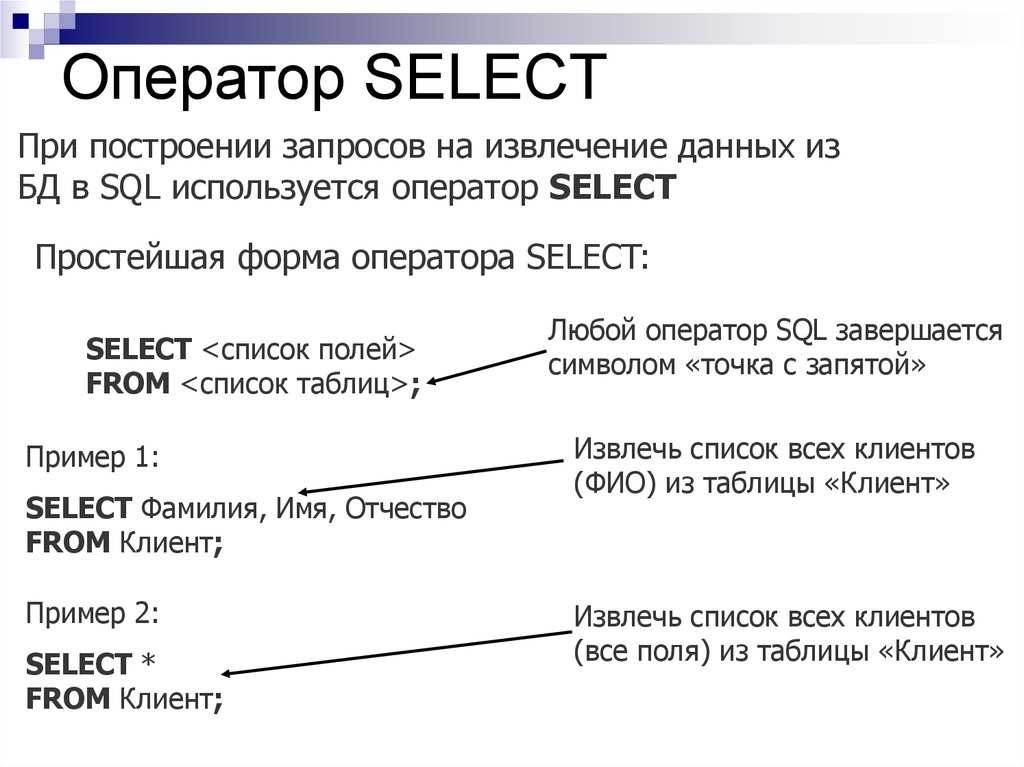 В лучшем случае это потребует дополнительного труда (найти все таблицы, где это имя упоминается), в худшем случае мы можем сделать ошибку, и поменяв имя в одном месте, забыть поменять его в другом. На базе из нескольких таблиц это маловероятно, но в больших системах таблиц могут быть детсяки и даже сотни. Получается, что несоблюдение принципов проектирования базы данных приводит к тому, что на написание кода будет уходить больше времени разработчиков.
В лучшем случае это потребует дополнительного труда (найти все таблицы, где это имя упоминается), в худшем случае мы можем сделать ошибку, и поменяв имя в одном месте, забыть поменять его в другом. На базе из нескольких таблиц это маловероятно, но в больших системах таблиц могут быть детсяки и даже сотни. Получается, что несоблюдение принципов проектирования базы данных приводит к тому, что на написание кода будет уходить больше времени разработчиков.
- https://habrahabr.ru/post/129195/
- https://habrahabr.ru/post/254773/
- http://club.shelek.ru/viewart.php?id=177
- http://alexvolkov.ru/database-normalizatio.html
Поскольку нормализация — это очень важная тема, я наверно напишу еще ниже про нее своими словами, на случай, если кто-то не прочел статьи, но не все понял.
А пока еще несколько полезных ссылок:
- сборник запросов на все случаи жизни (англ): http://www.artfulsoftware.com/infotree/queries.
 php
php - таблицы отличий в диалектах SQL в разных СУБД (англ): http://en.wikibooks.org/wiki/SQL_dialects_reference
- манга-учебник про SQL в картинках: http://www.nostarch.com/mg_databases.htm
Под Windows в командной строке не работают русские буквы
Надо выполнить команду SET NAMES cp866; после соединения: http://gahcep.github.io/blog/2013/01/05/mysql-utf8/
Еще ссылки на тему кодировок при соединении с mysql из php:
- http://fstrange.ru/coder/mysql/kodirovka-krakozyably.html
- http://phpfaq.ru/charset
На что стоит обратить внимание?
Вот список понятий, которые стоит знать если ты хочешь очень хорошо разбираться в MySQL:
- управление базами данных: CREATE DATABASE, DROP DATABASE, SHOW DATABASES
- управление таблицами: CREATE TABLE, ALTER TABLE, DROP TABLE, SHOW TABLES, SHOW CREATE TABLE, DESC table, TRUNCATE table
- управление правами доступа: GRANT, SHOW GRANTS
- типы колонок: ENUM, SET, CHAR, VARCHAR, TEXT, DATE, TIME, DATETIME, TIMESTAMP, INT, FLOAT, TINYINT, DECIMAL, MEDIUMTEXT, LONGTEXT.
 В чем разница между TIMESTAMP и DATETIME? Между FLOAT и DECIMAL? CHAR и VARCHAR?
В чем разница между TIMESTAMP и DATETIME? Между FLOAT и DECIMAL? CHAR и VARCHAR? - DECIMAL — тип с фиксированной точностью. В отличие от FLOAT/DOUBLE, которые приближенные и могут терять знаки после запятой, DECIMAL хранит заданное число знаков. Используется например, для хранения суммы денег.
- NULL и троичная логика (в БД NULL значит «неизвестно». Например, возраст пользователя неизвестен. Соответственно, все операции с NULL это учитывают: NULL + 5 тоже дает в итоге NULL (5 + неизвестное число дает неизвестное число), сравнение (NULL = NULL) возвращает ложь, чтобы проверить равно ли поле NULL надо использовать IS NULL/IS NOT NULL. http://ru.wikipedia.org/wiki/NULL_(SQL))
- можно ли искать пустые поля условием WHERE x = NULL?
- при создании таблицы можно сделать поля обязательными для заполнения, указав NOT NULL
- SELECT/INSERT/DELETE/UPDATE
- порядок выполнения запроса выборки: FROM+JOIN, WHERE, GROUP, HAVING, ORDER, LIMIT, SELECT (его надо знать наизусть)
- REPLACE, INSERT IGNORE, INSERT .
 . ON DUPLICATE KEY UPDATE
. ON DUPLICATE KEY UPDATE - выборка данных: DISTINCT, JOIN, ORDER BY, GROUP BY, HAVING, LIMIT
- группировка и аггрегатные функции: GROUP BY, COUNT, MAX, MIN, AVG, SUM
- транзакции: BEGIN, ROLLBACK, COMMIT
- внешние ключи: FOREIGN KEY. Внешний ключ — это поле, которое хранит id записи в другой таблице
- первичный ключ: естественный и искуственный
- обычные и уникальные индексы (ключи)
- оптимизация запросов, команда EXPLAIN
- отличие InnoDB от MyISAM
Теория по проектированию БД
Чтобы уметь проектировать базы данных и новые таблицы, нужно знать следующее:
- виды отношений между таблицами: один-к-одному, один-ко-многим, многие-ко-многим
- принципы нормализации БД. В интернете можно найти статьи где «нормальные формы» объясняют простыми словами, например http://club.shelek.ru/viewart.php?id=311 или https://habrahabr.ru/post/193756/
- способы хранения древовидных (иерархических) данных в БД.
 Ну например, это нужно для реализации дерева комментариев к статье или дерева категорий товаров в интернет-магазине. Есть такие паттерны: Adjacency List, Closure Path, Nested Sets, Materialized Path. Вот мой урок про них: https://github.com/codedokode/pasta/blob/master/db/trees.md
Ну например, это нужно для реализации дерева комментариев к статье или дерева категорий товаров в интернет-магазине. Есть такие паттерны: Adjacency List, Closure Path, Nested Sets, Materialized Path. Вот мой урок про них: https://github.com/codedokode/pasta/blob/master/db/trees.md - способы реализации наследования таблиц (когда есть похожие, но не одинаковые сущности с общим набором свойств: например Пользователи и Администраторы, или несколько видов приложений к сообщению: Видеозапись, Аудиозапись, Файл, Ссылка на сайт). Для таких случаев есть паттерны Single Table Inheritance, Concrete table Inheritance, Class Table Inheritance
- паттерн EAV (Entity-Attribute-Value), описание на англ., на русском. Этот паттерн можно исплоьзовать в тех случаях, когда есть сущности с разным набором свойств, и свойства могут добавляться (например объявление: объявления о сдаче квартиры и продаже машины имеют разный набор свойств). Также, в интернете можно найти много обсуждений по поводу того, зло это или нет.
 Есть также альтернативные подходы, например в PostgreSQL можно использовать индексируемые hstore (англ.) или json (англ.) колонки
Есть также альтернативные подходы, например в PostgreSQL можно использовать индексируемые hstore (англ.) или json (англ.) колонки
Вот цикл статей на Хабре, который подойдет в качестве вступления: 1-3, 4-6, 7-9, 10-13, 14-15, бонус
Чем отличаются движки для таблиц MyISAM и InnoDB?
- http://rtfm.co.ua/mysql-otlichiya-mezhdu-myisam-i-innodb/
- http://itif.ru/otlichiya-myisam-innodb/
Если кратко: MyISAM более простой и не поддеживает внешние ключи и транзакции. А они нужны почти всегда. Потому в 99% случаев тебе нужен InnoDB.
Индексы
Индексы позволяют ускорить поиск по условиям вроде x = ?, x < ?, x BETWEEN ? AND ?, x LIKE 'xxx%', x IN (?, ?, ?), а также сортировку (поля по которым идет сортировка должны идти в конце индекса). Разница на большой таблице может быть огромная — порядка 1 тысячной секунды против нескольких секунд. Ну например, если у нас есть таблица размером в миллион записей и мы делаем запрос
Ну например, если у нас есть таблица размером в миллион записей и мы делаем запрос
SELECT a, b FROM table ORDER BY y LIMIT 10
то без индекса MySQL вынуждена будет прочитать с диска в память миллион значений, отсортировать их только ради того, чтобы взять первые 10. Если же есть индекс по полю y (который хранит отсортированные по возрастанию значения этого поля) то MySQL просто возьмет из него первые 10 записей. Разница в скорости работы будет огромная.
Вот статьи для начинающих про индексы:
- http://ruhighload.com/post/%D0%A0%D0%B0%D0%B1%D0%BE%D1%82%D0%B0+%D1%81+%D0%B8%D0%BD%D0%B4%D0%B5%D0%BA%D1%81%D0%B0%D0%BC%D0%B8+%D0%B2+MySQL
- http://www.mysql.ru/docs/man/MySQL_indexes.html
- http://habrahabr.ru/post/211022/
Если ты все прочел внимательно, ответь на вопрос, может ли индекс (если да, то какой) ускорить такие запросы:
SELECT * FROM table WHERE x <> 1SELECT * FROM table WHERE x + y < 100SELECT MAX(a) FROM table WHERE b = 2SELECT * FROM table WHERE name LIKE '%Иван%'SELECT * FROM table WHERE b = 1 AND a < 10
Задачка про лайки
С полученными знаниями ты легко сможешь решить эту задачу: есть пользователи (id, имя) и они могут ставить друг другу лайки. Сделай таблицы для хранения всей этой информации и напиши запрос, который выведет такую таблицу:
Сделай таблицы для хранения всей этой информации и напиши запрос, который выведет такую таблицу:
- ид пользователя
- имя
- лайков получено
- лайков поставлено
- взаимных лайков
Далее, выведи список всех пользователей, которые лайкнули пользователей A и B, но при этом не лайкнули пользователя C. Тут есть несколько вариантов решения.
Сложно? Ну ок, давай начнем с более простой задачи: просто выведи 5 самых популярных пользователей.
- Если ты используешь несколько связанных друг с другом таблиц, связи необходимо пометить с помощью внешних ключей
- Желательно на уровне БД запретить возможность ставить пользователю лайк другому пользователю дважды
- Подсказка: эта задача решается без подзапросов
- Подсказка: достаточно использовать всего 2 джойна и группировку
Усложненная (но более жизненная) задача про лайки
В воображаемой социальной сети есть Пользователи (id, имя), Фото (id, название, автор) и Комментарии К Фото (id, текст, автор, к какому Фото относится). Необходимо добавить возможность для Пользователей ставить лайки другим Пользователям, Фото или Комментариям К Фото. Нужно реализовать такие возможности:
Необходимо добавить возможность для Пользователей ставить лайки другим Пользователям, Фото или Комментариям К Фото. Нужно реализовать такие возможности:
- пользователь не может поставить 2 лайка одной и той же сущности (например одному и тому же Фото)
- пользователь может отозвать лайк
- необходимо иметь возможность посчитать число полученных сущностью лайков и вывести список Пользователей, поставивших лайки
- в будущем могут появиться новые виды сущностей которые можно лайкать
Для начала, нужно решить задачу без оглядки на производительность. Очень желательно следовать принципам нормализации и помечать связи внешними ключами (а также на уровне Бд предотвратить возможность повторной отправки лайка). Далее, можно дополнить решение комментариями по поводу оптимизаций производительности.
Тут есть несколько вариантов решения.
Задачка про кинотеатр
Вот дополнительная, более сложная задачка. Есть кинотеатр, в нем идут фильмы. У фильма есть название, длительность (пусть для простоты будет 60, 90 или 120 минут), цена билета (в разное время и дни может быть разная), время начала сеанса (один фильм может быть показан несколько раз в разное время за разную цену). Также, есть информация о купленных билетах (номер билета, на какой сеанс).
Есть кинотеатр, в нем идут фильмы. У фильма есть название, длительность (пусть для простоты будет 60, 90 или 120 минут), цена билета (в разное время и дни может быть разная), время начала сеанса (один фильм может быть показан несколько раз в разное время за разную цену). Также, есть информация о купленных билетах (номер билета, на какой сеанс).
Задания:
- составь грамотную нормализованную схему хранения этих данных в БД. Внеси в нее 4-5 фильмов, расписание на один день и несколько проданных билетов.
Сделай запросы, считающие и выводящие в понятном виде:
- ошибки в расписании (фильмы накладываются друг на друга), отсортированные по возрастанию времени. Выводить надо колонки «фильм 1», «время начала», «длительность», «фильм 2», «время начала», «длительность».
- перерывы больше или равные 30 минут между фильмами, выводятся по уменьшению длительности перерыва. Выводить надо колонки «фильм 1», «время начала», «длительность», «время начала второго фильма», «длительность перерыва».

- список фильмов, для каждого указано общее число посетителей за все время, среднее число зрителей за сеанс и общая сумма сбора по каждому, отсортированные по убыванию прибыли. Внизу таблицы должна быть строчка «итого», содержащая данные по всем фильмам сразу.
- число посетителей и кассовые сборы, сгруппированные по времени начала фильма: с 9 до 15, с 15 до 18, с 18 до 21, с 21 до 00:00. (то есть сколько посетителей пришло с 9 до 15 часов, сколько с 15 до 18 и т.д.).
Сложная задача про календарь
Решил предыдущие задачи и они слишком простые? Ок, давай возьмемся за действительно сложную задачу. Напиши SQL-код, выводящий календарь на текущий месяц в виде:
| Пн | Вт | Ср | Чт | Пт | Сб | Вс |
|---|
| | | | | 1 | 2
3 | 4 | 5 | 6 | 7 | 8 | 9 10 | 11 | 12 | 13 | 14 | 15 | 16 17 | 18 | 19 | 20 | 21 | 22 | 23 24 | 25 | 26 | 27 | 28 | 29 | 30
- Подсказка: ты можешь делать запросы без таблиц, например
SELECT 2 + 3, 'Hello' - Подсказка: здесь не надо использовать циклы или процедуры
- Подсказка: функции работы с датой и временем ты можешь найти тут http://dev.
 mysql.com/doc/refman/5.0/en/date-and-time-functions.html (англ.)
mysql.com/doc/refman/5.0/en/date-and-time-functions.html (англ.) - Подсказка: для сокращения объема кода ты можешь использовать переменные (создаются командой
SET)
Межбазовый запрос на Transact-SQL | Info-Comp.ru
Речь сегодня пойдет об очень полезной возможности в SQL это межбазовый запрос. Данный вид запроса просто незаменим, если у Вас существует несколько баз данных на одном сервере или даже на разных серверах, а так как иногда требуется получить данные сразу отовсюду, например, для отчета, то межбазовый запрос лучшее решение этой задачи.
Примечание! Сразу хочу сказать, что все примеры будем пробовать на Transact-SQL MS Sql Server 2008 в Management Studio, так как в других СУБД синтаксис будет отличаться. Также хочу заметить, что все примеры ниже требуют начальных знаний SQL, поэтому советую для начала ознакомиться с материалами: Язык запросов SQL – Оператор SELECT, Добавляем в таблицу новую колонку на SQL, Сочетание строковых функций на Transact-SQL, Transact-sql – Табличные функции и временные таблицы эти статьи помогут Вам приобрести начальные знания в SQL.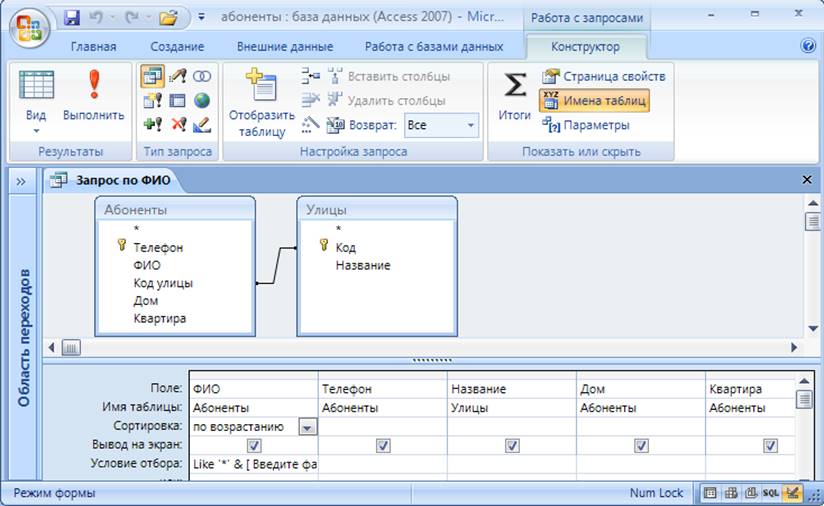
И так приступим, сначала как обычно немного теории, для того чтобы понять, что такое межбазовый запрос и для чего он служит, а потом как обычно рассмотрим несколько практических примеров.
Межбазовый запрос
Межбазовый запрос – это запрос, который в процессе своего выполнения подключается к разным базам данных, а также в некоторых случаях к разным серверам баз данных.
А теперь давайте определимся, для каких целей могут служить межбазовые запросы, допустим, у Вас есть 3 базы данных, 2 из них расположены на одном MSSQL сервере, а одна на другом. Все они служат для какой-то определенной задачи, может быть у них даже схожая структура, но это не важно и Вам как программисту иногда требуется выгружать данные из всех баз, например, для того чтобы предоставить эти данные начальству, и Вы скорей всего запускаете запросы из каждой базы или переключаетесь из менеджера запросов на работу с той ли иной базой, но гораздо удобней было бы запустить один запрос и получить сразу все данные. Именно для этого я пользуюсь данного вида запросами, но Вы, наверное, можете найти применение и для других задач. Если Вы сталкивались с такого рода задачами, то Вам просто необходимо узнать что такое межбазовый запрос.
Именно для этого я пользуюсь данного вида запросами, но Вы, наверное, можете найти применение и для других задач. Если Вы сталкивались с такого рода задачами, то Вам просто необходимо узнать что такое межбазовый запрос.
Примеры межбазовых запросов
И первый пример он достаточно простой, требуется тогда когда необходимо получить данные из нескольких баз расположенных на одном сервере. Для объединения этих данных будем использовать конструкцию union all, которую мы рассматривали в статье – union и union all на Transact-SQL .
И для начала, допустим, у нас есть две базы данных (test и test2), схемы dbo в которых мы создали вот такие таблицы:
Таблица в базе test
CREATE TABLE [dbo].[test_table_base_1](
[id] [bigint] NOT NULL,
[text] [varchar](50) NULL,
CONSTRAINT [PK_test_table] PRIMARY KEY CLUSTERED
(
[id] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF,
ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
) ON [PRIMARY]
GO
Таблица в базе test2
CREATE TABLE [dbo].[test_table_base_2]( [id] [bigint] NOT NULL, [text] [varchar](50) NULL, CONSTRAINT [PK_test_table] PRIMARY KEY CLUSTERED ( [id] ASC )WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY] ) ON [PRIMARY] GO
Я их заполнил тестовыми данными, сейчас увидите какими, и для того чтобы получить данные из этих таблиц напишем вот такой запрос:
Код:
select * from test.dbo.test_table_base_1 – Первая база select * from test2.dbo.test_table_base_2 –Вторая база
Как видите синтаксис очень простой:
Select * from [база].[схема].[таблица]
Но результата в вышеуказанном запросе будет два, и для того чтобы объединить эти запросы, используем конструкцию union all.
Код:
select * from test.dbo.test_table_base_1 – Первая база union all select * from test2.dbo.test_table_base_2 –Вторая база
И результат будет уже один. И с помощью данного межбазового запроса Вы легко можете объединить данные, а еще для удобства, чтобы каждый раз не писать текст запроса можете создать представление views, для того чтобы обращаться напрямую к этому представлению.
Теперь давайте рассмотрим пример посложней, когда требуется получить данные из базы, которая располагается на другом сервере.
Для этого мы будем использовать конструкцию opendatasource.
Сразу скажу, что opendatasource работает, только если на сервере выставлен параметр Ad Hoc Distributed Queries со значением 1. Для того чтобы посмотреть этот параметр выполните процедуру sp_configure и посмотрите значение данного параметра:
Где,
- config_value — это значение которое внеслось но еще не сохранилось, т.е. сервер еще не переконфигурировался;
- run_value – текущее значение данного параметра, т.
 е. с которым работает сервер в данный момент.
е. с которым работает сервер в данный момент.
Кстати данная процедура возвращает очень много конфигурационных параметров, которые Вы можете посмотреть.
И для того чтобы изменить данный параметр, используем туже самую процедуру, синтаксис:
exec sp_configure [Название параметра],[Значение]
А для того чтобы сконфигурировать сервер с новым значением, запустим процедуру reconfigure, и весь запрос будет выглядеть вот так:
exec sp_configure 'Ad Hoc Distributed Queries',1 reconfigure exec sp_configure
Ну а теперь можем приступать непосредственно к запросу, который подключится к серверу и получит необходимые данные. Для примера я буду подключаться сам к себе к тем же таблицам.
Код:
select * from
opendatasource ('sqlncli','Data Source=myserver;Integrated Security=SSPI')
.test.dbo.test_table_base_1
union all
select * from
opendatasource ('sqlncli','Data Source=myserver;Integrated Security=SSPI')
. test2.dbo.test_table_base_2
test2.dbo.test_table_base_2
Как видите результат тот же самый.
Здесь мы указали в первом параметре провайдер источника данных, т.е. SQL server (‘sqlncli’) и задали строку подключения:
Где,
- Data Source – это адрес сервера баз данных;
- Integrated Security=SSPI – при подключении использовать проверку подлинности Windows, т.е. аутентификация и авторизация пользователя будет проходить по учетным данным Windows, отлично подходит, если в сети развернута AD(Active Directory).
А если Вы хотите использовать проверку подлинности на уровне SQL сервера, то придется писать имя пользователя и пароль (которые должны быть созданы на SQL сервере) в строке подключения, например, абсолютно такой же результат, как и выше, получится, если мы напишем вот такой запрос:
select * from
opendatasource ('sqlncli','Data Source= myserver;user id = username; pwd=password')
.test.dbo.test_table_base_1
union all
select * from
opendatasource ('sqlncli','Data Source= myserver;user id = username; pwd=password')
. test2.dbo.test_table_base_2
test2.dbo.test_table_base_2
Т.е. вместо параметра Integrated Security мы укажем параметры:
- user id — логин на SQL сервере;
- pwd – соответственно пароль.
Примечание! Opendatasource может подключаться и другим отличным от SQL сервера источникам для этого в параметрах указываете нужный Вам провайдер, например, для подключения к Excel документу можете использовать вот такой запрос (Синтаксис):
SELECT * FROM OPENDATASOURCE('Microsoft.Jet.OLEDB.4.0',
'Data Source=C:\TestExcel.xls; Extended Properties=EXCEL 5.0')...[Sheet1$] ;
По межбазовым запросам все, надеюсь, данный материал был Вам интересен, и пригодится Вам на практике.
Заметка! Для комплексного изучения языка T-SQL рекомендую посмотреть мои видеокурсы по T-SQL, в которых используется последовательная методика обучения и рассматриваются все конструкции языка SQL и T-SQL.
SQL запрос SELECT в базах данных SQLite
Привет, посетитель сайта ZametkiNaPolyah. ru! Продолжаем изучать базы данных и наше знакомство с библиотекой SQLite3. SQL запросу SELECT я решил уделить целую тему, которая состоит из 15 частей. Первая запись будет вводной, из нее вы узнаете, что можно сделать при помощи запроса SELECT в реляционных базах данных. И поверьте, сделать можно немало. В этой записи вы не найдете ни одной строчки SQL кода, это просто словесное описание того, что может SELECT и для он нужен.
ru! Продолжаем изучать базы данных и наше знакомство с библиотекой SQLite3. SQL запросу SELECT я решил уделить целую тему, которая состоит из 15 частей. Первая запись будет вводной, из нее вы узнаете, что можно сделать при помощи запроса SELECT в реляционных базах данных. И поверьте, сделать можно немало. В этой записи вы не найдете ни одной строчки SQL кода, это просто словесное описание того, что может SELECT и для он нужен.
SQL запросы SELECT в базах данных SQLite
В этой записи мы сперва поговорим про назначение запроса SELECT, потом рассмотрим синтаксис SQL запроса в базах данных под управлением SQLite3. А далее начнем рассматривать особенности SELECT в SQL и базах данных SQLite: как составить условие при помощи всевозможных клаузул, как и какие SQL операторы можно использовать вместе с SELECT, как объединить два запроса, как объединить две таблицы в запросе SELECT, как правильно составить подзапрос SELECT. В общем, информации будет много, читайте, разбирайтесь, спрашивайте.
Использование и назначение SQL запросов SELECT в базах данных
Содержание статьи:
- Использование и назначение SQL запросов SELECT в базах данных
- Синтаксис SQL запроса SELECTв базах данных SQLite
- Клаузулы и предикаты. Уточняющие фразы для SQLзапроса SELECTв SQLite
- Объединение двух и более SQL запросов SELECT в базах данных SQLite
- Сравнение результатов двух SQL запросов SELECT в базах данных SQLite
- Использование SQL операторов вместе с SELECT в базах данных SQLite
- Подзапросы SELECT в базах данных SQLite
- Объединение двух таблиц SQLзапросом SELECTв базах данных SQLite
- Использование SQL запроса SELECT с другими командами SQLite
- Ускорение SQL запросов SELECT в реляционных базах данных
Реляционные базы данных – это один из самых естественных способов описать предмет реального мира: столбцы – это характеристики предмета, строки – это информация о предмете. Мы уже научились работать с объектами баз данных: создавать таблицы в базе данных и другие объекты, удалять объекты базы данных, модифицировать таблицы в базе данных. Мы умеем манипулировать данными в таблицах: добавлять строки в таблицы, удалять строки из таблиц и изменять данные в таблицах.
Мы умеем манипулировать данными в таблицах: добавлять строки в таблицы, удалять строки из таблиц и изменять данные в таблицах.
Но базы данных были бы бесполезны, если бы мы не могли получать информацию об описываемых предметах и объектах реального мира. Для получения информации из таблиц базы данных есть специальный SQL запрос SELECT. SQL запросы SELECT бывают очень громоздкими из-за чего их считают сложными, но в дальнейшем мы убедимся, что вся сложность SQL запроса SELECT заключается в соблюдении ряда определенных правил, которые, на самом деле, очень просты, понятны и естественны, как и сами реляционные базы данных.
Команда SELECT – это самый мощный инструмент языка запросов SQL, вы можете бегло получить информацию о том, как работают другие команды, а потом детально разобраться с тем, как работает SELECT и с уверенностью утверждать, что умеете работа с базами данных при помощи SQL запросов.
Итак, мы уже разобрались с тем, что SQL запрос SELECT позволяет получать данные из базы данных или иначе: SQL запрос SELECT делает выборку данных из базы данных. Мы будем разбираться с командой SELECT на протяжении 15 последующих частей, каждая часть – это небольшой пример того, как работает SELECT и что можно сделать при помощи SQL запроса SELECT, поверьте, сделать можно немало и в этом вы скоро убедитесь.
Мы будем разбираться с командой SELECT на протяжении 15 последующих частей, каждая часть – это небольшой пример того, как работает SELECT и что можно сделать при помощи SQL запроса SELECT, поверьте, сделать можно немало и в этом вы скоро убедитесь.
Мы чуть не забыли о самом главном, нам следует сказать, что результатом работы SQL запросы SELECT всегда является таблица. Если вы выполняете команду SELECT, то любая СУБД вам вернет таблицу при условии, что запрос составлен верно и в базе данных есть данные, удовлетворяющие вашему запросу, в противном случае вы ничего не получите или получите ошибку.
Синтаксис SQL запроса SELECTв базах данных SQLite
Синтаксис SQL запроса SELECT громоздкий и требует от разработчика соблюдения определенных правил и определённого порядка в использование ключевых слов. Ниже на рисунке представлен общий синтаксис SQL запроса SELECT в базах данных SQLite3.
Синтаксис SQL запроса SELECT в базах данных SQLite3
Хоть SQL запрос SELECT и громоздкий, но сложного в нем ничего нет, как и в принципе в SQL. Чтобы сказать SQLite о том, что мы хотим получить данные из базы данных, мы используем ключевое слово SELECT, затем мы перечисляем столбцы, из которых хотим получить данные.
Чтобы сказать SQLite о том, что мы хотим получить данные из базы данных, мы используем ключевое слово SELECT, затем мы перечисляем столбцы, из которых хотим получить данные.
Далее следует ключевое слово FROM, после которого указывается имя таблицы, из которой необходимо получить данные. Вместо имени таблицы может быть использован квалификатор. Квалификатор – это полное имя объекта базы данных, состоящее из имени базы данных и имени самого объекта.
А дальше начинается самое интересное, дальше идет то, что делает SQL запрос SELECT таким мощным средством реляционных баз данных: различные условия выборки данных.
SQL запрос SELECT имеет два модификатора: ALL и DISTINCT. По умолчанию SQLite использует модификатор ALL, поэтому его можно не писать. Особенностью модификатора ALL является то, что в этом случае SQL запрос выполняется и SQLite в результирующей таблице выводит нам все строки, даже те, которые повторяются.
Модификатор DISTINCT используется в том случае, когда нам нужно сделать выборку из базы данных и исключить повторяющиеся строки.
Клаузулы и предикаты. Уточняющие фразы для SQLзапроса SELECTв SQLite
Первое, о чем стоит упомянуть, так это о том, что SQL запрос SELECT позволяет использовать всевозможные клаузулы и предикаты. Клаузула или предикат – это уточняющая фраза, правильнее все-таки использовать термин клаузула. Уточняющие фразы помогают сделать точечную выборку из таблицы базы данных SQLite3 и других реляционных СУБД.
Порядок использования уточняющих фраз в базах данных SQLite очень важен, хотя мы можем и отбрасывать некоторые клаузулы, но общий порядок написания должен быть соблюден:
- Клаузула WHERE. WHERE позволяет наложить условие на выборку данных из таблицы базы данных под управлением SQLite
- Предикат GROUP BY. GROUP BY позволяет сделать группировку выборки данных в базах данных SQLite.
- Уточняющая фраза HAVING. HAVING используется для фильтрации группировки данных.
- Клаузула ORDER BY. ORDER BY позволяет упорядочить результаты выборки данных.
- Предикат LIMIT.
 LIMIT используется для ограничения количества строк в таблице, которая получается в результате выборки.
LIMIT используется для ограничения количества строк в таблице, которая получается в результате выборки.
Чтобы успешно составлять сложные SQL запросы вам нужно запомнить порядок использования уточняющих фраз и назначение каждой фразы. Кстати, никто не запрещает вам использовать сложные выражения.
Объединение двух и более SQL запросов SELECT в базах данных SQLite
SQL запросы SELECT бывают громоздкими не только из-за того, что используют сразу все уточняющие фразы, но и из-за того, чтоSQLite3 дает возможность объединять SQL запросы SELECT, вернее будет сказать объединять результаты двух запросов SELECT при помощи ключевого слова UNION. Зачастую использование UNION и SELECT могут дать очень интересные результаты. Синтаксис использования UNION в SQLite3 вы найдете на рисунке ниже.
Синтаксис UNION в SQL запросе SELECT
Таким образом, мы можем написать SQL запрос SELECT используя все уточняющие фразы, затем написать UNION и написать еще один десятиэтажный SELECT, и SQLite выполнит такой запрос, а у вас в результате будет одна таблица значения в которой будут из двух таблиц: сначала будут выведены строки из первой таблице, а затем к этим строкам будут добавлены строки из второй таблице. Но никто не запрещает вам объединять три и более запросов
Но никто не запрещает вам объединять три и более запросов
Сравнение результатов двух SQL запросов SELECT в базах данных SQLite
SQL запрос SELECT всегда возвращает нам таблицу, это очень важно для понимания его работы. Потому что SQL запрос SELECT не только делает выборку данных, но и позволяет сравнивать результаты выборки данных при помощи ключевых слов EXCEPT и INTERSECT. Первая ключевая фраза дает возможность получить только уникальные строки из двух или более промежуточных таблиц, а вторая позволяет записать в результирующую таблицу только повторяющиеся строки из двух таблиц, полученных в подзапросах.
Когда вы будете использовать SQL запрос SELECT, вы неизбежно столкнетесь с тем, что SQLite (на месте SQLite может быть любая другая СУБД) будет сравнивать значения в таблицах или сравнивать строки. Поэтому, во-первых, вам нужно понимать, как SQLite сравнивает значения. А во-вторых, знать про типы данных в SQLite:
- SQLite3 имеет динамическую типизацию данных.
- В SQLite понятие тип данных заменено на понятие класс данных.
- В SQLite3 нет ни булева типа данных, ни типа данных даты и времени.
- В SQLite3 столбцы имеют аффинированный тип данных, который не является ограничением уровня столбца, а нужен лишь для сравнения значений.
Обо всем этом мы говорили ранее и даже очень подробно.
Использование SQL операторов вместе с SELECT в базах данных SQLite
Для усложнения логики запросов на выборку данных мы можем использовать различные SQL операторы, о них мы говорили ранее и перечисляли их. SELECT может использовать логические выражение AND и OR, чтобы сделать условия выборки более точными. В SQL запросах SELECT мы можем использовать оператор BETWEEN. Оператор BETWEEN и SELECT позволяют получить значения в диапазоне, который как раз-таки и задается оператором BETWEEN.
Еще у нас есть возможность использовать оператор LIKE. Оператор LIKE и SELECT позволяют сделать поиск по шаблону или еще можно сказать, что при помощи комбинации LIKE мы можем осуществить сравнение строк с заданным шаблоном. А результатом выборки будет таблица, содержащая только те строки, в которых есть подстрока, указанная в шаблоне LIKE.
А результатом выборки будет таблица, содержащая только те строки, в которых есть подстрока, указанная в шаблоне LIKE.
Иногда бывает нужно, чтобы в результирующей таблице, полученной с помощью SQL запроса SELECT, были строки, содержащие в своих столбцах только определенный набор значений, для того, чтобы сделать такую выборку нам нужно использовать оператор IN. Результирующая таблица, полученная после комбинации оператор IN и SELECT будет содержать строки из определённого набора значений.
Подзапросы SELECT в базах данных SQLite
Подзапросы SELECT реализуются довольно просто: мы пишем основной или внешний запрос SELECT, далее задаем условие (если мы задаем условие, то неизбежно используем SQLоператор), но в качестве правого операнда мы задаем не какое-то конкретное значение, а пишем запрос SELECTв скобках.
Подзапросы получили такое название от того, что для их реализации используется две или более команды SELECT, получается так, что, например, один SELECTбудет вложен в другой. Первая команда SELECTназывается внешним запросом, а второй SQL запрос SELECT–внутренним подзапросом.
Первая команда SELECTназывается внешним запросом, а второй SQL запрос SELECT–внутренним подзапросом.
Чаще всего подзапросы SELECT используются с оператором EXISTS или с оператором IN. Если вы пишите подзапрос с использованием EXISTS, то вы увидите результат только в том случае, когда правый операнд (собственно, подзапрос или внутренний запрос) будет иметь значение TRUE, кстати, если подзапрос вернет NULL, то внешний запрос будет выполнен.
Другими словами: если подзапрос вернет значение FALSE, то внешний запрос даже не будет выполняться.
Объединение двух таблиц SQLзапросом SELECTв базах данных SQLite
Самая приятная часть SQL запроса SELECT, но в то же время и самая сложная, хотя сложность ее скорее надуманная, чем действительная. SQL запросы SELECT позволяют объединять таблицы базы данных. Объединение таблиц в SQL осуществляется при помощи ключевого слова JOIN. Стандарт SQL выделяет несколько видов объединения таблиц JOIN:
- Внутреннее объединение: INNER JOIN.
- Полное объединение: FULL JOIN.
- Правое внешнее объединение: RIGHT OUTER JOIN.
- Левое внешнее объединение: LEFT OUTER JOIN.
- Перекрестное объединение: CROSS JOIN.
Для внешнего объединение можно опускать ключевое слово OUTER, по крайней мере SQLite это позволяет сделать. Но, есть один минус у SQLite, в данной СУБД реализовано только три объединения: LEFT, CROSS и INNER. Вот такое вот ограничение творчества при написании SQL запросов SELECT ввели разработчики SQLite3.
Использование SQL запроса SELECT с другими командами SQLite
Мы не могли не упомянуть, что SQL запрос SELECT может быть использован с другими командами языка SQL. Естественно, мы можем выполнять запросы SELECT внутри транзакций, поэтому команды управления транзакциями даже не обсуждаются. В SQLite3 нет команд определения доступа к данным, поэтому их мы тоже трогать не будем.
Команды определения данных:
- Мы можем создавать таблицы в базе данных при помощи команды CREATE TABLE, но также SQLite дает нам возможность создавать таблицы с использованием ключевого слова AS и SQL запроса SELECT.

- Мы не можем использовать SQL запрос SELECT, когда хотим удалить таблицу из базы данных при помощи команды DROP.
- Также мы не можем использовать запрос SELECT, если мы хотим модифицировать таблицу или другой объект базы данных при помощи команды ALTER.
Последних два пункта обусловлены тем, что перечисленные выше команды работают на уровне объектов, а SELECT работает с данными.
Команды манипуляции данными:
- Когда мы добавляем строки в таблицу базы данных при помощи команды INSERT, то можем это делать при помощи подзапроса.
- Если у нас есть необходимость удалить строки из таблицы базы данных, мы используем команду DELETE не так часто, но всё же, мы можем выбрать строки для удаления при помощи SQL запроса SELECT.
- Для модификации данных в базе данных используется команда UPDATE. Чтобы она работала, мы должны выбрать строки, которые необходимо модифицировать. А что может быть лучше для выбора строк, чем SQL запрос SELECT?
Ускорение SQL запросов SELECT в реляционных базах данных
Мы можем оптимизировать работу команды SELECT в SQLite и других реляционных СУБД.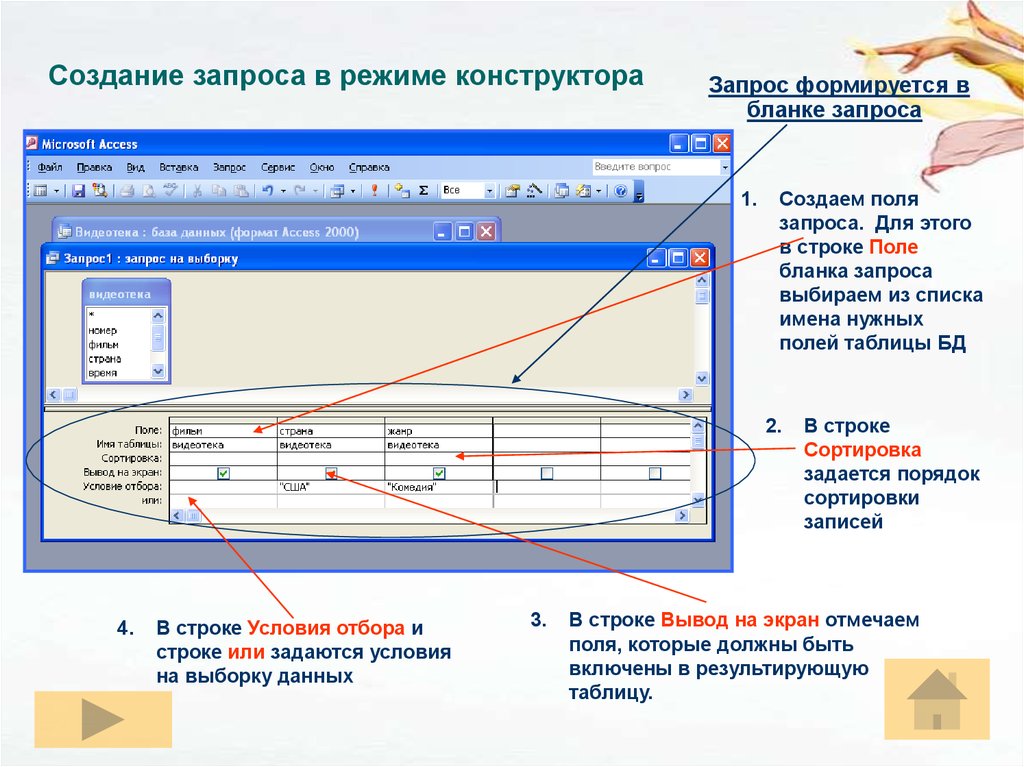 Ускорение выборки данных происходит за счет создания индексов в таблице базы данных. Индексы очень сильно ускоряют выборку данных, но в замен они делают другие операции манипуляции данными более дорогими. Мы ранее уже очень подробно говорили про индексы в базах данных SQLite3.
Ускорение выборки данных происходит за счет создания индексов в таблице базы данных. Индексы очень сильно ускоряют выборку данных, но в замен они делают другие операции манипуляции данными более дорогими. Мы ранее уже очень подробно говорили про индексы в базах данных SQLite3.
Напомним, что SQLite создает внутренний индекс для каждой таблицы (столбец ROWID), который может совпадать с индексом, созданным при помощи ограничения первичного ключа PRIMARY KEY (немного теории про ключи и ключевые атрибуты). Так же мы можем организовывать связь между таблицами при помощи ограничения внешнего ключа FOREIGN KEY, такой подход не только обеспечивает целостность данных в базе данных, но и ускоряет выборку данных. Это еще одно применение ограничений уровня таблицы в SQL и реляционных базах данных.
Итак, мы на самом деле сейчас дали краткую характеристику тому, что может сделать SQLзапрос SELECT. Здесь нет примеров, только словесное описание, которое заняло несколько страниц, но при этом мы говорим, что описание краткое.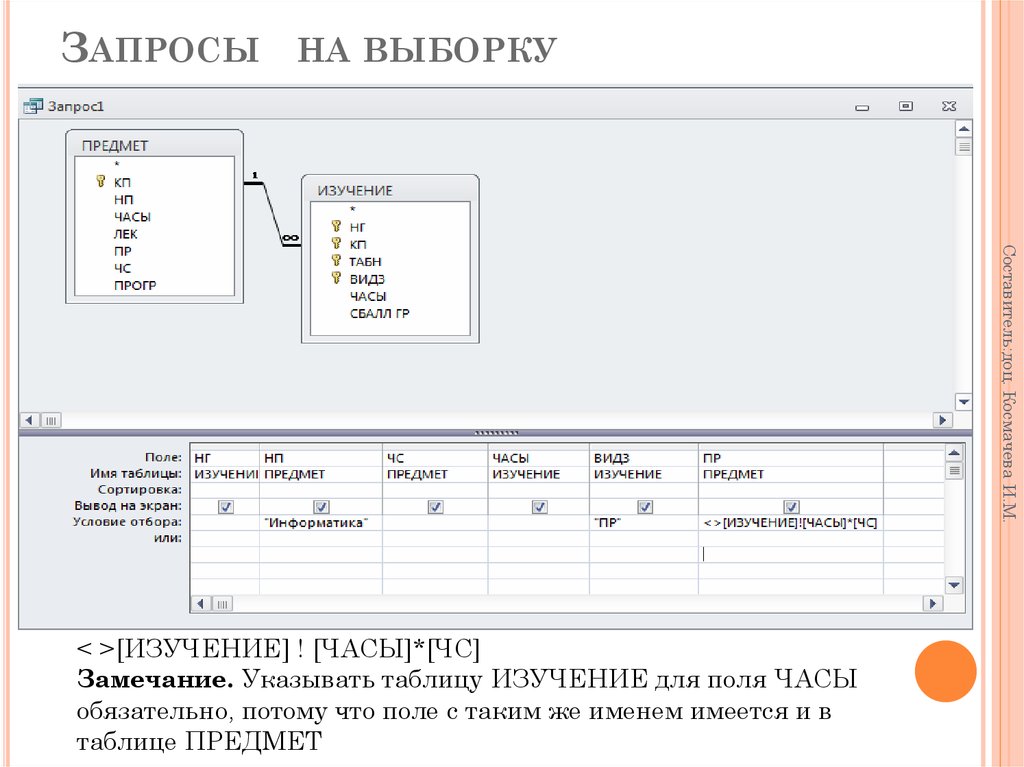 Да, SQLзапросы SELECT бывают очень длинными, но их нельзя назвать сложными, в этом вы сможете убедиться, посмотрев примеры, которые будут далее, а еще лучше, если вы своими руками будете их повторять.
Да, SQLзапросы SELECT бывают очень длинными, но их нельзя назвать сложными, в этом вы сможете убедиться, посмотрев примеры, которые будут далее, а еще лучше, если вы своими руками будете их повторять.
Запросить базу данных | Отдел информационных служб
В этом руководстве объясняется, как запросить новую базу данных с помощью портала запросов к базе данных.
Это руководство предназначено для:
- Персонала
- ИТ-администраторов
- Персонала SLMS
- Исследователей
Прежде чем начать…
- Пожалуйста, используйте Google Chrome. Этот процесс не будет работать в Microsoft Edge или Firefox.
- Запрашивайте только одну новую службу базы данных за раз.
- Вы не можете вернуться в портал. Если вы допустили ошибку, вам нужно будет запустить запрос снова.
- Портал автоматически создаст заявку Remedyforce по вашему запросу. Вам не нужно создавать билет Remedyforce вручную.
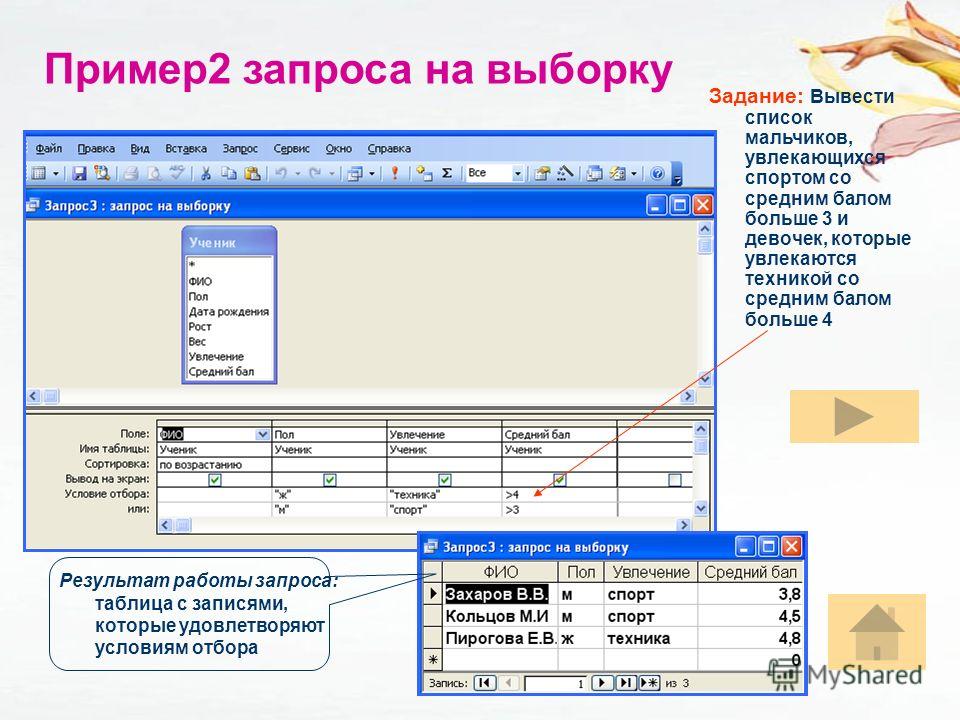
- Этот процесс предназначен только для запроса службы общей базы данных. Если требуется выделенная виртуальная машина базы данных (виртуальная машина), обратитесь в группу DBA Services.
- Поскольку это служба общей базы данных, на той же виртуальной машине будут работать другие базы данных.
Инструкции
Перейти на портал запросов к базе данных
- Вы войдете в систему с помощью единого входа (рис. 1) автозаполнение. Пожалуйста, измените это на , а не на .
Введите имя базы данных . Приведенный ниже URL-адрес содержит рекомендации по созданию имени для вашей базы данных. Портал ограничивает ввод имен, которые не соответствуют стандартам проектирования баз данных.
Примечание: Для всех типов баз данных портал добавит к вашей базе данных правильное исправление среды, поэтому вам не нужно включать его в имя вашей базы данных.
- Выберите базу данных Тип .
 Команда предлагает три службы общих баз данных:
Команда предлагает три службы общих баз данных:MySQL
Oracle
Microsoft SQL Server Выберите среду базы данных из приведенных ниже вариантов. Выбранная вами среда повлияет на стоимость, поскольку более высокие среды будут размещаться в обоих центрах обработки данных.
Dev
UAT
PreProd (всегда на двух сайтах)
Production (всегда на двух сайтах)
Обучение
ScratchPress Next
Выберите 4 для базы данных версии 90.
Примечание: По умолчанию версия базы данных будет заменена последней версией, предложенной командой базы данных, это следует изменить только в том случае, если есть особые требования (т. е. приложению требуется более ранняя версия базы данных).
Выберите Размер вычислительной базы данных (объем памяти, который, по вашему мнению, потребуется для базы данных).
 Предлагается ряд диапазонов, которые различаются в зависимости от выбранного типа базы данных. Понятно, что это будет оценка.
Предлагается ряд диапазонов, которые различаются в зависимости от выбранного типа базы данных. Понятно, что это будет оценка. Примечание: Если ожидаемый требуемый объем памяти превышает максимальное предлагаемое значение, то для базы данных, вероятно, потребуется изолированная виртуальная машина. Пожалуйста, обсудите это с командой DBA Services.
Выберите Размер хранилища базы данных (объем хранилища), который, по вашему мнению, потребуется для базы данных. Ниже представлен ряд диапазонов. Понятно, что это будет оценка.
XS (до 1 ГБ)
S (1–10 ГБ)
M (11–50 ГБ)
L (51–250 ГБ)
XL (251–1000 ГБ)Примечание: Если требуемый объем памяти выше самая высокая предлагаемая цифра означает, что для базы данных, вероятно, потребуется виртуальная машина Silo. Пожалуйста, обсудите это с командой DBA Services.
- По умолчанию Количество одновременных подключений равно 100.
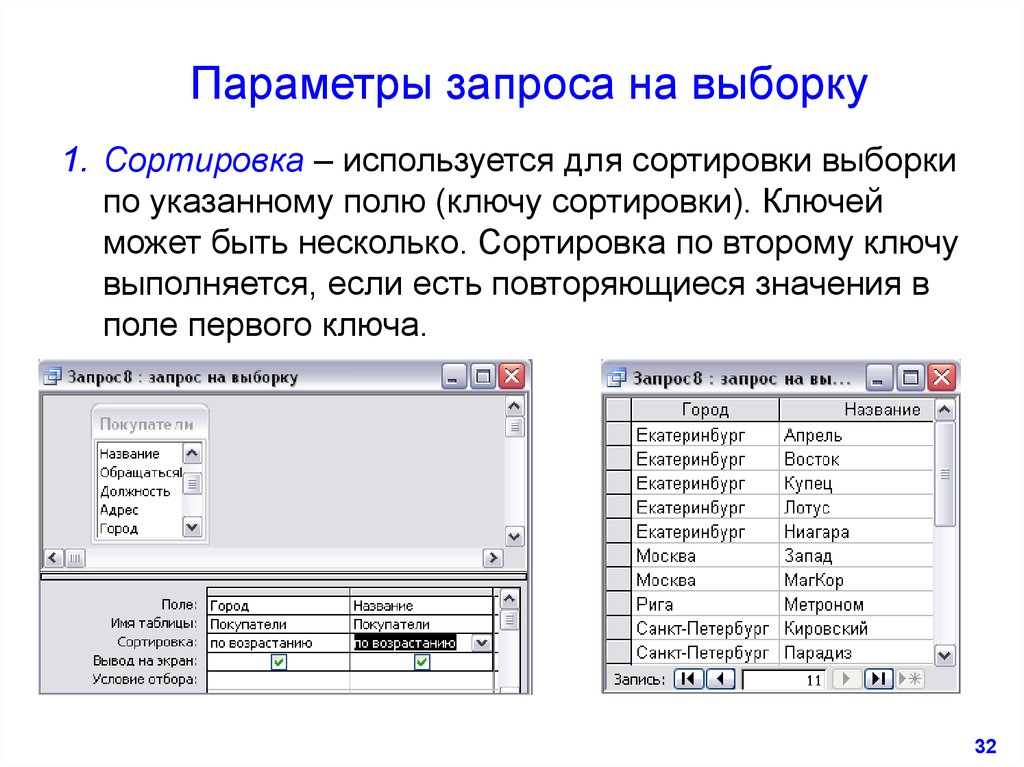 Если вы считаете, что вашей базе данных потребуется меньше 100, никаких действий не требуется. Если вы считаете, что потребуется более 100 подключений, обновите значение.
Если вы считаете, что вашей базе данных потребуется меньше 100, никаких действий не требуется. Если вы считаете, что потребуется более 100 подключений, обновите значение. Доступность базы данных по умолчанию будет либо обычной, либо высокой, в зависимости от типа базы данных и выбранной среды. Если доступность по умолчанию высокая, ее нельзя изменить. Однако, если по умолчанию установлено обычное значение, пользователь может изменить его на высокое.
Примечание. Высокая доступность означает, что база данных размещается в обоих центрах обработки данных UCL — это удваивает стоимость.
- Выберите требуемую продолжительность базы данных (от 1 до 5 лет)
- Нажмите Далее
Выберите Детали каталога услуг ISD — Бизнес-подразделение и затем нажмите 903 903 Далее 9043 Далее недоступно, но указано на странице «Идентификаторы служб и распределение бизнес-подразделений», поднимите заявку в гибридной инфраструктуре.
Выберите свой Сведения о каталоге услуг ISD — Идентификатор услуги (раскрывающийся список уточняется в зависимости от выбранного бизнес-подразделения), а затем нажмите Далее
Если ваш идентификатор услуги недоступен, но указан в идентификаторах услуг и страница распределения бизнес-подразделений, поднимите тикет с гибридной инфраструктурой.
Сведения о приложении требуются только в том случае, если база данных создается приложением. Если это не так, то никаких изменений не требуется. Пожалуйста, нажмите Далее .
Если база данных создается приложением, установите флажок и укажите имя приложения, которое будет создавать базу данных.
Окно обслуживания определяется на основе выбранной среды. Единственная среда с какой-либо гибкостью для выбора окон обслуживания — это Рабочая среда, все остальные — по умолчанию.
Примечание: Предлагаемые периоды обслуживания соответствуют графикам установки исправлений ОС.

Если запрос не для сервера Oracle, поля Табличное пространство Oracle и Имена серверов приложений будут по умолчанию равны N/A и могут быть проигнорированы.
Если запрос касается сервера Oracle, добавьте сведения, если они известны. Если неизвестно, укажите N/K. Это не обязательные поля.
Нажмите Далее
Пожалуйста, введите любую Дополнительную информацию , которая, по вашему мнению, будет полезна команде DBA Services для выполнения запроса, а затем нажмите Далее
Например:
Ограничения сеанса по умолчанию равны 3600 секундам, ожидаемая пиковая нагрузка с 9:00 до 13:00. Приложение может аварийно завершать работу, если база данных недоступна после 10 попыток подключения.
- Портал предоставит сводку (рис. 2) запрошенной базы данных. Эта сводка также будет отправлена вам по электронной почте для информации.
 Если ваш проект недоступен на портале, отправьте запрос группе гибридной инфраструктуры для исправления.
Если ваш проект недоступен на портале, отправьте запрос группе гибридной инфраструктуры для исправления. - Введите свой номер задачи и нажмите Далее
- Портал предоставит сводку запрошенной базы данных, код PTA и общую стоимость (рис. 3). Если все выглядит правильно, отметьте Да для подтверждения закупки и нажмите Отправить .Рис.3 – Экран подтверждения закупки
- Затем портал отправит запрос в Remedyforce, и будет возвращен запрос на обслуживание (Рис.4)Рис.4 – Запрос на обслуживание создан, экран
Запросы на базы данных — документация Xano
Документация Xano
Поиск…
Документация Xano
Добро пожаловать
Примечания к выпуску
Roadmap & запросы
Часто задаваемые вопросы
💡
СТАРЬ.
Что включено
Технология
Что такое серверная часть?
Зачем нужен отдельный Backend?
🤔
Основы
Начало работы с Xano
Проектирование вашей базы данных
Настройка вашего API
, подключающуюся к фронтальному
🗄 База данных
Основы базы данных
Типы поля
Отношения базы данных
Источники данных
Database. Импорт данных.0003
Импорт данных.0003
Автодокументация
Филиалы
Производительность API
🪄
Работа с данными
Основы
.
Есть запись
Редактировать запись
Удалить запись
Добавить запись
Добавить или изменить запись
Транзакция базы данных
Clear All Records
Bulk Add Records
Манипулирование данными
Security
Кэширование данных
Пользовательские функции
Утилиты
Загрузка содержимого
. Lambdas (JavaScript)
Дата и время
⚒️ Создание серверных функций
Регистрация и вход в систему
Ограничение доступа
Сброс пароля
Authless Auth (Magic Link)
Платежи
Уведомления по электронной почте
Местоположение
Генерация файлов CSV
Разделение данных
🚀
Data Caching
Schema SchemaRingsing
Dynamic Dynamic Dynamic Dynamic Dynamic. (Поделитесь своим API)
(Поделитесь своим API)
Фоновые задачи (Cron Jobs)
Управление файлами
📕
Практические руководства
Полные руководства по сборке
Манипулирование данными
Внешние API
Шифрование
Подробнее видеоуроки
☁ Ваша учетная запись xano
Помощь и поддержка
Страница учетной записи
Billing
. Настройка производительности сервера
План агентства
Пользовательский домен
Изменение региона сервера
Управление командой
Использование полосы пропускания
Синхронизация времени
Ограничение скорости API
API разработчика
Поделиться Xano. Зарабатывать деньги
🔒
Безопасность и соответствие
Лучшие практики
ISO 27001: 2013
ISO 9001: 2015
Соответствие PCI (ASV Network Scan).
🔨
Устранение неполадок
Очистить кэш
Bug Bounty
Устранение неполадок
Powered By GitBook
Запросы к базе данных
Запросы к базе данных — это функции, взаимодействующие с базой данных. Они позволяют вам манипулировать данными из различных таблиц базы данных в вашей рабочей области.
Они позволяют вам манипулировать данными из различных таблиц базы данных в вашей рабочей области.
Функции запроса к базе данных:
Получить запись — извлекает одну запись на основе поиска в поле.
Есть запись — Возвращает информацию о том, существует запись или нет, на основе поиска поля.
Редактировать запись — Обновляет запись на основе поиска поля.

Удалить запись — Удаляет запись на основе поиска поля.
Добавить запись — Добавляет новую запись в базу данных.
Добавить или изменить запись — Поиск записи на основе поиска в поле.
 Если запись не существует, будет добавлена новая запись. Если запись существует, она обновит существующую запись.
Если запись не существует, будет добавлена новая запись. Если запись существует, она обновит существующую запись. Транзакция базы данных — позволяет группировать вместе функции, которые вы хотите выполнить, только если каждая функция выполнена успешно. Обычно используется с двумя или более критически важными функциями.
Очистить все записи — безвозвратно удаляет все записи из таблицы базы данных.
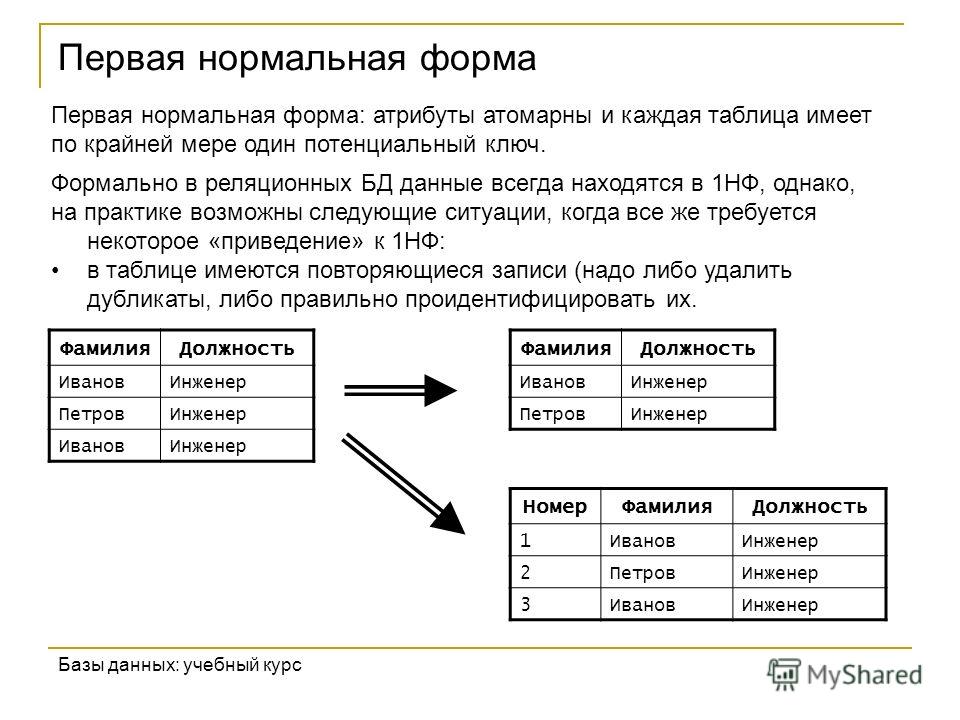
Работа с данными — Предыдущая
Функции
Следующая
Запросить все записи
Последнее изменение 1 год назад
Скопировать ссылку
Требуется внимание администратора | Запросы, которые требуют внимания и могут потребовать Действия со стороны администратора. |
Вся активность по серверам | Ответы на запросы, отсортированные по серверам. |
Все ошибки по дате | Ответы с обнаруженными ошибками, отсортированные по
свидание. |
Все ошибки по серверу | Ответы с обнаруженными ошибками, отсортированные по сервер. |
Все запросы по действиям | Запросы и ответы, отсортированные по действию. |
Все запросы по имени | Запросы и ответы, отсортированные по имени. |
Все запросы от автора-инициатора | Запросы отсортированы по имени сервера, администратор
имя или имя пользователя в зависимости от того, как был инициирован запрос. |
Все запросы по серверу | Запросы и ответы, отсортированные по серверам. |
Все запросы по времени инициирования | Сортирует все административные запросы по дате и время, когда запрос был инициирован. |
Запросы на изменение ЦС Конфигурация Обновления | Запросы, создавшие обновления для
Сертификат сертификата в Domino® Directory
и документ конфигурации центра сертификации в выданном
База данных списка сертификатов (ICL). Примечание. При открытии ADMIN4.NSF из каталог Domino, это представление называется «Обновления конфигурации». |
Обновления CA Recovery Информация о восстановлении Обновления | Запросы на обновление информации для восстановления для сертификатора. Это представление обычно контролируется администратором. который был назначен Удостоверяющим центром и Регистрационным органом. Примечание: Когда вы открываете ADMIN4.NSF из Domino Directory, это представление называется Recovery Информационные обновления. |
Запросы сертификатов | Запросы на создание интернет-сертификата
и запросы на создание сертификата Notes®.
Это представление обычно контролируется администратором, который был
уполномоченный орган по сертификации и орган по регистрации. |
Междоменный — Конфигурация | Междоменные конфигурации, отсортированные по доменам а затем по входящим запросам, которые приняты и исходящим запросам которые принимаются |
Междоменные — ошибки доставки | Запросы, которые не могут быть доставлены на входящий домен |
Заявки на регистрацию | Это представление еще не реализовано. |
Требуется индивидуальное одобрение | Показывает запросы, которые должны быть индивидуально
одобрены, то есть их нельзя одобрить, выбрав несколько запросов
в ADMIN4. |
Имя Запросы на перемещение | Запросы на перенос имени пользователя в имя иерархия |
Ожидает утверждения администратором | Запросы, ожидающие утверждения администратор. С этим представлением связаны дополнительные представления. Вот они:
Примечание. При открытии ADMIN4.NSF из каталога Domino Представление «Утверждение администратором» указано здесь вместо как отдельный вид. |
 Этот
вид позволяет одному администратору следить за активностью других администраторов
в базе данных Административных запросов.
Этот
вид позволяет одному администратору следить за активностью других администраторов
в базе данных Административных запросов.

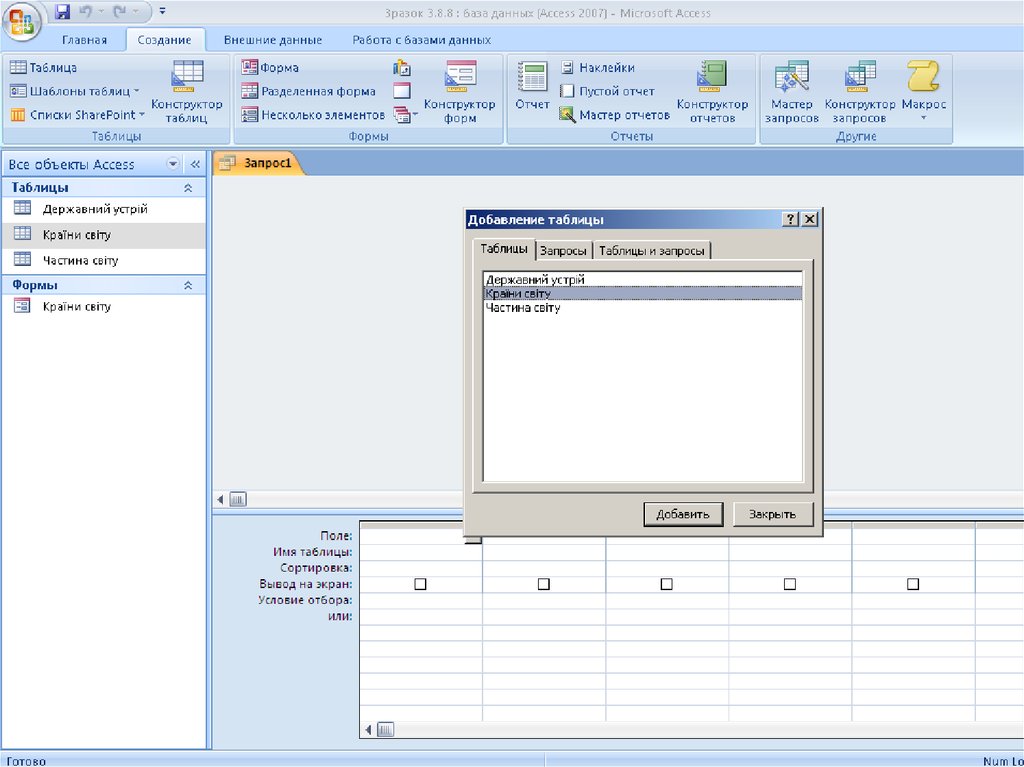 NSF и нажав Подтвердить
Выбранные запросы.
NSF и нажав Подтвердить
Выбранные запросы.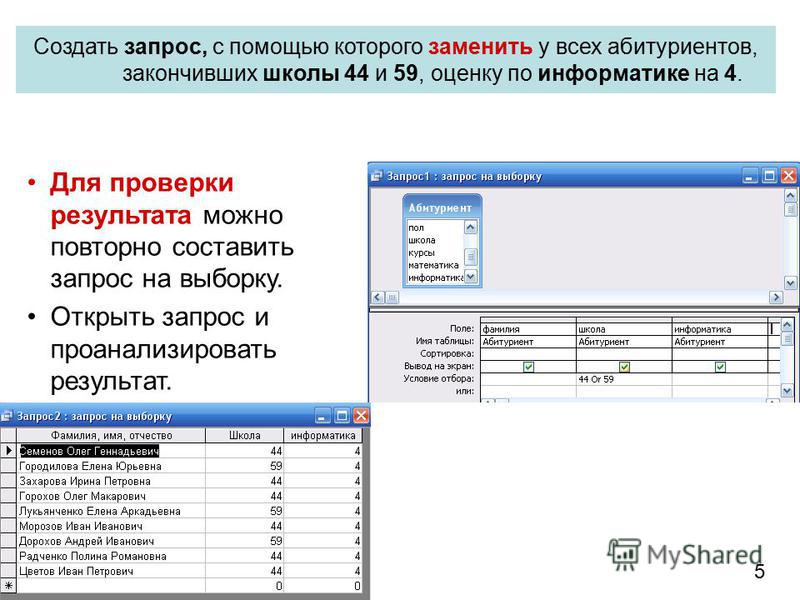 одобрение, отсортированное по имени сервера, на котором запрос будет
обрабатываться.
одобрение, отсортированное по имени сервера, на котором запрос будет
обрабатываться.Как сервер базы данных обрабатывает тысячи одновременных запросов? 🤔 | Нипун Арора | Как работает Интернет
Мы видим, что крупные веб-сайты электронной коммерции могут обслуживать тысячи клиентов в любой конкретный момент. Вы когда-нибудь задумывались, как они это делают, возможно, распределение клиентов по набору параллельных серверов является тривиальным шагом для начала, но как им удается поддерживать согласованность своей базы данных с их инвентарем? 🤔
иногда одному серверу приходится иметь дело с этим множеством клиентов 😜 Чтобы отвечать на несколько одновременных запросов, вы можете иметь пул потоков или рабочих, но как поддерживать согласованность. поддержание согласованности, но что я имею в виду под согласованностью .
Теперь предположим, что мы продаем iPhone на нашем веб-сайте электронной коммерции, и у нас есть 10 штук на складе.
Допустим, этот номер хранится в нашей базе данных как N
Теперь рассмотрим две параллельные транзакции T и P, каждая из которых покупает iPhone
Теперь предположим, что параллельное расписание T1->T2->P1->P2->T3->P3 iPhone в базе данных как 9, так как в P3 N = 9, тогда как у нас осталось только 8 в нашем инвентаре. Следовательно, мы видим, как случайное параллельное планирование может привести к несоответствиям 😤.
Что ж, ответ лежит в «I» из ACID набора свойств dbms, который равен Изоляция , как сервер базы данных изолирует одновременные запросы.
Ну, есть несколько явлений, описывающих конкретный уровень изоляции (книжные определения 😏 вы получите понятие при однократном чтении)
- Грязное чтение — Грязное чтение — это ситуация, когда еще не был зафиксирован.
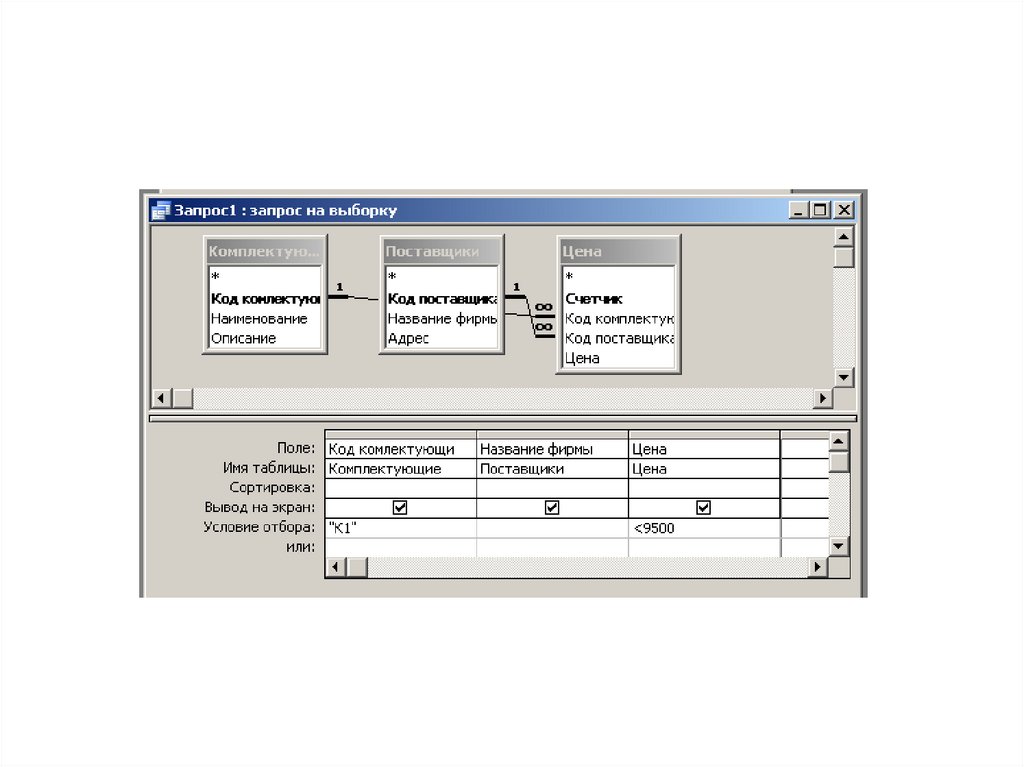 Например, допустим, транзакция 1 обновляет строку и оставляет ее незафиксированной, в то время как транзакция 2 читает обновленную строку. Если транзакция 1 откатывает изменение, транзакция 2 будет считывать данные, которые считаются никогда не существовавшими.
Например, допустим, транзакция 1 обновляет строку и оставляет ее незафиксированной, в то время как транзакция 2 читает обновленную строку. Если транзакция 1 откатывает изменение, транзакция 2 будет считывать данные, которые считаются никогда не существовавшими. - Неповторяемое чтение — Неповторяемое чтение происходит, когда транзакция дважды считывает одну и ту же строку и каждый раз получает другое значение. Например, предположим, что транзакция T1 считывает данные. Из-за параллелизма другая транзакция T2 обновляет те же данные и фиксирует их. Теперь, если транзакция T1 повторно считывает те же данные, она получит другое значение.
- Фантомное чтение — Фантомное чтение происходит, когда выполняются два одинаковых запроса, но извлекаемые ими строки различаются. Например, предположим, что транзакция T1 извлекает набор строк, удовлетворяющих некоторым критериям поиска. Теперь транзакция T2 создает несколько новых строк, соответствующих критериям поиска для транзакции T1.
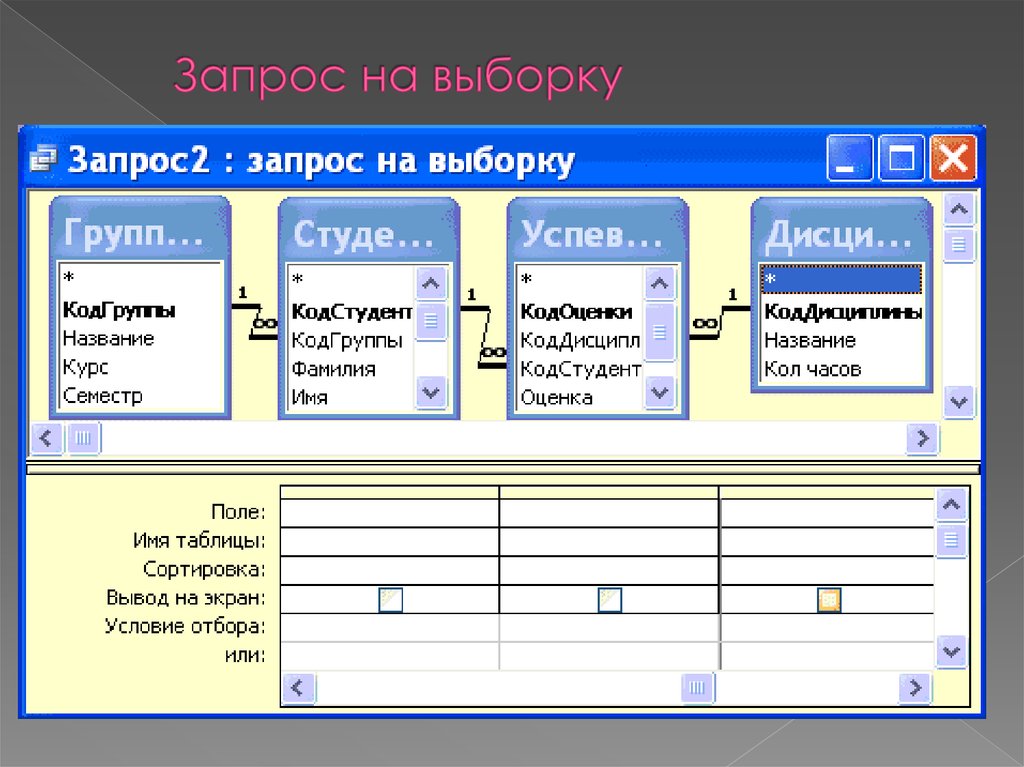 Если транзакция T1 повторно выполняет инструкцию, которая считывает строки, на этот раз она получает другой набор строк.
Если транзакция T1 повторно выполняет инструкцию, которая считывает строки, на этот раз она получает другой набор строк.
Далее мы проанализируем уровни изоляции примитивов.
- Read Uncommitted — Read Uncommitted — самый низкий уровень изоляции. На этом уровне одна транзакция может считывать еще не зафиксированные изменения, сделанные другой транзакцией, тем самым допуская грязное чтение. На этом уровне транзакции не изолированы друг от друга.
- Read Committed — Этот уровень изоляции гарантирует, что любые считанные данные фиксируются в момент их чтения. Таким образом, он не допускает грязного чтения. На этом уровне изоляции уровень транзакции удерживает блокировку чтения до конца оператора и блокировку записи до фиксации/отката транзакции.
- Повторяемое чтение — Это самый строгий уровень изоляции. Транзакция удерживает блокировки чтения для всех строк, на которые она ссылается, и блокировки записи для всех строк, которые она вставляет, обновляет или удаляет, пока транзакция не будет зафиксирована.
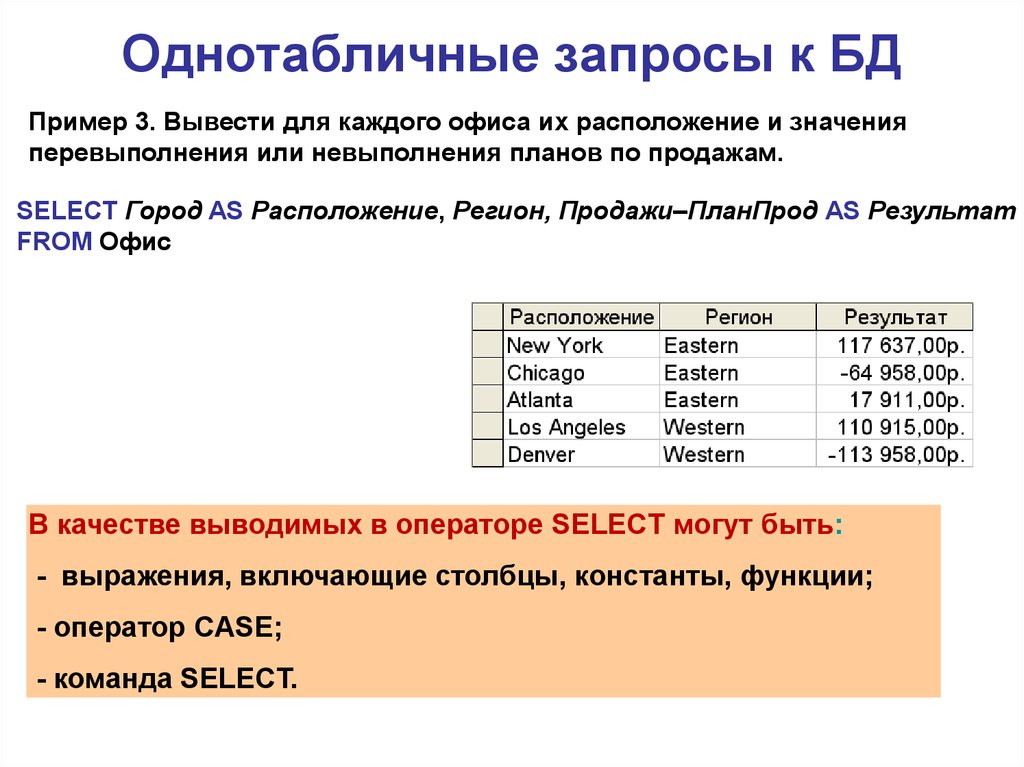 Поскольку другая транзакция не может читать, обновлять или удалять эти строки, следовательно, она избегает неповторяющегося чтения.
Поскольку другая транзакция не может читать, обновлять или удалять эти строки, следовательно, она избегает неповторяющегося чтения. - Сериализуемый — Это самый высокий уровень изоляции. Сериализуемое выполнение гарантированно будет сериализуемым. Сериализуемое выполнение определяется как выполнение операций, при котором одновременно выполняемые транзакции кажутся последовательно выполняемыми.
Вам может казаться, что сериализуемость — это правильный путь, но подождите……. Сериализуемый не работает с транзакциями, которые одновременно обновляют/удаляют одну и ту же строку 😐 (Рассмотрите наш пример с iPhone, нет соответствующего параллельного расписания, которое может сериализоваться конфликтом) .
Кроме того, получение и снятие блокировок в основном приводит к увеличению задержки.
Что такое изоляция моментальных снимков и управление версиями строк?
При управлении версиями строк обновленные версии строк для каждой транзакции сохраняются в базе данных tempdb. Уникальный порядковый номер транзакции идентифицирует каждую транзакцию, и эти уникальные номера записываются для каждой версии строки. Транзакция работает с самыми последними версиями строк, имеющими порядковый номер перед порядковым номером транзакции. Более новые версии строк, созданные после начала транзакции, игнорируются транзакцией.
Уникальный порядковый номер транзакции идентифицирует каждую транзакцию, и эти уникальные номера записываются для каждой версии строки. Транзакция работает с самыми последними версиями строк, имеющими порядковый номер перед порядковым номером транзакции. Более новые версии строк, созданные после начала транзакции, игнорируются транзакцией.
Термин «моментальный снимок» отражает тот факт, что все запросы в транзакции видят одну и ту же версию или моментальный снимок базы данных на основе состояния базы данных в момент начала транзакции.
Пример базы данных tempdb для приведенного выше примерного расписания, в котором мы даем номер транзакции 1 для T и 2 для P. всегда видеть значение количества равным 10, пока оно не обновится, так как при управлении версиями строк мы ссылаемся на строку с той же/ближайшей строкой номера транзакции.
Следовательно, С таким подходом мы можем легко избежать неповторяющихся фантомных чтений .
Теперь давайте посмотрим, как все вышеперечисленные уровни изоляции противоречат друг другу.
Подождите……подождите….подождите…. ✋ у вас может возникнуть ощущение, что, хотя мы обсуждали все виды уровней изоляции и бла-бла-бла 🙄(это очень важно), мы так и не нашли решения для приведенного выше примера с iPhone.
Уровень изоляции, обычно используемый в OLTP (онлайн-обработка транзакций), равен 9.0043 Изоляция зафиксированных моментальных снимков чтения с управлением версиями строк .(Я говорил вам, что это важно). Теперь вышеприведенный случай с iPhone — это случай потерянных обновлений, которые можно обрабатывать двумя способами, а не только потерянное обновление всех конфликтов параллелизма. можно рассматривать с помощью одной из следующих парадигм:
Пессимистический контроль параллелизма
- Система блокировок не позволяет пользователям изменять данные таким образом, чтобы это повлияло на других пользователей.
- После того, как пользователь выполнит действие, вызывающее применение блокировки, другие пользователи не смогут выполнять действия, конфликтующие с блокировкой, пока владелец не снимет ее.
- Это называется пессимистическим контролем, потому что он в основном используется в средах с высокой конкуренцией за данные, где стоимость защиты данных с помощью блокировок меньше, чем стоимость отката транзакций в случае возникновения конфликтов параллелизма.
Оптимистичный контроль параллелизма
- При оптимистическом управлении параллелизмом пользователи не блокируют данные при чтении. Когда пользователь обновляет данные, система проверяет, не изменил ли их другой пользователь после того, как они были прочитаны.
- Если другой пользователь обновил данные, возникает ошибка. Обычно пользователь, получающий сообщение об ошибке, откатывает транзакцию и начинает заново.
- Это называется оптимистичным, потому что в основном используется в средах с низкой конкуренцией за данные и где стоимость периодического отката транзакции ниже стоимости блокировки данных при чтении.

Таким образом, поскольку повторная попытка конкретной транзакции может быть перенесена на клиентскую сторону, мы предпочитаем оптимистичный контроль параллелизма.
В нашем примере с iPhone, когда второй человек нажимает кнопку покупки, первый запрос будет прерван, и политика повторных попыток, возможно, написанная на javascript, обеспечит второй запрос, который позволит человеку купить и БД на этот раз, на вторая попытка обновляет с 9 до 8 элементов.
Я знаю, что это больше теоретическая часть, но надеюсь, что это даст вам общее представление о том, как сервер базы данных обрабатывает миллионы одновременных запросов, сохраняя согласованность данных.
Существует еще большая область снижения задержки ввода-вывода в обновлениях БД с помощью кэширования, я буду обсуждать это подробнее в нашем рассказе о кэшировании в этой публикации.
Жду ваших ценных предложений и запросов в разделе ответов. 😃
😃
Политика запроса и поддержки базы данных
ПОЛИТИКА ЗАПРОСА И ПОДДЕРЖКИ БАЗЫ ДАННЫХ
В следующем документе излагаются требования и обзор поддержки, которым следует группа систем баз данных для всех систем, которые поддерживает команда.
Предварительные требования:
В следующем списке перечислены предварительные требования, которые должны быть выполнены для любой среды, поддерживаемой группой систем баз данных. Любые исключения из предварительных требований должны быть одобрены руководителем группы систем баз данных.
- Группа «База данных» будет управлять только теми системами, управление ОС которых осуществляется службой IT Services Data Center Services.
- База данных должна быть изначально установлена и настроена группой систем баз данных. Команда не будет брать на себя поддержку систем, созданных другими группами.
- База данных должна работать под управлением одной из программных технологий, поддерживаемых командами (Oracle/SQL Server/MySQL).
- Права администратора в базе данных ограничены группой систем баз данных.
- Любой запрос, указывающий, что он будет содержать конфиденциальные данные, указанные в Политике управления персоналом университета 601, будет передан группе безопасности ИТ-услуг.
- Программное обеспечение базы данных лицензировано должным образом. (Лицензирование должно соответствовать действующим лицензионным соглашениям сайта.)
- Команды приложений должны следовать всем политикам ИТ-служб, связанным с конфиденциальными данными (где это применимо). https://its.uchicago.edu/guidelines-secure-management-it-infrastructure-systems-process-transmit-or-store-confidential/
- Управление базой данных группой систем баз данных должно соответствовать текущим политикам управления изменениями ИТ-служб.
- Серверы базы данных являются одноразовыми системами и не запускают компоненты, не связанные со службой, поддерживаемой базой данных. Исключения из этого предварительного условия потребуют подписи группы ИТ-безопасности, если система также должна хранить конфиденциальные данные.

- Все непроизводственные работы должны планироваться в течение стандартного рабочего дня.
Специальные предварительные условия для MySQL:
- Все базы данных MySQL, поддерживаемые группой, работают на общих серверах, размещенных группой баз данных. Группа систем баз данных не поддерживает MySQL на других серверах.
- Запрещен доступ к серверам, на которых запущены размещенные базы данных MySQL.
- Все системы, работающие под управлением MySQL 5.6 и более поздних версий, должны следовать стандартной политике исправления программного обеспечения баз данных.
- Группа систем баз данных стандартизировала операционную систему Red Hat. Все новые системы должны соответствовать этому стандарту.
- Все системы должны соответствовать текущей политике программного обеспечения MySQL. Копия этого документа может быть предоставлена по запросу.
Предварительные требования Oracle:
- Группа систем баз данных стандартизировала операционную систему Red Hat.
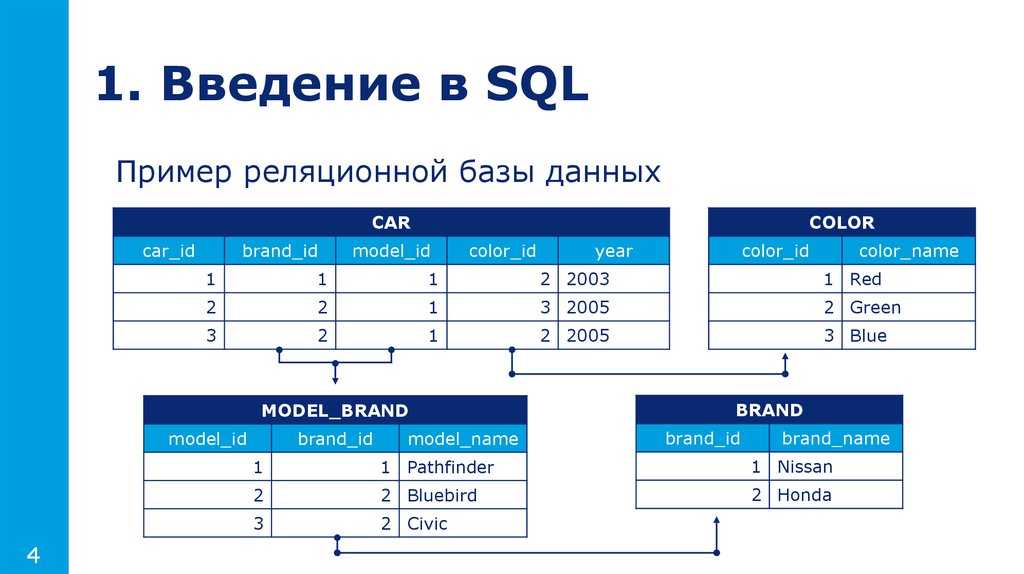 Все новые системы должны соответствовать этому стандарту.
Все новые системы должны соответствовать этому стандарту. - Все системы должны соответствовать текущей политике программного обеспечения Oracle. Копия этого документа может быть предоставлена по запросу.
Предварительные требования SQL Server:
- Все системы должны соответствовать текущей политике программного обеспечения SQL Server. Копия этого документа может быть предоставлена по запросу.
Краткое описание и обзор поддержки:
В следующем списке указаны обязанности и общие политики поддержки группы систем баз данных:
- Установка поддерживаемого программного обеспечения баз данных в соответствии с групповыми политиками программного обеспечения. Программное обеспечение будет установлено в соответствии с требованиями к версии приложения с согласия менеджера группы систем баз данных. Если требований к версии приложения нет, команда базы данных установит последнюю поддерживаемую версию в соответствии со стандартами группы.
 Любые программные компоненты базы данных, не установленные в соответствии с текущими стандартами, будут установлены по запросу.
Любые программные компоненты базы данных, не установленные в соответствии с текущими стандартами, будут установлены по запросу. - Обновления программного обеспечения базы данных будут выполняться по запросу команды приложения или для поддержания программного обеспечения базы данных в актуальном состоянии в соответствии с существующими групповыми политиками.
- Создание баз данных в соответствии с действующими стандартами группы. Копия действующего стандартного документа может быть предоставлена по запросу.
- Установка и настройка программного обеспечения для мониторинга баз данных в соответствии со стандартами группы.
- Доступность базы данных и мониторинг ошибок в соответствии с существующими стандартами технологии баз данных. Все оповещения о доступности будут отправлены в списки адресов электронной почты команды и в дежурные для производственных систем. Команда базы данных
- поможет внести изменения в модель данных посредством установки приложений или развертывания кода.
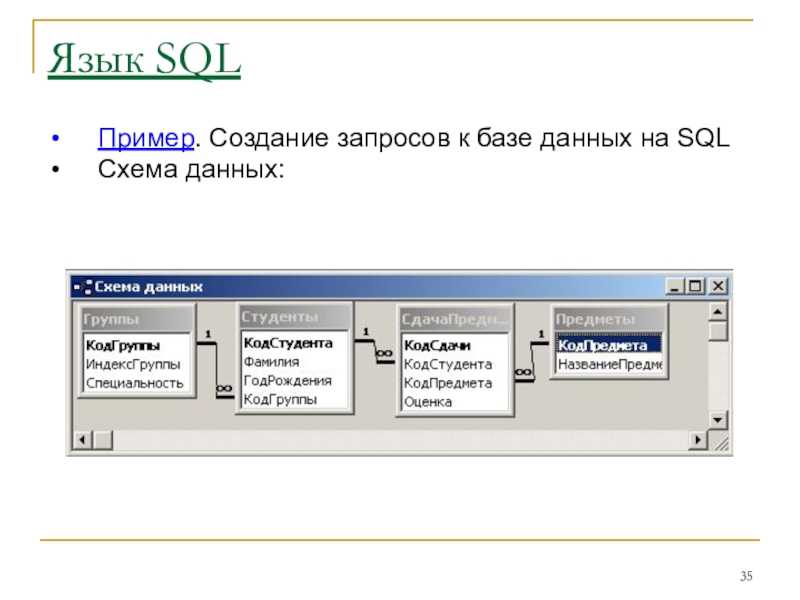
- Резервные копии базы данных будут настроены и контролироваться в соответствии с текущими стандартами резервного копирования. Подробности см. в последней документации по стандартам.
- Применение исправлений программного обеспечения базы данных во время периодов планового обслуживания. Группа систем баз данных будет поддерживать политики, связанные с исправлением программного обеспечения баз данных, в соответствии с рекомендациями поставщиков.
- Команда базы данных поможет устранить проблемы с базой данных или обработает запросы на обслуживание в течение рабочего дня с 8:30 до 17:00. Все запросы следует направлять по электронной почте в списки адресов электронной почты Database Systems или через Service Now. Ожидается, что сотрудники группы DBA ответят не позднее, чем через 24 часа после получения электронного письма. Не следует ожидать наличия персонала вне окна рабочего дня для непроизводственной работы.
- Команда базы данных откроет запросы в службу поддержки поставщику программного обеспечения базы данных для основного программного продукта.
 Персонал базы данных
Персонал базы данных - обеспечит представительство и поддержку реализации проекта. Это включает в себя сбор требований, планирование, участие в собраниях по проекту и поддержку базы данных в течение жизненного цикла проекта.
- Отслеживание проблем с помощью внутренней системы тикетов (ServiceNow) для отслеживания проблем и запросов от инициализации до разрешения.
- Помогите настроить производительность базы данных с помощью параметров установки и конфигурации базы данных.
- Обеспечьте непрерывную круглосуточную поддержку базы данных по проблемам, влияющим на доступность базы данных. Персонал в списке вызовов будет доступен, чтобы с персоналом можно было связаться напрямую, чтобы поддержать важные вопросы процесса и доступности.
- Работы по техническому обслуживанию производственных систем можно запланировать на стандартные периоды обслуживания в нерабочее время с 6:00 до 8:00 по средам или с 7:00 до 11:00 по воскресеньям.
- Будет обрабатывать все производственные изменения, внесенные командой базы данных, через Консультативный совет по изменениям ITS.
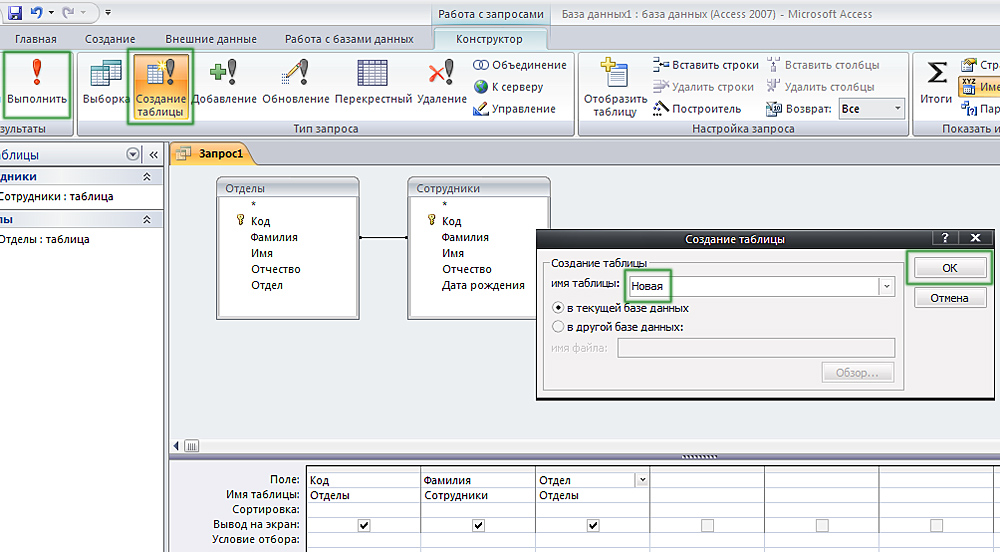
- Выполните анализ первопричин любых проблем, влияющих на доступность системы, и определено, что они связаны с основным продуктом базы данных.
- Помогите диагностировать проблемы с производительностью с помощью операторов SQL и предлагайте предложения по улучшению производительности, где это возможно.
- Будет работать с командами приложений и другими группами поддержки, чтобы попытаться определить узкие места производительности и возможные решения этих проблем.
Категория: Другое
Срок действия: 24 июня 2017 г.
Владелец политики: mschmitt
Как Flask обрабатывает запросы к базе данных?
Момин Имран Куреши
Grokking Интервью по проектированию современных систем для инженеров и менеджеров
Пройдите собеседование по проектированию систем и поднимите свою карьеру на новый уровень. Научитесь управлять дизайном таких приложений, как Netflix, Quora, Facebook, Uber и многих других, за 45-минутное интервью.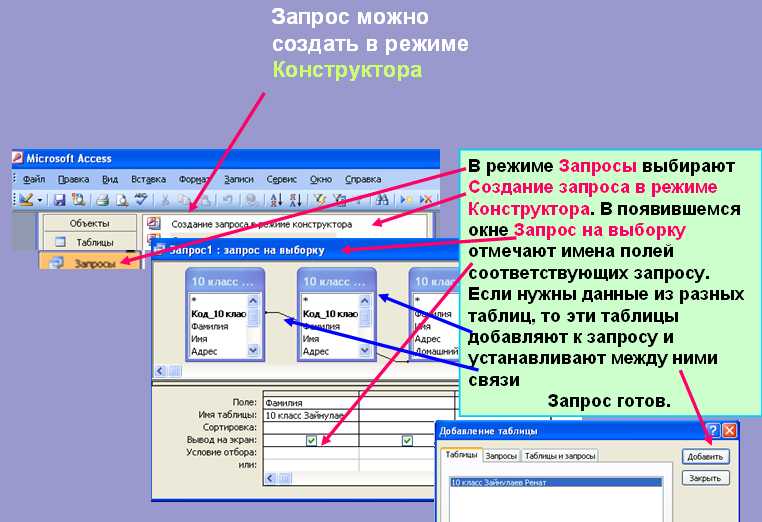 Изучите платформу RESHADED для разработки веб-приложений, определив требования, ограничения и допущения, прежде чем погрузиться в пошаговый процесс проектирования.
Изучите платформу RESHADED для разработки веб-приложений, определив требования, ограничения и допущения, прежде чем погрузиться в пошаговый процесс проектирования.
Запросы к базе данных в Flask
Flask — это среда Python, используемая для создания веб-приложений. Его можно комбинировать с набором инструментов SQLAlchemyA Python SQL и средством объектно-реляционного сопоставления (ORM) для обработки запросов к базе данных для баз данных SQL, таких как MySQL, PostgreSQL, SQLite и других. Мы будем использовать SQLite в качестве примера в этом ответе.
Предварительные условия
- Установленный компилятор Python.
- Установленный пип.
Что такое запросы к базе данных?
Для отправки данных из базы данных на веб-сайт запросы к базе данных обрабатываются внутренними языками, такими как Python, и фреймворками, такими как Flask, чтобы обеспечить правильную передачу данных на веб-страницу.
Как создавать таблицы в SQLite
- Сначала установите DB Browser для SQLite — приложение, обеспечивающее функциональные возможности для создания, проектирования и редактирования файлов базы данных, совместимых с SQLite.
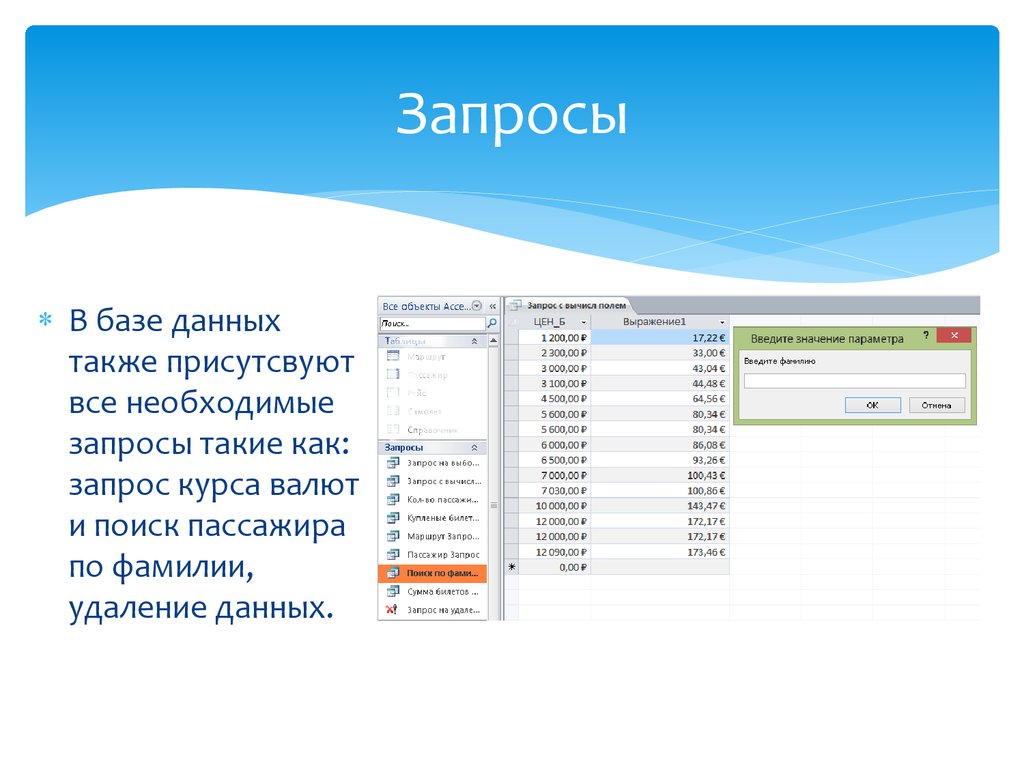
- В качестве примера мы будем использовать следующую базу данных:
база данных showroom.db
Как читать из таблиц в SQLite
Установите Flask и flask-sqlalchemy (если их еще нет), введя в терминале следующие команды:
pip install Flask
pip install flask-sqlalchemy
Код для установки Flask и flask-sqlalchemy
Тестирование подключения к базе данных
Введите следующее в редактор кода, такой как VSCode.
из фляги импорта Фляга
from flask_sqlalchemy import SQLAlchemy
from sqlalchemy.sql import text
app = Flask(__name__)
# имя базы данных; при необходимости добавьте путь
database_Name = 'showroom.db'
app.config['SQLALCHEMY_DATABASE_URI'] = 'sqlite:///' + database_Name
app.config['SQLALCHEMY_TRACK_MODIFICATIONS'] = True
# Переменная база данных будет использоваться для всех команд SQLAlchemy
database = SQLAlchemy(app)
@app.
route('/')
def main():
database.session.query(текст('1')).from_statement(текст('SELECT 1')).all()
return '
Test Successful
'if __name__ == '__main__':
app.run(debug=True)
Код для проверки подключения к базе данных
Объяснение
- Строки : Мы импортируем соответствующие библиотеки из
- Строка 5: Создаем
Flaskобъект приложения (app), который наследует все атрибуты и методы от классаFlask. - Строка 10: содержит строку подключения к базе данных, необходимую для подключения к базе данных.
- Строка 12:
SQLALCHEMY_TRACK_MODIFICATIONS— это ключ конфигурации, который, если установлено значение true, позволяет отслеживать модификации объектов и выдает сигналы. - Строка 15: мы создаем базу данных
объектов, которая содержит функции как из sqlalchemy, так и из sqlalchemy. orm. Он также объявляет класс с именем
orm. Он также объявляет класс с именем Model, который будет использоваться для чтения из базы данных. - Строки 17–20: используются для проверки соединения. Выделенная строка 19 взаимодействует с базой данных. Строка 20 возвращает синтаксис HTML, который отображает «Тестирование успешно» на вашей веб-странице.
- Строки 22–23: Часть синтаксиса, необходимая для запуска
Flask.
Flask и SQLAlchemy .Примечание. Убедитесь, что файл базы данных находится в той же папке, что и этот файл.
Чтение из базы данных
Сначала определите class для каждой таблицы в базе данных. Пример показан ниже для таблицы Car :
class Car(database.Model):
__tablename__ = 'cars'
id = database.Column(database.Integer, primary_key=True)
name = database.Column(database.String)
type = database.Column(database.String)
color = database.Column(database.
String)
price = database.Column(database.String)
Создание класса для нашей машины стол
Синтаксис
Column_name = db.Column (db.variable_type, ограничения (необязательные))
Чтобы получить информацию из базы данных, мы будем использовать две функции, показанные ниже:
@app.route( '/')
индекс определения():
# получить список уникальных значений в столбце стиля
типов = Car.query.with_entities(Car.type).distinct()
вернуть render_template('index.html', типы=типы)
@app.route('/inventory/
') определяемый инвентарь (тип):
попробовать:
автомобили = Car.query.filter_by(type=type).order_by(Car.name).all()
return render_template('list.html', cars=cars, type=type)
кроме Исключения как e:
# e содержит описание ошибки
error_text = "
Ошибка:
"
" + str(e) + "hed = '
Что-то сломалось.
'
возврат хед + error_text
Функции, которые считывают и отображают данные из базы данных
Объяснение
- Первая функция — это индексная функция, измененная для запроса к базе данных и возвращающая различные типы автомобилей.
- Строка 4:
Car.queryзапрашивает таблицу cars,метод with_entities()ограничивает столбцы, возвращаемые указанным столбцомCar.type. МетодDifferent()возвращает только уникальные значения в столбце. - Строка 5: типы отправляются в виде кортежа на страницу
index.html, где они отображаются в цикле. Страницаindex.htmlсодержит синтаксис jinja для отображения данных из серверной части. - Вторая функция принимает тип в качестве параметра и отображает все автомобили этого типа, запрашивая базу данных.
- Строка 11:
Car.queryзапрашивает таблицу cars,filter_by()ограничивает наш запрос аналогично предложению where в SQL,order_by()передается столбец для определения порядка данных (по возрастанию по умолчанию).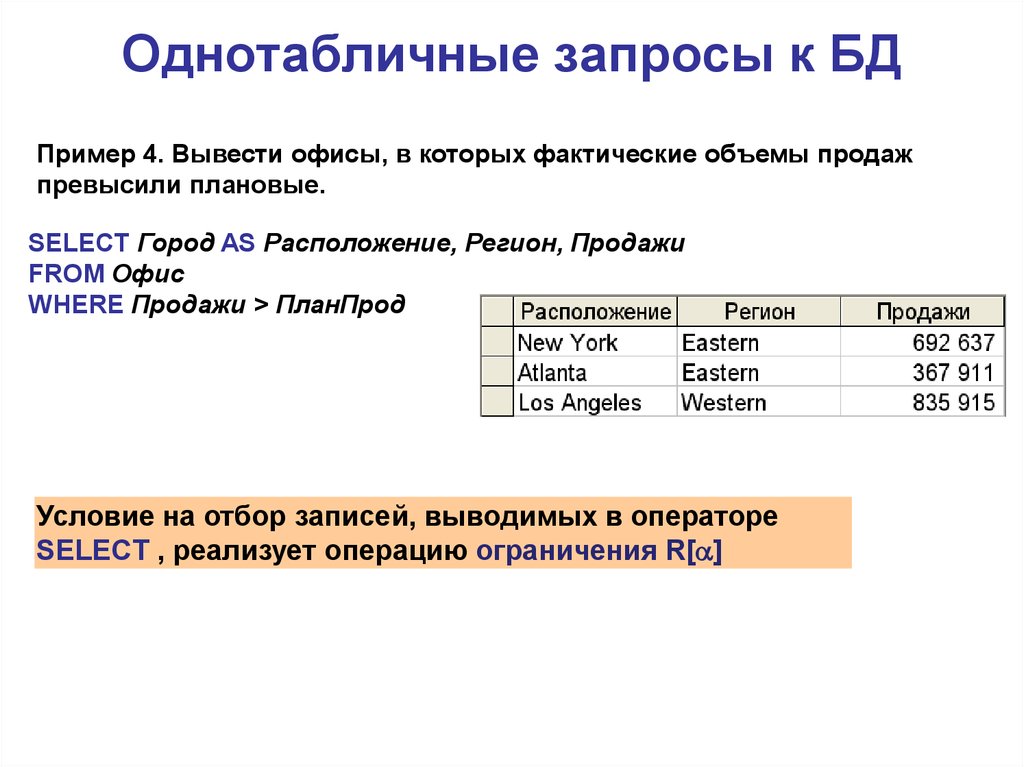 Метод
Метод all()гарантирует, что будет возвращено более одной записи. - Строка 12. Кортеж
carsвместе с их типами отправляется на страницуlist.html, где они отображаются в строках. - Строка 17: В случае ошибки обрабатывается исключение и отображается ошибка.
Пример кода
{% extends 'bootstrap/base.html' %}
{% стилей блоков %}
{{ супер() }} <стиль> тело {фон: #e8f1f9; } {% конечный блок%}
{% заголовок блока %}
Списки типов автомобилей
{% конечный блок%}
{% заблокировать содержимое %} <дел> <дел> <дел>Список автомобилей
Это список всех автомобилей {{ type }} введите наш инвентарь.
<таблица>Название автомобиля Тип Цвет Цена {{ car.