Выполнение запросов — Документация Django 1.9
После создания модели, Django автоматически создает API для работы с базой данных, который позволяет вам создавать, получать, изменять и удалять объекты. Этот раздел расскажет вам как использовать этот API. В описании моделей вы можете найти список всех существующих опций поиска.
В этом разделе(и последующих) мы будем использовать такие модели:
Создание объектов
Для представления данных таблицы в виде объектов Python, Django использует интуитивно понятную систему: класс модели представляет таблицу, а экземпляр модели — запись в этой таблице.
Чтобы создать объект, создайте экземпляр класса модели, указав необходимые поля в аргументах и вызовите метод save() чтобы сохранить его в базе данных.
Предположим, что модель находится в mysite/blog/models.py:
>>> from blog.models import Blog >>> b = Blog(name='Beatles Blog', tagline='All the latest Beatles news.') >>> b.save()
В результате выполнения этого кода будет создан INSERT SQL-запрос. Django не выполняет запросов к базе данных, пока не будет вызван метод save().
Метод save() ничего не возвращает.
См.также
save() принимает ряд аргументов, не описанных в этом разделе. Смотрите документацию о методе save() для подробностей.
Чтобы создать и сохранить объект используйте метод create().
Сохранение изменений в объектах
Для сохранения изменений в объект, который уже существует в базе данных, используйте save().
В данном примере изменяется название объекта Blog и обновляется запись в базе данных:
>>> b5.name = 'New name' >>> b5.save()
В результате выполнения этого кода будет создан UPDATE SQL запрос. Django не выполняет каких либо запросов к базе данных, пока не будет вызван метод save().
Сохранение полей
ForeignKey и ManyToManyFieldОбновление ForeignKey работает так же, как и сохранение обычных полей; просто назначьте полю объект необходимого типа. В этом примере обновляется атрибут blog модели Entry
entry, предполагается что в базе данных уже существуют используемые объекты:>>> from blog.models import Entry >>> entry = Entry.objects.get(pk=1) >>> cheese_blog = Blog.objects.get(name="Cheddar Talk") >>> entry.blog = cheese_blog >>> entry.save()
Обновление ManyToManyField работает немного по-другому; используйте метод add() поля, чтобы добавить связанный объект. В этом примере объект joe модели Author добавляется к объекту entry:
>>> from blog.models import Author >>> joe = Author.objects.create(name="Joe") >>> entry.authors.add(joe)

Для добавления сразу нескольких объектов в ManyToManyField, добавьте несколько аргументов в метод add(). Например:
>>> john = Author.objects.create(name="John") >>> paul = Author.objects.create(name="Paul") >>> george = Author.objects.create(name="George") >>> ringo = Author.objects.create(name="Ringo") >>> entry.authors.add(john, paul, george, ringo)
Django вызовет исключение, если вы попытаетесь добавить объект неверного типа.
Получение объектов
QuerySet через Manager модели.QuerySet представляет выборку объектов из базы данных. Он может не содержать, или содержать один или несколько фильтров – критерии для ограничения выборки по определенным параметрам. В терминах SQL, QuerySet — это оператор SELECT, а фильтры — условия такие, как WHERE или LIMIT.
Вы получаете QuerySet, используя Manager. Каждая модель содержит как минимум один Manager, и он называется objects
>>> Blog.objects
<django.db.models.manager.Manager object at ...>
>>> b = Blog(name='Foo', tagline='Bar')
>>> b.objects
Traceback:
...
AttributeError: "Manager isn't accessible via Blog instances."
Примечание
Обратиться к менеджерам можно только через модель и нельзя через ее экземпляр. Это сделано для разделения “table-level” операций и “record-level” операций.
Manager — главный источник QuerySet для модели. Например, Blog.objects.all() вернет QuerySet, который содержит все объекты Blog из базы данных.
Получение всех объектов
 Для этого используйте метод
Для этого используйте метод all() менеджера(Manager):>>> all_entries = Entry.objects.all()
Метод all() возвращает QuerySet всех объектов в базе данных.
Получение объектов через фильтры
QuerySet, возвращенный Manager, описывает все объекты в таблице базы данных. Обычно вам нужно выбрать только подмножество всех объектов.
Для создания такого подмножества, вы можете изменить QuerySet, добавив условия фильтрации. Два самых простых метода изменить
filter(**kwargs)Возвращает новый
QuerySet, который содержит объекты удовлетворяющие параметрам фильтрации.exclude(**kwargs)Возвращает новый
QuerySetсодержащий объекты, которые не удовлетворяют параметрам фильтрации.
Параметры фильтрации (**kwargs в определении функций выше) должны быть в формате описанном в разделе `Field lookups`_.
Например, для создания QuerySet чтобы получить записи с 2006, используйте
Entry.objects.filter(pub_date__year=2006)
Это аналогично:
Entry.objects.all().filter(pub_date__year=2006)
Цепочка фильтров
Результат изменения QuerySet — это новый QuerySet и можно использовать цепочки фильтров. Например:
>>> Entry.objects.filter( ... headline__startswith='What' ... ).exclude( ... pub_date__gte=datetime.date.today() ... ).filter( ... pub_date__gte=datetime(2005, 1, 30) ... )
В этом примере к начальному QuerySet, который возвращает все объекты, добавляется фильтр, затем исключающий фильтр, и еще один фильтр. Полученный
Отфильтрованный QuerySet – уникален
После каждого изменения QuerySet, вы получаете новый QuerySet, который никак не связан с предыдущим QuerySet. Каждый раз создается отдельный
Каждый раз создается отдельный QuerySet, который может быть сохранен и использован.
Например:
>>> q1 = Entry.objects.filter(headline__startswith="What") >>> q2 = q1.exclude(pub_date__gte=datetime.date.today()) >>> q3 = q1.filter(pub_date__gte=datetime.date.today())
Эти три QuerySets независимы. Первый – это базовый QuerySet, который содержит все объекты с заголовками, которые начинаются с “What”. Второй – это множество первых с дополнительным критерием фильтрации, который исключает объекты с pub_date больше, чем текущая дата. Третий – это множество первого, с отфильтрованными объектами, у которых pub_date больше, чем текущая дата. Первоначальный QuerySet (q1) не изменяется последующим добавлением фильтров.
QuerySets – ленивы
QuerySets – ленивы, создание QuerySet не выполняет запросов к базе данных. Вы можете добавлять фильтры хоть весь день и Django не выполнит ни один запрос, пока  Разберем такой пример:
Разберем такой пример:
>>> q = Entry.objects.filter(headline__startswith="What") >>> q = q.filter(pub_date__lte=datetime.date.today()) >>> q = q.exclude(body_text__icontains="food") >>> print(q)
Глядя на это можно подумать что было выполнено три запроса в базу данных. На самом деле был выполнен один запрос, в последней строке (print(q)). Результат QuerySet не будет получен из базы данных, пока вы не “попросите” об этом. Когда вы делаете это, QuerySet
Получение одного объекта с помощью
getfilter() всегда возвращает QuerySet, даже если только один объект возвращен запросом — в этом случае, это будет QuerySet содержащий один объект.
Если вы знаете, что только один объект возвращается запросом, вы можете использовать метод get() менеджера(Manager), который возвращает непосредственно объект:
>>> one_entry = Entry.objects.get(pk=1)
Вы можете использовать для get() аргументы, такие же, как и для filter() — смотрите `Field lookups`_ далее.
Учтите, что есть разница между использованием get() и filter() с [0]. Если результат пустой, get() вызовет исключение DoesNotExist. Это исключение является атрибутом модели, для которой выполняется запрос. Если в примере выше не существует объекта Entry с первичным ключом равным 1, Django вызовет исключение Entry.DoesNotExist.
Также Django отреагирует, если запрос get() вернет не один объект. В этом случае будет вызвано исключение MultipleObjectsReturned, которое также является атрибутом класса модели.
Другие методы QuerySet
В большинстве случаев вы будете использовать all(), get(), filter() и exclude() для получения объектов из базы данных.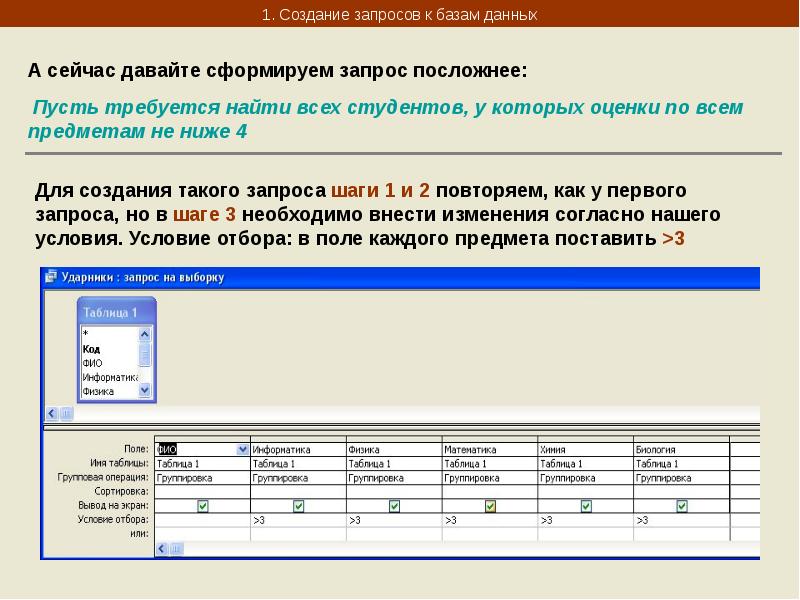 Однако это не все доступные возможности; смотрите документацию о QuerySet API для получения информации о всех существующих методах
Однако это не все доступные возможности; смотрите документацию о QuerySet API для получения информации о всех существующих методах QuerySet.
Ограничение выборки
Используйте синтаксис срезов для списков Python для ограничения результата выборки QuerySet. Это эквивалент таких операторов SQL как LIMIT и OFFSET.
Например, этот код возвращает 5 первых объектов (LIMIT 5):
>>> Entry.objects.all()[:5]
Этот возвращает с шестого по десятый (OFFSET 5 LIMIT 5):
>>> Entry.objects.all()[5:10]
Отрицательные индексы (например, Entry.objects.all()[-1]) не поддерживаются.
На самом деле, срез QuerySet возвращает новый QuerySet – запрос не выполняется. Исключением является использовании “шага” в срезе. Например, этот пример выполнил бы запрос, возвращающий каждый второй объект из первых 10:
>>> Entry.objects.all()[:10:2]
Для получения одного объекта, а не списка (например, SELECT foo FROM bar LIMIT 1), используйте индекс вместо среза. Например, этот код возвращает первый объект Entry в базе данных, после сортировки записей по заголовку:
>>> Entry.objects.order_by('headline')[0]
Это эквивалент:
>>> Entry.objects.order_by('headline')[0:1].get()
Заметим, что первый пример вызовет IndexError, в то время как второй — DoesNotExist, если запрос не вернёт ни одного объекта. Смотрите get() для подробностей.
Фильтры полей
Фильтры полей – это “операторы” для составления условий SQL WHERE. Они задаются как именованные аргументы для метода filter(), exclude() и get() в QuerySet.
Фильтры полей выглядят как field__lookuptype=value. (Используется двойное подчеркивание).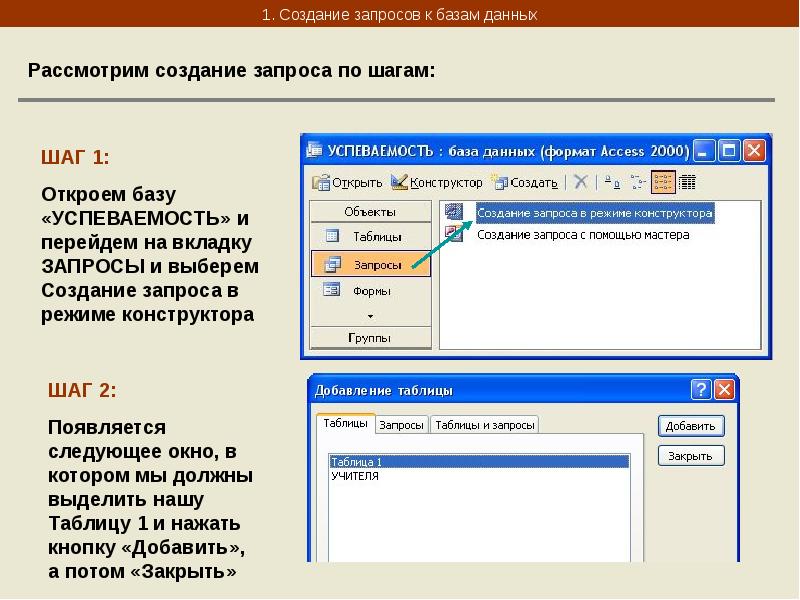 Например:
Например:
>>> Entry.objects.filter(pub_date__lte='2006-01-01')
будет транслировано в SQL:
SELECT * FROM blog_entry WHERE pub_date <= '2006-01-01';
Как это работает
Python позволяет определить функции, которые принимают именованные аргументы с динамически вычисляемыми названиями и значениями. Подробности смотрите в разделе Именованные аргументы в официальной документации Python.
Поля указанные при фильтрации должны быть полями модели. Есть одно исключение, для поля ForeignKey можно указать поле с суффиксом _id. В этом случае необходимо передать значение первичного ключа связанной модели. Например:
>>> Entry.objects.filter(blog_id=4)
При передаче неверного именованного аргумента, будет вызвано исключение TypeError.
API базы данных поддерживает около двух дюжин фильтров; полный список можно найти в разделе о фильтрах полей. Вот пример самых используемых фильтров:
exact“Точное” совпадение.
 Например:
Например:>>> Entry.objects.get(headline__exact="Cat bites dog")
Создаст такой SQL запрос:
SELECT ... WHERE headline = 'Cat bites dog';
Если вы не указали фильтр – именованный аргумент не содержит двойное подчеркивание – будет использован фильтр
exact.Например, эти два выражения идентичны:
>>> Blog.objects.get(id__exact=14) # Explicit form >>> Blog.objects.get(id=14) # __exact is implied
Это сделано для удобства, т.к.
exactсамый распространенный фильтр.iexactРегистронезависимое совпадение. Такой запрос:
>>> Blog.objects.get(name__iexact="beatles blog")
Найдет
Blogс названием"Beatles Blog","beatles blog", и даже"BeAtlES blOG".containsРегистрозависимая проверка на вхождение. Например:
Entry.
 objects.get(headline__contains='Lennon')
objects.get(headline__contains='Lennon')
Будет конвертировано в такой SQL запрос:
SELECT ... WHERE headline LIKE '%Lennon%';
Заметим, что этот пример найдет заголовок
'Today Lennon honored', но не найдет'today lennon honored'.Существуют также регистронезависимые версии,
icontains.startswith,endswithПоиск по началу и окончанию соответственно. Существуют также регистронезависимые версии
istartswithиiendswith.
Это только основные фильтры. Полный список ищите в разделе о фильтрах по полям.
Фильтры по связанным объектам
Django предлагает удобный и понятный интерфейс для фильтрации по связанным объектам, самостоятельно заботясь о JOIN в SQL. Для фильтра по полю из связанных моделей, используйте имена связывающих полей разделенных двойным нижним подчеркиванием, пока вы не достигните нужного поля.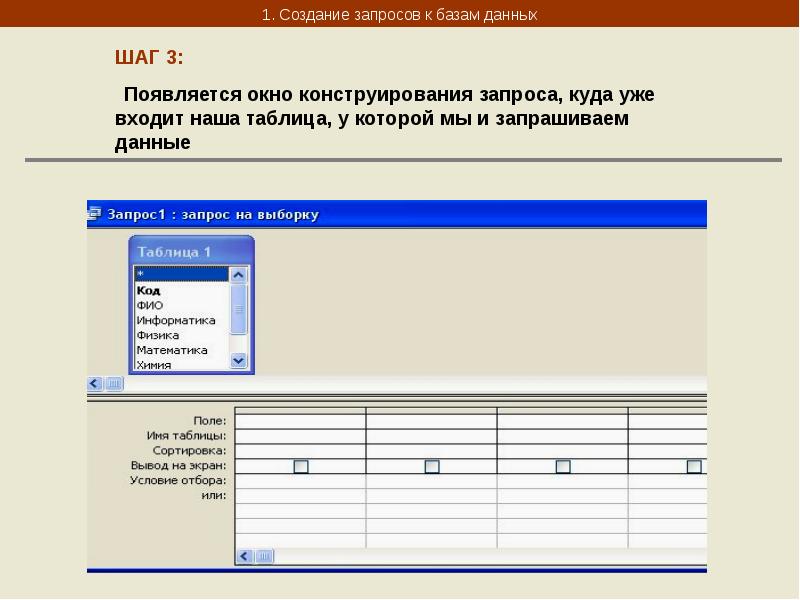
Этот пример получает все объекты Entry с Blog, name которого равен 'Beatles Blog':
>>> Entry.objects.filter(blog__name='Beatles Blog')
Этот поиск может быть столь глубоким, как вам будет угодно.
Все работает и в другую сторону. Чтобы обратиться к “обратной” связи, просто используйте имя модели в нижнем регистре.
Этот пример получает все объекты Blog, которые имеют хотя бы один связанный объект Entry с headline содержащим 'Lennon':
>>> Blog.objects.filter(entry__headline__contains='Lennon')
Если вы используйте фильтр через несколько связей и одна из промежуточных моделей не содержит подходящей связи, Django расценит это как пустое значение (все значения равны NULL). Исключение не будет вызвано. Например, в этом фильтре:
Blog.objects.filter(entry__authors__name='Lennon')
(при связанной модели Author), если нет объекта author связанного с entry, это будет расценено как отсутствие name, вместо вызова исключения т.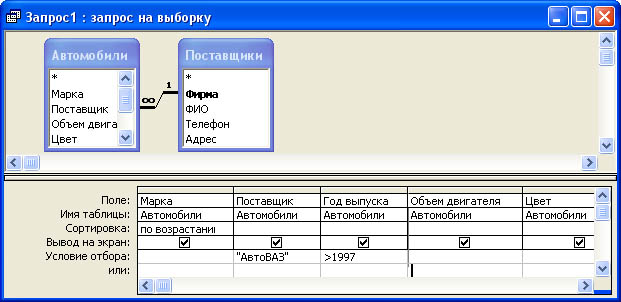 к.
к. author отсутствует. В большинстве случаев это то, что вам нужно. Единственный случай, когда это может работать не однозначно — при использовании isnull. Например:
Blog.objects.filter(entry__authors__name__isnull=True)
вернет объекты Blog у которого пустое поле name у author и также объекты, у которых пустой author``в ``entry. Если вы не хотите включать вторые объекты, используйте:
Blog.objects.filter(entry__authors__isnull=False,
entry__authors__name__isnull=True)
Фильтрация по связям многие-ко-многим
Когда вы используете фильтрацию по связанным через ManyToManyField объектам или по обратной связи для ForeignKey, может быть два вида фильтров. Рассмотрим связь Blog/Entry (от Blog к Entry – это связь один-ко-многим). Нам может понадобиться получить блоги с записями, у которых заголовок содержит “Lennon” и которые были опубликованы в 2008. Или нам могут понадобиться блоги с записями с “Lennon” в заголовке и в то же время блоги с записями опубликованными до 2008. Т.к. один
Или нам могут понадобиться блоги с записями с “Lennon” в заголовке и в то же время блоги с записями опубликованными до 2008. Т.к. один Blog может иметь несколько связанных Entry, оба варианта возможны.
Аналогичная ситуация и с ManyToManyField. Например, если Entry имеет ManyToManyField названное tags, нам могут понадобиться записи связанные с тегами “music” и “bands” или нам может понадобиться запись содержащая тег “music” и статусом “public”.
Чтобы обеспечить оба варианта, Django использует определенные правила для вызовов filter(). Все, что в одном вызове filter(), применяется одновременно, чтобы отфильтровать все объекты, соответствующие этим параметрам фильтрации. Успешные вызовы filter() каждый раз сокращают выборку объектов, но для множественных связей, они применяются каждый раз ко всем связанным объектам, а не только к объектам отфильтрованным предыдущим вызовом filter().
Звучит немного непонятно, но пример должен все прояснить. Для выбора всех блогов, содержащих записи и с “Lennon” в заголовке и опубликованные в 2008 (запись должна удовлетворять оба условия), мы будем использовать такой код:
Blog.objects.filter(entry__headline__contains='Lennon',
entry__pub_date__year=2008)
Для выбора блогов с записями, у которых заголовок содержит “Lennon”, а также с записями опубликованными в 2008, мы напишем:
Blog.objects.filter(entry__headline__contains='Lennon').filter(
entry__pub_date__year=2008)
Предположим, существует только один блог, и в нем есть записи со словом “Lennon” и записи 2008-го года, но ни одна запись 2008-го не содержит слово “Lennon”. Первый запрос вернет пустой ответ, второй запрос — один блог.
В этом примере, первый фильтр ограничит выборку блогами со связанными записями содержащими “Lennon” в заголовке. Второй фильтр далее ограничит выборку блогами с записями, опубликованными в 2008. Записи выбранные вторым фильтром могут быть такими же, как и из первого фильтра, а могут и не быть. Мы фильтруем объекты
Записи выбранные вторым фильтром могут быть такими же, как и из первого фильтра, а могут и не быть. Мы фильтруем объекты Blog с каждым вызовом filter(), а не объекты Entry.
Примечание
Поведение exclude() при запросе, который использует множественную связь, отличается от аналогичных запросов с filter(), поведение которых описано выше. Несколько условий в одном вызове exclude() не обязательно будут применяться к одной записи.
Например, следующий запрос исключит блоги, с записями, у которых заголовок содержит “Lennon”, а также с записями опубликованными в 2008:
Blog.objects.exclude(
entry__headline__contains='Lennon',
entry__pub_date__year=2008,
)
Однако, в отличии от filter(), этот запрос не отфильтрует блоги по записям, которые удовлетворяют двум условиям. Для того, чтобы выбрать все блоги, которые не содержат записи с “Lennon” и опубликованные в 2008, необходимо сделать два запроса:
Blog.objects.exclude( entry=Entry.objects.filter( headline__contains='Lennon', pub_date__year=2008, ), )
Фильтры могут ссылаться на поля модели
В примерах выше мы использовали фильтры, которые сравнивали поля с определенными значениями(константами). Но что, если вы хотите сравнить одно поле с другим полем одной модели?
Django предоставляет класс F для таких сравнений. Экземпляр F() рассматривается как ссылка на другое поле модели. Эти ссылки могут быть использованы для сравнения значений двух разных полей одного объекта модели.
Например, чтобы выбрать все записи, у которых количество комментариев больше, чем “pingback”, мы создаем объект F() с ссылкой на поле “pingback”, и используем этот объект F() в запросе:
>>> from django.db.models import F
>>> Entry.objects.filter(n_comments__gt=F('n_pingbacks'))
Django поддерживает операции суммирования, вычитания, умножения, деления и арифметический модуль для объектов F(), с константами или другими объектами F(). Чтобы найти все записи с количеством комментариев в два раза больше чем “pingbacks”, используем такой запрос:
Чтобы найти все записи с количеством комментариев в два раза больше чем “pingbacks”, используем такой запрос:
>>> Entry.objects.filter(n_comments__gt=F('n_pingbacks') * 2)
Чтобы найти все записи с рейтингом ниже суммы “pingback” и количества комментариев, необходимо выполнить такой запрос:
>>> Entry.objects.filter(rating__lt=F('n_comments') + F('n_pingbacks'))
Вы можете использовать два нижних подчеркивания для использования полей связанных объектов в F(). Объект F() с двойным нижним подчеркиванием обеспечит все необходимые JOIN для получения необходимых связанных объектов. Например, чтобы получить все записи, у которых имя автора совпадает с названием блога, нужно выполнить такой запрос:
>>> Entry.objects.filter(authors__name=F('blog__name'))
Для полей даты и времени вы можете использовать сумму или разницу объектов timedelta. Этот код вернет все записи, которые были отредактированы через 3 дня после публикации:
>>> from datetime import timedelta >>> Entry.objects.filter(mod_date__gt=F('pub_date') + timedelta(days=3))
Объект F() теперь позволяет использовать битовые операции .bitand() и .bitor(), например:
>>> F('somefield').bitand(16)
“Shortcut” для фильтрации по первичному ключу
Для удобства, Django предоставляет специальный фильтр pk для работы с первичным ключом.
Например, первичный ключ модели Blog – поле id. Эти три запроса идентичны:
>>> Blog.objects.get(id__exact=14) # Explicit form >>> Blog.objects.get(id=14) # __exact is implied >>> Blog.objects.get(pk=14) # pk implies id__exact
Использование pk не ограничено только фильтром __exact – любой фильтр может быть использован с pk:
# Get blogs entries with id 1, 4 and 7 >>> Blog.objects.filter(pk__in=[1,4,7]) # Get all blog entries with id > 14 >>> Blog.objects.filter(pk__gt=14)
pk работает также и для связей. Например, эти три запроса идентичны:
>>> Entry.objects.filter(blog__id__exact=3) # Explicit form >>> Entry.objects.filter(blog__id=3) # __exact is implied >>> Entry.objects.filter(blog__pk=3) # __pk implies __id__exact
Экранирование знака процента и нижнего подчеркивания для оператора LIKE
Фильтры, эквивалентные оператору LIKE в SQL(iexact, contains, icontains, startswith, istartswith, endswith и iendswith), автоматически экранируют два символа, используемых оператором LIKE – знак процента и нижнего подчеркивания. (В операторе LIKE, знак процента означает “wildcard” из нескольких символов, нижнего подчеркивания — односимвольный “wildcard”.)
Это делает работу с API интуитивно-понятной. Например, чтобы получить все записи со знаком процента, просто используйте символ знака процента как любой другой символ:
>>> Entry.objects.filter(headline__contains='%')
Django самостоятельно позаботится об экранировании; полученный SQL будет выглядеть приблизительно вот так:
SELECT ... WHERE headline LIKE '%\%%';
Также работает и символ нижнего подчеркивания. Оба, знак процента и нижнего подчеркивания, обрабатываются автоматически, прозрачно для вас.
Кэширование и QuerySets
Каждый QuerySet содержит кэш, для уменьшения количества запросов. Очень важно знать как он работает для эффективного использования Django.
В только что созданном QuerySet кеш пустой. После вычисления QuerySet и будет выполнен запрос к базе данных – Django сохраняет результат запроса в кеше QuerySet и возвращает необходимый результат (например, следующий элемент при итерации по QuerySet). Последующие вычисления QuerySet используют кеш.
Помните о кэшировании, чтобы использовать QuerySet правильно. Например, этот код создаст два экземпляра
Например, этот код создаст два экземпляра QuerySet и вычислит их не сохраняя:
>>> print([e.headline for e in Entry.objects.all()]) >>> print([e.pub_date for e in Entry.objects.all()])
Это означает, что один и тот же запрос будет выполнен дважды, удваивая нагрузку на базу данных. Также, есть вероятность, что списки могут содержать разные результаты, потому что запись Entry может быть добавлена или удалена в доли секунды между запросами.
Чтобы избежать этой проблемы, просто сохраните QuerySet и используйте его повторно:
>>> queryset = Entry.objects.all() >>> print([p.headline for p in queryset]) # Evaluate the query set. >>> print([p.pub_date for p in queryset]) # Re-use the cache from the evaluation.
Когда queryset не кэшируется
Queryset не всегда кэширует результаты. При выполнении только части queryset-а, кэш проверяется, но если кэш пустой, выполняется запрос без сохранения его результата в кэш. Это значит, что ограничение выборки, используя индекс или срез, как при использовании списков, не заполнит кэш.
Это значит, что ограничение выборки, используя индекс или срез, как при использовании списков, не заполнит кэш.
Например, при получении объекта по индексу несколько раз будет каждый раз выполнять запрос к базе данных:
>>> queryset = Entry.objects.all() >>> print queryset[5] # Queries the database >>> print queryset[5] # Queries the database again
Однако, если уже был загружен весь queryset, он будет использоваться для получения значения:
>>> queryset = Entry.objects.all() >>> [entry for entry in queryset] # Queries the database >>> print queryset[5] # Uses cache >>> print queryset[5] # Uses cache
Еще несколько примеров, когда загружается весь queryset и результат сохраняется в кэше:
>>> [entry for entry in queryset] >>> bool(queryset) >>> entry in queryset >>> list(queryset)
Примечание
Использование print с queryset не заполнит кэш т. к. будет вызван
к. будет вызван __repr__(), который показывает только часть объектов.
Сложные запросы с помощью объектов Q
Именованные аргументы функции filter() и др. – объединяются оператором “AND”. Если вам нужны более сложные запросы (например, запросы с оператором OR), вы можете использовать объекты Q.
Объект Q (django.db.models.Q) – объект, используемый для инкапсуляции множества именованных аргументов для фильтрации. Аргументы определяются так же, как и в примерах выше.
Например, этот объект Q определяет запрос LIKE:
from django.db.models import Q Q(question__startswith='What')
Объекты Q могут быть объединены операторами & и |, при этом будет создан новый объект Q.
Например, это определение представляет объект Q, который представляет операцию “OR” двух фильтров с "question__startswith":
Q(question__startswith='Who') | Q(question__startswith='What')
Этот фильтр равнозначен такому оператору SQL WHERE:
WHERE question LIKE 'Who%' OR question LIKE 'What%'
Вы можете комбинировать различные объекты Q с операторами & и | и использовать скобки. Можно использовать оператор
Можно использовать оператор ~ для отрицания(NOT) в запросе:
Q(question__startswith='Who') | ~Q(pub_date__year=2005)
Каждый метод для фильтрации, который принимает именованные аргументы (например, filter(), exclude(), get()get()) также может принимать объекты Q. Если вы передадите несколько объектов Q как аргументы, они будут объединены оператором “AND”. Например:
Poll.objects.get(
Q(question__startswith='Who'),
Q(pub_date=date(2005, 5, 2)) | Q(pub_date=date(2005, 5, 6))
)
… примерно переводится в SQL:
SELECT * from polls WHERE question LIKE 'Who%'
AND (pub_date = '2005-05-02' OR pub_date = '2005-05-06')
Вы можете использовать одновременно объекты Q и именованные аргументы. Все аргументы(будь то именованные аргументы или объекты Q) объединяются оператором “AND”. Однако, если присутствует объект Q, он должен следовать перед именованными аргументами. Например:
Например:
Poll.objects.get(
Q(pub_date=date(2005, 5, 2)) | Q(pub_date=date(2005, 5, 6)),
question__startswith='Who')
… правильный запрос, идентичный предыдущему примеру; но:
# INVALID QUERY
Poll.objects.get(
question__startswith='Who',
Q(pub_date=date(2005, 5, 2)) | Q(pub_date=date(2005, 5, 6)))
… будет неправильный`(Вообще Django здесь не причем. Синтаксис Python не позволяет передавать именованные аргументы перед позиционными – прим. переводчика)`.
Удаление объектов
Метод удаления соответственно называется delete(). Этот метод сразу удаляет объект и возвращает количество удаленных объектов, и словарь с количеством удаленных объектов для каждого типа. Например:
>>> e.delete()
(1, {'weblog.Entry': 1})
Изменено в Django 1.9:Было добавлено возвращение данных об удаленных объектах.
Можно также удалить несколько объектов сразу. Каждый QuerySet имеет метод delete(), который удаляет все объекты из QuerySet.
Например, этот код удаляет все объекты Entry с годом pub_date равным 2005:
>>> Entry.objects.filter(pub_date__year=2005).delete()
(5, {'webapp.Entry': 5})
Учтите, что при любой возможности будет использован непосредственно SQL запрос, то есть метод delete() объекта может и не использоваться при удалении. Если вы переопределяете метод delete() модели и хотите быть уверенным, что он будет вызван, вы должны “самостоятельно” удалить объект модели (например, использовать цикл по QuerySet и вызывать метод delete() для каждого объекта) не используя метод delete() QuerySet.
Было добавлено возвращение данных об удаленных объектах.
При удалении Django повторяет поведение SQL выражения ON DELETE CASCADE – другими словами, каждый объект, имеющий связь(ForeignKey) с удаляемым объектом, будет также удален. Например:
Например:
b = Blog.objects.get(pk=1) # This will delete the Blog and all of its Entry objects. b.delete()
Это поведение можно изменить, определив аргумент on_delete поля ForeignKey.
Метод delete() содержится только в QuerySet и не существует в Manager. Это сделано, чтобы вы случайно не выполнили Entry.objects.delete(), и не удалили все записи. Если вы на самом деле хотите удалить все объекты, сначала явно получите QuerySet, содержащий все записи:
Entry.objects.all().delete()
Изменение нескольких объектов
Если вам понадобиться установить значение поля для всех объектов в QuerySet, используйте метод update(). Например:
# Update all the headlines with pub_date in 2007. Entry.objects.filter(pub_date__year=2007).update(headline='Everything is the same')
Вы можете изменить только обычные поля или ForeignKey, используя этот метод. Для обычных полей просто определите новое значение как константу. Чтобы обновить
Для обычных полей просто определите новое значение как константу. Чтобы обновить ForeignKey, укажите объект связанной модели. Например:
>>> b = Blog.objects.get(pk=1) # Change every Entry so that it belongs to this Blog. >>> Entry.objects.all().update(blog=b)
Метод update() применяется мгновенно и возвращает количество записей, удовлетворяющих запросу(что может быть не равно количеству обновленных записей, если они уже содержат новые значения). Единственное ограничение для изменяемого QuerySet – он может изменять только одну таблицу в базе данных: главную таблицу модели. Вы можете использовать фильтры по связанным полям, но вы можете изменять поля только таблицы изменяемой модели. Например:
>>> b = Blog.objects.get(pk=1) # Update all the headlines belonging to this Blog. >>> Entry.objects.select_related().filter(blog=b).update(headline='Everything is the same')
Учтите, что метод update() использует непосредственно SQL запрос. Это операция для массового изменения. Метод
Это операция для массового изменения. Метод save() модели не будет вызван, сигналы pre_save или post_save не будут вызваны (которые являются следствием вызова save()), аргумент auto_now не будет учтен. Если вы хотите сохранить каждый объект в QuerySet и удостовериться что метод save() вызван для каждого объекта, вы не должны использовать какой-либо специальный метод. Просто используйте цикл и вызовите метод save():
for item in my_queryset:
item.save()
Метод update() может использовать объект F для обновления одного поля значением другого поля модели. Это особенно полезно для изменения счетчика. Например, увеличить значение n_pingbacks на один для каждой записи:
>>> Entry.objects.all().update(n_pingbacks=F('n_pingbacks') + 1)
Однако, в отличии от использования объектов F() в методах filter() и exclude(), вы не можете использовать связанные поля при обновлении. Если вы будете использовать связанное поле в объекте
Если вы будете использовать связанное поле в объекте F(), буде вызвано исключение FieldError:
# THIS WILL RAISE A FieldError
>>> Entry.objects.update(headline=F('blog__name'))
Связанные объекты
Используя связанные объекты в модели (например, ForeignKey, OneToOneField или ManyToManyField), в объект модели будет добавлен API для работы со связанными объектами.
Используя модели из примеров выше, например, объект e модели Entry, может получить связанные объекты Blog используя атрибут blog: e.blog.
(Это все работает благодаря дескрипторам Python. Это совсем не важно и упоминается для любознательных.)
Django также предоставляет доступ к связанным объектам с “другой” стороны – ссылка с связанного объекта на объект, который определяет связь. Например, объект b модели Blog имеет доступ ко всем связанным объектам Entry через атрибут entry_set: b.. entry_set.all()
entry_set.all()
Все примеры в этом разделе используют вышеупомянутые модели Blog, Author и Entry.
Связь один-к-многим
Прямая
Если модель содержит ForeignKey, объект этой модели может получить связанный объект через атрибут модели.
Например:
>>> e = Entry.objects.get(id=2) >>> e.blog # Returns the related Blog object.
Вы можете получить и изменить его через атрибут внешнего ключа. Как вы можете предполагать, изменения не будут сохранены в базу данных, пока не будет вызван метод save(). Например:
>>> e = Entry.objects.get(id=2) >>> e.blog = some_blog >>> e.save()
Если поле ForeignKey содержит null=True (то есть разрешено значение NULL), вы можете указать None для этого поля. Например:
>>> e = Entry.objects.get(id=2) >>> e.blog = None >>> e.save() # "UPDATE blog_entry SET blog_id = NULL ...;"
Прямой доступ для связи один-ко-многим кэширует полученное значение при первом обращении. Последующие обращения к внешнему ключу этого же объекта будут использовать кэшированное значение. Например:
>>> e = Entry.objects.get(id=2) >>> print(e.blog) # Hits the database to retrieve the associated Blog. >>> print(e.blog) # Doesn't hit the database; uses cached version.
Запомните, что вызов метода select_related() QuerySet рекурсивно заполняет кэш значениями для всех связей один-ко-многим. Например:
>>> e = Entry.objects.select_related().get(id=2) >>> print(e.blog) # Doesn't hit the database; uses cached version. >>> print(e.blog) # Doesn't hit the database; uses cached version.
“Обратная” связь
Если модель содержит ForeignKey, будет содержать Manager, который вернет все связанные объекты первой модели. По-умолчанию, этот
По-умолчанию, этот Manager называется FOO_set, где FOO название основной модели в нижнем регистре. Этот Manager возвращает QuerySets, который может быть отфильтрован и изменен как было описано в разделе “Получение объектов”.
Например:
>>> b = Blog.objects.get(id=1) >>> b.entry_set.all() # Returns all Entry objects related to Blog. # b.entry_set is a Manager that returns QuerySets. >>> b.entry_set.filter(headline__contains='Lennon') >>> b.entry_set.count()
Вы можете переопределить название FOO_set, установив параметр related_name при определении ForeignKey. Например, если бы модель Entry содержала blog = ForeignKey(Blog, on_delete=models.CASCADE, related_name='entries'), пример выше выглядел бы как:
>>> b = Blog.objects.get(id=1) >>> b.entries.all() # Returns all Entry objects related to Blog.# b.entries is a Manager that returns QuerySets. >>> b.entries.filter(headline__contains='Lennon') >>> b.entries.count()
Использование своего менеджера для обратных связей
По умолчанию для обратных связей используется менеджер RelatedManager, который является дочерним классом менеджера по умолчанию модели. Чтобы указать свой менеджер, используйте следующий подход:
from django.db import models
class Entry(models.Model):
#...
objects = models.Manager() # Default Manager
entries = EntryManager() # Custom Manager
b = Blog.objects.get(id=1)
b.entry_set(manager='entries').all()
Если EntryManager выполняет фильтрацию в методе get_queryset(), она будет выполнена и при вызове all().
Также вы можете вызывать методы указанного менеджера:
b.entry_set(manager='entries').is_published()
Связь многие-ко-многим
Обе “стороны” связи многое-ко-многим автоматически получают API для работы со связанными объектами. Этот API работает так же, как и “обратный” менеджер для связи один-ко-многим, описанный выше.
Этот API работает так же, как и “обратный” менеджер для связи один-ко-многим, описанный выше.
Единственное отличие: Модель, содержащая ManyToManyField, использует имя атрибута этого поля, в то время, как “обратная” модель использует название, состоящее из названия модели в нижнем регистре плюс '_set' (так же, как и для связи один-ко-многим).
Пример все разъяснит:
e = Entry.objects.get(id=3) e.authors.all() # Returns all Author objects for this Entry. e.authors.count() e.authors.filter(name__contains='John') a = Author.objects.get(id=5) a.entry_set.all() # Returns all Entry objects for this Author.
Так же, как и ForeignKey, ManyToManyField позволяет определить related_name. В примере выше, если поле ManyToManyField модели Entry содержит related_name='entries', тогда каждый объект модели Author будет с атрибутом entries вместо entry_set.
Связь один-к-одному
Связь один-к-одному похожа на связь многое-к-одному. При добавлении OneToOneField в модель, объект этой модели будет содержать ссылку на связанный объект через атрибут модели.
Например:
class EntryDetail(models.Model):
entry = models.OneToOneField(Entry, on_delete=models.CASCADE)
details = models.TextField()
ed = EntryDetail.objects.get(id=2)
ed.entry # Returns the related Entry object.
Разница в обратной связи. Связанная модель также имеет доступ к объекту Manager, но Manager представляет один объект, а не множество объектов:
e = Entry.objects.get(id=2) e.entrydetail # returns the related EntryDetail object
Если ни один объект не добавлен в связь, Django вызовет исключение DoesNotExist.
Объект может быть назначен через обратную связь так же, как и через прямую:
Как работает обратная связь?
Другие ORM требуют определять связь с обеих сторон. Разработчики Django считают, что это противоречит принципу DRY (Don’t Repeat Yourself — не повторяй себя), по этому принципу Django требует определить связь только для одной модели.
Разработчики Django считают, что это противоречит принципу DRY (Don’t Repeat Yourself — не повторяй себя), по этому принципу Django требует определить связь только для одной модели.
Но как это возможно, учитывая, что модель не знает, какие другие модели связаны с ней, пока классы этих моделей не будут загружены?
Все происходит при регистрации приложений. Когда запускается Django, происходит импорт всех приложений из INSTALLED_APPS, далее импорт модуля models этих приложений. Когда создается класс модели, Django добавляет обратные связи для всех связанных моделей. Если связанная модель еще не импортирована, Django запоминает эту модель и добавит связь при ее импорте.
Поэтому важно, чтобы все модели, которые вы используете, находились в приложениях из INSTALLED_APPS. Иначе связи не будут работать.
запросы базы данных — Перевод на английский — примеры русский
На основании Вашего запроса эти примеры могут содержать грубую лексику.
На основании Вашего запроса эти примеры могут содержать разговорную лексику.
позволяет создавать и редактировать запросы базы данных.
Предложить пример
Другие результаты
Команды предназначены для передачи запросов базе данных.
К концу третьего квартала 2005 года ПРООН передаст функции по подаче запросов базе данных по отчетности, с тем чтобы снизить нагрузку на систему.
UNDP will be moving the query execution capability forward to the reporting database by the end of the third quarter of 2005 to reduce the load on the production system. Мастер запросов помогает создавать запросы к базам данных.
Откроется окно для графического создания запроса к базе данных.
This will open a window in which you can graphically create a database query.Запрос далее указывает, что после этих процедур и на дату запроса базы данных на предмет разработки запроса на продление, задача включала 11128 районов площадью 648,4 кв. км, загрязненных противопехотными минами и затрагивающих 2454 общины.
The request further indicates that following these procedures and at the date of querying the database for the development of the extension request, the challenge amounted to 11,128 anti-personnel contaminated areas covering an area of 648.4 square kilometres and impacting 2,454 communities. Были предприняты первоначальные шаги в целях создания всеобъемлющей, открытой для запросов базы данных в области общественной информации в преддверии создания местной районной сети и установления связи ЮНИСЕФ с «Интернетом».
Поскольку эта запись содержит запросы к базе данных, ее также называют «контейнером запросов«.
Сотрудники могут непрерывно направлять запросы в базу данных, даже в ходе загрузки данных.
Так же у нас есть возможность создать дополнительные запросы к базе данных.
Используйте для этого запрос к базе данных или поиск пользователя в dbm-файле.
Perhaps by sending a query to a database, or by looking up the user in a dbm file.
Системные (new) и пользовательские запросы к базе данных используют единый механизм преобразования текста в UNICODE.
System (new and user queries to the database use united a mechanism of the conversion of text in UNICODE.SQL-92 — третья версия языка запросов к базам данных SQL.
Были разработаны запросы к базе данных, чтобы обнаружить свойства корзин.
Продолжая движение вперед, ПРООН переносит механизм генерирования запросов в базу данных по отчетности для снижения нагрузки на эксплуатационную систему.
Moving forward, UNDP is moving the query execution capability to the reporting database to reduce the load on the production system.
Информация, полученная путем текстовых запросов через базу данных РДЕФ, была представлена в качестве подтверждающей документации.
Information generated by queries/scripts from the remote data entry facility database was provided as supporting documentation.ГИП была информирована о помощи, предоставленной на основе запроса в базе данных.
The ISU has been informed that assistance has been provided as a result of a request in the database.Швейцария ведет мониторинг числа посетителей и запросов в базе данных за каждый месяц в качестве критерия осведомленности о швейцарском РВПЗ.
Switzerland monitors the number of visitors and database queries per month as a criterion for awareness about the Swiss PRTR.
Оптимизация коснется, в основном, внешнего вида отображаемых результатов и созданием дополнительных запросов к базе данных.
Optimization touches, mainly the look of the display of results and creation of additional queries to the database.За счет этого упрощается программирование запросов к базе данных.
Как сформировать SQL запросы в Excel? — Разработка на vc.ru
Представьте себе ситуацию, Вы получили целевую выборку из одной базы данных, но для полноты картины, как всегда, нужны дополнительные данные. Проблема может быть в том, что нужная информация хранится в другой базе данных и возможности создать на ней свою таблицу нет, подключиться используя link тоже нельзя, да и количество элементов, по которым нужно получить данные, несколько больше, чем допустимое на данном источнике. Вот и получается, что возможность написать SQL запрос и получить нужные данные есть, но написать придется не один запрос, а потом потратить время на объединение полученных данных.
Вот и получается, что возможность написать SQL запрос и получить нужные данные есть, но написать придется не один запрос, а потом потратить время на объединение полученных данных.
{«id»:158807,»url»:»https:\/\/vc.ru\/dev\/158807-kak-sformirovat-sql-zaprosy-v-excel»,»title»:»\u041a\u0430\u043a \u0441\u0444\u043e\u0440\u043c\u0438\u0440\u043e\u0432\u0430\u0442\u044c SQL \u0437\u0430\u043f\u0440\u043e\u0441\u044b \u0432 Excel?»,»services»:{«facebook»:{«url»:»https:\/\/www.facebook.com\/sharer\/sharer.php?u=https:\/\/vc.ru\/dev\/158807-kak-sformirovat-sql-zaprosy-v-excel»,»short_name»:»FB»,»title»:»Facebook»,»width»:600,»height»:450},»vkontakte»:{«url»:»https:\/\/vk.com\/share.php?url=https:\/\/vc.ru\/dev\/158807-kak-sformirovat-sql-zaprosy-v-excel&title=\u041a\u0430\u043a \u0441\u0444\u043e\u0440\u043c\u0438\u0440\u043e\u0432\u0430\u0442\u044c SQL \u0437\u0430\u043f\u0440\u043e\u0441\u044b \u0432 Excel?»,»short_name»:»VK»,»title»:»\u0412\u041a\u043e\u043d\u0442\u0430\u043a\u0442\u0435″,»width»:600,»height»:450},»twitter»:{«url»:»https:\/\/twitter. com\/intent\/tweet?url=https:\/\/vc.ru\/dev\/158807-kak-sformirovat-sql-zaprosy-v-excel&text=\u041a\u0430\u043a \u0441\u0444\u043e\u0440\u043c\u0438\u0440\u043e\u0432\u0430\u0442\u044c SQL \u0437\u0430\u043f\u0440\u043e\u0441\u044b \u0432 Excel?»,»short_name»:»TW»,»title»:»Twitter»,»width»:600,»height»:450},»telegram»:{«url»:»tg:\/\/msg_url?url=https:\/\/vc.ru\/dev\/158807-kak-sformirovat-sql-zaprosy-v-excel&text=\u041a\u0430\u043a \u0441\u0444\u043e\u0440\u043c\u0438\u0440\u043e\u0432\u0430\u0442\u044c SQL \u0437\u0430\u043f\u0440\u043e\u0441\u044b \u0432 Excel?»,»short_name»:»TG»,»title»:»Telegram»,»width»:600,»height»:450},»odnoklassniki»:{«url»:»http:\/\/connect.ok.ru\/dk?st.cmd=WidgetSharePreview&service=odnoklassniki&st.shareUrl=https:\/\/vc.ru\/dev\/158807-kak-sformirovat-sql-zaprosy-v-excel»,»short_name»:»OK»,»title»:»\u041e\u0434\u043d\u043e\u043a\u043b\u0430\u0441\u0441\u043d\u0438\u043a\u0438″,»width»:600,»height»:450},»email»:{«url»:»mailto:?subject=\u041a\u0430\u043a \u0441\u0444\u043e\u0440\u043c\u0438\u0440\u043e\u0432\u0430\u0442\u044c SQL \u0437\u0430\u043f\u0440\u043e\u0441\u044b \u0432 Excel?&body=https:\/\/vc.
com\/intent\/tweet?url=https:\/\/vc.ru\/dev\/158807-kak-sformirovat-sql-zaprosy-v-excel&text=\u041a\u0430\u043a \u0441\u0444\u043e\u0440\u043c\u0438\u0440\u043e\u0432\u0430\u0442\u044c SQL \u0437\u0430\u043f\u0440\u043e\u0441\u044b \u0432 Excel?»,»short_name»:»TW»,»title»:»Twitter»,»width»:600,»height»:450},»telegram»:{«url»:»tg:\/\/msg_url?url=https:\/\/vc.ru\/dev\/158807-kak-sformirovat-sql-zaprosy-v-excel&text=\u041a\u0430\u043a \u0441\u0444\u043e\u0440\u043c\u0438\u0440\u043e\u0432\u0430\u0442\u044c SQL \u0437\u0430\u043f\u0440\u043e\u0441\u044b \u0432 Excel?»,»short_name»:»TG»,»title»:»Telegram»,»width»:600,»height»:450},»odnoklassniki»:{«url»:»http:\/\/connect.ok.ru\/dk?st.cmd=WidgetSharePreview&service=odnoklassniki&st.shareUrl=https:\/\/vc.ru\/dev\/158807-kak-sformirovat-sql-zaprosy-v-excel»,»short_name»:»OK»,»title»:»\u041e\u0434\u043d\u043e\u043a\u043b\u0430\u0441\u0441\u043d\u0438\u043a\u0438″,»width»:600,»height»:450},»email»:{«url»:»mailto:?subject=\u041a\u0430\u043a \u0441\u0444\u043e\u0440\u043c\u0438\u0440\u043e\u0432\u0430\u0442\u044c SQL \u0437\u0430\u043f\u0440\u043e\u0441\u044b \u0432 Excel?&body=https:\/\/vc. ru\/dev\/158807-kak-sformirovat-sql-zaprosy-v-excel»,»short_name»:»Email»,»title»:»\u041e\u0442\u043f\u0440\u0430\u0432\u0438\u0442\u044c \u043d\u0430 \u043f\u043e\u0447\u0442\u0443″,»width»:600,»height»:450}},»isFavorited»:false}
ru\/dev\/158807-kak-sformirovat-sql-zaprosy-v-excel»,»short_name»:»Email»,»title»:»\u041e\u0442\u043f\u0440\u0430\u0432\u0438\u0442\u044c \u043d\u0430 \u043f\u043e\u0447\u0442\u0443″,»width»:600,»height»:450}},»isFavorited»:false}
2702 просмотров
Выйти из подобной ситуации поможет Excel.
Уверен, что ни для кого не секрет, что MS Excel имеет встроенный модуль VBA и надстройки, позволяющие подключаться к внешним источникам данных, то есть по сути является мощным инструментом для аналитики, а значит идеально подходит для решения подобных задач.
Для того чтобы обойти проблему, нам потребуется таблица с целевой выборкой, в которой содержатся идентификаторы, по которым можно достаточно корректно получить недостающую информацию (это может быть уникальный идентификатор, назовем его ID, или набор из данных, находящихся в разных столбцах), ПК с установленным MS Excel, и доступом к БД с недостающей информацией и, конечно, желание получить ту самую информацию.
Создаем в MS Excel книгу, на листе которой размещаем таблицу с идентификаторами, по которым будем в дальнейшем формировать запрос (если у нас есть уникальный идентификатор, для обеспечения максимальной скорости обработки таблицу лучше представить в виде одного столбца), сохраняем книгу в формате *.xlsm, после чего приступаем к созданию макроса.
Через меню «Разработчик» открываем встроенный VBA редактор и начинаем творить.
Sub job_sql() — Пусть наш макрос называется job_sql.
Пропишем переменные для подключения к БД, записи данных и запроса:
Dim cn As ADODB. Connection
Dim rs As ADODB.Recordset
Dim sql As String
Connection
Dim rs As ADODB.Recordset
Dim sql As String
Опишем параметры подключения:
sql = «Provider=SQLOLEDB.1;Integrated Security=SSPI;Persist Security Info=True;Data Source=Storoge.company.ru\ Storoge.»
Объявим процедуру свойства, для присвоения значения:
Set cn = New ADODB.Connection cn.Provider = » SQLOLEDB.1″ cn.ConnectionString = sql cn.ConnectionTimeout = 0 cn.Open
Вот теперь можно приступать непосредственно к делу.
Организуем цикл:
Как вы уже поняли конечное значение i=1000 здесь только для примера, а в реальности конечное значение соответствует количеству строк в Вашей таблице. В целях унификации можно использовать автоматический способ подсчета количества строк, например, вот такую конструкцию:
В целях унификации можно использовать автоматический способ подсчета количества строк, например, вот такую конструкцию:
Dim LastRow As Long LastRow = ActiveSheet.UsedRange.Row — 1 + ActiveSheet.UsedRange.Rows.Count
Тогда открытие цикла будет выглядеть так:
Как я уже говорил выше MS Excel является мощным инструментом для аналитики, и возможности Excel VBA не заканчиваются на простом переборе значений или комбинаций значений. При наличии известных Вам закономерностей можно ограничить объем выгружаемой из БД информации путем добавления в макрос простых условий, например:
If Cells(i, 2) = «Ваше условие» Then
Итак, мы определились с объемом и условиями выборки, организовали подключение к БД и готовы формировать запрос. Предположим, что нам нужно получить информацию о размере ежемесячного платежа [Ежемесячный платеж] из таблицы [payments].[refinans_credit], но только по тем случаям, когда размер ежемесячного платежа больше 0
Предположим, что нам нужно получить информацию о размере ежемесячного платежа [Ежемесячный платеж] из таблицы [payments].[refinans_credit], но только по тем случаям, когда размер ежемесячного платежа больше 0
sql = «select [Ежемесячный платеж] from [PAYMENTS].[refinans_credit] » & _ «where [Ежемесячный платеж]>0 and [Номер заявки] ='» & Cells(i, 1) & «‘ «
Если значений для формирования запроса несколько, соответственно прописываем их в запросе:
«where [Ежемесячный платеж]>0 and [Номер заявки] = ‘» & Cells(i, 1) & «‘ » & _ » and [Дата платежа]='» & Cells(i, 2) & «‘»
В целях самоконтроля я обычно записываю сформированный макросом запрос, чтобы иметь возможность проверить его корректность и работоспособность, для этого добавим вот такую строчку:
в третьем столбце записываются запросы.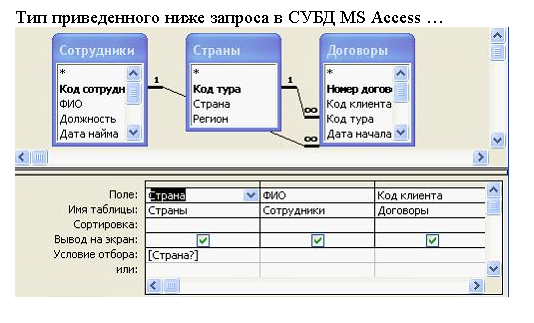
Выполняем SQL запрос:
А чтобы хоть как-то наблюдать за выполнением макроса выведем изменение i в статус-бар
Application.StatusBar = «Execute script …» & i Application.ScreenUpdating = False
Теперь нам нужно записать полученные результаты. Для этого будем использовать оператор Do While:
j = 0 Do While Not rs.EOF For ii = 0 To rs.Fields.Count — 1 Cells(i, 4 + j + ii) = rs.Fields(0 + ii) ‘& «;»
Указываем ячейки для вставки полученных данных (4 в примере это номер столбца с которого начинаем запись результатов)
Next ii
j = j + rs. Fields.Count
s.MoveNext
Loop
rs.Close
End If
Fields.Count
s.MoveNext
Loop
rs.Close
End If
— закрываем цикл If, если вводили дополнительные условия
Next i cn.Close Application.StatusBar = «Готово» End Sub
— закрываем макрос.
В дополнение хочу отметить, что данный макрос позволяет обращаться как к БД на MS SQL так и к БД Oracle, разница будет только в параметрах подключения и собственно в синтаксисе SQL запроса.
В приведенном примере для авторизации при подключении к БД используется доменная аутентификация.
А как быть если для аутентификации необходимо ввести логин и пароль? Ничего невозможного нет. Изменим часть макроса, которая отвечает за подключение к БД следующим образом:
Изменим часть макроса, которая отвечает за подключение к БД следующим образом:
sql = «Provider= SQLOLEDB.1;Password=********;User ID=********;Data Source= Storoge.company.ru\ Storoge;APP=SFM»
Но в этом случае при использовании макроса возникает риск компрометации Ваших учетных данных. Поэтому лучше программно удалять учетные данные после выполнения макроса. Разместим поля для ввода пароля и логина на листе и изменим макрос следующим образом:
sql = «Provider= SQLOLEDB.1;Password=» & Sheets(«Лист аутентификации»).TextBox1.Value & «;UserЛист аутентификации «).TextBox2.Value & «;Data Source= Storoge.company.ru\ Storoge;APP=SFM»
Место для расположения текстовых полей не принципиально, можно расположить их на листе с таблицей в первых строках, но мне удобней размещать поля на отдельном листе. Чтобы введенные учетные данные не сохранялись вместе с результатом выполнения макроса в конце исполняемого кода дописываем:
Чтобы введенные учетные данные не сохранялись вместе с результатом выполнения макроса в конце исполняемого кода дописываем:
Sheets(«Выгрузка»).TextBox1.Value = «« Sheets(»Выгрузка«).TextBox2.Value = »»
То есть просто присваиваем текстовым полям пустые значения, таким образом после выполнения макроса поля для ввода пароля и логина окажутся пустыми.
Вот такое вполне жизнеспособное решение, позволяющее сократить трудозатраты при получении и обработке данных, я использую. Надеюсь мой опыт применения SQL запросов в Excel будет полезен и вам в решении текущих задач.
Понятие и назначение SQL запроса: что такое SQL запрос
Содержание статьи:
Вступление
Для работы с различными реляционными базами данных, включая Oracle, MySQL, PostgreSQL, DBase, FoxPro, Clipper, Paradox был создан единый язык запросов к базам данных. Назвали его язык SQL, что означает Structured Query Language — структурированный язык запросов.
Назвали его язык SQL, что означает Structured Query Language — структурированный язык запросов.
В данной статье используем СУБД MySql. Именно для пользователя, СУБД MySql имеет наибольшее практическое применение, как в управлении различными расширениями, так и в их создании. Как-никак, все локальные сервера, CMS, платформы интернет магазинов работают именно с СУБД MySql.
Понятие и назначение SQL запроса для администрирования БД
Реляционная база данных это таблица с информацией, разнесенной по столбцам (поля или атрибуты) и строкам (записи или кортежи) таблицы. Чтобы изменить или удалить данные в столбцах и строках, а также данные в определенных ячейках (пресечение столбца и строки) можно воспользоваться прикладными инструментами (например, phpmyadmin) или сделать SQL запрос к базе данных, по которому выполнится нужное действие.
Что можно делать с помощью SQL запросов
При помощи запросов SQL можно:
- Создавать таблицы БД;
- Изменять таблицы БД;
- Удалять таблицы БД;
- Вставлять записи (строки) в таблицы БД;
- Редактировать записи в таблицах БД;
- Извлекать выборочную информацию из таблиц БД;
- Удалять выборочную информацию из БД.
Это не полный перечень возможностей SQL запросов, но и он дает представление, что с помощью SQL запросов можно сделать с базой данных всё что необходимо.
Операторы SQL запроса
Язык SQL имеет большой список различных операторов, каждый из которых «задает» определенную команду. Справочник по операторам тут: (http://www.mysql.ru/docs/man/Database_Administration.html/CREATE_TABLE.html). В следующих статьях будем рассматривать, как работают основные операторы SQL и как с их помощью управлять базами данных.
В завершении перечислю, операторы sql запросов, которые будем рассматривать в ближайших статьях раздела:
- CREATE TABLE – оператор sql для создания таблицы базы данных;
- ALTER TABLE – оператор sql для изменения таблицы БД;
- INSERT INTRO – вставка информации (строк) в таблицы БД;
- UPDATE – оператор для редактирования информации в таблицах БД;
- SELECT – извлечение информации из таблиц БД;
- DELET – удаление информации из таблиц БД.

©WebOnTo.ru
Другие статьи раздела: СУБД
Похожие статьи:
Настройка базы данных и клиентов для работы со слоями запросов—Справка
Чтобы создать слой запроса в пространственной базе данных, который будет работать с ArcGIS, вы должны выполнить следующее:
- Вы должны использовать версии системы управления баз данных, поддерживаемые версией ArcGIS, с которой вы работаете. Проверьте на веб-сайте Ресурсного центра ArcGIS требования к системе базы данных для получения информации о поддержке СУБД.
- Определение слоя запроса должно включать уникальный столбец без пустых значений (не null) или комбинацию столбцов, которые будут использоваться как ObjectID в слое запроса. Если в данных, которые вы хотите использовать, таковых не существует, вы должны добавить их. Более подробно см. Выбор поля уникального идентификатора.
- В каждой системе управления базами данных в зависимости от ее типа необходимо выполнить ту или иную конфигурацию, чтобы использовать пространственные типы.

- Необходимо установить и настроить клиенты системы управления базами данных на каждом из клиентских компьютеров, с которых вы планируете создавать подключения с помощью слоев запросов. Клиенты DB2, Informix, PostgreSQL и SQL Server можно загрузить с портала My Esri. Так как для установки программ вы должны иметь права администратора на своем компьютере, свяжитесь со своим ИТ-отделом, чтобы настроить компьютер для подключений слоев запроса (в том случае, если вы не являетесь членом группы администраторов Windows на своем компьютере).
Некоторые из этих задач зависят от типа системы управления базой данных (СУБД) и пространственного типа SQL, который вы хотите использовать. Более подробную информацию для вашей системы управления базами данных см. в следующих разделах:
ALTIBASE
Хотя ALTIBASE имеет пространственный тип, вам потребуется создать две системные таблицы для работы с пространственными данными в ALTIBASE. Для получения информации о создании этих системных таблиц см. раздел Работа с ALTIBASE в ArcGIS.
раздел Работа с ALTIBASE в ArcGIS.
Чтобы подключиться из ArcGIS к ALTIBASE, установите клиент ALTIBASE на компьютер с установленной клиентской частью ArcGIS. Более подробно см. в разделе Подключение к ALTIBASE из ArcGIS.
Базы данных IBM DB2
Чтобы использовать слой запроса для отображения пространственных данных из базы данных DB2, на компьютере, с которого вы будете к ней подключаться, должен быть установлен клиент IBM Data Server Runtime Client.
Установите клиентское приложение DB2 на клиентские компьютеры. Клиенты можно настроить для подключения к определенной базе данных DB2 или для использования строки подключения без имени источника данных (DSN) при подключении из ArcGIS. Скачать клиент IBM Data Server Runtime Client для DB2 вы можете с портала My Esri или обратиться за ним к компании IBM.
Инструкции по установке и настройке клиента см. в документации к DB2.
Базы данных IBM Informix
Чтобы использовать слой запроса для отображения пространственных данных из базы данных Informix, эта база данных должна быть зарегистрирована с Informix Spatial DataBlade, и на компьютере, с которого вы будете к ней подключаться, должен быть установлен и настроен клиент Informix IConnect.
Informix Spatial DataBlade
Для использования пространственного типа ST_Geometry база данных Informix должна быть зарегистрирована в приложении Informix Spatial DataBlade. Если вы не уверены в том, что в базе, к которой вы подключаетесь, доступен тип ST_Geometry, свяжитесь со своим администратором ГИС или администратором базы данных.
Informix IConnect
Установите на клиентский компьютер приложение Informix IConnect и настройте приложение Setnet32. Если вы не используете строку подключения без DSN для подключения к Informix, вы должны настроить подключение Open Database Connectivity (ODBC).
Загрузить клиентское приложение Informix вы можете с портала My Esri либо обратиться к компании IBM. См. документацию IBM Informix для информации об установке и настройке клиента Informix.
Базы данных Microsoft SQL Server
В SQL Server поддерживается два пространственных типа, которые можно использовать в слоях запросов: Geometry и Geography. Они автоматически присутствуют в базах данных SQL Server; вам не придется их устанавливать.
Чтобы использовать слой запроса для отображения пространственных данных из базы данных SQL Server, вы должны установить поддерживаемую версию SQL Server Native Client на ваш клиентский компьютер. Вы можете получить клиент SQL Server Native Client на сайте My Esri или обратиться к компании Microsoft.
Сведения об установке клиента SQL Server Native Client см. в документации к Microsoft SQL Server.
Устройства хранения данных Netezza
Чтобы использовать слой запроса для отображения пространственных данных из базы данных Netezza, вы должны установить пространственный пакет Netezza. Также вам следует установить драйвер Netezza ODBC на ваш компьютер клиента ArcGIS и настроить имя источника данных.
Пространственный пакет Netezza
Вы можете использовать с базой данных Netezza два пакета: устаревший Netezza Spatial Package и Netezza Spatial Esri Package.
Если вы используете устаревший Netezza Spatial Package, то ArcGIS потребуется, чтобы пространственный столбец назывался shape. Если имя столбца не shape, создайте представление таблицы и назначьте пространственному столбцу псевдоним shape.
Если имя столбца не shape, создайте представление таблицы и назначьте пространственному столбцу псевдоним shape.
Выбор пространственного пакета обуславливает требуемые настройки драйвера Netezza ODBC.
Драйвер Netezza ODBC
Вам следует установить драйвер Netezza ODBC на ваш компьютер ArcGIS клиента и настроить имя источника данных. Драйвер Netezza можно получить в IBM. Инструкции по установке и настройке драйвера ODBC см. в документации, предоставленной Netezza.
Если вы используете устаревший пространственный пакет Netezza, то при настройке имени источника данных ODBC выберите опцию Оптимизировать для набора символов ASCII (Optimize for ASCII character set).
Если вы используете Netezza Spatial Esri Package, то при настройке имени источника данных ODBC не включайте опцию Оптимизировать для набора символов ASCII (Optimize for ASCII character set).
Базы данных Oracle
Чтобы использовать слой запроса для отображения пространственных данных из базы данных Oracle, пространственный тип должен быть в базе данных. Также на компьютере, с которого вы будете подключаться к базе данных, должен быть установлен и настроен клиент Oracle.
Также на компьютере, с которого вы будете подключаться к базе данных, должен быть установлен и настроен клиент Oracle.
Пространственные типы в Oracle
В Oracle поддерживается два типа пространства, которые можно использовать в слоях запросов: ST_Geometry и SDO_Geometry.
Пространственный тип ST_Geometry устанавливается при создании многопользовательской базы геоданных Oracle. Также его можно установить в базе геоданных Oracle с помощью инструмента геообработки Создать пространственный тип (Create Spatial Type). Также вы должны конфигурировать Oracle EXTPROC, чтобы использовать ST_Geometry. Ваш ГИС-администратор или администратор базы данных может сказать, сконфигурирована ли база данных для использования пространственного типа. Сведения о настройке EXTPROC см. в разделе Конфигурация Oracle extproc и в документации Oracle.
Объекты Oracle Locator, включая тип SDO_Geometry, по умолчанию присутствуют в базах данных Oracle. Поэтому вы можете обращаться к типу SDO_Geometry без дополнительных установок, но, чтобы иметь доступ к функциям SDO_Geometry, вам может потребоваться установить в базе данных Oracle Spatial.
Клиент Oracle
Установите приложение Oracle Net на ваш клиентский компьютер. Получить клиент Oracle Instant, Runtime или Administrator Client можно от Oracle.
Информацию об установке и настройке клиента Oracle смотрите в наборе документации Oracle.
Базы данных PostgreSQL
Чтобы использовать слой запроса для отображения пространственных данных из базы данных PostgreSQL, пространственный тип должен быть в базе данных. В директории bin клиента ArcGIS, с которого вы будете подключаться к базе данных, должны быть файлы PostgreSQL libpq.
Пространственные типы в PostgreSQL
В PostgreSQL поддерживается два пространственных типа, которые можно использовать в слоях запросов: ST_Geometry и PostGIS Geometry.
Пространственный тип ST_Geometry устанавливается при создании многопользовательской базы геоданных PostgreSQL. Также его можно установить в базе геоданных PostgreSQL с помощью инструмента геообработки Создать пространственный тип (Create Spatial Type).
Тип PostGIS Geometry должен быть установлен отдельно на сервере базы данных PostgreSQL. База данных, которую вы будете использовать, должна быть создана при помощи шаблона базы данных PostGIS или настроена на использование PostGIS, чтобы в ней можно было хранить тип геометрии PostGIS Geometry.
Свяжитесь с вашим ГИС-администратором или администратором базы данных, чтобы установить, сконфигурирована ли база данных для использования этих пространственных типов.
Библиотеки PostgreSQL
ArcGIS for Desktop, ArcGIS for Server и ArcGIS Pro содержат библиотеки, необходимые для подключения к PostgreSQL. Для подключения из приложения ArcGIS Engine, загрузите файлы libpq с My Esri и поместите их в папку bin клиента ArcGIS Engine.
Устройства хранения данных SAP HANA
Пространственные данные хранятся в типе SAP HANA ST_Geometry, который по умолчанию входит в пакет установки хранилища SAP HANA. Чтобы использовать ArcGIS с SAP HANA, установите и настройте SAP HANA ODBC драйвер на клиентском компьютере ArcGIS, который будет подключаться к SAP HANA. Более подробно см. в разделе Подключение к SASP HANA из ArcGIS.
Более подробно см. в разделе Подключение к SASP HANA из ArcGIS.
Базы данных Teradata
Чтобы использовать слой запроса для отображения пространственных данных из базы данных Teradata, на компьютере, с которого вы будете к ней подключаться, должны быть установлены клиент Teradata GSS, библиотека ICU и драйвер ODBC, а также настроен источник данных.
Загрузите библиотеку Teradata ICU, клиент GSS и драйвер ODBC на ваш компьютер ArcGIS клиента (в указанном порядке). Вы можете получить эти файлы от Teradata.
Далее настройте имя источника данных для базы данных Teradata.
См. документацию Teradata для информации об установке файлов клиента и настройке имени источника данных. Также см. раздел Настройка подключения к Teradata (Setting up a connection to Teradata) для изучения специальных опций, которые должны быть выбраны для использования Teradata в ArcGIS.
ArcGIS требует, чтобы пространственный столбец в классе пространственных объектов Teradata назывался shape. Если имя столбца не shape, создайте представление таблицы и назначьте пространственному столбцу псевдоним shape.
Если имя столбца не shape, создайте представление таблицы и назначьте пространственному столбцу псевдоним shape.
Связанные темы
Отзыв по этому разделу?Microsoft Access
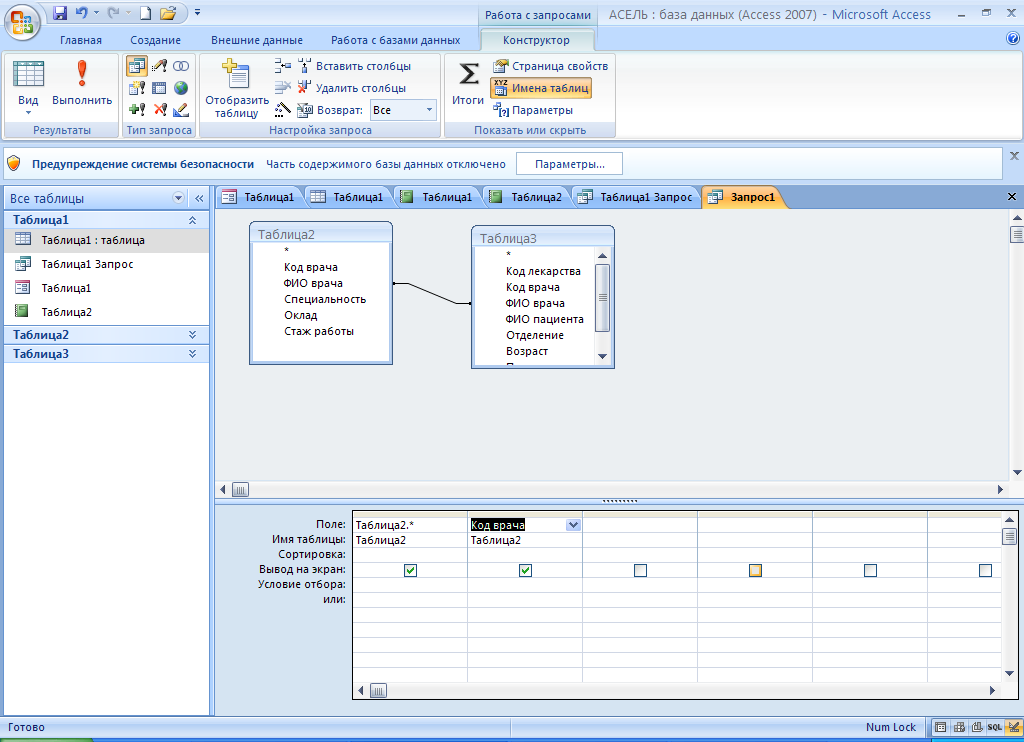
Одним из основных инструментов обработки данных в СУБД Access являются запросы. В Access имеется удобное для пользователя средство формирования запроса по образцу, с помощью которого легко может быть построен сложный запрос.
Запрос позволяет выбрать необходимые данные из одной или нескольких таблиц. Через запрос можно производить обновление данных в таблицах, добавление или удаление записей.
В Access может быть создано несколько видов запроса:
* Запрос на выборку;
* Запрос на создание таблицы;
* Запросы на обновление, добавление, удаление.
Запрос на выборку играет особую роль, так как на его основе строятся запросы другого вида. Запрос на выборку позволяет выбирать данные из одной или нескольких взаимосвязанных таблиц. Результаты выполнения запроса отображаются в виде временной таблицы. Окно запроса в режиме таблицы аналогично окну таблицы БД.
Результаты выполнения запроса отображаются в виде временной таблицы. Окно запроса в режиме таблицы аналогично окну таблицы БД.
Разработка запроса производится в режиме Конструктор запросов. Для создания запроса надо в окне БД выбрать вкладку Запрос и нажать кнопку Создать. В открывшемся окне Новый запрос выбрать Конструктор. В окне Добавление таблицы нужно выбрать таблицы данные из которых используются в запросе и нажать кнопку Добавить. Затем кнопкой Закрыть выйти из окна Добавление таблицы.
В результате появится окно Конструктора запросов : запрос на выборку. Окно Конструктора разделено на две панели. Верхняя панель содержит выбранные таблицы со списками полей. Нижняя панель является бланком запроса по образцу, который надо заполнить.
Каждый столбец бланка запроса относится к одному полю. Поля могут использоваться для включения их в результат выполнения запроса, для задания сортировки по ним, а также для задания условий отбора записей.
При заполнении бланка запроса необходимо:
* В строку Поле включить имена полей, используемых в запросе;
* В строке Вывод на экран отметить поля, которые должны быть включены в результирующую таблицу;
* В строке Условия отбора задать условия отбора записей;
* В строке Сортировка выбрать порядок сортировки записей в результирующей таблице.
Каждый столбец бланка запроса соответствует одному из полей таблиц, на которых строится запрос. Кроме того, здесь может размещаться вычисляемое поле, значение которого вычисляется на основе других полей. Для включения нужных полей из таблиц можно воспользоваться следующими приемами;
* В первой строке бланка запроса Поле щелчком мыши вызвать кнопку списка и, нажав ее, выбрать из списка нужное поле;
* Перетащить нужное поле из списка полей таблицы в строку Поле бланка запроса.
В списке полей каждой таблицы на первом месте стоит символ «*», который означает все поля таблицы. Этот пункт выбирается, если в запрос включаются все поля таблицы.
Этот пункт выбирается, если в запрос включаются все поля таблицы.
Запрос на создание таблицы используется для сохранения результата запроса. Необходимость в сохранении результатов запроса возникает, например, когда невозможно построить запрос непосредственно на другом запросе.
Для создания такого запроса нужно в окне базы данных вызвать нужный запрос в режиме Конструктора. Преобразовать этот запрос в запрос на создание таблицы можно, нажав кнопку Создание таблицы. В окне Создание таблицы нужно ввести имя создаваемой таблицы и нажать ОК.
Конструирование запроса на обновлениеЗапрос на обновление можно построить на основе таблицы созданной запросом на создание таблицы. Для формирования запроса нужно сначала создать запрос на выборку из таблицы. Преобразование этого запроса в запрос на обновление осуществляется нажатием кнопки на Панели инструментов Обновление.
В бланке запроса на обновление в строке Обновление нужно ввести имя поля из обновляемой таблицы в квадратных скобках.
В запросах на обновление можно использовать вычисляемые выражения. Для этого в строке Обновление бланка запроса нужно ввести выражение в виде [поле1] знак действия [поле2].
Конструирование перекрестных запросовПерекрестный запрос позволяющий получить данные в форме, подобной электронной таблице, можно построить в режиме Конструктора. Построение такого запроса начинается с запроса на выборку, после чего на Панели инструментов надо нажать кнопку Перекрестный.
Разновидностью перекрестного запроса является запрос на основе другого запроса. Для этого используются данные из ранее созданного запроса на равном основании с данными из таблиц.
Вернуться на главную
В начало
MS SQL Server и T-SQL
Первый запрос на T-SQL
Последнее обновление: 05.07.2017
В прошлой теме в SQL Management Studio была создана простенькая база данных с одной таблицей. Теперь определим и выполним первый SQL-запрос. Для этого откроем SQL Management Studio, нажмем правой кнопкой мыши на элемент самого верхнего уровня в Object Explorer (название сервера)
и в появившемся контекстном меню выберем пункт New Query:
Для этого откроем SQL Management Studio, нажмем правой кнопкой мыши на элемент самого верхнего уровня в Object Explorer (название сервера)
и в появившемся контекстном меню выберем пункт New Query:
После этого в центральной части программы откроется окно для ввода команд языка SQL.
Выполним запрос к таблице, которая была создана в прошлой теме, в частности, получим все данные из нее. База данных у нас называется university, а таблица — dbo.Students, поэтому для получения данных из таблицы введем следующий запрос:
SELECT * FROM university.dbo.Students
Оператор SELECT позволяет выбирать данные. FROM указывает источник, откуда брать данные. Фактически этим запросом мы говорим «ВЫБРАТЬ все ИЗ таблицы university.dbo.Students». Стоит отметить, что для названия таблицы используется полный ее путь с указанием базы данных и схемы.
После ввода запроса нажмем на панели инструментов на кнопку Execute, либо можно нажать на клавишу F5.
В результате выполнения запроса в нижней части программы появится небольшая таблица, которая отобразит результаты запроса — то есть все данные из таблицы Students.
Если необходимо совершить несколько запросов к одной и той же базе данных, то мы можем использовать команду USE, чтобы зафиксировать базу данных. В этом случае при запросах к таблицам достаточно указать их имя без имени бд и схемы:
USE university SELECT * FROM Students
В данном случае мы выполняем запрос в целом для сервера, мы можем обратиться к любой базе данных на сервере. Но также мы можем выполнять запросы только в рамках конкретной базы данных. Для этого необходимо нажать правой кнопкой мыши на нужную бд и в контекстном меню выбрать пункт New Query:
Если в этом случае мы захотим выполнить запрос к выше использованной таблице Students, то нам не пришлось бы указывать в запросе название базы данных и схему, так как эти значения итак уже были бы понятны:
SELECT * FROM Students
Что такое запрос? Разъяснение запроса к базе данных
Глоссарий
access_time 22 января 2020 г.
3min Read
На обычном английском языке запрос означает запрос информации. Что же тогда такое запрос в компьютерном программировании? Все просто, все то же самое — только информация берется из базы данных. Это удобно для манипулирования данными — добавления, удаления и изменения данных. Вот как мы будем использовать это слово в статье.
Однако вы не просто вводите случайный «запрос». Вы пишете свой запрос на основе набора предопределенного кода, поэтому ваша база данных понимает инструкцию. Мы называем этот код языком запросов.
Стандарт для управления базами данных — это язык структурированных запросов (SQL). Помните, что SQL отличается от MySQL: первый — это язык запросов, второй — это программное обеспечение , которое использует этот язык . Хотя это правда, что SQL — самый популярный выбор среди программного обеспечения для баз данных, он определенно не единственный.Некоторые другие — это AQL, Datalog и DMX.
Тем не менее, эти языки упрощают обмен данными с базами данных.
Приступая к разработке веб-сайтов? Мы предлагаем планы веб-хостинга с полной поддержкой для малого бизнеса и молодых талантливых разработчиков.
Подробнее
Как работает запрос ?Допустим, вы хотите заказать американо в Starbucks. Вы делаете запрос, говоря: «Можно мне американо?». Бариста поймет значение вашего запроса и передаст вам заказанный товар.
Запрос работает точно так же. Это придает смысл коду, используемому на любом языке запросов. Будь то SQL или что-то еще, и пользователь, и база данных всегда могут обмениваться информацией, если они «говорят» на одном языке.
Теперь вы можете подумать, что размещение запроса — единственный способ запросить данные. Фактически, довольно много опций программного обеспечения баз данных позволяют использовать другие методы. Наиболее популярные из них:
- Использование доступных параметров
Программа по умолчанию имеет списки параметров в своем меню.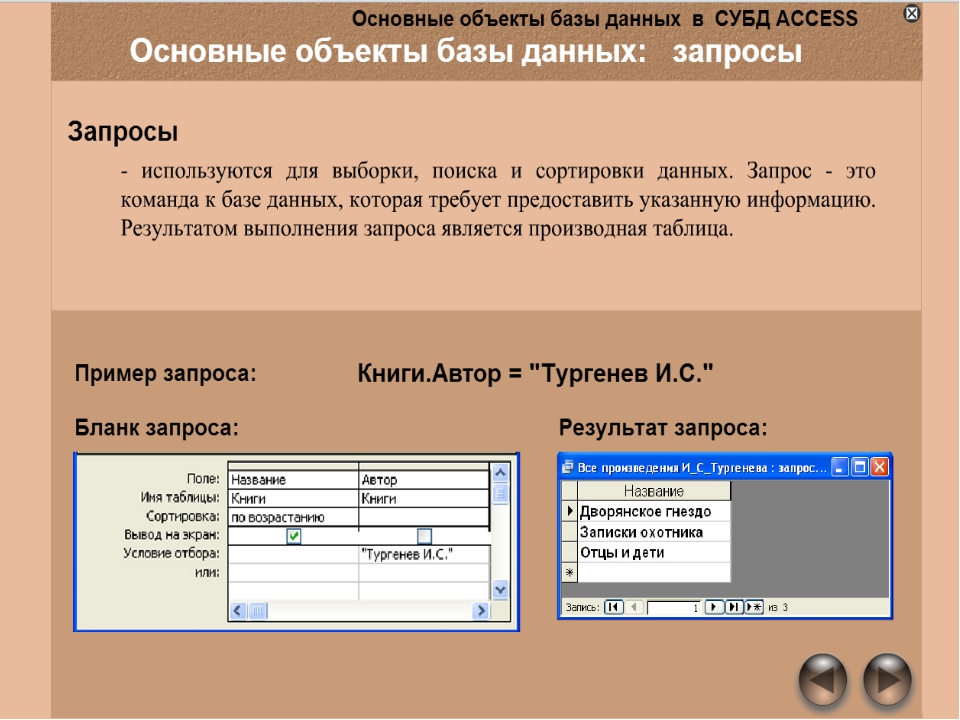 Пользователи могут выбрать один, и система затем поможет вам произвести желаемый результат. Это просто, но не гибко и предлагает ограниченные операции.
Пользователи могут выбрать один, и система затем поможет вам произвести желаемый результат. Это просто, но не гибко и предлагает ограниченные операции. - Запрос на примере
Система покажет вам набор кода с некоторыми пустыми областями, в которых вы можете написать и указать поля и значения ваших данных. - Язык запроса
Это то, о чем мы говорили. Вы должны писать запросы с нуля, когда хотите манипулировать данными. Этот метод требует понимания языка запросов, используемого вашим программным обеспечением базы данных.Хотя это сложно, он дает вам полный контроль над вашими данными.
Теперь, когда мы довольно много знаем о запросах, почему бы не попробовать написать их? Имейте в виду, что для этого упражнения мы используем SQL.
Источник данных : Участник (название таблицы)
Допустим, вы собрали некоторые данные из опроса. Ниже приведен фрагмент ваших данных.
| ID | Имя | Пол | Возраст | Род занятий | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 1 | Джон | Мужчина | 17 | Студент | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 2 | Питер | Мужской | 26 | Безработный | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 3 | Маргарет | Женский | 34 | Учитель | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 4 | Lea | Женский | 34 | Безработный | 9090

| Имя | Род занятий |
| Джон | Студент |
| Питер | Безработный |
| Маргарет | Учитель |
| Леа | Безработный |
- Удаление данных о безработных респондентах.
Заявление SQL :
УДАЛИТЬ ОТ участника, ГДЕ Профессия = «Безработный»
Вывод :ID Имя Пол Возраст Род занятий 1 Джон Мужской 17 Студент 3 Маргарет Женский 34 Учитель - Вставка новой строки, содержащей участника по имени Марио.

Заявление SQL :
ВСТАВИТЬ участника (идентификатор, имя, пол, возраст, род занятий) ЗНАЧЕНИЯ (‘5’, ‘Марио’, ‘Мужской’, ’67’, ‘На пенсии’)
Выходные данные :ID Имя Пол Возраст Род занятий 1 Джон Мужчина 17 Студент 2 Питер Мужской 26 Безработный 3 Маргарет Женский 34 Учитель 4 Lea Женский 34 Безработный 5 Марио Мужской 67 Пенсионер - Изменение профессии Маргарет на «Директор».
Заявление SQL :
UPDATE Участник SET Занятие = ‘Директор’ WHERE ID = ‘3’
Выходные данные :ID Имя Пол Возраст Род занятий 1 Джон Мужчина 17 Студент 2 Питер Мужчина 26 Безработный 3 Маргарет Женщина 34 Директор школы 4 Lea Женский 34 Безработный
Некоторые операторы SQL, подобные приведенным выше, являются твердым свидетельством того, что язык запросов может.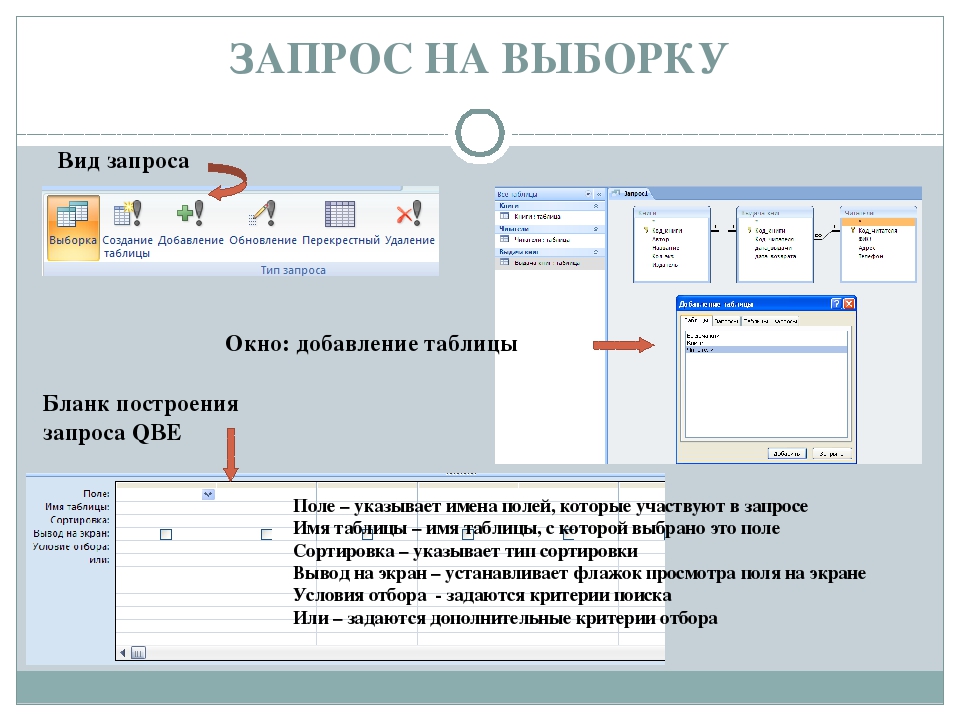 Это позволяет вам работать с вашими данными более эффективно. Представьте, что у вас есть тысячи строк данных. Управлять ими не должно быть сложно. Кроме того, большинство языков запросов интуитивно понятны, что означает, что их легко изучить, если вы поймете некоторые основные правила. Давайте запачкаем руки запросами к базе данных и разберемся с данными как профессионалы!
Это позволяет вам работать с вашими данными более эффективно. Представьте, что у вас есть тысячи строк данных. Управлять ими не должно быть сложно. Кроме того, большинство языков запросов интуитивно понятны, что означает, что их легко изучить, если вы поймете некоторые основные правила. Давайте запачкаем руки запросами к базе данных и разберемся с данными как профессионалы!
Введение в запросы к базе данных | edX
Это 1-й курс вводного курса для студентов бакалавриата, который составляет более крупную программу MicroBachelors «Введение в базы данных».Мы рекомендуем рассматривать их по порядку, если только у вас нет опыта в этих областях и вы не чувствуете себя комфортно, пропуская вперед.
- Введение в базы данных
- Расширенные запросы к базе данных
- Расширенное администрирование баз данных
Эти темы основаны на знаниях, которые преподаются в программе MicroBachelors «Основы компьютерных наук» вводного уровня, предлагаемой тем же преподавателем.
Этот курс представляет собой введение в основные концепции, модели организации и реализации баз данных с упором на реляционную модель.Среди затронутых тем — разработка простых запросов, которые извлекают и изменяют данные в базе данных. Язык манипулирования данными (DML) — это подмножество языка SQL, которое используется разработчиками баз данных для создания, поддержки и запроса фактов в базе данных. Студенты получают полное представление о синтаксисе DML и опциях, доступных при извлечении фактов из базы данных. Навыки разработки и администрирования баз данных требуются для выполнения большинства работ в области информационных технологий, разработки программного обеспечения, кибербезопасности и информатики.В курсе используется реляционная база данных MySQL с открытым исходным кодом. MySQL и его форк с открытым исходным кодом MariaDB используются в миллионах веб-приложений для сохранения данных приложения и обеспечения обработки запросов. Прикладные лабораторные работы по SQL расширяют возможности аудиторных лекций, чтобы предоставить студентам практический опыт работы с системой управления реляционными базами данных (СУБД) и языком структурированных запросов (SQL).
Если вы успешно завершите все курсы в рамках программы с проходной оценкой 70% или выше по проверенной (платной) трассе, вы не только получите сертификат, подтверждающий ваше достижение, но также сможете получить реальный колледж. кредит (включен в цену!), который вы можете засчитать для получения степени бакалавра.
Учебное пособие по SQL
SQL — стандартный язык для хранения, обработки и извлечения данных. в базах данных.
Наш учебник по SQL научит вас использовать SQL в: MySQL, SQL Server, MS Access, Oracle, Sybase, Informix, Postgres и другие системы баз данных.
Начните изучать SQL прямо сейчас »Примеры в каждой главе
С помощью нашего онлайн-редактора SQL вы можете редактировать операторы SQL и щелкать кнопку, чтобы просмотреть результат.
Щелкните кнопку «Попробуйте сами», чтобы увидеть, как это работает.
Упражнения SQL
Примеры SQL
Учись на примерах! Этот учебник дополняет все пояснения поясняющими примерами.
Просмотреть все примеры SQL
Тест-викторина по SQL
Проверьте свои навыки SQL в W3Schools!
Начать тест по SQL!
Ссылки на SQL
На W3Schools вы найдете полный справочник по ключевым словам и функциям:
Справочник по ключевым словам SQL
Функции MYSQL
Функции SQLServer
Функции доступа MS
Краткий справочник по SQL
Типы данных SQL
Типы данных и диапазоны для Microsoft Access, MySQL и SQL Server.
Типы данных SQL
Экзамен по SQL — получите свой диплом!
Интернет-сертификация W3Schools
Идеальное решение для профессионалов, которым необходимо совмещать работу, семью и карьеру.
Уже выдано более 30 000 сертификатов!
Получите сертификат »
Сертификат HTML документирует ваши знания HTML.
Сертификат CSS документирует ваши знания в области CSS.
Сертификат JavaScript документирует ваши знания JavaScript и HTML DOM.
Сертификат Python документирует ваши знания Python.
Сертификат Data Science Certificate документирует ваши знания в области Data Science.
Сертификат jQuery подтверждает ваши знания о jQuery.
Сертификат SQL документирует ваши знания SQL.
Сертификат PHP подтверждает ваши знания PHP и MySQL.
Сертификат Java документирует ваши знания Java.
Сертификат XML документирует ваши знания XML, XML DOM и XSLT.
Сертификат Bootstrap документирует ваши знания о среде Bootstrap.
Что такое определение запроса к базе данных?
Запрос к базе данных извлекает данные из базы данных и форматирует их в удобочитаемую форму. Запрос должен быть написан с использованием синтаксиса, необходимого для базы данных — обычно это вариант языка структурированных запросов.
Элементы SQL-запроса
alexsl / Getty Images Запросы SQL с использованием языка манипулирования данными (набор операторов SQL, которые обращаются к данным или изменяют их, в отличие от языка определения данных, который изменяет структуру самой базы данных) состоят из четырех блоков, первые два из которых не являются необязательными.
Как минимум, SQL-запрос имеет следующую форму:
выберите X из Y;
Здесь ключевое слово select определяет, какую информацию вы хотите отобразить, а ключевое слово из определяет, откуда эти данные и как эти источники данных связаны друг с другом. Необязательно, , где оператор устанавливает критерии ограничения, а группирует по и порядок по операторам связывает значения и отображает их в определенной последовательности.
Например:
ВЫБЕРИТЕ emp.ssn, emp.last_name, dept.department_name
ИЗ сотрудников emp ЛЕВОЕ ВНЕШНЕЕ СОЕДИНЕНИЕ отделов dept
ON emp.dept_no = dept.dept_no
WHERE emp.active_flag = 'Y'
ORDER BY 2 ASC;
Результатом этого запроса является сетка, которая показывает номер социального страхования, фамилию сотрудника и название отдела в указанном порядке столбцов, взятые из таблиц сотрудников и департаментов . Таблица сотрудников управляет, поэтому она будет показывать имена отделов только при наличии соответствующего поля номера отдела в обеих таблицах (левое внешнее соединение — это метод связывания таблиц, в котором в левой таблице отображаются все результаты и только совпадающие результаты из появится правая таблица).Кроме того, в сетке отображаются только сотрудники, активный флаг которых установлен на Y , а результат сортируется в порядке возрастания по названию отдела.
Таблица сотрудников управляет, поэтому она будет показывать имена отделов только при наличии соответствующего поля номера отдела в обеих таблицах (левое внешнее соединение — это метод связывания таблиц, в котором в левой таблице отображаются все результаты и только совпадающие результаты из появится правая таблица).Кроме того, в сетке отображаются только сотрудники, активный флаг которых установлен на Y , а результат сортируется в порядке возрастания по названию отдела.
Но все это исследование данных начинается с оператора select .
Оператор SQL SELECT
SQL использует оператор SELECT для выбора или извлечения определенных данных.
Рассмотрим пример, основанный на базе данных Northwind, которая часто поставляется с продуктами баз данных в качестве учебного пособия.Вот выдержка из таблицы сотрудников базы данных:
| EmployeeID | Фамилия | Имя | Название | Адрес | Город | Регион |
|---|---|---|---|---|---|---|
| 1 | Даволио | Нэнси | Торговый представитель | 20-я авеню 507, E. | Сиэтл | WA |
| 2 | Фуллер | Андрей | Вице-президент по продажам | 908 Вт.Capital Way | Такома | WA |
| 3 | Рычаг | Джанет | Торговый представитель | 722 Moss Bay Blvd. | Киркланд | WA |
Чтобы вернуть имя и должность сотрудника из базы данных, оператор SELECT будет выглядеть примерно так:
ВЫБЕРИТЕ FirstName, LastName, Title ОТ сотрудников;
Он вернется:
| Имя | Фамилия | Название |
|---|---|---|
| Нэнси | Даволио | Торговый представитель |
| Андрей | Фуллер | Вице-президент по продажам |
| Джанет | Рычаг | Торговый представитель |
Для дальнейшего уточнения результатов вы можете добавить предложение WHERE:
ВЫБЕРИТЕ Имя, Фамилию ОТ Сотрудников
ГДЕ Город = 'Такома';
Он возвращает имя и фамилию любого сотрудника из Такомы:
| Имя | Фамилия |
|---|---|
| Андрей | Фуллер |
SQL возвращает данные в виде строк и столбцов, аналогичных Microsoft Excel, что упрощает просмотр и работу с ними. Другие языки запросов могут возвращать данные в виде графика или диаграммы.
Другие языки запросов могут возвращать данные в виде графика или диаграммы.
Сила запросов
База данных может выявлять сложные тенденции и действия, но эта сила может быть задействована только при использовании запроса. Сложная база данных состоит из множества таблиц, в которых хранится большой объем данных. Запрос позволяет отфильтровать данные в единую таблицу, чтобы облегчить ее анализ.
Запросы также могут выполнять вычисления с вашими данными или автоматизировать задачи управления данными.Вы также можете просмотреть обновления своих данных, прежде чем вносить их в базу данных.
Спасибо, что сообщили нам!
Расскажите, почему!
Другой Недостаточно деталей Трудно понятьЧто такое запрос? — Определение из Техопедии
Для того, чтобы машина в первую очередь могла понять запрос информации, запрос должен быть написан в соответствии с кодом, известным как язык запросов. Например, если вы идете в банк и спрашиваете: «Можно мне эспрессо?» кассир может быть озадачен.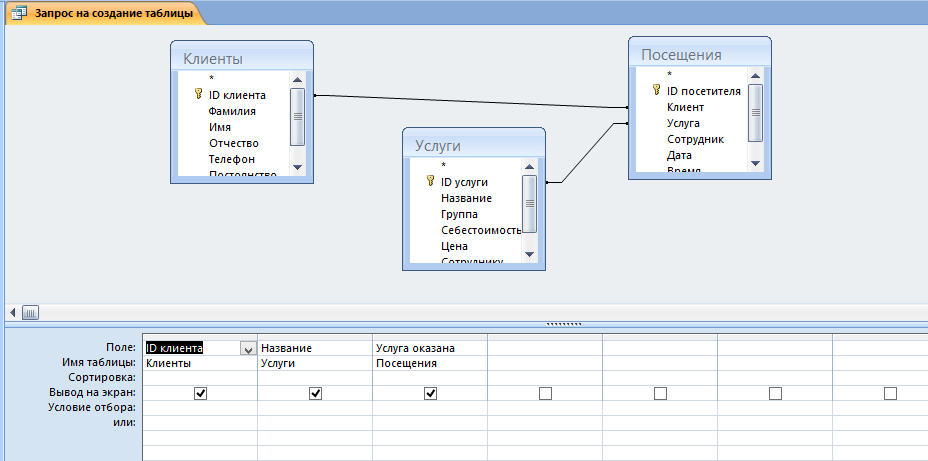
SQL представляет собой один из стандартных языков, используемых для управления базами данных, а MySQL — это программное обеспечение, использующее этот конкретный язык. Хотя SQL является довольно универсальным языком запросов, другие часто используемые языки включают DMX, Datalog и AQL.
Возможность запроса базы данных по необходимости равна возможности хранения данных. Таким образом, был разработан ряд языков запросов для различных механизмов и целей баз данных, но на сегодняшний день SQL является наиболее распространенным и известным.Фактически, начинающие администраторы баз данных часто удивляются, когда узнают о существовании других языков запросов.
Языки запросов генерируют разные типы данных в зависимости от функции. Например, SQL возвращает данные в аккуратных строках и столбцах и очень похож на Microsoft Excel по внешнему виду.
Другие языки запросов генерируют данные в виде графиков или других сложных манипуляций с данными, например, интеллектуального анализа данных, который представляет собой глубокий анализ информации, который выявляет ранее неизвестные тенденции и отношения между отдельными или расходящимися данными. Например, запрос компании-производителя SQL может показать, что месячный пик продаж приходится на июнь и июль, или что торговые представители-женщины постоянно превосходят своих коллег-мужчин в праздничные месяцы.
Например, запрос компании-производителя SQL может показать, что месячный пик продаж приходится на июнь и июль, или что торговые представители-женщины постоянно превосходят своих коллег-мужчин в праздничные месяцы.
Запросы к базе данных могут выполнять менее опытные пользователи, не обученные конкретному языку запросов. Использование предопределенного запроса, написанного на специальном языке запросов, для выполнения запроса — не единственный способ запросить информацию из базы данных.
Пользователь может выбрать доступные параметры из меню по умолчанию, которое поможет ему или ей в процессе поиска.Это простой, но менее гибкий метод. Система также может предоставить пользователю запись по умолчанию, в которой несколько пустых областей могут быть заполнены полями и значениями, определяющими запрос. Этот метод называется «запрос по примеру» (QBE).
запросов к базе данных — базы данных
Базы данных поддерживают необработанный SQL или построение запросов с использованием ядра SQLAlchemy.
Таблица объявлений
Если вы хотите делать запросы с использованием ядра SQLAlchemy, вам необходимо объявить ваши таблицы в коде.В любом случае это хорошая практика, поскольку намного проще синхронизировать схему базы данных с кодом, который обращается к Это. Он также позволяет использовать инструменты миграции базы данных для управления изменениями схемы.
импорт sqlalchemy
метаданные = sqlalchemy.MetaData ()
заметки = sqlalchemy.Table (
"заметки",
метаданные,
sqlalchemy.Column ("идентификатор", sqlalchemy.Integer, primary_key = True),
sqlalchemy.Column ("текст", sqlalchemy.String (length = 100)),
sqlalchemy.Column ("завершено", sqlalchemy.Булево),
)
Вы можете использовать любой из типов столбцов sqlalchemy, например sqlalchemy.JSON или
настраиваемые типы столбцов.
запросов
Теперь вы можете использовать любые основные запросы SQLAlchemy (официальное руководство).
из базы данных Импорт базы данных
database = База данных ('postgresql: // localhost / example')
# Установить пул соединений
ждать database. connect ()
# Выполнить
query = notes.insert ()
values = {"text": "example1", "completed": True}
ждите базу данных.выполнить (запрос = запрос, значения = значения)
# Выполнить много
query = notes.insert ()
значения = [
{"текст": "пример2", "завершено": ложь},
{"text": "example3", "completed": True},
]
await database.execute_many (запрос = запрос, значения = значения)
# Получить несколько строк
query = notes.select ()
rows = await database.fetch_all (запрос = запрос)
# Получить одну строку
query = notes.select ()
row = await database.fetch_one (запрос = запрос)
# Получить одно значение, по умолчанию `column = 0`.
query = notes.select ()
значение = ожидание базы данных.fetch_val (запрос = запрос)
# Получить несколько строк, не загружая их все сразу в память
query = notes.select ()
async для строки в database.iterate (query = query):
...
# Закройте все соединения в пуле соединений
ждать database.disconnect ()
connect ()
# Выполнить
query = notes.insert ()
values = {"text": "example1", "completed": True}
ждите базу данных.выполнить (запрос = запрос, значения = значения)
# Выполнить много
query = notes.insert ()
значения = [
{"текст": "пример2", "завершено": ложь},
{"text": "example3", "completed": True},
]
await database.execute_many (запрос = запрос, значения = значения)
# Получить несколько строк
query = notes.select ()
rows = await database.fetch_all (запрос = запрос)
# Получить одну строку
query = notes.select ()
row = await database.fetch_one (запрос = запрос)
# Получить одно значение, по умолчанию `column = 0`.
query = notes.select ()
значение = ожидание базы данных.fetch_val (запрос = запрос)
# Получить несколько строк, не загружая их все сразу в память
query = notes.select ()
async для строки в database.iterate (query = query):
...
# Закройте все соединения в пуле соединений
ждать database.disconnect ()
Подключения управляются как локальное состояние задачи с реализациями драйверов
прозрачно, используя пул соединений за кулисами.
Необработанные запросы
В дополнение к основным запросам SQLAlchemy вы также можете выполнять необработанные запросы SQL:
# Execute
query = "ВСТАВИТЬ примечания (текст, завершено) ЗНАЧЕНИЯ (: текст,: завершено)"
values = {"text": "example1", "completed": True}
ждите базу данных.выполнить (запрос = запрос, значения = значения)
# Выполнить много
query = "ВСТАВИТЬ примечания (текст, завершено) ЗНАЧЕНИЯ (: текст,: завершено)"
значения = [
{"текст": "пример2", "завершено": ложь},
{"text": "example3", "completed": True},
]
await database.execute_many (запрос = запрос, значения = значения)
# Получить несколько строк
query = "ВЫБРАТЬ * ИЗ заметок, ГДЕ завершено =: завершено"
rows = await database.fetch_all (query = query, values = {"completed": True})
# Получить одну строку
query = "ВЫБРАТЬ * ИЗ примечаний WHERE id =: id"
результат = ожидание базы данных.fetch_one (query = query, values = {"id": 1})
Обратите внимание, что аргументы запроса должны соответствовать стилю : query_arg .
запросов к базе данных с R
Существует множество способов запроса данных с помощью R. В этой статье показаны три наиболее распространенных способа:
- Использование
DBI - Использование
dplyrсинтаксис - Использование ноутбуков R
Фон
Несколько недавних улучшений пакета упрощают использование баз данных с R.Примеры запросов ниже демонстрируют некоторые возможности этих пакетов R.
- DBI. Спецификация
DBIв последнее время претерпела множество улучшений. При работе с базами данных вы всегда должны использовать пакеты, соответствующие стандартуDBI. - dplyr и
dbplyr. Пакетdplyrтеперь имеет общий SQL-сервер для взаимодействия с базами данных, а новый пакетdbplyrпереводит код R в варианты, специфичные для базы данных. На момент написания этой статьи варианты SQL поддерживаются для следующих баз данных: Oracle, Microsoft SQL Server, PostgreSQL, Amazon Redshift, Apache Hive и Apache Impala. Со временем последуют другие.
На момент написания этой статьи варианты SQL поддерживаются для следующих баз данных: Oracle, Microsoft SQL Server, PostgreSQL, Amazon Redshift, Apache Hive и Apache Impala. Со временем последуют другие. - odbc. Пакет
odbcR предоставляет стандартный способ подключения к любой базе данных, если у вас установлен драйвер ODBC. ПакетodbcR соответствует стандартуDBIи рекомендуется для соединений ODBC.
RStudio также недавно улучшила свои продукты, чтобы они лучше работали с базами данных.
- RStudio IDE (версия 1.1). С помощью последней версии RStudio IDE вы можете подключаться, исследовать и просматривать данные в различных базах данных. В среде IDE есть мастер для настройки новых подключений и вкладка для изучения установленных подключений. Эти новые функции являются расширяемыми и будут работать с любым пакетом R, имеющим контракт на подключение.
- RStudio Профессиональные драйверы. Если вы используете профессиональные продукты RStudio, вы можете загрузить профессиональные драйверы RStudio без дополнительных затрат.
 В приведенных ниже примерах используется драйвер Oracle ODBC. Если вы используете инструменты с открытым исходным кодом, вы можете принести свой собственный драйвер или использовать пакеты сообщества — существует множество драйверов с открытым исходным кодом и пакетов сообщества для подключения к различным базам данных.
В приведенных ниже примерах используется драйвер Oracle ODBC. Если вы используете инструменты с открытым исходным кодом, вы можете принести свой собственный драйвер или использовать пакеты сообщества — существует множество драйверов с открытым исходным кодом и пакетов сообщества для подключения к различным базам данных.
Использование баз данных с R — обширная тема, и предстоит еще много работы. Наше видение обсуждалось в предыдущем сообщении в блоге.
Пример: запрос данных банка в базе данных Oracle
В этом примере мы будем запрашивать банковские данные в базе данных Oracle.Мы подключаемся к базе данных с помощью пакетов DBI и odbc . Для этого конкретного подключения требуется драйвер базы данных и имя источника данных (DSN), которые были настроены системным администратором. Ваше соединение может использовать другой метод.
библиотека (DBI)
библиотека (dplyr)
библиотека (dbplyr)
библиотека (odbc)
con <- dbConnect (odbc :: odbc (), "Oracle DB") 1. Запрос с использованием
DBI Вы можете запросить данные с помощью DBI , используя функцию dbGetQuery () .Просто вставьте свой код SQL в функцию R в виде строки в кавычках. Этот метод иногда называют пропуском через код SQL , и это, вероятно, самый простой способ запросить ваши данные. Следует проявлять осторожность, чтобы при необходимости избегать цитат. Например, 'да' записывается как \ 'да \' .
dbGetQuery (con, '
выберите "month_idx", "год", "месяц",
сумма (случай, когда "term_deposit" = \ 'yes \', затем 1.0, иначе 0.0, конец) в качестве подписки,
считать (*) как общее
из "банка"
группировать по "month_idx", "год", "месяц"
') 2.Запрос с использованием синтаксиса dplyr
Вы можете написать свой код с синтаксисом dplyr , а dplyr переведет ваш код в SQL. Написание запросов с использованием синтаксиса dplyr дает несколько преимуществ: вы можете сохранить один и тот же согласованный язык как для объектов R, так и для таблиц базы данных, не требуется знание SQL или конкретного варианта SQL, и вы можете воспользоваться тем фактом, что dplyr использует ленивое вычисление. dplyr Синтаксис легко читается, но вы всегда можете проверить перевод SQL с помощью функции show_query () .
q1 <- tbl (con, "bank")%>%
group_by (month_idx, год, месяц)%>%
подвести итог(
подписаться = сумма (ifelse (term_deposit == "да", 1, 0)),
всего = n ())
show_query (q1)
ВЫБЕРИТЕ "month_idx", "год", "месяц", SUM (CASE WHEN ("term_deposit" = 'yes') THEN (1.0) ELSE (0.0) END) AS "подписаться", COUNT (*) AS "total"
ОТ ("банк")
ГРУППА ПО «month_idx», «год», «месяц» 3. Запрос с помощью R Notebooks
Знаете ли вы, что можно запускать код SQL в фрагменте кода R Notebook? Чтобы использовать SQL, откройте R Notebook в среде RStudio IDE в меню File> New File .Начните новый фрагмент кода с {sql} и укажите свое соединение с помощью параметра фрагмента кода connection = con . Если вы хотите отправить вывод запроса во фрейм данных R, используйте output.var = "mydataframe" в параметрах фрагмента кода. Если вы укажете output.var , вы сможете использовать вывод в последующих фрагментах кода R. В этом примере мы используем вывод ggplot2 .
`` `{sql, connection = con, output.var =" mydataframe "}
ВЫБЕРИТЕ "month_idx", "год", "месяц", SUM (CASE WHEN ("term_deposit" = 'yes') THEN (1.0) ИНАЧЕ (0.0) КОНЕЦ) КАК "подписаться",
COUNT (*) КАК "всего"
ОТ ("банк")
ГРУППА ПО "month_idx", "год", "месяц"
`` `` `{r}
библиотека (ggplot2)
ggplot (mydataframe, aes (всего, подписаться, цвет = год)) +
geom_point () +
xlab ("Всего контактов") +
ylab ("Подписки на срочный депозит") +
ggtitle ("Контактный объем")
`` Преимущества использования SQL в фрагменте кода заключаются в том, что вы можете вставить свой код SQL без каких-либо изменений. Например, вам не нужно экранировать кавычки.Если вы используете пресловутый спагетти-код , который состоит из сотен строк, то фрагмент кода SQL может быть хорошим вариантом. Еще одно преимущество заключается в том, что код SQL в фрагменте кода выделяется, что упрощает чтение. Для получения дополнительной информации о механизмах SQL см. Эту страницу о механизмах языка Knitr.
Резюме
Не существует единственного наилучшего способа запроса данных с помощью R. У вас есть много методов на выбор, и каждый из них имеет свои преимущества. Вот некоторые из преимуществ использования методов, описанных в этой статье.
|
|
|
|
|
|