По вашему запросу ничего не нашлось в Яндексе — что делать?
Поисковый сервис Yandex имеет довольно агрессивную политику навязывания своих услуг. Однако эта настойчивость никак не связана с качеством его работы. Данная статья посвящена проблемам поиска. Читайте, что же делать, если по вашему поисковому запросу ничего не нашлось в системе Яндексе.
Содержание
- Почему ничего не нашлось в Яндексе
- Что делать, если по вашему запросу нет результатов из-за фильтров
- Другие случаи, когда в системе Яндекс ничего не нашлось
- Видео-инструкция
Почему ничего не нашлось в Яндексе
Отметим самые распространенные причины на то, почему в Яндекс ничего не нашлось по запросу пользователя:
Каждую из вышеперечисленных проблем можно решить. Если ничего не помогает, напишите в службу технической поддержки. Сотрудники Яндекс постараются разобраться в ситуации и ответить на ваши вопросы. Теперь разберем, что же можно сделать, если по вашим поисковым запросам система ничего не находит.
Читайте также: Как отключить Яндекс Мессенджер.
Что делать, если по вашему запросу нет результатов из-за фильтров
Для каждой проблемы есть свое решение.
Что делать, если настройки расширенного поиска слишком строгие, и из-за этого по вашему запросу ничего не нашлось в Яндексе:
Если вы решили отключить фильтры, делайте следующее:
- Откройте страницу Yandex.
- Затем нажмите на значок в виде двух полос с полярно расположенными на них точками. Он находится справа от поисковой строки.
Включение расширенного поиска Яндекс
- Нажимайте на прямоугольные блоки с текстом, которые увидите под поисковой строкой. Это и есть фильтры.
Блоки фильтров в Яндексе
- Активные блоки будут отмечаться желтоватым цветом. Кликайте по ним, чтобы включить их.
Выбор фильтров в Яндексе
- Нажмите на кнопку «Найти», чтобы получить результат с настроенными фильтрами. Кнопка для поиска в поисковой системе
- Если нужно сделать все блоки неактивными, кликните по слову «Сбросить».
 Параметры выдачи сразу изменятся.
Параметры выдачи сразу изменятся.Сброс фильтров в Яндексе
- Если вы нажмете на иконку с двумя горизонтальными полосами еще раз, то блоки пропадут. Однако поисковик запомнит ваши настройки и будет показывать результаты с учетом заданных параметров.
Если вы делаете запрос с телефона, то текстовые подсказки будут отображаться под блоками фильтров. В браузере они перекрывают расширенные настройки. Наиболее актуальные запросы в автоматических подсказках от Яндекс обновляются каждый час.
Это может быть полезным: Как включить ВПН в Яндекс браузере.
Другие случаи, когда в системе Яндекс ничего не нашлось
Если доступ к сайту блокируется провайдером:
- Поставьте расширение Browsec или Frigate.
- Вы также можете попробовать зайти на нужный ресурс через Tor Browser.
Если блокировщики рекламы мешают поиску, настройте их работу в меню расширения.
Как это сделать:
- Откройте главную страницу сервиса.
- Нажмите на иконку расширения.
Иконка Адблок в браузере
- Откроется контекстное меню, в котором вам придется отключить активность расширения. Нужная кнопка может называться по-разному. Однако обычно она выглядит как самый большой тумблер в меню.
Переключатели Адблок
Вы также можете добавить сайт Yandex или любой онлайн-сервис в Белый список.
Для этого:
- Нажмите на значок расширения, расположенный справа и сверху.
- Кликните на символ в виде шестеренки.
Отключение Adblock в Yandex
- На новой странице перейдите в раздел Белый список.
Страница настроек расширения
- Вставьте адрес нужного сайта. Например, yandex.ru.
- Нажмите на клавишу «Добавить».
Настройки Белого списка в расширении
- Откройте страницу поисковика и обновите.
Данный способ подходит для любых браузеров. Различаться могут только названия сайтов, которые вам нужно добавить в Белый список.
Переполненный кэш следует почистить. Однако нужно всегда помнить, что удаление cookies в браузере всегда влияет на настройки поиска.
Как чистить кэш:
Закончив с любой из вышеперечисленных операций, проверьте результат выдачи в Яндекс по вашему запросу. Если вы по-прежнему видите надпись об отсутствии данных, попробуйте что-нибудь еще. Например, поработайте с поисковиком DuckDuckGo или откройте Google.
Несмотря на схожие принципы работы, все эти системы по-разному индексируют сайты и настраивают выдачу. Поэтому ее результаты могут сильно отличаться.
Почитайте также статью: Поиск по фото с телефона в Яндекс.
Видео-инструкция
В данном видео вы узнаете, что же делать, если по вашему запросу ничего не нашлось в поисковой системе Яндекс.
Главная » Браузеры » Yandex
Автор Мстислав Опубликовано Обновлено
Поисковые операторы Яндекс и Google 2021 для решения SEO задач
Привет, друзья. Первая часть заголовка подсказывает, что ниже будет инструкция из разряда — для дилетантов, которым использование кавычек, минуса или восклицательного знака будет казаться взломом поисковой системы или как минимум секретными операторами. Я, и правда, планировал перечислить несколько базовых операторов, известных большинству seo-специалистов, но в процессе обнаружился ряд интересных особенностей, когда операторы работали не так, как предполагалось, либо модификации и сочетание простых операторов выдавали совсем необычные результаты. Так что, работая над данным постом, я получил интересный опыт и открыл несколько вещей, о которых прежде не догадывался.
Даже если кажется, что вам известны все поисковые операторы и их свойства, рекомендую ознакомиться с постом.
Кроме этого, вторая половина поста состоит из рассмотрения ряда прикладных задач, которые доводилось решать мне и моим коллегам в процессе работы над клиентскими сайтами. Уверен, вы найдете для себя много полезного.
Уверен, вы найдете для себя много полезного.
В SEO есть список ключевых операторов ПС, которые необходимо знать наизусть, так как они используются постоянно и позволяют мгновенно проверять возникающие гипотезы.
Также есть операторы, которые редко используются, но знать об их существовании важно, чтобы в случае необходимости вспомнить, что вопрос решается элементарно, стоит лишь использовать нужный запрос.
Основная сложность заключается в приобретении навыка умелого сочетания простых элементов между собой с целью решения неочевидных на первый взгляд задач.
Не всегда и не во всех случаях операторы отрабатывают так как ожидается.
Поисковый запрос проходит через сервис исправления опечаток, по результатам которого и формируется выдача. Учитывается статистика по запросу, статистика совместной встречаемости слов, вероятность ошибки – и в итоге имеем то, что имеем.
Общие операторы для Яндекс и Google
Оператор
+ (плюс) и - (минус)С помощью этих операторов происходит поиск документов, которые обязательно содержат (или не содержат) указанное слово (или слова). Однако же на практике есть отличия от теории.
Однако же на практике есть отличия от теории.
Оператор «минус» отрабатывает при любых условиях – «заминусованное» слово никогда не попадет в выдачу.
Что касается оператора «плюс», сегодня у меня сложилось впечатление, что он просто не работает.
С одной стороны логично: если ты указал какое-то слово в поисковом запросе — ты хочешь его найти, и нет нужды что-то дополнительно отмечать плюсом. С другой стороны, если мы отмечаем одно слово в многословном запросе плюсом, можно было бы придавать ему максимальное значение при ранжировании, но мои попытки заметить хоть какую-то закономерность не увенчались успехом.
Например, поисковиками игнорируются союзы и предлоги из запроса, но можно было их «вернуть» как раз плюсом. Это работает в вордстате – сравните результат для вариантов «продвижение» и «продвижение +в». При этом, если во втором варианте вы уберете плюс перед «в», получите результат такой, как будто «в» вообще отсутствует.
Так же это работало и в обычном поиске, но, похоже, что-то изменилось.
Оператор
" " (кавычки)При использовании кавычек поисковая система будет искать точное совпадение фразы.
Можно использовать кавычки несколько раз в одном запросе и даже добавить «минус» перед одним из запросов.
Этот оператор тоже сложно назвать полезным, так как не понятно, как он работает на практике. Вот вам пример:
Яндекс говорит: «Точного совпадения не нашлось. Показаны результаты по запросу без кавычек.»
Фраза содержится в одном из последних постов на моем блоге, который точно в индексе, что подтверждается поиском по соседнему с искомой фразой предложению:
Обратите внимание, что в сниппете есть та самая фраза, которую мы изначально искали, но не нашли. Как это работает — одному Яндексу известно, так что я бы не стал полагаться на данный оператор.
Зачем я рассказываю о как бы нерабочих операторах? А затем, что знание особенностей (а точнее того, что операторы не всегда работают так, как заявлено) очень важно, чтобы однажды не наделать ложных выводов.
Оператор
* (звёздочка)В Яндексе используется для указания пропущенного слова в цитате.
Одна звездочка – одно слово. Применяется только с оператором " " (кавычки).
В Гугле используется для указания пропущенных слов в запросе. В справке указано, что одного слова, но на практике – любое количество слов.
Оператор
! (восклицательный знак)Осуществляет поиск документов, где слово содержится строго в заданной форме. В Гугле все четко:
В Яндексе это так не работает и, кажется, он считает накопленную статистику о том, как правильно задавать запросы, приоритетной перед поисковыми операторами.
То есть, согласно статистике, человек ошибся, написав «билет в москвА», вместо «билет в москвУ». Чуть лучше это работает с запросами «»купить !айфон»» и «»купить !iphone»», но тоже не так четко, как ожидаешь.
Оператор
site:Осуществляет поиск только по указанному домену и его поддоменам (в отличии от оператора url:, который ограничивает поиск только страницами указанного сайта).
формат: [фраза] site:[example.com]
пример: сайт site:narod.ru
В Гугле все работает по аналогии.
формат: [фраза] site:[example.com]
пример: тлен site:alaev.info
Далее мы рассмотрим некоторые операторы, уникальные для каждой поисковой системы, либо похожие с виду, но работающие по-разному.
Операторы поиска для Яндекса
Большая часть перечисленных ниже операторов не задокументированы в справке Яндекса. Какие-то действительно полезные, а для каких-то найти практическое применение довольно сложно. Так что все на ваше усмотрение, а можете сразу пролистать на 10 страниц вниз до заголовка про решение прикладных задач.
Оператор
& (амперсанд) и && (двойной амперсанд)формат: [слово] & [слово]
Первый оператор & позволяет искать документы, где слова, связанные оператором, находятся в одном предложении. А второй оператор
А второй оператор && позволяет искать слова в пределах одного документа.
Но понять, насколько корректно работают эти операторы, сложно, так как по запросам с операторами и без них результат очень схожий.
Оператор
<< (двойной знак меньше)формат: [слово] << [слово]
Поиск слов в пределах документа, но релевантность (она влияет на положение в результатах поиска) рассчитывается только по первому слову (которое до оператора). Выражение после << ищется, но не участвует в ранжировании.
Оператор
~ (тильда) и ~~ (двойная тильда)формат: [слово] ~ [слово]
пример: сериал ~ метод
Оператор ~ исключает из результатов поиска страницы, содержащие в одной фразе ключевое слово, идущее после тильды. Сравните обычную выдачу:
И выдачу, где есть «сериал», но нет «метод»:
Двойная тильда ~~ исключает из результатов страницы, где встречается ключевое слово до оператора и отсутствует слово, идущее после оператора.
На практике различие между операторами ~ и ~~ сложно заметить. Однако этот оператор используется в одном из методов определения аффилиатов сайтов.
Оператор
host:Исключает из выдачи поддомены указанного сайта (в отличии от оператора site:), то есть поиск будет осуществляться только по указанному домену.
формат: [слово] host:[example.com]
пример: сайт host:narod.ru
Оператор
rhost:Позволяет искать исключительно по поддоменам указанного сайта.
формат: [слово] rhost:[com.example.*]
пример: сайт rhost:ru.narod.*
Обратите внимание на формат указания сайта – в обратном порядке.
Оператор
domain:Позволяет искать по сайтам, расположенным в определенной доменной зоне.
формат: [слово] domain:[доменная зона]
пример: сайт domain:co
Как видите, указанная доменная зона не обязательно одиночная (. co), но может быть и такой: .co.ua. Чего только не обнаружишь, тестируя различные варианты ?
co), но может быть и такой: .co.ua. Чего только не обнаружишь, тестируя различные варианты ?
Оператор
url:Позволяет искать слово или фразу только на странице с указанным адресом.
формат: [фраза] url:[адрес страницы]
пример: полпути url:https://alaev.info
Поиск нашел нужное мне ключевое слово на обозначенной странице.
Еще вы можете использовать звездочку, чтобы найти все документы, адреса которых начинаются с указанного.
пример: полпути url:https://alaev.info/blog*
Оператор
inurl:Поиск ограничивается группой страниц, адреса которых содержат заданный фрагмент.
формат: [слово] inurl:[фрагмент адреса]
пример: сайт inurl:web
Обратите внимание, что часть адреса может содержаться как в названии домена, так и в адресе страницы.
Оператор
title:Позволяет искать только по заголовкам страниц (по тегу title).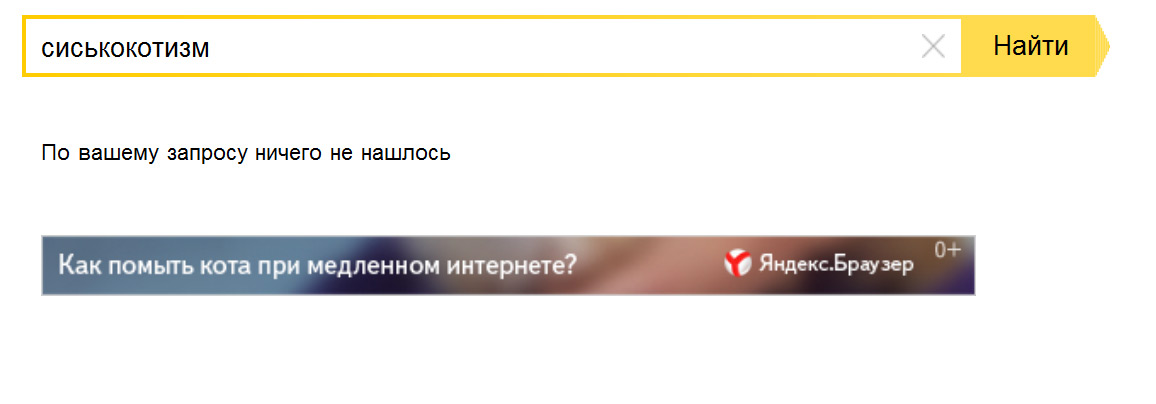
формат: title:[фраза]
пример: title:жирный таракан
К сожалению, практика показывает, что не «только», так как сразу же встречаются результаты, не содержащие часть фразы не только в title, но и в тексте:
Странно, что Яндекс учитывает операторы таким образом – не как строгое правило, а, скорее, как рекомендацию, которую чаще всего игнорирует. В отличии от Гугла, где все четко и предсказуемо.
Оператор
mime:Позволяет искать по документам и файлам, указанного расширения и типа.
формат: [слово] mime:[тип файла]
пример: коммерческое mime:doc*
В справке Яндекса заявлены следующие типы файлов: pdf, xls, ods, rtf, ppt, odp, swf, odt, odg, doc.
Посмотрев на этот список, я сразу подумал, что тут явно чего-то не хватает, например docx, ныне более распространенного, чем doc.
И я подумал, что можно искать одновременно и .doc и .docx, используя звездочку, как показано на скриншоте.
А потом пошел дальше. Захотелось мне .txt файлы поискать, ведь если они не заявлены в списке, то это не значит, что их нельзя искать. Но оказалось и правда нельзя. Зато помня про звездочку…
Вбил запрос 1 mime:t* и нашел txt, m3u, trf и еще всяких интересных вещей. Работает непредсказуемо и ищет не только файлы с расширением, начинающимся с буквы t. Таким образом можно перехитрить поиск!
Сочетая различные операторы между собой, можно найти много интересного, только я вам об этом, конечно же, ничего не говорил 🙂
Оператор
date:Ограничивает поиск документами по дате их последнего изменения.
Год указывается обязательно, а месяц и день можно заменить символом *.
формат: [фраза] date:[yyyymmdd]
пример: продвижение сайтов date:202001*
В данном случае показаны страницы и сайты про продвижение сайтов, созданные (а точнее — проиндексированные) в январе 2020 года.
И вот тут есть нюанс и некоторое несоответствие с описанием, предоставленным Яндексом. В справке говорится «по дате последнего изменения», но что такое изменение? Дата переиндексации или дата, когда при посещении роботом было замечено, что контент изменился относительно его прошлой копии?
Не то, и не другое. Я сначала было решил, что оператор date: делает выборку дате первой индексации страницы. Например, потому что я завел блог в конце 2009 года:
С тех пор контент много раз менялся на всех страницах, я три раза менял дизайн глобально. Вряд ли поисковик не заметил каких-либо изменений. Я был уверен, что это работает именно так. Тогда почему нет еще нескольких страниц, появившихся в 2009 году?
Я начал копать дальше и обнаружил в апреле 2019 года большое количество результатов:
А как раз в апреле я переезжал с http на https. Соответственно, старые страницы как бы пропали, а новые появились и проиндексировались. В каком-то смысле их дата первой индексации сбросилась. Но тогда почему же главная страница блога, которая тоже переехала на https до сих пор болтается в 2009 году?
В каком-то смысле их дата первой индексации сбросилась. Но тогда почему же главная страница блога, которая тоже переехала на https до сих пор болтается в 2009 году?
По определенным запросам я подтверждаю теорию о том, что оператор выбирает дату индексации, а не изменения – например: нашествие фестиваль date:2008*. А потом по схожему запросу нашествие фестиваль date:2018* убеждаюсь, что выдаются страницы, которые были созданы задолго до 2018 года.
Даже если посмотреть на примеры, которые приводит сам Яндекс:
- соответствует 10.10.2018: [фестиваль date:20201010];
- позднее 10.10.2018: [фестиваль date:>20181010];
- находится в интервале между 10.10.2018 и 10.11.2018 включительно: [фестиваль date:20181010..20181110];
- соответствует октябрю 2018 года: [фестиваль date:201810*];
- соответствует 2018 году: [фестиваль date:2018*].
Можно найти там недостоверные данные:
Короче, мы просто не знаем, что считает изменением сам Яндекс и в этом заключается недостоверность описанного метода.
Вообще в справке Яндекса есть целый раздел о том, как искать в Яндексе и как уточнить поиск, однако там приведены не все операторы, которые мы рассмотрели. По всей видимости, Яндекс не считает их столь уж необходимыми простым людям, но мы же сеошники ?
Кстати, основные операторы используются не только непосредственно в поиске, но и в других сервисах, например, в Яндекс Вордстате – у меня есть подробный обзор операторов и сочетаемости друг с другом. Хотя бы там операторы работают так, как ожидается и без всяких приколов.
Операторы поиска для Google
Оператор
cache:Возвращает последнюю кэшированную версию веб-страницы (при условии, что страница проиндексирована, конечно) вместе с датой и точным временем, когда снимок был сделан.
формат: cache:[example.com]
пример: cache:microsoft.com
Оператор
filetype:Ограничивает результаты поиска файлами определённого формата, например: pdf, docx, txt, ppt и т. д.
д.
формат: [фраза] filetype:[тип файла]
пример: seo filetype:txt
У данного оператора есть аналог ext: — работает аналогично, включая особенности.
Конечно, я сразу захотел проверить будет ли работать поиск по файлам txt, которые не ищет Яндекс.
Но вместо этого я обнаружил другую особенность работы данного оператора: он ищет не конкретно файлы, а url-адреса, которые оканчиваются на указанное расширение, в моем случае это .txt. То есть это могут быть и обычные страницы сайта, которые имеют искомое окончание. По этой причине на четвертом месте нашелся вот такой url: https://help.megagroup.ru/upravlenie-robots.txt. Неожиданно ?
Стоит добавить, что filetype: или ext: сочетаются, например, с операторами inurl: и intext:, что расширяет наши возможности по поиску «нужных» файлов!
Оператор
inurl:Осуществляет поиск фразы по страницам сайтов, содержащих в своем адресе одно или несколько слов, идущих после оператора.
формат: [фраза] inurl:[фрагмент url]
пример: протест inurl:в москве
При этом вы не обязаны указывать искомую фразу, можно указывать только часть адреса.
формат: inurl:[фрагмент url]
пример: inurl:в москве
В этом случае в выдачу попали абсолютно все известные поиску страницы, содержащие в своем адресе «в» или «москве».
Обратите внимание, что я использовал исключительно кириллические слова в качестве части url, и поиск меня понял.
Оператор
allinurl:Думаю, вы уже догадались на примере предыдущих описаний, что оператор allinurl: должен возвратить нам все страницы, адрес которых в обязательном порядке содержит все слова из фразы в указанной словоформе.
формат: allinurl:[фрагмент url]
пример: allinurl:seo bomzh
По моему запросу я и не ожидал найти много результатов, и это показывает нам, что оператор работает четко и не позволяет себе вольностей, как это бывает в Яндексе.
И есть одно важное отличие оператора allinurl: от inurl: — он не сочетается с каким-нибудь поисковым запросом. При попытке искать слово «alaev» по страницам, содержащим в адресе «seo» при помощи оператора: alaev allinurl:seo мы получаем результаты аналогичные поиску по трехсловной фразе «alaev allinurl seo».
Оператор
intitle:Ищет слова только по содержимому заголовков title страниц.
формат: intitle:[фраза]
пример: intitle:seo бомж
Оператор
allintitle:Работает по аналогии с вышеописанным intitle:, но обязательно в title должны содержаться все слова из искомой фразы и, как я в очередной раз убедился, обязательно в указанной словоформе.
формат: allintitle:[фраза]
пример: allintitle:seo бомж
Для примера я взял для обоих операторов один и тот же запрос «seo бомж». Но отличия для этих запросов не столь радикальное, как если вы введете поочередно: allintitle: в москву, allintitle:в москве, allintitle:в москва или даже allintitle:в москвой. Вот при этих запросах видно, как Гугл бескомпромиссно следует своим же правилам (операторам).
Вот при этих запросах видно, как Гугл бескомпромиссно следует своим же правилам (операторам).
Если вы хотите еще ужесточить запрос, чтобы слова фразы шли в определённом порядке, берем фразу в кавычки.
формат: allintitle:"[фраза]"
пример: allintitle:"в москвей"
Оператор
intext:Позволяет искать страницы, содержащие обязательно в тексте искомое слово или слова. Ну и что тут такого и зачем вообще нам нужен такой оператор, когда поисковик и так всегда ранжирует по вхождениям в текст (сайты, которые содержат фразу только в title и не содержат в тексте обычно ранжируются ниже и до них надо долго пролистывать, так что условно их можно игнорировать).
Но я придумал интересный вариант использования:
формат: intext:[фраза]
пример: intext:кондибобир
Вы можете использовать данный оператор для поиска какой-нибудь дичи, целенаправленно неверно написанных слов или чего-то другого, что вам в голову придет. При этом поисковик не будет говорить вам: «Возможно, вы имели в виду: …» и показывать результаты, где искомое слово встречается в транслите. Используя данный оператор, вы всегда найдете именно то и в том виде, в котором ищете.
При этом поисковик не будет говорить вам: «Возможно, вы имели в виду: …» и показывать результаты, где искомое слово встречается в транслите. Используя данный оператор, вы всегда найдете именно то и в том виде, в котором ищете.
Оператор
allintext:Будет искать обязательно все слова, указанные в запросе.
формат: allintext:[фраза]
пример: allintext:алаичъ плащ
Для оператора allintext: также можно использовать кавычки в запросе, чтобы искать нужные слова в определенной последовательности.
И еще я обнаружил интересную особенность, что allintext: ищет не только в тексте, но в том числе и в заголовке title (я встречал в выдаче документы, которые содержат искомую фразу только в title, а в тексте – нет).
Оператор
related:Согласно теории, данный оператор предназначен для поиска сайтов с похожим контентом.
формат: related:[example. com]
com]
пример: related:ya.ru
Забавно, что если я запрошу related:yandex.ru, то получу ответ «По запросу related:yandex.ru ничего не найдено.» И при запросе related:google.ru в выдаче будет показываться именно ya.ru, а не yandex.ru.
Также меня смутило, что нет никаких результатов для alaev.info и alaev.co, а по запросу related:maxitop.ru (это сайт одной из веб-студий Краснодара) показываются не веб-студии, а автомобильные сайты, техцентры, СТО и магазины автозапчастей.
Так что у меня большой вопрос к Гуглу, друг, а что учитывается при определении похожести сайтов?
На этом я закончу теорию и перейду к разбору прикладных задач, с которыми вы можете столкнуться в процессе продвижения сайтов.
И не забывайте, что у Гугла тоже есть справка о том, как уточнять поисковые запросы, но, как и в Яндексе, она содержит мало полезных нам, сеошникам, операторов.
Решение прикладных задач в SEO
Как быстро поменять регион поисковой выдачи в Яндексе:
&lr=Я считаю, это первое, что должен изучить seo-специалист, ежедневно работающий с поисковыми системами, — быстрое переключение региона.
Вот медленный способ переключения региона:
- Первый шаг – нажать на иконку, открывающую настройки.
- Второй шаг – нажать на кнопку редактирования названия региона.
- Третий шаг – ввести текстом название города (благо, там есть подсказки), выбрать его из списка и нажать «Найти» в поисковой строке.
Представьте, сколько действий надо совершить! Достичь аналогичных результатов можно всего в несколько кликов. Я привел тут этот алгоритм отнюдь не ради того, чтобы проиллюстрировать сложность, а чтобы мы могли узнать числовой код региона, который нам нужен.
Когда вы что-то ищете без всяких настроек, Яндекс будет подставлять вам тот регион (город), в котором вы находитесь (если он смог верно определить вашу геолокацию и, если она не заблокирована браузером). Я поищу «продвижение сайтов»:
Я выделил на скриншоте стрелкой параметр &lr=35, значение 35 которого показывает мой регион – Краснодар. У вас будет свой собственный код, например, 213 – Москва, 54 – Екатеринбург, 2 – СПб.
У Яндекса есть список основных городов — https://yandex.ru/dev/xml/doc/dg/reference/regions.html — но есть вероятность, что вы не найдете там город, выдачу в котором необходимо посмотреть.
Вариант первый – следуя пошаговому «сложному алгоритму», описанному выше, зайти в настройки и указать нужный вам город. Я решил выбрать Верхнюю Пышму – город-спутник Екатеринбурга, где живет 70 тысяч человек. В реальности, конечно, жители предпочтут найти исполнителя в самом ЕКБ, но моя задача показать, как это работает:
Я отметил на скриншоте два параметра &lr=35 и &rstr=-20720 – первый показывает, что я по-прежнему нахожусь в Краснодаре, а второй показывает, что я изменил регион, и значит код Верхней Пышмы – 20720.
Второй вариант – при условии, что мы знаем код нужного нам региона, то для поиска по этому региону надо будет в адресной строке просто изменить &lr= на 20720.
Так как сеошники в регионах, изучая коммерческие характеристики сайтов, смотрят не только на региональных конкурентов, но и часто на московских, имеет смысл в первую очередь запомнить параметр &lr= и код Москвы 213, это поможет вам сэкономить кучу времени!
Также существует полный список всех имеющихся регионов Яндекса отдельным файлом, который раньше лежал у Яндекса, но был удален, когда они решили закрыть свой Каталог, но добрые люди сохранили это наследство, так что я тоже залил файл к себе, чтобы он был всегда доступен, пока существует мой блог. Скачать список регионов Яндекса в .pdf
Как узнать количество страниц в индексе Яндекса для домена
Используем оператор host: с указанием домена.
формат: host:[example.com]
пример: host:alaev.info
Как видите, количество проиндексированных страниц моего блога – 340.
Как узнать количество страниц в индексе Яндекса для сайта и всех его поддоменов
Используем оператор site: с указанием домена.
формат: site:[example.com]
пример: site:alaev.info
Количество страниц вместе с поддоменами составляет около двух тысяч. К сожалению, Яндекс округляет результат, потому это лишь ориентировочное число.
Чтобы вы понимали, вот реальное количество страниц в индексе на тот же самый момент времени:
Как узнать проиндексирована ли страница в Яндексе
Используем оператор url: с указанием конкретного адреса страницы.
формат: url:[url страницы]
пример: url:https://alaev.info/blog/post/8742
Если выдача не пустая, значит страница проиндексирована. А если увидите «По вашему запросу ничего не нашлось» — значит страница не в индексе.
Как узнать сколько страниц (и каких) опубликовано на сайте за определенную дату
Используем следующие операторы:
site: – если хотим искать по основному домену и всем его поддоменам,host: – если нужно искать только по основному домену,date: – указываем дату появления в индексе (не забывайте, что я писал про данный оператор выше в разделе операторов Яндекса).
И еще есть замечательный оператор – * (звездочка) – с помощью которого мы можем указывать не только конкретный день, но и весь месяц или целый год.
формат: site:[example.com] date:[yyyymmdd]
пример: site:alaev.info date:2020*
На моем блоге за 2020 год появилось 5 новых постов, их появление повлекло за собой появление одной дополнительной страницы пагинации, и одна новая тема на форуме. Итого 7 штук!
А, например, в феврале 2021 года на блоге появились 2 новых поста и в одном из них я выкладывал чек-лист в форматах pdf и xlsx – они тоже проиндексировались и посчитались:
Напоминаю, что оператор date: работает не всегда так, как ожидаешь. Иногда результат совпадает, иногда нет. Чем дальше в историю (просмотр результатов за давнишние даты), тем выше вероятность получить неверный результат.
Как найти сайты, у которых в Title страницы имеется вхождение искомой фразы в Google
Например, у нас есть ключевой запрос «утюг недорого цена», и необходимо посмотреть, как реализовано вхождение этого запроса у конкурентов.
формат: allintitle:[ключевые слова]
пример: allintitle:утюг недорого цена
Пусть вас не смущает то, что в заголовке на выдаче не везде встречаются все три слова из нашего запроса. Во-первых, Гугл на свое усмотрение сокращает заголовки (в конце заголовка может поставить троеточие) и часть содержимого тега title с сайта не видна, во-вторых, Гугл на свое усмотрение может менять заголовок на более подходящий (по его мнению, разумеется). Во-вторых, если вы перейдете на сайты из выдачи, вы увидите, что в title каждого из них содержатся слова, которые мы указывали в запросе.
Как узнать, когда проиндексированы страницы в Яндексе
Чтобы отсортировать результаты поиска, необходимо в конец поисковой строки добавить &how=tm, и тогда напротив каждой страницы в выдаче появится отметка о времени индексации:
Жаль, что это не сочетается с другими операторами, например, site: или host:, а раньше это работало и можно было узнать, когда конкретно проиндексировались страницы сайта или конкретный url.
Как найти мусорные страницы по URL в Яндекс и Google
К мусорным страницам относятся, например: корзина (cart), регистрация (register, login), страницы пользователей (users), файлы (files), страницы сортировки (sort), страницы фильтров и поиска (filter, search).
Для того чтобы найти данные страницы, будем использовать оператор site: совместно с оператором inurl:, с помощью которого можно осуществлять поиск по страницам в URL которых есть заданный фрагмент.
формат: site:[example.com] inurl:[часть url]
пример: site:tatarcha.net inurl:auth
Смотрите, сколько дублирующихся ненужных страниц! Все это вредит продвижению, сами знаете.
В Google поиск осуществляется аналогичным способом. Только он предпочитает не показывать кучу одинаковых результатов.
Если в url запроса добавить &filter=0, то Гугл сразу будет показывать в выдаче все скрытые результаты (вдруг пригодится).
Не забывайте, что для поиска фразы, а не одного слова, стоит использовать оператор allinurl:.
Кроме поиска мусорных страниц сочетание site: и inurl: / allinurl: можно, например, применять для поиска всех страниц конкретного раздела и определения их числа в индексе.
формат: site:[example.com] inurl:[/раздел/]
пример: site:robinzonada.ru inurl:/camps/
И тут надо сделать оговорку. Мы видим на скриншоте число 37. Но, если досмотрим до самого низа, увидим, что Гугл скрыл часть результатов.
Окей, значит раз вверху было 37, а скрыто еще 40, значит страниц итого 77?
Жмем на «Показать скрытые результаты.»
Хм… уже 152! И как это работает вообще?
Осталось только спуститься в самый низ и перейти на следующую страницу, число снова изменится.
Реальное же (во всяком случае наиболее приближенное к реальному) число отобразится тогда, когда вы дойдете до последней страницы выдачи. В нашем случае наиболее точным числом оказалось 46.
Также я отметил один из результатов в сниппете которого написано «Информация об этой странице недоступна.» Это означает, что сайт не позволяет Google создать описание страницы, хотя она доступна посетителям. Проще говоря, страница закрыта в robots.txt, но ее адрес все равно индексирует робот Гугла, но саму страницу не сканирует.
В Яндексе такого не бывает, но в Гугле всегда происходит именно так, поэтому если вы хотите, чтобы страница не индексировалась, стоит использовать запрещающий meta robots, а не robots.txt.
Поиск одинаковых товаров по фрагменту URL + их число в выдаче
Частный случай из предыдущего пункта – нужно узнать в каких категориях лежит один и тот же товар. В некоторых интернет-магазинах бывает такая ситуация, если положить один товар в несколько разных категорий и при этом ЧПУ формируется согласно иерархии, страница товара будет дублироваться столько раз, скольким категориям или подкатегориям товар принадлежит.
формат: site:[example.com] inurl:[фрагмент URL товара]
пример: site:gikom.ru inurl:metallicheskie-stellazhi-skladskie-mkf-1570
Это работает и в Гугле, и в Яндексе, только если вы хотите искать в Яндексе по указанному домену, надо использовать вместо site: оператор host:, иначе будут показываться результаты и с поддоменов:
Проверка релевантности и каннибализации страниц
Если мы введем интересующий нас поисковый запрос и ограничим выдачу только страницами определенного сайта с помощью оператора site:, то поисковик выдаст нам страницы указанного сайта в порядке убывания релевантности запросу.
формат: [фраза] site:[example.com]
пример: перелинковка site:alaev.info
Что это нам даёт:
- Проверка страницы на фильтр переспама. Если на первом месте выдается не продвигаемая страница, а любая другая – есть вероятность, что мы имеем переспам по текстам.
 Необходимо проанализировать, почему наша целевая страница не является самой релевантной запросу.
Необходимо проанализировать, почему наша целевая страница не является самой релевантной запросу. - Если в топ-20 есть несколько страниц, заточенных под одинаковый ключ (мета-теги, h2, текст), – значит, есть риск получения каннибализации. Тогда велика вероятность, что поисковик будет считать релевантными разные страницы сайта, и в выдачу они будут попадать по переменке. Актуально для молодых сайтов, пока нет ссылочного профиля.
- Если на первом месте ранжируется нужная нам целевая страница, то все нижестоящие можно использовать для прокачки основной страницы за счет внутренней перелинковки, используя нужные ключевые слова. Это называется контекстная перелинковка страниц и, на мой взгляд, это самый эффективный вид перелинковки. Рекомендую ознакомиться с моим руководством по ссылке.
Поиск страниц с http в индексе Google
Наверняка вы уже перевели все свои или клиентские сайты на защищенный https протокол (если нет, читайте как перевести сайт с HTTP на HTTPS без потерь). И все же в Гугле переклейка страниц происходит довольно долго, а иногда и годы спустя в выдаче зачем-то остаются адреса страниц с http. Используя операторы site: и inurl:, мы вычитаем из поиска по домену результаты с https и получаем в остатке только http.
формат: site:[домен] -inurl:https
пример: site:www.yandex.ru -inurl:https
Задумка хороша, только вот реализация страдает. Гугл предпочитает в памяти хранить древние ископаемые. Начиная с того, что я уже больше двух лет назад переехал на https, а в индексе до сих пор болтается несколько http версий страниц форума. И заканчивая тем, что Гугл помнит, как в 2014 году случайно проиндексировалось зеркало моего диетного сайта на поддомене mail.alaev.info, который случайно появился при переезде на новый сервер. Я сразу же сделал 301-редирект, как только заметил это, но в индексе вот уже 7 лет болтаются эти результаты.
Так что когда будете проверять свой сайт, сначала проверьте, действительно ли проблема есть, либо это только кажется, как в моем случае.
Проверка поддоменов и числа их страниц в индексе Google
Мы можем посмотреть, какие поддомены есть в индексе Гугла, и сколько проиндексировано страниц в рамках этих поддоменов.
формат: site:*[example.com] -www
пример: site:*gikom.ru -www
В данном случае мы исключили из выдачи поддомен www, как зеркало основного сайта. Кроме того, что нам зачем-то понадобилось посмотреть количество страниц поддоменов в индексе (это актуально, когда мы только запускаем региональные поддомены и нам важно знать, как они индексируются), мы ведь можем найти то, чего не ожидаем, например, поддомены, которые мы не создавали, либо технические поддомены, на которых проиндексировалось зеркало сайта, как в предыдущем пункте про диетный сайт.
Как и говорил в самом начале, я открыл для себя несколько необычных свойств совершенно обычных операторов. А сколько интересного я не открыл?
Если вы знаете какие-то операторы, не упомянутые в посте, либо в своей работе используете определённые сочетания, о которых я не знаю, и я и все читатели блога будут вам благодарны, если вы поделитесь в комментариях.
Так что, возможно, будет продолжение 🙂
Спасибо за внимание, друзья! До связи!
«война». Как Google и «Яндекс» отвечают на популярные вопросы россиян о вторжении России в Украину
Фото: Shutterctock.com
Показываем, как выбор поисковика может повлиять на отношение людей к войне
Фактчек
Нажмите, чтобы увидеть ссылки на все документы и узнать методологию
- Редакция
31.08.2022
Поделиться
«Какой VPN лучше», «почему цены не падают», «куда летают самолеты из России», «что такое дефолт» — подобные запросы стали популярны после начала войны. Но россиян интересуют не только практические темы, в интернете они ищут ответы на вопросы о причинах войны, пытаются понять, где факты, а где фейки, разобраться в истории конфликта, узнать значение терминов, которыми окружена эта война.
Ответ, который получит интересующийся пользователь, во многом зависит от поисковика, в который он вобьет запрос. Мы сравнили выдачи, которые формируют Google и «Яндекс», и увидели, как блокировка «неправильных» сайтов делает даже поисковик источником пропаганды.
«Яндекс» не показывает пользователям из России статьи заблокированных медиа, поэтому в выдаче появляются только те СМИ, которые транслируют «правильный» взгляд на происходящее. Кроме этого, российский поисковик дает ощутимый приоритет сайтам с пользовательским контентом — «Яндекс.Дзену», «Пикабу», порталу «Проза.ру», платформам, где люди задают вопросы другим пользователям. На таких сайтах могут высказываться самые разные точки зрения, но чаще встречаются мнения, поддерживающие или как минимум не осуждающие войну.
Google в приоритете выдает ссылки на медиа: это могут быть и независимые издания; и государственные российские СМИ и информагентства; и украинские медиа. Поэтому на любой запрос пользователь может получить более разнообразные ответы.
При этом оба поисковика ставят в приоритет статьи «Википедии», в которых структурировано и безэмоционально описываются явления и события. В условиях военной цензуры, из-за которой в России заблокированы около семи тысяч сайтов, статьи в электронной энциклопедии становятся чуть ли не единственным доступным источником информации, которая расходится с позицией российских властей. Второй источник — некоторые видео на YouTube, которые поисковики выносят в блоки с видео.
«Роскомнадзор» регулярно требует от «Википедии» удалять статьи, которые распространяют «фейки» о «СВО», а в конце июля обязал поисковики маркировать материалы электронной энциклопедии как нарушающие российское законодательство.
Российское информагентство Regnum выпустило целую статью «Почему Яндекс доверил географию „Википедии“, враждебной России?». Автор обратил внимание, что в выдаче поисковика «уже освобожденный от нацистов Мариуполь <…> именуется <…> „городом в Украине“». Так происходит, потому что для быстрого ответа на запрос о городе «Яндекс» берет информацию из «Википедии».
Российские власти с 2010 года говорили о необходимости создать российскую версию электронной энциклопедии. С началом войны потребность в ней сильно возросла, и в июне запустился проект «Руниверсалис». На сайте проекта нет статьи о войне в Украине, а в статье «Специальная военная операция России на Украине» практически не представлена позиция украинских властей. Создатели «Руниверсалиса» заявили, что редактировать статьи смогут только те редакторы, которые пройдут отбор. Один из вопросов отбора — «Чей Крым?».
Как мы считали
Сервис Google Trends позволяет смотреть, какие запросы быстрее других набирали популярность в определенной стране в определенный период. Также можно посмотреть, какие сочетания с заданным словом активно становились популярными. Чтобы узнать, о чем россияне начали спрашивать поисковики после войны, мы проверили все вопросительные слова и выделили вопросы, которые набирали популярность после 24 февраля. Из них мы выделили вопросы, прямо или косвенно связанные с войной. В сервисе «Яндекса» «Подбор слов» мы проверяли, что конкретный запрос набирал популярность и у пользователей «Яндекса». На финальном этапе мы сравнивали, какие выдачи в ответ на один и тот же запрос выдают Google и «Яндекс».
В текст вошли наиболее показательные примеры. Мы описываем результаты, которые поисковики показывали на момент подготовки текста. Результаты выдач могут меняться со временем, на них влияют появившиеся новости и статьи по теме. Но они не меняют результаты поиска кардинально. Для чистоты эксперимента мы задавали вопросы поисковикам в режиме «инкогнито» с включенным российским VPN, то есть результаты выдачи были такие же, как если бы мы отправляли запрос, находясь в России.
Популярность «Яндекса» и Google среди российской аудитории сравнялась и держится примерно на одном уровне с марта 2022 года, показывают данные сайта для анализа веб-трафика Statcounter.
Зачем Россия начала войну
На вопрос «зачем Россия начала войну» Google отвечает статьей на «Википедии», которая осуждает вторжение, разбором «Радио Свободы», колонкой в «Важных историях» и итогами четырех месяцев войны на BBC. Ближе к концу выдачи статья «Как дело дошло до большой войны» на русскоязычном сайте Deutsche Welle и новость «Медузы» о том, что Путин не думал о последствиях санкций. В блоке с видео на вопрос о целях войны отвечает украинский канал, политик Илья Яшин и блогер Максим Кац.
«Яндекс» на вопрос о причинах войны выдает предупреждение: «Некоторые материалы в интернете могут содержать недостоверную информацию. Пожалуйста, будьте внимательны». Это предупреждение появляется после каждого запроса, связанного с войной в Украине.
Девять из десяти ссылок, которые попали на первую страницу выдачи российского поисковика, ведут на ресурсы, которые не осуждают или даже оправдывают вторжение — пост на «Пикабу», пропагандистский сайт «Царьград», пророссийский сайт «Украина.ру». В них пересказываются одни и те же тезисы: Россия борется с нацизмом; спецоперация заканчивает войну, которая идет много лет; информационная война Запада сделала из России агрессора.
Кто уехал из России и где Пугачева
Кто уехал из России, волнует россиян не меньше, чем количество погибших военных. И Google, и «Яндекс» в ответ предлагают примерно одинаковую выдачу, которая на 90 % состоит из списков уехавших звезд. Выдача «Яндекса» выделяется заметкой на «Царьграде», в которой Никита Михалков оценивает творческие навыки уехавших и приходит к выводу, что «ничего ценного эти деятели культуры уже не несут». Еще одно отличие «Яндекса» — блок новостей, посвященных решению Госдумы дать уехавшим артистам шанс исправиться и изменить отношение к «спецоперации». Для этого деятелям культуры предложили посетить зону спецоперации и посмотреть в глаза беженцам.
Особый интерес у россиян вызывал отъезд Аллы Пугачевой. Сейчас на запрос «куда уехала Пугачева» в выдаче «Яндекса» заголовки об отношении россиян к возвращению певицы-предательницы, ее планы «навести порядок в головах» и рассуждения о разводе «с опальным Максимом [Галкиным]».
До того, как стало известно о возвращении Пугачевой, все ссылки обсуждали ее отъезд. Заголовки первой страницы Яндекса показывали Пугачеву как «сбежавшую», «оставленную», «уставшую от скитаний» женщину, которая «уехала, „где лучше пригреют“», «оказалась никому не нужной» и «будет вынуждена вернуться», потому что уже оплатила учебу детей в дорогой гимназии.
В выдаче Google тоже много желтой прессы, но почти все заголовки написаны без эмоциональной окраски. Вот только «Комсомольская правда» называет Пугачеву «исхудавшей».
Что такое денацификация
Денацификация — одна из заявленных целей «специальной военной операции», но что скрывается за этим словом, понимают не все.
Google в ответ на вопрос «что такое денацификация» предлагает статью «Википедии», в которой есть раздел «„Денацификация“ как предлог для вторжения России на Украину». «Представление об Украине как о неонацистском государстве было отвергнуто историками и политическими наблюдателями как не соответствующее действительности», — написано в разделе.
«Яндекс» в выдаче на первое место выводит блок с видео. Одно из них объясняет значение слова и озвучивает две позиции о денацификации: борьба с националистической идеологией или стремление Кремля получить контроль над Украиной.
На втором месте после видео — та же статья в «Википедии», что и у Google. И это единственный ресурс в выдаче «Яндекса», отличный от официального российского взгляда на «денацификацию» Украины. Сразу после «Википедии» идет статья на «Дзене» «Денацификация от V до Z», в которой «украинство» называется националистической идеологией, а «так называемое гражданское общество» сравнивается с тоталитарной сектой, зацикленной на собственном превосходстве. Автор статьи сокрушается, что у России нет собственной идеологии, которую она могла бы предложить Украине после денацификации, зато предлагает поменять программу обучения в украинских школах и вузах и сменить флаг, сравнивает герб Украины со свастикой.
На четвертом месте — колонка на сайте topwar, автор которой считает денацификацию необходимой, но признает, что пока к процедуре больше вопросов, чем ответов.
Ближе к концу выдачи появляются статьи из словарей, которые описывают «денацификацию» как процесс, который проходил в XX веке, не связывая его с современными событиями.
Google после статьи в «Википедии» дает толкования термина из словарей. В середине выдачи есть видеоопрос «Настоящего времени» о том, как россияне понимают, а точнее не понимают, значение термина. Две статьи, оправдывающие «денацификацию», попали в конец выдачи на первой странице.
Бандеровцы это
«Бандеровцы» наравне с «нацистами» стали общим определением всего зла, которое есть в Украине. И если значение второго термина очевидно, то первый вызывает много вопросов. Пик запросов «бандеровцы это» пришелся на начало войны и повторился в начале августа.
И у Google, и у «Яндекса» на первом месте ссылка на статью «Википедии». В ней объясняется, что бандеровцы — участники фракции «Организации украинских националистов», которой с 1940 по 1959 год руководил Степан Бандера, но еще в СССР понятие «бандеровцы» стало нарицательным и начало применяться ко всем украинским националистам.
Остальные статьи в выдаче обоих поисковиков говорят о бандеровцах в однозначно негативном контексте. Выдачу Google отличают ссылки на исторический документ 1948 года «Кто такие бандеровцы и за что они борются», которая представляет бандеровцев как борцов за независимость от Советского Союза, и статья BBC «Четыре мифа о Степане Бандере», которая не идеализирует и не демонизирует последователей Бандеры, а предлагает более сложный взгляд на движение.
Что произошло в Буче
Каждый раз, когда случалась трагедия с гибелью мирных украинских жителей, российские власти называли это фейком. Но, судя по поисковым запросам, россияне все равно пытаются разобраться, что случилось на самом деле. Запросы со словом «фейк» стали резко популярны в начале марта и пошли на спад только к началу мая. Больше всего россиян волновало убийство мирных жителей в Буче. Эта трагедия — болевая точка российской власти. «Важные истории» подсчитали, что именно за упоминания Бучи россияне чаще всего получают уголовные сроки за «фейки».
Если вбивать запрос «Буча фейк», и Google, и «Яндекс» выдают ответы, которые «подтверждают» фейковость трагедии. Более разнообразные результаты можно получить на запросы, в которых нет слова «фейк», например «что произошло в Буче».
На запрос «что произошло в Буче» Google предлагает репортажи о трагедииВ выдаче «Яндекса» больше материалов, «разоблачающих фейки»В выдаче Google мнения разделились. На первом месте — статья «Википедии» о резне в Буче, в которой подробно опровергаются все тезисы российской пропаганды, после нее три видео Deutsche Welle, материал BBC с историей жителя Бучи Ивана Скибы, который чудом избежал расстрела в период оккупации. Вторая половина выдачи — статьи информационного агентства Regnum, «Комсомольской правды», РИА «Новости» и Life, которые доказывают, что Россия не имеет отношения к массовым убийствам, а образ агрессора создан западными странами.
В выдаче «Яндекса» на первом месте та же статья «Википедии» о массовых убийствах, но сразу за ней идут статьи пророссийских изданий и посты на форумах. Есть даже анонимное письмо жителей Бучи, опубликованное на сайте Dieta.ru о том, что русские никого не убивали, убивали украинцы. Помимо «Википедии» альтернативная позиция представлена только в видеоблоке, куда из YouTube попали записи жителей Ирпеня и Бучи и видео Deutsche Welle, который разбирает тезисы российской пропаганды.
Сколько военных погибло
В России нет официального публичного списка погибших военных. Последний раз — 25 марта — российский Генштаб сообщил о 1351 погибшем. При этом по данным украинской стороны, Россия потеряла уже больше 45 тысяч военнослужащих.
Отвечая на вопрос «сколько военных погибло на Украине» (формулировка с предлогом «в» менее популярна), Google в «выделенных описаниях» (краткий ответ крупным шрифтом перед выдачей) приводит число погибших, которые смогли верифицировать журналисты BBC и «Медиазоны». В выдаче есть статья «Википедии», в которой собраны разные оценки потерь. Три материала в конце выдачи говорят о потерях украинской армии.
Выдача «Яндекса» начинается с видео, которые показывают частные истории погибших и пытаются оценить реальные масштабы гибели российских военных. Так же как и в выдаче Google, «Яндекс» приводит количество верифицированных погибших — подсчеты «Важных историй» на сайте Moscow Times. При этом половина ссылок в выдаче ведет на тексты об «огромных» потерях ВСУ или вообще не связана с потерями военных.
После контрнаступления ВСУ под Херсоном 29 августа выдача «Яндекса» сильно изменилась. После статьи «Википедии» о потерях сторон, в которой собраны все известные оценки, одна за другой шли статьи о провале наступления ВСУ и больших потерях украинской армии. Ни один из материалов выдачи не говорил о потерях среди российских военных.
Когда закончится война
Вопрос «когда закончится война» достиг максимальной популярности уже в начале марта, потом начал довольно резко снижаться, но с начала мая держится почти на неизменном уровне: срок конца войны волнует россиян гораздо больше, чем причины ее начала.
Google предлагает разные прогнозы: украинского блогера и внештатного советника президента Украины Алексея Арестовича, журналиста Аркадия Бабченко, советника главы Офиса президента Украины Михаила Подоляка и даже астролога. Все говорят, что война продлится еще долго. Большая часть источников — украинские медиа. Разбор «Медузы» и прогноз от эксперта «Настоящего времени» — единственные неукраинские ресурсы. Из-за блокировки «Роскомнадзором» из России их невозможно открыть без VPN, зато некоторые украинские сайты открываются.
Google на запрос «когда закончится война» предлагает оценки экспертов из России и Украины«Яндекс» дает слово прорицателямВ выдаче «Яндекса» мистические прогнозы занимают половину выдачи: расклады таро, предсказания астролога, Ванги и Нострадамуса. Если верить последнему, война не затянется долго и Россия «в скором будущем восстановит свои братские отношения с Украиной». У Нострадамуса есть предсказания и относительно президента страны: «В 2022 году российский лидер погибнет от удара молнии в открытом море. Это произойдет ночью в теплое время года». А по прогнозу Ванги, к 2027 году Украина просто войдет в состав России.
Из более приземленных прогнозов — предположение сайта «Вузы МВД России» о том, что война закончится через год, и статья на сайте православного телеканала «Царьград». Само слово «война» «не найдено» в половине результатов в выдаче «Яндекса», используется термин «специальная военная операция».
Мне стыдно за Россию
Кроме конкретных вопросов мы старались найти популярные запросы, которые бы отражали чувства и переживания россиян после начала войны. Запросы «я плачу», «не могу спать», «мне страшно», «депрессия» и подобные либо вообще не росли после начала войны, либо их рост в итоге оказывался привязан к выходу песен с ключевыми словами запросов.
Нам удалось найти одну эмоцию, рост популярности которой напрямую связан с войной, — стыд. Запрос «стыдно» достиг пика своей популярности в марте. Google Trends показывает, что после начала войны самым популярным сочетанием с этим словом была фраза «мне стыдно за Россию».
Половина выдачи «Яндекса» — статьи с заголовками типа «Стыдно за что?», «Симоньян осадила тех, кому стыдно», «Мне не стыдно!», «Должно ли быть русским стыдно», основной посыл которых сводится к цитате Симоньян: «Если вам сейчас стыдно, что вы русские, не волнуйтесь, вы — не русские».
Вторая половина выдачи — архивные сообщения на форумах, где люди делятся своими причинами стыда за Россию. Лейтмотив всех сообщений — материальное неравенство в обществе и нищета народа.
Google начинает выдачу со статьи «Стыдно за что?» с цитатами Симоньян, но уже на втором месте статья Deutsche Welle, в которой россиянка, которая давно живет в Берлине, рефлексирует о том, как ей жить со стыдом за путинскую власть. На третьем месте — интервью BBC с деятелями культуры, которые решили уехать из страны.
Остальные ресурсы в выдаче поделились примерно пополам: есть статьи, цитирующие Путина, есть пост топ-менеджера Google Андрея Дороничева от 22 февраля о том, что ему стыдно за Россию и США.
Материал подготовлен при участии «Школы журналистики им. Бориса Немцова»
Редакторы: Алеся Мароховская, Максим Солюс
Поделиться
Теги
#google#yandex#война#поисковые запросы#пропаганда#яндекс
Яндекс.Браузер не открывает страницы: решение проблемы
Браузер от самой крупной интернет компании в России набирает популярность, но всё же ему пока далеко до того же Google Chrome. Зачастую проблемы, связанные с подключением к интернету в разных браузерах, решаются примерно одинаково. Для начала давайте ответим на вопрос – почему «Яндекс браузер» не открывает страницы:
- Интернет не подключен или есть сбои на линии у провайдера.
- Компьютер использует неправильные DNS адреса.
- Вирусы или сторонние программы каким-то образом побили системные файлы или изменили системные настройки. Например, внесли изменение в файл Hosts.
- Роутер, если через него идёт подключение – просто завис.
- Блокировка сайта.
- Поломка в самом браузере.
ПОМОЩЬ! Если в процессе возникнут трудности или вопросы – пишите об этом в комментариях и я сразу вам помогу. Также будет полезно узнать – какой способ помог именно вам.
Также можно лицезреть ошибку при поиске в Яндексе – «По вашему запросу ничего не найдено». Если страничка в браузере не открывается и произошло это очень резко, то в первую очередь позвоните вашему провайдеру и разузнайте у него – может есть поломка на линии. Также они могут вас прозвонить.
Содержание
- Первые действия
- DNS
- Сброс сетевых настроек
- Исправляем файл «hosts»
- Вирусы и сторонние программы
- Откат системы
- Рекомендации
- Задать вопрос автору статьи
Первые действия
Попробуйте сначала открыть другой сайт. Если не открывается только одна страница – то возможно данный ресурс заблокирован на территории вашей страны. Перезагрузите роутер, для этого выдерните его из розетки и вставьте питание обратно.
Проверьте, чтобы в правом нижнем углу над подключением не было красного крестика – что означает, что есть проблема с подключением. Проверьте целостность кабеля и вставьте его посильнее как в маршрутизатор, так и в сетевой разъёма на компе. Если подключение идёт по Wi-Fi – то переподключитесь к сети заново.
Попробуем открыть любую страницу через другой браузер, можете попробовать стандартный Internet Explorer. Если он открыл страницы, то значит проблема в самом браузере и стоит его переустановить.
- Открываем «Пуск».
- Вписываем «Программы и компоненты» и открываем раздел.
- Далее ставим сортировку по имени и ищем нашу программу. Удаляем её.
- После этого с рабочего браузера скачиваем новую версию Yandex браузера.
DNS
Иногда проблема встает из-за кривых ДНС-серверов. Но их можно прописать в конфигурации сети.
- Заходим в сетевое окружение, нажав + R и прописав команду «ncpa.cpl».
- Заходим в свойства четвертого протокола и ставим автономное определение ДНС. Устанавливаем значение как на картинке выше и жмём «ОК».
Сброс сетевых настроек
Заходим в командную строку из-под администратора и прописываем поочередно две команды:
route -f
ipconfig /flushdns
Перезагрузите компьютер и снова попытайтесь зайти на какой-нибудь сайт. Если не помогает – снова перезагрузите роутер, чтобы ПК поймал новые сетевые настройки.
Исправляем файл «hosts»
Заходим в директорию как на картинке ниже и открываем файл hosts с помощью блокнота. Для этого нажимаем правой кнопкой по файлу. Удалите все содержимое, сохранитесь и закройте файл.
Вирусы и сторонние программы
В первую очередь проверьте ваш ПК на вирусы антивирусной программой. Это должно помочь избавиться от большого количества мусора. После проверки вспомните не устанавливали ли вы ранее какую-то программу.
Некоторые приложения напрямую влияют на сетевое соединение и может менять конфигурацию или вовсе отключать интернет. Есть программы, который устанавливают виртуальные сетевые карты – например WPN приложения или проги, строящие виртуальные локальные соединения.
Зайдите в раздел установленных программ (как это сделать я писал выше) и поставьте сортировку по дате. Некоторое ПО может устанавливаться в фоновом режиме без вашего ведома. Посмотрите – нет ли подозрительных приложений. Если что – удалите их и перезапустите ЭВМ.
Откат системы
Система может быть поломана как вирусами, так и программами. Восстановить её можно двумя способами:
- С загрузочного диска.
- С помощью служебной программы Windows.
Мы будем использовать второй вариант. В поисковой строке пуска впишите «Восстановление системы» и запустите службу. Далее, ничего сложно нет, просто действуйте согласно инструкции. Лучше всего в процессе выбрать самую раннюю точку доступа. Когда служба будет запущена, подождите, пока система перезагрузится – и вы увидите окно об успешном выполнении процедуры.
Рекомендации
Чтобы соединение постоянно не отваливалось, соблюдайте эти правила:
- Всегда держите включенным антивирусную программу с последними базами данных. Лучше всего проверять свой ноут или компьютер на вирусы – как минимум раз в два месяца.
- Старайтесь скачивать программы только с официальных сайтов.
- Если роутер постоянно отваливается и Wi-Fi пропадает – то купите новый маршрутизатор.
- Старайтесь использовать проводное соединение.
- Обновляйте браузер – делается это в настройках ПО.
- Проверяйте «флэшки» антивирусом.
Как проверить индексацию конкретной страницы и всего сайта в Яндексе и Google?
#Оптимизация сайта #Индексация
#2
Ноябрь’17
27
Ноябрь’17
27
Индексация — процесс добавления сведений о сайте роботом в базу данных, которая потом используется для поиска. Бот индексирует ссылки, изображения, видео, и другие элементы на сайте. Если сайт или отдельная страница не проиндексированы, то поисковая система просто не их увидит. Рассказываем как проверить индексацию.
Яндекс
Проверка индексации страницы
Необходимо в строку поиска Яндекс написать следующий запрос:
url:domain.ru/page/
domain.ru/page/ — адрес проверяемой страницы. Важно! Вводить необходимо адрес с www, если страницы на сайте открываются с www, и без www, если на сайте они без www. Если вы не уверены — проверьте оба варианта.
url: — оператор для проверки индексации страницы.
Если в результатах поиска страница найдена, значит она проиндексирована данной поисковой системой. Пример.
Если по запросу ничего не найдено, страница не проиндексирована
Проверка индексации всего сайта в Яндексе
Для проверки индексации всего сайта в Яндекс необходимо использовать следующий запрос:
url:domain. ru/*
domain.ru — доменное имя проверяемого сайта.
url: — оператор для проверки индексации страницы.
* — оператор «любой символ».
Важно! Вводить необходимо адрес с www, если страницы на сайте открываются с www и без www, если на сайте они без www. Если вы не уверены — проверьте оба варианта.
В результате получаем список проиндексированных страниц, а справа от результатов выдачи написано, сколько всего страниц данного сайта находится в поиске. Пример.
Иногда данный запрос не работает и вместо него можно использовать оператор site:domain.ru
Проверка индексации страницы
Необходимо ввести в строку поиска Google запрос:
info:domain.ru/page
domain.ru/page — адрес проверяемой страницы.
info: — оператор для проверки индексации страницы.
Если страница проиндексирована, значит в результатах поиска будет ссылка на проверяемую страницу. Пример.
Проверка индексации всех страниц сайта в Google
Для проверки индексации страницы в поисковой системе Google необходимо ввести в строку поиска запрос:
site:domain.ru
domain.ru — доменное имя сайта.
site: — оператор проверки индексации всех страниц сайта.
В результатах поиска появится список страниц в поиске, а под поисковой строкой общее количество проиндексированных страниц. Пример.
Похожее
Оптимизация сайта Индексация
Атрибут rel=canonical
Оптимизация сайта Индексация
Индексация ссылок
Оптимизация сайта Индексация
#133
Атрибут rel=canonical
Сентябрь’22
9758
22Оптимизация сайта Индексация
#119
Индексация ссылок
Апрель’19
4110
30#111
Описание и настройка директивы Clean-param
Апрель’19
7520
24Оптимизация сайта Индексация
#104
Как привлечь быстроробота Яндекс
Февраль’19
2017
21Оптимизация сайта Индексация
#94
Проверка индекса сайта.
Декабрь’18
7846
28Оптимизация сайта Индексация
#86
Как закрыть ссылки и текст от поисковых систем
Ноябрь’18
4987
22Оптимизация сайта Индексация
#82
Почему Яндекс удаляет страницы из поиска
2813
19Оптимизация сайта Индексация
#60
Правильная индексация страниц пагинации
Февраль’18
6980
19Оптимизация сайта Индексация
#47
Как узнать дату индексации страницы
Ноябрь’17
6834
Оптимизация сайта Индексация
#46
Какие страницы надо закрывать от индексации
Ноябрь’17
9165
18Оптимизация сайта Индексация
#38
Как удалить страницу из индекса Яндекса и Google
Ноябрь’17
12257
20Оптимизация сайта Индексация
#37
Как добавить страницу в поиск Яндекса и Google
Апрель’17
17550
19Оптимизация сайта Индексация
#7
Как закрыть сайт от индексации
Ноябрь’17
8237
17Оптимизация сайта Индексация
#1
Как ускорить индексацию сайта
Ноябрь’17
Поисковая система Яндекс (Yandex.
ru) — отзывы. Негативные, нейтральные и положительные отзывы- Отрицательные.
- Нейтральные.
- Положительные.
- + Оставить отзыв
Отрицательные отзывы
Игорь
После обновления поисковая страница стала просто отвратительной. Но есть плюс. Перешел на мобильный поиск от яндекса (можно открывать на компе) — https://ya.ru/
Теперь перехожу на страницу без всего этого спама, новостей и прочего что засоряет жизнь. Всем советую, чувство, как будто хлам из дома выкинул)
Аленэксандр
Яндекс после обновления стал ещё хуже. И так то был еле еле сейчас вообще отстой
Ваня
Коммерческий поисковик. Выдает не то что ищешь, а за что заплатили. Заспамлен рекламой и всяким мусором. Постоянное навязывание скачать то, скачать это. Говнопоиск
Барсук
Стараюсь не оставлять негативных отзывов, но нынешнее обновление с его Яндекс дзеном — гимн идиотизму. Его авторов нужно взашей гнать, кроме фразы «жертвы ЕГЭ» в голову ничего не приходит.
Татьяна
Самый тупой поисковик в мире.
Борис
У Яндекса проблемы с искусственным интеллектом. Задаю одно поисковое слово, выдаёт всё что угодно, только не то что надо. Много мусора. Такое ощущение, что вываливают помойку, а дальше разбирайся сам.
vall 6300
тупой Ваш поисковик как и ваш назойливый Яндекс(торгаши позорные)
Ориф
Ваш поиск постоянно выдаёт не правильное моё место расположение. Как его исправить.
Margadon
Долго решал, где оставить отзыв о работе Яндекс новости…. Решил здесь!
Уважаемое руководство Яндекса!
Обратите внимание на своих сотрудников кто придумывает заголовки к новостям в разделе Авто, да и к самим новостям тоже!!!!
«Водителям посоветовали то то» , «автомобилистам рассказали сё то», «Россиян предупредили об исчезновении автомобилей с МКПП» и так далее… И вы считаете эти хайповые заголовки добавят вам уважения и внимания? Да вы и так самые популярные и считаю должны следить за имиджем, а этих блатных графоманов гнать надо поганой метлой.
Отвратительно работает! Мало того, что при поиске выдает кучи рекламного мусора, среди которого почти невозможно отыскать нужное, так еще через несколько страниц блокирует поиск дурацкой капчей, на ввод которой нужно отвлекаться!
Светлана
Здравствуйте! Очень ужасное понимание скажем так, о том когда люди запрашивают! Я делаю запрос о том если мама кореянка, а папа армянин……то выходчт статьи и картинки чего угодного, то есть, других национальностей, но только АБСОЛЮТНО не то, что я запрашивала!!!! Если у вас нет данных таких, так и пишете, что не найдено! НО не пихайте лишь бы дать! Разачарована! Будет возможность, всегда буду делать негативный отзыв на все ресурсы, где будет возможно!
Василий
Это навязчивый банер для регистрации, чтобы потом показывать мне свою рекламу.
Валерий
Когда уберут установки яндекс, то Алису. Отказывается все равно выскакивает ужас какой. На мозги действует, слишком часто выскакивает.
Андрей
Постоянно выскакивает установки Яндекс браузер на мозги действует. Как находился в поисковика Яндекс. Слишком часто ужас. Надоело отказывается, все равно выскакивает.
СА
Отвратительнее поисковика просто нет. От рекламы, которая всем уже «до блево-ты» избавиться невозможно. Умственно недалекие админы думают, что если они обходят блокировщика рекламы своими подлоизощренными программными средствами, раздражая тех, кто НЕ ХОЧЕТ видеть эту рыгламу, они растут в глазах пользователей? Таки, нет, скажу я вам, ненавистники русского народа, который вас кормит. Ухожу с яндекса однозначно.
карабас
херня полная я разочарован и зол.
boroda
Яндекс должен награждать специальной наклейкой лучшие места, по мнению пользователей. Наша организация — в числе лучших. Звонили на горячую линию в начале года, писали.Обещали выслать нашу звезду по почте на адрес организации, но наклейку так и не дождались, хотя уже сентябрь.
1nter32
Стало невозможно искать видео через поисковик Яндекса, такое ощущение, что Кинопоиск купил эту функцию. Я не желаю смотреть фильм, который мне подсовывает Кинопоиск, я хочу ВЫБИРАТЬ!!!
на грани нервного срыва
Что за не понятные вещи творятся с этим поисковиком???? Почему если я пишу одно, он мне выдает совсем другое и в огромных кол-вах. Если я на пример пишу купить аналог награды «Золотая бутса» зачем он мне выдает игровые бутсы золотого цвета???? Поисковик очень тупой, не реально тупой! Он ищет не то что тебе нужно, а то что ему удобно походу! Короче поисковик ВАТА!!!!!!
Вчера вечером опубликовала сообщение о отравлении собаки Лизы по адресу Рублевское Шоссе д. 91 корп.1 проживавшей во внутреннем магазина «Магнит» предположительно хозяйкой кулинарии по кличке Хасановна, которая неоднократно препятствовала местным женщинам-волонтерам подкармливать и ухаживать за Лизой в течении 12 лет. Автор вечером при очередном посещении обнаружила Лизу с разъезжающими ногами и парализованным мордочкой и пеной из рта. Вызвала ветеринара с Багрицкого, который зафиксировал факт отравления.
Оплатила из своей пенсии вызов ветеринара, перевозку и крематорий.
А Яндекс-район, опубликовал это сообщение, а потом удалил. Получается помог догхантерам и хасановнам уйти от публичной ответственности.
left
Все что не связывало с яндексом стараюсь обходить стороной. Деньги своровали с яндекс кошелька, постоянно пихают свои продукты куда непопадя, со своей алисой тупой везде достали . Вместо поиска сплошная реклама в результатах. Картинки подписывает вообще не относящиеся к поисковому запросу. Патриотизм патриотизмом, но яшка просто достал своей тупостью и наглостью.
Владимир
Яндекс в последнее время демонстрирует все более неуважительное отношение к клиентам! Никакие обращения не рассматриваются — максимум глупые отписки, звонки бесполезны. Советую никому не иметь с яндексом дело!
Михаил
Установил было на мобильном в качестве поисковика по умолчанию в хроме.
В итоге: яндекс начал в результатах выдачи на полэкрана рекламировать Яндерк браузер. В итоге поставил «утку». Патриотизм-патриотизмом, а всплывающие окна сейчас разве что во сне не открываются (и то не факт). И вот чего они добились? Так бы пользовался их поисковиком, а так — ушел к конкурентам, да еще и с негативом.
wektor
«Яндекс» бьёт себя со всех сторон, больше напоминая камикадзе, уничтожающего свою репутацию. Кроме всего прочего, поисковик всё больше склоняется к антироссийской информационной политике, активно продвигая на своей платформе русофобские СМИ. Всё это медленно, но уверенно ведёт корпорацию к полноценному краху, и спасти «Яндекс» могут лишь кардинальные изменения в работе всех структур компании.
Имя
Давно пользуюсь, и чем дальше, тем ну его на х.. Напихали всякой хрени, которая мешает и не удаляется. А по существу ничего не найти.На запросы выдаёт разную дичь,хоть ставь фильтр хоть нет.Полное ……, просто ……….
Alex
стало такое говно. одну рекламу подсовывает а конкретно по поиску ничего подходящего
Валентин Шарандин
самая конченая поисковая система. А особенно новости!!! такое ощущение что их составляют одни ублюдки которые не видят проблем в России по важнее. В России много проблем, кроме ******* собаками Панина. Очнитесь вы серите дебилы…..!!!!!!
адим
Вы пидоры, когда перестаните свой яндекс гавно пихать во все дыры
Koron
https://www.
Яндекс -засунь свой дебильный Дзен себе в. недалекое, но достойное тебя, место. Не могут ничего придумать, а бабки хочется иметь. Всякую чепуху суют в программу. Одно слово европейцы. Им это в охотку.
Andrew GLOVER
https://www.spr.ru/forum_vyvod.php?id_tema=4171399
Хоть один вменяемый из команды Яндекс скажет как с вами бороться? Впечатление древней деревни и бабушке яндекс хочет свой нос засунуть везде раздражаете, милуй меня Бог, Аминь. Суете себя родных во все. На вашу страницу заходить страшно, Яндекс. При запросе конкретном выдает все, только не о чем ты спрашивал. Я не могу в таком поисковике искать что-либо.
Georgia1210
https://irecommend.ru/content/o-bylom-velichii-i-nyneshnem-upadke
Достоинства:
- красиво
- много виджетов
- удобно
Недостатки:
- много рекламы
- находит в основном проплаченные сайты
- не самый лучший поисковик
Лет 7 назад в нем еще можно было найти ВСЁ и пользовалась я исключительно этим поисковиком, причем мной находилось очень много именно полезной информации. От видео уроков и интересующих меня статей, до поставщиков, которые меня интересуют. Отмечу что работаю я менеджером, и 30% моей работы составляет поиск в интернете. Сейчас очень трудно стало что-либо найти в поисковике яндекс, почти все первые страницы забиты какими-то проплаченными сайтами и коммерческой информацией… Ужасно..
Google работают в настоящее время примерно по тому же принципу, поэтому теперь, иногда приходится забивать информацию сразу в три системы, чтоб найти то, что мне нужно.. Или начинать поиск с 10-й страницы выдачи.
Яндекс как поисковик очень разочаровал. Поэтому особенно рекомендовать его не стану..
Стану рекомендовать отдельные составляющие, например Яндекс-карты, или Яндекс-закладки)))
AK-80
https://irecommend.ru/content/ranshe-byl-khoroshii-teper-odna-reklama
Начал пользоваться этой поисковой системой ещё на заре Рунета. Это была хорошая поисковая система, которая точно и быстро искала нужный материал.
Если вбиваешь в поиск слово — «расписание», то он выдавал сразу несколько сайтов с расписаниями поездов, электричек или самолётов. Теперь выдаёт в начале только свои проекты в каждой тематике. Переводы, платежи итд.
Ну это ещё терпеть можно, как-никак проект коммерческий и требует больших затрат на свою работу. Но поражает огромное количество рекламы сервиса «Директ».
Она как бельмо на глазу висит при каждом коммерческом запросе. Занимает первые 3-4 места в десятке. Интересно, кто-нибудь на них вообще реагирует? На эти рекламные объявления. Ведь если раньше интернет-магазин был в верху десятки Яндекса это происходило из-за его авторитетности среди пользователей и других интернет-ресурсов. А теперь заплатил — и ты в десятке Яндекса. Причём без разницы честный ты продавец или нет. Главное — заплати.
lexus zuev2016
https://otzovik.com/review_4991016.html
Достоинства:
- Ничего.
Недостатки:
- Беспорядки страницы в яндексе поисковике.
Я пытался нажать страницы «за сутки», «за 2 недели», «за месяц» и «числы, месяцы и годы от… и до… » но страницы упорядочивание не предусмотрено. Пожалуйста, сделайте по порядочные страницы числы, месяцы и годы. Чтобы эти сайты стало удобно и по порядочные страницы, чтобы могли почитать статьи и поискать страницы стало по удобнее эти сайты.
STALKER27
https://otzovik.com/review_5355627.html
Достоинства:
- нет
Недостатки:
- много ненужного
- поиск не работает
- в поиске выдает много ненужного и много рекламы.
Еще до 2012 года все как то было нормально. Пользовался яндекс поиском и что нужно находил. Но сегодня, это не поиск а свалка разного хлама который выдает на запрос. А хлам это не то что нужно. Куда делись фильтра тонкого — точного поиска? Мало того что оно выдает много не нужного, так оно выдает еще много много много рекламы! Я не ищу рекламу!
Я ищу конкретную информацию! Похожая информация где встречаются данные слова мне не интересна.
А также НАДОЕЛА реклама. Стоит вбить в поиск например какую то модель телевизора чтобы просто посмотреть характеристики, как тут же выскакивает реклама от яндекса где предлагают телевизоры. И так же со всем. Ищу информацию по некоторым автомобильным узлам, как тут же выскакивает реклама втюхиватель. И эта реклама есть ресурсы памяти ПК.
africanov
https://otzovik.com/review_5335049.html
Достоинства:
- нет
Недостатки:
- Вся сеть в России загажена этим словом
Уже около 10 лет я трачу время на то, чтобы отвязаться от услуг яндекса. Любой случайный клик мышкой может привести к тому, что потом полдня чистишь компьютер. Очень напоминает отца Фёдора из известного произведения Ильфа и Петрова. Одно время в туалет ходил с опаской — вдруг из унитаза выскочит яндекс! Очень жаль, что нет законных способов призывать к ответу таких пиратов.
Нейтральные отзывы
Ирина отзывы
https://otzovik.
Достоинства:
- разные сервисы
Недостатки:
- иногда не выдерживает конкуренции
В первую очередь, нравится яндекс музыка. Хорошее качество, звучание, намного лучше некоторых сайтов и социальных сетей.
Почта тоже есть на яндексе, переехала с гугл (лично моя). Удобство примерно наравне, у обоих есть заморочки, связанные с защитой доступа к паролю, с безопасностью, создающие проблемы и потерю времени, если заходишь с чужого компьютера, что-то забыто и надо срочно восстановить, если давно не использовалось.
Да и просто бывает — не пускает и всё. Это бывает связано с местными настройками, блокировками, качеством связи.
В целом, при наличии дополнительных вариантов для разных целей, можно пользоваться.
Остальные сервисы как-то не прижились, как и основная функция — поиск информации — всё же гугл выигрывает, несмотря ни на что.
Valentina737
https://irecommend.
Достоинства:
- погода
- свежие новости
- телепрограмма
Недостатки:
- не самый лучший поисковик
- проблемы с музыкальным разделом
- хамство в комментариях
Лучше всего этим сайтом пользоваться как информационным и по погоде. Там тоже всегда свежие новости по разделам: «Политика», «В мире», «Общество», «Культура», «Экономика», «Спорт», «Происшествия», «Наука», «Hi-Tech», «Интернет» и «Авто». Хотя я смотрела — хамства там тоже немало. Но с комментариями он выдаёт далеко не всегда.
Также есть телепрограмма, расписание электричек, погода, пробки. В отношении погоды это один из лучших сайтов.
Почты у меня там никогда не было — об этом мне сказать нечего.
Музыку сразу лучше не набирать: послушать можно, но я сколько раз заходила — висит один маленький список, и что ни нажимаю — ни с места. То же самое — с картинками. Я, конечно, не отрицаю возможности, что это какая-то несовместимость с моей операционной системой — но сама больше не буду с этим связываться.
Как поисковая система, Яндекс неплохой, но Гугл лучше. Я сравнивала несколько раз: часто именно на Яндексе выдавало немного не то или совсем чуть-чуть. Хотя, конечно, смотря что ищешь. И ищет он не так быстро, как Гугл: начнёт искать только когда забьёшь запрос целиком.
priz
http://irecommend.ru/content/privykla-k-yandeksu-tk-tam-osnovnaya-pochtai-iz-za-yandeks-deneg-i-poiskovik-ne-plokh
Достоинства:
- большой обьем полезной информации
- почта
- просто
- удобно
- яндекс-деньги
- яндекс-краски
- яндекс-маркет
Я в основном пользуюсь мейлом на Яндексе. Как-то так получилось, еще на заре моего интернет-путешествия, я зарегала 2 почты (на и на яндексе). Мейл как-то не прижился(((
Долго пользовалась поиском Яндекса, потому что у меня домашней страницей стояла их почта, поэтому поиск был постоянно на виду. В принципе и сейчас пользуюсь им, но периодически изменяю с Гуглом)))
Потом у меня были проблемы с вебмани, я искала альтернативу и нашла Яндекс-деньги. Да, ненадежно, да, слабо защищено и могут увести деньги, но очень долго пользовалась, т. к. многие мои расчеты шли в яндах. И я старалась предохраняться, меняла пароли, большие суммы переводила с кодом протекции. И слава Б, меня не кидали в яндах)))
Позже, когда до моей провинции докатился прогресс, стали открывать пункты выдачи интернет-магазинов, да и сама стала чаще платить банковской картой в интернет-магазинах , особенно пригодился Яндекс-маркет. В нем можно задать исходные данные и он подберет самый выгодный по цене вариант. И сразу же можно купить и оплатить картой. Я плачу кукурузой или картой ТКС Платинум, получая кэшбэк)))
Там же можно написать отзыв на покупку, зачастую откликаются работники магазинов (как у меня произошло с моим отзывом на Яндекс-маркете на интернет-магазин Озон).
Еще удобно прокладывать маршрут в Яндекс-картах, играть в он-лайн игрушки, смотреть погоду и последние новости… да еще куча возможностей, о которых я не знаю.
А самый младший член семьи — 5-летняя дочка любит Яндекс-краски!
Liubashka
http://irecommend.ru/content/bez-ego-vozmozhnostei-trudno-predstavit-nachalo-trudovogo-dnya
Интернет-сервис Яндекс – один из самых популярных. У большинства пользователей домашней страницей установлен именно сайт Яндекс. Без его возможностей трудно представить начало трудового дня в офисе. После запуска компьютера у меня вошло в привычку первым делом узнавать новости часа, справляться о погоде и котировках, и, конечно же, проверять почту. Почта, к слову, не самая удобная, но понятная. Из недостатков могу отметить отсутствие возможности прикрепления телефонного номера для информации о новых письмах и неудобную фильтрацию спама. На том же таких недочётов нет. О поисковых возможностях. В строку поиска достаточно ввести первые буквы запроса, и, если он часто востребован, то уже не нужно дописывать конец фразы – концовка находится сама.
В общем, Яндекс вполне устраивает, к тому же он постоянно улучшается и всячески совершенствуется.
Положительные отзывы
Анатолий
При попадании на Яндекс сразу попадаешь в что-то навязчивое и липкое. Постоянно всучивают свой браузер. Если нужна какая- либо информация , то вместо неё получаешь гору рекламы. Ответ на многие запросы в Яндексе вообще не по теме.
marsmag18
https://otzovik.com/review_4816286.html
Достоинства:
- интерфейс
- быстрота
- выдает нужную информацию
Недостатки:
- работает чуть медленее гугла
Здравствуйте! Сегодня решил написать отзыв о поисковой системе яндекс. Практически всегда пользуюсь поисковиком яндекс. Быстрый поиск, вывод нужной инфомации. На главной странице поиска можно, завести свою яндекс почту, посмотреть погоду в своем городе, проложить маршруты, узнать о пробках и т. п. Этот поисковик проводит быстрый анализ поисковой фразы и выводит нужные сайты в вашем регионе за считанные секунды. Гугл конечно работает чуть быстрее, анализирует уже при наборе фразы и имеет функцию голосового поиска. Но яндексом я пользуюсь, значительно чаще, очень нравится мне дизайн и работа яндекс поисковика, рекомедную!
alexeymihailenko
https://otzovik.com/review_4812877.html
Достоинства:
- Хорошая помощь в поиске.
Недостатки:
- Не нужные варианты поиска.
Яндекс это быстрый и удобный поисковик для работы в интернете, быстрая помощь в разных ситуациях, много вариантов ответов на заданный вопрос. Наперника уже все знакомы с этой системой. Помогает Мне в работе уже не первый год, так, как последнее время, Я работаю дома всемирной паутине интернете, с поисковой системой Яндекс уже с 2015 года работаю и получаю только положительные результаты, самый лучший поисковик за последнее время, есть ответ почти на любой вопрос. Все меняется, появляются новые сайты и и новации, но Яндекс по прежнему актуален в работе и нужен. Программа Яндекс также совершенствуется и улучшается, что наверни ка скажется положительно в дальнейшем при работе с этой программой.
mrsemechka
https://otzovik.com/review_4796615.html
Достоинства:
- быстрый
- информативный
- удобный
Недостатки:
- нету
До Яндекса всё время пользовался Google. Спустя время я наткнулся на Яндекс он оказался удобнее Google, всё на одной странице новости, афиша, погода всё для того чтобы быть в курсе последних событий. Очень быстро находит нужную информацию есть свои сервисы переводчик, навигатор и т. д . Показывает значки у сайтов что не мало важно в отличие от Google. Вся семья пользуется им.
Вообщем пользоваться данным поисковиком одно удовольствие, рекомендую!
manipulyator
https://otzovik.
Достоинства:
- Удобство
- быстрота
Недостатки:
- часто первые результаты поиска — реклама
Действительно, для меня Яндекс уже давно поисковик номер один. Именно что касается рунета, я уверен, что ему нет равных. Пользуюсь им, если не ошибаюсь с 2008 года примерно и ни разу не разочаровался. Быстрая, удобная выдача нужной информации, сразу показываются картинки по теме (часто это очень помогает). Само собой подсказки при введении слов, ну этим уже никого не удивишь.
В общем настолько хорош что уже давно является моей домашней страницей.
JustMiner
https://otzovik.com/review_3772169.html
Достоинства:
- Качество
- скорость и конечно оформление.
Недостатки:
- Индивидуально
Яндекс мне очень понравился — хороший поисковик и еще пояс с картами, новостями, картинками, видео, своей почтой и своей платежной системой.
Я пользуюсь в основном им. Вы скажете: и что же в нем такого, а я отвечу: хорошее оформление, его функции — это вообще отдельная тема, находит миллионы сайтов, видео, изображений на Ваш запрос. Его платежная система — Яндекс. деньги — сейчас очень популярна. Также Яндекс. диск — качественный отдел. Все это я пишу по многолетнему опыту пользования Яндексом. Мало какая поисковая система а может похвастаться таким высоким качеством. Конечно это лично мой мнение, и я не хочу убивать его другим, а вы можете думать по-другому, и это ваше дело.
Founder
https://otzovik.com/review_294710.html
Достоинства:
- Превью сайтов
- удобная выдача информации
- кнопки «подсказки»
Недостатки:
- отсутствует возможность поиска по изображениям.
Яндекс нравится гораздо больше гугла: возможность искать по городу, красивый и удобный дизайн, онлайн лицензионная музыка. Вообщем всё-то чего нет у гугла. А если установит Яндекс-Бар с кучей дополнительных функций — вообще красотень! Единственный его (яндекс-бара) минус — чересчур большая массивность (много места занимает). Ещё, что очень нравится у Яндекса и недостает у гугла — значки сайтов. Без них, дизайн гугла, выглядит каким-то безликим и неудобным. Особенно этот дискомфорт ощущается после Яндекса, с его приятным дизайном. А ещё у Яндекса доставляют «кнопки подсказки» (рекомендации), вот, например, ищешь информацию о автомобиле, он тебе сначала выдаст цены (с яндекс. авто, кстати) потом изображения и уже потом будет список сайтов. А в самом верху ещё кнопки, типа: «цена», «тех. характеристики», «отзывы» и тому подобное. Очень удобно! Ещё очень нравится наличие «Яндекс. маркета», очень часто выбираю и сравниваю товары там. В общем, яндеск мне очень импонирует, притом гораздо больше гугла.
Единственное что опечаливает, так это отсутствие функции «поиск по изображениям», надеюсь, Яндекс это когда-нибудь уже реализует. Жаль у них нет раздела «предложение и пожелания)
Gorod_Omsk
https://irecommend.ru/content/samyi-luchshii-poiskovik-v-runete
Достоинства:
- малый вес сайта
- много виджетов
- удобно
Недостатки:
- мало тем
Яндекс это не просто поисковик каких много. Его можно настроить под себя! Поставить виджеты на главную и постоянно быть в курсе самых последних новостей! Можно поставить виджет анекдоты, новости, картинки для рабочего стола и мобильного телефона и многое другое! Но поисковик не заканчивается на поиске! У Яндекса есть множество дополнительных сайтов. Список сайтов вы можете посмотреть тут [ссылка] Сайт ищет и в рунете и в интернете, так же можно искать определенно или в рунете или в интернете!
Секретно
https://irecommend.ru/content/nu-bez-nego-uzh-ya-nikuda
Достоинства:
- большой обьем полезной информации
- быстро
- качественно
- надёжно
- много виджетов
- удобно
Каааак же я люблю Яндекс!!!! )))))) одни достоинствааааа!! ))))) Я без интернета никуда, всегда пользуюсь интернетом. И конечно-же пользуюсь только яндексом! Googl мне конечно тоже нравится, там всё не так расширено , как здесь! Во-первых, здесь можно найти всё обо всём! )))) Во-вторых удобно и не запутано ничего. В третьих, независимо от скорости интернета у него всегда хорошая скорость, быстро работает всегда, никогда не тупит! ))))) Самое главное, спама почти нет! ))) + очень красивый дизайн! ))) Мне ещё нравится яндекс деньги. Всегда пользуюсь им и всегда конечно же довольна! Я готова хвалить яндекс часами.
Думаю многие из вас пользуются яндексом и вы меня поймёте! ))))) Ну, а кто не пользуется, советую) Не пожалеете. Там всё быстро, качественно, самое главное надёжно! )))))
Green_Eyes
https://irecommend.ru/content/tolko-69
Достоинства:
- большой обьем полезной информации
- много виджетов
- просто
- удобно
Поисковиков много, я работала с разными, и с уверенностью млгу сказать — яндекс лучший. Самое главное для поисковика — находить то, что нужно. А не «бездумно» все подряд как хваленый гугл. Симпатичный, не перегруженный дизайн. Быстрый и удобный просмотр новостей, как общероссийских и мировых, так и своего региона. Все под рукой — почта, можно полностью настроить под себя — оформления, заметки, пометки, группы, контакты Smile «яндекс-деньги», которые можно легко «привязать» к кредитке «Альфа-банка», одна беда — очень мало где востребованы «яндекс-деньги», везде «веб-мани» Sad возможность настроить еще и мобильную почту, фотки и т. д (я лично не пользуюсь, но многие знакомые — да). Удобная афиша, телепрограмма, погода. Для многих будут полезны пробки, котировки. Еще очень радуют виджеты, можно выбрать что нужно.
Александра
https://www.spr.ru/forum_vyvod.php?id_tema=3569428
Самый лучший поисковый сайт. Я впервые познакомилась с Яндексом очень давно и с тех пор, ежедневно он облегчает мою жизнь. Я каждый день нахожу в нем все новое и интересное. Как мне кажется, это самый удобный поисковик. Ищет быстро, предлагает удобно, внешне красиво оформлен. Я даже в телефоне, когда у меня в гугл хроме сначала вылезает гугл, ищу в нем яндекс, а уже потом делаю запрос. Чудесный Яндекс. маркет миллионы, наверное, мне уже сэкономил, а чудо карты не дали застрять в самых злачных местах города. Он извещает о праздниках, поздравляет с днем рождения, предлагает музыку и видео.
Я восхищаюсь Яндексом. Это лучший поисковик, я заявляю!
Формат запроса. Places API
Доступ к сервису осуществляется с помощью GET-запроса на адрес https://search-maps.yandex.ru/v1/. Обязательные параметры запроса: text, lang и apikey.
В ответ сервер возвращает найденные объекты, отсортированные по релевантности запросу. За один поисковый запрос можно получить не более 500 объектов.
https://search-maps.yandex.ru/v1/ ? [Ключ для доступа к сервису. Вы можете получить ключи и управлять ими в Личном кабинете разработчика.] & [\n Текст поискового запроса. Например, название географического объекта, адрес, координаты, название компании или номер телефона.
\nПримеры (без кодировки URL):
\n\n
text=лебединое озеро\n
text=55.750788,37.618534\n
text=Санкт-Петербург, ул. Блохина, 15\n
text=+7 495 739-70-70\n "}}">=<поисковый запрос>] & [\n
text=Яндекс, ОООТипы возвращаемых результатов.
\n \nПример:
\n\n "}}">=<типы объектов>] & [Предпочтительный язык ответа. Задайте идентификатор локали в формате
type=bizlang=language_region, где
- \n
language— Двухбуквенный код языка. Указано в формате ISO 639-1. Задает язык отображения названий найденных объектов. \nрегион— Двухбуквенный код страны. Указано в формате ISO 3166-1. Он определяет региональные особенности, такие как единицы измерения (для указания расстояния до найденного объекта).Примечание. Для регионов
RU,UAиTRрасстояние указано в километрах; дляUSотображается в милях. \n
Поддерживаемые значения:
Если параметр имеет значение языкового стандарта, которого нет в этом списке, служба выбирает язык, ближайший к заданному.
Пример: lang=uk_UA .
Центр области поиска. Определяется долготой и широтой, разделенными запятой. Долгота и широта указаны в градусах, представленных в виде десятичных знаков.
\nИспользуется вместе с параметром spn, определяющим размер области поиска.
\nИгнорируется при обратном геокодировании.
\n Пример: ll=37,618920,55.756994&spn=0.552069,0.400552
Размер области поиска. Определяется с помощью диапазона долготы и широты, разделенных запятой. Промежутки указаны в градусах, представленных в виде десятичных знаков.
\nИспользуется совместно с параметром ll, определяющим центр области поиска.
\nИгнорируется при обратном геокодировании.
\n Пример: ll=37. 618920,55.756994&spn=0.552069,0.400552
Альтернативный метод установки области поиска (см. ll+spn ).
Границы области поиска определяются как географические координаты левого нижнего и правого верхнего углов области (в порядке "долгота, широта").
\n Примечание. Если bbox и ll+spn устанавливаются одновременно, параметр bbox имеет приоритет.
Пример: bbox=36. 83,55.67~38.24,55.91
Указывает на «строгое» ограничение области поиска.
\n Если в области поиска ничего не найдено (задается параметрами ll + spn или bbox), сервис пытается найти результаты вне ее. Вы можете использовать параметр rspn , чтобы отключить поиск за пределами определенной области.
Возможные значения:
\n \n «}}»>=<не искать за пределами области поиска>] & [\nКоличество возвращаемых объектов. По умолчанию 10. Максимальное значение 500.
\n Пример: результатов=25 .
Количество объектов, которые необходимо пропустить в ответе (начиная с первого). Максимальное значение 1000.
Пример: пропуск=25 .
Имя функции JavaScript для передачи ответа (по соглашению JSONP).
\n Пример: callback=my_response_handler
apikey | Ключ для доступа к сервису. Вы можете получить ключи и управлять ими в Личном кабинете разработчика. |
текст | Текст поискового запроса. Например, название географического объекта, адрес, координаты, название компании или номер телефона. Примеры (без кодировки URL): |
type | Типы возвращаемых результатов. Возможные значения: Пример: |
lang | Предпочтительный язык ответа. Задайте идентификатор локали в формате lang=language_region , где
Поддерживаемые значения: Если параметр имеет значение языкового стандарта, которого нет в этом списке, служба выбирает язык, ближайший к установленному. Пример: |
ll | Центр района поиска. Определяется долготой и широтой, разделенными запятой. Долгота и широта указаны в градусах, представленных в виде десятичных знаков. Используется вместе с параметром spn, определяющим размер области поиска. Игнорируется при обратном геокодировании. Пример: |
spn | Размер области поиска. Определяется с помощью диапазона долготы и широты, разделенных запятой. Промежутки указаны в градусах, представленных в виде десятичных знаков. Используется вместе с параметром ll, определяющим центр области поиска. Игнорируется при обратном геокодировании. Пример: |
bbox | Альтернативный метод настройки области поиска (см. Границы области поиска определяются как географические координаты левого нижнего и правого верхнего углов области (в порядке «долгота, широта»). Примечание. Если Пример: |
rspn | Указывает на «строгое» ограничение области поиска. Если в области поиска ничего не найдено (задается с помощью параметров ll + spn или bbox), сервис пытается найти результаты вне ее. Вы можете использовать параметр Возможные значения: |
результаты | Количество возвращаемых объектов. По умолчанию 10. Максимальное значение равно 500. Пример: |
skip | Количество объектов, которые необходимо пропустить в ответе (начиная с первого). Максимальное значение равно 1000. Пример: |
обратный вызов | Имя функции JavaScript для передачи ответа (по соглашению JSONP). Пример: |
Была ли статья полезной?
FAQ — Мобильные Яндекс.Карты. Помощь
- Начало работы
- Поиск
- Маршруты
- Тип карты
- Оффлайн карты
- Дорожные события
- ДРУГИ
- Уведомления
- .
- 0502020202020202020202020202. можно ли редактировать информацию на карте?
Поддерживаемые платформы
Яндекс. Карты поддерживаются на iOS 10.0 и выше и на Android 4.1 и выше.
Приложение не поддерживается на следующих платформах: Symbian, Java, Windows Mobile, Windows CE, bada. Мы не можем гарантировать стабильную работу Яндекс.Карт на этих платформах.
Если вы установили приложение на свое устройство под управлением iOS 6 или более ранней версии, вы можете повторно загрузить более старую версию приложения на это устройство.
Как узнать версию моей операционной системы?
Чтобы узнать версию вашей операционной системы, перейдите в «Настройки» вашего устройства и выберите «Основные» → «Об этом устройстве».
Версия вашей операционной системы указана в разделе Версия.
Как узнать, какая у меня версия приложения?
Коснитесь Меню .
Перейдите в «Настройки» → «О программе».
Где скачать приложение?
Версию для Android можно скачать в Яндекс. Магазине.
Если у вас возникли проблемы с загрузкой приложения из Google Play, обратитесь в службу поддержки Google.
Чем Яндекс.Карты отличаются от Яндекс.Транспорта?
Яндекс.Навигатор предназначен для использования во время вождения. Приложение позволяет устанавливать маршруты движения и просматривать статистику поездок и информацию о парковке.
Яндекс.Карты позволяют прокладывать маршруты (автомобильные, пешие или на общественном транспорте), а также предоставлять подробную информацию о предприятиях.
Более подробное описание приложения можно найти в магазине приложений для вашего устройства.
Вы можете установить и использовать оба приложения, а затем выбрать то, которое больше соответствует вашим потребностям.
Поддерживаемые языки
Яндекс.Карты поддерживают русский, английский, украинский и турецкий языки.
Приложение запустится на английском языке, если в вашем телефоне выбран язык, не включенный в этот список.
Как быстро найти определенный вид бизнеса?
Нажмите на строку поиска.
На экране появится список категорий мест. Коснитесь одной из категорий (банкоматы, заправочные станции и т. д.), чтобы найти такие места поблизости.
Подробнее см. в разделе Найти на карте.
Как я могу связаться с организацией, которую я нашел?
Чтобы позвонить в найденную организацию, нажмите «Позвонить» в карточке места.
Чтобы перейти на сайт организации, нажмите «Сайт» в карточке места.
Как отобразить подробную карточку места?
Чтобы просмотреть подробную информацию о месте, нажмите на него в списке результатов поиска. Для получения дополнительной информации см. карточку места.
Как работают поисковые подсказки?
Вы можете использовать автоматические подсказки для быстрого ввода запроса.
Предложения включают список мест с названиями, похожими на введенный вами запрос. Эти места перечислены в порядке удаления от центра отображаемой карты.
Как я могу поделиться адресами, координатами или ссылками на организации или места?
Чтобы поделиться ссылкой на место, нажмите «Поделиться» (или). Эта кнопка находится на карточке места или в верхней части карты.
Как спланировать маршрут?
См. Установить маршрут.
Как проложить маршрут к определенной организации или месту?
Найдите организацию или место.
Нажмите и удерживайте точку на карте.
В появившемся контекстном меню нажмите «Сюда» .
Маршрут начнется от вашего текущего местоположения и закончится в выбранной точке.
Дополнительную информацию см. в разделе Настройка маршрута.
Как выбрать вариант маршрута и начать путешествие?
См. пункт Выбор маршрута.
Как я могу просмотреть свой маршрут?
См. Маршрут.
Как сбросить маршрут?
Нажмите «Отмена» или значок «Закрыть».
См. маршрут для получения дополнительной информации.
Как включить голосовые подсказки во время движения по маршруту?
Включите уведомления Play (Меню → Настройки → Маршруты → Звук).
Дополнительные сведения см. в разделах Перемещение по маршруту и ../concept/settings_2.html#marsrut.
Почему маршрут, который я запросил, не установлен?
На данный момент опция настройки маршрута доступна не везде. Если вы не можете установить свой маршрут, сообщите нам об этом.
Чем типы карт отличаются друг от друга?
См. раздел Тип карты.
Что такое ночной режим и как он работает?
См. ../concept/settings_2.html#interface__night_regim.
Что такое автономные карты и чем они полезны?
Офлайн-карты — это карты городов, которые сохраняются в памяти вашего телефона. С автономными картами приложение работает быстрее, и вы потребляете меньше данных.
Информацию о том, как загружать карты, см. в разделе Офлайн-карты.
Карта моего города недоступна для скачивания. Что я должен делать?
Если карты вашего города нет в списке доступных для скачивания, отправьте нам сообщение, и мы сообщим вам, когда она появится.
Что такое дорожно-транспортные происшествия?
Дорожные события — это точки на карте (установленные пользователями), которые обозначают аварии, дорожные работы, камеры контроля скорости, перекрытие дорог, поднятые мосты и т. д.
Кроме того, существует еще один тип «дорожных событий», называемый «разговорами». . Это точки на карте, где вы можете начать обсуждение на любую разрешенную тему (список запрещенных тем см. в ответе на вопрос «Почему меня заблокировали в разговорах?» 9).0003
См. «Дорожные события» для получения информации о том, как просмотреть или скрыть дорожные события и как добавить их на карту.
Как долго будет отображаться дорожное предупреждение?
Сообщения о дорожных событиях будут отображаться около 20 минут. Каждое подтверждение этого события, которое мы получаем от других пользователей, продлевает это время.
Если у вас есть информация о дорожном происшествии в определенном месте (например, если вы заметили камеру наблюдения), сообщите нам об этом, написав в поддержку Яндекс.Карт.
Модерируются ли дорожные события и разговоры?
Да. Правила модерации следующие:
События «ДТП, камеры, дорожные работы и прочее» должны содержать информацию только о самом дорожном событии.
«Беседы» предназначены только для обсуждения тем, связанных с текущей дорожной ситуацией.
Сообщение любого типа будет помечено при следующих обстоятельствах:
Это нарушает законы этой страны.
Содержит нецензурную или вульгарную лексику.
Сюда входят нецензурные выражения, в которых часть букв заменена звездочками или другими символами, но предполагаемое значение читается и понимается носителями языка.
Разжигание ненависти или попытки унизить человека или группу по признакам пола, расы, национальности, языка, страны происхождения, религиозных убеждений или принадлежности к определенной социальной группе.
Содержит рекламу.
Содержит непонятные группы слов или букв.
Содержит номер телефона или другую контактную информацию.
Содержит политические лозунги или призывы к действию.
Сообщает о взрыве бомбы или другой чрезвычайной ситуации, которую мы не можем проверить и которая может напугать других пользователей.
Если сообщения пользователя имеют неприемлемый контент, пользователь может быть забанен в приложении (см. Почему меня заблокировали в беседах?).
Почему меня заблокировали в «разговорах»?
Пользователь может быть заблокирован, если отправляет сообщения недопустимого содержания (см. Модерируются ли дорожные события и разговоры?).
Если вы впервые заблокированы, блокировка будет снята через 24 часа.
Блокировка не будет снята после вашего второго нарушения.
Подробнее о том, как работает Яндекс.Пробки, читайте в блоге Яндекса.
Как сообщить Яндексу о пробках?
Информация о вашем местоположении и скорости отправляется на серверы Яндекса при использовании приложения. Эти данные помогают анализировать загруженность дорог.
Внимание. Эти данные передаются анонимно и конфиденциально.
Насколько актуальна дорожная информация?
В Яндекс. Пробки отображаются данные Яндекс.Карт и Яндекс.Навигатора. Информацию о том, как отображаются данные, см. в разделе «Трафик».
Чем чаще поступают данные, тем актуальнее информация на карте. Отображение трафика изменяется в соответствии с появлением новых данных (если нет обновлений по истечении заданного времени, то трафик перестанет отображаться).
Если уведомление не отправляется
Если вам не удалось отправить push-уведомление на телефон или планшет, проверьте следующие настройки мобильного устройства:
Доступ к сети включен. Wi-Fi или мобильные данные включены.
Уведомления разрешены. Включите это разрешение.
Что Яндекс.Карты умеют получать уведомления. Включите это разрешение.
Расположение этих настроек зависит от марки вашего устройства. Больше информации:
для устройств iOS
для устройств Android
Почему приложение не может определить мое местоположение?
Возможно, вы не включили геолокацию на своем устройстве. Для включения:
Android 4.3 и более ранние версии: в меню Настройки → Мое местоположение включите Использование GPS.
Android 4.4: в меню Настройки → Местоположение → Режим включить Использование всех источников или Использование GPS.
iOS: в меню Настройки → Конфиденциальность включите Службу геолокации и Поделиться геолокацией (с приложением). Если эти параметры уже включены, убедитесь, что ничто не блокирует сигнал GPS (например, крыша вашего автомобиля).
Почему виджет не работает на iOS?
Возможно, приложение Яндекс.Карты не может получить доступ к вашему местоположению.
Перейдите в Настройки → Конфиденциальность и разрешите приложению Яндекс.Карты доступ к вашему местоположению.
Как открыть карты в браузере на мобильном устройстве?
Вы можете использовать Яндекс.Карты на мобильном устройстве через приложение Яндекс. Карты.
Если у вас нет приложения Яндекс.Карты, вы можете открывать карты на мобильном устройстве в браузере.
Для этого наберите в адресной строке yandex.com/maps .
Дополнительные сведения см. в справке по работе с картами в браузере на мобильном устройстве.
Как задать вопрос об использовании карты из браузера?
Вы можете задать любые вопросы о приложении или сообщить нам о своих предложениях на странице обратной связи.
Пожалуйста, опишите вашу ситуацию как можно подробнее, чтобы мы могли дать вам исчерпывающий ответ.
Вы можете сообщить нам о проблемах, которые возникают у вас при настройке маршрута или перемещении по маршруту, здесь:
Коснитесь Меню.
Перейдите в Настройки → Маршруты → Сохраненные маршруты.
В списке маршрутов выберите свой маршрут (информация о маршрутах сохраняется автоматически).
Напишите свои комментарии в появившейся форме и нажмите «Отправить» (или «Отмена», чтобы не отправлять).
Как добавить организацию на карту?
Как отредактировать информацию об организации?
Как изменить информацию о месте, отличном от организации?
Связаться со службой поддержки
Подразделения Яндекса — The Bell — Eng
Еженедельно 907:25 — 12 июля 2022 г.Здравствуйте! На этой неделе мы посмотрим на , как война в Украине взбудоражила Яндекс — «российский Google» — на фоне разных подходов к стратегии и ухода многих топ-менеджеров из страны. Мы также рассмотрим , почему государство решило, что газовый гигант «Газпром» не будет выплачивать дивиденды в этом году, и , почему рубль упал на прошлой неделе .
Война в Украине вызвала трещины в техническом гиганте Яндекс
Весь российский бизнес борется с последствиями войны и западных санкций, но, пожалуй, самые драматичные события развернулись в «Яндексе», «русском Google». Но компромиссы с властями — в довоенные времена неизбежное зло — завели ведущую ИТ-компанию страны в ловушку. Основатель Аркадий Волож и глава Тигран Худавердян попали под санкции Евросоюза. И Яндекс разделен внутренне. Некоторые топ-менеджеры уехали из страны и пытаются спасти то, что могут, из-за границы; другие остаются в Москве и полны решимости спасти российский бизнес Яндекса.
- Несколько лет назад Яндекс процветал. Еще в 2021 году она стоила до 23 миллиардов долларов — больше, чем любая другая российская технологическая компания. За 15 лет компании удалось отбиться от своего крупнейшего конкурента Google на своей территории, победить и выкупить Uber на рынке такси и позиционировать себя как будущего лидера на рынке беспилотных автомобилей. Основатель компании, бывший математик и программист Аркадий Волож, успешно отразил два враждебных поглощения, за которыми стояли лица, имеющие тесные связи с Кремлем — миллиардер Алишер Усманов и государственный банковский гигант Сбербанк. Во второй половине 2010-х «Волож» передал текущие операции команде молодых менеджеров во главе с бывшим директором «Яндекс.Такси» Тиграном Худавердяном. Сейчас Волож большую часть времени проводит в Израиле, но по-прежнему играет роль стратегического лидера и владеет контрольным пакетом голосующих акций «Яндекса».
- Спасение компании от враждебных поглощений дорого обошлось. В 2009 году «Яндекс» был вынужден передать «золотую акцию» государству — фактически предоставив Кремлю право вето на ключевые решения. Вдобавок к этому Яндекс, который остается самым популярным сайтом в России, был вынужден идти на компромисс с правительством по поводу своих медиапродуктов. Наиболее значительный из этих компрометаций был связан с Яндекс.Новости, популярным агрегатором новостей. Компания соблюдала каждый новый закон, так что, когда в феврале началась война, «Яндекс.Новости» использовали только одобренные государством СМИ.
- Вторжение в Украину практически сразу раскололо команду Яндекса на два лагеря. Первые разногласия возникли, когда Кремль созвал ведущие российские компании на встречу с президентом Владимиром Путиным через несколько дней после вторжения. Худавердян представлял на этой встрече «Яндекс». Хотя многие коллеги отговаривали его от посещения, в итоге было решено, что когда звонит глава государства, отвечать должен «Яндекс». В течение месяца Худавердян вместе со всеми остальными участниками встречи попал под санкции ЕС.
- В начале войны топ-менеджеры Яндекса оказались в разных странах, и команда постепенно разделилась на уехавших и оставшихся. «Мы быстро оказались в ситуации, когда каждая сторона начала оправдывать себя и свое решение. Те, кто остался, говорили о давлении и политике и встречали постоянную критику. Ушедшие остались в своем пузыре, далеком от реальности. В общем, это история человеческих трагедий», — сказал один из сотрудников Яндекса. Несмотря на то, что многие члены команды были давними друзьями, пропасть между ними быстро увеличивалась.
- Волож быстро решил, что готов избавиться от российских активов «Яндекса», рассказал The Bell один из его знакомых. Но это было не так просто. Компания теряла ценность, она была политически чувствительной, и его коллеги в России убедили Воложа «сидеть смирно». Одним из сторонников этой политики был Александр Волошин, бывший руководитель кремлевской администрации, ставший членом правления «Яндекса» и ключевым связным компании с властями.
- В конце концов, 3 июня Волож также подвергся санкциям ЕС, что сильно осложнило его мечту о построении крупного многонационального бизнеса на базе услуг Яндекса. Волож придумал много международных проектов, но ни один из них до начала войны не стал полноценным бизнесом. Наиболее развитой из них является компания по производству дронов, которую компания запустила в Соединенных Штатах. Однако испытания были остановлены сразу после вторжения.
- По мере того, как война затягивается, пропасть между менеджерами Яндекса дома и в эмиграции становится все больше. Волож по-прежнему хочет как можно быстрее забрать из Яндекса все, что можно спасти, и развивать его за пределами России. Но этот план нельзя было реализовать быстро: более 90% интеллектуальной собственности «Яндекса» находится в России, и трудно представить, что Кремль допустит такой шаг. Более того, зарубежный бизнес Яндекса невыгоден. Все попытки международной экспансии финансируются из того, что компания зарабатывает в России.
- Стремясь убедить Кремль в легитимности своего предложения, Волож обратился к Алексею Кудрину, главе Счетной палаты и доверенному лицу путинского окружения. На прошлой неделе независимое издание Meduza сообщило о возможном переходе Кудрина в «Яндекс». Источник в правительстве сообщил The Bell, что речь, скорее всего, идет о перспективе вхождения Кудрина в совет директоров. В начале войны Кудрин часто летал в Израиль, где живет Волож, а в середине июня на встрече с Путиным, возможно, поднял вопрос о «Яндексе», сообщил источник The Bell.
Полную историю разделения Яндекса и усилий акционеров и менеджмента по спасению крупнейшей российской ИТ-компании можно прочитать на сайте The Bell.
«Государственное мошенничество»: как российское правительство забрало у инвесторов $10 млрд
Российские инвесторы в этом году потеряли огромные суммы, но в прошлом месяце государство преподнесло им еще один неприятный сюрприз. Несмотря на обещания рекордных дивидендов в размере 1,244 трлн рублей (20 млрд долларов), правительство решило провести рейд на государственный газовый гигант «Газпром», чтобы компенсировать падение доходов. Несмотря на рекордную прибыль «Газпрома» — благодаря взлету цен на газ — впервые за 25 лет акционеры остались ни с чем.
- В январе глава «Газпрома» Алексей Миллер пообещал рекордные дивиденды от прошлогодней рекордной прибыли. В конце мая это была официальная рекомендация совета директоров. Однако в конце июня выяснилось, что правительство назначило «Газпром» основным источником дополнительных доходов для бюджета, перегруженного необходимостью найти 8 триллионов рублей (130 миллиардов долларов) для защиты экономики от последствий войны. Они решили обложить «Газпром» единовременным налогом на непредвиденные расходы в размере 1,248 трлн рублей — цифра, подозрительно похожая на общий прогнозируемый платеж акционерам. Государство, владеющее 50,3% акций «Газпрома», получило бы только половину этой суммы в виде дивидендов.
- На собрании акционеров «Газпрома» 30 июня было заявлено, что впервые с 1998 года компания не будет ничего платить. Инвесторы были возмущены, и акции «Газпрома» упали на 30 процентов до того, как торги были приостановлены.
- Но рейд на «Газпром» был сделан особенно цинично. Первые слухи о новом налоге для «Газпрома» — и их последующее подтверждение в виде поправок в Налоговый кодекс — были сформулированы таким образом, что рынок пришел к выводу, что обязательства составят 416 миллиардов рублей. Минфин ничего не сделал, чтобы исправить это недоразумение, и акции компании выросли. Официальное разъяснение поступило только после решения о приостановке выплаты дивидендов.
- Невыплатой обещанных дивидендов государство вызвало раздражение у сотен тысяч людей. «Газпром» — самая популярная акция среди российских мелких инвесторов: по данным на июнь, «Газпром» составляет 36,5% акций розничных инвесторов на Московской бирже (всего 19,8 млн человек). По данным самой компании, более 470 000 счетов включают акции «Газпрома».
- Почему государство не позаботилось о том, чтобы разозлить так много людей? По всей вероятности, он пришел к выводу, что во второй половине года хватать будет нечего: либо сейчас, либо никогда. Правительство, вероятно, предполагает, что объем экспорта газа в Европу останется низким или сократится почти до нуля, сказал Сергей Кауфман, аналитик FG Finan. Экспорт в Европу — самая уязвимая часть бизнеса «Газпрома», и его потеря в ближайшем будущем будет большим ударом. Власти могут решить использовать «Газпром» в качестве политического оружия, что также вызовет спад экспорта. Большое количество иностранных инвесторов среди акционеров «Газпрома» (до 25%) также может повлиять на решение правительства.
Почему мир должен заботиться
Решение «Газпрома» отказаться от дивидендов — наглядная демонстрация того, почему российский рынок — один из самых дешевых в мире. Когда самая популярная компания страны не выплачивает дивиденды, это негативно сказывается на всем. Тем временем для «Газпрома» инвестиции просто прекратятся. Корпоративное управление и отсутствие подотчетности могут быть прямым следствием текущей геополитической ситуации, но игра с дивидендами и экономически необоснованными налогами — это своего рода мошенничество со стороны правительства, сообщил The Bell источник в одной из инвестиционных компаний. Даже когда у российского рынка появится шанс восстановить свою репутацию, на преодоление подобных уловок уйдут годы.
Как долго рубль будет продолжать слабеть?
Россия одержала свою первую победу в битве с «валютным чудом», в результате которого курс рубля почти удвоился, несмотря на западные санкции, введенные в результате вторжения в Украину. После того, как министр финансов Антон Силуанов заявил, что правительство рассматривает возможность проведения валютных интервенций (что на самом деле было бы трудно сделать по отношению к доллару США или евро), рубль упал по отношению к доллару США на 25 процентов. Но аналитики не хотят заявлять, что ситуация изменилась.
- Падение рубля на прошлой неделе было таким же стремительным, как и его рост в середине марта, когда стало ясно, что при сокращении импорта почти вдвое валютная выручка от экспорта осталась на прежнем уровне. Это привело к мощному скачку рубля, удивившему многих. В начале марта, в разгар экономического шока после вторжения, рубль резко упал до 130 по отношению к доллару США, а через три недели поднялся до 50 по отношению к доллару США — уровня, невиданного с 2015 года. 902:05 Но в воскресенье рубль потерял более 25 процентов своей стоимости, достигнув отметки 64 по отношению к доллару США. Столь быстрое падение обусловлено сочетанием факторов. Во-первых, рынок явно поверил обещанию Минфина начать интервенцию на рынке с целью ослабления рубля. Силуанов заявил, что Минфин может начать скупать валюту у «дружественных стран» (по сути, китайский юань). Во-вторых, мы подошли к концу последнего раунда налоговых и дивидендных выплат в России, который заставил экспортеров покупать рубли.
- Ослабление рубля – это именно то, чего хочет российское правительство. Курс 50 рублей за доллар США — это катастрофа для российского бюджета и еще одно препятствие на пути несбыточной мечты правительства об «импортозамещении». Вице-премьер Андрей Белоусов не раз говорил, что курс должен вернуться к довоенным 70-80 рублям за доллар США, и даже предлагал отказаться от свободного плавания рубля. Глава Центробанка Эльвира Набиуллина, как и ожидалось, высказалась против этой идеи и, похоже, побеждает в споре.
Общая сумма дивидендов, выплаченных российскими компаниями, упала на 40% после того, как «Газпром» объявил, что не будет выплачивать ожидаемые 1,2 трлн рублей. В-третьих, на фоне растущих опасений рецессии в США резко упали цены на нефть — экономика России сейчас гораздо больше зависит от нефти, чем до войны.Почему мир должен заботиться
Аналитики давно говорят, что рост рубля не будет длиться вечно. Российские компании постепенно найдут новых поставщиков взамен западных, и дефицит импорта страны сократится. К концу года, по мнению большинства экспертов, рубль будет стоить около 70 за доллар США. Но не факт, что события прошлой недели стали окончательным разворотом: слишком много непредсказуемости. Чтобы полностью изменить эту тенденцию, России необходимо устойчивое восстановление импорта.
Вам также может понравиться
Рейтинг цифровых прав — Индекс корпоративной ответственности 2019 г. 12
Интернет-компании и компании мобильной экосистемы
Ключевые выводы
- Несмотря на ключевые улучшения, Яндекс не смог раскрыть достаточно информации о политике, влияющей на свободу выражения мнений и конфиденциальность пользователей.
- Компания добилась заметных успехов, опубликовав официальное обязательство уважать право пользователей на свободу выражения мнений и права на неприкосновенность частной жизни, но в остальном у нее не было доказательств надежного управления и надзора за обязательствами в области прав человека во всей деятельности компании.
- Яндекс почти ничего не раскрывал о том, как он обрабатывает требования правительства об ограничении контента или передаче пользовательских данных, хотя нет никаких юридических барьеров для раскрытия хотя бы некоторой информации о его процессах реагирования на такого рода запросы.
Оцененные услуги
- Яндекс Почта (Электронная почта)
- Яндекс Поиск (Поисковая система)
- Яндекс Диск (Облачный сервис)
Анализ
Общий балл
Яндекс занял восьмое место среди 12 компаний, оцениваемых в интернет- и мобильной экосистемах, мало раскрывая свою политику и практику, влияющие на свободу выражения мнений и конфиденциальность. 1 Компания внесла ряд существенных улучшений, в том числе опубликовав обязательство уважать право пользователей на свободу выражения мнений и права на неприкосновенность частной жизни. Он также улучшил раскрытие политики, влияющей на свободу выражения мнений пользователей и права на неприкосновенность частной жизни, но все еще отставал от большинства других оцениваемых компаний, занимающихся интернетом и мобильными экосистемами. Он почти ничего не раскрывал о запросах правительства на получение информации о пользователях, а раскрытие информации о его политике в отношении свободы слова отставало от его российского аналога Mail.Ru. Хотя Яндекс работает во все более ограничительной интернет-среде, которая препятствует компаниям публично брать на себя обязательства по защите прав человека, компания все же могла бы быть более прозрачной в отношении ключевых политик, влияющих на свободу выражения мнений и конфиденциальность пользователей.
Yandex N.V. предоставляет ряд интернет-услуг в России и за рубежом, включая продукты и услуги, включая поиск Яндекса, крупнейшую поисковую систему в России, а также электронную почту, облачное хранилище и карты.
Рыночная капитализация: 12,4 миллиарда долларов США 2
NasdaqGS: YNDX
Категория
Управление
- Оценка 2019
Яндекс сделал значительный шаг вперед, раскрыв обязательство уважать права пользователей на свободу выражения мнений и неприкосновенность частной жизни в соответствии с международными стандартами в области прав человека (G1), но в остальном слабо раскрывал информацию о своем управлении и надзоре за соблюдением прав человека, оценка ниже оценивается большинство компаний, работающих в сфере интернета и мобильной экосистемы. 3 Компания мало сообщила о том, проводит ли она комплексную проверку прав человека, хотя сообщила, что учитывает, как законы влияют на неприкосновенность частной жизни в юрисдикциях, в которых она работает (G4). Яндекс сообщил, что он предоставляет пользователям механизм подачи жалоб, связанных со свободой выражения мнений и конфиденциальностью, однако не раскрыл свои процедуры предоставления средств правовой защиты (G6).
Показатели
Сводка изменений
G1. Политическое обязательство
Яндекс раскрыл обязательство уважать свободу выражения мнений и права на неприкосновенность частной жизни пользователей в соответствии с международными стандартами в области прав человека.
Г3. Внутренняя реализация
Яндекс раскрыл программу информирования о нарушениях, с помощью которой сотрудники могут сообщать о проблемах, связанных со свободой выражения мнений и конфиденциальностью.
Категория
Свобода слова
- Оценка 2019
Яндекс мало раскрывал информацию о политике и практиках, влияющих на свободу выражения мнений пользователей. Условия обслуживания для Яндекс Диска было легко найти, но не для Яндекс Поиска, а его условия для Яндекс Почты найти было сложнее, чем в предыдущем году (F1). Эти условия не разъясняют, будут ли пользователи уведомлены об изменениях (F2) и каким образом. У компании также не было четкого и исчерпывающего раскрытия правил и того, как они применяются, хотя она уточнила, что ни государственные органы, ни частные организации не получают приоритетного внимания при пометке контента как ограниченного за нарушение правил компании (F3). Он также не раскрыл никаких данных о действиях, которые он предпринял для обеспечения соблюдения своих правил (F4).
Яндекс раскрыл некоторую информацию о том, как он обрабатывает государственные и частные запросы на ограничение контента или учетных записей (F5-F7), хотя это раскрытие было минимальным. Компания раскрыла ограниченную информацию о своем процессе ответа на правительственные и частные запросы на контент и ограничения учетной записи (F5) и не опубликовала данных о количестве правительственных и частных запросов, которые она получает или выполняет (F6, F7). Хотя Яндекс опубликовал некоторую информацию о контенте, удаленном в результате запросов, сделанных в соответствии с российским законом о праве на забвение, он потерял баллы, поскольку эта информация устарела (F7).
Показатели
Сводка изменений
F1. Доступ к условиям обслуживания
Яндекс усложнил пользователям поиск условий обслуживания Яндекс Почты.
Ф3. Процесс принудительного исполнения условий использования
Яндекс пояснил, что ни государственные органы, ни частные лица не получают приоритетного внимания при пометке контента как запрещенного за нарушение правил поиска Яндекса.
F7. Данные о частных запросах на контент или ограничение аккаунта
Данные Яндекса о запросах на удаление, которые он получил для поиска Яндекса в соответствии с российским законом о праве на забвение, устарели.
F8. Уведомление пользователей об ограничении контента и аккаунта
Яндекс улучшил раскрытие своих политик уведомления пользователей об ограничении их аккаунтов в Яндекс Почте и Яндекс Диске.
Категория
Конфиденциальность
- Оценка 2019
Несмотря на некоторые улучшения, Яндексу не хватало прозрачности в политике, влияющей на конфиденциальность в ключевых областях. Компания была особенно непрозрачна в отношении того, как она обрабатывает информацию о пользователях. Он раскрыл некоторую информацию о том, какие типы пользовательских данных он собирает (P3), делится (P4) и с какой целью (P5), но ничего не сообщил о своих политиках хранения данных (P6) или о том, могут ли пользователи получить копию информация о них, которой владеет компания (P8). Компания также не сообщила, отслеживает ли она пользователей в Интернете и каким образом (стр. 9).). Однако, несмотря на то, что у Яндекса не было ясности в отношении того, какие возможности у пользователей есть для контроля над тем, какие данные компания о них собирает и чем делится, это была одна из немногих компаний, которая раскрыла возможности, которые пользователи должны контролировать, как их данные используются для целевой рекламы (P7).
Яндекс почти ничего не раскрывает о том, как он обрабатывает сторонние запросы на информацию о пользователях (P10-P12). Компания заслужила некоторую похвалу за улучшение раскрытия информации о том, как она отвечает на правительственные запросы о пользовательских данных, но ее раскрытие информации о частных запросах было менее четким (P10). Он не предоставил данных об этих типах запросов, которые он получил и которые он выполнил (P11). Поскольку российские власти могут иметь прямой доступ к коммуникационным данным, компании могут не знать о частоте или объеме пользовательской информации, к которой обращаются власти. 4 Тем не менее, он может раскрыть свои процессы обработки запросов правительства в случае их возникновения.
Положительным моментом является то, что Яндекс раскрывал свою политику безопасности более тщательно, чем большинство компаний, занимающихся интернет- и мобильной экосистемой (P13-P18). Он получил второй по величине балл после Apple за раскрытие своих политик шифрования (P16) и предоставил относительно сильное раскрытие информации о своей программе вознаграждения за обнаружение ошибок для устранения уязвимостей безопасности (P14). Как и большинство его коллег, Яндекс не предоставил информацию о том, как он реагирует на утечку данных (P15).
Показатели
Сводка изменений
P2. Изменения в политике конфиденциальности
Яндекс улучшил раскрытие информации об уведомлении пользователей об изменениях в политике конфиденциальности.
С10. Процесс ответа на запросы третьих лиц о предоставлении информации о пользователях
Яндекс разъяснил свой процесс ответа на внесудебные запросы государственных органов и раскрыл обязательство проводить комплексную проверку государственных запросов на предоставление пользовательских данных, прежде чем принимать решение о том, как реагировать.
Footnotes
[1] Период исследования Индекса 2019 г. длился с 13 января 2018 г. по 8 февраля 2019 г. Политики, вступившие в силу после 8 февраля 2019 г., не оценивались в этом Индексе.
[2] Bloomberg Markets, по состоянию на 18 апреля 2019 г. , www.bloomberg.com/quote/YNDX:US
[3] «О Яндексе», yandex.com/company/general_info/yandex_today
[4] Андрей Солдатов и Ирина Бороган, «Внутри красной паутины: черный ход России в Интернет — выдержка», The Guardian, 8 сентября 2015 г., www.theguardian.com/world/2015/sep/08/red-web-book-russia -интернет
У Яндекса, крупнейшей российской технологической компании, проблемы? Один бывший член совета директоров говорит «да».
Это российская компания Google, многомиллиардная отечественная технологическая компания, которая доминирует в электронной коммерции страны, предлагая все, от результатов поиска и доставки еды до каршеринга и онлайн-рынка.
Яндекс — флагман высокотехнологичной экономики России в 21 веке.
Теперь, когда Россия бомбардирует Украину, а Запад обрушивает на Россию разрушительные санкции, будущее компании находится под вопросом.
7 марта Яндекс объявил об уходе в отставку двух членов правления, процитировав их слова: «В эти трудные времена мы всем сердцем со всей командой». Через неделю заместитель исполнительного директора подал в отставку после того, как попал под санкции Евросоюза. Затем Яндекс объявил, что собирается продать два своих наиболее заметных контент-подразделения, чтобы сосредоточиться на других направлениях своей деятельности.
Западные санкции тем временем привели к тому, что акции компании были заморожены на фондовых биржах США. Это, в свою очередь, побудило акционеров добиваться погашения гарантий по облигациям, но компания заявляет, что у нее нет 1,25 миллиарда долларов для покрытия этой суммы.
Президент России Владимир Путин (справа) посещает штаб-квартиру Яндекса в Москве в сентябре 2017 года.Акции, которые сейчас не торгуются, упали почти на 80 процентов по сравнению с ноябрем, когда наращивание военной мощи России на границе с Украиной впервые привлекло внимание общественности, уничтожив более 20 миллиардов долларов рыночной капитализации.
«Будущее Яндекса зависит от будущего России, а не наоборот», — заявила Эстер Дайсон, известный американский консультант по технологиям и инвестор, которая была одним из двух членов совета директоров, ушедших в отставку в начале этого месяца. интервью Радио Свобода.
Тоня Самсонова, руководившая службой вопросов и ответов под названием «Яндекс.Q», подала в отставку в начале этого месяца в знак протеста, обвинив компанию в цензуре войны на Украине в поисковой системе и службе новостей, которые ежедневно собирают миллионы просмотров.
Поскольку правительство президента Владимира Путина стремится добиться лояльности и заставить замолчать оппозицию войне, Яндекс рискует стать «двигателем пропаганды» для «диктатуры», сказала она.
«В этом виноваты и вы, мои бывшие коллеги»
В течение многих лет Кремль преследовал независимые журналисты и медиакомпании, используя закон об «иностранных агентах», чтобы очернить, а затем наказать ряд изданий, вещательных компаний и отдельных журналистов.
После вторжения 24 февраля в Украину власти предприняли дальнейшие шаги, введя уголовную ответственность за независимое освещение военных действий, наказывая тюремным заключением за распространение «заведомо ложной информации» об использовании вооруженных сил. Также незаконно дискредитировать военных.
Российские СМИ, в том числе некоторые из самых известных независимых изданий, подстроились. Некоторые известные организации были закрыты; журналисты начали бежать из страны.
Домашняя страница Яндекса является основным порталом русскоязычных новостей и, как и Google на Западе, основным источником трафика для других новостных агентств. Яндекс.Новости привлекают около 30 миллионов российских пользователей.
Однако заголовки стали направлять читателей к официальным, государственным или связанным с государством медиа-компаниям. Поиск в Яндекс Новостях по словам «война» или «вторжение» не дал результатов.
1 марта бывший глава Яндекс-Новостей Лев Гершензон опубликовал в Facebook письмо, в котором чуть ли не обвинил своих бывших сослуживцев в пособничестве российскому государству в сокрытии новостей о войне.
Водитель Яндекс.Такси за работой в Москве. (архивное фото) «Тот факт, что значительная часть населения России может считать, что войны нет, является основой и движущей силой этой войны. Яндекс сегодня — ключевой элемент в сокрытии информации о войне. Каждый день и час таких «новостей» — это человеческие жизни. И вы, мои бывшие коллеги, также несете за это ответственность», — написал он.
На связь с Радио Свобода Гершензон, покинувший «Яндекс» в 2012 году, отказался от дальнейших комментариев, заявив лишь, что «если бы они послушались меня и сделали то, что я предложил, этого бы не произошло».
«Я сказал все, что хотел, обо всей этой ситуации. Думаю, этого достаточно», — сказал он в сообщении.
18 марта Яндекс объявил, что хочет продавать новости Яндекса, а также информационно-развлекательный канал Яндекс Дзен, и вместо этого сосредоточится на развитии других направлений бизнеса, таких как реклама, услуги такси, электронная коммерция, беспилотные автомобили и другие. предприятия.
Дайсон, которая была одним из членов правления Яндекса дольше всех, отказалась сообщить подробности о том, что привело к ее отставке, которая произошла после того, что еще один человек назвал спорным заседанием правления в феврале.
«В текущей политической обстановке в России для команды стало невозможным продолжать предоставлять свободную и открытую информационную платформу для российской общественности, не нарушая закон и не подвергая риску компанию и ее сотрудников», — говорится в сообщении компании. В заявлении от 7 марта об их отставке говорится.
Дайсон также отказался описать внутренние обсуждения, связанные с новостями и функциями поисковой системы.
«Теперь вы получаете все больше и больше результатов пропаганды, прежде чем вы получите результаты поиска», — сказала она. «Сначала реклама, потом пропаганда, потом новости. Вы больше не можете получить эту информацию [о войне] на Яндексе».
СМОТРИТЕ ТАКЖЕ:
Брифинг в прямом эфире: Россия вторгается в Украину
На вопрос, был ли издан приказ или указ со стороны компании или государственного органа, Дайсон отказался отвечать прямо.
«Это не значит, что солнце внезапно садится, а на следующее утро все меняется. Это происходит, как и все эти вещи, несколько постепенно», — сказала она. «Это было как бы перед вторжением в Украину, но после обсуждения вторжения… опять же, вещи не происходят в одночасье, вы как бы чувствуете, что они происходят».
Другой член правления, который ушел в отставку, Илья Стребулаев, профессор финансов Стэнфордского университета в Калифорнии, отказался от комментариев.
Яндекс не ответил на многочисленные электронные письма от RFE/RL с просьбой прокомментировать. Секретарь, ответивший на телефонный звонок в штаб-квартире компании в Москве, сказал, что немедленных комментариев не будет, и не было немедленных ответов на вопросы, отправленные по электронной почте.
«Мой отец был в отрицании после начала войны», — Самсонова, бывший московский репортер, чей сервис вопросов и ответов был куплен Яндексом в 2019 году и переименован в Яндекс.Q.
Предоставленная Радио Свобода фотография заявления об увольнении Тони Самсоновой, бывшей журналистки, уволившейся из российского технологического гиганта «Яндекс» 2 марта в знак протеста против нежелания компании предоставлять своим читателям точную информацию о войне России на Украине.Она рассказала Радио Свобода, что через три дня после вторжения «я зашла на Яндекс.ру, чтобы посмотреть пять главных новостей. Ничего [о войне] не было. Я только что понял, что он, не говорящий по-английски, никак не может знать о новостях, о войне».
2 марта Самсонова, которая несколько месяцев вела переговоры о выходе из компании, подала в отставку «в связи с тем, что Яндекс не публикует на своей домашней странице Яндекс.ру информацию о том, что российские войска обстреливают украинские города и убивают невинные люди.»
«Я считаю сегодняшние действия компании преступлениями и [они] соучастниками вторжения и войны», — написала она.
«Яндекс был создан не для этого»
Еще до войны в Яндексе уже закручивались гайки, в котором сейчас работает около 18 000 человек, большинство из которых работает в штаб-квартире в Москве.
Три года назад Кремль попытался изменить свою структуру управления и, по сути, добиться права вето на свое правление. Компромиссный план привел к тому, что правительство получило два места в совете директоров и «золотую акцию», что дало государству «право блокировать транзакции и временно смещать руководство Яндекса, если оно сочтет это в национальных интересах», согласно Financial Times. .
Эти усилия также совпали с судебным преследованием Майкла Калви, американского инвестора, который два десятилетия назад вложил в «Яндекс» начальные инвестиции в размере 5 миллионов долларов. Судебное преследование Калви, приговоренного к пяти с половиной годам лишения свободы условно за растрату, насторожило бизнес-сообщество, как российское, так и зарубежное.
Доходы Яндекса, в значительной степени обусловленные рекламой, могут резко упасть, поскольку российская экономика движется к самому резкому спаду, по крайней мере, с начала 1990-х годов. Экономисты говорят, что в этом году валовой внутренний продукт России может сократиться на 15 процентов.
Работники Yandex Eats доставляют еду в Москву во время пандемии COVID-19 в апреле 2020 года.Другие виды деятельности Яндекса, помимо «контента», продолжают приносить компании значительный доход. Yandex Eats, например, является лидером в области доставки еды и, как и его западные коллеги — Uber Eats, Grubhub, Deliveroo, Frichti — процветал во время COVID-19.Карантинные меры введены в Москве и других городах России.
Яндекс Еды попал в новости на этой неделе после того, как хакеры получили доступ к базе данных, содержащей тысячи имен и адресов по всей России, и утекли в нее. Регуляторы заявили, что проводят расследование.
Продажа отдела новостей неизбежна, сказал Дайсон.
«Как сторонний наблюдатель, я бы сказала, что чем раньше они это сделают [тем лучше]. И под «продать» я подразумеваю «продать» в кавычках», — сказала она. «Он будет продан».
«Если контент будет представлять правительство, он может также принадлежать правительству. Или людьми, близкими к нему», — сказала она.
«У меня нет вопросов к самой компании. У меня есть вопросы о его способности… [продолжать] предоставлять реальную информацию», — сказал Дайсон Азаттыку. «Я держалась, пока могла», — сказала она.
Самсонова предсказала, что Яндекс продолжит работу в России, даже несмотря на то, что правительство еще больше ограничивает свободный поток информации.
«Яндекс останется в России, никуда не денется», — сказала она.
«Но чем бы ни был Яндекс сейчас — есть здание, есть бухгалтеры, инженеры, специалисты по слияниям и поглощениям — это не то, для чего Яндекс создавался», — сказала она.
«Кем будет Яндекс при военной диктатуре?» она сказала. «Это будет двигатель пропаганды».
Непростое сосуществование Яндекса и Кремля
Технологическая политика
Крупнейшая российская технологическая компания представляет собой почти Силиконовую долину. Но это имеет свою цену.
Автор:
- Эван ГершковичСтраница архива
19 августа 2020 г.
Марцин Вольски С конца марта до середины июня, пока Москва находилась на карантине из-за коронавируса, российская столица практически опустела. Во время прогулки в супермаркет или аптеку меня обгоняли потоки велосипедистов в фирменной желтой форме службы доставки еды Яндекса. На дороге немногочисленные транспортные средства, кроме полицейских машин и автобусов, были такси — продезинфицированными на недавно открытых станциях — компании Яндекса.
Яндекс, который на Западе часто называют российским Google, на самом деле больше похож на Google, Amazon, Uber и, возможно, еще несколько компаний вместе взятых. Россияне обращаются к Алисе, виртуальному помощнику компании, с просьбой помочь им заказать товары онлайн на Яндекс Маркете. Они используют его систему электронной почты, слушают его музыкальный проигрыватель и посещают его веб-сайт с рекомендациями фильмов. За чашечкой кофе читают утренние новости агрегатора Яндекс.Новости. Они отправляют друг другу деньги через Яндекс Кошелек. И находят дорогу через Яндекс-навигатор, аналог Google Maps. Аркадий Волож, генеральный директор и соучредитель компании, торгуемой на Nasdaq, описал ее не просто как часть российской Силиконовой долины, но как российскую Силиконовую долину.
Новые сервисы появляются с головокружительной скоростью. Под Москвой Яндекс тестирует парк из более чем 100 беспилотных автомобилей, работу, которую не смог остановить даже коронавирус. Яндекс Лавка («Яндекс Магазин»), приложение для доставки продуктов, запущенное в июне прошлого года, гарантирует доставку в течение 15 минут, быстрее, чем все, что предлагает Amazon. Один из идейных вдохновителей проекта, 33-летний Илья Красильщик, помнит, как во время бурного перехода России к рыночной экономике в начале 1990-х его мать вернулась из поездки с ведром какао-порошка на случай, если семья не возможность получить его дома. Теперь, спустя десятилетия, у москвичей излишки под рукой: самая популярная вещь Лавки летом 2019 годабыл арбуз на 4 части, доставленный, разумеется, холодным.
велосипедиста Яндекса по доставке еды оставались повсеместными на улицах Москвы даже во время карантина из-за COVID-19.АНАТОЛИЙ ЖДАНОВ/КОММЕРСАНТ/СИПА США
Снежным днем в конце февраля, незадолго до того, как Россию охватила пандемия, я свернул с оживленной московской улицы в тихий двор. Я встречался с Ростиславом Мещерским, 28-летним менеджером одного из так называемых «темных магазинов» Лавки, мест, где продукты, заказанные в Интернете, скрытно складируются для распространения. Мещерский подвел меня к открытой двери гаража в задней части двора, которая вела в подвал, заставленный полками со всем, от макарон до фруктовых соков и туалетной бумаги. «Я шучу с друзьями, что сразу знаю, куда идти в Москве в случае апокалипсиса», — сказал он.
Всего несколько недель спустя это была не такая уж шутка. В апреле «Лавка» получила около 900 000 заказов от россиян, застрявших дома на карантине, в то время как число клиентов сервисов общественного питания «Яндекса», включая доставку из ресторана, увеличилось более чем в два раза. Несмотря на то, что компания пострадала в таких сферах бизнеса, как райдшеринг, когда весь ее автопарк был снят с улиц во время карантина в России, люди, застрявшие дома, увеличили трафик на поисковых платформах компании и платформах потокового видео.
Но за успех Яндекса приходится платить. Кремль долгое время рассматривал Интернет как поле битвы в условиях эскалации напряженности в отношениях с Западом и все больше беспокоился о том, что такая компания, как «Яндекс», с кучей данных о российских гражданах, которые у нее есть, может однажды попасть в руки иностранцев.
Это означает, что управление технологическим гигантом в России — дело тонкое. С одной стороны Кремль; с другой — Нью-Йорк, где инвесторы требуют, чтобы компания сохраняла свою независимость. Но в охваченном пандемией мире, который все больше озабочен защитой границ и регулированием технологической отрасли, дилемма Яндекса может быть связана не только с Россией.
Золотая аранжировка
Яндекс — сокращение от «еще один индексатор» — не всегда во всем держал свои пальцы. После своего начала в 1997 года компания годами соперничала за первенство в местных поисковых системах с другой российской компанией Rambler.
В итоге Rambler стал Yahoo для Яндекса Google. Но вскоре на рынок вышел и сам Google, и хотя Яндекс имел преимущество, укоренив свой поисковый алгоритм в особенностях русского языка, его калифорнийский конкурент начал догонять. «Примерно за полгода до публичного размещения Google сделал предложение о покупке Яндекса, и я должен сказать, что мы очень серьезно относились к этому предложению», — сказал мне Леонид Богуславский, один из первых инвесторов компании.
Предложение было сделано в 2003 году. Но один из соучредителей «Яндекса» Илья Сегалович сказал: «Давайте бороться», — вспоминал Богуславский. Хотя Сегалович умер в 2013 году после приступа рака желудка, борьба продолжается по сей день: хотя Google периодически обгоняет Яндекс, российская фирма в настоящее время имеет около 59% российского поискового трафика по сравнению с 39% Google.
В том же году, когда умер Сегалович, «Яндекс» нанял Грега Абовского, уроженца Украины, выпускника Гарвардской школы бизнеса, аналитика хедж-фондов, который начал свою карьеру в Morgan Stanley в Нью-Йорке. «Примерно в то время, когда я пришел сюда, мы поняли, что в какой-то момент поиск замедлится», — говорит Абовский, который сейчас является одновременно и финансовым директором, и главным операционным директором. Когда он присоединился, реклама из поиска составляла около 99% от выручки компании. Сегодня это около 64%, а общая выручка выросла с $1,2 млрд в 2013 году до $2,8 млрд в 2019 году.
Один из первых моментов был в августе 2008 года, когда Россия вела пятидневную войну с соседней Грузией. По мере развития конфликта в новостях Яндекса появлялись русскоязычные статьи, освещающие обе стороны конфликта. В следующем месяце, по словам журналистов Андрея Солдатова и Ирины Бороган в их книге The Red Web , два кремлевских чиновника посетили штаб-квартиру Яндекса. Одним из них был Владислав Сурков, заместитель главы администрации президента России — человек, который придумал оруэлловский термин «суверенная демократия» для описания российской системы управления, которая не терпит иностранного вмешательства в свои дела.
В 2008 году, когда Россия вела пятидневную войну с Грузией, в новостях Яндекса публиковались русскоязычные статьи по обе стороны границы. В следующем месяце два кремлевских чиновника посетили штаб-квартиру «Яндекса».
Льву Гершензону, тогдашнему директору Яндекс Новостей, было поручено объяснить официальным посетителям, как работает сервис. Согласно книге, он вспомнил, как показывал скриншоты статей, которые алгоритм агрегатора выбрал в качестве главных новостей. — прервал его Сурков. «Это наш враг», — сказал он, указывая на либеральную газету. «Это то, что нам не нужно!»
С этого момента компания пообещала поддерживать открытую линию с Кремлем, хотя Гершензон сказал, что всегда будет повторять, что алгоритм, а не человек, выбирает главные новости. Тем не менее, он не всегда соглашался с тем, как поддерживалась линия связи.
«Мы с Воложем несколько раз подходили к зданию администрации президента, и я ему говорю: «Слушай, у тебя такой мощный бизнес — зачем ты к ним ходишь? Если очень нужно, пусть к вам придут», — вспоминал Гершензон в документальном мини-сериале «Священная война » о русскоязычном интернете. «Даже такой выродок, как я, знал, что если вы наклонитесь для них, они никогда не позволят вам снова выпрямиться».
В том же году «Яндекс» отбил потенциальное поглощение связанным с Кремлем олигархом Алишером Усмановым, который лоббировал поддержку президента Дмитрия Медведева по соображениям национальной безопасности. В 2009, чтобы удовлетворить интересы правительства, Яндекс передал крупнейшему кредитору России, государственному Сбербанку, так называемую золотую акцию, которая позволила банку наложить вето на сделки с участием более четверти акций Яндекса. На десятилетие такая договоренность успокаивала российские власти, пока не перестала.
Канатная прогулка
В мае прошлого года в России был принят закон о создании так называемого «суверенного интернета» — государственной коммуникационной инфраструктуры, которая позволила бы стране отрезать себя от глобального интернета, оставаясь онлайн в пузыре российских сервисов. Закон требует, чтобы интернет-провайдеры устанавливали оборудование, предоставленное государством для противодействия широко определенным «угрозам» стабильности и целостности Интернета, и дает властям широкие полномочия по установлению контроля над сетью в случае появления таких угроз. Прошлой зимой за чаем в своем офисе Игорь Ашманов, который в начале нулевых какое-то время был директором конкурирующей с Яндексом компании «Рамблер», а теперь выступает за суверенный интернет на государственном телевидении и на правительственных слушаниях, изложил его цель.
«Представьте, что вы живете в маленьком поселке рядом с городом, который обеспечивает вас электричеством, и мэр города сказал, что вы его враги и что если он может вам навредить, то он это сделает», — сказал мне Ашманов. «Возможно, вы решите купить генератор, чтобы обеспечить бесперебойную подачу электричества на случай, если этот сумасшедший мэр выключит выключатель. Вот что такое суверенный интернет».
Возможно, для Кремля важнее то, что суверенный интернет также даст России больший контроль над тем, что ее граждане могут видеть в Интернете. В 2011 году Арабская весна, поддерживаемая социальными сетями, прокатилась по Ближнему Востоку. В декабре того же года, после того как Владимир Путин объявил, что снова будет баллотироваться в президенты после временного пребывания на посту премьер-министра, массовые протесты, запланированные на Facebook, потрясли Россию. После демонстраций Кремль начал рассматривать иностранные технологические компании как инструменты, используемые другими правительствами для вмешательства в его дела. Сам Путин озвучил эти опасения на пресс-конференции в 2014 году, когда он назвал Интернет «проектом ЦРУ» и намекнул, что на сам «Яндекс» «вынуждали» включать иностранцев в свое управление и что он был зарегистрирован за границей «не только для целей налогообложения, но и для по другим причинам». (Материнская компания зарегистрирована в Нидерландах, и шесть из 12 нынешних членов совета директоров не являются гражданами России, включая Джона Бойнтона, председателя, который базируется в Массачусетсе.)
Этот страх перед иностранным вмешательством с годами только усилился. Во время правительственных слушаний по национальной безопасности в 2018 году Ашманов назвал Facebook, Instagram и Twitter американским оружием, направленным против России. «Что могли сделать американцы с такой компанией, как «Яндекс», в их руках, я даже думать не хочу, — сказал мне Ашманов.
По словам Бойнтона, председателя совета директоров, Яндекс изо всех сил пытался сохранить равновесие. «Мы сделали все возможное, чтобы держаться подальше от политики», — сказал он в телефонном интервью. И все же, добавил он, компания обнаружила, что ее все больше «втягивают в области, в которых мы не обязательно хотим быть».
Ситуация достигла апогея в четверг утром в октябре 2018 года, когда просочились слухи о том, что Сбербанк ведет переговоры о покупке до 30% акций Яндекса, чтобы защитить компанию от «потенциальных проблем». Когда в Нью-Йорке открылись торги, ее акции упали на 9,4%, потеряв рыночную стоимость более 1 миллиарда долларов из-за опасений, что государственный кредитор может взять компанию под контроль. «Это был момент, когда мы поняли, что затевается что-то большее, — вспоминал Бойнтон.
На следующий день компания потеряла еще один миллиард долларов. Как сообщила Financial Times, на экстренном совещании, которое состоялось рано утром в субботу, Волож решил не продолжать сделку со Сбербанком.
Яндекс начал переговоры с администрацией Путина о новой структуре управления, но давление на него продолжало усиливаться. В июне 2019 года малоизвестный депутат Антон Горелкин внес законопроект об ограничении иностранного участия в компаниях, которые российское правительство считает «значительными информационными ресурсами». Внешним инвесторам будет разрешено владеть только 20% таких компаний — серьезный удар по «Яндексу», 85% акций которого торгуются на рынках США. Когда несколько месяцев спустя Кремль выступил в поддержку закона Горелкина, опасения в Нью-Йорке снизили стоимость «Яндекса» еще на 1,5 миллиарда долларов за один день.
В ноябре прошлого года, после 13 месяцев изнурительных переговоров, Яндекс объявил о решении. Он передал бы золотую акцию Сбербанка — право вето на крупные сделки — недавно созданному «фонду общественных интересов», имеющему тесные связи с правительством. Право вето также будет расширено за счет сделок и сделок, связанных с интеллектуальной собственностью или передачей данных российских пользователей. Хотя в совете нового фонда будет 11 мест, только три будут принадлежать Яндексу; остальное будет разделено между влиятельными бизнес-группами и государственными университетами. Возможно, наиболее важным с точки зрения Кремля является то, что новый фонд сможет заблокировать «Яндекс» от заключения соглашений с любым иностранным правительством.
Кажется, это сняло жар. Горелкин сказал, что вернет свой закон к чертежной доске. Несколько дней спустя российский парламент принял закон, требующий автоматической предварительной загрузки российских технологий на устройства, продаваемые в России. Аналитики подсчитали, что этот шаг повысит стоимость Яндекса на 1,4 миллиарда долларов. Через несколько недель после этого Путин, который несколькими годами ранее критиковал зарубежные связи «Яндекса», похвалил его проекты с иностранными партнерами и положительно отозвался о закрытой встрече с высшим руководством.
Но даже если Кремль и кажется умиротворенным, то не все. Власть в российском правительстве разделена между соперничающими группами, а Путин выступает посредником между ними. Для электората, известного как силовиков — чиновников, связанных с правоохранительными органами, — фонд «Яндекс» считался полупобедой, говорит Татьяна Становая, основатель политико-аналитического сайта «Р.Политик». «С одной стороны, они видят, что «Яндекс» косвенно обязан правительству, — говорит она. «С другой стороны, это чисто техническое. Яндекс не будет просто так выполнять любые требования. И если конфронтация с Западом продолжит обостряться, [власти] могут переосмыслить этот расклад».
Когда прошлой зимой я разговаривал с Бойнтоном после того, как улеглась пыль, он был в приподнятом настроении. Но он также отметил, что все может снова быстро измениться. «В России, — сказал он, — ничто не гарантировано».
Шаблон для Big Tech?
Если силовиков считают Яндекс ненадежным сотрудником, то либеральные критики видят все больше признаков того, что он находится в кармане властей. Например, в конце февраля полицейский, обвиняемый в подбрасывании наркотиков репортеру-расследователю, заявил, что нашел адрес журналиста, попросив «Яндекс-такси» предоставить его. «Яндекс» ответил, что всегда уступает просьбам спецслужб «помочь спасать жизни», хотя «Роскомсвобода», группа по борьбе с цензурой, указала, что это не всегда требуется по закону.
По мере роста пандемии вопросы о независимости компании становились все более острыми. В начале апреля появились новости о том, что московские власти рассматривают возможность слежки за иностранными туристами с помощью данных их мобильных телефонов после того, как границы снова откроются, и что Яндекс может разработать этот инструмент. Компания отвергла иск.
Генеральный директор Яндекса Аркадий Волож (слева) с президентом Владимиром Путиным, который посетил офис Яндекса в 2017 году, чтобы отметить его 20-летие.ИТАРТАСС ИНФОРМАГЕНТСТВО/АЛАМЫ ФОТО
Затем, когда рядом с правительственными зданиями в Яндекс-навигаторе стали появляться критические комментарии от активистов оппозиции, как своего рода цифровая альтернатива уличным протестам, Яндекс удалил сообщения, заявив, что они не по теме. Наконец, однажды вечером в конце апреля некоторые интернет-пользователи заметили, что поисковые запросы лидера оппозиции Алексея Навального в Яндексе возвращают в основном негативный контент. Яндекс извинился, заявив, что это был «эксперимент», который показали только небольшому количеству пользователей. Один из российских комментаторов Александр Плющев отметил, что такое тестирование распространено на всех технологических платформах, но добавил: «Любой инцидент с Яндексом теперь интерпретируется через призму его контроля со стороны властей».
Если Яндекс слишком сильно капитулирует перед государственным контролем, он рискует потерять свой самый ценный актив: свой талант. «Я всегда говорю, что мои основные конкуренты — это [московские аэропорты] Шереметьево и Домодедово», — говорит Миша Биленко, возглавляющий подразделение машинного анализа и исследований Яндекса.
В феврале полицейский, обвиняемый в подбрасывании наркотиков репортеру-расследователю, заявил, что нашел адрес журналиста, попросив «Яндекс-такси» предоставить его.
Сам Биленко провел 23 года в Соединенных Штатах, в том числе десять лет в Microsoft, прежде чем вернуться в Россию несколько лет назад. Что привлекло его, по его словам, так это доступ к множеству различных ресурсов в Яндексе и возможность помочь улучшить жизнь россиян в массовом порядке. Но, как сказал мне один сотрудник, попросивший об анонимности, «Яндекс» потеряет такую привлекательность и власть, если правительство слишком сильно попытается его укротить. «У нас здесь много прогрессивных людей, — сказал человек. «Если нам не понравится то, что мы увидим, мы уйдем».
Сегодня Яндекс, по крайней мере публично, утверждает, что все хорошо. Его уступки Кремлю могли быть гораздо большими. Они также являются теми, которые другие могут вскоре рассмотреть. «То, что сделал «Яндекс», актуально не только в контексте путинской России», — заявил в прошлом году обозреватель Bloomberg Леонид Бершидский. «Это можно рассматривать как шаблон для Big Tech».
Подобно «Яндексу», продолжил Бершидский, такие компании, как Google или Facebook, могут создавать квазиавтономные структуры управления с правом вето на определенные решения. «Если такая структура сможет получить одобрение даже от авторитарного режима, такого как российский… она, вероятно, сможет удовлетворить большинство критиков больших технологий и в демократических странах», — написал он.
Действительно, в мае этого года Facebook назвал первых членов своего «наблюдательного совета» в ответ на гнев по поводу непрозрачного процесса модерации контента. В состав группы входят известные юристы и правозащитники, которые могут пересмотреть и отменить некоторые решения платформы. Хотя правление не имеет ничего общего с силой фонда общественных интересов Яндекса, это была большая уступка со стороны компании, которая всегда яростно защищала свой контроль над тем, что происходит на ее платформе.
Поскольку политики на обоих концах политического спектра США призывают к усилению регулирования больших технологий, такие шаги, вероятно, будут продолжаться. Та гибкость, которой пришлось научиться Яндексу, может оказаться необходимой для компаний, которые хотят не только выжить, но и процветать.
Эван Гершкович
Проблема технонационализма
Эта история была частью нашего выпуска за сентябрь/октябрь 2020 года.
Исследуйте проблемуГлубокое погружение
Техническая политика
Почему технологии не могут решить гендерную проблему?
Новое поколение технических активистов, организаторов и осведомителей, большинство из которых женщины, цветные, представители разных полов или квиры, наконец-то могут принести перемены.
Оставайтесь на связи
Иллюстрация Роуз Вонг
Откройте для себя специальные предложения, главные новости, предстоящие события и многое другое.
Введите адрес электронной почты
Политика конфиденциальностиСпасибо за отправку вашего электронного письма!
Ознакомьтесь с другими информационными бюллетенями
Похоже, что-то пошло не так.
У нас возникли проблемы с сохранением ваших настроек.