Формирование SQL-запроса с помощью конструктора
Формирование SQL-запроса с помощью конструктора Пожалуйста, включите JavaScript в браузере!Формирование SQL-запроса с помощью конструктора
В KUMA вы можете сформировать SQL-запрос для фильтрации событий с помощью конструктора запросов.
Чтобы сформировать SQL-запрос с помощью конструктора:
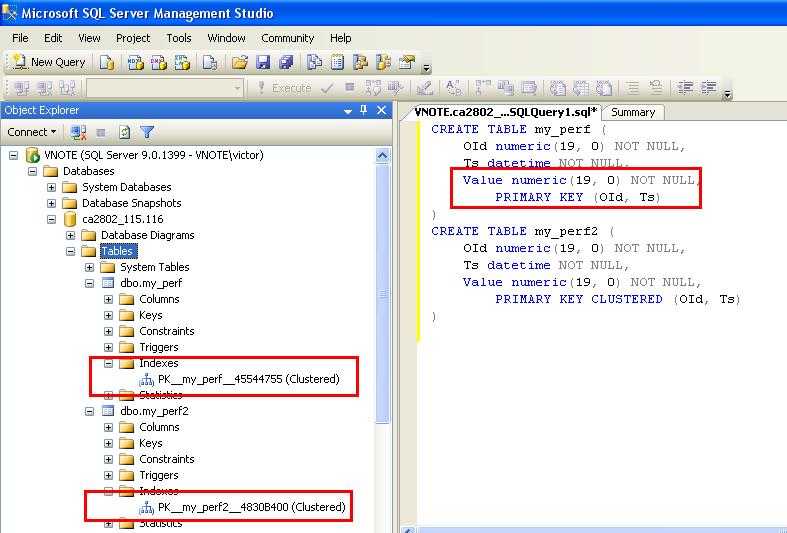
- В разделе События веб-интерфейса KUMA нажмите на кнопку .
Откроется окно конструктора запросов.
- Сформулируйте поисковый запрос, указав данные в следующих блоках параметров:
- SELECT – поля событий, которые следует возвращать. По умолчанию выбрано значение *, означающее, что необходимо возвращать все доступные поля события. Для оптимизации поиска в раскрывающемся списке вы можете выбрать определенные поля, тогда данные из других полей загружаться не будут.
Выбрав поле события, вы можете в поле справа от раскрывающегося списка указать псевдоним для столбца выводимых данных, а в крайнем правом раскрывающемся списке можно выбрать операцию, которую следует произвести над данными: count, max, min, avg, sum.

Если вы используете в запросе функции агрегации, настройка отображения таблицы событий, сортировка событий по возрастанию и убыванию, получение статистики, а также ретроспективная проверка недоступны.
В режиме детализированного анализа при фильтрации по событиям, связанным с алертами, невозможно производить операции над данными полей событий и присваивать названия столбцам выводимых данных.
- FROM – источник данных. Выберите значение events.
- WHERE – условия фильтрации событий.
Условия и группы условий можно добавить с помощью кнопок Добавить условие и Добавить группу. По умолчанию в группе условий выбрано значение оператора AND, однако если на него нажать, оператор можно изменить. Доступные значения: AND, OR, NOT. Структуру условий и групп условий можно менять, перетаскивая выражения с помощью мыши за значок .
Добавление условий фильтра:
- В раскрывающемся списке слева выберите поле события, которое вы хотите использовать для фильтрации.
- В среднем раскрывающемся списке выберите нужный оператор. Доступные операторы зависят от типа значения выбранного поля события.
- Введите значение условия. В зависимости от выбранного типа поля вам потребуется ввести значение вручную, выбрать его в раскрывающемся списке или выбрать в календаре.
Условия фильтра можно удалить с помощью кнопки . Группы условий удаляются с помощью кнопки Удалить группу.
- В раскрывающемся списке слева выберите поле события, которое вы хотите использовать для фильтрации.
- GROUP BY – поля событий или псевдонимы, по которым следует группировать возвращаемые данные.
Если вы используете в запросе группировку данных, настройка отображения таблицы событий, сортировка событий по возрастанию и убыванию, получение статистики, а также ретроспективная проверка недоступны.
В режиме детализированного анализа при фильтрации по событиям, связанным с алертами, невозможно группировать возвращаемые данные.
- ORDER BY – столбцы, по которым следует сортировать возвращаемые данные. В раскрывающемся списке справа можно выбрать порядок: DESC – по убыванию, ASC – по возрастанию.

- LIMIT – количество отображаемых в таблице строк.
Значение по умолчанию – 250.
Если при фильтрации событий по пользовательскому периоду количество строк в результатах поиска превышает заданное значение, вы можете отобразить в таблице дополнительные строки, нажав на кнопку Показать больше записей. Кнопка не отображается при фильтрации событий по стандартному периоду.
- SELECT – поля событий, которые следует возвращать. По умолчанию выбрано значение *, означающее, что необходимо возвращать все доступные поля события. Для оптимизации поиска в раскрывающемся списке вы можете выбрать определенные поля, тогда данные из других полей загружаться не будут.
- Нажмите на кнопку Применить.
Текущий SQL-запрос будет перезаписан. В поле поиска отобразится сформированный SQL-запрос.
Если вы хотите сбросить настройки конструктора, нажмите на кнопку Запрос по умолчанию.
Если вы хотите закрыть конструктор, не перезаписывая существующий запрос, нажмите на кнопку .
- Для отображения данных в таблице нажмите на кнопку .
В таблице отобразятся результаты поиска по сформированному SQL-запросу.
При переходе в другой раздел веб-интерфейса сформированный в конструкторе запрос не сохраняется. Если вы повторно вернетесь в раздел События, в конструкторе будет отображаться запрос по умолчанию.
Если вы повторно вернетесь в раздел События, в конструкторе будет отображаться запрос по умолчанию.
После обновления KUMA до версии 1.6 при фильтрации событий с помощью SQL-запроса, содержащего условие inSubnet, может возвращаться ошибка Code: 441. DB::Exception: Invalid IPv4 value. В таких случаях необходимо на серверах хранилища (на каждой машине кластера ClickHouse) в файле /opt/kaspersky/kuma/clickhouse/cfg/config.d/users.xml в разделе profiles → default добавить директиву <cast_ipv4_ipv6_default_on_conversion_error>true</cast_ipv4_ipv6_default_on_conversion_error>.
Подробнее об SQL см. в справке ClickHouse. Также см. поддерживаемые KUMA SQL-функции и операторы.
В начало
Запуск запросов: режим «только для чтения», планировщик, SQL-журнал
Консоль запросов
По опыту знаем, что консоль запросов — лучшее место для повседневной работы с SQL. Для каждого источника данных предусмотрена собственная консоль по умолчанию. Чтобы ее открыть, выберите Open Console в контекстном меню или нажмите F4.
Чтобы ее открыть, выберите Open Console в контекстном меню или нажмите F4.
Здесь вы можете написать SQL-запрос, запустить его и получить результат. Все просто.
Если вы вдруг захотите создать другую консоль для источника данных, сделайте это в меню: Context menu → New → Console.
Переключатель схем
Создавайте столько консолей запросов, сколько вам нужно, и запускайте запросы одновременно. У каждой консоли есть переключатель схем и баз данных. Если вы работаете с PostgreSQL , составьте здесь search_path.
Запуск выделенного фрагмента
Выделите фрагмент кода и запустите только его. Выбранный запрос посылается в базу «как есть», без дополнительной обработки jdbc-драйвером. Это может быть полезно, когда по той или иной причине IDE думает, что в запросе есть ошибка.
Настройки выполнения
Выполнять запрос можно несколькими способами. Поведение запуска запросов под кареткой можно настраивать. Возможные варианты того, что можно запустить: подзапрос, весь запрос, все после каретки, весь скрипт или предложить выбор.
Возможные варианты того, что можно запустить: подзапрос, весь запрос, все после каретки, весь скрипт или предложить выбор.
Можно настроить три варианта поведения для запуска (Execute). По умолчанию, сочетание клавиш есть только у первого, но вы можете выбрать их и для остальных. Например, настроим два поведения: «показать выбор» и «запустить весь скрипт».
На видео пример, как сначала выполнено одно действие, затем второе.
Режим «только для чтения»
Режим «только для чтения» включайте в настройках источника данных: флажок Read-Only. Этот флажок включает сразу два режима: на уровне IDE и на уровне jdbc-драйвера .
На уровне jdbc-драйвера в режиме «для чтения» запросы, которые вносят изменения, нельзя запускать в базах: MySQL, PostgreSQL, AWS Redshift, h3 и Derby. В других СУБД этот режим не работает.
Поэтому мы сделали свой режим «только для чтения». Он включается одновременно с режимом на уровне драйвера. IDE понимает, какие запросы приведут к изменениям, и подчеркивает их. При запуске запроса DataGrip покажет предупреждение. Такой запрос можно запустить, нажав
IDE понимает, какие запросы приведут к изменениям, и подчеркивает их. При запуске запроса DataGrip покажет предупреждение. Такой запрос можно запустить, нажав
DataGrip также индексирует все исходники функций и процедур и строит внутри дерево вызовов. Это значит, что если вы запускаете процедуру, которая запускает процедуру (повторите n раз), которая что-то меняет в базе, DataGrip вас предупредит.
Контроль транзакций
Выберите контроль транзакций, который больше подходит вашей работе. Эта настройка есть в свойствах источника данных. В автоматическим режиме (флажок Auto) вам не надо каждый раз фиксировать транзакцию, а вот в ручном режиме (Manual), очевидно, надо.
Быстрый просмотр результата
Результаты запроса или выражения можно посмотреть во всплывающем окне. В других IDE на платформе IntelliJ Ctrl+Alt+F8 показывает результат вычисления выражения. В DataGrip то же самое работает для отображения результатов запуска. Если нажать эту комбинацию когда курсор на столбце, вы увидите ожидаемые значения этого столбца в результатах запроса. Та же самая операция на любом ключевом слове запроса покажет всплывающее окно с результатом. Клик мышкой при зажатом Alt работает так же.
В DataGrip то же самое работает для отображения результатов запуска. Если нажать эту комбинацию когда курсор на столбце, вы увидите ожидаемые значения этого столбца в результатах запроса. Та же самая операция на любом ключевом слове запроса покажет всплывающее окно с результатом. Клик мышкой при зажатом Alt работает так же.
История запущенных запросов
На панели инструментов каждой консоли есть такая кнопка: . Нажмите ее, чтобы увидеть историю всех запросов, выполненных в этом источнике данных из DataGrip. Еще здесь работает быстрый поиск!
Не забудьте и о локальной истории каждого файла.
Полный SQL-журнал
Буквально все запросы, которые запускает DataGrip, записываются в текстовый файл. Чтобы открыть его, используйте меню Help | Show SQL log.
Запуск хранимых процедур
DataGrip умеет генерировать код для запуска процедур. Укажите значения для параметров и нажмите OK.
Когда процедура открыта в редакторе, вы можете ее запустить, нажав Run на панели инструментов. Или используйте контекстное меню и выберите пункт Execute…
Или используйте контекстное меню и выберите пункт Execute…
Небезопасные запросы
DataGrip предупредит, если вы собираетесь запустить запросы DELETE и UPDATE без предложения WHERE.
Планировщик запросов
План запросов покажет, как база данных собирается выполнить ваш запрос. Это помогает в оптимизации.
План запросов может быть представлен в виде дерева или диаграммы.
Запросы с параметрами
В запросе могут быть параметры. DataGrip умеет запускать такие запросы.
Описать синтаксис параметров можно в Settings/Preferences → Database → User Parameters. Регулярные выражения для их описания подсвечиваются, а еще для каждого вида параметров можно указать SQL-диалект.
Структурный вид
Каждую консоль или файл можно открыть в структурном виде: в окне появится список запросов. Чтобы открыть структурный вид, используйте сочетание клавиш Ctrl+F12.
Результат запроса
Результат запроса
В DataGrip данные в результате простого запроса можно изменять. Используйте все возможности редактора данных: добавляйте, удаляйте строки, выбирайте режим контроля транзакций.
Сравнение результатов
Два результата можно сравнить, используя инструмент поиска различий. DataGrip подсветит те строчки, которые не являются общими для двух результатов. Параметр Tolerance используется для того, чтобы указать, сколько колонок могут иметь разные значения, чтобы строчки все равно считались одинаковыми. Из сравнения можно исключить любой столбец.
Нажмите кнопку сравнения на панели инструментов и выберите результат запроса, с которым нужно сравнить текущий результат.
Имена вкладок
Вы сами можете называть вкладки результатов: напишите имя в комментарии перед запросом.
Если вам не нравится, что любой предшествующий комментарий становится именем, укажите слово, после которого будет идти строка для заголовка. Это делается в соответствующих настройках: поле Prefix.
Это делается в соответствующих настройках: поле Prefix.
Быстрое изменение размера страницы
Меняйте размер страницы в редакторе данных, не заходя в настройки.
вложенные запросы и временные таблицы
Добро пожаловать в следующую статью из цикла про SQL! В предыдущей статье мы считали Transactions и Gross для приложения на двух платформах и получили отдельный результат для каждого приложения.
Но что если мы хотим обобщить его и для каждой метрики иметь только одно значение? Для этого мы будем использовать результат, получившийся с помощью операции union, как таблицу в операторе from. И затем в select вычислять сумму по полю transactions и gross из объединенной таблицы (скриншот выше).
Залогиньтесь на сайте, зайдите в демо и найдите SQL отчёт во вкладке Reports.
Результат запроса. Скриншот из демо devtodevselect ‘Metrics for all projects’ as «App»
, sum(transactions) as «Transactions»
, sum(gross) as «Gross»
from (
select count() as transactions, sum(priceusd) as gross
from p102968.payments
where eventtime > current_date — interval ‘7 day’ and eventtime < current_dateunion all
select count() as «Transactions»
, sum(priceusd) as «Gross»
from p104704.payments
where eventtime > current_date — interval ‘7 day’ and eventtime < current_date
) as metrics_by_platform
Оператор from теперь содержит целый запрос внутри себя, который обращается сразу к двум таблицам. Тоже самое можно провернуть и с внутренним запросом, добавив в каждый из
) as metrics_by_platform
Такую конструкцию можно использовать во всех операторах, обращающихся к таблицам. Например, в join.
Inner join (select … from … where …) as join_table
on join_table.param = t.param
Метрики по отдельным приложениям и суммарно по всем
Давайте в одном запросе посчитаем суммарные метрики по всем приложениям, а также выведем расшифровку (метрики по каждому из приложений) ниже.
Результат запроса. Скриншот из демо devtodevselect ‘Metrics for all projects’ as «App»
, sum(transactions) as «Transactions»
, sum(gross) as «Gross»
from (
select ‘3 in a row. iOS’ as «App»
, count() as transactions
, sum(priceusd) as gross
from p102968.payments
where eventtime > current_date — interval ‘7 day’ and eventtime < current_dateunion all
select ‘3 in a row. Android’ as «App»
, count() as transactions
, sum(priceusd) as gross
from p104704.paymentswhere eventtime > current_date — interval ‘7 day’ and eventtime < current_date
) metrics_by_platformunion all
select ‘3 in a row.iOS’ as «App»
, count() as transactions
, sum(priceusd) as gross
from p102968.payments
where eventtime > current_date — interval ‘7 day’ and eventtime < current_dateunion
select ‘3 in a row. Android’ as «App»
, count() as «Transactions»
, sum(priceusd) as «Gross»
from p104704.payments
where eventtime > current_date — interval ‘7 day’ and eventtime < current_date
order by 3 desc
Получается довольно громоздкий запрос, в котором мы по два раза обращаемся к каждой из таблиц payments, и к тому же мы два раза написали один и тот же код (при изменении запроса нам придётся вносить изменения в двух местах).
Чтобы избежать этого, мы можем создать представление (Common Table Expression – CTE), и затем в ходе запроса обращаться к нему несколько раз. Конструкция может содержать в себе сколь угодно сложные запросы и обращаться к другим представлениям. Она выглядит следующим образом:
Она выглядит следующим образом:
with temp_table_name as
(select … from …)
Можно сказать, что мы создаем временную таблицу, которая рассчитывается один раз в ходе выполнения запроса даже если вы обращаетесь к ней из разных мест. Использование представлений CTE также сильно упрощает чтение запроса и его последующее редактирование.
Вот как вышеуказанный запрос будет выглядеть с использованием представлений CTE:
with metrics_by_platform as (
select ‘3 in a row. iOS’ as app
, count() as transactions
, sum(priceusd) as gross
from p102968.payments
where eventtime > current_date — interval ‘9 day’ and eventtime < current_dateunion all
select ‘3 in a row. Android’ as app
, count() as transactions
, sum(priceusd) as gross
from p104704.payments
where eventtime > current_date — interval ‘9 day’ and eventtime < current_date
)
select ‘Metrics for all projects’ as «App»
, sum(transactions) as «Transactions»
, sum(gross) as «Gross»
from metrics_by_platformunion all
select app
, transactions
, gross
from metrics_by_platform
order by 3 desc
Выглядит проще, не правда ли? Если мы добавим новое приложение и захотим анализировать и его метрики, мы просто добавим его в представление metrics_by_platform, а расчет самих метрик и итоговый вывод результатов никак не зависит от количества приложений.
Доля пользователей, совершивших максимальное количество платежей (вложенные запросы)
Рассмотрим более сложный пример. Давайте узнаем, какое максимальное число платежей совершено одним пользователем за 7 дней и сколько таких пользователей.
Сложные запросы всегда лучше писать частями, и начнем мы с максимального количества платежей.
У нас есть таблица со всеми платежами пользователей from p102968.payment. Из нее мы посчитаем количество совершенных платежей для каждого из пользователей, сгруппировав их по devtodevid, а потом найдем максимальное число таких платежей с помощью max().
Результат запроса.select max(user_payments) as «max_payments»
from (
select devtodevid
, count() user_payments
from p102968.payments
where eventtime > current_date — interval ‘9 day’ and eventtime < current_date
group by devtodevid
) as payments_count
 Скриншот из демо devtodev
Скриншот из демо devtodevОсталось узнать, сколько пользователей совершили 12 платежей за это же время. Для этого только что выполненный запрос мы помещаем в фильтр where user_payments = (запрос), который оставит нам только пользователей с соответствующим максимальному количеством платежей. Сам запрос будет возвращать число таких пользователей select count() as «Users» и максимальное количество платежей max(user_payments) as «Max payments count» из таблицы from (…) as payments_count.
Результат запроса. Скриншот из демо devtodevselect count(devtodevid) as «Users»
, max(user_payments) as «Max payments count»
from (
select devtodevid
, count() user_payments
from p102968.payments
where eventtime > current_date — interval ‘7 day’ and eventtime < current_date
group by devtodevid
) as payments_countwhere user_payments = (select max(user_payments)
from
(select devtodevid
, count() user_payments
from p102968.payments
where eventtime > current_date — interval ‘7 day’ and eventtime < current_date
group by devtodevid) as payments_count
)
При выполнении для каждой строчки из внешнего запроса будет производиться сравнение максимального количества платежей пользователей where user_payments = (…) . В коде мы два раза использовали один и тот же запрос, поэтому давайте оптимизируем его с помощью представления CTE.
with payments_count as (
select devtodevid
, count() user_payments
from p102968.payments
where eventtime > current_date — interval ‘7 day’ and eventtime < current_date
group by devtodevid
)select count() as «Users»
, max(user_payments) as «Payments count»
from payments_count
where user_payments = (select max(user_payments)
from payments_count
А какова доля пользователей с таким количеством платежей среди всех платящих пользователей? Может быть он всего один и платил?
Чтобы узнать это, мы должны добавить вложенный запрос прямо в select, который посчитает всех платящих пользователей. На это число мы затем и поделим количество пользователей с максимальным платежом.
На это число мы затем и поделим количество пользователей с максимальным платежом.
Результат запроса. Скриншот из демо devtodevwith payments_count as (
select devtodevid
, count() user_payments
from p102968.payments
where eventtime > current_date — interval ‘7 day’ and eventtime < current_date
group by devtodevid
)select count() as «Users with max payments count»
, max(user_payments) as «Payments count»
, round(count()*100::numeric / (select count(distinct devtodevid)
from p102968.payments
where eventtime > current_date — interval ‘7 day’ and eventtime < current_date
, 2) ||’%’ as «% of all payers»
from payments_count
where user_payments = (select max(user_payments)
from payments_count)
Вложенные запросы внутри select – довольно распространенная практика. Они часто используются для расчета доли от чего-либо, либо отображения информации из другой таблицы без использования join.
Они часто используются для расчета доли от чего-либо, либо отображения информации из другой таблицы без использования join.
P.S.
В этой статье мы рассмотрели несколько примеров использования временных таблиц и вложенных запросов. В следующий раз вы научитесь заполнять пустые даты на графиках и формировать гистограмму распределения.
Использование SQL с онлайн-классом C++
- Все темы
- Технологии
- Разработка программного обеспечения
- Языки программирования
С Биллом Вайнманом Понравилось 420 пользователям
Продолжительность: 1ч 27м Уровень мастерства: средний Дата выпуска: 12.08.2021
Начать бесплатную пробную версию на 1 месяц
Детали курса
C++ — это мощный язык для приложений баз данных, который может быть отличным инструментом для использования с SQL. В этом курсе инструктор Билл Вейнман расскажет вам, как использовать возможности C++ в SQL, начиная с основ, таких как подключение к базе данных, выполнение простых запросов и чтение строк из таблицы. Он также объясняет, как использовать подготовленные операторы и переменные связывания, а также как создать класс-оболочку для оптимизации интерфейса SQL. Наконец, он показывает вам, как построить специализированный класс приложения, чтобы вы могли создать приложение, используя то, что вы узнали. Если вы опытный разработчик C++ и хотите научиться использовать C++ с SQL, этот курс для вас.
В этом курсе инструктор Билл Вейнман расскажет вам, как использовать возможности C++ в SQL, начиная с основ, таких как подключение к базе данных, выполнение простых запросов и чтение строк из таблицы. Он также объясняет, как использовать подготовленные операторы и переменные связывания, а также как создать класс-оболочку для оптимизации интерфейса SQL. Наконец, он показывает вам, как построить специализированный класс приложения, чтобы вы могли создать приложение, используя то, что вы узнали. Если вы опытный разработчик C++ и хотите научиться использовать C++ с SQL, этот курс для вас.
Навыки, которые вы приобретете
- SQL
- С++
Получите общий сертификат
Поделитесь тем, что вы узнали, и станьте выдающимся профессионалом в желаемой отрасли с сертификатом, демонстрирующим ваши знания, полученные на курсе.
Обучение LinkedIn Обучение
Сертификат об окончанииДемонстрация в вашем профиле LinkedIn в разделе «Лицензии и сертификаты»
Загрузите или распечатайте в формате PDF, чтобы поделиться с другими
Поделитесь изображением в Интернете, чтобы продемонстрировать свое мастерство
Познакомьтесь с инструктором
Билл Вайнман
Отзывы учащихся
30 оценок
Общий рейтинг рассчитывается на основе среднего значения представленных оценок. Оценки и обзоры могут быть отправлены только тогда, когда неанонимные учащиеся завершат не менее 40% курса. Это помогает нам избежать поддельных отзывов и спама.
Оценки и обзоры могут быть отправлены только тогда, когда неанонимные учащиеся завершат не менее 40% курса. Это помогает нам избежать поддельных отзывов и спама.
- 5 звезд Текущее значение: 20 66%
- 4 звезды Текущее значение: 9 30%
- 3 звезды Текущее значение: 1 3%
Георгий Петросян
Старший инженер-программист
5/5
14 мая 2022 г.
Этот курс хорош для начинающих. Но я думаю, что готовые примеры бесполезны. Полезнее будет написать код с объяснением каждой функции и ее параметров.
Полезный · Отчет
Марк ФинлиМарк Финли
Студент Университета Вэлли Вью
Содержание
Что включено
- Практикуйтесь, пока учитесь 1 файл с упражнениями
- Проверьте свои знания 4 викторины
- Учитесь на ходу Доступ на планшете и телефоне
Похожие курсы
Скачать курсы
Используйте приложение LinkedIn Learning для iOS или Android и смотрите курсы на своем мобильном устройстве без подключения к Интернету.
запрос.скала
query.scala // Перейти к …
- СУО
- Учебники
- запрос.скала
¶
Коммерческие системы баз данных и системы баз данных с открытым исходным кодом состоят из миллионов строк оптимизированный код C. Тем не менее, их производительность по отдельным запросам падает в 10 или 100 раз. за исключением того, что может написать написанная от руки специализированная реализация того же запроса. достигать.
В этом руководстве мы создадим небольшой механизм обработки SQL, состоящий из всего около 500 строк высокоуровневого кода Scala. В то время как другие системы интерпретируют запрос планы, оператор за оператором, мы будем использовать LMS для генерации и компиляции низкоуровневого C код для целых запросов.
Мы намеренно сделали запрос простым. Более совершенный двигатель
который обрабатывает полный набор тестов TPCH и состоит примерно из 3000 строк
код был разработан в проекте LegoBase, который недавно получил
приз за лучшую статью на VLDB’14.
См. также:
- Создание эффективных механизмов запросов на языке высокого уровня (PDF)
Яннис Клонатос, Кристоф Кох, Тиарк Ромпф, Хассан Чафи. ВЛДБ’14 - Функциональная жемчужина: компилятор SQL в C в 500 строках кода (PDF)
Тиарк Ромпф, Нада Амин. ICFP’15
Схема:
Подготовка к сцене
Давайте проведем несколько быстрых тестов, чтобы получить представление об относительной производительности различных системы обработки данных. Мы берем образец данных из проекта Google Books NGram Viewer. Файл размером 2 ГБ, содержащий статистику по словам, начинающимся с буквы «А», является хорошим кандидатом для запуска. несколько простых запросов. Нас могут заинтересовать все вхождения слова «Auswanderung»:
выберите * из 1gram_a, где n_gram = «Auswanderung»
Вот некоторые тайминги:
Загрузка файла CSV в базу данных MySQL занимает > 5 минут, выполнение запроса около 50 секунд.
Загрузка PostgreSQL занимает 3 минуты, первый запуск запроса занимает 46 секунд, но последующие запуски со временем выполняются быстрее (до 7 секунд).
Сценарий AWK, обрабатывающий файл CSV напрямую, занимает 45 секунд.
Интерпретатор запросов, написанный на Scala, занимает 39 секунд.
Написанная вручную специализированная программа на языке Scala выполняется за 13 сек.
Аналогичная написанная от руки программа на C работает немного быстрее, но с большей оптимизацией мы можем получить целых 3,2 секунды.
Процессор запросов, который мы разработаем в этом руководстве, соответствует производительности рукописных запросов Scala и C (13 с и 3 с соответственно).
Дополнительные сведения о выполнении тестов доступны здесь. Теперь перейдем к нашей фактической реализации.
пакет scala.lms.tutorial импортировать scala.lms.common._
¶
Реляционная алгебра AST
Ядром любого механизма обработки запросов является представление AST операторы реляционной алгебры.
признак QueryAST {
тип Таблица
тип Схема = Вектор[Строка]
// операции реляционной алгебры
запечатанный абстрактный класс Оператор
класс case Scan (имя: таблица, схема: схема, разделитель: Char, extSchema: Boolean) расширяет оператор
класс case PrintCSV (родитель: оператор) расширяет оператор
case class Project (outSchema: Schema, inSchema: Schema, parent: Operator) расширяет оператор
класс case Filter (предыдущий: предикат, родитель: оператор) расширяет оператор
класс case Join (родительский1: оператор, родительский2: оператор) расширяет оператор
Группа классов case (ключи: Схема, agg: Схема, родитель: Оператор) расширяет Оператор
класс case HashJoin (parent1: оператор, parent2: оператор) расширяет оператор
// фильтровать предикаты
запечатанный абстрактный класс Predicate
case class Eq(a: Ref, b: Ref) расширяет предикат
запечатанный абстрактный класс Ref
поле класса случая (имя: строка) расширяет ссылку
case class Value(x: Any) extends Ref
// некоторые умные конструкторы
Схема защиты (схема: строка *): Схема = схема. toVector
def Scan(tableName: String): Scan = Scan(tableName, None, None)
def Scan(tableName: String, schema: Option[Schema], delim: Option[Char]): Scan
}
9(s => Значение (s.toInt))
def parseAll (ввод: строка): Оператор = parseAll (stm, input) match {
case Success(res,_) => res
case res => генерировать новое исключение (res.toString)
}
}
}
¶
Итеративная разработка обработчика запросов
Мы разрабатываем наш механизм SQL в несколько этапов. Каждый шаг ведет к работающий процессор, и каждый последующий шаг либо добавляет функцию, либо оптимизация.
Шаг 1: (простой) интерпретатор запросов
Начнем с простого процессора запросов: интерпретатора.
- query_unstaged.scala
Шаг 2. Поэтапный интерпретатор запросов (= компилятор)
Постановка нашего интерпретатора запросов дает компилятор запросов. В первой итерации мы генерируем код Scala, но не учитываем операторы, требующие внутренних структур данных:
- query_staged0
Шаг 3.
 Специализация структур данных
Специализация структур данныхСледующая итерация добавляет оптимизированные реализации структур данных которые следуют макету хранилища столбцов. Это включает в себя специализированный хэш таблицы для операторов groupBy и join:
- query_staged
Шаг 4: переход на C и оптимизация ввода-вывода
Для дополнительной низкоуровневой оптимизации мы переключаемся на генерацию C код:
- query_optc
На уровне C мы оптимизируем уровень ввода-вывода, напрямую сопоставляя файлы в память, и мы дополнительно специализируемся на внутренних структурах данных чтобы свести к минимуму преобразования данных и включить представление строковых объектов непосредственно как указатели на отображаемый в памяти входной файл.
Сантехника
Для фактического запуска запросов и тестирования различных реализаций.
сбоку, немного сантехники необходимо. Мы определяем общий
интерфейс для всех обработчиков запросов (обычных или поэтапных, Scala или C).
признак QueryProcessor расширяет QueryAST {
версия по умолчанию: строка
val defaultFieldDelimiter = ','
def filePath (таблица: строка): строка = таблица
def dynamicFilePath (таблица: строка): таблица
def Scan(tableName: String, schema: Option[Schema], delim: Option[Char]): Scan = {
val dfile = dynamicFilePath (tableName)
val (schema1, externalSchema) = schema.map(s=>(s,true)).getOrElse((loadSchema(filePath(tableName)),false))
Scan(dfile, schema1, delim.getOrElse(defaultFieldDelimiter), externalSchema)
}
def loadSchema (имя файла: строка): Схема = {
val s = новый сканер (имя файла)
схема val = Схема (s.next ('\ n'). Split (defaultFieldDelimiter): _ *)
с.закрыть
схема
}
def execQuery(q: Оператор): Единица измерения
}
черта PlainQueryProcessor расширяет QueryProcessor {
тип Таблица = Строка
}
черта StagedQueryProcessor расширяет QueryProcessor с помощью Dsl {
type Table = Rep[String] // динамическое имя файла
переопределить def filePath(table: String) = if (table == "?") throw new Exception("путь к файлу для таблицы? недоступен") else super. filePath(table)
}
¶
Интерактивный режим
Примеры:
test:run unstaged "select * from ? schema Phrase, Year, MatchCount, VolumeCount delim \\t where Phrase='Auswanderung'" src/data/t1gram.csv test:run c "select * from ? schema Phrase, Year, MatchCount, VolumeCount delim \\t where Phrase='Auswanderung'" src/data/t1gram.csv
Черта Engine расширяет QueryProcessor с помощью SQLParser {
деф-запрос: строка
def имя файла: Строка
def liftTable(n: String): Таблица
Оценка по умолчанию: Единица измерения
подготовка по определению: единица = {}
def run: Unit = execQuery (PrintCSV (parseSql (запрос)))
переопределить определение dynamicFilePath (таблица: строка): Таблица =
liftTable(if (table == "?") имя файла еще путь к файлу(таблица))
защита evalString = {
val источник = новый java.io.ByteArrayOutputStream()
utils.withOutputFull (новый java.io.PrintStream (источник)) {
оценка
}
источник.toString
}
}
черта StagedEngine расширяет Engine с помощью StagedQueryProcessor {
переопределить def liftTable(n: String) = unit(n)
}
объект Выполнить {
переменная qu: строка = _
переменная fn: строка = _
черта MainEngine расширяет Engine {
переопределить запрос def = qu
переопределить имя файла по умолчанию = fn
}
def unstaged_engine: Двигатель =
новый движок с MainEngine с query_unstaged. QueryInterpreter {
переопределить def liftTable(n: Table) = n
переопределить def eval = запустить
}
защита scala_engine =
новый DslDriver[String,Unit] со ScannerExp
с StagedEngine с MainEngine с query_staged.QueryCompiler { q =>
переопределить val codegen = новый DslGen со ScalaGenScanner {
val IR: q.type = q
}
override def snippet(fn: Table): Rep[Unit] = run
переопределить def prepare: Unit = precompile
переопределить def eval: Unit = eval(имя файла)
}
защита c_engine =
новый DslDriverC[String,Unit] со ScannerLowerExp
с StagedEngine с MainEngine с query_optc.QueryCompiler { q =>
переопределить val codegen = новый DslGenC с CGenScannerLower {
val IR: q.type = q
}
override def snippet(fn: Table): Rep[Unit] = run
переопределить определение подготовки: Unit = {}
переопределить def eval: Unit = eval(имя файла)
}
def main(аргументы: Массив[Строка]) {
если (args.length < 2) {
println("Синтаксис:")
println(" test:run (unstaged|scala|c) sql [файл]")
println()
println("пример использования:")
println(" test:run c \"select * from ? schema Phrase, Year, MatchCount, VolumeCount delim \\t where Phrase='Auswanderung'\" src/data/t1gram. csv")
возвращаться
}
val версия = аргументы (0)
val engine = соответствие версии {
случай "с" => c_engine
case "скала" => scala_engine
case "unstaged" => unstaged_engine
case _ => println("предупреждение: неожиданный движок, по умолчанию используется 'unstaged'")
unstaged_engine
}
ц = аргументы (1)
если (args.length > 2)
fn = аргументы (2)
пытаться {
двигатель.подготовить
utils.time(engine.eval)
} ловить {
случай пример: Исключение =>
println("ОШИБКА: " + пример)
}
}
}
¶
Модульные тесты
class QueryTest extends TutorialFunSuite {
значение под = "запрос_"
trait TestDriver расширяет SQLParser с помощью QueryProcessor с ExpectedASTs {
Def runtest: Единица измерения
переопределить def filePath (таблица: строка) = dataFilePath (таблица)
имя защиты: строка
деф-запрос: строка
def parsedQuery: Оператор = если (query.isEmpty) ожидаемыйAstForTest(имя) else parseSql(запрос)
}
trait PlainTestDriver расширяет TestDriver с помощью PlainQueryProcessor {
переопределить def dynamicFilePath(table: String): Table = if (table == "?") defaultEvalTable else filePath(table)
def eval(fn: Table): Unit = {
execQuery (PrintCSV (parsedQuery))
}
}
trait StagedTestDriver расширяет TestDriver с помощью StagedQueryProcessor {
переменная dynamicFileName: Таблица = _
переопределить определение dynamicFilePath(table: String): Table = if (table == "?") dynamicFileName else unit(filePath(table))
def snippet(fn: Table): Rep[Unit] = {
динамическое имя_файла = fn
execQuery (PrintCSV (parsedQuery))
}
}
абстрактный класс ScalaPlainQueryDriver (val name: String, val query: String) расширяет PlainTestDriver с помощью QueryProcessor { q =>
переопределить определение runtest: Unit = {
тест(версия+" "+имя) {
for (expectedParsedQuery <- expectAstForTest. get(name)) {
утверждать (ожидаемыйParsedQuery == parsedQuery)
}
checkOut(имя, "csv", eval(defaultEvalTable))
}
}
}
абстрактный класс ScalaStagedQueryDriver(val name: String, val query: String) расширяет DslDriver[String,Unit] с помощью StagedTestDriver с StagedQueryProcessor со ScannerExp { q =>
переопределить val codegen = новый DslGen со ScalaGenScanner {
val IR: q.type = q
}
переопределить определение runtest: Unit = {
if (версия == "query_staged0" && List("Group","HashJoin").exists(parsedQuery.toString содержит _)) return ()
тест(версия+" "+имя) {
for (expectedParsedQuery <- expectAstForTest.get(name)) {
утверждать (ожидаемыйParsedQuery == parsedQuery)
}
проверить (имя, код)
предварительная компиляция
checkOut(имя, "csv", eval(defaultEvalTable))
}
}
}
абстрактный класс CStagedQueryDriver(val name: String, val query: String) расширяет DslDriverC[String,Unit] с помощью StagedTestDriver с StagedQueryProcessor с помощью ScannerLowerExp { q =>
переопределить val codegen = новый DslGenC с CGenScannerLower {
val IR: q. type = q
}
переопределить определение runtest: Unit = {
тест(версия+" "+имя) {
for (expectedParsedQuery <- expectAstForTest.get(name)) {
утверждать (ожидаемыйParsedQuery == parsedQuery)
}
проверить(имя, код, "с")
//прекомпилировать
checkOut(имя, "csv", eval(defaultEvalTable))
}
}
}
def testquery (имя: строка, запрос: строка = "") {
val драйверы: Список[TestDriver] =
Список(
новый ScalaPlainQueryDriver(имя, запрос) с query_unstaged.QueryInterpreter,
новый ScalaStagedQueryDriver(имя, запрос) с query_staged0.QueryCompiler,
новый ScalaStagedQueryDriver(имя, запрос) с query_staged.QueryCompiler,
новый CStagedQueryDriver (имя, запрос) с query_optc.QueryCompiler {
// FIXME: взломать, чтобы мне не нужно было заменять Value -> #Value во всех файлах прямо сейчас
переопределить def isNumericCol(s: String) = s == "Value" || super.isNumericCol(s)
}
)
driver. foreach(_.runtest)
}
// ПРИМЕЧАНИЕ: мы можем использовать "выбрать * из?" использовать динамические имена файлов (сейчас здесь не используется)
трейт ExpectedASTs расширяет QueryAST {
val scan_t = сканирование ("t.csv")
val scan_t1gram = Scan("?", Some(Schema("Phrase", "Year", "MatchCount", "VolumeCount")), Some('\t'))
val ожидаемоеAstForTest = Карта(
"t1" -> scan_t,
"t2" -> Проект(Схема("Имя"), Схема("Имя"), scan_t),
"t3" -> Проект(Схема("Имя"), Схема("Имя"),
Фильтр(Уравнение(Поле("Флаг"), Значение("да")),
скан_т)),
"t4" -> Присоединиться (scan_t,
Проект(Схема("Имя1"), Схема("Имя"), scan_t)),
"t5" -> Присоединиться (scan_t,
Проект(Схема("Имя"), Схема("Имя"), scan_t)),
"t4h" -> HashJoin(scan_t,
Проект(Схема("Имя1"), Схема("Имя"), scan_t)),
"t5h" -> HashJoin(scan_t,
Проект(Схема("Имя"), Схема("Имя"), scan_t)),
«t6» -> Группа (Схема («Имя»), Схема («Значение»), scan_t),
"t1gram1" -> scan_t1gram,
"t1gram2" -> Filter(Eq(Field("Phrase"), Value("Auswanderung")), scan_t1gram)
)
}
testquery("t1", "выбрать * из t. csv")
testquery("t2", "выберите имя из t.csv")
testquery ("t3", "выберите имя из t.csv, где флаг = 'да'")
testquery("t4", "выберите * из вложенных циклов t.csv join (выберите имя как Name1 из t.csv)")
testquery("t5", "выбрать * из вложенных циклов t.csv join (выбрать имя из t.csv)")
testquery("t4h","выберите * из соединения t.csv (выберите Имя как Имя1 из t.csv)")
testquery("t5h","выберите * из соединения t.csv (выберите имя из t.csv)")
testquery("t6", "выберите * из группы t.csv по значению суммы имени") // не на 100% правильный синтаксис, но эй...
val defaultEvalTable = dataFilePath("t1gram.csv")
val t1gram = "? schema Phrase, Year, MatchCount, VolumeCount delim \\t"
testquery("t1gram1", s"выбрать * из $t1gram")
testquery("t1gram2", s"выберите * из $t1gram, где Phrase='Auswanderung'")
testquery("t1gram2n", s"выберите * из вложенных циклов words.csv join (выберите Phrase as Word, Year, MatchCount, VolumeCount из $t1gram)")
testquery("t1gram2h", s"select * from words. csv join (выберите Phrase as Word, Year, MatchCount, VolumeCount из $t1gram)")
testquery("t1gram3", s"выбрать * из вложенных циклов words.csv join (выбрать * из $t1gram)")
testquery("t1gram3h", s"выбрать * из words.csv присоединиться (выбрать * из $t1gram)")
testquery("t1gram4", s"выберите * из вложенных циклов words.csv join (выберите Phrase as Word, Year, MatchCount, VolumeCount из $t1gram)")
testquery("t1gram4h", s"select * from words.csv join (выберите Phrase as Word, Year, MatchCount, VolumeCount из $t1gram)")
}
csv")
testquery("t2", "выберите имя из t.csv")
testquery ("t3", "выберите имя из t.csv, где флаг = 'да'")
testquery("t4", "выберите * из вложенных циклов t.csv join (выберите имя как Name1 из t.csv)")
testquery("t5", "выбрать * из вложенных циклов t.csv join (выбрать имя из t.csv)")
testquery("t4h","выберите * из соединения t.csv (выберите Имя как Имя1 из t.csv)")
testquery("t5h","выберите * из соединения t.csv (выберите имя из t.csv)")
testquery("t6", "выберите * из группы t.csv по значению суммы имени") // не на 100% правильный синтаксис, но эй...
val defaultEvalTable = dataFilePath("t1gram.csv")
val t1gram = "? schema Phrase, Year, MatchCount, VolumeCount delim \\t"
testquery("t1gram1", s"выбрать * из $t1gram")
testquery("t1gram2", s"выберите * из $t1gram, где Phrase='Auswanderung'")
testquery("t1gram2n", s"выберите * из вложенных циклов words.csv join (выберите Phrase as Word, Year, MatchCount, VolumeCount из $t1gram)")
testquery("t1gram2h", s"select * from words. csv join (выберите Phrase as Word, Year, MatchCount, VolumeCount из $t1gram)")
testquery("t1gram3", s"выбрать * из вложенных циклов words.csv join (выбрать * из $t1gram)")
testquery("t1gram3h", s"выбрать * из words.csv присоединиться (выбрать * из $t1gram)")
testquery("t1gram4", s"выберите * из вложенных циклов words.csv join (выберите Phrase as Word, Year, MatchCount, VolumeCount из $t1gram)")
testquery("t1gram4h", s"select * from words.csv join (выберите Phrase as Word, Year, MatchCount, VolumeCount из $t1gram)")
}
¶
Предложения по упражнениям
Механизм запросов, который мы представили, определенно прост, чтобы представить сквозная система, которую можно понять в целом. Ниже приведены несколько предложения по интересным расширениям.
Реализовать сканер, который считывает URL-адрес по запросу.
(Прикольно: новый оператор, который печатает только первые N результатов.)
(просто) Реализовать типизированную схему в версии Scala, чтобы типы столбцов известны статически, а значения — нет.
(Подсказка: версия C уже делает это, но также требует больше усилий из-за представлений пользовательского типа.)
(просто) Реализовать больше предикатов (например,
LessThan) и предикат комбинаторы (например,И,Или) для того, чтобы запускать интереснее запросы.(средний) Реализовать настоящую базу данных, ориентированную на столбцы, где каждый столбец имеет свою собственный файл, чтобы его можно было прочитать независимо.
(жесткий) Реализуйте оптимизатор реляционной алгебры перед генерацией кода. (Подсказка: умные конструкторы могут помочь.)
Оптимизатор запросов должен переупорядочить деревья операторов запросов для лучшего порядка соединений, т. е. решить, выполнять ли соединения для отношений S0 x S1 x S2 как (S0 x (S1 x S2)) или ((S0 x S1) x S2).
Используйте алгоритм динамического программирования, который для n объединений в таблицах S0 x S1 x …x Sn сначала пытается найти оптимальное решение для S1 x .
 . x Sn, а затем оптимальную комбинацию с S0.
. x Sn, а затем оптимальную комбинацию с S0.Чтобы найти оптимальное сочетание, попробуйте все варианты и оцените стоимость каждого. Стоимость может быть приблизительно измерена как количество обработанных записей. В качестве простого приближения можно использовать размер каждой входной таблицы и предположить, что все предикаты фильтра совпадают с вероятностью 0,5.
Комментарии? Предложения по улучшению? Посмотреть этот файл на GitHub.
- СУО
- Учебники
- запрос.скала
Рекомендации по написанию SQL-запросов: как структурировать код
Категории
SQLGuides
удобочитаемость.
Язык структурированных запросов является абсолютно необходимым навыком в отрасли обработки данных. SQL — это не только написание запросов, вы также должны убедиться, что ваши запросы производительны, быстры и удобочитаемы. Таким образом, также необходимо, чтобы вы знали, как эффективно писать SQL-запросы.
Эта статья расскажет вам о лучших методах структурирования SQL-запросов. Даже когда ваш код SQL работает правильно, его все равно можно улучшить, особенно когда речь идет о производительности и удобочитаемости. Это важно, потому что на технических собеседованиях цель состоит не только в том, чтобы проверить, способен ли кандидат предложить работающее решение проблемы, но и в том, может ли он подготовить эффективное и понятное решение. То же самое и в рабочей среде: сделать запросы быстрыми и понятными для других так же важно, как и сделать их правильными.
Давайте воспользуемся реальным примером вопросов для собеседования по науке о данных, которые можно решить с помощью SQL-запроса. У нас будет решение, которое дает правильный вывод, но оно очень неэффективно и чрезвычайно трудно читаемо. Затем мы рассмотрим несколько ключевых рекомендаций по написанию SQL-запросов и применим их к коду, чтобы улучшить его, чтобы его можно было использовать в качестве ответа на вопрос на собеседовании.
Вопрос собеседования по SQL
Премиум против Freemium
Вопрос собеседования по техническим вопросам Microsoft
Мы будем использовать этот вопрос на собеседовании по SQL в качестве примера, взятого из технических собеседований в Microsoft и озаглавленного «Premium vs Freemium». Задача состоит в том, чтобы найти общее количество загрузок для платных и неплатящих пользователей по дате и включить только те записи, где у неплатящих клиентов больше загрузок, чем у платных. Более того, этот вопрос связан с набором данных, разделенным на три таблицы, которые необходимо объединить.
Исходное решение
Давайте получим исходное решение этой задачи SQL, которое мы будем использовать в качестве отправной точки. Мы не найдем, как это решение работает или как его можно получить — это не цель этой статьи. Вместо этого мы будем использовать его только как иллюстрацию синтаксических приемов, универсальных для любого SQL-запроса.
Это решение может быть использовано для получения правильного вывода для этой проблемы:
SELECT date, "NonPaying",
оплата
ИЗ
(ВЫБЕРИТЕ стр. дату,
p.sum AS платит,
n.nonpaying AS "Неплатежеспособный"
ИЗ
(ВЫБЕРИТЕ дату, сумму(загрузки)
ОТ ms_user_dimension a
ВНУТРЕННЕЕ СОЕДИНЕНИЕ ms_acc_dimension b ON a.acc_id = b.acc_id
ВНУТРЕННЕЕ СОЕДИНЕНИЕ ms_download_facts c ON a.user_id=c.user_id
ГДЕ pay_customer = 'да'
СГРУППИРОВАТЬ ПО дате
ЗАКАЗАТЬ ПО дате) стр
ПРИСОЕДИНИТЬСЯ
(ВЫБЕРИТЕ дату, сумму(загрузки) КАК БЕСПЛАТНО
ОТ ms_user_dimension a
ВНУТРЕННЕЕ СОЕДИНЕНИЕ ms_acc_dimension b ON a.acc_id = b.acc_id
ВНУТРЕННЕЕ СОЕДИНЕНИЕ ms_download_facts c ON a.user_id=c.user_id
ГДЕ pay_customer = 'нет'
СГРУППИРОВАТЬ ПО дате
ORDER BY date) n ON p.date = n.date
ЗАКАЗАТЬ ПО п.дата) с
СГРУППИРОВАТЬ ПО дате, "Неоплачиваемый",
оплата
ИМЕЕТ ("NonPaying" - платит) >0
ЗАКАЗАТЬ ПО дате ASC
дату,
p.sum AS платит,
n.nonpaying AS "Неплатежеспособный"
ИЗ
(ВЫБЕРИТЕ дату, сумму(загрузки)
ОТ ms_user_dimension a
ВНУТРЕННЕЕ СОЕДИНЕНИЕ ms_acc_dimension b ON a.acc_id = b.acc_id
ВНУТРЕННЕЕ СОЕДИНЕНИЕ ms_download_facts c ON a.user_id=c.user_id
ГДЕ pay_customer = 'да'
СГРУППИРОВАТЬ ПО дате
ЗАКАЗАТЬ ПО дате) стр
ПРИСОЕДИНИТЬСЯ
(ВЫБЕРИТЕ дату, сумму(загрузки) КАК БЕСПЛАТНО
ОТ ms_user_dimension a
ВНУТРЕННЕЕ СОЕДИНЕНИЕ ms_acc_dimension b ON a.acc_id = b.acc_id
ВНУТРЕННЕЕ СОЕДИНЕНИЕ ms_download_facts c ON a.user_id=c.user_id
ГДЕ pay_customer = 'нет'
СГРУППИРОВАТЬ ПО дате
ORDER BY date) n ON p.date = n.date
ЗАКАЗАТЬ ПО п.дата) с
СГРУППИРОВАТЬ ПО дате, "Неоплачиваемый",
оплата
ИМЕЕТ ("NonPaying" - платит) >0
ЗАКАЗАТЬ ПО дате ASC
Не волнуйтесь, если вы не сразу поймете, что здесь происходит. Это на самом деле вещь, это решение намеренно длинное, запутанное и запутанное, и задача будет заключаться в том, чтобы очистить его, используя лучшие практики синтаксиса SQL. Но самое интересное, что это решение работает — мы можем его запустить и посмотреть, сколько загрузок от платных и неплатящих клиентов было в каждую дату. Но даже при том, что это решение правильное, интервьюер, вероятно, не обрадуется такому ответу. Итак, давайте посмотрим, какие лучшие практики написания SQL-запросов нам здесь не хватает и как повысить наши шансы произвести впечатление на интервьюера.
Но самое интересное, что это решение работает — мы можем его запустить и посмотреть, сколько загрузок от платных и неплатящих клиентов было в каждую дату. Но даже при том, что это решение правильное, интервьюер, вероятно, не обрадуется такому ответу. Итак, давайте посмотрим, какие лучшие практики написания SQL-запросов нам здесь не хватает и как повысить наши шансы произвести впечатление на интервьюера.
Передовой опыт написания SQL-запросов: как структурировать код
1. Удалите несколько вложенных запросов
Даже не понимая, что именно делает код, мы видим, что он имеет несколько вложенных запросов. Есть основной запрос, в котором выбираются три столбца, затем в его предложении FROM есть еще один длинный запрос, называемый внутренним запросом. У него есть псевдоним «s». Но тогда сам этот внутренний запрос «s» также имеет два дополнительных и почти идентичных внутренних запроса, «p» и «n», которые объединяются вместе с помощью оператора JOIN. Хотя иметь один внешний запрос и один внутренний запрос абсолютно нормально, более двух запросов, вложенных друг в друга, считаются не очень читабельными, и их следует избегать.
Один из подходов к избавлению от такого количества вложенных запросов состоит в том, чтобы определить некоторые или все из них в форме общих табличных выражений или CTE — конструкций, которые используют ключевое слово WITH и позволяют повторно использовать один запрос несколько раз. Итак, пусть это будет наш первый шаг — мы можем превратить все три вложенных запроса «s», «p» и «n» в CTE.
С р КАК
(ВЫБЕРИТЕ дату, сумму(загрузки)
ОТ ms_user_dimension a
ВНУТРЕННЕЕ СОЕДИНЕНИЕ ms_acc_dimension b ON a.acc_id = b.acc_id
ВНУТРЕННЕЕ СОЕДИНЕНИЕ ms_download_facts c ON a.user_id=c.user_id
ГДЕ pay_customer = 'да'
СГРУППИРОВАТЬ ПО дате
ЗАКАЗАТЬ ПО дате),
н КАК
(ВЫБЕРИТЕ дату, сумму(загрузки) КАК БЕСПЛАТНО
ОТ ms_user_dimension a
ВНУТРЕННЕЕ СОЕДИНЕНИЕ ms_acc_dimension b ON a.acc_id = b.acc_id
ВНУТРЕННЕЕ СОЕДИНЕНИЕ ms_download_facts c ON a.user_id=c.user_id
ГДЕ pay_customer = 'нет'
СГРУППИРОВАТЬ ПО дате
ЗАКАЗАТЬ ПО дате),
с АС
(ВЫБЕРИТЕ стр. дату,
p.sum AS платит,
n.nonpaying AS "Неплатежеспособный"
С р
ПРИСОЕДИНЯЙТЕСЬ n ON p.date = n.date
ЗАКАЗАТЬ ПО п.дате)
ВЫБЕРИТЕ дату, "Неоплачиваемый",
оплата
ОТ с
СГРУППИРОВАТЬ ПО дате, "Неоплачиваемый",
оплата
ИМЕЕТ ("NonPaying" - платит) >0
ЗАКАЗАТЬ ПО дате ASC
дату,
p.sum AS платит,
n.nonpaying AS "Неплатежеспособный"
С р
ПРИСОЕДИНЯЙТЕСЬ n ON p.date = n.date
ЗАКАЗАТЬ ПО п.дате)
ВЫБЕРИТЕ дату, "Неоплачиваемый",
оплата
ОТ с
СГРУППИРОВАТЬ ПО дате, "Неоплачиваемый",
оплата
ИМЕЕТ ("NonPaying" - платит) >0
ЗАКАЗАТЬ ПО дате ASC
Теперь этот запрос уже стал немного легче читать. Даже не понимая точно, что происходит, мы можем видеть, что есть два очень похожих шага, ‘p’ и ‘n’, которые должны быть выполнены сначала, чтобы активировать ‘s’, а затем результат ‘s’ можно использовать в основной запрос. Но что же это за «р», «н», «с» и другие псевдонимы? Это подводит нас ко второму пункту.
2. Обеспечить согласованность псевдонимов
Псевдонимы в SQL могут быть назначены столбцам, запросам и таблицам для изменения их первоначальных имен. Их необходимо использовать при объединении таблиц с одинаковыми именами столбцов, чтобы избежать двусмысленности в именах столбцов. Псевдонимы также полезны для облегчения понимания кода другими и для замены имен столбцов по умолчанию при использовании аналитических функций (например, СУММ() или СЧЁТ()).
Существует также несколько неписаных правил относительно псевдонимов, которым следует следовать, поскольку неправильно используемый псевдоним может скорее запутать, чем помочь. Начнем с псевдонимов таблицы и запроса. Хорошо, когда это немного больше, чем просто одна буква, и они позволяют нам понять, что находится в таблице или что выдает запрос. В нашем случае первый CTE, который в настоящее время называется «p», используется для подсчета количества загрузок, сделанных платными клиентами, поэтому более информативным названием будет, например, «платный». Стоит отметить, что псевдонимы, хотя и информативные, не должны быть слишком длинными, например, «paying_customers» может быть немного длинным. Затем второй CTE, «n», такой же, но для неплатящих клиентов, поэтому, следуя схеме, его можно назвать «бесплатным».
Наконец, CTE ‘s’ объединяет два значения: количество загрузок платных и бесплатных клиентов, но пока не фильтрует их, потому что это происходит в основном запросе. Таким образом, его имя может быть, например, «all_downloads». Теперь обратите внимание, что это еще не все таблицы, которым присвоены псевдонимы. Это связано с тем, что в первых двух CTE мы объединяем три таблицы друг с другом, и, поскольку они имеют общие имена столбцов, им нужно дать псевдонимы. В настоящее время это просто «a», «b» и «c», но более информативными названиями будут «users», «accounts» и «downlds» — аббревиатура здесь, потому что в этой таблице уже есть столбец «downloads».
Таким образом, его имя может быть, например, «all_downloads». Теперь обратите внимание, что это еще не все таблицы, которым присвоены псевдонимы. Это связано с тем, что в первых двух CTE мы объединяем три таблицы друг с другом, и, поскольку они имеют общие имена столбцов, им нужно дать псевдонимы. В настоящее время это просто «a», «b» и «c», но более информативными названиями будут «users», «accounts» и «downlds» — аббревиатура здесь, потому что в этой таблице уже есть столбец «downloads».
И последнее, что касается псевдонимов таблиц, — это согласованность их использования. Обычно их лучше либо использовать со всеми именами столбцов, либо только в абсолютно необходимых местах (например, только при определении JOIN) или вообще не использовать. Давайте решим использовать псевдонимы таблиц во всех случаях, когда несколько таблиц объединены, то есть во всех CTE, и не использовать их, когда все столбцы поступают только из одной таблицы, как в основном запросе.
С оплатой AS (ВЫБРАТЬ загрузки.дата, сумма(загрузки.загрузки) ОТ пользователей ms_user_dimension ВНУТРЕННЕЕ СОЕДИНЕНИЕ ms_acc_dimension account ON users.acc_id = account.acc_id INNER JOIN ms_download_facts downlds ON users.user_id=downlds.user_id ГДЕ account.paying_customer = 'да' СГРУППИРОВАТЬ ПО downlds.date ЗАКАЗАТЬ ПО downlds.date), неплатежный AS (ВЫБЕРИТЕ загрузки.дата, сумма(загрузки.загрузки) КАК неоплачиваемые ОТ пользователей ms_user_dimension ВНУТРЕННЕЕ СОЕДИНЕНИЕ ms_acc_dimension account ON users.acc_id = account.acc_id INNER JOIN ms_download_facts downlds ON users.user_id=downlds.user_id ГДЕ account.paying_customer = 'нет' СГРУППИРОВАТЬ ПО downlds.date ЗАКАЗАТЬ ПО downlds.date), all_downloads КАК (ВЫБЕРИТЕ дату оплаты, pay.sum КАК платит, nonpaying.nonpaying AS "Неплатежеспособный" ОТ оплаты ПРИСОЕДИНЯЙТЕСЬ к nonpaying ON pay.date = nonpaying.date ЗАКАЗАТЬ ПО ОПЛАТЕ.ДАТА) ВЫБЕРИТЕ дату, "Неоплачиваемый", оплата ИЗ all_downloads СГРУППИРОВАТЬ ПО дате, "Неоплачиваемый", оплата ИМЕЕТ ("NonPaying" - платит) >0 ЗАКАЗАТЬ ПО дате ASC
Это были псевдонимы таблицы и запроса, теперь давайте посмотрим на псевдонимы, присвоенные столбцам. Во-первых, дать псевдонимы результатам аналитических функций. Взгляните на первый запрос. Есть функция SUM(), но к ней не добавляется псевдоним, хотя позже этот столбец используется повторно. Вот почему в CTE all_downloads нам нужно написать pay.sum, чтобы выбрать его. Добавим псевдоним, например n_paying.
Во-первых, дать псевдонимы результатам аналитических функций. Взгляните на первый запрос. Есть функция SUM(), но к ней не добавляется псевдоним, хотя позже этот столбец используется повторно. Вот почему в CTE all_downloads нам нужно написать pay.sum, чтобы выбрать его. Добавим псевдоним, например n_paying.
Еще одна вещь — обеспечить соответствие псевдонимов столбцов в именах, а также избежать конфликтов с другими псевдонимами. Как и в CTE nonpaying, есть функция SUM(), которая правильно назначается как псевдоним, но этот псевдоним совпадает с псевдонимом CTE, что может сбивать с толку. Давайте придерживаться того же соглашения об именах, что и раньше, и изменим этот псевдоним на n_nonpaying.
Теперь в CTE all_downloads происходит много всего. Во-первых, псевдоним «paying», назначенный второму столбцу, совпадает с псевдонимом одного из CTE. И сразу после этого псевдоним третьего столбца — «NonPaying» в кавычках. Хотя SQL позволяет нам назначать такие псевдонимы, использовать такие псевдонимы опасно, потому что каждый раз, когда мы хотим использовать его повторно, нам нужно снова использовать кавычки и сопоставлять все заглавные и строчные буквы в псевдониме. Мы могли бы изменить эти два псевдонима на что-то другое и без кавычек. Но на самом деле даже не обязательно использовать эти алиасы, ведь аналитических функций здесь нет, поэтому имена столбцов из предыдущих, ‘n_paying’ и n_nonpaying’ остаются прежними и на них можно ссылаться в основном запросе, не вызывая проблем.
Мы могли бы изменить эти два псевдонима на что-то другое и без кавычек. Но на самом деле даже не обязательно использовать эти алиасы, ведь аналитических функций здесь нет, поэтому имена столбцов из предыдущих, ‘n_paying’ и n_nonpaying’ остаются прежними и на них можно ссылаться в основном запросе, не вызывая проблем.
С оплатой КАК
(ВЫБРАТЬ downlds.date, sum(downlds.downloads) AS n_paying
ОТ пользователей ms_user_dimension
ВНУТРЕННЕЕ СОЕДИНЕНИЕ ms_acc_dimension account ON users.acc_id = account.acc_id
INNER JOIN ms_download_facts downlds ON users.user_id=downlds.user_id
ГДЕ account.paying_customer = 'да'
СГРУППИРОВАТЬ ПО downlds.date
ЗАКАЗАТЬ ПО downlds.date),
неплатежный AS
(SELECTdownlds.date, sum(downlds.downloads) AS n_nonpaying
ОТ пользователей ms_user_dimension
ВНУТРЕННЕЕ СОЕДИНЕНИЕ ms_acc_dimension account ON users.acc_id = account.acc_id
INNER JOIN ms_download_facts downlds ON users.user_id=downlds.user_id
ГДЕ account.paying_customer = 'нет'
СГРУППИРОВАТЬ ПО downlds. date
ЗАКАЗАТЬ ПО downlds.date),
all_downloads КАК
(ВЫБЕРИТЕ дату оплаты,
оплата.n_paying,
неоплачиваемый.n_неоплачиваемый
ОТ оплаты
ПРИСОЕДИНЯЙТЕСЬ к nonpaying ON pay.date = nonpaying.date
ЗАКАЗАТЬ ПО ОПЛАТЕ.ДАТА)
ВЫБЕРИТЕ дату, n_nonpaying,
n_paying
ИЗ all_downloads
СГРУППИРОВАТЬ ПО дате, n_nonpaying,
n_paying
ИМЕЕТ (n_nonpaying - n_paying) >0
ЗАКАЗАТЬ ПО дате ASC
date
ЗАКАЗАТЬ ПО downlds.date),
all_downloads КАК
(ВЫБЕРИТЕ дату оплаты,
оплата.n_paying,
неоплачиваемый.n_неоплачиваемый
ОТ оплаты
ПРИСОЕДИНЯЙТЕСЬ к nonpaying ON pay.date = nonpaying.date
ЗАКАЗАТЬ ПО ОПЛАТЕ.ДАТА)
ВЫБЕРИТЕ дату, n_nonpaying,
n_paying
ИЗ all_downloads
СГРУППИРОВАТЬ ПО дате, n_nonpaying,
n_paying
ИМЕЕТ (n_nonpaying - n_paying) >0
ЗАКАЗАТЬ ПО дате ASC
Не существует особых правил форматирования псевдонимов, но большинство людей используют только строчные буквы и знак подчеркивания, если псевдоним состоит из нескольких слов.
3. Удалите ненужные предложения ORDER BY
Теперь, когда мы позаботились о псевдонимах, давайте начнем сокращать объем кода в нашем решении. Первая вещь довольно второстепенна, но все же способствует удобочитаемости запроса. Речь идет о предложениях ORDER BY. Они, очевидно, используются для сортировки данных в таблице и часто полезны или даже необходимы. В конце концов, иногда необходимо использовать предложение ORDER BY в сочетании с оконной функцией или при выборе верхних строк таблицы с помощью ключевого слова LIMIT. Мы также можем захотеть расположить окончательные результаты в определенном порядке на собеседованиях, иногда это даже может быть требованием.
Мы также можем захотеть расположить окончательные результаты в определенном порядке на собеседованиях, иногда это даже может быть требованием.
Но если у нас есть несколько запросов, обычно нет необходимости добавлять одно и то же предложение ORDER BY в каждый из них. Посмотрите на наш запрос, например, мы сортируем результаты по дате, но делаем это во всех возможных запросах и подзапросах. Это не только бесполезно, но и неэффективно, потому что каждое предложение ORDER BY добавляет немного сложности и, следовательно, времени, необходимого для выполнения запроса, особенно при работе с большими наборами данных. Поэтому, если у каждого запроса есть собственное предложение сортировки, хорошо подумать, действительно ли оно необходимо. В нашем случае можно оставить его только в последнем запросе.
С оплатой КАК (ВЫБРАТЬ downlds.date, sum(downlds.downloads) AS n_paying ОТ пользователей ms_user_dimension ВНУТРЕННЕЕ СОЕДИНЕНИЕ ms_acc_dimension account ON users.acc_id = account.acc_id INNER JOIN ms_download_facts downlds ON users.user_id=downlds.user_id ГДЕ account.paying_customer = 'да' СГРУППИРОВАТЬ ПО downlds.date), неплатежный AS (SELECTdownlds.date, sum(downlds.downloads) AS n_nonpaying ОТ пользователей ms_user_dimension ВНУТРЕННЕЕ СОЕДИНЕНИЕ ms_acc_dimension account ON users.acc_id = account.acc_id INNER JOIN ms_download_facts downlds ON users.user_id=downlds.user_id ГДЕ account.paying_customer = 'нет' СГРУППИРОВАТЬ ПО downlds.date), all_downloads КАК (ВЫБЕРИТЕ дату оплаты, оплата.n_paying, неоплачиваемый.n_неоплачиваемый ОТ оплаты ПРИСОЕДИНЯЙТЕСЬ к nonpaying ON pay.date = nonpaying.date) ВЫБЕРИТЕ дату, n_nonpaying, n_paying ИЗ all_downloads СГРУППИРОВАТЬ ПО дате, n_nonpaying, n_paying ИМЕЕТ (n_nonpaying - n_paying) >0 ЗАКАЗАТЬ ПО дате ASC
4. Удаление ненужных подзапросов и CTE
Далее, есть гораздо более серьезная тема, чем удаление ненужных предложений ORDER BY — удаление ненужных подзапросов и CTE. Мы говорили о них раньше, когда разбивали вложенные запросы на CTE, но тогда мы просто оставили их как есть, не анализируя, действительно ли они нам нужны.
Мы говорили о них раньше, когда разбивали вложенные запросы на CTE, но тогда мы просто оставили их как есть, не анализируя, действительно ли они нам нужны.
Оказывается, иногда два запроса делают одно и то же или могут быть объединены в один с помощью других предложений или операторов. В конце концов, каждый запрос увеличивает сложность и время, необходимое для выполнения запроса. В нашем случае четыре разных запроса приводят к тому, что движку четыре раза требуется доступ к таблице для выбора данных из нее. Более того, в трех из этих запросов мы объединяем несколько таблиц, используя JOIN — операции, которые могут занять много времени, особенно если таблицы большие.
Чтобы уменьшить количество запросов в нашем случае, есть два направления. Одной из возможностей было бы объединить запрос all_downloads с основным запросом. В конце концов, эти два запроса почти идентичны, и если бы мы только добавили фильтр, поэтому выражение, говорящее, что разница между n_nonpaying и n_paying должна быть больше 0, к запросу в all_downloads, дало бы те же результаты. Мы могли бы безопасно избавиться от CTE all_downloads и вместо этого объединить платные и неоплачиваемые CTE в основном запросе. Таким образом, мы можем сократить количество запросов до 3. Но можем ли мы добиться большего?
Мы могли бы безопасно избавиться от CTE all_downloads и вместо этого объединить платные и неоплачиваемые CTE в основном запросе. Таким образом, мы можем сократить количество запросов до 3. Но можем ли мы добиться большего?
Можем, потому что оказывается, что первые два CTE, а именно «платный» и «неплатный», могут быть выполнены внутри CTE «all_downloads». Это потому, что эти первые два CTE почти идентичны, а главное отличие заключается в предложении WHERE. Мы выбираем одни и те же типы данных из одних и тех же таблиц, но в разных условиях. Но в SQL есть другой способ выбора и даже выполнения арифметических операций над данными с использованием разных условий только в одном запросе: нам нужно использовать CASES.
Мы можем использовать их для преобразования строк «да» и «нет» из столбца «paying_customer» в количество загрузок, а затем суммировать их, чтобы получить общее количество. Это означает, что весь первый CTE можно заменить следующим фрагментом кода:
sum(CASE
КОГДА pay_customer = 'да', ТОГДА загрузки
КОНЕЦ)
Это будет очень похоже на неплатежеспособных клиентов. Обе эти инструкции могут быть выполнены прямо в CTE all_downloads, если мы объединим три таблицы, пользователей, учетные записи и загрузки и включим оператор данных GROUP BY также в это CTE.
Обе эти инструкции могут быть выполнены прямо в CTE all_downloads, если мы объединим три таблицы, пользователей, учетные записи и загрузки и включим оператор данных GROUP BY также в это CTE.
С all_downloads КАК
(ВЫБЕРИТЕ дату загрузки,
сумма(СЛУЧАЙ
КОГДА account.paying_customer = 'yes', ТО downlds.downloads
КОНЕЦ) КАК n_paying,
сумма(СЛУЧАЙ
КОГДА account.paying_customer = 'no', ТО downlds.downloads
КОНЕЦ) AS n_nonpaying
ОТ пользователей ms_user_dimension
ВНУТРЕННЕЕ СОЕДИНЕНИЕ ms_acc_dimension account ON users.acc_id = account.acc_id
INNER JOIN ms_download_facts downlds ON users.user_id=downlds.user_id
СГРУППИРОВАТЬ ПО downlds.date)
ВЫБЕРИТЕ дату, n_nonpaying,
n_paying
ИЗ all_downloads
СГРУППИРОВАТЬ ПО дате, n_nonpaying,
n_paying
ИМЕЕТ (n_nonpaying - n_paying) >0
ЗАКАЗАТЬ ПО дате ASC
С этими изменениями у нас осталось всего два запроса, один набор из нескольких JOIN и два случая, когда данные нужно выбирать из таблицы вместо четырех. В то же время мы не можем решить этот вопрос, используя только один запрос, потому что столбцы «n_paying» и «n_nonpaying» должны быть определены в одном запросе, прежде чем использоваться в фильтре в другом запросе.
В то же время мы не можем решить этот вопрос, используя только один запрос, потому что столбцы «n_paying» и «n_nonpaying» должны быть определены в одном запросе, прежде чем использоваться в фильтре в другом запросе.
5. HAVING vs WHERE
Говоря о производительности и эффективности, в нашем запросе есть еще одна деталь, которая излишне замедляет его. Эта деталь — предложение HAVING в основном запросе. Но почему именно ИМЕЕТ, а не ГДЕ? Два пункта очень похожи друг на друга и позволяют фильтровать данные на основе некоторых условий. Как и в этом случае, когда разница между значениями n_nonpaying и n_paying должна быть больше 0. Это условие можно определить как с ключевыми словами WHERE, так и с ключевыми словами HAVING, но одно из них гораздо более подходит в этой ситуации. Ключевое отличие состоит в том, что предложение HAVING может включать агрегатные функции, например. СУММ() или СЧЕТ(). Он позволяет создавать условия на основе суммы, среднего, минимального или максимального значения или количества элементов в наборе данных или в разделах, определенных с помощью предложения GROUP BY. Именно по этой причине предложение HAVING всегда должно сопровождаться оператором GROUP BY.
Именно по этой причине предложение HAVING всегда должно сопровождаться оператором GROUP BY.
Многие пользователи SQL не знают, что предложение HAVING следует использовать только тогда, когда необходимо создать условие с помощью агрегатной функции. Во всех остальных случаях предложение WHERE является лучшим выбором? Почему? Все упирается в эффективность. Предложение WHERE выполняется вместе с остальной частью запроса, поэтому, если это более эффективно, механизм SQL может решить ограничить количество экземпляров в наборе данных, используя условие из WHERE, прежде чем выполнять другие операции. С другой стороны, оператор HAVING всегда выполняется после запроса, хотя в коде он является его частью. Это почти всегда приводит к немного большему времени вычислений.
В нашем примере условие основано на арифметической операции с двумя столбцами, но это не то же самое, что агрегатная функция. По этой причине это условие вполне может быть определено в предложении WHERE. При этом, помимо повышения эффективности, мы также избавляемся от лишнего предложения GROUP BY.
С all_downloads КАК
(ВЫБЕРИТЕ дату загрузки,
сумма(СЛУЧАЙ
КОГДА account.paying_customer = 'yes', ТО downlds.downloads
КОНЕЦ) КАК n_paying,
сумма(СЛУЧАЙ
КОГДА account.paying_customer = 'no', ТО downlds.downloads
КОНЕЦ) AS n_nonpaying
ОТ пользователей ms_user_dimension
ВНУТРЕННЕЕ СОЕДИНЕНИЕ ms_acc_dimension account ON users.acc_id = account.acc_id
INNER JOIN ms_download_facts downlds ON users.user_id=downlds.user_id
СГРУППИРОВАТЬ ПО downlds.date)
ВЫБЕРИТЕ дату, n_nonpaying,
n_paying
ИЗ all_downloads
ГДЕ (n_nonpaying - n_paying) > 0
ЗАКАЗАТЬ ПО дате ASC
6. Форматирование текста
Последнее, что повышает читабельность запросов, — это форматирование кода. Это, по сравнению с другими частицами, о которых мы упоминали, не имеет ничего общего с эффективностью, а связано с простотой понимания кода всеми. Это также та деталь, о которой все забывают при написании SQL-запроса, особенно в стрессовой обстановке собеседования. Или все привыкли к другому стилю форматирования текста и путаются, видя другие подходы.
Или все привыкли к другому стилю форматирования текста и путаются, видя другие подходы.
В SQL нет официальных правил форматирования текста в запросах, но есть некоторые неофициальные рекомендации, которым следуют многие пользователи SQL. Вероятно, наиболее распространенным и известным является то, что все ключевые слова, такие как SELECT, FROM, WHERE, GROUP BY, ORDER BY и т. д., должны быть написаны заглавными буквами. Это также относится к другим встроенным ключевым словам, которые появляются внутри предложений, таких как JOIN, AS, IN, ON или ASC и DESC. Когда дело доходит до названий функций, таких как SUM() или COUNT(), нет единого мнения о том, должны ли они быть написаны полностью заглавными или только строчными буквами, но, вероятно, лучше использовать их также с заглавной буквы, чтобы лучше отличать их от столбцов. имена, которые должны быть написаны с маленькой буквы.
Еще одно важное правило заключается в том, что, хотя для работы кода не обязательно, каждое предложение, такое как SELECT, FROM, WHERE, GROUP BY и т. д., должно находиться в новой строке. Для дальнейшего повышения удобочитаемости также рекомендуется иметь новую строку для каждого имени столбца в предложении SELECT. Более того, если мы используем подзапросы или CTE, хорошим подходом является использование таблиц, чтобы визуально отличить внутреннюю часть скобки от остальной части запроса.
д., должно находиться в новой строке. Для дальнейшего повышения удобочитаемости также рекомендуется иметь новую строку для каждого имени столбца в предложении SELECT. Более того, если мы используем подзапросы или CTE, хорошим подходом является использование таблиц, чтобы визуально отличить внутреннюю часть скобки от остальной части запроса.
Код из нашего примера уже в основном хорошо отформатирован. Но мы по-прежнему можем добавлять новые строки в предложение SELECT основного запроса и использовать заглавные буквы в именах функций SUM().
С all_downloads КАК
(ВЫБЕРИТЕ дату загрузки,
СУММА(СЛУЧАЙ
КОГДА account.paying_customer = 'yes', ТО downlds.downloads
КОНЕЦ) КАК n_paying,
СУММА(СЛУЧАЙ
КОГДА account.paying_customer = 'no', ТО downlds.downloads
КОНЕЦ) AS n_nonpaying
ОТ пользователей ms_user_dimension
ВНУТРЕННЕЕ СОЕДИНЕНИЕ ms_acc_dimension account ON users.acc_id = account.acc_id
INNER JOIN ms_download_facts downlds ON users. user_id=downlds.user_id
СГРУППИРОВАТЬ ПО downlds.date)
ВЫБЕРИТЕ дату,
n_бесплатно,
n_paying
ИЗ all_downloads
ГДЕ (n_nonpaying - n_paying) > 0
ЗАКАЗАТЬ ПО дате ASC
user_id=downlds.user_id
СГРУППИРОВАТЬ ПО downlds.date)
ВЫБЕРИТЕ дату,
n_бесплатно,
n_paying
ИЗ all_downloads
ГДЕ (n_nonpaying - n_paying) > 0
ЗАКАЗАТЬ ПО дате ASC
Мы знаем, что иногда бывает сложно запомнить все правила форматирования текста или настроить все вручную, например, сделать ключевые слова заглавными или добавить таблицы. Таким образом, полезно иметь привычку использовать эти правила форматирования при написании запросов, потому что это облегчает понимание кода для нас самих и позволяет писать более читаемый код на собеседованиях.
Заключение
В заключение еще раз приведем список рекомендаций по написанию SQL-запросов:
- Удалить несколько вложенных запросов
- Обеспечить согласованность псевдонимов
- Удалить ненужные предложения ORDER BY
- Удалить ненужные подзапросы
- Если возможно, используйте WHERE, а не HAVING несколько вложенных запросов, вы можете превратить их в CTE — хорошее эмпирическое правило состоит в том, что один подзапрос в порядке, но несколько подзапросов или подзапрос, повторяющийся несколько раз, должны стать CTE.

Согласованность псевдонимов включает в себя их информативность, длину более 1 буквы, но и не слишком большую длину. Будьте последовательны, используете ли вы псевдонимы или нет. Добавляйте псевдонимы к столбцам, созданным аналитическими функциями. Придерживайтесь некоторых соглашений об именах и избегайте столбцов или таблиц, использующих один и тот же псевдоним. Используйте строчные буквы для псевдонимов и символы подчеркивания, если в нем несколько слов. Не используйте кавычки для определения псевдонима.
Чтобы удалить предложение ORDER BY, помните, что часто его не нужно повторять в нескольких запросах. Если это так, посмотрите, возможно ли иметь его только в последнем.
Иногда подзапросы или CTE могут быть объединены вместе. Ищите подзапросы, которые выглядят одинаково или приводят к одним и тем же столбцам — часто их проще всего комбинировать. Один из приемов — заменить предложение WHERE на CASE.
Используйте предложение HAVING только в сочетании с агрегатными функциями, почти во всех остальных случаях следует выбирать WHERE.