Расшифровка файла robots.txt — База знаний uCoz
В данной статье мы рассмотрим материал: Расшифровка файла Robots.txt для uCoz и uWeb, в котором подробно рассмотрим какая директива и для чего предназначена и как можно улучшить роботс и что можно удалить.
На данный момент в uCoz и uWeb robots.txt настроен так, чтобы запретить к индексации лишь необходимые страницы, точнее системные ненужные и страницы дубли, которые не должны отображаться в поиске. Соответственно, все остальное доступно к индексации, так как что не запрещено значит разрешено, хотя для робота Google нет слова запрещено с временем вы это поймете.
Отметим, если вы не понимаете зачем создан системный файл роботс и для чего в нем приписаны и запреты и разрешения, удалять не обдумав ничего нельзя и устанавливать сторонний роботс, который вы нашли в сети интернет, который не предназначен для Юкоз так же не нужно.
Если вы необдуманно удалите системный и установите сторонний роботс, на таких сайтах с временем в поиске появляются тысячи системных страниц, которые там не должны быть, которые вредят посещаемости сайта.
Как выглядит системный файл Robots.txt ?
User-agent: * Allow: /*.js Allow: /*.css Allow: /*.jpg Allow: /*.png Allow: /*.gif Allow: /*?page Allow: /*?ref= Disallow: /*? Disallow: /stat/ Disallow: /index/1 Disallow: /index/3 Disallow: /register Disallow: /index/5 Disallow: /index/7 Disallow: /index/8 Disallow: /index/9 Disallow: /index/sub/ Disallow: /panel/ Disallow: /admin/ Disallow: /informer/ Disallow: /secure/ Disallow: /poll/ Disallow: /search/ Disallow: /abnl/ Disallow: /*_escaped_fragment_= Disallow: /*-*-*-*-987$ Disallow: /shop/order/ Disallow: /shop/printorder/ Disallow: /shop/checkout/ Disallow: /shop/user/ Disallow: /shop/search Disallow: /*0-*-0-17$ Disallow: /*-0-0- Sitemap: http://sitename.ucoz.ru/sitemap.xml Sitemap: http://sitename.ucoz.ru/sitemap-forum.xml
Расшифровка Robots.txt
Описание каждой строки файла robots.txt для uCoz и uWeb:
User-agent: *
общее обращение ко всем сканерам, читающим файл robots. txt
txt
Allow: /*.js
Allow: /*.css
Allow: /*.jpg
Allow: /*.png
Allow: /*.gif
Эти директивы разрешают индексирование скриптов, картинок, файлов стилей. нужны они для избежания ошибок заблокированные ресурсы на проверках эмуляторов
Allow: /*?page
Разрешение страниц пагинации на главных страницах модулей (связанно со строчкой Disallow: /*? )
Allow: /*?ref=
Нужна для правильной переиндексации компонентов социальной регистрации
Disallow: /*?
Запрет к индексации поисковых запросов, кода безопасности на uCoz, проксированных ссылок, компонентов рекламного баннера, дублей главной страницы и блога (компоненты кода системы, связанные с сессиями ssid), дубли ссылок на изображения в фотоальбомах, других мусорных компонентов системы
Disallow: /stat/
Запрет индексации компонента счетчика статистики (картинка с данными)
Disallow: /index/1
Техническая страница входа / авторизации
Disallow: /index/3
Запрет индексации страницы регистрации (локальная регистрация)
Disallow: /register
Запрет индексации страницы регистрации (социальная и uID регистрация)
Disallow: /index/5
Запрет к индексации аякс окна напоминания пароля в старой форме входа
Disallow: /index/7
Служебная страница выбора аватара из коллекции
Disallow: /index/8
Запрет к индексации профилей пользователей (один из способов защиты от спама)
Disallow: /index/9
Запрет индексации аякс окна Доступ запрещен
Disallow: /index/sub/
Запрет к индексации локальной авторизации (связано со старой формой входа)
Disallow: /panel/
Запрет к индексации входа в панель управления
Disallow: /admin/
Запрет к индексации входа в панель управления
Disallow: /informer/
Запрет к индексации информеров, вставленных скриптом (при этом содержимое информеров, вставленных системным кодом $MYINF_х$ будет индексироваться свободно)
Disallow: /secure/
Запрет на индексацию кода безопасности (связано со строчкой Disallow: /*?)
Disallow: /poll/
Запрет индексации служебной папки опросов
Disallow: /search/
Запрет индексации страницы поиска, тегов и поисковых запросов (связано со строчкой Disallow: /*?)
Disallow: /abnl/
Запрет индексации компонентов системного рекламного баннера (для сайтов с не отключенной рекламой)
Disallow: /*_escaped_fragment_=
Запрет технического компонента кода
Disallow: /*-*-*-*-987$
Запрет дублей страниц в модулях Новости и Блог, связанных с кодом комментариев на странице
Disallow: /shop/checkout/
Запрет к индексации корзины и кода оформления заказа для Интернет магазина
Disallow: /shop/user/
Запрет к индексации пользователей магазина (субагенты)
Disallow: /*0-*-0-17$
Запрет к индексации различных фильтров, страниц материалов пользователя, ссылки на последнее сообщение форума, дублей системы и т. д
д
Disallow: /*-0-0-
Запрет к индексации страниц добавления материалов, списков материалов пользователей, ленточного варианта форума (некоторые дублирующие URL), страниц со списком пользователей (некоторые дублирующие URL), поиска по форуму, правил форума, добавления тем на форуме, различные фильтры (с дублями), страницы с редиректами на залитые на сервер файлы
Sitemap: //адрес сайта/sitemap.xml
Общая карта сайта
Sitemap: //адрес сайта/sitemap-forum.xml
Карта форума (оставлять в файле, если активирован модуль форум)
Sitemap: //адрес сайта/sitemap-shop.xml
Карта магазина (прописывать только, если активирован модуль Интернет магазин)
Host: адрес сайта без https://
Прописывать, если прикреплен домен для определения главного зеркала. директива прописывается в любом месте robots, предназначена для Яндекса, при этом отдельное обращение к роботам Яндекса не нужно. Google игнорируется. На данный момент директива Host Яндексом перестала учитываться и прописывать её не надо.
Google игнорируется. На данный момент директива Host Яндексом перестала учитываться и прописывать её не надо.
От чего можно избавиться в файле Robots.txt ?
Если вы не используете модуль Интернет-магазин, с файла роботс можно удалить следующие директивы:
Disallow: /shop/order/ Disallow: /shop/printorder/ Disallow: /shop/checkout/ Disallow: /shop/user/ Disallow: /shop/search Sitemap: //адрес сайта/sitemap-shop.xml
Если вы не используете модуль Форум, можно удалить карту сайта для форума:
Sitemap: //адрес сайта/sitemap-forum.xml
Что можно добавить, чтобы улучшить файл Robots.txt ?
Можно добавить в самом начале файла роботс перед всем содержимым директиву с доступом для мобильного робота гугла:
User-agent:Googlebot-Mobile Allow: /
это позволит мобильному роботу без проблем сканировать ваш сайт.
С наших рекомендаций, после директив с доступом индексировать изображения сайта, стоит и добавить доступ к индексации шрифтов на сайте, чтобы роботы имели полный доступ к сайту и корректно его видели с шрифтами, которые на сайте подключены.
В роботс стоит добавить директивы:
Allow: /*.ttf Allow: /*.woff Allow: /*.woff2 Allow: /*.eot Allow: /*.svg
это существенно улучшит отображение вашего сайта для поисковиков и они будут корректно видеть сайт с вашими шрифтами.
В дополнение, было замечено по отчетам с индексации яндекса, что робот посещает страницу регистрации и находит сгенерированные урл подобно /confirm/ и индексирует их. Для решения данной проблемы рекомендую в роботс добавить директиву:
Disallow: /confirm/
это сохранит ваш сайт от индексации мусора.
Для борьбы с дублями в модуле Интернет-магазин, в роботс можно добавить такие директы:
Disallow: /shop/*comm Disallow: /shop/*spec Disallow: /shop/*imgs Disallow: /shop/all/ Disallow: /shop/*;
эти директивы закроют от индексации подстраницы модуля магазин, которые не несут пользы в поиске и страницы переключателей страниц в модуле магазин.
На данном этапе мы закончим материал, если будут обновления, мы их добавим в статью.![]() Всем спасибо!
Всем спасибо!
Что такое Robots.txt? | Глоссарий Интернет-маркетинга
Что такое Robots.txt?
После создания файла robots.txt, его нужно поместить в корневой каталог сайта. Поисковый робот всегда обращается к файлу по URL /robots.txt.
После того, как сайт загружен на хостинг и прописаны DNS, роботы поисковых систем получают возможность для обхода сайта и индексации его страниц. Отсутствие файла robots.txt может служить поводом для возникновения проблем со скоростью обхода сайта и присутствия мусора в индексе. А неправильная настройка приводит к исключению из индекса важных частей ресурса или присутствию в выдаче ненужных страниц. Это способствует трудностям с продвижением сайта.
Функции robots.txt
Основная задача этого файла — информирование роботов индексации. Главные указания или директивы robots. txt — это:
txt — это:
- «Allow» (отвечает за разрешение индексации определенного раздела или файла).
- «Disallow» (соответственно, запрещает индексацию),
- «User-agent» (определяет, к каким именно роботам относятся разрешительные и запрещающие директивы).
Но следует знать, что указания robots.txt носят рекомендательный характер. Это значит, что при определенных условиях робот может проигнорировать их.
Символы в robots.txt
Символы, которые чаще всего используют в данном файле — «/, *, $, #».
С помощью «/» можно показать, что нужно закрыть от индексации. Например, если поставить один слеш в правиле Disallow, то он будет означать запрет на сканирование всего сайта. Применив два знака, запрещают сканирование отдельного раздела, например: /tovary/. Такая запись говорит, что запрещена индексация всего содержимого папки tovary. Но если прописать /tovary, то запрет распространится на все ссылки на сайте, которые будут начинаться на /tovary.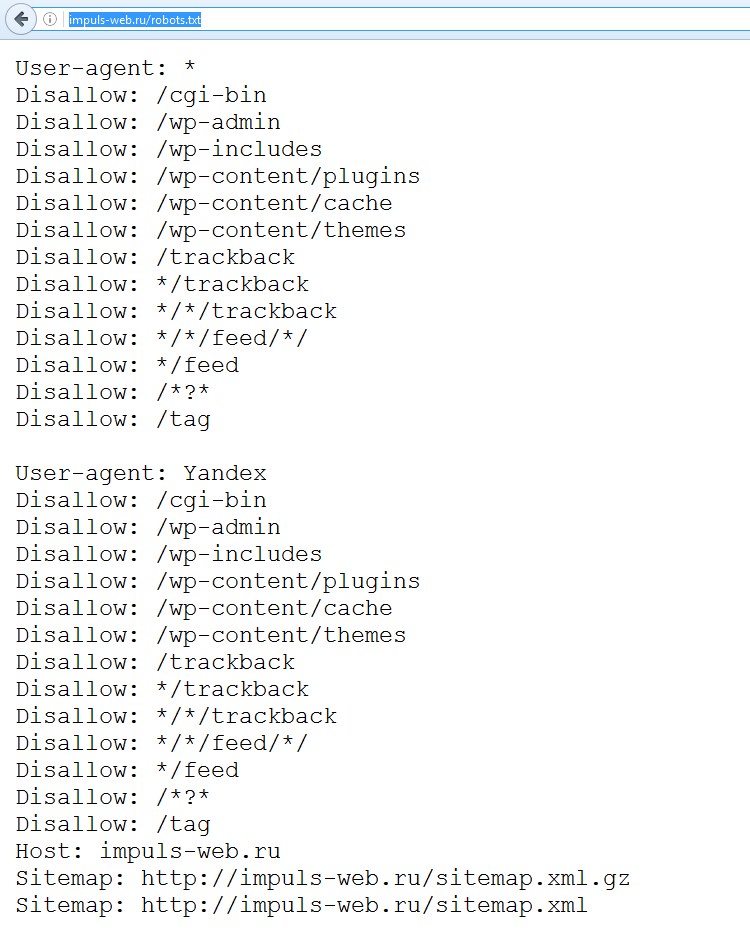
Звездочка «*» имеет значение любой последовательности символов в файле. Ее ставят после каждого правила.
Эта запись говорит, что все роботы не должны индексировать любые файлы с расширением .gif в папке /catalog/
Знак доллара «$» нужен для ограничения знака «*». Если нужно запретить все содержимое папки catalog, но при этом нельзя запретить url-адреса, которые содержат /catalog, то запись в индексном файле будет такой:
Решетка «#» используется для комментариев, которые веб-мастер оставляет для себя или других веб-мастеров. Робот не будет их учитывать при сканировании сайта.
Требования к файлу robots.txt
Веб-мастер всегда должен помнить, что отсутствие в корневом каталоге сайта файла robots.txt или его неправильная настройка потенциально угрожают посещаемости сайта и доступности в поиске.
По стандартам, в файле robots.txt запрещено использование кириллических символов. Поэтому для работы с кириллическими доменами нужно применять Punycode. При этом кодировка адресов страниц должна соответствовать кодировке применяемой структуры сайта.
Поэтому для работы с кириллическими доменами нужно применять Punycode. При этом кодировка адресов страниц должна соответствовать кодировке применяемой структуры сайта.
Индексация
Ранжирование
Уровень вложенности
Анкор
Disavow
Лучшие практики, распространенные проблемы и решения
Техническое SEO — это хорошо реализованная стратегия, которая учитывает различные сигналы ранжирования на странице и за ее пределами, чтобы помочь вашему сайту занять более высокое место в поисковой выдаче. Каждая тактика SEO играет важную роль в повышении рейтинга вашей страницы, гарантируя, что поисковые роботы смогут легко сканировать, ранжировать и индексировать ваш веб-сайт.
От времени загрузки страницы до правильных тегов заголовков — существует множество сигналов ранжирования, с которыми может помочь техническое SEO. Но знаете ли вы, что один из самых важных файлов для SEO вашего сайта также находится на вашем сервере?
Файл robots. txt — это код, сообщающий поисковым роботам, какие страницы вашего веб-сайта они могут сканировать, а какие — нет. Это может показаться пустяком, но если ваш файл robots.txt настроен неправильно, это может оказать серьезное негативное влияние на SEO вашего сайта.
txt — это код, сообщающий поисковым роботам, какие страницы вашего веб-сайта они могут сканировать, а какие — нет. Это может показаться пустяком, но если ваш файл robots.txt настроен неправильно, это может оказать серьезное негативное влияние на SEO вашего сайта.
В этом сообщении блога мы обсудим все, что вам нужно знать о robots.txt, от того, что такое файл robots.txt в SEO, до лучших практик и правильных способов устранения распространенных проблем.
Что такое файл robots.txt и почему он важен для SEO?Файл Robots.txt — это файл, расположенный на вашем сервере, который сообщает поисковым роботам, к каким страницам они могут и не могут получить доступ. Если поисковый робот попытается просканировать страницу, заблокированную в файле robots.txt, это будет считаться программной ошибкой 404.
Хотя программная ошибка 404 не повлияет на рейтинг вашего сайта, она все равно считается ошибкой. И слишком много ошибок на вашем веб-сайте может привести к снижению скорости сканирования, что в конечном итоге может повредить вашему рейтингу из-за снижения скорости сканирования.
Если на вашем веб-сайте много страниц, заблокированных файлом robots.txt, это также может привести к трате краулингового бюджета. Бюджет сканирования — это количество страниц, которые Google будет сканировать на вашем веб-сайте во время каждого посещения.
Еще одна причина, по которой файлы robots.txt важны для поисковой оптимизации, заключается в том, что они дают вам больший контроль над тем, как робот Googlebot сканирует и индексирует ваш веб-сайт. Если у вас есть веб-сайт с большим количеством страниц, вы можете заблокировать определенные страницы от индексации, чтобы они не перегружали поисковые роботы и не ухудшали ваш рейтинг.
Если у вас есть блог с сотнями сообщений, вы можете разрешить Google индексировать только самые последние статьи. Если у вас есть веб-сайт электронной коммерции с большим количеством страниц продуктов, вы можете разрешить Google индексировать только страницы основных категорий.
Правильная настройка файла robots.txt может помочь вам контролировать то, как робот Googlebot сканирует и индексирует ваш веб-сайт, что в конечном итоге может помочь улучшить ваш рейтинг.
Теперь, когда мы рассмотрели, почему файлы robots.txt важны для SEO, давайте обсудим некоторые рекомендации, рекомендованные Google.
Создайте файл с именем robots.txtПервым шагом является создание файла с именем robots.txt . Этот файл необходимо поместить в корневой каталог вашего веб-сайта — каталог самого высокого уровня, содержащий все остальные файлы и каталоги на вашем веб-сайте.
Вот пример правильного размещения файла robots.txt: на сайте apple.com корневым каталогом будет apple.com/.
Вы можете создать файл robots.txt в любом текстовом редакторе, но многие CMS, такие как WordPress, автоматически создадут его для вас.
Добавление правил в файл robots.txt После создания файла robots.txt следующим шагом будет добавление правил. Эти правила сообщат поисковым роботам, к каким страницам они могут и не могут получить доступ.
Существует два типа синтаксиса robot.txt, которые вы можете добавить: Разрешить и Запретить.
Разрешающие правила сообщают поисковым роботам, что им разрешено сканировать определенную страницу.
Правила запрета сообщают поисковым роботам, что им не разрешено сканировать определенную страницу.
Например, если вы хотите разрешить поисковым роботам сканировать вашу домашнюю страницу, добавьте следующее правило:
Разрешить: /
Если вы хотите запретить поисковым роботам сканировать определенный субдомен или подпапку в вашем блоге , вы используете: Disallow: /
Загрузите файл robots.txt на свой сайтПосле того, как вы добавили правила в файл robots.txt, следующим шагом будет его загрузка на ваш сайт. Вы можете сделать это с помощью FTP-клиента или панели управления хостингом.
Если вы не знаете, как загрузить файл, обратитесь к своему веб-хостингу, и они должны вам помочь.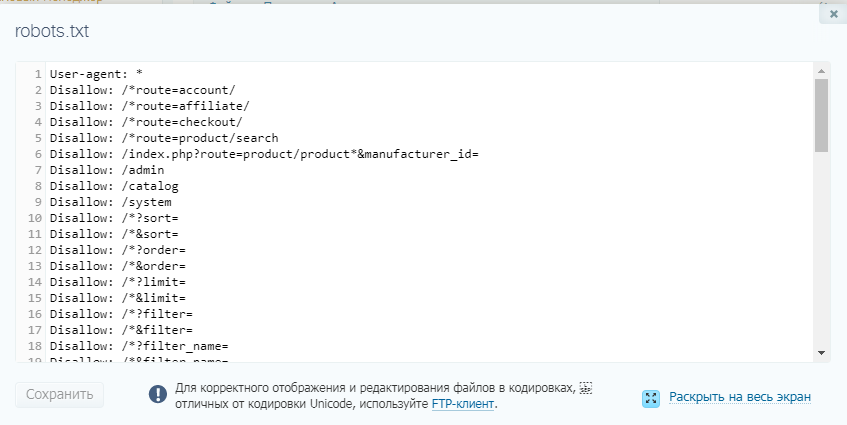
После того как вы загрузили файл robots.txt на свой веб-сайт, следующим шагом будет его проверка, чтобы убедиться, что он работает правильно. Google предоставляет бесплатный инструмент под названием robots.txt Tester в Google Search Console, который вы можете использовать для проверки своего файла. Его можно использовать только для файлов robots.txt, которые находятся в корневом каталоге вашего сайта.
Чтобы использовать тестер robots.txt, введите URL своего веб-сайта в инструмент тестер robots.txt, а затем протестируйте его. Затем Google покажет вам содержимое вашего файла robots.txt, а также все найденные ошибки.
Используйте библиотеку роботов Google с открытым исходным кодомЕсли вы более опытный разработчик, у Google также есть библиотека роботов с открытым исходным кодом, которую вы можете использовать для локального управления файлом robots.txt на своем компьютере.
Что может случиться с SEO вашего сайта, если файл robots. txt поврежден или отсутствует?
txt поврежден или отсутствует? Если файл robots.txt поврежден или отсутствует, поисковые роботы могут индексировать нежелательные для вас страницы. В конечном итоге это может привести к ранжированию этих страниц в Google, что не идеально. Это также может привести к перегрузке сайта, поскольку поисковые роботы пытаются проиндексировать все на вашем сайте.
Неисправный или отсутствующий файл robots.txt также может привести к тому, что сканеры поисковых систем пропустят важные страницы на вашем веб-сайте. Если у вас есть страница, которую вы хотите проиндексировать, но она заблокирована поврежденным или отсутствующим файлом robots.txt, она может никогда не проиндексироваться.
Короче говоря, важно убедиться, что ваш файл robots.txt работает правильно и находится в корневом каталоге вашего веб-сайта. Исправьте эту проблему, создав новые правила или загрузив файл в корневой каталог, если он отсутствует.
Рекомендации по работе с файлами robots. txt
txt Теперь, когда вы знаете основы работы с файлами robots.txt, давайте рассмотрим некоторые рекомендации. Это то, что вы должны сделать, чтобы убедиться, что ваш файл эффективен и работает правильно.
Используйте новую строку для каждой директивыКогда вы добавляете правила в файл robots.txt, важно использовать новую строку для каждой директивы, чтобы не запутать роботов поисковых систем. Это включает в себя правила разрешения и запрета.
Например, если вы хотите запретить поисковым роботам сканировать ваш блог и страницу контактов, вы должны добавить следующие правила:
Запретить: /blog/
Запретить: /contact/
Используйте подстановочные знаки для упрощения инструкций Если у вас много страниц, которые вы хотите заблокировать, добавление правила для каждой из них может занять много времени. К счастью, вы можете использовать подстановочные знаки для упрощения инструкций.
Подстановочный знак — это символ, который может представлять один или несколько символов. Наиболее распространенным подстановочным знаком является звездочка (*).
Например, если вы хотите заблокировать все файлы с расширением .jpg, добавьте следующее правило:
Запретить: /*.jpg
Используйте «$» для указания конца URL-адресаЗнак доллара ($) — это еще один подстановочный знак, который можно использовать для указания конца URL-адреса. Это полезно, если вы хотите заблокировать определенную страницу, но не страницы, следующие за ней.
Например, если вы хотите заблокировать страницу контактов, но не страницу успешного контакта, вы должны добавить следующее правило:
Запретить: /contact$
Использовать каждый пользовательский агент только один раз К счастью, когда вы добавляете правила в файл robots.txt, Google не возражает, если вы используете один и тот же User-agent несколько раз. Однако рекомендуется использовать каждый пользовательский агент только один раз.
Однако рекомендуется использовать каждый пользовательский агент только один раз.
Когда речь идет о файлах robots.txt, специфичность является ключевым моментом. Чем конкретнее вы описываете свои правила, тем меньше вероятность того, что вы совершите ошибку, которая может повредить SEO вашего сайта.
Используйте комментарии, чтобы объяснить людям ваш файл robots.txtНесмотря на то, что ваши файлы robots.txt сканируются ботами, людям по-прежнему необходимо понимать, поддерживать и управлять ими. Это особенно актуально, если над вашим сайтом работает несколько человек.
В файл robots.txt можно добавлять комментарии, поясняющие, что делают определенные правила. Комментарии должны быть в своей строке и начинаться с #.
Например, если вы хотите заблокировать все файлы, оканчивающиеся на .jpg, вы можете добавить следующий комментарий:
Запретить: /*. jpg # Блокировать все файлы, оканчивающиеся на .jpg
jpg # Блокировать все файлы, оканчивающиеся на .jpg
Это поможет любому, кому нужно управлять вашим файлом robots.txt, понять, для чего это правило и почему оно существует.
Используйте отдельный файл robots.txt для каждого субдоменаЕсли у вас есть веб-сайт с несколькими субдоменами, лучше создать отдельный файл robots.txt для каждого из них. Это помогает поддерживать порядок и облегчает поисковым роботам понимание ваших правил.
Распространенные ошибки в файле robots.txt и способы их исправленияПонимание наиболее распространенных ошибок, допускаемых людьми при работе с файлами robots.txt, поможет вам избежать их самостоятельно. Вот некоторые из наиболее распространенных ошибок и способы их устранения.
Отсутствует файл robots.txt Самая распространенная ошибка в файле robots.txt — его отсутствие. Если у вас нет файла robots.txt, сканеры поисковых систем будут считать, что им разрешено сканировать весь ваш сайт.
Чтобы это исправить, вам нужно создать файл robots.txt и добавить его в корневой каталог вашего сайта.
Файл robots.txt отсутствует в каталогеЕсли у вас нет файла robots.txt в корневом каталоге вашего веб-сайта, сканеры поисковых систем не смогут его найти. В результате они будут считать, что им разрешено сканировать весь ваш сайт.
Это должно быть одно имя текстового файла, которое должно быть помещено не во вложенные папки, а в корневой каталог.
Нет URL-адреса карты сайтаВаш файл robots.txt всегда должен содержать ссылку на карту сайта вашего веб-сайта. Это помогает сканерам поисковых систем находить и индексировать ваши страницы.
Отсутствие URL-адреса карты сайта в файле robots.txt является распространенной ошибкой, которая не повредит поисковой оптимизации вашего сайта, но ее добавление улучшит ее.
Блокировка CSS и JS По словам Джона Мюллера, вы должны избегать блокировки файлов CSS и JS, поскольку поисковые роботы Google требуют, чтобы они отображали страницу правильно.
Естественно, если боты не смогут отрисовать ваши страницы, они не будут проиндексированы.
Использование NoIndex в robots.txtС 2019 г., метатег noindex robots устарел и больше не поддерживается Google. Поэтому вам следует избегать его использования в файле robots.txt.
Если вы все еще используете метатег noindex robots, вам следует как можно скорее удалить его со своего веб-сайта.
Неправильное использование подстановочных знаковНеправильное использование подстановочных знаков приведет только к ограничению доступа к файлам и каталогам, к которым вы не стремились.
При использовании подстановочных знаков будьте как можно точнее. Это поможет вам избежать ошибок, которые могут повредить SEO вашего сайта. Кроме того, придерживайтесь поддерживаемых подстановочных знаков, то есть звездочки и символа доллара.
Неверное расширение типа файла Как следует из названия, файл robot. txt должен быть текстовым файлом, оканчивающимся на .txt. Это не может быть файл HTML, изображение или файл любого другого типа. Он должен быть создан в формате UTF-8. Полезным вводным ресурсом является руководство Google robots.txt и часто задаваемые вопросы Google Robots.txt.
txt должен быть текстовым файлом, оканчивающимся на .txt. Это не может быть файл HTML, изображение или файл любого другого типа. Он должен быть создан в формате UTF-8. Полезным вводным ресурсом является руководство Google robots.txt и часто задаваемые вопросы Google Robots.txt.
Файл robots.txt — это мощный инструмент, который можно использовать для улучшения SEO вашего сайта. Однако важно правильно его использовать.
При правильном использовании файл robots.txt может помочь вам контролировать, какие страницы индексируются поисковыми системами, и улучшить возможности сканирования вашего веб-сайта. Это также может помочь вам избежать проблем с дублированием контента.
С другой стороны, при неправильном использовании файл robots.txt может принести больше вреда, чем пользы. Важно избегать распространенных ошибок и следовать передовым методам, которые помогут вам использовать файл robots.txt в полной мере и улучшить SEO вашего веб-сайта. В дополнение к профессиональной навигации по файлам Robot.txt, динамический рендеринг с помощью создавать статический HTML для сложных веб-сайтов Javascript. Теперь вы можете разрешить более быструю индексацию, более быстрое время отклика и общее улучшение взаимодействия с пользователем.
В дополнение к профессиональной навигации по файлам Robot.txt, динамический рендеринг с помощью создавать статический HTML для сложных веб-сайтов Javascript. Теперь вы можете разрешить более быструю индексацию, более быстрое время отклика и общее улучшение взаимодействия с пользователем.
Что такое Robots.txt и как он влияет на SEO?
Является ли robots.txt соломинкой, которая сломает хребет вашему SEO-верблюду? Поисковая оптимизация (SEO) включает в себя большие и малые изменения сайта. Файл robots.txt может показаться второстепенным техническим элементом SEO, но он может сильно повлиять на видимость и рейтинг вашего сайта.
После объяснения robots.txt вы можете увидеть важность этого файла для функциональности и структуры вашего сайта. Продолжайте читать, чтобы узнать о лучших методах robots.txt для улучшения вашего рейтинга на странице результатов поисковой системы (SERP). Хотите эффективные SEO-стратегии с полным спектром услуг от ведущего агентства?
WebFX предлагает надежные услуги и команду из более чем 500 человек, которые добавляют опыт в вашу кампанию. Свяжитесь с нами онлайн или позвоните нам по телефону 888-601-5359 сейчас.
Свяжитесь с нами онлайн или позвоните нам по телефону 888-601-5359 сейчас.
Что такое файл robots.txt?
Файл robots.txt — это директива, которая сообщает роботам поисковых систем или сканерам, как действовать на сайте. В процессах сканирования и индексирования директивы действуют как приказы, чтобы направлять роботов поисковых систем, таких как Googlebot, на нужные страницы.
Файлы robots.txt также относятся к категории обычных текстовых файлов и находятся в корневом каталоге сайтов. Если ваш домен «www.robotsrock.com», файл robots.txt находится по адресу «www.robotsrock.com/robots.txt». Файлы robots.txt выполняют две основные функции для ботов:
- Запретить (заблокировать) сканирование пути URL. Однако файл robots.txt — это не то же самое, что метадирективы noindex, которые препятствуют индексации страниц.
- Разрешить

Robots.txt больше похожи на предложения, чем на нерушимые правила для ботов — и ваши страницы все равно могут оказаться в индексе и в результатах поиска по выбранным ключевым словам. В основном файлы контролируют нагрузку на ваш сервер и управляют частотой и глубиной сканирования. Файл определяет пользовательские агенты, которые либо применяются к конкретному боту поисковой системы, либо распространяют порядок на всех ботов.
Например, если вы хотите, чтобы только Google сканировал страницы, а не Bing, вы можете отправить им директиву в качестве пользовательского агента. Разработчики или владельцы веб-сайтов могут запретить ботам сканировать определенные страницы или разделы сайта с помощью файла robots.txt.
Зачем использовать файлы robots.txt?
Вы хотите, чтобы Google и его пользователи легко находили страницы на вашем веб-сайте — в этом весь смысл SEO, верно? Ну, это не обязательно правда.
Вы хотите, чтобы Google и его пользователи легко находили нужных страниц на вашем сайте. Как и на большинстве сайтов, у вас, вероятно, есть страницы благодарности, которые отслеживают конверсии или транзакции. Можно ли считать страницы благодарности идеальным выбором для ранжирования и регулярного сканирования?
Как и на большинстве сайтов, у вас, вероятно, есть страницы благодарности, которые отслеживают конверсии или транзакции. Можно ли считать страницы благодарности идеальным выбором для ранжирования и регулярного сканирования?
Маловероятно. Также часто промежуточные сайты и страницы входа запрещены в файле robots.txt. Постоянное сканирование второстепенных страниц может замедлить работу вашего сервера и создать другие проблемы, которые мешают вашим усилиям по SEO.
Robots.txt — это решение для модерации того, что и когда сканируют боты. Одна из причин, по которой файлы robots.txt помогают SEO, заключается в обработке новых действий по оптимизации. Их проверки сканирования регистрируются, когда вы меняете теги заголовков, метаописания и использование ключевых слов, и эффективные сканеры поисковых систем ранжируют ваш сайт в соответствии с положительными изменениями как можно скорее.
Когда вы реализуете свою SEO-стратегию или публикуете новый контент, вы хотите, чтобы поисковые системы распознавали вносимые вами изменения и чтобы результаты отражали эти изменения. Если у вас низкая скорость сканирования сайта, свидетельства улучшения вашего сайта могут отставать. Robots.txt может сделать ваш сайт аккуратным и эффективным, хотя они напрямую не поднимают вашу страницу выше в поисковой выдаче.
Если у вас низкая скорость сканирования сайта, свидетельства улучшения вашего сайта могут отставать. Robots.txt может сделать ваш сайт аккуратным и эффективным, хотя они напрямую не поднимают вашу страницу выше в поисковой выдаче.
Они косвенно оптимизируют ваш сайт, чтобы он не налагал штрафов, не истощал ваш краулинговый бюджет, не замедлял работу вашего сервера и не загружал неправильные страницы, полные ссылочного веса.
4 способа улучшить SEO с помощью файлов robots.txt Они являются неотъемлемым техническим компонентом SEO, который обеспечивает бесперебойную работу вашего сайта и удовлетворяет посетителей. SEO направлено на быструю загрузку вашей страницы для пользователей, доставку оригинального контента и повышение релевантности ваших страниц.
Robots.txt помогает сделать ваш сайт доступным и полезным. Вот четыре способа улучшить SEO с помощью файлов robots.txt.
1. Сохраняйте краулинговый бюджет
Сканирование ботами поисковых систем ценно, но сканирование может привести к перегрузке сайтов, которые не в состоянии справиться с посещениями ботов и пользователей. Робот Googlebot выделяет часть бюджета для каждого сайта, которая соответствует его желательности и характеру. Некоторые сайты крупнее, другие обладают огромным авторитетом, поэтому они получают больше от Googlebot.
Робот Googlebot выделяет часть бюджета для каждого сайта, которая соответствует его желательности и характеру. Некоторые сайты крупнее, другие обладают огромным авторитетом, поэтому они получают больше от Googlebot.
Google не дает четкого определения краулингового бюджета, но они говорят, что цель состоит в том, чтобы расставить приоритеты, что сканировать, когда сканировать и насколько тщательно это сканировать. По сути, «краулинговый бюджет» — это выделенное количество страниц, которые робот Googlebot просматривает и индексирует на сайте в течение определенного периода времени. У краулингового бюджета есть два движущих фактора: 9.0003
- Ограничение скорости сканирования ограничивает поведение поисковой системы при сканировании, чтобы не перегружать ваш сервер.
- Спрос на сканирование , популярность и актуальность определяют потребность сайта в большем или меньшем сканировании.
Поскольку у вас нет неограниченных возможностей для сканирования, вы можете установить robots. txt, чтобы Googlebot не открывал лишние страницы и направлял их на значимые. Это устраняет потери вашего краулингового бюджета и избавляет вас и Google от беспокойства о нерелевантных страницах.
txt, чтобы Googlebot не открывал лишние страницы и направлял их на значимые. Это устраняет потери вашего краулингового бюджета и избавляет вас и Google от беспокойства о нерелевантных страницах.
2. Предотвратить следы дублированного контента
Поисковые системы, как правило, осуждают дублированный контент, хотя они специально не хотят манипулятивного дублирующегося контента. Дублированный контент, такой как PDF или версии для печати ваших страниц, не наказывает ваш сайт. Однако вам не нужны боты для сканирования дублирующихся страниц контента и отображения их в поисковой выдаче.
Robots.txt — это один из способов свести к минимуму доступный для сканирования дублированный контент. Существуют и другие методы информирования Google о дублирующемся контенте, такие как канонизация — что является рекомендацией Google — но вы также можете отключить дублированный контент с помощью файлов robots.txt, чтобы сэкономить свой краулинговый бюджет.
3. Направляйте ссылочный вес на нужные страницы
Ссылочный вес от внутренних ссылок — это специальный инструмент для повышения вашего SEO. Ваши самые эффективные страницы могут повысить доверие к плохим и средним страницам в глазах Google. Тем не менее, файлы robots.txt сообщают ботам о том, что они должны отправиться в поход, как только они перейдут на страницу с директивой.
Ваши самые эффективные страницы могут повысить доверие к плохим и средним страницам в глазах Google. Тем не менее, файлы robots.txt сообщают ботам о том, что они должны отправиться в поход, как только они перейдут на страницу с директивой.
Это означает, что они не следуют связанным путям и не приписывают ранжирование этим страницам, если подчиняются вашему приказу. Ваш ссылочный вес является мощным, и когда вы правильно используете robots.txt, ссылочный вес переходит на страницы, которые вы действительно хотите поднять, а не на те, которые должны оставаться в фоновом режиме. Используйте файлы robots.txt только для страниц, которым не нужны ссылки на страницы.
4. Назначение инструкций по сканированию для выбранных ботов
Даже в рамках одной и той же поисковой системы существуют разные боты. У Google есть сканеры помимо основного «Googlebot», в том числе Googlebot Images, Googlebot Videos, AdsBot и другие. С помощью файла robots.txt вы можете запретить поисковым роботам файлы, которые вы не хотите отображать в результатах поиска. Например, если вы хотите, чтобы файлы не отображались при поиске в Google Картинках, вы можете поместить директивы disallow в свои файлы изображений.
Например, если вы хотите, чтобы файлы не отображались при поиске в Google Картинках, вы можете поместить директивы disallow в свои файлы изображений.
В личных каталогах файл robots.txt может сдерживать роботов поисковых систем, но помните, что он не защищает конфиденциальную и личную информацию.
Где найти файл robots.txt?
Теперь, когда вы знаете основы файла robots.txt и знаете, как его использовать в поисковой оптимизации, важно знать, как найти файл robots.txt. Простой метод просмотра, который работает для любого сайта, заключается в том, чтобы ввести URL-адрес домена в строку поиска вашего браузера и добавить /robots.txt в конце. Это работает, потому что файл robots.txt всегда должен находиться в корневом каталоге веб-сайта.
Что делать, если вы не видите файл robots.txt?
Если файл robots.txt веб-сайта не отображается, возможно, он пуст или отсутствует в корневом каталоге (вместо этого возвращается ошибка 404).
Время от времени проверяйте, можно ли найти файл robots.