Robots.txt Generator — Создание файла robots.txt мгновенно
Robots.txt Проведи для Краулеров – Использование Google Роботы Txt Генератор
Robots.txt это файл, который содержит инструкции о том, как сканировать веб-сайт. Он также известен как протокол исключений для роботов, и этот стандарт используется сайтами сказать боты, какая часть их веб-сайта нуждается индексацией. Кроме того, вы можете указать, какие области вы не хотите, чтобы обрабатываемого этих гусеничные; такие области содержат дублированный контент или находятся в стадии разработки. Поисковые системы, такие как вредоносные детекторы, почтовые комбайны не следует этому стандарту и будут проверять слабые места в ваших ценных бумагах, и существует значительная вероятность того, что они начнут рассмотрение вашего сайта из областей, которые не хотят быть проиндексированы.
Полный Robots.txt файл содержит «User-Agent», а под ним, вы можете написать другие директивы, такие как «Разрешить», «Disallow», «Crawl-Delay» и т. д., если написано вручную это может занять много времени, и вы можете ввести несколько строк команд в одном файле. Если вы хотите исключить страницы, вам нужно будет написать «Disallow: ссылка не хотите ботов посетить» То же самое касается разрешительной атрибута. Если вы думаете, что это все есть в файле robots.txt, то это не так просто, одна неправильная линия может исключить страницу из очереди индексации. Таким образом, это лучше оставить задачу профи, пусть наш Robots.txt генератор Заботьтесь файла для вас.
д., если написано вручную это может занять много времени, и вы можете ввести несколько строк команд в одном файле. Если вы хотите исключить страницы, вам нужно будет написать «Disallow: ссылка не хотите ботов посетить» То же самое касается разрешительной атрибута. Если вы думаете, что это все есть в файле robots.txt, то это не так просто, одна неправильная линия может исключить страницу из очереди индексации. Таким образом, это лучше оставить задачу профи, пусть наш Robots.txt генератор Заботьтесь файла для вас.
Что такое робот Txt в SEO?
Вы знаете, это небольшой файл, это способ, чтобы разблокировать более ранг для вашего сайта?
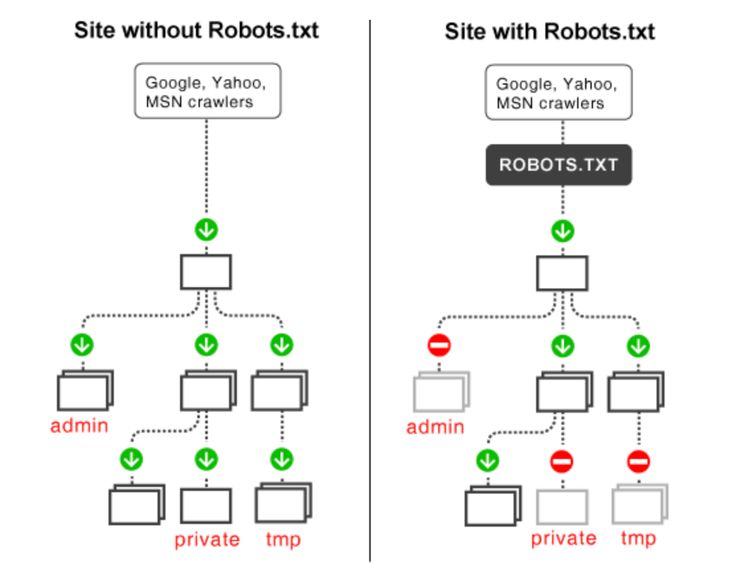
Первые поиска файлов двигатели боты посмотреть на это текстовый файл робота, если он не найден, то есть вероятность того, что массовый сканерам не будет индексировать все страницы вашего сайта. Этот крошечный файл может быть изменен позже, когда вы добавляете больше страниц с помощью маленьких инструкций, но убедитесь, что вы не добавляете главную страницу в Disallow directive.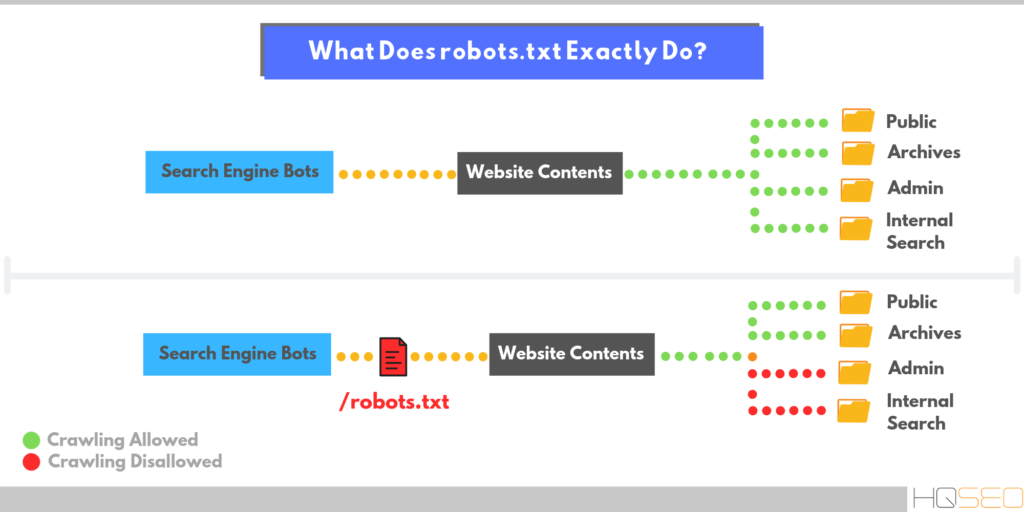 Google работает на бюджете ползания; этот бюджет основан на пределе ползать. Предел ползать является количество времени гусеничном будет тратить на веб-сайте, но если Google узнает, что ползает ваш сайт встряхивая опыт пользователя, то он будет сканировать сайт медленнее. Это означает, что медленнее, каждый раз, когда Google посылает паук, он будет проверять только несколько страниц вашего сайта и самого последнего поста потребуется время, чтобы получить индексироваться. Для снятия этого ограничения, ваш сайт должен иметь карту сайта и файл robots.txt.
Google работает на бюджете ползания; этот бюджет основан на пределе ползать. Предел ползать является количество времени гусеничном будет тратить на веб-сайте, но если Google узнает, что ползает ваш сайт встряхивая опыт пользователя, то он будет сканировать сайт медленнее. Это означает, что медленнее, каждый раз, когда Google посылает паук, он будет проверять только несколько страниц вашего сайта и самого последнего поста потребуется время, чтобы получить индексироваться. Для снятия этого ограничения, ваш сайт должен иметь карту сайта и файл robots.txt.
Так как каждый бот имеет ползать котировку на веб-сайт, это делает необходимым иметь лучший файл робот для сайта WordPress, а также. Причина заключается в том, что содержит много страниц, которые не нуждаются в индексации вы можете даже генерировать WP роботов текстовый файл с нашими инструментами. Кроме того, если у вас нет робототехники текстового файла, сканеры все равно будет проиндексировать ваш сайт, если это блог и сайт не имеет много страниц, то это не обязательно иметь один.
Цель директив в файле robots.txt
Если вы создаете файл вручную, то вы должны быть осведомлены о руководящих принципах, используемых в файле. Вы даже можете изменить файл позже, после обучения, как они работают.
- Crawl-оттянуть
Эту директива используются для предотвращения сканеров от перегрузки хозяина, слишком много запросов могут перегрузить сервер , который приведет к плохому опыту пользователя. Crawl задержка трактуется по- разному различными ботами из поисковых систем, Bing, Google, Яндекс лечить эту директиву по – разному. Для Яндекса это между последовательными визитами, для Bing, это как временное окно , в котором боты будут посещать сайт только один раз, и для Google, вы можете использовать поисковую консоль для управления визитами бот. - Разрешение
Позволяющей директивы используются для включения индексации по следующему адресу. Вы можете добавить столько же URL , как вы хотите , особенно если это торговый сайт , то ваш список может быть большим. Тем не менее, использовать только файл роботов , если ваш сайт имеет страницы , которые вы не хотите , чтобы получить индексироваться.
Тем не менее, использовать только файл роботов , если ваш сайт имеет страницы , которые вы не хотите , чтобы получить индексироваться. - Запрет
Основное назначение файла роботов является мусоровозов гусеничном от посещения указанных ссылок, каталоги и т.д. Эти каталоги, однако, доступ к другим роботам , которые необходимо проверить на наличие вредоносных программ , потому что они не сотрудничают со стандартом.
Разница между файлом Sitemap и robots.txt,
Карта сайт имеет жизненно важное значение для всех сайтов, так как он содержит полезную информацию для поисковых систем. Карта сайт говорит ботам, как часто вы обновляете свой сайт, какой контент вашего сайта предоставляет. Его основным мотивом является извещением в поисковых системах всех страниц вашего сайта имеет, что нужно просматривать в то время как робототехника TXT файл для поисковых роботов. Он сообщает сканерам, какие страницы ползать и которые не в. Карта сайта необходима для того, чтобы ваш сайт индексируется, тогда как TXT робота нет (если у вас нет страниц, которые не должны быть проиндексированы).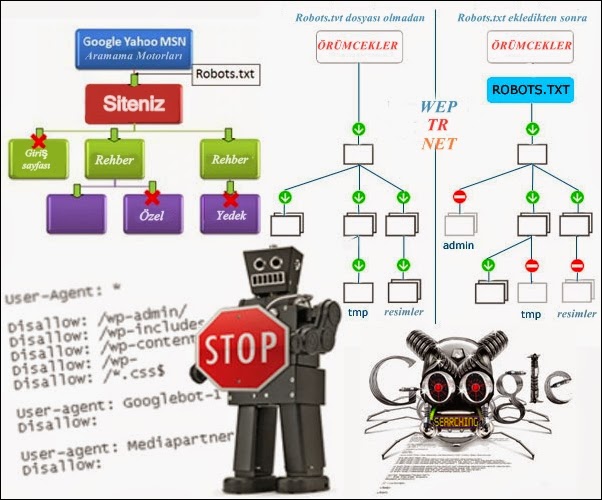
Как сделать робота, используя Google роботов генератор файлов?
Роботы текстового файла легко сделать, но люди, которые не знают о том, как они должны следовать следующим инструкциям, чтобы сэкономить время.
- Когда вы приземлились на странице новых роботов тхт генератора , вы увидите несколько вариантов, не все параметры являются обязательными, но вам нужно тщательно выбирать. Первая строка содержит значение по умолчанию для всех роботов , и если вы хотите сохранить ползания задержки. Оставьте их , как они, если вы не хотите , чтобы изменить их , как показано на рисунке ниже:
- Вторая строка о карте сайта, убедитесь, что у вас есть один и не забудьте упомянуть об этом в текстовом файле робота.
- После этого, вы можете выбрать один из нескольких вариантов для поисковых систем, если вы хотите, чтобы поисковые системы роботов сканировать или нет, второй блок для изображений, если вы собираетесь разрешить их индексации третьего столбца для мобильной версии Веб-сайт.

- Последний вариант для запрещая, где вы будете ограничивать искатель индексировать области страницы. Убедитесь в том, чтобы добавить слэш перед заполнением поля с адресом каталога или страницы.
Другие языки: English, русский, 日本語, italiano, français, Português, Español, Deutsche, 中文
Настройка Robots.txt. Подробное руководство
Почти каждый проект, который приходит к нам на аудит либо продвижение, имеет некорректный файл robots.txt, а часто он вовсе отсутствует. Так происходит, потому что при создании файла все руководствуются своей фантазией, а не правилами. Давайте разберем, как правильно составить этот файл, чтобы поисковые роботы эффективно с ним работали.
Зачем нужна настройка robots.txt?
Robots.txt — это файл, размещенный в корневом каталоге сайта, который сообщает роботам поисковых систем, к каким разделам и страницам сайта они могут получить доступ, а к каким нет.
Настройка robots. txt — важная часть SEO-работ по повышению позиций сайта в выдаче поисковых систем, правильно настроенный robots также увеличивает производительность сайта. Отсутствие Robots.txt не остановит поисковые системы сканировать и индексировать сайт, но если этого файла у вас нет, у вас могут появиться две проблемы:
txt — важная часть SEO-работ по повышению позиций сайта в выдаче поисковых систем, правильно настроенный robots также увеличивает производительность сайта. Отсутствие Robots.txt не остановит поисковые системы сканировать и индексировать сайт, но если этого файла у вас нет, у вас могут появиться две проблемы:
-
Поисковый робот будет считывать весь сайт, что «подорвет» краулинговый бюджет. Краулинговый бюджет — это число страниц, которые поисковый робот способен обойти за определенный промежуток времени.
Без файла robots, поисковик получит доступ к черновым и скрытым страницам, к сотням страниц, используемых для администрирования CMS. Он их проиндексирует, а когда дело дойдет до нужных страниц, на которых представлен непосредственный контент для посетителей, «закончится» краулинговый бюджет.
-
В индекс может попасть страница входа на сайт, другие ресурсы администратора, поэтому злоумышленник сможет легко их отследить и провести ddos атаку или взломать сайт.

Как поисковые роботы видят сайт с robots.txt и без него:
Синтаксис robots.txt
Прежде чем начать разбирать синтаксис и настраивать robots.txt, посмотрим на то, как должен выглядеть «идеальный файл»:
Но не стоит сразу же его применять. Для каждого сайта чаще всего необходимы свои настройки, так как у всех у нас разная структура сайта, разные CMS. Разберем каждую директиву по порядку.
Читайте также Медленные сайты убивают продажи — как это исправить
User-agent
User-agent — определяет поискового робота, который обязан следовать описанным в файле инструкциям. Если необходимо обратиться сразу ко всем, то используется значок *. Также можно обратиться к определенному поисковому роботу. Например, Яндекс и Google:
Disallow
С помощью этой директивы, робот понимает какие файлы и папки индексировать запрещено.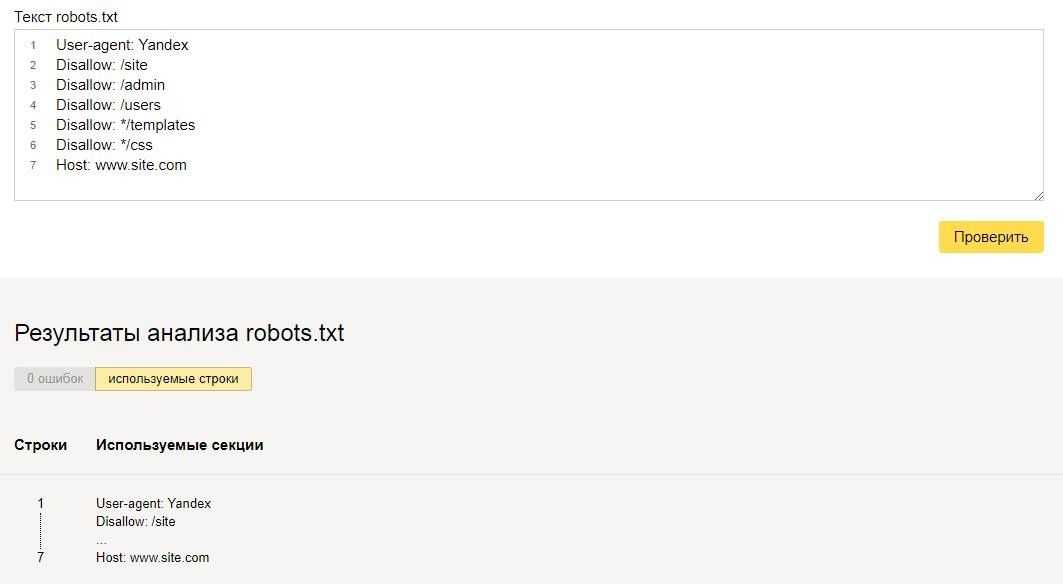
Мы можем запретить доступ к определенной папке, файлу или расширению файла. В нашем примере, мы обращаемся ко всем поисковым роботам, закрываем доступ к папке bitrix, search и расширению pdf.
Allow
Allow принудительно открывает для индексирования страницы и разделы сайта. На примере выше мы обращаемся к поисковому роботу Google, закрываем доступ к папке bitrix, search и расширению pdf. Но в папке bitrix мы принудительно открываем 3 папки для индексирования: components, js, tools.
Host — зеркало сайта
Зеркало сайта — это дубликат основного сайта. Зеркала используются для самых разных целей: смена адреса, безопасность, снижение нагрузки на сервер и т. д.
Host — одно из самых важных правил. Если прописано данное правило, то робот поймет, какое из зеркал сайта стоит учитывать для индексации. Данная директива необходима для роботов Яндекса и Mail.ru. Другие роботы это правило будут игнорировать. Host прописывается только один раз!
Если прописано данное правило, то робот поймет, какое из зеркал сайта стоит учитывать для индексации. Данная директива необходима для роботов Яндекса и Mail.ru. Другие роботы это правило будут игнорировать. Host прописывается только один раз!
Для протоколов «https://» и «http://», синтаксис в файле robots.txt будет разный.
Sitemap — карта сайта
Карта сайта — это форма навигации по сайту, которая используется для информирования поисковых систем о новых страницах. С помощью директивы sitemap, мы «насильно» показываем роботу, где расположена карта.
Символы в robots.txt
Символы, применяемые в файле: «/, *, $, #».
Проверка работоспособности после настройки robots.txt
После того как вы разместили Robots.txt на своем сайте, вам необходимо добавить и проверить его в вебмастере Яндекса и Google.
Проверка Яндекса:
-
Перейдите по ссылке.

- Выберите: Настройка индексирования — Анализ robots.txt.
Проверка Google:
- Перейдите по ссылке.
- Выберите: Сканирование — Инструмент проверки файла robots.txt.
Таким образом вы сможете проверить свой robots.txt на ошибки и внести необходимые настройки, если потребуется.
В заключение приведу 6 главных рекомендаций по работе с файлом Robots.txt:
- Содержимое файла необходимо писать прописными буквами.
- В директиве Disallow нужно указывать только один файл или директорию.
- Строка «User-agent» не должна быть пустой.
- User-agent всегда должна идти перед Disallow.
- Не стоит забывать прописывать слэш, если нужно запретить индексацию директории.
- Перед загрузкой файла на сервер, обязательно нужно проверить его на наличие синтаксических и орфографических ошибок.

Успехов вам!
Видеообзор 3 методов создания и настройки файла Robots.txt
-
Хотите, чтобы ваш сайт реально продавал? Готовы работать вместе с нами? Оформите заявку
Создание и настройка файла robots.txt
Файл robots.txt сообщает веб-роботам, как сканировать веб-страницы на вашем веб-сайте. Вы можете использовать веб-интерфейс Fastly для создания и настройки файла robots.txt. Если вы будете следовать инструкциям в этом руководстве, Fastly будет обслуживать файл robots.txt из кеша, чтобы запросы не попали в ваш источник.
Создание файла robots.txt
Чтобы создать и настроить файл robots.txt, выполните следующие действия:
- Войдите в веб-интерфейс Fastly.
- На домашней странице выберите соответствующую службу.
 Вы можете использовать поле поиска для поиска по идентификатору, имени или домену.
Вы можете использовать поле поиска для поиска по идентификатору, имени или домену. - Нажмите кнопку Изменить конфигурацию и выберите параметр для клонирования активной версии. Появится страница Домены.
- Щелкните ссылку Content . Появится страница содержимого.
Щелкните переключатель robots.txt , чтобы включить ответ robots.txt.
- В поле TXT Response настройте ответ для файла robots.txt.
- Нажмите кнопку Сохранить , чтобы сохранить ответ.
- Нажмите кнопку Активировать , чтобы развернуть изменения конфигурации.
Создание и настройка файла robots.txt вручную
Если вам нужно настроить ответ robots.txt, вы можете выполнить следующие действия, чтобы вручную создать синтетический ответ и условие:
- Войдите в веб-интерфейс Fastly.
- На домашней странице выберите соответствующую службу.
 Вы можете использовать поле поиска для поиска по идентификатору, имени или домену.
Вы можете использовать поле поиска для поиска по идентификатору, имени или домену. - Нажмите кнопку Изменить конфигурацию и выберите параметр для клонирования активной версии. Появится страница Домены.
- Щелкните ссылку Content . Появится страница содержимого.
Нажмите кнопку Настроить расширенный ответ . Появится страница Создать синтетический ответ.
- Заполните поля Создайте синтетический ответ
- В поле Имя введите соответствующее имя. Например
robots.txt. - Оставьте в меню Статус значение по умолчанию
200 OK. - В поле MIME Type введите
text/plain. - В поле Response введите хотя бы одну строку User-agent и одну строку Disallow. Например, приведенный выше пример сообщает всем пользовательским агентам (через
Агент пользователя: * строка) им не разрешено сканировать что-либо после каталога/tmp/или файла/foo.(через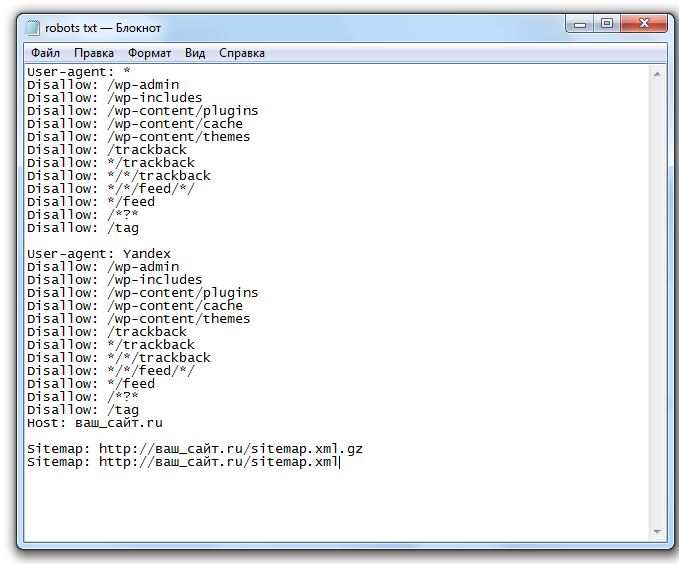
Disallow: /tmp/*иDisallow: /foo. htmlстрок соответственно).
- В поле Имя введите соответствующее имя. Например
- Нажмите кнопку Создать . Ваш новый ответ появится в списке ответов.
Щелкните ссылку Прикрепить условие справа от только что созданного ответа. Появится окно Создать новое условие.
- Заполните поля Создать условие следующим образом:
- В меню Тип выберите требуемое условие (например,
Запрос). - В поле Имя введите значимое имя для вашего состояния (например,
Роботы). - В поле Применить, если введите логическое выражение для выполнения в VCL, чтобы определить, разрешается ли условие как истинное или ложное. В этом случае логичным выражением будет расположение вашего файла robots.txt (например,
req.url.). path == "/robots.txt"
path == "/robots.txt"
- В меню Тип выберите требуемое условие (например,
- Нажмите кнопку Сохранить .
- Нажмите кнопку Активировать , чтобы развернуть изменения конфигурации.
Подробное описание создания пользовательских ответов см. в нашем Учебнике по ответам.
Почему я не могу настроить файл robots.txt с помощью global.prod.fastly.net?
Добавление расширения .global.prod.fastly.net в ваш домен (например, www.example.com.global.prod.fastly.net ) через браузер или в команде curl можно использовать для проверки того, как ваш рабочий сайт будет работать с использованием сервисов Fastly.
Чтобы предотвратить случайное сканирование Google этого тестового URL-адреса, мы предоставляем внутренний файл robots.txt, который указывает поисковым роботам Google игнорировать все страницы для всех имен хостов, оканчивающихся на .prod.fastly.net .
Этот внутренний файл robots. txt нельзя настроить через веб-интерфейс Fastly до тех пор, пока вы не настроите DNS-запись CNAME для своего домена так, чтобы она указывала на 9.0078 global.prod.fastly.net .
txt нельзя настроить через веб-интерфейс Fastly до тех пор, пока вы не настроите DNS-запись CNAME для своего домена так, чтобы она указывала на 9.0078 global.prod.fastly.net .
Как создать файл robots.txt в cPanel
Если вы когда-либо создавали свой собственный веб-сайт, возможно, вы слышали о файле robotx.txt и задавались вопросом, для чего этот файл? Ну, вы в правильном месте! Ниже мы рассмотрим, что это за файл и почему он важен.Что такое файл robots.txt?
Во-первых, robots.txt — это не что иное, как обычный текстовый файл (ASCII или UTF-8), расположенный в корневом каталоге вашего домена , который блокирует (или разрешает) поисковым системам доступ к определенным областям вашего сайта. robots.txt содержит простой набор команд (или директив) и обычно применяется для ограничения трафика поисковых роботов на ваш сервер, что предотвращает нежелательное использование ресурсов.
Поисковые системы используют так называемые сканеры (или боты) для индексации частей веб-сайта и возврата их в качестве результатов поиска.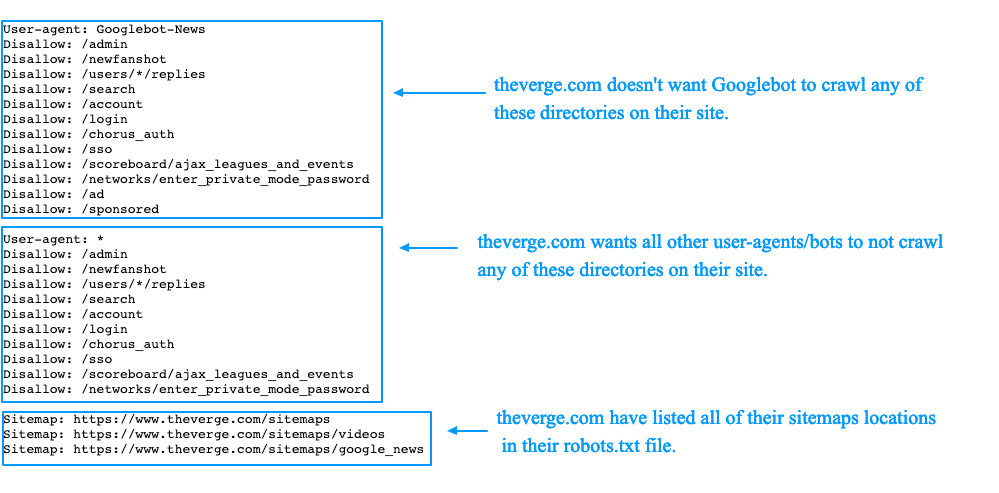 Возможно, вы захотите, чтобы определенные конфиденциальные данные, хранящиеся на вашем сервере, были недоступны для веб-поиска. Файл robots.txt поможет вам сделать это.
Возможно, вы захотите, чтобы определенные конфиденциальные данные, хранящиеся на вашем сервере, были недоступны для веб-поиска. Файл robots.txt поможет вам сделать это.
Примечание: Файлы или страницы на вашем веб-сайте не полностью отключаются от поисковых роботов, если эти файлы индексируются/ссылаются с других веб-сайтов. Чтобы должным образом защитить ваш URL от появления в поисковых системах Google, вы можете защитить файлы паролем непосредственно с вашего сервера.
Как создать файл robots.txt
Чтобы создать файл robots.txt (если он еще не существует), просто выполните следующие действия:
1. Войдите в свою учетную запись cPanel
2. Перейдите в раздел ФАЙЛЫ и нажмите Диспетчер файлов
cPanel > Файлы > Диспетчер файлов Файл 3. public_html ), затем нажмите « Новый файл » >> Введите «robots. txt» >> Нажмите « Создать новый файл ».
txt» >> Нажмите « Создать новый файл ».
4. Теперь вы можете редактировать содержимое этого файла, дважды щелкнув по нему.
Примечание: вы можете создать только один файл r obots.txt для каждого домена. Дубликаты не допускаются на одном и том же корневом пути. Каждый домен или поддомен должен содержать собственный файл robots.txt .
Примеры правил использования и синтаксиса
Обычно файл robots.txt содержит одно или несколько правил, каждое из которых находится в отдельной строке. Каждое правило блокирует или разрешает доступ данному сканеру к указанному пути к файлу или ко всему веб-сайту.
- Запретить всем поисковым роботам (пользовательским агентам) доступ к каталогам журналов и ssl .
Агент пользователя:* Запретить: /журналы/ Disallow: /ssl/
- Заблокировать все поисковые роботы для индексации всего сайта.

Агент пользователя: * Disallow: /
- Разрешить всем пользовательским агентам доступ ко всему сайту.
Агент пользователя: * Разрешить: /
- Блокировать индексацию всего сайта от определенного поискового робота.
Агент пользователя: Bot1 Disallow: /
- Разрешить индексацию для определенного поискового робота и предотвратить индексацию от других.
Агент пользователя: Googlebot Запретить: Пользовательский агент: * Disallow: /
- Под User-agent : вы можете ввести имя конкретного поискового робота. Вы также можете включить все поисковые роботы, просто введя символ звездочки (*). С помощью этой команды вы можете отфильтровать все поисковые роботы, кроме сканеров AdBot, которые необходимо перечислить явно. Вы можете найти список всех сканеров в Интернете.