Антиплагиат Текстовод для проверки текста на уникальность
Главная
/Статьи
/Антиплагиат Текстовод для проверки текста на уникальностьСервис проверки уникальности Текстовод популярен среди студентов и копирайтеров: на сайте можно заказать уникальную статью или продающий текст. Биржа копирайтинга — не единственное преимущество системы. В статье мы расскажем про бесплатные и полезные услуги для создания качественного текста.
Как работать с сервисом?Чтобы проверить текст на антиплагиат бесплатно, необходимо вставить его в окно и нажать кнопку «Уникальность». Сайт выдаст процент оригинальности работы:
— до 10 % — полный плагиат;
— от 10 до 30 % — текст нужно обязательно доработать;
— от 30 до 60 % — приемлемый, но требующий доработки фрагмент;
— от 60 до 80 % — оптимальный процент уникальности работы;
— от 80 % и выше — качественный результат: текст является оригинальным.
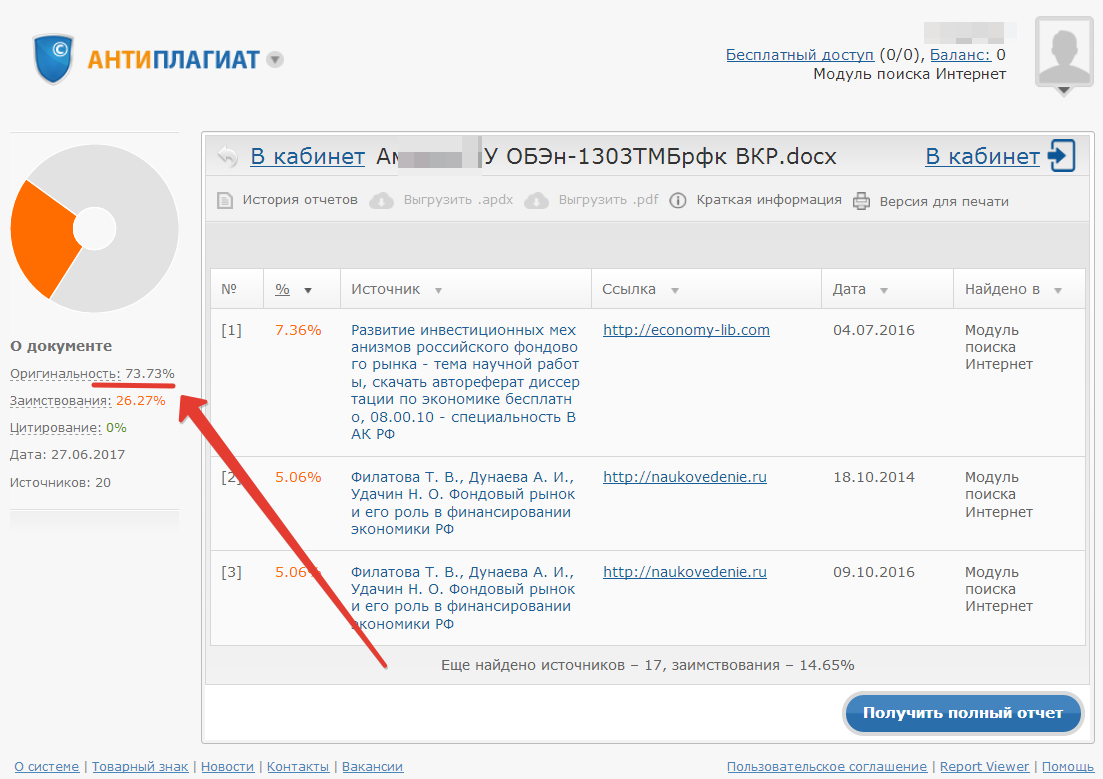
Антиплагиат показывает заимствованные источники. Для соотнесения части текста с определенным сайтом необходимо нажать на процент схожести (значение в скобках): программа выделит конкретные заимствованные текстовые блоки.
Ограничения по количеству символовБесплатная проверка на плагиат:
— при гостевом входе с ограничением до 10 тыс. знаков;
— для зарегистрированных пользователей — до 15 тыс. символов.
Анализ объемной текстовой работы до 200 тыс. символов возможно при использовании PRO проверки. Особенности: платная услуга (65 коп. за 1000 символов), отдельная очередь, ускоренная скорость проверки.
Преимущества и недостатки антиплагиатаОсновное достоинство программы — качественная проверка на уникальность. Обмануть сервис перестановкой слов, заменой каждого пятого слова или изменением окончаний не получится.
Дополнительные полезные услуги:
— проверка орфографии;
— синонимайзер;
— подсчет символов;
— разбор предложений и много другое.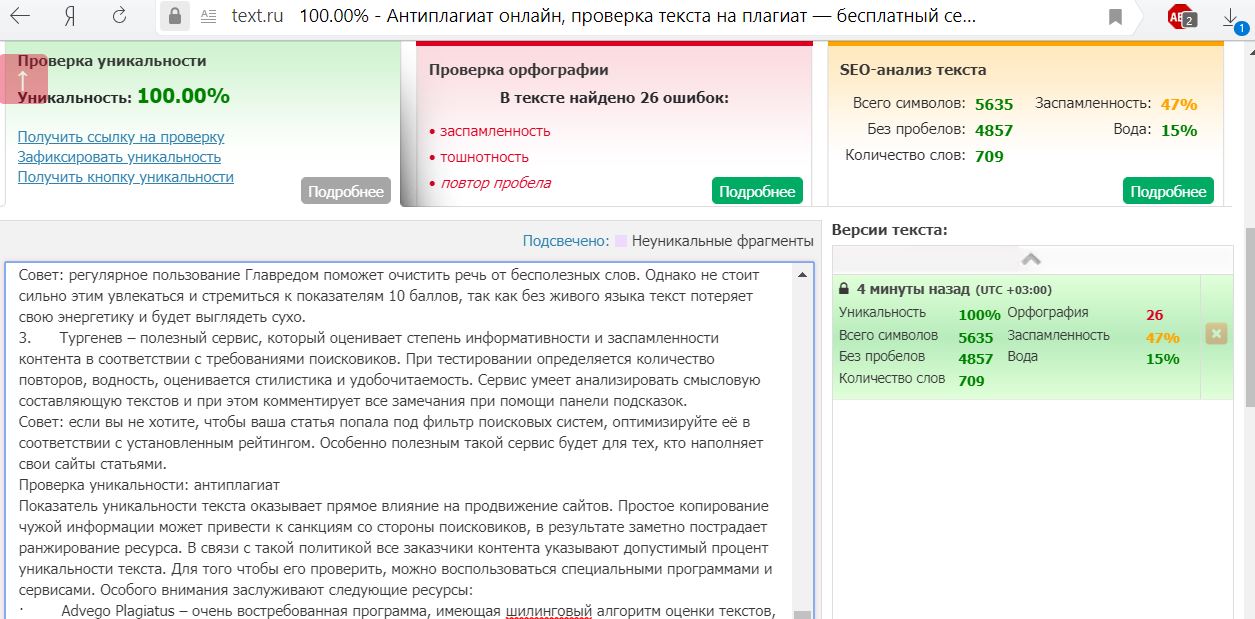
Среди недостатков выделяется ограничение по количеству символов.
Как повысить уникальность?Ориентиром служат выделенные области в тексте. Детальная работа с подсвеченными словами позволит добиться более высокого результата. Эффективные методы: подбор синонимов и перефразирование предложений.
Возможно, вам также будет интересно узнать подробнее про сервис ETXT
Если у вас имеются какие-то вопросы — позвоните нам, у нас круглосуточная поддержка клиентов!
8-800-550-55-87 звонок бесплатный
Сегодня 9 студентов повысили уникальность своих работ. А всего — 534385 студентов
← Проблема самоцитирования в дипломных раб…Как проверить на антиплагиат большой тек… →
машинное обучение — проверка актуальности текстового содержимого
спросил
Изменено 4 года, 8 месяцев назад
Просмотрено 130 раз
Часть коллектива НЛП Мне нужно проверить актуальность контента на определенной веб-странице.
- машинное обучение
- nlp
- тематическое моделирование
Ваш вопрос немного расплывчатый, когда вы говорите:
Как лучше всего проверить, соответствует ли заголовок страницы контент на странице.
Как определяется релевантность в контексте вашей проблемы?
Я не знаю, хотите ли вы этого, но мне на ум приходит пара вещей, которые, по сути, сравнивают, насколько похожи два документа, один документ имеет название, а другой — описание.
Вы можете подумать о методах создания векторных представлений для обоих и сравнить, насколько они похожи.
- Сходство Жаккара с использованием жетонов как элементов обоих наборов (т. е. документов)
- Взвешенные векторы TF-IDF и сравнение их с косинусным сходством
- Вычислить модель темы распространения/LDA для каждого документа и сравнить их с помощью расхождения Кульбака-Лейблера
- Закодируйте документы в какой-нибудь плотный вектор (doc2vec или прочитайте их через LSTM и сохраните последнее состояние), а затем сравните оба вектора.
Единственным соображением является то, что размер заголовка очень мал по сравнению с содержимым веб-страницы.
Зарегистрируйтесь или войдите в систему
Зарегистрируйтесь с помощью Google Зарегистрироваться через Facebook Зарегистрируйтесь, используя электронную почту и парольОпубликовать как гость
Электронная почтаТребуется, но не отображается
Опубликовать как гость
Электронная почтаТребуется, но не отображается
Нажимая «Опубликовать свой ответ», вы соглашаетесь с нашими условиями обслуживания и подтверждаете, что прочитали и поняли нашу политику конфиденциальности и кодекс поведения.
python — Концепции для измерения «релевантности» текста теме?
спросил
Изменено 4 года, 3 месяца назад
Просмотрено 721 раз
Часть коллектива НЛПЯ подрабатываю, пишу/улучшаю веб-приложение исследовательского проекта для нескольких политологов. Это приложение собирает статьи, относящиеся к Верховному суду США, и проводит их анализ, и спустя почти полтора года у нас есть база данных, насчитывающая около 10 000 статей (и она растет) для работы.
Одной из основных задач проекта является возможность определить «релевантность» статьи, то есть основное внимание уделяется федеральному Верховному суду США (и/или его судьям), а не местному или иностранному верховному суду.
Я достиг точки в разработке, когда я могу больше сосредоточиться на этом аспекте проекта, но я не совсем уверен, с чего начать. Все, что я знаю, это то, что я ищу метод анализа текста статьи, чтобы определить его отношение к федеральному суду, и ничего больше. Я предполагаю, что это повлечет за собой некоторое машинное обучение, но у меня практически нет опыта в этой области. Я немного почитал о таких вещах, как взвешивание tf-idf, моделирование векторного пространства и word2vec (+ модели CBOW и Skip-Gram), но пока не вижу «общей картины», которая показывает мне, как именно применимы эти понятия могут быть к моей проблеме.
- машинное обучение
- nlp
- наука о данных
Формулирование проблемы
При запуске нового проекта машинного обучения Таким образом, есть несколько фундаментальных вопросов, которые нужно обдумать, чтобы улучшить проблема и освещенный обзор + эксперимент более эффективно.
У вас есть данные для построения модели? У вас есть около 10 000 статей, которые будут входными данными для вашей модели, однако, чтобы использовать подход к обучению с учителем, вам потребуются надежные метки для всех статей, которые будут использоваться при обучении модели. Похоже, вы уже сделали это.
Какие показатели использовать для количественной оценки успеха. Как вы можете измерить, делает ли ваша модель то, что вы хотите? В вашем конкретном случае это звучит как проблема бинарной классификации — вы хотите иметь возможность помечать статьи как релевантные или нет.
.png)
Насколько хорошо вы справитесь со случайным или наивным подходом. После того, как набор данных и метрика были установлены, вы можете количественно оценить, насколько хорошо вы можете справиться со своей задачей с помощью базового подхода. Это может быть просто вычисление вашей метрики для модели, которая выбирает случайным образом, но в вашем случае у вас есть модель анализатора ключевых слов, которая является идеальным способом установить контрольную точку. Оцените, насколько хорошо ваш подход к синтаксическому анализу ключевых слов подходит для вашего набора данных, чтобы вы могли определить, когда модель машинного обучения работает хорошо.
Извините, если это было очевидно и банально для вас, но я хотел убедиться, что это было в ответе.
Подходы к машинному обучению
Как предложили Эван Мата и Стефан Г., лучший подход — сначала преобразовать ваши статьи в функции. Это можно сделать без машинного обучения (например, модель векторного пространства) или с машинным обучением (word2vec и другие приведенные вами примеры). Для вашей проблемы я думаю, что что-то вроде BOW имеет смысл попробовать в качестве отправной точки.
Когда у вас есть представление ваших статей с помощью функции, вы почти закончили, и есть ряд моделей бинарной классификации, которые хорошо себя зарекомендовали. Поэкспериментируйте отсюда, чтобы найти лучшее решение.
В Википедии есть хороший пример простого способа использования этого двухэтапного подхода к фильтрации спама, аналогичной проблемы (см. раздел Пример использования в статье).
Удачи, звучит как интересный проект!
Если у вас достаточно помеченных данных — не только для «да, эта статья актуальна», но и для «нет, эта статья неактуальна» (вы в основном создаете бинарную модель между релевантными да/нет — поэтому я бы исследовал спам фильтры), то вы можете обучить справедливую модель. Я не знаю, есть ли у вас приличное количество данных без данных. Если вы это сделаете, вы можете обучить относительно простую модель с учителем, выполнив (песудокод) следующее:0005
Корпус = предварительная обработка(Корпус) #(удалить стоп-слова и т.д.) Векторы = BOW (Корпус) # Или TFIDF или любая другая модель, которую вы хотите использовать SomeModel.train(Vectors[~3/4 из них], Labels[соответствующие 3/4]) #Labels = 1, если применимо, 0, если нет SomeModel.evaluate(Vectors[remainder], Labels[remainder]) #Убедитесь, что модель не подходит больше SomeModel.Predict(new_document)
Точная модель будет зависеть от ваших данных. Простой метод Наивного Байеса может (вероятно, будет) работать нормально, если вы сможете получить приличное количество документов без документов. Одно замечание: вы подразумеваете, что у вас есть два вида бездокументов — те, которые достаточно близки (Верховный суд Индии), или те, которые совершенно не имеют значения (скажем, Налоги). Вы должны протестировать обучение с «близкими» ошибочными случаями с отфильтрованными «далекими» ошибочными случаями, как вы это делаете сейчас, по сравнению с «близкими» ошибочными случаями и «дальними» ошибочными случаями и посмотреть, какой из них выходит лучше.
Одно замечание: вы подразумеваете, что у вас есть два вида бездокументов — те, которые достаточно близки (Верховный суд Индии), или те, которые совершенно не имеют значения (скажем, Налоги). Вы должны протестировать обучение с «близкими» ошибочными случаями с отфильтрованными «далекими» ошибочными случаями, как вы это делаете сейчас, по сравнению с «близкими» ошибочными случаями и «дальними» ошибочными случаями и посмотреть, какой из них выходит лучше.
Есть много способов сделать это, и лучший метод меняется в зависимости от проекта. Возможно, самый простой способ сделать это — выполнить поиск по ключевым словам в ваших статьях, а затем эмпирическим путем выбрать пороговую оценку. Хотя это просто, на самом деле это работает довольно хорошо, особенно в такой теме, как эта, где вы можете придумать небольшой список слов, которые с большой вероятностью появятся где-нибудь в соответствующей статье.
Когда тема более широкая, например, «бизнес» или «спорт», поиск по ключевым словам может быть запретительным и отсутствовать. Именно тогда подход машинного обучения может стать лучшей идеей. Если машинное обучение — это то, к чему вы стремитесь, то есть два шага: 9.0005
Именно тогда подход машинного обучения может стать лучшей идеей. Если машинное обучение — это то, к чему вы стремитесь, то есть два шага: 9.0005
- Встраивайте свои статьи в векторы признаков
- Тренируйте свою модель
Шаг 1 может быть чем-то простым, например вектором TFIDF. Тем не менее, встраивание ваших документов само по себе может быть глубоким обучением. Здесь в игру вступают CBOW и Skip-Gram. Популярный способ сделать это — Doc2Vec (PV-DM). Прекрасная реализация находится в библиотеке Python Gensim. Современные и более сложные встраивания символов, слов и документов представляют собой гораздо более сложную задачу для начала, но они очень полезны. Примерами этого являются вложения ELMo или BERT.
Шаг 2 может быть типичной моделью, так как теперь это просто бинарная классификация. Вы можете попробовать многослойную нейронную сеть, либо полносвязную, либо сверточную, или вы можете попробовать более простые вещи, такие как логистическая регрессия или Наивный Байес.