30+ примеров настройки robots.txt
Как настроить корректную индексацию сайта поисковыми роботами? Как закрыть доступ сканирующих роботов к техническим файлам сайта?
Файл robots.txt ограничивает доступ поисковых роботов к файлам на сервере — в файле написаны инструкции для сканирующих роботов. Поисковый робот проверяет возможность индексации очередной страницы сайта — есть ли подходящее исключение. Чтобы поисковые роботы имели доступ к robots.txt, он должен быть доступен в корне сайта по адресу mysite.ru/robots.txt.
Пример полного доступа на индексацию сайта без ограничений:
User-agent: *
Allow: /
Применение в SEO
По умолчанию поисковые роботы сканируют все страницы сайта, к которым они имеют доступ. Попасть на страницу поисковый робот может из карты сайта, ссылки на другой странице, наличии трафика на данной странице и т.п.. Не все страницы, которые были найден поисковым роботом следует показывать в результатах поиска.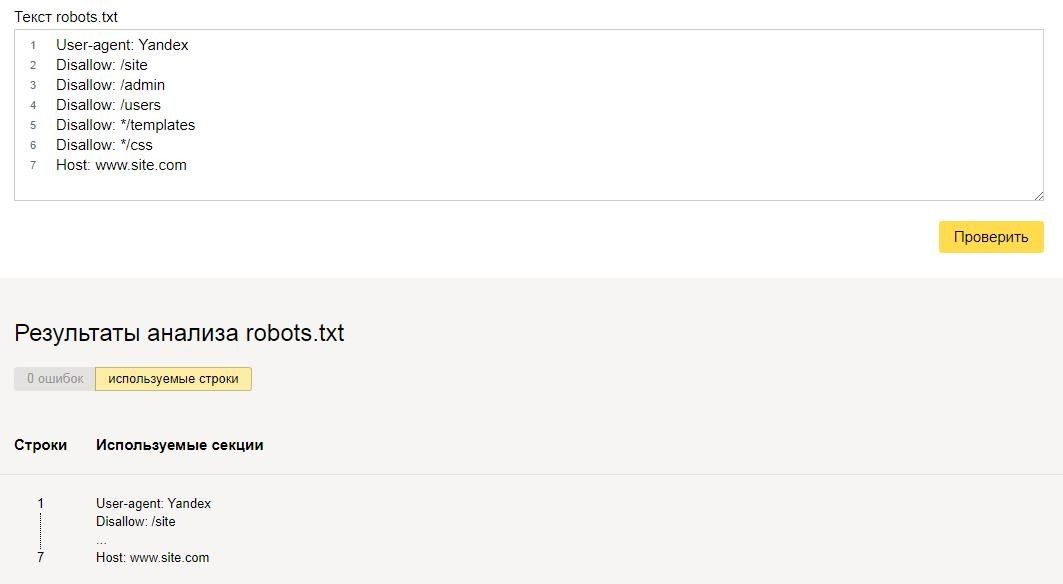
Файл robots.txt позволяет закрыть от индексации дубли страниц, технические файлы, страницы фильтрации и поиска. Любая страница на сайте может быть закрыта от индексации, если на это есть необходимость..
Правила синтаксиса robots.txt
Логика и структура файла robots.txt должны строго соблюдаться и не содержать лишних данных:
- Любая новая директива начинается с новой строки.
- В начале строки не должно быть пробелов.
- Все значения одной директивы должны быть размещены на этой же строке.
- Не использовать кавычки для параметров директив.
- Не использовать запятые и точки с запятыми для указания параметров.
- Все комментарии пишутся после символа #.
- Пустая строка обозначает конец действия текущего User-agent.
- Каждая директива закрытия индексации или открытия содержит только один параметр.
- Название файла должно быть написано прописными буквами, файлы Robots.
 txt или ROBOTS.TXT являются другими файлами и игнорируются поисковыми роботами.
txt или ROBOTS.TXT являются другими файлами и игнорируются поисковыми роботами. - Если директива относится к категории, то название категории оформляется слешами «/categorya/».
- Размер файла robots.txt не должен превышать 32 кб, иначе он трактуется как разрешающий индексацию всего.
- Пустой файл robots.txt считается разрешающим индексацию всего сайта.
- При указании нескольких User-agent без пустой строки между ними обрабатываться будет только первая
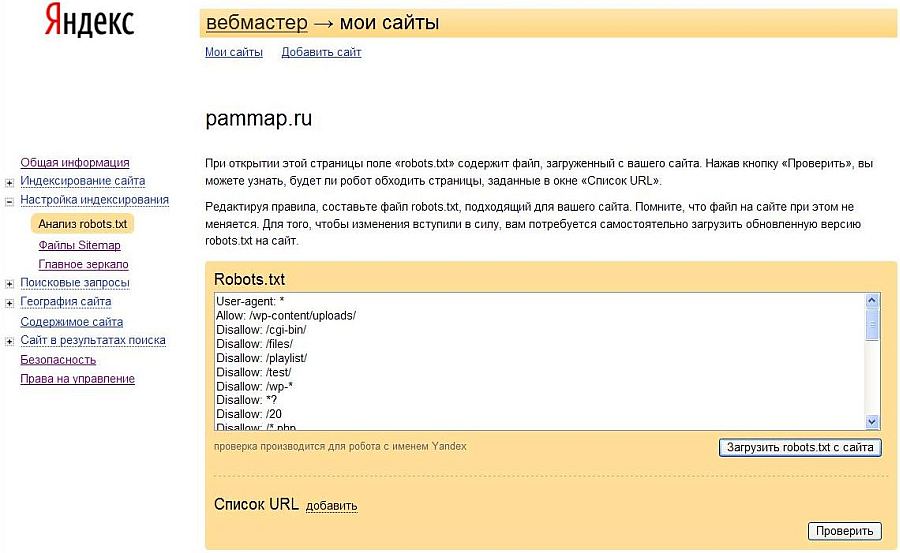
Проверка robots.txt
Поисковые системы Яндекс и Google дают возможность проверить корректность составления robots.txt:
- В Вебмастер.Яндекс — анализ robots.txt.
- В Google Search Console — ссылка, необходимо сначала добавить сайт в систему.
Примеры настройки robots.txt
Первой строкой в robots.txt является директива, указывающая для какого робота написаны исключения.
Директива User-agent
# Все сканирующие роботы
User-agent: *
# Все роботы Яндекса
User-agent: Yandex
# Основной индексирующий робот Яндекса
User-agent: YandexBot
# Все роботы Google
User-agent: Googlebot
Все директивы следующие ниже за User-agent распространяют свое действие только на указанного робота.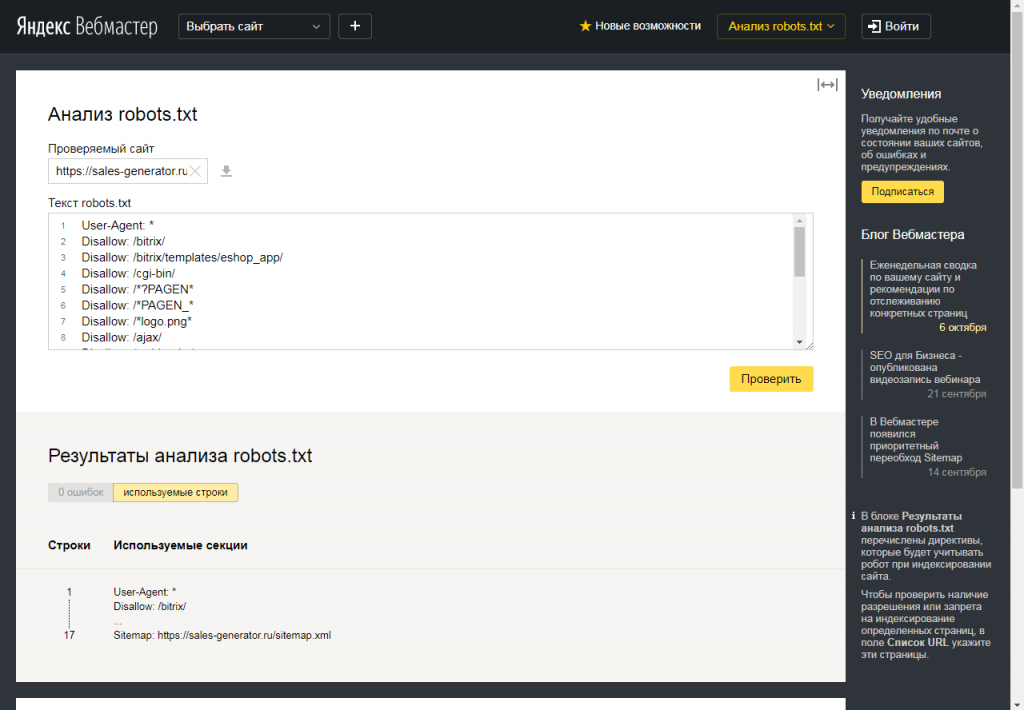 Для указания данных другому роботу следует еще раз написать директиву User-agent. Пример с несколькими User-agent:
Для указания данных другому роботу следует еще раз написать директиву User-agent. Пример с несколькими User-agent:
Использование нескольких User-agent
# Будет использована основным роботом ЯндексаUser-agent: YandexBot
Disallow: *request_* # Будет использована всеми роботами Google
User-agent: Googlebot
Disallow: *elem_id* # Будет использована всеми роботами Mail.ru
User-agent: Mail.Ru
Allow: *SORT_*
Сразу после указания User-agent следует написать инструкции для выбранного робота. Нельзя указывать пустые сроки между командами в robots.txt, это будет не правильно понято сканирующими роботами.
Разрешающие и запрещающие директивы
Для запрета индексации используется директива «Disallow», для разрешения индексации «Allow»:
User-agent: *
Allow: /abc/
Disallow: /blog/
Указано разрешение на индексацию раздела /abc/ и запрет на индексацию /blog/.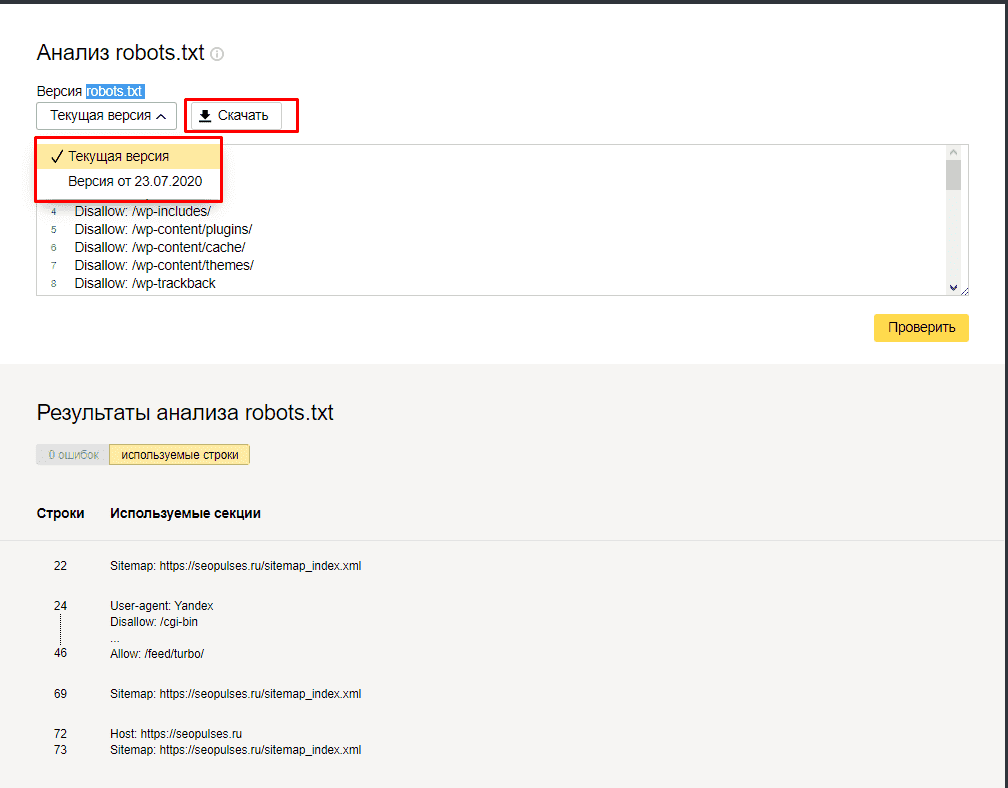 По умолчанию все страницы сайта разрешены на индексацию и не нужно указывать для всех папок директиву Allow. Директива Allow необходима при открытии на индексацию подраздела. Например открыть индексацию для подраздела с ужатыми изображениями, но не открывать доступ к другим файлам в папке:
По умолчанию все страницы сайта разрешены на индексацию и не нужно указывать для всех папок директиву Allow. Директива Allow необходима при открытии на индексацию подраздела. Например открыть индексацию для подраздела с ужатыми изображениями, но не открывать доступ к другим файлам в папке:
User-agent: *
Disallow: /upload/
Allow: /upload/resize_image/
Последовательность написания директив имеет значение. Сначала закрывается все папка от индексации, а затем открывается её подраздел.
Запрещение индексации — Disallow
Директива для запрета на сканирование — Disallow, индексация запрещается в зависимости от параметров, указанных в директиве.
Полный запрет индексации
User-agent: *
Disallow: /
Сайт закрывается от сканирования всех роботов.
Существуют специальные символы «*» и «$», которые позволяют производить более тонкое управление индексацией:
Disallow: /cat*
Disallow: /cat
Символ звездочка означает любое количество любых символов, которые могут идти следом. Вторая директива имеет тот же смысл.
Вторая директива имеет тот же смысл.
Disallow: *section_id*
Запрещает индексацию всех Url, где встречается значение внутри звездочек.
Disallow: /section/
Закрывает от индексации раздел и все вложенные файлы и подразделы.
Разрешение индексации — Allow
Задача директивы Allow открывать для индексации url, которые подходят под условие. Синтаксис Allow сходен с синтаксисом Disallow.
User-agent: *
Disallow: /
Allow: /fuf/
Весь сайт закрыт от индексации, кроме раздел /fuf/.
Директива Host
Данная директива нужна для роботов поисковой системы Яндекс. Она указывает главное зеркало сайта. Если сайт доступен по нескольким доменам, то это позволяет поисковой системе определить дубли и не включать их в поисковый индекс.
User-agent: *
Disallow: /bitrix/
Host: mysite.ru
В файле robots.txt директиву Host следует использовать только один раз, последующие указания игнорируются.
Если сайт работает по защищенному протоколу https, то следует указывать домен с полным адресом:
User-agent: *
Disallow: /bitrix/
Host: https://domain.ru
Директива Sitemap
Для ускорения индексации страниц сайта поисковым роботам можно передать карту сайта в формате xml. Директива Sitemap указывает адрес, по которому карта сайта доступна для скачивания.
User-agent: *
Disallow: /bitrix/
Sitemap: http://domain.ru/sitemap.xml
Исключение страниц с динамическими параметрами
Директива Clean-param позволяет бороться с динамическими дублями страниц, когда содержимое страницы не меняется, но добавление Get-параметра делает Url уникальным. При составлении директивы сначала указывается название параметра, а затем область применения данной директивы:
Clean-param: get1[&get2&get3&get4&..&getN] [Путь]

Простой пример для страницы http://domain.ru/catalog/?&get1=1&get2=2&get3=3. Директива будет иметь вид:
Clean-param: get1&get2&get3 /catalog/
Данная директива будет работать для раздела /catalog/, можно сразу прописать действие директивы на весь сайт:
Clean-param: get1&get2&get3 /
Снижение нагрузки — Crawl-delay
Если сервер не выдерживает частое обращение поисковых роботов, то директива Crawl-delay поможет снизить нагрузку на сервер. Поисковая система Яндекс поддерживает данную директиву с 2008 года.
User-agent: *
Disallow: /search/
Crawl-delay: 4
Поисковый робот будет делать один запрос, затем ждать 4 секунды и снова делать запрос.
Типовой robots.txt для сайта на Bitrix
В заключении полноценный файл robots.txt для системы 1С-Битрикс, который включает все типовые разделы:
User-agent: *
Disallow: /bitrix/
Disallow: /admin/
Disallow: /auth/
Disallow: /personal/
Disallow: /cgi-bin/
Disallow: /search/
Disallow: /upload/
Allow: /upload/resize_cache/
Allow: /upload/iblock/
Disallow: *bxajaxid*
Sitemap: http://domain.ru/sitemap.xml
Host: domain.ru
Robots.txt для сайта: правила и примеры
Что такое robots.txt и для чего нужен?
SEO-продвижение сайта подразумевает его оптимизацию под требования поисковых систем. Главная цель – это улучшение позиций в органической выдаче поисковиков, и как следствие, привлечение целевого трафика. При этом не все страницы сайта имеют ценность для потенциальной аудитории, и, соответственно, часть из них не должна участвовать в ранжировании.
Перед процессом ранжирования, поисковики собирают информацию со страниц сайта, индексируя ее с помощью специальных роботов – краулеров. Владелец сайта имеет в своем распоряжении инструмент, который позволяет запрещать или разрешать индексацию тех или иных страниц для конкретно выбранных поисковых краулеров. Этим инструментом и выступает файл robots.txt.
Приведем перечень страниц, которые наверняка не должны участвовать в поисковом ранжировании:
- Файлы и страницы административной части сайта.

- Различные формы, например, авторизации пользователей и т.д.
- Страницы поисковых инструментов внутри сайта.
- Опции сравнения товаров в интернет-магазинах. Не путать с фильтрами в категориях товаров.
- Дубли страниц.
- Прочие служебные страницы, к примеру, личный кабинет.
Подобные страницы, если они доступны для сканирования, могут приводить к ряду проблем:
- На сканирование сайта выделяется краулинговый бюджет, определяющий количество страниц, которые поисковый робот обойдет за условный промежуток времени. Нецелевые документы, которые не решают задач сайта, будут тратить этот бюджет понапрасну. Если сайт большой, то могут возникнуть задержки в процессе индексации целевых страниц. Другими словами, новые или измененные страницы в поисковой выдаче могут появляться с задержками.
- Представим ситуацию, когда нецелевая страница попала в органическую выдачу.
 Перейдя на нее, пользователь с большой долей вероятности покинет ее, негативно повлияв при этом на процент отказов. Который в свою очередь, является важнейшим фактором ранжирования не только одного конкретно взятого документа, но и иногда сайта в целом. Так что одной из основных задач при комплексном SEO-продвижении является снижение количества отказов.
Перейдя на нее, пользователь с большой долей вероятности покинет ее, негативно повлияв при этом на процент отказов. Который в свою очередь, является важнейшим фактором ранжирования не только одного конкретно взятого документа, но и иногда сайта в целом. Так что одной из основных задач при комплексном SEO-продвижении является снижение количества отказов. - В некоторых случаях в индекс могут попадать дубликаты страниц. Это приведет к тому, что поисковые алгоритмы попытаются самостоятельно определить каноническую (главную) версию документа, и часто в индексе вместо нее остается дубликат.
Правила создания robots.txt
Структура файла состоит из групп правил, адресованных поисковым роботам.
Следует понимать следующие принципы заполнения файла:
- Структура представляет собой набор разделов и непосредственно правил-директив.
- Разделы начинаются с директивы User-agent, обозначающей название поискового робота, на которого распространяется запрет/разрешение, указанное в текущей секции.

- При этом каждый из разделов является самостоятельной единицей и обрабатываются краулерами отдельно друг от друга. Другими словами, предыдущие правила переписывают последующие.
- Разделы обрабатываются сверху вниз, по порядку.
- Если в robots.txt отсутствует директива для документа, то по умолчанию его разрешено индексировать всем краулерам.
- Следует учитывать регистр букв в написании подстрок, т.е., /file.html и /FILE.HTML – разные документы.
- Для комментирования используется символ решетки (#). Им удобно пользоваться, когда требуется временно отключить определенные директивы.
- Каждый из наборов правил для определенных ботов должен разделяться пустой строкой.
- Между правилами для одного бота пустые строки должны отсутствовать.
Технические требования к файлу:
- Размер файла не должен превышать 500 КБ.
- Формат файла – TXT, сохраненного в кодировке UTF-8.
- Должен быть расположен в корневой директории сайта. В ином случае краулером будет зафиксировано его отсутствие.
- Доступ к файлу должен быть открытым, а при посещении возвращать код 200.
- Допускается использование одного файла в рамках одного ресурса.
- Заполняется исключительно в латинице. Если в домен входят кириллические символы, то он должен быть сконвертирован с помощью Punycode в латиницу.
Директивы
Robots.txt содержит в себе набор инструкций, распространяющихся на всех или некоторых поисковых краулеров.
Синтаксис файла включает в себя следующие символы:
- # – комментарии, та текстовая часть файла, которая не учитывается ботами.
- * – этот символ допускает любой набор символов после себя. Т.е., например, директива «Disallow: *» закрывает все директории ресурса от индексации.
- $ – перекрывает действие *, обозначает, что после этого символа следует остановиться.
Теперь разберем директивы файла robots.txt для сайта.
User-agent
Относится к обязательным директивам, с нее должна начинаться каждая группа правил. В этом поле указывается тип краулера, на которого распространяется действие группы правил.
User-agent содержит в себе название поискового робота, но если инструкция распространяется на все типы ботов, то указывается «*».
Список основных ботов, которые можно указывать в robots.txt:
- Yandex – касается всех роботов Яндекса.
- YandexBot – основной краулер Яндекса, отвечает за индексацию текстового контента.
- YandexImages – также краулер от Яндекса, который индексирует изображения.
- YandexMedia – бот Яндекса, который индексирует мультимедийный контент по типу видео.
- Google – все роботы Google.

- Googlebot – основной бот Google.
- Googlebot-Image – робот Google, целью работы которого является индексация изображений.
Одну и ту же директорию сайта можно запретить или разрешить для индексирования разным поисковым ботам.
Пример – не забываем вставлять пустую строку между правилами:
User-agent: Google Disallow: /main/ User-agent: Yandex Allow: /main/
Пример с набором нескольких директив для одного робота. Между директивами не должно быть пустых строк:
# Правильно: User-agent: Google Disallow: /files/ Disallow: /wp-admin/ # Неправильно User-agent: Google Disallow: /files/ Disallow: /wp-admin/
Как говорилось выше, файл считывается роботами сверху вниз по порядку. Все последующие инструкции для конкретно взятого робота игнорируются. Т.е., в приоритете всегда первая директива.
# Директива для робота Googlebot-Image.В ней разрешается индексация папки images: User-agent: Googlebot-Image Allow: /images/ # Директива для всех ботов, запрещающая индексацию папки images. При этом правило не будет распространяться на Googlebot-Image: User-agent: * Disallow: /images/
Disallow
Это обязательная директива – в каждой из групп правил должно содержаться Disallow или Allow. Суть ее заключается в указании документа или каталога на сайте, запрещенного для индексирования. Для документов (страниц) следует прописывать полный путь, а для каталога достаточно завершить его название символом «/» – в этом случае, все последующие директории также будут закрыты от индексации.
# Запрет на индексацию всего сайта: User-agent: * Disallow: / # Запрет индексирования конкретного раздела (директории): User-agent: * Disallow: /main/ # Запрет на индексацию всех URL-адресов, начинающихся с /main: User-agent: * Disallow: /main
Если в «Disallow» не указана директория, то правило игнорируется:
# Весь сайт доступен для индексации: User-agent: * Disallow:
Allow
Allow содержит в себе адрес документа или каталога, для которых разрешена индексация. Аналогичным образом, если указывается страница, то для нее прописывается полный URL-адрес, если это каталог, то после его названия ставится символ «/».
Аналогичным образом, если указывается страница, то для нее прописывается полный URL-адрес, если это каталог, то после его названия ставится символ «/».
С помощью следующей комбинации Allow и Disallow можно строить правила исключений, например:
# Запрет на индексацию директории main, при этом ее подкаталог images доступен для сканирования: User-agent: * Disallow: /main/ # индексирование запрещено Allow: /main/ images/ # данный подкаталог доступен для индексации всеми поисковиками
Если в правилах указаны противоречащие друг другу директивы: Allow и Disallow, то Allow имеет приоритет:
# Запрет на индексацию директории main, при этом ее подкаталог images доступен для сканирования: User-agent: * Disallow: /main/ # индексирование запрещено Allow: /main/ images/ # данный подкаталог доступен для индексации всеми поисковиками
Sitemap
С помощью этой директивы можно подсказать роботам расположение файла карты сайта.
Sitemap: https://sitename.com/sitemap.xml
Допускается указание нескольких файлов карт.
Замечание: просмотр файла robots.txt доступен для всех, а с помощью карты сайта любой желающий может найти недавно опубликованные, но не проиндексированные страницы.
Clean-param
Если URL-адрес содержит в себе какие-либо динамические параметры, например, UTM-метки, но не влияющие на отображение документа, то это можно указать в директиве Clean-param.
Схема директивы: <параметр> <URL-адрес документа (страницы) для которой не учитывается параметр>:
User-agent: * Disallow: /main/ # Указывает на то, что параметры utm в URL-адресе с cat.php не обладают какой-либо значимостью. # (например, в адресе sitename.com/cat.php?utm=1 параметр utm не учитывается. Clean-param: utm cat.php
Эта директива призвана помочь алгоритмам Яндекса в определении тех страниц, URL-адреса которых должны попасть в органическую выдачу.
Также допускается указание нескольких директив «Clean-param» в одной группе правил.
Примеры robots.txt для разных CMS
Ниже представлены варианты robots.txt для некоторых CMS, их можно использовать по умолчанию, но не стоит использовать их вслепую, предварительно ознакомьтесь с основными директивами и спецсимволами.
WordPress
User-agent: * Disallow: /wp-admin Disallow: /wp-includes Disallow: /wp-content/plugins Disallow: /wp-content/cache Disallow: /wp-json/ Disallow: /xmlrpc.php Disallow: /readme.html Disallow: /*? Disallow: /?s= Allow: /*.css Allow: /*.js Sitemap: https://site.ru/sitemap.xml
Joomla
Robots.txt для Joomla, скрыты от индексации основные директории со служебным контентом.
User-agent: * Disallow: /administrator/ Disallow: /cache/ Disallow: /includes/ Disallow: /installation/ Disallow: /language/ Disallow: /libraries/ Disallow: /media/ Disallow: /modules/ Disallow: /plugins/ Disallow: /templates/ Disallow: /tmp/ Disallow: /xmlrpc/ Sitemap: https://sitename.com/sitemap.xml
1С-Битрикс
User-agent: * Disallow: /cgi-bin Disallow: /bitrix/ Disallow: /local/ Disallow: /*index.php$ Disallow: /auth/ Disallow: *auth= Disallow: /personal/ Disallow: *register= Disallow: *forgot_password= Disallow: *change_password= Disallow: *login= Disallow: *logout= Disallow: */search/ Disallow: *action= Disallow: *print= Disallow: *?new=Y Disallow: *?edit= Disallow: *?preview= Disallow: *backurl= Disallow: *back_url= Disallow: *back_url_admin= Disallow: *captcha Disallow: */feed Disallow: */rss Disallow: *?FILTER*= Sitemap:
Каждый из представленных robots.txt следует дорабатывать под особенности своего проекта, это лишь примеры расширенных вариантов базовых файлов.
Проверка robots.txt
Первым делом следует проверить файл на доступность. Сделать это можно в панели Вебмастера от Яндекса: «Инструменты – Проверка ответов сервера».
Проверяем ответ сервера
Файл должен отдавать 200 код ответа.
Затем переходим по следующему пути: «Инструменты – Анализ robots.txt».
Здесь будут показаны ошибки, если они есть, а также можно удобно изучить структуру файла.
Анализ robots.txt в Яндекс.Вебмастере
Далее переходим в инструмент Google Search Console «Анализ robots.txt» и проверяем наш файл повторно.
Пример отчета
Robots.txt является важнейшим файлом при SEO-продвижении, к его созданию следует подходить основательно. Неправильная его настройка может привести к тому, что сайт перестанет индексироваться или в индекс попадут «мусорные» страницы.
Все о файле «robots.txt» по-русски — как составить robots.txt
Файл robots.txt
Все поисковые роботы при заходе на сайт в первую очередь ищут файл robots. txt. Если вы – вебмастер, вы должны знать назначение и синтаксис robots.txt.
txt. Если вы – вебмастер, вы должны знать назначение и синтаксис robots.txt.
Файл robots.txt – это текстовый файл, находящийся в корневой директории сайта, в котором записываются специальные инструкции для поисковых роботов. Эти инструкции могут запрещать к индексации некоторые разделы или страницы на сайте, указывать на правильное «зеркалирование» домена, рекомендовать поисковому роботу соблюдать определенный временной интервал между скачиванием документов с сервера и т.д.
Создание robots.txt
Файл с указанным расширением – простой текстовый документ. Он создается с помощью обычного блокнота, программ Notepad или Sublime, а также любого другого редактора текстов. Важно, что в его названии должен быть нижний регистр букв – robots.txt.
Также существует ограничение по количеству символов и, соответственно, размеру. Например, в Google максимальный вес установлен как 500 кб, а у Yandex – 32 кб. В случае их превышения корректность работы может быть нарушена.
Создается документ в кодировке UTF-8, и его действие распространяется на протоколы HTTP, HTTPS, FTP.
При написании содержимого файла запрещается использование кириллицы. Если есть необходимость применения кириллических доменов, необходимо прибегать к помощи Punycode. Кодировка адресов отдельных страниц должна происходить в соответствии с кодировкой структуры сайта, которая была применена.
После того как файл создан, его следует запустить в корневой каталог. При этом используется FTP-клиент, проверяется возможность доступа по ссылке https://site.com./robots.txt и полнота отображения данных.
Важно помнить, что для каждого поддомена сайта оформляется свой файл с ограничениями.
Описание robots.txt
Чтобы правильно написать robots.txt, предлагаем вам изучить разделы этого сайта. Здесь собрана самая полезная информация о синтаксисе robots. txt, о формате robots.txt, примеры использования, а также описание основных поисковых роботов Рунета.
txt, о формате robots.txt, примеры использования, а также описание основных поисковых роботов Рунета.
- Как работать с robots.txt — узнайте, что вы можете сделать, чтобы управлять роботами, которые посещают ваш веб-сайт.
- Роботы Рунета — разделы по роботам поисковых систем, популярных на просторах Рунета.
- Частые ошибки в robots.txt — список наиболее частых ошибок, допускаемых при написании файла robots.txt.
- ЧаВо по веб-роботам — часто задаваемые вопросы о роботах от пользователей, авторов и разработчиков.
- Ссылки по теме — аналог оригинального раздела «WWW Robots Related Sites», но дополненый и расширенный, в основном по русскоязычной тематике.
Где размещать файл robots.txt
Робот просто запрашивает на вашем сайте URL «/robots.txt», сайт в данном случае – это определенный хост на определенном порту.
На сайте может быть только один файл «/robots.txt». Например, не следует помещать файл robots.txt в пользовательские поддиректории – все равно роботы не будут их там искать.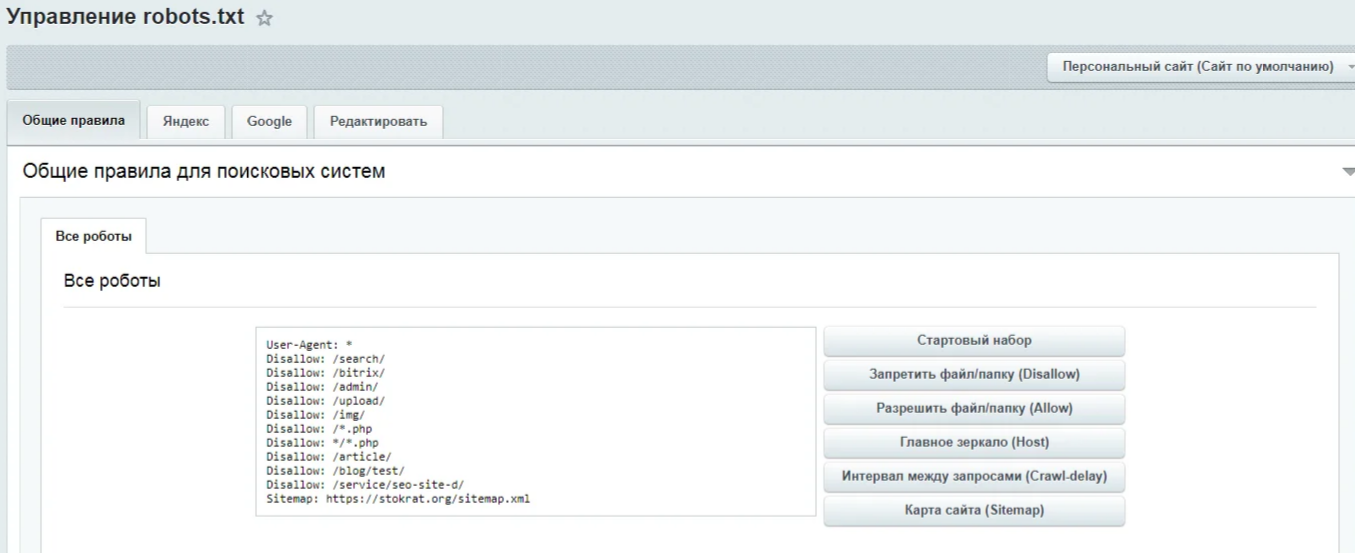 Если вы хотите иметь возможность создавать файлы robots.txt в поддиректориях, то вам нужен способ программно собирать их в один файл robots.txt, расположенный в корне сайта. Вместо этого можно использовать Мета-тег Robots.
Если вы хотите иметь возможность создавать файлы robots.txt в поддиректориях, то вам нужен способ программно собирать их в один файл robots.txt, расположенный в корне сайта. Вместо этого можно использовать Мета-тег Robots.
Не забывайте, что URL-ы чувствительны к регистру, и название файла «/robots.txt» должно быть написано полностью в нижнем регистре.
Как видите, файл robots.txt нужно класть исключительно в корень сайта.
Что писать в файл robots.txt
В файл robots.txt обычно пишут нечто вроде:
User-agent: *
Disallow: /cgi-bin/
Disallow: /tmp/
Disallow: /~joe/
В этом примере запрещена индексация трех директорий.
Затметьте, что каждая директория указана на отдельной строке – нельзя написать «Disallow: /cgi-bin/ /tmp/». Нельзя также разбивать одну инструкцию Disallow или User-agent на несколько строк, т.к. перенос строки используется для отделения инструкций друг от друга.
Регулярные выражения и символы подстановки так же нельзя использовать. «Звездочка» (*) в инструкции User-agent означает «любой робот». Инструкции вида «Disallow: *.gif» или «User-agent: Ya*» не поддерживаются.
«Звездочка» (*) в инструкции User-agent означает «любой робот». Инструкции вида «Disallow: *.gif» или «User-agent: Ya*» не поддерживаются.
Конкретные инструкции в robots.txt зависят от вашего сайта и того, что вы захотите закрыть от индексации. Вот несколько примеров:
Запретить весь сайт для индексации всеми роботами
User-agent: *
Disallow: /
Разрешить всем роботам индексировать весь сайт
User-agent: *
Disallow:
Или можете просто создать пустой файл «/robots.txt».
Закрыть от индексации только несколько каталогов
User-agent: *
Disallow: /cgi-bin/
Disallow: /tmp/
Disallow: /private/
Запретить индексацию сайта только для одного робота
User-agent: BadBot
Disallow: /
Разрешить индексацию сайта одному роботу и запретить всем остальным
User-agent: Yandex
Disallow:
User-agent: *
Disallow: /
Запретить к индексации все файлы кроме одного
Это довольно непросто, т.к. не существует инструкции “Allow”. Вместо этого можно переместить все файлы кроме того, который вы хотите разрешить к индексации в поддиректорию и запретить ее индексацию:
User-agent: *
Disallow: /docs/
Либо вы можете запретить все запрещенные к индексации файлы:
User-agent: *
Disallow: /private.html
Disallow: /foo.html
Disallow: /bar.html
Инфографика
Проверка
Оценить правильность созданного документа robots.txt можно с помощью специальных проверочных ресурсов:
- Анализ robots.txt. – при работе с Yandex.
- robots.txt Tester – для Google.
Важно помнить, что неправильно созданный или прописанный документ может являться угрозой для посещаемости и ранжирования сайта.
О сайте
Этот сайт — некоммерческий проект. Значительная часть материалов — это переводы www.robotstxt.org, другая часть — оригинальные статьи. Мы не хотим ограничиваться только robots.txt, поэтому в некоторых статьях описаны альтернативные методы «ограничения» роботов.
Полезное и интересное » Как правильно составить Robots.txt
Файл robots.txt является одним из самых важных при оптимизации любого сайта. Его отсутствие может привести к высокой нагрузке на сайт со стороны поисковых роботов и медленной индексации и переиндексации, а неправильная настройка к тому, что сайт полностью пропадет из поиска или просто не будет проиндексирован. Следовательно, не будет искаться в Яндексе, Google и других поисковых системах. Давайте разберемся во всех нюансах правильной настройки robots.txt.
Для начала короткое видео, которое создаст общее представление о том, что такое файл robots.txt.
Как влияет robots.txt на индексацию сайта
Поисковые роботы будут индексировать ваш сайт независимо от наличия файла robots.txt. Если же такой файл существует, то роботы могут руководствоваться правилами, которые в этом файле прописываются. При этом некоторые роботы могут игнорировать те или иные правила, либо некоторые правила могут быть специфичными только для некоторых ботов. В частности, GoogleBot не использует директиву Host и Crawl-Delay, YandexNews с недавних пор стал игнорировать директиву Crawl-Delay, а YandexDirect и YandexVideoParser игнорируют более общие директивы в роботсе (но руководствуются теми, которые указаны специально для них).
Подробнее об исключениях:
Исключения Яндекса
Стандарт исключений для роботов (Википедия)
Максимальную нагрузку на сайт создают роботы, которые скачивают контент с вашего сайта. Следовательно, указывая, что именно индексировать, а что игнорировать, а также с какими временны́ми промежутками производить скачивание, вы можете, с одной стороны, значительно снизить нагрузку на сайт со стороны роботов, а с другой стороны, ускорить процесс скачивания, запретив обход ненужных страниц.
К таким ненужным страницам относятся скрипты ajax, json, отвечающие за всплывающие формы, баннеры, вывод каптчи и т.д., формы заказа и корзина со всеми шагами оформления покупки, функционал поиска, личный кабинет, админка.
Для большинства роботов также желательно отключить индексацию всех JS и CSS. Но для GoogleBot и Yandex такие файлы нужно оставить для индексирования, так как они используются поисковыми системами для анализа удобства сайта и его ранжирования (пруф Google, пруф Яндекс).
Директивы robots.txt
Директивы — это правила для роботов. Есть спецификация W3C от 30 января 1994 года и расширенный стандарт от 1996 года. Однако не все поисковые системы и роботы поддерживают те или иные директивы. В связи с этим для нас полезнее будет знать не стандарт, а то, как руководствуются теми или иными директивы основные роботы.
Давайте рассмотрим по порядку.
User-agent
Это самая главная директива, определяющая для каких роботов далее следуют правила.
Для всех роботов:User-agent: *
Для конкретного бота:User-agent: GoogleBot
Обратите внимание, что в robots.txt не важен регистр символов. Т.е. юзер-агент для гугла можно с таким же успехом записать соледующим образом:user-agent: googlebot
Ниже приведена таблица основных юзер-агентов различных поисковых систем.
| Бот | Функция |
|---|---|
| Googlebot | основной индексирующий робот Google |
| Googlebot-News | Google Новости |
| Googlebot-Image | Google Картинки |
| Googlebot-Video | видео |
| Mediapartners-Google | Google AdSense, Google Mobile AdSense |
| Mediapartners | Google AdSense, Google Mobile AdSense |
| AdsBot-Google | проверка качества целевой страницы |
| AdsBot-Google-Mobile-Apps | Робот Google для приложений |
| Яндекс | |
| YandexBot | основной индексирующий робот Яндекса |
| YandexImages | Яндекс.Картинки |
| YandexVideo | Яндекс.Видео |
| YandexMedia | мультимедийные данные |
| YandexBlogs | робот поиска по блогам |
| YandexAddurl | робот, обращающийся к странице при добавлении ее через форму «Добавить URL» |
| YandexFavicons | робот, индексирующий пиктограммы сайтов (favicons) |
| YandexDirect | Яндекс.Директ |
| YandexMetrika | Яндекс.Метрика |
| YandexCatalog | Яндекс.Каталог |
| YandexNews | Яндекс.Новости |
| YandexImageResizer | робот мобильных сервисов |
| Bing | |
| Bingbot | основной индексирующий робот Bing |
| Yahoo! | |
| Slurp | основной индексирующий робот Yahoo! |
| Mail.Ru | |
| Mail.Ru | основной индексирующий робот Mail.Ru |
| Rambler | |
| StackRambler | Ранее основной индексирующий робот Rambler. Однако с 23.06.11 Rambler перестает поддерживать собственную поисковую систему и теперь использует на своих сервисах технологию Яндекса. Более не актуально. |
Disallow и Allow
Disallow закрывает от индексирования страницы и разделы сайта.
Allow принудительно открывает для индексирования страницы и разделы сайта.
Но здесь не все так просто.
Во-первых, нужно знать дополнительные операторы и понимать, как они используются — это *, $ и #.
* — это любое количество символов, в том числе и их отсутствие. При этом в конце строки звездочку можно не ставить, подразумевается, что она там находится по умолчанию.
$ — показывает, что символ перед ним должен быть последним.
# — комментарий, все что после этого символа в строке роботом не учитывается.
Примеры использования:
Disallow: *?s=
Disallow: /category/$
Следующие ссылки будут закрыты от индексации:
http://site.ru/?s=
http://site.ru/?s=keyword
http://site.ru/page/?s=keyword
http://site.ru/category/
Следующие ссылки будут открыты для индексации:
http://site.ru/category/cat1/
http://site.ru/category-folder/
Во-вторых, нужно понимать, каким образом выполняются вложенные правила.
Помните, что порядок записи директив не важен. Наследование правил, что открыть или закрыть от индексации определяется по тому, какие директории указаны. Разберем на примере.
Allow: *.css
Disallow: /template/
http://site.ru/template/ — закрыто от индексирования
http://site.ru/template/style.css — закрыто от индексирования
http://site.ru/style.css — открыто для индексирования
http://site.ru/theme/style.css — открыто для индексирования
Если нужно, чтобы все файлы .css были открыты для индексирования придется это дополнительно прописать для каждой из закрытых папок. В нашем случае:
Allow: *.css
Allow: /template/*.css
Disallow: /template/
Повторюсь, порядок директив не важен.
Sitemap
Директива для указания пути к XML-файлу Sitemap. URL-адрес прописывается так же, как в адресной строке.
Например,
Sitemap: http://site.ru/sitemap.xml
Директива Sitemap указывается в любом месте файла robots.txt без привязки к конкретному user-agent. Можно указать несколько правил Sitemap.
Host
Директива для указания главного зеркала сайта (в большинстве случаев: с www или без www). Обратите внимание, что главное зеркало указывается БЕЗ http://, но С https://. Также если необходимо, то указывается порт.
Директива поддерживается только ботами Яндекса и Mail.Ru. Другими роботами, в частности GoogleBot, команда не будет учтена. Host прописывается только один раз!
Пример 1:Host: site.ru
Пример 2:Host: https://site.ru
Crawl-delay
Директива для установления интервала времени между скачиванием роботом страниц сайта. Поддерживается роботами Яндекса, Mail.Ru, Bing, Yahoo. Значение может устанавливаться в целых или дробных единицах (разделитель — точка), время в секундах.
Пример 1:Crawl-delay: 3
Пример 2:Crawl-delay: 0.5
Если сайт имеет небольшую нагрузку, то необходимости устанавливать такое правило нет. Однако если индексация страниц роботом приводит к тому, что сайт превышает лимиты или испытывает значительные нагрузки вплоть до перебоев работы сервера, то эта директива поможет снизить нагрузку.
Чем больше значение, тем меньше страниц робот загрузит за одну сессию. Оптимальное значение определяется индивидуально для каждого сайта. Лучше начинать с не очень больших значений — 0.1, 0.2, 0.5 — и постепенно их увеличивать. Для роботов поисковых систем, имеющих меньшее значение для результатов продвижения, таких как Mail.Ru, Bing и Yahoo можно изначально установить бо́льшие значения, чем для роботов Яндекса.
Clean-param
Это правило сообщает краулеру, что URL-адреса с указанными параметрами не нужно индексировать. Для правила указывается два аргумента: параметр и URL раздела. Директива поддерживается Яндексом.
Пример 1:
Clean-param: author_id http://site.ru/articles/
http://site.ru/articles/?author_id=267539 — индексироваться не будет
Пример 2:
Clean-param: author_id&sid http://site.ru/articles/
http://site.ru/articles/?author_id=267539&sid=0995823627 — индексироваться не будет
Яндекс также рекомендует использовать эту директиву для того, чтобы не учитывались UTM-метки и идентификаторы сессий. Пример:
Clean-Param: utm_source&utm_medium&utm_campaign
Другие параметры
В расширенной спецификации robots.txt можно найти еще параметры Request-rate и Visit-time. Однако они на данный момент не поддерживаются ведущими поисковыми системами.
Смысл директив:
Request-rate: 1/5 — загружать не более одной страницы за пять секунд
Visit-time: 0600-0845 — загружать страницы только в промежуток с 6 утра до 8:45 по Гринвичу.
Закрывающий robots.txt
Если вам нужно настроить, чтобы ваш сайт НЕ индексировался поисковыми роботами, то вам нужно прописать следующие директивы:
User-agent: * Disallow: /
Проверьте, чтобы на тестовых площадках вашего сайта были прописаны эти директивы.
Правильная настройка robots.txt
Для России и стран СНГ, где доля Яндекса ощутима, следует прописывать директивы для всех роботов и отдельно для Яндекса и Google.
Чтобы правильно настроить robots.txt воспользуйтесь следующим алгоритмом:
- Закройте от индексирования админку сайта
- Закройте от индексирования личный кабинет, авторизацию, регистрацию
- Закройте от индексирования корзину, формы заказа, данные по доставке и заказам
- Закройте от индексирования ajax, json-скрипты
- Закройте от индексирования папку cgi
- Закройте от индексирования плагины, темы оформления, js, css для всех роботов, кроме Яндекса и Google
- Закройте от индексирования функционал поиска
- Закройте от индексирования служебные разделы, которые не несут никакой ценности для сайта в поиске (ошибка 404, список авторов)
- Закройте от индексирования технические дубли страниц, а также страницы, на которых весь контент в том или ином виде продублирован с других страниц (календари, архивы, RSS)
- Закройте от индексирования страницы с параметрами фильтров, сортировки, сравнения
- Закройте от индексирования страницы с параметрами UTM-меток и сессий
- Проверьте, что проиндексировано Яндексом и Google с помощью параметра «site:» (в поисковой строке наберите «site:site.ru»). Если в поиске присутствуют страницы, которые также нужно закрыть от индексации, добавьте их в robots.txt
- Укажите Sitemap и Host
- По необходимости пропишите Crawl-Delay и Clean-Param
- Проверьте корректность robots.txt через инструменты Google и Яндекса (описано ниже)
- Через 2 недели перепроверьте, появились ли в поисковой выдаче новые страницы, которые не должны индексироваться. В случае необходимости повторить выше перечисленные шаги.
Пример robots.txt
# Пример файла robots.txt для настройки гипотетического сайта https://site.ru User-agent: * Disallow: /admin/ Disallow: /plugins/ Disallow: /search/ Disallow: /cart/ Disallow: */?s= Disallow: *sort= Disallow: *view= Disallow: *utm= Crawl-Delay: 5 User-agent: GoogleBot Disallow: /admin/ Disallow: /plugins/ Disallow: /search/ Disallow: /cart/ Disallow: */?s= Disallow: *sort= Disallow: *view= Disallow: *utm= Allow: /plugins/*.css Allow: /plugins/*.js Allow: /plugins/*.png Allow: /plugins/*.jpg Allow: /plugins/*.gif User-agent: Yandex Disallow: /admin/ Disallow: /plugins/ Disallow: /search/ Disallow: /cart/ Disallow: */?s= Disallow: *sort= Disallow: *view= Allow: /plugins/*.css Allow: /plugins/*.js Allow: /plugins/*.png Allow: /plugins/*.jpg Allow: /plugins/*.gif Clean-Param: utm_source&utm_medium&utm_campaign Crawl-Delay: 0.5 Sitemap: https://site.ru/sitemap.xml Host: https://site.ru
Как добавить и где находится robots.txt
После того как вы создали файл robots.txt, его необходимо разместить на вашем сайте по адресу site.ru/robots.txt — т.е. в корневом каталоге. Поисковый робот всегда обращается к файлу по URL /robots.txt
Как проверить robots.txt
Проверка robots.txt осуществляется по следующим ссылкам:
Типичные ошибки в robots.txt
В конце статьи приведу несколько типичных ошибок файла robots.txt
- robots.txt отсутствует
- в robots.txt сайт закрыт от индексирования (Disallow: /)
- в файле присутствуют лишь самые основные директивы, нет детальной проработки файла
- в файле не закрыты от индексирования страницы с UTM-метками и идентификаторами сессий
- в файле указаны только директивы
Allow: *.css
Allow: *.js
Allow: *.png
Allow: *.jpg
Allow: *.gif
при этом файлы css, js, png, jpg, gif закрыты другими директивами в ряде директорий - директива Host прописана несколько раз
- в Host не указан протокол https
- путь к Sitemap указан неверно, либо указан неверный протокол или зеркало сайта
P.S.
Если у вас есть дополнения к статье или вопросы, пишите ниже в комментариях.
Если у вас сайт на CMS WordPress, вам будет полезна статья «Как настроить правильный robots.txt для WordPress».
P.S.2
Полезное видео от Яндекса (Внимание! Некоторые рекомендации подходят только для Яндекса).
robots.txt для Shop-Script — Webasyst
Правила для файла robots.txt нужно вписывать в бекенде приложения «Сайт». Перейдите в раздел «Настройки» и найдите в нем поле «robots.txt».
Как отменить индексацию лишних страниц
Примеры директив составлены для витрины интернет-магазина в корне домена, например: mydomain.ru.
Если в адресе витрины вашего магазина есть название поддиректории (например, mydomain.ru/shop/), то имя поддиректории нужно подставить вместо символа косой черты («/») в начале правила.
Например, для витрины с адресом mydomain.ru/shop/ правило
Disallow: /tag/
примет вид
Disallow: /shop/tag/
Примеры
| Disallow: /search/?query= | Страница с результатами поиска товаров. |
| Disallow: /compare/ | Страница с результатами сравнения товаров. |
| Disallow: /tag/ | Страница с результатами поиска по тегам. |
| Disallow: *&sort= Disallow: */?sort= |
Страница с результатами сортировки товаров в категории. |
| Disallow: /cart/ | Страница корзины покупателя. |
| Disallow: /order/ | Страница оформления заказа в корзине. |
| Disallow: /checkout/ | Страницы пошагового оформления заказа. |
| Disallow: /my/ | Личный кабинет покупателя. |
| Disallow: /signup/ | Страница регистрации покупателя. |
| Disallow: /login/ | Страница входа в личный кабинет. |
| Disallow: /forgotpassword/ | Страница напоминания пароля. |
| Disallow: /webasyst/ |
Страница для входа в бекенд Webasyst. |
Как снизить нагрузку на сервер
Нагрузку на сервер от поисковых роботов можно уменьшить с помощью директивы Crawl-delay. Она добавляет паузу после между посещениями поискового робота. Размер паузы указывайте в секундах.
Пример
Crawl-delay: 10
Некоторые поисковые системы могут не учитывать этот параметр. Например, регулировать частоту индексации страниц сайта поисковыми роботами «Яндекса» и «Гугла» нужно в личном кабинете на сайтах сервисов «Яндекс.Вебмастер» и Google Search Console.
Файл robots txt для сайта
Robots.txt – это служебный файл, инструкция для поисковых роботов для индексации сайта. В файле указываются каталоги, которые не требуется индексировать. Обычно это администраторская панель, кеш, служебные файлы. Размещается в корневой папке веб-ресурса. Его использование необходимо для лучшей индексации страниц, защиты приватной информации и повышения безопасности сайта.
Часто используется веб-мастерами вместе с другим служебным файлом, предусмотренным протоколом sitemap ( написанном на языке XML), который действует наоборот, предоставляя карту сайта с разрешенными к чтению роботами страницами.
Robots.txt и его влияние на индексацию сайта
На индексацию сайта также влияют скорость и надежность хостинга. Быстрый и надежный хостинг со скидкой до 30%!
После создания сайта его корневая папка на хосте становится доступной для поисковых систем. Роботы читают все, что найдут, без разбора.
В каталогах динамических сайтов, находящихся под управлением CMS, они не найдут никакой информации, ведь она хранится в базах данных MYSQL. Роботы, если им этого не запретить, беспрепятственно перебирают файлы в директориях, которые закрыты для посещения всем, кроме администратора. Это опасно для сайта и отнимает время у поисковиков, снижая скорость индексации веб-ресурса.
Для хакеров и прочих компьютерных злоумышленников доступные к чтению служебные файлы – это еще не дверь, но замочная скважина, в которую они обязательно залезут с электронной отмычкой для получения контроля над всем сайтом. Если в файле robots.txt указать, что читать надо только индексные файлы, то знакомство поисковой системы с динамическим сайтом произойдет быстрее, а его безопасность повысится.
Для статических веб-ресурсов этот файл станет небольшой гарантией, что хранящиеся конфиденциальные данные (телефоны, адреса электронной почты и другие) не окажутся в открытом доступе.
Веб-мастер, создавая файл robots.txt, может запретить роботам поисковых систем посещение всего сайта или дать доступ к его индексации только одной из категорий или страниц сайта.
Какие страницы стоит запретить и закрыть в robots.txt?
Если на хосте, где размещен сайт, есть панель управления, то этот файл можно создать, открыв корневую папку и нажав кнопку «новый файл» (бывают варианты в названиях). Но лучше создать файл на домашнем компьютере, а для загрузки воспользоваться каналом FTP.
Самой удобной программой для создания файла robots.txt является Notepad++. Но не возбраняется использовать обычный блокнот из набора Windows или текстовый редактор Word. Сохранять файл надо с расширением .txt.
Даже если он написан неправильно, это не приведет к потере работоспособности сайта, как это происходит с неправильным файлом .htaccess.
— Если не хочется ни изучать синтаксис файла, ни создавать его самостоятельно, то можно обратиться, например на http://pr-cy.ru/robots/, где его сгенерируют автоматически.
Директивы файла — user agent, host и т.д.
Директивы (команды) файла пишутся на латинице, после каждой из них ставится двоеточие и указывается объект управления.
Директивы бывают стандартные:
- User-agent – имя поискового робота;
- Allow – разрешить;
- Disallow – запретить;
- Sitemap – адрес, где находится sitemap.xml;
- * – для всех.
И расширенные:
- Craw-delay– промежуток времени между чтением директорий;
- Request-rate – количество страниц, просмотренных за одну секунду;
- Visit-time – желаемое время посещения сайта роботом.
Расширенные директивы снижают нагрузку на сервер и защищают сайт от слишком назойливых парсеров.
Google, Яндекс и настройка роботс
Поисковые системы Гугл и Яндекс одинаково хорошо читают этот файл, но рассчитывать, что его наличие послужит установлению каких-либо особенных отношений поисковых систем с сайтом – это ненужный романтизм, лишенный оснований. Есть некоторые отличия в том как можно обратиться к поисковому роботу, ведь у каждой системы их целый набор:
- YandexBot и Googlebot – это обращение к основным поисковым роботам;
- YandexNews и Googlebot-news – роботы, специализирующиеся на новостном контенте;
- YandexImages и Googlebot-image – индексаторы картинок.
У Яндекса поисковых роботов девять, а у Google восемь. Если требуется общая индексация, то после директивы User-agent пишется Yandex или Googlebot.
У Яндекса есть еще одна особенность: его роботы читают директиву Host, указывающую на «зеркало» сайта. Гугл ее не понимает.
Нужен красивый домен для Вашего проекта? Проверить и купить домен дешево болеее чем в 300 зонах!
Как составить robots.txt для Joomla
Вот как может выглядеть этот файл для новостного сайта на CMS Joomla.
User-agent: YandexNews
Disallow: /administrator
Disallow: /components
Disallow: /libraries
Allow: /index1.php
Allow: /index2.php
Request-rate: 1/20
Visit-time: 0200-0600
В нем для индексации «приглашен» новостной бот Яндекса, которому запрещено читать директории administrator, components и libraries (папка, где собственно и содержится «движок»). Индексировать можно 1 страницу за 20 секунд, а посещать сайт с двух ночи до шести утра по Гринвичу.
Проверить правильность написания файла robots.txt можно обратившись в Яндексе к сервису «Вебмастеру». Такой же Центр Веб-мастеров есть и у Google.
Не нужно использовать этот файл как основу – в нем просто показано использование директив.
Пример правильного файла robots.txt для WordPress — как запретить все лишнее
А это – рабочий файл robots.txt для CMS WordPress.
User-agent: *
Disallow: /wp-login.php
Disallow: /wp-register.php
Disallow: /cgi-bin/
Disallow: /wp-admin/
Disallow: /archives/
Disallow: /*?*
Disallow: *?replytocom
Disallow: /wp-*
Disallow: /comments/feed/
User-agent: Yandex
Disallow: /wp-login.php
Disallow: /wp-register.php
Disallow: /cgi-bin/
Disallow: /wp-admin/
Disallow: /archives/
Disallow: /*?*
Disallow: *?replytocom
Disallow: /wp-*
Disallow: /comments/feed/
Host: http://вашсайт.ру
Sitemap: http://вашсайт.ру/sitemap.xml
В первом блоке написаны директивы для всех поисковых роботов, они же дублируются для Яндекса, только с уточнением основной версии сайта. Как видно, из индекса исключена пагинация, служебные файлы и каталоги.
iPipe – надёжный хостинг-провайдер с опытом работы более 15 лет.
Мы предлагаем:
Зачем нужен robots.txt на веб-сайте?
Robots.txt это файл, предназначенный для поисковых роботов, в котором указаны ограничения для индексации содержимого сайта. Обычно используется для запрета обхода роботами технической и конфиденциальной информации, чтобы она не выводилась в поисковых системах. Находится он в корневом каталоге вашего сайта, например,
«/Web/user/htdocs/example.com/robots.txt»
В браузере его можно найти по адресу http://example.com/robots.txt.
Что писать в файл robots.txt?
В настоящее время в файле robots.txt имеется только три основных оператора:
Disallow: / path
allow: / путь
sitemap: http://example.com/sitemap.xml
+ еще
host: http://example.com (для Яндекса)
Содержимое файла robots.txt состоит из разделов, посвященных определенным роботам-сканерам. Если вам нечего скрывать от индексации, то ваш файл robots.txt выглядит так:
User-agent: *
Disallow:
Allow: /
Sitemap: http://example.com/sitemap.xml
Если вам нравится Google, а Yandex нет, напишите:
User-agent: *
Disallow:
User-agent: Googlebot
Disallow:
User-agent: Yandex
disallow: /
Обратите внимание, что вы должны завершить работу каждого раздела пустой строкой.
Из приведенных выше примеров вы узнали, что каждая поисковая система имеет свое имя. Вы можете найти имена роботов-сканеров, посетив раздел веб-мастера поисковой системы и записать их в виде User-agent: [имя робота] в начале раздела.
Имя робота «*» означает универсальный веб-робот, это означает, что, если ваш файл robots.txt не имеет раздела для конкретного робота, он будет использовать директивы «*», и, если у вас есть раздел для конкретного робота, он будет игнорировать раздел «*». Другими словами, если вы создаете раздел для робота, перед редактированием кода вы должны дублировать все инструкции из раздела «Все роботы» («user-agent: *»).
Теперь к директивам. Самая важная директива — Disallow: / path
«Disallow» означает, что робот не должен получать содержимое из URI, которые соответствуют «/ path».
URI всегда относятся к корню веб-пространства, поэтому, если вы копируете и вставляете URL-адреса http://example.com/content/, то удалите часть http://example.com, но не /content/
Т.е. получится Disallow: /content/
Далее идет Allow:
«allow» — разрешает индексировать путь /
Нужен чтобы уточнить Disallow: утверждения, к примеру запись
User-agent: Googlebot
Disallow: /
Allow: / content /
Позволяет роботу гугла сканировать только в пределах http://example.com/content/
Карта сайта Sitemap: http://example.com/sitemap.xml
Указывает местоположение карты сайта, на которой есть ссылки на все страницы сайта. Подобно оглавлению книги – карта сайта ускоряет поиск и индексацию страниц сайта.
Можно ли автоматически генерировать файл robots.txt?
Да, можно. Но это возможно в случае, если ваш CMS поддерживает соответствующие плагины. Так же есть специализированные сайты, которые помогут генерировать карту для вашего сайта. Но не забывайте своевременно ее обновлять.
YandexBot Web Robot • VNTweb
Краткое описание Интернет-робота YandexBot . Включая сведения о владельце, описание, пользовательский агент HTTP и соответствие этого робота стандарту исключения роботов.
Кому принадлежит робот ЯндексБот ? Робот хороший или плохой? И почему он посещает ваш сайт?
Ниже показан образец записи файла журнала для веб-робота ЯндексБота. Он получен из файла журнала веб-сервера Apache. Из записи журнала дается информация о том, как робот идентифицирует себя, HTTP-агент пользователя и где он размещается.
Файл журнала сервера
vntweb.co.uk 5.45.207.28 - - [30 / апр / 2019: 00: 43: 33 +0100] "GET / html-marquee-tag / HTTP / 1.1" 200 8442 "-" "Mozilla / 5.0 (совместимый ; ЯндексБот / 3.0; + http: //yandex.com/bots) "
HTTP User Agent
ЯндексБот / 3.0
IP-адреса
Наблюдаемый IP-адрес: 5.45.207.28 .
Команда WHOIS DNS предоставляет следующую информацию об IP-адресе:
| inetnum: | 5.45.207.0 — 5.45.207.255 |
| сетевое имя: | ЯНДЕКС-5-45-207 |
| адрес: | ООО «Яндекс» |
| адрес: | ул. Льва Толстого, 16 |
| адрес: | 119021 |
| адрес: | Москва |
| адрес: | Российская Федерация |
| последнее изменение: | 2018-08-03T07: 15: 46Z |
As can Как видно из вышеизложенного, наблюдаемый IP-адрес является частью блока, присвоенного ООО «Яндекс».
Владелец
ООО «Яндекс»
Страна
Российская Федерация
Исключение
Строка user-agent содержит ссылку на сайт http://yandex.com/bots. В меню слева есть ссылка на использование robots.txt, где дается информация о настройке ботов Яндекса и конкретная информация для каждого из них.
Указанный веб-сайт подтверждает, что бот поддерживает текст исключения для роботов, а также соблюдает задержку сканирования.
На веб-сайте Яндекса представлена подробная информация о том, как их робот соответствует стандарту исключения robots.txt, который был описан на http://www.robotstxt.org/wc/exclusion.html#robotstxt, но в настоящее время недоступен. Информация доступна на том же веб-сайте https://www.robotstxt.org/robotstxt.html, а также на веб-сайте w3c по адресу https://www.w3.org/TR/html4/appendix/notes.html#hB.4.1. .1.
Приведены подробные сведения о предотвращении индексирования веб-сайта роботом и о том, как настроить скорость его сканирования.
Их совет — включить следующую запись в файл robots.txt, чтобы ЯндексБот не заходил на ваш сайт
Пользователь-агент: ЯндексБот Disallow: /
Также для управления частотой посещения Яндекс-ботом ваш сайт можно установить минимально допустимую задержку между последовательными запросами, добавив в файл robots.txt следующее:
Пользователь-агент: ЯндексБот Задержка сканирования: 10
В этом примере задержка установлена на 10 секунд.
Как это обычно бывает со сканерами веб-сайтов, существует задержка между изменениями, внесенными в файл robots.txt , и внесением изменений.
Позаботьтесь о внесении изменений в файл robots.txt. Неправильное понимание конфигурации или ошибка конфигурации может привести к тому, что важные поисковые системы исключат ваш веб-сайт.
Дополнительная информация
Яндекс — один из роботов Интернета. Он ассоциируется с одноименной российской поисковой системой.
Яндекс — самая популярная поисковая система в России и одна из крупнейших интернет-компаний в Европе.
У Яндекса есть несколько страниц с информацией о своем боте. Эта страница — хорошее место для начала http://help.yandex.com/search/
# # robots.txt # # Этот файл предназначен для предотвращения сканирования и индексации определенных частей # вашего сайта поисковыми роботами и пауками, управляемыми такими сайтами, как Yahoo! # и Google. Сообщая этим «роботам», куда нельзя заходить на вашем сайте, # вы экономите трафик и ресурсы сервера.# # Этот файл будет проигнорирован, если он не находится в корне вашего хоста: # Используется: http://example.com/robots.txt # Игнорируется: http://example.com/site/robots.txt # # Дополнительную информацию о стандарте robots.txt см. В следующих статьях: # http://www.robotstxt.org/robotstxt.html Пользовательский агент: SemrushBot Запретить: / Пользовательский агент: SemanticScholarBot Запретить: / Пользовательский агент: PetalBot Запретить: / #Baiduspider Пользовательский агент: Baiduspider Запретить: / # Яндекс User-agent: Яндекс Запретить: / Пользовательский агент: trendictionbot Запретить: / Пользовательский агент: * Задержка сканирования: 10 # CSS, JS, изображения Разрешить: / misc / *.css $ Разрешить: /misc/*.css? Разрешить: /misc/*.js$ Разрешить: /misc/*.js? Разрешить: /misc/*.gif Разрешить: /misc/*.jpg Разрешить: /misc/*.jpeg Разрешить: /misc/*.png Разрешить: /modules/*.css$ Разрешить: /modules/*.css? Разрешить: /modules/*.js$ Разрешить: /modules/*.js? Разрешить: /modules/*.gif Разрешить: /modules/*.jpg Разрешить: /modules/*.jpeg Разрешить: /modules/*.png Разрешить: /profiles/*.css$ Разрешить: /profiles/*.css? Разрешить: /profiles/*.js$ Разрешить: /profiles/*.js? Разрешить: /profiles/*.gif Разрешить: /profiles/*.jpg Разрешить: /profiles/*.jpeg Разрешить: / profiles / *.PNG Разрешить: /themes/*.css$ Разрешить: /themes/*.css? Разрешить: /themes/*.js$ Разрешить: /themes/*.js? Разрешить: /themes/*.gif Разрешить: /themes/*.jpg Разрешить: /themes/*.jpeg Разрешить: /themes/*.png # Каталоги Disallow: / включает / Запретить: / misc / Запретить: / modules / Запретить: / profiles / Запретить: / scripts / Запретить: / themes / # Файлов Запретить: /CHANGELOG.txt Запретить: /cron.php Запретить: /INSTALL.mysql.txt Запретить: /INSTALL.pgsql.txt Запретить: /INSTALL.sqlite.txt Запретить: /install.php Запретить: /INSTALL.txt Запрещено: / ЛИЦЕНЗИЯ.текст Запретить: /MAINTAINERS.txt Запретить: /update.php Запретить: /UPGRADE.txt Запретить: /xmlrpc.php # Пути (чистые URL) Запретить: / admin / Запретить: / комментарий / ответ / Запретить: / filter / tips / Запретить: / узел / добавить / Запретить: / поиск / Запретить: / пользователь / регистрация / Запретить: / пользователь / пароль / Запретить: / пользователь / логин / Запретить: / пользователь / выход из системы / # Пути (без чистых URL) Запретить: /? Q = admin / Запретить: /? Q = комментарий / ответ / Запретить: /? Q = filter / tips / Запретить: /? Q = узел / добавить / Запретить: /? Q = search / Запретить: /? Q = пользователь / пароль / Запретить: /? Q = пользователь / регистрация / Запретить: /? Q = пользователь / логин / Запретить: /? Q = пользователь / выход из системы /
роботов Архивы | Digital Growth World
Сегодня мы подробнее рассмотрим txt-файл robots — что это такое, зачем он нужен и как с ним работать.Термин robots txt описан на многих сайтах и в блогах. Однако везде статьи на эту тему существенно отличаются друг от друга. А потому, что пользователи в них запутались, как рыба в сетях.
Роботы txt файл — что за страшный зверь?
Robots.txt — это файл. Это стандартный текстовый документ, сохраненный в кодировке UTF-8. Он создан специально для работы с такими протоколами, как:
Файл несет важную функцию — он нужен для того, чтобы показать поисковому роботу, что именно нужно сканировать, а что закрыто от сканирования.
Все правила, требования, рекомендации, которые указаны в robots.txt, актуальны только для конкретного хоста, а также протокола и номера порта, на котором непосредственно находится описанный нами файл.
Кстати, сам файл robots.txt находится в корневом каталоге и представляет собой стандартный текстовый документ. Его адрес https://admin.com /robots.txt., Где admin.com — название вашего сайта.
В других файлах ставится специальная метка Byte Order Mark или ее еще называют аббревиатурой PTO.Этот знак является символом Unicode — он необходим для установления четкой последовательности считываемой информации в байтах. Код символа — U + FEFF.
Но в начале нашего robots.txt упускается возможность последовательного чтения.
Отметим непосредственно технические характеристики robots.txt. В частности, заслуживает упоминания тот факт, что файл представляет собой описание в форме BNF. И применяются правила RFC 822.
Что именно и как файл обрабатывается?Считывая команды, указанные в файле, роботы поисковых систем получают на выполнение следующие команды (одна из следующих):
- сканирование только отдельных страниц — это называется частичным доступом;
- сканирование всего сайта целиком — полный доступ;
- запрет на сканирование.
При обработке сайта роботы получают определенные ответы, которые могут быть следующими:
- 2xx — сайт просканирован успешно;
- 3xx — робот продолжает пересылку до тех пор, пока ему не удастся получить следующий ответ. В большинстве случаев требуется пять попыток, чтобы найти ответ, отличный от 3xx. Если при пяти попытках ответа не будет, будет записана ошибка 404;
- 4xx — робот уверен, что должен просканировать весь сайт;
- 5xx — такой ответ расценивается как временная ошибка сервера, и сканирование запрещено.Поисковый робот будет «стучать» по файлу до тех пор, пока не получит ответ. При этом робот от Google оценивает правильность или неправильность ответов. При этом следует сказать, что если вместо традиционной ошибки 404 получен ответ 5xx, то в этой ситуации робот обработает страницу с ответом 404.
Robots txt file директив — для чего нужны они нужны?
Например, бывают ситуации, когда необходимо ограничить посещение роботов:
- страниц, содержащих личную информацию о владельце;
- страниц, на которых размещены те или иные формы для передачи информации;
- зеркала сайта;
- страниц, отображающих результаты поиска и т. Д.
Как создать текстовый файл robots: подробные инструкции
Вы можете использовать практически любой текстовый редактор для создания такого файла, например:
- Блокнот;
- Ноутбук;
- Sublime et al.
Этот «документ» описывает инструкцию User-agent, а также указывает правило Disallow, но есть и другие, не очень важные, но необходимые правила / инструкции для поисковых роботов.
User-agent: кому это возможно, а кому нет
Самая важная часть «документа» — User-agent.Он указывает, какие именно поисковые роботы должны «смотреть» на инструкции, описанные в самом файле.
В настоящее время насчитывается 302 робота. Чтобы не регистрировать каждого отдельного робота в документе лично, необходимо указать запись в файле:
User-agent: *
Отметка означает, что правила в файле ориентированы на всех поисковых роботов. .
У Google есть основная поисковая машина Googlebot. Чтобы правила были разработаны только для него, необходимо в файле записать:
User-agent: Googlebot_
Если такая запись есть в файле, другие поисковые роботы будут оценивать материалы сайта согласно их основным директивам, которые предусматривают обработку пустых роботов.текст.
Яндекс имеет основного поискового робота Яндекса, и для него запись в файле будет выглядеть так:
User-agent: Яндекс
Если такая запись есть в файле, другие поисковые роботы будут оценивать материалы сайта согласно их основным директивам, которые предусматривают обработку пустого файла robots.txt.
Другие специальные поисковые роботы
- Googlebot-News — используется для сканирования новостных сообщений;
- Mediapartners-Google — специально разработан для сервиса Google AdSense;
- AdsBot-Google — оценивает общее качество конкретной целевой страницы;
- YandexImages — индексирует картинки Яндекс;
- Googlebot-Image — для сканирования изображений;
- ЯндексМетрика — сервисный робот Яндекс Метрик;
- ЯндексМедиа — робот, индексирующий мультимедиа;
- YaDirectFetcher — Яндекс.Прямой робот;
- Googlebot-Video — для индексации видео;
- Googlebot-Mobile — создан специально для мобильной версии сайтов;
- ЯндексДиректДин — робот для генерации динамических баннеров;
- ЯндексБлоги — поисковый робот по блогам; сканирует не только посты, но и комментарии;
- ЯндексДирект — предназначен для анализа содержания партнерских сайтов Рекламной сети. Это позволяет вам определять тематику каждого сайта и более эффективно выбирать релевантные объявления;
- YandexPagechecker — валидатор микромаркировок.
Других роботов перечислять не будем, но, повторяем, всего их более 300 тонн. Каждый из них ориентирован на определенные параметры.
Что такое Disallow?
Disallow — указывает, что не подлежит проверке на сайте. Чтобы весь сайт был открыт для сканирования поисковыми роботами, вы должны вставить запись:
User-agent: *
Disallow:
И если вы хотите, чтобы весь сайт был закрыт для сканирования поисковыми роботами введите в файл следующую «команду»:
User-agent: *
Disallow: /
Такая «запись» в файле будет актуальна, если сайт еще не полностью готов, вы планируете внести в него изменения, но так, чтобы в текущем состоянии он не отображался в результатах поиска.
И еще несколько примеров, как прописать ту или иную команду в файле robots.txt.
Чтобы запретить роботам просматривать определенную папку на сайте:
User-agent: *
Disallow: / papka /
Чтобы заблокировать сканирование определенного URL:
User-agent : *
Disallow: /private-info.html
Чтобы закрыть определенный файл из сканирования:
User-agent: *
Disallow: / image / имя файла и его расширение
Чтобы закрыть все файлы с определенным разрешением из сканирования:
User-agent: *
Disallow: / *.имя расширения и значок $ (без пробела)
Разрешить — команда для управления роботами
Разрешить — эта команда дает разрешение на сканирование определенных данных:
- файл;
- директив;
- страниц и т. Д.
В качестве примера рассмотрим ситуацию, когда важно, чтобы роботы могли просматривать только страницы, начинающиеся с / catalog, а все остальное содержимое на сайте должно быть закрыто. Команда в файле robots.txt будет выглядеть так:
User-agent: *
Allow: / catalog
Disallow: /
Host + to robots txt file or how to выберите зеркало для своего сайта
Добавление команды host + в txt-файл robots — одна из нескольких обязательных задач, которые вы должны выполнить в первую очередь.Это предусмотрено для того, чтобы поисковый робот понимал, какое зеркало сайта подлежит индексации, а какие не следует учитывать при сканировании страниц сайта.
Такая команда позволит роботу избежать недоразумений при обнаружении зеркала, а также понять, что является главным зеркалом ресурса — это указано в файле robots.txt.
При этом адрес сайта указывается без «https: //», однако, если ваш ресурс работает по HTTPS, в этом случае должен быть указан соответствующий префикс .
Это правило записывается следующим образом:
User-agent: * (имя поискового робота)
Разрешить: / catalog
Disallow: /
Host: имя сайта
Если сайт использует HTTPS, команда будет записана следующим образом:
User-agent: * (имя поискового робота)
Разрешить: / catalog
Disallow: /
Хост: https: // имя сайта
Карта сайта — что это и как с ней работать?
Карта сайта необходима для передачи информации поисковым роботам о том, что все URL-адреса сайтов, открытые для сканирования и индексации, расположены по адресу https: // site.ua / sitemap.xml.
Во время каждого посещения и обхода сайта поисковый робот будет точно изучать, какие изменения были внесены в этот файл, тем самым обновляя информацию о сайте в своей базе данных.
Вот как пишутся эти «команды» в файле robots.txt:
User-agent: *
Allow: / catalog
Disallow: /
Sitemap: https: // site.ua/sitemap.xml.
Crawl-delay — если сервер слабый
Crawl-delay — необходимый параметр для тех сайтов, которые расположены на слабых серверах.С его помощью у вас есть возможность установить определенный период, через который будут загружаться страницы вашего ресурса.
Действительно, слабые серверы провоцируют формирование задержек при доступе к ним поисковых роботов. Такие задержки фиксируются в секундах.
Вот пример написания этой команды:
User-agent: *
Allow: / catalog
Disallow: /
Crawl-delay: 3
Clean-param — при наличии дублированного содержимого
Clean-param — предназначен для «борьбы» с get-параметрами.Это необходимо для того, чтобы исключить возможное дублирование контента, который со временем будет доступен поисковым роботам по различным динамическим адресам. Подобные адреса появляются, если у ресурса разные сортировки и т.п.
Например, конкретная страница может быть доступна по следующим адресам:
- www.vip-site.com/foto/tele.ua?ref=page_1&tele_id=1
- www.vip-site .com / foto / tele.ua? ref = page_2 & tele_id = 1
- www.vip-site.com/foto/tele.ua?ref=page_3&tele_id=1
В аналогичной ситуации в файле robots.txt будет присутствовать следующая команда:
User-agent: Яндекс
Disallow:
Clean-param: ref / foto / tele.ua
В данном случае параметр ref показывает, откуда идет ссылка, и поэтому он пишется прямо в самом начале, и только после этого пишется остальная часть адреса.
Какие символы используются в robots.txt
Чтобы не ошибиться при написании файла, вы должны знать все символы, которые используются, а также понимать их значение.
Вот главные герои:
/ — надо что-то закрыть от сканирования поисковыми роботами. Например, если вы поставите / catalog / — в начале и в конце отдельной директории сайта, то эта папка будет полностью закрыта от сканирования. Если команда имеет вид / catalog, то все ссылки на сайте, начало которых написано как / catalog, будут закрыты на сайте.
* — указывает любую последовательность символов в файле и устанавливается в конце каждого правила.
Например, запись:
User-agent: *
Disallow: /catalog/*.gif$
В такой записи говорится, что всем роботам запрещено сканировать и индексировать файлы с .gif, которые размещаются в папке сайта каталога.
«$» — используется для введения ограничений на действия знака *. Например, вам нужно запретить все, что находится в папке каталога, но вы также можете не запрещать URL-адреса, в которых присутствует / catalog, вы должны сделать следующую запись:
User-agent: *
Disallow: / каталог?
— «#» — этот значок предназначен для комментариев, заметок, которые веб-мастер создает для себя или других веб-мастеров, которые также будут работать с сайтом.Этот значок предотвращает сканирование этих комментариев.
Запись будет выглядеть так (например):
User-agent: *
Разрешить: / catalog
Disallow: /
Карта сайта: https://site.ua/ sitemap.xml.
# инструкции
Идеальный файл robots.txt: что это такое?
Вот пример практически идеального файла robots.txt, который подходит если не всем, то многим сайтам.
User-agent: *
Disallow:
User-agent: GoogleBot
Disallow:
Host: https: // site name 9000: // site name 0 https : // название сайта / sitemap.xml.
Давайте проанализируем, что это за файл robots.txt. Таким образом, он позволяет вам проиндексировать все страницы сайта и весь контент, который там размещен. Он также указывает хост и карту сайта, поэтому поисковые системы будут видеть все адреса открытыми для индексации.
Кроме того, отдельно указаны рекомендации для роботов Google.
Однако не следует просто копировать этот файл для своего сайта. Во-первых, для каждого ресурса должны быть даны отдельные правила и рекомендации. Они напрямую зависят от платформы, на которой вы создали сайт. Поэтому запомните все правила заполнения файла.
Другие ошибки
- Ошибки в имени файла. Имя — только robots.txt, но не Robots.txt, ROBOTS.TXT и никак иначе!
- Правило User-agent должно быть заполнено — необходимо указать, какой именно робот должен его учитывать, или вообще.
- Наличие лишних символов.
- Присутствуют в файле страницы, которые не следует индексировать.
Что мы узнали о txt-файле robots
txt-файле robots — играет важную роль для каждого отдельного сайта. В частности, необходимо установить определенные правила для поисковых роботов, а также продвигать свой сайт, компанию.
robots.txt — Помогите посетителям веб-сайта HigherEd найти интересное
Пусть боты делают свою работу
Четкий план должен направлять все действия, предпринимаемые для привлечения посетителей на веб-сайт.На практике некоторые из этих действий происходят в открытом виде, в то время как другие действуют в большей степени в фоновом режиме.
Следующие две публикации посвящены негласным шагам, которые улучшают индексацию веб-сайта и повышают вероятность того, что посетители сайта смогут быстро найти релевантный контент. В этом посте мы объясняем использование так называемого файла robots.txt, чтобы дать поисковым системам указания об индексировании веб-сайта. В следующем посте мы обсудим использование читаемых поисковой системой карт сайта, чтобы помочь посетителям найти релевантный контент.
Даже если поисковые рефералы не являются основным источником трафика на сайте, небольшие вложения в понимание того, как использовать файлы robots.txt, обеспечивают долгосрочную отдачу в виде эффективной индексации сайта и повышения качества обслуживания посетителей. Google Analytics и аналогичные службы веб-аналитики могут определять историческую долю трафика сайта, на которую ссылаются поисковые системы, и определять наиболее релевантные поисковые системы.
Поисковые системы
Для веб-сайтов университетов и колледжей, особенно тех, кто хочет привлечь иностранных студентов, есть четыре поисковые системы или индексирующие роботы, которые могут быть актуальны: Google, Bing, Baidu и Яндекс.
Помещая директивы в файл robots.txt, Google, Bing и другие поисковые системы получают подробные инструкции о том, что и что не следует индексировать на сайте. Другими словами, поисковые системы могут быть направлены на индексирование релевантного контента и игнорирование «менее релевантного контента».
Давайте проанализируем «менее релевантный контент». Информационные бюллетени и календари 1999 года менее актуальны для большинства посетителей сайта, чем версии этого года. Как и файлы, используемые для работы сайта, доступа к вашей системе управления контентом или некоторым динамически генерируемым страницам сайта.
Почему бы не направлять поисковые системы на хорошие вещи и игнорировать менее актуальные? Контент по-прежнему доступен, как и все ссылки, поэтому посетители по-прежнему могут получить к нему доступ. Контент с меньшей вероятностью загромождает результаты поиска, и поисковые системы не тратят время на индексацию контента, имеющего малую потенциальную ценность для посетителей сайта.
Механизм управления поисковыми системами заключается в размещении набора инструкций в файле robots.txt, который хранится в верхнем или корневом каталоге веб-сайта.
Баланс этого руководства объясняет, как robots.txt работает, разъясняет некоторые распространенные заблуждения о robots.txt и описывает то, что мы находим в реальных условиях на веб-сайтах университетов и колледжей.
robots.txt или нет robots.txt
Без файла robots.txt поисковые роботы будут посещать каждую страницу, переходить по каждой ссылке на сайте и использовать базовые алгоритмы индексирования, чтобы определять, какие результаты будут представлены в результатах поиска. Такой подход вовсе не обязательно плохой. Почему? Потому что краулеры делают две вещи:
- Они рекурсивно переходят по URL-адресам (ссылкам) веб-сайтов и содержимому этих ссылок, доступному в браузере.Если файл robots.txt отсутствует, осуществляется доступ к каждой ссылке.
- Второе, что делают сканеры, — это визуализировать контент, для которого требуется JavaScript или другие файлы отображения, чтобы это содержимое также можно было добавить в индекс сайта. Во многих случаях директивы файла robots.txt непреднамеренно блокируют доступ к скриптам или файлам визуализации таблиц стилей. В результате индексация может быть неполной. Возможно, большее беспокойство вызывает то, что Google использует рендеринг для оценки удобства сайта для мобильных устройств: блокировка файлов скриптов и таблиц стилей влияет на удобство использования для мобильных устройств.А мобильное удобство повышает рейтинг результатов поиска. Если нет файла robots.txt, индексация будет завершена и блокировки ресурсов не будет.
Каковы недостатки отсутствия файла robots.txt? Три вещи.
Во-первых, на веб-сайте есть много каталогов или папок, содержащих файлы, которые не имеют отношения к доступу браузера, и нет веских причин для индексации этих файлов. Есть также материалы, которые со временем становятся менее актуальными, но могут оставаться на сайте по нормативным или другим причинам: учебные и академические календари, расписания занятий и тому подобное.Посетители сайта лучше обслуживаются, если их направляют к текущим материалам, чем к просмотру текущих и старых.
Вторая причина заключается в том, что файл robots.txt может использоваться для указания поисковым системам, где найти соответствующую карту сайта в формате XML или карты сайта.
Наконец, можно использовать файл robots.txt для блокировки поисковых роботов, которым вы не хотите получать доступ к вашему сайту. Однако, поскольку соблюдение директив robots.txt является добровольным, злонамеренные «боты», скорее всего, проигнорируют любые директивы.
При подготовке этого руководства мы рассмотрели основные или межсетевые домены около 200 (n = 206) веб-сайтов университетов и колледжей, принадлежащих канадским высшим учебным заведениям, чтобы понять текущую практику.Мы обсудим наши выводы немного позже, но 20% сайтов (18,9% или 39/206) не используют файл robots.txt. И нет никакого вреда.
Контроль места сканирования поисковых роботов
Если вы хотите контролировать индексацию поисковой системы, вы можете сделать это с помощью директив файла robots.txt. Сканеры опрашивают файл robots.txt, чтобы определить ограничения их активности. Директивы в каждой строке или записи в файле содержат инструкции для поискового робота.
Google, Bing, Baidu и Яндекс распознают четыре элемента поля со следующей структурой:
| Поле | Значения | Комментарий | Наблюдение | ||
|---|---|---|---|---|---|
| пользовательский агент | : | [значение] | # | необязательный комментарий | user-agent = поисковый робот, обращающийся к сайту |
| разрешить | : | [путь] | # | необязательный комментарий | Директиваразрешает доступ |
| запретить | : | [путь] | # | необязательный комментарий | директива disallow запрещает доступ |
| карта сайта | : | [URL] | # | необязательный комментарий | Указывает поисковому роботу найти XML-файл по указанному URL-адресу.При необходимости это может быть на другом сервере. |
Поля могут быть организованы в группы, отсортированные по пользовательскому агенту для любого количества индивидуальных пользовательских агентов (например, Googlebot, Bingbot, Baiduspider, YandexBot и т. Д.) По мере необходимости.
Не существует ограничений на количество директив или записей, которые может содержать файл robots.txt, но Google игнорирует любое содержимое robots.txt после первых 500 КБ: это примерно равно 9 250 или более записям. Яндекс устанавливает меньший лимит файла — 32 КБ и предполагает, что если размер файла превышает лимит, разрешено все.В ходе нашего опроса мы не обнаружили файла robots.txt размером более 7 КБ.
[значение] это может быть текст для определенного поискового робота, например Робот Googlebot или Bingbot или подстановочный знак «*» для обозначения всех поисковых роботов. Большинство файлов robots.txt для высшего образования разрешают доступ к сайту всем сканерам.
[путь] путь работает как индикатор относительного положения относительно местоположения файла robots.txt. В результате / указывает на самый верхний или корневой каталог или папку. Каталоги или файлы, расположенные ниже по иерархии, можно указать по их относительному положению относительно самой верхней папки.
Будьте внимательны к написанию, так как [путь] может быть чувствительным к регистру, в зависимости от сервера и его конфигурации. Кроме того, если сервер «чувствителен к регистру», а контент предполагает, что это не так, это приведет к неработающим ссылкам (404 ошибки), а директивы robots.txt могут не иметь ожидаемого эффекта.
[URL] полный URL-адрес, а не относительное местоположение, сообщает поисковому роботу, где найти какие-либо карты сайта. В принципе, карты сайта могут находиться в другом домене; на практике карты сайта в формате XML обычно помещаются в корневой каталог.
Если сложить все вместе, «полный» файл robots.txt может выглядеть так:
# В этом файле перечислены локальные URL-адреса, которые нормальные роботы должны игнорировать
Пользовательский агент: *
Disallow: / registrar / archives # old stuff
Disallow: / art / culture / # old stuff
Disallow: / education / coursework / # old stuff
Disallow: /events/day.php # поисковым системам требуется только одно представление календаря, поэтому скройте остальные
Карта сайта: https: //www.examplecollege.ca / sitemap.xml
Очерчивающие комментарии # должны игнорироваться поисковым роботом, но вставляться для удобства чтения. Сканеры игнорируют пустые строки, но это также улучшает читаемость.
Конфликтующие директивы
файлов robots.txt могут содержать несколько директив. Попытки включить некоторые каталоги для сканирования при исключении других могут привести к возникновению противоречивых инструкций. Чтобы решить эту проблему, сканеры обрабатывают директивы на основе приоритета. Принцип состоит в том, что наиболее конкретное правило имеет приоритет, а другие директивы игнорируются.Например:
пользовательский агент: *
disallow: / # запретить индексацию сайта
allow: / Physics # разрешить индексацию каталога Physics и всех его подкаталогов и их содержимого.
Сканер обнаруживает каталог http://www.exampleu.ca/physics. Поскольку правило разрешения является более конкретным, чем правило запрета, оно имеет приоритет, и каталог будет проиндексирован.
Расположение файла robots.txt
Для того, чтобы направить краулера по назначению, файл robots.txt должен находиться в самом верхнем или корневом каталоге для определенного хоста, протокола и номера порта. Чтобы объяснить:
Сканеры видят http://example.edu/ и http://cs.example.edu/ как два разных хоста или домена. Размещение файла robots.txt по адресу http://example.edu/robots.txt не повлияет на домен http://cs.example.edu/. Если вы не хотите указывать, как будет сканироваться http://cs.example.edu/, ничего страшного. Если вы действительно хотите управлять деятельностью, вам необходимо разместить отдельный (но, возможно, одинаковый) файл robots.txt по адресу http://cs.example.edu/robots.txt
. Поисковые роботырассматривают http://example.ac.uk/, https://example.ac.uk и ftp://example.ac.uk как три разных протокола (каковыми они и являются). Если эти протоколы используют стандартные порты (80, 443 и 21 соответственно), * и * результирующий хост и контент являются одним и тем же, то требуется только один файл robots.txt. Если, однако, используется нестандартный порт, то файл robots.txt, доступ к которому осуществляется таким образом, будет применяться только к этой службе, и, следовательно, для остальных потребуется отдельный применимый файл robots.txt, помещенный в каждый из корневых каталогов.
Проблема поиска файла robots.txt особенно важна для веб-сайтов высшего образования. Типичные веб-сайты университетов или колледжей структурированы как федерации подсайтов: некоторые из них являются отдельными доменами, а иногда — внутри подкаталогов. В первом случае в каждом поддомене необходимы отдельные файлы robots.txt, а во втором случае файл robot.txt в корневом каталоге — единственный способ обеспечить желаемое поведение сканирования.
Проблемы с обработкой файла robots.txt
Сканеры пытаются извлечь файл robots.txt из предполагаемого местоположения или установить, что действительный файл не существует. А сканеры обращают внимание на коды ответа, полученные при попытке, и могут изменять свое поведение. Мы суммировали возможные ответы в таблице.
| 2XX Успех | 3XX перенаправление | 4XX Не найдено | 5XX Ошибка сервера | |
|---|---|---|---|---|
| допуск | ✔︎ | ✔︎ | ✔︎ | X |
| запретить | ✔︎ | X | X | ✔︎ |
| условно | ✔︎ | X | X | X |
| комментарий | Конкретная обработка зависит от роботов.txt контент | Если перенаправление приводит к 2xx, то обработка будет такой, как описано в столбце 2xx, в противном случае обработка будет выполняться, как описано в столбце 4xx | Предполагается, что файл robots.txt отсутствует, поэтому будут просканированы все файлы. | Предполагает временную ошибку, при которой сканирование файлов не выполняется. |
Что мы находим на практике?
Мы опросили чуть более 200 (n = 206) веб-сайтов канадских университетов и колледжей и исследовали роботов.txt, расположенные в каталоге верхнего уровня домена шлюза.
Тридцать девять (39) сайтов (18,9%) не имели файла robots.txt. Как мы заявили ранее, это просто означает, что эти сайты сканируются полностью — за исключением любых страниц, которые имеют специфичные для страницы метатеги, указывающие, что страница не должна индексироваться или отслеживаться. В следующем сообщении в блоге мы рассмотрим текущие методы работы с картами сайта для высшего образования, чтобы увидеть, существует ли корреляция между отсутствием файла robots.txt и отсутствием или наличием актуальной карты сайта XML.
Остаток 167 сайтов (81,1%) можно разделить на три различных формулировки robots.txt следующим образом:
Формулировка 1 — директивы файла robots.txt структурированы одним из двух основных способов
пользовательский агент: * или пользовательский агент: *
разрешить: / запретить:
Эти два подхода функционально эквивалентны друг другу и вообще не имеют файла robots.txt. Эти конфигурации происходят примерно в 5% случаев.
Формулировка 2 — директивы файла robots.txt имеют две альтернативы:
пользовательский агент: * или пользовательский агент: *
запретить: разрешить: /
запретить: [путь] запретить: [путь]
Эти два подхода функционально эквивалентны друг другу. Ничего не запрещать и разрешать все, а затем указывать конкретное местоположение для запрета можно добиться, просто включив директиву disallow: [path].Эти конфигурации происходят в 32% случаев.
Формулировка 3 — директивы файла robots.txt имеют структуру
Пользовательский агент: *
запретить: [путь2]
запретить: [путь3]
запретить: [путьN]
Эта конфигурация встречается в 63% случаев и, на наш взгляд, это конфигурация, наименее подверженная путанице. Около десяти процентов сайтов также включают директиву, указывающую конкретное местоположение, в котором можно найти карту сайта или карты сайта, и все они используют формулу 3 для своих роботов.txt структура.
Заключение
Совершенно нормально не иметь файла robots.txt: такой подход просто приводит к индексации всех каталогов на веб-сайте. С другой стороны, очень просто создать файл robots.txt, который тщательно разделяет релевантный контент для индексации и помещает менее релевантный контент в каталоги, которые будут игнорироваться. Кроме того, файл robots.txt может также указывать местоположение для карты сайта или карты сайта, что может еще больше повысить эффективность индексации и, таким образом, возможность посетителей сайта находить полезные материалы.
Изображение в блоге: unsplash.com / pexels.com
# # robots.txt # # Этот файл предназначен для предотвращения сканирования и индексации определенных частей # вашего сайта поисковыми роботами и пауками, управляемыми такими сайтами, как Yahoo! # и Google. Сообщая этим «роботам», куда нельзя заходить на вашем сайте, # вы экономите трафик и ресурсы сервера. # # Этот файл будет проигнорирован, если он не находится в корне вашего хоста: # Используется: http: // example.ru / robots.txt # Игнорируется: http://example.com/site/robots.txt # # Дополнительную информацию о стандарте robots.txt см. В следующих статьях: # http://www.robotstxt.org/robotstxt.html Пользовательский агент: * Задержка сканирования: 10 Пользовательский агент: dotbot Запретить: / Пользовательский агент: Coccocbot Запретить: / Пользовательский агент: SemrushBot Запретить: / Пользовательский агент: linkdexbot Запретить: / User-agent: Яндекс Запретить: / Пользовательский агент: Pinterest Запретить: / Пользовательский агент: BLEXBot Запретить: / Пользовательский агент: LivelapBot Запретить: / Пользовательский агент: DnyzBot Запретить: / Пользовательский агент: Traacker Запретить: / Пользовательский агент: PaperLiBot Запретить: / Пользовательский агент: Даум Запретить: / Пользовательский агент: PrimalBot Запретить: / Пользовательский агент: changedetection Запретить: / Пользовательский агент: EveryoneSocialBot Запретить: / Пользовательский агент: WikiDo Запретить: / Пользовательский агент: Почта.RU Запретить: / Пользовательский агент: SeznamBot Запретить: / Пользовательский агент: TinEye-bot Запретить: / Пользовательский агент: MJ12bot Запретить: / Пользовательский агент: SEOkicks-Robot Запретить: / Пользовательский агент: Yeti Запретить: / Пользовательский агент: TurnitinBot Запретить: / Пользовательский агент: Baidu Запретить: / Пользовательский агент: AhrefsBot Запретить: / Пользовательский агент: Twitterbot Запретить: # CSS, JS, изображения Разрешить: /misc/*.css$ Разрешить: /misc/*.css? Разрешить: /misc/*.js$ Разрешить: /misc/*.js? Разрешить: /misc/*.gif Разрешить: /misc/*.jpg Разрешить: /misc/*.jpeg Разрешить: /misc/*.png Разрешить: / modules / *.css $ Разрешить: /modules/*.css? Разрешить: /modules/*.js$ Разрешить: /modules/*.js? Разрешить: /modules/*.gif Разрешить: /modules/*.jpg Разрешить: /modules/*.jpeg Разрешить: /modules/*.png Разрешить: /profiles/*.css$ Разрешить: /profiles/*.css? Разрешить: /profiles/*.js$ Разрешить: /profiles/*.js? Разрешить: /profiles/*.gif Разрешить: /profiles/*.jpg Разрешить: /profiles/*.jpeg Разрешить: /profiles/*.png Разрешить: /themes/*.css$ Разрешить: /themes/*.css? Разрешить: /themes/*.js$ Разрешить: /themes/*.js? Разрешить: /themes/*.gif Разрешить: /themes/*.jpg Разрешить: /themes/*.jpeg Разрешить: / themes / *.PNG # Каталоги Disallow: / включает / Запретить: / misc / Запретить: / modules / Запретить: / profiles / Запретить: / scripts / Запретить: / themes / # Файлов Запретить: /CHANGELOG.txt Запретить: /cron.php Запретить: /INSTALL.mysql.txt Запретить: /INSTALL.pgsql.txt Запретить: /INSTALL.sqlite.txt Запретить: /install.php Запретить: /INSTALL.txt Запрещено: /LICENSE.txt Запретить: /MAINTAINERS.txt Запретить: /update.php Запретить: /UPGRADE.txt Запретить: /xmlrpc.php # Пути (чистые URL) Запретить: / admin / Запретить: / комментарий / ответ / Запретить: / filter / tips / Запретить: / узел / добавить / Запретить: / поиск / Запретить: / пользователь / регистрация / Запретить: / пользователь / пароль / Запретить: / пользователь / логин / Запретить: / пользователь / выход из системы / # Пути (без чистых URL) Запретить: /? Q = admin / Запретить: /? Q = комментарий / ответ / Запретить: /? Q = filter / tips / Запретить: /? Q = узел / добавить / Запретить: /? Q = search / Запретить: /? Q = пользователь / пароль / Запретить: /? Q = пользователь / регистрация / Запретить: /? Q = пользователь / логин / Запретить: /? Q = пользователь / выход из системы /
Как заблокировать серверы разработки с помощью robots.текст? | SEO вопросы и ответы
Добавлен тег X robots в заголовки на наших сайтах разработки.
Просто примечание — если вы используете apache и у вас установлен mod_pagespeed, это приведет к конфликту стен и страницам, и тег X robots будет удален.
BrowserMatchNoCase Googlebot bad_bot
BrowserMatchNoCase bingbot bad_bot
BrowserMatchNoCase OmniExplorer_Bot / 6.11.1 bad_bot
BrowserMatchNoCase omniexplorer_bot Bad_batchMatchNoCase omniexplorer_bot bad_batchNoider 2 Browserbatch
C bad_batchbatchNoider Browserbot 20 bad_bot
BrowserMatchNoCase Яндексу bad_bot
BrowserMatchNoCase yandeximages bad_bot
BrowserMatchNoCase Spinn3r bad_bot
BrowserMatchNoCase Sogou bad_bot
BrowserMatchNoCase Sogouwebspider / 3,0 bad_bot
BrowserMatchNoCase Sogouwebspider / 4.0 bad_bot
BrowserMatchNoCase sosospider + bad_bot
BrowserMatchNoCase jikespider bad_bot
BrowserMatchNoCase ia_archiver bad_bot
BrowserMatchNoCase PaperLiBot bad_bot
BrowserMatchNoCase ahrefsbot bad_bot
BrowserMatchNoCase ahrefsbot / 1.0 bad_bot
BrowserMatchNoCase SiteBot / 0,1 bad_bot
BrowserMatchNoCase DNS-Диггер / 1.0 bad_bot
BrowserMatchNoCase DNS-Диггер-Explorer / 1.0 bad_bot
BrowserMatchNoCase boardreader bad_bot
BrowserMatchNoCase Radian6 bad_bot
BrowserMatchNoCase R6_FeedFetcher bad_bot
BrowserMatchNoCase R6_CommentReader bad_bot
BrowserMatchNoCase ScoutJet bad_bot
BrowserMatchNoCase ezooms bad_bot
BrowserMatchNoCase CC-rget / 5.818 bad_bot
BrowserMatchNoCase libwww-perl / 5.813 bad_bot
BrowserMatchNoCase сороки-гусеничного 1.1 bad_bot
BrowserMatchNoCase Jakarta bad_bot
BrowserMatchNoCase discobot / 1,0 bad_bot
BrowserMatchNoCase MJ12bot bad_bot
BrowserMatchNoCase MJ12bot / v1.2.0 bad_bot
BrowserMatchNoCase MJ12bot / v1.2.5 bad_bot
BrowserMatchNoCase SemrushBot / 0,9 bad_bot
BrowserMatchNoCase MLBot bad_bot
BrowserMatchNoCase butterfly bad_bot
BrowserMatchNoCase SeznamBot / 3.0 bad_bot
BrowserMatchNoCase HuaweiSymantecSpider bad_bot
BrowserMatchNoCase Exabot / 2.0 bad_bot
BrowserMatchNoCase Netseer / 0,1 bad_bot
BrowserMatchNoCase Netseer гусеничного / 2.0 bad_bot
BrowserMatchNoCase Netseer / Nutch-0,9 bad_bot
BrowserMatchNoCase psbot / 0,1 bad_bot
BrowserMatchNoCase Moreoverbot / x.00 bad_bot
BrowserMatchNoCase moreoverbot / 5,0 bad_bot
BrowserMatchNoCase Jakarta Commons-HttpClient / 3.0 bad_bot
BrowserMatchNoCase SocialSpider-Finder / 0.2 bad_bot
BrowserMatchNoCase MaxPointCrawler / Nutch-1.1 bad_bot
BrowserMatchNoCase willow bad_bot
Запретить, разрешить
Запретить с env = bad_bot
Заголовочный набор X-Robots-Tag «noindex, nofollow»
BrowserMatchNoCase Googlebot bad_bot
BrowserMatchNoCase bingbot bad_bot
BrowserMatchNoCase OmniExplorer_Bot / 6.11.1 bad_bot
BrowserMatchNoCase omniexplorer_bot bad_bot
BrowserMatchNoCase Baiduspider bad_bot
BrowserMatchNoCase Baiduspider / 2.0 bad_bot
BrowserMatchNoCase Яндексу bad_bot
BrowserMatchNoCase yandeximages bad_bot
BrowserMatchNoCase Spinn3r bad_bot
BrowserMatchNoCase Sogou bad_bot
BrowserMatchNoCase Sogouwebspider / 3,0 bad_bot
BrowserMatchNoCase Sogouwebspider / 4.0 bad_bot
BrowserMatchNoCase sosospider + bad_bot
BrowserMatchNoCase jikespider bad_bot
BrowserMatchNoCase ia_archiver bad_bot
BrowserMatchNoCase PaperLiBot bad_bot
BrowserMatchNoCase ahrefsbot bad_bot
BrowserMatchNoCase ahrefsbot / 1.0 bad_bot
BrowserMatchNoCase SiteBot / 0,1 bad_bot
BrowserMatchNoCase DNS-Диггер / 1.0 bad_bot
BrowserMatchNoCase DNS-Диггер-Explorer / 1.0 bad_bot
BrowserMatchNoCase boardreader bad_bot
BrowserMatchNoCase Radian6 bad_bot
BrowserMatchNoCase R6_FeedFetcher bad_bot
BrowserMatchNoCase R6_CommentReader bad_bot
BrowserMatchNoCase ScoutJet bad_bot
BrowserMatchNoCase ezooms bad_bot
BrowserMatchNoCase CC-rget / 5.818 bad_bot
BrowserMatchNoCase libwww-perl / 5.813 bad_bot
BrowserMatchNoCase сороки-гусеничного 1.1 bad_bot
BrowserMatchNoCase Jakarta bad_bot
BrowserMatchNoCase discobot / 1,0 bad_bot
BrowserMatchNoCase MJ12bot bad_bot
BrowserMatchNoCase MJ12bot / v1.2.0 bad_bot
BrowserMatchNoCase MJ12bot / v1.2.5 bad_bot
BrowserMatchNoCase SemrushBot / 0,9 bad_bot
BrowserMatchNoCase MLBot bad_bot
BrowserMatchNoCase butterfly bad_bot
BrowserMatchNoCase SeznamBot / 3.0 bad_bot
BrowserMatchNoCase HuaweiSymantecSpider bad_bot
BrowserMatchNoCase Exabot / 2.0 bad_bot
BrowserMatchNoCase Netseer / 0,1 bad_bot
BrowserMatchNoCase Netseer гусеничного / 2.0 bad_bot
BrowserMatchNoCase Netseer / Nutch-0,9 bad_bot
BrowserMatchNoCase psbot / 0,1 bad_bot
BrowserMatchNoCase Moreoverbot / x.00 bad_bot
BrowserMatchNoCase moreoverbot / 5,0 bad_bot
BrowserMatchNoCase Jakarta Commons-HttpClient / 3.0 bad_bot
BrowserMatchNoCase SocialSpider-Finder / 0.2 bad_bot
BrowserMatchNoCase MaxPointCrawler / Nutch-1.1 bad_bot
BrowserMatchNoCase willow bad_bot
Запретить, разрешить
Запретить с env = bad_bot
Заголовочный набор X-Robots-Tag «noindex, nofollow»
Карта сайта: https: // www.bonpasteur.com/sitemap.xml.gz # Определить ограничения доступа для роботов / пауков # http://www.robotstxt.org/wc/norobots.html # см. http://opensourcehacker.com/2009/08/07/seo-tips-query-strings-multiple-languages-forms-and-other-content-management-system-issues/ # Googlebot разрешает использование регулярных выражений в синтаксисе # Блокировать все URL-адреса, включая строки запроса (шаблон?) — содержательные объекты предоставляют строку запроса только для действий или отчетов о состоянии, которые # может запутать результаты поиска. # Это также заблокирует? Set_language Пользовательский агент: Googlebot Disallow: / *? * Disallow: / * folder_factories $ Запретить: / * send_as_pdf * Disallow: / * download_as_pdf * Запретить: / параметры / Запретить: / информационный бюллетень / Disallow: / abonnez-vous / Запрещено: / don-en-ligne / Запретить: / portal_checkouttool / Disallow: / Members / # Разрешить бота AdSense на всем сайте Пользовательский агент: Mediapartners-Google Запретить: Позволять: / Disallow: / * folder_factories $ Запретить: / * send_as_pdf * Disallow: / * download_as_pdf * Запретить: / параметры / Запретить: / информационный бюллетень / Disallow: / abonnez-vous / Запретить: / don-en-ligne / Запретить: / portal_checkouttool / Disallow: / Members / Пользовательский агент: Yahoo! Чавкать Disallow: / *? * Disallow: / * folder_factories $ Запретить: / * send_as_pdf * Disallow: / * download_as_pdf * Запретить: / параметры / Запретить: / информационный бюллетень / Disallow: / abonnez-vous / Запрещено: / don-en-ligne / Запретить: / portal_checkouttool / Disallow: / Members / Частота запросов: 1/10 Задержка сканирования: 10 Время посещения: 0100-0600 Пользовательский агент: bingbot Disallow: / *? * Disallow: / * folder_factories $ Запретить: / * send_as_pdf * Disallow: / * download_as_pdf * Запретить: / параметры / Запретить: / информационный бюллетень / Disallow: / abonnez-vous / Запрещено: / don-en-ligne / Запретить: / portal_checkouttool / Disallow: / Members / Частота запросов: 1/10 Задержка сканирования: 10 Время посещения: 0100-0600 Пользовательский агент: Baiduspider Disallow: / *? * Disallow: / * folder_factories $ Запретить: / * send_as_pdf * Disallow: / * download_as_pdf * Запретить: / параметры / Запретить: / информационный бюллетень / Disallow: / abonnez-vous / Запретить: / don-en-ligne / Запретить: / portal_checkouttool / Disallow: / Members / Частота запросов: 1/10 Задержка сканирования: 10 Время посещения: 0100-0400 Пользовательский агент: msnbot Запретить: / # Заблокируйте MJ12bot, так как это просто шум Пользовательский агент: MJ12bot Запретить: / # Блокировать Ahrefs Пользовательский агент: AhrefsBot Запретить: / # Блок Согоу Пользовательский агент: sogou spider Запретить: / # Блокировать SEOkicks Пользовательский агент: SEOkicks-Robot Запретить: / # SEOkicks Пользовательский агент: SEOkicks Запретить: / # Dicoveryengine.ком Пользовательский агент: дискобот Запретить: / # Блэккобот Пользовательский агент: Blekkobot Запретить: / # Блокировать BlexBot Пользовательский агент: BLEXBot Запретить: / # Блок SISTRIX Пользовательский агент: SISTRIX Crawler Запретить: / # Блокировать время работы робота Пользовательский агент: UptimeRobot / 2.0 Запретить: / Пользовательский агент: 008 Запретить: / # Блокировать робота Ezooms Пользовательский агент: Ezooms Robot Запретить: / # Блокировать Perl LWP Пользовательский агент: Perl LWP Запретить: / # Блокировать сканер netEstate NE Пользовательский агент: netEstate NE Crawler Запретить: / # Блокировать робота WiseGuys Пользовательский агент: WiseGuys Robot Запретить: / # Блокировать Turnitin Robot Пользовательский агент: Turnitin Robot Запретить: / # Экзабот Пользовательский агент: Exabot Запретить: / # Яндекс User-agent: Яндекс Запретить: / # Babya Discoverer Пользовательский агент: Babya Discoverer Запретить: / Пользовательский агент: * # Каталоги Запретить: / параметры / Запретить: / информационный бюллетень / Disallow: / abonnez-vous / Запретить: / don-en-ligne / Запретить: / portal_checkouttool / Disallow: / Members / # Request-rate: определяет соотношение страниц / секунд для сканирования.