Robots.txt — как настроить и загрузить на сайт
Михаил Шумовский
07 октября, 2022
Кому нужен robots.txt Как настроить robots.txt Как создать robots.txt Требования к файлу robots.txt Как проверить правильность Robots.txt
Мы в Telegram
В канале «Маркетинговые щи» только самое полезное: подборки, инструкции, кейсы.
Не всегда на серьёзных щах — шуточки тоже шутим =)
Подписаться
Станьте email-рокером 🤘
Пройдите бесплатный курс и запустите свою первую рассылку
Подробнее
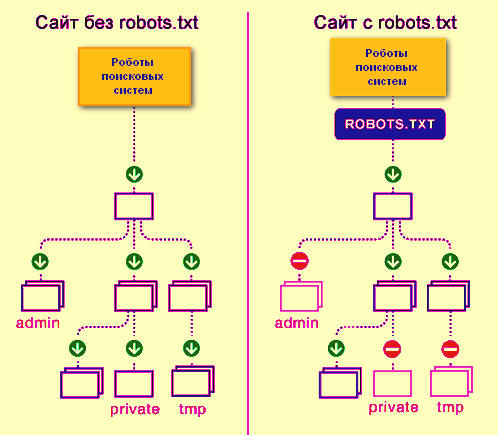
Robots.txt — документ, который нужен для индексирования и продвижения сайта.
Если у сайта нет robots.txt, поисковые роботы считают все страницы ресурса открытыми для индексирования. Если файл есть, владелец сайта может запретить роботам индексировать определённые страницы.
Например, контентным ресурсам или медиа можно работать без robots.txt — тут все страницы участвуют в индексации.
На других ресурсах могут быть страницы, которые не нужно показывать поисковым роботам:
- Админ-панели сайта: пути, которые начинаются с /user, /admin, /administrator и т.д.
- Пустые страницы ресурса: если на них нет контента, в индексации они не помогут.
- Формы регистрации.
- Личные страницы в интернет-магазинах: кабинеты пользователей, корзины и т.
 д.
д.
Начну с основных параметров.
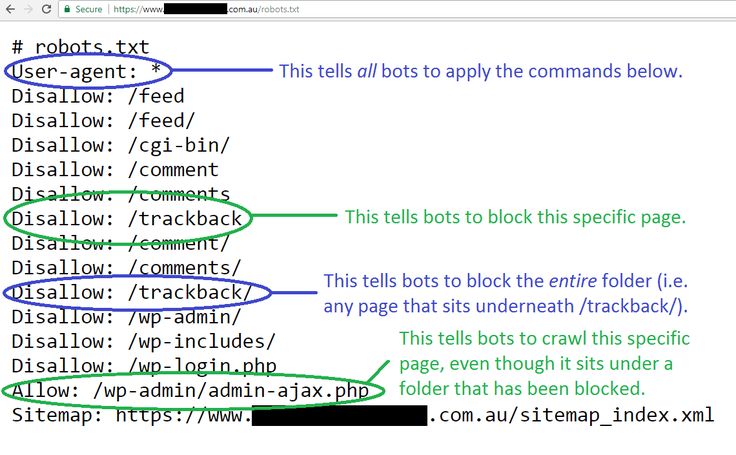
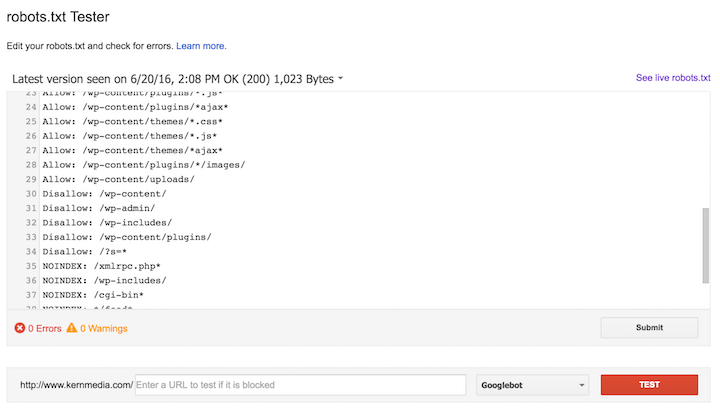
User-agent: Yandex
Disallow: catalog/
Allow: /catalog/cucumbers/
Sitemap: http://www.example.com/sitemap.xml
User-agent — указывает название робота, к которому применяется правило. Например, User-agent: Yandex означает, что правило применяется к роботу Яндекса.
А user-agent: * означает, что правило применяется ко всем роботам. Но о звёздочках поговорим ниже.
Основные типы роботов, которые можно указать в User-agent:
- Yandex. Все роботы Яндекса.
- YandexBot. Основной робот Яндекса
- YandexImages. Индексирует изображения.
- YandexMedia. Индексирует видео и другие мультимедийные данные.
- Google. Все роботы Google.
- Googlebot. Основной робот Google.
- Googlebot-Image.

Disallow. Указывает на каталог или страницу ресурса, которые роботы индексировать не будут. Если нельзя индексировать конкретную страницу, например, определённый раздел в каталоге, нужно указывать полный путь к ней — как в поисковой строке браузера.
В начале строки должен быть символ /. Если правило касается каталога, строка должна заканчиваться символом /.
Например, disallow: /catalog/gloves. Так мы запретим индексацию раздела с перчаткам.
Если оставить disallow пустым, роботы будут индексировать все страницы сайта.
Allow. Указывает на каталог или страницу, которые можно сканировать роботу. Его используют, чтобы внести исключения в пункт
Если требуется индексировать конкретную страницу, нужно указывать к ней полный путь. Как и в disallow. Например, allow: /story/marketing. Так мы разрешили индексировать статью о маркетинге.
Так мы разрешили индексировать статью о маркетинге.
Если правило касается каталога, строка должна заканчиваться символом /.
Если allow пустой, робот не будет индексировать никакие страницы.
Sitemap. Необязательная директива, которая может повторяться несколько раз или не использоваться совсем. Её используют, чтобы описать структуру сайта и помочь роботам индексировать страницы.
Лендингам и небольшим сайтам sitemap не нужен. А вот таким ресурсам без sitemap не обойтись:
- Cайтам без хлебных крошек (навигационных цепочек).
- Большим ресурсам. Например, если сайт содержит большой объём мультимедиа или новостного контента.
- Сайтам с глубокой вложенностью. Например, «Главная/Каталог/Перчатки/Резиновые».
- Молодым ресурсам, на которые мало внешних ссылок, — их роботам сложно найти.
- Сайтам с большим архивом страниц, которые изолированы или не связаны друг с другом.
Файл нужно прописывать в XML-формате. Создание sitemap — тема для отдельной статьи. Подробную инструкцию читайте на Google Developers или в Яндекс.Справке.
Основные моменты robots.txt разобрали. Теперь расскажу про дополнительные параметры, которые используют в коде.
Для начала посмотрим на robots.txt Unisender. Для этого в поисковой строке браузера пишем Unisender.com/robots.txt.
По такой же формуле можно проверять файлы на всех сайтах: URL сайта + домен/robots.txt.
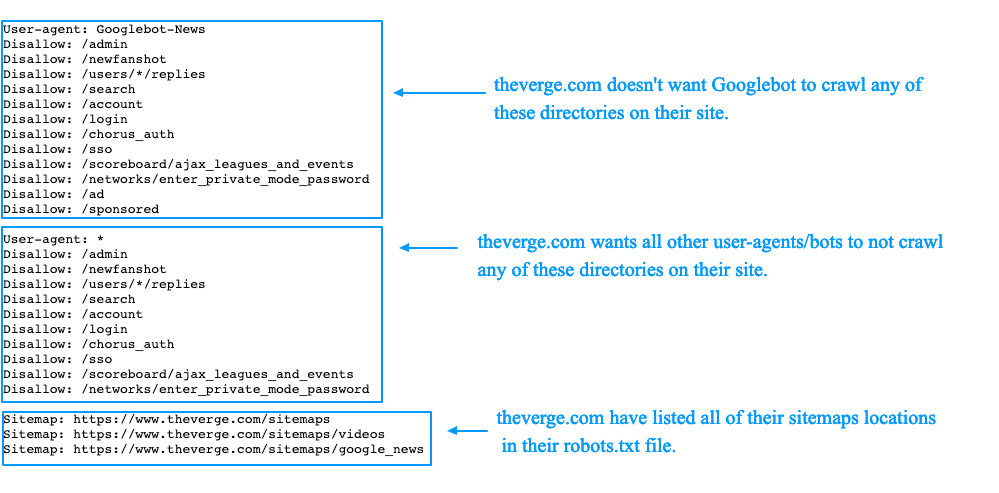
Robots.txt Unisender отличается от файла, который я приводил в пример. Дело в том, что здесь использованы дополнительные параметры:
Директива # (решётка) — комментарий. Решётки прописывают для себя, а поисковые роботы комментариев не видят.
User-agent: Yandex
Allow: /example/* # разрешает ‘/example/blog’
# разрешает ‘/example/blog/test’
Звёздочку роботы видят, а решётку — нет
Директива * (звёздочка) — любая последовательность символов после неё.
Например, если поставить звёздочку в поле
User-agent: Yandex
Disallow: /example/* # запрещает ‘/example/blog’
# запрещает ‘/example/blog/test’
Disallow: */shop # запрещает не только ‘/shop’,
# но и ‘/example/shop’
Также и с полем allow: всё, что стоит на месте звёздочки, — разрешено для индексации.
User-agent: Yandex
Allow: /example/* # разрешает ‘/example/blog’
# разрешает ‘/example/blog/test’
Allow: */shop # разрешает не только ‘/shop’,
# но и ‘/example/shop’
Например, у Google есть особенность: компания рекомендует не закрывать от поисковых роботов файлы с css-стилями и js-скриптами. Вот как это нужно прописывать:
User-agent: Googlebot
Disallow: /site
Allow: *.css
Allow: *. js
js
Директива $ (знак доллара) — точное соответствие указанному параметру.
Например, использование доллара в disallow запретит доступ к определённому пути.
User-agent: Yandex
Disallow: /example # запрещает ‘/example’,
# запрещает ‘/example.html’
Disallow: /example$ # запрещает ‘/example’,
# не запрещает ‘/example1’
# не запрещает ‘/example-new’
Таким способом можно исключить из сканирования все файлы определённого типа, например, GIF или JPG. Для этого нужно совместить * и $. Звёздочку ставим до расширения, а $ — после.
User-agent: Yandex
Disallow: / *.gif$ # вместо * могут быть любые символы,
# $ запретит индексировать файлы gif
Директива Clean-param — новый параметр Яндекс-роботов, который не будет сканировать дублированную информацию и поможет быстрее анализировать ресурс.
Дело в том, что из-за повторяющейся информации роботы медленнее проверяют сайт, а изменения на ресурсе дольше попадают в результаты поиска. Когда роботы Яндекса увидят эту директиву, не будут несколько раз перезагружать дубли информации и быстрее проверят сайт, а нагрузка на сервер снизится.
www.example.com/dir/get_card.pl?ref=site_1&card_id=10
www.example.com/dir/get_card.pl?ref=site_2&card_id=10
Параметр ref нужен, чтобы отследить, с какого ресурса сделан запрос. Он не меняет содержимое страницы, значит два адреса покажут одну и ту же страницу с книгой card_id=10. Поэтому директиву можно указать так:
User-agent: Yandex
Disallow:
Clean-param: ref /dir/get_card.pl
Робот Яндекса сведёт страницы к одной: www.example.com/dir/get_card.pl?card_id=10
Чтобы директива применялась к параметрам на страницах по любому адресу, не указывайте адрес:
User-agent: Yandex
Disallow:
Clean-param: utm
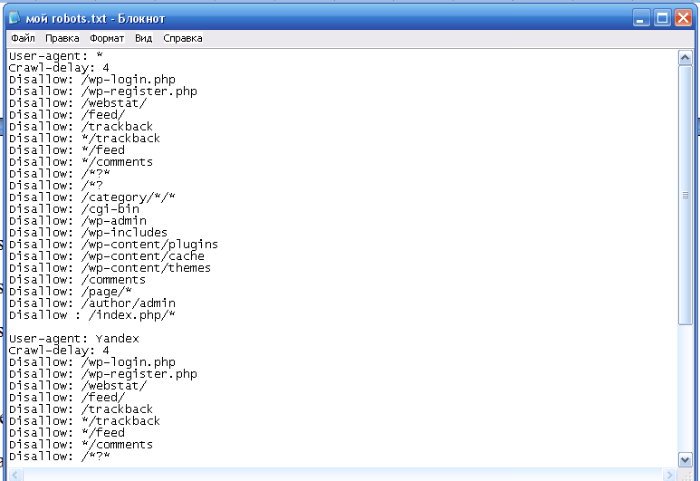
Директива Crawl-delay — устанавливает минимальный интервал в секундах между обращениями робота к сайту. Это помогает снизить нагрузку на сервер ресурса. Чем выше указанное значение, тем меньше страниц робот загрузит за сессию.
Это помогает снизить нагрузку на сервер ресурса. Чем выше указанное значение, тем меньше страниц робот загрузит за сессию.
Значения можно указывать целыми или дробными числами через точку.
User-agent: Yandex
Disallow:
Crawl-delay: 0.5
Для Яндекса максимальное значение в crawl-delay — 2. Более высокое значение можно установить инструментами Яндекс.Вебмастер.
Для Google-бота можно установить частоту обращений в панели вебмастера Search Console.
Директива Host — инструкция для робота Яндекса, которая указывает главное зеркало сайта. Нужна, если у сайта есть несколько доменов, по которым он доступен. Вот как её указывают:
User-agent: Yandex
Disallow: /example/
Host: example.ru
Если главное зеркало сайта — домен с протоколом HTTPS, его указывают так:
Host: https://site.ru
Как создать robots.txtСпособ 1. Понадобится текстовый редактор: блокнот, TextEdit, Vi, Emacs или любой другой. Не используйте приложения Microsoft Office, потому что они сохраняют файлы в неподходящем формате или добавляют в них лишние символы, которые не распознаются поисковыми роботами.
Не используйте приложения Microsoft Office, потому что они сохраняют файлы в неподходящем формате или добавляют в них лишние символы, которые не распознаются поисковыми роботами.
Способ 2. Создать на CMS с помощью плагинов — в этом случае robots.txt установится сам.
Если вы используете CMS хостинга, редактировать файл robots.txt не потребуется. Скорее всего, у вас даже не будет такой возможности. Вместо этого провайдер будет указывать поисковым системам, нужно ли сканировать контент, с помощью страницы настроек поиска или другого инструмента.
Способ 3. Воспользоваться генератором robots.txt — век технологий всё-таки.
Сгенерировать файл можно на PR-CY, IKSWEB, Smallseotools.
Требования к файлу robots.txtКогда создадите текстовый файл, сохраните его в кодировке utf-8. Иначе поисковые роботы не смогут прочитать документ. После создания загрузите файл в корневую директорию на сайте хостинг-провайдера. Корневая директория — это папка public. html.
html.
Папка, в которой нужно искать robots.txt. Источник
Если файла нет, его придётся создавать самостоятельно.
Требования, которым должен соответствовать robots.txt:
- Каждая директива начинается с новой строки.
- Одна директива в строке, сам параметр также написан в одну строку.
- В начале строки нет пробелов.
- Нет кавычек в директивах.
- Директивы не нужно закрывать точкой или точкой с запятой.
- Файл должен называться robots.txt. Нельзя называть его Robots.txt или ROBOTS.TXT.
- Размер файла не должен превышать 500 КБ.
- robots.txt должен быть написан на английском языке. Буквы других алфавитов не разрешаются.
Если файл не соответствует одному из требований, весь сайт считается открытым для индексирования.
Как проверить правильность Robots.txtПроверить robots. txt помогают сервисы от Яндекс и Google. В Яндексе можно проверять файл даже без сайта — например, если вы написали robots.txt, но пока не загрузили его на сайт.
txt помогают сервисы от Яндекс и Google. В Яндексе можно проверять файл даже без сайта — например, если вы написали robots.txt, но пока не загрузили его на сайт.
Вот как это сделать:
- Перейдите на Яндекс.Вебмастер.
- В открывшееся окно вставьте текст robots.txt и нажмите проверить.
Если файл написан правильно, Яндекс.Вебмастер не увидит ошибок.
А если увидит ошибку — подсветит её и опишет возможную проблему.
На Яндекс.Вебмастер можно проверить robots.txt и по URL сайта. Для этого нужно указать запрос: URL сайта/robots.txt. Например, unisender.com/robots.txt.
Ещё один вариант — проверить файл robots.txt через Google Search Console. Но сначала нужно подтвердить владение сайтом. Пошаговый алгоритм проверки robots.txt описан в видеоинструкции:
Поделиться
СВЕЖИЕ СТАТЬИ
Другие материалы из этой рубрики
Не пропускайте новые статьи
Подписывайтесь на соцсети
Делимся новостями и свежими статьями, рассказываем о новинках сервиса
«Честно» — авторская рассылка от редакции Unisender
Искренние письма о работе и жизни. Свежие статьи из блога. Эксклюзивные кейсы
и интервью с экспертами диджитала.
Свежие статьи из блога. Эксклюзивные кейсы
и интервью с экспертами диджитала.
Наш юрист будет ругаться, если вы не примете 🙁
Как запустить email-маркетинг с нуля?
В бесплатном курсе «Rock-email» мы за 15 писем расскажем, как настроить email-маркетинг в компании. В конце каждого письма даем отбитые татуировки об email ⚡️
*Вместе с курсом вы будете получать рассылку блога Unisender
Оставляя свой email, я принимаю Политику конфиденциальностиНаш юрист будет ругаться, если вы не примете 🙁
Robots.
 txt — как настроить и загрузить на сайт
txt — как настроить и загрузить на сайтМихаил Шумовский
07 октября, 2022
Кому нужен robots.txt Как настроить robots.txt Как создать robots.txt Требования к файлу robots.txt Как проверить правильность Robots.txt
Мы в Telegram
В канале «Маркетинговые щи» только самое полезное: подборки, инструкции, кейсы.
Не всегда на серьёзных щах — шуточки тоже шутим =)
Подписаться
Станьте email-рокером 🤘
Пройдите бесплатный курс и запустите свою первую рассылку
Подробнее
Robots.txt — документ, который нужен для индексирования и продвижения сайта.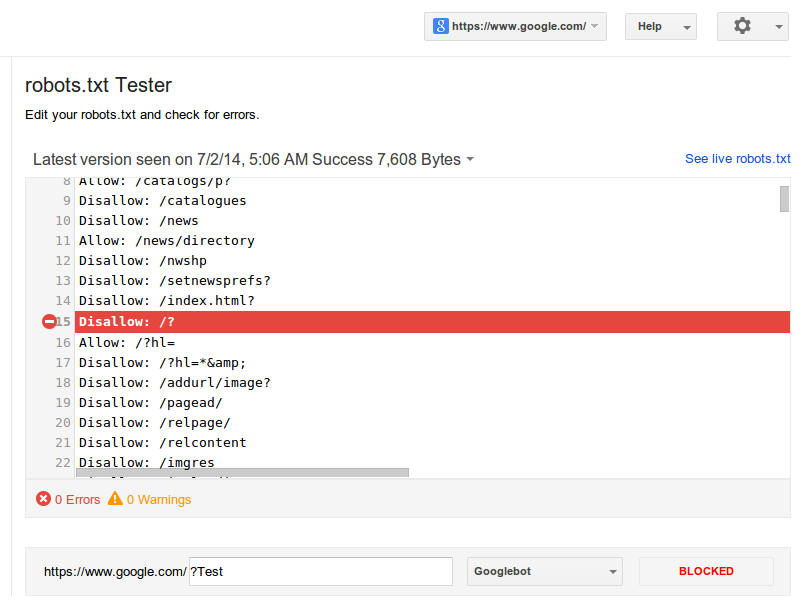 С помощью этого файла владелец сайта подсказывает поисковым системам, какие разделы ресурса нужно учитывать, а какие — нет. Объясняю особенности его составления и настройки такого текстового файла.
С помощью этого файла владелец сайта подсказывает поисковым системам, какие разделы ресурса нужно учитывать, а какие — нет. Объясняю особенности его составления и настройки такого текстового файла.
Если у сайта нет robots.txt, поисковые роботы считают все страницы ресурса открытыми для индексирования. Если файл есть, владелец сайта может запретить роботам индексировать определённые страницы.
Например, контентным ресурсам или медиа можно работать без robots.txt — тут все страницы участвуют в индексации.
На других ресурсах могут быть страницы, которые не нужно показывать поисковым роботам:
- Админ-панели сайта: пути, которые начинаются с /user, /admin, /administrator и т.д.
- Пустые страницы ресурса: если на них нет контента, в индексации они не помогут.
- Формы регистрации.
- Личные страницы в интернет-магазинах: кабинеты пользователей, корзины и т.
 д.
д.
Начну с основных параметров.
User-agent: Yandex
Disallow: catalog/
Allow: /catalog/cucumbers/
Sitemap: http://www.example.com/sitemap.xml
User-agent — указывает название робота, к которому применяется правило. Например, User-agent: Yandex означает, что правило применяется к роботу Яндекса.
А user-agent: * означает, что правило применяется ко всем роботам. Но о звёздочках поговорим ниже.
Основные типы роботов, которые можно указать в User-agent:
- Yandex. Все роботы Яндекса.
- YandexBot. Основной робот Яндекса
- YandexImages. Индексирует изображения.
- YandexMedia. Индексирует видео и другие мультимедийные данные.
- Google. Все роботы Google.
- Googlebot. Основной робот Google.
- Googlebot-Image.
 Индексирует изображения.
Индексирует изображения.
Disallow. Указывает на каталог или страницу ресурса, которые роботы индексировать не будут. Если нельзя индексировать конкретную страницу, например, определённый раздел в каталоге, нужно указывать полный путь к ней — как в поисковой строке браузера.
В начале строки должен быть символ /. Если правило касается каталога, строка должна заканчиваться символом /.
Например, disallow: /catalog/gloves. Так мы запретим индексацию раздела с перчаткам.
Если оставить disallow пустым, роботы будут индексировать все страницы сайта.
Allow. Указывает на каталог или страницу, которые можно сканировать роботу. Его используют, чтобы внести исключения в пункт disallow и разрешить сканирование подкаталога или страницы в каталоге, который закрыт для обработки.
Если требуется индексировать конкретную страницу, нужно указывать к ней полный путь. Как и в disallow. Например, allow: /story/marketing. Так мы разрешили индексировать статью о маркетинге.
Так мы разрешили индексировать статью о маркетинге.
Если правило касается каталога, строка должна заканчиваться символом /.
Если allow пустой, робот не будет индексировать никакие страницы.
Sitemap. Необязательная директива, которая может повторяться несколько раз или не использоваться совсем. Её используют, чтобы описать структуру сайта и помочь роботам индексировать страницы.
Лендингам и небольшим сайтам sitemap не нужен. А вот таким ресурсам без sitemap не обойтись:
- Cайтам без хлебных крошек (навигационных цепочек).
- Большим ресурсам. Например, если сайт содержит большой объём мультимедиа или новостного контента.
- Сайтам с глубокой вложенностью. Например, «Главная/Каталог/Перчатки/Резиновые».
- Молодым ресурсам, на которые мало внешних ссылок, — их роботам сложно найти.
- Сайтам с большим архивом страниц, которые изолированы или не связаны друг с другом.

Файл нужно прописывать в XML-формате. Создание sitemap — тема для отдельной статьи. Подробную инструкцию читайте на Google Developers или в Яндекс.Справке.
Основные моменты robots.txt разобрали. Теперь расскажу про дополнительные параметры, которые используют в коде.
Для начала посмотрим на robots.txt Unisender. Для этого в поисковой строке браузера пишем Unisender.com/robots.txt.
По такой же формуле можно проверять файлы на всех сайтах: URL сайта + домен/robots.txt.
Robots.txt Unisender отличается от файла, который я приводил в пример. Дело в том, что здесь использованы дополнительные параметры:
Директива # (решётка) — комментарий. Решётки прописывают для себя, а поисковые роботы комментариев не видят.
User-agent: Yandex
Allow: /example/* # разрешает ‘/example/blog’
# разрешает ‘/example/blog/test’
Звёздочку роботы видят, а решётку — нет
Директива * (звёздочка) — любая последовательность символов после неё.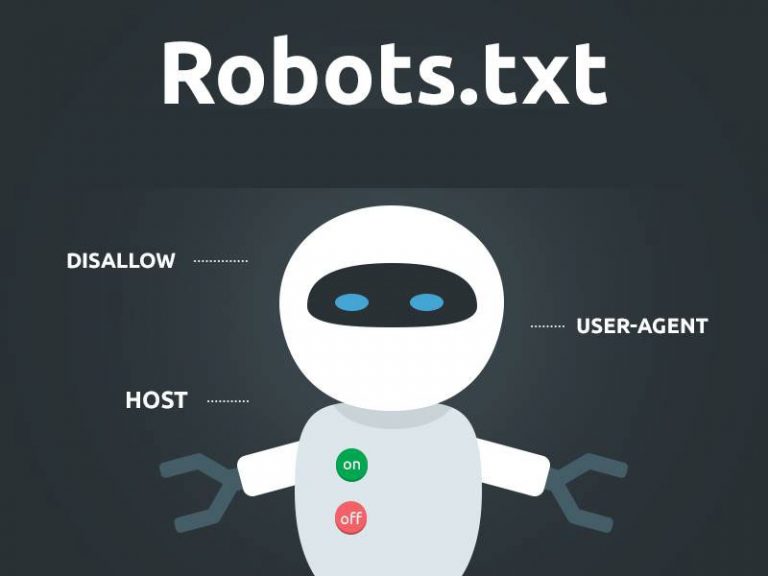
Например, если поставить звёздочку в поле disallow, то всё, что находится на её месте, будет запрещено.
User-agent: Yandex
Disallow: /example/* # запрещает ‘/example/blog’
# запрещает ‘/example/blog/test’
Disallow: */shop # запрещает не только ‘/shop’,
# но и ‘/example/shop’
Также и с полем allow: всё, что стоит на месте звёздочки, — разрешено для индексации.
User-agent: Yandex
Allow: /example/* # разрешает ‘/example/blog’
# разрешает ‘/example/blog/test’
Allow: */shop # разрешает не только ‘/shop’,
# но и ‘/example/shop’
Например, у Google есть особенность: компания рекомендует не закрывать от поисковых роботов файлы с css-стилями и js-скриптами. Вот как это нужно прописывать:
User-agent: Googlebot
Disallow: /site
Allow: *.css
Allow: *.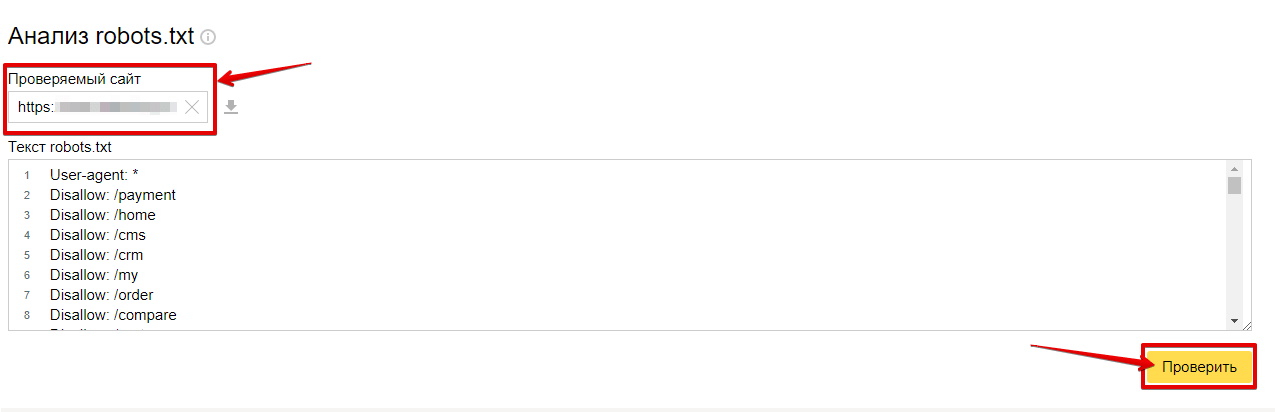 js
js
Директива $ (знак доллара) — точное соответствие указанному параметру.
Например, использование доллара в disallow запретит доступ к определённому пути.
User-agent: Yandex
Disallow: /example # запрещает ‘/example’,
# запрещает ‘/example.html’
Disallow: /example$ # запрещает ‘/example’,
# не запрещает ‘/example.html’
# не запрещает ‘/example1’
# не запрещает ‘/example-new’
Таким способом можно исключить из сканирования все файлы определённого типа, например, GIF или JPG. Для этого нужно совместить * и $. Звёздочку ставим до расширения, а $ — после.
User-agent: Yandex
Disallow: / *.gif$ # вместо * могут быть любые символы,
# $ запретит индексировать файлы gif
Директива Clean-param — новый параметр Яндекс-роботов, который не будет сканировать дублированную информацию и поможет быстрее анализировать ресурс.
Дело в том, что из-за повторяющейся информации роботы медленнее проверяют сайт, а изменения на ресурсе дольше попадают в результаты поиска. Когда роботы Яндекса увидят эту директиву, не будут несколько раз перезагружать дубли информации и быстрее проверят сайт, а нагрузка на сервер снизится.
www.example.com/dir/get_card.pl?ref=site_1&card_id=10
www.example.com/dir/get_card.pl?ref=site_2&card_id=10
Параметр ref нужен, чтобы отследить, с какого ресурса сделан запрос. Он не меняет содержимое страницы, значит два адреса покажут одну и ту же страницу с книгой card_id=10. Поэтому директиву можно указать так:
User-agent: Yandex
Disallow:
Clean-param: ref /dir/get_card.pl
Робот Яндекса сведёт страницы к одной: www.example.com/dir/get_card.pl?card_id=10
Чтобы директива применялась к параметрам на страницах по любому адресу, не указывайте адрес:
User-agent: Yandex
Disallow:
Clean-param: utm
Директива Crawl-delay — устанавливает минимальный интервал в секундах между обращениями робота к сайту.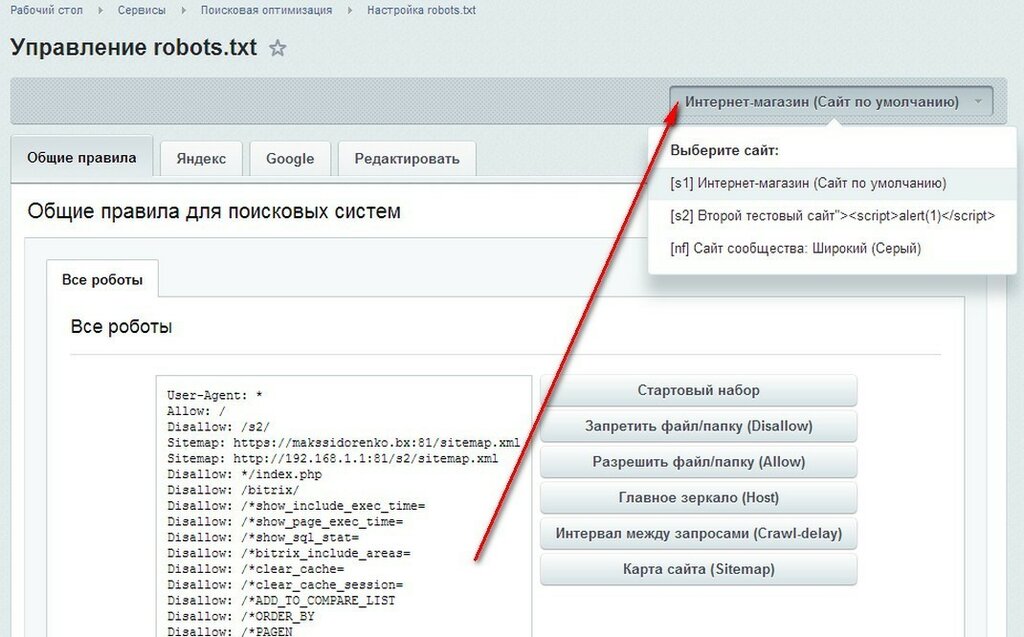 Это помогает снизить нагрузку на сервер ресурса. Чем выше указанное значение, тем меньше страниц робот загрузит за сессию.
Это помогает снизить нагрузку на сервер ресурса. Чем выше указанное значение, тем меньше страниц робот загрузит за сессию.
Значения можно указывать целыми или дробными числами через точку.
User-agent: Yandex
Disallow:
Crawl-delay: 0.5
Для Яндекса максимальное значение в crawl-delay — 2. Более высокое значение можно установить инструментами Яндекс.Вебмастер.
Для Google-бота можно установить частоту обращений в панели вебмастера Search Console.
Директива Host — инструкция для робота Яндекса, которая указывает главное зеркало сайта. Нужна, если у сайта есть несколько доменов, по которым он доступен. Вот как её указывают:
User-agent: Yandex
Disallow: /example/
Host: example.ru
Если главное зеркало сайта — домен с протоколом HTTPS, его указывают так:
Host: https://site.ru
Как создать robots.txtСпособ 1. Понадобится текстовый редактор: блокнот, TextEdit, Vi, Emacs или любой другой.![]() Не используйте приложения Microsoft Office, потому что они сохраняют файлы в неподходящем формате или добавляют в них лишние символы, которые не распознаются поисковыми роботами.
Не используйте приложения Microsoft Office, потому что они сохраняют файлы в неподходящем формате или добавляют в них лишние символы, которые не распознаются поисковыми роботами.
Способ 2. Создать на CMS с помощью плагинов — в этом случае robots.txt установится сам.
Если вы используете CMS хостинга, редактировать файл robots.txt не потребуется. Скорее всего, у вас даже не будет такой возможности. Вместо этого провайдер будет указывать поисковым системам, нужно ли сканировать контент, с помощью страницы настроек поиска или другого инструмента.
Способ 3. Воспользоваться генератором robots.txt — век технологий всё-таки.
Сгенерировать файл можно на PR-CY, IKSWEB, Smallseotools.
Требования к файлу robots.txtКогда создадите текстовый файл, сохраните его в кодировке utf-8. Иначе поисковые роботы не смогут прочитать документ. После создания загрузите файл в корневую директорию на сайте хостинг-провайдера. Корневая директория — это папка public. html.
html.
Папка, в которой нужно искать robots.txt. Источник
Если файла нет, его придётся создавать самостоятельно.
Требования, которым должен соответствовать robots.txt:
- Каждая директива начинается с новой строки.
- Одна директива в строке, сам параметр также написан в одну строку.
- В начале строки нет пробелов.
- Нет кавычек в директивах.
- Директивы не нужно закрывать точкой или точкой с запятой.
- Файл должен называться robots.txt. Нельзя называть его Robots.txt или ROBOTS.TXT.
- Размер файла не должен превышать 500 КБ.
- robots.txt должен быть написан на английском языке. Буквы других алфавитов не разрешаются.
Если файл не соответствует одному из требований, весь сайт считается открытым для индексирования.
Как проверить правильность Robots.txtПроверить robots. txt помогают сервисы от Яндекс и Google. В Яндексе можно проверять файл даже без сайта — например, если вы написали robots.txt, но пока не загрузили его на сайт.
txt помогают сервисы от Яндекс и Google. В Яндексе можно проверять файл даже без сайта — например, если вы написали robots.txt, но пока не загрузили его на сайт.
Вот как это сделать:
- Перейдите на Яндекс.Вебмастер.
- В открывшееся окно вставьте текст robots.txt и нажмите проверить.
Если файл написан правильно, Яндекс.Вебмастер не увидит ошибок.
А если увидит ошибку — подсветит её и опишет возможную проблему.
На Яндекс.Вебмастер можно проверить robots.txt и по URL сайта. Для этого нужно указать запрос: URL сайта/robots.txt. Например, unisender.com/robots.txt.
Ещё один вариант — проверить файл robots.txt через Google Search Console. Но сначала нужно подтвердить владение сайтом. Пошаговый алгоритм проверки robots.txt описан в видеоинструкции:
Поделиться
СВЕЖИЕ СТАТЬИ
Другие материалы из этой рубрики
Не пропускайте новые статьи
Подписывайтесь на соцсети
Делимся новостями и свежими статьями, рассказываем о новинках сервиса
«Честно» — авторская рассылка от редакции Unisender
Искренние письма о работе и жизни.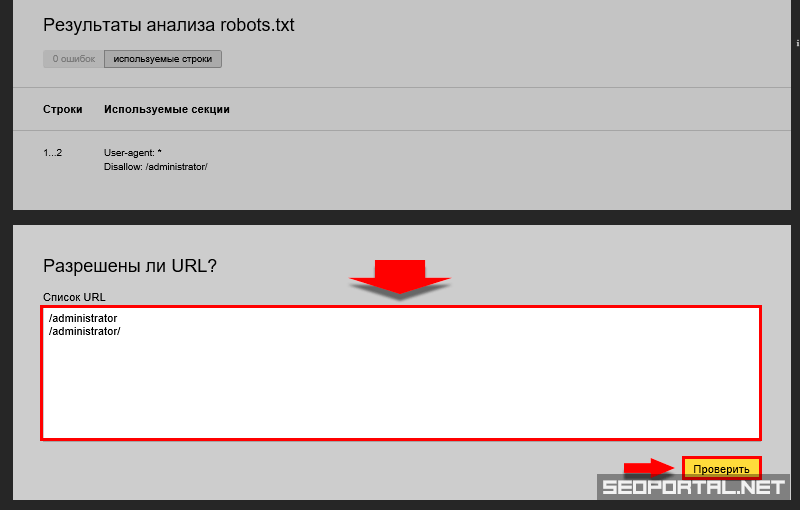 Свежие статьи из блога. Эксклюзивные кейсы
и интервью с экспертами диджитала.
Свежие статьи из блога. Эксклюзивные кейсы
и интервью с экспертами диджитала.
Наш юрист будет ругаться, если вы не примете 🙁
Как запустить email-маркетинг с нуля?
В бесплатном курсе «Rock-email» мы за 15 писем расскажем, как настроить email-маркетинг в компании. В конце каждого письма даем отбитые татуировки об email ⚡️
*Вместе с курсом вы будете получать рассылку блога Unisender
Оставляя свой email, я принимаю Политику конфиденциальностиНаш юрист будет ругаться, если вы не примете 🙁
АнализRobots.
 txt — Вебмастер. Справка
txt — Вебмастер. Справка- Как проверить файл
- Как узнать, будет ли робот сканировать определенный URL-адрес
- Как отслеживать изменения файла
- FAQ
Инструмент анализа Robots.txt поможет вам проверить, сканирует ли robots. txt файл правильный. Вы можете ввести содержимое файла, проверить его, а затем скопировать в robots.txt.
Этот инструмент также поможет вам отслеживать изменения в файле и загружать его конкретную версию.
- Как проверить файл
- Как узнать, будет ли робот сканировать определенный URL
- Как отслеживать изменения в файле
- FAQ
- Если сайт был добавлен в Яндекс.Вебмастер и были права на управление сайтом Verified
Содержимое файла появится на странице анализа Инструменты → Robots.txt, как только будут подтверждены права на управление сайтом.
Если содержимое отображается на странице анализа Robots.txt, щелкните Проверить.
- Если сайт не добавлен в Яндекс.
 Вебмастер
Вебмастер Перейти на страницу анализа robots.txt.
В поле Проверяемый сайт введите адрес вашего сайта. Например, https://example.com.
Щелкните значок. Содержимое файла robots.txt и результаты анализа будут показаны ниже.
В разделах, предназначенных для робота Яндекса (User-agent: Яндекс или User-agent: *), валидатор проверяет директивы, используя условия использования robots.txt. Остальные разделы проверяются на соответствие стандарту.
После проверки вы можете увидеть:
Предупреждения. Они сообщают об отклонении от правил, которое может быть исправлено самим инструментом. Предупреждения также указывают на потенциальную проблему с опечатками или неточностями в директивах.
Ошибки в файле. Это означает, что инструмент не может обработать строку, раздел или весь файл из-за серьезных синтаксических ошибок в директивах.
Дополнительные сведения см. в разделе Ошибки синтаксического анализа файла robots.txt.
При загрузке файла robots.txt в Яндекс.Вебмастер на странице анализа Robots.txt отображается блок Проверить, разрешены ли ссылки.
В поле списка URL введите адрес страницы, которую хотите проверить. Вы можете указать URL полностью или относительно корневого каталога сайта. Например, https://example.com/page/ или /page/.
Нажмите Проверить.
Если URL-адрес разрешен для индексации ботами Яндекса, рядом с ним появится значок . В противном случае адрес будет выделен красным цветом.
Примечание. Доступна полугодовая история изменений. Максимальное количество сохраняемых версий — 100.
Чтобы оперативно узнавать об изменениях в файле robots.txt, настройте уведомления.
Яндекс.Вебмастер регулярно проверяет файл на наличие обновлений и сохраняет версии вместе с датой и временем изменения. Чтобы просмотреть их, перейдите в Инструменты → Анализ Robots.txt.
Чтобы просмотреть их, перейдите в Инструменты → Анализ Robots.txt.
Список версий отображается при соблюдении всех следующих условий:
Вы добавили сайт в Яндекс.Вебмастер и подтвердили право на управление сайтом.
Яндекс.Вебмастер хранит информацию об изменениях в robots.txt.
Вы можете:
- Просмотреть текущую и предыдущую версии файла
В списке версий robots.txt выберите версию файла. Поле ниже показывает файл robots.txt вместе с результатами синтаксического анализа.
- Скачать версию выбранного файла
В списке версий robots.txt выберите версию файла.
Нажмите кнопку «Загрузить». Файл будет сохранен на вашем устройстве в формате TXT.
Ошибка «Этот URL не принадлежит вашему домену»
Скорее всего, вы включили зеркало в список URL вашего сайта. Например, http://example.com вместо http://www.example.com (технически это два разных URL-адреса). Технически это два разных URL. URL-адреса в списке должны принадлежать сайту, для которого проверяется файл robots.txt.
Например, http://example.com вместо http://www.example.com (технически это два разных URL-адреса). Технически это два разных URL. URL-адреса в списке должны принадлежать сайту, для которого проверяется файл robots.txt.
Укажите инструмент, в котором вы обнаружили ошибку, максимально подробно опишите ситуацию и, если необходимо, прикрепите скриншот, иллюстрирующий ее.
Метатег robots и HTTP-заголовок X-Robots-Tag
Вы можете указать для роботов правила загрузки и индексации определенных страниц сайта одним из следующих способов:
Поместить метатег robots внутрь элемента head HTML-кода страницы.
Настройте заголовок HTTP X-Robots-Tag для определенного URL-адреса на сервере вашего сайта.
Примечание. Если страница запрещена в файле robots.txt, директива метатега или заголовка не применяется.
По умолчанию поисковые роботы учитывают метатег и заголовок. Вы можете указать директивы для определенных роботов.
- Директивы, поддерживаемые Яндексом
- Задание нескольких директив
- Инструкции для конкретных роботов
| Directive | Description | Robots meta tag | X-Robots-Tag header |
|---|---|---|---|
| noindex | Prohibits indexing the page text. Страница не будет включена в результаты поиска. | ||
| nofollow | Запрещает переход по ссылкам на странице. Робот не будет переходить по ссылкам при сканировании сайта, но может узнать о них из других источников. Например, на других страницах или сайтах. | ||
| нет | Аналогично директивам noindex и nofollow.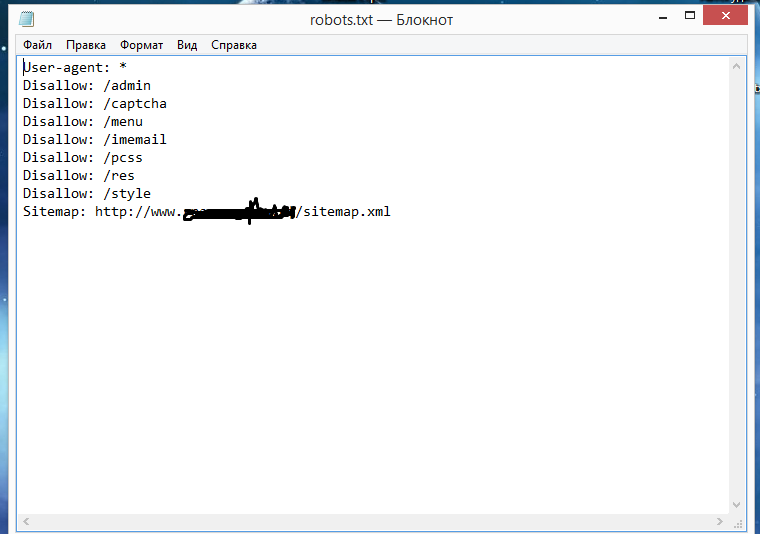 | ||
| noarchive | Запрещает показывать ссылку на сохраненную копию на странице результатов поиска. | ||
| noyaca | Запрещает использование автоматически сгенерированного описания. | — | |
| индекс | следовать | архив | Отключает соответствующие запрещающие директивы. | — | |
| все | Позволяет индексировать текст и ссылки на странице, аналогично индексу и следуя директивам.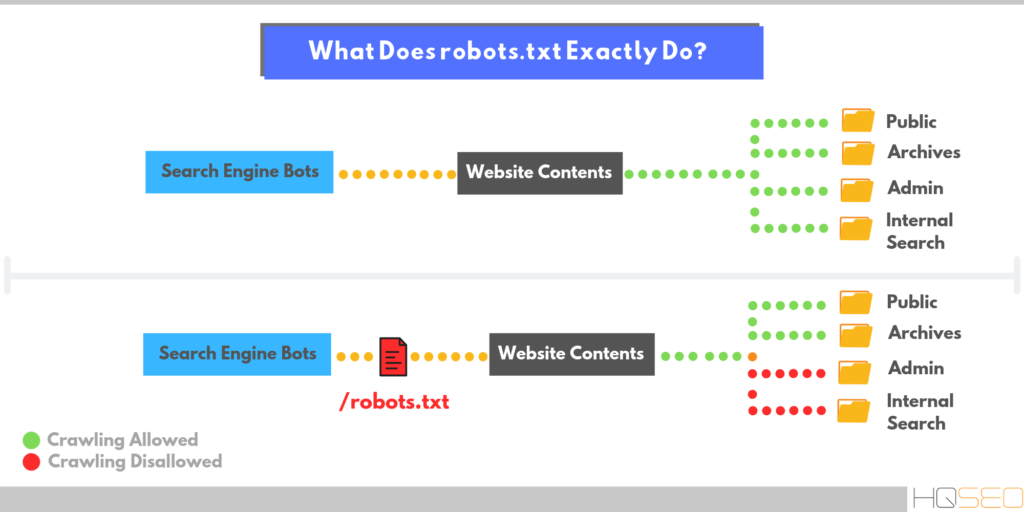 | — |
По умолчанию робот использует разрешающие директивы, поэтому их можно не указывать, если нет других директив. Разрешающие директивы имеют приоритет над запрещающими директивами, если есть комбинация обоих. Пример.
Роботы из других поисковых систем и сервисов могут по-разному интерпретировать директивы.
Пример:
Элемент, отключающий индексацию страницы.
<голова>
<тело>...
Ответ HTTP с заголовком, запрещающим индексирование страницы.
HTTP/1.1 200 ОК Дата: вторник, 25 мая 2010 г., 21:42:43 по Гринвичу X-Robots-Tag: noindex
Можно указать несколько директив, разделенных запятыми.
В одном ответе можно передать несколько заголовков и список директив, разделенных запятыми.
HTTP/1.1 200 ОК Дата: вторник, 25 мая 2010 г., 21:42:43 по Гринвичу X-Robots-Tag: noindex, nofollow X-Robots-Tag: noarchive
Если для робота Яндекса указаны конфликтующие директивы, он будет считать положительное значение. Пример директив метатегов:
С помощью метатега robots можно дать директиву только роботам Яндекса. Пример:
Если перечислить общие директивы и директивы для роботов Яндекса, поисковик учтет их все.
Робот Яндекса будет интерпретировать эти директивы как noindex, nofollow .