Правильный Robots.txt для WordPress
Всем привет! Сегодня статья о том, каким должен быть правильный файл robots.txt для WordPress. С функциями и предназначением robots.txt мы разбирались несколько дней назад, а сейчас разберём конкретный пример для ВордПресс.
С помощью этого файла у нас есть возможность задать основные правила индексации для различных поисковых систем, а также назначить права доступа для отдельных поисковых ботов. На примере я разберу как составить правильный robots.txt для WordPress. За основу возьму две основные поисковые системы — Яндекс и Google.
В узких кругах вебмастеров можно столкнуться с мнением, что для Яндекса необходимо составлять отдельную секцию, обращаясь к нему по User-agent: Yandex. Давайте вместе разберёмся, на чём основаны эти убеждения.
Яндекс поддерживает директивы Clean-param и Host, о которых Google ничего не знает и не использует при обходе.
Разумно использовать их только для Yandex, но есть нюанс — это межсекционные директивы, которые допустимо размещать в любом месте файла, а Гугл просто не станет их учитывать.
User-agent: * для всех поисковых роботов.При обращении к роботам по User-agent важно помнить, что чтение и обработка файла происходит сверху вниз, поэтому используя User-agent: Yandex или User-agent: Googlebot необходимо размещать эти секции в начале файла.
Сразу хочу предупредить: не существует идеального файла, который подойдет абсолютно всем сайтам, работающим на ВордПресс! Не идите на поводу, слепо копируя содержимое файла без проведения анализа под ваш конкретный случай! Многое зависит от выбранных настроек постоянных ссылок, структуры сайта и даже установленных плагинов. Я рассматриваю пример, когда используется ЧПУ и постоянные ссылки вида
WordPress, как и любая система управления контентом, имеет свои административные ресурсы, каталоги администрирования и прочее, что не должно попасть в индекс поисковых систем. Для защиты таких страниц от доступа необходимо запретить их индексацию в данном файле следующими строками:
Для защиты таких страниц от доступа необходимо запретить их индексацию в данном файле следующими строками:
Disallow: /cgi-bin Disallow: /wp-
Директива во второй строке закроет доступ по всем каталогам, начинающимся на
- wp-admin
- wp-content
- wp-includes
Но мы знаем, что изображения по умолчанию загружаются в папку uploads, которая находится внутри каталога wp-content. Разрешим их индексацию строкой:
Allow: */uploads
Служебные файлы закрыли, переходим к исключению дублей с основным содержимым, которые снижают уникальность контента в пределах одного домена и увеличивают вероятность наложения на сайт фильтра со стороны ПС. К дублям относятся страницы категорий, авторов, тегов, RSS-фидов, а также постраничная навигация, трекбеки и отдельные страницы с комментариями. Обязательно запрещаем их индексацию:
Disallow: /category/ Disallow: /author/ Disallow: /page/ Disallow: /tag/ Disallow: */feed/ Disallow: */trackback Disallow: */comments
Далее хотелось бы уделить особое внимание такому аспекту как постоянные ссылки. Если вы используете ЧПУ, то страницы содержащие в URL знаки вопроса зачастую являются «лишними» и опять же дублируют основной контент. Такие страницы с параметрами следует запрещать аналогичным образом:
Если вы используете ЧПУ, то страницы содержащие в URL знаки вопроса зачастую являются «лишними» и опять же дублируют основной контент. Такие страницы с параметрами следует запрещать аналогичным образом:
Disallow: */?
Это правило распространяется на простые постоянные ссылки ?p=1, страницы с поисковыми запросами 20*, тем самым запрещая индексирование архивов по годам:
Disallow: /20*
Для ускорения и полноты индексации добавим путь к расположению карты сайта. Робот обработает файл и при следующем посещении сайта будет его использовать для приоритетного обхода страниц.
Sitemap: https://webliberty.ru/sitemap.xml
В файле robots.txt можно разместить дополнительную информацию для роботов, повышающую качество индексации. Среди них директива Host — указывает на главное зеркало для Яндекса:
Host: webliberty.ru

При работе сайта по HTTPS необходимо указать протокол:
Host: https://webliberty.ru
С 20 марта 2018 года Яндекс официально прекратил поддержку директивы Host. Её можно удалить из robots.txt, а если оставить, то робот её просто игнорирует.
Подводя итог, я объединил всё выше сказанное воедино и получил содержимое файла robots.txt для WordPress, который использую уже несколько лет и при этом в индексе нет дублей:
User-agent: * Disallow: /cgi-bin Disallow: /wp- Disallow: /category/ Disallow: /author/ Disallow: /page/ Disallow: /tag/ Disallow: */feed/ Disallow: /20* Disallow: */trackback Disallow: */comments Disallow: */? Allow: */uploads Sitemap: https://webliberty.ru/sitemap.xml
Постоянно следите за ходом индексации и вовремя корректируйте файл в случае появления дублей.
От того правильно или нет составлен файл зависит очень многое, поэтому обратите особо пристальное внимание к его составлению, чтобы поисковики быстро и качественно индексировали сайт. Если у вас возникли вопросы — задавайте, с удовольствием отвечу!
Если у вас возникли вопросы — задавайте, с удовольствием отвечу!
ТОП4 способа как создать Robots txt для WordPress
Хотите, чтобы поисковые системы корректно индексировали страницы и разделы вашего блога? Отличное решение — сделать правильный файл Robots txt для WordPress. Разберемся как и что в нем прописать.
Содержание
- Для чего нужен Robots.txt?
- Где лежит Robots?
- Не могу найти этот файл
- Из чего состоит robots.txt
- Пример стандартного robots.txt для ВордПресс
- Как создать правильный robots.txt для сайта
- Вручную
- Clearfy Pro
- Yoast SEO
- All in One SEO Pack
- Настройка для интернет-магазинов на основе WooCommerce
Для чего нужен Robots.txt?
Он предназначен для поисковых систем, их роботов и правильной индексации. Директивы файла указывают, какие разделы сайта нужно выдавать в поиске, а какие скрыть. Это позволяет нацелить поисковик на попадание нужного контента в выдаче. Например, если человек в Google введет «как отремонтировать холодильник», то ему нужно показать инструкцию по ремонту, а не страницу регистрации или информацию о сайте.
Например, если человек в Google введет «как отремонтировать холодильник», то ему нужно показать инструкцию по ремонту, а не страницу регистрации или информацию о сайте.
Результат поисковой выдачи после изменений robots.txt вы заметите не сразу. Может пройти от недели до нескольких месяцев. Правильно будет его создать уже во время разработки сайта.
Где лежит Robots?
Это обычный текстовый файл, который располагается в корневой папке сайта и доступен по адресу
https://site.com/robots.txt
По умолчанию Роботс не создается. Его нужно создавать вручную или использовать инструменты, которые делают это автоматически. Разберем их ниже.
Не могу найти этот файл
Если по указанной выше ссылке файл доступен онлайн, но в корне сайта его нет, то это означает, что он создан виртуально. Для поисковой системы нет разницы. Главное, чтобы его содержимое можно было получить по адресу https://site.com/robots.. txt
txt
Из чего состоит robots.txt
Имеет 4 основных директивы:
- User-agent — задает правила для поисковых роботов.
- Disalow — запрещает доступ.
- Allow — разрешает.
- Sitemap — полный путь (URL-адрес) XML-карты.
Пример стандартного robots.txt для ВордПресс
Вариаций этого файла много. На каждом сайте он может отличаться.
Вот пример рабочего Роботс. Посмотрим что означает каждая его строка и для чего нужна.
User-agent: *
Disallow: /cgi-bin
Disallow: /wp-admin
Disallow: /wp-content/cache
Disallow: /wp-json/
Disallow: /wp-login.php
Disallow: /wp-register.php
Disallow: /xmlrpc.php
Disallow: /license.txt
Disallow: /readme.html
Disallow: /trackback/
Disallow: /comments/feed/
Disallow: /*?replytocom
Disallow: */feed
Disallow: */rss
Disallow: /author/
Disallow: /?
Disallow: /*?
Disallow: /?s=
Disallow: *&s=
Disallow: /search
Disallow: *?attachment_id=
Allow: /*. css
css
Allow: /*.js
Allow: /wp-content/uploads/
Allow: /wp-content/themes/
Allow: /wp-content/plugins/
Sitemap: https://site.com/sitemap_index.xml
Первая строка говорит, что ссылки сайта могут обходить все поисковые роботы.
Строки с Disallow запрещают индексировать служебные папки и файлы, кэшированные страницы, страницы авторизации и регистрации, RSS (Feed), страницы авторов, поиска и вложений.
Директивы с Allow наоборот разрешают добавлять в индекс поисковиков скрипты, стили, файлы загрузок, тем и плагинов.
Последняя строка указывает на адрес карты XML.
По этому примеру вы можете составить свой Роботс, который будет «заточен» под ваш ресурс.
Идеального содержимого этого файла для всех сайтов не существует. Его всегда нужно формировать под конкретный ресурс.
Как создать правильный robots.txt для сайта
Есть несколько способов.
Вручную
Это можно сделать обычным ручным способом. Например, в Блокноте (если локальный сайт) или через FTP-клиент (на сервере хостинга).
Например, в Блокноте (если локальный сайт) или через FTP-клиент (на сервере хостинга).
Если вы не доверяете сторонним решениям и хотите все сделать самостоятельно, то наиболее подходящий вариант — создать файл в любом текстовом редакторе и скопировать его на сайт по FTP-протоколу.
Для передачи данных на хостинг можно воспользоваться довольно удобным FTP-клиентом FileZilla. Отметим, что файл robots.txt должен быть скопирован в корневой каталог вашего сайта (рядом с файлами wp-config.php, wp-settings.php).
После того, как файл будет создан и скопирован на хостинг, Вы, перейдя по адресу site.ru/robots.txt, сможете посмотреть его содержимое.
Также это можно сделать с помощью ВП-плагинов. Разберем лучшие.
Clearfy Pro
Виртуальный файл поможет создать премиум-плагин Clearfy Pro, который имеет целый набор функций для SEO и оптимизации сайта.
- Установите и активируйте расширение.

- Откройте админ-раздел Clearfy Pro.
- Перейдите на вкладку SEO.
- Активируйте опцию Создать правильный robots.txt.
- Заполните содержимое директивами.
- Нажмите кнопку Сохранить изменения.
Всегда можно отредактировать содержимое Robots. Просто измените/дополните его нужным содержимым и сохраните изменения.
Активировать промокод на 15%
Yoast SEO
Этот мощный СЕО-модуль для WP также корректно решит задачу.
- Откройте SEO > Инструменты.
- Кликните по Редактор файлов.
- Если этого файла в корне сайта нет, нажмите Создать файл robots.txt.
- Если существует, то откроется редактор, в котором можно вносить правки.
- Если изменили Роботс, кликните по кнопке ниже.
All in One SEO Pack
В этом популярном для поисковой оптимизации решении тоже есть инструменты чтобы создать/отредактировать Robots.
- После активации перейдите All in One SEO > Модули.
- Из списка выберите одноименное название модуля и нажмите Activate.
- Откройте All in One SEO > Robots.txt.
- С помощью полей добавьте директивы.
Настройка для интернет-магазинов на основе WooCommerce
Для WordPress-ресурсов с использованием этого расширения есть свои директивы. Просто добавьте их к своим.
Disallow: /cart/ Disallow: /checkout/ Disallow: /*add-to-cart=* Disallow: /my-account/
Файл robots.txt предназначен указания поисковым системам (роботам ПС), что на сайте можно выводить в поиске, а что нет. Поэтому от его корректного заполнения напрямую зависит трафик на вашем сайте.
Better Robots.txt Rules for WordPress
Очистив свои файлы во время недавнего редизайна, я понял, что несколько лет каким-то образом прошло с тех пор, как в последний раз я вообще просматривал файл robots. сайта. Я думаю, это хорошо, но со всеми изменениями в структуре и содержании сайта снова настало время для восхитительной возни с robots.txt.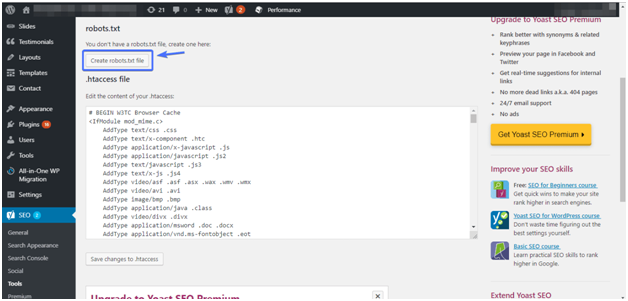 txt
txt
Этот пост подытоживает мои исследования и дает вам почти идеальный файл robots, так что вы можете копировать/вставлять полностью «как есть» или использовать шаблон, чтобы дать вам отправную точку для вашей собственной настройки.
Robots.txt за 30 секунд
Прежде всего, директивы для роботов запрещают послушным паукам доступ к определенным частям вашего сайта. Они также могут явно «разрешать» доступ к определенным файлам и каталогам. Таким образом, в основном они используются, чтобы сообщить Google, Bing и другим, куда они могут перейти при посещении вашего сайта. Вы также можете делать отличные вещи, такие как инструктировать конкретных пользовательских агентов и объявлять карты сайта. Для простого текстового файла robots.txt обладает значительной мощностью. И мы хотим использовать любую силу, которую мы можем получить, для нашей наибольшей выгоды.
Лучший robots.txt для WordPress
Запустив WordPress, вы хотите, чтобы поисковых систем сканировали и индексировали ваши сообщения и страницы, но не ваши основные файлы и каталоги WP. Вы также хотите убедиться, что каналы и обратные ссылки не включены в результаты поиска. Также рекомендуется объявить карту сайта. Имея это в виду, вот новые и улучшенные правила robots.txt для WordPress :
User-agent: * Запретить: /wp-admin/ Запретить: /трекбэк/ Запретить: /xmlrpc.php Запретить: /кормить/ Разрешить: /wp-admin/admin-ajax.php Карта сайта: https://example.com/sitemap.xml
Требуется только одно небольшое редактирование: изменить Карта сайта , чтобы она соответствовала местоположению вашей карты сайта (или удалить строку, если карта сайта недоступна).
Важно: Начиная с версии 5.5, WordPress автоматически создает карту сайта для вашего сайта. Для получения дополнительной информации ознакомьтесь с этим подробным руководством по WP Sitemaps.
Usage
Чтобы добавить код правил robots на ваш сайт на базе WordPress, просто скопируйте/вставьте код в пустой файл с именем robots.txt . Затем добавьте файл в доступный через Интернет корневой каталог, например:
https://perishablepress.com/robots.txt
Если вы посмотрите на содержимое файла robots.txt для скоропортящейся прессы, вы Обратите внимание на дополнительную директиву для роботов, которая запрещает доступ сканирования к черной дыре сайта для плохих ботов. Давайте посмотрим:
Агент пользователя: * Запретить: /wp-admin/ Запретить: /трекбэк/ Запретить: /xmlrpc.php Запретить: /кормить/ Запретить: /черная дыра/ Разрешить: /wp-admin/admin-ajax.php Карта сайта: https://perishablepress.com/wp-sitemap.xml
Паукам не нужно ничего ползать по адресу /wp-admin/ , так что это запрещено. Точно так же не нужно сканировать обратные ссылки, xmlrpc и фиды, поэтому мы их тоже запрещаем. Также обратите внимание, что мы добавляем явную директиву Allow , которая разрешает доступ к Ajax-файлу WordPress, чтобы сканеры и боты имели доступ к любому содержимому, созданному Ajax. Наконец, мы обязательно объявляем местоположение нашей карты сайта, просто чтобы сделать ее официальной.
Примечания и обновления
Обновление! Следующие директивы были удалены из проверенных правил robots.txt, чтобы удовлетворить новые требования Google, согласно которым роботу googlebot всегда разрешается полный доступ для сканирования к любому общедоступному файлу.
Запретить: /wp-content/ Запретить: /wp-includes/
Поскольку /wp-content/ и /wp-includes/ содержат некоторые общедоступные файлы CSS и JavaScript, рекомендуется всегда разрешать роботу Googlebot полный доступ к обоим каталогам.
Судя по всему, Google настолько усердно относится к этому новому требованию 1 , что фактически наказывает сайты (МНОГО) за несоблюдение 2 . Плохие новости для сотен тысяч владельцев сайтов, у которых есть дела поважнее, чем следить за постоянными, часто произвольными изменениями Google.
- 1 Google требует полного доступа ко всем общедоступным файлам.
- 2 Обратите внимание, что может быть приемлемо запретить доступ бота к
/wp-content/и/wp-includes/для других (не Google) ботов. Проведите исследование, прежде чем делать какие-либо предположения.
Ранее на robots.txt..
Как уже упоминалось, мой предыдущий файл robots.txt оставался неизменным в течение нескольких лет (который просто исчез в мгновение ока). Предыдущие правила оказались весьма эффективными, особенно с совместимыми пауками, такими как googlebot . К сожалению, он содержит язык, который понимают (и, следовательно, подчиняются) лишь немногие из крупных поисковых систем. Рассмотрим следующие правила роботов, которые использовались здесь, на Perishable Press 9.0011 путь назад день.
Важно! Пожалуйста, не используйте следующие правила ни на одном действующем сайте. Они предназначены только для справки и обучения. Для действующих сайтов используйте правила Better robots.txt, приведенные в предыдущем разделе.
Агент пользователя: * Запретить: /мята/ Запретить: /labs/ Запретить: /*/wp-* Запретить: /*/кормить/* Запретить: /*/*?s=* Запретить: /*/*.js$ Запретить: /*/*.inc$ Запретить: /передача/ Запретить: /*/cgi-bin/* Запретить: /*/черная дыра/* Запретить: /*/трекбек/* Запретить: /*/xmlrpc.php Разрешить: /*/20*/wp-* Разрешить: /press/feed/$ Разрешить: /press/tag/feed/$ Разрешить: /*/wp-content/онлайн/* Карта сайта: https://perishablepress.com/sitemap.xml Агент пользователя: ia_archiver Запретить: /
По-видимому, подстановочный знак не распознается меньшими ботами, и я думаю, что символ конца шаблона (знак доллара $ ), вероятно, также не очень хорошо поддерживается, хотя Google, безусловно, его понимает.
Возможно, в будущем эти шаблоны будут поддерживаться лучше, но в будущем нет причин их включать. Как видно из правил «улучшенных роботов» (выше), такое же сопоставление шаблонов возможно без с использованием подстановочных знаков и знаков доллара, что позволяет всех ботов, совместимых с , чтобы понять ваши предпочтения сканирования.
Подробнее…
Ознакомьтесь со следующими рекомендуемыми источниками, чтобы узнать больше о robots.txt, SEO и многом другом:
- http://www.robotstxt.
 org/
org/ - https://moz.com/learn/seo/robotstxt
Google robots
Об авторе
Джефф Старр = веб-разработчик. Автор книги. Тайно важно.
Файл WordPress robots.txt… Что это такое и что он делает
Вы когда-нибудь задумывались, что такое файл robots.txt и для чего он? Robots.txt используется для связи с поисковыми роботами (известными как боты), используемыми Google и другими поисковыми системами. Он сообщает им, какие части вашего сайта индексировать, а какие игнорировать. Таким образом, файл robots.txt может помочь (или потенциально сломать!) ваши усилия по SEO. Если вы хотите, чтобы ваш веб-сайт хорошо ранжировался, важно хорошо понимать robots.txt!
Где находится robots.txt?
WordPress обычно запускает так называемый «виртуальный» файл robots.txt, что означает, что он недоступен через SFTP. Однако вы можете просмотреть его основное содержимое, перейдя по адресу yourdomain.com/robots.txt. Вы, вероятно, увидите что-то вроде этого:
Агент пользователя: * Запретить: /wp-admin/ Разрешить: /wp-admin/admin-ajax.php
В первой строке указывается, к каким ботам будут применяться правила. В нашем примере звездочка означает, что правила будут применяться ко всем ботам (например, от Google, Bing и так далее).
Вторая строка определяет правило, запрещающее ботам доступ к папке /wp-admin, а третья строка указывает, что ботам разрешено анализировать файл /wp-admin/admin-ajax.php.
Добавьте свои собственные правила
Для простого веб-сайта WordPress правил по умолчанию, применяемых WordPress к файлу robots.txt, может быть более чем достаточно. Однако, если вы хотите больше контроля и возможность добавлять свои собственные правила, чтобы дать более конкретные инструкции роботам поисковых систем о том, как индексировать ваш веб-сайт, вам нужно будет создать свой собственный физический файл robots.txt и поместить его в корень. каталог вашей установки.
Есть несколько причин, по которым может потребоваться перенастроить файл robots.txt и определить, что именно этим ботам будет разрешено сканировать. Одна из основных причин связана со временем, затрачиваемым ботом на сканирование вашего сайта. Google (и другие) не позволяют ботам проводить неограниченное время на каждом веб-сайте… с триллионами страниц им приходится применять более тонкий подход к тому, что их боты будут сканировать, а что проигнорируют в попытке извлечь наиболее полезную информацию. о веб-сайте.
Одна из основных причин связана со временем, затрачиваемым ботом на сканирование вашего сайта. Google (и другие) не позволяют ботам проводить неограниченное время на каждом веб-сайте… с триллионами страниц им приходится применять более тонкий подход к тому, что их боты будут сканировать, а что проигнорируют в попытке извлечь наиболее полезную информацию. о веб-сайте.
Разместите свой сайт с Pressidium
60-ДНЕВНАЯ ГАРАНТИЯ ВОЗВРАТА ДЕНЕГ
ПОСМОТРЕТЬ НАШИ ПЛАНЫ Когда вы разрешаете ботам сканировать все страницы вашего веб-сайта, часть времени сканирования тратится на страницы, которые не являются важными или даже релевантными. Это оставляет им меньше времени, чтобы проработать наиболее важные области вашего сайта. Запрещая доступ ботов к некоторым частям вашего веб-сайта, вы увеличиваете время, доступное ботам для извлечения информации из наиболее важных частей вашего сайта (которые, как мы надеемся, в конечном итоге будут проиндексированы). Поскольку сканирование происходит быстрее, Google с большей вероятностью повторно посетит ваш веб-сайт и обновит индекс вашего сайта. Это означает, что новые сообщения в блогах и другой свежий контент, скорее всего, будут индексироваться быстрее, что является хорошей новостью.
Это означает, что новые сообщения в блогах и другой свежий контент, скорее всего, будут индексироваться быстрее, что является хорошей новостью.
Примеры редактирования файла robots.txt
В файле robots.txt достаточно места для настройки. Поэтому мы предоставили ряд примеров правил, которые можно использовать для определения того, как боты индексируют ваш сайт.
Разрешение или запрещение ботов
Во-первых, давайте посмотрим, как мы можем ограничить конкретного бота. Для этого все, что нам нужно сделать, это заменить звездочку (*) на имя пользовательского агента бота, который мы хотим заблокировать, например «MSNBot». Полный список известных пользовательских агентов доступен здесь.
Агент пользователя: MSNBot Disallow: /
Поставив прочерк во второй строке, вы ограничите доступ бота ко всем директориям.
Чтобы позволить только одному боту сканировать наш сайт, мы будем использовать двухэтапный процесс. Сначала мы бы сделали этого бота исключением, а затем запретили бы всех ботов следующим образом:
User-agent: Google Запретить: Пользовательский агент: * Disallow: /
Чтобы разрешить доступ всем ботам ко всему контенту добавляем эти две строчки:
User-agent: * Запретить:
Тот же эффект можно получить, просто создав файл robots. txt и оставив его пустым.
txt и оставив его пустым.
Блокировка доступа к определенным файлам
Хотите запретить ботам индексировать определенные файлы на вашем веб-сайте? Это легко! В приведенном ниже примере мы запретили поисковым системам доступ ко всем файлам .pdf на нашем веб-сайте.
Агент пользователя: * Disallow: /*.pdf$
Символ «$» используется для обозначения конца URL-адреса. Поскольку это чувствительно к регистру, файл с именем my.PDF все равно будет просканирован (обратите внимание на CAPS).
Сложные логические выражения
Некоторые поисковые системы, такие как Google, понимают использование более сложных регулярных выражений. Однако важно отметить, что не все поисковые системы могут понимать логические выражения в файле robots.txt.
Одним из примеров этого является использование символа $. В файлах robots.txt этот символ указывает на конец URL-адреса. Итак, в следующем примере мы заблокировали поисковым ботам чтение и индексацию файлов, которые заканчиваются на . php
php
Это означает, что /index.php нельзя индексировать, но /index.php?p=1 можно. Это полезно только в очень специфических обстоятельствах и должно использоваться с осторожностью, иначе вы рискуете заблокировать доступ бота к файлам, которые вы не хотели!
Вы также можете установить разные правила для каждого бота, указав правила, которые применяются к ним индивидуально. Приведенный ниже пример кода ограничит доступ к папке wp-admin для всех ботов и в то же время заблокирует доступ ко всему сайту для поисковой системы Bing. Вам не обязательно это делать, но это полезная демонстрация того, насколько гибкими могут быть правила в файле robots.txt.
Агент пользователя: * Запретить: /wp-admin/ Агент пользователя: Bingbot Disallow: /
XML-карты сайта
XML-карты сайта действительно помогают поисковым роботам понять структуру вашего сайта. Но чтобы быть полезным, боту нужно знать, где находится карта сайта. «Директива карты сайта» используется для того, чтобы сообщить поисковым системам, что а) карта вашего сайта существует и б) где ее можно найти.
Карта сайта: http://www.example.com/sitemap.xml Пользовательский агент: * Disallow:
Вы также можете указать несколько местоположений карты сайта:
Карта сайта: http://www.example.com/sitemap_1.xml Карта сайта: http://www.example.com/sitemap_2.xml Пользователь-агент:* Disallow
Задержки сканирования ботов
Еще одна функция, которую можно реализовать с помощью файла robots.txt, — это указание ботам «замедлить» сканирование вашего сайта. Это может быть необходимо, если вы обнаружите, что ваш сервер перегружен высоким уровнем трафика ботов. Для этого вы должны указать пользовательский агент, который вы хотите замедлить, а затем добавить задержку.
Агент пользователя: BingBot Запретить: /wp-admin/ Задержка сканирования: 10
Цифра в кавычках (10) в этом примере означает задержку между сканированием отдельных страниц вашего сайта. Итак, в приведенном выше примере мы попросили бота Bing делать паузу в десять секунд между каждой страницей, которую он сканирует, тем самым давая нашему серверу немного передышки.
Единственная плохая новость об этом конкретном правиле robots.txt заключается в том, что бот Google его не соблюдает. Однако вы можете приказать их ботам замедлить работу из консоли поиска Google.
Примечания к правилам robots.txt:
- Все правила robots.txt чувствительны к регистру. Введите внимательно!
- Убедитесь, что перед командой в начале строки нет пробелов.
- Изменения, внесенные в robots.txt, могут быть отмечены ботами в течение 24-36 часов.
Как протестировать и отправить файл robots.txt для WordPress
Когда вы создали новый файл robots.txt, стоит проверить, нет ли в нем ошибок. Вы можете сделать это с помощью Google Search Console.
Во-первых, вам нужно будет указать свой домен (если у вас еще нет учетной записи Search Console для настройки веб-сайта). Google предоставит вам запись TXT, которую необходимо добавить в ваш DNS, чтобы подтвердить ваш домен.
Как только это обновление DNS будет распространено (чувство нетерпения… попробуйте использовать Cloudflare для управления своим DNS), вы можете посетить тестер robots.