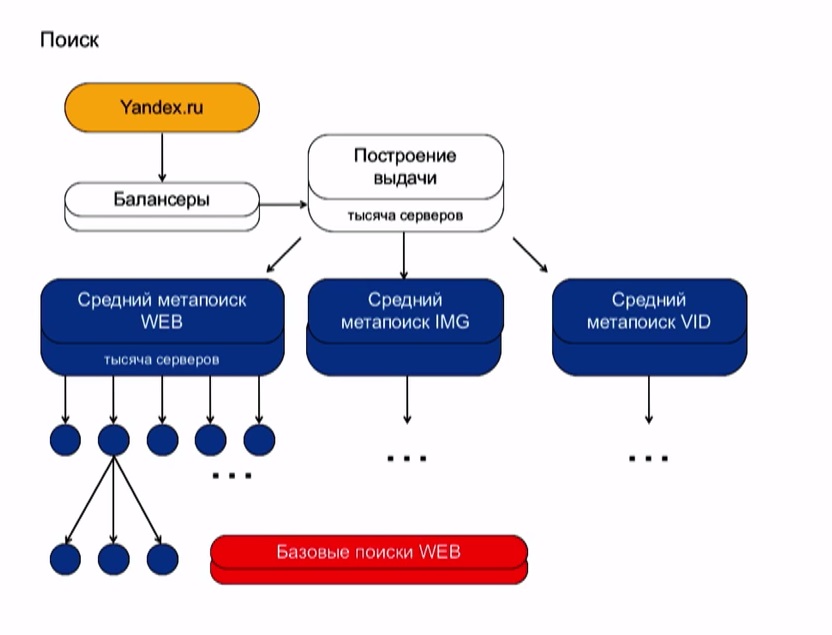
метрики Proxima, Профицит и Антикачество
Во время конференции Optimization-2021 были затронуты вопросы об изменениях, которые произошли в алгоритмах поисковой системы Яндекс. В течение последнего времени были внедрены новые сигналы качества и метрики, о которых должен знать каждый вебмастер, владелец сайта. Главная цель изменений – оценка реального качества сайтов, чтобы обеспечить максимально точные ответы на запросы пользователей. Разбираем нововведения и определяем, какое влияние они окажут на ранжирование в 2022 году.
Метрика Proxima
Метрика Proxima была внедрена примерно год назад, предназначение – определение качества сайтов. Метрика основывается на многочисленных сигналах: экспертность, конверсионность, коммерческая составляющая – все, что оказывает влияние на опыт, лояльность пользователей.
Доверие
Сайты, освещающие финансовые, юридические, медицинские, образовательные и другие тематики, наполняются контентом, написанным с применением терминов, сложных формулировок.
Ценность ресурса
Для продвижения e-commerce-бизнеса и монетизации трафика давно используются инструменты цифрового маркетинга. С точки зрения алгоритмов поисковых систем такое продвижение не демонстрирует ценность бизнеса. Если сайт не имеет для пользователей ценности, то он рискует попасть в зону риска. Показатель оценивается по разными факторам, например, после проведения экспертизы компании, являющейся поставщиком услуг. От этого фактора зависит уникальное торговое предложение, качество продуктов, позиционирование. Поисковая система определяет, как пользователи выделяют ресурсы и обратили бы они внимание на них, если бы не существовало ранжирования или инструментов платного продвижения.
Читайте также:
Ноябрьские изменения, произошедшие в Яндекс: пессимизация, кросс-девайс аналитика и другие
#SEO продвижение #Аналитика
Антикачество
Несколькими неделями ранее владельцы сайтов и вебмастера заметили изменения, произошедшие в позициях – это результат запуска алгоритма, получившего название «Антикачество». Алгоритм работает в поисковой системе Яндекс, он представляет угрозу для недобросовестных ресурсов.
Определение недобросовестности осуществляется по сценариям сайта: оценивается пользовательское восприятие. На первый план выступают репутационные факторы, отзывы, информационная составляющая, другие параметры. Конечно, один клиент, недовольный качеством полученной услуги, не снизит позиции сайта. В рамках алгоритма все проблемы будут разделяться на регулярные и критические.
К критическим факторам можно отнести явное мошенничество: компания получила деньги, но не дает обратную связь, интернет-магазин требует большую оплату, чем указано на сайте, услуга не предоставлена или предоставлена частично, но клиент не может вернуть средства.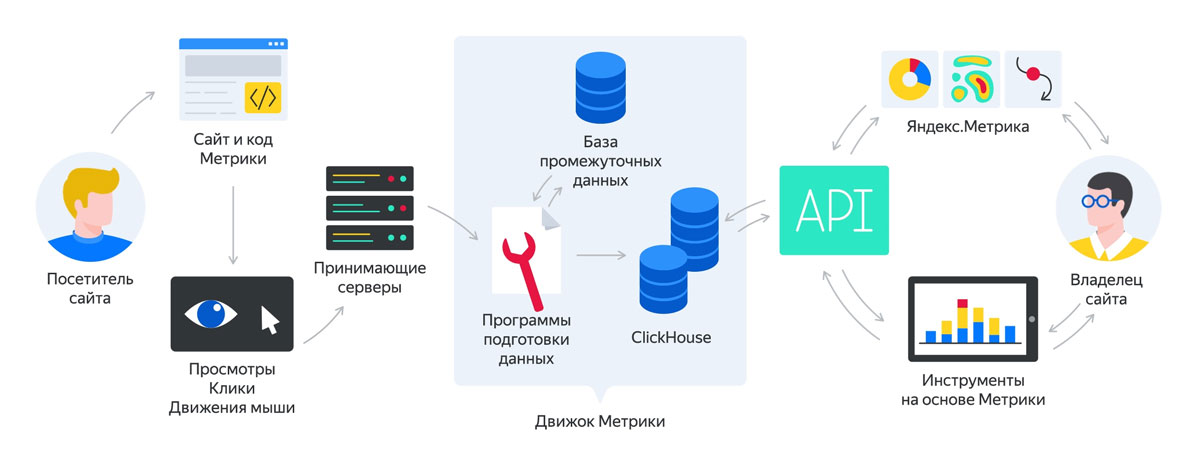 Существуют и менее глобальные проблемы, которые снижают покупательский опыт, но не относятся к разнообразным мошенническим схемам: клиенты сталкиваются с гарантийными случаями, опаздывает курьер, заказы отменяются из-за отсутствия товара на складе (с обязательным возвратом средств).
Существуют и менее глобальные проблемы, которые снижают покупательский опыт, но не относятся к разнообразным мошенническим схемам: клиенты сталкиваются с гарантийными случаями, опаздывает курьер, заказы отменяются из-за отсутствия товара на складе (с обязательным возвратом средств).
Метрика «Профицит»
«Профицит» и Proxima: в чем разница
Метрика Proxima передает сигналы о качестве бизнеса поисковым системам, она учитывает отдельные элементы выдачи (не зависит от размера). Метрика Proxima – отдельные элементы, а не общая оценка взаимодействия. Для интегральной оценки площадки используется метрика «Профицит». Поисковые системы применяют большое количество метрик, в основе которых – индивидуальные принципы работы с разными сигналами.
В заключение
В 2022 году нужно работать не только с маркетинговыми инструментами или сайтом, но и ориентироваться на повышение качества, как продукта, так и бизнеса в целом. Важно формировать благоприятный информационный фон: положительные отзывы, наращивание упоминаний, нивелирование негатива, внедрение программ лояльности – эти и другие решения помогут получить лучшие позиции в ранжировании. Рекомендуется упростить уникальное торговое предложение: оно должно быть ориентировано не на менеджеров или руководителей компании, а на обычных пользователей.
Алгоритмы Яндекса — Создание сайтов, продвижение в Волгограде, Москве, России. Оптимизация, обслуживание сайтов. Веб-студия ONVOLGA (Волгоград)
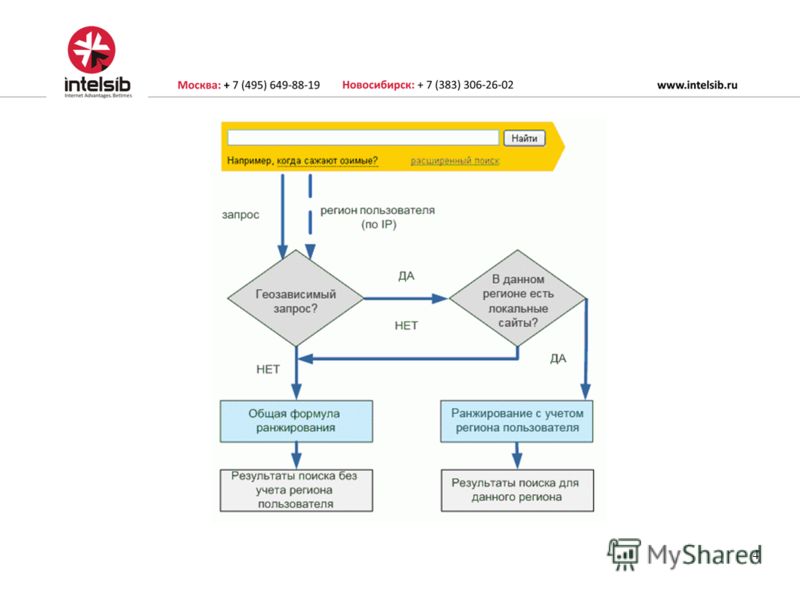
Яндекс стремится с каждым днем всё лучше находить ответы на запрос пользователя, предоставляя на странице результатов поиска максимально релевантную информацию. Поиск развивается улучшая алгоритмы понимания, что нужно пользователям, и какая информация является для нас — Пользователей — ценной.
Алгоритмы Яндекса борются за качество
Яндекс регулярно на протяжении последнего десятилетия улучшал свои алгоритмы ранжирования. Изменения алгоритмов приводили к изменению методов продвижения сайта и способов seo -оптимизации. Еще 10 лет назад вывести сайт в ТОП можно было просто купив (или разместив бесплатно) энное количество ссылок. Яндекс покончил с этим, совершенствуя свои алгоритмы и сегодня продвижение сайта — упорная кропотливая работа интернет-маркетологов, seo-оптимизаторов, аналитиков. Основной принцип — ориентация на пользователя.
Июль 2007
Алгоритм «Версия 7». Алгоритм новой формулы ранжирования, увеличение числа факторов.
Декабрь 2007, Январь 2008
Алгоритм «Версия 8» и «Восьмерка SP1». Авторитетные ресурсы получили значимый плюс в ранжировании. Внедрение фильтрации «прогонов» для накрутки ссылочных факторов -для псевдо-оптимизаторов наступили трудные времена..
Май, июль 2008
Алгоритм «Магадан» — значимый алгоритм, микрореволюция поисковой выдачи.
Скорость обработки запросов была увеличена при сохранении качества поиска.
Яндекс стал понимать аббревиатуры, транслитерацию и переводить слова.

С появлением алгоритма Яндекс Магадан поисковик стал обрабатывать запросы на дореволюционном написании русского языка.
То есть совершается некий переход от анализа поверхностных, внешних к сайту и странице факторов продвижения к анализу составляющих сам текст компонент.
Яндекс начал наконец индексировать сайты на других языках и теперь российские пользователи, которые знают больше одного языка, смогли видеть в поисковой выдаче английские, немецкие сайты.
Также алгоритм Магадан смог понимать однокоренные слова на русском языке.
С приходом Магадана улучшилась обработка запросов из нескольких слов, которые находятся далеко друг от друга в семантических коридорах.

Сентябрь 2008
Алгоритм «Находка» . Особенности алгоритма — учёт стоп-слов в поисковом запросе, новый подход к машинному обучению, тезаурус. Основные изменения связаны с отличиями в способе учета стоп-слов (выросло качество ранжирования по запросам со стоп-словами) и новым подходом к машинному обучению. Заметно расширен тезаурус путем автоматического анализа проиндексированного корпуса текстов. Например, в нем появились сочетания слов, которые в раздельном написании означают то же самое.
Апрель -сентябрь 2009
Алгоритм «Анадырь» Особенности алгоритма — учёт региона пользователя, снятие омонимии. Яндекс научился еще лучше понимать русский язык, разрешая неоднозначности слов в запросах. Арзамас — продолжение Анадырь — новая региональная формула для ряда городов, кроме Москвы, Санкт-Петербурга и Екатеринбурга. Арзамас 1.2 — введен новый классификатор геозависимости запросов, Арзамас+16 -независимые формулы для 16 регионов России, Арзамас 1. 5 -новая общая формула для геонезависимых запросов, Арзамас 1.5 SP1 — улучшенная региональная формула для геозависимых запросов.
5 -новая общая формула для геонезависимых запросов, Арзамас 1.5 SP1 — улучшенная региональная формула для геозависимых запросов.
Ноябрь 2009
Алгоритм «Снежинск». Ззапуск технологии машинного обучения MatrixNet, кратный рост числа факторов ранжирования, 19 локальных формул для крупнейших регионов России, сильнейшие изменения выдачи.
Декабрь 2009, март 2010
Алгоритм «Конаково» (неофициальное название, но далее будет называться «Обнинск») — свои формулы для 1250 городов по всей России. Конаково 1.1 (Снежинск 1.1) — обновление формулы для геонезависимых запросов. новая программа улучшает ранжирование по гео-независимым запросам, а таких в потоке до 70 процентов.
Сентябрь 2010
Алгоритм «Обнинск» -перенастройка формулы, повышение производительности, новые факторы и ранжирование для геонезависимых запросов, доля которых в потоке составляет более 70%.
Декабрь 2010
Алгоритм «Краснодар» — технология «Спектр» и повышение разнообразия выдачи, разложение запроса пользователя на интенты, далее: повышение локализации выдачи по геозависимым запросам, независимые формулы для 1250 городов России.
Август 2011
Алгоритм «Рейкьявик» — учёт языковых предпочтений пользователей, первый шаг персонализации выдачи.
Декабрь 2012
Алгоритм «Калининград» — существенная персонализация выдачи: подсказки, учёт долгосрочных интересов пользователя, повышение релевантности для «любимых» сайтов.
Май 2013
Алгоритм «Дублин» — дальнейшая персонализация выдачи: учёт сиюминутных интересов пользователей, подстройка результатов выдачи под пользователя прямо во время поисковой сессии.
Март 2014
Алгоритм «Началово» — «Без ссылок» -отмена учета ссылок / ряда ссылочных факторов в ранжировании для групп коммерческих запросов в Московском регионе. Один из самых обсуждаемых алгоритмов.
Июнь 2014
Алгоритм «Одесса» — «Острова». Новый «островной» дизайн выдачи и сервисов, внедрение интерактивных ответов. В дальнейшем эксперимент были признан неуспешным и завершен.
Апрель 2015
Алгоритм «Амстердам» -«Объектный ответ» — дополнительная карточка с общей информацией о предмете запроса справа от результатов выдачи, Яндекс классифицировал и хранит в базе десятки миллионов различных объектов поиска.
Май 2015
Алгоритм «Минусинск» — понижение в ранжировании сайтов с избыточным числом и долей SEO-ссылок в ссылочном профиле, массовое снятие SEO-ссылок, дальнейшее возвращение учёта ссылочных факторов в ранжировании по всем запросам в Московском регионе. (Многие до сих пор считают, что Минусинск получил название от слова «минусовать», а не по названию города.) Алгоритм «Минусинск» определяет сайты, которые используют SEO-ссылки для поискового продвижения, и ограничивает эти сайты в ранжировании на срок от одного до нескольких месяцев. Теперь использование SEO-ссылок может привести к значительной потере трафика из поисковых систем. SEO-ссылка — это ссылка, созданная с целью повлиять на поисковые алгоритмы. Возможность разместить SEO-ссылки на сайтах-посредниках часто покупают на специальных сервисах — ссылочных биржах или агрегаторах. Поэтому их часто называют «покупными» или «продажными».
Возможность разместить SEO-ссылки на сайтах-посредниках часто покупают на специальных сервисах — ссылочных биржах или агрегаторах. Поэтому их часто называют «покупными» или «продажными».
Признаком того, что сайт находится под ограничением алгоритма «Минусинск» является резкое падение трафика и позиций сайта в результатах Поиска Яндекса по большинству запросов. Чтобы снять ограничение, достаточно полностью отказаться от SEO-ссылок.
Сентябрь 2015
Алгоритм «Киров» — «Многорукие Бандиты Яндекса» — рандомизированная добавка к численному значению релевантности ряда документов с оценкой «Rel+», с целью сбора дополнительной поведенческой информации в Московском регионе, в дальнейшем — рандомизация была внедрена и в регионах России.
Февраль 2016
Алгоритм «Владивосток» — учёт адаптированности сайта к просмотру с переносных устройств, повышение в результатах мобильной выдачи адаптированных проектов. Новая формула ранжирования, учитывающая пригодность сайта для мобильных устройств.
Ноябрь 2016
Алгоритм «Палех» — соответствие поисковому запросу семантического вектора в трёхсотмерном пространстве с целью определения близости данного вектора к заголовкам/Title проиндексированных документов в сети. Алгоритм основан на базе искусственных нейронных сетей. Основная цель — повышение качества поиска для редких запросов и запросов, заданных на естественном языке. Новый алгоритм позволяет поиску Яндекса лучше отвечать на сложные запросы из «длинного хвоста» — уникальных и просто редких запросов очень много — около ста миллионов в день. За сопоставление смысла запросов и документов отвечает поисковая модель на основе нейронных сетей. Поисковый алгоритм «Палех» позволяет поиску Яндекса точнее понимать, о чём его спрашивают люди. Благодаря «Палеху» поиск лучше находит веб-страницы, которые соответствуют запросам не только по ключевым словам, но и по смыслу.
Применены ли к сайту санкции Яндекса
Алгоритм изменился? Как проверить, применены ли к сайту санкции и фильтры? Не поленитесь прочитать в блоге Яндека особенности нового алгоритма. Если Вы не почувствовали влияние алгоритма на своих позициях, то возможно что изменения проявятся в ближайшее время и чем раньше Вы внесете изменения на сайт, тем лучше. Проверить, применяются ли к сайту ограничения в ранжировании, также можно в разделе Нарушения и безопасность Яндекс.Вебмастера.
Если Вы не почувствовали влияние алгоритма на своих позициях, то возможно что изменения проявятся в ближайшее время и чем раньше Вы внесете изменения на сайт, тем лучше. Проверить, применяются ли к сайту ограничения в ранжировании, также можно в разделе Нарушения и безопасность Яндекс.Вебмастера.
Как понравиться алгоритмам Яндекса
Какие бы алгоритмы не вводились Яндексом основные принципы остаются неизменными — наилучший поиск ответов на вопросы. Поэтому:
Создавайте сайты с оригинальным контентом или сервисом. Реклама не является той ценностью, ради которой пользователи приходят на сайт.
Думайте о пользователях, а не о поисковых системах. Стали бы вы создавать сайт, страницу или ее элемент, если бы не существовало поисковиков? Приходят ли пользователи на ваш сайт или интернет-магазин не только из поисковых систем?
Ставьте только те ссылки, которые будут полезны и интересны пользователям вашего ресурса. Не ссылайтесь только потому, что вас попросили сослаться.
Тщательно продумайте дизайн — он должен помогать пользователям увидеть главную информацию, ради которой сайт создан.
Если продвижением вашего сайта занимаются сторонние подрядчики, рекомендуем явно указывать в договоре требование не применять SEO-ссылки и другие методы псевдооптимизации при работе с вашим ресурсом.
Будьте честны. Привлечь пользователей по запросам, на которые ваш сайт не может достойно ответить, не значит удержать их. Думайте о том, что пользователь получит, придя на ваш сайт.
В алгоритмах Яндекса используются несколько сотен параметров при ранжировании сайтов. Чтобы Ваш сайт хорошо ранжировался, обратитесь к специалистам, которые помогут Вам развивать сайт, учитывая совремнные тенденции поискового продвижения и интернет-маркетинга.
Новые алгоритмы Яндекса в 2022 году – метрики качества Proxima и Антикачество
Метрика Proxima: оценка качества сайта
Проксима — это метрика качества, определяющая, какой должна быть выдача.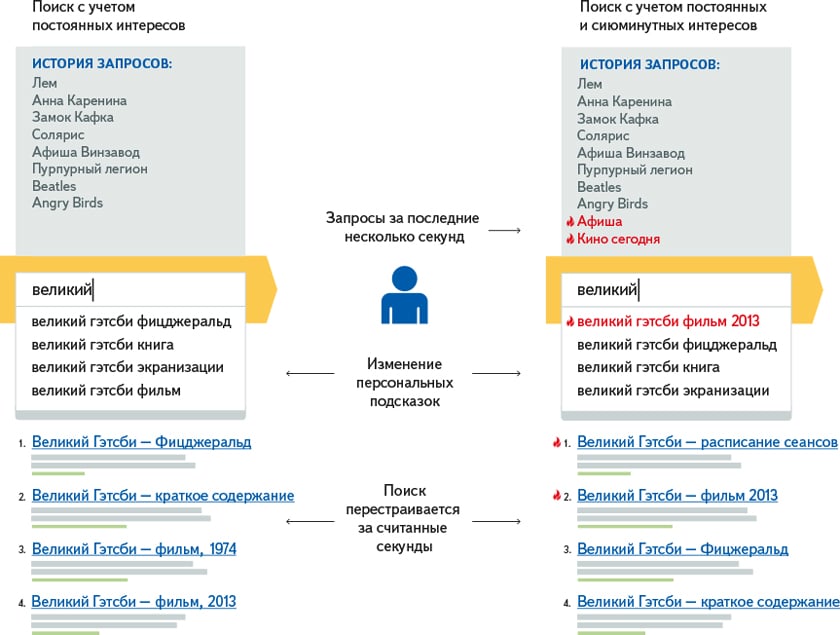 Для этого оцениваются сразу несколько факторов, в том числе релевантность запросу, способность решить проблему пользователя, степень лояльности к сайту со стороны посетителей, соотношение рекламного, маркетингового, полезного контента, его качество по сравнению с конкурентами. При этом, сигналы качества были разделены на коммерческие и дополнительные.
Для этого оцениваются сразу несколько факторов, в том числе релевантность запросу, способность решить проблему пользователя, степень лояльности к сайту со стороны посетителей, соотношение рекламного, маркетингового, полезного контента, его качество по сравнению с конкурентами. При этом, сигналы качества были разделены на коммерческие и дополнительные.
Как открыть и вести бизнес в России? Читайте в авторском телеграм-канале Романа Джунусова
.
Сигналы коммерческого качества
Сигналы коммерческого качества распространяются не только на сам сайт, но и на бизнес в целом. К ним можно отнести: этапы оформления заказа, доставку и количество ее вариантов, качество описаний товара и информации в целом, способы оплаты и т.д. Сигнал показывает, насколько пользователю удобно находить, выбирать, покупать, получать товар.
Сигнал ценности ресурса
Грамотное использование маркетинговых инструментов и привлечение трафика не всегда указывает на ценность ресурса. В метрике Proxima предусмотрен системный анализ, который включает оценку качества продукта, наличие уникального торгового предложения, общее позиционирование компании, информативность, отношение к сайту пользователей и т.д. То есть результаты выдачи зависят от того, насколько полезен ресурс по сравнению с аналогичными, и помогает ли он закрыть потребности клиента.
В метрике Proxima предусмотрен системный анализ, который включает оценку качества продукта, наличие уникального торгового предложения, общее позиционирование компании, информативность, отношение к сайту пользователей и т.д. То есть результаты выдачи зависят от того, насколько полезен ресурс по сравнению с аналогичными, и помогает ли он закрыть потребности клиента.
Сигнал доверия к сайту
Пользователи хотят получать нужную, точную и экспертную информацию, поэтому Яндекс учитывает наполнение сайта. Поисковой системе важно, чтобы люди видели контент, которому могут доверять. В первую очередь факторы доверия касаются ресурсов, занимающихся сложными тематиками, где предоставление некорректных сведений или неправильная интерпретация информации могут стать критическими: финансы, медицина, юриспруденция. Алгоритмы ранжирования размещают на первых позициях те ресурсы, которые предлагают пользователям более понятный и профессионально написанный контент.
Алгоритм Антикачество
Алгоритм Антикачество направлен на оценку репутации бизнеса. Он учитывает отзывы о товарах и услугах компании, реагирует на систематические негативные отклики и регулярные проблемы. Разовая жалоба неудовлетворенного клиента или несколько негативных отзывов на фоне стабильно позитивных реакций не повлияют на позиции сайта, но выявление фактов, когда компания не привозит оплаченный товар и не возвращает деньги, пытается требовать дополнительную оплату, не выполняет условия договора и т.д., будет отнесено к попытке мошенничества.
Он учитывает отзывы о товарах и услугах компании, реагирует на систематические негативные отклики и регулярные проблемы. Разовая жалоба неудовлетворенного клиента или несколько негативных отзывов на фоне стабильно позитивных реакций не повлияют на позиции сайта, но выявление фактов, когда компания не привозит оплаченный товар и не возвращает деньги, пытается требовать дополнительную оплату, не выполняет условия договора и т.д., будет отнесено к попытке мошенничества.
Метрика профицит: оценка качества поиска
Профицит — метрика, которая выявляет, насколько быстро и успешно пользователь закрыл свою проблему, взаимодействуя с результатами выдачи. Яндекс пытается максимально удовлетворять потребности пользователей, поэтому все неудачные взаимодействия уменьшают показатель профицита и понижают сайт в выдаче, а ресурсы, которые успешно справляются с задачей, перемещаются в топ. Для работы с этой метрикой нужно работать над структурой и удобством страниц, чтобы пользователи могли максимально быстрой найти то, что им необходимо.
IndexNow: изменение поискового индексирования
IndexNow — протокол для мгновенного индексирования, который позволяет оповещать поисковую систему об изменениях на сайте. До этого публикация нового контента или обновление существующего фиксировались поисковыми роботами при посещении сайта, при этом процесс обнаружения изменений на сайте мог занимать довольно много времени – от нескольких дней до нескольких недель. Благодаря быстрой индексации новых страниц, они будут практически сразу доступны в поисковой выдаче
Что изменилось в поиске
Чтобы пользователи имели возможность быстрее находить информацию и экономить время, Яндекс обновил поиск. Основные улучшения, которые внедрены:
- В поиске улучшили быстрые ответы — они стали намного разнообразнее, и теперь включают в себя ответы на более широкие запросы, которые совершали другие пользователи по этой теме.
- Поиск научился по смыслу текстового запроса находить нужный фрагмент внутри видео, в котором содержится ответ.

- Теперь в поиске можно узнать рейтинг организаций: в выдаче отображается оценка, основанная на анализе отзывов клиентов.
- Поиск по фото также получил обновление. Теперь Яндекс использует умную камеру, которая способна распознать различные предметы, может дать подсказку о стоимости вещи и о том, где ее можно купить.
Ссылка на статью “Как продвигать интернет-магазин в Яндексе 2022 году”.
Таким образом, новые алгоритмы и изменения в Яндексе требуют глобального улучшения качества сайта и размещенного на нем контента, а также повышения качества клиентского сервиса, работы с отзывами клиентов и негативом.
Des: Что представляют собой новые алгоритмы Яндекса в 2022 году. Метрики Proxima и Профицит: как поисковая система будет оценивать качество сайтов и поиска. Что изменилось в индексации страниц: протокол IndexNow. Как изменился поиск Яндекса в 2022 году.
Подпишитесь на рассылку FireSEO
и получайте подборки статей, полезных сервисов, анонсы и бонусы. Присоединяйтесь!
Присоединяйтесь!
Настоящим подтверждаю, что я ознакомлен и согласен с условиями политики конфиденциальности на отправку данных.
Автор:
Андрей Дудич
Интернет-маркетолог, специалист по контент-маркетингу и контекстной рекламе.
Все статьи этого автора
Последние статьи автора:
AI AI -алгоритм Yandex — Уровень человека
, написанный Anastasia Kurmakaeva
Содержание
- 1 PALEHH
- 2 Korolyov
- 3 Andromeda
- 4 Выводы
- Алгоритм Яндекса эволюционировал за последние несколько лет и его ключевые обновления, которые стали поворотным моментом в том, как поисковая система анализирует поисковые запросы и выдает результаты на основе потребностей пользователей. Палех (2016 г.), Королев (2017 г.) и Андромеда (2018 г.) полагаются на искусственный интеллект нейронных сетей, чтобы лучше понять цель поиска , сделав еще один шаг от анализа простых ключевых слов к пониманию их значения .
Несмотря на монополию Google в большинстве стран мира, доля рынка Яндекса в России по-прежнему превышает долю калифорнийского гиганта . Учитывая неудержимое расширение и технологическое развитие первого, не похоже, что что-то изменится в ближайшие годы.
🎯 По данным SEJournal, в 2019 году 52% русскоязычных пользователей по-прежнему предпочитают использовать Яндекс, в отличие от 46% интернет-пользователей, которые выбирают Google.
В том же интервью с командой Яндекса, опубликованном в SEJournal, мы также выяснили, что проникновение мобильного поиска и голосового поиска становится все более значительным среди российских пользователей, составляя соответственно 56% и 20% от общего числа.
Палех
После внедрения Палеха в ноябре 2016 года Яндекс продолжает совершенствовать и улучшать алгоритм поиска на основе нейронных сетей, чтобы иметь возможность давать ответы на более сложные поисковые намерения и поисковые запросы с помощью машинного обучения, обращая особое внимание на длиннохвостые .
 Его первый выпуск был ограничен, так как он мог анализировать только заголовки веб-страниц, но не их содержимое в целом. Он также был значительно медленнее, чем его преемник (мы поговорим об этом через секунду), обрабатывая около 40% из 280 миллионов ежедневных запросов к поисковой системе.
Его первый выпуск был ограничен, так как он мог анализировать только заголовки веб-страниц, но не их содержимое в целом. Он также был значительно медленнее, чем его преемник (мы поговорим об этом через секунду), обрабатывая около 40% из 280 миллионов ежедневных запросов к поисковой системе.Используемая Палехом технология « семантических векторов » основана на дистрибутивной семантике. Как они объясняют в своем блоге на русском языке, слова миллиардов запросов конвертируются в числа, вернее, в группы по 300 чисел. Они распределяются по 300-мерному пространству, где каждый документ имеет свой собственный вектор. Если числа, соответствующие запросу, находятся рядом с числами, соответствующими документу в том же пространстве, результат считается релевантным. Чем ближе они друг к другу, тем более релевантным будет результат, который поисковая система возвращает пользователю.
Небольшая местность Палех в России послужила источником вдохновения для названия алгоритма, который использует свой своеобразный герб, представляющий огненную птицу благодаря ее очень отчетливому длинному хвосту.
Яндекс распределяет длинных хвостов ключевых слов по различным категориям, от менее до более конкретных. Наиболее релевантные запросы и результаты не всегда будут иметь общие слова, что действительно усложняет работу поисковой системы. Например:
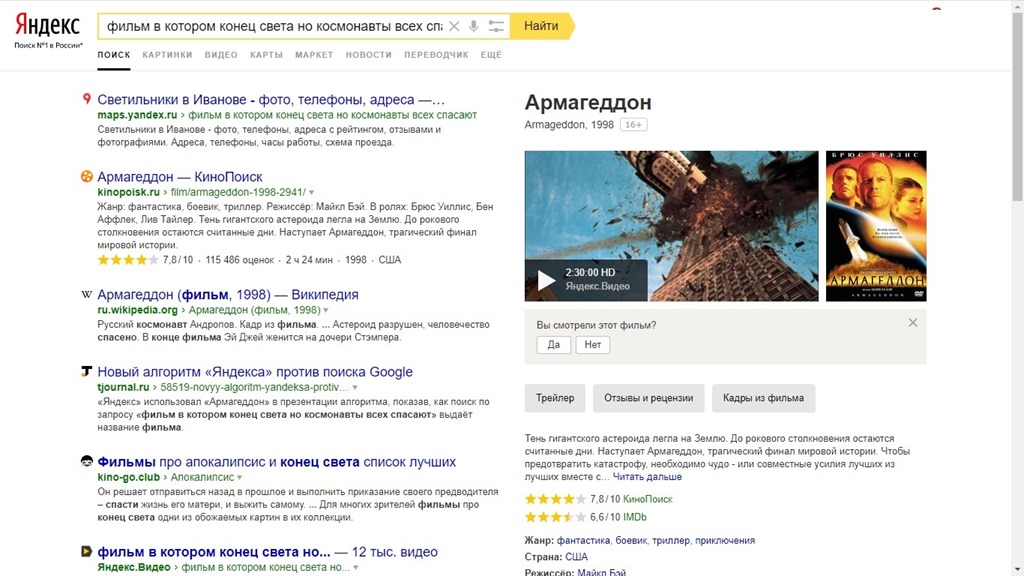
- Поисковые запросы, в которых человек не помнит название недавно просмотренного фильма, но в памяти запечатлелась одна конкретная сцена: «фильм о человеке, который выращивает картошку на другой планете». > Марсианин.
- Люди, чаще дети, которые толком не понимают, как им пользоваться поисковой системой, и говорят с ней, как с самостоятельным существом: «Яндекс, дайте мне, пожалуйста, рекомендации крутые игры для планшетов с феями» > Цель их поиска, вероятно, можно выразить на странице с рекомендациями фэнтезийных игр для мобильных платформ iOS или Android.
И здесь алгоритм нужно научить понимать и отвечать на более естественные и «человеческие» запросы.
Яндекс предоставляет для нас, смертных, следующее графическое представление в двух измерениях, чтобы объяснить, как работает Палех:
Королев
Почти год спустя, в августе 2017 года, произошло очередное большое обновление алгоритма ИИ Яндекса: Королев.

Королёв строит на Палехе, но ещё мощнее. В то время как предыдущее обновление было сосредоточено только на теге заголовка, чтобы найти соответствие между поисковым запросом, введенным пользователем, и результатами, Korolyov читает и анализирует все содержимое страницы , чтобы получить более точные результаты, отвечающие поисковому запросу пользователя. И это еще не все: его возможности обработки документов в реальном времени умножаются в тысячу раз. Более того, будучи системой на основе ИИ, ее нейронная сеть продолжает учиться благодаря тщательному анализу поведения пользователя при представлении результатов. Он сравнивает текущий запрос с другими запросами, которые ранее приводили пользователя к тому же контенту. Или он учитывает время, которое пользователь провел на странице после того, как попал туда через X-запрос, среди других показателей релевантности.
С другой стороны, расчет семантического вектора выполняется на этапе индексации, что позволяет поисковой системе быстро и эффективно устанавливать связи.
 Это обеспечивает значительную экономию ресурсов, поскольку алгоритму достаточно обработать фрагмент контента только один раз, чтобы иметь возможность сравнить вектор запроса с векторами контента, которые он уже знает.
Это обеспечивает значительную экономию ресурсов, поскольку алгоритму достаточно обработать фрагмент контента только один раз, чтобы иметь возможность сравнить вектор запроса с векторами контента, которые он уже знает.В том же году, когда был выпущен Королев, Яндекс также запустил своего ИИ-помощника: Алису. Этот выпуск увеличил использование голосового поиска в поисковой системе.
Андромеда
В 2018 году наступает Андромеда. Это последнее обновление принесло новые улучшения в поисковую систему, дальнейшее развитие и обогащение возможностей обучения интеллектуального алгоритма. Это делает поиск информации гораздо более интуитивным и простым для пользователей, а контент, представленный в результатах, гораздо более актуальным, надежным и поступающим из более качественных источников.
Мы также видим появление новых функций, таких как быстрые ответы . Эта функциональность заключается в предоставлении прямых и четких результатов на простые запросы.
 Например:
Например:- Когда [праздник]
- Какие футбольные команды играют сегодня.
- Кафе рядом со мной.
Еще одна новая функция — Яндекс Эксперт , где пользователи могут задавать вопросы на самые разные темы настоящим экспертам, если не находят подходящего ответа на свой запрос в результатах поиска.
Выводы
Что мы можем извлечь из пути, по которому Яндекс идет последние несколько лет? Как это влияет на SEO в России? Короче говоря, мы не видим больших различий между Google и Яндексом в этом отношении.
- Создание релевантного и качественного контента по-прежнему жизненно важно для процветания веб-сайта. Когда мы создаем контент на нашем веб-сайте, мы должны ориентировать его на нашего пользователя, а не на поисковую систему. То, что мы пишем, должно быть правильным, последовательным и ценным.
- Веб-сайты должны обеспечивать лучший пользовательский интерфейс, работать быстро и эффективно, чтобы успешно адаптироваться к мобильным устройствам, как мы видели в этом посте.
 Мобильный просмотр также преобладает среди русскоязычных пользователей Интернета, как и в остальном мире.
Мобильный просмотр также преобладает среди русскоязычных пользователей Интернета, как и в остальном мире. - Голосовой поиск будет расширяться.
Как вы думаете, что нового мы можем ожидать от Яндекса в этом году?
Графические технологии Яндекс.Такси: идеальный поиск без маршрутизации запросов к API | от Яндекс.Такси: Под капотом
Артем Бондаренко и Сергей Воронцов, Яндекс.Такси Маркетплейс Эффективность
тратят меньше времени на ожидание, и они проводят меньше времени за рулем бесплатно. Как правило, служба совместного использования использует API-интерфейс маршрутизации, предоставляемый Google Maps и т. д., чтобы проверять ожидаемое время прибытия, сравнивать его и выбирать для вас лучший автомобиль. Но этот простой поиск очень затратен и неэффективен в больших масштабах. В Яндекс.Такси мы нашли элегантное решение этой проблемы. Наш новый алгоритм на основе графа каждый раз находит самый быстрый автомобиль, исключая дорогостоящие вызовы API.

Пятнадцать лет назад, когда мы еще жили в мире без агрегаторов такси, время посадки могло достигать получаса и более. Диспетчеры вручную выбирали ближайший автомобиль из относительно небольшого количества. Когда на сцену вышли агрегаторы, количество доступных автомобилей резко возросло, а поиск ближайших водителей был автоматизирован. Но сегодня эффективность этого процесса оставляет райдшеринговые компании неудовлетворенными.
Когда речь идет о крупных участниках рынка, этот процесс необходимо оптимизировать вместе с требуемыми вычислительными ресурсами. Это как раз та задача, которую мы любим исследовать в Яндекс.Такси. В этом посте мы объясним, как мы придумали алгоритм, который элегантно решает эту проблему.
Начнем со «старого» прямого подхода.
В реальном мире автомобили передвигаются по дорогам. Но в электронном мире агрегаторы знают только свои координаты на плоскости. Они понятия не имеют о том, на какой улице находится транспортное средство или по какому пути оно должно ехать, чтобы подобрать водителя.
 Легко понять, почему знание дорожной сети и дорожного движения имеет решающее значение для определения того, какой автомобиль быстрее доберется туда. Вот тут-то и приходят на помощь службы маршрутизации.
Легко понять, почему знание дорожной сети и дорожного движения имеет решающее значение для определения того, какой автомобиль быстрее доберется туда. Вот тут-то и приходят на помощь службы маршрутизации.Приложения для совместных поездок хотят рассчитать время прибытия в пункт выдачи для каждого доступного автомобиля. Традиционно они используют службу маршрутизации для отображения маршрутов для каждого транспортного средства на основе текущего трафика.
Но вот в чем проблема: запросы маршрутизации стоят денег. Невозможно каждый раз спрашивать маршрутную службу о каждой машине в городе, не разорившись. Предположим, есть город со 100 000 запросов в день и 1 000 доступных автомобилей в любой момент времени. Оценка времени прибытия каждой машины в город может стоить десятки или даже сотни тысяч долларов в день, что непозволительно дорого.
Для нашего метода мы использовали услуги маршрутизации нашей материнской компании, предоставляемые Яндекс-картами.
 Иметь собственную службу маршрутизации — огромное преимущество, но каждый дополнительный запрос маршрутизации по-прежнему не был бесплатным, потому что увеличивал нагрузку на наш сервер.
Иметь собственную службу маршрутизации — огромное преимущество, но каждый дополнительный запрос маршрутизации по-прежнему не был бесплатным, потому что увеличивал нагрузку на наш сервер.Значит, нужно было еще как-то ограничить количество проверяемых машин. Но поскольку все, что вы знаете об автомобилях, это их координаты, вы можете выбрать только ближайшие автомобили по геометрическому расстоянию (то есть по кругу). Действительно, проверять водителей на другом конце города было бы бессмысленно.
К сожалению, бывают случаи, когда круг вокруг пункта выдачи, который обычно работает нормально, не будет содержать ближайшую машину. Подумайте о всаднике, ожидающем на одной стороне реки, и нескольких водителях, ожидающих на другой стороне без каких-либо близлежащих мостов. Этот случай может показаться редким, но по мере того, как ваше приложение масштабируется и начинает обслуживать миллионы людей, вы обнаружите, что теряете оптимальные совпадения в значительном количестве случаев.
 Это означает, что, когда вы ограничиваете запросы службы маршрутизации меньшим кругом вокруг точки посадки, вы увеличиваете риск того, что вы не найдете машину, которая может быстро забрать водителя.
Это означает, что, когда вы ограничиваете запросы службы маршрутизации меньшим кругом вокруг точки посадки, вы увеличиваете риск того, что вы не найдете машину, которая может быстро забрать водителя.Это приводит к следующему компромиссу:
● Экономия на количестве путей, запрошенных у службы маршрутизации, но есть риск не найти самый быстрый автомобиль
● Или всегда находить водителя с самым быстрым временем посадки, но оплачивать до конца зубы в плате за услуги маршрутизации.
Разработанный нами новый алгоритм устраняет компромисс между эффективностью и ценой: он гарантирует, что каждый раз будет найден самый быстрый автомобиль, и делает излишними запросы к дорогостоящим службам маршрутизации. Это может звучать как волшебство, но за этим стоит тяжелая работа. Нам пришлось разобрать весь процесс сопоставления и собрать новый с новыми структурами данных и новыми алгоритмами, оптимизированными в каждом дюйме для задачи.
Мы начали с рассмотрения технических сервисов маршрутизации, используемых для обработки запросов от приложений для совместного использования.
 Обычно он основан на данных городской дорожной сети и трафика, включая расположение улиц, их соединения, направления движения на этих улицах и скорость движения. Служба маршрутизации находит самый быстрый маршрут из одной точки в другую и прогнозирует время, которое потребуется машине, чтобы проехать по нему. Затем приложение для совместного использования сравнивает ожидаемое время прибытия всех доступных водителей в определенной близости, чтобы выбрать самого быстрого. Поэтому приложения для совместного использования полагаются на внешние службы маршрутизации, чтобы знать, как быстро водители могут добраться до места посадки.
Обычно он основан на данных городской дорожной сети и трафика, включая расположение улиц, их соединения, направления движения на этих улицах и скорость движения. Служба маршрутизации находит самый быстрый маршрут из одной точки в другую и прогнозирует время, которое потребуется машине, чтобы проехать по нему. Затем приложение для совместного использования сравнивает ожидаемое время прибытия всех доступных водителей в определенной близости, чтобы выбрать самого быстрого. Поэтому приложения для совместного использования полагаются на внешние службы маршрутизации, чтобы знать, как быстро водители могут добраться до места посадки.Легко понять, что если бы у нас были все эти знания, мы могли бы каждый раз правильно находить самую быструю машину. Вот почему мы решили интегрировать структуру дорожных сетей в наши системы. Мы построили структуру данных графа с ребрами, представляющими улицы, узлами, представляющими перекрестки, и всеми характеристиками, необходимыми для расчета оптимального маршрута и времени прибытия, включая ограничения движения и скорость движения на каждом ребре.
 Теперь Яндекс.Такси видит автомобили не как массу точек на поверхности, а как местоположения в структуре данных графа.
Теперь Яндекс.Такси видит автомобили не как массу точек на поверхности, а как местоположения в структуре данных графа.Имея эту структуру, мы используем один из наших алгоритмов «обхода графа» для поиска на графе и определения водителя, который первым достигнет точки посадки. Более того, алгоритм может найти любое заданное количество автомобилей в порядке ожидаемого времени прибытия.
Обратите внимание, что без данных о трафике в режиме реального времени было бы невозможно правильно предсказать время прибытия автомобилей. Знать систему дорог недостаточно, потому что текущие условия движения сильно влияют на то, сколько времени потребуется, чтобы добраться из пункта А в пункт Б.
Как упоминалось выше , Яндекс.Такси имеет огромное преимущество перед другими компаниями, предоставляющими услуги такси, когда речь идет о картографии и навигации в реальном времени. У нас есть доступ к картам и предельно точным, регулярно обновляемым данным о дорожной инфраструктуре от собственных геосервисов Яндекса, нашей материнской компании.
 Кроме того, мы полагаемся на геосервисы Яндекса для получения данных о пробках в режиме реального времени, что необходимо для точной оценки времени прибытия. Яндекс.Такси использует эти тесные отношения для создания лучших в своем классе технологий и услуг.
Кроме того, мы полагаемся на геосервисы Яндекса для получения данных о пробках в режиме реального времени, что необходимо для точной оценки времени прибытия. Яндекс.Такси использует эти тесные отношения для создания лучших в своем классе технологий и услуг.Две части — график и данные о трафике в режиме реального времени — взаимодействуют в гармонии, образуя совершенно новый способ сопоставления гонщиков и водителей. Мы устранили необходимость запрашивать время прибытия каждого автомобиля поблизости от службы маршрутизации. Имея дорожную инфраструктуру и данные о трафике в реальном времени под одним капотом, мы создали алгоритм, который просматривает дорожный граф и находит автомобили строго в порядке времени посадки. Другими словами, мы решили задачу «ближайшая машина» максимально точно, без необходимости многочисленных запросов маршрутизации. И вишенка на торте: наш подход также определяет произвольное количество ближайших автомобилей с максимальной эффективностью.
Созданная нами новая технология раз и навсегда решает проблему компромисса между качеством поиска и стоимостью маршрутизации запросов:
1.
 Миллионы запросов API маршрутизации в день в алгоритмах поиска полностью исключены.
Миллионы запросов API маршрутизации в день в алгоритмах поиска полностью исключены.2. Снижены средние сроки посадки, в том числе до 15% в районах со сложной дорожной структурой: вблизи многоуровневых развязок, железных дорог и рек.
3. Мы заложили основу для переосмысления целой группы плоскостных алгоритмов на графе. Скачковое ценообразование — один из таких алгоритмов — он может работать более эффективно в графовой инфраструктуре. Например, он может распознавать различный баланс спроса и предложения на противоположных сторонах дороги. Иногда это происходит из-за асимметрии имеющихся автомобилей, вызванной пробками и ограничениями разворота.
Google по-русски: Что алгоритм говорит о предвзятости?
2 января 2019
Страна: Россия
Автор: Михаил Яковлев
Через два года после того, как Дональд Трамп был избран президентом, «онлайн-рука» Кремля, начиная с его выборов, вмешивалась во все 2016 г.
 Попытка государственного переворота в Черногории. Впервые появившись во время украинского кризиса 2015 года, российские боты стали важной частью усилий Кремля по увеличению своей «мягкой силы» на международном уровне. Вдохновленная журналисткой The Guardian Кэрол Кадвалладр в 2016 году, разоблачающей способность Google Search коварно распространять ненависть и дезинформацию, MDI решила воспроизвести свой эксперимент с поисковой системой в Интернете, только на этот раз на русском языке.
Попытка государственного переворота в Черногории. Впервые появившись во время украинского кризиса 2015 года, российские боты стали важной частью усилий Кремля по увеличению своей «мягкой силы» на международном уровне. Вдохновленная журналисткой The Guardian Кэрол Кадвалладр в 2016 году, разоблачающей способность Google Search коварно распространять ненависть и дезинформацию, MDI решила воспроизвести свой эксперимент с поисковой системой в Интернете, только на этот раз на русском языке.Сначала мы повторили англоязычные запросы Кадавалладра. Во время ее эксперимента Google выдал ряд проблемных предложений. Например, когда она начала вводить вопрос «женщины ли женщины» в строку поиска, Google первым подсказал: «женщины — зло». Точно так же четвертый прогноз Google на вопрос, начинающийся со слов «евреи…», был «евреи — зло».
Мы заметили, что Google, кажется, изменил свой алгоритм с момента выхода ее статьи в 2016 году. Они больше не побуждают пользователей искать, являются ли евреи или женщины «злыми», и добавили функцию, которая позволяет сообщать о неуместных прогнозах.
 Это реальный прогресс по сравнению с их предыдущей стратегией, заключавшейся в размещении предупреждения со звездочкой рядом с вредоносным или триггерным контентом, например жестоким обращением с детьми, без удаления самого контента.
Это реальный прогресс по сравнению с их предыдущей стратегией, заключавшейся в размещении предупреждения со звездочкой рядом с вредоносным или триггерным контентом, например жестоким обращением с детьми, без удаления самого контента.Понятно, что широко распространенное общественное возмущение алгоритмами Google и негативные последствия таких статей, как статья Кадавалладра, заставили их изменить свою политику. Но переводятся ли эти изменения на другие языки?
Многие крупные интернет-компании борются с контентом не на английском языке. Например, Facebook подвергался широкой критике за систематическую неспособность выявлять и удалять ненавистнические высказывания против рохинджа на бирманском языке. По-видимому, есть две основные причины таких неудач. Во-первых, неспособность алгоритмов ИИ точно идентифицировать и удалять язык ненависти, особенно если он публикуется на других языках, кроме английского. Конечно, пользователи Facebook сейчас настолько разнообразны в культурном и географическом отношении, что «пользователи, политики и правительства вообще редко соглашаются с правилами».
 Во-вторых, Facebook и подобные веб-сайты просто не нанимают модераторов, не говорящих по-английски, для выполнения этой работы. Что характерно, Facebook регулярно отказывается сообщать, сколько модераторов они нанимают для каждого языка.
Во-вторых, Facebook и подобные веб-сайты просто не нанимают модераторов, не говорящих по-английски, для выполнения этой работы. Что характерно, Facebook регулярно отказывается сообщать, сколько модераторов они нанимают для каждого языка.Так что там с русским Гуглом? — мы думали.
Пока западные СМИ зациклены на «кремлевской пропаганде» и российских ботах, им стоит обратить больше внимания на то, что ищут и находят в сети рядовые русскоязычные. Мы решили применить методологию Кэрол Кадавалладр для исследования Google Search на русском языке.
То, что мы обнаружили, указывает на тревожную тенденцию.
Как и Cadawalladr, мы приняли решение не предоставлять ссылки на ненавистнический контент, который мы обнаружили, чтобы избежать распространения ненависти. Точно так же все цитаты и описания ненавистного контента сведены к минимуму.
В точности повторяя эксперимент Кадавалладра, мы начали поиск, введя слово «евреи» по-русски в строку поиска Google. Мы были рады видеть, что Google предложил ряд безобидных вопросов, таких как «Кто такие евреи» и «Являются ли евреи национальностью».
 Более того, Google не дал никаких прогнозов для русскоязычных эквивалентов таких уничижительных слов, как «пидор». Однако, когда мы искали слово « баба », что буквально означает «старуха», вторым предсказанием было «женщины — животные», а седьмым — «женщины — зло».
Более того, Google не дал никаких прогнозов для русскоязычных эквивалентов таких уничижительных слов, как «пидор». Однако, когда мы искали слово « баба », что буквально означает «старуха», вторым предсказанием было «женщины — животные», а седьмым — «женщины — зло».Хотя слово «баба» не всегда оскорбительно само по себе, когда оно используется как общий термин для всех женщин, оно становится уничижительным. Мы сообщили об этих оскорбительных прогнозах в Google. На момент написания эти прогнозы все еще существуют.
А сами результаты поиска?
Далее мы проанализировали сами результаты поиска. В то время как первые два результата для «Кто такие евреи» были уместными и информативными, третьим было видео под названием «Кто такие евреи — действительно шокирует!!!». Это видео начинается с ошибочного заявления о том, что Талмуд утверждает, что «только евреи люди — настоящие люди, а все остальные — гои, что означает «звери» или «животные».
 Оставшиеся одиннадцать минут в этом видео перечислены деконтекстуализированные утверждения из еврейских священных писаний, чтобы подкрепить нарративы, указывающие на глобальный еврейский заговор.
Оставшиеся одиннадцать минут в этом видео перечислены деконтекстуализированные утверждения из еврейских священных писаний, чтобы подкрепить нарративы, указывающие на глобальный еврейский заговор.Другим важным моментом является то, что в русском языке еврей имеет два слова. До сих пор мы использовали относительно нейтральное « еврей ». Что произойдет, если мы будем искать уничижительное « жыд»? ‘
Честно говоря, для « жыд » нет подсказок по запросу « жыд «. ряд фотографий мужчин в ортодоксальной еврейской одежде, рядом с фотографией бывшего мэра Москвы Юрия Лужкова в кипа и изображение Петра Порошенко, действующего Президента Украины, предполагающее, что это « жыдс ».
Размещая такой контент, в котором ложно утверждается, что эти неоднозначные, если не непопулярные, политики являются евреями, Google помогает укреплять правые антисемитские теории заговора, утверждающие, что международное иудео-масонское лобби контролирует большинство правительств в мире.
 Эти антисемитские заговоры, возможно, знакомые большинству читателей по навязчивой идее правых СМИ очернить Джорджа Сороса, становятся явно жуткими в контексте России и Украины. Кремль не только стремился заручиться внутренней поддержкой своей интервенции в Украине, обвиняя евреев в «руководстве украинской революцией», собственное правительство Петра Порошенко предприняло «нетерпеливые попытки стереть из памяти антисемитизм, жестокость и пособничество нацистам». История Украины, согласно старейшей газете Израиля Гаарец .
Эти антисемитские заговоры, возможно, знакомые большинству читателей по навязчивой идее правых СМИ очернить Джорджа Сороса, становятся явно жуткими в контексте России и Украины. Кремль не только стремился заручиться внутренней поддержкой своей интервенции в Украине, обвиняя евреев в «руководстве украинской революцией», собственное правительство Петра Порошенко предприняло «нетерпеливые попытки стереть из памяти антисемитизм, жестокость и пособничество нацистам». История Украины, согласно старейшей газете Израиля Гаарец .За этими фотографиями последовал еще более антисемитский контент. Сразу ниже было три видео, два из которых продолжили тему заговора еврейского Мирового Правительства. Как видно из скриншота, один из них использовал в качестве миниатюры ту самую фотографию Лужкова в кипе . Название этого видео спрашивает: «Почему жыды правят Россией?»
Хотя в третьем видео не упоминалась политика, оно было столь же проблематичным. Это видео было организовано человеком, выдававшим себя за православного священника, который довольно подробно обсуждал разницу между словами «9».
 0113 еврей » и « жыд ». Среди прочего, этот человек утверждал, что слово « жыд » далеко не уничижительное или оскорбительное, а просто описательное, потому что евреи действительно «хитрые», «спекулянты» и «коварные».
0113 еврей » и « жыд ». Среди прочего, этот человек утверждал, что слово « жыд » далеко не уничижительное или оскорбительное, а просто описательное, потому что евреи действительно «хитрые», «спекулянты» и «коварные».Эти видеоролики сопровождались ссылками на семь веб-сайтов, две из которых вели нас непосредственно на веб-сайты антисемитского заговора.
В целом, мы заметили, что русскоязычные результаты Google часто содержат контент, который использует культурный авторитет Русской православной церкви для распространения патриархальной, гомофобной и антисемитской ненависти.
Другой пример: из трех видео, которые Google выдал по запросу «феминизм», только одно было положительным.
Двое других были глубоко патриархальными. Один из них [злоупотреблял] использовал русское православное учение для продвижения глубоко сексистского и патриархального послания. Например, утверждалось, что истинная христианская «женственность достигается через страдание, особенно через боль деторождения», а не через «неестественное» равенство с мужчинами.
 Примечательно, что титры под этим видео предполагают, что оно было профинансировано организацией, связанной с Русской Православной Церковью, и подготовлено церковными сановниками. Систематическое включение Google таких видео, в которых неправильно используются христианские учения, указывает на фундаментальную проблему с их русскоязычными алгоритмами.
Примечательно, что титры под этим видео предполагают, что оно было профинансировано организацией, связанной с Русской Православной Церковью, и подготовлено церковными сановниками. Систематическое включение Google таких видео, в которых неправильно используются христианские учения, указывает на фундаментальную проблему с их русскоязычными алгоритмами.Beyond Google
В своей статье Кадавалладр написала: «Google — это поиск. Это глагол для Google».
Конечно, она не ошиблась, сказав это. Но для русскоязычных Google важнее другой поисковой системы. Местный и немного более старый Яндекс остается лидером с чуть более 50% всех поисковых запросов на российском рынке по сравнению с 45% Google. Хотя Яндекс гораздо менее доминирующий, он также является мощным игроком в соседних странах, таких как Украина, где он официально запрещен, и Казахстан.
Следуя нашей линии запроса о том, как поисковые системы относятся к антисемитскому контенту, мы искали « жыд » на Яндексе.
 Как и Google, Яндекс не делал прогнозов.
Как и Google, Яндекс не делал прогнозов.Но когда мы набрали нейтральный термин «еврей» — который в Google был относительно безобиден — первым прогнозом было аграмматическое «евреи в правительстве Российской Федерации — настоящие фамилии 2018 года». Как и ожидалось, когда мы последовали этому прогнозу, Яндекс выдал ряд ссылок на антисемитские конспирологические сайты, распространяющие слухи о том, что российские депутаты и чиновники на самом деле евреи, сменившие свои еврейские фамилии на звучащие по-русски.
Очередная проблема с Яндексом. В отличие от минималистского домашнего экрана Google, Яндекс предлагает постоянно обновляемую информацию, такую как главные новости, курсы обмена валют и прогнозы погоды. Когда пользователь нажимает на одну из новостей, он попадает на краткую сводку и ряд ссылок для получения дополнительной информации. В большинстве случаев первая ссылка, которую предлагает Яндекс, — это русскоязычный сервис Russia Today. Несмотря на то, что это крупный новостной канал, наблюдатели обвиняют RT в том, что он является не более чем рупором Кремля.

Еще более проблематично то, что процедура сообщения о нежелательном контенте на веб-сайте чрезвычайно «загадочна», в отличие от сегодняшнего Google. Их условия трудно найти и еще труднее понять. Что особенно важно, им не хватает четких указаний относительно того, что представляет собой запрещенный контент.
Сама функция «Сообщить о содержании» нигде на сайте не видна. Доступ к нему возможен только через направленный поиск в Яндексе или Google. Другими словами, чтобы найти эту функцию, вы уже должны знать, что она существует. Что еще хуже, у Яндекса, похоже, нет ни одного модератора.
Как отмечает Кадавалладр, то, как поисковые системы расставляют приоритеты в информации, может изменить наше мнение, даже если мы этого не заметим. Когда Яндекс указывает Russia Today в качестве основного источника новостей для статьи, это косвенно побуждает нас думать, что российская государственная сеть является надежным источником новостей. Если пользователь ищет в Интернете, чтобы лучше узнать о теме, важно, чтобы контент был должным образом проверен.

Еще один способ заставить меньшинства замолчать — обычная практика в России и соседних странах. Поисковые системы в Интернете должны следить за тем, чтобы они не способствовали этому замалчиванию, отдавая приоритет результатам, распространяющим ненависть в отношении феминисток или представителей ЛГБТ.
Что делать?
Важно отметить, что мы не призываем к цензуре всего сексистского или гомофобного контента. Однако поисковые системы должны следить за тем, чтобы их результаты на первой странице не отдавали предпочтение одной точке зрения над другой и отражали широту аргументированного мнения по рассматриваемой теме.
Многие из оскорбительных видео, которые мы обсуждали, размещены на Youtube — бесплатной службе потокового видео, принадлежащей Google. Хотя можно утверждать, что Google не может и не должен запрещать весь потенциально оскорбительный сторонний контент в своих результатах поиска, у компаний Google нет абсолютно никаких причин размещать такой контент внутри компании.

Одним из примеров этого является продолжающийся спор по поводу алгоритмов YouTube, предлагающих детям контент с насилием. Хотя с тех пор Google обновил свою политику монетизации, чтобы не допустить, чтобы эти видео приносили доход от рекламы, до сих пор неясно, насколько эффективно Google отслеживает и проверяет результаты поиска, которые он выдает. Данные указывают на то, что онлайн-платформы предпочитают непристойный контент, который приносит клики и страницы. взгляды на предоставление точной и ответственной информации.
Кадвалладр заканчивает свою статью цифрой призыв к оружию –
Это наш интернет. Не Google. Не Facebook. Не правые пропагандисты. И мы единственные, кто может его восстановить.
Три года спустя ее слова оправдались. В то время как законодательство в демократических странах часто не успевает за развитием технологий, общественное давление, как было показано, быстро дает желаемые результаты — даже в более репрессивных условиях.

9008