Как узнать частотность поисковых запросов в Яндекс и Гугл
Зная частотность ключевых слов, что это такое и как ее правильно применять, можно продвигать определенные страницы в выдаче поисковых систем. Такой навык полезен SEO-специалистам, интернет-маркетологам, SMM-специалистам и даже копирайтерам. О методах сбора запросов и классификации их по частотности расскажем далее.
Содержание
- Что такое частотность поискового запроса и зачем ее нужно знать
- Классификация запросов по частотности
- Определение частотностей с помощью сервисов
- Определение частотности по Яндекс.Вордстат
- Определение частотности по Google Ads
- Сбор частотностей программой Key Collector
- Заключение
Что такое частотность поискового запроса и зачем ее нужно знать
Частотностью запроса называют количество ввода конкретной фразы в поиск за определенный временной интервал (чаще всего за месяц). Эти данные фиксируют поисковые системы для оценки трафика и популярности фраз пользователей. Специалисты могут узнать сведения с помощью сервисов Google и Яндекс, а также сторонних программ.
Специалисты могут узнать сведения с помощью сервисов Google и Яндекс, а также сторонних программ.
Для SEO-специалиста знание частотности слов позволяет:
- спрогнозировать потенциальный трафик на сайт;
- составлять качественное семантическое ядро для сайта;
- подобрать фразы для быстрого продвижения конкретной страницы.
Имея данные по популярности фразы, можно с легкостью отфильтровать запросы-пустышки (имеющие нулевую или близкую к ней частотность). Это помогает сконцентрировать бюджет и ресурсы на наиболее важных фразах, заняться вплотную их продвижением.
Простой пример: вряд ли здравомыслящий сеошник будет продвигать страницу по запросу «купить круиз по Ангаре», да еще и зимой. Частотность этой фразы равна нулю.
Фраза «купить круиз по Волге» в этом плане для продвижения более привлекательна: общая частотность равна 301.
Классификация запросов по частотности
Чтобы сконцентрироваться на наиболее важных запросах, их группируют по частотности. Каждая группа называется по-своему:
Каждая группа называется по-своему:
- Низкочастотные фразы (НЧ) — запрашиваемые пользователями менее 150 раз в месяц. Чаще всего НЧ используется для продвижения конкретного товара, услуги, а также в блогах.
- Среднечастотные фразы (СЧ) — запрашиваются в поисковых системах до 1500 раз. Используются на разных страницах сайта, в том числе для продвижения рубрик (категорий).
- Высокочастотные фразы (ВЧ) — запрашиваются более 1500 раз за месяц. Эти фразы используют для продвижения главной страницы сайта.
Лучший результат достигается при комбинировании на одной странице фраз из разных групп. Например, низкочастотные слова помогут более полно раскрыть тему или рассказать о сайте, а потому могут быть и на главной странице.
Классификация условна и меняется в зависимости от ниши или региональности. Например, запрос «торт на заказ», используемый для сайта кондитера из Владимира, будет относиться к числу высокочастотных, хоть и имеет частоту 855 в месяц. Более популярного запроса в этом регионе и в этой нише нет.
В нишах с высокой конкуренцией даже фразы с частотностью 2000 могут считаться низкочастотными. Точно определить принадлежность к определенной категории можно с помощью сервиса, позволяющего оценить частотность поисковых запросов.
Определение частотностей с помощью сервисов
Популярность фраз анализируют поисковики, логичнее обратиться к ним для получения нужной информации. В России для этой цели используют сервисы Яндекс.Вордстат и Google Ads. Можно воспользоваться сторонними сервисами — Serpstat, Букварикс и другими, но они также будут обращаться к базам поисковых систем, а потому результат будет схожим.
Определение частотности по Яндекс.Вордстат
Сервис Яндекс.Вордстат служит для составления прогнозов количества показа рекламных объявлений по определенным запросам. Его же используют и для сбора поисковых фраз, определения их частотности, сезонности, региональности. Дополнительно тут используются специальные символы.
Перед тем, как узнавать частотность запросов в Яндексе, нужно авторизоваться в системе.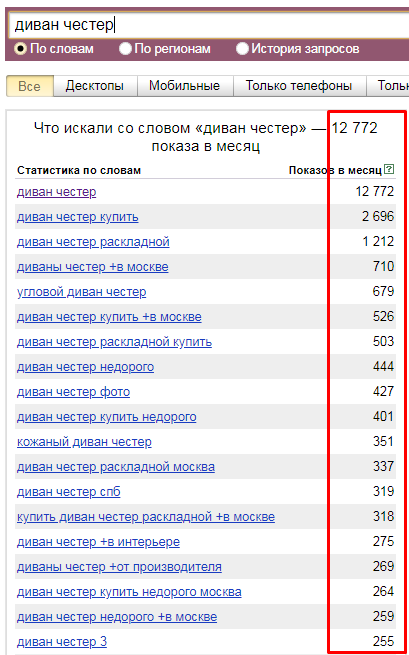 После этого можно перейти на страницу Яндекс.Вордстат и начать работу.
После этого можно перейти на страницу Яндекс.Вордстат и начать работу.
Функционал сервиса простой, для описываемых задач понадобятся следующие функции:
- «По словам» — включена по умолчанию, позволяет узнать популярность в Яндекс конкретного слова или фразы.
- «По регионам» — поможет узнать распределение популярности по заданным регионам.
- «Регион» — по умолчанию включены все регионы. Позволяет узнать частоту запросов в Яндексе для конкретного региона или населенного пункта.
Исследуемый запрос вводится в специальное поле, если нужно — сопровождается спецсимволами. Затем нужно нажать на кнопку «Подобрать» (4). Сервис генерирует результаты автоматически. Пример для запроса «купить экскаватор» на скриншоте.
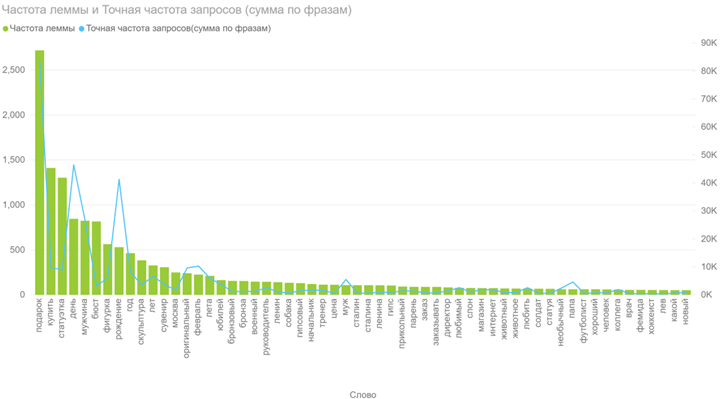
В результатах в левой колонке можно увидеть общую частоту запроса (127 348). Тут учитываются все варианты фраз, которые вводили пользователи, желающие купить экскаватор. Эта частотность называется базовой, является неточной. На нашем примере она отражает запросы «купить б/у экскаватор», «купить новый экскаватор» и даже «купить игрушечный экскаватор на пульте управления».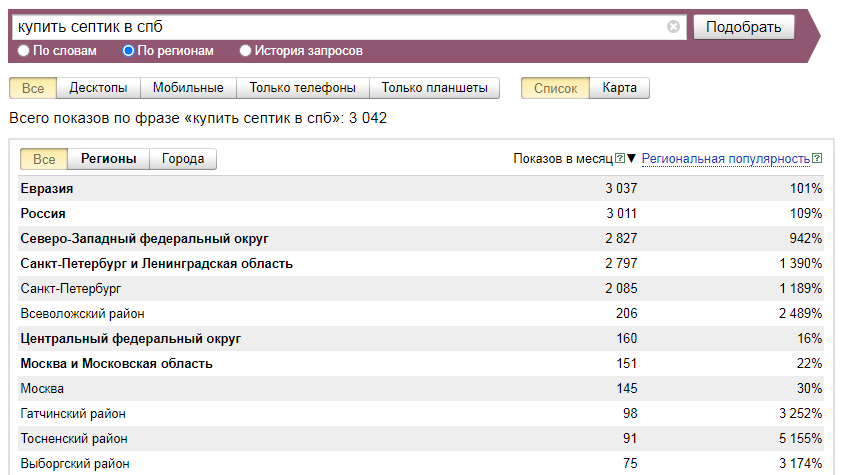 Использовать базовую частотность для составления стратегии продвижения веб-ресурса нельзя.
Использовать базовую частотность для составления стратегии продвижения веб-ресурса нельзя.
Для уточнения запроса в Яндекс.Вордстат используют специальные операторы. Например, с помощью оператора «»«» (кавычки) можно узнать фразовую частотность. Для этого фразу «купить экскаватор» нужно заключить в кавычки.
Фразовая частотность показывает, сколько раз вводили именно эту фразу, без других слов. На нашем примере базовая (1) и фразовая (2) частотности имеют существенную разницу. Тут уже не учитываются вариации покупки новой, подержанной техники, игрушечных экскаваторов и прочего.
Иногда нужно дать прогноз по частоте набора слов в точном виде, без учета различных окончаний и числа. На нашем примере нужно узнать, сколько раз пользователи вводили запрос «купить экскаватор», без учета «купить экскаваторы» и прочих вариантов. Для этого фразу заключить в кавычки, а перед каждым словом ставим оператор «!».
Мы видим точную частоту для запроса 2070. Она существенно отличается от базового значения и немного ниже фразового.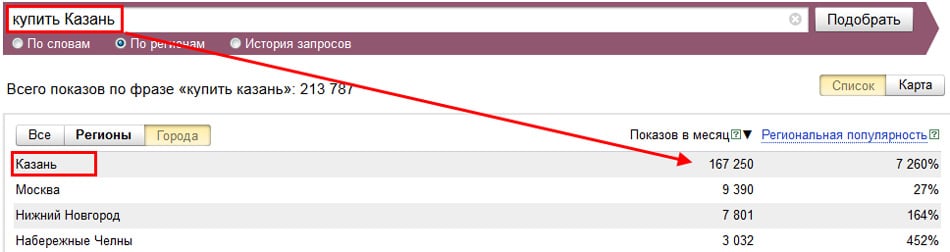 Применяя операторы, можно узнать точные значения в зависимости от заданных целей и более качественно составить прогноз по трафику.
Применяя операторы, можно узнать точные значения в зависимости от заданных целей и более качественно составить прогноз по трафику.
Определение частотности по Google Ads
Сервис Google Ads используется для составления рекламных объявлений в поисковой системе Google и расчета рекламного бюджета, но можно его использовать и для проверки частотности фраз. Для этого нужно войти в систему (необходим аккаунт в Google).
Перейдите в кабинет Google Ads, нажмите на «Инструменты».
В выпадающем списке найдите раздел «Планировщик ключевых слов».
Выберите блок «новые ключевые слова».
Введите исследуемые фразы. В нашем примере используем ту же фразу «купить экскаватор».
Сервис обработает ваши данные, после чего появится результат.
Тут можно узнать примерную частотность фразы «купить экскаватор» (от 100 до 1 тыс.), узнать уровень конкуренции, просмотреть варианты дополнительных ключевых слов (указаны в таблице в соответствующем разделе).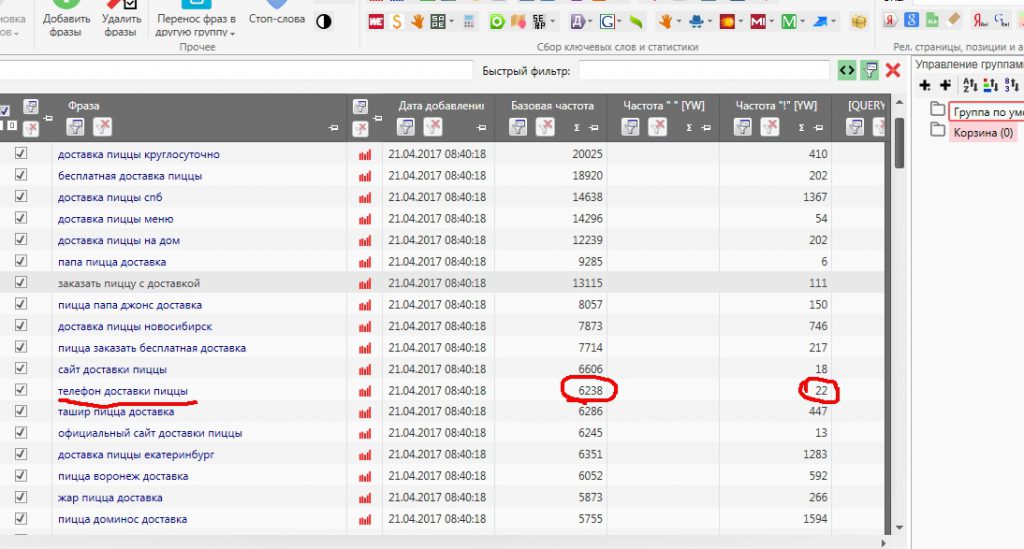 В сравнении с Яндекс.Вордстат сервис имеет скудные возможности по изучению частоты запросов. Просматривать базовую, фразовую и точную частотности тут нельзя. В планировщике Google Ads можно получить лишь приблизительное представление о популярности слова или словосочетания.
В сравнении с Яндекс.Вордстат сервис имеет скудные возможности по изучению частоты запросов. Просматривать базовую, фразовую и точную частотности тут нельзя. В планировщике Google Ads можно получить лишь приблизительное представление о популярности слова или словосочетания.
Сбор частотностей программой Key Collector
Сервисы изучения поисковых фраз Google и Яндекс хороши для проверки небольших семантических ядер и отдельных поисковых запросов. Если же нужно собирать частотности к большому семантическому ядру, лучше воспользоваться специальными программами, например, Key Collector.
Кей коллектор — это софт для автоматизированного парсинга ключевых фраз с учетом их частотностей, включая точную. Процесс сбора тут максимально упрощен. Для выяснения фразовой и точной частотностей не нужно использовать специальные символы, из заменяют функции программы. После настройки нужных параметров можно заняться другими делами — программа проанализирует все данные и выдаст результат самостоятельно.
Порядок работы по проверке частотности ключевых слов:
- Укажите исследуемые фразы. Для этого нажмите на иконку «сбор запросов из левой колонки Вордстат» или вызовете контекстное меню правой кнопкой мыши, затем выберете пункт «добавить фразы».
- Нажмите на кнопку «Директ» и задайте нужные параметры — сбор базовой, фразовой или точной частотности.
- Нажмите «Получить результаты».
Кей Коллектор обращается напрямую к Яндекс.Директ, потому результаты по частотностям будут получены быстро. Программа позволяет проверить частоту поисковых запросов в Яндексе, собрать фразы из Google, добавить поисковые подсказки. Результаты будут собраны в удобную таблицу, в дальнейшем можно удалить фразы-пустышки и сгруппировать оставшиеся словосочетания.
Key Collector — это платная программа с мощным функционалом. Для ограниченного числа задач можно установить ее бесплатный аналог «Словоёб» С его помощью также можно парсить ключевые слова и собирать к ним частотность. Процесс более медленный, потому для больших семантических ядер программа не подходит.
Процесс более медленный, потому для больших семантических ядер программа не подходит.
Заключение
Знание частотности ключевых слов поможет точнее прогнозировать трафик на сайт из поисковых систем, поможет в составлении семантического ядра и в продвижении определенных страниц. Чтобы получить нужные данные, можно воспользоваться сервисами Яндекс.Вордстат или Планировщиком ключевых слов Google Ads. Подойдут и программы для парсинга ключей, например Key Collector или Словоёб.
Подбирайте инструмент, исходя из конкретных целей и возможностей, не пренебрегайте сбором частотностей поисковых фраз. Только в этом случае можно быть уверенным в эффективности мероприятий по продвижению конкретной страницы или сайта в поиске.
Какую частотность Wordstat (Вордстат) использовать для продвижения сайта?
Редакция от 04 апреля 2022 года
Чем собрать частотность запросов всем известно, а вот вопрос какую частотность использовать — остается открытым. На этот счет существует множество мнений: кто то считает, что нужно оставлять запросы с частотностью не ниже 50 по «! «, а кто то работает с запросами частотностью от 1 по «! «. В данном руководстве мы подробно ответим на все вопросы, касающиеся данной темы.
На этот счет существует множество мнений: кто то считает, что нужно оставлять запросы с частотностью не ниже 50 по «! «, а кто то работает с запросами частотностью от 1 по «! «. В данном руководстве мы подробно ответим на все вопросы, касающиеся данной темы.
Пожалуй стоит начать с того, частотность каких запросов мы оцениваем. Прежде всего, это подсказки и запросы, полученные из «левой колонки» Wordstat. Разница в том, что в подсказках гораздо более «свежие» и «живые» запросы пользователей, в то время как в «левой колонке» Wordstat гораздо большее количество «накрученных» оптимизаторами и различным сервисами (например сервисами сбора позиций) запросов. Плюс Wordstat отдает данные на месяц назад от даты съема частотности. Подробнее о нашем парсере Wordstat>>
При сборе подсказок Яндекса существует проблема так называемых «фантомных» подсказок — подсказки которые Яндекс автоматические генерирует на основе персонализации или других данных. Наши алгоритмы эффективно находят такие подсказки и вырезают их, позволяя вам экономить множество времени и денег.
Что мы имеем в итоге:
- более частотные, но, часто накрученные, запросы из «левой колонки» Wordstat
- нетипичные для русского языка, накрученные запросы вроде «коляска детская москва купить»
- менее частотные, но реальные, живые запросы пользователей из поисковых подсказок
- *поисковые запросы из Яндекс Метрики и Google Analytics
* Такие запросы могут быть выгружены за большой период времени и в момент сбора частотности могут иметь нулевую частотность из-за сезонности или неактуальности запроса в момент сбора частотности.
Я собрал подсказки, но многие из них имеют небольшую частотность «!ws», стоит ли их использовать?
Безусловно стоит. Наш сервис призван найти как можно больше целевых ключевых слов, которые можно использовать и о которых не знают конкуренты. Большинство таких ключевых слов — низкочастотные и они приносят до 70% поискового трафика на веб-сайты в любой стране мира. Плюс, как уже было сказано выше, это живые запросы пользователей, которые актуальны в данный момент времени и могут (часто так и происходит) достаточно быстро набирать популярность, создавая новые семантические тренды и срезы.
Ключевые слова ниже какой частотности отбрасывать?
Здесь все зависит от тематики вашего сайта:
В тематиках, где поисковый спрос узкий (как пример — ремонт телефонов Vertu) — целесообразно использовать даже ключевые слова с частотностью «!» = 1 т.к. здесь важен каждый пользователь из поисковых систем — их в принципе немного.
Для электронной коммерции, например магазинов электроники/подарков/одежды, где очень большой поисковый спрос — можно отбрасывать все ключевые слова с частотностью менее «!» = 5, сконцентрировав усилия на более частотных запросах, а к совсем непопулярным НЧ вернуться позже, при второй итерации.
Для информационных сайтов, таких, как сайты рецептов, сайты кино-тематики, сайты рефератов, автомобильные порталы и для других аналогичных сайтов — можно отбрасывать все ключевые слова с частотностью менее «!» = 50 т.к. спрос в этих нишах просто огромный и физически нереально работать над всем семантическим ядром. Идите от самых популярных потребностей пользователей, к менее популярным. Работайте итерациями.
Работайте итерациями.
Как не потерять нужные запросы и не выкинуть лишнее?
Бывают такие ситуации и тематики, в которых:
- поискового спроса очень мало в принципе
- преобладают многословные запросы в различных словоформах и переформулировках
а) Первый вариант — оставлять запросы с частотностью от «!» = 1, как было сказано выше. Но не везде это возможно, в некоторых тематиках такие запросы или слишком конкретные (не имеют общих URL в SERP с другими запросами и не кластеризуются) и продвигать их нецелесообразно (нет смысла создавать отдельную страницу под такой низкий спрос) или не совсем целевые.
б) Второй вариант — использовать » «, вместо «!». Этот способ работает, когда в вашей семантике преобладают многословные запросы в различных словоформах и переформулировках. Дело в том, что «!» закрепляет конкретную словоформу, а так как многословный запрос может иметь огромное множество переформулировок, а «!» учитывает только одну конкретную, все остальные вы потеряете.
Не забываем про сезонность
Так же необходимо учитывать сезонность для некоторых запросов. Ее можно просмотреть в Яндекс Wordstat, если выбрать «История запросов» после ввода ключевого слова.
Так, например запросы связанные с Новогодними праздниками начинают увеличиваться в частотности с сентября, а с середины декабря уже падают.
Так же очень важно учитывать то, что Яндекс показывает данные за прошлый месяц. И если у вас новый запрос, такой, что только что появился, данных о нем может и не быть, либо будет низкая частотность. Или, возможен вариант, что вы снимаете частотность в «низкий сезон». Если вы имеете примерное представление о популярности запросов, но частотности по ним получились сильно меньше, чем вы ожидали, проверьте сезонность и не спешите отказываться от этих запросов! Начиная продвигать запросы в «низкий сезон», вы получите преимущество перед конкурентами, которые начнут продвигать те же запросы в «высокий сезон».
Была ли статья полезной?
5
0
Навигация по статье
- Я собрал подсказки, но многие из них имеют небольшую частотность «!ws», стоит ли их использовать?
- Ключевые слова ниже какой частотности отбрасывать?
- Как не потерять нужные запросы и не выкинуть лишнее?
- Не забываем про сезонность
Как составить семантическое ядро (СЯ) для сайта — программы и сервисы для сбора ядра
6 Января 2022
Наиболее эффективным источником привлечения трафика на сайт является органический поиск. Для обеспечения использования данного способа привлечения трафика необходимо определить в чем заключается интерес вашей аудитории и на основе этого составить семантическое ядро.
Для обеспечения использования данного способа привлечения трафика необходимо определить в чем заключается интерес вашей аудитории и на основе этого составить семантическое ядро.
Содержание
- Что такое семантическое ядро сайта?
- Задачи семантического ядра
- Что такое ключевые слова?
- Что такое частотность ключевого слова?
- Классификация ключевых слов
- По частотности
- По коммерческости
- По геозависимости
- По типу
- Как составить семантическое ядро?
- Шаг 1. Поиск (подбор) ключевых фраз
- Шаг 2. Поиск синонимов
- Шаг 3. Расширение ядра
- Шаг 4. Удаление лишних фраз
- Шаг 5. Определение точной частотности для фраз
- Шаг 6. Проверка конкурентности
- Итоговый чек-лист
- Пример семантического ядра интернет-магазина
- Что делать с семантическим ядром после составления?
- Кластеризация семантического ядра
- Сервисы для составления семантического ядра
- Key Collector
- SlovoEB
- Wordstat Яндекса
- Системы аналитики
- Анализ семантического ядра конкурентов
- Принцип работы сервисов
- Megaindex Premium Analytics
- Keys.

- Spywords.ru
- Бесплатные сервисы
- Заключение
Наиболее эффективным источником привлечения трафика на сайт является органический поиск. Для обеспечения использования данного способа привлечения трафика необходимо определить в чем заключается интерес вашей аудитории и на основе этого составить семантическое ядро.
Что такое семантическое ядро сайта
Семантическое ядро — это структурированное описание сайта, которое имеет вид списка слов и словосочетаний.
- Ядро отражает всю тематику сайта, учитывая пользовательский спрос и интересы.
- Ядро характеризуют услуги, товары или вид деятельности, предлагаемые сайтом.
Причины составления семантического ядра:
- лучшение видимости сайта роботами Google и Яндекса;
- правильность выдачи пользователям релевантных результатов в поисковиках;
- удобство поиска необходимой информации на странице сайта.

В выдачу поисковиков на первые местапопадают те сайты, которые поисковые системы считают наиболее подходящий сайт под конкретный запрос.
До составления семантического ядра нужно ответить на главный вопрос: какую именно информацию можно найти на сайте. Поэтому поисковые запросы из смыслового ядра важно распределять по конкретным страницам сайта. Работа с ядром позволяет определить какая именно страница подходит под конкретные фразы или группы поисковых запросов.
Задачи семантического ядра
- Определение структуры вашего ресурса. Поисковое ядро позволяет проработать и составить полную архитектуру разделов и страниц сайта, а также навигацию по ним. Наиболее упрощенная иерархия ресурса позволит пользователям и поисковым роботам ориентироваться по структуре сайта.
- Оптимизация страниц. Поисковые фразы позволяют на их основе правильно составить или скорректировать заголовки и метатеги страницы. Ключевые слова позволяют значительно повысить эффективность создания контента и наполнения страниц сайта.
- Контент-план. Поисковые запросы делают возможным составлять ассортимент ресурса или интернет-магазина, а также отталкиваться от них для создания необходимых сайту статей, видео, либо дать ответы на вопросы пользователей.
- Расширение ассортимента компании. Актуализация семантического поискового ядра позволяет изучить пользовательский спрос и их новые интересы, поэтому на основе этого стоит задуматься над расширением ассортимента ресурса, например, новыми услугами или товарами.
- Перелинковка разделов и страниц. Страницы ресурса должны иметь корректную перелинковку и тематически связываться ссылками с другими разделами для наиболее простой навигации по сайту и правильного распределения ссылочного веса между страницами.
- Запуск поисковой контекстной рекламы. Семантическое ядро позволяет корректно отразить потребности пользователей и точно настроить контекстную рекламу.
Что такое ключевые слова
Ключевые слова (фразы) — это поисковые запросы, которые используют пользователи поисковых систем для нахождения необходимой им информации. Пользователи, использующие ключевую фразу “купить носки”, непосредственно ищут интернет-магазины для покупки носков. А пользователи, которые вводят в поисковой строке ключевое слово “фотограф”, ищут сайты с услугами фотографов.
Пользователи, использующие ключевую фразу “купить носки”, непосредственно ищут интернет-магазины для покупки носков. А пользователи, которые вводят в поисковой строке ключевое слово “фотограф”, ищут сайты с услугами фотографов.
Что такое частотность ключевого слова
Частотность поискового запроса — это количественная величина числа обращений пользователей по конкретным ключевым фразам за определенный расчетный период времени. Другими словами — частотность ввода ключевых слов в поисковой строке.
Частота запроса выражает общую степень спроса или популярности той или иной фразы в течение месяца. Частотность, во-первых, зависит от тематики или направления бизнеса, а также от сезонности поискового спроса, конкретного региона поиска и алгоритмов расчета поисковых систем.
Определение частотности ключевых слов возможно при помощи полностью бесплатных сервисов Яндекс.Wordstat и Google AdWords. При этом есть и платные сервисы и программы, которые непосредственно используют поисковую выдачу Яндекса и Google: Key Collector, Serpstat, Букварикс и другие.
Классификация ключевых слов
Все ключевые слова можно условно классифицировать на несколько видов, работа с каждым из которых имеет свои особенности. Мы рассмотрим 4 основных типа параметров, по которым разделяются поисковые фразы.
По частотности
Все ключевые слова можно условно классифицировать на несколько видов, работа с каждым из которых имеет свои особенности. Мы рассмотрим 4 основных типа параметров, по которым разделяются поисковые фразы.
- Высокочастотные (ВЧ) – фразы, описывающие общую тему. Чаще всего посадочной для них является главная страница. ВЧ запросы стоит включать в семантическое ядро в том случае, если ваш сайт уже уверенно стоит в ТОПе по низкочастотным и среднечастотным запросам.
- Среднечастотные (СЧ) – отдельные направления в теме. Подходят для продвижения разделов, подразделов и каталожных страниц коммерческого сайта, а также для крупных информационных статей.
- Низкочастотные (НЧ) – запросы нацеленные на поиск конкретного ответа на вопрос.
 Под такие фразы чаще всего оптимизируются карточки товаров или определенные статьи. С них часто начинается продвижение молодого сайта, у которого пока нет позиций и трафика.
Под такие фразы чаще всего оптимизируются карточки товаров или определенные статьи. С них часто начинается продвижение молодого сайта, у которого пока нет позиций и трафика. - Микронизкочастотные (МНЧ) – это фразы, которые спрашивают один раз в месяц (по данным Яндекс.Вордстат). Нет смысла включать такие запросы в семантическое ядро. По ним легко выйти в ТОП, но будучи на первых позициях вы не получите трафика.
Определить к какой группе по частотности относится та или иная ключевая фраза можно только после определения популярности тематики. Разница в частотности для разных тематик может значительно отличаться. Например, фраза “ключевые слова” будет иметь более частотные запросы, чем фраза “детский спортивный клуб”, поэтому будут и разными группы по частотности.
По коммерческости
Коммерческий запрос — фраза, которую пользователь вводит в поисковую строку с целью совершить покупку (купить самокат, велопрокат прайс).
Некоммерческий запрос — фраза, с помощью которой пользователь ищет информацию без осуществления покупки (станок характеристики, микроволновка отзывы).
Семантическое ядро интернет-магазинов и прочих продающих сайтов обязательно должно включать в себя коммерческие запросы и составлять его основу. Это не значит, что нельзя включать в СЯ некоммерческие запросы: они могут вести на страницы со статьями, советами, обзорами. Однако вы должны понимать, что такие запросы не принесут продаж.
По геозависимости
Геозависимые запросы — ключевые фразы, по которым результаты выдачи в поиске отличаются при смене региона. Например:
- мультфильм шрек в кино
- заказать пиццу
- ресторан морепродуктов
Если пользователь ищет «кинотеатры», находясь в Новосибирске, то ему не интересны кинотеатры в Москве, Санкт-Петербурге и других городах.
Геонезависимые — ключевые фразы, по которым результаты выдачи в поиске НЕ отличаются при смене региона. Например:
- мультфильм шрек оценки
- купить кровать в омске
- как приготовить кулич
Если в том же Новосибирске вводится запрос «кинотеатры в москве», то становится понятно, что нужны результаты по Москве, независимо от того, в каком городе пользователь находится.
По геонезависимым запросам намного тяжелее выйти в ТОП из-за большой конкуренции. Но коммерческие запросы редко бывают геонезависимыми — ведь чем ближе географически к пользователю расположена компания предлагающая услуги или товары, тем ему удобнее. Поэтому основная часть семантического ядра коммерческого сайта будет состоять из геозависимых запросов. Однако существуют исключения, все зависит от тематики сайта. Поэтому всегда проверяйте продвигаемые фразы на геозависимость.
По типу
- Информационные — запросы, с помощью которых осуществляется поиск полезной информации (как связать носки).
- Брендовые — запросы включающие в себя название определенной компании. Брендовыми также являются запросы с различными вариантами написания домена, в том числе на русском и с ошибками (алиэкспересс, али экспрес, ali express). Такие запросы можно брать в семантическое ядро, если только ваш бренд, марка или компания достаточно известны и пользователи ищут вас в сети.

- Транзакционные — фразы, которые используют для поиска товаров и услуг с дальнейшим желанием покупки или заказа. Транзакционные аналогичны коммерческим. По некоторым транзакционным запросам в ТОПе выдачи находится большое количество сайтов-агрегаторов. И для обычных интернет-магазинов остается 1-2 места, либо его вообще нет. Поэтому лучше подобрать более реальный запрос для продвижения.
- Навигационные — ключевые слова, по которым ищут какое-то место или событие (конференция сбербанк 2021).
Как составить семантическое ядро
Представление структуры сайта имеет схему в виде иерархии страниц. Структура решает следующие задачи: логическое расположение информации, соответствие требованиям поисковых систем и обеспечение юзабилити. Разберем основные этапы через которые нужно пройти для составления будущего семантического ядра.
Шаг 1. Поиск (подбор) ключевых фраз
Если у вас уже есть сайт, то нужно начать со сбора таких ключевых фраз, по которым на данный момент посетители уже приходят на сайт. Для этого можно использовать бесплатные инструменты аналитики, например, Яндекс.Метрика.
Для этого можно использовать бесплатные инструменты аналитики, например, Яндекс.Метрика.
Для нового ресурса определитесь что именно будет продавать ваш сайт, наметьте основные разделы товаров. Собирать семантическое ядро необходимо с учетом интересов аудитории сайта и собственных целей.
Для начала нужно собрать первичный список общих основных слов и словосочетаний, охватывающих тематику (ВЧ). Также такие запросы называются маркерами. Это могут быть названия направлений сайта (можно использовать названия разделов и подразделов).
При подборе маркерных фраз удобнее всего использовать Яндекс.Вордстат. Вбивая в него ключевую фразу, слева вы можете увидеть вариации этого словосочетания с использованием различных слов, а справа — похожие запросы, которые можно взять для дальнейшего расширения темы.
Также показывается базовая частотность фразы за месяц во всех словоформах и с добавлением любых слов. Но нам такая частотность в данный момент не нужна, ведь нас будет интересовать частота всех итоговых фраз ядра “в кавычках”, т. е. учитывается частота во всех словоформах, но без добавления дополнительных слов.
е. учитывается частота во всех словоформах, но без добавления дополнительных слов.
Представьте, что вы решили продвигать свой блог для сео, значит часть основных запросов будет примерно такая:
Для наглядности разберем как на каждом шагу происходит подбор фраз на основе маркерной фразы “семантическое ядро”, а для остальных тем всё можно сделать аналогично примеру.
Шаг 2. Поиск синонимов
Дополнять смысловое ядро нужно учитывая потребности посетителей, которые приходят на ваш сайт. Это могут быть такие слова, которые используют некоторую профессиональную терминологию, сокращения, жаргонные слова и слова на английском. Необходимо учитывать ваши преимущества для покупателя при заказе или покупке, а также качества непосредственно самого товара.
Пользователи при написании запроса в поисковой строке могут использовать слова близкие по смыслу. Чтобы максимально охватить ядро тематики нам нужно найти все возможные синонимы и словоформы к основным словам. Для этого можно воспользоваться следующим:
Для этого можно воспользоваться следующим:
- Мозговой штурм. Поставьте себя на место пользователя и подумайте какими другими словами вы могли бы сформулировать вопрос.
- Правый столбец в Яндекс.Вордстат.
- Запросы, сформулированные на кириллице (seo/сео, polaris/поларис).
- Аббревиатуры, сленговые фразы и различные термины, относящиеся к тематике.
- Подсказки в поисковой строке Яндекс и Google, а также фразы в блоке “Вместе с … ищут”.
После всех действий по выбранной теме получится подобный список фраз:
Шаг 3. Расширение ядра
Этот шаг удобно выполнять с помощью уже знакомого инструмента Wordstat. С помощью этого сервиса нужно провести анализ по всем фразам, которые были получены на прошлом этапе, и скопировать всё, что будет находиться в левой колонке в отдельный файл. Также иногда нужно поглядывать и на правую колонку, потому что иногда Яндекс будет предлагать вам и другие слова, которые вы могли пропустить ранее.
В результате выполнения этого шага у вас должен получиться список фраз из Yandex.Wordstat для каждого ключа, полученного на втором этапе.
Шаг 4. Удаление лишних фраз
Этот этап для вас будет самым долгим и трудозатратным, т. к. выполняется он вручную. Нужно внимательно просмотреть каждую поисковую фразу и удалить неподходящие по смыслу.
Рассмотрим примеры запросов, которые нужно сразу убирать из будущего ядра:
- ключи с названиями брендов конкурентов;
- ключи с названиями товаров или услуг, которые вы не предоставляете и не собираетесь с ними работать в дальнейшем;
- ключи с использованием неподходящих регионов и адресов;
- фразы написанные с ошибками и опечатками.
После удаления лишних фраз получится перечень запросов для маркерного ключа “семантическое ядро”. Далее рассмотрим ещё несколько шагов, в процессе которых будут вноситься корректировки в полученный список.
Шаг 5. Определение точной частотности для фраз
Для массового определения точной частотности “в кавычках” нужно воспользоваться сервисами, например, Key Collector или SlovoEB. Подробнее о них мы разберем в этой статье позже.
После определения точной частотности всех фраз, нужно удалить все нулевики, т. к. такие запросы в точности никто не вводит, а значит трафик они вам не принесут.
Шаг 6. Проверка конкурентности
Здесь нужно анализировать выдачу в ТОП-10 по запросам. Обратите внимание на количество главных страниц (морд сайтов), тип контента конкурентов (статья, товар или каталожная страница), вложенность адресов страниц и их формат, а также тип сайтов конкурентов (информационные, коммерческие, агрегаторы). После анализа выдачи вы сможете понять, насколько жесткая борьба за позиции по определенному запросу и на сколько велика вероятность попадания в ТОП вашего сайта. Если становится понятным, что ваш сайт не сможет составить конкуренцию в выдаче, то такие запросы нужно убирать из ядра.
Также возможно продолжить исследование сайтов компаний конкурентов, которые тесно связаны с тематикой вашего ресурса. Нахождение ключевых фраз на данном этапе заключается в поиске слов в текстах, которые имеют пересечения с вашим сайтом.
После прохождения всех шагов, представленных выше, для каждой базовой поисковой фразы, вы получите готовое ядро для сайта.
Также возможно продолжить исследование сайтов компаний конкурентов, которые тесно связаны с тематикой вашего ресурса. Нахождение ключевых фраз на данном этапе заключается в поиске слов в текстах, которые имеют пересечения с вашим сайтом.
Итоговый чек-лист
- Подбираем базовые запросы, которые описывают тематику. Берез за основу структуру сайта и типы предоставляемых товаров или услуг.
- Ищем синонимы ключевых слов с помощью Яндекс.Вордстат и парсинга подсказок поисковых систем.
- Расширяем ядро с помощью левой части в Wordstat.

- Очищаем список от лишних фраз.
- Определяем точную частотность для всех запросов и удаляем нулевики.
- Проверяем конкурентность запросов и проводим окончательную чистку семантического ядра.
Пример семантического ядра интернет-магазина
Здесь вы можете увидеть пример части семантического ядра интернет-магазина.
Такое представление помогает оценить всю ситуации продвижения, а также увидеть подобные проблемы:
- нет страницы, которая подходит для продвижения по данному запросу, нужно создать новую
- эффективность продвижения страниц сайта
- соответствуют ли посадочные и ранжируемые страницы
Что делать с семантическим ядром после составления?
Вы составили семантическое ядро для своего сайта, но затем возникают вопросы: “Что делать после сбора ядра?”, “Как размещать семантическое ядро на сайте?”. Давайте рассмотрим следующие шаги продвижения сайта:
- Кластеризация запросов и распределение их по посадочным страницам. На данный момент ваше семантическое ядро является разрозненным списком фраз. Для дальнейшей работы вам необходимо провести их кластеризацию, т. е. объединить в группы по смыслу. А затем уже подобрать для каждой группы страницу продвижения (выбрать из существующих на сайте или создать новую).
- Составление оптимизированных заголовков и описаний для посадочных страниц. Используем самый высокочастотный запрос, описывающий содержимое страницы для заголовка h2. Менее частотные фразы добавляем в заголовок title и описание description с разбавлением дополнительными словами, не относящимися к тематике.
- Наполнение страницы контентом. Проанализируйте запросы, подобранные для продвигаемых страниц. Необходимо выявить потребности пользователей, которые вводят эти поисковые фразы. Какую информацию они хотят найти, перейдя на ваш сайт? Далее составляем план текста и пишем его сами, либо отправляем задание копирайтеру. Только после этого вбиваете основную поисковую фразу, продвигаемую на выбранную вами страницу, и смотрите наполняемость страниц конкурентов, чтобы сделать похожее.
Теперь ваши посадочные страницы оптимизированы под фразы из семантического ядра.
Кластеризация семантического ядра
Первым и важным шагом после сбора семантического ядра является разбиение всех запросов на кластеры, то есть — кластеризация.
Кластеризация запросов семантического ядра — это группировка ключевых запросов на основе поисковой выдачи. Запросы объединяются в группы для определения целевых страниц для дальнейшего продвижения. Есть несколько методов кластеризации запросов.
Ручной метод кластеризации запросов удобно использовать для значительно небольшого ядра, визуально осматриваемого, около 500 запросов. Здесь используем непосредственно способ группировки с вычислением определенного интента запросов. Поисковые фразы, для которых определение кластера затруднено, нужно анализировать поисковую выдачу в ТОП-10. Если выдача содержит одинаковую поисковую выдачу под разные запросы, то определяем данные запросы в один кластер.
Автоматический метод кластеризации может быть осуществлен при помощи популярных сервисов по кластеризации запросов. Основа алгоритма распределения по группам — это группировка запросов по ТОПу. Используя данные сервисы появляются неточности в данных кластеризаторов, поэтому всегда необходимо проверять вручную итоговые группы. Среди сервисов можно выделить:
- Coolakov.ru
- Stoolz.ru
- SERanking.ru
- Topvisor.com
- Just-magic.ru
Распределение запросов может быть разных уровней, то есть с большей или меньшей общей проработкой. Это могут быть как наиболее конкретные группы или что-то более обширное. Например, список ключевых фраз можно распределить на группу «Мужские серебрянные браслеты», либо выделить среди запросов отдельно две группы «Мужские серебрянные браслеты с камнями» и «Мужские серебрянные браслеты в Новосибирске».
Сервисы для составления семантического ядра
Есть большое количество онлайн сервисов, которые ускоряют и автоматизируют процесс сбора семантического ядра. Вы можете воспользоваться как платными, так и бесплатными программами. Рассмотрим несколько таких сервисов и их принцип работы.
Key Collector
Эта программа окажет вам непосильную помощь, если вы хотите собрать обширное ядро для большого сайта с достаточно разветвленной структурой. Список основных функций этого сервиса:
- Сбор ключевых слов через Яндекс.Вордстат.
- Парсинг подсказок поисковых систем.
- Удаление неподходящих слов с помощью стоп-слов.
- Определение базовой и точной частотности.
- Фильтрация запросов по различным показателям.
- Определение сезонности.
Сервис Key Collector платный. Все эти задачи можно выполнить и в бесплатных аналогах, но придется использовать несколько программ.
SlovoEB
Это бесплатный сервис от разработчиков Key Collector. Его основные функции — это сбор ключевиков через Wordstat, парсинг подсказок и определение частотности фраз.
Интерфейс будет достаточно понятен даже для людей, которые не имеют опыта работы с подобными сервисами. Для начала работы нужно создать новый проект, а затем на вкладке “Данные” перейти на “Добавить фразу”. Отметьте там предполагаемые фразы по которым пользователи могут найти ваш сайт, продукт или услуги на нем.
Сервис сам подберет ключевые фразы, а также поможет автоматизировать задачи для последующего анализа и очистки будущего ядра.
Wordstat Яндекса
Яндекс.Вордстат — сервис с помощью которого вы сможете бесплатно собрать и проанализировать семантическое ядро вашего сайта онлайн. Давайте немного подробнее рассмотрим функционал сервиса:
Предоставляет статистику показов в месяц по ключевому слову, а также поисковым фразам, которые включают указанное вами ключевое слово. Можно проанализировать общие данные или заострить внимание на запросах именно мобильной аудитории.
- Показывает данные по регионам
- Предоставляет историю показов фраз в динамике
- Предоставляет статистику запросов по определенным регионам
Этот сервис очень удобен для подборки ключевых фраз для семантического ядра, но дальше проводить анализ и группировать запросы придется вручную.
Системы аналитики
При сборе семантического ядра для уже существующего сайта можно воспользоваться такими системами аналитики, как Яндекс.Вебмастер, Яндекс.Метрика или Google Analytics. Там вы сможете найти с помощью каких фраз посетители находят ваш сайт и выбрать из них подходящие для продвижения.
Анализ семантического ядра конкурентов
Для сбора семантического ядра есть немного другой подход. Можно провести анализ семантического ядра конкурентов. В итоге вы получите список фраз, который можно использовать при продвижении сайта. В большинстве своем такие сервисы платные.
Принцип работы сервисов
Сервисы для анализа семантики конкурентов не имеют прямого доступа к статистике сайта. Алгоритм их работы основывается на периодическом сборе и анализе информации с поисковых систем. Информация записывается в базу и выдается пользователю инструмента по запросу. Следовательно, если база сервиса обновляется редко — есть шанс получить уже устаревшую, не актуальную и бесполезную информацию.
Megaindex Premium Analytics
Модуль «Видимость сайта» платформы Megaindex дает нам достаточно обширный набор инструментов для получения ключевых фраз конкурентов: можно посмотреть и выгрузить ключевые фразы по которым ранжируется сайт; найти схожие по семантике сайты, которые тоже могут быть использованы в качестве доноров. Сервис платный.
Keys.so
Был создан как инструмент для анализа семантики конкурентов. Необходимо ввести url интересующего нас сайта, отобрать доноров по количеству общих ключей, проанализировать их сайты и выгрузить ключи. Все делается быстро и без лишних телодвижений. Приятный, свежий интерфейс, только нужная информация.
Spywords.ru
Помимо анализа видимости предоставляет статистику по объявлениям в директе. Интерфейс немного перегружен, но если разобраться, то сервис свою задачу в целом решает. Можно проанализировать сайты конкурентов, посмотреть пересечения по семантическому ядру, выгрузить фразы по которым продвигаются конкуренты. К недостаткам можно отнести довольно слабую базу — всего 23 млн ключевых слов.
Бесплатные сервисы
XTool – популярный сервис которым пользуется большое количество новичков. Он может показывать видимость сайтов в поисковых системах, их траст, а также некоторые другие данные. Количество проверок лимитировано. Стоимость каждой проверки, которая превышает этот лимит – 1 рубль.
Букварикс – бесплатно позволяет анализировать семантическое ядро чужих ресурсов, что в конечном итоге позволяет пользователям получать доступ к нужной информации, не заплатив ни копейки. Очень распространен среди фрилансеров на всевозможных биржах, т. к. даже бесплатный аккаунт позволяет пользоваться инструментом на достаточно приличном уровне.
Заключение
В этой статье мы рассмотрели все этапы по сбору качественного и полного семантического ядра для сайта, а также некоторые сервисы, которые помогут вам в этом деле. Выполняя каждый шаг в описанной выше инструкции вы сможете собрать ядро, которое будет максимально охватывать тематику вашего сайта, а это значит, что вы сможете составить правильную стратегию продвижения и быстро выбраться в ТОП выдачи поисковых систем.
определение единичной и массовой частотности
Содержание статьи
- Что такое частота ключевого слова
- Как проверить частотность запроса
- Wordstat (Яндекс)
- Mail.ru
- Rambler
- Как проверить массово частотность запросов
- Key Collector
- Rush Analytics
Очень важно убедиться, что запросы, по которым вы собрались продвигаться, вообще кто-то ищет. Если вы наберете «семантическое ядро», где все ключи будут с нулевой частотностью — то ваш сайт и будет нулём. Поэтому давайте не будем вола нагибать, а приступим.
Что такое частота ключевого слова
Очевидно, что различные запросы имеют разную популярность среди пользователей поисковых систем. Число ввода конкретного запроса в поисковик берется за один месяц. Таким образом, частота ключевых слов — это количество вводов запросов за месяц.
Вполне возможно, что даже тут есть запросы-пустышки
Для продвижения вашего сайта необходимо создавать оригинальный контент. Например, если вы пишете статьи, уникальность вашего текста должна быть, как правило, выше 90%. В теории, уникальный контент приносит высокий показатель посещаемости, состоящий в большей мере из переходов с Яндекса и Гугла. Однако в реальных условиях ранжирования написать уникальную статью — только половина успеха.
Поисковые системы обращают внимание не только на уникальность текста, но и на содержания в нем ключевых запросов, соответствующих тематике статьи или любого другого текстового контента. Правильное распределение ключевых слов в статье называют текстовой оптимизацией. Уникальная, но не оптимизированная статья, содержащие неопределенные запросы, может и вовсе не привлечь на сайт посетителей. Такая ситуация будет означать зря потраченные время и ресурсы на создание контента.
Для оптимизаторов, частотность это критерий по выбору того или иного запроса для его использования в тексте. В зависимости от частотности, ключи разделяют на высокочастотные (ВЧ), среднечастотные (СЧ) и низкочастотные (НЧ) запросы. При оптимизации статьи, в первую очередь, обращают внимание на ВЧ и СЧ запросы. Однако с каждым годом продвижение новых сайтов становится все затруднительным, а оптимизация все тоньше. Сейчас считается, что использование НЧ ключей также может принести некоторый объем трафика.
Как проверить частотность запроса
Частотность ключевых слов можно узнать с помощью соответствующих сервисов поисковых систем, а также специальных программ по составлению семантического ядра. Поисковики предоставляют свои сервисы с расчетом подбора запросов для контекстной рекламы.
Wordstat (Яндекс)
Wordstat — cервис Яндекса по определению статистики ключевых запросов. Вордстат использует большинство оптимизаторов не только в целях составления коммерческих запросов под рекламу, но и для добычи ключевых слов в рамках обычной текстовой оптимизации. У Вордстата выделяют три вида частотностей:
- Частотность WS — базовая частотность запроса в Вордстате.
- Частотность «» WS — частотность по точному вводу запроса. Например, статистика по запросу [«автомобиль»] будет соответствовать запросу [автомобиль] без добавлений других слов.
- Частотность «!» WS — частотность по точному вводу каждого слова в запросе, исключая склонения и т.п. Запрос [!китайский] означает, что будет выдана статистика по слову [китайский] без возможных склонений (китайская, китайское).
По запросу [автомобиль] текущая частотность превышает десять миллионов показов. Однако базовый показатель предполагает добавление всевозможных слов к ключевому слову, по которым будет ранжироваться статья.
Если заключить запрос в кавычки, то статистика сократится с десяти миллионов до 28 тысяч. Для оптимизатора может оказаться полезной правая колонка с похожими запросами, которые дополняют семантический сбор.
Вкладка «По словам» означает, что статистика приводится по общей сумме показов введенного запроса. На вкладке «по регионам» отображается статистика показов в разных регионах страны. А на «Истории запросов» можно отследить по графике изменение частотности запроса в течении месяца или недели, а также статистику по по запросам через ПК или мобильные устройства.
Сервис Google AdWords сам по себе более заточен под контекстную рекламу, нежели Вордстат. В разделе «Инструменты» можно подобрать необходимые ключи под нужный запрос. В колонке «Таргетинг» задается нужный регион показов и язык. Также можно указывать минус-слова.
В отличии от Вордстата, где указывается статистика за месяц, в AdWords можно выбирать месячный диапазон показов в колонке «Диапазон дат». Недостатком является усредненный число результатов. Сама статистика разделена на два блока:
- Ключевые слова — аналог частотности «» Вордстата;
- Ключевые слова (по релевантности) — аналог базовой частотности и похожих запросов WS.
Плюсами являются присутствие уровня конкурентности, а также возможность скачать подобранные слова в CSV-файл или на Гугл Диск.
Помимо AdWords, Гугл имеет еще один инструмент по анализу запросов под названием Google Trends. Данный сервис оценивает популярность введенного запроса на определенный период времени и представляет статистику в виде графика. Можно сравнивать несколько ключевых запросов между собой. Также отображается статистика по регионам.
Для графика используются не точные числа, а относительные, основанные в том числе на релевантных запросах.
Mail.ru
Mail.ru также имеет в сервисе для вебмастеров инструмент по статистике поисковых запросов. Помимо общих показов, в таблице представлены распределение запросов по полу и возрасту пользователей.
Не секрет, что Mail сотрудничает с Яндексом, так как поисковик размещает рекламу Яндекса.
Rambler
Rambler с каждым годом теряет свою популярность, однако их Wordstat может оказаться весьма полезным. Дело в том, что статистика запросов в Яндексе и Гугле не всегда может отображать реальное положение вещей. Многие компании могут вводить «в холостую» коммерческие запросы в целях слежки за конкурентами, т.е. для анализа ТОПа, тайтлов и т.д.
По причине низкой популярности Рамблера, статистика их Вордстата обладает меньшей заспамленностью и может внести некоторую ясность для оптимизаторов. В общем, в качестве дополнительного инструмента вполне сгодится.
Как проверить массово частотность запросов
Большинство оптимизаторов выбирают для сбора и анализа семантического ядра такие программы, как Key Collector или Slovoeb. Также существуют онлайн-сервисы по определению частотностей.
Key Collector
Получить необходимые ключи для семантического ядра и массово проверить их частотность можно при помощи десктопной программы Key Collector. Открываем Вордстат, в поле заносим основные ключи с новой строки по вашей тематике и нажимаем «Начать сбор».
В настройках можно задавать требуемый регион для сбора, а также стоп-слова. После того как ключи соберутся, определяем частотности через Директ.
В итоге у вас будет таблица с ключами и частотой показов. Сразу удаляем все ключи, у которых точная частотность «!» равна нулю. Для этого делаем фильтрацию в колонке «Частотность !». Кликаем на синюю иконку. Появится окно с фильтром. Выбираем «больше или равно» > «1» и жмем «Применить».
Для получения большего списка ключей можно собрать поисковые подсказки с Яндекса. Делаем новую группу (окно справа).
Прежде чем парсить подсказки, нужно настроить глубину их поиска. Заходим в настройки и выбираем вкладку «Подсказки» и в значение поля «Глубина парсинга» ставим «2».
Также убедитесь, что включена галка «Собирать только ТОП подсказок без перебора…». Теперь кликаем на созданную группу – откроется новая пустая вкладка. Жмем иконку сбора поисковых подсказок.
Включаем галку «Не добавлять фразу, если она уже есть в любой другой группе» — чтобы потом не было дублей ключей. Выбираем парсить с Yandex. В поле фраз вводим наши основные ключи.
После сбора фраз делаем то же самое, что и при парсинге Вордстата: снимаем частотности, убираем неподходящие по смыслу фразы и фразы, где частотность «!» равна нулю.
Аналогично с помощью Key Collector можно собрать ключи и частотности с Гугла.
Rush Analytics
Сервис Rush Analytics является онлайн-альтернативой Key Collector. Плюсом инструмента по сбору ключей является отсутствие необходимости использовать прокси, антикапчу и т.п.
Для сбора частотности с Вордстата, необходимо перейти на вкладку «Сбор частотности» и поставить галочку напротив !ключевое слово, то есть точной частотности. Далее заносим ключевые слова. После того, как сервис посчитает затраты, нажимаем «Создать новый проект».
Как собрать семантическое ядро для продвижения сайта: инструкция от агентства интернет-маркетинга
Нравится статья?
Понравится и работать с нами.
Начать
- Что должно получиться в итоге
- Как оформить результат
- Порядок сбора ядра
- Каких ошибок избегать при сборе семантического ядра
- Что делать с семантическим ядром дальше
Семантическое ядро – это список ключевых запросов, по которым вы будете продвигать свой сайт в поисковых системах. Разберемся, в каком порядке его собирать, как расширять и каких ошибок избегать в работе с семантикой.
Что должно получиться в итоге
Ваша цель – составить полный список ключевых запросов, по которым аудитория ищет ваши товары и услуги. Важно четко понимать, за какой информацией люди приходят на сайт и какие запросы вбивают в поисковую строку.
Критерии хорошего ядра:
- Содержит самые конверсионные (близкие к покупке) запросы.
- Общая и точная частотность, правильные формы слов. Например, общая частотность запроса «уборка офиса» – 17 000 в мес. – это все запросы, включающие любые формы слов«уборка» и «офис». Запросов, в которых используются только эти два слова в любых формах – 1 270. Точных запросов «Уборка офиса» – 274.
- Тематическая плотность – запросы плотно охватывают определенную тематику, а не надерганы из разных. Не упущены хорошие альтернативные запросы.
Как оформить результат
Удобнее всего собирать ядро в формате таблицы в любой привычной для вас программе. Какие колонки в ней должны быть:
- Сами ключевые фразы и слова, каждая позиция отдельной строкой. Полезно также визуально разделить тематические группы – цветом, пустой строкой.
- Характеристика запроса – коммерческий или информационный. Коммерческие ключи содержат слово «купить / заказать / цена», а по информационным люди ищут полезные материалы в вашей сфере (например, «как рассчитать количество плитки для пола»).
- Место для URL страниц (пригодится,когда вы будете распределять запросы по сайту).
- Частотность запроса (количество упоминаний в поисковиках за месяц), чтобы в дальнейшем вам было проще разбить запросы на группы и распределить их по страницам. Частоту запросов удобно смотреть в сервисе Яндекс.Вордстат.
Яндекс.Вордстат. Вверху списка – самые высокочастотные запросы, они сортируются по убывающей.
Что еще почитать: Идеальный каталог для продвижения сайта
Когда таблица для работы готова, можно переходить к сбору семантического ядра. Очень советуем делать это, большей частью, вручную – никакой сервис не заменит здесь аналитические способности человека, знающего свой бизнес.
Порядок сбора ядра
Шаг 1 – находим базовые запросы
Начинаем с базовых запросов – это основа семантического ядра сайта, самые очевидные «ключи» в вашей тематике.
Откуда их брать:
- Буквально из головы – советуем устроить мозговой штурм и записать все слова и сочетания слов, которые описывают ваш бизнес. Например, для сайта автосервиса это могут быть запросы кузовной ремонт, шиномонтаж, замена масла, автосервис в Звенигородеи т.д. Тут может помочь и ваш прайс-лист со всеми товарами/услугами, но нужны также и общие запросы по сфере в целом. Запишите все идеи, позже вы сможете их проверить и отфильтровать.
- В сервисе Яндекс.Вордстат. Введите в поисковую строку любой ключ из базового списка, и сервис покажет, в каких сочетаниях и формах его используют реальные пользователи. А в дополнительной правой колонке вы увидите синонимичные и связанные запросы – обязательно скопируйте себе подходящие.
Примеры дополнительных запросов для сайта автосервиса – «ремонт автомобилей», «обслуживание автомобилей» и т.д.
- Из отчетов систем аналитики Яндекс.Метрика или Google Analytics – только если вы составляете семантическое ядро для уже действующего сайта. Зайдите в разделы «Анализ поисковых запросов» или «Популярные запросы», чтобы увидеть, по каким фразам вас находит реальная аудитория сайта.
Скорее всего, в списке ваших базовых запросов окажутся преимущественно ВЧ (высокочастотные) ключи, по которым в поисковиках большая конкуренция. Их нужно разбавить средне- и низкочастотными запросами, поэтому делаем следующий шаг.
Шаг 2 – расширяем смысловое ядро
Посмотрите на ключи в базовом списке – большинство из них будут состоять только из «тела», то есть, просто называть услуги, товары, сферу деятельности.
Чтобы семантическое ядро сайта получилось объемным, нужно нарастить на основные ключи:
- Слова-спецификаторы, которые выражают намерение – «купить», «заказать», «записаться» и пр.
- Так называемые «хвосты» – слова, которые уточняют запрос и делают его средне- и низкочастотным. Например, не просто «записаться к терапевту», а «записаться к терапевту в Новокосино» или «записаться к терапевту онлайн».
В результате на месте каждого базового запроса у вас получится целая группа ключей разной частотности.
Часть работы можно сделать вручную, но советуем использовать на этом этапе специальные сервисы. Так вы ускорите процесс и сразу проверите, какие запросы люди вводят в поисковиках на самом деле.
Кроме уже знакомого нам Яндекс.Вордстат, попробуйте и другие инструменты:
1. Планировщик ключевых словGoogle– сервис для тех, кто уже запускал контекстную рекламу в Google.Ads. Планировщик быстро подберет для вас связанные по смыслу ключевые запросы и проанализирует их.
Для начала работы нужно просто ввести любой ключ из вашего базового списка.
2.KeyCollector. Платная утилита, которая собирает семантику сразу из нескольких источников – не придется обращаться к каждому по отдельности.
3. Сервисы для конкурентного анализа. Например, SEMrush, Searchmetrics, SpyWords или Serpstat. Они покажут, по каким запросам продвигаются другие сайты в вашей нише – возьмите на заметку самые удачные идеи.
Кроме анализа конкурентов, некоторые из этих сервисов умеют подбирать связанные ключи к запросам из вашей базы. Например, так работает SpyWords
Что еще почитать: Чек-лист для анализа конкурентов в SEO
Шаг 3 – фильтруем список
На втором этапе мы с помощью сервисов собрали объемный список запросов, но часть из них не нужна в семантическом ядре сайта. Поэтому теперь снова включаемся в работу сами и вручную чистим список – убираем те фразы, которые не подходят для сайта по смыслу и могут привести нецелевую аудиторию. Подчеркнем еще раз: обращайте внимание именно на смысл, а не на частотность и другие численные характеристики.
Как понять, что ключевой запрос вам не подходит:
- В нем упоминается товар или услуга, которых нет в вашем ассортименте.
- Ключ дублирует другие запросы. Например, в списке могут оказаться одновременно «репетитор по русскому языку» и «русский язык репетитор» – одну из фраз убираем.
- В запросе есть упоминание компании-конкурента.
- В запросе упоминаются города и районы, с которыми вы не работаете.
- В запросе есть стоп-слова «бесплатно», «своими руками», «скачать» и прочие, которые не направлены на покупку.
Есть спорные категории ключей. Некоторые компании сразу отсекают запросы со словами «недорого / дешево», некоторым мы советуем их оставить. Так же и запросы с ошибками: самые частотные из них иногда можно использовать в текстах на неосновных страницах, но если сомневаетесь, тоже убирайте.
Далее, все запросы можно разделить на три типа:
- Витальные/брендовые – самые конверсионные запросы. Например, «куртка Bogner», «кроссовки Nike», «кафе Шоколадница».
- Транзакционные. Такие запросы набирают люди, которые имеют намерение приобрести товар или услугу. Признаки – слова «купить», «в Москве», «цена», «с доставкой» и т.д.
- Информационные. Например, «как выбрать подарок мужу».
Ядро должно состоять в первую очередь из первых двух категорий запросов, а информационные можно вынести отдельно – на основе них вы сможете в будущем писать статьи в блог и ответы на вопросы.
Каких ошибок избегать при сборе семантического ядра
- Отсеивать высокочастотные ключевые запросы. Да, по ним высокая конкуренция и сложнее продвигаться, но ведь ВЧ запросы и не рассматриваются, как основной источник трафика. Важно оставить их в семантическом ядре, потому что именно эти фразы описывают сферу вашей работы и ключевые услуги («бытовая техника», «фотостудия в Москве» и пр.).
- Отсеивать низкочастотные и микро-низкочастотные запросы – другая крайность. На самом деле, мы рекомендуем расширять семантическое ядро сайта именно за счет таких ключей. Ведь «купить в Москве настольную лампу BM614» введет в поиске тот, кто, скорее всего, уже сделал выбор и готов заказать. К тому же, 60-80% всех запросов, которые вводят пользователи – низкочастотные.
- Слишком долго и скрупулезно собирать смысловое ядро, если у вас пока небольшой бизнес. В этом случае важнее в принципе запустить сайт и начать продвижение, а расширить структуру и список запросов вы сможете в процессе. Для начала используйте 1-2 источника базовых запросов – Яндекс.Вордстат, Планировщик Google – а дополнительные каналы задействуете позже при необходимости.
- Собирать семантическое ядро раз и навсегда и больше к нему не возвращаться. На самом деле, список ключевых запросов нужно регулярно расширять и пересматривать: увеличивается ассортимент, растет ваш сайт – должно расти и смысловое ядро.
Что еще почитать: Гибкий подход Agile в разработке и продвижении сайтов
Что делать с семантическим ядром дальше
Когда семантическое ядро собрано, важно грамотно сгруппировать запросы по смыслу и распределить их по страницам сайта с помощью текстов и метатегов, причем чаще всего для этого нужно перекраивать и расширять всю структуру целиком. Для этого есть платные и бесплатные сервисы, но они могут только сократить время на кластеризацию – их результат всегда требует ручной доработки, поэтому лучше доверить продвижение сайта профессионалам.
В «Эврике» за вашим проектом будет закреплен опытный SEO аналитик, который глубоко изучит ваш бизнес и разработает индивидуальную стратегию продвижения исходя из ваших целей.
Продвижение сайтов в «Эврике»
Технологии, кейсы, стоимость
Обсудить проект
Поделитесь с друзьями
Еще по теме
Чек-лист для анализа конкурентов в SEO
Основы SEO: зачем оглядываться на других и как это делать правильно
Как разработать стратегию SEO продвижения сайта
Основы SEO: что нужно сделать до начала любых работ по сайту
SEO продвижение сайта автосервиса
Особенности тематики и проверенные приемы от агентства интернет-маркетинга
SEO-продвижение В2В сайтов
Особенности продвижения продуктов для бизнеса в поисковых системах
SEO продвижение сайтов строительных компаний
Ключевые особенности тематики и проверенные приемы продвижения в поиске
SEO продвижение сайтов медицинской тематики
Особенности продвижения клиник и других сайтов в медицинской сфере
Подписаться
Отзывы клиентов
www.
energyc.ruЭлектролаборатория
2 года эффективной работы
ООО «Комплексный Энерго Подряд» является клиентом ООО «Эврика» с 2016 г. Сотрудники вашей компании зарекомендовали себя как профессионалы своего дела. Всегда обеспечен быстрый ответ на интересующие вопросы. Работа ведется непрерывно и результативно, о чем свидетельствует обращение в нашу компанию новых заказчиков.
Читать полностью
www.gormed.su
Многопрофильная клиника
Результатами мы довольны
Раньше я платил за клики, не представляя, что клики и звонки – разные вещи. Работа с системой Calltouch поразила меня тем, насколько можно увеличить количество звонков. Не кликов, а именно звонков, уменьшив при этом расходы с помощью достаточно простых манипуляций. Результат впечатляющий.
Читать полностью
mir-nagrad.ru
Магазин наград
Благодаря «Эврике» не закрыл магазин
Я доволен своим интернет-магазином и уверен, что он полностью удовлетворяет запросы моих дорогих покупателей! Понравилось отношение ко мне и моему проекту, очень дружелюбное, и некоторые нюансы (правки по сайту, консультации по непонятной мне теме) проходят быстро, гладко, без нервов и без ударов по карману.
Читать полностью
eurotech-group.ru
Аэродромная техника
Рекомендуем!
Компания «ЕвроТэк» благодарит компанию «Эврика» за оказанные услуги и быстрый отклик на любую проблему. За период работы сайт eurotech-group.ru поднялся в ТОП по отрасли.
Читать полностью
www.seniorgroup.ru
Сеть пансионов для пожилых
Группа компаний Senior Group благодарит
рекламное агентство «Эврика» за ведение эффективных рекламных кампаний в Google Adwords, Яндекс.Директ и социальных сетях, а также ведение интернет-сайта www.seniorgroup.ru.
Читать полностью
Оставьте заявку
Ваше имя
Электронная почта
Телефон *
Нажимая на кнопку Отправить, я даю согласие на обработку персональных данныхКак проверить частотность точного запроса
Для грамотной работы со статистикой поисковых запросов WordStat нам потребуется изучить и применить на практике два базовых и пять вспомогательных операторов. Данную статью можно рассматривать как инструкция по применению Яндекс.Вордстат.
Известно, что если просто ввести интересующий нас запрос в статистику Яндекса по адресу https://wordstat.yandex.ru/ , то будет представлена частота, которая отражает общее число показов результатов выдачи за предыдущей отчетный период в ответ на все запросы с содержанием заданной фразы. Так, число рядом со словом «магазин» отражает суммарную частоту показов по всем запросам со словом «магазин» — «интернет-магазин», «магазин сотовой техники», «статистика магазина», «как правильно выбрать магазин для покупок» и так далее.
В большом числе случаев, это не очень информативные и не самые полезные данные и требуется применять ряд вспомогательных операторов и приёмов о которых и пойдет речь в данной статье.
Данные операторы используются для целого ряда задач — прогнозирования трафика из органического поиска и спецразмещения, прогнозирования отдачи от SEO и других.
К базовым операторам, без использования которых невозможно правильное понимание результатов работы статистики ВордСтат мы отнесем операторы «Кавычки» и «Восклицательный знак». Их определение и использование представлены ниже.
Как видно из примера, с помощью оператора «Восклицательный знак» можно быстро найти запросы с нужной нам словоформой одного или нескольких слов из фразы.
Совместное использование операторов «Кавычки» и «Восклицательный знак» позволяет получить так называемую «Точную частоту запроса» исходя из которой и строится прогноз трафика на сайт из контекста или органической выдачи. Требуется лишь верно предсказать показатель CTR (число кликов на 100 показов) для выбранной или занимаемой позиции.
Вспомогательные приёмы и операторы
Ещё большие возможности при работе с WordStat от Яндекса открываются с применением пяти дополнительных операторов. Это:
Оператор «Или» — задается символом «|» и полезен, когда требуется сравнить или «смещать» несколько фраз в статистике, а также для быстрого подбора семантики на страницу.
Оператор «Квадратные скобки» — задается символами «[]» между которым заключена фраза. Позволяет зафиксировать порядок следования слов в запросе. Важен для оценки популярности близких фраз, особенно по частотным запросам.
Оператор «Плюс» — задается символом «+» и полезен, когда требуется найти поисковые запросы со стоп-словами (предлогами, союзами, частицами).
Оператор «Минус» — задается символом «-» и полезен, когда требуется исключить запросы с использованием ряда слов.
Оператор «Группировка» — задается символами скобки «()» и полезен, когда требуется сгруппировать использование описанных выше операторов.
Примеры использования
Приведем примеры использования каждого из операторов, код запроса в WordStat для самостоятельного задания и таблицу поисковых запросов до и после из применения.
Пример кода:
шпаклевка | шпатлевка
«Квадратные скобки» и получение точной частоты запроса
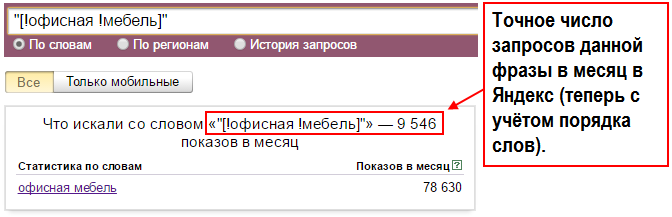
Пример кода:
«[!офисная !мебель]»
Пример кода:
дела +на
«Минус»
Пример кода:
окна -пластиковые
«Группировка» и более сложный запрос
Пример кода:
(ворд стат | вордстат | wordstat | word stat) (операторы | приёмы | +какие | фишки | правила | +как)
Дополнительные возможности
На иллюстрации выше, цифрами отмечены: 1 — сам запрос, 2 — дата обновления статистики Яндекса по данным фразам, 3 — суммарное число показов по фразам которые соответствуют запросу, 4 — общее число показов по фразе.
Здесь очень важно не путать общее число показов из колонки 4 и число точных запросов по фразе, которое можно получить с использованием операторов «Кавычки», «Восклицательный знак» и «Квадратные скобки».
К дополнительным возможностям WordStat отнесем изучение истории (сезонности) спроса в тематике, получение частоты в заданном регионе и анализ популярности фраз в мобильном поиске (планшеты, мобильные телефоны).
Данные функции часто оказываются полезны при планировании рекламных кампаний.
История запроса
Можно быстро понять, как меняется интерес к выходу новой модели «IPhone 6S». К сожалению, в текущий момент история запросов не поддерживает операторы («ИЛИ», «Группировка», «Квадратные скобки»).
Изучение динамики по запросу [Новый год]. Хорошо видны резкие сезонные всплески и провалы после наступления января.
Частота в заданном регионе
Отдельного упоминания заслуживает получение частоты запроса в заданном регионе. С помощью разделения общей частоты запроса по регионам можно оценить как частоту заданного запроса в интересующей нас регионе (Москва, Москва и область, Санкт-Петербург и т. д.), так и относительную популярность того или иного запроса в регионе.
Из примера приведенного ниже видно, что запросы со словами «купить» и «Казань» преимущественно задают жители г. Казань, что весьма очевидно. Использование данной функции на практике иногда открывает и более неожиданные закономерности.
Сбор (парсинг) запросов заданной длинны
На практике бывает полезным использовать приём парсинга запросов заданной длинны (из 2, 3, 4 слов и так далее) с вхождением ключевого слова. Данная возможность оказывается особенно актуальной, если вы работаете в популярной тематике и сбор первых 41 страниц не позволяет получить все поисковые фразы.
Для сбора всех фраз с длиной в 3 слова используется конструкция вида:
«IPhone IPhone IPhone»
Данный запрос позволяет собрать уже не просто 41 страницу поисковых фраз произвольной длины, а 41 страницу фраз из трёх слов с вхождением «IPhone». Последовательный анализ запросов с длиной от 2 до 7 слов позволяет существенно увеличить охват целевой аудитории.
Для ускорения сбора частот, быстрого парсинга Яндекс.Вордстат и хранения целевых ядер, рекомендуется использовать программы и онлайн-сервисы автоматизации, к числу которых можно отнести «Пиксель Тулс». После быстрой настройки параметров сбора, можно получить широкое семантического ядро в рамках тематики.
Анализ проведён с помощью инструментов в сервисе Пиксель Тулс.
Детальный анализ словоформ для ВЧ-запросов
Для ВЧ-запросов длиной в 2 и более слов может пригодиться анализ частоты встречаемости словоформ. Для этого требуется ввести исходную фразу, скажем, «продвижение сайтов» и далее последовательно исключать точные популярные написания с помощью комбинации операторов вида — -«[!продвижение !сайтов]», что приводит к исключению наиболее частотной формы написания из статистики и появлению второй по популярности версии. Далее процедуру можно повторить.
Выводы
Мы рассмотрели все основные функциональные возможности сервиса статистики WordStat. Теперь вам остается лишь правильно применить полученные знания на практике для своих проектов.
Мы оставим «в рукаве» ещё две интересных и скрытых возможности ВордСтат для наших подписчиков. Хотите узнать их? Тогда оформите подписку на обновления проекта «Продвижение самостоятельно». Удачи!
У нас иногда спрашивают:
«Почему мой сайт в ТОПе по такому на первый взгляд «жирному» запросу как «металлоконструкции», но трафика на сайт с этого ключевика совсем мало. Какие-то 50-100 человек в месяц! Но ведь частотность у этого запроса огромная, аж 250 тысяч в месяц! Почему такое происходит?»
И правда, если вбить в wordstat.yandex.ru такой запрос, то частотность он нам покажет довольно внушительную:
При такой частотности позиция даже на 10 месте в выдаче должна приносить много трафика, но на деле все происходит совершенно иначе. В чем же причина? Давайте разбираться по порядку. Здесь есть несколько моментов, которые нужно учитывать. Начнем с самых простых и далее – по нарастающей.
Регион
Первое, про что все часто забывают, – это выбор региона при съеме частотности. Ни один коммерческий сайт не может продвигаться сразу по всем регионам, если он, конечно, не имеет офисы в каждом из них. Поэтому частотность снимается именно по тому региону, где находится офис компании. Если регионов несколько – отмечаем их все.
Например, компания, которая специализируется на поставках металлоконструкций и металлопроката, имеет офис в Москве, который добавлен в Яндекс.Справочник. Таким образом, ни по каким другим регионам данный сайт ранжироваться не будет, поэтому и ориентироваться надо в первую очередь на посетителей из Москвы. Значит, в wordstat нужно выставить соответствующий регион: Москва.Ключевой момент – наличие организации в Яндекс.Справочнике, так как именно по нему происходит привязка региона сайту.
Иногда клиенты нам говорят:
«Я хочу продвигаться по всей России, мой интернет-магазин доставляет товар в любой регион».
И здесь мы вынуждены их разочаровать: к сожалению, даже внутри России интернет-магазин не может ранжироваться, если у него нет филиалов в соответствующих регионах. Под филиалами подразумевается привязанная в Яндекс.Справочнике карточка организации с подтвержденным офисом в регионе.Таким образом, при оценке спроса всегда нужно строго определять региональность.
Виды частотности
После выбора региона сразу видно, что частотность значительно уменьшилась.
Однако все равно это не реальные цифры конкретных фраз и, чтобы точно определить частотность каждого ключевика, нужно использовать специальный синтаксис.
Базовая частотность
Пока что мы собрали так называемую «Базовую частотность». Такой частотностью называют ту, которую мы получаем при вводе запроса в wordstat без какого-либо синтаксиса, выбрав регион или нет. Такая частотность представляет собой сумму частотностей всех фраз, где встречаются слова из запроса в любых словоформах и в любом порядке. Например, в нашем случае запрос «Металлоконструкции» без указания региона имел частотность около 250 тыс. в месяц по всему миру и 33 тыс по Москве. В эту частотность вошли все фразы, которые содержат слово «металлоконструкции». Причем слово может иметь разные окончания, то есть сюда войдут фразы: «завод металлоконструкций», «сварные металлоконструкции», «купить металлоконструкции недорого» и т.п.
Частотность в кавычках
Если мы хотим узнать частотность поискового запроса более точно, например, отсечь из нее те запросы, где присутствуют другие слова, то нужно брать запрос в кавычки. Иными словами, если вбить в wordstat запрос в таком виде – “металлоконструкции” – то получим следующую цифру:
Теперь мы видим, что отдельно слово «металлоконструкции» по Москве запрашивают в Яндексе только 948 человек. Однако сюда все равно еще подмешиваются словоформы, например, «металлоконструкций» «металлоконструкция». Чтобы их убрать, воспользуемся следующим видом частотности.
Частотность в кавычках и с восклицательным знаком (точная частотность)
Если задать запрос в wordstat в таком виде – “!металлоконструкции” – мы получим самую точную частотность. То есть будет отображаться частотность данного слова именно в таком виде, как мы написали:
В многословных запросах восклицательный знак нужно ставить перед каждым словом, так как данный оператор фиксирует словоформу каждого слова запроса по отдельности.
Таким образом, видна существенная разница в финальной частотности однословного запроса «металлоконструкции» по сравнению с изначальной базовой.
Точная частотность с учетом порядка слов
Однако, если мы подобным образом будем оценивать запрос, состоящий из двух слов, например, «купить металлоконструкции», то нужно еще учитывать порядок слов.
Так, например, если мы проверим точную частотность запросов: “!купить !металлоконструкции” и “!металлоконструкции !купить”, то обнаружим, что странным образом частотность у них будет одинаковая:
Это происходит по той причине, что операторы «кавычки» и «восклицательный знак» не учитывают порядок слов.Чтобы собрать точную частотность фразы «купить металлоконструкции» с учетом порядка слов, нужно использовать оператор «скобки» и вводить фразу следующим образом: “[!купить !металлоконструкции]”:
Таким образом, мы видим, что «купить металлоконструкции» ищут чаще, чем «металлоконструкции купить».
В результате мы разобрались, что основным фактором в оценке спроса по ключевым запросам, который обязательно нужно учитывать, является правильный съем частотности для семантического ядра. В качестве примера мы сравнили базовую и точную частотность для первых трех десятков фраз, которые выдает wordstat по запросу «металлоконструкции». В приведенной таблице в колонке «Показов в месяц» указана базовая частотность, которую выдал Яндекс без учета региона. В колонке «Реальная частотность» указана уже точная частотность по региону Москва и снятая с использованием операторов «кавычки», «восклицательный знак» и «квадратные скобки».
Как видно, точная частотность значительно меньше базовой. Если исходить из такой методики оценки спроса, то картина, при которой позиция в ТОП-10 Яндекса по ключевой фразе «металлоконструкции», имеющей частотность 839, приносит 50-100 посетителей, уже выглядит более реальной.
Распределение кликабельности на первой странице выдачи
Но можно справедливо возразить:
Неужели при позиции в ТОП-10 с ключевика частотностью 839 будет всего лишь 50-100 посещений?
По разным оценкам распределение CTR в органической выдаче в ТОП-10 примерно такое:
Подсчеты, конечно, очень обобщенные, но примерно отражают актуальную картину: 3 или даже 4 блока контекстной рекламы забирают больше половины всего CTR. Далее могут идти сервисы Яндекса: маркет, картинки, карты, что делает кликабельность на обычные сайты еще меньше. Учитывая еще то, что позиция в Яндексе редко у какого сайта бывает стабильной в ТОП-10 вследствие работы так называемого алгоритма «бандита», можно смело заключить, что вышеприведенные цифры по количеству трафика являются нормальными.
Оценка CTR через Яндекс.Директ
Наши слова легко проверить – достаточно зайти в Яндекс.Директ в прогноз бюджета и посмотреть там прогнозируемый CTR в зависимости от позиции в блоках контекстной рекламы на поиске.
Яндекс обычно слишком занижает показатели кликабельности в своих прогнозах, но это еще раз показывает, что даже высокая позиция по какому-либо запросу не гарантирует большого количества посетителей.
Заключение
В заключении подытожим, что для правильной оценки спроса и составления на ее основе стратегии поискового продвижения сайта важно собирать максимально полное семантическое ядро и правильно снимать частотность у всех фраз, а также задавать регион. Абсолютно неправильно «зацикливаться» на отдельных и предположительно самых «жирных» поисковых фразах и полагать, что, продвинувшись по ним в ТОП-10, сайт станет лидером тематики. Лидерство сайта в поисковом продвижении определяется исключительно совокупной видимостью сайта по определенному семантическому ядру, то есть многочисленному списку поисковых запросов различной частотности и длины.
Очень важно убедиться, что запросы, по которым вы собрались продвигаться, вообще кто-то ищет. Если вы наберете «семантическое ядро», где все ключи будут с нулевой частотностью — то ваш сайт и будет нулём. Поэтому давайте не будем вола нагибать, а приступим.
Что такое частота ключевого слова
Очевидно, что различные запросы имеют разную популярность среди пользователей поисковых систем. Число ввода конкретного запроса в поисковик берется за один месяц. Таким образом, частота ключевых слов — это количество вводов запросов за месяц.
Для продвижения вашего сайта необходимо создавать оригинальный контент. Например, если вы пишете статьи, уникальность вашего текста должна быть, как правило, выше 90%. В теории, уникальный контент приносит высокий показатель посещаемости, состоящий в большей мере из переходов с Яндекса и Гугла. Однако в реальных условиях ранжирования написать уникальную статью — только половина успеха.
Поисковые системы обращают внимание не только на уникальность текста, но и на содержания в нем ключевых запросов, соответствующих тематике статьи или любого другого текстового контента. Правильное распределение ключевых слов в статье называют текстовой оптимизацией. Уникальная, но не оптимизированная статья, содержащие неопределенные запросы, может и вовсе не привлечь на сайт посетителей. Такая ситуация будет означать зря потраченные время и ресурсы на создание контента.
Для оптимизаторов, частотность это критерий по выбору того или иного запроса для его использования в тексте. В зависимости от частотности, ключи разделяют на высокочастотные (ВЧ), среднечастотные (СЧ) и низкочастотные (НЧ) запросы. При оптимизации статьи, в первую очередь, обращают внимание на ВЧ и СЧ запросы. Однако с каждым годом продвижение новых сайтов становится все затруднительным, а оптимизация все тоньше. Сейчас считается, что использование НЧ ключей также может принести некоторый объем трафика.
Как проверить частотность запроса
Частотность ключевых слов можно узнать с помощью соответствующих сервисов поисковых систем, а также специальных программ по составлению семантического ядра. Поисковики предоставляют свои сервисы с расчетом подбора запросов для контекстной рекламы.
Wordstat (Яндекс)
Wordstat — cервис Яндекса по определению статистики ключевых запросов. Вордстат использует большинство оптимизаторов не только в целях составления коммерческих запросов под рекламу, но и для добычи ключевых слов в рамках обычной текстовой оптимизации. У Вордстата выделяют три вида частотностей:
- Частотность WS — базовая частотность запроса в Вордстате.
- Частотность «» WS — частотность по точному вводу запроса. Например, статистика по запросу [«автомобиль»] будет соответствовать запросу [автомобиль] без добавлений других слов.
- Частотность «!» WS — частотность по точному вводу каждого слова в запросе, исключая склонения и т.п. Запрос [!китайский] означает, что будет выдана статистика по слову [китайский] без возможных склонений (китайская, китайское).
По запросу [автомобиль] текущая частотность превышает десять миллионов показов. Однако базовый показатель предполагает добавление всевозможных слов к ключевому слову, по которым будет ранжироваться статья.
Если заключить запрос в кавычки, то статистика сократится с десяти миллионов до 28 тысяч. Для оптимизатора может оказаться полезной правая колонка с похожими запросами, которые дополняют семантический сбор.
Вкладка «По словам» означает, что статистика приводится по общей сумме показов введенного запроса. На вкладке «по регионам» отображается статистика показов в разных регионах страны. А на «Истории запросов» можно отследить по графике изменение частотности запроса в течении месяца или недели, а также статистику по по запросам через ПК или мобильные устройства.
Сервис Google AdWords сам по себе более заточен под контекстную рекламу, нежели Вордстат. В разделе «Инструменты» можно подобрать необходимые ключи под нужный запрос. В колонке «Таргетинг» задается нужный регион показов и язык. Также можно указывать минус-слова.
В отличии от Вордстата, где указывается статистика за месяц, в AdWords можно выбирать месячный диапазон показов в колонке «Диапазон дат». Недостатком является усредненный число результатов. Сама статистика разделена на два блока:
- Ключевые слова — аналог частотности «» Вордстата;
- Ключевые слова (по релевантности) — аналог базовой частотности и похожих запросов WS.
Плюсами являются присутствие уровня конкурентности, а также возможность скачать подобранные слова в CSV-файл или на Гугл Диск.
Помимо AdWords, Гугл имеет еще один инструмент по анализу запросов под названием Google Trends. Данный сервис оценивает популярность введенного запроса на определенный период времени и представляет статистику в виде графика. Можно сравнивать несколько ключевых запросов между собой. Также отображается статистика по регионам.
Для графика используются не точные числа, а относительные, основанные в том числе на релевантных запросах.
Mail.ru
Mail.ru также имеет в сервисе для вебмастеров инструмент по статистике поисковых запросов. Помимо общих показов, в таблице представлены распределение запросов по полу и возрасту пользователей.
Не секрет, что Mail сотрудничает с Яндексом, так как поисковик размещает рекламу Яндекса.
Rambler
Rambler с каждым годом теряет свою популярность, однако их Wordstat может оказаться весьма полезным. Дело в том, что статистика запросов в Яндексе и Гугле не всегда может отображать реальное положение вещей. Многие компании могут вводить «в холостую» коммерческие запросы в целях слежки за конкурентами, т.е. для анализа ТОПа, тайтлов и т.д.
Как проверить массово частотность запросов
Большинство оптимизаторов выбирают для сбора и анализа семантического ядра такие программы, как Key Collector или Slovoeb. Также существуют онлайн-сервисы по определению частотностей.
Key Collector
Получить необходимые ключи для семантического ядра и массово проверить их частотность можно при помощи десктопной программы Key Collector . Открываем Вордстат, в поле заносим основные ключи с новой строки по вашей тематике и нажимаем «Начать сбор».
В настройках можно задавать требуемый регион для сбора, а также стоп-слова. После того как ключи соберутся, определяем частотности через Директ.
В итоге у вас будет таблица с ключами и частотой показов. Сразу удаляем все ключи, у которых точная частотность «!» равна нулю. Для этого делаем фильтрацию в колонке «Частотность !». Кликаем на синюю иконку. Появится окно с фильтром. Выбираем «больше или равно» > «1» и жмем «Применить».
Для получения большего списка ключей можно собрать поисковые подсказки с Яндекса. Делаем новую группу (окно справа).
Прежде чем парсить подсказки, нужно настроить глубину их поиска. Заходим в настройки и выбираем вкладку «Подсказки» и в значение поля «Глубина парсинга» ставим «2».
Также убедитесь, что включена галка «Собирать только ТОП подсказок без перебора…». Теперь кликаем на созданную группу – откроется новая пустая вкладка. Жмем иконку сбора поисковых подсказок.
Включаем галку «Не добавлять фразу, если она уже есть в любой другой группе» — чтобы потом не было дублей ключей. Выбираем парсить с Yandex. В поле фраз вводим наши основные ключи.
После сбора фраз делаем то же самое, что и при парсинге Вордстата: снимаем частотности, убираем неподходящие по смыслу фразы и фразы, где частотность «!» равна нулю.
Аналогично с помощью Key Collector можно собрать ключи и частотности с Гугла.
Rush Analytics
Сервис Rush Analytics является онлайн-альтернативой Key Collector. Плюсом инструмента по сбору ключей является отсутствие необходимости использовать прокси, антикапчу и т.п.
Для сбора частотности с Вордстата, необходимо перейти на вкладку «Сбор частотности» и поставить галочку напротив !ключевое слово, то есть точной частотности. Далее заносим ключевые слова. После того, как сервис посчитает затраты, нажимаем «Создать новый проект».
Справка NVivo 11 для Windows
Для получения списка наиболее часто встречающиеся слова или понятия в ваших источниках.
В этой теме
- Понять Частотные запросы слов
- Создайте запрос частоты слова с помощью мастера
- Создайте запрос частоты слов вне мастера
- Понять результаты, достижения
- См. все ссылки для выбранного слова
- Что слова подсчитываются в запросе Word Frequency?
- Исключить определенные слова при выполнении запросов Word Frequency
- Создать узел для ссылок на слово в результатах
- Выполнить запрос текстового поиска для слова, показанного в результатах запроса
Понять Частотные запросы
Используйте запросы Word Frequency для получения списка наиболее часто
встречающиеся слова или понятия в ваших источниках.
Вы можете использовать запрос Word Frequency для:
Определите возможные темы, особенно на ранних стадиях проекта
Анализировать наиболее часто используемые слова в определенной демографической группе. Например, проанализируйте наиболее общие слова, используемые фермерами. Вы можете сделать кодовый запрос, чтобы собрать весь контент, закодированный в узлах дел с помощью атрибута farmer, — затем выберите узел результата в качестве критерия для запроса Частота слов.
Если вы используете NVivo Pro или NVivo Plus, вы можете также используйте запрос Word Frequency для:
Ищите точные слова, или расширьте поиск, чтобы найти наиболее часто встречающиеся понятия. Например, если вы ищете наиболее часто встречающиеся слова в наборе данных обследования, вы можете обнаружить, что вода, здоровье, и вредные чаще всего встречающиеся слова. Однако, если вы сгруппируете похожие слова вместе, вы может обнаружить, что концепция загрязнения (включая загрязняющие вещества, загрязнения, загрязненные, и загрязняет) встречается наиболее часто.
Перед выполнением запроса Word Frequency убедитесь, что язык текстового содержимого установлен на языке ваших исходных материалов — см. установить язык содержимого текста и стоп-слова для получения дополнительной информации.
Если вы запускаете запрос Word Frequency, созданный в другом версию NVivo, он может искать источники, которые не поддерживаются в вашей версия. Вы увидите точные результаты, но не сможете открыть или просмотреть некоторые ссылки. См. О программе запросы (Работа с запросами в разных выпусках) для получения дополнительной информации.
Верх стр.
Создайте запрос частоты слова с помощью мастера
По запросу на вкладке «Создать» нажмите «Мастер запросов».
| Шаг мастера | Описание |
Выбрать запрос, который вы хотите выполнить. | Нажмите
Определение часто встречающихся терминов
в содержании. |
Указать термины, которые вы хотите найти. | В в поле Отображаемые слова укажите количество слов, отображаемых в результатах — например, показать только первые 20 слов. В минимальном слове поле длины, введите количество символов наименьшего слово, которое вы хотите включить. Например, длина слова 4 будет исключать из результатов маленькие слова. Выберите группу
вариант. Выберите, чтобы найти точные совпадения или сгруппировать слова с одинаковыми
объединяться — например, вы можете искать спорт
и найти спорт. |
Выбрать где вы хотите посчитать слова. | Выбрать
хотите ли вы подсчитывать слова во всех ваших источниках или ограничить
количество слов в выбранных элементах или папках. |
Выберите, следует ли чтобы добавить запрос в свой проект. | Вы можете бежать запрос один раз или добавьте его в свой проект (и запустите его). Если вы решите добавить его в свой проект, вы необходимо ввести имя. При желании вы можете ввести описание. |
Нажмите Бегать.
ПРИМЕЧАНИЕ. Если вы хотите использовать функции запроса Word Frequency, которые недоступны через Мастер — например, подсчитывать слова только в источниках, созданных конкретными пользователями — вы можете добавить запрос в свой проект и обновить его позже. Если вы знакомы с запросами NVivo вы можете предпочесть создать запрос вне Мастера.
Верх из страницы
Создайте запрос Word Frequency вне мастера
Если вы не знакомы с запросами NVivo, вы можете
хотите создать запрос частоты слов с помощью мастера — мастер направляет
вам в процессе установки критериев запроса. Тем не менее, не все
функции запросов доступны в мастере, поэтому иногда вам может понадобиться
для создания запросов частоты слов вне Мастера.
По запросу на вкладке «Создать» нажмите «Частота слов».
Выберите, где вы хотите для поиска подходящего текста:
- Все источники — поиск для контента во всех источниках вашего проекта, включая внешние и памятки
- Выбранные элементы — ограничение ваш поиск по выбранным элементам (например, набору, содержащему интервью стенограммы)
- Выбранные папки — ограничение ваш поиск содержимого в выбранных папках (например, папка стенограмм интервью)
Укажите, сколько слов вы хотите отобразить:
- <номер> наиболее частые — включают определенное количество слов. Например, вы можете отобразить 100 наиболее часто встречающихся слов.
- Все — включая
все слова, найденные в выбранных элементах проекта.
(Необязательно) Введите минимальная длина слова, чтобы исключить из результатов короткие слова, например, введите 5, чтобы отобразить только слова с пятью или более буквами.
Выберите группу вариант. Выберите, чтобы найти точные совпадения или сгруппировать слова с одинаковыми объединяться — например, искать спорт и найти спорт. Если у вас есть NVivo Pro или NVivo Plus вы можете настроить ползунок чтобы расширить поиск и найти похожие концепции. Например, найти спорт, игра и отдых. Обратитесь к Пониманию настройки соответствия текста для получения дополнительной информации.
Выберите, хотите ли вы хотите искать закодированный контент во всех ваших источниках или ограничить поиск по выбранным элементам или папкам — нажмите кнопку Выбрать кнопку для выбора конкретных элементов проекта.
Нажмите кнопку «Выполнить» Кнопка запроса в верхней части подробного представления.
ПРИМЕЧАНИЕ Чтобы сохранить Word Частотный запрос, нажмите Добавить в проект кнопку и введите имя и описание (необязательно) в поле Общие вкладка
Верх стр.
Понять результаты
Когда вы запускаете запрос Word Frequency, результаты отображается в подробном представлении. В зависимости от вашего издания их может быть до четырех. вкладки, отображаемые справа — Резюме, Word Облако, Древовидная карта и Кластер Вкладки анализа. Вы можете изменить, какая вкладка отображается по умолчанию — см. к параметрам отображения в Set параметры приложения для получения дополнительной информации.
Вкладка «Сводка»
1 Самый часто встречающиеся слова, за исключением любой остановки слова. Если вы настроили ползунок так, чтобы он возвращал похожие слова, наиболее в этом столбце отображается часто встречающееся слово из группы.
2 Длина — количество букв или символов в слове.
3 Считать —
количество раз, когда это слово встречается в искомых элементах проекта. Если
вы настроили ползунок, чтобы включить похожие слова, это количество
сумма для всех похожих слов.
4 Взвешенный Процент — частота слова по отношению к общему количеству подсчитанных слов. Если вы настроили ползунок, чтобы включить похожие слова, слово может быть частью из более чем одной группы однотипных слов. Взвешенный процент назначает часть частоты слова каждой группе, так что общая сумма не превышает 100%.
5 Похожие Слова — другие слова, которые были включены в результате включения основы или похожие слова — например, если вы включаете слова с одной и той же основой, затем загрязнители, загрязнение и загрязнение были бы сгруппированы. Этот столбец недоступен, если вы используете «Точный только совпадение».
Вкладка Word Cloud
На этой вкладке отображается до 100 слов с различным шрифтом размеров, где часто встречающиеся слова выделены более крупным шрифтом.
Когда вы просматриваете результаты в виде облака слов, вы
можно изменить стиль — в облаке слов
на вкладке (ленте) выберите из галереи стилей.
Вкладка Tree Map
Эта функция доступна в NVivo Pro и НВиво Плюс.
Вкладка Древовидная карта отображает до 100 слов в виде ряда прямоугольников, где часто встречающиеся слова в больших прямоугольниках.
Вкладка «Кластерный анализ»
Эта функция доступна в NVivo Pro и НВиво Плюс.
Кластерный анализ Вкладка отображает до 100 слов в виде горизонтальной дендрограммы, где слова, которые сосуществующие сгруппированы вместе.
Если щелкнуть диаграмму кластерного анализа, становится доступной вкладка Кластерный анализ (на ленте), вы можете использовать команды на этой вкладке ленты:
Измените тип диаграммы — вы может отображать данные в виде горизонтальной или вертикальной дендрограммы, круга график или двухмерная или трехмерная карта кластеров
В 2D или 3D кластерных картах, установите флажок Частота слов если вы хотите использовать частоту слов, чтобы определить размер пузырьков на карте кластера.
Для получения дополнительной информации см. Изменение внешний вид или содержание диаграммы кластерного анализа.
Верх стр.
См. все ссылки для выбранного слова
При выполнении запроса Word Frequency узел предварительного просмотра создается для каждого слова — это позволяет видеть все ссылки на слово. Чтобы открыть узел предварительного просмотра, дважды щелкните слово, которое хотите изучить.
В узле предварительного просмотра вы видите каждое вхождение выбранное ключевое слово в контексте:
Отображается контекст (текст вокруг слова) серым — по умолчанию это «узкий» контекст. Чтобы расширить контекст для выбранная ссылка на вкладке Узел, в группе Вид нажмите Контекст кодирования и выберите контекст кодирования.
ПРИМЕЧАНИЕ Для других
типы узлов, название вкладки ленты отличается. Например,
если вы в настоящее время работаете в узле дела, вы получите доступ к вышеуказанному
команды на вкладке Дело.
Верх стр.
При определении частотности слов NVivo применяет следующие правила:
Слов, содержащих знаки препинания (например, дефисы, точки и другие символы) разделены на отдельные слова. Например, неполный рабочий день будет считаться как часть и время.
Слова, содержащие апострофы (например, o’clock и d’accord) рассматриваются как одно слово, но если за апострофом следует ‘s тогда s не включается (том Тома будет считаться Томом).
В аудио- и видеорасшифровках, только слова в поле Содержание (столбец) подсчитываются — любые слова в настраиваемых полях расшифровки игнорируются.
В наборах данных только слова в кодируемых полях (столбцах) подсчитываются любые слова в классифицирующих полях игнорируются.
При поиске текста в выбранные узлы, если слово закодировано для нескольких узлов, оно считается один раз для каждого узла. Точно так же, если слово было закодировано несколькими пользователей на один и тот же узел, он считается один раз для каждого пользователя.
запросов частоты слова не включайте «стоп-слова» — см. «Исключить». определенные слова при выполнении запросов Word Frequency для более Информация.
Частотный запрос слова не ищет текст в сводках матриц фреймворка
запросов частоты слова не искать текст в изображениях. PDF-файлы, созданные путем сканирования бумажных документов может содержать только изображения — каждая страница представляет собой отдельное изображение. Если ты хочешь используйте запросы Word Frequency для изучения текста в этих PDF-файлах, а затем вам следует рассмотреть возможность использования оптического распознавания символов (OCR) для преобразования отсканированные изображения в текст (перед импортом PDF-файлов в NVivo).
Если язык содержимого текста является японским, «базовая форма» указана в результатах запроса, но count включает в себя любые альтернативные формы слова — см. Рабочие с японским текстом в запросах для получения дополнительной информации.
Верх стр.
Исключить определенные слова при выполнении запросов Word Frequency
Запросы Word Frequency не включают «стоп-слова» — по по умолчанию это менее значимые слова, такие как союзы или предлоги, это может не иметь значения для вашего анализа. Вы можете просматривать и редактировать список стоп-слов, см. Set язык текстового содержимого и стоп-слова для получения дополнительной информации.
Вы можете добавить слово, отображаемое в результатах вашего запроса к списку стоп-слов — выберите слово, которое хотите исключить из запроса результатов, затем нажмите «Добавить в список стоп-слов», в группе Действия в Запросе вкладка Слова, которые вы добавите в список стоп-слов, будут исключены в следующий раз. время, когда вы запускаете запрос частоты слова или текстовый поиск.
ПРИМЕЧАНИЕ. На сервере
проекты, только владельцы проектов могут добавлять слова в список стоп-слов — см.
сотрудничать
в серверном проекте для получения дополнительной информации.
Верх of Page
Вы можете создать узел, включающий все ссылки к слову, выбранному вами в результатах запроса Word Frequency.
В результатах запроса выберите слово, которое вы хотите использовать для создания узла.
При создании на вкладке «Элементы» нажмите «Создать как узел».
Выберите место и назовите узел.
Нажмите OK.
ПРИМЕЧАНИЕ. Если текст язык содержимого — японский, узел будет содержать ссылки на базовая форма или любые альтернативные формы слова — см. Рабочие с японским текстом в запросах для получения дополнительной информации.
Верх из страницы
Вы можете выполнить запрос текстового поиска для выбранного слова в результатах запроса Word Frequency.
По запросу вкладку, в группе Действия щелкните Другие действия, а затем щелкните Выполнить запрос текстового поиска.
(Необязательно) Измените Критерии текстового поиска или запрос Опции.
См. Выполнить
запрос текстового поиска для получения дополнительной информации.Нажмите «Выполнить».
ПРИМЕЧАНИЕ. Если текст язык содержимого — японский, запрос Text Search найдет все вхождения базовой формы или любых альтернативных форм слова — см. Рабочие с японским текстом в запросах для получения дополнительной информации.
Верх стр.
Справка NVivo для Mac — запуск запроса частоты слов
Для получения списка наиболее часто встречающиеся слова в ваших источниках.
В этой теме
- Посмотреть видеоинструкцию
- Понять Частотные запросы слов
- Создать запрос частоты слова
- Понять результаты, достижения
- Что слова подсчитываются в запросе Word Frequency?
- Исключить определенные слова при выполнении запросов Word Frequency
- Выполнить запрос текстового поиска для слова, показанного в результатах запроса
Посмотреть обучающее видео
Верх стр.
Понять Запросы Word Frequency
Используйте запросы Word Frequency для получения списка наиболее часто встречающиеся слова в ваших источниках. Вы можете выбрать исходный контент, который вы хотите искать, выбирая источники, узлы, наборы или папки.
Вы можете использовать запрос Word Frequency для
Определите возможные темы, особенно на ранних стадиях проекта.
Анализировать наиболее часто используемые слова в определенной демографической группе. Например, проанализируйте наиболее общие слова, используемые фермерами при обсуждении изменения климата. Ты мог бы выполнить запрос кодирования, чтобы собрать весь контент, закодированный в климате change и в узлах case с атрибутом farmer — затем выберите узел результата в качестве критерия для запроса Частота слов.
Вы можете искать точные слова или включать слова с той же основой. Например, если вы поищите наиболее часто встречающиеся слова в наборе интервью, вы можете найти ту воду, здоровье, и вредны наиболее часто встречающиеся слова. Однако если включить слова с тем же стеблем, вы можете обнаружить, что загрязнение (включая загрязняющие вещества, загрязнение, загрязняется и загрязняется) встречается наиболее часто.
Перед выполнением запроса Word Frequency убедитесь, что язык текстового содержимого установлен на языке ваших исходных материалов — см. установить язык содержимого текста и стоп-слова для получения дополнительной информации.
Верх Страница
Создать запрос Частоты слов
По запросу на вкладке «Создать» нажмите «Частота слов».
Выберите, где вы хотите для поиска подходящего текста:
Все источники — поиск контента во всех источниках вашего проекта, включая внешние документы и памятки
Выбрано Элементы — ограничьте поиск выбранными элементами (например, комплект с расшифровками интервью)
шт.
в выбранных папках — ограничить поиск содержимым в выбранных
папки (например, папка стенограмм интервью)
(необязательно) Выберите «Включить слова с основами», если вы хотите включить слова с той же основой (например, ищите «говорить», а также находите «говорить») при поиске совпадений. По умолчанию, Выбирается только точное совпадение.
(необязательно) Вы можете выберите для отображения:
Все чтобы включить все слова, найденные в выбранных элементах проекта.
<номер> чаще всего включать определенное количество слов, например, вы можете отобразить 100 наиболее часто встречающихся слов.
(Необязательно) Введите Минимальная длина, исключающая короткие слова. из результатов — например, введите 7 для отображения только слов с семью или более буквами.
Нажмите кнопку «Выполнить» Кнопка запроса в верхней части подробного представления.
ПРИМЕЧАНИЕ
См. Выбор элементы проекта для получения информации о том, как выбирать источники, узлы или другие элементы проекта, в которых вы хотите выполнить поиск.
В этом выпуске вы не можете найти совпадения для слов со схожим значением (синонимы, специализации и обобщения). Если вы работаете с NVivo проект, созданный на платформе Windows, вы не можете выполнять запросы которые ищут синонимы, специализации и обобщения.
Верх стр.
Понять результаты
Когда вы запускаете запрос Word Frequency, результаты отображается в подробном представлении. Вы можете просмотреть результаты в виде списка в сводке. панели или как визуализация на панели Word Cloud.
Панель сводки
1 Критерии запроса
оставаться видимым в верхней части подробного представления — если вы хотите больше места для просмотра
результаты запроса, щелкните треугольник раскрытия, чтобы скрыть критерии.
2 Самый часто встречающиеся слова, за исключением любой остановки слова. Если вы решили включить слова с основой, наиболее часто встречающееся слово из группы отображается в этом столбце.
3 Длина — количество букв или символов в слове.
4 Считать — количество раз, когда это слово встречается в искомых элементах проекта. Если вы решили включить слова с основой, это количество является общим для всех слова с одной основой.
5 Взвешенный Процент — частота слова по отношению к общему количеству подсчитанных слов. взвешенный процент присваивает часть частоты слова каждому группировать так, чтобы общая сумма не превышала 100%.
6 Похожие Слова — другие слова, которые были включены в результате выбора включать однокоренные слова, например, загрязняющие вещества, загрязнение, а загрязнение будет быть сгруппированы вместе. Этот столбец недоступен, если вы используете Exact только совпадение’
Панель Word Cloud
1 Критерии запроса
оставаться видимым в верхней части подробного представления — если вы хотите больше места для просмотра
результаты запроса, щелкните треугольник раскрытия, чтобы скрыть критерии.
2 Слово облачная визуализация отображает до 100 слов с разным размером шрифта, где часто встречающиеся слова выделены более крупным шрифтом.
3 Нажмите здесь, чтобы выбрать из галереи стилей.
ПРИМЕЧАНИЕ. Вы можете экспортировать облако слов в виде файла изображения, которое можно включать в отчеты и презентации — см. экспортировать результаты запроса (Экспорт визуализации запроса в виде файла изображения) для Дополнительная информация.
Верх стр.
При определении частотности слов NVivo применяет следующие правила:
Слов, содержащих знаки препинания (например, дефисы, точки и другие символы) разделены на отдельные слова. Например, неполный рабочий день будет считаться как часть и время.
Слова, содержащие апострофы (например, o’clock и d’accord) рассматриваются как одно слово, но если за апострофом следует ‘s тогда s не включается (том Тома будет считаться Томом).
В аудио- и видеорасшифровках, только слова в поле Transcript (столбец) подсчитываются.
В наборах данных только слова в кодируемых полях (столбцах) подсчитываются любые слова в классифицирующих полях игнорируются.
При поиске текста в выбранные узлы, если слово закодировано для нескольких узлов, оно считается один раз для каждого узла. Точно так же, если слово было закодировано несколькими пользователей на один и тот же узел, он считается один раз для каждого пользователя.
запросов частоты слова не включайте «стоп-слова» — см. «Исключить». определенные слова при выполнении запросов Word Frequency для более Информация.
запросов частоты слова не искать текст в изображениях. PDF-файлы, созданные путем сканирования бумажных документов может содержать только изображения — каждая страница представляет собой отдельное изображение. Если ты хочешь используйте запросы Word Frequency для изучения текста в этих PDF-файлах, а затем вам следует рассмотреть возможность использования оптического распознавания символов (OCR) для преобразования отсканированные изображения в текст (перед импортом PDF-файлов в NVivo).
Верх стр.
Исключить определенные слова при выполнении запросов Word Frequency
Запросы Word Frequency не включают «стоп-слова» — по по умолчанию это менее значимые слова, такие как союзы или предлоги, это может не иметь значения для вашего анализа. Вы можете просматривать и редактировать список стоп-слов, см. Set язык текстового содержимого и стоп-слова для получения дополнительной информации.
Вы можете добавить слово, отображаемое в результатах вашего запроса к списку стоп-слов — выберите слово, которое хотите исключить из запроса результатов, затем нажмите «Добавить в список стоп-слов», в группе Действия в Запросе вкладка Слова, которые вы добавите в список стоп-слов, будут исключены в следующий раз. время, когда вы запускаете запрос частоты слова или текстовый поиск.
Верх из страницы
Вы можете выполнить запрос текстового поиска для выбранного слова в результатах запроса Word Frequency.
По запросу вкладку, в группе Действия щелкните Другие действия, а затем щелкните Запустите текстовый поисковый запрос.
(Необязательно) Измените Критерии поиска текста. См. Запуск запроса текстового поиска для Дополнительная информация.
Нажмите «Выполнить» Запрос.
ПРИМЕЧАНИЕ Можно также дважды щелкнуть слово в облаке слов для выполнения запроса текстового поиска.
Верх стр.
elasticsearch — получение частоты документа для терминов в результатах запроса с агрегированием
Для некоторых из моих запросов к ElasticSearch я хочу вернуть три части информации:
- Какие термины T встречались в результирующем наборе документов?
- Как часто каждый элемент T встречается в результирующем наборе документов?
- Как часто каждый элемент T встречается во всем индексе (—> частота документа)?
Первые точки легко определяются с помощью фасета терма по умолчанию или, в настоящее время, с помощью метода агрегации терма. Так что мой вопрос действительно о третьем пункте.
До ElasticSearch 1.x, то есть до перехода на парадигму «агрегации», я мог использовать грань термина с параметром «глобальный», установленным на 9.0631 true и QueryFilter для получения частоты документа («глобальные подсчеты») точных терминов, встречающихся в наборе документов, указанном QueryFilter .
Сначала я думал, что смогу сделать то же самое, используя глобальную агрегацию , но, похоже, не могу. Причина в том, если я правильно понимаю, что исходный механизм аспекта был сосредоточен вокруг терминов, тогда как сегменты агрегации определяются набором документов, принадлежащих каждому сегменту.
т.е. указание глобальная опция фасета термина с QueryFilter сначала определила термины, попадающие под действие фильтра, а затем вычислила значения фасета. Поскольку фасет был глобальным , я получил бы количество документов.
С агрегатами все иначе. Глобальная агрегация может использоваться только как верхняя агрегация, в результате чего агрегация игнорирует текущие результаты запроса и вычисляет агрегацию, например. агрегация терминов — по всем документам индекса. Так что для меня это слишком много, так как я ХОЧУ ограничить возвращаемые термины («сегменты») терминами в наборе результатов документа. Но если я использую фильтр-субагрегацию с терминами-субагрегацией, я бы снова ограничил сегменты терминов фильтром, таким образом, не извлекая частоты документов, а обычное количество фасетов. Причина в том, что корзины определяются после фильтра, поэтому они «слишком маленькие». Но я не хочу ограничивать размер ведра, я хочу ограничить ведра терминами в наборе результатов запроса.
Как я могу получить документированную частоту этих терминов в наборе результатов запроса с помощью агрегирования (поскольку фасеты устарели и будут удалены)?
Спасибо за ваше время!
РЕДАКТИРОВАТЬ : Вот пример того, как я пытался добиться желаемого поведения. Я определю две агрегации:
- global_agg_with_filter_and_terms
- global_agg_with_terms_and_filter
Оба имеют глобальную агрегацию в своих вершинах, потому что это единственная допустимая позиция для нее. Затем в первой агрегации я сначала фильтрую результаты по исходному запросу, а затем применяю термин-субагрегацию.
Во второй агрегации я делаю в основном то же самое, только здесь агрегация фильтров является субагрегацией агрегации терминов. Отсюда и похожие названия, отличается только порядок агрегации.
{
"запрос": {
"Строка запроса": {
"query": "текст: моя строка запроса"
}
},
"аггс": {
"global_agg_with_filter_and_terms": {
"Глобальный": {},
"аггс": {
"filter_agg": {
"фильтр": {
"запрос": {
"Строка запроса": {
"query": "текст: моя строка запроса"
}
}
},
"аггс": {
"terms_agg": {
"условия": {
"поле": "грани"
}
}
}
}
}
},
"global_agg_with_terms_and_filter": {
"Глобальный": {},
"аггс": {
"частота_документа": {
"условия": {
"поле": "грани"
},
"аггс": {
"term_count": {
"фильтр": {
"запрос": {
"Строка запроса": {
"query": "текст: моя строка запроса"
}
}
}
}
}
}
}
}
}
}
Ответ:
{
"взял": 18,
"timed_out": ложь,
"_осколки": {
"всего": 5,
"успешно": 5,
"неудачно": 0
},
"хиты": {
"всего": 221,
"max_score": 0,9839197,
"хиты": <опущено>
},
"агрегации": {
"global_agg_with_filter_and_terms": {
"число_документов": 1978 г. ,
"filter_agg": {
"doc_count": 221,
"terms_agg": {
"doc_count_error_upper_bound": 0,
"sum_other_doc_count": 0,
"ведра": [
{
"ключ": "fid8",
"doc_count": 155
},
{
"ключ": "fid6",
"doc_count": 40
},
{
"ключ": "fid9",
"doc_count": 10
},
{
"ключ": "fid5",
"doc_count": 9
},
{
"ключ": "fid13",
"число_документов": 5
},
{
"ключ": "fid7",
"число_документов": 2
}
]
}
}
},
"global_agg_with_terms_and_filter": {
"doc_count": 1978,
"частота_документа": {
"doc_count_error_upper_bound": 0,
"sum_other_doc_count": 0,
"ведра": [
{
"ключ": "fid8",
"doc_count": 1050,
"term_count": {
"doc_count": 155
}
},
{
"ключ": "fid6",
"doc_count": 668,
"term_count": {
"doc_count": 40
}
},
{
"ключ": "fid9",
"doc_count": 67,
"term_count": {
"doc_count": 10
}
},
{
"ключ": "fid5",
"doc_count": 65,
"term_count": {
"doc_count": 9
}
},
{
"ключ": "fid7",
"doc_count": 63,
"term_count": {
"число_документов": 2
}
},
{
"ключ": "fid13",
"doc_count": 55,
"term_count": {
"число_документов": 5
}
},
{
"ключ": "fid10",
"doc_count": 11,
"term_count": {
"число_документов": 0
}
},
{
"ключ": "fid11",
"doc_count": 9,
"term_count": {
"число_документов": 0
}
},
{
"ключ": "fid12",
"doc_count": 5,
"term_count": {
"число_документов": 0
}
}
]
}
}
}
}
Во-первых, пожалуйста, взгляните на первые два возвращенных блока терминов обеих агрегаций с ключами fid8 и fid6 . Легко видеть, что эти термины появлялись в наборе результатов 155 и 40 раз соответственно. Теперь взгляните на вторую агрегацию, global_agg_with_terms_and_filter . Агрегация терминов находится в рамках глобальной агрегации, поэтому здесь мы можем видеть частоты документов, 1050 и 668 соответственно. Так что эта часть выглядит хорошо. Проблема возникает, когда вы сканируете список корзин терминов дальше вниз, в корзины с ключами fid10 до fid12 . В то время как мы получаем частоту их документов, мы также можем видеть, что их term_count равен 0. Это связано с тем, что эти термины не встречались в нашем запросе, который мы также использовали для фильтр-субагрегации. Таким образом, проблема заключается в том, что для ВСЕХ терминов (глобальная область!) возвращается их частота документа и количество аспектов в отношении фактического результата запроса. Но мне нужно, чтобы это было сделано именно для тех терминов, которые встретились в результате запроса, т. е. для тех точных терминов, которые вернула первая агрегация global_agg_with_filter_and_terms .
Возможно, есть возможность определить какой-то фильтр, который удаляет все корзины, где их подфильтр-агрегация term_count имеет ноль doc_count ?
Как работает оценка в Elasticsearch
Как работает оценка в Elasticsearch
ОпубликованоВ этой статье мы рассмотрим, как выполняется оценка релевантности в Elasticsearch, коснемся концепций поиска информации и механизмов, используемых для определения оценки релевантности документа для заданного запроса. Мы также укажем на некоторые «подводные камни» и распространенные непонятные моменты.
Релевантность, как и красота, в глазах смотрящего. Алгоритмы поиска пытаются привнести в эту область некоторый эмпиризм, используя модели, правила и математические расчеты для возврата и надлежащего ранжирования результатов, ожидаемых большинством людей. Как правило, они довольно хороши в этом, потому что область информационного поиска постоянно совершенствуется, и эти алгоритмы с каждым днем становятся все более и более изощренными. Однако, поскольку релевантность субъективна, невозможно вернуть идеальный набор результатов. Однако существуют различные подходы и инструменты, которые можно использовать для настройки набора результатов для получения наиболее оптимальных результатов для ваших пользователей.
В нашей следующей статье мы обсудим стратегии и методы использования встроенных инструментов Elasticsearch, которые мы можем использовать для управления оценками релевантности, но сначала нам нужно иметь четкое представление о том, как определяются эти оценки, прежде чем мы начните возиться с ручками и поворачивать циферблаты.
Прежде чем Elasticsearch начнет оценивать документы, он сначала сокращает количество документов-кандидатов, применяя логический тест — соответствует ли документ запросу? Как только результаты, которые совпадают, получены, оценка, которую они получают, будет определять, как они ранжируются по релевантности.
Оценка документа определяется на основе совпадений полей из указанного запроса и любых дополнительных конфигураций, примененных к поиску. Через минуту мы перейдем к деталям оценки, но сначала имейте в виду, что наличие совпадения не означает, что документ имеет отношение к вашим пользователям. Например, пользователь, выполняющий поиск по слову «яблоко», может иметь в виду компанию или фрукт, но совпадения могут встречаться в документах как для компании, так и для фруктов. Некоторые способы справиться с этой ситуацией включают фильтрацию совпадений по индексу, типу документа (или другим аспектам) или применение некоторой контекстной или персонализированной логики, но суть, которую мы пытаемся здесь подчеркнуть, заключается в том, что просто получение совпадения с одним или несколькими термины в поле документа не приравниваются к релевантности. Точно так же, только потому, что мы не нашли совпадения, не означает, что документ не имеет отношения к делу.
Elasticsearch запускает Lucene под капотом, поэтому по умолчанию он использует функцию практической оценки Lucene. Это модель подобия, основанная на частоте терминов (tf) и обратной частоте документов (idf), которая также использует модель векторного пространства (vsm) для запросов с несколькими терминами. Если весь этот жаргон заставляет вас чувствовать себя потерянным, не волнуйтесь. Все это обрабатывается для вас за кулисами, поэтому вам нужно иметь только базовое представление о моделях, чтобы следовать им. Эта статья здесь, чтобы помочь с этим. Если вы хотите узнать больше об оценке из официального источника, ознакомьтесь с документацией Lucene по оценке.
Давайте начнем с простого обзора формулы по умолчанию из раздела Elasticsearch — The Definitive Guide , посвященного релевантности. Он показывает нам, какие механизмы играют роль в определении релевантности:
Оценка (Q, D) =
QueryNorm (Q)
* Координатор (Q, D)
* Сумма (
TF (T in D),
IDF (T) ²,
T.GetBoost (),
norm(t,d)
) (t в q)
- score(q,d) — оценка релевантности документа d для запроса q.
- queryNorm(q) — коэффициент нормализации запроса.
- coord(q,d) — коэффициент координации.
- Сумма весов для каждого термина t в запросе q для документа d.
- tf(t in d) — частота термина t в документе d.
- idf(t) — обратная частота документа для термина t.
- t.getBoost() — это усиление, примененное к запросу.
- norm(t,d) — это норма длины поля в сочетании с повышением уровня поля индексного времени, если таковое имеется.
Теперь давайте поближе познакомимся с каждым из механизмов подсчета очков, составляющих функцию практического подсчета очков:
- Частота термина (tf) : Это квадратный корень из числа раз, когда термин появляется в поле документа:
tf = sqrt(termFreq)
Частота термина явно предполагает, что чем больше термин появляется в документе, тем выше должна быть его релевантность. Обычно это так, и вы, вероятно, будете продолжать использовать этот механизм оценки, но если вам просто нужно знать, что термин вообще появляется в документе, и вам все равно, сколько раз, вы можете настроить поле так, чтобы термин игнорировался. частота во время индексации. Однако лучший способ справиться с этой ситуацией — применить фильтр, используя термин во время запроса. Также обратите внимание, что обратную частоту документа нельзя отключить, поэтому, даже если вы отключите частоту термина, обратная частота документа все равно будет играть роль в подсчете очков. Наконец, обратите внимание, что в непроанализированных полях (как правило, в тех, где вы ожидаете точное совпадение) будет автоматически отключена частота терминов.
- Обратная частота документов (idf) : это единица плюс натуральный логарифм (как в «логарифме», а не «файл журнала») документов в индексе, деленный на количество документов, содержащих термин:
idf = 1 + ln(maxDocs/(docFreq + 1))
Обратная частота документов показывает, что если многие документы в указателе содержат этот термин, то этот термин на самом деле менее важен, чем другой термин, если этот термин содержится в нескольких документах.
- Координация (coord) : подсчитывает количество терминов из запроса, которые появляются в документе.
С механизмом координации, если у нас есть запрос с 3 терминами, а документ содержит 2 из этих терминов, то он будет оценен выше, чем документ, содержащий только 1 из этих терминов. Как и частотность терминов, согласование можно отключить, но обычно это делается только в том случае, если термины являются синонимами друг друга (и, следовательно, наличие более одного из них не повышает релевантность). Однако лучший способ справиться с этой ситуацией — заполнить файл синонимов для автоматической обработки синонимов.
- Нормализация длины поля (норма) : Это обратный квадратный корень из числа терминов в поле:
норма = 1/sqrt(numFieldTerms)
Для нормализации длины поля совпадение термина, найденное в поле с небольшим количеством терминов, будет более важным, чем совпадение, найденное в поле с большим количеством терминов. Как и в случае с частотой терминов и координацией, вы можете не применять нормы длины поля в документе (настройка применяется ко всем полям в документе). Хотя вы можете сэкономить память, отключив эту функцию, вы можете потерять некоторые ценные данные. Единственный случай, когда может иметь смысл отключить эту функцию, аналогичен случаю отключения частоты терминов — когда не имеет значения, сколько терминов существует, а важно только то, что термин запроса существует. Тем не менее, есть и другие способы справиться с такой ситуацией (например, вместо этого использовать фильтр). Обратите внимание, что для неанализируемых полей нормализация длины поля будет отключена по умолчанию.
- Нормализация запроса (queryNorm) : Обычно это сумма квадратов весов терминов в запросе.
Нормализация запросов используется, чтобы можно было сравнивать разные запросы. Однако для любого отдельного запроса он использует одну и ту же оценку для каждого документа (эффективно сводя на нет его влияние на отдельный запрос), поэтому нам не нужно тратить на это время.
- Повышение индекса : Это процентное или абсолютное число, используемое для повышения любого поля во время индексирования.
Обратите внимание, что на практике увеличение индекса сочетается с нормализацией длины поля, так что для обоих в индексе будет храниться только одно число; однако Elasticsearch настоятельно не рекомендует использовать повышения на уровне индекса, поскольку с этим механизмом связано много побочных эффектов.
- Повышение запроса : Это процентное или абсолютное число, которое можно использовать для повышения любого предложения запроса во время запроса.
Усиление запроса позволяет нам указать, что некоторые части запроса должны быть более важными, чем другие части. Документы будут оцениваться в соответствии с их соответствием для каждой части. Его также можно использовать для повышения определенного индекса, если вы выполняете поиск по нескольким индексам и хотите, чтобы один из них имел большее значение. Существует довольно много вариантов, которые можно использовать для повышения оценки во время запроса, но нам придется сохранить эти детали для нашей следующей статьи, так как здесь их слишком много. Обратите внимание, что на практике эти бусты сочетаются с queryNorm при применении , объяснение (которое мы рассмотрим ниже), поэтому вы увидите queryNorms с разными значениями, если вы использовали повышение во время запроса и выполнили объяснение .
Обратите внимание, что частота термина, обратная частота документа и нормализация длины поля сохраняются для каждого документа во время индексирования. Они используются для определения веса термина в документе.
Давайте приведем пример, чтобы вы могли увидеть, как применяется формула Практической функции подсчета очков.
В нашем экземпляре Elasticsearch мы проиндексировали 250 лучших фильмов по мнению голосовавших на IMDB. Давайте посмотрим, как определяются оценки релевантности с помощью API объяснения. Приготовьтесь заняться математикой!
объяснение требует имя индекса (в нашем случае это «top_films»), тип документа (для нас это «фильм») и идентификационный номер конкретного документа (здесь мы используем идентификатор 172… Монти Python «Жизнь Брайана»). Мы запускаем простой запрос на соответствие в поле заголовка термина «жизнь»:
curl -XGET 'https://aws-us-east-1-portal10.dblayer.com:10019/top_films/film/172/_explain?pretty=1' -d '
{
"запрос" : {
"соответствие" : {
"название": "жизнь"
}
}
}
Вот что объясняет нам о матче и счете:
{
"_type": "фильм",
"_index": "top_films",
"_id": "172",
«совпало»: правда,
"объяснение" : {
"description": "вес(название:жизнь в 38) [PerFieldSimilarity], результат:",
«значение»: 1,53,
"Детали" : [
{
"Детали" : [
{
"description" : "queryWeight, продукт:",
«значение»: 0,999999940000001,
"Детали" : [
{
"описание": "idf(docFreq=2, maxDocs=50)",
"значение": 3,8134108
},
{
"значение": 0,26223242,
«описание» : «норма запроса»
}
]
},
{
"description" : "fieldWeight в 38, произведение:",
«значение»: 1,
54, г.
"Детали" : [
{
"описание": "tf(частота=1.0), с частотой:",
"Детали" : [
{
"значение": 1,
"описание": "termFreq=1.0"
}
],
"значение": 1
},
{
"значение": 3,8134108,
"описание": "idf(docFreq=2, maxDocs=50)"
},
{
«значение»: 0,5,
"описание": "fieldNorm(doc=38)"
}
]
}
],
«значение»: 1,
53, г.
"описание": "оценка (doc=38,freq=1.0), продукт:"
}
]
}
}
Во-первых, мы видим, что результаты подтверждают имя индекса, тип документа и идентификатор документа, которые мы запросили. Далее мы видим, что «совпало» верно. Это логическая часть функции — документ либо соответствует, либо нет. Помните, что оценка выполняется только для совпадающих документов. Поскольку у нас есть совпадение, у нас есть подробное объяснение оценки релевантности и значения окончательной оценки. Давайте возьмем это по частям.
Первый элемент «описание» — это просто краткое описание того, как вычислялась оценка («38», которую вы видите, — это просто внутренний идентификатор документа — на самом деле это ничего не значит для расчета). Что наиболее важно, так это окончательная оценка релевантности, определенная для этого документа для нашего запроса, которая составила 1,
53. В разделе «Подробности» рассказывается, как рассчитывалась оценка, и, как вы можете видеть, в деталях содержатся детали для подсчетов. На самом деле у нас есть два набора деталей — один для веса запроса и один для веса поля — до того, как будет получена окончательная оценка.
Давайте сосредоточимся на деталях веса поля, так как именно здесь мы можем оказать влияние, как только начнем манипулировать счетом с помощью встроенных инструментов.
Разбор веса поля
Сначала мы видим термин «частота», который имеет значение 1. Это потому, что в заголовке «Жизнь Брайана» термин «жизнь» встречается только один раз, а квадратный корень из 1 равен 1.
Далее мы видим обратную частоту документа со значением 3,8134108, используя «docFreq=2» и «maxDocs=50». Это рассчитывается как:
1 + ln(maxDocs/(docFreq + 1))
Итак, если мы подставим числа, мы получим:
1 + ln(50/(2 + 1)) = 3,8134108
Если вы ломаете голову, потому что у нас в maxDocs число 50, но вы знаете, что мы сказали, что проиндексировали 250 лучших фильмов, держите эту мысль! Вы пришли к чему-то важному, и мы расскажем об этом в следующем разделе.
Наконец, мы видим нормализацию длины поля. Имеет значение 0,5. Это рассчитывается как:
1/sqrt(numFieldTerms)
В нашем случае, поскольку в названии «Жизнь Брайана» 3 термина, это…
1/кв. (3) = 0,57735
Однако, поскольку в Elasticsearch нормы хранятся в виде одного байта, наша норма длины поля усекается до 0,5, и мы теряем десятичную точность. Обратите внимание на квалификатор «(doc=38)». Вот только внутренний идентификатор документа для этого запроса, о котором мы также упоминали, фигурирует в «описании». Это не имеет ничего общего с расчетом, кроме ссылки на этот конкретный документ.
Реконструкция веса поля
Итак, если мы перемножим эти три показателя вместе (tf * idf * norm), мы получим значение 1,
54 для веса поля. Если мы затем умножим это на оценку, определенную в разделе веса запроса (0,999999940000001), которая используется для определения относительной важности нашего запроса по сравнению с другими запросами, мы получим окончательную оценку 1,
53.
Что мы не видим здесь из формулы Практической функции подсчета очков, так это наш коэффициент координации. Это потому, что это 1. Мы искали только один термин, и он был найден, поэтому расчет координации не повлияет на окончательную оценку этого документа. Он просто умножается на вес поля и вес запроса. Наш окончательный счет будет таким же.
Кроме того, мы не применяли повышения индекса или запросов, поскольку хотели показать поведение оценки по умолчанию. О том, как и когда устанавливать повышения, мы поговорим в нашей следующей статье.
Теперь помните, что 50 maxDocs в обратном расчете частоты документов из приведенного выше примера? Почему 50 вместо 250 фильмов, которые мы проиндексировали? Как вы могли догадаться из названия этого раздела, это связано с шардингом.
Compose Развертывания Elasticsearch автоматически включают 5 сегментов. Когда мы индексировали наши документы, мы не делали каких-либо указаний о том, как следует применять сегментирование, поэтому документы распределялись равномерно по каждому из сегментов — 50 документов на каждом из наших 5 сегментов = 250 документов.
Таким образом, когда наш запрос нашел совпадение с нашим документом, он подсчитал количество документов, найденных в этом конкретном осколке, для использования в обратном расчете частоты документов.
Другая проблема, вызванная этим поведением, связана с docFreq (общее количество документов, для которых было совпадение). На самом деле в индексе было 3 документа, которые должны были соответствовать нашему запросу, а не 2. Проблема в том, что только 2 совпадения были найдены в конкретном осколке, где хранилась «Жизнь Брайана». Третье совпадение находилось в другом осколке, поэтому его не удалось идентифицировать. Помимо того, что 50 maxDocs были неточными, docFreq 2 также был неточным. Должно было быть 3. Да… Попался!
Вы видите, как эффект сегментирования может значительно повлиять на показатели релевантности вашего набора результатов. При прочих равных условиях документ, найденный в сегменте с большим количеством документов, будет оценен ниже, чем документ в сегменте с меньшим количеством документов. Документ, найденный на осколке с большим количеством дополнительных совпадающих документов, будет оценен ниже, чем документ, найденный на осколке с меньшим количеством дополнительных совпадающих документов или без них. Не так хорошо, как хотелось бы.
Как бороться с эффектом осколков? Есть несколько разных способов.
Маршрутизация документов : вы можете использовать маршрутизацию документов, чтобы убедиться, что все документы из одного индекса направляются в один сегмент, используя значение указанного поля. Это предполагает, что ваши поиски будут выполняться по одному индексу или по нескольким индексам, которые находятся в одном сегменте. Вы захотите использовать поле маршрутизации в своем поисковом запросе, а также во время индексации.
Тип поиска : Тип поиска позволяет указать порядок событий, в котором должен выполняться поиск. В этой ситуации «dfs_query_then_fetch» решит нашу проблему. Он запросит все осколки, чтобы получить частоты, распределенные по ним, а затем выполнит вычисления для соответствующих документов.
Использование типа поиска
Поскольку нам не хотелось переиндексировать наши документы, мы выбрали решение типа поиска. К сожалению, его нельзя использовать напрямую с API объяснения, но мы можем использовать API поиска для выполнения поиска с использованием типа поиска «dfs_query_then_fetch» и добавить параметр «explain = true», чтобы получить объяснение оценки. . Вот наш поисковый запрос:
curl -XGET 'https://aws-us-east-1-portal7.dblayer.com:10304/top_films/film/_search?explain=1&pretty=1&search_type=dfs_query_then_fetch' -d '
{
"запрос" : {
"соответствие" : {
"название": "жизнь"
}
}
}
Обратите внимание: поскольку здесь мы выполняем полноценный поиск, нам не нужно указывать идентификатор интересующего нас документа. Вместо этого все совпадающие результаты будут возвращены с подробным объяснением их оценки. Хотя использование «explain=true» в поиске — отличный инструмент для настройки результатов поиска для оптимальной релевантности, убедитесь, что он не установлен в ваших рабочих запросах, так как это будет очень затратным по производительности вызовом для каждого поиска.
На самом деле мы получили 3 результата этого поиска (как упоминалось выше), но давайте просто посмотрим на часть результата для «Жизнь Брайана», чтобы мы могли сравнить его с тем, что мы видели выше:
{
"_index": "top_films",
"_node": "IpZTwukkTFuz2_yHnEFMpw",
"_type": "фильм",
"_score": 2,5675833,
"_осколок": 3,
"_id": 172,
"_объяснение" : {
"Детали" : [
{
"Детали" : [
{
"Детали" : [
{
"значение": 1,
"описание": "termFreq=1.0"
}
],
"описание": "tf(частота=1.0), с частотой:",
"значение": 1
},
{
"значение": 5.1351666,
"описание": "idf(docFreq=3, maxDocs=250)"
},
{
«значение»: 0,5,
"описание": "полеНорма(doc=40)"
}
],
«значение»: 2,5675833,
"description" : "fieldWeight в 40, продукт:"
}
],
«значение»: 2,5675833,
"description": "вес (название: жизнь в 40) [PerFieldSimilarity], результат:"
}
Прежде всего, вы заметите, что вместе с объяснением извлекаются узел, осколок и счет. Источник документа также извлекается вместе с результатами поиска, но мы не приводим его здесь для простоты.
Итак, здесь внутренний идентификатор документа для этого запроса равен 40. Опять же, это не то, что фигурирует в расчетах, но мы просто хотим уточнить, что вы видите, где отображается «(doc=40)» и где это упоминается. в описании. Наша терминальная частота по-прежнему имеет значение 1, а нормализация длины поля по-прежнему имеет значение 0,5, поскольку ни один из этих расчетов не изменился. Где мы видим разницу, так это в обратной частоте документа. Теперь, когда мы сравниваем все 250 документов, оценка намного выше, поскольку очень немногие документы действительно содержат термин «жизнь» в названии. На самом деле всего 3. И знание того, что есть 3 совпадения, а не 2 или 1, также влияет на счет.
Обратная оценка частоты документа для этого документа теперь рассчитывается следующим образом:
1 + ln(250/(3 + 1)) = 5,1351666
Это большая разница!
Настройка параметров поиска
Наконец, вас может заинтересовать еще одна полезная настройка поиска:
- Настройка поиска : Вы можете использовать настройку поиска, чтобы указать узлы, сегменты, первичные или реплики, к которым вы хотите применить поиск. Хотя это не решает проблему эффекта сегментирования, оно включено сюда, чтобы, в зависимости от того, как вы индексируете свои сегменты и настраиваете свои реплики, вы знали, что можете точно контролировать, где выполняются ваши поиски.
Мы надеемся, что обзор некоторых основных концепций и рассмотрение простого примера в этой статье помогли прояснить, как работает оценка по умолчанию в Elasticsearch. Мы также попытались указать на некоторые соображения, которые следует учитывать, и предупредить вас о некоторых вещах, на которые следует обратить внимание, чтобы вы могли настроить свой Elasticsearch для получения оптимальных результатов. Далее мы начнем крутить циферблаты и возиться с ручками…
Лиза Смит — будь проще. Нравится эта статья? Перейдите на страницу автора Лизы Смит, чтобы продолжить чтение.Советы и методы запросов Microsoft Access с SQL и кодом VBA
Самые простые запросы Select извлекают указанные вами записи из таблицы. Вы можете выбрать поля из таблицы для отображения,
и указать критерии отбора записей. В большинстве случаев при просмотре результатов запроса вы можете изменить
данные и обновить исходные записи. Эти обновляемые представления чрезвычайно эффективны.
Выбор таблицы и полей
Первым шагом в создании запроса является указание используемой таблицы или таблиц и отображаемых полей. Выбор столов прост. Просто выберите таблицу из списка при первом создании запроса или используйте команду «Добавить таблицу» из окна «Запрос». меню. Выбранная таблица помещается в верхнюю часть окна конструктора запросов. Оттуда вы можете выбрать поля для запроса дважды щелкнув по ним или выбрав несколько полей (используя Shift-Click или Ctrl-Click) и перетащив их в нижняя часть: сетка запросов по примерам (QBE). Убедитесь, что опция Показать отмечена, чтобы отобразить поле.
Сортировка и изменение порядка полей
После размещения полей в сетке QBE вы можете изменить порядок полей, щелкнув столбец и перетащив его в нужное место. Чтобы отсортировать результаты, укажите параметр «Сортировка» под полями для сортировки. Вы можете выбрать По возрастанию или
В порядке убывания. Обратите внимание, что вы можете отключить параметр «Показать» и выполнить сортировку по полю, которое не отображается на дисплее.
Переименование полей
Очень приятной особенностью запросов Microsoft Access является возможность переименовывать поля. Ваши данные могут храниться в именах полей, которые не легко понять пользователям. Используя выражение запроса, вы можете изменить имя поля, которое видит пользователь. Например, поле с именем «CustID» можно изменить на «Customer ID», поместив новое имя, за которым следует двоеточие и исходное имя в ячейке поля QBE: Customer ID:[CustID].
Использование вычисляемых полей (выражений)
Помимо извлечения полей из таблицы, запрос Select также может отображать вычисления (выражения).
Конечно, выражения не могут быть обновлены, так как они не существуют в исходной таблице. Выражения чрезвычайно эффективны и позволяют вам
легко отображать сложные расчеты. Существует построитель выражений, упрощающий выбор полей и функций. По умолчанию,
поля выражений называются «Expr1», «Expr2» и т. д.; поэтому вы обычно хотите переименовать их во что-то более понятное.
Поля выражений также полезны для сортировки записей. Вот пример использования вычисляемого поля для Сортировка по нескольким полям даты (или числовым) с пустыми значениями в запросе Microsoft Access.
Настройка свойств запроса
При разработке запроса можно выбрать View | Свойства или щелкните правой кнопкой мыши верхнюю часть запроса и выберите Свойства, чтобы просмотреть и изменить свойства запроса.
Описание
Это свойство позволяет предоставить описание запроса, чтобы помочь вам запомнить его назначение.
Представление по умолчанию
Показать результаты в виде таблицы, сводной диаграммы или сводной таблицы.
Вывод всех полей
Для этого параметра обычно установлено значение Нет. Если изменить его на Да, будут показаны все поля всех таблиц в запросе.
Как правило, вы должны оставить это свойство в покое и указать нужные поля в сетке QBE.
Верхние значения
Вместо извлечения всех записей можно указать первые n записей или n процентов, где n — указанное здесь значение.
Уникальные значения
По умолчанию установлено значение Нет, и извлекаются все записи. Если это изменить на Да, каждая извлекаемая запись будет содержать уникальные значения. (SQL использует команду SELECT DISTINCT). То есть нет идентичных извлеченных записей.
Например, вы можете выполнить запрос для поля «Состояние» таблицы «Пациент». Если для этого параметра установлено значение «Нет», результатом будет запись для каждого пациента. Если установлено значение Да, отображается только список уникальных состояний. Если задано значение Да, запрос не подлежит обновлению.
Уникальные записи
По умолчанию установлено значение Нет, и извлекаются все записи. Для запросов к одной таблице это свойство игнорируется.
Для многотабличных запросов, если установлено значение Да (аналогично использованию DISTINCTROW в операторе SQL), извлекаются только уникальные записи в базовых таблицах.
Свойства Уникальные записи и Уникальные значения связаны между собой, и только одно из них может иметь значение Да (оба могут быть Нет). Если для уникальных записей задано значение «Да», для параметра «Уникальные значения» автоматически устанавливается значение «Нет». Если для обоих свойств задано значение «Нет», возвращаются все записи.
Разница между DISTINCT и DISTINCTROW
Эти параметры иногда дают одинаковые результаты, но между ними есть существенные различия.
DISTINCT проверяет результаты запроса и удаляет повторяющиеся строки. Эти запросы (уникальные значения = Да) не подлежат обновлению.
Они представляют собой моментальный снимок ваших данных и не отражают последующие изменения данных пользователями. Это похоже на
запуск итогового запроса (например, с использованием предложения Group By).
DISTINCTROW проверяет все поля в таблице, а затем удаляет повторяющиеся строки. Результаты запроса с DISTINCTROW (Unique Records = Yes) могут быть обновлены и отражают изменения в извлеченных записях (но запрос не автоматически запускаться снова, если данные изменяются для извлечения других строк).
Разница в том, что DISTINCT проверяет только поля в результатах, а DISTINCTROW проверяет все поля в базовых таблицах. Если ваш запрос объединяет несколько таблиц и отображает записи только из одной, параметр DISTINCTROW позволяет просматривать и редактировать результаты.
Дополнительные сведения см. на странице Distinct и DistinctRow в запросах Microsoft Access.
Необновляемые запросы
Некоторые запросы не подлежат обновлению. Для получения дополнительной информации прочитайте нашу статью, посвященную предупреждающему сообщению, которое вы видите: Этот набор записей не подлежит обновлению: работа с необновляемыми запросами в Microsoft Access
Свойства SQL Server
Существует несколько свойств, связанных с таблицами SQL Server, которые носят более технический характер и редко нуждаются в изменении. Для получения дополнительной информации обратитесь к интерактивной справочной системе Microsoft Access.
Фильтровать, Упорядочивать, Фильтровать при загрузке, Упорядочивать при загрузке
Как и в форме, для запроса можно указать параметры Фильтр и Упорядочить. Однако обычно это часть оператора SQL запроса. При использовании свойств «Фильтровать» и «Упорядочивать по» у вас есть дополнительное преимущество: можно указать свойства «Фильтровать при загрузке» и «Упорядочивать при загрузке», чтобы применять их или нет.
Имя подтаблицы, поля связи и размер
Если вы хотите отобразить подтаблицу, чтобы показать отношение «один ко многим» между результатами этого запроса и данными из другой таблицы, Вы можете указать их здесь. Наличие подтаблиц значительно снижает производительность, поэтому добавляйте их только в том случае, если они вам нужны.
Настройка свойств поля
В дополнение к свойствам запроса каждое поле также имеет свойства, которые можно установить. Перейдите к полю в сетке QBE и щелкните правой кнопкой мыши.
В зависимости от типа поля доступны различные свойства. Наиболее важные свойства относятся к числовым полям и полям даты.
Вы можете указать, как форматируются поля при выполнении запроса.
Просмотр результатов и эквивалента SQL
После выполнения запроса можно просмотреть его результаты, переключившись с представления «Проект» на представление «Таблица». Вы также можете просмотреть эквивалент SQL. Вы даже можете напрямую редактировать синтаксис SQL и просматривать результаты и/или переключаться в режим конструктора.
TF-IDF с нуля в Python на реальном наборе данных. | Уильям Скотт
- Что такое TF-IDF?
- Предварительная обработка данных.
- Вес к названию и телу.
- Поиск документа с использованием оценки совпадения TF-IDF .
- Поиск документа с использованием косинусного сходства TF-IDF .
TF-IDF расшифровывается как «Term Frequency — Inverse Document Frequency» Это метод количественной оценки слов в наборе документов. Обычно мы подсчитываем баллы для каждого слова, чтобы обозначить его важность в документе и корпусе. Этот метод широко используется в информационном поиске и анализе текста.
Если я дам вам предложение, например, «Это здание такое высокое». Нам легко понять предложение, поскольку мы знаем семантику слов и предложения. Но как любая программа (например, Python) может интерпретировать это предложение? Любому языку программирования проще понимать текстовые данные в виде числового значения. Итак, по этой причине нам нужно векторизовать весь текст, чтобы он был лучше представлен.
Путем векторизации документов мы можем дополнительно выполнять несколько задач, таких как поиск соответствующих документов, ранжирование, кластеризация и т. д. Именно этот метод используется при выполнении поиска в Google (теперь они обновлены до новых методов преобразования). Веб-страницы называются документами, а поисковый текст, с помощью которого вы ищете, называется запросом. Поисковая система поддерживает фиксированное представление всех документов. Когда вы выполняете поиск по запросу, поисковая система находит соответствие запроса всем документам, ранжирует их в порядке релевантности и показывает вам k лучших документов. Весь этот процесс выполняется с использованием векторизованной формы запроса и документов.
Теперь вернемся к нашему TF-IDF,
TF-IDF = Частота термина (TF) * Обратная частота документа (IDF)
Терминология
- t — термин (слово)
- d — документ (набор слов )
- N — количество корпусов
- корпус — общий набор документов
Измеряет частоту встречаемости слова в документе. Это сильно зависит от длины документа и общего характера слова, например, очень распространенное слово, такое как «был» может встречаться в документе несколько раз. Но если мы возьмем два документа со 100 словами и 10 000 слов соответственно, есть большая вероятность, что общее слово «было» присутствует больше в документе из 10 000 слов. Но мы не можем сказать, что более длинный документ важнее более короткого. Именно по этой причине мы выполняем нормализацию значения частоты, мы делим частоту на общее количество слов в документе.
Напомним, что нам нужно окончательно векторизовать документ. Когда мы планируем векторизовать документы, мы не можем просто учитывать слова, присутствующие в этом конкретном документе. Если мы это сделаем, то длина вектора будет разной для обоих документов, и вычислить сходство будет невозможно. Итак, что мы делаем, так это векторизируем документы на словарный запас . Vocab — это список всех возможных миров в корпусе.
Нам нужно количество слов во всех словарных словах и длина документа для вычисления TF. Если термин не существует в конкретном документе, это конкретное значение TF будет равно 0 для этого конкретного документа. В крайнем случае, если все слова в документе одинаковы, то TF будет равен 1. Окончательное значение нормализованного значения TF будет находиться в диапазоне от [0 до 1]. 0, 1 включительно.
ТФ индивидуален для каждого документа и слова, следовательно, мы можем сформулировать ТФ следующим образом:
tf(t,d) = количество t в d / количество слов в d
Если мы уже вычислили значение TF и если это создает векторизованную форму документа, почему бы не использовать только TF для поиска соответствие между документами? Зачем нам ЦАХАЛ?
Позвольте мне объяснить, что слова, которые являются наиболее распространенными, такие как «есть», «являются», будут иметь очень высокие значения, что придает этим словам очень большое значение. Но использование этих слов для вычисления релевантности приводит к плохим результатам. Такие общеупотребительные слова называются стоп-словами. Хотя мы удалим стоп-слова позже на этапе предварительной обработки, поиск присутствия слова в документах и каким-то образом уменьшим их вес является более идеальным.
Частота документов Этот измеряет важность документов во всей совокупности корпуса. Это очень похоже на TF, но с той лишь разницей, что TF — это счетчик частоты для термина t в документе d, тогда как DF — это подсчет вхождений термина t в наборе документов N. Другими словами, DF — это счетчик частоты. количество документов, в которых присутствует это слово. Мы считаем одно вхождение, если термин присутствует в документе хотя бы один раз, нам не нужно знать, сколько раз термин присутствует.
df(t) = встречаемость t в N документах
Чтобы сохранить это также в диапазоне, мы нормализуем путем деления на общее количество документов. Наша главная цель — узнать информативность терма, а DF — точная обратная ей. вот почему мы инвертируем DF
Обратная частота документа IDF является обратной частотой документа, которая измеряет информативность термина t. Когда мы вычисляем IDF, он будет очень низким для наиболее часто встречающихся слов, таких как стоп-слова (поскольку они присутствуют почти во всех документах, и N/df даст очень низкое значение этому слову). Это, наконец, дает то, что мы хотим, относительный вес.
idf(t) = N/df
Теперь есть несколько других проблем с IDF, когда у нас большой размер корпуса, скажем, N=10000, значение IDF резко возрастает. Так что для гашения эффекта берем лог IDF.
Во время запроса, когда слово отсутствует в нет в словаре, оно будет просто проигнорировано. Но в некоторых случаях мы используем фиксированный словарь, и несколько слов словаря могут отсутствовать в документе, в таких случаях df будет равен 0. Поскольку мы не можем делить на 0, мы сглаживаем значение, добавляя 1 к знаменателю. .
idf(t) = log(N/(df + 1))
Наконец, взяв мультипликативное значение TF и IDF, мы получим показатель TF-IDF. Существует множество различных вариантов TF-IDF, но пока давайте сосредоточимся на этой базовой версии.
tf-idf(t, d) = tf(t, d) * log(N/(df + 1))
Я старший специалист по данным и исследователь ИИ в области NLP и DL.
Свяжитесь со мной: Twitter, LinkedIn.
Теперь, когда мы узнали, что такое TF-IDF, давайте вычислим показатель подобия для набора данных.
Набор данных, который мы собираемся использовать, представляет собой архив нескольких историй, этот набор данных содержит множество документов в разных форматах. Загрузите набор данных и откройте свои блокноты, я имею в виду блокноты Jupyter 😜.
Ссылка на набор данных: http://archives.textfiles.com/stories.zip
Шаг 1. Анализ набора данных
Первым шагом любой задачи машинного обучения является анализ данных. Итак, если мы посмотрим на набор данных, на первый взгляд мы увидим все документы со словами на английском языке. Каждый документ имеет разные имена и в нем есть две папки.
Сейчас одной из важных задач является выявление заголовка в теле, если проанализировать документы, то есть разные закономерности выравнивания заголовка. Но большинство заголовков выравниваются по центру. Теперь нам нужно найти способ извлечь заголовок. Но прежде чем мы накачаемся и начнем кодировать, давайте немного проанализируем набор данных.
Потратьте несколько минут, чтобы самостоятельно проанализировать набор данных. Попробуйте исследовать…
При более тщательном осмотре мы можем заметить, что в каждой папке (включая корень) есть файл index.html, который содержит все имена документов и их заголовки. Так что будем считать, что нам повезло, так как заголовки даны нам, без исчерпывающего извлечения заголовков из каждого документа.
Шаг 2: Извлечение заголовка и тела:
Нет конкретного способа сделать это, это полностью зависит от имеющейся постановки задачи и анализа, который мы проводим с набором данных.
Поскольку мы уже обнаружили, что заголовки и имена документов находятся в index.html, нам нужно извлечь эти имена и заголовки. Нам повезло, что в index.html есть теги, которые мы можем использовать в качестве шаблонов для извлечения необходимого содержимого.
Прежде чем мы начнем извлекать заголовки и имена файлов, так как у нас разные папки, сначала просканируем папки, чтобы потом сразу прочитать все файлы index. html.
[x[0] for x в os.walk(str(os.getcwd())+'/stories/')]
os.walk дает нам файлы в каталоге, os.getcwd дает нам текущий каталог и заголовок, и мы собираемся искать в текущем каталоге + папке историй, так как наши файлы данных находятся в папке историй.
Всегда предполагайте , что вы имеете дело с огромным набором данных, это помогает автоматизировать код.
Теперь мы можем обнаружить, что папки дают дополнительные / для корневой папки, поэтому мы собираемся удалить ее.
folders[0] = folders[0][:len(folders[0])-1]
Вышеприведенный код удаляет последний символ для 0-го индекса в папках, который является корневой папкой
Теперь давайте просканируем через все index.html, чтобы извлечь их заголовки. Для этого нам нужно найти шаблон, чтобы убрать заголовок. Так как это в html, наша работа будет немного проще.
давайте посмотрим…
Мы можем ясно видеть, что имя каждого файла заключено между ( > Следующий код дает список всех значений, соответствующих этому шаблону. поэтому переменные имен и заголовков имеют список всех имен и заголовков.
name = re.findall('>', text)
titles = re.findall('
(.*)\n', text) Теперь, когда у нас есть код для извлечения значений из индекса, нам просто нужно выполнить итерацию по всем папкам и получить заголовок и имя файла из всех файлов index.html
— прочитать файл из индексных файлов
— извлечь заголовок и имена
— перейти к следующей папке
набор данных = []for i в папках:
file = open(i+"/index.html", ' r')
text = file.read().strip()
file.close() file_name = re.findall('>', text)
file_title = re.findall ('
(.*)\n', текст) для j в диапазоне (len(file_name)):
dataset.append((str(i) + str(file_name[j]), file_title [ж]))
Это подготавливает индексы набора данных, который представляет собой кортеж местоположения файла и его заголовка. Есть небольшая проблема, в корневой папке index.html также есть папки и ссылки на них, нам нужно их удалить.
просто используйте условную проверку, чтобы удалить его.
if c == False:
имя_файла = имя_файла[2:]
c = True
Предварительная обработка — один из основных шагов, когда мы имеем дело с любой текстовой моделью. На этом этапе мы должны посмотреть на распределение наших данных, какие методы необходимы и насколько глубоко мы должны очищать.
Этот шаг никогда не имеет однозначного правила и полностью зависит от постановки задачи. Немногие обязательные предварительные обработки: преобразование в нижний регистр, удаление знаков препинания, удаление стоп-слов и лемматизация/выделение корней. В нашей постановке задачи кажется, что основных шагов предварительной обработки будет достаточно.
Нижний регистр
Во время обработки текста каждое предложение разбивается на слова, и после предварительной обработки каждое слово считается токеном. Языки программирования считают текстовые данные конфиденциальными, а это означает, что отличается от . мы, люди, знаем, что они оба принадлежат одному и тому же токену, но из-за кодировки символов они считаются разными токенами. Преобразование в нижний регистр является обязательным этапом предварительной обработки. Поскольку у нас есть все наши данные в списке, у numpy есть метод, который может сразу преобразовать список списков в нижний регистр.
np.char.lower(data)
Стоп-слова
Стоп-слова — это наиболее часто встречающиеся слова, которые не придают никакого дополнительного значения вектору документа. на самом деле их удаление повысит эффективность вычислений и пространства. В библиотеке nltk есть метод для загрузки стоп-слов, поэтому вместо того, чтобы явно указывать все стоп-слова, мы можем просто использовать библиотеку nltk, перебрать все слова и удалить стоп-слова. Есть много эффективных способов сделать это, но я приведу простой метод.
мы будем перебирать все стоп-слова и не добавлять их в список, если это стоп-слова
new_text = ""
для слова в словах:
если слово не в стоп-словах:
+ слово
Пунктуация
Пунктуация — это набор ненужных символов, которые есть в наших корпусных документах. Мы должны быть немного осторожны с тем, что мы делаем с этим, может быть несколько проблем, таких как США — мы, «Соединенные Штаты», преобразуются в «нас» после предварительной обработки. дефис, и обычно с ним следует обращаться с небольшой осторожностью. Но для этой постановки задачи мы просто удалим эти 9_`{|}~\n»
для i в символах:
data = np.char.replace(data, i, ‘ ‘)
Мы собираемся хранить все наши символы в переменной и повторять эту переменную, удаляя это
Апостроф
Обратите внимание, что в знаках препинания нет апострофа. Потому что, когда мы сначала удалите знаки препинания, он преобразует «не» в «не», и это стоп-слово, которое не будет удалено Вместо этого мы будем удалять стоп-слова, за которыми следуют символы, а затем, наконец, повторять удаление стоп-слов, поскольку несколько слов могут все еще имеют апостроф, который не является стоп-словом. 0003
return np.char.replace(data, "'", "")
Одиночные символы
Отдельные символы не очень полезны для понимания важности документа, и несколько последних одиночных символов могут быть нерелевантными символами, поэтому всегда хорошо удалять отдельные символы.
new_text = ""
для w в словах:
если len(w) > 1:
new_text = new_text + " " + w
Нам просто нужно перебрать все слова и не добавлять слово, если длина не более 1,
Stemming
Это последняя и самая важная часть предварительной обработки. стемминг преобразует слова в их основу.
Например, игра и игра — это слова одного типа, которые в основном обозначают действие игра. Стеммер делает именно это, он сводит слово к его основе. мы собираемся использовать библиотеку под названием porter-stemmer, основанную на правилах. Портер-Стеммер идентифицирует и удаляет суффикс или аффикс слова. Слова, заданные стеммером, не обязательно должны быть осмысленными несколько раз, но они будут идентифицированы как один токен для модели.
Лемматизация
Лемматизация — это способ сведения слова к корневому синониму слова. В отличие от стемминга, лемматизация гарантирует, что сокращенное слово снова станет словарным словом (словом, присутствующим в том же языке). WordNetLemmatizer можно использовать для лемматизации любого слова.
Stemming vs Lemmatization
Stemming — не обязательно словарное слово, удаляет префикс и аффикс на основе нескольких правил
lemmatization — будет словарным словом. сводится к корневому синониму.
Более эффективный способ действий состоит в том, чтобы сначала лемматизировать, а затем сформулировать, но одно стеммирование также подходит для некоторых задач, здесь мы не будем лемматизировать.
Преобразование чисел
Когда пользователь вводит запрос, такой как 100 долларов или сто долларов. Для пользователя оба условия поиска одинаковы. но наша модель IR рассматривает их отдельно, так как мы храним 100 долларов, сто как разные токены. Итак, чтобы сделать наш ИК-режим немного лучше, нам нужно преобразовать 100 в сто. Для этого мы будем использовать библиотеку под названием 9.0661 число2слово .
Если мы внимательно посмотрим на приведенный выше вывод, то увидим, что он дает нам несколько символов и предложений, таких как «сто и два», но, черт возьми, мы только что очистили наши данные, тогда как мы с этим справимся? Не беспокойтесь, мы просто снова запустим пунктуацию и стоп-слова после преобразования чисел в слова.
Предварительная обработка
Наконец, мы поместим все эти методы предварительной обработки выше в другой метод и назовем этот метод предварительной обработки.
def preprocess(data):
data = convert_lower_case(data)
data = remove_punctuation(data)
data = remove_apostrophe(data)
data = remove_single_characters(data)
data = convert_numbers(data)
data = remove_stop_words(data)
данные = корень (данные)
данные = удалить_пунктуацию (данные)
данные = преобразовать_числа (данные)
Если вы внимательно посмотрите, некоторые из методов предварительной обработки повторяются снова. Как уже говорилось, это просто помогает очистить данные немного глубже. Теперь нам нужно прочитать документы и сохранить их заголовок и тело отдельно, так как мы собираемся использовать их позже. В нашей постановке задачи у нас очень разные типы документов, это может вызвать несколько ошибок при чтении документов из-за совместимости кодировок. чтобы решить эту проблему, просто используйте encoding=»utf8″, errors=’ignore’ в методе open().
Шаг 3: Расчет TF-IDF
Напомним, что нам нужно присвоить разные веса заголовку и телу. Теперь, как мы собираемся решить эту проблему? как в этом случае будет работать расчет TF-IDF?
Придание разного веса заголовку и основной части является очень распространенным подходом. Нам просто нужно рассматривать документ как тело + заголовок, используя это, мы можем найти словарный запас. И нам нужно придать разный вес словам в заголовке и разный вес словам в теле. Чтобы лучше объяснить это, давайте рассмотрим пример.
title = «Это новая статья»
body = «Эта статья состоит из обзора многих статей»
Теперь нам нужно рассчитать TF-IDF для тела и для заголовка. Пока давайте рассмотрим только слово paper и забудем об удалении стоп-слов.
Что такое ТФ слова бумага в названии? 1/4?
Нет, это 3/13. Как? word paper появляется в заголовке и теле 3 раза, а общее количество слов в заголовке и теле равно 13. Как я упоминал ранее, нас всего считать слово в заголовке иметь разный вес, но все же при расчете TF-IDF мы учитываем весь документ.
Тогда ТФ бумаги и в заголовке, и в теле одинаковы? Да, это то же самое! это просто разница в весе, который мы собираемся дать. Если слово присутствует и в заголовке, и в теле, то никакого уменьшения значения TF-IDF не будет. Если слово присутствует только в названии, то вес тела для этого конкретного слова не будет добавляться к ТФ этого слова, и наоборот.
документ = тело + заголовок
TF-IDF(документ) = TF-IDF(заголовок) * альфа + TF-IDF(тело) * (1-альфа)
Расчет DF
предварительно рассчитать ДФ. Нам нужно перебрать все слова во всех документах и сохранить идентификатор документа для каждого слова. Для этого мы будем использовать словарь, так как мы можем использовать слово в качестве ключа и набор документов в качестве значения. Я упомянул набор, потому что, даже если мы пытаемся добавить документ несколько раз, набор не будет просто принимать повторяющиеся значения.
DF = {}
для i в диапазоне (len(processed_text)):
токены = обрабатываемый_текст[i]
для w в токенах:
попытка:
DF[w].add(i)
за исключением:
DF[ w] = {i} Мы создадим набор, если у слова еще нет набора, иначе добавим его в набор. Это условие проверяется блоком try. Здесь обрабатываемый_текст — это тело документа, и мы собираемся повторить то же самое и для заголовка, так как нам нужно учитывать DF всего документа.
len(DF) даст уникальные слова
DF будет иметь слово в качестве ключа и список идентификаторов документов в качестве значения. но для DF нам на самом деле не нужен список документов, нам просто нужно количество. поэтому мы собираемся заменить список его счетчиком.
Вот и все необходимое для всех слов. Чтобы найти общее количество уникальных слов в нашем словаре, нам нужно взять все ключи DF.
Вычисление TF-IDF
Напомним, что нам необходимо поддерживать разные веса для заголовка и основного текста. Чтобы рассчитать TF-IDF тела или названия, нам нужно учитывать и название, и тело. Чтобы немного облегчить нашу работу, давайте воспользуемся словарем с числом 9.0721 (документ, токен) Пара в качестве ключа и любая оценка TF-IDF в качестве значения. Нам просто нужно перебрать все документы, мы можем использовать Coutner, который может дать нам частоту токенов, вычислить tf и idf и, наконец, сохранить как пару (doc, token) в tf_idf. Словарь tf_idf предназначен для тела, мы будем использовать ту же логику для создания словаря tf_idf_title для слов в заголовке.
tf_idf = {}
для i в диапазоне (N):
токены = обрабатываемый_текст[i]
счетчик = счетчик(токены + обработанный_название[i])
для токена в np. unique(токены):
tf = counter[token]/words_count
df = doc_freq(token)
idf = np.log(N/(df+1))
tf_idf[doc, token] = tf*idf Приступаем к расчету разных весов. Во-первых, нам нужно поддерживать значение альфа, которое является весом для тела, тогда, очевидно, 1-альфа будет весом для заголовка. Теперь давайте немного углубимся в математику, мы обсуждали, что значение слова в TF-IDF будет одинаковым как для тела, так и для заголовка, если слово присутствует в обоих местах. Мы будем поддерживать два разных словаря tf-idf, один для тела и один для заголовка.
То, что мы собираемся сделать, немного умнее, мы рассчитаем TF-IDF для тела; умножить значения TF-IDF всего тела на альфа; повторять токены в заголовке; заменить значение заголовка TF-IDF в теле значения TF-IDF пары (документ, токен) существует. Потратьте некоторое время, чтобы обработать это: P
Поток:
— Рассчитать TF-IDF для тела для всех документов
— Рассчитать TF-IDF для заголовка для всех документов
— умножить TF-IDF тела на альфа-канал
— Итерация заголовка IF-IDF для каждого (документа, токена)
— если токен находится в теле, замените значение Body(doc, token) значением в Title(doc, token)
Я знаю, что сначала это не просто понять, но все же позвольте мне объяснить, почему вышесказанное поток работает, так как мы знаем, что tf-idf для тела и заголовка будет одинаковым, если токен находится в обоих местах. Веса, которые мы используем для тела и заголовка, в сумме составляют единицу
TF-IDF = body_tf-idf * body_weight + title_tf-idf*title_weight
body_weight + title_weight = 1
Когда токен находится в обоих местах, окончательный TF-IDF будет таким же, как если бы он принимал тело или заголовок tf_idf. Это именно то, что мы делаем в приведенном выше потоке. Итак, наконец, у нас есть словарь tf_idf со значениями в виде пары (doc, token).
Оценка совпадения — это самый простой способ расчета сходства. В этом методе мы добавляем значения tf_idf токенов, которые находятся в запросе для каждого документа . Например, для запроса «привет, мир» нам нужно проверить в каждом документе, существуют ли эти слова, и если слово существует, то значение tf_idf добавляется к оценке соответствия этого конкретного doc_id. В конце мы отсортируем и выберем k лучших документов.
Упомянутое выше является теоретической концепцией, но поскольку мы используем словарь для хранения нашего набора данных, мы собираемся сделать итерацию по всем значениям в словаре и проверить, присутствует ли значение в токене. Поскольку наш словарь является ключом (документ, токен), когда мы находим токен, который находится в запросе, мы добавим идентификатор документа в другой словарь вместе со значением tf-idf. Наконец, мы просто снова возьмем первые k документов.
определение match_score(запрос):
query_weights = {}
для ключа в tf_idf:
if key[1] в tokens:
query_weights[key[0]] += tf_idf[key]
key[0] — это documentid, key[1] — это токен.
Когда у нас есть идеально работающий показатель соответствия , зачем нам снова нужно косинусное сходство? хотя Matching Score дает соответствующие документы, он совершенно не работает, когда мы даем длинные запросы, он не сможет правильно их ранжировать. Косинус аналогично делает то, что он помечает все документы как векторы токенов tf-idf и измеряет сходство в косинусном пространстве (угол между векторами. Несколько раз длина запроса будет небольшой, но она может быть тесно связана с документом. в таких случаях косинусное сходство лучше всего подходит для поиска релевантности.0003
Обратите внимание на приведенный выше график, синие векторы — это документы, а красный вектор — это запрос, как мы можем ясно видеть, хотя манхэттенское расстояние (зеленая линия) очень велико для документа d1, запрос все еще близок к документу d1 . В таких случаях косинусное сходство было бы лучше, поскольку оно учитывает угол между этими двумя векторами. Но Matching Score вернет документ d3, но это не очень тесно связано.
Matching Score вычисляет манхэттенское расстояние (прямая линия от наконечников)
Оценка косинуса учитывает угол векторов.
Векторизация
Чтобы вычислить что-либо из вышеперечисленного, самый простой способ — преобразовать все в вектор, а затем вычислить косинусное сходство. Итак, давайте преобразуем запрос и документы в векторы. Мы собираемся использовать переменную total_vocab, которая содержит весь список уникальных токенов, для создания индекса для каждого токена, и мы будем использовать numpy of shape (docs, total_vocab) для хранения векторов документов.
# Векторизация документа
D = np.zeros((N, total_vocab_size))
для i в tf_idf:
ind = total_vocab.index(i[1])
D[i[0]][ind] = tf_idf[i]
Для вектор, нам нужно вычислить значения TF-IDF, TF мы можем вычислить из самого запроса, и мы можем использовать DF, который мы создали для частоты документа. Наконец, мы будем хранить в массиве numpy (1, vocab_size) значения tf-idf, индекс токена будет определяться из списка total_voab
Q = np.zeros((len(total_vocab)))
counter = Счетчик (жетонов)
words_count = len(токены)
query_weights = {}
для токена в np.unique(токены):
tf = counter[token]/words_count
df = doc_freq(token)
idf = math.log((N+1 )/(df+1))
Теперь все, что нам нужно сделать, это вычислить косинусное сходство для всех документов и вернуть максимум k документов. Косинусное сходство определяется следующим образом.
np.dot(a, b)/(norm(a)*norm(b))
Я взял текст из doc_id 200 (для меня) и вставил некоторый контент с длинным запросом и коротким запросом в как совпадающая оценка, так и косинусное сходство.