Страница не найдена
2022 №3, Статьи →
Долинская Владимира Владимировна ФГБОУ ВО «Московский государственный юридический университет имени О.Е. Кутафина (МГЮА)», Москва, Россия Профессор кафедры гражданского права АНО ВО «Университет мировых цивилизаций имени В.В. Жириновского», Москва, Россия Профессор кафедры гражданско-правовых дисциплин член Научно-консультативного совета при Верховном Суде РФ …
24.03.2023
Читать далее…
2022 №3, Статьи →
Бакунин Сергей Николаевич ФГБОУ ВО «Рязанский государственный университет имени С.А. Есенина», Рязань, Россия Профессор кафедры «Гражданского права» Кандидат юридических наук, профессор E-mail: [email protected] Аннотация. В статье анализируется реализация конституционного права гражданина на жизнь. Подтверждается, что юридический аспект категории «жизнь» должен …
14.10.2022
Читать далее…
2022 №3, Статьи →
Сафронский Георгий Эмилевич АНО ВО «Университет мировых цивилизаций имени В. В. Жириновского», Москва, Россия Доцент кафедры «Адвокатуры и правоприменительной деятельности» Кандидат юридических наук E-mail: [email protected] Ленивкина Анастасия Дмитриевна АНО ВО «Университет мировых цивилизаций имени В.В. Жириновского», Москва, Россия Магистрант 2 курса …
В. Жириновского», Москва, Россия Доцент кафедры «Адвокатуры и правоприменительной деятельности» Кандидат юридических наук E-mail: [email protected] Ленивкина Анастасия Дмитриевна АНО ВО «Университет мировых цивилизаций имени В.В. Жириновского», Москва, Россия Магистрант 2 курса …
14.10.2022
Читать далее…
2022 №3, Статьи →
Половикова Юлия Святославовна Магистрант E-mail: [email protected] Прокофьев Михаил Николаевич ФГОБУ ВО «Финансовый университет при Правительстве Российской Федерации», Москва, Россия Доцент кафедры «Государственное и муниципальное управление» Кандидат экономических наук E-mail: [email protected] Аннотация. В статье рассматриваются вопросы, касающиеся регионального управления на базе …
23.07.2022
Читать далее…
2022 №3, Статьи →
Корень Валерий Лукич ФГКВОУ ВО «Военный университет» Министерства обороны Российской Федерации, Москва, Россия Преподаватель кафедры «Философии и религиоведения» ГКОУ ВО «Российская таможенная академия», Москва, Россия Доцент Кандидат юридических наук, доцент РИНЦ: https://elibrary. ru/author_profile.asp?id=350873 Корень Игорь Валерьевич ФГКВОУ ВО «Военный университет» Министерства …
ru/author_profile.asp?id=350873 Корень Игорь Валерьевич ФГКВОУ ВО «Военный университет» Министерства …
11.07.2022
Читать далее…
2022 №1, Статьи →
Сомова Инна Юрьевна НАНО ВО «Институт мировых цивилизаций», Москва, Россия Заведующая кафедрой «Иностранных языков для нелингвистических специальностей», доцент факультета «Международных отношений и геополитики» Кандидат исторических наук E-mail: [email protected] РИНЦ: https://elibrary.ru/author_profile.asp?id=440982 Пархалова Оксана Владимировна НАНО ВО «Институт мировых цивилизаций», Москва, Россия …
15.06.2022
Читать далее…
2022 №2, Статьи →
Барсукова Наталия Ивановна АНО ВО «Национальный институт дизайна», Москва, Россия Профессор кафедры «Рисунка и живописи» Доктор искусствоведения E-mail: [email protected] Аннотация. В статье рассматривается новое явление для проектной практики — конгруэнтность как феномен, при котором создаются условия аутентичного поведения человека в …
13. 06.2022
06.2022
Читать далее…
2022 №2, Статьи →
Анищенко Ксения Леонидовна НАНО ВО «Институт мировых цивилизаций», Москва, Россия Заведующая кафедрой «Цивилизационной журналистики» E-mail: [email protected] Аннотация. Журналистское расследование на протяжении долгих лет востребовано у аудитории и вызывает у нее интерес. Одна из его отличительных черт — отражение современной действительности …
13.06.2022
Читать далее…
2022 №2, Статьи →
Заикин Виталий Викторович ФГАОУ ВО «Северо-Кавказский федеральный университет», Ставрополь, Россия Доцент кафедры «Административного и финансового права» Кандидат юридических наук Динаева Алина Муратовна ФГАОУ ВО «Северо-Кавказский федеральный университет», Ставрополь, Россия Магистр 1 курса «Юридического» факультета Аннотация. В статье рассматриваются российские и …
13.06.2022
Читать далее…
2022 №2, Статьи →
Петушкова Татьяна Анатольевна НАНО ВО «Институт мировых цивилизаций», Москва, Россия Доцент кафедры «Цивилизационного дизайна» Кандидат искусствоведения E-mail: tapetushkova01@gmail. com Абдуллин Вагиз Рустамович НАНО ВО «Институт мировых цивилизаций», Москва, Россия Магистрант кафедры «Цивилизационного дизайна» E-mail: [email protected] Аннотация. При разработке плакатов для различных …
com Абдуллин Вагиз Рустамович НАНО ВО «Институт мировых цивилизаций», Москва, Россия Магистрант кафедры «Цивилизационного дизайна» E-mail: [email protected] Аннотация. При разработке плакатов для различных …
13.06.2022
Читать далее…
Журнал Международная жизнь — Латиница вместо кириллицы… Зачем?
Отказ некоторых постсоветских республик от кириллического алфавита в пользу латиницы — процесс, продолжающийся до сих пор. Первым распрощался с кириллицей Азербайджан, сегодня ей «машет рукой» Казахстан. Между Азербайджаном и Казахстаном латинизацией алфавита занимались Молдавия, Узбекистан, Туркмения. Казахстанские власти ещё в 2017 г. объявили отказ от кириллицы «принципиальным вопросом, который нация должна решить» (1). Это, скорее всего, значит, что от идеи латинизации казахского языка и культуры не откажутся.
Приводимые сторонниками латиницы доводы в её пользу звучат не совсем логично. Как правило, ссылаются на положительный опыт Турции. Латинский алфавит, действительно, закрепился в Турции относительно легко, но этот «относительно лёгкий» процесс занял не один десяток лет.
Латинский алфавит, действительно, закрепился в Турции относительно легко, но этот «относительно лёгкий» процесс занял не один десяток лет.
Турция хотела быть ближе к Европе, у которой с ней общая граница. Исторически непростые отношения с соседними Грецией и Болгарией обусловили невозможность перехода Турции на кириллическую азбуку. Ведь её авторы — жившие в Греции болгары Кирилл и Мефодий. Турция веками конкурировала с арабами и персами за лидерство в исламском мире, поэтому не могла взять за основу нового алфавита ни арабскую вязь, ни фарси. Зато Турция часто вступала в политические союзы со странами Западной Европы, что и определило выбор нового алфавита, которым стала латиница.
Как видим, не столько культурные, сколько геополитические соображения скрываются за выбором в пользу латинского алфавита. То же самое актуально и для республик бывшего СССР. Ссылки на то, что на латинице можно точнее и полнее передать звучание их языков — это отговорка, маскирующая истинные причины. Речь идёт, по сути, о цивилизационно-геополитической трансформации тюркской части постсоветского пространства, как это произошло с Молдавией, где вместе с латиницей пришла пропаганда идеи о том, что молдаване — это дубликат румын.
Речь идёт, по сути, о цивилизационно-геополитической трансформации тюркской части постсоветского пространства, как это произошло с Молдавией, где вместе с латиницей пришла пропаганда идеи о том, что молдаване — это дубликат румын.
Перечислим основные мифы, приводимые в защиту латиницы:
Латиница модернизирует сознание. Автоматического равенства между модернизацией и латинизацией нет. Япония, Южная Корея, Китай вырвались в экономические лидеры без латиницы. Система транскрибирования китайского языка на латинице (пиньин) предназначена больше для передачи звучания китайских слов для иностранцев и на начальном этапе обучения. Взрослые китайцы поголовно пишут иероглифами.
Латиница повышает шансы на экономический успех. Обилие государств с латинской азбукой, но без экономических успехов, служит конкретным опровержением этого тезиса. Албанию, страны Африки сложно назвать экономическими лидерами. Если бы латиница была синонимом финансового процветания, сербы и гагаузы не сохранили бы кириллицу, которую настойчиво используют наряду с латиницей, причём сербы не расстаются с кириллицей веками. Экономические успехи Узбекистана и Туркмении тоже скромны.
Экономические успехи Узбекистана и Туркмении тоже скромны.
Большая часть трудовых мигрантов приезжает в Россию из Средней Азии. Здесь кириллица, а не латиница служит залогом их быстрой и комфортной интеграции в российскую социально-экономическую действительность. Латиница лишь затрудняет им жизнь. На фоне угрозы латинизации увеличивается отток специалистов из Казахстана, в основном медиков, педагогов, архитекторов, юристов (2). Как без этих кадров можно поднимать экономику?
Латиница способствует интеграции с внешним миром и единству с народами латинской азбучной письменности. Народы, использующие латиницу, слишком разнятся в культурно-цивилизационном плане, чтобы имело смысл говорить об их единстве. Венгры, финны, эстонцы — это финно-угры. Турки, казахи, азербайджанцы — тюрки. Англичане, немцы, голландцы — германцы. Хорваты, чехи, словаки — славяне. Португальцы, французы, испанцы, румыны, итальянцы — это латинские народы. Условиями интеграции в современном мире являются не столько языки, сколько политические системы и экономические проекты. Евросоюз, ЕврАзЭС и другие союзы тому пример.
Евросоюз, ЕврАзЭС и другие союзы тому пример.
Латиница защитит языки тюркских народов бывшего СССР от русизмов. Добавим: но не защитит от латинизмов. Некоторые польские лингвисты уже сейчас критикуют вставки латинских слов в польскую речь. Латинизация польского языка особенно активно проходила в XIV-XVII вв., разные Сonfiteor… (Признаюсь…), Assentior (Согласен), Nullo modo (Никоим образом) звучат неуклюже и неестественно в славянской речи. Не случится ли то же самое с казахским, узбекским, туркменским и др. языками? Примеров юмористического звучания некоторых серьёзных тюркских слов в латинской графике хватает.
Латиница расширяет коммуникативные горизонты общества. Благополучие государства зависит, в первую очередь, от взаимовыгодных отношений с соседями. Принципиальный и бескомпромиссный отказ постсоветских республик от кириллицы не расширит, а сузит горизонты общения с самым крупным соседом — Россией. Народы бывшего СССР разделены государственными границами, а теперь к этому добавляется разъединение по выбору графики. Это не будет способствовать интеграции евразийского пространства и теоретически может снизить темпы сотрудничества. О каких тогда экономических успехах можно говорить? И как быть с десятками тысяч, а в случае с Казахстаном — с 3,5 миллионами граждан, русских по национальности? Вряд ли их удастся латинизировать настолько, что не возникнет совершенно никаких проблем на культурно-национальной почве.
Это не будет способствовать интеграции евразийского пространства и теоретически может снизить темпы сотрудничества. О каких тогда экономических успехах можно говорить? И как быть с десятками тысяч, а в случае с Казахстаном — с 3,5 миллионами граждан, русских по национальности? Вряд ли их удастся латинизировать настолько, что не возникнет совершенно никаких проблем на культурно-национальной почве.
Латиница — символ отказа от «колониального» прошлого в составе Российской империи и СССР. По статистике, латиницу используют около 40% населения земного шара. Такая результативность — следствие колониальной политики западных держав, а не добровольного выбора. Латиница в Америке и Африке — это, скорее, символ колониализма, а не символ свободы. Коренные малочисленные народы Российской империи/СССР поголовному уничтожению вовсе не подвергались, получив позже письменность на основе кириллицы и развитие национальных литератур. Американских индейцев латиница от истребления не спасла.
Приверженцы латиницы непоследовательны в своих обвинениях. Перевод языков народов СССР на латиницу в 1920-х они называли примером культурного насилия (и были правы), а сегодня называют переход на латиницу оправданным шагом (и в этом, на мой взгляд, неправы). Доходит до слов о том, что русский язык и кириллица спровоцировали кризис духовной нравственности! Вот уж беда в головах… Разделение языков на нравственные и не нравственные — это что-то в стиле культурно-языковой евгеники с политическим душком.
В истории бывшего СССР был пример превращения вопроса латинизации в кровавый гражданский конфликт — Приднестровье. Неразумное стремление тогдашних молдавских властей заставить приднестровцев быстро забыть кириллический вариант молдавского языка и полюбить латиницу, вместе с курсом на сближение с Румынией вызвал отторжение и желание защитить свою культурную и политическую идентичность с оружием в руках. Негибкость в языковых вопросах всегда чревата последствиями. Нельзя сказать, что власти республик, перешедших на латиницу или принявших решение это сделать, не осознают эту проблему. Но нельзя также сказать, что готовы отказаться от этой неконструктивной затеи. Ведь в отличии от алфавита соседей поменять невозможно.
Но нельзя также сказать, что готовы отказаться от этой неконструктивной затеи. Ведь в отличии от алфавита соседей поменять невозможно.
Мнение автора может не совпадать с позицией Редакции
1) https://e-history.kz/ru/news/show/5091/
2) В Казахстане сообщили об оттоке населения из страны
Читайте другие материалы журнала «Международная жизнь» на нашем канале Яндекс.Дзен.
Подписывайтесь на наш Telegram – канал: https://t.me/interaffairs
FAQ — Латиница и кириллица
В: Где найти латиницу и кириллицу символов в стандарте Unicode?
Раскладка латиницы и кириллицы в стандарте Unicode является артефактом истории Unicode и ISO/IEC 10646. Стандарт Unicode начался с основного латинского алфавита и дополнения к латинице-1, изложенных в соответствии со стандартом ISO / IEC 8859-7, а также с кириллицей, аналогично изложенной в соответствии с устаревшими стандартами.
В составе
нарушение стандартов, что привело к синхронизации
Стандарт Unicode с проектами ISO/IEC 10646, стандарт Unicode приобрел
коллекция предварительно составленных латинских символов. Их нужно было где-то разместить, и
блок был создан в U+1E00..U+1EFF для их размещения.
Их нужно было где-то разместить, и
блок был создан в U+1E00..U+1EFF для их размещения.
С тех пор было выделено много дополнительных блоков как для латиницы, так и для кириллицы, некоторые из которых находятся в первой дополнительной плоскости, а это означает, что для каждого символа требуется 2 единицы кода в UTF-16. С улучшенной поддержкой современное программное обеспечение должно нормально обрабатывать такие дополнительные символы, но устаревшие инструменты могут иметь более ограниченную поддержку.
Добавлены расширения для дополнительных языков и систем фонетической транскрипции в дополнительных блоках или путем заполнения пробелов в существующих блоках. В результате ни латинские, ни кириллические символы не находятся в каком-либо последовательном алфавитном порядке. Чтобы найти все блоки символов латиницы или кириллицы, используйте указатель таблиц кодов символов Unicode. [АФ]
В: Когда я использую комбинированные метки?
Символы латиницы и кириллицы можно использовать с символами из блока «Комбинирование диакритических знаков». Для многих, если не для большинства комбинированных последовательностей, широко используемых в данном языке, существуют предварительно составленные символы. Если ожидается, что данные будут в форме нормализации NFD, вы всегда должны использовать последовательности, за исключением случаев, когда определен только предварительно составленный символ. Например, латинское «Ø» O СО ШТРИХОМ не имеет разложения на O плюс «̸» ОБЪЕДИНЕНИЕ НАЛОЖЕНИЯ ДЛИННОГО СОЛИДУСА. То же самое верно для многих других букв с наложением штрихов или штрихов.
Для многих, если не для большинства комбинированных последовательностей, широко используемых в данном языке, существуют предварительно составленные символы. Если ожидается, что данные будут в форме нормализации NFD, вы всегда должны использовать последовательности, за исключением случаев, когда определен только предварительно составленный символ. Например, латинское «Ø» O СО ШТРИХОМ не имеет разложения на O плюс «̸» ОБЪЕДИНЕНИЕ НАЛОЖЕНИЯ ДЛИННОГО СОЛИДУСА. То же самое верно для многих других букв с наложением штрихов или штрихов.
Если вместо этого ожидается, что данные будут в NFC, вы всегда должны использовать предварительно составленные формы, где они доступны, и объединяющие последовательности только там, где нет эквивалентного предварительно составленного символа. Необходимость в этом возникает относительно редко. Поскольку он соответствует устаревшей практике, NFC, как правило, используется в более широком диапазоне контекстов, чем NFD. [АФ]
В: Почему не унифицированы латиница и кириллица?
Латиница и кириллица имеют общего предка (грека) и тесно связаны между собой. Некоторые символы имеют очень похожий внешний вид, и во многих, если не в большинстве шрифтов, они идентичны. На самом деле, многие английские слова можно «написать» полностью кириллическими буквами, и читатель не будет знать о замене. Это поднимает вопрос, почему они не рассматриваются (вместе с греческим) как единый алфавит, где каждый из многих языков использует то подмножество, которое им требуется.
Некоторые символы имеют очень похожий внешний вид, и во многих, если не в большинстве шрифтов, они идентичны. На самом деле, многие английские слова можно «написать» полностью кириллическими буквами, и читатель не будет знать о замене. Это поднимает вопрос, почему они не рассматриваются (вместе с греческим) как единый алфавит, где каждый из многих языков использует то подмножество, которое им требуется.
Несмотря на то, что некоторые буквы, такие как латинская «В» и кириллица «В» (и греческая «В»), могут выглядеть одинаково, их эквиваленты в нижнем регистре — «b» и «в» (или «β») и поэтому не выглядят одинаковый. Давним принципом стандарта Unicode является разделение символов, которые не имеют одинаковых сопоставлений регистров, чтобы сопоставления регистров были максимально уникальными.
Еще одна задача обработки, которая зависит от отдельного идентификатора сценария, — сопоставление. Даже при сортировке по английским правилам термины на кириллице сортируются вместе, а не рядом с любым английским термином, на который они могут быть похожи.
Q: Что делать с похожими латинскими и кириллическими буквами?
В обычном тексте не должно быть проблем при смешивании скриптов из-за вставленной кавычки или случайной замены похожего символа из другого скрипта. Причина в том, что клавиатуры, как правило, специфичны для языка и ограничены используемым шрифтом, и читатели заботятся только о том, чтобы отображаемая форма имела смысл в контексте.
Ситуация сильно отличается в контекстах, связанных с безопасностью, таких как сетевые идентификаторы. В тех случаях, если кодовая точка отличается от того, что пользователь предполагает по внешнему виду, замена может облегчить подделку. Подходы к смягчению последствий варьируются от запрета идентификаторов со смешанным шрифтом до пометки необычного использования шрифта или обработки любой латинской метки, которая выглядит как данная кириллическая метка, как эквивалентной последней. Такую эквивалентность можно использовать для предотвращения дублирования регистрации похожих идентификаторов или для обеспечения того, чтобы один и тот же внешний вид всегда разрешался в один и тот же сетевой ресурс.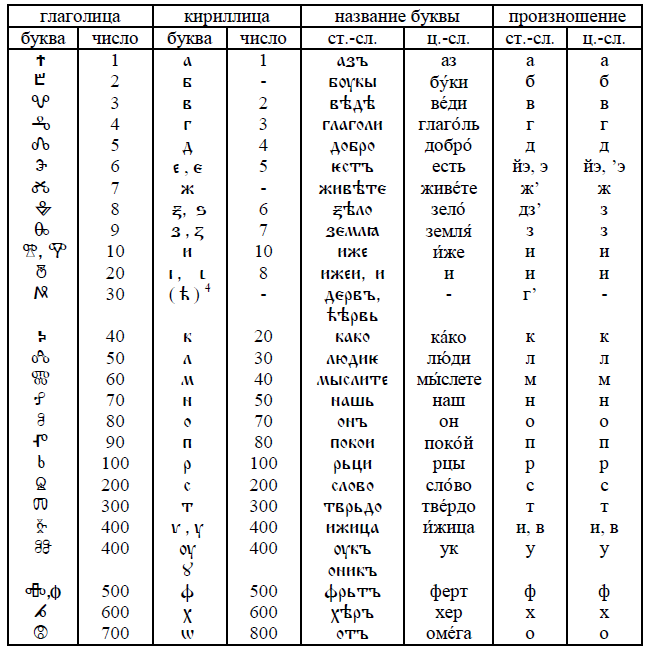
См. UTS # 39 Механизмы безопасности Unicode для получения данных о путанице и стратегиях по устранению проблемы. [АФ]
Q: Как поступить с текстом, в котором орфография содержит одновременно латинские и кириллические буквы? Стоит ли предлагать латинские (или кириллические) буквы, которых нет в Юникоде?
Системы письма могут заимствовать символы из разных письменностей (сравните с японским языком). Как правило, не рекомендуется предлагать новый кириллический символ, который в точности напоминает латинский символ (или добавлять латинскую букву, идентичную существующей кириллической букве), если только эта буква не соответствует одному из следующих критериев:
- это письмо широко используется сегодня, и регулярно создается новый контент.
- буква имеет уникальные характеристики, не присущие исходному письму (например, буква имеет различные регистры, отсутствующие в исходном письме) Показано, что
- доказуемых проблем реализации возникают при смешивании скриптов в словах.

Это имеет особое значение для систем обозначений, которые не используются в качестве орфографии.
В: Как должны быть представлены исторические текстовые материалы из Российской империи и бывшего Советского Союза, алфавиты которых содержат латиницу и кириллицу?
В течение девятнадцатого и начала двадцатого веков было разработано несколько экспериментальных орфографий для представления различных языков и диалектов Российской империи и бывшего Советского Союза. Во многих случаях типографии смешивали и сопоставляли сортировку подвижным шрифтом как с кириллицей, так и с латиницей при публикации текста. Многие из этих орфографий, найденных в печатных произведениях, не сохранились до наших дней. Для представления этих исторических текстов, содержащих переходные орфографии, следует использовать специализированные шрифты, в которых используются существующие символы, а не предлагается добавление новых символов.
Вопрос: Сколько языков написано латиницей или кириллицей?
И латиница, и кириллица используются для письма на самых разных языках, но латиница повсеместно используется для наибольшего числа языков для любой письменности. Многие из этих языков могут иметь очень небольшое население или могут больше не писаться с помощью рассматриваемого письма (или преимущественно писаться каким-то другим письмом). Тем не менее, значительное количество затронутых языков широко используются в наши дни. Например, для латиницы из нескольких тысяч языков, написанных или транскрибированных в этом сценарии, существует около 200 языков, которые написаны и используются достаточно широко, чтобы предположить необходимость поддержки интернет-идентификаторов; для кириллицы эта цифра составляет 30 языков из примерно 160.
Многие из этих языков могут иметь очень небольшое население или могут больше не писаться с помощью рассматриваемого письма (или преимущественно писаться каким-то другим письмом). Тем не менее, значительное количество затронутых языков широко используются в наши дни. Например, для латиницы из нескольких тысяч языков, написанных или транскрибированных в этом сценарии, существует около 200 языков, которые написаны и используются достаточно широко, чтобы предположить необходимость поддержки интернет-идентификаторов; для кириллицы эта цифра составляет 30 языков из примерно 160.
В: Как представить текст, набранный во Fraktur?
Для обычного текста Unicode считает Fraktur (черная буква) стилем шрифта латиницы, который поэтому кодируется обычными латинскими символами. Рендеринг как Fraktur требует выбора соответствующего шрифта. [АФ]
Q: Почему Unicode содержит алфавит Fraktur?
В отличие от обычного текста, использование Fraktur для переменных в математических выражениях не считается стилем, а несет в себе глубокое семантическое различие (например, пометка переменной как вектора). Для этого был закодирован отдельный математический алфавит, содержащий базовый набор форм букв Фрактура. (Подобные математические алфавиты существуют, например, для букв с двойным ударом). Использование этих кодов символов для обычного текста в стиле Fraktur не рекомендуется. [АФ]
Для этого был закодирован отдельный математический алфавит, содержащий базовый набор форм букв Фрактура. (Подобные математические алфавиты существуют, например, для букв с двойным ударом). Использование этих кодов символов для обычного текста в стиле Fraktur не рекомендуется. [АФ]
Q: Как представить текст, набранный гэльским или островным стилем?
Гэльский текст (островной сценарий) будет закодирован с использованием стандартных латинских букв с выбранным подходящим шрифтом. Есть некоторые исключения, такие как INSULAR G, для некоторых букв очень специфического вида. [АФ]
Q: Как представить текст, набранный в старом/раннем кириллическом алфавите?
Старая или ранняя кириллица, также иногда называемая «старославянской кириллицей», представляет собой стиль кириллицы, использовавшийся до 1708 года. Его не следует путать с глаголицей, которая отдельно кодируется в Unicode.
Unicode рассматривает старую кириллицу как стиль шрифта кириллицы, закодированный с использованием обычных символов кириллицы с выбранным подходящим шрифтом. Unicode отдельно закодировал небольшое количество букв старой кириллицы, внешний вид которых сильно отличается от их современных кириллических эквивалентов, таких как U+A657 ꙗ CYRILLIC SMALL LETTER IOTIFIED A и U+A64B ꙋ CYRILLIC SMALL LETTER MONOGRAPH UK. [ BY ]
Unicode отдельно закодировал небольшое количество букв старой кириллицы, внешний вид которых сильно отличается от их современных кириллических эквивалентов, таких как U+A657 ꙗ CYRILLIC SMALL LETTER IOTIFIED A и U+A64B ꙋ CYRILLIC SMALL LETTER MONOGRAPH UK. [ BY ]
.NET Core Утилита преобразования кириллицы в латиницу (C#) — примеры кода
- Пример кода
Код просмотра
cyrillic-to-latin — это утилита командной строки, которая транслитерирует современные символы кириллицы. до их латинских эквивалентов. Он использует модифицированную систему Библиотеки Конгресса для транслитерация. Его синтаксис:
CyrillicToLatin <исходный файл> <целевой файл>
, где sourceFile — это путь и имя текстового файла, содержащего современную кириллицу.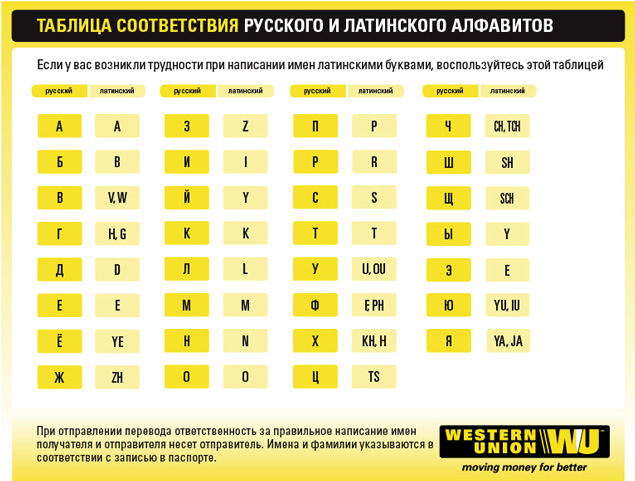 персонажей и destinationFile — это имя текстового файла, в котором будет храниться
исходный текст с заменой кириллических символов на транслитерированные латинские символы.
Если путь к файлу включен в destinationFile и любая часть этого пути
не существует, утилита завершает работу.
персонажей и destinationFile — это имя текстового файла, в котором будет храниться
исходный текст с заменой кириллических символов на транслитерированные латинские символы.
Если путь к файлу включен в destinationFile и любая часть этого пути
не существует, утилита завершает работу.
Специфические сопоставления прописных и строчных кириллических символов
на латинские символы указаны в конструкторе CyrillicToLatinFallback class, где записи таблицы сопоставления прецедентов с именем таблицы определены.
Утилита иллюстрирует расширяемость кодировки символов в .NET
Рамки. Система кодирования состоит из кодера и декодера. Кодер
отвечает за преобразование последовательности символов в последовательность байтов.
декодер отвечает за перевод последовательности байтов в последовательность
персонажи. .NET Core поддерживает ASCII, а также стандартный Unicode.
кодировки и позволяет переопределить класс Encoding для поддержки других
неподдерживаемые кодировки. Это также позволяет кодировщику и декодеру обрабатывать
несопоставленные символы и байты для настройки. В широком смысле кодировщик или декодер может обрабатывать данные, которые он не может отобразить, выбрасывая исключение или используя какое-либо альтернативное сопоставление. Дополнительные сведения см. в разделе Кодировка символов в .NET Framework.
Это также позволяет кодировщику и декодеру обрабатывать
несопоставленные символы и байты для настройки. В широком смысле кодировщик или декодер может обрабатывать данные, которые он не может отобразить, выбрасывая исключение или используя какое-либо альтернативное сопоставление. Дополнительные сведения см. в разделе Кодировка символов в .NET Framework.
Утилита транслитерации создает экземпляр объекта Encoding, представляющего кодировку ASCII, которая поддерживает символы ASCII в диапазоне от U+00 до U+FF. Поскольку современные символы кириллицы занимают диапазон от U+0410 до U+044F, они не сопоставляются автоматически с кодировкой ASCII. Когда утилита создает экземпляр своего объекта Encoding, она передает своему конструктору экземпляр класса с именем CyrillicToLatinFallback , производного от EncoderFallback. Этот класс поддерживает внутреннюю таблицу, которая сопоставляет современные кириллические символы с одним или несколькими латинскими символами.
Когда кодировщик встречает символ, который он не может кодировать, он вызывает резервный вариант.