Кэширование данных для оптимизации производительности — Microsoft Azure Well-Architected Framework
Twitter LinkedIn Facebook Адрес электронной почты
- Статья
- Чтение занимает 2 мин
Кэширование — это стратегия, при которой вы храните копию данных наряду с основным хранилищем данных. Преимущества кэширования включают уменьшение времени отклика и возможность быстро обслуживать данные, что может улучшить взаимодействие с пользователем. Хранилище кэша обычно размещается ближе к клиенту, чем основное хранилище.
Преимущества кэширования включают уменьшение времени отклика и возможность быстро обслуживать данные, что может улучшить взаимодействие с пользователем. Хранилище кэша обычно размещается ближе к клиенту, чем основное хранилище.
Кэширование становится наиболее эффективным, когда экземпляр клиента несколько раз считывает те же данные, особенно в том случае, если к исходному хранилищу данных применяются все указанные далее условия.
- Оно остается относительно статичным.
- Оно является медленным по сравнению со скоростью кэша.
- Оно является объектом высокого числа конкурентных запросов.
- Оно находится далеко, из-за чего задержки в сети могут вызвать снижение скорости доступа.
Кэширование может значительно повысить производительность, масштабируемость и доступность данных. Преимущества кэширования становятся все заметнее с увеличением объемов данных и числа пользователей, которым необходим доступ к этим данным. Это происходит потому, что кэширование снижает задержку и число конфликтов, связанных с обработкой больших объемов параллельных запросов в хранилище исходных данных.
Включение соответствующего кэширования также позволяет сократить задержку за счет исключения повторяющихся вызовов микрослужб, API-интерфейсов и репозиториев данных. Ключом к эффективному использованию кэша является определение наиболее подходящих данных для помещения в кэш и их кэширование в правильный момент времени. Данные могут добавляться в кэш по требованию, как только они впервые извлекаются приложением. Это означает, что приложению будет необходимо извлечь данные из хранилища данных только один раз, а последующий доступ к ним уже может осуществляться с помощью кэша. Дополнительные сведения см. в разделе Определение способа эффективного кэширования данных.
Дополнительные сведения см. в разделе Кэширование.
Кэш Azure для Redis
Кэш Azure для Redis повышает производительность и масштабируемость приложения. Он обрабатывает большие объемы запросов приложений, сохраняя часто используемые данные в памяти сервера, в которой их можно быстро записать и считать. Кэш Azure для Redis на основе программного обеспечения Redis предоставляет хранилище данных с критически низкой задержкой и высокой пропускной способностью для современных приложений.
Кэш Azure для Redis также повышает производительность приложений за счет поддержки стандартных шаблонов архитектуры приложений. Некоторые из наиболее распространенных шаблонов включают кэш данных и кэш содержимого. Наиболее распространенные шаблоны и их описания см. в разделе Общие шаблоны архитектуры приложений.
Сеть доставки содержимого (CDN) Azure
Сеть доставки содержимого (CDN) является распределенной сетью серверов, которая позволяет эффективно доставлять пользователям веб-содержимое. Сети CDN хранят кэшированное содержимое на пограничных серверах в расположениях точек подключения, находящихся рядом с пользователями. Это позволяет свести задержки к минимуму. Дополнительные сведения о CDN см. в статье Что такое сеть доставки содержимого в Azure?
Azure CDN предлагает следующие основные возможности:
- Динамическое ускорение сайтов (DSA) — предоставляет пользователям быстрые, надежные и настраиваемые веб-решения, которые не зависят от браузера, местоположения, устройства или сети.

- Правила кэширования CDN — управление режимом кэширования Azure CDN.
- Поддержка пользовательского домена HTTPS — безопасная доставка конфиденциальных данных при их передаче через Интернет и защита веб-приложений от атак.
- Журналы диагностики Azure — экспорт основных метрик использования из конечной точки CDN в различные типы источников для их последующей настройки.
- Сжатие файлов — увеличение скорости передачи файлов и повышение производительности загрузки страницы за счет уменьшения размера файлов перед их отправкой с сервера.
- Геофильтрация — ограничение доступа к содержимому по стране или региону путем создания правил для конкретных путей в конечной точке CDN.
Следующий
Секция
Кэширование данных в web приложениях. Использование memcached / Хабр
Я немного расскажу вам про кэширование.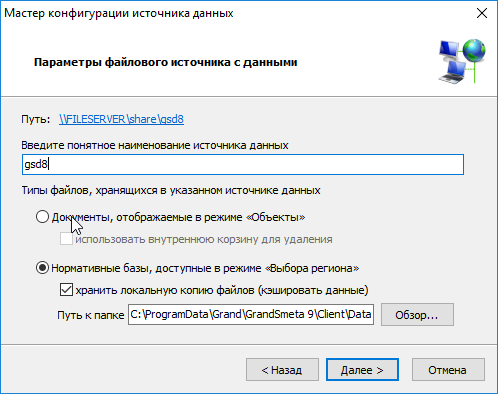 Кэширование, в общем-то, не сильно интересно, берешь и кэшируешь, поэтому я еще расскажу про memcached, довольно интимные подробности.
Кэширование, в общем-то, не сильно интересно, берешь и кэшируешь, поэтому я еще расскажу про memcached, довольно интимные подробности.
Про кэширование начнем с того, что просят вас разработать фабрику по производству омнониевых торсиометров. Это стандартная задача, главное делать скучное лицо и говорить: «Ну, мы применим типовую схему для разработки фабрики».
Вообще, это ближе к фабричному производству, т.е. откуда проблема пошла? Фабрика работает очень быстро, производит наши торсиометры. А для калибровки каждого прибора нужен чистый омноний, за которым надо летать куда-то далеко и, соответственно, пока мы в процессе добычи этого омнония, приборы лежат некалиброванные, и, по сути дела, все производство останавливается. Поэтому мы строим рядом с фабрикой склад. Но это не бесплатно.
Переходим к терминологии. Просто, чтобы мы общались про кэширование на одном языке есть довольно устоявшаяся терминология.
Источник называется origin; объем склада, т.
У данных — у нашего омнониума — есть freshness, буквально — это свежесть. Fresheness используется везде. Как только данные теряют свою природную свежесть, они становятся stale data.
Процесс проверки данных на годность называется validation, а момент, когда мы говорим, что данные негодные, и выбрасываем их со склада — это называется
Иногда случается такая обидная ситуация, когда у нас не остается места, но нам лучше держать свежий омнониум, поэтому мы находим по каким-то критериям самый старый и выбрасываем. Это называется eviction.
Схема такая, что от нашего браузера до бэкенда есть масса звеньев в цепи. Вопрос: где кэшировать? На самом деле, кэшировать надо абсолютно везде. И, хотите вы этого или нет, данные будут кэшироваться, т.е. вопрос, скорее, — как мы можем на это повлиять?
И, хотите вы этого или нет, данные будут кэшироваться, т.е. вопрос, скорее, — как мы можем на это повлиять?
Для начала нужно найти хорошие данные для кэширования. В связи с тем, что мы делаем какой-то кэш, у нас появляется еще одно промежуточное звено в цепи, и необязательно, что кэш что-то ускорит. Если мы плохо подберем данные, то, в лучшем случае, он не повлияет на скорость, а в худшем — еще и замедлит процесс всего производства, всей системы.
Нет смысла кэшировать данные, которые часто меняются. Нужно кэшировать данные, которые используются часто. Размер данных имеет значение, т.е. если мы решаем кэшировать в памяти blu-ray фильм — классно, мы его очень быстро достанем из памяти, но, скорее всего, нам потом его придется перекачать куда-нибудь по сети, и это будет очень медленно. Такой большой объем данных не соизмерим со скоростью доставки, т.е. нам нет смысла держать такие данные в памяти. Можем на диске держать, но нужно сравнивать по скорости.
Кстати, можете погуглить «programming latencies».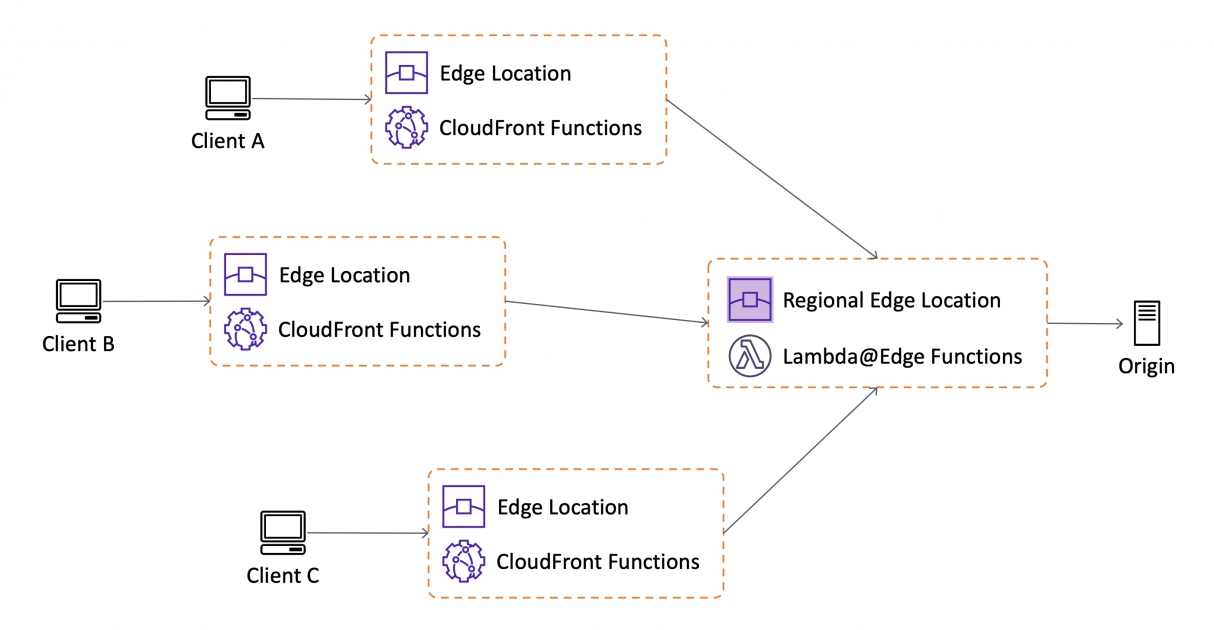 Там на сайте очень хорошо даны все стандартные задержки, например, скорость доступа в CPU cache, скорость отправки Round Trip пакета в дата-центре. И когда вы проектируете, что-то прикидываете, хорошо смотреть, там очень наглядно показано, что сколько времени и по сравнению с чем занимает.
Там на сайте очень хорошо даны все стандартные задержки, например, скорость доступа в CPU cache, скорость отправки Round Trip пакета в дата-центре. И когда вы проектируете, что-то прикидываете, хорошо смотреть, там очень наглядно показано, что сколько времени и по сравнению с чем занимает.
Это готовые рецепты для кэширования:
Это релевантный HTTP Headers:
Я немного расскажу про некоторые, но, вообще-то, про это надо читать. В принципе, в вебе единственное, как мы можем влиять на кэширование — это правильно устанавливая вот эти header’ы.
Expires использовался раньше. Мы устанавливаем freshness для наших данных, мы буквально говорим: «Все, этот контент годен до такого вот числа». И сейчас этот header нужно использовать, но только как fallback, т.к. есть более новый header. Опять-таки, эта цепочка очень длинная, вы можете попасть на какую-то прокси, которая понимает только вот этот header — Expires.
Новый header, который сейчас отвечает за кэширование, — это Cache-Control:
Тут вы можете указать сразу же и freshness, и validation механизм, и invalidation механизм, указать, это public данные или private, как их кэшировать…
Кстати, no-cache — это очень интересно.
Если мы хотим, вообще, выключить кэширование для контента, то говорим «no-store»:
Эти «no-cache», «no-store» очень часто применяются для форм аутентификации, т.е. мы не хотим кэшировать неаутентифицированных пользователей, чтобы не получилось странного, чтобы они не увидели лишнего или не было недопонимания. И, кстати, про этот Cache-Control: no-cache… Если, допустим, Cache-Control header не поддерживается, то его поведение можно симулировать. Мы можем взять header Expires и установить дату какую-нибудь в прошлом.
Эти все header’ы, включая даже Content-Length, для кэша актуальны. Некоторые кэшируюшие прокси могут просто даже не кэшировать, если нет Content-Length.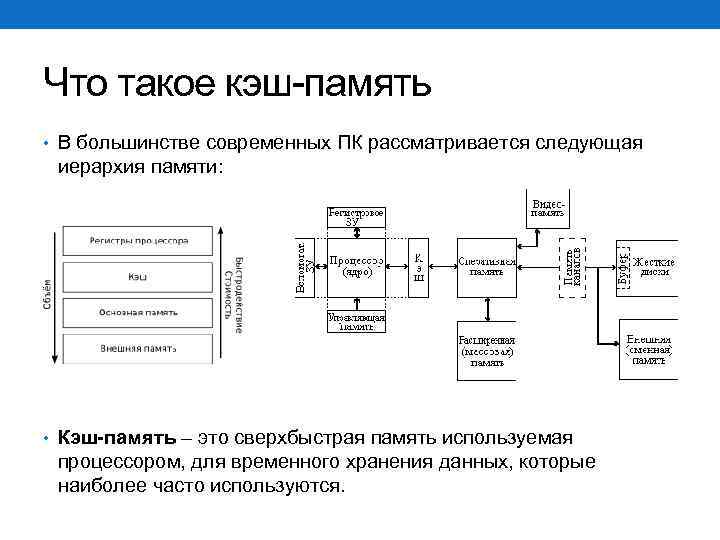
Собственно, мы приходим к memcached, к кэшу на стороне бэкенда.
Опять же мы можем кэшировать по-разному, т.е. мы достали какие-то данные из базы, что-то в коде с ними делаем, но, по сути дела, это кэш, — мы один раз их достали, чтобы много раз переиспользовать. Мы можем использовать в коде какой-то компонент, фреймворк. Этот компонент для кэширования нужен, потому что у нас должны быть разумные лимитэйшны на наш продукт. Все начинается с того, что приходит какой-то инженер по эксплуатации и говорит: «Объясни мне требования на свой продукт». И вы должны ему сказать, что это будет столько-то оперативной памяти, столько-то места на диске, такой-то прогнозируемый объем роста у приложения… Поэтому, если мы что-то кэшируем, мы хотим иметь ограничения. Допустим, первое ограничение, которое мы можем легко обеспечить, — по числу элементов в кэше. Но если у нас элементы разного размера, тогда мы хотим это закрыть рамками фиксированного объема памяти. Т.е. мы говорим какой-нибудь размер кэша — это самый главный лимит, самый главный boundary. Мы используем библиотеку, которая может такую штуку делать.
Мы используем библиотеку, которая может такую штуку делать.
Ну, или же мы используем отдельный кэширующий сервис, вообще stand-alone. Зачем нам нужен какой-то отдельный кэширующий сервис? Чаще всего бэкенд — это не что-то такое монолитное, один процесс. У нас есть какие-то разрозненные процессы, какие-то скрипты, и если у нас есть отдельный кэширующий сервис, то есть возможность у всей инфраструктуры бэкенда видеть этот кэш, использовать данные из него. Это здорово.
Второй момент — у нас есть возможность расти. Например, мы ставим один сервис, у нас заканчивается кэшсайз, мы ставим еще один сервис. Естественно, это не бесплатно, т.е. «а сегодня мы решили отмасштабироваться» не может случиться. Нужно планировать такие вещи заранее, но отдельный кэширующий сервис такую возможность дает.
Кэш еще дает нам availability практически за бесплатно. Допустим, у нас есть какие-то данные в кэше, и мы пытаемся достать эти данные из кэша. У нас что-то где-то падает, а мы делаем вид, что ничего не упало, отдаем данные с кэша. Оно, может, в это время переподнимется как-то, и будет даже availability.
Оно, может, в это время переподнимется как-то, и будет даже availability.
Собственно, мы подобрались к memcached. Memcached — это типичный noSQL.
Почему noSQL для кэширования — это хорошо?
По структуре. У нас есть обычная хэш-таблица, т.е. мы получаем низкий latency. В случае с memcached и аналогичными key-value storage’ами — это не просто низкий latency, а в нотации big-O у нас сложность большинства операций — это константа от единицы. И поэтому мы можем говорить, что у нас какой-то временной constraint. У нас, например, запрос занимает не больше 10 мс., т.е. можно даже договариваться о каком-то контракте на основании этих latency. Это хорошо.
Чаще всего мы кэшируем что попало — картинки вперемешку с CCS’ом с JS’ом, какие-то фрагменты форм прирендеренных, что-то еще. Это непонятно, какие данные, и структура key-value позволяет их хранить довольно легко. Мы можем завести нотацию, что у нас account.300.avatar — это картинка, и оно там работает. 300 — это ID аккаунта в нашем случае.
Немаловажный момент — то, что упрощается код самого storage’а, если у нас key-value noSQL, потому что самое страшное, что может быть — это мы как-то испортим или потеряем данные. Чем меньше кода работает с данными, тем меньше шанса испортить, поэтом простой кэш с простой структурой — это хорошо.
Про memcached key-value. Можно указывать вместе с данными expiration. Поддерживается работа в фиксированном объеме памяти. Можно устанавливать 16-битные флаги со значением произвольно — они для memcached прозрачны, но чаще всего вы будете с memcached работать и с какого-то клиента, и скорее всего, этот клиент уже загреб эти 16 бит под себя, т.е. он их как-то использует. Такая возможность есть.
memcached может работать с поддержкой викшинов, т.е. когда у нас кончается место, мы самые старые данные выпихиваем, самые новые добавляем. Или же мы можем сказать: «Не удаляй никакие данные», тогда при добавлении новых данных она будет возвращать ошибку out of memory — это флажок «-М».
Структурированной единой документации по memcached нет, лучше всего читать описание протокола. В принципе, если вы наберете в Google «memcached протокол», это будет первая ссылка. В протоколе описаны не только форматы команд — отправка, что мы отправляем, что приходит в ответ… Там описано, что вот эта команда, она будет вести себя вот так и так, т.е. там какие-то корнер кейсы.
Коротенько по командам:
get — получить данные;
set/ add/ delete/ replace — как мы сторим эти данные, т.е.:
- set — это сохранить, добавить новые, либо заменить,
- add — это добавить только, если такого ключа нет,
- delete — удалить;
- replace — заменить, только если такой ключ есть, иначе — ошибка.
Это в среде, когда у нас есть шард. Когда у нас есть кластер, это никакой консистентности нам не гарантирует. Но с одним инстансом консистанси можно поддерживать этими командами. Более или менее можно такие constraint’ы выстраивать.
Но с одним инстансом консистанси можно поддерживать этими командами. Более или менее можно такие constraint’ы выстраивать.
prepend/ append — это мы берем и перед нашими данными вставляем какой-то кусочек или после наших данных вставляем какой-то кусочек. Они не очень эффективно реализованы внутри memcached, т.е. у вас все равно будет выделяться новый кусок памяти, разницы между ними и set функционально нет.
Мы можем данным, которые сохраняем, указать какой-то expiration и потом мы можем эти данные трогать командой touch, и мы продляем жизнь конкретно вот этому ключу, т.е. он не удалится.
Есть команды инкремента и декремента — incr/decr. Работает оно следующим образом: вы сторите какое-то число в виде строки, потом говорит incr и даете значение какое-то. Оно суммирует. Декремент — то же самое, но вычитает. Там есть интересный момент, например, 2 — 3 = 0, с точки зрения memcached, т.е. она автоматически хэндлит андерфлоу, но она не дает нам сделать отрицательное число, в любом случае вернется ноль.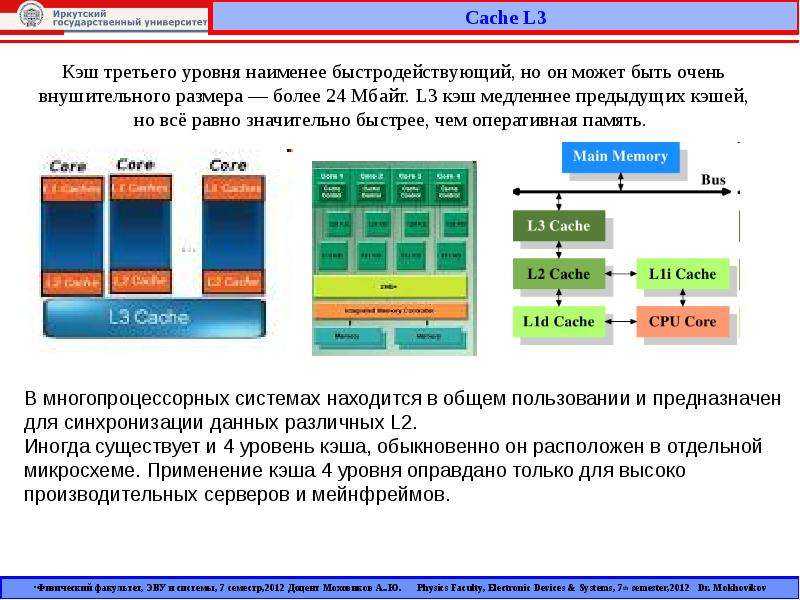
Единственная команда, с помощью которой можно сделать какую-то консистентность, — это cas (это атомарная операция compare and swap). Мы сравниваем два каких-то значения, если эти значения совпадают, то мы заменяем данные на новые. Значение, которое мы сравниваем, — это глобальный счетчик внутри
memcached, и каждый раз, когда мы добавляем туда данные, этот счетчик инкрементится, и наша пара key-value получает какое-то значение. С помощью команд gets мы получаем это значение и потом в команде cas мы его можем использовать. У этой команды есть все те же проблемы, которые есть у обычных атомиков, т.е. можно наделать кучу raise condition’ов интересных, тем более, что у memcached нет никаких гарантий на порядок выполнения команд.
Есть у memcached ключик «-С» — он выключает cas. Т.е. что происходит? Этот счетчик пропадает из key-value pair, если вы добавляете ключик «-С», то вы экономите 8 байт, потому что это 64-хбитный счетчик на каждом значении. Если у вас значения небольшие, ключи небольшие, то это может быть существенная экономия.
Если у вас значения небольшие, ключи небольшие, то это может быть существенная экономия.
Как работать с memcached эффективно?
Она задизайнена, чтобы работать с множеством сессий. Множества — это сотни. Т.е. начинается от сотен. И дело в том, что в терминах RPS — request per second — вы не выжмете из memcached многого, используя 2-3 сессии, т.е. для того, чтобы ее раскачать, надо много подключений. Сессии должны быть долгоиграющие, потому что создание сессии внутри memcached — довольно дорогостоящий процесс, поэтому вы один раз прицепились и все, эту сессию надо держать.
Запросы надо batch’ить, т.е. мы должны отправлять запросы пачками. Для get-команды у нас есть возможность передать несколько ключей, этим надо пользоваться. Т.е. мы говорим get и ключ-ключ-ключ. Для остальных команд такой возможности нет, но мы все равно можем делать batch, т.е. мы можем формировать запрос у себя, локально, на стороне клиента с использованием нескольких команд, а потом этот запрос целиком отправлять.
memcached многопоточна, но она не очень хорошо многопоточна. У нее внутри много блокировок, довольно ad-hoc, поэтому больше четырех потоков вызывают очень сильный контеншн внутри. Мне верить не надо, надо все перепроверять самим, надо с живыми данными, на живой системе делать какие-то эксперименты, но очень большое число потоков работать не будет. Надо поиграться, подобрать какое-то оптимальное число ключиком «-t».
memcached поддерживает UDP. Это патч, который был добавлен в memcached facebook’ом. То, как использует facebook memcached — они делают все сеты, т.е. всю модификацию данных по TCP, а get’ы они делают по UDP. И получается, когда объем данных существенно большой, то UDP дает серьезный выигрыш за счет того, что меньше размер пакета. Они умудряются больше данных прокачать через сетку.
Я вам рассказывал про incr/decr — эти команды идеально подходят для того, чтобы хранить статистику бэкенда.
Статистика в HighLoad’e — это вещь незаменимая, т.е. вы не сможете понять, что, как, откуда происходит конкретная проблема, если у вас не будет статистики, потому что после получаса работы «система ведет себя странно» и все… Чтобы добавить конкретики, например, каждый тысячный запрос фейлится, нам нужна какая-то статистика. Чем больше статистики будет, тем лучше. И даже, в принципе, чтобы понять, что у нас есть проблема, нам нужна какая-то статистика. Например, бэкенд отдавал за 30 мс страницу, начал за 40, взглядом отличить невозможно, но у нас перформанс просел на четверть — это ужасно.
Чем больше статистики будет, тем лучше. И даже, в принципе, чтобы понять, что у нас есть проблема, нам нужна какая-то статистика. Например, бэкенд отдавал за 30 мс страницу, начал за 40, взглядом отличить невозможно, но у нас перформанс просел на четверть — это ужасно.
Memcached тоже сама по себе поддерживает статистику, и если вы уже используете memcached в своей инфраструктуре, то статистика memcached — это часть вашей статистики, поэтому туда заглядывать надо, туда надо смотреть, чтобы понимать, правильно ли бэкенд использует кэш, хорошо ли он данные кэширует.
Первое — по каждой команде есть hits и misses. Когда мы обратились к кэшу, и нам отдали данные, поинкрементился hit по этой команде. Например, сделали delete ключ, у нас будет delete hits 1, так по каждой команде. Естественно, надо, чтобы hits была 100%, misses не было вообще. Надо смотреть. Допустим, у нас может быть очень высокий miss ratio. Самая банальная причина — мы просто лезем не за теми данными. Может быть такой вариант, что мы выделили под кэш мало памяти, и мы постоянно переиспользуем кэш, т. е. мы данные какие-то добавили-добавили-добавили, на каком-то моменте там первые данные выпали из кэша, мы за ними полезли, их там уже нет. Мы полезли за другими, их там тоже нет. И оно вот так все крутится. Т.е. надо либо со стороны бэкенда уменьшить нагрузку на memcached, либо можно увеличить параметром «-m» объем памяти, который мы разрешаем использовать.
е. мы данные какие-то добавили-добавили-добавили, на каком-то моменте там первые данные выпали из кэша, мы за ними полезли, их там уже нет. Мы полезли за другими, их там тоже нет. И оно вот так все крутится. Т.е. надо либо со стороны бэкенда уменьшить нагрузку на memcached, либо можно увеличить параметром «-m» объем памяти, который мы разрешаем использовать.
Evictions — это очень важный момент. Ситуация, про которую я рассказываю, она будет видна из того, что evictions rate будет очень высокий. Это количество, когда пригодные данные не експайред, т.е. они свежие, хорошие выбрасываются из кэша, у нас тогда растет число evictions.
Я говорил, что надо использовать batch’и. Как подобрать размер batch’a? Серебряной пули нет, надо экспериментально это все подбирать. Зависит все от вашей инфраструктуры, от сети, которую вы используете, от числа инстансов и прочих факторов. Но когда у нас batch очень большой… Представьте ситуацию, что мы выполняем batch, и все остальные конекншны стоят и ждут, пока batch выполнится.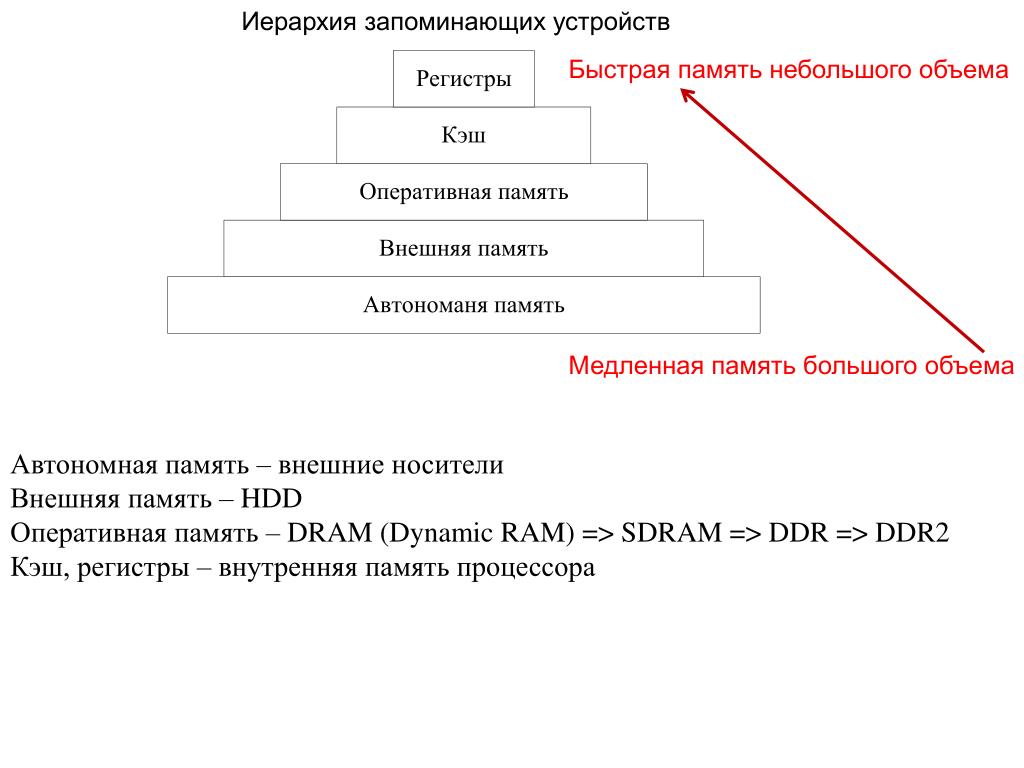 Это называется starvation — голодание, т.е. когда остальные конекшны голодают и ждут, пока выполнится один жирный. Чтобы этого избежать, внутри memcached есть механизм, который прерывает выполнение batch’a насильно. Реализовано это довольно грубо, есть ключик «-R», который говорит сколько команд может выполнить один конекшн подряд. По умолчанию это значение 20. И вы, когда посмотрите на статистику, если у вас conn_yields stat будет каким-то очень высоким, это значит, что вы используете batch больше, чем может memcached прожевать, и ему приходится насильно часто переключать контекст этого конекшна. Тут можно либо увеличить размер batch’а ключиком «-R», либо не использовать со стороны бэкенда такие batch’и.
Это называется starvation — голодание, т.е. когда остальные конекшны голодают и ждут, пока выполнится один жирный. Чтобы этого избежать, внутри memcached есть механизм, который прерывает выполнение batch’a насильно. Реализовано это довольно грубо, есть ключик «-R», который говорит сколько команд может выполнить один конекшн подряд. По умолчанию это значение 20. И вы, когда посмотрите на статистику, если у вас conn_yields stat будет каким-то очень высоким, это значит, что вы используете batch больше, чем может memcached прожевать, и ему приходится насильно часто переключать контекст этого конекшна. Тут можно либо увеличить размер batch’а ключиком «-R», либо не использовать со стороны бэкенда такие batch’и.
Еще я говорил, что memcached выбрасывает из памяти самые старые данные. Так вот, я соврал. На самом деле это не так. Внутри memcached есть свой memory менеджер, чтобы эффективно работать с этой памятью, чтобы выбрасывать эти атомы. Он устроен таким образом, что у нас есть slabs (буквально «огрызок»). Это устоявшийся термин в программировании memory менеджеров для какого-то куска памяти, т.е. у нас есть просто какой-то большой кусок памяти, который, в свою очередь, делится на pages. Pages внутри memcached по Мб, поэтому вы не сможете создать там данные «ключ-значение» больше одного Мб. Это физическое ограничение — memcached не может создать данные больше, чем одна страница. И, в итоге, все страницы побиты на чанки, это то, что вы видите на картинке по 96, 120 — они определенного размера. Т.е. идут куски по 96 Мб, потом куски по 120, с коэффициентом 1.25, от 32-х до 1 Мб. В пределах этого куска есть двусвязный список. Когда мы добавляем какое-то новое значение, memcached смотрит на размер этого значения (это ключ + значение + экспирейшн + флаги + системная информация, которая memcached нужна (порядка 24-50 байт)), выбирает размер этого чанка и добавляет в двусвязный список наши данные. Она всегда добавляет данные в head. Когда мы к каким-то данным обращаемся, то memcached вынимает их из двусвязного списка и опять бросает в head.
Это устоявшийся термин в программировании memory менеджеров для какого-то куска памяти, т.е. у нас есть просто какой-то большой кусок памяти, который, в свою очередь, делится на pages. Pages внутри memcached по Мб, поэтому вы не сможете создать там данные «ключ-значение» больше одного Мб. Это физическое ограничение — memcached не может создать данные больше, чем одна страница. И, в итоге, все страницы побиты на чанки, это то, что вы видите на картинке по 96, 120 — они определенного размера. Т.е. идут куски по 96 Мб, потом куски по 120, с коэффициентом 1.25, от 32-х до 1 Мб. В пределах этого куска есть двусвязный список. Когда мы добавляем какое-то новое значение, memcached смотрит на размер этого значения (это ключ + значение + экспирейшн + флаги + системная информация, которая memcached нужна (порядка 24-50 байт)), выбирает размер этого чанка и добавляет в двусвязный список наши данные. Она всегда добавляет данные в head. Когда мы к каким-то данным обращаемся, то memcached вынимает их из двусвязного списка и опять бросает в head. Т.о., те данные, которые мало используются, переползают в tail, и в итоге они удаляются.
Т.о., те данные, которые мало используются, переползают в tail, и в итоге они удаляются.
Если памяти нам не хватает, то memcached начинает удалять память с конца. Механизм list recently used работает в пределах одного чанка, т.е. эти списки выделены для какого-то размера, это не фиксированный размер — это диапазон от 96 до 120 попадут в 120-ый чанк и т.д. Влиять на этот механизм со стороны memcached мы никак не можем, только со стороны бэкенда надо подбирать эти данные.
Можно посмотреть статистику по этим slab’ам. Смотреть статистику по memcached проще всего — протокол полностью текстовый, и мы можем Telnet’ом подсоединиться, набрать stats, Enter, и она вывалит «простыню». Точно так же мы можем набрать stats slabs, stats items — это в принципе, похожая информация, но stats slabs дает картину, больше размазанную во времени, там такие stat’ы — что было, что происходило за весь тот период пока memcached работал, а stat items — там больше о том, что у нас есть сейчас, сколько есть чего. В принципе, обе эти вещи надо смотреть, надо учитывать.
В принципе, обе эти вещи надо смотреть, надо учитывать.
Вот мы подобрались к масштабированию. Естественно, мы поставили еще один сервер memcached — здорово. Что будем делать? Как-то надо выбирать. Либо мы на стороне клиента решаем, к какому из серверов будем присоединяться и почему. Если у нас availability, то все просто — записали туда, записали сюда, читаем откуда-нибудь, не важно, можно Round Robin’ом, как угодно. Либо мы ставим какой-то брокер, и для бэкенда у нас получается, что это выглядит как один инстанс memcached, но на самом деле за этим брокером прячется кластер.
Для чего используется брокер? Чтобы упростить инфраструктуру бэкенда. Например, нам надо из дата-центра в дата-центр поперевозить сервера, и все клиенты должны об этом знать. Либо мы можем хак за этим брокером сделать, и для бэкенда все прозрачно пройдет.
Но вырастает latency. 90% запросов — это сетевой round trip, т.е. memcached внутри себя запрос обрабатывает за мкс — это очень быстро, а по сети данные ходят долго. Когда у нас есть брокер, у нас появляется еще одно звено, т.е. все еще дольше выполняется. Если клиент сразу знает, на какой кластер memcached ему идти, то он данные достанет быстро. А, собственно, как клиент узнает, на какой кластер memcached ему идти? Мы берем, считаем хэш от нашего ключа, берем остаток от деления этого хэша на количество инстанса в memcached и идем на этот кластер — самый простой солюшн.
Когда у нас есть брокер, у нас появляется еще одно звено, т.е. все еще дольше выполняется. Если клиент сразу знает, на какой кластер memcached ему идти, то он данные достанет быстро. А, собственно, как клиент узнает, на какой кластер memcached ему идти? Мы берем, считаем хэш от нашего ключа, берем остаток от деления этого хэша на количество инстанса в memcached и идем на этот кластер — самый простой солюшн.
Но добавился у нас еще один кластер в инфраструктуру, значит, сейчас нам нужно грохнуть весь кэш, потому что он стал неконсистентным, не валидным, и заново все пересчитать — это плохо.
Для этого есть механизм — consistent hashing ring. Т.е. что мы делаем? Мы берем хэш значения, все возможные хэш значения, например int32, берем все возможные значения и располагаем как будто на циферблате часов. Так. мы можем сконфигурировать — допустим, хэши с такого-то по такой-то идут на этот кластер. Мы конфигурируем рэнджи и конфигурируем кластеры, которые отвечают за эти рэнджи. Таким образом, мы можем тасовать сервера как угодно, т.е. нам надо будет поменять в одном месте это кольцо, перегенерировать, и сервера, клиенты или роутер, брокер — у них будет консистентное представление о том, где лежат данные.
Таким образом, мы можем тасовать сервера как угодно, т.е. нам надо будет поменять в одном месте это кольцо, перегенерировать, и сервера, клиенты или роутер, брокер — у них будет консистентное представление о том, где лежат данные.
Я еще бы хотел немного сказать про консистентность данных. Как только у нас появляется новое звено, как только мы кэшируем где-либо, у нас появляется дубликат данных. И у нас появляется проблема, чтобы эти данные были консистентными. Потому что есть много таких ситуаций — например, мы записываем данные в кэш — локальный или удаленный, потом идем и пишем эти данные в базу, в этот момент база падает, у нас конекшн с базой пропал. По сути дела, по логике, этих данных у нас нет, но в это же время клиенты читают их из кэша — это проблема.
memcached плохо подходит для consistancy каких-то решений, т.е. это больше решения на availability, но в то же время, есть какие-то возможности с cas’ом что-то наколхозить.
Контакты
» cachelot@cachelot. io
io
» http://cachelot.io/
Этот доклад — расшифровка одного из лучших выступлений на обучающей конференции разработчиков высоконагруженных систем HighLoad++ Junior.Также некоторые из этих материалов используются нами в обучающем онлайн-курсе по разработке высоконагруженных систем HighLoad.Guide — это цепочка специально подобранных писем, статей, материалов, видео. Уже сейчас в нашем учебнике более 30 уникальных материалов. Подключайтесь!
Ну и главная новость — мы начали подготовку весеннего фестиваля «Российские интернет-технологии», в который входит восемь конференций, включая HighLoad++ Junior.
Кэширование данных Tile-сервера
Кэширование данных Tile-сервера
При работе с Tile-сервером кэширование – это сохранение на жестком диске полученных с сервера растровых изображений с целью их дальнейшего многократного использования без повторных обращений к серверу.
Если кэш содержит достаточное количество данных для работы, пользователь может работать
с этими данными off-line, не загружая глобальную сеть.
Изображения, сохраняемые на диске, должны быть определенным образом организованы.
Текущая версия ZuluGIS и ZuluServer для организации кэшируемых файлов использует файловую структуру кэша программы Sas.Планета.
<Корневая папка>\z[Z+1]\[X/1024]\x[X]\[Y/1024]\[Y].<EXT>
Следует отметить, что независимо от системы отсчета плиток в исходной тайловой-системе, в кэш плитки складываются всегда в системе координат Lat0 = 90, Lon0 = -180, ось X – на восток, ось Y — на юг. То есть для записи в кэш нового файла, его исходные параметры X, Y, Z сначала преобразуются в новые параметры X, Y, Z для кэша. При совпадении систем координат тайлового слоя и кэша, параметры X, Y, Z не изменятся.
Корневая папка
Местоположение корневой папки кэша, создаваемого ZuluGIS или ZuluServer на компьютере, определяется следующим образом:
<Папка приложений для всех пользователей>\Zulu\ztc_<Код кэша>\
Папка приложений для всех пользователей – это системная папка, для
создания приложениями данных для всех пользователей компьютера.
В зависимости от используемой операционной системы, путь папки может быть разным.
Windows XP:
C:\Documents and Settings\All Users\Application Data\
Windows 7:
C:\ProgramData\
Код кэша – числовой код, автоматически формируемый ZuluGIS, как контрольная сумма строки с шаблоном запроса (значение параметра Address в описателе).
Пример:
Address:
http://www.maps-for-free.com/layer/relief/
Папка кэша:
WindowsXP
C:\Documents and Settings\All Users\Application Data\Zulu\ztc_2138735954\
Windows 7
C:\ProgramData\Zulu\ztc_2138735954\
Для плитки Z = 15, X = 19141, Y = 9525 имя файла в формате PNG в Windows 7 сформируется так:
C:\ProgramData\Zulu\ztc_2138735954\z16\18\x19141\9\y9525.png
Выбор общей для всего компьютера папки и создание единого кода для разных описателей с
одинаковым шаблоном запроса, позволяет избежать дублирования кэша для одних и тех же
данных.
| Примечание | |
|---|---|
Корневая папка для кэширования тайловых данных, отличная от папки по умолчанию может быть задана через меню Сервис|Параметры|Сеть. |
Варианты кэширования
Возможны несколько вариантов использования механизма кэширования.
Первый вариант. Описатель слоя расположен на том же компьютере и в шаблоне запроса указана связь с данными по протоколу HTTP.
Address: http://<шаблон запроса>
В этом случае запросы на получение плиток идут непосредственно к указанному в шаблоне серверу. Полученные плитки складываются в кэш на этом компьютере.
При этом если в организации несколько компьютеров обращаются к одному и тому же ресурсу
глобальной сети, на каждой машине будет создаваться свой кэш, а общая нагрузка на глобальную
сеть возрастет пропорционально количеству пользователей.
Второй вариант. Описатель тайлового слоя можно разместить на компьютере, где установлен ZuluServer и опубликовать данный слой как слой ZuluServer, создав соответствующий описатель.
Например, если в область данных сервера поместить описатель sample.zww, то для его публикации на сервере достаточно создать в той же папке текстовый описатель sample.zl с одной строкой:
Path: sample.zww
В этом случае клиенты ZuluServer будут обращаться за данными не прямо к серверу тайловых данных, а к тайловому слою, опубликованному на ZuluServer (например, Zulu://zs_host:6473/sample.zl).
При обращении клиента к ZuluServer за плиткой, ZuluServer проверит, нет ли такого
изображения в кэше сервера. Если изображение найдено в кэше сервера, оно будет отправлено
клиенту без обращения в глобальную сеть. Если изображение в кэше отсутствует, ZuluServer
запросит его из глобальной сети, положит себе в кэш и отправит клиенту.
Таким образом, ZuluServer может выступать как посредник в предоставлении данных тайл-сервера клиенту.
Удобство такого варианта в том, что для всех клиентов ZuluServer кэш будет создаваться в одном месте, на диске сервера, сильно сокращая количество запросов в глобальную сеть и существенно экономя дисковое пространство клиентских машин.
Кроме того, при таком подходе клиентские машины вообще могут не иметь доступа в интернет.
Третий вариант. Кэш располагается на локальном компьютере, но данные для него получать не из глобальной сети, а от ZuluServer.
Для этого нужно создать на локальной машине описатель, с моделью «Тайловый слой ZuluServer» и в шаблоне запроса указать имя тайлового слоя на сервере:
Method: ZS Address: Zulu://zs_host:6473/sample.zl
В этом случае для получения изображения клиент проверяет, нет ли его в локальном кэше.
Если нет, клиент обращается за изображением на ZuluServer. ZuluServer проверяет, нет ли
изображения в его кэше.
ZuluServer проверяет, нет ли
изображения в его кэше.
Если нет, ZuluServer обращается за изображением в глобальную сеть, получает изображение, сохраняет его в своем кэше, и отправляет клиенту.
Клиент, получив изображение от ZuluServer, кладет изображение в свой кэш.
При таком комбинированном варианте клиент нагружает ZuluServer только по необходимости, а ZuluServer только по необходимости загружает глобальную сеть.
Новости компании
Предлагаем ознакомиться с переводом статьи Антонелло Занини о кешировании: что это такое, как оно работает и какие типы кеширования являются наиболее важными.
За последние несколько лет информационные технологии значительно улучшили любой вид бизнеса. Между тем архитектуры программного обеспечения становятся все более сложными, и число их пользователей растет в геометрической прогрессии. Это вызывает проблемы с точки зрения работы любого приложения. Низкая производительность может подорвать стратегические цели любой компании, поэтому очень важно найти разумные способы ее улучшения. Как следствие, необходимо избежать накладных расходов и сократить время поиска и обработки данных. Вот почему в игру вступает кеширование, и ни один разработчик больше не может его игнорировать.
Как следствие, необходимо избежать накладных расходов и сократить время поиска и обработки данных. Вот почему в игру вступает кеширование, и ни один разработчик больше не может его игнорировать.
Сперва углубимся в концепцию кеширования, поймем, почему это важно, и возможные риски, связанные с этим. Затем мы изучим наиболее важные типы кеширования.
Что такое кеширование
Кеширование — это механизм повышения производительности любого типа приложений. Технически кеширование — это процесс хранения и доступа к данным из кеша. Но подождите, что такое кеш? Кеш — это программный или аппаратный компонент, предназначенный для хранения данных, будущие запросы на которые могли бы обслуживаться быстрее.
Основная причина появления кеширования заключается в том, что доступ к данным из постоянной памяти занимает значительное время. Таким образом, всякий раз, когда данные извлекаются или обрабатываются, они должны храниться в быстрой оперативной памяти. Мы называем такую память «кешем», рассматриваемым как высокоскоростной уровень хранения данных, основная цель которого — уменьшить потребность в доступе к более медленным слоям хранения данных. Чтобы быть рентабельными и эффективными, кеши должны быть относительно небольшими, особенно по сравнению с традиционной памятью. Вот почему они обычно реализуются с использованием оборудования с быстрым доступом, такого как RAM (Random Access Memory, или оперативная память), плюс программный компонент.
Чтобы быть рентабельными и эффективными, кеши должны быть относительно небольшими, особенно по сравнению с традиционной памятью. Вот почему они обычно реализуются с использованием оборудования с быстрым доступом, такого как RAM (Random Access Memory, или оперативная память), плюс программный компонент.
Благодаря кешам можно реализовать механизм для эффективного повторного использования ранее извлеченных или вычисленных данных. При поступлении нового запроса запрашиваемые данные сначала ищутся в кэше. Попадание в кеш происходит, когда запрашиваемые данные могут быть найдены в кеше. Напротив, промах в кеш-памяти происходит тогда, когда запрашиваемые данные отсутствуют в кеше. Очевидно, предполагается, что считывание нужных данных из кешей происходит быстрее, чем повторное вычисление результата или его чтение из исходного хранилища данных. Таким образом, чем больше запросов обработается из кеша, тем быстрее будет работать система.
В заключение, кеширование — довольно простой способ добиться повышения производительности. Это особенно верно по сравнению с оптимизацией алгоритмов, которая обычно является очень сложной и трудоемкой задачей.
Это особенно верно по сравнению с оптимизацией алгоритмов, которая обычно является очень сложной и трудоемкой задачей.
В чем значимость кеширования
Кеширование чрезвычайно важно, поскольку позволяет разработчикам добиться повышения производительности, иногда значительно. Как говорилось выше, это жизненно необходимо.
В частности, ни пользователи, ни разработчики не хотят, чтобы приложения долго обрабатывали запросы. Как разработчикам, нам хотелось бы создавать наиболее производительную версию приложений. Как пользователи, мы не готовы ждать несколько секунд, а иногда и миллисекунд. На самом деле никто не любит тратить время на загрузку сообщений.
Кроме того, важность обеспечения высокой производительности настолько критична, что кеширование быстро стало неизбежной концепцией в компьютерных технологиях. Это значит, что все больше и больше сервисов используют его, так что оно практически вездесуще. Как следствие, если мы хотим конкурировать с множеством приложений на рынке, нужно правильно реализовать системы кеширования.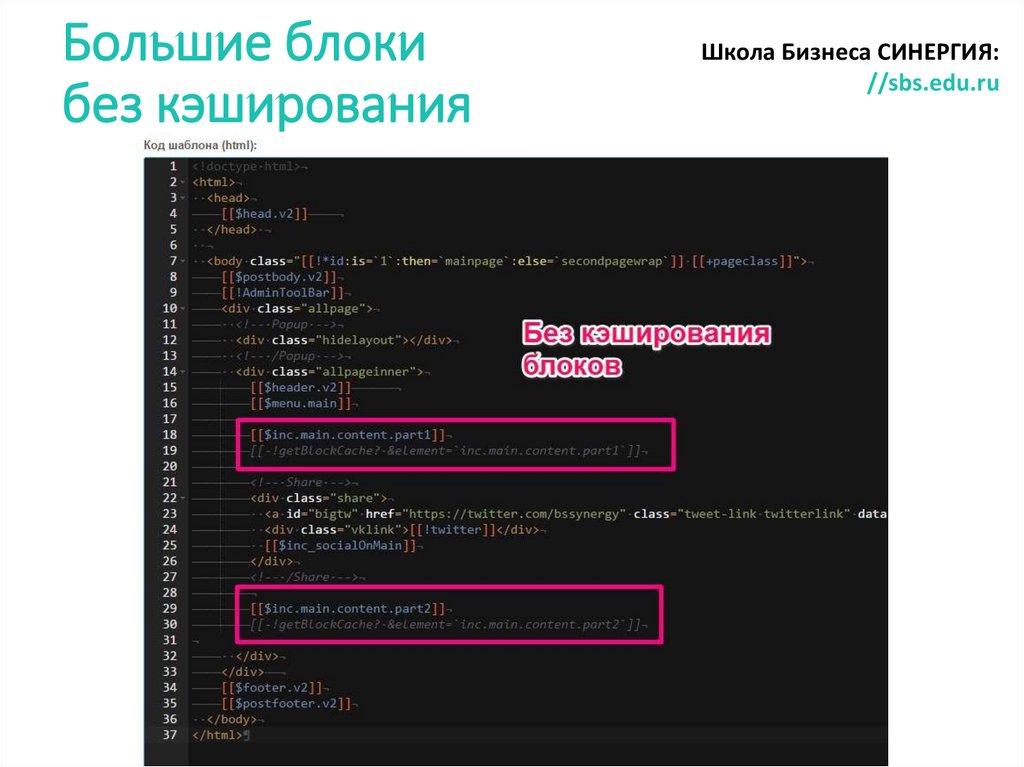 Более того, достаточно проблематично объяснять пользователям, почему наши системы медленные.
Более того, достаточно проблематично объяснять пользователям, почему наши системы медленные.
Еще один значимый аспект кеширования — оно позволяет нам каждый раз избегать создания новых запросов или повторной обработки данных. Так что можно избежать накладных расходов, таких как накладные расходы на сеть, и уменьшить использование центрального процессора, особенно если запросы связаны со сложной обработкой. Это может продлить срок службы машин или серверов. Кроме того, отказ от создания новых запросов снижает общее количество необходимых запросов, что может снизить стоимость вашей инфраструктуры. Фактически, при работе с облачными платформами или поставщиками общедоступных API, например, принято выставлять счет за любую сетевую связь между их службами. Отличные побочные эффекты, не правда ли?
Проблемы
Кеширование — отнюдь не простая практика, и этому предмету присущи неизбежные проблемы. Давайте разберемся с самыми коварными.
Проблема согласованности
Поскольку всякий раз, когда данные кешируются, создается их копия, существует теперь две копии одних и тех же данных.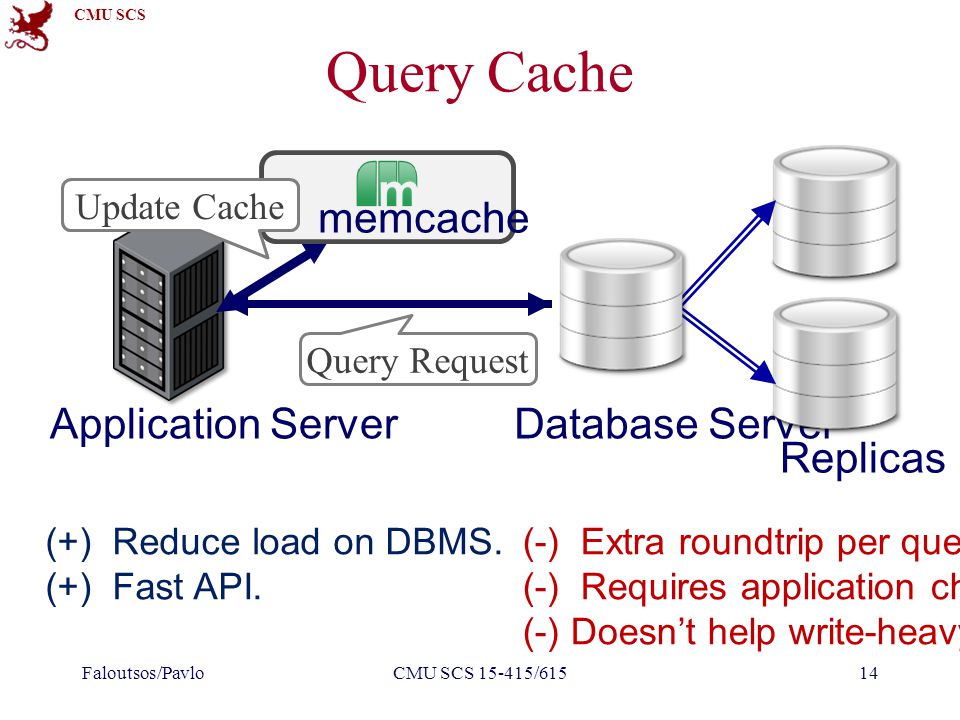 Это значит, что со временем они могут расходиться. В двух словах, это вопрос согласованности — наиболее важная и сложная проблема, связанная с кешированием. Не существует конкретного решения, которое было бы предпочтительнее другого, и лучший подход зависит от требований. Определение наилучшего механизма обновления или аннулирования кеша — одна из самых больших проблем, связанных с кешированием, и, возможно, одна из самых сложных задач в научных изысканиях.
Это значит, что со временем они могут расходиться. В двух словах, это вопрос согласованности — наиболее важная и сложная проблема, связанная с кешированием. Не существует конкретного решения, которое было бы предпочтительнее другого, и лучший подход зависит от требований. Определение наилучшего механизма обновления или аннулирования кеша — одна из самых больших проблем, связанных с кешированием, и, возможно, одна из самых сложных задач в научных изысканиях.
Выбор данных для кэширования
Кешировать можно практически любые данные. Значит, выбор того, что должно находиться в нашем кеше, а что следует исключить, открывает бесконечные возможности и, соответственно, может стать очень сложным. При решении этой проблемы необходимо учитывать некоторые аспекты. Во-первых, если мы ожидаем, что данные будут часто меняться, не следует кешировать их слишком долго. В противном случае мы можем предложить пользователям неточные данные. С другой стороны, это также зависит от того, сколько времени мы готовы хранить устаревшие данные. Во-вторых, кеш должен хранить часто запрашиваемые данные, для генерации или извлечения которых требуется много времени. Идентификация этих данных — непростая задача, и вы рискуете заполнить кеш бесполезными данными. В-третьих, кешируя большие данные, можно очень быстро заполнить кеш или, что еще хуже, использовать всю доступную память. Если оперативная память используется совместно приложением и системой кеширования, это легко может стать проблемой, поэтому следует ограничить объем оперативной памяти, зарезервированной для кеширования.
Во-вторых, кеш должен хранить часто запрашиваемые данные, для генерации или извлечения которых требуется много времени. Идентификация этих данных — непростая задача, и вы рискуете заполнить кеш бесполезными данными. В-третьих, кешируя большие данные, можно очень быстро заполнить кеш или, что еще хуже, использовать всю доступную память. Если оперативная память используется совместно приложением и системой кеширования, это легко может стать проблемой, поэтому следует ограничить объем оперативной памяти, зарезервированной для кеширования.
Работа с кеш-промахами
Промахи кеша увеличивают время, расходуемое на использование кеша. Фактически, недочеты в кеше приводят к задержкам, которых не было бы в системе, не использующей кеширование. Таким образом, для получения выгоды от увеличения скорости, обусловленной наличием кэша, количество промахов в кэше должно быть относительно низким. В частности, они должны быть минимальными по сравнению с попаданиями в кеш. Достичь этого результата непросто, а если его не достичь, система кэширования может превратиться в не более чем накладные расходы.
Типы кеширования
Хотя кеширование — это общая концепция, есть несколько типов, которые выделяются среди остальных. Они представляют собой ключевые концепции для любых разработчиков, заинтересованных в понимании наиболее распространенных подходов к кешированию, и их нельзя пропустить. Рассмотрим их все.
Кеширование в памяти
При таком подходе кэшированные данные хранятся непосредственно в оперативной памяти, которая, предположительно, работает быстрее, чем типичная система хранения, в которой расположены исходные данные. Наиболее распространенная реализация этого типа кэширования основана на базах данных типа «ключ-значение». Их можно рассматривать как наборы пар «ключ-значение». Ключ представлен уникальным идентификатором, а значение — кешированными данными.
По сути, это значит, что каждая часть данных идентифицируется уникальным значением. Указав это значение, база данных «ключ-значение» вернет связанные данные. Такое решение быстрое, эффективное и простое для понимания.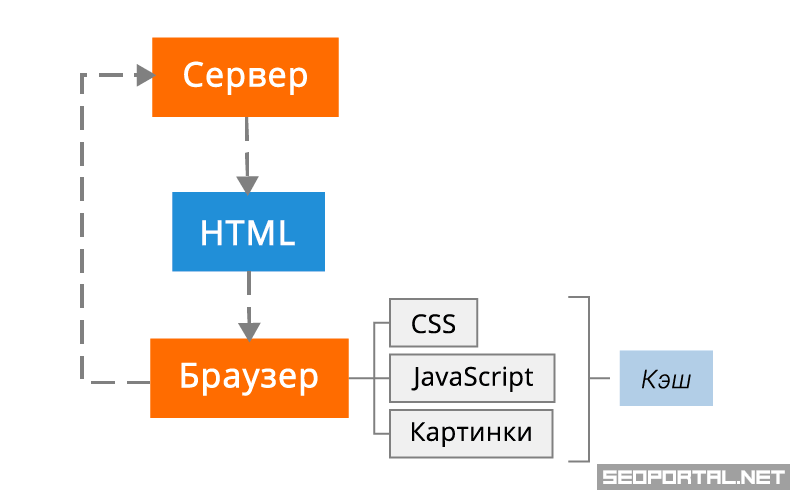 Вот почему разработчики, пытаясь создать слой кеширования, обычно предпочитают такой подход.
Вот почему разработчики, пытаясь создать слой кеширования, обычно предпочитают такой подход.
Кеширование базы данных
Каждая база данных обычно имеет определенный уровень кеширования. В частности, внутренний кеш обычно используется, чтобы избежать чрезмерных запросов к базе данных. Кешируя результат последних выполненных запросов, база данных может немедленно предоставить ранее кешированные данные. Таким образом, в течение периода времени, когда желаемые кешированные данные действительны, база данных может избегать выполнения запросов. Хотя каждая база данных реализует это по-разному, наиболее популярный подход основан на использовании хеш-таблицы, в которой хранятся пары ключ-значение. Как и раньше, ключ используется для поиска значения. Обратите внимание, что такой тип кеша обычно предоставляется по умолчанию технологиями ORM (Object Relational Mapping).
Веб-кеширование
Его можно разделить на две дополнительные подкатегории:
Кеширование веб-клиента
Этот тип кеша знаком большинству пользователей Интернета и хранится на клиентах. Поскольку он обычно является частью браузеров, его также называют кешированием веб-браузера. Он работает очень интуитивно. При первой загрузке веб-страницы браузер сохраняет ресурсы страницы, такие как текст, изображения, таблицы стилей, сценарии и мультимедийные файлы. При следующем открытии той же страницы браузер может поискать в кеше ресурсы, которые ранее были кешированы, и получить их с компьютера пользователя. Обычно это намного быстрее, чем загружать их из сети.
Поскольку он обычно является частью браузеров, его также называют кешированием веб-браузера. Он работает очень интуитивно. При первой загрузке веб-страницы браузер сохраняет ресурсы страницы, такие как текст, изображения, таблицы стилей, сценарии и мультимедийные файлы. При следующем открытии той же страницы браузер может поискать в кеше ресурсы, которые ранее были кешированы, и получить их с компьютера пользователя. Обычно это намного быстрее, чем загружать их из сети.
Кеширование веб-сервера
Это механизм, предназначенный для хранения ресурсов на стороне сервера для повторного использования. В частности, такой подход полезен при работе с динамически генерируемым контентом, для создания которого требуется время. И наоборот, он бесполезен в случае статического содержимого. Кеширование веб-сервера позволяет избежать перегрузки серверов, сокращая объем работы, которую необходимо выполнить, и улучшает скорость доставки страниц.
Кеширование CDN
CDN расшифровывается как Content Delivery Network, и он предназначен для кеширования контента, такого как веб-страницы, таблицы стилей, сценарии и мультимедийные файлы, на прокси-серверах. Его можно рассматривать как систему шлюзов между пользователем и исходным сервером, хранящую его ресурсы. Когда пользователю требуется ресурс, прокси-сервер перехватывает его и проверяет, есть ли у него копия. Если есть, ресурс немедленно доставляется пользователю; в противном случае запрос пересылается на исходный сервер. Прокси-серверы размещены в огромном количестве мест по всему миру, а запросы пользователей динамически направляются к ближайшему из них. Таким образом, ожидается, что они будут ближе к конечным пользователям, чем исходные серверы, что подразумевает сокращение задержки в сети. Кроме того, это также снижает количество запросов к исходным серверам.
Его можно рассматривать как систему шлюзов между пользователем и исходным сервером, хранящую его ресурсы. Когда пользователю требуется ресурс, прокси-сервер перехватывает его и проверяет, есть ли у него копия. Если есть, ресурс немедленно доставляется пользователю; в противном случае запрос пересылается на исходный сервер. Прокси-серверы размещены в огромном количестве мест по всему миру, а запросы пользователей динамически направляются к ближайшему из них. Таким образом, ожидается, что они будут ближе к конечным пользователям, чем исходные серверы, что подразумевает сокращение задержки в сети. Кроме того, это также снижает количество запросов к исходным серверам.
Заключение
В этой статье мы рассмотрели, что такое кеширование и почему оно приобретает всё большее значение в информатике. В то же время важно учитывать угрозы и риски, связанные с кешированием. Внедрение работающей системы кеширования — непростая задача, требующая времени и опыта. Вот почему знание наиболее важных типов кеша является основополагающим для разработки правильной системы. Освоить их все — миссия каждого разработчика.
Освоить их все — миссия каждого разработчика.
Переведено со статьи, полный текст доступен по ссылке.
Кэш | Основы Redis
Зарегистрируйтесь для доступа к 15+ бесплатным курсам по программированию с тренажером
На сегодняшний день время отклика на запрос является критичной метрикой для любого проекта. Пользователи не очень любят, когда web-страница формируется долго (несколько секунд или дольше). Поэтому разработчики стремятся уменьшить время ответа на запрос клиента, для чего прибегают к кэшированию.
Представим, что разрабатывается торговая платформа и есть личный кабинет с аналитикой сделок пользователя. Нужно выводить количество сделок, прибыль, средний оборот и тд. Большинство метрик являются агрегационными, то есть их нужно высчитывать. Если использовать только РСУБД, то среднее время ответа будет сотни миллисекунд, а при большой нагрузке — секунды. Можно подключить подходящие аналитические базы данных, но чаще всего это слишком дорого в средних проектах.
Самая распространенная практика решения сегодня — это кэш. Сложные вычисления кэшируются, то есть записываются в оперативную память. Обращение к оперативной памяти займет сотни наносекунд, примерно в миллион раз быстрее, чем вычислить данные из РСУБД. Новая схема взаимодействия будет включать кэширующий сервер. Алгоритм следующий:
- клиент делает запрос
- бекенд проверяет кэш. Если значение есть в кэше, то оно просто возвращается клиенту
- если значения в кэше нет, то сервер вычисляет все из базы, записывает числа в кэш и отдает клиенту. Теперь все последующие запросы будут возвращать результаты вычислений из кэша
Подводные камни
Как у любого решения в разработке, кэширование — не серебряная пуля и имеет свои недостатки. Несколько моментов, которые стоит держать в уме при использовании кэша:
- приложение должно уметь работать без кэша. Кэширующий сервер упал или недоступен? Пользователь все равно должен получать все данные просто с небольшой задержкой.
 Завязывать какую-то логику продукта на кэш (например, хранить данные аналитики только в кэше) — нельзя, потому что это ненадежное хранилище.
Завязывать какую-то логику продукта на кэш (например, хранить данные аналитики только в кэше) — нельзя, потому что это ненадежное хранилище. - с введением нового звена в архитектуру всегда следует усложнение разработки и поддержки продукта. Проверка и запись значений в кэше — это дополнительная логика в коде, которая требует дополнительного времени на тестирование и исправление потенциальных ошибок.
- сколько времени должно храниться значение в кэше? Что делать, если значение невалидно, так как пользователь открыл новую сделку или получил прибыль? Эти вопросы будут возникать постоянно, и в каждом проекте ответы будут уникальными.
Redis как кэш
Redis чаще всего используют именно как кэширующий сервер. Он имеет богатый встроенный функционал для этих целей. Рассмотрим основные команды, с помощью которых кэшируют значения в Redis.
Кэширование
Представим, что нужно записать количество сделок пользователя в кэш. Запишем, что у пользователя с ID 33 имеется 5 сделок.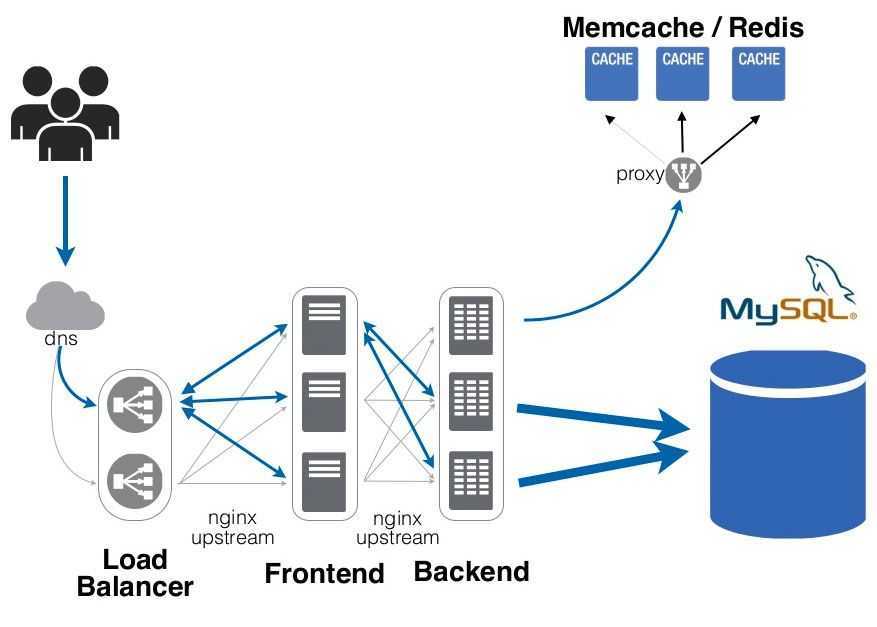 Используем обычную команду
Используем обычную команду set:
127.0.0.1:6379> set user:33:deals_count 5 OK
Данные записаны. Однако они будут храниться вечно до следующей перезагрузки сервера или пока не будут удалены вручную. Одно из основных свойств кэша — это то, что он хранится короткий промежуток времени. Данных может быть много, а ресурсы серверов не бесконечны. К счастью в Redis можно указать время жизни ключа (время экспирации), по истечении которого ключ будет удален. Для этого достаточно добавить префикс ex количество_секунд к команде set:
127.0.0.1:6379> set user:33:deals_count 5 ex 120 OK
Проверить, через сколько ключ удалится можно командой ttl:
127.0.0.1:6379> ttl user:33:deals_count (integer) 115
В данном случае ключ user:33:deals_count исчезнет через 115 секунд.
Если попытаться получить значение спустя это время, то вернется пустой ответ:
127.0.0.1:6379> get user:33:deals_count (nil)
Время жизни можно задавать не только в секундах, но и в миллисекундах с помощью префикса px количество_миллисекунд:
set user:33:deals_count 5 px 10000
Проверка времени жизни осуществляется командой pttl:
127.0.0.1:6379> pttl user:33:deals_count (integer) 7484
Вывод выше показывает, что ключ user:33:deals_count исчезнет через 7484 миллисекунд (~7.4 секунд).
Инвалидация кэша
Любой кэш может стать неактуальным раньше времени жизни. В нашем примере со сделками это может произойти при возникновении новой сделки у пользователя. В этом случае нужно удалить ключ в кэше, чтобы при следующем запросе произошел пересчет значения. Может возникнуть вопрос: а почему бы просто не добавить значение в имеющийся ключ? В данном примере это было бы наилучшим решением, но действовать необходимо не «в лоб». При увеличении значения двумя командами get + set может получиться неконсистентное состояние (подробнее эта проблема будет рассмотрена в следующем уроке). Также обновление значения не всегда возможно, например, в случае если значение — это среднее арифметическое.
Удаление ключа происходит командой del:
127.0.0.1:6379> del user:33:deals_count (integer) 1
Вернувшееся значение 1 означает, что ключ существовал и был успешно удален. Если ключа не было, то вернулся бы 0.
Если ключа не было, то вернулся бы 0.
Иногда требуется удалить тысячи ключей за раз. Например, у поставщика цен на акции произошел сбой и все сделки за период сбоя оказались недействительными. В этом случае нельзя использовать N вызовов команды del, потому что это будет выполняться очень долго и заберет все ресурсы Redis. Для множественного удаления существует команда unlink, которую можно безопасно использовать в продакшен-среде:
127.0.0.1:6379> unlink user:1:deals_count user:2:deals_count user:3:deals_count (integer) 1
Все ключи для удаления указываются через пробел. Стоит учитывать, что ключи удаляются асинхронно, то есть могут существовать после unlink короткий промежуток времени.
Резюме
ASP.NET Углубленый. Кэширование данных в ASP.NET
- Главная >
 org/ListItem»> Каталог >
org/ListItem»> Каталог >- ASP.NET Углубленный >
- Кэширование данных в ASP.NET
Для прохождения теста нужно авторизироваться
Войти Регистрация
×
Вы открыли доступ к тесту! Пройти тест
Войдите или зарегестрируйтесь для того чтоб продолжить просмотр бесплатного видео
Войти Регистрация
№1
Архитектура IIS. Жизненный цикл HttpApplication
1:04:40
Материалы урокаДомашние заданияТестирование
Первый видео урок посвящен архитектуре IIS. Также, автор подробно разъясняет жизненный цикл и способы конфигурации ASP.NET приложений.
В этом видео уроке будут рассмотрены следующие темы:
- архитектура IIS сервера;
- жизненный цикл ASP.
 NET-приложения;
NET-приложения; - класс Global.asax;
- жизненный цикл веб-страницы;
- настройка приложения, иерархия config-файлов.
Читать дальше…
Http модули и обработчики
0:50:13
Материалы урокаДомашние заданияТестирование
В этом видео уроке будут рассмотрены следующие темы:
- Создание пользовательского HTTP обработчика
- Интерфейс IHttpHandler.
- Использование ASHX файлов.
- Создание пользовательских HTTP модулей. Интерфейс IHttpModule.
- Варианты использования HTTP модулей.
Читать дальше…
Асинхронные страницы в ASP.NET
1:14:35
Материалы урокаДомашние заданияТестирование
В этом видео уроке будут рассмотрены следующие темы:
- Обработка запросов на стороне сервера.
 Принцип использования потоков из пула потоков ASP.NET
Принцип использования потоков из пула потоков ASP.NET - Создание асинхронных страниц с использованием AddOnPreRenderCompleteAsync
- Создание асинхронных страниц с использованием PageTaskAsync
- Введение в TPL. Использование async await
- Асинхронные страницы в 4 Framework
- Асинхронные обработчики и интерфейс IHttpHandler
- Замер производительности с помощью Visual Studio
Читать дальше…
№4
Пользовательские элементы управления
0:51:29
Материалы урокаДомашние заданияТестирование
В этом видео уроке будут рассмотрены следующие темы:
- Создание и регистрация контроллера
- Определение свойств
- Определение событий
- Пример создание пользовательского элемента управления TabControl
- Динамическое создание элементов управления
Читать дальше…
Пользовательские серверные элементы управления
0:58:36
Материалы урокаДомашние заданияТестирование
В этом видео уроке будут рассмотрены следующие темы:
- Создание простейшего элемента управления.

- Базовый класс WebControl
- Создание контролов на основе готовых элементов управления.
- Использование класса CompositeControl
- Использование элементов управления, отправляющих обратные запросы
Читать дальше…
Элементы управления, связанные с данными
1:00:59
Материалы урокаДомашние заданияТестирование
В этом видео уроке будут рассмотрены следующие темы:
- Создание элемента управления, который поддерживает работу с данными, используя класс DataBoundControl.
- Привязка данных с использованием свойства DataSource и DataSourceId.
- Создание списочного элемента управления.
- Создание элемента управления, который поддерживает работу с шаблонами.
- Использование атрибутов.
Читать дальше…
Кэширование данных в ASP.NET
0:53:54
Материалы урокаДомашние заданияТестирование
В этом видео уроке будут рассмотрены следующие темы:
- Кэширование данных
- Настройки кэширования
- Повышение производительности приложений
Читать дальше. ..
..
Кэширование вывода в ASP.NET
0:50:08
Материалы урокаДомашние заданияТестирование
В этом видео уроке будут рассмотрены следующие темы:
- Атрибуты директивы OutputCache
- Использование кэширования вывода для UserControl
- Использовать элемент управления Substitution
- Создавать кэш вывода, который будет зависеть от SQL базы данных.
Читать дальше…
Membership API
1:03:28
Материалы урокаДомашние заданияТестирование
В этом видео уроке будут рассмотрены следующие темы:
- Настройка аутентификации через формы. Работа с классом FormsAuthentication
- Создание приложения с регистрацией и авторизацией с использованием MembershipAPI
- Создание приложения с регистрацией и авторизацией с использованием стандартных элементов управления
- Настройка доступа к приложению по ролям
Читать дальше. ..
..
Следующий курс:
Основы ASP.NET MVC
ПОКАЗАТЬ ВСЕ
основные темы, рассматриваемые на уроке
0:00:34
Кэширование (определение)
0:04:43
Кэширование данных
0:07:13
Примеры кэширования данных
0:16:53
Пример использования времени жизни кэша
0:21:00
Пример использования приоритета и вызова обратной функции
0:23:01
Пример использования приоритета и вызова обратной функции
0:33:41
Пример использования Aggregate Dependency
0:39:00
Пример настройки SQL Data Source для использования кэшировая
0:42:03
Пример создания пользовательской зависимости
ПОКАЗАТЬ ВСЕ
Рекомендуемая литература
ASP.NET Углубленный курс Дино Эспозито
Microsoft ASP.NET 4 с примерами на C# 2010 для профессионалов Мэтью Мак-Дональд, Адам Фримен, Марио Шпушта
Титры видеоурока
Титров к данному уроку не предусмотрено
ПОДРОБНЕЕ
ПОДРОБНЕЕ
ПОДРОБНЕЕ
ПОДРОБНЕЕ
Регистрация через
✖или E-mail
Нажав на кнопку «Зарегистрироваться»,
Вы соглашаетесь с условиями использования.
Уже есть аккаунт
Получите курс бесплатно
✖Вы выбрали курс для изучения
«»
Чтобы получить доступ к курсу, зарегистрируйтесь на сайте.
РЕГИСТРАЦИЯ
Спасибо за регистрацию
✖Перейдите на почту и подтвердите Ваш аккаунт,
чтобы получить доступ ко всем
бесплатным урокам и вебинарам на сайте ITVDN.com
ПОДТВЕРДИТЬ ПОЧТУ НАЧАТЬ ОБУЧЕНИЕ
Спасибо за регистрацию
✖Ваш аккаунт успешно подтвержден.
Начать обучение вы можете через Личный кабинет
пользователя или непосредственно на странице курса.
НАЧАТЬ ОБУЧЕНИЕ
Подтверждение аккаунта
На Ваш номер телефона было отправлено смс с кодом активации аккаунта. Пожалуйста, введите код в поле ввода.
Отправить код еще раз
Изменить номер телефона
Ошибка
✖Что такое кэшированные данные? Почему и как вы должны его очистить?
Кэшированные данные — это информация, сохраняемая на вашем компьютере или устройстве после посещения веб-сайта. Разработчики используют кешированные данные, чтобы улучшить ваш опыт работы в Интернете.
Разработчики используют кешированные данные, чтобы улучшить ваш опыт работы в Интернете.
Большинство потребителей ожидают, что веб-сайт загрузится в течение двух-трех секунд. Еще немного, и они могли бы перейти к конкуренту. Они могут больше никогда не вернуться на ваш сайт.
Цель кэширования данных — ускорить загрузку сайта. Вашему устройству не придется долго болтать с сервером, чтобы загрузить весь текст, изображения и формы на сайте. Некоторые из этих битов и байтов будут храниться на вашем устройстве.
Но у некоторых из этих сохраненных данных есть и темная сторона. Хакеры могут использовать его для запуска атаки, которая может поставить под угрозу вашу безопасность.
Как работают кэшированные данные?
Думайте о кеше как о хранилище данных веб-сайта, которые вы используете все время. Каждый раз, когда вы посещаете этот веб-сайт, ваше устройство должно получать эту информацию. Если он хранится в кеше, ваше устройство пропускает шаг, и вы экономите драгоценное время.
Вы не можете выбирать, что помещается в кэш. Разработчики делают эту работу за вас, основываясь на том, что, по их мнению, обеспечивает самое быстрое время загрузки и лучший опыт.
Если вы живете в районе со слабым доступом в Интернет, кэшированные данные могут быть спасением. Вы можете ждать и ждать, пока загрузится весь сайт. Если часть из них кэшируется, вы можете очень быстро получить нужные биты.
Кэш-память — не единственная форма памяти, которую использует ваш компьютер. На самом деле разработчики используют так называемую иерархию памяти компьютера, чтобы описать, как большинство устройств хранят данные и получают к ним доступ.
Кэшированные данные отличаются от других форм тем, что их можно удалить с помощью нескольких простых действий пользователя.
Что даст очистка кэшированных данных?
В большинстве устройств предусмотрена некоторая форма очистки кэша. Поступают новые данные, а старая информация удаляется. Эта система гарантирует, что ваше устройство не будет загружено таким большим объемом памяти, что оно не сможет справиться с чем-то новым.
Но вы также можете очистить кеш. Общие причины для этого включают:
- Скорость и производительность. Для полного кеша нужна память, а если вы заполнены, переполненная память не работает очень быстро. Очистка отставания может ускорить работу вашего устройства.
- Очистка от взлома. После атаки разработчики могут восстановить работоспособность сайта. Если на вашем устройстве есть кешированная версия неработающего сайта, ее повторный запуск может по-прежнему означать запуск атаки. Подобный скомпрометированный кеш сайта может быть очень опасным.
- Защита конфиденциальности. Кто-то, вошедший в ваше устройство, может увидеть, куда вы пошли и что вы сделали, просматривая ваши кешированные данные. Если вы используете общедоступное устройство, например компьютер в библиотеке, ваш кеш может стать воротами для атаки.
Некоторые пользователи просто никогда не очищают кэшированные данные. Но поскольку эти риски реальны, стоит добавить очистку к своим регулярным задачам обслуживания.
Но поскольку эти риски реальны, стоит добавить очистку к своим регулярным задачам обслуживания.
Как очистить кэшированные данные
Веб-сайты хранят информацию на любом устройстве, имеющем доступ в Интернет, включая компьютеры и мобильные устройства. Мы рассмотрим несколько примеров, чтобы помочь вам понять, как навести порядок.
Очистите кеш в распространенных веб-браузерах, таких как:
- Google Chrome. Коснитесь трех точек в правом верхнем углу экрана. Откройте «Настройки», затем «Дополнительно», затем «Конфиденциальность и безопасность» и «Очистить данные браузера». Удалите кэшированные изображения и файлы, установив соответствующий флажок.
- Internet Explorer. Коснитесь значка шестеренки и прокрутите до «Свойства обозревателя». Установите флажок «Удалить историю просмотров».
- Сафари. Откройте меню «История» и нажмите «Очистить историю».
- Firefox. Коснитесь трех горизонтальных полос в углу и выберите «Параметры», затем «Конфиденциальность и безопасность».
 Установите флажок «История просмотров и загрузок».
Установите флажок «История просмотров и загрузок».
Может быть немного сложно понять, как очистить кеш на мобильном устройстве. Ваш тип и версия программного обеспечения определяют, как вы будете решать эту задачу. Но в большинстве случаев вы будете следовать одному из двух типов указаний в зависимости от производителя вашего устройства. Если вы используете:
- Apple , перейдите в «Настройки» и выберите свой веб-браузер. Затем нажмите «Очистить историю и данные веб-сайта».
- Android , перейдите в «Настройки», а затем в «Хранилище». Выберите приложение веб-браузера, а затем нажмите «Очистить кэш».
Вы не запретите своему компьютеру или устройству сохранять больше данных каждый раз, когда вы посещаете другой сайт. Процесс продолжается. Но как только вы привыкнете к шагам, вам будет легко выполнять их по установленному вами расписанию.
Помощь от Okta
Что еще нужно сделать, чтобы защитить свой компьютер и устройства от хакеров? Позвольте нам помочь.
В Okta мы специализируемся на защите данных для больших и малых компаний. Мы будем рады помочь вам. Связаться с нами, чтобы узнать больше.
Ссылки
Врум! Почему важна скорость сайта. (май 2017 г.). Предприниматель .
Точка зрения специалиста по безопасности о кэше браузера. Кибер Вож.
Отравление кеша. (апрель 2009 г.). Фонд ОВАСП.
5 распространенных угроз безопасности браузера, как с ними справляться. (апрель 2018 г.). ТехРеспублика.
Как очистить кэш в любом браузере. (август 2019 г.). Журнал ПК.
Очистите историю и файлы cookie из Safari на вашем iPhone, iPad или iPod Touch. Яблоко.
Как, зачем и когда следует очищать кэш приложений или данные на Android. (май 2020 г.). Полиция Андроид.
Что такое кэшированные данные и следует ли их сохранить или очистить?
Не уверен, заметили ли вы, но открытие приложения или посещение веб-сайта в первый раз может занять некоторое время.
Ладно, «пока» может быть чрезмерным, но эти дополнительные несколько секунд времени загрузки имеют значение для нас при просмотре веб-страниц или прокрутке наших приложений.
Хотя это происходит не случайно. В основном это связано с тем, что на наших устройствах нет кэшированных данных для определенного приложения или веб-сайта.
Если вы не совсем понимаете, что такое кэшированные данные, давайте быстро их рассмотрим.
Что такое кэшированные данные на моем телефоне?
Кэшированные данные — это файлы, сценарии, изображения и другие мультимедиа, сохраняемые на вашем устройстве после открытия приложения или посещения веб-сайта в первый раз. Затем эти данные используются для быстрого сбора информации о приложении или веб-сайте при каждом повторном посещении, что сокращает время загрузки.
Что такое кэшированные данные?
С каждым открытым приложением или посещенным веб-сайтом происходит обмен информацией.
Пользователь получает доступ к контенту в обмен на информацию о местоположении, используемом устройстве, используемом браузере, времени, проведенном на страницах, и других действиях пользователя.
Кэшированные данные.
Ноутбуки, планшеты, смартфоны, не важно. Все наши устройства имеют определенный уровень зарезервированного пространства для хранения данных этого типа для быстрого доступа.
Метод сохранения данных кэша или файлов кэша в качестве истории на телефоне или веб-браузере для улучшения взаимодействия с пользователем при будущих посещениях веб-сайта или приложения называется кэшированием.
Как работают кэшированные данные?
Чтобы кешированные данные сохранялись для повторного доступа, на вашем устройстве должно быть достаточно памяти или места для хранения. С технической точки зрения кэш занимает очень высокое место в иерархии компьютерной памяти. Вот изображение этой иерархии для справки:
Вы можете увидеть чуть ниже регистра ЦП — небольших строительных блоков процессора компьютера — несколько уровней кэш-памяти.
- L1 или уровень 1 — это основной уровень кэш-памяти, встроенный в микросхему микропроцессора.

- L2 и L3, или уровни 2 и 3, являются вторичным уровнем кэша, который питает L1. Он медленнее L1 на наносекунды.
Кэш-память имеет чрезвычайно низкую задержку, что означает очень быстрый доступ к ней. Вы можете проверить это, открыв новое приложение или посетив веб-сайт, на котором вы никогда раньше не были, а затем повторно посетить его и сравнить скорости.
Примечание: Ваш второй раз должен быть заметно быстрее.
Обратная сторона низкой задержки означает, что можно хранить не так много памяти. Вот почему файлы небольшого размера, такие как веб-текст и изображения, хранятся в кеше.
Важны ли кэшированные данные?
Кэшированные данные не важны по своей сути, поскольку они считаются только «временным хранилищем». Тем не менее, он существует для улучшения пользовательского опыта.
Для загрузки таких элементов страницы, как изображения, видео и даже текст, требуется некоторое время. Когда эти данные кэшируются, мы можем снова открыть приложение или повторно посетить страницу с уверенностью, что это не займет столько времени.
Когда эти данные кэшируются, мы можем снова открыть приложение или повторно посетить страницу с уверенностью, что это не займет столько времени.
Кэш-память также сохраняет состояния. Например, если я закрою свое приложение Twitter и снова открою его через 10 минут, я смогу прокрутить вниз и увидеть сообщения, которые были загружены ранее. Без кеша все пришлось бы перезагружать.
Должен ли я очистить кэш?
Итак, если кешированные данные не так важны, безопасно ли их стирать? Ну, это зависит.
Если вы обнаружите, что память вашего мобильного устройства истощается из-за кэшированных данных, вам, вероятно, следует очистить ее. В конце концов, кешированные данные не являются жизненно важными для производительности приложения или веб-сайта; это просто означает, что файлы на нем должны быть перезагружены.
Хотя постоянная очистка кеша не является постоянным решением, поскольку в какой-то момент вам придется повторно открывать приложения и повторно посещать веб-сайты. Данные будут повторно кэшированы, и цикл продолжится.
Данные будут повторно кэшированы, и цикл продолжится.
Если вам не хватает памяти, рассмотрите возможность удаления старых текстовых сообщений, изображений или видеофайлов на вашем устройстве. Также стоит изучить облачное хранилище файлов и программное обеспечение для обмена, такое как Google Drive или Dropbox, если вы хотите сохранить свои файлы. Эти варианты обычно предлагают бесплатное количество облачного пространства.
Как очистить кэшированные данные
Если вы всецело хотите очистить кеш, вот как это сделать в разных операционных системах:
Очистить кеш на iPhone
Выполните следующие простые действия, чтобы очистить кеш на устройствах iOS:
Перейдите в Настройки > Общие > iPhone Хранилище .Отсюда у вас есть несколько вариантов. Ваш первый вариант — очистить весь кеш приложений, которые вы почти не используете или никогда не используете. Это соответствует рекомендации «Разгрузить неиспользуемые приложения .
 » Термин «разгрузка» — это просто причудливая фраза iOS для очистки кеша.
» Термин «разгрузка» — это просто причудливая фраза iOS для очистки кеша.Второй вариант — прокрутить вниз и коснуться отдельных приложений с большим количеством кэшированных данных на вашем устройстве. Как вы можете это сказать? Apple перечислит эти приложения из самое высокое использование памяти до самое низкое .
Просто разгрузите отдельное приложение, чтобы освободить временное пространство на вашем устройстве.
Совет: Очистка кэша просто удаляет временные файлы. Он не удалит учетные данные для входа, загруженные файлы или пользовательские настройки.
Очистить кеш на Android
Очистить кэш на устройствах Android можно следующими способами.
Очистить кэш в приложении Chrome
- Откройте приложение Google Chrome на телефоне или планшете Android.

- Нажмите Еще на три точки в правом верхнем углу веб-страницы.
- Коснитесь История , а затем коснитесь Очистить данные браузера и выберите временной диапазон вверху.
- Выберите временной диапазон и установите флажки рядом с «Кэшированные файлы изображений».
- Нажмите Очистить данные , чтобы освободить кеш браузера в Chrome.
Совет: Вы можете очистить кэшированные файлы в Chrome даже в автономном режиме.
Очистить кеш приложения
Давайте возьмем Samsung Galaxy Note 8 в качестве примера, чтобы понять, как очистить кэш приложений на устройствах Android.
- Откройте меню Настройки на телефоне Android и выберите Приложения из списка
- В зависимости от версии Android у вас может быть возможность открывать установленные приложения, все приложения, включенные, отключенные и другие приложения.
 Выберите Все при использовании Samsung Galaxy Note 8 .
Выберите Все при использовании Samsung Galaxy Note 8 . - Выберите подходящий вариант и перейдите к приложению, кеш которого нужно очистить
- Выберите приложение и нажмите Хранилище в списке параметров в данных приложения
- Коснитесь Очистить кэш , чтобы освободить место на устройстве
Очистить кеш в Firefox
Очистить кеш Firefox довольно просто. Выполните следующие пять шагов:
- Выберите параметры, нажав Меню на странице Firefox.
2. Коснитесь панели «Конфиденциальность и безопасность».
3. Нажмите «Очистить данные» на вкладке «Файлы cookie и данные сайтов».
4. Снимите флажки напротив всех остальных параметров и установите флажок Кэшированный веб-контент.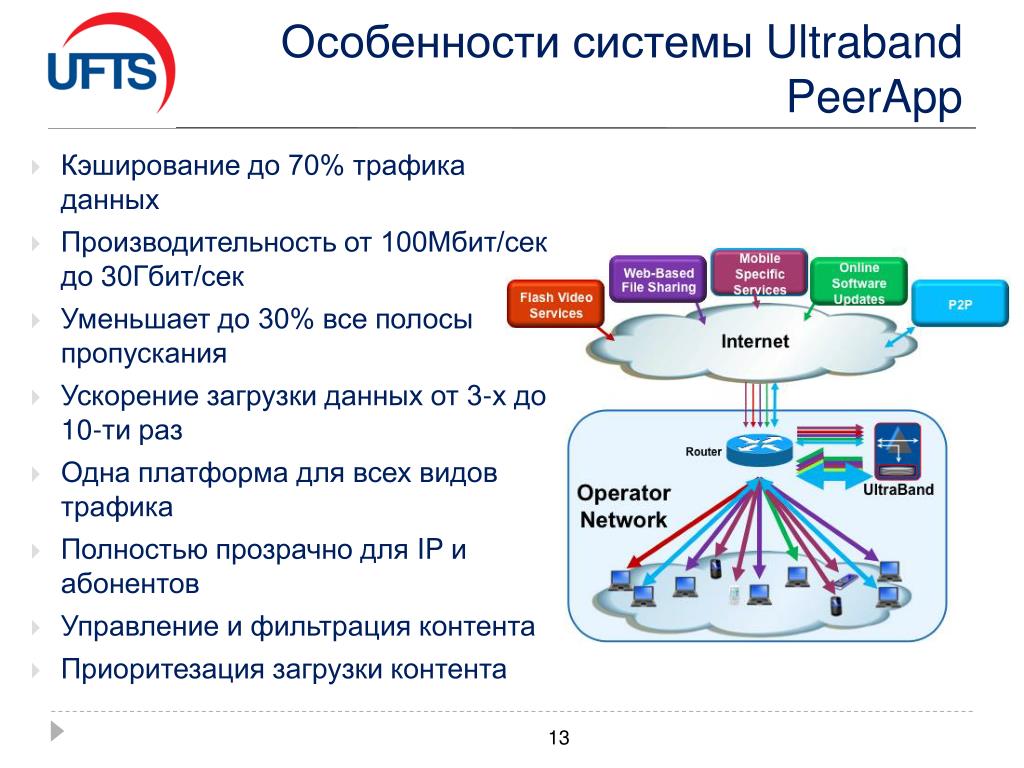
Что происходит после очистки кеша?
- Некоторые настройки на сайтах удаляются. Например, если вы вошли в систему, вам потребуется войти снова.
- Если вы включите синхронизацию в Chrome, вы останетесь в аккаунте Google, с которым синхронизируетесь, чтобы удалить свои данные на всех своих устройствах.
- Некоторые сайты могут казаться медленнее, потому что контент, например изображения, должен загружаться снова. ~ Служба поддержки Google
Что делает очистка кеша?
Теперь у вас есть достаточно полное представление о том, что такое кэшированные данные, где они хранятся и какова их важность для производительности устройства.
Неплохо время от времени очищать кэшированные данные. Некоторые называют эти данные «мусорными файлами», что означает, что они просто сидят и накапливаются на вашем устройстве. Очистка кеша помогает поддерживать чистоту, но не полагайтесь на него как на надежный метод для создания нового пространства.
Теперь, когда вы знаете, как очистить кэш для повышения производительности вашего устройства, сделайте его более безопасным с помощью двухфакторной аутентификации.
Защитите свой парк мобильных телефоновОптимизируйте функциональность и безопасность мобильных устройств на вашем предприятии с помощью лучшего программного обеспечения для управления мобильными устройствами.
Обзор программного обеспечения
Девин Пикелл
Девин — бывший старший специалист по контенту в G2. До G2 он помогал запускать стартапы на ранней стадии развития с бурно развивающейся технологической сцены Чикаго. Вне работы он любит смотреть своих любимых Детенышей, играть в бейсбол и другие игры. (он/его/его)
Все, что касается кэширования: варианты использования, преимущества, стратегии, выбор технологии кэширования, знакомство с некоторыми популярными продуктами | by Kousik Nath
Изображение Christian Wiediger на unsplash. com
comПочти все знакомы с кэшированием, несмотря на то, что эта технология настолько распространена в настоящее время, начиная от процессора и заканчивая браузером и любым веб-приложением — все программное обеспечение в определенной степени зависит от кэширования для обеспечения высокой производительности. быстрый ответ. Задержка в несколько миллисекунд может привести к потерям в миллиарды долларов, поэтому отклик менее чем за миллисекунду становится повседневной необходимостью. На рынке доступно огромное количество решений для кэширования. Но это не означает, что использование какой-либо технологии решает вашу проблему. Итак, в этом посте я попытаюсь объяснить различные параметры, которые помогут вам выбрать технологию, а также мы обсудим функции и некоторые реальные варианты использования уже доступных на рынке решений, чтобы, прежде чем использовать их, вы знали их общие варианты использования.
Прежде чем принять решение о уровне кэширования, вам нужно задать себе следующие вопросы:
- Какие бизнес-варианты использования в вашей системе требуют высокой пропускной способности, быстрого отклика или низкой задержки?
- У вас все в порядке с несогласованностью данных, если вы используете кеш?
- Какие данные вы хотите хранить? Объекты, статические данные, простые пары ключ-значение или структуры данных в памяти?
- Вам нужно поддерживать кэш для транзакционных/мастер-данных?
- Вам нужен внутрипроцессный кеш или общий кеш на одном узле или распределенный кеш для n узлов?
- Вам нужно решение для кэширования с открытым исходным кодом, коммерческое или предоставляемое платформой?
- Если вы используете распределенный кэш, как насчет производительности, надежности, масштабируемости и доступности?
Эффективное кэширование помогает как потребителям контента, так и его поставщикам.
Вот некоторые преимущества кэширования для доставки контента:
Снижение сетевых затрат: Контент может кэшироваться в различных точках сетевого пути между потребителем контента и источником контента. Когда содержимое кешируется ближе к потребителю, запросы не вызывают дополнительной сетевой активности за пределами кеша.
Повышенная скорость отклика: Кэширование позволяет быстрее извлекать содержимое, поскольку нет необходимости в круговом обходе всей сети. Кэши, поддерживаемые рядом с пользователем, такие как кэш браузера, могут сделать это извлечение почти мгновенным.
Повышение производительности на том же оборудовании: Для сервера, на котором создан контент, можно добиться большей производительности на том же оборудовании, разрешив агрессивное кэширование. Владелец контента может использовать мощные серверы на пути доставки, чтобы взять на себя основную нагрузку при загрузке определенного контента.
Доступность содержимого во время сбоев в сети: С помощью определенных политик можно использовать кэширование для предоставления содержимого конечным пользователям, даже если оно может быть недоступно в течение коротких периодов времени с исходных серверов.

Давайте рассмотрим некоторые популярные варианты использования кэширования, возможно, ваш вариант использования может пересекаться с одним из них:
Поиск данных в памяти: профиль пользователя, некоторые исторические / статические данные или некоторый ответ API в соответствии с вашими вариантами использования. Кэширование поможет в хранении таких данных. Кроме того, когда вы создаете решение динамического программирования для какой-либо задачи, двумерные массивы или хэш-карты работают как кэширование.
Ускорение РСУБД: Реляционные базы данных работают медленно, когда дело доходит до работы с миллионами строк. Ненужные данные или старые данные, большие объемы данных могут замедлить их индексирование, независимо от того, выполняете ли вы сегментирование или секционирование, один узел всегда может испытывать задержку и задержку ответа на запрос, когда база данных заполнена своей емкостью. В таких сценариях, вероятно, многие запросы «SELECT» или запросы на чтение могут кэшироваться извне, по крайней мере, на какое-то небольшое временное окно. Реляционные базы данных также используют собственное кэширование, но для повышения производительности внешнее кэширование может иметь гораздо большую емкость, чем внутреннее кэширование. Это один из самых популярных вариантов использования кэширования.
Реляционные базы данных также используют собственное кэширование, но для повышения производительности внешнее кэширование может иметь гораздо большую емкость, чем внутреннее кэширование. Это один из самых популярных вариантов использования кэширования.
Управление всплеском в веб-приложениях и мобильных приложениях: Часто популярные веб-приложения и мобильные приложения испытывают сильный всплеск, когда они привлекают большое количество пользователей. Многие из таких вызовов могут заканчиваться запросами на чтение в базе данных, вызовами внешних веб-сервисов, некоторые могут быть вычисленными данными, такими как вычисление предыдущих платежей на лету, некоторые могут быть некритическими динамическими данными, такими как количество подписчиков для пользователя, количество подписчиков. повторные твиты, количество просмотров и т. д. Кэширование может использоваться для обслуживания таких данных.
Хранилище сеансов: Активные веб-сеансы — это данные, к которым очень часто обращаются — независимо от того, хотите ли вы выполнить аутентификацию API или хотите сохранить последнюю информацию о корзине в приложении электронной коммерции, кеш может хорошо служить сеансу.
Кэширование токенов: Токены API могут кэшироваться в памяти для обеспечения высокопроизводительной аутентификации и проверки пользователей.
Игры: Профиль игрока и таблица лидеров — это 2 экрана, которые очень часто просматривают геймеры, особенно в многопользовательских онлайн-играх. Таким образом, с миллионами игроков становится чрезвычайно важно очень быстро обновлять и получать такие данные. Кэширование подходит и для этого варианта использования.
Кэширование веб-страницы: Чтобы сделать мобильное/веб-приложение легким и гибким пользовательским интерфейсом, вы можете создавать динамические веб-страницы на сервере и обслуживать их через API вместе с соответствующими данными. Таким образом, если у вас есть миллионы пользователей, вы можете обслуживать такие на лету созданные полные/фрагментированные веб-страницы из кеша в течение определенного периода времени.
Генерация глобального идентификатора или счетчика: Если у вас есть переменное количество, скажем, экземпляров реляционной базы данных на узлах, и вы хотите сгенерировать для них автоматически увеличивающийся первичный ключ или когда вы хотите назначить уникальный идентификатор своим пользователям, вы можете использовать кэширование для извлечения и обновления таких данных в масштабе.
Быстрый доступ к любым подходящим данным: Часто мы думаем, что кеш используется только для хранения часто используемых данных для чтения. Хотя в основном это правильно, такое поведение может варьироваться в зависимости от вариантов использования. Кэш можно использовать для хранения менее частых данных, если вам действительно нужен быстрый доступ к этим данным. Мы используем кеш для очень быстрого доступа к данным, поэтому сохранение наиболее частых/наименее частых данных — это просто вопрос использования.
Дизайн приложения/системы во многом зависит от используемых стратегий доступа к данным. Они диктуют отношения между источником данных и системой кэширования. Поэтому очень важно выбрать правильную стратегию доступа к данным. Прежде чем выбрать какую-либо стратегию, проанализируйте схему доступа к данным и постарайтесь, чтобы ваше приложение соответствовало любому из следующих параметров.
Сквозное чтение/отложенная загрузка: Загружать данные в кэш только при необходимости. Если приложению нужны данные для какого-то ключа x , сначала выполните поиск в кеше. Если данные присутствуют, верните данные, в противном случае извлеките данные из источника данных, поместите их в кеш и затем верните.
Если приложению нужны данные для какого-то ключа x , сначала выполните поиск в кеше. Если данные присутствуют, верните данные, в противном случае извлеките данные из источника данных, поместите их в кеш и затем верните.
Преимущества:
- Он не загружает и не хранит все данные вместе, это по запросу. Подходит для случаев, когда вы знаете, что вашему приложению может не понадобиться кэшировать все данные из источника данных в определенной категории.
- Если таких узлов кэша несколько и один из них выходит из строя, это не наносит вреда приложению, хотя в такой ситуации приложение сталкивается с повышенной задержкой. По мере того, как новый узел кеша появляется в сети, через него проходит все больше и больше запросов, и он продолжает заполнять необходимые данные при каждом промахе кеша.
Недостатки:
- Для промаха кеша есть 3 сетевых обхода. Проверить в кеше, получить из базы данных, залить данные в кеш.
 Таким образом, кеш вызывает заметную задержку ответа.
Таким образом, кеш вызывает заметную задержку ответа. - Устаревшие данные могут стать проблемой. Если данные изменяются в базе данных, а срок действия ключа кэша еще не истек, в приложение будут переданы устаревшие данные.
Сквозная запись: При вставке или обновлении данных в базе данных также обновляйте данные в кэше. Таким образом, обе эти операции должны выполняться в одной транзакции, иначе данные будут устаревать.
Преимущества:
- Нет устаревших данных. Он устраняет проблему устаревания кэша сквозного чтения.
- Подходит для тяжелых систем чтения, которые плохо переносят устаревание.
Недостатки:
- Это система штрафов за запись. Каждая операция записи выполняет 2 сетевые операции — запись данных в источник данных, затем запись в кеш.
- Переполнение кэша: Если большая часть данных никогда не будет прочитана, в кэше будут храниться бесполезные данные.
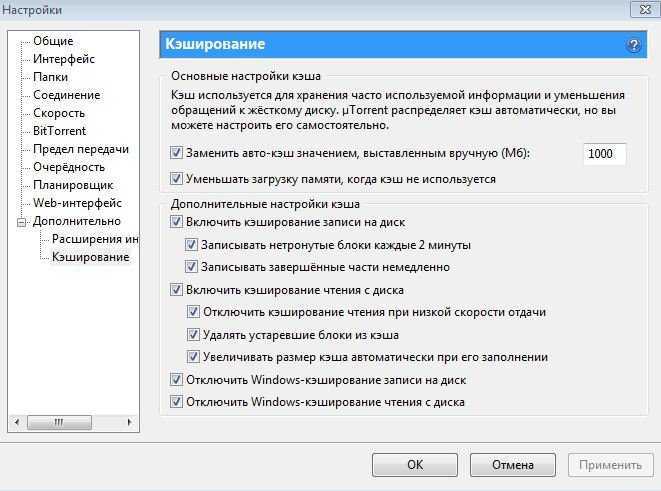 Это можно контролировать с помощью TTL или истечения срока действия.
Это можно контролировать с помощью TTL или истечения срока действия. - В целях обеспечения согласованности между кешем и источником данных при записи данных, если какой-либо из узлов вашего кеша отсутствует, операция записи завершается сбоем.
Запись после кэширования: В этой стратегии приложение записывает данные непосредственно в систему кэширования. Затем через определенный настроенный интервал записанные данные асинхронно синхронизируются с базовым источником данных. Итак, здесь служба кэширования должна поддерживать очередь операций «записи», чтобы их можно было синхронизировать в порядке вставки.
Преимущества:
- Поскольку приложение записывает данные только в службу кэширования, ему не нужно ждать, пока данные будут записаны в базовый источник данных. Чтение и запись происходят на стороне кэширования. Таким образом улучшается производительность.
- Приложение защищено от сбоя базы данных.
 В случае сбоя базы данных элементы в очереди можно повторить или повторно поставить в очередь.
В случае сбоя базы данных элементы в очереди можно повторить или повторно поставить в очередь. - Подходит для систем с высокой пропускной способностью чтения и записи.
Недостатки:
- Возможная согласованность между базой данных и системой кэширования. Таким образом, любая прямая операция с базой данных или операция присоединения могут использовать устаревшие данные.
Ограничения дизайна приложения со стратегией отложенной записи:
- Поскольку в этой стратегии сначала записывается кэш, а затем база данных — они не записываются в транзакцию, если кэшированные элементы не могут быть записаны в базу данных, должен выполняться некоторый процесс отката для обеспечения согласованности в течение временного окна.
- Кэширование с отложенной записью может привести к неупорядоченным обновлениям базы данных, поэтому база данных должна иметь возможность ослаблять ограничения внешнего ключа.
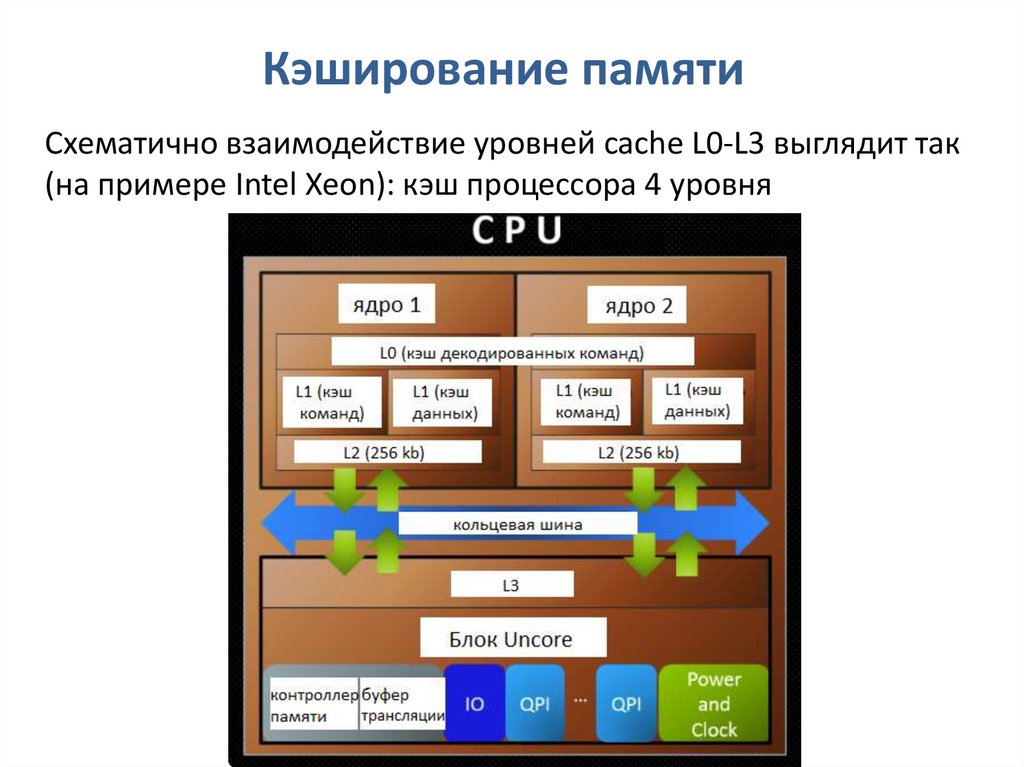 Кроме того, если база данных является общей базой данных, другие приложения также могут использовать ее, поэтому невозможно узнать, будут ли обновления кэша с отложенной записью конфликтовать с другими внешними обновлениями. Это должно быть обработано вручную или эвристическим путем.
Кроме того, если база данных является общей базой данных, другие приложения также могут использовать ее, поэтому невозможно узнать, будут ли обновления кэша с отложенной записью конфликтовать с другими внешними обновлениями. Это должно быть обработано вручную или эвристическим путем.
Кэширование с предварительным обновлением: Это метод, при котором кэшированные данные обновляются до истечения срока их действия. Когерентность Oracle использует этот метод.
Время упреждающего обновления выражается в процентах от времени истечения срока действия записи. Например, предположим, что время истечения срока действия записей в кэше установлено на 60 секунд, а коэффициент упреждающего обновления установлен на 0,5. Если доступ к кэшированному объекту осуществляется через 60 секунд, Coherence выполнит синхронный считывается из хранилища кеша, чтобы обновить его значение. Однако, если запрос выполняется для записи старше 30, но менее 60 секунд, возвращается текущее значение в кэше, и Coherence планирует асинхронную перезагрузку из хранилища кэша.

Итак, что делает кэширование с упреждающим обновлением, так это то, что оно по существу обновляет кеш с настроенным интервалом непосредственно перед следующим возможным доступом к кешу, хотя обновление данных может занять некоторое время из-за сетевой задержки, а тем временем уже может произойти несколько тысяч операций чтения. в очень читаемой тяжелой системе всего за несколько миллисекунд.
Преимущества:
- Это полезно, когда большое количество пользователей использует одни и те же ключи кэша. Поскольку данные периодически и часто обновляются, устаревшие данные не являются постоянной проблемой.
- Уменьшенная задержка по сравнению с другими методами, такими как кеш со сквозным чтением.
Недостатки:
- Вероятно, это немного сложно реализовать, поскольку служба кэширования требует дополнительного давления для обновления всех ключей по мере обращения к ним. Но в условиях интенсивного чтения это того стоит.

Суть обсуждения стратегий заключается в том, что при проектировании системы вы знаете, какую систему вы проектируете, будь то система с интенсивным чтением, интенсивная запись или сочетание того и другого в очень большом масштабе. Различные системы будут иметь разные требования, поэтому очень сложно придумать несколько надежных вариантов использования и полностью проверенную стратегию. Вы можете выбрать одну или несколько стратегий, как описано выше, в зависимости от вашего варианта использования.
Политика вытеснения позволяет кэшу гарантировать, что размер кэша не превышает максимальный предел. Для этого существующие элементы удаляются из кэша в зависимости от политики исключения, но ее можно настроить в соответствии с требованиями приложения.
Решение для кэширования может предоставлять различные политики вытеснения, но перед выбором технологии кэширования полезно знать, какая политика вытеснения может потребоваться вашему приложению. Может случиться так, что вашему приложению нужны разные политики вытеснения для разных вариантов использования, это прекрасно, но знание этого поможет вам лучше выбрать технологию кэширования.
Может случиться так, что вашему приложению нужны разные политики вытеснения для разных вариантов использования, это прекрасно, но знание этого поможет вам лучше выбрать технологию кэширования.
- Наименее недавно использовавшиеся (LRU): Одной из наиболее часто используемых стратегий является LRU. В большинстве случаев кэширования приложения снова и снова обращаются к одним и тем же данным. Скажем, в любой поисковой системе Google, когда вы что-то ищете, вы снова и снова будете получать одни и те же результаты, по крайней мере, в течение некоторого промежутка времени. Когда вы ищете авиабилеты, автобусы или поезда, вы получаете одни и те же маршруты до тех пор, пока какой-либо маршрут не будет деактивирован или полностью зарезервирован. В таких случаях кэшированные данные, которые не использовались в последнее время, или неиспользуемые данные могут быть безопасно удалены.
Преимущества:
1. Наиболее близок к наиболее оптимальному алгоритму
2.Выбирает и удаляет элементы, которые в последнее время не используются к элементу обращались больше, чем когда к нему обращались в последний раз
- Наименее часто используемые (LFU):
Ваша мобильная клавиатура использует
LFU. Когда вы вводите несколько букв, вы можете увидеть несколько предложенных слов в верхней части клавиатуры, совпадающих с введенными вами буквами. В начале, когда приложение клавиатуры 9Кэш 0570 пуст, он может показать вам эти 4 слова (Предположим, вы набрали буквы «STA». Предлагаемые слова могут появиться, например, старт, стенд, статуя, посох). Идея здесь в том, что, основываясь на словах, которые вы используете, он будет игнорировать словоLRUв предложениях через определенное время. Вы можете не увидеть слово «персонал» в предложениях позже, если вы его не использовали.Если у вас есть случай, когда вы знаете, что данные довольно повторяющиеся, обязательно выберите
LFU, чтобы избежатькешпромах.Кажется, что они оба совершенно независимы и имеют изолирующее значение. Это зависит от варианта использования, где вы хотите использовать любой из них.
Преимущества:
1. Учитывает возраст элемента
2. Учитывает опорную частоту элемента
3. Лучше работает при высокой нагрузке, когда быстро запрашивается много элементов (меньше ложных выселений)
Недостатки:
1. Часто используемый элемент будет удален только после большого количества промахов
2. Более важно аннулировать элементы, которые могут изменяться
- Последние использованные (MRU): Давайте рассмотрим Tinder. Tinder персонализирует для вас совпадающие профили и буферизует результаты в кеш или высокопроизводительный кеш. Таким образом, вы можете предположить, что некоторое пространство для каждого пользователя выделено для очереди соответствующих персонализированных результатов. Когда вы видите страницу рекомендаций Tinder, в тот момент, когда вы проводите пальцем вправо или влево, вам больше не нужен этот вид рекомендаций.
 Таким образом, в этом случае Tinder может удалить рекомендацию из очереди этого пользователя и освободить место в памяти. Эта стратегия удаляет самые последние использованные элементы, поскольку они не потребуются, по крайней мере, в ближайшем будущем.
Таким образом, в этом случае Tinder может удалить рекомендацию из очереди этого пользователя и освободить место в памяти. Эта стратегия удаляет самые последние использованные элементы, поскольку они не потребуются, по крайней мере, в ближайшем будущем. - First In, First Out (FIFO): Это больше похоже на MRU, но следует строгому порядку вставленных элементов данных. MRU не выполняет заказ на вставку.
В некоторых случаях может потребоваться применить комбинацию политик вытеснения, например LRU + LFU, чтобы решить, какие данные вытеснять. Это зависит от вашего варианта использования, поэтому старайтесь выбирать такие технологии, которые соответствуют политике выселения, о которой вы подумали.
Различные технологии кэширования хорошо подходят для разных типов данных благодаря их внутренней структуре. Таким образом, выбор правильной технологии также зависит от того, какой тип данных они могут эффективно хранить.
Хранилище объектов: Подходит для хранения неизменяемых объектов, таких как объект ответа HTTP, набор результатов базы данных, обработанная HTML-страница и т. д. Пример: Memcached.
д. Пример: Memcached.
Хранилище значения простого ключа: Сохранение простого строкового ключа в строковое значение практически поддерживается любым кэшем. Пример: Redis, Memcached, Hazelcast, Couchbase и т. д.
Кэш собственной структуры данных: Если ваш вариант использования поддерживает сохранение и извлечение данных из изначально поддерживаемых структур данных, то Redis и Aerospike — хороший выбор.
Кэширование в памяти: Подходит для хранения любого значения ключа или объектов, напрямую доступных через оперативную память, в том же узле. Пример: HashMap, Guava Cache и т. д., кэширование запросов Hibernate и MySQL.
Кэш статических файлов: Подходит для кэширования изображений, файлов, статических файлов, таких как файлы css или javascript. Пример: Akamai CDN, Memcached в определенной степени.
Кэширование одного узла (в процессе):
Это стратегия кэширования для нераспределенных систем. Приложения создают и управляют своими собственными или сторонними объектами кэша. И приложение, и кеш находятся в одном и том же пространстве памяти.
Приложения создают и управляют своими собственными или сторонними объектами кэша. И приложение, и кеш находятся в одном и том же пространстве памяти.
Этот тип кэша используется для кэширования сущностей базы данных, но также может использоваться в качестве своего рода пула объектов, например, объединения последних использованных сетевых подключений для повторного использования на более позднем этапе.
Преимущества: Локально доступные данные, высокая скорость, простота обслуживания.
Недостатки: Высокое потребление памяти в одном узле, кеш делит память с приложением. Если несколько приложений используют один и тот же набор данных, может возникнуть проблема дублирования данных.
Вариант использования: Выберите эту стратегию, когда вы создаете автономные приложения, такие как мобильные приложения или веб-интерфейсные приложения, где вы хотите временно кэшировать данные веб-сайта, полученные из серверного API, или другие материалы, такие как изображения, css, java. содержимое скрипта. Эта стратегия также полезна, когда вы хотите совместно использовать объекты, которые, возможно, вы создали из ответа API, для разных методов в разных классах вашего внутреннего приложения.
содержимое скрипта. Эта стратегия также полезна, когда вы хотите совместно использовать объекты, которые, возможно, вы создали из ответа API, для разных методов в разных классах вашего внутреннего приложения.
Распределенное кэширование:
Когда мы говорим о веб-приложениях масштаба Интернета, мы на самом деле говорим о миллионах запросов в минуту, петабайтах или терабайтах данных в контексте. Таким образом, одна или две специализированные мощные машины не смогут справиться с такими огромными масштабами. Нам нужно несколько машин для обработки таких сценариев. Несколько машин от десятков до сотен составляют кластер, и в очень большом масштабе нам нужно несколько таких кластеров.
Основные требования к эффективному распределенному кэшированию:
Ниже приведены наиболее важные требования для распределенного кэширования.
- Производительность: Кэш должен постоянно поддерживать требования к пропускной способности с точки зрения запросов на чтение или запись от приложения.
 Таким образом, чем больше он может использовать ресурсы, такие как ОЗУ, SSD или флэш-память, процессор и т. д., тем лучше он производит результат.
Таким образом, чем больше он может использовать ресурсы, такие как ОЗУ, SSD или флэш-память, процессор и т. д., тем лучше он производит результат. - Масштабируемость: Система кэширования должна поддерживать стабильную производительность, даже если количество операций, запросов, пользователей и объем потока данных увеличивается. Он должен иметь возможность масштабироваться линейно без каких-либо неблагоприятных последствий. Таким образом, эластичный рост вверх или вниз является важной характеристикой.
- Доступность: Высокая доступность является высшим требованием современных систем. Получить устаревшие данные — это нормально (в зависимости от варианта использования), но нежелательны недоступные системы. Независимо от того, запланировано или незапланировано отключение, произошел сбой части системы или из-за стихийного бедствия какой-либо центр обработки данных не работает, кэш должен быть доступен все время.
- Управляемость: Простое развертывание, мониторинг, полезная информационная панель, матрицы реального времени упрощают жизнь каждого разработчика и SRE.

- Простота: При прочих равных простота всегда лучше. Добавление кэша в ваше развертывание не должно приводить к ненужной сложности или создавать дополнительную работу для разработчиков.
- Доступность: При принятии любого ИТ-решения всегда учитываются затраты, как на начальное внедрение, так и на текущие расходы. Ваша оценка должна учитывать общую стоимость владения, включая лицензионные сборы, а также оборудование, услуги, обслуживание и поддержку.
Таким образом, в зависимости от ваших вариантов использования вы можете решить, какой тип кэширования использовать. В большинстве случаев корпоративные системы или хорошо зарекомендовавшие себя стартапы, которые обслуживают миллионы клиентов, используют распределенное кэширование с использованием нескольких кластеров. Малые и средние компании также используют несколько узлов для кэширования, но им не всегда нужны решения корпоративного уровня. Как уже упоминалось, внутрипроцессный кеш можно использовать только в автономных приложениях или локальном кешировании на устройствах пользователей.
Давайте рассмотрим некоторые популярные технологии кэширования в реальной жизни, которые могут решить наши повседневные потребности в кэшировании.
Memcached
Бесплатная высокопроизводительная система кэширования объектов с распределенной памятью с открытым исходным кодом , универсальная по своей природе, но предназначенная для использования в ускорении динамических веб-приложений за счет снижения нагрузки на базу данных. Memcached — это хранилище ключей и значений в памяти для небольших произвольных данных (строк, объектов).
Особенности:
- Memcached разработан как высокопроизводительное решение для кэширования, которое может удовлетворить пропускную способность очень больших интернет-приложений.
- Memcached очень прост в установке и развертывании, так как по замыслу он представляет собой кеш-память.
- Очень недорогое решение, лицензированное в соответствии с пересмотренной лицензией BSD.

- Простое хранилище значений ключей. Memcached не понимает, что сохраняет приложение — он может хранить значения String и Object, ключи всегда имеют тип String. Это позволяет хранить объект как значение в сериализованной форме. Поэтому перед сохранением любого объекта вы должны его сериализовать, после извлечения вы должны соответственно его десериализовать.
- В распределенных настройках узлы Memcached не разговаривают друг с другом, нет ни синхронизации, ни репликации. Таким образом, по сути, он включает в себя простой дизайн, в котором клиент должен выбрать узел, на котором он должен читать/записывать определенные данные.
- Многопоточный. Таким образом, он может использовать преимущества нескольких ядер ЦП.
- Все команды memcahed выполняются максимально быстро и без блокировок. Таким образом, скорость запроса почти детерминирована для всех случаев.
- Клиент сохраняет логику для сопоставления ключей кэша с узлами, если доступно несколько узлов.
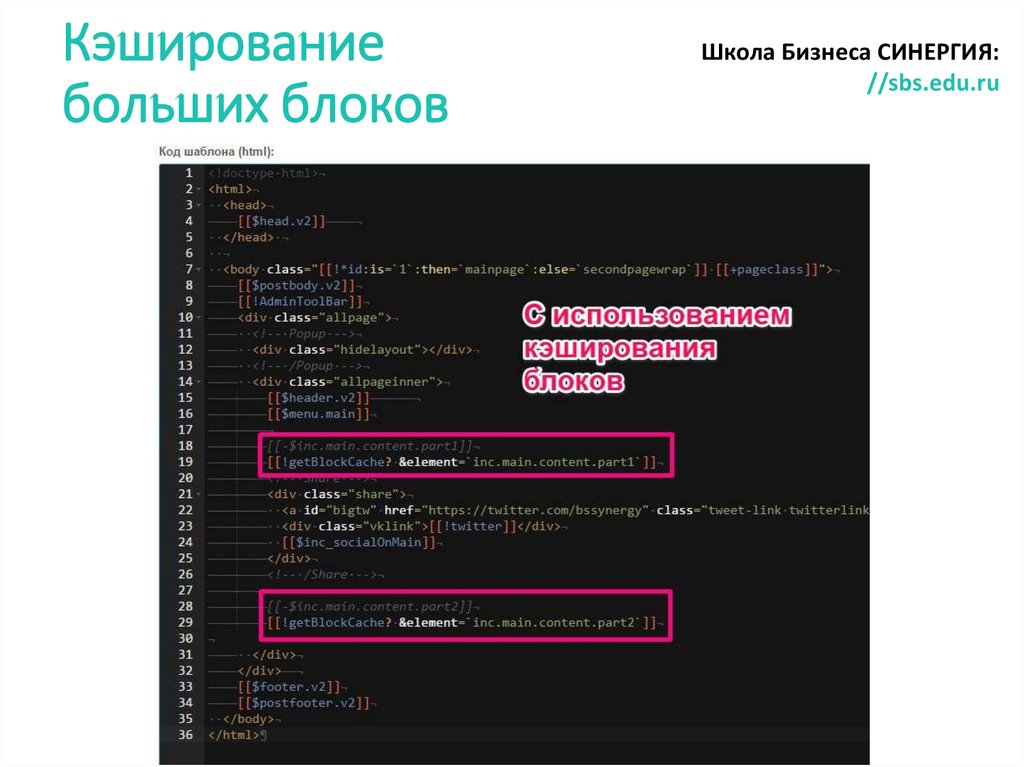
- Помимо операций получения, установки и удаления, memcached предлагает другие функции, такие как истечение срока действия ключа (TTL), полная очистка базы данных, облегченные счетчики, поддерживающие операции увеличения и уменьшения, собственная структура данных списка, которая поддерживает добавление и начало операции с элементами, потокобезопасная операция CAS (Compare & Swap) с поддержкой множества.
- Инвалидация кеша проста, так как клиент отслеживает, какой ключ идет к какому узлу, он может просто удалить этот ключ из этого узла.
Ниже приводится сводка всех операций:
Предоставлено: HerokuМетодика управления памятью: Memcached поддерживает только управление памятью LRU. Поэтому тщательно проанализируйте свой вариант использования, прежде чем выбирать это решение.
Подходящие варианты использования: Храните простые пары строк «ключ-значение». Хранить объект набора результатов базы данных, ответ HTTP API или сериализуемые объекты в памяти, документ JSON/XML в виде значения со строковым ключом, результаты рендеринга страницы и т. д.
д.
Ограничения:
- Поскольку постоянства нет, то при каждом сбое или перезапуске нужно каждый раз прогревать или пополнять данные.
- Если вы хотите хранить большие объекты или наборы данных, сериализованное представление данных может занять больше места и привести к фрагментации памяти.
- Memcached ограничивает размер данных до 1 МБ на ключ.
- Избегайте вариантов использования операций чтения-изменения-записи. Поскольку вам нужно сериализовать/десериализовать объекты при вставке/извлечении данных, операции обновления кажутся очень затратными. Старайтесь как можно больше хранить неизменяемые объекты со сроком действия.
- Memcached не подходит для корпоративных сценариев использования. Он не предлагает многих функций, таких как автоматическое управление эластичными кластерами, сложный высокий уровень доступности, автоматический переход на другой ресурс, перебалансировку нагрузки, репликацию между центрами обработки данных и т.
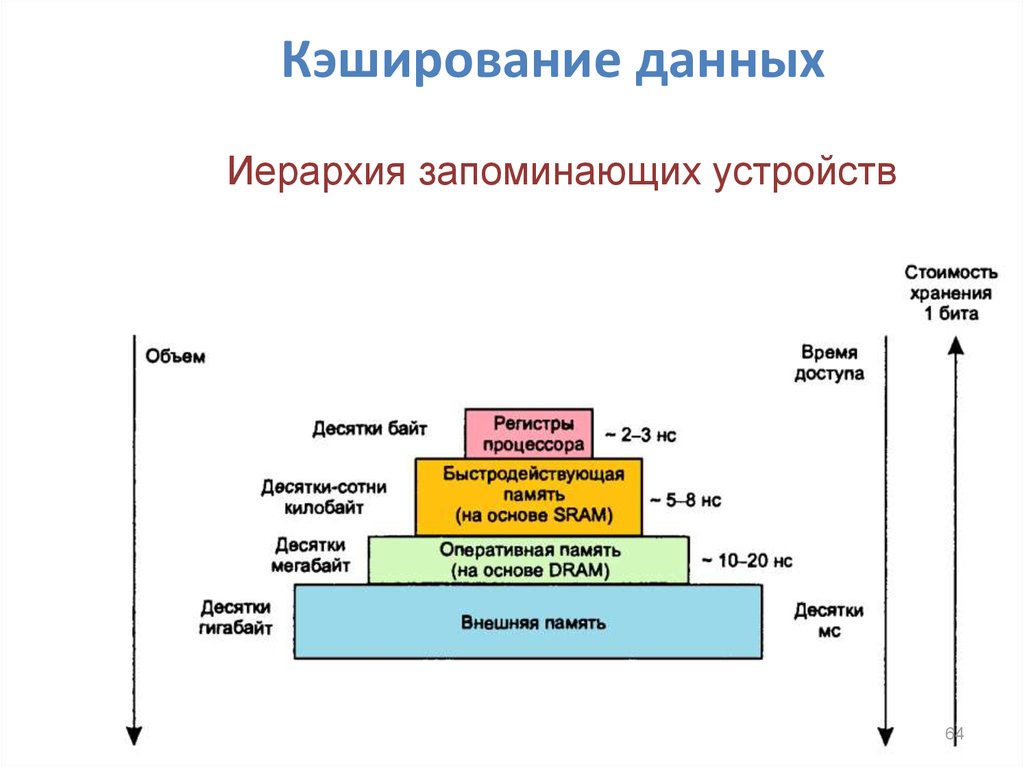 д. Если вы столкнетесь с какой-либо проблемой, вам придется полагаться либо на свой ресурс, либо на сообщество Memcached, его не поддерживает коммерческая организация.
д. Если вы столкнетесь с какой-либо проблемой, вам придется полагаться либо на свой ресурс, либо на сообщество Memcached, его не поддерживает коммерческая организация.
LinkedIn начали использовать Memcached в 2010 году, но к 2012 году столкнулись со многими проблемами и были вынуждены избавиться от него. Следующие фрагменты взяты из инженерного блога LinkedIn, они дают хорошее представление о том, почему Memcached не подходит для предприятий:
Дни Memcached
Впервые Memcached был представлен LinkedIn в начале 2010-х годов как быстрое решение для распределенного кэширования в оперативной памяти, когда нам нужно было масштабировать наши хранилища исходных данных для обработки растущего трафика. Он хорошо работал для того, что он давал:
Одноразрядные миллисекундные GET и SET для приложений, которые нуждались в кэшировании перед своими хранилищами данных источника правды.
Предоставление кластера было простым, и процесс запуска был очень быстрым.
Однако по мере того, как количество кластеров Memcached росло вместе с количеством приложений, которые начали его использовать, мы быстро столкнулись с проблемами работоспособности, одними из основных из которых были:
Отсутствие постоянства. Memcached был хранилищем в памяти. Хотя быстрое время отклика было самой сильной стороной Memcached, оно также было жестоким, когда нам нужно было перезапустить процесс Memcached по причинам обслуживания, поскольку мы также теряли все содержимое кеша.
Разрыв хэш-кольца. Изменение размера кластеров (т. е. расширение кластера за счет большего количества узлов) было невозможно без разрыва хэш-кольца и аннулирования частей кеша. Последовательные алгоритмы хеширования помогли, но не решили проблему полностью.
Замена хостов. Наш алгоритм хеширования был основан на имени хоста узлов в кластере, поэтому каждый раз, когда мы заменяли хост другим именем хоста, это не только делало бы недействительным кеш на замененном узле, но и нарушало кольцо хеширования.
Отсутствие функции копирования кеша. Допустим, мы хотели построить новый центр обработки данных и скопировать содержимое кэша. Это было непросто. В итоге мы создали некоторые инструменты для перебора ключей для заполнения нового кеша, но это не было ни идеальным, ни элегантным.
Вы можете понять, почему Memcached был так легко принят в LinkedIn (обеспечивал быстрые и легкие победы), но в то же время почему работать с ним в масштабе было так раздражающе.


известных пользователей Memcached: YouTube, Reddit, Craigslist, Zynga, Facebook, Twitter, Tumblr, Wikipedia.
Redis
Один из самых популярных кешей в памяти, когда-либо известных на рынке.
Redis часто называют сервером структур данных . Это означает, что Redis предоставляет доступ к изменяемым структурам данных через набор команд, которые отправляются с использованием модели сервер-клиент с сокетами TCP и простым протоколом.
Таким образом, разные процессы могут запрашивать и изменять одни и те же структуры данных общим способом.
Особенности:
- Redis поддерживает собственные изменяемые структуры данных, а именно — список, набор, отсортированный набор, строку, хэш. Он также поддерживает запросы диапазона, растровые изображения, гиперлоги, геопространственные индексы с запросами радиуса.
- Redis хранит все данные в памяти, по сути, Redis — это большой словарь в памяти. Так что это очень быстро. Он может запускать команды в конвейере.
- Данные могут быть асинхронно сохранены на диск после настроенного интервала или определенного количества операций.
- Redis обычно называют однопоточным. Это означает, что логика приложения, которая напрямую обслуживает клиентов, представляет собой только один поток. При синхронизации данных на диске Redis запускает фоновый поток, который напрямую не работает с клиентами.
- Redis поддерживает готовую репликацию master-slave.
 Это просто настройки конфигурации, и репликация запущена.
Это просто настройки конфигурации, и репликация запущена. - Redis поддерживает транзакции. Все команды в транзакции сериализуются и выполняются последовательно. Как обычно, транзакции Redis также гарантируют, что либо все команды будут пройдены, либо ни одна не будет обработана.
- Поддерживаются ключи Redis с TTL или сроком действия.
- Redis имеет встроенную поддержку механизма pub-sub. В нем есть команды, которые включают pub-sub.
- Автоматический переход на другой ресурс поддерживается Redis Sentinel.
- Redis поддерживает сценарии Lua на стороне сервера. Таким образом, пакет команд может выполняться без особых проблем со связью между сервером и клиентом.
- Redis является переносимым, работает практически на всех версиях Linux, Windows, Mac и т. д.
- Поддержка размера значения до 512 МБ на ключ.
- Кроме того, корпоративная версия Redis поддерживает гораздо больше функций.
Метод управления памятью: Redis поддерживает следующие методы:
- allkeys-lru : Исключает наименее использовавшиеся ключи из всех ключей.
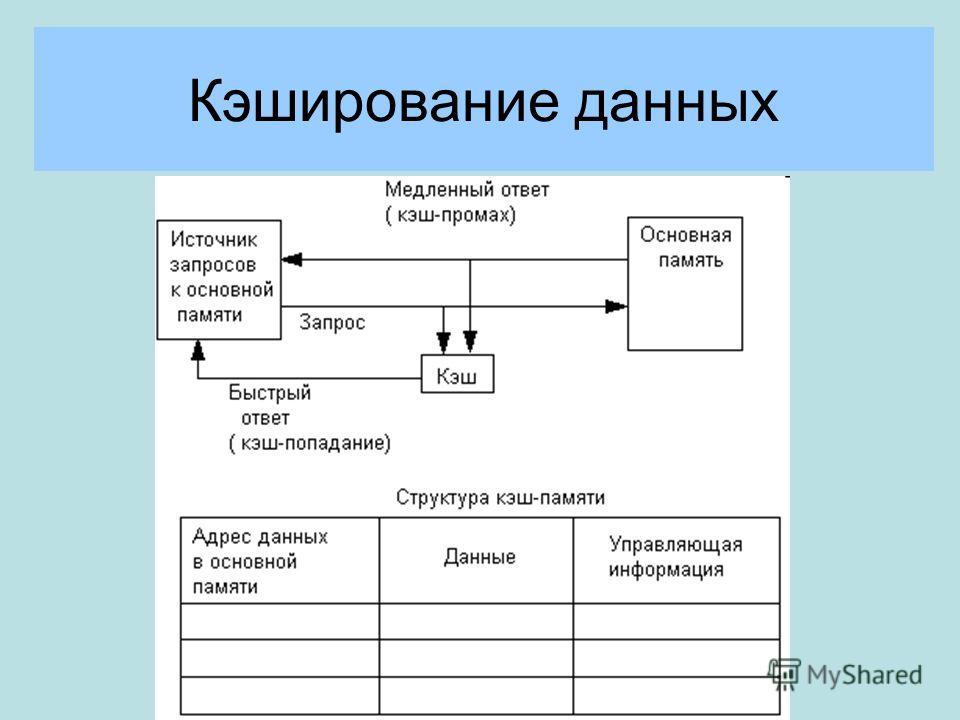
- allkeys-random : Случайным образом удаляет ключи из всех ключей.
- volatile-lru : Удаление наименее использовавшихся ключей из всех ключей с установленным полем «expire».
- volatile-ttl : Удаляет ключи с самым коротким временем жизни (из всех ключей с установленным полем «expire»).
- volatile-random : Удаляет ключи с установленным полем «expire».
- без вытеснения : Redis не будет вытеснять какие-либо ключи, и запись будет невозможна до тех пор, пока не будет освобождено больше памяти.
Подходящие варианты использования: У Redis есть много-много прибыльных вариантов использования:
- Хэш Redis можно использовать вместо реляционных таблиц, если вы можете соответствующим образом моделировать свои данные и ваши варианты использования не требуют каких-либо гарантий транзакций.
- pub-sub Redis можно использовать для рассылки сообщений нескольким подписчикам.

- Список Redis можно использовать как очередь сообщений. Celery — распределенная система обработки задач, использующая структуры данных Redis для управления задачами.
- Хранилище сеансов — очень популярный вариант использования Redis. Постоянная способность Redis делает его подходящим для такого случая.
- Отсортированные наборы Redis можно использовать для управления списками лидеров в онлайн-играх.
- Redis может хранить, увеличивать и уменьшать целые числа. Его можно использовать для генерации глобального идентификатора для любых вариантов использования.
Другие варианты использования можно найти здесь и здесь.
Ограничения:
- Redis не поддерживает вторичный индекс.
- Redis предлагает запрос/сканирование данных на основе поиска регулярных выражений по именам ключей. Поэтому, прежде чем решить использовать структуры данных Redis, такие как хэш, отсортированные наборы и т. д., подумайте о том, как ваши приложения вписываются в Redis и каков ваш шаблон доступа к данным, если вы используете эти структуры данных.
 Для простых вариантов использования ключ-значение это круто, вам не нужно много думать.
Для простых вариантов использования ключ-значение это круто, вам не нужно много думать.
Известные пользователи Redis: Twitter, GitHub, Weibo, Pinterest, Snapchat, Craigslist, Digg, StackOverflow, Flickr Одним из важных преимуществ Aerospike является то, что он имеет гибридную модель памяти — это означает, что если ваш сервер максимально использует оперативную память, SSD (если сервер использует) можно использовать в качестве альтернативы. Встроенные возможности кластеризации, меньшие затраты на эксплуатацию и обслуживание, высокая доступность делают Aerospike отличным выбором для безумно масштабируемых систем.
Особенности:
- Aerospike оптимизирован для флэш-накопителей, таких как SSD, PCI, NVMe. Aerospike использует флешки для вертикального масштабирования. SSD обеспечивает огромное вертикальное масштабирование при снижении общей стоимости владения в 5 раз по сравнению с чистой оперативной памятью. Как правило, количество операций ввода-вывода в секунду (ввод-вывод в секунду) для устройств продолжает увеличиваться.
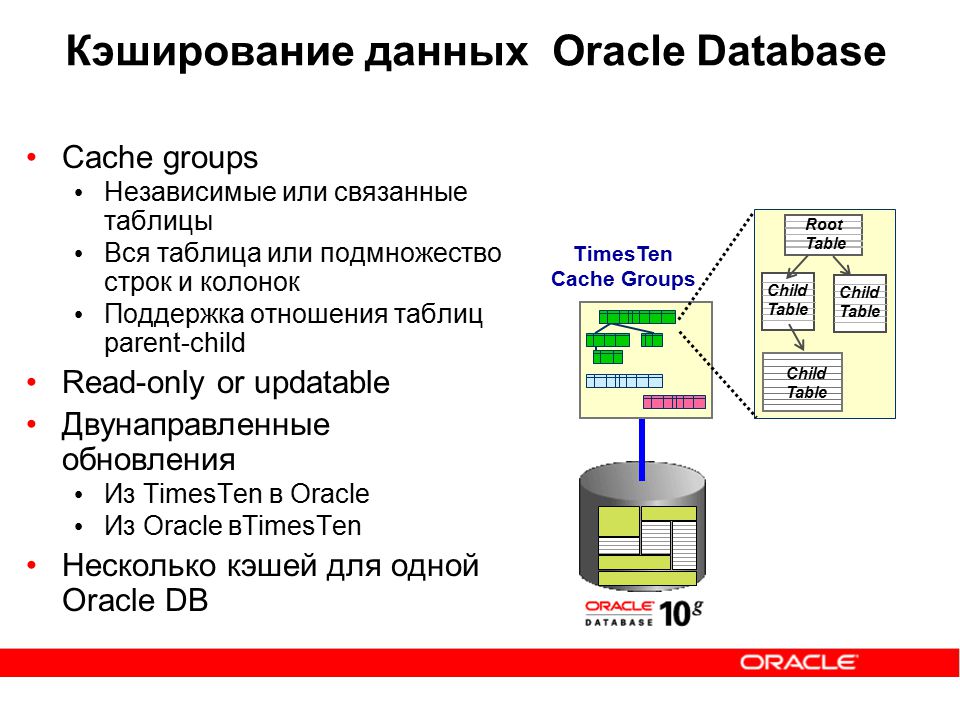 SSD могут хранить на порядок больше данных на узел, чем DRAM. Диски NVMe теперь могут выполнять 100 000 операций ввода-вывода в секунду на каждый диск. Aerospike использует эти возможности, поэтому он может постоянно выполнять до миллионов операций в секунду с задержкой менее миллисекунды.
SSD могут хранить на порядок больше данных на узел, чем DRAM. Диски NVMe теперь могут выполнять 100 000 операций ввода-вывода в секунду на каждый диск. Aerospike использует эти возможности, поэтому он может постоянно выполнять до миллионов операций в секунду с задержкой менее миллисекунды. - Поддерживает хранение ключевых значений, пакетные запросы, сканирование, запросы вторичного индекса, агрегацию и т. д.
- Поддерживает работу в кластерной среде. Он имеет возможность автоматически управлять кластером, добавление и удаление узлов автоматически идентифицируется, и распределение данных происходит соответствующим образом.
- Не содержит схемы.
- Поддерживает истечение TTL для всех записей.
- Поддерживает строки, целые числа, большие двоичные объекты, списки, карты и сериализованные объекты.
- Aerospike выполняет репликацию данных между центрами обработки данных (XDCR), она постоянно копирует данные между узлами кластера, что помогает создать очень высокодоступную отказоустойчивую систему.

- Aerospike выполняет запись больших блоков и чтение небольших блоков для повышения производительности.
- Многопоточный.
- Сценарии Lua на стороне сервера поддерживаются. Это ускоряет пакетные операции на стороне сервера.
- AQL — язык запросов Aerospike поддерживается, чтобы помочь разработчикам запрашивать значения ключей в хранилище данных.
Подходящие варианты использования:
- Отрасль рекламных технологий: Различные варианты использования, такие как хранение профилей пользователей, истории пользователей, данных сеансов, счетчиков рекламных показов, хорошо сочетаются с Aerospike благодаря возможности хранения ключевых значений.
При создании любой формы рекламного или маркетингового приложения вам потребуется хранить профили пользователей. Эти профили часто содержат недавнее поведение пользователей, сегменты, загруженные из аналитической системы, файлы cookie партнеров и множество других данных.
Меньшие размеры — например, от 1 КБ до 10 КБ — на профиль являются обычным явлением. Помимо чистых профилей, вам потребуются сопоставление файлов cookie, бюджеты и статус кампаний, а также другие внешние данные.
2. Aerospike предлагает структуру данных под названием LDT — Large Data Type. Его можно использовать для хранения миллионов элементов (скажем, целых чисел или строк) для каждого ключа. Поэтому, если вы хотите сохранить список подписчиков знаменитости, сопоставленный с идентификатором знаменитости, вы можете сделать это с помощью LDT. Это просто очень простой и детальный вариант использования.
3. Aerospike может использоваться для хранения вложенных данных, т.е. структура данных под другой структурой данных. Таким образом, собственный список может содержаться на карте и так далее.
4. Если вы хотите кэшировать быстро меняющиеся динамические данные, Aerospike — хороший выбор.
5. Аналитика данных: Хранение поведения потребителей, как в финансовой индустрии, какие транзакции выполняет потребитель и идентификация, является ли это мошеннической транзакцией, система должна очень быстро записывать и извлекать данные потребителей, чтобы анализ мог происходить быстро путем анализа. правила или заинтересованная служба. Aerospike хорошо подходит для такого большого количества операций чтения и записи.
правила или заинтересованная служба. Aerospike хорошо подходит для такого большого количества операций чтения и записи.
6. Механизм рекомендаций:
Механизм рекомендаций использует инновационную математику в сочетании с знанием предметной области для повышения вовлеченности в Интернете. Если вы разрабатываете его, вам понадобится быстрый уровень данных — для поддержки нескольких запросов на рекомендацию — и гибкий, поскольку вам потребуется либо большая пропускная способность, либо больше данных по мере развития вашей системы. Вам понадобится тот, который поддерживает высокую пропускную способность записи при ETL-обработке данных от ваших специалистов по данным или если вы записываете недавнее поведение, которое будут использовать ваши алгоритмы.
Aerospike — отличная база данных для систем рекомендаций. Ключевыми функциями являются большие списки (для эффективной записи поведения), оптимизированная поддержка Flash для обработки наборов данных от терабайтов до петабайтов, запросы и агрегации для отчетов в реальном времени, а также мощная поддержка таких языков, как Python и Go.

7. Может использоваться для очень больших наборов данных, таких как хэш геолокации. Если вы хотите хранить данные о расстоянии и продолжительности времени между двумя местоположениями и хотите кэшировать миллионы таких точек данных, Aerospike может вам помочь.
Техника управления памятью: Можно найти здесь.
Известные пользователи Aerospike: InMobi, Flipkart, Adobe, Snapdeal, AppsFlyer, PubMatric, Swiggy.
Hazelcast
Hazlecast — это сетка данных в памяти, представляющая собой кластерную систему с высокой доступностью и масштабируемостью. Это очень быстро, потому что автоматически распределяет и реплицирует данные между узлами. Это система кэширования на основе Java, которая хорошо вписывается в экосистему Java, хотя клиенты Hazlecast доступны и на других основных языках.
Hazelcast — это хранилище данных в памяти без схемы, которое примерно в 1000 раз быстрее, чем реляционная СУБД, достигая времени запроса и обновления, измеряемого в микросекундах для больших объемов данных.

Особенности:
- Hazlecast не имеет главного узла. Все узлы похожи на master. Они поддерживают информацию метаданных, называемую «таблицей разделов». В таблице разделов хранится информация о деталях участников, состоянии кластера, информации о резервном копировании, перераспределении разделов и т. д. Клиенты Hazlecast также имеют доступ к этой «таблице разделов», поэтому они могут напрямую запрашивать связанный узел, где находятся данные.
- Hazlecast распределяет копии данных по всем узлам в кластере. Поэтому, если узел выходит из строя, данные не теряются.
- По мере появления все большего количества данных Hazlecast может расти и масштабироваться по горизонтали.
- Многопоточный. Следовательно, потенциально могут использоваться все ядра процессора.
Дополнительные функции здесь.
Подходящие варианты использования:
- Hazlecast повторно реализует List, Map, Set, AtomicLong, AtomicReference, Countdown lath, чтобы их можно было безопасно использовать в кластерной/распределенной среде при доступе из приложений, работающих на нескольких узлах .

- Hazlecast можно использовать для создания уникального идентификатора для многораздельных баз данных или других вариантов использования.
- Он также реализует несколько распределенных вычислений, таких как запланированный исполнитель, служба исполнителя и т. д., которые будут использоваться в распределенной среде.
4.
Hazelcast IMDG обеспечивает кластеризацию веб-сеансов. Сеансы пользователей поддерживаются в кластере Hazelcast с использованием нескольких копий для обеспечения избыточности. В случае сбоя сервера приложений балансировщик нагрузки перенаправляется на новый сервер приложений, который имеет доступ к сеансу пользователя. Переход к новому серверу приложений для пользователя не вызывает затруднений. Это обеспечивает высочайший уровень клиентского опыта. Пример использования кластеризации веб-сеансов доступен для Tomcat и Jetty с использованием встроенной интеграции и любого сервера приложений с использованием фильтров.
5. Hazlecast также предпочтительнее в финансовой сфере. Подробнее здесь.
Hazlecast также предпочтительнее в финансовой сфере. Подробнее здесь.
Здесь также больше вариантов использования.
Технология управления памятью: Hazlecast поддерживает LRU, LFU или ничего из этого.
Известные пользователи Hazelcast: Ola cabs (Индия), American Express, Credit Suisse, Hyperwallet Systems, PayPal, Atlassian, Apache Camel, Twilio, Vert.x и т. д. хранилище документов NoSQL корпоративного уровня (можно использовать как ключ-значение или хранилище документов), которое представляет собой нечто большее, чем просто решение для кэширования, и предлагает функции, которые делают его менее сложным и адаптируемым большим количеством корпоративных игроков.
Couchbase был разработан для решения основных проблем, которые часто связаны с кэшированием, но на самом деле являются просто стандартными проблемами производительности и масштабируемости. Кроме того, Couchbase решает проблемы, связанные с высокой доступностью приложений, а также всесторонней надежностью данных с вариантами аварийного переключения.
Особенности:
- Couchbase имеет архитектуру памяти в первую очередь, вся база данных может работать в памяти, что делает ее пригодной для сценариев кэширования. Couchbase создан для высокой производительности, он обеспечивает задержку менее миллисекунды.
Он также может обслуживать данные, выходящие за пределы памяти, используя эффективные методы доступа к данным, которые поддерживают загрузку памяти последними обновлениями.
2. Couchbase также предлагает постоянство. Поэтому, если узел выходит из строя, данные не теряются.
3. Эластичная масштабируемость — это то, что если у вас есть много данных и вы хотите распределить их по узлам или кластерам, Couchbase может сделать это без большой нагрузки.
4. Couchbase предлагает репликацию между кластерами и центрами обработки данных (XCDR) для обеспечения высокой доступности.
5. Couchbase поддерживает запросы данных JSON с помощью собственного языка запросов N1QL.
6. Он также предлагает аналитические запросы в реальном времени, полнотекстовый поиск, обработку событий на стороне сервера.
7. Поддерживает автоматическое переключение приложений между кластерами.
8. Couchbase предлагает автоматическое сегментирование и использует клиентов с поддержкой кластера. Поэтому, когда вводится новая нода или нода уходит, вам не нужно делать шардинг, все будет происходить за кулисами.
9. Доступна корпоративная поддержка.
Подходящие варианты использования : Крупные предприятия, которым требуется кэширование + сценарии использования NoSQL с простотой обслуживания, высокой доступностью и отказоустойчивостью, высокой пропускной способностью с автоматическим переключением при отказе, автоматическим сегментированием, простым мониторингом и административной поддержкой и т. д.
Ограничения : Можно найти здесь.
Некоторые известные пользователи: PayPal, Intuit, Viber, Tesco, AT&T, Verizon, Ebay и т. д.
д.
На крупных предприятиях используется распределенный общий кэш. Таким образом, вы можете напрямую добавить зависимость для конкретного кеша в свое приложение, чтобы начать его использовать. Но это не очень подходящий метод, так как может случиться так, что в ближайшем будущем появится еще одно фантастическое решение для кэширования, и ваша организация решит его использовать. Таким образом, чтобы абстрагировать уровень кэширования от будущих проблем, кеш можно скрыть за службой. Все различные приложения могут взаимодействовать с кешем через вызовы API. Он инкапсулирует внутренние детали кеша, и команда кэширования сможет быстро вносить любые необходимые изменения, не меняя открытый интерфейс. Но как только вы решите пойти по этому пути, вы должны убедиться, что служба кэширования работает круглосуточно и без выходных. Таким образом, все проблемы, связанные с архитектурой микросервисов, будут справедливы для этого случая, но, тем не менее, вид абстракции и гибкости, которые должен предлагать сервис, бесценны для крупной организации.
В этом посте мы рассмотрели различные параметры при выборе и разработке собственной службы кэширования. Это не только большое / популярное название технологии или ваше знакомство с технологией, которая решает, что вы выберете, но и больше вариантов использования наших приложений, шаблон доступа к данным, тип объектов, которые мы хотим кэшировать, желаемая продолжительность данных, политика вытеснения , требования к инфраструктуре, желательное сохранение данных, требования к масштабируемости и кластеризации, доступность, объем данных и т. д., которые решают, какую технологию выбрать. Инженеры сами решают, как много внимания они хотят иметь, прежде чем выбрать что-то — это вполне нормальное поведение, когда люди выбирают технологию, к которой они уже привыкли, но точное знание всех этих параметров поможет вам принять лучшее дизайнерское решение.
Пожалуйста, дайте мне знать, если вы можете что-то добавить к этому сообщению, или я могу что-то улучшить, добавив комментарий ниже.
Ссылка:
[1] https://dzone.com/articles/introduction-amp-assimilating-caching-quick-read-fo
[2] https://www.itpro.co.uk /virtualisation/30271/our-5-minute-guide-to-distributed-caching
[3] https://docs.oracle.com/cd/E15357_01/coh.360/e15723/cache_rtwtwbra.htm#COHDG5181
[4] https://blogs.dropbox.com/tech/2012/10/caching-in-theory-and-practice/
[5] https://stackoverflow.com/questions/17759560/какая-есть-разница-между-lru-and-lfu
[6] https://stackoverflow.com/questions/44343510/in -what-case-lfu-is-better-than-lru
[7] https://devcenter.heroku.com/articles/advanced-memcache
[8] https://www.quora.com/What -use-cases-is-Redis-suitable-not-suitable-for-in-a-high-traffic-web-application-as-of-early-2016
[9] http://www.tothenew.com /блог/кеширование-что-почему-и-как-с-hazelcast/
[10] https://blog.hazelcast.com/hazelcast-use-cases/
[11] https://hazelcast.com/why-hazelcast/imdg/
[12] https://www . aerospike.com/products/features/
aerospike.com/products/features/
Что такое кэширование? | Microsoft Azure
Разработчики и ИТ-специалисты используют кэширование для сохранения и доступа к данным типа «ключ-значение» во временной памяти быстрее и с меньшими усилиями, чем данные, хранящиеся в обычном хранилище данных. Кэши полезны в нескольких сценариях с несколькими технологиями, такими как кэширование компьютера с оперативной памятью (ОЗУ), сетевое кэширование в сети доставки контента, веб-кэш для веб-мультимедийных данных или облачный кеш, чтобы помочь сделать облачные приложения более отказоустойчивыми. . Разработчики часто разрабатывают приложения для кэширования обработанных данных, а затем переназначают их для обслуживания запросов быстрее, чем при стандартных запросах к базе данных.
Вы можете использовать кэширование для снижения затрат на базу данных, обеспечения более высокой пропускной способности и меньшей задержки, чем может предложить большинство баз данных, а также для повышения производительности облачных и веб-приложений.
Как кэширование работает для баз данных?
Разработчики могут дополнить первичную базу данных кэшем базы данных, который они могут поместить в базу данных или приложение или настроить как отдельный уровень. Хотя они обычно полагаются на обычную базу данных для хранения больших, надежных и полных наборов данных, они используют кэш для хранения временных подмножеств данных для быстрого поиска.
Вы можете использовать кэширование со всеми типами хранилищ данных, включая базы данных NoSQL, а также реляционные базы данных, такие как SQL Server, MySQL или MariaDB. Кэширование также хорошо работает со многими конкретными платформами данных, такими как База данных Azure для PostgreSQL, База данных SQL Azure или Управляемый экземпляр Azure SQL. Мы рекомендуем изучить, какой тип хранилища данных лучше всего соответствует вашим требованиям, прежде чем вы начнете настраивать архитектуру данных. Например, вы хотели бы понять, что такое PostgreSQL, прежде чем использовать его для объединения реляционных и неструктурированных хранилищ данных.
Преимущества слоев кеша и что такое Redis?
Разработчики используют многоуровневые кэши, называемые уровнями кэша, для хранения различных типов данных в отдельных кэшах в соответствии с требованиями. Добавляя слой кэша или несколько, вы можете значительно улучшить пропускную способность и показатели задержки уровня данных.
Redis — это популярная структура данных в памяти с открытым исходным кодом, используемая для создания высокопроизводительных слоев кэша и других хранилищ данных. Недавнее исследование показало, что добавление кэша Azure для Redis к образцу приложения увеличило пропускную способность данных более чем на 800 % и уменьшило задержку более чем на 1000 %9.1198 1 .
Кэши также могут снизить совокупную стоимость владения (TCO) для уровня данных. Используя кэши для обслуживания наиболее распространенных запросов и снижения нагрузки на базу данных, вы можете снизить потребность в избыточном выделении экземпляров базы данных, что приведет к значительной экономии средств и снижению совокупной стоимости владения.
Типы кэширования
Ваша стратегия кэширования зависит от того, как ваше приложение читает и записывает данные. Ваше приложение требует интенсивной записи или данные записываются один раз и часто считываются? Всегда ли возвращаемые данные уникальны? Различные шаблоны доступа к данным будут влиять на то, как вы настраиваете кэш. К распространенным типам кэширования относятся резервное кэширование, сквозное чтение/сквозная запись и отложенная/обратная запись.
Cache-aside
Для приложений с большими рабочими нагрузками по чтению разработчики часто используют шаблон программирования без кэширования, или «побочный кэш». Они размещают дополнительный кэш за пределами приложения, которое затем может подключаться к кешу для запроса и извлечения данных или напрямую к базе данных, если данных нет в кеше. Когда приложение извлекает данные, оно копирует их в кеш для будущих запросов.
Дополнительный кэш можно использовать для повышения производительности приложений, обеспечения согласованности между кэшем и хранилищем данных и предотвращения устаревания данных в кэше.
Кэш со сквозной записью/чтением
Кэш со сквозной записью постоянно обновляется, а при кэшировании со сквозной записью приложение записывает данные в кеш, а затем в базу данных. Оба кеша находятся на одной линии с базой данных, и приложение рассматривает их как основное хранилище данных.
Кэш сквозного чтения помогает упростить приложения, в которых одни и те же данные запрашиваются снова и снова, но сам кэш сложнее, а двухэтапный процесс сквозной записи может создавать задержки. Разработчики объединяют их, чтобы обеспечить согласованность данных между кешем и базой данных, уменьшить задержку кеша сквозной записи и упростить обновление кеша сквозного чтения.
С помощью кэширования со сквозной записью и чтением разработчики могут упростить код приложения, повысить масштабируемость кэша и минимизировать нагрузку на базу данных.
Кэш отложенной/обратной записи
В этом сценарии приложение записывает данные в кеш, что немедленно подтверждается, а затем сам кеш записывает данные обратно в базу данных в фоновом режиме. Кэши с отложенной записью, иногда называемые кэшами с обратной записью, лучше всего подходят для рабочих нагрузок с интенсивной записью и повышают производительность записи, поскольку приложению не нужно ждать завершения записи, прежде чем переходить к следующей задаче.
Распределенный кэш и хранилище сеансов
Люди часто путают распределенные кэши с хранилищами сеансов, которые похожи, но имеют разные требования и цели. Вместо использования распределенного кеша для дополнения базы данных разработчики реализуют хранилища сеансов, которые являются временными хранилищами данных на пользовательском уровне для профилей, сообщений и других пользовательских данных в приложениях, ориентированных на сеансы, таких как веб-приложения.
Что такое хранилище сеансов?
Приложения, ориентированные на сеанс, отслеживают действия, предпринимаемые пользователями, когда они вошли в приложения. Чтобы сохранить эти данные при выходе пользователя из системы, вы можете хранить их в хранилище сеансов, что улучшает управление сеансами, снижает затраты и повышает производительность приложений.
Чем использование хранилища сеансов отличается от кэширования базы данных?
В хранилище сеансов данные не распределяются между разными пользователями, а при кэшировании разные пользователи могут получить доступ к одному и тому же кэшу. Разработчики используют кэширование для повышения производительности базы данных или экземпляра хранилища, а хранилища сеансов — для повышения производительности приложений за счет записи данных в хранилище в памяти, что устраняет необходимость доступа к базе данных вообще.
Данные, записанные в хранилище сеансов, обычно недолговечны, в то время как данные, кэшированные в первичной базе данных, обычно предназначены для гораздо более длительного хранения. Хранилище сеансов требует репликации, высокой доступности и надежности данных, чтобы гарантировать, что транзакционные данные не будут потеряны, а пользователи останутся вовлеченными. С другой стороны, если данные в стороннем кеше теряются, их копия всегда есть в постоянной базе данных.
Преимущества кэширования
Улучшена производительность приложений
Чтение данных из кэша в памяти выполняется намного быстрее, чем доступ к данным из дискового хранилища данных. А благодаря более быстрому доступу к данным общая работа с приложением значительно улучшается.
Сокращение использования базы данных и затрат
Кэширование приводит к меньшему количеству запросов к базе данных, повышению производительности и снижению затрат за счет ограничения необходимости масштабирования инфраструктуры базы данных и снижения платы за пропускную способность.
Масштабируемая и предсказуемая производительность
Один экземпляр кэша может обрабатывать миллионы запросов в секунду, предлагая уровень пропускной способности и масштабируемости, с которым не могут сравниться базы данных. Кэширование также обеспечивает гибкость, которая вам нужна, независимо от того, масштабируете ли вы свои приложения и хранилища данных. Тогда ваше приложение может разрешить нескольким пользователям одновременный доступ к одним и тем же файлам без увеличения нагрузки на серверные базы данных. И если приложение часто испытывает пики использования и высокую пропускную способность, кэши в памяти могут уменьшить задержку.
Для чего используется кэширование?
Кэширование вывода
Кэширование вывода помогает повысить производительность веб-страницы за счет сохранения полного исходного кода страниц, такого как HTML и клиентские сценарии, которые сервер отправляет в браузеры для отображения. Каждый раз, когда пользователь просматривает страницу, сервер кэширует выходной код в памяти приложения. Это позволяет приложению обслуживать запросы без запуска кода страницы или взаимодействия с другими серверами.
Кэширование данных и кэширование базы данных
Скорость и пропускная способность базы данных могут быть ключевыми факторами общей производительности приложения. Кэширование базы данных используется для частых обращений к данным, которые редко меняются, например к данным о ценах или запасах. Это помогает веб-сайтам и приложениям загружаться быстрее, увеличивая пропускную способность и снижая задержку при извлечении данных из серверных баз данных.
Хранение данных сеанса пользователя
Пользователи приложений часто создают данные, которые необходимо хранить в течение коротких периодов времени. Хранилище данных в памяти, такое как Redis, идеально подходит для эффективного и надежного хранения больших объемов данных сеанса, таких как пользовательский ввод, записи в корзине покупок или настройки персонализации, при меньших затратах, чем хранение или базы данных.
Брокеры сообщений и архитектуры публикации/подписки
Облачным приложениям часто необходимо обмениваться данными между службами, и они могут использовать кэширование для реализации архитектур публикации/подписки или брокера сообщений, которые уменьшают задержку и ускоряют управление данными.
Приложения и API
Как и браузеры, приложения сохраняют важные файлы и данные для быстрой перезагрузки этой информации при необходимости. Кэшированные ответы API устраняют потребность или нагрузку на серверы приложений и базы данных, обеспечивая более быстрое время отклика и лучшую производительность.
1 Заявления о производительности основаны на данных исследования, которое было заказано Microsoft и проведено GigaOm в октябре 2020 года. В исследовании сравнивалась производительность тестового приложения с использованием базы данных Azure с реализацией кэширования Azure для Redis и без нее. решение. В качестве элемента базы данных в исследовании использовались База данных SQL Azure и База данных Azure для PostgreSQL. Экземпляр базы данных SQL Azure общего назначения с 2 виртуальными ядрами Gen5 и экземпляр базы данных Azure общего назначения с 2 виртуальными ядрами для PostgreSQL использовались с 6-гигабайтным экземпляром P1 Premium Azure для Redis. Эти результаты сравнивались с 8, 16, 24 и 32 экземплярами виртуального ядра Gen5 общего назначения базы данных SQL Azure и 8, 16, 24 и 32 экземплярами виртуального ядра общего назначения базы данных Azure для PostgreSQL без кэша Azure для Redis. Эталонные данные взяты из нагрузочного теста базы данных веб-приложения GigaOm, который имитирует обычное веб-приложение и серверную базу данных, которые заблокированы увеличением количества HTTP-запросов. Фактические результаты могут отличаться в зависимости от конфигурации и региона. См. полное исследование.
Добавьте в свое приложение гибкий уровень кэширования с помощью полностью управляемой службы Redis: узнайте, как начать работу с Azure Cache для Redis.
Начать
Если вы хотите использовать гибкое файловое кэширование для высокопроизводительных приложений, прочтите о кэше Azure HPC.
Кэш Azure HPC
Мы можем вам помочь?
Техники кэширования: нужно знать | by Utkarsh Malpani
За кулисами кэширования и важные аспекты, которые удивят вас
Обзор:
- Что такое кэширование
- Типы кэширования
- Топология кэширования, которая меньше и быстрее хранит кэш 6 90 копии часто используемых данных.
 Содержимое, такое как HTML-страницы, изображения, файлы, веб-объекты и т. д., хранится в кеше для повышения эффективности и общей производительности приложения.
Содержимое, такое как HTML-страницы, изображения, файлы, веб-объекты и т. д., хранится в кеше для повышения эффективности и общей производительности приложения.Кэш обычно хранится в памяти или на диске. Кэш памяти обычно читается быстрее, чем кеш диска. Но, не выдерживает перезагрузки системы.
Кэши широко используются в большинстве приложений с большими объемами для:
- уменьшения задержки
- увеличения емкости
- повышения доступности приложений
В веб-разработке используются четыре основных типа кэширования. О каждом из этих тайников мы узнаем в следующем наборе карточек.
Types- Web Caching (Browser/Proxy/Gateway)
- Data Caching
- Application/Output Caching
- Distributed Caching
W eb Caching (Browser/Proxy/Gateway)
Web Caching helps reduce общий сетевой трафик и задержка.
Кэширование браузера помогает отдельным пользователям быстро перемещаться по недавно посещенным страницам.
Этот процесс требует наличия заголовков Cache-Control и ETag, чтобы указать браузеру пользователя кэшировать определенные файлы в течение определенного периода времени.Кэш прокси-сервера и шлюза позволяет совместно использовать кэшированную информацию большим группам пользователей. Данные, которые не изменяются часто и могут храниться в кэше в течение более длительного периода времени, кэшируются на прокси-серверах или серверах шлюза. Например: данные DNS, которые преобразуют доменные имена в IP-адреса.
D ata Кэширование
- Кэширование данных очень важно для приложений, управляемых БД.
- Сохраняет данные в локальной памяти на сервере и помогает избежать лишних обращений к БД для получения неизменившихся Данных.
- Для большинства решений БД кэшируйте часто используемые запросы, чтобы сократить время обработки.
- Стандартной практикой является очистка любых данных кэша после их изменения.
Примечание. Чрезмерное использование кэширования данных может вызвать проблемы с памятью, если данные постоянно добавляются в кэш и удаляются из него.
A Кэширование репликации/вывода
В то время как
Кэширование данныххранит необработанные наборы данных,Кэширование приложений/выводаиспользует методы кэширования на уровне сервера, которые кэшируют необработанный HTML. Это может быть страница или части страницы (верхние/нижние колонтитулы), но обычно это HTML-разметка.Этот тип кэширования может значительно сократить время загрузки веб-сайта и снизить нагрузку на сервер.
D Распределенное кэширование
Приложения большого объема, такие как Google, YouTube и Amazon, используют Кластерное распределенное кэширование . Распределенный кеш обычно состоит из кластера более дешевых машин, обслуживающих только память. После настройки кластера:
- Новая машина памяти может быть добавлена в любое время без прерывания работы пользователей.
- Позволяет веб-серверам извлекать и сохранять данные из распределенной памяти сервера.
- Позволяет веб-серверу просто обслуживать страницы и не беспокоиться о нехватке памяти.
Несколько популярных используемых систем — GemFire, Memcached, Redis, Ehcache и т. д.
Топология кэширования — это, по сути, стратегия хранения данных в кластерном кэше. Существует богатый набор топологий кэширования на выбор.
Цель состоит в том, чтобы обслуживать как небольшие, так и очень большие кластеры кэша, состоящие из сотен серверов кэша. Несколько ключевых топологий кэширования:
- Реплицированный кэш
- Разделенный кэш
- Локальный кэш
- Ближний кэш
R Реплицированная топология
Реплицированный кэш содержит два или более серверов в кластере.
- Данные полностью реплицируются на каждый сервер в кластере, что делает его
отказоустойчивым - Обновления кеш-памяти на любом сервере применяются синхронно ко всем остальным серверам в кластере0571 поскольку любой сервер, к которому подключается клиент, имеет весь кеш и, следовательно, считывает данные из своей собственной памяти
- Стоимость операции обновления
не очень масштабируемаесли в реплицированный кэш необходимо добавить больше серверов. - Масштабируемость зависит от количества участников, частоты и размера обновлений.
Рекомендуется для небольших кэшей с интенсивным чтением.
P разделенная топология
В секционированном кэше данные поровну разделены на разделы, и все разделы поровну разделены между участвующими серверами кластера.
- Разделение кэша основано на алгоритме хэш-карты, и карта распределения создается и отправляется всем клиентам, которая сообщает клиентам, в каком разделе находятся данные.
- Позволяет клиентам напрямую обращаться к кэш-серверу, на котором есть данные, которые он ищет.
- Ровно один сервер в кластере отвечает за каждую часть данных в кэше.
- Обновления выполняются только для одного сервера. Следовательно, операции GET, UPDATE выполняются намного быстрее и остаются таковыми и для больших кластеров кеша.
- Все кэш-серверы обеспечивают отработку отказа и откат путем явного резервного копирования данных на разные физические серверы.
- Кластеры с включенным локальным хранилищем будут предоставлять кеш и резервную копию для секционированного кеша
- Все узлы кластера будут иметь одинаковое представление данных благодаря прозрачности расположения
Линейное масштабирование и рекомендуется для больших кластеров кеша с чтением и записью -интенсивные варианты использования.
L Топология локального кэша
Каждый клиент имеет облегченный встроенный локальный кэш, который изначально пуст.
- При первом чтении данных они загружаются с главного устройства в локальный кеш (ленивая загрузка)
- При следующем чтении тех же данных они быстро извлекаются из локального кеша без доступа к сети
- Позже данные либо обновляются с мастера, либо удаляются из кэша.
- Главный кэш может быть кластеризован в любой из других топологий: реплицированной, разделенной и т. д.
- Локальный кэш повышает скорость чтения часто используемых данных.
Полезным практическим правилом является использование локального кэша, когда более 80% всех операций являются повторяющимися операциями чтения.
N Топология ушного кэша
Ближний кэш обеспечивает как экстремальную производительность Реплицированного кэша, так и исключительную масштабируемость Распределенного кэша, обеспечивая быстрый доступ на чтение 9 к 9034 распределенному кэшу.0099 Последние использованные (MRU) и Наиболее часто используемые (MFU) данные.
Ближний кэш — это реализация, объединяющая два кэша: передний кэш
- «Передний кеш» обеспечивает доступ к локальному кешу. Это довольно недорого, так как быстро и ограничено по размеру.
- «Задний кеш» может быть централизованным или многоуровневым и может загружаться по требованию в случае промахов локального кеша.
Некоторые из хороших статей, которые я написал, ознакомьтесь с ними:
Хочу бросить работу
Топ-5 самых высокооплачиваемых рабочих мест Текущий сценарий
здесь Windows
Что нового появилось в Microsoft Windows 11, вы можете ознакомиться здесь. Щелкните здесь: Windows 11
5 Возможности Python для начинающих: следует знать
Работа из дома или работа из офиса: что выбрать?
Внедрение дизайн-мышления: способ продемонстрировать
В приведенной выше статье мы обсуждали методы кэширования: нужно знать, что вы думаете?
Дайте свой ответ и оставайтесь на связи, чтобы узнать больше 🙂
Это еще не все 🙂
Надеюсь, вам понравилась статья.
Спасибо за прочтение!
Стать участником Medium: https://medium.com/@utkarsh77786/membership
Кэширование в клиенте Apollo — документы Apollo GraphQL
Клиент Apollo сохраняет результаты ваших запросов GraphQL в локальном нормализованном кэше в памяти.
Это позволяет клиенту Apollo практически мгновенно отвечать на запросы уже кэшированных данных, даже не отправляя сетевой запрос.Например, первый раз, когда ваше приложение запрашивает объект
Apollo ClientInMemoryCacheGraphQL ServerQueries для книги с идентификатором 5Book:5 не найден в кеше! serverServer отвечает BookBook:5 is cachedReturns BookApollo ClientInMemoryCacheGraphQL ServerBookс идентификатором5, поток выглядит следующим образом:И каждый раз спустя раз ваше приложение запрашивает тот же самый объект, вместо этого поток выглядит следующим образом: Кэш клиента Apollo легко настраивается. Вы можете настроить его поведение для отдельных типов и полей в вашей схеме и даже использовать его для хранения и взаимодействия с локальными данными, которые не являются полученными с вашего сервера GraphQL.
Клиент Apollo
InMemoryCacheхранит данные в виде плоской таблицы поиска объектов, которые могут ссылаться друг на друга. Эти объекты соответствуют объектам, возвращаемым вашими запросами GraphQL. Один кэшированный объект может включать поля, возвращаемые несколькими запросами, если эти запросы извлекают различных полей одного и того же объекта .Кэш плоский, но объекты, возвращаемые запросом GraphQL, часто не являются ! На самом деле их вложенность может быть сколь угодно глубокой. Взгляните на этот пример ответа на запрос:
2
"Данные": {
3
"Person": {
4
"__typeName": "Person",
5
"ID": "cgvvcgxloje =",
":" cgvvcgxloje = ",
": "cgvvcgxl 6
"имя": "Люк Скайуокер",
7
"родной мир": {
8
"__typename": "Планета",
9
2 "id": "cGczxxhb",
02 "id": "cGczxxhb" 10
"имя": "Татуин"
Этот ответ содержит объект
Person, который, в свою очередь, содержит 9Объект 0570 Планета в поле родного мира .Итак, как
InMemoryCacheхранит вложенных данных в плоской таблице поиска ? Перед сохранением этих данных кэш должен их нормализовать .Нормализация данных
Всякий раз, когда кэш клиента Apollo получает данные ответа на запрос, он выполняет следующие действия:
1. Идентифицирует объекты
Сначала кэш идентифицирует все отдельные объекты, включенные в ответ на запрос. В приведенном выше примере есть два объекта:
- A
PersonwithidcGVvcGxlOjE= - A
PlanetwithidcGxhbmV0czox
2. Generate cache IDs
After identifying all objects, the cache generates a cache ID за каждого. Идентификатор кэша однозначно идентифицирует конкретный объект, пока он находится в
InMemoryCache.По умолчанию идентификатор кэша объекта представляет собой объединение 9 идентификаторов объекта.
0570 __typename и id(или_id), разделенные двоеточием (:).Итак, идентификаторы кеша по умолчанию для объектов в приведенном выше примере:
-
Person:cGVvcGxlOjE= -
Planet:cGxhbmV0czox
Вы можете настроить формат кеша для определенного типа ID объекта. См. раздел Настройка идентификаторов кэша.
Если кэш не может сгенерировать идентификатор кэша для определенного объекта (например, если нет
idили_id), этот объект кэшируется непосредственно внутри своего родительского объекта , и на него нужно ссылаться через родителя (это означает, что кеш не всегда полностью плоский).3. Замените поля объекта ссылками
Затем кэш берет каждое поле, содержащее объект, и заменяет его значение ссылкой на соответствующий объект.
Например, вот объект
Personиз примера выше перед заменой ссылки :
2 и2
"__typename": "Person",
3
"id": "cGVvcGxlOjE=",
4
"name": 0",0
"name": 5
"Homeworld": {
6
"__typename": «Планета»,
7
«ID»: «CGXHBMV0CZOX»,
8
«Имя»: «TATOOONE»
«:» TATOOONE «
62
и
«: «TATOOONE».
вот тот самый объект после замены :2
"__typename": "Персона",
3
"id": "cGVvcGxlOjE=",
4
"имя": "Люк Скайуокер",
5 02
"дом": 02
"домой" 6
"__ref": "Planet:cGxhbmV0czox"
Поле homeworld теперь содержит ссылку на соответствующий нормализованный объект
Planet.Эта замена , а не происходит для определенного объекта, если на предыдущем шаге не удалось сгенерировать идентификатор кэша для этого объекта. Вместо этого остается исходный объект.
Позже, если вы запросите другого
Person, который имеет тот же самыйhomeworld, этот нормализованный объектPersonбудет содержать ссылку на тот же кэшированный объект ! Нормализация может значительно уменьшить дублирование данных, а также помогает поддерживать актуальность локальных данных на вашем сервере.4.
Сохранение нормализованных объектовНаконец, все результирующие объекты сохраняются в плоской таблице поиска кэша.
Всякий раз, когда входящий объект имеет тот же идентификатор кэша, что и существующий кэшированный объект, поля этих объектов объединяются:
- Если входящий объект и существующий объект имеют общие поля, входящий объект перезаписывает кэшированные значения для этих полей.
- Поля, которые появляются в только существующем объекте или только входящем объекте сохраняются.
Нормализация создает частичную копию вашего графика на вашем клиенте в формате, оптимизированном для чтения и обновления при изменении состояния вашего приложения.
Чтобы лучше понять структуру кэшированных данных, мы настоятельно рекомендуем установить Apollo Client Devtools.
Это расширение браузера включает в себя инспектор, который позволяет просматривать все нормализованные объекты, содержащиеся в вашем кэше:
Пример
Допустим, мы используем клиент Apollo для выполнения следующего запроса к демонстрационному API SWAPI:
1
query {
2
allPeople(first:3) { # Вернуть первые 3 элемента
3
people {
6
homeworld {
Этот запрос возвращает следующий результат для трех объектов
Person, каждому из которых соответствуетhomeworld(каждый объект Planet13): в результат входит поле
__typename , хотя наша строка запроса не включала это поле.