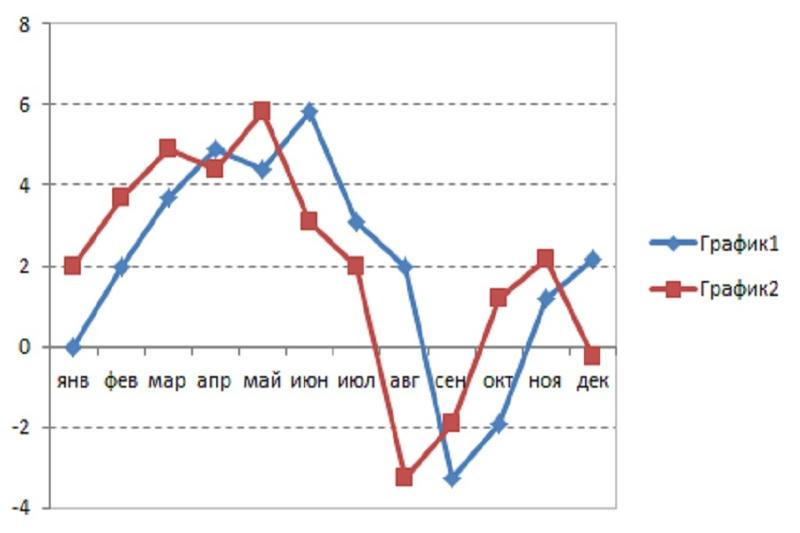
Программы для создания диаграмм и схем в презентации
Когда нужно визуализировать большой объем цифровой информации, помогут диаграммы и схемы. Оформить их так, чтобы любая аудитория вас поняла, помогут ресурсы ниже.
Ресурс, подготовленный одной из самых надежных команд в сфере подготовки презентаций в мире. На сайте 4000 схем с выгрузкой прямо в PowerPoint. Удобный выбор нужной визуализации: тип схемы — 2D/3D (правильный ответ 2D) число элементов цвет. Бесплатно через регистрацию.
Продвинутый софт для построения диаграмм в виде расширения для PowerPoint. Think-cell визуализирует и структурирует информацию — содержание презентации или описание процесса. Бесплатный пробный период 30 дней.
Софт интегрируется с PowerPoint и Excel для создания продвинутых графиков и диаграмм. Подойдет для визуализации большого объёма данных. Работает на PC и на Mac. Бесплатно пробовать можно 30 дней. Платная версия стоит $ 300 в год.
Облачный софт для рисования диаграмм, который предлагает интеграцию с приложениями Google, Google Drive и JIRA. Совместим с MS Visio. Выгрузка диаграмм возможна во всех удобных форматах: от MS Word до PNG. Можно пользоваться бесплатной версией с ограничением в 100 доступных шаблонов, а можно купить премиум подписку за $ 9,95 в месяц и получить неограниченный доступ ко всей базе данных.
Совместим с MS Visio. Выгрузка диаграмм возможна во всех удобных форматах: от MS Word до PNG. Можно пользоваться бесплатной версией с ограничением в 100 доступных шаблонов, а можно купить премиум подписку за $ 9,95 в месяц и получить неограниченный доступ ко всей базе данных.
Программа для создания диаграмм и схем, которая интегрируется с Excel, Outlook, Google Docs и Dropbox. SmartDraw работает в облаке на любых устройствах. Встроены умное форматирование и более 70 шаблонов для диаграмм. Онлайн версия программы стоит $ 9,95 в месяц при оплате годовой подписки. Есть пробный период 7 дней. Программа для Windows стоит $ 297. Платите один раз — пользуетесь всю жизнь.
Продукт семейства ConceptDraw, профессиональный софт для создания диаграмм и рисования схем. Встроенная технология «Live Object» позволяет делать изображение динамичным и интерактивным.
Позиционирует себя как аналог MS Visio. Цены начинаются от $ 199. Число пользователей не ограничено. Пробовать бесплатно можно 21 день.
Ресурс для рисования схем, графиков, диаграмм и майндкарт. Можете выбрать из 30 шаблонов или нарисовать график с нуля. Шаблоны для удобства распределены по разделам: рисование, брэйнсторминг, графики для компаний и организация пространства. Профессиональная версия даёт возможность работать со слоями, экспортировать графики в SVG и создавать схемы с помощью клавиатуры. Стандартная версия стоит $ 149,99, профессиональная — $ 249,99. Работает на Mac и iOS.
Ресурс для быстрого создания инфографики. Выберите существующий шаблон или создайте свой с нуля: фигуры, картинки, шрифты, географические карты, иконки и поля для текста в помощь. Бесплатно можно выбирать из 60 картинок и 10 шрифтов. $ 4 в месяц снимают ограничения: 600 000 картинок, более 50 шрифтов и постоянно обновляющиеся шаблоны для инфографики. Есть специальные тарифы для студентов и учителей.
Ресурс для создания графиков и диаграмм. Предоставляет неограниченные возможности для схематического изображения данных: рисуйте сами или используйте шаблоны.![]() Меняйте стиль, цвета графиков, добавляйте к ним комментарии и отправляйте по почте. Диаграммы и географические карты можно анимировать.
Меняйте стиль, цвета графиков, добавляйте к ним комментарии и отправляйте по почте. Диаграммы и географические карты можно анимировать.
Есть базовый бесплатный тариф с ограниченным функционалом, в котором можно создавать до 10 графиков за месяц. Профессиональная версия за $ 19 в месяц даёт возможность создавать до 100 диаграмм в месяц, версия «Business» за $ 67 — 1000.
Программа для создания интерактивного контента: инфографики, презентаций, каталогов и даже майндкарт. Их элементы будут двигаться и перемещаться с помощью анимации. Цель, которая достигается с помощью «оживления» презентации — привлечение внимания аудитории. И главное: софт бесплатный.
Ресурс для создания инфографики, в котором удобно работать с графиками и диаграммами для визуализации статистики и анимировать данные. На изображение можно добавлять собственные картинки, графики и логотипы. В бесплатной версии 5 шаблонов, за премиум-темплэйты для индивидуального использования придётся заплатить $ 19 в месяц. Версия для бизнеса с брендированными элементами стоит $ 49 в месяц.
Версия для бизнеса с брендированными элементами стоит $ 49 в месяц.
Онлайн-сервис для создания инфографики, презентаций, постеров и документов. Открывает доступ к анимированным диаграммам, графикам, иконкам, интерактивным географическим картам и сотням вариантов оформления текста. Можно легко добавлять фото, видео, менять стили и шрифты, есть интеграция с Google таблицами и другими сервисами.
В бесплатной версии только 8 шаблонов, можно скачать в jpg и png. Чтобы снять ограничения, можно купить подписку PRO за $ 24,17 в месяц. С ней можно создавать неограниченное количество схем, выбирать цвета и шрифты, экспортировать данные в разных форматах. Есть отдельный план для командной работы PRO TEAM за $ 82,50. Он открывает доступ к совместному редактированию. Специальные предложения действуют для образовательных и некоммерческих организаций.
★ — рекомендованный ресурс esprezo.
| Написать комментарий |
Посмотрите другие подборки ресурсов для презентаций и выступлений
Добавление графики, текста и изображений в компоновку—ArcGIS Pro
Наверх
В этом разделе
- Оставить активным последний инструмент
- Символ по умолчанию
Чтобы создать полноценную компоновку, вы можете добавить графику, текст и рисунки.
Эти инструкции предназначены для добавления графики в компоновку. Чтобы добавить графику на карту, см. Добавление графического слоя.
Чтобы добавить графику, текст или изображения в компоновку, выберите элемент из галереи Графика и текст на вкладке Вставка. Доступны следующие элементы:
| Тип элемента | Описание |
|---|---|
Текст в прямоугольнике | Текст в прямоугольнике. Текст в прямоугольнике сохраняет заданный размер шрифта и автоматически переносит длинный текст в новые строки. |
Текст в полигоне | Текст в многоугольнике заданной вами формы. Текст в многоугольнике сохраняет заданный размер шрифта и автоматически переносит длинный текст в новые строки. |
Текст в круге | Текст в круге. Текст в круге сохраняет заданный размер шрифта и автоматически переносит длинный текст в новые строки. |
Текст в эллипсе | Текст в эллипсе. Текст в эллипсе сохраняет заданный размер шрифта и автоматически переносит длинный текст в новые строки. |
Прямой текст | Текст в прямой строке. Размер шрифта автоматически увеличивается и уменьшается в соответствии с изменением размера элемента. Заданные разрывы строк в тексте поддерживаются, но текст не переносится на новые строки. |
Изогнутый текст | Текст в изогнутой линии. |
Точка | Графический символ точки. |
Рисунок | Рисунок. При выборе этого элемента открывается окно Вставить рисунок, в котором можно перейти к файлу изображения. Щелкните, чтобы добавить рисунок в исходном размере, или нарисуйте прямоугольник, чтобы установить размер рисунка. Если добавить рисунок, он сохранится в проекте и потеряет связь с исходным файлом изображения. Если исходный файл рисунка обновится, то все проекты, которые используют этот файл рисунка, необходимо обновить вручную, чтобы изменения вступили в силу. Динамические изображения доступны для пространственных серий карт. Для получения дополнительной информации см. |
Прямоугольник | Графический прямоугольник. |
Полигон | Графический многоугольник, созданный путем рисования соединенных отрезков линий. |
Круг | Графическая окружность Когда вы рисуете круг, щелкните там, где вы хотите сделать центр, а затем перетащите, чтобы изменить размер круга. |
Эллипс | Графический эллипс. Он похож на круг, но его вертикальный радиус больше, чем горизонтальный, или наоборот. |
Лассо | Графическая фигура, созданная путем рисования эскиза от руки. |
Кривая | Кривая линия, созданная путем рисования кривой Безье. |
Произвольная линия | Линия, созданная путем рисования эскиза от руки. |
Линия | Линия, состоящая из прямых сегментов. |
 Изогнутый текст сохраняет заданный размер шрифта. Разрывы строк и перенос слов не поддерживаются.
Изогнутый текст сохраняет заданный размер шрифта. Разрывы строк и перенос слов не поддерживаются.

Элементы динамического текста, которые обновляются автоматически, также могут быть добавлены на вашу компоновку.
Оставить активным последний инструмент
По умолчанию после добавления к компоновке графики, изображения или текста приложение переключается в режим выборки, позволяющий изменять вашу графику. Если вы собираетесь добавить на компоновку несколько таких элементов, вы можете оставить последний инструмент активным и продолжать добавлять графику, текст, изображения или другие элементы компоновки вместо переключения в режим выборки.
Чтобы оставить последний инструмент активным, раскройте галерею Графика и текст на вкладке Вставка и выберите Оставить активным последний инструмент. Теперь, когда вы добавляете элемент, инструмент остается активным, и вы можете продолжать добавлять элемент.
Символ по умолчанию
Текст, линии, многоугольники и точки добавляются с помощью символа по умолчанию. После добавления элементов они могут быть изменены, и символ может быть изменен.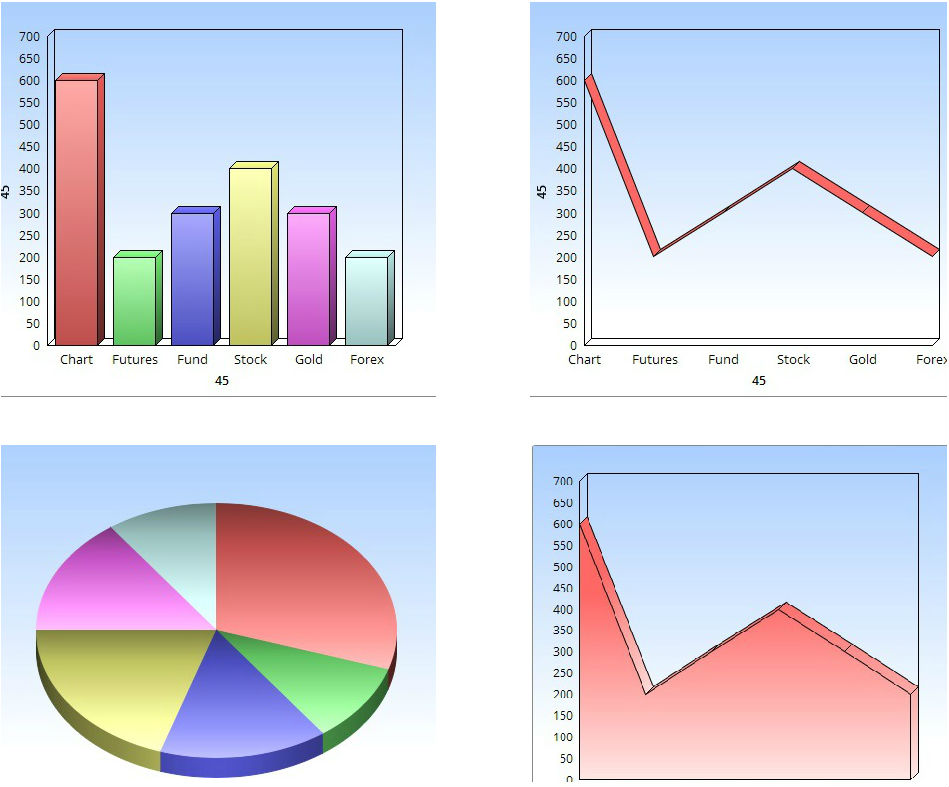 Чтобы задать символ по умолчанию для каждого типа элемента, см. Установка параметров по умолчанию для графических элементов.
Чтобы задать символ по умолчанию для каждого типа элемента, см. Установка параметров по умолчанию для графических элементов.
Связанные разделы
Отзыв по этому разделу?
В этом разделе
- Оставить активным последний инструмент
- Символ по умолчанию
Как нарисовать графики и диаграммы в Atlassian Confluence / Хабр
Atlassian Confluence — мощное решение для развертывания Enterprise Wiki в организации (хотя, нет никаких технических проблем с тем, чтобы использовать его и дома — лицензия на 10 пользователей стоит всего 10 американских долларов в год). И лично мне Confluence нравится тем, что имеет дружелюбный интерфейс и позволяет интуитивно понятно редактировать контент, с легкостью дополняя его визуальными составляющими, что позволяет в итоге получить красивые и удобные для просмотра страницы. Кстати, этот пост тоже написан в Confluence.
Как известно многим, визуализация имеет большое влияние на то, как контент будет восприниматься.
 В последнее время в любых соцсетях и тематических сообществах прослеживается четкий тренд: если ваш пост не содержит визуальной информации, например, тех же картинок с котиками, его мало кто будет читать. А если он еще и длиннее одной страницы… Итак, пользоваться графикой нужно. И тут я сошлюсь на пост комрадов из DevExpress, где они привели интересные факты о визуализации (увы, без пруфов, но цифры на мой взгляд очень похожи на правду):
В последнее время в любых соцсетях и тематических сообществах прослеживается четкий тренд: если ваш пост не содержит визуальной информации, например, тех же картинок с котиками, его мало кто будет читать. А если он еще и длиннее одной страницы… Итак, пользоваться графикой нужно. И тут я сошлюсь на пост комрадов из DevExpress, где они привели интересные факты о визуализации (увы, без пруфов, но цифры на мой взгляд очень похожи на правду):- 90% информации человек воспринимает через зрение
- 70% сенсорных рецепторов находятся в глазах
- около половины нейронов головного мозга человека задействованы в обработке визуальной информации
- на 19% меньше при работе с визуальными данными используется когнитивная функция мозга, отвечающая за обработку и анализ информации
- на 17% выше производительность человека, работающего с визуальной информацией
- на 4,5% лучше воспоминаются подробные детали визуальной информации
Учитывая столь очевидную полезность грамотной визуализации и корпоративную направленность Confluence, попробуем немного порисовать прямо на страничках вики. Рисовать там можно достаточно много вещей, но вот «из коробки» функционал позволяет разве что нарисовать графики и вставить картинки. Но это нас не остановит, поскольку в экосистеме Atlassian силами сторонних вендоров производится огромное количество аддонов на любой вкус и цвет, причем даже самый крутой и дорогой продукт можно взять и попробовать бесплатно в течение месяца. И так, если память не изменяет, до шести раз подряд, что дает совершенно легальные полгода на раздумья, что будет легче — начать себе отказывать в удобстве от аддона или
Рисовать там можно достаточно много вещей, но вот «из коробки» функционал позволяет разве что нарисовать графики и вставить картинки. Но это нас не остановит, поскольку в экосистеме Atlassian силами сторонних вендоров производится огромное количество аддонов на любой вкус и цвет, причем даже самый крутой и дорогой продукт можно взять и попробовать бесплатно в течение месяца. И так, если память не изменяет, до шести раз подряд, что дает совершенно легальные полгода на раздумья, что будет легче — начать себе отказывать в удобстве от аддона или
прописать затраты в бюджет и купить наконец продукт.
Диаграммы в Confluence
Как я упоминал выше, «из коробки» порисовать не очень-то получится. Зато, если мы обратим свое внимание на аддоны, то для рисования разного рода диаграмм их найдется немало. Попробуем рассмотреть те, которые больше всего на слуху и первые попались в заботливые руки поисковой выдачи.
- Confluence Diagramming by Creately
- Draw.io Diagrams for Confluence
- Lucidchart for Confluence
- Gliffy Diagrams for Confluence
- Graphviz Diagrams for Confluence
Первые четыре продукта, с моей точки зрения, очень похожи друг на друга. Возможно, даже имел факт «заимствования» тех или иных элементов функциональности друг у друга. Они понимают формат Visio, что позволяет не ломать голову над вопросом «а зачем нам все наши диаграммы перерисовывать» — можно просто импортировать имеющиеся файлы. Очень похож и процесс рисования диаграмм — из библиотек изображений на страницу добавляются элементы, связи между ними, подписи. Многие из поставщиков аддонов предлагают использовать их веб-версии диаграмм.
Несколько особняком стоит Graphviz Diagrams от Боба Свифта. Этот продукт несколько нарушает принципы экосистемы Atlassian, где все реализовано очень просто и интуитивно понятно, но в нем есть свой особый шарм. Да, вам потребуется не просто добавить аддон в Confluence, но еще и поставить на ваш сервер библиотеку визуализации графов graphviz. Зато потом вы сможете использовать мощный язык DOT для автоматической визуализации ваших данных (наверняка на Хабре есть люди, которые без графов и DOT жизни не представляют).
Да, вам потребуется не просто добавить аддон в Confluence, но еще и поставить на ваш сервер библиотеку визуализации графов graphviz. Зато потом вы сможете использовать мощный язык DOT для автоматической визуализации ваших данных (наверняка на Хабре есть люди, которые без графов и DOT жизни не представляют).
Примеры того, как можно нарисовать диаграммы при помощи аддонов для Confluence и веб-версий диаграмм:
Объединяет эти аддоны тот факт, что с помощью любого из них можно нарисовать недурственные диаграммы и схемы (или просто импортировать из Visio), но вот графики у них как-то не задались. Либо такая функциональность (построение графиков по таблице с данными) отсутствует, ограничиваясь схематичными представлениями графиков, либо реализована неудобно и рядовому пользователю будет непросто этим воспользоваться.
Пример того, как можно использовать язык DOT и библиотеку Graphviz:
A -> B C -> B B -> C D -> A A -> D
e;
subgraph clusterA {
a -- b;
subgraph clusterC {
C -- D;
}
}
subgraph clusterB {
d -- f
}
d -- D
e -- clusterB
clusterC -- clusterB
Трудно сказать, какой аддон лучше выбрать. Скорее всего, на выбор повлияют какие-то вторичные для функционала вещи. Например, способность работать на сервере автономно без доступа в Интернет или гибкое лицензирование, позволяющее не покупать сразу 500 лицензий в большой организации, где рисованием подобных диаграмм занимается пять человек. В наше время и цена лицензии часто имеет решающее значение. Я попытался свести основные нефункциональные характеристики в таблицу:
Скорее всего, на выбор повлияют какие-то вторичные для функционала вещи. Например, способность работать на сервере автономно без доступа в Интернет или гибкое лицензирование, позволяющее не покупать сразу 500 лицензий в большой организации, где рисованием подобных диаграмм занимается пять человек. В наше время и цена лицензии часто имеет решающее значение. Я попытался свести основные нефункциональные характеристики в таблицу:
| Аддон | Поддержка Server/Cloud |
Необходим Интернет |
Гибкое лицензирование |
Цена лицензии 500 пользователей Server/Cloud |
Поддержка импорта/экспорта файлов Visio |
Наличие веб-версии |
|---|---|---|---|---|---|---|
| ConfluenceDiagramming by Creately | Да/Нет | Да | Нет | $2000/Нет | Да | Нет |
| Draw.ioDiagrams forConfluence | Да/Да | Да | Нет | $3000/Бесплатно | Да | Да |
| Lucidchart forConfluence | Да/Да | Да | Да | Гибкая/Бесплатно | Да | Да |
| GliffyDiagrams forConfluence | Да/Да | Нет | Нет | $6000/$3000 | Да | Да |
| GraphvizDiagrams forConfluence | Да/Нет | Нет | Нет | $580/Нет | Нет | Нет |
Графики в Confluence
Погуглив «confluence charts», на первой странице я получил вот что (откровенно говоря, негусто):
- Chart Macro от Atlassian (самое приятное, что этот продукт уже включен в Confluence «из коробки» и за него не нужно доплачивать)
- Table Filter and Charts от StiltSoft
- Lucidchart (этот продукт упоминался выше, к сожалению, графики с его помощью быстро и удобно не порисуешь, иначе он был бы однозначным моим фаворитом)
Поэтому будем рассматривать первые два.
В любом случае, для того, чтобы нарисовать график, вам потребуется таблица с данными. Эта таблица может появиться в Confluence совершенно разными способами, например быть созданной с нуля, импортированной из CSV, копипастой из Excel и даже сформированной запросом из СУБД при помощи SQL for Confluence. Как сформированы данные в таблице — решающего значения не имеет, они просто должны быть. А из уже имеющихся данных мы можем построить графики.
Chart Macro из поставки Confluence
Это встроенный в Confluence макрос, который умеет отрисовывать следующие типы графиков:
- Pie Chart
- Bar Chart
- 3D Bar Chart
- Time Series Chart
- XY Line Chart
- XY Area Chart
- Area Charts
- Gantt Chart
Макрос имеет большое количество настроек для того, чтобы ваш график выглядел именно так, как вам нужно. Он покрывает все распространенные сценарии, в которых вам нужно нарисовать графики, но есть ложка дегтя (даже две) — это обязательный переход в режим редактирования страницы, даже если нужно только немного поменять настройки графика, и огромное количество этих самых настроек, что неподготовленного пользователя может напугать.![]() Правда, эти ложки дополняются бочкой меда — бесплатность и документация с примерами, которая позволяет понять, как же оно работает и построить самые простые графики.
Правда, эти ложки дополняются бочкой меда — бесплатность и документация с примерами, которая позволяет понять, как же оно работает и построить самые простые графики.
Вот так, например, выглядит Area chart:
… а вот так 3D Bar chart:
… можно посмотреть соотношение продаж разной рыбы в виде наглядной диаграммы Pie chart (круговой диаграммы):
Table Filter and Charts
Аддон разработан компанией StiltSoft, которая является Atlassian Expert и Atlassian Verified Vendor. У него есть свои плюсы и минусы. В плюсах отмечу следующее:
- аддон позволяет не только строить графики, а еще и имеет мощный механизм фильтрации таблиц (и даже умеет строить сводные таблицы с аггрегацией данных)
- очень просто настраивается
- настройки можно менять прямо из режима просмотра, не переходя в режим редактирования страницы (и сохранять их из режима просмотра)
- график можно скачать в один клик
Но, как водится, должен быть и минус. Он всего один — за аддон нужно платить (процесс установки аддона в Confluence очень прост и считать его минусом трудно).
Он всего один — за аддон нужно платить (процесс установки аддона в Confluence очень прост и считать его минусом трудно).
Аддон нам предлагает три макроса:
- Table Filter
- Pivot Table
- Chart from Table
Первый из них позволяет «на лету» прямо из режима просмотра фильтровать сложные таблицы в Confluence. Фильтрация есть и в режиме редактирования, что иногда может быть удобно. Макрос Pivot Table позволяет построить сводную таблицу, содержащую аггрегированные и суммированные значения из больших таблиц с повторяющимися значениями. И, наконец, самое интересное — Chart from Table. Вот он-то и умеет рисовать графики, вот список возможных графиков:
- Pie
- Donut
- 3D Donut
- Column
- Stacked Column
- Bar
- Stacked Bar
- Line
- Area
- Time Line
- Time Area
Примеры графиков, полученных с помощью Chart from Table
Уже знакомая по Charts круговая диаграмма про рыбу:
| Fish Type | 2011 |
|---|---|
| Herring | 9500 |
| Salmon | 2900 |
| Tuna | 1500 |
Вот так выглядит график типа stacked column (гугл утверждает, что это гистограмма):
| 2009 | 2010 | 2011 | |
|---|---|---|---|
| Revenue | 12. 4 4 |
31.8 | 41.1 |
| Expense | 43.6 | 41.8 | 31.1 |
… а вот так выглядит столбчатая диаграмма с накоплением (multi-column chart):
| Period | Opened Tickets |
Pending Tickets |
Succesfully Closed Tickets |
Tickets Closed w/o Response |
Unsuccesfully Closed Tickets |
Total Tickets |
|---|---|---|---|---|---|---|
| Q1 2015 | 207 | 42 | 381 | 20 | 14 | 664 |
| Q2 2015 | 278 | 31 | 247 | 58 | 39 | 653 |
| Q3 2015 | 227 | 27 | 200 | 23 | 31 | 508 |
| Q4 2015 | 257 | 20 | 237 | 58 | 40 | 612 |
Получившийся график можно скачать в один клик как картинку, или можно прямо из режима просмотра поменять настройки графика, используя панель настроек. Панель настроек можно скрыть, равно как и таблицу с исходными данными.
Панель настроек можно скрыть, равно как и таблицу с исходными данными.
К-к-к-комбо!
Самая мякотка, непосредственно затрагивающая тему графиков. Компоненты аддона (три макроса, входящие в комплект — графики, фильтрацию и сводные таблицы) можно смело и умело комбинировать. Что позволяет строить графики уже недоступные стандартному макросу Charts в достаточно легкой и непринужденной манере. Можно запросто построить график по отфильтрованной сводной таблице, например. Для этого вкладываем таблицу в макрос Table Filter (здесь можно будет фильтровать данные, уменьшив их количество), затем вкладываем Table Filter с таблицей в макрос Pivot Table (он построит сводную таблицу), и в качестве вишенки на торте получившуюся конструкцию помещаем в макрос Chart from Table (этот макрос нарисует график). Звучит страшновато, конструкция похожа на известную всем по сказкам Кощееву смерть. Тем не менее, в реальности все это делается достаточно быстро.
После того, как мы один раз выстроили иерархию данных и макросов — мы можем прямо из режима просмотра страницы менять настройки фильтрации исходных данных, настройки сводной таблицы и настройки графика — все будет тут же пересчитываться и перерисовываться. Настройки можно тут же сохранить, а можно поиграться и оставить как есть — страница вернется в исходное состояние при перезагрузке.
Настройки можно тут же сохранить, а можно поиграться и оставить как есть — страница вернется в исходное состояние при перезагрузке.
Погодите, а как же JIRA?
И здесь у ребят из Atlassian есть решение прямо «из коробки». Для начала, если вы еще не настроили — вам потребуется application link между Confluence и JIRA, стандартный для продуктов Atlassian. После этого Confluence сможет получать данные из JIRA. Для визуализации же этих данных в состав Confluence включен макрос JIRA Charts (который, к слову, поддерживает фильтры JIRA и даже jql-запросы для получения нужных вам данных). А для графического отображения полученных данных есть три типа графиков:
- Pie Chart from JIRA (стандартная круговая диаграмма)
- Created vs Resolved Chart from JIRA (созданные и решенные задачи)
- JIRA Two-Dimensional Chart (двумерная диаграмма)
Пример стандартной круговой диаграммы, отражающей количественное соотношение задач по товарищам, которые их выполнили:
… а вот так выглядит сравнительная диаграмма созданных и решенных задач:
Пример двумерной диаграммы (по сути простая таблица):
Разумеется, полученные из JIRA данные можно обработать и отрисовать при помощи макросов, входящих в состав Table Filter and Charts. Можно, разумеется, применять фильтры уже в процессе получения данных из JIRA, чтобы не тащить и потом не фильтровать лишнее. А можно по-простому затянуть минимально отфильтрованные данные и дофильтровать их по месту, потом привести к формату сводной таблицы и построить график либо по исходным отфильтрованным данным, либо по уже получившейся сводной таблице. А если что-то выглядит не так, как ожидается — аккуратно и быстро поменять настройки фильтров или графиков. Комбо!
Можно, разумеется, применять фильтры уже в процессе получения данных из JIRA, чтобы не тащить и потом не фильтровать лишнее. А можно по-простому затянуть минимально отфильтрованные данные и дофильтровать их по месту, потом привести к формату сводной таблицы и построить график либо по исходным отфильтрованным данным, либо по уже получившейся сводной таблице. А если что-то выглядит не так, как ожидается — аккуратно и быстро поменять настройки фильтров или графиков. Комбо!
Вместо заключения
Навыки правильной визуализации данных, когда все графики и картинки приходятся к месту и помогают, а не мешают восприятию информации, нужно нарабатывать. Но с хорошими инструментами их нарабатывать гораздо проще, потому что отвлекаться на сам процесс рисования придется меньше. Надеюсь, после этой статьи кто-нибудь перестанет считать Confluence очередной унылой корпоративной википедией и начнет использовать всю мощь этого решения, вовлекая в процесс окружающих.
Yatoro: «На AMD ######## графика – намного лучше, чем на Nvidia.
 Там очень четкая картинка» — Dota 2
Там очень четкая картинка» — Dota 2Yatoro сравнил видеокарты Nvidia и AMD.
Кукинг-стрим, трек на стриме или что-то еще? Выбери челлендж для стримеров и забирай крутой скин
«Я заметил, что у нас на мейджоре [в Арлингтоне] были компы с видеокартой AMD, а не на Nvidia. Там графика намного ##### [лучше]. У меня же Nvidia не спонсор, я надеюсь?
На AMD ######## [отличная] графика – намного лучше, чем на Nvidia. Там прямо очень четкая картинка», – заявил на стриме керри Spirit Илья «Yatoro» Мулярчук.
Ранее Yatoro на стриме спросили, как он относится к Ивану «Pure» Москаленко.
Коллапс послал ##### легенду дотерских пабликов VK. Вот его интервью – объяснил, почему душит наших
LGD проигрывает финалы из-за Конфуция, Будды и Лао-Цзы. Восточная философия просто не работает в важных матчах
Опрос
Конечно, отличный игрок!
39%
Нет, даже квалы не пройдет.
61%
Материалы по теме
Главные новости
- Nikobaby: «Я очень многому научился за то время, что пробыл в Alliance, это было великое путешествие, которое изменило мою жизнь» 3
- PSG.LGD выпустила новую джерси перед TI11 3
- Leamare: «Работаю на TI11 в качестве статистика. Англоязычная студия, нанят Valve»
- Евгений Золотарев: «Будем с некоторыми командами адресовать вопрос русскоязычной студии к Valve и PGL» 34
- Фото Alliance распустила состав по Dota 2 8
 TopNews»> 32% из вас будет не хватать на Инте NS’а, 20% — Вилата, 16% — Лоста 8
TopNews»> 32% из вас будет не хватать на Инте NS’а, 20% — Вилата, 16% — Лоста 8- Аналитик Spirit Sword_Art дал прогнозы на Last Chance: «Ставлю на Xtreme и VP»
- Adekvat: «Безумно рад за инвайт Шторма – он для меня лучший талант русскоязычного каста Dota 2 в этом году» 5
- Фото Наклейка Финаргота подорожала в 19 раз – она пропала из капсулы The International 2022 2
- Artstyle о NAVI Junior: «Пройти молодым составом во второй дивизион – это будет очень хороший старт» 2
- Видео «Как минимум не «Рекрут 1».
 Чемпион мира по Warcraft 3 откалибровался на «Рекрута 5» 3
Чемпион мира по Warcraft 3 откалибровался на «Рекрута 5» 3 - NS анонсировал «Старперхаб», посвященный The International 2022 3
- Iceberg: «В чате Твича в большинстве своем сидят самые ####### челы, которым не хватает общения» 3
- Фото Лекса добавили в список комментаторов русскоязычной студии TI11 2
- Фото Наклейку Финаргота нельзя выбить из капсулы. Она доступна только на торговой площадке 1
- NotInMyHouse: «Если приглашения на освещение главного турнира года получают Владиславы, Киберстепаны и Димы Ковали, это говорит о плачевном состоянии освещения Доты на русском» 6
 TopNews»> Видео Quinn (Soniqs) ливнул из игры, когда Bryle (TSM) на нем сделал ФБ. Средний MMR в игре был 10,988 1
TopNews»> Видео Quinn (Soniqs) ливнул из игры, когда Bryle (TSM) на нем сделал ФБ. Средний MMR в игре был 10,988 1- Cooman о 7.32c: «Что в голове у людей, которые вот эти вот патчи выпускают?» 2
- NS об инвайтах на TI11: «Я, когда увидел Blowyourbrain’а, подумал: «Фига, а Vigoss где?»
- Фото Ephey, Slacks, Cap, Sheever и Pieliedie вошли в англоязычную студию TI11 2
ПОСЛЕДНИЕ НОВОСТИ
- Шанс выпадения фразы нужного вам комментатора – 0,08%
- XBOCT: «В аналитике, скорее всего, вы меня и не увидите» 3
 TopNews»> Maestorm: «Меня в списке инвайтов не должно было быть, вообще. Огромное спасибо Fissure и RuHub за то, что они договорились» 3
TopNews»> Maestorm: «Меня в списке инвайтов не должно было быть, вообще. Огромное спасибо Fissure и RuHub за то, что они договорились» 3- Fishman: «В голос с крип-крипочка от VP, точно куплю» 4
- Storm о приглашении на TI11: «Я к этому шел 1.5 года, работая не покладая рук и параллельно смахивая пот со лба» 1
- Списки комментаторов TI11 (45 человек в русскоязычной студии), фанатские бандлы участников Инта, Саудовская Аравия хочет инвестировать 38 млрд долларов в киберспорт и другие новости утра
- Вакансия 📝 Мы ищем новостника! 23
 TopNews»> Фото SirActionSlacks использовал фото в костюме ЦМки для наклейки TI11. Его автограф с Io и Axe (но мы не уверены насчет Акса) 3
TopNews»> Фото SirActionSlacks использовал фото в костюме ЦМки для наклейки TI11. Его автограф с Io и Axe (но мы не уверены насчет Акса) 3- Видео Dendi озвучил фразу NAVI, «Крип-крипочек» у VP, фразы BetBoom и еще 8 команд не работают. В игру добавили фанатские бандлы участников TI11 2
- Lex: «Какая-то путаница. Вроде как приглашение получил». Лекса нет в списке комментаторов русскоязычной студии TI11 2
- Фото На TI впервые будет работать афроамериканец в англоязычной студии освещения. У него 300 подписчиков на ютубе и 6000 на Твиче 7
- Mila впервые вошла в студию освещения The International 9
 TopNews»> V1lat, Olsior, NS, Casper и LightOfHeaven не вошли в русскоязычную студию освещения TI11 12
TopNews»> V1lat, Olsior, NS, Casper и LightOfHeaven не вошли в русскоязычную студию освещения TI11 12- Фото Bafik, XBOCT, Jotm, Petushara и Finargot будут освещать TI11 на русском языке. Всего в русскоязычной студии 45 талантов 29
- Наклейки студии и команд из отборов The International 2022 добавили в Dota 2 1
- Pure о пабах ЮВА: «Парень на SF буквально продал свою задницу за деньги (ранее был забанен Valve за 322). Очень надеюсь, что его навсегда забанят и в пабах» 1
- Fly выложил фото с нарезанным манго: «Игроки на Undying объединяйтесь». Это шутка про стартовый закуп героя 2
 TopNews»> Саудовская Аравия хочет инвестировать 38 млрд долларов в киберспорт и игровую индустрию 4
TopNews»> Саудовская Аравия хочет инвестировать 38 млрд долларов в киберспорт и игровую индустрию 4- Korb3n: «Мантии под фонтан – это тоже оскорбление. Время сейчас другое, если бы мы были в начале 00-х, в казахстанском компьютерном клубе, то у Аммара бы уже лица не стало сразу же после этих мувов» 12
- Видео Баг в Dota 2: Vengeful Spirit c Aghanim’s Scepter возрождается с эффектом неуязвимости фонтана. В любом месте карты
- Korb3n: «Как по мне, VP очень плохо задрафтила – драфты были отвратительные в финале» 2
- Adekvat о Last Chance Qualifier на TI11: «Xtreme и Polaris пройдут в групповую стадию»
 TopNews»> На второй сезон МСКЛ+ заявилось 140 учебных заведений
TopNews»> На второй сезон МСКЛ+ заявилось 140 учебных заведений- Korb3n: «По сути Fishman прав, проблемы с питанием на мейджоре в Арлингтоне были, но просто потому, что организации как таковой не было»
- Alwayswannafly: «Все высказались, что им не понравился True Sight. Мне ###### понравилось» 1
Архив новостей
Опрос
Вилата
20%
Лоста
15%
Олсиора
10%
НСа
33%
Каспера
11%
Кого-то другого
5%
Всех моих любимых кастеров позвали
6%
Графические методы анализа данных
Графические методы анализа данныхГрафические методы анализа данных
Краткий обзор типов графиков
2М графики 2М категоризованные графики 3М XYZ графики 3М Тернарные графики Матричные графики |
3М последовательные графики 3М категоризованные графики Тернарные категоризованные графики n-мерные пиктографики |
Типичные методы визуализации
- Категоризованные графики
- Что такое категоризованные графики?
- Методы категоризации
- Гистограммы
- Диаграммы рассеяния
- Вероятностные графики
- Графики квантиль-квантиль
- Графики вероятность-вероятность
- Линейные графики
- Диаграммы размаха
- Круговые диаграммы
- Графики пропущенных значений и диапазонов
- 3М графики
- Тернарные графики
- Закрашивание
- Сглаживание двумерных распределений
- Послойное сжатие
- Проекции трехмерных наборов данных
- Пиктографики
- Анализ пиктографиков
- Систематизация пиктографиков
- Стандартизация значений
- Применения
- Близкие способы графического представления
- Типы графиков
- Маркировка пиктограмм
- Выборка данных
- Вращение (в трехмерном пространстве)
Категоризованные графики
Одним из наиболее мощных аналитических методов
исследования является разделение
(«разбиение») данных на группы для сравнения
структуры получившихся подмножеств. Эти методы
широко применяются как в разведочном
анализе данных, так и при проверке гипотез и
известны под разными названиями (классификация,
группировка, категоризация, разбиение,
расслоение и пр.). Например, взаимосвязь между
возрастом и риском инфаркта может отличаться для
мужчин и женщин (для мужчин эта зависимость
сильнее). Или например, зависимость между приемом
лекарств и снижением уровня холестерина может
наблюдаться только для женщин с пониженным
давлением и в возрасте 30-40 лет.
Производительность или гистограммы
мощности могут различаться для временных
промежутков, когда управление осуществляется
разными операторами. Разным экспериментальным
группам также могут соответствовать разные
наклоны линий регрессии.
Эти методы
широко применяются как в разведочном
анализе данных, так и при проверке гипотез и
известны под разными названиями (классификация,
группировка, категоризация, разбиение,
расслоение и пр.). Например, взаимосвязь между
возрастом и риском инфаркта может отличаться для
мужчин и женщин (для мужчин эта зависимость
сильнее). Или например, зависимость между приемом
лекарств и снижением уровня холестерина может
наблюдаться только для женщин с пониженным
давлением и в возрасте 30-40 лет.
Производительность или гистограммы
мощности могут различаться для временных
промежутков, когда управление осуществляется
разными операторами. Разным экспериментальным
группам также могут соответствовать разные
наклоны линий регрессии.
Для количественного описания различий между
группами наблюдений разработаны многочисленные
вычислительные методы, основанные на
группировке данных (например, дисперсионный
анализ). Однако графические средства (такие как
рассматриваемые в этом разделе категоризованные
графики) дают особые преимущества и
позволяют выявить закономерности, которые
трудно поддаются количественному описанию и
которые весьма сложно обнаружить с помощью
вычислительных процедур (например, сложные
взаимосвязи, исключения или аномалии). В этих
случаях графические методы предоставляют
уникальные возможности многомерного
аналитического исследования или «добычи» данных.
Однако графические средства (такие как
рассматриваемые в этом разделе категоризованные
графики) дают особые преимущества и
позволяют выявить закономерности, которые
трудно поддаются количественному описанию и
которые весьма сложно обнаружить с помощью
вычислительных процедур (например, сложные
взаимосвязи, исключения или аномалии). В этих
случаях графические методы предоставляют
уникальные возможности многомерного
аналитического исследования или «добычи» данных.
Что такое категоризованные графики
Термин «категоризованные графики» впервые
был использован в программе STATISTICA компании
StatSoft в 1990 году (кроме того, Becker, Cleveland и Clark из Bell Labs
называют их графиками на решетке). Эти
графики представляют собой наборы двумерных,
трехмерных, тернарных или n-мерных графиков
(таких как гистограммы,
диаграммы рассеяния,
линейные графики, поверхности,
тернарные
диаграммы рассеяния и пр. ), по одному графику
для каждой выбранной категории
(подмножества) наблюдений, например,
опрашиваемых из Нью-Йорка, Чикаго или Далласа.
Эти «входящие» графики располагаются
последовательно в одном графическом окне,
позволяя сравнивать структуру данных для каждой
из указанных подгрупп (например, городов).
), по одному графику
для каждой выбранной категории
(подмножества) наблюдений, например,
опрашиваемых из Нью-Йорка, Чикаго или Далласа.
Эти «входящие» графики располагаются
последовательно в одном графическом окне,
позволяя сравнивать структуру данных для каждой
из указанных подгрупп (например, городов).
Для выбора подгрупп можно использовать множество методов, самый простой из них — это введение категориальной переменной (например, переменной City с значениями New York, Chicago и Dallas). На следующем графике показаны гистограммы переменной, представляющей данные о самооценке стресса жителями каждого из трех городов.
На основе этих данных можно сделать вывод о том, что жители Далласа не очень подвержены стрессам, в то время как распределения уровня стресса в Нью-Йорке и Чикаго довольно похожи.
Некоторые программы (например, система STATISTICA)
поддерживают двухвходовую или многомерную
категоризацию, где для задания подгрупп
используется не один (например, City), а два или
более критериев (например, City и Time ). Двухвходовые категоризованные графики можно
рассматривать как «таблицы графиков», где
каждый входящий график находится на
«пересечении» определенных значений первой
(например, City) и второй (например, Time) группирующих
переменных.
Двухвходовые категоризованные графики можно
рассматривать как «таблицы графиков», где
каждый входящий график находится на
«пересечении» определенных значений первой
(например, City) и второй (например, Time) группирующих
переменных.
Добавление второго фактора показывает, что картины стрессовых нагрузок в Нью-Йорке и Чикаго в действительности сильно различаются, если учитывается время опроса, в то время как фактор времени практически ничего не меняет в Далласе.
Категоризованные и матричные графики. Матричные графики
также состоят из нескольких графиков; однако
здесь каждый из них основывается (или может
основываться) на одном и том же множестве
наблюдений, и графики строятся для всех
комбинаций переменных из одного или двух
списков. Для категоризованных графиков
требуется такой же выбор переменных, как и для
некатегоризованных графиков соответствующего
типа (например, две переменных для диаграммы
рассеяния). В то же время для категоризованных
графиков необходимо указать по крайней мере одну
группирующую
переменную (или способ разбиения наблюдений
на категории), где содержалась бы информация о
принадлежности каждого наблюдения к
определенной подгруппе (например, Chicago, Dallas).
Группирующая
переменная не будет непосредственно
изображена на графике (т.е. не будет построена),
однако она будет служить критерием для
разделения всех анализируемых наблюдений на
отдельные подгруппы. Как показано выше, для
каждой группы (категории), определяемой
группирующей переменной, будет построен один
график.
В то же время для категоризованных
графиков необходимо указать по крайней мере одну
группирующую
переменную (или способ разбиения наблюдений
на категории), где содержалась бы информация о
принадлежности каждого наблюдения к
определенной подгруппе (например, Chicago, Dallas).
Группирующая
переменная не будет непосредственно
изображена на графике (т.е. не будет построена),
однако она будет служить критерием для
разделения всех анализируемых наблюдений на
отдельные подгруппы. Как показано выше, для
каждой группы (категории), определяемой
группирующей переменной, будет построен один
график.
Общие и независимые шкалы. Каждый элементарный график, входящий в состав категоризованного графика, может быть масштабирован в соответствии со своим собственным диапазоном значений (независимые шкалы).
Или все графики могут иметь общую шкалу,
достаточно широкую, чтобы охватить весь диапазон
значений.
Общий масштаб позволяет сравнивать диапазоны и распределения значений разных категорий. Однако, если эти диапазоны сильно различаются (что приводит к очень большой общей шкале), то исследование некоторых графиков может быть затруднено. Использование независимого масштаба может упростить выявление трендов и определенных закономерностей внутри категорий, но в то же время затруднить сравнение диапазонов значений разных подгрупп.
Методы категоризации
Существует пять основных методов
категоризации значений, которые будут кратко
описаны в этом разделе: целые числа, категории,
границы, коды и сложные подгруппы. Обратите
внимание, что одни и те же методы категоризации
можно использовать как для разбиения наблюдений
по входящим графикам, так и для категоризации
наблюдений внутри входящих графиков ( например,
на гистограммах
или диаграммах
размаха).
Целые числа. При использовании этого режима для определения категорий будут использованы целые значения выбранной группирующей переменной, и для всех наблюдений, принадлежащих каждой категории (заданной этими целыми числами), будет построено по одному графику. Если выбранная группирующая переменная содержит не целочисленные значения, то программа автоматически округлит каждое значение выделенной переменной до целого числа.
Категории. В этом режиме категоризации нужно указать желаемое число категорий. Программа разделит весь диапазон значений выбранной группирующей переменной (от минимального до максимального) на указанное число интервалов равной длины.
Границы. Метод границ также представляет
собой интервальную категоризацию, однако в этом
случае интервалы могут иметь произвольную
(например, различную) длину, определяемую
пользователем (например, «меньше -10»,
«больше или равно -10, но меньше 0», «больше
или равно 0, но меньше 10» и «больше или равно
10»).
Коды. Этот метод следует использовать в том случае, если выбранная группирующая переменная содержит «коды » (т.е. особые смысловые значения, такие как Male, Female), по которым можно разбить данные на категории.
Сложные подгруппы. Этот метод дает возможность пользователю использовать для выделения подгрупп более одной переменной. Другими словами, категоризация, основанная на выделении сложных подгрупп, может представлять не распределения конкретных переменных, а распределения частот определенных «событий» при заданной комбинации значений любого числа переменных текущего набора данных. Например, можно указать шесть категорий, задаваемых комбинациями значений трех переменных Gender, Age и Employment.
Гистограммы
Гистограммы
используются для изучения распределений частот
значений переменных. Такое частотное
распределение показывает, какие именно
конкретные значения или диапазоны значений
исследуемой переменной встречаются наиболее
часто, насколько различаются эти значения,
расположено ли большинство наблюдений около среднего значения,
является распределение симметричным
или асимметричным, многомодальным
(т.е. имеет две или более вершины) или одномодальным и
т.д. Гистограммы
также используются для сравнения наблюдаемых и
теоретических или ожидаемых распределений.
Такое частотное
распределение показывает, какие именно
конкретные значения или диапазоны значений
исследуемой переменной встречаются наиболее
часто, насколько различаются эти значения,
расположено ли большинство наблюдений около среднего значения,
является распределение симметричным
или асимметричным, многомодальным
(т.е. имеет две или более вершины) или одномодальным и
т.д. Гистограммы
также используются для сравнения наблюдаемых и
теоретических или ожидаемых распределений.
Категоризованные гистограммы представляют собой наборы гистограмм, соответствующих различным значениям одной или нескольких категоризующих переменных или наборам логических условий категоризации (см. Методы категоризации).
Частотные распределения могут представлять интерес по двум основным причинам.
- По форме распределения можно судить о природе
исследуемой переменной (например, бимодальное
распределение позволяет предположить, что
выборка не является однородной и содержит
наблюдения, принадлежащие двум различным
множествам, которые в свою очередь нормально
распределены).

- Многие статистики основываются на определенных предположениях о распределениях анализируемых переменных; гистограммы позволяют проверить, выполняются ли эти предположения.
Как правило, работа с новым набором данных начинается с построения гистограмм всех переменных.
Гистограммы и группировка. Категоризованные
гистограммы предоставляют такую же информацию о
данных, как и группировка (например, среднее, медиану, минимум,
максимум, разброс и т.п.; см. главу Основные
статистики и таблицы). Хотя конкретные
(числовые) значения описательных статистик легко
увидеть в таблице, в то же время общую структуру и
глобальные характеристики распределения проще
изучать на графике. Более того, график дает
качественную информацию о распределении,
которую невозможно отразить с помощью
какого-либо одного параметра. Например, по асимметрии
распределения значений дохода можно сделать
вывод о том, что большинство населения имеет
низкий, а не высокий уровень доходов. Если помимо
этого провести группировку данных по
этническому и половому признакам, то можно
обнаружить, что в некоторых подгруппах эта
структура распределения станет еще более ярко
выраженной. Хотя эта информация содержится в
значении коэффициента асимметрии
(для каждой подгруппы), но она легче
воспринимается и запоминается, будучи
графически представленной на гистограмме. Кроме
того, на гистограмме можно наблюдать некоторые
«впадины и выпуклости», которые могут
свидетельствовать о социальном расслоении в
исследуемой группе населения или об аномалиях в
распределении дохода отдельных подгрупп,
связанных с недавней налоговой реформой.
Если помимо
этого провести группировку данных по
этническому и половому признакам, то можно
обнаружить, что в некоторых подгруппах эта
структура распределения станет еще более ярко
выраженной. Хотя эта информация содержится в
значении коэффициента асимметрии
(для каждой подгруппы), но она легче
воспринимается и запоминается, будучи
графически представленной на гистограмме. Кроме
того, на гистограмме можно наблюдать некоторые
«впадины и выпуклости», которые могут
свидетельствовать о социальном расслоении в
исследуемой группе населения или об аномалиях в
распределении дохода отдельных подгрупп,
связанных с недавней налоговой реформой.
Категоризованные гистограммы и диаграммы
рассеяния. Полезное применение категоризации
для непрерывных переменных — это представление
взаимосвязи трех переменных одновременно. Ниже
показана диаграмма рассеяния для двух
переменных Load 1 и Load 2.
Предположим, к ним нужно добавить третью переменную (Output) и исследовать ее распределение при различных значения совместного распределения переменных Load 1 и Load 2. Для этого можно построить следующий график:
На этом графике обе переменные Load 1 и Load 2 сгруппированы в 5 интервалов, и для каждой комбинации этих интервалов вычислено распределение переменной Output. Обратите внимание, что внутри «прямоугольника» (параллелограмма) находятся наблюдения, одинаковые для обоих показанных выше графиков.
Диаграммы рассеяния
Двумерные диаграммы
рассеяния используются для визуализации
взаимосвязей между двумя переменными X и Y
(например, весом и ростом). На этих диаграммах
отдельные точки данных представлены маркерами
на плоскости, где оси соответствуют переменным.
Две координаты (X и Y), определяющие положение
точки, соответствуют значениям переменных. Если
между переменными существует сильная
взаимосвязь, то точки на графике образуют
упорядоченную структуру (например, прямую линию
или характерную кривую). Если переменные не
взаимосвязаны, то точки образуют «облако».
Если
между переменными существует сильная
взаимосвязь, то точки на графике образуют
упорядоченную структуру (например, прямую линию
или характерную кривую). Если переменные не
взаимосвязаны, то точки образуют «облако».
Можно построить также категоризованные диаграммы рассеяния, сгруппированные по значениям одной или нескольких переменных, а с помощью метода сложных подгрупп (см. Методы категоризации) — диаграммы рассеяния, категоризованные по заданным логическим условиям выбора подгрупп наблюдений.
Категоризованные диаграммы рассеянияпредставляют собой мощный исследовательский и аналитический метод для изучения взаимосвязей между двумя и более переменными среди различных подгрупп.
Однородность двумерных распределений (форма
взаимосвязей).Диаграммы
рассеяния обычно используются для выявления
природы взаимосвязи двух переменных (например,
кровяного давления и уровня холестерина),
поскольку они предоставляют гораздо больше
информации, чем коэффициент корреляции.
Например, неоднородность выборки, по которой рассчитываются корреляции, может привести к искажению значений коэффициента корреляции. Предположим, коэффициент корреляции рассчитывается по данным, полученным в двух экспериментальных группах, но этот факт при вычислениях игнорируется. Пусть эксперимент в одной из подгрупп привел к увеличению значений обеих переменных, и на диаграмме рассеяния данные из каждой группы образуют отдельные «облака» (как показано на картинке).
В этом примере большое значение коэффициента корреляции целиком обусловлено распределением по группам и не отражает «истинную» взаимосвязь между двумя переменными, которая практически близка к 0 (это хорошо видно, если рассматривать каждую группу отдельно).
Если вы предполагаете, что подобная структура
присутствует и в ваших данных, и знаете, каким
образом выделить «подгруппы» наблюдений, то
имеет смысл построить категоризованную
диаграмму рассеяния.
Такой график поможет вам прояснить структуру взаимосвязей между переменными X и Y внутри каждой подгруппы (после соответствующего разбиения наблюдений).
Нелинейные зависимости. С помощью диаграмм рассеяния можно исследовать и нелинейные взаимосвязи между переменными. При этом не существует каких-либо «автоматических» или простых способов оценки нелинейности. Стандартный коэффициент корреляции Пирсона r позволяет оценить только линейность связи, а некоторые непараметрические корреляции, например, Спирмена R, дают возможность оценить нелинейность, но только для монотонных зависимостей. На диаграммах рассеяния можно изучить структуру взаимосвязей, чтобы затем с помощью преобразования привести данные к линейному виду или выбрать подходящую нелинейную подгонку.
Дополнительную информацию можно найти в
разделах Основные статистики, Непараметрическая статистика и
распределения, Множественная
регрессия и Нелинейное
оценивание.![]()
Вероятностные графики
Существует три типа категоризованных вероятностных графиков: нормальные, полунормальные и с исключенным трендом. Нормальные вероятностные графики — это быстрый способ визуальной проверки степени соответствия данных нормальному распределению.
В свою очередь категоризованные вероятностные графики дают возможность исследовать близость к нормальному распределению различных подгрупп данных .
Категоризованные нормальные вероятностные графики представляют собой эффективный инструмент для исследования однородности группы наблюдений с точки зрения соответствия нормальному распределению.
Графики квантиль-квантиль
Категоризованные графики
квантиль-квантиль (или К-К) используются для
поиска в определенном семействе распределений
того распределения, которое наилучшим образом
описывает имеющиеся данные.
В случае категоризованных графиков К-К строится набор графиков квантиль-квантиль, по одному для каждого значения категориальных переменных (X или X и Y) или для заданных условий выбора сложных подгрупп (см. Методы категоризации). Для графиков К-К используются следующие семейства распределений: экспоненциальное, экстремальное, нормальное, Релея, бета-, гамма-, логнормальное и Вейбулла.
Графики вероятность-вероятность
Категоризованные графики вероятность-вероятность (или В-В) используются для проверки соответствия конкретного теоретического распределения имеющимся исходным данным. На этих графиках для каждого значения категориальных переменных (X или X и Y) или для заданных условий выбора сложных подгрупп (см. Методы категоризации) создается по одному графику вероятность-вероятность.
На графиках В-В строится наблюдаемая функция
распределения (доля непропущенных значений x) в зависимости от
теоретической функции распределения, чтобы
оценить соответствие этой теоретической функции
наблюдаемым данным. Если все точки этого графика
располагаются на диагонали (содержащей точку 0 и
имеющей наклон 1), то можно заключить, что
наблюдаемое распределение хорошо
аппроксимируется данной теоретической функцией.
Если все точки этого графика
располагаются на диагонали (содержащей точку 0 и
имеющей наклон 1), то можно заключить, что
наблюдаемое распределение хорошо
аппроксимируется данной теоретической функцией.
Если не все точки данных располагаются на диагональной линии, то на таком графике можно визуально выделить группы наблюдений, соответствующие и не соответствующие искомому распределению (если, к примеру, точки образуют кривую S-образной формы вокруг диагональной линии, то к ним можно применить определенное преобразование для приведения к нужной форме распределения).
Линейные графики
На линейных
графиках отдельные точки данных
соединяются линиями. Это простой способ
визуального представления последовательности
значений (например, цены на фондовом рынке за
несколько дней торгов). Категоризованные
линейные графики строятся в том случае, если
необходимо разбить данные на несколько групп
(категоризовать) с помощью группирующей
переменной (например, цены при закрытии
рынка по понедельникам, вторникам и т. д.) или с
помощью логических условий, составленных по
нескольким переменным (например, цены при
закрытии рынка в те дни, когда две другие акции и
индекс Доу Джонса выросли по сравнению с другими
ценами закрытия; см. Методы
категоризации).
д.) или с
помощью логических условий, составленных по
нескольким переменным (например, цены при
закрытии рынка в те дни, когда две другие акции и
индекс Доу Джонса выросли по сравнению с другими
ценами закрытия; см. Методы
категоризации).
Диаграммы размаха
На диаграммах размаха (этот термин был впервые использован Тьюки в 1970 году) представлены диапазоны значений выбранной переменной (или переменных) для отдельных групп наблюдений. Для выделения этих групп используются от одной до трех категориальных (группирующих) переменных или набор логических условий выбора подгрупп.
Для каждой группы наблюдений вычисляется
центральная тенденция (медиана
или среднее), а также
размах или изменчивость (квартили,
стандартные ошибки
или стандартные
отклонения). Выбранные параметры отображаются
на графике одним из пяти способов (Прямоугольники-Отрезки,
Отрезки, Прямоугольники, Столбцы или
Верхние-нижние засечки). На этом графике можно
показать и выбросы (см. разделы о выбросах и крайних точках).
На этом графике можно
показать и выбросы (см. разделы о выбросах и крайних точках).
На следующем графике, например, выбор факторов можно было бы считать вполне удачным, если бы не «досадное» несоответствие, на которое указывают выделенные на рисунке выбросы (в данном случае это значения, попадающие за пределы 1,5 квартильных размахов):
А на следующем рисунке не показаны ни выбросы, ни крайние точки.
Можно выделить два основных направления
использования диаграмм
размаха: (a) отображение диапазонов значений
отдельных элементов, наблюдений или выборок
(например, типичные минимаксные графики цен на
акции или товары или графики агрегированных
данных с диапазонами), (б) отображение изменения
значений в отдельных группах или выборках
(например, когда точкой внутри прямоугольника
представлено среднее
значение для каждой выборки, сам прямоугольник
соответствует значениям стандартной ошибки, а
меньший прямоугольник или пара «отрезков»
обозначает стандартное
отклонение от среднего).
С помощью диаграмм размаха, на которых представлены характеристики изменчивости, можно быстро оценить и «интуитивно представить» силу связи между группирующей и зависимой переменной. Предположив, что зависимая переменная нормально распределена, и зная долю наблюдений, попадающих, к примеру, в интервал ±1 или ±2 стандартных отклонения от среднего (см. Элементарные понятия статистики), можно сделать, например, вывод о том, что 95% наблюдений из экспериментальной группы 1 попадают в другой диапазон значений, нежели 95% наблюдений из группы 2.
На этих графиках можно изобразить и так называемые усеченные средние (этот термин был впервые использован Тьюки в 1962 году), которые вычисляются после исключения заданного пользователем процента наблюдений с концов (хвостов) распределения.
Круговые диаграммы
Одним из наиболее широко используемых типов
графического представления данных являются круговые диаграммы, на
которых показаны пропорции или сами значения
переменных. Категоризованные графики этого типа
состоят из нескольких круговых диаграмм, где
данные разделены по группам с помощью одной или
нескольких группирующих
переменных (например, gender) или
категоризованы согласно логическим условиям
выбора подгрупп (см. Методы
категоризации).
Категоризованные графики этого типа
состоят из нескольких круговых диаграмм, где
данные разделены по группам с помощью одной или
нескольких группирующих
переменных (например, gender) или
категоризованы согласно логическим условиям
выбора подгрупп (см. Методы
категоризации).
В дальнейшем, говоря о категоризации этих
графиков, мы будем иметь ввиду круговые диаграммы
частот (в противоположность круговым диаграммам
значений). Эти типы графиков, называемые также
частотными круговыми диаграммами, представляют
данные аналогично гистограммам.
Все значения выбранной переменной
категоризуются с помощью заданного метода
категоризации, а затем относительные значения
частот отображаются в виде сегментов круговой
диаграммы пропорционального размера. Таким
образом, эти графики являются альтернативным
представлением гистограммы частот (см. раздел
о категоризованных
гистограммах).
Диаграммы рассеяния круговых диаграмм. Еще одно очень полезное применение категоризованных круговых диаграмм — это представление относительных частот значений какой-либо переменной в различных «местах» совместного распределения двух других переменных. Например:
Обратите внимание, что круговые диаграммы изображены только в тех «местах», где имеются данные. Показанный выше график напоминает диаграмму рассеяния (переменных L1 и L2), где маркерами точек являются круговые диаграммы. Однако помимо обычной информации, содержащейся в диаграмме рассеяния, здесь в каждой точке дополнительно показано относительное распределение третьей переменной (а именно, доля значений Low, Medium и High Quality).
Графики пропущенных значений и данных вне диапазона
На этих графиках можно наглядно представить
структуру распределения точек данных,
содержащих пропущенные значения или находящихся
«вне диапазонов», заданных пользователем. При этом строится по одной двумерной диаграмме
для каждой группы наблюдений, выделенной с
помощью группирующих
переменных или с помощью условий выбора
сложных подгрупп (см. Методы
категоризации).
При этом строится по одной двумерной диаграмме
для каждой группы наблюдений, выделенной с
помощью группирующих
переменных или с помощью условий выбора
сложных подгрупп (см. Методы
категоризации).
Эти типы графиков используются в разведочном анализе данных, чтобы определить, является ли случайным распределение точек с пропущенными значениями, а также для оценки их диапазона.
Трехмерные (3М) графики
Трехмерные
диаграммы рассеяния (пространственные,
спектральные, трассировочные и диаграммы отклонений),
карты линий уровня и
поверхности
также можно построить для подгрупп
наблюдений, заданных с помощью выбранной
категориальной переменной или логических
условий выбора (см. Методы
категоризации). Основная задача этих графиков -
упростить сравнение взаимосвязей между тремя и
более переменными для различных групп или
категорий наблюдений.![]()
Применения. Трехмерные графики в координатах XYZ отображают взаимосвязи между тремя переменными. С помощью различных способов категоризации можно исследовать эти зависимости при различных условиях (т.е. в разных группах).
Изучая, например, показанный ниже категоризованный график поверхности, можно сделать вывод о том, что величина допуска прибора не влияет на измерения (переменные Depend1, Depend2 и Height), кроме случая, когда она 3.
Этот вывод становится еще более очевидным, если использовать вместо поверхности карту линий уровня.
Тернарные графики
Категоризованные тернарные
графики используются для исследования
взаимосвязей между тремя и более переменными,
три из которых представляют собой компоненты
смеси (т.е. для каждого наблюдения значения их
суммы являются постоянной величиной), при этом
отдельный график строится для каждого уровня группирующей
переменной.
Для построения тернарных графиков используется треугольная система координат на плоскости или в пространстве и строится зависимость между четырьмя (или более) переменными (компонентами X, Y и Z и откликами V1, V2 и т.д.). При этом накладываются ограничения на относительные значения каждой из компонент, чтобы они в сумме давали одинаковую величину для каждого наблюдения (например, 1).
На категоризованных тернарных графиках строится по одному графику для каждого значения группирующей переменной (или заданного пользователем подмножества данных), и все они отображаются в одном графическом окне, чтобы можно было сравнивать различные подгруппы наблюдений.
Применения. Эти графики применяются для
анализа результатов эксперимента, в котором
измеряемый отклик зависит от относительного
соотношения трех компонент (например, трех
химических веществ при составлении
смесей), которое варьируется с целью
определения его оптимального значения. Эти
типы графического представления можно
использовать и в других случаях, когда
взаимосвязь между переменными, на которые
наложены определенные ограничения, необходимо
исследовать для различных групп или категорий
наблюдений.
Эти
типы графического представления можно
использовать и в других случаях, когда
взаимосвязь между переменными, на которые
наложены определенные ограничения, необходимо
исследовать для различных групп или категорий
наблюдений.
| В начало |
Закрашивание
Закрашивание является одним из первых и, по-видимому, наиболее широко распространенных методов, известных как графический разведочный анализ данных. Этот метод позволяет интерактивно выделять на экране отдельные точки или подмножества данных и задавать их характеристики, или исследовать их влияние на взаимосвязи между переменными (например, на матрицах диаграмм рассеяния) и идентифицировать выбросы(например, с помощью меток).
Связи между переменными можно наглядно
представить с помощью аппроксимирующих функций
(например, двумерных кривых или трехмерных
поверхностей) и доверительных интервалов. Интерактивно удаляя или добавляя определенные
подгруппы наблюдений, можно наблюдать за
изменениями этих функций и их параметров. Одно из
применений метода закрашивания — это, например,
выделение на матричной
диаграмме рассеяния всех точек данных,
принадлежащих определенной категории (например,
на показанном ниже рисунке на правом верхнем
графике выделена группа наблюдений,
соответствующих значению «среднего» уровня
дохода).
Интерактивно удаляя или добавляя определенные
подгруппы наблюдений, можно наблюдать за
изменениями этих функций и их параметров. Одно из
применений метода закрашивания — это, например,
выделение на матричной
диаграмме рассеяния всех точек данных,
принадлежащих определенной категории (например,
на показанном ниже рисунке на правом верхнем
графике выделена группа наблюдений,
соответствующих значению «среднего» уровня
дохода).
Такое исследование помогает определить, как эти конкретные наблюдения влияют на связи между другими переменными того же набора данных (например, на корреляцию между «расходами» и «активами»).
В режиме «динамического закрашивания» (см.
следующий пример) или «автоматического
обновления функции подгонки» можно задать
движение кисти по определенным последовательным
диапазонам выбранной переменной (например,
непрерывной, а не дискретной, как на показанном
ранее примере) и исследовать динамику вклада
этой переменной в связи между другими
переменными этого набора данных.
| В начало |
Сглаживание двумерных распределений
Для наглядного представления таблицы значений двух переменных используются трехмерные гистограммы. Их можно рассматривать как объединение двух простых гистограмм для совместного анализа частот значений двух переменных. Чаще всего на этом графике для каждой «ячейки» таблицы нарисован один трехмерный столбец, а его высота соответствует частоте значений в этой ячейке. При построении трехмерной гистограммы для каждой из двух переменных можно использовать свой метод категоризации (см. ниже).
Когда предусмотрены процедуры сглаживания
данных, то трехмерное представление частот
значений можно аппроксимировать поверхностью.
Такое сглаживание можно осуществить для любой
трехмерной гистограммы. Для достаточно простой
структуры данных (как на предыдущем рисунке)
такое сглаживание не имеет особого смысла.
Однако, в случае более сложной картины распределения частот эта процедура может оказаться эффективным инструментом разведочного анализа данных
и позволит выявить особенности, которые трудно обнаружить на обычной трехмерной гистограмме (например, показанную выше «волновую структуру» поверхности).
| В начало |
Послойное сжатие
На графиках этого типа за счет сокращения области основного графика освобождается место для графиков на полях, которые располагаются в правой и верхней части графического окна (включая маленький угловой график). Эти графики на полях представляют собой соответственно вертикально и горизонтально сжатые изображения основного графика.
Послойное сжатие двумерных графиков является
методом разведочного анализа данных, который
дает возможность скрытые тренды и структуры
двумерных наборов данных.![]() Рассмотрим следующий
рисунок.
Рассмотрим следующий
рисунок.
Здесь на примере, приведенном Кливландом (Cleveland, 1993), можно убедиться, что в каждом цикле солнечной активности число пятен уменьшается гораздо медленнее, чем нарастает в начале цикла. Такое поведение совершенно не очевидно при исследовании обычного линейного графика, в то время как сжатый график позволяет обнаружить эту скрытую картину.
| В начало |
Проекции трехмерных наборов данных
Полезным методом изучения и аналитического исследования структуры поверхности (созданной, как правило, по трехмерным наборам данных) является построение ее проекции на плоскость в виде карты линий уровня.
Эти графики менее эффективны для быстрого визуального анализа формы трехмерных структур по сравнению с графиками поверхности,
однако их преимущество заключается в возможности точного исследования формы поверхности —
на картах линий уровня отображается ряд не
искаженных горизонтальных «сечений».
| В начало |
Пиктографики
На пиктографиках каждое наблюдение
представлено в виде многомерного символа, что
позволяет использовать эти типы графического
представления данных в качестве не очень
простого, но мощного исследовательского
инструмента. Главная идея такого метода анализа
основана на человеческой способности
«автоматически» фиксировать сложные связи
между многими переменными, если они проявляются
в последовательности элементов (в данном случае
«пиктограмм»). Иногда понимание (или
«чувство») того, что некоторые элементы
«чем-то похожи» друг на друга, приходит
раньше, чем наблюдатель (аналитик) может
объяснить, какие именно переменные
обусловливают это сходство (Lewicki, Hill, & Czyzewska, 1992).
Конкретную природу проявившихся взаимосвязей
между переменными позволяет выявить уже
последующий анализ данных, основанный на
изучении этого интуитивно обнаруженного
сходства.
Основная идея пиктографиков заключается в представлении элементарных наблюдений как отдельных графических объектов, где значения переменных соответствуют определенным чертам или размерам объекта (обычно одно наблюдение = одному объекту). Это соответствие устанавливается таким образом, чтобы общий вид объекта менялся в зависимости от конфигурации значений.
Таким образом, объекты имеют определенный «внешний вид», который уникален для каждой конфигурации значений и может быть идентифицирован наблюдателем. Изучение таких пиктограмм помогает выявить как простые связи, так и сложные взаимодействия между переменными.
Анализ пиктографиков
Целесообразно проводить анализ пиктографиков в пять этапов.
- Сначала выберите порядок анализируемых
переменных. В большинстве случаев наилучшим
вариантом оказывается случайная
последовательность.
 Кроме того, можно
попробовать расположить их в порядке,
соответствующем полученному уравнению множественной регрессии, факторным
нагрузкам или объясняемым факторам (см. главу Факторный анализ). Таким образом
можно упростить и сделать более
«однородным» общий вид пиктограмм, чтобы
легче идентифицировать слабо выраженные
различия. В то же время такой подход может
затруднить идентификацию некоторых структур. На
этом этапе можно дать только один универсальный
совет: прежде чем использовать какие-либо
сложные методы, попробуйте наиболее простой и
быстрый вариант, а именно, случайную
последовательность переменных.
Кроме того, можно
попробовать расположить их в порядке,
соответствующем полученному уравнению множественной регрессии, факторным
нагрузкам или объясняемым факторам (см. главу Факторный анализ). Таким образом
можно упростить и сделать более
«однородным» общий вид пиктограмм, чтобы
легче идентифицировать слабо выраженные
различия. В то же время такой подход может
затруднить идентификацию некоторых структур. На
этом этапе можно дать только один универсальный
совет: прежде чем использовать какие-либо
сложные методы, попробуйте наиболее простой и
быстрый вариант, а именно, случайную
последовательность переменных. - Попробуйте обнаружить какие-либо
закономерности, например, сходства между
группами пиктограмм, выбросы
или определенные связи между элементами
(например, » если первые два луча звезды
длинные, то как правило, с другой стороны есть
один или два коротких луча»).
 На этом этапе
лучше использовать пиктографики кругового
типа.
На этом этапе
лучше использовать пиктографики кругового
типа. - При обнаружении закономерностей постарайтесь сформулировать их в терминах конкретных переменных.
- Измените соответствие переменных и элементов пиктограмм (или переключитесь на один из последовательных пиктографиков), чтобы проверить обнаруженную структуру взаимосвязей (например, попробуйте переместить ближе друг к другу элементы, между которыми обнаружена связь). В некоторых случаях в конце этого этапа целесообразно исключить из рассмотрения те переменные, которые не вносят явного вклада в обнаруженную структуру.
- И наконец, используйте один из численных
методов (таких как регрессионный
анализ, нелинейное оценивание, дискриминантный или кластерный
анализ), чтобы проверить и попытаться
количественно оценить обнаруженные
закономерности или хотя бы их часть.

Систематизация пиктографиков
Большинство пиктографиков можно отнести к одной из двух групп: круговые и последовательные.
Круговые пиктографики. Круговые пиктографики (звезды, лучи, многоугольники) имеют вид «велосипедного колеса», на них значения переменных представлены расстояниями между центром пиктограммы («втулкой») и их концами.
Такие графики могут помочь в обнаружении связей между переменными, которые проявляются в общей структуре пиктограмм и зависят от конфигурации значений самих переменных.
Чтобы описать такую » общую картину» в терминах конкретных моделей или проверить имеющиеся предположения, имеет смысл использовать последовательные пиктографики, которые могут оказаться более эффективными, если уже известно, что именно требуется обнаружить.
Последовательные пиктографики. Последовательные пиктографики (столбцы, профили,
линии) представляют собой набор картинок с
маленькими последовательными графиками
(различных типов).
Последовательные пиктографики (столбцы, профили,
линии) представляют собой набор картинок с
маленькими последовательными графиками
(различных типов).
Значения переменных представлены здесь расстояниями между основанием пиктограммы и последовательными точками (например, высотами показанных выше столбцов). Эти графики менее эффективны на начальной стадии разведочного анализа, поскольку пиктограммы очень похожи между собой. Однако, как уже упоминалось ранее, такое представление может быть весьма полезным для проверки уже сформулированной гипотезы.
Пиктограммы круговых диаграмм. Эти пиктографики нельзя однозначно отнести к одной из двух групп. Все они имеют круговую форму, но в то же время последовательно разделены в соответствии с значениями переменных.
Их можно отнести скорее к последовательным, чем
к круговым пиктографикам, но можно использовать
и в том, и в другом случае.
«Лица Чернова». Этот тип пиктографиков составляет отдельную группу. Здесь каждое наблюдение представляет собой схематичное изображение лица, определенным чертам которого соответствуют относительные значения выбранных переменных.
Некоторые исследователи рассматривают этот способ графического представления данных как уникальный многомерный метод разведочного анализа, позволяющий выявить такие скрытые картины взаимосвязей между переменными, которые не могут быть обнаружены другими методами. Вероятно, такое заявление можно считать преувеличением. Кроме того, следует заметить, что этот способ исследования весьма непрост в применении и требует большого опыта в том, что касается сопоставления переменных чертам лица. См. также раздел Методы «добычи данных» .
Стандартизация значений
Как правило, при построении пиктографиков
значения переменных должны быть
стандартизованы, чтобы их можно было сравнивать
в пределах одной пиктограммы. Исключения
составляют те случаи, когда на пиктограммах
необходимо отобразить глобальные различия
диапазонов выбранных переменных. Поскольку
масштаб пиктограммы определяется наибольшим
значением, то на пиктограмме могут отсутствовать
те переменные, которые имеют значения другого
порядка малости, например, на пиктограмме звезды
некоторые лучи могут оказаться настолько
короткими, что совсем не будут видны..
Исключения
составляют те случаи, когда на пиктограммах
необходимо отобразить глобальные различия
диапазонов выбранных переменных. Поскольку
масштаб пиктограммы определяется наибольшим
значением, то на пиктограмме могут отсутствовать
те переменные, которые имеют значения другого
порядка малости, например, на пиктограмме звезды
некоторые лучи могут оказаться настолько
короткими, что совсем не будут видны..
Применения
Пиктографики обычно используются: (1) для обнаружения структур или кластеров наблюдений и (2) для исследования сложных взаимосвязей между несколькими переменными. Первый вариант соответствует кластерному анализу; т.е. процедуре классификации наблюдений.
Предположим, вы изучали характеры актеров и
записали их ответы на вопросы анкеты. С помощью
пиктографика можно определить, существуют ли
группы артистов, которые отличаются по их
ответам на заданные вопросы (можно, к примеру,
обнаружить, что некоторые артисты являются
творческими, недисциплинированными и
независимыми личностями, в то время как другая
группа состоит из умных, дисциплинированных
людей, которые ценят свою популярность).
Другая область применений — изучение взаимосвязей между переменными — напоминает факторный анализ, который используется для исследования вопроса о зависимости переменных. Предположим, изучалось мнение группы людей о различных марках автомобилей. В файле данных записаны средние оценки по каждому из свойств (рассматриваемых как переменные) для каждого из автомобилей (рассматриваемых как наблюдения).
При изучении «лиц Чернова» (где каждое лицо
представляет мнение об одном из автомобилей)
может оказаться, что улыбающиеся лица обычно
имеют большие уши; при этом, если цене
соответствует «ширина» улыбки, а
динамическим качествам — размер ушей, то это
«открытие» означает, что быстрые машины
являются более дорогими. Разумеется, это очень
простой пример; однако при реальном анализе
данных применение этого метода может сделать
более очевидными сложные взаимосвязи между
многими переменными.
Близкие способы графического представления
Связи между переменными из одного или двух списков могут быть представлены на матричных графиках. Использование матричных графиков одновременно с выделением подгрупп позволяет получить информацию, подобную той, которая отображается на пиктографиках.
Если использовать методы выделения подгрупп на диаграммах рассеяния, то для исследования взаимосвязей между двумя переменными можно использовать обычные 2М диаграммы рассеяния; а в случае трех переменных — 3Мдиаграммы рассеяния.
Типы графиков
Существуют различные типы пиктографиков.
«Лица Чернова». Для каждого наблюдения
рисуется отдельное «лицо»; при этом
относительные значения выбранных переменных
соответствуют форме и размерам определенных его
черт (например, длине носа, изгибу бровей, ширине
лица).
Дополнительно см. абзац «Лица Чернова» в разделе Систематизация пиктографиков.
Звезды. Это пиктографики кругового типа. Для каждого наблюдения рисуется пиктограмма в виде звезды; относительные значения выбранных переменных соответствуют относительным длинам лучей каждой звезды (по часовой стрелке, начиная с 12:00). Концы лучей соединены линиями.
Лучи. Эти пиктографики также относятся к круговому типу. Для каждого наблюдения строится одна пиктограмма. Каждый луч соответствует одной из выбранных переменных (по часовой стрелке, начиная с 12:00), и на нем отложено значение соответствующей переменной. Эти значения соединены линиями.
Многоугольники. Это пиктографикикругового типа. Для каждого
наблюдения рисуется отдельный многоугольник;
относительные значения выбранных переменных
соответствуют расстояниям вершин от центра
многоугольника (по часовой стрелке, начиная с
12:00).
Круговые диаграммы. Это пиктографики кругового типа. Для каждого наблюдения рисуется круговая диаграмма; относительные значения выбранных переменных соответствуют размерам сегментов диаграммы (по часовой стрелке, начиная с 12:00).
Столбцы. Это пиктографики последовательного типа. Для каждого наблюдения строится столбчатая диаграмма; относительные значения выбранных переменных соответствуют высотам последовательных столбцов.
Линии. Это пиктографики последовательного типа.
Для каждого наблюдения строится линейный график; относительные значения выбранных переменных соответствуют расстояниям точек излома линии от основания графика.
Профили. Это пиктографики последовательного
типа. Для каждого наблюдения строится зонный
график; относительные значения выбранных
переменных соответствуют расстояниям
последовательных пиков сечения над линией
основания.
Маркировка пиктограмм
Если программа позволяет вам выделять подгруппы наблюдений, то это свойство можно использовать и для маркировки соответствующих пиктограмм. При этом вокруг выделенных пиктограмм будут нарисованы рамки.
Шаблоны рамок, идентифицирующих заданные подгруппы, будут показаны в условных обозначениях рядом с текстом соответствующих условий выбора наблюдений. На следующем графике показан пример маркированных подгрупп.
Все наблюдения, удовлетворяющие условию для подгруппы 1 (значение переменной Iristype равно значению переменной Setosa и номер наблюдения меньше 100), обозначены специальной рамкой вокруг пиктограммы.
А все наблюдения, которые удовлетворяют
условию для подгруппы 2 (значение переменной Iristype
равно значению переменной Virginic и номер
наблюдения меньше 100), обозначены на графике
рамкой другого цвета.
| В начало |
Выборка данных
Иногда отображение на графике слишком большого числа точек данных затрудняет изучение их структуры (см. следующий рисунок). Если файл данных слишком большой, то имеет смысл показать на графике лишь подмножество наблюдений, чтобы общая картина не была скрыта маркерами точек.
Некоторые программы предлагают методы выборки (или оптимизации) данных, которые в ряде случаев могут оказаться весьма полезны. При этом пользователь может задать целое число n, меньшее числа наблюдений в файле данных, а программа случайным образом выберет из этого файла приблизительно n допустимых наблюдений и именно их построит на графике.
Заметим, что такие методы сокращения набора
данных (или размера выборки) эффективно
отображают случайную структуру этих данных. Очевидно, эти методы принципиально отличаются от
методов выделения конкретного подмножества или
подгруппы наблюдений с помощью определенных
критериев (например, по полу, области или уровню
холестерина). Последние можно применять
интерактивно (например, в режиме динамического закрашивания)
или каким-либо другим способом (например, на категоризованных
графиках или с помощью условий выбора
наблюдений). Все эти методы в равной мере могут
помочь в идентификации сложной структуры
большого набора данных.
Очевидно, эти методы принципиально отличаются от
методов выделения конкретного подмножества или
подгруппы наблюдений с помощью определенных
критериев (например, по полу, области или уровню
холестерина). Последние можно применять
интерактивно (например, в режиме динамического закрашивания)
или каким-либо другим способом (например, на категоризованных
графиках или с помощью условий выбора
наблюдений). Все эти методы в равной мере могут
помочь в идентификации сложной структуры
большого набора данных.
| В начало |
Вращение (в трехмерном пространстве)
Изменение угла зрения при отображении
трехмерной диаграммы рассеяния (простой, спектральной или пространственной)
может оказаться эффективным средством для
выявления некоторой структуры, которая видна
только при определенном повороте «облака»
точек (см. следующий рисунок).
Некоторые программы предоставляют полезный инструмент для интерактивного изменения перспективы и вращения изображения. Эти средства контроля изображения позволяют подобрать подходящий угол зрения и перспективу, чтобы найти наиболее удачное расположение «точки зрения» на график, а также дают возможность управлять его вращением в горизонтальной и вертикальной плоскости.
Эти инструменты могут оказаться весьма полезными не только при начальном разведочном анализе данных, но и при исследовании факторного пространства (см.Факторный анализ) или пространства размерностей (см. Многомерное шкалирование).
| В начало |
Все права на материалы электронного учебника принадлежат компании StatSoft
Векторная графика достоинства, недостатки, применение
71673
Все графические файлы можно разделить на две большие группы: растровые и векторные. В данной статье рассмотрим более подробно вторую группу.
- 1. За счет чего векторные рисунки можно изменять без ущерба качеству?
- 2. Недостатки векторных рисунков
- 3. Программы, работающие с векторной графикой
За счет чего векторные рисунки можно изменять без ущерба качеству?
Изображения, которые образуются при помощи различных линий (векторов: прямых и изогнутых), называются векторными. Такое строение элементов позволяет изменять любые параметры: размер, вариант окрашивания, форму. Главное достоинство векторной графики – возможность изменения размеров изображения без потери качества картинки. Это значительно упрощает работу с графикой и повышает качество конечного результата.
Любые данные, в том числе и данные о простейших графических объектах, хранятся в памяти компьютера в виде различных математических формул. При масштабировании векторных изображений происходит пересчет этих формул и такие визуальные элементы, как линия, окружность или любая другая геометрическая фигура, остаются неизменными. Таким же остается и качество картинки в целом.
При масштабировании векторных изображений происходит пересчет этих формул и такие визуальные элементы, как линия, окружность или любая другая геометрическая фигура, остаются неизменными. Таким же остается и качество картинки в целом.
Кроме того, размер файлов, в которых содержатся векторные изображения, значительно меньше, чем файлы с растровой графикой такого же качества, даже если речь идет об изображении значительного размера с хорошей детализацией.
Дополняет достоинства векторной графики работа как с отдельными примитивными объектами, так и наличие возможности объединять их в группы, сливать, обрезать и выполнять еще очень большое количество различных действий. Изображение при этом является послойным, как в растровом редакторе Фотошоп. Это все лишь основные достоинства векторной графики.
Недостатки векторных рисунков
- Отсутствие возможности создавать реалистичную картинку, близкую по качеству к фотографии, это значительно уменьшает применение векторной графики.

- Обширная библиотека фильтров, которые создают интереснейшие эффекты при работе с растровыми картинками, в случае работы с кривыми абсолютно бесполезны.
- В отличие от растровых изображений, файлы, содержащие картинки в векторе, можно редактировать только в той программе, в которой они были созданы изначально; но из этого правила есть исключения, существуют универсальные форматы, они изменяются в большинстве векторных редакторов.
Пример векторной графики
Программы, работающие с векторной графикой
Существуют различные программы и редакторы, которые позволяют работать с векторными изображениями. Возможности их очень широкие: они могут создавать сложные рисунки при помощи простых геометрических фигур, позволяют придать этим изображениям объем, работать с текстом, позволяя изменять его тем или иным образом.
Есть несколько основных инструментов, которые присутствуют практически во всех программах, работающих с векторной графикой:
- кривая Безье – инструмент, позволяющий изменять форму линий, создавать фигуры любой формы, за счет работы с узловыми точками и проходящими через них касательными линиями;
- заливка – позволяет заполнять цветом замкнутые объекты любой формы, так же дает возможность создавать произвольные градиенты, которые делают работу с цветом более интересной;
- текст – возможности графических редакторов позволяют создавать из обычных слов художественные объекты: распределять слова вокруг определенных фигур, менять интервалы между буквами или строками, при переведении текстовой информации в кривые, шрифт не будет искажаться, даже если у другого пользователя он отсутствует;
- в программе существует набор простейших фигур, который значительно облегчает создание рисунка;
- сохраняется возможность «рисования» — инструмент-карандаш повторяет движение руки, полученный таким образом рисунок можно редактировать при помощи кривой Безье.
Пример растровой графики
В последнее время некоторые растровые редакторы предоставляют своим пользователям совершать определенные действия и с векторными объектами, а векторные программы дают возможность немного изменять растровые изображения, но эти возможности крайне ограничены и не дают всех тех эффектов, которых можно достичь редактируя изображение в соответствующей программе.
Самые популярные «векторные» программы — Adobe Illustrator, CorelDraw, Adobe FreeHand.
Векторный и растровый формат изображения отличаются друг от друга не только особенностями обработки и редактирования. Применение векторной графики ограничено в основном областью полиграфии: логотипы, иллюстрации, технические рисунки и схемы. Растровая же графика применяется значительно шире.
Начальная загрузка графов знаний из изображений и текста
1.
 Введение
ВведениеЧеловеческим младенцам, по-видимому, легко научиться рассуждать об отношениях между любыми двумя объектами. Младенцы демонстрируют эту способность, потому что они учатся понимать мир и усваивают язык, интегрируя кросс-модальную информацию. В частности, они не только изучают референты в языке путем статистического сопоставления слов с появлением объектов в окружающей среде, но также начинают понимать характеристики и возможности объектов. Однако системы ИИ обычно разрабатываются на основе отдельных модальностей или задач с ограниченным доступом к контексту. Поскольку важным аспектом современных систем ИИ является изучение соответствующих представлений для назначенных задач, кажется особенно важным отразить кросс-модальное обучение также в изучении этих представлений. Для изучения реляционных представлений рассмотрим следующий пример. В Девочка со спичками Сон Ганса Христиана Андерсена написал:
На столе была расстелена белоснежная скатерть; на нем стоял великолепный фарфоровый сервиз, а жареный гусь с начинкой из яблок и чернослива лихо дымился.
Либо из текста, либо из изображения, фиксирующего сцену (Рисунок 1), нетрудно заключить, что Скатерть находится на столе, а яблоко находится внутри гуся, который находится на фарфоровом блюде, поставленном на скатерть. Теперь давайте зададим другой вопрос: какова связь между Apple и Table? На рис. 2 показана цепочка рассуждений.
Рисунок 1 . Сцена 1 .
Рисунок 2 . Результирующий семантический граф сцены из сна Андерсена «Девочка со спичками ».
Для нас, людей, это не требует особых усилий, даже младенцы могут получить ответ On. Однако современные вычислительные архитектуры почти не поддерживают его, даже для ограниченных целей.
Описанный выше процесс можно в более широком смысле описать как извлечение отношения, которое заключается в определении отношения между объектами (сущностями), которые появляются в текстовом абзаце или в визуальной сцене. Мы сосредоточимся на проблеме извлечения условного отношения, которое генерирует граф относительно определенного абзаца или изображения, где каждое ребро представляет экземпляр отношения (субъект, объект, отношение) , например (Apple, Table, On). Мы называем полученный граф «Семантический граф» для текстовых абзацев (Сорокин и Гуревич, 2017) и «Граф сцены» для визуальных изображений (Сюй и др., 2017) соответственно. Объединяя извлечение текстовых и визуальных отношений, нас особенно интересуют зависимости между обеими модальностями и то, как синергия приводит к более надежному обучению представлению. Кроме того, извлечение отношений имеет множество потенциальных применений, включая ответы на вопросы (Xu et al., 2016), проверку фактов (Vlachos and Riedel, 2014), устранение неоднозначности смысла слов (Okamoto and Ishizaki, 2007) и обобщение документов (Hachey, 2009).).
Мы называем полученный граф «Семантический граф» для текстовых абзацев (Сорокин и Гуревич, 2017) и «Граф сцены» для визуальных изображений (Сюй и др., 2017) соответственно. Объединяя извлечение текстовых и визуальных отношений, нас особенно интересуют зависимости между обеими модальностями и то, как синергия приводит к более надежному обучению представлению. Кроме того, извлечение отношений имеет множество потенциальных применений, включая ответы на вопросы (Xu et al., 2016), проверку фактов (Vlachos and Riedel, 2014), устранение неоднозначности смысла слов (Okamoto and Ishizaki, 2007) и обобщение документов (Hachey, 2009).).
В новейшей литературе (Sorokin and Gurevych, 2017; Xu et al., 2017) создание графов знаний (KG) разбивается на две фазы: (1) обнаружение сущностей (или объектов) как узлов и ( 2) извлечение отношений между сущностями как ребер. Первый этап можно свести к распознаванию именованных объектов для текстовых абзацев (Lample et al., 2016) или обнаружению объектов для изображений (Ren et al. , 2015). Обычно более сложной частью, которой уделяется больше внимания, является то, как определить отношения между объектами, и обычно это рассматривается как проблема классификации. Критическое различие между извлечением отношений и типичными задачами классификации [например, классификация изображений (Крижевский и др., 2012) или вывод на естественном языке (Боуман и др., 2015)] заключается в существовании зависимостей между экземплярами отношений. То есть два объекта, даже если они разделены в пространстве, могут образовывать отношения, когда они оба связаны с одним или несколькими другими объектами (в приведенном выше случае Apple и Table взаимодействуют со Tablecloth, Dish и т. д.).
, 2015). Обычно более сложной частью, которой уделяется больше внимания, является то, как определить отношения между объектами, и обычно это рассматривается как проблема классификации. Критическое различие между извлечением отношений и типичными задачами классификации [например, классификация изображений (Крижевский и др., 2012) или вывод на естественном языке (Боуман и др., 2015)] заключается в существовании зависимостей между экземплярами отношений. То есть два объекта, даже если они разделены в пространстве, могут образовывать отношения, когда они оба связаны с одним или несколькими другими объектами (в приведенном выше случае Apple и Table взаимодействуют со Tablecloth, Dish и т. д.).
Чтобы решить эту проблему, мы расширяем второй шаг — извлечение отношений между объектами — применяя набор дифференцируемых логических правил для извлечения дополнительных отношений на основе текущего KG. Отметим, что процесс прогнозирования неизвестных отношений на основе текущего (неполного) KG имеет некоторые общие черты с завершением графа знаний (KGC). Модуль рассуждений нашей модели предсказывает неизвестные отношения, применяя логические правила первого порядка, которые можно естественным образом заменить предыдущими методами KGC. Тем не менее, большинство предыдущих подходов для KGC завершаются изучением представлений сущностей и отношений и рассмотрением отношений как переводов между сущностями (Bordes et al., 2013; Wang et al., 2014; Ji et al., 2015; Lin et al., 2015). др., 2015). Напротив, мы применяем логические рассуждения, основанные на правилах, чтобы найти неизвестные отношения, подобно Янгу и др. (2017). Однако, хотя модель Янга и соавт. (2017) работает только для глобального KGC, наш подход находит неизвестные отношения контекстуальным образом.
Модуль рассуждений нашей модели предсказывает неизвестные отношения, применяя логические правила первого порядка, которые можно естественным образом заменить предыдущими методами KGC. Тем не менее, большинство предыдущих подходов для KGC завершаются изучением представлений сущностей и отношений и рассмотрением отношений как переводов между сущностями (Bordes et al., 2013; Wang et al., 2014; Ji et al., 2015; Lin et al., 2015). др., 2015). Напротив, мы применяем логические рассуждения, основанные на правилах, чтобы найти неизвестные отношения, подобно Янгу и др. (2017). Однако, хотя модель Янга и соавт. (2017) работает только для глобального KGC, наш подход находит неизвестные отношения контекстуальным образом.
Неформально, учитывая набор сущностей, определение отношения между ними можно рассматривать как смесь двух подзадач: (1) извлечение первичных отношений из входных данных и (2) завершение KG с рассуждениями. Первичные отношения в основном буквальные, как, например, в примере со спичками (Скатерть, Стол, На). С другой стороны, завершение KG требует рассуждений об этих первичных отношениях и разрешения зависимостей или корреляций.
С другой стороны, завершение KG требует рассуждений об этих первичных отношениях и разрешения зависимостей или корреляций.
В прошлом было показано, что методы, основанные на нейронных сетях, успешно решают широкий круг задач в различных областях (LeCun et al., 2015). Отдельные подходы пытаются устранить зависимости между экземплярами отношений путем моделирования других отношений как «контекста» конкретных парных сущностей. В этом направлении был проведен ряд исследований, таких как кодирование на основе внимания (Сорокин и Гуревич, 2017) или передача сообщений на основе графа (Xu et al., 2017). На рисунке 3 слева показана общая структура для экстракторов отношений на основе нейронных сетей. У таких контекстных кодировщиков есть несколько недостатков:
1. С систематической точки зрения, хотя нейронные сети являются полными по Тьюрингу (Siegelmann and Sontag, 1995) и могут быть подключены для имитации любой компьютерной схемы, на практике они больше подходят для обработки ассоциаций, чем правил. Например, начиная с (Фодор и Пилишин, 1988 г.), ведутся длительные дебаты по проблеме систематичности (например, понимания рекурсивных систем) в таких коннекционистских моделях (Фодор и Маклафлин, 1990 г.; Хэдли, 1994 г.; Янсен и др.). Вода, 2012). В случае извлечения отношений рассуждения обычно выполняются цепным или рекурсивным способом (например, рассмотрим отношение между Apple и Table в примере девушки со спичками), которое контекстные автокодировщики не воспроизводят.
Например, начиная с (Фодор и Пилишин, 1988 г.), ведутся длительные дебаты по проблеме систематичности (например, понимания рекурсивных систем) в таких коннекционистских моделях (Фодор и Маклафлин, 1990 г.; Хэдли, 1994 г.; Янсен и др.). Вода, 2012). В случае извлечения отношений рассуждения обычно выполняются цепным или рекурсивным способом (например, рассмотрим отношение между Apple и Table в примере девушки со спичками), которое контекстные автокодировщики не воспроизводят.
2. С точки зрения реализации извлечение отношений требует обработки реляционных данных высокого порядка и кванторов. Например, чтобы применить транзитивность: (Скатерть, Стол, На) ∧ (Фарфор, Скатерть, На) ⇒ (Фарфор, Стол, На), нам нужно рассмотреть отношение между тройкой символов (Стол, Скатерть, Фарфор) . Это выходит за рамки типичных нейронных сетей с графовой структурой (Kipf and Welling, 2016).
3. В большинстве наборов данных распределение отношений неравномерно и имеет длинный шлейф из редко встречающихся отношений между конкретными объектами. Подходы, основанные исключительно на нейронных сетях, имеют проблемы с изучением этих редких троек объектных отношений из-за ограниченного количества вхождений в обучающих данных и часто не могут обобщить их на объекты, не замеченные во время обучения. Напротив, используя индуктивное рассуждение, мы можем включить предыдущие знания о характеристиках отношений в процесс генерации KG, чтобы помочь извлечь редкие отношения и повысить обобщаемость. Индуктивное рассуждение может быть особенно эффективным для транзитивных отношений [например, геометрических (левое, правое) или притяжательных (является частью) отношений], которые составляют большинство отношений во многих наборах данных (Zellers et al., 2018). Многие наборы данных фактически пропускают метки для взаимосвязей, возникающих в данных, из-за неполной маркировки (Wan et al., 2018), а это означает, что модели, обученные исключительно на (помеченных) данных, не узнают об этих взаимосвязях.
Подходы, основанные исключительно на нейронных сетях, имеют проблемы с изучением этих редких троек объектных отношений из-за ограниченного количества вхождений в обучающих данных и часто не могут обобщить их на объекты, не замеченные во время обучения. Напротив, используя индуктивное рассуждение, мы можем включить предыдущие знания о характеристиках отношений в процесс генерации KG, чтобы помочь извлечь редкие отношения и повысить обобщаемость. Индуктивное рассуждение может быть особенно эффективным для транзитивных отношений [например, геометрических (левое, правое) или притяжательных (является частью) отношений], которые составляют большинство отношений во многих наборах данных (Zellers et al., 2018). Многие наборы данных фактически пропускают метки для взаимосвязей, возникающих в данных, из-за неполной маркировки (Wan et al., 2018), а это означает, что модели, обученные исключительно на (помеченных) данных, не узнают об этих взаимосвязях.
4. Недавняя работа также указывает на то, что чисто нейронные подходы не обобщают изученные отношения (например, пространственные), по крайней мере, не в области зрения (Kim et al. , 2018; Bahdanau et al., 2019). Это означает, что простые выученные отношения, такие как «слева от», обычно не обобщаются на новые комбинации объектов. В настоящее время единственным способом обобщения этих нейронных архитектур является использование идеальной архитектуры модели, специально адаптированной для предметной области (набора данных), такой как оптимально построенные сети нейронных модулей (Andreas et al., 2016). Это сложно, потому что для этого нам нужно идеальное знание данных и отношений, что невозможно для реальных наборов данных. Наша гипотеза состоит в том, что логические рассуждения имплицитно лучше подходят для обработки обобщений отношений, поскольку это символический подход и моделирует отношения независимо от объектов, к которым они относятся.
, 2018; Bahdanau et al., 2019). Это означает, что простые выученные отношения, такие как «слева от», обычно не обобщаются на новые комбинации объектов. В настоящее время единственным способом обобщения этих нейронных архитектур является использование идеальной архитектуры модели, специально адаптированной для предметной области (набора данных), такой как оптимально построенные сети нейронных модулей (Andreas et al., 2016). Это сложно, потому что для этого нам нужно идеальное знание данных и отношений, что невозможно для реальных наборов данных. Наша гипотеза состоит в том, что логические рассуждения имплицитно лучше подходят для обработки обобщений отношений, поскольку это символический подход и моделирует отношения независимо от объектов, к которым они относятся.
5. Еще одна проблема заключается в том, что в области зрения обработка обычно выполняется с помощью сверточных нейронных сетей (CNN), которые выполняют только локальные рассуждения на уровне пикселей (Chen et al., 2018), что затрудняет извлечение отношений между объектами. что далеко друг от друга. Однако, особенно для транзитивных отношений (которые можно извлечь с помощью логических правил), очень распространены большие расстояния (в пространстве пикселей) между объектами.
что далеко друг от друга. Однако, особенно для транзитивных отношений (которые можно извлечь с помощью логических правил), очень распространены большие расстояния (в пространстве пикселей) между объектами.
Рисунок 3 . Иллюстрация сравнения типичных экстракторов отношений на основе нейронных сетей и предлагаемого экстрактора гибридных отношений. (Слева) Общая структура для типичных экстракторов отношений на основе нейронных сетей. Зависимости или корреляции между экземплярами отношения моделируются путем рассмотрения других отношений как «контекста». Пунктирные соединения обозначают межпарные соединения, которые могут включать механизм внимания (Sorokin and Gurevych, 2017) или передачу сообщений (Xu et al., 2017). (Справа) Предлагаемый экстрактор гибридных отношений (HRE) работает итеративно. Когда селектор пар взаимодействует с предиктором, он естественным образом разрешает зависимости или корреляции между экземплярами отношения. Модуль прогнозирования пар работает с моделью индукции отношений, основанной на объяснительных логических правилах. Подробнее см. в разделе 3.
Чтобы решить вышеуказанные проблемы, в этой статье мы предлагаем гибридный конструктор KG, который объединяет две процедуры в унифицированную структуру и создает KG с нуля, используя визуальную или текстовую информацию. Как более подробно описано в разделе 3, мы используем (1) средство извлечения нейронных отношений, обнаруживающее первичные отношения из входных данных, и (2) модель дифференцируемого индуктивного логического программирования (Muggleton, 1991), которая итеративно завершает KG. Мы предлагаем экстрактор нейронных отношений в качестве ключевого элемента, потому что отношения между сущностями обычно тесно переплетены в рамках высокой размерности, а нейронные сети особенно хороши в изучении распределенных представлений. С другой стороны, элемент системы программируемой логической индукции особенно силен в извлечении структуры фактов из естественного языка и изображений. В этой структуре отношения между объектами обнаруживаются совместными усилиями нейронного модуля, а также логического модуля.
В ходе обширных экспериментов в разделе 4 мы сравниваем нашу структуру с базовыми уровнями извлечения сильных отношений как в текстовой, так и в визуальной областях, в наборе данных на основе Викиданных и наборе данных Visual Genome соответственно. Эмпирические результаты показывают превосходство и гибкость предложенного нами метода. Более того, мы показываем значительный выигрыш по сравнению с базовыми показателями и другими предыдущими работами в подмножестве базы данных, которое содержит плотные графы 2 , т. е. большее, чем среднее, количество отношений на пару сущностей. Мы обсуждаем родственные работы в разделе 2 и делаем выводы в разделе 5.
2. Связанные работы
Извлечение отношений является важной задачей и необходимо для получения подробного понимания текстов или изображений. Далее мы сначала опишем современные подходы к извлечению отношений из текстовых данных, а затем продолжим описание извлечения отношений из изображений.
2.1.
Извлечение отношений из текстов Извлечение отношений широко используется для получения структурированных знаний из простого текста. Полученные в результате структурированные реляционные факты имеют решающее значение для понимания крупномасштабных корпусов и могут использоваться для автоматического заполнения отсутствующих фактов в KG. Ранние методы извлечения нейронных связей, как правило, пытались использовать контролируемую парадигму (Zeng et al., 2014; Nguyen and Grishman, 2015; Santos et al., 2015) и в значительной степени полагались на наборы данных, помеченные человеком. Однако аннотирование этих наборов данных является трудоемким и требует много времени. Последние методы извлечения отношений решают эту проблему, создавая крупномасштабные обучающие данные с помощью удаленного наблюдения. Однако предположение о дистанционном наблюдении очень сильное и часто вносит шум. Была проделана большая работа, чтобы облегчить проблему неправильной маркировки в дистанционном наблюдении и извлечь глобальные отношения между двумя объектами из нескольких поддерживающих предложений (Riedel et al. , 2010; Zeng et al., 2015; Lin et al., 2017). ; Фэн и др., 2018; Цинь и др., 2018). В последнее время многие подходы также исследуют извлечение отношений между сущностями на уровне предложения в богатом контексте (Сорокин и Гуревич, 2017; Цзэн и др., 2017; Кристопулу и др., 2019).; Чжу и др., 2019).
Минц и др. (2009) предлагают дистанционное наблюдение для автоматического создания крупномасштабного набора данных для извлечения отношений путем сопоставления простого текста с графами знаний. Предположение о дистанционном надзоре состоит в том, что все предложения, содержащие объект, будут выражать соответствующее отношение в KG. Цзэн и др. (2015) дополнительно формулируют извлечение отношений с дистанционным наблюдением как задачу обучения с несколькими экземплярами, где наборы экземпляров состоят из нескольких предложений, содержащих пару объектов, и принимают во внимание неопределенность метки экземпляра, выбирая наиболее надежный поддерживающий экземпляр для предсказания отношения. Лин и др. (2017) предлагают получать представления мешков с помощью семантической композиции экземпляров, где веса экземпляров определяются избирательным вниманием. Фэн и др. (2018) предлагают фильтровать случаи ложноположительных отношений с помощью обучения с подкреплением. Цинь и др. (2018) предлагают состязательную структуру, которая совместно обучает генератор и дискриминатор отличать экземпляры ложноположительных отношений от удаленного наблюдения.
Сорокин и Гуревич (2017) определяют отношение на уровне предложения между парами сущностей в богатом контексте. Они предсказывают отношения между каждой парой сущностей, рассматривая все другие возможные пары сущностей в том же предложении в качестве контекста и моделируя корреляцию отношений с помощью механизма внимания. Кристопулу и др. (2019) моделируют контекст пары сущностей путем итеративного агрегирования путей обхода между целевой парой сущностей на графе и достигают сопоставимых результатов без использования внешних лингвистических инструментов. Чжу и др. (2019) моделировать неявные рассуждения посредством передачи сообщений между парами объектов контекста. В этой работе мы также сосредоточимся на извлечении отношений на уровне предложений. Принципиальное отличие состоит в том, что мы последовательно извлекаем отношения внутри предложения или абзаца, чтобы явно смоделировать структуру рассуждений об отношениях. Цзэн и др. (2017) явно используют специальное логическое правило первого порядка для моделирования зависимостей отношений внутри предложения. Важным отличием нашей модели является то, что мы можем моделировать общие, а также длинные цепочки рассуждений, рекурсивно применяя правила.
2.2. Извлечение отношений из изображений
Чтобы понять и рассуждать о контексте изображения, нам нужна не только информация об объектах в сцене, но и об отношениях между этими объектами. Таким образом, выделение взаимосвязей между объектами (например, внутри/на/под, поддержка и т. д.) дает лучшее понимание сцены по сравнению с простым распознаванием объектов и их индивидуальных свойств (Elliott and de Vries, 2015). Хотя отношения можно прогнозировать попарно (Chao et al., 2015; Ramanathan et al., 2015), большая часть текущих работ сосредоточена на создании ориентированного графа, обычно называемого графом сцены (Johnson et al., 2015; Xu и др., 2017; Чжан и др., 2017). Графы сцен — это способ структурированного представления контекста изображения для повышения производительности таких задач, как визуальные ответы на вопросы или поиск изображений. Существующие генераторы графов сцен обычно расширяют структуру обнаружения объектов, которая сначала определяет ограничивающие рамки для объектов, затем извлекает визуальные признаки и классифицирует объекты внутри ограничивающих рамок и, наконец, параллельно предсказывает отношения между объектами. Одна из проблем заключается в том, что количество возможных отношений растет экспоненциально с количеством объектов на изображении. Это усложняет вычисление всех возможных взаимосвязей. Поэтому многие подходы работают над тем, чтобы исключить маловероятные отношения из графа или сосредоточиться только на наиболее вероятных отношениях с самого начала.
Ли и др. (2017) объединяют три задачи — обнаружение объектов, создание графа сцены и создание подписей к регионам — и показывают, что одновременное изучение всех трех задач приводит к повышению общей производительности, поскольку изученные функции могут быть общими для разных задач. Сюй и др. (2017) предлагают сквозной обучаемый подход для создания графа сцены на основе изображений, который состоит из категорий объектов, ограничивающих рамок для отдельных объектов и отношений между парами объектов путем итеративного уточнения его прогнозов. Лян и др. (2017) выполняют прогнозирование вместе с обходом графа, по существу, последовательно. Однако он принимает во внимание только два последних результата прогнозирования и, таким образом, не может выполнять общие логические индукции на основе частичного результата вывода.
Ли и Гупта (2018) учатся преобразовывать представления 2D-изображения в графическое представление, где узлы представляют области изображения, а ребра моделируют сходство между этими областями изображения, в то время как Чен и соавт. (2018) вводят структуру графа специально для облегчения рассуждений между областями, которые находятся далеко друг от друга на изображении. Ян и др. (2018) делают создание графа сцены более удобным и эффективным за счет использования сети предложений отношений, которая определяет вероятные ребра в графе сцены, и сверточной сети графа для обновления объектов и их отношений на основе соседей объектов. Ву и др. (2018) предлагают модуль реляционного встраивания для совместного представления связей между всеми объектами вместо того, чтобы сосредотачиваться на объектах по отдельности.
В связи с нашим подходом Wan et al. (2018) работают над завершением существующих графов сцен с учетом изображения и соответствующего графа сцены. Однако они не используют логические рассуждения, а вместо этого используют нейронную сеть для извлечения неопознанных отношений между существующими узлами в графе сцены, чтобы получить улучшенные графы сцены с более точными отношениями. Однако этот подход по-прежнему полностью зависит от данных, и поэтому неясно, как он справляется с длинным хвостом редко встречающихся отношений и как он обобщается на новые тройки объектных отношений.
Зеллерс и др. (2018) отмечают, что метки объектов в значительной степени предсказывают метки отношений (но не наоборот), и используют это понимание для разработки как новой базовой линии, так и сети, которая принимает это во внимание путем постановки прогнозов ограничивающих рамок, идентичности объектов (в ограничивающих рамках). ), и отношения в иерархическом порядке. Чен и др. (2019) показывают, что использование знаний о корреляциях между объектами и связанными отношениями может быть явно представлено в KG. Затем новая сеть маршрутизации облегчает создание графа сцены, используя предварительные статистические знания о взаимодействии объектов и отношений.
Гу и др. (2019) включают знания здравого смысла в процесс создания графа сцены с помощью внешнего KG, а Qi et al. (2019) используют лингвистические знания для повышения эффективности обнаружения семантических отношений с помощью модуля семантического преобразования для сопоставления визуальных характеристик и встраивания слов в общее семантическое пространство. До сих пор большая часть работ по извлечению графов сцен из изображений основывалась исключительно на обучении на основе данных с помощью нейронных сетей. Это создает проблемы с масштабируемостью (особенно для изображений со многими объектами) и страдает от длинного хвоста отношений в обучающих данных, который трудно изучить для подходов на основе нейронных сетей. Кроме того, неясно, способны ли эти подходы обобщать изученные отношения в новых условиях. Напротив, наш подход сочетает в себе нейронные сети, управляемые данными, с дифференцируемой моделью, которая применяет логические правила для извлечения отношений. Это позволяет нам вводить в нашу модель предварительные знания об определенных отношениях (например, транзитивности), что может помочь с обобщаемостью (поскольку отношения теперь отделены от объектов), масштабируемостью (мы можем эффективно оценивать изученные правила) и длинным хвостом отношения в обучающих данных (как только правило кодирует одно из этих отношений, мы можем легко применить его и к другим объектам).
3. Методы
Мы строим наш экстрактор гибридных отношений (HRE), объединяя экстрактор нейронных отношений, обнаруживающий первичные отношения из входных данных, и модель на основе индуктивной логики, которая итеративно завершает KG. Показанная на Рисунке 3 справа структура работает итеративно и выявляет отношения за счет совместной работы нейронного модуля и логического модуля. Как обсуждалось в предыдущем разделе, при моделировании рассуждений об отношениях возникают две основные проблемы:
1. Цепочки или рекурсии. Мы разрешаем зависимости между отношениями путем итеративного обнаружения ребер. В частности, мы предлагаем использовать селектор пар, работающий совместно с предсказателем отношений.
2. Высокий порядок и квантификаторы. Мы моделируем рассуждения об отношениях с помощью модели дифференцируемого индуктивного логического программирования (ILP) (Muggleton, 1991). Модель обнаруживает вероятностные правила из примеров с помощью индуктивных рассуждений.
В остальной части бумаги пишем ( субъект, объект, отношение ) для обозначения определенного реляционного триплета, в то время как rel ( объект , субъект ) используется для обозначения распределения по отношениям для пары сущностей, а rel ( объект, субъект ) i есть вероятность того, что отношение i будет истинным. Теперь мы начнем знакомство с моделью с обзора.
3.1. Обзор фреймворка
Мы строим наш фреймворк на основе извлеченных сущностей либо с помощью алгоритмов распознавания именованных сущностей (Lample et al., 2016), либо с помощью детекторов объектов (Ren et al., 2015). В частности, для каждого абзаца или изображения мы сначала используем детекторы сущностей, чтобы найти все сущности и локализовать их. В случае текстового абзаца мы сопоставляем все токены и фразы в абзацах с сущностями, появившимися в наборе данных Викиданных. В случае визуального изображения мы используем Faster-RCNN (Ren et al. , 2015), современный детектор объектов на основе CNN, чтобы найти все объекты и определить их метки классов. Подробный анализ набора данных и предварительная обработка см. в разделе 4.
После предварительной обработки экстрактор отношений принимает все возможные пары сущностей в качестве входных данных и присваивает каждой паре соответствующие отношения. Как показано на рис. 3, HRE содержит два модуля, селектор пар и предиктор отношения, и работает итеративно раз. На каждом временном шаге селектор пар просматривает все пары P-=(si,oi)i=0k- из (субъект, объект) , которые не были связаны отношением, и выбирает следующую пару сущностей р * = ( s * , o * ), отношение которых необходимо определить. Предсказатель отношения использует информацию, содержащуюся во всех парах P+=(si,oi,r)i=0k+, отношения которых были определены, и контекстную информацию (из необработанных текстов или изображений) пары p * , чтобы сделать предсказание отношения. Затем результат прогноза добавляется к P + и дает преимущества для будущих прогнозов.
Селектор пар и предиктор отношений работают совместно и фокусируются на разных подзадачах задачи. Цель предиктора — использовать уже определенные отношения, чтобы сделать правильный прогноз для следующей пары сущностей. Селектор, с другой стороны, работает как сотрудник предсказателя с целью выяснить следующее отношение, которое должно быть определено. В идеале выбор p * , сделанные селектором, должны удовлетворять условию, что все отношения, которые повлияют на предсказание предиктора на p * , должны быть отправлены предсказателю раньше p * .
3.2. Relation Predictor
Relation Predictor состоит из двух модулей: нейронного модуля, предсказывающего отношения N между сущностями на основе заданного контекста (т.0005 P + (множество пар, отношения которых уже определены). Оба модуля предсказывают отношение между парой объектов s * и o * по отдельности как relN(s*,o*) и relL(s*,o*). Эти прогнозы представляют собой классификации по категориальному распределению всех отношений: relN(s*,o*)i=Pr[relN(s*,o*)=i] и relL(s*,o*)i=Pr[relL( с*,о*)=i]. Выходной прогноз для пары p * представляет собой смесь 3 двух отдельных прогнозов:
отн(s*,o*)i∝relN(s*,o*)i×relL(s*,o*)i.
Экстрактор нейронных отношений rel N зависит от предметной области. Оставляем реализацию rel N на экспериментальный раздел (раздел 4). В реальных приложениях этот модуль можно заменить любой совместимой реализацией. Далее мы представляем нашу модель L для рассуждений КГ, которая представляет собой дифференцируемый вариант индуктивного логического программирования (Muggleton, 19).91).
Мы разрабатываем программируемый модуль для рассуждений КГ, который сильно мотивирован предыдущими работами по индуктивному логическому программированию (ILP) (Muggleton, 1991) и его современным расширениям (Kersting et al. , 2000; Richardson and Domingos, 2006; Kimmig et др., 2012). ILP фокусируется на проблеме того, как обнаружить правила из известных фактов и применить их для вывода неизвестных фактов.
Чтобы получить интуитивное представление о том, как работает ПИЖ, возьмем в качестве примера сон Девочки со спичками . Нам нужна модель, способная выполнять логическую дедукцию:
(Скатерть, Стол, На) ∧ (Фарфор, Скатерть, На) ⇒ (Фарфор, Стол, На).
Это логическое правило может быть записано в виде определенного предложения :
(x,y,On)∧(y,z,On)⇒(x,z,On),
, где x, y , и z — это переменные, которые можно заменить ( заземление ) любыми объектами, такими как Скатерть, Стол и Фарфор.
ILP — это общая среда программирования, обеспечивающая более высокий уровень абстракции логических правил. Например, вышеприведенное логическое правило может быть получено ( экземпляр ) следующим метаправилом в ILP:
r1=rel(s*,x)∈P+∧ r2=rel(x,o*)∈P+⇒ rel(s*,o*)= r3. (1)
При реализации метаправила r 1 , r 2 и r 3 будут реализованы как (On, On, On, On, On, On, ). Другой возможный экземпляр может быть (Inside, On, On). Интуитивно тройка сущностей ( s * , x, o * ) по существу образует «треугольник отношений», и мы используем два уже известных нам ребра — ( s * , x ) и ( x , o * ) — для определения последнего ребра ( s * , o5 * ).
Практически основная логика является вероятностной логикой. То есть мы будем говорить
Pr[r3=rel(s*,o*)]∝Pr[r1=rel(s*,x)] × Pr[r2=rel(x,o*)] × confidence( r1,r2,r3),
где достоверность ( r 1 , r 2 , r 3 ) — достоверность (плавающее число), связанная с примененным правилом. Мы реализуем логическое индукционное программирование дифференцируемым образом. Если явно не указано иное, все правила выводятся из уравнения (1) в этой статье. Во время вывода прогнозируются отношения между всеми парами сущностей. Таким образом, длинная цепочка рассуждений (например, Стол, Скатерть, Блюдо, Гусь в сне Девочки со спичками ) может быть решена с помощью нескольких шагов примитивной логической дедукции. В этом случае простого «треугольного» логического правила (уравнение 1) достаточно, чтобы разрешить длинную цепочку рассуждений.
Учитывая набор правил R, конкретизированный из предварительно запрограммированного набора метаправил, мы перечисляем все правила и вычисляем окончательный прогноз из модуля индуктивной логики L как:
relL(s*, o*)i ∝ maxrule∈ ℛ rule(s*,o*;P−)i ∝ maxj,k,x(rel(s*, x)j × rel(x, o*)k × доверие(j,k,i))
тензор достоверность , как представление логических правил, оптимизируется посредством обратного распространения во время обучения.
При заданном наборе экземпляров отношения вышеупомянутое логическое правило — это всего лишь один из вариантов выполнения индукции. На практике можно разработать собственные правила на основе характеристик набора данных или базового приложения. В разделе экспериментов мы показываем, что система совместима с другими правилами и дает разные результаты.
3.3. Селектор пар
Селектор пар работает вместе с модулем прогнозирования отношений и выбирает пары субъект-объект для прогнозирования. На каждом временном шаге селектор пар просматривает все пары отношений в P-=(si,oi)i=0k-, отношения которых не были определены, и выводит индекс i ∈ [ k − ] = {0, 1, ⋯ k − } в качестве индекса для пары сущностей, отношение которых будет добавлено к P + предиктором на этом временном шаге.
Мы реализуем селектор пар как жадный селектор, который всегда выбирает пару сущностей из P − для добавления к P + в качестве пары сущностей, в прогнозировании которых предиктор отношений наиболее уверен. Вероятность выхода предиктора отношения Pr( r = rel ( s * , o * )) (раздел 3.2) можно интерпретировать как его достоверность для присвоения отношения
5 r0006 в пару ( s * , o * ):
conf(s*,o*)=maxr Pr(r=rel(s*,o*)).
Таким образом, для того, чтобы выбрать пару, относительно которой предиктор отношения является наиболее уверенным, селектор пар выбирает i таким образом, что:
i=maxiconf(si,oi).
4. Эксперименты и результаты
Мы оцениваем нашу модель на задачах для двух модальностей: извлечения текстовых и визуальных отношений. Наша цель — изучить, как на извлечение гибридных отношений влияет различное кодирование и как оно масштабируется для различной сложности. Наши эксперименты показывают, что он заметно превосходит другие подходы при работе с плотными графами сущностей.
4.1. Извлечение текстовых отношений
4.1.1. Кодирование пары сущностей в тексте
Напомним, что нам нужно предсказать отношение для каждой возможной пары сущностей. Для задачи извлечения текстовых отношений мы кодируем признаки пары сущностей, следуя Сорокину и Гуревичу (2017), как показано на рисунке 4. Сначала мы предварительно обрабатываем предложение и запускаем распознавание названных сущностей, чтобы найти все соответствующие сущности. Затем мы добавляем дополнительное вложение в качестве маркера, указывающего на все появления данной головы (субъекта, с e s ) и хвост (объект, с e o ) пары сущностей. Все остальные символы контекста помечены e c . Вложения { e s , e o , e c } инициализируются случайным образом совместно с моделью.
Рисунок 4 . Кодировщик для пар текстовых сущностей. Мы используем конкатенацию встраивания маркеров и встраивания слов с моделью LSTM (Hochreiter and Schmidhuber, 19).97; Greff et al., 2016) для кодирования функции.
Вложение маркера объединяется со словом встраивание (Pennington et al., 2014) и передается в двунаправленный LSTM (Hochreiter and Schmidhuber, 1997; Graves and Schmidhuber, 2005; Greff et al., 2016). Мы используем стандартный двунаправленный LSTM с одним слоем, 256 единиц LSTM, функцию активации TANH и коэффициент отсева 0,5 Srivastava et al. (2014). Окончательные результаты LSTM как прямого, так и обратного проходов объединяются в качестве окончательного кодирования для этой пары объектов. Мы применяем двухслойный многослойный персептрон, за которым следует слой softmax для функции извлечения нейронных отношений: отн. N . Этот процесс повторяется для каждой возможной пары сущностей в предложении, т. е. n × ( n −1) раз для предложения с n пар сущностей.
4.
1.2. Генерация данных с удаленным наблюдениемМы представляем новый набор данных, сгенерированный из Викиданных (Врандечич и Крётч, 2014 г.), чтобы оценить нашу структуру в задаче извлечения текстовых отношений. Викиданные — это KG, в котором знания хранятся в виде структурированных троек (например, Земля, гора Эверест, самая высокая точка). Мы сопоставляем Викиданные со статьями англоязычной Википедии посредством дистанционного наблюдения (Минц и др., 2009 г.).; Цзэн и др., 2015 г.; Сорокин, Гуревич, 2017). Мы выбираем 86 наиболее часто встречающихся свойств (отношений) для формирования набора свойств.
Мы генерируем абзацы, соединяя два предложения, выбранные из одной и той же статьи. Выбранные предложения должны иметь хотя бы одну общую сущность. Это частично смягчает разреженность отношений. Для пар сущностей без отношения мы вручную помечаем их отношение как N/A (специальное отношение). Мы также отфильтровываем абзацы, содержащие менее 2 экземпляров положительных отношений. Следуя условиям предыдущей работы (Lu et al., 2016; Xu et al., 2017), в наших экспериментах мы случайным образом разделили набор данных на обучающий и тестовый наборы и настроили гиперпараметры всех моделей в тестовом наборе. . Мы вручную оцениваем 500 предложений из тестового набора и обнаруживаем, что 83,2% из них правильно помечены при дистанционном наблюдении. В таблице 1 показана статистика нашего набора данных.
Таблица 1 . Статистика набора данных, сгенерированного из Викиданных.
Набор данных, сгенерированный из Викиданных, очень разреженный в отношении экземпляров отношения: каждое предложение содержит в среднем только 2,7 экземпляра отношения, а доля экземпляров отношения в парах сущностей составляет менее 0,12. Чтобы лучше сосредоточиться на оценке способности нашей модели к рассуждению, мы выбираем плотный набор тестов, в котором могут быть выведены семантические графы 4 . В плотном подмножестве цепочки рассуждений встречаются значительно чаще, что требует, чтобы модель выполняла как обнаружение первичного отношения, так и рассуждение об отношении. Плотный тестовый набор покрывает ~ 2% всего набора данных. Мы принимаем кривую точности-отзыва, широко используемую метрику при извлечении текстовых отношений. k -я точка на кривой вычисляется по точности и полноте k лучших достоверных прогнозов. Мы также сообщаем о балле F 1 (Goutte and Gaussier, 2005), который рассчитывается на основе среднего гармонического значения точности и полноты наиболее достоверных прогнозов каждой пары объектов. Особое отношение N/A не влияет на полноту, а только на точность.
Мы обучаем нашу модель на всем обучающем наборе и оцениваем производительность на плотном тестовом наборе. На рисунке 5 и в таблице 2 экспериментальные результаты показывают, что наша модель значительно превосходит базовые методы (всего rel N ) на плотном тестовом наборе. Чтобы еще больше увеличить масштаб, мы сравним показатель полноты всех фреймворков с умеренной точностью (например, 0,8) в таблице 3. Сильный базовый уровень идентичен модели, использованной Сорокиным и Гуревичем (2017), и является ее повторной реализацией. ).
Рисунок 5 . Точность отзыва на плотном тестовом наборе.
Таблица 2 . F1 получает баллы на плотном тестовом наборе.
Таблица 3 . Вспомните с разными уровнями точности на плотном тестовом наборе.
Мы также показываем сопоставимый результат для всего набора тестов (рис. 6 и табл. 4). В этом случае логическая дедукция, по-видимому, приносит в результат как точные прогнозы, так и шум (обратите внимание на снижение точности, поскольку модель будет оштрафована, если обнаружит ложное срабатывание). Лучший способ включения логических правил в приложения на больших и разреженных KG оставлен для будущей работы.
Рисунок 6 . Точность отзыва на всем наборе тестов.
Таблица 4 . F1 получает баллы по всему набору тестов.
Включение новых правил
Мы также пытаемся включить новые правила в систему индукции. В частности, мы добавляем метаправило: r1=отношение(s*,x)∈P+⇒отношение(s*,o*)=r2. Интуитивно это моделирует логику, что если объект s * имеет отношение r 1 с другим объектом x , то существует повышенная вероятность другого отношения r 2 к любому другому объекту. объект или * . Например, если мужчина едет верхом, вероятность того, что он носит шляпу, возрастает. В более общем случае, когда объект поддерживает одно отношение, он, скорее всего, будет поддерживать и другие отношения. Экспериментальные результаты показали значительное увеличение отзыва, но снижение точности структуры. Это приводит к выводу, что логические правила, используемые системой, должны быть тщательно разработаны на основе базового приложения.
4.2. Извлечение визуальных отношений
4.2.1. Кодирование пар объектов в изображениях
На рис. 7 показана общая архитектура кодировщика пар визуальных объектов. Каждый объект отображается в виде ограничивающей рамки на визуальном изображении. Обнаружение, классификация и локализация выполняются с помощью структуры Faster-RCNN (Ren et al., 2015). Мы расширяем метод, предложенный Lu et al. (2016) для извлечения признаков F(s,o) пары объектов ( s, o ). Для получения нейронных отношений rel N мы применяем двухслойный персептрон, за которым следует слой softmax на извлеченных функциях F(s,o).
Рисунок 7 . Кодировщик для пар визуальных объектов. Мы расширяем кодировщик Union Box, предложенный Lu et al. (2016) и добавьте характеристики объекта (что это такое) и его местоположение (где он находится) в вектор встраивания.
Чтобы эффективно закодировать признаки пары сущностей в распределенные представления F(s,o), мы извлекаем признаки субъекта, объекта и среды их взаимодействия. Обозначим feat в качестве извлеченных признаков всего входного изображения. Эти функции извлекаются с помощью сети VGG-16, предварительно обученной на MS-COCO (Xu et al., 2017). Элементы данной области, заданные ограничивающей рамкой, обозначаются как feat [ box ]. Эти функции получены с помощью операции объединения регионов интереса (ROI), введенной Girshick (2015). feat [ box { s, o } ] затем обозначает признаки отдельного объекта (предмет или объект), извлеченные из признаков изображения подвиг в заданном расположении ограничивающей рамки с операцией объединения ROI.
Мы моделируем среду взаимодействия пары сущностей с помощью блока объединения их ограничивающих прямоугольников box s , box o . Затем характеристики среды взаимодействия обозначаются как feat [ box u ]. Подобно внедрению маркера при извлечении текстовых отношений, мы указываем местоположения субъекта и объекта в среде взаимодействия, добавляя маску к функциям после объединения ROI. Маска представляет собой бинарную матрицу той же формы, что и функция после объединения областей интереса в объединенной рамке. Каждый элемент функции после объединения ROI соответствует области сетки на исходном изображении. Тогда каждый ненулевой элемент маски соответствует Intersection-over-Union (IoU) ограничивающей рамки объекта и ограничивающей рамки бина. Формально индексы ненулевых элементов Ind { s, o } даются:
Indi,j{s,o}=IoU(Region(boxu)i,j,box{s,o}),
где Region ( bo x u ) i, j — соответствующая область на изображении сетки, расположенная в строке i и столбце 50006 окна ROI
6 j 90.
и .Формально, учитывая особенности предмета feat [ Box S ], объект Feat [ Box O ] и Union Feat [ Box U ]. ( s, o ) пары объектов вычисляются следующим образом:
F(s,o)=feat[boxs] ⊗feat[boxo] ⊗feat[boxu] ⊗feat[boxu]⊗Inds ⊗feat[ boxu]⊙Indo,
, где ⊗ — операция конкатенации объектов, а ⊙ — поэлементное умножение.
4.2.2. Visual Genome
Visual Genome (Krishna et al., 2016) представляет собой набор данных, состоящий из 108 077 изображений. В среднем каждое изображение содержит 21,2 объекта и 17,7 экземпляра отношения. Из-за низкого качества аннотаций мы следуем Xu et al. (2017) для ручной очистки набора данных. Далее мы удаляем повторяющиеся отношения в каждом изображении. Окончательный набор данных содержит в среднем 11,0 отдельных объектов и 6,0 экземпляров отношений на изображение. Средняя доля отношений по парам сущностей составляет ~ 6%. Мы также генерируем плотный тестовый набор, который является подмножеством всего тестового набора, где доля отношений по парам сущностей составляет не менее 15%. Плотный тестовый набор содержит 2 361 изображение, в среднем 4,2 различных объекта и 5,3 отношения на изображение.
Следуя (Lu et al., 2016; Xu et al., 2017), мы используем Recall@k (R@k) для оценки моделей в задаче извлечения визуальных отношений. R@k измеряет долю правильных прогнозов среди 90 005 тыс. 90 006 надежных прогнозов. Мы не принимаем AP (средняя точность, которую можно рассматривать как площадь под кривой точности-отзыва) в качестве нашей оценочной метрики, потому что отношения не имеют исчерпывающей маркировки, как это проанализировано в Lu et al. (2016).
Как показано в таблице 5, оснащенный модулем логического вывода, мы получаем значительное улучшение по сравнению с базовыми показателями (всего отн N ), а также другие существующие методы. Базовый уровень идентичен базовой модели, использованной в Xu et al. (2017), кроме экстрактора признаков. Производительность нашей базовой модели демонстрирует эффективность встраивания пары сущностей.
Таблица 5 . Экспериментальные результаты извлечения визуальных отношений на всем наборе тестов Visual Genome.
Интересно, что мы наблюдаем, что наша модель достигает почти одинаковой производительности с точки зрения метрики Recall@k на плотном и всем тестовом наборе. Поскольку метрика Recall@k не штрафует за ложноположительные предсказания отношения, шум, создаваемый модулем индукции, значительно снижается по сравнению с текстовым случаем.
4.3. Детали реализации
Для моделей извлечения визуальных отношений F сущность имеет 512 каналов, а F объединение имеет 256 каналов. Размер окна ROI Pooling установлен равным 7 × 7. Все полносвязные слои, кроме тех, которые используются в модели внимания, имеют 4096 каналов, соответствующих типичной структуре VGG-16. Мы используем 512-мерный вектор для представления вектора внимания e i .
Для моделей извлечения текстовых отношений мы используем GloVe50 (Pennington et al., 2014) в качестве встраивания слов и 256 в качестве значения скрытого размера LSTM и полносвязных слоев.
Мы реализовали модель на основе пакета PyTorch с открытым исходным кодом (Paszke et al., 2017). Мы оптимизируем модель, включая кодировщик пары сущностей и предиктор отношений, сквозным образом с Адамом (Kingma and Ba, 2014) и используем кросс-энтропийную потерю для классификации отношений. Среднее время обучения составляет 0,17 с для одного предложения и 0,48 с для изображения на GeForce GTX 1080 Ti.
5. Заключение и будущая работа
Мы предложили новую модель последовательного прогнозирования для условного извлечения нейронных отношений, которая явно принимает во внимание ранее определенные или известные отношения пар сущностей для лучшего прогнозирования будущих отношений. Мы достигли этого с помощью системы индукции, основанной на правилах объяснительной логики. Экспериментальные результаты показывают превосходство предложенной модели как в текстовых, так и в визуальных задачах предсказания отношений. Наша модель превосходит другие существующие работы, когда графы сущностей становятся более плотными.
Интересное наблюдение наших экспериментов заключается в том, что модель предсказания показывает стабильное улучшение производительности независимо от того, используется ли кодировщик текстового или визуального объекта. Поскольку оба кодировщика полагаются на пространство представления высокой размерности, которое по своей сути кодирует семантическую близость сущностей (Lu et al. , 2016; Sorokin and Gurevych, 2017), кажется, что предиктор отношения во многих случаях способен получить прогноз для точка данных, которая включает новые или необычные сущности. Подобно обучению младенцев, кодировщики изучали характеристики объектов статистически из данных. Как следствие, эта работа не только улучшает экстракторы отношений, но также создает мост между нейронными сетями, вдохновленными мозгом, и системами логической индукции, а также другими моделями завершения KG. Для прикладных целей полученная структура легко настраивается и программируется, что открывает новый путь к лучшей системе машинного мышления.
По сравнению с большинством предыдущих подходов наш метод может лучше работать с длинным хвостом в распределении по отношениям. Благодаря использованию логических правил и модуля прогнозирования пар наш подход может работать с редкими отношениями и правильно применять их к ранее невиданным парам объектов. Это ключевое преимущество, поскольку работа с асимметричным распределением отношений и обобщение отношений на невидимые пары объектов является ключевым требованием для успешного извлечения отношений из текста или изображений. Кроме того, благодаря использованию дифференцируемой индуктивной логики наша модель обучаема сквозным образом, что означает минимальное участие человека и всего несколько правил, созданных вручную.
Однако добавление селектора пар увеличивает размер нашей модели и количество параметров. Кроме того, правила для индуктивной логики все еще должны быть созданы вручную, и мы оценили модель только с одним метаправилом. Поэтому в будущей работе следует оценить, насколько хорошо подход работает с несколькими сложными логическими правилами или возможно ли вообще изучить новые, действительные правила. Еще одно ограничение заключается в том, что наш подход в настоящее время работает только с прогнозированием текстовых или визуальных отношений. В будущей работе мы хотим объединить предсказание текстовых и визуальных отношений. Наша модель легко позволяет комбинировать мультимодальные функции, например, путем подачи объединенных визуальных и текстовых функций на вход HRE (рис. 3, справа). Это актуально для взаимодействия человека и робота, где диалог содержит не только чисто лингвистические объекты, но и ссылки на объекты в окружающей сцене. Согласование текстового ввода, например, из расшифрованной речи, с визуальным вводом позволит лучшему лингвистическому пониманию встроенным агентом, который сопоставляет вербально воспринимаемые отношения со сценой, например, для устранения неоднозначности объекта среди других.
Заявление о доступности данных
Наборы данных, созданные для этого исследования, доступны по запросу соответствующему автору.
Вклад авторов
JM и YY внесли свой вклад в разработку модели. JM, YY, SH и TH участвовали в экспериментах и написании статей. CW, SW, ZL и MS внесли ценные предложения и помогли отредактировать документ.
Финансирование
Авторы благодарят за поддержку Немецкий исследовательский фонд (DFG) и Национальный научный фонд Китая (NSFC) в рамках проекта Crossmodal Learning (TRR-169).Семантический граф может быть выведен, если он содержит не менее трех связных объектов, т. е. не менее 1 цепочки рассуждений.
Ссылки
Андреас Дж. , Рорбах М., Даррелл Т. и Кляйн Д. (2016). «Сети нейронных модулей», в материалах Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (Лас-Вегас, Невада), 39–48.
Google Scholar
Багданау Д., Мурти С., Ноухович М., Нгуен Т. Х., де Врис Х. и Курвиль А. (2019 г.). «Систематическое обобщение: что требуется и можно ли этому научиться?», Proceedings of the International Conference on Learning Representations (ICLR) (Новый Орлеан, Луизиана).
Google Scholar
Бордес А., Усюнье Н., Гарсия-Дюран А., Уэстон Дж. и Яхненко О. (2013). «Перевод вложений для моделирования многореляционных данных», в Advances in Neural Information Processing Systems (NIPS) (Lake Tahoe, CA), 2787–2795.
Google Scholar
Боуман, С. Р., Анджели, Г., Поттс, К., и Мэннинг, К. Д. (2015). «Большой аннотированный корпус для изучения вывода на естественном языке», в Proceedings of the Conference on Empirical Methods in Natural Language Processing (EMNLP 2015) (Лиссабон), 632–642.
Google Scholar
Chao, Y.-W., Wang, Z., He, Y., Wang, J., and Deng, J. (2015). «HICO: тест для распознавания взаимодействия человека с объектом на изображениях», в Proceedings of the IEEE International Conference on Computer Vision (ICCV) г. (Сантьяго), 1017–1025 гг.
Google Scholar
Чен Т., Ю В., Чен Р. и Лин Л. (2019). «Сеть маршрутизации со встроенными знаниями для создания графа сцены», в Трудах конференции IEEE по компьютерному зрению и распознаванию образов (CVPR) (Лонг-Бич, Калифорния).
Google Scholar
Чен X., Ли Л.-Дж., Фей-Фей Л. и Гупта А. (2018). «Итеративное визуальное мышление за пределами извилин», в материалах Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (Солт-Лейк-Сити, Юта), 7239–7248.
Google Scholar
Кристопулу Ф., Мива М. и Ананиаду С. (2019). Модель на основе обхода графов сущностей для извлечения отношений. препринт arXiv arXiv:1902. 07023.
Google Scholar
Эллиот Д. и де Врис А. (2015). «Описание изображений с использованием предполагаемых представлений визуальной зависимости», в материалах 53-го ежегодного собрания Ассоциации вычислительной лингвистики и 7-й Международной объединенной конференции по обработке естественного языка (ACLL-IJCNLP 2015) , Том. 1 (Пекин), 42–52.
Google Scholar
Фэн Дж., Хуан М., Чжао Л., Ян Ю. и Чжу Х. (2018). «Обучение с подкреплением для классификации отношений на основе зашумленных данных», в материалах 32-й конференции AAAI по искусственному интеллекту (AAAI) (Новый Орлеан, Луизиана), 5779–5786.
Google Scholar
Фодор Дж. и Маклафлин Б.П. (1990). Коннекционизм и проблема системности: почему не работает решение Смоленского. Познание 35, 183–204. doi: 10.1016/0010-0277(90)-B
PubMed Abstract | Полный текст перекрестной ссылки | Google Scholar
Фодор Дж. А. и Пилишин З. В. (1988). Коннекционизм и когнитивная архитектура: критический анализ. Познание 28, 3–71. doi: 10.1016/0010-0277(88)
PubMed Abstract | Полный текст перекрестной ссылки | Google Scholar
Гиршик, Р. (2015). «Fast R-CNN», в Proceedings of the IEEE International Conference on Computer Vision (ICCV 2015) (Сантьяго), 1440–1448 гг.
Google Scholar
Goutte, C., and Gaussier, E. (2005). «Вероятностная интерпретация точности, отзыва и f-показателя с учетом оценки», в European Conference on Information Retrieval (Santiago de Compostela: Springer), 345–359.
Google Scholar
Грейвс А. и Шмидхубер Дж. (2005). Фреймовая классификация фонем с двунаправленным LSTM и другими архитектурами нейронных сетей. Нейронная сеть. 18, 602–610. doi: 10.1016/j.neunet.2005.06.042
PubMed Abstract | Полный текст перекрестной ссылки | Google Scholar
Грефф К., Сривастава Р. К., Кутник Дж., Стейнебринк Б. Р. и Шмидхубер Дж. (2016). LSTM: одиссея поискового пространства. IEEE Trans. Нейронная сеть. Учиться. Сист. 28, 2222–2232. doi: 10.1109/TNNLS.2016.2582924
PubMed Abstract | Полный текст перекрестной ссылки | Google Scholar
Гу Дж., Чжао Х., Линь З., Ли С., Цай Дж. и Линг М. (2019). «Создание графа сцены с использованием внешних знаний и реконструкции изображения», в Материалы конференции IEEE по компьютерному зрению и распознаванию образов (CVPR) (Лонг-Бич, Калифорния).
Google Scholar
Хачи, Б. (2009). «Обобщение нескольких документов с использованием извлечения общих отношений», в Proceedings of the Conference on Empirical Methods in Natural Language Processing (EMNLP) (Сингапур), 420–429.
Google Scholar
Hadley, RF (1994). Систематичность в коннекционистском изучении языка. Язык разума. 9, 247–272. doi: 10.1111/j.1468-0017.1994.tb00225.x
Полный текст CrossRef | Google Scholar
Хохрайтер С. и Шмидхубер Дж. (1997). Длинная кратковременная память. Нейронные вычисления. 9, 1735–1780. doi: 10.1162/neco.1997.9.8.1735
PubMed Abstract | Полный текст перекрестной ссылки | Google Scholar
Янсен, П. А., и Уоттер, С. (2012). Сильная систематичность благодаря сенсомоторному концептуальному обоснованию: неконтролируемый развивающий подход к коннекционистской обработке предложений. Подключить. науч. 24, 25–55. doi: 10.1080/09540091.2012.664121
CrossRef Полный текст | Google Scholar
Ji, G., He, S., Xu, L., Liu, K., and Zhao, J. (2015). «Внедрение графа знаний с помощью матрицы динамического отображения», в материалах 53-го ежегодного собрания Ассоциации вычислительной лингвистики и 7-й Международной совместной конференции по обработке естественного языка (ACL-IJCNLP) , Vol. 1 (Пекин), 687–696.
Google Scholar
Джонсон Дж., Кришна Р., Старк М., Ли Л.-Дж., Шамма Д., Бернштейн М. и др. (2015). «Поиск изображений с использованием графов сцен», в Материалы конференции IEEE по компьютерному зрению и распознаванию образов (CVPR) (Бостон, Массачусетс), 3668–3678.
Google Scholar
Керстинг К., Де Рэдт Л. и Крамер С. (2000). «Интерпретация байесовских логических программ», в материалах семинара AAAI-2000 по изучению статистических моделей на основе реляционных данных (Остин, Техас), 29–35.
Google Scholar
Ким Дж., Риччи М. и Серр Т. (2018). Not-So-CLEVR: изучение взаимосвязей «одно и то же» нагружает нейронные сети с прямой связью. Фокус интерфейса 8:20180011. doi: 10.1098/rsfs.2018.0011
PubMed Abstract | Полный текст перекрестной ссылки | Google Scholar
Киммиг А., Бах С., Брохелер М., Хуанг Б. и Гетур Л. (2012). «Краткое введение в вероятностную мягкую логику», в материалах Proceedings of the NIPS Workshop on Probabilistic Programming: Foundations and Applications (Lake Tahoe, CA), 1–4.
Google Scholar
Кингма, Д. П., и Ба, Дж. (2014). Адам: Метод стохастической оптимизации. препринт arXiv arXiv:1412.6980.
Google Scholar
Кипф, Т. Н., и Веллинг, М. (2016). Полууправляемая классификация с помощью графовых сверточных сетей. препринт arXiv arXiv:1609.02907.
Google Scholar
Кришна Р., Чжу Ю., Грот О., Джонсон Дж., Хата К., Кравиц Дж. и др. (2016). Визуальный геном: соединение языка и зрения с помощью краудсорсинговых плотных аннотаций изображений. Междунар. Дж. Вычисл. Видение 123, 32–73. дои: 10.1007/s11263-016-0981-7
Полнотекстовая перекрестная ссылка | Google Scholar
Крижевский А., Суцкевер И. и Хинтон Г. Э. (2012). «Классификация Imagenet с использованием глубоких сверточных нейронных сетей», в Advances in Neural Information Processing Systems (NIPS) (Lake Tahoe, CA), 1097–1105.
Google Scholar
Лэмпл Г., Баллестерос М., Субраманиан С., Каваками К. и Дайер К. (2016). «Нейронные архитектуры для распознавания именованных объектов», в Proceedings of the Annual Conference of the North American Chapter of the Association for Computational Linguistics (NAACL-HLT 2016) (Сан-Диего, Калифорния), 260–270.
Google Scholar
ЛеКун Ю., Бенжио Ю. и Хинтон Г. (2015). Глубокое обучение. Природа 521:436. doi: 10.1038/nature14539
PubMed Abstract | Полный текст перекрестной ссылки | Google Scholar
Ли, Ю., и Гупта, А. (2018). «Помимо сеток: изучение графических представлений для визуального распознавания», в Advances in Neural Information Processing Systems (NIPS) (Монреаль, QC), 9225–9235.
Google Scholar
Ли, Ю., Оуян, В., Чжоу, Б., Ван, К., и Ван, X. (2017). «Создание графа сцены из объектов, фраз и заголовков регионов», в материалах Международной конференции IEEE по компьютерному зрению (ICCV) (Венеция), 1261–1270.
Google Scholar
Лян X., Ли Л. и Син Э. П. (2017). «Глубокое вариационно-структурированное обучение с подкреплением для обнаружения визуальных отношений и атрибутов», в Трудах конференции IEEE по компьютерному зрению и распознаванию образов (CVPR 2017) (Гонолулу, Гавайи: IEEE), 4408–4417.
Google Scholar
Линь Ю., Лю З. и Сун М. (2017). «Извлечение нейронных отношений с многоязычным вниманием», в материалах 55-го ежегодного собрания Ассоциации вычислительной лингвистики (ACL) , Vol. 1 (Ванкувер, Британская Колумбия), 34–43.
Google Scholar
Линь Ю., Лю З., Сунь М., Лю Ю. и Чжу Х. (2015). «Внедрение обучающих объектов и отношений для завершения графа знаний», в Proceedings of the AAAI Conference on Artificial Intelligence (AAAI) , Том. 15 (Остин, Техас), 2181–2187.
Google Scholar
Лу, К., Кришна, Р., Бернштейн, М., и Фей-Фей, Л. (2016). «Обнаружение визуальной взаимосвязи с языковыми априорами», в Proceedings of the European Conference on Computer Vision (ECCV) (Амстердам: Springer), 852–869.
Google Scholar
Минц М., Биллс С., Сноу Р. и Джурафски Д. (2009). «Удаленное наблюдение за извлечением отношений без помеченных данных», в Трудах 47-го ежегодного собрания Ассоциации компьютерной лингвистики (ACL 2009). ) (Сингапур), 1003–1011.
Google Scholar
Маглтон, С. (1991). Индуктивное логическое программирование. Новый генерал вычисл. 8, 295–318. doi: 10.1007/BF03037089
CrossRef Полный текст | Google Scholar
Нгуен, Т. Х., и Гришман, Р. (2015). «Извлечение отношений: перспектива сверточных нейронных сетей», в материалах семинара NAACL по моделированию векторного пространства для NLP (Денвер, Колорадо), 39–48.
Google Scholar
Окамото, Дж., и Ишизаки, С. (2007). «Устранение неоднозначности смысла слова в контекстуальной динамической сети с использованием словаря ассоциативных понятий», в материалах 10-й конференции Тихоокеанской ассоциации компьютерной лингвистики (PACL) (Мельбурн, Виктория), 94–103.
Google Scholar
Пашке А., Гросс С., Чинтала С., Чанан Г., Ян Э., ДеВито З. и др. (2017). «Автоматическое дифференцирование в PyTorch», в Autodiff Workshop, Будущее программного обеспечения и методов машинного обучения на основе градиента, NIPS 2017 (Лонг-Бич, Калифорния).
Google Scholar
Пеннингтон Дж., Сочер Р. и Мэннинг С. Д. (2014). «Перчатка: глобальные векторы для представления слов», в эмпирических методах обработки естественного языка (EMNLP) (Доха), 1532–1543.
Google Scholar
Ци М., Ли В., Ян З., Ван Ю. и Луо Дж. (2019). «Внимательные реляционные сети для сопоставления изображений с графами сцен», в Трудах конференции IEEE по компьютерному зрению и распознаванию образов (CVPR) (Лонг-Бич, Калифорния).
Google Scholar
Цинь П., Сюй В. и Ван В. Ю. (2018). DSGAN: генеративно-состязательное обучение для извлечения отношений дистанционного наблюдения. препринт arXiv arXiv:1805.09929.
Google Scholar
Ramanathan, V., Li, C., Deng, J., Han, W., Li, Z., Gu, K., et al. (2015). «Изучение семантических отношений для лучшего поиска действий в изображениях», в Трудах конференции IEEE по компьютерному зрению и распознаванию образов (CVPR) (Бостон, Массачусетс), 11:00–11:09.
Google Scholar
Рен С., Хе К., Гиршик Р. и Сун Дж. (2015). «Быстрее R-CNN: на пути к обнаружению объектов в реальном времени с помощью сетей региональных предложений», в «Улучшения в системах обработки нейронной информации» (NIPS) (Монреаль, КК), 91–99.
Реферат PubMed | Google Scholar
Ричардсон М. и Домингос П. (2006). Логические сети Маркова. Машинное обучение. 62, 107–136. doi: 10.1007/s10994-006-5833-1
Полнотекстовая перекрестная ссылка | Google Scholar
Ридель С., Яо Л. и МакКаллум А. (2010). «Моделирование отношений и их упоминания без маркированного текста», в материалах Европейской конференции по машинному обучению и принципам и практике обнаружения знаний в базах данных (ECML-PKDD) (Барселона), 148–163.
Google Scholar
Сантос, С.Н.Д., Сян, Б., и Чжоу, Б. (2015). «Классификация отношений путем ранжирования с помощью сверточных нейронных сетей», в Материалы 53-го ежегодного собрания Ассоциации компьютерной лингвистики и 7-й Международной совместной конференции по обработке естественного языка (ACLL-IJCNLP 2015) (Пекин), 626–634.
Google Scholar
Зигельманн Х.Т. и Зонтаг Э.Д. (1995). О вычислительной мощности нейронных сетей. Дж. Вычисл. Сист. науч. 50, 132–150. doi: 10.1006/jcss.1995.1013
CrossRef Полный текст | Google Scholar
Сорокин Д., Гуревич И. (2017). «Контекстно-зависимые представления для извлечения отношений базы знаний», в Материалы конференции 2017 г. по эмпирическим методам обработки естественного языка (EMNLP) (Копенгаген), 1784–1789.
Google Scholar
Шривастава Н., Хинтон Г., Крижевский А., Суцкевер И. и Салахутдинов Р. (2014). Dropout: простой способ предотвратить переоснащение нейронных сетей. Дж. Маха. Учиться. Рез. 15, 1929–1958 гг.
Google Scholar
Влахос А. и Ридель С. (2014). «Проверка фактов: определение задачи и построение набора данных», в Материалы семинара ACL 2014 по языковым технологиям и вычислительным социальным наукам (Балтимор, Мэриленд), 18–22.
Google Scholar
Врандечич, Д. , и Крётч, М. (2014). Викиданные: бесплатная совместная база знаний. Комм. АСМ 57, 78–85. doi: 10.1145/2629489
CrossRef Полный текст | Google Scholar
Ван Х., Луо Ю., Пэн Б. и Чжэн В.-С. (2018). «Обучение представлению для завершения графа сцены посредством совместного структурного и визуального встраивания», в Материалы Международной объединенной конференции по искусственному интеллекту (IJCAI) (Стокгольм), 949–956.
Google Scholar
Wang, Z., Zhang, J., Feng, J., and Chen, Z. (2014). «Внедрение графа знаний путем перевода на гиперплоскости», в материалах Proceedings of the AAAI Conference on Artificial Intelligence (AAAI) , Vol. 14 (Квебек), 1112–1119 гг.
Google Scholar
Ву С., Ким Д., Чо Д. и Квеон И. С. (2018). «Linknet: реляционное встраивание для графа сцены», в Достижения в области систем обработки нейронной информации (NIPS) (Монреаль, Квебек), 560–570.
Google Scholar
Сюй Д., Чжу Ю. , Чой С. Б. и Фей-Фей Л. (2017). «Генерация графа сцены путем итеративной передачи сообщений», в Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (Гонолулу, Гавайи), 5410–5419.
Google Scholar
Сюй К., Редди С., Фэн Ю., Хуанг С. и Чжао Д. (2016). «Ответы на вопросы на freebase с помощью извлечения отношений и текстовых свидетельств», в Материалы 54-го ежегодного собрания Ассоциации компьютерной лингвистики (Том 1: Длинные статьи) (Берлин), 2326–2336.
Google Scholar
Ян Ф., Ян З. и Коэн В. В. (2017). Дифференцируемое изучение логических правил для пополнения базы знаний. препринт arXiv arXiv:1702.08367.
Google Scholar
Ян Дж., Лу Дж., Ли С., Батра Д. и Парих Д. (2018). «Graph R-CNN для генерации графа сцены», в Материалы Европейской конференции по компьютерному зрению (ECCV) (Мюнхен), 670–685.
Google Scholar
Зеллерс Р., Ятскар М., Томсон С. и Чой Ю. (2018). «Нейронные мотивы: анализ графа сцены с глобальным контекстом», в Трудах конференции IEEE по компьютерному зрению и распознаванию образов (CVPR) (Солт-Лейк-Сити, Юта), 5831–5840.
Google Scholar
Цзэн Д., Лю К., Чен Ю. и Чжао Дж. (2015). «Дистанционное наблюдение за извлечением отношений с помощью кусочно-сверточных нейронных сетей», в Материалы конференции 2015 г. по эмпирическим методам обработки естественного языка (EMNLP) (Лиссабон), 1753–1762.
Google Scholar
Цзэн Д., Лю К., Лай С., Чжоу Г. и Чжао Дж. (2014). «Классификация отношений с помощью сверточной глубокой нейронной сети», в материалах Международной конференции по вычислительной лингвистике (COLING) (Дублин), 2335–2344.
Google Scholar
Цзэн В., Линь Ю., Лю З. и Сун М. (2017). «Включение путей отношений в извлечение нейронных отношений», в Материалы конференции 2017 г. по эмпирическим методам обработки естественного языка (Ванкувер, Британская Колумбия), 1768–1777.
Google Scholar
Чжан Х., Кьяу З., Чанг С.-Ф. и Чуа Т.-С. (2017). «Сеть внедрения визуального перевода для обнаружения визуальных отношений», в материалах Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , Vol. 2 (Гонолулу, Гавайи), 4.
Google Scholar
Zhu, H., Lin, Y., Liu, Z., Fu, J., Chua, T.-S., and Sun, M. (2019). Граф нейронных сетей с сгенерированными параметрами для извлечения отношений. препринт arXiv arXiv:1902.00756.
Google Scholar
Знакомство с изображениями, графиками и другими объектами в Pages на iPhone
Pages
Искать в этом руководстве
- Добро пожаловать
- Введение в страницы
- Обработка текста или макет страницы?
- Знакомство с изображениями, графиками и другими объектами
- Создайте свой первый документ
- Введение в создание книги
- Используйте шаблоны
- Найти документ
- Откройте документ
- Сохранить и назвать документ
- Распечатать документ или конверт
- Отменить или повторить изменения
- Предотвращение случайного редактирования
- Быстрая навигация
- Введение в символы форматирования
- Показать линейку
- Просмотр страниц рядом
- Быстрое форматирование текста и объектов
- Просмотр оптимизированной версии документа
- Копировать текст и объекты между приложениями
- Основные жесты сенсорного экрана
- Создайте документ с помощью VoiceOver
- Используйте VoiceOver для предварительного просмотра комментариев и отслеживания изменений
- Выберите текст и поместите точку вставки
- Добавить и заменить текст
- Скопируйте и вставьте текст
- Добавить, изменить или удалить поле слияния
- Управление информацией об отправителе
- Добавление, изменение или удаление исходного файла в Pages на iPhone
- Заполнение и создание настраиваемых документов
- Форматирование документа для другого языка
- Используйте фонетические справочники
- Использовать двунаправленный текст
- Используйте вертикальный текст
- Добавить математические уравнения
- Закладки и ссылки
- Добавить ссылки
- Изменить внешний вид текста
- Установить шрифт по умолчанию
- Изменить заглавные буквы текста
- Используйте стили текста
- Копировать и вставлять стили текста
- Автоматически форматировать дроби
- Лигатуры
- Добавить буквицы
- Сделать символы надстрочными или подстрочными
- Форматирование китайского, японского или корейского текста
- Формат дефисов и кавычек
- Установить интервалы между строками и абзацами
- Установить поля абзаца
- Форматировать списки
- Установить позиции табуляции
- Выравнивание и выравнивание текста
- Добавить разрывы строк и страниц
- Форматировать столбцы текста
- Связать текстовые поля
- Установите размер и ориентацию бумаги
- Установить поля документа
- Настройка разворота страниц
- Шаблоны страниц
- Добавить страницы
- Добавляйте и форматируйте разделы
- Изменение порядка страниц или разделов
- Дублирование страниц или разделов
- Удалить страницы или разделы
- Оглавление
- Сноски и концевые сноски
- Заголовки и колонтитулы
- Добавьте номера страниц
- Изменить фон страницы
- Добавить рамку вокруг страницы
- Добавляйте водяные знаки и фоновые объекты
- Добавить изображение
- Добавить галерею изображений
- Редактировать изображение
- Добавить и изменить фигуру
- Объединяйте или разбивайте фигуры
- Сохранение фигуры в библиотеке фигур
- Добавление и выравнивание текста внутри фигуры
- Добавьте линии и стрелки
- Добавляйте и редактируйте рисунки
- Добавить видео и аудио
- Запись видео и аудио
- Редактировать видео и аудио
- Установите формат фильма
- Размещение и выравнивание объектов
- Размещайте объекты с текстом
- Используйте направляющие для выравнивания
- Слой, группировка и блокировка объектов
- Изменить прозрачность объекта
- Заполнение фигур и текстовых полей цветом или изображением
- Добавить границу к объекту
- Добавить подпись или заголовок
- Добавьте отражение или тень
- Используйте стили объектов
- Изменение размера, поворот и отражение объектов
- Добавить или удалить таблицу
- Выбор таблиц, ячеек, строк и столбцов
- Добавление или удаление строк и столбцов таблицы
- Переместить строки и столбцы таблицы
- Изменение размера строк и столбцов таблицы
- Объединение или разъединение ячеек таблицы
- Изменение внешнего вида текста таблицы
- Показать, скрыть или изменить заголовок таблицы
- Изменение линий и цветов сетки таблицы
- Используйте стили таблиц
- Изменение размера, перемещение или блокировка стола
- Добавлять и редактировать содержимое ячейки
- Формат даты, валюта и многое другое
- Форматирование таблиц для двунаправленного текста
- Условное выделение ячеек
- Алфавит или сортировка данных таблицы
- Добавить или удалить график
- Преобразование графика из одного типа в другой
- Изменить данные графика
- Переместить, изменить размер и повернуть график
- Изменение внешнего вида рядов данных
- Добавьте легенду, линии сетки и другую маркировку
- Изменение внешнего вида текста и меток графика
- Добавить границу к графику
- Используйте стили графика
- Проверять орфографию
- Поиск слов
- Найти и заменить текст
- Заменить текст автоматически
- Показать количество слов и другую статистику
- Аннотировать документ
- Установите имя автора для комментариев
- Выделите текст
- Добавить и распечатать комментарии
- Отслеживать изменения
- Отправить документ
- Опубликовать книгу в Apple Books
- Введение в сотрудничество
- Приглашайте других к сотрудничеству
- Совместная работа над общим документом
- Изменение настроек общего документа
- Прекратить совместное использование документа
- Общие папки и совместная работа
- Используйте Box для совместной работы
- Использовать режим докладчика
- Используйте iCloud Drive со страницами
- Экспорт в Word, PDF или другой формат файла
- Восстановить более раннюю версию документа
- Переместить документ
- Удалить документ
- Защитить документ паролем
- Создание пользовательских шаблонов и управление ими
- Передача документов с помощью AirDrop
- Передача документов с Handoff
- Перенос документов с помощью Finder
- Горячие клавиши
- Символы сочетания клавиш
- Авторские права
Объект — это любой элемент, который вы размещаете на странице. Таблицы, графики, текстовые поля, фигуры и фотографии являются примерами объектов. Когда вы нажимаете на панели инструментов, а затем на кнопку, вы видите различные стили таблиц, графиков, фигур и мультимедиа, которые вы можете добавить на свои страницы.
Вы можете изменить внешний вид объекта, изменив его отдельные атрибуты, такие как цвет заливки, граница, тень и т. д., или вы можете быстро изменить общий вид объекта, применив предварительно разработанный стиль объекта к Это. Стили объектов — это комбинации атрибутов, разработанные в соответствии с используемым вами шаблоном.
Нажмите, чтобы увидеть элементы управления для изменения внешнего вида объектов. Каждый объект имеет свои собственные параметры форматирования; например, когда вы выбираете фигуру, вы видите только элементы управления для форматирования фигур.
Вы можете накладывать объекты друг на друга, изменять их размер и управлять тем, как текст обтекает их на странице. Например, вы можете обтекать объект текстом или размещать объект в строке, чтобы он располагался на той же строке, что и текст, и перемещался вместе с текстом по мере ввода. Некоторые объекты также могут быть вложены в текст внутри текстового блока или фигуры.
См. также Добавление текста в текстовое полеДобавление изображения в Pages на iPhoneДобавление и редактирование фигуры в Pages на iPhoneДобавление или удаление таблицы в Pages на iPhoneДобавление или удаление графика в Pages на iPhoneРазмещение объектов с текстом в Pages на iPhone
Максимальное количество символов: 250
Пожалуйста, не указывайте личную информацию в своем комментарии.
Максимальное количество символов — 250.
Спасибо за отзыв.
Что такое графическое изображение? | График изображения | Фотографии графиков
Что такое графическая картинка? Это один из самых полезных способов, который позволяет пояснить информацию, статистические данные в наглядной форме с помощью рисунков. ConceptDraw DIAGRAM, дополненный решением Picture Graphs из области Graphs and Charts, предлагает вам самый простой способ рисования Picture Graphs.
График с картинками — это популярный и широко используемый тип гистограммы, который представляет данные в различных категориях с помощью изображений. ConceptDraw DIAGRAM, дополненный решением Picture Graphs из раздела Графики и диаграммы в ConceptDraw Solution Park, является лучшим программным обеспечением для быстрого и простого рисования профессионально выглядящих графических изображений.
Программное обеспечение ConceptDraw DIAGRAM для построения диаграмм и векторного рисования, дополненное решением Picture Graphs из области графиков и диаграмм, является лучшим выбором для создания профессионально выглядящих изображений графиков и красочных графических изображений.
Графическая диаграмма (графическая диаграмма, иллюстрированная диаграмма) представляет собой тип гистограммы, отображающей числовые данные с использованием символов и пиктограмм.
В области экономики и финансов используют графическую картинку со столбцами в виде монет. Для статистики сравнения населения используйте диаграмму со столбцами в виде манекенов. Чтобы показать увеличение или уменьшение данных, используйте гистограммы со стрелками.
Шаблон стрелочной диаграммы «График изображения» для программного обеспечения ConceptDraw PRO для построения диаграмм и векторного рисования включен в решение Basic Picture Graphs из области «Графики и диаграммы» в ConceptDraw Solution Park.
Шаблон гистограммы со стрелками
Используемые решения
Графики и диаграммы >
Графики изображений
Библиотека векторных трафаретов «Picture Graphs» содержит 4 шаблона графических диаграмм. Используйте его для создания графических гистограмм в программном обеспечении для построения диаграмм и векторной графики ConceptDraw PRO.
«Иллюстрированная гистограмма.
Иногда упоминается как пиктограмма. Графическая гистограмма — это диаграмма, в которой прямоугольные столбцы заполнены изображениями, эскизами, значками и т. д. или где прямоугольные столбцы заменены изображениями, эскизами, значками и т. д. В обоих вариантах в каждом баре может использоваться один или несколько символов. Две основные причины использования наглядных графиков — сделать график более привлекательным визуально и облегчить общение». [Информационная графика: всеобъемлющий иллюстрированный справочник. Р. Л. Харрис. 1999. с.41]
Пример шаблонов диаграмм «Элементы дизайна — графические изображения» включен в решение Basic Picture Graphs из области «Графики и диаграммы» в ConceptDraw Solution Park.
Шаблоны графических диаграмм
Используемые решения
Графики и диаграммы >
Графики изображений
Библиотека векторных шаблонов «Picture Graphs» содержит 35 шаблонов графических изображений для визуального сравнения данных и временных рядов.
Перетащите шаблон из библиотеки в документ, задайте количество тактов, введите метки категорий, выберите такты и введите свои данные.
Используйте эти фигуры, чтобы рисовать гистограммы в программе ConceptDraw PRO для построения диаграмм и векторной графики.
Библиотека векторных шаблонов Picture Graphs включена в решение Picture Graphs из области Graphs and Charts в ConceptDraw Solution Park.
Стрелка
Капля воды
Food
зерна
Сельскохозяйственное хозяйство
лекарства
Дома
Здания
Money Bags
Основательные барьмы
Electrical Power
Ячевые барьмы
.
Химическая промышленность
Горнодобывающая промышленность
Золотые слитки
Монеты
Человек
Мужчины, женщины и дети
Мужчина
Женщина
Ребенок
Молоко
Мясо
Фрукты
Овощи
Компьютер
Мобильный телефон
Airliner
CAR
Bus
CARGO
SHIB
CARGO
SHIBCARGO
SHIB
CARGO
. Графики и диаграммы
>Графики изображений
Что такое инфографика >
Иллюстрированная инфографика
Библиотека векторных трафаретов «Иллюстрированные гистограммы» содержит 35 шаблонов наглядных диаграмм. Используйте его для визуализации сравнения данных и временных рядов с программным обеспечением ConceptDraw PRO для построения диаграмм и векторного рисования.
«Иллюстрированная гистограмма.
г. Иногда упоминается как пиктограмма. Графическая гистограмма — это диаграмма, в которой прямоугольные столбцы заполнены изображениями, эскизами, значками и т. д. или где прямоугольные столбцы заменены изображениями, эскизами, значками и т. д. В обоих вариантах в каждом баре может использоваться один или несколько символов. Две основные причины использования наглядных графиков — сделать график более привлекательным визуально и облегчить общение». [Информационная графика: всеобъемлющий иллюстрированный справочник. Р. Л. Харрис. 1999. с.41]
Пример графических диаграмм «Элементы дизайна — гистограммы изображений» включен в решение «Графики изображений» из области «Графики и диаграммы» в ConceptDraw Solution Park.
Шаблоны
Используемые решения
Графики и диаграммы >
Графики изображений
Что такое инфографика >
Иллюстрированная инфографика
Программное обеспечение ConceptDraw DIAGRAM для построения диаграмм и векторного рисования предлагает решение Area Charts из области Graphs and Charts в ConceptDraw Solution Park для быстрого и легкого рисования зональных диаграмм любой сложности.
Как правило, Picture Graph имеет очень широкое применение. Они много раз успешно использовались в маркетинге, менеджменте и производстве. Решение Picture Graphs расширяет возможности ConceptDraw DIAGRAM с помощью шаблонов, образцов и библиотеки профессионально разработанных векторных трафаретов для создания графических изображений.
Это решение расширяет возможности ConceptDraw DIAGRAM (или более поздней версии) с помощью шаблонов, образцов и библиотеки векторных трафаретов для рисования графических изображений.
Charting Software позволяет создавать диаграммы, диаграммы, графики, блок-схемы и другую бизнес-графику. ConceptDraw DIAGRAM включает простые инструменты для рисования фигур, примеры, шаблоны и библиотеки символов.
В этом примере показана гистограмма коэффициентов кредитного плеча для двух крупных инвестиционных банков. Коэффициент кредитного плеча — это отношение общего долга к общему капиталу; это мера риска, взятого на себя банком. Чем выше коэффициент левериджа, тем больше риск, тем большие риски могут привести к кризису ипотечных кредитов.
Этот образец был создан в программном обеспечении для построения диаграмм и векторного рисования ConceptDraw DIAGRAM с использованием решения для круговых диаграмм из области графиков и диаграмм в парке решений ConceptDraw.
Этот образец показывает круговую диаграмму приблизительного состава воздуха. На этой круговой диаграмме вы можете увидеть процентное содержание кислорода, азота и других газов в воздухе.
ConceptDraw предоставляет интерактивную диаграмму xy и символы точечной диаграммы, которые предлагают расширенные функции, но при этом просты в использовании.
Круговая диаграмма — очень популярный вид диаграмм, который широко используется в различных областях науки и жизнедеятельности. ConceptDraw DIAGRAM, дополненный решением для круговых диаграмм из области «Графики и диаграммы», является лучшим программным обеспечением для рисования рабочих листов круговых диаграмм.
Как нарисовать организационную диаграмму. Инновационная технология ConceptDraw Arrows10, включенная в ConceptDraw DIAGRAM, представляет собой мощный инструмент для рисования, меняющий способ создания диаграмм.
Делая процесс рисования проще и быстрее.
Видеоруководство по созданию оргдиаграммы с помощью продуктов ConceptDraw. Попробуйте ConceptDraw для создания профессиональных презентаций в виде оргдиаграмм!
Этот образец гистограммы показывает рост населения Барри с 1981 по 2006 год. Он был разработан на основе файла Wikimedia Commons: Barrie Population.jpg.
[commons.wikimedia.org/ wiki/ File:Barrie_ Population.jpg]
«Барри — город в Центральном Онтарио, Канада, на западном берегу озера Симко. Несмотря на то, что он расположен в округе Симко, город политически независим. Барри находится в северной части Большой Золотой Подковы, густонаселенного и промышленно развитого региона. Онтарио.
По переписи 2011 года население города первоначально составляло 135 711 человек, что делало его 34-м по величине в Канаде. Население города в 2011 году было впоследствии изменено до 136 063 человек. В столичном районе переписи Барри (CMA) проживало 187 013 жителей, что делает его 21-м по величине CMA в Канаде». [Барри. Википедия]
Пример графической диаграммы «Население Барри» был создан с использованием программного обеспечения для построения диаграмм и векторной графики ConceptDraw PRO, дополненного решением Picture Graphs из области Graphs and Charts в ConceptDraw Solution Park.
Гистограмма изображения
Используемые решения
Графики и диаграммы >
Графики изображений
Что такое инфографика >
Иллюстрированная инфографика
Создатель блок-схем — это программа, показывающая взаимодействие, последовательность или организацию. Он также известен как средство создания блок-схем или стандарт ConceptDraw DIAGRAM, поставляемый с различными типами коллекций символов: стандартные символы, фирменный набор и авторские. Он используется строго для улучшения научных или деловых документов с помощью абстрактных пояснительных картинок.
Деловые графические приложения отображают специальные представления знаний и включают в себя множество функций для создания схематических изображений. Эти графические инструменты известны как программа для создания блок-схем или программа для создания блок-схем.
Этот пример гистограммы с изображением показывает рост населения региона с 2010 по 2016 год. Он был разработан с использованием данных из статьи Википедии Список континентов по численности населения.
[en.wikipedia.org/ wiki/ Список_ континентов_ по_ населению]
«География населения — это раздел географии человека. Это изучение способов, которыми пространственные вариации в распределении, составе, миграции и росте населения связаны с природой мест. География населения включает демографию в географической перспективе. , Он фокусируется на характеристиках распределения населения, которые меняются в пространственном контексте». [География населения. Википедия]
Пример графической диаграммы «Прирост населения региона с 2010 по 2016 год» был создан с использованием программного обеспечения для построения диаграмм и векторной графики ConceptDraw PRO, дополненного решением Picture Graphs из области «Графики и диаграммы» в ConceptDraw Solution Park.
Таблица изображений
Используемые решения
Графики и диаграммы >
Графики изображений
Что такое линейный график? Линейная диаграмма — это базовый тип диаграммы, представленный рядом точек данных, соединенных прямой линией. Объяснение значения фразы «Что такое линейная диаграмма?» удобно использовать иллюстрации с профессионально выглядящими линейными диаграммами, разработанными в программном обеспечении для построения диаграмм и векторного рисования ConceptDraw DIAGRAM, дополненном решением Line Graphs из области Graphs and Charts.
Включение изображений, диаграмм и графиков
9.3 Включение изображений, диаграмм и графиков
Цели обучения
- Знать, как вставлять изображения в основной текст.

- Понимать роль визуальной риторики в споре и других жанрах общения.
- Помните о стандартных рекомендациях по выбору изображений.
Диаграммы и графики уже давно являются частью исследовательских работ. С ростом возможностей компьютеров, которые могут визуально фиксировать мир, исследовательские работы сегодня обычно включают больше диаграмм, графиков и изображений, чем те, которые были созданы в предыдущие годы.
Физическое размещение изображений в тексте
Когда вы вставляете изображение в текст, вы должны принять некоторые физические решения. Один из наиболее распространенных вариантов — разместить изображение справа или слева от текста.
Рисунок 9.6
Другой вариант — переместить текст вниз, чтобы освободить место для изображения на всю страницу. В таких ситуациях изображение обычно помещается над соответствующим текстом. Этот формат обычно используется в начале документа, где обработка изображения не разбивает текст.
Использование и злоупотребление визуальной риторикой
Вам следует выбирать визуальные эффекты для продвижения аргументов, а не только для украшения ваших страниц. Точно так же, как вы не должны включать пустые слова, вы не должны включать бессмысленные изображения.
Кроме того, так же, как вы стремитесь избежать использования ложных сведений в своем тексте, вы также должны быть осторожны, чтобы не использовать ложные визуальные эффекты. (См. главу 4 «Присоединение к беседе», раздел 4.3 «Риторика и аргументация», чтобы узнать больше об ошибках.) Например, если вы приводите доводы за или против утверждения о том, что большие собаки являются хорошими домашними животными для семьи, вы можете показать изображение ротвейлер. Рисунок 9На рис.
Благодаря обычным программам, таким как Photoshop, вы можете легко изменить фотографию, но убедитесь, что делаете это с соблюдением этических норм. Например, скажите, что вы приводите аргумент, что компания «Мозер» несправедливо нанимает только молодых людей и увольняет сотрудников по мере их старения. Вы решаете показать фотографию некоторых сотрудников, чтобы подчеркнуть свою точку зрения. Вы обрезаете исходную фотографию на рисунке 9..7 (Moser Company A) в версию, показанную как Moser Company B. Этот выбор кадрирования был бы примером фальшивой, вводящей в заблуждение фотографии и был бы неэтичным.
Скорее всего, вы видели таблицы или графики, изображающие не совсем точную реальность. Например, два графика на рис. 9.7 можно использовать в качестве доказательства того, что «вдвое больше» учителей старших классов, чем учителей начальных классов, предпочитают использовать компьютерные доски. График А, кажется, хорошо подтверждает это утверждение. Однако, если вы посмотрите на диаграмму B, вы поймете, что вся выборка включает только трех учителей, поэтому «в два раза больше» буквально означает двух из трех — неадекватная выборка, которая не дает ни впечатляющих, ни убедительных данных. Будьте очень осторожны, чтобы не исказить данные с помощью таблиц и графиков, намеренно или случайно.
Взвешивание ваших вариантов визуальных образов
Наглядные материалы, такие как устный или письменный текст, могут вызывать этические, логические и эмоциональные призывы. (См. главу 4 «Вступление в беседу», раздел 4.2 «Распознавание риторической ситуации» для получения дополнительной информации о риторических призывах.) Два примера этических призывов — уважаемый логотип и фотография автора в профессиональной одежде. Графики, диаграммы и таблицы являются примерами логических апелляций. По большей части почти 91 575 всех 91 576 наглядных материалов, поскольку они быстро привлекают внимание читателя, воздействуют на эмоциональный уровень — даже те, которые предназначены для этических и логических призывов.
При выборе визуальных материалов для своей работы рассмотрите следующие варианты:
- Выберите визуальные эффекты, которые ваша аудитория поймет и оценит. Помимо добавления информации, визуальные эффекты могут помочь вам найти общий язык с вашей аудиторией.
- Подумайте о возможных эмоциональных реакциях на ваши визуальные эффекты и решите, хотите ли вы вызвать их.
- Убедитесь, что вы делаете этичный выбор при использовании изображений для этического призыва. Например, недопустимо пользоваться агентством для авторитета, если у вас нет прав доступа, или предполагаемая связь ненастоящая.
- Убедитесь, что вы представляете информацию точно и сбалансированно, используя изображения, такие как диаграммы и таблицы, для создания логической привлекательности.
- Ищите бесплатные изображения или создавайте свои собственные, если вы не готовы платить за изображения.
- Потратьте некоторое время на просмотр возможных изображений в надежде увидеть что-то, что делает утверждение, которое работает с вашим аргументом, если вы не знаете, какое утверждение вы пытаетесь сделать с помощью изображения. (Предостережение: вы можете потратить много времени на поиск наглядных материалов, поэтому не ищите наглядные материалы в ущерб чтению и письму. )
- Убедитесь, что вы выбираете изображения, соответствующие этическим стандартам вашей работы, потому что изображения могут быстро повлиять на читателей. Если ваш текст строго этичен, но ваши изображения вызывают раздражение, вы можете поставить под угрозу этику всей своей работы.
- Подписи должны быть краткими, если они вам нужны. Некоторые изображения несут смысл без каких-либо объяснений. Если вы не можете сделать заголовок кратким, вам, вероятно, нужен другой визуальный элемент или лучший контекст для визуального элемента в тексте вашего эссе.
Ключевые выводы
- При вставке изображений вы можете обтекать текст, чтобы получить прямоугольное пустое пространство, плотно прилегающее пустое пространство или пустое пространство шириной с бумагу.
- Визуальные элементы коммуникации являются особенно мощными риторическими инструментами, которыми легко злоупотреблять, но их также можно использовать ответственно и эффективно.
- Коммерческие (или политические) сообщения, представленные визуально, могут легко ввести в заблуждение потребителей (или избирателей), но гораздо труднее воспользоваться преимуществами того, кто знает, как работает визуальная риторика.
Упражнения
- Создайте одну страницу текста. Вставьте изображение справа от текста, одно слева и одно по ширине страницы.
- Соберите десять веб-сайтов и рекламных объявлений. Изучите каждый для использования визуальной риторики. Выявите любые случаи неэтичного использования визуальной привлекательности на веб-сайтах и в рекламе.
Напишите запись в журнале или блоге или короткое эссе, отвечающее на некоторые или все следующие вопросы:
- Как вы представляете себя другим в социальных сетях, таких как Facebook?
- Какую фотографию для профиля вы выбрали и как вы ее выбрали?
- Как часто вы меняете изображение профиля и почему?
- Как ваши друзья представляют себя миру через такие сайты?
- Каковы основные типы (или жанры) изображений профиля в социальных сетях?
- Какие сообщения пытается передать каждый жанр?
Типы графиков и диаграмм и их использование: с примерами и изображениями
Если вам интересно, каковы различные типы графиков и диаграмм , их использование и названия, на этой странице они приведены с примерами и изображениями.
Поскольку различные виды графиков предназначены для представления данных, они используются во многих областях, таких как: статистика, наука о данных, математика, экономика, бизнес и т. д.
Каждый тип графика представляет собой визуальное представление данных на диаграммах (например, гистограмма, круговая диаграмма, линейная диаграмма), которые показывают различные типы тенденций графика и отношения между переменными.
Хотя трудно сказать, что это за все типы графиков, эта страница содержит все распространенные типы статистических графиков и диаграмм (и их значения), широко используемые в любой науке.
1. Линейные графики
Линейная диаграмма графически отображает данные, которые непрерывно изменяются во времени. Каждый линейный график состоит из точек, которые соединяют данные, чтобы показать тенденцию (непрерывное изменение). Линейные графики имеют ось X и ось Y. В большинстве случаев время распределяется по горизонтальной оси.
Использование линейных графиков:
- Когда вы хотите показать тренды . Например, как цены на жилье выросли с течением времени.
- Если вы хотите, чтобы делал прогнозы на основе истории данных с течением времени.
- При сравнении двух или более различных переменных, ситуаций и информации за определенный период времени.
Пример:
На следующем линейном графике показаны годовые продажи конкретной коммерческой компании за шесть лет подряд:
Примечание: приведенный выше пример имеет 1 строку. Однако на одном линейном графике можно сравнивать несколько трендов по нескольким линиям распределения.
2. Гистограммы
Гистограммы представляют категориальные данные с помощью прямоугольных столбцов (чтобы понять, что такое категориальные данные, см. примеры категориальных данных). Гистограммы являются одними из самых популярных типов графиков и диаграмм в экономике, статистике, маркетинге и визуализации в цифровом клиентском опыте. Они обычно используются для сравнения нескольких категорий данных.
Длина и высота каждой прямоугольной полосы пропорциональны значениям, которые они представляют.
На одной оси гистограммы представлены сравниваемые категории. Другая ось показывает измеренное значение.
Гистограммы Использование:
- Когда вы хотите отобразить данные, сгруппированные по номинальным или порядковым категориям (см. номинальные и порядковые данные).
- Для сравнения данных по разным категориям.
- Гистограммы также могут отображать большой изменение данных с течением времени.
- Гистограммы идеально подходят для визуализации распределения данных при наличии более трех категорий.
Пример:
На приведенной ниже гистограмме представлена общая сумма продаж продукта А и продукта Б за три года.
Стержни бывают 2-х типов: вертикальные или горизонтальные. Неважно, какой вид вы будете использовать. Вышеупомянутый является вертикальным типом.
3. Круговые диаграммы
Когда дело доходит до статистических типов графиков и диаграмм, круговая диаграмма (или круговая диаграмма) имеет решающее значение и значение. Он отображает данные и статистику в простом для понимания формате «срезов пирога» и иллюстрирует числовую пропорцию.
Размер каждой части круговой диаграммы зависит от размера конкретной категории в данной группе в целом. Другими словами, круговая диаграмма разбивает группу на более мелкие части. Он показывает отношения часть-целое.
Чтобы построить круговую диаграмму, вам нужен список категориальных переменных и числовых переменных.
Круговая диаграмма Использование:
- Когда вы хотите создать и представить композицию чего-либо.
- Это очень полезно для отображения номинальных или порядковых категорий данных.
- Для показать проценты или пропорциональные данные.
- Когда сравнения областей роста в рамках бизнеса, таких как прибыль.
- Круговые диаграммы лучше всего подходят для отображения данных для 3–7 категорий.
Пример:
На приведенной ниже круговой диаграмме представлена пропорция видов транспорта, используемых 1000 учащимися для поездки в школу.
Круговые диаграммы широко используются маркетологами, работающими с данными, для отображения маркетинговых данных.
4. Гистограмма
Гистограмма показывает непрерывные данные в упорядоченных прямоугольных столбцах (чтобы понять, что такое непрерывные данные, см. нашу публикацию о дискретных и непрерывных данных). Обычно между столбцами нет пробелов .
На гистограмме отображается частотное распределение (форма) набора данных. На первый взгляд гистограммы похожи на гистограммы. Однако между ними есть ключевое различие. Гистограмма представляет собой категориальные данные, а гистограмма представляет непрерывные данные.
Гистограмма Использование:
- Когда данные непрерывны .
- Если вы хотите представить форму распределения данных .
- Если вы хотите увидеть, отличаются ли выходные данные двух или более процессов.
- Чтобы суммировать больших наборов данных графически.
- Для быстрой передачи данных другим.
Пример:
На приведенной ниже гистограмме представлен доход на душу населения для пяти возрастных групп.
Гистограммы очень широко используются в статистике, бизнесе и экономике.
5. Точечная диаграмма
Точечная диаграмма представляет собой диаграмму X-Y, которая показывает взаимосвязь между двумя переменными. Он используется для построения точек данных по вертикальной и горизонтальной осям. Цель состоит в том, чтобы показать, насколько одна переменная влияет на другую.
Обычно при наличии связи между двумя переменными первая называется независимой. Вторая переменная называется зависимой, потому что ее значения зависят от первой переменной.
Диаграммы рассеяния также помогают прогнозировать поведение одной переменной (зависимой) на основе измерения другой переменной (независимой).
Точечная диаграмма использует:
- При попытке выяснить, существует ли связь между двумя переменными .
- Предсказать поведение зависимой переменной на основе меры независимой переменной.
- При наличии парных числовых данных.
- При работе с инструментами анализа первопричин для выявления потенциальных проблем.
- Когда вы просто хотите визуализировать корреляцию между двумя большими наборами данных без учета времени .
Пример:
На приведенном ниже точечном графике представлены данные по 7 интернет-магазинам, их ежемесячным продажам электронной коммерции и затратам на интернет-рекламу за последний год.
Оранжевая линия, которую вы видите на графике, называется «линия наилучшего соответствия» или «линия тренда». Эта линия используется, чтобы помочь нам делать прогнозы, основанные на прошлых данных.
Точечные диаграммы широко используются в науке о данных и статистике. Они являются отличным инструментом для визуализации моделей линейной регрессии.
Дополнительные примеры и объяснения для точечных диаграмм вы можете увидеть в нашем посте, что показывает точечная диаграмма, и простые примеры линейной регрессии.
6. Диаграмма Венна
Диаграмма Венна (также называемая основной диаграммой, диаграммой множества или логической диаграммой) использует перекрывающиеся круги для визуализации логических отношений между двумя или более группами элементов.
Диаграмма Венна — это один из типов графиков и диаграмм, используемых в научных и инженерных презентациях, в компьютерных приложениях, в математике и статистике.
Базовая структура диаграммы Венна обычно представляет собой перекрывающиеся круги. Элементы в перекрывающемся разделе имеют определенные общие характеристики. Предметы во внешних частях кругов не имеют общих черт.
Диаграмма Венна Использование:
- Когда вы хотите, чтобы сравнил и сопоставил групп вещей.
- Для классификации или группировки предметов.
- Чтобы проиллюстрировать логических отношений из различных наборов данных.
- Чтобы определить все возможные отношения между коллекциями наборов данных.
Пример:
В следующем научном примере диаграммы Венна сравниваются особенности птиц и летучих мышей.
7. Диаграммы с областями
Диаграммы с областями показывают изменение одной или нескольких величин с течением времени. Они очень похожи на линейный график. Однако область между осью и линией обычно заполняется цветом.
Несмотря на то, что линейные диаграммы и диаграммы с областями поддерживают один и тот же тип анализа, их не всегда можно использовать взаимозаменяемо. Линейные диаграммы часто используются для представления нескольких наборов данных. Диаграммы с областями не могут четко отображать несколько наборов данных, поскольку диаграммы с областями показывают заштрихованную область под линией.
Диаграмма с областями Использование:
- Если вы хотите, чтобы отображал тренды , а не выражал конкретные значения.
- Чтобы показать простое сравнение тенденции наборов данных за период времени.
- Для отображения величины изменения.
- Для сравнения небольшого количества категорий.
Диаграмма с областями имеет 2 варианта: вариант с наложением графиков данных друг на друга и вариант с графиками данных, наложенными друг на друга (известный как диаграмма с областями с накоплением — как показано в следующем примере).
Пример:
На приведенной ниже диаграмме с областями показаны квартальные продажи продуктов категорий A и B за последний год.
На этой диаграмме с областями показано быстрое сравнение динамики квартальных продаж продукта А и продукта В за период прошлого года.
8. Сплайн-диаграмма
Сплайн-диаграмма — один из наиболее распространенных типов графиков и диаграмм, используемых в статистике. Это форма линейной диаграммы, которая представляет плавные кривые через различные точки данных.
Сплайн-диаграммы обладают всеми характеристиками линейных диаграмм, за исключением того, что сплайн-диаграммы имеют подогнанную изогнутую линию для соединения точек данных. Для сравнения, линейные диаграммы соединяют точки данных прямыми линиями.
Сплайн-диаграмма Используется:
- Когда вы хотите отобразить данные, требующие использования аппроксимации кривой, например , диаграмму жизненного цикла продукта или диаграмму импульсной реакции.
- Сплайн-диаграммы часто используются при разработке диаграмм Парето .
- Сплайн-диаграмма также часто используется для моделирования данных при ограниченном количестве точек данных и оценке промежуточных значений.
Пример:
В следующем примере сплайн-диаграммы показаны продажи компании за несколько месяцев года:
числовых данных через их квартили. Он отображает частотное распределение данных.
Диаграмма с ячейками и усами помогает отображать разброс и асимметрию для заданного набора данных, используя принцип сводки из пяти чисел: минимум, максимум, медиана, нижняя и верхняя квартили. Принцип «сводки по пяти числам» позволяет предоставить статистическую сводку для определенного набора чисел. Он показывает диапазон (минимальное и максимальное число), разброс (верхний и нижний квартили) и центр (медиану) для набора чисел данных.
Очень простое изображение графика с прямоугольниками и усами, которое вы можете увидеть ниже:
Диаграмма с прямоугольниками и усами Использование:
- Когда вы хотите, чтобы наблюдал верхние и нижние квартили, среднее значение, медиану, отклонения и т. д. , для большого набора данных.
- Если вы хотите быстро просмотреть распределение набора данных .
- Когда у вас есть несколько наборов данных , которые поступают из независимых источников и каким-то образом связаны друг с другом.
- Когда вам нужно для сравнения данных из разных категорий.
Пример:
В приведенной ниже таблице и диаграммах в виде прямоугольников и усов показаны результаты тестов по математике и литературе для одного и того же класса.
| Maths | 35 | 77 | 92 | 43 | 55 | 66 | 73 | 70 |
| Literature | 35 | 43 | 40 | 43 | 50 | 60 | 70 | 92 |
Во многих областях, таких как статистический анализ данных, анализ результатов, маркетинговый анализ и диаграммы и т. д.
10. Пузырьковая диаграмма
Пузырьковая диаграмма — очень полезный тип графиков для сравнения взаимосвязей между данными в трех измерениях числовых данных: данные по оси Y, данные по оси X, и данные, отражающие размер пузырьков.
Пузырьковая диаграмма очень похожа на точечную диаграмму по осям XY, но пузырьковая диаграмма обладает большей функциональностью — третье измерение данных, которое может быть чрезвычайно ценным.
Обе оси (X и Y) пузырьковой диаграммы являются числовыми.
Пузырьковая диаграмма Использование:
- Когда вам нужно отобразить три или четыре измерения данных.
- Если вы хотите сравнить и отобразить отношения между категоризированными кругами, используя пропорции.
Пример:
На приведенной ниже пузырьковой диаграмме показано соотношение между стоимостью (ось X), прибылью (ось Y) и вероятностью успеха (%) (размер кружка).
11. Пиктограммы
Пиктограмма или пиктограмма — это один из наиболее визуально привлекательных типов графиков и диаграмм, которые отображают числовую информацию с использованием значков или графических символов для представления наборов данных.
Очень удобный для чтения статистический способ визуализации данных. Пиктограмма показывает частоту данных в виде изображений или символов. Каждое изображение/символ может представлять одну или несколько единиц данного набора данных.
Пиктограмма Использование:
- Когда ваша аудитория предпочитает и лучше понимает дисплеи со значками и иллюстрациями. Веселье может способствовать обучению.
- Для инфографики привычно использование пиктограммы.
- Когда вы хотите, чтобы сравнил две точки сильным эмоциональным образом.
Пример:
Следующая пиктограмма представляет количество компьютеров, проданных коммерческой компанией за период с января по март.
Пиктографический пример выше показывает, что в январе было продано 20 компьютеров (4×5 = 20), в феврале было продано 30 компьютеров (6×5 = 30), а в марте было продано 15 компьютеров.
12. Точечный график
Точечный график или точечный график — это лишь один из многих типов графиков и диаграмм для организации статистических данных. Он использует точки для представления данных. Точечный график используется для относительно небольших наборов данных, а значения попадают в ряд дискретных категорий.
Если значение появляется более одного раза, точки располагаются одна над другой. Таким образом, высота столбца точек показывает частоту этого значения.
Точечный график Использование:
- Для построения графика подсчета частоты, когда у вас есть небольшое количество категорий .
- Точечные диаграммы очень полезны, когда переменная является количественной или категориальной .
- Точечные графики также используются для одномерных данных (данные только с одной переменной, которую можно измерить).
Пример:
Предположим, у вас есть класс из 26 учеников. Их просят назвать свой любимый цвет. Точечный график ниже представляет их выбор:
Очевидно, что ученики этого класса предпочитают синий цвет.
13. Радарная диаграмма
Радарная диаграмма — один из самых современных типов графиков и диаграмм — идеально подходит для множественных сравнений. Радарные диаграммы используют круговой дисплей с несколькими различными количественными осями, похожими на спицы на колесе. Каждая ось показывает количество для различных категориальных значений.
Радиолокационные карты также известны как паутинные карты, паутинные карты, звездные графики, неправильные многоугольники, полярные карты, паутинные карты или диаграмма Кивиата.
Радарная диаграмма в настоящее время имеет множество применений в статистике, математике, бизнесе, спортивном анализе, анализе данных и т. д.
Радарная диаграмма Используется:
- каждой переменной.
- Для представления множественных сравнений .
- Когда вы хотите увидеть, какие переменные имеют низкие или высокие оценки в наборе данных. Это делает радарную диаграмму идеальной для , отображающей производительность .
Пример:
Например, мы можем сравнить эффективность работы сотрудника по шкале от 1 до 8 по таким предметам, как пунктуальность, решение проблем, соблюдение сроков, маркетинговые знания, коммуникации. Точка, расположенная ближе к центру оси, показывает более низкое значение и худшую производительность.
| Label | Punctuality | Problem-solving | Meeting Deadlines | Marketing Knowledge | Communications |
| Jane | 6 | 5 | 8 | 7 | 8 |
| Саманта | 7 | 5 | 5 | 4 | 8 |
Производительность явно лучше, чем у Джейнтаман.
14. Пирамидальная диаграмма
Когда дело доходит до понятных и красивых типов графиков и диаграмм, пирамидальная диаграмма занимает первое место.
Пирамидальная диаграмма представляет собой диаграмму в форме пирамиды или треугольника. Эти типы диаграмм лучше всего подходят для данных, организованных в какой-либо иерархии. Уровни показывают прогрессивный порядок.
Пирамидальная диаграмма Использование:
- Когда вы хотите, чтобы указывал уровень иерархии среди тем или других типов данных.
- Пирамидальный график часто используется для представления прогрессивных порядков, таких как: «от более старых к более новым», «от более важных к менее важным», «конкретные к менее специфичным» и т. д.
- Когда у вас есть пропорциональные или взаимосвязанные отношения между данными наборы.
Пример:
Классическим примером диаграммы пирамиды является пирамида здорового питания, которая показывает, что жиры, масла и сахар (вверху) следует есть меньше, чем многие другие продукты, такие как овощи и фрукты (внизу пирамиды). ).
Заключение:
Вы, наверное, знаете, что выбор правильного типа диаграммы — дело непростое.
На практике выбор зависит от двух основных факторов: от типа анализа, который вы хотите выполнить, и от типа имеющихся у вас данных.
Обычно, когда мы стремимся облегчить сравнение, мы используем гистограмму или лепестковую диаграмму. Когда мы хотим показать тенденции во времени, мы используем линейную диаграмму или диаграмму с областями и т. д.
В любом случае, у вас есть широкий выбор типов графиков и диаграмм. При правильном использовании они являются мощным оружием, которое поможет вам сделать ваши отчеты и презентации профессиональными и четкими.
Какие ваши любимые типы графиков и диаграмм? Поделитесь своими мыслями в поле ниже.
Изображения графиков, фото и фотографии
- ТВОРЧЕСКИЕ
- РЕДАКЦИОННЫЕ
- ВИДЕО
- Лучшее Übereinstimmung 0 92
- 16 Ältestes
- Am beliebtesten
Alle Zeiträume24 Stunden48 Stunden72 Stunden7 Tage30 Tage12 MonateAngepasster Zeitraum
- Lizenzfrei
- Lizenzpflichtig
- RF und RM
Lizenzfreie Kollektionen auswählen >Editorial-Kollektionen auswählen >
Bilder zum Einbetten
Durchstöbern Есть 122,637
изображений графиков Стоковая фотография и фотографии.