Файл robots.txt: полное руководство | CRYSTAL
Оглавление
- Зачем нужен этот файл?
- Тонкости
- Требования к robots.txt
- Как создать?
- Автогенерация
- Как проверить?
- Структура robots.txt
- Основные директивы
- Sitemap
- User-agent
- Disallow и Allow
- Clean-param
- Crawl-delay
- Host
- Рекомендации
- Вывод
Сеть набита информацией. Каждый в ней ищет что-то свое. Разработчиков волнует, насколько качественно проделана их работа. Пользователи хотят решить бытовые проблемы. А поисковые машины наблюдают и за первыми, и за вторыми. И тоже копят информацию.
Как они это делают? По сети ползают пауки. Они заглядывают всюду. Цель паука — проникнуть как можно дальше и понять как можно больше.
Информация от пауков, по-другому роботов, важна для поисковых систем. Она помимо прочего влияет и на ранжирование ресурсов в выдаче.
Движения пауков случайны. Это вызывает проблемы, так как они могут залезть туда, куда не следует.
Файл robots.txt прекратит лишние поползновения. Настройте его сразу. Тогда в индекс ваш сайт попадёт быстро, а сервер будет работать без перегруза.
При запуске сайта с нуля нужно сделать массу вещей. Но отладка этого инструмента сэкономит вам в будущем силы и время.
Зачем нужен этот файл?
Показать роботу, что нельзя, а что можно сканировать. Именно сканировать. Не про индексацию речь. Это разные понятия.
Файл запрещает переход робота на страницу. Но это не единственная дверь, туда ведущая. Есть и другие. Внутренние и внешние ссылки, например.
Исключить страницу из поиска этот файл может, но не всегда. Зато он не заменим, когда нужно снизить нагрузку на сервер или перераспределить ресурс роботов.
Закрывайте от сканирования:
- Административные папки
- Системные файлы сервера
- Динамические параметры адресов (не для Google)
- Медиафайлы, которые вы не хотите видеть в поиске
Не стоит заносить в файл:
- Работающие страницы сайта
- Скрипты со структурой и правилами оформления страниц (Java scripts и прочее)
- Медиафайлы, которые должны быть в выдаче
Вы можете командовать тем, какие пауки и что именно могут делать.
Тонкости
Для Google это просто рекомендация. Логика использования — чем больше ограничений для пауков на сайте, тем меньше его загруженность.
Можно скрыть медиафайлы — чтобы в поиске не показывались картинки с вашего сайта или видео. Для этого пропишите запрет регулярными выражениями в файле.
Если нужно спрятать так, чтобы гарантированно не вылезло в поиске, действуйте иначе (мета-тег robots noindex или установка пароля).
С Яндексом ситуация другая. Он разрешает бороться с дублями с помощью файла. Просто запрещать сканирование или использовать Clean-param для меток.
По умолчанию пауки смотрят всё. Часть из них может даже игнорировать указания.
Требования к robots.txt
- Важны правильное название файла и формат. Нельзя добавлять лишние символы, менять регистр.
- Он должен лежать в корневом каталоге и только на главном зеркале.
 Для других субдоменов, портов и протоколов его указания не будут работать.
Для других субдоменов, портов и протоколов его указания не будут работать. - Никакого русского языка в адресах внутри файла. Преобразуйте их через Punycode в допустимые — каноничные символы ASCII. Кодировка — UTF-8.
- Файл должен выдавать
Как создать?
- Напишите простой текстовый документ с директивами вручную и сохраните как .txt. В тексте не должно быть никаких служебных пометок или знаков разметки, расставленных офисными программами.
- Проверьте, что документ составлен корректно.
- Загрузите в корневой каталог.
- Убедитесь, что он доступен по ссылке: <ваш домен>/robots.txt
Автогенерация
Системы Управления Содержимым могут стать альтернативой ручному методу. Они предлагают выбрать параметры на странице с графическим интерфейсом, потом сами преобразуют их в директивы кода файла.
Есть специализированные программы. Делают они практически то же самое. Пример — PR-CY. Скопируйте получившийся текст или скачайте файл. Далее следуйте пунктам 2-4 из инструкции выше.
Как проверить?
В кабинетах Вебмастеров укажите адрес файла. После этого можно использовать их инструменты анализа.
Вебмастер Google:
- Выделит ошибки синтаксиса и логики.
- Проведёт симуляцию. Для этого выберете страницу и паука (из числа принадлежащих Google) и посмотрите, открыт ли доступ.
- Не сможет проверить субдомены и протоколы кроме тех, по которым расположен файл.
- Даст вам править текст в редакторе, но полученный результат надо будет скопировать в файл вручную.
Яндексовский проверяет только синтаксис и логику. Выведет список директив, на которые отреагирует его бот. Тут же можно задать адреса для проверки.
Этот инструмент чуть проще по функционалу, но для его использования не обязательна авторизация.
Альтернативой вебмастерам будут программы для проверки кода файла или краулеры для симуляции поведения роботов. Их легко найти в поиске.
Структура robots.txt
Директивы пишутся с новой строки. Вид такой: <directive>: <parameter>. Между группами логически связанных команд оставляют пустые строки.
Регистр не важен для <directive>, но важен для <parameter>.
В плохо организованном файле легко запутаться. Можно комментировать код — пользуйтесь этой возможностью. Всё после “#” прочтут только люди. Но помните, что файл общедоступен — любой может его открыть, зная адрес корневого каталога.
Не допускайте противоречий. Исполнена будет команда с более длинным <parameter>.
Пробелы игнорируются роботом. Но они удобны человеку, читающему файл. Вы его не один раз и навсегда делаете. Могут потребоваться правки и не факт, что их будете делать именно вы. Пишите понятно.
Пишите понятно.
Основные директивы
Директив, допускаемых файлом, не так много. Мы обсудим каждую отдельно ниже. Пока поговорим про параметр.
Параметры включают в себя указание адресов, без доменного имени (исключением будет только Sitemap).
<directive>: /pagename
По умолчанию, в конце адреса параметра может быть добавлено сколько угодно символов. На <directive>: /jewellery будет отзываться и your-address.com/jewellery и your-address.com/jewellery3f47 .
<parameter> задают регулярными выражениями. Есть два специальных символа для этого.
Знак “$” — указывает на конец адреса. На <directive>: /accessory$ будет отзываться только your-address.com/accessory .
Знак “ * ” — заменяет сколько угодно символов. На конце его ставить бессмысленно, но можно упомянуть в середине или в начале адреса параметра.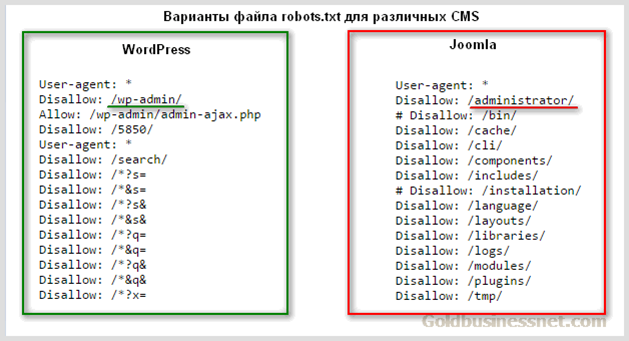 <directive>: *pdf — относится ко всем адресам с _pdf_ в любом месте адреса. Обратите внимание, что для вызова именно файлов формата .pdf лучше написать так: <directive>: *.pdf$
<directive>: *pdf — относится ко всем адресам с _pdf_ в любом месте адреса. Обратите внимание, что для вызова именно файлов формата .pdf лучше написать так: <directive>: *.pdf$
Sitemap
Директива отличается от последующих: она не привязана к группе и исполнителю, требует указания полного адреса.
Цель — показать, где лежит карта сайта. Этот документ не дает паукам потеряться и подсказывает, куда ещё можно заглянуть.
Sitemap: your-address.com/some/mysitemap.xml
Если вы ещё не создали карту, сделайте это. Не забудьте проверить, что файл с ней лежит на том же домене, что и robots.txt. Иначе, обратиться к карте паук не сможет.
User-agent
Есть в начале всех групп команд. Показывает — кто исполнитель. Прежде чем прибегать к ней, проанализируйте списки пауков целевых поисковиков. Выберите значимые.
Ею можно:
- Скомандовать любым готовым слушать: <parameter> = “ * ”
- Дать общее указание (через “ * ” ) и кому-нибудь — другое.

- Указать несколько исполнителей.
Для наглядности:
User-agent: *
<directive 1>: /mailboxUser-agent: SEbot1
User-agent: SEbot2
<directive 2>: /system-files
<directive 3>: /useless-mail
Все, кроме SEbot1 и SEbot2 выполняют предписание 1, SEbot1 и SEbot2 делают 2 и 3.
То есть, если мы специфицируем хоть один параметр для бота, то “для всех” на него больше не распространяется.
Disallow и Allow
Управляют перемещениями пауков. Они закрывают и открывают двери. Так можно контролировать сканирование. Ниже показано, как они применяются.
User-agent: * #
Кто готов слушаться:
Disallow: / # Вход закрыт полностью
Allow: /fireworks/*png$ # Смотреть можно только картинки из папки “фейерверки”.
User-agent: SEbot1 # Отдельно для SEbot1:
Disallow: /fireworks # Сначала сказали, что можно всё кроме “фейерверков”.
Allow: /fireworks # Теперь можно и “фейерверки” тоже.
Если параметры одинаково длинные, но приказ Allow сильнее.
Без инструкций роботы сканируют всё. Поэтому группа Яндекса в примере бессмысленна: противоречивая команда приводит к тому, что ограничений для этой ПС нет. Логичнее было бы прописать
Clean-param
Работает с метками в адресах. Они добавляются после “?” к URL и нужны для отслеживания отдельных посетителей, задания страниц каталога и тп. Эти метки — источник дублей на сайте.
Директива их скрывает и перенаправляет вес на страницу без метки. Такой способ сокрытия зеркал признаёт только Яндекс.
Метка добавляется после адреса и “?”. Состоит из “pattern1=value1&pattern1= value2…” — паттернов и их значений. Пропишите название паттерна (или нескольких). Опционально добавьте регулярное выражение для URL, по которому нужно искать.
Состоит из “pattern1=value1&pattern1= value2…” — паттернов и их значений. Пропишите название паттерна (или нескольких). Опционально добавьте регулярное выражение для URL, по которому нужно искать.
Clean-param: pattern1&pattern2&..&patternN /directory #длина строки не больше 500 знаков.
Если вы прописываете отдельную группу для Яндекса, добавьте эту директиву туда.
Crawl-delay
Когда пауки ползают по страницам, они нагружают сервер. Заставить их заходить пореже может эта директива. Сайт будет работать быстрее.
Неприменимо для Яндекс и Google. Они имеют встроенные инструменты для такого, а указания в файле игнорируют. Остальные поисковики правила соблюдают.
Crawl-delay: 3 #Между двумя актами сканирования мы задаем задержку 3 секунды.
Не тормозите пауков слишком сильно — это повредит вам в первую очередь. Очень долго придётся ждать индексации. Прикиньте краулинговый бюджет и объем работы, прежде чем выбирать время задержки.
Прикиньте краулинговый бюджет и объем работы, прежде чем выбирать время задержки.
Host
Устарела. Больше не принимается роботами. Прописывать её нет необходимости.
Когда-то директива указывала на каноническое зеркало сайта и использовалась для борьбы с дублями. Сейчас лучше делать перенаправления.
Рекомендации
Пауки реагируют не на все команды. Google работает с запретом/разрешением сканирования, картой сайта и указанием исполнителя. Яндекс обрабатывает помимо их еще и запрет на индексирование меток.
Сначала дайте предписание “по умолчанию” для всех роботов.
Потом пропишите группы для каждого отдельно интересующего вас. Пауки имеют иерархию. Это упростит обращение к ним.
Большинство роботов Google отзываются на “googlebot”. Но если работающий с картинками Googlebot-Image получит отдельные предписания, то общие для своего семейства он будет игнорировать.
Не упоминайте одного и того же исполнителя в двух разных группах. Соберите вместе все директивы одному исполнителю. Это уменьшит объем файла, поможет избежать противоречивых директив.
Соберите вместе все директивы одному исполнителю. Это уменьшит объем файла, поможет избежать противоречивых директив.
Вывод
Сделайте короткими и простым файл robots.txt. Избавьтесь от лишних бессмысленных команд, они могут нарушить выполнение всех остальных. Проверяйте: свой код, предпочтения пауков, изменения в метриках.
Хотите сделать сайт для своего проекта?
Обратитесь к намкак создать, настройка, закрыть, индексация, правильный robots для Яндекса и Google, пример файла
Зачем сайту файл robots.txt и как его создать
Запускаете сайт? Поздравляем! Прежде чем устремиться к вершинам топа Яндекс или Google, проверьте, не забыта ли одна маленькая, но значительная деталь — файл robots.txt
Robots.txt — текстовый файл в главной директории веб-ресурса, который инструктирует роботов-поисковиков. В первую очередь, содержание файла подсказывает, какие страницы нужно индексировать, а какие — не стоит.
Наличие файла robots.txt на сайте — непременное условие: он полезен для продвижения, кроме того, без него невозможно добиться высоких позиций в выдаче Яндекс, Google и других поисковых систем.
Зачем нужен файл robots.txt
Перед тем, как начать индексировать сайт, дружелюбный робот-поисковик сразу обратит внимание на robots.txt — прочитает инструкции и лишь затем приступит к работе. От того, как составлен файл, напрямую зависит успех или неудача кампании по продвижению, а также сохранность приватных данных на сайте.
Если robots.txt заполнен верно, ресурс получи:
- быструю и правильную индексацию страниц
Без файла robots.txt или при неверном его составлении поисковая машина может добавить в результаты выдачи нерелевантные страницы — например, экран авторизации и регистрации. Такой “мусор” будет конкурировать с целевыми страницами, и в поисковой выдаче окажется совсем не то, что хотелось бы видеть.
К тому же, это негативно повлияет на поведенческие факторы, а значит, сайт “просядет” в выдаче.
- защиту приватной информации и личных данных
Чтобы администраторская панель сайта, а также личные данные и пароли, не оказались доступны всем пользователям интернета — закройте приватные страницы от индексации в файле robots.txt.
Как создать и настроить файл robots.txt
Создать файл robots.txt нетрудно, настроить — немного сложнее, однако это тоже можно сделать без специальных знаний.
Создание
Откройте текстовый редактор — стандартный Блокнот или, например, более продвинутый editor для программистов — Notepad++. Создайте файл в формате .txt, дайте ему имя “robots” и приступайте к заполнению.
Ещё один способ — создать robots.txt онлайн. Генератор предложит заполнить поля, сам пропишет синтаксис и позволит скачать уже готовый robots.txt. В сети множество инструментов для создания такого типа файлов. К примеру, сервис Seolib.
Интерфейс генератора robots.txt
Редактирование
Если файл создан вручную, текст внутри придётся написать самостоятельно. Если скачан из онлайн-генератора — внимательно проверить и отредактировать содержимое.
Если скачан из онлайн-генератора — внимательно проверить и отредактировать содержимое.
Пример блока в файле robots.txt
User-agent — поисковый робот, которому даётся инструкция: например, Googlebot, Yandexbot или * (все роботы).
Allow — разрешающая директива, Disallow — запрещающая.
Host и Sitemap — также обязательные директивы для robots.txt. Первая подсказывает, какое из зеркал сайта следует индексировать, вторая — объясняет, “как пройти” к карте сайта.
В примере мы закрыли роботам доступ к панели администратора, разрешили индексировать содержимое страницы content, правда, исключая файл picture.png. Кроме того, указали основное зеркало сайта и путь к карте сайта.
Заполняя файл robots.txt, стремитесь к краткости — не путайте машину слишком подробными указаниями. Старайтесь сделать инструкцию смысловой и конкретной.
Следите за размером файла robots.txt — у бота Google, к примеру, есть ограничение для него в 500 кб.
Загрузка на сайт
Поместите файл robots.txt в корневую директорию сайта. Он должен отображаться по адресу: имя-сайта.ru/robots.txt. Если файл окажется в другом месте, поисковый робот не станет его искать и просто проигнорирует.
Чтобы загрузить файл robots.txt на сайт, как правило, требуется доступ к протоколу FTP. У популярных CMS также есть функция редактирования файла на панели администратора: по умолчанию или после установки специального модуля.
Проверяем robots.txt
Узнать, на месте ли файл robots.txt, проще простого — перейдите по адресу его расположения: имя-сайта.ru/robots.txt.
Хотите проверить синтаксис и структуру файла? На помощь придут специальные сервисы поисковых систем для вебмастеров: Яндекс.Вебмастер и Search Console Google.
Анализ robots.txt в Яндекс.Вебмастер
Robots.txt — необходимый “винтик” в механизме веб-ресурса. Возможно, не потребуется он только сайтам-одностраничникам, которые почти не участвуют в seo. Но подстраховаться всё равно можно, тем более что создание файла для сайта с простейшей структурой займёт всего несколько минут.
Но подстраховаться всё равно можно, тем более что создание файла для сайта с простейшей структурой займёт всего несколько минут.
Подписывайтесь на наш канал в Яндекс.Дзен!
Нажмите «Подписаться на канал», чтобы читать DigitalNews в ленте «Яндекса» .
Есть вопрос по теме «
«?
Аэрофлот vs кот Виктор: epic fail или иначе не могло быть?Подводя итоги года, мы решили написать про самое яркое событие в мире соцсетей: конфликте «Аэрофлота…
Просмотров: 17,376
Бесплатные инструменты от Click.ruВ 2019 году еще есть люди, которые платят за связь и ЖКУ с комиссией, покупают товары и услуги тольк…
Просмотров: 28,747
Скликивание бюджета в Яндекс.ДиректДаже среди опытных пользователей Директа нет единого мнения о том, можно ли свернуть рекламную кампа…
Просмотров: 11,817
Яндекс для бизнеса: подключение диалоговЯндекс.
 Диалоги — новый сервис для разработчиков сайтов, при помощи которого можно наладить общение с…
Диалоги — новый сервис для разработчиков сайтов, при помощи которого можно наладить общение с…Просмотров: 12,131
Как создать файл robots.txt
В ЭТОЙ СТАТЬЕ:
Объяснение SEO людям может быть трудным, потому что есть много маленьких шагов, которые могут показаться не очень важными на первый взгляд, но они в сумме приносят большие выгоды в поисковые рейтинги, когда все сделано правильно.
Один из важных шагов, который легко упустить из виду, — дать роботам поисковых систем знать, какие страницы индексировать, а какие нет. Это можно сделать с помощью файла robots.txt.
В сегодняшней статье я собираюсь объяснить, как именно создать файл robots.txt, чтобы вы могли привести в порядок эту фундаментальную часть своего сайта и убедиться, что поисковые роботы взаимодействуют с вашим сайтом так, как вы хотите.
Что такое файл robots.txt?
Файл robots.txt представляет собой простую директиву, сообщающую поисковым роботам, какие страницы вашего сайта следует сканировать и индексировать.
Это часть протокола исключения роботов (REP), семейства стандартных процедур, которые определяют, как роботы поисковых систем сканируют Интернет, оценивают и индексируют контент сайта, а затем предоставляют этот контент пользователям. В этом файле указывается, где сканерам разрешено сканировать, а где нет. Он также может содержать информацию, которая может помочь поисковым роботам более эффективно сканировать веб-сайт.
REP также включает «мета-теги роботов», которые представляют собой директивы, включенные в HTML-код страницы и содержащие конкретные инструкции о том, как поисковые роботы должны сканировать и индексировать определенные веб-страницы, а также изображения или файлы, которые они содержат.
В чем разница между Robots.txt и тегом Meta Robots?
Как я уже упоминал, протокол исключения роботов также включает «мета-теги роботов», которые представляют собой фрагменты кода, включенные в HTML-код страницы. Они отличаются от файлов robots. txt тем, что указывают направление поисковым роботам на определенные веб-страницы , запрещающие доступ либо ко всей странице, либо к определенным файлам, содержащимся на странице, таким как фотографии и видео.
txt тем, что указывают направление поисковым роботам на определенные веб-страницы , запрещающие доступ либо ко всей странице, либо к определенным файлам, содержащимся на странице, таким как фотографии и видео.
Файлы robots.txt, напротив, предназначены для предотвращения индексации целых сегментов веб-сайта, например подкаталогов, предназначенных только для внутреннего использования. Файл robots.txt находится в корневом домене вашего сайта, а не на конкретной странице, а директивы структурированы таким образом, что они влияют на все страницы, содержащиеся в каталогах или подкаталогах, на которые они ссылаются.
Зачем мне нужен файл robots.txt?
Файл robots.txt — обманчиво простой текстовый файл, имеющий большое значение. Без него поисковые роботы будут просто индексировать каждую найденную страницу.
Почему это важно?
Во-первых, сканирование всего сайта требует времени и ресурсов. Все это стоит денег, поэтому Google ограничивает объем сканирования сайта, особенно если этот сайт очень большой. Это известно как «краулинговый бюджет». Бюджет сканирования ограничен несколькими техническими факторами, включая время отклика, малоценные URL-адреса и количество обнаруженных ошибок.
Это известно как «краулинговый бюджет». Бюджет сканирования ограничен несколькими техническими факторами, включая время отклика, малоценные URL-адреса и количество обнаруженных ошибок.
Кроме того, если вы разрешите поисковым системам беспрепятственный доступ ко всем вашим страницам и позволите их поисковым роботам индексировать их, вы можете столкнуться с раздуванием индекса. Это означает, что Google может ранжировать неважные страницы, которые вы не хотите показывать в результатах поиска. Эти результаты могут вызвать у посетителей плохой опыт, и они могут даже конкурировать со страницами, для которых вы хотите ранжироваться.
Когда вы добавляете файл robots.txt на свой сайт или обновляете существующий файл, вы можете сократить краулинговый бюджет и ограничить раздувание индекса.
Где найти файл robots.txt?
Есть простой способ узнать, есть ли на вашем сайте файл robots.txt: найдите его в Интернете.
Просто введите URL-адрес любого сайта и добавьте в конец «/robots. txt». Например: victoriousseo.com/robots.txt показывает вам наш.
txt». Например: victoriousseo.com/robots.txt показывает вам наш.
Попробуйте сами, введя URL своего сайта и добавив в конце «/robots.txt». Вы должны увидеть одну из трех вещей:
- Несколько строк текста, указывающих на действительный файл robots.txt
- Совершенно пустая страница, указывающая на отсутствие фактического файла robots.txt
- Ошибка 404
Если вы проверяете свой сайт и получаете один из двух вторых результатов, вам нужно создать файл robots.txt чтобы помочь поисковым системам лучше понять, на чем они должны сосредоточить свои усилия.
Как создать файл robots.txt
Файл robots.txt содержит определенные команды, которые роботы поисковых систем могут читать и выполнять. Вот некоторые из терминов, которые вы будете использовать при создании файла robots.txt.
Общие термины Robots.txt, которые следует знать
User-Agent : User-agent — это любая часть программного обеспечения, задача которой заключается в извлечении и представлении веб-контента конечным пользователям. В то время как веб-браузеры, медиаплееры и подключаемые модули могут считаться примерами пользовательских агентов, в контексте файлов robot.txt пользовательский агент — это поисковый робот или паук (например, Googlebot), который сканирует и индексирует Ваш сайт.
В то время как веб-браузеры, медиаплееры и подключаемые модули могут считаться примерами пользовательских агентов, в контексте файлов robot.txt пользовательский агент — это поисковый робот или паук (например, Googlebot), который сканирует и индексирует Ваш сайт.
Разрешить: Если эта команда содержится в файле robots.txt, она позволяет агентам пользователя сканировать любые страницы, следующие за ней. Например, если команда гласит «Разрешить: /», это означает, что любой поисковый робот может получить доступ к любой странице, которая следует за косой чертой в «https://www.example.com/». Вам не нужно добавлять это для всего, что вы хотите сканировать, поскольку все, что не запрещено в robots.txt, неявно разрешено. Вместо этого используйте его, чтобы разрешить доступ к подкаталогу, находящемуся на запрещенном пути. Например, на сайтах WordPress часто есть директива disallow для папки /wp-admin/, что, в свою очередь, требует от них добавления директивы allow, позволяющей поисковым роботам получать доступ к /wp-admin/admin-ajax. php, не обращаясь ни к чему другому в папке. основная папка.
php, не обращаясь ни к чему другому в папке. основная папка.
Disallow: Эта команда запрещает определенным пользовательским агентам просматривать страницы, следующие за указанной папкой. Например, если команда гласит «Запретить: /blog/», это означает, что пользовательский агент не может сканировать любые URL-адреса, содержащие подкаталог /blog/, что исключит весь блог из поиска. Вы, вероятно, никогда не хотели бы этого делать, но вы могли бы. Вот почему очень важно учитывать последствия использования директивы disallow каждый раз, когда вы думаете о внесении изменений в файл robots.txt.
Crawl-delay: Хотя эта команда считается неофициальной, она предназначена для защиты серверов от потенциально перегруженных запросов поисковых роботов. Обычно это реализуется на веб-сайтах, где слишком много запросов могут вызвать проблемы с сервером. Некоторые поисковые системы поддерживают его, но Google — нет. Вы можете настроить скорость сканирования для Google, открыв Google Search Console, перейдя на страницу настроек скорости сканирования вашего ресурса и отрегулировав там ползунок. Это работает только в том случае, если Google считает, что это не оптимально. Если вы считаете, что это неоптимально, и Google с этим не согласен, вам может потребоваться отправить специальный запрос на его корректировку. Это потому, что Google предпочитает, чтобы вы позволяли им оптимизировать скорость сканирования вашего сайта.
Это работает только в том случае, если Google считает, что это не оптимально. Если вы считаете, что это неоптимально, и Google с этим не согласен, вам может потребоваться отправить специальный запрос на его корректировку. Это потому, что Google предпочитает, чтобы вы позволяли им оптимизировать скорость сканирования вашего сайта.
Карта сайта XML: Эта директива делает именно то, что вы и предполагали: сообщает поисковым роботам, где находится ваша карта сайта в формате XML. Он должен выглядеть примерно так: «Карта сайта: https://www.example.com/sitemap.xml». Вы можете узнать больше о лучших методах работы с картами сайта здесь.
Пошаговые инструкции по созданию файла robots.txt
Чтобы создать собственный файл robots.txt, вам потребуется доступ к простому текстовому редактору, например Блокноту или TextEdit. Важно не использовать текстовый процессор, так как он обычно сохраняет файлы в проприетарных формах и может добавлять в файл специальные символы.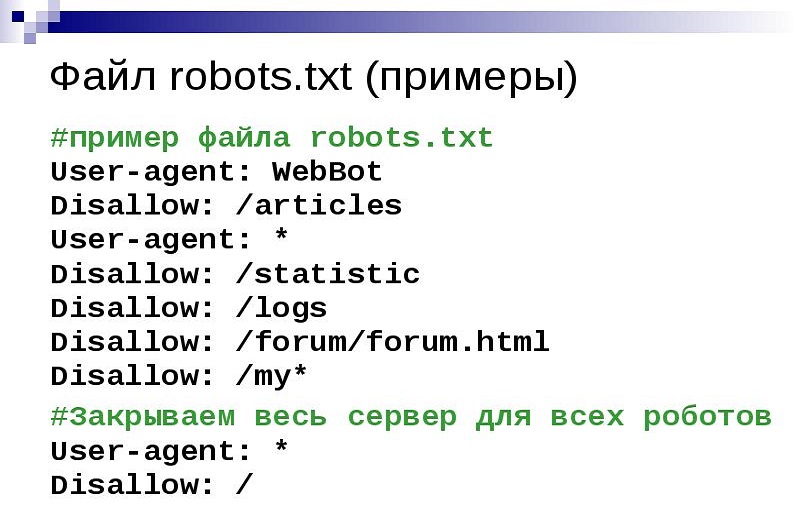
Для простоты мы будем использовать «www.example.com».
Начнем с настройки параметров пользовательского агента. В первой строке введите:
User-agent: *
Звездочка означает, что всем поисковым роботам разрешено посещать ваш сайт.
Некоторые веб-сайты используют разрешающую директиву, указывающую, что ботам разрешено сканирование, но в этом нет необходимости. Любые части сайта, которые вы не запретили, неявно разрешены.
Далее мы введем параметр запрета, если это необходимо. Дважды нажмите «возврат», чтобы вставить разрыв после строки пользовательского агента, затем введите параметр disallow, за которым следует каталог, который вы не хотите сканировать. Вот как выглядит наш:
Запретить: /wp/wp-admin/
Запретить: /*?*
Первая команда гарантирует, что наши страницы администратора WordPress (где мы редактируем такие вещи, как эта статья) не сканируются. Это страницы, которые мы не хотим ранжировать в поиске, и было бы пустой тратой времени Google сканировать их, потому что они защищены паролем. Вторая команда запрещает поисковым роботам сканировать URL-адреса, содержащие вопросительный знак, например внутренние страницы результатов поиска по блогам.
Это страницы, которые мы не хотим ранжировать в поиске, и было бы пустой тратой времени Google сканировать их, потому что они защищены паролем. Вторая команда запрещает поисковым роботам сканировать URL-адреса, содержащие вопросительный знак, например внутренние страницы результатов поиска по блогам.
После того, как вы выполнили свои команды, создайте ссылку на карту сайта. Хотя этот шаг не является обязательным с технической точки зрения, это рекомендуемая передовая практика, поскольку она указывает веб-паукам на наиболее важные страницы вашего сайта и делает архитектуру вашего сайта понятной. После вставки другого разрыва строки введите:
Карта сайта: https://www.example.com/sitemap.xml
Теперь ваш веб-разработчик может загрузить ваш файл на ваш сайт.
Создание файла Robots.txt в WordPress
Если у вас есть доступ администратора к вашему WordPress, вы можете изменить файл robots.txt с помощью плагина Yoast SEO или AIOSEO.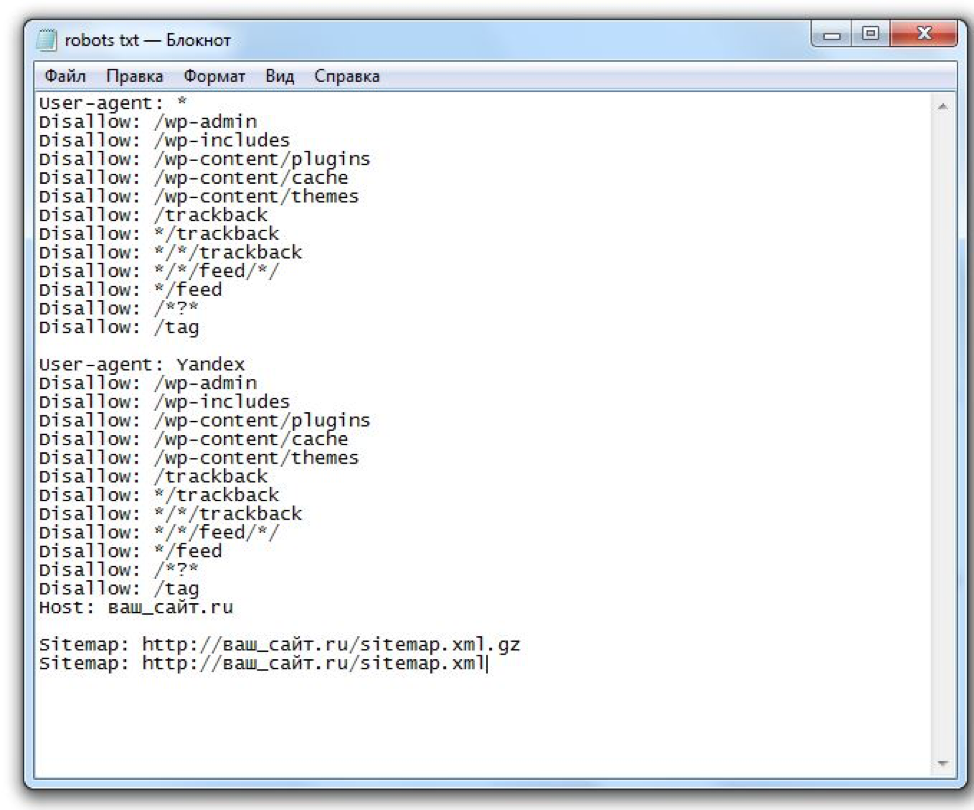 Кроме того, ваш веб-разработчик может использовать клиент FTP или SFTP для подключения к вашему сайту WordPress и доступа к корневому каталогу.
Кроме того, ваш веб-разработчик может использовать клиент FTP или SFTP для подключения к вашему сайту WordPress и доступа к корневому каталогу.
Не перемещайте файл robots.txt куда-либо, кроме корневого каталога. Хотя некоторые источники предлагают разместить его в подкаталоге или поддомене, в идеале он должен находиться в корневом домене:0014 www.example.com/robots.txt.
Как протестировать файл robots.txt
Теперь, когда вы создали файл robots.txt, пришло время протестировать его. К счастью, Google упрощает это, предоставляя тестер robots.txt как часть Google Search Console.
После того, как вы откроете тестер для своего сайта, вы увидите все синтаксические предупреждения и выделенные логические ошибки.
Чтобы проверить, как определенный робот Googlebot «видит» вашу страницу, введите URL-адрес вашего сайта в текстовое поле внизу страницы, а затем выберите один из различных роботов Googlebot в раскрывающемся списке справа. Нажатие «TEST» смоделирует поведение выбранного вами бота и покажет, не запрещают ли роботу Googlebot доступ к странице какие-либо директивы.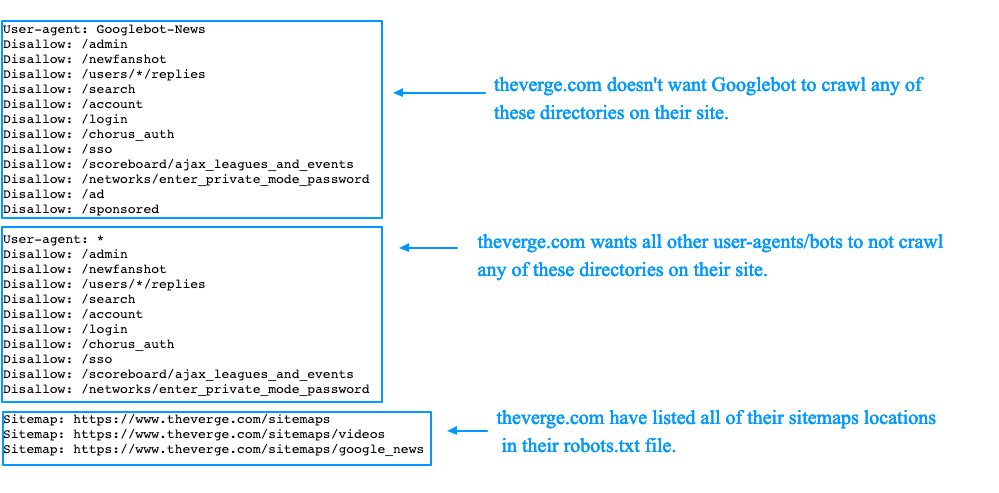
Недостатки Robots.txt
Файлы robots.txt очень полезны, но у них есть свои ограничения.
Файлы robots.txt не должны использоваться для защиты или сокрытия частей вашего веб-сайта (это может привести к нарушению Закона о защите данных). Помните, я предлагал вам найти собственный файл robots.txt? Это означает, что любой может получить к нему доступ, а не только вы. Если есть информация, которую необходимо защитить, лучше всего защитить паролем определенные страницы или документы.
Кроме того, директивы вашего файла robots.txt являются просто запросами. Вы можете ожидать, что Googlebot и другие законные поисковые роботы будут подчиняться вашим указаниям, но другие боты могут просто их игнорировать.
Наконец, даже если вы попросите сканеры не индексировать определенные URL-адреса, они не будут невидимыми. Другие веб-сайты могут ссылаться на них. Если вы не хотите, чтобы определенная информация на вашем веб-сайте была доступна для всеобщего обозрения, вам следует защитить ее паролем. Если вы хотите убедиться, что он не будет проиндексирован, рассмотрите возможность добавления на страницу тега noindex.
Если вы хотите убедиться, что он не будет проиндексирован, рассмотрите возможность добавления на страницу тега noindex.
Узнайте больше о техническом SEO: загрузите наш контрольный список
Хотите узнать больше о SEO, включая пошаговые инструкции о том, как взять SEO вашего сайта в свои руки? Загрузите наш Контрольный список SEO на 2023 год, чтобы получить исчерпывающий список дел, включая ценные ресурсы, которые помогут вам повысить рейтинг в поисковых системах и привлечь больше органического трафика на ваш сайт.
Контрольный список SEO & Инструменты планирования
Готовы ли вы изменить направление SEO? Получите интерактивный контрольный список и инструменты планирования и приступайте к работе!
НАЧНИТЕ РЕЙТИНГ СЕГОДНЯ
Получите бесплатную консультацию по SEO
Заполните форму для бесплатного анализа сайта.
Имя *
Фамилия *
Электронная почта компании *
Сколько вы хотите инвестировать в SEO? *
— Пожалуйста, выберите — я еще не уверен / мне нужна помощь с этим $2,999–5 000 деней в месяц 5 000–10 000 долларов США в месяц 10 000 – 20 000 долларов США в месяц 20 000 долларов США+ в месяц
Как найти и отредактировать файл Robots.
 txt для SEO -Валл-И из мультфильма Pixar или другого известного робота в поп-культуре.
txt для SEO -Валл-И из мультфильма Pixar или другого известного робота в поп-культуре.Файлы robots.txt на самом деле играют чрезвычайно важную роль для владельцев веб-сайтов и маркетологов. Мы уже писали о сканировании сайта, так как файл robots.txt является одним из наиболее важных инструментов, если вы хотите оптимизировать свой сайт и повысить свой рейтинг.
Этот пост становится немного более техническим, когда дело доходит до поисковой оптимизации. Если вы новичок в SEO, ознакомьтесь с нашим полным введением в SEO здесь!
В этом сообщении блога рассматриваются основы файла robots.txt, его важность и способы его настройки на разных платформах управления контентом.
Продолжайте читать или пролистайте вперед, нажав на выбранную платформу для получения инструкций по настройке файла robots.txt:
Что такое файл robots.txt?
Хотя robots.txt может показаться пугающим, это довольно простая концепция.
Файл robots.txt — это набор файлов для веб-сайта, который сообщает сканерам поисковых систем, какие страницы сканер может или не может анализировать и индексировать.
Другими словами, он сообщает Google, какие страницы запрещены для анализа и отображения в результатах поиска. При поиске в Интернете информации об этих файлах вы также можете увидеть термин протокол исключения роботов, используемый для обозначения того же понятия.
Вам может быть интересно, почему я хочу, чтобы любых страниц были скрыты от Google. В конце концов, чем больше контента у Google с веб-сайта, тем лучше, верно?
Закрыть — не весь контент представляет ценность, и вы будете удивлены, увидев, как много страниц автоматически создается для веб-сайта, которые либо не заслуживают показа в результатах поиска, либо потенциально содержат личную информацию, которую вообще нельзя индексировать.
Например, наш веб-сайт создан с помощью WordPress, и в результате многие страницы создаются автоматически для различных тегов и категорий, которые есть у нас для нашего блога. Эти страницы категорий мало что значат, поскольку они просто перечисляют страницы нашего блога.
Другим примером может быть интернет-магазин со страницами оформления заказа или выставления счетов, которые не следует сканировать и индексировать. Эти страницы содержат личную информацию или могут скрываться за логином, поэтому единственным контентом, который Google увидит, будет сообщение об ошибке. В любом случае, эти страницы не стоит индексировать.
Хотя высокий рейтинг в SEO является важной целью, вы должны думать о качестве и количестве страниц на вашем веб-сайте.
Когда вы отправляете веб-сайт для сканирования, сканер анализирует каждую страницу вашего веб-сайта. Работа Google заключается в оценке качества веб-сайта путем просмотра всех страниц, к которым у него есть доступ. Предоставление Google доступа к страницам, которые не добавляют ценности, может отрицательно сказаться на вашем рейтинге и помешать вашей способности появляться в результатах поиска.
Также важно управлять количеством страниц, к которым Google имеет доступ, и ограничивать количество страниц, сканируемых их поисковыми роботами. Google устанавливает «бюджет сканирования» при сканировании сайта, который ограничен двумя факторами.
Google устанавливает «бюджет сканирования» при сканировании сайта, который ограничен двумя факторами.
Во-первых, ограничение скорости сканирования. Ограничение скорости сканирования ограничивает максимальную выборку для данного сайта. Это число представляет собой количество параллельных подключений, которые сканер использует для обхода сайта, а также время между выборками.
Второй фактор известен как спрос на сканирование. Если предел обхода не достигнут, но спрос на индексирование низкий, активность сканера будет низкой. Популярность веб-сайта — это один из способов определить, будет ли страница сканироваться чаще, чем другие.
Из-за этого краулингового бюджета вы хотите сообщить Google, какие страницы являются наиболее важными для вашего веб-сайта. Вы же не хотите, чтобы поисковый робот тратил свое время на анализ страниц, которые не генерируют больше всего трафика. Именно здесь вступают в игру возможности файлов robots.txt.
Как выглядит файл Robots.
 txt?
txt?После прочтения всего этого сам файл robots.txt может немного разочаровать. Все, что есть в файле robots.txt, — это простой список URL-адресов, которые Google не может сканировать. Обычно он выглядит примерно так:
Агент пользователя: *
Запретить: /wp-admin/
Запретить: /wp-login.php
Запретить: /author/
Запретить: /category/
Запретить: /tag/
Следует отметить два момента здесь: пользовательский агент и путь запрета.
Пользовательский агент назначает сканеру имя для блокировки. Звездочка (*) означает, что каждому сканеру/поисковику запрещено анализировать следующие URL-адреса. Некоторые файлы robots.txt будут более сложными и содержат имена конкретных поисковых роботов для настройки правил для каждой поисковой системы, но для большинства веб-сайтов это не обязательно.
После пользовательского агента следует ряд строк, начинающихся со слова Disallow . Каждый из них представляет путь URL-адреса, который сканеры не могут анализировать. Это не полные URL-адреса, а фрагмент URL-адреса, который вы не хотите анализировать ни одной поисковой системой. В результате любой URL-адрес, содержащий этот путь, не будет просканирован.
Это не полные URL-адреса, а фрагмент URL-адреса, который вы не хотите анализировать ни одной поисковой системой. В результате любой URL-адрес, содержащий этот путь, не будет просканирован.
Где я могу найти файл robots.txt на своем веб-сайте?
Сканеры всегда ищут файл robots.txt в одном определенном месте: в основном каталоге вашего веб-сайта.
Это означает, что они ищут его по URL-адресу yourdomain/robots.txt , например, наш можно найти по адресу www.centori.io/robots.txt. Если бы файл robots.txt существовал, но с другим URL-адресом, скажем, yourdomain.com/index/robotst.xt , поисковые роботы не нашли бы его (они умны, но не настолько).
Не беспокойтесь — любая система управления контентом настроит это автоматически, вам не нужно беспокоиться о том, что ваш файл robots.txt не будет найден. Если вы когда-нибудь захотите увидеть свой файл robots.txt, просто добавьте «/robots.txt» после URL-адреса вашей домашней страницы, и вы сможете просмотреть его.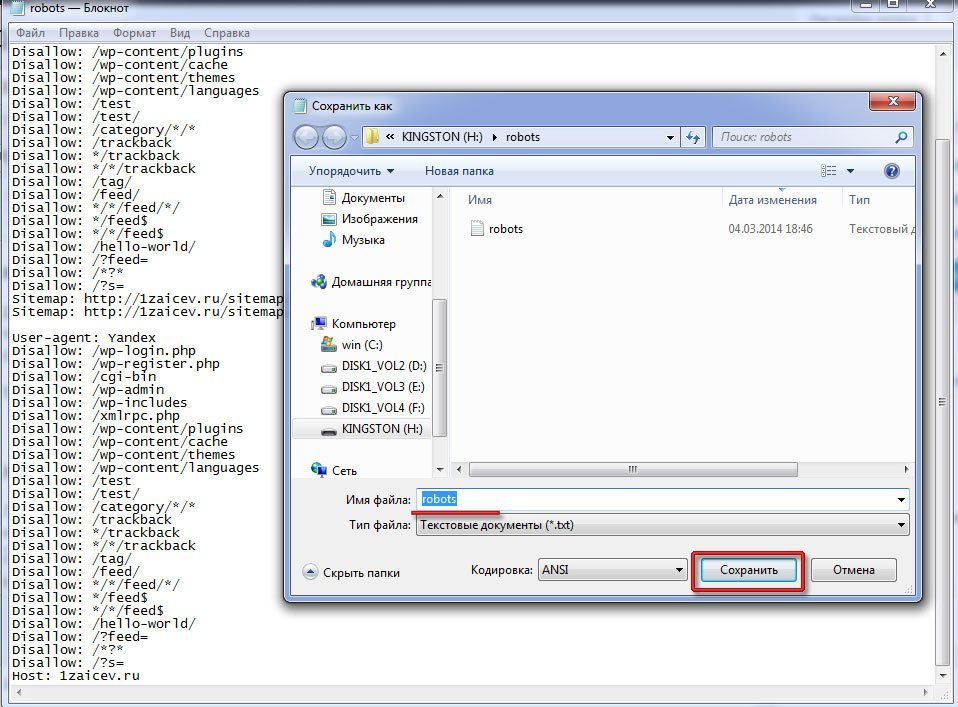
Как редактировать файлы robots.txt в WordPress
Чтобы получить доступ к файлам robots.txt для WordPress, вам необходимо загрузить плагин. Самый простой из них — Yoast.
Вы можете скачать бесплатный плагин Yoast по этой ссылке или в каталоге плагинов. Мы используем WordPress для нашего собственного сайта, и хотя нам это нравится, следует помнить об одном: ваш сайт не будет иметь полных возможностей SEO, если вы не добавите к нему дополнительные возможности.
Загрузив подключаемый модуль, вы сможете редактировать файлы robots.txt с помощью простого в использовании интерфейса. Сначала перейдите к Yoast в боковом меню и выберите Инструменты .
Оттуда вы попадете в список инструментов Yoast, оттуда выберите Редактор файлов .
И вуаля! У вас есть настроенный файл robots.txt, который вы можете легко редактировать.
Теперь, что мы добавим в этот файл?
Предположим на мгновение, что вы хотите, чтобы сайт сканировал все, кроме страниц администратора в WordPress. Вот что вы должны ввести:
Вот что вы должны ввести:
User-agent: *
Disallow: /wp-admin/
Disallow: /wp-login.php
В этом примере GoogleBot (и другие поисковые роботы, которые прослушивают robots.txt) сообщают, что следует избегать часто конфиденциального контента на вашем веб-сайте, что позволяет поисковому роботу сосредоточиться в первую очередь на том, что видит ваша аудитория.
Как редактировать файлы Robots.txt в SquareSpace
Там, где WordPress полностью «подключи и работай», SquareSpace занимает противоположную позицию — они настраивают robots.txt для вас.
Итак, краткий ответ: «Вы не можете», но давайте немного раскроем это.
SquareSpace не разрешает доступ к управлению файлом robots.txt вашего собственного веб-сайта, поскольку они устанавливают стандартный файл для всех веб-сайтов, созданных на их платформе. Они автоматически просят Google не сканировать определенные страницы, поскольку они предназначены только для внутреннего использования или содержат дублированный контент.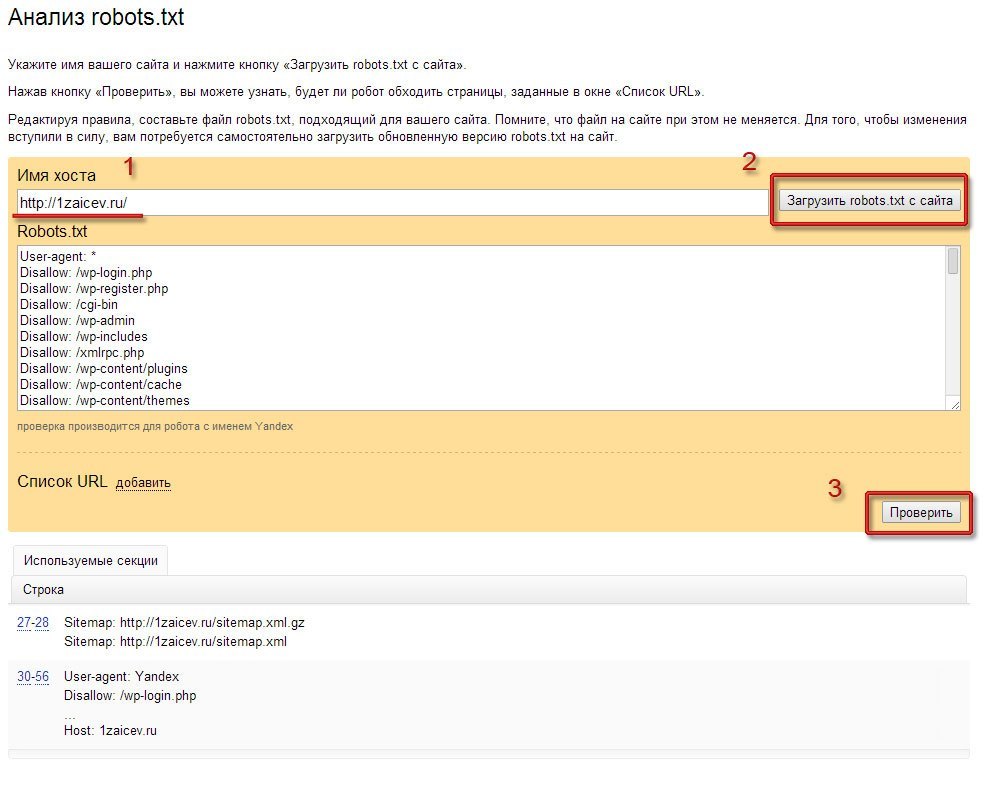
Вы можете увидеть полный список того, что они разрешают и запрещают для сканирования сайта, в этом образце файла robots.txt. Если вас беспокоит настройка, SquareSpace может быть не CMS для вас, хотя для нетехнических людей это обеспечивает отличное решение сложной проблемы.
Как редактировать файлы robots.txt на Wix
Wix похож на SquareSpace тем, что они также не позволяют редактировать файл robots.txt для вашего веб-сайта.
Wix не позволяет автоматически сканировать страницы администраторов, поскольку поисковые системы не получают от них никакой пользы. Как и SquareSpace, они прикроют вас там.
Вы можете обойти эту проблему и скрыть страницу от поисковой системы, добавив к отдельной странице тег «no index», который скроет страницу из результатов поиска.
Как редактировать файлы robots.txt в HubSpot
HubSpot предоставляет полный доступ к файлу robots.txt, предоставляя вам полную настройку в довольно удобном интерфейсе.
Просто перейдите в настройки, щелкнув значок шестеренки в главном меню, затем выберите Веб-сайт и Страницы в боковом меню. Выберите домен, который вы хотите изменить (если у вас их несколько), а затем перейдите на страницу SEO & Crawlers , которая откроет редактор robots.txt.
Выберите домен, который вы хотите изменить (если у вас их несколько), а затем перейдите на страницу SEO & Crawlers , которая откроет редактор robots.txt.
Нажмите Сохранить и готово!
Как редактировать файлы robots.txt в Webflow
Как и HubSpot, Webflow предоставляет полный доступ к вашему файлу robots.txt через простой интерфейс.
Перейдите к Настройки проекта , затем SEO и Индексирование , после чего вы попадете в редактор robots.txt. Добавьте свои правила и сохраните изменения, после чего все готово! Довольно легко, верно?
Как редактировать файлы Robots.txt в Shopify
Как и другие платформы, стремящиеся к простоте, Shopify не позволяет вам напрямую редактировать файл robots.txt.
Однако, как и в случае с Wix, лучшим обходным решением является добавление тега «без индекса» к страницам, которые вы не хотите индексировать в Google.
Shopfiy советует пользователям добавить этот фрагмент кода в раздел
страницы, если они хотят его скрыть: {% если дескриптор содержит дескриптор страницы, который вы хотите исключить’ %}
{% endif %}
Или, если вы хотите исключить шаблон результатов поиска, вы можете добавить это:
{% если шаблон содержит ‘search’ %}
{% endif %}
Вперёд
Надеюсь, это поможет вам стать мастером поисковой оптимизации и сканирования!
«Мастер» сейчас может показаться сильным словом, но настройка и оптимизация файла robots.