Как работает поиск Яндекса — Статьи
Поиск находит информацию практически моментально, но что в это время происходит внутри него? Как он понимает, какой ответ подойдет пользователю лучше всего? Руководитель Поиска Яндекса Максим Загребин рассказывает, как алгоритмы обрабатывают запросы и почему ссылка на сайт — не всегда лучший ответ.
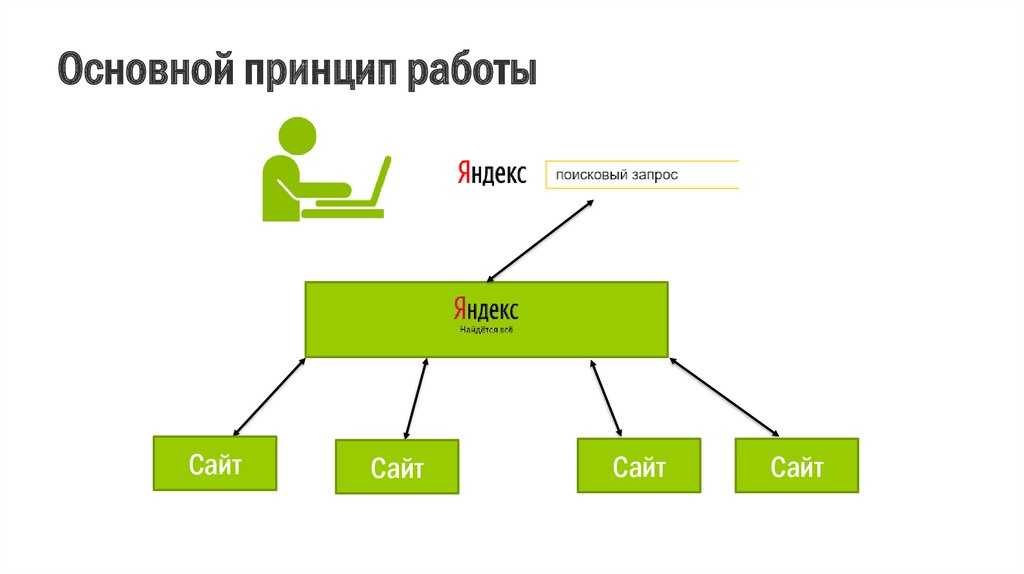
Как устроен поиск?Поиск в интернете состоит из двух частей:
- Поисковик обходит интернет, создавая его образ на своих серверах
- Выбрать из этих образов самую полезную информацию по запросу
Ежедневно Яндекс обрабатывает запросов больше, чем живет людей в России. Примерно половина из них никогда раньше не задавалась. Понятно, что отслеживать все эти показатели руками – невозможно. Невозможно написать для поисковой системы такую программу, в которой предусмотрен каждый запрос и для каждого запроса известен лучший ответ.
Сначала поиск выбирает из миллиардов ответов, потом из миллионов, и через какое-то количество этапов остаются те 10 сайтов на первой странице, которые лучше всего решают задачу пользователя. А для человека это все происходит моментально.
Люди не приходят в поиск, чтобы убить время, человек спрашивает что-то в Яндексе, когда у него есть какая-то конкретная задача. Например, найти какой-то фильм, который он помнит по описанию, но не помнит, как называется. Поэтому задача поиска – не просто найти и показать какую-то информацию, а помочь решить задачу пользователя. И страницу выдачи Яндекс формирует так, чтобы она лучше всего делала именно это – решала ту задачу, которую пользователь сформулировал в строке запроса.
При этом важно, чтобы поиск делал это быстро и удобно. Чтобы человеку не нужно было собирать всю информацию по крупицам с разных сайтов и не приходилось перепроверять ее, если сайт какой-то подозрительный. Например, если пользователь ищет ресторан или кафе, чтобы была сразу понятная шкала с проверенными отзывами: вот в этом ресторане чаще хвалят кухню, а здесь лучше интерьер и атмосфера.
Обычно пользователю нужно обойти несколько отзовиков или сайтов, чтобы собрать эту информацию самому. Почему бы не показать это сразу на странице выдачи?
Как понять, что поиск справился?В Яндексе работают инженеры, поэтому во всем они ориентируются на цифры и показатели. В данном случае показатели бывают двух типов.
Например, на запрос и на ответ на него может посмотреть человек, или сразу много разных людей – они называются асессорами – и оценить, насколько этот результат полезен и помогает решить задачу. Понятно, чт не всегда человек может оценить это, это довольно субъективно. Поэтом важно также смотреть на то, как пользователи ведут себя на странице результатов.
Если человек на запрос [как научить собаку ходить на поводке] чаще выбирает сайт с курсами дрессировки, который находится ниже, чем страница с общей инструкцией, то поисковая машина поднимает сайт с курсами выше в выдаче, потому что понимает, что он лучше решает задачу по этому запросу. Это называется принципом или показателем профицита*.
Это называется принципом или показателем профицита*.
Профицит – это метрика, которая определяет полезность объекта в поиске по кликам пользователя.
Раньше просто оценивались переходы, Яндекс считал, что если человек перешел на какой-то сайт и провел там продолжительное время, это значит, что он для него уже оказался полезным. Но понятно, что это не всегда так. Поэтому Яндекс начал смотреть на то, решил ли человек свою конечную задачу на этом сайте.
Например, если он искал кофеварку, положил ли он ее в корзину, после перехода на сайт, оплатил ли заказ. Чтобы поиск мог это понять, сайты сами передают эту информацию через Яндекс.Метрику. Теперь Яндекс может показывать выше в выдаче те результаты, которые лучше решают задачу уже на самом сайте.
Как поиск этому научился?Поиск Яндекса использует машинное обучение. Именно потому, что невозможно каждый раз оценивать профицит того или иного сайта. Точно также, как инженеры поиска смотрят на все эти показатели – на оценки асессоров и на поведение пользователя на странице – алгоритм учится их оценивать и находить такие результаты, которые эти показатели улучшают.
Поисковая система должна уметь принимать решения самостоятельно и очень быстро, то есть выбирать из сотен миллиардов документов тот, который лучше всего отвечает пользователю. Алгоритмам машинного обучения демонстрируются примеры, огромное количество примеров, что вот тут человек решил свою задачу, а вот тут – нет. И дальше машинно-обученный алгоритм создает для себя такое правило и подбирает результаты.
Откуда берутся короткие ответы?Иногда поиск понимает, что человеку нужно получить ответ на свой вопрос быстро, но емко. Например, если пользователь задает запрос [почему море соленое], он не хочет читать подробную статью о морской воде, а хочет получить ответ сразу. Тогда пользователь показывает ему быстрый ответ на вопрос. А если человек хочет найти обувную мастерскую, то гораздо лучше решит его задачу карта, на которой будут все обувные мастерские его района, а не просто куча ссылок для них.
Такие ответы появляются по тем запросам, где поиск точно видит, что они полезнее, чем набор ссылок – то есть их профицит намного выше.
А если человек хочет почитать подробнее про состав морской воды, или про конкретную обувную мастерскую, он переходит на сайт. На самом деле поиск уже уходит от того, чтобы искать просто сайты: технологии идут к тому, чтобы поиск стал универсальным и искал сразу по контенту.
Например, пользователь ищет фильм «Семнадцать мгновений весны», поиск должен понять смысл того, что тот ищет, и найти этот фильм на 5 онлайн-кинотеатрах. А дальше пользователь уже сам выберет, где именно этот фильм посмотреть.
Как работает поисковик Яндекс — схемы и описания алгоритмов работы
Мы увеличиваем посещаемость и позиции в выдаче. Вы получаете продажи и платите только за реальный результат, только за целевые переходы из поисковых систем
Заказывайте честное и прозрачное продвижение
Получи нашу книгу «Контент-маркетинг в социальных сетях: Как засесть в голову подписчиков и влюбить их в свой бренд».
Подпишись на рассылку и получи книгу в подарок!
Интернет — просто охренеть какая огромная штука. И в нем есть все. Общение с друзьями? Вот, пожалуйста — Facebook. Фотоальбом — в Instagram. Купить дачу? У меня уже есть «Веселый фермер». А энциклопедией давно пользовались? Зачем, ведь есть поисковики, которые знают все. И сегодня мне бы хотелось отдать должное этим чудо-сервисам. А точнее рассказать вам о том, как работает Яндекс поиск.
И в нем есть все. Общение с друзьями? Вот, пожалуйста — Facebook. Фотоальбом — в Instagram. Купить дачу? У меня уже есть «Веселый фермер». А энциклопедией давно пользовались? Зачем, ведь есть поисковики, которые знают все. И сегодня мне бы хотелось отдать должное этим чудо-сервисам. А точнее рассказать вам о том, как работает Яндекс поиск.
Помните Гермиону из саги о Гарри Поттере? Как вы думаете: почему она была такой сверхэрудированной всезнайкой? Правильно, потому что постоянно ходила где-то читала про всякие зелья, изучала разные заклинания, допытывалась до учителей по всем непонятным моментам. В общем, делала все, чтобы расширить свою базу знаний. Точно так же работает Яндекс поисковик. Еще до того, как вы задали ему вопрос, он уже кое-что узнал про вашу тему и сохранил себе в копилочку.
Как формируется поисковая база Яндекса
Пауки всемирной паутины
Поисковик Яндекс знает несколько триллионов урлов. И каждый день он изучает по паре миллиардов из них. Делают это специальные роботы-пауки, краулеры. Они заходят на страницу, анализируют содержимое, делают копию и отправляют на сервер. А затем уходят по ссылкам на другие страницы. Так происходит знакомство поисковика с сайтом. Далее следует этап индексикации.
Делают это специальные роботы-пауки, краулеры. Они заходят на страницу, анализируют содержимое, делают копию и отправляют на сервер. А затем уходят по ссылкам на другие страницы. Так происходит знакомство поисковика с сайтом. Далее следует этап индексикации.
Если произвести нехитрые математические расчеты, то можно выявить, что пауки Яндекса обойдут все известные страницы приблизительно за 2 года. Но это будет неверно, так как количество урлов постоянно увеличивается
=> работа по созданию поисковой базы бесконечна.
Индексикация
Определение индекса сайта — это процесс добавления всей важной информации о странице в базу поисковика. То есть определяется язык, формируются данные об отдельных словах и вытаскиваются все ссылки исходящие на другие страницы. Кроме того у Yandex есть специальный инструмент, который называется логи Яндекса. Он изучает, как пользователь ведет себя в выдаче: на что кликает, а на что не кликает. Опираясь на все полученные параметры и задается поисковый индекс сайта.
Логи Яндекса широко применяются не только при индексикации, но и при ранжировании.
Составление поисковой базы
Поисковые индексы, полученные в ходе предыдущего этапа, отправляются в поисковую базу. У Яндекс поиска она функционирует на программной платформе мапредьюс YT. Здесь данные превращаются файлы и «остаются жить».
Суммарный объем данных YT приблизительно 50 петабайт = 51 200ТБ.
У поисковой базы данных есть еженедельное обновление — апдейт. Это тот момент, когда поисковый робот Яндекса, накачав определенное количество файлов и рассчитав для них все необходимые характеристики, принимает решение, что можно добавить эту информацию в поиск.
Согласно статистическим данным Игоря Ашманова — специалиста по поисковым системам в интернете, полнота поисковой базы у Яндекса (красные на графике) в несколько раз выше, чем у их ближайшего конкурента Google (черные).
Пока индекс — времязатратный и протекает комплексно сразу для большого количества данных. Поэтому у Яндекса есть специальный быстрый контур, который может добавлять и доносить до пользователя отдельные, срочные файлы. Ну, например, новости в реальном времени.
Поэтому у Яндекса есть специальный быстрый контур, который может добавлять и доносить до пользователя отдельные, срочные файлы. Ну, например, новости в реальном времени.
Как работает сам Яндекс поиск
Любой запрос в поисковой системе Яндекс проходит по следующей схеме.
Балансеры — это машины, которые агрегируют выдачу.
Построение выдачи формируется из результатов трех средних метапоисков. Поясню, что это значит. В выдаче вы видите результаты запроса по страницам, картинкам и видео. Происходит это потому, что ваш запрос проходит по трем разным индексам. И по ним он спускается в самую-самую глубь поисковой базы, разделенную на несколько тысяч кусков. Этот процесс обозначается, как поисковая кластеризация.
Работа поискового кластера состоит из функционирования более миллиона экземпляров различных программ. Они выполняют всяческого рода задачи, у них разные системные требования и всем им нужно где-то «жить». Поэтому поисковая кластеризация занимает еще и огроменное количество компьютерного железного хостинга.
Для хранения и передачи всех программ и данных к ним Яндекс использует внутренний торрент-трекер. Число раздач на нем больше, чем на крупнейшем в мире пиратском трекере The Pirate Bay.
Вернемся к результатам выдачи.
В поисковую выдачу попадают наиболее релевантные, соответствующие поисковому запросу документы. Дальше происходит ранжирование — упорядочивание результатов поиска. Проходит оно с помощью специальной формулы. Чтобы порядок результатов каждый раз был качественным, актуальным и максимально релевантным разработчики Яндекса придумали одну очень крутую штуку.
Матрикснет — метод машинного обучения, с помощью которого строится формула ранжирования Яндекс. Он постоянно модернизирует эту схему: выстраивает комбинации, добавляет и убирает факторы, выставляет коэффициенты. Другая важная характеристика этого метода — возможность индивидуальной настройки формулы ранжирования для узкопрофильных категорий запросов. То есть для отдельных запросов, например, про кино или компьютерные игры, можно улучшить качество поиска.
Первая формула ранжирования Яндекса составляла примерно 10 байт. На сегодняшний момент — около 100 мегабайт.
Задача поисковика не просто находить иголки в сеновалах, но и определять самые острые из них. И самое удивительное то, как работает Яндекс поиск. Результат выдается за доли секунд. Десять первых наиболее релевантных запросов — как правило, это все, что нужно пользователю. Если в этих запросах мы не находим то, что искали, то мы пробуем или другой запрос, или меняем поисковик. Но рано или поздно: «Найдется все!»
Скриншоты взяты из лекции Петра Попова.
Читайте также: Как купить отзывы в интернете и оказаться на дне.
icon by Arthur Shlain
Как работает яндекс | Вокруг Света
ИсторииНаука
Каждый из нас считает себя уникальным. Каждый из нас думает, что прекрасно знает себя. Каждый ответ поисковой системы на любой наш запрос доказывает обратное
- Фото
- Shutterstock
Мы не так уникальны, как думаем: миллионы людей до нас озадачивали и миллионы после нас озадачат поисковик почти одинаковыми вопросами. С другой стороны, мы слишком непредсказуемы: на формулировку нашего запроса влияет огромное количество неосознаваемых нами факторов. И хотя бы поэтому запрос каждого из нас, каким бы банальным он ни был, требует индивидуального подхода.
С другой стороны, мы слишком непредсказуемы: на формулировку нашего запроса влияет огромное количество неосознаваемых нами факторов. И хотя бы поэтому запрос каждого из нас, каким бы банальным он ни был, требует индивидуального подхода.
Фактически вся работа поисковика «Яндекс» сводится к двум простым вещам: понять, что на самом деле хочет узнать человек, и за несколько секунд найти для него среди миллиардов документов в Сети подходящие.
Снять отпечатки
Система работы поисковика чем-то похожа на «Матрицу», а поисковый робот (созданная ею сложная, самостоятельно принимающая решения программа) — на агента Смита.
В 1997 году, когда «Яндекс» только открылся, для работы хватало одного сервера. Через три года компания арендовала четыре стойки, где размещалось около 40 компьютеров. Эти несколько десятков и стали основой первого дата-центра. Сегодня у «Яндекса» разветвленная и независимая от офисов сеть центров, в которых размещено несколько тысяч серверов. Фото: ЯНДЕКС
Чтобы не обыскивать весь Интернет каждый раз, когда кому-то что-то нужно узнать, поисковик делает часть работы заранее — проверяет, что есть в Сети и где это лежит, с помощью тысяч поисковых роботов. Они бывают двух типов: основной и быстрый. Основной обходит и обрабатывает Интернет в целом, а быстрый — документы, появившиеся минуту или даже пару секунд назад. Задача программ-роботов — отобрать годную и полезную для пользователей информацию, переработать ее, отсеяв все устаревшее и ненужное. В чем-то это напоминает сортировку мусора: бумага в один контейнер, стекло в другой, пластик в третий, пищевые отходы в четвертый…
Они бывают двух типов: основной и быстрый. Основной обходит и обрабатывает Интернет в целом, а быстрый — документы, появившиеся минуту или даже пару секунд назад. Задача программ-роботов — отобрать годную и полезную для пользователей информацию, переработать ее, отсеяв все устаревшее и ненужное. В чем-то это напоминает сортировку мусора: бумага в один контейнер, стекло в другой, пластик в третий, пищевые отходы в четвертый…
Собранная роботами информация образует так называемый слепок Интернета. Он хранится на тысячах серверов «Яндекса» и постоянно обновляется. Слепок похож на список, в котором указано, в каком месте какую информацию можно найти. В этом списке у каждого ключевого слова указана не одна, а миллионы «страниц». Чтобы все обновления слепка были доступны пользователям, их переносят из хранилища на «базовый поиск». Данные от основного робота переносятся раз в несколько дней, а от быстрого робота — в реальном времени.
Вывести на чистую воду
Разыскивая ответ на заданный вопрос в подготовленной базе, машина сталкивается с двумя основными сложностями. Первая сложность — язык. Прежде чем искать ответ на вопрос, машине важно понять, на каком языке это делать.
Первая сложность — язык. Прежде чем искать ответ на вопрос, машине важно понять, на каком языке это делать.
Иллюстрация: Евгений Тонконогий
Например, для русскоязычного человека на запрос «дружина князя Игоря» поиск найдет документы с информацией о войске, а для украинца на «дружина князя Iгоря» выдаст также документы, упоминающие княгиню Ольгу, его супругу, так как по-украински «жена» — это «дружина». Да и в богатом русском языке одно и то же слово или его производные могут означать разные вещи. Например, слово «стали» — это одна из форм существительного «сталь» и глагола «стать». Вторая сложность — человеческая психология. Вводя запрос, мы ожидаем быстрого и точного ответа, не заботясь, естественно, о соответствии формулировки запроса принципам математического анализа, по которым работает мозг машины. Например, введя в поисковую строку слово «наполеон», что человек хочет получить: рецепт торта или биографию французского императора, купить коньяк или найти адрес психиатрической больницы?
- Фото
- Shutterstock
В таких ситуациях в дело вступают сразу несколько технологий.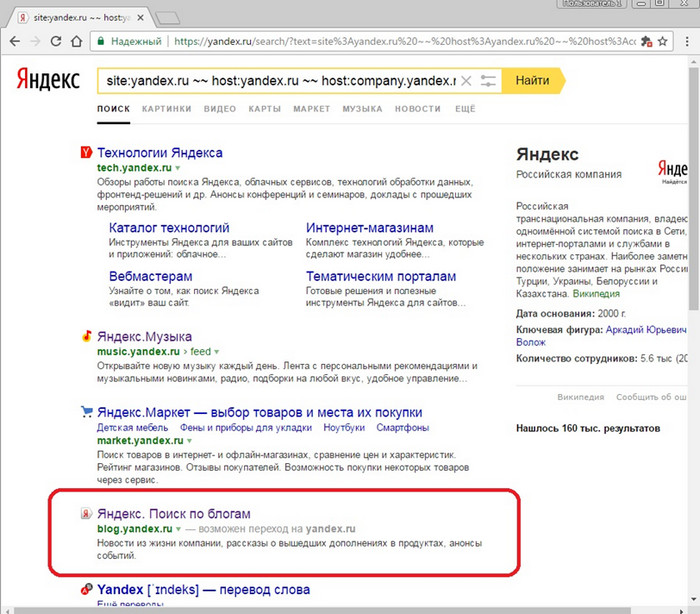 Можно выдать вам под строкой поиска несколько подсказок, конкретизирующих запрос. Мол, выберите, что вам нужно: «наполеон — рецепты» или «Наполеон — Бонапарт». Если пользователь не реагирует на просьбу машины и не добавляет к «наполеону» слов, то делу помогает технология «Спектр»: не надеясь на помощь, машина сразу ищет информацию по нескольким категориям (и про торт, и про императора, и про коньяк…). Кроме того, понять пользователя помогают механизмы персонализации — знания машины о том, что этот пользователь искал со своего компьютера день-два-три-месяц назад: если вы часто задавали «Яндексу» вопросы про кулинарию, то машина вначале покажет вам результаты, говорящие, что наполеон — торт.
Можно выдать вам под строкой поиска несколько подсказок, конкретизирующих запрос. Мол, выберите, что вам нужно: «наполеон — рецепты» или «Наполеон — Бонапарт». Если пользователь не реагирует на просьбу машины и не добавляет к «наполеону» слов, то делу помогает технология «Спектр»: не надеясь на помощь, машина сразу ищет информацию по нескольким категориям (и про торт, и про императора, и про коньяк…). Кроме того, понять пользователя помогают механизмы персонализации — знания машины о том, что этот пользователь искал со своего компьютера день-два-три-месяц назад: если вы часто задавали «Яндексу» вопросы про кулинарию, то машина вначале покажет вам результаты, говорящие, что наполеон — торт.
Комбинации: клубы по интересам
Задача поисковой машины не сводится к тому, чтобы просто отобрать документы, в которых встречаются слова и словосочетания из поискового запроса. Машина должна понять, какие документы соответствуют нашим противоречивым требованиям и почему они им соответствуют. Хотим ли мы получить информацию о наполеоне-пирожном, или, может быть, мы пару лет посещали фитнес-клуб с пафосным названием, а то и вовсе озабочены комплексами людей невысокого роста. В любом случае решение задачи требует нетривиального подхода.
Хотим ли мы получить информацию о наполеоне-пирожном, или, может быть, мы пару лет посещали фитнес-клуб с пафосным названием, а то и вовсе озабочены комплексами людей невысокого роста. В любом случае решение задачи требует нетривиального подхода.
- Фото
- Shutterstock
Создатели поисковой программы «Яндекс» нашли такой подход, делегировав право выбора машине. С одной стороны, бездушная, но очень быстрая и умная машина не знает и не хочет ничего знать о нас как о личностях, а с другой — она старается выяснить о каждом как можно больше.
Помимо географического положения пользователя и лингвистического анализа его запросов, поисковая машина использует несколько тысяч критериев, совершенно неочевидных для человека.
Фокус в том, что эти критерии машина разрабатывает и обновляет самостоятельно.
Она просто использует данные о предпочтениях и пользовательском поведении миллионов людей и связывает это «среднее арифметическое» с историей наших запросов. Принципы, которыми руководствуется «Матрица» внутри себя, сопоставляя тысячи разработанных ею категорий пользовательских интересов, часто не укладываются в традиционные человеческие представления о том, какими в принципе могут быть «интересы». Их десятки тысяч. Они создают друг с другом разные, порой забавные, комбинации. К примеру, одной из таких комбинаций может являться соответствие результатов поиска интересам человека, разводящего тритонов. При этом человек не просто интересуется тритонами, а уже разводит их, но только первый год.
Принципы, которыми руководствуется «Матрица» внутри себя, сопоставляя тысячи разработанных ею категорий пользовательских интересов, часто не укладываются в традиционные человеческие представления о том, какими в принципе могут быть «интересы». Их десятки тысяч. Они создают друг с другом разные, порой забавные, комбинации. К примеру, одной из таких комбинаций может являться соответствие результатов поиска интересам человека, разводящего тритонов. При этом человек не просто интересуется тритонами, а уже разводит их, но только первый год.
Оценки. Руки помощи
- Фото
- Shutterstock
«Матрица», конечно, сама решает (с помощью высшей математики), что и в какой последовательности нужно показать пользователям на основании десятков тысяч критериев. Но живых людей «Матрица» тоже использует — 1000 сотрудников «Яндекса», так называемых асессоров, оценивают результаты поиска по тому или иному запросу (конечно, не каждый запрос подвергается оценке, и делается это не в режиме реального времени) на предмет их соответствия ожиданиям обычного пользователя: не такого рационального, как машина, не такого точного в формулировках, противоречивого и эмоционального.
Материал опубликован в журнале «Вокруг света» № 3, март 2014
Алиса Кирсанова
Теги
- интернет
- технологии
Как работает поиск Яндекса
Поисковая система Яндекса отвечает на запросы пользователей релевантными веб-документами, которые она находит в Интернете. Однако размер Интернета в настоящее время исчисляется эксабайтами — квинтиллионами или миллиардами миллиардов байтов информации. Излишне говорить, что поисковая система Яндекса не просматривает эту огромную кучу данных каждый раз, когда отвечает на новый поисковый запрос. Система, так сказать, делает свою домашнюю работу.
Для выполнения поиска Яндекс использует поисковый индекс, который представляет собой базу данных всех слов и их местоположений, известных поисковой системе. Расположение слова — это комбинация его положения на веб-странице и адреса веб-страницы в Интернете. Индекс поиска похож на глоссарий или телефонный справочник. В отличие от глоссария, который содержит только избранные термины, индекс поиска регистрирует каждое слово, с которым когда-либо сталкивалась поисковая система. И, в отличие от телефонной книги, в которой перечислены имена и адреса, поисковый индекс содержит более одного «зарегистрированного адреса» для каждого слова.
В отличие от глоссария, который содержит только избранные термины, индекс поиска регистрирует каждое слово, с которым когда-либо сталкивалась поисковая система. И, в отличие от телефонной книги, в которой перечислены имена и адреса, поисковый индекс содержит более одного «зарегистрированного адреса» для каждого слова.
Поисковая система работает в два этапа. Во-первых, он сканирует Интернет, сохраняя свою «копию» на своих серверах. Во-вторых, он отвечает на поисковый запрос пользователя, получая ответ со своих серверов.
Прежде чем поисковая система Яндекса сможет начать поиск, она должна подготовить информацию, которую она находит в Интернете, для поиска. Этот процесс называется индексацией. Специальная компьютерная система — поисковый робот — регулярно просматривает Интернет, загружает новые веб-страницы и обрабатывает их. Он создает своего рода «точную копию Интернета», которая хранится на серверах поисковой системы и обновляется после каждого сканирования.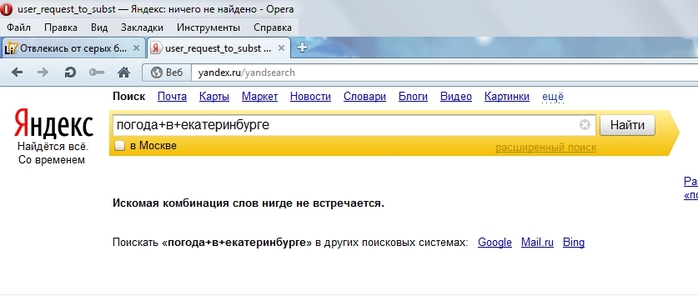
В Яндексе два краулера: один из них, основной, индексирует все попавшиеся веб-страницы, а другой, известный как Orange, выполняет экспресс-индексацию, чтобы гарантировать, что самые свежие документы, в том числе появившиеся в Интернете за несколько минут или даже секунд до сканирования доступны в индексе поисковой системы. У обоих сканеров есть «списки ожидания» веб-страниц, которые необходимо проиндексировать. В списки постоянно добавляются новые ссылки, которые поисковые роботы находят на страницах, которые они посещают. Новые ссылки также могут появиться в листах ожидания после того, как владельцы сайтов добавят свои страницы в индекс с помощью сервиса Яндекс Вебмастер. Администраторы веб-сайтов также могут предоставить дополнительную информацию, например, как часто обновляется их веб-сайт и т. д.
Перед началом сканирования специальная программа – планировщик – создает расписание, порядок посещения веб-страниц. Планирование основано на ряде факторов, необходимых для поиска информации, таких как популярность ссылок или частота обновления страниц. После составления расписания за дело берется другой компонент поисковой системы — паук. Паук регулярно посещает страницы поисковой системы Яндекса, происходит по расписанию. Если веб-сайт доступен для паука и функционирует, программа загружает страницы веб-сайта по расписанию. Он определяет формат (HTML, pdf, SWF и т. д.), код и язык загруженного документа, а затем отправляет эту информацию на серверы для хранения.
После составления расписания за дело берется другой компонент поисковой системы — паук. Паук регулярно посещает страницы поисковой системы Яндекса, происходит по расписанию. Если веб-сайт доступен для паука и функционирует, программа загружает страницы веб-сайта по расписанию. Он определяет формат (HTML, pdf, SWF и т. д.), код и язык загруженного документа, а затем отправляет эту информацию на серверы для хранения.
На сервере хранения другая программа очищает веб-документ от разметки HTML, оставляя только текст. Затем он извлекает информацию о расположении каждого слова и добавляет все слова в этом веб-документе в индекс.
Исходный документ также хранится на сервере до следующего сканирования. Это позволяет поисковой системе Яндекса предлагать своим пользователям возможность просматривать веб-документы, даже если веб-сайт временно недоступен. Если сайт закрывается, веб-документ удаляется или обновляется, Яндекс удаляет его со своих серверов или заменяет более новой версией.
Индекс поиска вместе с копиями всех проиндексированных документов, включая их тип, код и язык, образует базу данных поиска. Чтобы идти в ногу с постоянно меняющимся характером интернет-контента и убедиться, что поисковая система может находить самую последнюю и наиболее актуальную информацию в ответ на поисковые запросы пользователей, базу данных поиска необходимо регулярно обновлять. Прежде чем поисковая система Яндекса сможет найти и вернуть результаты конечным пользователям, каждое новое обновление базы данных сначала отправляется на серверы «базового поиска». Базовые поисковые серверы содержат только существенную часть базы данных поиска — без спама, зеркальных сайтов или других нерелевантных документов. Это часть базы данных поиска, которая непосредственно отвечает на запросы пользователей.
Обновления базы данных поиска отправляются с серверов хранения основного сканера на основные поисковые серверы в «пакетах» раз в несколько дней. Это очень ресурсоемкий процесс. Чтобы снизить нагрузку на серверы, данные передаются ночью — когда поисковый трафик на Яндексе минимален. Новые части базы данных сравниваются по ряду параметров с последней версией, доступной при предыдущем обходе, чтобы гарантировать, что обновление не ухудшит качество результатов поиска. После успешной проверки качества поисковой системы Яндекса старая версия заменяется последним обновлением.
Чтобы снизить нагрузку на серверы, данные передаются ночью — когда поисковый трафик на Яндексе минимален. Новые части базы данных сравниваются по ряду параметров с последней версией, доступной при предыдущем обходе, чтобы гарантировать, что обновление не ухудшит качество результатов поиска. После успешной проверки качества поисковой системы Яндекса старая версия заменяется последним обновлением.
Поисковый робот Orange предназначен для поиска в реальном времени. И его планировщик, и паук настроены на поиск последних веб-документов и выбор из огромного количества страниц тех, которые могут представлять интерес. Эти документы мгновенно обрабатываются и отправляются прямо на основные поисковые серверы. Поскольку количество этих документов относительно невелико, обновление может происходить в режиме реального времени даже в течение дня без риска перегрузки серверов.
Веб-поисковик, грубо говоря, работает в два этапа. Первый — сканирование сети, индексация страниц, подготовка их к поиску. Другой — поиск ответа на конкретный запрос пользователя в ранее созданной поисковой базе.
Другой — поиск ответа на конкретный запрос пользователя в ранее созданной поисковой базе.
Источник: Yandex.com
Как работает поиск Яндекса?
Содержание
Как работает поиск Яндекса?
Яндекс работает как любой другой поисковик. Есть панель поиска, где пользователь просто вводит свой поисковый запрос, нажимает «Ввод», и появляется множество результатов. Список связанных веб-страниц появится вместе с некоторыми изображениями и видео в зависимости от условия поиска.
Для чего нужен Яндекс?
Яндекс — самая популярная поисковая система в России и пятая по популярности в мире. Его акции торгуются на Nasdaq, а рыночная капитализация превышает 14 миллиардов долларов.
Что делает Яндекс Браузер?
Яндекс.Браузер — бесплатный веб-браузер, использующий защиту от спуфинга DNS для сканирования файлов и веб-сайтов на наличие вирусов, блокировки мошеннических веб-страниц, защиты паролей и данных банковских карт.
Чем Яндекс отличается от Google?
На момент написания статьи Яндексу принадлежало 44 % рынка в России (по поиску) по сравнению с 53 % Google, что делает его одним из самых близких полей битвы Google за превосходство. Однако Яндекс — это гораздо больше, чем поисковая система. За последние два десятилетия она диверсифицировалась и превратилась в потребительскую технологическую компанию.
Однако Яндекс — это гораздо больше, чем поисковая система. За последние два десятилетия она диверсифицировалась и превратилась в потребительскую технологическую компанию.
Для чего люди используют Яндекс?
Яндекс — крупнейший медиацентр во всей России, и для многих россиян Яндекс.ру — это место, где начинается их день. По сути, Яндекс — крупнейшая медиасобственность во всей России. Как и Google, Яндекс предлагает бесплатную электронную почту, карты пробок в реальном времени, музыку, видео, хранилище фотографий и многое другое. 6 августа 2014 г.
Безопасно ли искать на Яндексе?
Нет Яндекс это не вирус, это легальный российский поисковик. Какой веб-браузер самый безопасный? Все браузеры предлагают ту или иную форму безопасности, но благодаря встроенному VPN Opera является одним из самых безопасных браузеров на рынке. Никакой Яндекс не вирус, это легитимный российский поисковик.
Какой поисковой системой пользуется Яндекс?
Google Search
Что такое Яндекс и как вы им пользуетесь?
Яндекс — это портал Как и Google, Яндекс предлагает бесплатную электронную почту, карты пробок в реальном времени, музыку, видео, хранилище фотографий и многое другое. Многие из этих функций являются продуктами, которые Google использовал для расширения своего распространения во всем мире, знакомя пользователей с брендом Google. 6 августа 2014 г.
Многие из этих функций являются продуктами, которые Google использовал для расширения своего распространения во всем мире, знакомя пользователей с брендом Google. 6 августа 2014 г.
Является ли Яндекс вирусом?
Яндекс (Яндекс) является законной российской поисковой системой, однако существует множество угонщиков браузера, которые меняют домашнюю страницу вашего браузера на https://www.yandex.ru/ без вашего согласия. Это перенаправление браузера происходит из-за того, что на вашем компьютере установлено вредоносное расширение или программа браузера.
Яндекс хорошая поисковая система?
Как упоминалось выше, Яндекс является самой популярной поисковой системой в России с долей рынка 48,79% по сравнению с 47,88% Google. По данным Similarweb, Yandex.ru также является самым посещаемым сайтом в России. Однако Яндекс также очень популярен во многих других странах, кроме России.
Как отключить безопасный поиск на Яндексе?
— Перейти к настройкам поиска.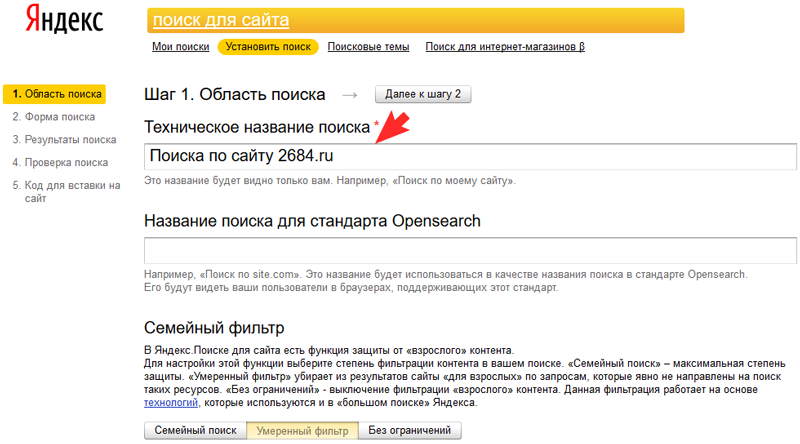
— В результатах поиска «Фильтровать» выберите соответствующий режим.
— В нижней части страницы нажмите «Сохранить».
Что лучше Яндекс или Гугл?
Яндекс лучше для русскоязычного поиска В целом, Google не так эффективен в анализе намерений пользователя по правописанию в неанглоязычном поиске, но еще слабее в русском. Например, русский язык сильно изменчив, и некоторые слова могут иметь до 20 разных окончаний. 6 августа 2014 г.
Какая поисковая система для русского языка самая лучшая?
Яндекс
Почему моя поисковая система сменилась на Яндекс?
Ваш браузер перенаправляется на Яндекс, потому что на вашем компьютере установлено вредоносное расширение или программа для браузера. Часто этот тип программ предлагается через рекламу или в комплекте с другим программным обеспечением, оставляя пользователя в недоумении, откуда взялось это программное обеспечение.
Насколько приватен Яндекс?
Режим инкогнито позволяет сохранить ваши поисковые запросы и посещаемые сайты в тайне. В режиме инкогнито Яндекс.Браузер не сохраняет ваши пароли, данные автозаполнения, поисковые запросы, историю и посещенные страницы. Все изменения настроек, загруженных файлов и закладок сохраняются.
В режиме инкогнито Яндекс.Браузер не сохраняет ваши пароли, данные автозаполнения, поисковые запросы, историю и посещенные страницы. Все изменения настроек, загруженных файлов и закладок сохраняются.
Какой поисковой системой пользуется Россия?
Яндекс поиск
Безопасно ли пользоваться Яндекс браузером?
Яндекс Браузер безопасен Поскольку сам браузер имеет встроенную защиту, и при переходе на опасную страницу сайта или даже автоматические всплывающие окна Браузер сам автоматически БЛОКИРУЕТ ИХ, сообщая пользователю, что этот сайт или что-то еще не является безопасно или обнаружены вирусы.
Есть ли в Яндексе безопасный поиск?
Также можно настроить безопасный поиск с помощью этих ресурсов: Яндекс. В файл нужно ввести IP-адрес Яндекса с предустановленным семейным поиском.
Какие недостатки у Яндекса?
Недостаток Яндекса в том, что он содержит очень большой объем контента, он отвлекает внимание пользователя. Это также загромождало результат веб-страницы. Он не покажет таких результатов, как планировали Google и Bing. 7 марта 2021 г.
Он не покажет таких результатов, как планировали Google и Bing. 7 марта 2021 г.
В чем разница между Google и Яндексом?
В отличие от Google, у Яндекса проблемы со сканированием и индексированием JavaScript-сайтов. Одностраничные приложения, разработанные исключительно на JavaScript и не подвергавшиеся предварительному (или динамическому) рендерингу, не будут индексироваться Яндексом. Яндекс запутал проблему, когда объявил об обновлении алгоритма Vega ближе к концу 2019 года..
Яндекс безопаснее Google?
Для жителей Северной Америки есть некоторые преимущества конфиденциальности. поскольку Яндекс является конкурентом Google, приложения Яндекса не будут свободно делиться информацией с Google или их приложениями. Это может сделать приложения Яндекса менее опасными для безопасности, чем приложения Google или многие, если не большинство приложений для мобильных телефонов, если вы не являетесь международной корпорацией.
Какие плюсы и минусы у Яндекса?
– Плюсы.
— российская интернет-держава. Яндекс — №
— Экономика. Россия является одной из ведущих развивающихся экономик мира.
– Талант. Поисковые системы невероятно сложны.
– Минусы.
— Зависимость. Большая часть доходов Яндекса поступает от рекламы.
— Политика.
— Конкуренция.
Есть ли в России свой поисковик?
Яндекс Поиск (Яндекс) — поисковая система. Он принадлежит Яндексу, базирующемуся в России. По данным LiveInternet, в январе 2015 года поиск Яндекса генерировал 51,2% всего поискового трафика в России.
Как работает поисковая система Яндекс?
Поисковая система Яндекса отвечает на запросы пользователей релевантными веб-документами, которые находит в Интернете. Поисковая система работает в два этапа. Во-первых, он сканирует Интернет, сохраняя свою «копию» на своих серверах. Во-вторых, он отвечает на поисковый запрос пользователя, получая ответ со своих серверов.
Отличия поисковых систем: Google, Bing, Yandex и др.
Сэм Марсден
SEO и Content Manager
Давайте поделимся
Теперь, когда мы рассмотрели основы работы поисковых систем, стоит воспользоваться этой возможностью, чтобы разобрать некоторые ключевые различия между некоторыми из основных поисковых систем: Google , Bing, Яндекс и Baidu.
- Google — Google был запущен в 1998 году, и если вы не жили на другой планете, вы знаете, что Google на сегодняшний день является наиболее широко используемой поисковой системой с точки зрения объема поиска и является основным направлением для больше всего в поисковой оптимизации (SEO).
- Bing — Bing, принадлежащий Microsoft, запущен в 2009 году и занимает второе место в мире по объему поиска.
- Яндекс – Популярная поисковая система в России и крупнейшая технологическая компания в России.
- Baidu — доминирующая поисковая система, используемая в Китае, и 4-й по популярности сайт согласно рейтингу Alexa 500.
Теперь, когда вы знаете, что есть на рынке поисковых систем, давайте рассмотрим несколько областей, в которых они различаются.
Индексация устройств
Компания Google делает шаг к индексации, ориентированной на мобильные устройства, при которой они будут использовать мобильную версию контента сайта для ранжирования страниц с этого сайта, а не версию для ПК.
В 2018 году Google также планирует выпустить обновление скорости страницы для мобильных устройств, что означает, что скорость страницы станет фактором ранжирования в мобильном поиске.
Кристи Олсон, глава отдела евангелизации поиска Bing в Microsoft, заявила, что у них нет планов по развертыванию мобильного индекса, аналогичного Google.
Яндекс начал помечать страницы, оптимизированные для мобильных устройств, в своем индексе с ноября 2015 года, а в 2016 году внедрил алгоритм для мобильных устройств.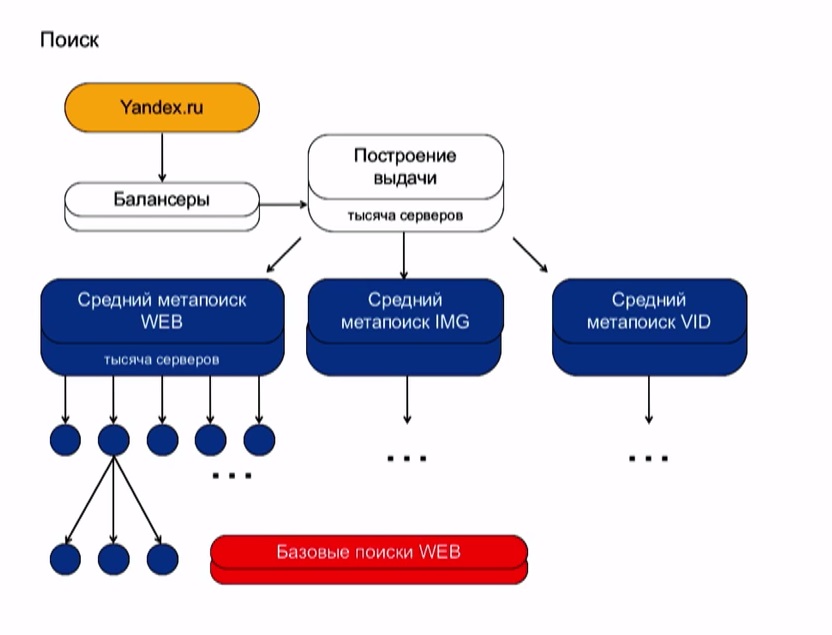
Алгоритм для мобильных устройств под кодовым названием считались удобными для мобильных устройств и удалялись из результатов поиска, но было заявлено, что такие страницы потенциально не будут иметь такого заметного рейтинга для пользователей поиска, использующих мобильные устройства.
«Внедрение во Владивостоке не означает, что веб-страницы, не оптимизированные для мобильных устройств, теперь исчезнут из результатов поиска, но их позиция в SERPS может различаться в зависимости от того, выполняет ли пользователь поиск на своем мобильном или настольном компьютере»,
Результаты мобильного поиска Baidu существенно различаются в зависимости от того, считается ли страница удобной для мобильных устройств. Также стоит отметить, что Baidu использует транскодирование для преобразования веб-страниц, не оптимизированных для мобильных устройств, в страницы, созданные Baidu для мобильных устройств.
Обратные ссылки как сигнал ранжирования
Google фокусируется на качестве обратных ссылок, а не на их объеме, согласно эмпирическим и неподтвержденным данным.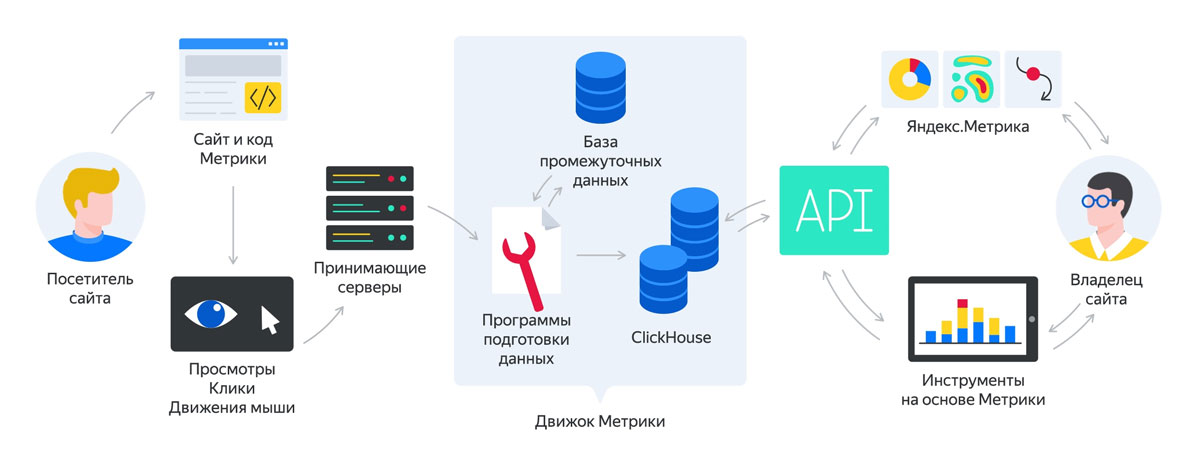
Раньше объем обратных ссылок был ключевым сигналом ранжирования, что приводило к получению множества низкокачественных ссылок компаниями, покупающими обратные ссылки в ссылочных фермах и сетях.
Bing использует информацию об обратных ссылках почти так же, как и Google, в соответствии с их рекомендациями для веб-мастеров, а также в отдельных отчетах.
Руководство Bing для веб-мастеров гласит:
«Дело в том, что Bing хочет видеть качественные ссылки, ведущие на ваш сайт. Часто даже нескольких качественных внешних ссылок с надежных веб-сайтов достаточно, чтобы повысить ваш рейтинг. Как и в случае с контентом, когда дело доходит до ссылок, качество важнее всего».
Яндекс прекратили использовать данные обратных ссылок в своих алгоритмах ранжирования в определенных вертикалях с 2014 года.
Примерно через год данные обратных ссылок были повторно введены в их алгоритмы, и теперь они предоставляют следующее предупреждение об использовании купленных ссылок, предназначенных для повышения поискового рейтинга:
«Публикация SEO-ссылок на других сайтах для продвижения собственного сайта.
К таким ссылкам относятся, в частности, ссылки, которые покупаются через биржи ссылок и агрегаторы».
Известно, что, подобно Google и Bing, Яндекс ищет качественные релевантные ссылки из авторитетных источников, но сами по себе обратные ссылки не являются решающим фактором ранжирования.
Baidu ценит обратные ссылки с веб-сайтов из Китая гораздо больше, чем с иностранных сайтов. Сообщается, что Baidu отстает от других основных поисковых систем в отношении обнаружения ссылочного спама.
Тактика ссылочного спама по-прежнему эффективна для повышения рейтинга в результатах поиска Baidu и поэтому продолжает использоваться для продвижения китайских веб-сайтов.
Социальные сети как фактор ранжирования
Google официально не использует социальные сети в качестве фактора ранжирования. Мэтт Каттс объяснил, что это связано с трудностями понимания социальной идентичности, а также с тем, что Google хочет избежать использования данных, которые могут быть неполными или вводящими в заблуждение.