Файл robots txt — основные директивы и инструкция по редактированию в Нубексе
Robots.txt — это текстовый файл, который содержит специальные инструкции для роботов-поисковиков, исследующих ваш сайт в интернете. Такие инструкции — они называются директивами — могут запрещать к индексации некоторые страницы сайта, указывать на правильное «зеркалирование» домена и т.д.
Для сайтов, работающих на платформе «Нубекс», файл с директивами создается автоматически и располагается по адресу domen.ru/robots.txt, где domen.ru — доменное имя сайта. Например, с содержанием файла для сайта nubex.ru можно ознакомиться по адресу nubex.ru/robots.txt.
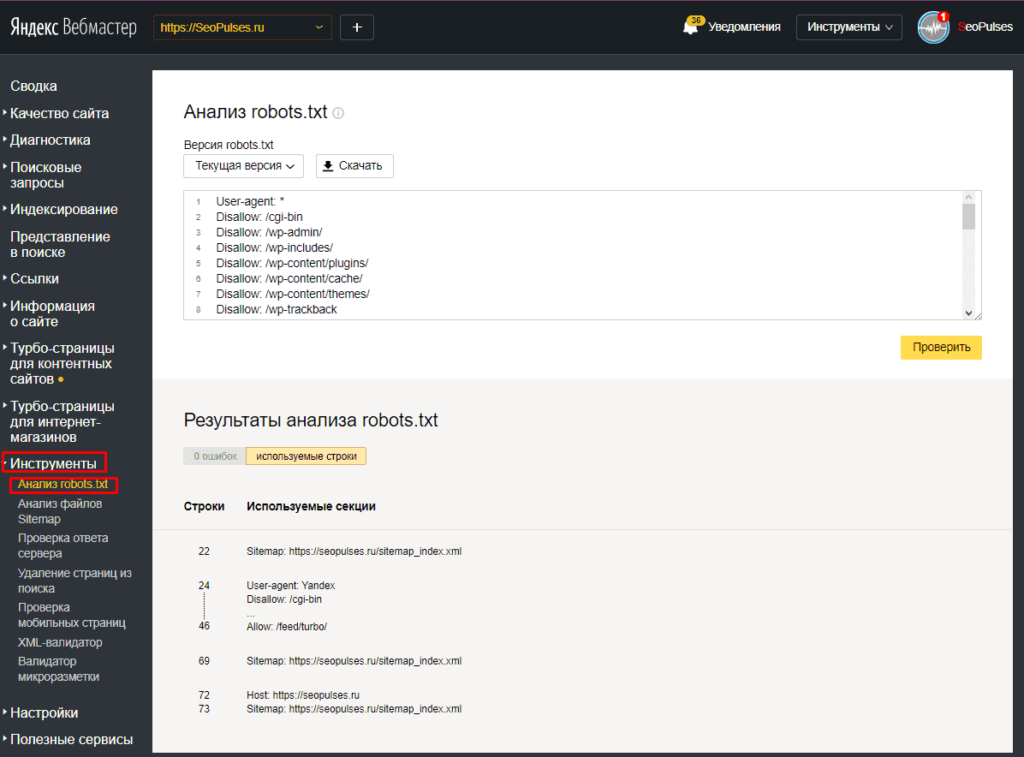
Изменить robots.txt и прописать дополнительные директивы для поисковиков можно в админке сайта. Для этого на панели управления выберите раздел «Настройки», а в нем — пункт «SEO».
Найдите поле «Текст файла robots.txt» и пропишите в нем нужные директивы. Желательно активировать галочку «Добавить в robots.txt ссылку на автоматически генерируемый файл sitemap.xml»: так поисковый бот сможет загрузить карту сайта и найти все необходимые страницы для индексации.
Желательно активировать галочку «Добавить в robots.txt ссылку на автоматически генерируемый файл sitemap.xml»: так поисковый бот сможет загрузить карту сайта и найти все необходимые страницы для индексации.
Не забудьте сохранить страницу после внесения необходимых изменений.
Загружая robots.txt, поисковый робот первым делом ищет запись, начинающуюся с User-agent: значением этого поля должно являться имя робота, которому в этой записи устанавливаются права доступа. Т.е. директива User-agent — это своего рода обращение к роботу.
1. Если в значении поля User-agent указан символ «*», то заданные в этой записи права доступа распространяются на любых поисковых роботов, запросивших файл /robots.txt.
2. Если в записи указано более одного имени робота, то права доступа распространяются для всех указанных имен.
3. Заглавные или строчные символы роли не играют.
4. Если обнаружена строка User-agent: ИмяБота, директивы для User-agent: * не учитываются (это в том случае, если вы делаете несколько записей для различных роботов). Т.е. робот сначала просканирует текст на наличие записи User-agent: МоеИмя, и если найдет, будет следовать этим указаниям; если нет — будет действовать по инструкциям записи User-agent: * (для всех ботов).
Если обнаружена строка User-agent: ИмяБота, директивы для User-agent: * не учитываются (это в том случае, если вы делаете несколько записей для различных роботов). Т.е. робот сначала просканирует текст на наличие записи User-agent: МоеИмя, и если найдет, будет следовать этим указаниям; если нет — будет действовать по инструкциям записи User-agent: * (для всех ботов).
Кстати, перед каждой новой директивой User-agent рекомендуется вставлять пустой перевод строки (Enter).
5. Если строки User-agent: ИмяБота и User-agent: * отсутствуют, считается, что доступ роботу не ограничен.
Запрет и разрешение индексации сайта: директивы Disallow и Allow
Чтобы запретить или разрешить поисковым ботам доступ к определенным страницам сайта, используются директивы Disallow и Allow соответственно.
В значении этих директив указывается полный или частичный путь к разделу:
- Disallow: /admin/ — запрещает индексацию всех страниц, находящихся внутри раздела admin;
- Disallow: /help — запрещает индексацию и /help.
 html, и /help/index.html;
html, и /help/index.html; - Disallow: /help/ — закрывает только /help/index.html;
- Disallow: / — блокирует доступ ко всему сайту.
Если значение Disallow не указано, то доступ не ограничен:
- Disallow: — разрешена индексация всех страниц сайта.
Для настройки исключений можно использовать разрешающую директиву Allow. Например, такая запись запретит роботам индексировать все разделы сайта, кроме тех, путь к которым начинается с /search:
User-agent: *
Allow: /search
Disallow: /
Неважно, в каком порядке будут перечислены директивы запрета и разрешения индексации. При чтении робот все равно рассортирует их по длине префикса URL (от меньшего к большему) и применит последовательно. То есть пример выше в восприятии бота будет выглядеть так:
User-agent: *
Disallow: /
Allow: /search
— разрешено индексировать только страницы, начинающиеся на /search. Таким образом, порядок следования директив никак не повлияет на результат.
Таким образом, порядок следования директив никак не повлияет на результат.
Директива Host: как указать основной домен сайта
Если к вашему сайту привязано несколько доменных имен (технические адреса, зеркала и т.д.), поисковик может решить, что все это — разные сайты. Причем с одинаковым наполнением. Решение? В бан! И одному боту известно, какой из доменов будет «наказан» — основной или технический.
Чтобы избежать этой неприятности, нужно сообщить поисковому роботу, по какому из адресов ваш сайт участвует в поиске. Этот адрес будет обозначен как основной, а остальные сформируют группу зеркал вашего сайта.
Сделать это можно с помощью директивы Host. Ее нужно добавить в запись, начинающуюся с User-Agent, непосредственно после директив Disallow и Allow. В значении директивы Host нужно указать основной домен с номером порта (по умолчанию 80). Например:
User-Agent: *
Disallow:
Host: test-o-la-la.ru
Такая запись означает, что сайт будет отображаться в результатах поиска со ссылкой на домен test-o-la-la. ru, а не www.test-o-la-la.ru и s10364.nubex.ru (см. скриншот выше).
ru, а не www.test-o-la-la.ru и s10364.nubex.ru (см. скриншот выше).
В конструкторе «Нубекс» директива Host добавляется в текст файла robots.txt автоматически, когда вы указываете в админке, какой домен является основным.
В тексте robots.txt директива host может использоваться только единожды. Если вы пропишите ее несколько раз, робот воспримет только первую по порядку запись.
Директива Crawl-delay: как задать интервал загрузки страниц
Чтобы обозначить роботу минимальный интервал между окончанием загрузки одной страницы и началом загрузки следующей, используйте директиву Crawl-delay. Ее нужно добавить в запись, начинающуюся с User-Agent, непосредственно после директив Disallow и Allow. В значении директивы укажите время в секундах.
User-Agent: *
Disallow:
Crawl-delay: 3
Использование такой задержки при обработке страниц будет удобным для перегруженных серверов.
Существуют также и другие директивы для поисковых роботов, но пяти описанных — User-Agent, Disallow, Allow, Host и Crawl-delay — обычно достаточно для составления текста файла robots. txt.
txt.
Настройка Robots.txt. Подробное руководство
Зачем нужна настройка robots.txt?
Robots.txt — это файл, размещенный в корневом каталоге сайта, который сообщает роботам поисковых систем, к каким разделам и страницам сайта они могут получить доступ, а к каким нет.
Настройка robots.txt — важная часть SEO-работ по повышению позиций сайта в выдаче поисковых систем, правильно настроенный robots также увеличивает производительность сайта. Отсутствие Robots.txt не остановит поисковые системы сканировать и индексировать сайт, но если этого файла у вас нет, у вас могут появиться две проблемы:
-
Поисковый робот будет считывать весь сайт, что «подорвет» краулинговый бюджет.
 Краулинговый бюджет — это число страниц, которые поисковый робот способен обойти за определенный промежуток времени.
Краулинговый бюджет — это число страниц, которые поисковый робот способен обойти за определенный промежуток времени.
Без файла robots, поисковик получит доступ к черновым и скрытым страницам, к сотням страниц, используемых для администрирования CMS. Он их проиндексирует, а когда дело дойдет до нужных страниц, на которых представлен непосредственный контент для посетителей, «закончится» краулинговый бюджет.
-
В индекс может попасть страница входа на сайт, другие ресурсы администратора, поэтому злоумышленник сможет легко их отследить и провести ddos атаку или взломать сайт.
Как поисковые роботы видят сайт с robots.txt и без него:
Синтаксис robots.txt
Прежде чем начать разбирать синтаксис и настраивать robots.txt, посмотрим на то, как должен выглядеть «идеальный файл»:
Но не стоит сразу же его применять. Для каждого сайта чаще всего необходимы свои настройки, так как у всех у нас разная структура сайта, разные CMS. Разберем каждую директиву по порядку.
Для каждого сайта чаще всего необходимы свои настройки, так как у всех у нас разная структура сайта, разные CMS. Разберем каждую директиву по порядку.
Читайте также Медленные сайты убивают продажи — как это исправить
User-agent
User-agent — определяет поискового робота, который обязан следовать описанным в файле инструкциям. Если необходимо обратиться сразу ко всем, то используется значок *. Также можно обратиться к определенному поисковому роботу. Например, Яндекс и Google:
Disallow
С помощью этой директивы, робот понимает какие файлы и папки индексировать запрещено. Если вы хотите, чтобы весь ваш сайт был открыт для индексации оставьте значение Disallow пустым. Чтобы скрыть весь контент на сайте после Disallow поставьте “/”.
Мы можем запретить доступ к определенной папке, файлу или расширению файла. В нашем примере, мы обращаемся ко всем поисковым роботам, закрываем доступ к папке bitrix, search и расширению pdf.
В нашем примере, мы обращаемся ко всем поисковым роботам, закрываем доступ к папке bitrix, search и расширению pdf.
Allow
Allow принудительно открывает для индексирования страницы и разделы сайта. На примере выше мы обращаемся к поисковому роботу Google, закрываем доступ к папке bitrix, search и расширению pdf. Но в папке bitrix мы принудительно открываем 3 папки для индексирования: components, js, tools.
Host — зеркало сайта
Зеркало сайта — это дубликат основного сайта. Зеркала используются для самых разных целей: смена адреса, безопасность, снижение нагрузки на сервер и т. д.
Host — одно из самых важных правил. Если прописано данное правило, то робот поймет, какое из зеркал сайта стоит учитывать для индексации. Данная директива необходима для роботов Яндекса и Mail.ru. Другие роботы это правило будут игнорировать. Host прописывается только один раз!
Для протоколов «https://» и «http://», синтаксис в файле robots. txt будет разный.
txt будет разный.
Sitemap — карта сайта
Карта сайта — это форма навигации по сайту, которая используется для информирования поисковых систем о новых страницах. С помощью директивы sitemap, мы «насильно» показываем роботу, где расположена карта.
Символы в robots.txt
Символы, применяемые в файле: «/, *, $, #».
Проверка работоспособности после настройки robots.txt
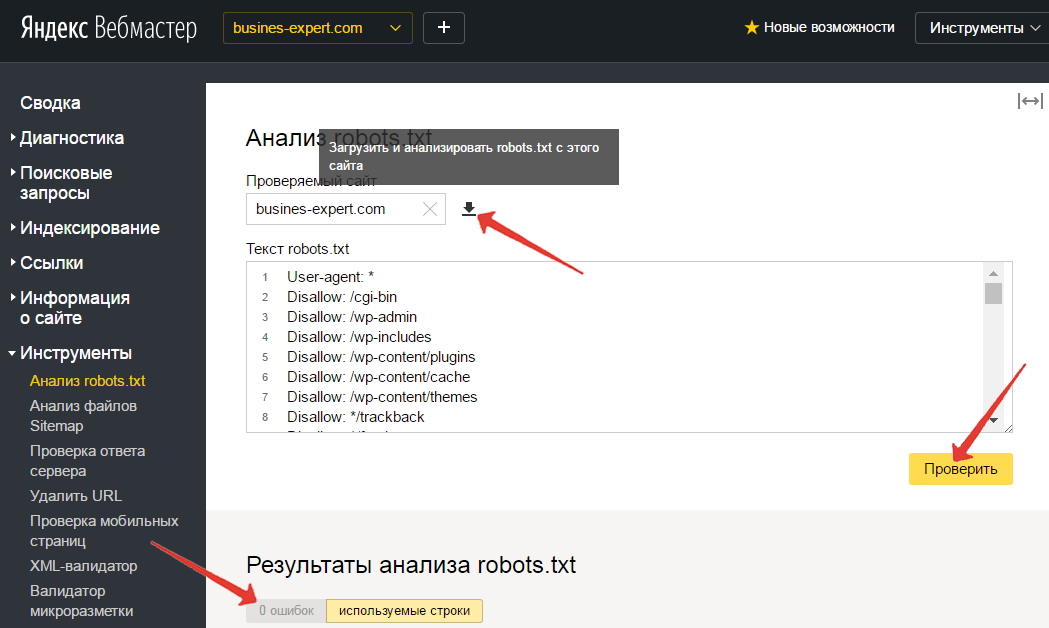
После того как вы разместили Robots.txt на своем сайте, вам необходимо добавить и проверить его в вебмастере Яндекса и Google.
Проверка Яндекса:
- Перейдите по ссылке.
- Выберите: Настройка индексирования — Анализ robots.txt.
Проверка Google:
- Перейдите по ссылке.
- Выберите: Сканирование — Инструмент проверки файла robots.txt.
Таким образом вы сможете проверить свой robots. txt на ошибки и внести необходимые настройки, если потребуется.
txt на ошибки и внести необходимые настройки, если потребуется.
В заключение приведу 6 главных рекомендаций по работе с файлом Robots.txt:
- Содержимое файла необходимо писать прописными буквами.
- В директиве Disallow нужно указывать только один файл или директорию.
- Строка «User-agent» не должна быть пустой.
- User-agent всегда должна идти перед Disallow.
- Не стоит забывать прописывать слэш, если нужно запретить индексацию директории.
- Перед загрузкой файла на сервер, обязательно нужно проверить его на наличие синтаксических и орфографических ошибок.
Успехов вам!
Видеообзор 3 методов создания и настройки файла Robots.txt
-
Хотите, чтобы ваш сайт реально продавал? Готовы работать вместе с нами? Оформите заявку
Как создать файл robots.
 txt в cPanel Искать
txt в cPanel ИскатьСодержание
Если вы когда-либо создавали свой веб-сайт, возможно, вы слышали о файле robotx.txt и задавались вопросом, для чего этот файл? Ну, вы в правильном месте! Ниже мы рассмотрим этот файл и его важность.Что такое файл robots.txt?
Во-первых, robots.txt — это не что иное, как обычный текстовый файл (ASCII или UTF-8), расположенный в корневом каталоге вашего домена , который блокирует (или разрешает) поисковым системам доступ к определенным областям вашего сайта. robots.txt содержит простой набор команд (или директив) и обычно применяется для ограничения трафика поисковых роботов на ваш сервер, что предотвращает нежелательное использование ресурсов.
Поисковые системы используют так называемые сканеры (или боты) для индексации частей веб-сайта и возврата их в качестве результатов поиска. Возможно, вы захотите, чтобы определенные конфиденциальные данные, хранящиеся на вашем сервере, были недоступны для веб-поиска.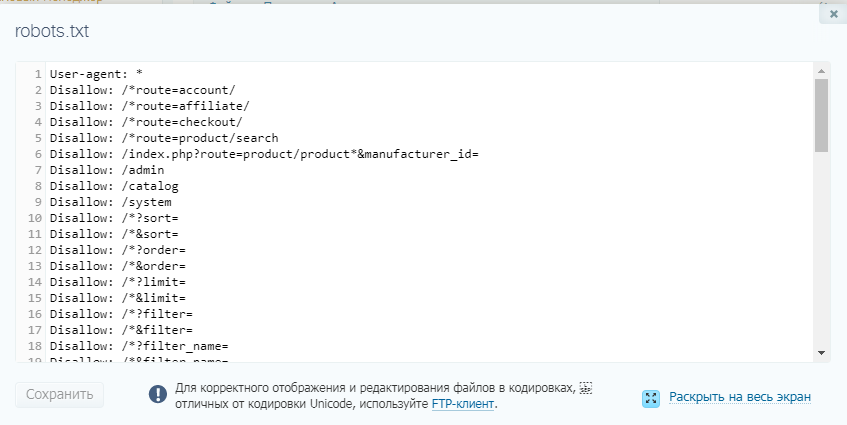 Файл robots.txt поможет вам сделать это.
Файл robots.txt поможет вам сделать это.
Примечание: Файлы или страницы на вашем веб-сайте не удаляются полностью из поисковых роботов, если эти файлы проиндексированы или на них есть ссылки с других веб-сайтов. Чтобы ваш URL не отображался в поисковых системах Google, вы можете защитить файлы паролем прямо с вашего сервера.
Как создать файл robots.txt
Чтобы создать файл robots.txt (если он еще не существует), выполните следующие действия:
1. Войдите в свою учетную запись cPanel
2. Перейдите в раздел ФАЙЛЫ и нажмите Диспетчер файлов
cPanel > Файлы > Диспетчер файлов Файл ” >> Введите «robots.txt» >> Нажмите « Создать новый файл ».4. Теперь вы можете редактировать содержимое этого файла, дважды щелкнув по нему.
Примечание: можно создать только один r файл obots.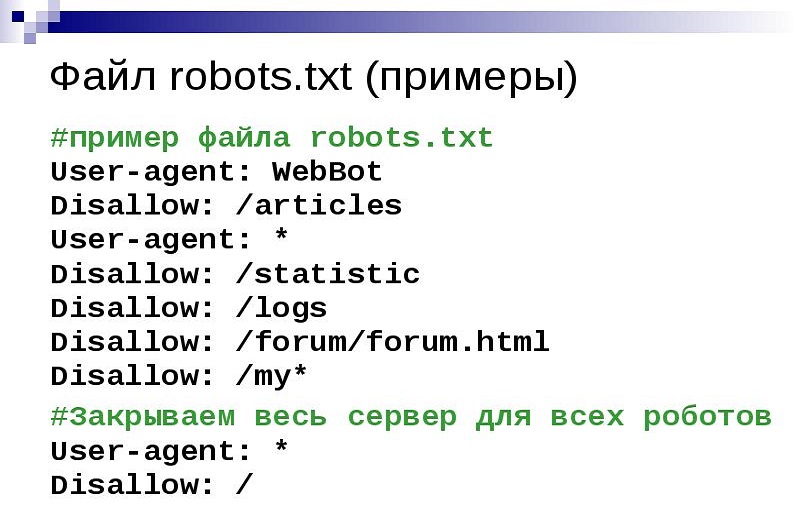 txt для каждого домена. Дубликаты не допускаются на одном и том же корневом пути. Каждый домен или субдомен должен содержать собственный файл robots.txt .
txt для каждого домена. Дубликаты не допускаются на одном и том же корневом пути. Каждый домен или субдомен должен содержать собственный файл robots.txt .
Примеры правил использования и синтаксиса
Обычно файл robots.txt содержит одно или несколько правил, каждое из которых находится в отдельной строке. Каждое правило блокирует или разрешает доступ данному сканеру к указанному пути к файлу или ко всему веб-сайту.
- Запретить всем сканерам (пользовательским агентам) доступ к каталогам журналов и ssl .
Агент пользователя:* Запретить: /журналы/ Запретить: /ssl/
- Заблокировать все поисковые роботы для индексации всего сайта.
Агент пользователя: * Disallow: /
- Разрешить всем пользовательским агентам доступ ко всему сайту.
Агент пользователя: * Разрешить: /
- Запретить индексацию всего сайта от определенного поискового робота.

Агент пользователя: Bot1 Disallow: /
- Разрешить индексирование для определенного поискового робота и предотвратить индексирование другими.
Агент пользователя: Googlebot Запретить: Пользовательский агент: * Disallow: /
- Под User-agent : вы можете ввести имя конкретного поискового робота. Вы также можете включить все поисковые роботы, просто введя символ звездочки (*). С помощью этой команды вы можете отфильтровать все поисковые роботы, кроме сканеров AdBot, которые необходимо перечислить явно. Вы можете найти список всех сканеров в Интернете.
- Кроме того, чтобы команды Allow и Disallow работали только для определенного файла или папки, вы всегда должны включать их имена между « / ».
- Заметили, что обе команды чувствительны к регистру? Особенно важно знать, что по умолчанию агенты сканера имеют доступ к любой странице или каталогу, если они не заблокированы правилом Disallow : .

Примечание: Полные правила и примеры синтаксиса можно найти здесь.
Обновлено 13 января 2023 г.
Была ли эта статья полезной?
Да Нет
Статьи по теме
🔥 Время Супер Экономии!
Получите скидку 65% на хостинг-планы + бесплатный домен и SSL!
👉 Начать сохранение
Редактировать файл robots.txt
Файл robots.txt определяет, как веб-роботы получают доступ и индексируют страницы вашего магазина.
Для получения дополнительной информации о robots.txt и исключение роботов
Протокол, посетите www.robotstxt.org.
Если вы запускаете несколько сайтов в одном экземпляре Commerce, каждый сайт имеет свой собственный файл robots.txt .
См. Настройка
Сайты, чтобы научиться создавать несколько
места.
Чтобы просмотреть текущий файл robots.txt вашего магазина:
- Введите следующий URL-адрес в адресную строку браузера:
https://[адрес магазина]/robots.txt, где [URL-адрес магазина] — это базовый URL-адрес вашего магазина.
- Commerce отображает содержимое текущего
файл robots.txt.
Если вы запускаете несколько сайтов и храните языковые версии в каталогах, например, example.com/de/, example.com/es/, вам не нужно создавать отдельный файл robot.txt для каждой версии. Это только случай для нескольких сайтов на поддоменах.
Торговля robots.txt В приведенном ниже файле показан обновленный
содержание после того, как эти рекомендации были сделаны:
Агент пользователя: * Запретить: /корзина Запретить: /en/cart Запретить: /checkout Запретить: /en/checkout Запретить: /профиль Запретить: /ru/профиль Запретить: /searchresults Запретить: /en/searchresults Запретить: /подтверждение Запретить: /en/confirmation Запретить: /wishlist_settings Запретить: /en/wishlist_settings Запретить: /список желаний Запретить: /en/wishlist Карта сайта: http://[URL-адрес магазина]:8080/sitemap.xml
User-agent: * означает, что правила исключения должны применяться ко всем роботам. Вы можете заменить * (звездочку) на имя конкретного робота, чтобы исключить, например, Googlebot или Bingbot.
Каждая запись Disallow: /[page] указывает на страницу, которую роботы не должны посещать. Не следует удалять какие-либо записи Disallow: из стандартного файла robots.txt , хотя вы можете включить дополнительные страницы, которые вы хотите, чтобы роботы игнорировали. Если вы тестируете свой магазин и не хотите, чтобы какие-либо роботы сканировали какие-либо страницы, вы можете захотеть, чтобы ваш файл robots.txt выглядел следующим образом:
User-agent: * Disallow: /
Если вы планируете использовать свой промежуточный сайт в качестве рабочего сайта при разработке и
тестирование завершено, вам нужно будет изменить содержимое в
robots.txt к пользовательским настройкам, представленным выше. Если вы
проверено на отдельном промежуточном домене, Commerce вводит для вас действительный файл robots.txt по умолчанию для вашего производства.
витрина магазина, когда вы выходите в эфир.
Если вы
проверено на отдельном промежуточном домене, Commerce вводит для вас действительный файл robots.txt по умолчанию для вашего производства.
витрина магазина, когда вы выходите в эфир.
Вы не можете редактировать файл robots.txt в пользовательском интерфейсе администратора. Вы должны отредактировать его с помощью REST API коммерческого администратора. См. Использование REST API для получения информации об REST API.
Чтобы обновить файл robots.txt , отправьте запрос PUT на адрес /ccadmin/v1/merchant/robots . Тело запроса должно включать все содержимое файла в текстовом/простом формате.
При обновлении файла robots.txt он не будет перезаписан до тех пор, пока следующий запрос PUT не будет отправлен на адрес /ccadmin/v1/merchant/robots .
Если вы запускаете несколько сайтов в одном экземпляре Commerce, вы должны указать сайт, чей robots.txt файл вы
обновление заголовка x-ccsite в запросе PUT. Если вы сделаете
не указывать сайт, запрос обновляет сайт по умолчанию файл robots.txt .
В следующем примере показан запрос PUT, который добавляет вашу страницу с ошибкой в список страниц, которые роботы должны игнорировать.
ПОЛОЖИТЬ /ccadmin/v1/торговец/роботы HTTP/1.1 Content-Type: текстовый/обычный Авторизация: носитель{ Пользовательский агент: * Запретить: /корзина Запретить: /checkout Запретить: /профиль Запретить: /searchresults Запретить: /подтверждение Запретить: /wishlist_settings Запретить: /список желаний Запретить: /ошибка Карта сайта: http://{occs-host}/sitemap. xml}
Примечание. XML-карта сайта — это индекс URL-адресов страниц в вашем магазине, доступный для сканирования поисковыми системами. Это помогает поисковым системам сканировать ваш сайт более разумно. В созданные карты сайта включаются только те страницы, продукты и коллекции, которые могут просматривать анонимные покупатели (то есть посетители вашего магазина, которые не вошли в систему). Каждый файл sitemap.xml содержит тег , который содержит дату и время последней публикации элемента. Дополнительную информацию см. в разделе Общие сведения о картах сайта XML.
Загрузить пользовательский robots.txt файл
Конечная точка updateRobotsFile позволяет вам
загрузить пользовательский robots.txt файл. Однако в предыдущих версиях Commerce при публикации или запуске RobotsManager
автоматически заменил этот обычай robots. с
автоматически сгенерированный. В этом случае было целесообразно
связаться со службой поддержки, которые должны были вручную
отключить автоматический  txt
txt robots.txt поколение.
В текущей версии Commerce конечная точка updateRobotsFile автоматически отключает автоматическую robots.txt генерация файла. Кроме того, новая конечная точка /ccadmin/v1/merchant/seoConfig позволяет запрашивать или обновлять статус
автоматической генерации файла robots.txt .
Понимание страниц результатов внутреннего поиска
Внутренний поиск относится к параметру поиска на вашем собственном веб-сайте при создании страниц результатов внутреннего поиска. Во избежание создания некачественных страниц результаты внутреннего поиска исключаются из сканирования в robots.