Запуск запросов: режим «только для чтения», планировщик, SQL-журнал
Консоль запросов
По опыту знаем, что консоль запросов — лучшее место для повседневной работы с SQL. Для каждого источника данных предусмотрена собственная консоль по умолчанию. Чтобы ее открыть, выберите Open Console в контекстном меню или нажмите F4.
Здесь вы можете написать SQL-запрос, запустить его и получить результат. Все просто.
Если вы вдруг захотите создать другую консоль для источника данных, сделайте это в меню: Context menu → New → Console.
Переключатель схем
Создавайте столько консолей запросов, сколько вам нужно, и запускайте запросы одновременно. У каждой консоли есть переключатель схем и баз данных. Если вы работаете с PostgreSQL , составьте здесь search_path.
Запуск выделенного фрагмента
Выделите фрагмент кода и запустите только его. Выбранный запрос посылается в базу «как есть», без дополнительной обработки jdbc-драйвером. Это может быть полезно, когда по той или иной причине IDE думает, что в запросе есть ошибка.
Это может быть полезно, когда по той или иной причине IDE думает, что в запросе есть ошибка.
Настройки выполнения
Выполнять запрос можно несколькими способами. Поведение запуска запросов под кареткой можно настраивать. Возможные варианты того, что можно запустить: подзапрос, весь запрос, все после каретки, весь скрипт или предложить выбор.
Можно настроить три варианта поведения для запуска (Execute). По умолчанию, сочетание клавиш есть только у первого, но вы можете выбрать их и для остальных. Например, настроим два поведения: «показать выбор» и «запустить весь скрипт».
На видео пример, как сначала выполнено одно действие, затем второе.
Режим «только для чтения»
Режим «только для чтения» включайте в настройках источника данных: флажок Read-Only. Этот флажок включает сразу два режима: на уровне IDE и на уровне jdbc-драйвера .
На уровне jdbc-драйвера в режиме «для чтения» запросы, которые вносят изменения, нельзя запускать в базах: MySQL,
PostgreSQL, AWS Redshift, h3 и Derby. В других СУБД этот режим не работает.
В других СУБД этот режим не работает.
Поэтому мы сделали свой режим «только для чтения». Он включается одновременно с режимом на уровне драйвера. IDE понимает, какие запросы приведут к изменениям, и подчеркивает их. При запуске запроса DataGrip покажет предупреждение. Такой запрос можно запустить, нажав Execute на всплывающей панели, если вы точно уверены в том, что делаете.
DataGrip также индексирует все исходники функций и процедур и строит внутри дерево вызовов. Это значит, что если вы запускаете процедуру, которая запускает процедуру (повторите
Контроль транзакций
Выберите контроль транзакций, который больше подходит вашей работе. Эта настройка есть в свойствах источника данных. В автоматическим режиме (флажок Auto) вам не надо каждый раз фиксировать транзакцию, а вот в ручном режиме (Manual), очевидно, надо.
Быстрый просмотр результата
Результаты запроса или выражения можно посмотреть во всплывающем окне. В других IDE на платформе IntelliJ Ctrl+Alt+F8 показывает результат вычисления выражения. В DataGrip то же самое работает для отображения результатов запуска. Если нажать эту комбинацию когда курсор на столбце, вы увидите ожидаемые значения этого столбца в результатах запроса. Та же самая операция на любом ключевом слове запроса покажет всплывающее окно с результатом. Клик мышкой при зажатом Alt работает так же.
В других IDE на платформе IntelliJ Ctrl+Alt+F8 показывает результат вычисления выражения. В DataGrip то же самое работает для отображения результатов запуска. Если нажать эту комбинацию когда курсор на столбце, вы увидите ожидаемые значения этого столбца в результатах запроса. Та же самая операция на любом ключевом слове запроса покажет всплывающее окно с результатом. Клик мышкой при зажатом Alt работает так же.
История запущенных запросов
На панели инструментов каждой консоли есть такая кнопка: . Нажмите ее, чтобы увидеть историю всех запросов, выполненных в этом источнике данных из DataGrip. Еще здесь работает быстрый поиск!
Не забудьте и о локальной истории каждого файла.
Полный SQL-журнал
Буквально все запросы, которые запускает DataGrip, записываются в текстовый файл. Чтобы открыть его, используйте меню Help | Show SQL log.
Запуск хранимых процедур
DataGrip умеет генерировать код для запуска процедур. Укажите значения для параметров и нажмите OK.
Укажите значения для параметров и нажмите OK.
Когда процедура открыта в редакторе, вы можете ее запустить, нажав Run на панели инструментов. Или используйте контекстное меню и выберите пункт Execute…
Небезопасные запросы
DataGrip предупредит, если вы собираетесь запустить запросы DELETE и UPDATE без предложения WHERE.
Планировщик запросов
План запросов покажет, как база данных собирается выполнить ваш запрос. Это помогает в оптимизации.
План запросов может быть представлен в виде дерева или диаграммы.
Запросы с параметрами
В запросе могут быть параметры. DataGrip умеет запускать такие запросы.
Описать синтаксис параметров можно в Settings/Preferences → Database → User Parameters. Регулярные выражения для их описания подсвечиваются, а еще для каждого вида параметров можно указать SQL-диалект.
Структурный вид
Каждую консоль или файл можно открыть в структурном виде: в окне появится список запросов. Чтобы открыть структурный вид, используйте сочетание клавиш Ctrl+F12.
Чтобы открыть структурный вид, используйте сочетание клавиш Ctrl+F12.
Результат запроса
Результат запроса
В DataGrip данные в результате простого запроса можно изменять. Используйте все возможности редактора данных: добавляйте, удаляйте строки, выбирайте режим контроля транзакций.
Сравнение результатов
Два результата можно сравнить, используя инструмент поиска различий. DataGrip подсветит те строчки, которые не являются общими для двух результатов. Параметр Tolerance используется для того, чтобы указать, сколько колонок могут иметь разные значения, чтобы строчки все равно считались одинаковыми. Из сравнения можно исключить любой столбец.
Нажмите кнопку сравнения на панели инструментов и выберите результат запроса, с которым нужно сравнить текущий результат.
Имена вкладок
Вы сами можете называть вкладки результатов: напишите имя в комментарии перед запросом.
Если вам не нравится, что любой предшествующий комментарий становится именем, укажите слово, после которого будет идти строка для заголовка. Это делается в соответствующих настройках: поле Prefix.
Это делается в соответствующих настройках: поле Prefix.
Быстрое изменение размера страницы
Меняйте размер страницы в редакторе данных, не заходя в настройки.
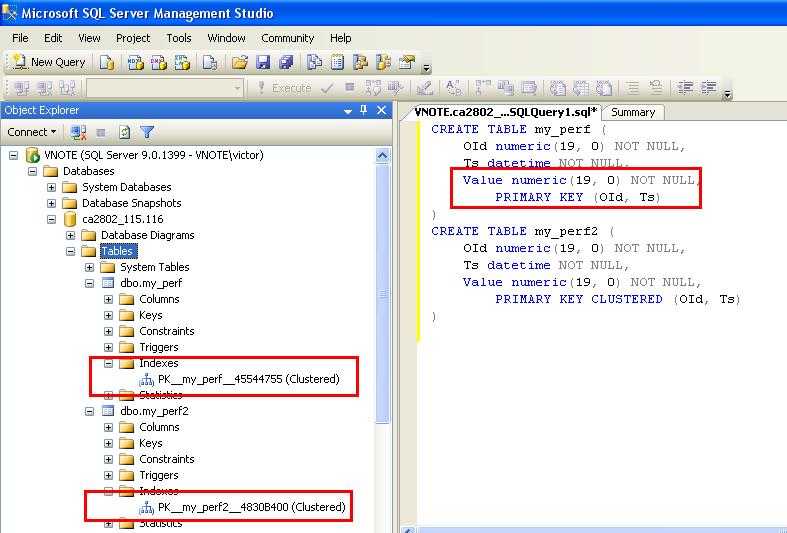
проектирование — Redis, как кэш для SQL запросов в веб-приложении
Вы столкнулись с некоторыми вещами, которые не очень хорошо помещаются в тот мир, в котором вы работали раньше. В какой-то степени можно это назвать просто NoSQL, но это не совсем так, в любом случае могу поздравить с важным шагом в карьере.
Дублирование данных
Первое, о чем хотелось бы сказать:
самое важное — много дублирующихся данных
Дублирующиеся данные сами по себе нормальны. Нормализация базы данных SQL невольно учит нас тому, чтобы данные были в единичном экземпляре, но это, на самом деле, не аксиома. Дублирующиеся данные сложнее поддерживать, но само их наличие в целях улучшения работы приложения — это абсолютно нормально. Кроме этого, стоит вставить мою любимую ремарку про модель работы приложения: если сейчас у вас это де-факто pull-on-change
 Представьте себе некую социальную сеть с лентой новостей. При стандартном подходе (и SQL-бэкенде) придется формировать гигантский SQL-запрос, который будет проверять необходимость показа каждой записи, наличие доступа к ней (мы же не хотим показывать приватные записи, верно?) и прочие атрибуты. Push-on-change же предлагает в этом случае в момент обновления записи в ленте вычислять, кому она должна быть показана, и формировать таблицу вида ‘id пользователя | id записи | datetime’, чтобы просто доставать из нее N первых записей, по которым уже формировать запрос по новостям. Данные в этом случае де-факто будут продублированы, но это необходимо, чтобы ускорить многократные read-операции за счет однократной write-операции. С переходом в хайлоад это становится особенно актуально, потому что один сервер не в состоянии хранить все данные и/или выдержать нагрузку, а поэтому необходимо разделять ответственность между серверами (что может поставить запрет на джойны, например). Однако,
Представьте себе некую социальную сеть с лентой новостей. При стандартном подходе (и SQL-бэкенде) придется формировать гигантский SQL-запрос, который будет проверять необходимость показа каждой записи, наличие доступа к ней (мы же не хотим показывать приватные записи, верно?) и прочие атрибуты. Push-on-change же предлагает в этом случае в момент обновления записи в ленте вычислять, кому она должна быть показана, и формировать таблицу вида ‘id пользователя | id записи | datetime’, чтобы просто доставать из нее N первых записей, по которым уже формировать запрос по новостям. Данные в этом случае де-факто будут продублированы, но это необходимо, чтобы ускорить многократные read-операции за счет однократной write-операции. С переходом в хайлоад это становится особенно актуально, потому что один сервер не в состоянии хранить все данные и/или выдержать нагрузку, а поэтому необходимо разделять ответственность между серверами (что может поставить запрет на джойны, например). Однако,Отказ от подготовки ответов на все запросы
геометрическая прогрессия, конечно, не позволяет подготовить заранее готовые ответы на все возможные запросы:
Вы представьте сколько уже есть дублирующих данных в редисе, а если мы дадим пользователю выбирать кол-во выводимых записей, то тогда появятся такие ключи: articles:list:page_1_55
поэтому от вышеприведенного примера действительно стоит отказаться — у Redis нет столько оперативки (как и от :all — тут проблема не в оперативке, а в количестве данных, которые надо будет передать по сети и затем разобрать). Конкретно в вашем случае есть две вещи, которые я считаю необходимым отметить
Конкретно в вашем случае есть две вещи, которые я считаю необходимым отметить
- Текущий подход работает, де-факто, на кэширование конкретных запросов
- Redis используется как KeyValue-кэш
Первое подразумевает тот самый рост данных в геометрической прогрессии со степенью, зависящей от количества параметров, по которым может проводиться выборка. Вам не обязательно получать из Redis уже готовый ответ — вы можете получать его либо по частям, либо бОльшим куском. В случае со страницами по 55 записей вы можете просто хранить «верхушку» таблицы в редисе:
# пусть верхушка состоит из 500 записей
from = 63
to = 63 + 55
if to < 500:
top_entries = redis.get 'articles:top'
# в редисе может не оказаться ничего или оказаться устаревший и слишком короткий список
if top_entries && top_entries.length > to:
return top_entries.slice from, to
return article_repository.get_slice from, to
В этом случае приложение знает, что у него (возможно) есть кусман на 500 записей в редисе, и запрос, скорее всего, проще обслужить оттуда, поэтому пытается сделать именно это.
В случае со сложной иерархической структурой проще наоборот, разбить сущность на составляющие:
article = redis.get 'article:' + id
if not article:
article = article_repository.get id
if not article:
throw new ResourceNotFoundException
comments = redis.get 'comments:by-article:' + id
if not comments:
comments = comment_repository.get_by_article id
likes = redis.get '
В этом случае вы делаете из сущностей некоторое подобие строительного материала, который не слишком сильно дублируется и позволяет собирать различные результаты на основе одних и тех же источников (например, поиск по статьям в любом случае пойдет через БД, но лайки для них можно вытащить из Redis без особых затрат по времени). Это не самый богатый арсенал, но он поможет избежать избыточного дублирования, которое может возникнуть, если иерархические сущности кэшируются целиком, и, заодно, уменьшит развесистость операции, необходимой для обновления одной атомарной сущности (т.е. не придется сбрасывать половину кэша из-за одного проставленного лайка).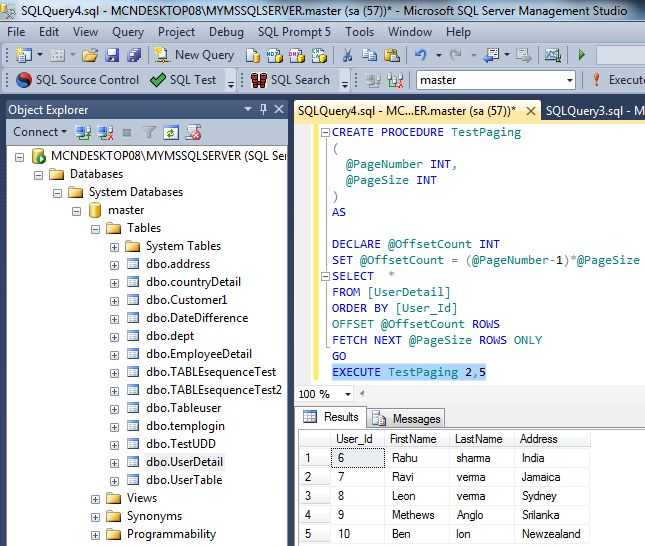
Закешировать всё
Кроме всего вышеописанного, я бы относился немного более практично к идее закешировать всё. Сейчас вы пытаетесь уменьшить нагрузку на сервис за счет кэширования, но переносите в Redis буквально вообще все, но это вам не нужно. До десятой страницы новостей доберется один читатель из сотни — вам действительно нужно оптимизировать ее быстродействие? В том случае, если она срендерится за 100 мс, а не за 10, пользователь это не почувствует, и сервер тоже не почувствует, потому что основная нагрузка у него идет на получение первых записей.
LazyLoad
Все вышеописанное только вскользь говорило о том, как данные попадают в Redis — что в случае добавления записи необходимо пересчитать специально подготовленную выборку. Однако мы знаем, что записи в любом in-memory кэш-сервисе (будь то Redis, Memcache, Aerospike) вечны максимум вплоть до первой перезагрузки машины, и даже подготовленные выборки в этом случае умрут. В этом случае поможет механизм ленивой загрузки — если грубо, то он пытается получить данные из некоего источника данных А, и, если не находит, загружает их из источника Б, кладет в А, и возвращает.
private heavy_object
private settings
get_heavy_object():
if not heavy_object:
heavy_object = new HeavyObject
return heavy_object
get_settings():
if not settings:
settings = read_settings_from_database()
return settings
В случае с кэшем хранилищем А является не переменная, а кэш, а хранилищем Б — БД:
get_article(id):
redis_id = 'article:' + id
article = redis.get redis_id
if not article: # не обнаружен в Redis - ищем в БД
article = repository.get id
if not article: # значит, он вообще не существует
return null
redis.put id, article # кладем в Redis для последующих вызовов
return article
Если вы будете применять эту парадигму везде, то приложению можно будет хоть живьем подменить Redis, оно все равно будет работать. Кроме того — для меня это самый важный пункт — в этом случае можно спокойно инвалидировать существующий кэш, не боясь за само приложение (но, конечно, стоит иметь в виду резко возрастающую нагрузку на БД).
Инвалидация (и немного про CAP)
Следующий вопрос, который у вас так же возникает — это инвалидация данных, т.е., когда они должны исчезнуть из кэша или обновиться. Самый напроломный вариант — это обновление данных in-place, т.е., как только обновилась сущность, обновились и все связи в кэше. Однако, это плохой вариант — точнее, он отличный, но его невероятно сложно реализовать, не забыв про что-то и не раздув код до невероятных размеров. В случае, если кэш условно-бесконечен, и какой-то тип записей не обновляется, то все пользователи будут видеть устаревшие данных и спрашивать у вас, почему на разных страницах у одной и той же статьи разные комментарии. Тут на помощь приходят две стратегии инвалидации, которые есть в Redis:
- TTL (Time To Live).
 Запись с указанным TTL может быть удалена по истечении этого TTL (может быть — в связи с проблемами в выполнении задачи не могу сказать, насколько вовремя это сделает Redis, но вряд ли задержка составит больше трех секунд). Именно это я и хочу предложить в качестве серебряной пули — делайте всем записям TTL в пределах 1-60 секунд, и устаревшие данные у вас гарантированно не продержатся дольше минуты, а благодаря lazy load воскреснут вновь.
Запись с указанным TTL может быть удалена по истечении этого TTL (может быть — в связи с проблемами в выполнении задачи не могу сказать, насколько вовремя это сделает Redis, но вряд ли задержка составит больше трех секунд). Именно это я и хочу предложить в качестве серебряной пули — делайте всем записям TTL в пределах 1-60 секунд, и устаревшие данные у вас гарантированно не продержатся дольше минуты, а благодаря lazy load воскреснут вновь.
Резюмируя, проще всего задавать небольшое время жизни записям, и сильно не беспокоиться об инвалидации, пока продукт не вышел на поддержку. В этом случае у вас страдает целостность данных (consistency), но в большинстве случаев она на самом деле не является критичной, более того, существует применимая к распределенным системам теорема CAP (NB: обсуждаемое в этом ответе приложение — это не распределенная система), которая (если очень грубо) говорит о том, что невозможно одновременно поддерживать доступность и согласованность данных — это просто некоторое свойство нашей вселенной, и небольшая задержка в обновлении данных чаще всего не только остается незамеченной, но и не всегда может быть замеченной (если у вас есть задержка в обновлении выдачи статей, то пользователь не ожидает получить новую в тот же момент, когда она была написана — он не знает момента написания).
Dogpile effect
В связи с параграфом про TTL и lazyload нельзя пропустить так называемый эффект собачьей стаи. С момента запроса обнаружения пустоты в кэше первым клиентом до момента его обновления проходит некоторое время X, за которое могут прийти еще N клиентов. Приложение в этом случае добросовестно попытается реконструировать кэш еще N раз. Единого решения у этой проблемы нет, но вы можете либо ставить лок на время обновления кэша (но если у вас приложение стоит более, чем на одном сервере, то придется использовать сервис, поддерживающий распределенные блокировки — например, consul, etcd или даже реализация с помощью самого Redis — см. Redlock), либо просто считать, что в SLA приложения добавлена возможность работать без кэша вообще (если за кэшем у вас скрывается один запрос для одной записи в БД, то почему бы и нет).
Поиск
И, наконец, самое веселое. Как объединить сам поиск и подготовку данных для него? В общем случае — никак, ищите по базе, вы не сможете запихнуть все необходимое для запроса в KV-хранилище. Но если вас интересует, как это решается в серьезных случаях (имеется в виду поиск по базе данных, а не уровня яндекса/гугла, конечно), то есть специализированные решения, например, Lucene (и построенный на его основе ElasticSearch), Solr, Sphinx, YoctoDB. В общем случае поиск сводится к построению индексов из полей документа, поиску по этим индексам и агрегированию результата.
Но если вас интересует, как это решается в серьезных случаях (имеется в виду поиск по базе данных, а не уровня яндекса/гугла, конечно), то есть специализированные решения, например, Lucene (и построенный на его основе ElasticSearch), Solr, Sphinx, YoctoDB. В общем случае поиск сводится к построению индексов из полей документа, поиску по этим индексам и агрегированию результата.
Микросервисная архитектура
Предложенные мной решения по разбиению на building blocks так или иначе приведут к появлению в приложении менеджеров каждой сущности, каждый из которых заведует отдельной сущностью. Хочется сказать, что это разбиение может продолжиться и вне приложения — приложение можно разбить на отдельные приложения, каждое из которых будет заниматься своим доменом. Это так же убьет всякую возможность джойнов, но, на самом деле, она и не нужна. Если пользователи у вас лежат в одном приложении на одном кластере, а статьи, в которых автор указан в виде идентификатор — в другом приложении на другом кластере, то вряд ли вам потребуется искать все статьи, в имени автора которого стоит «Андрей».
Как обо всем позаботиться?
Скорее всего, через весь ответ так и сквозят вопросы вроде «какой TTL ставить», «нужно ли кэшировать Х» и «какйо прирост производительности я получу». Ответ простой — это вообще никак не узнать, это выясняется только на практике. Деплойте приложение, анализируйте статистику, и через некоторое время вы просто поймете, где оно подтормаживает. Если оно не подтормаживает в месте, где вы забыли поставить кэш — возможно, там и нет смертельной необходимости в нем, и к этому месту нужно будет вернуться, если вообще не останется других задач?
Просто пара слов про Redis
Во-первых просто хотелось сказать, что кроме Redis есть еще сервисы, выполняющие те же функции (мой любимый — Aerospike). Redis довольно прост в использовании, но не умеет, например, шардиться, у него были проблемы с фрагментацией памяти (порог в 100 мб теоретически имел право забрать до 200 мб оперативки), он однопоточный и в мире NoSQL довольно похож на MySQL в мире баз данных. Тем не менее, с небольшим приложением по меркам интернет-гигантов он наверняка справится без особых проблем.
Тем не менее, с небольшим приложением по меркам интернет-гигантов он наверняка справится без особых проблем.
Access SQL: основные понятия, словарный запас и синтаксис
Когда вы хотите получить данные из базы данных, вы запрашиваете данные с помощью языка структурированных запросов или SQL. SQL — это компьютерный язык, очень похожий на английский, но понятный программам баз данных. Каждый выполняемый вами запрос использует SQL за кулисами.
Понимание того, как работает SQL, может помочь вам создавать более качественные запросы и упростить понимание того, как исправить запрос, который не возвращает нужных вам результатов.
Это одна из статей о Access SQL. В этой статье описывается основное использование SQL для выбора данных и используются примеры для иллюстрации синтаксиса SQL.
В этой статье
Что такое SQL?
Основные предложения SQL: SELECT, FROM и WHERE.
Сортировка результатов: ORDER BY
Работа с суммированными данными: GROUP BY и HAVING
Объединение результатов запроса: UNION
Что такое SQL?
SQL — это компьютерный язык для работы с наборами фактов и отношениями между ними. Программы реляционных баз данных, такие как Microsoft Office Access, используют SQL для работы с данными. В отличие от многих компьютерных языков, SQL несложно читать и понимать даже новичку. Как и многие компьютерные языки, SQL является международным стандартом, признанным такими органами стандартизации, как ISO и ANSI.
Вы используете SQL для описания наборов данных, которые могут помочь вам ответить на вопросы. Когда вы используете SQL, вы должны использовать правильный синтаксис. Синтаксис — это набор правил, по которым правильно сочетаются элементы языка. Синтаксис SQL основан на синтаксисе английского языка и использует многие из тех же элементов, что и синтаксис Visual Basic для приложений (VBA).
Когда вы используете SQL, вы должны использовать правильный синтаксис. Синтаксис — это набор правил, по которым правильно сочетаются элементы языка. Синтаксис SQL основан на синтаксисе английского языка и использует многие из тех же элементов, что и синтаксис Visual Basic для приложений (VBA).
Например, простой оператор SQL, который извлекает список фамилий для контактов, чье имя — Мария, может выглядеть следующим образом:
ВЫБЕРИТЕ Фамилию
ИЗ Контактов
ГДЕ Имя = 'Мэри';
Примечание. SQL используется не только для управления данными, но также для создания и изменения структуры объектов базы данных, таких как таблицы. Часть SQL, используемая для создания и изменения объектов базы данных, называется языком определения данных (DDL). В этом разделе не рассматривается DDL. Дополнительные сведения см. в статье Создание или изменение таблиц или индексов с помощью запроса определения данных.
Операторы SELECT
Чтобы описать набор данных с помощью SQL, вы пишете оператор SELECT. Оператор SELECT содержит полное описание набора данных, которые вы хотите получить из базы данных. В том числе:
Какие таблицы содержат данные.
Как связаны данные из разных источников.
Какие поля или вычисления будут создавать данные.
Критерии, которым должны соответствовать данные для включения.
Нужно ли и как сортировать результаты.
Предложения SQL
Как и предложение, оператор SQL имеет разделы. Каждое предложение выполняет функцию оператора SQL. Некоторые предложения необходимы в операторе SELECT. В следующей таблице перечислены наиболее распространенные предложения SQL.
Пункт SQL | Что он делает | Обязательно |
ВЫБЕРИТЕ | Список полей, содержащих интересующие данные. | Да |
ИЗ | Список таблиц, содержащих поля, перечисленные в предложении SELECT. | Да |
ГДЕ | Указывает критерии поля, которым должна соответствовать каждая запись, чтобы быть включенной в результаты. | № |
ЗАКАЗАТЬ | Указывает, как сортировать результаты. | № |
СГРУППИРОВАТЬ ПО | В операторе SQL, содержащем агрегатные функции, перечислены поля, которые не суммируются в предложении SELECT. | Только при наличии таких полей |
ИМЕЮЩИЙ | В операторе SQL, содержащем агрегатные функции, задает условия, которые применяются к полям, суммируемым в операторе SELECT. | № |


Термины SQL
Каждое предложение SQL состоит из терминов — сравнимых с частями речи. В следующей таблице перечислены типы терминов SQL.
В следующей таблице перечислены типы терминов SQL.
Термин SQL | Сопоставимая часть речи | Определение | Пример |
идентификатор | существительное | Имя, которое вы используете для идентификации объекта базы данных, например имя поля. | Клиенты. [Номер телефона] |
оператор | глагол или наречие | Ключевое слово, которое представляет действие или изменяет действие. | КАК |
константа | существительное | Неизменяемое значение, например число или NULL. | 42 |
выражение | прилагательное | Комбинация идентификаторов, операторов, констант и функций, результатом которой является одно значение. | >= Товары. [Цена за единицу] |

Верх страницы
Основные предложения SQL: SELECT, FROM и WHERE
Оператор SQL имеет общий вид:
ВЫБЕРИТЕ поле_1
ИЗ таблицы_1
ГДЕ критерий_1
;
Примечания:
Access игнорирует разрывы строк в операторе SQL. Однако рассмотрите возможность использования строки для каждого предложения, чтобы улучшить читаемость ваших операторов SQL для себя и других.
Каждый оператор SELECT заканчивается точкой с запятой (;).
 Точка с запятой может стоять в конце последнего предложения или в отдельной строке в конце оператора SQL.
Точка с запятой может стоять в конце последнего предложения или в отдельной строке в конце оператора SQL.
Пример в Access
Ниже показано, как может выглядеть оператор SQL для простого запроса на выборку в Access:
1. Предложение SELECT
2. ИЗ статьи
3. ГДЕ пункт
В этом примере инструкция SQL гласит: «Выберите данные, хранящиеся в полях с именами «Адрес электронной почты» и «Компания», из таблицы «Контакты», в частности те записи, в которых значением поля «Город» является Сиэтл».
Давайте рассмотрим пример, по одному предложению за раз, чтобы увидеть, как работает синтаксис SQL.
Предложение SELECT
ВЫБЕРИТЕ [Адрес электронной почты], Компания
Это предложение SELECT. Он состоит из оператора (SELECT), за которым следуют два идентификатора ([Адрес электронной почты] и Компания).
Он состоит из оператора (SELECT), за которым следуют два идентификатора ([Адрес электронной почты] и Компания).
Если идентификатор содержит пробелы или специальные символы (например, «Адрес электронной почты»), он должен быть заключен в квадратные скобки.
Предложение SELECT не должно указывать, какие таблицы содержат поля, и не может указывать какие-либо условия, которым должны соответствовать данные, которые должны быть включены.
Предложение SELECT всегда появляется перед предложением FROM в операторе SELECT.
Пункт FROM
ОТ Контакты
Это предложение FROM. Он состоит из оператора (FROM), за которым следует идентификатор (Contacts).
В предложении FROM не указаны поля для выбора.
Пункт WHERE
ГДЕ Город=»Сиэтл»
Это предложение WHERE. Он состоит из оператора (WHERE), за которым следует выражение (City=»Seattle»).
Он состоит из оператора (WHERE), за которым следует выражение (City=»Seattle»).
Примечание. В отличие от предложений SELECT и FROM, предложение WHERE не является обязательным элементом инструкции SELECT.
Многие действия, которые позволяет выполнять SQL, можно выполнять с помощью предложений SELECT, FROM и WHERE. Дополнительные сведения о том, как вы используете эти пункты, представлены в следующих дополнительных статьях:
.Доступ к SQL: предложение SELECT
Доступ к SQL: предложение FROM
 org/ListItem»>
org/ListItem»>Доступ к SQL: предложение WHERE
Верх страницы
Сортировка результатов: ПОРЯДОК ПО
Как и Microsoft Excel, Access позволяет сортировать результаты запроса в таблице. Вы также можете указать в запросе, как вы хотите сортировать результаты при выполнении запроса, используя предложение ORDER BY. Если вы используете предложение ORDER BY, это последнее предложение в операторе SQL.
Предложение ORDER BY содержит список полей, которые вы хотите использовать для сортировки, в том же порядке, в котором вы хотите применять операции сортировки.
Например, предположим, что вы хотите, чтобы ваши результаты сначала отсортировались по значению поля «Компания» в порядке убывания, а — если есть записи с таким же значением для компании — затем отсортированы по значениям в поле «Адрес электронной почты» в порядке возрастания.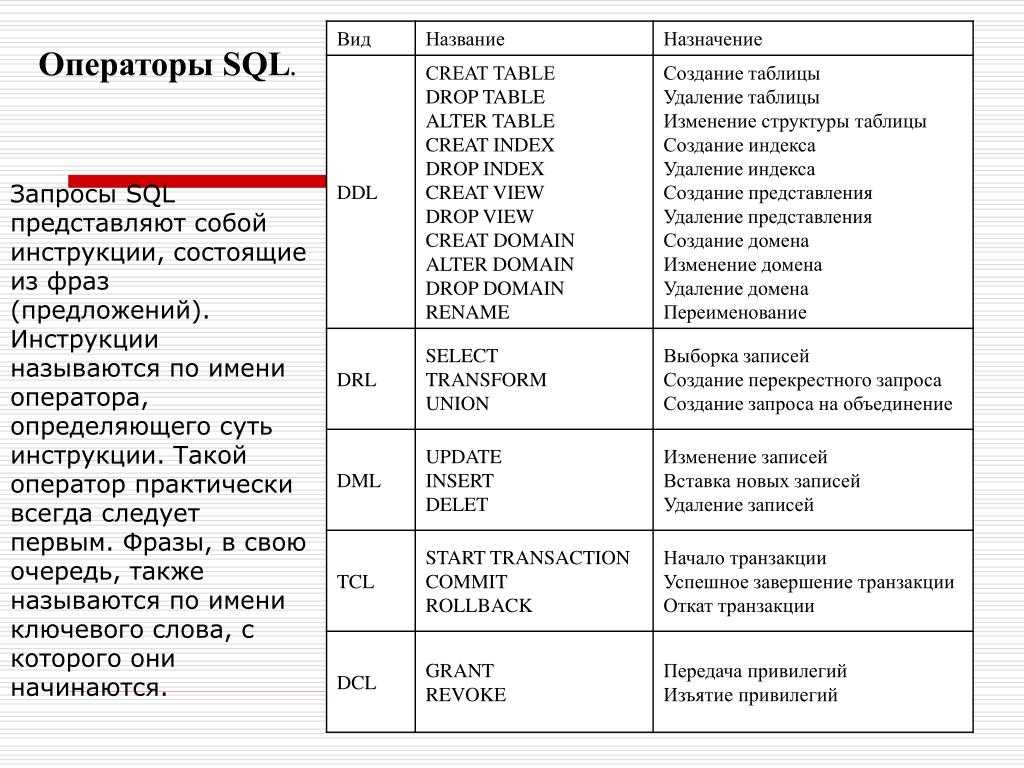 заказ. Ваше предложение ORDER BY будет выглядеть следующим образом:
заказ. Ваше предложение ORDER BY будет выглядеть следующим образом:
ЗАКАЗАТЬ Компания DESC, [Адрес электронной почты]
Примечание. По умолчанию Access сортирует значения в порядке возрастания (от A до Z, от меньшего к большему). Вместо этого используйте ключевое слово DESC для сортировки значений в порядке убывания.
Дополнительные сведения о предложении ORDER BY см. в разделе Предложение ORDER BY.
Верх страницы
Работа со сводными данными: GROUP BY и HAVING
Иногда вам нужно работать со сводными данными, такими как общий объем продаж за месяц или самые дорогие товары в инвентаре. Для этого вы применяете агрегатную функцию к полю в предложении SELECT. Например, если вы хотите, чтобы ваш запрос отображал количество адресов электронной почты, перечисленных для каждой компании, ваше предложение SELECT может выглядеть следующим образом:
ВЫБЕРИТЕ COUNT([Адрес электронной почты]), Компания
Доступные для использования агрегатные функции зависят от типа данных в поле или выражении, которые вы хотите использовать.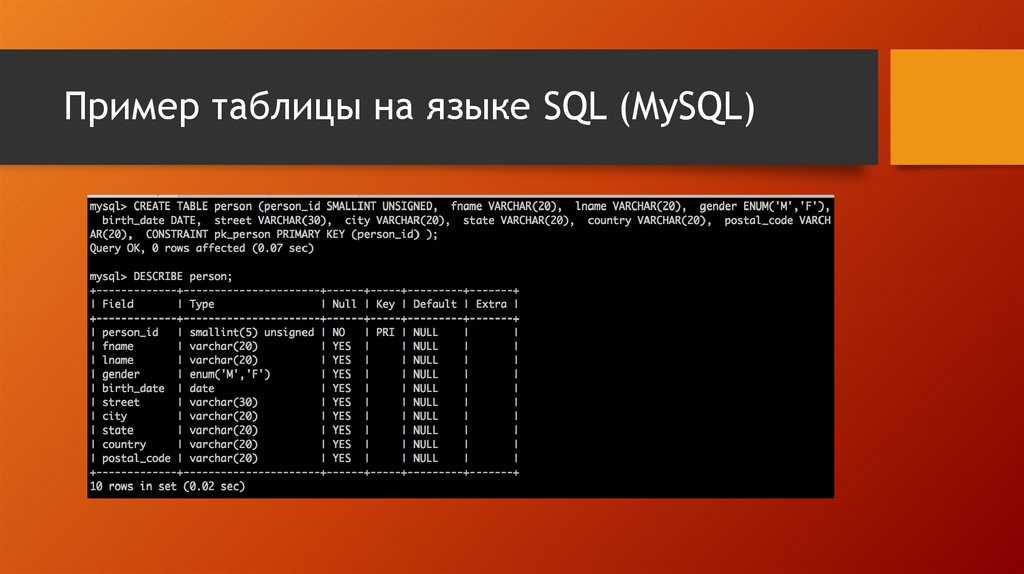 Дополнительные сведения о доступных агрегатных функциях см. в статье Агрегатные функции SQL.
Дополнительные сведения о доступных агрегатных функциях см. в статье Агрегатные функции SQL.
Указание полей, которые не используются в агрегатной функции: предложение GROUP BY
При использовании агрегатных функций обычно необходимо также создать предложение GROUP BY. В предложении GROUP BY перечислены все поля, к которым не применяется агрегатная функция. Если вы применяете агрегатные функции ко всем полям запроса, вам не нужно создавать предложение GROUP BY.
Предложение GROUP BY следует непосредственно за предложением WHERE или предложением FROM, если предложение WHERE отсутствует. Предложение GROUP BY перечисляет поля в том виде, в каком они появляются в предложении SELECT.
Например, продолжая предыдущий пример, если ваше предложение SELECT применяет агрегатную функцию к [Адрес электронной почты], но не к компании, ваше предложение GROUP BY будет выглядеть следующим образом:
ГРУППА КОМПАНИЙ
Дополнительные сведения о предложении GROUP BY см. в разделе Предложение GROUP BY.
в разделе Предложение GROUP BY.
Ограничение совокупных значений с помощью групповых критериев: предложение HAVING
Если вы хотите использовать критерии для ограничения результатов, но поле, к которому вы хотите применить критерии, используется в агрегатной функции, вы не можете использовать предложение WHERE. Вместо этого вы используете предложение HAVING. Предложение HAVING работает так же, как предложение WHERE, но используется для агрегированных данных.
Например, предположим, что вы используете функцию AVG (которая вычисляет среднее значение) с первым полем в предложении SELECT:
ВЫБЕРИТЕ COUNT([Адрес электронной почты]), Компания
Если вы хотите, чтобы запрос ограничивал результаты на основе значения этой функции COUNT, вы не можете использовать критерий для этого поля в предложении WHERE. Вместо этого вы помещаете критерии в предложение HAVING.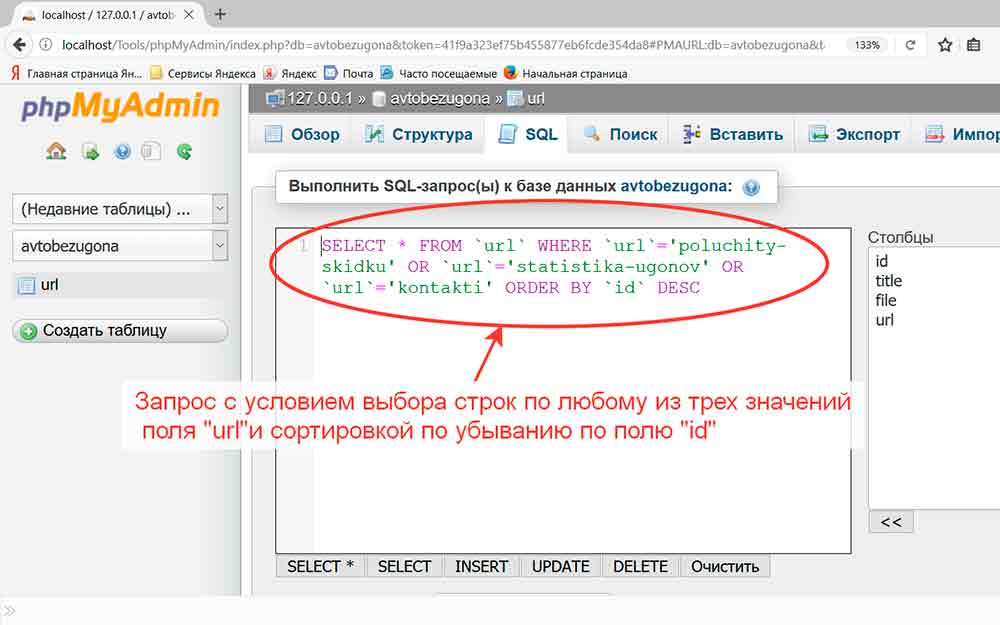 Например, если вы хотите, чтобы запрос возвращал строки только в том случае, если с компанией связано несколько адресов электронной почты, предложение HAVING может выглядеть следующим образом:
Например, если вы хотите, чтобы запрос возвращал строки только в том случае, если с компанией связано несколько адресов электронной почты, предложение HAVING может выглядеть следующим образом:
HAVING COUNT([Адрес электронной почты])>1
Примечание. Запрос может содержать предложение WHERE и предложение HAVING — критерии для полей, которые не используются в агрегатной функции, указываются в предложении WHERE, а критерии для полей, которые используются с агрегатными функциями, — в предложении HAVING.
Дополнительные сведения о предложении HAVING см. в разделе Предложение HAVING.
Верх страницы
Объединение результатов запроса: UNION
Если вы хотите просмотреть все данные, которые возвращаются несколькими похожими запросами на выборку вместе, как объединенный набор, вы используете оператор UNION.
Оператор UNION позволяет объединить два оператора SELECT в один. Объединяемые операторы SELECT должны иметь одинаковое количество выходных полей, в том же порядке и с одинаковыми или совместимыми типами данных. Когда вы запускаете запрос, данные из каждого набора соответствующих полей объединяются в одно выходное поле, так что выходные данные запроса имеют то же количество полей, что и каждый из операторов select.
Примечание. Для целей запроса на объединение типы данных Number и Text совместимы.
При использовании оператора UNION можно также указать, должны ли результаты запроса включать повторяющиеся строки, если они существуют, с помощью ключевого слова ALL.
Базовый синтаксис SQL для запроса на объединение, который объединяет две инструкции SELECT, выглядит следующим образом:
ВЫБЕРИТЕ поле_1
ИЗ таблицы_1
UNION [ALL]
SELECT field_a
FROM table_a
;
Например, предположим, что у вас есть таблица с именем «Продукты» и другая таблица с именем «Службы». В обеих таблицах есть поля, содержащие название продукта или услуги, цену, гарантию или наличие гарантии, а также то, предлагаете ли вы продукт или услугу исключительно. Хотя в таблице «Продукты» хранится информация о гарантии, а в таблице «Услуги» хранится информация о гарантии, основная информация одинакова (независимо от того, включает ли конкретный продукт или услуга обещание качества). Вы можете использовать запрос на объединение, например следующий, чтобы объединить четыре поля из двух таблиц:
ВЫБЕРИТЕ название, цена, гарантия_доступна, эксклюзивное_предложение
ИЗ Продукты
СОЮЗ ВСЕХ
ВЫБЕРИТЕ название, цена, гарантия_доступна, эксклюзивное_предложение
ИЗ Услуги
;
Дополнительные сведения о том, как объединить инструкции SELECT с помощью оператора UNION, см. в разделе Объединение результатов нескольких запросов на выборку с помощью запроса на объединение.
Верх страницы
Передовой опыт написания SQL-запросов: структурирование кода
Категории
SQLGuides
удобочитаемость.
Язык структурированных запросов является абсолютно необходимым навыком в отрасли обработки данных. SQL — это не только написание запросов, вы также должны убедиться, что ваши запросы производительны, быстры и удобочитаемы. Таким образом, также необходимо, чтобы вы знали, как эффективно писать SQL-запросы.
Эта статья расскажет вам о лучших методах структурирования SQL-запросов. Даже когда ваш код SQL работает правильно, его все равно можно улучшить, особенно когда речь идет о производительности и удобочитаемости. Это важно, потому что на технических собеседованиях цель состоит не только в том, чтобы проверить, способен ли кандидат предложить работающее решение проблемы, но и в том, может ли он подготовить эффективное и понятное решение. То же самое и в рабочей среде: сделать запросы быстрыми и понятными для других так же важно, как и сделать их правильными.
Давайте воспользуемся реальным примером вопросов для собеседования по науке о данных, которые можно решить с помощью SQL-запроса. У нас будет решение, которое дает правильный вывод, но оно очень неэффективно и чрезвычайно трудно читаемо. Затем мы рассмотрим несколько ключевых рекомендаций по написанию SQL-запросов и применим их к коду, чтобы улучшить его, чтобы его можно было использовать в качестве ответа на вопрос на собеседовании.
Вопрос для собеседования по SQL Пример для практики написания эффективных запросов SQL
Вопрос для собеседования Дата: ноябрь 2020 г.
MicrosoftHardInterview QuestionsID 10300
Найдите общее количество загрузок для платных и бесплатных пользователей по дате. Включайте только те записи, в которых неоплачиваемые клиенты имеют больше загрузок, чем платные клиенты. Вывод должен быть сначала отсортирован по самой ранней дате и содержать дату в 3 столбцах, бесплатные загрузки, платные загрузки.
Таблицы: ms_user_dimension, ms_acc_dimension, ms_download_facts
Ссылка на вопрос: https://platform.stratascratch.com/coding/10300-premium-vs-freemium
Мы будем использовать этот вопрос на собеседовании по SQL в качестве примера, взятого из технических собеседований в Microsoft и озаглавленного «Premium vs Freemium». Задача состоит в том, чтобы найти общее количество загрузок для платных и неплатящих пользователей по дате и включить только те записи, где у неплатящих клиентов больше загрузок, чем у платных. Более того, этот вопрос связан с набором данных, разделенным на три таблицы, которые необходимо объединить.
Исходное решение
Давайте получим исходное решение этой задачи SQL, которое мы будем использовать в качестве отправной точки. Мы не найдем, как это решение работает или как его можно получить — это не цель этой статьи. Вместо этого мы будем использовать его только как иллюстрацию синтаксических приемов, универсальных для любого SQL-запроса.
Это решение может быть использовано для получения правильного вывода для этой проблемы:
ВЫБЕРИТЕ дату, "Неоплачиваемый",
оплата
ОТ
(ВЫБЕРИТЕ стр.дату,
p.sum AS платит,
n.nonpaying AS "Неплатежеспособный"
ОТ
(ВЫБЕРИТЕ дату, сумму(загрузки)
ОТ ms_user_dimension a
ВНУТРЕННЕЕ СОЕДИНЕНИЕ ms_acc_dimension b ON a. acc_id = b.acc_id
ВНУТРЕННЕЕ СОЕДИНЕНИЕ ms_download_facts c ON a.user_id=c.user_id
ГДЕ pay_customer = 'да'
СГРУППИРОВАТЬ ПО дате
ЗАКАЗАТЬ ПО дате) стр
ПРИСОЕДИНИТЬСЯ
(ВЫБЕРИТЕ дату, сумму(загрузки) КАК БЕСПЛАТНО
ОТ ms_user_dimension a
ВНУТРЕННЕЕ СОЕДИНЕНИЕ ms_acc_dimension b ON a.acc_id = b.acc_id
ВНУТРЕННЕЕ СОЕДИНЕНИЕ ms_download_facts c ON a.user_id=c.user_id
ГДЕ pay_customer = 'нет'
СГРУППИРОВАТЬ ПО дате
ORDER BY date) n ON p.date = n.date
ЗАКАЗАТЬ ПО п.дата) с
СГРУППИРОВАТЬ ПО дате, "Неоплачиваемый",
оплата
ИМЕЕТ ("NonPaying" - платит) >0
ЗАКАЗАТЬ ПО дате ASC
acc_id = b.acc_id
ВНУТРЕННЕЕ СОЕДИНЕНИЕ ms_download_facts c ON a.user_id=c.user_id
ГДЕ pay_customer = 'да'
СГРУППИРОВАТЬ ПО дате
ЗАКАЗАТЬ ПО дате) стр
ПРИСОЕДИНИТЬСЯ
(ВЫБЕРИТЕ дату, сумму(загрузки) КАК БЕСПЛАТНО
ОТ ms_user_dimension a
ВНУТРЕННЕЕ СОЕДИНЕНИЕ ms_acc_dimension b ON a.acc_id = b.acc_id
ВНУТРЕННЕЕ СОЕДИНЕНИЕ ms_download_facts c ON a.user_id=c.user_id
ГДЕ pay_customer = 'нет'
СГРУППИРОВАТЬ ПО дате
ORDER BY date) n ON p.date = n.date
ЗАКАЗАТЬ ПО п.дата) с
СГРУППИРОВАТЬ ПО дате, "Неоплачиваемый",
оплата
ИМЕЕТ ("NonPaying" - платит) >0
ЗАКАЗАТЬ ПО дате ASC Не беспокойтесь, если вы не сразу поймете, что здесь происходит. Это на самом деле вещь, это решение намеренно длинное, запутанное и запутанное, и задача будет заключаться в том, чтобы очистить его, используя лучшие практики синтаксиса SQL. Но самое интересное, что это решение работает — мы можем его запустить и посмотреть, сколько загрузок от платных и неплатящих клиентов было в каждую дату. Но даже при том, что это решение правильное, интервьюер, вероятно, не обрадуется такому ответу. Итак, давайте посмотрим, какие лучшие практики написания SQL-запросов нам здесь не хватает и как повысить наши шансы произвести впечатление на интервьюера.
Передовой опыт написания SQL-запросов: как структурировать код
1. Удалите несколько вложенных запросов
Даже не понимая, что именно делает код, мы видим, что он имеет несколько вложенных запросов. Есть основной запрос, в котором выбираются три столбца, затем в его предложении FROM есть еще один длинный запрос, называемый внутренним запросом. У него есть псевдоним «s». Но тогда сам этот внутренний запрос «s» также имеет два дополнительных и почти идентичных внутренних запроса, «p» и «n», которые объединяются вместе с помощью оператора JOIN. Хотя иметь один внешний запрос и один внутренний запрос абсолютно нормально, более двух запросов, вложенных друг в друга, считаются не очень читабельными, и их следует избегать.
Один из подходов к избавлению от такого большого количества вложенных запросов состоит в том, чтобы определить некоторые или все из них в форме общих табличных выражений или CTE — конструкций, которые используют ключевое слово WITH и позволяют повторно использовать один запрос несколько раз. Итак, пусть это будет наш первый шаг — мы можем превратить все три вложенных запроса «s», «p» и «n» в CTE.
С р АС
(ВЫБЕРИТЕ дату, сумму(загрузки)
ОТ ms_user_dimension a
ВНУТРЕННЕЕ СОЕДИНЕНИЕ ms_acc_dimension b ON a.acc_id = b.acc_id
ВНУТРЕННЕЕ СОЕДИНЕНИЕ ms_download_facts c ON a.user_id=c.user_id
ГДЕ pay_customer = 'да'
СГРУППИРОВАТЬ ПО дате
ЗАКАЗАТЬ ПО дате),
н КАК
(ВЫБЕРИТЕ дату, сумму(загрузки) КАК БЕСПЛАТНО
ОТ ms_user_dimension a
ВНУТРЕННЕЕ СОЕДИНЕНИЕ ms_acc_dimension b ON a.acc_id = b.acc_id
ВНУТРЕННЕЕ СОЕДИНЕНИЕ ms_download_facts c ON a.user_id=c.user_id
ГДЕ pay_customer = 'нет'
СГРУППИРОВАТЬ ПО дате
ЗАКАЗАТЬ ПО дате),
с АС
(ВЫБЕРИТЕ стр. дату,
p.sum AS платит,
n.nonpaying AS "Неплатежеспособный"
С р
ПРИСОЕДИНЯЙТЕСЬ n ON p.date = n.date
ЗАКАЗАТЬ ПО п.дате)
ВЫБЕРИТЕ дату, "Неоплачиваемый",
оплата
ОТ с
СГРУППИРОВАТЬ ПО дате, "Неоплачиваемый",
оплата
ИМЕЕТ ("NonPaying" - платит) >0
ЗАКАЗАТЬ ПО дате ASC Теперь этот запрос уже стал немного легче читать. Даже не понимая точно, что происходит, мы можем видеть, что есть два очень похожих шага, ‘p’ и ‘n’, которые должны быть выполнены сначала, чтобы активировать ‘s’, а затем результат ‘s’ можно использовать в основной запрос. Но что же это за «р», «н», «с» и другие псевдонимы? Это подводит нас ко второму пункту.
2. Обеспечить согласованность псевдонимов
Псевдонимы в SQL могут быть назначены столбцам, запросам и таблицам для изменения их первоначальных имен. Их необходимо использовать при объединении таблиц с одинаковыми именами столбцов, чтобы избежать двусмысленности в именах столбцов. Псевдонимы также полезны для облегчения понимания кода другими и для замены имен столбцов по умолчанию при использовании аналитических функций (например, СУММ() или СЧЁТ()).
Существует также несколько неписаных правил относительно псевдонимов, которым следует следовать, поскольку неправильно используемый псевдоним может скорее запутать, чем помочь. Начнем с псевдонимов таблицы и запроса. Хорошо, когда это немного больше, чем просто одна буква, и они позволяют нам понять, что находится в таблице или что выдает запрос. В нашем случае первый CTE, который в настоящее время называется «p», используется для подсчета количества загрузок, сделанных платными клиентами, поэтому более информативным названием будет, например, «платный». Стоит отметить, что псевдонимы, хотя и информативные, не должны быть слишком длинными, например, «paying_customers» может быть немного длинным. Затем второй CTE, «n», такой же, но для неплатящих клиентов, поэтому, следуя схеме, его можно назвать «бесплатным».
Наконец, CTE ‘s’ объединяет два значения: количество загрузок платных и неплатящих клиентов, но пока не фильтрует их, потому что это происходит в основном запросе. Таким образом, его имя может быть, например, «all_downloads». Теперь обратите внимание, что это еще не все таблицы, которым присвоены псевдонимы. Это связано с тем, что в первых двух CTE мы объединяем три таблицы друг с другом, и, поскольку они имеют общие имена столбцов, им нужно дать псевдонимы. В настоящее время это просто «a», «b» и «c», но более информативными названиями будут «users», «accounts» и «downlds» — аббревиатура здесь, потому что в этой таблице уже есть столбец «downloads».
Последнее, что касается псевдонимов таблиц, — это согласованность их использования. Обычно их лучше либо использовать со всеми именами столбцов, либо только в абсолютно необходимых местах (например, только при определении JOIN) или вообще не использовать. Давайте решим использовать псевдонимы таблиц во всех случаях, когда несколько таблиц объединены, то есть во всех CTE, и не использовать их, когда все столбцы поступают только из одной таблицы, как в основном запросе.
С оплатой AS (ВЫБРАТЬ загрузки.
Это были псевдонимы таблицы и запроса, теперь давайте посмотрим на псевдонимы, присвоенные столбцам. Во-первых, дать псевдонимы результатам аналитических функций. Взгляните на первый запрос. Есть функция SUM(), но к ней не добавляется псевдоним, хотя позже этот столбец используется повторно. Вот почему в CTE all_downloads нам нужно написать pay.sum, чтобы выбрать его. Добавим псевдоним, например n_paying.
Еще одна вещь — поддерживать согласованность псевдонимов столбцов в именах, а также избегать конфликтов с другими псевдонимами. Как и в CTE nonpaying, есть функция SUM(), которая правильно назначается как псевдоним, но этот псевдоним совпадает с псевдонимом CTE, что может сбивать с толку. Давайте придерживаться того же соглашения об именах, что и раньше, и изменим этот псевдоним на n_nonpaying.
Теперь в CTE all_downloads происходит много всего. Во-первых, псевдоним «paying», назначенный второму столбцу, совпадает с псевдонимом одного из CTE. И сразу после этого псевдоним третьего столбца — «NonPaying» в кавычках. Хотя SQL позволяет нам назначать такие псевдонимы, использовать такие псевдонимы опасно, потому что каждый раз, когда мы хотим использовать его повторно, нам нужно снова использовать кавычки и сопоставлять все заглавные и строчные буквы в псевдониме. Мы могли бы изменить эти два псевдонима на что-то другое и без кавычек. Но на самом деле даже не обязательно использовать эти алиасы, ведь аналитических функций здесь нет, поэтому имена столбцов из предыдущих, ‘n_paying’ и n_nonpaying’ остаются прежними и на них можно ссылаться в основном запросе, не вызывая проблем.
С оплатой AS
(ВЫБРАТЬ downlds.date, sum(downlds.downloads) AS n_paying
ОТ пользователей ms_user_dimension
ВНУТРЕННЕЕ СОЕДИНЕНИЕ ms_acc_dimension account ON users.acc_id = account.acc_id
INNER JOIN ms_download_facts downlds ON users.user_id=downlds.user_id
ГДЕ account.paying_customer = 'да'
СГРУППИРОВАТЬ ПО downlds.date
ЗАКАЗАТЬ ПО downlds.date),
неплатежный AS
(SELECTdownlds.date, sum(downlds.downloads) AS n_nonpaying
ОТ пользователей ms_user_dimension
ВНУТРЕННЕЕ СОЕДИНЕНИЕ ms_acc_dimension account ON users.acc_id = account.acc_id
INNER JOIN ms_download_facts downlds ON users.user_id=downlds.user_id
ГДЕ account.paying_customer = 'нет'
СГРУППИРОВАТЬ ПО downlds. date
ЗАКАЗАТЬ ПО downlds.date),
all_downloads КАК
(ВЫБЕРИТЕ дату оплаты,
оплата.n_paying,
неоплачиваемый.n_неоплачиваемый
ОТ оплаты
ПРИСОЕДИНЯЙТЕСЬ к nonpaying ON pay.date = nonpaying.date
ЗАКАЗАТЬ ПО ОПЛАТЕ.ДАТА)
ВЫБЕРИТЕ дату, n_nonpaying,
n_paying
ИЗ all_downloads
СГРУППИРОВАТЬ ПО дате, n_nonpaying,
n_paying
ИМЕЕТ (n_nonpaying - n_paying) >0
ЗАКАЗАТЬ ПО дате ASC Не существует особых правил форматирования псевдонимов, но большинство людей используют только строчные буквы и знак подчеркивания, если псевдоним состоит из нескольких слов.
3. Удалите ненужные предложения ORDER BY
Теперь, когда мы позаботились о псевдонимах, давайте начнем сокращать объем кода в нашем решении. Первая вещь довольно второстепенна, но все же способствует удобочитаемости запроса. Речь идет о предложениях ORDER BY. Они, очевидно, используются для сортировки данных в таблице и часто полезны или даже необходимы. В конце концов, иногда необходимо использовать предложение ORDER BY в сочетании с оконной функцией или при выборе верхних строк таблицы с помощью ключевого слова LIMIT. Мы также можем захотеть расположить окончательные результаты в определенном порядке на собеседованиях, иногда это даже может быть требованием.
Но если у нас есть несколько запросов, обычно нет необходимости добавлять одно и то же предложение ORDER BY в каждый из них. Посмотрите на наш запрос, например, мы сортируем результаты по дате, но делаем это во всех возможных запросах и подзапросах. Это не только бесполезно, но и неэффективно, потому что каждое предложение ORDER BY добавляет немного сложности и, следовательно, времени, необходимого для выполнения запроса, особенно при работе с большими наборами данных. Поэтому, если у каждого запроса есть собственное предложение сортировки, хорошо подумать, действительно ли оно необходимо. В нашем случае можно оставить его только в последнем запросе.
С оплатой AS (ВЫБРАТЬ downlds.date, sum(downlds.downloads) AS n_paying ОТ пользователей ms_user_dimension ВНУТРЕННЕЕ СОЕДИНЕНИЕ ms_acc_dimension account ON users.acc_id = account.
4. Удаление ненужных подзапросов и CTE
Далее, есть гораздо более серьезная тема, чем удаление ненужных предложений ORDER BY — удаление ненужных подзапросов и CTE. Мы говорили о них раньше, когда разбивали вложенные запросы на CTE, но тогда мы просто оставили их как есть, не анализируя, действительно ли они нам нужны.
Оказывается, иногда два запроса делают одно и то же или могут быть объединены в один с помощью других предложений или операторов. В конце концов, каждый запрос увеличивает сложность и время, необходимое для выполнения запроса. В нашем случае четыре разных запроса приводят к тому, что движку четыре раза требуется доступ к таблице для выбора данных из нее. Более того, в трех из этих запросов мы объединяем несколько таблиц, используя JOIN — операции, которые могут занять много времени, особенно если таблицы большие.
Чтобы уменьшить количество запросов в нашем случае, есть два направления. Одной из возможностей было бы объединить запрос all_downloads с основным запросом. В конце концов, эти два запроса почти идентичны, и если бы мы только добавили фильтр, поэтому выражение, говорящее, что разница между n_nonpaying и n_paying должна быть больше 0, к запросу в all_downloads, дало бы те же результаты. Мы могли бы безопасно избавиться от CTE all_downloads и вместо этого объединить платные и неоплачиваемые CTE в основном запросе. Таким образом, мы можем сократить количество запросов до 3. Но можем ли мы добиться большего?
Можем, потому что оказывается, что первые два CTE, а именно «платный» и «неплатный», могут быть выполнены внутри CTE «all_downloads». Это потому, что эти первые два CTE почти идентичны, а главное отличие заключается в предложении WHERE. Мы выбираем одни и те же типы данных из одних и тех же таблиц, но в разных условиях. Но в SQL есть другой способ выбора и даже выполнения арифметических операций над данными с использованием разных условий только в одном запросе: нам нужно использовать CASES.
Мы можем использовать их для преобразования строк «да» и «нет» из столбца «paying_customer» в количество загрузок, а затем суммировать их, чтобы получить общее количество. Это означает, что весь первый CTE можно заменить следующим фрагментом кода:
sum(CASE
КОГДА pay_customer = 'да', ТОГДА загрузки
КОНЕЦ) Это будет очень похоже на неплатежеспособных клиентов. Обе эти инструкции могут быть выполнены прямо в CTE all_downloads, если мы объединим три таблицы, пользователей, учетные записи и загрузки и включим оператор данных GROUP BY также в это CTE.
С all_downloads КАК
(ВЫБЕРИТЕ дату загрузки,
сумма(СЛУЧАЙ
КОГДА account.paying_customer = 'yes', ТО downlds.downloads
КОНЕЦ) КАК n_paying,
сумма(СЛУЧАЙ
КОГДА account.paying_customer = 'no', ТО downlds.downloads
КОНЕЦ) AS n_nonpaying
ОТ пользователей ms_user_dimension
ВНУТРЕННЕЕ СОЕДИНЕНИЕ ms_acc_dimension account ON users.acc_id = account.acc_id
INNER JOIN ms_download_facts downlds ON users.user_id=downlds.user_id
СГРУППИРОВАТЬ ПО downlds.date)
ВЫБЕРИТЕ дату, n_nonpaying,
n_paying
ИЗ all_downloads
СГРУППИРОВАТЬ ПО дате, n_nonpaying,
n_paying
ИМЕЕТ (n_nonpaying - n_paying) >0
ЗАКАЗАТЬ ПО дате ASC С этими изменениями осталось всего два запроса, один набор из нескольких JOIN и два случая, когда данные нужно выбирать из таблицы вместо четырех. В то же время мы не можем решить этот вопрос, используя только один запрос, потому что столбцы «n_paying» и «n_nonpaying» должны быть определены в одном запросе, прежде чем использоваться в фильтре в другом запросе.
5. HAVING vs WHERE
Говоря о производительности и эффективности, в нашем запросе есть еще одна деталь, которая излишне замедляет его. Эта деталь — предложение HAVING в основном запросе. Но почему именно ИМЕЕТ, а не ГДЕ? Два пункта очень похожи друг на друга и позволяют фильтровать данные на основе некоторых условий. Как и в этом случае, когда разница между значениями n_nonpaying и n_paying должна быть больше 0. Это условие можно определить как с ключевыми словами WHERE, так и с ключевыми словами HAVING, но одно из них гораздо более подходит в этой ситуации. Ключевое отличие состоит в том, что предложение HAVING может включать агрегатные функции, например. СУММ() или СЧЕТ(). Он позволяет создавать условия на основе суммы, среднего, минимального или максимального значения или количества элементов в наборе данных или в разделах, определенных с помощью предложения GROUP BY. Именно по этой причине предложение HAVING всегда должно сопровождаться оператором GROUP BY.
Многие пользователи SQL не знают, что предложение HAVING следует использовать только тогда, когда необходимо создать условие с помощью агрегатной функции. Во всех остальных случаях предложение WHERE является лучшим выбором? Почему? Все упирается в эффективность. Предложение WHERE выполняется вместе с остальной частью запроса, поэтому, если это более эффективно, механизм SQL может решить ограничить количество экземпляров в наборе данных, используя условие из WHERE, прежде чем выполнять другие операции. С другой стороны, оператор HAVING всегда выполняется после запроса, хотя в коде он является его частью. Это почти всегда приводит к немного большему времени вычислений.
В нашем примере условие основано на арифметической операции с двумя столбцами, но это не то же самое, что агрегатная функция. По этой причине это условие вполне может быть определено в предложении WHERE. При этом, помимо повышения эффективности, мы также избавляемся от лишнего предложения GROUP BY.
С all_downloads КАК
(ВЫБЕРИТЕ дату загрузки,
сумма(СЛУЧАЙ
КОГДА account.paying_customer = 'yes', ТО downlds.downloads
КОНЕЦ) КАК n_paying,
сумма(СЛУЧАЙ
КОГДА account.paying_customer = 'no', ТО downlds.downloads
КОНЕЦ) AS n_nonpaying
ОТ пользователей ms_user_dimension
ВНУТРЕННЕЕ СОЕДИНЕНИЕ ms_acc_dimension account ON users.acc_id = account.acc_id
INNER JOIN ms_download_facts downlds ON users.user_id=downlds.user_id
СГРУППИРОВАТЬ ПО downlds.date)
ВЫБЕРИТЕ дату, n_nonpaying,
n_paying
ИЗ all_downloads
ГДЕ (n_nonpaying - n_paying) > 0
ЗАКАЗАТЬ ПО дате ASC 6. Форматирование текста
Последнее, что повышает читабельность запросов, — это форматирование кода. Это, по сравнению с другими частицами, о которых мы упоминали, не имеет ничего общего с эффективностью, а связано с простотой понимания кода всеми. Это также та деталь, о которой все забывают при написании SQL-запроса, особенно в стрессовой обстановке собеседования. Или все привыкли к другому стилю форматирования текста и путаются, видя другие подходы.
В SQL нет официальных правил форматирования текста в запросах, но есть некоторые неофициальные рекомендации, которым следуют многие пользователи SQL. Вероятно, наиболее распространенным и известным является то, что все ключевые слова, такие как SELECT, FROM, WHERE, GROUP BY, ORDER BY и т. д., должны быть написаны заглавными буквами. Это также относится к другим встроенным ключевым словам, которые появляются внутри предложений, таких как JOIN, AS, IN, ON или ASC и DESC. Когда дело доходит до названий функций, таких как SUM() или COUNT(), нет единого мнения о том, должны ли они быть написаны полностью заглавными или только строчными буквами, но, вероятно, лучше использовать их также с заглавной буквы, чтобы лучше отличать их от столбцов. имена, которые должны быть написаны с маленькой буквы.
Еще одно важное правило заключается в том, что, хотя для работы кода не обязательно, каждое предложение, такое как SELECT, FROM, WHERE, GROUP BY и т. д., должно находиться в новой строке. Для дальнейшего повышения удобочитаемости также рекомендуется иметь новую строку для каждого имени столбца в предложении SELECT. Более того, если мы используем подзапросы или CTE, хорошим подходом является использование таблиц, чтобы визуально отличить внутреннюю часть скобки от остальной части запроса.
Код из нашего примера уже в основном хорошо отформатирован. Но мы по-прежнему можем добавлять новые строки в предложение SELECT основного запроса и использовать заглавные буквы в именах функций SUM().
С all_downloads КАК
(ВЫБЕРИТЕ дату загрузки,
СУММА(СЛУЧАЙ
КОГДА account.paying_customer = 'yes', ТО downlds.downloads
КОНЕЦ) КАК n_paying,
СУММА(СЛУЧАЙ
КОГДА account.paying_customer = 'no', ТО downlds.downloads
КОНЕЦ) AS n_nonpaying
ОТ пользователей ms_user_dimension
ВНУТРЕННЕЕ СОЕДИНЕНИЕ ms_acc_dimension account ON users.acc_id = account.acc_id
INNER JOIN ms_download_facts downlds ON users. user_id=downlds.user_id
СГРУППИРОВАТЬ ПО downlds.date)
ВЫБЕРИТЕ дату,
n_бесплатно,
n_paying
ИЗ all_downloads
ГДЕ (n_nonpaying - n_paying) > 0
ЗАКАЗАТЬ ПО дате ASC Мы знаем, что иногда бывает трудно запомнить все правила форматирования текста или настроить все вручную, например, сделать ключевые слова заглавными или добавить таблицы. Таким образом, полезно иметь привычку использовать эти правила форматирования при написании SQL-запросов, потому что это облегчает понимание кода для нас самих и позволяет писать более читаемый код на собеседованиях.
Заключение
В заключение еще раз приведем список рекомендаций по написанию SQL-запросов:
- Удалить несколько вложенных запросов
- Обеспечить согласованность псевдонимов
- Удалить ненужные предложения ORDER BY
- Удалить ненужные подзапросы
- Если возможно, используйте WHERE, а не HAVING удаляя несколько вложенных запросов, вы можете превратить их в CTE — хорошее эмпирическое правило состоит в том, что один подзапрос в порядке, но несколько подзапросов или подзапрос, повторяющийся несколько раз, должны стать CTE.
Согласованность псевдонимов включает в себя их информативность, длину более 1 буквы, но и не слишком большую длину. Будьте последовательны, используете ли вы псевдонимы или нет. Добавляйте псевдонимы к столбцам, созданным аналитическими функциями. Придерживайтесь некоторых соглашений об именах и избегайте столбцов или таблиц, использующих один и тот же псевдоним. Используйте строчные буквы для псевдонимов и символы подчеркивания, если в нем несколько слов. Не используйте кавычки для определения псевдонима.
Чтобы удалить предложение ORDER BY, помните, что часто его не нужно повторять в нескольких запросах. Если это так, посмотрите, возможно ли иметь его только в последнем.
Иногда подзапросы или CTE могут быть объединены вместе. Ищите подзапросы, которые выглядят одинаково или приводят к одним и тем же столбцам — часто их проще всего комбинировать. Один из приемов — заменить предложение WHERE на CASE.
Используйте предложение HAVING только в сочетании с агрегатными функциями, почти во всех остальных случаях следует выбирать WHERE.