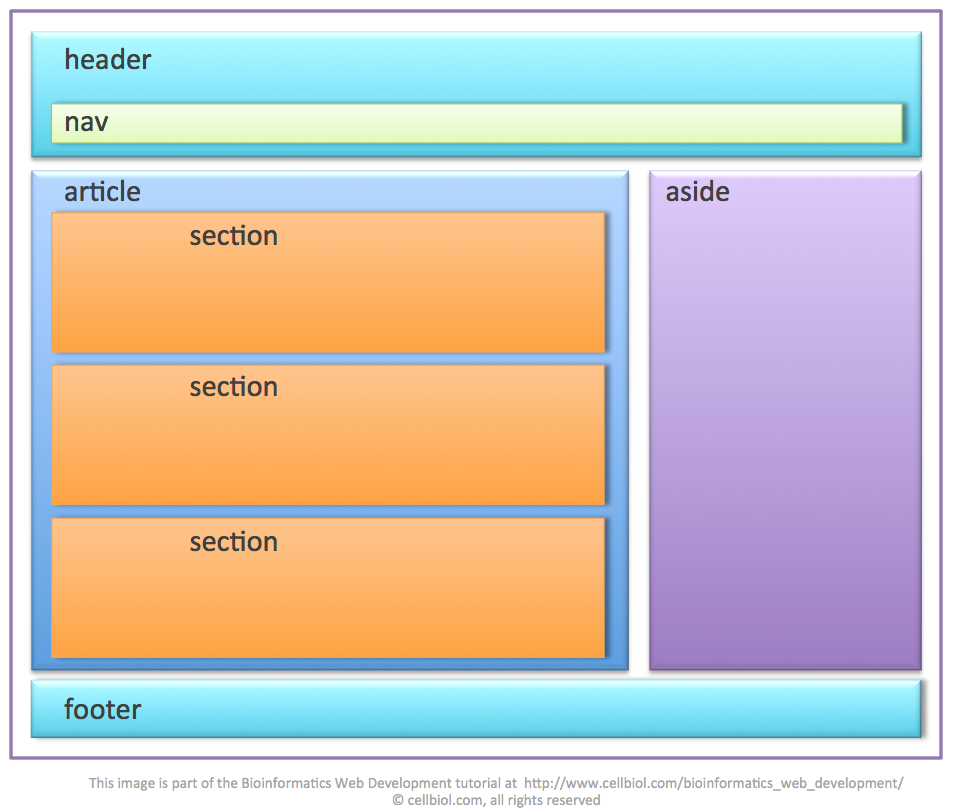
Модуль BeautifulSoup4 в Python, разбор HTML.
Извлечение данных из документов HTML и XML.
BeautifulSoup4 (bs4) — это библиотека Python для извлечения данных из файлов HTML и XML. Для естественной навигации, поиска и изменения дерева HTML, модуль BeautifulSoup4, по умолчанию использует встроенный в Python парсер html.parser. BS4 так же поддерживает ряд сторонних парсеров Python, таких как lxml, html5lib и xml (для разбора XML-документов).
Установка BeautifulSoup4 в виртуальное окружение:
# создаем виртуальное окружение, если нет $ python3 -m venv .venv --prompt VirtualEnv # активируем виртуальное окружение $ source .venv/bin/activate # ставим модуль beautifulsoup4 (VirtualEnv):~$ python3 -m pip install -U beautifulsoup4Содержание:
- Выбор парсера для использования в BeautifulSoup4.
- Парсер
lxml. - Парсер
html5lib. - Встроенный в Python парсер
html.. parser
parser
- Парсер
- Основные приемы работы с BeautifulSoup4.
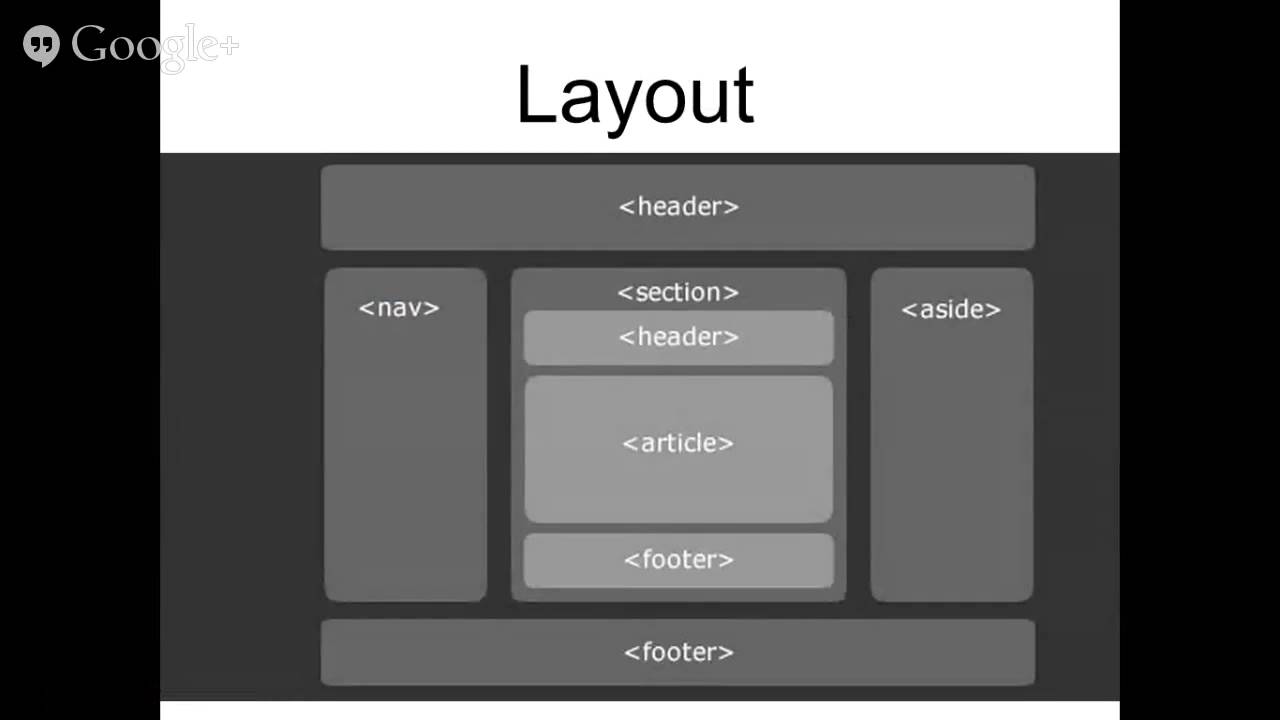
- Навигация по структуре HTML-документа.
- Извлечение URL-адресов.
- Извлечение текста HTML-страницы.
- Поиск тегов по HTML-документу.
- Поиск тегов при помощи CSS селекторов.
- Дочерние элементы.
- Родительские элементы.
- Изменение имен тегов HTML-документа.
- Добавление новых тегов в HTML-документ.
- Удаление и замена тегов в HTML-документе.
- Изменение атрибутов тегов HTML-документа.
 parser
parserВыбор парсера для использования в BeautifulSoup4.
BeautifulSoup4 представляет один интерфейс для разных парсеров, но парсеры неодинаковы. Разные парсеры, анализируя один и того же документ создадут различные деревья HTML. Самые большие различия будут между парсерами HTML и XML. Так же парсеры различаются скоростью разбора HTML документа.
Если дать BeautifulSoup4 идеально оформленный документ HTML, то различий построенного HTML-дерева не будет. Один парсер будет быстрее другого, но все они будут давать структуру, которая выглядит точно так же, как оригинальный документ HTML. Но если документ оформлен с ошибками, то различные парсеры дадут разные результаты.
Один парсер будет быстрее другого, но все они будут давать структуру, которая выглядит точно так же, как оригинальный документ HTML. Но если документ оформлен с ошибками, то различные парсеры дадут разные результаты.
Различия в построении HTML-дерева разными парсерами, разберем на короткой HTML-разметке: <a></p>.
Парсер
lxml.Характеристики:
- Для запуска примера, необходимо установить модуль
lxml. - Очень быстрый, имеет внешнюю зависимость от языка C.
- Нестрогий.
>>> from bs4 import BeautifulSoup
>>> BeautifulSoup("<a></p>", "lxml")
# <html><body><a></a></body></html>
Обратите внимание, что тег <a> заключен в теги <body> и <html>, а висячий тег </p> просто игнорируется.
Парсер
html5lib.Характеристики:
- Для запуска примера, необходимо установить модуль
html5lib.
- Ну очень медленный.
- Разбирает страницы так же, как это делает браузер, создавая валидный HTML5.
>>> from bs4 import BeautifulSoup
>>> BeautifulSoup("<a></p>", "html5lib")
# <html><head></head><body><a><p></p></a></body></html>
Обратите внимание, что парсер html5lib НЕ игнорирует висячий тег </p>, и к тому же добавляет открывающий тег <p>. Также html5lib добавляет пустой тег <head> (lxml этого не сделал).
Встроенный в Python парсер
html.parser.Характеристики:
- Не требует дополнительной установки.
- Приличная скорость, но не такой быстрый, как
lxml. - Более строгий, чем
html5lib.
>>> from bs4 import BeautifulSoup
>>> BeautifulSoup("<a></p>", 'html. parser')
# <a></a>
parser')
# <a></a>
Как и lxml, встроенный в Python парсер игнорирует закрывающий тег </p>. В отличие от html5lib, этот парсер не делает попытки создать правильно оформленный HTML-документ, добавив теги <html> или <body>.
Вывод: Парсер html5lib
Основные приемы работы с BeautifulSoup4.
Чтобы разобрать HTML-документ, необходимо передать его в конструктор класса BeautifulSoup(). Можно передать строку или открытый дескриптор файла:
from bs4 import BeautifulSoup
# передаем объект открытого файла
with open("index.html") as fp:
soup = BeautifulSoup(fp, 'html.parser')
# передаем строку
soup = BeautifulSoup("<html>a web page</html>", 'html.parser')
Первым делом документ конвертируется в Unicode, а HTML-мнемоники конвертируются в символы Unicode:
>>> from bs4 import BeautifulSoup >>> html = "<html><head></head><body>Sacré bleu!</body></html>" >>> parse = BeautifulSoup(html, 'html.parser') >>> print(parse) # <html><head></head><body>Sacré bleu!</body></html>

Дальнейшие примеры будут разбираться на следующей HTML-разметке.
html_doc = """<html><head><title>The Dormouse's story</title></head> <body> <p><b>The Dormouse's story</b></p> <p>Once upon a time there were three little sisters; and their names were <a href="http://example.com/elsie">Elsie</a>, <a href="http://example.com/lacie">Lacie</a> and <a href="http://example.com/tillie">Tillie</a>; and they lived at the bottom of a well.</p> <p>...</p>"""
Передача этого HTML-документа в конструктор класса BeautifulSoup() создает объект, который представляет документ в виде вложенной структуры:
>>> from bs4 import BeautifulSoup >>> soup = BeautifulSoup(html_doc, 'html.parser') >>> print(soup.prettify()) # <html> # <head> # <title> # The Dormouse's story # </title> # </head> # <body> # <p> # <b> # The Dormouse's story # </b> # </p> # <p> # Once upon a time there were three little sisters; and their names were # <a href="http://example.com/elsie"> # Elsie # </a> # , # <a href="http://example.com/lacie"> # Lacie # </a> # and # <a href="http://example.com/tillie"> # Tillie # </a> # ; and they lived at the bottom of a well. # </p> # <p> # ... # </p> # </body> # </html>

Навигация по структуре HTML-документа:
# извлечение тега `title` >>> soup.title # <title>The Dormouse's story</title> # извлечение имя тега >>> soup.title.name # 'title' # извлечение текста тега >>> soup.title.string # 'The Dormouse's story' # извлечение первого тега `<p>` >>> soup. p # <p><b>The Dormouse's story</b></p> # извлечение второго тега `<p>` и # представление его содержимого списком >>> soup.find_all('p')[1].contents # ['Once upon a time there were three little sisters; and their names were\n', # <a href="http://example.com/elsie">Elsie</a>, # ',\n', # <a href="http://example.com/lacie">Lacie</a>, # ' and\n', # <a href="http://example.com/tillie">Tillie</a>, # ';\nand they lived at the bottom of a well.'] # выдаст то же самое, только в виде генератора >>> soup.find_all('p')[1].strings # <generator object Tag._all_strings at 0x7ffa2eb43ac0>
Перемещаться по одному уровню можно при помощи атрибутов .previous_sibling и .next_sibling. Например, в представленном выше HTML, теги <a> обернуты в тег <p> — следовательно они находятся на одном уровне.
>>> first_a = soup.a >>> first_a # <a href="http://example.com/elsie">Elsie</a> >>> first_a.previous_sibling # 'Once upon a time there were three little sisters; and their names were\n' >>> next = first_a.next_sibling >>> next # ',\n' >>> next.next_sibling # <a href="http://example.com/lacie">Lacie</a>

Так же можно перебрать одноуровневые элементы данного тега с помощью .next_siblings или .previous_siblings.
for sibling in soup.a.next_siblings:
print(repr(sibling))
# ',\n'
# <a href="http://example.com/lacie">Lacie</a>
# ' and\n'
# <a href="http://example.com/tillie">Tillie</a>
# '; and they lived at the bottom of a well.'
for sibling in soup.find(id="link3").previous_siblings:
print(repr(sibling))
# ' and\n'
# <a href="http://example.com/lacie">Lacie</a>
# ',\n'
# <a href="http://example.com/elsie">Elsie</a>
# 'Once upon a time there were three little sisters; and their names were\n'
Атрибут . строки или HTML-тега указывает на то, что было разобрано непосредственно после него. Это могло бы быть тем же, что и  next_element
next_element.next_sibling, но обычно результат резко отличается.
Возьмем последний тег <a>, его .next_sibling является строкой: конец предложения, которое было прервано началом тега <a>:
last_a = soup.find("a",)
last_a
# <a href="http://example.com/tillie">Tillie</a>
last_a.next_sibling
# ';\nand they lived at the bottom of a well.'
Однако .next_element этого тега <a> — это то, что было разобрано сразу после тега <a> — это слово Tillie, а не остальная часть предложения.
last_a_tag.next_element # 'Tillie'
Это потому, что в оригинальной разметке слово Tillie появилось перед точкой с запятой. Парсер обнаружил тег </a>, затем точку с запятой и оставшуюся часть предложения. Точка с запятой находится на том же уровне, что и тег
Точка с запятой находится на том же уровне, что и тег <a>, но слово Tillie встретилось первым.
Атрибут .previous_element является полной противоположностью .next_element. Он указывает на элемент, который был обнаружен при разборе непосредственно перед текущим:
last_a_tag.previous_element # ' and\n' last_a_tag.previous_element.next_element # <a href="http://example.com/tillie">Tillie</a>
При помощи атрибутов .next_elements и .previous_elements можно получить список элементов, в том порядке, в каком он был разобран парсером.
for element in last_a_tag.next_elements:
print(repr(element))
# 'Tillie'
# ';\nand they lived at the bottom of a well.'
# '\n'
# <p>...</p>
# '...'
# '\n'
Извлечение URL-адресов.
Одна из распространенных задач, это извлечение URL-адресов, найденных на странице в HTML-тегах <a>:
>>> for a in soup.find_all('a'): ... print(a.get('href')) # http://example.com/elsie # http://example.com/lacie # http://example.com/tillie
Извлечение текста HTML-страницы.
Другая распространенная задача — извлечь весь текст со HTML-страницы:
# Весь текст HTML-страницы с разделителями `\n`
>>> soup.get_text('\n', strip='True')
# "The Dormouse's story\nThe Dormouse's story\n
# Once upon a time there were three little sisters; and their names were\n
# Elsie\n,\nLacie\nand\nTillie\n;\nand they lived at the bottom of a well.\n..."
# а можно создать список строк, а потом форматировать как надо
>>> [text for text in soup.stripped_strings]
# ["The Dormouse's story",
# "The Dormouse's story",
# 'Once upon a time there were three little sisters; and their names were',
# 'Elsie',
# ',',
# 'Lacie',
# 'and',
# 'Tillie',
# ';\nand they lived at the bottom of a well.',
# '...']
Поиск тегов по HTML-документу:
Найти первый совпавший HTML-тег можно методом BeautifulSoup., а всех совпавших элементов —  find()
find()BeautifulSoup.find_all().
# ищет все теги `<title>`
>>> soup.find_all("title")
# [<title>The Dormouse's story</title>]
# ищет все теги `<a>` и все теги `<b>`
>>> soup.find_all(["a", "b"])
# [<b>The Dormouse's story</b>,
# <a href="http://example.com/elsie">Elsie</a>,
# <a href="http://example.com/lacie">Lacie</a>,
# <a href="http://example.com/tillie">Tillie</a>]
# ищет все теги `<p>` с CSS классом "title"
>>> soup.find_all("p", "title")
# [<p><b>The Dormouse's story</b></p>]
# ищет все теги с CSS классом, в именах которых встречается "itl"
soup.find_all(class_=re.compile("itl"))
# [<p><b>The Dormouse's story</b></p>]
# ищет все теги с
>>> soup.find_all(id="link2")
# [<a href="http://example.com/lacie">Lacie</a>]
# ищет все теги `<a>`, содержащие указанные атрибуты
>>> soup. b")):
print(tag.name)
# body
# b
# ищет все теги в документе, но не текстовые строки
for tag in soup.find_all(True):
print(tag.name)
# html
# head
# title
# body
# p
# b
# p
# a
# a
# a
# p
b")):
print(tag.name)
# body
# b
# ищет все теги в документе, но не текстовые строки
for tag in soup.find_all(True):
print(tag.name)
# html
# head
# title
# body
# p
# b
# p
# a
# a
# a
# p
Поиск тегов при помощи CSS селекторов:
>>> soup.select("title")
# [<title>The Dormouse's story</title>]
>>> soup.select("p:nth-of-type(3)")
# [<p>...</p>]
Поиск тега под другими тегами:
>>> soup.select("body a")
# [<a href="http://example.com/elsie">Elsie</a>,
# <a href="http://example.com/lacie" >Lacie</a>,
# <a href="http://example.com/tillie">Tillie</a>]
>>> soup.select("html head title")
# [<title>The Dormouse's story</title>]
Поиск тега непосредственно под другими тегами:
>>> soup.select("head > title")
# [<title>The Dormouse's story</title>]
>>> soup.select("p > a:nth-of-type(2)")
# [<a href="http://example. com/lacie">Lacie</a>]
>>> soup.select("p > #link1")
# [<a href="http://example.com/elsie">Elsie</a>]
com/lacie">Lacie</a>]
>>> soup.select("p > #link1")
# [<a href="http://example.com/elsie">Elsie</a>]
Поиск одноуровневых элементов:
# поиск всех `.sister` в которых нет `#link1`
>>> soup.select("#link1 ~ .sister")
# [<a href="http://example.com/lacie">Lacie</a>,
# <a href="http://example.com/tillie" >Tillie</a>]
# поиск всех `.sister` в которых есть `#link1`
>>> soup.select("#link1 + .sister")
# [<a href="http://example.com/lacie">Lacie</a>]
# поиск всех `<a>` у которых есть сосед `<p>`
Поиск тега по классу CSS:
>>> soup.select(".sister")
# [<a href="http://example.com/elsie">Elsie</a>,
# <a href="http://example.com/lacie">Lacie</a>,
# <a href="http://example.com/tillie">Tillie</a>]
Поиск тега по ID:
>>> soup.select("#link1")
# [<a href="http://example.com/elsie">Elsie</a>]
>>> soup. select("a#link2")
# [<a href="http://example.com/lacie">Lacie</a>]
select("a#link2")
# [<a href="http://example.com/lacie">Lacie</a>]
Дочерние элементы.
Извлечение НЕПОСРЕДСТВЕННЫХ дочерних элементов тега. Если посмотреть на HTML-разметку в коде ниже, то, непосредственными дочерними элементами первого <ul> будут являться три тега <li> и тег <ul> со всеми вложенными тегами.
Обратите внимание, что все переводы строк \n и пробелы между тегами, так же будут считаться дочерними элементами. Так что имеет смысл заранее привести исходный HTML к «нормальному виду«, например так: re.sub(r'>\s+<', '><', html.replace('\n', ''))
html = """
<div>
<ul>
<li>текст 1</li>
<li>текст 2</li>
<ul>
<li>текст 2-1</li>
<li>текст 2-2</li>
</ul>
<li>текст 3</li>
</ul>
</div>
"""
>>> from bs4 import BeautifulSoup
>>> root = BeautifulSoup(html, 'html. parser')
# найдем в дереве первый тег `<ul>`
>>> first_ul = root.ul
# извлекаем список непосредственных дочерних элементов
# переводы строк `\n` и пробелы между тегами так же
# распознаются как дочерние элементы
>>> first_ul.contents
# ['\n', <li>текст 1</li>, '\n', <li>текст 2</li>, '\n', <ul>
# <li>текст 2-1</li>
# <li>текст 2-2</li>
# </ul>, '\n', <li>текст 3</li>, '\n']
# убираем переводы строк `\n` как из списка, так и из тегов
# лучше конечно сразу убрать переводы строк из исходного HTML
>>> [str(i).replace('\n', '') for i in first_ul.contents if str(i) != '\n']
# ['<li>текст 1</li>',
# '<li>текст 2</li>',
# '<ul><li>текст 2-1</li><li>текст 2-2</li></ul>',
# '<li>текст 3</li>']
# то же самое, что и `first_ul.contents`
# только в виде итератора
>>> first_ul.children
# <list_iterator object at 0x7ffa2eb52460>
parser')
# найдем в дереве первый тег `<ul>`
>>> first_ul = root.ul
# извлекаем список непосредственных дочерних элементов
# переводы строк `\n` и пробелы между тегами так же
# распознаются как дочерние элементы
>>> first_ul.contents
# ['\n', <li>текст 1</li>, '\n', <li>текст 2</li>, '\n', <ul>
# <li>текст 2-1</li>
# <li>текст 2-2</li>
# </ul>, '\n', <li>текст 3</li>, '\n']
# убираем переводы строк `\n` как из списка, так и из тегов
# лучше конечно сразу убрать переводы строк из исходного HTML
>>> [str(i).replace('\n', '') for i in first_ul.contents if str(i) != '\n']
# ['<li>текст 1</li>',
# '<li>текст 2</li>',
# '<ul><li>текст 2-1</li><li>текст 2-2</li></ul>',
# '<li>текст 3</li>']
# то же самое, что и `first_ul.contents`
# только в виде итератора
>>> first_ul.children
# <list_iterator object at 0x7ffa2eb52460>
Извлечение ВСЕХ дочерних элементов.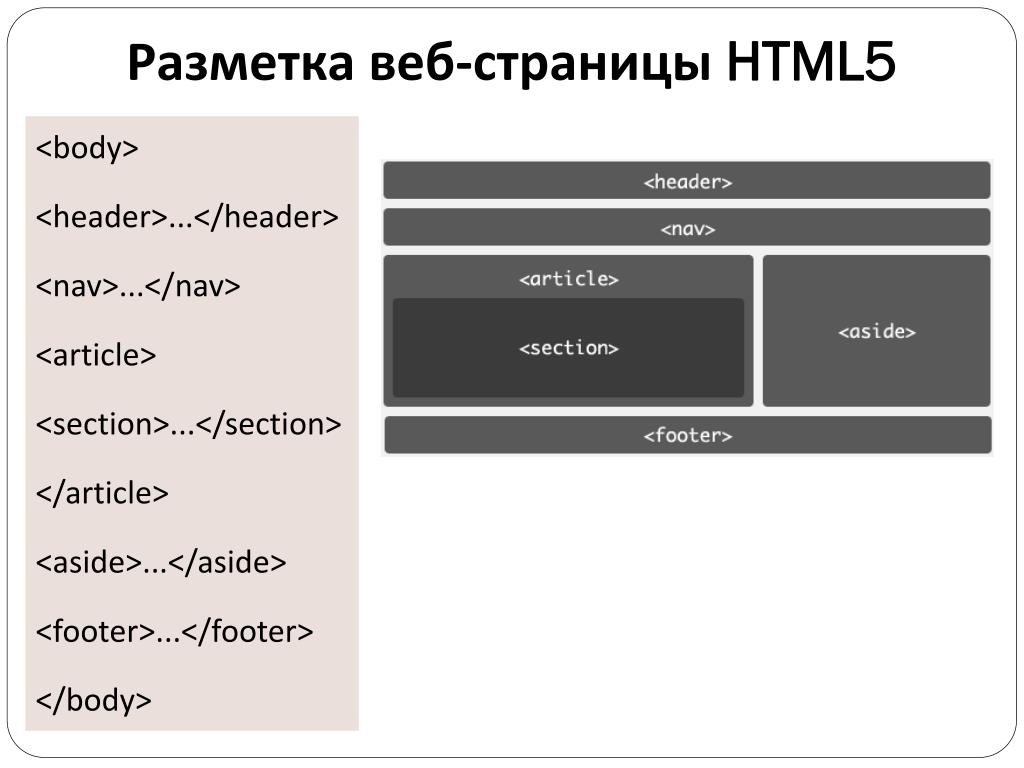 Эта операция похожа на рекурсивный обход HTML-дерева в глубину от выбранного тега.
Эта операция похожа на рекурсивный обход HTML-дерева в глубину от выбранного тега.
>>> import re
# сразу уберем переводы строк из исходного HTML
>>> html = re.sub(r'>\s+<', '><', html.replace('\n', ''))
>>> root = BeautifulSoup(html, 'html.parser')
# найдем в дереве первый тег `<ul>`
>>> first_ul = root.ul
# извлекаем список ВСЕХ дочерних элементов
>>> list(first_ul.descendants)
# [<li>текст 1</li>,
# 'текст 1',
# <li>текст 2</li>,
# 'текст 2',
# <ul><li>текст 2-1</li><li>текст 2-2</li></ul>,
# <li>текст 2-1</li>,
# 'текст 2-1',
# <li>текст 2-2</li>,
# 'текст 2-2',
# <li>текст 3</li>,
# 'текст 3']
Обратите внимание, что простой текст, который находится внутри тега, так же считается дочерним элементом этого тега.
Если внутри тега есть более одного дочернего элемента (как в примерен выше) и необходимо извлечь только текст, то можно использовать атрибут . или генератор  strings
strings.stripped_strings.
Генератор .stripped_strings дополнительно удаляет все переводы строк \n и пробелы между тегами в исходном HTML-документе.
>>> list(first_ul.strings) # ['текст 1', 'текст 2', 'текст 2-1', 'текст 2-2', 'текст 3'] >>> first_ul.stripped_strings # <generator object Tag.stripped_strings at 0x7ffa2eb43ac0> >>> list(first_ul.stripped_strings) # ['текст 1', 'текст 2', 'текст 2-1', 'текст 2-2', 'текст 3']
Родительские элементы.
Что бы получить доступ к родительскому элементу, необходимо использовать атрибут .parent.
html = """
<div>
<ul>
<li>текст 1</li>
<li>текст 2</li>
<ul>
<li>текст 2-1</li>
<li>текст 2-2</li>
</ul>
<li>текст 3</li>
</ul>
</div>
"""
>>> from bs4 import BeautifulSoup
>>> import re
# сразу уберем переводы строк и пробелы
# между тегами из исходного HTML
>>> html = re. sub(r'>\s+<', '><', html.replace('\n', ''))
>>> root = BeautifulSoup(html, 'html.parser')
# найдем теги `<li>` вложенные во второй `<ul>`,
# используя CSS селекторы
>>> child_ul = root.select('ul > ul > li')
>>> child_ul
# [<li>текст 2-1</li>, <li>текст 2-2</li>]
# получаем доступ к родителю
>>> child_li[0].parent
# <ul><li>текст 2-1</li><li>текст 2-2</li></ul>
# доступ к родителю родителя
>>> child_li[0].parent.parent.contents
[<li>текст 1</li>,
<li>текст 2</li>,
<ul><li>текст 2-1</li><li>текст 2-2</li></ul>,
<li>текст 3</li>]
sub(r'>\s+<', '><', html.replace('\n', ''))
>>> root = BeautifulSoup(html, 'html.parser')
# найдем теги `<li>` вложенные во второй `<ul>`,
# используя CSS селекторы
>>> child_ul = root.select('ul > ul > li')
>>> child_ul
# [<li>текст 2-1</li>, <li>текст 2-2</li>]
# получаем доступ к родителю
>>> child_li[0].parent
# <ul><li>текст 2-1</li><li>текст 2-2</li></ul>
# доступ к родителю родителя
>>> child_li[0].parent.parent.contents
[<li>текст 1</li>,
<li>текст 2</li>,
<ul><li>текст 2-1</li><li>текст 2-2</li></ul>,
<li>текст 3</li>]
Taк же можно перебрать всех родителей элемента с помощью атрибута .parents.
>>> child_li[0] # <li>текст 2-1</li> >>> [parent.name for parent in child_li[0].parents] # ['ul', 'ul', 'div', '[document]']
Изменение имен тегов HTML-документа:
>>> soup = BeautifulSoup('<p><b>Extremely bold</b></p>', 'html. parser')
>>> tag = soup.b
# присваиваем новое имя тегу
>>> tag.name = "blockquote"
>>> tag
# <blockquote>Extremely bold</blockquote>
>>> soup
# <p><blockquote>Extremely bold</blockquote></p>
parser')
>>> tag = soup.b
# присваиваем новое имя тегу
>>> tag.name = "blockquote"
>>> tag
# <blockquote>Extremely bold</blockquote>
>>> soup
# <p><blockquote>Extremely bold</blockquote></p>
Изменение HTML-тега <p> на тег <div>:
>>> soup = BeautifulSoup('<p><b>Extremely bold</b></p>', 'html.parser')
>>> soup.p.name = 'div'
>>> soup
# <div><b>Extremely bold</b></div>
Добавление новых тегов в HTML-документ.
Добавление нового тега в дерево HTML:
>>> soup = BeautifulSoup("<p><b></b></p>", 'html.parser')
>>> original_tag = soup.b
# создание нового тега `<a>`
>>> new_tag = soup.new_tag("a", href="http://example.com")
# строка нового тега `<a>`
>>> new_tag.string = "Link text"
# добавление тега `<a>` внутрь `<b>`
>>> original_tag. append(new_tag)
>>> original_tag
# <b><a href="http://example.com">Link text.</a></b>
>>> soup
# <p><b><a href="http://example.com">Link text</a></b></p>
append(new_tag)
>>> original_tag
# <b><a href="http://example.com">Link text.</a></b>
>>> soup
# <p><b><a href="http://example.com">Link text</a></b></p>
Добавление новых тегов до/после определенного тега или внутрь тега.
>>> soup = BeautifulSoup("<p><b>leave</b></p>", 'html.parser')
>>> tag = soup.new_tag("i",)
>>> tag.string = "Don't"
# добавление нового тега <i> до тега <b>
>>> soup.b.insert_before(tag)
>>> soup.b
# <p><i>Don't</i><b>leave</b></p>
# добавление нового тега <i> после тега <b>
>>> soup.b.insert_after(tag)
>>> soup
# <p><b>leave</b><i>Don't</i></p>
# добавление нового тега <i> внутрь тега <b>
>>> soup.b.string.insert_before(tag)
>>> soup.b
# <p><b><i>Don't</i>leave</b></p>
Удаление и замена тегов в HTML-документе.

Удаляем тег или строку из дерева HTML:
>>> html = '<a href="http://example.com/">I linked to <i>example.com</i></a>' >>> soup = BeautifulSoup(html, 'html.parser') >>> a_tag = soup.a # удаляем HTML-тег `<i>` с сохранением # в переменной `i_tag` >>> i_tag = soup.i.extract() # смотрим что получилось >>> a_tag # <a href="http://example.com/">I linked to</a> >>> i_tag # <i>example.com</i>
Заменяем тег и/или строку в дереве HTML:
>>> html = '<a href="http://example.com/">I linked to <i>example</i></a>'
>>> soup = BeautifulSoup(html, 'html.parser')
>>> a_tag = soup.a
# создаем новый HTML тег
>>> new_tag = soup.new_tag("b")
>>> new_tag.string = "sample"
# производим замену тега `<i>` внутри тега `<a>`
>>> a_tag.i.replace_with(new_tag)
>>> a_tag
# <a href="http://example. com/">I linked to <b>sample</b></a>
com/">I linked to <b>sample</b></a>
Изменение атрибутов тегов HTML-документа.
У тега может быть любое количество атрибутов. Тег <b id = "boldest"> имеет атрибут id, значение которого равно boldest. Доступ к атрибутам тега можно получить, обращаясь с тегом как со словарем:
>>> soup = BeautifulSoup('<p><b>bolder</b></p>', 'html.parser')
>>> tag = soup.b
>>> tag['id']
# 'boldest'
# доступ к словарю с атрибутами
>>> tag.attrs
# {'id': 'boldest'}
Можно добавлять и изменять атрибуты тега.
# изменяем `id` >>> tag['id'] = 'bold' # добавляем несколько значений в `class` >>> tag['class'] = ['new', 'bold'] # или >>> tag['class'] = 'new bold' >>> tag # <b>bolder</b>
А так же производить их удаление.
>>> del tag['id'] >>> del tag['class'] >>> tag # <b>bolder</b> >>> tag.get('id') # None
Соскоб веб-страниц в Python с красивым супом: основы
В предыдущем уроке я показал вам, как использовать модуль Requests для доступа к веб-страницам с использованием Python . Учебное пособие охватывало множество тем, таких как выполнение запросов GET / POST и загрузка таких программ, как изображения или PDF-файлы. Единственное, чего не хватало в этом руководстве, было руководство по очистке веб-страниц, к которым вы обращались, используя Запросы для извлечения необходимой вам информации.
В этом руководстве вы узнаете о Beautiful Soup – библиотеке Python для извлечения данных из файлов HTML. Основное внимание в этом руководстве будет уделено изучению основ библиотеки, а более сложные темы будут рассмотрены в следующем руководстве. Обратите внимание, что в этом руководстве используется Beautiful Soup 4 для всех примеров.
Вы можете установить Beautiful Soup 4, используя pip . Название пакета – beautifulsoup4 . Он должен работать как на Python 2, так и на Python 3.
Он должен работать как на Python 2, так и на Python 3.
1 | $ pip install beautifulsoup4 |
Если в вашей системе не установлен pip, вы можете напрямую загрузить архив с исходным кодом Beautiful Soup 4 и установить его с помощью setup.py .
1 | $ python setup.py install |
BeautifulSoup изначально упакован как код Python 2. Когда вы устанавливаете его для использования с Python 3, он автоматически обновляется до кода Python 3. Код не будет преобразован, если вы не установите пакет. Вот несколько распространенных ошибок, которые вы можете заметить:
- Ошибка
ImportError«Нет модуля с именем HTMLParser» возникает при запуске версии кода Python 2 под Python 3. - Ошибка «Не
ImportErrorмодуль с именем html. parser» возникает при запуске версии кода Python 3 под Python 2.
parser» возникает при запуске версии кода Python 3 под Python 2.
Обе ошибки, описанные выше, можно исправить, удалив и переустановив Beautiful Soup.
Прежде чем обсуждать различия между различными парсерами, которые вы можете использовать с Beautiful Soup, давайте напишем код для создания супа.
1 2 3 | from bs4 import BeautifulSoup
soup = BeautifulSoup(“<html><p>This is <b>invalid HTML</p></html>”, “html.parser”) |
Объект BeautifulSoup может принимать два аргумента. Первый аргумент – это фактическая разметка, а второй аргумент – это анализатор, который вы хотите использовать. Разные парсеры: html.parser , lxml и html5lib . У парсера lxml есть две версии: парсер HTML и парсер XML.
html.parser – это встроенный синтаксический анализатор, и он не очень хорошо работает в старых версиях Python. Вы можете установить другие парсеры, используя следующие команды:
Вы можете установить другие парсеры, используя следующие команды:
1 2 | $ pip install lxml $ pip install html5lib |
Анализатор lxml очень быстрый и может быть использован для быстрого анализа заданного HTML. С другой стороны, синтаксический анализатор html5lib очень медленный, но он также чрезвычайно снисходительный. Вот пример использования каждого из этих парсеров:
01 02 03 04 05 06 07 08 09 10 11 12 13 14 15 16 | soup = BeautifulSoup(“<html><p>This is <b>invalid HTML</p></html>”, “html.parser”) print(soup) # <html><p>This is <b>invalid HTML</b></p></html>
soup = BeautifulSoup(“<html><p>This is <b>invalid HTML</p></html>”, “lxml”) print(soup) # <html><body><p>This is <b>invalid HTML</b></p></body></html>
soup = BeautifulSoup(“<html><p>This is <b>invalid HTML</p></html>”, “xml”) print(soup) # <?xml version=”1. # <html><p>This is <b>invalid HTML</b></p></html>
soup = BeautifulSoup(“<html><p>This is <b>invalid HTML</p></html>”, “html5lib”) print(soup) # <html><head></head><body><p>This is <b>invalid HTML</b></p></body></html> |
 0″ encoding=”utf-8″?>
0″ encoding=”utf-8″?> Различия, показанные в приведенном выше примере, имеют значение только при разборе неверного HTML. Тем не менее, большая часть HTML в сети искажена, и знание этих различий поможет вам отладить некоторые ошибки синтаксического анализа и решить, какой анализатор вы хотите использовать в проекте. Как правило, анализатор lxml – очень хороший выбор.
Beautiful Soup разбирает данный HTML-документ на дерево объектов Python. Есть четыре основных объекта Python, о которых вам нужно знать: Tag , NavigableString , BeautifulSoup и Comment .
Объект Tag ссылается на фактический тег XML или HTML в документе. Вы можете получить доступ к имени тега, используя tag.name . Вы также можете установить имя тега на что-то другое. Изменение имени будет видно в разметке, созданной Beautiful Soup.
Вы можете получить доступ к различным атрибутам, таким как класс и идентификатор тега, используя tag['class'] и tag['id'] соответственно. Вы также можете получить доступ ко всему словарю атрибутов, используя tag.attrs . Вы также можете добавлять, удалять или изменять атрибуты тега. Атрибуты, такие как class элемента, который может принимать несколько значений, хранятся в виде списка.
Текст внутри тега сохраняется в виде NavigableString в Beautiful Soup. У него есть несколько полезных методов, таких как replace_with("string") для замены текста внутри тега. Вы также можете преобразовать NavigableString в строку unicode() используя unicode() .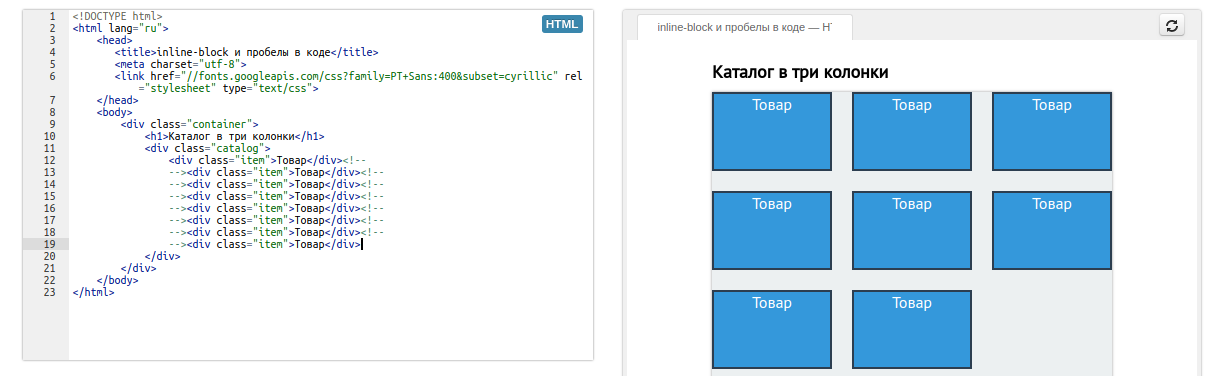
Красивый суп также позволяет получить доступ к комментариям на веб-странице. Эти комментарии хранятся в виде объекта Comment , который также является в основном NavigableString .
Вы уже узнали об объекте BeautifulSoup в предыдущем разделе. Он используется для представления документа в целом. Поскольку это не фактический объект, он не имеет ни имени, ни атрибутов.
Вы можете легко извлечь заголовок страницы и другие подобные данные, используя Beautiful Soup. Давайте почистим страницу Википедии о Python . Во-первых, вам нужно получить разметку страницы, используя следующий код на основе учебного пособия модуля Запросы для доступа к веб-страницам .
1 2 3 4 5 | import requests from bs4 import BeautifulSoup
req = requests.get(‘https://en.wikipedia.org/wiki/Python_(programming_language)’) soup = BeautifulSoup(req. |
 text, “lxml”)
text, “lxml”)Теперь, когда вы создали суп, вы можете получить заголовок веб-страницы, используя следующий код:
1 2 3 4 5 6 7 8 | soup.title # <title>Python (programming language) – Wikipedia</title>
soup.title.name # ‘title’
soup.title.string # ‘Python (programming language) – Wikipedia’ |
Вы также можете очистить веб-страницу для получения другой информации, такой как основной заголовок или первый абзац, их классы или атрибут id .
01 02 03 04 05 06 07 08 09 10 11 12 13 14 15 16 17 18 19 20 21 22 | soup. # <h2 class=”firstHeading” id=”firstHeading” lang=”en”>Python (programming language)</h2>
soup.h2.string # ‘Python (programming language)’
soup.h2[‘class’] # [‘firstHeading’]
soup.h2[‘id’] # ‘firstHeading’
soup.h2.attrs # {‘class’: [‘firstHeading’], ‘id’: ‘firstHeading’, ‘lang’: ‘en’}
soup.h2[‘class’] = ‘firstHeading, mainHeading’ soup.h2.string.replace_with(“Python – Programming Language”) del soup.h2[‘lang’] del soup.h2[‘id’]
soup.h2 # <h2 class=”firstHeading, mainHeading”>Python – Programming Language</h2> |
 h2
h2Точно так же вы можете перебирать все ссылки или подзаголовки в документе, используя следующий код:
1 2 3 4 | for sub_heading in soup.find_all(‘h3’): print(sub_heading. # all the sub-headings like Contents, History[edit]… |
 text)
text) Вы можете перемещаться по дереву DOM, используя обычные имена тегов. Связывание этих имен тегов может помочь вам более глубоко ориентироваться в дереве. Например, вы можете получить первую ссылку в первом абзаце данной страницы Википедии, используя soup.pa Все ссылки в первом абзаце могут быть доступны с помощью soup.p.find_all('a') .
Вы также можете получить доступ ко всем tag.contents тега в виде списка с помощью tag.contents . Чтобы получить детей по определенному индексу, вы можете использовать tag.contents[index] . Вы также можете перебирать дочерние теги, используя атрибут .children .
И .children и .contents полезны только тогда, когда вы хотите получить доступ к прямым или .contents потомкам тега. Чтобы получить всех потомков, вы можете использовать атрибут . . descendants
descendants
01 02 03 04 05 06 07 08 09 10 11 12 13 14 15 | print(soup.p.contents) # [<b>Python</b>, ‘ is a widely used ‘,…..the full list]
print(soup.p.contents[10]) # <a href=”/wiki/Readability” title=”Readability”>readability</a>
for child in soup.p.children: print(child.name) # b # None # a # None # a # None # … and so on. |
Вы также можете получить доступ к родительскому элементу, используя атрибут .parent . Точно так же вы можете получить доступ ко всем предкам элемента, используя атрибут .parents . Родителем тега <html> верхнего уровня является сам объект BeautifulSoup , а его родителем – None.
01 02 03 04 05 06 07 08 09 10 11 | print(soup.p.parent.name) # div
for parent in soup.p.parents: print(parent.name) # div # div # div # body # html # [document] |
Вы можете получить доступ к предыдущему и следующему брату элемента, используя .previous_sibling и .next_sibling .
Чтобы два элемента были братьями и сестрами, они должны иметь одного и того же родителя. Это означает, что первый дочерний элемент не будет иметь предыдущего родного брата. Точно так же у последнего потомка элемента не будет следующего родного брата. На реальных веб-страницах предыдущий и следующий братья и сестры элемента, скорее всего, будут символом новой строки.
Вы также можете перебрать все элементы одного элемента, используя . и  previous_siblings
previous_siblings.next_siblings .
01 02 03 04 05 06 07 08 09 10 11 | soup.head.next_sibling # ‘\n’
soup.panext_sibling # ‘ for ‘
soup.paprevious_sibling # ‘ is a widely used ‘
print(soup.pbprevious_sibling) # None |
Вы можете перейти к элементу, который идет сразу после текущего элемента, используя атрибут .next_element . Чтобы получить доступ к элементу, который находится непосредственно перед текущим элементом, используйте атрибут .previous_element .
Точно так же вы можете перебирать все элементы, которые идут до и после текущего элемента, используя .previous_elements и .next_elements соответственно.
После завершения этого урока вы должны хорошо понимать основные различия между различными HTML-парсерами. Теперь вы также должны иметь возможность перемещаться по веб-странице и извлекать важные данные. Это может быть полезно, если вы хотите проанализировать все заголовки или ссылки на данном веб-сайте.
Теперь вы также должны иметь возможность перемещаться по веб-странице и извлекать важные данные. Это может быть полезно, если вы хотите проанализировать все заголовки или ссылки на данном веб-сайте.
В следующей части серии вы узнаете, как использовать библиотеку Beautiful Soup для поиска и изменения DOM.
Пакет html5lib — документация по html5lib 1.2-dev
Пакет html5lib — документация по html5lib 1.2-devБиблиотека синтаксического анализа HTML, основанная на спецификации HTML WHATWG. Парсер предназначен для совместимости с существующий HTML, найденный в дикой природе, и реализует четко определенное восстановление после ошибок, которое в значительной степени совместим с современными настольными веб-браузерами.
Пример использования:
импорт html5lib
с open("my_document.html", "rb") как f:
дерево = html5lib.parse(f)
Для удобства этот модуль реэкспортирует следующие имена:
-
parse() -
фрагмент фрагмента() -
Парсер HTML -
getTreeBuilder() -
getTreeWalker() -
сериализовать()
-
html5lib.
__версия__= ‘1.2-dev’ Номер версии дистрибутива.
константы Модуль- исключение
html5lib.constants.DataLossWarning[источник] Базы:
UserWarningВозникает, когда текущее дерево не может представить входные данные
Модуль html5parser - класс
html5lib.html5parser.HTMLParser( tree=None , strict=False , namespaceHTMLElements=True , отладка=ложь )[источник] Базы:
объектПарсер HTML
Генерирует древовидную структуру из потока (возможно, искаженного) HTML.
-
__init__( tree = None , strict = False , namespaceHTMLelements = True , debug = False ) [ источник ] Параметры: - дерево — класс построителя дерева, управляющий типом дерева, которое будет
вернулся.
 Доступ к встроенным конструкторам деревьев можно получить через
html5lib.treebuilders.getTreeBuilder(treeType)
Доступ к встроенным конструкторам деревьев можно получить через
html5lib.treebuilders.getTreeBuilder(treeType) - strict — вызывать исключение при обнаружении ошибки синтаксического анализа
- namespaceHTMLElements – следует ли использовать HTML-элементы пространства имен
- отладка – включать или нет режим отладки, который регистрирует вещи
Пример:
>>> из html5lib.html5parser импортировать HTMLParser >>> parser = HTMLParser() # генерирует синтаксический анализатор с помощью построителя etree >>> parser = HTMLParser('lxml', strict=True) # генерирует парсер со строгим компоновщиком lxml- дерево — класс построителя дерева, управляющий типом дерева, которое будет
вернулся.
-
документКодировка Имя кодировки символов, которая использовалась для декодирования входного потока, или
Нет, если это еще не определено
-
разбор( поток , *args , **kwargs ) [источник] Разобрать HTML-документ в правильно сформированное дерево
Параметры: - поток —
файлоподобный объект или строка, содержащая HTML для анализа
Необязательный параметр кодирования должен быть строкой, указывающей кодировка.
 Если указано, эта кодировка будет использоваться,
независимо от любой спецификации или более позднего объявления (например, в мета
элемент).
Если указано, эта кодировка будет использоваться,
независимо от любой спецификации или более позднего объявления (например, в мета
элемент). - scripting — обрабатывать элементы noscript так, как если бы JavaScript был включен
Возвраты: проанализированное дерево
Пример:
>>> из html5lib.html5parser импортировать HTMLParser >>> парсер = HTMLParser() >>> parser.parse('Это документ
') <Элемент u'{http://www.w3.org/1999/xhtml}html' по адресу 0x7feac4909db0>- поток —
-
parseFragment( поток , *args , **kwargs ) [источник] Разобрать фрагмент HTML в правильно сформированный фрагмент дерева
Параметры: - контейнер — имя элемента, который мы устанавливаем innerHTML свойство, если установлено значение «Нет», по умолчанию «div»
- поток –
файлоподобный объект или строка, содержащая HTML для анализа
Необязательный параметр кодирования должен быть строкой, указывающей кодировка.
 Если указано, эта кодировка будет использоваться,
независимо от любой спецификации или более позднего объявления (например, в мета
элемент)
Если указано, эта кодировка будет использоваться,
независимо от любой спецификации или более позднего объявления (например, в мета
элемент) - scripting — обрабатывать элементы noscript так, как если бы JavaScript был включен
Возвраты: проанализированное дерево
Пример:
>>> из html5lib.html5libparser импортировать HTMLParser >>> парсер = HTMLParser() >>> parser.parseFragment('это фрагмент') <Элемент u'DOCUMENT_FRAGMENT' по адресу 0x7feac484b090>
-
- исключение
html5lib.html5parser.ParseError[источник] Базы:
ИсключениеОшибка в проанализированном документе
-
html5lib.html5парсер.разбор( doc , treebuilder=’etree’ , namespaceHTMLElements=True , **kwargs )[источник] Анализ HTML-документа как строки или файлового объекта в виде дерева
Параметры: - doc – документ для анализа как строка или файлоподобный объект
- построитель дерева — построитель дерева для использования при разборе
- namespaceHTMLElements – следует ли использовать HTML-элементы пространства имен
Возвраты: проанализированное дерево
Пример:
>>> из html5lib.
 html5parser импортировать разбор
>>> parse('
html5parser импортировать разбор
>>> parse('Это документ
') <Элемент u'{http://www.w3.org/1999/xhtml}html' по адресу 0x7feac4909db0>
-
html5lib.html5парсер.parseFragment( doc , container=’div’ , treebuilder=’etree’ , namespaceHTMLElements=True , **kwargs 9004 3 )[источник] Разобрать HTML-фрагмент как строку или файловый объект в дерево
Параметры: - doc – фрагмент для разбора как строка или файловый объект
- container — контекст контейнера для разбора фрагмента в
- построитель дерева — построитель дерева для использования при разборе
- namespaceHTMLElements – следует ли использовать HTML-элементы пространства имен
Возвраты: проанализированное дерево
Пример:
>>> из html5lib.
 html5libparser импортировать parseFragment
>>> parseFragment('это фрагмент')
<Элемент u'DOCUMENT_FRAGMENT' по адресу 0x7feac484b090>
html5libparser импортировать parseFragment
>>> parseFragment('это фрагмент')
<Элемент u'DOCUMENT_FRAGMENT' по адресу 0x7feac484b090>
сериализатор Модуль- исключение
html5lib.serializer.SerializeError[источник] Базы:
ИсключениеОшибка в сериализованном дереве
-
html5lib.serializer.сериализовать( input , tree=’etree’ , encoding=None , **serializer_opts )[источник] Сериализирует поток входных токенов, используя указанный обходчик дерева
Параметры: - ввод — поток токенов для сериализации
- дерево – деревоход для использования
- encoding – используемая кодировка
- serializer_opts — любые параметры для передачи
html5lib., который создается serializer.HTMLSerializer
serializer.HTMLSerializer
Возвраты: дерево, сериализованное как строка
Пример:
>>> из html5lib.html5parser импортировать разбор >>> из html5lib.serializer импортировать сериализовать >>> token_stream = parse('Привет!
') >>> сериализовать (токен_поток, опустить_необязательные_теги = ложь) 'Привет!
'
-
html5lib.serializer.xmlcharrefreplace_errors() Реализует обработку ошибок xmlcharrefreplace, которая заменяет некодируемый символ соответствующей ссылкой на символ XML.
- класс
html5lib.serializer.HTMLSerializer( **kwargs )[источник] Базы:
объект-
__инициализация__( **kwargs )[источник] Инициализировать HTMLSerializer
Параметры: - inject_meta_charset –
Внедрять метакодировку или нет.

По умолчанию
Правда. - quote_attr_values –
Следует ли заключать в кавычки значения атрибутов, которые не требуют цитирования для устаревшего поведения браузера (
"устаревший"), когда требуется по стандарту ("spec") или всегда ("всегда").По умолчанию
"старый". - quote_char –
Использовать данный символ кавычки для цитирования атрибута.
По умолчанию
", которые будут использовать двойные кавычки, если атрибут value содержит двойную кавычку, в этом случае одинарные кавычки использовал. - escape_lt_in_attrs –
Следует ли экранировать
<в атрибуте ценности.По умолчанию
Ложь. - escape_rcdata –
Следует ли экранировать символы, которые необходимо экранирован внутри обычных элементов внутри элементов rcdata, таких как стиль.
По умолчанию
Ложь. - resolve_entities –
Следует ли разрешать именованные символы, которые появляются в исходном дереве. Предопределенные объекты XML < > &ампер; " ' эта настройка не влияет.
По умолчанию
Правда. - strip_whitespace –
Удалять ли семантически бессмысленное пробел. (Это сжимает все пробелы в один пробел кроме
до.)По умолчанию
Ложь. - Minim_boolean_attributes –
Сокращает логические атрибуты, чтобы дать просто значение атрибута, например:
<вход отключен = "отключен">
становится:
<ввод отключен>
По умолчанию
Правда. - use_trailing_solidus –
Включает косую черту в конце тега начальный тег пустых элементов (пустые элементы, конечный тег которых запрещенный).
 Например.
Например. <ч/>.По умолчанию
Ложь. - space_before_trailing_solidus –
Помещает пробел непосредственно перед закрывающая косая черта в теге с завершающей косой чертой. Например.
<ч />. Требуетсяuse_trailing_solidus=True.По умолчанию
Правда. - sanitize –
Удаление всех небезопасных или неизвестных конструкций из вывода. См.
html5lib.filters.sanitizer.Filter.По умолчанию
Ложь. - omit_Optional_tags –
Пропускать необязательные начальные/конечные теги.
По умолчанию
Правда. - Alphabetical_attributes –
Изменить порядок атрибутов в алфавитном порядке.
По умолчанию
Ложь.
- inject_meta_charset –
-
рендеринг( древолаз , кодировка=нет )[источник] Сериализирует поток из древохода в строку
Параметры: - treewalker – treewalker для сериализации
- encoding – кодировка строки для использования
Возвращает: сериализованное дерево
Пример:
>>> из разбора импорта html5lib, getTreeWalker >>> из html5lib.
 serializer импортировать HTMLSerializer
>>> token_stream = parse('Привет!')
>>> Walker = getTreeWalker('etree')
>>> сериализатор = HTMLSerializer (опустить_необязательные_теги = ложь)
>>> serializer.render (ходок (token_stream))
'Привет!'
serializer импортировать HTMLSerializer
>>> token_stream = parse('Привет!')
>>> Walker = getTreeWalker('etree')
>>> сериализатор = HTMLSerializer (опустить_необязательные_теги = ложь)
>>> serializer.render (ходок (token_stream))
'Привет!'
-
Дополнительные комплекты
- Комплект фильтров
-
ОснованиеМодуль -
алфавитные атрибутыМодуль -
inject_meta_charsetМодуль -
ворсМодуль -
дополнительные тегиМодуль -
дезинфицирующее средствоМодуль -
пробелМодуль
-
- treebuilders Package
-
baseModule -
домМодуль -
etreeМодуль -
etree_lxmlМодуль
-
- Treewalkers Пакет
-
БазаМодуль -
домМодуль -
etreeМодуль -
etree_lxmlМодуль -
ГеншиМодуль
-
- древовидные адаптеры Пакет
- Версии
- последний
- стабильный
- Загрузки
- пдф
- HTML
- epub
- При прочтении документов
- Дом проекта
- Строит
Бесплатный хостинг документов предоставляется Read the Docs.

python — ошибка при попытке установить html5lib
Задавать вопрос
спросил
Изменено 6 лет, 1 месяц назад
Просмотрено 2к раз
Я все еще новичок в python, и мне нужна html5lib для проекта, но когда я запускаю pip install html5lib , вот что я получаю:
Ошибка: [('/System/Library/Frameworks/Python.framework/Versions/2.7/Extras/lib/python/_markerlib/ init .py', '/var/folders/yr/8762117x5h7_pwb9fx5f0tzr0000gn/T/pip- uiZ0aQ-uninstall/System/Library/Frameworks/Python.framework/Versions/2.7/Extras/lib/python/_markerlib/ init .py', "[Errno 1] Операция не разрешена: '/var/folders/yr/ 8762117x5h7_pwb9fx5f0tzr0000gn/T/pip-uiZ0aQ-uninstall/System/Library/Frameworks/Python.
framework/Versions/2.7/Extras/lib/python/_markerlib/ init .py'"), ('/System/Library/Frameworks/Python.framework/Versions/2.7/Extras/lib/python/_markerlib/ init .pyc', '/var/folders/yr/8762117x5h7_pwb9fx5f0tzr0000gn /T/pip-uiZ0aQ-uninstall/System/Library/Frameworks/Python.framework/Versions/2.7/Extras/lib/python/_markerlib/ init .pyc', "[Errno 1] Операция не разрешена: '/var /folders/yr/8762117x5h7_pwb9fx5f0tzr0000gn/T/pip-uiZ0aQ-uninstall/System/Library/Frameworks/Python.framework/Versions/2.7/Extras/lib/python/_markerlib/ init .pyc'"), ('/System/Library/Frameworks/Python.framework/Versions/2.7/Extras/lib/python/_markerlib/markers.py', '/var/folders/yr/8762117x5h7_pwb9fx5f0tzr0000gn/T /pip-uiZ0aQ-uninstall/System/Library/Frameworks/Python.framework/Versions/2.7/Extras/lib/python/_markerlib/markers.py', "[Errno 1] Операция не разрешена: '/var/folders/yr /8762117x5h7_pwb9fx5f0tzr0000gn/T/pip-uiZ0aQ-uninstall/System/Library/Frameworks/Python.
framework/Versions/2.7/Extras/lib/python/_markerlib/markers.py'"), ('/System/Library/Frameworks/Python .framework/Versions/2.7/Extras/lib/python/_markerlib/markers.pyc', '/var/folders/yr/8762117x5h7_pwb9fx5f0tzr0000gn/T/pip-uiZ0aQ-uninstall/System/Library/Frameworks/Python.framework/Versions/2.7/Extras/lib/python/_markerlib/markers.pyc', "[Errno 1] Операция не разрешена: '/var/ folders/yr/8762117x5h7_pwb9fx5f0tzr0000gn/T/pip-uiZ0aQ-uninstall/System/Library/Frameworks/Python.framework/Versions/2.7/Extras/lib/python/_markerlib/markers.pyc'"), ('/System/Library/ Frameworks/Python.framework/Versions/2.7/Extras/lib/python/_markerlib', '/var/folders/yr/8762117x5h7_pwb9fx5f0tzr0000gn/T/pip-uiZ0aQ-uninstall/System/Library/Frameworks/Python.framework/Versions/2.7 /Extras/lib/python/_markerlib', "[Errno 1] Операция не разрешена: '/var/folders/yr/8762117x5h7_pwb9fx5f0tzr0000gn/T/pip-uiZ0aQ-uninstall/System/Library/Frameworks/Python.framework/Versions/2.7/Extras/lib/python/_markerlib'")]
Я знаю, действительно длинная грубая ошибка, но я не уверен, что происходит. На самом деле у меня были ошибки при попытке установить другие пакеты Python, и я не уверен, в чем проблема. Любая помощь или понимание будут очень благодарны, спасибо!
На самом деле у меня были ошибки при попытке установить другие пакеты Python, и я не уверен, в чем проблема. Любая помощь или понимание будут очень благодарны, спасибо!
- питон
- питон-2.7
- html5lib
Думаю, у вас Mac.
И похоже, что вы пытаетесь установить Python в каталоги системного уровня без полномочий root (отсюда и «Операция не разрешена»). , а затем прочитайте об этом, чтобы узнать, как его использовать. (Вы действительно этого хотите.)
2Обновите свой pip с помощью
pip install --upgrade pip
Затем следуйте инструкциям на странице https://apple.stackexchange.com/questions/209572/how-to-use-pip-after-the-os-x-el-capitan-upgrade
.Зарегистрируйтесь или войдите в систему
Зарегистрируйтесь с помощью Google Зарегистрироваться через Facebook Зарегистрируйтесь, используя электронную почту и парольОпубликовать как гость
Электронная почтаОбязательно, но не отображается
Опубликовать как гость
Электронная почтаТребуется, но не отображается
Нажимая «Опубликовать свой ответ», вы соглашаетесь с нашими условиями обслуживания и подтверждаете, что прочитали и поняли нашу политику конфиденциальности и кодекс поведения.