Зачем вам нужен файл robots.txt, и как его создать?
Файл robots.txt, он же стандарт исключений для роботов — это текстовый файл, в котором хранятся определенные указания для роботов поисковых систем.Прежде, чем сайт попадает в поисковую выдачу и занимает там определенное место, его исследуют роботы. Именно они передают информацию поисковым системам, и далее ваш ресурс отображается в поисковой строке.
Robots.txt выполняет важную функцию — он может защитить весь сайт или некоторые его разделы от индексации. Особенно это актуально для интернет-магазинов и других ресурсов, через которые совершаются онлайн-оплаты. Вам же не хочется, чтобы кредитные счета ваших клиентов вдруг стали известны всему интернету? Для этого и существует файл robots.txt.
Про директивы
Поисковые роботы по умолчанию сканируют все ссылки подряд, если только не установить им ограничений. Для этого в файле robots.txt составляют определенные команды или инструкции к действию. Такие инструкции называются директивами.Главная директива-приветствие, с которой начинается индексация файла — это user-agent
User-agent: Yandex
Или так:User-agent: *
Или вот так:
User-agent: GoogleBot
User-agent обращается к конкретному роботу, и дальнейшие руководства к действию будут относиться только к нему.
Так, в первом случае инструкции будут касаться только роботов Яндекс, во втором — роботов всех поисковых систем, в последнем — команды предназначены главному роботу Google.
Резонно спросить: зачем обращаться к роботам по отдельности? Дело в том, что разные поисковые “посланцы” по разному подходят к индексации файла. Так, роботы Google беспрекословно соблюдают директиву sitemap (о ней написано ниже), в то время как роботы Яндекса относятся к ней нейтрально. А вот директива clean-param, которая позволяет исключать дубли страниц, работает исключительно для поисковиков Яндекс.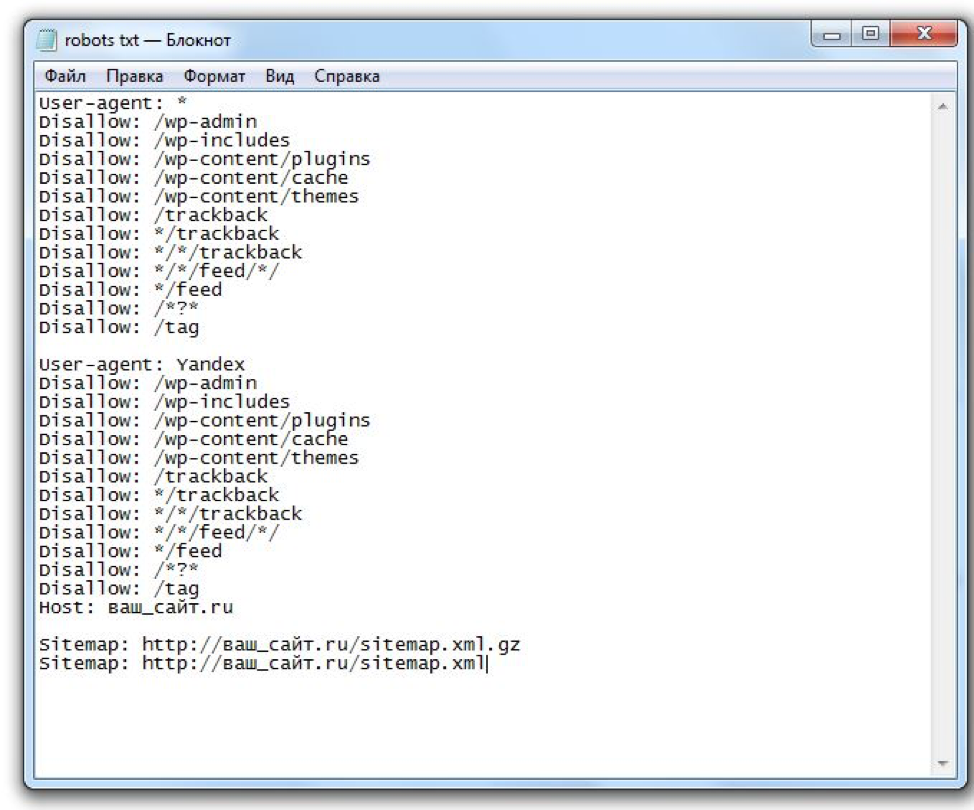
Однако, если у вас простой сайт с несложными разделами, рекомендуем не делать исключений и обращаться ко всем роботам сразу, используя символ *.
Вторая по значимости директива — disallow
Она запрещает роботам сканировать определенные страницы. Как правило, с помощью disallow закрывают административные файлы, дубликаты страниц и конфиденциальные данные.На наш взгляд, любая персональная или корпоративная информация должна охраняться более строго, то есть требовать аутентификации. Но, все же, в целях профилактики рекомендуем запретить индексацию таких страниц и в robots.txt.
Директива может выглядеть так:
User-agent: *
Disallow: /wp-admin/
Или так:
User-Agent: Googlebot
Disallow: */index.php
Disallow: */section.php
В первом примере мы закрыли от индексации системную панель сайта, а во втором запретили роботам сканировать страницы index.php и section.php. Знак * переводится для роботов как “любой текст”, / — знак запрета.
Следующая директива — allow
В противовес предыдущей, это команда разрешает индексировать информацию.
Может показаться странным: зачем что-то разрешать, если поисковой робот по умолчанию готов всё сканировать? Оказывается, это нужно для выборочного доступа. К примеру, вы хотите запретить раздел сайта с названием /korobka/.
Тогда команда будет выглядеть так:
User-agent: *
Disallow: /korobka/
Но в то же время в разделе коробки есть сумка и зонт, который вы не прочь показать другим пользователям.
Тогда:
User-agent: *
Disallow: /korobka/
Allow: /korobka/sumka/
Allow: /korobka/zont/
Таким образом, вы закрыли общий раздел korobka, но открыли доступ к страницам с сумкой и зонтом.
Sitemap — еще одна важная директива. По названию можно предположить, что эта инструкция как-то связана с картой сайта.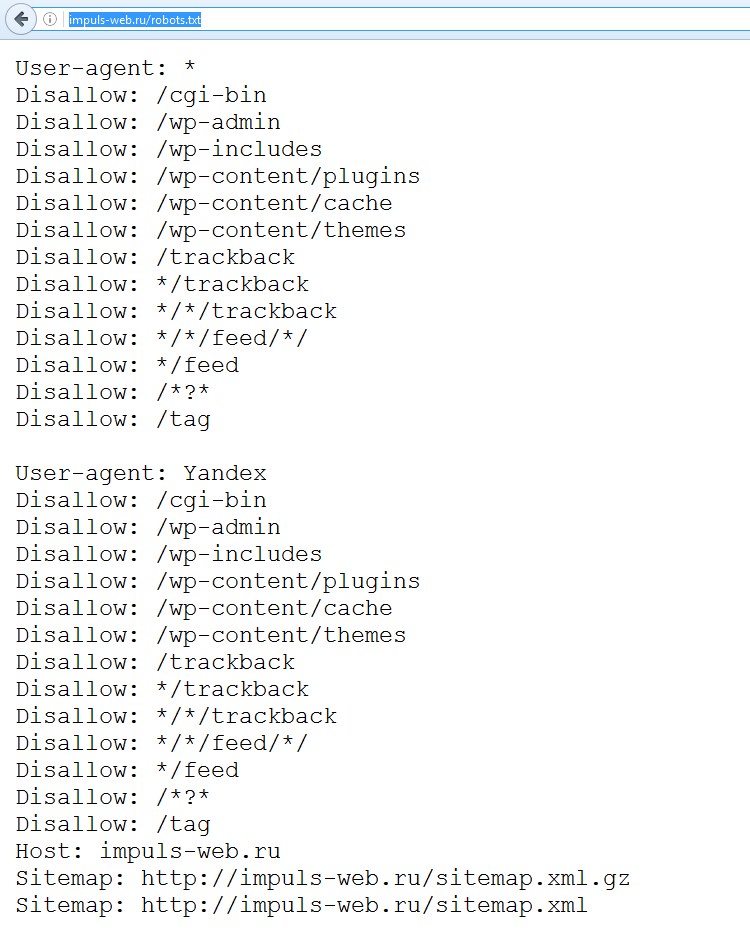
Если вы хотите, чтобы при сканировании вашего сайта поисковые роботы в первую очередь заходили в определенные разделы, нужно в корневом каталоге сайта разместить вашу карту — файл sitemap. В отличие от robots.txt, этот файл хранится в формате xml.
Если представить, что поисковой робот — это турист, который попал в ваш город (он же сайт), логично предположить, что ему понадобится карта. С ней он будет лучше ориентироваться на местности и знать, какие места посетить (то есть проиндексировать) в первую очередь. Директива sitemap послужит роботу указателем — мол, карта вон там. А дальше он уже легко разберется в навигации по вашему сайту.
Как создать и проверить robots.txt
Стандарт исключений для роботов обычно создают в простом текстовом редакторе (например, в Блокноте). Файлу дают название robots и сохраняют формате txt.Далее его надо поместить в корневой каталог сайта. Если вы все сделаете правильно, то он станет доступен по адресу “название вашего сайта”/robots.txt.
Самостоятельно прописать директивы и во всем разобраться вам помогут справочные сервисы. Воспользуйтесь любыми на выбор: Яндекс или Google. С их помощью за 1 час даже неопытный пользователь сможет разобраться в основах.
Когда файл будет готов, его обязательно стоит проверить на наличие ошибок. Для этого у главных поисковых систем есть специальные веб-мастерские. Сервис для проверки robots.txt от Яндекс:
Сервис для проверки robots.txt от Google:
https://www.google.com/webmasters/tools/home?hl=ru
Когда забываешь про robots.txt
Как вы уже поняли, файл robots совсем не сложно создать. Однако, многие даже крупные компании почему-то забывают добавлять его в корневую структуру сайта. В результате — попадание нежелательной информации в просторы интернета или в руки мошенников плюс огромный общественный резонанс.Так, в июле 2018 года СМИ говорили об утечке в Сбербанке: в поисковую выдачу Яндекс попала персональная информация клиентов банка — со скриншотами паспортов, личными счетами и номерами билетов.

Не стоит пренебрегать элементарными правилами безопасности сайта и ставить под сомнение репутацию своей компании. Лучше не рисковать и позаботиться о правильной работе robots.txt. Пусть этот маленький файл станет вашим надежным другом в деле поисковой оптимизации сайтов.
Robots.txt: что это такое?
Robots.txt – специальный файл, который используется для регулирования процесса индексации сайта поисковыми системами. Место его размещения – корневой каталог. Различные разделы этого файла содержат директивы, которые открывают или закрывают доступ индексирующим ботам к разделам и страницам сайта. При этом поисковые роботы различных систем используют отдельные алгоритмы обработки этого файла, которые могут отличаться друг от друга. Никакие настройки robots.txt не влияют на обработку ссылок на страницы сайта с других сайтов.
Функции robots.txt
Основная функция этого файла – размещение указаний для индексирующих роботов. Главные директивы robots.txt – Allow (разрешает индексацию определенного файла или раздела) и Disallow (соответственно, запрещает индексацию), а также User-agent (определяет, к каким именно роботам относятся разрешительные и запрещающие директивы).
Нужно помнить, что инструкции robots.txt носят рекомендательный характер. Значит, они могут быть в различных случаях проигнорированы роботами.
Рассмотрим примеры.
Файл следующего содержания запрещает индексацию сайта для всех роботов:
User-agent: *
Disallow: /
Чтобы запретить индексацию для основного робота поисковой системы Yandex только директории /private/, применяется robots.txt такого содержания:
User-agent: Yandex
Disallow: /private/
Как создать и где разместить robots.txt
Файл должен иметь расширение txt. После создания его нужно закачать в корневой каталог сайта с использованием любого FTP-клиента и проверить доступность файла по адресу site.com/robots.txt. При обращении по этому адресу он должен отображаться браузером в полном объеме.
Требования к файлу robots.txt
Веб-мастер всегда должен помнить, что отсутствие в корневом каталоге сайта файла robots.txt или его неправильная настройка потенциально угрожают посещаемости сайта и доступности в поиске.
По стандартам, в файле robots.txt запрещено использование кириллических символов. Поэтому для работы с кириллическими доменами нужно применять Punycode. При этом кодировка адресов страниц должна соответствовать кодировке применяемой структуры сайта.
Другие директивы файла
Host
Эта директива используется роботами всех поисковых систем. Она дает возможность указать зеркало сайта, которое будет главным к индексированию. Это позволит избежать попадания в индекс страниц разных зеркал одного сайта, появления дублей в выдаче ПС.
Примеры использования
Если для группы сайтов главное зеркало именно https://onesite.com, то:
User-Agent: Yandex
Disallow: /blog
Disallow: /custom
Host: https://onesite.com
Если в файле robots.txt есть несколько значений директивы Host, то индексирующий робот использует только первую из них, остальные будут проигнорированы.
Sitemap
Для быстрой и правильной индексации сайтов используется специальный файл Sitemap или группа таких файлов. Сама директива является межсекционной – она будет учитываться роботом при размещении в любом месте robots.txt. Но обычно ее принято размещать в конце.
При обработке этой директивы робот запомнит и переработает данные. Именно эта информация ложится в основу формирования следующих сессий загрузки страниц сайта для его индексации.
Примеры использования:
User-agent: *
Allow: /catalog
sitemap: https://mysite.com/my_sitemaps0.xml
sitemap: https://mysite.com/my_sitemaps1.xml
Clean-param
Это дополнительная директива для ботов поисковой системы Yandex. Современные сайты имеют сложную структуру названий. Часто системы управления контентом формируют в названиях страниц динамические параметры. Через них может передаваться дополнительная информация о реферерах, сессиях пользователей и так далее.
Стандартный синтаксис этой директивы описывается следующим образом:
Clean-param: s0[&s1&s2&..&sn] [path]
В первом поле мы видим параметры, которые нужно не учитывать. Они разделяются символом &. А второе поле содержит префикс пути страниц, которые подпадают под действие этого правила.
Допустим, на некотором форуме движок сайта при обращении пользователя к страницам генерирует длинные ссылки типа http://forum.com/index.php?id=128955&topic=55, причем содержание страниц одинаковое, а параметр id для каждого посетителя свой. Чтобы все множество страниц с различными id не попали в индекс, используется такой файл robots.txt:
User-agent: *
Disallow:
Clean-param: id /forum.com/index.php
Crawl-delay
Эта директива предназначается для тех случаев, когда индексирующие роботы создают на сервер сайта слишком высокую нагрузку. В ней указывается минимальное время между концом загрузки страницы сайта и обращением робота к следующей. Период времени задается в секундах. Робот поисковой системы «Яндекс» успешно считывает и дробные значения, например 0.3 секунды.
Примеры использования:
User-agent: *
Disallow: /cgi
Crawl-delay: 4.1 # таймаут 4.1 секунды для роботов
На настоящее время эта директива не учитывается роботами поисковой системы Google.
$ и другие спецсимволы
Нужно помнить, что при внесении любых директив по умолчанию в конце приписывается спецсимвол *. В результате получается, что действие указания распространяется на все разделы или страницы сайта, начинающиеся с определенной комбинации символов.
Чтобы отметить действие по умолчанию, применяется специальный символ $.
Пример использования:
User-agent: Googlebot
Disallow: /pictures$ # запрещает ‘/pictures’,
# но не запрещает ‘/pictures.html’
Стандарт использования файла robots. txt рекомендует, чтобы после каждой группы директив User-agent вставлялся пустой перевод строки. При этом специальный символ # применяется для размещения в файле комментариев. Роботы не будут учитывать содержание в строке, которое размещено за символом # до знака пустого перевода.
txt рекомендует, чтобы после каждой группы директив User-agent вставлялся пустой перевод строки. При этом специальный символ # применяется для размещения в файле комментариев. Роботы не будут учитывать содержание в строке, которое размещено за символом # до знака пустого перевода.
Как запретить индексацию сайта или его разделов
Запретить индексацию каких-то страниц, разделов или всего сайта через директиву Disallow можно следующим образом.
Пример:
User-agent: *
Disallow: /
# блокирует доступ ко всему сайту
User-agent: Yandex
Disallow: / bin
# блокирует доступ к страницам,
# которые начинаются с ‘/bin’
Как проверить robots.txt на правильность
Проверка правильности файла robots.txt – обязательная операция после внесения в него любых изменений. Ведь случайная ошибка в размещении символа может привести к серьезным проблемам. Как минимум нужно проверить robots.txt в инструментах для веб-мастеров «Яндекса». Аналогичную проверку необходимо произвести и в поисковой системе Google. Для успешной проверки нужно зарегистрироваться для работы в панели вебмастера и внести в нее данные своего сайта.
Файл robots.txt: полное руководство | SEO-портал
Стандарт robots.txt отличается оригинальным синтаксисом. Существуют общие для всех роботов директивы (правила), а также директивы, понятные только роботам определенных поисковых систем.
Стандартные директивы
Директивами для robots.txt называются правила, состоящие из названия и значения (параметра), идущего после знака двоеточия. Например:
# Директива User-agent со значением Yandex: User-agent: Yandex
Регистр символов в названиях директив не учитывается.
Для большинства директив стандарта в качестве значения применяется URL-префикс (часть URL-адреса). Например:
User-agent: Yandex # URL-префикс в качестве значения: Disallow: /admin/
Регистр символов учитывается роботами при обработке URL-префиксов.
Директива User-agent
Правило User-agent указывает, для каких роботов составлены следующие под ним инструкции.
Значения User-agent
В качестве значения директивы User-agent указывается конкретный тип робота или символ *. Например:
# Последовательность инструкций для робота YandexBot: User-agent: YandexBot Disallow: /
Основные типы роботов, указываемые в User-agent:
- Yandex
- Подразумевает всех роботов Яндекса.
- YandexBot
- Основной индексирующий робот Яндекса
- YandexImages
- Робот Яндекса, индексирующий изображения.
- YandexMedia
- Робот Яндекса, индексирующий видео и другие мультимедийные данные.
- Подразумевает всех роботов Google.
- Googlebot
- Основной индексирующий робот Google.
- Googlebot-Image
- Робот Google, индексирующий изображения.
Регистр символов в значениях директивы User-agent не учитывается.
Обработка User-agent
Чтобы указать, что нижеперечисленные инструкции составлены для всех типов роботов, в качестве значения директивы User-agent применяется символ * (звездочка). Например:
# Последовательность инструкций для всех роботов: User-agent: * Disallow: /
Перед каждым последующим набором правил для определённых роботов, которые начинаются с директивы User-agent, следует вставлять пустую строку.
User-agent: * Disallow: / User-agent: Yandex Allow: /
При этом нельзя допускать наличия пустых строк между инструкциями для конкретных роботов, идущими после User-agent:
# Нужно: User-agent: * Disallow: /administrator/ Disallow: /files/ # Нельзя: User-agent: * Disallow: /administrator/ Disallow: /files/
Обязательно следует помнить, что при указании инструкций для конкретного робота, остальные инструкции будут им игнорироваться:
# Инструкции для робота YandexImages: User-agent: YandexImages Disallow: / Allow: /images/ # Инструкции для всех роботов Яндекса, кроме YandexImages User-agent: Yandex Disallow: /images/ # Инструкции для всех роботов, кроме роботов Яндекса User-agent: * Disallow:
Директива Disallow
Правило Disallow применяется для составления исключающих инструкций (запретов) для роботов. В качестве значения директивы указывается URL-префикс. Первый символ
В качестве значения директивы указывается URL-префикс. Первый символ / (косая черта) задает начало относительного URL-адреса. Например:
# Запрет сканирования всего сайта: User-agent: * Disallow: / # Запрет сканирования конкретной директории: User-agent: * Disallow: /images/ # Запрет сканирования всех URL-адресов, начинающихся с /images: User-agent: * Disallow: /images
Применение директивы Disallow без значения равносильно отсутствию правила:
# Разрешение сканирования всего сайта: User-agent: * Disallow:
Директива Allow
Правило Allow разрешает доступ и применяется для добавления исключений по отношению к правилам Disallow. Например:
# Запрет сканирования директории, кроме одной её поддиректории: User-agent: * Disallow: /images/ # запрет сканирования директории Allow: /images/icons/ # добавление исключения из правила Disallow для поддиректории
При равных значениях приоритет имеет директива Allow:
User-agent: * Disallow: /images/ # запрет доступа Allow: /images/ # отмена запрета
Директива Sitemap
Добавить ссылку на файл Sitemap в можно с помощью одноименной директивы.
В качестве значения директивы Sitemap в указывается прямой (с указанием протокола) URL-адрес карты сайта:
User-agent: * Disallow: # Директив Sitemap может быть несколько: Sitemap: https://seoportal.net/sitemap-1.xml Sitemap: https://seoportal.net/sitemap-2.xml
Директива Sitemap является межсекционной и может размещаться в любом месте robots. txt. Удобнее всего размещать её в конце файла, отделяя пустой строкой.
txt. Удобнее всего размещать её в конце файла, отделяя пустой строкой.
Следует учитывать, что robots.txt является общедоступным, и благодаря директиве Sitemap злоумышленники могут получить доступ к новым страницам раньше поисковых роботов, что может повлечь за собой воровство контента.
Использование директивы Sitemap в robots.txt может повлечь воровство контента сайта.
Регулярные выражения
В robots.txt могут применяться специальные регулярные выражения в URL-префиксах с помощью символов * и $.
Символ /
Символ / (косая черта) является разделителем URL-префиксов, отражая степень вложенности страниц. Важно понимать, что URL-префикс с символом / на конце и аналогичный префикс, но без косой черты, поисковые роботы могут воспринимать как разные страницы:
# разные запреты: Disallow: /catalog/ # запрет для вложенных URL (/catalog/1), но не для /catalog Disallow: /catalog # запрет для /catalog и всех URL, начинающихся с /catalog, в том числе: # /catalog1 # /catalog1 # /catalog1/2
Символ *
Символ * (звездочка) предполагает любую последовательность символов. Он неявно приписывается к концу каждого URL-префикса директив
Он неявно приписывается к концу каждого URL-префикса директив Disallow и Allow:
User-agent: Googlebot Disallow: /catalog/ # запрет всех URL-адресов, начинающихся с "/catalog/" Disallow: /catalog/* # то же самое
Символ * может применяться в любом месте URL-префикса:
User-agent: Googlebot Disallow: /*catalog/ # запрещает все URL-адреса, содержащие "/catalog/": # /1catalog/ # /necatalog/1 # images/catalog/1 # /catalog/page.htm # и др. # но не /catalog
Символ $
Символ $ (знак доллара) применяется для отмены неявного символа * в окончаниях URL-префиксов:
User-agent: Google Disallow: /*catalog/$ # запрещает все URL-адреса, заканчивающиеся символами "catalog/": # /1/catalog/ # но не: # /necatalog/1 # /necatalog # /catalog
Символ $ (доллар) не отменяет явный символ * в окончаниях URL-префиксов:
User-agent: Googlebot Disallow: /catalog/* # запрет всех URL-адресов, начинающихся с "/catalog/" Disallow: /catalog/*$ # то же самое # Но: Disallow: /catalog/ # запрет всех URL-адресов, начинающихся с "/catalog/" Disallow: /catalog/$ # запрет только URL-адреса "/catalog/"
Директивы Яндекса
Роботы Яндекса способны понимать три специальных директивы:
- Host (устарела),
- Crawl-delay,
- Clean-param.
Директива Host
Директива Host является устаревшей и в настоящее время не учитывается. Вместо неё необходимо настраивать  htaccess.<div class="seog-tooltip-more-link"><a href="/terminy/redirekt">Подробнее</a></div>
»>редирект на страницы главного зеркала.
htaccess.<div class="seog-tooltip-more-link"><a href="/terminy/redirekt">Подробнее</a></div>
»>редирект на страницы главного зеркала.
Директива Crawl-delay
Если сервер сильно нагружен и не успевает отрабатывать запросы на загрузку, воспользуйтесь директивой Crawl-delay. Она позволяет задать поисковому роботу минимальный период времени (в секундах) между окончанием загрузки одной страницы и началом загрузки следующей.
Яндекс.Помощь
Правило Crawl-delay следует размещать в группу правил, которая начинается с директивы User-Agent, но после стандартных для всех роботов директив Disallow и Allow:
User-agent: * Disallow: Crawl-delay: 1 # задержка между посещениями страниц 1 секунда
В качестве значений Crawl-delay могут использоваться дробные числа:
User-agent: * Disallow: Crawl-delay: 2.5 # задержка между посещениями страниц 2.5 секунд
Директива Clean-param
Директива Clean-param помогает роботу Яндекса верно определить страницу для индексации, URL-адрес которой может содержать различные параметры, не влияющие на смысловое содержание страницы.
Если адреса страниц сайта содержат динамические параметры, которые не влияют на их содержимое (например: идентификаторы сессий, пользователей, рефереров и т. п.), вы можете описать их с помощью директивы Clean-param.
Яндекс.Помощь
В качестве значения правила Clean-param указывается параметр и URL-префикс адресов, для которых не следует учитывать данный параметр. Параметр и URL-префикс должны быть разделены пробелом:
User-agent: * Disallow: # Указывает на отсутствие значимости параметра id в URL-адресе с index.htm # (например, в адресе seoportal.net/index.htm?id=1 параметр id не станет учитываться, # а в индекс, вероятно, попадёт страница с URL-адресом seoportal.net/index.htm): Clean-param: id index.htm
Для указания 2-х и более незначительных параметров в одном правиле Clean-param применяется символ &:
User-agent: * Disallow: # Указывает на отсутствие значимости параметров id и num в URL-адресе с index.htm Clean-param: id&num index.htm
Директива Clean-param может быть указана в любом месте robots.txt. Все указанные правила Clean-param будут учтены роботом Яндекса:
User-agent: * Allow: / # Для разных страниц с одинаковыми параметрами в URL-адресах: Clean-param: id index Clean-param: id admin
Robots.txt — Словарь— PromoPult.ru
Robots.txt — это текстовый файл в кодировке UTF-8, который содержит рекомендации поисковым роботам, какие страницы / документы индексировать, а какие нет.
Robots.txt размещается в корневой папке сайта и доступен по адресу вида https://somesite.ru/robots.txt
Этот стандарт утвержден Консорциумом Всемирной паутины W3C в 1994 году. Использование Robots.txt является добровольным как для владельцев сайтов, так и для поисковиков.
Назначение файла Robots.txt
Основная задача — управление поведением поисковых машин на сайте.
Приходя на сайт, робот сразу загружает содержимое Robots.txt. Если файл отсутствует, робот будет индексировать все документы из корневой и вложенных папок (если они не закрыты от индексации другими методами). В результате могут возникнуть следующие проблемы:
- в индекс попадают лишние страницы и конфиденциальные документы (например, профили пользователей), которые не должны участвовать в поиске;
- до основного важного контента робот может не добраться, так его ресурс и время на сайте ограничены.
Обрабатывая файл, роботы получают инструкции: индексировать, индексировать частично, запрещено к индексации.
Как правило, от индексации закрывают следующие документы и разделы:
- административную панель,
- системные файлы,
- кэшированные данные,
- страницы загрузки,
- поиск, фильтры и сортировки,
- корзины товаров,
- личные кабинеты,
- формы регистрации.
Что содержит Robots.txt
User-agent
Правило, указывающее, каким роботам оно предназначается. Если не указывать все роботы, а только прописать знак *, это будет значить, что правило действительно для любого известного робота, посетившего сайт.
Правило для робота «Яндекса»:
User-agent: Yandex
Правило для робота Google:
User-agent: Googlebot
Disallow
Правило, указывающее роботам, какую информацию индексировать запрещено. Это могут быть отдельные документы, разделы сайта или сайт целиком (в том случае, если он еще находится в разработке).
Правило, запрещающее индексировать весь сайт:
Disallow: /
Запрет обхода страниц, находящихся в определенном каталоге:
Disallow: /catalogue
Запрет обхода конкретной страницы (указать URL):
Disallow: /user-data.html
Allow
Данная директива разрешает индексировать содержимое сайта. Может потребоваться, когда нужно выборочно разрешить к индексации какой-либо контент. Обычно используется в комбинации с Disallow.
Правило, запрещающее индексировать все, кроме указанных страниц:
User-agent: Googlebot Allow: /cgi-bin Disallow: /
Host
Данная директива сообщает роботу о главном зеркале сайта. С марта 2018 года «Яндекс» полностью отказался от этой директивы, поэтому ее можно не прописывать в Robots. Однако важно, чтобы на всех не главных зеркалах сайта теперь стоял 301-й постраничный редирект.
Crawl-delay
Правило задает скорость обхода сайта. В секундах задается минимальный период времени между окончанием загрузки одной страницы и началом загрузки следующей. Необходимо при сильной нагрузке на сервер, когда робот не успевает обрабатывать страницы.
Необходимо при сильной нагрузке на сервер, когда робот не успевает обрабатывать страницы.
Установка тайм-аута в две секунды:
User-agent: Yandex Crawl-delay: 2.0
Clean-param
Правило задается для динамических страниц GET-параметром или страниц с рекламными метками (идентификатор сессии, пользователей и т. д.), чтобы робот не индексировал дублирующуюся информацию.
Запрет индексации страниц с рекламной меткой — параметром ref:
User-agent: Yandex Disallow: Clean-param: ref /video/how_to_look.ru
Sitemap
Правило сообщает роботам, что все URL сайта, обязательные для индексации, находятся в файле Sitemap.xml. Прописывается путь к этой карте сайта. При каждом новом визите робот будет обращаться к этому файлу и вносить в индекс новую информацию, если она появилась на сайте.
User-agent: Yandex Allow: / sitemap: https://somesite.ru/sitemaps.xml
Как создать файл Robots.txt
Файл создается в текстовом редакторе с присвоением имени robots.txt. В этом файле прописываются инструкции с учетом озвученных выше правил. Далее файл загружается в корневую директорию сайта.
Для блога или новостного сайта можно скачать стандартный robots.txt с сайта движка или форума разработчиков, подкорректировав под свои особенности.
Как проверить Robots.txt
Проверка валидности файла Robots.txt проводится с помощью инструментов веб-мастеров Google и «Яндекса».
См. также
Что такое robots.txt [Основы для новичков]
Успешная индексация нового сайта зависит от многих слагаемых. Один из них — файл robots.txt, с правильным заполнением которого должен быть знаком любой начинающий веб-мастер. Обновили материал для новичков.
Подробно о правилах составления файла в полном руководстве «Как составить robots.txt самостоятельно».
А в этом материале основы для начинающих, которые хотят быть в курсе профессиональных терминов.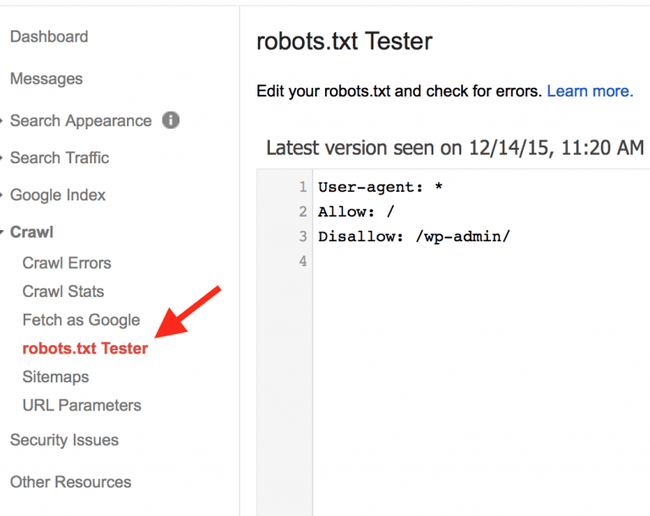
Что такое robots.txt
Файл robots.txt — это документ в формате .txt, содержащий инструкции по индексации конкретного сайта для поисковых ботов. Он указывает поисковикам, какие страницы веб-ресурса стоит проиндексировать, а какие не нужно допустить к индексации.
Поисковый робот, придя к вам на сайт, первым делом пытается отыскать robots.txt. Если робот не нашел файл или он составлен неправильно, бот будет изучать сайт по своему собственному усмотрению. Далеко не факт, что он начнет с тех страниц, которые нужно вводить в поиск в первую очередь (новые статьи, обзоры, фотоотчеты и так далее). Индексация нового сайта может затянуться. Поэтому веб-мастеру нужно вовремя позаботиться о создании правильного файла robots.txt.
На некоторых конструкторах сайтов файл формируется сам. Например, Wix автоматически создает robots.txt. Чтобы посмотреть файл, добавьте к домену «/robots.txt». Если вы увидите там странные элементы типа «noflashhtml» и «backhtml», не пугайтесь: они относятся к структуре сайтов на платформе и не влияют на отношение поисковых систем.
Зачем нужен robots.txt
Казалось бы, зачем запрещать индексировать какое-то содержимое сайта? Далеко не весь контент, из которого состоит сайт, нужен поисковым роботам. Есть системные файлы, есть дубликаты страниц, есть рубрики ключевых слов и много чего еще есть, что вовсе не обязательно индексировать. Есть одно но:
Содержимое файла robots.txt — это рекомендации для ботов, а не жесткие правила. Рекомендации боты могут проигнорировать.
Google предупреждает, что через robots.txt нельзя заблокировать страницы для показа в Google. Даже если вы закроете доступ к странице в robots.txt, если на какой-то другой странице будет ссылка на эту, она может попасть в индекс. Лучше использовать и ограничения в robots, и другие методы запрета:
Запрет индексирования сайта, Яндекс
Блокировка индексирования, Google
Тем не менее, без robots. txt больше вероятность, что информация, которая должна быть скрыта, попадет в выдачу, а это бывает чревато раскрытием персональных данных и другими проблемами.
txt больше вероятность, что информация, которая должна быть скрыта, попадет в выдачу, а это бывает чревато раскрытием персональных данных и другими проблемами.
Из чего состоит robots.txt
Файл должен называться только «robots.txt» строчными буквами и никак иначе. Его размещают в корневом каталоге — https://site.com/robots.txt в единственном экземпляре. В ответ на запрос он должен отдавать HTTP-код со статусом 200 ОК. Вес файла не должен превышать 32 КБ. Это максимум, который будет воспринимать Яндекс, для Google robots может весить до 500 КБ.
Внутри все должно быть на латинице, все русские названия нужно перевести с помощью любого Punycode-конвертера. Каждый префикс URL нужно писать на отдельной строке.
В robots.txt с помощью специальных терминов прописываются директивы (команды или инструкции). Кратко о директивах для поисковых ботах:
«Us-agent:» — основная директива robots.txt
Используется для конкретизации поискового робота, которому будут давать указания. Например, User-agent: Googlebot или User-agent: Yandex.
В файле robots.txt можно обратиться ко всем остальным поисковым системам сразу. Команда в этом случае будет выглядеть так: User-agent: *. Под специальным символом «*» принято понимать «любой текст».
После основной директивы «User-agent:» следуют конкретные команды.
Команда «Disallow:» — запрет индексации в robots.txt
При помощи этой команды поисковому роботу можно запретить индексировать веб-ресурс целиком или какую-то его часть. Все зависит от того, какое расширение у нее будет.
User-agent: Yandex Disallow: /
Такого рода запись в файле robots.txt означает, что поисковому роботу Яндекса вообще не позволено индексировать данный сайт, так как запрещающий знак «/» не сопровождается какими-то уточнениями.
User-agent: Yandex Disallow: /wp-admin
На этот раз уточнения имеются и касаются они системной папки wp-admin в CMS WordPress. То есть индексирующему роботу рекомендовано отказаться от индексации всей этой папки.
То есть индексирующему роботу рекомендовано отказаться от индексации всей этой папки.
Команда «Allow:» — разрешение индексации в robots.txt
Антипод предыдущей директивы. При помощи тех же самых уточняющих элементов, но используя данную команду в файле robots.txt, можно разрешить индексирующему роботу вносить нужные вам элементы сайта в поисковую базу.
User-agent: * Allow: /catalog Disallow: /
Разрешено сканировать все, что начинается с «/catalog», а все остальное запрещено.
На практике «Allow:» используется не так уж и часто. В ней нет надобности, поскольку она применяется автоматически. В robots «разрешено все, что не запрещено». Владельцу сайта достаточно воспользоваться директивой «Disallow:», запретив к индексации какое-то содержимое, а весь остальной контент ресурса воспринимается поисковым роботом как доступный для индексации.
Директива «Sitemap:» — указание на карту сайта
«Sitemap:» указывает индексирующему роботу правильный путь к так Карте сайта — файлам sitemap.xml и sitemap.xml.gz в случае с CMS WordPress.
User-agent: * Sitemap: http://pr-cy.ru/sitemap.xml Sitemap: http://pr-cy.ru/sitemap.xml.gz
Прописывание команды в файле robots.txt поможет поисковому роботу быстрее проиндексировать Карту сайта. Это ускорит процесс попадания страниц ресурса в выдачу.
Файл robots.txt готов — что дальше
Итак, вы создали текстовый документ robots.txt с учетом особенностей вашего сайта. Его можно сделать автоматически, к примеру, с помощью нашего инструмента.
Что делать дальше:
- проверить корректность созданного документа, например, посредством сервиса Яндекса;
- при помощи FTP-клиента закачать готовый файл в корневую папку своего сайта. В ситуации с WordPress речь обычно идет о системной папке Public_html.

Дальше остается только ждать, когда появятся поисковые роботы, изучат ваш robots.txt, а после возьмутся за индексацию вашего сайта.
Как посмотреть robots.txt чужого сайта
Если вам интересно сперва посмотреть на готовые примеры файла robots.txt в исполнении других, то нет ничего проще. Для этого в адресной строке браузера достаточно ввести site.ru/robots.txt. Вместо «site.ru» — название интересующего вас ресурса.
Создать и настроить robots.txt в битриксе
Важно передать поисковикам актуальную информацию о страницах, которые закрыты от индексации, о главном зеркале и карте сайта (sitemap.xml). Для этого в корне сайта создается файл robots.tx и заполняется директивами.
Рассмотрим как в самом общем случае в битриксе создать файл robots.txt.
Первое, переходим на страницу Рабочий стол -> Маркетинг -> Поисковая оптимизация -> Настройка robots.txt
Второе, указываем основные правила.
На первой строчке видим User-agent: * , это означает, что директивы указаны для всех роботов всех поисковых систем.
Закрываем от индексации страницу авторизации, личного кабинета и другие директории и страницы, которые не должны попасть в результаты поиска.
Для того, чтобы закрыть директорию пишем правило:
Disallow: /auth/
Третье, указываем главное зеркало сайта с помощью директивы Host. Учтите www, если главным выбран домен с www.
Четвертое, в директиве Sitemap прописываем ссылку к файлк sitemap.xml.
В целом, это все что требуется, для того, чтобы передать файл в вебмастера Яндекса и Google.
В интерфейсе cms битрикс, есть возможность работать с каждым роботом(у поисковиков есть несколько ботов(роботов), которые занимаются отдельными действиями).
Вот роботы Яндекса:
- YandexBot — основной индексирующий
- YandexDirect — скачивает информацию о контенте сайтов-партнеров Рекламной сети, чтобы уточнить их тематику для подбора релевантной рекламы
- YandexMedia — робот, индексирующий мультимедийные данные
- YandexImages — индексатор Яндекс.
 Картинок
Картинок - YandexBlogs поиска по блогам — робот, индексирующий посты и комментарии
- YandexNews — робот Яндекс.Новостей
- YandexMetrika — робот Яндекс.Метрики
- YandexMarket — робот Яндекс.Маркета
Например, вам не нужно индексировать картинки, находящиеся в папке /include/, но вы хотите, чтобы статьи из этого раздела индексировались. Для этого, следует закрыть директивой Disallow папку /include/ для робота YandexImages.
User-agent: YandexImages
Disallow: /include/
Семен Голиков.
Файл robots txt, роботс тхт, файл роботс
Читайте подробнее.1. Рекомендуем использовать robots.txt следующего вида для сайтов у которых не подключен ssl-сертификат:
User-agent: *
Allow: /
Host: site.ru
Sitemap: http://site.ru/sitemap.xmlгде site.ru — имя Вашего основного домена.
2. Рекомендуем использовать robots.txt следующего вида для сайтов у которых подключен ssl-сертификат:
User-agent: *
Allow: /
Host: https://site.ru
Sitemap: https://site.ru/sitemap.xml
3. Рекомендуем использовать robots.txt следующего вида для сайтов с кириллическим доменом у которых не подключен ssl-сертификат:
Host: xn--d1abbgf6aiiy.xn--p1ai
Sitemap: http://xn--d1abbgf6aiiy.xn--p1ai/sitemap.xml
где xn--d1abbgf6aiiy.xn--p1ai — имя Вашего основного домена.
4. Рекомендуем использовать robots.txt следующего вида для сайтов с кириллическим доменом у которых подключен ssl-сертификат:Host: https://xn--d1abbgf6aiiy.xn--p1ai
Sitemap: https://xn--d1abbgf6aiiy. xn--p1ai/sitemap.xml
xn--p1ai/sitemap.xml
где xn--d1abbgf6aiiy.xn--p1ai — имя Вашего основного домена.
5. Рекомендуем использовать robots.txt следующего вида для сайтов у которых не подключен ssl-сертификат и домен с www установлен основным:User-agent: *
Allow: /
Host: www.site.ru
Sitemap: http://www.site.ru/sitemap.xmlгде www.site.ru — имя Вашего основного домена.
6. Рекомендуем использовать robots.txt следующего вида для сайтов у которых подключен ssl-сертификат и домен с www установлен основным:
User-agent: *
Allow: /
Host: https://www.site.ru
Sitemap: https://www.site.ru/sitemap.xml
где www.site.ru — имя Вашего основного домена.
7. Рекомендуем использовать robots.txt следующего вида для сайтов с кириллическим доменом у которых подключен ssl-сертификат и домен с www установлен основным:Host: https://www.xn--d1abbgf6aiiy.xn--p1ai
Sitemap: https://www.xn--d1abbgf6aiiy.xn--p1ai/sitemap.xml
где www.xn--d1abbgf6aiiy.xn--p1ai — имя Вашего основного домена.
Обратите внимание!- Файл robots.txt расположен в разделе Настройки — SEO настройки — Robots.txt
Также читайте:
Была ли статья вам полезна? Да Нет
Файлы Robots.txt
Файл /robots.txt — это текстовый файл, который инструктирует автоматизированных веб-ботов о том, как сканировать и / или индексировать веб-сайт. Веб-группы используют их, чтобы предоставить информацию о том, какие каталоги сайта следует или не следует сканировать, как быстро следует обращаться к контенту и какие боты приветствуются на сайте.
Веб-группы используют их, чтобы предоставить информацию о том, какие каталоги сайта следует или не следует сканировать, как быстро следует обращаться к контенту и какие боты приветствуются на сайте.
Как должен выглядеть мой файл robots.txt?
Пожалуйста, обратитесь к протоколу robots.txt (Внешняя ссылка) для получения подробной информации о том, как и где создавать роботов.текст. Ключевые моменты, о которых следует помнить:
- Файл должен находиться в корне домена, и каждому поддомену нужен свой собственный файл.
- Протокол robots.txt чувствителен к регистру.
- Легко случайно заблокировать сканирование всего
-
Disallow: /означает запретить все -
Disallow:означает ничего не запрещать, тем самым разрешая все -
Разрешить: /означает разрешить все -
Разрешить:означает ничего не разрешать, таким образом запрещая все
-
- Инструкции в robots.txt — это руководство для ботов, а не обязательные требования.
Как мне оптимизировать свой robots.txt для Search.gov?
Задержка сканирования
Файл robots.txt может указывать директиву «задержки сканирования» для одного или нескольких пользовательских агентов, которая сообщает боту, как быстро он может запрашивать страницы с веб-сайта. Например, задержка сканирования 10 указывает, что поисковый робот не должен запрашивать новую страницу чаще, чем каждые 10 секунд.
500 000 URL
x 10 секунд между запросами
5 000 000 секунд на все запросы
5 000 000 секунд = 58 дней на однократное индексирование сайта. Мы рекомендуем задержку сканирования в 2 секунды для нашего пользовательского агента usasearch и установить более высокую задержку сканирования для всех остальных ботов. Чем меньше задержка сканирования, тем быстрее Search.gov сможет проиндексировать ваш сайт.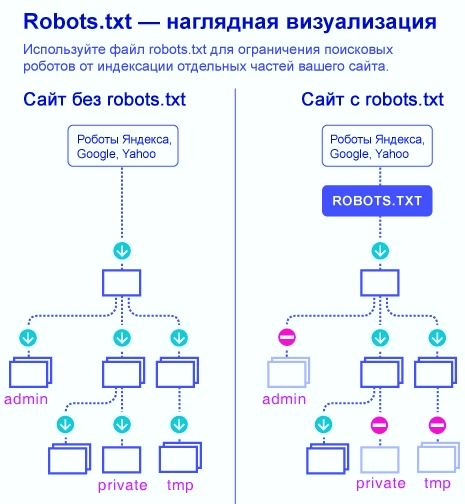 В файле robots.txt это будет выглядеть так:
В файле robots.txt это будет выглядеть так:
Пользовательский агент: usasearch
Задержка сканирования: 2
Пользовательский агент: *
Задержка сканирования: 10
XML-файлы Sitemap
В вашем файле robots.txt также должна быть указана одна или несколько ваших XML-карт сайта.Например:
Карта сайта: https://www.exampleagency.gov/sitemap.xml
Карта сайта: https://www.exampleagency.gov/independent-subsection-sitemap.xml
- Отображает только карты сайта для домена, в котором находится файл robots.txt. Карта сайта другого субдомена должна быть указана в файле robots.txt этого субдомена.
Разрешить только тот контент, который должен быть доступен для поиска
Мы рекомендуем запретить использование любых каталогов или файлов, которые не должны быть доступны для поиска.Например:
Запретить: / archive /
Disallow: / новости-1997 /
Запретить: /reports/duplicative-page.html
- Обратите внимание: если вы запретите использование каталога после того, как он был проиндексирован поисковой системой, это может не привести к удалению этого содержания из индекса. Чтобы запросить удаление, вам нужно будет открыть инструменты для веб-мастеров поисковой системы.
- Также обратите внимание, что поисковые системы могут индексировать отдельные страницы в запрещенной папке, если поисковая система узнает об URL-адресе из метода без сканирования, например ссылки с другого сайта или вашей карты сайта.Чтобы гарантировать, что данная страница недоступна для поиска, установите на этой странице метатег robots.
Настройка параметров для разных ботов
Вы можете установить разные разрешения для разных ботов. Например, если вы хотите, чтобы мы проиндексировали ваш заархивированный контент, но не хотите, чтобы Google или Bing индексировали его, вы можете указать это:
Пользовательский агент: usasearch
Задержка сканирования: 2
Разрешить: / archive /
Пользовательский агент: *
Задержка сканирования: 10
Запретить: / архив /
Контрольный список Robots.
 txt
txt 1.В корневом каталоге сайта создан файл robots.txt ( https://exampleagency.gov/robots.txt )
2. Файл robots.txt запрещает любые каталоги и файлы, которые автоматические роботы не должны сканировать.
3. В файле robots.txt перечислены одна или несколько карт сайта XML
4. Формат файла robots.txt прошел проверку (Внешняя ссылка)
Дополнительные ресурсы
Полное руководство по роботам Yoast SEO.txt (Внешняя ссылка)
Google «Узнайте о файлах robots.txt» (Внешняя ссылка)
Файл Robots.txt — что это? Как это использовать? // WEBRIS
Короче говоря, файл Robots.txt управляет доступом поисковых систем к вашему сайту.
Этот текстовый файл содержит «директивы», которые диктуют поисковым системам, какие страницы должны «разрешать» и «запрещать» доступ поисковой системе.
Скриншот наших роботов.txt файл
Добавление неправильных директив здесь может негативно повлиять на ваш рейтинг, поскольку это может помешать поисковым системам сканировать страницы (или весь ваш) веб-сайт.
3 подсказки для 3-х потенциальных клиентов от Google
Мы помогли сотням веб-сайтов получить больше потенциальных клиентов с помощью поиска Google. Нажмите ниже, чтобы получить бесплатную инструкцию.
Что такое «роботы» (в отношении SEO)?
Роботы — это приложения, которые «ползают» по веб-сайтам, документируя (т.е. «Индексация») охватываемой ими информации.
Что касается файла Robots.txt, эти роботы называются пользовательскими агентами.
Вы также можете услышать их зовут:
- Пауки
- Боты
- Веб-сканеры
Это , а не официальные имена User-agent сканеров поисковых систем. Другими словами, вы не стали бы «Запрещать» «Crawler», вам нужно будет получить официальное название поисковой системы (сканер Google называется «Googlebot»).
Другими словами, вы не стали бы «Запрещать» «Crawler», вам нужно будет получить официальное название поисковой системы (сканер Google называется «Googlebot»).
Вы можете найти полный список веб-роботов здесь.
Изображение предоставлено
На этих ботов влияют разные способы, включая контент, который вы создаете, и ссылки, ведущие на ваш сайт.
Ваш файл Robots.txt позволяет напрямую обращаться к ботам поисковых систем , давая им четкие указания о том, какие части вашего сайта вы хотите сканировать (или не сканировать).
Как пользоваться роботами.txt файл?
Вам необходимо понимать «синтаксис», в котором создается файл Robots.txt.
1. Определите User-agent
Укажите имя робота, о котором вы говорите (например, Google, Yahoo и т. Д.). Опять же, вам нужно обратиться за помощью к полному списку пользовательских агентов.
2. Запретить
Если вы хотите заблокировать доступ к страницам или разделу своего веб-сайта, укажите здесь URL-путь.
3. Разрешить
Если вы хотите разблокировать путь URL-адреса в заблокированном родительском элементе напрямую, введите здесь путь к подкаталогу этого URL-адреса.
Файл Robots.txt из Википедии.
Короче говоря, вы можете использовать robots.txt, чтобы сообщить этим сканерам: «Индексируйте эти страницы, но не индексируйте другие».
Почему так важен Robots.txt
Может показаться нелогичным «блокировать» страницы от поисковых систем. Для этого есть ряд причин и случаев:
1. Блокировка конфиденциальной информации
Справочники — хороший пример.
Вероятно, вы захотите скрыть те, которые могут содержать конфиденциальные данные, например:
- / тележка /
- / cgi-bin /
- / скрипты /
- / wp-admin /
2.
 Блокировка некачественных страниц
Блокировка некачественных страницGoogle неоднократно заявлял, что очень важно «очищать» свой веб-сайт от страниц низкого качества. Наличие большого количества мусора на вашем сайте может снизить производительность.
Для получения более подробной информации ознакомьтесь с нашим аудитом содержания.
3. Блокировка повторяющегося контента
Вы можете исключить любые страницы, содержащие дублированный контент. Например, если вы предлагаете «печатные версии» некоторых страниц, вы не хотите, чтобы Google индексировал повторяющиеся версии, поскольку дублированный контент может повредить вашему рейтингу.
Однако имейте в виду, что люди по-прежнему могут посещать эти страницы и ссылаться на них, поэтому, если информация относится к тому типу, который вы не хотите, чтобы другие видели, вам нужно будет использовать защиту паролем, чтобы сохранить ее конфиденциальность.
Это потому, что, вероятно, есть страницы, содержащие конфиденциальную информацию, которую вы не хотите показывать в поисковой выдаче.
Robots.txt: разрешенные и запрещенные форматы
Robots.txt на самом деле довольно прост в использовании.
Вы буквально говорите роботам, какие страницы нужно «разрешить» (что означает, что они будут их индексировать), а какие — «запретить» (которые они будут игнорировать).
Вы будете использовать последний только один раз, чтобы перечислить страницы, которые не должны сканировать пауки.Команда «Разрешить» используется только в том случае, если вы хотите, чтобы страница сканировалась, но для ее родительской страницы установлено значение «Запрещено».
Вот как выглядит robot.txt для моего сайта:
Начальная команда user-agent сообщает всем веб-роботам (т.е. *), а не только для определенных поисковых систем, что эти инструкции применимы к ним.
Как настроить robots.txt для вашего веб-сайта
Во-первых, вам нужно будет записать ваши директивы в текстовый файл.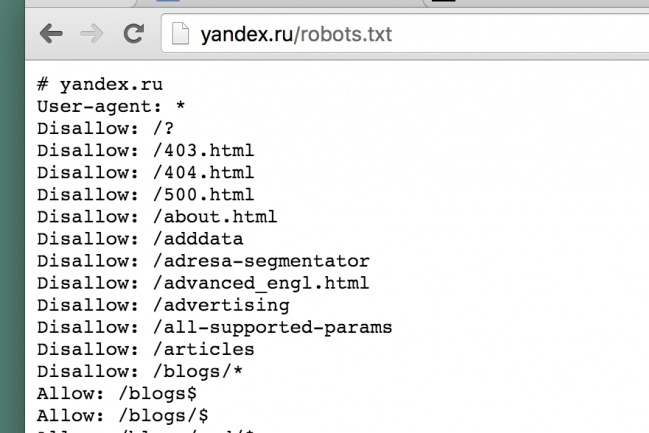
Затем загрузите текстовый файл в каталог верхнего уровня вашего сайта — его нужно добавить через Cpanel.
Изображение предоставлено
Ваш живой файл всегда будет располагаться сразу после «.com /» в вашем URL-адресе. Наш, например, находится по адресу https://webris.org/robot.txt.
Если бы он был расположен по адресу www.webris.com/blog/robot.txt, сканеры даже не стали бы его искать, и ни одна из его команд не была бы выполнена.
Если у вас есть поддомены, убедитесь, что у них есть собственные robots.txt файлы. Например, в нашем поддомене training.webris.org есть собственный набор директив — это невероятно важно проверять при проведении аудита SEO.
Тестирование файла Robots.txt
Google предлагает бесплатный тестер robots.txt, который можно использовать для проверки.
Он расположен в Google Search Console в разделе Crawl> Robots.txt Tester.
Использование Robots.txt для улучшения SEO
Теперь, когда вы понимаете этот важный элемент SEO, проверьте свой собственный сайт, чтобы убедиться, что поисковые системы индексируют нужные вам страницы и игнорируют те, которые вы хотите исключить из результатов поиска.
В дальнейшем вы можете продолжать использовать robot.txt для информирования поисковых систем о том, как они должны сканировать ваш сайт.
Пользовательский агент: *
Запретить: / поиск
Разрешить: / search / about
Разрешить: / search / static
Разрешить: / search / howsearchworks
Disallow: / sdch
Disallow: / groups
Запретить: /index.html?
Запретить: /?
Разрешить: /? Hl =
Запретить: /? Hl = * &
Разрешить: /? Hl = * & gws_rd = ssl $
Запретить: /? Hl = * & * & gws_rd = ssl
Разрешить: /? Gws_rd = ssl $
Разрешить: /? Pt1 = true $
Запретить: / imgres
Запретить: / u /
Запретить: / предпочтения
Запретить: / setprefs
Запретить: / по умолчанию
Disallow: / м?
Disallow: / m /
Разрешить: / м / финансы
Запретить: / wml?
Запретить: / wml /?
Запретить: / wml / search?
Запретить: / xhtml?
Запретить: / xhtml /?
Запретить: / xhtml / search?
Запретить: / xml?
Запретить: / imode?
Запретить: / imode /?
Запретить: / imode / search?
Disallow: / jsky?
Запретить: / jsky /?
Запретить: / jsky / search?
Disallow: / pda?
Запретить: / pda /?
Запретить: / pda / search?
Запретить: / sprint_xhtml
Запретить: / sprint_wml
Disallow: / pqa
Disallow: / palm
Запретить: / gwt /
Disallow: / покупки
Disallow: / local?
Запретить: / local_url
Disallow: / shihui?
Запретить: / shihui /
Disallow: / products?
Запретить: / product_
Запрещено: / products_
Disallow: / products;
Запретить: / print
Disallow: / books /
Запретить: / bkshp? * Q = *
Disallow: / books? * Q = *
Запретить: / books? * Output = *
Disallow: / books? * Pg = *
Запретить: / books? * Jtp = *
Запретить: / books? * Jscmd = *
Disallow: / books? * Buy = *
Запретить: / books? * Zoom = *
Разрешить: / books? * Q = related: *
Разрешить: / books? * Q = editions: *
Разрешить: / books? * Q = subject: *
Разрешить: / books / about
Разрешить: / правообладатели
Разрешить: / books? * Zoom = 1 *
Разрешить: / books? * Zoom = 5 *
Разрешить: / books / content? * Zoom = 1 *
Разрешить: / books / content? * Zoom = 5 *
Disallow: / ebooks /
Disallow: / ebooks? * Q = *
Запретить: / ebooks? * Output = *
Disallow: / ebooks? * Pg = *
Запретить: / ebooks? * Jscmd = *
Disallow: / ebooks? * Buy = *
Disallow: / ebooks? * Zoom = *
Разрешить: / электронные книги? * Q = related: *
Разрешить: / ebooks? * Q = editions: *
Разрешить: / электронные книги? * Q = subject: *
Разрешить: / ebooks? * Zoom = 1 *
Разрешить: / ebooks? * Zoom = 5 *
Запретить: / патенты?
Запретить: / патенты / скачать /
Запрещено: / патенты / pdf /
Запретить: / патенты / связанные /
Запрещено: / ученый
Disallow: / citations?
Разрешить: / citations? User =
Disallow: / citations? * Cstart =
Разрешить: / citations? View_op = new_profile
Разрешить: / citations? View_op = top_hibited
Разрешить: / scholar_share
Disallow: / s?
Разрешить: / maps? * Output = classic *
Разрешить: / maps? * File =
Разрешить: / maps / d /
Запретить: / maps?
Запретить: / mapstt?
Запретить: / mapslt?
Запретить: / maps / stk /
Запретить: / maps / br?
Запретить: / mapabcpoi?
Запретить: / maphp?
Запретить: / mapprint?
Запретить: / maps / api / js /
Разрешить: / maps / api / js
Запретить: / maps / api / place / js /
Запретить: / maps / api / staticmap
Запретить: / maps / api / streetview
Запретить: / maps / _ / sw / manifest. json
Disallow: / mld?
Запретить: / staticmap?
Запретить: / maps / preview
Запретить: / карты / место
Запретить: / maps / timeline /
Запретить: / help / maps / streetview / partners / welcome /
Запретить: / help / maps / Indoormaps / partners /
Disallow: / lochp?
Disallow: / center
Disallow: / ie?
Запретить: / blogsearch /
Запретить: / blogsearch_feeds
Запретить: / advanced_blog_search
Запретить: / uds /
Disallow: / chart?
Disallow: / transit?
Разрешить: / calendar $
Разрешить: / calendar / about /
Запретить: / календарь /
Запретить: / cl2 / feeds /
Запретить: / cl2 / ical /
Запретить: / coop / directory
Запретить: / coop / manage
Disallow: / Trends?
Запретить: / тенденции / музыка?
Disallow: / Trends / hottrends?
Запретить: / тенденции / viz?
Запретить: / тенденции / встраивать.js?
Запретить: / тенденции / fetchComponent?
Запретить: / тенденции / бета
Запретить: / тенденции / темы
Запретить: / musica
Запретить: / musicad
Запретить: / musicas
Запретить: / musicl
Запретить: / музыка
Запретить: / musicsearch
Запретить: / musicsp
Запретить: / musiclp
Запретить: / urchin_test /
Disallow: / movies?
Запретить: / wapsearch?
Разрешить: / безопасный просмотр / диагностика
Разрешить: / safebrowsing / report_badware /
Разрешить: / safebrowsing / report_error /
Разрешить: / safebrowsing / report_phish /
Запретить: / обзоры / поиск?
Запретить: / orkut / альбомы
Disallow: / cbk
Disallow: / подзарядка / приборная панель / автомобиль
Disallow: / recharge / dashboard / static /
Запретить: / profiles / me
Разрешить: / profiles
Запретить: / s2 / profiles / me
Разрешить: / s2 / profiles
Разрешить: / s2 / oz
Разрешить: / s2 / photos
Разрешить: / s2 / search / social
Разрешить: / s2 / static
Disallow: / s2
Запретить: / transconsole / portal /
Запретить: / gcc /
Запретить: / aclk
Disallow: / cse?
Запретить: / cse / home
Запретить: / cse / panel
Запретить: / cse / manage
Запретить: / tbproxy /
Запретить: / imesync /
Запретить: / shenghuo / search?
Запретить: / поддержка / форум / поиск?
Запретить: / reviews / polls /
Запретить: / hosted / images /
Запретить: / ppob /?
Disallow: / ppob?
Запретить: / accounts / ClientLogin
Запретить: / accounts / ClientAuth
Disallow: / accounts / o8
Разрешить: / accounts / o8 / id
Запретить: / topicsearch? Q =
Запретить: / xfx7 /
Запрещено: / в квадрате / api
Запретить: / в квадрате / поиск
Запрещение: / в квадрате / таблица
Disallow: / qnasearch?
Запретить: / приложение / обновления
Запретить: / sidewiki / entry /
Запретить: / quality_form?
Запретить: / labs / popgadget / search
Запретить: / buzz / post
Запретить: / сжатие /
Запретить: / analytics / feeds /
Запретить: / аналитика / партнеры / комментарии /
Запретить: / analytics / portal /
Запретить: / analytics / uploads /
Разрешить: / предупреждения / управление
Разрешить: / alerts / remove
Запретить: / alerts /
Разрешить: / alerts / $
Запретить: / ads / search?
Запретить: / ads / plan / action_plan?
Запретить: / ads / plan / api /
Disallow: / ads / hotels / partners
Запретить: / phone / compare /?
Запретить: / путешествия / clk
Disallow: / путешествия / отельер / условия /
Запретить: / hotelfinder / rpc
Disallow: / hotels / rpc
Запретить: / commercesearch / services /
Запретить: / оценка /
Запретить: / chrome / browser / mobile / tour
Запретить: / сравнить / * / применить *
Запретить: / forms / perks /
Запретить: / покупки / поставщики / поиск
Запретить: / ct /
Запретить: / edu / cs4hs /
Запретить: / доверенные магазины / с /
Disallow: / доверенные магазины / tm2
Запретить: / доверенные магазины / проверить
Запретить: / adwords / offer
Disallow: / shopping? *
Запретить: / shopping / product /
Запрещено: / покупка / продавец
Запретить: / покупки / рейтинги / аккаунт / метрики
Запретить: / покупки / рейтинги / продавец / immersivedetails
Запретить: / shopping / reviewer
Disallow: / о / карьера / приложения /
Запретить: / приземление / выход.
json
Disallow: / mld?
Запретить: / staticmap?
Запретить: / maps / preview
Запретить: / карты / место
Запретить: / maps / timeline /
Запретить: / help / maps / streetview / partners / welcome /
Запретить: / help / maps / Indoormaps / partners /
Disallow: / lochp?
Disallow: / center
Disallow: / ie?
Запретить: / blogsearch /
Запретить: / blogsearch_feeds
Запретить: / advanced_blog_search
Запретить: / uds /
Disallow: / chart?
Disallow: / transit?
Разрешить: / calendar $
Разрешить: / calendar / about /
Запретить: / календарь /
Запретить: / cl2 / feeds /
Запретить: / cl2 / ical /
Запретить: / coop / directory
Запретить: / coop / manage
Disallow: / Trends?
Запретить: / тенденции / музыка?
Disallow: / Trends / hottrends?
Запретить: / тенденции / viz?
Запретить: / тенденции / встраивать.js?
Запретить: / тенденции / fetchComponent?
Запретить: / тенденции / бета
Запретить: / тенденции / темы
Запретить: / musica
Запретить: / musicad
Запретить: / musicas
Запретить: / musicl
Запретить: / музыка
Запретить: / musicsearch
Запретить: / musicsp
Запретить: / musiclp
Запретить: / urchin_test /
Disallow: / movies?
Запретить: / wapsearch?
Разрешить: / безопасный просмотр / диагностика
Разрешить: / safebrowsing / report_badware /
Разрешить: / safebrowsing / report_error /
Разрешить: / safebrowsing / report_phish /
Запретить: / обзоры / поиск?
Запретить: / orkut / альбомы
Disallow: / cbk
Disallow: / подзарядка / приборная панель / автомобиль
Disallow: / recharge / dashboard / static /
Запретить: / profiles / me
Разрешить: / profiles
Запретить: / s2 / profiles / me
Разрешить: / s2 / profiles
Разрешить: / s2 / oz
Разрешить: / s2 / photos
Разрешить: / s2 / search / social
Разрешить: / s2 / static
Disallow: / s2
Запретить: / transconsole / portal /
Запретить: / gcc /
Запретить: / aclk
Disallow: / cse?
Запретить: / cse / home
Запретить: / cse / panel
Запретить: / cse / manage
Запретить: / tbproxy /
Запретить: / imesync /
Запретить: / shenghuo / search?
Запретить: / поддержка / форум / поиск?
Запретить: / reviews / polls /
Запретить: / hosted / images /
Запретить: / ppob /?
Disallow: / ppob?
Запретить: / accounts / ClientLogin
Запретить: / accounts / ClientAuth
Disallow: / accounts / o8
Разрешить: / accounts / o8 / id
Запретить: / topicsearch? Q =
Запретить: / xfx7 /
Запрещено: / в квадрате / api
Запретить: / в квадрате / поиск
Запрещение: / в квадрате / таблица
Disallow: / qnasearch?
Запретить: / приложение / обновления
Запретить: / sidewiki / entry /
Запретить: / quality_form?
Запретить: / labs / popgadget / search
Запретить: / buzz / post
Запретить: / сжатие /
Запретить: / analytics / feeds /
Запретить: / аналитика / партнеры / комментарии /
Запретить: / analytics / portal /
Запретить: / analytics / uploads /
Разрешить: / предупреждения / управление
Разрешить: / alerts / remove
Запретить: / alerts /
Разрешить: / alerts / $
Запретить: / ads / search?
Запретить: / ads / plan / action_plan?
Запретить: / ads / plan / api /
Disallow: / ads / hotels / partners
Запретить: / phone / compare /?
Запретить: / путешествия / clk
Disallow: / путешествия / отельер / условия /
Запретить: / hotelfinder / rpc
Disallow: / hotels / rpc
Запретить: / commercesearch / services /
Запретить: / оценка /
Запретить: / chrome / browser / mobile / tour
Запретить: / сравнить / * / применить *
Запретить: / forms / perks /
Запретить: / покупки / поставщики / поиск
Запретить: / ct /
Запретить: / edu / cs4hs /
Запретить: / доверенные магазины / с /
Disallow: / доверенные магазины / tm2
Запретить: / доверенные магазины / проверить
Запретить: / adwords / offer
Disallow: / shopping? *
Запретить: / shopping / product /
Запрещено: / покупка / продавец
Запретить: / покупки / рейтинги / аккаунт / метрики
Запретить: / покупки / рейтинги / продавец / immersivedetails
Запретить: / shopping / reviewer
Disallow: / о / карьера / приложения /
Запретить: / приземление / выход. html
Запретить: / webmasters / sitemaps / ping?
Запретить: / ping?
Запретить: / галерея /
Disallow: / Landing / Now / ontap /
Разрешить: / searchhistory /
Разрешить: / карты / резерв
Разрешить: / карты / резерв / партнеры
Запретить: / maps / reserve / api /
Запретить: / карты / резерв / поиск
Disallow: / карты / резерв / бронирования
Запретить: / карты / резерв / настройки
Запретить: / карты / резерв / управлять
Запретить: / карты / резерв / оплата
Запретить: / карты / резерв / квитанция
Запретить: / карты / резерв / продавцы
Запретить: / карты / резерв / платежи
Запретить: / карты / резерв / обратная связь
Запретить: / карты / резерв / условия
Disallow: / maps / reserve / m /
Запретить: / карты / резерв / б /
Запретить: / карты / резерв / партнерская панель управления
Запретить: / about / views /
Запретить: / intl / * / about / views /
Disallow: / local / Dining /
Запретить: / local / place / products /
Запретить: / местное / место / отзывы /
Disallow: / local / place / rap /
Запретить: / local / tab /
Запретить: / localservices / *
Разрешить: / finance
Разрешить: / js /
Запретить: / nonprofits / account / # AdsBot
Пользовательский агент: AdsBot-Google
Запретить: / maps / api / js /
Разрешить: / maps / api / js
Запретить: / maps / api / place / js /
Запретить: / maps / api / staticmap
Запретить: / maps / api / streetview # Некоторые сайты социальных сетей занесены в белый список, чтобы поисковые роботы могли получать доступ к разметке страницы при ссылках на Google.com / imgres * являются общими. Чтобы узнать больше, свяжитесь с [email protected].
Пользовательский агент: Twitterbot
Разрешить: / imgres Пользовательский агент: facebookexternalhit
Разрешить: / imgres Карта сайта: https://www.google.com/sitemap.xml
html
Запретить: / webmasters / sitemaps / ping?
Запретить: / ping?
Запретить: / галерея /
Disallow: / Landing / Now / ontap /
Разрешить: / searchhistory /
Разрешить: / карты / резерв
Разрешить: / карты / резерв / партнеры
Запретить: / maps / reserve / api /
Запретить: / карты / резерв / поиск
Disallow: / карты / резерв / бронирования
Запретить: / карты / резерв / настройки
Запретить: / карты / резерв / управлять
Запретить: / карты / резерв / оплата
Запретить: / карты / резерв / квитанция
Запретить: / карты / резерв / продавцы
Запретить: / карты / резерв / платежи
Запретить: / карты / резерв / обратная связь
Запретить: / карты / резерв / условия
Disallow: / maps / reserve / m /
Запретить: / карты / резерв / б /
Запретить: / карты / резерв / партнерская панель управления
Запретить: / about / views /
Запретить: / intl / * / about / views /
Disallow: / local / Dining /
Запретить: / local / place / products /
Запретить: / местное / место / отзывы /
Disallow: / local / place / rap /
Запретить: / local / tab /
Запретить: / localservices / *
Разрешить: / finance
Разрешить: / js /
Запретить: / nonprofits / account / # AdsBot
Пользовательский агент: AdsBot-Google
Запретить: / maps / api / js /
Разрешить: / maps / api / js
Запретить: / maps / api / place / js /
Запретить: / maps / api / staticmap
Запретить: / maps / api / streetview # Некоторые сайты социальных сетей занесены в белый список, чтобы поисковые роботы могли получать доступ к разметке страницы при ссылках на Google.com / imgres * являются общими. Чтобы узнать больше, свяжитесь с [email protected].
Пользовательский агент: Twitterbot
Разрешить: / imgres Пользовательский агент: facebookexternalhit
Разрешить: / imgres Карта сайта: https://www.google.com/sitemap.xml
Как добавить файл Robots.txt
Как добавить файл robots.txt на свой сайт
Текстовый файл robots или файл robots.txt (часто ошибочно называемый файлом robot.txt) необходим на каждом веб-сайте. Добавление файла robots. txt в корневую папку вашего сайта — очень простой процесс, и наличие этого файла на самом деле является «признаком качества» для поисковых систем.Давайте посмотрим на параметры файла robots.txt, доступные для вашего сайта.
txt в корневую папку вашего сайта — очень простой процесс, и наличие этого файла на самом деле является «признаком качества» для поисковых систем.Давайте посмотрим на параметры файла robots.txt, доступные для вашего сайта.
Что такое текстовый файл роботов?
Файл robots.txt — это просто файл в формате ASCII или обычный текстовый файл, который сообщает поисковым системам, где им не разрешено заходить на сайт — также известный как Стандарт исключения для роботов. Любые файлы или папки, перечисленные в этом документе, не будут сканироваться и индексироваться пауками поисковых систем. Наличие даже пустого файла robots.txt показывает, что вы признаете, что поисковые системы разрешены на вашем сайте и что они могут иметь свободный доступ к нему.Мы рекомендуем добавить текстовый файл роботов к вашему основному домену и всем субдоменам на вашем сайте.
Параметры форматирования файла robots.txt
Создание robots.txt — простой процесс. Выполните следующие простые шаги:
- Откройте Блокнот, Microsoft Word или любой текстовый редактор и сохраните файл как «robots», все в нижнем регистре, не забудьте выбрать .txt в качестве расширения типа файла (в Word выберите «Обычный текст»).
- Затем добавьте в файл следующие две строки текста:
User-agent: *
Disallow:
«Пользовательский агент» — это другое слово для роботов или пауков поисковых систем.Звездочка (*) означает, что эта строка относится ко всем паукам. Здесь нет файла или папки, перечисленных в строке Disallow, что означает, что любой каталог на вашем сайте может быть доступен. Это базовый текстовый файл для роботов.
- Одной из опций robots.txt является также блокировка «пауков» поисковых систем со всего сайта. Для этого добавьте в файл эти две строчки:
User-agent: *
Disallow: /
- Если вы хотите заблокировать доступ пауков к определенным областям вашего сайта, ваш robots.txt может выглядеть примерно так:
User-agent: *
Disallow: / database /
Disallow: / scripts /

Три вышеперечисленных строки сообщают всем роботам, что им не разрешен доступ к чему-либо в базе данных и каталогах или подкаталогах сценариев. Помните, что в строке Disallow можно использовать только один файл или папку. Вы можете добавить столько строк Disallow, сколько вам нужно.
- Не забудьте добавить удобный для поисковой системы XML-файл карты сайта в текстовый файл robots.Это гарантирует, что «пауки» найдут вашу карту сайта и легко проиндексируют все страницы вашего сайта. Используйте этот синтаксис:
Карта сайта: http://www.mydomain.com/sitemap.xml
- По завершении сохраните и загрузите файл robots.txt в корневой каталог вашего сайта. Например, если ваш домен www.mydomain.com, вы разместите файл по адресу www.mydomain.com/robots.txt.
- Когда файл будет на месте, проверьте файл robots.txt на наличие ошибок.
Search Guru может помочь реализовать этот и другие технические элементы SEO.Свяжитесь с нами сегодня чтобы начать!
Настройте файл robots.txt
На файлыRobots.txt ссылаются поисковые системы для индексации содержания вашего веб-сайта. Они могут быть полезны для предотвращения возврата в результатах поисковой системы определенного контента, например, предложения контента, скрытого за формой.
Обратите внимание: Google и другие поисковые системы не могут задним числом удалять страницы из результатов поиска после реализации метода файла robots.txt.Хотя это говорит ботам не сканировать страницу, поисковые системы все равно могут индексировать ваш контент, если, например, есть входящие ссылки на вашу страницу с других веб-сайтов. Если ваша страница уже проиндексирована и вы хотите, чтобы она была удалена из поисковых систем задним числом, вы, вероятно, захотите использовать метод метатега «Без индекса».
Как работают файлы robots.txt
Ваш файл robots.txt сообщает поисковым системам, как сканировать страницы, размещенные на вашем веб-сайте. Два основных компонента вашего файла robots.txt:
Два основных компонента вашего файла robots.txt:
- User-agent: Определяет поисковую систему или веб-бот, к которому применяется правило. Звездочка (*) может использоваться как подстановочный знак с User-agent для включения всех поисковых систем.
- Disallow: Советует поисковой системе не сканировать и не индексировать файл, страницу или каталог.
Чтобы узнать больше о том, как настроить файлы robots.txt для результатов поиска Google, ознакомьтесь с документацией для разработчиков Google. Вы также можете использовать файл robots.txt для создания вашего файла.
Обратите внимание: , чтобы заблокировать файл в файловом менеджере, настройте файл так, чтобы он размещался в одном из ваших доменов. Затем вы можете добавить URL-адрес файла в свой файл robots.txt.
Обновите файл robots.txt в HubSpot
В своей учетной записи HubSpot щелкните значок настроек Настройки на главной панели навигации.
В меню левой боковой панели перейдите на Веб-сайт > Страницы .
Используйте раскрывающееся меню Изменение , чтобы выбрать домен для обновления.
- Щелкните вкладку SEO & Crawlers .
- Прокрутите вниз до раздела Robots.tx t и внесите изменения в файл robots.txt в текстовое поле.
Обратите внимание: , если вы используете на своем веб-сайте модуль поиска HubSpot, звездочка в поле агента пользователя заблокирует сканирование вашего сайта функцией поиска.Вам нужно будет включить HubSpotContentSearchBot в качестве пользовательского агента в файл robots.txt, чтобы функция поиска могла сканировать ваши страницы.
Целевые страницы Блог Настройки аккаунта Страницы веб-сайта
Что такое роботы.
Знаете ли вы, что у вас есть полный контроль над тем, кто сканирует и индексирует ваш сайт, вплоть до отдельных страниц?
Это делается с помощью файла Robots.txt.
Robots.txt — это простой текстовый файл, который размещается в корневом каталоге вашего сайта. Он сообщает «роботам» (например, паукам поисковых систем), какие страницы сканировать на вашем сайте, а какие игнорировать.
Хотя это и не обязательно, файл Robots.txt дает вам полный контроль над тем, как Google и другие поисковые системы видят ваш сайт.
При правильном использовании это может улучшить сканирование и даже повлиять на SEO.
Но как именно создать эффективный файл Robots.txt? После создания, как вы его используете? И каких ошибок следует избегать при его использовании?
В этом посте я поделюсь всем, что вам нужно знать о файле Robots.txt и о том, как использовать его в своем блоге.
Давайте нырнем:
Что такое роботы.txt файл?
Еще на заре Интернета программисты и инженеры создали «роботов» или «пауков» для сканирования и индексации страниц в сети. Этих роботов также называют «пользовательскими агентами».
Иногда эти роботы пробирались на страницы, которые владельцы сайтов не хотели индексировать. Например, строящийся сайт или частный сайт.
Для решения этой проблемы голландский инженер Мартин Костер, создавший первую в мире поисковую систему (Aliweb), предложил набор стандартов, которых должен придерживаться каждый робот.Эти стандарты были впервые предложены в феврале 1994 года.
30 июня 1994 г. ряд авторов роботов и пионеров Интернета пришли к консенсусу по поводу стандартов.
Эти стандарты были приняты как «Протокол исключения роботов» (REP).
Файл Robots.txt является реализацией этого протокола.
REP определяет набор правил, которым должен следовать каждый законный поисковый робот или паук. Если Robots.txt предписывает роботам не индексировать веб-страницу, каждый законный робот — от Googlebot до MSNbot — должен следовать инструкциям.
Если Robots.txt предписывает роботам не индексировать веб-страницу, каждый законный робот — от Googlebot до MSNbot — должен следовать инструкциям.
Примечание: Список легальных поисковых роботов можно найти здесь.
Имейте в виду, что некоторые роботы-мошенники — вредоносные программы, шпионское ПО, сборщики электронной почты и т. Д. — могут не следовать этим протоколам. Вот почему вы можете видеть трафик ботов на страницах, заблокированных через файл Robots.txt.
Есть также роботы, не соблюдающие стандарты REP, которые не используются ни для чего сомнительного.
Вы можете просмотреть robots.txt любого веб-сайта, перейдя по этому адресу:
http: // [website_domain] / robots.txt
Например, вот файл Robots.txt Facebook:
А вот файл Google Robots.txt:
.Использование Robots.txt
Robots.txt не является важным документом для веб-сайта. Ваш сайт может отлично ранжироваться и расти без этого файла.
Однако использование Robots.txt дает некоторые преимущества:
- Запретить ботам сканировать личные папки — Хотя это и не идеально, запрет ботам сканировать личные папки значительно затруднит их индексирование — по крайней мере, законными ботами (такими как пауки поисковых систем).
- Контроль использования ресурсов — Каждый раз, когда бот просматривает ваш сайт, он истощает вашу полосу пропускания и ресурсы сервера — ресурсы, которые лучше потратить на реальных посетителей. Для сайтов с большим количеством контента это может привести к увеличению затрат и ухудшить впечатление реальных посетителей. Вы можете использовать Robots.txt, чтобы заблокировать доступ к скриптам, неважным изображениям и т. Д. Для экономии ресурсов.
- Расставьте приоритеты для важных страниц — Вы хотите, чтобы пауки поисковых систем сканировали важные страницы вашего сайта (например, информационные страницы), а не тратили впустую ресурсы на бесполезные страницы (например, результаты поисковых запросов).
 Блокируя такие бесполезные страницы, вы можете определить приоритеты, на которых боты сосредоточены.
Блокируя такие бесполезные страницы, вы можете определить приоритеты, на которых боты сосредоточены.
Как найти файл Robots.txt
Как следует из названия, Robots.txt — это простой текстовый файл.
Этот файл хранится в корневом каталоге вашего веб-сайта. Чтобы найти его, просто откройте свой инструмент FTP и перейдите в каталог своего веб-сайта в public_html.
Это крошечный текстовый файл — у меня чуть больше 100 байт.
Чтобы открыть его, используйте любой текстовый редактор, например Блокнот.Вы можете увидеть что-то вроде этого:
Есть вероятность, что вы не увидите ни одного файла Robots.txt в корневом каталоге вашего сайта. В этом случае вам придется создать файл Robots.txt самостоятельно.
Вот как:
Как создать файл Robot.txt
Поскольку Robots.txt — это простой текстовый файл, создать его ОЧЕНЬ просто — просто откройте текстовый редактор и сохраните пустой файл с именем robots.txt .
Чтобы загрузить этот файл на свой сервер, используйте свой любимый FTP-инструмент (я рекомендую использовать WinSCP) для входа на ваш веб-сервер.Затем откройте папку public_html и откройте корневой каталог вашего сайта.
В зависимости от того, как настроен ваш веб-хостинг, корневой каталог вашего сайта может находиться непосредственно в папке public_html. Или это может быть папка внутри него.
После того, как вы откроете корневой каталог вашего сайта, просто перетащите в него файл Robots.txt.
Вы также можете создать файл Robots.txt прямо из редактора FTP.
Для этого откройте корневой каталог вашего сайта и щелкните правой кнопкой мыши -> Создать новый файл.
В диалоговом окне введите «robots.txt» (без кавычек) и нажмите «ОК».
Внутри вы должны увидеть новый файл robots.txt:
Наконец, убедитесь, что вы установили правильные права доступа для файла Robots. txt. Вы хотите, чтобы владелец — вы сами — читал и записывал файл, но не для других или общественности.
txt. Вы хотите, чтобы владелец — вы сами — читал и записывал файл, но не для других или общественности.
В вашем файле Robots.txt должно быть указано «0644» в качестве кода доступа.
Если это не так, щелкните правой кнопкой мыши файл Robots.txt и выберите «Права доступа к файлу…».
Вот и все — полнофункциональные роботы.txt файл!
Но что на самом деле можно сделать с этим файлом?
Далее я покажу вам несколько общих инструкций, которые вы можете использовать для управления доступом к своему сайту.
Как использовать Robots.txt
Помните, что Robots.txt по сути определяет, как роботы взаимодействуют с вашим сайтом.
Хотите заблокировать доступ поисковых систем к вашему сайту? Просто измените разрешения в Robots.txt.
Хотите запретить Bing индексировать вашу страницу контактов? Вы тоже можете это сделать.
Сам по себе файл Robots.txt не улучшит ваше SEO, но вы можете использовать его для управления поведением роботов на вашем сайте.
Чтобы добавить или изменить файл, просто откройте его в редакторе FTP и добавьте текст напрямую. Как только вы сохраните файл, изменения будут немедленно отражены.
Вот несколько команд, которые можно использовать в файле Robots.txt:
1. Заблокируйте доступ всех ботов на свой сайт
Хотите запретить всем роботам сканировать ваш сайт?
Добавьте этот код в свой Robots.txt файл:
Агент пользователя: *
Запрещено: /
Вот как это будет выглядеть в фактическом файле:
Проще говоря, эта команда сообщает каждому пользовательскому агенту (*) не обращаться ни к каким файлам или папкам на вашем сайте.
Вот полное объяснение того, что именно здесь происходит:
- User-agent: * — Звездочка (*) — это «подстановочный знак», который применяется к для каждого объекта (например, имени файла или, в данном случае, бота).
 Если вы выполните поиск «* .txt» на своем компьютере, он будет отображать все файлы с расширением .txt. Здесь звездочка означает, что ваша команда применяется к через каждый пользовательский агент .
Если вы выполните поиск «* .txt» на своем компьютере, он будет отображать все файлы с расширением .txt. Здесь звездочка означает, что ваша команда применяется к через каждый пользовательский агент . - Disallow: / — «Disallow» — это команда robots.txt, запрещающая ботам сканировать папку. Одиночная косая черта (/) означает, что вы применяете эту команду к корневому каталогу.
Примечание: Это идеальный вариант, если у вас есть какой-либо частный веб-сайт, например сайт членства.Но имейте в виду, что это остановит сканирование вашего сайта всеми законными ботами, такими как Google. Используйте с осторожностью.
2. Запретить всем ботам доступ к определенной папке
Что делать, если вы хотите запретить ботам сканировать и индексировать определенную папку?
Например, папка / images?
Используйте эту команду:
User-agent: *
Disallow: / [имя_папки] /
Если вы хотите запретить ботам доступ к папке / images, вот как будет выглядеть команда:
Эта команда полезна, если у вас есть папка ресурсов, которую вы не хотите перегружать запросами роботов-роботов.Это может быть папка с неважными скриптами, устаревшими изображениями и т. Д.
Примечание: Папка / images является исключительно примером. Я не говорю, что вы должны запретить ботам сканировать эту папку. Это зависит от того, чего вы пытаетесь достичь.
Поисковые системы обычно недовольны тем, что веб-мастера блокируют своим ботам сканирование папок без изображений, поэтому будьте осторожны при использовании этой команды. Ниже я перечислил некоторые альтернативы Robots.txt, которые не позволяют поисковым системам индексировать определенные страницы.
3. Заблокируйте доступ определенных ботов на свой сайт
Что делать, если вы хотите заблокировать доступ к вашему сайту определенному роботу, например роботу Googlebot?
Вот команда для этого:
User-agent: [имя робота]
Disallow: /
Например, если вы хотите заблокировать доступ робота Googlebot к своему сайту, вы должны использовать следующее:
У каждого легитимного бота или пользовательского агента есть определенное имя. Например, паук Google просто называется «робот Googlebot».Microsoft использует как «msnbot», так и «bingbot». Бот Yahoo называется Yahoo! Хлебать ».
Например, паук Google просто называется «робот Googlebot».Microsoft использует как «msnbot», так и «bingbot». Бот Yahoo называется Yahoo! Хлебать ».
Чтобы узнать точные имена различных пользовательских агентов (таких как Googlebot, bingbot и т. Д.), Используйте эту страницу.
Примечание: Приведенная выше команда блокирует доступ определенного бота ко всему вашему сайту. Робот Googlebot используется исключительно в качестве примера. В большинстве случаев вам никогда не захочется мешать Google сканировать ваш сайт. Один из конкретных вариантов использования блокировки определенных ботов — удерживать ботов, которые приносят вам пользу, приходя на ваш сайт, и останавливать тех, которые не приносят пользу вашему сайту.
4. Запретить сканирование определенного файла
Протокол исключения роботов дает вам точный контроль над тем, какие файлы и папки вы хотите заблокировать для роботов.
Вот команда, которую вы можете использовать, чтобы запретить сканирование файла любым роботом:
Агент пользователя: *
Запретить: / [имя_папки] / [имя_файла.расширение]
Итак, если вы хотите заблокировать файл с именем «img_0001.png» из папки «images», вы должны использовать эту команду:
5.Блокировать доступ к папке, но разрешить индексирование файла
Команда «Запретить» запрещает ботам доступ к папке или файлу.
Команда «Разрешить» делает обратное.
Команда «Разрешить» заменяет команду «Запретить», если первая нацелена на отдельный файл.
Это означает, что вы можете заблокировать доступ к папке, но разрешить пользовательским агентам по-прежнему получать доступ к отдельному файлу в папке.
Вот используемый формат:
Агент пользователя: *
Запретить: / [имя_папки] /
Разрешить: / [имя_папки] / [имя_файла.extension] /
Например, если вы хотите запретить Google сканирование папки «изображения», но все же хотите предоставить ему доступ к файлу «img_0001. png», хранящемуся в ней, вы должны использовать следующий формат:
В приведенном выше примере это будет выглядеть так:
Это остановит индексирование всех страниц в каталоге / search /.
Что делать, если вы хотите, чтобы все страницы, соответствующие определенному расширению (например, «.php» или «.png»), не индексировались?
Используйте это:
User-agent: *
Disallow: / *.расширение $
Знак ($) здесь означает конец URL-адреса, то есть расширение — это последняя строка в URL-адресе.
Если вы хотите заблокировать все страницы с расширением «.js» (для Javascript), вы бы использовали следующее:
Эта команда особенно эффективна, если вы хотите запретить ботам сканировать скрипты.
6. Не позволяйте ботам слишком часто сканировать ваш сайт
В приведенных выше примерах вы могли видеть эту команду:
Агент пользователя: *
Задержка сканирования: 20
Эта команда предписывает всем ботам ждать не менее 20 секунд между запросами сканирования.
Команда Crawl-Delay часто используется на крупных сайтах с часто обновляемым содержанием (например, в Twitter). Эта команда указывает ботам подождать минимальное время между последующими запросами.
Это гарантирует, что сервер не будет перегружен слишком большим количеством запросов одновременно от разных ботов.
Например, это файл Robots.txt Твиттера, в котором ботам предписывается ждать минимум 1 секунду между запросами:
Вы даже можете контролировать задержку сканирования для отдельных ботов.Это гарантирует, что слишком много ботов не будут сканировать ваш сайт одновременно.
Например, у вас может быть такой набор команд:
Примечание: На самом деле вам не нужно использовать эту команду, если только вы не используете большой сайт с тысячами новых страниц, создаваемых каждую минуту (например, Twitter).
Распространенные ошибки, которых следует избегать при использовании Robots.txt
Файл Robots.txt — это мощный инструмент для управления поведением ботов на вашем сайте.
Однако это также может привести к катастрофе SEO, если не использовать его правильно.Не помогает и то, что в Интернете существует ряд неправильных представлений о Robots.txt.
Вот некоторые ошибки, которых следует избегать при использовании Robots.txt:
Ошибка №1 — Использование Robots.txt для предотвращения индексации контента
Если вы «Запретите» папку в файле Robots.txt, легальные боты не будут сканировать ее.
Но это по-прежнему означает две вещи:
- Боты БУДУТ сканировать содержимое папки, на которую есть ссылки из внешних источников.Скажем, если другой сайт ссылается на файл в вашей заблокированной папке, боты будут его проиндексировать.
- Боты-мошенники — спамеры, шпионское ПО, вредоносное ПО и т. Д. — обычно игнорируют инструкции Robots.txt и в любом случае индексируют ваш контент.
Это делает Robots.txt плохим инструментом для предотвращения индексации контента.
Вот что вам следует использовать вместо этого: используйте тег meta noindex.
Добавьте следующий тег на страницы, которые не нужно индексировать:
Это рекомендуемый, оптимизированный для SEO метод предотвращения индексации страницы (хотя он по-прежнему не блокирует спамеров).
Примечание: Если вы используете плагин WordPress, такой как Yoast SEO или All in One SEO; вы можете сделать это без редактирования кода. Например, в плагине Yoast SEO вы можете добавить тег noindex для каждой публикации / страницы следующим образом:
Просто откройте и разместите / страницу и щелкните шестеренку внутри поля Yoast SEO. Затем щелкните раскрывающееся меню рядом с «Индексом мета-роботов».
Кроме того, с 1 сентября Google перестанет поддерживать использование «noindex» в файлах robots.txt.В этой статье SearchEngineLand есть дополнительная информация.
Ошибка № 2 — Использование Robots.txt для защиты личного содержания
Если у вас есть частный контент — скажем, PDF-файлы для курса электронной почты — блокировка каталога с помощью файла Robots.txt поможет, но этого недостаточно.
Вот почему:
Ваш контент все равно может быть проиндексирован, если на него есть ссылки из внешних источников. Кроме того, его все равно будут сканировать боты-мошенники.
Лучший способ — сохранить весь личный контент за логином.Это гарантирует, что никто — законные или мошеннические боты — не получит доступа к вашему контенту.
Обратной стороной является то, что у ваших посетителей есть дополнительный обруч, через который можно прыгнуть. Но ваш контент будет более безопасным.
Ошибка № 3 — Использование Robots.txt для предотвращения индексации дублированного контента
Дублированный контент — большой запрет, когда дело доходит до SEO.
Однако использование Robots.txt для предотвращения индексации этого контента не является решением.Опять же, нет никакой гарантии, что пауки поисковых систем не найдут этот контент из внешних источников.
Вот еще 3 способа передать дублированный контент:
- Удалить повторяющееся содержимое — Это полностью избавит от содержимого. Однако это означает, что вы ведете поисковые системы к 404 страницам — не идеально. По этой причине удаление не рекомендуется .
- Использовать перенаправление 301 — Перенаправление 301 сообщает поисковым системам (и посетителям) о том, что страница переместилась в новое место.Просто добавьте 301 редирект на дублированный контент, чтобы посетители переходили к вашему исходному контенту.
- Добавить тег rel = «canonical» — этот тег является «мета» версией перенаправления 301.
 Тег rel = canonical сообщает Google, какой URL-адрес является исходным для конкретной страницы. Например, этот код:
Тег rel = canonical сообщает Google, какой URL-адрес является исходным для конкретной страницы. Например, этот код:
http://example.com/original-page.html ” rel = ”canonical” />
Сообщает Google, что страница — original-page.html — это «оригинальная» версия дублирующей страницы.Если вы используете WordPress, этот тег легко добавить с помощью Yoast SEO или All in One SEO.
Если вы хотите, чтобы посетители могли получить доступ к повторяющемуся контенту, используйте тег rel = «canonical» . Если вы не хотите, чтобы посетители или боты получали доступ к контенту, используйте 301 редирект.
Будьте осторожны при реализации любого из них, потому что они повлияют на ваше SEO.
К вам
Файл Robots.txt является полезным союзником в формировании способа взаимодействия пауков поисковых систем и других ботов с вашим сайтом.При правильном использовании они могут положительно повлиять на ваш рейтинг и облегчить сканирование вашего сайта.
Используйте это руководство, чтобы понять, как работает Robots.txt, как он устанавливается и некоторые общие способы его использования. И избегайте любых ошибок, о которых мы говорили выше.
Связанное чтение:
Что такое Robots.txt?
Robots.txt — это файл, связанный с вашим веб-сайтом, который используется для запроса различных поисковых роботов сканировать или не сканировать части вашего сайта.
Файл robots.txt в основном используется для указания того, какие части вашего веб-сайта должны сканироваться пауками или поисковыми роботами. Он может указывать разные правила для разных пауков.
Googlebot — пример паука. Он развертывается Google для сканирования Интернета и записи информации о веб-сайтах, чтобы знать, насколько высоко ранжируются различные веб-сайты в результатах поиска.
Использование файла robots.txt на вашем веб-сайте является веб-стандартом.Пауки ищут файл robots.txt в каталоге хоста (или в основной папке) вашего веб-сайта. Этот текстовый файл всегда называется «robots.txt». Вы можете найти свой файл robots.txt по адресу:
yourwebsite.com/robots.txt
Большинство обычных пауков подчиняются указаниям, указанным в файлах robots.txt, но гнусные пауки не могут. Содержимое файлов robot.txt общедоступно. Вы можете попытаться заблокировать нежелательных пауков, отредактировав файл .htaccess, связанный с вашим сайтом.
Важно, чтобы маркетологи проверяли свой файл robots.txt, чтобы убедиться, что поисковым системам предлагается сканировать важные страницы. Если вы попросите поисковые системы не сканировать ваш сайт, он не появится в результатах поиска.
Вы также можете использовать файл robots.txt, чтобы показать поисковым роботам, где найти карту сайта вашего веб-сайта, что может сделать ваш контент более доступным для обнаружения.
Вы также можете указать задержку сканирования или сколько секунд роботы должны ждать, прежде чем собирать дополнительную информацию.Некоторым веб-сайтам может потребоваться использовать этот параметр, если боты съедают пропускную способность и заставляют ваш веб-сайт загружаться медленнее для посетителей.
Пример файла Robots.txt
Вот что может появиться в файле robots.txt:
User-agent: *
Disallow: /ebooks/*.pdf
Disallow: / staging /
User-agent: Googlebot-Image
Disallow: / images /
Вот что означает каждая строка на простом английском языке.
User-agent: * — Первая строка объясняет, что следующие правила должны соблюдаться всеми поисковыми роботами.В данном контексте звездочка означает всех пауков.
Disallow: /ebooks/*.pdf — В сочетании с первой строкой эта ссылка означает, что все веб-сканеры не должны сканировать какие-либо файлы PDF в папке электронных книг на этом веб-сайте.