что означает и как правильно использовать
В данной статье речь пойдет о самых популярных директивах Dissalow и Allow в файле robots.txt.
Disallow
Allow
Совместная интерпретация директив
Пустые Allow и Disallow
Специальные символы в директивах
Примеры совместного применения Allow и Disallow
Disallow
Disallow – директива, запрещающая индексирование отдельных страниц, групп страниц, их отдельных файлов и разделов сайта(папок). Это наиболее часто используемая директива, которая исключает из индекса:
- страницы с результатами поиска на сайте;
- страницы посещаемости ресурса;
- дубли;
- сервисные страницы баз данных;
- различные логи;
- страницы, содержащие персональные данные пользователей.
Примеры директивы Disallow в robots.
# запрет на индексацию всего веб-ресурса User-agent: Yandex Disallow: /
# запрет на обход страниц, адрес которых начинается с /category User-agent: Yandex Disallow: /category
# запрет на обход страниц, URL которых содержит параметры User-agent: Yandex Disallow: /page?
# запрет на индексацию всего раздела wp-admin User-agent: Yandex Disallow: /wp-admin
# запрет на индексацию подраздела plugins User-agent: Yandex Disallow: /wp-content/plugins
# запрет на индексацию конкретного изображения в папке img User-agent: Yandex Disallow: /img/images.jpg
# запрет индексации конкретного PDF документа User-agent: Yandex Disallow: /dogovor.pdf
# запрет на индексацию не только /my, но и /folder/my или /folder/my User-agent: Yandex Disallow: /*my
Правило Disallow работает с масками, позволяющими проводить операции с группами файлов или папок.
После данной директивы необходимо ставить пробел, а в конце строки пробел недопустим.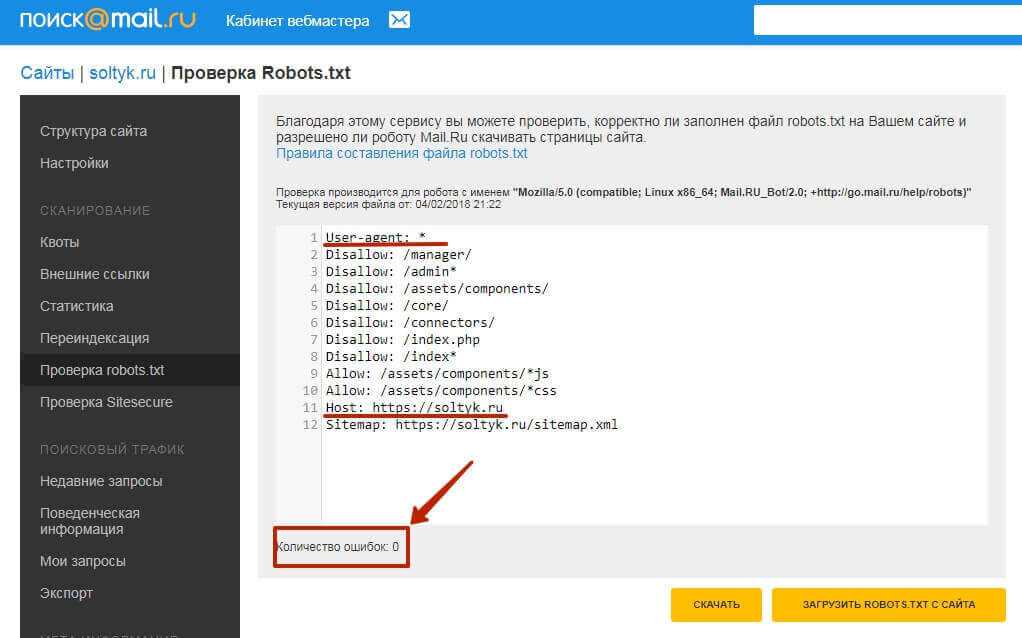 В одной строке с Disallow через пробел можно написать комментарий после символа “#”.
В одной строке с Disallow через пробел можно написать комментарий после символа “#”.
Allow
В отличие от Disallow, данное указание разрешает индексацию определенных страниц, разделов или файлов сайта. У директивы Allow схожий синтаксис, что и у Disallow.
Примеры Allow в robots.txt:
# разрешает индексацию всего каталога /img/ User-agent: Yandex Allow: /img/
# разрешает индексацию PDF документа User-agent: Yandex Allow: /prezentaciya.pdf
# открывает доступ к индексированию определенной HTML страницы User-agent: Yandex Allow: /page.html
# разрешает индексацию по маске *your User-agent: Yandex Allow: /*your
# запрещает индексировать все, кроме страниц, начинающихся с /cgi-bin User-agent: Yandex Allow: /cgi-bin Disallow: /
Для директивы применяются аналогичные правила, что и для Disallow.
Совместная интерпретация директив
Поисковые системы используют Allow и Disallow из одного User-agent блока последовательно, сортируя их по длине префикса URL, начиная от меньшего к большему. Если для конкретной страницы веб-сайта подходит применение нескольких правил, поисковый бот выбирает последний из списка. Поэтому порядок написания директив в robots никак не сказывается на их использовании роботами.
На заметку. Если директивы имеют одинаковую длину префиксов и при этом конфликтуют между собой, то предпочтительнее будет Allow.
Пример robots.txt написанный оптимизатором:
User-agent: Yandex Allow: / Allow: /catalog/phones Disallow: /catalog
Пример отсортированного файл robots.txt поисковой системой:
User-agent: Yandex Allow: / Disallow: /catalog Allow: /catalog/phones # запрещает посещать страницы, начинающиеся с /catalog, # но разрешает индексировать страницы, начинающиеся с /catalog/phones
Пустые Allow и Disallow
Когда в директивах отсутствуют какие-либо параметры, поисковый бот интерпретирует их так:
# то же, что и Allow: / значит разрешает индексировать весь сайт User-agent: Yandex Disallow:
# не учитывается роботом User-agent: Yandex Allow:
Специальные символы в директивах
Специальный символ “*” разрешает индексировать все страницы с параметром, указанным в директиве. К примеру, параметр /katalog* значит, что для ботов открыты страницы /katalog, /katalog-tovarov, /katalog-1 и прочие. Спецсимвол означает все возможные последовательности символов, даже пустые.
Примеры:
User-agent: Yandex
Disallow: /cgi-bin/*.aspx # запрещает /cgi-bin/example.aspx
# и /cgi-bin/private/test.aspx
Disallow: /*private # запрещает не только /private
# но и /cgi-bin/privateПо стандарту в конце любой инструкции, описанной в Robots, указывается специальный символ “*”, но делать это не обязательно.
Пример:
User-agent: Yandex
Disallow: /cgi-bin* # закрывает доступ к страницам
# начинающимся с /cgi-bin
Disallow: /cgi-bin # означает то же самоеДля отмены данного спецсимвола в конце директивы применяют другой спецсимвол – “$”.
Пример:
User-agent: Yandex
Disallow: /example$ # закрывает /example,
# но не запрещает /example.
html
User-agent: Yandex
Disallow: /example # запрещает и /example
# и /example.htmlНа заметку. Символ “$” не запрещает прописанный в конце “*”.
Пример:
User-agent: Yandex
Disallow: /example$ # закрывает только /example
Disallow: /example*$ # аналогично, как Disallow: /example
# запрещает и /example.html и /exampleБолее сложные примеры:
User-agent: Yandex
Allow: /obsolete/private/*.html$ # разрешает HTML файлы
# по пути /obsolete/private/...
Disallow: /*.php$ # запрещает все *.php на сайте
Disallow: /*/private/ # запрещает все подпути содержащие /private/
# но Allow выше отменяет часть запрета
Disallow: /*/old/*.zip$ # запрещает все .zip файлы, содержащие в пути /old/
User-agent: Yandex
Disallow: /add.php?*user=
# запрещает все скрипты add.php? с параметром userПримеры совместного применения Allow и Disallow
User-agent: Yandex Allow: / Disallow: / # разрешено индексировать весь веб-ресурс User-agent: Yandex Allow: /$ Disallow: / # запрещено включать в индекс все, кроме главной страницы User-agent: Yandex Disallow: /private*html # заблокирован и /private*html, # и /private/test.html, и /private/html/test.aspx и т.п. User-agent: Yandex Disallow: /private$ # запрещается только /private User-agent: * Disallow: / User-agent: Yandex Allow: / # так как робот Яндекса # выделяет записи по наличию его названия в строке User-agent: # тогда весь сайт будет доступен для индексирования
Я всегда стараюсь следить за актуальностью информации на сайте, но могу пропустить ошибки, поэтому буду благодарен, если вы на них укажете. Если вы нашли ошибку или опечатку в тексте, пожалуйста, выделите фрагмент текста и нажмите Ctrl+Enter.
страниц запрещены в robots.txt, но проиндексированы Google. Как это возможно?
спросил
Изменено 3 года, 4 месяца назад
Просмотрено 1к раз
Проблемы с отображением моего веб-сайта в Google Search Console.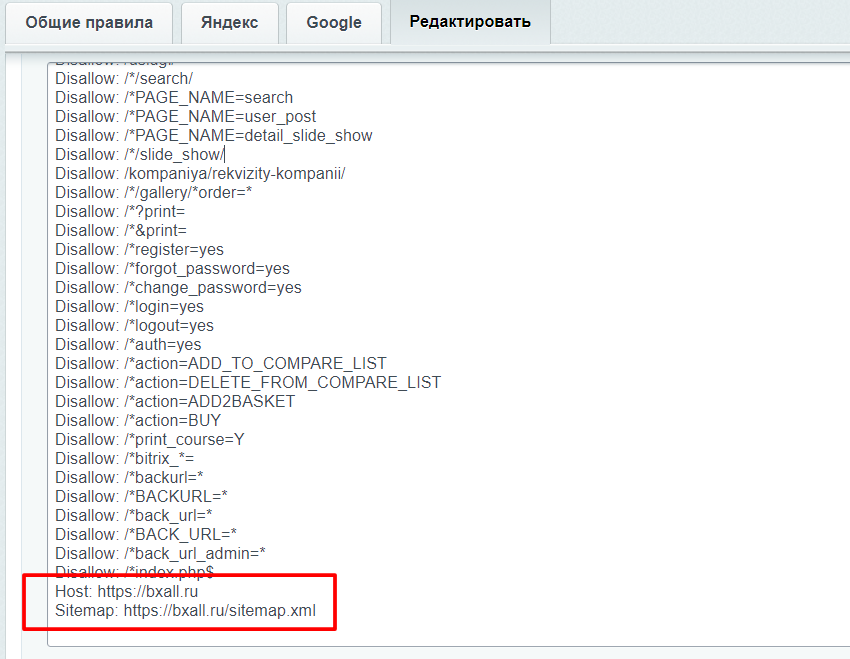 Проверьте следующее сообщение Google в GSC:
Проверьте следующее сообщение Google в GSC:
Проиндексировано, но заблокировано robots.txt
Я запрещаю страницу своей учетной записи ( https://www.joujou.com.au/account/) в robots.txt, но она индексируется Google. Можно ли проиндексировать страницу в Google, если эта страница уже запрещена в файле robots.txt?
- google-search
- robots.txt
Robots.txt просто не позволяет роботу Googlebot просматривать содержимое страницы. Однако если кто-то ссылается на вашу страницу, даже если Google не видит содержимого, Google знает, что по этому целевому URL-адресу есть веб-страница.
Если на страницу ссылается достаточное количество людей, Google может принять решение о ее добавлении и отображении в индексе. Много раз Google будет собирать контекст этой веб-страницы из контента, который ссылается на нее, и якорного текста ссылок.
Если вы действительно не хотите, чтобы URL-адрес был в индексе Google, есть 2 рекомендуемых подхода.
- Добавьте метатег robots на страницу с помощью команды NOINDEX. примечание: Вам нужно будет разрешить Google сканировать URL-адрес, чтобы он увидел команду NOINDEX. Поэтому вам придется отменить команду disallow в файле robots.txt 9.0022
- Добавить базовую HTTP-аутентификацию на страницу
Любой подход гарантирует, что Google не добавит URL-адрес в индекс. Однако время от времени Google по-прежнему будет сканировать URL-адрес.
Для большего контекста представитель Google Джон Мюллер недавно заявил об этом в Твиттере.
… robots.txt обязательно заблокирует сканирование контента (если запрещено), хотя это и не обязательно индексация URL-адресов. [однако] без содержание, трудно занять 9 место0005
Зарегистрируйтесь или войдите в систему
Зарегистрируйтесь с помощью Google
Зарегистрироваться через Facebook
Зарегистрируйтесь, используя адрес электронной почты и пароль
Опубликовать как гость
Электронная почта
Обязательно, но не отображается
Опубликовать как гость
Электронная почта
Требуется, но не отображается
Как запретить страницы поиска из robots.
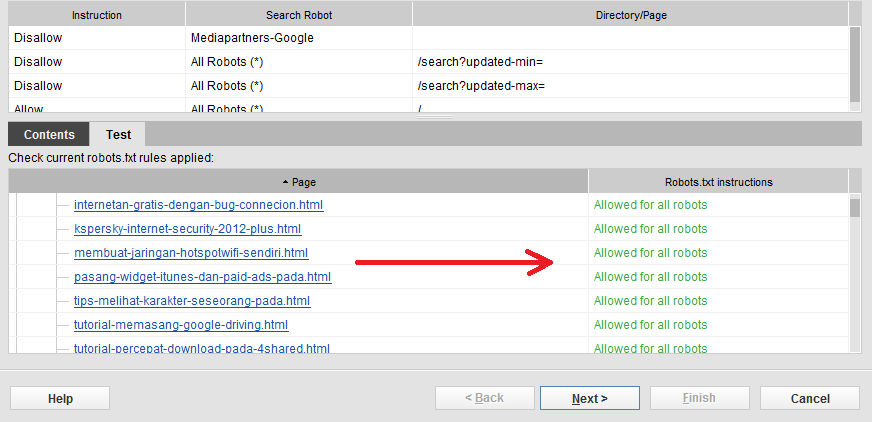 txt
txtспросил
Изменено 10 лет, 1 месяц назад
Просмотрено 23 тысячи раз
Мне нужно запретить индексацию http://example.com/startup?page=2 поисковых страниц.
Я хочу, чтобы http://example.com/startup индексировался, но не http://example.com/startup?page=2 и page3 и так далее.
Кроме того, запуск может быть случайным, например, http://example.com/XXXXX?page
- robots.txt
Что-то вроде этого работает, как подтверждает функция Google Webmaster Tools «test robots.txt»:
Агент пользователя: * Запретить: /startup?page=
Запретить Значение этого поля указывает частичный URL-адрес, который не быть посещенным. Это может быть полный путь, или частичный путь; любой URL, который начинается с этим значением не будет получено.
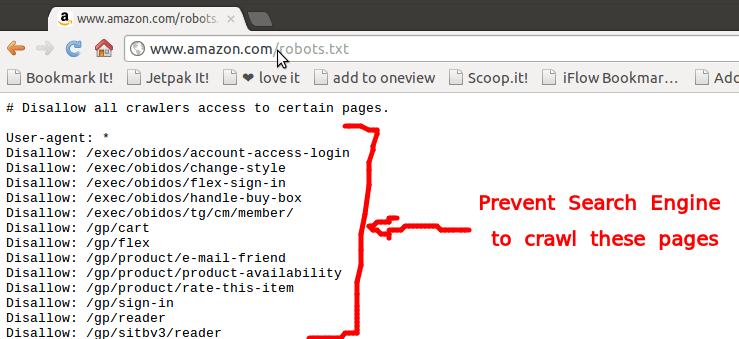
Однако, , если первая часть URL-адреса изменится на , вы должны использовать подстановочные знаки:
User-Agent: * Запретить: /startup?page= Запретить: *страница= Запретить: *?page=
0
Вы можете поместить это на страницы, которые вы не хотите индексировать:
Это говорит роботам не индексировать страницу.
На странице поиска может быть интереснее использовать:
Указывает роботам не индексировать текущую страницу, но по-прежнему переходить по ссылкам на этой странице, что позволяет им попадать на страницы, найденные в поиске.
- Создайте текстовый файл и назовите его: robots.txt
- Добавить пользовательские агенты и запретить разделы (см. пример ниже)
- Поместите файл в корень вашего сайта
Образец:
################################ #Мой файл robots.
