- Зачем robots.txt в SEO?
- Создаем robots самостоятельно
- Синтаксис robots.txt
- Обращение к индексирующему роботу
- Запрет индексации Disallow
- Разрешение индексации Allow
- Директива host robots.txt
- Sitemap.xml в robots.txt
- Использование директивы Clean-param
- Использование директивы Crawl-delay
- Комментарии в robots.txt
- Маски в robots.txt
- Как правильно настроить robots.txt?
- Проверяем свой robots.txt
Robots — это обыкновенный текстовой файл (.txt), который располагается в корне сайта наряду c index.php и другими системными файлами. Его можно загрузить через FTP или создать в файловом менеджере у хост-провайдера. Создается данный файл как обыкновенный текстовой документ с самым простым форматом — TXT. Далее файлу присваивается имя ROBOTS. Выглядит это следующим образом:

(robots.txt в корневой папке WordPress)
После создание самого файла нужно убедиться, что он доступен по ссылке ваш домен/robots.txt. Именно по этому адресу поисковая система будет искать данный файл.
В большинстве систем управления сайтами роботс присутствует по умолчанию, однако зачастую он настроен не полностью или совсем пуст. В любом случае, нам придется его править, так как для 95% проектов шаблонный вариант не подойдет.
Зачем robots.txt в SEO?
Первое, на что обращает внимание оптимизатор при анализе/начале продвижения сайта — это роботс. Именно в нем располагаются все главные инструкции, которые касаются действий индексирующего робота. Именно в robots.txt мы исключаем из поиска страницы, прописываем пути к карте сайта, определяем главной зеркало сайта, а так же вносим другие важные инструкции.
Ошибки в директивах могут привести к полному исключению сайта из индекса. Отнестись к настройкам данного файла нужно осознано и очень серьезно, от этого будет зависеть будущий органический трафик.
Создаем robots самостоятельно
Сам процесс создания файла до безобразия прост. Необходимо просто создать текстовой документ, назвав его «robots». После этого, подключившись через FTP соединение, загрузить в корневую папку Вашего сайта. Обязательно проверьте, что бы роботс был доступен по адресу
Если Вы пользуетесь web ftp — файловым менеджером, который доступен в панели управления у любого хост-провайдера, то файл можно создать прямо там.
В итоге, у нас получается пустой роботс. Все инструкции мы будем вписывать вручную. Как это сделать, мы опишем ниже.
Используем online генераторы
Если создание своими руками это не для Вас, то существует множество online генераторов, которые помогут в этом. Но нужно помнить, что никакой генератор не сможет без Вас исключить из поиска весь «мусор» и не добавит главное зеркало, если Вы не знаете какое оно. Данный вариант подойдет лишь тем, кто не хочет писать рутинные повторяющиеся для большинства сайтов инструкции.
Сгенерированный онлайн роботс нужно будет в любом случае править «руками», поэтому без знаний синтаксиса и основ Вам не обойтись и в этом случае.
Используем готовые шаблоны
В Интернете есть множество шаблонов для распространенных CMS, таких как WordPress, Joomla!, MODx и т.д. От онлайн генераторов они отличаются только тем, что сам текстовой файл Вам нужно будет сделать самостоятельно. Шаблон позволяет не писать большинство стандартных директив, однако он не гарантирует правильную и полную настройку для Вашего ресурса. При использовании шаблонов так же нужны знания.
Синтаксис robots.txt
Использование правильного синтаксиса при настройке — это основа всего. Пропущенная запятая, слэш, звездочка или проблем могут «сбить» всю настройку. Безусловно, есть системы проверки файла, однако без знания синтаксиса они все равно не помогу. Мы по порядку рассмотрим все возможные инструкции, которые применяются при настройке robots.txt. Сначала самые популярные.
Обращение к индексирующему роботу
Любой файл robots начинается с директивы User-agent:, которая указывает для какой поисковой системы или для какого робота приведены инструкции ниже. Пример использования:
User-agent: Yandex User-agent: YandexBot User-agent: Googlebot
Строка 1 — Инструкции для всех роботов Яндекса
Строка 2 — Инструкции для основного индексирующего робота Яндекса
Строка 3 — Инструкции для основного индексирующего робота Google
Яндекс и Гугл имеют не один и даже не два робота. Действиями каждого можно управлять в нашем robots.txt. Давайте рассмотрим, какие бывают роботы и зачем они нужны.
Роботы Yandex
| Название | Описание | Предназначение |
| YandexBot | Основной индексирующий робот | Отвечает за основную органическую выдачу Яндекса. |
| YandexDirect | Работ контекстной рекламы | Оценивает сайты с точки зрения расположения на них контекстных объявлений. |
| YandexDirectDyn | Так же робот контекста | Отличается от предыдущего тем, что работает с динамическими баннерами. |
| YandexMedia | Индексация мультимедийных данных. | Отвечает, загружает и оценивает все, что связано с мультимедийными данными. |
| YandexImages | Индексация изображений | Отвечает за раздел Яндекса «Картинки» |
| YaDirectFetcher | Так же робот Яндекс Директ | Его особенность в том, что он интерпретирует файл robots особым образом. Подробнее о нем можно прочесть у Яндекса. |
| YandexBlogs | Индексация блогов | Данный робот отвечает за посты, комментарии, ответы и т.д. |
| YandexNews | Новостной робот | Отвечает за раздел «Новости». Индексирует все, что связано с периодикой. |
| YandexPagechecker | Робот микроразметки | Данный робот отвечает за индексацию и распознание микроразметки сайта. |
| YandexMetrika | Робот Яндекс Метрики | Тут все и так ясно. |
| YandexMarket | Робот Яндекс Маркета | Отвечает за индексацию товаров, описаний, цен и всего того, что относится к Маркету. |
| YandexCalendar | Робот Календаря | Отвечает за индексацию всего, что связано с Яндекс Календарем. |
Роботы Google
| Название | Описание | Предназначение |
| Googlebot | (Googlebot) Основной индексирующий роботом Google. | Индексирует основной текстовой контент страницы. Отвечает за основную органическую выдачу. Запрет приведет к полному отсутствия сайта в поиске. |
| Googlebot-News | (Googlebot News) Новостной робот. | Отвечает за индексирование сайта в новостях. Запрет приведет к отсутствию сайта в разделе «Новости» |
| Googlebot-Image | (Googlebot Images) Индексация изображений. | Отвечает за графический контент сайта. Запрет приведет к отсутствию сайта в выдаче в разделе «Изображения» |
| Googlebot-Video | (Googlebot Video) Индексация видео файлов. | Отвечает за видео контент. Запрет приведет к отсутствию сайта в выдаче в разделе «Видео» |
| Googlebot | (Google Smartphone) Робот для смартфонов. | Основной индексирующий робот для мобильных устройств. |
| Mediapartners-Google | (Google Mobile AdSense) Робот мобильной контекстной рекламы | Индексирует и оценивает сайт с целью размещения релевантных мобильных объявлений. |
| Mediapartners-Google | (Google AdSense) Робот контекстной рекламы | Индексирует и оценивает сайт с целью размещения релевантных объявлений. |
| AdsBot-Google | (Google AdsBot) Проверка качества страницы. | Отвечает за качество целевой страницы — контент, скорость загрузки, навигация и т.д. |
| AdsBot-Google-Mobile-Apps | Робот Google для приложений | Сканирование для мобильных приложений. Оценивает качество так же, как и предыдущий робот AdsBot |
Обычно robots.txt настраивается для всех роботов Яндекса и Гугла сразу. Очень редко приходится делать отдельные настройки для каждого конкретного краулера. Однако это возможно.
Другие поисковые системы, такие как Bing, Mail, Rambler, так же индексируют сайт и обращаются к robots.txt, однако мы не будем заострять на них внимание. Про менее популярные поисковики мы напишем отдельную статью.
Запрет индексации Disallow
Без сомнения самая популярная директива. Именно при помощи disallow страницы исключаются из индекса. Disallow — буквально означает запрет на индексацию страницы, раздела, файла или группы страниц (при помощи маски). Рассмотрим пример:
Disallow: /wp-admin Disallow: /wp-content/plugins Disallow: /img/images.jpg Disallow: /dogovor.pdf Disallow: */trackback Disallow: /*my
Строка 1 — запрет на индексацию всего раздела wp-admin
Строка 2 — запрет на индексацию подраздела plugins
Строка 3 — запрет на индексацию изображения в папке img
Строка 4 — запрет индексации документа
Строка 5 — запрет на индексацию trackback в любой папке на 1 уровень
Строка 6 — запрет на индексацию не только /my, но и /folder/my или /foldermy
Данная директива поддерживает маски, о которых мы подробнее напишем ниже.
После Disallow в обязательном порядке ставится пробел, а вот в конце строки пробела быть не должно. Так же, допускается написание комментария в одной строке с директивой через пробел после символа «#», однако это не рекомендуется.
Указание нескольких каталогов в одной инструкции не допускается!
Разрешение индексации Allow
Обратная Disallow директива Allow разрешает индексацию конкретного раздела. Заходить на Ваш сайт или нет решает поисковая система, но данная директива ей это позволяет. Обычно Allow не применяется, так как поисковая система старается индексировать весь материал сайта, который может быть полезен человеку.
Пример использования Allow
Allow: /img/ Allow: /dogovor.pdf Allow: /trackback.html Allow: /*my
Строка 1 — разрешает индексацию всего каталога /img/
Строка 2 — разрешает индексацию документа
Строка 3 — разрешает индексацию страницы
Строка 4 — разрешает индексацию по маске *my
Данная директива поддерживает и подчиняется всем тем же правилам, которые справедливы для Disallow.
Директива host robots.txt
Данная директива позволяет обозначить главное зеркало сайта. Обычно, зеркала отличаются наличием или отсутствием www. Данная директива применяется в каждом robots и учитывается большинством поисковых систем.
Пример использования:
Host: dh-agency.ru
Если вы не пропишите главное зеркало сайта через host, Яндекс сообщит Вам об этом в Вебмастере.

Не знаете главное зеркало сайта? Определить довольно просто. Вбейте в поиск Яндекса адрес своего сайта и посмотрите выдачу. Если перед доменом присутствует www, то значит главное зеркало у вас с www.
Если же сайт еще не участвует в поиске, то в Яндекс Вебмастере в разделе «Переезд сайта» Вы можете задать главное зеркало самостоятельно.
Sitemap.xml в robots.txt
Данную директиву желательно иметь в каждом robots.txt, так как ее используют yandex, google, а так же все основные поисковые системы. Директива представляет из себя ссылку на файл sitemap.xml в котором содержатся все страницы, которые предназначены для индексирования. Так же в sitemap указываются приоритеты и даты изменения.
Пример использования:
Sitemap: http://dh-agency.ru/sitemap.xml
О том, как правильно создавать sitemap.xml мы напишем чуть позже.
Использование директивы Clean-param
Очень полезная, но мало кем применяющаяся директива. Clean-param позволяет описать динамические части URL, которые не меняют содержимое страницы. Такими динамическими частями могут быть:
- Идентификаторы сессий;
- Идентификаторы пользователей;
- Различные индивидуальные префиксы не меняющие содержимое;
- Другие подобные элементы.
Clean-param позволяет поисковым системам не загружать один и тот же материал многократно, что делает обход сайта роботом намного эффективнее.
Объясним на примере. Предположим, что для определения с какого сайта перешел пользователь мы взяли параметр site. Данный параметр будет меняться в зависимости от ресурса, но контент страницы будет одним и тем же.
http://dh-agency.ru/folder/page.php?site=x&r_id=985 http://dh-agency.ru/folder/page.php?site=y&r_id=985 http://dh-agency.ru/folder/page.php?site=z&r_id=985
Все три ссылки разные, но они отдают одинаковое содержимое страницы, поэтому индексирующий робот загрузит 3 копии контента. Что бы этого избежать пропишем следующие директивы:
User-agent: Yandex Disallow: Clean-param: site /folder/page.php
В данном случае робот Яндекса либо сведет все страницы к одному варианту, либо проиндексирует ссылку без параметра. Если такая конечно есть.
Использование директивы Crawl-delay
Довольно редко используемая директива, которая позволяет задать роботу минимальный промежуток между загружаемыми страницами. Crawl-delay применяется, когда сервер нагружен и не успевает отвечать на запросы. Промежуток задается в секундах. К примеру:
User-agent: Yandex Crawl-delay: 3
В данном случае таймаут будет 3 секунды. Кстати, стоит отметить, что Яндекс поддерживает и не целые значения в данной директиве. К примеру, 0.4 секунды.
Комментарии в robots.txt
Хороший robots.txt всегда пишется с комментариями. Это упростит работу Вам и поможет будущим специалистам.
Что бы написать комментарий, который будет игнорировать робот поисковой системы, необходимо поставить символ «#». К примеру:
#мой роботс Disallow: /wp-admin Disallow: /wp-content/plugins
Так же возможно, но не желательно, использовать комментарий в одной строке с инструкцией.
Disallow: /wp-admin #исключаем wp admin Disallow: /wp-content/plugins
На данный момент никаких технических запретов по написанию комментария в одной строке с инструкцией нету, однако это считается плохим тоном.
Маски в robots.txt
Применение масок в robots.txt не только упрощает работу, но зачастую просто необходимо. Напомним, маска — это условная запись, которая содержит в себе имена нескольких файлов или папок. Маски применяются для групповых операций с файлами/папками. Предположим, что у нас есть список файлов в папке /documents/

Среди этих файлов есть презентации в формате pdf. Мы не хотим, что бы их сканировал робот, поэтому исключаем из поиска.
Мы можем перечислять все файлы формата .pdf «в ручную»
Disallow: /documents/admin.pdf Disallow: /documents/r7.pdf Disallow: /documents/leto.pdf Disallow: /documents/sity.pdf Disallow: /documents/afrika.pdf Disallow: /documents/t-12.pdf
А можем сделать простую маску *.pdf и скрыть все файлы в одной инструкции.
Disallow: /documents/*.pdf
Удобно, не правда ли?
Маски создаются при помощи спецсимвола «*». Он обозначает любую последовательность символов, в том числе и пробел. Примеры использования:
Disallow: *.pdf Disallow: admin*.pdf Disallow: a*m.pdf Disallow: /img/*.* Disallow: img.* Disallow: &=*
Стоит отметить, что по умолчанию спецсимвол «*» добавляется в конце каждой инструкции, которую Вы прописываете. То есть,
Disallow: /wp-admin # равносильно инструкции ниже Disallow: /wp-admin*
То есть, мы исключаем все, что находится в папке /wp-admin, а так же /wp-admin.html, /wp-admin.pdf и т.д. Для того, что бы этого не происходило необходимо в конце инструкции поставить другой спецсимвол — «$».
Disallow: /wp-admin$ #
В таком случае, мы уже не запрещаем файлы /wp-admin.html, /wp-admin.pdf и т.д
Как правильно настроить robots.txt?
С синтаксисом robots.txt мы разобрались выше, поэтому сейчас напишем как правильно настроить данный файл. Если для популярных CMS, таких как WordPress и Joomla!, уже есть готовые robots, то для самописного движка или редкой СУ Вам придется все настраивать вручную.
(Даже несмотря на наличие готовых robots.txt редактировать и удалять «уникальный мусор» Вам придется и в ВордПресс. Поэтому этот раздел будет полезен и для владельцев сайтов на ТОПовых CMS)
Что нужно исключать из индекса?
А.) В первую очередь из индекса исключаются дубликаты страниц в любом виде. Страница на сайте должна быть доступна только по одному адресу. То есть, при обращении к ресурсу робот должен получать по каждому URL уникальный контент.
Зачастую дубликаты появляются у систем управления сайтом при создании страниц. К примеру, одна и та же страница может быть доступна по техническому адресу /?p=391&preview=true и одновременно с этим иметь ЧПУ. Так же дубли могут возникать при работе с динамическими ссылками.
Всех их необходимо при помощи масок исключать из индекса.
Disallow: /*?* Disallow: /*% Disallow: /index.php Disallow: /*?page= Disallow: /*&page=
Б.) Все страницы, которые имеют не уникальный контент, желательно убрать из индекса еще до того, как это сделает поисковая система.
В.) Из индекса должны быть исключены все страницы, которые используются при работе сценариев. К примеру, страница «Спасибо, сообщение отправлено!».
Г.) Желательно исключить все страницы, которые имеют индикаторы сессий
Disallow: *PHPSESSID= Disallow: *session_id=
Д.) В обязательном порядке из индекса должны быть исключены все файлы вашей cms. Это файлы панели администрации, различных баз, тем, шаблонов и т.д.
Disallow: /wp-admin Disallow: /wp-includes Disallow: /wp-content/plugins Disallow: /wp-content/cache Disallow: /wp-content/themes Disallow: /trackback
Е.) Пустые страницы и разделы, «не нужный» пользователям контент, результаты поиска и работы калькулятора так же должны быть недоступны роботу.
«Держа в чистоте» Ваш индекс Вы упрощаете жизнь и себе и индексирующему роботу.
Что нужно разрешать индексировать?
Да по сути все, что не запрещено. Есть только один нюанс. Поисковые системы по умолчанию индексируют любой полезный контент Вашего сайта, поэтому использовать директиву Allow в 90% случаев не нужно.
Корректный файл sitemap.xml и качественная перелинковка дадут гарантию, что все «нужные» страницы Вашего сайта будут проиндексированы.
Обязательны ли директивы host и sitemap?
Да, данные директивы обязательны. Прописать их не составит труда, но они гарантируют, что робот точно найдет sitemap.xml, и будет «знать» главное зеркало сайта.
Для каких поисковиков настраивать?
Инструкции файла robots.txt понимают все популярные поисковые системы. Если различий в инструкциях нету, то Вы можете прописать User-agent: * (Все директивы для всех поисковиков).
Однако, если Вы укажите инструкции для конкретного робота, к примеру Yandex, то все другие директивы Яндексом будут проигнорированы.
Нужны ли мне директивы Crawl-delay и Clean-param?
Если Вы используете динамические ссылки или же передаете параметры в URL, то Вам скорее всего понадобиться Clean-param, дабы не вводить робота в заблуждение. Использование данной директивы мы описали выше. Данная директива поможет Вам избежать ненужных дубликатов в поиске, что очень важно.
Использование Crawl-delay зависит исключительно от Вашего хостинга. Если Вы чувствуете, что сервер уже не справляется запросами, то желательно увеличить время межу ними.
Проверяем свой robots.txt
После настройки файла его необходимо проверить. Сделать это возможно через Ваш Вебмастер в разделе «Инструменты» -> «Анализ robots.txt»

Но нужно понимать, что данный онлайн инструмент сможет лишь найти синтаксическую ошибку. Он никак не убережет Вас от лишней исключенной страницы, а так же от мусора в выдаче.
robots.txt host — директива. Как указать главное зеркало?
Есть официальная документация у поисковиков на тему данной директивы, но к примеру у Google данная директива не задокументирована, но и не считается ошибкой в валидаторе…
Ну что ж приступим…
Как правильно прописать host в robots txt?
Яндекс
User-Agent: *
Disallow: /forum
Disallow: /cgi-bin
Host: https://soltyk.ruВалидатор для проверки в Яндексе
Про главное зеркало:
«Директива Host не гарантирует выбор указанного главного зеркала, тем не менее, алгоритм при принятии решения учитывает ее с высоким приоритетом.»
Примечание. Для каждого файла robots.txt обрабатывается только одна директива Host. Если в файле указано несколько директив, робот использует первую.
Директива Host должна содержать:
- Протокол HTTPS, если зеркало доступно только по защищенному каналу. Если вы используете протокол HTTP, то его указывать необязательно.
- Одно корректное доменное имя, соответствующего RFC 952 и не являющегося IP-адресом.
- Номер порта, если необходимо (Host: myhost.ru:8080).
Некорректно составленные директивы Host игнорируются.
Официальная документация.
Вот как выглядит это в вебмастере (ошибок и предупреждений нет):
![]()
Про главное зеркало:
«Директивой можно указать роботу главный сайт, в том случае если вы используете сайты-зеркала. Значением в данной строке выступает доменное имя. Для поддержания формата файла robots.txt директива должна идти внутри записи, начинающейся с User-agent.»
Пример:
User-agent: *
Disallow: # обязательная для каждой записи строка с директивой Disallow
Host: https://soltyk.ruОфициальная документация
Валидатор в вебмастере
Аналогичная проверка (ошибок и предупреждений нет):
![]()
А теперь самое интересное…
Есть официальная документация, но в ней ничего не сказано про данную директиву…
Можно выделить 3 основных задокументированных факта:
- Инструкции robots.txt носят рекомендательный характер
- Каждый поисковый робот использует собственный алгоритм обработки файла robots.txt
- Страница, заблокированная для поисковых роботов, все же может быть обработана, если на других сайтах есть ссылки на нее
А вот что выдает валидатор в вебмастере Google (смотрим и делаем выводы):
![]()
Выводы, предположения и возможная польза…
Так что можно смело предположить при использовании валидатора robots от Google не возникает ни предупреждений, ни ошибок. В 2016 — начало 2017 такая картина еще наблюдалась (помечалось как ошибка). Следовательно, можно предположить, что они решили использовать данную директиву host как рекомендацию. Также проводя тесты на клиентских сайтах при переходе на https (без применения междоменного 301-редиректа), было замечено, как Гугл начинал потихоньку индексировать https версию. И к тому времени, когда Яндекс завершал склейку, в Google-вебмастере было видно, как часть индекса перетекала уже на новый хост.
Конечно это только догадки, основанные на практических тестах. Поэтому я составляю одну общую конфигурацию для всех роботов:
User-agent: *Поэтому, если у Вас также есть опыт в определении такого стандарта для Google, то можете написать мне или в комментариях ниже.
Обновлено: 19.07.2020 5491
что это такое, что будет, если она отсутствует
Мы увеличиваем посещаемость и позиции в выдаче. Вы получаете продажи и платите только за реальный результат, только за целевые переходы из поисковых систем

Получи нашу книгу «Контент-маркетинг в социальных сетях: Как засесть в голову подписчиков и влюбить их в свой бренд».
Подпишись на рассылку и получи книгу в подарок!

Часто возникает необходимость, чтобы поисковая система не индексировала некоторые страницы сайта или его зеркала. Например, ресурс находится на одном сервере, однако в интернете есть идентичное доменное имя, по которому осуществляется индексация и отображение в результатах поисковой выдачи.
Поисковые роботы Яндекса обходят страницы сайтов и добавляют собранную информацию в базу данных по собственному графику. В процессе индексации они самостоятельно решают, какую страницу необходимо обработать. К примеру, роботы обходят стороной различные форумы, доски объявлений, каталоги и прочие ресурсы, где индексация бессмысленна. Также они могут определять главный сайт и зеркала. Первые подлежат индексации, вторые – нет. В процессе часто возникают ошибки. Повлиять на это можно посредством использования директивы Host в файл Robots.txt.
Зачем нужен файл Robots.txt
Robots – это обычный текстовый файл. Его можно создать через блокнот, однако работать с ним (открывать и редактировать информацию) рекомендуется в текстовом редакторе Notepad++. Необходимость данного файла при оптимизации веб-ресурсов обуславливается несколькими факторами:
- Если файл Robots.txt отсутствует, сайт будет постоянно перегружен из-за работы поисковых машин.
- Существует риск, что индексироваться будут лишние страницы или сайты зеркала.
Индексация будет проходить гораздо медленнее, а при неправильно установленных настройках он вовсе может исчезнуть из результатов поисковой выдачи Google и Яндекс.
Как оформить директиву Host в файле Robots.txt
Файл Robots включает в себя директиву Host – инструкцию для поисковой машины о том, где главный сайт, а где его зеркала.
Директива имеет следующую форму написания: Host: [необязательный пробел] [значение] [необязательный пробел]. Правила написания директивы требуют соблюдения следующих пунктов:
- Наличие в директиве Host протокола HTTPS для поддержки шифрования. Его необходимо использовать, если доступ к зеркалу осуществляется только по защищенному каналу.
- Доменное имя, не являющееся IP-адресом, а также номер порта веб-ресурса.
Корректно составленная директива позволит веб-мастеру обозначить для поисковых машин, где главное зеркало. Остальные будут считаться второстепенными и, следовательно, индексироваться не будут. Как правило, зеркала можно отличить по наличию или отсутствию аббревиатуры www. Если пользователь не укажет главное зеркало веб-ресурса посредством Host, поисковая система Яндекс пришлет соответствующее уведомление в Вебмастер. Также уведомление будет выслано, если в файле Роботс задана противоречивая директива Host.
Определить, где главное зеркало сайта можно через поисковик. Необходимо вбить в поисковую строку адрес ресурса и посмотреть на результаты выдачи: сайт, где перед доменом в адресной строке стоит www, является главным доменом.
В случае, если ресурс не отображается на странице выдачи, пользователь может самостоятельно назначить его главным зеркалом, перейдя в соответствующий раздел в Яндекс.Вебмастере. Если веб-мастеру необходимо, чтобы доменное имя сайта не содержало www, следует не указывать его в Хосте.
Многие веб-мастера используют кириллические домены в качестве дополнительных зеркал для своих сайтов. Однако в директиве Host кириллица не поддерживается. Для этого необходимо дублировать слова на латинице, с условием, что их можно будет легко узнать, скопировав адрес сайта из адресной строки.
Хост в файле Роботс
Главное предназначение данной директивы состоит в решении проблем с дублирующими страницами. Использовать Host необходимо в случае, если работа веб-ресурса ориентирована на русскоязычную аудиторию и, соответственно, сортировка сайта должна проходить в системе Яндекса.
Не все поисковики поддерживают работу директивы Хост. Функция доступна только в Яндексе. При этом даже здесь нет гарантий, что домен будет назначен в качестве главного зеркала, но по заверениям самого Яндекса, приоритет всегда остается за именем, которое указано в хосте.
Чтобы поисковые машины правильно считывали информацию при обработке файла robots.txt, необходимо прописывать директиву Host в соответствующую группу, начинающуюся после слов User-Agent. Однако, роботы смогут использовать Host независимо от того, будет директива прописана по правилам или нет, поскольку она является межсекционной.
Robots.txt – это служебный файл, который служит рекомендацией по ограничению доступа к содержимому веб-документов для поисковых систем. В данной статье мы разберем настройку Robots.txt, описание директив и составление его для популярных CMS.
Находится данный файл Робота в корневом каталоге вашего сайта и открывается/редактируется простым блокнотом, я рекомендую Notepad++. Для тех, кто не любит читать — есть ВИДЕО, смотрите в конце статьи 😉
- В чем его польза
- Директивы и правила написания
- Мета-тег Robots и его директивы
- Правильные роботсы для популярных CMS
- Проверка робота
- Видео-руководство
- Популярные вопросы
Зачем нужен robots.txt
Как я уже говорил выше – с помощью файла robots.txt мы можем ограничить доступ поисковых ботов к документам, т.е. мы напрямую влияем на индексацию сайта. Чаще всего закрывают от индексации:
- Служебные файлы и папки CMS
- Дубликаты
- Документы, которые не несут пользу для пользователя
- Не уникальные страницы
Разберем конкретный пример:
Интернет-магазин по продаже обуви и реализован на одной из популярных CMS, причем не лучшим образом. Я могу сразу сказать, что будут в выдаче страницы поиска, пагинация, корзина, некоторые файлы движка и т.д. Все это будут дубли и служебные файлы, которые бесполезны для пользователя. Следовательно, они должны быть закрыты от индексации, а если еще есть раздел «Новости» в которые копипастятся разные интересные статьи с сайтов конкурентов – то и думать не надо, сразу закрываем.
Поэтому обязательно получаемся файлом robots.txt, чтобы в выдачу не попадал мусор. Не забываем, что файл должен открываться по адресу http://site.ru/robots.txt.
Директивы robots.txt и правила настройки
User-agent. Это обращение к конкретному роботу поисковой системы или ко всем роботам. Если прописывается конкретное название робота, например «YandexMedia», то общие директивы user-agent не используются для него. Пример написания:
User-agent: YandexBot Disallow: /cart # будет использоваться только основным индексирующим роботом Яндекса
Disallow/Allow. Это запрет/разрешение индексации конкретного документа или разделу. Порядок написания не имеет значения, но при 2 директивах и одинаковом префиксе приоритет отдается «Allow». Считывает поисковый робот их по длине префикса, от меньшего к большему. Если вам нужно запретить индексацию страницы — просто введи относительный путь до нее (Disallow: /blog/post-1).
User-agent: Yandex Disallow: / Allow: /articles # Запрещаем индексацию сайта, кроме 1 раздела articles
Регулярные выражения с * и $. Звездочка означает любую последовательность символов (в том числе и пустую). Знак доллара означает прерывание. Примеры использования:
Disallow: /page* # запрещает все страницы, конструкции http://site.ru/page Disallow: /arcticles$ # запрещаем только страницу http://site.ru/articles, разрешая страницы http://site.ru/articles/new
Директива Sitemap. Если вы используете карту сайта (sitemap.xml) – то в robots.txt она должна указываться так:
Sitemap: http://site.ru/sitemap.xml
Директива Host. Как вам известно у сайтов есть зеркала (читаем, Как склеить зеркала сайта). Данное правило указывает поисковому боту на главное зеркало вашего ресурса. Относится к Яндексу. Если у вас зеркало без WWW, то пишем:
Host: site.ru
Crawl-delay. Задает задержу (в секундах) между скачками ботом ваших документов. Прописывается после директив Disallow/Allow.
Crawl-delay: 5 # таймаут в 5 секунд
Clean-param. Указывает поисковому боту, что не нужно скачивать дополнительно дублирующую информацию (идентификаторы сессий, рефереров, пользователей). Прописывать Clean-param следует для динамических страниц:
Clean-param: ref /category/books # указываем, что наша страница основная, а http://site.ru/category/books?ref=yandex.ru&id=1 это та же страница, но с параметрами
Главное правило: robots.txt должен быть написан в нижнем регистре и лежать в корне сайта. Пример структуры файла:
User-agent: Yandex Disallow: /cart Allow: /cart/images Sitemap: http://site.ru/sitemap.xml Host: site.ru Crawl-delay: 2
Мета-тег robots и как он прописывается
Данный вариант запрета страниц лучше учитывается поисковой системой Google. Яндекс одинаково хорошо учитывает оба варианта.
Директив у него 2: follow/nofollow и index/noindex. Это разрешение/запрет перехода по ссылкам и разрешение/запрет на индексацию документа. Директивы можно прописывать вместе, смотрим пример ниже.
Для любой отдельной страницы вы можете прописать в теге <head> </head> следующее:

Правильные файлы robots.txt для популярных CMS
Пример Robots.txt для WordPress
Ниже вы можете увидеть мой вариант с данного Seo блога.
User-agent: Yandex Disallow: /wp-content/uploads/ Allow: /wp-content/uploads/*/*/ Disallow: /wp-login.php Disallow: /wp-register.php Disallow: /xmlrpc.php Disallow: /template.html Disallow: /cgi-bin Disallow: /wp-admin Disallow: /wp-includes Disallow: /wp-content/plugins Disallow: /wp-content/cache Disallow: /wp-content/themes Disallow: /wp-trackback Disallow: /wp-feed Disallow: /wp-comments Disallow: */trackback Disallow: */feed Disallow: */comments Disallow: /tag Disallow: /archive Disallow: */trackback/ Disallow: */feed/ Disallow: */comments/ Disallow: /?feed= Disallow: /?s= Host: romanus.ru User-agent: * Disallow: /wp-content/uploads/ Allow: /wp-content/uploads/*/*/ Disallow: /wp-login.php Disallow: /wp-register.php Disallow: /xmlrpc.php Disallow: /template.html Disallow: /cgi-bin Disallow: /wp-admin Disallow: /wp-includes Disallow: /wp-content/plugins Disallow: /wp-content/cache Disallow: /wp-content/themes Disallow: /wp-trackback Disallow: /wp-feed Disallow: /wp-comments Disallow: */trackback Disallow: */feed Disallow: */comments Disallow: /tag Disallow: /archive Disallow: */trackback/ Disallow: */feed/ Disallow: */comments/ Disallow: /?feed= Disallow: /?s= Sitemap: https://romanus.ru/sitemap.xml
Трэкбэки запрещаю потому что это дублирует кусок статьи в комментах. А если трэкбэков много — вы получите кучу одинаковых комментариев.
Служебные папки и файлы любой CMS я стараюсь я закрываю, т.к. не хочу чтобы они попадали в индекс (хотя поисковики уже и так не берут, но хуже не будет).
Фиды (feed) стоит закрывать, т.к. это частичные либо полные дубли страниц.
Теги закрываем, если мы их не используем или нам лень их оптимизировать.
Примеры для других CMS
Чтобы скачать правильный robots для нужной CMS просто кликните по соответствующей ссылке.
Как проверить корректность работы файла
Анализ robots.txt в Яндекс Вебмастере – тут.

Указываем адрес своего сайта, нажимаем кнопку «Загрузить» (или вписываем его вручную) – бот качает ваш файл. Далее просто указываем нужные нам УРЛы в списке, которые мы хотим проверить и жмем «Проверить».
Смотрим и корректируем, если это нужно.
Популярные вопросы о robots.txt
Как закрыть сайт от индексации?
Как запретить индексацию страницы?
Как запретить индексацию зеркала?
Для магазина стоит закрывать cart (корзину)?
- Да, я бы закрывал.
У меня сайт без CMS, нужен ли мне robots?
- Да, чтобы указать Host и Sitemap. Если у вас есть дубли — то исходя из ситуации закрывайте их.
Понравился пост? Сделай репост и подпишись!

Файл robots.txt — текстовый файл в формате .txt, ограничивающий поисковым роботам доступ к содержимому на http-сервере.
Как определение, Robots.txt — это стандарт исключений для роботов, который был принят консорциумом W3C 30 января 1994 года, и который добровольно использует большинство поисковых систем. Файл robots.txt состоит из набора инструкций для поисковых роботов, которые запрещают индексацию определенных файлов, страниц или каталогов на сайте. Рассмотрим описание robots.txt для случая, когда сайт не ограничивает доступ роботам к сайту.
Простой пример:
User-agent: * Allow: /
Здесь роботс полностью разрешает индексацию всего сайта.
Файл robots.txt необходимо загрузить в корневой каталог вашего сайта, чтобы он был доступен по адресу:
ваш_сайт.ru/robots.txt
Для размещения файла в корне сайта обычно необходим доступ через FTP. Однако, некоторые системы управления (CMS) дают возможность создать robots.txt непосредственно из панели управления сайтом или через встроенный FTP-менеджер.
Если файл доступен, то вы увидите содержимое в браузере.
Для чего нужен robots.txt
Сформированный файл для сайта является важным аспектом поисковой оптимизации. Зачем нужен robots.txt? Например, в SEO robots.txt нужен для того, чтобы исключать из индексации страницы, не содержащие полезного контента и многое другое. Как, что, зачем и почему исключается уже было описано в статье про запрет индексации страниц сайта, здесь не будем на этом останавливаться. Нужен ли файл robots.txt всем сайтам? И да и нет. Если использование подразумевает исключение страниц из поиска, то для небольших сайтов с простой структурой и статичными страницами подобные исключения могут быть лишними. Однако, и для небольшого сайта могут быть полезны некоторые директивы, например директива Host или Sitemap, но об этом ниже.
Как создать robots.txt
Поскольку это текстовый файл, нужно воспользоваться любым текстовым редактором, например Блокнотом. Как только вы открыли новый текстовый документ, вы уже начали создание robots.txt, осталось только составить его содержимое, в зависимости от ваших требований, и сохранить в виде текстового файла с названием robots в формате txt. Все просто, и создание файла не должно вызвать проблем даже у новичков. О том, как составить и что писать в роботсе на примерах покажу ниже.
Cоздать robots.txt онлайн
Вариант для ленивых: скачать в уже в готовом виде. Создание robots txt онлайн предлагает множество сервисов, выбор за вами. Главное — четко понимать, что будет запрещено и что разрешено, иначе создание файла robots.txt online может обернуться трагедией, которую потом может быть сложно исправить. Особенно, если в поиск попадет то, что должно было быть закрытым. Будьте внимательны — проверьте свой файл роботс, прежде чем выгружать его на сайт. Все же пользовательский файл robots.txt точнее отражает структуру ограничений, чем тот, что был сгенерирован автоматически и скачан с другого сайта. Читайте дальше, чтобы знать, на что обратить особое внимание при редактировании robots.txt.
Редактирование robots.txt
После того, как вам удалось создать файл robots.txt онлайн или своими руками, вы можете редактировать robots.txt. Изменить его содержимое можно как угодно, главное — соблюдать некоторые правила и синтаксис robots.txt. В процессе работы над сайтом, файл роботс может меняться, и если вы производите редактирование robots.txt, то не забывайте выгружать на сайте обновленную, актуальную версию файла со всем изменениями. Далее рассмотрим правила настройки файла, чтобы знать, как изменить файл robots.txt и «не нарубить дров».
Правильная настройка robots.txt
Правильная настройка robots.txt позволяет избежать попадания частной информации в результаты поиска крупных поисковых систем. Однако, не стоит забывать, что команды robots.txt не более чем руководство к действию, а не защита. Роботы надежных поисковых систем, вроде Яндекс или Google, следуют инструкциям robots.txt, однако прочие роботы могут легко игнорировать их. Правильное понимание и применение robots.txt — залог получения результата.
Чтобы понять, как сделать правильный robots txt, для начала необходимо разобраться с общими правилами, синтаксисом и директивами файла robots.txt.
Правильный robots.txt начинается с директивы User-agent, которая указывает, к какому роботу обращены конкретные директивы.
Примеры User-agent в robots.txt:
# Указывает директивы для всех роботов одновременно User-agent: * # Указывает директивы для всех роботов Яндекса User-agent: Yandex # Указывает директивы для только основного индексирующего робота Яндекса User-agent: YandexBot # Указывает директивы для всех роботов Google User-agent: Googlebot
Учитывайте, что подобная настройка файла robots.txt указывает роботу использовать только директивы, соответствующие user-agent с его именем.
Пример robots.txt с несколькими вхождениями User-agent:
# Будет использована всеми роботами Яндекса User-agent: Yandex Disallow: /*utm_ # Будет использована всеми роботами Google User-agent: Googlebot Disallow: /*utm_ # Будет использована всеми роботами кроме роботов Яндекса и Google User-agent: * Allow: /*utm_
Директива User-agent создает лишь указание конкретному роботу, а сразу после директивы User-agent должна идти команда или команды с непосредственным указанием условия для выбранного робота. В примере выше используется запрещающая директива «Disallow», которая имеет значение «/*utm_». Таким образом, закрываем все страницы с UTM-метками. Правильная настройка robots.txt запрещает наличие пустых переводов строки между директивами «User-agent», «Disallow» и директивами следующими за «Disallow» в рамках текущего «User-agent».
Пример неправильного перевода строки в robots.txt:
User-agent: Yandex Disallow: /*utm_ Allow: /*id= User-agent: * Disallow: /*utm_ Allow: /*id=
Пример правильного перевода строки в robots.txt:
User-agent: Yandex Disallow: /*utm_ Allow: /*id= User-agent: * Disallow: /*utm_ Allow: /*id=
Как видно из примера, указания в robots.txt поступают блоками, каждый из которых содержит указания либо для конкретного робота, либо для всех роботов «*».
Кроме того, важно соблюдать правильный порядок и сортировку команд в robots.txt при совместном использовании директив, например «Disallow» и «Allow». Директива «Allow» — разрешающая директива, является противоположностью команды robots.txt «Disallow» — запрещающей директивы.
Пример совместного использования директив в robots.txt:
User-agent: * Allow: /blog/page Disallow: /blog
Данный пример запрещает всем роботам индексацию всех страниц, начинающихся с «/blog», но разрешает индексации страниц, начинающиеся с «/blog/page».
Прошлый пример robots.txt в правильной сортировке:
User-agent: * Disallow: /blog Allow: /blog/page
Сначала запрещаем весь раздел, потом разрешаем некоторые его части.
Еще один правильный пример robots.txt с совместными директивами:
User-agent: * Allow: / Disallow: /blog Allow: /blog/page
Обратите внимание на правильную последовательность директив в данном robots.txt.
Директивы «Allow» и «Disallow» можно указывать и без параметров, в этом случае значение будет трактоваться обратно параметру «/».
Пример директивы «Disallow/Allow» без параметров:
User-agent: * Disallow: # равнозначно Allow: / Disallow: /blog Allow: /blog/page
Как составить правильный robots.txt и как пользоваться трактовкой директив — ваш выбор. Оба варианта будут правильными. Главное — не запутайтесь.
Для правильного составления robots.txt необходимо точно указывать в параметрах директив приоритеты и то, что будет запрещено для скачивания роботам. Более полно использование директив «Disallow» и «Allow» мы рассмотрим чуть ниже, а сейчас рассмотрим синтаксис robots.txt. Знание синтаксиса robots.txt приблизит вас к тому, чтобы создать идеальный robots txt своими руками.
Синтаксис robots.txt
Роботы поисковых систем добровольно следуют командам robots.txt — стандарту исключений для роботов, однако не все поисковые системы трактуют синтаксис robots.txt одинаково. Файл robots.txt имеет строго определённый синтаксис, но в то же время написать robots txt не сложно, так как его структура очень проста и легко понятна.
Вот конкретные список простых правил, следуя которым, вы исключите частые ошибки robots.txt:
- Каждая директива начинается с новой строки;
- Не указывайте больше одной директивы в одной строке;
- Не ставьте пробел в начало строки;
- Параметр директивы должен быть в одну строку;
- Не нужно обрамлять параметры директив в кавычки;
- Параметры директив не требуют закрывающих точки с запятой;
- Команда в robots.txt указывается в формате — [Имя_директивы]:[необязательный пробел][значение][необязательный пробел];
- Допускаются комментарии в robots.txt после знака решетки #;
- Пустой перевод строки может трактоваться как окончание директивы User-agent;
- Директива «Disallow: » (с пустым значением) равнозначна «Allow: /» — разрешить все;
- В директивах «Allow», «Disallow» указывается не более одного параметра;
- Название файла robots.txt не допускает наличие заглавных букв, ошибочное написание названия файла — Robots.txt или ROBOTS.TXT;
- Написание названия директив и параметров заглавными буквами считается плохим тоном и если по стандарту, robots.txt и нечувствителен к регистру, часто к нему чувствительны имена файлов и директорий;
- Если параметр директивы является директорией, то перед название директории всегда ставится слеш «/», например: Disallow: /category
- Слишком большие robots.txt (более 32 Кб) считаются полностью разрешающими, равнозначными «Disallow: »;
- Недоступный по каким-либо причинам robots.txt может трактоваться как полностью разрешающий;
- Если robots.txt пустой, то он будет трактоваться как полностью разрешающий;
- В результате перечисления нескольких директив «User-agent» без пустого перевода строки, все последующие директивы «User-agent», кроме первой, могут быть проигнорированы;
- Использование любых символов национальных алфавитов в robots.txt не допускается.
Поскольку разные поисковые системы могут трактовать синтаксис robots.txt по-разному, некоторые пункты можно опустить. Так например, если прописать несколько директив «User-agent» без пустого перевода строки, все директивы «User-agent» будут восприняты корректно Яндексом, так как Яндекс выделяет записи по наличию в строке «User-agent».
В роботсе должно быть указано строго только то, что нужно, и ничего лишнего. Не думайте, как прописать в robots txt все, что только можно и чем его заполнить. Идеальный robots txt — это тот, в котором меньше строк, но больше смысла. «Краткость — сестра таланта». Это выражение здесь как нельзя кстати.
Как проверить robots.txt
Для того, чтобы проверить robots.txt на корректность синтаксиса и структуры файла, можно воспользоваться одной из онлайн-служб. К примеру, Яндекс и Google предлагают собственные сервисы анализа сайта для вебмастеров, которые включают анализ robots.txt:
Проверка файла robots.txt в Яндекс.Вебмастер: http://webmaster.yandex.ru/robots.xml
Проверка файла robots.txt в Google: https://www.google.com/webmasters/tools/siteoverview?hl=ru
Для того, чтобы проверить robots.txt онлайн необходимо загрузить robots.txt на сайт в корневую директорию. Иначе, сервис может сообщить, что не удалось загрузить robots.txt. Рекомендуется предварительно проверить robots.txt на доступность по адресу где лежит файл, например: ваш_сайт.ru/robots.txt.
Кроме сервисов проверки от Яндекс и Google, существует множество других онлайн валидаторов robots.txt.
Robots.txt vs Яндекс и Google
Есть субъективное мнение, что указание отдельного блока директив «User-agent: Yandex» в robots.txt Яндекс воспринимает более позитивно, чем общий блок директив с «User-agent: *». Аналогичная ситуация robots.txt и Google. Указание отдельных директив для Яндекс и Google позволяет управлять индексацией сайта через robots.txt. Возможно, им льстит персонально обращение, тем более, что для большинства сайтов содержимое блоков robots.txt Яндекса, Гугла и для других поисковиков будет одинаково. За редким исключением, все блоки «User-agent» будут иметь стандартный для robots.txt набор директив. Так же, используя разные «User-agent» можно установить запрет индексации в robots.txt для Яндекса, но, например не для Google.
Отдельно стоит отметить, что Яндекс учитывает такую важную директиву, как «Host», и правильный robots.txt для яндекса должен включать данную директиву для указания главного зеркала сайта. Подробнее директиву «Host» рассмотрим ниже.
Запретить индексацию: robots.txt Disallow
Disallow — запрещающая директива, которая чаще всего используется в файле robots.txt. Disallow запрещает индексацию сайта или его части, в зависимости от пути, указанного в параметре директивы Disallow.
Пример как в robots.txt запретить индексацию сайта:
User-agent: * Disallow: /
Данный пример закрывает от индексации весь сайт для всех роботов.
В параметре директивы Disallow допускается использование специальных символов * и $:
* — любое количество любых символов, например, параметру /page* удовлетворяет /page, /page1, /page-be-cool, /page/kak-skazat и т.д. Однако нет необходимости указывать * в конце каждого параметра, так как например, следующие директивы интерпретируются одинаково:
User-agent: Yandex Disallow: /page
User-agent: Yandex Disallow: /page*
$ — указывает на точное соответствие исключения значению параметра:
User-agent: Googlebot Disallow: /page$
В данном случае, директива Disallow будет запрещать /page, но не будет запрещать индексацию страницы /page1, /page-be-cool или /page/kak-skazat.
Если закрыть индексацию сайта robots.txt, в поисковые системы могут отреагировать на так ход ошибкой «Заблокировано в файле robots.txt» или «url restricted by robots.txt» (url запрещенный файлом robots.txt). Если вам нужно запретить индексацию страницы, можно воспользоваться не только robots txt, но и аналогичными html-тегами:
- <meta name=»robots» content=»noindex»/> — не индексировать содержимое страницы;
- <meta name=»robots» content=»nofollow»/> — не переходить по ссылкам на странице;
- <meta name=»robots» content=»none»/> — запрещено индексировать содержимое и переходить по ссылкам на странице;
- <meta name=»robots» content=»noindex, nofollow»/> — аналогично content=»none».
Разрешить индексацию: robots.txt Allow
Allow — разрешающая директива и противоположность директиве Disallow. Эта директива имеет синтаксис, сходный с Disallow.
Пример, как в robots.txt запретить индексацию сайта кроме некоторых страниц:
User-agent: * Disallow: / Allow: /page
Запрещается индексировать весь сайт, кроме страниц, начинающихся с /page.
Disallow и Allow с пустым значением параметра
Пустая директива Disallow:
User-agent: * Disallow:
Не запрещать ничего или разрешить индексацию всего сайта и равнозначна:
User-agent: * Allow: /
Пустая директива Allow:
User-agent: * Allow:
Разрешить ничего или полный запрет индексации сайта, равнозначно:
User-agent: * Disallow: /
Главное зеркало сайта: robots.txt Host
Директива Host служит для указания роботу Яндекса главного зеркала Вашего сайта. Из всех популярных поисковых систем, директива Host распознаётся только роботами Яндекса. Директива Host полезна в том случае, если ваш сайт доступен по нескольким доменам, например:
mysite.ru mysite.com
Или для определения приоритета между:
mysite.ru www.mysite.ru
Роботу Яндекса можно указать, какое зеркало является главным. Директива Host указывается в блоке директивы «User-agent: Yandex» и в качестве параметра, указывается предпочтительный адрес сайта без «http://».
Пример robots.txt с указанием главного зеркала:
User-agent: Yandex Disallow: /page Host: mysite.ru
В качестве главного зеркала указывается доменное имя mysite.ru без www. Таки образом, в результатах поиска буде указан именно такой вид адреса.
User-agent: Yandex Disallow: /page Host: www.mysite.ru
В качестве основного зеркала указывается доменное имя www.mysite.ru.
Директива Host в файле robots.txt может быть использована только один раз, если же директива Хост будет указана более одного раза, учитываться будет только первая, прочие директивы Host будут игнорироваться.
Если вы хотите указать главное зеркало для робота Google, воспользуйтесь сервисом Google Инструменты для вебмастеров.
Карта сайта: robots.txt sitemap
При помощи директивы Sitemap, в robots.txt можно указать расположение на сайте файла карты сайта sitemap.xml.
Пример robots.txt с указанием адреса карты сайта:
User-agent: * Disallow: /page Sitemap: http://www.mysite.ru/sitemap.xml
Указание адреса карты сайта через директиву Sitemap в robots.txt позволяет поисковому роботу узнать о наличии карты сайта и начать ее индексацию.
Директива Clean-param
Директива Clean-param позволяет исключить из индексации страницы с динамическими параметрами. Подобные страницы могут отдавать одинаковое содержимое, имея различные URL страницы. Проще говоря, будто страница доступна по разным адресам. Наша задача убрать все лишние динамические адреса, которых может быть миллион. Для этого исключаем все динамические параметры, используя в robots.txt директиву Clean-param.
Синтаксис директивы Clean-param:
Clean-param: parm1[&parm2&parm3&parm4&..&parmn] [Путь]
Рассмотрим на примере страницы со следующим URL:
www.mysite.ru/page.html?&parm1=1&parm2=2&parm3=3
Пример robots.txt Clean-param:
Clean-param: parm1&parm2&parm3 /page.html # только для page.html
или
Clean-param: parm1&parm2&parm3 / # для всех
Директива Crawl-delay
Данная инструкция позволяет снизить нагрузку на сервер, если роботы слишком часто заходят на ваш сайт. Данная директива актуальна в основном для сайтов с большим объемом страниц.
Пример robots.txt Crawl-delay:
User-agent: Yandex Disallow: /page Crawl-delay: 3
В данном случае мы «просим» роботов яндекса скачивать страницы нашего сайта не чаще, чем один раз в три секунды. Некоторые поисковые системы поддерживают формат дробных чисел в качестве параметра директивы Crawl-delay robots.txt.
Комментарии в robots.txt
Комментарий в robots.txt начинаются с символа решетки — #, действует до конца текущей строки и игнорируются роботами.
Примеры комментариев в robots.txt:
User-agent: * # Комментарий может идти от начала строки Disallow: /page # А может быть продолжением строки с директивой # Роботы # игнорируют # комментарии Host: www.mysite.ru
В заключении
Файл robots.txt — очень важный и нужный инструмент взаимодействия с поисковыми роботами и один из важнейших инструментов SEO, так как позволяет напрямую влиять на индексацию сайта. Используйте роботс правильно и с умом.
Если у вас есть вопросы — пишите в комментариях.
Рекомендуйте статью друзьям и не забывайте подписываться на блог.
Новые интересные статьи каждый день.
Когда ваш сайт выдается в результатах поиска, у него есть определенное доменное имя, на которое ведет ссылка:
Например, здесь это webkyrs.info.
Что делать если поисковая система выбрала это доменное имя не правильно? Например, я хочу, чтобы поисковая система переносила меня не на webkyrs.info, а на www.webkyrs.info или наоборот.
Как этого добиться?
Кроме основной директивы Disallow, которая используется в файле robots.txt, мы можем использовать еще ряд дополнительных директив. Одной из них является директива host.
Именно эта директива может помочь решить проблему.
Основное ее назначение указать основной домен вашего сайта, среди зеркал, который будет для поисковой системы главным.
Практически у всех сайтов есть зеркала, например, мы можем обратиться к сайту:
site.ru
и точно также можно обратиться к нему же по адресу
www.site.ru
Это разные домены, но ведут они на один и тот же сайт. Это и есть те самые зеркала.
Чтобы поисковая система могла определиться, что здесь является главным, и какое доменное имя использовать в результатах поисковой выдачи, в файл robots.txt добавляют директиву host.
Например,
host: site.ru
Обратите внимание, что если ваш сайт работает на протоколе http, здесь его указывать нельзя.
host: http://site.ru – Это не правильная форма записи.
Но, если ваш сайт работает на протоколе https, то указывать его в директиве host обязательно:
host: https://site.ru – Это правильная форма записи.
Как правило, директива host указывается в самом конце файла robots.txt.
User-agent: * Disallow: /cgi-bin Host: www.site.ru
Таким образом, добавив всего одну строку кода в файл robots.txt, мы можем сообщить поисковой системе о главном зеркале сайта.
Еще мои уроки по основам SEO и поисковому продвижению здесь.
Robots.txt — Как создать правильный robots.txt
Файл robots.txt является одним из самых важных при оптимизации любого сайта. Его отсутствие может привести к высокой нагрузке на сайт со стороны поисковых роботов и медленной индексации и переиндексации, а неправильная настройка к тому, что сайт полностью пропадет из поиска или просто не будет проиндексирован. Следовательно, не будет искаться в Яндексе, Google и других поисковых системах. Давайте разберемся во всех нюансах правильной настройки robots.txt.
Для начала короткое видео, которое создаст общее представление о том, что такое файл robots.txt.
Как влияет robots.txt на индексацию сайта
Поисковые роботы будут индексировать ваш сайт независимо от наличия файла robots.txt. Если же такой файл существует, то роботы могут руководствоваться правилами, которые в этом файле прописываются. При этом некоторые роботы могут игнорировать те или иные правила, либо некоторые правила могут быть специфичными только для некоторых ботов. В частности, GoogleBot не использует директиву Host и Crawl-Delay, YandexNews с недавних пор стал игнорировать директиву Crawl-Delay, а YandexDirect и YandexVideoParser игнорируют более общие директивы в роботсе (но руководствуются теми, которые указаны специально для них).
Подробнее об исключениях:
Исключения Яндекса
Стандарт исключений для роботов (Википедия)
Максимальную нагрузку на сайт создают роботы, которые скачивают контент с вашего сайта. Следовательно, указывая, что именно индексировать, а что игнорировать, а также с какими временны́ми промежутками производить скачивание, вы можете, с одной стороны, значительно снизить нагрузку на сайт со стороны роботов, а с другой стороны, ускорить процесс скачивания, запретив обход ненужных страниц.

К таким ненужным страницам относятся скрипты ajax, json, отвечающие за всплывающие формы, баннеры, вывод каптчи и т.д., формы заказа и корзина со всеми шагами оформления покупки, функционал поиска, личный кабинет, админка.
Для большинства роботов также желательно отключить индексацию всех JS и CSS. Но для GoogleBot и Yandex такие файлы нужно оставить для индексирования, так как они используются поисковыми системами для анализа удобства сайта и его ранжирования (пруф Google, пруф Яндекс).
Директивы robots.txt
Директивы — это правила для роботов. Есть спецификация W3C от 30 января 1994 года и расширенный стандарт от 1996 года. Однако не все поисковые системы и роботы поддерживают те или иные директивы. В связи с этим для нас полезнее будет знать не стандарт, а то, как руководствуются теми или иными директивы основные роботы.
Давайте рассмотрим по порядку.
User-agent
Это самая главная директива, определяющая для каких роботов далее следуют правила.
Для всех роботов:User-agent: *
Для конкретного бота:User-agent: GoogleBot
Обратите внимание, что в robots.txt не важен регистр символов. Т.е. юзер-агент для гугла можно с таким же успехом записать соледующим образом:user-agent: googlebot
Ниже приведена таблица основных юзер-агентов различных поисковых систем.
| Бот | Функция |
|---|---|
| Googlebot | основной индексирующий робот Google |
| Googlebot-News | Google Новости |
| Googlebot-Image | Google Картинки |
| Googlebot-Video | видео |
| Mediapartners-Google | Google AdSense, Google Mobile AdSense |
| Mediapartners | Google AdSense, Google Mobile AdSense |
| AdsBot-Google | проверка качества целевой страницы |
| AdsBot-Google-Mobile-Apps | Робот Google для приложений |
| Яндекс | |
| YandexBot | основной индексирующий робот Яндекса |
| YandexImages | Яндекс.Картинки |
| YandexVideo | Яндекс.Видео |
| YandexMedia | мультимедийные данные |
| YandexBlogs | робот поиска по блогам |
| YandexAddurl | робот, обращающийся к странице при добавлении ее через форму «Добавить URL» |
| YandexFavicons | робот, индексирующий пиктограммы сайтов (favicons) |
| YandexDirect | Яндекс.Директ |
| YandexMetrika | Яндекс.Метрика |
| YandexCatalog | Яндекс.Каталог |
| YandexNews | Яндекс.Новости |
| YandexImageResizer | робот мобильных сервисов |
| Bing | |
| Bingbot | основной индексирующий робот Bing |
| Yahoo! | |
| Slurp | основной индексирующий робот Yahoo! |
| Mail.Ru | |
| Mail.Ru | основной индексирующий робот Mail.Ru |
| Rambler | |
| StackRambler | Ранее основной индексирующий робот Rambler. Однако с 23.06.11 Rambler перестает поддерживать собственную поисковую систему и теперь использует на своих сервисах технологию Яндекса. Более не актуально. |
Disallow и Allow
Disallow закрывает от индексирования страницы и разделы сайта.
Allow принудительно открывает для индексирования страницы и разделы сайта.
Но здесь не все так просто.
Во-первых, нужно знать дополнительные операторы и понимать, как они используются — это *, $ и #.
* — это любое количество символов, в том числе и их отсутствие. При этом в конце строки звездочку можно не ставить, подразумевается, что она там находится по умолчанию.
$ — показывает, что символ перед ним должен быть последним.
# — комментарий, все что после этого символа в строке роботом не учитывается.
Примеры использования:
Disallow: *?s=
Disallow: /category/$
Следующие ссылки будут закрыты от индексации:
http://site.ru/?s=
http://site.ru/?s=keyword
http://site.ru/page/?s=keyword
http://site.ru/category/
Следующие ссылки будут открыты для индексации:
http://site.ru/category/cat1/
http://site.ru/category-folder/
Во-вторых, нужно понимать, каким образом выполняются вложенные правила.
Помните, что порядок записи директив не важен. Наследование правил, что открыть или закрыть от индексации определяется по тому, какие директории указаны. Разберем на примере.
Allow: *.css
Disallow: /template/
http://site.ru/template/ — закрыто от индексирования
http://site.ru/template/style.css — закрыто от индексирования
http://site.ru/style.css — открыто для индексирования
http://site.ru/theme/style.css — открыто для индексирования
Если нужно, чтобы все файлы .css были открыты для индексирования придется это дополнительно прописать для каждой из закрытых папок. В нашем случае:
Allow: *.css
Allow: /template/*.css
Disallow: /template/
Повторюсь, порядок директив не важен.
Sitemap
Директива для указания пути к XML-файлу Sitemap. URL-адрес прописывается так же, как в адресной строке.
Например,
Sitemap: http://site.ru/sitemap.xml
Директива Sitemap указывается в любом месте файла robots.txt без привязки к конкретному user-agent. Можно указать несколько правил Sitemap.
Host
Директива для указания главного зеркала сайта (в большинстве случаев: с www или без www). Обратите внимание, что главное зеркало указывается БЕЗ http://, но С https://. Также если необходимо, то указывается порт.
Директива поддерживается только ботами Яндекса и Mail.Ru. Другими роботами, в частности GoogleBot, команда не будет учтена. Host прописывается только один раз!
Пример 1:Host: site.ru
Пример 2:Host: https://site.ru
Crawl-delay
Директива для установления интервала времени между скачиванием роботом страниц сайта. Поддерживается роботами Яндекса, Mail.Ru, Bing, Yahoo. Значение может устанавливаться в целых или дробных единицах (разделитель — точка), время в секундах.
Пример 1:Crawl-delay: 3
Пример 2:Crawl-delay: 0.5
Если сайт имеет небольшую нагрузку, то необходимости устанавливать такое правило нет. Однако если индексация страниц роботом приводит к тому, что сайт превышает лимиты или испытывает значительные нагрузки вплоть до перебоев работы сервера, то эта директива поможет снизить нагрузку.
Чем больше значение, тем меньше страниц робот загрузит за одну сессию. Оптимальное значение определяется индивидуально для каждого сайта. Лучше начинать с не очень больших значений — 0.1, 0.2, 0.5 — и постепенно их увеличивать. Для роботов поисковых систем, имеющих меньшее значение для результатов продвижения, таких как Mail.Ru, Bing и Yahoo можно изначально установить бо́льшие значения, чем для роботов Яндекса.
Clean-param
Это правило сообщает краулеру, что URL-адреса с указанными параметрами не нужно индексировать. Для правила указывается два аргумента: параметр и URL раздела. Директива поддерживается Яндексом.
Пример 1:
Clean-param: author_id http://site.ru/articles/
http://site.ru/articles/?author_id=267539 — индексироваться не будет
Пример 2:
Clean-param: author_id&sid http://site.ru/articles/
http://site.ru/articles/?author_id=267539&sid=0995823627 — индексироваться не будет
Яндекс также рекомендует использовать эту директиву для того, чтобы не учитывались UTM-метки и идентификаторы сессий. Пример:
Clean-Param: utm_source&utm_medium&utm_campaign
Другие параметры
В расширенной спецификации robots.txt можно найти еще параметры Request-rate и Visit-time. Однако они на данный момент не поддерживаются ведущими поисковыми системами.
Смысл директив:
Request-rate: 1/5 — загружать не более одной страницы за пять секунд
Visit-time: 0600-0845 — загружать страницы только в промежуток с 6 утра до 8:45 по Гринвичу.
Закрывающий robots.txt
Если вам нужно настроить, чтобы ваш сайт НЕ индексировался поисковыми роботами, то вам нужно прописать следующие директивы:
User-agent: *
Disallow: /
Проверьте, чтобы на тестовых площадках вашего сайта были прописаны эти директивы.
Правильная настройка robots.txt
 Для России и стран СНГ, где доля Яндекса ощутима, следует прописывать директивы для всех роботов и отдельно для Яндекса и Google.
Для России и стран СНГ, где доля Яндекса ощутима, следует прописывать директивы для всех роботов и отдельно для Яндекса и Google.
Чтобы правильно настроить robots.txt воспользуйтесь следующим алгоритмом:
- Закройте от индексирования админку сайта
- Закройте от индексирования личный кабинет, авторизацию, регистрацию
- Закройте от индексирования корзину, формы заказа, данные по доставке и заказам
- Закройте от индексирования ajax, json-скрипты
- Закройте от индексирования папку cgi
- Закройте от индексирования плагины, темы оформления, js, css для всех роботов, кроме Яндекса и Google
- Закройте от индексирования функционал поиска
- Закройте от индексирования служебные разделы, которые не несут никакой ценности для сайта в поиске (ошибка 404, список авторов)
- Закройте от индексирования технические дубли страниц, а также страницы, на которых весь контент в том или ином виде продублирован с других страниц (календари, архивы, RSS)
- Закройте от индексирования страницы с параметрами фильтров, сортировки, сравнения
- Закройте от индексирования страницы с параметрами UTM-меток и сессий
- Проверьте, что проиндексировано Яндексом и Google с помощью параметра «site:» (в поисковой строке наберите «site:site.ru»). Если в поиске присутствуют страницы, которые также нужно закрыть от индексации, добавьте их в robots.txt
- Укажите Sitemap и Host
- По необходимости пропишите Crawl-Delay и Clean-Param
- Проверьте корректность robots.txt через инструменты Google и Яндекса (описано ниже)
- Через 2 недели перепроверьте, появились ли в поисковой выдаче новые страницы, которые не должны индексироваться. В случае необходимости повторить выше перечисленные шаги.
Пример robots.txt
# Пример файла robots.txt для настройки гипотетического сайта https://site.ru User-agent: * Disallow: /admin/ Disallow: /plugins/ Disallow: /search/ Disallow: /cart/ Disallow: */?s= Disallow: *sort= Disallow: *view= Disallow: *utm= Crawl-Delay: 5 User-agent: GoogleBot Disallow: /admin/ Disallow: /plugins/ Disallow: /search/ Disallow: /cart/ Disallow: */?s= Disallow: *sort= Disallow: *view= Disallow: *utm= Allow: /plugins/*.css Allow: /plugins/*.js Allow: /plugins/*.png Allow: /plugins/*.jpg Allow: /plugins/*.gif User-agent: Yandex Disallow: /admin/ Disallow: /plugins/ Disallow: /search/ Disallow: /cart/ Disallow: */?s= Disallow: *sort= Disallow: *view= Allow: /plugins/*.css Allow: /plugins/*.js Allow: /plugins/*.png Allow: /plugins/*.jpg Allow: /plugins/*.gif Clean-Param: utm_source&utm_medium&utm_campaign Crawl-Delay: 0.5 Sitemap: https://site.ru/sitemap.xml Host: https://site.ru
Как добавить и где находится robots.txt
После того как вы создали файл robots.txt, его необходимо разместить на вашем сайте по адресу site.ru/robots.txt — т.е. в корневом каталоге. Поисковый робот всегда обращается к файлу по URL /robots.txt
Как проверить robots.txt
Проверка robots.txt осуществляется по следующим ссылкам:
Типичные ошибки в robots.txt
 В конце статьи приведу несколько типичных ошибок файла robots.txt
В конце статьи приведу несколько типичных ошибок файла robots.txt
- robots.txt отсутствует
- в robots.txt сайт закрыт от индексирования (Disallow: /)
- в файле присутствуют лишь самые основные директивы, нет детальной проработки файла
- в файле не закрыты от индексирования страницы с UTM-метками и идентификаторами сессий
- в файле указаны только директивы
Allow: *.css
Allow: *.js
Allow: *.png
Allow: *.jpg
Allow: *.gif
при этом файлы css, js, png, jpg, gif закрыты другими директивами в ряде директорий - директива Host прописана несколько раз
- в Host не указан протокол https
- путь к Sitemap указан неверно, либо указан неверный протокол или зеркало сайта
P.S.
Если у вас есть дополнения к статье или вопросы, пишите ниже в комментариях.
Если у вас сайт на CMS WordPress, вам будет полезна статья «Как настроить правильный robots.txt для WordPress».
P.S.2
Полезное видео от Яндекса (Внимание! Некоторые рекомендации подходят только для Яндекса).
Файл robots.txt объяснил и проиллюстрировал
«Используйте файл robots.txt на вашем веб-сервере.
— из руководства Google для веб-мастеров 1
Что такое файл robots.txt?
- Файл robots.txt — это простой текстовый файл, размещаемый на вашем веб-сервере, который сообщает веб-сканерам, таким как Googlebot, следует ли им обращаться к файлу или нет.
Основные примеры robots.txt
Вот некоторые распространенные роботы.Настройки TXT (они будут объяснены подробно ниже).
Блок одной папки
User-agent: *
Disallow: / folder /
Блок один файл
User-agent: *
Disallow: /file.html
Почему вы должны узнать о robots.txt?
- Неправильное использование файла robots.txt может повредить ваш рейтинг
- Файл robots.txt контролирует, как пауки поисковых систем видят и взаимодействуют с вашими веб-страницами
- Этот файл упоминается в нескольких руководствах Google
- Этот файл и боты, с которыми они взаимодействуют, являются фундаментальной частью работы поисковых систем.
Подсказка: посмотреть, работают ли ваши роботы.TXT блокирует любые важные файлы, используемые Google, используйте инструмент рекомендаций Google.
Поисковая система пауков
Первое, на что паук поисковой системы, такой как Googlebot, смотрит при посещении страницы, это файл robots.txt.
Это происходит потому, что он хочет знать, есть ли у него разрешение на доступ к этой странице или файлу. Если в файле robots.txt указано, что он может войти, паук поисковой системы затем перейдет к файлам подкачки.
Если у вас есть инструкции для робота поисковой системы, вы должны сообщить ему эти инструкции.То, как вы это делаете, — это файл robots.txt. 2
Приоритеты для вашего сайта
Есть три важных вещи, которые должен сделать любой веб-мастер, когда дело доходит до файла robots.txt.
- Определите, есть ли у вас файл robots.txt
- Если у вас есть, убедитесь, что это не вредит вашему рейтингу или блокирует контент, который вы не хотите заблокировать
- Определите, нужен ли вам файл robots.txt
Определение наличия роботов.TXT
Вы можете войти на веб-сайт ниже, нажать кнопку «Перейти», и он обнаружит, есть ли на сайте файл robots.txt, и отобразит то, что в файле написано (он показывает результаты здесь на этой странице) .
Если вы не хотите использовать вышеуказанный инструмент, вы можете проверить это в любом браузере. Файл robots.txt всегда находится в одном и том же месте на любом веб-сайте, поэтому легко определить, есть ли у него такой сайт. Просто добавьте «/robots.txt» в конец имени домена, как показано ниже.
www.yourwebsite.com/robots.TXT
Если у вас есть файл, это ваш файл robots.txt. Вы либо найдете файл со словами в нем, либо найдете файл без слов, либо не найдете файл вообще.
Определите, блокирует ли ваш robots.txt важные файлы
Вы можете использовать инструмент рекомендаций Google, который предупредит вас, если вы блокируете определенные ресурсы страницы, которые необходимы Google для понимания ваших страниц.
Если у вас есть доступ и разрешение, вы можете использовать консоль поиска Google для проверки своих роботов.текстовый файл. Инструкции для этого можно найти здесь (инструмент не публичный — требуется логин) .
Чтобы полностью понять, что ваш файл robots.txt не блокирует ничего, что вы не хотите, чтобы он блокировал, вам нужно понять, что он говорит. Мы рассмотрим это ниже.
Вам нужен файл robots.txt?
Возможно, вам даже не нужен файл robots.txt на вашем сайте. На самом деле это часто бывает вам не нужно.
Причины, по которым вы хотите иметь роботов.текстовый файл:
- У вас есть контент, который вы хотите заблокировать в поисковых системах
- Вы используете платные ссылки или рекламные объявления, которые требуют специальных инструкций для роботов
- Вы хотите точно настроить доступ к вашему сайту от авторитетных роботов
- Вы разрабатываете живой сайт, но пока не хотите, чтобы поисковые системы его проиндексировали.
- Они помогают вам следовать некоторым рекомендациям Google в некоторых ситуациях.
- Вам необходимо выполнить некоторые или все вышеперечисленные действия, но у вас нет полного доступа к вашему веб-серверу и способам его настройки.
Каждая из вышеперечисленных ситуаций может контролироваться другими методами, кроме роботов.TXT-файл является хорошим центральным местом, чтобы заботиться о них, и большинство веб-мастеров имеют возможность и доступ, необходимые для создания и использования файла robots.txt.
Причины, по которым вы можете , а не , хотеть иметь файл robots.txt:
- Это просто и без ошибок
- У вас нет файлов, которые вы хотите или должны быть заблокированы поисковыми системами
- Вы не окажетесь ни в одной из ситуаций, перечисленных в приведенных выше причинах, чтобы иметь файл robots.txt
Можно не иметь роботов.текстовый файл.
Если у вас нет файла robots.txt, роботы поисковых систем, такие как Googlebot, будут иметь полный доступ к вашему сайту. Это нормальный и простой метод, который очень распространен.
Как сделать файл robots.txt
Если вы можете печатать или копировать и вставлять, вы также можете создать файл robots.txt.
Файл — это просто текстовый файл, что означает, что вы можете использовать блокнот или любой другой текстовый редактор для его создания. Вы также можете сделать их в редакторе кода. Вы даже можете скопировать и вставить их.
Вместо того, чтобы думать «я создаю файл robots.txt», просто подумайте: «Я пишу заметку», — это практически один и тот же процесс.
Что должен сказать robots.txt?
Это зависит от того, что вы хотите сделать.
Все инструкции robots.txt приводят к одному из следующих трех результатов
- Полное разрешение: весь контент может быть просканирован.
- Полный запрет: контент не может быть сканирован.
- Условное разрешение: директивы в роботах.TXT определяет способность сканировать определенный контент.
Давайте объясним каждый.
Полное разрешение — весь контент может быть просканирован
Большинство людей хотят, чтобы роботы посещали все на своем сайте. Если это так с вами, и вы хотите, чтобы робот индексировал Во всех частях вашего сайта есть три варианта, чтобы роботы знали, что они приветствуются.
1) Нет файла robots.txt
Если на вашем сайте нет роботов.TXT-файл, то это то, что происходит …
Робот, как Googlebot приходит в гости. Он ищет файл robots.txt. Он не находит его, потому что его там нет. Робот тогда чувствует свободно посещать все ваши веб-страницы и контент, потому что это то, что он запрограммирован делать в этой ситуации.
2) Создайте пустой файл и назовите его robots.txt
Если на вашем сайте есть файл robots.txt, в котором ничего нет, то это то, что происходит …
Робот, как Googlebot приходит в гости.Он ищет файл robots.txt. Он находит файл и читает его. Там нечего читать, поэтому Затем робот может свободно посещать все ваши веб-страницы и контент, потому что это то, для чего он запрограммирован в этой ситуации.
3) Создайте файл с именем robots.txt и напишите в нем следующие две строки …
Если на вашем сайте есть файл robots.txt с этими инструкциями, то вот что происходит …
Робот, как Googlebot приходит в гости. Это выглядит для роботов.текстовый файл. Он находит файл и читает его. Это читает первую строку. Затем это читает вторую строку. Затем робот может свободно посещать все ваши веб-страницы и контент, потому что именно это вы и сказали (я объясню ниже).
Полное запрещение — нельзя сканировать содержимое
Предупреждение. Это означает, что Google и другие поисковые системы не будут индексировать или отображать ваши веб-страницы.
Чтобы заблокировать всех известных пауков поисковых систем с вашего сайта, вы должны иметь эти инструкции в своих роботах.TXT:
Не рекомендуется делать это, так как это не приведет к индексации ни одной из ваших веб-страниц.
Инструкция robot.txt и их значение
Вот объяснение того, что означают разные слова в файле robots.txt
User-agent
Часть «Пользователь-агент» предназначена для указания направлений для конкретного робота, если это необходимо. Есть два способа использовать это в твой файл
Если вы хотите сказать всем роботам одно и то же, вы должны поставить «*» после «User-agent». Это будет выглядеть так…
В приведенной выше строке написано «эти указания относятся ко всем роботам».
Если вы хотите что-то сказать конкретному роботу (в этом примере Googlebot), это будет выглядеть так …
В приведенной выше строке написано «эти указания относятся только к Googlebot».
Запретить:
Часть «Disallow» предназначена для того, чтобы сообщить роботам, на какие папки они не должны смотреть. Это означает, что, например, если вы не хотите, чтобы поисковые системы индексировали фотографии на вашем сайте, вы можете поместить эти фотографии в одну папку и исключить ее.
Допустим, вы поместили все эти фотографии в папку с именем «photos». Теперь вы хотите сказать поисковым системам не индексировать эта папка.
Вот как должен выглядеть ваш файл robots.txt в этом сценарии:
User-agent: *
Disallow: / photos
Приведенные выше две строки текста в файле robots.txt не позволят роботам посещать папку с фотографиями. «Пользователь-агент *» Часть говорит: «Это относится ко всем роботам». Часть «Disallow: / photos» гласит: «Не посещайте и не индексируйте папку с моими фотографиями».
Googlebot конкретные инструкции
Робот, который Google использует для индексации своей поисковой системы, называется Googlebot. Он понимает несколько больше инструкций, чем другие роботы.
В дополнение к «User-name» и «Disallow» робот Googlebot также использует инструкцию «Разрешить».
Разрешить
Инструкции «Разрешить:» позволяют сообщать роботу, что можно просматривать файл в папке, которая была «запрещена» по другим инструкциям. Чтобы проиллюстрировать это, давайте возьмем приведенный выше пример того, как роботу не нужно посещать или индексировать ваши фотографии.Мы поместили все фотографии в одну папку с именем «photos» и создали файл robots.txt, который выглядел следующим образом …
User-agent: *
Disallow: / photos
Теперь предположим, что в этой папке была фотография mycar.jpg, которую вы хотите проиндексировать роботом Google. С разрешением: инструкция, мы можем сказать Googlebot сделать это, это будет выглядеть так …
Пользователь-агент: *
Запретить: / photos
Разрешить: /photos/mycar.jpg
Это скажет роботу Google, что он может посетить «mycar.jpg «в папке с фотографиями, хотя папка» фото «в противном случае не входит.
Тестирование файла robots.txt
Чтобы узнать, заблокирована ли отдельная страница файлом robots.txt, вы можете использовать этот технический инструмент SEO, который сообщит вам, блокируются ли важные для Google файлы, а также отобразить содержимое файла robots.txt.
Ключевые понятия
- Если вы используете файл robots.txt, убедитесь, что он используется правильно
- Неправильные роботы.TXT-файл может заблокировать робот Googlebot от индексации вашей страницы
- Убедитесь, что вы не блокируете страницы, которые нужны Google для ранжирования ваших страниц
 Патрик Секстон
Патрик Секстон
.
Your Robots.txt Руководство по началу работы
- WooRank
- SEO Руководства
- Роботы и Вы: Руководство к Robots.txt
А роботы.TXT-файл — это простой текстовый файл, который указывает, должен ли сканер иметь или не должен обращаться к определенным папкам, подпапкам или страницам вместе с другой информацией о вашем сайте. В файле используется стандарт исключения роботов, протокол, установленный в 1994 году для веб-сайтов для связи со сканерами и другими ботами. Абсолютно необходимо использовать простой текстовый файл: создание файла robots.txt с использованием HTML или текстового процессора будет включать код, который сканеры поисковых систем будут игнорировать, если они не могут прочитать.
Как это работает?
Сканеры— это инструменты, которые анализируют ваши веб-страницы и могут быть использованы для выявления проблем. WooRank’s Site Crawl делает это, чтобы помочь веб-мастерам находить и исправлять ошибки сканирования.
Когда владелец сайта хочет дать некоторые рекомендации сканерам, они помещают свой файл robots.txt в корневой каталог своего сайта, например, https://www.example.com/robots.txt. Боты, которые следуют этому протоколу, будут извлекать и читать файл, прежде чем загружать любой другой файл с сайта.Если на сайте нет файла robots.txt, сканер предположит, что веб-мастер не хочет давать какие-либо конкретные инструкции, и продолжит сканирование всего сайта.
Robots.txt состоит из двух основных частей: User-agent и директив.
User-Agent
User-agent — это имя адресуемого паука, в то время как директивные строки содержат инструкции для этого конкретного user-agent. Строка User-agent всегда идет перед строками директив в каждом наборе директив.Очень простой robots.txt выглядит так:
Пользователь-агент: Googlebot
Disallow: /
Эти директивы предписывают пользовательскому агенту Googlebot, веб-сканеру Google, держаться подальше от всего сервера — он не будет сканировать ни одну страницу на сайте. Если вы хотите дать инструкции нескольким роботам, создайте набор пользовательских агентов и запретите директивы для каждого из них.
Пользователь-агент: Googlebot
Disallow: /
Пользователь-агент: Bingbot
Disallow: /
Теперь и пользовательские агенты Google, и Bing знают, как обходить весь сайт.Если вы хотите установить одинаковое требование для всех роботов, вы можете использовать так называемый подстановочный знак, обозначенный звездочкой (*). Поэтому, если вы хотите разрешить всем роботам сканировать весь ваш сайт, ваш файл robots.txt должен выглядеть следующим образом:
Пользователь-агент: *
Disallow:
Стоит отметить, что поисковые системы будут выбирать наиболее конкретные директивы агента пользователя, которые они смогут найти. Например, скажем, у вас есть четыре набора пользовательских агентов: один с использованием подстановочного знака (*), один для Googlebot, один для Googlebot-News и один для Bingbot, а ваш сайт посещает пользователь Googlebot-Images- агент.Этот бот будет следовать инструкциям для Googlebot, так как это самый специфический набор директив, применимых к нему.
Наиболее распространенными пользовательскими агентами поисковой системы являются:
| User-Agent | Поисковая система | Поле |
| Baiduspider | Baidu | Генерал |
| baiduspider-image | Baidu | изображений |
| baiduspider-mobile | Baidu | Мобильный |
| baiduspider-news | Baidu | Новости |
| baiduspider-video | Baidu | Видео |
| Bingbot | Bing | Генерал |
| MSNBOT | Bing | Генерал |
| msnbot-media | Bing | изображений и видео |
| adidxbot | Bing | объявлений |
| Googlebot | Генерал | |
| Googlebot-Image | изображений | |
| Googlebot-Mobile | Мобильный | |
| Googlebot-News | Новости | |
| Googlebot-Video | Видео | |
| Mediapartners-Google | AdSense | |
| AdsBot-Google | AdWords | |
| глоток | Yahoo! | Генерал |
| яндекс | Яндекс | Генерал |
Запретить
Вторая часть роботов.TXT — запретная линия. Эта директива сообщает паукам, какие страницы им запрещено сканировать. В каждом наборе директив может быть несколько запрещенных строк, но только один пользовательский агент.
Вам не нужно указывать какое-либо значение для директивы disallow; Боты будут интерпретировать пустое значение disallow, чтобы означать, что вы ничего не запрещаете, и получите доступ ко всему сайту. Как мы упоминали ранее, если вы хотите запретить доступ ко всему сайту боту (или всем ботам), используйте косую черту (/).
Вы можете получить детализацию с директивами disallow, указав конкретные страницы, каталоги, подкаталоги и типы файлов.Чтобы заблокировать сканеры с определенной страницы, используйте относительную ссылку этой страницы в строке запрета:
Пользователь-агент: *
Disallow: /directory/page.html
Блокировать доступ ко всем каталогам таким же образом:
Пользователь-агент: *
Disallow: / folder1 /
Disallow: / folder2 /
Вы также можете использовать robots.txt, чтобы запретить роботам сканировать определенные типы файлов, используя подстановочный знак и тип файла в строке запрета:
Пользователь-агент: *
Disallow: / *.п.п.
Disallow: /images/*.jpg
Disallow: /duplicatecontent/copy*.html
Хотя протокол robots.txt технически не поддерживает использование подстановочных знаков, роботы поисковых систем могут распознавать и интерпретировать их. Таким образом, в приведенных выше директивах робот автоматически расширяет звездочку в соответствии с путем к имени файла. Например, он мог бы выяснить, что www.example.com/presentations/slideshow.ppt и www.example.com/images/example.jpg запрещены, пока www.example.com / Presentations / slideshowtranscript.html не является. Третий запрещает сканирование любого файла в каталоге / duplicatecontent /, который начинается с «copy» и заканчивается на «.html». Так что эти страницы заблокированы:
- /duplicatecontent/copy.html
- /duplicatecontent/copy1.html
- /duplicatecontent/copy2.html
- /duplicatecontent/copy.html?id=1234
Тем не менее, он не будет запрещать любые экземпляры «copy.html», хранящиеся в другом каталоге или подкаталоге.
Одна проблема, с которой вы можете столкнуться с файлом robots.txt, заключается в том, что некоторые URL-адреса содержат исключенные шаблоны в URL-адресах, которые мы на самом деле хотим сканировать. Из нашего более раннего примера Disallow: /images/*.jpg этот каталог может содержать файл с именем «description-of-.jpg.html». Эта страница не будет сканироваться, поскольку она соответствует шаблону исключения. Чтобы решить эту проблему, добавьте символ доллара ($), чтобы обозначить, что он представляет конец строки. Это скажет сканерам поисковых систем избегать только тех файлов, которые заканчиваются шаблоном исключения.Поэтому Disallow: /images/*.jpg$ блокирует только файлы, заканчивающиеся на «.jpg», в то же время разрешая файлы, которые содержат «.jpg» в заголовке.
Разрешить
Иногда вам может потребоваться исключить каждый файл в каталоге, кроме одного. Вы можете сделать это трудным способом, написав запрещающую строку для каждого файла, кроме того, который вы хотите сканировать. Или вы можете использовать директиву Allow. Он работает почти так же, как и следовало ожидать: добавьте строку «Разрешить» в группу директив для пользовательского агента:
Пользователь-агент: *
Разрешить: / папка / подпапка / файл.HTML
Disallow: / папка / подпапка /
Подстановочные знаки и правила сопоставления с образцом работают для директивы Allow так же, как и для Disallow.
Нестандартные директивы
Есть несколько других директив, которые вы можете использовать в файле robots.txt, которые не являются общепризнанными поисковыми системами. Одним из них является директива Host. Это признано Яндексом, самой популярной поисковой системой в России, и работает как решение www. Однако, как кажется, Яндекс является единственной крупной поисковой системой, которая поддерживает директиву Host, мы не рекомендуем использовать ее.Лучший способ справиться с разрешением www — это использовать 301 редирект.
Еще одна директива, поддерживаемая некоторыми поисковыми системами, — это задержка сканирования. Он задает числовое значение, которое представляет количество секунд — линия задержки сканирования должна выглядеть как задержка сканирования: 15 . Он используется по-разному в Yahoo !, Bing и Yandex. Yahoo! и Bing использует это значение как время ожидания между действиями по сканированию, в то время как Яндекс будет использовать его как время ожидания для доступа к вашему сайту. Если у вас есть большой сайт, вы, вероятно, не хотите использовать эту директиву, поскольку она может серьезно ограничить число просматриваемых страниц.Однако, если вы не получаете почти никакого трафика от этих поисковых систем, вы можете использовать crawl-delay для экономии пропускной способности.
Вы также можете установить задержку сканирования для определенных пользовательских агентов. Например, вы можете обнаружить, что ваш сайт часто сканируется с помощью инструментов SEO, которые могут замедлить ваш сайт. Вы также можете заблокировать их все вместе, если не чувствуете, что они вам помогают.
Наконец, вы можете использовать свой файл robots.txt, чтобы сообщить поисковым системам, где найти вашу карту сайта, добавив строку Sitemap: в любом месте файла.Эта директива не зависит от пользовательского агента, поэтому боты смогут интерпретировать ее, куда бы вы ее ни поместили, но лучше поставить ее в конце, чтобы облегчить себе задачу. Создайте новую строку Sitemap для каждого имеющегося у вас файла Sitemap, включая ваши файлы изображений и видео, а также индексный файл Sitemap. Если вы предпочитаете, чтобы местоположение вашей карты сайта было недоступно для всех, вы можете предпочесть не указывать это и вместо этого отправлять карты сайта в поисковые системы напрямую.
Подробнее о том, как создать и оптимизировать карту сайта XML, можно узнать здесь.
Зачем вам нужен?
Если поиск, индексирование и ранжирование вашего сайта в результатах поисковой системы — это весь смысл SEO, зачем вам вообще исключать файлы на своем сайте? Есть несколько причин, по которым вы хотите заблокировать доступ ботов к разделам вашего сайта:
У вас есть личные папки, подпапки или файлы на вашем сайте — просто помните, что любой может прочитать ваш файл robots.txt, поэтому выделение местоположения частного файла с помощью директивы disallow откроет его для всего мира.
Блокируя менее важные страницы на вашем сайте, вы определяете приоритет бюджета сканирования ботов. Это означает, что они будут тратить больше времени на сканирование и индексацию ваших самых важных страниц.
Если вы получаете много трафика от других сканеров, которые не являются поисковыми системами (например, инструменты SEO), сэкономьте пропускную способность, запретив их пользовательским агентам.
Вы также можете использовать robots.txt, чтобы поисковые системы не индексировали дублирующийся контент. Если вы используете параметры URL, которые приводят к тому, что на вашем сайте размещается один и тот же контент на нескольких страницах, используйте символы подстановки, чтобы исключить эти URL:
Пользователь-агент: *
Disallow: / *?
Это предотвратит доступ сканеров к любым страницам с вопросительными знаками в URL-адресе, что часто приводит к добавлению параметров.Это особенно полезно для сайтов электронной коммерции, которые имеют множество параметров URL, что приводит к тонне дублированного контента из-за фильтрации и сортировки товаров.
Рекомендуется блокировать доступ к вашему сайту во время редизайна или миграции, о чем мы подробно говорили ранее. Заблокируйте доступ ко всему новому сайту, чтобы он не связывался с дублирующимся контентом, что в будущем будет препятствовать его ранжированию.
Распространенные проблемы с Robots.txt и как их исправить
Чтобы проверить, есть ли у вас проблемы с вашими роботами.TXT, откройте консоль поиска Google. Посмотрите в своем отчете «Статистика сканирования», чтобы убедиться, что количество просканированных страниц за день значительно сократилось; это может указывать на проблему с вашим файлом robots.txt.
Возможно, самая большая проблема с файлами robots.txt — это случайный запрет страниц, которые вы действительно хотите сканировать. Эту информацию можно найти в отчете об ошибках сканирования GSC. Проверьте страницы, которые возвращают код ответа 500. Этот код часто возвращается для страниц, заблокированных robots.txt.
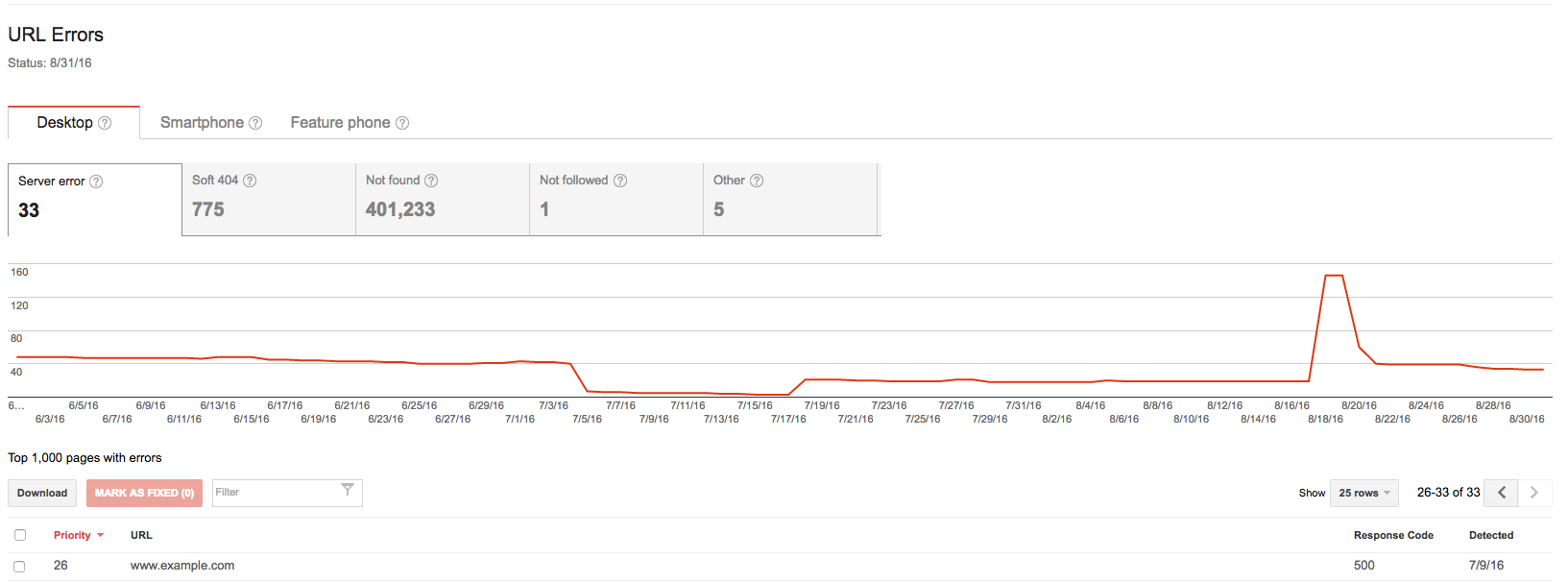
Проверьте все URL-адреса, которые возвращают код ошибки 500 в соответствии с вашими директивами disallow в файле robots.txt.
Некоторые другие распространенные проблемы с файлами robots.txt:
Случайное добавление косой черты в конце имени файла. Даже если ваш канонический URL-адрес может содержать косую черту, добавление этого в конец строки в файле robots.txt заставит ботов интерпретировать его как каталог, а не файл, блокируя каждую страницу в папке.Дважды проверьте ваши запрещенные линии на наличие косых черт, которых там быть не должно.
Блокировка ресурсов, таких как коды CSS и JavaScript, с использованием robots.txt. Однако это повлияет на то, как поисковые системы увидят вашу страницу. Некоторое время назад Google заявил, что запрет CSS и Javascript будет считаться вашим SEO. Google может прочитать ваш код CSS и JS и использовать его, чтобы сделать выводы о вашем сайте. Когда он видит заблокированные ресурсы, подобные этой, он не может правильно отобразить вашу страницу, что удержит вас от рейтинга так высоко, как вы могли бы в противном случае.
Использование более одной директивы User-agent на строку. Поисковые системы игнорируют директивы, включающие в себя более одного пользовательского агента в строке, что может привести к неправильному сканированию вашего сайта.
Неправильная капитализация каталогов, подкаталогов и имен файлов. Хотя фактические директивы, используемые в robots.txt, не чувствительны к регистру, их значения. Так что поисковые системы видят
Disallow: page.html,Disallow: Page.htmlиDisallow: страница.HTMLв виде трех отдельных файлов. Если ваш файл robots.txt содержит директивы для «Page.html», но канонический URL-адрес указан строчными буквами, эта страница будет просканирована.Использование директивы noindex. Ни Google, ни Bing не поддерживают использование noindex в файлах robots.txt.
Противоречие с вашей картой сайта в файле robots.txt. Скорее всего, это произойдет, если вы используете различные инструменты для создания файлов Sitemap и robots.txt. Противоречить себя перед поисковыми системами всегда плохая идея.К счастью, это довольно легко найти и исправить. Отправьте и сканируйте свою карту сайта через GSC. Он предоставит вам список ошибок, которые вы затем сможете проверить в файле robots.txt, чтобы узнать, исключили ли вы его там.

- Запрет страниц в вашем файле robots.txt, которые используют метатег noindex. Сканеры, заблокированные от доступа к странице, не смогут видеть тег noindex, который может привести к тому, что ваша страница появится в результатах поиска, если она связана с другой страницей.
Распространено также бороться с синтаксисом robots.txt, особенно если у вас мало технических знаний. Одно из решений заключается в том, чтобы кто-то, знакомый с протоколом роботов, просматривал ваш файл на предмет синтаксических ошибок. Другой, и, возможно, лучший вариант, это пойти прямо в Google для тестирования. Откройте тестер в консоли поиска Google, вставьте файл robots.txt и нажмите «Тест». Что действительно удобно, так это то, что он не только обнаружит ошибки в вашем файле, но вы также сможете увидеть, не разрешаете ли вы страницы, проиндексированные Google.
При создании или изменении файла robots.txt вы действительно должны тщательно протестировать его с помощью этого инструмента. Добавление файла robots.txt с ошибками, вероятно, серьезно повлияет на способность вашего сайта сканироваться и индексироваться, что может привести к тому, что он выйдет из рейтинга поиска. Вы можете даже заблокировать весь ваш сайт от появления в результатах поиска!
Правильно ли реализован ваш файл robots.txt? Проведите аудит своего сайта с помощью WooRank, чтобы убедиться, что вы оптимизированы по более чем 70 критериям, в том числе на странице, технические и местные факторы.
,Управление файлами Robots.txt и Sitemap
- 7 минут, чтобы прочитать
В этой статье
Руслан Якушев
Инструментарий поисковой оптимизации IIS включает в себя функцию Исключение роботов , которую можно использовать для управления контентом роботов.TXT-файл для вашего веб-сайта, включает в себя функцию Sitemap и Sitemap Indexes , которую вы можете использовать для управления картами сайта вашего сайта. В этом пошаговом руководстве объясняется, как и зачем использовать эти функции.
Фон
Сканерыбудут тратить ограниченное время и ресурсы на ваш веб-сайт. Поэтому важно сделать следующее:
- Запретить сканерам индексировать контент, который не важен или не должен отображаться на страницах результатов поиска.
- Направьте сканеры на контент, который вы считаете наиболее важным для индексации.
Для выполнения этих задач обычно используются два протокола: протокол исключения роботов и протокол Sitemaps.
Протокол исключения роботов используется, чтобы сообщить сканерам поисковых систем, какие URL-адреса НЕ следует запрашивать при сканировании веб-сайта. Инструкции по исключению помещаются в текстовый файл с именем Robots.txt, который находится в корне веб-сайта.Большинство сканеров поисковых систем обычно ищут этот файл и следуют инструкциям в нем.
Протокол Sitemaps используется для информирования сканеров поисковых систем об URL-адресах, доступных для сканирования на вашем веб-сайте. Кроме того, файлы Sitemap используются для предоставления некоторых дополнительных метаданных об URL-адресах сайта, таких как время последнего изменения, частота изменения, относительный приоритет и т. Д. Поисковые системы могут использовать эти метаданные при индексации вашего веб-сайта.
Предпосылки
1.Настройка веб-сайта или приложения
Для выполнения этого пошагового руководства вам потребуется веб-сайт IIS 7 или более поздней версии или веб-приложение, которым вы управляете. Если у вас его нет, вы можете установить его из галереи веб-приложений Microsoft. Для этого пошагового руководства мы будем использовать популярное приложение для ведения блогов DasBlog.
2. Анализ веб-сайта
Если у вас есть веб-сайт или веб-приложение, вы можете проанализировать его, чтобы понять, как типичная поисковая система будет сканировать его содержимое.Для этого выполните действия, описанные в статьях «Использование анализа сайта для сканирования веб-сайта» и «Использование отчетов анализа сайта». Когда вы будете проводить анализ, вы, вероятно, заметите, что у вас есть определенные URL-адреса, доступные поисковым системам для сканирования, но нет никакой реальной выгоды в том, что они сканируются или индексируются. Например, поисковые роботы не должны запрашивать страницы входа или страницы ресурсов. Такие URL-адреса должны быть скрыты от поисковых систем, добавляя их в роботов.текстовый файл.
Управление файлом Robots.txt
Можно использовать функцию исключения роботов IIS SEO Toolkit для создания файла Robots.txt, который сообщает поисковым системам, какие части веб-сайта не следует сканировать или индексировать. Следующие шаги описывают, как использовать этот инструмент.
- Откройте консоль управления IIS, введя INETMGR в меню «Пуск».
- Перейдите на свой веб-сайт с помощью дерева в левой части (например, веб-сайт по умолчанию).
- Щелкните по значку Поисковая оптимизация в разделе «Управление»:
- На главной странице SEO нажмите ссылку задачи « Добавить новое запрещающее правило » в разделе Исключение роботов .
Добавление правил запрета и разрешения
Диалоговое окно «Добавить запретить правила» откроется автоматически:
Протокол исключения роботовиспользует директивы «Разрешить» и «Запретить» для информирования поисковых систем о путях URL, которые можно сканировать, и о тех, которые нельзя.Эти директивы могут быть указаны для всех поисковых систем или для конкретных пользовательских агентов, определенных HTTP-заголовком user-agent. В диалоговом окне «Добавить запретить правила» вы можете указать, к какому поисковому механизму поисковой системы будет применяться данная директива, введя пользовательский агент сканера в поле «Робот (пользовательский агент)».
Представление дерева пути URL-адреса используется для выбора того, какие URL-адреса следует запретить. При выборе путей URL можно выбрать один из нескольких вариантов с помощью раскрывающегося списка «Структура URL»:
- Физическое местоположение — вы можете выбрать пути из макета физической файловой системы вашего веб-сайта.
- Из Site Analysis (имя анализа) — вы можете выбрать пути из виртуальной структуры URL, которая была обнаружена при анализе сайта с помощью инструмента IIS Site Analysis.
- <Запустить новый анализ сайта ...> — вы можете запустить новый анализ сайта, чтобы получить структуру виртуального URL-адреса для вашего веб-сайта, а затем выбрать пути URL-адреса оттуда.
После выполнения шагов, описанных в разделе предварительных условий, вам будет доступен анализ сайта. Выберите анализ в раскрывающемся списке, а затем проверьте URL-адреса, которые необходимо скрыть от поисковых систем, используя флажки в представлении дерева «URL-пути»:
После выбора всех каталогов и файлов, которые необходимо запретить, нажмите ОК.Вы увидите новые запрещенные записи в главном представлении функции:
Кроме того, файл Robots.txt для сайта будет обновлен (или создан, если он не существует). Его содержание будет выглядеть примерно так:
Пользователь-агент: *
Disallow: /EditConfig.aspx
Disallow: /EditService.asmx/
Disallow: / images /
Disallow: /Login.aspx
Disallow: / scripts /
Disallow: /SyndicationService.asmx/
Чтобы увидеть, как работает Robots.txt, вернитесь к функции анализа сайта и повторно запустите анализ для сайта.На странице «Сводка отчетов» в категории Ссылки выберите Ссылки, заблокированные Robots.txt . В этом отчете будут отображаться все ссылки, которые не были просканированы, поскольку они были запрещены только что созданным файлом Robots.txt.
Управление файлами Sitemap
Можно использовать функцию Sitemaps и Sitemap Indexes в IIS SEO Toolkit для создания файлов Sitemap на вашем веб-сайте, чтобы информировать поисковые системы о страницах, которые следует сканировать и индексировать.Для этого выполните следующие действия:
- Откройте диспетчер IIS, введя INETMGR в меню Пуск .
- Перейдите на свой веб-сайт, используя древовидное представление слева.
- Щелкните по значку Поисковая оптимизация в разделе «Управление»:
- На главной странице SEO щелкните ссылку задачи « Создать новую карту сайта » в разделе Sitemap и Sitemap Indexes .
- Диалог Добавить файл Sitemap откроется автоматически.
- Введите имя для файла карты сайта и нажмите ОК . Откроется диалоговое окно Добавить URL .
Добавление URL на карту сайта
Добавить URL диалог выглядит так:
Файл Sitemap в основном представляет собой простой XML-файл, в котором перечислены URL-адреса вместе с некоторыми метаданными, такими как частота изменений, дата последнего изменения и относительный приоритет. Вы используете диалог Добавить URL , чтобы добавить новые записи URL в файл Sitemap xml.Каждый URL-адрес в карте сайта должен иметь полный формат URI (т. Е. Он должен содержать префикс протокола и имя домена). Итак, первое, что вы должны указать, это домен, который будет использоваться для URL-адресов, которые вы собираетесь добавить в карту сайта.
Представление «Путь к URL-адресу» используется для выбора URL-адресов, которые необходимо добавить в карту сайта для индексации. Вы можете выбрать один из нескольких вариантов, используя раскрывающийся список «Структура URL»:
- Физическое местоположение — вы можете выбрать URL-адреса из макета физической файловой системы вашего веб-сайта.
- Из Site Analysis (имя анализа) — вы можете выбрать URL из виртуальной структуры URL, которая была обнаружена при анализе сайта с помощью инструмента Site Analysis.
- <Запустить новый анализ сайта ...> — вы можете запустить новый анализ сайта, чтобы получить структуру виртуального URL-адреса для вашего веб-сайта, а затем выбрать пути URL-адреса, которые вы хотите добавить для индексации.
После того, как вы выполните шаги в разделе предварительных условий, у вас будет доступный анализ сайта.Выберите его в раскрывающемся списке, а затем проверьте URL-адреса, которые необходимо добавить в карту сайта.
При необходимости измените параметры Изменить частоту , Дата последнего изменения и Приоритет , а затем нажмите ОК , чтобы добавить URL-адреса в карту сайта. Файл sitemap.xml будет обновлен (или создан, если он не существует), и его содержимое будет выглядеть следующим образом:
Http: // MyBlog / 2009/03/11 / CongratulationsYouveInstalledDasBlogWithWebDeploy.ASPX
2009-06-03T16: 05: 02
еженедельно
<Приоритет> 0,5
Http: //myblog/2009/06/02/ASPNETAndURLRewriting.aspx
2009-06-03T16: 05: 01
еженедельно
<Приоритет> 0,5
Добавление местоположения карты сайта в роботов.TXT-файл
Теперь, когда вы создали карту сайта, вам нужно сообщить поисковым системам, где она находится, чтобы они могли начать ее использовать. Самый простой способ сделать это — добавить URL-адрес местоположения карты сайта в файл Robots.txt.
В функции Sitemaps и Sitemap Indexes выберите только что созданную карту сайта и нажмите Добавить в Robots.txt на панели Действия :
Ваш файл Robots.txt будет выглядеть примерно так:
Пользователь-агент: *
Disallow: / EditService.ASMX /
Disallow: / images /
Disallow: / scripts /
Disallow: /SyndicationService.asmx/
Disallow: /EditConfig.aspx
Disallow: /Login.aspx
Карта сайта: http: //myblog/sitemap.xml
Регистрация карт сайта в поисковых системах
Помимо добавления местоположения карты сайта в файл Robots.txt, рекомендуется отправлять URL-адрес местоположения карты сайта в основные поисковые системы. Это позволит вам получить полезный статус и статистику о вашем веб-сайте из инструментов веб-мастеров поисковой системы.
Резюме
В этом пошаговом руководстве вы узнали, как использовать функции исключения роботов и файлов Sitemap и индексов файлов Sitemap из набора IIS Search Engine Optimization Toolkit для управления файлами Robots.txt и файлами Sitemap на вашем веб-сайте. IIS Search Engine Optimization Toolkit предоставляет интегрированный набор инструментов, которые работают вместе, чтобы помочь вам создать и проверить правильность файлов Robots.txt и sitemap, прежде чем поисковые системы начнут их использовать.
,Разрешить только один файл каталога в robots.txt?
Переполнение стека- Товары
- Клиенты
- Случаи использования
- Переполнение стека Публичные вопросы и ответы
- Команды Частные вопросы и ответы для вашей команды
- предприятие Частные вопросы и ответы для вашего предприятия
- работы Программирование и связанные с ним технические возможности карьерного роста
- Талант Нанимать технический талант
- реклама Связаться с разработчиками по всему миру
Загрузка…
- Авторизоваться зарегистрироваться