Подгрузка контента при прокрутке — JavaScript — Дока
Кратко
Скопировано
В вебе хорошим тоном считается не загружать в браузер ничего лишнего. Например, стили, скрипты и изображения, которые пользователю не понадобятся, можно считать лишними и не загружать. С контентом дело обстоит так же — по возможности мы хотим загружать только то, что пользователю понадобится «прямо сейчас».
В этой статье мы разберёмся, зачем нам это нужно и какие приёмы используются, чтобы этого добиться.
Лишний код
Скопировано
Сперва поймём, почему мы не хотим держать в проекте лишний код и загружать его в браузер. На это у нас несколько причин.
Трафик дорожает
Скопировано
В первую очередь, ненужный код — это лишний сетевой трафик. Он может быть дорогим, особенно мобильный, особенно в Европе. Сайт или приложение, которые загружают ненужное (особенно изображения), могут оказаться в прямом смысле дорогими.
Время исполнения увеличивается
Скопировано
Это в меньшей степени относится к изображениям и в большей — к JS-файлам. Чем больше JS-кода браузеру необходимо распарсить и выполнить, тем больше времени это займёт. Потраченное время мы украдём у пользователей, пока они будут «ждать загрузки».
Особенно остро это будет досаждать людям с «медленными» устройствами: относительно старыми телефонами или компьютерами. На таких устройствах время исполнения может увеличиваться в разы.
Удобство работы уменьшается
Скопировано
Чем больше кода, который не используется, но занимает место, тем больше времени у разработчиков будет уходить на исправление багов и реализацию фич.
Навигация внутри проекта и «загрузка проекта в голову» требуют времени и усилий. Чем больше проект, тем сложнее его охватить и понять. Лишний код только сбивает с мысли и не даёт сосредоточиться на важном.
Код и контент
Скопировано
Стратегий борьбы с лишним кодом много: код-сплиттинг и минификация, оптимизация изображений, кэширование, рефакторинг и удаление старого кода.
С контентом ситуация и похожа, и непохожа одновременно. С одной стороны, мы так же не хотим загружать то, что пользователю не нужно, с другой стороны — мы не знаем, что именно пользователю понадобится, и не можем предсказать, на какую страницу он решит перейти. Да и сам контент может постоянно меняться — как в соцсетях.
Поэтому из всех стратегий «сплиттинг» нам подходит больше всего.
💡
Сплиттингом мы будем называть передачу контента по кускам: когда первый кусок отдаётся автоматически, а остальные — по запросу пользователя.
Такая стратегия используется уже давно, и скорее всего вы уже встречались с её реализацией в виде пагинаторов.
Пагинаторы
Скопировано
📄
Пагинатор — элемент интерфейса, который помогает переходить между «частями» контента. Раньше такие части всегда были отдельными страницами на сайте, отсюда и название.
Когда сайты были проще, а AJAX и JSON ещё не были распространены, пагинаторы были единственным способом поделить большое количество контента на куски.
Их и сейчас можно встретить, например, на Google.com:
Пример пагинатора.
Когда же JSON и AJAX стали обычным делом, у разработчиков и дизайнеров появилось больше возможностей «делить» контент на части и показывать его пользователю. Одна из таких возможностей — это бесконечный скролл.
Бесконечная прокрутка
Скопировано
📜
Бесконечная прокрутка (ещё говорят бесконечный скролл) — это приём, когда при прокрутке страницы ближе к концу на сервер отправляется запрос за новой порцией контента, которая встраивается в конец «ленты».
Чаще всего такой приём можно увидеть в соцсетях: Twitter, Facebook, Instagram и прочих. Когда пользователь докручивает до «конца» страницы, браузер получает от сервера новую порцию постов, и лента становится бесконечной.
Давайте навестим нашу печально известную соцсеть Switter, знакомую нам по статье о безопасности веб-приложений, и поможем её разработчикам создать такую бесконечную загрузку.
(Может быть, хотя бы это убережёт их акции от полного краха.)
Switter сейчас
Скопировано
Сейчас Switter выглядит как лента со свитами и пагинатор внизу.
Наша задача — реализовать бесконечную прокрутку. Нам стоит учесть:
- Switter — маленькая соцсеть, и контент пользователя всё-таки может закончиться. Поэтому нужно предусмотреть ситуацию, когда мы больше не отправляем запросы за новыми порциями.
- Если прокрутка будет работать на страницах, которые видны всем, пользователи могут захотеть поделиться конкретной страницей. Нам нужно сохранять текущую страницу в адресной строке, чтобы ей можно было поделиться.
- Нам не хочется, чтобы пользователи постоянно «упирались» в дно страницы. Поэтому нужно, чтобы «контент уже ждал пользователя», а не наоборот.
Заглушка для сервера
Скопировано
Первым делом мы сделаем заглушку для сервера, чтобы имитировать запросы к нему. Для краткости мы скроем шаг с созданием.
Для краткости мы скроем шаг с созданием.
Вначале создадим «базу данных».
Это объект поста, которые мы будем отдавать в качестве новой порции контента:
const post = { title: 'Заголовок поста', body: 'Текст поста в лучшей на свете социальной сети Switter. Все совпадения вымышлены и случайны.', likes: 77, reposts: 7,}
const post = {
title: 'Заголовок поста',
body:
'Текст поста в лучшей на свете социальной сети Switter. Все совпадения вымышлены и случайны.',
likes: 77,
reposts: 7,
}
Теперь создадим «сервер API»:
// Метод posts возвращает Promise, имитируя асинхронное общение// между клиентом и сервером («запрос/ответ»).const server = { // Аргумент page — курсор, номер страницы, которую надо загрузить. // С этим номером мы определяем, какую порцию контента отправить. // В нашем примере порции отличаться не будут, но в жизни // курсор бы влиял на то, какой диапазон постов сервер бы доставал из БД.
posts(page = 1) { // В нашем случае, если текущая страница — 5-я, // мы считаем, что контент закончился. const finished = page >= 5 // Иначе сервер отправляет курсор next. // Он указывает, какая страница будет по счёту следующей. // Так клиент будет знать, стоит ли ему отправлять запрос // за новой порцией контента. const next = finished ? null : page + 1 // В качестве постов отправляем массив из 5 объектов post. const posts = Array(5).fill(post) return new Promise((resolve) => { // Таймаут имитирует сетевую «задержку». setTimeout(() => { resolve({ posts, next }) }, 150) }) },}
// Метод posts возвращает Promise, имитируя асинхронное общение
// между клиентом и сервером («запрос/ответ»).
const server = {
// Аргумент page — курсор, номер страницы, которую надо загрузить.
// С этим номером мы определяем, какую порцию контента отправить.
// В нашем примере порции отличаться не будут, но в жизни
// курсор бы влиял на то, какой диапазон постов сервер бы доставал из БД.
posts(page = 1) {
// В нашем случае, если текущая страница — 5-я,
// мы считаем, что контент закончился.
const finished = page >= 5
// Иначе сервер отправляет курсор next.
// Он указывает, какая страница будет по счёту следующей.
// Так клиент будет знать, стоит ли ему отправлять запрос
// за новой порцией контента.
const next = finished ? null : page + 1
// В качестве постов отправляем массив из 5 объектов post.
const posts = Array(5).fill(post)
return new Promise((resolve) => {
// Таймаут имитирует сетевую «задержку».
setTimeout(() => {
resolve({ posts, next })
}, 150)
})
},
}
Вызывать метод для получения новых постов posts мы будем с помощью await:
const response = await server.posts()
const response = await server.posts()
Клиент
Скопировано
Когда сервер готов, мы можем приступать к разработке клиентской части. Первым делом спроектируем, как должно работать приложение.
Первым делом спроектируем, как должно работать приложение.
Проектирование
Скопировано
Мы хотим подгружать новый контент, когда пользователь докручивает до конца страницы. Здесь можно выделить несколько задач:
- Следить за положением прокрутки. Когда мы приближаемся к концу страницы, нужно запрашивать следующую порцию данных.
- Уметь общаться с сервером. Нам нужно отправлять запросы и обрабатывать ответы.
- Преобразовывать данные в вёрстку на странице и отображать её.
- Не забыть о правильной обработке события прокрутки, чтобы ничего не тормозило.
Начнём с вёрстки.
Вёрстка и шаблоны
Скопировано
Свит свёрстан как <article>, внутри есть заголовок, текст и кнопки «Нравится» и «Ресвитнуть»:
<article> <h2>Заголовок поста</h2> <p> Текст поста в лучшей на свете социальной сети Switter. Все совпадения вымышлены и случайны.</p> <footer> <button type="button">❤️ 20</button> <button type="button">🔄 20</button> </footer></article> <article> <h2>Заголовок поста</h2> <p> Текст поста в лучшей на свете социальной сети Switter. Все совпадения вымышлены и случайны. </p> <footer> <button type="button">❤️ 20</button> <button type="button">🔄 20</button> </footer> </article>
Вёрстка нас устраивает. (<menu>, но в целом ок.)
Из этой вёрстки мы сделаем шаблон для будущих свитов, которые мы будем загружать с сервера. Шаблон нужен, потому что с сервера мы будем загружать только данные. Как эти данные должны отображаться, сервер не знает. Шаблон будет нужен именно для этого — чтобы браузер мог правильно отобразить данные на странице.
Данные с сервера будут заполнять шаблон, в итоге получится компонент свита.
<!-- Тег template используется, чтобы хранить куски кода, которые не должен видеть пользователь. --><template> <!-- Внутри повторяем разметку свита, удаляя все тексты и числа. Оставляем только «скелет» компонента. --> <article> <h3></h3> <p></p> <footer> <button type="button">❤️ </button> <button type="button">🔄 </button> </footer> </article></template>
<!-- Тег template используется, чтобы хранить куски кода,
которые не должен видеть пользователь. -->
<template>
<!-- Внутри повторяем разметку свита,
удаляя все тексты и числа.
Оставляем только «скелет» компонента. -->
<article>
<h3></h3>
<p></p>
<footer>
<button type="button">❤️ </button>
<button type="button">🔄 </button>
</footer>
</article>
</template>
Если мы добавим этот код на страницу, то визуально ничего не изменится, но у нас появится возможность «штамповать» новые свиты с помощью JS-кода. Подробнее об этом мы поговорим чуть ниже.
Подробнее об этом мы поговорим чуть ниже.
Отслеживание положения скролла
Скопировано
Дальше нам потребуется написать функцию, которая будет определять, когда пора отправлять новый запрос.
function checkPosition() { // Нам потребуется знать высоту документа и высоту экрана: const height = document.body.offsetHeight const screenHeight = window.innerHeight // Они могут отличаться: если на странице много контента, // высота документа будет больше высоты экрана (отсюда и скролл). // Записываем, сколько пикселей пользователь уже проскроллил: const scrolled = window.scrollY // Обозначим порог, по приближении к которому // будем вызывать какое-то действие. // В нашем случае — четверть экрана до конца страницы: const threshold = height - screenHeight / 4 // Отслеживаем, где находится низ экрана относительно страницы: const position = scrolled + screenHeight if (position >= threshold) { // Если мы пересекли полосу-порог, вызываем нужное действие.
}}
function checkPosition() {
// Нам потребуется знать высоту документа и высоту экрана:
const height = document.body.offsetHeight
const screenHeight = window.innerHeight
// Они могут отличаться: если на странице много контента,
// высота документа будет больше высоты экрана (отсюда и скролл).
// Записываем, сколько пикселей пользователь уже проскроллил:
const scrolled = window.scrollY
// Обозначим порог, по приближении к которому
// будем вызывать какое-то действие.
// В нашем случае — четверть экрана до конца страницы:
const threshold = height - screenHeight / 4
// Отслеживаем, где находится низ экрана относительно страницы:
const position = scrolled + screenHeight
if (position >= threshold) {
// Если мы пересекли полосу-порог, вызываем нужное действие.
}
}
Когда мы докрутим и пересечём порог, отправим запрос за новой порцией контента.
Теперь сделаем эту функцию обработчиком события прокрутки и изменения размера окна:
;(() => { window.
addEventListener('scroll', checkPosition) window.addEventListener('resize', checkPosition)})()
;(() => {
window.addEventListener('scroll', checkPosition)
window.addEventListener('resize', checkPosition)
})()
Улучшение производительности
Скопировано
Обработку прокрутки стоит немного притормаживать, чтобы она выполнялась чуть реже и таким образом меньше нагружала браузер.
Добавим функцию throttle:
function throttle(callee, timeout) { let timer = null return function perform(...args) { if (timer) return timer = setTimeout(() => { callee(...args) clearTimeout(timer) timer = null }, timeout) }}
function throttle(callee, timeout) {
let timer = null
return function perform(...args) {
if (timer) return
timer = setTimeout(() => {
callee(...args)
clearTimeout(timer)
timer = null
}, timeout)
}
}
И теперь назначим обработчиком событий слегка заторможенную функцию:
;(() => { window. addEventListener('scroll', throttle(checkPosition, 250)) window.addEventListener('resize', throttle(checkPosition, 250))})()
addEventListener('scroll', throttle(checkPosition, 250)) window.addEventListener('resize', throttle(checkPosition, 250))})()
;(() => {
window.addEventListener('scroll', throttle(checkPosition, 250))
window.addEventListener('resize', throttle(checkPosition, 250))
})()
Запросы к серверу
Скопировано
Дальше создадим функцию для запросов к серверу:
async function fetchPosts() { const { posts, next } = await server.posts(nextPage) // Делаем что-то с posts и next.}
async function fetchPosts() {
const { posts, next } = await server.posts(nextPage)
// Делаем что-то с posts и next.
}
И используем её в check. Так как fetch асинхронная, check тоже станет асинхронной:
async function checkPosition() { // . ..Старый код. if (position >= threshold) { await fetchPosts() }}
..Старый код. if (position >= threshold) { await fetchPosts() }}
async function checkPosition() {
// ...Старый код.
if (position >= threshold) {
await fetchPosts()
}
}
Обработка данных от сервера
Скопировано
В функции fetch мы получаем список постов, каждый из которых мы хотим добавить на страницу. Напишем функцию append, которая будет этим заниматься:
function appendPost(postData) { // Если данных нет, ничего не делаем: if (!postData) return // Храним ссылку на элемент, внутрь которого // добавим новые элементы-свиты: const main = document.querySelector('main') // Используем функцию composePost, // которую напишем чуть позже — // она превращает данные в HTML-элемент: const postNode = composePost(postData) // Добавляем созданный элемент в main: main. append(postNode)}
append(postNode)}
function appendPost(postData) {
// Если данных нет, ничего не делаем:
if (!postData) return
// Храним ссылку на элемент, внутрь которого
// добавим новые элементы-свиты:
const main = document.querySelector('main')
// Используем функцию composePost,
// которую напишем чуть позже —
// она превращает данные в HTML-элемент:
const postNode = composePost(postData)
// Добавляем созданный элемент в main:
main.append(postNode)
}
Функция append использует внутри себя compose. Напишем и её тоже:
function composePost(postData) { // Если ничего не передано, ничего не возвращаем: if (!postData) return // Обращаемся к шаблону, который создали ранее: const template = document.getElementById('post_template') // ...и вытаскиваем его содержимое. // В нашем случае содержимым будет «скелет» свита, элемент article. // Указываем, что нам необходимо его склонировать, а не использовать сам элемент, // иначе он изменится сам, и мы не сможем сделать несколько свитов: const post = template.content.cloneNode(true) // Из postData получаем всю необходимую информацию: const { title, body, likes, reposts } = postData // Добавляем соответствующие тексты и числа в нужные места в «скелете»: post.querySelector('h2').innerText = title post.querySelector('p').innerText = body post.querySelector('button:first-child').innerText += likes post.querySelector('button:last-child').innerText += reposts // Возвращаем созданный элемент, // чтобы его можно было добавить на страницу: return post}
// Указываем, что нам необходимо его склонировать, а не использовать сам элемент, // иначе он изменится сам, и мы не сможем сделать несколько свитов: const post = template.content.cloneNode(true) // Из postData получаем всю необходимую информацию: const { title, body, likes, reposts } = postData // Добавляем соответствующие тексты и числа в нужные места в «скелете»: post.querySelector('h2').innerText = title post.querySelector('p').innerText = body post.querySelector('button:first-child').innerText += likes post.querySelector('button:last-child').innerText += reposts // Возвращаем созданный элемент, // чтобы его можно было добавить на страницу: return post}
function composePost(postData) {
// Если ничего не передано, ничего не возвращаем:
if (!postData) return
// Обращаемся к шаблону, который создали ранее:
const template = document.getElementById('post_template')
// ...и вытаскиваем его содержимое.
// В нашем случае содержимым будет «скелет» свита, элемент article. // Указываем, что нам необходимо его склонировать, а не использовать сам элемент,
// иначе он изменится сам, и мы не сможем сделать несколько свитов:
const post = template.content.cloneNode(true)
// Из postData получаем всю необходимую информацию:
const { title, body, likes, reposts } = postData
// Добавляем соответствующие тексты и числа в нужные места в «скелете»:
post.querySelector('h2').innerText = title
post.querySelector('p').innerText = body
post.querySelector('button:first-child').innerText += likes
post.querySelector('button:last-child').innerText += reposts
// Возвращаем созданный элемент,
// чтобы его можно было добавить на страницу:
return post
}
// Указываем, что нам необходимо его склонировать, а не использовать сам элемент,
// иначе он изменится сам, и мы не сможем сделать несколько свитов:
const post = template.content.cloneNode(true)
// Из postData получаем всю необходимую информацию:
const { title, body, likes, reposts } = postData
// Добавляем соответствующие тексты и числа в нужные места в «скелете»:
post.querySelector('h2').innerText = title
post.querySelector('p').innerText = body
post.querySelector('button:first-child').innerText += likes
post.querySelector('button:last-child').innerText += reposts
// Возвращаем созданный элемент,
// чтобы его можно было добавить на страницу:
return post
}
Представить это можно как цепочку событий: запрашиваем данные, получаем ответ, для каждого поста наполняем шаблон данными, получившиеся элементы встраиваем на страницу.
В реальном приложении нам бы потребовалось ещё повесить обработчики кликов по кнопкам в этом новом свите. Без обработчиков кнопки не будут ничего делать. Но для краткости эту часть в статье мы опустим.
Но для краткости эту часть в статье мы опустим.
Добавим обработку данных в fetch:
async function fetchPosts() { const { posts, next } = await server.posts(nextPage) posts.forEach(appendPost)}
async function fetchPosts() {
const { posts, next } = await server.posts(nextPage)
posts.forEach(appendPost)
}
Осталось лишь правильно обработать случаи, когда мы отправили запрос и ждём ответа, и когда контент закончился.
Обработка промежуточных и крайних случаев
Скопировано
Если сейчас запустить приложение, то оно будет работать. Но при прокрутке к концу страницы вместо одной порции контента будет присылать несколько. (И никогда не закончит это делать 😁)
Чтобы решить эти проблемы, нужно завести переменные, которые будут следить за состоянием приложения:
// Какая страница следующая:let nextPage = 2// Если отправили запрос, но ещё не получили ответ,// не нужно отправлять ещё один запрос:let isLoading = false// Если контент закончился, вообще больше не нужно// отправлять никаких запросов:let shouldLoad = true
// Какая страница следующая:
let nextPage = 2
// Если отправили запрос, но ещё не получили ответ,
// не нужно отправлять ещё один запрос:
let isLoading = false
// Если контент закончился, вообще больше не нужно
// отправлять никаких запросов:
let shouldLoad = true
Подправим функцию fetch:
async function fetchPosts() { // Если мы уже отправили запрос, или новый контент закончился, // то новый запрос отправлять не надо: if (isLoading || !shouldLoad) return // Предотвращаем новые запросы, пока не закончится этот: isLoading = true const { posts, next } = await server. posts(nextPage) posts.forEach(appendPost) // В следующий раз запрашиваем страницу с номером next: nextPage = next // Если мы увидели, что контент закончился, // отмечаем, что больше запрашивать ничего не надо: if (!next) shouldLoad = false // Когда запрос выполнен и обработан, // снимаем флаг isLoading: isLoading = false}
posts(nextPage) posts.forEach(appendPost) // В следующий раз запрашиваем страницу с номером next: nextPage = next // Если мы увидели, что контент закончился, // отмечаем, что больше запрашивать ничего не надо: if (!next) shouldLoad = false // Когда запрос выполнен и обработан, // снимаем флаг isLoading: isLoading = false}
async function fetchPosts() {
// Если мы уже отправили запрос, или новый контент закончился,
// то новый запрос отправлять не надо:
if (isLoading || !shouldLoad) return
// Предотвращаем новые запросы, пока не закончится этот:
isLoading = true
const { posts, next } = await server.posts(nextPage)
posts.forEach(appendPost)
// В следующий раз запрашиваем страницу с номером next:
nextPage = next
// Если мы увидели, что контент закончился,
// отмечаем, что больше запрашивать ничего не надо:
if (!next) shouldLoad = false
// Когда запрос выполнен и обработан,
// снимаем флаг isLoading:
isLoading = false
}
Теперь функция работает правильно.
Что можно улучшить ещё
Скопировано
Мы создали базовую функциональность подгрузки, но есть ряд улучшений, о которых стоит помнить в реальном приложении. Они чаще всего сложны в реализации, поэтому в этом подразделе мы поговорим о таких улучшениях, но не будем реализовывать их.
Изменение адресной строки
Скопировано
Хорошим тоном считается, когда мы можем дать ссылку на публичную страницу, и другой человек увидит всё в точности, как мы: сортировку контента, его количество, начало и конец. Для этого используется адресная строка и URL-страницы.
В нашем случае при изменении номера текущей страницы мы можем изменять часть адреса.
☝️
Для таких задач можно использовать History API.
Восстановление прокрутки при открытии страницы
Скопировано
При открытии страницы нам надо будет проверить адрес. Если там указано, что нам нужно «прокрутить» контент к какой-то странице, мы это сделаем программно.![]()
Эту задачу часто решают на сервере. Это может быть проще и эффективнее, потому что сервер в таком случае заранее знает, какие данные нужно достать и отдать клиенту. Получается меньше запросов, и приложение для пользователя субъективно быстрее.
Результат
Скопировано
В результате мы получим переработанную страницу Switter, которая будет получать контент в тот момент, когда он нужен пользователю.
Открыть демо в новой вкладкеНа практике
Скопировано
Саша Беспоясов советует
Скопировано
Используйте throttle для подобных задач, чтобы улучшать производительность.
Бесконечная прокрутка страницы. Часть 1
Вы когда-нибудь изучали, как люди потребляют веб контент? Они просматривают
сотни страниц в день. Читают на ходу, останавливаясь на картинках и тексте,
выделенном жирным шрифтом. Более того, они в большей степени сканируют страницу,
а не читают.
Более того, они в большей степени сканируют страницу,
а не читают.
Поэтому бесконечная прокрутка и стала столь популярной; она сохраняет время при чтении страниц сайта. Движимые постоянной боязнью пропустить что-либо люди предпочитают получать весь контент на лету внутри одной страницы.
В данной статье мы погрузимся в исследование отдельного метода потребления контента – бесконечной прокрутки и посмотрим на некоторые интересные примеры.
Что такое бесконечный скроллинг?
Бесконечный скроллинг это техника, которая позволяет загружать новый контент
на страницу при ее проматывании. В зависимости от сценария, содержимое может
быть загружено сразу или разделено на подразделы, которые появляются по
требованию, одним нажатием кнопки.
Предположительно, бесконечная прокрутка была разработана как более быстрая и
удобная для пользователя альтернатива разбивке на страницы. Но верно ли это?
Фактически, все зависит от ситуации. Нет причин загружать сразу сто страниц
контента для плавной навигации; есть вероятность, что многие люди просто уйдут
на полпути. Поэтому представляется целесообразным разделить варианты
использования на те, которые хороши для бесконечной прокрутки, и те, которые
нуждаются в альтернативе.
Поэтому представляется целесообразным разделить варианты
использования на те, которые хороши для бесконечной прокрутки, и те, которые
нуждаются в альтернативе.
Где использовать бесконечную прокрутку?
Основная причина использования бесконечной прокрутки на странице — это объемный контент, который должен привлекать внимание посетителей. Кажется все просто, но контент должен быть большим и иметь плоскую иерархию. В противном случае нужно рассматривать альтернативы.
Для социальных сетей
В социальных сетях и блогах все записи относительно равны. Ну, некоторые из них могут быть более или менее интересными, но слишком субъективно разделять их на подкатегории. Такие платформы, как Facebook или Twitter, обновляются в реальном времени и оставляют предыдущую историю сообщений. Это делает их по-настоящему бездонными.
Для не менее важного контента
Допустим, есть некоторый веб-сайт (интерактивная галерея искусств), целью
которого является вдохновить того, кто просматривает, представленные на нем
изображения. В такой ситуации, как правило, люди не ищут что-то конкретное.
Скорее, они будут прокручивать страницу снова и снова, пока не найдут что-то,
что бросается в глаза. Здесь, самое большее, что вы можете сделать, это
позволить им сортировать результаты на основе новизны или популярности.
В такой ситуации, как правило, люди не ищут что-то конкретное.
Скорее, они будут прокручивать страницу снова и снова, пока не найдут что-то,
что бросается в глаза. Здесь, самое большее, что вы можете сделать, это
позволить им сортировать результаты на основе новизны или популярности.
Для мобильных интерфейсов
Смартфоны и планшеты сделали бесконечную прокрутку интуитивно понятным действием для мобильных пользователей. Она позволяет пользователю не загружать весь контент одновременно, тем самым делая приложение или мобильный сайт более легкими.
Для повествования
«Что будет дальше?» Это вопрос, который заставляет людей прокручивать вниз. Макеты меняются, но история продолжается. Воспитывайте любопытство и подпитывайте его привлекательным контентом.
Таким образом, как бесконечная прокрутка имеет важное значение в поддержании
заинтересованности и вовлеченности пользователя. Однако ее необходимо применять
с умом, только там, где это действительно необходимо.
- Создано 01.11.2018 10:03:22
- Михаил Русаков
Копирование материалов разрешается только с указанием автора (Михаил Русаков) и индексируемой прямой ссылкой на сайт (http://myrusakov.ru)!
Добавляйтесь ко мне в друзья ВКонтакте: http://vk.com/myrusakov.
Если Вы хотите дать оценку мне и моей работе, то напишите её в моей группе: http://vk.com/rusakovmy.
Если Вы не хотите пропустить новые материалы на сайте,
то Вы можете подписаться на обновления: Подписаться на обновления
Если у Вас остались какие-либо вопросы, либо у Вас есть желание высказаться по поводу этой статьи, то Вы можете оставить свой комментарий внизу страницы.
Если Вам понравился сайт, то разместите ссылку на него (у себя на сайте, на форуме, в контакте):
Бесконечная прокрутка с фотогалереей в ванильном Javascript | Майкл Тонг
Фото Винсентаса Лискаускаса на Unsplash Как и у большинства людей в мире, у вас, вероятно, есть учетная запись на Facebook.
Вы когда-нибудь задумывались, почему, когда вы прокручиваете главную страницу вниз, появляется больше сообщений?
Сегодня мы объясним, как это работает с ванильным javascript, css и html.
Чтобы понять, как все это работает, давайте сначала разберемся, как все приложение будет построено вместе. Здесь есть три компонента:
- html, который содержит изображения и индикатор загрузки
- файл css, который управляет анимацией индикатора загрузки и размером изображений
- файл javascript, который содержит логику для получения изображений, логику для обнаружения, когда пользователь прокручивается вниз страницы, а также логика тайм-аута, чтобы дать время для загрузки новых изображений, когда пользователь прокручивает вниз, чтобы получить больше изображений.
Давайте взглянем на следующий HTML-файл:
Здесь у нас есть контейнер, в котором в данный момент нет изображений. Что касается извлечения изображений, это будет объяснено после того, как я покажу, как написана логика javascript.
Вторая часть — это загрузочная часть. Анимация индикатора загрузки будет управляться файлом css. Этот индикатор загрузки по умолчанию скрыт, но для отображения индикатора загрузки будет доступно правило css. Когда пользователь прокручивает страницу вниз, прослушиватель событий добавит класс show в div загрузки, чтобы отобразить индикатор загрузки.
Теперь давайте взглянем на часть css:
Хорошо, это очень много, так что позвольте мне разобрать это по частям.
Давайте посмотрим на правило загрузки css. Обратите внимание, что непрозрачность равна 0; это скрывает индикатор загрузки с экрана. У нас также есть дополнительное правило .loading.show. Это будет применяться только в том случае, если элемент div, содержащий класс загрузки, также содержит класс показа. Класс show будет добавлен в файл javascript, когда пользователь прокрутит страницу вниз.
Чтобы было очевидно, вот как это будет выглядеть за кадром в html, когда индикатор загрузки:
Я расскажу о том, как удаляется класс show, как только мы перейдем к файлу javascript. Что более важно, так это то, что с .loading.show он будет отображать индикатор загрузки с непрозрачностью 1.
Что более важно, так это то, что с .loading.show он будет отображать индикатор загрузки с непрозрачностью 1.
Давайте посмотрим на свойство .ball css: и ниже индикатора загрузки. Он также резервирует всю строку специально для самого индикатора загрузки. Я также установил свойство animation-duration, которое определяет, как долго будет работать анимация индикатора загрузки.
Функция времени анимации определяет, как будет развиваться анимация (например, медленное скольжение, скольжение по одному шагу, медленное скольжение, но повторяющееся скольжение).
На этом снимке экрана не показана анимация, но должно быть видно, как она выглядит:
В нашем случае мы позволяем кругам загрузки (часть индикатора загрузки) скользить, но повторяться бесконечно, поэтому анимация Свойство -iteration-count установлено на бесконечность. Это определяет, как часто происходит анимация.
Давайте подробнее рассмотрим еще несколько правил css с мячами:
Давайте посмотрим, что означает @keyframes.
@keyframes определяет код анимации. Он имеет два значения: значение from и значение to. Это указывает, что эффект анимации, который будет иметь место, постепенно изменится на что-то другое.
Например, со свойством раскрытия у нас изначально есть анимация масштабирования круга до очень маленького и масштабирования по мере того, как он медленно раскрывается.
При скольжении мы описываем только то, какой будет его анимация, то есть скольжение по горизонтали на 1em.
Давайте посмотрим на css для каждого шара div. Все эти шарики представляют собой точки, формирующие индикатор загрузки. С первыми двумя шариками мы хотим медленно отображать индикатор загрузки, а затем масштабировать его, отображая анимацию загрузки. С 3-м шаровым div мы просто хотим скользить вправо, а с 4-м шаровым div мы открываем точку загрузки, а затем реверсируем анимацию (через свойство animation-direction).
Фото Клинта Паттерсона на Unsplash Много нужно переварить, верно? CSS делает много причудливых анимационных эффектов с индикатором загрузки. Давайте держаться подальше от логики css и посмотрим, как логика javascript обрабатывает вещи за кулисами:
Давайте держаться подальше от логики css и посмотрим, как логика javascript обрабатывает вещи за кулисами:
Здесь всего несколько компонентов. Одна — это функция для получения изображений, а другая — прослушиватель событий для прокрутки, который определяет, когда отображать индикатор загрузки и получать новые изображения.
Давайте посмотрим на функцию getImages. Здесь мы делаем вызов API для получения фотографий со страницей и лимитом в качестве параметров URL. Страница указывает, с какой страницы из URL-адреса мы получаем фотографии, и эта страница увеличивается каждый раз, когда вызывается эта функция, каждый раз отображая разные изображения.
Когда API возвращает информацию об изображении, мы создаем 4 разных элемента изображения, присоединяя URL-адрес, который указывает на фактическое изображение, в качестве атрибута src. После этого мы добавляем каждый из этих элементов img в контейнер. Поскольку мы только что загрузили новые изображения, мы также можем удалить класс show из div-контейнера, эффективно скрывая индикатор загрузки.
У нас есть еще одна функция, называемая showLoading. Ищем div индикатора загрузки и добавляем в него класс show. Логика css изменит непрозрачность индикатора загрузки на 1, когда класс show является частью div индикатора загрузки.
И последнее, но не менее важное: мы вызываем функцию window.addEventListener для прокрутки. Здесь мы пытаемся получить доступ к высоте прокрутки и высоте клиента из корневого документа, который по сути является корневым узлом html-страницы.
Тогда что такое scrollTop, scrollHeight или clientHeight?
Давайте посмотрим на следующее изображение:
Когда у нас есть страница, полная сообщений, для просмотра которых потребуется несколько прокруток, у нас есть clientHeight, что мы и видим в данный момент. У нас есть scrollTop, который представляет собой высоту всего содержимого над текущими сообщениями, которые мы видим в данный момент. У нас также есть scrollHeight, который представляет собой высоту всего содержимого на фактической странице, видимого или невидимого. Здесь мы проверяем, если clientHeight + scrollTop ≥ scrollHeight -5, мы получим больше изображений.
Здесь мы проверяем, если clientHeight + scrollTop ≥ scrollHeight -5, мы получим больше изображений.
Что это значит? Это означает, что если значение clientHeight + scrollTop почти равно или превышает значение scrollHeight, у нас заканчивается содержимое для прокрутки вниз. Именно тогда мы знаем, что можем получить больше фотографий, как часть требования, чтобы получить бесконечную фотогалерею.
Фото Эвана Денниса на UnsplashИтак, мы уже рассмотрели все части, но какое это имеет значение?
Во-первых, бесконечная прокрутка сегодня довольно распространена на многих платформах, таких как Twitter и Facebook. Если вы идете на собеседование с фронтенд-разработчиком, велика вероятность, что вам зададут этот вопрос.
Во-вторых, это поможет вам лучше понять, как работают CSS-анимации, как запускаются вызовы API при инициализации и так далее.
Вот оно! Попробуйте реализовать это сами и посмотрите, что получится! Если вы хотите увидеть, как это реализовано в реакции, вы также можете прочитать следующую статью:
https://kaleongtong282. medium.com/infinite-scroll-with-photo-gallery-in-react-c7219b8be2a0
medium.com/infinite-scroll-with-photo-gallery-in-react-c7219b8be2a0
Happy кодирование.
Бесконечная прокрутка с фотогалереей в React | Майкл Тонг | Еженедельные веб-подсказки
Фото Кими Ли на UnsplashЧтобы понять контекст того, что и как работает бесконечная прокрутка, вы можете прочитать следующую статью: https://medium.com/dev-genius/infinite-scroll-with-photo-gallery-in -vanilla-javascript-9dc1d3896cf7
Эта статья в значительной степени представляет собой реактивную версию статьи, которую я только что включил. Цель этой статьи — понять, как работает бесконечная прокрутка, а также как отображать индикатор загрузки при извлечении изображений. Читая эту статью, я предполагаю, что у вас есть опыт и опыт программирования в React и javascript в целом.
Как упоминалось в предоставленной статье, мы должны понимать три вещи:
- HTML, который содержит изображения и индикатор загрузки
- файл CSS, который управляет анимацией индикатора загрузки и размером изображений
- javascript файл, который содержит логику для получения изображений, логику для определения, когда пользователь прокручивает страницу до конца, а также логику тайм-аута, чтобы дать время для загрузки новых изображений, когда пользователь прокручивает вниз, чтобы получить больше изображений.

Если это назначение выполняется в простом ванильном javascript, мы должны использовать непрозрачность, чтобы скрыть/отобразить индикатор загрузки:
Прокрутите вниз, и вы увидите правило CSS .loading и .loading.show. Это та часть, где, если div, содержащий индикатор загрузки, имеет подкласс show (добавляется, когда пользователь прокручивает страницу вниз), отображаются значки загрузки.
С React нам больше не нужно использовать непрозрачность, и вместо этого мы можем использовать jsx для условного отображения индикатора загрузки.
Photo by Ferenc Almasi on UnsplashReact позволяет нам разбить на модули большую часть нашего кода, а это означает, что мы также можем разбить на модули индикатор загрузки, а также фотогалерею.
Исходя из этого, мы можем разделить наш код на следующие:
- компонент фотогалереи
- компонент индикатора загрузки
Ух ты! Структура выглядит совсем иначе, чем в реализации ванильного javascript, в которой есть HTML, js и файл CSS.
Технически мы можем разделить файлы js и CSS в один, используемый для фотогалереи и индикатора загрузки. Однако мы можем случайно перепутать правила CSS, если есть правила CSS из компонента фотогалереи и компонента индикатора загрузки с одинаковыми именами.
Произойдет следующее: одно правило CSS перезапишет другое, и поэтому я сохранил все только в одном файле HTML, одном js и одном файле CSS.
Для начала вам нужно запустить npx create-react-project Infinite-Gallery.
После этого в папке src создайте папку компонентов и создайте PhotoGallery.js:
Давайте разобьем на части, которые мы можем понять. В нашем конструкторе мы устанавливаем наше начальное состояние, чтобы иметь местозаполнитель для списка фотографий, текущую страницу для извлечения фотографий, а также логическое значение загрузки. Это логическое значение помогает нам определить, показывать индикатор загрузки или нет. Логическое значение становится истинным только тогда, когда пользователь прокручивает страницу вниз.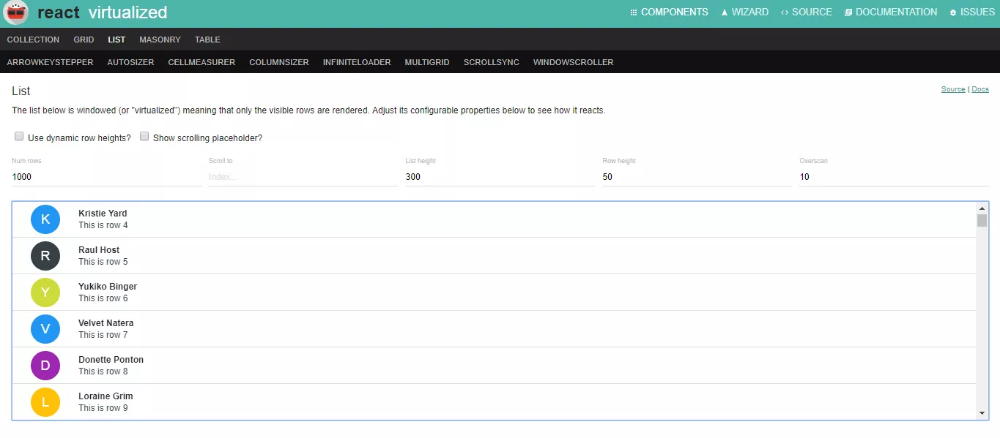
Также в конструкторе мы добавили прослушиватель событий onscroll. Мы получаем scrollTop, clientHeight и scrollHeight, которые используются для определения того, находимся ли мы внизу страницы:
Если мы находимся внизу страницы, состояние загрузки фотогалереи устанавливается равным true, эффективно отображая индикатор загрузки. После этого мы увеличиваем количество страниц, поэтому при вызове нашего API мы каждый раз будем получать разные изображения.
После получения изображений мы добавляем наши изображения поверх тех, которые у нас есть, и устанавливаем состояние загрузки на false. Вдобавок ко всему этому мы оборачиваем вызов API и setState в функцию устранения дребезга. Что это будет делать, так это ждать 1000 мс (может быть столько, сколько вы хотите), прежде чем будет вызван API. Это делается для предотвращения чрезмерных вызовов API для получения изображений, поскольку пользователь может снова прокрутить страницу до конца, прежде чем будут получены новые изображения.
Как насчет начальной загрузки страницы? Вот тут-то и появляется componentDidMount. С помощью метода жизненного цикла componentDidMount мы можем получать фотографии и заполнять страницу еще до того, как страница будет отображена.
После того, как страница отобразится, мы заполним фотографии, которые у нас есть, и если состояние загрузки включено, появится индикатор загрузки.
Фото Джен Теодор на UnsplashМы достаточно поговорили о том, как работает фотогалерея. Как насчет индикатора загрузки? Как это выглядит?
В папке src/components создайте PhotoGallery.js со следующим содержимым:
Подобно тому, что мы видели в реализации ванильного javascript, у нас есть ключевые кадры, которые определяют, как точки внутри индикатора загрузки перемещаются.
Однако нам нужно обернуть ключевые кадры в глобальный CSS, чтобы другие правила CSS, использующие ключевые кадры анимации, понимали, что они из себя представляют.
В CSS мяча мы устанавливаем его ширину и высоту, а также характер и продолжительность анимации. AnimationTimingFunction определяет характер, animationDuration определяет, сколько времени это займет, а animationIteration определяет, как часто происходит анимация.
AnimationTimingFunction определяет характер, animationDuration определяет, сколько времени это займет, а animationIteration определяет, как часто происходит анимация.
Кто-то может спросить… зачем создавать это в приложении для реагирования, а не в простом приложении с ванильным javascript?
Во-первых, React предоставляет удивительный механизм для начальной загрузки данных на страницу. С ванильным javascript вам нужно создать функцию для извлечения данных из API и добавить их к определенному элементу в HTML через jquery. Это не обязательно самый чистый способ инициализации некоторого фрагмента данных на странице.
Что делать, если есть изменения в имени класса или идентификаторе конкретного div? Теперь ваш код сломан, и вам нужно зайти в файл javascript и изменить идентификатор/класс, который вы использовали для запроса фотографий к div.
С React вам не нужно ни о чем беспокоиться! Все, о чем вам нужно беспокоиться, — это определить правильный метод жизненного цикла и выполнить вызов API для сброса данных в локальное состояние.