Виды ключевых запросов по частотности: НЧ, СЧ, ВЧ
Категории
Viktor Kotlyar
27 октября | 2021
Viktor Kotlyar
27 октября | 2021
Для продвижения сайта в поисковых системах по нужным ключевым словам, понадобится качественно оптимизированный текст. Чтобы его составить, начните со сбора ключевых слов.
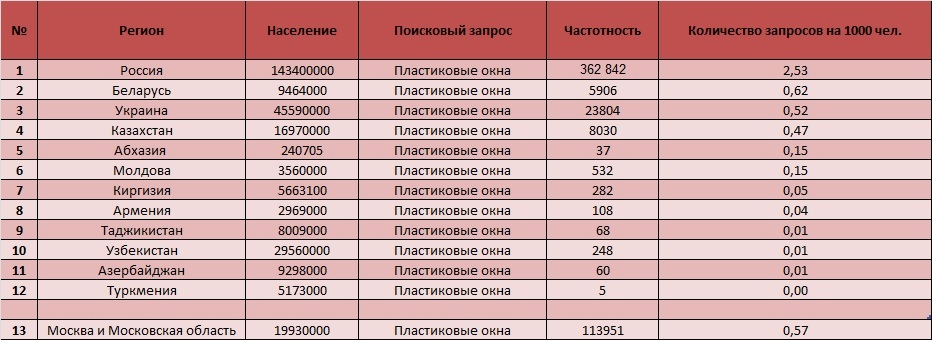
Американское консалтинговое агентство iMPACT проводило интересное исследование. По их данным, только Google получает 360 млрд запросов за 2021 год. Ежедневно в поисковик приходит по 15% новых ключей. За всей этой массой нужно следить и вовремя обрабатывать.
Как понять, какие из найденных ключей лучше использовать и будет ли востребованным наш текст у читателя? С этой проблемой нам поможет понятие «частотность запросов».
Частотность запросов — это количественный показатель того, как часто пользователи вводят в поиск определенный ключ за заданный период времени. Чем популярнее запрос, тем больше трафика можно спрогнозировать на странице, где будет размещён текст.
Виды запросов по частотности
Запросы могут делиться на несколько видов:
- Низкочастотные (НЧ) — часто не превышают 100 показов в месяц. По таким ключам продвигаться легче и дешевле из-за слабого интереса пользователей. Пренебрегать низкочастотными запросами не стоит, т.к. по ним проще продвигаться. Выйдя в топ по нескольким НЧ ключам, можно рассчитывать на ощутимый прирост трафика.
- Среднечастотные (СЧ) — имеют 500-10000 показов в месяц в поисковых системах. По этим запросам продвигаться не на много сложнее, чем по НЧ. При этом, они поставляют хороший прирост трафика.
- Высокочастотные (ВЧ) — свыше 10000 показов в месяц.

Важно уточнить: частота ключей — достаточно вариативный показатель. Это значит, что в разных нишах классификация запросов по частоте может отличаться.
Например: заходим в планировщик ключевых слов Google и вводим ключ «бытовая техника». Получаем список новых ключевых слов. Отсортировав их по частоте, мы видим, что какие-то ключевики являются высокочастотными и имеют частотность свыше 10000:
Есть низкочастотные запросы с частотностью около 10 показов в месяц:
Если мы возьмем другую менее популярную нишу, то увидим, что высокочастотные ключи там имеют более низкую частотность показов в месяц:
Как определить частотностьВ каждой поисковой системе частота ключей может отличаться. Разберём, как можно определить частотность в двух самых популярных поисковых системах:
Разберём, как можно определить частотность в двух самых популярных поисковых системах:
- Яндекс.
Как узнать частотность поисковых запросов в Google
Из примера выше видно, что я использую инструмент «Планировщик ключевых слов» сервиса «Google Ads». Это инструмент от Google, в котором можно искать новые ключевые слова и сразу же оценивать их частотность.
С помощью данного инструмента можно искать ключи по странам, языку и временным диапазонам.
Результаты нам показывают:
- Новые ключевые слова.
- Минимальную и максимальную частотность.
- Уровень конкуренции.
Как узнать частотность поисковых запросов в Яндекс
Для этого используем сервис Яндекса — Вордстат. Интерфейс достаточно простой. Всего лишь необходимо ввести поисковое слово в строку. Сервис покажет вам частоту введенного слова и подберет новые ключи, основываясь на интересах пользователей.
Небольшое напутствие читателю
Понимание правил работы с семантическим ядром и навыки дробления его по частотности — основная база для SEO-специалиста и продвижения любого сайта. Здесь есть свои особенности и их понимание упростит выход в топ вашему ресурсу.
В статье я постарался просто рассказать о частотности ключей и где их собирать. Этих знаний более чем достаточно для составления базовой эффективной семантики. Вы можете работать с ними сами, а можете обратиться к нам в UAATEAM. Мы проработаем глубокую семантику и предложим оптимальную стратегию продвижения.
- #Keyword
- #SEO
- #SEO-продвижение
Подписаться
Блог
Vacancy
Подписаться
Блог
Vacancy
Получить спецпредложение
Некорректно введен Email
Пожалуйста, заполните поля отмеченныеUP
Частотность поисковых запросов — сервис для определения частотности
Частота ключевых слов и SEO
Если вы пытаетесь занять место по ключевому слову органически , важно знать частоту ваших ключевых слов. Если частота ваших ключевых слов слишком низкая, у вас возникнут проблемы с рейтингом по этому ключевому слову, если только уровень конкуренции не будет очень низким. Поисковые системы, такие как Google, должны видеть «доказательство» в виде ключевых слов, что ваш контент действительно соответствует запросу.
Если частота ваших ключевых слов слишком низкая, у вас возникнут проблемы с рейтингом по этому ключевому слову, если только уровень конкуренции не будет очень низким. Поисковые системы, такие как Google, должны видеть «доказательство» в виде ключевых слов, что ваш контент действительно соответствует запросу.
Однако, если частота вашего ключевого слова слишком высока, это посылает негативный сигнал поисковым системам. Избегайте черных методов, известного как «наполнение ключевыми словами», когда частота ваших ключевых слов неестественно высока и отвлекает пользователей.
Как определить частотность
Веб-мастер и SEO-специалист определяет частотность запроса при помощи специализированных сервисов. Например, в Яндексе это Вордстат (читайте, как это сделать в нашей статье). Если воспользоваться кавычками, перед запросом и после него, то в итоге система выдает данные о частоте, учитывая необходимую последовательность слов. Для получения точных данных по частоте с имеющейся морфологией, перед словом следует ставить «!».
Какая частота ключевых слов считается хорошей?
Новички в SEO и платном поиске часто спрашивают, какая частота ключевых слов «хорошая» или какие рекомендации им следует соблюдать, когда дело доходит до определения правильной плотности ключевых слов. К сожалению, как и в случае со многими элементами SEO и интернет-рекламы, существует несколько настоящих «правил» относительно частоты ключевых слов. Однако есть некоторые общепринятые передовые методы, которым вы, возможно, захотите следовать.
Вообще говоря, многие профессионалы SEO согласны с тем, что ключевое слово не должно появляться чаще одного раза на 200 слов текста. Это означает, что из каждых 200 слов текста на веб-странице данное ключевое слово не должно появляться более одного раза.
Сюда входят близкие варианты ключевого слова. Например, «подержанные автомобили» — это вариант ключевого слова «подержанные автомобили». Хотя эти два термина различны, они тесно связаны семантически; их значения идентичны, и только их формулировка отличает их друг от друга. Это означает, что вам следует попытаться разделить варианты ключевых слов, как если бы вы использовали несколько экземпляров одного и того же ключевого слова.
Это означает, что вам следует попытаться разделить варианты ключевых слов, как если бы вы использовали несколько экземпляров одного и того же ключевого слова.
Насколько важна частота ключевых слов?
Хотя частота ключевых слов может повлиять на степень обнаружения сайта или веб-страницы, это лишь один из многих таких факторов.
В прошлом многие сайты обходились без «наполнения ключевыми словами» — практики запихивания как можно большего количества ключевых слов и вариантов на одной веб-странице в попытке манипулировать рейтингом страницы. Однако сегодня алгоритмы поиска значительно сложнее, что делает такие методы в значительной степени бесполезными и потенциально даже вредными.
Частота ключевых слов и пользовательский опыт
Возможно, было бы более эффективно думать о частоте ключевых слов не в контексте внутреннего SEO, а скорее в контексте пользовательского опыта.
Независимо от того, какой тип контента содержит веб-страница — список продуктов, сообщение в блоге, целевая страница, страница с благодарностью — всегда учитывайте взаимодействие с пользователем. Все тексты должны читаться легко и естественно, а включение вынужденных, неудобных ключевых слов — один из самых быстрых способов испортить впечатление вашей аудитории.
Все тексты должны читаться легко и естественно, а включение вынужденных, неудобных ключевых слов — один из самых быстрых способов испортить впечатление вашей аудитории.
Заблуждения, связанные с частотностью
Миф первый. Частотность по Wordstat соответствует частоте запросов в поисковой системе Яндекс
Число, которое размещенное напротив определенного запроса, является только предварительным прогнозным значением показов в течение месяца. Точная информация может быть получена исключительно по факту. Для этого необходимо выбрать запрос как ключ и проверить статистику на основании отчетного промежутка времени.
Для получения более точного прогнозного значения необходимо помнить о специализированных операторах – восклицательный знак и кавычки. Также можно указывать регион и использовать прочий инструментарий, предлагаемый сервисом.
Миф второй. Трафик можно предсказывать с помощью информации из Wordstat Результаты экспериментов, которые проводили оптимизаторы, продемонстрировали, что если сайт находится в ТОП-10 по высокочастотному запросу, то это не гарантирует ему трафик.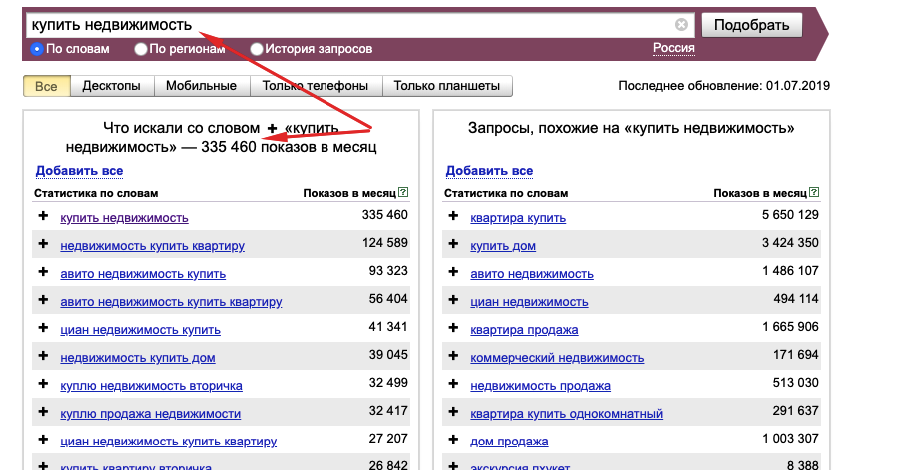
Миф третий. Информация о частоте запросов из Вордстат позволяет составить семантическое ядро
Информация, предлагаемая данным сервисом, не может считаться полноценным источником формирования семантического ядра для продвижения. Конкурентным и целевым может считаться менее частотный запрос. С помощью таких запросов удается увеличить не только прирост трафика, но и увеличение продаж. Даже если напротив запроса указана цифра 9, то это еще не значит, что данный запрос никто не вводит в строку поиска. Высокочастотный запрос иногда не имеет соответствующего частоте трафикового потенциала. Анализ рынка и опыт специалиста является залогом успеха.
РуководствоBNCweb: Списки частот Руководство
BNCweb: Списки частот| [Стандартный запрос | Лемма-запрос | Просмотр файла | Поиск слова | Сканировать ключевые слова/заголовки | Исследуйте жанровые ярлыки | Списки частот | Настройки пользователя | История запросов | Сохраненные запросы | Создать/Редактировать подкорпуса | Параметры пост-запроса ] |
Функция Частотный список позволяет составлять упорядоченные списки лексических единиц и форм лемм на основе
ряд определяемых пользователем параметров.
Текст | Опция/кнопка | Пояснение/совет |
Частоты POS-тегов | ||
Выберите один или несколько POS-тегов: | нет ограничений любой глагол любое существительное любое соединение любое прилагательное любое наречие любое местоимение AJ0 АЕК АЖС АТ0 АВ0 АВП АВК ЗАО ЗАО CJT CRD ДПС ДТ0 ДТК EX0 ITJ NN0 NN1 NN2 NP0 ОРД ПНИ ПНП PNQ ПНКС POS ЧПИ ПРП ТО0 UNC ВББ ВБД ВБГ ВБИ ВБН ВБЗ ВДБ ВДД ВДГ VDI ВДН ВДЗ ВХБ VHD ВХГ ДМС ВХН ВГЗ ВМ0 ВВБ ВВД ВВГ ВВИ ВВН ВВЗ ХХ0 ZZ0 AJ0_AV0 AJ0_NN1 AJ0_VVD AJ0_VVG AJ0_VVN AV0_AJ0 AVP_PRP AVQ_CJS CJS_AVQ CJS_PRP CJT_DT0 CRD_PNI DT0_CJT NN1_AJ0 NN1_NP0 NN1_VVB NN1_VVG НН2_ВВЗ NP0_NN1 PNI_CRD PRP_AVP PRP_CJS VVB_NN1 VVD_AJ0 ВВД_ВВН ВВГ_АЖ0 ВВГ_НН1 ВВН_АЖ0 ВВН_ВВД ВВЗ_НН2 ПУЛ PUN PUQ ПУР | Чтобы выбрать несколько элементов в одном слоте/позиции (например, все теги
начало VB-):
|
| Показать слова | начиная с и заканчивая содержащим | Применяет шаблон регулярного выражения в качестве фильтра. Вы можете ввести строку буквенно-цифровых символов
(например, ing ), чтобы получить слова, которые начинаются с/заканчиваются/содержат соответствующие вашему вводу. Вы также можете ввести
регулярное выражение для применения более гибкого фильтра (например, Вы можете ввести строку буквенно-цифровых символов
(например, ing ), чтобы получить слова, которые начинаются с/заканчиваются/содержат соответствующие вашему вводу. Вы также можете ввести
регулярное выражение для применения более гибкого фильтра (например, |
Диапазон текстов: | Весь BNCТолько разговорные текстыТолько письменные тексты | Выбирает, будет ли список частот основываться на всем корпусе или только на устном или письменном компоненте. Другие типы
ограничения (например, текстовый домен, возраст автора и т. д.) недоступны, поскольку для необходимых баз данных потребуются огромные объемы
дискового пространства. |
Диапазон частот (опционально): | от до | Сокращает список частот до элементов, которые встречаются в определенном частотном диапазоне. |
Тип заказа: | по убываниюпо возрастанию | Влияет на то, будет ли наиболее часто встречающийся элемент отображаться первым или последним в списке. |
Количество элементов, отображаемых на странице: | 10 50 100 250 350 500 1000 | Установка для этого параметра более высокого значения может сэкономить ваше время, если вас интересуют не только самые верхние элементы результирующего списка.
Причина: Возможна навигация по списку частот (см. ниже), но смена страницы может занять много времени, т. к.
запрос должен быть повторно выполнен для каждой отдельной страницы. к.
запрос должен быть повторно выполнен для каждой отдельной страницы. |
Показать частоты отдельных тегов: | Если вы выбрали несколько тегов (или диапазон тегов, таких как любое существительное ), вы можете выбрать, будут ли элементы в частоте список будет сгруппирован по лексической/леммной форме или частота каждой пары слово-тег будет отображаться отдельно. | |
На следующем снимке экрана показаны первые 15 записей в частотном списке для существительных (с POS-тегом NN1), отфильтровано с помощью регулярного выражения ун.{7,9}нес :
Вы можете перемещаться по списку частот с помощью этих трех элементов:
- |< — перейти на первую страницу списка частот
- << — переход на предыдущую страницу списка частот
- >> — переход на следующую страницу списка частот
Поскольку запрос на составление частотного списка приходится выполнять повторно, навигация между разными страницами может занять некоторое время. Не нажимайте на ссылку снова, если вы не получите немедленный ответ, так как это только замедлит работу сервера для вас и других пользователей.
Не нажимайте на ссылку снова, если вы не получите немедленный ответ, так как это только замедлит работу сервера для вас и других пользователей.
Щелчок по слову выполняет поиск комбинации слово-тег (или комбинации лемма-тип леммы в случае частоты леммы list) и отображает решения в результате запроса BNC . Этот параметр доступен только в том случае, если отображаемые элементы основаны на одном POS-тег. Если несколько POS-тегов сгруппированы вместе (см. объяснение выше), ссылка будет недоступна.
Вы также можете сохранить весь список частот на жесткий диск, выбрав Загрузить весь список частот во всплывающем окне меню. Обратите внимание, что, хотя BNCweb не мешает вам загрузить частотный список всех лексических элементов в BNC, это займет долго завершается из-за медленного соединения! Вместо этого вы можете захотеть установить нижний предел количества вхождений, необходимых для включение в список.
ПОДСКАЗКА: С помощью функции списка частот можно (в некоторой степени) обойти
ограничение, заключающееся в том, что SARA не может выполнять запросы POS-меток с самого начала. Например, если вас интересует
интенсификации, в идеале вам нужно искать все случаи, когда наречие предшествует прилагательному. Однако с BNCweb это невозможно.
вместо этого вам придется работать со списком лексических единиц. Но какие лексические единицы? Используя функцию списка частот, вы можете определить, какие
самые распространенные наречия, оканчивающиеся на -лы . 25 лучших записей этого списка охватывают значительное количество всех наречий в BNC.
Таким образом, если вы можете сказать, что проверили усиление с этими 25 наиболее часто встречающимися наречиями, оканчивающимися
в -ly ваша методологическая база более прочна, чем когда то же самое исследование делается на основе списка, составленного интуицией.
Например, если вас интересует
интенсификации, в идеале вам нужно искать все случаи, когда наречие предшествует прилагательному. Однако с BNCweb это невозможно.
вместо этого вам придется работать со списком лексических единиц. Но какие лексические единицы? Используя функцию списка частот, вы можете определить, какие
самые распространенные наречия, оканчивающиеся на -лы . 25 лучших записей этого списка охватывают значительное количество всех наречий в BNC.
Таким образом, если вы можете сказать, что проверили усиление с этими 25 наиболее часто встречающимися наречиями, оканчивающимися
в -ly ваша методологическая база более прочна, чем когда то же самое исследование делается на основе списка, составленного интуицией.
| Примечания |
- Частота слов, возвращаемая этой функцией, может иногда немного отличаться от количества совпадений, полученных стандартным запросом.
 В основном это связано с различиями в том, как обрабатываются многословные единицы. Мы пытались свести к минимуму расхождения, но, возможно, не всегда
был успешным.
В основном это связано с различиями в том, как обрабатываются многословные единицы. Мы пытались свести к минимуму расхождения, но, возможно, не всегда
был успешным. - Вам также может быть полезно посетить веб-сайт, прилагаемый к
следующая книга:
Leech, G., Rayson, P., and Wilson, A. (2001). частот слов в письменном и разговорном английском: на основе британского Национальный корпус . Лонгман, Лондон.
Содержит списки частот для весь BNC (версия 1), для устных и письменных компонентов, для разговорных (то есть демографических) и ориентированных на задачи (т. е. зависящие от контекста) части устного компонента, а также образные и информативные части письменного компонента. Он также ранжирует списки частотных слов в соответствии с частями речи (например, все существительные, все союзы) на основе всего корпуса BNC. (версия 1), а также частоты для отдельных тегов частей речи (например, NN1, VDG) на основе BNC Sampler.
Хотя списки частот для этой книги были основаны на всех 4124 файлах оригинального корпуса BNC версии 1, текстовые классификации и Используемые POS-теги были обновленными и более точными, реализованными в BNC World Edition.
| [Стандартный запрос | Лемма-запрос | Просмотр файла | Поиск слова | Сканировать ключевые слова/заголовки | Исследуйте жанровые ярлыки | Списки частот | Настройки пользователя | История запросов | Сохраненные запросы | Создать/Редактировать подкорпуса | Параметры пост-запроса ] |
Решено: Максимальный последовательный подсчет частоты в Power Query
Привет @Darko_Giac,
Пожалуйста, загрузите демонстрацию из приложения. Боюсь, вы разместили код в неправильном порядке. Во-первых, нам нужно импортировать данные в Power BI или Excel с помощью папки или файла. Затем мы можем добавить больше настраиваемых столбцов. Это может быть, как показано ниже.
лет
Source = Folder.Files("D:\Downloads\TestQueryWorkbook\RawDataFiles(SourceFolder)"),
ValuesToCount = {0..3, 99},
#"Расширенные атрибуты" = Таблица. ExpandRecordColumn(Источник, "Атрибуты", {"Тип контента", "Вид", "Размер", "Только для чтения", "Скрытый", "Система", "Каталог", "Архив", "Устройство", "Обычный", "Временный", "Разреженный файл", "ReparsePoint", "Сжатый", "Автономный", "NotContentIndexed", "Зашифрованный"}, {"Attributes.Content Type", "Attributes.Kind" , "Атрибуты.Размер", "Атрибуты.ТолькоЧтение", "Атрибуты.Скрытые", "Атрибуты.Система", "Атрибуты.Каталог", "Атрибуты.Архив", "Атрибуты.Устройство", "Атрибуты.Обычный", " Attributes.Temporary", "Attributes.SparseFile", "Attributes.ReparsePoint", "Attributes.Compressed", "Attributes.Offline", "Attributes.NotContentIndexed", "Attributes.Encrypted"}),
#"Отфильтрованные скрытые файлы1" = Table.SelectRows(#"Расширенные атрибуты", каждый [Атрибут]?[Скрытый]? <> true),
#"Отфильтрованные скрытые файлы2" = Table.SelectRows(#"Отфильтрованные скрытые файлы1", каждый [Атрибуты]?[Скрытые]? <> true),
#"Вызов пользовательской функции1" = Table.AddColumn(#"Отфильтрованные скрытые файлы2", "Преобразование файла из запроса1", каждый #"Преобразование файла из запроса1"([Содержимое])),
#"Удалены другие столбцы1" = Table.
ExpandRecordColumn(Источник, "Атрибуты", {"Тип контента", "Вид", "Размер", "Только для чтения", "Скрытый", "Система", "Каталог", "Архив", "Устройство", "Обычный", "Временный", "Разреженный файл", "ReparsePoint", "Сжатый", "Автономный", "NotContentIndexed", "Зашифрованный"}, {"Attributes.Content Type", "Attributes.Kind" , "Атрибуты.Размер", "Атрибуты.ТолькоЧтение", "Атрибуты.Скрытые", "Атрибуты.Система", "Атрибуты.Каталог", "Атрибуты.Архив", "Атрибуты.Устройство", "Атрибуты.Обычный", " Attributes.Temporary", "Attributes.SparseFile", "Attributes.ReparsePoint", "Attributes.Compressed", "Attributes.Offline", "Attributes.NotContentIndexed", "Attributes.Encrypted"}),
#"Отфильтрованные скрытые файлы1" = Table.SelectRows(#"Расширенные атрибуты", каждый [Атрибут]?[Скрытый]? <> true),
#"Отфильтрованные скрытые файлы2" = Table.SelectRows(#"Отфильтрованные скрытые файлы1", каждый [Атрибуты]?[Скрытые]? <> true),
#"Вызов пользовательской функции1" = Table.AddColumn(#"Отфильтрованные скрытые файлы2", "Преобразование файла из запроса1", каждый #"Преобразование файла из запроса1"([Содержимое])),
#"Удалены другие столбцы1" = Table. SelectColumns(#"Вызов пользовательской функции1", {"Преобразование файла из запроса1"}),
#"Expanded Table Column1" = Table.ExpandTableColumn(#"Удалены другие столбцы1", "Преобразование файла из Query1", Table.ColumnNames(#"Преобразование файла из Query1"(#"Пример файла"))),
#"Измененный тип" = Table.TransformColumnTypes(#"Expanded Table Column1",{{"Идентификатор ответа", Int64.Type}, {"Страна", введите текст}, {"Пол", Int64.Type}, {" Race", Int64.Type}, {"PFi1", Int64.Type}, {"PFi2", Int64.Type}, {"PFi3", Int64.Type}, {"PFi4", Int64.Type}, {" PFi5", Int64.Type}, {"PFi6", Int64.Type}, {"PFi7", Int64.Type}, {"PFi8", Int64.Type}, {"PFi9", Int64.Type}, {"PFi10", Int64.Type}}),
Добавленные столбцы =
Список.Накопить(
Список.Позиции(ValuesToCount),
#"Измененный тип",
(аккум, ток) =>
если ValuesToCount{curr} = 99, то
Таблица.ДобавитьКолонку(
аккум,
"Пропущено",
каждый List.
SelectColumns(#"Вызов пользовательской функции1", {"Преобразование файла из запроса1"}),
#"Expanded Table Column1" = Table.ExpandTableColumn(#"Удалены другие столбцы1", "Преобразование файла из Query1", Table.ColumnNames(#"Преобразование файла из Query1"(#"Пример файла"))),
#"Измененный тип" = Table.TransformColumnTypes(#"Expanded Table Column1",{{"Идентификатор ответа", Int64.Type}, {"Страна", введите текст}, {"Пол", Int64.Type}, {" Race", Int64.Type}, {"PFi1", Int64.Type}, {"PFi2", Int64.Type}, {"PFi3", Int64.Type}, {"PFi4", Int64.Type}, {" PFi5", Int64.Type}, {"PFi6", Int64.Type}, {"PFi7", Int64.Type}, {"PFi8", Int64.Type}, {"PFi9", Int64.Type}, {"PFi10", Int64.Type}}),
Добавленные столбцы =
Список.Накопить(
Список.Позиции(ValuesToCount),
#"Измененный тип",
(аккум, ток) =>
если ValuesToCount{curr} = 99, то
Таблица.ДобавитьКолонку(
аккум,
"Пропущено",
каждый List.