онлайн сервис для распознавания, обхода и автоматического решения капч
Процесс решения обычной капчи заключается в следующем: мы забираем изображение капчи со страницы ее размещения и передаем в сервис ruCaptcha, где ее решает работник, после чего нам возвращается ответ, который необходимо ввести в соответствующее поле для решения капчи
API демонстрацияКак решитьПроцесс решения текстовой капчи заключается в следующем: мы забираем текстовый вопрос капчи со страницы ее размещения и передаем в сервис ruCaptcha, где ее решает работник, после чего нам возвращается ответ, который необходимо ввести в соответствующее поле для решения капчи
API демонстрацияКак решитьПроцесс решения заключается в следующем: мы забираем изображение капчи со страницы ее размещения и инструкцию, по каким картинкам необходимо кликать и передаем в сервис ruCaptcha, где ее решает работник, после чего нам возвращается ответ в виде набора координат точек на изображении, по которым необходимо кликнуть для решения капчи
API демонстрацияКак решитьПроцесс решения Rotate Captcha заключается в следующем: мы забираем изображение капчи со страницы ее размещения и передаем в сервис ruCaptcha, где ее решает работник, после чего нам возвращается ответ в виде значения угла поворота изображения, на который необходимо повернуть изображение для решения капчи
API демонстрацияКак решитьПроцесс решения reCAPTCHA V2 заключается в следующем: мы забираем параметры капчи, необходимые для ее решения в виде параметра data-sitekey и адреса страницы размещения капчи и передаем их в сервис ruCaptcha, где ее решает работник, после чего нам возвращается ответ в виде токена, который необходимо ввести в соответствующее поле для решения капчи
API демонстрацияКак решитьПроцесс решения reCAPTCHA V2 Callback не отличается от аналогичного процесса решения reCAPTCHA V2: мы забираем параметры капчи, необходимые для ее решения в виде параметра data-sitekey и адреса страницы размещения капчи и передаем их в сервис ruCaptcha, где ее решает работник, после чего нам возвращается ответ в виде токена, который необходимо ввести в соответствующее поле для решения капчи. Иногда вы не найдете кнопки, отправляющей форму. Вместо нее может использоваться callback-функция. Эта функция выполняется, когда капча распознана. Обычно callback-функция определена в параметре data-callback или как параметр callback у функции grecaptcha.render
Иногда вы не найдете кнопки, отправляющей форму. Вместо нее может использоваться callback-функция. Эта функция выполняется, когда капча распознана. Обычно callback-функция определена в параметре data-callback или как параметр callback у функции grecaptcha.render
Процесс решения невидимой капчи reCAPTCHA V2 Invisible аналогичен распознаванию reCAPTCHA V2 и заключается в следующем: мы забираем параметры капчи, необходимые для ее решения в виде параметра data-sitekey и адреса страницы размещения капчи и передаем их в сервис ruCaptcha, где ее решает работник, после чего нам возвращается ответ в виде токена, который необходимо ввести в соответствующее поле для решения капчи
API демонстрацияКак решитьПроцесс решения reCAPTCHA V3 следующий: мы забираем параметры капчи, необходимые для ее решения в виде параметра data-sitekey, параметра action и адреса страницы размещения капчи и передаем их в сервис ruCaptcha, где ее решает работник с соответствующим рейтингом «человечности”, после чего нам возвращается ответ в виде токена, который необходимо ввести в соответствующее поле для решения капчи. Во многом новый вид капчи похож на reCAPTCHA V2, т.е. основной принцип остался тем же — пользователь получает от API ruCaptcha токен, который отправляется в POST-запросе к сайту, а сайт верифицирует токен через API reCAPTCHA
Во многом новый вид капчи похож на reCAPTCHA V2, т.е. основной принцип остался тем же — пользователь получает от API ruCaptcha токен, который отправляется в POST-запросе к сайту, а сайт верифицирует токен через API reCAPTCHA
Процесс решения reCAPTCHA Enterprise заключается в следующем: определяем тип reCAPTCHA, он может быть V2 или V3, после чего мы забираем параметры капчи, необходимые для ее решения в виде параметра data-sitekey и адреса страницы размещения капчи и передаем их в сервис ruCaptcha, где ее решает работник, после чего нам возвращается ответ в виде токена, который необходимо ввести в соответствующее поле для решения капчи
Как решитьПроцесс решения KeyCaptcha заключается в следующем: мы забираем набор необходимых параметров со страницы ее размещения и передаем в сервис ruCaptcha, где ее решает работник, после чего нам возвращается ответ в виде набора уже других параметров, который необходимо передать в соответствующие поля для решения капчи
API демонстрацияКак решитьПроцесс решения GeeTest Captcha заключается в следующем: мы забираем набор необходимых параметров со страницы ее размещения и передаем в сервис ruCaptcha, где ее решает работник, после чего нам возвращается ответ в виде набора уже других параметров, который необходимо передать в соответствующие поля для решения капчи
API демонстрацияКак решитьПроцесс решения заключается в следующем: мы забираем параметры капчи, необходимые для ее решения в виде параметра data-sitekey и адреса страницы размещения капчи ruCaptcha и передаем их в сервис ruCaptcha, где ее решает работник, после чего нам возвращается ответ в виде токена, который необходимо ввести в соответствующее поле для решения капчи
API демонстрацияКак решитьПроцесс решения FunCaptcha Arkose Labs заключается в следующем: мы забираем набор необходимых параметров со страницы ее размещения и передаем в сервис ruCaptcha, где ее решает работник, после чего нам возвращается ответ в виде набора уже других параметров, который необходимо передать в соответствующие поля для решения капчи
Как решитьПроцесс решения Capy Puzzle Captcha заключается в следующем: мы забираем набор необходимых параметров со страницы ее размещения и передаем в сервис ruCaptcha, где ее решает работник, после чего нам возвращается ответ в виде набора уже других параметров, который необходимо передать в соответствующие поля для решения капчи
Как решитьПроцесс решения TikTok Captcha основан на cookies, которые нужно использовать не позднее трех секунд после решения капчи нашими работниками. Необходимо собрать все cookies со страницы, где размещена капча, передать в сервис ruCaptcha, где произойдет решение, а полученный в ответ набор cookies применить перед совершением действия, защищенного капчей на странице размещения капчи
Необходимо собрать все cookies со страницы, где размещена капча, передать в сервис ruCaptcha, где произойдет решение, а полученный в ответ набор cookies применить перед совершением действия, защищенного капчей на странице размещения капчи
Процесс решения капчи от Яндекс заключается в следующих действиях: выгружаем изображение капчи со страницы размещения и передаем в сервис ruCaptcha, далее работник решает капчу, после чего мы передаем ответ, который требуется ввести в поле для решения капчи.
Как решитьПроцесс решения капчи VK следующий: мы импортируем изображение капчи со страницы размещения и отправляем в ruCaptcha, после чего капчу решает работник, и нам возвращается ответ, который необходимо ввести в соответствующее поле для решения капчи.
Как решитьТекстовая CAPTCHA в 2022 / Хабр
В этой статье я попробую пройти весь путь в распознавании text-based CAPTCHA, от эвристик до полностью автоматических систем распознавания. Попробую проанализировать, жива ли еще капча(речь про текстовую), или пора ей на покой.
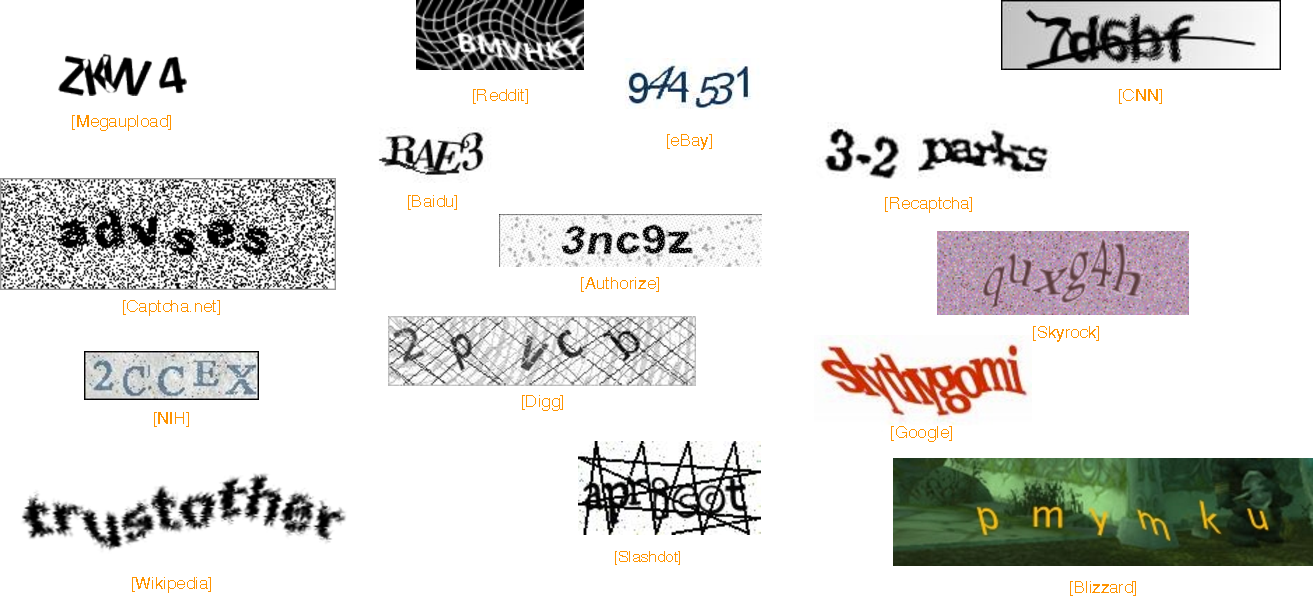
Впервые текстовая капча(text-based CAPTCHA), дальше я ее буду называть просто капча, использовалась в поисковике AltaVista, это был 1997 год, она предотвращала автоматическое добавление URL в поисковую систему. В те годы это была надежная защита от ботов, но прогресс не стоял на месте, и эту защиту начали обходить, используя доступные на то время OCR(например, FineReader).
Капча начала усложняться, в неё добавляли небольшой шум, искажения, чтобы распространенные OCR не могли распознать текст. Тогда начали появляться написанные под конкретные капчи OCR, что требовало дополнительных затрат и знаний у атакующей стороны. И от разработчиков капчей требовалось понимание, в чем сейчас трудности у атакующего, и какие искажения нужно внести, чтобы было сложно автоматизировать распознавание капчи. Часто из-за непонимания, как работает OCR, вносились искажения, которые больше создавали проблем человеку, чем машине. OCR для разных типов капч писались с использованием эвристик, и одним из сложных этапов была сегментация капчи на отдельные символы, которые потом можно было легко распознать с помощью тех же CNN(например LeNet-5), да и SVM покажут неплохой результат даже на сырых пикселях.
В качестве объекта распознавания возьму капчу Яндекса с сайта Yandex.com. На русскоязычной версии сайта капчи немного сложнее из-за того, что используются как русские, так и английские слова.
Примеры капчНа первый взгляд, достаточно правильно бинаризировать картинку(перевести в черно-белый вариант) и дело в шляпе, можно получить большой процентов правильных распознаваний, так как сегментация на отдельные буквы выглядит довольно простой.
Для снижения эффективности эвристических алгоритмов Яндекс сделал упор на сложность бинаризации: есть капчи, для которых в каждой области изображения будет свой порог бинаризации, и надо подбирать его адаптивно. В среднем капча содержит 14 символов. Даже если мы сделаем классификатор с точностью 99%, и все капчи будем правильно сегментировать, то это нам даст точность в 87% распознавания всей капчи из двух слов. Здесь еще стоит упомянуть, что на сложность модели влияет количество классов(букв, цифр, знаков), используемых во всем наборе капч — чем их больше, тем сложнее достичь высоких процентов распознавания отдельных символов на простых моделях, поэтому капча на яндекс. ру будет сложнее, т.к. в ней используются русские и английские слова.
ру будет сложнее, т.к. в ней используются русские и английские слова.
Из слабых мест этой капчи можно отметить, что буквы легко сегментируются при правильной бинаризации, и можно использовать проверку по словарю.
Далее будет описан эвристический алгоритм распознавания, а также я оставлю здесь ссылку на обучающую и тренировочную выборки.
Подготовительный этап
Для начала скачаем капчи и разделим их на тренировочную выборку и тестовую. Скачивание изображений капчи происходило через ВПН(с сайта yandex.com). При попытке сделать аккаунт вручную через браузер система меня распознавала ботом(думаю, из-за ВПН). Поэтому, предполагаю, я получил капчи с повышенной сложностью — «Если на втором этапе мы по-прежнему считаем запрос подозрительным, но степень уверенности в этом не такая высокая, то показываем простейшую капчу. А вот если мы уверены, что перед нами робот, то можем сложность и приподнять. Простое, но эффективное решение. » https://habr.com/ru/company/yandex/blog/549996/ Тип браузера, похоже, на результат не влиял (Opera, Chrome, Edge).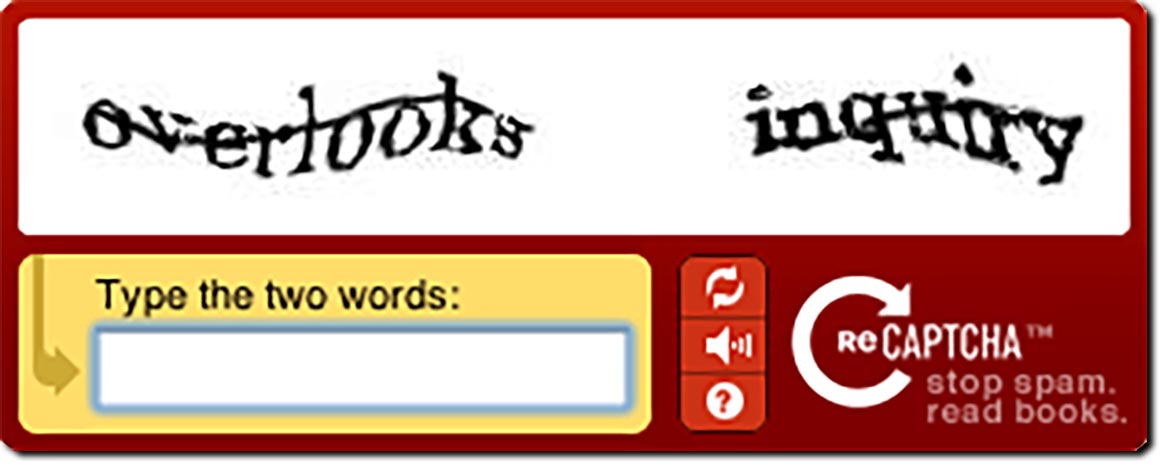
Итого набралось 4847 капч в тренировочную выбрку, и 354 — в тестовую. На распознавание обеих выборок было потрачено несколько долларов на сервисе decaptcher.com.
Эвристический алгоритм распознавания
Алгоритм будет состоять из нескольких шагов, это бинаризация, очистка от шума, извлечение двух слов, при необходимости — нормализация наклона для каждого слова, потом сегментация и распознавание.
1. Бинаризируем картинку — перевод цветного изображения, или изображения в градациях серого в черно-белое изображения. Цель — получение фона(0) и объекта(1), и уменьшение шума после бинаризации. Алгоритмы бинаризации будут описаны ближе к концу. Далее для каждого этапа сформируем параметры, которые будем потом оптимизировать. С этого момента работаем только с бинарным изображением.
2. Бинарное изображение очищаем от шума. Извлекаем связанные области из изображения — это наши объекты. Далее по количеству пикселей, которые входят в объект, разделяем их на шум и полезный объект. Все, что входит в наш интервал от А до В (по числу пикселей), это полезные объекты, остальное отсеиваем. В этом случае, например, у буквы i точка может быть определена как шум, чтобы этого не происходило, введем еще третью величину, расстояние С, это расстояние шума малого размера(эту величину мы тоже будем подбирать) до полезного объекта. Параметры А,В и С найдем простым перебором на тренировочном наборе, где максимизируем количество правильно распознанных капч.
Все, что входит в наш интервал от А до В (по числу пикселей), это полезные объекты, остальное отсеиваем. В этом случае, например, у буквы i точка может быть определена как шум, чтобы этого не происходило, введем еще третью величину, расстояние С, это расстояние шума малого размера(эту величину мы тоже будем подбирать) до полезного объекта. Параметры А,В и С найдем простым перебором на тренировочном наборе, где максимизируем количество правильно распознанных капч.
3. Извлекаем из изображения 2 слова. Пробел между словами находится примерно по центру изображения. Величину «примерно» будем искать в окне ширины X, это будет еще одним параметром для оптимизации. Далее получаем горизонтальную гистограмму яркости в этом окне, вводим еще одно значение — порог, который будет нам показывать в этом столбце пробел, или объект, наибольшее кол-во пробелов подряд будут нам говорить о том, что это место разделения двух слов. В этой процедуре нам нужно подобрать 2 параметра, оптимальная ширина окна в центре изображения, и порог, который нам показывает, объект это, или пробел.
В этой процедуре нам нужно подобрать 2 параметра, оптимальная ширина окна в центре изображения, и порог, который нам показывает, объект это, или пробел.
4. Нормализация наклона текста(для тех капч, где она нужна). Чтобы получить точность распознавания отдельных букв выше, нужно в некоторых капчах нормализовать наклон. Для этого мы проводим морфологическую операцию закрытие, и у нас получается единый объект. Далее находим ориентацию этого объекта, это угол между осью Х и главной осью элипса, в который вписывается наш объект.
Примеры нормализации наклона5. Сегментация. На этом этапе у нас есть изображения 2-х слов, теперь нужно разбить их на отдельные буквы, для дальнейшего распознавания. Так как в нашем случае буквы не соприкасаются вместе, то можем извлечь связные области из изображения, это и будут наши символы, пригодные для дальнейшего распознавания.
Примеры символов извлеченные из двух изображений6. Распознавание символов. Для распознавания я использовал сверточную сеть Lenet-5, только в моем случае классов было 26, в оригинале — 10. Для предобучения сети я сделал выборку в 52 тыс. изображений букв(по 2 тыс. на класс), отобрал несколько шрифтов, добавил различные искажения и обучил сверточную сеть. Подбирая параметры к алгоритму бинаризации и сегментации, мы получаем выборку для обучения классификатора. Эта выборка будет использована на втором и последующих шагах обучения классификатора, первый шаг обучения проходил с искуственно сгенерированными символами. Процесс итерационный, итого я смог насобирать 47 тыс. изображений букв с капч. Классы распределялись неравномерно, но это ожидаемо, так как в капче используют слова, а не случайные наборы букв. Итоговый классификатор имел точность 98.48%.
Для распознавания я использовал сверточную сеть Lenet-5, только в моем случае классов было 26, в оригинале — 10. Для предобучения сети я сделал выборку в 52 тыс. изображений букв(по 2 тыс. на класс), отобрал несколько шрифтов, добавил различные искажения и обучил сверточную сеть. Подбирая параметры к алгоритму бинаризации и сегментации, мы получаем выборку для обучения классификатора. Эта выборка будет использована на втором и последующих шагах обучения классификатора, первый шаг обучения проходил с искуственно сгенерированными символами. Процесс итерационный, итого я смог насобирать 47 тыс. изображений букв с капч. Классы распределялись неравномерно, но это ожидаемо, так как в капче используют слова, а не случайные наборы букв. Итоговый классификатор имел точность 98.48%.
Теперь, в зависимости от метода бинаризации, я представлю результаты распознаваний. Сначала я использовал один порог бинаризации для всех капч, порог подобрал на тренировочной выборке, и получил 15% правильно распознанных капч на тренировочной и 15% на тестовой.
Использование алгоритма Оцу дало 13.6% на тренировочной и 12.25% на тестовой.
Метод бинаризации Sauvola, после подбора параметров он дал 26.01% на тренировочной и 25.8% на тестовой.
Подметив, что капчи можно разделить по фону на группы, сделаем кластеризацию. Признаки извлечем с помощью метода Zoning. Суть метода такова — изображение делится на непересекающиеся области заданного размера, после чего извлекаем из каждой области среднее значение яркости. Чем меньше у нас размер окна, тем точнее описывается изображение. Для разделения на кластеры используем алгоритм кластеризации k-means. Классические методы определения оптимального количества кластеров показывали 2 кластера. Эмпирически я выбрал количество кластеров равное 5. Разбивка по кластерам получилась такая: в первом — 842 шт, во втором — 1300 шт, в третьем -1237 шт, в четвертом — 770 шт, в — пятом 698 шт изображений. Для каждого кластера подбираем свои параметры бинаризации алгоритма Sauvola на тренировочном наборе. В итоге получаем точность в 31.22%, на тестовом — 30.8%.
В итоге получаем точность в 31.22%, на тестовом — 30.8%.
Примеры кластеров:
Кластер 1Кластер 2Кластер 3Кластер 4Кластер 5Теперь у нас есть капчи, которые мы правильно бинаризировали, можно попробовать что-нибудь потяжелее, например U-Net для бинаризации, сеть с 13.5+ млн. параметров. Получили на тренировочных данных 39,2% правильных ответов, на тесте — 38.7%.
Для каждого нового типа капч, нам приходилось бы придумывать какие то новые схемы бинаризации, сегментации, что делает задачу трудоемкой в зависимости от капчи, но не невозможной. И затраты на разработку такой системы был порогом, который не каждый мог преодолеть для автоматического распознавания капчи и использования сервиса ботами.
А что на счет полностью автоматизированного процесса создания модели для распознавания, где не надо ничего придумывать, никакой эвристики? На вход — капчи с ответами, на выходе — готовая модель. Относительно недавно на сайте библиотеки Keras появились исходники, которые, при небольшой модификации, можно использовать для распознавания любых текстовых капч https://keras. io/examples/vision/captcha_ocr/
io/examples/vision/captcha_ocr/
На Яндекс капче у меня получились такие цифры: на тренировочных данных сеть показала точность 55%, на тестовых — 39%. Из-за слишком маленькой тренировочной выборки для такой большой сети происходило быстро переобучение, но при правильно подобранных параметрах регуляризации сеть могла обучаться. Если увеличить тренировочную выборку, добавив туда отраженные картинки, то получим на тренировочных 58% точности, а на тесте — 43%. Увеличение тренировочной выборки новыми капчами даст еще прирост правильных ответов.
Сеть чаще всего ошибается на капчах такого вида:
Типы капч на которых система чаще всего ошибаетсяЭто коррелирует с тезисом авторов Яндекс капчи, в своей статье они писали -«Наиболее сложные датасеты с распознаванием слов на сегодняшний день представляют собой сильно искривлённые тексты (irregular text recognition).» Но в данном случае это скорее ограничение архитектуры используемой сети. Полученные фичи после слоев CNN мы распознаем lstm слоем последовательно слева направо, и в некоторых срезах возможного символа у нас находится сразу несколько символов. Это легко показать, сделав набор вот таких «капч»(рис. 1 ) в 10 тыс тренеровочных и 1 тыс тестовых. Обучив сетку, получим правильных ответов всего 20%, и 80% ошибок.
Это легко показать, сделав набор вот таких «капч»(рис. 1 ) в 10 тыс тренеровочных и 1 тыс тестовых. Обучив сетку, получим правильных ответов всего 20%, и 80% ошибок.
Но если сделать капчи, написав текст в одну строчку и добавив в текст искажения, усложняя ее (рис. 2), то получим 97% правильных ответов и 3% ошибочных.
Рис. 2Для увеличения процента успешных распознаваний яндекс капч можно использовать детектор текста, после чего нормализовать наклон и далее распознать нейронной сетью. Примеры сложных яндекс капч и детектора текста(рис. 3)
Рис. 3Если использовать детектор текста, то мы получим на тренировочных 60% точности, а на тесте — 51%. Я использовал уже предобученный на синтетике детектор текса — CRAFT: Character-Region Awareness For Text detection, а распознаванием отдельных слов занималась уже обученная модель на самой Яндекс капче.
Разработчики из Яндекса при проектировании капчи решали сразу две проблемы — уменьшение потенциальной эффективности ОЦР при «дружелюбности» для человека. Но чаще встречается такой подход к созданию текстовых капч — если человеку трудно ее распознать, то сложно и машине(рис. 4)
Но чаще встречается такой подход к созданию текстовых капч — если человеку трудно ее распознать, то сложно и машине(рис. 4)
Но это не так, нейронные сети без труда «ломают» такие капчи и могут показать уровень расознавания выше человеческого. При этом не нужно придумывать какие-то эвристические алгоритмы, достаточно скачать готовую сетку и обучить, 99% текстовых капч она решит.
Если подвести итог, то проектирование текстовой капчи в текущих реалиях требует понимания методов и подходов, которыми будет пользоваться злоумышленник для ее распознавания и исходя из этого проектировать капчу, которая эффективно сможет противостоять роботам, и при этом будет простой для восприятия человеком.
Прошу вас поделиться своими мыслями в комментариях, как может выглядеть текстовая капча, которая будет сложной для распознавания машиной.
Cloudfare предложило способ, который заменит тест CAPTCHA
Прохождение тестов «докажите, что вы не робот», которые также называются «капча», суммарно отнимает у человечества около 500 лет ежедневно — к такому выводу пришла компания Cloudfare. Для того чтобы избавить мир от капчи, был предложен альтернативный способ для идентификации людей в интернете. Как он будет работать и каковы его преимущества перед привычной всем CAPTCHA — в материале «Газеты.Ru».
Для того чтобы избавить мир от капчи, был предложен альтернативный способ для идентификации людей в интернете. Как он будет работать и каковы его преимущества перед привычной всем CAPTCHA — в материале «Газеты.Ru».
Каждый интернет-пользователь мира сталкивался с таким явлением как капча — это автоматизированный публичный тест Тьюринга, применяющийся при авторизации на сайтах. Иногда для его прохождения требуется вводить буквы или слова, иногда — искать на фотографиях дорожные знаки или велосипеды. Как бы то ни было, любое столкновение с капчой вызывает негатив — мало того, что на нее тратится время, так еще система часто дает сбой и предлагает снова и снова проходить тест до успешного результата.
Инженер-исследователь компании Cloudfare Тибо Менье подсчитал, что каждый день человечество суммарно тратит на прохождение капчи 500 лет, сообщает Motherboard.
«Среднестатистическому пользователю нужно около 32 секунд, чтобы пройти капчу. Интернетом пользуются 4,6 млрд людей. Мы предполагаем, что пользователь сталкивается с CAPTCHA примерно раз в десять дней. Простые математические вычисления приводят нас к тому, что каждый день тратится около 500 человеческих лет просто на то, чтобы доказать нашу принадлежность к виду», — заявил Менье.
Мы предполагаем, что пользователь сталкивается с CAPTCHA примерно раз в десять дней. Простые математические вычисления приводят нас к тому, что каждый день тратится около 500 человеческих лет просто на то, чтобы доказать нашу принадлежность к виду», — заявил Менье.
Чтобы избавиться от капчи, Cloudfare разработал систему Cryptographic Attestation of Personhood [рус. Криптографическое подтверждение личности]. Вместо того, чтобы вводить буквы или рассматривать картинки, пользователь при возникновении необходимости будет вставлять в свой компьютер USB-флешку с кнопкой, которую понадобится просто нажать, чтобы тест был пройден.
«Зачем уничтожать капчу? Все просто — мы же все ее ненавидим», — утверждает Менье.
Несмотря на то, что предложенный способ тоже требует дополнительных телодвижений, Cloudfare утверждает, что он может действительно подтвердить, что вы — человек, а не робот, тем более, что уже существует масса ботов, способных справиться с любой капчой. Но станет ли новый способ удобнее и надежнее капчи?
По словам Дмитрия Бондаря, директора центра компетенций управления доступом Solar inRights компании «Ростелеком-Солар», доступ через физический USB-ключ происходит быстрее и проще, чем ввод капчи. Однако для этого способа верификации требуется постоянно иметь при себе физический ключ, а как раз это способно создать определенные неудобства.
Однако для этого способа верификации требуется постоянно иметь при себе физический ключ, а как раз это способно создать определенные неудобства.
«Для постоянных пользователей различных сервисов этот способ действительно будет удобнее, но едва ли человеку понравится постоянно носить с собой устройство, если он пользуется им раз в неделю или еще реже. В этом плане у капчи преимущество – для верификации через нее не требуется никаких дополнительных инструментов», — заявил эксперт.
Двухфакторная аутентификация с физическим носителем ключа давно используется в банковской сфере, рассказывает Дмитрий Пятунин, директор по ИТ компании Oberon.
По его словам, Cloudflare имеет все шансы увеличить популярность такой технологии среди широкого круга пользователей.
«Она имеет упрощенный порядок регистрации и отзыва ключа, но приобрести сам физический носитель все же придётся. Это удобное альтернативное решение технологии CAPTCHA, но только для тех, кому надоело разгадывать ребусы с картинками. Основным препятствием распространения может быть обеспокоенность пользователей в части сохранности конфиденциальности данных, так как ключ будет идентификатором, который позволит привязать действия пользователя к личности через механизм анализа больших данных», — предупреждает Пятунин.
Основным препятствием распространения может быть обеспокоенность пользователей в части сохранности конфиденциальности данных, так как ключ будет идентификатором, который позволит привязать действия пользователя к личности через механизм анализа больших данных», — предупреждает Пятунин.
Разработка новых систем подтверждения, которые придут на смену капче, это закономерный процесс развития общества и цифровых технологий в целом, считает Артем Деев, руководитель аналитического департамента AMarkets. По его словам, логично, что на рынке будут появляться новые способы, которые вытеснят привычное заполнение цифр и букв для подтверждения.
Однако, несмотря на все минусы, которые несет с собой капча (долгое введение символов, плохо читаемые изображения), она дает и ряд преимуществ.
«Для введения данных достаточно устройства, с которого осуществляется выход в сеть. Не нужны дополнительные приспособления, которые можно потерять.
Криптографическая аттестация личности может в будущем пользоваться популярностью и даже заменить капчу, но пока имеет ряд существенных минусов, которые будут тормозить ее продвижение. Во-первых, физические носители можно подключить не ко всем устройствам (например, не все планшеты имеют USB-выходы для того, чтобы в них вставить ключ). Во-вторых, есть риск потери и порчи физического носителя. В-третьих, потребуется некоторое время, чтобы пользователи поверили, что этот способ более надежный, легкий и безопасный. Также существует вероятность, что в будущем полноценной заменой капчи станет универсальная двухфакторная аутентификация, которая уже применяется на сайтах и позволяет не только быстро зайти на нужный сайт, но и вернуть доступ к аккаунту в случае потери пароля», — считает Деев.
Во-первых, физические носители можно подключить не ко всем устройствам (например, не все планшеты имеют USB-выходы для того, чтобы в них вставить ключ). Во-вторых, есть риск потери и порчи физического носителя. В-третьих, потребуется некоторое время, чтобы пользователи поверили, что этот способ более надежный, легкий и безопасный. Также существует вероятность, что в будущем полноценной заменой капчи станет универсальная двухфакторная аутентификация, которая уже применяется на сайтах и позволяет не только быстро зайти на нужный сайт, но и вернуть доступ к аккаунту в случае потери пароля», — считает Деев.
Эксперт по ИБ компании AT Consulting (входит в Лигу Цифровой Экономики) Андрей Слободчиков добавил, что замену CAPTCHA пытаются найти с 2000-х годов, и с тех пор использование этого теста только набирает обороты.
«Решение усложняется и изменяется, но суть остаётся прежней: человек должен доказать, что он человек. Уверен, если решение Cloudfare станут применять массово, злоумышленники быстро найдут новые способы обхода», — заключил Слободчиков.
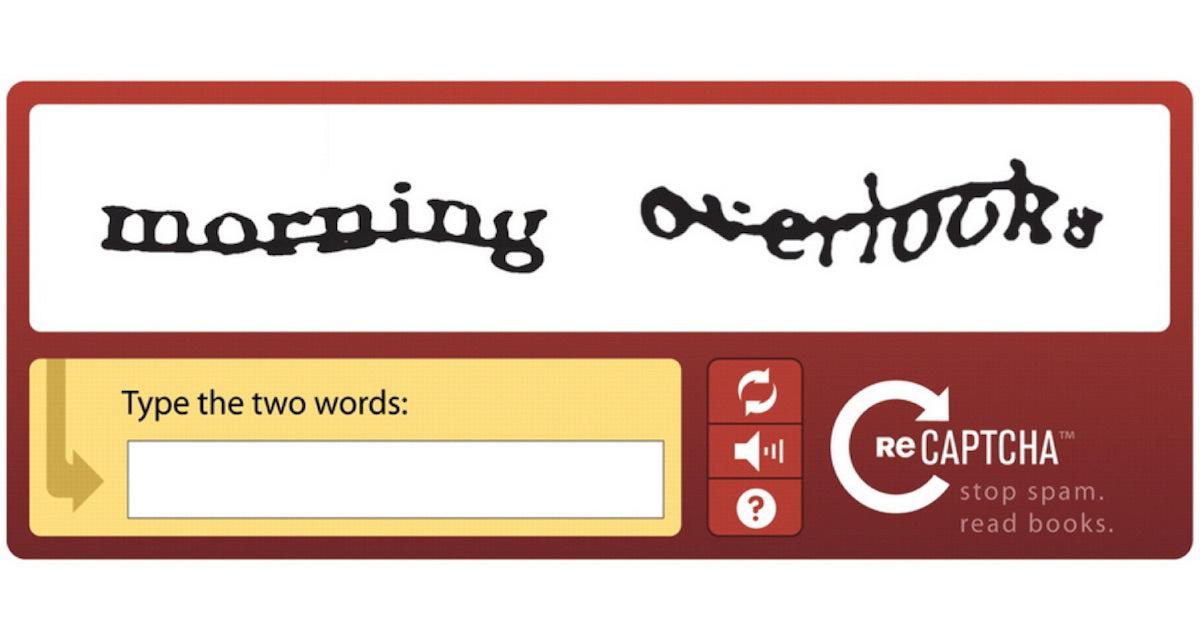
CAPTCHA — это программа, которая защищает веб-сайты от ботов, создавая и оценивая тесты, которые люди могут пройти, но современные компьютерные программы не могут. Например, люди могут читать искаженный текст, как показано ниже, но современные компьютерные программы не могут: придуман в 2000 году Луисом фон Аном, Мануэлем Блюмом, Николас Хоппер и Джон Лэнгфорд из Университета Карнеги-Меллона. Бесплатная, безопасная и доступная реализация CAPTCHA доступна в проекте reCAPTCHA . Простые в установке плагины и элементы управления
доступно для WordPress, MediaWiki, PHP,
АСП.НЕТ,
Perl, Python, Java и многие другие
среды. reCAPTCHA также поставляется со звуковым тестом, чтобы убедиться, что слепые пользователи могут свободно перемещаться по вашему сайту. reCAPTCHA официально рекомендуется
Реализация CAPTCHA.
CAPTCHA имеет несколько применений для практической безопасности, включая (но не ограничиваясь):
Если ваш сайт нуждается в защите от злоупотреблений, рекомендуется использовать CAPTCHA. Существует множество реализаций CAPTCHA, некоторые лучше, чем другие. Следующие рекомендации настоятельно рекомендуются для любого кода CAPTCHA:
Иногда ходят слухи, что спамеры используют порнографические сайты для решения CAPTCHA: изображения CAPTCHA отправляются на порносайт, а пользователи порносайта спросил решить CAPTCHA, прежде чем увидеть порнографическое изображение. Тесты CAPTCHA основаны на открытых проблемах искусственного интеллекта (ИИ): например, декодирование изображений искаженного текста выходит далеко за рамки возможностей
современные компьютеры.
|

/fptshop.com.vn/uploads/images/tin-tuc/140521/Originals/kill-captcha_800x450.png)
 CAPTCHA обеспечивает эффективный механизм для сокрытия вашего адреса электронной почты от веб-скраперов. Идея состоит в том, чтобы требовать от пользователей
решить CAPTCHA, прежде чем показать свой адрес электронной почты. Бесплатную и безопасную реализацию, которая использует CAPTCHA для запутывания адреса электронной почты, можно найти на reCAPTCHA.
ПочтаСкрыть.
CAPTCHA обеспечивает эффективный механизм для сокрытия вашего адреса электронной почты от веб-скраперов. Идея состоит в том, чтобы требовать от пользователей
решить CAPTCHA, прежде чем показать свой адрес электронной почты. Бесплатную и безопасную реализацию, которая использует CAPTCHA для запутывания адреса электронной почты, можно найти на reCAPTCHA.
ПочтаСкрыть.
 Боты поисковых систем, поскольку они
обычно принадлежат крупным компаниям, уважайте веб-страницы, которые не хотят их пускать. Однако для того, чтобы по-настоящему
гарантировать, что боты не зайдут на веб-сайт, необходимы CAPTCHA.
Боты поисковых систем, поскольку они
обычно принадлежат крупным компаниям, уважайте веб-страницы, которые не хотят их пускать. Однако для того, чтобы по-настоящему
гарантировать, что боты не зайдут на веб-сайт, необходимы CAPTCHA. Такие CAPTCHA
может сделать сайт несовместимым с Разделом 508 в США. Любая реализация CAPTCHA должна позволять слепым
пользователей, чтобы обойти барьер, например, разрешив пользователям выбирать звуковую или звуковую CAPTCHA.
Такие CAPTCHA
может сделать сайт несовместимым с Разделом 508 в США. Любая реализация CAPTCHA должна позволять слепым
пользователей, чтобы обойти барьер, например, разрешив пользователям выбирать звуковую или звуковую CAPTCHA.

 Таким образом, CAPTCHA также предлагает четко определенные задачи для сообщества ИИ и обеспечивает безопасность.
исследователей, а также злонамеренных программистов для работы над развитием области ИИ. Таким образом, CAPTCHA является беспроигрышной ситуацией: либо CAPTCHA не
сломан, и есть способ отличить людей от компьютеров, или CAPTCHA сломана, и проблема с ИИ решена.
Таким образом, CAPTCHA также предлагает четко определенные задачи для сообщества ИИ и обеспечивает безопасность.
исследователей, а также злонамеренных программистов для работы над развитием области ИИ. Таким образом, CAPTCHA является беспроигрышной ситуацией: либо CAPTCHA не
сломан, и есть способ отличить людей от компьютеров, или CAPTCHA сломана, и проблема с ИИ решена. В Еврокрипт .
В Еврокрипт .Справка по reCAPTCHA
О reCAPTCHA
- Что такое reCAPTCHA?
Использование reCAPTCHA V2
- Как использовать reCAPTCHA?
- Специальные возможности
- Эта CAPTCHA слишком сложна
- Мой компьютер отправляет автоматические запросы
Справка для пользователей reCAPTCHA
- Требования браузера для reCAPTCHA
- Не видите флажок и хотите более простую задачу?
Помощь владельцам веб-сайтов
- Как мне интегрировать reCAPTCHA на свой сайт?
- Часто задаваемые вопросы
О reCAPTCHA
Что такое reCAPTCHA?
reCAPTCHA — это бесплатная служба Google, которая помогает защитить веб-сайты от спама и злоупотреблений.
 «CAPTCHA» — это тест Тьюринга, позволяющий отличить человека от бота. Людям легко решить эту проблему, но трудно понять «ботам» и другим вредоносным программам. Добавив reCAPTCHA на сайт, вы можете заблокировать автоматизированное программное обеспечение, облегчая вход своим приветствуемым пользователям. Попробуйте на странице https://www.google.com/recaptcha/api2/demo.
«CAPTCHA» — это тест Тьюринга, позволяющий отличить человека от бота. Людям легко решить эту проблему, но трудно понять «ботам» и другим вредоносным программам. Добавив reCAPTCHA на сайт, вы можете заблокировать автоматизированное программное обеспечение, облегчая вход своим приветствуемым пользователям. Попробуйте на странице https://www.google.com/recaptcha/api2/demo.
Чтобы узнать больше о reCAPTCHA, посетите наш официальный веб-сайт или наш сайт технической документации.
Использование reCAPTCHA V2
Как использовать reCAPTCHA?
Просто установите флажок:
Если вы видите зеленую галочку, поздравляем! Вы прошли наш тест робота (да, это так просто). Вы можете продолжать то, что вы делали.
Иногда нам нужна дополнительная информация от вас, чтобы убедиться, что вы человек, а не робот, поэтому мы просим вас решить задачу:
Просто следуйте инструкциям на экране, чтобы решить головоломку, а затем продолжайте выполнять свою задачу.

Специальные возможности
reCAPTCHA работает с основными программами чтения с экрана, такими как ChromeVox (Chrome OS), JAWS (IE/Edge/Chrome в Windows), NVDA (IE/Edge/Chrome в Windows) и VoiceOver (Safari/Chrome на Mac). ОПЕРАЦИОННЫЕ СИСТЕМЫ). reCAPTCHA предупредит программы чтения с экрана об изменениях статуса, например о завершении проверки reCAPTCHA. Статус также можно найти, найдя заголовок «статус recaptcha» в разделе «виджет recaptcha» на странице. Дополнительные сведения см. в разделе Сообщения о статусе reCAPTCHA ARIA.
Пожалуйста, выполните следующие шаги, чтобы решить аудио задачу:
Если у вас проблемы со зрением, найдите и нажмите кнопку.
В зависимости от того, используете ли вы мобильное устройство, вам будет предложена одна из двух версий звукового испытания.
Нажмите PLAY и введите цифры, которые вы услышите, в поле ввода текста, расположенное после кнопки PLAY или элемента управления звуком.
 Если ваш фокус не устанавливается автоматически на поле ввода текста после нажатия кнопки PLAY, нажмите Tab, чтобы перейти к нему. Когда вы закончите вводить цифры из аудио, нажмите ENTER или нажмите кнопку «Подтвердить», чтобы отправить свой ответ.
Если ваш фокус не устанавливается автоматически на поле ввода текста после нажатия кнопки PLAY, нажмите Tab, чтобы перейти к нему. Когда вы закончите вводить цифры из аудио, нажмите ENTER или нажмите кнопку «Подтвердить», чтобы отправить свой ответ.Если ваш ответ неверный, вам будет предложено другое звуковое задание.
Если ваш ответ правильный, аудиовызов будет закрыт, а флажок reCAPTCHA станет установлен. ReCAPTCHA также уведомит программу чтения с экрана об успешной проверке.
Обратите внимание, что срок действия проверки истечет через некоторое время, и в этом случае вам нужно будет начать заново. Вы будете уведомлены, если срок действия подтверждения истечет.
Если звук не воспроизводится, попробуйте загрузить его, найдя ссылку и нажав на нее.
Находясь в поле ввода текста, вы можете нажать кнопку «R», чтобы воспроизвести звук с самого начала
Чтобы получить другое звуковое задание, найдите и нажмите кнопку.
Срок действия проверки reCAPTCHA истекает через определенное время, поэтому лучше завершить проверку reCAPTCHA последней на посещаемом веб-сайте.
Некоторые программы чтения с экрана могут испытывать трудности при переходе в режим форм. Если это произойдет, используйте функции программы чтения с экрана, чтобы включить режим форм.
Сообщение о состоянии
Подробное описание
Рекапча требует проверки
Исходное состояние: для работы на этом веб-сайте требуется проверка reCAPTCHA. Установите флажок, чтобы получить запрос на проверку.
Вызов проверки открытия
Флажок установлен, и задание загружается.
 Вы мгновенно верифицированы, если статус изменится на «Вы верифицированы». В противном случае вам необходимо пройти проверку.
Вы мгновенно верифицированы, если статус изменится на «Вы верифицированы». В противном случае вам необходимо пройти проверку.Срок действия запроса на проверку истек, установите флажок еще раз для нового запроса
Срок действия запроса проверки истек из-за тайм-аута или бездействия. Нажмите на флажок еще раз для нового испытания.
Вы подтверждены
Вы прошли проверку. Теперь вы можете продолжить работу на сайте.
Срок действия подтверждения истек, установите флажок еще раз для нового вызова
Срок действия проверки истек из-за тайм-аута или бездействия. Нажмите на флажок еще раз для нового испытания.
Эта CAPTCHA слишком сложная
Не волнуйтесь.
 Некоторые CAPTCHA сложны. Просто нажмите кнопку перезагрузки рядом с изображением, чтобы получить другое.
Некоторые CAPTCHA сложны. Просто нажмите кнопку перезагрузки рядом с изображением, чтобы получить другое.Мой компьютер отправляет автоматические запросы
На нашей необычной странице справки о дорожном движении описано, что делать, если вы видите это сообщение:
«К сожалению, ваш компьютер или сеть могут отправлять автоматические запросы. Чтобы защитить наших пользователей, мы не можем обработать ваш запрос прямо сейчас».
Справка для пользователей reCAPTCHA
Требования к браузеру для reCAPTCHA
Мы поддерживаем две самые последние основные версии:
- рабочий стол (Windows, Linux, Mac)
- Хром
- Фаерфокс
- Сафари
- Хромированная кромка
- IE до 2022 г. 15 июня
- мобильный
- Хром
- Сафари
- Родной браузер Android
- рабочий стол (Windows, Linux, Mac)
Не видите флажок и хотите более легкую задачу?
Если вы видите эту задачу reCAPTCHA, значит, среда вашего браузера не поддерживает виджет-флажок reCAPTCHA.

Есть несколько шагов, которые вы можете предпринять, чтобы улучшить свой опыт:
- Убедитесь, что ваш браузер полностью обновлен (см. минимальные требования к браузеру)
- Убедитесь, что в вашем браузере включен JavaScript
- Попробуйте отключить плагины, которые могут конфликтовать с reCAPTCHA
Обратите внимание, что некоторые сайты могут быть неправильно интегрированы с reCAPTCHA – в этом случае обратитесь к веб-мастеру сайта.
Помощь владельцам веб-сайтов
Как мне интегрировать reCAPTCHA на свой сайт?
Использовать reCAPTCHA на вашем сайте очень просто. Сначала зарегистрируйте свой сайт здесь, а затем следуйте кратким инструкциям на экране.
Часто задаваемые вопросы
Если у вас возникли какие-либо технические проблемы на вашем сайте, обратитесь к нашим часто задаваемым вопросам. Если вы не видите свою проблему в списке, обратитесь на наш форум поддержки.

Что означает CAPTCHA? | Типы и примеры CAPTCHA
Что такое CAPTCHA
CAPTCHA означает полностью автоматизированный публичный тест Тьюринга, позволяющий различать компьютеры и людей. CAPTCHA — это инструменты, которые вы можете использовать, чтобы отличить реальных пользователей от автоматизированных пользователей, таких как боты. CAPTCHA ставит перед компьютером задачи, которые сложно выполнить, но относительно легко выполнить людям. Например, определение растянутых букв или цифр или нажатие в определенной области.
Для чего используются CAPTCHA
CAPTCHA используются любым веб-сайтом, который желает ограничить использование ботами. Конкретные области применения включают:
- Поддержание точности опроса — CAPTCHA может предотвратить перекос опроса, гарантируя, что каждый голос вводится человеком. Хотя это не ограничивает общее количество голосов, которые могут быть сделаны, это увеличивает время, необходимое для каждого голоса, препятствуя многократным голосованиям.
- Ограничение регистрации для сервисов — сервисы могут использовать CAPTCHA, чтобы предотвратить рассылку ботами спама в системы регистрации для создания поддельных учетных записей. Ограничение создания учетной записи предотвращает нерациональное использование ресурсов службы и снижает возможности для мошенничества.
- Предотвращение завышения цен на билеты — билетные системы могут использовать CAPTCHA, чтобы ограничить возможность спекулянтов покупать большое количество билетов для перепродажи. Его также можно использовать для предотвращения ложных регистраций на бесплатные мероприятия.
- Предотвращение ложных комментариев — CAPTCHA может помешать ботам рассылать спам на доски объявлений, контактные формы или сайты отзывов. Дополнительный шаг, требуемый CAPTCHA, также может сыграть роль в снижении онлайн-преследований из-за неудобств.
Как работает CAPTCHA
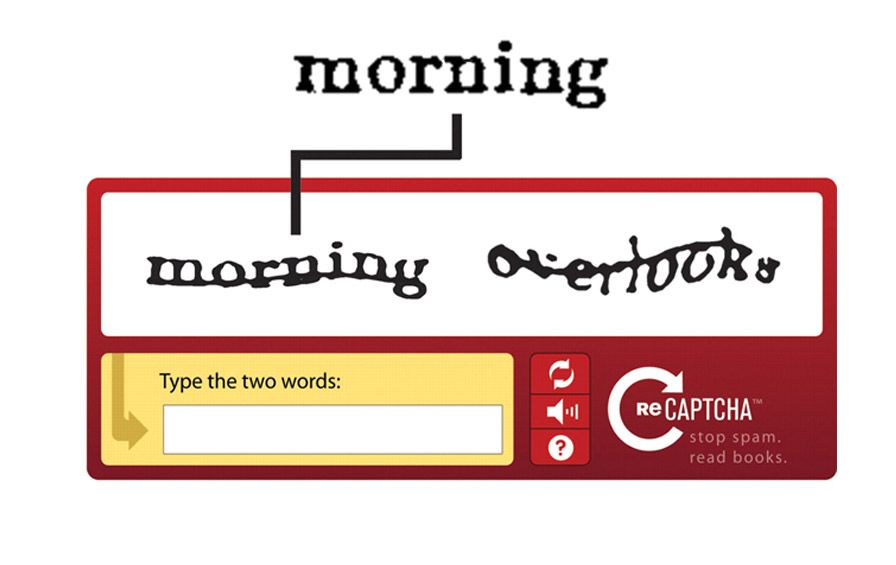
CAPTCHA работает, предоставляя пользователю информацию для интерпретации.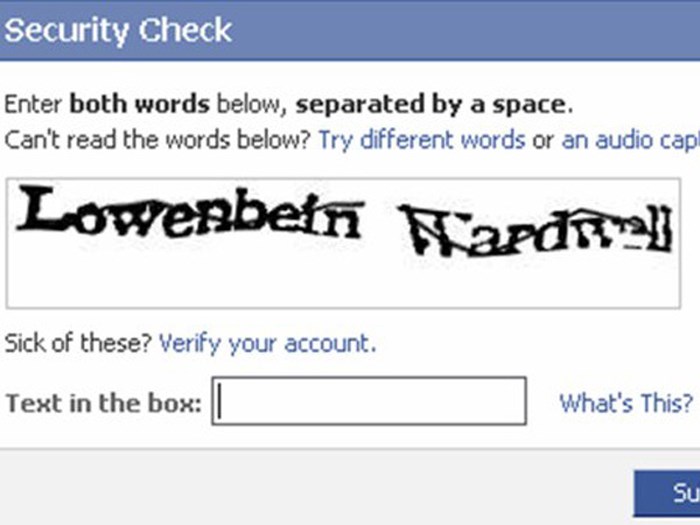 Традиционные CAPTCHA предоставляли искаженные или перекрывающиеся буквы и цифры, которые пользователь затем должен был отправить через поле формы. Искажение букв затрудняло интерпретацию текста ботами и блокировало доступ до тех пор, пока символы не были проверены.
Традиционные CAPTCHA предоставляли искаженные или перекрывающиеся буквы и цифры, которые пользователь затем должен был отправить через поле формы. Искажение букв затрудняло интерпретацию текста ботами и блокировало доступ до тех пор, пока символы не были проверены.
Этот тип CAPTCHA основан на способности человека обобщать и распознавать новые шаблоны на основе переменного прошлого опыта. Напротив, боты часто могут следовать установленным шаблонам или вводить случайные символы. Это ограничение делает маловероятным, что боты угадают правильную комбинацию.
С момента введения CAPTCHA были разработаны боты, использующие машинное обучение. Эти боты лучше распознают традиционные CAPTCHA с помощью алгоритмов, обученных распознаванию образов. Благодаря этому развитию новые методы CAPTCHA основаны на более сложных тестах. Например, для reCAPTCHA требуется щелкнуть в определенной области и подождать, пока не истечет время на таймере.
Недостатки использования CAPTCHA
Огромным преимуществом CAPTCHA является то, что она очень эффективна против всех вредоносных ботов, кроме самых изощренных. Однако механизмы CAPTCHA могут негативно повлиять на работу пользователей на вашем сайте:
Однако механизмы CAPTCHA могут негативно повлиять на работу пользователей на вашем сайте:
- Разочаровывает и разочаровывает пользователей
- Может быть трудно понять или использовать для некоторых аудиторий
- Некоторые типы CAPTCHA не поддерживаются всеми браузерами
- Некоторые типы CAPTCHA недоступны для пользователей, которые просматривают веб-сайт с помощью программ чтения с экрана или вспомогательных устройств
Типы CAPTCHA: Примеры
Современные CAPTCHA делятся на три основные категории: текстовые, графические и звуковые.
Текстовые CAPTCHA
Текстовые CAPTCHA — это оригинальный способ проверки людей. Эти CAPTCHA могут использовать известные слова или фразы или случайные комбинации цифр и букв. Некоторые текстовые CAPTCHA также включают варианты использования заглавных букв.
CAPTCHA представляет эти символы отчужденно и требует интерпретации. Отчуждение может заключаться в масштабировании, вращении, искажении символов.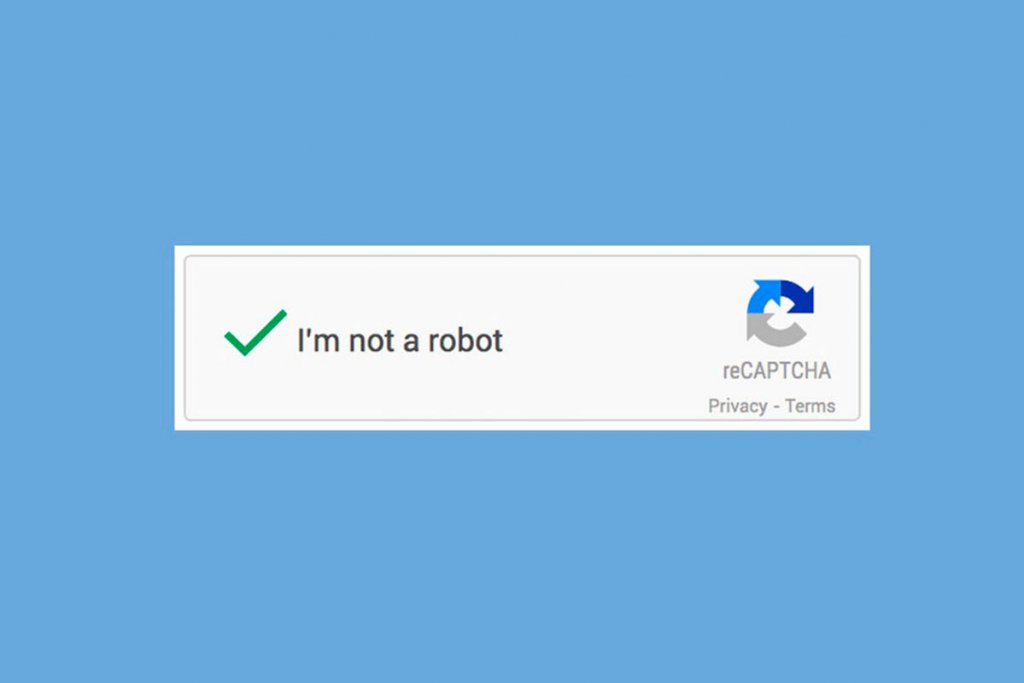 Это также может включать перекрытие символов с графическими элементами, такими как цвет, фоновый шум, линии, дуги или точки. Это отчуждение обеспечивает защиту от ботов с недостаточными алгоритмами распознавания текста, но также может быть трудным для интерпретации людьми.
Это также может включать перекрытие символов с графическими элементами, такими как цвет, фоновый шум, линии, дуги или точки. Это отчуждение обеспечивает защиту от ботов с недостаточными алгоритмами распознавания текста, но также может быть трудным для интерпретации людьми.
Текстовые шаблоны CAPTCHA
Методы создания текстовых CAPTCHA включают:
- Gimpy — выбирает произвольное количество слов из словаря на 850 слов и предоставляет эти слова в искаженном виде.
- EZ-Gimpy — — это разновидность Gimpy, в которой используется только одно слово.
- Gimpy-r — выбирает случайные буквы, затем искажает символы и добавляет к ним фоновый шум.
- Simard’s HIP — выбирает случайные буквы и цифры, затем искажает символы дугами и цветами.
CAPTCHA Изображение
CAPTCHA на основе изображений были разработаны для замены текстовых. В этих CAPTCHA используются узнаваемые графические элементы, такие как фотографии животных, фигуры или сцены.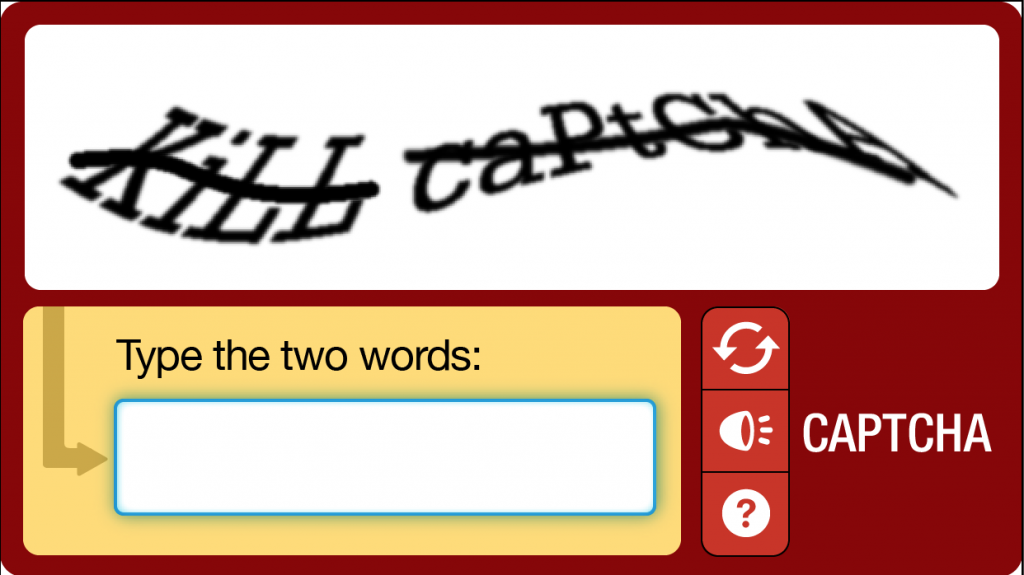 Как правило, CAPTCHA на основе изображений требует, чтобы пользователи выбирали изображения, соответствующие теме, или определяли изображения, которые не подходят.
Как правило, CAPTCHA на основе изображений требует, чтобы пользователи выбирали изображения, соответствующие теме, или определяли изображения, которые не подходят.
Вы можете увидеть пример этого типа CAPTCHA ниже. Обратите внимание, что он определяет тему, используя изображение вместо текста.
Пример CAPTCHA на основе изображений
CAPTCHA на основе изображений обычно легче интерпретировать людям, чем текстовые. Однако эти инструменты представляют определенные проблемы с доступностью для пользователей с нарушениями зрения. Для ботов CAPTCHA на основе изображений труднее интерпретировать, чем текст, поскольку эти инструменты требуют как распознавания изображений, так и семантической классификации.
Аудио CAPTCHA
Аудио CAPTCHA были разработаны как альтернатива, обеспечивающая доступность для слабовидящих пользователей. Эти CAPTCHA часто используются в сочетании с текстовыми или графическими CAPTCHA. Аудио CAPTCHA представляет собой аудиозапись серии букв или цифр, которые затем вводит пользователь.
Эти CAPTCHA основаны на том, что боты не могут отличить соответствующие символы от фонового шума. Как и текстовые CAPTCHA, эти инструменты могут быть трудны для интерпретации как людьми, так и ботами.
Математические или словесные задачи
Некоторые механизмы CAPTCHA просят пользователей решить простую математическую задачу, такую как «3+4» или «18-3». Предполагается, что боту будет трудно определить вопрос и придумать ответ. Другой вариант — это задача со словами, в которой пользователю предлагается ввести пропущенное слово в предложении или заполнить последовательность из нескольких связанных терминов. Эти типы проблем доступны для пользователей с ослабленным зрением, но в то же время их может быть легче решить плохим ботам.
Вход в систему через социальные сети
Популярная альтернатива CAPTCHA требует от пользователей входа в систему с помощью профиля в социальной сети, такой как Facebook, Google или LinkedIn. Данные пользователя будут автоматически заполнены с помощью функции единого входа (SSO), предоставляемой веб-сайтом социальной сети.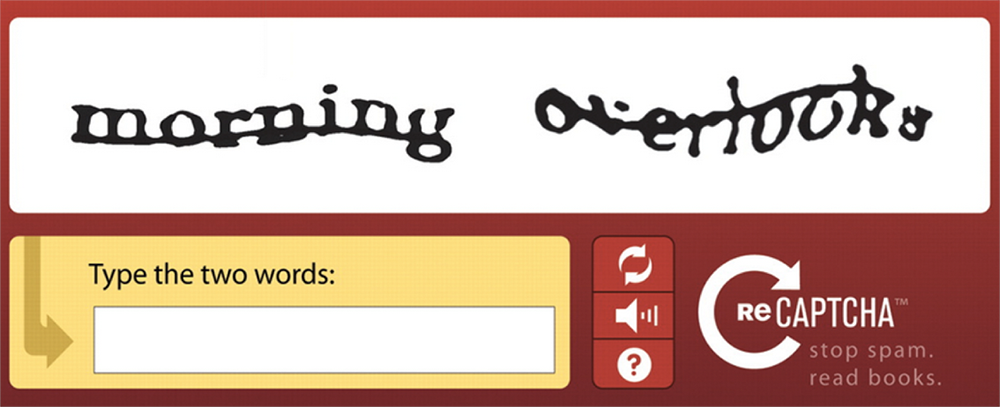
Это все еще разрушительно, но на самом деле пользователю может быть проще, чем другие формы CAPTCHA. Дополнительным преимуществом является то, что это удобный механизм регистрации.
Нет CAPTCHA ReCAPTCHA
Этот тип CAPTCHA, известный тем, что его использует Google, намного проще для пользователей, чем большинство других типов. Он предоставляет флажок с надписью «Я не робот», который пользователи должны выбрать — и все. Он работает, отслеживая движения пользователей и определяя, напоминают ли клик и другие действия пользователя на странице действия человека или действия бота. Если проверка не пройдена, reCAPTCHA предлагает традиционную проверку CAPTCHA выбора изображения, но в большинстве случаев проверки флажка достаточно для проверки пользователя.
Обнаружение ботов Imperva: CAPTCHA как последняя линия защиты
Imperva предлагает решение для обнаружения ботов, которое создано для минимального нарушения работы бизнеса. Он предлагает несколько типов вызовов, которые отфильтровывают плохой трафик ботов с минимальным воздействием на пользователей-людей, включая снятие отпечатков пальцев устройств, вызовы файлов cookie и вызовы JavaScript.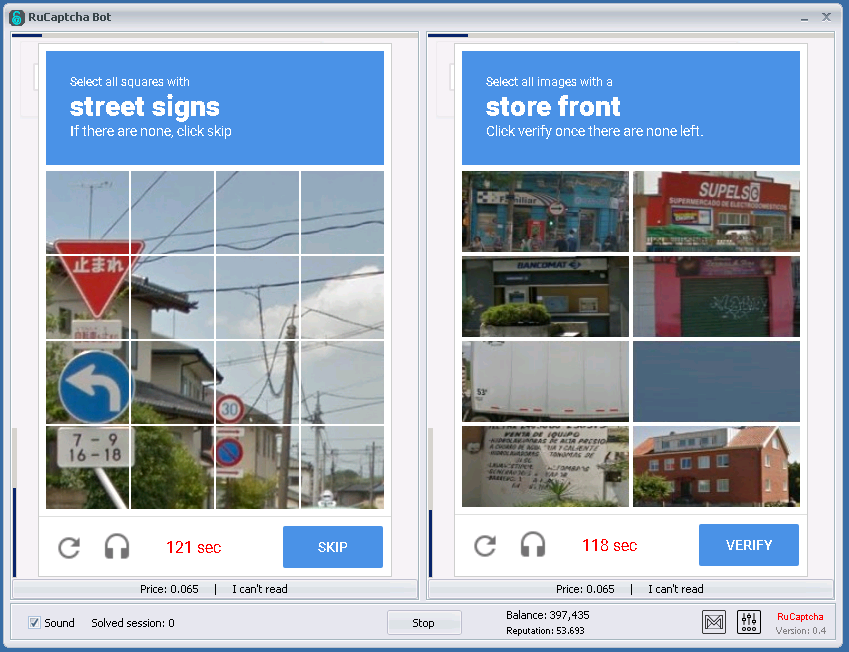
Imperva предоставляет возможность развертывания CAPTCHA, но использует ее в качестве последней линии защиты, если все другие механизмы идентификации ботов не работают. Это означает, что он будет использоваться для очень небольшого процента пользовательского трафика. Imperva предоставляет возможность вручную применять CAPTCHA для веб-сайтов, которым требуется более строгий подход к расширенной защите от ботов.
В дополнение к защите от вредоносных ботов, Imperva обеспечивает многоуровневую защиту, чтобы веб-сайты и приложения были доступны, легко доступны и безопасны. Решение по безопасности приложений Imperva включает в себя:
- Защита от DDoS-атак — поддержание бесперебойной работы в любых ситуациях. Предотвратите любой тип DDoS-атаки любого масштаба, препятствующий доступу к вашему веб-сайту и сетевой инфраструктуре.
- CDN — повысьте производительность веб-сайта и сократите расходы на пропускную способность с помощью CDN, предназначенной для разработчиков.
