Алгоритмы Яндекса — новые и старые, хронология за 2007-2017 года
Привет уважаемые читатели seoslim.ru! Тем, кто интересуется SEO и пытается развивать сайты правильно будет полезно узнать обо всех алгоритмах Яндекса, чтобы лучше понимать по каким критериям поисковая машина их ранжирует.
На протяжении всего времени Yandex постоянно вносит правки в работу алгоритмов: используются нейронные сети, устраняются ошибки, дорабатывается функционал, появляются новые фильтры и так далее.
Делается всё, чтобы выдача максимально точно отвечала на запросы пользователя.
По приведенным ссылкам вы узнаете о истории развитии компании, принципах работы поисковой машины и всех известных фильтрах.
В этой статье предлагаю всем освежить память и восстановить хронологию, дабы посмотреть, как происходила эволюция поисковых алгоритмов ранжирования Яндекса за период 2007 — 2017 годов.
| Номер | Дата | Название | Логотип |
|---|---|---|---|
| 1 | июль 2007 | Версия 7 | Нет |
| 2 | январь 2008 | 8 SP1 | Нет |
| 3 | май 2008 | Магадан | |
| 4 | сентябрь 2008 | Находка | |
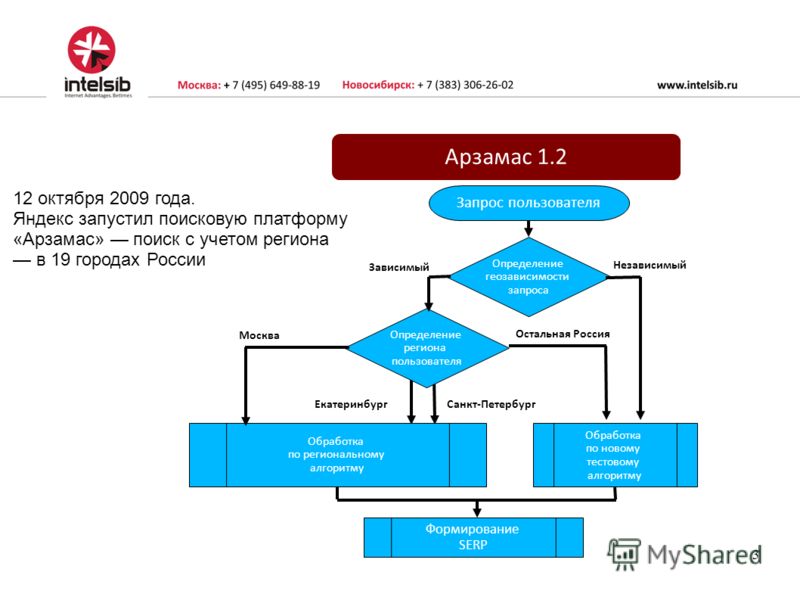
| 5 | апрель 2009 | Анадырь (Арзамас) | |
| 6 | ноябрь 2009 | Снежинск | |
| 7 | декабрь 2009 | Конаково | Нет |
| 8 | сентябрь 2010 | Обнинск | |
| 9 | декабрь 2010 | Краснодар | |
| 10 | август 2011 | Рейкьявик | |
| 11 | декабрь 2012 | Калининград | |
| 12 | май 2013 | Дублин | |
| 13 | июль 2013 | Острова | |
| 14 | апрель 2015 | Объектный ответ | Нет |
| 15 | май 2015 | Минусинск | |
| 16 | февраль 2016 | Владивосток | |
| 17 | ноябрь 2016 | Палех | |
| 18 | март 2017 | Баден-Баден | |
| 19 | август 2017 | Королёв |
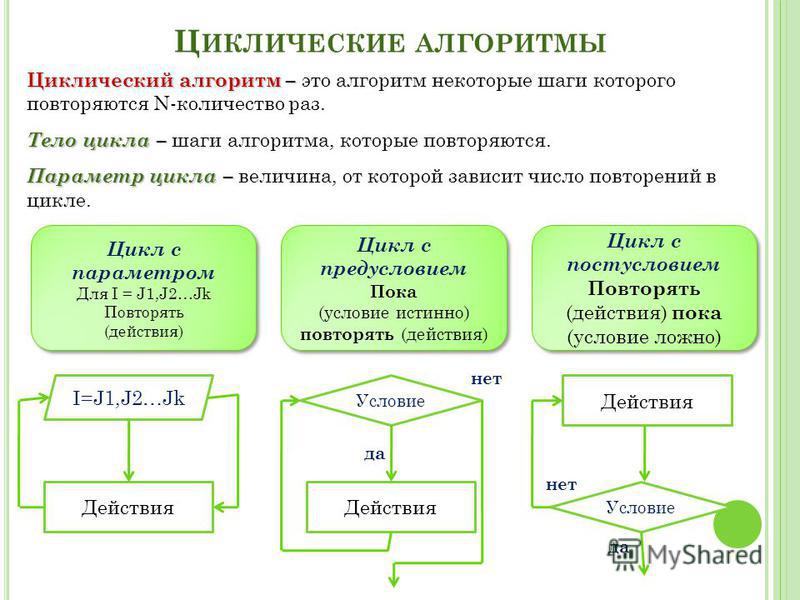
Далее о каждом из них более подробно.
«Безымянный или Версия 7» (июль 2007) — первый алгоритм, о котором было объявлено публике, цель которого улучшить релевантность выдачи.
Анонс на searchengines.guru
«8 SP1» (январь 2008) — после обновления в ТОП стали попадать старые авторитетные сайты, а ссылки стали товаром.
«Магадан» (май 2008) — запуск новой версии поиска, теперь поисковая программа могла решать ряд задач:
- Количество факторов ранжирования было удвоено.
- Алгоритмы могу быстро находить релевантные страницы, не дожидаясь обработки всех документов.
- Яндекс научился понимать слова, написанные транслитом и аббревиатуры.
- В выдаче стали отображаться сайты, не смотря на опечатки, которые исправляются автоматически.
- Расширение базы в несколько миллиардов страниц.
Анонс на yandex.ru/blog/
«Находка» (сентябрь 2008) — упор был сделан на изменения факторов ранжирования.
- Новый поход к машинному обучения.
- Учёт стоп-слов.
- Произошло расширение словарей Яндекса.
Анонс на yandex.ru/blog/
«Анадырь-Арзамас» (апрель 2009) — нововведения сильно пошатнули ТОП-выдачу.
Теперь молодым сайтам стало еще сложнее продвигаться, так как Яшка не могу определить их региональную принадлежность.
- Внедрение алгоритма «снятие омонимии», теперь Яндекс научился лучше понимать русский язык.
- Стал учитываться регион пользователя, и выдача менялась в зависимости от него.
- Был создан классификатор гео-зависимости запросов, когда в зависимости от запроса мог учитываться регион пользователя.
Релиз в yandex.ru/blog/
«Снежинск» (ноябрь 2009) — изменен подход к построению ранжирования, что позволило еще больше улучшить качество поиска.
- Появились фильтры АГС.
- Тестирование самообучающейся системы MatrixNet.
- Запуск дополнительных региональных факторов.

- Ухудшено ранжирование страниц с портянками текста.
- Первые места в выдаче отдаются первоисточнику, копипаст ранжируется хуже.
Анонс на yandex.ru/blog/webmaster/
«Конаково» (декабрь 2009) — был обновлением предыдущего алгоритма Снежинск.
- Появление новых операторов в поиске (*, / и др.).
- Расширение базы регионального ранжирования (добавлено 1250 городов России).
Релиз на yandex.ru/blog/webmaster/
«Обнинск» (сентябрь 2010) — запуск нового алгоритма, цель которого улучшить ранжирование по гео-независимым запросам.
- Снижено влияние seo-ссылок на поиск.
- Увеличен объем формулы ранжирования, который достиг 280 МБ.
- Расширение словаря транслитерации.
- Появилось понятие автор контента.
Подробнее в yandex.ru/blog/
«Краснодар» (декабрь 2010) — основой данного алгоритма стала технология «Спектр», которая могла отвечать на неточные запросы пользователей, благодаря разбавленным ответам из 60-ти категорий.
- Яндекс проиндексировал социальную сеть Вконтакте.
- Запросам стала присваиваться категория.
- Обновлено ранжирование по геозависимым запросам.
- Появились расширенные сниппеты.
Источник yandex.ru/blog/
«Рейкьявик» (август 2011) — теперь поиск стал персонализированным, то есть для каждого отображалась своя выдача.
- Появление колдунщиков, что позволило производить расчёты прямо в поиске.
- Обновлен алгоритм поисковых подсказок для новостных ресурсов.
- Тестирование программы «Оригинальные тексты».
Анонс запуска на yandex.ru/blog/company/
«Калининград» (декабрь 2012) — глобальная персонализация поисковой выдачи для запросов и подсказок.
- Обновление поисковых подсказок.
- Продвигать сайты теперь надо комплексно, теперь для Яндекса важны: ссылки, ключевые слова, дизайн, контент, юзабилити, соц. сигналы и другие факторы.
Источник yandex. ru/blog/
ru/blog/
«Дублин» (май 2013) — следствие обновление предыдущего алгоритма Калининград.
Теперь персонализированный поиск мог реагировать на сиюминутные запросы пользователя.
Если раньше Яндекс обновлял данные об интересах пользователей раз в сутки, то теперь Яшка стал анализировать текущую поисковую сессию.
Подробнее на yandex.ru/company/
«Острова» (июль 2013) — запуск новой островной выдачи и сервисов.
Предполагалось, что пользователь будет решать свои вопросы прямо в выдаче без перехода на сайт с помощью интерактивных блоков, например, купить билет в кино или на самолёт, заказать столик в кафе и др.
Подробнее в yandex.ru/blog/company/
«Объектный ответ» (апрель 2015) — после запуска данной технологии в поиске справа, появилась карточка с общей информацией о предмете запроса. Подобное решение имеется и у Google.
Пример смотрите на yandex.ru/company/
«Минусинск» (май 2015) — цель этого алгоритма занижение позиций сайтов в выдаче, которые для продвижения используют SEO-ссылок в ссылочном профиле.
Яндекс рекомендуют вебмастерам больше уделять внимание улучшению сервисов на сайте, контенту и дизайну.
Подробнее yandex.ru/blog/webmaster/
«Владивосток» (февраль 2016) — новый алгоритм нацелен на учёт факторов мобилопригодности сайтов. Теперь в мобильном поиске будет большее значение отводиться сайтам, адаптированным под мобильный интернет.
Особенности алгоритма на yandex.ru/blog/
«Палех» (ноябрь 2016) — благодаря новому алгоритму Яндекс научился отвечать на сложные запросы пользователей.
Впервые в поиске стал использоваться искусственный интеллект, который с помощью нейронных сетей может понимать запросы пользователей не по словам, а по смыслу.
Подробно про работу алгоритма yandex.ru/blog/
«Баден-Баден» (март 2017) — алгоритм, который направлен на борьбу с переоптимизированными страницами. Если на сайте будут найдены подобные тексты, то позиции таких страниц или всего сайта в выдаче будут ухудшены.
Подобные нарушения отображаются в Яндекс.Вебмастере, раздел «Диагностика» — «Безопасность и нарушения».
Анонс алгоритма в yandex.ru/blog/webmaster/
«Королёв»
Искусственный интеллект собирает данные на основе оценок пользователей, поисковой статистики, асессоров и толокеров.
Подробнее читайте на yandex.ru/blog/webmaster/
На этом все, с выходом нового алгоритма статья будет дополняться, так что добавьте ее в закладки, чтобы быть в курсе последний нововведений Яндекса.
Хронология методов продвижения сайтов от VIPro
Продвижение сайта — история термина по версии VIPRO
Истории не известен человек, который первый получил деньги от владельца сайта за услугу, целью которой было улучшить положение данного сайта в поисковой выдаче. Скорее всего, это была небольшая сумма в долларах и получил её американец индийского происхождения примерно в 1995 — 1996 годах в США. Трудно предположить, чему был посвящен этот сайт. Возможно, популярной тогда продаже компьютеров и комплектующих. Продвижение сайтов в те годы выполнялось путем корректного заполнения метатегов. Этого было достаточно для кардинального улучшения позиций продвигаемого сайта в выдаче Yahoo или Altavista, поскольку сайты-конкуренты в подавляющем большинстве не имели корректно заполненных метатегов. С тех пор прошло уже больше четырнадцати лет и продвижение сайтов сильно изменилось. Возникли новые международные и национальные поисковые системы, произошло несколько кардинальных изменений алгоритмов работы поисковых систем, возникла индустрия продвижения сайтов со своими специфическими особенностями в разных языковых и национальных секторах Интернета. Но не изменился базис продвижения: владельцы сайтов по-прежнему хотят быть первыми в поисковой выдаче. С одной стороны — поисковые системы заинтересованы в корректной индексации сайтов, которые они ранжируют,с другой — опасаются постороннего влияния на это ранжирование, а оптимизаторы, как всегда, готовы помочь владельцам продвинуть сайт в результатах поиска.
Скорее всего, это была небольшая сумма в долларах и получил её американец индийского происхождения примерно в 1995 — 1996 годах в США. Трудно предположить, чему был посвящен этот сайт. Возможно, популярной тогда продаже компьютеров и комплектующих. Продвижение сайтов в те годы выполнялось путем корректного заполнения метатегов. Этого было достаточно для кардинального улучшения позиций продвигаемого сайта в выдаче Yahoo или Altavista, поскольку сайты-конкуренты в подавляющем большинстве не имели корректно заполненных метатегов. С тех пор прошло уже больше четырнадцати лет и продвижение сайтов сильно изменилось. Возникли новые международные и национальные поисковые системы, произошло несколько кардинальных изменений алгоритмов работы поисковых систем, возникла индустрия продвижения сайтов со своими специфическими особенностями в разных языковых и национальных секторах Интернета. Но не изменился базис продвижения: владельцы сайтов по-прежнему хотят быть первыми в поисковой выдаче. С одной стороны — поисковые системы заинтересованы в корректной индексации сайтов, которые они ранжируют,с другой — опасаются постороннего влияния на это ранжирование, а оптимизаторы, как всегда, готовы помочь владельцам продвинуть сайт в результатах поиска.
Светлые страницы (с активным участием VIPRO)
Любопытное это явление — продвижение сайтов. Оно есть. С одной стороны — это большая индустрия. Только в Москве продвижением сайтов занимается несколько тысяч человек. С другой стороны — поисковые системы «не замечают» продвижения сайтов. Здесь нужно углубиться в историю продвижения сайтов. Проблема в том, что периодов,когда взаимоотношения оптимизаторов и поисковых систем были взаимовыгодными и взаимополезными было немного. Наверное, таким был период на начальном этапе продвижения сайтов, когда оптимизаторы совершенно бесплатно для поисковых систем делали сайты удобными для индексации и добавляли их в индекс. Это увеличивало количество сайтов в поисковых системах и само качество поиска. Именно таким продвижением сайтов занимается компания VIPRO с 1999 года. Далее был тёмный период конфликтов, который, мы надеемся, закончился, и теперь продвижение сайтов будет полезной услугой как для владельцев сайтов, так и для поисковых систем, за выполнение которой оптимизаторы смогут легально получать оплату за продвижение сайтов.
Черные страницы (без участия VIPRO)
Не хотелось бы рассматривать период истории продвижения сайтов с 1997 по 2008 год как время постоянных конфликтов между поисковыми системами и специалистами по продвижению сайтов. Хотя следует признать, что среди оптимизаторов встречались и встречаются люди, преследующие сиюминутные интересы и готовые испортить поисковую выдачу ради получения нужного им результата. Несколько раз за этот период ситуация была настолько критической, что складывалось впечатление, будто результаты поиска формируют не поисковые системы, а подрядчики по продвижению сайтов.
Спам метатегов
В первый раз это случилось, когда стало ясно, что выдача формируется в основном по метатегам. В ту пору все гнались за посещаемостью сайтов, не обращая внимания на качество и тематичность посетителей. Максимальную посещаемость составляли метатеги продвигаемых сайтов, состоящие из наиболее частотных поисковых запросов (работа, халява, Москва, Россия, mp3 и т.д). Быстро нашлись подрядчики, и у огромного количества разных сайтов оказались некорректно заполнены метатеги. Это был первый конфликт поисковых систем, владельцев сайтов и специалистов по продвижению сайтов. И последняя романтическая страница в отношениях этих трех субъектов. Работать на доверии стало невозможно. Появились первые санкции и первые регламенты. Поисковые системы перестроили алгоритмы ранжирования сайтов. Теперь основным фактором, влияющим на продвижение сайтов, стал реальный контент, а не метатеги.
Это был первый конфликт поисковых систем, владельцев сайтов и специалистов по продвижению сайтов. И последняя романтическая страница в отношениях этих трех субъектов. Работать на доверии стало невозможно. Появились первые санкции и первые регламенты. Поисковые системы перестроили алгоритмы ранжирования сайтов. Теперь основным фактором, влияющим на продвижение сайтов, стал реальный контент, а не метатеги.
«Дорвейная лихорадка»
Вторая критическая ситуация, связанная с продвижением сайтов — это история с «продвижением сайтов» дорвейщиками. Примерно в 2001 — 2002 году появились технологии переадресации посетителей поисковых систем с дорвейных на реальные сайты. Работало это примерно так: создавались сотни сайтов с «мусорным» контентом, все они были оптимизированы под конкретный поисковый запрос. Стоимость создания такого сайта была равна стоимости домена плюс 3-5$ за мусорный контент. Поисковая система ранжировала такие сайты, из-за большого количества текста они становились лидерами выдачи. При клике на такой сайт происходило автоматическое перенаправление посетителя на сайт с реальным контентом. Продвижение нормальных сайтов стало практически невозможным. Количество дорвейных сайтов росло лавинообразно. Возник термин «дорвейная лихорадка». За короткий срок поисковые системы сделали дорвейную технологию продвижения сайтов нерентабельной. И этот вид продвижения сайтов практически перестал существовать. Были и другие конфликты. Не хочется утомлять внимание читателя их перечислением. Компания VIPRO не применяла ни одной из вышеперечисленных технологий продвижения сайтов. Мы чтим регламенты поисковых систем и предлагаем исключительно легальные услуги продвижения сайтов.
При клике на такой сайт происходило автоматическое перенаправление посетителя на сайт с реальным контентом. Продвижение нормальных сайтов стало практически невозможным. Количество дорвейных сайтов росло лавинообразно. Возник термин «дорвейная лихорадка». За короткий срок поисковые системы сделали дорвейную технологию продвижения сайтов нерентабельной. И этот вид продвижения сайтов практически перестал существовать. Были и другие конфликты. Не хочется утомлять внимание читателя их перечислением. Компания VIPRO не применяла ни одной из вышеперечисленных технологий продвижения сайтов. Мы чтим регламенты поисковых систем и предлагаем исключительно легальные услуги продвижения сайтов.
Ссылочное ранжирование
Примерно до 1998 года все было спокойно. Мировой рынок поиска устойчиво разделился, большинство поисковых систем работало по похожему алгоритму, анализируя прежде всего тексты сайтов. И тут пришел Сергей Брин, а точнее Google. Без всякой рекламы ему удалось за очень короткий срок стать лидирующей международной поисковой системой. Google предлагал пользователям более качественную выдачу, поскольку анализировал не только тексты сайтов, но и ссылки на них. Кардинально изменилось и продвижение сайтов. С тех пор продвижение сайта состоит из двух частей: внутренняя оптимизация сайта (работа с контентом) и внешняя оптимизация сайта (установка внешних ссылок). Естественно, со стороны потерявших работу дорвейщиков и примкнувших к ним черных оптимизаторов, возникли различные сервисы, позволяющие для продвижения сайта установить на него любое число внешних ссылок. Некоторое время эти схемы были эффективны для продвижения сайтов. Выдача снова начала портиться и поисковые системы научились фильтровать и не учитывать платные внешние ссылки, установленные для поисковых систем, а не для пользователей. С тех пор на продвижение сайтов примерно в равной степени влияют 2 фактора: релевантный контент и ссылочное ранжирование.
Google предлагал пользователям более качественную выдачу, поскольку анализировал не только тексты сайтов, но и ссылки на них. Кардинально изменилось и продвижение сайтов. С тех пор продвижение сайта состоит из двух частей: внутренняя оптимизация сайта (работа с контентом) и внешняя оптимизация сайта (установка внешних ссылок). Естественно, со стороны потерявших работу дорвейщиков и примкнувших к ним черных оптимизаторов, возникли различные сервисы, позволяющие для продвижения сайта установить на него любое число внешних ссылок. Некоторое время эти схемы были эффективны для продвижения сайтов. Выдача снова начала портиться и поисковые системы научились фильтровать и не учитывать платные внешние ссылки, установленные для поисковых систем, а не для пользователей. С тех пор на продвижение сайтов примерно в равной степени влияют 2 фактора: релевантный контент и ссылочное ранжирование.
Текущая ситуация в мире
Google.com на сегодняшний день занимает около 68% мирового рынка поиска. В 2003 году был запущен алгоритм «Флорида», окончательно погубивший платные внешние ссылки в «большом Гугле». Любопытно, что изначальный алгоритм Гугла имеет русские корни (точнее Брин из Одессы), а «Флорида» — индийские. Так же любопытно существенное различие учета ссылок в «большом Гугле» и Google.ru. В итоге, современное продвижение сайтов в «большом Гугле» ( без России и Китая) находится под сильным индийским влиянием. Его выполняют индийские аутсорсинговые компании по продвижению сайтов или сотрудники американских или английских компаний по продвижению сайтов часто индийского происхождения. Делается это в два этапа. Сначала тщательно анализируется семантическое ядро и анализируется возможность продвижения сайта по всему вееру запросов: от низкочастотных до высокочастотных. Далее продвигаемый сайт максимально корректно наполняется необходимым контентом (выполняется внутренняя оптимизация). Далее начинается необходимая для продвижения сайта работа с внешними ссылками. Поскольку ставить платные ссылки опасно, предпочтение отдается массовому размещению ссылок в блогах, форумах, качественных справочниках и системах публикации пресс-релизов.
В 2003 году был запущен алгоритм «Флорида», окончательно погубивший платные внешние ссылки в «большом Гугле». Любопытно, что изначальный алгоритм Гугла имеет русские корни (точнее Брин из Одессы), а «Флорида» — индийские. Так же любопытно существенное различие учета ссылок в «большом Гугле» и Google.ru. В итоге, современное продвижение сайтов в «большом Гугле» ( без России и Китая) находится под сильным индийским влиянием. Его выполняют индийские аутсорсинговые компании по продвижению сайтов или сотрудники американских или английских компаний по продвижению сайтов часто индийского происхождения. Делается это в два этапа. Сначала тщательно анализируется семантическое ядро и анализируется возможность продвижения сайта по всему вееру запросов: от низкочастотных до высокочастотных. Далее продвигаемый сайт максимально корректно наполняется необходимым контентом (выполняется внутренняя оптимизация). Далее начинается необходимая для продвижения сайта работа с внешними ссылками. Поскольку ставить платные ссылки опасно, предпочтение отдается массовому размещению ссылок в блогах, форумах, качественных справочниках и системах публикации пресс-релизов. Чем более частотный запрос, тем больше тематического контента и внешних ссылок необходимо для продвижения сайтов. Все это актуально для текущей ситуации в продвижении сайтов. В Google уже выдумали новый алгоритм и запустят его в ближайшее время. Как он будет работать пока не ясно, обещают что лучше и быстрее. Естественно, это повлияет на индустрию продвижения сайтов.
Чем более частотный запрос, тем больше тематического контента и внешних ссылок необходимо для продвижения сайтов. Все это актуально для текущей ситуации в продвижении сайтов. В Google уже выдумали новый алгоритм и запустят его в ближайшее время. Как он будет работать пока не ясно, обещают что лучше и быстрее. Естественно, это повлияет на индустрию продвижения сайтов.
Текущая ситуация в России
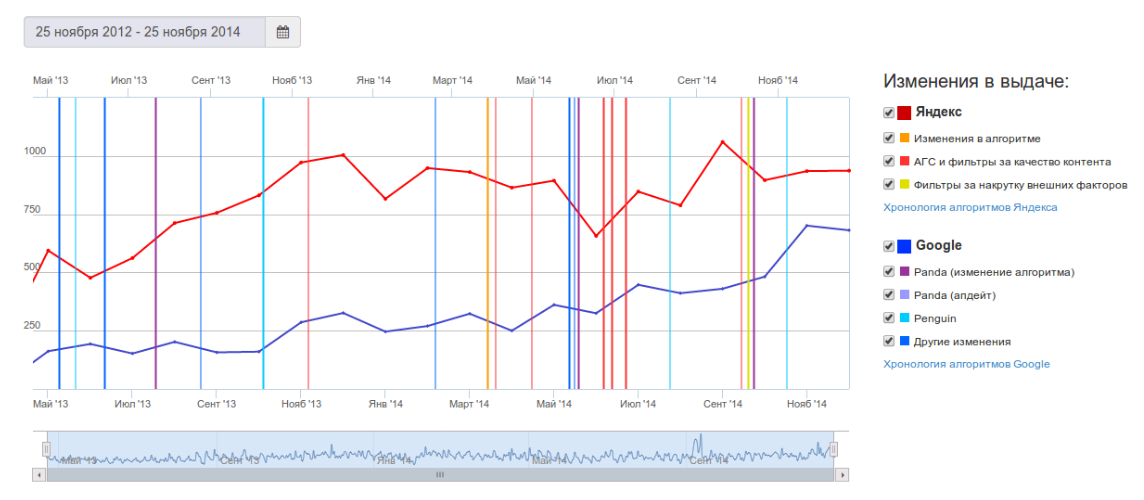
Последние семь лет основной поисковой системой Рунета является Яндекс (58% рынка поиска в России). Сегодняшнюю страницу в истории рунетовского продвижения сайтов следует начать с решения Яндекса, принятого летом 2008 года, закрыть веб-мастерам и оптимизаторам доступ к информации о внешних ссылках, установленных на сайт. В результате перестали быть эффективными системы автоматического анализа ссылок, которые применяли для влияния на выдачу наиболее продвинутые специалисты по продвижению сайтов. Продвижение сайтов стало более ручным. Для выполнения этой работы снова нужны мозги, а не навыки по расстановке ссылок на линкопомойках. Далее были три мощных изменения алгоритмов («Магадан», «Находка» и «Арзамас»). В результате в поисковой выдаче Яндекса появилось 16 региональных фронтов, выдающих результаты с учетом региональной составляющей. Если запрос гео-зависимый, например: «стоматология», пользователи Калининграда получают сайты компаний западной части России, Владивостока — восточной. Это, конечно, влияет на продвижение сайтов, теперь оно выполняется с учетом регионального фактора. Самым существенным различием между российским и зарубежным продвижением сайтов остается использование в России бирж ссылок. До сих пор в Рунете биржи ссылок оказывают влияние на результаты поиска. Также следует отметить на много меньшее доверие российских поисковых систем к ссылкам из блогов и форумов.
Далее были три мощных изменения алгоритмов («Магадан», «Находка» и «Арзамас»). В результате в поисковой выдаче Яндекса появилось 16 региональных фронтов, выдающих результаты с учетом региональной составляющей. Если запрос гео-зависимый, например: «стоматология», пользователи Калининграда получают сайты компаний западной части России, Владивостока — восточной. Это, конечно, влияет на продвижение сайтов, теперь оно выполняется с учетом регионального фактора. Самым существенным различием между российским и зарубежным продвижением сайтов остается использование в России бирж ссылок. До сих пор в Рунете биржи ссылок оказывают влияние на результаты поиска. Также следует отметить на много меньшее доверие российских поисковых систем к ссылкам из блогов и форумов.
Взаимодействие поисковых систем, оптимизаторов и владельцев сайтов
Невозможно понять продвижение сайтов, без анализа участников этого явления и взаимосвязи между поисковыми системами, подрядчиками по продвижению сайтов и владельцами сайтов. Постараемся разобраться:
Постараемся разобраться:
Продвижение сайтов и их владельцы
Более десяти лет компания VIPRO работает в области продвижения сайтов. Каждый день нам приходится общаться с владельцами сайтов, которые хотят быть в «десятке» Яндекса, Рамблера или Гугла по нужным для них запросам. Большинство предпочитает и ценит предлагаемые нами «белые» методы продвижения сайтов. Но есть и меньшинство. Не скрывающее своих намерений достичь победы любой ценой и в самый короткий срок. Обычно такие люди имеют несколько сайтов в такой тематике. Их задача заполнить первую десятку в своей теме, только своими сайтами. В ход идут любые методы продвижения сайтов. Чаще всего «черные». Мы не участвуем в таких «конкурсах». Это не интересно. Интересно и приятно видеть, как развивается бизнес наших партнеров, поручивших нам весь комплекс работ по созданию, поддержке и продвижению сайтов в поисковых системах.
Поисковые системы и продвижение сайтов
Уже давно поисковые системы превратились в основной генератор трафика. Не будет преувеличением назвать их основой современного Интернета, его важнейшей составляющей. Без них найти что-либо нужное в Сети будет намного сложнее. Без них продвижение сайтов будет не возможным. Все поисковые системы с помощью собственных роботов обходят интересующий их сегмент Интернета и индексируют сайты. Далее эти сайты появляются в выдаче в порядке, который определяет алгоритм поисковой системы. Все поисковые системы продают контекстную рекламу, которую покупают владельцы сайтов. С учетом вышеописанного, любой полезный для посетителей сайт является для поисковой системы информационным партнером, предоставляющим информацию в обмен на трафик, и одновременно рекламодателем, покупающим дополнительный трафик с помощью контекстной рекламы. Взаимоотношения поисковых систем и компаний по продвижению сайтов более сложны. С одной стороны, специалисты по продвижению сайтов делают сайты более удобными для поисковых систем, без их помощи роботы поисковых систем не смогли бы собрать столь обширную базу сайтов, поскольку до сих пор огромное число сайтов, использующих flash, навигацию с помощью картинок и запутанные системы управления являются непрозрачными для роботов поисковых систем.
Не будет преувеличением назвать их основой современного Интернета, его важнейшей составляющей. Без них найти что-либо нужное в Сети будет намного сложнее. Без них продвижение сайтов будет не возможным. Все поисковые системы с помощью собственных роботов обходят интересующий их сегмент Интернета и индексируют сайты. Далее эти сайты появляются в выдаче в порядке, который определяет алгоритм поисковой системы. Все поисковые системы продают контекстную рекламу, которую покупают владельцы сайтов. С учетом вышеописанного, любой полезный для посетителей сайт является для поисковой системы информационным партнером, предоставляющим информацию в обмен на трафик, и одновременно рекламодателем, покупающим дополнительный трафик с помощью контекстной рекламы. Взаимоотношения поисковых систем и компаний по продвижению сайтов более сложны. С одной стороны, специалисты по продвижению сайтов делают сайты более удобными для поисковых систем, без их помощи роботы поисковых систем не смогли бы собрать столь обширную базу сайтов, поскольку до сих пор огромное число сайтов, использующих flash, навигацию с помощью картинок и запутанные системы управления являются непрозрачными для роботов поисковых систем. С другой стороны, всю историю продвижения сайтов находились оптимизаторы, пытавшиеся искажать поисковую выдачу в своих интересах. Также необходимо учитывать, что многие компании по продвижению сайтов одновременно являются крупными продавцами контекстной рекламы, помогая поисковым системам собирать деньги с владельцев сайтов и популяризируя данный вид рекламы.
С другой стороны, всю историю продвижения сайтов находились оптимизаторы, пытавшиеся искажать поисковую выдачу в своих интересах. Также необходимо учитывать, что многие компании по продвижению сайтов одновременно являются крупными продавцами контекстной рекламы, помогая поисковым системам собирать деньги с владельцев сайтов и популяризируя данный вид рекламы.
Подрядчики по продвижению сайтов
Традиционно специалистов по продвижению сайтов делили на черных, серых и белых оптимизаторов.
«Черное» продвижение сайтов
Первые (черные оптимизаторы) опасны и вредны. Они обманывают и поисковые системы, и владельцев продвигаемых ими сайтов. Их методы продвижения сайтов явно нарушают регламенты поисковых систем, часто портят выдачу. Поисковые системы безжалостно удаляют из индекса сайты, которые продвигают черными методами. Отметим, что эти регламенты не всегда нарушаются сознательно. Бывают горе-оптимизаторы, которые»не ведают, что творят», начитавшись советов на форумах.
«Серое» продвижение сайтов
Поскольку регламенты поисковых систем в некоторых вопросах крайне расплывчаты, границы между «серым» продвижением сайтов и «белым» продвижением сайтов весьма условны. Для России «серое» продвижение сайтов является основным. Оно исключает явно запрещенные поисковыми системами методы продвижения сайтов. Выполняются классические работы, необходимые для продвижения сайта: наполнение тематическим контентом, оптимизация сайта, установка естественных ссылок в качественных каталогах и грамотная, аккуратная покупка ссылок на сайтах, заслуживающих доверия.
«Белое» продвижение сайтов
Однозначно «белое» продвижение сайтов не использует покупку ссылок. Основной упор — внутренняя оптимизация и сообщения в блогах, форумах и статьях. Это сложная и трудоемкая работа, но она даёт стабильный и предсказуемый результат. Компания VIPRO всегда применяет «белое» продвижение сайтов при работе с низко- и среднечастотными запросами. К сожалению «белое» продвижение сайтов по высокочастотным запросам малоэффективно. Приходится вписываться в реалии российского рынка продвижения сайтов. Хотя будущее, безусловно, за «белым» продвижением сайтов.
Приходится вписываться в реалии российского рынка продвижения сайтов. Хотя будущее, безусловно, за «белым» продвижением сайтов.
Результаты для «Яндекс (поисковая система)» — Википедия — Study in China 2023
Результаты для «Яндекс (поисковая система)» — Википедия — Study in China 2023 — Wiki Русский Яндекс (поисковая система)
«Я́ндекс» — поисковая система, принадлежащая российской корпорации «Яндекс», основной продукт компании. Доля «Яндекс.Поиска» составляет 56 % на рынке…
Яндекс
предоставлял более 50 различных веб-служб. Поисковая система «Яндекс» являлась в 2013 году четвёртой среди поисковых систем мира по количеству обрабатываемых запросов…
Результаты для «Яндекс (поисковая система)» — Википедия — Study in China 2023 — Wiki Русский Индексация в поисковых системах
Индексирование в поисковых системах (веб-индексирование) — процесс добавления сведений (о сайте) роботом поисковой машины в базу данных, впоследствии.
 ..
..Апорт (поисковая система)
разработка была прекращена — поисковая система стала резко сдавать позиции, заметно уступая по популярности Рамблеру и Яндексу. В 2000-е годы Апорт являлся…
Поисковая система
Поиско́вая систе́ма (англ. search engine) — алгоритмы и реализующая их совокупность компьютерных программ (в широком смысле этого понятия, включая аналоговые…
История «Яндекса»
Поисковая система Яndex-Web была представлена широкой публике 23 сентября 1997 года на выставке Softool. Первая рабочая версия поискового приложения под…
Яндекс.Диск
Яндекс Диск — облачный сервис, принадлежащий компании Яндекс, позволяющий пользователям хранить свои данные на серверах в «облаке» и передавать их другим…
Результаты для «Яндекс (поисковая система)» — Википедия — Study in China 2023 — Wiki Русский Яндекс.
 Почта
ПочтаЯ́ндекс По́чта — бесплатная служба электронной почты от компании Яндекс. Запущена 26 июня 2000 года. Присутствует автоматическая фильтрация спама при…
Алиса (голосовой помощник) (перенаправление с Алиса (Яндекс))
появился в поисковом приложении Яндекса для Android и iOS и бета-версии голосового помощника для Microsoft Windows. Согласно статистике Яндекса, опубликованной…
Результаты для «Яндекс (поисковая система)» — Википедия — Study in China 2023 — Wiki Русский Поисковая оптимизация
Вместе с появлением и развитием поисковых систем в середине 1990-х появилась поисковая оптимизация. В то время поисковые системы придавали большое значение…
DuckDuckGo (категория Поисковые системы)
делает большинство поисковых систем, таких как Google, Bing, Яндекс и т. д. (Использование «пузыря фильтров» означает, что поисковая система показывает только.
 ..
..Google (поисковая система)
Google (МФА [ɡuːɡl]) — крупнейшая в мире поисковая система интернета, принадлежащая корпорации Google Inc.. Основана в 1998 году Ларри Пейджем и Сергеем…
Спутник (поисковая система)
государственная поисковая система и интернет-портал, созданная компанией «Ростелеком». Разработчик — компания «КМ Медиа», позже ООО «Поисковый портал „Спутник“»…
Результаты для «Яндекс (поисковая система)» — Википедия — Study in China 2023 — Wiki Русский META (поисковая система)
Министров Украины. В это же время компания проектирует линейку поисковых продуктов: поисковая система для сайтов siteMETA, программа для поиска по персональному…
Результаты для «Яндекс (поисковая система)» — Википедия — Study in China 2023 — Wiki Русский Поисковая реклама
Поисковая реклама — частный случай контекстной рекламы, применяемый в поисковых системах.
 Отличительной особенностью является то, что выбор демонстрируемых…
Отличительной особенностью является то, что выбор демонстрируемых…Яндекс.Такси
Яндекс Go Такси — одна из самостоятельных бизнес-единиц «Яндекса», предлагающая сервисы агрегатора такси и доставки еды и продуктов, а также мобильные…
Результаты для «Яндекс (поисковая система)» — Википедия — Study in China 2023 — Wiki Русский Яндекс Видео
Яндекс сообщил в блоге портала: С сегодняшнего дня на Яндекс.Видео отключена возможность загрузки видеофайлов. На сервисе остается только поисковая часть…
Результаты для «Яндекс (поисковая система)» — Википедия — Study in China 2023 — Wiki Русский Ранжирование (перенаправление с Ранжирование (поисковые системы))
ссылок, релевантность текста к поисковому запросу, на основании которых поисковая система формирует список сайтов в поисковой выдаче. Алгоритм ранжирования.
 ..
..Дзен (блог-платформа) (перенаправление с Яндекс Дзен)
пользователя используются знания Яндекса о посещаемых сайтах, а также указанный пользователем круг интересов. Система анализирует любимые ресурсы пользователя…
Результаты для «Яндекс (поисковая система)» — Википедия — Study in China 2023 — Wiki Русский Яндекс.Метрика
Яндекс. Метрика является третьей по размеру системой веб-аналитики в Европе. Яндекс.Метрика была создана весной 2007 года как часть рекламной системы…
#Wikipedia® is a registered trademark of the Wikimedia Foundation, Inc. Wiki (Study in China) is an independent company and has no affiliation with Wikimedia Foundation.
This article uses material from the Wikipedia article , which is released under the Creative Commons Attribution-ShareAlike 3.0 license («CC BY-SA 3.0»); additional terms may apply. (view authors). Images, videos and audio are available under their respective licenses.
Images, videos and audio are available under their respective licenses.
🌐 Wiki languages: 1,000,000+ articlesEnglishРусскийDeutschItalianoPortuguês日本語Français中文العربيةEspañol한국어NederlandsSvenskaPolskiУкраїнськаمصرى粵語DanskفارسیTiếng ViệtWinaraySinugboanong Binisaya
🔥 Top trends keywords Русский Wiki:
Заглавная страницаСлужебная:ПоискКолтрейн, РоббиСтрелков, Игорь ИвановичРоссияГруппа ВагнераАндерсен-Шисс, ГабриэлаYouTubeВторжение России на Украину (2022)Бандера, Степан АндреевичДамер, ДжеффриСоединённые Штаты АмерикиВКонтактеМаск, ИлонПенициллин (комплекс артразведки)Пригожин, Евгений ВикторовичДень отцаПутин, Владимир ВладимировичВластелин колец: Кольца властиМоскваСписок умерших в 2022 годуУкраинаСанкт-ПетербургСуровикин, Сергей ВладимировичС-60Сташинский, Богдан НиколаевичДом ДраконаБратья РадченкоКинжал (гиперзвуковой ракетный комплекс)Рубеус ХагридRobloxStarlinkГуревич, Александр ВитальевичУткин, Дмитрий ВалерьевичРусский языкТаджикистанДевятов, Владимир СергеевичGoogle (компания)RuTracker. orgМэрилин МонроЗеленский, Владимир АлександровичБуккакэКалифорнияРахмон, ЭмомалиСердце Пармы (фильм)Покров Пресвятой БогородицыКошкаСауронСоциальная сетьБелгородС-300PythonФокс, Майкл ДжейОднопользовательская игра15 октябряГарри Поттер (серия фильмов)Список фильмов кинематографической вселенной MarvelПосейдон (подводный аппарат)Российско-украинская войнаБатальонGoСкарвер, КристоферTelegramМногопользовательская играСоюз Советских Социалистических РеспубликСан-БруноПереводчикХэллоуинЯндексВетреный (сериал, Турция)VK (компания)Чикатило, Андрей РомановичЛучшие в адуМонстр: История Джеффри ДамераАватар (телешоу)Содружество Независимых ГосударствShaman (певец)Елизавета IIСписок стран по численности вооружённых сил и военизированных формирований🡆 More
orgМэрилин МонроЗеленский, Владимир АлександровичБуккакэКалифорнияРахмон, ЭмомалиСердце Пармы (фильм)Покров Пресвятой БогородицыКошкаСауронСоциальная сетьБелгородС-300PythonФокс, Майкл ДжейОднопользовательская игра15 октябряГарри Поттер (серия фильмов)Список фильмов кинематографической вселенной MarvelПосейдон (подводный аппарат)Российско-украинская войнаБатальонGoСкарвер, КристоферTelegramМногопользовательская играСоюз Советских Социалистических РеспубликСан-БруноПереводчикХэллоуинЯндексВетреный (сериал, Турция)VK (компания)Чикатило, Андрей РомановичЛучшие в адуМонстр: История Джеффри ДамераАватар (телешоу)Содружество Независимых ГосударствShaman (певец)Елизавета IIСписок стран по численности вооружённых сил и военизированных формирований🡆 More
Что такое алгоритм поиска в Интернете и как он работает?
Все еще не знаете, что такое алгоритм поиска в Интернете , или не понимаете, как работают некоторые из них? Если у вас есть онлайн-бизнес или веб-сайт, вы интуитивно поймете, что знание основных операций поисковых систем , таких как Google, поможет вам создавать контент, адаптированный к тому, что они считают «заслуживающим» ранжирования в первую очередь.
Дело в том, что если до сих пор вы писали в своем блоге или в своем бизнес-контенте, не принимая во внимание, как минимум, работу алгоритма поиска, возможно, вы слепы.
Кроме того, наверняка среди всей информации, которую вы читали и слышали на сегодняшний день о пингвинах, пандах и многих других животных, возможно, вы так и не проясняете различия между ними. И чтобы хорошо начать, нет ничего лучше, чем взглянуть на общее определение того, что такое алгоритм.
Что такое алгоритм?
Алгоритм – это упорядоченный и систематизированный набор правил и логических операций, который позволяет выполнять вычисления для поиска решения определенного типа задач.
Теперь, если мы возьмем этот термин, чтобы связать его с поиском в сети, мы могли бы определить его:
Что такое алгоритмы поиска в Интернете?
Алгоритм поиска в Интернете – это набор инструкций, описывающих процедуру, которой необходимо следовать, чтобы найти конкретный и конкретный результат в сети в более крупной структуре данных.
Возможно, такое объяснение звучит сложно, но если мы подойдем к этому термину с компьютерной точки зрения, мы найдем более ясное объяснение, поскольку алгоритм является фундаментальным понятием в этой области.
Это слово предполагает точное предписание действий, которые необходимо выполнить для достижения определенной цели.
Таким образом, можно считать, что любая инструкция является алгоритмом, если:
- Ее пункты не допускают различных вариантов развития.
- Индикация предоставляется для всех возможных сценариев.
Но о чем мы говорим, когда спрашиваем себя, что такое алгоритм поиска в Интернете?
Когда мы что-то ищем (например, в Google ), нам нужен точный и отфильтрованный ответ , а не миллионы страниц, которые не имеют ничего общего с нашим запросом.
Таким образом, алгоритм является идеальным инструментом для ограничения поиска до минимального выражения, поскольку это компьютерная программа, которая ищет подсказки, чтобы дать вам именно то, что вы просили.
В то же время это также формулы, которые идентифицируют ваши вопросы и превращают их в список возможных ответов. Для этого Google алгоритмы поиска полагаются на сотни уникальных сигналов или факторов .
Эти факторы позволяют почти угадать, что вы действительно ищете в Интернете, чтобы предложить вам список возможных ответов, упорядоченных от самого высокого к самому низкому в соответствии с их релевантностью для данного конкретного поиска.
Итак, могу ли я узнать, как работает алгоритм поиска, подобный Google?
Хотя по понятным причинам мы не можем его полностью расшифровать, мы можем знать некоторые основные аспекты и благодаря им вывести минимальные требования, которые учитывал этот алгоритм.
И, конечно же, мы можем получить информацию о том, как это работает для оптимизации нашей стратегии SEO . Однако получить такую информацию не всегда просто.
Поэтому я расскажу вам об особенностях алгоритмов поиска в Интернете и истории трех основных поисковых систем на сегодняшний день.
Как работают 3 самых популярных алгоритма поиска в Интернете?
Сегодня я хочу поделиться с вами темой, которая интересует все больше и больше людей в Интернете: как алгоритм поиска работает и какой из них сегодня сильнее.
Как мы хорошо знаем, говоря об Интернете, мы почти говорим о нашем друге Google, который периодически обновляет свой поисковый алгоритм , еще больше улучшая его и делая умнее.
Несколько его задач на некоторое время, например, заключаются в том, чтобы сделать приоритетным WPO веб-сайта и навигацию с мобильных устройств, которые все чаще используются в нашем обществе.
Но этим аспектом интересовался не только Google, но и все основные поисковые системы, стремящиеся к постоянному совершенствованию.
Короче говоря, перед нами платформа, которая со своим поисковым алгоритмом все больше вознаграждает за качественный контент и, прежде всего, предлагает пользователям контент, который наилучшим образом соответствует их поисковым намерениям или «запросу».

Бинг, Yahoo! o Yandex также находится в процессе улучшения своих поисковых алгоритмов , чтобы пользователи добивались наилучших результатов, «вкладывая» как можно меньше времени в поиск в Интернете.
Конечно, эти изменения затрагивают SEO-позиционирование, стратегии маркетологов и владельцев веб-доменов.
Говоря о самых важных средствах, конечно, включая самые популярные поисковые системы:
- Бинг
- Яндекс
Конечно же, именно с этими тремя мы и будем иметь дело в этом посте.
Начнем?
Какие самые известные поисковые системы и каковы их поисковые алгоритмы?
Далее мы рассмотрим самые популярные поисковые системы в мире и рассмотрим эволюцию их формул и обновлений.
► Яндекс
Эта программа создана в 1988 году компанией CompTek, хотя поисковая система Яндекс-Веб была представлена миру 23 сентября 1997 года.
Первая версия поисковой программы под названием «Яндекс» появилась в 1993 года, хотя на тот момент это был скорее инструмент для поиска информации в рамках одного сайта.
«Яндекс» не первая родившаяся в России поисковая система (до него уже существовали Рамблер и Апорт), но вскоре увидев свет, она быстро начинает набирать аудиторию. Настолько, что в 2001 году он стал самым известным поисковиком в российском сегменте, став лидером этого рынка.
На сегодняшний день «Яндекс» — крупнейшая интернет-компания Европы , с капитализацией 10 миллиардов долларов (по данным 2013 года).
Со своей стороны, поисковая система «Яндекс.Поиск» на начало 2013 года была четвертой в мире с 4,84 млрд поисковых запросов и второй среди неанглоязычных поисковых систем после «Baidu».
Алгоритм поиска Яндекса и обновления
В 2008 году Яндекс выпустил обновление Магадан (кстати, Яндекс называет свои обновления по названиям разных городов России).
В этом обновлении решена проблема расшифровки аббревиатур и транслитерации и, кроме того, соотношения между однокоренными словами.
Это обновление обновляется через несколько месяцев, добавляя дополнительные факторы ранжирования (например, приоритет эксклюзивного контента ).
В 2008 и 2009 годах свет увидели Находка и Арзамас, целью которых является улучшение результатов для «запросов» с союзами и предлогами.
Таким образом, поисковая выдача предлагает более информативные результаты по сравнению с предыдущей долей предыдущих результатов; Также отсюда делают акцент на аспектах, связанных с геолокацией при поиске.
В конце 2009 года Яндекс анонсирует обновление Снежинск : более сложную технологию, анализирующую содержимое страницы с учетом большего количества факторов.
Таким образом, актуальный и качественный контент стал важным фактором.
Наступает сентябрь 2010 года, и появляется Обнинск, сосредотачивающийся на SEO-ссылках (платных обратных ссылках ) и снижающий их влияние на позиционирование страницы.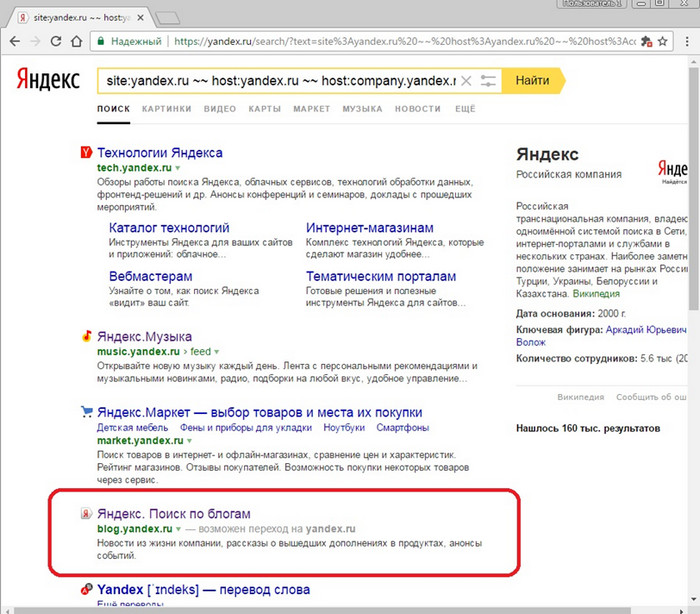
В августе 2010 года поиск начинает персонализироваться, но именно в декабре 2012 года родился Калининград, который обеспечивает глобальную настройку поиска в соответствии с интересами пользователя.
Благодаря Калининграду, информация о действиях этого пользователя будет обновляться раз в сутки, и будет сегментироваться с учетом длительности поиска и настройки поиска.
Таким образом, SEO влияет не только на обратные ссылки и поиск важных ключевых слов, но и на все вместе: дизайн, удобство использования, контент и т. д.
поисковая система начинает запоминать последние действия пользователя.
Недавно, в апреле 2015 года, платные обратные ссылки больше не являются фактором, влияющим на ранжирование веб-страниц.
Когда домены платных ссылок начинают терять позиции, Яндекс стремится избавиться от ссылочного спама и для владельцев доменов, чтобы они сосредоточили свои усилия по поисковой оптимизации на улучшении содержания, удобства использования, дизайна и обслуживания.
Это означает (чтобы закрыть тему обновлений Яндекса), что с этого момента уже не имеет значения получение тех обратных ссылок, которые были так важны в рамках SEO-стратегии в рунете.
► Bing
Bing — основной веб-браузер Microsoft, представленный в мае 2009 г.
В июле 2009 г. Microsoft и Yahoo! Объявить Bing вместо Yahoo! Поиск , когда они также запускают нового веб-паука под названием MSN bot 2 (ранее называвшегося MSN Search).
Все это говорит о том, что это относительно новая поисковая система. Несмотря на это, Bing занимает второе место в рейтинге самых популярных поисковых систем по объему трафика.
Несмотря на эту популярность, изменения в его алгоритме поиска не так известны, как изменения Google или Яндекса, и, в отличие от этих двух, Bing не раскрывает обновляет сделал и не дает им имен, как это делают Яндекс и Google.
Поэтому нам не остается ничего, кроме описания различий в результатах поиска и позиционировании.
В течение многих лет служба Bing уделяла особое внимание:
- Изображениям.
- Вспышка.
- Видео.
- Аудио.
Несмотря на то, что технология Flash сегодня немного устарела (заменена HTML5), не так давно это было преимуществом, которым могла похвастаться эта поисковая система.
Сегодня эта поисковая система уделяет больше внимания прямым ключевым словам . Поэтому, если вы хотите адаптировать свой сайт для лучшего позиционирования в Bing, вы обязаны строить свою SEO-стратегию на определенных и конкретных ключевых словах.
В октябре 2011 года Microsoft объявила о том, что работает над обновлением, получившим название «Тигр» (в данном случае оно его так и назвало), целью которого является предоставление более релевантных и более быстрых результатов для пользователя после улучшения обработки Что вы смеетесь.
Обратные ссылки, в отличие от активности в социальных сетях, не в пользу Bing. На самом деле, он всегда демонстрировал гораздо большую склонность к взаимодействию на социальных платформах.
На самом деле, он всегда демонстрировал гораздо большую склонность к взаимодействию на социальных платформах.
Пришло время поговорить о крупнейшей и самой известной в мире поисковой системе.
Эта система (с долей рынка 77,05%) обрабатывает 41,345 миллиона запросов и индексирует более 25 миллионов веб-страниц… в месяц!
На конференции, закрытой в начале мая 2014 года, представитель Google упомянул, что 60 миллиардов документов проиндексированы сегодня. Представьте текущую сумму, уже в конце 2018 года…
Как видно из результатов теста, счетчик поиска Google ограничен 25 270 000 000, на это количество также влияют фильтры, встроенные в алгоритм выдачи.
Поисковая система Google была создана в качестве школьного проекта студентами Стэнфордского университета Ларри Пейджем и Сергеем Брином.
В 1996 году они работали в поисковой системе под названием 9.0003 BackRub и на его основе два года спустя создают новую поисковую систему: Google.
С самого начала начинают применять прозрачный метод контроля OKR, который в дальнейшем определяет корпоративную линию компании в плане планирования и развития.
Какие алгоритмы поиска использовались Google на протяжении всей его истории?
Ниже я покажу вам различные варианты алгоритма Google, все в хронологическом порядке и в соответствии со значением и функцией каждого обновления:
1. Google Panda (обновление «Кофеин»)
10 августа 2009 г. было объявлено об обновлении под названием «Кофеин», которое обещает более быстрое сканирование, расширение и интеграцию индексации и ранжирование почти в реальном времени.
Запуск состоится, наконец, в июне 2010 года.
В феврале 2011 года Google запустил Panda , широкомасштабное обновление, затрагивающее 12% поисковых запросов .
Это обновление предназначено для принятия активных мер против спама, ферм контента, веб-скрапинга и веб-сайтов с высоким процентом рекламы по сравнению с процентом контента.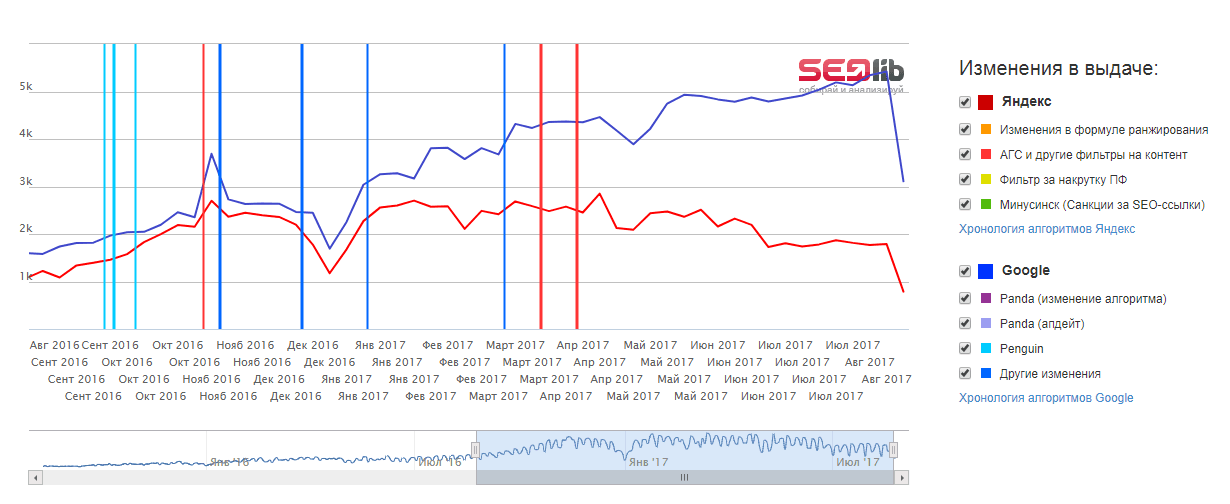
В течение 2011 года Google обновляет Panda и переходит на Panda версии 2.1.
Интернет-гигант вносит постоянные изменения с целью значительного улучшения как индексации, так и пользовательского опыта и его значительного улучшения.
После запуска Panda 2.4 алгоритм поиска также начинает работать на всех языках, кроме китайского, японского и корейского.
В мае 2014 года выходит Panda 4.0, чтобы завершить год обновлением до версии 4.1.
А в 2015 году Google интегрирует Panda в свой общий поиск core .
» Пример штрафа Google Panda
2. Алгоритм «Свежесть»
Свежесть выпущен в ноябре 2011 года, обновление, которое отдает приоритет последним результатам поиска .
Но только в феврале 2012 года, после запуска Venice, результаты поиска стали приоритетными в отношении геолокации.
3. Google Penguin (прощай, «черная шляпа»)
В апреле того же года вышло обновление Google Penguin.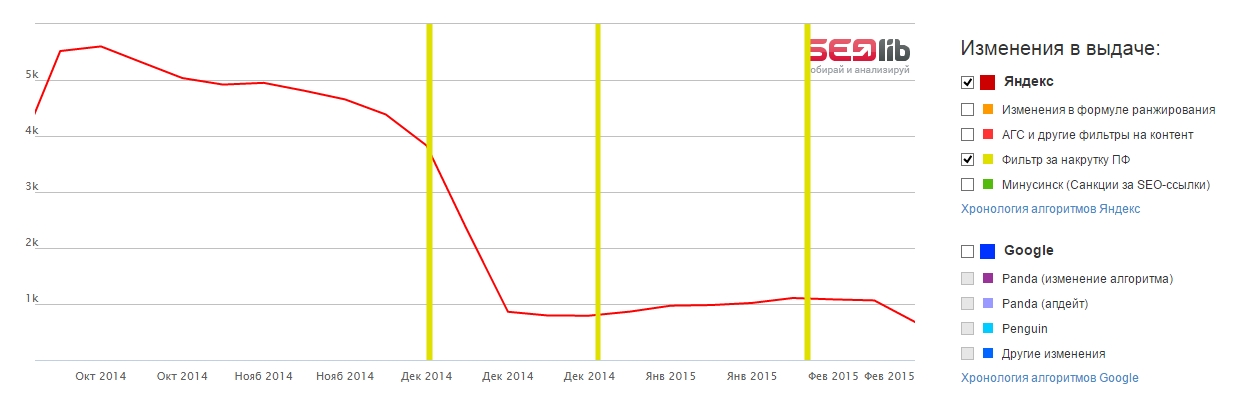
Это обновление было создано с идеей наказания веб-сайтов, которые используют методы «черного SEO» для искусственного улучшения позиционирования домена.
Google Penguin считает первоочередной задачей прекратить спам-индексацию , то есть один из методов манипулирования релевантностью проиндексированных поисковой системой страниц.
При этом основной задачей является вывод наиболее качественных веб-сайтов в топ результатов поиска Google.
В сентябре 2016 года Пингвин интегрирован в основной алгоритм поиска . Теперь он работает в режиме реального времени и гораздо более детализирован.
Больше не влияет на рейтинг всего веб-сайта, а влияет на каждый URL в отдельности.
»Пример штрафа Google Penguin
4. Google Hummingbird
В период с августа по сентябрь 2013 г. появляется Google Hummingbird, который считается первым крупным обновлением после Caffeine и нацелен в первую очередь на улучшение процесса индексации .
В отличие от других поисковых алгоритмов , более ориентированных на каждое слово запроса в отдельности, Google Hummingbird (в дополнение к учету каждого слова) отдает приоритет общему запросу на основе фразы или предложения.
Цель Google Hummingbird состоит в том, чтобы поисковая система понимала взаимосвязь между различными ключевыми словами и несколькими понятиями.
При всем этом Google стремится сделать поиск более гуманным, и для этого делает ставку на семантические поиски, чтобы получить более релевантные результаты для пользователя.
Надо сказать, что обновление Hummingbird не оказывает большого влияния на поисковую оптимизацию, а скорее направлено на обеспечение того, чтобы наилучшие результаты подкреплялись естественным и релевантным контентом .
Таким образом, Google Hummingbird обеспечивает лучшее позиционирование ключевых слов с длинным хвостом , которые становятся более естественными для ответов на реальные вопросы пользователей.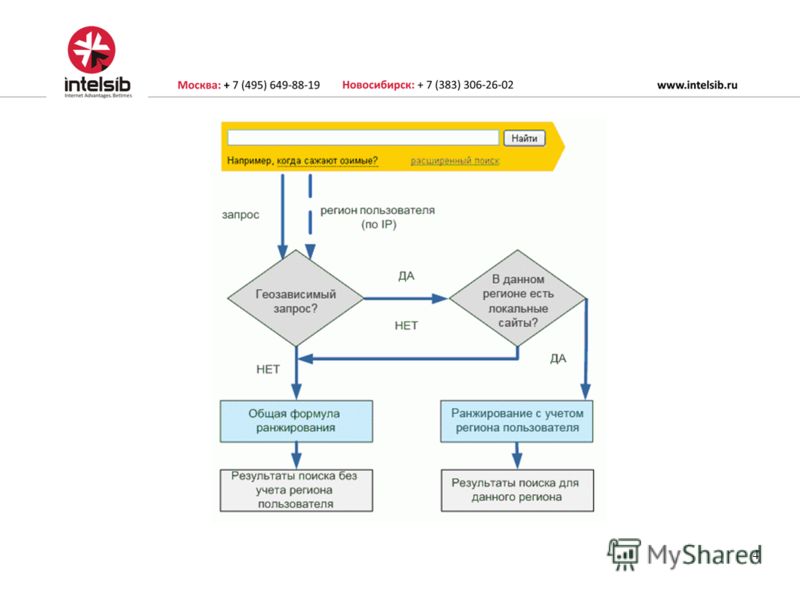
Как этот алгоритм поиска влияет на создателей контента?
Это, по логике, делает его более податливым, приводя в соответствие с естественным использованием языка, приспособленным к реальным разговорам, а не к чистому и жестких ключевых слов, которые специалисты по SEO приписывают своим веб-страницам.
Еще одно крупное обновление, Google Pigeon , было запущено в 2014 году с целью приоритизации результатов поиска, что очень полезно для местного бизнеса и предпринимателей (и, конечно же, для пользователя).
Кроме того, из соображений безопасности в том же году Google объявила о своем предпочтении веб-сайтов, использующих протокол HTTPS.
В 2015 году поисковая система выпустила новое обновление, в котором приоритет отдается веб-сайтам, которые лучше всего отображаются на мобильных, отзывчивых устройствах, не затрагивая результаты поиска с компьютера (на данный момент…). В свою очередь, Google настаивает на том, что веб-сайты «удобны для мобильных устройств».
С этой целью в начале марта того же года он предупредил веб-мастеров о своем намерении запустить обновление, позволяющее пользователям получать еще более релевантные и удобные результаты для своих мобильных устройств.
Ниже я делюсь с вами инфографикой, обобщающей все руководство, которое может продолжаться до ближайших лет, в которых алгоритмов поиска Google и основные движки, существующие в сети, наверняка будут обновлены.
Источник: josefacchin.com/
Откройте для себя устройство
#машинное обучение #алгоритмы #НЛП #анализ текста
#программная инженерия #алгоритмы #CS-теория
#программная инженерия #программный дизайн #алгоритмы #UX
 grab.com)
grab.com)#программная инженерия #алгоритмы #граф
#алгоритмы #исследования #конфиденциальность
#машинное обучение #алгоритмы #GeoData
#СУБД #алгоритмы #производительность #большие данные #GeoData
#алгоритмы #исследования #график
#алгоритмы #оптимизация #математика
#программная инженерия #машинное обучение #алгоритмы
#алгоритмы #структуры данных #исследования
 uber.com)
uber.com)#машинное обучение #алгоритмы #масштабирование
#машинное обучение #алгоритмы #математика #статистика
#алгоритмы #масштабирование #большие данные #обработка графов
#наука о данных #машинное обучение #алгоритмы
#алгоритмы #НЛП #анализ текста #исследования
#СУБД #алгоритмы #производительность #GPU
#алгоритмы #оптимизация #обработка графов
 nvidia.com)
nvidia.com)#алгоритмы #обработка графов #математика #параллельные вычисления
#наука о данных #алгоритмы #исследования
#дизайн программного обеспечения #алгоритмы #поиск
#наука о данных #машинное обучение #алгоритмы #исследования
#программная инженерия #алгоритмы
#архитектура программного обеспечения #алгоритмы #распределенные-системы
#наука о данных #архитектура программного обеспечения #алгоритмы #аналитика
 infoq.com)
infoq.com)#СУБД #алгоритмы #поиск #elastisearch
#архитектура программного обеспечения #инфра #алгоритмы #обработка графов
#дизайн программного обеспечения #машинное обучение #алгоритмы #большие данные
#алгоритмы #сжатие #медиа
#наука о данных #алгоритмы #математика
#инженерия программного обеспечения #архитектура программного обеспечения #алгоритмы #разработчик игр
#наука о данных #алгоритмы #нейронная сеть #исследования
 infoq.com)
infoq.com)#машинное обучение #алгоритмы #аналитика #большие данные
#глубокое обучение #алгоритмы #нейронная сеть
#машинное обучение #алгоритмы #исследования #квантовые вычисления
#программная инженерия #алгоритмы #производительность #системы
#алгоритмы #аналитика #геоданные #карты
#infra #algorithms #backend #compression #media
#СУБД #алгоритмы #распределенные-системы #инженерия данных
 com)
com)#машинное обучение #алгоритмы #аналитика #график
#машинное обучение #алгоритмы #исследования #математика
#обработка изображений #алгоритмы #сжатие #медиа
#машинное обучение #алгоритмы #аналитика
#алгоритмы #масштабирование #распределенные-системы #балансировка нагрузки
#алгоритмы #оптимизация #apache-kafka #обработка графов
#алгоритмы #оптимизация #apache-kafka #graph
 wayfair.com)
wayfair.com)#наука о данных #алгоритмы #большие данные #математика
#программная инженерия #алгоритмы #оптимизация #практики
#алгоритмы #оптимизация #аналитика #математика
#алгоритмы #математика #шифрование
#алгоритмы #математика #криптография #шифрование
#алгоритмы #VR #сжатие #медиа
#СУБД #алгоритмы #производительность #системы #инженерия данных
#наука о данных #алгоритмы #математика #статистика
 twitter.com)
twitter.com)#алгоритмы #распределенные-системы #балансировка нагрузки
#СУБД #алгоритмы #системы #инженерия данных
#алгоритмы #regex #parsing #computation
#СУБД #алгоритмы #поиск #производительность
#обработка изображений #алгоритмы #производительность #GPU #параллельные вычисления
#машинное обучение #алгоритмы #GPU #большие данные
#алгоритмы #большие данные #обработка графов #математика
 com)
com)#алгоритмы #сжатие #медиа #потоковая передача
#алгоритмы #производительность #HTML #разбор
#наука о данных #обработка изображений #алгоритмы #GPU
#алгоритмы #производительность #HTML #разбор
#наука о данных #обработка изображений #алгоритмы #исследования
#алгоритмы #блокчейн #CS-теория #haskell
#обработка сигналов #алгоритмы #временные ряды #математика #биотехнологии
 infoq.com)
infoq.com)#алгоритмы #квантовые вычисления #вычисления
#алгоритмы #математика #статистика
#алгоритмы #производительность #GPU #обработка графов
#программное обеспечение #алгоритмы #Геоданные #карты
#наука о данных #машинное обучение #алгоритмы #статистика
#алгоритмы #сенсоры #GeoData #карты
#алгоритмы #безопасность #интернет #криптография
 grab.com)
grab.com)#наука о данных #разработка программного обеспечения #архитектура программного обеспечения #алгоритмы #большие данные
#наука о данных #машинное обучение #алгоритмы #математика
#наука о данных #машинное обучение #алгоритмы
#наука о данных #алгоритмы #обработка аудио #исследования #обработка видео
#наука о данных #машинное обучение #алгоритмы #практики
#наука о данных #алгоритмы #математика #статистика
#дизайн программного обеспечения #алгоритмы #безопасность
 com)
com)#архитектура программного обеспечения #алгоритмы #распределенные системы #инженерия данных
#машинное обучение #алгоритмы #НЛП #анализ текста
#СУБД #алгоритмы #сжатие #инженерия данных
#СУБД #алгоритмы #сжатие #инженерия данных
#алгоритмы #производительность #обработка графов
#data-science #algorithms #big-data #GeoData #maps
#наука о данных #алгоритмы #анализ текста #статистика
 io)
io)#алгоритмы #kubernetes #балансировка нагрузки
#СУБД #алгоритмы #производительность #большие данные
#машинное обучение #алгоритмы #нейронная сеть
#алгоритмы #оптимизация #аналитика #математика
#архитектура программного обеспечения #СУБД #алгоритмы #распределенные-системы #инженерия данных
#машинное обучение #алгоритмы #нейронная сеть #математика
#алгоритмы #большие данные #GeoData #карты
 com)
com)#алгоритмы #блокчейн #случайные числа #эфириум
#машинное обучение #алгоритмы #обработка графов
#дизайн программного обеспечения #алгоритмы #оптимизация
#ИИ #алгоритмы #железо #VR #сенсоры
#алгоритмы #производительность #GPU #рендеринг #браузеры
#наука о данных #машинное обучение #алгоритмы #оптимизация
#наука о данных #алгоритмы #обработка графов
 linkedin.com)
linkedin.com)#наука о данных #алгоритмы #аналитика #большие данные
#архитектура программного обеспечения #алгоритмы #масштабирование #бэкенд
#алгоритмы #производительность #структуры данных #планировщик
#алгоритмы #НЛП #анализ текста #исследование
#наука о данных #машинное обучение #алгоритмы
#СУБД #алгоритмы #оптимизация #инженерия данных
#СУБД #алгоритмы #поиск #инженерия данных
 com)
com)#архитектура программного обеспечения #инфра #алгоритмы #аналитика
#машинное обучение #обработка изображений #алгоритмы #python
#data-pipeline #алгоритмы #производительность #data-engineering
#дизайн программного обеспечения #архитектура программного обеспечения #алгоритмы #распределенные системы #системы
#СУБД #алгоритмы #оптимизация #внутренности
#наука о данных #ИИ #машинное обучение #алгоритмы #исследования
#наука о данных #алгоритмы #аналитика #большие данные
 com)
com)#глубокое обучение #ИИ #алгоритмы #математика
#наука о данных #алгоритмы #GPU #нейронная сеть #исследования
#машинное обучение #обработка изображений #алгоритмы #исследования
#наука о данных #алгоритмы #аналитика
#наука о данных #машинное обучение #алгоритмы
#алгоритмы #НЛП #анализ текста
#наука о данных #машинное обучение #алгоритмы
 infoq.com)
infoq.com)#наука о данных #машинное обучение #алгоритмы #python
#машинное обучение #алгоритмы #обработка графов #исследования
#наука о данных #машинное обучение #алгоритмы
#обработка изображений #алгоритмы #GPU #VR
#алгоритмы #GPU #рендеринг #графика
#алгоритмы #распределенные системы #синхронизация #децентрализованная
#обработка изображений #алгоритмы #история #медиа
 com)
com)#глубокое обучение #наука о данных #алгоритмы #нейронная сеть #исследования
#машинное обучение #обработка изображений #алгоритмы #нейронная сеть #исследования
#алгоритмы #оптимизация #обработка графов
#наука о данных #алгоритмы #большие данные #математика
#наука о данных #машинное обучение #алгоритмы #математика
#обработка сигналов #алгоритмы #аппаратные средства #сенсоры
#алгоритмы #производительность #C++
 uber.com)
uber.com)#программное обеспечение #алгоритмы #Геоданные #карты
#программная инженерия #программный дизайн #алгоритмы #структуры данных
#алгоритмы #кодирование #сжатие #обработка видео
#глубокое обучение #алгоритмы #НЛП #нейронная сеть
#наука о данных #алгоритмы #нейронная сеть #исследования
#обработка изображений #алгоритмы #кодирование #сжатие
#алгоритмы #производительность #разбор #rust
 grab.com)
grab.com)#дизайн программного обеспечения #архитектура программного обеспечения #алгоритмы #GPS
#алгоритмы #распределенные-системы #облако #синхронизация
#алгоритмы #GPU #рендеринг #графика
#алгоритмы #производительность #сети #cs-теория
#дизайн программного обеспечения #алгоритмы #производительность #график
#javascript #алгоритмы #поиск
#алгоритмы #сеть #GPU #планировщик
 com)
com)#наука о данных #машинное обучение #алгоритмы #нейронная сеть
#архитектура ПО #алгоритмы #производительность #рендеринг #графика
#ИИ #обработка изображений #алгоритмы #исследования #робототехника
#алгоритмы #производительность #сжатие #параллельные вычисления #многопоточность
#дизайн программного обеспечения #алгоритмы #аналитика #большие данные
#наука о данных #ИИ #алгоритмы #аналитика
#машинное обучение #обработка изображений #алгоритмы #python
 com)
com)#алгоритмы #масштабирование #распределенные-системы
#наука о данных #машинное обучение #алгоритмы #математика
#алгоритмы #аналитика данных #визуализация
#машинное обучение #обработка изображений #алгоритмы #поиск #большие данные
#алгоритмы #GPU #параллельные вычисления #computation
#алгоритмы #оптимизация #python
#алгоритмы #масштабирование #распределенные-системы #системы
 sqreen.io)
sqreen.io)#дизайн программного обеспечения #алгоритмы #безопасность #сети
#дизайн программного обеспечения #архитектура программного обеспечения #СУБД #алгоритмы
#алгоритмы #НЛП #анализ текста
#алгоритмы #распределенные-системы #доступность #CS-теория
#алгоритмы #блокчейн #биткойн #CQRS #децентрализованный
#наука о данных #машинное обучение #алгоритмы
#алгоритмы #производительность #математика #случайные числа
 com)
com)#наука о данных #машинное обучение #обработка изображений #алгоритмы
#алгоритмы #мобильное #оборудование #сенсоры #GeoData
#наука о данных #машинное обучение #алгоритмы #GPU
#архитектура программного обеспечения #алгоритмы #производительность #SQL
#алгоритмы #большие данные #обработка графов #визуализация
#архитектура программного обеспечения #алгоритмы #распределенные системы #децентрализованные
#дизайн программного обеспечения #архитектура программного обеспечения #алгоритмы #машина состояний
 zalando.com)
zalando.com)#наука о данных #алгоритмы #большие данные #обработка графов
#алгоритмы #рендеринг #исследования #математика
#ИИ #машинное обучение #алгоритмы #исследования
#алгоритмы #поиск #информационно-поисковые #большие данные
#алгоритмы #распределенные-системы #блокчейн #децентрализованный
#наука о данных #алгоритмы #аналитика
#алгоритмы #сжатие #обработка видео
 nvidia.com)
nvidia.com)#глубокое обучение #алгоритмы #мобильный #обработка звука в реальном времени
#алгоритмы #обработка графов #GeoData
#алгоритмы #кодирование #стриминг #обработка видео
#алгоритмы #GPU #рендеринг #графика
#программная инженерия #алгоритмы #дизайн
#алгоритмы #распределенные-системы #режим реального времени #интерфейс #редактор
#архитектура программного обеспечения #алгоритмы #распределенные-системы #отказоустойчивость
 nvidia.com)
nvidia.com)#алгоритмы #рендеринг в реальном времени #графика
#машинное обучение #алгоритмы #обработка графов #парсинг
#обработка изображений #алгоритмы #математика
#ИИ #машинное обучение #алгоритмы
#алгоритмы #GPU #рендеринг #графика
#алгоритмы #распределенные-системы #структуры-данных #реальное время #синхронизация
#обработка изображений #алгоритмы #CV
 cloudflare.com)
cloudflare.com)#алгоритмы #безопасность #протоколы
#алгоритмы #сканирование #скрапинг #веб
#ИИ #алгоритмы #python
#дизайн программного обеспечения #машинное обучение #алгоритмы #математика
#наука о данных #машинное обучение #алгоритмы
#алгоритмы #структуры данных #GoLang #исследования
#архитектура программного обеспечения #СУБД #алгоритмы #производительность #структуры данных
 com)
com)#обработка изображений #алгоритмы #сжатие
#алгоритмы #обработка звука #исследования
#data-pipeline #data-science #algorithms
#архитектура программного обеспечения #алгоритмы #noSQL #распределенные-системы #системы
#архитектура программного обеспечения #алгоритмы #блокчейн #децентрализованный
#алгоритмы #обработка графов #математика
#наука о данных #алгоритмы #структуры данных
 com)
com)#наука о данных #алгоритмы #обработка графов
#наука о данных #алгоритмы #оптимизация
#архитектура программного обеспечения #алгоритмы
#алгоритмы #GPU #нейронная сеть
#алгоритмы #открытый код #квантовые вычисления
#архитектура программного обеспечения #алгоритмы #реальное время
#алгоритмы #GeoData #карты #GPS
#обработка сигналов #алгоритмы #обработка звука #веб
 com)
com)#архитектура программного обеспечения #алгоритмы #блокчейн #децентрализованный
#алгоритмы #структуры данных #граф
#машинное обучение #алгоритмы #поиск
#алгоритмы #блокчейн #синхронизация #децентрализовано
#архитектура программного обеспечения #обработка изображений #алгоритмы #обработка видео
#обработка изображений #алгоритмы #рендеринг
#алгоритмы #производительность #сжатие
 com)
com)#дизайн программного обеспечения #алгоритмы #масштабирование
#алгоритмы #структуры данных
#машинное обучение #алгоритмы #сенсоры #GPS
#алгоритмы #сжатие #обработка видео
#наука о данных #алгоритмы #аналитика данных
#алгоритмы #большие данные #обработка графов
#алгоритмы #большие данные #обработка графов #исследования
#машинное обучение #алгоритмы #обработка звука
 com)
com)#наука о данных #алгоритмы
#наука о данных #алгоритмы #аналитика #визуализация
#наука о данных #машинное обучение #обработка изображений #алгоритмы
#алгоритмы #распределенные-системы #блокчейн #децентрализованный
#алгоритмы #структуры данных
#машинное обучение #алгоритмы #социальные сети
#алгоритмы #блокчейн #децентрализованный
fb.com)#алгоритмы #сети #системы
#алгоритмы #распределенные-системы #блокчейн
#наука о данных #алгоритмы #аналитика данных
#алгоритмы #карты #график
#алгоритмы #распределенные-системы #блокчейн
#алгоритмы #производительность #график
#алгоритмы #параллельные вычисления
#алгоритмы #распределенные-системы #блокчейн
com)#алгоритмы #финтех
#архитектура программного обеспечения #алгоритмы #обработка звука #сеть
#алгоритмы #распределенные-системы #блокчейн
#алгоритмы #питон #математика
#наука о данных #машинное обучение #алгоритмы
#алгоритмы #оптимизация #обработка графов
#алгоритмы #математика
#алгоритмы #оптимизация #нейронная сеть
com)#алгоритмы #структуры данных
#ИИ #алгоритмы
#алгоритмы #оптимизация #графический процессор #функциональное программирование #параллельные вычисления
#программная инженерия #алгоритмы #аналитика
#алгоритмы #режим реального времени #редактор
#алгоритмы #исследования #математика #обработка видео
#алгоритмы #аналитика данных #математика
io)#обработка изображений #алгоритмы #CV
#алгоритмы #оптимизация #визуализация #моделирование
#машинное обучение #алгоритмы #классификатор
#data-pipeline #algorithms #data-analytics
#наука о данных #машинное обучение #алгоритмы
#СУБД #алгоритмы #поиск #структуры данных
#машинное обучение #алгоритмы #аналитика данных
#алгоритмы #поиск #regex
stitchfix.com)#алгоритмы #аналитика данных #классификатор
#алгоритмы #поиск
#алгоритмы #безопасность #криптография #квантовые вычисления
#машинное обучение #алгоритмы #аналитика данных
#алгоритмы #график
#алгоритмы #сложность
#ИИ #алгоритмы #исследование игр #структуры данных
#машинное обучение #алгоритмы #вероятностное моделирование
expedia.com)#машинное обучение #алгоритмы
#конвейер данных #машинное обучение #алгоритмы
#СУБД #алгоритмы #noSQL
15 обязательных алгоритмов машинного обучения | by Soner Yıldırım
Полное руководство по машинному обучению
Photo by Solé Bicycles на UnsplashВ последние годы машинное обучение пережило бурный рост. Мы знаем, чего можно достичь с помощью машинного обучения, больше, чем когда-либо. Растущее количество высококачественных данных и прогресс в области вычислений еще больше ускорили распространение машинного обучения.
Существует множество алгоритмов машинного обучения, которые можно сгруппировать в три основные категории:
- Алгоритмы контролируемого обучения моделируют взаимосвязь между признаками (независимыми переменными) и меткой (целью) с учетом набора наблюдений.
 Затем модель используется для прогнозирования метки новых наблюдений с использованием функций. В зависимости от характеристик целевой переменной это может быть классификация (дискретная целевая переменная) или регрессия (непрерывная целевая переменная) задача.
Затем модель используется для прогнозирования метки новых наблюдений с использованием функций. В зависимости от характеристик целевой переменной это может быть классификация (дискретная целевая переменная) или регрессия (непрерывная целевая переменная) задача. - Обучение без учителя Алгоритмы пытаются найти структуру в неразмеченных данных.
- Обучение с подкреплением работает по принципу вознаграждения за действие. Агент учится достигать цели, многократно вычисляя вознаграждение своих действий.
В этой статье я кратко объясню 15 популярных алгоритмов машинного обучения в контролируемых и неконтролируемых категориях.
Алгоритмы, которые мы рассмотрим,:
- Линейная регрессия
- Логистическая регрессия
- Вектор поддержки.
- CatBoost
- XGBoost
- Кластеризация K-средних
- Иерархическая кластеризация
- Кластеризация DBSCAN
- Анализ главных компонентов
1.
Линейная регрессияЛинейная регрессия — это контролируемый алгоритм обучения, который моделирует взаимосвязь между непрерывной целевой переменной и одной или несколькими независимыми переменными путем подбора линейного уравнения к данным.
Чтобы линейная регрессия была хорошим выбором, должна существовать линейная связь между независимыми переменными и целевой переменной. Мы можем использовать графики рассеяния или остаточные графики для проверки линейности.
Модель линейной регрессии пытается подобрать линию регрессии к точкам данных, которые лучше всего представляют отношения или корреляции. Наиболее распространенным методом является метод наименьших квадратов (OLE), который находит наилучшую линию регрессии путем минимизации суммы квадратов расстояния между точками данных и линией регрессии.
На следующем графике показана линия линейной регрессии, которая пытается смоделировать взаимосвязь между переменными speed и dist на основе заданных точек данных.
2. Логистическая регрессия
Логистическая регрессия — это контролируемый алгоритм обучения, который в основном предпочтительнее для задач бинарной классификации, таких как прогнозирование оттока, обнаружение спама и прогнозирование кликов по рекламе.
Основной частью логистической регрессии является логистическая (то есть сигмовидная) функция. Он принимает любое действительное число и сопоставляет его со значением от 0 до 1.
(изображение автора)Модель логистической регрессии принимает линейное уравнение в качестве входных данных для сигмовидной функции и использует логарифмические шансы для выполнения задачи бинарной классификации.
Логистическая регрессия возвращает значения вероятности. Ниже представлена типичная кривая логистической регрессии.
Кривая логистической регрессии (изображение автора) Мы можем использовать значения вероятности или преобразовать их в метки (например, 1 и 0). Например, если вероятность больше 50%, прогноз относится к положительному классу (1). В противном случае прогноз имеет отрицательный класс (0).
Значение, которое служит порогом между положительным и отрицательным классом, зависит от проблемы. Мы можем настроить порог, который отделяет положительный класс от отрицательного класса. Если он установлен как 70%, только наблюдения с прогнозируемой вероятностью более 70% будут классифицированы как положительный класс.
3. Метод опорных векторов (SVM)
SVM — это алгоритм обучения с учителем, который в основном используется для задач классификации.
SVM создает границу решения для разделения классов. Перед созданием границы решения каждое наблюдение (или строка) отображается в n-мерном пространстве (n — количество признаков). Например, если мы используем «длину» и «ширину» для классификации различных «ячеек», наблюдения отображаются в двумерном пространстве, а граница решения — линия.
Опорные векторы — это ближайшие точки данных к границе решения. Граница решения рисуется таким образом, чтобы расстояние до опорных векторов было максимальным.
Если граница решения слишком близка к опорному вектору, она будет очень чувствительна к шумам и плохо обобщается. Даже очень небольшие изменения в функциях могут изменить прогноз.
Неправильный выбор границы решения (изображение автора)Если точки данных не являются линейно разделимыми, SVM использует трюк ядра, который измеряет сходство (или близость) точек данных в пространстве более высокого измерения. SVM с ядром фактически не преобразует точки данных в пространство более высокого измерения, что было бы неэффективно. Он измеряет сходство только в пространстве более высокого измерения.
Стандартный SVM пытается разделить все точки данных на разные классы и не допускает неправильной классификации точек. Это приводит к переоснащению модели или, в некоторых случаях, невозможно найти границу решения с помощью стандартного SVM.
Лучшей альтернативой является SVM с мягким запасом, который пытается решить проблему оптимизации со следующими целями:
- Увеличить расстояние границы решения до классов (или опорных векторов)
- Максимально увеличить количество точек, которые правильно классифицируются при обучении набор
Алгоритм допускает неправильную классификацию некоторых точек данных для определения более надежной и обобщенной границы решения.
Существует компромисс между двумя целями, перечисленными выше. Этот компромисс контролируется параметром C , который добавляет штраф за каждую ошибочно классифицированную точку данных. Если c мало, штраф за ошибочную классификацию баллов будет низким, поэтому граница решения с большим запасом выбирается за счет большего количества ошибочных классификаций. Если c велико, SVM пытается свести к минимуму количество неправильно классифицированных примеров из-за высокого штрафа, что приводит к границе решения с меньшим запасом. Штраф не одинаков для всех неправильно классифицированных примеров. Оно прямо пропорционально расстоянию до границы решения.
4. Наивный байесовский алгоритм
Наивный байесовский алгоритм обучения, используемый для задач классификации.
Наивный Байес предполагает, что признаки независимы друг от друга и между признаками нет корреляции. Однако в реальной жизни это не так. Это наивное предположение о некоррелированности признаков является причиной того, что этот алгоритм называется «наивным».
Как следует из названия, основным элементом этого алгоритма является теорема Байеса.
(изображение автора)p(A|B): вероятность события A при условии, что событие B уже произошло
p(B|A): вероятность события B при условии, что событие A уже произошло
p(A): вероятность события A
p(B): Вероятность события B
Наивный байесовский метод вычисляет вероятность класса с заданным набором значений признаков (т. е. p(yi | x1, x2, …, xn)). В предположении, что признаки независимы, мы можем использовать эту вероятность и теорему Байеса для достижения:
(изображение автора)Алгоритм преобразует сложную условную вероятность в произведение гораздо более простых условных вероятностей.
Предположение о том, что все признаки независимы, делает наивный алгоритм Байеса очень быстрым по сравнению со сложными алгоритмами. В некоторых случаях скорость предпочтительнее высокой точности. С другой стороны, это же предположение делает наивный алгоритм Байеса менее точным, чем сложные алгоритмы. Скорость имеет свою цену!
5. K-ближайших соседей
K-ближайших соседей (kNN) — это контролируемый алгоритм обучения, который можно использовать для решения задач как классификации, так и регрессии. Основная идея заключается в том, что значение или класс точки данных определяется точками данных вокруг нее.
Классификатор kNN определяет класс точки данных по принципу мажоритарного голосования. Например, если k установлено равным 5, проверяются классы 5 ближайших точек. Прогноз делается по мажоритарному классу. Точно так же регрессия kNN принимает среднее значение 5 ближайших точек.
Самая большая проблема kNN — определить оптимальное значение k. Очень маленькие значения k имеют тенденцию приводить к переобучению, потому что модель слишком специфична для обучающей выборки и плохо обобщается. С другой стороны, модели с очень большими значениями k не являются хорошими предикторами как для обучающих, так и для тестовых наборов. Они имеют тенденцию быть недооцененными.
kNN прост и удобен для интерпретации. Он не делает никаких предположений, поэтому его можно реализовать в нелинейных задачах. kNN становится очень медленным по мере увеличения количества точек данных, потому что модели необходимо хранить все точки данных. Таким образом, это также неэффективно с точки зрения памяти. Еще одним недостатком kNN является то, что он чувствителен к выбросам.
6. Дерево решений
Дерево решений — это алгоритм обучения с учителем. Он разделяет точки данных (то есть строки), итеративно задавая вопросы.
(изображение автора)Сплиты определяются не случайно. Выбираются те, которые приводят к наибольшему приросту информации. Разбиения, повышающие чистоту узлов, более информативны.
Чистота узла обратно пропорциональна распределению различных классов в этом узле. Вопросы, которые нужно задавать, выбираются таким образом, чтобы повысить чистоту или уменьшить нечистоту.
Алгоритм продолжает задавать вопросы, пока все узлы не станут чистыми. Чистые узлы содержат наблюдения только одного определенного класса. Однако это была бы слишком конкретная модель, и она не могла бы хорошо обобщать. Алгоритм дерева решений можно легко переобучить, если мы не установим ограничение на глубину. Глубина дерева управляется параметром max_depth.
Алгоритм дерева решений обычно не требует нормализации или масштабирования признаков. Он также подходит для работы со смесью типов данных признаков (непрерывные, категориальные, двоичные).
7. Случайный лес
Случайный лес — это алгоритм обучения с учителем. Случайный лес — это ансамбль деревьев решений в сочетании с методом, называемым бэггингом.
В бэггинге деревья решений используются в качестве параллельных оценок. Параллельное объединение множества деревьев решений значительно снижает риск переобучения и приводит к гораздо более точной модели.
Успех случайного леса во многом зависит от использования некоррелированных деревьев решений. Если мы используем одинаковые или очень похожие деревья, общий результат не будет сильно отличаться от результата одного дерева решений. Случайные леса имеют некоррелированные деревья решений за счет начальной загрузки и случайности.
Бутсрэпинг — это случайный выбор выборок из обучающих данных с заменой. Их называют бутстрап-сэмплами.
Случайность признаков достигается путем случайного выбора признаков для каждого дерева решений в случайном лесу. Количество функций, используемых для каждого дерева в случайном лесу, можно контролировать с помощью параметра max_features.
Принцип работы алгоритма случайного леса (изображение автора)Случайный лес — это высокоточная модель для многих различных задач, не требующая нормализации или масштабирования.
8. Деревья решений с градиентным усилением (GBDT)
GBDT — это алгоритм обучения с учителем, который строится путем объединения деревьев решений с методом, называемым повышением. Таким образом, GBDT также является ансамблевым методом.
Повышение означает последовательное объединение алгоритма обучения для получения сильного ученика из множества последовательно соединенных слабых учеников.
Каждое дерево пытается минимизировать ошибки предыдущего дерева. Деревья в бустинге плохо учатся, но последовательное добавление множества деревьев, каждое из которых фокусируется на ошибках предыдущего, делает бустинг высокоэффективной и точной моделью. В отличие от бэггинга, бустинг не требует начальной выборки. Каждый раз, когда добавляется новое дерево, оно соответствует измененной версии исходного набора данных.
Принцип работы алгоритма GBDT (изображение автора)Поскольку деревья добавляются последовательно, алгоритмы повышения обучаются медленно. В статистическом обучении модели, которые обучаются медленно, работают лучше.
Скорость обучения и n_estimators — два важнейших гиперпараметра для GBDT. Скорость обучения, обозначаемая как α, просто означает, насколько быстро обучается модель. Каждое новое дерево изменяет общую модель. Величина модификации контролируется скоростью обучения. N_estimator — это количество деревьев, используемых в модели. Если скорость обучения низкая, нам нужно больше деревьев для обучения модели. Однако нам нужно быть очень осторожными при выборе количества деревьев. Это создает высокий риск переобучения при использовании слишком большого количества деревьев.
GBDT очень эффективен как в задачах классификации, так и в задачах регрессии и обеспечивает более точные прогнозы по сравнению со случайными лесами. Он может обрабатывать смешанные типы функций, и предварительная обработка не требуется. GBDT требует тщательной настройки гиперпараметров, чтобы предотвратить переоснащение модели.
Алгоритм GBDT настолько мощный, что было реализовано множество его обновленных версий, таких как XGBOOST, LightGBM, CatBoost.
9. LightGBM
LightGBM, созданный исследователями Microsoft, представляет собой реализацию деревьев решений с градиентным усилением.
Деревья решений строятся путем разделения наблюдений (т. е. экземпляров данных) на основе значений признаков. Вот как дерево решений «обучается». Алгоритм ищет наилучшее разделение, которое приводит к наибольшему приросту информации.
Поиск наилучшего разделения оказывается самой трудоемкой частью процесса изучения деревьев решений. По мере увеличения размера данных это становится узким местом. LightGBM призван решить эту проблему эффективности, особенно при работе с большими наборами данных.
Чтобы решить эту проблему, LightGBM использует два метода:
- GOSS (градиентная односторонняя выборка)
- EFB (эксклюзивное объединение функций)
Я не буду вдаваться в подробности, но вот более подробная статья, которую я написал чтобы объяснить, как работает LightGBM.
Понимание LightGBM
Что делает его быстрее и эффективнее
в направлении datascience.com
10. CatBoost
LightGBM, созданный исследователями Яндекса, представляет собой еще одну реализацию деревьев решений с градиентным усилением.
Поскольку мы уже рассмотрели GBDT, я упомяну только характерные особенности CatBoost.
CatBoost реализует специальную версию бустинга, которая называется упорядоченным бустингом. Это обеспечивает лучший подход к обработке переобучения. CatBoost также отлично справляется с категориальными функциями. Еще одна отличительная черта — использование симметричных деревьев.
Официальная документация и это руководство содержат исчерпывающее руководство по пониманию и использованию алгоритма CatBoost.
11. XGBoost
XGBoost — еще одна реализация GBDT. Он был настолько мощным, что доминировал на некоторых крупных соревнованиях kaggle. Цель XGboost, как указано в его документации, «состоит в том, чтобы расширить пределы вычислительных возможностей машин, чтобы предоставить масштабируемую, переносимую и точную библиотеку».
Одной из общих черт XGBoost, LightGBM и CatBoost является то, что они требуют тщательной настройки гиперпараметров. Производительность моделей сильно зависит от выбора оптимальных значений гиперпараметров.
Например, ниже приведен типичный список гиперпараметров для модели XGBoost для решения задачи классификации нескольких классов.
params_xgb = {
'boosting_type': 'dart',
'objective': 'multi: softmax',
'num_class': 9,
'max_depth': 7,
'min_child_weight': 20,
'gamma' :1,
'subsample':0.8,
'colsample_bytree':0.7,
'tree_method':'hist',
'eval_metric':'mlogloss',
'eta':0.04,
'alpha': 1,
'подробный': 2
} - Max_depth: Максимальная глубина дерева.
- Min_child_weight: Минимальная сумма веса экземпляра, необходимая для дочернего элемента. Высокий уровень не позволяет ребенку быть слишком конкретным и, таким образом, помогает избежать переобучения.
- Гамма: Минимальное снижение потерь, необходимое для создания дальнейшего раздела на листовом узле дерева. Опять же, чем больше игра, тем меньше вероятность переобучения модели.
- Подвыборка: Доля строк, выбранных случайным образом перед выращиванием деревьев. Подвыборка также может использоваться, чтобы избежать переобучения.
- Эта: скорость обучения. Поддержание его на высоком уровне ускоряет обучение модели, но в то же время увеличивает вероятность переобучения.
- Альфа: член регуляризации L1.
Полный список гиперпараметров XGBoost можно найти здесь.
12. Кластеризация K-средних
Кластеризация K-средних — это алгоритм обучения без учителя. Он направлен на разделение данных на k кластеров таким образом, чтобы точки данных в одном и том же кластере были похожи, а точки данных в разных кластерах находились дальше друг от друга. Таким образом, это метод кластеризации на основе разделов. Сходство двух точек определяется расстоянием между ними.
Важно отметить, что это отличается от классификации, когда мы прикрепляли метки к точкам данных в обучающем наборе. При кластеризации точки данных не имеют меток. Ожидается, что алгоритм найдет структуру данных для группировки точек данных в кластеры.
Кластеризация K-средних пытается минимизировать расстояния внутри кластера и максимизировать расстояние между разными кластерами.
Самая большая проблема кластеризации методом k-средних состоит в том, чтобы определить оптимальное значение числа кластеров. Алгоритм не может определить количество кластеров, поэтому нам нужно указать его.
Исходные точки данных (изображение автора) Точки данных сгруппированы в кластеры (изображение автора)Кластеризация K-средних выполняется относительно быстро и легко интерпретируется. Он также может разумно выбирать положения начальных центроидов (центр кластера), что ускоряет сходимость.
13. Иерархическая кластеризация
Иерархическая кластеризация — это алгоритм обучения без учителя. Он создает дерево кластеров путем многократного группирования или разделения точек данных. Существует два типа иерархической кластеризации:
- Агломеративная кластеризация
- Разделительная кластеризация
Агломеративный подход является наиболее часто используемым подходом. Сначала предполагается, что каждая точка данных представляет собой отдельный кластер. Затем аналогичные кластеры итеративно объединяются.
Одним из преимуществ иерархической кластеризации является то, что нам не нужно заранее указывать количество кластеров. Однако нецелесообразно объединять все точки данных в один кластер. В какой-то момент мы должны перестать объединять кластеры.
Иерархическая кластеризация всегда создает одни и те же кластеры. Кластеризация K-средних может привести к различным кластерам в зависимости от того, как инициируются центроиды (центр кластера). Однако это более медленный алгоритм по сравнению с k-средними. Иерархическая кластеризация занимает много времени, особенно для больших наборов данных.
14. Кластеризация DBSCAN
Методы кластеризации на основе разделов и иерархической кластеризации очень эффективны для кластеров нормальной формы. Однако, когда дело доходит до кластеров произвольной формы или обнаружения выбросов, методы на основе плотности более эффективны.
DBSCAN означает d энсити- b ased s пациал c блеск a аппликации с n уаз. Он может находить кластеры произвольной формы и кластеры с шумом (т.е. выбросы).
Основная идея DBSCAN заключается в том, что точка принадлежит кластеру, если она близка ко многим точкам из этого кластера.
Есть два ключевых параметра DBSCAN:
- eps : Расстояние, определяющее окрестности. Две точки считаются соседями, если расстояние между ними меньше или равно eps.
- minPts: Минимальное количество точек данных для определения кластера.
На основании этих двух параметров точки классифицируются как основные, граничные или выбросы:
- Центральная точка: ) в его окрестностях с радиусом eps.
- Пограничная точка: Точка считается пограничной, если она достижима из центральной точки и количество точек в ее окрестностях меньше minPts.
- Выброс: Точка является выбросом, если она не является базовой точкой и не достижима ни из одной базовой точки.
DBSCAN не требует заранее указывать количество кластеров. Он устойчив к выбросам и способен обнаруживать выбросы.
В некоторых случаях определить подходящее расстояние окрестности (eps) непросто, и для этого требуются знания предметной области.
15. Анализ главных компонент (АГК)
АПК представляет собой алгоритм уменьшения размерности, который в основном извлекает новые функции из существующих с сохранением как можно большего количества информации. PCA — это алгоритм обучения без учителя, но он также широко используется в качестве этапа предварительной обработки для алгоритмов обучения с учителем.
PCA получает новые признаки, находя связи между признаками в наборе данных.
PCA — алгоритм уменьшения линейной размерности. Существуют также нелинейные методы.
Целью PCA является максимально возможное объяснение дисперсии в исходном наборе данных с использованием меньшего количества признаков (или столбцов).