Robots.txt для WordPress, идеальный вариант robots.txt для WP
Файл robots.txt это первоначальный, и один из главнейших инструментов для корректной индексации ваших сайтов и их контента. Отсутствие данного файла приведет к печальным последствиям которые тяжело будет исправить. От того как вы настроите robots.txt зависит что попадет в выдачу по запросам в поисковых системах. Сейчас рассмотрим правильный файл robots.txt для WordPress сайта.
Для чего использовать robots.txt?
Перед тем как приступать к созданию и наполнению давайте разберем саму суть данного файла.
Ваш сайт это набор файлов и папок, некоторые из которых нужно защитить от чтения от сторонних глаз, которыми являются так же и поисковые роботы, пришедшие прочитать и запомнить наш контент, для дальнейшей выдачи в поиске.
Чем занимается поисковой робот на сайте?
Итак, к примеру ваш сайт посетил поисковой робот, что он делает в первую очередь? Во-первых пытается найти уникальную информацию, которую сможет занести в свою базу данных. Если роботс отсутствует, а именно к нему в первую очередь обращается робот, тогда он начинает “читать” файлы находящиеся в корне сайта, что конечно же нам не очень понравиться, ведь он не только не найдет там нужную ему информацию, а и прочитает наши данные настроек, которые созданы для нашей личной цели. Именно для этого и существует robots.txt. Он дает указания роботу куда ходить нужно, а куда заглядывать не стоит.
Если роботс отсутствует, а именно к нему в первую очередь обращается робот, тогда он начинает “читать” файлы находящиеся в корне сайта, что конечно же нам не очень понравиться, ведь он не только не найдет там нужную ему информацию, а и прочитает наши данные настроек, которые созданы для нашей личной цели. Именно для этого и существует robots.txt. Он дает указания роботу куда ходить нужно, а куда заглядывать не стоит.
Создание и размещение файла на сайте WordPress.
Для того что бы создать путеводитель для роботов, вам потребуется обычный блокнот windows, в котором вы будете прописывать нужные команды для поисковых роботов. После этого нужно сохранить файл в формате “txt”, под названием “robots”. На этом создание завершено, далее в статье мы рассмотрим какие же команды должны находиться в robots.txt для WordPress.
Где размещать?
Robots.txt размещается на вашем хостинге, непосредственно в корневой папке сайта, куда мы перенесли наш сайт. Теперь поисковой робот перед тем как лазить по нашему сайту, сначала спросит разрешение куда ему можно, а куда запрещено заходить.
Теперь поисковой робот перед тем как лазить по нашему сайту, сначала спросит разрешение куда ему можно, а куда запрещено заходить.
Важно: при размещении документа в подкаталогах, роботы не смогут найти этот файл.
Зайдя к вам на сайт робот заходит смотрит предназначеную для него “инструкцию” и начинает его изучать. Изучив до конца он пойдет по выбранному вами пути индексации, и будет игнорировать те директории, папки и URL к которым вы запретили обращаться.
Что включает в себя роботс?
Robots.txt несет в себе информативные данные для поисковых роботов и включает в себя такие основные “команды”:
User-agent
Указывает на имя потенциального робота посетителя. Синтаксис “User-agent: *” будет означать что данным командам должны следовать все роботы. Варианты для отдельных роботов рассматривать не будем, их очень много. По этому для примера будет только два варианта (для всех роботов и отдельно для Яндекс).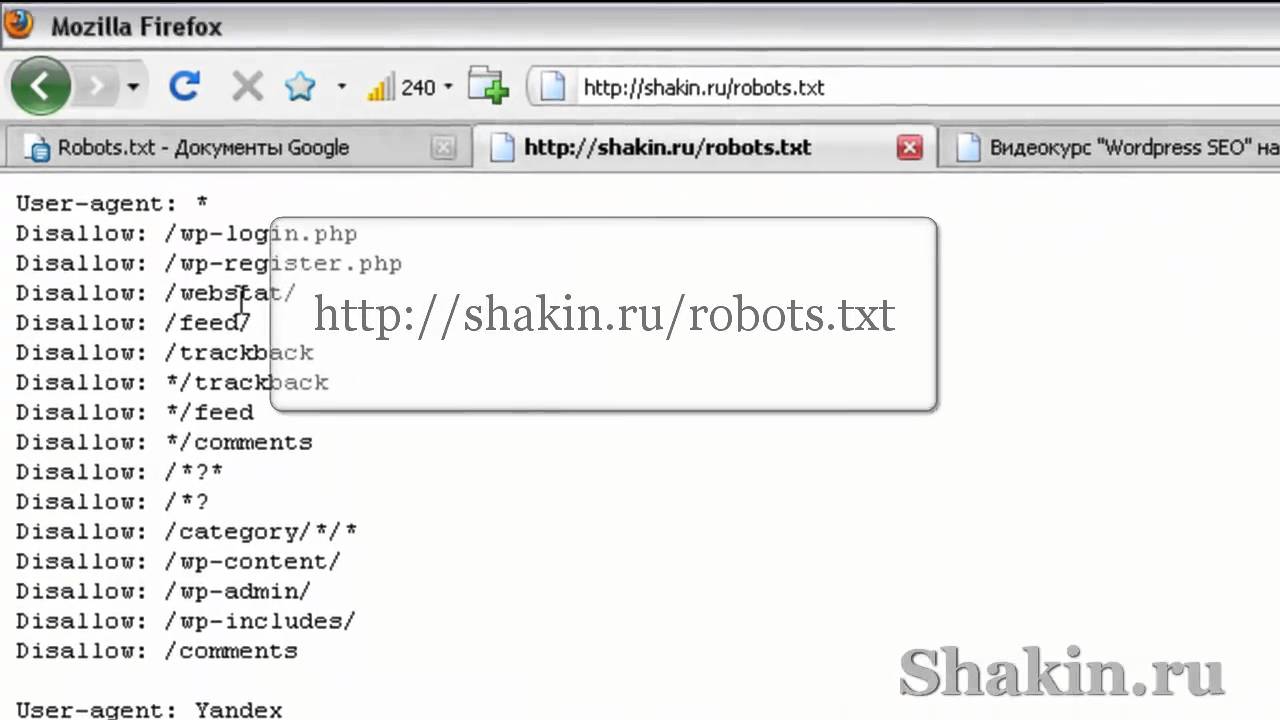
Disallow
Команда для роботов, рассказывающая о том куда ходить не стоит, запрещает чтение указанных адресов и файлов.
Allow
Команда которая рекомендует “направление” на индексирования данного адреса или файла.
Host
Данная команда указывает роботу, какой из вариантов сайта будет нашим главным зеркалом сайта.
Sitemap
Место нахождения xml карты сайта по которой должен пробежаться посетивший нас робот, в той части за которой он пришел (контент сайта).
Правильный robots.txt для сайта на CMS WordPress.
Для того что бы правильно настроить файл robots.txt специально под “движок” WordPress нужно для начала понимать что ищут роботы и что им будет интересно.
А наши паучки ищут контент нашего ресурса, и им совершенно не нужно знать о всех остальных конфигурационных данных наших сайтов. Во первых они им приходятся не по вкусу, и от переедания таковых они могут покинуть наш сайт так и не найдя то что нам бы хотелось да еще и вынесут наши запрещенные для общего глаза данные на общее обозрение.
Во первых они им приходятся не по вкусу, и от переедания таковых они могут покинуть наш сайт так и не найдя то что нам бы хотелось да еще и вынесут наши запрещенные для общего глаза данные на общее обозрение.
Говоря о требуемых размещения директорий в robots.txt для WordPress, нам нужно разобраться с главной (корневой) папкой нашего сайта, в которой мы обнаружим огромное количество стандартных файлов и папок. Роботам незачем их читать, они не найдут там то что ищут, по этому нужно запрещать индексировать по возможности весь “лишний мусор”.
Подумайте сами чем может сулить нам например индексация нашего wp-config.php. Робот просто возьмет и “расскажет” всем о наших вводных данных к нашим базам данных, а это крайне плохо для нас.
Сейчас я покажу готовый вариант. Затем разберем каждую строчку в расширенном описании. Итак, правильный robots.txt для WordPress должен выглядеть так:
Disallow: /wp-
Disallow: */trackback
Disallow: /*?*
Disallow: /?s=*
Disallow: */author
Disallow: /2016
Disallow: /xmlrpc. php
php
Allow: /wp-content/uploads/
Allow: *.js
Allow: *.css
Host: site.ru
Sitemap: http://site.ru/sitemap.xml
Теперь посмотрим как мы смогли добиться такого короткого содержания файла robots.txt для WordPress, рассмотрим расширенную версию файла и постепенно уберем повторы:
Disallow: /wp-admin # Блокируем индексацию папки admin
Disallow: /wp-includes # папки includes
Disallow: /wp-content/languages # папки content/languages
Disallow: /wp-content/plugins # папки content/plugins
Disallow: /wp-content/cache # папки content/cache
Disallow: /wp-content/themes # папки content/themes
Disallow: /trackback # блокируем индекс всех возможных трекбеков
Disallow: */trackback
Disallow: */*/trackback
Disallow: */feed # блокируем индексацию фидов, новостных лент всех вариантов
Disallow: /feed/
Disallow: /?feed=
Disallow: */*/feed
Disallow: */*/feed/*/
Disallow: /*?* # запрет индекса всех ссылок (защита от дублей)
Disallow: /tag # каталоги находящихся в разных директориях ( метки, категории )
Disallow: /tag/*
Disallow: /?s=*
Disallow: /page/* # запрещаем лишние страницы в WP, создающие дубли
Disallow: /author # блокировка индексации автора
Disallow: /2015 # дублирование ссылок с архива # далее блокировка всех административных файлов
Disallow: /xmlrpc.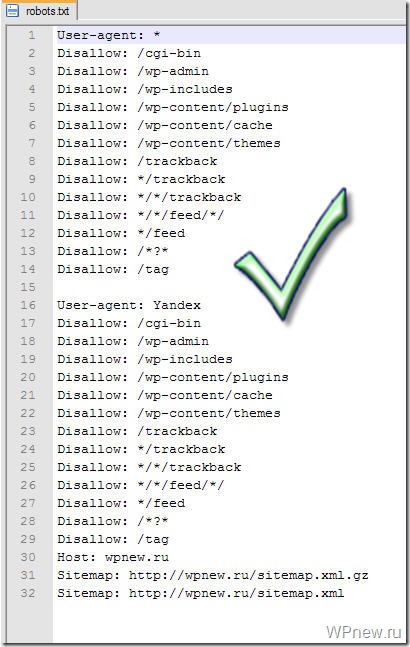 php
php
Disallow: /wp-activate.php
Disallow: /wp-blog-header.php
Disallow: /wp-comments-post.php
Disallow: /wp-config.php
Disallow: /wp-cron.php
Disallow: /wp-links-opml.php
Disallow: /wp-load.php
Disallow: /wp-login.php
Disallow: /wp-mail.php
Disallow: /wp-register.php
Disallow: /wp-settings.php
Disallow: /wp-signup.php
Disallow: /wp-trackback.php
Disallow: /wp-config-sample.php
Allow: /wp-content/uploads/ # Разрешаем индексировать наши загруженные картинки
Host: site.ru # Указываем основное зеркало
Sitemap: http://site.ru/sitemap.xml # Направляем робота на наши страницы контента
Указанный выше пример заблокирует от индексации все ненужные для поисковой оптимизации файлы и ссылки и укажет на тот материал который должен быть проиндексирован.
Ну уж очень длинный у нас вышел пример, сейчас мы его будем упрощать. Для начала возьмемся за файлы и папки с префиксом “wp-“ их все можно объединить воедино.
Disallow: /wp-
Disallow: /trackback
Disallow: */trackback
Disallow: */*/trackback
Disallow: */feed
Disallow: /feed/
Disallow: /?feed=
Disallow: */*/feed
Disallow: */*/feed/*/
Disallow: /*?*
Disallow: /tag
Disallow: /tag/*
Disallow: /?s=*
Disallow: /page/*
Disallow: /author
Disallow: /2015
Disallow: /xmlrpc.php
Allow: /wp-content/uploads/
Allow: *.js
Allow: *.css
Host: site.ru
Sitemap: http://site.ru/sitemap.xml
Значительно уменьшили, но это не предел, пойдем немножко дальше и постараемся еще сократить, да еще и проделать необходимые внутренние настройки.
Все дело в том что при таком варианте файла, Google все равно внесет запрещенные вами страницы в индекс, но выглядеть они будут иначе:
Это не столь опасно как открытые дубли, но все же лучше от этого избавляться. Для того что бы исправить данную ситуацию можно воспользоваться сразу несколькими методами. Я расскажу о самом быстром и простом — запрет индексирования страниц с помощью Google Webmasters Tools “Параметры URL”. Кстати в рекомендациях для Яндекса лучше оставить параметр “feed” в указанном варианте.
Кстати в рекомендациях для Яндекса лучше оставить параметр “feed” в указанном варианте.
Избавились от feed с помощью Google, теперь для альтернативы запретим индексирование пагинации с помощью плагина, который скорее всего используется вами, если же это не так, тогда альтернативный так же подойдет. Речь идет о All in One SEO и его настройках тегов “robots” и “canonical”.
Для того что бы запретить индексировать поисковикам не нужные нам страницы, такие как страницы пагинации всех видов (главной, рубрик и меток) нужно всего навсего поставить галочки в нужных местах.
Сперва включим канонические ссылки на главные страницы, для избежания их дублирования.
Что мы сделали? В общем все что было нужно, мы указали на страницах которые дублируют наш контент ссылку на основную страницу, что укажет роботу что именно нужно сканировать и считать за основной контент. Теперь добавим еще мета тег robots.
После проведенных настроек, снова обращаемся к нашему варианту файла и смотрим что получилось:
Disallow: /wp-
Disallow: /trackback
Disallow: */trackback
Disallow: */*/trackback
Disallow: /*?*
Disallow: /?s=*
Disallow: /author
Disallow: /2015
Disallow: /xmlrpc. php
php
Allow: /wp-content/uploads/
Allow: *.js
Allow: *.css
Host: site.ru
Sitemap: http://site.ru/sitemap.xml
По поводу меток и рубрик вопрос спорный, вы можете оптимизировать рубрики, и добиться результата с которым ваши страницы категорий будут не вредны, а наоборот принесут дополнительный трафик. Метки можно подогнать под поисковики аналогично рубрикам.
Если тема, которую вы установили использует картинки, тогда лучше открыть их для индекса:
Allow: /wp-content/themes/название вашей темы/images
Если вы проигнорируете это, у вас могут возникнуть проблемы с поисковиками, они не любят когда от них скрывают важную информацию.
Пример можно расширять, например добавлением запрета для индексации определенных ссылок на страницы, обычно это страницы повторы которые вредят нашей оптимизации.
В документе обычно не указывают конкретно для всех поисковых роботов по отдельности, а делаю два набора команд один для всех второй для Яндекса.
User-agent: *
Disallow: /wp-
…
User-agent: Yandex
Disallow: /wp-
…
Host: site.ru
Sitemap: http://site.ru/sitemap.xml
Host — нужно обязательно указывать, пренебрежение приведет к дублирования индексации ваших страниц между www.site.ru и site.ru, что рассеет ваш трафик и пагубно скажется на вашем сайте.
Как правильно создать карту сайта можно почитать в отдельных уроках по WordPress.
На этом урок по созданию файла robots.txt заканчивается, и помните что от этого по большей степени зависит судьба индексации ваших страниц.
Рекомендую почитать:
Правильный robots txt для WordPress сайта – инструкция на 2019-2020 год без плагинов
Для чего нужен robots.txt
Robots.txt создан для регулирования поведения поисковых роботов на сайтах, а именно куда им заходить можно и брать в поиск, а куда нельзя. Лет 10 назад сила данного файла была велика, по его правилам работали все поисковые системы, но сейчас он скорее как рекомендация, чем правило.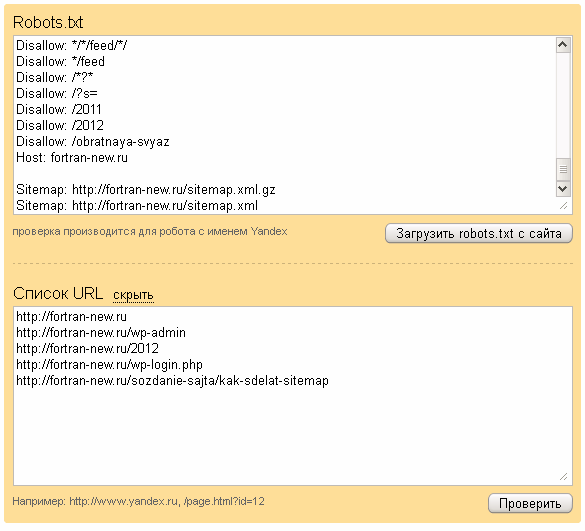
Но пока не отменили, вебмастера должны делать его и настраивать правильно исходя из структуры и иерархии сайтов. Отдельная тема это WordPress, потому что CMS содержит множество элементов, которые не нужно сканировать и отдавать в индекс. Разберемся как правильно составить robots.txt
Где лежит файл robots в WordPress
На любом из ресурсов robots.txt должен лежать в корневой папке. В случае с вордпресс, там где находится папка wp-admin и ей подобные.
Расположение на сервереЕсли не создавался и не загружался администратором сайта, то по умолчанию на сервере не найти. Стандартная сборка WordPress не предусматривает наличие такого объекта.
Как создать правильный robots txt
Создать правильный robots txt задача не трудная, сложнее прописать в нем правильные директивы. Сначала создадим документ, открываем программу блокнот и нажимаем сохранить как.
Сохраняем документВ следующем окне задаем название robots, оставляем расширение txt, кодировку ANSI и нажимаем сохранить. Объект появится в папке куда произошло сохранение. Пока документ пустой и ничего не содержит в себе, давайте разберемся какие именно директивы он может поддерживать.
Объект появится в папке куда произошло сохранение. Пока документ пустой и ничего не содержит в себе, давайте разберемся какие именно директивы он может поддерживать.
Сохранение роботсаПри желании можете сразу скачать его на сервер в корень через программу FileZilla.
Настройка команд
Выделю четыре основные команды:
- User-agent: показывает правила для разных поисковых роботов, либо для всех, либо для отдельных
- Disalow: запрещает доступ
- Allow: разрешаем доступ
- Sitemap: адрес до XML карты
Устаревшие и ненужные конфигурации:
- Host: указывает главное зеркало, стало не нужным, потому что поиск сам определит правильный вариант
- Crawl-delay: ограничивает время на пребывание робота на странице, сейчас сервера мощные и беспокоится о производительности не нужно
- Clean-param: ограничивает загрузку дублирующегося контента, прописать можно, но толку не будет, поисковик проиндексирует все, что есть на сайте и возьмет по–максимому страниц
Рабочий пример инструкций для WordPress
Дело в том что поисковой робот не любит запрещающие директивы, и все равно возьмет в оборот, что ему нужно.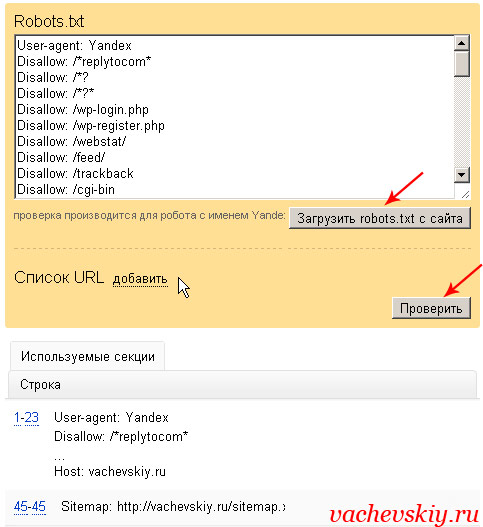 Запрет на индексацию должен быть объектов, которые 100% не должны быть в поиске и в базе Яндекса и Гугла. Данный рабочий пример кода помещаем в robots txt.
Запрет на индексацию должен быть объектов, которые 100% не должны быть в поиске и в базе Яндекса и Гугла. Данный рабочий пример кода помещаем в robots txt.
User-agent: * Disallow: /wp- Disallow: /tag/ Disallow: */trackback Disallow: */page Disallow: /author/* Disallow: /template.html Disallow: /readme.html Disallow: *?replytocom Allow: */uploads Allow: *.js Allow: *.css Allow: *.png Allow: *.gif Allow: *.jpg Sitemap: https://ваш домен/sitemap.xml
Разберемся с текстом и посмотрим что именно мы разрешили, а что запретили:
- User-agent, поставили знак *, тем самым сообщив что все поисковые машины должны подчиняться правилам
- Блок с Disallow запрещает к индексу все технические страницы и дубли. обратите внимание что я заблокировал папки начинающиеся на wp-
- Блок Allow разрешает сканировать скрипты, картинки и css файлы, это необходимо для правильного представления проекта в поиске иначе вы получите портянку без оформления
- Sitemap: показывает путь до XML карты сайта, обязательно нужно ее сделать, а так же заменить надпись”ваш домен”
Остальные директивы рекомендую не вносить, после сохранения и внесения правок, загружаем стандартный robots txt в корень WordPress. Для проверки наличия открываем такой адрес https://your-domain/robots.txt, заменяем домен на свой, должно отобразится так.
Для проверки наличия открываем такой адрес https://your-domain/robots.txt, заменяем домен на свой, должно отобразится так.
Как проверить работу robots.txt
Стандартный способ проверить через сервис yandex webmaster. Для лучшего анализа нужно зарегистрировать и установить на сайт сервис. Вверху видим загрузившийся robots, нажимаем проверить.
Проверка документа в yandexНиже появится блок с ошибками, если их нет то переходим к следующему шагу, если неверно отображается команда, то исправляем и снова проверяем.
Проверим правильно ли Яндекс обрабатывает команды, спускаемся чуть ниже, введем два запрещенных и разрешенных адреса, не забываем нажать проверить. На снимке видим что инструкция сработала, красным помечено что вход запрещен, а зеленой галочкой, что индексирование записей разрешена.
Проверка папок и страниц в яндексеПроверили, все срабатывает, перейдем к следующему способу это настройка robots с помощью плагинов. Если процесс не понятен, то смотрите наше видео.
Если процесс не понятен, то смотрите наше видео.
Плагин–генератор Virtual Robots.txt
Если не хочется связываться с FTP подключением, то приходит на помощь один отличный WordPress плагин–генератор называется Virtual Robots.txt. Устанавливаем стандартно из админки вордпресс поиском или загрузкой архива, выглядит так.
Как выглядит Virtual Robots.txtПереходим в админку Настройки > Virtual Robots.txt, видим знакомую конфигурацию, но нам нужно ее заменить, на нашу из статьи. Копируем и вставляем, не забываем сохранять.
Настройка Virtual Robots.txt
Добавить с помощью Yoast SEO
Знаменитый плагин Yoast SEO предоставляет возможность добавить и изменить robots.txt из панели WordPress. Причем созданный файл появляется на сервере (а не виртуально) и находится в корне сайта, то есть после удаления или деактивации роботс остается. Переходим в Инструменты > Редактор.
Yoast SEO редактор файловВыйдет текстовая область, записываем, имеющийся текст из универсальной конфигурации и сохраняем. Можно проверить по FTP соединению документ появится.
Изменить модулем в All in One SEO
Старый плагин All in One SEO умеет изменять robots txt, чтобы активировать возможность переходим в раздел модули и находим одноименный пункт, нажимаем Activate.
Модули в All In one SeoВ меню All in One SEO появится новый раздел, заходим, видим функционал конструктора.
Работа в модуле AIOS- Записываем имя агента, в нашем случае * или оставляем пустым
- Разрешаем или запрещаем индексацию
- Директория или страница куда не нужно идти
- Результат
Модуль не удобный, создать по такому принципу валидный и корректный robots. txt трудно. Лучше используйте другие инструменты.
txt трудно. Лучше используйте другие инструменты.
Правильная настройка для плагина WooCommerce
Чтобы сделать правильную настройку для плагина интернет магазина на WordPress WooCommerce, добавьте эти строки к остальным:
Disallow: /cart/
Disallow: /checkout/
Disallow: /*add-to-cart=*
Disallow: /my-account/
Делаем аналогичные действия и загружаем на сервер через FTP или плагином.
Итог
Подведем итог что нужно сделать чтобы на сайте WordPress был корректный файл для поисковиков:
- Создаем вручную или с помощью плагина файл
- Записываем в него инструкции из статьи
- Загружаем на сервер
- Проверяем в валидаторе Yandex
- Не пользуйтесь генераторами robots txt в интернете, пошевелите немного руками
Совершенствуйте свои блоги на WordPress, продвигайтесь и правильно настраивайте все параметры, а мы в этом поможем, успехов!
Пожалуйста, оцените материал: Мне нравится18Не нравитсяКак создать файл robots.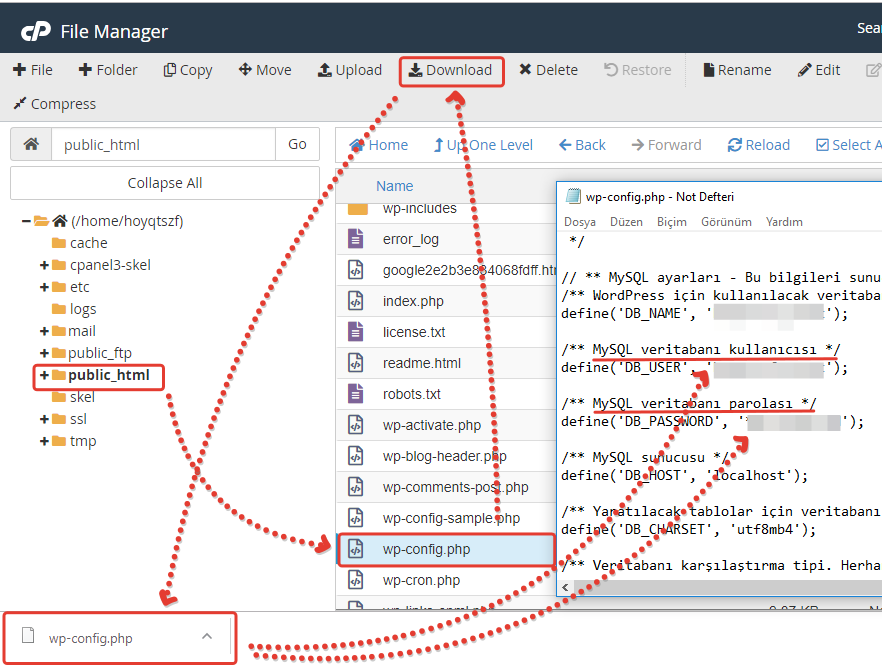 txt для WordPress. 4 способа
txt для WordPress. 4 способа
Всем, привет! Сегодня небольшой пост — как автоматически создать файл robots.txt для WordPress? Друзья, вы можете создать правильный robots.txt для WordPress в пару кликов, прочитав данное руководство. Создание правильного файла robots.txt для WordPress очень важно. Благодаря ему поисковые системы будут знать, какие страницы индексировать и показывать в поиске. То есть, результаты поиска будут именно такими, как вам нужно, без дублирования страниц WordPress.
robots.txt для сайта WordPressЧитайте, дамы и господа — WordPress robots.txt: лучшие примеры для SEO.
Файл robots.txt для WordPress
WordPress robots.txt где лежит/находится? По умолчанию WordPress автоматически создает виртуальный файл robots.txt для вашего сайта. Таким образом, даже если вы ни чего не делали, на вашем сайте ВордПресс уже должен быть файл robots.txt. Вы можете проверить, так ли это, добавив /robots.txt в конец вашего доменного имени. Например, так https://ваш сайт/robots.txt
Например, так https://ваш сайт/robots.txt
Поскольку этот файл является виртуальным, вы не можете его редактировать. Однако, если вы хотите отредактировать свой файл robots.txt WordPress как надо, вам необходимо создать физический файл на вашем хостинге. Создайте свой правильный robots.txt для WordPress, который вы сможете легко редактировать по мере необходимости.
Как создать файл robots.txt для WordPress
Robots.txt — это текстовый файл, который содержит параметры индексирования сайта для роботов поисковых систем.
Файл robots.txt сообщает поисковым роботам, какие страницы или файлы на вашем сайте можно или нельзя обрабатывать.
Яндекс и Google
Для начала напомню вам, создать (и редактировать) файл robots.txt для WordPress можно вручную и с помощью плагина Yoast SEO
Создать файл robots.txtДрузья, имейте ввиду, что Yoast SEO устанавливает свои правила по умолчанию, которые перекрывают правила существующего виртуального файла robots. txt ВордПресс:
txt ВордПресс:
Что должно быть в правильно составленного robots.txt? Идеального файла не существует. Например, сайт Yoast SEO использует такой robots.txt для WordPress:
User-agent: *
И всё. Для большинства сайтов WordPress лучший пример. Вот даже скриншот сделал у Yoast SEO:
Правильный robots.txt на сайте yoast.comЧто это значит? Директива говорит что, все поисковые роботы могут свободно сканировать этот сайт без ограничений. Этого хватит для правильной индексации сайта WP. А наша SEO специалисты рекомендуют почти тоже самое. Пример, правильно составленного robots.txt для WordPress сайта:
User-agent: *
Disallow:
Sitemap: https://mysite.ru/sitemap.xmlДанная запись в файле роботс делает доступным для индексирования полностью сайт для роботов всех известных поисковиков. Здесь, также прописан путь к карте сайта XML.
Создать и редактировать файл также можно при помощи All in One SEO Pack прямо из интерфейса SEO плагина. Модуль robots.txt в SEO-пакете Все в одном позволяет вам настроить файл robots.txt для вашего сайта, который переопределит файл robots.txt по умолчанию, который создает WordPress:
Модуль robots.txt в SEO-пакете Все в одном позволяет вам настроить файл robots.txt для вашего сайта, который переопределит файл robots.txt по умолчанию, который создает WordPress:
Вы сможете управлять своим файлом Robots.txt, в разделе All in One SEO Pack — Robots.txt. Сам официальный сайт плагина использует вот такой роботс:
Пример файла RobotsПравила по умолчанию, которые отображаются в поле Создать файл Robots.txt (показано на снимке экрана выше), требуют, чтобы роботы не сканировали ваши основные файлы WordPress. Для поисковых систем нет необходимости обращаться к этим файлам напрямую, потому что они не содержат какого-либо релевантного контента сайта.
А если вы не используете данные SEO модули, то предлагаю вам воспользоваться специальным плагином — Robots.txt Editor.
Плагин Robots.txt Editor
Плагин Robots.txt для WordPress — создание и редактирование файла robots.txt для сайта ВордПресс. Очень простой, лёгкий и эффективный плагин.
Плагин Robots.txt Editor (редактор) позволяет создать и редактировать файл robots.txt на вашем сайте WordPress.
Плагин Robots.txt возможности
- Работает в сети сайтов Multisite на поддоменах;
- Пример правильного файла robots.txt для WordPress;
- Не требует дополнительных настроек;
- Абсолютно бесплатный.
Как использовать? Установите плагин robots.txt стандартным способом. То есть, из админки. Плагины — Добавить новый. Введите в окно поиска его название — Robots.txt Editor:
Добавить плагин Robots.txt EditorУстановили и сразу активировали. Всё, готово. Теперь смотрим, что получилось. Заходим, Настройки — Чтение и видим результат. Автоматически созданный правильный файл robots.txt для WordPress со ссылкой на ваш файл Sitemap. Пример, правильный robots.txt для сайта ВордПресс:
Созданный файл robots.txt WordPressЕстественно, вы можете его легко отредактировать под свои нужды. А также просмотреть, нажав соответствующею ссылку — Просмотр robots. txt.
txt.
Как создать robots.txt вручную
Если вы не захотите использовать плагины, которые предлагают функцию robots.txt, вы все равно можете создать и управлять своим файлом robots.txt на своём хостинге. Как создать файл robots.txt самостоятельно?
В текстовом редакторе создайте файл с именем robots в формате txt и заполните его:
Создать файл с именем robots.txtФайл должен иметь имя robots.txt и никакое другое больше. Сохраните данный файл локально на компьютере. А затем, загрузите созданный файл в корневую директорию вашего сайта.
Корневая папка (корневая директория/корневой каталог/корень документа) — это основная папка, в которой хранятся все файлы сайта. Обычно, это папка public_html (там где находятся файлы — .htaccess, wp-config.php и другие). Именно в эту папку загружается файл robots.txt:
Загрузите файл в корневую папку вашего сайтаЧтобы проверить, получилось ли у вас положить файл в нужное место, перейдите по адресу: https://ваш_сайт.ru/robots. txt
txt
Теперь, когда ваш файл robots.txt создан и загружен на сайт, вы можете проверить его на ошибки.
Проверка вашего файла robots.txt
Вы можете проверить файл robots.txt WordPress в Google Search Console и Яндекс.Вебмастер, чтобы убедиться, что он правильно составлен.
Например, проверка файла robots.txt WordPress в Яндекса.Вебмастер. В блоке Результаты анализа robots.txt перечислены директивы, которые будет учитывать робот при индексировании сайта.
Анализ robots.txt в Яндекс.ВебмастерЕсли будет найдена ошибка, информация об этом будет показана вам.
В заключение
Для некоторых сайтов WordPress нет необходимости срочно изменять стандартный виртуальный файл robots.txt (по умолчанию). Но, если вам нужен физический файл robots.txt, то используйте плагины Robots.txt Editor, All in One SEO Pack или Yoast SEO. С ними можно легко редактировать файл прямо из панели инструментов WordPress, чтобы добавить свои собственные правила.
До новых встреч, друзья и я надеюсь, что вам понравилось это маленькое руководство. index\.php$ — [L]
RewriteCond %{REQUEST_FILENAME} !-f
RewriteCond %{REQUEST_FILENAME} !-d
RewriteRule . /index.php [L]
</IfModule>
# BEGIN W3TC Browser Cache
<IfModule mod_deflate.c>
<IfModule mod_headers.c>
Header append Vary User-Agent env=!dont-vary
</IfModule>
AddOutputFilterByType DEFLATE text/css text/x-component application/x-javascript application/javascript text/javascript text/x-js text/html text/richtext image/svg+xml text/plain text/xsd text/xsl text/xml image/bmp application/java application/msword application/vnd.ms-fontobject application/x-msdownload image/x-icon application/json application/vnd.ms-access application/vnd.ms-project application/x-font-otf application/vnd.ms-opentype application/vnd.oasis.opendocument.database application/vnd.oasis.opendocument.chart application/vnd.oasis.opendocument.formula application/vnd.oasis.opendocument.graphics application/vnd.oasis.opendocument.presentation application/vnd.oasis.opendocument.
index\.php$ — [L]
RewriteCond %{REQUEST_FILENAME} !-f
RewriteCond %{REQUEST_FILENAME} !-d
RewriteRule . /index.php [L]
</IfModule>
# BEGIN W3TC Browser Cache
<IfModule mod_deflate.c>
<IfModule mod_headers.c>
Header append Vary User-Agent env=!dont-vary
</IfModule>
AddOutputFilterByType DEFLATE text/css text/x-component application/x-javascript application/javascript text/javascript text/x-js text/html text/richtext image/svg+xml text/plain text/xsd text/xsl text/xml image/bmp application/java application/msword application/vnd.ms-fontobject application/x-msdownload image/x-icon application/json application/vnd.ms-access application/vnd.ms-project application/x-font-otf application/vnd.ms-opentype application/vnd.oasis.opendocument.database application/vnd.oasis.opendocument.chart application/vnd.oasis.opendocument.formula application/vnd.oasis.opendocument.graphics application/vnd.oasis.opendocument.presentation application/vnd.oasis.opendocument.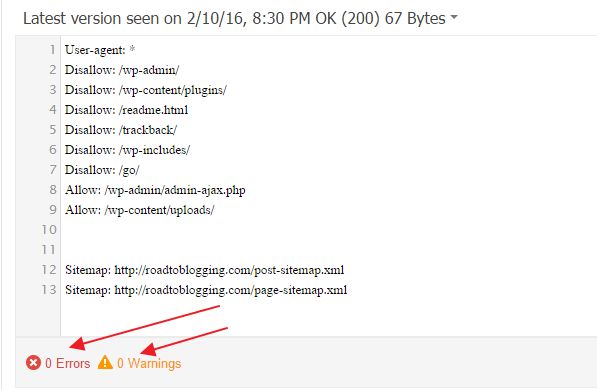 spreadsheet application/vnd.oasis.opendocument.text audio/ogg application/pdf application/vnd.ms-powerpoint application/x-shockwave-flash image/tiff application/x-font-ttf application/vnd.ms-opentype audio/wav application/vnd.ms-write application/font-woff application/font-woff2 application/vnd.ms-excel
<IfModule mod_mime.c>
# DEFLATE by extension
AddOutputFilter DEFLATE js css htm html xml
</IfModule>
</IfModule>
<FilesMatch «\.(bmp|class|doc|docx|eot|exe|ico|json|mdb|mpp|otf|_otf|odb|odc|odf|odg|odp|ods|odt|ogg|pdf|pot|pps|ppt|pptx|svg|svgz|swf|tif|tiff|ttf|ttc|_ttf|wav|wri|woff|woff2|xla|xls|xlsx|xlt|xlw|BMP|CLASS|DOC|DOCX|EOT|EXE|ICO|JSON|MDB|MPP|OTF|_OTF|ODB|ODC|ODF|ODG|ODP|ODS|ODT|OGG|PDF|POT|PPS|PPT|PPTX|SVG|SVGZ|SWF|TIF|TIFF|TTF|TTC|_TTF|WAV|WRI|WOFF|WOFF2|XLA|XLS|XLSX|XLT|XLW)$»>
<IfModule mod_headers.c>
Header unset Last-Modified
</IfModule>
</FilesMatch>
# END W3TC Browser Cache
# BEGIN W3TC CDN
<FilesMatch «\.
spreadsheet application/vnd.oasis.opendocument.text audio/ogg application/pdf application/vnd.ms-powerpoint application/x-shockwave-flash image/tiff application/x-font-ttf application/vnd.ms-opentype audio/wav application/vnd.ms-write application/font-woff application/font-woff2 application/vnd.ms-excel
<IfModule mod_mime.c>
# DEFLATE by extension
AddOutputFilter DEFLATE js css htm html xml
</IfModule>
</IfModule>
<FilesMatch «\.(bmp|class|doc|docx|eot|exe|ico|json|mdb|mpp|otf|_otf|odb|odc|odf|odg|odp|ods|odt|ogg|pdf|pot|pps|ppt|pptx|svg|svgz|swf|tif|tiff|ttf|ttc|_ttf|wav|wri|woff|woff2|xla|xls|xlsx|xlt|xlw|BMP|CLASS|DOC|DOCX|EOT|EXE|ICO|JSON|MDB|MPP|OTF|_OTF|ODB|ODC|ODF|ODG|ODP|ODS|ODT|OGG|PDF|POT|PPS|PPT|PPTX|SVG|SVGZ|SWF|TIF|TIFF|TTF|TTC|_TTF|WAV|WRI|WOFF|WOFF2|XLA|XLS|XLSX|XLT|XLW)$»>
<IfModule mod_headers.c>
Header unset Last-Modified
</IfModule>
</FilesMatch>
# END W3TC Browser Cache
# BEGIN W3TC CDN
<FilesMatch «\. (ttf|ttc|otf|eot|woff|woff2|font.css)$»>
<IfModule mod_headers.c>
Header set Access-Control-Allow-Origin «*»
</IfModule>
</FilesMatch>
# END W3TC CDN
# BEGIN W3TC Page Cache core
<IfModule mod_rewrite.c>
RewriteEngine On
RewriteBase /
RewriteCond %{HTTP:Accept-Encoding} gzip
RewriteRule .* — [E=W3TC_ENC:_gzip]
RewriteCond %{HTTP_COOKIE} w3tc_preview [NC]
RewriteRule .* — [E=W3TC_PREVIEW:_preview]
RewriteCond %{REQUEST_METHOD} !=POST
RewriteCond %{QUERY_STRING} =»»
RewriteCond %{HTTP_COOKIE} !(comment_author|wp\-postpass|w3tc_logged_out|wordpress_logged_in|wptouch_switch_toggle) [NC]
RewriteCond «%{DOCUMENT_ROOT}/wp-content/cache/page_enhanced/%{HTTP_HOST}/%{REQUEST_URI}/_index%{ENV:W3TC_PREVIEW}.html%{ENV:W3TC_ENC}» -f
RewriteRule .* «/wp-content/cache/page_enhanced/%{HTTP_HOST}/%{REQUEST_URI}/_index%{ENV:W3TC_PREVIEW}.html%{ENV:W3TC_ENC}» [L]
</IfModule>
# END W3TC Page Cache core
# BEGIN WordPress
<IfModule mod_rewrite.
(ttf|ttc|otf|eot|woff|woff2|font.css)$»>
<IfModule mod_headers.c>
Header set Access-Control-Allow-Origin «*»
</IfModule>
</FilesMatch>
# END W3TC CDN
# BEGIN W3TC Page Cache core
<IfModule mod_rewrite.c>
RewriteEngine On
RewriteBase /
RewriteCond %{HTTP:Accept-Encoding} gzip
RewriteRule .* — [E=W3TC_ENC:_gzip]
RewriteCond %{HTTP_COOKIE} w3tc_preview [NC]
RewriteRule .* — [E=W3TC_PREVIEW:_preview]
RewriteCond %{REQUEST_METHOD} !=POST
RewriteCond %{QUERY_STRING} =»»
RewriteCond %{HTTP_COOKIE} !(comment_author|wp\-postpass|w3tc_logged_out|wordpress_logged_in|wptouch_switch_toggle) [NC]
RewriteCond «%{DOCUMENT_ROOT}/wp-content/cache/page_enhanced/%{HTTP_HOST}/%{REQUEST_URI}/_index%{ENV:W3TC_PREVIEW}.html%{ENV:W3TC_ENC}» -f
RewriteRule .* «/wp-content/cache/page_enhanced/%{HTTP_HOST}/%{REQUEST_URI}/_index%{ENV:W3TC_PREVIEW}.html%{ENV:W3TC_ENC}» [L]
</IfModule>
# END W3TC Page Cache core
# BEGIN WordPress
<IfModule mod_rewrite.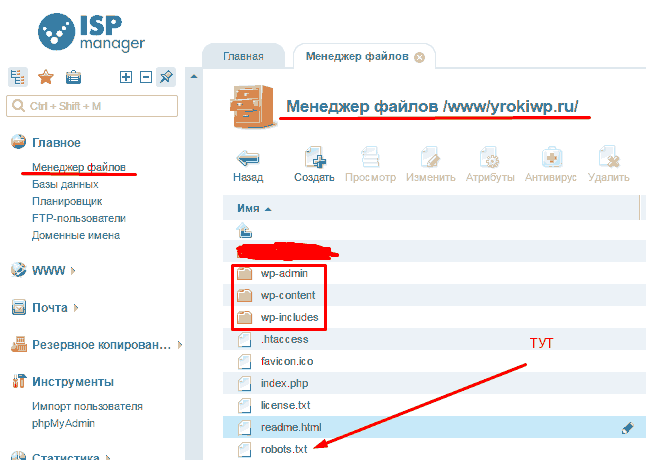 index\.php$ — [L]
RewriteCond %{REQUEST_FILENAME} !-f
RewriteCond %{REQUEST_FILENAME} !-d
RewriteRule . /index.php [L]
</IfModule>
index\.php$ — [L]
RewriteCond %{REQUEST_FILENAME} !-f
RewriteCond %{REQUEST_FILENAME} !-d
RewriteRule . /index.php [L]
</IfModule>
И снова про robots.txt для WordPress (шпаргалка начинающим) / Хабр
Перед каждым блогером (продвинутым, да) рано или поздно встает вопрос: «Чего бы такого написать в robots.txt, чтобы было все в шоколаде?»Совершенно естественно встал данный вопрос и передо мной, а написать хотелось грамотно и с пользой. Полез гуглить и все что нашел, были неуклюжие примеры robots.txt стянутые с официального сайта, которые некоторыми авторами выдавались за собственные поделки, продиктованные редкой музой веб-строительства.
Думаю не стоит и говорить, что такие примеры слабо подходили под наши с вами реалии (читай ПС Яндекс — прим. автора).
Поэтому собрав воедино всю информацию найденную в сети, а также собственные мысли и понимание того «как должно быть» написал следующий вариант.
Что имеем?
Во-первых что важно — разные конструкции для Гугла (и остальных) и для Яндекса.
Обусловлено следующим: Для Гугла в дубликатах прописывается мета-тег canonical (в шаблоне вручную, или при помощи многочисленных сео-плагинов), который должен решать проблему дублирующегося контента, а Яндекс пока этого не понимает, там другие штучки…
Во-вторых у Яндекса прописан Host — что в любом случае не помешает.
В-третьих задача разрешить как можно больше страниц для сапы не стояла, поэтому все лишнее закрыто.
В-четвертых используются более-менее принятые настройки ЧПУ и ссылок. Если у вас иерархия ЧПУ и ссылок другая (например изменены каким-либо плагином) — корректируйте исходя их своих настроек.
Основные ошибки виденные мной:
— зачастую для Яндекса прописывают только директива Host, оставляя Dissalow пустым, но такая конструкция дает право Яндексу опять индексировать все что угодно, несмотря на запреты в первой секции, что, впрочем, логично.
— закрывая категории не закрывают архивы по дате и архив автора.
— не закрывают системные адреса (трекбэки, вход и регистрацию)
Остальное я как мог вынес в комментарии, которые можно смело удалить, если вы со всем разобрались.
Не думаю что он универсален и идеален, но думаю послужит многим хорошей отправной точкой. robots.txt:
User-agent: *
Disallow: /cgi-bin
# запрещаем индексацию системных папок
Disallow: /wp-admin
Disallow: /wp-includes
Disallow: /wp-content/plugins
Disallow: /wp-content/cache
Disallow: /wp-content/themes
# запрещаем индексацию страницы входа и регистрации
Disallow: /wp-login.php
Disallow: /wp-register.php
# запрещаем индексацию трекбеков, rss-ленты
Disallow: /trackback
Disallow: /feed
Disallow: /rss
Disallow: */trackback
Disallow: */feed
Disallow: */rss
Disallow: /xmlrpc.php
# запрещаем индексацию архива автора
Disallow: /author*
# запрещаем индексацию постраничных комментариев
Disallow: */comments
Disallow: */comment-page*
# запрещаем индексацию результатов поиска и другого возможного "мусора"
Disallow: /*?*
Disallow: /*?
# разрешаем индексацию вложений, особо мнительным можно запретить папку wp-content целиком
Allow: /wp-content/uploads
User-agent: Yandex
Disallow: /cgi-bin
# запрещаем индексацию системных папок
Disallow: /wp-admin
Disallow: /wp-includes
Disallow: /wp-content/plugins
Disallow: /wp-content/cache
Disallow: /wp-content/themes
# запрещаем индексацию категорий
Disallow: /category*
# запрещаем индексацию архивов по датам. Прописываем вручную актуальные года
Прописываем вручную актуальные года
Disallow: /2008*
Disallow: /2009*
# запрещаем индексацию архива автора
Disallow: /author*
# запрещаем индексацию страницы входа и регистрации
Disallow: /wp-login.php
Disallow: /wp-register.php
# запрещаем индексацию трекбеков, rss-ленты
Disallow: /trackback
Disallow: /feed
Disallow: /rss
Disallow: */trackback
Disallow: */feed
Disallow: */rss
Disallow: /xmlrpc.php
# запрещаем индексацию постраничных комментариев
Disallow: */comments
Disallow: */comment-page*
# запрещаем индексацию результатов поиска и другого возможного «мусора»
Disallow: /*?*
Disallow: /*?
# разрешаем индексацию вложений, особо мнительным можно запретить папку wp-content целиком
Allow: /wp-content/uploads
# прописываем директиву Host
Host: mysite. ru
User-agent: Googlebot-Image
Disallow:
Allow: /*
# разрешаем индексировать изображения
User-agent: YandexBlog
Disallow:
Allow: /*
# разрешаем индексировать rss-ленту
PS. Данный файл использую на своих блогах, валидность и правильность проверял в панели веб-мастера, добиваясь нужного мне результата. Поэтому если что-то не устраивает — проверяйте и дописывайте свое.
PPS. Я еще не матерый сеошник, посему где-то могу ошибаться. С robots.txt не ошибается тот, у кого такого файла вообще нет)
Правильный robots.txt для wordpress: Яндекс и Google
Привет, читатель блога GuideComputer! У меня хорошая новость, я наконец-то разобрался как правильно составить robots.txt. Всех заинтересованных прошу незамедлительно пройти к чтению статьи:
Начну с того, что лет 7 назад я создавал сайты на Ucoz, а затем на Joomla. В поисковой выдаче всегда творился ад – дубли, дубли и служебные страницы… Позже я узнал, можно говорить поисковикам, что нужно индексировать и добавлять в поисковую выдачу, а что нельзя с помощью robots. txt.
txt.
Что такое robots.txt?
Роботс (на русский манер) – это текстовый файл, дающий рекомендации поисковым роботам : какие страницы/файлы стоит сканировать.
Где лежит robots.txt в wordpress?
Находится файл в корневой папке сайта и располагается по адресу site.ru/robots.txt. Кстати, таким образом вы можете посмотреть роботс не только моего веб-ресураса, но и любого другого.
Сейчас я покажу пример правильного robots.txt для сайта на WordPress:
Строки выше необходимо скопировать, вставить в текстовый документ, сохранить с именем robots.txt и загрузить в корневую папку сайта. К сожалению, из-за популярности кода, мне пришлось его вставить в виде картинки, иначе уникальность статьи падает до 45%.
Не расстраивайтесь, что вам придется переписывать вручную, я приготовил файл, в котором нужно поменять всего две строчки. Написать название своего ресурса и расположение карты sitemap.xml – Загрузить robots.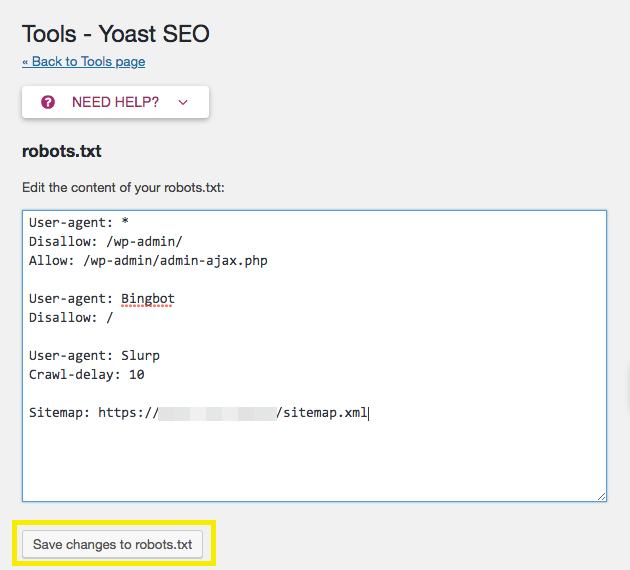 txt.
txt.
Для тех, кому вышесказанное показалось сложным существует более простое решение! Если на вашем сайте установлен плагин Yoast Seo, то существует возможность создать robots.txt прямо из админ панели WordPress. Показываю как:
Заходим в настройки плагина, открываем вкладку инструменты:
Открываем редактор файлов.
Вставляем код, который вы загрузили выше, и не забываем сохранить!
Ниже находится файл .htaccess – без знаний что это такое советую туда не лезть. С этим файлом нужно обращаться очень осторожно, потому что изменения могут привести к ошибкам, в следствии которых сайт может перестать загружаться.
Синтаксис
Особо не стоит заморачиваться над синтаксисом файла, поэтому я расскажу лишь об основных частях кода.
User-agent: – данное выражение отвечает для каких поисковых роботов будут применяться правила. Например, * – обозначается для всех, Yandex – для Яндекса, Googlebot – для Гугл робота.
Disallow – выражение, отвечает за запрет индексирования разделов. Если вы не хотите дублей или технических страниц в поиске, то таким образом можете запретить доступ. Например, вот таким образом Disallow: /tag я не разрешаю индексирование тегов.
Host – данное выражение отвечает за главное зеркало сайта. Учтите, что http, https, www и без – это 4 разных варианта. Необходимо выбрать только один и именно его прописать в роботс.
Sitemap – данное выражение задает адрес по которому располагается карта сайта. На моем веб-ресурсе она создана автоматически с помощью плагина Yoast Seo.
Впервые слышишь о карте сайта? – Читай, что такое sitemap и как его создать для wordpress.
Проблемы без ЧПУ
Я уже рассказывал о важности настройки ЧПУ WordPress для сайта. Этот раздел посвящен тем, кто проигнорировал мои рекомендации:
Без ЧПУ ссылки сайта выглядят следующим образом – guidecomputer.ru/?p=123. Строчка Disallow: /*?* запрещает индексирование статей, поэтому её необходимо удалить. Для невнимательных, в коде выше она встречается 2 раза.
Строчка Disallow: /*?* запрещает индексирование статей, поэтому её необходимо удалить. Для невнимательных, в коде выше она встречается 2 раза.
Проверка robots.txt
Чтобы проверить правильность составленного файла – необходимо провести анализ. Для этого существуют два наиболее популярных инструмента:
Проверка robots.txt в Яндекс вебмастере или с помощью инструментов Google. ( Если вы еще не зарегистрировались в сервисах для Вебмастеров – советую это сделать незамедлительно. )
Я покажу как воспользоваться обеими вариантами, выбирайте сами какой больше нравиться. А еще лучше воспользуйтесь каждым, тем более это не займет больше пары минут.
Проверка с помощью Яндекс Вебмастера
Заходим в инструменты в левом меню, и выбираем первый пункт Анализ robots.txt:
Добавляем ссылку на проверяемый сайт, нажимаем кнопку загрузки, а затем проверить.
Немного ждем и смотрим Результаты анализа, в моем случае 0 ошибок.
Проверка с помощью Search Console
Заходим в Сканирование, выбираем раздел инструменты проверки файла:
Вставляем robots.txt и кликаем отправить.
В 3-ем пункте выбираем отправить и смотрим на количество ошибок.
Заключение
Не стоит откладывать с применением вышесказанного: настройка robots.txt – это одно из важнейших первичных действий при создании веб-ресурса. Значительность которого можно сравнить с дверями вашего дома, которые оберегают от непрошеных гостей и обеспечивает безопасность.
После того, как построен каркас дома ставят двери. Так же должно происходить с сайтом – покупка домена и хостинга, установка CMS WordPress, а затем роботс.
Надеюсь, что раскрыл все моменты связанные с правильной настройкой файла robots.txt для wordpress. Но если у вас остались вопросы, с удовольствием отвечу – Добро пожаловать в комментарии!
Как оптимизировать ваш Robots.txt для SEO в WordPress (Руководство для начинающих)
Недавно один из наших читателей попросил нас дать советы о том, как оптимизировать файл robots. txt для улучшения SEO. Файл Robots.txt сообщает поисковым системам, как сканировать ваш сайт, что делает его невероятно мощным инструментом SEO. В этой статье мы покажем вам, как создать идеальный файл robots.txt для SEO.
txt для улучшения SEO. Файл Robots.txt сообщает поисковым системам, как сканировать ваш сайт, что делает его невероятно мощным инструментом SEO. В этой статье мы покажем вам, как создать идеальный файл robots.txt для SEO.
Что такое файл robots.txt?
Robots.txt — это текстовый файл, который владельцы веб-сайтов могут создать, чтобы сообщить роботам поисковых систем, как сканировать и индексировать страницы на своем сайте.
Обычно он хранится в корневом каталоге, также известном как основная папка вашего веб-сайта. Базовый формат файла robots.txt выглядит так:
Пользовательский агент: [имя пользовательского агента] Disallow: [строка URL не сканироваться] Пользовательский агент: [имя пользовательского агента] Разрешить: [строка URL для сканирования] Карта сайта: [URL-адрес вашего XML-файла Sitemap]
У вас может быть несколько строк инструкций, чтобы разрешить или запретить определенные URL-адреса и добавить несколько карт сайта. Если вы не запрещаете URL-адрес, роботы поисковых систем предполагают, что им разрешено сканировать его.
Если вы не запрещаете URL-адрес, роботы поисковых систем предполагают, что им разрешено сканировать его.
Вот как может выглядеть файл примера robots.txt:
Пользовательский агент: * Разрешить: / wp-content / uploads / Запретить: / wp-content / plugins / Запретить: / wp-admin / Карта сайта: https://example.com/sitemap_index.xml
В приведенном выше примере robots.txt мы разрешили поисковым системам сканировать и индексировать файлы в нашей папке загрузки WordPress.
После этого мы запретили поисковым роботам сканировать и индексировать плагины и папки администратора WordPress.
Наконец, мы предоставили URL-адрес нашей XML-карты сайта.
Вам нужен файл Robots.txt для вашего сайта WordPress?
Если у вас нет файла robots.txt, поисковые системы все равно будут сканировать и индексировать ваш сайт. Однако вы не сможете указать поисковым системам, какие страницы или папки им не следует сканировать.
Это не окажет большого влияния, когда вы впервые создаете блог и у вас мало контента.
Однако по мере того, как ваш веб-сайт растет и у вас появляется много контента, вы, вероятно, захотите лучше контролировать то, как ваш веб-сайт сканируется и индексируется.
Вот почему.
У поисковых роботов есть квота сканирования для каждого веб-сайта.
Это означает, что они просматривают определенное количество страниц во время сеанса сканирования. Если они не завершат сканирование всех страниц вашего сайта, они вернутся и возобновят сканирование в следующем сеансе.
Это может снизить скорость индексации вашего сайта.
Вы можете исправить это, запретив поисковым роботам пытаться сканировать ненужные страницы, такие как ваши административные страницы WordPress, файлы плагинов и папку тем.
Запрещая ненужные страницы, вы сохраняете квоту сканирования. Это помогает поисковым системам сканировать еще больше страниц на вашем сайте и как можно быстрее их индексировать.
Еще одна веская причина использовать файл robots. txt — это когда вы хотите, чтобы поисковые системы не индексировали сообщение или страницу на вашем веб-сайте.
txt — это когда вы хотите, чтобы поисковые системы не индексировали сообщение или страницу на вашем веб-сайте.
Это не самый безопасный способ скрыть контент от широкой публики, но он поможет вам предотвратить их появление в результатах поиска.
Что делают идеальные роботы.txt должен выглядеть как файл?
Многие популярные блоги используют очень простой файл robots.txt. Их содержание может отличаться в зависимости от потребностей конкретного сайта:
Пользовательский агент: * Запретить: Карта сайта: http://www.example.com/post-sitemap.xml Карта сайта: http://www.example.com/page-sitemap.xml
Этот файл robots.txt позволяет всем ботам индексировать весь контент и предоставляет им ссылку на XML-карту сайта веб-сайта.
Для сайтов WordPress мы рекомендуем следующие правила в файле robots.txt файл:
Пользовательский агент: * Разрешить: / wp-content / uploads / Запретить: / wp-content / plugins / Запретить: / wp-admin / Запретить: /readme.html Запретить: / ссылаться / Карта сайта: http://www.example.com/post-sitemap.xml Карта сайта: http://www.example.com/page-sitemap.xml
Указывает поисковым роботам индексировать все изображения и файлы WordPress. Он запрещает поисковым роботам индексировать файлы плагинов WordPress, область администрирования WordPress, файл readme WordPress и партнерские ссылки.
Добавляя карты сайта в файл robots.txt, вы упрощаете роботам Google поиск всех страниц на вашем сайте.
Теперь, когда вы знаете, как выглядит идеальный файл robots.txt, давайте посмотрим, как создать файл robots.txt в WordPress.
Как создать файл Robots.txt в WordPress?
Есть два способа создать файл robots.txt в WordPress. Вы можете выбрать наиболее подходящий для вас метод.
Метод 1. Редактирование роботов.txt с помощью Yoast SEO
Если вы используете плагин Yoast SEO, он поставляется с генератором файлов robots.txt.
Вы можете использовать его для создания и редактирования файла robots.txt прямо из админки WordPress.
Просто перейдите на страницу SEO »Инструменты в админке WordPress и щелкните ссылку« Редактор файлов ».
На следующей странице Yoast SEO покажет существующий файл robots.txt.
Если у вас нет файла robots.txt, то Yoast SEO сгенерирует для вас файл robots.txt.
По умолчанию генератор файлов robots.txt Yoast SEO добавляет в файл robots.txt следующие правила:
Пользовательский агент: * Запретить: /
Это важно, , чтобы вы удалили этот текст, потому что он блокирует сканирование вашего сайта всеми поисковыми системами.
После удаления текста по умолчанию вы можете продолжить и добавить свои собственные правила robots.txt. Мы рекомендуем использовать идеальных роботов.txt, который мы использовали выше.
Когда вы закончите, не забудьте нажать кнопку «Сохранить файл robots.txt», чтобы сохранить изменения.
Метод 2. Отредактируйте файл Robots.txt вручную с помощью FTP
Для этого метода вам нужно будет использовать FTP-клиент для редактирования файла robots.txt.
Просто подключитесь к своей учетной записи хостинга WordPress с помощью FTP-клиента.
Попав внутрь, вы сможете увидеть файл robots.txt в корневой папке вашего веб-сайта.
Если вы его не видите, скорее всего, у вас нет robots.txt файл. В этом случае вы можете просто создать его.
Robots.txt — это простой текстовый файл, что означает, что вы можете загрузить его на свой компьютер и отредактировать с помощью любого текстового редактора, такого как Блокнот или TextEdit.
После сохранения изменений вы можете загрузить их обратно в корневую папку вашего сайта.
Как проверить файл robots.txt?
После создания файла robots.txt всегда полезно протестировать его с помощью инструмента тестирования robots.txt.
Существует множество инструментов для тестирования robots.txt, но мы рекомендуем использовать тот, который находится в Google Search Console.
Просто войдите в свою учетную запись Google Search Console, а затем переключитесь на старый сайт поисковой консоли Google.
Вы попадете в старый интерфейс Google Search Console. Отсюда вам нужно запустить тестер robots.txt, расположенный в меню «Сканирование».
Инструмент автоматически загрузит роботов с вашего сайта.txt и выделите ошибки и предупреждения, если они были обнаружены.
Последние мысли
Цель оптимизации файла robots.txt — запретить поисковым системам сканировать страницы, которые не являются общедоступными. Например, страницы в папке wp-plugins или страницы в папке администратора WordPress.
Среди экспертов по SEO распространен миф о том, что блокировка категорий, тегов и архивных страниц WordPress улучшит скорость сканирования и приведет к более быстрой индексации и повышению рейтинга.
Это неправда. Это также противоречит рекомендациям Google для веб-мастеров.
Мы рекомендуем использовать указанный выше формат robots.txt для создания файла robots.txt для своего веб-сайта.
Мы надеемся, что эта статья помогла вам узнать, как оптимизировать файл robots.txt WordPress для SEO. Вы также можете ознакомиться с нашим полным руководством по SEO для WordPress и лучшими инструментами WordPress для SEO для развития вашего сайта.
Если вам понравилась эта статья, то подпишитесь на наш канал YouTube для видеоуроков по WordPress.Вы также можете найти нас в Twitter и Facebook.
Как оптимизировать ваш WordPress Robots.txt
Что такое файл Robots.txt?
robots.txt — это очень маленький, но важный файл, расположенный в корневом каталоге вашего веб-сайта. Он сообщает поисковым роботам (роботам), какие страницы или каталоги можно сканировать, а какие — нельзя.
Файл robots.txt можно использовать для полной блокировки сканеров поисковых систем или просто для ограничения их доступа к определенным областям вашего веб-сайта. Ниже приведен пример очень простого робота WordPress.txt файл:
Сначала это может показаться немного запутанным, поэтому я расскажу, что некоторые из этих вещей означают.
- User-agent: позволяет указать направление к конкретному роботу. В этом случае мы использовали «*», который относится ко всем роботам.
- Disallow: указывает роботам, какие файлы и папки им не следует сканировать.
- Разрешить: сообщает роботу, что можно сканировать файл в запрещенной папке.
- Sitemap: используется для указания местоположения вашей карты сайта.
Существуют и другие правила, которые можно использовать в файле robots.txt, например Host: и Crawl-delay: но они необычны и используются только в определенных ситуациях.
Для чего используется файл Robots.txt?
Каждый веб-сайт, сканируемый Google, имеет краулинговый бюджет. Бюджет сканирования — это в основном ограниченное количество страниц, которые Google может сканировать в любой момент времени. Вы не хотите тратить свой бюджет сканирования на страницы низкого качества, спамерские или неважные.
Здесь на помощь приходит файл robots.txt. Вы можете использовать файл robots.txt, чтобы указать, какие страницы, файлы и каталоги Google (и другие поисковые системы) должны игнорировать. Это позволит роботам поисковых систем сохранять приоритет вашего важного высококачественного контента.
Ниже приведены некоторые важные вещи, которые вы, возможно, захотите заблокировать на своем веб-сайте WordPress:
- Фасетная навигация и идентификаторы сеанса
- Дублированный контент на сайте
- Страницы с программными ошибками
- Взломанные страницы
- Бесконечные пробелы и прокси-серверы
- Низкое качество и спам-контент
Этот список взят прямо из центрального блога Google для веб-мастеров.Расходование бюджета сканирования на такие страницы, как перечисленные выше, снизит активность сканирования на страницах, которые действительно имеют ценность. Это может вызвать значительную задержку в индексировании важного контента на вашем сайте.
Чего не следует использовать в файле robots.txt для
Файл robots.txt не должен использоваться как способ контролировать, какие страницы индексируются поисковыми системами. Если вы пытаетесь предотвратить включение определенных страниц в результаты поисковой системы, вам следует использовать теги или директивы noindex либо защитить свою страницу паролем.
Причина этого в том, что файл robots.txt на самом деле не указывает поисковым системам не индексировать контент. Он просто говорит им не ползать по нему. Хотя Google не будет сканировать запрещенные области на вашем собственном веб-сайте, они заявляют, что если внешняя ссылка указывает на страницу, которую вы исключили, она все равно может быть просканирована и проиндексирована.
Требуется ли в WordPress файл Robots.txt?
Разумеется, наличие файла robots.txt для вашего веб-сайта WordPress не требуется.Поисковые системы по-прежнему будут сканировать и индексировать ваш сайт, как обычно.
Однако вы не сможете исключить какие-либо страницы, файлы или папки, которые без необходимости истощают ваш краулинговый бюджет. Как я объяснил выше, это может значительно увеличить время, необходимое Google (и другим поисковым системам) для обнаружения нового и обновленного контента на вашем веб-сайте.
Итак, в общем, я бы сказал, что файл robots.txt не требуется для WordPress, но он определенно рекомендуется.Настоящий вопрос здесь должен быть: «Почему бы вам не захотеть?»
Как создать файл WordPress Robots.txt
Теперь, когда вы знаете, что такое robots.txt и для чего он используется, мы рассмотрим, как вы можете его создать. Есть три разных метода, и ниже я рассмотрю каждый из них.
1. Используйте подключаемый модуль для создания файла Robots.txt
Плагины SEO, такие как Yoast, имеют возможность создавать и редактировать файл robots.txt из панели управления WordPress.Это, наверное, самый простой вариант.
2. Загрузите файл Robots.txt с помощью FTP
Другой вариант — просто создать файл .txt на вашем компьютере с помощью блокнота (или чего-то подобного) и назвать его robots.txt. Затем вы можете загрузить файл в корневой каталог своего веб-сайта, используя FTP (протокол передачи файлов), например FileZilla.
3. Создайте Robots.txt в cPanel
Если ни один из вышеперечисленных вариантов вам не подходит, вы всегда можете войти в свою cPanel и создать файл вручную.Убедитесь, что вы создали файл в корневом каталоге.
Как оптимизировать ваш Robots.txt для WordPress
Итак, что должно быть в вашем файле robots.txt WordPress? Вы можете найти это удивительным, но не очень. Ниже я объясню почему.
Google (и другие поисковые системы) постоянно развиваются и совершенствуются, поэтому то, что раньше считалось лучшим, больше не работает. В настоящее время Google получает не только HTML-код ваших веб-сайтов, но и файлы CSS и JS.По этой причине им не нравится, когда вы блокируете любые файлы или папки, необходимые для рендеринга страницы.
В прошлом можно было блокировать такие вещи, как папки / wp-includes / и / wp-content /. Это уже не так. Простой способ проверить это — войти в свою учетную запись Google для веб-мастеров и протестировать действующий URL. Если какие-либо ресурсы блокируются в Google Bot, они будут жаловаться на это на вкладке «Ресурсы страницы».
Ниже я собрал пример файла robots.txt, который, я думаю, станет отличной отправной точкой для всех, кто использует WordPress.
Пользовательский агент: *
# Заблокировать всю папку wp-admin.
Запретить: / wp-admin /
# Блокирует реферальные ссылки для партнерских программ.
Запрещено: / ссылка /
# Заблокируйте все страницы, которые, по вашему мнению, могут быть спамом.
Запретить: / spammy-page /
# Заблокировать любые страницы с дублированным содержанием.
Запретить: / duplicate-content-page /
# Заблокируйте любые неважные страницы низкого качества.
Disallow: / low-quality-page /
# Предотвращение программных ошибок 404 путем блокировки страниц поиска.
Запрещено: /? S =
# Разрешить admin-ajax.php внутри wp-admin.
Разрешить: /wp-admin/admin-ajax.php
# Ссылка на вашу карту сайта WordPress.
Карта сайта: https://example.com/sitemap_index.xml
Некоторые вещи, которые я включил в этот файл, являются просто примерами.Если вы не чувствуете, что какие-либо из ваших страниц дублируются, содержат спам или имеют низкое качество, вам не нужно добавлять эту часть. Это всего лишь ориентир, ситуация у всех будет разная.
Не забывайте соблюдать осторожность при внесении изменений в robots.txt своего сайта. Хотя эти изменения могут улучшить ваш поисковый трафик, они также могут принести больше вреда, чем пользы, если вы сделаете ошибку.
Проверьте свой файл robots.txt WordPress
После того, как вы создали и настроили файл robots.txt, всегда полезно проверить его.Войдите в свою учетную запись Google для веб-мастеров и используйте этот инструмент тестирования роботов. Этот инструмент работает так же, как робот Googlebot, проверяя ваш файл robots.txt и проверяя, правильно ли заблокирован ваш URL.
Как и на картинке выше, вы увидите предварительный просмотр вашего файла robots.txt в том виде, в каком его увидит Google. Убедитесь, что все выглядит правильно и нет никаких предупреждений или ошибок.
Вот и все! вы должны быть настроены и готовы к работе.
Мои последние мысли
Как видите, файл robots.txt — важная часть поисковой оптимизации вашего сайта. При правильном использовании он может ускорить сканирование и значительно ускорить индексацию нового и обновленного контента. Тем не менее, неправильное использование этого файла может нанести большой ущерб вашему рейтингу в поисковых системах, поэтому будьте осторожны при внесении любых изменений.
Надеюсь, эта статья дала вам лучшее представление о вашем файле robots.txt и о том, как его оптимизировать для ваших конкретных нужд WordPress. Обязательно оставьте комментарий, если у вас возникнут дополнительные вопросы.
Эми Грин — писатель-фрилансер, фронтенд-разработчик и предприниматель. Вы можете найти ее в Zuziko для написания учебных пособий, руководств и обзоров популярной системы управления контентом WordPress.
Связанные
Просканировано роботом Googlebot? | появляется в индексе? | Потребляет PageRank | Риски? Трата? | Формат | |
| robots.txt | нет | Если на документ есть ссылка, он может отображаться только по URL-адресу или с данными из ссылок или доверенных сторонних источников данных, таких как ODP | да | Люди могут смотреть на ваших роботов.txt, чтобы увидеть, какой контент вы не хотите индексировать. Многие новые запуски обнаруживаются людьми, которые следят за изменениями в файле robots.txt. Неправильное использование подстановочных знаков может быть дорогостоящим! | Пользовательский агент: * ИЛИ Пользовательский агент: * Также можно использовать сложные подстановочные знаки. |
| мета тег noindex роботов | да | нет | Да, но может передать большую часть своего PageRank, ссылаясь на другие страницы | Ссылки на странице noindex по-прежнему сканируются поисковыми пауками, даже если страница не отображается в результатах поиска (если они не используются вместе с nofollow). Страница, использующая мета-nofollow роботов (1 строка ниже) в сочетании с noindex, может накапливать PageRank, но не передавать его другим страницам. | ИЛИ можно использовать с nofollow likeo |
| мета-тег nofollow для роботов | целевая страница сканируется только в том случае, если на нее есть ссылки из других документов | Целевая страницаотображается, только если на нее есть ссылка из других документов | нет, PageRank не передан по назначению | Если вы увеличиваете значительный PageRank на странице и не позволяете PageRank исходить с этой страницы, вы можете потерять значительную долю ссылочного рейтинга. | ИЛИ может использоваться с noindex likeo |
| ссылка rel = nofollow | целевая страница сканируется только в том случае, если на нее есть ссылки из других документов | Целевая страницаотображается, только если на нее есть ссылка из других документов | Использование этого может привести к потере некоторого PageRank.Рекомендуется использовать в областях контента, создаваемых пользователями. | Если вы делаете что-то на грани спама и используете nofollow для внутренних ссылок для увеличения PageRank, то вы больше похожи на оптимизатора поисковых систем и, скорее всего, будете наказаны инженером Google за «поисковый спам» | текст ссылки |
| rel = canonical | да.может сканироваться несколько версий страницы, и они могут появиться в индексе | страниц по-прежнему отображаются в индексе. это воспринимается как подсказка, а не директива. | PageRank должен накапливаться до целевой цели | С такими инструментами, как переадресация 301 и rel = canonical, может возникнуть небольшое снижение рейтинга страниц, особенно с rel = canonical, поскольку обе версии страницы остаются в поисковом индексе. | |
| Ссылка Javascript | в целом да, если целевой URL легко доступен в частях ссылки a href или onclick. | Целевая страницаотображается только в том случае, если на нее имеется ссылка из других документов | обычно да, PageRank обычно передается получателю | Хотя многие из них отслеживаются Google, другие поисковые системы могут не отслеживать их. |